diff --git a/docs/transformers/docs/source/en/fsdp.md b/docs/transformers/docs/source/en/fsdp.md
new file mode 100644
index 0000000000000000000000000000000000000000..944c5a18e109356195fd4b5eb2cf176174af9693
--- /dev/null
+++ b/docs/transformers/docs/source/en/fsdp.md
@@ -0,0 +1,145 @@
+
+
+# FullyShardedDataParallel
+
+[Fully Sharded Data Parallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) is a [parallelism](./perf_train_gpu_many) method that combines the advantages of data and model parallelism for distributed training.
+
+Unlike [DistributedDataParallel (DDP)](./perf_train_gpu_many#distributeddataparallel), FSDP saves more memory because it doesn't replicate a model on each GPU. It shards the models parameters, gradients and optimizer states across GPUs. Each model shard processes a portion of the data and the results are synchronized to speed up training.
+
+This guide covers how to set up training a model with FSDP and [Accelerate](https://hf.co/docs/accelerate/index), a library for managing distributed training.
+
+```bash
+pip install accelerate
+```
+
+## Configuration options
+
+Always start by running the [accelerate config](https://hf.co/docs/accelerate/package_reference/cli#accelerate-config) command to help Accelerate set up the correct distributed training environment.
+
+```bash
+accelerate config
+```
+
+The section below discusses some of the more important FSDP configuration options. Learn more about other available options in the [fsdp_config](https://hf.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.fsdp_config) parameter.
+
+### Sharding strategy
+
+FSDP offers several sharding strategies to distribute a model. Refer to the table below to help you choose the best strategy for your setup. Specify a strategy with the `fsdp_sharding_strategy` parameter in the configuration file.
+
+| sharding strategy | description | parameter value |
+|---|---|---|
+| `FULL_SHARD` | shards model parameters, gradients, and optimizer states | `1` |
+| `SHARD_GRAD_OP` | shards gradients and optimizer states | `2` |
+| `NO_SHARD` | don't shard the model | `3` |
+| `HYBRID_SHARD` | shards model parameters, gradients, and optimizer states within each GPU | `4` |
+| `HYBRID_SHARD_ZERO2` | shards gradients and optimizer states within each GPU | `5` |
+
+### CPU offload
+
+Offload model parameters and gradients when they aren't being used to the CPU to save additional GPU memory. This is useful for scenarios where a model is too large even with FSDP.
+
+Specify `fsdp_offload_params: true` in the configuration file to enable offloading.
+
+### Wrapping policy
+
+FSDP is applied by wrapping each layer in the network. The wrapping is usually applied in a nested way where the full weights are discarded after each forward pass to save memory for the next layer.
+
+There are several wrapping policies available, but the *auto wrapping* policy is the simplest and doesn't require any changes to your code. Specify `fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP` to wrap a Transformer layer and `fsdp_transformer_layer_cls_to_wrap` to determine which layer to wrap (for example, `BertLayer`).
+
+Size-based wrapping is also available. If a layer exceeds a certain number of parameters, it is wrapped. Specify `fsdp_wrap_policy: SIZED_BASED_WRAP` and `min_num_param` to set the minimum number of parameters for a layer to be wrapped.
+
+### Checkpoints
+
+Intermediate checkpoints should be saved as a sharded state dict because saving the full state dict - even with CPU offloading - is time consuming and can cause `NCCL Timeout` errors due to indefinite hanging during broadcasting.
+
+Specify `fsdp_state_dict_type: SHARDED_STATE_DICT` in the configuration file to save the sharded state dict. Now you can resume training from the sharded state dict with [`~accelerate.Accelerator.load_state`].
+
+```py
+accelerator.load_state("directory/containing/checkpoints")
+```
+
+Once training is complete though, you should save the full state dict because the sharded state dict is only compatible with FSDP.
+
+```py
+if trainer.is_fsdp_enabled:
+ trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
+
+trainer.save_model(script_args.output_dir)
+```
+
+### TPU
+
+[PyTorch XLA](https://pytorch.org/xla/release/2.1/index.html), a package for running PyTorch on XLA devices, enables FSDP on TPUs. Modify the configuration file to include the parameters below. Refer to the [xla_fsdp_settings](https://github.com/pytorch/xla/blob/2e6e183e0724818f137c8135b34ef273dea33318/torch_xla/distributed/fsdp/xla_fully_sharded_data_parallel.py#L128) parameter for additional XLA-specific parameters you can configure for FSDP.
+
+```yaml
+xla: True # must be set to True to enable PyTorch/XLA
+xla_fsdp_settings: # XLA specific FSDP parameters
+xla_fsdp_grad_ckpt: True # enable gradient checkpointing
+```
+
+## Training
+
+After running [accelerate config](https://hf.co/docs/accelerate/package_reference/cli#accelerate-config), your configuration file should be ready. An example configuration file is shown below that fully shards the parameter, gradient and optimizer states on two GPUs. Your file may look different depending on how you set up your configuration.
+
+```yaml
+compute_environment: LOCAL_MACHINE
+debug: false
+distributed_type: FSDP
+downcast_bf16: 'no'
+fsdp_config:
+ fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
+ fsdp_backward_prefetch_policy: BACKWARD_PRE
+ fsdp_cpu_ram_efficient_loading: true
+ fsdp_forward_prefetch: false
+ fsdp_offload_params: true
+ fsdp_sharding_strategy: 1
+ fsdp_state_dict_type: SHARDED_STATE_DICT
+ fsdp_sync_module_states: true
+ fsdp_transformer_layer_cls_to_wrap: BertLayer
+ fsdp_use_orig_params: true
+machine_rank: 0
+main_training_function: main
+mixed_precision: bf16
+num_machines: 1
+num_processes: 2
+rdzv_backend: static
+same_network: true
+tpu_env: []
+tpu_use_cluster: false
+tpu_use_sudo: false
+use_cpu: false
+```
+
+Run the [accelerate launch](https://hf.co/docs/accelerate/package_reference/cli#accelerate-launch) command to launch a training script with the FSDP configurations you chose in the configuration file.
+
+```bash
+accelerate launch my-training-script.py
+```
+
+It is also possible to directly specify some of the FSDP arguments in the command line.
+
+```bash
+accelerate launch --fsdp="full shard" --fsdp_config="path/to/fsdp_config/" my-training-script.py
+```
+
+## Resources
+
+FSDP is a powerful tool for training large models with fewer GPUs compared to other parallelism strategies. Refer to the following resources below to learn even more about FSDP.
+
+- Follow along with the more in-depth Accelerate guide for [FSDP](https://hf.co/docs/accelerate/usage_guides/fsdp).
+- Read the [Introducing PyTorch Fully Sharded Data Parallel (FSDP) API](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) blog post.
+- Read the [Scaling PyTorch models on Cloud TPUs with FSDP](https://pytorch.org/blog/scaling-pytorch-models-on-cloud-tpus-with-fsdp/) blog post.
diff --git a/docs/transformers/docs/source/en/generation_features.md b/docs/transformers/docs/source/en/generation_features.md
new file mode 100644
index 0000000000000000000000000000000000000000..19ac987807261da527b9de5358fd007fe474087e
--- /dev/null
+++ b/docs/transformers/docs/source/en/generation_features.md
@@ -0,0 +1,82 @@
+
+
+# Generation features
+
+The [`~GenerationMixin.generate`] API supports a couple features for building applications on top of it.
+
+This guide will show you how to use these features.
+
+## Streaming
+
+Streaming starts returning text as soon as it is generated so you don't have to wait to see the entire generated response all at once. It is important in user-facing applications because it reduces perceived latency and allows users to see the generation progression.
+
+
+
+
+
+> [!TIP]
+> Learn more about streaming in the [Text Generation Inference](https://huggingface.co/docs/text-generation-inference/en/conceptual/streaming) docs.
+
+Create an instance of [`TextStreamer`] with the tokenizer. Pass [`TextStreamer`] to the `streamer` parameter in [`~GenerationMixin.generate`] to stream the output one word at a time.
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
+
+tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
+model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
+inputs = tokenizer(["The secret to baking a good cake is "], return_tensors="pt")
+streamer = TextStreamer(tokenizer)
+
+_ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
+```
+
+The `streamer` parameter is compatible with any class with a [`~TextStreamer.put`] and [`~TextStreamer.end`] method. [`~TextStreamer.put`] pushes new tokens and [`~TextStreamer.end`] flags the end of generation. You can create your own streamer class as long as they include these two methods, or you can use Transformers' basic streamer classes.
+
+## Watermarking
+
+Watermarking is useful for detecting whether text is generated. The [watermarking strategy](https://hf.co/papers/2306.04634) in Transformers randomly "colors" a subset of the tokens green. When green tokens are generated, they have a small bias added to their logits, and a higher probability of being generated. You can detect generated text by comparing the proportion of green tokens to the amount of green tokens typically found in human-generated text.
+
+Watermarking is supported for any generative model in Transformers and doesn't require an extra classification model to detect the watermarked text.
+
+Create a [`WatermarkingConfig`] with the bias value to add to the logits and watermarking algorithm. The example below uses the `"selfhash"` algorithm, where the green token selection only depends on the current token. Pass the [`WatermarkingConfig`] to [`~GenerationMixin.generate`].
+
+> [!TIP]
+> The [`WatermarkDetector`] class detects the proportion of green tokens in generated text, which is why it is recommended to strip the prompt text, if it is much longer than the generated text. Padding can also have an effect on [`WatermarkDetector`].
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM, WatermarkDetector, WatermarkingConfig
+
+model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
+tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
+tokenizer.pad_token_id = tokenizer.eos_token_id
+tokenizer.padding_side = "left"
+
+inputs = tokenizer(["This is the beginning of a long story", "Alice and Bob are"], padding=True, return_tensors="pt")
+input_len = inputs["input_ids"].shape[-1]
+
+watermarking_config = WatermarkingConfig(bias=2.5, seeding_scheme="selfhash")
+out = model.generate(**inputs, watermarking_config=watermarking_config, do_sample=False, max_length=20)
+```
+
+Create an instance of [`WatermarkDetector`] and pass the model output to it to detect whether the text is machine-generated. The [`WatermarkDetector`] must have the same [`WatermarkingConfig`] used during generation.
+
+```py
+detector = WatermarkDetector(model_config=model.config, device="cpu", watermarking_config=watermarking_config)
+detection_out = detector(out, return_dict=True)
+detection_out.prediction
+array([True, True])
+```
diff --git a/docs/transformers/docs/source/en/gguf.md b/docs/transformers/docs/source/en/gguf.md
new file mode 100644
index 0000000000000000000000000000000000000000..5043da792155ff9a18832eaee2fe0e9a66906b27
--- /dev/null
+++ b/docs/transformers/docs/source/en/gguf.md
@@ -0,0 +1,53 @@
+
+
+# GGUF
+
+[GGUF](https://github.com/ggerganov/ggml/blob/master/docs/gguf.md) is a file format used to store models for inference with [GGML](https://github.com/ggerganov/ggml), a fast and lightweight inference framework written in C and C++. GGUF is a single-file format containing the model metadata and tensors.
+
+
+
+
+
+The GGUF format also supports many quantized data types (refer to [quantization type table](https://hf.co/docs/hub/en/gguf#quantization-types) for a complete list of supported quantization types) which saves a significant amount of memory, making inference with large models like Whisper and Llama feasible on local and edge devices.
+
+Transformers supports loading models stored in the GGUF format for further training or finetuning. The GGUF checkpoint is **dequantized to fp32** where the full model weights are available and compatible with PyTorch.
+
+> [!TIP]
+> Models that support GGUF include Llama, Mistral, Qwen2, Qwen2Moe, Phi3, Bloom, Falcon, StableLM, GPT2, Starcoder2, and [more](https://github.com/huggingface/transformers/blob/main/src/transformers/integrations/ggml.py)
+
+Add the `gguf_file` parameter to [`~PreTrainedModel.from_pretrained`] to specify the GGUF file to load.
+
+```py
+# pip install gguf
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+model_id = "TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF"
+filename = "tinyllama-1.1b-chat-v1.0.Q6_K.gguf"
+
+torch_dtype = torch.float32 # could be torch.float16 or torch.bfloat16 too
+tokenizer = AutoTokenizer.from_pretrained(model_id, gguf_file=filename)
+model = AutoModelForCausalLM.from_pretrained(model_id, gguf_file=filename, torch_dtype=torch_dtype)
+```
+
+Once you're done tinkering with the model, save and convert it back to the GGUF format with the [convert-hf-to-gguf.py](https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py) script.
+
+```py
+tokenizer.save_pretrained("directory")
+model.save_pretrained("directory")
+
+!python ${path_to_llama_cpp}/convert-hf-to-gguf.py ${directory}
+```
diff --git a/docs/transformers/docs/source/en/glossary.md b/docs/transformers/docs/source/en/glossary.md
new file mode 100644
index 0000000000000000000000000000000000000000..d9fdac2475f23bcda4685330086fb730848dd666
--- /dev/null
+++ b/docs/transformers/docs/source/en/glossary.md
@@ -0,0 +1,522 @@
+
+
+# Glossary
+
+This glossary defines general machine learning and 🤗 Transformers terms to help you better understand the
+documentation.
+
+## A
+
+### attention mask
+
+The attention mask is an optional argument used when batching sequences together.
+
+
+
+This argument indicates to the model which tokens should be attended to, and which should not.
+
+For example, consider these two sequences:
+
+```python
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-cased")
+
+>>> sequence_a = "This is a short sequence."
+>>> sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
+
+>>> encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
+>>> encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
+```
+
+The encoded versions have different lengths:
+
+```python
+>>> len(encoded_sequence_a), len(encoded_sequence_b)
+(8, 19)
+```
+
+Therefore, we can't put them together in the same tensor as-is. The first sequence needs to be padded up to the length
+of the second one, or the second one needs to be truncated down to the length of the first one.
+
+In the first case, the list of IDs will be extended by the padding indices. We can pass a list to the tokenizer and ask
+it to pad like this:
+
+```python
+>>> padded_sequences = tokenizer([sequence_a, sequence_b], padding=True)
+```
+
+We can see that 0s have been added on the right of the first sentence to make it the same length as the second one:
+
+```python
+>>> padded_sequences["input_ids"]
+[[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]]
+```
+
+This can then be converted into a tensor in PyTorch or TensorFlow. The attention mask is a binary tensor indicating the
+position of the padded indices so that the model does not attend to them. For the [`BertTokenizer`], `1` indicates a
+value that should be attended to, while `0` indicates a padded value. This attention mask is in the dictionary returned
+by the tokenizer under the key "attention_mask":
+
+```python
+>>> padded_sequences["attention_mask"]
+[[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
+```
+
+### autoencoding models
+
+See [encoder models](#encoder-models) and [masked language modeling](#masked-language-modeling-mlm)
+
+### autoregressive models
+
+See [causal language modeling](#causal-language-modeling) and [decoder models](#decoder-models)
+
+## B
+
+### backbone
+
+The backbone is the network (embeddings and layers) that outputs the raw hidden states or features. It is usually connected to a [head](#head) which accepts the features as its input to make a prediction. For example, [`ViTModel`] is a backbone without a specific head on top. Other models can also use [`VitModel`] as a backbone such as [DPT](model_doc/dpt).
+
+## C
+
+### causal language modeling
+
+A pretraining task where the model reads the texts in order and has to predict the next word. It's usually done by
+reading the whole sentence but using a mask inside the model to hide the future tokens at a certain timestep.
+
+### channel
+
+Color images are made up of some combination of values in three channels: red, green, and blue (RGB) and grayscale images only have one channel. In 🤗 Transformers, the channel can be the first or last dimension of an image's tensor: [`n_channels`, `height`, `width`] or [`height`, `width`, `n_channels`].
+
+### connectionist temporal classification (CTC)
+
+An algorithm which allows a model to learn without knowing exactly how the input and output are aligned; CTC calculates the distribution of all possible outputs for a given input and chooses the most likely output from it. CTC is commonly used in speech recognition tasks because speech doesn't always cleanly align with the transcript for a variety of reasons such as a speaker's different speech rates.
+
+### convolution
+
+A type of layer in a neural network where the input matrix is multiplied element-wise by a smaller matrix (kernel or filter) and the values are summed up in a new matrix. This is known as a convolutional operation which is repeated over the entire input matrix. Each operation is applied to a different segment of the input matrix. Convolutional neural networks (CNNs) are commonly used in computer vision.
+
+## D
+
+### DataParallel (DP)
+
+Parallelism technique for training on multiple GPUs where the same setup is replicated multiple times, with each instance
+receiving a distinct data slice. The processing is done in parallel and all setups are synchronized at the end of each training step.
+
+Learn more about how DataParallel works [here](perf_train_gpu_many#dataparallel-vs-distributeddataparallel).
+
+### decoder input IDs
+
+This input is specific to encoder-decoder models, and contains the input IDs that will be fed to the decoder. These
+inputs should be used for sequence to sequence tasks, such as translation or summarization, and are usually built in a
+way specific to each model.
+
+Most encoder-decoder models (BART, T5) create their `decoder_input_ids` on their own from the `labels`. In such models,
+passing the `labels` is the preferred way to handle training.
+
+Please check each model's docs to see how they handle these input IDs for sequence to sequence training.
+
+### decoder models
+
+Also referred to as autoregressive models, decoder models involve a pretraining task (called causal language modeling) where the model reads the texts in order and has to predict the next word. It's usually done by
+reading the whole sentence with a mask to hide future tokens at a certain timestep.
+
+
+
+### deep learning (DL)
+
+Machine learning algorithms which use neural networks with several layers.
+
+## E
+
+### encoder models
+
+Also known as autoencoding models, encoder models take an input (such as text or images) and transform them into a condensed numerical representation called an embedding. Oftentimes, encoder models are pretrained using techniques like [masked language modeling](#masked-language-modeling-mlm), which masks parts of the input sequence and forces the model to create more meaningful representations.
+
+
+
+## F
+
+### feature extraction
+
+The process of selecting and transforming raw data into a set of features that are more informative and useful for machine learning algorithms. Some examples of feature extraction include transforming raw text into word embeddings and extracting important features such as edges or shapes from image/video data.
+
+### feed forward chunking
+
+In each residual attention block in transformers the self-attention layer is usually followed by 2 feed forward layers.
+The intermediate embedding size of the feed forward layers is often bigger than the hidden size of the model (e.g., for
+`google-bert/bert-base-uncased`).
+
+For an input of size `[batch_size, sequence_length]`, the memory required to store the intermediate feed forward
+embeddings `[batch_size, sequence_length, config.intermediate_size]` can account for a large fraction of the memory
+use. The authors of [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) noticed that since the
+computation is independent of the `sequence_length` dimension, it is mathematically equivalent to compute the output
+embeddings of both feed forward layers `[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n`
+individually and concat them afterward to `[batch_size, sequence_length, config.hidden_size]` with `n = sequence_length`, which trades increased computation time against reduced memory use, but yields a mathematically
+**equivalent** result.
+
+For models employing the function [`apply_chunking_to_forward`], the `chunk_size` defines the number of output
+embeddings that are computed in parallel and thus defines the trade-off between memory and time complexity. If
+`chunk_size` is set to 0, no feed forward chunking is done.
+
+### finetuned models
+
+Finetuning is a form of transfer learning which involves taking a pretrained model, freezing its weights, and replacing the output layer with a newly added [model head](#head). The model head is trained on your target dataset.
+
+See the [Fine-tune a pretrained model](https://huggingface.co/docs/transformers/training) tutorial for more details, and learn how to fine-tune models with 🤗 Transformers.
+
+## H
+
+### head
+
+The model head refers to the last layer of a neural network that accepts the raw hidden states and projects them onto a different dimension. There is a different model head for each task. For example:
+
+ * [`GPT2ForSequenceClassification`] is a sequence classification head - a linear layer - on top of the base [`GPT2Model`].
+ * [`ViTForImageClassification`] is an image classification head - a linear layer on top of the final hidden state of the `CLS` token - on top of the base [`ViTModel`].
+ * [`Wav2Vec2ForCTC`] is a language modeling head with [CTC](#connectionist-temporal-classification-ctc) on top of the base [`Wav2Vec2Model`].
+
+## I
+
+### image patch
+
+Vision-based Transformers models split an image into smaller patches which are linearly embedded, and then passed as a sequence to the model. You can find the `patch_size` - or resolution - of the model in its configuration.
+
+### inference
+
+Inference is the process of evaluating a model on new data after training is complete. See the [Pipeline for inference](https://huggingface.co/docs/transformers/pipeline_tutorial) tutorial to learn how to perform inference with 🤗 Transformers.
+
+### input IDs
+
+The input ids are often the only required parameters to be passed to the model as input. They are token indices,
+numerical representations of tokens building the sequences that will be used as input by the model.
+
+
+
+Each tokenizer works differently but the underlying mechanism remains the same. Here's an example using the BERT
+tokenizer, which is a [WordPiece](https://arxiv.org/pdf/1609.08144.pdf) tokenizer:
+
+```python
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-cased")
+
+>>> sequence = "A Titan RTX has 24GB of VRAM"
+```
+
+The tokenizer takes care of splitting the sequence into tokens available in the tokenizer vocabulary.
+
+```python
+>>> tokenized_sequence = tokenizer.tokenize(sequence)
+```
+
+The tokens are either words or subwords. Here for instance, "VRAM" wasn't in the model vocabulary, so it's been split
+in "V", "RA" and "M". To indicate those tokens are not separate words but parts of the same word, a double-hash prefix
+is added for "RA" and "M":
+
+```python
+>>> print(tokenized_sequence)
+['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
+```
+
+These tokens can then be converted into IDs which are understandable by the model. This can be done by directly feeding the sentence to the tokenizer, which leverages the Rust implementation of [🤗 Tokenizers](https://github.com/huggingface/tokenizers) for peak performance.
+
+```python
+>>> inputs = tokenizer(sequence)
+```
+
+The tokenizer returns a dictionary with all the arguments necessary for its corresponding model to work properly. The
+token indices are under the key `input_ids`:
+
+```python
+>>> encoded_sequence = inputs["input_ids"]
+>>> print(encoded_sequence)
+[101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102]
+```
+
+Note that the tokenizer automatically adds "special tokens" (if the associated model relies on them) which are special
+IDs the model sometimes uses.
+
+If we decode the previous sequence of ids,
+
+```python
+>>> decoded_sequence = tokenizer.decode(encoded_sequence)
+```
+
+we will see
+
+```python
+>>> print(decoded_sequence)
+[CLS] A Titan RTX has 24GB of VRAM [SEP]
+```
+
+because this is the way a [`BertModel`] is going to expect its inputs.
+
+## L
+
+### labels
+
+The labels are an optional argument which can be passed in order for the model to compute the loss itself. These labels
+should be the expected prediction of the model: it will use the standard loss in order to compute the loss between its
+predictions and the expected value (the label).
+
+These labels are different according to the model head, for example:
+
+- For sequence classification models, ([`BertForSequenceClassification`]), the model expects a tensor of dimension
+ `(batch_size)` with each value of the batch corresponding to the expected label of the entire sequence.
+- For token classification models, ([`BertForTokenClassification`]), the model expects a tensor of dimension
+ `(batch_size, seq_length)` with each value corresponding to the expected label of each individual token.
+- For masked language modeling, ([`BertForMaskedLM`]), the model expects a tensor of dimension `(batch_size,
+ seq_length)` with each value corresponding to the expected label of each individual token: the labels being the token
+ ID for the masked token, and values to be ignored for the rest (usually -100).
+- For sequence to sequence tasks, ([`BartForConditionalGeneration`], [`MBartForConditionalGeneration`]), the model
+ expects a tensor of dimension `(batch_size, tgt_seq_length)` with each value corresponding to the target sequences
+ associated with each input sequence. During training, both BART and T5 will make the appropriate
+ `decoder_input_ids` and decoder attention masks internally. They usually do not need to be supplied. This does not
+ apply to models leveraging the Encoder-Decoder framework.
+- For image classification models, ([`ViTForImageClassification`]), the model expects a tensor of dimension
+ `(batch_size)` with each value of the batch corresponding to the expected label of each individual image.
+- For semantic segmentation models, ([`SegformerForSemanticSegmentation`]), the model expects a tensor of dimension
+ `(batch_size, height, width)` with each value of the batch corresponding to the expected label of each individual pixel.
+- For object detection models, ([`DetrForObjectDetection`]), the model expects a list of dictionaries with a
+ `class_labels` and `boxes` key where each value of the batch corresponds to the expected label and number of bounding boxes of each individual image.
+- For automatic speech recognition models, ([`Wav2Vec2ForCTC`]), the model expects a tensor of dimension `(batch_size,
+ target_length)` with each value corresponding to the expected label of each individual token.
+
+
+
+Each model's labels may be different, so be sure to always check the documentation of each model for more information
+about their specific labels!
+
+
+
+The base models ([`BertModel`]) do not accept labels, as these are the base transformer models, simply outputting
+features.
+
+### large language models (LLM)
+
+A generic term that refers to transformer language models (GPT-3, BLOOM, OPT) that were trained on a large quantity of data. These models also tend to have a large number of learnable parameters (e.g. 175 billion for GPT-3).
+
+## M
+
+### masked language modeling (MLM)
+
+A pretraining task where the model sees a corrupted version of the texts, usually done by
+masking some tokens randomly, and has to predict the original text.
+
+### multimodal
+
+A task that combines texts with another kind of inputs (for instance images).
+
+## N
+
+### Natural language generation (NLG)
+
+All tasks related to generating text (for instance, [Write With Transformers](https://transformer.huggingface.co/), translation).
+
+### Natural language processing (NLP)
+
+A generic way to say "deal with texts".
+
+### Natural language understanding (NLU)
+
+All tasks related to understanding what is in a text (for instance classifying the
+whole text, individual words).
+
+## P
+
+### pipeline
+
+A pipeline in 🤗 Transformers is an abstraction referring to a series of steps that are executed in a specific order to preprocess and transform data and return a prediction from a model. Some example stages found in a pipeline might be data preprocessing, feature extraction, and normalization.
+
+For more details, see [Pipelines for inference](https://huggingface.co/docs/transformers/pipeline_tutorial).
+
+### PipelineParallel (PP)
+
+Parallelism technique in which the model is split up vertically (layer-level) across multiple GPUs, so that only one or
+several layers of the model are placed on a single GPU. Each GPU processes in parallel different stages of the pipeline
+and working on a small chunk of the batch. Learn more about how PipelineParallel works [here](perf_train_gpu_many#from-naive-model-parallelism-to-pipeline-parallelism).
+
+### pixel values
+
+A tensor of the numerical representations of an image that is passed to a model. The pixel values have a shape of [`batch_size`, `num_channels`, `height`, `width`], and are generated from an image processor.
+
+### pooling
+
+An operation that reduces a matrix into a smaller matrix, either by taking the maximum or average of the pooled dimension(s). Pooling layers are commonly found between convolutional layers to downsample the feature representation.
+
+### position IDs
+
+Contrary to RNNs that have the position of each token embedded within them, transformers are unaware of the position of
+each token. Therefore, the position IDs (`position_ids`) are used by the model to identify each token's position in the
+list of tokens.
+
+They are an optional parameter. If no `position_ids` are passed to the model, the IDs are automatically created as
+absolute positional embeddings.
+
+Absolute positional embeddings are selected in the range `[0, config.max_position_embeddings - 1]`. Some models use
+other types of positional embeddings, such as sinusoidal position embeddings or relative position embeddings.
+
+### preprocessing
+
+The task of preparing raw data into a format that can be easily consumed by machine learning models. For example, text is typically preprocessed by tokenization. To gain a better idea of what preprocessing looks like for other input types, check out the [Preprocess](https://huggingface.co/docs/transformers/preprocessing) tutorial.
+
+### pretrained model
+
+A model that has been pretrained on some data (for instance all of Wikipedia). Pretraining methods involve a
+self-supervised objective, which can be reading the text and trying to predict the next word (see [causal language
+modeling](#causal-language-modeling)) or masking some words and trying to predict them (see [masked language
+modeling](#masked-language-modeling-mlm)).
+
+Speech and vision models have their own pretraining objectives. For example, Wav2Vec2 is a speech model pretrained on a contrastive task which requires the model to identify the "true" speech representation from a set of "false" speech representations. On the other hand, BEiT is a vision model pretrained on a masked image modeling task which masks some of the image patches and requires the model to predict the masked patches (similar to the masked language modeling objective).
+
+## R
+
+### recurrent neural network (RNN)
+
+A type of model that uses a loop over a layer to process texts.
+
+### representation learning
+
+A subfield of machine learning which focuses on learning meaningful representations of raw data. Some examples of representation learning techniques include word embeddings, autoencoders, and Generative Adversarial Networks (GANs).
+
+## S
+
+### sampling rate
+
+A measurement in hertz of the number of samples (the audio signal) taken per second. The sampling rate is a result of discretizing a continuous signal such as speech.
+
+### self-attention
+
+Each element of the input finds out which other elements of the input they should attend to.
+
+### self-supervised learning
+
+A category of machine learning techniques in which a model creates its own learning objective from unlabeled data. It differs from [unsupervised learning](#unsupervised-learning) and [supervised learning](#supervised-learning) in that the learning process is supervised, but not explicitly from the user.
+
+One example of self-supervised learning is [masked language modeling](#masked-language-modeling-mlm), where a model is passed sentences with a proportion of its tokens removed and learns to predict the missing tokens.
+
+### semi-supervised learning
+
+A broad category of machine learning training techniques that leverages a small amount of labeled data with a larger quantity of unlabeled data to improve the accuracy of a model, unlike [supervised learning](#supervised-learning) and [unsupervised learning](#unsupervised-learning).
+
+An example of a semi-supervised learning approach is "self-training", in which a model is trained on labeled data, and then used to make predictions on the unlabeled data. The portion of the unlabeled data that the model predicts with the most confidence gets added to the labeled dataset and used to retrain the model.
+
+### sequence-to-sequence (seq2seq)
+
+Models that generate a new sequence from an input, like translation models, or summarization models (such as
+[Bart](model_doc/bart) or [T5](model_doc/t5)).
+
+### Sharded DDP
+
+Another name for the foundational [ZeRO](#zero-redundancy-optimizer-zero) concept as used by various other implementations of ZeRO.
+
+### stride
+
+In [convolution](#convolution) or [pooling](#pooling), the stride refers to the distance the kernel is moved over a matrix. A stride of 1 means the kernel is moved one pixel over at a time, and a stride of 2 means the kernel is moved two pixels over at a time.
+
+### supervised learning
+
+A form of model training that directly uses labeled data to correct and instruct model performance. Data is fed into the model being trained, and its predictions are compared to the known labels. The model updates its weights based on how incorrect its predictions were, and the process is repeated to optimize model performance.
+
+## T
+
+### Tensor Parallelism (TP)
+
+Parallelism technique for training on multiple GPUs in which each tensor is split up into multiple chunks, so instead of
+having the whole tensor reside on a single GPU, each shard of the tensor resides on its designated GPU. Shards gets
+processed separately and in parallel on different GPUs and the results are synced at the end of the processing step.
+This is what is sometimes called horizontal parallelism, as the splitting happens on horizontal level.
+Learn more about Tensor Parallelism [here](perf_train_gpu_many#tensor-parallelism).
+
+### token
+
+A part of a sentence, usually a word, but can also be a subword (non-common words are often split in subwords) or a
+punctuation symbol.
+
+### token Type IDs
+
+Some models' purpose is to do classification on pairs of sentences or question answering.
+
+
+
+These require two different sequences to be joined in a single "input_ids" entry, which usually is performed with the
+help of special tokens, such as the classifier (`[CLS]`) and separator (`[SEP]`) tokens. For example, the BERT model
+builds its two sequence input as such:
+
+```python
+>>> # [CLS] SEQUENCE_A [SEP] SEQUENCE_B [SEP]
+```
+
+We can use our tokenizer to automatically generate such a sentence by passing the two sequences to `tokenizer` as two
+arguments (and not a list, like before) like this:
+
+```python
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-cased")
+>>> sequence_a = "HuggingFace is based in NYC"
+>>> sequence_b = "Where is HuggingFace based?"
+
+>>> encoded_dict = tokenizer(sequence_a, sequence_b)
+>>> decoded = tokenizer.decode(encoded_dict["input_ids"])
+```
+
+which will return:
+
+```python
+>>> print(decoded)
+[CLS] HuggingFace is based in NYC [SEP] Where is HuggingFace based? [SEP]
+```
+
+This is enough for some models to understand where one sequence ends and where another begins. However, other models,
+such as BERT, also deploy token type IDs (also called segment IDs). They are represented as a binary mask identifying
+the two types of sequence in the model.
+
+The tokenizer returns this mask as the "token_type_ids" entry:
+
+```python
+>>> encoded_dict["token_type_ids"]
+[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
+```
+
+The first sequence, the "context" used for the question, has all its tokens represented by a `0`, whereas the second
+sequence, corresponding to the "question", has all its tokens represented by a `1`.
+
+Some models, like [`XLNetModel`] use an additional token represented by a `2`.
+
+### transfer learning
+
+A technique that involves taking a pretrained model and adapting it to a dataset specific to your task. Instead of training a model from scratch, you can leverage knowledge obtained from an existing model as a starting point. This speeds up the learning process and reduces the amount of training data needed.
+
+### transformer
+
+Self-attention based deep learning model architecture.
+
+## U
+
+### unsupervised learning
+
+A form of model training in which data provided to the model is not labeled. Unsupervised learning techniques leverage statistical information of the data distribution to find patterns useful for the task at hand.
+
+## Z
+
+### Zero Redundancy Optimizer (ZeRO)
+
+Parallelism technique which performs sharding of the tensors somewhat similar to [TensorParallel](#tensor-parallelism-tp),
+except the whole tensor gets reconstructed in time for a forward or backward computation, therefore the model doesn't need
+to be modified. This method also supports various offloading techniques to compensate for limited GPU memory.
+Learn more about ZeRO [here](perf_train_gpu_many#zero-data-parallelism).
diff --git a/docs/transformers/docs/source/en/gpu_selection.md b/docs/transformers/docs/source/en/gpu_selection.md
new file mode 100644
index 0000000000000000000000000000000000000000..57623ed74a14f7b71ce995785e131e220e8d7d85
--- /dev/null
+++ b/docs/transformers/docs/source/en/gpu_selection.md
@@ -0,0 +1,94 @@
+
+
+# GPU selection
+
+During distributed training, you can specify the number of GPUs to use and in what order. This can be useful when you have GPUs with different computing power and you want to use the faster GPU first. Or you could only use a subset of the available GPUs. The selection process works for both [DistributedDataParallel](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html) and [DataParallel](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html). You don't need Accelerate or [DeepSpeed integration](./main_classes/deepspeed).
+
+This guide will show you how to select the number of GPUs to use and the order to use them in.
+
+## Number of GPUs
+
+For example, if there are 4 GPUs and you only want to use the first 2, run the command below.
+
+
+
+
+Use the `--nproc_per_node` to select how many GPUs to use.
+
+```bash
+torchrun --nproc_per_node=2 trainer-program.py ...
+```
+
+
+
+
+Use `--num_processes` to select how many GPUs to use.
+
+```bash
+accelerate launch --num_processes 2 trainer-program.py ...
+```
+
+
+
+
+Use `--num_gpus` to select how many GPUs to use.
+
+```bash
+deepspeed --num_gpus 2 trainer-program.py ...
+```
+
+
+
+
+### Order of GPUs
+
+To select specific GPUs to use and their order, configure the `CUDA_VISIBLE_DEVICES` environment variable. It is easiest to set the environment variable in `~/bashrc` or another startup config file. `CUDA_VISIBLE_DEVICES` is used to map which GPUs are used. For example, if there are 4 GPUs (0, 1, 2, 3) and you only want to run GPUs 0 and 2:
+
+```bash
+CUDA_VISIBLE_DEVICES=0,2 torchrun trainer-program.py ...
+```
+
+Only the 2 physical GPUs (0 and 2) are "visible" to PyTorch and these are mapped to `cuda:0` and `cuda:1` respectively. You can also reverse the order of the GPUs to use 2 first. The mapping becomes `cuda:1` for GPU 0 and `cuda:0` for GPU 2.
+
+```bash
+CUDA_VISIBLE_DEVICES=2,0 torchrun trainer-program.py ...
+```
+
+You can also set the `CUDA_VISIBLE_DEVICES` environment variable to an empty value to create an environment without GPUs.
+
+```bash
+CUDA_VISIBLE_DEVICES= python trainer-program.py ...
+```
+
+> [!WARNING]
+> As with any environment variable, they can be exported instead of being added to the command line. However, this is not recommended because it can be confusing if you forget how the environment variable was set up and you end up using the wrong GPUs. Instead, it is common practice to set the environment variable for a specific training run on the same command line.
+
+`CUDA_DEVICE_ORDER` is an alternative environment variable you can use to control how the GPUs are ordered. You can order according to the following.
+
+1. PCIe bus IDs that matches the order of [`nvidia-smi`](https://developer.nvidia.com/nvidia-system-management-interface) and [`rocm-smi`](https://rocm.docs.amd.com/projects/rocm_smi_lib/en/latest/.doxygen/docBin/html/index.html) for NVIDIA and AMD GPUs respectively.
+
+```bash
+export CUDA_DEVICE_ORDER=PCI_BUS_ID
+```
+
+2. GPU compute ability.
+
+```bash
+export CUDA_DEVICE_ORDER=FASTEST_FIRST
+```
+
+The `CUDA_DEVICE_ORDER` is especially useful if your training setup consists of an older and newer GPU, where the older GPU appears first, but you cannot physically swap the cards to make the newer GPU appear first. In this case, set `CUDA_DEVICE_ORDER=FASTEST_FIRST` to always use the newer and faster GPU first (`nvidia-smi` or `rocm-smi` still reports the GPUs in their PCIe order). Or you could also set `export CUDA_VISIBLE_DEVICES=1,0`.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/how_to_hack_models.md b/docs/transformers/docs/source/en/how_to_hack_models.md
new file mode 100644
index 0000000000000000000000000000000000000000..cc229f6b01481f9896f87d6323d5149079f1820d
--- /dev/null
+++ b/docs/transformers/docs/source/en/how_to_hack_models.md
@@ -0,0 +1,156 @@
+
+
+# Customizing model components
+
+Another way to customize a model is to modify their components, rather than writing a new model entirely, allowing you to tailor a model to your specific use case. For example, you can add new layers or optimize the attention mechanism of an architecture. Customizations are applied directly to a Transformers model so that you can continue to use features such as [`Trainer`], [`PreTrainedModel`], and the [PEFT](https://huggingface.co/docs/peft/en/index) library.
+
+This guide will show you how to customize a models attention mechanism in order to apply [Low-Rank Adaptation (LoRA)](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) to it.
+
+> [!TIP]
+> The [clear_import_cache](https://github.com/huggingface/transformers/blob/9985d06add07a4cc691dc54a7e34f54205c04d40/src/transformers/utils/import_utils.py#L2286) utility is very useful when you're iteratively modifying and developing model code. It removes all cached Transformers modules and allows Python to reload the modified code without constantly restarting your environment.
+>
+> ```py
+> from transformers import AutoModel
+> from transformers.utils.import_utils import clear_import_cache
+>
+> model = AutoModel.from_pretrained("bert-base-uncased")
+> # modifications to model code
+> # clear cache to reload modified code
+> clear_import_cache()
+> # re-import to use updated code
+> model = AutoModel.from_pretrained("bert-base-uncased")
+> ```
+
+## Attention class
+
+[Segment Anything](./model_doc/sam) is an image segmentation model, and it combines the query-key-value (`qkv`) projection in its attention mechanisms. To reduce the number of trainable parameters and computational overhead, you can apply LoRA to the `qkv` projection. This requires splitting the `qkv` projection so that you can separately target the `q` and `v` with LoRA.
+
+1. Create a custom attention class, `SamVisionAttentionSplit`, by subclassing the original `SamVisionAttention` class. In the `__init__`, delete the combined `qkv` and create a separate linear layer for `q`, `k` and `v`.
+
+```py
+import torch
+import torch.nn as nn
+from transformers.models.sam.modeling_sam import SamVisionAttention
+
+class SamVisionAttentionSplit(SamVisionAttention, nn.Module):
+ def __init__(self, config, window_size):
+ super().__init__(config, window_size)
+ # remove combined qkv
+ del self.qkv
+ # separate q, k, v projections
+ self.q = nn.Linear(config.hidden_size, config.hidden_size, bias=config.qkv_bias)
+ self.k = nn.Linear(config.hidden_size, config.hidden_size, bias=config.qkv_bias)
+ self.v = nn.Linear(config.hidden_size, config.hidden_size, bias=config.qkv_bias)
+ self._register_load_state_dict_pre_hook(self.split_q_k_v_load_hook)
+```
+
+2. The `_split_qkv_load_hook` function splits the pretrained `qkv` weights into separate `q`, `k`, and `v` weights when loading the model to ensure compatibility with any pretrained model.
+
+```py
+ def split_q_k_v_load_hook(self, state_dict, prefix, *args):
+ keys_to_delete = []
+ for key in list(state_dict.keys()):
+ if "qkv." in key:
+ # split q, k, v from the combined projection
+ q, k, v = state_dict[key].chunk(3, dim=0)
+ # replace with individual q, k, v projections
+ state_dict[key.replace("qkv.", "q.")] = q
+ state_dict[key.replace("qkv.", "k.")] = k
+ state_dict[key.replace("qkv.", "v.")] = v
+ # mark the old qkv key for deletion
+ keys_to_delete.append(key)
+
+ # remove old qkv keys
+ for key in keys_to_delete:
+ del state_dict[key]
+```
+
+3. In the `forward` pass, `q`, `k`, and `v` are computed separately while the rest of the attention mechanism remains the same.
+
+```py
+ def forward(self, hidden_states: torch.Tensor, output_attentions=False) -> torch.Tensor:
+ batch_size, height, width, _ = hidden_states.shape
+ qkv_shapes = (batch_size * self.num_attention_heads, height * width, -1)
+ query = self.q(hidden_states).reshape((batch_size, height * width,self.num_attention_heads, -1)).permute(0,2,1,3).reshape(qkv_shapes)
+ key = self.k(hidden_states).reshape((batch_size, height * width,self.num_attention_heads, -1)).permute(0,2,1,3).reshape(qkv_shapes)
+ value = self.v(hidden_states).reshape((batch_size, height * width,self.num_attention_heads, -1)).permute(0,2,1,3).reshape(qkv_shapes)
+
+ attn_weights = (query * self.scale) @ key.transpose(-2, -1)
+
+ if self.use_rel_pos:
+ attn_weights = self.add_decomposed_rel_pos(
+ attn_weights, query, self.rel_pos_h, self.rel_pos_w, (height, width), (height, width)
+ )
+
+ attn_weights = torch.nn.functional.softmax(attn_weights, dtype=torch.float32, dim=-1).to(query.dtype)
+ attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
+ attn_output = (attn_probs @ value).reshape(batch_size, self.num_attention_heads, height, width, -1)
+ attn_output = attn_output.permute(0, 2, 3, 1, 4).reshape(batch_size, height, width, -1)
+ attn_output = self.proj(attn_output)
+
+ if output_attentions:
+ outputs = (attn_output, attn_weights)
+ else:
+ outputs = (attn_output, None)
+ return outputs
+```
+
+Assign the custom `SamVisionAttentionSplit` class to the original models `SamVisionAttention` module to replace it. All instances of `SamVisionAttention` in the model is replaced with the split attention version.
+
+Load the model with [`~PreTrainedModel.from_pretrained`].
+
+```py
+from transformers import SamModel
+from transformers.models.sam import modeling_sam
+
+# replace the attention class in the modeling_sam module
+modeling_sam.SamVisionAttention = SamVisionAttentionSplit
+
+# load the pretrained SAM model
+model = SamModel.from_pretrained("facebook/sam-vit-base")
+```
+
+## LoRA
+
+With separate `q`, `k`, and `v` projections, apply LoRA to `q` and `v`.
+
+Create a [LoraConfig](https://huggingface.co/docs/peft/package_reference/config#peft.PeftConfig) and specify the rank `r`, `lora_alpha`, `lora_dropout`, `task_type`, and most importantly, the modules to target.
+
+```py
+from peft import LoraConfig, get_peft_model
+
+config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ # apply LoRA to q and v
+ target_modules=["q", "v"],
+ lora_dropout=0.1,
+ task_type="mask-generation"
+)
+```
+
+Pass the model and [LoraConfig](https://huggingface.co/docs/peft/package_reference/config#peft.PeftConfig) to [get_peft_model](https://huggingface.co/docs/peft/package_reference/peft_model#peft.get_peft_model) to apply LoRA to the model.
+
+```py
+model = get_peft_model(model, config)
+```
+
+Call [print_trainable_parameters](https://huggingface.co/docs/peft/package_reference/peft_model#peft.PeftMixedModel.print_trainable_parameters) to view the number of parameters you're training as a result versus the total number of parameters.
+
+```py
+model.print_trainable_parameters()
+"trainable params: 608,256 || all params: 94,343,728 || trainable%: 0.6447"
+```
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/hpo_train.md b/docs/transformers/docs/source/en/hpo_train.md
new file mode 100644
index 0000000000000000000000000000000000000000..303ff6fb53b471d0f8388aed608247fd99fb7696
--- /dev/null
+++ b/docs/transformers/docs/source/en/hpo_train.md
@@ -0,0 +1,167 @@
+
+
+# Hyperparameter search
+
+Hyperparameter search discovers an optimal set of hyperparameters that produces the best model performance. [`Trainer`] supports several hyperparameter search backends - [Optuna](https://optuna.readthedocs.io/en/stable/index.html), [SigOpt](https://docs.sigopt.com/), [Weights & Biases](https://docs.wandb.ai/), [Ray Tune](https://docs.ray.io/en/latest/tune/index.html) - through [`~Trainer.hyperparameter_search`] to optimize an objective or even multiple objectives.
+
+This guide will go over how to set up a hyperparameter search for each of the backends.
+
+```bash
+pip install optuna/sigopt/wandb/ray[tune]
+```
+
+To use [`~Trainer.hyperparameter_search`], you need to create a `model_init` function. This function includes basic model information (arguments and configuration) because it needs to be reinitialized for each search trial in the run.
+
+> [!WARNING]
+> The `model_init` function is incompatible with the [optimizers](./main_classes/trainer#transformers.Trainer.optimizers) parameter. Subclass [`Trainer`] and override the [`~Trainer.create_optimizer_and_scheduler`] method to create a custom optimizer and scheduler.
+
+An example `model_init` function is shown below.
+
+```py
+def model_init(trial):
+ return AutoModelForSequenceClassification.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=True if model_args.use_auth_token else None,
+ )
+```
+
+Pass `model_init` to [`Trainer`] along with everything else you need for training. Then you can call [`~Trainer.hyperparameter_search`] to start the search.
+
+[`~Trainer.hyperparameter_search`] accepts a [direction](./main_classes/trainer#transformers.Trainer.hyperparameter_search.direction) parameter to specify whether to minimize, maximize, or minimize and maximize multiple objectives. You'll also need to set the [backend](./main_classes/trainer#transformers.Trainer.hyperparameter_search.backend) you're using, an [object](./main_classes/trainer#transformers.Trainer.hyperparameter_search.hp_space) containing the hyperparameters to optimize for, the [number of trials](./main_classes/trainer#transformers.Trainer.hyperparameter_search.n_trials) to run, and a [compute_objective](./main_classes/trainer#transformers.Trainer.hyperparameter_search.compute_objective) to return the objective values.
+
+> [!TIP]
+> If [compute_objective](./main_classes/trainer#transformers.Trainer.hyperparameter_search.compute_objective) isn't defined, the default [compute_objective](./main_classes/trainer#transformers.Trainer.hyperparameter_search.compute_objective) is called which is the sum of an evaluation metric like F1.
+
+```py
+from transformers import Trainer
+
+trainer = Trainer(
+ model=None,
+ args=training_args,
+ train_dataset=small_train_dataset,
+ eval_dataset=small_eval_dataset,
+ compute_metrics=compute_metrics,
+ processing_class=tokenizer,
+ model_init=model_init,
+ data_collator=data_collator,
+)
+trainer.hyperparameter_search(...)
+```
+
+The following examples demonstrate how to perform a hyperparameter search for the learning rate and training batch size using the different backends.
+
+
+
+
+[Optuna](https://optuna.readthedocs.io/en/stable/tutorial/10_key_features/002_configurations.html#sphx-glr-tutorial-10-key-features-002-configurations-py) optimizes categories, integers, and floats.
+
+```py
+def optuna_hp_space(trial):
+ return {
+ "learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
+ "per_device_train_batch_size": trial.suggest_categorical("per_device_train_batch_size", [16, 32, 64, 128]),
+ }
+
+best_trials = trainer.hyperparameter_search(
+ direction=["minimize", "maximize"],
+ backend="optuna",
+ hp_space=optuna_hp_space,
+ n_trials=20,
+ compute_objective=compute_objective,
+)
+```
+
+
+
+
+[Ray Tune](https://docs.ray.io/en/latest/tune/api/search_space.html) optimizes floats, integers, and categorical parameters. It also offers multiple sampling distributions for each parameter such as uniform and log-uniform.
+
+```py
+def ray_hp_space(trial):
+ return {
+ "learning_rate": tune.loguniform(1e-6, 1e-4),
+ "per_device_train_batch_size": tune.choice([16, 32, 64, 128]),
+ }
+
+best_trials = trainer.hyperparameter_search(
+ direction=["minimize", "maximize"],
+ backend="ray",
+ hp_space=ray_hp_space,
+ n_trials=20,
+ compute_objective=compute_objective,
+)
+```
+
+
+
+
+[SigOpt](https://docs.sigopt.com/ai-module-api-references/api_reference/objects/object_parameter) optimizes double, integer, and categorical parameters.
+
+```py
+def sigopt_hp_space(trial):
+ return [
+ {"bounds": {"min": 1e-6, "max": 1e-4}, "name": "learning_rate", "type": "double"},
+ {
+ "categorical_values": ["16", "32", "64", "128"],
+ "name": "per_device_train_batch_size",
+ "type": "categorical",
+ },
+ ]
+
+best_trials = trainer.hyperparameter_search(
+ direction=["minimize", "maximize"],
+ backend="sigopt",
+ hp_space=sigopt_hp_space,
+ n_trials=20,
+ compute_objective=compute_objective,
+)
+```
+
+
+
+
+[Weights & Biases](https://docs.wandb.ai/guides/sweeps/sweep-config-keys) also optimizes integers, floats, and categorical parameters. It also includes support for different search strategies and distribution options.
+
+```py
+def wandb_hp_space(trial):
+ return {
+ "method": "random",
+ "metric": {"name": "objective", "goal": "minimize"},
+ "parameters": {
+ "learning_rate": {"distribution": "uniform", "min": 1e-6, "max": 1e-4},
+ "per_device_train_batch_size": {"values": [16, 32, 64, 128]},
+ },
+ }
+
+best_trials = trainer.hyperparameter_search(
+ direction=["minimize", "maximize"],
+ backend="wandb",
+ hp_space=wandb_hp_space,
+ n_trials=20,
+ compute_objective=compute_objective,
+)
+```
+
+
+
+
+## Distributed Data Parallel
+
+[`Trainer`] only supports hyperparameter search for distributed data parallel (DDP) on the Optuna and SigOpt backends. Only the rank-zero process is used to generate the search trial, and the resulting parameters are passed along to the other ranks.
diff --git a/docs/transformers/docs/source/en/image_processors.md b/docs/transformers/docs/source/en/image_processors.md
new file mode 100644
index 0000000000000000000000000000000000000000..2e5e466cd5d2f055fc9c28cd973e2292377cadc0
--- /dev/null
+++ b/docs/transformers/docs/source/en/image_processors.md
@@ -0,0 +1,222 @@
+
+
+# Image processors
+
+Image processors converts images into pixel values, tensors that represent image colors and size. The pixel values are inputs to a vision or video model. To ensure a pretrained model receives the correct input, an image processor can perform the following operations to make sure an image is exactly like the images a model was pretrained on.
+
+- [`~BaseImageProcessor.center_crop`] to resize an image
+- [`~BaseImageProcessor.normalize`] or [`~BaseImageProcessor.rescale`] pixel values
+
+Use [`~ImageProcessingMixin.from_pretrained`] to load an image processors configuration (image size, whether to normalize and rescale, etc.) from a vision model on the Hugging Face [Hub](https://hf.co) or local directory. The configuration for each pretrained model is saved in a [preprocessor_config.json](https://huggingface.co/google/vit-base-patch16-224/blob/main/preprocessor_config.json) file.
+
+```py
+from transformers import AutoImageProcessor
+
+image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
+```
+
+Pass an image to the image processor to transform it into pixel values, and set `return_tensors="pt"` to return PyTorch tensors. Feel free to print out the inputs to see what the image looks like as a tensor.
+
+```py
+from PIL import Image
+import requests
+
+url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/image_processor_example.png"
+image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+inputs = image_processor(image, return_tensors="pt")
+```
+
+This guide covers the image processor class and how to preprocess images for vision models.
+
+## Image processor classes
+
+Image processors inherit from the [`BaseImageProcessor`] class which provides the [`~BaseImageProcessor.center_crop`], [`~BaseImageProcessor.normalize`], and [`~BaseImageProcessor.rescale`] functions. There are two types of image processors.
+
+- [`BaseImageProcessor`] is a Python implementation.
+- [`BaseImageProcessorFast`] is a faster [torchvision-backed](https://pytorch.org/vision/stable/index.html) version. For a batch of [torch.Tensor](https://pytorch.org/docs/stable/tensors.html) inputs, this can be up to 33x faster. [`BaseImageProcessorFast`] is not available for all vision models at the moment. Refer to a models API documentation to check if it is supported.
+
+Each image processor subclasses the [`ImageProcessingMixin`] class which provides the [`~ImageProcessingMixin.from_pretrained`] and [`~ImageProcessingMixin.save_pretrained`] methods for loading and saving image processors.
+
+There are two ways you can load an image processor, with [`AutoImageProcessor`] or a model-specific image processor.
+
+
+
+
+The [AutoClass](./model_doc/auto) API provides a convenient method to load an image processor without directly specifying the model the image processor is associated with.
+
+Use [`~AutoImageProcessor.from_pretrained`] to load an image processor, and set `use_fast=True` to load a fast image processor if it's supported.
+
+```py
+from transformers import AutoImageProcessor
+
+image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224", use_fast=True)
+```
+
+
+
+
+Each image processor is associated with a specific pretrained vision model, and the image processors configuration contains the models expected size and whether to normalize and resize.
+
+The image processor can be loaded directly from the model-specific class. Check a models API documentation to see whether it supports a fast image processor.
+
+```py
+from transformers import ViTImageProcessor
+
+image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224")
+```
+
+To load a fast image processor, use the fast implementation class.
+
+```py
+from transformers import ViTImageProcessorFast
+
+image_processor = ViTImageProcessorFast.from_pretrained("google/vit-base-patch16-224")
+```
+
+
+
+
+## Fast image processors
+
+[`BaseImageProcessorFast`] is based on [torchvision](https://pytorch.org/vision/stable/index.html) and is significantly faster, especially when processing on a GPU. This class can be used as a drop-in replacement for [`BaseImageProcessor`] if it's available for a model because it has the same design. Make sure [torchvision](https://pytorch.org/get-started/locally/#mac-installation) is installed, and set the `use_fast` parameter to `True`.
+
+```py
+from transformers import AutoImageProcessor
+
+processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50", use_fast=True)
+```
+
+Control which device processing is performed on with the `device` parameter. Processing is performed on the same device as the input by default if the inputs are tensors, otherwise they are processed on the CPU. The example below places the fast processor on a GPU.
+
+```py
+from torchvision.io import read_image
+from transformers import DetrImageProcessorFast
+
+images = read_image("image.jpg")
+processor = DetrImageProcessorFast.from_pretrained("facebook/detr-resnet-50")
+images_processed = processor(images, return_tensors="pt", device="cuda")
+```
+
+
+Benchmarks
+
+The benchmarks are obtained from an [AWS EC2 g5.2xlarge](https://aws.amazon.com/ec2/instance-types/g5/) instance with a NVIDIA A10G Tensor Core GPU.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+## Preprocess
+
+Transformers' vision models expects the input as PyTorch tensors of pixel values. An image processor handles the conversion of images to pixel values, which is represented by the batch size, number of channels, height, and width. To achieve this, an image is resized (center cropped) and the pixel values are normalized and rescaled to the models expected values.
+
+Image preprocessing is not the same as *image augmentation*. Image augmentation makes changes (brightness, colors, rotatation, etc.) to an image for the purpose of either creating new training examples or prevent overfitting. Image preprocessing makes changes to an image for the purpose of matching a pretrained model's expected input format.
+
+Typically, images are augmented (to increase performance) and then preprocessed before being passed to a model. You can use any library ([Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb), [Kornia](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb)) for augmentation and an image processor for preprocessing.
+
+This guide uses the torchvision [transforms](https://pytorch.org/vision/stable/transforms.html) module for augmentation.
+
+Start by loading a small sample of the [food101](https://hf.co/datasets/food101) dataset.
+
+```py
+from datasets import load_dataset
+
+dataset = load_dataset("food101", split="train[:100]")
+```
+
+From the [transforms](https://pytorch.org/vision/stable/transforms.html) module, use the [Compose](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html) API to chain together [RandomResizedCrop](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html) and [ColorJitter](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html). These transforms randomly crop and resize an image, and randomly adjusts an images colors.
+
+The image size to randomly crop to can be retrieved from the image processor. For some models, an exact height and width are expected while for others, only the `shortest_edge` is required.
+
+```py
+from torchvision.transforms import RandomResizedCrop, ColorJitter, Compose
+
+size = (
+ image_processor.size["shortest_edge"]
+ if "shortest_edge" in image_processor.size
+ else (image_processor.size["height"], image_processor.size["width"])
+)
+_transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5)])
+```
+
+Apply the transforms to the images and convert them to the RGB format. Then pass the augmented images to the image processor to return the pixel values.
+
+The `do_resize` parameter is set to `False` because the images have already been resized in the augmentation step by [RandomResizedCrop](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html). If you don't augment the images, then the image processor automatically resizes and normalizes the images with the `image_mean` and `image_std` values. These values are found in the preprocessor configuration file.
+
+```py
+def transforms(examples):
+ images = [_transforms(img.convert("RGB")) for img in examples["image"]]
+ examples["pixel_values"] = image_processor(images, do_resize=False, return_tensors="pt")["pixel_values"]
+ return examples
+```
+
+Apply the combined augmentation and preprocessing function to the entire dataset on the fly with [`~datasets.Dataset.set_transform`].
+
+```py
+dataset.set_transform(transforms)
+```
+
+Convert the pixel values back into an image to see how the image has been augmented and preprocessed.
+
+```py
+import numpy as np
+import matplotlib.pyplot as plt
+
+img = dataset[0]["pixel_values"]
+plt.imshow(img.permute(1, 2, 0))
+```
+
+
+
+
+ before
+
+
+
+ after
+
+
+
+For other vision tasks like object detection or segmentation, the image processor includes post-processing methods to convert a models raw output into meaningful predictions like bounding boxes or segmentation maps.
+
+### Padding
+
+Some models, like [DETR](./model_doc/detr), applies [scale augmentation](https://paperswithcode.com/method/image-scale-augmentation) during training which can cause images in a batch to have different sizes. Images with different sizes can't be batched together.
+
+To fix this, pad the images with the special padding token `0`. Use the [pad](https://github.com/huggingface/transformers/blob/9578c2597e2d88b6f0b304b5a05864fd613ddcc1/src/transformers/models/detr/image_processing_detr.py#L1151) method to pad the images, and define a custom collate function to batch them together.
+
+```py
+def collate_fn(batch):
+ pixel_values = [item["pixel_values"] for item in batch]
+ encoding = image_processor.pad(pixel_values, return_tensors="pt")
+ labels = [item["labels"] for item in batch]
+ batch = {}
+ batch["pixel_values"] = encoding["pixel_values"]
+ batch["pixel_mask"] = encoding["pixel_mask"]
+ batch["labels"] = labels
+ return batch
+```
diff --git a/docs/transformers/docs/source/en/index.md b/docs/transformers/docs/source/en/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..5c3898ce78831f68b9eddceff3f68a7d18570cf5
--- /dev/null
+++ b/docs/transformers/docs/source/en/index.md
@@ -0,0 +1,45 @@
+
+
+# Transformers
+
+Transformers is a library of pretrained natural language processing, computer vision, audio, and multimodal models for inference and training. Use Transformers to train models on your data, build inference applications, and generate text with large language models.
+
+Explore the [Hugging Face Hub](https://huggingface.com) today to find a model and use Transformers to help you get started right away.
+
+## Features
+
+Transformers provides everything you need for inference or training with state-of-the-art pretrained models. Some of the main features include:
+
+- [Pipeline](./pipeline_tutorial): Simple and optimized inference class for many machine learning tasks like text generation, image segmentation, automatic speech recognition, document question answering, and more.
+- [Trainer](./trainer): A comprehensive trainer that supports features such as mixed precision, torch.compile, and FlashAttention for training and distributed training for PyTorch models.
+- [generate](./llm_tutorial): Fast text generation with large language models (LLMs) and vision language models (VLMs), including support for streaming and multiple decoding strategies.
+
+## Design
+
+> [!TIP]
+> Read our [Philosophy](./philosophy) to learn more about Transformers' design principles.
+
+Transformers is designed for developers and machine learning engineers and researchers. Its main design principles are:
+
+1. Fast and easy to use: Every model is implemented from only three main classes (configuration, model, and preprocessor) and can be quickly used for inference or training with [`Pipeline`] or [`Trainer`].
+2. Pretrained models: Reduce your carbon footprint, compute cost and time by using a pretrained model instead of training an entirely new one. Each pretrained model is reproduced as closely as possible to the original model and offers state-of-the-art performance.
+
+
+
diff --git a/docs/transformers/docs/source/en/installation.md b/docs/transformers/docs/source/en/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..911c84858f9ef6ce9c92f4ef9996e0e19209fdc2
--- /dev/null
+++ b/docs/transformers/docs/source/en/installation.md
@@ -0,0 +1,223 @@
+
+
+# Installation
+
+Transformers works with [PyTorch](https://pytorch.org/get-started/locally/), [TensorFlow 2.0](https://www.tensorflow.org/install/pip), and [Flax](https://flax.readthedocs.io/en/latest/). It has been tested on Python 3.9+, PyTorch 2.1+, TensorFlow 2.6+, and Flax 0.4.1+.
+
+## Virtual environment
+
+A virtual environment helps manage different projects and avoids compatibility issues between dependencies. Take a look at the [Install packages in a virtual environment using pip and venv](https://packaging.python.org/en/latest/guides/installing-using-pip-and-virtual-environments/) guide if you're unfamiliar with Python virtual environments.
+
+
+
+
+Create and activate a virtual environment in your project directory with [venv](https://docs.python.org/3/library/venv.html).
+
+```bash
+python -m venv .env
+source .env/bin/activate
+```
+
+
+
+
+[uv](https://docs.astral.sh/uv/) is a fast Rust-based Python package and project manager.
+
+```bash
+uv venv .env
+source .env/bin/activate
+```
+
+
+
+
+## Python
+
+You can install Transformers with pip or uv.
+
+
+
+
+[pip](https://pip.pypa.io/en/stable/) is a package installer for Python. Install Transformers with pip in your newly created virtual environment.
+
+```bash
+pip install transformers
+```
+
+
+
+
+[uv](https://docs.astral.sh/uv/) is a fast Rust-based Python package and project manager.
+
+```bash
+uv pip install transformers
+```
+
+
+
+
+For GPU acceleration, install the appropriate CUDA drivers for [PyTorch](https://pytorch.org/get-started/locally) and [TensorFlow](https://www.tensorflow.org/install/pip).
+
+Run the command below to check if your system detects an NVIDIA GPU.
+
+```bash
+nvidia-smi
+```
+
+To install a CPU-only version of Transformers and a machine learning framework, run the following command.
+
+
+
+
+```bash
+pip install 'transformers[torch]'
+uv pip install 'transformers[torch]'
+```
+
+
+
+
+For Apple M1 hardware, you need to install CMake and pkg-config first.
+
+```bash
+brew install cmake
+brew install pkg-config
+```
+
+Install TensorFlow 2.0.
+
+```bash
+pip install 'transformers[tf-cpu]'
+uv pip install 'transformers[tf-cpu]'
+```
+
+
+
+
+```bash
+pip install 'transformers[flax]'
+uv pip install 'transformers[flax]'
+```
+
+
+
+
+Test whether the install was successful with the following command. It should return a label and score for the provided text.
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('hugging face is the best'))"
+[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
+```
+
+### Source install
+
+Installing from source installs the *latest* version rather than the *stable* version of the library. It ensures you have the most up-to-date changes in Transformers and it's useful for experimenting with the latest features or fixing a bug that hasn't been officially released in the stable version yet.
+
+The downside is that the latest version may not always be stable. If you encounter any problems, please open a [GitHub Issue](https://github.com/huggingface/transformers/issues) so we can fix it as soon as possible.
+
+Install from source with the following command.
+
+```bash
+pip install git+https://github.com/huggingface/transformers
+```
+
+Check if the install was successful with the command below. It should return a label and score for the provided text.
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('hugging face is the best'))"
+[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
+```
+
+### Editable install
+
+An [editable install](https://pip.pypa.io/en/stable/topics/local-project-installs/#editable-installs) is useful if you're developing locally with Transformers. It links your local copy of Transformers to the Transformers [repository](https://github.com/huggingface/transformers) instead of copying the files. The files are added to Python's import path.
+
+```bash
+git clone https://github.com/huggingface/transformers.git
+cd transformers
+pip install -e .
+```
+
+> [!WARNING]
+> You must keep the local Transformers folder to keep using it.
+
+Update your local version of Transformers with the latest changes in the main repository with the following command.
+
+```bash
+cd ~/transformers/
+git pull
+```
+
+## conda
+
+[conda](https://docs.conda.io/projects/conda/en/stable/#) is a language-agnostic package manager. Install Transformers from the [conda-forge](https://anaconda.org/conda-forge/transformers) channel in your newly created virtual environment.
+
+```bash
+conda install conda-forge::transformers
+```
+
+## Set up
+
+After installation, you can configure the Transformers cache location or set up the library for offline usage.
+
+### Cache directory
+
+When you load a pretrained model with [`~PreTrainedModel.from_pretrained`], the model is downloaded from the Hub and locally cached.
+
+Every time you load a model, it checks whether the cached model is up-to-date. If it's the same, then the local model is loaded. If it's not the same, the newer model is downloaded and cached.
+
+The default directory given by the shell environment variable `TRANSFORMERS_CACHE` is `~/.cache/huggingface/hub`. On Windows, the default directory is `C:\Users\username\.cache\huggingface\hub`.
+
+Cache a model in a different directory by changing the path in the following shell environment variables (listed by priority).
+
+1. [HF_HUB_CACHE](https://hf.co/docs/huggingface_hub/package_reference/environment_variables#hfhubcache) or `TRANSFORMERS_CACHE` (default)
+2. [HF_HOME](https://hf.co/docs/huggingface_hub/package_reference/environment_variables#hfhome)
+3. [XDG_CACHE_HOME](https://hf.co/docs/huggingface_hub/package_reference/environment_variables#xdgcachehome) + `/huggingface` (only if `HF_HOME` is not set)
+
+Older versions of Transformers uses the shell environment variables `PYTORCH_TRANSFORMERS_CACHE` or `PYTORCH_PRETRAINED_BERT_CACHE`. You should keep these unless you specify the newer shell environment variable `TRANSFORMERS_CACHE`.
+
+### Offline mode
+
+To use Transformers in an offline or firewalled environment requires the downloaded and cached files ahead of time. Download a model repository from the Hub with the [`~huggingface_hub.snapshot_download`] method.
+
+> [!TIP]
+> Refer to the [Download files from the Hub](https://hf.co/docs/huggingface_hub/guides/download) guide for more options for downloading files from the Hub. You can download files from specific revisions, download from the CLI, and even filter which files to download from a repository.
+
+```py
+from huggingface_hub import snapshot_download
+
+snapshot_download(repo_id="meta-llama/Llama-2-7b-hf", repo_type="model")
+```
+
+Set the environment variable `HF_HUB_OFFLINE=1` to prevent HTTP calls to the Hub when loading a model.
+
+```bash
+HF_HUB_OFFLINE=1 \
+python examples/pytorch/language-modeling/run_clm.py --model_name_or_path meta-llama/Llama-2-7b-hf --dataset_name wikitext ...
+```
+
+Another option for only loading cached files is to set `local_files_only=True` in [`~PreTrainedModel.from_pretrained`].
+
+```py
+from transformers import LlamaForCausalLM
+
+model = LlamaForCausalLM.from_pretrained("./path/to/local/directory", local_files_only=True)
+```
diff --git a/docs/transformers/docs/source/en/internal/audio_utils.md b/docs/transformers/docs/source/en/internal/audio_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..e6a39c7c1c49a9311934a02aa46fe503d3301ec2
--- /dev/null
+++ b/docs/transformers/docs/source/en/internal/audio_utils.md
@@ -0,0 +1,39 @@
+
+
+# Utilities for `FeatureExtractors`
+
+This page lists all the utility functions that can be used by the audio [`FeatureExtractor`] in order to compute special features from a raw audio using common algorithms such as *Short Time Fourier Transform* or *log mel spectrogram*.
+
+Most of those are only useful if you are studying the code of the audio processors in the library.
+
+## Audio Transformations
+
+[[autodoc]] audio_utils.hertz_to_mel
+
+[[autodoc]] audio_utils.mel_to_hertz
+
+[[autodoc]] audio_utils.mel_filter_bank
+
+[[autodoc]] audio_utils.optimal_fft_length
+
+[[autodoc]] audio_utils.window_function
+
+[[autodoc]] audio_utils.spectrogram
+
+[[autodoc]] audio_utils.power_to_db
+
+[[autodoc]] audio_utils.amplitude_to_db
diff --git a/docs/transformers/docs/source/en/internal/file_utils.md b/docs/transformers/docs/source/en/internal/file_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..6f5657f7743cd44000801133093614bbcbfc61ae
--- /dev/null
+++ b/docs/transformers/docs/source/en/internal/file_utils.md
@@ -0,0 +1,50 @@
+
+
+# General Utilities
+
+This page lists all of Transformers general utility functions that are found in the file `utils.py`.
+
+Most of those are only useful if you are studying the general code in the library.
+
+
+## Enums and namedtuples
+
+[[autodoc]] utils.ExplicitEnum
+
+[[autodoc]] utils.PaddingStrategy
+
+[[autodoc]] utils.TensorType
+
+## Special Decorators
+
+[[autodoc]] utils.add_start_docstrings
+
+[[autodoc]] utils.add_start_docstrings_to_model_forward
+
+[[autodoc]] utils.add_end_docstrings
+
+[[autodoc]] utils.add_code_sample_docstrings
+
+[[autodoc]] utils.replace_return_docstrings
+
+## Special Properties
+
+[[autodoc]] utils.cached_property
+
+## Other Utilities
+
+[[autodoc]] utils._LazyModule
diff --git a/docs/transformers/docs/source/en/internal/generation_utils.md b/docs/transformers/docs/source/en/internal/generation_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..d8931342ee45f85fc12b84ddbb26a28569216724
--- /dev/null
+++ b/docs/transformers/docs/source/en/internal/generation_utils.md
@@ -0,0 +1,446 @@
+
+
+# Utilities for Generation
+
+This page lists all the utility functions used by [`~generation.GenerationMixin.generate`].
+
+## Generate Outputs
+
+The output of [`~generation.GenerationMixin.generate`] is an instance of a subclass of
+[`~utils.ModelOutput`]. This output is a data structure containing all the information returned
+by [`~generation.GenerationMixin.generate`], but that can also be used as tuple or dictionary.
+
+Here's an example:
+
+```python
+from transformers import GPT2Tokenizer, GPT2LMHeadModel
+
+tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
+model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
+
+inputs = tokenizer("Hello, my dog is cute and ", return_tensors="pt")
+generation_output = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
+```
+
+The `generation_output` object is a [`~generation.GenerateDecoderOnlyOutput`], as we can
+see in the documentation of that class below, it means it has the following attributes:
+
+- `sequences`: the generated sequences of tokens
+- `scores` (optional): the prediction scores of the language modelling head, for each generation step
+- `hidden_states` (optional): the hidden states of the model, for each generation step
+- `attentions` (optional): the attention weights of the model, for each generation step
+
+Here we have the `scores` since we passed along `output_scores=True`, but we don't have `hidden_states` and
+`attentions` because we didn't pass `output_hidden_states=True` or `output_attentions=True`.
+
+You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you
+will get `None`. Here for instance `generation_output.scores` are all the generated prediction scores of the
+language modeling head, and `generation_output.attentions` is `None`.
+
+When using our `generation_output` object as a tuple, it only keeps the attributes that don't have `None` values.
+Here, for instance, it has two elements, `loss` then `logits`, so
+
+```python
+generation_output[:2]
+```
+
+will return the tuple `(generation_output.sequences, generation_output.scores)` for instance.
+
+When using our `generation_output` object as a dictionary, it only keeps the attributes that don't have `None`
+values. Here, for instance, it has two keys that are `sequences` and `scores`.
+
+We document here all output types.
+
+
+### PyTorch
+
+[[autodoc]] generation.GenerateDecoderOnlyOutput
+
+[[autodoc]] generation.GenerateEncoderDecoderOutput
+
+[[autodoc]] generation.GenerateBeamDecoderOnlyOutput
+
+[[autodoc]] generation.GenerateBeamEncoderDecoderOutput
+
+### TensorFlow
+
+[[autodoc]] generation.TFGreedySearchEncoderDecoderOutput
+
+[[autodoc]] generation.TFGreedySearchDecoderOnlyOutput
+
+[[autodoc]] generation.TFSampleEncoderDecoderOutput
+
+[[autodoc]] generation.TFSampleDecoderOnlyOutput
+
+[[autodoc]] generation.TFBeamSearchEncoderDecoderOutput
+
+[[autodoc]] generation.TFBeamSearchDecoderOnlyOutput
+
+[[autodoc]] generation.TFBeamSampleEncoderDecoderOutput
+
+[[autodoc]] generation.TFBeamSampleDecoderOnlyOutput
+
+[[autodoc]] generation.TFContrastiveSearchEncoderDecoderOutput
+
+[[autodoc]] generation.TFContrastiveSearchDecoderOnlyOutput
+
+### FLAX
+
+[[autodoc]] generation.FlaxSampleOutput
+
+[[autodoc]] generation.FlaxGreedySearchOutput
+
+[[autodoc]] generation.FlaxBeamSearchOutput
+
+## LogitsProcessor
+
+A [`LogitsProcessor`] can be used to modify the prediction scores of a language model head for
+generation.
+
+### PyTorch
+
+[[autodoc]] AlternatingCodebooksLogitsProcessor
+ - __call__
+
+[[autodoc]] ClassifierFreeGuidanceLogitsProcessor
+ - __call__
+
+[[autodoc]] EncoderNoRepeatNGramLogitsProcessor
+ - __call__
+
+[[autodoc]] EncoderRepetitionPenaltyLogitsProcessor
+ - __call__
+
+[[autodoc]] EpsilonLogitsWarper
+ - __call__
+
+[[autodoc]] EtaLogitsWarper
+ - __call__
+
+[[autodoc]] ExponentialDecayLengthPenalty
+ - __call__
+
+[[autodoc]] ForcedBOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] ForcedEOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] HammingDiversityLogitsProcessor
+ - __call__
+
+[[autodoc]] InfNanRemoveLogitsProcessor
+ - __call__
+
+[[autodoc]] LogitNormalization
+ - __call__
+
+[[autodoc]] LogitsProcessor
+ - __call__
+
+[[autodoc]] LogitsProcessorList
+ - __call__
+
+[[autodoc]] MinLengthLogitsProcessor
+ - __call__
+
+[[autodoc]] MinNewTokensLengthLogitsProcessor
+ - __call__
+
+[[autodoc]] MinPLogitsWarper
+ - __call__
+
+[[autodoc]] NoBadWordsLogitsProcessor
+ - __call__
+
+[[autodoc]] NoRepeatNGramLogitsProcessor
+ - __call__
+
+[[autodoc]] PrefixConstrainedLogitsProcessor
+ - __call__
+
+[[autodoc]] RepetitionPenaltyLogitsProcessor
+ - __call__
+
+[[autodoc]] SequenceBiasLogitsProcessor
+ - __call__
+
+[[autodoc]] SuppressTokensAtBeginLogitsProcessor
+ - __call__
+
+[[autodoc]] SuppressTokensLogitsProcessor
+ - __call__
+
+[[autodoc]] SynthIDTextWatermarkLogitsProcessor
+ - __call__
+
+[[autodoc]] TemperatureLogitsWarper
+ - __call__
+
+[[autodoc]] TopKLogitsWarper
+ - __call__
+
+[[autodoc]] TopPLogitsWarper
+ - __call__
+
+[[autodoc]] TypicalLogitsWarper
+ - __call__
+
+[[autodoc]] UnbatchedClassifierFreeGuidanceLogitsProcessor
+ - __call__
+
+[[autodoc]] WhisperTimeStampLogitsProcessor
+ - __call__
+
+[[autodoc]] WatermarkLogitsProcessor
+ - __call__
+
+
+### TensorFlow
+
+[[autodoc]] TFForcedBOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] TFForcedEOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] TFForceTokensLogitsProcessor
+ - __call__
+
+[[autodoc]] TFLogitsProcessor
+ - __call__
+
+[[autodoc]] TFLogitsProcessorList
+ - __call__
+
+[[autodoc]] TFLogitsWarper
+ - __call__
+
+[[autodoc]] TFMinLengthLogitsProcessor
+ - __call__
+
+[[autodoc]] TFNoBadWordsLogitsProcessor
+ - __call__
+
+[[autodoc]] TFNoRepeatNGramLogitsProcessor
+ - __call__
+
+[[autodoc]] TFRepetitionPenaltyLogitsProcessor
+ - __call__
+
+[[autodoc]] TFSuppressTokensAtBeginLogitsProcessor
+ - __call__
+
+[[autodoc]] TFSuppressTokensLogitsProcessor
+ - __call__
+
+[[autodoc]] TFTemperatureLogitsWarper
+ - __call__
+
+[[autodoc]] TFTopKLogitsWarper
+ - __call__
+
+[[autodoc]] TFTopPLogitsWarper
+ - __call__
+
+### FLAX
+
+[[autodoc]] FlaxForcedBOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxForcedEOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxForceTokensLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxLogitsProcessorList
+ - __call__
+
+[[autodoc]] FlaxLogitsWarper
+ - __call__
+
+[[autodoc]] FlaxMinLengthLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxSuppressTokensAtBeginLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxSuppressTokensLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxTemperatureLogitsWarper
+ - __call__
+
+[[autodoc]] FlaxTopKLogitsWarper
+ - __call__
+
+[[autodoc]] FlaxTopPLogitsWarper
+ - __call__
+
+[[autodoc]] FlaxWhisperTimeStampLogitsProcessor
+ - __call__
+
+## StoppingCriteria
+
+A [`StoppingCriteria`] can be used to change when to stop generation (other than EOS token). Please note that this is exclusively available to our PyTorch implementations.
+
+[[autodoc]] StoppingCriteria
+ - __call__
+
+[[autodoc]] StoppingCriteriaList
+ - __call__
+
+[[autodoc]] MaxLengthCriteria
+ - __call__
+
+[[autodoc]] MaxTimeCriteria
+ - __call__
+
+[[autodoc]] StopStringCriteria
+ - __call__
+
+[[autodoc]] EosTokenCriteria
+ - __call__
+
+## Constraints
+
+A [`Constraint`] can be used to force the generation to include specific tokens or sequences in the output. Please note that this is exclusively available to our PyTorch implementations.
+
+[[autodoc]] Constraint
+
+[[autodoc]] PhrasalConstraint
+
+[[autodoc]] DisjunctiveConstraint
+
+[[autodoc]] ConstraintListState
+
+## BeamSearch
+
+[[autodoc]] BeamScorer
+ - process
+ - finalize
+
+[[autodoc]] BeamSearchScorer
+ - process
+ - finalize
+
+[[autodoc]] ConstrainedBeamSearchScorer
+ - process
+ - finalize
+
+## Streamers
+
+[[autodoc]] TextStreamer
+
+[[autodoc]] TextIteratorStreamer
+
+[[autodoc]] AsyncTextIteratorStreamer
+
+## Caches
+
+[[autodoc]] Cache
+ - update
+
+[[autodoc]] CacheConfig
+ - update
+
+[[autodoc]] QuantizedCacheConfig
+ - validate
+
+[[autodoc]] DynamicCache
+ - update
+ - get_seq_length
+ - reorder_cache
+ - to_legacy_cache
+ - from_legacy_cache
+
+[[autodoc]] QuantizedCache
+ - update
+ - get_seq_length
+
+[[autodoc]] QuantoQuantizedCache
+
+[[autodoc]] HQQQuantizedCache
+
+[[autodoc]] SinkCache
+ - update
+ - get_seq_length
+ - reorder_cache
+
+[[autodoc]] OffloadedCache
+ - update
+ - prefetch_layer
+ - evict_previous_layer
+
+[[autodoc]] StaticCache
+ - update
+ - get_seq_length
+ - reset
+
+[[autodoc]] OffloadedStaticCache
+ - update
+ - get_seq_length
+ - reset
+
+[[autodoc]] HybridCache
+ - update
+ - get_seq_length
+ - reset
+
+[[autodoc]] SlidingWindowCache
+ - update
+ - reset
+
+[[autodoc]] EncoderDecoderCache
+ - get_seq_length
+ - to_legacy_cache
+ - from_legacy_cache
+ - reset
+ - reorder_cache
+
+[[autodoc]] MambaCache
+ - update_conv_state
+ - update_ssm_state
+ - reset
+
+## Watermark Utils
+
+[[autodoc]] WatermarkingConfig
+ - __call__
+
+[[autodoc]] WatermarkDetector
+ - __call__
+
+[[autodoc]] BayesianDetectorConfig
+
+[[autodoc]] BayesianDetectorModel
+ - forward
+
+[[autodoc]] SynthIDTextWatermarkingConfig
+
+[[autodoc]] SynthIDTextWatermarkDetector
+ - __call__
+
+## Compile Utils
+
+[[autodoc]] CompileConfig
+ - __call__
+
diff --git a/docs/transformers/docs/source/en/internal/image_processing_utils.md b/docs/transformers/docs/source/en/internal/image_processing_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..42f99f361703c153865f13914c4adc8a8af4f7aa
--- /dev/null
+++ b/docs/transformers/docs/source/en/internal/image_processing_utils.md
@@ -0,0 +1,48 @@
+
+
+# Utilities for Image Processors
+
+This page lists all the utility functions used by the image processors, mainly the functional
+transformations used to process the images.
+
+Most of those are only useful if you are studying the code of the image processors in the library.
+
+## Image Transformations
+
+[[autodoc]] image_transforms.center_crop
+
+[[autodoc]] image_transforms.center_to_corners_format
+
+[[autodoc]] image_transforms.corners_to_center_format
+
+[[autodoc]] image_transforms.id_to_rgb
+
+[[autodoc]] image_transforms.normalize
+
+[[autodoc]] image_transforms.pad
+
+[[autodoc]] image_transforms.rgb_to_id
+
+[[autodoc]] image_transforms.rescale
+
+[[autodoc]] image_transforms.resize
+
+[[autodoc]] image_transforms.to_pil_image
+
+## ImageProcessingMixin
+
+[[autodoc]] image_processing_utils.ImageProcessingMixin
diff --git a/docs/transformers/docs/source/en/internal/import_utils.md b/docs/transformers/docs/source/en/internal/import_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..93daa2ced3a6fbfc348552a294f7515be3855df3
--- /dev/null
+++ b/docs/transformers/docs/source/en/internal/import_utils.md
@@ -0,0 +1,91 @@
+
+
+# Import Utilities
+
+This page goes through the transformers utilities to enable lazy and fast object import.
+While we strive for minimal dependencies, some models have specific dependencies requirements that cannot be
+worked around. We don't want for all users of `transformers` to have to install those dependencies to use other models,
+we therefore mark those as soft dependencies rather than hard dependencies.
+
+The transformers toolkit is not made to error-out on import of a model that has a specific dependency; instead, an
+object for which you are lacking a dependency will error-out when calling any method on it. As an example, if
+`torchvision` isn't installed, the fast image processors will not be available.
+
+This object is still importable:
+
+```python
+>>> from transformers import DetrImageProcessorFast
+>>> print(DetrImageProcessorFast)
+
+```
+
+However, no method can be called on that object:
+
+```python
+>>> DetrImageProcessorFast.from_pretrained()
+ImportError:
+DetrImageProcessorFast requires the Torchvision library but it was not found in your environment. Checkout the instructions on the
+installation page: https://pytorch.org/get-started/locally/ and follow the ones that match your environment.
+Please note that you may need to restart your runtime after installation.
+```
+
+Let's see how to specify specific object dependencies.
+
+## Specifying Object Dependencies
+
+### Filename-based
+
+All objects under a given filename have an automatic dependency to the tool linked to the filename
+
+**TensorFlow**: All files starting with `modeling_tf_` have an automatic TensorFlow dependency.
+
+**Flax**: All files starting with `modeling_flax_` have an automatic Flax dependency
+
+**PyTorch**: All files starting with `modeling_` and not valid with the above (TensorFlow and Flax) have an automatic
+PyTorch dependency
+
+**Tokenizers**: All files starting with `tokenization_` and ending with `_fast` have an automatic `tokenizers` dependency
+
+**Vision**: All files starting with `image_processing_` have an automatic dependency to the `vision` dependency group;
+at the time of writing, this only contains the `pillow` dependency.
+
+**Vision + Torch + Torchvision**: All files starting with `image_processing_` and ending with `_fast` have an automatic
+dependency to `vision`, `torch`, and `torchvision`.
+
+All of these automatic dependencies are added on top of the explicit dependencies that are detailed below.
+
+### Explicit Object Dependencies
+
+We add a method called `requires` that is used to explicitly specify the dependencies of a given object. As an
+example, the `Trainer` class has two hard dependencies: `torch` and `accelerate`. Here is how we specify these
+required dependencies:
+
+```python
+from .utils.import_utils import requires
+
+@requires(backends=("torch", "accelerate"))
+class Trainer:
+ ...
+```
+
+Backends that can be added here are all the backends that are available in the `import_utils.py` module.
+
+## Methods
+
+[[autodoc]] utils.import_utils.define_import_structure
+
+[[autodoc]] utils.import_utils.requires
diff --git a/docs/transformers/docs/source/en/internal/model_debugging_utils.md b/docs/transformers/docs/source/en/internal/model_debugging_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..6d30668c634badf713760a95947635f7ae8a1366
--- /dev/null
+++ b/docs/transformers/docs/source/en/internal/model_debugging_utils.md
@@ -0,0 +1,213 @@
+
+
+# Model debugging toolboxes
+
+This page lists all the debugging and model adding tools used by the library, as well as the utility functions it provides for it.
+
+Most of those are only useful if you are adding new models in the library.
+
+
+## Model addition debuggers
+
+
+### Model addition debugger - context manager for model adders
+
+This context manager is a power user tool intended for model adders.
+It tracks all forward calls within a model forward and logs a slice of each input and output on a nested Json.
+To note, this context manager enforces `torch.no_grad()`.
+
+### Rationale
+
+Because when porting models to transformers, even from python to python, model adders often have to do a lot of manual operations, involving saving and loading tensors, comparing dtypes, etc. This small tool can hopefully shave off some time.
+
+### Usage
+
+Add this context manager as follows to debug a model:
+
+```python
+import torch
+from PIL import Image
+import requests
+from transformers import LlavaProcessor, LlavaForConditionalGeneration
+from transformers.model_debugging_utils import model_addition_debugger_context
+torch.random.manual_seed(673)
+
+# load pretrained model and processor
+model_id = "llava-hf/llava-1.5-7b-hf"
+processor = LlavaProcessor.from_pretrained(model_id)
+model = LlavaForConditionalGeneration.from_pretrained(model_id, low_cpu_mem_usage=True)
+
+# create random image input
+random_image = Image.fromarray(torch.randint(0, 256, (224, 224, 3), dtype=torch.uint8).numpy())
+
+# prompt
+prompt = "Describe this image."
+
+# process inputs
+inputs = processor(text=prompt, images=random_image, return_tensors="pt")
+
+# call forward method (not .generate!)
+with model_addition_debugger_context(
+ model,
+ debug_path="optional_path_to_your_directory",
+ do_prune_layers=False # This will output ALL the layers of a model.
+ ):
+ output = model.forward(**inputs)
+
+```
+
+
+### Reading results
+
+The debugger generates two files from the forward call, both with the same base name,
+but ending either with `_SUMMARY.json` or with `_FULL_TENSORS.json`.
+
+The first one will contain a summary of each module's _input_ and _output_ tensor values and shapes.
+
+```json
+{
+ "module_path": "MolmoForConditionalGeneration",
+ "inputs": {
+ "args": [],
+ "kwargs": {
+ "input_ids": {
+ "shape": "torch.Size([1, 589])",
+ "dtype": "torch.int64"
+ },
+ "attention_mask": {
+ "shape": "torch.Size([1, 589])",
+ "dtype": "torch.int64"
+ },
+ "pixel_values": {
+ "shape": "torch.Size([1, 5, 576, 588])",
+ "dtype": "torch.float32",
+ "mean": "tensor(-8.9514e-01, device='cuda:0')",
+ "std": "tensor(9.2586e-01, device='cuda:0')",
+ "min": "tensor(-1.7923e+00, device='cuda:0')",
+ "max": "tensor(1.8899e+00, device='cuda:0')"
+ }
+ },
+ "children": [
+ {
+ "module_path": "MolmoForConditionalGeneration.language_model.model.embed_tokens",
+ "inputs": {
+ "args": [
+ {
+ "shape": "torch.Size([1, 589])",
+ "dtype": "torch.int64"
+ }
+ ]
+ },
+ "outputs": {
+ "shape": "torch.Size([1, 589, 3584])",
+ "dtype": "torch.float32",
+ "mean": "tensor(6.5460e-06, device='cuda:0')",
+ "std": "tensor(2.3807e-02, device='cuda:0')",
+ "min": "tensor(-3.3398e-01, device='cuda:0')",
+ "max": "tensor(3.9453e-01, device='cuda:0')"
+ }
+ },
+ {
+ "module_path": "MolmoForConditionalGeneration.vision_tower",
+ "inputs": {
+ "args": [
+ {
+ "shape": "torch.Size([5, 1, 576, 588])",
+ "dtype": "torch.float32",
+ "mean": "tensor(-8.9514e-01, device='cuda:0')",
+ "std": "tensor(9.2586e-01, device='cuda:0')",
+ "min": "tensor(-1.7923e+00, device='cuda:0')",
+ "max": "tensor(1.8899e+00, device='cuda:0')"
+ }
+ ],
+ "kwargs": {
+ "output_hidden_states": "True"
+ }
+ },
+ "children": [
+ { ... and so on
+```
+
+The `_FULL_TENSORS.json` file will display a full view of all tensors, which is useful
+for comparing two files.
+```json
+ "pixel_values": {
+ "shape": "torch.Size([1, 5, 576, 588])",
+ "dtype": "torch.float32",
+ "value": [
+ "tensor([[[[-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " ...,",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00]],",
+ "",
+ " [[-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " ...,",
+ " [-1.4857e+00, -1.4820e+00, -1.2100e+00, ..., -6.0979e-01, -5.9650e-01, -3.8527e-01],",
+ " [-1.6755e+00, -1.7221e+00, -1.4518e+00, ..., -7.5577e-01, -7.4658e-01, -5.5592e-01],",
+ " [-7.9957e-01, -8.2162e-01, -5.7014e-01, ..., -1.3689e+00, -1.3169e+00, -1.0678e+00]],",
+ "",
+ " [[-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " ...,",
+ " [-3.0322e-01, -5.0645e-01, -5.8436e-01, ..., -6.2439e-01, -7.9160e-01, -8.1188e-01],",
+ " [-4.4921e-01, -6.5653e-01, -7.2656e-01, ..., -3.4702e-01, -5.2146e-01, -5.1326e-01],",
+ " [-3.4702e-01, -5.3647e-01, -5.4170e-01, ..., -1.0915e+00, -1.1968e+00, -1.0252e+00]],",
+ "",
+ " [[-1.1207e+00, -1.2718e+00, -1.0678e+00, ..., 1.2013e-01, -1.3126e-01, -1.7197e-01],",
+ " [-6.9738e-01, -9.1166e-01, -8.5454e-01, ..., -5.5050e-02, -2.8134e-01, -4.2793e-01],",
+ " [-3.4702e-01, -5.5148e-01, -5.8436e-01, ..., 1.9312e-01, -8.6235e-02, -2.1463e-01],",
+ " ...,",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00]],",
+ "",
+ " [[-1.0039e+00, -9.5669e-01, -6.5546e-01, ..., -1.4711e+00, -1.4219e+00, -1.1389e+00],",
+ " [-1.0039e+00, -9.5669e-01, -6.5546e-01, ..., -1.7193e+00, -1.6771e+00, -1.4091e+00],",
+ " [-1.6317e+00, -1.6020e+00, -1.2669e+00, ..., -1.2667e+00, -1.2268e+00, -8.9720e-01],",
+ " ...,",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00],",
+ " [-1.7923e+00, -1.7521e+00, -1.4802e+00, ..., -1.7923e+00, -1.7521e+00, -1.4802e+00]]]], device='cuda:0')"
+ ],
+ "mean": "tensor(-8.9514e-01, device='cuda:0')",
+ "std": "tensor(9.2586e-01, device='cuda:0')",
+ "min": "tensor(-1.7923e+00, device='cuda:0')",
+ "max": "tensor(1.8899e+00, device='cuda:0')"
+ },
+```
+
+### Comparing between implementations
+
+Once the forward passes of two models have been traced by the debugger, one can compare the `json` output files. See below: we can see slight differences between these two implementations' key projection layer. Inputs are mostly identical, but not quite. Looking through the file differences makes it easier to pinpoint which layer is wrong.
+
+
+
+
+
+### Limitations and scope
+
+This feature will only work for torch-based models, and would require more work and case-by-case approach for say `jax`-based models that are usually compiled. Models relying heavily on external kernel calls may work, but trace will probably miss some things. Regardless, any python implementation that aims at mimicking another implementation can be traced once instead of reran N times with breakpoints.
+
+If you pass `do_prune_layers=False` to your model debugger, ALL the layers will be outputted to `json`. Else, only the first and last layer will be shown. This is useful when some layers (typically cross-attention) appear only after N layers.
+
+[[autodoc]] model_addition_debugger_context
diff --git a/docs/transformers/docs/source/en/internal/modeling_utils.md b/docs/transformers/docs/source/en/internal/modeling_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..1c7d16ad06102fe9f89c930a0f3abd90038f9468
--- /dev/null
+++ b/docs/transformers/docs/source/en/internal/modeling_utils.md
@@ -0,0 +1,78 @@
+
+
+# Custom Layers and Utilities
+
+This page lists all the custom layers used by the library, as well as the utility functions and classes it provides for modeling.
+
+Most of those are only useful if you are studying the code of the models in the library.
+
+## Layers
+
+[[autodoc]] GradientCheckpointingLayer
+
+## Attention Functions
+
+[[autodoc]] AttentionInterface
+ - register
+
+## Rotary Position Embedding Functions
+
+[[autodoc]] dynamic_rope_update
+
+## Pytorch custom modules
+
+[[autodoc]] pytorch_utils.Conv1D
+
+## PyTorch Helper Functions
+
+[[autodoc]] pytorch_utils.apply_chunking_to_forward
+
+[[autodoc]] pytorch_utils.find_pruneable_heads_and_indices
+
+[[autodoc]] pytorch_utils.prune_layer
+
+[[autodoc]] pytorch_utils.prune_conv1d_layer
+
+[[autodoc]] pytorch_utils.prune_linear_layer
+
+## TensorFlow custom layers
+
+[[autodoc]] modeling_tf_utils.TFConv1D
+
+[[autodoc]] modeling_tf_utils.TFSequenceSummary
+
+## TensorFlow loss functions
+
+[[autodoc]] modeling_tf_utils.TFCausalLanguageModelingLoss
+
+[[autodoc]] modeling_tf_utils.TFMaskedLanguageModelingLoss
+
+[[autodoc]] modeling_tf_utils.TFMultipleChoiceLoss
+
+[[autodoc]] modeling_tf_utils.TFQuestionAnsweringLoss
+
+[[autodoc]] modeling_tf_utils.TFSequenceClassificationLoss
+
+[[autodoc]] modeling_tf_utils.TFTokenClassificationLoss
+
+## TensorFlow Helper Functions
+
+[[autodoc]] modeling_tf_utils.get_initializer
+
+[[autodoc]] modeling_tf_utils.keras_serializable
+
+[[autodoc]] modeling_tf_utils.shape_list
diff --git a/docs/transformers/docs/source/en/internal/pipelines_utils.md b/docs/transformers/docs/source/en/internal/pipelines_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..6ea6de9a61b8ab5db6fe79ccafa1ed4855d78e9c
--- /dev/null
+++ b/docs/transformers/docs/source/en/internal/pipelines_utils.md
@@ -0,0 +1,44 @@
+
+
+# Utilities for pipelines
+
+This page lists all the utility functions the library provides for pipelines.
+
+Most of those are only useful if you are studying the code of the models in the library.
+
+
+## Argument handling
+
+[[autodoc]] pipelines.ArgumentHandler
+
+[[autodoc]] pipelines.ZeroShotClassificationArgumentHandler
+
+[[autodoc]] pipelines.QuestionAnsweringArgumentHandler
+
+## Data format
+
+[[autodoc]] pipelines.PipelineDataFormat
+
+[[autodoc]] pipelines.CsvPipelineDataFormat
+
+[[autodoc]] pipelines.JsonPipelineDataFormat
+
+[[autodoc]] pipelines.PipedPipelineDataFormat
+
+## Utilities
+
+[[autodoc]] pipelines.PipelineException
diff --git a/docs/transformers/docs/source/en/internal/time_series_utils.md b/docs/transformers/docs/source/en/internal/time_series_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..11c562fbe32af5a123f122b44cf0e27db8ab61c9
--- /dev/null
+++ b/docs/transformers/docs/source/en/internal/time_series_utils.md
@@ -0,0 +1,29 @@
+
+
+# Time Series Utilities
+
+This page lists all the utility functions and classes that can be used for Time Series based models.
+
+Most of those are only useful if you are studying the code of the time series models or you wish to add to the collection of distributional output classes.
+
+## Distributional Output
+
+[[autodoc]] time_series_utils.NormalOutput
+
+[[autodoc]] time_series_utils.StudentTOutput
+
+[[autodoc]] time_series_utils.NegativeBinomialOutput
diff --git a/docs/transformers/docs/source/en/internal/tokenization_utils.md b/docs/transformers/docs/source/en/internal/tokenization_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..5aa65099176031bc55e24fa286783d876e2b13ce
--- /dev/null
+++ b/docs/transformers/docs/source/en/internal/tokenization_utils.md
@@ -0,0 +1,42 @@
+
+
+# Utilities for Tokenizers
+
+This page lists all the utility functions used by the tokenizers, mainly the class
+[`~tokenization_utils_base.PreTrainedTokenizerBase`] that implements the common methods between
+[`PreTrainedTokenizer`] and [`PreTrainedTokenizerFast`] and the mixin
+[`~tokenization_utils_base.SpecialTokensMixin`].
+
+Most of those are only useful if you are studying the code of the tokenizers in the library.
+
+## PreTrainedTokenizerBase
+
+[[autodoc]] tokenization_utils_base.PreTrainedTokenizerBase
+ - __call__
+ - all
+
+## SpecialTokensMixin
+
+[[autodoc]] tokenization_utils_base.SpecialTokensMixin
+
+## Enums and namedtuples
+
+[[autodoc]] tokenization_utils_base.TruncationStrategy
+
+[[autodoc]] tokenization_utils_base.CharSpan
+
+[[autodoc]] tokenization_utils_base.TokenSpan
diff --git a/docs/transformers/docs/source/en/internal/trainer_utils.md b/docs/transformers/docs/source/en/internal/trainer_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..1bc5e2baae2d6fd329dca311aebe8eb6a8011427
--- /dev/null
+++ b/docs/transformers/docs/source/en/internal/trainer_utils.md
@@ -0,0 +1,49 @@
+
+
+# Utilities for Trainer
+
+This page lists all the utility functions used by [`Trainer`].
+
+Most of those are only useful if you are studying the code of the Trainer in the library.
+
+## Utilities
+
+[[autodoc]] EvalPrediction
+
+[[autodoc]] IntervalStrategy
+
+[[autodoc]] enable_full_determinism
+
+[[autodoc]] set_seed
+
+[[autodoc]] torch_distributed_zero_first
+
+## Callbacks internals
+
+[[autodoc]] trainer_callback.CallbackHandler
+
+## Distributed Evaluation
+
+[[autodoc]] trainer_pt_utils.DistributedTensorGatherer
+
+## Trainer Argument Parser
+
+[[autodoc]] HfArgumentParser
+
+## Debug Utilities
+
+[[autodoc]] debug_utils.DebugUnderflowOverflow
diff --git a/docs/transformers/docs/source/en/kv_cache.md b/docs/transformers/docs/source/en/kv_cache.md
new file mode 100644
index 0000000000000000000000000000000000000000..36a3d69d64cf717c4756d66258f2580c22208be7
--- /dev/null
+++ b/docs/transformers/docs/source/en/kv_cache.md
@@ -0,0 +1,359 @@
+
+
+# KV cache strategies
+
+The key-value (KV) vectors are used to calculate attention scores. For autoregressive models, KV scores are calculated *every* time because the model predicts one token at a time. Each prediction depends on the previous tokens, which means the model performs the same computations each time.
+
+A KV *cache* stores these calculations so they can be reused without recomputing them. Efficient caching is crucial for optimizing model performance because it reduces computation time and improves response rates. Refer to the [Caching](./cache_explanation) doc for a more detailed explanation about how a cache works.
+
+Transformers offers several [`Cache`] classes that implement different caching mechanisms. Some of these [`Cache`] classes are optimized to save memory while others are designed to maximize generation speed. Refer to the table below to compare cache types and use it to help you select the best cache for your use case.
+
+| Cache Type | Memory Efficient | Supports torch.compile() | Initialization Recommended | Latency | Long Context Generation |
+|------------------------|------------------|--------------------------|----------------------------|---------|-------------------------|
+| Dynamic Cache | No | No | No | Mid | No |
+| Static Cache | No | Yes | Yes | High | No |
+| Offloaded Cache | Yes | No | No | Low | Yes |
+| Offloaded Static Cache | No | Yes | Yes | High | Yes |
+| Quantized Cache | Yes | No | No | Low | Yes |
+| Sliding Window Cache | No | Yes | Yes | High | No |
+| Sink Cache | Yes | No | Yes | Mid | Yes |
+
+This guide introduces you to the different [`Cache`] classes and shows you how to use them for generation.
+
+## Default cache
+
+The [`DynamicCache`] is the default cache class for most models. It allows the cache size to grow dynamically in order to store an increasing number of keys and values as generation progresses.
+
+Disable the cache by configuring `use_cache=False` in [`~GenerationMixin.generate`].
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16).to("cuda:0")
+inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device)
+
+model.generate(**inputs, do_sample=False, max_new_tokens=20, use_cache=False)
+```
+
+Cache classes can also be initialized first before calling and passing it to the models [past_key_values](https://hf.co/docs/transformers/internal/generation_utils#transformers.generation.GenerateDecoderOnlyOutput.past_key_values) parameter. This cache initialization strategy is only recommended for some cache types.
+
+In most other cases, it's easier to define the cache strategy in the [cache_implementation](https://hf.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig.cache_implementation) parameter.
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM, DynamicCache
+
+tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16).to("cuda:0")
+inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device)
+
+past_key_values = DynamicCache()
+out = model.generate(**inputs, do_sample=False, max_new_tokens=20, past_key_values=past_key_values)
+```
+
+## Memory efficient caches
+
+The KV cache can occupy a significant portion of memory and become a [bottleneck](https://hf.co/blog/llama31#inference-memory-requirements) for long-context generation. Memory efficient caches focus on trading off speed for reduced memory usage. This is especially important for large language models (LLMs) and if your hardware is memory constrained.
+
+### Offloaded cache
+
+The [`OffloadedCache`] saves GPU memory by moving the KV cache for most model layers to the CPU. Only the current layer cache is maintained on the GPU during a models `forward` iteration over the layers. [`OffloadedCache`] asynchronously prefetches the next layer cache and sends the previous layer cache back to the CPU.
+
+This cache strategy always generates the same result as [`DynamicCache`] and works as a drop-in replacement or fallback. You may want to use [`OffloadedCache`] if you have a GPU and you're getting out-of-memory (OOM) errors.
+
+> [!WARNING]
+> You may notice a small degradation in generation throughput compared to [`DynamicCache`] depending on your model and generation choices (context size, number of generated tokens, number of beams, etc.).
+
+Enable [`OffloadedCache`] by configuring `cache_implementation="offloaded"` in either [`GenerationConfig`] or [`~GenerationMixin.generate`].
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+ckpt = "microsoft/Phi-3-mini-4k-instruct"
+tokenizer = AutoTokenizer.from_pretrained(ckpt)
+model = AutoModelForCausalLM.from_pretrained(ckpt, torch_dtype=torch.float16).to("cuda:0")
+inputs = tokenizer("Fun fact: The shortest", return_tensors="pt").to(model.device)
+
+out = model.generate(**inputs, do_sample=False, max_new_tokens=23, cache_implementation="offloaded")
+print(tokenizer.batch_decode(out, skip_special_tokens=True)[0])
+Fun fact: The shortest war in history was between Britain and Zanzibar on August 27, 1896.
+```
+
+The example below shows how you can fallback on [`OffloadedCache`] if you run out of memory.
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+def resilient_generate(model, *args, **kwargs):
+ oom = False
+ try:
+ return model.generate(*args, **kwargs)
+ except torch.cuda.OutOfMemoryError as e:
+ print(e)
+ print("retrying with cache_implementation='offloaded'")
+ oom = True
+ if oom:
+ torch.cuda.empty_cache()
+ kwargs["cache_implementation"] = "offloaded"
+ return model.generate(*args, **kwargs)
+
+ckpt = "microsoft/Phi-3-mini-4k-instruct"
+tokenizer = AutoTokenizer.from_pretrained(ckpt)
+model = AutoModelForCausalLM.from_pretrained(ckpt, torch_dtype=torch.float16).to("cuda:0")
+prompt = ["okay "*1000 + "Fun fact: The most"]
+inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
+beams = { "num_beams": 40, "num_beam_groups": 40, "num_return_sequences": 40, "diversity_penalty": 1.0, "max_new_tokens": 23, "early_stopping": True, }
+out = resilient_generate(model, **inputs, **beams)
+responses = tokenizer.batch_decode(out[:,-28:], skip_special_tokens=True)
+```
+
+### Quantized cache
+
+The [`QuantizedCache`] reduces memory requirements by quantizing the KV values to a lower precision. [`QuantizedCache`] currently supports two quantization backends.
+
+- [`HQQQuantizedCache`] supports int2, int4, and int8 datatypes.
+- [`QuantoQuantizedCache`] supports int2 and int4 datatypes. This is the default quantization backend.
+
+> [!WARNING]
+> Quantizing the cache can harm latency if the context length is short and there is enough GPU memory available for generation without enabling cache quantization. Try to find a balance between memory efficiency and latency.
+
+Enable [`QuantizedCache`] by configuring `cache_implementation="quantized"` in [`GenerationConfig`], and indicate the quantization backend in [`QuantizedCacheConfig`]. Any additional quantization related parameters should also be passed either as a dict or an instance of [`QuantizedCacheConfig`]. You should use the default values for these additional parameters unless you're running out-of-memory. In that case, consider decreasing the residual length.
+
+
+
+
+For [`HQQQuantizedCache`], we recommend setting the `axis-key` and `axis-value` parameters to `1`.
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM, HQQQuantizedCache, QuantizedCacheConfig
+
+tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16).to("cuda:0")
+inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device)
+
+out = model.generate(**inputs, do_sample=False, max_new_tokens=20, cache_implementation="quantized", cache_config={"axis-key": 1, "axis-value": 1, "backend": "hqq"})
+print(tokenizer.batch_decode(out, skip_special_tokens=True)[0])
+I like rock music because it's loud and energetic. It's a great way to express myself and rel
+```
+
+
+
+
+For [`QuantoQuantizedCache`], we recommend setting the `axis-key` and `axis-value` parameters to `0`.
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM, QuantoQuantizedCache, QuantizedCacheConfig
+
+tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16).to("cuda:0")
+inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device)
+
+out = model.generate(**inputs, do_sample=False, max_new_tokens=20, cache_implementation="quantized", cache_config={"nbits": 4, "axis-key": 0, "axis-value": 0, "backend": "quanto"})
+print(tokenizer.batch_decode(out, skip_special_tokens=True)[0])
+I like rock music because it's loud and energetic. It's a great way to express myself and rel
+```
+
+
+
+
+### Sink cache
+
+[`SinkCache`] is capable of generating very long sequences ("infinite length" according to the paper) by only retaining a few initial tokens from the sequence. These are called the *sink tokens* because they account for a significant portion of the attention scores during generation. Subsequent tokens are discarded on a sliding windowed basis, and only the latest `window_size` tokens are kept. This means most of the previous knowledge is discarded.
+
+The sink tokens allow a model to maintain stable performance even when it's dealing with very long text sequences.
+
+Enable [`SinkCache`] by initializing it first with the [window_length](https://hf.co/docs/transformers/main/en/internal/generation_utils#transformers.SinkCache.window_length) and [num_sink_tokens](https://hf.co/docs/transformers/main/en/internal/generation_utils#transformers.SinkCache.num_sink_tokens) parameters before passing it to [past_key_values](https://hf.co/docs/transformers/internal/generation_utils#transformers.generation.GenerateDecoderOnlyOutput.past_key_values) in [`~GenerationMixin.generate`].
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM, SinkCache
+
+tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16).to("cuda:0")
+inputs = tokenizer("This is a long story about unicorns, fairies and magic.", return_tensors="pt").to(model.device)
+
+past_key_values = SinkCache(window_length=256, num_sink_tokens=4)
+out = model.generate(**inputs, do_sample=False, max_new_tokens=30, past_key_values=past_key_values)
+tokenizer.batch_decode(out, skip_special_tokens=True)[0]
+"This is a long story about unicorns, fairies and magic. It is a fantasy world where unicorns and fairies live together in harmony. The story follows a young girl named Lily"
+```
+
+## Speed optimized caches
+
+The default [`DynamicCache`] prevents you from taking advantage of just-in-time (JIT) optimizations because the cache size isn't fixed. JIT optimizations enable you to maximize latency at the expense of memory usage. All of the following cache types are compatible with JIT optimizations like [torch.compile](./llm_optims#static-kv-cache-and-torchcompile) to accelerate generation.
+
+### Static cache
+
+A [`StaticCache`] pre-allocates a specific maximum cache size for the kv pairs. You can generate up to the maximum cache size without needing to modify it.
+
+Enable [`StaticCache`] by configuring `cache_implementation="static"` in [`~GenerationMixin.generate`].
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16, device_map="auto")
+inputs = tokenizer("Hello, my name is", return_tensors="pt").to(model.device)
+
+out = model.generate(**inputs, do_sample=False, max_new_tokens=20, cache_implementation="static")
+tokenizer.batch_decode(out, skip_special_tokens=True)[0]
+"Hello, my name is [Your Name], and I am a [Your Profession] with [Number of Years] of"
+```
+
+### Offloaded static cache
+
+The [`OffloadedStaticCache`] is very similar to the [OffloadedCache](#offloaded-cache) except the cache size is set to a maximum cache size. Otherwise, [`OffloadedStaticCache`] only keeps the current layer cache on the GPU and the rest are moved to the CPU.
+
+Enable [`OffloadedStaticCache`] by configuring `cache_implementation="offloaded_static"` in [`~GenerationMixin.generate`].
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16, device_map="auto")
+inputs = tokenizer("Hello, my name is", return_tensors="pt").to(model.device)
+
+out = model.generate(**inputs, do_sample=False, max_new_tokens=20, cache_implementation="offloaded_static")
+tokenizer.batch_decode(out, skip_special_tokens=True)[0]
+"Hello, my name is [Your Name], and I am a [Your Profession] with [Number of Years] of"
+```
+Cache offloading requires a CUDA GPU.
+
+### Sliding window cache
+
+[`SlidingWindowCache`] implements a sliding window over the previous kv pairs, and only keeps the last `sliding_window` tokens. This cache type is designed to only work with models that support *sliding window attention*, such as [Mistral](./model_doc/mistral). Older kv states are discarded and replaced by new kv states.
+
+Enable [`SlidingWindowCache`] by configuring `cache_implementation="sliding_window"` in [`~GenerationMixin.generate`].
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM, SinkCache
+
+tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
+model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16).to("cuda:0")
+inputs = tokenizer("Yesterday I was on a rock concert and.", return_tensors="pt").to(model.device)
+
+out = model.generate(**inputs, do_sample=False, max_new_tokens=30, cache_implementation="sliding_window")
+tokenizer.batch_decode(out, skip_special_tokens=True)[0]
+```
+
+## Model caches
+
+Some model types, like encoder-decoder models or [Gemma2](./model_doc/gemma2) and [Mamba](./model_doc/mamba), have dedicated cache classes.
+
+### Encoder-decoder cache
+
+[`EncoderDecoderCache`] is designed for encoder-decoder models. It manages both the self-attention and cross-attention caches to ensure storage and retrieval of previous kv pairs. It is possible to individually set a different cache type for the encoder and decoder.
+
+This cache type doesn't require any setup. It can be used when calling [`~GenerationMixin.generate`] or a models `forward` method.
+
+> [!TIP]
+> The [`EncoderDecoderCache`] currently only supports [Whisper](./model_doc/whisper).
+
+### Model-specific caches
+
+Some models have a unique way of storing past kv pairs or states that is not compatible with any other cache classes.
+
+[Gemma2](./model_doc/gemma2) requires [`HybridCache`], which uses a combination of [`SlidingWindowCache`] for sliding window attention and [`StaticCache`] for global attention under the hood.
+
+[Mamba](./model_doc/mamba) requires [`MambaCache`] because the model doesn't have an attention mechanism or kv states.
+
+## Iterative generation
+
+A cache can also work in iterative generation settings where there is back-and-forth interaction with a model (chatbots). Like regular generation, iterative generation with a cache allows a model to efficiently handle ongoing conversations without recomputing the entire context at each step.
+
+For iterative generation with a cache, start by initializing an empty cache class and then you can feed in your new prompts. Keep track of dialogue history with a [chat template](./chat_templating).
+
+If you're using [`SinkCache`], the inputs need to be truncated to the maximum length because [`SinkCache`] can generate text that exceeds its maximum window size. However, the first input shouldn't exceed the maximum cache length.
+
+The example below demonstrates how to use a cache for iterative generation.
+
+```py
+import torch
+from transformers import AutoTokenizer,AutoModelForCausalLM
+from transformers.cache_utils import (
+ DynamicCache,
+ SinkCache,
+ StaticCache,
+ SlidingWindowCache,
+ QuantoQuantizedCache,
+ QuantizedCacheConfig,
+)
+
+model_id = "meta-llama/Llama-2-7b-chat-hf"
+model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map='auto')
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+
+user_prompts = ["Hello, what's your name?", "Btw, yesterday I was on a rock concert."]
+
+past_key_values = DynamicCache()
+max_cache_length = past_key_values.get_max_length()
+
+messages = []
+for prompt in user_prompts:
+ messages.append({"role": "user", "content": prompt})
+ inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt", return_dict=True).to(model.device)
+ if isinstance(past_key_values, SinkCache):
+ inputs = {k: v[:, -max_cache_length:] for k, v in inputs.items()}
+ input_length = inputs["input_ids"].shape[1]
+ outputs = model.generate(**inputs, do_sample=False, max_new_tokens=256, past_key_values=past_key_values)
+ completion = tokenizer.decode(outputs[0, input_length: ], skip_special_tokens=True)
+ messages.append({"role": "assistant", "content": completion})
+```
+
+## Prefill a cache
+
+In some situations, you may want to fill a [`Cache`] with kv pairs for a certain prefix prompt and reuse it to generate different sequences.
+
+The example below initializes a [`StaticCache`], and then caches an initial prompt. Now you can generate several sequences from the prefilled prompt.
+
+```py
+import copy
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer, DynamicCache, StaticCache
+
+model_id = "meta-llama/Llama-2-7b-chat-hf"
+model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="cuda")
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+
+# Init StaticCache with big enough max-length (1024 tokens for the below example)
+# You can also init a DynamicCache, if that suits you better
+prompt_cache = StaticCache(config=model.config, max_batch_size=1, max_cache_len=1024, device="cuda", dtype=torch.bfloat16)
+
+INITIAL_PROMPT = "You are a helpful assistant. "
+inputs_initial_prompt = tokenizer(INITIAL_PROMPT, return_tensors="pt").to("cuda")
+# This is the common prompt cached, we need to run forward without grad to be able to copy
+with torch.no_grad():
+ prompt_cache = model(**inputs_initial_prompt, past_key_values = prompt_cache).past_key_values
+
+prompts = ["Help me to write a blogpost about travelling.", "What is the capital of France?"]
+responses = []
+for prompt in prompts:
+ new_inputs = tokenizer(INITIAL_PROMPT + prompt, return_tensors="pt").to("cuda")
+ past_key_values = copy.deepcopy(prompt_cache)
+ outputs = model.generate(**new_inputs, past_key_values=past_key_values,max_new_tokens=20)
+ response = tokenizer.batch_decode(outputs)[0]
+ responses.append(response)
+
+print(responses)
+```
diff --git a/docs/transformers/docs/source/en/llm_optims.md b/docs/transformers/docs/source/en/llm_optims.md
new file mode 100644
index 0000000000000000000000000000000000000000..e8e20dab5db60d7158b393020ed216ace870618a
--- /dev/null
+++ b/docs/transformers/docs/source/en/llm_optims.md
@@ -0,0 +1,420 @@
+
+
+# Optimizing inference
+
+Inference with large language models (LLMs) can be challenging because they have to store and handle billions of parameters. To load a 70B parameter [Llama 2](https://hf.co/meta-llama/Llama-2-70b-hf) model, it requires 256GB of memory for full precision weights and 128GB of memory for half-precision weights. The most powerful GPUs today - the A100 and H100 - only have 80GB of memory.
+
+On top of the memory requirements, inference is slow because LLMs are called repeatedly to generate the next token. The input sequence increases as generation progresses, which takes longer and longer to process.
+
+This guide will show you how to optimize LLM inference to accelerate generation and reduce memory usage.
+
+> [!TIP]
+> Try out [Text Generation Inference (TGI)](https://hf.co/docs/text-generation-inference), a Hugging Face library dedicated to deploying and serving highly optimized LLMs for inference.
+
+## Static kv-cache and torch.compile
+
+LLMs compute key-value (kv) values for each input token, and it performs the same kv computation each time because the generated output becomes part of the input. However, performing the same kv computation every time is not very efficient.
+
+A *kv-cache* stores the past keys and values instead of recomputing them each time. As a result, the kv-cache is dynamic and it grows with each generation step which prevents you from taking advantage of [torch.compile](./perf_torch_compile), a powerful optimization method that fuses PyTorch code into optimized kernels.
+
+The *static kv-cache* solves this issue by pre-allocating the kv-cache size to a maximum value, so you can combine it with [torch.compile](./perf_torch_compile) for up to a 4x speed up. Your speed up may vary depending on the model size (larger models have a smaller speed up) and hardware.
+
+> [!WARNING]
+> Follow this [issue](https://github.com/huggingface/transformers/issues/28981) to track which models (Llama, Gemma, Mistral, etc.) support a static kv-cache and torch.compile.
+
+Depending on your task, there are several ways you can use the static kv-cache.
+
+1. For basic use cases, set [cache_implementation](https://hf.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig.cache_implementation) to `"static"` (recommended).
+2. For multi-turn generation or a custom generation loop, initialize and handle [`StaticCache`] directly.
+3. For more unique hardware or use cases, it may be better to compile the entire [`~GenerationMixin.generate`] function into a single graph.
+
+> [!TIP]
+> Regardless of how you use the static kv-cache and torch.compile, left-pad your inputs with [pad_to_multiple_of](https://hf.co/docs/transformers/main_classes/tokenizer#transformers.PreTrainedTokenizer.__call__.pad_to_multiple_of) to a limited set of values to avoid shape-related recompilations.
+
+
+
+
+1. Set the [cache_implementation](https://hf.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig.cache_implementation) to `"static"` in a models [`GenerationConfig`].
+2. Call [torch.compile](./perf_torch_compile) to compile the forward pass with the static kv-cache.
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM
+import torch
+import os
+os.environ["TOKENIZERS_PARALLELISM"] = "false" # To prevent long warnings :)
+
+tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
+model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", torch_dtype="auto", device_map="auto")
+
+model.generation_config.cache_implementation = "static"
+
+model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)
+input_text = "The theory of special relativity states "
+input_ids = tokenizer(input_text, return_tensors="pt").to(model.device.type)
+
+outputs = model.generate(**input_ids)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['The theory of special relativity states 1. The speed of light is constant in all inertial reference']
+```
+
+Under the hood, [`~GenerationMixin.generate`] attempts to reuse the same cache object to avoid recompilation at each call, which is critical to get the most out of [torch.compile](./perf_torch_compile). Be aware of the following to avoid triggering recompilation or if generation is slower than expected.
+
+1. If the batch size changes or the maximum output length increases between calls, the cache is reinitialized and recompiled.
+2. The first several calls of the compiled function are slower because it is being compiled.
+
+
+
+
+Directly initialize a [`StaticCache`] object and pass it to the `past_key_values` parameter in [`~GenerationMixin.generate`]. The [`StaticCache`] keeps the cache contents, so you can pass it to a new [`~GenerationMixin.generate`] call to continue generation, similar to a dynamic cache.
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM, StaticCache
+import torch
+import os
+os.environ["TOKENIZERS_PARALLELISM"] = "false" # To prevent long warnings :)
+
+tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
+model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", torch_dtype="auto", device_map="auto")
+
+model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)
+input_text = "The theory of special relativity states "
+input_ids = tokenizer(input_text, return_tensors="pt").to(model.device.type)
+prompt_length = input_ids.input_ids.shape[1]
+model.generation_config.max_new_tokens = 16
+
+past_key_values = StaticCache(
+ config=model.config,
+ max_batch_size=1,
+ # If you plan to reuse the cache, make sure the cache length is large enough for all cases
+ max_cache_len=prompt_length+(model.generation_config.max_new_tokens*2),
+ device=model.device,
+ dtype=model.dtype
+)
+outputs = model.generate(**input_ids, past_key_values=past_key_values)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['The theory of special relativity states 1. The speed of light is constant in all inertial reference frames. 2']
+
+# pass in the generated text and the same cache object to continue generation from where it left off. Optionally, in a
+# multi-turn conversation, append the new user input to the generated text.
+new_input_ids = outputs
+outputs = model.generate(new_input_ids, past_key_values=past_key_values)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['The theory of special relativity states 1. The speed of light is constant in all inertial reference frames. 2. The speed of light is constant in all inertial reference frames. 3.']
+```
+
+> [!TIP]
+> To reuse [`StaticCache`] on a new prompt, use [`~StaticCache.reset`] to reset the cache contents between calls.
+
+Another option for using [`StaticCache`] is to pass it to a models forward pass using the same `past_key_values` argument. This allows you to write your own custom decoding function to decode the next token given the current token, position, and cache position of previously generated tokens.
+
+```py
+from transformers import LlamaTokenizer, LlamaForCausalLM, StaticCache, logging
+from transformers.testing_utils import CaptureLogger
+import torch
+from accelerate.test_utils.testing import get_backend
+
+prompts = [
+ "Simply put, the theory of relativity states that ",
+ "My favorite all time favorite condiment is ketchup.",
+]
+
+NUM_TOKENS_TO_GENERATE = 40
+torch_device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
+
+tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", pad_token="", padding_side="right")
+model = LlamaForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", device_map="sequential")
+inputs = tokenizer(prompts, return_tensors="pt", padding=True).to(model.device)
+
+def decode_one_tokens(model, cur_token, input_pos, cache_position, past_key_values):
+ logits = model(
+ cur_token,
+ position_ids=input_pos,
+ cache_position=cache_position,
+ past_key_values=past_key_values,
+ return_dict=False,
+ use_cache=True
+ )[0]
+ new_token = torch.argmax(logits[:, -1], dim=-1)[:, None]
+ return new_token
+```
+
+To enable static kv-cache and [torch.compile](./perf_torch_compile) with [`StaticCache`], follow the steps below.
+
+1. Initialize [`StaticCache`] before using the model for inference to configure parameters like the maximum batch size and sequence length.
+2. Call [torch.compile](./perf_torch_compile) on the model to compile the forward pass with the static kv-cache.
+3. se SDPBackend.MATH in the [torch.nn.attention.sdpa_kernel](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html) context manager to enable the native PyTorch C++ implementation of scaled dot product attention to speed up inference even more.
+
+```py
+from torch.nn.attention import SDPBackend, sdpa_kernel
+
+batch_size, seq_length = inputs["input_ids"].shape
+with torch.no_grad():
+ past_key_values = StaticCache(
+ config=model.config, max_batch_size=2, max_cache_len=4096, device=torch_device, dtype=model.dtype
+ )
+ cache_position = torch.arange(seq_length, device=torch_device)
+ generated_ids = torch.zeros(
+ batch_size, seq_length + NUM_TOKENS_TO_GENERATE + 1, dtype=torch.int, device=torch_device
+ )
+ generated_ids[:, cache_position] = inputs["input_ids"].to(torch_device).to(torch.int)
+
+ logits = model(
+ **inputs, cache_position=cache_position, past_key_values=past_key_values,return_dict=False, use_cache=True
+ )[0]
+ next_token = torch.argmax(logits[:, -1], dim=-1)[:, None]
+ generated_ids[:, seq_length] = next_token[:, 0]
+
+ decode_one_tokens = torch.compile(decode_one_tokens, mode="reduce-overhead", fullgraph=True)
+ cache_position = torch.tensor([seq_length + 1], device=torch_device)
+ for _ in range(1, NUM_TOKENS_TO_GENERATE):
+ with sdpa_kernel(SDPBackend.MATH):
+ next_token = decode_one_tokens(model, next_token.clone(), None, cache_position, past_key_values)
+ generated_ids[:, cache_position] = next_token.int()
+ cache_position += 1
+
+text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+text
+['Simply put, the theory of relativity states that 1) the speed of light is constant, 2) the speed of light is the same for all observers, and 3) the laws of physics are the same for all observers.',
+ 'My favorite all time favorite condiment is ketchup. I love it on everything. I love it on my eggs, my fries, my chicken, my burgers, my hot dogs, my sandwiches, my salads, my p']
+```
+
+
+
+
+Compiling the entire [`~GenerationMixin.generate`] function also compiles the input preparation logit processor operations, and more, in addition to the forward pass. With this approach, you don't need to initialize [`StaticCache`] or set the [cache_implementation](https://hf.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig.cache_implementation) parameter.
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM
+import torch
+import os
+os.environ["TOKENIZERS_PARALLELISM"] = "false" # To prevent long warnings :)
+
+tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
+model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", torch_dtype="auto", device_map="auto")
+
+model.generate = torch.compile(model.generate, mode="reduce-overhead", fullgraph=True)
+input_text = "The theory of special relativity states "
+input_ids = tokenizer(input_text, return_tensors="pt").to(model.device.type)
+
+outputs = model.generate(**input_ids)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['The theory of special relativity states 1. The speed of light is constant in all inertial reference']
+```
+
+This usage pattern is more appropriate for unique hardware or use cases, but there are several drawbacks to consider.
+
+1. Compilation is much slower.
+2. Parameters must be configured through [`GenerationConfig`].
+3. Many warnings and exceptions are suppressed. We recommend testing the uncompiled model first.
+4. Many features are unavailable at the moment. For example, generation does not stop if an `EOS` token is selected.
+
+
+
+
+## Decoding strategies
+
+Decoding can also be optimized to accelerate generation. You can use a lightweight assistant model to generate candidate tokens faster than the LLM itself or you can use a variant of this decoding strategy that works especially well for input-grounded tasks.
+
+### Speculative decoding
+
+> [!TIP]
+> For a more in-depth explanation, take a look at the [Assisted Generation: a new direction toward low-latency text generation](https://hf.co/blog/assisted-generation) blog post!
+
+For each input token, the model weights are loaded each time during the forward pass, which is slow and cumbersome when a model has billions of parameters. Speculative decoding alleviates this slowdown by using a second smaller and faster assistant model to generate candidate tokens that are verified by the larger model in a single forward pass. If the verified tokens are correct, the LLM essentially gets them for "free" without having to generate them itself. There is no degradation in accuracy because the verification forward pass ensures the same outputs are generated as if the LLM had generated them on its own.
+
+To get the largest speed up, the assistant model should be a lot smaller than the LLM so that it can generate tokens quickly. The assistant and LLM model must also share the same tokenizer to avoid re-encoding and decoding tokens.
+
+> [!WARNING]
+> Speculative decoding is only supported for the greedy search and sampling decoding strategies, and it doesn't support batched inputs.
+
+Enable speculative decoding by loading an assistant model and passing it to [`~GenerationMixin.generate`].
+
+
+
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+import torch
+from accelerate.test_utils.testing import get_backend
+
+device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
+
+tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
+inputs = tokenizer("Einstein's theory of relativity states", return_tensors="pt").to(device)
+
+model = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b", torch_dtype="auto").to(device)
+assistant_model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m").to(device)
+outputs = model.generate(**inputs, assistant_model=assistant_model)
+tokenizer.batch_decode(outputs, skip_special_tokens=True)
+["Einstein's theory of relativity states that the speed of light is constant. "]
+```
+
+
+
+
+For speculative sampling decoding, add the [do_sample](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.GenerationConfig.do_sample) and [temperature](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.GenerationConfig.temperature) parameters to [`~GenerationMixin.generate`].
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+import torch
+from accelerate.test_utils.testing import get_backend
+
+device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
+
+tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
+inputs = tokenizer("Einstein's theory of relativity states", return_tensors="pt").to(device)
+
+model = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b", torch_dtype="auto").to(device)
+assistant_model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m").to(device)
+outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.7)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+["Einstein's theory of relativity states that motion in the universe is not a straight line.\n"]
+```
+
+
+
+
+### Prompt lookup decoding
+
+Prompt lookup decoding is a variant of speculative decoding that is also compatible with greedy search and sampling. Prompt lookup works especially well for input-grounded tasks - such as summarization - where there is often overlapping words between the prompt and output. These overlapping n-grams are used as the LLM candidate tokens.
+
+To enable prompt lookup decoding, specify the number of tokens that should be overlapping in the [prompt_lookup_num_tokens](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.GenerationConfig.prompt_lookup_num_tokens) parameter. Then pass this parameter to [`~GenerationMixin.generate`].
+
+
+
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+import torch
+from accelerate.test_utils.testing import get_backend
+
+device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
+
+tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
+inputs = tokenizer("The second law of thermodynamics states", return_tensors="pt").to(device)
+
+model = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b", torch_dtype="auto").to(device)
+assistant_model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m").to(device)
+outputs = model.generate(**inputs, prompt_lookup_num_tokens=3)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['The second law of thermodynamics states that entropy increases with temperature. ']
+```
+
+
+
+
+For prompt lookup decoding with sampling, add the [do_sample](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.GenerationConfig.do_sample) and [temperature](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.GenerationConfig.temperature) parameters to [`~GenerationMixin.generate`].
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+import torch
+from accelerate.test_utils.testing import get_backend
+
+device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
+
+tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
+inputs = tokenizer("The second law of thermodynamics states", return_tensors="pt").to(device)
+
+model = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b", torch_dtype="auto").to(device)
+outputs = model.generate(**inputs, prompt_lookup_num_tokens=3, do_sample=True, temperature=0.7)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+["The second law of thermodynamics states that energy cannot be created nor destroyed. It's not a"]
+```
+
+
+
+
+## Attention
+
+A known issue with transformer models is that the self-attention mechanism grows quadratically in compute and memory with the number of input tokens. This limitation is only magnified in LLMs which handles much longer sequences. To address this, try FlashAttention2 or PyTorch's scaled dot product attention (SDPA), which are more memory efficient attention implementations.
+
+### FlashAttention-2
+
+FlashAttention and [FlashAttention-2](./perf_infer_gpu_one#flashattention-2) break up the attention computation into smaller chunks and reduces the number of intermediate read/write operations to the GPU memory to speed up inference. FlashAttention-2 improves on the original FlashAttention algorithm by also parallelizing over sequence length dimension and better partitioning work on the hardware to reduce synchronization and communication overhead.
+
+To use FlashAttention-2, set [attn_implementation](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.PreTrainedModel.from_pretrained.attn_implementation) to `"flash_attention_2"` in [`~PreTrainedModel.from_pretrained`].
+
+```py
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+
+quant_config = BitsAndBytesConfig(load_in_8bit=True)
+model = AutoModelForCausalLM.from_pretrained(
+ "google/gemma-2b",
+ quantization_config=quant_config,
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+```
+
+### PyTorch scaled dot product attention
+
+Scaled dot product attention (SDPA) is automatically enabled in PyTorch 2.0 and it supports FlashAttention, xFormers, and PyTorch's C++ implementation. SDPA chooses the most performant attention algorithm if you're using a CUDA backend. For other backends, SDPA defaults to the PyTorch C++ implementation.
+
+> [!TIP]
+> SDPA automaticallysupports FlashAttention-2 as long as you have the latest PyTorch version installed.
+
+Use the [torch.nn.attention.sdpa_kernel](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html) context manager to explicitly enable or disable any of the four attention algorithms. For example, use `SDPBackend.FLASH_ATTENTION` to enable FlashAttention.
+
+```py
+import torch
+from torch.nn.attention import SDPBackend, sdpa_kernel
+from transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained(
+ "google/gemma-2b",
+ torch_dtype=torch.bfloat16,
+)
+
+with sdpa_kernel(SDPBackend.FLASH_ATTENTION):
+ outputs = model.generate(**inputs)
+```
+
+## Quantization
+
+Quantization reduces the size of model weights by storing them in a lower precision. This translates to lower memory usage and makes loading LLMs for inference more accessible if you're constrained by GPU memory.
+
+If you aren't limited by your GPU, you don't necessarily need to quantize your model because it can increase latency slightly (except for AWQ and fused AWQ modules) due to the extra step required to quantize and dequantize the weights.
+
+> [!TIP]
+> There are many quantization libraries (see the [Quantization](./quantization) guide for more details) available, such as Quanto, AQLM, VPTQ, AWQ, and AutoGPTQ. Feel free to try them out and see which one works best for your use case. We also recommend reading the [Overview of natively supported quantization schemes in 🤗 Transformers](https://hf.co/blog/overview-quantization-transformers) blog post which compares AutoGPTQ and bitsandbytes.
+
+Use the Model Memory Calculator below to estimate and compare how much memory is required to load a model. For example, try estimating the memory required to load [Mistral-7B-v0.1](https://hf.co/mistralai/Mistral-7B-v0.1).
+
+
+
+To load a model in half-precision, set the [torch_dtype](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.PreTrainedModel.from_pretrained.torch_dtype) parameter in [`~transformers.AutoModelForCausalLM.from_pretrained`] to `torch.bfloat16`. This requires 13.74GB of memory.
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM
+import torch
+
+model = AutoModelForCausalLM.from_pretrained(
+ "mistralai/Mistral-7B-v0.1", torch_dtype=torch.bfloat16, device_map="auto",
+)
+```
+
+To load a quantized model (8-bit or 4-bit), try [bitsandbytes](https://hf.co/docs/bitsandbytes) and set the [load_in_4bit](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.BitsAndBytesConfig.load_in_4bit) or [load_in_8bit](https://hf.co/docs/transformers/main/en/main_classes/text_generation#transformers.BitsAndBytesConfig.load_in_8bit) parameters to `True`. Loading the model in 8-bits only requires 6.87 GB of memory.
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
+import torch
+
+quant_config = BitsAndBytesConfig(load_in_8bit=True)
+model = AutoModelForCausalLM.from_pretrained(
+ "mistralai/Mistral-7B-v0.1", quantization_config=quant_config, device_map="auto"
+)
+```
diff --git a/docs/transformers/docs/source/en/llm_tutorial.md b/docs/transformers/docs/source/en/llm_tutorial.md
new file mode 100644
index 0000000000000000000000000000000000000000..d86765720241d08805b8f3fd49b9a45fadb83726
--- /dev/null
+++ b/docs/transformers/docs/source/en/llm_tutorial.md
@@ -0,0 +1,289 @@
+
+
+# Text generation
+
+[[open-in-colab]]
+
+Text generation is the most popular application for large language models (LLMs). A LLM is trained to generate the next word (token) given some initial text (prompt) along with its own generated outputs up to a predefined length or when it reaches an end-of-sequence (`EOS`) token.
+
+In Transformers, the [`~GenerationMixin.generate`] API handles text generation, and it is available for all models with generative capabilities.
+
+This guide will show you the basics of text generation with [`~GenerationMixin.generate`] and some common pitfalls to avoid.
+
+## Default generate
+
+Before you begin, it's helpful to install [bitsandbytes](https://hf.co/docs/bitsandbytes/index) to quantize really large models to reduce their memory usage.
+
+```bash
+!pip install -U transformers bitsandbytes
+```
+Bitsandbytes supports multiple backends in addition to CUDA-based GPUs. Refer to the multi-backend installation [guide](https://huggingface.co/docs/bitsandbytes/main/en/installation#multi-backend) to learn more.
+
+Load a LLM with [`~PreTrainedModel.from_pretrained`] and add the following two parameters to reduce the memory requirements.
+
+- `device_map="auto"` enables Accelerates' [Big Model Inference](./models#big-model-inference) feature for automatically initiating the model skeleton and loading and dispatching the model weights across all available devices, starting with the fastest device (GPU).
+- `quantization_config` is a configuration object that defines the quantization settings. This examples uses bitsandbytes as the quantization backend (see the [Quantization](./quantization/overview) section for more available backends) and it loads the model in [4-bits](./quantization/bitsandbytes).
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_4bit=True)
+model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", device_map="auto", quantization_config=quantization_config)
+```
+
+Tokenize your input, and set the [`~PreTrainedTokenizer.padding_side`] parameter to `"left"` because a LLM is not trained to continue generation from padding tokens. The tokenizer returns the input ids and attention mask.
+
+> [!TIP]
+> Process more than one prompt at a time by passing a list of strings to the tokenizer. Batch the inputs to improve throughput at a small cost to latency and memory.
+
+```py
+tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
+model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")
+```
+
+Pass the inputs to [`~GenerationMixin.generate`] to generate tokens, and [`~PreTrainedTokenizer.batch_decode`] the generated tokens back to text.
+
+```py
+generated_ids = model.generate(**model_inputs)
+tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+"A list of colors: red, blue, green, yellow, orange, purple, pink,"
+```
+
+## Generation configuration
+
+All generation settings are contained in [`GenerationConfig`]. In the example above, the generation settings are derived from the `generation_config.json` file of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1). A default decoding strategy is used when no configuration is saved with a model.
+
+Inspect the configuration through the `generation_config` attribute. It only shows values that are different from the default configuration, in this case, the `bos_token_id` and `eos_token_id`.
+
+```py
+from transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", device_map="auto")
+model.generation_config
+GenerationConfig {
+ "bos_token_id": 1,
+ "eos_token_id": 2
+}
+```
+
+You can customize [`~GenerationMixin.generate`] by overriding the parameters and values in [`GenerationConfig`]. Some of the most commonly adjusted parameters are [max_new_tokens](https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig.max_new_tokens), [num_beams](https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig.num_beams), [do_sample](https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig.do_sample), and [num_return_sequences](https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig.num_return_sequences).
+
+```py
+# enable beam search sampling strategy
+model.generate(**inputs, num_beams=4, do_sample=True)
+```
+
+[`~GenerationMixin.generate`] can also be extended with external libraries or custom code. The `logits_processor` parameter accepts custom [`LogitsProcessor`] instances for manipulating the next token probability distribution. `stopping_criteria` supports custom [`StoppingCriteria`] to stop text generation. Check out the [logits-processor-zoo](https://github.com/NVIDIA/logits-processor-zoo) for more examples of external [`~GenerationMixin.generate`]-compatible extensions.
+
+Refer to the [Generation strategies](./generation_strategies) guide to learn more about search, sampling, and decoding strategies.
+
+### Saving
+
+Create an instance of [`GenerationConfig`] and specify the decoding parameters you want.
+
+```py
+from transformers import AutoModelForCausalLM, GenerationConfig
+
+model = AutoModelForCausalLM.from_pretrained("my_account/my_model")
+generation_config = GenerationConfig(
+ max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
+)
+```
+
+Use [`~GenerationConfig.save_pretrained`] to save a specific generation configuration and set the `push_to_hub` parameter to `True` to upload it to the Hub.
+
+```py
+generation_config.save_pretrained("my_account/my_model", push_to_hub=True)
+```
+
+Leave the `config_file_name` parameter empty. This parameter should be used when storing multiple generation configurations in a single directory. It gives you a way to specify which generation configuration to load. You can create different configurations for different generative tasks (creative text generation with sampling, summarization with beam search) for use with a single model.
+
+```py
+from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
+
+tokenizer = AutoTokenizer.from_pretrained("google-t5/t5-small")
+model = AutoModelForSeq2SeqLM.from_pretrained("google-t5/t5-small")
+
+translation_generation_config = GenerationConfig(
+ num_beams=4,
+ early_stopping=True,
+ decoder_start_token_id=0,
+ eos_token_id=model.config.eos_token_id,
+ pad_token=model.config.pad_token_id,
+)
+
+translation_generation_config.save_pretrained("/tmp", config_file_name="translation_generation_config.json", push_to_hub=True)
+
+generation_config = GenerationConfig.from_pretrained("/tmp", config_file_name="translation_generation_config.json")
+inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
+outputs = model.generate(**inputs, generation_config=generation_config)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+```
+
+## Pitfalls
+
+The section below covers some common issues you may encounter during text generation and how to solve them.
+
+### Output length
+
+[`~GenerationMixin.generate`] returns up to 20 tokens by default unless otherwise specified in a models [`GenerationConfig`]. It is highly recommended to manually set the number of generated tokens with the [`max_new_tokens`] parameter to control the output length. [Decoder-only](https://hf.co/learn/nlp-course/chapter1/6?fw=pt) models returns the initial prompt along with the generated tokens.
+
+```py
+model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
+```
+
+
+
+
+```py
+generated_ids = model.generate(**model_inputs)
+tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+'A sequence of numbers: 1, 2, 3, 4, 5'
+```
+
+
+
+
+```py
+generated_ids = model.generate(**model_inputs, max_new_tokens=50)
+tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
+```
+
+
+
+
+### Decoding strategy
+
+The default decoding strategy in [`~GenerationMixin.generate`] is *greedy search*, which selects the next most likely token, unless otherwise specified in a models [`GenerationConfig`]. While this decoding strategy works well for input-grounded tasks (transcription, translation), it is not optimal for more creative use cases (story writing, chat applications).
+
+For example, enable a [multinomial sampling](./generation_strategies#multinomial-sampling) strategy to generate more diverse outputs. Refer to the [Generation strategy](./generation_strategies) guide for more decoding strategies.
+
+```py
+model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
+```
+
+
+
+
+```py
+generated_ids = model.generate(**model_inputs)
+tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+```
+
+
+
+
+```py
+generated_ids = model.generate(**model_inputs, do_sample=True)
+tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+```
+
+
+
+
+### Padding side
+
+Inputs need to be padded if they don't have the same length. But LLMs aren't trained to continue generation from padding tokens, which means the [`~PreTrainedTokenizer.padding_side`] parameter needs to be set to the left of the input.
+
+
+
+
+```py
+model_inputs = tokenizer(
+ ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
+).to("cuda")
+generated_ids = model.generate(**model_inputs)
+tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+'1, 2, 33333333333'
+```
+
+
+
+
+```py
+tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
+tokenizer.pad_token = tokenizer.eos_token
+model_inputs = tokenizer(
+ ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
+).to("cuda")
+generated_ids = model.generate(**model_inputs)
+tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+'1, 2, 3, 4, 5, 6,'
+```
+
+
+
+
+### Prompt format
+
+Some models and tasks expect a certain input prompt format, and if the format is incorrect, the model returns a suboptimal output. You can learn more about prompting in the [prompt engineering](./tasks/prompting) guide.
+
+For example, a chat model expects the input as a [chat template](./chat_templating). Your prompt should include a `role` and `content` to indicate who is participating in the conversation. If you try to pass your prompt as a single string, the model doesn't always return the expected output.
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
+model = AutoModelForCausalLM.from_pretrained(
+ "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
+)
+```
+
+
+
+
+```py
+prompt = """How many cats does it take to change a light bulb? Reply as a pirate."""
+model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
+input_length = model_inputs.input_ids.shape[1]
+generated_ids = model.generate(**model_inputs, max_new_tokens=50)
+print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
+"Aye, matey! 'Tis a simple task for a cat with a keen eye and nimble paws. First, the cat will climb up the ladder, carefully avoiding the rickety rungs. Then, with"
+```
+
+
+
+
+```py
+messages = [
+ {
+ "role": "system",
+ "content": "You are a friendly chatbot who always responds in the style of a pirate",
+ },
+ {"role": "user", "content": "How many cats does it take to change a light bulb?"},
+]
+model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to("cuda")
+input_length = model_inputs.shape[1]
+generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=50)
+print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
+"Arr, matey! According to me beliefs, 'twas always one cat to hold the ladder and another to climb up it an’ change the light bulb, but if yer looking to save some catnip, maybe yer can
+```
+
+
+
+
+## Resources
+
+Take a look below for some more specific and specialized text generation libraries.
+
+- [Optimum](https://github.com/huggingface/optimum): an extension of Transformers focused on optimizing training and inference on specific hardware devices
+- [Outlines](https://github.com/dottxt-ai/outlines): a library for constrained text generation (generate JSON files for example).
+- [SynCode](https://github.com/uiuc-focal-lab/syncode): a library for context-free grammar guided generation (JSON, SQL, Python).
+- [Text Generation Inference](https://github.com/huggingface/text-generation-inference): a production-ready server for LLMs.
+- [Text generation web UI](https://github.com/oobabooga/text-generation-webui): a Gradio web UI for text generation.
+- [logits-processor-zoo](https://github.com/NVIDIA/logits-processor-zoo): additional logits processors for controlling text generation.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/llm_tutorial_optimization.md b/docs/transformers/docs/source/en/llm_tutorial_optimization.md
new file mode 100644
index 0000000000000000000000000000000000000000..c7c53765a2f8a9fc20dc12c9b1fc9223a1cc1d95
--- /dev/null
+++ b/docs/transformers/docs/source/en/llm_tutorial_optimization.md
@@ -0,0 +1,782 @@
+
+
+# Optimizing LLMs for Speed and Memory
+
+[[open-in-colab]]
+
+Large Language Models (LLMs) such as GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), and [Llama](https://huggingface.co/meta-llama/Llama-2-70b-hf) are rapidly advancing in their ability to tackle human-centric tasks, establishing themselves as essential tools in modern knowledge-based industries.
+Deploying these models in real-world tasks remains challenging, however:
+
+- To exhibit near-human text understanding and generation capabilities, LLMs currently require to be composed of billions of parameters (see [Kaplan et al](https://arxiv.org/abs/2001.08361), [Wei et. al](https://arxiv.org/abs/2206.07682)). This consequently amplifies the memory demands for inference.
+- In many real-world tasks, LLMs need to be given extensive contextual information. This necessitates the model's capability to manage very long input sequences during inference.
+
+The crux of these challenges lies in augmenting the computational and memory capabilities of LLMs, especially when handling expansive input sequences.
+
+In this guide, we will go over the effective techniques for efficient LLM deployment:
+
+1. **Lower Precision:** Research has shown that operating at reduced numerical precision, namely [8-bit and 4-bit](./main_classes/quantization.md) can achieve computational advantages without a considerable decline in model performance.
+
+2. **Flash Attention:** Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
+
+3. **Architectural Innovations:** Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are [Alibi](https://arxiv.org/abs/2108.12409), [Rotary embeddings](https://arxiv.org/abs/2104.09864), [Multi-Query Attention (MQA)](https://arxiv.org/abs/1911.02150) and [Grouped-Query-Attention (GQA)]((https://arxiv.org/abs/2305.13245)).
+
+Throughout this guide, we will offer an analysis of auto-regressive generation from a tensor's perspective. We delve into the pros and cons of adopting lower precision, provide a comprehensive exploration of the latest attention algorithms, and discuss improved LLM architectures. While doing so, we run practical examples showcasing each of the feature improvements.
+
+## 1. Lower Precision
+
+Memory requirements of LLMs can be best understood by seeing the LLM as a set of weight matrices and vectors and the text inputs as a sequence of vectors. In the following, the definition *weights* will be used to signify all model weight matrices and vectors.
+
+At the time of writing this guide, LLMs consist of at least a couple billion parameters. Each parameter thereby is made of a decimal number, e.g. `4.5689` which is usually stored in either [float32](https://en.wikipedia.org/wiki/Single-precision_floating-point_format), [bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format), or [float16](https://en.wikipedia.org/wiki/Half-precision_floating-point_format) format. This allows us to easily compute the memory requirement to load the LLM into memory:
+
+> *Loading the weights of a model having X billion parameters requires roughly 4 * X GB of VRAM in float32 precision*
+
+Nowadays, models are however rarely trained in full float32 precision, but usually in bfloat16 precision or less frequently in float16 precision. Therefore the rule of thumb becomes:
+
+> *Loading the weights of a model having X billion parameters requires roughly 2 * X GB of VRAM in bfloat16/float16 precision*
+
+For shorter text inputs (less than 1024 tokens), the memory requirement for inference is very much dominated by the memory requirement to load the weights. Therefore, for now, let's assume that the memory requirement for inference is equal to the memory requirement to load the model into the GPU VRAM.
+
+To give some examples of how much VRAM it roughly takes to load a model in bfloat16:
+
+- **GPT3** requires 2 \* 175 GB = **350 GB** VRAM
+- [**Bloom**](https://huggingface.co/bigscience/bloom) requires 2 \* 176 GB = **352 GB** VRAM
+- [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf) requires 2 \* 70 GB = **140 GB** VRAM
+- [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b) requires 2 \* 40 GB = **80 GB** VRAM
+- [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b) requires 2 \* 30 GB = **60 GB** VRAM
+- [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder) requires 2 \* 15.5 = **31 GB** VRAM
+
+As of writing this document, the largest GPU chip on the market is the A100 & H100 offering 80GB of VRAM. Most of the models listed before require more than 80GB just to be loaded and therefore necessarily require [tensor parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#tensor-parallelism) and/or [pipeline parallelism](https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
+
+🤗 Transformers now supports tensor parallelism for supported models having `base_tp_plan` in their respective config classes. Learn more about Tensor Parallelism [here](perf_train_gpu_many#tensor-parallelism). Furthermore, if you're interested in writing models in a tensor-parallelism-friendly way, feel free to have a look at [the text-generation-inference library](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models/custom_modeling).
+
+Naive pipeline parallelism is supported out of the box. For this, simply load the model with `device="auto"` which will automatically place the different layers on the available GPUs as explained [here](https://huggingface.co/docs/accelerate/v0.22.0/en/concept_guides/big_model_inference).
+Note, however that while very effective, this naive pipeline parallelism does not tackle the issues of GPU idling. For this more advanced pipeline parallelism is required as explained [here](https://huggingface.co/docs/transformers/en/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism).
+
+If you have access to an 8 x 80GB A100 node, you could load BLOOM as follows
+
+```bash
+!pip install transformers accelerate bitsandbytes optimum
+```
+```python
+from transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)
+```
+
+By using `device_map="auto"` the attention layers would be equally distributed over all available GPUs.
+
+In this guide, we will use [bigcode/octocoder](https://huggingface.co/bigcode/octocoder) as it can be run on a single 40 GB A100 GPU device chip. Note that all memory and speed optimizations that we will apply going forward, are equally applicable to models that require model or tensor parallelism.
+
+Since the model is loaded in bfloat16 precision, using our rule of thumb above, we would expect the memory requirement to run inference with `bigcode/octocoder` to be around 31 GB VRAM. Let's give it a try.
+
+We first load the model and tokenizer and then pass both to Transformers' [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) object.
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
+import torch
+
+model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
+tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
+
+pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+```
+
+```python
+prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
+
+result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
+result
+```
+
+**Output**:
+```
+Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
+```
+
+Nice, we can now directly use the result to convert bytes into Gigabytes.
+
+```python
+def bytes_to_giga_bytes(bytes):
+ return bytes / 1024 / 1024 / 1024
+```
+
+Let's call [`torch.cuda.max_memory_allocated`](https://pytorch.org/docs/stable/generated/torch.cuda.max_memory_allocated.html) to measure the peak GPU memory allocation.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**Output**:
+```bash
+29.0260648727417
+```
+
+Close enough to our back-of-the-envelope computation! We can see the number is not exactly correct as going from bytes to kilobytes requires a multiplication of 1024 instead of 1000. Therefore the back-of-the-envelope formula can also be understood as an "at most X GB" computation.
+Note that if we had tried to run the model in full float32 precision, a whopping 64 GB of VRAM would have been required.
+
+> Almost all models are trained in bfloat16 nowadays, there is no reason to run the model in full float32 precision if [your GPU supports bfloat16](https://discuss.pytorch.org/t/bfloat16-native-support/117155/5). Float32 won't give better inference results than the precision that was used to train the model.
+
+If you are unsure in which format the model weights are stored on the Hub, you can always look into the checkpoint's config under `"torch_dtype"`, *e.g.* [here](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9/config.json#L21). It is recommended to set the model to the same precision type as written in the config when loading with `from_pretrained(..., torch_dtype=...)` except when the original type is float32 in which case one can use both `float16` or `bfloat16` for inference.
+
+
+Let's define a `flush(...)` function to free all allocated memory so that we can accurately measure the peak allocated GPU memory.
+
+```python
+del pipe
+del model
+
+import gc
+import torch
+
+def flush():
+ gc.collect()
+ torch.cuda.empty_cache()
+ torch.cuda.reset_peak_memory_stats()
+```
+
+Let's call it now for the next experiment.
+
+```python
+flush()
+```
+From the Accelerate library, you can also use a device-agnostic utility method called [release_memory](https://github.com/huggingface/accelerate/blob/29be4788629b772a3b722076e433b5b3b5c85da3/src/accelerate/utils/memory.py#L63), which takes various hardware backends like XPU, MLU, NPU, MPS, and more into account.
+
+```python
+from accelerate.utils import release_memory
+# ...
+
+release_memory(model)
+```
+
+Now what if your GPU does not have 32 GB of VRAM? It has been found that model weights can be quantized to 8-bit or 4-bits without a significant loss in performance (see [Dettmers et al.](https://arxiv.org/abs/2208.07339)).
+Model can be quantized to even 3 or 2 bits with an acceptable loss in performance as shown in the recent [GPTQ paper](https://arxiv.org/abs/2210.17323) 🤯.
+
+Without going into too many details, quantization schemes aim at reducing the precision of weights while trying to keep the model's inference results as accurate as possible (*a.k.a* as close as possible to bfloat16).
+Note that quantization works especially well for text generation since all we care about is choosing the *set of most likely next tokens* and don't really care about the exact values of the next token *logit* distribution.
+All that matters is that the next token *logit* distribution stays roughly the same so that an `argmax` or `topk` operation gives the same results.
+
+There are various quantization techniques, which we won't discuss in detail here, but in general, all quantization techniques work as follows:
+
+- 1. Quantize all weights to the target precision
+- 2. Load the quantized weights, and pass the input sequence of vectors in bfloat16 precision
+- 3. Dynamically dequantize weights to bfloat16 to perform the computation with their input vectors in bfloat16 precision
+
+In a nutshell, this means that *inputs-weight matrix* multiplications, with \\( X \\) being the *inputs*, \\( W \\) being a weight matrix and \\( Y \\) being the output:
+
+$$ Y = X * W $$
+
+are changed to
+
+$$ Y = X * \text{dequantize}(W) $$
+
+for every matrix multiplication. Dequantization and re-quantization is performed sequentially for all weight matrices as the inputs run through the network graph.
+
+Therefore, inference time is often **not** reduced when using quantized weights, but rather increases.
+Enough theory, let's give it a try! To quantize the weights with Transformers, you need to make sure that
+the [`bitsandbytes`](https://github.com/bitsandbytes-foundation/bitsandbytes) library is installed.
+
+```bash
+!pip install bitsandbytes
+```
+
+We can then load models in 8-bit quantization by simply adding a `load_in_8bit=True` flag to `from_pretrained`.
+
+```python
+model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
+```
+
+Now, let's run our example again and measure the memory usage.
+
+```python
+pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+
+result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
+result
+```
+
+**Output**:
+```
+Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
+```
+
+Nice, we're getting the same result as before, so no loss in accuracy! Let's look at how much memory was used this time.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**Output**:
+```
+15.219234466552734
+```
+
+Significantly less! We're down to just a bit over 15 GBs and could therefore run this model on consumer GPUs like the 4090.
+We're seeing a very nice gain in memory efficiency and more or less no degradation to the model's output. However, we can also notice a slight slow-down during inference.
+
+
+We delete the models and flush the memory again.
+```python
+del model
+del pipe
+```
+
+```python
+flush()
+```
+
+Let's see what peak GPU memory consumption 4-bit quantization gives. Quantizing the model to 4-bit can be done with the same API as before - this time by passing `load_in_4bit=True` instead of `load_in_8bit=True`.
+
+```python
+model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
+
+pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+
+result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
+result
+```
+
+**Output**:
+```
+Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument
+```
+
+We're almost seeing the same output text as before - just the `python` is missing just before the code snippet. Let's see how much memory was required.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**Output**:
+```
+9.543574333190918
+```
+
+Just 9.5GB! That's really not a lot for a >15 billion parameter model.
+
+While we see very little degradation in accuracy for our model here, 4-bit quantization can in practice often lead to different results compared to 8-bit quantization or full `bfloat16` inference. It is up to the user to try it out.
+
+Also note that inference here was again a bit slower compared to 8-bit quantization which is due to the more aggressive quantization method used for 4-bit quantization leading to \\( \text{quantize} \\) and \\( \text{dequantize} \\) taking longer during inference.
+
+```python
+del model
+del pipe
+```
+```python
+flush()
+```
+
+Overall, we saw that running OctoCoder in 8-bit precision reduced the required GPU VRAM from 32G GPU VRAM to only 15GB and running the model in 4-bit precision further reduces the required GPU VRAM to just a bit over 9GB.
+
+4-bit quantization allows the model to be run on GPUs such as RTX3090, V100, and T4 which are quite accessible for most people.
+
+For more information on quantization and to see how one can quantize models to require even less GPU VRAM memory than 4-bit, we recommend looking into the [`AutoGPTQ`](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#autogptq-integration%60) implementation.
+
+> As a conclusion, it is important to remember that model quantization trades improved memory efficiency against accuracy and in some cases inference time.
+
+If GPU memory is not a constraint for your use case, there is often no need to look into quantization. However many GPUs simply can't run LLMs without quantization methods and in this case, 4-bit and 8-bit quantization schemes are extremely useful tools.
+
+For more in-detail usage information, we strongly recommend taking a look at the [Transformers Quantization Docs](https://huggingface.co/docs/transformers/main_classes/quantization#general-usage).
+Next, let's look into how we can improve computational and memory efficiency by using better algorithms and an improved model architecture.
+
+## 2. Flash Attention
+
+Today's top-performing LLMs share more or less the same fundamental architecture that consists of feed-forward layers, activation layers, layer normalization layers, and most crucially, self-attention layers.
+
+Self-attention layers are central to Large Language Models (LLMs) in that they enable the model to understand the contextual relationships between input tokens.
+However, the peak GPU memory consumption for self-attention layers grows *quadratically* both in compute and memory complexity with number of input tokens (also called *sequence length*) that we denote in the following by \\( N \\) .
+While this is not really noticeable for shorter input sequences (of up to 1000 input tokens), it becomes a serious problem for longer input sequences (at around 16000 input tokens).
+
+Let's take a closer look. The formula to compute the output \\( \mathbf{O} \\) of a self-attention layer for an input \\( \mathbf{X} \\) of length \\( N \\) is:
+
+$$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ with } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$
+
+\\( \mathbf{X} = (\mathbf{x}_1, ... \mathbf{x}_{N}) \\) is thereby the input sequence to the attention layer. The projections \\( \mathbf{Q} \\) and \\( \mathbf{K} \\) will each consist of \\( N \\) vectors resulting in the \\( \mathbf{QK}^T \\) being of size \\( N^2 \\) .
+
+LLMs usually have multiple attention heads, thus doing multiple self-attention computations in parallel.
+Assuming, the LLM has 40 attention heads and runs in bfloat16 precision, we can calculate the memory requirement to store the \\( \mathbf{QK^T} \\) matrices to be \\( 40 * 2 * N^2 \\) bytes. For \\( N=1000 \\) only around 50 MB of VRAM are needed, however, for \\( N=16000 \\) we would need 19 GB of VRAM, and for \\( N=100,000 \\) we would need almost 1TB just to store the \\( \mathbf{QK}^T \\) matrices.
+
+Long story short, the default self-attention algorithm quickly becomes prohibitively memory-expensive for large input contexts.
+
+As LLMs improve in text comprehension and generation, they are applied to increasingly complex tasks. While models once handled the translation or summarization of a few sentences, they now manage entire pages, demanding the capability to process extensive input lengths.
+
+How can we get rid of the exorbitant memory requirements for large input lengths? We need a new way to compute the self-attention mechanism that gets rid of the \\( QK^T \\) matrix. [Tri Dao et al.](https://arxiv.org/abs/2205.14135) developed exactly such a new algorithm and called it **Flash Attention**.
+
+In a nutshell, Flash Attention breaks the \\(\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T\\)) computation apart and instead computes smaller chunks of the output by iterating over multiple softmax computation steps:
+
+$$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \times \text{Softmax}(\mathbf{QK}^T_{i,j}) \text{ for multiple } i, j \text{ iterations} $$
+
+with \\( s^a_{ij} \\) and \\( s^b_{ij} \\) being some softmax normalization statistics that need to be recomputed for every \\( i \\) and \\( j \\) .
+
+Please note that the whole Flash Attention is a bit more complex and is greatly simplified here as going in too much depth is out of scope for this guide. The reader is invited to take a look at the well-written [Flash Attention paper](https://arxiv.org/abs/2205.14135) for more details.
+
+The main takeaway here is:
+
+> By keeping track of softmax normalization statistics and by using some smart mathematics, Flash Attention gives **numerical identical** outputs compared to the default self-attention layer at a memory cost that only increases linearly with \\( N \\) .
+
+Looking at the formula, one would intuitively say that Flash Attention must be much slower compared to the default self-attention formula as more computation needs to be done. Indeed Flash Attention requires more FLOPs compared to normal attention as the softmax normalization statistics have to constantly be recomputed (see [paper](https://arxiv.org/abs/2205.14135) for more details if interested)
+
+> However, Flash Attention is much faster in inference compared to default attention which comes from its ability to significantly reduce the demands on the slower, high-bandwidth memory of the GPU (VRAM), focusing instead on the faster on-chip memory (SRAM).
+
+Essentially, Flash Attention makes sure that all intermediate write and read operations can be done using the fast *on-chip* SRAM memory instead of having to access the slower VRAM memory to compute the output vector \\( \mathbf{O} \\) .
+
+In practice, there is currently absolutely no reason to **not** use Flash Attention if available. The algorithm gives mathematically the same outputs, and is both faster and more memory-efficient.
+
+Let's look at a practical example.
+
+Our OctoCoder model now gets a significantly longer input prompt which includes a so-called *system prompt*. System prompts are used to steer the LLM into a better assistant that is tailored to the users' task.
+In the following, we use a system prompt that will make OctoCoder a better coding assistant.
+
+```python
+system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
+The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
+The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
+It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
+That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
+
+The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
+The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
+
+-----
+
+Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
+
+Answer: Sure. Here is a function that does that.
+
+def alternating(list1, list2):
+ results = []
+ for i in range(len(list1)):
+ results.append(list1[i])
+ results.append(list2[i])
+ return results
+
+Question: Can you write some test cases for this function?
+
+Answer: Sure, here are some tests.
+
+assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
+assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
+assert alternating([], []) == []
+
+Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
+
+Answer: Here is the modified function.
+
+def alternating(list1, list2):
+ results = []
+ for i in range(min(len(list1), len(list2))):
+ results.append(list1[i])
+ results.append(list2[i])
+ if len(list1) > len(list2):
+ results.extend(list1[i+1:])
+ else:
+ results.extend(list2[i+1:])
+ return results
+
+-----
+"""
+```
+For demonstration purposes, we duplicate the system prompt by ten so that the input length is long enough to observe Flash Attention's memory savings.
+We append the original text prompt `"Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"`
+
+```python
+long_prompt = 10 * system_prompt + prompt
+```
+
+We instantiate our model again in bfloat16 precision.
+
+```python
+model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
+tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
+
+pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+```
+
+Let's now run the model just like before *without Flash Attention* and measure the peak GPU memory requirement and inference time.
+
+```python
+import time
+
+start_time = time.time()
+result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
+
+print(f"Generated in {time.time() - start_time} seconds.")
+result
+```
+
+**Output**:
+```
+Generated in 10.96854019165039 seconds.
+Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
+````
+
+We're getting the same output as before, however this time, the model repeats the answer multiple times until it's 60 tokens cut-off. This is not surprising as we've repeated the system prompt ten times for demonstration purposes and thus cued the model to repeat itself.
+
+**Note** that the system prompt should not be repeated ten times in real-world applications - one time is enough!
+
+Let's measure the peak GPU memory requirement.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**Output**:
+```bash
+37.668193340301514
+```
+
+As we can see the peak GPU memory requirement is now significantly higher than in the beginning, which is largely due to the longer input sequence. Also the generation takes a little over a minute now.
+
+We call `flush()` to free GPU memory for our next experiment.
+
+```python
+flush()
+```
+
+For comparison, let's run the same function, but enable Flash Attention instead.
+To do so, we convert the model to [BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview) and by doing so enabling PyTorch's [SDPA self-attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) which in turn is able to use Flash Attention.
+
+```python
+model.to_bettertransformer()
+```
+
+Now we run the exact same code snippet as before and under the hood Transformers will make use of Flash Attention.
+
+```py
+start_time = time.time()
+with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
+ result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
+
+print(f"Generated in {time.time() - start_time} seconds.")
+result
+```
+
+**Output**:
+```
+Generated in 3.0211617946624756 seconds.
+ Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
+```
+
+We're getting the exact same result as before, but can observe a very significant speed-up thanks to Flash Attention.
+
+Let's measure the memory consumption one last time.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**Output**:
+```
+32.617331981658936
+```
+
+And we're almost back to our original 29GB peak GPU memory from the beginning.
+
+We can observe that we only use roughly 100MB more GPU memory when passing a very long input sequence with Flash Attention compared to passing a short input sequence as done in the beginning.
+
+```py
+flush()
+```
+
+For more information on how to use Flash Attention, please have a look at [this doc page](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#flashattention-2).
+
+## 3. Architectural Innovations
+
+So far we have looked into improving computational and memory efficiency by:
+
+- Casting the weights to a lower precision format
+- Replacing the self-attention algorithm with a more memory- and compute efficient version
+
+Let's now look into how we can change the architecture of an LLM so that it is most effective and efficient for task that require long text inputs, *e.g.*:
+- Retrieval augmented Questions Answering,
+- Summarization,
+- Chat
+
+Note that *chat* not only requires the LLM to handle long text inputs, but it also necessitates that the LLM is able to efficiently handle the back-and-forth dialogue between user and assistant (such as ChatGPT).
+
+Once trained, the fundamental LLM architecture is difficult to change, so it is important to make considerations about the LLM's tasks beforehand and accordingly optimize the model's architecture.
+There are two important components of the model architecture that quickly become memory and/or performance bottlenecks for large input sequences.
+
+- The positional embeddings
+- The key-value cache
+
+Let's go over each component in more detail
+
+### 3.1 Improving positional embeddings of LLMs
+
+Self-attention puts each token in relation to each other's tokens.
+As an example, the \\( \text{Softmax}(\mathbf{QK}^T) \\) matrix of the text input sequence *"Hello", "I", "love", "you"* could look as follows:
+
+
+
+Each word token is given a probability mass at which it attends all other word tokens and, therefore is put into relation with all other word tokens. E.g. the word *"love"* attends to the word *"Hello"* with 5%, to *"I"* with 30%, and to itself with 65%.
+
+A LLM based on self-attention, but without position embeddings would have great difficulties in understanding the positions of the text inputs to each other.
+This is because the probability score computed by \\( \mathbf{QK}^T \\) relates each word token to each other word token in \\( O(1) \\) computations regardless of their relative positional distance to each other.
+Therefore, for the LLM without position embeddings each token appears to have the same distance to all other tokens, *e.g.* differentiating between *"Hello I love you"* and *"You love I hello"* would be very challenging.
+
+For the LLM to understand sentence order, an additional *cue* is needed and is usually applied in the form of *positional encodings* (or also called *positional embeddings*).
+Positional encodings, encode the position of each token into a numerical presentation that the LLM can leverage to better understand sentence order.
+
+The authors of the [*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) paper introduced sinusoidal positional embeddings \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\) .
+where each vector \\( \mathbf{p}_i \\) is computed as a sinusoidal function of its position \\( i \\) .
+The positional encodings are then simply added to the input sequence vectors \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) thereby cueing the model to better learn sentence order.
+
+Instead of using fixed position embeddings, others (such as [Devlin et al.](https://arxiv.org/abs/1810.04805)) used learned positional encodings for which the positional embeddings
+\\( \mathbf{P} \\) are learned during training.
+
+Sinusoidal and learned position embeddings used to be the predominant methods to encode sentence order into LLMs, but a couple of problems related to these positional encodings were found:
+
+ 1. Sinusoidal and learned position embeddings are both absolute positional embeddings, *i.e.* encoding a unique embedding for each position id: \\( 0, \ldots, N \\) . As shown by [Huang et al.](https://arxiv.org/abs/2009.13658) and [Su et al.](https://arxiv.org/abs/2104.09864), absolute positional embeddings lead to poor LLM performance for long text inputs. For long text inputs, it is advantageous if the model learns the relative positional distance input tokens have to each other instead of their absolute position.
+ 2. When using learned position embeddings, the LLM has to be trained on a fixed input length \\( N \\), which makes it difficult to extrapolate to an input length longer than what it was trained on.
+
+Recently, relative positional embeddings that can tackle the above mentioned problems have become more popular, most notably:
+
+- [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864)
+- [ALiBi](https://arxiv.org/abs/2108.12409)
+
+Both *RoPE* and *ALiBi* argue that it's best to cue the LLM about sentence order directly in the self-attention algorithm as it's there that word tokens are put into relation with each other. More specifically, sentence order should be cued by modifying the \\( \mathbf{QK}^T \\) computation.
+
+Without going into too many details, *RoPE* notes that positional information can be encoded into query-key pairs, *e.g.* \\( \mathbf{q}_i \\) and \\( \mathbf{x}_j \\) by rotating each vector by an angle \\( \theta * i \\) and \\( \theta * j \\) respectively with \\( i, j \\) describing each vectors sentence position:
+
+$$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta, i -j} \mathbf{{x}}_j. $$
+
+\\( \mathbf{R}_{\theta, i - j} \\) thereby represents a rotational matrix. \\( \theta \\) is *not* learned during training, but instead set to a pre-defined value that depends on the maximum input sequence length during training.
+
+> By doing so, the probability score between \\( \mathbf{q}_i \\) and \\( \mathbf{q}_j \\) is only affected if \\( i \ne j \\) and solely depends on the relative distance \\( i - j \\) regardless of each vector's specific positions \\( i \\) and \\( j \\) .
+
+*RoPE* is used in multiple of today's most important LLMs, such as:
+
+- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
+- [**Llama**](https://arxiv.org/abs/2302.13971)
+- [**PaLM**](https://arxiv.org/abs/2204.02311)
+
+As an alternative, *ALiBi* proposes a much simpler relative position encoding scheme. The relative distance that input tokens have to each other is added as a negative integer scaled by a pre-defined value `m` to each query-key entry of the \\( \mathbf{QK}^T \\) matrix right before the softmax computation.
+
+
+
+As shown in the [ALiBi](https://arxiv.org/abs/2108.12409) paper, this simple relative positional encoding allows the model to retain a high performance even at very long text input sequences.
+
+*ALiBi* is used in multiple of today's most important LLMs, such as:
+
+- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
+- [**BLOOM**](https://huggingface.co/bigscience/bloom)
+
+Both *RoPE* and *ALiBi* position encodings can extrapolate to input lengths not seen during training whereas it has been shown that extrapolation works much better out-of-the-box for *ALiBi* as compared to *RoPE*.
+For ALiBi, one simply increases the values of the lower triangular position matrix to match the length of the input sequence.
+For *RoPE*, keeping the same \\( \theta \\) that was used during training leads to poor results when passing text inputs much longer than those seen during training, *c.f* [Press et al.](https://arxiv.org/abs/2108.12409). However, the community has found a couple of effective tricks that adapt \\( \theta \\), thereby allowing *RoPE* position embeddings to work well for extrapolated text input sequences (see [here](https://github.com/huggingface/transformers/pull/24653)).
+
+> Both RoPE and ALiBi are relative positional embeddings that are *not* learned during training, but instead are based on the following intuitions:
+ - Positional cues about the text inputs should be given directly to the \\( QK^T \\) matrix of the self-attention layer
+ - The LLM should be incentivized to learn a constant *relative* distance positional encodings have to each other
+ - The further text input tokens are from each other, the lower the probability of their query-value probability. Both RoPE and ALiBi lower the query-key probability of tokens far away from each other. RoPE by decreasing their vector product by increasing the angle between the query-key vectors. ALiBi by adding large negative numbers to the vector product
+
+In conclusion, LLMs that are intended to be deployed in tasks that require handling large text inputs are better trained with relative positional embeddings, such as RoPE and ALiBi. Also note that even if an LLM with RoPE and ALiBi has been trained only on a fixed length of say \\( N_1 = 2048 \\) it can still be used in practice with text inputs much larger than \\( N_1 \\), like \\( N_2 = 8192 > N_1 \\) by extrapolating the positional embeddings.
+
+### 3.2 The key-value cache
+
+Auto-regressive text generation with LLMs works by iteratively putting in an input sequence, sampling the next token, appending the next token to the input sequence, and continuing to do so until the LLM produces a token that signifies that the generation has finished.
+
+Please have a look at [Transformer's Generate Text Tutorial](https://huggingface.co/docs/transformers/llm_tutorial#generate-text) to get a more visual explanation of how auto-regressive generation works.
+
+Let's run a quick code snippet to show how auto-regressive works in practice. We will simply take the most likely next token via `torch.argmax`.
+
+```python
+input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
+
+for _ in range(5):
+ next_logits = model(input_ids)["logits"][:, -1:]
+ next_token_id = torch.argmax(next_logits,dim=-1)
+
+ input_ids = torch.cat([input_ids, next_token_id], dim=-1)
+ print("shape of input_ids", input_ids.shape)
+
+generated_text = tokenizer.batch_decode(input_ids[:, -5:])
+generated_text
+```
+
+**Output**:
+```
+shape of input_ids torch.Size([1, 21])
+shape of input_ids torch.Size([1, 22])
+shape of input_ids torch.Size([1, 23])
+shape of input_ids torch.Size([1, 24])
+shape of input_ids torch.Size([1, 25])
+[' Here is a Python function']
+```
+
+As we can see every time we increase the text input tokens by the just sampled token.
+
+With very few exceptions, LLMs are trained using the [causal language modeling objective](https://huggingface.co/docs/transformers/tasks/language_modeling#causal-language-modeling) and therefore mask the upper triangle matrix of the attention score - this is why in the two diagrams above the attention scores are left blank (*a.k.a* have 0 probability). For a quick recap on causal language modeling you can refer to the [*Illustrated Self Attention blog*](https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention).
+
+As a consequence, tokens *never* depend on previous tokens, more specifically the \\( \mathbf{q}_i \\) vector is never put in relation with any key, values vectors \\( \mathbf{k}_j, \mathbf{v}_j \\) if \\( j > i \\) . Instead \\( \mathbf{q}_i \\) only attends to previous key-value vectors \\( \mathbf{k}_{m < i}, \mathbf{v}_{m < i} \text{ , for } m \in \{0, \ldots i - 1\} \\). In order to reduce unnecessary computation, one can therefore cache each layer's key-value vectors for all previous timesteps.
+
+In the following, we will tell the LLM to make use of the key-value cache by retrieving and forwarding it for each forward pass.
+In Transformers, we can retrieve the key-value cache by passing the `use_cache` flag to the `forward` call and can then pass it with the current token.
+
+```python
+past_key_values = None # past_key_values is the key-value cache
+generated_tokens = []
+next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
+
+for _ in range(5):
+ next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
+ next_logits = next_logits[:, -1:]
+ next_token_id = torch.argmax(next_logits, dim=-1)
+
+ print("shape of input_ids", next_token_id.shape)
+ print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
+ generated_tokens.append(next_token_id.item())
+
+generated_text = tokenizer.batch_decode(generated_tokens)
+generated_text
+```
+
+**Output**:
+```
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 20
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 21
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 22
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 23
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 24
+[' Here', ' is', ' a', ' Python', ' function']
+```
+
+As one can see, when using the key-value cache the text input tokens are *not* increased in length, but remain a single input vector. The length of the key-value cache on the other hand is increased by one at every decoding step.
+
+> Making use of the key-value cache means that the \\( \mathbf{QK}^T \\) is essentially reduced to \\( \mathbf{q}_c\mathbf{K}^T \\) with \\( \mathbf{q}_c \\) being the query projection of the currently passed input token which is *always* just a single vector.
+
+Using the key-value cache has two advantages:
+- Significant increase in computational efficiency as less computations are performed compared to computing the full \\( \mathbf{QK}^T \\) matrix. This leads to an increase in inference speed
+- The maximum required memory is not increased quadratically with the number of generated tokens, but only increases linearly.
+
+> One should *always* make use of the key-value cache as it leads to identical results and a significant speed-up for longer input sequences. Transformers has the key-value cache enabled by default when making use of the text pipeline or the [`generate` method](https://huggingface.co/docs/transformers/main_classes/text_generation). We have an entire guide dedicated to caches [here](./kv_cache).
+
+
+
+Note that, despite our advice to use key-value caches, your LLM output may be slightly different when you use them. This is a property of the matrix multiplication kernels themselves -- you can read more about it [here](https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535).
+
+
+
+#### 3.2.1 Multi-round conversation
+
+The key-value cache is especially useful for applications such as chat where multiple passes of auto-regressive decoding are required. Let's look at an example.
+
+```
+User: How many people live in France?
+Assistant: Roughly 75 million people live in France
+User: And how many are in Germany?
+Assistant: Germany has ca. 81 million inhabitants
+```
+
+In this chat, the LLM runs auto-regressive decoding twice:
+ 1. The first time, the key-value cache is empty and the input prompt is `"User: How many people live in France?"` and the model auto-regressively generates the text `"Roughly 75 million people live in France"` while increasing the key-value cache at every decoding step.
+ 2. The second time the input prompt is `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"`. Thanks to the cache, all key-value vectors for the first two sentences are already computed. Therefore the input prompt only consists of `"User: And how many in Germany?"`. While processing the shortened input prompt, its computed key-value vectors are concatenated to the key-value cache of the first decoding. The second Assistant's answer `"Germany has ca. 81 million inhabitants"` is then auto-regressively generated with the key-value cache consisting of encoded key-value vectors of `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"`.
+
+Two things should be noted here:
+ 1. Keeping all the context is crucial for LLMs deployed in chat so that the LLM understands all the previous context of the conversation. E.g. for the example above the LLM needs to understand that the user refers to the population when asking `"And how many are in Germany"`.
+ 2. The key-value cache is extremely useful for chat as it allows us to continuously grow the encoded chat history instead of having to re-encode the chat history again from scratch (as e.g. would be the case when using an encoder-decoder architecture).
+
+In `transformers`, a `generate` call will return `past_key_values` when `return_dict_in_generate=True` is passed, in addition to the default `use_cache=True`. Note that it is not yet available through the `pipeline` interface.
+
+```python
+# Generation as usual
+prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
+model_inputs = tokenizer(prompt, return_tensors='pt')
+generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
+decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
+
+# Piping the returned `past_key_values` to speed up the next conversation round
+prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
+model_inputs = tokenizer(prompt, return_tensors='pt')
+generation_output = model.generate(
+ **model_inputs,
+ past_key_values=generation_output.past_key_values,
+ max_new_tokens=60,
+ return_dict_in_generate=True
+)
+tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]
+```
+
+**Output**:
+```
+ is a modified version of the function that returns Mega bytes instead.
+
+def bytes_to_megabytes(bytes):
+ return bytes / 1024 / 1024
+
+Answer: The function takes a number of bytes as input and returns the number of
+```
+
+Great, no additional time is spent recomputing the same key and values for the attention layer! There is however one catch. While the required peak memory for the \\( \mathbf{QK}^T \\) matrix is significantly reduced, holding the key-value cache in memory can become very memory expensive for long input sequences or multi-turn chat. Remember that the key-value cache needs to store the key-value vectors for all previous input vectors \\( \mathbf{x}_i \text{, for } i \in \{1, \ldots, c - 1\} \\) for all self-attention layers and for all attention heads.
+
+Let's compute the number of float values that need to be stored in the key-value cache for the LLM `bigcode/octocoder` that we used before.
+The number of float values amounts to two times the sequence length times the number of attention heads times the attention head dimension and times the number of layers.
+Computing this for our LLM at a hypothetical input sequence length of 16000 gives:
+
+```python
+config = model.config
+2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head
+```
+
+**Output**:
+```
+7864320000
+```
+
+Roughly 8 billion float values! Storing 8 billion float values in `float16` precision requires around 15 GB of RAM which is circa half as much as the model weights themselves!
+Researchers have proposed two methods that allow to significantly reduce the memory cost of storing the key-value cache, which are explored in the next subsections.
+
+#### 3.2.2 Multi-Query-Attention (MQA)
+
+[Multi-Query-Attention](https://arxiv.org/abs/1911.02150) was proposed in Noam Shazeer's *Fast Transformer Decoding: One Write-Head is All You Need* paper. As the title says, Noam found out that instead of using `n_head` key-value projections weights, one can use a single head-value projection weight pair that is shared across all attention heads without that the model's performance significantly degrades.
+
+> By using a single head-value projection weight pair, the key value vectors \\( \mathbf{k}_i, \mathbf{v}_i \\) have to be identical across all attention heads which in turn means that we only need to store 1 key-value projection pair in the cache instead of `n_head` ones.
+
+As most LLMs use between 20 and 100 attention heads, MQA significantly reduces the memory consumption of the key-value cache. For the LLM used in this notebook we could therefore reduce the required memory consumption from 15 GB to less than 400 MB at an input sequence length of 16000.
+
+In addition to memory savings, MQA also leads to improved computational efficiency as explained in the following.
+In auto-regressive decoding, large key-value vectors need to be reloaded, concatenated with the current key-value vector pair to be then fed into the \\( \mathbf{q}_c\mathbf{K}^T \\) computation at every step. For auto-regressive decoding, the required memory bandwidth for the constant reloading can become a serious time bottleneck. By reducing the size of the key-value vectors less memory needs to be accessed, thus reducing the memory bandwidth bottleneck. For more detail, please have a look at [Noam's paper](https://arxiv.org/abs/1911.02150).
+
+The important part to understand here is that reducing the number of key-value attention heads to 1 only makes sense if a key-value cache is used. The peak memory consumption of the model for a single forward pass without key-value cache stays unchanged as every attention head still has a unique query vector so that each attention head still has a different \\( \mathbf{QK}^T \\) matrix.
+
+MQA has seen wide adoption by the community and is now used by many of the most popular LLMs:
+
+- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
+- [**PaLM**](https://arxiv.org/abs/2204.02311)
+- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
+- [**BLOOM**](https://huggingface.co/bigscience/bloom)
+
+Also, the checkpoint used in this notebook - `bigcode/octocoder` - makes use of MQA.
+
+#### 3.2.3 Grouped-Query-Attention (GQA)
+
+[Grouped-Query-Attention](https://arxiv.org/abs/2305.13245), as proposed by Ainslie et al. from Google, found that using MQA can often lead to quality degradation compared to using vanilla multi-key-value head projections. The paper argues that more model performance can be kept by less drastically reducing the number of query head projection weights. Instead of using just a single key-value projection weight, `n < n_head` key-value projection weights should be used. By choosing `n` to a significantly smaller value than `n_head`, such as 2,4 or 8 almost all of the memory and speed gains from MQA can be kept while sacrificing less model capacity and thus arguably less performance.
+
+Moreover, the authors of GQA found out that existing model checkpoints can be *uptrained* to have a GQA architecture with as little as 5% of the original pre-training compute. While 5% of the original pre-training compute can still be a massive amount, GQA *uptraining* allows existing checkpoints to be useful for longer input sequences.
+
+GQA was only recently proposed which is why there is less adoption at the time of writing this notebook.
+The most notable application of GQA is [Llama-v2](https://huggingface.co/meta-llama/Llama-2-70b-hf).
+
+> As a conclusion, it is strongly recommended to make use of either GQA or MQA if the LLM is deployed with auto-regressive decoding and is required to handle large input sequences as is the case for example for chat.
+
+
+## Conclusion
+
+The research community is constantly coming up with new, nifty ways to speed up inference time for ever-larger LLMs. As an example, one such promising research direction is [speculative decoding](https://arxiv.org/abs/2211.17192) where "easy tokens" are generated by smaller, faster language models and only "hard tokens" are generated by the LLM itself. Going into more detail is out of the scope of this notebook, but can be read upon in this [nice blog post](https://huggingface.co/blog/assisted-generation).
+
+The reason massive LLMs such as GPT3/4, Llama-2-70b, Claude, PaLM can run so quickly in chat-interfaces such as [Hugging Face Chat](https://huggingface.co/chat/) or ChatGPT is to a big part thanks to the above-mentioned improvements in precision, algorithms, and architecture.
+Going forward, accelerators such as GPUs, TPUs, etc... will only get faster and allow for more memory, but one should nevertheless always make sure to use the best available algorithms and architectures to get the most bang for your buck 🤗
diff --git a/docs/transformers/docs/source/en/main_classes/backbones.md b/docs/transformers/docs/source/en/main_classes/backbones.md
new file mode 100644
index 0000000000000000000000000000000000000000..5f1fc1dcbe1f202d9527441a6f625e5049054e9a
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/backbones.md
@@ -0,0 +1,60 @@
+
+
+# Backbone
+
+A backbone is a model used for feature extraction for higher level computer vision tasks such as object detection and image classification. Transformers provides an [`AutoBackbone`] class for initializing a Transformers backbone from pretrained model weights, and two utility classes:
+
+* [`~utils.BackboneMixin`] enables initializing a backbone from Transformers or [timm](https://hf.co/docs/timm/index) and includes functions for returning the output features and indices.
+* [`~utils.BackboneConfigMixin`] sets the output features and indices of the backbone configuration.
+
+[timm](https://hf.co/docs/timm/index) models are loaded with the [`TimmBackbone`] and [`TimmBackboneConfig`] classes.
+
+Backbones are supported for the following models:
+
+* [BEiT](../model_doc/beit)
+* [BiT](../model_doc/bit)
+* [ConvNext](../model_doc/convnext)
+* [ConvNextV2](../model_doc/convnextv2)
+* [DiNAT](../model_doc/dinat)
+* [DINOV2](../model_doc/dinov2)
+* [FocalNet](../model_doc/focalnet)
+* [MaskFormer](../model_doc/maskformer)
+* [NAT](../model_doc/nat)
+* [ResNet](../model_doc/resnet)
+* [Swin Transformer](../model_doc/swin)
+* [Swin Transformer v2](../model_doc/swinv2)
+* [ViTDet](../model_doc/vitdet)
+
+## AutoBackbone
+
+[[autodoc]] AutoBackbone
+
+## BackboneMixin
+
+[[autodoc]] utils.BackboneMixin
+
+## BackboneConfigMixin
+
+[[autodoc]] utils.BackboneConfigMixin
+
+## TimmBackbone
+
+[[autodoc]] models.timm_backbone.TimmBackbone
+
+## TimmBackboneConfig
+
+[[autodoc]] models.timm_backbone.TimmBackboneConfig
diff --git a/docs/transformers/docs/source/en/main_classes/callback.md b/docs/transformers/docs/source/en/main_classes/callback.md
new file mode 100644
index 0000000000000000000000000000000000000000..99f76b7b05e43f855d2f76485bc8cbed42618541
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/callback.md
@@ -0,0 +1,137 @@
+
+
+# Callbacks
+
+Callbacks are objects that can customize the behavior of the training loop in the PyTorch
+[`Trainer`] (this feature is not yet implemented in TensorFlow) that can inspect the training loop
+state (for progress reporting, logging on TensorBoard or other ML platforms...) and take decisions (like early
+stopping).
+
+Callbacks are "read only" pieces of code, apart from the [`TrainerControl`] object they return, they
+cannot change anything in the training loop. For customizations that require changes in the training loop, you should
+subclass [`Trainer`] and override the methods you need (see [trainer](trainer) for examples).
+
+By default, `TrainingArguments.report_to` is set to `"all"`, so a [`Trainer`] will use the following callbacks.
+
+- [`DefaultFlowCallback`] which handles the default behavior for logging, saving and evaluation.
+- [`PrinterCallback`] or [`ProgressCallback`] to display progress and print the
+ logs (the first one is used if you deactivate tqdm through the [`TrainingArguments`], otherwise
+ it's the second one).
+- [`~integrations.TensorBoardCallback`] if tensorboard is accessible (either through PyTorch >= 1.4
+ or tensorboardX).
+- [`~integrations.WandbCallback`] if [wandb](https://www.wandb.com/) is installed.
+- [`~integrations.CometCallback`] if [comet_ml](https://www.comet.com/site/) is installed.
+- [`~integrations.MLflowCallback`] if [mlflow](https://www.mlflow.org/) is installed.
+- [`~integrations.NeptuneCallback`] if [neptune](https://neptune.ai/) is installed.
+- [`~integrations.AzureMLCallback`] if [azureml-sdk](https://pypi.org/project/azureml-sdk/) is
+ installed.
+- [`~integrations.CodeCarbonCallback`] if [codecarbon](https://pypi.org/project/codecarbon/) is
+ installed.
+- [`~integrations.ClearMLCallback`] if [clearml](https://github.com/allegroai/clearml) is installed.
+- [`~integrations.DagsHubCallback`] if [dagshub](https://dagshub.com/) is installed.
+- [`~integrations.FlyteCallback`] if [flyte](https://flyte.org/) is installed.
+- [`~integrations.DVCLiveCallback`] if [dvclive](https://dvc.org/doc/dvclive) is installed.
+- [`~integrations.SwanLabCallback`] if [swanlab](http://swanlab.cn/) is installed.
+
+If a package is installed but you don't wish to use the accompanying integration, you can change `TrainingArguments.report_to` to a list of just those integrations you want to use (e.g. `["azure_ml", "wandb"]`).
+
+The main class that implements callbacks is [`TrainerCallback`]. It gets the
+[`TrainingArguments`] used to instantiate the [`Trainer`], can access that
+Trainer's internal state via [`TrainerState`], and can take some actions on the training loop via
+[`TrainerControl`].
+
+
+## Available Callbacks
+
+Here is the list of the available [`TrainerCallback`] in the library:
+
+[[autodoc]] integrations.CometCallback
+ - setup
+
+[[autodoc]] DefaultFlowCallback
+
+[[autodoc]] PrinterCallback
+
+[[autodoc]] ProgressCallback
+
+[[autodoc]] EarlyStoppingCallback
+
+[[autodoc]] integrations.TensorBoardCallback
+
+[[autodoc]] integrations.WandbCallback
+ - setup
+
+[[autodoc]] integrations.MLflowCallback
+ - setup
+
+[[autodoc]] integrations.AzureMLCallback
+
+[[autodoc]] integrations.CodeCarbonCallback
+
+[[autodoc]] integrations.NeptuneCallback
+
+[[autodoc]] integrations.ClearMLCallback
+
+[[autodoc]] integrations.DagsHubCallback
+
+[[autodoc]] integrations.FlyteCallback
+
+[[autodoc]] integrations.DVCLiveCallback
+ - setup
+
+[[autodoc]] integrations.SwanLabCallback
+ - setup
+
+## TrainerCallback
+
+[[autodoc]] TrainerCallback
+
+Here is an example of how to register a custom callback with the PyTorch [`Trainer`]:
+
+```python
+class MyCallback(TrainerCallback):
+ "A callback that prints a message at the beginning of training"
+
+ def on_train_begin(self, args, state, control, **kwargs):
+ print("Starting training")
+
+
+trainer = Trainer(
+ model,
+ args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ callbacks=[MyCallback], # We can either pass the callback class this way or an instance of it (MyCallback())
+)
+```
+
+Another way to register a callback is to call `trainer.add_callback()` as follows:
+
+```python
+trainer = Trainer(...)
+trainer.add_callback(MyCallback)
+# Alternatively, we can pass an instance of the callback class
+trainer.add_callback(MyCallback())
+```
+
+## TrainerState
+
+[[autodoc]] TrainerState
+
+## TrainerControl
+
+[[autodoc]] TrainerControl
diff --git a/docs/transformers/docs/source/en/main_classes/configuration.md b/docs/transformers/docs/source/en/main_classes/configuration.md
new file mode 100644
index 0000000000000000000000000000000000000000..0cfef06d3ce9caba4b91ed57e99124ba7c32122a
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/configuration.md
@@ -0,0 +1,32 @@
+
+
+# Configuration
+
+The base class [`PretrainedConfig`] implements the common methods for loading/saving a configuration
+either from a local file or directory, or from a pretrained model configuration provided by the library (downloaded
+from HuggingFace's AWS S3 repository).
+
+Each derived config class implements model specific attributes. Common attributes present in all config classes are:
+`hidden_size`, `num_attention_heads`, and `num_hidden_layers`. Text models further implement:
+`vocab_size`.
+
+
+## PretrainedConfig
+
+[[autodoc]] PretrainedConfig
+ - push_to_hub
+ - all
diff --git a/docs/transformers/docs/source/en/main_classes/data_collator.md b/docs/transformers/docs/source/en/main_classes/data_collator.md
new file mode 100644
index 0000000000000000000000000000000000000000..0da904f1131a9ecdc7adaead8bbbef0b87393678
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/data_collator.md
@@ -0,0 +1,76 @@
+
+
+# Data Collator
+
+Data collators are objects that will form a batch by using a list of dataset elements as input. These elements are of
+the same type as the elements of `train_dataset` or `eval_dataset`.
+
+To be able to build batches, data collators may apply some processing (like padding). Some of them (like
+[`DataCollatorForLanguageModeling`]) also apply some random data augmentation (like random masking)
+on the formed batch.
+
+Examples of use can be found in the [example scripts](../examples) or [example notebooks](../notebooks).
+
+
+## Default data collator
+
+[[autodoc]] data.data_collator.default_data_collator
+
+## DefaultDataCollator
+
+[[autodoc]] data.data_collator.DefaultDataCollator
+
+## DataCollatorWithPadding
+
+[[autodoc]] data.data_collator.DataCollatorWithPadding
+
+## DataCollatorForTokenClassification
+
+[[autodoc]] data.data_collator.DataCollatorForTokenClassification
+
+## DataCollatorForSeq2Seq
+
+[[autodoc]] data.data_collator.DataCollatorForSeq2Seq
+
+## DataCollatorForLanguageModeling
+
+[[autodoc]] data.data_collator.DataCollatorForLanguageModeling
+ - numpy_mask_tokens
+ - tf_mask_tokens
+ - torch_mask_tokens
+
+## DataCollatorForWholeWordMask
+
+[[autodoc]] data.data_collator.DataCollatorForWholeWordMask
+ - numpy_mask_tokens
+ - tf_mask_tokens
+ - torch_mask_tokens
+
+## DataCollatorForPermutationLanguageModeling
+
+[[autodoc]] data.data_collator.DataCollatorForPermutationLanguageModeling
+ - numpy_mask_tokens
+ - tf_mask_tokens
+ - torch_mask_tokens
+
+## DataCollatorWithFlattening
+
+[[autodoc]] data.data_collator.DataCollatorWithFlattening
+
+# DataCollatorForMultipleChoice
+
+[[autodoc]] data.data_collator.DataCollatorForMultipleChoice
diff --git a/docs/transformers/docs/source/en/main_classes/deepspeed.md b/docs/transformers/docs/source/en/main_classes/deepspeed.md
new file mode 100644
index 0000000000000000000000000000000000000000..0b9e28656c0938be4264ae945e999b728a8e0fe7
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/deepspeed.md
@@ -0,0 +1,32 @@
+
+
+# DeepSpeed
+
+[DeepSpeed](https://github.com/deepspeedai/DeepSpeed), powered by Zero Redundancy Optimizer (ZeRO), is an optimization library for training and fitting very large models onto a GPU. It is available in several ZeRO stages, where each stage progressively saves more GPU memory by partitioning the optimizer state, gradients, parameters, and enabling offloading to a CPU or NVMe. DeepSpeed is integrated with the [`Trainer`] class and most of the setup is automatically taken care of for you.
+
+However, if you want to use DeepSpeed without the [`Trainer`], Transformers provides a [`HfDeepSpeedConfig`] class.
+
+
+
+Learn more about using DeepSpeed with [`Trainer`] in the [DeepSpeed](../deepspeed) guide.
+
+
+
+## HfDeepSpeedConfig
+
+[[autodoc]] integrations.HfDeepSpeedConfig
+ - all
diff --git a/docs/transformers/docs/source/en/main_classes/executorch.md b/docs/transformers/docs/source/en/main_classes/executorch.md
new file mode 100644
index 0000000000000000000000000000000000000000..3178085c9135be8a9721d2f24dfd3b427dbe5259
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/executorch.md
@@ -0,0 +1,33 @@
+
+
+
+# ExecuTorch
+
+[`ExecuTorch`](https://github.com/pytorch/executorch) is an end-to-end solution for enabling on-device inference capabilities across mobile and edge devices including wearables, embedded devices and microcontrollers. It is part of the PyTorch ecosystem and supports the deployment of PyTorch models with a focus on portability, productivity, and performance.
+
+ExecuTorch introduces well defined entry points to perform model, device, and/or use-case specific optimizations such as backend delegation, user-defined compiler transformations, memory planning, and more. The first step in preparing a PyTorch model for execution on an edge device using ExecuTorch is to export the model. This is achieved through the use of a PyTorch API called [`torch.export`](https://pytorch.org/docs/stable/export.html).
+
+
+## ExecuTorch Integration
+
+An integration point is being developed to ensure that 🤗 Transformers can be exported using `torch.export`. The goal of this integration is not only to enable export but also to ensure that the exported artifact can be further lowered and optimized to run efficiently in `ExecuTorch`, particularly for mobile and edge use cases.
+
+[[autodoc]] TorchExportableModuleWithStaticCache
+ - forward
+
+[[autodoc]] convert_and_export_with_cache
diff --git a/docs/transformers/docs/source/en/main_classes/feature_extractor.md b/docs/transformers/docs/source/en/main_classes/feature_extractor.md
new file mode 100644
index 0000000000000000000000000000000000000000..d79c531be6df0dd4802aa7b8eddf9f6ecfe916ea
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/feature_extractor.md
@@ -0,0 +1,39 @@
+
+
+# Feature Extractor
+
+A feature extractor is in charge of preparing input features for audio or vision models. This includes feature extraction from sequences, e.g., pre-processing audio files to generate Log-Mel Spectrogram features, feature extraction from images, e.g., cropping image files, but also padding, normalization, and conversion to NumPy, PyTorch, and TensorFlow tensors.
+
+
+## FeatureExtractionMixin
+
+[[autodoc]] feature_extraction_utils.FeatureExtractionMixin
+ - from_pretrained
+ - save_pretrained
+
+## SequenceFeatureExtractor
+
+[[autodoc]] SequenceFeatureExtractor
+ - pad
+
+## BatchFeature
+
+[[autodoc]] BatchFeature
+
+## ImageFeatureExtractionMixin
+
+[[autodoc]] image_utils.ImageFeatureExtractionMixin
diff --git a/docs/transformers/docs/source/en/main_classes/image_processor.md b/docs/transformers/docs/source/en/main_classes/image_processor.md
new file mode 100644
index 0000000000000000000000000000000000000000..cbf6ae95577f70ab2c58785874484368bd4629fc
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/image_processor.md
@@ -0,0 +1,79 @@
+
+
+# Image Processor
+
+An image processor is in charge of preparing input features for vision models and post processing their outputs. This includes transformations such as resizing, normalization, and conversion to PyTorch, TensorFlow, Flax and Numpy tensors. It may also include model specific post-processing such as converting logits to segmentation masks.
+
+Fast image processors are available for a few models and more will be added in the future. They are based on the [torchvision](https://pytorch.org/vision/stable/index.html) library and provide a significant speed-up, especially when processing on GPU.
+They have the same API as the base image processors and can be used as drop-in replacements.
+To use a fast image processor, you need to install the `torchvision` library, and set the `use_fast` argument to `True` when instantiating the image processor:
+
+```python
+from transformers import AutoImageProcessor
+
+processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50", use_fast=True)
+```
+Note that `use_fast` will be set to `True` by default in a future release.
+
+When using a fast image processor, you can also set the `device` argument to specify the device on which the processing should be done. By default, the processing is done on the same device as the inputs if the inputs are tensors, or on the CPU otherwise.
+
+```python
+from torchvision.io import read_image
+from transformers import DetrImageProcessorFast
+
+images = read_image("image.jpg")
+processor = DetrImageProcessorFast.from_pretrained("facebook/detr-resnet-50")
+images_processed = processor(images, return_tensors="pt", device="cuda")
+```
+
+Here are some speed comparisons between the base and fast image processors for the `DETR` and `RT-DETR` models, and how they impact overall inference time:
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+These benchmarks were run on an [AWS EC2 g5.2xlarge instance](https://aws.amazon.com/ec2/instance-types/g5/), utilizing an NVIDIA A10G Tensor Core GPU.
+
+
+## ImageProcessingMixin
+
+[[autodoc]] image_processing_utils.ImageProcessingMixin
+ - from_pretrained
+ - save_pretrained
+
+## BatchFeature
+
+[[autodoc]] BatchFeature
+
+## BaseImageProcessor
+
+[[autodoc]] image_processing_utils.BaseImageProcessor
+
+
+## BaseImageProcessorFast
+
+[[autodoc]] image_processing_utils_fast.BaseImageProcessorFast
diff --git a/docs/transformers/docs/source/en/main_classes/keras_callbacks.md b/docs/transformers/docs/source/en/main_classes/keras_callbacks.md
new file mode 100644
index 0000000000000000000000000000000000000000..c9932300dbc56986f107650a474a03233dcc3ae6
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/keras_callbacks.md
@@ -0,0 +1,28 @@
+
+
+# Keras callbacks
+
+When training a Transformers model with Keras, there are some library-specific callbacks available to automate common
+tasks:
+
+## KerasMetricCallback
+
+[[autodoc]] KerasMetricCallback
+
+## PushToHubCallback
+
+[[autodoc]] PushToHubCallback
diff --git a/docs/transformers/docs/source/en/main_classes/logging.md b/docs/transformers/docs/source/en/main_classes/logging.md
new file mode 100644
index 0000000000000000000000000000000000000000..5cbdf9ae27ed1ce61b1a45556c569c7b9eb4b628
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/logging.md
@@ -0,0 +1,119 @@
+
+
+# Logging
+
+🤗 Transformers has a centralized logging system, so that you can setup the verbosity of the library easily.
+
+Currently the default verbosity of the library is `WARNING`.
+
+To change the level of verbosity, just use one of the direct setters. For instance, here is how to change the verbosity
+to the INFO level.
+
+```python
+import transformers
+
+transformers.logging.set_verbosity_info()
+```
+
+You can also use the environment variable `TRANSFORMERS_VERBOSITY` to override the default verbosity. You can set it
+to one of the following: `debug`, `info`, `warning`, `error`, `critical`, `fatal`. For example:
+
+```bash
+TRANSFORMERS_VERBOSITY=error ./myprogram.py
+```
+
+Additionally, some `warnings` can be disabled by setting the environment variable
+`TRANSFORMERS_NO_ADVISORY_WARNINGS` to a true value, like *1*. This will disable any warning that is logged using
+[`logger.warning_advice`]. For example:
+
+```bash
+TRANSFORMERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
+```
+
+Here is an example of how to use the same logger as the library in your own module or script:
+
+```python
+from transformers.utils import logging
+
+logging.set_verbosity_info()
+logger = logging.get_logger("transformers")
+logger.info("INFO")
+logger.warning("WARN")
+```
+
+
+All the methods of this logging module are documented below, the main ones are
+[`logging.get_verbosity`] to get the current level of verbosity in the logger and
+[`logging.set_verbosity`] to set the verbosity to the level of your choice. In order (from the least
+verbose to the most verbose), those levels (with their corresponding int values in parenthesis) are:
+
+- `transformers.logging.CRITICAL` or `transformers.logging.FATAL` (int value, 50): only report the most
+ critical errors.
+- `transformers.logging.ERROR` (int value, 40): only report errors.
+- `transformers.logging.WARNING` or `transformers.logging.WARN` (int value, 30): only reports error and
+ warnings. This is the default level used by the library.
+- `transformers.logging.INFO` (int value, 20): reports error, warnings and basic information.
+- `transformers.logging.DEBUG` (int value, 10): report all information.
+
+By default, `tqdm` progress bars will be displayed during model download. [`logging.disable_progress_bar`] and [`logging.enable_progress_bar`] can be used to suppress or unsuppress this behavior.
+
+## `logging` vs `warnings`
+
+Python has two logging systems that are often used in conjunction: `logging`, which is explained above, and `warnings`,
+which allows further classification of warnings in specific buckets, e.g., `FutureWarning` for a feature or path
+that has already been deprecated and `DeprecationWarning` to indicate an upcoming deprecation.
+
+We use both in the `transformers` library. We leverage and adapt `logging`'s `captureWarnings` method to allow
+management of these warning messages by the verbosity setters above.
+
+What does that mean for developers of the library? We should respect the following heuristics:
+- `warnings` should be favored for developers of the library and libraries dependent on `transformers`
+- `logging` should be used for end-users of the library using it in every-day projects
+
+See reference of the `captureWarnings` method below.
+
+[[autodoc]] logging.captureWarnings
+
+## Base setters
+
+[[autodoc]] logging.set_verbosity_error
+
+[[autodoc]] logging.set_verbosity_warning
+
+[[autodoc]] logging.set_verbosity_info
+
+[[autodoc]] logging.set_verbosity_debug
+
+## Other functions
+
+[[autodoc]] logging.get_verbosity
+
+[[autodoc]] logging.set_verbosity
+
+[[autodoc]] logging.get_logger
+
+[[autodoc]] logging.enable_default_handler
+
+[[autodoc]] logging.disable_default_handler
+
+[[autodoc]] logging.enable_explicit_format
+
+[[autodoc]] logging.reset_format
+
+[[autodoc]] logging.enable_progress_bar
+
+[[autodoc]] logging.disable_progress_bar
diff --git a/docs/transformers/docs/source/en/main_classes/model.md b/docs/transformers/docs/source/en/main_classes/model.md
new file mode 100644
index 0000000000000000000000000000000000000000..15345a7b2af3fb0db28358e9904bf83df4aff272
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/model.md
@@ -0,0 +1,73 @@
+
+
+# Models
+
+The base classes [`PreTrainedModel`], [`TFPreTrainedModel`], and
+[`FlaxPreTrainedModel`] implement the common methods for loading/saving a model either from a local
+file or directory, or from a pretrained model configuration provided by the library (downloaded from HuggingFace's AWS
+S3 repository).
+
+[`PreTrainedModel`] and [`TFPreTrainedModel`] also implement a few methods which
+are common among all the models to:
+
+- resize the input token embeddings when new tokens are added to the vocabulary
+- prune the attention heads of the model.
+
+The other methods that are common to each model are defined in [`~modeling_utils.ModuleUtilsMixin`]
+(for the PyTorch models) and [`~modeling_tf_utils.TFModuleUtilsMixin`] (for the TensorFlow models) or
+for text generation, [`~generation.GenerationMixin`] (for the PyTorch models),
+[`~generation.TFGenerationMixin`] (for the TensorFlow models) and
+[`~generation.FlaxGenerationMixin`] (for the Flax/JAX models).
+
+
+## PreTrainedModel
+
+[[autodoc]] PreTrainedModel
+ - push_to_hub
+ - all
+
+Custom models should also include a `_supports_assign_param_buffer`, which determines if superfast init can apply
+on the particular model. Signs that your model needs this are if `test_save_and_load_from_pretrained` fails. If so,
+set this to `False`.
+
+## ModuleUtilsMixin
+
+[[autodoc]] modeling_utils.ModuleUtilsMixin
+
+## TFPreTrainedModel
+
+[[autodoc]] TFPreTrainedModel
+ - push_to_hub
+ - all
+
+## TFModelUtilsMixin
+
+[[autodoc]] modeling_tf_utils.TFModelUtilsMixin
+
+## FlaxPreTrainedModel
+
+[[autodoc]] FlaxPreTrainedModel
+ - push_to_hub
+ - all
+
+## Pushing to the Hub
+
+[[autodoc]] utils.PushToHubMixin
+
+## Sharded checkpoints
+
+[[autodoc]] modeling_utils.load_sharded_checkpoint
diff --git a/docs/transformers/docs/source/en/main_classes/onnx.md b/docs/transformers/docs/source/en/main_classes/onnx.md
new file mode 100644
index 0000000000000000000000000000000000000000..81d31c97e88dde23f3807cbcbc05820c3f06a48d
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/onnx.md
@@ -0,0 +1,54 @@
+
+
+# Exporting 🤗 Transformers models to ONNX
+
+🤗 Transformers provides a `transformers.onnx` package that enables you to
+convert model checkpoints to an ONNX graph by leveraging configuration objects.
+
+See the [guide](../serialization) on exporting 🤗 Transformers models for more
+details.
+
+## ONNX Configurations
+
+We provide three abstract classes that you should inherit from, depending on the
+type of model architecture you wish to export:
+
+* Encoder-based models inherit from [`~onnx.config.OnnxConfig`]
+* Decoder-based models inherit from [`~onnx.config.OnnxConfigWithPast`]
+* Encoder-decoder models inherit from [`~onnx.config.OnnxSeq2SeqConfigWithPast`]
+
+### OnnxConfig
+
+[[autodoc]] onnx.config.OnnxConfig
+
+### OnnxConfigWithPast
+
+[[autodoc]] onnx.config.OnnxConfigWithPast
+
+### OnnxSeq2SeqConfigWithPast
+
+[[autodoc]] onnx.config.OnnxSeq2SeqConfigWithPast
+
+## ONNX Features
+
+Each ONNX configuration is associated with a set of _features_ that enable you
+to export models for different types of topologies or tasks.
+
+### FeaturesManager
+
+[[autodoc]] onnx.features.FeaturesManager
+
diff --git a/docs/transformers/docs/source/en/main_classes/optimizer_schedules.md b/docs/transformers/docs/source/en/main_classes/optimizer_schedules.md
new file mode 100644
index 0000000000000000000000000000000000000000..24c978e6fe3ced5eb39e1e3f0e1f956f36c83247
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/optimizer_schedules.md
@@ -0,0 +1,76 @@
+
+
+# Optimization
+
+The `.optimization` module provides:
+
+- an optimizer with weight decay fixed that can be used to fine-tuned models, and
+- several schedules in the form of schedule objects that inherit from `_LRSchedule`:
+- a gradient accumulation class to accumulate the gradients of multiple batches
+
+
+## AdaFactor (PyTorch)
+
+[[autodoc]] Adafactor
+
+## AdamWeightDecay (TensorFlow)
+
+[[autodoc]] AdamWeightDecay
+
+[[autodoc]] create_optimizer
+
+## Schedules
+
+### Learning Rate Schedules (PyTorch)
+
+[[autodoc]] SchedulerType
+
+[[autodoc]] get_scheduler
+
+[[autodoc]] get_constant_schedule
+
+[[autodoc]] get_constant_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+
+
+[[autodoc]] get_linear_schedule_with_warmup
+
+
+
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+[[autodoc]] get_inverse_sqrt_schedule
+
+[[autodoc]] get_wsd_schedule
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## Gradient Strategies
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
diff --git a/docs/transformers/docs/source/en/main_classes/output.md b/docs/transformers/docs/source/en/main_classes/output.md
new file mode 100644
index 0000000000000000000000000000000000000000..300213d4513ebbf832e22828ac8be3164d5b95e6
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/output.md
@@ -0,0 +1,321 @@
+
+
+# Model outputs
+
+All models have outputs that are instances of subclasses of [`~utils.ModelOutput`]. Those are
+data structures containing all the information returned by the model, but that can also be used as tuples or
+dictionaries.
+
+Let's see how this looks in an example:
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
+outputs = model(**inputs, labels=labels)
+```
+
+The `outputs` object is a [`~modeling_outputs.SequenceClassifierOutput`], as we can see in the
+documentation of that class below, it means it has an optional `loss`, a `logits`, an optional `hidden_states` and
+an optional `attentions` attribute. Here we have the `loss` since we passed along `labels`, but we don't have
+`hidden_states` and `attentions` because we didn't pass `output_hidden_states=True` or
+`output_attentions=True`.
+
+
+
+When passing `output_hidden_states=True` you may expect the `outputs.hidden_states[-1]` to match `outputs.last_hidden_state` exactly.
+However, this is not always the case. Some models apply normalization or subsequent process to the last hidden state when it's returned.
+
+
+
+
+You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you
+will get `None`. Here for instance `outputs.loss` is the loss computed by the model, and `outputs.attentions` is
+`None`.
+
+When considering our `outputs` object as tuple, it only considers the attributes that don't have `None` values.
+Here for instance, it has two elements, `loss` then `logits`, so
+
+```python
+outputs[:2]
+```
+
+will return the tuple `(outputs.loss, outputs.logits)` for instance.
+
+When considering our `outputs` object as dictionary, it only considers the attributes that don't have `None`
+values. Here for instance, it has two keys that are `loss` and `logits`.
+
+We document here the generic model outputs that are used by more than one model type. Specific output types are
+documented on their corresponding model page.
+
+## ModelOutput
+
+[[autodoc]] utils.ModelOutput
+ - to_tuple
+
+## BaseModelOutput
+
+[[autodoc]] modeling_outputs.BaseModelOutput
+
+## BaseModelOutputWithPooling
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
+
+## BaseModelOutputWithCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
+
+## BaseModelOutputWithPoolingAndCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
+
+## BaseModelOutputWithPast
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPast
+
+## BaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
+
+## Seq2SeqModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqModelOutput
+
+## CausalLMOutput
+
+[[autodoc]] modeling_outputs.CausalLMOutput
+
+## CausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
+
+## CausalLMOutputWithPast
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithPast
+
+## MaskedLMOutput
+
+[[autodoc]] modeling_outputs.MaskedLMOutput
+
+## Seq2SeqLMOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqLMOutput
+
+## NextSentencePredictorOutput
+
+[[autodoc]] modeling_outputs.NextSentencePredictorOutput
+
+## SequenceClassifierOutput
+
+[[autodoc]] modeling_outputs.SequenceClassifierOutput
+
+## Seq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
+
+## MultipleChoiceModelOutput
+
+[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
+
+## TokenClassifierOutput
+
+[[autodoc]] modeling_outputs.TokenClassifierOutput
+
+## QuestionAnsweringModelOutput
+
+[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
+
+## Seq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
+
+## Seq2SeqSpectrogramOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqSpectrogramOutput
+
+## SemanticSegmenterOutput
+
+[[autodoc]] modeling_outputs.SemanticSegmenterOutput
+
+## ImageClassifierOutput
+
+[[autodoc]] modeling_outputs.ImageClassifierOutput
+
+## ImageClassifierOutputWithNoAttention
+
+[[autodoc]] modeling_outputs.ImageClassifierOutputWithNoAttention
+
+## DepthEstimatorOutput
+
+[[autodoc]] modeling_outputs.DepthEstimatorOutput
+
+## Wav2Vec2BaseModelOutput
+
+[[autodoc]] modeling_outputs.Wav2Vec2BaseModelOutput
+
+## XVectorOutput
+
+[[autodoc]] modeling_outputs.XVectorOutput
+
+## Seq2SeqTSModelOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqTSModelOutput
+
+## Seq2SeqTSPredictionOutput
+
+[[autodoc]] modeling_outputs.Seq2SeqTSPredictionOutput
+
+## SampleTSPredictionOutput
+
+[[autodoc]] modeling_outputs.SampleTSPredictionOutput
+
+## TFBaseModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
+
+## TFBaseModelOutputWithPooling
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPooling
+
+## TFBaseModelOutputWithPoolingAndCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions
+
+## TFBaseModelOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPast
+
+## TFBaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions
+
+## TFSeq2SeqModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqModelOutput
+
+## TFCausalLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutput
+
+## TFCausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions
+
+## TFCausalLMOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithPast
+
+## TFMaskedLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFMaskedLMOutput
+
+## TFSeq2SeqLMOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqLMOutput
+
+## TFNextSentencePredictorOutput
+
+[[autodoc]] modeling_tf_outputs.TFNextSentencePredictorOutput
+
+## TFSequenceClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutput
+
+## TFSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
+
+## TFMultipleChoiceModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFMultipleChoiceModelOutput
+
+## TFTokenClassifierOutput
+
+[[autodoc]] modeling_tf_outputs.TFTokenClassifierOutput
+
+## TFQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFQuestionAnsweringModelOutput
+
+## TFSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
+
+## FlaxBaseModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutput
+
+## FlaxBaseModelOutputWithPast
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPast
+
+## FlaxBaseModelOutputWithPooling
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPooling
+
+## FlaxBaseModelOutputWithPastAndCrossAttentions
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions
+
+## FlaxSeq2SeqModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqModelOutput
+
+## FlaxCausalLMOutputWithCrossAttentions
+
+[[autodoc]] modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions
+
+## FlaxMaskedLMOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxMaskedLMOutput
+
+## FlaxSeq2SeqLMOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqLMOutput
+
+## FlaxNextSentencePredictorOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxNextSentencePredictorOutput
+
+## FlaxSequenceClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSequenceClassifierOutput
+
+## FlaxSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput
+
+## FlaxMultipleChoiceModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxMultipleChoiceModelOutput
+
+## FlaxTokenClassifierOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxTokenClassifierOutput
+
+## FlaxQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxQuestionAnsweringModelOutput
+
+## FlaxSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput
diff --git a/docs/transformers/docs/source/en/main_classes/peft.md b/docs/transformers/docs/source/en/main_classes/peft.md
new file mode 100644
index 0000000000000000000000000000000000000000..85790f120ebf41a249bd0776ee2d45bfa3c92a41
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/peft.md
@@ -0,0 +1,23 @@
+
+
+# PEFT
+
+The [`~integrations.PeftAdapterMixin`] provides functions from the [PEFT](https://huggingface.co/docs/peft/index) library for managing adapters with Transformers. This mixin currently supports LoRA, IA3, and AdaLora. Prefix tuning methods (prompt tuning, prompt learning) aren't supported because they can't be injected into a torch module.
+
+[[autodoc]] integrations.PeftAdapterMixin
+ - load_adapter
+ - add_adapter
+ - set_adapter
+ - disable_adapters
+ - enable_adapters
+ - active_adapters
+ - get_adapter_state_dict
diff --git a/docs/transformers/docs/source/en/main_classes/pipelines.md b/docs/transformers/docs/source/en/main_classes/pipelines.md
new file mode 100644
index 0000000000000000000000000000000000000000..59e474fcc49f7523f74a44cf761738e4aea9fcea
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/pipelines.md
@@ -0,0 +1,501 @@
+
+
+# Pipelines
+
+The pipelines are a great and easy way to use models for inference. These pipelines are objects that abstract most of
+the complex code from the library, offering a simple API dedicated to several tasks, including Named Entity
+Recognition, Masked Language Modeling, Sentiment Analysis, Feature Extraction and Question Answering. See the
+[task summary](../task_summary) for examples of use.
+
+There are two categories of pipeline abstractions to be aware about:
+
+- The [`pipeline`] which is the most powerful object encapsulating all other pipelines.
+- Task-specific pipelines are available for [audio](#audio), [computer vision](#computer-vision), [natural language processing](#natural-language-processing), and [multimodal](#multimodal) tasks.
+
+## The pipeline abstraction
+
+The *pipeline* abstraction is a wrapper around all the other available pipelines. It is instantiated as any other
+pipeline but can provide additional quality of life.
+
+Simple call on one item:
+
+```python
+>>> pipe = pipeline("text-classification")
+>>> pipe("This restaurant is awesome")
+[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+```
+
+If you want to use a specific model from the [hub](https://huggingface.co) you can ignore the task if the model on
+the hub already defines it:
+
+```python
+>>> pipe = pipeline(model="FacebookAI/roberta-large-mnli")
+>>> pipe("This restaurant is awesome")
+[{'label': 'NEUTRAL', 'score': 0.7313136458396912}]
+```
+
+To call a pipeline on many items, you can call it with a *list*.
+
+```python
+>>> pipe = pipeline("text-classification")
+>>> pipe(["This restaurant is awesome", "This restaurant is awful"])
+[{'label': 'POSITIVE', 'score': 0.9998743534088135},
+ {'label': 'NEGATIVE', 'score': 0.9996669292449951}]
+```
+
+To iterate over full datasets it is recommended to use a `dataset` directly. This means you don't need to allocate
+the whole dataset at once, nor do you need to do batching yourself. This should work just as fast as custom loops on
+GPU. If it doesn't don't hesitate to create an issue.
+
+```python
+import datasets
+from transformers import pipeline
+from transformers.pipelines.pt_utils import KeyDataset
+from tqdm.auto import tqdm
+
+pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
+dataset = datasets.load_dataset("superb", name="asr", split="test")
+
+# KeyDataset (only *pt*) will simply return the item in the dict returned by the dataset item
+# as we're not interested in the *target* part of the dataset. For sentence pair use KeyPairDataset
+for out in tqdm(pipe(KeyDataset(dataset, "file"))):
+ print(out)
+ # {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
+ # {"text": ....}
+ # ....
+```
+
+For ease of use, a generator is also possible:
+
+
+```python
+from transformers import pipeline
+
+pipe = pipeline("text-classification")
+
+
+def data():
+ while True:
+ # This could come from a dataset, a database, a queue or HTTP request
+ # in a server
+ # Caveat: because this is iterative, you cannot use `num_workers > 1` variable
+ # to use multiple threads to preprocess data. You can still have 1 thread that
+ # does the preprocessing while the main runs the big inference
+ yield "This is a test"
+
+
+for out in pipe(data()):
+ print(out)
+ # {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
+ # {"text": ....}
+ # ....
+```
+
+[[autodoc]] pipeline
+
+## Pipeline batching
+
+All pipelines can use batching. This will work
+whenever the pipeline uses its streaming ability (so when passing lists or `Dataset` or `generator`).
+
+```python
+from transformers import pipeline
+from transformers.pipelines.pt_utils import KeyDataset
+import datasets
+
+dataset = datasets.load_dataset("imdb", name="plain_text", split="unsupervised")
+pipe = pipeline("text-classification", device=0)
+for out in pipe(KeyDataset(dataset, "text"), batch_size=8, truncation="only_first"):
+ print(out)
+ # [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
+ # Exactly the same output as before, but the content are passed
+ # as batches to the model
+```
+
+
+
+However, this is not automatically a win for performance. It can be either a 10x speedup or 5x slowdown depending
+on hardware, data and the actual model being used.
+
+Example where it's mostly a speedup:
+
+
+
+```python
+from transformers import pipeline
+from torch.utils.data import Dataset
+from tqdm.auto import tqdm
+
+pipe = pipeline("text-classification", device=0)
+
+
+class MyDataset(Dataset):
+ def __len__(self):
+ return 5000
+
+ def __getitem__(self, i):
+ return "This is a test"
+
+
+dataset = MyDataset()
+
+for batch_size in [1, 8, 64, 256]:
+ print("-" * 30)
+ print(f"Streaming batch_size={batch_size}")
+ for out in tqdm(pipe(dataset, batch_size=batch_size), total=len(dataset)):
+ pass
+```
+
+```
+# On GTX 970
+------------------------------
+Streaming no batching
+100%|██████████████████████████████████████████████████████████████████████| 5000/5000 [00:26<00:00, 187.52it/s]
+------------------------------
+Streaming batch_size=8
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:04<00:00, 1205.95it/s]
+------------------------------
+Streaming batch_size=64
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:02<00:00, 2478.24it/s]
+------------------------------
+Streaming batch_size=256
+100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:01<00:00, 2554.43it/s]
+(diminishing returns, saturated the GPU)
+```
+
+Example where it's most a slowdown:
+
+```python
+class MyDataset(Dataset):
+ def __len__(self):
+ return 5000
+
+ def __getitem__(self, i):
+ if i % 64 == 0:
+ n = 100
+ else:
+ n = 1
+ return "This is a test" * n
+```
+
+This is a occasional very long sentence compared to the other. In that case, the **whole** batch will need to be 400
+tokens long, so the whole batch will be [64, 400] instead of [64, 4], leading to the high slowdown. Even worse, on
+bigger batches, the program simply crashes.
+
+
+```
+------------------------------
+Streaming no batching
+100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 183.69it/s]
+------------------------------
+Streaming batch_size=8
+100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 265.74it/s]
+------------------------------
+Streaming batch_size=64
+100%|██████████████████████████████████████████████████████████████████████| 1000/1000 [00:26<00:00, 37.80it/s]
+------------------------------
+Streaming batch_size=256
+ 0%| | 0/1000 [00:00
+ for out in tqdm(pipe(dataset, batch_size=256), total=len(dataset)):
+....
+ q = q / math.sqrt(dim_per_head) # (bs, n_heads, q_length, dim_per_head)
+RuntimeError: CUDA out of memory. Tried to allocate 376.00 MiB (GPU 0; 3.95 GiB total capacity; 1.72 GiB already allocated; 354.88 MiB free; 2.46 GiB reserved in total by PyTorch)
+```
+
+There are no good (general) solutions for this problem, and your mileage may vary depending on your use cases. Rule of
+thumb:
+
+For users, a rule of thumb is:
+
+- **Measure performance on your load, with your hardware. Measure, measure, and keep measuring. Real numbers are the
+ only way to go.**
+- If you are latency constrained (live product doing inference), don't batch.
+- If you are using CPU, don't batch.
+- If you are using throughput (you want to run your model on a bunch of static data), on GPU, then:
+
+ - If you have no clue about the size of the sequence_length ("natural" data), by default don't batch, measure and
+ try tentatively to add it, add OOM checks to recover when it will fail (and it will at some point if you don't
+ control the sequence_length.)
+ - If your sequence_length is super regular, then batching is more likely to be VERY interesting, measure and push
+ it until you get OOMs.
+ - The larger the GPU the more likely batching is going to be more interesting
+- As soon as you enable batching, make sure you can handle OOMs nicely.
+
+## Pipeline chunk batching
+
+`zero-shot-classification` and `question-answering` are slightly specific in the sense, that a single input might yield
+multiple forward pass of a model. Under normal circumstances, this would yield issues with `batch_size` argument.
+
+In order to circumvent this issue, both of these pipelines are a bit specific, they are `ChunkPipeline` instead of
+regular `Pipeline`. In short:
+
+
+```python
+preprocessed = pipe.preprocess(inputs)
+model_outputs = pipe.forward(preprocessed)
+outputs = pipe.postprocess(model_outputs)
+```
+
+Now becomes:
+
+
+```python
+all_model_outputs = []
+for preprocessed in pipe.preprocess(inputs):
+ model_outputs = pipe.forward(preprocessed)
+ all_model_outputs.append(model_outputs)
+outputs = pipe.postprocess(all_model_outputs)
+```
+
+This should be very transparent to your code because the pipelines are used in
+the same way.
+
+This is a simplified view, since the pipeline can handle automatically the batch to ! Meaning you don't have to care
+about how many forward passes you inputs are actually going to trigger, you can optimize the `batch_size`
+independently of the inputs. The caveats from the previous section still apply.
+
+## Pipeline FP16 inference
+Models can be run in FP16 which can be significantly faster on GPU while saving memory. Most models will not suffer noticeable performance loss from this. The larger the model, the less likely that it will.
+
+To enable FP16 inference, you can simply pass `torch_dtype=torch.float16` or `torch_dtype='float16'` to the pipeline constructor. Note that this only works for models with a PyTorch backend. Your inputs will be converted to FP16 internally.
+
+## Pipeline custom code
+
+If you want to override a specific pipeline.
+
+Don't hesitate to create an issue for your task at hand, the goal of the pipeline is to be easy to use and support most
+cases, so `transformers` could maybe support your use case.
+
+
+If you want to try simply you can:
+
+- Subclass your pipeline of choice
+
+```python
+class MyPipeline(TextClassificationPipeline):
+ def postprocess():
+ # Your code goes here
+ scores = scores * 100
+ # And here
+
+
+my_pipeline = MyPipeline(model=model, tokenizer=tokenizer, ...)
+# or if you use *pipeline* function, then:
+my_pipeline = pipeline(model="xxxx", pipeline_class=MyPipeline)
+```
+
+That should enable you to do all the custom code you want.
+
+
+## Implementing a pipeline
+
+[Implementing a new pipeline](../add_new_pipeline)
+
+## Audio
+
+Pipelines available for audio tasks include the following.
+
+### AudioClassificationPipeline
+
+[[autodoc]] AudioClassificationPipeline
+ - __call__
+ - all
+
+### AutomaticSpeechRecognitionPipeline
+
+[[autodoc]] AutomaticSpeechRecognitionPipeline
+ - __call__
+ - all
+
+### TextToAudioPipeline
+
+[[autodoc]] TextToAudioPipeline
+ - __call__
+ - all
+
+
+### ZeroShotAudioClassificationPipeline
+
+[[autodoc]] ZeroShotAudioClassificationPipeline
+ - __call__
+ - all
+
+## Computer vision
+
+Pipelines available for computer vision tasks include the following.
+
+### DepthEstimationPipeline
+[[autodoc]] DepthEstimationPipeline
+ - __call__
+ - all
+
+### ImageClassificationPipeline
+
+[[autodoc]] ImageClassificationPipeline
+ - __call__
+ - all
+
+### ImageSegmentationPipeline
+
+[[autodoc]] ImageSegmentationPipeline
+ - __call__
+ - all
+
+### ImageToImagePipeline
+
+[[autodoc]] ImageToImagePipeline
+ - __call__
+ - all
+
+### ObjectDetectionPipeline
+
+[[autodoc]] ObjectDetectionPipeline
+ - __call__
+ - all
+
+### VideoClassificationPipeline
+
+[[autodoc]] VideoClassificationPipeline
+ - __call__
+ - all
+
+### ZeroShotImageClassificationPipeline
+
+[[autodoc]] ZeroShotImageClassificationPipeline
+ - __call__
+ - all
+
+### ZeroShotObjectDetectionPipeline
+
+[[autodoc]] ZeroShotObjectDetectionPipeline
+ - __call__
+ - all
+
+## Natural Language Processing
+
+Pipelines available for natural language processing tasks include the following.
+
+### FillMaskPipeline
+
+[[autodoc]] FillMaskPipeline
+ - __call__
+ - all
+
+### QuestionAnsweringPipeline
+
+[[autodoc]] QuestionAnsweringPipeline
+ - __call__
+ - all
+
+### SummarizationPipeline
+
+[[autodoc]] SummarizationPipeline
+ - __call__
+ - all
+
+### TableQuestionAnsweringPipeline
+
+[[autodoc]] TableQuestionAnsweringPipeline
+ - __call__
+
+### TextClassificationPipeline
+
+[[autodoc]] TextClassificationPipeline
+ - __call__
+ - all
+
+### TextGenerationPipeline
+
+[[autodoc]] TextGenerationPipeline
+ - __call__
+ - all
+
+### Text2TextGenerationPipeline
+
+[[autodoc]] Text2TextGenerationPipeline
+ - __call__
+ - all
+
+### TokenClassificationPipeline
+
+[[autodoc]] TokenClassificationPipeline
+ - __call__
+ - all
+
+### TranslationPipeline
+
+[[autodoc]] TranslationPipeline
+ - __call__
+ - all
+
+### ZeroShotClassificationPipeline
+
+[[autodoc]] ZeroShotClassificationPipeline
+ - __call__
+ - all
+
+## Multimodal
+
+Pipelines available for multimodal tasks include the following.
+
+### DocumentQuestionAnsweringPipeline
+
+[[autodoc]] DocumentQuestionAnsweringPipeline
+ - __call__
+ - all
+
+### FeatureExtractionPipeline
+
+[[autodoc]] FeatureExtractionPipeline
+ - __call__
+ - all
+
+### ImageFeatureExtractionPipeline
+
+[[autodoc]] ImageFeatureExtractionPipeline
+ - __call__
+ - all
+
+### ImageToTextPipeline
+
+[[autodoc]] ImageToTextPipeline
+ - __call__
+ - all
+
+### ImageTextToTextPipeline
+
+[[autodoc]] ImageTextToTextPipeline
+ - __call__
+ - all
+
+### MaskGenerationPipeline
+
+[[autodoc]] MaskGenerationPipeline
+ - __call__
+ - all
+
+### VisualQuestionAnsweringPipeline
+
+[[autodoc]] VisualQuestionAnsweringPipeline
+ - __call__
+ - all
+
+## Parent class: `Pipeline`
+
+[[autodoc]] Pipeline
diff --git a/docs/transformers/docs/source/en/main_classes/processors.md b/docs/transformers/docs/source/en/main_classes/processors.md
new file mode 100644
index 0000000000000000000000000000000000000000..5e943fc9fdd5cc8f55daf78efd3c767ae4975e7a
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/processors.md
@@ -0,0 +1,163 @@
+
+
+# Processors
+
+Processors can mean two different things in the Transformers library:
+- the objects that pre-process inputs for multi-modal models such as [Wav2Vec2](../model_doc/wav2vec2) (speech and text)
+ or [CLIP](../model_doc/clip) (text and vision)
+- deprecated objects that were used in older versions of the library to preprocess data for GLUE or SQUAD.
+
+## Multi-modal processors
+
+Any multi-modal model will require an object to encode or decode the data that groups several modalities (among text,
+vision and audio). This is handled by objects called processors, which group together two or more processing objects
+such as tokenizers (for the text modality), image processors (for vision) and feature extractors (for audio).
+
+Those processors inherit from the following base class that implements the saving and loading functionality:
+
+[[autodoc]] ProcessorMixin
+
+## Deprecated processors
+
+All processors follow the same architecture which is that of the
+[`~data.processors.utils.DataProcessor`]. The processor returns a list of
+[`~data.processors.utils.InputExample`]. These
+[`~data.processors.utils.InputExample`] can be converted to
+[`~data.processors.utils.InputFeatures`] in order to be fed to the model.
+
+[[autodoc]] data.processors.utils.DataProcessor
+
+[[autodoc]] data.processors.utils.InputExample
+
+[[autodoc]] data.processors.utils.InputFeatures
+
+## GLUE
+
+[General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com/) is a benchmark that evaluates the
+performance of models across a diverse set of existing NLU tasks. It was released together with the paper [GLUE: A
+multi-task benchmark and analysis platform for natural language understanding](https://openreview.net/pdf?id=rJ4km2R5t7)
+
+This library hosts a total of 10 processors for the following tasks: MRPC, MNLI, MNLI (mismatched), CoLA, SST2, STSB,
+QQP, QNLI, RTE and WNLI.
+
+Those processors are:
+
+- [`~data.processors.utils.MrpcProcessor`]
+- [`~data.processors.utils.MnliProcessor`]
+- [`~data.processors.utils.MnliMismatchedProcessor`]
+- [`~data.processors.utils.Sst2Processor`]
+- [`~data.processors.utils.StsbProcessor`]
+- [`~data.processors.utils.QqpProcessor`]
+- [`~data.processors.utils.QnliProcessor`]
+- [`~data.processors.utils.RteProcessor`]
+- [`~data.processors.utils.WnliProcessor`]
+
+Additionally, the following method can be used to load values from a data file and convert them to a list of
+[`~data.processors.utils.InputExample`].
+
+[[autodoc]] data.processors.glue.glue_convert_examples_to_features
+
+
+## XNLI
+
+[The Cross-Lingual NLI Corpus (XNLI)](https://www.nyu.edu/projects/bowman/xnli/) is a benchmark that evaluates the
+quality of cross-lingual text representations. XNLI is crowd-sourced dataset based on [*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/): pairs of text are labeled with textual entailment annotations for 15
+different languages (including both high-resource language such as English and low-resource languages such as Swahili).
+
+It was released together with the paper [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053)
+
+This library hosts the processor to load the XNLI data:
+
+- [`~data.processors.utils.XnliProcessor`]
+
+Please note that since the gold labels are available on the test set, evaluation is performed on the test set.
+
+An example using these processors is given in the [run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) script.
+
+
+## SQuAD
+
+[The Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) is a benchmark that
+evaluates the performance of models on question answering. Two versions are available, v1.1 and v2.0. The first version
+(v1.1) was released together with the paper [SQuAD: 100,000+ Questions for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250). The second version (v2.0) was released alongside the paper [Know What You Don't
+Know: Unanswerable Questions for SQuAD](https://arxiv.org/abs/1806.03822).
+
+This library hosts a processor for each of the two versions:
+
+### Processors
+
+Those processors are:
+
+- [`~data.processors.utils.SquadV1Processor`]
+- [`~data.processors.utils.SquadV2Processor`]
+
+They both inherit from the abstract class [`~data.processors.utils.SquadProcessor`]
+
+[[autodoc]] data.processors.squad.SquadProcessor
+ - all
+
+Additionally, the following method can be used to convert SQuAD examples into
+[`~data.processors.utils.SquadFeatures`] that can be used as model inputs.
+
+[[autodoc]] data.processors.squad.squad_convert_examples_to_features
+
+
+These processors as well as the aforementioned method can be used with files containing the data as well as with the
+*tensorflow_datasets* package. Examples are given below.
+
+
+### Example usage
+
+Here is an example using the processors as well as the conversion method using data files:
+
+```python
+# Loading a V2 processor
+processor = SquadV2Processor()
+examples = processor.get_dev_examples(squad_v2_data_dir)
+
+# Loading a V1 processor
+processor = SquadV1Processor()
+examples = processor.get_dev_examples(squad_v1_data_dir)
+
+features = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=max_query_length,
+ is_training=not evaluate,
+)
+```
+
+Using *tensorflow_datasets* is as easy as using a data file:
+
+```python
+# tensorflow_datasets only handle Squad V1.
+tfds_examples = tfds.load("squad")
+examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
+
+features = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=max_query_length,
+ is_training=not evaluate,
+)
+```
+
+Another example using these processors is given in the [run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) script.
diff --git a/docs/transformers/docs/source/en/main_classes/quantization.md b/docs/transformers/docs/source/en/main_classes/quantization.md
new file mode 100644
index 0000000000000000000000000000000000000000..c137d51b5a504a7b188ae8cdae375a67779e1553
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/quantization.md
@@ -0,0 +1,98 @@
+
+
+# Quantization
+
+Quantization techniques reduce memory and computational costs by representing weights and activations with lower-precision data types like 8-bit integers (int8). This enables loading larger models you normally wouldn't be able to fit into memory, and speeding up inference. Transformers supports the AWQ and GPTQ quantization algorithms and it supports 8-bit and 4-bit quantization with bitsandbytes.
+
+Quantization techniques that aren't supported in Transformers can be added with the [`HfQuantizer`] class.
+
+
+
+Learn how to quantize models in the [Quantization](../quantization) guide.
+
+
+
+## QuantoConfig
+
+[[autodoc]] QuantoConfig
+
+## AqlmConfig
+
+[[autodoc]] AqlmConfig
+
+## VptqConfig
+
+[[autodoc]] VptqConfig
+
+## AwqConfig
+
+[[autodoc]] AwqConfig
+
+## EetqConfig
+[[autodoc]] EetqConfig
+
+## GPTQConfig
+
+[[autodoc]] GPTQConfig
+
+## BitsAndBytesConfig
+
+[[autodoc]] BitsAndBytesConfig
+
+## HfQuantizer
+
+[[autodoc]] quantizers.base.HfQuantizer
+
+## HiggsConfig
+
+[[autodoc]] HiggsConfig
+
+## HqqConfig
+
+[[autodoc]] HqqConfig
+
+## FbgemmFp8Config
+
+[[autodoc]] FbgemmFp8Config
+
+## CompressedTensorsConfig
+
+[[autodoc]] CompressedTensorsConfig
+
+## TorchAoConfig
+
+[[autodoc]] TorchAoConfig
+
+## BitNetConfig
+
+[[autodoc]] BitNetConfig
+
+## SpQRConfig
+
+[[autodoc]] SpQRConfig
+
+## FineGrainedFP8Config
+
+[[autodoc]] FineGrainedFP8Config
+
+## QuarkConfig
+
+[[autodoc]] QuarkConfig
+
+## AutoRoundConfig
+
+[[autodoc]] AutoRoundConfig
diff --git a/docs/transformers/docs/source/en/main_classes/text_generation.md b/docs/transformers/docs/source/en/main_classes/text_generation.md
new file mode 100644
index 0000000000000000000000000000000000000000..76a0f1381cd6bc413d575c80ec974fe26682bb75
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/text_generation.md
@@ -0,0 +1,59 @@
+
+
+# Generation
+
+Each framework has a generate method for text generation implemented in their respective `GenerationMixin` class:
+
+- PyTorch [`~generation.GenerationMixin.generate`] is implemented in [`~generation.GenerationMixin`].
+- TensorFlow [`~generation.TFGenerationMixin.generate`] is implemented in [`~generation.TFGenerationMixin`].
+- Flax/JAX [`~generation.FlaxGenerationMixin.generate`] is implemented in [`~generation.FlaxGenerationMixin`].
+
+Regardless of your framework of choice, you can parameterize the generate method with a [`~generation.GenerationConfig`]
+class instance. Please refer to this class for the complete list of generation parameters, which control the behavior
+of the generation method.
+
+To learn how to inspect a model's generation configuration, what are the defaults, how to change the parameters ad hoc,
+and how to create and save a customized generation configuration, refer to the
+[text generation strategies guide](../generation_strategies). The guide also explains how to use related features,
+like token streaming.
+
+## GenerationConfig
+
+[[autodoc]] generation.GenerationConfig
+ - from_pretrained
+ - from_model_config
+ - save_pretrained
+ - update
+ - validate
+ - get_generation_mode
+
+## GenerationMixin
+
+[[autodoc]] GenerationMixin
+ - generate
+ - compute_transition_scores
+
+## TFGenerationMixin
+
+[[autodoc]] TFGenerationMixin
+ - generate
+ - compute_transition_scores
+
+## FlaxGenerationMixin
+
+[[autodoc]] FlaxGenerationMixin
+ - generate
diff --git a/docs/transformers/docs/source/en/main_classes/tokenizer.md b/docs/transformers/docs/source/en/main_classes/tokenizer.md
new file mode 100644
index 0000000000000000000000000000000000000000..83d2ae5df6a7fb1179edb400ff6ee8b616680db8
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/tokenizer.md
@@ -0,0 +1,104 @@
+
+
+# Tokenizer
+
+A tokenizer is in charge of preparing the inputs for a model. The library contains tokenizers for all the models. Most
+of the tokenizers are available in two flavors: a full python implementation and a "Fast" implementation based on the
+Rust library [🤗 Tokenizers](https://github.com/huggingface/tokenizers). The "Fast" implementations allows:
+
+1. a significant speed-up in particular when doing batched tokenization and
+2. additional methods to map between the original string (character and words) and the token space (e.g. getting the
+ index of the token comprising a given character or the span of characters corresponding to a given token).
+
+The base classes [`PreTrainedTokenizer`] and [`PreTrainedTokenizerFast`]
+implement the common methods for encoding string inputs in model inputs (see below) and instantiating/saving python and
+"Fast" tokenizers either from a local file or directory or from a pretrained tokenizer provided by the library
+(downloaded from HuggingFace's AWS S3 repository). They both rely on
+[`~tokenization_utils_base.PreTrainedTokenizerBase`] that contains the common methods, and
+[`~tokenization_utils_base.SpecialTokensMixin`].
+
+[`PreTrainedTokenizer`] and [`PreTrainedTokenizerFast`] thus implement the main
+methods for using all the tokenizers:
+
+- Tokenizing (splitting strings in sub-word token strings), converting tokens strings to ids and back, and
+ encoding/decoding (i.e., tokenizing and converting to integers).
+- Adding new tokens to the vocabulary in a way that is independent of the underlying structure (BPE, SentencePiece...).
+- Managing special tokens (like mask, beginning-of-sentence, etc.): adding them, assigning them to attributes in the
+ tokenizer for easy access and making sure they are not split during tokenization.
+
+[`BatchEncoding`] holds the output of the
+[`~tokenization_utils_base.PreTrainedTokenizerBase`]'s encoding methods (`__call__`,
+`encode_plus` and `batch_encode_plus`) and is derived from a Python dictionary. When the tokenizer is a pure python
+tokenizer, this class behaves just like a standard python dictionary and holds the various model inputs computed by
+these methods (`input_ids`, `attention_mask`...). When the tokenizer is a "Fast" tokenizer (i.e., backed by
+HuggingFace [tokenizers library](https://github.com/huggingface/tokenizers)), this class provides in addition
+several advanced alignment methods which can be used to map between the original string (character and words) and the
+token space (e.g., getting the index of the token comprising a given character or the span of characters corresponding
+to a given token).
+
+
+# Multimodal Tokenizer
+
+Apart from that each tokenizer can be a "multimodal" tokenizer which means that the tokenizer will hold all relevant special tokens
+as part of tokenizer attributes for easier access. For example, if the tokenizer is loaded from a vision-language model like LLaVA, you will
+be able to access `tokenizer.image_token_id` to obtain the special image token used as a placeholder.
+
+To enable extra special tokens for any type of tokenizer, you have to add the following lines and save the tokenizer. Extra special tokens do not
+have to be modality related and can ne anything that the model often needs access to. In the below code, tokenizer at `output_dir` will have direct access
+to three more special tokens.
+
+```python
+vision_tokenizer = AutoTokenizer.from_pretrained(
+ "llava-hf/llava-1.5-7b-hf",
+ extra_special_tokens={"image_token": "", "boi_token": "", "eoi_token": ""}
+)
+print(vision_tokenizer.image_token, vision_tokenizer.image_token_id)
+("", 32000)
+```
+
+## PreTrainedTokenizer
+
+[[autodoc]] PreTrainedTokenizer
+ - __call__
+ - add_tokens
+ - add_special_tokens
+ - apply_chat_template
+ - batch_decode
+ - decode
+ - encode
+ - push_to_hub
+ - all
+
+## PreTrainedTokenizerFast
+
+The [`PreTrainedTokenizerFast`] depend on the [tokenizers](https://huggingface.co/docs/tokenizers) library. The tokenizers obtained from the 🤗 tokenizers library can be
+loaded very simply into 🤗 transformers. Take a look at the [Using tokenizers from 🤗 tokenizers](../fast_tokenizers) page to understand how this is done.
+
+[[autodoc]] PreTrainedTokenizerFast
+ - __call__
+ - add_tokens
+ - add_special_tokens
+ - apply_chat_template
+ - batch_decode
+ - decode
+ - encode
+ - push_to_hub
+ - all
+
+## BatchEncoding
+
+[[autodoc]] BatchEncoding
diff --git a/docs/transformers/docs/source/en/main_classes/trainer.md b/docs/transformers/docs/source/en/main_classes/trainer.md
new file mode 100644
index 0000000000000000000000000000000000000000..21ba9ed935e2731e9872d767295b13b2d11df50f
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/trainer.md
@@ -0,0 +1,54 @@
+
+
+# Trainer
+
+The [`Trainer`] class provides an API for feature-complete training in PyTorch, and it supports distributed training on multiple GPUs/TPUs, mixed precision for [NVIDIA GPUs](https://nvidia.github.io/apex/), [AMD GPUs](https://rocm.docs.amd.com/en/latest/rocm.html), and [`torch.amp`](https://pytorch.org/docs/stable/amp.html) for PyTorch. [`Trainer`] goes hand-in-hand with the [`TrainingArguments`] class, which offers a wide range of options to customize how a model is trained. Together, these two classes provide a complete training API.
+
+[`Seq2SeqTrainer`] and [`Seq2SeqTrainingArguments`] inherit from the [`Trainer`] and [`TrainingArguments`] classes and they're adapted for training models for sequence-to-sequence tasks such as summarization or translation.
+
+
+
+The [`Trainer`] class is optimized for 🤗 Transformers models and can have surprising behaviors
+when used with other models. When using it with your own model, make sure:
+
+- your model always return tuples or subclasses of [`~utils.ModelOutput`]
+- your model can compute the loss if a `labels` argument is provided and that loss is returned as the first
+ element of the tuple (if your model returns tuples)
+- your model can accept multiple label arguments (use `label_names` in [`TrainingArguments`] to indicate their name to the [`Trainer`]) but none of them should be named `"label"`
+
+
+
+## Trainer[[api-reference]]
+
+[[autodoc]] Trainer
+ - all
+
+## Seq2SeqTrainer
+
+[[autodoc]] Seq2SeqTrainer
+ - evaluate
+ - predict
+
+## TrainingArguments
+
+[[autodoc]] TrainingArguments
+ - all
+
+## Seq2SeqTrainingArguments
+
+[[autodoc]] Seq2SeqTrainingArguments
+ - all
diff --git a/docs/transformers/docs/source/en/model_doc/albert.md b/docs/transformers/docs/source/en/model_doc/albert.md
new file mode 100644
index 0000000000000000000000000000000000000000..21cd57675e536c916e31a41d6c4739184f696869
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/albert.md
@@ -0,0 +1,307 @@
+
+
+# ALBERT
+
+
+
+
+
+
+
+
+## Overview
+
+The ALBERT model was proposed in [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942) by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma,
+Radu Soricut. It presents two parameter-reduction techniques to lower memory consumption and increase the training
+speed of BERT:
+
+- Splitting the embedding matrix into two smaller matrices.
+- Using repeating layers split among groups.
+
+The abstract from the paper is the following:
+
+*Increasing model size when pretraining natural language representations often results in improved performance on
+downstream tasks. However, at some point further model increases become harder due to GPU/TPU memory limitations,
+longer training times, and unexpected model degradation. To address these problems, we present two parameter-reduction
+techniques to lower memory consumption and increase the training speed of BERT. Comprehensive empirical evidence shows
+that our proposed methods lead to models that scale much better compared to the original BERT. We also use a
+self-supervised loss that focuses on modeling inter-sentence coherence, and show it consistently helps downstream tasks
+with multi-sentence inputs. As a result, our best model establishes new state-of-the-art results on the GLUE, RACE, and
+SQuAD benchmarks while having fewer parameters compared to BERT-large.*
+
+This model was contributed by [lysandre](https://huggingface.co/lysandre). This model jax version was contributed by
+[kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/ALBERT).
+
+## Usage tips
+
+- ALBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
+ than the left.
+- ALBERT uses repeating layers which results in a small memory footprint, however the computational cost remains
+ similar to a BERT-like architecture with the same number of hidden layers as it has to iterate through the same
+ number of (repeating) layers.
+- Embedding size E is different from hidden size H justified because the embeddings are context independent (one embedding vector represents one token), whereas hidden states are context dependent (one hidden state represents a sequence of tokens) so it's more logical to have H >> E. Also, the embedding matrix is large since it's V x E (V being the vocab size). If E < H, it has less parameters.
+- Layers are split in groups that share parameters (to save memory).
+Next sentence prediction is replaced by a sentence ordering prediction: in the inputs, we have two sentences A and B (that are consecutive) and we either feed A followed by B or B followed by A. The model must predict if they have been swapped or not.
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```
+from transformers import AlbertModel
+model = AlbertModel.from_pretrained("albert/albert-base-v1", torch_dtype=torch.float16, attn_implementation="sdpa")
+...
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+On a local benchmark (GeForce RTX 2060-8GB, PyTorch 2.3.1, OS Ubuntu 20.04) with `float16`, we saw the
+following speedups during training and inference.
+
+#### Training for 100 iterations
+
+|batch_size|seq_len|Time per batch (eager - s)| Time per batch (sdpa - s)| Speedup (%)| Eager peak mem (MB)| sdpa peak mem (MB)| Mem saving (%)|
+|----------|-------|--------------------------|--------------------------|------------|--------------------|-------------------|---------------|
+|2 |256 |0.028 |0.024 |14.388 |358.411 |321.088 |11.624 |
+|2 |512 |0.049 |0.041 |17.681 |753.458 |602.660 |25.022 |
+|4 |256 |0.044 |0.039 |12.246 |679.534 |602.660 |12.756 |
+|4 |512 |0.090 |0.076 |18.472 |1434.820 |1134.140 |26.512 |
+|8 |256 |0.081 |0.072 |12.664 |1283.825 |1134.140 |13.198 |
+|8 |512 |0.170 |0.143 |18.957 |2820.398 |2219.695 |27.062 |
+
+#### Inference with 50 batches
+
+|batch_size|seq_len|Per token latency eager (ms)|Per token latency SDPA (ms)|Speedup (%) |Mem eager (MB)|Mem BT (MB)|Mem saved (%)|
+|----------|-------|----------------------------|---------------------------|------------|--------------|-----------|-------------|
+|4 |128 |0.083 |0.071 |16.967 |48.319 |48.45 |-0.268 |
+|4 |256 |0.148 |0.127 |16.37 |63.4 |63.922 |-0.817 |
+|4 |512 |0.31 |0.247 |25.473 |110.092 |94.343 |16.693 |
+|8 |128 |0.137 |0.124 |11.102 |63.4 |63.66 |-0.409 |
+|8 |256 |0.271 |0.231 |17.271 |91.202 |92.246 |-1.132 |
+|8 |512 |0.602 |0.48 |25.47 |186.159 |152.564 |22.021 |
+|16 |128 |0.252 |0.224 |12.506 |91.202 |91.722 |-0.567 |
+|16 |256 |0.526 |0.448 |17.604 |148.378 |150.467 |-1.388 |
+|16 |512 |1.203 |0.96 |25.365 |338.293 |271.102 |24.784 |
+
+This model was contributed by [lysandre](https://huggingface.co/lysandre). This model jax version was contributed by
+[kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/ALBERT).
+
+
+## Resources
+
+
+The resources provided in the following sections consist of a list of official Hugging Face and community (indicated by 🌎) resources to help you get started with AlBERT. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+
+
+- [`AlbertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification).
+
+
+- [`TFAlbertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification).
+
+- [`FlaxAlbertForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb).
+- Check the [Text classification task guide](../tasks/sequence_classification) on how to use the model.
+
+
+
+
+
+- [`AlbertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification).
+
+
+- [`TFAlbertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
+
+
+
+- [`FlaxAlbertForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
+- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
+- Check the [Token classification task guide](../tasks/token_classification) on how to use the model.
+
+
+
+- [`AlbertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
+- [`TFAlbertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
+- [`FlaxAlbertForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
+- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
+- Check the [Masked language modeling task guide](../tasks/masked_language_modeling) on how to use the model.
+
+
+
+- [`AlbertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
+- [`TFAlbertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
+- [`FlaxAlbertForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering).
+- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
+- Check the [Question answering task guide](../tasks/question_answering) on how to use the model.
+
+**Multiple choice**
+
+- [`AlbertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb).
+- [`TFAlbertForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
+
+- Check the [Multiple choice task guide](../tasks/multiple_choice) on how to use the model.
+
+
+## AlbertConfig
+
+[[autodoc]] AlbertConfig
+
+## AlbertTokenizer
+
+[[autodoc]] AlbertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## AlbertTokenizerFast
+
+[[autodoc]] AlbertTokenizerFast
+
+## Albert specific outputs
+
+[[autodoc]] models.albert.modeling_albert.AlbertForPreTrainingOutput
+
+[[autodoc]] models.albert.modeling_tf_albert.TFAlbertForPreTrainingOutput
+
+
+
+
+## AlbertModel
+
+[[autodoc]] AlbertModel
+ - forward
+
+## AlbertForPreTraining
+
+[[autodoc]] AlbertForPreTraining
+ - forward
+
+## AlbertForMaskedLM
+
+[[autodoc]] AlbertForMaskedLM
+ - forward
+
+## AlbertForSequenceClassification
+
+[[autodoc]] AlbertForSequenceClassification
+ - forward
+
+## AlbertForMultipleChoice
+
+[[autodoc]] AlbertForMultipleChoice
+
+## AlbertForTokenClassification
+
+[[autodoc]] AlbertForTokenClassification
+ - forward
+
+## AlbertForQuestionAnswering
+
+[[autodoc]] AlbertForQuestionAnswering
+ - forward
+
+
+
+
+
+## TFAlbertModel
+
+[[autodoc]] TFAlbertModel
+ - call
+
+## TFAlbertForPreTraining
+
+[[autodoc]] TFAlbertForPreTraining
+ - call
+
+## TFAlbertForMaskedLM
+
+[[autodoc]] TFAlbertForMaskedLM
+ - call
+
+## TFAlbertForSequenceClassification
+
+[[autodoc]] TFAlbertForSequenceClassification
+ - call
+
+## TFAlbertForMultipleChoice
+
+[[autodoc]] TFAlbertForMultipleChoice
+ - call
+
+## TFAlbertForTokenClassification
+
+[[autodoc]] TFAlbertForTokenClassification
+ - call
+
+## TFAlbertForQuestionAnswering
+
+[[autodoc]] TFAlbertForQuestionAnswering
+ - call
+
+
+
+
+## FlaxAlbertModel
+
+[[autodoc]] FlaxAlbertModel
+ - __call__
+
+## FlaxAlbertForPreTraining
+
+[[autodoc]] FlaxAlbertForPreTraining
+ - __call__
+
+## FlaxAlbertForMaskedLM
+
+[[autodoc]] FlaxAlbertForMaskedLM
+ - __call__
+
+## FlaxAlbertForSequenceClassification
+
+[[autodoc]] FlaxAlbertForSequenceClassification
+ - __call__
+
+## FlaxAlbertForMultipleChoice
+
+[[autodoc]] FlaxAlbertForMultipleChoice
+ - __call__
+
+## FlaxAlbertForTokenClassification
+
+[[autodoc]] FlaxAlbertForTokenClassification
+ - __call__
+
+## FlaxAlbertForQuestionAnswering
+
+[[autodoc]] FlaxAlbertForQuestionAnswering
+ - __call__
+
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/align.md b/docs/transformers/docs/source/en/model_doc/align.md
new file mode 100644
index 0000000000000000000000000000000000000000..b2920bdc2bace29574350689cc7f9ee91576b948
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/align.md
@@ -0,0 +1,108 @@
+
+
+# ALIGN
+
+
+
+
+
+## Overview
+
+The ALIGN model was proposed in [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig. ALIGN is a multi-modal vision and language model. It can be used for image-text similarity and for zero-shot image classification. ALIGN features a dual-encoder architecture with [EfficientNet](efficientnet) as its vision encoder and [BERT](bert) as its text encoder, and learns to align visual and text representations with contrastive learning. Unlike previous work, ALIGN leverages a massive noisy dataset and shows that the scale of the corpus can be used to achieve SOTA representations with a simple recipe.
+
+The abstract from the paper is the following:
+
+*Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge. For vision applications, representations are mostly learned using datasets with explicit class labels such as ImageNet or OpenImages. For vision-language, popular datasets like Conceptual Captions, MSCOCO, or CLIP all involve a non-trivial data collection (and cleaning) process. This costly curation process limits the size of datasets and hence hinders the scaling of trained models. In this paper, we leverage a noisy dataset of over one billion image alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. A simple dual-encoder architecture learns to align visual and language representations of the image and text pairs using a contrastive loss. We show that the scale of our corpus can make up for its noise and leads to state-of-the-art representations even with such a simple learning scheme. Our visual representation achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations enables zero-shot image classification and also set new state-of-the-art results on Flickr30K and MSCOCO image-text retrieval benchmarks, even when compared with more sophisticated cross-attention models. The representations also enable cross-modality search with complex text and text + image queries.*
+
+This model was contributed by [Alara Dirik](https://huggingface.co/adirik).
+The original code is not released, this implementation is based on the Kakao Brain implementation based on the original paper.
+
+## Usage example
+
+ALIGN uses EfficientNet to get visual features and BERT to get the text features. Both the text and visual features are then projected to a latent space with identical dimension. The dot product between the projected image and text features is then used as a similarity score.
+
+[`AlignProcessor`] wraps [`EfficientNetImageProcessor`] and [`BertTokenizer`] into a single instance to both encode the text and preprocess the images. The following example shows how to get the image-text similarity scores using [`AlignProcessor`] and [`AlignModel`].
+
+```python
+import requests
+import torch
+from PIL import Image
+from transformers import AlignProcessor, AlignModel
+
+processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
+model = AlignModel.from_pretrained("kakaobrain/align-base")
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+candidate_labels = ["an image of a cat", "an image of a dog"]
+
+inputs = processor(images=image ,text=candidate_labels, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+# this is the image-text similarity score
+logits_per_image = outputs.logits_per_image
+
+# we can take the softmax to get the label probabilities
+probs = logits_per_image.softmax(dim=1)
+print(probs)
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ALIGN.
+
+- A blog post on [ALIGN and the COYO-700M dataset](https://huggingface.co/blog/vit-align).
+- A zero-shot image classification [demo](https://huggingface.co/spaces/adirik/ALIGN-zero-shot-image-classification).
+- [Model card](https://huggingface.co/kakaobrain/align-base) of `kakaobrain/align-base` model.
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it. The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## AlignConfig
+
+[[autodoc]] AlignConfig
+ - from_text_vision_configs
+
+## AlignTextConfig
+
+[[autodoc]] AlignTextConfig
+
+## AlignVisionConfig
+
+[[autodoc]] AlignVisionConfig
+
+## AlignProcessor
+
+[[autodoc]] AlignProcessor
+
+## AlignModel
+
+[[autodoc]] AlignModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## AlignTextModel
+
+[[autodoc]] AlignTextModel
+ - forward
+
+## AlignVisionModel
+
+[[autodoc]] AlignVisionModel
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/altclip.md b/docs/transformers/docs/source/en/model_doc/altclip.md
new file mode 100644
index 0000000000000000000000000000000000000000..0dfbf797a033de541187619f2432e57c07264a2a
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/altclip.md
@@ -0,0 +1,116 @@
+
+
+# AltCLIP
+
+
+
+
+
+## Overview
+
+The AltCLIP model was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679v2) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu. AltCLIP
+(Altering the Language Encoder in CLIP) is a neural network trained on a variety of image-text and text-text pairs. By switching CLIP's
+text encoder with a pretrained multilingual text encoder XLM-R, we could obtain very close performances with CLIP on almost all tasks, and extended original CLIP's capabilities such as multilingual understanding.
+
+The abstract from the paper is the following:
+
+*In this work, we present a conceptually simple and effective method to train a strong bilingual multimodal representation model.
+Starting from the pretrained multimodal representation model CLIP released by OpenAI, we switched its text encoder with a pretrained
+multilingual text encoder XLM-R, and aligned both languages and image representations by a two-stage training schema consisting of
+teacher learning and contrastive learning. We validate our method through evaluations of a wide range of tasks. We set new state-of-the-art
+performances on a bunch of tasks including ImageNet-CN, Flicker30k- CN, and COCO-CN. Further, we obtain very close performances with
+CLIP on almost all tasks, suggesting that one can simply alter the text encoder in CLIP for extended capabilities such as multilingual understanding.*
+
+This model was contributed by [jongjyh](https://huggingface.co/jongjyh).
+
+## Usage tips and example
+
+The usage of AltCLIP is very similar to the CLIP. the difference between CLIP is the text encoder. Note that we use bidirectional attention instead of casual attention
+and we take the [CLS] token in XLM-R to represent text embedding.
+
+AltCLIP is a multi-modal vision and language model. It can be used for image-text similarity and for zero-shot image
+classification. AltCLIP uses a ViT like transformer to get visual features and a bidirectional language model to get the text
+features. Both the text and visual features are then projected to a latent space with identical dimension. The dot
+product between the projected image and text features is then used as a similar score.
+
+To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
+which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image. The authors
+also add absolute position embeddings, and feed the resulting sequence of vectors to a standard Transformer encoder.
+The [`CLIPImageProcessor`] can be used to resize (or rescale) and normalize images for the model.
+
+The [`AltCLIPProcessor`] wraps a [`CLIPImageProcessor`] and a [`XLMRobertaTokenizer`] into a single instance to both
+encode the text and prepare the images. The following example shows how to get the image-text similarity scores using
+[`AltCLIPProcessor`] and [`AltCLIPModel`].
+
+```python
+>>> from PIL import Image
+>>> import requests
+
+>>> from transformers import AltCLIPModel, AltCLIPProcessor
+
+>>> model = AltCLIPModel.from_pretrained("BAAI/AltCLIP")
+>>> processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
+
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
+```
+
+
+
+This model is based on `CLIPModel`, use it like you would use the original [CLIP](clip).
+
+
+
+## AltCLIPConfig
+
+[[autodoc]] AltCLIPConfig
+ - from_text_vision_configs
+
+## AltCLIPTextConfig
+
+[[autodoc]] AltCLIPTextConfig
+
+## AltCLIPVisionConfig
+
+[[autodoc]] AltCLIPVisionConfig
+
+## AltCLIPProcessor
+
+[[autodoc]] AltCLIPProcessor
+
+## AltCLIPModel
+
+[[autodoc]] AltCLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## AltCLIPTextModel
+
+[[autodoc]] AltCLIPTextModel
+ - forward
+
+## AltCLIPVisionModel
+
+[[autodoc]] AltCLIPVisionModel
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/aria.md b/docs/transformers/docs/source/en/model_doc/aria.md
new file mode 100644
index 0000000000000000000000000000000000000000..7b58f59cab7ee9e33cdf4c592920f3aa2dd99e9e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/aria.md
@@ -0,0 +1,112 @@
+
+
+# Aria
+
+
+
+
+
+
+
+## Overview
+
+The Aria model was proposed in [Aria: An Open Multimodal Native Mixture-of-Experts Model](https://huggingface.co/papers/2410.05993) by Li et al. from the Rhymes.AI team.
+
+Aria is an open multimodal-native model with best-in-class performance across a wide range of multimodal, language, and coding tasks. It has a Mixture-of-Experts architecture, with respectively 3.9B and 3.5B activated parameters per visual token and text token.
+
+The abstract from the paper is the following:
+
+*Information comes in diverse modalities. Multimodal native AI models are essential to integrate real-world information and deliver comprehensive understanding. While proprietary multimodal native models exist, their lack of openness imposes obstacles for adoptions, let alone adaptations. To fill this gap, we introduce Aria, an open multimodal native model with best-in-class performance across a wide range of multimodal, language, and coding tasks. Aria is a mixture-of-expert model with 3.9B and 3.5B activated parameters per visual token and text token, respectively. It outperforms Pixtral-12B and Llama3.2-11B, and is competitive against the best proprietary models on various multimodal tasks. We pre-train Aria from scratch following a 4-stage pipeline, which progressively equips the model with strong capabilities in language understanding, multimodal understanding, long context window, and instruction following. We open-source the model weights along with a codebase that facilitates easy adoptions and adaptations of Aria in real-world applications.*
+
+This model was contributed by [m-ric](https://huggingface.co/m-ric).
+The original code can be found [here](https://github.com/rhymes-ai/Aria).
+
+## Usage tips
+
+Here's how to use the model for vision tasks:
+```python
+import requests
+import torch
+from PIL import Image
+
+from transformers import AriaProcessor, AriaForConditionalGeneration
+
+model_id_or_path = "rhymes-ai/Aria"
+
+model = AriaForConditionalGeneration.from_pretrained(
+ model_id_or_path, device_map="auto"
+)
+
+processor = AriaProcessor.from_pretrained(model_id_or_path)
+
+image = Image.open(requests.get("http://images.cocodataset.org/val2017/000000039769.jpg", stream=True).raw)
+
+messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"text": "what is the image?", "type": "text"},
+ ],
+ }
+]
+
+text = processor.apply_chat_template(messages, add_generation_prompt=True)
+inputs = processor(text=text, images=image, return_tensors="pt")
+inputs.to(model.device)
+
+output = model.generate(
+ **inputs,
+ max_new_tokens=15,
+ stop_strings=["<|im_end|>"],
+ tokenizer=processor.tokenizer,
+ do_sample=True,
+ temperature=0.9,
+)
+output_ids = output[0][inputs["input_ids"].shape[1]:]
+response = processor.decode(output_ids, skip_special_tokens=True)
+```
+
+
+## AriaImageProcessor
+
+[[autodoc]] AriaImageProcessor
+
+## AriaProcessor
+
+[[autodoc]] AriaProcessor
+
+## AriaTextConfig
+
+[[autodoc]] AriaTextConfig
+
+## AriaConfig
+
+[[autodoc]] AriaConfig
+
+## AriaTextModel
+
+[[autodoc]] AriaTextModel
+
+## AriaTextForCausalLM
+
+[[autodoc]] AriaTextForCausalLM
+
+## AriaForConditionalGeneration
+
+[[autodoc]] AriaForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/audio-spectrogram-transformer.md b/docs/transformers/docs/source/en/model_doc/audio-spectrogram-transformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..14669ce0fb1b02b689ee99c0e49810cdd0b0cd70
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/audio-spectrogram-transformer.md
@@ -0,0 +1,109 @@
+
+
+# Audio Spectrogram Transformer
+
+
+
+
+
+
+
+## Overview
+
+The Audio Spectrogram Transformer model was proposed in [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
+The Audio Spectrogram Transformer applies a [Vision Transformer](vit) to audio, by turning audio into an image (spectrogram). The model obtains state-of-the-art results
+for audio classification.
+
+The abstract from the paper is the following:
+
+*In the past decade, convolutional neural networks (CNNs) have been widely adopted as the main building block for end-to-end audio classification models, which aim to learn a direct mapping from audio spectrograms to corresponding labels. To better capture long-range global context, a recent trend is to add a self-attention mechanism on top of the CNN, forming a CNN-attention hybrid model. However, it is unclear whether the reliance on a CNN is necessary, and if neural networks purely based on attention are sufficient to obtain good performance in audio classification. In this paper, we answer the question by introducing the Audio Spectrogram Transformer (AST), the first convolution-free, purely attention-based model for audio classification. We evaluate AST on various audio classification benchmarks, where it achieves new state-of-the-art results of 0.485 mAP on AudioSet, 95.6% accuracy on ESC-50, and 98.1% accuracy on Speech Commands V2.*
+
+
+
+ Audio Spectrogram Transformer architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/YuanGongND/ast).
+
+## Usage tips
+
+- When fine-tuning the Audio Spectrogram Transformer (AST) on your own dataset, it's recommended to take care of the input normalization (to make
+sure the input has mean of 0 and std of 0.5). [`ASTFeatureExtractor`] takes care of this. Note that it uses the AudioSet
+mean and std by default. You can check [`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py) to see how
+the authors compute the stats for a downstream dataset.
+- Note that the AST needs a low learning rate (the authors use a 10 times smaller learning rate compared to their CNN model proposed in the
+[PSLA paper](https://arxiv.org/abs/2102.01243)) and converges quickly, so please search for a suitable learning rate and learning rate scheduler for your task.
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```
+from transformers import ASTForAudioClassification
+model = ASTForAudioClassification.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32` and `MIT/ast-finetuned-audioset-10-10-0.4593` model, we saw the following speedups during inference.
+
+| Batch size | Average inference time (ms), eager mode | Average inference time (ms), sdpa model | Speed up, Sdpa / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 27 | 6 | 4.5 |
+| 2 | 12 | 6 | 2 |
+| 4 | 21 | 8 | 2.62 |
+| 8 | 40 | 14 | 2.86 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with the Audio Spectrogram Transformer.
+
+
+
+- A notebook illustrating inference with AST for audio classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/AST).
+- [`ASTForAudioClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb).
+- See also: [Audio classification](../tasks/audio_classification).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## ASTConfig
+
+[[autodoc]] ASTConfig
+
+## ASTFeatureExtractor
+
+[[autodoc]] ASTFeatureExtractor
+ - __call__
+
+## ASTModel
+
+[[autodoc]] ASTModel
+ - forward
+
+## ASTForAudioClassification
+
+[[autodoc]] ASTForAudioClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/auto.md b/docs/transformers/docs/source/en/model_doc/auto.md
new file mode 100644
index 0000000000000000000000000000000000000000..059312850876d2b5b7a53c5f43f42a91c9eb3594
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/auto.md
@@ -0,0 +1,387 @@
+
+
+# Auto Classes
+
+In many cases, the architecture you want to use can be guessed from the name or the path of the pretrained model you
+are supplying to the `from_pretrained()` method. AutoClasses are here to do this job for you so that you
+automatically retrieve the relevant model given the name/path to the pretrained weights/config/vocabulary.
+
+Instantiating one of [`AutoConfig`], [`AutoModel`], and
+[`AutoTokenizer`] will directly create a class of the relevant architecture. For instance
+
+
+```python
+model = AutoModel.from_pretrained("google-bert/bert-base-cased")
+```
+
+will create a model that is an instance of [`BertModel`].
+
+There is one class of `AutoModel` for each task, and for each backend (PyTorch, TensorFlow, or Flax).
+
+## Extending the Auto Classes
+
+Each of the auto classes has a method to be extended with your custom classes. For instance, if you have defined a
+custom class of model `NewModel`, make sure you have a `NewModelConfig` then you can add those to the auto
+classes like this:
+
+```python
+from transformers import AutoConfig, AutoModel
+
+AutoConfig.register("new-model", NewModelConfig)
+AutoModel.register(NewModelConfig, NewModel)
+```
+
+You will then be able to use the auto classes like you would usually do!
+
+
+
+If your `NewModelConfig` is a subclass of [`~transformers.PretrainedConfig`], make sure its
+`model_type` attribute is set to the same key you use when registering the config (here `"new-model"`).
+
+Likewise, if your `NewModel` is a subclass of [`PreTrainedModel`], make sure its
+`config_class` attribute is set to the same class you use when registering the model (here
+`NewModelConfig`).
+
+
+
+## AutoConfig
+
+[[autodoc]] AutoConfig
+
+## AutoTokenizer
+
+[[autodoc]] AutoTokenizer
+
+## AutoFeatureExtractor
+
+[[autodoc]] AutoFeatureExtractor
+
+## AutoImageProcessor
+
+[[autodoc]] AutoImageProcessor
+
+## AutoProcessor
+
+[[autodoc]] AutoProcessor
+
+## Generic model classes
+
+The following auto classes are available for instantiating a base model class without a specific head.
+
+### AutoModel
+
+[[autodoc]] AutoModel
+
+### TFAutoModel
+
+[[autodoc]] TFAutoModel
+
+### FlaxAutoModel
+
+[[autodoc]] FlaxAutoModel
+
+## Generic pretraining classes
+
+The following auto classes are available for instantiating a model with a pretraining head.
+
+### AutoModelForPreTraining
+
+[[autodoc]] AutoModelForPreTraining
+
+### TFAutoModelForPreTraining
+
+[[autodoc]] TFAutoModelForPreTraining
+
+### FlaxAutoModelForPreTraining
+
+[[autodoc]] FlaxAutoModelForPreTraining
+
+## Natural Language Processing
+
+The following auto classes are available for the following natural language processing tasks.
+
+### AutoModelForCausalLM
+
+[[autodoc]] AutoModelForCausalLM
+
+### TFAutoModelForCausalLM
+
+[[autodoc]] TFAutoModelForCausalLM
+
+### FlaxAutoModelForCausalLM
+
+[[autodoc]] FlaxAutoModelForCausalLM
+
+### AutoModelForMaskedLM
+
+[[autodoc]] AutoModelForMaskedLM
+
+### TFAutoModelForMaskedLM
+
+[[autodoc]] TFAutoModelForMaskedLM
+
+### FlaxAutoModelForMaskedLM
+
+[[autodoc]] FlaxAutoModelForMaskedLM
+
+### AutoModelForMaskGeneration
+
+[[autodoc]] AutoModelForMaskGeneration
+
+### TFAutoModelForMaskGeneration
+
+[[autodoc]] TFAutoModelForMaskGeneration
+
+### AutoModelForSeq2SeqLM
+
+[[autodoc]] AutoModelForSeq2SeqLM
+
+### TFAutoModelForSeq2SeqLM
+
+[[autodoc]] TFAutoModelForSeq2SeqLM
+
+### FlaxAutoModelForSeq2SeqLM
+
+[[autodoc]] FlaxAutoModelForSeq2SeqLM
+
+### AutoModelForSequenceClassification
+
+[[autodoc]] AutoModelForSequenceClassification
+
+### TFAutoModelForSequenceClassification
+
+[[autodoc]] TFAutoModelForSequenceClassification
+
+### FlaxAutoModelForSequenceClassification
+
+[[autodoc]] FlaxAutoModelForSequenceClassification
+
+### AutoModelForMultipleChoice
+
+[[autodoc]] AutoModelForMultipleChoice
+
+### TFAutoModelForMultipleChoice
+
+[[autodoc]] TFAutoModelForMultipleChoice
+
+### FlaxAutoModelForMultipleChoice
+
+[[autodoc]] FlaxAutoModelForMultipleChoice
+
+### AutoModelForNextSentencePrediction
+
+[[autodoc]] AutoModelForNextSentencePrediction
+
+### TFAutoModelForNextSentencePrediction
+
+[[autodoc]] TFAutoModelForNextSentencePrediction
+
+### FlaxAutoModelForNextSentencePrediction
+
+[[autodoc]] FlaxAutoModelForNextSentencePrediction
+
+### AutoModelForTokenClassification
+
+[[autodoc]] AutoModelForTokenClassification
+
+### TFAutoModelForTokenClassification
+
+[[autodoc]] TFAutoModelForTokenClassification
+
+### FlaxAutoModelForTokenClassification
+
+[[autodoc]] FlaxAutoModelForTokenClassification
+
+### AutoModelForQuestionAnswering
+
+[[autodoc]] AutoModelForQuestionAnswering
+
+### TFAutoModelForQuestionAnswering
+
+[[autodoc]] TFAutoModelForQuestionAnswering
+
+### FlaxAutoModelForQuestionAnswering
+
+[[autodoc]] FlaxAutoModelForQuestionAnswering
+
+### AutoModelForTextEncoding
+
+[[autodoc]] AutoModelForTextEncoding
+
+### TFAutoModelForTextEncoding
+
+[[autodoc]] TFAutoModelForTextEncoding
+
+## Computer vision
+
+The following auto classes are available for the following computer vision tasks.
+
+### AutoModelForDepthEstimation
+
+[[autodoc]] AutoModelForDepthEstimation
+
+### AutoModelForImageClassification
+
+[[autodoc]] AutoModelForImageClassification
+
+### TFAutoModelForImageClassification
+
+[[autodoc]] TFAutoModelForImageClassification
+
+### FlaxAutoModelForImageClassification
+
+[[autodoc]] FlaxAutoModelForImageClassification
+
+### AutoModelForVideoClassification
+
+[[autodoc]] AutoModelForVideoClassification
+
+### AutoModelForKeypointDetection
+
+[[autodoc]] AutoModelForKeypointDetection
+
+### AutoModelForMaskedImageModeling
+
+[[autodoc]] AutoModelForMaskedImageModeling
+
+### TFAutoModelForMaskedImageModeling
+
+[[autodoc]] TFAutoModelForMaskedImageModeling
+
+### AutoModelForObjectDetection
+
+[[autodoc]] AutoModelForObjectDetection
+
+### AutoModelForImageSegmentation
+
+[[autodoc]] AutoModelForImageSegmentation
+
+### AutoModelForImageToImage
+
+[[autodoc]] AutoModelForImageToImage
+
+### AutoModelForSemanticSegmentation
+
+[[autodoc]] AutoModelForSemanticSegmentation
+
+### TFAutoModelForSemanticSegmentation
+
+[[autodoc]] TFAutoModelForSemanticSegmentation
+
+### AutoModelForInstanceSegmentation
+
+[[autodoc]] AutoModelForInstanceSegmentation
+
+### AutoModelForUniversalSegmentation
+
+[[autodoc]] AutoModelForUniversalSegmentation
+
+### AutoModelForZeroShotImageClassification
+
+[[autodoc]] AutoModelForZeroShotImageClassification
+
+### TFAutoModelForZeroShotImageClassification
+
+[[autodoc]] TFAutoModelForZeroShotImageClassification
+
+### AutoModelForZeroShotObjectDetection
+
+[[autodoc]] AutoModelForZeroShotObjectDetection
+
+## Audio
+
+The following auto classes are available for the following audio tasks.
+
+### AutoModelForAudioClassification
+
+[[autodoc]] AutoModelForAudioClassification
+
+### AutoModelForAudioFrameClassification
+
+[[autodoc]] TFAutoModelForAudioClassification
+
+### TFAutoModelForAudioFrameClassification
+
+[[autodoc]] AutoModelForAudioFrameClassification
+
+### AutoModelForCTC
+
+[[autodoc]] AutoModelForCTC
+
+### AutoModelForSpeechSeq2Seq
+
+[[autodoc]] AutoModelForSpeechSeq2Seq
+
+### TFAutoModelForSpeechSeq2Seq
+
+[[autodoc]] TFAutoModelForSpeechSeq2Seq
+
+### FlaxAutoModelForSpeechSeq2Seq
+
+[[autodoc]] FlaxAutoModelForSpeechSeq2Seq
+
+### AutoModelForAudioXVector
+
+[[autodoc]] AutoModelForAudioXVector
+
+### AutoModelForTextToSpectrogram
+
+[[autodoc]] AutoModelForTextToSpectrogram
+
+### AutoModelForTextToWaveform
+
+[[autodoc]] AutoModelForTextToWaveform
+
+## Multimodal
+
+The following auto classes are available for the following multimodal tasks.
+
+### AutoModelForTableQuestionAnswering
+
+[[autodoc]] AutoModelForTableQuestionAnswering
+
+### TFAutoModelForTableQuestionAnswering
+
+[[autodoc]] TFAutoModelForTableQuestionAnswering
+
+### AutoModelForDocumentQuestionAnswering
+
+[[autodoc]] AutoModelForDocumentQuestionAnswering
+
+### TFAutoModelForDocumentQuestionAnswering
+
+[[autodoc]] TFAutoModelForDocumentQuestionAnswering
+
+### AutoModelForVisualQuestionAnswering
+
+[[autodoc]] AutoModelForVisualQuestionAnswering
+
+### AutoModelForVision2Seq
+
+[[autodoc]] AutoModelForVision2Seq
+
+### TFAutoModelForVision2Seq
+
+[[autodoc]] TFAutoModelForVision2Seq
+
+### FlaxAutoModelForVision2Seq
+
+[[autodoc]] FlaxAutoModelForVision2Seq
+
+### AutoModelForImageTextToText
+
+[[autodoc]] AutoModelForImageTextToText
diff --git a/docs/transformers/docs/source/en/model_doc/autoformer.md b/docs/transformers/docs/source/en/model_doc/autoformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..2c5e27153e03188ca08bcecc83d419d9f8481ecb
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/autoformer.md
@@ -0,0 +1,54 @@
+
+
+# Autoformer
+
+
+
+
+
+## Overview
+
+The Autoformer model was proposed in [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
+
+This model augments the Transformer as a deep decomposition architecture, which can progressively decompose the trend and seasonal components during the forecasting process.
+
+The abstract from the paper is the following:
+
+*Extending the forecasting time is a critical demand for real applications, such as extreme weather early warning and long-term energy consumption planning. This paper studies the long-term forecasting problem of time series. Prior Transformer-based models adopt various self-attention mechanisms to discover the long-range dependencies. However, intricate temporal patterns of the long-term future prohibit the model from finding reliable dependencies. Also, Transformers have to adopt the sparse versions of point-wise self-attentions for long series efficiency, resulting in the information utilization bottleneck. Going beyond Transformers, we design Autoformer as a novel decomposition architecture with an Auto-Correlation mechanism. We break with the pre-processing convention of series decomposition and renovate it as a basic inner block of deep models. This design empowers Autoformer with progressive decomposition capacities for complex time series. Further, inspired by the stochastic process theory, we design the Auto-Correlation mechanism based on the series periodicity, which conducts the dependencies discovery and representation aggregation at the sub-series level. Auto-Correlation outperforms self-attention in both efficiency and accuracy. In long-term forecasting, Autoformer yields state-of-the-art accuracy, with a 38% relative improvement on six benchmarks, covering five practical applications: energy, traffic, economics, weather and disease.*
+
+This model was contributed by [elisim](https://huggingface.co/elisim) and [kashif](https://huggingface.co/kashif).
+The original code can be found [here](https://github.com/thuml/Autoformer).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- Check out the Autoformer blog-post in HuggingFace blog: [Yes, Transformers are Effective for Time Series Forecasting (+ Autoformer)](https://huggingface.co/blog/autoformer)
+
+## AutoformerConfig
+
+[[autodoc]] AutoformerConfig
+
+## AutoformerModel
+
+[[autodoc]] AutoformerModel
+ - forward
+
+## AutoformerForPrediction
+
+[[autodoc]] AutoformerForPrediction
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/aya_vision.md b/docs/transformers/docs/source/en/model_doc/aya_vision.md
new file mode 100644
index 0000000000000000000000000000000000000000..17daf4949206578f9805ef7b1e1fa2494cc6a48f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/aya_vision.md
@@ -0,0 +1,243 @@
+
+
+# AyaVision
+
+## Overview
+
+The Aya Vision 8B and 32B models is a state-of-the-art multilingual multimodal models developed by Cohere For AI. They build on the Aya Expanse recipe to handle both visual and textual information without compromising on the strong multilingual textual performance of the original model.
+
+Aya Vision 8B combines the `Siglip2-so400-384-14` vision encoder with the Cohere CommandR-7B language model further post-trained with the Aya Expanse recipe, creating a powerful vision-language model capable of understanding images and generating text across 23 languages. Whereas, Aya Vision 32B uses Aya Expanse 32B as the language model.
+
+Key features of Aya Vision include:
+- Multimodal capabilities in 23 languages
+- Strong text-only multilingual capabilities inherited from CommandR-7B post-trained with the Aya Expanse recipe and Aya Expanse 32B
+- High-quality visual understanding using the Siglip2-so400-384-14 vision encoder
+- Seamless integration of visual and textual information in 23 languages.
+
+
+
+Tips:
+
+- Aya Vision is a multimodal model that takes images and text as input and produces text as output.
+- Images are represented using the `` tag in the templated input.
+- For best results, use the `apply_chat_template` method of the processor to format your inputs correctly.
+- The model can process multiple images in a single conversation.
+- Aya Vision can understand and generate text in 23 languages, making it suitable for multilingual multimodal applications.
+
+This model was contributed by [saurabhdash](https://huggingface.co/saurabhdash) and [yonigozlan](https://huggingface.co/yonigozlan).
+
+
+## Usage
+
+Here's how to use Aya Vision for inference:
+
+```python
+from transformers import AutoProcessor, AutoModelForImageTextToText
+import torch
+
+model_id = "CohereForAI/aya-vision-8b"
+torch_device = "cuda:0"
+
+# Use fast image processor
+processor = AutoProcessor.from_pretrained(model_id, use_fast=True)
+model = AutoModelForImageTextToText.from_pretrained(
+ model_id, device_map=torch_device, torch_dtype=torch.float16
+)
+
+# Format message with the aya-vision chat template
+messages = [
+ {"role": "user",
+ "content": [
+ {"type": "image", "url": "https://pbs.twimg.com/media/Fx7YvfQWYAIp6rZ?format=jpg&name=medium"},
+ {"type": "text", "text": "चित्र में लिखा पाठ क्या कहता है?"},
+ ]},
+ ]
+
+# Process image on CUDA
+inputs = processor.apply_chat_template(
+ messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt", device=torch_device
+).to(model.device)
+
+gen_tokens = model.generate(
+ **inputs,
+ max_new_tokens=300,
+ do_sample=True,
+ temperature=0.3,
+)
+
+gen_text = print(processor.tokenizer.decode(gen_tokens[0][inputs.input_ids.shape[1]:], skip_special_tokens=True))
+```
+### Pipeline
+
+```python
+from transformers import pipeline
+
+pipe = pipeline(model="CohereForAI/aya-vision-8b", task="image-text-to-text", device_map="auto")
+
+# Format message with the aya-vision chat template
+messages = [
+ {"role": "user",
+ "content": [
+ {"type": "image", "url": "https://media.istockphoto.com/id/458012057/photo/istanbul-turkey.jpg?s=612x612&w=0&k=20&c=qogAOVvkpfUyqLUMr_XJQyq-HkACXyYUSZbKhBlPrxo="},
+ {"type": "text", "text": "Bu resimde hangi anıt gösterilmektedir?"},
+ ]},
+ ]
+outputs = pipe(text=messages, max_new_tokens=300, return_full_text=False)
+
+print(outputs)
+```
+
+### Multiple Images and Batched Inputs
+
+Aya Vision can process multiple images in a single conversation. Here's how to use it with multiple images:
+
+```python
+from transformers import AutoProcessor, AutoModelForImageTextToText
+import torch
+
+model_id = "CohereForAI/aya-vision-8b"
+
+processor = AutoProcessor.from_pretrained(model_id)
+model = AutoModelForImageTextToText.from_pretrained(
+ model_id, device_map="cuda:0", torch_dtype=torch.float16
+)
+
+# Example with multiple images in a single message
+messages = [
+ {
+ "role": "user",
+ "content": [
+ {
+ "type": "image",
+ "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg",
+ },
+ {
+ "type": "image",
+ "url": "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg",
+ },
+ {
+ "type": "text",
+ "text": "These images depict two different landmarks. Can you identify them?",
+ },
+ ],
+ },
+]
+
+inputs = processor.apply_chat_template(
+ messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt"
+).to(model.device)
+
+gen_tokens = model.generate(
+ **inputs,
+ max_new_tokens=300,
+ do_sample=True,
+ temperature=0.3,
+)
+
+gen_text = processor.tokenizer.decode(gen_tokens[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
+print(gen_text)
+```
+
+For processing batched inputs (multiple conversations at once):
+
+```python
+from transformers import AutoProcessor, AutoModelForImageTextToText
+import torch
+
+model_id = "CohereForAI/aya-vision-8b"
+
+processor = AutoProcessor.from_pretrained(model_id)
+model = AutoModelForImageTextToText.from_pretrained(
+ model_id, device_map="cuda:0", torch_dtype=torch.float16
+)
+
+# Prepare two different conversations
+batch_messages = [
+ # First conversation with a single image
+ [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+ {"type": "text", "text": "Write a haiku for this image"},
+ ],
+ },
+ ],
+ # Second conversation with multiple images
+ [
+ {
+ "role": "user",
+ "content": [
+ {
+ "type": "image",
+ "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg",
+ },
+ {
+ "type": "image",
+ "url": "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg",
+ },
+ {
+ "type": "text",
+ "text": "These images depict two different landmarks. Can you identify them?",
+ },
+ ],
+ },
+ ],
+]
+
+# Process each conversation separately and combine into a batch
+batch_inputs = processor.apply_chat_template(
+ batch_messages,
+ padding=True,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+# Generate responses for the batch
+batch_outputs = model.generate(
+ **batch_inputs,
+ max_new_tokens=300,
+ do_sample=True,
+ temperature=0.3,
+)
+
+# Decode the generated responses
+for i, output in enumerate(batch_outputs):
+ response = processor.tokenizer.decode(
+ output[batch_inputs.input_ids.shape[1]:],
+ skip_special_tokens=True
+ )
+ print(f"Response {i+1}:\n{response}\n")
+```
+
+## AyaVisionProcessor
+
+[[autodoc]] AyaVisionProcessor
+
+## AyaVisionConfig
+
+[[autodoc]] AyaVisionConfig
+
+## AyaVisionForConditionalGeneration
+
+[[autodoc]] AyaVisionForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/bamba.md b/docs/transformers/docs/source/en/model_doc/bamba.md
new file mode 100644
index 0000000000000000000000000000000000000000..c6e1bcec56a2745e6ed1db7750f6479cc3ba0bb1
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bamba.md
@@ -0,0 +1,69 @@
+
+
+# Bamba
+
+
+
+
+
+
+
+## Overview
+
+Bamba-9B is a decoder-only language model based on the [Mamba-2](https://github.com/state-spaces/mamba) architecture and is designed to handle a wide range of text generation tasks. It is trained from scratch using a two-stage training approach. In the first stage, the model is trained on 2 trillion tokens from the Dolma v1.7 dataset. In the second stage, it undergoes additional training on 200 billion tokens, leveraging a carefully curated blend of high-quality data to further refine its performance and enhance output quality.
+
+Checkout all Bamba-9B model checkpoints [here](https://github.com/foundation-model-stack/bamba).
+
+## BambaConfig
+
+| Model | Params | # Layers | Hidden Dim. | Attention Heads | GQA | KV Heads | Context Length | Tied Embeddings |
+|-------------------|--------------|----------|-------------|-----------------|-----|----------|----------------|------------------|
+| Bamba | 9B (9.78B) | 32 | 4096 | 32 | Yes | 8 | 4096 | True |
+
+[[autodoc]] BambaConfig
+
+
+
+## BambaForCausalLM
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("ibm-fms/Bamba-9B")
+tokenizer = AutoTokenizer.from_pretrained("ibm-fms/Bamba-9B")
+
+message = ["Mamba is a snake with following properties "]
+inputs = tokenizer(message, return_tensors='pt', return_token_type_ids=False)
+response = model.generate(**inputs, max_new_tokens=64)
+print(tokenizer.batch_decode(response, skip_special_tokens=True)[0])
+```
+
+[[autodoc]] BambaForCausalLM
+ - forward
+
+This HF implementation is contributed by [ani300](https://github.com/ani300) and [fabianlim](https://github.com/fabianlim).
diff --git a/docs/transformers/docs/source/en/model_doc/bark.md b/docs/transformers/docs/source/en/model_doc/bark.md
new file mode 100644
index 0000000000000000000000000000000000000000..912f552fa7c0c503534ac6517053658de2a717c7
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bark.md
@@ -0,0 +1,237 @@
+
+
+# Bark
+
+
+
+
+
+
+## Overview
+
+Bark is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark).
+
+Bark is made of 4 main models:
+
+- [`BarkSemanticModel`] (also referred to as the 'text' model): a causal auto-regressive transformer model that takes as input tokenized text, and predicts semantic text tokens that capture the meaning of the text.
+- [`BarkCoarseModel`] (also referred to as the 'coarse acoustics' model): a causal autoregressive transformer, that takes as input the results of the [`BarkSemanticModel`] model. It aims at predicting the first two audio codebooks necessary for EnCodec.
+- [`BarkFineModel`] (the 'fine acoustics' model), this time a non-causal autoencoder transformer, which iteratively predicts the last codebooks based on the sum of the previous codebooks embeddings.
+- having predicted all the codebook channels from the [`EncodecModel`], Bark uses it to decode the output audio array.
+
+It should be noted that each of the first three modules can support conditional speaker embeddings to condition the output sound according to specific predefined voice.
+
+This model was contributed by [Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) and [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi).
+The original code can be found [here](https://github.com/suno-ai/bark).
+
+### Optimizing Bark
+
+Bark can be optimized with just a few extra lines of code, which **significantly reduces its memory footprint** and **accelerates inference**.
+
+#### Using half-precision
+
+You can speed up inference and reduce memory footprint by 50% simply by loading the model in half-precision.
+
+```python
+from transformers import BarkModel
+import torch
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
+```
+
+#### Using CPU offload
+
+As mentioned above, Bark is made up of 4 sub-models, which are called up sequentially during audio generation. In other words, while one sub-model is in use, the other sub-models are idle.
+
+If you're using a CUDA device, a simple solution to benefit from an 80% reduction in memory footprint is to offload the submodels from GPU to CPU when they're idle. This operation is called *CPU offloading*. You can use it with one line of code as follows:
+
+```python
+model.enable_cpu_offload()
+```
+
+Note that 🤗 Accelerate must be installed before using this feature. [Here's how to install it.](https://huggingface.co/docs/accelerate/basic_tutorials/install)
+
+#### Using Better Transformer
+
+Better Transformer is an 🤗 Optimum feature that performs kernel fusion under the hood. You can gain 20% to 30% in speed with zero performance degradation. It only requires one line of code to export the model to 🤗 Better Transformer:
+
+```python
+model = model.to_bettertransformer()
+```
+
+Note that 🤗 Optimum must be installed before using this feature. [Here's how to install it.](https://huggingface.co/docs/optimum/installation)
+
+#### Using Flash Attention 2
+
+Flash Attention 2 is an even faster, optimized version of the previous optimization.
+
+##### Installation
+
+First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features). If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered [above](https://huggingface.co/docs/transformers/main/en/model_doc/bark#using-better-transformer).
+
+Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+
+##### Usage
+
+To load a model using Flash Attention 2, we can pass the `attn_implementation="flash_attention_2"` flag to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). We'll also load the model in half-precision (e.g. `torch.float16`), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
+
+```python
+model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
+```
+
+##### Performance comparison
+
+
+The following diagram shows the latency for the native attention implementation (no optimisation) against Better Transformer and Flash Attention 2. In all cases, we generate 400 semantic tokens on a 40GB A100 GPU with PyTorch 2.1. Flash Attention 2 is also consistently faster than Better Transformer, and its performance improves even more as batch sizes increase:
+
+
+
+
+
+To put this into perspective, on an NVIDIA A100 and when generating 400 semantic tokens with a batch size of 16, you can get 17 times the [throughput](https://huggingface.co/blog/optimizing-bark#throughput) and still be 2 seconds faster than generating sentences one by one with the native model implementation. In other words, all the samples will be generated 17 times faster.
+
+At batch size 8, on an NVIDIA A100, Flash Attention 2 is also 10% faster than Better Transformer, and at batch size 16, 25%.
+
+
+#### Combining optimization techniques
+
+You can combine optimization techniques, and use CPU offload, half-precision and Flash Attention 2 (or 🤗 Better Transformer) all at once.
+
+```python
+from transformers import BarkModel
+import torch
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+
+# load in fp16 and use Flash Attention 2
+model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
+
+# enable CPU offload
+model.enable_cpu_offload()
+```
+
+Find out more on inference optimization techniques [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
+
+### Usage tips
+
+Suno offers a library of voice presets in a number of languages [here](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c).
+These presets are also uploaded in the hub [here](https://huggingface.co/suno/bark-small/tree/main/speaker_embeddings) or [here](https://huggingface.co/suno/bark/tree/main/speaker_embeddings).
+
+```python
+>>> from transformers import AutoProcessor, BarkModel
+
+>>> processor = AutoProcessor.from_pretrained("suno/bark")
+>>> model = BarkModel.from_pretrained("suno/bark")
+
+>>> voice_preset = "v2/en_speaker_6"
+
+>>> inputs = processor("Hello, my dog is cute", voice_preset=voice_preset)
+
+>>> audio_array = model.generate(**inputs)
+>>> audio_array = audio_array.cpu().numpy().squeeze()
+```
+
+Bark can generate highly realistic, **multilingual** speech as well as other audio - including music, background noise and simple sound effects.
+
+```python
+>>> # Multilingual speech - simplified Chinese
+>>> inputs = processor("惊人的!我会说中文")
+
+>>> # Multilingual speech - French - let's use a voice_preset as well
+>>> inputs = processor("Incroyable! Je peux générer du son.", voice_preset="fr_speaker_5")
+
+>>> # Bark can also generate music. You can help it out by adding music notes around your lyrics.
+>>> inputs = processor("♪ Hello, my dog is cute ♪")
+
+>>> audio_array = model.generate(**inputs)
+>>> audio_array = audio_array.cpu().numpy().squeeze()
+```
+
+The model can also produce **nonverbal communications** like laughing, sighing and crying.
+
+
+```python
+>>> # Adding non-speech cues to the input text
+>>> inputs = processor("Hello uh ... [clears throat], my dog is cute [laughter]")
+
+>>> audio_array = model.generate(**inputs)
+>>> audio_array = audio_array.cpu().numpy().squeeze()
+```
+
+To save the audio, simply take the sample rate from the model config and some scipy utility:
+
+```python
+>>> from scipy.io.wavfile import write as write_wav
+
+>>> # save audio to disk, but first take the sample rate from the model config
+>>> sample_rate = model.generation_config.sample_rate
+>>> write_wav("bark_generation.wav", sample_rate, audio_array)
+```
+
+## BarkConfig
+
+[[autodoc]] BarkConfig
+ - all
+
+## BarkProcessor
+
+[[autodoc]] BarkProcessor
+ - all
+ - __call__
+
+## BarkModel
+
+[[autodoc]] BarkModel
+ - generate
+ - enable_cpu_offload
+
+## BarkSemanticModel
+
+[[autodoc]] BarkSemanticModel
+ - forward
+
+## BarkCoarseModel
+
+[[autodoc]] BarkCoarseModel
+ - forward
+
+## BarkFineModel
+
+[[autodoc]] BarkFineModel
+ - forward
+
+## BarkCausalModel
+
+[[autodoc]] BarkCausalModel
+ - forward
+
+## BarkCoarseConfig
+
+[[autodoc]] BarkCoarseConfig
+ - all
+
+## BarkFineConfig
+
+[[autodoc]] BarkFineConfig
+ - all
+
+## BarkSemanticConfig
+
+[[autodoc]] BarkSemanticConfig
+ - all
+
diff --git a/docs/transformers/docs/source/en/model_doc/bart.md b/docs/transformers/docs/source/en/model_doc/bart.md
new file mode 100644
index 0000000000000000000000000000000000000000..aaccd78047db100da208b1cab8757562bfd49315
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bart.md
@@ -0,0 +1,228 @@
+
+
+# BART
+
+
+
+
+
+
+
+
+
+## Overview
+
+The Bart model was proposed in [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation,
+Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
+Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer on 29 Oct, 2019.
+
+According to the abstract,
+
+- Bart uses a standard seq2seq/machine translation architecture with a bidirectional encoder (like BERT) and a
+ left-to-right decoder (like GPT).
+- The pretraining task involves randomly shuffling the order of the original sentences and a novel in-filling scheme,
+ where spans of text are replaced with a single mask token.
+- BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It
+ matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new
+ state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains
+ of up to 6 ROUGE.
+
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/bart).
+
+## Usage tips:
+
+- BART is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+- Sequence-to-sequence model with an encoder and a decoder. Encoder is fed a corrupted version of the tokens, decoder is fed the original tokens (but has a mask to hide the future words like a regular transformers decoder). A composition of the following transformations are applied on the pretraining tasks for the encoder:
+
+ * mask random tokens (like in BERT)
+ * delete random tokens
+ * mask a span of k tokens with a single mask token (a span of 0 tokens is an insertion of a mask token)
+ * permute sentences
+ * rotate the document to make it start at a specific token
+
+## Implementation Notes
+
+- Bart doesn't use `token_type_ids` for sequence classification. Use [`BartTokenizer`] or
+ [`~BartTokenizer.encode`] to get the proper splitting.
+- The forward pass of [`BartModel`] will create the `decoder_input_ids` if they are not passed.
+ This is different than some other modeling APIs. A typical use case of this feature is mask filling.
+- Model predictions are intended to be identical to the original implementation when
+ `forced_bos_token_id=0`. This only works, however, if the string you pass to
+ [`fairseq.encode`] starts with a space.
+- [`~generation.GenerationMixin.generate`] should be used for conditional generation tasks like
+ summarization, see the example in that docstrings.
+- Models that load the *facebook/bart-large-cnn* weights will not have a `mask_token_id`, or be able to perform
+ mask-filling tasks.
+
+## Mask Filling
+
+The `facebook/bart-base` and `facebook/bart-large` checkpoints can be used to fill multi-token masks.
+
+```python
+from transformers import BartForConditionalGeneration, BartTokenizer
+
+model = BartForConditionalGeneration.from_pretrained("facebook/bart-large", forced_bos_token_id=0)
+tok = BartTokenizer.from_pretrained("facebook/bart-large")
+example_english_phrase = "UN Chief Says There Is No in Syria"
+batch = tok(example_english_phrase, return_tensors="pt")
+generated_ids = model.generate(batch["input_ids"])
+assert tok.batch_decode(generated_ids, skip_special_tokens=True) == [
+ "UN Chief Says There Is No Plan to Stop Chemical Weapons in Syria"
+]
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BART. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+- A blog post on [Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq).
+- A notebook on how to [finetune BART for summarization with fastai using blurr](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb). 🌎
+- A notebook on how to [finetune BART for summarization in two languages with Trainer class](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb). 🌎
+- [`BartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb).
+- [`TFBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb).
+- [`FlaxBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization).
+- An example of how to train [`BartForConditionalGeneration`] with a Hugging Face `datasets` object can be found in this [forum discussion](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904)
+- [Summarization](https://huggingface.co/course/chapter7/5?fw=pt#summarization) chapter of the 🤗 Hugging Face course.
+- [Summarization task guide](../tasks/summarization)
+
+
+
+- [`BartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
+- [`TFBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
+- [`FlaxBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
+- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+
+
+
+- A notebook on how to [finetune mBART using Seq2SeqTrainer for Hindi to English translation](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb). 🌎
+- [`BartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb).
+- [`TFBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/translation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb).
+- [Translation task guide](../tasks/translation)
+
+See also:
+- [Text classification task guide](../tasks/sequence_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Distilled checkpoints](https://huggingface.co/models?search=distilbart) are described in this [paper](https://arxiv.org/abs/2010.13002).
+
+## BartConfig
+
+[[autodoc]] BartConfig
+ - all
+
+## BartTokenizer
+
+[[autodoc]] BartTokenizer
+ - all
+
+## BartTokenizerFast
+
+[[autodoc]] BartTokenizerFast
+ - all
+
+
+
+
+
+## BartModel
+
+[[autodoc]] BartModel
+ - forward
+
+## BartForConditionalGeneration
+
+[[autodoc]] BartForConditionalGeneration
+ - forward
+
+## BartForSequenceClassification
+
+[[autodoc]] BartForSequenceClassification
+ - forward
+
+## BartForQuestionAnswering
+
+[[autodoc]] BartForQuestionAnswering
+ - forward
+
+## BartForCausalLM
+
+[[autodoc]] BartForCausalLM
+ - forward
+
+
+
+
+## TFBartModel
+
+[[autodoc]] TFBartModel
+ - call
+
+## TFBartForConditionalGeneration
+
+[[autodoc]] TFBartForConditionalGeneration
+ - call
+
+## TFBartForSequenceClassification
+
+[[autodoc]] TFBartForSequenceClassification
+ - call
+
+
+
+
+## FlaxBartModel
+
+[[autodoc]] FlaxBartModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForConditionalGeneration
+
+[[autodoc]] FlaxBartForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForSequenceClassification
+
+[[autodoc]] FlaxBartForSequenceClassification
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForQuestionAnswering
+
+[[autodoc]] FlaxBartForQuestionAnswering
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForCausalLM
+
+[[autodoc]] FlaxBartForCausalLM
+ - __call__
+
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/barthez.md b/docs/transformers/docs/source/en/model_doc/barthez.md
new file mode 100644
index 0000000000000000000000000000000000000000..131b1dd8e185437905832c10120edf13f1e03b7a
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/barthez.md
@@ -0,0 +1,67 @@
+
+
+# BARThez
+
+
+
+
+
+
+
+## Overview
+
+The BARThez model was proposed in [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis on 23 Oct,
+2020.
+
+The abstract of the paper:
+
+
+*Inductive transfer learning, enabled by self-supervised learning, have taken the entire Natural Language Processing
+(NLP) field by storm, with models such as BERT and BART setting new state of the art on countless natural language
+understanding tasks. While there are some notable exceptions, most of the available models and research have been
+conducted for the English language. In this work, we introduce BARThez, the first BART model for the French language
+(to the best of our knowledge). BARThez was pretrained on a very large monolingual French corpus from past research
+that we adapted to suit BART's perturbation schemes. Unlike already existing BERT-based French language models such as
+CamemBERT and FlauBERT, BARThez is particularly well-suited for generative tasks, since not only its encoder but also
+its decoder is pretrained. In addition to discriminative tasks from the FLUE benchmark, we evaluate BARThez on a novel
+summarization dataset, OrangeSum, that we release with this paper. We also continue the pretraining of an already
+pretrained multilingual BART on BARThez's corpus, and we show that the resulting model, which we call mBARTHez,
+provides a significant boost over vanilla BARThez, and is on par with or outperforms CamemBERT and FlauBERT.*
+
+This model was contributed by [moussakam](https://huggingface.co/moussakam). The Authors' code can be found [here](https://github.com/moussaKam/BARThez).
+
+
+
+BARThez implementation is the same as BART, except for tokenization. Refer to [BART documentation](bart) for information on
+configuration classes and their parameters. BARThez-specific tokenizers are documented below.
+
+
+
+## Resources
+
+- BARThez can be fine-tuned on sequence-to-sequence tasks in a similar way as BART, check:
+ [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
+
+
+## BarthezTokenizer
+
+[[autodoc]] BarthezTokenizer
+
+## BarthezTokenizerFast
+
+[[autodoc]] BarthezTokenizerFast
diff --git a/docs/transformers/docs/source/en/model_doc/bartpho.md b/docs/transformers/docs/source/en/model_doc/bartpho.md
new file mode 100644
index 0000000000000000000000000000000000000000..b3749516323d5fb6481cf60317bf9c0328f1b650
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bartpho.md
@@ -0,0 +1,93 @@
+
+
+# BARTpho
+
+
+
+
+
+
+
+## Overview
+
+The BARTpho model was proposed in [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+
+The abstract from the paper is the following:
+
+*We present BARTpho with two versions -- BARTpho_word and BARTpho_syllable -- the first public large-scale monolingual
+sequence-to-sequence models pre-trained for Vietnamese. Our BARTpho uses the "large" architecture and pre-training
+scheme of the sequence-to-sequence denoising model BART, thus especially suitable for generative NLP tasks. Experiments
+on a downstream task of Vietnamese text summarization show that in both automatic and human evaluations, our BARTpho
+outperforms the strong baseline mBART and improves the state-of-the-art. We release BARTpho to facilitate future
+research and applications of generative Vietnamese NLP tasks.*
+
+This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BARTpho).
+
+## Usage example
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bartpho = AutoModel.from_pretrained("vinai/bartpho-syllable")
+
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bartpho-syllable")
+
+>>> line = "Chúng tôi là những nghiên cứu viên."
+
+>>> input_ids = tokenizer(line, return_tensors="pt")
+
+>>> with torch.no_grad():
+... features = bartpho(**input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> from transformers import TFAutoModel
+
+>>> bartpho = TFAutoModel.from_pretrained("vinai/bartpho-syllable")
+>>> input_ids = tokenizer(line, return_tensors="tf")
+>>> features = bartpho(**input_ids)
+```
+
+## Usage tips
+
+- Following mBART, BARTpho uses the "large" architecture of BART with an additional layer-normalization layer on top of
+ both the encoder and decoder. Thus, usage examples in the [documentation of BART](bart), when adapting to use
+ with BARTpho, should be adjusted by replacing the BART-specialized classes with the mBART-specialized counterparts.
+ For example:
+
+```python
+>>> from transformers import MBartForConditionalGeneration
+
+>>> bartpho = MBartForConditionalGeneration.from_pretrained("vinai/bartpho-syllable")
+>>> TXT = "Chúng tôi là nghiên cứu viên."
+>>> input_ids = tokenizer([TXT], return_tensors="pt")["input_ids"]
+>>> logits = bartpho(input_ids).logits
+>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
+>>> probs = logits[0, masked_index].softmax(dim=0)
+>>> values, predictions = probs.topk(5)
+>>> print(tokenizer.decode(predictions).split())
+```
+
+- This implementation is only for tokenization: "monolingual_vocab_file" consists of Vietnamese-specialized types
+ extracted from the pre-trained SentencePiece model "vocab_file" that is available from the multilingual XLM-RoBERTa.
+ Other languages, if employing this pre-trained multilingual SentencePiece model "vocab_file" for subword
+ segmentation, can reuse BartphoTokenizer with their own language-specialized "monolingual_vocab_file".
+
+## BartphoTokenizer
+
+[[autodoc]] BartphoTokenizer
diff --git a/docs/transformers/docs/source/en/model_doc/beit.md b/docs/transformers/docs/source/en/model_doc/beit.md
new file mode 100644
index 0000000000000000000000000000000000000000..24dfabf682b6bf652dc9055e5fba2e503b67f891
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/beit.md
@@ -0,0 +1,196 @@
+
+
+# BEiT
+
+
+
+
+
+
+
+## Overview
+
+The BEiT model was proposed in [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by
+Hangbo Bao, Li Dong and Furu Wei. Inspired by BERT, BEiT is the first paper that makes self-supervised pre-training of
+Vision Transformers (ViTs) outperform supervised pre-training. Rather than pre-training the model to predict the class
+of an image (as done in the [original ViT paper](https://arxiv.org/abs/2010.11929)), BEiT models are pre-trained to
+predict visual tokens from the codebook of OpenAI's [DALL-E model](https://arxiv.org/abs/2102.12092) given masked
+patches.
+
+The abstract from the paper is the following:
+
+*We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation
+from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image
+modeling task to pretrain vision Transformers. Specifically, each image has two views in our pre-training, i.e, image
+patches (such as 16x16 pixels), and visual tokens (i.e., discrete tokens). We first "tokenize" the original image into
+visual tokens. Then we randomly mask some image patches and fed them into the backbone Transformer. The pre-training
+objective is to recover the original visual tokens based on the corrupted image patches. After pre-training BEiT, we
+directly fine-tune the model parameters on downstream tasks by appending task layers upon the pretrained encoder.
+Experimental results on image classification and semantic segmentation show that our model achieves competitive results
+with previous pre-training methods. For example, base-size BEiT achieves 83.2% top-1 accuracy on ImageNet-1K,
+significantly outperforming from-scratch DeiT training (81.8%) with the same setup. Moreover, large-size BEiT obtains
+86.3% only using ImageNet-1K, even outperforming ViT-L with supervised pre-training on ImageNet-22K (85.2%).*
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The JAX/FLAX version of this model was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/beit).
+
+## Usage tips
+
+- BEiT models are regular Vision Transformers, but pre-trained in a self-supervised way rather than supervised. They
+ outperform both the [original model (ViT)](vit) as well as [Data-efficient Image Transformers (DeiT)](deit) when fine-tuned on ImageNet-1K and CIFAR-100. You can check out demo notebooks regarding inference as well as
+ fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (you can just replace
+ [`ViTFeatureExtractor`] by [`BeitImageProcessor`] and
+ [`ViTForImageClassification`] by [`BeitForImageClassification`]).
+- There's also a demo notebook available which showcases how to combine DALL-E's image tokenizer with BEiT for
+ performing masked image modeling. You can find it [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BEiT).
+- As the BEiT models expect each image to be of the same size (resolution), one can use
+ [`BeitImageProcessor`] to resize (or rescale) and normalize images for the model.
+- Both the patch resolution and image resolution used during pre-training or fine-tuning are reflected in the name of
+ each checkpoint. For example, `microsoft/beit-base-patch16-224` refers to a base-sized architecture with patch
+ resolution of 16x16 and fine-tuning resolution of 224x224. All checkpoints can be found on the [hub](https://huggingface.co/models?search=microsoft/beit).
+- The available checkpoints are either (1) pre-trained on [ImageNet-22k](http://www.image-net.org/) (a collection of
+ 14 million images and 22k classes) only, (2) also fine-tuned on ImageNet-22k or (3) also fine-tuned on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
+ images and 1,000 classes).
+- BEiT uses relative position embeddings, inspired by the T5 model. During pre-training, the authors shared the
+ relative position bias among the several self-attention layers. During fine-tuning, each layer's relative position
+ bias is initialized with the shared relative position bias obtained after pre-training. Note that, if one wants to
+ pre-train a model from scratch, one needs to either set the `use_relative_position_bias` or the
+ `use_relative_position_bias` attribute of [`BeitConfig`] to `True` in order to add
+ position embeddings.
+
+
+
+ BEiT pre-training. Taken from the original paper.
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```
+from transformers import BeitForImageClassification
+model = BeitForImageClassification.from_pretrained("microsoft/beit-base-patch16-224", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+On a local benchmark (NVIDIA GeForce RTX 2060-8GB, PyTorch 2.5.1, OS Ubuntu 20.04) with `float16` and
+`microsoft/beit-base-patch16-224` model, we saw the following improvements during training and inference:
+
+#### Training
+
+| num_training_steps | batch_size | image_size | is_cuda | Time per batch (eager - s) | Time per batch (sdpa - s) | Speedup (%) | Eager peak mem (MB) | SDPA peak mem (MB) | Mem saving (%) |
+|--------------------|------------|--------------|---------|----------------------------|---------------------------|-------------|----------------------|--------------------|----------------|
+| 50 | 2 | (1048, 640) | True | 0.984 | 0.746 | 31.975 | 6738.915 | 4319.886 | 55.998 |
+
+#### Inference
+
+| Image batch size | Eager (s/iter) | Eager CI, % | Eager memory (MB) | SDPA (s/iter) | SDPA CI, % | SDPA memory (MB) | SDPA speedup | SDPA memory saved (%) |
+|-------------------:|-----------------:|:--------------|--------------------:|----------------:|:-------------|-------------------:|---------------:|----------------------:|
+| 1 | 0.012 | ±0.3% | 3.76657e+08 | 0.011 | ±0.5% | 3.75739e+08 | 1.05 | 0.244 |
+| 4 | 0.013 | ±0.1% | 4.03147e+08 | 0.011 | ±0.2% | 3.90554e+08 | 1.178 | 3.225 |
+| 16 | 0.045 | ±0.1% | 4.96697e+08 | 0.035 | ±0.1% | 4.51232e+08 | 1.304 | 10.076 |
+| 32 | 0.088 | ±0.1% | 6.24417e+08 | 0.066 | ±0.1% | 5.33488e+08 | 1.325 | 17.044 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
+
+
+
+- [`BeitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+**Semantic segmentation**
+- [Semantic segmentation task guide](../tasks/semantic_segmentation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## BEiT specific outputs
+
+[[autodoc]] models.beit.modeling_beit.BeitModelOutputWithPooling
+
+[[autodoc]] models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling
+
+## BeitConfig
+
+[[autodoc]] BeitConfig
+
+## BeitFeatureExtractor
+
+[[autodoc]] BeitFeatureExtractor
+ - __call__
+ - post_process_semantic_segmentation
+
+## BeitImageProcessor
+
+[[autodoc]] BeitImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
+
+
+
+## BeitModel
+
+[[autodoc]] BeitModel
+ - forward
+
+## BeitForMaskedImageModeling
+
+[[autodoc]] BeitForMaskedImageModeling
+ - forward
+
+## BeitForImageClassification
+
+[[autodoc]] BeitForImageClassification
+ - forward
+
+## BeitForSemanticSegmentation
+
+[[autodoc]] BeitForSemanticSegmentation
+ - forward
+
+
+
+
+## FlaxBeitModel
+
+[[autodoc]] FlaxBeitModel
+ - __call__
+
+## FlaxBeitForMaskedImageModeling
+
+[[autodoc]] FlaxBeitForMaskedImageModeling
+ - __call__
+
+## FlaxBeitForImageClassification
+
+[[autodoc]] FlaxBeitForImageClassification
+ - __call__
+
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/bert-generation.md b/docs/transformers/docs/source/en/model_doc/bert-generation.md
new file mode 100644
index 0000000000000000000000000000000000000000..0c42adbeb56473069df6b0bfd40a4c1bf84b6d82
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bert-generation.md
@@ -0,0 +1,111 @@
+
+
+# BertGeneration
+
+
+
+
+
+## Overview
+
+The BertGeneration model is a BERT model that can be leveraged for sequence-to-sequence tasks using
+[`EncoderDecoderModel`] as proposed in [Leveraging Pre-trained Checkpoints for Sequence Generation
+Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+
+The abstract from the paper is the following:
+
+*Unsupervised pretraining of large neural models has recently revolutionized Natural Language Processing. By
+warm-starting from the publicly released checkpoints, NLP practitioners have pushed the state-of-the-art on multiple
+benchmarks while saving significant amounts of compute time. So far the focus has been mainly on the Natural Language
+Understanding tasks. In this paper, we demonstrate the efficacy of pre-trained checkpoints for Sequence Generation. We
+developed a Transformer-based sequence-to-sequence model that is compatible with publicly available pre-trained BERT,
+GPT-2 and RoBERTa checkpoints and conducted an extensive empirical study on the utility of initializing our model, both
+encoder and decoder, with these checkpoints. Our models result in new state-of-the-art results on Machine Translation,
+Text Summarization, Sentence Splitting, and Sentence Fusion.*
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://tfhub.dev/s?module-type=text-generation&subtype=module,placeholder).
+
+## Usage examples and tips
+
+The model can be used in combination with the [`EncoderDecoderModel`] to leverage two pretrained BERT checkpoints for
+subsequent fine-tuning:
+
+```python
+>>> # leverage checkpoints for Bert2Bert model...
+>>> # use BERT's cls token as BOS token and sep token as EOS token
+>>> encoder = BertGenerationEncoder.from_pretrained("google-bert/bert-large-uncased", bos_token_id=101, eos_token_id=102)
+>>> # add cross attention layers and use BERT's cls token as BOS token and sep token as EOS token
+>>> decoder = BertGenerationDecoder.from_pretrained(
+... "google-bert/bert-large-uncased", add_cross_attention=True, is_decoder=True, bos_token_id=101, eos_token_id=102
+... )
+>>> bert2bert = EncoderDecoderModel(encoder=encoder, decoder=decoder)
+
+>>> # create tokenizer...
+>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-large-uncased")
+
+>>> input_ids = tokenizer(
+... "This is a long article to summarize", add_special_tokens=False, return_tensors="pt"
+... ).input_ids
+>>> labels = tokenizer("This is a short summary", return_tensors="pt").input_ids
+
+>>> # train...
+>>> loss = bert2bert(input_ids=input_ids, decoder_input_ids=labels, labels=labels).loss
+>>> loss.backward()
+```
+
+Pretrained [`EncoderDecoderModel`] are also directly available in the model hub, e.g.:
+
+```python
+>>> # instantiate sentence fusion model
+>>> sentence_fuser = EncoderDecoderModel.from_pretrained("google/roberta2roberta_L-24_discofuse")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/roberta2roberta_L-24_discofuse")
+
+>>> input_ids = tokenizer(
+... "This is the first sentence. This is the second sentence.", add_special_tokens=False, return_tensors="pt"
+... ).input_ids
+
+>>> outputs = sentence_fuser.generate(input_ids)
+
+>>> print(tokenizer.decode(outputs[0]))
+```
+
+Tips:
+
+- [`BertGenerationEncoder`] and [`BertGenerationDecoder`] should be used in
+ combination with [`EncoderDecoder`].
+- For summarization, sentence splitting, sentence fusion and translation, no special tokens are required for the input.
+ Therefore, no EOS token should be added to the end of the input.
+
+## BertGenerationConfig
+
+[[autodoc]] BertGenerationConfig
+
+## BertGenerationTokenizer
+
+[[autodoc]] BertGenerationTokenizer
+ - save_vocabulary
+
+## BertGenerationEncoder
+
+[[autodoc]] BertGenerationEncoder
+ - forward
+
+## BertGenerationDecoder
+
+[[autodoc]] BertGenerationDecoder
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/bert-japanese.md b/docs/transformers/docs/source/en/model_doc/bert-japanese.md
new file mode 100644
index 0000000000000000000000000000000000000000..33a720318b63718ef65a316145a92750e69fb9c1
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bert-japanese.md
@@ -0,0 +1,89 @@
+
+
+# BertJapanese
+
+
+
+
+
+
+
+## Overview
+
+The BERT models trained on Japanese text.
+
+There are models with two different tokenization methods:
+
+- Tokenize with MeCab and WordPiece. This requires some extra dependencies, [fugashi](https://github.com/polm/fugashi) which is a wrapper around [MeCab](https://taku910.github.io/mecab/).
+- Tokenize into characters.
+
+To use *MecabTokenizer*, you should `pip install transformers["ja"]` (or `pip install -e .["ja"]` if you install
+from source) to install dependencies.
+
+See [details on cl-tohoku repository](https://github.com/cl-tohoku/bert-japanese).
+
+Example of using a model with MeCab and WordPiece tokenization:
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese")
+>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese")
+
+>>> ## Input Japanese Text
+>>> line = "吾輩は猫である。"
+
+>>> inputs = tokenizer(line, return_tensors="pt")
+
+>>> print(tokenizer.decode(inputs["input_ids"][0]))
+[CLS] 吾輩 は 猫 で ある 。 [SEP]
+
+>>> outputs = bertjapanese(**inputs)
+```
+
+Example of using a model with Character tokenization:
+
+```python
+>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese-char")
+>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-char")
+
+>>> ## Input Japanese Text
+>>> line = "吾輩は猫である。"
+
+>>> inputs = tokenizer(line, return_tensors="pt")
+
+>>> print(tokenizer.decode(inputs["input_ids"][0]))
+[CLS] 吾 輩 は 猫 で あ る 。 [SEP]
+
+>>> outputs = bertjapanese(**inputs)
+```
+
+This model was contributed by [cl-tohoku](https://huggingface.co/cl-tohoku).
+
+
+
+This implementation is the same as BERT, except for tokenization method. Refer to [BERT documentation](bert) for
+API reference information.
+
+
+
+
+## BertJapaneseTokenizer
+
+[[autodoc]] BertJapaneseTokenizer
diff --git a/docs/transformers/docs/source/en/model_doc/bert.md b/docs/transformers/docs/source/en/model_doc/bert.md
new file mode 100644
index 0000000000000000000000000000000000000000..94425336d5b141a3b8f8c94bd848893de3adab76
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bert.md
@@ -0,0 +1,259 @@
+
+
+
+
+
+
+
+
+
+
+
+# BERT
+
+[BERT](https://huggingface.co/papers/1810.04805) is a bidirectional transformer pretrained on unlabeled text to predict masked tokens in a sentence and to predict whether one sentence follows another. The main idea is that by randomly masking some tokens, the model can train on text to the left and right, giving it a more thorough understanding. BERT is also very versatile because its learned language representations can be adapted for other NLP tasks by fine-tuning an additional layer or head.
+
+You can find all the original BERT checkpoints under the [BERT](https://huggingface.co/collections/google/bert-release-64ff5e7a4be99045d1896dbc) collection.
+
+> [!TIP]
+> Click on the BERT models in the right sidebar for more examples of how to apply BERT to different language tasks.
+
+The example below demonstrates how to predict the `[MASK]` token with [`Pipeline`], [`AutoModel`], and from the command line.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="fill-mask",
+ model="google-bert/bert-base-uncased",
+ torch_dtype=torch.float16,
+ device=0
+)
+pipeline("Plants create [MASK] through a process known as photosynthesis.")
+```
+
+
+
+
+```py
+import torch
+from transformers import AutoModelForMaskedLM, AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained(
+ "google-bert/bert-base-uncased",
+)
+model = AutoModelForMaskedLM.from_pretrained(
+ "google-bert/bert-base-uncased",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+inputs = tokenizer("Plants create [MASK] through a process known as photosynthesis.", return_tensors="pt").to("cuda")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+ predictions = outputs.logits
+
+masked_index = torch.where(inputs['input_ids'] == tokenizer.mask_token_id)[1]
+predicted_token_id = predictions[0, masked_index].argmax(dim=-1)
+predicted_token = tokenizer.decode(predicted_token_id)
+
+print(f"The predicted token is: {predicted_token}")
+```
+
+
+
+
+```bash
+echo -e "Plants create [MASK] through a process known as photosynthesis." | transformers-cli run --task fill-mask --model google-bert/bert-base-uncased --device 0
+```
+
+
+
+
+## Notes
+
+- Inputs should be padded on the right because BERT uses absolute position embeddings.
+
+## BertConfig
+
+[[autodoc]] BertConfig
+ - all
+
+## BertTokenizer
+
+[[autodoc]] BertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BertTokenizerFast
+
+[[autodoc]] BertTokenizerFast
+
+## BertModel
+
+[[autodoc]] BertModel
+ - forward
+
+## BertForPreTraining
+
+[[autodoc]] BertForPreTraining
+ - forward
+
+## BertLMHeadModel
+
+[[autodoc]] BertLMHeadModel
+ - forward
+
+## BertForMaskedLM
+
+[[autodoc]] BertForMaskedLM
+ - forward
+
+## BertForNextSentencePrediction
+
+[[autodoc]] BertForNextSentencePrediction
+ - forward
+
+## BertForSequenceClassification
+
+[[autodoc]] BertForSequenceClassification
+ - forward
+
+## BertForMultipleChoice
+
+[[autodoc]] BertForMultipleChoice
+ - forward
+
+## BertForTokenClassification
+
+[[autodoc]] BertForTokenClassification
+ - forward
+
+## BertForQuestionAnswering
+
+[[autodoc]] BertForQuestionAnswering
+ - forward
+
+## TFBertTokenizer
+
+[[autodoc]] TFBertTokenizer
+
+## TFBertModel
+
+[[autodoc]] TFBertModel
+ - call
+
+## TFBertForPreTraining
+
+[[autodoc]] TFBertForPreTraining
+ - call
+
+## TFBertModelLMHeadModel
+
+[[autodoc]] TFBertLMHeadModel
+ - call
+
+## TFBertForMaskedLM
+
+[[autodoc]] TFBertForMaskedLM
+ - call
+
+## TFBertForNextSentencePrediction
+
+[[autodoc]] TFBertForNextSentencePrediction
+ - call
+
+## TFBertForSequenceClassification
+
+[[autodoc]] TFBertForSequenceClassification
+ - call
+
+## TFBertForMultipleChoice
+
+[[autodoc]] TFBertForMultipleChoice
+ - call
+
+## TFBertForTokenClassification
+
+[[autodoc]] TFBertForTokenClassification
+ - call
+
+## TFBertForQuestionAnswering
+
+[[autodoc]] TFBertForQuestionAnswering
+ - call
+
+## FlaxBertModel
+
+[[autodoc]] FlaxBertModel
+ - __call__
+
+## FlaxBertForPreTraining
+
+[[autodoc]] FlaxBertForPreTraining
+ - __call__
+
+## FlaxBertForCausalLM
+
+[[autodoc]] FlaxBertForCausalLM
+ - __call__
+
+## FlaxBertForMaskedLM
+
+[[autodoc]] FlaxBertForMaskedLM
+ - __call__
+
+## FlaxBertForNextSentencePrediction
+
+[[autodoc]] FlaxBertForNextSentencePrediction
+ - __call__
+
+## FlaxBertForSequenceClassification
+
+[[autodoc]] FlaxBertForSequenceClassification
+ - __call__
+
+## FlaxBertForMultipleChoice
+
+[[autodoc]] FlaxBertForMultipleChoice
+ - __call__
+
+## FlaxBertForTokenClassification
+
+[[autodoc]] FlaxBertForTokenClassification
+ - __call__
+
+## FlaxBertForQuestionAnswering
+
+[[autodoc]] FlaxBertForQuestionAnswering
+ - __call__
+
+## Bert specific outputs
+
+[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
+
+[[autodoc]] models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
+
+[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/bertweet.md b/docs/transformers/docs/source/en/model_doc/bertweet.md
new file mode 100644
index 0000000000000000000000000000000000000000..be489643173f72a95d7885dd27b8e14e19965a6c
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bertweet.md
@@ -0,0 +1,76 @@
+
+
+# BERTweet
+
+
+
+
+
+
+
+## Overview
+
+The BERTweet model was proposed in [BERTweet: A pre-trained language model for English Tweets](https://www.aclweb.org/anthology/2020.emnlp-demos.2.pdf) by Dat Quoc Nguyen, Thanh Vu, Anh Tuan Nguyen.
+
+The abstract from the paper is the following:
+
+*We present BERTweet, the first public large-scale pre-trained language model for English Tweets. Our BERTweet, having
+the same architecture as BERT-base (Devlin et al., 2019), is trained using the RoBERTa pre-training procedure (Liu et
+al., 2019). Experiments show that BERTweet outperforms strong baselines RoBERTa-base and XLM-R-base (Conneau et al.,
+2020), producing better performance results than the previous state-of-the-art models on three Tweet NLP tasks:
+Part-of-speech tagging, Named-entity recognition and text classification.*
+
+This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/BERTweet).
+
+## Usage example
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bertweet = AutoModel.from_pretrained("vinai/bertweet-base")
+
+>>> # For transformers v4.x+:
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base", use_fast=False)
+
+>>> # For transformers v3.x:
+>>> # tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base")
+
+>>> # INPUT TWEET IS ALREADY NORMALIZED!
+>>> line = "SC has first two presumptive cases of coronavirus , DHEC confirms HTTPURL via @USER :cry:"
+
+>>> input_ids = torch.tensor([tokenizer.encode(line)])
+
+>>> with torch.no_grad():
+... features = bertweet(input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> # from transformers import TFAutoModel
+>>> # bertweet = TFAutoModel.from_pretrained("vinai/bertweet-base")
+```
+
+
+
+This implementation is the same as BERT, except for tokenization method. Refer to [BERT documentation](bert) for
+API reference information.
+
+
+
+## BertweetTokenizer
+
+[[autodoc]] BertweetTokenizer
diff --git a/docs/transformers/docs/source/en/model_doc/big_bird.md b/docs/transformers/docs/source/en/model_doc/big_bird.md
new file mode 100644
index 0000000000000000000000000000000000000000..32ca5a2062a2ee6aa5b95f384a8437809889fd44
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/big_bird.md
@@ -0,0 +1,184 @@
+
+
+# BigBird
+
+
+
+
+
+
+## Overview
+
+The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by
+Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon,
+Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others. BigBird, is a sparse-attention
+based transformer which extends Transformer based models, such as BERT to much longer sequences. In addition to sparse
+attention, BigBird also applies global attention as well as random attention to the input sequence. Theoretically, it
+has been shown that applying sparse, global, and random attention approximates full attention, while being
+computationally much more efficient for longer sequences. As a consequence of the capability to handle longer context,
+BigBird has shown improved performance on various long document NLP tasks, such as question answering and
+summarization, compared to BERT or RoBERTa.
+
+The abstract from the paper is the following:
+
+*Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP.
+Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence
+length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that
+reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and
+is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our
+theoretical analysis reveals some of the benefits of having O(1) global tokens (such as CLS), that attend to the entire
+sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to
+8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context,
+BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also
+propose novel applications to genomics data.*
+
+This model was contributed by [vasudevgupta](https://huggingface.co/vasudevgupta). The original code can be found
+[here](https://github.com/google-research/bigbird).
+
+## Usage tips
+
+- For an in-detail explanation on how BigBird's attention works, see [this blog post](https://huggingface.co/blog/big-bird).
+- BigBird comes with 2 implementations: **original_full** & **block_sparse**. For the sequence length < 1024, using
+ **original_full** is advised as there is no benefit in using **block_sparse** attention.
+- The code currently uses window size of 3 blocks and 2 global blocks.
+- Sequence length must be divisible by block size.
+- Current implementation supports only **ITC**.
+- Current implementation doesn't support **num_random_blocks = 0**
+- BigBird is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## BigBirdConfig
+
+[[autodoc]] BigBirdConfig
+
+## BigBirdTokenizer
+
+[[autodoc]] BigBirdTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BigBirdTokenizerFast
+
+[[autodoc]] BigBirdTokenizerFast
+
+## BigBird specific outputs
+
+[[autodoc]] models.big_bird.modeling_big_bird.BigBirdForPreTrainingOutput
+
+
+
+
+## BigBirdModel
+
+[[autodoc]] BigBirdModel
+ - forward
+
+## BigBirdForPreTraining
+
+[[autodoc]] BigBirdForPreTraining
+ - forward
+
+## BigBirdForCausalLM
+
+[[autodoc]] BigBirdForCausalLM
+ - forward
+
+## BigBirdForMaskedLM
+
+[[autodoc]] BigBirdForMaskedLM
+ - forward
+
+## BigBirdForSequenceClassification
+
+[[autodoc]] BigBirdForSequenceClassification
+ - forward
+
+## BigBirdForMultipleChoice
+
+[[autodoc]] BigBirdForMultipleChoice
+ - forward
+
+## BigBirdForTokenClassification
+
+[[autodoc]] BigBirdForTokenClassification
+ - forward
+
+## BigBirdForQuestionAnswering
+
+[[autodoc]] BigBirdForQuestionAnswering
+ - forward
+
+
+
+
+## FlaxBigBirdModel
+
+[[autodoc]] FlaxBigBirdModel
+ - __call__
+
+## FlaxBigBirdForPreTraining
+
+[[autodoc]] FlaxBigBirdForPreTraining
+ - __call__
+
+## FlaxBigBirdForCausalLM
+
+[[autodoc]] FlaxBigBirdForCausalLM
+ - __call__
+
+## FlaxBigBirdForMaskedLM
+
+[[autodoc]] FlaxBigBirdForMaskedLM
+ - __call__
+
+## FlaxBigBirdForSequenceClassification
+
+[[autodoc]] FlaxBigBirdForSequenceClassification
+ - __call__
+
+## FlaxBigBirdForMultipleChoice
+
+[[autodoc]] FlaxBigBirdForMultipleChoice
+ - __call__
+
+## FlaxBigBirdForTokenClassification
+
+[[autodoc]] FlaxBigBirdForTokenClassification
+ - __call__
+
+## FlaxBigBirdForQuestionAnswering
+
+[[autodoc]] FlaxBigBirdForQuestionAnswering
+ - __call__
+
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/bigbird_pegasus.md b/docs/transformers/docs/source/en/model_doc/bigbird_pegasus.md
new file mode 100644
index 0000000000000000000000000000000000000000..499d40b3149b4d8989a3da4ba0fc3bc35af041ce
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bigbird_pegasus.md
@@ -0,0 +1,99 @@
+
+
+# BigBirdPegasus
+
+
+
+
+
+## Overview
+
+The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by
+Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon,
+Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others. BigBird, is a sparse-attention
+based transformer which extends Transformer based models, such as BERT to much longer sequences. In addition to sparse
+attention, BigBird also applies global attention as well as random attention to the input sequence. Theoretically, it
+has been shown that applying sparse, global, and random attention approximates full attention, while being
+computationally much more efficient for longer sequences. As a consequence of the capability to handle longer context,
+BigBird has shown improved performance on various long document NLP tasks, such as question answering and
+summarization, compared to BERT or RoBERTa.
+
+The abstract from the paper is the following:
+
+*Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP.
+Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence
+length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that
+reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and
+is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our
+theoretical analysis reveals some of the benefits of having O(1) global tokens (such as CLS), that attend to the entire
+sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to
+8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context,
+BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also
+propose novel applications to genomics data.*
+
+The original code can be found [here](https://github.com/google-research/bigbird).
+
+## Usage tips
+
+- For an in-detail explanation on how BigBird's attention works, see [this blog post](https://huggingface.co/blog/big-bird).
+- BigBird comes with 2 implementations: **original_full** & **block_sparse**. For the sequence length < 1024, using
+ **original_full** is advised as there is no benefit in using **block_sparse** attention.
+- The code currently uses window size of 3 blocks and 2 global blocks.
+- Sequence length must be divisible by block size.
+- Current implementation supports only **ITC**.
+- Current implementation doesn't support **num_random_blocks = 0**.
+- BigBirdPegasus uses the [PegasusTokenizer](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pegasus/tokenization_pegasus.py).
+- BigBird is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## BigBirdPegasusConfig
+
+[[autodoc]] BigBirdPegasusConfig
+ - all
+
+## BigBirdPegasusModel
+
+[[autodoc]] BigBirdPegasusModel
+ - forward
+
+## BigBirdPegasusForConditionalGeneration
+
+[[autodoc]] BigBirdPegasusForConditionalGeneration
+ - forward
+
+## BigBirdPegasusForSequenceClassification
+
+[[autodoc]] BigBirdPegasusForSequenceClassification
+ - forward
+
+## BigBirdPegasusForQuestionAnswering
+
+[[autodoc]] BigBirdPegasusForQuestionAnswering
+ - forward
+
+## BigBirdPegasusForCausalLM
+
+[[autodoc]] BigBirdPegasusForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/biogpt.md b/docs/transformers/docs/source/en/model_doc/biogpt.md
new file mode 100644
index 0000000000000000000000000000000000000000..ab8aea6c29e855ad07db816b8a27644bb2f9dc47
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/biogpt.md
@@ -0,0 +1,121 @@
+
+
+# BioGPT
+
+
+
+
+
+
+## Overview
+
+The BioGPT model was proposed in [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu. BioGPT is a domain-specific generative pre-trained Transformer language model for biomedical text generation and mining. BioGPT follows the Transformer language model backbone, and is pre-trained on 15M PubMed abstracts from scratch.
+
+The abstract from the paper is the following:
+
+*Pre-trained language models have attracted increasing attention in the biomedical domain, inspired by their great success in the general natural language domain. Among the two main branches of pre-trained language models in the general language domain, i.e. BERT (and its variants) and GPT (and its variants), the first one has been extensively studied in the biomedical domain, such as BioBERT and PubMedBERT. While they have achieved great success on a variety of discriminative downstream biomedical tasks, the lack of generation ability constrains their application scope. In this paper, we propose BioGPT, a domain-specific generative Transformer language model pre-trained on large-scale biomedical literature. We evaluate BioGPT on six biomedical natural language processing tasks and demonstrate that our model outperforms previous models on most tasks. Especially, we get 44.98%, 38.42% and 40.76% F1 score on BC5CDR, KD-DTI and DDI end-to-end relation extraction tasks, respectively, and 78.2% accuracy on PubMedQA, creating a new record. Our case study on text generation further demonstrates the advantage of BioGPT on biomedical literature to generate fluent descriptions for biomedical terms.*
+
+This model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/BioGPT).
+
+## Usage tips
+
+- BioGPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than the left.
+- BioGPT was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next token in a sequence. Leveraging this feature allows BioGPT to generate syntactically coherent text as it can be observed in the run_generation.py example script.
+- The model can take the `past_key_values` (for PyTorch) as input, which is the previously computed key/value attention pairs. Using this (past_key_values or past) value prevents the model from re-computing pre-computed values in the context of text generation. For PyTorch, see past_key_values argument of the BioGptForCausalLM.forward() method for more information on its usage.
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```
+from transformers import BioGptForCausalLM
+model = BioGptForCausalLM.from_pretrained("microsoft/biogpt", attn_implementation="sdpa", torch_dtype=torch.float16)
+```
+
+On a local benchmark (NVIDIA GeForce RTX 2060-8GB, PyTorch 2.3.1, OS Ubuntu 20.04) with `float16` and `microsoft/biogpt` model with a CausalLM head,
+we saw the following speedups during training.
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+| num_training_steps | batch_size | seq_len | is cuda | Time per batch (eager - s) | Time per batch (sdpa - s) | Speedup (%) | Eager peak mem (MB) | sdpa peak mem (MB) | Mem saving (%) |
+|--------------------|------------|---------|---------|----------------------------|---------------------------|-------------|---------------------|--------------------|----------------|
+| 100 | 1 | 128 | False | 0.038 | 0.031 | 21.301 | 1601.862 | 1601.497 | 0.023 |
+| 100 | 1 | 256 | False | 0.039 | 0.034 | 15.084 | 1624.944 | 1625.296 | -0.022 |
+| 100 | 2 | 128 | False | 0.039 | 0.033 | 16.820 | 1624.567 | 1625.296 | -0.045 |
+| 100 | 2 | 256 | False | 0.065 | 0.059 | 10.255 | 1672.164 | 1672.164 | 0.000 |
+| 100 | 4 | 128 | False | 0.062 | 0.058 | 6.998 | 1671.435 | 1672.164 | -0.044 |
+| 100 | 4 | 256 | False | 0.113 | 0.100 | 13.316 | 2350.179 | 1848.435 | 27.144 |
+| 100 | 8 | 128 | False | 0.107 | 0.098 | 9.883 | 2098.521 | 1848.435 | 13.530 |
+| 100 | 8 | 256 | False | 0.222 | 0.196 | 13.413 | 3989.980 | 2986.492 | 33.601 |
+
+On a local benchmark (NVIDIA GeForce RTX 2060-8GB, PyTorch 2.3.1, OS Ubuntu 20.04) with `float16` and `microsoft/biogpt` model with a simple AutoModel head,
+we saw the following speedups during inference.
+
+| num_batches | batch_size | seq_len | is cuda | is half | use mask | Per token latency eager (ms) | Per token latency SDPA (ms) | Speedup (%) | Mem eager (MB) | Mem BT (MB) | Mem saved (%) |
+|-------------|------------|---------|---------|---------|----------|------------------------------|-----------------------------|-------------|----------------|--------------|---------------|
+| 50 | 1 | 64 | True | True | True | 0.115 | 0.098 | 17.392 | 716.998 | 716.998 | 0.000 |
+| 50 | 1 | 128 | True | True | True | 0.115 | 0.093 | 24.640 | 730.916 | 730.916 | 0.000 |
+| 50 | 2 | 64 | True | True | True | 0.114 | 0.096 | 19.204 | 730.900 | 730.900 | 0.000 |
+| 50 | 2 | 128 | True | True | True | 0.117 | 0.095 | 23.529 | 759.262 | 759.262 | 0.000 |
+| 50 | 4 | 64 | True | True | True | 0.113 | 0.096 | 18.325 | 759.229 | 759.229 | 0.000 |
+| 50 | 4 | 128 | True | True | True | 0.186 | 0.178 | 4.289 | 816.478 | 816.478 | 0.000 |
+
+
+## Resources
+
+- [Causal language modeling task guide](../tasks/language_modeling)
+
+## BioGptConfig
+
+[[autodoc]] BioGptConfig
+
+
+## BioGptTokenizer
+
+[[autodoc]] BioGptTokenizer
+ - save_vocabulary
+
+
+## BioGptModel
+
+[[autodoc]] BioGptModel
+ - forward
+
+
+## BioGptForCausalLM
+
+[[autodoc]] BioGptForCausalLM
+ - forward
+
+
+## BioGptForTokenClassification
+
+[[autodoc]] BioGptForTokenClassification
+ - forward
+
+
+## BioGptForSequenceClassification
+
+[[autodoc]] BioGptForSequenceClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/bit.md b/docs/transformers/docs/source/en/model_doc/bit.md
new file mode 100644
index 0000000000000000000000000000000000000000..0813b67af9e992adb46f8a8484d1413f47d8a472
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bit.md
@@ -0,0 +1,74 @@
+
+
+# Big Transfer (BiT)
+
+
+
+
+
+## Overview
+
+The BiT model was proposed in [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
+BiT is a simple recipe for scaling up pre-training of [ResNet](resnet)-like architectures (specifically, ResNetv2). The method results in significant improvements for transfer learning.
+
+The abstract from the paper is the following:
+
+*Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the model on a target task. We scale up pre-training, and propose a simple recipe that we call Big Transfer (BiT). By combining a few carefully selected components, and transferring using a simple heuristic, we achieve strong performance on over 20 datasets. BiT performs well across a surprisingly wide range of data regimes -- from 1 example per class to 1M total examples. BiT achieves 87.5% top-1 accuracy on ILSVRC-2012, 99.4% on CIFAR-10, and 76.3% on the 19 task Visual Task Adaptation Benchmark (VTAB). On small datasets, BiT attains 76.8% on ILSVRC-2012 with 10 examples per class, and 97.0% on CIFAR-10 with 10 examples per class. We conduct detailed analysis of the main components that lead to high transfer performance.*
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/google-research/big_transfer).
+
+## Usage tips
+
+- BiT models are equivalent to ResNetv2 in terms of architecture, except that: 1) all batch normalization layers are replaced by [group normalization](https://arxiv.org/abs/1803.08494),
+2) [weight standardization](https://arxiv.org/abs/1903.10520) is used for convolutional layers. The authors show that the combination of both is useful for training with large batch sizes, and has a significant
+impact on transfer learning.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BiT.
+
+
+
+- [`BitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## BitConfig
+
+[[autodoc]] BitConfig
+
+## BitImageProcessor
+
+[[autodoc]] BitImageProcessor
+ - preprocess
+
+## BitImageProcessorFast
+
+[[autodoc]] BitImageProcessorFast
+ - preprocess
+
+## BitModel
+
+[[autodoc]] BitModel
+ - forward
+
+## BitForImageClassification
+
+[[autodoc]] BitForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/blenderbot-small.md b/docs/transformers/docs/source/en/model_doc/blenderbot-small.md
new file mode 100644
index 0000000000000000000000000000000000000000..647a865de339ad9a1cdde43641a6c9c962329915
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/blenderbot-small.md
@@ -0,0 +1,130 @@
+
+
+# Blenderbot Small
+
+
+
+
+
+
+
+Note that [`BlenderbotSmallModel`] and
+[`BlenderbotSmallForConditionalGeneration`] are only used in combination with the checkpoint
+[facebook/blenderbot-90M](https://huggingface.co/facebook/blenderbot-90M). Larger Blenderbot checkpoints should
+instead be used with [`BlenderbotModel`] and
+[`BlenderbotForConditionalGeneration`]
+
+## Overview
+
+The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
+Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston on 30 Apr 2020.
+
+The abstract of the paper is the following:
+
+*Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that
+scaling neural models in the number of parameters and the size of the data they are trained on gives improved results,
+we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of
+skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to
+their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent
+persona. We show that large scale models can learn these skills when given appropriate training data and choice of
+generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models
+and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn
+dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing
+failure cases of our models.*
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The authors' code can be
+found [here](https://github.com/facebookresearch/ParlAI).
+
+## Usage tips
+
+Blenderbot Small is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+the left.
+
+
+## Resources
+
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## BlenderbotSmallConfig
+
+[[autodoc]] BlenderbotSmallConfig
+
+## BlenderbotSmallTokenizer
+
+[[autodoc]] BlenderbotSmallTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## BlenderbotSmallTokenizerFast
+
+[[autodoc]] BlenderbotSmallTokenizerFast
+
+
+
+
+## BlenderbotSmallModel
+
+[[autodoc]] BlenderbotSmallModel
+ - forward
+
+## BlenderbotSmallForConditionalGeneration
+
+[[autodoc]] BlenderbotSmallForConditionalGeneration
+ - forward
+
+## BlenderbotSmallForCausalLM
+
+[[autodoc]] BlenderbotSmallForCausalLM
+ - forward
+
+
+
+
+## TFBlenderbotSmallModel
+
+[[autodoc]] TFBlenderbotSmallModel
+ - call
+
+## TFBlenderbotSmallForConditionalGeneration
+
+[[autodoc]] TFBlenderbotSmallForConditionalGeneration
+ - call
+
+
+
+
+## FlaxBlenderbotSmallModel
+
+[[autodoc]] FlaxBlenderbotSmallModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBlenderbotForConditionalGeneration
+
+[[autodoc]] FlaxBlenderbotSmallForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/blenderbot.md b/docs/transformers/docs/source/en/model_doc/blenderbot.md
new file mode 100644
index 0000000000000000000000000000000000000000..ec24d5ed7495191393cfca0afca97b26c5c26887
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/blenderbot.md
@@ -0,0 +1,151 @@
+
+
+# Blenderbot
+
+
+
+
+
+
+
+## Overview
+
+The Blender chatbot model was proposed in [Recipes for building an open-domain chatbot](https://arxiv.org/pdf/2004.13637.pdf) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu,
+Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston on 30 Apr 2020.
+
+The abstract of the paper is the following:
+
+*Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that
+scaling neural models in the number of parameters and the size of the data they are trained on gives improved results,
+we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of
+skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to
+their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent
+persona. We show that large scale models can learn these skills when given appropriate training data and choice of
+generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models
+and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn
+dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing
+failure cases of our models.*
+
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The authors' code can be found [here](https://github.com/facebookresearch/ParlAI) .
+
+## Usage tips and example
+
+Blenderbot is a model with absolute position embeddings so it's usually advised to pad the inputs on the right
+rather than the left.
+
+An example:
+
+```python
+>>> from transformers import BlenderbotTokenizer, BlenderbotForConditionalGeneration
+
+>>> mname = "facebook/blenderbot-400M-distill"
+>>> model = BlenderbotForConditionalGeneration.from_pretrained(mname)
+>>> tokenizer = BlenderbotTokenizer.from_pretrained(mname)
+>>> UTTERANCE = "My friends are cool but they eat too many carbs."
+>>> inputs = tokenizer([UTTERANCE], return_tensors="pt")
+>>> reply_ids = model.generate(**inputs)
+>>> print(tokenizer.batch_decode(reply_ids))
+[" That's unfortunate. Are they trying to lose weight or are they just trying to be healthier?"]
+```
+
+## Implementation Notes
+
+- Blenderbot uses a standard [seq2seq model transformer](https://arxiv.org/pdf/1706.03762.pdf) based architecture.
+- Available checkpoints can be found in the [model hub](https://huggingface.co/models?search=blenderbot).
+- This is the *default* Blenderbot model class. However, some smaller checkpoints, such as
+ `facebook/blenderbot_small_90M`, have a different architecture and consequently should be used with
+ [BlenderbotSmall](blenderbot-small).
+
+
+## Resources
+
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## BlenderbotConfig
+
+[[autodoc]] BlenderbotConfig
+
+## BlenderbotTokenizer
+
+[[autodoc]] BlenderbotTokenizer
+ - build_inputs_with_special_tokens
+
+## BlenderbotTokenizerFast
+
+[[autodoc]] BlenderbotTokenizerFast
+ - build_inputs_with_special_tokens
+
+
+
+
+
+## BlenderbotModel
+
+See [`~transformers.BartModel`] for arguments to *forward* and *generate*
+
+[[autodoc]] BlenderbotModel
+ - forward
+
+## BlenderbotForConditionalGeneration
+
+See [`~transformers.BartForConditionalGeneration`] for arguments to *forward* and *generate*
+
+[[autodoc]] BlenderbotForConditionalGeneration
+ - forward
+
+## BlenderbotForCausalLM
+
+[[autodoc]] BlenderbotForCausalLM
+ - forward
+
+
+
+
+## TFBlenderbotModel
+
+[[autodoc]] TFBlenderbotModel
+ - call
+
+## TFBlenderbotForConditionalGeneration
+
+[[autodoc]] TFBlenderbotForConditionalGeneration
+ - call
+
+
+
+
+## FlaxBlenderbotModel
+
+[[autodoc]] FlaxBlenderbotModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBlenderbotForConditionalGeneration
+
+[[autodoc]] FlaxBlenderbotForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/blip-2.md b/docs/transformers/docs/source/en/model_doc/blip-2.md
new file mode 100644
index 0000000000000000000000000000000000000000..94331d9a5f6e7c069070ea8069e858d24fe6eb66
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/blip-2.md
@@ -0,0 +1,111 @@
+
+
+# BLIP-2
+
+
+
+
+
+## Overview
+
+The BLIP-2 model was proposed in [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by
+Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi. BLIP-2 leverages frozen pre-trained image encoders and large language models (LLMs) by training a lightweight, 12-layer Transformer
+encoder in between them, achieving state-of-the-art performance on various vision-language tasks. Most notably, BLIP-2 improves upon [Flamingo](https://arxiv.org/abs/2204.14198), an 80 billion parameter model, by 8.7%
+on zero-shot VQAv2 with 54x fewer trainable parameters.
+
+The abstract from the paper is the following:
+
+*The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pre-trained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model. BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model's emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions.*
+
+
+
+ BLIP-2 architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207).
+
+## Usage tips
+
+- BLIP-2 can be used for conditional text generation given an image and an optional text prompt. At inference time, it's recommended to use the [`generate`] method.
+- One can use [`Blip2Processor`] to prepare images for the model, and decode the predicted tokens ID's back to text.
+
+> [!NOTE]
+> BLIP models after release v4.46 will raise warnings about adding `processor.num_query_tokens = {{num_query_tokens}}` and expand model embeddings layer to add special `` token. It is strongly recommended to add the attributes to the processor if you own the model checkpoint, or open a PR if it is not owned by you. Adding these attributes means that BLIP will add the number of query tokens required per image and expand the text with as many `` placeholders as there will be query tokens. Usually it is around 500 tokens per image, so make sure that the text is not truncated as otherwise there wil be failure when merging the embeddings.
+The attributes can be obtained from model config, as `model.config.num_query_tokens` and model embeddings expansion can be done by following [this link](https://gist.github.com/zucchini-nlp/e9f20b054fa322f84ac9311d9ab67042).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BLIP-2.
+
+- Demo notebooks for BLIP-2 for image captioning, visual question answering (VQA) and chat-like conversations can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BLIP-2).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## Blip2Config
+
+[[autodoc]] Blip2Config
+ - from_vision_qformer_text_configs
+
+## Blip2VisionConfig
+
+[[autodoc]] Blip2VisionConfig
+
+## Blip2QFormerConfig
+
+[[autodoc]] Blip2QFormerConfig
+
+## Blip2Processor
+
+[[autodoc]] Blip2Processor
+
+## Blip2VisionModel
+
+[[autodoc]] Blip2VisionModel
+ - forward
+
+## Blip2QFormerModel
+
+[[autodoc]] Blip2QFormerModel
+ - forward
+
+## Blip2Model
+
+[[autodoc]] Blip2Model
+ - forward
+ - get_text_features
+ - get_image_features
+ - get_qformer_features
+
+## Blip2ForConditionalGeneration
+
+[[autodoc]] Blip2ForConditionalGeneration
+ - forward
+ - generate
+
+## Blip2ForImageTextRetrieval
+
+[[autodoc]] Blip2ForImageTextRetrieval
+ - forward
+
+## Blip2TextModelWithProjection
+
+[[autodoc]] Blip2TextModelWithProjection
+
+## Blip2VisionModelWithProjection
+
+[[autodoc]] Blip2VisionModelWithProjection
diff --git a/docs/transformers/docs/source/en/model_doc/blip.md b/docs/transformers/docs/source/en/model_doc/blip.md
new file mode 100644
index 0000000000000000000000000000000000000000..efb6b27082afd0e3e020018442bb417ee3ce2901
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/blip.md
@@ -0,0 +1,156 @@
+
+
+# BLIP
+
+
+
+
+
+
+## Overview
+
+The BLIP model was proposed in [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
+
+BLIP is a model that is able to perform various multi-modal tasks including:
+- Visual Question Answering
+- Image-Text retrieval (Image-text matching)
+- Image Captioning
+
+The abstract from the paper is the following:
+
+*Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks.
+However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision. In this paper, we propose BLIP, a new VLP framework which transfers flexibly to both vision-language understanding and generation tasks. BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. We achieve state-of-the-art results on a wide range of vision-language tasks, such as image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), and VQA (+1.6% in VQA score). BLIP also demonstrates strong generalization ability when directly transferred to videolanguage tasks in a zero-shot manner. Code, models, and datasets are released.*
+
+
+
+This model was contributed by [ybelkada](https://huggingface.co/ybelkada).
+The original code can be found [here](https://github.com/salesforce/BLIP).
+
+## Resources
+
+- [Jupyter notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) on how to fine-tune BLIP for image captioning on a custom dataset
+
+## BlipConfig
+
+[[autodoc]] BlipConfig
+ - from_text_vision_configs
+
+## BlipTextConfig
+
+[[autodoc]] BlipTextConfig
+
+## BlipVisionConfig
+
+[[autodoc]] BlipVisionConfig
+
+## BlipProcessor
+
+[[autodoc]] BlipProcessor
+
+## BlipImageProcessor
+
+[[autodoc]] BlipImageProcessor
+ - preprocess
+
+## BlipImageProcessorFast
+
+[[autodoc]] BlipImageProcessorFast
+ - preprocess
+
+
+
+
+## BlipModel
+
+`BlipModel` is going to be deprecated in future versions, please use `BlipForConditionalGeneration`, `BlipForImageTextRetrieval` or `BlipForQuestionAnswering` depending on your usecase.
+
+[[autodoc]] BlipModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## BlipTextModel
+
+[[autodoc]] BlipTextModel
+ - forward
+
+## BlipTextLMHeadModel
+
+[[autodoc]] BlipTextLMHeadModel
+- forward
+
+## BlipVisionModel
+
+[[autodoc]] BlipVisionModel
+ - forward
+
+## BlipForConditionalGeneration
+
+[[autodoc]] BlipForConditionalGeneration
+ - forward
+
+## BlipForImageTextRetrieval
+
+[[autodoc]] BlipForImageTextRetrieval
+ - forward
+
+## BlipForQuestionAnswering
+
+[[autodoc]] BlipForQuestionAnswering
+ - forward
+
+
+
+
+## TFBlipModel
+
+[[autodoc]] TFBlipModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFBlipTextModel
+
+[[autodoc]] TFBlipTextModel
+ - call
+
+## TFBlipTextLMHeadModel
+
+[[autodoc]] TFBlipTextLMHeadModel
+- forward
+
+## TFBlipVisionModel
+
+[[autodoc]] TFBlipVisionModel
+ - call
+
+## TFBlipForConditionalGeneration
+
+[[autodoc]] TFBlipForConditionalGeneration
+ - call
+
+## TFBlipForImageTextRetrieval
+
+[[autodoc]] TFBlipForImageTextRetrieval
+ - call
+
+## TFBlipForQuestionAnswering
+
+[[autodoc]] TFBlipForQuestionAnswering
+ - call
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/bloom.md b/docs/transformers/docs/source/en/model_doc/bloom.md
new file mode 100644
index 0000000000000000000000000000000000000000..9de98705957475c3fa0bd551aff0733c0a854626
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bloom.md
@@ -0,0 +1,115 @@
+
+
+# BLOOM
+
+
+
+
+
+
+## Overview
+
+The BLOOM model has been proposed with its various versions through the [BigScience Workshop](https://bigscience.huggingface.co/). BigScience is inspired by other open science initiatives where researchers have pooled their time and resources to collectively achieve a higher impact.
+The architecture of BLOOM is essentially similar to GPT3 (auto-regressive model for next token prediction), but has been trained on 46 different languages and 13 programming languages.
+Several smaller versions of the models have been trained on the same dataset. BLOOM is available in the following versions:
+
+- [bloom-560m](https://huggingface.co/bigscience/bloom-560m)
+- [bloom-1b1](https://huggingface.co/bigscience/bloom-1b1)
+- [bloom-1b7](https://huggingface.co/bigscience/bloom-1b7)
+- [bloom-3b](https://huggingface.co/bigscience/bloom-3b)
+- [bloom-7b1](https://huggingface.co/bigscience/bloom-7b1)
+- [bloom](https://huggingface.co/bigscience/bloom) (176B parameters)
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BLOOM. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+- [`BloomForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
+
+See also:
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+
+
+⚡️ Inference
+- A blog on [Optimization story: Bloom inference](https://huggingface.co/blog/bloom-inference-optimization).
+- A blog on [Incredibly Fast BLOOM Inference with DeepSpeed and Accelerate](https://huggingface.co/blog/bloom-inference-pytorch-scripts).
+
+⚙️ Training
+- A blog on [The Technology Behind BLOOM Training](https://huggingface.co/blog/bloom-megatron-deepspeed).
+
+## BloomConfig
+
+[[autodoc]] BloomConfig
+ - all
+
+## BloomTokenizerFast
+
+[[autodoc]] BloomTokenizerFast
+ - all
+
+
+
+
+
+## BloomModel
+
+[[autodoc]] BloomModel
+ - forward
+
+## BloomForCausalLM
+
+[[autodoc]] BloomForCausalLM
+ - forward
+
+## BloomForSequenceClassification
+
+[[autodoc]] BloomForSequenceClassification
+ - forward
+
+## BloomForTokenClassification
+
+[[autodoc]] BloomForTokenClassification
+ - forward
+
+## BloomForQuestionAnswering
+
+[[autodoc]] BloomForQuestionAnswering
+ - forward
+
+
+
+
+## FlaxBloomModel
+
+[[autodoc]] FlaxBloomModel
+ - __call__
+
+## FlaxBloomForCausalLM
+
+[[autodoc]] FlaxBloomForCausalLM
+ - __call__
+
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/bort.md b/docs/transformers/docs/source/en/model_doc/bort.md
new file mode 100644
index 0000000000000000000000000000000000000000..04cc2feb063b99b87d9a2bd7931d9f422d6bc4b2
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bort.md
@@ -0,0 +1,64 @@
+
+
+# BORT
+
+
+
+
+
+
+
+
+
+This model is in maintenance mode only, we do not accept any new PRs changing its code.
+
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
+You can do so by running the following command: `pip install -U transformers==4.30.0`.
+
+
+
+## Overview
+
+The BORT model was proposed in [Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) by
+Adrian de Wynter and Daniel J. Perry. It is an optimal subset of architectural parameters for the BERT, which the
+authors refer to as "Bort".
+
+The abstract from the paper is the following:
+
+*We extract an optimal subset of architectural parameters for the BERT architecture from Devlin et al. (2018) by
+applying recent breakthroughs in algorithms for neural architecture search. This optimal subset, which we refer to as
+"Bort", is demonstrably smaller, having an effective (that is, not counting the embedding layer) size of 5.5% the
+original BERT-large architecture, and 16% of the net size. Bort is also able to be pretrained in 288 GPU hours, which
+is 1.2% of the time required to pretrain the highest-performing BERT parametric architectural variant, RoBERTa-large
+(Liu et al., 2019), and about 33% of that of the world-record, in GPU hours, required to train BERT-large on the same
+hardware. It is also 7.9x faster on a CPU, as well as being better performing than other compressed variants of the
+architecture, and some of the non-compressed variants: it obtains performance improvements of between 0.3% and 31%,
+absolute, with respect to BERT-large, on multiple public natural language understanding (NLU) benchmarks.*
+
+This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/alexa/bort/).
+
+## Usage tips
+
+- BORT's model architecture is based on BERT, refer to [BERT's documentation page](bert) for the
+ model's API reference as well as usage examples.
+- BORT uses the RoBERTa tokenizer instead of the BERT tokenizer, refer to [RoBERTa's documentation page](roberta) for the tokenizer's API reference as well as usage examples.
+- BORT requires a specific fine-tuning algorithm, called [Agora](https://adewynter.github.io/notes/bort_algorithms_and_applications.html#fine-tuning-with-algebraic-topology) ,
+ that is sadly not open-sourced yet. It would be very useful for the community, if someone tries to implement the
+ algorithm to make BORT fine-tuning work.
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/bridgetower.md b/docs/transformers/docs/source/en/model_doc/bridgetower.md
new file mode 100644
index 0000000000000000000000000000000000000000..4b8601bf8a9534aca5f0ca654f701a6b1f7236a4
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bridgetower.md
@@ -0,0 +1,179 @@
+
+
+# BridgeTower
+
+
+
+
+
+## Overview
+
+The BridgeTower model was proposed in [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan. The goal of this model is to build a
+bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder thus achieving remarkable performance on various downstream tasks with almost negligible additional performance and computational costs.
+
+This paper has been accepted to the [AAAI'23](https://aaai.org/Conferences/AAAI-23/) conference.
+
+The abstract from the paper is the following:
+
+*Vision-Language (VL) models with the TWO-TOWER architecture have dominated visual-language representation learning in recent years.
+Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a deep cross-modal encoder, or feed the last-layer uni-modal representations from the deep pre-trained uni-modal encoders into the top cross-modal encoder.
+Both approaches potentially restrict vision-language representation learning and limit model performance. In this paper, we propose BRIDGETOWER, which introduces multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the crossmodal encoder.
+This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations of different semantic levels of pre-trained uni-modal encoders in the cross-modal encoder. Pre-trained with only 4M images, BRIDGETOWER achieves state-of-the-art performance on various downstream vision-language tasks.
+In particular, on the VQAv2 test-std set, BRIDGETOWER achieves an accuracy of 78.73%, outperforming the previous state-of-the-art model METER by 1.09% with the same pre-training data and almost negligible additional parameters and computational costs.
+Notably, when further scaling the model, BRIDGETOWER achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets.*
+
+
+
+ BridgeTower architecture. Taken from the original paper.
+
+This model was contributed by [Anahita Bhiwandiwalla](https://huggingface.co/anahita-b), [Tiep Le](https://huggingface.co/Tile) and [Shaoyen Tseng](https://huggingface.co/shaoyent). The original code can be found [here](https://github.com/microsoft/BridgeTower).
+
+## Usage tips and examples
+
+BridgeTower consists of a visual encoder, a textual encoder and cross-modal encoder with multiple lightweight bridge layers.
+The goal of this approach was to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder.
+In principle, one can apply any visual, textual or cross-modal encoder in the proposed architecture.
+
+The [`BridgeTowerProcessor`] wraps [`RobertaTokenizer`] and [`BridgeTowerImageProcessor`] into a single instance to both
+encode the text and prepare the images respectively.
+
+The following example shows how to run contrastive learning using [`BridgeTowerProcessor`] and [`BridgeTowerForContrastiveLearning`].
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs
+```
+
+The following example shows how to run image-text retrieval using [`BridgeTowerProcessor`] and [`BridgeTowerForImageAndTextRetrieval`].
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs.logits[0, 1].item()
+```
+
+The following example shows how to run masked language modeling using [`BridgeTowerProcessor`] and [`BridgeTowerForMaskedLM`].
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+>>> text = "a looking out of the window"
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # prepare inputs
+>>> encoding = processor(image, text, return_tensors="pt")
+
+>>> # forward pass
+>>> outputs = model(**encoding)
+
+>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
+
+>>> print(results)
+.a cat looking out of the window.
+```
+
+Tips:
+
+- This implementation of BridgeTower uses [`RobertaTokenizer`] to generate text embeddings and OpenAI's CLIP/ViT model to compute visual embeddings.
+- Checkpoints for pre-trained [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) and [bridgetower masked language modeling and image text matching](https://huggingface.co/BridgeTower/bridgetower-base-itm-mlm) are released.
+- Please refer to [Table 5](https://arxiv.org/pdf/2206.08657.pdf) for BridgeTower's performance on Image Retrieval and other down stream tasks.
+- The PyTorch version of this model is only available in torch 1.10 and higher.
+
+
+## BridgeTowerConfig
+
+[[autodoc]] BridgeTowerConfig
+
+## BridgeTowerTextConfig
+
+[[autodoc]] BridgeTowerTextConfig
+
+## BridgeTowerVisionConfig
+
+[[autodoc]] BridgeTowerVisionConfig
+
+## BridgeTowerImageProcessor
+
+[[autodoc]] BridgeTowerImageProcessor
+ - preprocess
+
+## BridgeTowerImageProcessorFast
+
+[[autodoc]] BridgeTowerImageProcessorFast
+ - preprocess
+
+## BridgeTowerProcessor
+
+[[autodoc]] BridgeTowerProcessor
+ - __call__
+
+## BridgeTowerModel
+
+[[autodoc]] BridgeTowerModel
+ - forward
+
+## BridgeTowerForContrastiveLearning
+
+[[autodoc]] BridgeTowerForContrastiveLearning
+ - forward
+
+## BridgeTowerForMaskedLM
+
+[[autodoc]] BridgeTowerForMaskedLM
+ - forward
+
+## BridgeTowerForImageAndTextRetrieval
+
+[[autodoc]] BridgeTowerForImageAndTextRetrieval
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/bros.md b/docs/transformers/docs/source/en/model_doc/bros.md
new file mode 100644
index 0000000000000000000000000000000000000000..baa658e598fbc6a5c1c83c41077a148ffdb0c1f7
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/bros.md
@@ -0,0 +1,118 @@
+
+
+# BROS
+
+
+
+
+
+## Overview
+
+The BROS model was proposed in [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
+
+BROS stands for *BERT Relying On Spatiality*. It is an encoder-only Transformer model that takes a sequence of tokens and their bounding boxes as inputs and outputs a sequence of hidden states. BROS encode relative spatial information instead of using absolute spatial information.
+
+It is pre-trained with two objectives: a token-masked language modeling objective (TMLM) used in BERT, and a novel area-masked language modeling objective (AMLM)
+In TMLM, tokens are randomly masked, and the model predicts the masked tokens using spatial information and other unmasked tokens.
+AMLM is a 2D version of TMLM. It randomly masks text tokens and predicts with the same information as TMLM, but it masks text blocks (areas).
+
+`BrosForTokenClassification` has a simple linear layer on top of BrosModel. It predicts the label of each token.
+`BrosSpadeEEForTokenClassification` has an `initial_token_classifier` and `subsequent_token_classifier` on top of BrosModel. `initial_token_classifier` is used to predict the first token of each entity, and `subsequent_token_classifier` is used to predict the next token of within entity. `BrosSpadeELForTokenClassification` has an `entity_linker` on top of BrosModel. `entity_linker` is used to predict the relation between two entities.
+
+`BrosForTokenClassification` and `BrosSpadeEEForTokenClassification` essentially perform the same job. However, `BrosForTokenClassification` assumes input tokens are perfectly serialized (which is very challenging task since they exist in a 2D space), while `BrosSpadeEEForTokenClassification` allows for more flexibility in handling serialization errors as it predicts next connection tokens from one token.
+
+`BrosSpadeELForTokenClassification` perform the intra-entity linking task. It predicts relation from one token (of one entity) to another token (of another entity) if these two entities share some relation.
+
+BROS achieves comparable or better result on Key Information Extraction (KIE) benchmarks such as FUNSD, SROIE, CORD and SciTSR, without relying on explicit visual features.
+
+The abstract from the paper is the following:
+
+*Key information extraction (KIE) from document images requires understanding the contextual and spatial semantics of texts in two-dimensional (2D) space. Many recent studies try to solve the task by developing pre-trained language models focusing on combining visual features from document images with texts and their layout. On the other hand, this paper tackles the problem by going back to the basic: effective combination of text and layout. Specifically, we propose a pre-trained language model, named BROS (BERT Relying On Spatiality), that encodes relative positions of texts in 2D space and learns from unlabeled documents with area-masking strategy. With this optimized training scheme for understanding texts in 2D space, BROS shows comparable or better performance compared to previous methods on four KIE benchmarks (FUNSD, SROIE*, CORD, and SciTSR) without relying on visual features. This paper also reveals two real-world challenges in KIE tasks-(1) minimizing the error from incorrect text ordering and (2) efficient learning from fewer downstream examples-and demonstrates the superiority of BROS over previous methods.*
+
+This model was contributed by [jinho8345](https://huggingface.co/jinho8345). The original code can be found [here](https://github.com/clovaai/bros).
+
+## Usage tips and examples
+
+- [`~transformers.BrosModel.forward`] requires `input_ids` and `bbox` (bounding box). Each bounding box should be in (x0, y0, x1, y1) format (top-left corner, bottom-right corner). Obtaining of Bounding boxes depends on external OCR system. The `x` coordinate should be normalized by document image width, and the `y` coordinate should be normalized by document image height.
+
+```python
+def expand_and_normalize_bbox(bboxes, doc_width, doc_height):
+ # here, bboxes are numpy array
+
+ # Normalize bbox -> 0 ~ 1
+ bboxes[:, [0, 2]] = bboxes[:, [0, 2]] / width
+ bboxes[:, [1, 3]] = bboxes[:, [1, 3]] / height
+```
+
+- [`~transformers.BrosForTokenClassification.forward`, `~transformers.BrosSpadeEEForTokenClassification.forward`, `~transformers.BrosSpadeEEForTokenClassification.forward`] require not only `input_ids` and `bbox` but also `box_first_token_mask` for loss calculation. It is a mask to filter out non-first tokens of each box. You can obtain this mask by saving start token indices of bounding boxes when creating `input_ids` from words. You can make `box_first_token_mask` with following code,
+
+
+```python
+def make_box_first_token_mask(bboxes, words, tokenizer, max_seq_length=512):
+
+ box_first_token_mask = np.zeros(max_seq_length, dtype=np.bool_)
+
+ # encode(tokenize) each word from words (List[str])
+ input_ids_list: List[List[int]] = [tokenizer.encode(e, add_special_tokens=False) for e in words]
+
+ # get the length of each box
+ tokens_length_list: List[int] = [len(l) for l in input_ids_list]
+
+ box_end_token_indices = np.array(list(itertools.accumulate(tokens_length_list)))
+ box_start_token_indices = box_end_token_indices - np.array(tokens_length_list)
+
+ # filter out the indices that are out of max_seq_length
+ box_end_token_indices = box_end_token_indices[box_end_token_indices < max_seq_length - 1]
+ if len(box_start_token_indices) > len(box_end_token_indices):
+ box_start_token_indices = box_start_token_indices[: len(box_end_token_indices)]
+
+ # set box_start_token_indices to True
+ box_first_token_mask[box_start_token_indices] = True
+
+ return box_first_token_mask
+
+```
+
+## Resources
+
+- Demo scripts can be found [here](https://github.com/clovaai/bros).
+
+## BrosConfig
+
+[[autodoc]] BrosConfig
+
+## BrosProcessor
+
+[[autodoc]] BrosProcessor
+ - __call__
+
+## BrosModel
+
+[[autodoc]] BrosModel
+ - forward
+
+
+## BrosForTokenClassification
+
+[[autodoc]] BrosForTokenClassification
+ - forward
+
+## BrosSpadeEEForTokenClassification
+
+[[autodoc]] BrosSpadeEEForTokenClassification
+ - forward
+
+## BrosSpadeELForTokenClassification
+
+[[autodoc]] BrosSpadeELForTokenClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/byt5.md b/docs/transformers/docs/source/en/model_doc/byt5.md
new file mode 100644
index 0000000000000000000000000000000000000000..7e95bae53e87fdcebebd6c0f4e512c22a36fff41
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/byt5.md
@@ -0,0 +1,162 @@
+
+
+# ByT5
+
+
+
+
+
+
+
+## Overview
+
+The ByT5 model was presented in [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir
+Kale, Adam Roberts, Colin Raffel.
+
+The abstract from the paper is the following:
+
+*Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units.
+Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from
+the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they
+can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by
+removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token
+sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of
+operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with
+minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count,
+training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level
+counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on
+tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of
+pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our
+experiments.*
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://github.com/google-research/byt5).
+
+
+
+ByT5's architecture is based on the T5v1.1 model, refer to [T5v1.1's documentation page](t5v1.1) for the API reference. They
+only differ in how inputs should be prepared for the model, see the code examples below.
+
+
+
+Since ByT5 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
+fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
+
+
+## Usage example
+
+ByT5 works on raw UTF-8 bytes, so it can be used without a tokenizer:
+
+```python
+>>> from transformers import T5ForConditionalGeneration
+>>> import torch
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
+
+>>> num_special_tokens = 3
+>>> # Model has 3 special tokens which take up the input ids 0,1,2 of ByT5.
+>>> # => Need to shift utf-8 character encodings by 3 before passing ids to model.
+
+>>> input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + num_special_tokens
+
+>>> labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + num_special_tokens
+
+>>> loss = model(input_ids, labels=labels).loss
+>>> loss.item()
+2.66
+```
+
+For batched inference and training it is however recommended to make use of the tokenizer:
+
+```python
+>>> from transformers import T5ForConditionalGeneration, AutoTokenizer
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/byt5-small")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-small")
+
+>>> model_inputs = tokenizer(
+... ["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt"
+... )
+>>> labels_dict = tokenizer(
+... ["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt"
+... )
+>>> labels = labels_dict.input_ids
+
+>>> loss = model(**model_inputs, labels=labels).loss
+>>> loss.item()
+17.9
+```
+
+Similar to [T5](t5), ByT5 was trained on the span-mask denoising task. However,
+since the model works directly on characters, the pretraining task is a bit
+different. Let's corrupt some characters of the
+input sentence `"The dog chases a ball in the park."` and ask ByT5 to predict them
+for us.
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google/byt5-base")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/byt5-base")
+
+>>> input_ids_prompt = "The dog chases a ball in the park."
+>>> input_ids = tokenizer(input_ids_prompt).input_ids
+
+>>> # Note that we cannot add "{extra_id_...}" to the string directly
+>>> # as the Byte tokenizer would incorrectly merge the tokens
+>>> # For ByT5, we need to work directly on the character level
+>>> # Contrary to T5, ByT5 does not use sentinel tokens for masking, but instead
+>>> # uses final utf character ids.
+>>> # UTF-8 is represented by 8 bits and ByT5 has 3 special tokens.
+>>> # => There are 2**8+2 = 259 input ids and mask tokens count down from index 258.
+>>> # => mask to "The dog [258]a ball [257]park."
+
+>>> input_ids = torch.tensor([input_ids[:8] + [258] + input_ids[14:21] + [257] + input_ids[28:]])
+>>> input_ids
+tensor([[ 87, 107, 104, 35, 103, 114, 106, 35, 258, 35, 100, 35, 101, 100, 111, 111, 257, 35, 115, 100, 117, 110, 49, 1]])
+
+>>> # ByT5 produces only one char at a time so we need to produce many more output characters here -> set `max_length=100`.
+>>> output_ids = model.generate(input_ids, max_length=100)[0].tolist()
+>>> output_ids
+[0, 258, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 257, 35, 108, 113, 35, 119, 107, 104, 35, 103, 108, 118, 102, 114, 256, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49, 35, 87, 107, 104, 35, 103, 114, 106, 35, 108, 118, 35, 119, 107, 104, 35, 114, 113, 104, 35, 122, 107, 114, 35, 103, 114, 104, 118, 35, 100, 35, 101, 100, 111, 111, 35, 108, 113, 255, 35, 108, 113, 35, 119, 107, 104, 35, 115, 100, 117, 110, 49]
+
+>>> # ^- Note how 258 descends to 257, 256, 255
+
+>>> # Now we need to split on the sentinel tokens, let's write a short loop for this
+>>> output_ids_list = []
+>>> start_token = 0
+>>> sentinel_token = 258
+>>> while sentinel_token in output_ids:
+... split_idx = output_ids.index(sentinel_token)
+... output_ids_list.append(output_ids[start_token:split_idx])
+... start_token = split_idx
+... sentinel_token -= 1
+
+>>> output_ids_list.append(output_ids[start_token:])
+>>> output_string = tokenizer.batch_decode(output_ids_list)
+>>> output_string
+['', 'is the one who does', ' in the disco', 'in the park. The dog is the one who does a ball in', ' in the park.']
+```
+
+
+## ByT5Tokenizer
+
+[[autodoc]] ByT5Tokenizer
+
+See [`ByT5Tokenizer`] for all details.
diff --git a/docs/transformers/docs/source/en/model_doc/camembert.md b/docs/transformers/docs/source/en/model_doc/camembert.md
new file mode 100644
index 0000000000000000000000000000000000000000..9066ee360c6c97301ec164a7c4985abe327390df
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/camembert.md
@@ -0,0 +1,141 @@
+
+
+# CamemBERT
+
+
+
+
+
+
+
+## Overview
+
+The CamemBERT model was proposed in [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by
+[Louis Martin](https://huggingface.co/louismartin), [Benjamin Muller](https://huggingface.co/benjamin-mlr), [Pedro Javier Ortiz Suárez](https://huggingface.co/pjox), Yoann Dupont, Laurent Romary, Éric Villemonte de la
+Clergerie, [Djamé Seddah](https://huggingface.co/Djame), and [Benoît Sagot](https://huggingface.co/sagot). It is based on Facebook's RoBERTa model released in 2019. It is a model
+trained on 138GB of French text.
+
+The abstract from the paper is the following:
+
+*Pretrained language models are now ubiquitous in Natural Language Processing. Despite their success, most available
+models have either been trained on English data or on the concatenation of data in multiple languages. This makes
+practical use of such models --in all languages except English-- very limited. Aiming to address this issue for French,
+we release CamemBERT, a French version of the Bi-directional Encoders for Transformers (BERT). We measure the
+performance of CamemBERT compared to multilingual models in multiple downstream tasks, namely part-of-speech tagging,
+dependency parsing, named-entity recognition, and natural language inference. CamemBERT improves the state of the art
+for most of the tasks considered. We release the pretrained model for CamemBERT hoping to foster research and
+downstream applications for French NLP.*
+
+This model was contributed by [the ALMAnaCH team (Inria)](https://huggingface.co/almanach). The original code can be found [here](https://camembert-model.fr/).
+
+
+
+This implementation is the same as RoBERTa. Refer to the [documentation of RoBERTa](roberta) for usage examples as well
+as the information relative to the inputs and outputs.
+
+
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## CamembertConfig
+
+[[autodoc]] CamembertConfig
+
+## CamembertTokenizer
+
+[[autodoc]] CamembertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CamembertTokenizerFast
+
+[[autodoc]] CamembertTokenizerFast
+
+
+
+
+## CamembertModel
+
+[[autodoc]] CamembertModel
+
+## CamembertForCausalLM
+
+[[autodoc]] CamembertForCausalLM
+
+## CamembertForMaskedLM
+
+[[autodoc]] CamembertForMaskedLM
+
+## CamembertForSequenceClassification
+
+[[autodoc]] CamembertForSequenceClassification
+
+## CamembertForMultipleChoice
+
+[[autodoc]] CamembertForMultipleChoice
+
+## CamembertForTokenClassification
+
+[[autodoc]] CamembertForTokenClassification
+
+## CamembertForQuestionAnswering
+
+[[autodoc]] CamembertForQuestionAnswering
+
+
+
+
+## TFCamembertModel
+
+[[autodoc]] TFCamembertModel
+
+## TFCamembertForCausalLM
+
+[[autodoc]] TFCamembertForCausalLM
+
+## TFCamembertForMaskedLM
+
+[[autodoc]] TFCamembertForMaskedLM
+
+## TFCamembertForSequenceClassification
+
+[[autodoc]] TFCamembertForSequenceClassification
+
+## TFCamembertForMultipleChoice
+
+[[autodoc]] TFCamembertForMultipleChoice
+
+## TFCamembertForTokenClassification
+
+[[autodoc]] TFCamembertForTokenClassification
+
+## TFCamembertForQuestionAnswering
+
+[[autodoc]] TFCamembertForQuestionAnswering
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/canine.md b/docs/transformers/docs/source/en/model_doc/canine.md
new file mode 100644
index 0000000000000000000000000000000000000000..cd1cce34c79c3fac14b5cc977dcf51b65ce99540
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/canine.md
@@ -0,0 +1,149 @@
+
+
+# CANINE
+
+
+
+
+
+## Overview
+
+The CANINE model was proposed in [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
+Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting. It's
+among the first papers that trains a Transformer without using an explicit tokenization step (such as Byte Pair
+Encoding (BPE), WordPiece or SentencePiece). Instead, the model is trained directly at a Unicode character-level.
+Training at a character-level inevitably comes with a longer sequence length, which CANINE solves with an efficient
+downsampling strategy, before applying a deep Transformer encoder.
+
+The abstract from the paper is the following:
+
+*Pipelined NLP systems have largely been superseded by end-to-end neural modeling, yet nearly all commonly-used models
+still require an explicit tokenization step. While recent tokenization approaches based on data-derived subword
+lexicons are less brittle than manually engineered tokenizers, these techniques are not equally suited to all
+languages, and the use of any fixed vocabulary may limit a model's ability to adapt. In this paper, we present CANINE,
+a neural encoder that operates directly on character sequences, without explicit tokenization or vocabulary, and a
+pre-training strategy that operates either directly on characters or optionally uses subwords as a soft inductive bias.
+To use its finer-grained input effectively and efficiently, CANINE combines downsampling, which reduces the input
+sequence length, with a deep transformer stack, which encodes context. CANINE outperforms a comparable mBERT model by
+2.8 F1 on TyDi QA, a challenging multilingual benchmark, despite having 28% fewer model parameters.*
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/google-research/language/tree/master/language/canine).
+
+## Usage tips
+
+- CANINE uses no less than 3 Transformer encoders internally: 2 "shallow" encoders (which only consist of a single
+ layer) and 1 "deep" encoder (which is a regular BERT encoder). First, a "shallow" encoder is used to contextualize
+ the character embeddings, using local attention. Next, after downsampling, a "deep" encoder is applied. Finally,
+ after upsampling, a "shallow" encoder is used to create the final character embeddings. Details regarding up- and
+ downsampling can be found in the paper.
+- CANINE uses a max sequence length of 2048 characters by default. One can use [`CanineTokenizer`]
+ to prepare text for the model.
+- Classification can be done by placing a linear layer on top of the final hidden state of the special [CLS] token
+ (which has a predefined Unicode code point). For token classification tasks however, the downsampled sequence of
+ tokens needs to be upsampled again to match the length of the original character sequence (which is 2048). The
+ details for this can be found in the paper.
+
+Model checkpoints:
+
+ - [google/canine-c](https://huggingface.co/google/canine-c): Pre-trained with autoregressive character loss,
+ 12-layer, 768-hidden, 12-heads, 121M parameters (size ~500 MB).
+ - [google/canine-s](https://huggingface.co/google/canine-s): Pre-trained with subword loss, 12-layer,
+ 768-hidden, 12-heads, 121M parameters (size ~500 MB).
+
+
+## Usage example
+
+CANINE works on raw characters, so it can be used **without a tokenizer**:
+
+```python
+>>> from transformers import CanineModel
+>>> import torch
+
+>>> model = CanineModel.from_pretrained("google/canine-c") # model pre-trained with autoregressive character loss
+
+>>> text = "hello world"
+>>> # use Python's built-in ord() function to turn each character into its unicode code point id
+>>> input_ids = torch.tensor([[ord(char) for char in text]])
+
+>>> outputs = model(input_ids) # forward pass
+>>> pooled_output = outputs.pooler_output
+>>> sequence_output = outputs.last_hidden_state
+```
+
+For batched inference and training, it is however recommended to make use of the tokenizer (to pad/truncate all
+sequences to the same length):
+
+```python
+>>> from transformers import CanineTokenizer, CanineModel
+
+>>> model = CanineModel.from_pretrained("google/canine-c")
+>>> tokenizer = CanineTokenizer.from_pretrained("google/canine-c")
+
+>>> inputs = ["Life is like a box of chocolates.", "You never know what you gonna get."]
+>>> encoding = tokenizer(inputs, padding="longest", truncation=True, return_tensors="pt")
+
+>>> outputs = model(**encoding) # forward pass
+>>> pooled_output = outputs.pooler_output
+>>> sequence_output = outputs.last_hidden_state
+```
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## CanineConfig
+
+[[autodoc]] CanineConfig
+
+## CanineTokenizer
+
+[[autodoc]] CanineTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+
+## CANINE specific outputs
+
+[[autodoc]] models.canine.modeling_canine.CanineModelOutputWithPooling
+
+## CanineModel
+
+[[autodoc]] CanineModel
+ - forward
+
+## CanineForSequenceClassification
+
+[[autodoc]] CanineForSequenceClassification
+ - forward
+
+## CanineForMultipleChoice
+
+[[autodoc]] CanineForMultipleChoice
+ - forward
+
+## CanineForTokenClassification
+
+[[autodoc]] CanineForTokenClassification
+ - forward
+
+## CanineForQuestionAnswering
+
+[[autodoc]] CanineForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/chameleon.md b/docs/transformers/docs/source/en/model_doc/chameleon.md
new file mode 100644
index 0000000000000000000000000000000000000000..3810b3590a00650e58ae58f6a5ab0547e3606791
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/chameleon.md
@@ -0,0 +1,208 @@
+
+
+# Chameleon
+
+
+
+
+
+
+
+## Overview
+
+The Chameleon model was proposed in [Chameleon: Mixed-Modal Early-Fusion Foundation Models
+](https://arxiv.org/abs/2405.09818v1) by META AI Chameleon Team. Chameleon is a Vision-Language Model that use vector quantization to tokenize images which enables the model to generate multimodal output. The model takes images and texts as input, including an interleaved format, and generates textual response. Image generation module is not released yet.
+
+
+The abstract from the paper is the following:
+
+*We present Chameleon, a family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence. We outline a stable training
+approach from inception, an alignment recipe, and an architectural parameterization tailored for the
+early-fusion, token-based, mixed-modal setting. The models are evaluated on a comprehensive range
+of tasks, including visual question answering, image captioning, text generation, image generation, and
+long-form mixed modal generation. Chameleon demonstrates broad and general capabilities, including
+state-of-the-art performance in image captioning tasks, outperforms Llama-2 in text-only tasks while
+being competitive with models such as Mixtral 8x7B and Gemini-Pro, and performs non-trivial image
+generation, all in a single model. It also matches or exceeds the performance of much larger models,
+including Gemini Pro and GPT-4V, according to human judgments on a new long-form mixed-modal
+generation evaluation, where either the prompt or outputs contain mixed sequences of both images and
+text. Chameleon marks a significant step forward in unified modeling of full multimodal documents*
+
+
+
+
+ Chameleon incorporates a vector quantizer module to transform images into discrete tokens. That also enables image generation using an auto-regressive transformer. Taken from the original paper.
+
+This model was contributed by [joaogante](https://huggingface.co/joaogante) and [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
+The original code can be found [here](https://github.com/facebookresearch/chameleon).
+
+
+## Usage tips
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to set `processor.tokenizer.padding_side = "left"` before generating.
+
+- Note that Chameleon was tuned for safety alignment. If the model is refusing to answer, consider asking a more concrete question, instead of an open question.
+
+- Chameleon generates in chat format which means that the generated text will always be the "assistant's turn". You can enable a text completion generation by passing `return_for_text_completion=True` when calling the processor.
+
+> [!NOTE]
+> Chameleon implementation in Transformers uses a special image token to indicate where to merge image embeddings. For special image token we didn't add a new one but used one of the reserved tokens: ``. You have to add `` to your prompt in the place where the image should be embedded for correct generation.
+
+## Usage example
+
+### Single image inference
+
+Chameleon is a gated model so make sure to have access and login to Hugging Face Hub using a token.
+Here's how to load the model and perform inference in half-precision (`torch.bfloat16`):
+
+```python
+from transformers import ChameleonProcessor, ChameleonForConditionalGeneration
+import torch
+from PIL import Image
+import requests
+
+processor = ChameleonProcessor.from_pretrained("facebook/chameleon-7b")
+model = ChameleonForConditionalGeneration.from_pretrained("facebook/chameleon-7b", torch_dtype=torch.bfloat16, device_map="cuda")
+
+# prepare image and text prompt
+url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+image = Image.open(requests.get(url, stream=True).raw)
+prompt = "What do you see in this image?"
+
+inputs = processor(images=image, text=prompt, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+# autoregressively complete prompt
+output = model.generate(**inputs, max_new_tokens=50)
+print(processor.decode(output[0], skip_special_tokens=True))
+```
+
+### Multi image inference
+
+Chameleon can perform inference with multiple images as input, where images either belong to the same prompt or different prompts (in batched inference). Here is how you can do it:
+
+```python
+from transformers import ChameleonProcessor, ChameleonForConditionalGeneration
+import torch
+from PIL import Image
+import requests
+
+processor = ChameleonProcessor.from_pretrained("facebook/chameleon-7b")
+
+model = ChameleonForConditionalGeneration.from_pretrained("facebook/chameleon-7b", torch_dtype=torch.bfloat16, device_map="cuda")
+
+# Get three different images
+url = "https://www.ilankelman.org/stopsigns/australia.jpg"
+image_stop = Image.open(requests.get(url, stream=True).raw)
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image_cats = Image.open(requests.get(url, stream=True).raw)
+
+url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
+image_snowman = Image.open(requests.get(url, stream=True).raw)
+
+# Prepare a batched prompt, where the first one is a multi-image prompt and the second is not
+prompts = [
+ "What do these images have in common?",
+ "What is shown in this image?"
+]
+
+# We can simply feed images in the order they have to be used in the text prompt
+# Each "" token uses one image leaving the next for the subsequent "" tokens
+inputs = processor(images=[image_stop, image_cats, image_snowman], text=prompts, padding=True, return_tensors="pt").to(device="cuda", dtype=torch.bfloat16)
+
+# Generate
+generate_ids = model.generate(**inputs, max_new_tokens=50)
+processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
+```
+
+## Model optimization
+
+### Quantization using Bitsandbytes
+
+The model can be loaded in 8 or 4 bits, greatly reducing the memory requirements while maintaining the performance of the original model. First make sure to install bitsandbytes, `pip install bitsandbytes` and to have access to a GPU/accelerator that is supported by the library.
+
+
+
+bitsandbytes is being refactored to support multiple backends beyond CUDA. Currently, ROCm (AMD GPU) and Intel CPU implementations are mature, with Intel XPU in progress and Apple Silicon support expected by Q4/Q1. For installation instructions and the latest backend updates, visit [this link](https://huggingface.co/docs/bitsandbytes/main/en/installation#multi-backend).
+
+We value your feedback to help identify bugs before the full release! Check out [these docs](https://huggingface.co/docs/bitsandbytes/main/en/non_cuda_backends) for more details and feedback links.
+
+
+
+Simply change the snippet above with:
+
+```python
+from transformers import ChameleonForConditionalGeneration, BitsAndBytesConfig
+
+# specify how to quantize the model
+quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.bfloat16,
+)
+
+model = ChameleonForConditionalGeneration.from_pretrained("facebook/chameleon-7b", quantization_config=quantization_config, device_map="cuda")
+```
+
+### Use Flash-Attention 2 and SDPA to further speed-up generation
+
+The models supports both, Flash-Attention 2 and PyTorch's [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) which can be enables for optimization. SDPA is the default options when you load the model, If you want to switch for Flash Attention 2, first make sure to install flash-attn. Refer to the [original repository](https://github.com/Dao-AILab/flash-attention) regarding that package installation. Simply change the snippet above with:
+
+```python
+from transformers import ChameleonForConditionalGeneration
+
+model_id = "facebook/chameleon-7b"
+model = ChameleonForConditionalGeneration.from_pretrained(
+ model_id,
+ torch_dtype=torch.bfloat16,
+ low_cpu_mem_usage=True,
+ attn_implementation="flash_attention_2"
+).to(0)
+```
+
+## ChameleonConfig
+
+[[autodoc]] ChameleonConfig
+
+## ChameleonVQVAEConfig
+
+[[autodoc]] ChameleonVQVAEConfig
+
+## ChameleonProcessor
+
+[[autodoc]] ChameleonProcessor
+
+## ChameleonImageProcessor
+
+[[autodoc]] ChameleonImageProcessor
+ - preprocess
+
+## ChameleonVQVAE
+
+[[autodoc]] ChameleonVQVAE
+ - forward
+
+## ChameleonModel
+
+[[autodoc]] ChameleonModel
+ - forward
+
+## ChameleonForConditionalGeneration
+
+[[autodoc]] ChameleonForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/chinese_clip.md b/docs/transformers/docs/source/en/model_doc/chinese_clip.md
new file mode 100644
index 0000000000000000000000000000000000000000..f44cdbd145646d3136b711b805de40e0fa6224e1
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/chinese_clip.md
@@ -0,0 +1,121 @@
+
+
+# Chinese-CLIP
+
+
+
+
+
+## Overview
+
+The Chinese-CLIP model was proposed in [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
+Chinese-CLIP is an implementation of CLIP (Radford et al., 2021) on a large-scale dataset of Chinese image-text pairs. It is capable of performing cross-modal retrieval and also playing as a vision backbone for vision tasks like zero-shot image classification, open-domain object detection, etc. The original Chinese-CLIP code is released [at this link](https://github.com/OFA-Sys/Chinese-CLIP).
+
+The abstract from the paper is the following:
+
+*The tremendous success of CLIP (Radford et al., 2021) has promoted the research and application of contrastive learning for vision-language pretraining. In this work, we construct a large-scale dataset of image-text pairs in Chinese, where most data are retrieved from publicly available datasets, and we pretrain Chinese CLIP models on the new dataset. We develop 5 Chinese CLIP models of multiple sizes, spanning from 77 to 958 million parameters. Furthermore, we propose a two-stage pretraining method, where the model is first trained with the image encoder frozen and then trained with all parameters being optimized, to achieve enhanced model performance. Our comprehensive experiments demonstrate that Chinese CLIP can achieve the state-of-the-art performance on MUGE, Flickr30K-CN, and COCO-CN in the setups of zero-shot learning and finetuning, and it is able to achieve competitive performance in zero-shot image classification based on the evaluation on the ELEVATER benchmark (Li et al., 2022). Our codes, pretrained models, and demos have been released.*
+
+The Chinese-CLIP model was contributed by [OFA-Sys](https://huggingface.co/OFA-Sys).
+
+## Usage example
+
+The code snippet below shows how to compute image & text features and similarities:
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import ChineseCLIPProcessor, ChineseCLIPModel
+
+>>> model = ChineseCLIPModel.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
+>>> processor = ChineseCLIPProcessor.from_pretrained("OFA-Sys/chinese-clip-vit-base-patch16")
+
+>>> url = "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> # Squirtle, Bulbasaur, Charmander, Pikachu in English
+>>> texts = ["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]
+
+>>> # compute image feature
+>>> inputs = processor(images=image, return_tensors="pt")
+>>> image_features = model.get_image_features(**inputs)
+>>> image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True) # normalize
+
+>>> # compute text features
+>>> inputs = processor(text=texts, padding=True, return_tensors="pt")
+>>> text_features = model.get_text_features(**inputs)
+>>> text_features = text_features / text_features.norm(p=2, dim=-1, keepdim=True) # normalize
+
+>>> # compute image-text similarity scores
+>>> inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+>>> probs = logits_per_image.softmax(dim=1) # probs: [[1.2686e-03, 5.4499e-02, 6.7968e-04, 9.4355e-01]]
+```
+
+Currently, following scales of pretrained Chinese-CLIP models are available on 🤗 Hub:
+
+- [OFA-Sys/chinese-clip-vit-base-patch16](https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16)
+- [OFA-Sys/chinese-clip-vit-large-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14)
+- [OFA-Sys/chinese-clip-vit-large-patch14-336px](https://huggingface.co/OFA-Sys/chinese-clip-vit-large-patch14-336px)
+- [OFA-Sys/chinese-clip-vit-huge-patch14](https://huggingface.co/OFA-Sys/chinese-clip-vit-huge-patch14)
+
+## ChineseCLIPConfig
+
+[[autodoc]] ChineseCLIPConfig
+ - from_text_vision_configs
+
+## ChineseCLIPTextConfig
+
+[[autodoc]] ChineseCLIPTextConfig
+
+## ChineseCLIPVisionConfig
+
+[[autodoc]] ChineseCLIPVisionConfig
+
+## ChineseCLIPImageProcessor
+
+[[autodoc]] ChineseCLIPImageProcessor
+ - preprocess
+
+## ChineseCLIPImageProcessorFast
+
+[[autodoc]] ChineseCLIPImageProcessorFast
+ - preprocess
+
+## ChineseCLIPFeatureExtractor
+
+[[autodoc]] ChineseCLIPFeatureExtractor
+
+## ChineseCLIPProcessor
+
+[[autodoc]] ChineseCLIPProcessor
+
+## ChineseCLIPModel
+
+[[autodoc]] ChineseCLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## ChineseCLIPTextModel
+
+[[autodoc]] ChineseCLIPTextModel
+ - forward
+
+## ChineseCLIPVisionModel
+
+[[autodoc]] ChineseCLIPVisionModel
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/clap.md b/docs/transformers/docs/source/en/model_doc/clap.md
new file mode 100644
index 0000000000000000000000000000000000000000..e060662c01a9edd0acfa176f0fdb306f92b612c6
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/clap.md
@@ -0,0 +1,83 @@
+
+
+# CLAP
+
+
+
+
+
+## Overview
+
+The CLAP model was proposed in [Large Scale Contrastive Language-Audio pretraining with
+feature fusion and keyword-to-caption augmentation](https://arxiv.org/pdf/2211.06687.pdf) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
+
+CLAP (Contrastive Language-Audio Pretraining) is a neural network trained on a variety of (audio, text) pairs. It can be instructed in to predict the most relevant text snippet, given an audio, without directly optimizing for the task. The CLAP model uses a SWINTransformer to get audio features from a log-Mel spectrogram input, and a RoBERTa model to get text features. Both the text and audio features are then projected to a latent space with identical dimension. The dot product between the projected audio and text features is then used as a similar score.
+
+The abstract from the paper is the following:
+
+*Contrastive learning has shown remarkable success in the field of multimodal representation learning. In this paper, we propose a pipeline of contrastive language-audio pretraining to develop an audio representation by combining audio data with natural language descriptions. To accomplish this target, we first release LAION-Audio-630K, a large collection of 633,526 audio-text pairs from different data sources. Second, we construct a contrastive language-audio pretraining model by considering different audio encoders and text encoders. We incorporate the feature fusion mechanism and keyword-to-caption augmentation into the model design to further enable the model to process audio inputs of variable lengths and enhance the performance. Third, we perform comprehensive experiments to evaluate our model across three tasks: text-to-audio retrieval, zero-shot audio classification, and supervised audio classification. The results demonstrate that our model achieves superior performance in text-to-audio retrieval task. In audio classification tasks, the model achieves state-of-the-art performance in the zeroshot setting and is able to obtain performance comparable to models' results in the non-zero-shot setting. LAION-Audio-6*
+
+This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ) .
+The original code can be found [here](https://github.com/LAION-AI/Clap).
+
+## ClapConfig
+
+[[autodoc]] ClapConfig
+ - from_text_audio_configs
+
+## ClapTextConfig
+
+[[autodoc]] ClapTextConfig
+
+## ClapAudioConfig
+
+[[autodoc]] ClapAudioConfig
+
+## ClapFeatureExtractor
+
+[[autodoc]] ClapFeatureExtractor
+
+## ClapProcessor
+
+[[autodoc]] ClapProcessor
+
+## ClapModel
+
+[[autodoc]] ClapModel
+ - forward
+ - get_text_features
+ - get_audio_features
+
+## ClapTextModel
+
+[[autodoc]] ClapTextModel
+ - forward
+
+## ClapTextModelWithProjection
+
+[[autodoc]] ClapTextModelWithProjection
+ - forward
+
+## ClapAudioModel
+
+[[autodoc]] ClapAudioModel
+ - forward
+
+## ClapAudioModelWithProjection
+
+[[autodoc]] ClapAudioModelWithProjection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/clip.md b/docs/transformers/docs/source/en/model_doc/clip.md
new file mode 100644
index 0000000000000000000000000000000000000000..4ab9fe3f21ac6f59a9b2b073f650529f3490288c
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/clip.md
@@ -0,0 +1,213 @@
+
+
+
+
+
+
+
+
+
+
+
+
+# CLIP
+
+[CLIP](https://huggingface.co/papers/2103.00020) is a is a multimodal vision and language model motivated by overcoming the fixed number of object categories when training a computer vision model. CLIP learns about images directly from raw text by jointly training on 400M (image, text) pairs. Pretraining on this scale enables zero-shot transfer to downstream tasks. CLIP uses an image encoder and text encoder to get visual features and text features. Both features are projected to a latent space with the same number of dimensions and their dot product gives a similarity score.
+
+You can find all the original CLIP checkpoints under the [OpenAI](https://huggingface.co/openai?search_models=clip) organization.
+
+> [!TIP]
+> Click on the CLIP models in the right sidebar for more examples of how to apply CLIP to different image and language tasks.
+
+The example below demonstrates how to calculate similarity scores between multiple text descriptions and an image with [`Pipeline`] or the [`AutoModel`] class.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+clip = pipeline(
+ task="zero-shot-image-classification",
+ model="openai/clip-vit-base-patch32",
+ torch_dtype=torch.bfloat16,
+ device=0
+)
+labels = ["a photo of a cat", "a photo of a dog", "a photo of a car"]
+clip("http://images.cocodataset.org/val2017/000000039769.jpg", candidate_labels=labels)
+```
+
+
+
+
+```py
+import requests
+import torch
+from PIL import Image
+from transformers import AutoProcessor, AutoModel
+
+model = AutoModel.from_pretrained("openai/clip-vit-base-patch32", torch_dtype=torch.bfloat16, attn_implementation="sdpa")
+processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+labels = ["a photo of a cat", "a photo of a dog", "a photo of a car"]
+
+inputs = processor(text=labels, images=image, return_tensors="pt", padding=True)
+
+outputs = model(**inputs)
+logits_per_image = outputs.logits_per_image
+probs = logits_per_image.softmax(dim=1)
+most_likely_idx = probs.argmax(dim=1).item()
+most_likely_label = labels[most_likely_idx]
+print(f"Most likely label: {most_likely_label} with probability: {probs[0][most_likely_idx].item():.3f}")
+```
+
+
+
+
+## Notes
+
+- Use [`CLIPImageProcessor`] to resize (or rescale) and normalizes images for the model.
+
+## CLIPConfig
+
+[[autodoc]] CLIPConfig
+ - from_text_vision_configs
+
+## CLIPTextConfig
+
+[[autodoc]] CLIPTextConfig
+
+## CLIPVisionConfig
+
+[[autodoc]] CLIPVisionConfig
+
+## CLIPTokenizer
+
+[[autodoc]] CLIPTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CLIPTokenizerFast
+
+[[autodoc]] CLIPTokenizerFast
+
+## CLIPImageProcessor
+
+[[autodoc]] CLIPImageProcessor
+ - preprocess
+
+## CLIPImageProcessorFast
+
+[[autodoc]] CLIPImageProcessorFast
+ - preprocess
+
+## CLIPFeatureExtractor
+
+[[autodoc]] CLIPFeatureExtractor
+
+## CLIPProcessor
+
+[[autodoc]] CLIPProcessor
+
+
+
+
+## CLIPModel
+
+[[autodoc]] CLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPTextModel
+
+[[autodoc]] CLIPTextModel
+ - forward
+
+## CLIPTextModelWithProjection
+
+[[autodoc]] CLIPTextModelWithProjection
+ - forward
+
+## CLIPVisionModelWithProjection
+
+[[autodoc]] CLIPVisionModelWithProjection
+ - forward
+
+## CLIPVisionModel
+
+[[autodoc]] CLIPVisionModel
+ - forward
+
+## CLIPForImageClassification
+
+[[autodoc]] CLIPForImageClassification
+ - forward
+
+
+
+
+## TFCLIPModel
+
+[[autodoc]] TFCLIPModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFCLIPTextModel
+
+[[autodoc]] TFCLIPTextModel
+ - call
+
+## TFCLIPVisionModel
+
+[[autodoc]] TFCLIPVisionModel
+ - call
+
+
+
+
+## FlaxCLIPModel
+
+[[autodoc]] FlaxCLIPModel
+ - __call__
+ - get_text_features
+ - get_image_features
+
+## FlaxCLIPTextModel
+
+[[autodoc]] FlaxCLIPTextModel
+ - __call__
+
+## FlaxCLIPTextModelWithProjection
+
+[[autodoc]] FlaxCLIPTextModelWithProjection
+ - __call__
+
+## FlaxCLIPVisionModel
+
+[[autodoc]] FlaxCLIPVisionModel
+ - __call__
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/clipseg.md b/docs/transformers/docs/source/en/model_doc/clipseg.md
new file mode 100644
index 0000000000000000000000000000000000000000..f594dbc3e0f3a238eaa701d286f7a8e0246ed86d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/clipseg.md
@@ -0,0 +1,108 @@
+
+
+# CLIPSeg
+
+
+
+
+
+## Overview
+
+The CLIPSeg model was proposed in [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke
+and Alexander Ecker. CLIPSeg adds a minimal decoder on top of a frozen [CLIP](clip) model for zero-shot and one-shot image segmentation.
+
+The abstract from the paper is the following:
+
+*Image segmentation is usually addressed by training a
+model for a fixed set of object classes. Incorporating additional classes or more complex queries later is expensive
+as it requires re-training the model on a dataset that encompasses these expressions. Here we propose a system
+that can generate image segmentations based on arbitrary
+prompts at test time. A prompt can be either a text or an
+image. This approach enables us to create a unified model
+(trained once) for three common segmentation tasks, which
+come with distinct challenges: referring expression segmentation, zero-shot segmentation and one-shot segmentation.
+We build upon the CLIP model as a backbone which we extend with a transformer-based decoder that enables dense
+prediction. After training on an extended version of the
+PhraseCut dataset, our system generates a binary segmentation map for an image based on a free-text prompt or on
+an additional image expressing the query. We analyze different variants of the latter image-based prompts in detail.
+This novel hybrid input allows for dynamic adaptation not
+only to the three segmentation tasks mentioned above, but
+to any binary segmentation task where a text or image query
+can be formulated. Finally, we find our system to adapt well
+to generalized queries involving affordances or properties*
+
+
+
+ CLIPSeg overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/timojl/clipseg).
+
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] adds a decoder on top of [`CLIPSegModel`]. The latter is identical to [`CLIPModel`].
+- [`CLIPSegForImageSegmentation`] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text
+(provided to the model as `input_ids`) or an image (provided to the model as `conditional_pixel_values`). One can also provide custom
+conditional embeddings (provided to the model as `conditional_embeddings`).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIPSeg. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+- A notebook that illustrates [zero-shot image segmentation with CLIPSeg](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/CLIPSeg/Zero_shot_image_segmentation_with_CLIPSeg.ipynb).
+
+## CLIPSegConfig
+
+[[autodoc]] CLIPSegConfig
+ - from_text_vision_configs
+
+## CLIPSegTextConfig
+
+[[autodoc]] CLIPSegTextConfig
+
+## CLIPSegVisionConfig
+
+[[autodoc]] CLIPSegVisionConfig
+
+## CLIPSegProcessor
+
+[[autodoc]] CLIPSegProcessor
+
+## CLIPSegModel
+
+[[autodoc]] CLIPSegModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPSegTextModel
+
+[[autodoc]] CLIPSegTextModel
+ - forward
+
+## CLIPSegVisionModel
+
+[[autodoc]] CLIPSegVisionModel
+ - forward
+
+## CLIPSegForImageSegmentation
+
+[[autodoc]] CLIPSegForImageSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/clvp.md b/docs/transformers/docs/source/en/model_doc/clvp.md
new file mode 100644
index 0000000000000000000000000000000000000000..cfa4f97b828614ee817666d9324afc8f9b2ad1e6
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/clvp.md
@@ -0,0 +1,130 @@
+
+
+# CLVP
+
+
+
+
+
+## Overview
+
+The CLVP (Contrastive Language-Voice Pretrained Transformer) model was proposed in [Better speech synthesis through scaling](https://arxiv.org/abs/2305.07243) by James Betker.
+
+The abstract from the paper is the following:
+
+*In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise - an expressive, multi-voice text-to-speech system.*
+
+
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
+The original code can be found [here](https://github.com/neonbjb/tortoise-tts).
+
+
+## Usage tips
+
+1. CLVP is an integral part of the Tortoise TTS model.
+2. CLVP can be used to compare different generated speech candidates with the provided text, and the best speech tokens are forwarded to the diffusion model.
+3. The use of the [`ClvpModelForConditionalGeneration.generate()`] method is strongly recommended for tortoise usage.
+4. Note that the CLVP model expects the audio to be sampled at 22.05 kHz contrary to other audio models which expects 16 kHz.
+
+
+## Brief Explanation:
+
+- The [`ClvpTokenizer`] tokenizes the text input, and the [`ClvpFeatureExtractor`] extracts the log mel-spectrogram from the desired audio.
+- [`ClvpConditioningEncoder`] takes those text tokens and audio representations and converts them into embeddings conditioned on the text and audio.
+- The [`ClvpForCausalLM`] uses those embeddings to generate multiple speech candidates.
+- Each speech candidate is passed through the speech encoder ([`ClvpEncoder`]) which converts them into a vector representation, and the text encoder ([`ClvpEncoder`]) converts the text tokens into the same latent space.
+- At the end, we compare each speech vector with the text vector to see which speech vector is most similar to the text vector.
+- [`ClvpModelForConditionalGeneration.generate()`] compresses all of the logic described above into a single method.
+
+
+Example :
+
+```python
+>>> import datasets
+>>> from transformers import ClvpProcessor, ClvpModelForConditionalGeneration
+
+>>> # Define the Text and Load the Audio (We are taking an audio example from HuggingFace Hub using `datasets` library).
+>>> text = "This is an example text."
+
+>>> ds = datasets.load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> ds = ds.cast_column("audio", datasets.Audio(sampling_rate=22050))
+>>> sample = ds[0]["audio"]
+
+>>> # Define processor and model.
+>>> processor = ClvpProcessor.from_pretrained("susnato/clvp_dev")
+>>> model = ClvpModelForConditionalGeneration.from_pretrained("susnato/clvp_dev")
+
+>>> # Generate processor output and model output.
+>>> processor_output = processor(raw_speech=sample["array"], sampling_rate=sample["sampling_rate"], text=text, return_tensors="pt")
+>>> generated_output = model.generate(**processor_output)
+```
+
+
+## ClvpConfig
+
+[[autodoc]] ClvpConfig
+ - from_sub_model_configs
+
+## ClvpEncoderConfig
+
+[[autodoc]] ClvpEncoderConfig
+
+## ClvpDecoderConfig
+
+[[autodoc]] ClvpDecoderConfig
+
+## ClvpTokenizer
+
+[[autodoc]] ClvpTokenizer
+ - save_vocabulary
+
+## ClvpFeatureExtractor
+
+[[autodoc]] ClvpFeatureExtractor
+ - __call__
+
+## ClvpProcessor
+
+[[autodoc]] ClvpProcessor
+ - __call__
+ - decode
+ - batch_decode
+
+## ClvpModelForConditionalGeneration
+
+[[autodoc]] ClvpModelForConditionalGeneration
+ - forward
+ - generate
+ - get_text_features
+ - get_speech_features
+
+## ClvpForCausalLM
+
+[[autodoc]] ClvpForCausalLM
+
+## ClvpModel
+
+[[autodoc]] ClvpModel
+
+## ClvpEncoder
+
+[[autodoc]] ClvpEncoder
+
+## ClvpDecoder
+
+[[autodoc]] ClvpDecoder
+
diff --git a/docs/transformers/docs/source/en/model_doc/code_llama.md b/docs/transformers/docs/source/en/model_doc/code_llama.md
new file mode 100644
index 0000000000000000000000000000000000000000..09499ca547572099d97a9684ccbe077d588fad89
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/code_llama.md
@@ -0,0 +1,181 @@
+
+
+
+
+
+
+
+
+
+# CodeLlama
+
+[Code Llama](https://huggingface.co/papers/2308.12950) is a specialized family of large language models based on [Llama 2](./llama2) for coding tasks. It comes in different flavors - general code, Python-specific, and instruction-following variant - all available in 7B, 13B, 34B, and 70B parameters. Code Llama models can generate, explain, and even fill in missing parts of your code (called "infilling"). It can also handle very long contexts with stable generation up to 100k tokens, even though it was trained on sequences of 16K tokens.
+
+You can find all the original Code Llama checkpoints under the [Code Llama](https://huggingface.co/collections/meta-llama/code-llama-family-661da32d0a9d678b6f55b933) collection.
+
+> [!TIP]
+> Click on the Code Llama models in the right sidebar for more examples of how to apply Code Llama to different coding tasks.
+
+The example below demonstrates how to generate code with [`Pipeline`], or the [`AutoModel`], and from the command line.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipe = pipeline(
+ "text-generation",
+ model="meta-llama/CodeLlama-7b-hf",
+ torch_dtype=torch.float16,
+ device_map=0
+)
+
+# basic code generation
+result = pipe("# Function to calculate the factorial of a number\ndef factorial(n):", max_new_tokens=256)
+print(result[0]['generated_text'])
+
+# infilling
+infill_result = pipe("def remove_non_ascii(s: str) -> str:\n \"\"\" \n return result", max_new_tokens=200)
+print(infill_result[0]['generated_text'])
+```
+
+
+
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("meta-llama/CodeLlama-7b-hf")
+model = AutoModelForCausalLM.from_pretrained(
+ "meta-llama/CodeLlama-7b-hf",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+
+# basic code generation
+prompt = "# Function to calculate the factorial of a number\ndef factorial(n):"
+input_ids = tokenizer(prompt, return_tensors="pt").to("cuda")
+
+output = model.generate(
+ **input_ids,
+ max_new_tokens=256,
+ cache_implementation="static"
+)
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+
+# infilling
+infill_prompt = "def remove_non_ascii(s: str) -> str:\n \"\"\" \n return result"
+input_ids = tokenizer(infill_prompt, return_tensors="pt").to(model.device)
+
+filled_output = model.generate(**input_ids, max_new_tokens=200)
+filled_text = tokenizer.decode(filled_output[0], skip_special_tokens=True)
+print(filled_text)
+```
+
+
+
+
+```bash
+echo -e "# Function to calculate the factorial of a number\ndef factorial(n):" | transformers-cli run --task text-generation --model meta-llama/CodeLlama-7b-hf --device 0
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes) to only quantize the weights to 4-bits.
+
+```py
+# pip install bitsandbytes
+import torch
+from transformers import AutoModelForCausalLM, CodeLlamaTokenizer, BitsAndBytesConfig
+
+bnb_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16, bnb_4bit_quant_type="nf4", bnb_4bit_use_double_quant=True)
+tokenizer = CodeLlamaTokenizer.from_pretrained("meta-llama/CodeLlama-34b-hf")
+model = AutoModelForCausalLM.from_pretrained(
+ "meta-llama/CodeLlama-34b-hf",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ quantization_config=bnb_config
+)
+
+prompt = "# Write a Python function to check if a string is a palindrome\ndef is_palindrome(s):"
+input_ids = tokenizer(prompt, return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, max_new_tokens=200, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+Use the [AttentionMaskVisualizer](https://github.com/huggingface/transformers/blob/beb9b5b02246b9b7ee81ddf938f93f44cfeaad19/src/transformers/utils/attention_visualizer.py#L139) to better understand what tokens the model can and cannot attend to.
+
+```py
+from transformers.utils.attention_visualizer import AttentionMaskVisualizer
+
+visualizer = AttentionMaskVisualizer("meta-llama/CodeLlama-7b-hf")
+visualizer("""def func(a, b):
+ return a + b""")
+```
+
+
+
+
+
+## Notes
+
+- Infilling is only available in the 7B and 13B base models, and not in the Python, Instruct, 34B, or 70B models.
+- Use the `` token where you want your input to be filled. The tokenizer splits this token to create a formatted input string that follows the [original training pattern](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402). This is more robust than preparing the pattern yourself.
+ ```py
+ from transformers import LlamaForCausalLM, CodeLlamaTokenizer
+
+ tokenizer = CodeLlamaTokenizer.from_pretrained("meta-llama/CodeLlama-7b-hf")
+ model = LlamaForCausalLM.from_pretrained("meta-llama/CodeLlama-7b-hf")
+ PROMPT = '''def remove_non_ascii(s: str) -> str:
+ """
+ return result
+ '''
+ input_ids = tokenizer(PROMPT, return_tensors="pt")["input_ids"]
+ generated_ids = model.generate(input_ids, max_new_tokens=128)
+
+ filling = tokenizer.batch_decode(generated_ids[:, input_ids.shape[1]:], skip_special_tokens = True)[0]
+ print(PROMPT.replace("", filling))
+ ```
+- Use `bfloat16` for further training or fine-tuning and `float16` for inference.
+- The `BOS` character is not used for infilling when encoding the prefix or suffix, but only at the beginning of each prompt.
+- The tokenizer is a byte-pair encoding model based on [SentencePiece](https://github.com/google/sentencepiece). During decoding, if the first token is the start of the word (for example, “Banana”), the tokenizer doesn’t prepend the prefix space to the string.
+
+## CodeLlamaTokenizer
+
+[[autodoc]] CodeLlamaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CodeLlamaTokenizerFast
+
+[[autodoc]] CodeLlamaTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - update_post_processor
+ - save_vocabulary
diff --git a/docs/transformers/docs/source/en/model_doc/codegen.md b/docs/transformers/docs/source/en/model_doc/codegen.md
new file mode 100644
index 0000000000000000000000000000000000000000..465c8e5445b898dedc28dd900dd14b4b6c7459dd
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/codegen.md
@@ -0,0 +1,94 @@
+
+
+# CodeGen
+
+
+
+
+
+## Overview
+
+The CodeGen model was proposed in [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong.
+
+CodeGen is an autoregressive language model for program synthesis trained sequentially on [The Pile](https://pile.eleuther.ai/), BigQuery, and BigPython.
+
+The abstract from the paper is the following:
+
+*Program synthesis strives to generate a computer program as a solution to a given problem specification. We propose a conversational program synthesis approach via large language models, which addresses the challenges of searching over a vast program space and user intent specification faced in prior approaches. Our new approach casts the process of writing a specification and program as a multi-turn conversation between a user and a system. It treats program synthesis as a sequence prediction problem, in which the specification is expressed in natural language and the desired program is conditionally sampled. We train a family of large language models, called CodeGen, on natural language and programming language data. With weak supervision in the data and the scaling up of data size and model size, conversational capacities emerge from the simple autoregressive language modeling. To study the model behavior on conversational program synthesis, we develop a multi-turn programming benchmark (MTPB), where solving each problem requires multi-step synthesis via multi-turn conversation between the user and the model. Our findings show the emergence of conversational capabilities and the effectiveness of the proposed conversational program synthesis paradigm. In addition, our model CodeGen (with up to 16B parameters trained on TPU-v4) outperforms OpenAI's Codex on the HumanEval benchmark. We make the training library JaxFormer including checkpoints available as open source contribution: [this https URL](https://github.com/salesforce/codegen).*
+
+This model was contributed by [Hiroaki Hayashi](https://huggingface.co/rooa).
+The original code can be found [here](https://github.com/salesforce/codegen).
+
+## Checkpoint Naming
+
+* CodeGen model [checkpoints](https://huggingface.co/models?other=codegen) are available on different pre-training data with variable sizes.
+* The format is: `Salesforce/codegen-{size}-{data}`, where
+ * `size`: `350M`, `2B`, `6B`, `16B`
+ * `data`:
+ * `nl`: Pre-trained on the Pile
+ * `multi`: Initialized with `nl`, then further pre-trained on multiple programming languages data
+ * `mono`: Initialized with `multi`, then further pre-trained on Python data
+* For example, `Salesforce/codegen-350M-mono` offers a 350 million-parameter checkpoint pre-trained sequentially on the Pile, multiple programming languages, and Python.
+
+## Usage example
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> checkpoint = "Salesforce/codegen-350M-mono"
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+>>> text = "def hello_world():"
+
+>>> completion = model.generate(**tokenizer(text, return_tensors="pt"))
+
+>>> print(tokenizer.decode(completion[0]))
+def hello_world():
+ print("Hello World")
+
+hello_world()
+```
+
+## Resources
+
+- [Causal language modeling task guide](../tasks/language_modeling)
+
+## CodeGenConfig
+
+[[autodoc]] CodeGenConfig
+ - all
+
+## CodeGenTokenizer
+
+[[autodoc]] CodeGenTokenizer
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CodeGenTokenizerFast
+
+[[autodoc]] CodeGenTokenizerFast
+
+## CodeGenModel
+
+[[autodoc]] CodeGenModel
+ - forward
+
+## CodeGenForCausalLM
+
+[[autodoc]] CodeGenForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/cohere.md b/docs/transformers/docs/source/en/model_doc/cohere.md
new file mode 100644
index 0000000000000000000000000000000000000000..48b924e1ff13c5f570712e65d26a932e93139dd6
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/cohere.md
@@ -0,0 +1,136 @@
+
+
+
+
+
+
+
+
+
+# Cohere
+
+Cohere Command-R is a 35B parameter multilingual large language model designed for long context tasks like retrieval-augmented generation (RAG) and calling external APIs and tools. The model is specifically trained for grounded generation and supports both single-step and multi-step tool use. It supports a context length of 128K tokens.
+
+You can find all the original Command-R checkpoints under the [Command Models](https://huggingface.co/collections/CohereForAI/command-models-67652b401665205e17b192ad) collection.
+
+
+> [!TIP]
+> Click on the Cohere models in the right sidebar for more examples of how to apply Cohere to different language tasks.
+
+The example below demonstrates how to generate text with [`Pipeline`] or the [`AutoModel`], and from the command line.
+
+
+
+
+```python
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="text-generation",
+ model="CohereForAI/c4ai-command-r-v01",
+ torch_dtype=torch.float16,
+ device=0
+)
+pipeline("Plants create energy through a process known as")
+```
+
+
+
+
+```python
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("CohereForAI/c4ai-command-r-v01")
+model = AutoModelForCausalLM.from_pretrained("CohereForAI/c4ai-command-r-v01", torch_dtype=torch.float16, device_map="auto", attn_implementation="sdpa")
+
+# format message with the Command-R chat template
+messages = [{"role": "user", "content": "How do plants make energy?"}]
+input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
+output = model.generate(
+ input_ids,
+ max_new_tokens=100,
+ do_sample=True,
+ temperature=0.3,
+ cache_implementation="static",
+)
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+
+
+
+```bash
+# pip install -U flash-attn --no-build-isolation
+transformers-cli chat --model_name_or_path CohereForAI/c4ai-command-r-v01 --torch_dtype auto --attn_implementation flash_attention_2
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes) to quantize the weights to 4-bits.
+
+```python
+import torch
+from transformers import BitsAndBytesConfig, AutoTokenizer, AutoModelForCausalLM
+
+bnb_config = BitsAndBytesConfig(load_in_4bit=True)
+tokenizer = AutoTokenizer.from_pretrained("CohereForAI/c4ai-command-r-v01")
+model = AutoModelForCausalLM.from_pretrained("CohereForAI/c4ai-command-r-v01", torch_dtype=torch.float16, device_map="auto", quantization_config=bnb_config, attn_implementation="sdpa")
+
+# format message with the Command-R chat template
+messages = [{"role": "user", "content": "How do plants make energy?"}]
+input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
+output = model.generate(
+ input_ids,
+ max_new_tokens=100,
+ do_sample=True,
+ temperature=0.3,
+ cache_implementation="static",
+)
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+Use the [AttentionMaskVisualizer](https://github.com/huggingface/transformers/blob/beb9b5b02246b9b7ee81ddf938f93f44cfeaad19/src/transformers/utils/attention_visualizer.py#L139) to better understand what tokens the model can and cannot attend to.
+
+```py
+from transformers.utils.attention_visualizer import AttentionMaskVisualizer
+
+visualizer = AttentionMaskVisualizer("CohereForAI/c4ai-command-r-v01")
+visualizer("Plants create energy through a process known as")
+```
+
+
+
+
+
+
+## Notes
+- Don’t use the torch_dtype parameter in [`~AutoModel.from_pretrained`] if you’re using FlashAttention-2 because it only supports fp16 or bf16. You should use [Automatic Mixed Precision](https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html), set fp16 or bf16 to True if using [`Trainer`], or use [torch.autocast](https://pytorch.org/docs/stable/amp.html#torch.autocast).
+
+## CohereConfig
+
+[[autodoc]] CohereConfig
+
+## CohereTokenizerFast
+
+[[autodoc]] CohereTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - update_post_processor
+ - save_vocabulary
+
+## CohereModel
+
+[[autodoc]] CohereModel
+ - forward
+
+
+## CohereForCausalLM
+
+[[autodoc]] CohereForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/cohere2.md b/docs/transformers/docs/source/en/model_doc/cohere2.md
new file mode 100644
index 0000000000000000000000000000000000000000..3b0b6e1740a976d2bce8ce147043d5fe9aaaa5b7
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/cohere2.md
@@ -0,0 +1,57 @@
+# Cohere
+
+
+
+
+
+
+
+## Overview
+[C4AI Command R7B](https://cohere.com/blog/command-r7b) is an open weights research release of a 7B billion parameter model developed by Cohere and Cohere For AI. It has advanced capabilities optimized for various use cases, including reasoning, summarization, question answering, and code. The model is trained to perform sophisticated tasks including Retrieval Augmented Generation (RAG) and tool use. The model also has powerful agentic capabilities that can use and combine multiple tools over multiple steps to accomplish more difficult tasks. It obtains top performance on enterprise-relevant code use cases. C4AI Command R7B is a multilingual model trained on 23 languages.
+
+The model features three layers with sliding window attention (window size 4096) and ROPE for efficient local context modeling and relative positional encoding. A fourth layer uses global attention without positional embeddings, enabling unrestricted token interactions across the entire sequence.
+
+The model has been trained on 23 languages: English, French, Spanish, Italian, German, Portuguese, Japanese, Korean, Arabic, Chinese, Russian, Polish, Turkish, Vietnamese, Dutch, Czech, Indonesian, Ukrainian, Romanian, Greek, Hindi, Hebrew, and Persian.
+
+## Usage tips
+The model and tokenizer can be loaded via:
+
+```python
+# pip install transformers
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+model_id = "CohereForAI/c4ai-command-r7b-12-2024"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = AutoModelForCausalLM.from_pretrained(model_id)
+
+# Format message with the command-r chat template
+messages = [{"role": "user", "content": "Hello, how are you?"}]
+input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
+
+gen_tokens = model.generate(
+ input_ids,
+ max_new_tokens=100,
+ do_sample=True,
+ temperature=0.3,
+)
+
+gen_text = tokenizer.decode(gen_tokens[0])
+print(gen_text)
+```
+
+## Cohere2Config
+
+[[autodoc]] Cohere2Config
+
+## Cohere2Model
+
+[[autodoc]] Cohere2Model
+ - forward
+
+
+## Cohere2ForCausalLM
+
+[[autodoc]] Cohere2ForCausalLM
+ - forward
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/colpali.md b/docs/transformers/docs/source/en/model_doc/colpali.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb6efc42056c961c179879f2daee81efe327eb2e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/colpali.md
@@ -0,0 +1,151 @@
+
+
+
+
+
+
+
+
+# ColPali
+
+[ColPali](https://huggingface.co/papers/2407.01449) is a model designed to retrieve documents by analyzing their visual features. Unlike traditional systems that rely heavily on text extraction and OCR, ColPali treats each page as an image. It uses [Paligemma-3B](./paligemma) to capture not only text, but also the layout, tables, charts, and other visual elements to create detailed embeddings. This offers a more comprehensive understanding of documents and enables more efficient and accurate retrieval.
+
+You can find all the original ColPali checkpoints under the [ColPali](https://huggingface.co/collections/vidore/hf-native-colvision-models-6755d68fc60a8553acaa96f7) collection.
+
+> [!TIP]
+> Click on the ColPali models in the right sidebar for more examples of how to use ColPali for image retrieval.
+
+
+
+
+```py
+import requests
+import torch
+from PIL import Image
+from transformers import ColPaliForRetrieval, ColPaliProcessor
+
+# Load model (bfloat16 support is limited; fallback to float32 if needed)
+model = ColPaliForRetrieval.from_pretrained(
+ "vidore/colpali-v1.2-hf",
+ torch_dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float32,
+ device_map="auto", # "cpu", "cuda", or "mps" for Apple Silicon
+).eval()
+
+processor = ColPaliProcessor.from_pretrained(model_name)
+
+url1 = "https://upload.wikimedia.org/wikipedia/commons/8/89/US-original-Declaration-1776.jpg"
+url2 = "https://upload.wikimedia.org/wikipedia/commons/thumb/4/4c/Romeoandjuliet1597.jpg/500px-Romeoandjuliet1597.jpg"
+
+images = [
+ Image.open(requests.get(url1, stream=True).raw),
+ Image.open(requests.get(url2, stream=True).raw),
+]
+
+queries = [
+ "Who printed the edition of Romeo and Juliet?",
+ "When was the United States Declaration of Independence proclaimed?",
+]
+
+# Process the inputs
+inputs_images = processor(images=images, return_tensors="pt").to(model.device)
+inputs_text = processor(text=queries, return_tensors="pt").to(model.device)
+
+# Forward pass
+with torch.no_grad():
+ image_embeddings = model(**inputs_images).embeddings
+ query_embeddings = model(**inputs_text).embeddings
+
+scores = processor.score_retrieval(query_embeddings, image_embeddings)
+
+print("Retrieval scores (query x image):")
+print(scores)
+```
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes.md) to quantize the weights to int4.
+
+```py
+import requests
+import torch
+from PIL import Image
+from transformers import ColPaliForRetrieval, ColPaliProcessor
+from transformers import BitsAndBytesConfig
+
+# 4-bit quantization configuration
+bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.float16,
+)
+
+model_name = "vidore/colpali-v1.2-hf"
+
+# Load model
+model = ColPaliForRetrieval.from_pretrained(
+ model_name,
+ quantization_config=bnb_config,
+ device_map="cuda"
+).eval()
+
+processor = ColPaliProcessor.from_pretrained(model_name)
+
+url1 = "https://upload.wikimedia.org/wikipedia/commons/8/89/US-original-Declaration-1776.jpg"
+url2 = "https://upload.wikimedia.org/wikipedia/commons/thumb/4/4c/Romeoandjuliet1597.jpg/500px-Romeoandjuliet1597.jpg"
+
+images = [
+ Image.open(requests.get(url1, stream=True).raw),
+ Image.open(requests.get(url2, stream=True).raw),
+]
+
+queries = [
+ "Who printed the edition of Romeo and Juliet?",
+ "When was the United States Declaration of Independence proclaimed?",
+]
+
+# Process the inputs
+inputs_images = processor(images=images, return_tensors="pt").to(model.device)
+inputs_text = processor(text=queries, return_tensors="pt").to(model.device)
+
+# Forward pass
+with torch.no_grad():
+ image_embeddings = model(**inputs_images).embeddings
+ query_embeddings = model(**inputs_text).embeddings
+
+scores = processor.score_retrieval(query_embeddings, image_embeddings)
+
+print("Retrieval scores (query x image):")
+print(scores)
+```
+
+## Notes
+
+- [`~ColPaliProcessor.score_retrieval`] returns a 2D tensor where the first dimension is the number of queries and the second dimension is the number of images. A higher score indicates more similarity between the query and image.
+
+## ColPaliConfig
+
+[[autodoc]] ColPaliConfig
+
+## ColPaliProcessor
+
+[[autodoc]] ColPaliProcessor
+
+## ColPaliForRetrieval
+
+[[autodoc]] ColPaliForRetrieval
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/conditional_detr.md b/docs/transformers/docs/source/en/model_doc/conditional_detr.md
new file mode 100644
index 0000000000000000000000000000000000000000..52de280ce84a77e7184756b0b667fed4388d937b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/conditional_detr.md
@@ -0,0 +1,83 @@
+
+
+# Conditional DETR
+
+
+
+
+
+## Overview
+
+The Conditional DETR model was proposed in [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang. Conditional DETR presents a conditional cross-attention mechanism for fast DETR training. Conditional DETR converges 6.7× to 10× faster than DETR.
+
+The abstract from the paper is the following:
+
+*The recently-developed DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings for localizing the four extremities and predicting the box, which increases the need for high-quality content embeddings and thus the training difficulty. Our approach, named conditional DETR, learns a conditional spatial query from the decoder embedding for decoder multi-head cross-attention. The benefit is that through the conditional spatial query, each cross-attention head is able to attend to a band containing a distinct region, e.g., one object extremity or a region inside the object box. This narrows down the spatial range for localizing the distinct regions for object classification and box regression, thus relaxing the dependence on the content embeddings and easing the training. Empirical results show that conditional DETR converges 6.7× faster for the backbones R50 and R101 and 10× faster for stronger backbones DC5-R50 and DC5-R101. Code is available at https://github.com/Atten4Vis/ConditionalDETR.*
+
+
+
+ Conditional DETR shows much faster convergence compared to the original DETR. Taken from the original paper.
+
+This model was contributed by [DepuMeng](https://huggingface.co/DepuMeng). The original code can be found [here](https://github.com/Atten4Vis/ConditionalDETR).
+
+## Resources
+
+- Scripts for finetuning [`ConditionalDetrForObjectDetection`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- See also: [Object detection task guide](../tasks/object_detection).
+
+## ConditionalDetrConfig
+
+[[autodoc]] ConditionalDetrConfig
+
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+ - preprocess
+
+## ConditionalDetrImageProcessorFast
+
+[[autodoc]] ConditionalDetrImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrFeatureExtractor
+
+[[autodoc]] ConditionalDetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrModel
+
+[[autodoc]] ConditionalDetrModel
+ - forward
+
+## ConditionalDetrForObjectDetection
+
+[[autodoc]] ConditionalDetrForObjectDetection
+ - forward
+
+## ConditionalDetrForSegmentation
+
+[[autodoc]] ConditionalDetrForSegmentation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/convbert.md b/docs/transformers/docs/source/en/model_doc/convbert.md
new file mode 100644
index 0000000000000000000000000000000000000000..e52bbd5c4772ec62e2f06e0dece55abab09b801d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/convbert.md
@@ -0,0 +1,141 @@
+
+
+# ConvBERT
+
+
+
+
+
+
+## Overview
+
+The ConvBERT model was proposed in [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng
+Yan.
+
+The abstract from the paper is the following:
+
+*Pre-trained language models like BERT and its variants have recently achieved impressive performance in various
+natural language understanding tasks. However, BERT heavily relies on the global self-attention block and thus suffers
+large memory footprint and computation cost. Although all its attention heads query on the whole input sequence for
+generating the attention map from a global perspective, we observe some heads only need to learn local dependencies,
+which means the existence of computation redundancy. We therefore propose a novel span-based dynamic convolution to
+replace these self-attention heads to directly model local dependencies. The novel convolution heads, together with the
+rest self-attention heads, form a new mixed attention block that is more efficient at both global and local context
+learning. We equip BERT with this mixed attention design and build a ConvBERT model. Experiments have shown that
+ConvBERT significantly outperforms BERT and its variants in various downstream tasks, with lower training cost and
+fewer model parameters. Remarkably, ConvBERTbase model achieves 86.4 GLUE score, 0.7 higher than ELECTRAbase, while
+using less than 1/4 training cost. Code and pre-trained models will be released.*
+
+This model was contributed by [abhishek](https://huggingface.co/abhishek). The original implementation can be found
+here: https://github.com/yitu-opensource/ConvBert
+
+## Usage tips
+
+ConvBERT training tips are similar to those of BERT. For usage tips refer to [BERT documentation](bert).
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## ConvBertConfig
+
+[[autodoc]] ConvBertConfig
+
+## ConvBertTokenizer
+
+[[autodoc]] ConvBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## ConvBertTokenizerFast
+
+[[autodoc]] ConvBertTokenizerFast
+
+
+
+
+## ConvBertModel
+
+[[autodoc]] ConvBertModel
+ - forward
+
+## ConvBertForMaskedLM
+
+[[autodoc]] ConvBertForMaskedLM
+ - forward
+
+## ConvBertForSequenceClassification
+
+[[autodoc]] ConvBertForSequenceClassification
+ - forward
+
+## ConvBertForMultipleChoice
+
+[[autodoc]] ConvBertForMultipleChoice
+ - forward
+
+## ConvBertForTokenClassification
+
+[[autodoc]] ConvBertForTokenClassification
+ - forward
+
+## ConvBertForQuestionAnswering
+
+[[autodoc]] ConvBertForQuestionAnswering
+ - forward
+
+
+
+
+## TFConvBertModel
+
+[[autodoc]] TFConvBertModel
+ - call
+
+## TFConvBertForMaskedLM
+
+[[autodoc]] TFConvBertForMaskedLM
+ - call
+
+## TFConvBertForSequenceClassification
+
+[[autodoc]] TFConvBertForSequenceClassification
+ - call
+
+## TFConvBertForMultipleChoice
+
+[[autodoc]] TFConvBertForMultipleChoice
+ - call
+
+## TFConvBertForTokenClassification
+
+[[autodoc]] TFConvBertForTokenClassification
+ - call
+
+## TFConvBertForQuestionAnswering
+
+[[autodoc]] TFConvBertForQuestionAnswering
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/convnext.md b/docs/transformers/docs/source/en/model_doc/convnext.md
new file mode 100644
index 0000000000000000000000000000000000000000..576e95ee043d11e46d5ba583459ff00c7702669d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/convnext.md
@@ -0,0 +1,104 @@
+
+
+# ConvNeXT
+
+
+
+
+
+
+## Overview
+
+The ConvNeXT model was proposed in [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them.
+
+The abstract from the paper is the following:
+
+*The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model.
+A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers
+(e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide
+variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive
+biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually "modernize" a standard ResNet toward the design
+of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models
+dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy
+and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.*
+
+
+
+ ConvNeXT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [ariG23498](https://github.com/ariG23498),
+[gante](https://github.com/gante), and [sayakpaul](https://github.com/sayakpaul) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ConvNeXT.
+
+
+
+- [`ConvNextForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## ConvNextConfig
+
+[[autodoc]] ConvNextConfig
+
+## ConvNextFeatureExtractor
+
+[[autodoc]] ConvNextFeatureExtractor
+
+## ConvNextImageProcessor
+
+[[autodoc]] ConvNextImageProcessor
+ - preprocess
+
+## ConvNextImageProcessorFast
+
+[[autodoc]] ConvNextImageProcessorFast
+ - preprocess
+
+
+
+
+## ConvNextModel
+
+[[autodoc]] ConvNextModel
+ - forward
+
+## ConvNextForImageClassification
+
+[[autodoc]] ConvNextForImageClassification
+ - forward
+
+
+
+
+## TFConvNextModel
+
+[[autodoc]] TFConvNextModel
+ - call
+
+## TFConvNextForImageClassification
+
+[[autodoc]] TFConvNextForImageClassification
+ - call
+
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/convnextv2.md b/docs/transformers/docs/source/en/model_doc/convnextv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..87a261b8dede7bc140fb010e19bd790e71ea6b92
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/convnextv2.md
@@ -0,0 +1,73 @@
+
+
+# ConvNeXt V2
+
+
+
+
+
+
+## Overview
+
+The ConvNeXt V2 model was proposed in [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+ConvNeXt V2 is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, and a successor of [ConvNeXT](convnext).
+
+The abstract from the paper is the following:
+
+*Driven by improved architectures and better representation learning frameworks, the field of visual recognition has enjoyed rapid modernization and performance boost in the early 2020s. For example, modern ConvNets, represented by ConvNeXt, have demonstrated strong performance in various scenarios. While these models were originally designed for supervised learning with ImageNet labels, they can also potentially benefit from self-supervised learning techniques such as masked autoencoders (MAE). However, we found that simply combining these two approaches leads to subpar performance. In this paper, we propose a fully convolutional masked autoencoder framework and a new Global Response Normalization (GRN) layer that can be added to the ConvNeXt architecture to enhance inter-channel feature competition. This co-design of self-supervised learning techniques and architectural improvement results in a new model family called ConvNeXt V2, which significantly improves the performance of pure ConvNets on various recognition benchmarks, including ImageNet classification, COCO detection, and ADE20K segmentation. We also provide pre-trained ConvNeXt V2 models of various sizes, ranging from an efficient 3.7M-parameter Atto model with 76.7% top-1 accuracy on ImageNet, to a 650M Huge model that achieves a state-of-the-art 88.9% accuracy using only public training data.*
+
+
+
+ ConvNeXt V2 architecture. Taken from the original paper.
+
+This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt-V2).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ConvNeXt V2.
+
+
+
+- [`ConvNextV2ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## ConvNextV2Config
+
+[[autodoc]] ConvNextV2Config
+
+## ConvNextV2Model
+
+[[autodoc]] ConvNextV2Model
+ - forward
+
+## ConvNextV2ForImageClassification
+
+[[autodoc]] ConvNextV2ForImageClassification
+ - forward
+
+## TFConvNextV2Model
+
+[[autodoc]] TFConvNextV2Model
+ - call
+
+
+## TFConvNextV2ForImageClassification
+
+[[autodoc]] TFConvNextV2ForImageClassification
+ - call
diff --git a/docs/transformers/docs/source/en/model_doc/cpm.md b/docs/transformers/docs/source/en/model_doc/cpm.md
new file mode 100644
index 0000000000000000000000000000000000000000..8a1826a25c6d2bcc027036875907e8a1b69dc33b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/cpm.md
@@ -0,0 +1,62 @@
+
+
+# CPM
+
+
+
+
+
+
+
+## Overview
+
+The CPM model was proposed in [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin,
+Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen,
+Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+
+The abstract from the paper is the following:
+
+*Pre-trained Language Models (PLMs) have proven to be beneficial for various downstream NLP tasks. Recently, GPT-3,
+with 175 billion parameters and 570GB training data, drew a lot of attention due to the capacity of few-shot (even
+zero-shot) learning. However, applying GPT-3 to address Chinese NLP tasks is still challenging, as the training corpus
+of GPT-3 is primarily English, and the parameters are not publicly available. In this technical report, we release the
+Chinese Pre-trained Language Model (CPM) with generative pre-training on large-scale Chinese training data. To the best
+of our knowledge, CPM, with 2.6 billion parameters and 100GB Chinese training data, is the largest Chinese pre-trained
+language model, which could facilitate several downstream Chinese NLP tasks, such as conversation, essay generation,
+cloze test, and language understanding. Extensive experiments demonstrate that CPM achieves strong performance on many
+NLP tasks in the settings of few-shot (even zero-shot) learning.*
+
+This model was contributed by [canwenxu](https://huggingface.co/canwenxu). The original implementation can be found
+here: https://github.com/TsinghuaAI/CPM-Generate
+
+
+
+
+CPM's architecture is the same as GPT-2, except for tokenization method. Refer to [GPT-2 documentation](gpt2) for
+API reference information.
+
+
+
+
+## CpmTokenizer
+
+[[autodoc]] CpmTokenizer
+
+## CpmTokenizerFast
+
+[[autodoc]] CpmTokenizerFast
diff --git a/docs/transformers/docs/source/en/model_doc/cpmant.md b/docs/transformers/docs/source/en/model_doc/cpmant.md
new file mode 100644
index 0000000000000000000000000000000000000000..f8e2b3b515ece21689dafffb3ac3869ff659fb9c
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/cpmant.md
@@ -0,0 +1,51 @@
+
+
+# CPMAnt
+
+
+
+
+
+## Overview
+
+CPM-Ant is an open-source Chinese pre-trained language model (PLM) with 10B parameters. It is also the first milestone of the live training process of CPM-Live. The training process is cost-effective and environment-friendly. CPM-Ant also achieves promising results with delta tuning on the CUGE benchmark. Besides the full model, we also provide various compressed versions to meet the requirements of different hardware configurations. [See more](https://github.com/OpenBMB/CPM-Live/tree/cpm-ant/cpm-live)
+
+This model was contributed by [OpenBMB](https://huggingface.co/openbmb). The original code can be found [here](https://github.com/OpenBMB/CPM-Live/tree/cpm-ant/cpm-live).
+
+## Resources
+
+- A tutorial on [CPM-Live](https://github.com/OpenBMB/CPM-Live/tree/cpm-ant/cpm-live).
+
+## CpmAntConfig
+
+[[autodoc]] CpmAntConfig
+ - all
+
+## CpmAntTokenizer
+
+[[autodoc]] CpmAntTokenizer
+ - all
+
+## CpmAntModel
+
+[[autodoc]] CpmAntModel
+ - all
+
+## CpmAntForCausalLM
+
+[[autodoc]] CpmAntForCausalLM
+ - all
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/ctrl.md b/docs/transformers/docs/source/en/model_doc/ctrl.md
new file mode 100644
index 0000000000000000000000000000000000000000..0253d4e007e04421591181aab2b1a2f495ec53de
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/ctrl.md
@@ -0,0 +1,110 @@
+
+
+# CTRL
+
+
+
+
+
+
+## Overview
+
+CTRL model was proposed in [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and
+Richard Socher. It's a causal (unidirectional) transformer pre-trained using language modeling on a very large corpus
+of ~140 GB of text data with the first token reserved as a control code (such as Links, Books, Wikipedia etc.).
+
+The abstract from the paper is the following:
+
+*Large-scale language models show promising text generation capabilities, but users cannot easily control particular
+aspects of the generated text. We release CTRL, a 1.63 billion-parameter conditional transformer language model,
+trained to condition on control codes that govern style, content, and task-specific behavior. Control codes were
+derived from structure that naturally co-occurs with raw text, preserving the advantages of unsupervised learning while
+providing more explicit control over text generation. These codes also allow CTRL to predict which parts of the
+training data are most likely given a sequence. This provides a potential method for analyzing large amounts of data
+via model-based source attribution.*
+
+This model was contributed by [keskarnitishr](https://huggingface.co/keskarnitishr). The original code can be found
+[here](https://github.com/salesforce/ctrl).
+
+## Usage tips
+
+- CTRL makes use of control codes to generate text: it requires generations to be started by certain words, sentences
+ or links to generate coherent text. Refer to the [original implementation](https://github.com/salesforce/ctrl) for
+ more information.
+- CTRL is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+- CTRL was trained with a causal language modeling (CLM) objective and is therefore powerful at predicting the next
+ token in a sequence. Leveraging this feature allows CTRL to generate syntactically coherent text as it can be
+ observed in the *run_generation.py* example script.
+- The PyTorch models can take the `past_key_values` as input, which is the previously computed key/value attention pairs.
+ TensorFlow models accepts `past` as input. Using the `past_key_values` value prevents the model from re-computing
+ pre-computed values in the context of text generation. See the [`forward`](model_doc/ctrl#transformers.CTRLModel.forward)
+ method for more information on the usage of this argument.
+
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Causal language modeling task guide](../tasks/language_modeling)
+
+## CTRLConfig
+
+[[autodoc]] CTRLConfig
+
+## CTRLTokenizer
+
+[[autodoc]] CTRLTokenizer
+ - save_vocabulary
+
+
+
+
+## CTRLModel
+
+[[autodoc]] CTRLModel
+ - forward
+
+## CTRLLMHeadModel
+
+[[autodoc]] CTRLLMHeadModel
+ - forward
+
+## CTRLForSequenceClassification
+
+[[autodoc]] CTRLForSequenceClassification
+ - forward
+
+
+
+
+## TFCTRLModel
+
+[[autodoc]] TFCTRLModel
+ - call
+
+## TFCTRLLMHeadModel
+
+[[autodoc]] TFCTRLLMHeadModel
+ - call
+
+## TFCTRLForSequenceClassification
+
+[[autodoc]] TFCTRLForSequenceClassification
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/cvt.md b/docs/transformers/docs/source/en/model_doc/cvt.md
new file mode 100644
index 0000000000000000000000000000000000000000..fec632ed84d1091b360ddfe3196cb2ba484c7f93
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/cvt.md
@@ -0,0 +1,92 @@
+
+
+# Convolutional Vision Transformer (CvT)
+
+
+
+
+
+
+## Overview
+
+The CvT model was proposed in [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan and Lei Zhang. The Convolutional vision Transformer (CvT) improves the [Vision Transformer (ViT)](vit) in performance and efficiency by introducing convolutions into ViT to yield the best of both designs.
+
+The abstract from the paper is the following:
+
+*We present in this paper a new architecture, named Convolutional vision Transformer (CvT), that improves Vision Transformer (ViT)
+in performance and efficiency by introducing convolutions into ViT to yield the best of both designs. This is accomplished through
+two primary modifications: a hierarchy of Transformers containing a new convolutional token embedding, and a convolutional Transformer
+block leveraging a convolutional projection. These changes introduce desirable properties of convolutional neural networks (CNNs)
+to the ViT architecture (\ie shift, scale, and distortion invariance) while maintaining the merits of Transformers (\ie dynamic attention,
+global context, and better generalization). We validate CvT by conducting extensive experiments, showing that this approach achieves
+state-of-the-art performance over other Vision Transformers and ResNets on ImageNet-1k, with fewer parameters and lower FLOPs. In addition,
+performance gains are maintained when pretrained on larger datasets (\eg ImageNet-22k) and fine-tuned to downstream tasks. Pre-trained on
+ImageNet-22k, our CvT-W24 obtains a top-1 accuracy of 87.7\% on the ImageNet-1k val set. Finally, our results show that the positional encoding,
+a crucial component in existing Vision Transformers, can be safely removed in our model, simplifying the design for higher resolution vision tasks.*
+
+This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/microsoft/CvT).
+
+## Usage tips
+
+- CvT models are regular Vision Transformers, but trained with convolutions. They outperform the [original model (ViT)](vit) when fine-tuned on ImageNet-1K and CIFAR-100.
+- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (you can just replace [`ViTFeatureExtractor`] by [`AutoImageProcessor`] and [`ViTForImageClassification`] by [`CvtForImageClassification`]).
+- The available checkpoints are either (1) pre-trained on [ImageNet-22k](http://www.image-net.org/) (a collection of 14 million images and 22k classes) only, (2) also fine-tuned on ImageNet-22k or (3) also fine-tuned on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
+ images and 1,000 classes).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CvT.
+
+
+
+- [`CvtForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## CvtConfig
+
+[[autodoc]] CvtConfig
+
+
+
+
+## CvtModel
+
+[[autodoc]] CvtModel
+ - forward
+
+## CvtForImageClassification
+
+[[autodoc]] CvtForImageClassification
+ - forward
+
+
+
+
+## TFCvtModel
+
+[[autodoc]] TFCvtModel
+ - call
+
+## TFCvtForImageClassification
+
+[[autodoc]] TFCvtForImageClassification
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/dab-detr.md b/docs/transformers/docs/source/en/model_doc/dab-detr.md
new file mode 100644
index 0000000000000000000000000000000000000000..d19b45b486b0a1d432d58a10d228dca8c8cfa6d1
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/dab-detr.md
@@ -0,0 +1,123 @@
+
+
+# DAB-DETR
+
+
+
+
+
+## Overview
+
+The DAB-DETR model was proposed in [DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR](https://arxiv.org/abs/2201.12329) by Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, Lei Zhang.
+DAB-DETR is an enhanced variant of Conditional DETR. It utilizes dynamically updated anchor boxes to provide both a reference query point (x, y) and a reference anchor size (w, h), improving cross-attention computation. This new approach achieves 45.7% AP when trained for 50 epochs with a single ResNet-50 model as the backbone.
+
+
+
+The abstract from the paper is the following:
+
+*We present in this paper a novel query formulation using dynamic anchor boxes
+for DETR (DEtection TRansformer) and offer a deeper understanding of the role
+of queries in DETR. This new formulation directly uses box coordinates as queries
+in Transformer decoders and dynamically updates them layer-by-layer. Using box
+coordinates not only helps using explicit positional priors to improve the query-to-feature similarity and eliminate the slow training convergence issue in DETR,
+but also allows us to modulate the positional attention map using the box width
+and height information. Such a design makes it clear that queries in DETR can be
+implemented as performing soft ROI pooling layer-by-layer in a cascade manner.
+As a result, it leads to the best performance on MS-COCO benchmark among
+the DETR-like detection models under the same setting, e.g., AP 45.7% using
+ResNet50-DC5 as backbone trained in 50 epochs. We also conducted extensive
+experiments to confirm our analysis and verify the effectiveness of our methods.*
+
+This model was contributed by [davidhajdu](https://huggingface.co/davidhajdu).
+The original code can be found [here](https://github.com/IDEA-Research/DAB-DETR).
+
+## How to Get Started with the Model
+
+Use the code below to get started with the model.
+
+```python
+import torch
+import requests
+
+from PIL import Image
+from transformers import AutoModelForObjectDetection, AutoImageProcessor
+
+url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+image = Image.open(requests.get(url, stream=True).raw)
+
+image_processor = AutoImageProcessor.from_pretrained("IDEA-Research/dab-detr-resnet-50")
+model = AutoModelForObjectDetection.from_pretrained("IDEA-Research/dab-detr-resnet-50")
+
+inputs = image_processor(images=image, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.3)
+
+for result in results:
+ for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
+ score, label = score.item(), label_id.item()
+ box = [round(i, 2) for i in box.tolist()]
+ print(f"{model.config.id2label[label]}: {score:.2f} {box}")
+```
+This should output
+```
+cat: 0.87 [14.7, 49.39, 320.52, 469.28]
+remote: 0.86 [41.08, 72.37, 173.39, 117.2]
+cat: 0.86 [344.45, 19.43, 639.85, 367.86]
+remote: 0.61 [334.27, 75.93, 367.92, 188.81]
+couch: 0.59 [-0.04, 1.34, 639.9, 477.09]
+```
+
+There are three other ways to instantiate a DAB-DETR model (depending on what you prefer):
+
+Option 1: Instantiate DAB-DETR with pre-trained weights for entire model
+```py
+>>> from transformers import DabDetrForObjectDetection
+
+>>> model = DabDetrForObjectDetection.from_pretrained("IDEA-Research/dab-detr-resnet-50")
+```
+
+Option 2: Instantiate DAB-DETR with randomly initialized weights for Transformer, but pre-trained weights for backbone
+```py
+>>> from transformers import DabDetrConfig, DabDetrForObjectDetection
+
+>>> config = DabDetrConfig()
+>>> model = DabDetrForObjectDetection(config)
+```
+Option 3: Instantiate DAB-DETR with randomly initialized weights for backbone + Transformer
+```py
+>>> config = DabDetrConfig(use_pretrained_backbone=False)
+>>> model = DabDetrForObjectDetection(config)
+```
+
+
+## DabDetrConfig
+
+[[autodoc]] DabDetrConfig
+
+## DabDetrModel
+
+[[autodoc]] DabDetrModel
+ - forward
+
+## DabDetrForObjectDetection
+
+[[autodoc]] DabDetrForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/dac.md b/docs/transformers/docs/source/en/model_doc/dac.md
new file mode 100644
index 0000000000000000000000000000000000000000..3ee4d92b58e0277b868db701596adf1ea3c95023
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/dac.md
@@ -0,0 +1,84 @@
+
+
+# DAC
+
+
+
+
+
+## Overview
+
+
+The DAC model was proposed in [Descript Audio Codec: High-Fidelity Audio Compression with Improved RVQGAN](https://arxiv.org/abs/2306.06546) by Rithesh Kumar, Prem Seetharaman, Alejandro Luebs, Ishaan Kumar, Kundan Kumar.
+
+The Descript Audio Codec (DAC) model is a powerful tool for compressing audio data, making it highly efficient for storage and transmission. By compressing 44.1 KHz audio into tokens at just 8kbps bandwidth, the DAC model enables high-quality audio processing while significantly reducing the data footprint. This is particularly useful in scenarios where bandwidth is limited or storage space is at a premium, such as in streaming applications, remote conferencing, and archiving large audio datasets.
+
+The abstract from the paper is the following:
+
+*Language models have been successfully used to model natural signals, such as images, speech, and music. A key component of these models is a high quality neural compression model that can compress high-dimensional natural signals into lower dimensional discrete tokens. To that end, we introduce a high-fidelity universal neural audio compression algorithm that achieves ~90x compression of 44.1 KHz audio into tokens at just 8kbps bandwidth. We achieve this by combining advances in high-fidelity audio generation with better vector quantization techniques from the image domain, along with improved adversarial and reconstruction losses. We compress all domains (speech, environment, music, etc.) with a single universal model, making it widely applicable to generative modeling of all audio. We compare with competing audio compression algorithms, and find our method outperforms them significantly. We provide thorough ablations for every design choice, as well as open-source code and trained model weights. We hope our work can lay the foundation for the next generation of high-fidelity audio modeling.*
+
+This model was contributed by [Kamil Akesbi](https://huggingface.co/kamilakesbi).
+The original code can be found [here](https://github.com/descriptinc/descript-audio-codec/tree/main?tab=readme-ov-file).
+
+
+## Model structure
+
+The Descript Audio Codec (DAC) model is structured into three distinct stages:
+
+1. Encoder Model: This stage compresses the input audio, reducing its size while retaining essential information.
+2. Residual Vector Quantizer (RVQ) Model: Working in tandem with the encoder, this model quantizes the latent codes of the audio, refining the compression and ensuring high-quality reconstruction.
+3. Decoder Model: This final stage reconstructs the audio from its compressed form, restoring it to a state that closely resembles the original input.
+
+## Usage example
+
+Here is a quick example of how to encode and decode an audio using this model:
+
+```python
+>>> from datasets import load_dataset, Audio
+>>> from transformers import DacModel, AutoProcessor
+>>> librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+
+>>> model = DacModel.from_pretrained("descript/dac_16khz")
+>>> processor = AutoProcessor.from_pretrained("descript/dac_16khz")
+>>> librispeech_dummy = librispeech_dummy.cast_column("audio", Audio(sampling_rate=processor.sampling_rate))
+>>> audio_sample = librispeech_dummy[-1]["audio"]["array"]
+>>> inputs = processor(raw_audio=audio_sample, sampling_rate=processor.sampling_rate, return_tensors="pt")
+
+>>> encoder_outputs = model.encode(inputs["input_values"])
+>>> # Get the intermediate audio codes
+>>> audio_codes = encoder_outputs.audio_codes
+>>> # Reconstruct the audio from its quantized representation
+>>> audio_values = model.decode(encoder_outputs.quantized_representation)
+>>> # or the equivalent with a forward pass
+>>> audio_values = model(inputs["input_values"]).audio_values
+```
+
+## DacConfig
+
+[[autodoc]] DacConfig
+
+## DacFeatureExtractor
+
+[[autodoc]] DacFeatureExtractor
+ - __call__
+
+## DacModel
+
+[[autodoc]] DacModel
+ - decode
+ - encode
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/data2vec.md b/docs/transformers/docs/source/en/model_doc/data2vec.md
new file mode 100644
index 0000000000000000000000000000000000000000..62ddbd8ff184b63ec36df8c2a5c7df8df6ae66d6
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/data2vec.md
@@ -0,0 +1,233 @@
+
+
+# Data2Vec
+
+
+
+
+
+
+
+## Overview
+
+The Data2Vec model was proposed in [data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/pdf/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu and Michael Auli.
+Data2Vec proposes a unified framework for self-supervised learning across different data modalities - text, audio and images.
+Importantly, predicted targets for pre-training are contextualized latent representations of the inputs, rather than modality-specific, context-independent targets.
+
+The abstract from the paper is the following:
+
+*While the general idea of self-supervised learning is identical across modalities, the actual algorithms and
+objectives differ widely because they were developed with a single modality in mind. To get us closer to general
+self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech,
+NLP or computer vision. The core idea is to predict latent representations of the full input data based on a
+masked view of the input in a selfdistillation setup using a standard Transformer architecture.
+Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which
+are local in nature, data2vec predicts contextualized latent representations that contain information from
+the entire input. Experiments on the major benchmarks of speech recognition, image classification, and
+natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
+Models and code are available at www.github.com/pytorch/fairseq/tree/master/examples/data2vec.*
+
+This model was contributed by [edugp](https://huggingface.co/edugp) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+[sayakpaul](https://github.com/sayakpaul) and [Rocketknight1](https://github.com/Rocketknight1) contributed Data2Vec for vision in TensorFlow.
+
+The original code (for NLP and Speech) can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/data2vec).
+The original code for vision can be found [here](https://github.com/facebookresearch/data2vec_vision/tree/main/beit).
+
+## Usage tips
+
+- Data2VecAudio, Data2VecText, and Data2VecVision have all been trained using the same self-supervised learning method.
+- For Data2VecAudio, preprocessing is identical to [`Wav2Vec2Model`], including feature extraction
+- For Data2VecText, preprocessing is identical to [`RobertaModel`], including tokenization.
+- For Data2VecVision, preprocessing is identical to [`BeitModel`], including feature extraction.
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+The SDPA implementation is currently available for the Data2VecAudio and Data2VecVision models.
+
+```
+from transformers import Data2VecVisionForImageClassification
+model = Data2VecVisionForImageClassification.from_pretrained("facebook/data2vec-vision-base", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+For the Data2VecVision model, on a local benchmark (NVIDIA GeForce RTX 2060-8GB, PyTorch 2.5.1, OS Ubuntu 20.04)
+with `float16` and `facebook/data2vec-vision-base` model, we saw the following improvements during training and
+inference:
+
+#### Training
+
+| num_training_steps | batch_size | image_size | is_cuda | Time per batch (eager - s) | Time per batch (sdpa - s) | Speedup (%) | Eager peak mem (MB) | SDPA peak mem (MB) | Mem saving (%) |
+|--------------------|------------|--------------|---------|----------------------------|---------------------------|-------------|----------------------|--------------------|----------------|
+| 50 | 2 | (1048, 640) | True | 0.996 | 0.754 | 32.147 | 6722.198 | 4264.653 | 57.626 |
+
+#### Inference
+
+| Image batch size | Eager (s/iter) | Eager CI, % | Eager memory (MB) | SDPA (s/iter) | SDPA CI, % | SDPA memory (MB) | SDPA speedup | SDPA memory saved |
+|-------------------:|-----------------:|:--------------|--------------------:|----------------:|:-------------|-------------------:|---------------:|--------------------:|
+| 1 | 0.011 | ±0.3% | 3.76143e+08 | 0.01 | ±0.3% | 3.74397e+08 | 1.101 | 0.466 |
+| 4 | 0.014 | ±0.1% | 4.02756e+08 | 0.012 | ±0.2% | 3.91373e+08 | 1.219 | 2.909 |
+| 16 | 0.046 | ±0.3% | 4.96482e+08 | 0.035 | ±0.2% | 4.51017e+08 | 1.314 | 10.081 |
+| 32 | 0.088 | ±0.1% | 6.23903e+08 | 0.067 | ±0.1% | 5.32974e+08 | 1.33 | 17.061 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Data2Vec.
+
+
+
+- [`Data2VecVisionForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- To fine-tune [`TFData2VecVisionForImageClassification`] on a custom dataset, see [this notebook](https://colab.research.google.com/github/sayakpaul/TF-2.0-Hacks/blob/master/data2vec_vision_image_classification.ipynb).
+
+**Data2VecText documentation resources**
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+**Data2VecAudio documentation resources**
+- [Audio classification task guide](../tasks/audio_classification)
+- [Automatic speech recognition task guide](../tasks/asr)
+
+**Data2VecVision documentation resources**
+- [Image classification](../tasks/image_classification)
+- [Semantic segmentation](../tasks/semantic_segmentation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## Data2VecTextConfig
+
+[[autodoc]] Data2VecTextConfig
+
+## Data2VecAudioConfig
+
+[[autodoc]] Data2VecAudioConfig
+
+## Data2VecVisionConfig
+
+[[autodoc]] Data2VecVisionConfig
+
+
+
+
+## Data2VecAudioModel
+
+[[autodoc]] Data2VecAudioModel
+ - forward
+
+## Data2VecAudioForAudioFrameClassification
+
+[[autodoc]] Data2VecAudioForAudioFrameClassification
+ - forward
+
+## Data2VecAudioForCTC
+
+[[autodoc]] Data2VecAudioForCTC
+ - forward
+
+## Data2VecAudioForSequenceClassification
+
+[[autodoc]] Data2VecAudioForSequenceClassification
+ - forward
+
+## Data2VecAudioForXVector
+
+[[autodoc]] Data2VecAudioForXVector
+ - forward
+
+## Data2VecTextModel
+
+[[autodoc]] Data2VecTextModel
+ - forward
+
+## Data2VecTextForCausalLM
+
+[[autodoc]] Data2VecTextForCausalLM
+ - forward
+
+## Data2VecTextForMaskedLM
+
+[[autodoc]] Data2VecTextForMaskedLM
+ - forward
+
+## Data2VecTextForSequenceClassification
+
+[[autodoc]] Data2VecTextForSequenceClassification
+ - forward
+
+## Data2VecTextForMultipleChoice
+
+[[autodoc]] Data2VecTextForMultipleChoice
+ - forward
+
+## Data2VecTextForTokenClassification
+
+[[autodoc]] Data2VecTextForTokenClassification
+ - forward
+
+## Data2VecTextForQuestionAnswering
+
+[[autodoc]] Data2VecTextForQuestionAnswering
+ - forward
+
+## Data2VecVisionModel
+
+[[autodoc]] Data2VecVisionModel
+ - forward
+
+## Data2VecVisionForImageClassification
+
+[[autodoc]] Data2VecVisionForImageClassification
+ - forward
+
+## Data2VecVisionForSemanticSegmentation
+
+[[autodoc]] Data2VecVisionForSemanticSegmentation
+ - forward
+
+
+
+
+## TFData2VecVisionModel
+
+[[autodoc]] TFData2VecVisionModel
+ - call
+
+## TFData2VecVisionForImageClassification
+
+[[autodoc]] TFData2VecVisionForImageClassification
+ - call
+
+## TFData2VecVisionForSemanticSegmentation
+
+[[autodoc]] TFData2VecVisionForSemanticSegmentation
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/dbrx.md b/docs/transformers/docs/source/en/model_doc/dbrx.md
new file mode 100644
index 0000000000000000000000000000000000000000..11463e93d16024411f9232fc57f69a9a95028814
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/dbrx.md
@@ -0,0 +1,125 @@
+
+
+# DBRX
+
+
+
+
+
+
+
+## Overview
+
+DBRX is a [transformer-based](https://www.isattentionallyouneed.com/) decoder-only large language model (LLM) that was trained using next-token prediction.
+It uses a *fine-grained* mixture-of-experts (MoE) architecture with 132B total parameters of which 36B parameters are active on any input.
+It was pre-trained on 12T tokens of text and code data.
+Compared to other open MoE models like Mixtral-8x7B and Grok-1, DBRX is fine-grained, meaning it uses a larger number of smaller experts. DBRX has 16 experts and chooses 4, while Mixtral-8x7B and Grok-1 have 8 experts and choose 2.
+This provides 65x more possible combinations of experts and we found that this improves model quality.
+DBRX uses rotary position encodings (RoPE), gated linear units (GLU), and grouped query attention (GQA).
+It is a BPE based model and uses the GPT-4 tokenizer as described in the [tiktoken](https://github.com/openai/tiktoken) repository.
+We made these choices based on exhaustive evaluation and scaling experiments.
+
+DBRX was pretrained on 12T tokens of carefully curated data and a maximum context length of 32K tokens.
+We estimate that this data is at least 2x better token-for-token than the data we used to pretrain the MPT family of models.
+This new dataset was developed using the full suite of Databricks tools, including Apache Spark™ and Databricks notebooks for data processing, and Unity Catalog for data management and governance.
+We used curriculum learning for pretraining, changing the data mix during training in ways we found to substantially improve model quality.
+
+
+More detailed information about DBRX Instruct and DBRX Base can be found in our [technical blog post](https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm).
+
+This model was contributed by [eitan-turok](https://huggingface.co/eitanturok) and [abhi-db](https://huggingface.co/abhi-db). The original code can be found [here](https://github.com/databricks/dbrx-instruct), though this may not be up to date.
+
+## Usage Examples
+
+The `generate()` method can be used to generate text using DBRX. You can generate using the standard attention implementation, flash-attention, and the PyTorch scaled dot product attention. The last two attention implementations give speed ups.
+
+```python
+from transformers import DbrxForCausalLM, AutoTokenizer
+import torch
+
+tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", token="YOUR_HF_TOKEN")
+model = DbrxForCausalLM.from_pretrained(
+ "databricks/dbrx-instruct",
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+ token="YOUR_HF_TOKEN",
+ )
+
+input_text = "What does it take to build a great LLM?"
+messages = [{"role": "user", "content": input_text}]
+input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
+
+outputs = model.generate(**input_ids, max_new_tokens=200)
+print(tokenizer.decode(outputs[0]))
+```
+
+If you have flash-attention installed (`pip install flash-attn`), it is possible to generate faster. (The HuggingFace documentation for flash-attention can be found [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2).)
+```python
+from transformers import DbrxForCausalLM, AutoTokenizer
+import torch
+
+tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", token="YOUR_HF_TOKEN")
+model = DbrxForCausalLM.from_pretrained(
+ "databricks/dbrx-instruct",
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+ token="YOUR_HF_TOKEN",
+ attn_implementation="flash_attention_2",
+ )
+
+input_text = "What does it take to build a great LLM?"
+messages = [{"role": "user", "content": input_text}]
+input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
+
+outputs = model.generate(**input_ids, max_new_tokens=200)
+print(tokenizer.decode(outputs[0]))
+```
+
+You can also generate faster using the PyTorch scaled dot product attention. (The HuggingFace documentation for scaled dot product attention can be found [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one#pytorch-scaled-dot-product-attention).)
+```python
+from transformers import DbrxForCausalLM, AutoTokenizer
+import torch
+
+tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", token="YOUR_HF_TOKEN")
+model = DbrxForCausalLM.from_pretrained(
+ "databricks/dbrx-instruct",
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+ token="YOUR_HF_TOKEN",
+ attn_implementation="sdpa",
+ )
+
+input_text = "What does it take to build a great LLM?"
+messages = [{"role": "user", "content": input_text}]
+input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
+
+outputs = model.generate(**input_ids, max_new_tokens=200)
+print(tokenizer.decode(outputs[0]))
+```
+
+## DbrxConfig
+
+[[autodoc]] DbrxConfig
+
+
+## DbrxModel
+
+[[autodoc]] DbrxModel
+ - forward
+
+
+## DbrxForCausalLM
+
+[[autodoc]] DbrxForCausalLM
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/deberta-v2.md b/docs/transformers/docs/source/en/model_doc/deberta-v2.md
new file mode 100644
index 0000000000000000000000000000000000000000..2e48a3e9a7fca3b9fa004250be2bc8233c5e9b37
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/deberta-v2.md
@@ -0,0 +1,173 @@
+
+
+# DeBERTa-v2
+
+
+
+
+
+
+## Overview
+
+The DeBERTa model was proposed in [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen It is based on Google's
+BERT model released in 2018 and Facebook's RoBERTa model released in 2019.
+
+It builds on RoBERTa with disentangled attention and enhanced mask decoder training with half of the data used in
+RoBERTa.
+
+The abstract from the paper is the following:
+
+*Recent progress in pre-trained neural language models has significantly improved the performance of many natural
+language processing (NLP) tasks. In this paper we propose a new model architecture DeBERTa (Decoding-enhanced BERT with
+disentangled attention) that improves the BERT and RoBERTa models using two novel techniques. The first is the
+disentangled attention mechanism, where each word is represented using two vectors that encode its content and
+position, respectively, and the attention weights among words are computed using disentangled matrices on their
+contents and relative positions. Second, an enhanced mask decoder is used to replace the output softmax layer to
+predict the masked tokens for model pretraining. We show that these two techniques significantly improve the efficiency
+of model pretraining and performance of downstream tasks. Compared to RoBERTa-Large, a DeBERTa model trained on half of
+the training data performs consistently better on a wide range of NLP tasks, achieving improvements on MNLI by +0.9%
+(90.2% vs. 91.1%), on SQuAD v2.0 by +2.3% (88.4% vs. 90.7%) and RACE by +3.6% (83.2% vs. 86.8%). The DeBERTa code and
+pre-trained models will be made publicly available at https://github.com/microsoft/DeBERTa.*
+
+
+The following information is visible directly on the [original implementation
+repository](https://github.com/microsoft/DeBERTa). DeBERTa v2 is the second version of the DeBERTa model. It includes
+the 1.5B model used for the SuperGLUE single-model submission and achieving 89.9, versus human baseline 89.8. You can
+find more details about this submission in the authors'
+[blog](https://www.microsoft.com/en-us/research/blog/microsoft-deberta-surpasses-human-performance-on-the-superglue-benchmark/)
+
+New in v2:
+
+- **Vocabulary** In v2 the tokenizer is changed to use a new vocabulary of size 128K built from the training data.
+ Instead of a GPT2-based tokenizer, the tokenizer is now
+ [sentencepiece-based](https://github.com/google/sentencepiece) tokenizer.
+- **nGiE(nGram Induced Input Encoding)** The DeBERTa-v2 model uses an additional convolution layer aside with the first
+ transformer layer to better learn the local dependency of input tokens.
+- **Sharing position projection matrix with content projection matrix in attention layer** Based on previous
+ experiments, this can save parameters without affecting the performance.
+- **Apply bucket to encode relative positions** The DeBERTa-v2 model uses log bucket to encode relative positions
+ similar to T5.
+- **900M model & 1.5B model** Two additional model sizes are available: 900M and 1.5B, which significantly improves the
+ performance of downstream tasks.
+
+This model was contributed by [DeBERTa](https://huggingface.co/DeBERTa). This model TF 2.0 implementation was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/microsoft/DeBERTa).
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## DebertaV2Config
+
+[[autodoc]] DebertaV2Config
+
+## DebertaV2Tokenizer
+
+[[autodoc]] DebertaV2Tokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## DebertaV2TokenizerFast
+
+[[autodoc]] DebertaV2TokenizerFast
+ - build_inputs_with_special_tokens
+ - create_token_type_ids_from_sequences
+
+
+
+
+## DebertaV2Model
+
+[[autodoc]] DebertaV2Model
+ - forward
+
+## DebertaV2PreTrainedModel
+
+[[autodoc]] DebertaV2PreTrainedModel
+ - forward
+
+## DebertaV2ForMaskedLM
+
+[[autodoc]] DebertaV2ForMaskedLM
+ - forward
+
+## DebertaV2ForSequenceClassification
+
+[[autodoc]] DebertaV2ForSequenceClassification
+ - forward
+
+## DebertaV2ForTokenClassification
+
+[[autodoc]] DebertaV2ForTokenClassification
+ - forward
+
+## DebertaV2ForQuestionAnswering
+
+[[autodoc]] DebertaV2ForQuestionAnswering
+ - forward
+
+## DebertaV2ForMultipleChoice
+
+[[autodoc]] DebertaV2ForMultipleChoice
+ - forward
+
+
+
+
+## TFDebertaV2Model
+
+[[autodoc]] TFDebertaV2Model
+ - call
+
+## TFDebertaV2PreTrainedModel
+
+[[autodoc]] TFDebertaV2PreTrainedModel
+ - call
+
+## TFDebertaV2ForMaskedLM
+
+[[autodoc]] TFDebertaV2ForMaskedLM
+ - call
+
+## TFDebertaV2ForSequenceClassification
+
+[[autodoc]] TFDebertaV2ForSequenceClassification
+ - call
+
+## TFDebertaV2ForTokenClassification
+
+[[autodoc]] TFDebertaV2ForTokenClassification
+ - call
+
+## TFDebertaV2ForQuestionAnswering
+
+[[autodoc]] TFDebertaV2ForQuestionAnswering
+ - call
+
+## TFDebertaV2ForMultipleChoice
+
+[[autodoc]] TFDebertaV2ForMultipleChoice
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/deberta.md b/docs/transformers/docs/source/en/model_doc/deberta.md
new file mode 100644
index 0000000000000000000000000000000000000000..39afe83f5fe3f1794b8f3fc0067c154dae08ec94
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/deberta.md
@@ -0,0 +1,169 @@
+
+
+# DeBERTa
+
+
+
+
+
+
+## Overview
+
+The DeBERTa model was proposed in [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen It is based on Google's
+BERT model released in 2018 and Facebook's RoBERTa model released in 2019.
+
+It builds on RoBERTa with disentangled attention and enhanced mask decoder training with half of the data used in
+RoBERTa.
+
+The abstract from the paper is the following:
+
+*Recent progress in pre-trained neural language models has significantly improved the performance of many natural
+language processing (NLP) tasks. In this paper we propose a new model architecture DeBERTa (Decoding-enhanced BERT with
+disentangled attention) that improves the BERT and RoBERTa models using two novel techniques. The first is the
+disentangled attention mechanism, where each word is represented using two vectors that encode its content and
+position, respectively, and the attention weights among words are computed using disentangled matrices on their
+contents and relative positions. Second, an enhanced mask decoder is used to replace the output softmax layer to
+predict the masked tokens for model pretraining. We show that these two techniques significantly improve the efficiency
+of model pretraining and performance of downstream tasks. Compared to RoBERTa-Large, a DeBERTa model trained on half of
+the training data performs consistently better on a wide range of NLP tasks, achieving improvements on MNLI by +0.9%
+(90.2% vs. 91.1%), on SQuAD v2.0 by +2.3% (88.4% vs. 90.7%) and RACE by +3.6% (83.2% vs. 86.8%). The DeBERTa code and
+pre-trained models will be made publicly available at https://github.com/microsoft/DeBERTa.*
+
+
+This model was contributed by [DeBERTa](https://huggingface.co/DeBERTa). This model TF 2.0 implementation was
+contributed by [kamalkraj](https://huggingface.co/kamalkraj) . The original code can be found [here](https://github.com/microsoft/DeBERTa).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DeBERTa. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+- A blog post on how to [Accelerate Large Model Training using DeepSpeed](https://huggingface.co/blog/accelerate-deepspeed) with DeBERTa.
+- A blog post on [Supercharged Customer Service with Machine Learning](https://huggingface.co/blog/supercharge-customer-service-with-machine-learning) with DeBERTa.
+- [`DebertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
+- [`TFDebertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
+- [Text classification task guide](../tasks/sequence_classification)
+
+
+
+- [`DebertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb).
+- [`TFDebertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
+- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
+- [Byte-Pair Encoding tokenization](https://huggingface.co/course/chapter6/5?fw=pt) chapter of the 🤗 Hugging Face Course.
+- [Token classification task guide](../tasks/token_classification)
+
+
+
+- [`DebertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
+- [`TFDebertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
+- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+
+
+
+- [`DebertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
+- [`TFDebertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
+- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
+- [Question answering task guide](../tasks/question_answering)
+
+## DebertaConfig
+
+[[autodoc]] DebertaConfig
+
+## DebertaTokenizer
+
+[[autodoc]] DebertaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## DebertaTokenizerFast
+
+[[autodoc]] DebertaTokenizerFast
+ - build_inputs_with_special_tokens
+ - create_token_type_ids_from_sequences
+
+
+
+
+## DebertaModel
+
+[[autodoc]] DebertaModel
+ - forward
+
+## DebertaPreTrainedModel
+
+[[autodoc]] DebertaPreTrainedModel
+
+## DebertaForMaskedLM
+
+[[autodoc]] DebertaForMaskedLM
+ - forward
+
+## DebertaForSequenceClassification
+
+[[autodoc]] DebertaForSequenceClassification
+ - forward
+
+## DebertaForTokenClassification
+
+[[autodoc]] DebertaForTokenClassification
+ - forward
+
+## DebertaForQuestionAnswering
+
+[[autodoc]] DebertaForQuestionAnswering
+ - forward
+
+
+
+
+## TFDebertaModel
+
+[[autodoc]] TFDebertaModel
+ - call
+
+## TFDebertaPreTrainedModel
+
+[[autodoc]] TFDebertaPreTrainedModel
+ - call
+
+## TFDebertaForMaskedLM
+
+[[autodoc]] TFDebertaForMaskedLM
+ - call
+
+## TFDebertaForSequenceClassification
+
+[[autodoc]] TFDebertaForSequenceClassification
+ - call
+
+## TFDebertaForTokenClassification
+
+[[autodoc]] TFDebertaForTokenClassification
+ - call
+
+## TFDebertaForQuestionAnswering
+
+[[autodoc]] TFDebertaForQuestionAnswering
+ - call
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/decision_transformer.md b/docs/transformers/docs/source/en/model_doc/decision_transformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..fb932ce3ec7a6aceee46673ef80f90cdabf4e991
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/decision_transformer.md
@@ -0,0 +1,57 @@
+
+
+# Decision Transformer
+
+
+
+
+
+## Overview
+
+The Decision Transformer model was proposed in [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
+by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+
+The abstract from the paper is the following:
+
+*We introduce a framework that abstracts Reinforcement Learning (RL) as a sequence modeling problem.
+This allows us to draw upon the simplicity and scalability of the Transformer architecture, and associated advances
+ in language modeling such as GPT-x and BERT. In particular, we present Decision Transformer, an architecture that
+ casts the problem of RL as conditional sequence modeling. Unlike prior approaches to RL that fit value functions or
+ compute policy gradients, Decision Transformer simply outputs the optimal actions by leveraging a causally masked
+ Transformer. By conditioning an autoregressive model on the desired return (reward), past states, and actions, our
+ Decision Transformer model can generate future actions that achieve the desired return. Despite its simplicity,
+ Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL baselines on
+ Atari, OpenAI Gym, and Key-to-Door tasks.*
+
+This version of the model is for tasks where the state is a vector.
+
+This model was contributed by [edbeeching](https://huggingface.co/edbeeching). The original code can be found [here](https://github.com/kzl/decision-transformer).
+
+## DecisionTransformerConfig
+
+[[autodoc]] DecisionTransformerConfig
+
+
+## DecisionTransformerGPT2Model
+
+[[autodoc]] DecisionTransformerGPT2Model
+ - forward
+
+## DecisionTransformerModel
+
+[[autodoc]] DecisionTransformerModel
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/deepseek_v3.md b/docs/transformers/docs/source/en/model_doc/deepseek_v3.md
new file mode 100644
index 0000000000000000000000000000000000000000..c3322a102f6e4e8416e683956b3e90b99d3d8895
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/deepseek_v3.md
@@ -0,0 +1,184 @@
+
+
+# DeepSeek-V3
+
+## Overview
+
+The DeepSeek-V3 model was proposed in [DeepSeek-V3 Technical Report](https://arxiv.org/abs/2412.19437) by DeepSeek-AI Team.
+
+The abstract from the paper is the following:
+We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
+
+## Limitations and call for contribution!
+
+We are super happy to make this code community-powered, and would love to see how you can best optimize the following:
+
+- current implementation uses the "naive" attention compution (so not really MLA)
+- current implementation loops through the experts. This should be replaced. Pointers to use `get_packed_weights` from `intetrations/tensor_parallel`.
+- current implementation uses the eleuther formula for ROPE, using the orginal one would be more efficient! (should still follow our API)
+- static cache is not supported (this should be just a generation config issue / config shape issues)
+
+### Usage tips
+The model uses Multi-head Latent Attention (MLA) and DeepSeekMoE architectures for efficient inference and cost-effective training. It employs an auxiliary-loss-free strategy for load balancing and multi-token prediction training objective. The model can be used for various language tasks after being pre-trained on 14.8 trillion tokens and going through Supervised Fine-Tuning and Reinforcement Learning stages.
+
+You can run the model in `FP8` automatically, using 2 nodes of 8 H100 should be more than enough!
+
+```python
+# `run_deepseek_v1.py`
+from transformers import AutoModelForCausalLM, AutoTokenizer
+import torch
+torch.manual_seed(30)
+
+tokenizer = AutoTokenizer.from_pretrained("deepseek-r1")
+
+chat = [
+ {"role": "user", "content": "Hello, how are you?"},
+ {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
+ {"role": "user", "content": "I'd like to show off how chat templating works!"},
+]
+
+
+model = AutoModelForCausalLM.from_pretrained("deepseek-r1", device_map="auto", torch_dtype=torch.bfloat16)
+inputs = tokenizer.apply_chat_template(chat, tokenize=True, add_generation_prompt=True, return_tensors="pt").to(model.device)
+import time
+start = time.time()
+outputs = model.generate(inputs, max_new_tokens=50)
+print(tokenizer.batch_decode(outputs))
+print(time.time()-start)
+```
+This generated:
+
+``````
+<|Assistant|>
+Okay, the user wants to demonstrate how chat templating works. Let me break down what that means. Chat templating is about structuring the conversation data, especially for models that need specific input formats. Maybe they're referring to something like how messages are formatted with roles (user, assistant, system) in APIs like OpenAI.
+
+First, I should explain what chat templating is. It's the process of formatting conversation data into a structured format that the model can understand. This usually includes roles and content. For example, user messages, assistant responses, and system messages each have their own role tags.
+
+They might want an example. Let me think of a simple conversation. The user says "Hello, how are you?" and the assistant responds "I'm doing great. How can I help you today?" Then the user follows up with wanting to show off chat templating. So the example should include the history and the new message.
+
+In some frameworks, like Hugging Face's Transformers, chat templates are applied using Jinja2 templates. The template might look something like combining system messages, then looping through user and assistant messages with appropriate tags. For instance, using {% for message in messages %} and assigning roles like <|user|>, <|assistant|>, etc.
+
+I should structure the example with the messages array, showing each role and content. Then apply a hypothetical template to convert that into a formatted string the model uses. Also, mention that different models have different templating requirements, like using special tokens or varying role labels.
+
+Wait, the user mentioned "chat templating" in the context of showing off. Maybe they want a practical example they can present. So providing a code snippet or a structured data example would be helpful. Let me outline a typical messages array and then the templated output.
+
+Also, it's important to note that proper templating ensures the model knows the conversation flow, which is crucial for generating coherent responses. Maybe include a note about why it's important, like maintaining context and role-specific processing.
+
+Let me check if there are any common mistakes or things to avoid. For example, not closing tags properly, or mismatching roles. But maybe that's too detailed unless the user asks. Focus on the positive example first.
+
+Putting it all together, the response should have an example messages array, the applied template, and the final formatted string. Maybe use angle brackets or special tokens as placeholders. Also, mention that this helps in training or fine-tuning models with structured data.
+
+I think that's a solid approach. Let me structure it step by step to make it clear.
+
+
+Chat templating is a way to structure conversation data (e.g., user/assistant interactions) into a format that language models understand. This is especially important for models trained to handle multi-turn dialogues, where the input must explicitly separate roles (user, assistant, system, etc.) and messages. Let’s break this down with an example!
+
+---
+
+### **Step 1: Raw Conversation History**
+Suppose we have this conversation:
+- **User**: "Hello, how are you?"
+- **Assistant**: "I'm doing great. How can I help you today?"
+- **User**: "I'd like to show off how chat templating works!"
+
+---
+
+### **Step 2: Structured Messages**
+In frameworks like Hugging Face Transformers or OpenAI, conversations are often formatted as a list of dictionaries with `role` and `content`:
+```python
+messages = [
+ {"role": "user", "content": "Hello, how are you?"},
+ {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
+ {"role": "user", "content": "I'd like to show off how chat templating works!"},
+]
+```
+
+---
+
+### **Step 3: Apply a Chat Template**
+A **chat template** converts this structured data into a single string formatted for the model. For example, using a Jinja-style template (common in Hugging Face):
+
+```jinja
+{% for message in messages %}
+ {% if message['role'] == 'user' %}
+ <|user|>{{ message['content'] }}<|end|>
+ {% elif message['role'] == 'assistant' %}
+ <|assistant|>{{ message['content'] }}<|end|>
+ {% endif %}
+{% endfor %}
+<|assistant|>
+```
+
+---
+
+### **Step 4: Final Templated Output**
+Applying the template to our `messages` list would produce:
+```text
+<|user|>Hello, how are you?<|end|>
+<|assistant|>I'm doing great. How can I help you today?<|end|>
+<|user|>I'd like to show off how chat templating works!<|end|>
+<|assistant|>
+```
+
+This tells the model:
+1. The conversation history (user/assistant turns).
+2. The model’s turn to generate a response (`<|assistant|>` at the end).
+
+---
+
+### **Key Notes**:
+- **Role Separation**: Tags like `<|user|>` and `<|assistant|>` help the model distinguish speakers.
+- **Special Tokens**: Models often use unique tokens (e.g., `<|end|>`) to mark message boundaries.
+- **Flexibility**: Templates vary by model (e.g., OpenAI uses `{"role": "user", "content": "..."}` instead of tags).
+
+---
+
+### **Why This Matters**:
+- **Consistency**: Ensures the model understands dialogue structure.
+- **Context Preservation**: Maintains the flow of multi-turn conversations.
+- **Alignment**: Matches the format the model was trained on for better performance.
+
+Want to dive deeper or see a specific framework’s implementation (e.g., OpenAI, Llama, Mistral)? Let me know! 😊<|end▁of▁sentence|>
+``````
+
+Use the following to run it
+```bash
+torchrun --nproc_per_node=8 --nnodes=2 --node_rank=0|1 --rdzv-id an_id --rdzv-backend c10d --rdzv-endpoint master_addr:master_port run_deepseek_r1.py
+```
+
+If you have:
+```bash
+[rank0]: ncclInternalError: Internal check failed.
+[rank0]: Last error:
+[rank0]: Bootstrap : no socket interface found
+```
+error, it means NCCL was probably not loaded.
+
+
+## DeepseekV3Config
+
+[[autodoc]] DeepseekV3Config
+
+## DeepseekV3Model
+
+[[autodoc]] DeepseekV3Model
+ - forward
+
+## DeepseekV3ForCausalLM
+
+[[autodoc]] DeepseekV3ForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/deformable_detr.md b/docs/transformers/docs/source/en/model_doc/deformable_detr.md
new file mode 100644
index 0000000000000000000000000000000000000000..5b83f23cf5b3f98a629527825871ee779a41b296
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/deformable_detr.md
@@ -0,0 +1,85 @@
+
+
+# Deformable DETR
+
+
+
+
+
+## Overview
+
+The Deformable DETR model was proposed in [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
+Deformable DETR mitigates the slow convergence issues and limited feature spatial resolution of the original [DETR](detr) by leveraging a new deformable attention module which only attends to a small set of key sampling points around a reference.
+
+The abstract from the paper is the following:
+
+*DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Transformer attention modules in processing image feature maps. To mitigate these issues, we proposed Deformable DETR, whose attention modules only attend to a small set of key sampling points around a reference. Deformable DETR can achieve better performance than DETR (especially on small objects) with 10 times less training epochs. Extensive experiments on the COCO benchmark demonstrate the effectiveness of our approach.*
+
+
+
+ Deformable DETR architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
+
+## Usage tips
+
+- Training Deformable DETR is equivalent to training the original [DETR](detr) model. See the [resources](#resources) section below for demo notebooks.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Deformable DETR.
+
+
+
+- Demo notebooks regarding inference + fine-tuning on a custom dataset for [`DeformableDetrForObjectDetection`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Deformable-DETR).
+- Scripts for finetuning [`DeformableDetrForObjectDetection`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- See also: [Object detection task guide](../tasks/object_detection).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DeformableDetrImageProcessor
+
+[[autodoc]] DeformableDetrImageProcessor
+ - preprocess
+ - post_process_object_detection
+
+## DeformableDetrImageProcessorFast
+
+[[autodoc]] DeformableDetrImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+
+## DeformableDetrFeatureExtractor
+
+[[autodoc]] DeformableDetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+
+## DeformableDetrConfig
+
+[[autodoc]] DeformableDetrConfig
+
+## DeformableDetrModel
+
+[[autodoc]] DeformableDetrModel
+ - forward
+
+## DeformableDetrForObjectDetection
+
+[[autodoc]] DeformableDetrForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/deit.md b/docs/transformers/docs/source/en/model_doc/deit.md
new file mode 100644
index 0000000000000000000000000000000000000000..57cfee1f11c5e906c9cc90128247755cd6361852
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/deit.md
@@ -0,0 +1,187 @@
+
+
+# DeiT
+
+
+
+
+
+
+
+
+## Overview
+
+The DeiT model was proposed in [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre
+Sablayrolles, Hervé Jégou. The [Vision Transformer (ViT)](vit) introduced in [Dosovitskiy et al., 2020](https://arxiv.org/abs/2010.11929) has shown that one can match or even outperform existing convolutional neural
+networks using a Transformer encoder (BERT-like). However, the ViT models introduced in that paper required training on
+expensive infrastructure for multiple weeks, using external data. DeiT (data-efficient image transformers) are more
+efficiently trained transformers for image classification, requiring far less data and far less computing resources
+compared to the original ViT models.
+
+The abstract from the paper is the following:
+
+*Recently, neural networks purely based on attention were shown to address image understanding tasks such as image
+classification. However, these visual transformers are pre-trained with hundreds of millions of images using an
+expensive infrastructure, thereby limiting their adoption. In this work, we produce a competitive convolution-free
+transformer by training on Imagenet only. We train them on a single computer in less than 3 days. Our reference vision
+transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop evaluation) on ImageNet with no external
+data. More importantly, we introduce a teacher-student strategy specific to transformers. It relies on a distillation
+token ensuring that the student learns from the teacher through attention. We show the interest of this token-based
+distillation, especially when using a convnet as a teacher. This leads us to report results competitive with convnets
+for both Imagenet (where we obtain up to 85.2% accuracy) and when transferring to other tasks. We share our code and
+models.*
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts).
+
+## Usage tips
+
+- Compared to ViT, DeiT models use a so-called distillation token to effectively learn from a teacher (which, in the
+ DeiT paper, is a ResNet like-model). The distillation token is learned through backpropagation, by interacting with
+ the class ([CLS]) and patch tokens through the self-attention layers.
+- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
+ of the final hidden state of the class token and not using the distillation signal, or (2) by placing both a
+ prediction head on top of the class token and on top of the distillation token. In that case, the [CLS] prediction
+ head is trained using regular cross-entropy between the prediction of the head and the ground-truth label, while the
+ distillation prediction head is trained using hard distillation (cross-entropy between the prediction of the
+ distillation head and the label predicted by the teacher). At inference time, one takes the average prediction
+ between both heads as final prediction. (2) is also called "fine-tuning with distillation", because one relies on a
+ teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds to
+ [`DeiTForImageClassification`] and (2) corresponds to
+ [`DeiTForImageClassificationWithTeacher`].
+- Note that the authors also did try soft distillation for (2) (in which case the distillation prediction head is
+ trained using KL divergence to match the softmax output of the teacher), but hard distillation gave the best results.
+- All released checkpoints were pre-trained and fine-tuned on ImageNet-1k only. No external data was used. This is in
+ contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for
+ pre-training.
+- The authors of DeiT also released more efficiently trained ViT models, which you can directly plug into
+ [`ViTModel`] or [`ViTForImageClassification`]. Techniques like data
+ augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
+ (while only using ImageNet-1k for pre-training). There are 4 variants available (in 3 different sizes):
+ *facebook/deit-tiny-patch16-224*, *facebook/deit-small-patch16-224*, *facebook/deit-base-patch16-224* and
+ *facebook/deit-base-patch16-384*. Note that one should use [`DeiTImageProcessor`] in order to
+ prepare images for the model.
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```
+from transformers import DeiTForImageClassification
+model = DeiTForImageClassification.from_pretrained("facebook/deit-base-distilled-patch16-224", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32` and `facebook/deit-base-distilled-patch16-224` model, we saw the following speedups during inference.
+
+| Batch size | Average inference time (ms), eager mode | Average inference time (ms), sdpa model | Speed up, Sdpa / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 8 | 6 | 1.33 |
+| 2 | 9 | 6 | 1.5 |
+| 4 | 9 | 6 | 1.5 |
+| 8 | 8 | 6 | 1.33 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DeiT.
+
+
+
+- [`DeiTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+Besides that:
+
+- [`DeiTForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DeiTConfig
+
+[[autodoc]] DeiTConfig
+
+## DeiTFeatureExtractor
+
+[[autodoc]] DeiTFeatureExtractor
+ - __call__
+
+## DeiTImageProcessor
+
+[[autodoc]] DeiTImageProcessor
+ - preprocess
+
+## DeiTImageProcessorFast
+
+[[autodoc]] DeiTImageProcessorFast
+ - preprocess
+
+
+
+
+## DeiTModel
+
+[[autodoc]] DeiTModel
+ - forward
+
+## DeiTForMaskedImageModeling
+
+[[autodoc]] DeiTForMaskedImageModeling
+ - forward
+
+## DeiTForImageClassification
+
+[[autodoc]] DeiTForImageClassification
+ - forward
+
+## DeiTForImageClassificationWithTeacher
+
+[[autodoc]] DeiTForImageClassificationWithTeacher
+ - forward
+
+
+
+
+## TFDeiTModel
+
+[[autodoc]] TFDeiTModel
+ - call
+
+## TFDeiTForMaskedImageModeling
+
+[[autodoc]] TFDeiTForMaskedImageModeling
+ - call
+
+## TFDeiTForImageClassification
+
+[[autodoc]] TFDeiTForImageClassification
+ - call
+
+## TFDeiTForImageClassificationWithTeacher
+
+[[autodoc]] TFDeiTForImageClassificationWithTeacher
+ - call
+
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/deplot.md b/docs/transformers/docs/source/en/model_doc/deplot.md
new file mode 100644
index 0000000000000000000000000000000000000000..d3c0de7b7f84f44f720e2288bbd3ba77ea2c6268
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/deplot.md
@@ -0,0 +1,70 @@
+
+
+# DePlot
+
+
+
+
+
+## Overview
+
+DePlot was proposed in the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) from Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
+
+The abstract of the paper states the following:
+
+*Visual language such as charts and plots is ubiquitous in the human world. Comprehending plots and charts requires strong reasoning skills. Prior state-of-the-art (SOTA) models require at least tens of thousands of training examples and their reasoning capabilities are still much limited, especially on complex human-written queries. This paper presents the first one-shot solution to visual language reasoning. We decompose the challenge of visual language reasoning into two steps: (1) plot-to-text translation, and (2) reasoning over the translated text. The key in this method is a modality conversion module, named as DePlot, which translates the image of a plot or chart to a linearized table. The output of DePlot can then be directly used to prompt a pretrained large language model (LLM), exploiting the few-shot reasoning capabilities of LLMs. To obtain DePlot, we standardize the plot-to-table task by establishing unified task formats and metrics, and train DePlot end-to-end on this task. DePlot can then be used off-the-shelf together with LLMs in a plug-and-play fashion. Compared with a SOTA model finetuned on more than >28k data points, DePlot+LLM with just one-shot prompting achieves a 24.0% improvement over finetuned SOTA on human-written queries from the task of chart QA.*
+
+DePlot is a model that is trained using `Pix2Struct` architecture. You can find more information about `Pix2Struct` in the [Pix2Struct documentation](https://huggingface.co/docs/transformers/main/en/model_doc/pix2struct).
+DePlot is a Visual Question Answering subset of `Pix2Struct` architecture. It renders the input question on the image and predicts the answer.
+
+## Usage example
+
+Currently one checkpoint is available for DePlot:
+
+- `google/deplot`: DePlot fine-tuned on ChartQA dataset
+
+
+```python
+from transformers import AutoProcessor, Pix2StructForConditionalGeneration
+import requests
+from PIL import Image
+
+model = Pix2StructForConditionalGeneration.from_pretrained("google/deplot")
+processor = AutoProcessor.from_pretrained("google/deplot")
+url = "https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/5090.png"
+image = Image.open(requests.get(url, stream=True).raw)
+
+inputs = processor(images=image, text="Generate underlying data table of the figure below:", return_tensors="pt")
+predictions = model.generate(**inputs, max_new_tokens=512)
+print(processor.decode(predictions[0], skip_special_tokens=True))
+```
+
+## Fine-tuning
+
+To fine-tune DePlot, refer to the pix2struct [fine-tuning notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb). For `Pix2Struct` models, we have found out that fine-tuning the model with Adafactor and cosine learning rate scheduler leads to faster convergence:
+```python
+from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
+
+optimizer = Adafactor(self.parameters(), scale_parameter=False, relative_step=False, lr=0.01, weight_decay=1e-05)
+scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=40000)
+```
+
+
+
+DePlot is a model trained using `Pix2Struct` architecture. For API reference, see [`Pix2Struct` documentation](pix2struct).
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/depth_anything.md b/docs/transformers/docs/source/en/model_doc/depth_anything.md
new file mode 100644
index 0000000000000000000000000000000000000000..ea52dea915ddd24e601ed41f87ba616f7bdb47c6
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/depth_anything.md
@@ -0,0 +1,88 @@
+
+
+
+
+
+
+
+
+# Depth Anything
+
+[Depth Anything](https://huggingface.co/papers/2401.10891) is designed to be a foundation model for monocular depth estimation (MDE). It is jointly trained on labeled and ~62M unlabeled images to enhance the dataset. It uses a pretrained [DINOv2](./dinov2) model as an image encoder to inherit its existing rich semantic priors, and [DPT](./dpt) as the decoder. A teacher model is trained on unlabeled images to create pseudo-labels. The student model is trained on a combination of the pseudo-labels and labeled images. To improve the student model's performance, strong perturbations are added to the unlabeled images to challenge the student model to learn more visual knowledge from the image.
+
+You can find all the original Depth Anything checkpoints under the [Depth Anything](https://huggingface.co/collections/LiheYoung/depth-anything-release-65b317de04eec72abf6b55aa) collection.
+
+> [!TIP]
+> Click on the Depth Anything models in the right sidebar for more examples of how to apply Depth Anything to different vision tasks.
+
+The example below demonstrates how to obtain a depth map with [`Pipeline`] or the [`AutoModel`] class.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipe = pipeline(task="depth-estimation", model="LiheYoung/depth-anything-base-hf", torch_dtype=torch.bfloat16, device=0)
+pipe("http://images.cocodataset.org/val2017/000000039769.jpg")["depth"]
+```
+
+
+
+
+```py
+import torch
+import requests
+import numpy as np
+from PIL import Image
+from transformers import AutoImageProcessor, AutoModelForDepthEstimation
+
+image_processor = AutoImageProcessor.from_pretrained("LiheYoung/depth-anything-base-hf")
+model = AutoModelForDepthEstimation.from_pretrained("LiheYoung/depth-anything-base-hf", torch_dtype=torch.bfloat16)
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+inputs = image_processor(images=image, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+post_processed_output = image_processor.post_process_depth_estimation(
+ outputs,
+ target_sizes=[(image.height, image.width)],
+)
+predicted_depth = post_processed_output[0]["predicted_depth"]
+depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
+depth = depth.detach().cpu().numpy() * 255
+Image.fromarray(depth.astype("uint8"))
+```
+
+
+
+
+## Notes
+
+- [DepthAnythingV2](./depth_anything_v2), released in June 2024, uses the same architecture as Depth Anything and is compatible with all code examples and existing workflows. It uses synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions.
+
+## DepthAnythingConfig
+
+[[autodoc]] DepthAnythingConfig
+
+## DepthAnythingForDepthEstimation
+
+[[autodoc]] DepthAnythingForDepthEstimation
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/depth_anything_v2.md b/docs/transformers/docs/source/en/model_doc/depth_anything_v2.md
new file mode 100644
index 0000000000000000000000000000000000000000..c98017d2bbc510afe68b46c8021659958d835692
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/depth_anything_v2.md
@@ -0,0 +1,112 @@
+
+
+# Depth Anything V2
+
+## Overview
+
+Depth Anything V2 was introduced in [the paper of the same name](https://arxiv.org/abs/2406.09414) by Lihe Yang et al. It uses the same architecture as the original [Depth Anything model](depth_anything), but uses synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions.
+
+The abstract from the paper is the following:
+
+*This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with precise annotations and diverse scenes to facilitate future research.*
+
+
+
+ Depth Anything overview. Taken from the original paper.
+
+The Depth Anything models were contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/DepthAnything/Depth-Anything-V2).
+
+## Usage example
+
+There are 2 main ways to use Depth Anything V2: either using the pipeline API, which abstracts away all the complexity for you, or by using the `DepthAnythingForDepthEstimation` class yourself.
+
+### Pipeline API
+
+The pipeline allows to use the model in a few lines of code:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # load pipe
+>>> pipe = pipeline(task="depth-estimation", model="depth-anything/Depth-Anything-V2-Small-hf")
+
+>>> # load image
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # inference
+>>> depth = pipe(image)["depth"]
+```
+
+### Using the model yourself
+
+If you want to do the pre- and post-processing yourself, here's how to do that:
+
+```python
+>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
+>>> import torch
+>>> import numpy as np
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = AutoImageProcessor.from_pretrained("depth-anything/Depth-Anything-V2-Small-hf")
+>>> model = AutoModelForDepthEstimation.from_pretrained("depth-anything/Depth-Anything-V2-Small-hf")
+
+>>> # prepare image for the model
+>>> inputs = image_processor(images=image, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> # interpolate to original size and visualize the prediction
+>>> post_processed_output = image_processor.post_process_depth_estimation(
+... outputs,
+... target_sizes=[(image.height, image.width)],
+... )
+
+>>> predicted_depth = post_processed_output[0]["predicted_depth"]
+>>> depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
+>>> depth = depth.detach().cpu().numpy() * 255
+>>> depth = Image.fromarray(depth.astype("uint8"))
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Depth Anything.
+
+- [Monocular depth estimation task guide](../tasks/monocular_depth_estimation)
+- [Depth Anything V2 demo](https://huggingface.co/spaces/depth-anything/Depth-Anything-V2).
+- A notebook showcasing inference with [`DepthAnythingForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Depth%20Anything/Predicting_depth_in_an_image_with_Depth_Anything.ipynb). 🌎
+- [Core ML conversion of the `small` variant for use on Apple Silicon](https://huggingface.co/apple/coreml-depth-anything-v2-small).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DepthAnythingConfig
+
+[[autodoc]] DepthAnythingConfig
+
+## DepthAnythingForDepthEstimation
+
+[[autodoc]] DepthAnythingForDepthEstimation
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/depth_pro.md b/docs/transformers/docs/source/en/model_doc/depth_pro.md
new file mode 100644
index 0000000000000000000000000000000000000000..42fd725a9abefb52fdf3af82e966983268af436f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/depth_pro.md
@@ -0,0 +1,187 @@
+
+
+# DepthPro
+
+
+
+
+
+## Overview
+
+The DepthPro model was proposed in [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/abs/2410.02073) by Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun.
+
+DepthPro is a foundation model for zero-shot metric monocular depth estimation, designed to generate high-resolution depth maps with remarkable sharpness and fine-grained details. It employs a multi-scale Vision Transformer (ViT)-based architecture, where images are downsampled, divided into patches, and processed using a shared Dinov2 encoder. The extracted patch-level features are merged, upsampled, and refined using a DPT-like fusion stage, enabling precise depth estimation.
+
+The abstract from the paper is the following:
+
+*We present a foundation model for zero-shot metric monocular depth estimation. Our model, Depth Pro, synthesizes high-resolution depth maps with unparalleled sharpness and high-frequency details. The predictions are metric, with absolute scale, without relying on the availability of metadata such as camera intrinsics. And the model is fast, producing a 2.25-megapixel depth map in 0.3 seconds on a standard GPU. These characteristics are enabled by a number of technical contributions, including an efficient multi-scale vision transformer for dense prediction, a training protocol that combines real and synthetic datasets to achieve high metric accuracy alongside fine boundary tracing, dedicated evaluation metrics for boundary accuracy in estimated depth maps, and state-of-the-art focal length estimation from a single image. Extensive experiments analyze specific design choices and demonstrate that Depth Pro outperforms prior work along multiple dimensions.*
+
+
+
+ DepthPro Outputs. Taken from the official code.
+
+This model was contributed by [geetu040](https://github.com/geetu040). The original code can be found [here](https://github.com/apple/ml-depth-pro).
+
+## Usage Tips
+
+The DepthPro model processes an input image by first downsampling it at multiple scales and splitting each scaled version into patches. These patches are then encoded using a shared Vision Transformer (ViT)-based Dinov2 patch encoder, while the full image is processed by a separate image encoder. The extracted patch features are merged into feature maps, upsampled, and fused using a DPT-like decoder to generate the final depth estimation. If enabled, an additional Field of View (FOV) encoder processes the image for estimating the camera's field of view, aiding in depth accuracy.
+
+```py
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+>>> from transformers import DepthProImageProcessorFast, DepthProForDepthEstimation
+
+>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = DepthProImageProcessorFast.from_pretrained("apple/DepthPro-hf")
+>>> model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf").to(device)
+
+>>> inputs = image_processor(images=image, return_tensors="pt").to(device)
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> post_processed_output = image_processor.post_process_depth_estimation(
+... outputs, target_sizes=[(image.height, image.width)],
+... )
+
+>>> field_of_view = post_processed_output[0]["field_of_view"]
+>>> focal_length = post_processed_output[0]["focal_length"]
+>>> depth = post_processed_output[0]["predicted_depth"]
+>>> depth = (depth - depth.min()) / depth.max()
+>>> depth = depth * 255.
+>>> depth = depth.detach().cpu().numpy()
+>>> depth = Image.fromarray(depth.astype("uint8"))
+```
+
+### Architecture and Configuration
+
+
+
+ DepthPro architecture. Taken from the original paper.
+
+The `DepthProForDepthEstimation` model uses a `DepthProEncoder`, for encoding the input image and a `FeatureFusionStage` for fusing the output features from encoder.
+
+The `DepthProEncoder` further uses two encoders:
+- `patch_encoder`
+ - Input image is scaled with multiple ratios, as specified in the `scaled_images_ratios` configuration.
+ - Each scaled image is split into smaller **patches** of size `patch_size` with overlapping areas determined by `scaled_images_overlap_ratios`.
+ - These patches are processed by the **`patch_encoder`**
+- `image_encoder`
+ - Input image is also rescaled to `patch_size` and processed by the **`image_encoder`**
+
+Both these encoders can be configured via `patch_model_config` and `image_model_config` respectively, both of which are separate `Dinov2Model` by default.
+
+Outputs from both encoders (`last_hidden_state`) and selected intermediate states (`hidden_states`) from **`patch_encoder`** are fused by a `DPT`-based `FeatureFusionStage` for depth estimation.
+
+### Field-of-View (FOV) Prediction
+
+The network is supplemented with a focal length estimation head. A small convolutional head ingests frozen features from the depth estimation network and task-specific features from a separate ViT image encoder to predict the horizontal angular field-of-view.
+
+The `use_fov_model` parameter in `DepthProConfig` controls whether **FOV prediction** is enabled. By default, it is set to `False` to conserve memory and computation. When enabled, the **FOV encoder** is instantiated based on the `fov_model_config` parameter, which defaults to a `Dinov2Model`. The `use_fov_model` parameter can also be passed when initializing the `DepthProForDepthEstimation` model.
+
+The pretrained model at checkpoint `apple/DepthPro-hf` uses the FOV encoder. To use the pretrained-model without FOV encoder, set `use_fov_model=False` when loading the model, which saves computation.
+```py
+>>> from transformers import DepthProForDepthEstimation
+>>> model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf", use_fov_model=False)
+```
+
+To instantiate a new model with FOV encoder, set `use_fov_model=True` in the config.
+```py
+>>> from transformers import DepthProConfig, DepthProForDepthEstimation
+>>> config = DepthProConfig(use_fov_model=True)
+>>> model = DepthProForDepthEstimation(config)
+```
+
+Or set `use_fov_model=True` when initializing the model, which overrides the value in config.
+```py
+>>> from transformers import DepthProConfig, DepthProForDepthEstimation
+>>> config = DepthProConfig()
+>>> model = DepthProForDepthEstimation(config, use_fov_model=True)
+```
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```py
+from transformers import DepthProForDepthEstimation
+model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf", attn_implementation="sdpa", torch_dtype=torch.float16)
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32` and `google/vit-base-patch16-224` model, we saw the following speedups during inference.
+
+| Batch size | Average inference time (ms), eager mode | Average inference time (ms), sdpa model | Speed up, Sdpa / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 7 | 6 | 1.17 |
+| 2 | 8 | 6 | 1.33 |
+| 4 | 8 | 6 | 1.33 |
+| 8 | 8 | 6 | 1.33 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DepthPro:
+
+- Research Paper: [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/pdf/2410.02073)
+- Official Implementation: [apple/ml-depth-pro](https://github.com/apple/ml-depth-pro)
+- DepthPro Inference Notebook: [DepthPro Inference](https://github.com/qubvel/transformers-notebooks/blob/main/notebooks/DepthPro_inference.ipynb)
+- DepthPro for Super Resolution and Image Segmentation
+ - Read blog on Medium: [Depth Pro: Beyond Depth](https://medium.com/@raoarmaghanshakir040/depth-pro-beyond-depth-9d822fc557ba)
+ - Code on Github: [geetu040/depthpro-beyond-depth](https://github.com/geetu040/depthpro-beyond-depth)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DepthProConfig
+
+[[autodoc]] DepthProConfig
+
+## DepthProImageProcessor
+
+[[autodoc]] DepthProImageProcessor
+ - preprocess
+ - post_process_depth_estimation
+
+## DepthProImageProcessorFast
+
+[[autodoc]] DepthProImageProcessorFast
+ - preprocess
+ - post_process_depth_estimation
+
+## DepthProModel
+
+[[autodoc]] DepthProModel
+ - forward
+
+## DepthProForDepthEstimation
+
+[[autodoc]] DepthProForDepthEstimation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/deta.md b/docs/transformers/docs/source/en/model_doc/deta.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3859341a71af9ec7ae0d74ba9cfb4882587fe6a
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/deta.md
@@ -0,0 +1,77 @@
+
+
+# DETA
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+The DETA model was proposed in [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
+DETA (short for Detection Transformers with Assignment) improves [Deformable DETR](deformable_detr) by replacing the one-to-one bipartite Hungarian matching loss
+with one-to-many label assignments used in traditional detectors with non-maximum suppression (NMS). This leads to significant gains of up to 2.5 mAP.
+
+The abstract from the paper is the following:
+
+*Detection Transformer (DETR) directly transforms queries to unique objects by using one-to-one bipartite matching during training and enables end-to-end object detection. Recently, these models have surpassed traditional detectors on COCO with undeniable elegance. However, they differ from traditional detectors in multiple designs, including model architecture and training schedules, and thus the effectiveness of one-to-one matching is not fully understood. In this work, we conduct a strict comparison between the one-to-one Hungarian matching in DETRs and the one-to-many label assignments in traditional detectors with non-maximum supervision (NMS). Surprisingly, we observe one-to-many assignments with NMS consistently outperform standard one-to-one matching under the same setting, with a significant gain of up to 2.5 mAP. Our detector that trains Deformable-DETR with traditional IoU-based label assignment achieved 50.2 COCO mAP within 12 epochs (1x schedule) with ResNet50 backbone, outperforming all existing traditional or transformer-based detectors in this setting. On multiple datasets, schedules, and architectures, we consistently show bipartite matching is unnecessary for performant detection transformers. Furthermore, we attribute the success of detection transformers to their expressive transformer architecture.*
+
+
+
+ DETA overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/jozhang97/DETA).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DETA.
+
+- Demo notebooks for DETA can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETA).
+- Scripts for finetuning [`DetaForObjectDetection`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- See also: [Object detection task guide](../tasks/object_detection).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DetaConfig
+
+[[autodoc]] DetaConfig
+
+## DetaImageProcessor
+
+[[autodoc]] DetaImageProcessor
+ - preprocess
+ - post_process_object_detection
+
+## DetaModel
+
+[[autodoc]] DetaModel
+ - forward
+
+## DetaForObjectDetection
+
+[[autodoc]] DetaForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/detr.md b/docs/transformers/docs/source/en/model_doc/detr.md
new file mode 100644
index 0000000000000000000000000000000000000000..4614d549a180fe51d9d1947471dabc8c126fbc11
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/detr.md
@@ -0,0 +1,227 @@
+
+
+# DETR
+
+
+
+
+
+## Overview
+
+The DETR model was proposed in [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by
+Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko. DETR
+consists of a convolutional backbone followed by an encoder-decoder Transformer which can be trained end-to-end for
+object detection. It greatly simplifies a lot of the complexity of models like Faster-R-CNN and Mask-R-CNN, which use
+things like region proposals, non-maximum suppression procedure and anchor generation. Moreover, DETR can also be
+naturally extended to perform panoptic segmentation, by simply adding a mask head on top of the decoder outputs.
+
+The abstract from the paper is the following:
+
+*We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the
+detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression
+procedure or anchor generation that explicitly encode our prior knowledge about the task. The main ingredients of the
+new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via
+bipartite matching, and a transformer encoder-decoder architecture. Given a fixed small set of learned object queries,
+DETR reasons about the relations of the objects and the global image context to directly output the final set of
+predictions in parallel. The new model is conceptually simple and does not require a specialized library, unlike many
+other modern detectors. DETR demonstrates accuracy and run-time performance on par with the well-established and
+highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily
+generalized to produce panoptic segmentation in a unified manner. We show that it significantly outperforms competitive
+baselines.*
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/facebookresearch/detr).
+
+## How DETR works
+
+Here's a TLDR explaining how [`~transformers.DetrForObjectDetection`] works:
+
+First, an image is sent through a pre-trained convolutional backbone (in the paper, the authors use
+ResNet-50/ResNet-101). Let's assume we also add a batch dimension. This means that the input to the backbone is a
+tensor of shape `(batch_size, 3, height, width)`, assuming the image has 3 color channels (RGB). The CNN backbone
+outputs a new lower-resolution feature map, typically of shape `(batch_size, 2048, height/32, width/32)`. This is
+then projected to match the hidden dimension of the Transformer of DETR, which is `256` by default, using a
+`nn.Conv2D` layer. So now, we have a tensor of shape `(batch_size, 256, height/32, width/32).` Next, the
+feature map is flattened and transposed to obtain a tensor of shape `(batch_size, seq_len, d_model)` =
+`(batch_size, width/32*height/32, 256)`. So a difference with NLP models is that the sequence length is actually
+longer than usual, but with a smaller `d_model` (which in NLP is typically 768 or higher).
+
+Next, this is sent through the encoder, outputting `encoder_hidden_states` of the same shape (you can consider
+these as image features). Next, so-called **object queries** are sent through the decoder. This is a tensor of shape
+`(batch_size, num_queries, d_model)`, with `num_queries` typically set to 100 and initialized with zeros.
+These input embeddings are learnt positional encodings that the authors refer to as object queries, and similarly to
+the encoder, they are added to the input of each attention layer. Each object query will look for a particular object
+in the image. The decoder updates these embeddings through multiple self-attention and encoder-decoder attention layers
+to output `decoder_hidden_states` of the same shape: `(batch_size, num_queries, d_model)`. Next, two heads
+are added on top for object detection: a linear layer for classifying each object query into one of the objects or "no
+object", and a MLP to predict bounding boxes for each query.
+
+The model is trained using a **bipartite matching loss**: so what we actually do is compare the predicted classes +
+bounding boxes of each of the N = 100 object queries to the ground truth annotations, padded up to the same length N
+(so if an image only contains 4 objects, 96 annotations will just have a "no object" as class and "no bounding box" as
+bounding box). The [Hungarian matching algorithm](https://en.wikipedia.org/wiki/Hungarian_algorithm) is used to find
+an optimal one-to-one mapping of each of the N queries to each of the N annotations. Next, standard cross-entropy (for
+the classes) and a linear combination of the L1 and [generalized IoU loss](https://giou.stanford.edu/) (for the
+bounding boxes) are used to optimize the parameters of the model.
+
+DETR can be naturally extended to perform panoptic segmentation (which unifies semantic segmentation and instance
+segmentation). [`~transformers.DetrForSegmentation`] adds a segmentation mask head on top of
+[`~transformers.DetrForObjectDetection`]. The mask head can be trained either jointly, or in a two steps process,
+where one first trains a [`~transformers.DetrForObjectDetection`] model to detect bounding boxes around both
+"things" (instances) and "stuff" (background things like trees, roads, sky), then freeze all the weights and train only
+the mask head for 25 epochs. Experimentally, these two approaches give similar results. Note that predicting boxes is
+required for the training to be possible, since the Hungarian matching is computed using distances between boxes.
+
+## Usage tips
+
+- DETR uses so-called **object queries** to detect objects in an image. The number of queries determines the maximum
+ number of objects that can be detected in a single image, and is set to 100 by default (see parameter
+ `num_queries` of [`~transformers.DetrConfig`]). Note that it's good to have some slack (in COCO, the
+ authors used 100, while the maximum number of objects in a COCO image is ~70).
+- The decoder of DETR updates the query embeddings in parallel. This is different from language models like GPT-2,
+ which use autoregressive decoding instead of parallel. Hence, no causal attention mask is used.
+- DETR adds position embeddings to the hidden states at each self-attention and cross-attention layer before projecting
+ to queries and keys. For the position embeddings of the image, one can choose between fixed sinusoidal or learned
+ absolute position embeddings. By default, the parameter `position_embedding_type` of
+ [`~transformers.DetrConfig`] is set to `"sine"`.
+- During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help
+ the model output the correct number of objects of each class. If you set the parameter `auxiliary_loss` of
+ [`~transformers.DetrConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses
+ are added after each decoder layer (with the FFNs sharing parameters).
+- If you want to train the model in a distributed environment across multiple nodes, then one should update the
+ _num_boxes_ variable in the _DetrLoss_ class of _modeling_detr.py_. When training on multiple nodes, this should be
+ set to the average number of target boxes across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/detr/blob/a54b77800eb8e64e3ad0d8237789fcbf2f8350c5/models/detr.py#L227-L232).
+- [`~transformers.DetrForObjectDetection`] and [`~transformers.DetrForSegmentation`] can be initialized with
+ any convolutional backbone available in the [timm library](https://github.com/rwightman/pytorch-image-models).
+ Initializing with a MobileNet backbone for example can be done by setting the `backbone` attribute of
+ [`~transformers.DetrConfig`] to `"tf_mobilenetv3_small_075"`, and then initializing the model with that
+ config.
+- DETR resizes the input images such that the shortest side is at least a certain amount of pixels while the longest is
+ at most 1333 pixels. At training time, scale augmentation is used such that the shortest side is randomly set to at
+ least 480 and at most 800 pixels. At inference time, the shortest side is set to 800. One can use
+ [`~transformers.DetrImageProcessor`] to prepare images (and optional annotations in COCO format) for the
+ model. Due to this resizing, images in a batch can have different sizes. DETR solves this by padding images up to the
+ largest size in a batch, and by creating a pixel mask that indicates which pixels are real/which are padding.
+ Alternatively, one can also define a custom `collate_fn` in order to batch images together, using
+ [`~transformers.DetrImageProcessor.pad_and_create_pixel_mask`].
+- The size of the images will determine the amount of memory being used, and will thus determine the `batch_size`.
+ It is advised to use a batch size of 2 per GPU. See [this Github thread](https://github.com/facebookresearch/detr/issues/150) for more info.
+
+There are three ways to instantiate a DETR model (depending on what you prefer):
+
+Option 1: Instantiate DETR with pre-trained weights for entire model
+```py
+>>> from transformers import DetrForObjectDetection
+
+>>> model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
+```
+
+Option 2: Instantiate DETR with randomly initialized weights for Transformer, but pre-trained weights for backbone
+```py
+>>> from transformers import DetrConfig, DetrForObjectDetection
+
+>>> config = DetrConfig()
+>>> model = DetrForObjectDetection(config)
+```
+Option 3: Instantiate DETR with randomly initialized weights for backbone + Transformer
+```py
+>>> config = DetrConfig(use_pretrained_backbone=False)
+>>> model = DetrForObjectDetection(config)
+```
+
+As a summary, consider the following table:
+
+| Task | Object detection | Instance segmentation | Panoptic segmentation |
+|------|------------------|-----------------------|-----------------------|
+| **Description** | Predicting bounding boxes and class labels around objects in an image | Predicting masks around objects (i.e. instances) in an image | Predicting masks around both objects (i.e. instances) as well as "stuff" (i.e. background things like trees and roads) in an image |
+| **Model** | [`~transformers.DetrForObjectDetection`] | [`~transformers.DetrForSegmentation`] | [`~transformers.DetrForSegmentation`] |
+| **Example dataset** | COCO detection | COCO detection, COCO panoptic | COCO panoptic | |
+| **Format of annotations to provide to** [`~transformers.DetrImageProcessor`] | {'image_id': `int`, 'annotations': `List[Dict]`} each Dict being a COCO object annotation | {'image_id': `int`, 'annotations': `List[Dict]`} (in case of COCO detection) or {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} (in case of COCO panoptic) | {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} and masks_path (path to directory containing PNG files of the masks) |
+| **Postprocessing** (i.e. converting the output of the model to Pascal VOC format) | [`~transformers.DetrImageProcessor.post_process`] | [`~transformers.DetrImageProcessor.post_process_segmentation`] | [`~transformers.DetrImageProcessor.post_process_segmentation`], [`~transformers.DetrImageProcessor.post_process_panoptic`] |
+| **evaluators** | `CocoEvaluator` with `iou_types="bbox"` | `CocoEvaluator` with `iou_types="bbox"` or `"segm"` | `CocoEvaluator` with `iou_tupes="bbox"` or `"segm"`, `PanopticEvaluator` |
+
+In short, one should prepare the data either in COCO detection or COCO panoptic format, then use
+[`~transformers.DetrImageProcessor`] to create `pixel_values`, `pixel_mask` and optional
+`labels`, which can then be used to train (or fine-tune) a model. For evaluation, one should first convert the
+outputs of the model using one of the postprocessing methods of [`~transformers.DetrImageProcessor`]. These can
+be provided to either `CocoEvaluator` or `PanopticEvaluator`, which allow you to calculate metrics like
+mean Average Precision (mAP) and Panoptic Quality (PQ). The latter objects are implemented in the [original repository](https://github.com/facebookresearch/detr). See the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) for more info regarding evaluation.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DETR.
+
+
+
+- All example notebooks illustrating fine-tuning [`DetrForObjectDetection`] and [`DetrForSegmentation`] on a custom dataset can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR).
+- Scripts for finetuning [`DetrForObjectDetection`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- See also: [Object detection task guide](../tasks/object_detection).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DetrConfig
+
+[[autodoc]] DetrConfig
+
+## DetrImageProcessor
+
+[[autodoc]] DetrImageProcessor
+ - preprocess
+ - post_process_object_detection
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
+## DetrImageProcessorFast
+
+[[autodoc]] DetrImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
+## DetrFeatureExtractor
+
+[[autodoc]] DetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
+## DETR specific outputs
+
+[[autodoc]] models.detr.modeling_detr.DetrModelOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrObjectDetectionOutput
+
+[[autodoc]] models.detr.modeling_detr.DetrSegmentationOutput
+
+## DetrModel
+
+[[autodoc]] DetrModel
+ - forward
+
+## DetrForObjectDetection
+
+[[autodoc]] DetrForObjectDetection
+ - forward
+
+## DetrForSegmentation
+
+[[autodoc]] DetrForSegmentation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/dialogpt.md b/docs/transformers/docs/source/en/model_doc/dialogpt.md
new file mode 100644
index 0000000000000000000000000000000000000000..33d7e3b16d8869218a0c198e31cfbc195989989e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/dialogpt.md
@@ -0,0 +1,63 @@
+
+
+# DialoGPT
+
+
+
+
+
+
+
+## Overview
+
+DialoGPT was proposed in [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
+Jianfeng Gao, Jingjing Liu, Bill Dolan. It's a GPT2 Model trained on 147M conversation-like exchanges extracted from
+Reddit.
+
+The abstract from the paper is the following:
+
+*We present a large, tunable neural conversational response generation model, DialoGPT (dialogue generative pre-trained
+transformer). Trained on 147M conversation-like exchanges extracted from Reddit comment chains over a period spanning
+from 2005 through 2017, DialoGPT extends the Hugging Face PyTorch transformer to attain a performance close to human
+both in terms of automatic and human evaluation in single-turn dialogue settings. We show that conversational systems
+that leverage DialoGPT generate more relevant, contentful and context-consistent responses than strong baseline
+systems. The pre-trained model and training pipeline are publicly released to facilitate research into neural response
+generation and the development of more intelligent open-domain dialogue systems.*
+
+The original code can be found [here](https://github.com/microsoft/DialoGPT).
+
+## Usage tips
+
+- DialoGPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
+ than the left.
+- DialoGPT was trained with a causal language modeling (CLM) objective on conversational data and is therefore powerful
+ at response generation in open-domain dialogue systems.
+- DialoGPT enables the user to create a chat bot in just 10 lines of code as shown on [DialoGPT's model card](https://huggingface.co/microsoft/DialoGPT-medium).
+
+Training:
+
+In order to train or fine-tune DialoGPT, one can use causal language modeling training. To cite the official paper: *We
+follow the OpenAI GPT-2 to model a multiturn dialogue session as a long text and frame the generation task as language
+modeling. We first concatenate all dialog turns within a dialogue session into a long text x_1,..., x_N (N is the
+sequence length), ended by the end-of-text token.* For more information please confer to the original paper.
+
+
+
+DialoGPT's architecture is based on the GPT2 model, refer to [GPT2's documentation page](gpt2) for API reference and examples.
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/diffllama.md b/docs/transformers/docs/source/en/model_doc/diffllama.md
new file mode 100644
index 0000000000000000000000000000000000000000..c4a170c265724dae6010ddb31d4e7e7cd296af13
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/diffllama.md
@@ -0,0 +1,65 @@
+
+
+# DiffLlama
+
+
+
+
+
+
+
+## Overview
+
+The DiffLlama model was proposed in [Differential Transformer](https://arxiv.org/abs/2410.05258) by Kazuma Matsumoto and .
+This model is combine Llama model and Differential Transformer's Attention.
+
+The abstract from the paper is the following:
+
+*Transformer tends to overallocate attention to irrelevant context. In this work, we introduce Diff Transformer, which amplifies attention to the relevant context while canceling noise. Specifically, the differential attention mechanism calculates attention scores as the difference between two separate softmax attention maps. The subtraction cancels noise, promoting the emergence of sparse attention patterns. Experimental results on language modeling show that Diff Transformer outperforms Transformer in various settings of scaling up model size and training tokens. More intriguingly, it offers notable advantages in practical applications, such as long-context modeling, key information retrieval, hallucination mitigation, in-context learning, and reduction of activation outliers. By being less distracted by irrelevant context, Diff Transformer can mitigate hallucination in question answering and text summarization. For in-context learning, Diff Transformer not only enhances accuracy but is also more robust to order permutation, which was considered as a chronic robustness issue. The results position Diff Transformer as a highly effective and promising architecture to advance large language models.*
+
+### Usage tips
+The hyperparameters of this model is the same as Llama model.
+
+
+## DiffLlamaConfig
+
+[[autodoc]] DiffLlamaConfig
+
+## DiffLlamaModel
+
+[[autodoc]] DiffLlamaModel
+ - forward
+
+## DiffLlamaForCausalLM
+
+[[autodoc]] DiffLlamaForCausalLM
+ - forward
+
+## DiffLlamaForSequenceClassification
+
+[[autodoc]] DiffLlamaForSequenceClassification
+ - forward
+
+## DiffLlamaForQuestionAnswering
+
+[[autodoc]] DiffLlamaForQuestionAnswering
+ - forward
+
+## DiffLlamaForTokenClassification
+
+[[autodoc]] DiffLlamaForTokenClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/dinat.md b/docs/transformers/docs/source/en/model_doc/dinat.md
new file mode 100644
index 0000000000000000000000000000000000000000..cd1d67073be68770b94ff4442887853fbf788bc5
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/dinat.md
@@ -0,0 +1,95 @@
+
+
+# Dilated Neighborhood Attention Transformer
+
+
+
+
+
+## Overview
+
+DiNAT was proposed in [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001)
+by Ali Hassani and Humphrey Shi.
+
+It extends [NAT](nat) by adding a Dilated Neighborhood Attention pattern to capture global context,
+and shows significant performance improvements over it.
+
+The abstract from the paper is the following:
+
+*Transformers are quickly becoming one of the most heavily applied deep learning architectures across modalities,
+domains, and tasks. In vision, on top of ongoing efforts into plain transformers, hierarchical transformers have
+also gained significant attention, thanks to their performance and easy integration into existing frameworks.
+These models typically employ localized attention mechanisms, such as the sliding-window Neighborhood Attention (NA)
+or Swin Transformer's Shifted Window Self Attention. While effective at reducing self attention's quadratic complexity,
+local attention weakens two of the most desirable properties of self attention: long range inter-dependency modeling,
+and global receptive field. In this paper, we introduce Dilated Neighborhood Attention (DiNA), a natural, flexible and
+efficient extension to NA that can capture more global context and expand receptive fields exponentially at no
+additional cost. NA's local attention and DiNA's sparse global attention complement each other, and therefore we
+introduce Dilated Neighborhood Attention Transformer (DiNAT), a new hierarchical vision transformer built upon both.
+DiNAT variants enjoy significant improvements over strong baselines such as NAT, Swin, and ConvNeXt.
+Our large model is faster and ahead of its Swin counterpart by 1.5% box AP in COCO object detection,
+1.3% mask AP in COCO instance segmentation, and 1.1% mIoU in ADE20K semantic segmentation.
+Paired with new frameworks, our large variant is the new state of the art panoptic segmentation model on COCO (58.2 PQ)
+and ADE20K (48.5 PQ), and instance segmentation model on Cityscapes (44.5 AP) and ADE20K (35.4 AP) (no extra data).
+It also matches the state of the art specialized semantic segmentation models on ADE20K (58.2 mIoU),
+and ranks second on Cityscapes (84.5 mIoU) (no extra data). *
+
+
+
+ Neighborhood Attention with different dilation values.
+Taken from the original paper.
+
+This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
+The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
+
+## Usage tips
+
+DiNAT can be used as a *backbone*. When `output_hidden_states = True`,
+it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, height, width, num_channels)`.
+
+Notes:
+- DiNAT depends on [NATTEN](https://github.com/SHI-Labs/NATTEN/)'s implementation of Neighborhood Attention and Dilated Neighborhood Attention.
+You can install it with pre-built wheels for Linux by referring to [shi-labs.com/natten](https://shi-labs.com/natten), or build on your system by running `pip install natten`.
+Note that the latter will likely take time to compile. NATTEN does not support Windows devices yet.
+- Patch size of 4 is only supported at the moment.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiNAT.
+
+
+
+- [`DinatForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DinatConfig
+
+[[autodoc]] DinatConfig
+
+## DinatModel
+
+[[autodoc]] DinatModel
+ - forward
+
+## DinatForImageClassification
+
+[[autodoc]] DinatForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/dinov2.md b/docs/transformers/docs/source/en/model_doc/dinov2.md
new file mode 100644
index 0000000000000000000000000000000000000000..5d495de4d4e55bb684cc54efd3432e4bdb6fb1ed
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/dinov2.md
@@ -0,0 +1,174 @@
+
+
+
+
+
+
+
+
+
+
+
+
+# DINOv2
+
+[DINOv2](https://huggingface.co/papers/2304.07193) is a vision foundation model that uses [ViT](./vit) as a feature extractor for multiple downstream tasks like image classification and depth estimation. It focuses on stabilizing and accelerating training through techniques like a faster memory-efficient attention, sequence packing, improved stochastic depth, Fully Sharded Data Parallel (FSDP), and model distillation.
+
+You can find all the original DINOv2 checkpoints under the [Dinov2](https://huggingface.co/collections/facebook/dinov2-6526c98554b3d2576e071ce3) collection.
+
+> [!TIP]
+> Click on the DINOv2 models in the right sidebar for more examples of how to apply DINOv2 to different vision tasks.
+
+The example below demonstrates how to obtain an image embedding with [`Pipeline`] or the [`AutoModel`] class.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipe = pipeline(
+ task="image-classification",
+ model="facebook/dinov2-small-imagenet1k-1-layer",
+ torch_dtype=torch.float16,
+ device=0
+)
+
+pipe("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg")
+```
+
+
+
+
+```py
+import requests
+from transformers import AutoImageProcessor, AutoModelForImageClassification
+from PIL import Image
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+processor = AutoImageProcessor.from_pretrained("facebook/dinov2-small-imagenet1k-1-layer")
+model = AutoModelForImageClassification.from_pretrained(
+ "facebook/dinov2-small-imagenet1k-1-layer",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+
+inputs = processor(images=image, return_tensors="pt")
+logits = model(**inputs).logits
+predicted_class_idx = logits.argmax(-1).item()
+print("Predicted class:", model.config.id2label[predicted_class_idx])
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [torchao](../quantization/torchao) to only quantize the weights to int4.
+
+```py
+# pip install torchao
+import requests
+from transformers import TorchAoConfig, AutoImageProcessor, AutoModelForImageClassification
+from torchao.quantization import Int4WeightOnlyConfig
+from PIL import Image
+
+url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+image = Image.open(requests.get(url, stream=True).raw)
+
+processor = AutoImageProcessor.from_pretrained('facebook/dinov2-giant-imagenet1k-1-layer')
+
+quant_config = Int4WeightOnlyConfig(group_size=128)
+quantization_config = TorchAoConfig(quant_type=quant_config)
+
+model = AutoModelForImageClassification.from_pretrained(
+ 'facebook/dinov2-giant-imagenet1k-1-layer',
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ quantization_config=quantization_config
+)
+
+inputs = processor(images=image, return_tensors="pt")
+outputs = model(**inputs)
+logits = outputs.logits
+predicted_class_idx = logits.argmax(-1).item()
+print("Predicted class:", model.config.id2label[predicted_class_idx])
+```
+
+## Notes
+
+- Use [torch.jit.trace](https://pytorch.org/docs/stable/generated/torch.jit.trace.html) to speedup inference. However, it will produce some mismatched elements. The difference between the original and traced model is 1e-4.
+
+ ```py
+ import torch
+ from transformers import AutoImageProcessor, AutoModel
+ from PIL import Image
+ import requests
+
+ url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+ image = Image.open(requests.get(url, stream=True).raw)
+
+ processor = AutoImageProcessor.from_pretrained('facebook/dinov2-base')
+ model = AutoModel.from_pretrained('facebook/dinov2-base')
+
+ inputs = processor(images=image, return_tensors="pt")
+ outputs = model(**inputs)
+ last_hidden_states = outputs[0]
+
+ # We have to force return_dict=False for tracing
+ model.config.return_dict = False
+
+ with torch.no_grad():
+ traced_model = torch.jit.trace(model, [inputs.pixel_values])
+ traced_outputs = traced_model(inputs.pixel_values)
+
+ print((last_hidden_states - traced_outputs[0]).abs().max())
+ ```
+
+## Dinov2Config
+
+[[autodoc]] Dinov2Config
+
+
+
+
+## Dinov2Model
+
+[[autodoc]] Dinov2Model
+ - forward
+
+## Dinov2ForImageClassification
+
+[[autodoc]] Dinov2ForImageClassification
+ - forward
+
+
+
+
+## FlaxDinov2Model
+
+[[autodoc]] FlaxDinov2Model
+ - __call__
+
+
+## FlaxDinov2ForImageClassification
+
+[[autodoc]] FlaxDinov2ForImageClassification
+ - __call__
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/dinov2_with_registers.md b/docs/transformers/docs/source/en/model_doc/dinov2_with_registers.md
new file mode 100644
index 0000000000000000000000000000000000000000..3b12d314a5a0d4acd5a71ae4a78cc7eb377738fd
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/dinov2_with_registers.md
@@ -0,0 +1,60 @@
+
+
+# DINOv2 with Registers
+
+
+
+
+
+
+
+## Overview
+
+The DINOv2 with Registers model was proposed in [Vision Transformers Need Registers](https://arxiv.org/abs/2309.16588) by Timothée Darcet, Maxime Oquab, Julien Mairal, Piotr Bojanowski.
+
+The [Vision Transformer](vit) (ViT) is a transformer encoder model (BERT-like) originally introduced to do supervised image classification on ImageNet.
+
+Next, people figured out ways to make ViT work really well on self-supervised image feature extraction (i.e. learning meaningful features, also called embeddings) on images without requiring any labels. Some example papers here include [DINOv2](dinov2) and [MAE](vit_mae).
+
+The authors of DINOv2 noticed that ViTs have artifacts in attention maps. It’s due to the model using some image patches as “registers”. The authors propose a fix: just add some new tokens (called "register" tokens), which you only use during pre-training (and throw away afterwards). This results in:
+- no artifacts
+- interpretable attention maps
+- and improved performances.
+
+The abstract from the paper is the following:
+
+*Transformers have recently emerged as a powerful tool for learning visual representations. In this paper, we identify and characterize artifacts in feature maps of both supervised and self-supervised ViT networks. The artifacts correspond to high-norm tokens appearing during inference primarily in low-informative background areas of images, that are repurposed for internal computations. We propose a simple yet effective solution based on providing additional tokens to the input sequence of the Vision Transformer to fill that role. We show that this solution fixes that problem entirely for both supervised and self-supervised models, sets a new state of the art for self-supervised visual models on dense visual prediction tasks, enables object discovery methods with larger models, and most importantly leads to smoother feature maps and attention maps for downstream visual processing.*
+
+
+
+ Visualization of attention maps of various models trained with vs. without registers. Taken from the original paper.
+
+Tips:
+
+- Usage of DINOv2 with Registers is identical to DINOv2 without, you'll just get better performance.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/facebookresearch/dinov2).
+
+
+## Dinov2WithRegistersConfig
+
+[[autodoc]] Dinov2WithRegistersConfig
+
+## Dinov2WithRegistersModel
+
+[[autodoc]] Dinov2WithRegistersModel
+ - forward
+
+## Dinov2WithRegistersForImageClassification
+
+[[autodoc]] Dinov2WithRegistersForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/distilbert.md b/docs/transformers/docs/source/en/model_doc/distilbert.md
new file mode 100644
index 0000000000000000000000000000000000000000..cb906234501c87727efe19a62994296d953264ae
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/distilbert.md
@@ -0,0 +1,219 @@
+
+
+
+
+
+
+
+
+
+
+
+
+# DistilBERT
+
+[DistilBERT](https://huggingface.co/papers/1910.01108) is pretrained by knowledge distillation to create a smaller model with faster inference and requires less compute to train. Through a triple loss objective during pretraining, language modeling loss, distillation loss, cosine-distance loss, DistilBERT demonstrates similar performance to a larger transformer language model.
+
+You can find all the original DistilBERT checkpoints under the [DistilBERT](https://huggingface.co/distilbert) organization.
+
+> [!TIP]
+> Click on the DistilBERT models in the right sidebar for more examples of how to apply DistilBERT to different language tasks.
+
+The example below demonstrates how to classify text with [`Pipeline`], [`AutoModel`], and from the command line.
+
+
+
+
+
+```py
+from transformers import pipeline
+
+classifier = pipeline(
+ task="text-classification",
+ model="distilbert-base-uncased-finetuned-sst-2-english",
+ torch_dtype=torch.float16,
+ device=0
+)
+
+result = classifier("I love using Hugging Face Transformers!")
+print(result)
+# Output: [{'label': 'POSITIVE', 'score': 0.9998}]
+```
+
+
+
+
+
+```py
+import torch
+from transformers import AutoModelForSequenceClassification, AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained(
+ "distilbert/distilbert-base-uncased-finetuned-sst-2-english",
+)
+model = AutoModelForSequenceClassification.from_pretrained(
+ "distilbert/distilbert-base-uncased-finetuned-sst-2-english",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+inputs = tokenizer("I love using Hugging Face Transformers!", return_tensors="pt").to("cuda")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+predicted_class_id = torch.argmax(outputs.logits, dim=-1).item()
+predicted_label = model.config.id2label[predicted_class_id]
+print(f"Predicted label: {predicted_label}")
+```
+
+
+
+
+
+```bash
+echo -e "I love using Hugging Face Transformers!" | transformers-cli run --task text-classification --model distilbert-base-uncased-finetuned-sst-2-english
+```
+
+
+
+
+
+## Notes
+
+- DistilBERT doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
+ separate your segments with the separation token `tokenizer.sep_token` (or `[SEP]`).
+- DistilBERT doesn't have options to select the input positions (`position_ids` input). This could be added if
+ necessary though, just let us know if you need this option.
+
+## DistilBertConfig
+
+[[autodoc]] DistilBertConfig
+
+## DistilBertTokenizer
+
+[[autodoc]] DistilBertTokenizer
+
+## DistilBertTokenizerFast
+
+[[autodoc]] DistilBertTokenizerFast
+
+
+
+
+## DistilBertModel
+
+[[autodoc]] DistilBertModel
+ - forward
+
+## DistilBertForMaskedLM
+
+[[autodoc]] DistilBertForMaskedLM
+ - forward
+
+## DistilBertForSequenceClassification
+
+[[autodoc]] DistilBertForSequenceClassification
+ - forward
+
+## DistilBertForMultipleChoice
+
+[[autodoc]] DistilBertForMultipleChoice
+ - forward
+
+## DistilBertForTokenClassification
+
+[[autodoc]] DistilBertForTokenClassification
+ - forward
+
+## DistilBertForQuestionAnswering
+
+[[autodoc]] DistilBertForQuestionAnswering
+ - forward
+
+
+
+
+## TFDistilBertModel
+
+[[autodoc]] TFDistilBertModel
+ - call
+
+## TFDistilBertForMaskedLM
+
+[[autodoc]] TFDistilBertForMaskedLM
+ - call
+
+## TFDistilBertForSequenceClassification
+
+[[autodoc]] TFDistilBertForSequenceClassification
+ - call
+
+## TFDistilBertForMultipleChoice
+
+[[autodoc]] TFDistilBertForMultipleChoice
+ - call
+
+## TFDistilBertForTokenClassification
+
+[[autodoc]] TFDistilBertForTokenClassification
+ - call
+
+## TFDistilBertForQuestionAnswering
+
+[[autodoc]] TFDistilBertForQuestionAnswering
+ - call
+
+
+
+
+## FlaxDistilBertModel
+
+[[autodoc]] FlaxDistilBertModel
+ - __call__
+
+## FlaxDistilBertForMaskedLM
+
+[[autodoc]] FlaxDistilBertForMaskedLM
+ - __call__
+
+## FlaxDistilBertForSequenceClassification
+
+[[autodoc]] FlaxDistilBertForSequenceClassification
+ - __call__
+
+## FlaxDistilBertForMultipleChoice
+
+[[autodoc]] FlaxDistilBertForMultipleChoice
+ - __call__
+
+## FlaxDistilBertForTokenClassification
+
+[[autodoc]] FlaxDistilBertForTokenClassification
+ - __call__
+
+## FlaxDistilBertForQuestionAnswering
+
+[[autodoc]] FlaxDistilBertForQuestionAnswering
+ - __call__
+
+
+
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/dit.md b/docs/transformers/docs/source/en/model_doc/dit.md
new file mode 100644
index 0000000000000000000000000000000000000000..8848948375e85e5c7e1a68bf869a1469e467d4be
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/dit.md
@@ -0,0 +1,92 @@
+
+
+# DiT
+
+
+
+
+
+
+## Overview
+
+DiT was proposed in [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+DiT applies the self-supervised objective of [BEiT](beit) (BERT pre-training of Image Transformers) to 42 million document images, allowing for state-of-the-art results on tasks including:
+
+- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
+ 400,000 images belonging to one of 16 classes).
+- document layout analysis: the [PubLayNet](https://github.com/ibm-aur-nlp/PubLayNet) dataset (a collection of more
+ than 360,000 document images constructed by automatically parsing PubMed XML files).
+- table detection: the [ICDAR 2019 cTDaR](https://github.com/cndplab-founder/ICDAR2019_cTDaR) dataset (a collection of
+ 600 training images and 240 testing images).
+
+The abstract from the paper is the following:
+
+*Image Transformer has recently achieved significant progress for natural image understanding, either using supervised (ViT, DeiT, etc.) or self-supervised (BEiT, MAE, etc.) pre-training techniques. In this paper, we propose DiT, a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human labeled document images. We leverage DiT as the backbone network in a variety of vision-based Document AI tasks, including document image classification, document layout analysis, as well as table detection. Experiment results have illustrated that the self-supervised pre-trained DiT model achieves new state-of-the-art results on these downstream tasks, e.g. document image classification (91.11 → 92.69), document layout analysis (91.0 → 94.9) and table detection (94.23 → 96.55). *
+
+
+
+ Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378).
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
+
+## Usage tips
+
+One can directly use the weights of DiT with the AutoModel API:
+
+```python
+from transformers import AutoModel
+
+model = AutoModel.from_pretrained("microsoft/dit-base")
+```
+
+This will load the model pre-trained on masked image modeling. Note that this won't include the language modeling head on top, used to predict visual tokens.
+
+To include the head, you can load the weights into a `BeitForMaskedImageModeling` model, like so:
+
+```python
+from transformers import BeitForMaskedImageModeling
+
+model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")
+```
+
+You can also load a fine-tuned model from the [hub](https://huggingface.co/models?other=dit), like so:
+
+```python
+from transformers import AutoModelForImageClassification
+
+model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")
+```
+
+This particular checkpoint was fine-tuned on [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/), an important benchmark for document image classification.
+A notebook that illustrates inference for document image classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiT.
+
+
+
+- [`BeitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+ As DiT's architecture is equivalent to that of BEiT, one can refer to [BEiT's documentation page](beit) for all tips, code examples and notebooks.
+
diff --git a/docs/transformers/docs/source/en/model_doc/donut.md b/docs/transformers/docs/source/en/model_doc/donut.md
new file mode 100644
index 0000000000000000000000000000000000000000..fe2d2d4fe00bdff7677c32c4a8720841b4cb51ab
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/donut.md
@@ -0,0 +1,238 @@
+
+
+
+
+
+
+
+
+# Donut
+
+[Donut (Document Understanding Transformer)](https://huggingface.co/papers2111.15664) is a visual document understanding model that doesn't require an Optical Character Recognition (OCR) engine. Unlike traditional approaches that extract text using OCR before processing, Donut employs an end-to-end Transformer-based architecture to directly analyze document images. This eliminates OCR-related inefficiencies making it more accurate and adaptable to diverse languages and formats.
+
+Donut features vision encoder ([Swin](./swin)) and a text decoder ([BART](./bart)). Swin converts document images into embeddings and BART processes them into meaningful text sequences.
+
+You can find all the original Donut checkpoints under the [Naver Clova Information Extraction](https://huggingface.co/naver-clova-ix) organization.
+
+> [!TIP]
+> Click on the Donut models in the right sidebar for more examples of how to apply Donut to different language and vision tasks.
+
+The examples below demonstrate how to perform document understanding tasks using Donut with [`Pipeline`] and [`AutoModel`]
+
+
+
+
+```py
+# pip install datasets
+import torch
+from transformers import pipeline
+from PIL import Image
+
+pipeline = pipeline(
+ task="document-question-answering",
+ model="naver-clova-ix/donut-base-finetuned-docvqa",
+ device=0,
+ torch_dtype=torch.float16
+)
+dataset = load_dataset("hf-internal-testing/example-documents", split="test")
+image = dataset[0]["image"]
+
+pipeline(image=image, question="What time is the coffee break?")
+```
+
+
+
+
+```py
+# pip install datasets
+import torch
+from datasets import load_dataset
+from transformers import AutoProcessor, AutoModelForVision2Seq
+
+processor = AutoProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa")
+model = AutoModelForVision2Seq.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa")
+
+dataset = load_dataset("hf-internal-testing/example-documents", split="test")
+image = dataset[0]["image"]
+question = "What time is the coffee break?"
+task_prompt = f"{question}"
+inputs = processor(image, task_prompt, return_tensors="pt")
+
+outputs = model.generate(
+ input_ids=inputs.input_ids,
+ pixel_values=inputs.pixel_values,
+ max_length=512
+)
+answer = processor.decode(outputs[0], skip_special_tokens=True)
+print(answer)
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [torchao](../quantization/torchao) to only quantize the weights to int4.
+
+```py
+# pip install datasets torchao
+import torch
+from datasets import load_dataset
+from transformers import TorchAoConfig, AutoProcessor, AutoModelForVision2Seq
+
+quantization_config = TorchAoConfig("int4_weight_only", group_size=128)
+processor = AutoProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa")
+model = AutoModelForVision2Seq.from_pretrained("naver-clova-ix/donut-base-finetuned-docvqa", quantization_config=quantization_config)
+
+dataset = load_dataset("hf-internal-testing/example-documents", split="test")
+image = dataset[0]["image"]
+question = "What time is the coffee break?"
+task_prompt = f"{question}"
+inputs = processor(image, task_prompt, return_tensors="pt")
+
+outputs = model.generate(
+ input_ids=inputs.input_ids,
+ pixel_values=inputs.pixel_values,
+ max_length=512
+)
+answer = processor.decode(outputs[0], skip_special_tokens=True)
+print(answer)
+```
+
+## Notes
+
+- Use Donut for document image classification as shown below.
+
+ ```py
+ >>> import re
+ >>> from transformers import DonutProcessor, VisionEncoderDecoderModel
+ >>> from datasets import load_dataset
+ >>> import torch
+
+ >>> processor = DonutProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-rvlcdip")
+ >>> model = VisionEncoderDecoderModel.from_pretrained("naver-clova-ix/donut-base-finetuned-rvlcdip")
+
+ >>> device = "cuda" if torch.cuda.is_available() else "cpu"
+ >>> model.to(device) # doctest: +IGNORE_RESULT
+
+ >>> # load document image
+ >>> dataset = load_dataset("hf-internal-testing/example-documents", split="test")
+ >>> image = dataset[1]["image"]
+
+ >>> # prepare decoder inputs
+ >>> task_prompt = ""
+ >>> decoder_input_ids = processor.tokenizer(task_prompt, add_special_tokens=False, return_tensors="pt").input_ids
+
+ >>> pixel_values = processor(image, return_tensors="pt").pixel_values
+
+ >>> outputs = model.generate(
+ ... pixel_values.to(device),
+ ... decoder_input_ids=decoder_input_ids.to(device),
+ ... max_length=model.decoder.config.max_position_embeddings,
+ ... pad_token_id=processor.tokenizer.pad_token_id,
+ ... eos_token_id=processor.tokenizer.eos_token_id,
+ ... use_cache=True,
+ ... bad_words_ids=[[processor.tokenizer.unk_token_id]],
+ ... return_dict_in_generate=True,
+ ... )
+
+ >>> sequence = processor.batch_decode(outputs.sequences)[0]
+ >>> sequence = sequence.replace(processor.tokenizer.eos_token, "").replace(processor.tokenizer.pad_token, "")
+ >>> sequence = re.sub(r"<.*?>", "", sequence, count=1).strip() # remove first task start token
+ >>> print(processor.token2json(sequence))
+ {'class': 'advertisement'}
+ ```
+
+- Use Donut for document parsing as shown below.
+
+ ```py
+ >>> import re
+ >>> from transformers import DonutProcessor, VisionEncoderDecoderModel
+ >>> from datasets import load_dataset
+ >>> import torch
+
+ >>> processor = DonutProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-cord-v2")
+ >>> model = VisionEncoderDecoderModel.from_pretrained("naver-clova-ix/donut-base-finetuned-cord-v2")
+
+ >>> device = "cuda" if torch.cuda.is_available() else "cpu"
+ >>> model.to(device) # doctest: +IGNORE_RESULT
+
+ >>> # load document image
+ >>> dataset = load_dataset("hf-internal-testing/example-documents", split="test")
+ >>> image = dataset[2]["image"]
+
+ >>> # prepare decoder inputs
+ >>> task_prompt = ""
+ >>> decoder_input_ids = processor.tokenizer(task_prompt, add_special_tokens=False, return_tensors="pt").input_ids
+
+ >>> pixel_values = processor(image, return_tensors="pt").pixel_values
+
+ >>> outputs = model.generate(
+ ... pixel_values.to(device),
+ ... decoder_input_ids=decoder_input_ids.to(device),
+ ... max_length=model.decoder.config.max_position_embeddings,
+ ... pad_token_id=processor.tokenizer.pad_token_id,
+ ... eos_token_id=processor.tokenizer.eos_token_id,
+ ... use_cache=True,
+ ... bad_words_ids=[[processor.tokenizer.unk_token_id]],
+ ... return_dict_in_generate=True,
+ ... )
+
+ >>> sequence = processor.batch_decode(outputs.sequences)[0]
+ >>> sequence = sequence.replace(processor.tokenizer.eos_token, "").replace(processor.tokenizer.pad_token, "")
+ >>> sequence = re.sub(r"<.*?>", "", sequence, count=1).strip() # remove first task start token
+ >>> print(processor.token2json(sequence))
+ {'menu': {'nm': 'CINNAMON SUGAR', 'unitprice': '17,000', 'cnt': '1 x', 'price': '17,000'}, 'sub_total': {'subtotal_price': '17,000'}, 'total':
+ {'total_price': '17,000', 'cashprice': '20,000', 'changeprice': '3,000'}}
+ ```
+
+## DonutSwinConfig
+
+[[autodoc]] DonutSwinConfig
+
+## DonutImageProcessor
+
+[[autodoc]] DonutImageProcessor
+ - preprocess
+
+## DonutImageProcessorFast
+
+[[autodoc]] DonutImageProcessorFast
+ - preprocess
+
+## DonutFeatureExtractor
+
+[[autodoc]] DonutFeatureExtractor
+ - __call__
+
+## DonutProcessor
+
+[[autodoc]] DonutProcessor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+
+## DonutSwinModel
+
+[[autodoc]] DonutSwinModel
+ - forward
+
+## DonutSwinForImageClassification
+
+[[autodoc]] transformers.DonutSwinForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/dpr.md b/docs/transformers/docs/source/en/model_doc/dpr.md
new file mode 100644
index 0000000000000000000000000000000000000000..0f6b19c90014b0eef86c9c0c57cb115443ae79f7
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/dpr.md
@@ -0,0 +1,125 @@
+
+
+# DPR
+
+
+
+
+
+
+
+## Overview
+
+Dense Passage Retrieval (DPR) is a set of tools and models for state-of-the-art open-domain Q&A research. It was
+introduced in [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by
+Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih.
+
+The abstract from the paper is the following:
+
+*Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional
+sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can
+be practically implemented using dense representations alone, where embeddings are learned from a small number of
+questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets,
+our dense retriever outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage
+retrieval accuracy, and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA
+benchmarks.*
+
+This model was contributed by [lhoestq](https://huggingface.co/lhoestq). The original code can be found [here](https://github.com/facebookresearch/DPR).
+
+## Usage tips
+
+- DPR consists in three models:
+
+ * Question encoder: encode questions as vectors
+ * Context encoder: encode contexts as vectors
+ * Reader: extract the answer of the questions inside retrieved contexts, along with a relevance score (high if the inferred span actually answers the question).
+
+## DPRConfig
+
+[[autodoc]] DPRConfig
+
+## DPRContextEncoderTokenizer
+
+[[autodoc]] DPRContextEncoderTokenizer
+
+## DPRContextEncoderTokenizerFast
+
+[[autodoc]] DPRContextEncoderTokenizerFast
+
+## DPRQuestionEncoderTokenizer
+
+[[autodoc]] DPRQuestionEncoderTokenizer
+
+## DPRQuestionEncoderTokenizerFast
+
+[[autodoc]] DPRQuestionEncoderTokenizerFast
+
+## DPRReaderTokenizer
+
+[[autodoc]] DPRReaderTokenizer
+
+## DPRReaderTokenizerFast
+
+[[autodoc]] DPRReaderTokenizerFast
+
+## DPR specific outputs
+
+[[autodoc]] models.dpr.modeling_dpr.DPRContextEncoderOutput
+
+[[autodoc]] models.dpr.modeling_dpr.DPRQuestionEncoderOutput
+
+[[autodoc]] models.dpr.modeling_dpr.DPRReaderOutput
+
+
+
+
+## DPRContextEncoder
+
+[[autodoc]] DPRContextEncoder
+ - forward
+
+## DPRQuestionEncoder
+
+[[autodoc]] DPRQuestionEncoder
+ - forward
+
+## DPRReader
+
+[[autodoc]] DPRReader
+ - forward
+
+
+
+
+## TFDPRContextEncoder
+
+[[autodoc]] TFDPRContextEncoder
+ - call
+
+## TFDPRQuestionEncoder
+
+[[autodoc]] TFDPRQuestionEncoder
+ - call
+
+## TFDPRReader
+
+[[autodoc]] TFDPRReader
+ - call
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/dpt.md b/docs/transformers/docs/source/en/model_doc/dpt.md
new file mode 100644
index 0000000000000000000000000000000000000000..95e422dee862a3b9bde9b5cbcdd7adac50ef7bb7
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/dpt.md
@@ -0,0 +1,96 @@
+
+
+# DPT
+
+
+
+
+
+
+
+## Overview
+
+The DPT model was proposed in [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+DPT is a model that leverages the [Vision Transformer (ViT)](vit) as backbone for dense prediction tasks like semantic segmentation and depth estimation.
+
+The abstract from the paper is the following:
+
+*We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art.*
+
+
+
+ DPT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/isl-org/DPT).
+
+## Usage tips
+
+DPT is compatible with the [`AutoBackbone`] class. This allows to use the DPT framework with various computer vision backbones available in the library, such as [`VitDetBackbone`] or [`Dinov2Backbone`]. One can create it as follows:
+
+```python
+from transformers import Dinov2Config, DPTConfig, DPTForDepthEstimation
+
+# initialize with a Transformer-based backbone such as DINOv2
+# in that case, we also specify `reshape_hidden_states=False` to get feature maps of shape (batch_size, num_channels, height, width)
+backbone_config = Dinov2Config.from_pretrained("facebook/dinov2-base", out_features=["stage1", "stage2", "stage3", "stage4"], reshape_hidden_states=False)
+
+config = DPTConfig(backbone_config=backbone_config)
+model = DPTForDepthEstimation(config=config)
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DPT.
+
+- Demo notebooks for [`DPTForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DPT).
+
+- [Semantic segmentation task guide](../tasks/semantic_segmentation)
+- [Monocular depth estimation task guide](../tasks/monocular_depth_estimation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DPTConfig
+
+[[autodoc]] DPTConfig
+
+## DPTFeatureExtractor
+
+[[autodoc]] DPTFeatureExtractor
+ - __call__
+ - post_process_semantic_segmentation
+
+## DPTImageProcessor
+
+[[autodoc]] DPTImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
+## DPTModel
+
+[[autodoc]] DPTModel
+ - forward
+
+## DPTForDepthEstimation
+
+[[autodoc]] DPTForDepthEstimation
+ - forward
+
+## DPTForSemanticSegmentation
+
+[[autodoc]] DPTForSemanticSegmentation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/efficientformer.md b/docs/transformers/docs/source/en/model_doc/efficientformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..f05ccacc3dbf596ad590ce001b9b3480565bed90
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/efficientformer.md
@@ -0,0 +1,109 @@
+
+
+# EfficientFormer
+
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+The EfficientFormer model was proposed in [EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/abs/2206.01191)
+by Yanyu Li, Geng Yuan, Yang Wen, Eric Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren. EfficientFormer proposes a
+dimension-consistent pure transformer that can be run on mobile devices for dense prediction tasks like image classification, object
+detection and semantic segmentation.
+
+The abstract from the paper is the following:
+
+*Vision Transformers (ViT) have shown rapid progress in computer vision tasks, achieving promising results on various benchmarks.
+However, due to the massive number of parameters and model design, e.g., attention mechanism, ViT-based models are generally
+times slower than lightweight convolutional networks. Therefore, the deployment of ViT for real-time applications is particularly
+challenging, especially on resource-constrained hardware such as mobile devices. Recent efforts try to reduce the computation
+complexity of ViT through network architecture search or hybrid design with MobileNet block, yet the inference speed is still
+unsatisfactory. This leads to an important question: can transformers run as fast as MobileNet while obtaining high performance?
+To answer this, we first revisit the network architecture and operators used in ViT-based models and identify inefficient designs.
+Then we introduce a dimension-consistent pure transformer (without MobileNet blocks) as a design paradigm.
+Finally, we perform latency-driven slimming to get a series of final models dubbed EfficientFormer.
+Extensive experiments show the superiority of EfficientFormer in performance and speed on mobile devices.
+Our fastest model, EfficientFormer-L1, achieves 79.2% top-1 accuracy on ImageNet-1K with only 1.6 ms inference latency on
+iPhone 12 (compiled with CoreML), which { runs as fast as MobileNetV2×1.4 (1.6 ms, 74.7% top-1),} and our largest model,
+EfficientFormer-L7, obtains 83.3% accuracy with only 7.0 ms latency. Our work proves that properly designed transformers can
+reach extremely low latency on mobile devices while maintaining high performance.*
+
+This model was contributed by [novice03](https://huggingface.co/novice03) and [Bearnardd](https://huggingface.co/Bearnardd).
+The original code can be found [here](https://github.com/snap-research/EfficientFormer). The TensorFlow version of this model was added by [D-Roberts](https://huggingface.co/D-Roberts).
+
+## Documentation resources
+
+- [Image classification task guide](../tasks/image_classification)
+
+## EfficientFormerConfig
+
+[[autodoc]] EfficientFormerConfig
+
+## EfficientFormerImageProcessor
+
+[[autodoc]] EfficientFormerImageProcessor
+ - preprocess
+
+
+
+
+## EfficientFormerModel
+
+[[autodoc]] EfficientFormerModel
+ - forward
+
+## EfficientFormerForImageClassification
+
+[[autodoc]] EfficientFormerForImageClassification
+ - forward
+
+## EfficientFormerForImageClassificationWithTeacher
+
+[[autodoc]] EfficientFormerForImageClassificationWithTeacher
+ - forward
+
+
+
+
+## TFEfficientFormerModel
+
+[[autodoc]] TFEfficientFormerModel
+ - call
+
+## TFEfficientFormerForImageClassification
+
+[[autodoc]] TFEfficientFormerForImageClassification
+ - call
+
+## TFEfficientFormerForImageClassificationWithTeacher
+
+[[autodoc]] TFEfficientFormerForImageClassificationWithTeacher
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/efficientnet.md b/docs/transformers/docs/source/en/model_doc/efficientnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..17a96aeb5ad42c1a74e56052b928cbdea2fff234
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/efficientnet.md
@@ -0,0 +1,60 @@
+
+
+# EfficientNet
+
+
+
+
+
+## Overview
+
+The EfficientNet model was proposed in [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)
+by Mingxing Tan and Quoc V. Le. EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, yet being an order-of-magnitude smaller and faster than previous models.
+
+The abstract from the paper is the following:
+
+*Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
+To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.3% top-1 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters.*
+
+This model was contributed by [adirik](https://huggingface.co/adirik).
+The original code can be found [here](https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet).
+
+
+## EfficientNetConfig
+
+[[autodoc]] EfficientNetConfig
+
+## EfficientNetImageProcessor
+
+[[autodoc]] EfficientNetImageProcessor
+ - preprocess
+
+## EfficientNetImageProcessorFast
+
+[[autodoc]] EfficientNetImageProcessorFast
+ - preprocess
+
+## EfficientNetModel
+
+[[autodoc]] EfficientNetModel
+ - forward
+
+## EfficientNetForImageClassification
+
+[[autodoc]] EfficientNetForImageClassification
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/electra.md b/docs/transformers/docs/source/en/model_doc/electra.md
new file mode 100644
index 0000000000000000000000000000000000000000..9506d6dba1c08f1750264fe0215be4cbaa47f56b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/electra.md
@@ -0,0 +1,250 @@
+
+
+
+
+
+
+
+
+
+
+
+# ELECTRA
+
+[ELECTRA](https://huggingface.co/papers/2003.10555) modifies the pretraining objective of traditional masked language models like BERT. Instead of just masking tokens and asking the model to predict them, ELECTRA trains two models, a generator and a discriminator. The generator replaces some tokens with plausible alternatives and the discriminator (the model you'll actually use) learns to detect which tokens are original and which were replaced. This training approach is very efficient and scales to larger models while using considerably less compute.
+
+This approach is super efficient because ELECTRA learns from every single token in the input, not just the masked ones. That's why even the small ELECTRA models can match or outperform much larger models while using way less computing resources.
+
+You can find all the original ELECTRA checkpoints under the [ELECTRA](https://huggingface.co/collections/google/electra-release-64ff6e8b18830fabea30a1ab) release.
+
+> [!TIP]
+> Click on the right sidebar for more examples of how to use ELECTRA for different language tasks like sequence classification, token classification, and question answering.
+
+The example below demonstrates how to classify text with [`Pipeline`] or the [`AutoModel`] class.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+classifier = pipeline(
+ task="text-classification",
+ model="bhadresh-savani/electra-base-emotion",
+ torch_dtype=torch.float16,
+ device=0
+)
+classifier("This restaurant has amazing food!")
+```
+
+
+
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForSequenceClassification
+
+tokenizer = AutoTokenizer.from_pretrained(
+ "bhadresh-savani/electra-base-emotion",
+)
+model = AutoModelForSequenceClassification.from_pretrained(
+ "bhadresh-savani/electra-base-emotion",
+ torch_dtype=torch.float16
+)
+inputs = tokenizer("ELECTRA is more efficient than BERT", return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+ logits = outputs.logits
+ predicted_class_id = logits.argmax(dim=-1).item()
+ predicted_label = model.config.id2label[predicted_class_id]
+print(f"Predicted label: {predicted_label}")
+```
+
+
+
+
+```bash
+echo -e "This restaurant has amazing food." | transformers-cli run --task text-classification --model bhadresh-savani/electra-base-emotion --device 0
+```
+
+
+
+
+## Notes
+
+- ELECTRA consists of two transformer models, a generator (G) and a discriminator (D). For most downstream tasks, use the discriminator model (as indicated by `*-discriminator` in the name) rather than the generator.
+- ELECTRA comes in three sizes: small (14M parameters), base (110M parameters), and large (335M parameters).
+- ELECTRA can use a smaller embedding size than the hidden size for efficiency. When `embedding_size` is smaller than `hidden_size` in the configuration, a projection layer connects them.
+- When using batched inputs with padding, make sure to use attention masks to prevent the model from attending to padding tokens.
+
+ ```py
+ # Example of properly handling padding with attention masks
+ inputs = tokenizer(["Short text", "This is a much longer text that needs padding"],
+ padding=True,
+ return_tensors="pt")
+ outputs = model(**inputs) # automatically uses the attention_mask
+ ```
+
+- When using the discriminator for a downstream task, you can load it into any of the ELECTRA model classes ([`ElectraForSequenceClassification`], [`ElectraForTokenClassification`], etc.).
+
+## ElectraConfig
+
+[[autodoc]] ElectraConfig
+
+## ElectraTokenizer
+
+[[autodoc]] ElectraTokenizer
+
+## ElectraTokenizerFast
+
+[[autodoc]] ElectraTokenizerFast
+
+## Electra specific outputs
+
+[[autodoc]] models.electra.modeling_electra.ElectraForPreTrainingOutput
+
+[[autodoc]] models.electra.modeling_tf_electra.TFElectraForPreTrainingOutput
+
+
+
+
+## ElectraModel
+
+[[autodoc]] ElectraModel
+ - forward
+
+## ElectraForPreTraining
+
+[[autodoc]] ElectraForPreTraining
+ - forward
+
+## ElectraForCausalLM
+
+[[autodoc]] ElectraForCausalLM
+ - forward
+
+## ElectraForMaskedLM
+
+[[autodoc]] ElectraForMaskedLM
+ - forward
+
+## ElectraForSequenceClassification
+
+[[autodoc]] ElectraForSequenceClassification
+ - forward
+
+## ElectraForMultipleChoice
+
+[[autodoc]] ElectraForMultipleChoice
+ - forward
+
+## ElectraForTokenClassification
+
+[[autodoc]] ElectraForTokenClassification
+ - forward
+
+## ElectraForQuestionAnswering
+
+[[autodoc]] ElectraForQuestionAnswering
+ - forward
+
+
+
+
+## TFElectraModel
+
+[[autodoc]] TFElectraModel
+ - call
+
+## TFElectraForPreTraining
+
+[[autodoc]] TFElectraForPreTraining
+ - call
+
+## TFElectraForMaskedLM
+
+[[autodoc]] TFElectraForMaskedLM
+ - call
+
+## TFElectraForSequenceClassification
+
+[[autodoc]] TFElectraForSequenceClassification
+ - call
+
+## TFElectraForMultipleChoice
+
+[[autodoc]] TFElectraForMultipleChoice
+ - call
+
+## TFElectraForTokenClassification
+
+[[autodoc]] TFElectraForTokenClassification
+ - call
+
+## TFElectraForQuestionAnswering
+
+[[autodoc]] TFElectraForQuestionAnswering
+ - call
+
+
+
+
+## FlaxElectraModel
+
+[[autodoc]] FlaxElectraModel
+ - __call__
+
+## FlaxElectraForPreTraining
+
+[[autodoc]] FlaxElectraForPreTraining
+ - __call__
+
+## FlaxElectraForCausalLM
+
+[[autodoc]] FlaxElectraForCausalLM
+ - __call__
+
+## FlaxElectraForMaskedLM
+
+[[autodoc]] FlaxElectraForMaskedLM
+ - __call__
+
+## FlaxElectraForSequenceClassification
+
+[[autodoc]] FlaxElectraForSequenceClassification
+ - __call__
+
+## FlaxElectraForMultipleChoice
+
+[[autodoc]] FlaxElectraForMultipleChoice
+ - __call__
+
+## FlaxElectraForTokenClassification
+
+[[autodoc]] FlaxElectraForTokenClassification
+ - __call__
+
+## FlaxElectraForQuestionAnswering
+
+[[autodoc]] FlaxElectraForQuestionAnswering
+ - __call__
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/emu3.md b/docs/transformers/docs/source/en/model_doc/emu3.md
new file mode 100644
index 0000000000000000000000000000000000000000..4ac7d0b0c4f1ae161a49dfe95d1269024f6ca7d7
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/emu3.md
@@ -0,0 +1,185 @@
+
+
+# Emu3
+
+
+
+
+
+
+
+## Overview
+
+The Emu3 model was proposed in [Emu3: Next-Token Prediction is All You Need](https://arxiv.org/abs/2409.18869) by Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, Zhongyuan Wang.
+
+Emu3 is a multimodal LLM that uses vector quantization to tokenize images into discrete tokens. Discretized image tokens are later fused with text token ids for image and text generation. The model can additionally generate images by predicting image token ids.
+
+
+The abstract from the paper is the following:
+
+*While next-token prediction is considered a promising path towards artificial general intelligence, it has struggled to excel in multimodal tasks, which are still dominated by diffusion models (e.g., Stable Diffusion) and compositional approaches (e.g., CLIP combined with LLMs). In this paper, we introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction. By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences. Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship models such as SDXL and LLaVA-1.6, while eliminating the need for diffusion or compositional architectures. Emu3 is also capable of generating high-fidelity video via predicting the next token in a video sequence. We simplify complex multimodal model designs by converging on a singular focus: tokens, unlocking great potential for scaling both during training and inference. Our results demonstrate that next-token prediction is a promising path towards building general multimodal intelligence beyond language. We open-source key techniques and models to support further research in this direction.*
+
+Tips:
+
+- We advise users to set `processor.tokenizer.padding_side = "left"` before batched generation as it leads to more accurate results.
+
+- Note that the model has been trained with a specific prompt format for chatting. Use `processor.apply_chat_template(my_conversation_dict)` to correctly format your prompts.
+
+- Emu3 has two different checkpoints for image-generation and text-generation, make sure to use the correct checkpoint when loading the model. To generate an image, it is advised to use `prefix_constraints` so that the generated tokens are sampled only from possible image tokens. See more below for usage examples.
+
+> [!TIP]
+> Emu3 implementation in Transformers uses a special image token to indicate where to merge image embeddings. The special image token isn't new and uses one of the reserved tokens: `<|extra_0|>`. You have to add `` to your prompt in the place where the image should be embedded for correct generation.
+
+
+This model was contributed by [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
+The original code can be found [here](https://github.com/baaivision/Emu3).
+
+
+## Usage example
+
+### Text generation inference
+
+Here's how to load the model and perform inference in half-precision (`torch.bfloat16`) to generate textual output from text or text and image inputs:
+
+```python
+from transformers import Emu3Processor, Emu3ForConditionalGeneration
+import torch
+from PIL import Image
+import requests
+
+processor = Emu3Processor.from_pretrained("BAAI/Emu3-Chat-hf")
+model = Emu3ForConditionalGeneration.from_pretrained("BAAI/Emu3-Chat-hf", torch_dtype=torch.bfloat16, device_map="cuda")
+
+# prepare image and text prompt
+url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+image = Image.open(requests.get(url, stream=True).raw)
+prompt = "What do you see in this image?"
+
+inputs = processor(images=image, text=prompt, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+# autoregressively complete prompt
+output = model.generate(**inputs, max_new_tokens=50)
+print(processor.decode(output[0], skip_special_tokens=True))
+```
+
+### Image generation inference
+
+Emu3 can also generate images from textual input. Here is how you can do it:
+
+```python
+processor = Emu3Processor.from_pretrained("BAAI/Emu3-Gen-hf")
+model = Emu3ForConditionalGeneration.from_pretrained("BAAI/Emu3-Gen-hf", torch_dtype="bfloat16", device_map="auto", attn_implementation="flash_attention_2")
+
+
+inputs = processor(
+ text=["a portrait of young girl. masterpiece, film grained, best quality.", "a dog running under the rain"],
+ padding=True,
+ return_tensors="pt",
+ return_for_image_generation=True,
+)
+inputs = inputs.to(device="cuda:0", dtype=torch.bfloat16)
+
+neg_prompt = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry."
+neg_inputs = processor(text=[neg_prompt] * 2, return_tensors="pt").to(device="cuda:0")
+
+image_sizes = inputs.pop("image_sizes")
+HEIGHT, WIDTH = image_sizes[0]
+VISUAL_TOKENS = model.vocabulary_mapping.image_tokens
+
+def prefix_allowed_tokens_fn(batch_id, input_ids):
+ height, width = HEIGHT, WIDTH
+ visual_tokens = VISUAL_TOKENS
+ image_wrapper_token_id = torch.tensor([processor.tokenizer.image_wrapper_token_id], device=model.device)
+ eoi_token_id = torch.tensor([processor.tokenizer.eoi_token_id], device=model.device)
+ eos_token_id = torch.tensor([processor.tokenizer.eos_token_id], device=model.device)
+ pad_token_id = torch.tensor([processor.tokenizer.pad_token_id], device=model.device)
+ eof_token_id = torch.tensor([processor.tokenizer.eof_token_id], device=model.device)
+ eol_token_id = processor.tokenizer.encode("<|extra_200|>", return_tensors="pt")[0]
+
+ position = torch.nonzero(input_ids == image_wrapper_token_id, as_tuple=True)[0][0]
+ offset = input_ids.shape[0] - position
+ if offset % (width + 1) == 0:
+ return (eol_token_id, )
+ elif offset == (width + 1) * height + 1:
+ return (eof_token_id, )
+ elif offset == (width + 1) * height + 2:
+ return (eoi_token_id, )
+ elif offset == (width + 1) * height + 3:
+ return (eos_token_id, )
+ elif offset > (width + 1) * height + 3:
+ return (pad_token_id, )
+ else:
+ return visual_tokens
+
+
+out = model.generate(
+ **inputs,
+ max_new_tokens=50_000, # make sure to have enough tokens for one image
+ prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
+ return_dict_in_generate=True,
+ negative_prompt_ids=neg_inputs.input_ids, # indicate for Classifier-Free Guidance
+ negative_prompt_attention_mask=neg_inputs.attention_mask,
+)
+
+image = model.decode_image_tokens(out.sequences[:, inputs.input_ids.shape[1]: ], height=HEIGHT, width=WIDTH)
+images = processor.postprocess(list(image.float()), return_tensors="PIL.Image.Image") # internally we convert to np but it's not supported in bf16 precision
+for i, image in enumerate(images['pixel_values']):
+ image.save(f"result{i}.png")
+
+```
+
+
+## Emu3Config
+
+[[autodoc]] Emu3Config
+
+## Emu3VQVAEConfig
+
+[[autodoc]] Emu3VQVAEConfig
+
+## Emu3TextConfig
+
+[[autodoc]] Emu3TextConfig
+
+## Emu3Processor
+
+[[autodoc]] Emu3Processor
+
+## Emu3ImageProcessor
+
+[[autodoc]] Emu3ImageProcessor
+ - preprocess
+
+## Emu3VQVAE
+
+[[autodoc]] Emu3VQVAE
+ - forward
+
+## Emu3TextModel
+
+[[autodoc]] Emu3TextModel
+ - forward
+
+## Emu3ForCausalLM
+
+[[autodoc]] Emu3ForCausalLM
+ - forward
+
+## Emu3ForConditionalGeneration
+
+[[autodoc]] Emu3ForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/encodec.md b/docs/transformers/docs/source/en/model_doc/encodec.md
new file mode 100644
index 0000000000000000000000000000000000000000..893954d5cf867d54c2578960e7a3b4c71b56b6f0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/encodec.md
@@ -0,0 +1,69 @@
+
+
+# EnCodec
+
+
+
+
+
+## Overview
+
+The EnCodec neural codec model was proposed in [High Fidelity Neural Audio Compression](https://arxiv.org/abs/2210.13438) by Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi.
+
+The abstract from the paper is the following:
+
+*We introduce a state-of-the-art real-time, high-fidelity, audio codec leveraging neural networks. It consists in a streaming encoder-decoder architecture with quantized latent space trained in an end-to-end fashion. We simplify and speed-up the training by using a single multiscale spectrogram adversary that efficiently reduces artifacts and produce high-quality samples. We introduce a novel loss balancer mechanism to stabilize training: the weight of a loss now defines the fraction of the overall gradient it should represent, thus decoupling the choice of this hyper-parameter from the typical scale of the loss. Finally, we study how lightweight Transformer models can be used to further compress the obtained representation by up to 40%, while staying faster than real time. We provide a detailed description of the key design choices of the proposed model including: training objective, architectural changes and a study of various perceptual loss functions. We present an extensive subjective evaluation (MUSHRA tests) together with an ablation study for a range of bandwidths and audio domains, including speech, noisy-reverberant speech, and music. Our approach is superior to the baselines methods across all evaluated settings, considering both 24 kHz monophonic and 48 kHz stereophonic audio.*
+
+This model was contributed by [Matthijs](https://huggingface.co/Matthijs), [Patrick Von Platen](https://huggingface.co/patrickvonplaten) and [Arthur Zucker](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/facebookresearch/encodec).
+
+## Usage example
+
+Here is a quick example of how to encode and decode an audio using this model:
+
+```python
+>>> from datasets import load_dataset, Audio
+>>> from transformers import EncodecModel, AutoProcessor
+>>> librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+
+>>> model = EncodecModel.from_pretrained("facebook/encodec_24khz")
+>>> processor = AutoProcessor.from_pretrained("facebook/encodec_24khz")
+>>> librispeech_dummy = librispeech_dummy.cast_column("audio", Audio(sampling_rate=processor.sampling_rate))
+>>> audio_sample = librispeech_dummy[-1]["audio"]["array"]
+>>> inputs = processor(raw_audio=audio_sample, sampling_rate=processor.sampling_rate, return_tensors="pt")
+
+>>> encoder_outputs = model.encode(inputs["input_values"], inputs["padding_mask"])
+>>> audio_values = model.decode(encoder_outputs.audio_codes, encoder_outputs.audio_scales, inputs["padding_mask"])[0]
+>>> # or the equivalent with a forward pass
+>>> audio_values = model(inputs["input_values"], inputs["padding_mask"]).audio_values
+```
+
+## EncodecConfig
+
+[[autodoc]] EncodecConfig
+
+## EncodecFeatureExtractor
+
+[[autodoc]] EncodecFeatureExtractor
+ - __call__
+
+## EncodecModel
+
+[[autodoc]] EncodecModel
+ - decode
+ - encode
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/encoder-decoder.md b/docs/transformers/docs/source/en/model_doc/encoder-decoder.md
new file mode 100644
index 0000000000000000000000000000000000000000..d0a676fb33a6d6c60e006f60976a8fa8ee26e00e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/encoder-decoder.md
@@ -0,0 +1,188 @@
+
+
+# Encoder Decoder Models
+
+
+
+
+
+
+
+
+## Overview
+
+The [`EncoderDecoderModel`] can be used to initialize a sequence-to-sequence model with any
+pretrained autoencoding model as the encoder and any pretrained autoregressive model as the decoder.
+
+The effectiveness of initializing sequence-to-sequence models with pretrained checkpoints for sequence generation tasks
+was shown in [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by
+Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+
+After such an [`EncoderDecoderModel`] has been trained/fine-tuned, it can be saved/loaded just like
+any other models (see the examples for more information).
+
+An application of this architecture could be to leverage two pretrained [`BertModel`] as the encoder
+and decoder for a summarization model as was shown in: [Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345) by Yang Liu and Mirella Lapata.
+
+## Randomly initializing `EncoderDecoderModel` from model configurations.
+
+[`EncoderDecoderModel`] can be randomly initialized from an encoder and a decoder config. In the following example, we show how to do this using the default [`BertModel`] configuration for the encoder and the default [`BertForCausalLM`] configuration for the decoder.
+
+```python
+>>> from transformers import BertConfig, EncoderDecoderConfig, EncoderDecoderModel
+
+>>> config_encoder = BertConfig()
+>>> config_decoder = BertConfig()
+
+>>> config = EncoderDecoderConfig.from_encoder_decoder_configs(config_encoder, config_decoder)
+>>> model = EncoderDecoderModel(config=config)
+```
+
+## Initialising `EncoderDecoderModel` from a pretrained encoder and a pretrained decoder.
+
+[`EncoderDecoderModel`] can be initialized from a pretrained encoder checkpoint and a pretrained decoder checkpoint. Note that any pretrained auto-encoding model, *e.g.* BERT, can serve as the encoder and both pretrained auto-encoding models, *e.g.* BERT, pretrained causal language models, *e.g.* GPT2, as well as the pretrained decoder part of sequence-to-sequence models, *e.g.* decoder of BART, can be used as the decoder.
+Depending on which architecture you choose as the decoder, the cross-attention layers might be randomly initialized.
+Initializing [`EncoderDecoderModel`] from a pretrained encoder and decoder checkpoint requires the model to be fine-tuned on a downstream task, as has been shown in [the *Warm-starting-encoder-decoder blog post*](https://huggingface.co/blog/warm-starting-encoder-decoder).
+To do so, the `EncoderDecoderModel` class provides a [`EncoderDecoderModel.from_encoder_decoder_pretrained`] method.
+
+```python
+>>> from transformers import EncoderDecoderModel, BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = EncoderDecoderModel.from_encoder_decoder_pretrained("google-bert/bert-base-uncased", "google-bert/bert-base-uncased")
+```
+
+## Loading an existing `EncoderDecoderModel` checkpoint and perform inference.
+
+To load fine-tuned checkpoints of the `EncoderDecoderModel` class, [`EncoderDecoderModel`] provides the `from_pretrained(...)` method just like any other model architecture in Transformers.
+
+To perform inference, one uses the [`generate`] method, which allows to autoregressively generate text. This method supports various forms of decoding, such as greedy, beam search and multinomial sampling.
+
+```python
+>>> from transformers import AutoTokenizer, EncoderDecoderModel
+
+>>> # load a fine-tuned seq2seq model and corresponding tokenizer
+>>> model = EncoderDecoderModel.from_pretrained("patrickvonplaten/bert2bert_cnn_daily_mail")
+>>> tokenizer = AutoTokenizer.from_pretrained("patrickvonplaten/bert2bert_cnn_daily_mail")
+
+>>> # let's perform inference on a long piece of text
+>>> ARTICLE_TO_SUMMARIZE = (
+... "PG&E stated it scheduled the blackouts in response to forecasts for high winds "
+... "amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were "
+... "scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."
+... )
+>>> input_ids = tokenizer(ARTICLE_TO_SUMMARIZE, return_tensors="pt").input_ids
+
+>>> # autoregressively generate summary (uses greedy decoding by default)
+>>> generated_ids = model.generate(input_ids)
+>>> generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+>>> print(generated_text)
+nearly 800 thousand customers were affected by the shutoffs. the aim is to reduce the risk of wildfires. nearly 800, 000 customers were expected to be affected by high winds amid dry conditions. pg & e said it scheduled the blackouts to last through at least midday tomorrow.
+```
+
+## Loading a PyTorch checkpoint into `TFEncoderDecoderModel`.
+
+[`TFEncoderDecoderModel.from_pretrained`] currently doesn't support initializing the model from a
+pytorch checkpoint. Passing `from_pt=True` to this method will throw an exception. If there are only pytorch
+checkpoints for a particular encoder-decoder model, a workaround is:
+
+```python
+>>> # a workaround to load from pytorch checkpoint
+>>> from transformers import EncoderDecoderModel, TFEncoderDecoderModel
+
+>>> _model = EncoderDecoderModel.from_pretrained("patrickvonplaten/bert2bert-cnn_dailymail-fp16")
+
+>>> _model.encoder.save_pretrained("./encoder")
+>>> _model.decoder.save_pretrained("./decoder")
+
+>>> model = TFEncoderDecoderModel.from_encoder_decoder_pretrained(
+... "./encoder", "./decoder", encoder_from_pt=True, decoder_from_pt=True
+... )
+>>> # This is only for copying some specific attributes of this particular model.
+>>> model.config = _model.config
+```
+
+## Training
+
+Once the model is created, it can be fine-tuned similar to BART, T5 or any other encoder-decoder model.
+As you can see, only 2 inputs are required for the model in order to compute a loss: `input_ids` (which are the
+`input_ids` of the encoded input sequence) and `labels` (which are the `input_ids` of the encoded
+target sequence).
+
+```python
+>>> from transformers import BertTokenizer, EncoderDecoderModel
+
+>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = EncoderDecoderModel.from_encoder_decoder_pretrained("google-bert/bert-base-uncased", "google-bert/bert-base-uncased")
+
+>>> model.config.decoder_start_token_id = tokenizer.cls_token_id
+>>> model.config.pad_token_id = tokenizer.pad_token_id
+
+>>> input_ids = tokenizer(
+... "The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side.During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930. It was the first structure to reach a height of 300 metres. Due to the addition of a broadcasting aerial at the top of the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft).Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct.",
+... return_tensors="pt",
+... ).input_ids
+
+>>> labels = tokenizer(
+... "the eiffel tower surpassed the washington monument to become the tallest structure in the world. it was the first structure to reach a height of 300 metres in paris in 1930. it is now taller than the chrysler building by 5. 2 metres ( 17 ft ) and is the second tallest free - standing structure in paris.",
+... return_tensors="pt",
+... ).input_ids
+
+>>> # the forward function automatically creates the correct decoder_input_ids
+>>> loss = model(input_ids=input_ids, labels=labels).loss
+```
+
+Detailed [colab](https://colab.research.google.com/drive/1WIk2bxglElfZewOHboPFNj8H44_VAyKE?usp=sharing#scrollTo=ZwQIEhKOrJpl) for training.
+
+This model was contributed by [thomwolf](https://github.com/thomwolf). This model's TensorFlow and Flax versions
+were contributed by [ydshieh](https://github.com/ydshieh).
+
+
+## EncoderDecoderConfig
+
+[[autodoc]] EncoderDecoderConfig
+
+
+
+
+## EncoderDecoderModel
+
+[[autodoc]] EncoderDecoderModel
+ - forward
+ - from_encoder_decoder_pretrained
+
+
+
+
+## TFEncoderDecoderModel
+
+[[autodoc]] TFEncoderDecoderModel
+ - call
+ - from_encoder_decoder_pretrained
+
+
+
+
+## FlaxEncoderDecoderModel
+
+[[autodoc]] FlaxEncoderDecoderModel
+ - __call__
+ - from_encoder_decoder_pretrained
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/ernie.md b/docs/transformers/docs/source/en/model_doc/ernie.md
new file mode 100644
index 0000000000000000000000000000000000000000..82f2a0d5ba817fc38f7db64b696e97980e760b3a
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/ernie.md
@@ -0,0 +1,119 @@
+
+
+# ERNIE
+
+
+
+
+
+## Overview
+ERNIE is a series of powerful models proposed by baidu, especially in Chinese tasks,
+including [ERNIE1.0](https://arxiv.org/abs/1904.09223), [ERNIE2.0](https://ojs.aaai.org/index.php/AAAI/article/view/6428),
+[ERNIE3.0](https://arxiv.org/abs/2107.02137), [ERNIE-Gram](https://arxiv.org/abs/2010.12148), [ERNIE-health](https://arxiv.org/abs/2110.07244), etc.
+
+These models are contributed by [nghuyong](https://huggingface.co/nghuyong) and the official code can be found in [PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP) (in PaddlePaddle).
+
+### Usage example
+Take `ernie-1.0-base-zh` as an example:
+
+```Python
+from transformers import AutoTokenizer, AutoModel
+tokenizer = AutoTokenizer.from_pretrained("nghuyong/ernie-1.0-base-zh")
+model = AutoModel.from_pretrained("nghuyong/ernie-1.0-base-zh")
+```
+
+### Model checkpoints
+
+| Model Name | Language | Description |
+|:-------------------:|:--------:|:-------------------------------:|
+| ernie-1.0-base-zh | Chinese | Layer:12, Heads:12, Hidden:768 |
+| ernie-2.0-base-en | English | Layer:12, Heads:12, Hidden:768 |
+| ernie-2.0-large-en | English | Layer:24, Heads:16, Hidden:1024 |
+| ernie-3.0-base-zh | Chinese | Layer:12, Heads:12, Hidden:768 |
+| ernie-3.0-medium-zh | Chinese | Layer:6, Heads:12, Hidden:768 |
+| ernie-3.0-mini-zh | Chinese | Layer:6, Heads:12, Hidden:384 |
+| ernie-3.0-micro-zh | Chinese | Layer:4, Heads:12, Hidden:384 |
+| ernie-3.0-nano-zh | Chinese | Layer:4, Heads:12, Hidden:312 |
+| ernie-health-zh | Chinese | Layer:12, Heads:12, Hidden:768 |
+| ernie-gram-zh | Chinese | Layer:12, Heads:12, Hidden:768 |
+
+You can find all the supported models from huggingface's model hub: [huggingface.co/nghuyong](https://huggingface.co/nghuyong), and model details from paddle's official
+repo: [PaddleNLP](https://paddlenlp.readthedocs.io/zh/latest/model_zoo/transformers/ERNIE/contents.html)
+and [ERNIE](https://github.com/PaddlePaddle/ERNIE/blob/repro).
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## ErnieConfig
+
+[[autodoc]] ErnieConfig
+ - all
+
+## Ernie specific outputs
+
+[[autodoc]] models.ernie.modeling_ernie.ErnieForPreTrainingOutput
+
+## ErnieModel
+
+[[autodoc]] ErnieModel
+ - forward
+
+## ErnieForPreTraining
+
+[[autodoc]] ErnieForPreTraining
+ - forward
+
+## ErnieForCausalLM
+
+[[autodoc]] ErnieForCausalLM
+ - forward
+
+## ErnieForMaskedLM
+
+[[autodoc]] ErnieForMaskedLM
+ - forward
+
+## ErnieForNextSentencePrediction
+
+[[autodoc]] ErnieForNextSentencePrediction
+ - forward
+
+## ErnieForSequenceClassification
+
+[[autodoc]] ErnieForSequenceClassification
+ - forward
+
+## ErnieForMultipleChoice
+
+[[autodoc]] ErnieForMultipleChoice
+ - forward
+
+## ErnieForTokenClassification
+
+[[autodoc]] ErnieForTokenClassification
+ - forward
+
+## ErnieForQuestionAnswering
+
+[[autodoc]] ErnieForQuestionAnswering
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/ernie_m.md b/docs/transformers/docs/source/en/model_doc/ernie_m.md
new file mode 100644
index 0000000000000000000000000000000000000000..3ce3b40c44638f3b0750dafba78396e63dac1fb4
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/ernie_m.md
@@ -0,0 +1,102 @@
+
+
+# ErnieM
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+The ErnieM model was proposed in [ERNIE-M: Enhanced Multilingual Representation by Aligning
+Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun,
+Hao Tian, Hua Wu, Haifeng Wang.
+
+The abstract from the paper is the following:
+
+*Recent studies have demonstrated that pre-trained cross-lingual models achieve impressive performance in downstream cross-lingual tasks. This improvement benefits from learning a large amount of monolingual and parallel corpora. Although it is generally acknowledged that parallel corpora are critical for improving the model performance, existing methods are often constrained by the size of parallel corpora, especially for lowresource languages. In this paper, we propose ERNIE-M, a new training method that encourages the model to align the representation of multiple languages with monolingual corpora, to overcome the constraint that the parallel corpus size places on the model performance. Our key insight is to integrate back-translation into the pre-training process. We generate pseudo-parallel sentence pairs on a monolingual corpus to enable the learning of semantic alignments between different languages, thereby enhancing the semantic modeling of cross-lingual models. Experimental results show that ERNIE-M outperforms existing cross-lingual models and delivers new state-of-the-art results in various cross-lingual downstream tasks.*
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato). The original code can be found [here](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/transformers/ernie_m).
+
+
+## Usage tips
+
+- Ernie-M is a BERT-like model so it is a stacked Transformer Encoder.
+- Instead of using MaskedLM for pretraining (like BERT) the authors used two novel techniques: `Cross-attention Masked Language Modeling` and `Back-translation Masked Language Modeling`. For now these two LMHead objectives are not implemented here.
+- It is a multilingual language model.
+- Next Sentence Prediction was not used in pretraining process.
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## ErnieMConfig
+
+[[autodoc]] ErnieMConfig
+
+
+## ErnieMTokenizer
+
+[[autodoc]] ErnieMTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+
+## ErnieMModel
+
+[[autodoc]] ErnieMModel
+ - forward
+
+## ErnieMForSequenceClassification
+
+[[autodoc]] ErnieMForSequenceClassification
+ - forward
+
+
+## ErnieMForMultipleChoice
+
+[[autodoc]] ErnieMForMultipleChoice
+ - forward
+
+
+## ErnieMForTokenClassification
+
+[[autodoc]] ErnieMForTokenClassification
+ - forward
+
+
+## ErnieMForQuestionAnswering
+
+[[autodoc]] ErnieMForQuestionAnswering
+ - forward
+
+## ErnieMForInformationExtraction
+
+[[autodoc]] ErnieMForInformationExtraction
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/esm.md b/docs/transformers/docs/source/en/model_doc/esm.md
new file mode 100644
index 0000000000000000000000000000000000000000..6061d8eea987fd7a9faaf79c07fd0017ab030fa0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/esm.md
@@ -0,0 +1,167 @@
+
+
+# ESM
+
+
+
+
+
+
+## Overview
+
+This page provides code and pre-trained weights for Transformer protein language models from Meta AI's Fundamental
+AI Research Team, providing the state-of-the-art ESMFold and ESM-2, and the previously released ESM-1b and ESM-1v.
+Transformer protein language models were introduced in the paper [Biological structure and function emerge from scaling
+unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by
+Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott,
+C. Lawrence Zitnick, Jerry Ma, and Rob Fergus.
+The first version of this paper was [preprinted in 2019](https://www.biorxiv.org/content/10.1101/622803v1?versioned=true).
+
+ESM-2 outperforms all tested single-sequence protein language models across a range of structure prediction tasks,
+and enables atomic resolution structure prediction.
+It was released with the paper [Language models of protein sequences at the scale of evolution enable accurate
+structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie,
+Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido and Alexander Rives.
+
+Also introduced in this paper was ESMFold. It uses an ESM-2 stem with a head that can predict folded protein
+structures with state-of-the-art accuracy. Unlike [AlphaFold2](https://www.nature.com/articles/s41586-021-03819-2),
+it relies on the token embeddings from the large pre-trained protein language model stem and does not perform a multiple
+sequence alignment (MSA) step at inference time, which means that ESMFold checkpoints are fully "standalone" -
+they do not require a database of known protein sequences and structures with associated external query tools
+to make predictions, and are much faster as a result.
+
+
+The abstract from
+"Biological structure and function emerge from scaling unsupervised learning to 250
+million protein sequences" is
+
+
+*In the field of artificial intelligence, a combination of scale in data and model capacity enabled by unsupervised
+learning has led to major advances in representation learning and statistical generation. In the life sciences, the
+anticipated growth of sequencing promises unprecedented data on natural sequence diversity. Protein language modeling
+at the scale of evolution is a logical step toward predictive and generative artificial intelligence for biology. To
+this end, we use unsupervised learning to train a deep contextual language model on 86 billion amino acids across 250
+million protein sequences spanning evolutionary diversity. The resulting model contains information about biological
+properties in its representations. The representations are learned from sequence data alone. The learned representation
+space has a multiscale organization reflecting structure from the level of biochemical properties of amino acids to
+remote homology of proteins. Information about secondary and tertiary structure is encoded in the representations and
+can be identified by linear projections. Representation learning produces features that generalize across a range of
+applications, enabling state-of-the-art supervised prediction of mutational effect and secondary structure and
+improving state-of-the-art features for long-range contact prediction.*
+
+
+The abstract from
+"Language models of protein sequences at the scale of evolution enable accurate structure prediction" is
+
+*Large language models have recently been shown to develop emergent capabilities with scale, going beyond
+simple pattern matching to perform higher level reasoning and generate lifelike images and text. While
+language models trained on protein sequences have been studied at a smaller scale, little is known about
+what they learn about biology as they are scaled up. In this work we train models up to 15 billion parameters,
+the largest language models of proteins to be evaluated to date. We find that as models are scaled they learn
+information enabling the prediction of the three-dimensional structure of a protein at the resolution of
+individual atoms. We present ESMFold for high accuracy end-to-end atomic level structure prediction directly
+from the individual sequence of a protein. ESMFold has similar accuracy to AlphaFold2 and RoseTTAFold for
+sequences with low perplexity that are well understood by the language model. ESMFold inference is an
+order of magnitude faster than AlphaFold2, enabling exploration of the structural space of metagenomic
+proteins in practical timescales.*
+
+The original code can be found [here](https://github.com/facebookresearch/esm) and was
+was developed by the Fundamental AI Research team at Meta AI.
+ESM-1b, ESM-1v and ESM-2 were contributed to huggingface by [jasonliu](https://huggingface.co/jasonliu)
+and [Matt](https://huggingface.co/Rocketknight1).
+
+ESMFold was contributed to huggingface by [Matt](https://huggingface.co/Rocketknight1) and
+[Sylvain](https://huggingface.co/sgugger), with a big thank you to Nikita Smetanin, Roshan Rao and Tom Sercu for their
+help throughout the process!
+
+## Usage tips
+
+- ESM models are trained with a masked language modeling (MLM) objective.
+- The HuggingFace port of ESMFold uses portions of the [openfold](https://github.com/aqlaboratory/openfold) library. The `openfold` library is licensed under the Apache License 2.0.
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+
+## EsmConfig
+
+[[autodoc]] EsmConfig
+ - all
+
+## EsmTokenizer
+
+[[autodoc]] EsmTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+
+
+
+## EsmModel
+
+[[autodoc]] EsmModel
+ - forward
+
+## EsmForMaskedLM
+
+[[autodoc]] EsmForMaskedLM
+ - forward
+
+## EsmForSequenceClassification
+
+[[autodoc]] EsmForSequenceClassification
+ - forward
+
+## EsmForTokenClassification
+
+[[autodoc]] EsmForTokenClassification
+ - forward
+
+## EsmForProteinFolding
+
+[[autodoc]] EsmForProteinFolding
+ - forward
+
+
+
+
+## TFEsmModel
+
+[[autodoc]] TFEsmModel
+ - call
+
+## TFEsmForMaskedLM
+
+[[autodoc]] TFEsmForMaskedLM
+ - call
+
+## TFEsmForSequenceClassification
+
+[[autodoc]] TFEsmForSequenceClassification
+ - call
+
+## TFEsmForTokenClassification
+
+[[autodoc]] TFEsmForTokenClassification
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/falcon.md b/docs/transformers/docs/source/en/model_doc/falcon.md
new file mode 100644
index 0000000000000000000000000000000000000000..72c7c3274c244e0e88ffb78aa9c15c9ee2bd5349
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/falcon.md
@@ -0,0 +1,153 @@
+
+
+
+
+
+
+
+
+
+
+# Falcon
+
+[Falcon](https://huggingface.co/papers/2311.16867) is a family of large language models, available in 7B, 40B, and 180B parameters, as pretrained and instruction tuned variants. This model focuses on scaling pretraining over three categories, performance, data, and hardware. Falcon uses multigroup attention to significantly reduce inference memory requirements and rotary positional embeddings (RoPE). These models are pretrained on [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb), a high-quality and deduplicated 5T token dataset.
+
+You can find all the original Falcon checkpoints under the [Falcon](https://huggingface.co/collections/tiiuae/falcon-64fb432660017eeec9837b5a) collection.
+
+> [!TIP]
+> Click on the Falcon models in the right sidebar for more examples of how to apply Falcon to different language tasks.
+
+The example below demonstrates how to generate text with [`Pipeline`], [`AutoModel`], and from the command line.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="text-generation",
+ model="tiiuae/falcon-7b-instruct",
+ torch_dtype=torch.bfloat16,
+ device=0
+)
+pipeline(
+ "Write a short poem about coding",
+ max_length=100,
+ do_sample=True,
+ temperature=0.7
+)
+```
+
+
+
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-7b-instruct")
+model = AutoModelForCausalLM.from_pretrained(
+ "tiiuae/falcon-7b-instruct",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ attn_implementation="sdpa",
+)
+
+input_ids = tokenizer("Write a short poem about coding", return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids)
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+
+
+
+```bash
+# pip install -U flash-attn --no-build-isolation
+transformers-cli chat --model_name_or_path tiiuae/falcon-7b-instruct --torch_dtype auto --attn_implementation flash_attention_2 --device 0
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes) to only quantize the weights to 4-bits.
+
+```python
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_compute_dtype=torch.bfloat16,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_use_double_quant=True,
+)
+
+tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-7b")
+model = AutoModelForCausalLM.from_pretrained(
+ "tiiuae/falcon-7b",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ quantization_config=quantization_config,
+)
+
+inputs = tokenizer("In quantum physics, entanglement means", return_tensors="pt").to("cuda")
+outputs = model.generate(**inputs, max_new_tokens=100)
+print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+```
+
+## Notes
+
+- If you're upgrading from an older custom code checkpoint, remember to convert it to the official Transformers format for better stability and performance using the conversion script located in the [Falcon model directory](https://github.com/huggingface/transformers/tree/main/src/transformers/models/falcon).
+
+ ```bash
+ python convert_custom_code_checkpoint.py --checkpoint_dir my_model
+ ```
+
+## FalconConfig
+
+[[autodoc]] FalconConfig
+ - all
+
+## FalconModel
+
+[[autodoc]] FalconModel
+ - forward
+
+## FalconForCausalLM
+
+[[autodoc]] FalconForCausalLM
+ - forward
+
+## FalconForSequenceClassification
+
+[[autodoc]] FalconForSequenceClassification
+ - forward
+
+## FalconForTokenClassification
+
+[[autodoc]] FalconForTokenClassification
+ - forward
+
+## FalconForQuestionAnswering
+
+[[autodoc]] FalconForQuestionAnswering
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/falcon3.md b/docs/transformers/docs/source/en/model_doc/falcon3.md
new file mode 100644
index 0000000000000000000000000000000000000000..276548be77ad7e9a5e991fc62242999fc1c464f8
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/falcon3.md
@@ -0,0 +1,35 @@
+
+
+# Falcon3
+
+
+
+
+
+
+## Overview
+
+Falcon3 represents a natural evolution from previous releases, emphasizing expanding the models' science, math, and code capabilities. This iteration includes five base models: Falcon3-1B-Base, Falcon3-3B-Base, Falcon3-Mamba-7B-Base, Falcon3-7B-Base, and Falcon3-10B-Base. In developing these models, we incorporated several key innovations aimed at improving the models' performances while reducing training costs:
+
+One pre-training: We conducted a single large-scale pretraining run on the 7B model, using 2048 H100 GPU chips, leveraging 14 trillion tokens featuring web, code, STEM, and curated high-quality and multilingual data.
+Depth up-scaling for improved reasoning: Building on recent studies on the effects of model depth, we upscaled the 7B model to a 10B parameters model by duplicating the redundant layers and continuing pre-training with 2TT of high-quality data. This yielded Falcon3-10B-Base which achieves state-of-the-art zero-shot and few-shot performance for models under 13B parameters.
+Knowledge distillation for better tiny models: To provide compact and efficient alternatives, we developed Falcon3-1B-Base and Falcon3-3B-Base by leveraging pruning and knowledge distillation techniques, using less than 100GT of curated high-quality data, thereby redefining pre-training efficiency.
+
+## Resources
+- [Blog post](https://huggingface.co/blog/falcon3)
+- [Models on Huggingface](https://huggingface.co/collections/tiiuae/falcon3-67605ae03578be86e4e87026)
diff --git a/docs/transformers/docs/source/en/model_doc/falcon_mamba.md b/docs/transformers/docs/source/en/model_doc/falcon_mamba.md
new file mode 100644
index 0000000000000000000000000000000000000000..ef346e89892efc213be8352da0456bbeee4930cb
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/falcon_mamba.md
@@ -0,0 +1,125 @@
+
+
+
+
+
+
+
+
+# FalconMamba
+
+[FalconMamba](https://huggingface.co/papers/2410.05355) is a 7B large language model, available as pretrained and instruction-tuned variants, based on the [Mamba](./mamba). This model implements a pure Mamba design that focuses on computational efficiency while maintaining strong performance. FalconMamba is significantly faster at inference and requires substantially less memory for long sequence generation. The models are pretrained on a diverse 5.8T token dataset including [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb), technical content, code, and mathematical data.
+
+You can find the official FalconMamba checkpoints in the [FalconMamba 7B](https://huggingface.co/collections/tiiuae/falconmamba-7b-66b9a580324dd1598b0f6d4a) collection.
+
+> [!TIP]
+> Click on the FalconMamba models in the right sidebar for more examples of how to apply FalconMamba to different language tasks.
+
+The examples below demonstrate how to generate text with [`Pipeline`], [`AutoModel`], and from the command line.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ "text-generation",
+ model="tiiuae/falcon-mamba-7b-instruct",
+ torch_dtype=torch.bfloat16,
+ device=0
+)
+pipeline(
+ "Explain the difference between transformers and SSMs",
+ max_length=100,
+ do_sample=True,
+ temperature=0.7
+)
+```
+
+
+
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-mamba-7b-instruct")
+model = AutoModelForCausalLM.from_pretrained(
+ "tiiuae/falcon-mamba-7b-instruct",
+ torch_dtype=torch.bfloat16,
+ device_map="auto"
+)
+
+input_ids = tokenizer("Explain the difference between transformers and SSMs", return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, max_new_tokens=100, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+
+
+
+```bash
+transformers-cli chat --model_name_or_path tiiuae/falcon-mamba-7b-instruct --torch_dtype auto --device 0
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes) to quantize the weights to 4-bits.
+
+```python
+import torch
+from transformers import AutoTokenizer, FalconMambaForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_compute_dtype=torch.bfloat16,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_use_double_quant=True,
+)
+
+tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-mamba-7b")
+model = FalconMambaForCausalLM.from_pretrained(
+ "tiiuae/falcon-mamba-7b",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ quantization_config=quantization_config,
+)
+
+inputs = tokenizer("Explain the concept of state space models in simple terms", return_tensors="pt").to("cuda")
+outputs = model.generate(**inputs, max_new_tokens=100)
+print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+```
+
+## FalconMambaConfig
+
+[[autodoc]] FalconMambaConfig
+
+## FalconMambaModel
+
+[[autodoc]] FalconMambaModel
+ - forward
+
+## FalconMambaLMHeadModel
+
+[[autodoc]] FalconMambaForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/fastspeech2_conformer.md b/docs/transformers/docs/source/en/model_doc/fastspeech2_conformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..aeb055ceae40dffbdb3cc002b3a391e89aae89b4
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/fastspeech2_conformer.md
@@ -0,0 +1,138 @@
+
+
+# FastSpeech2Conformer
+
+
+
+
+
+## Overview
+
+The FastSpeech2Conformer model was proposed with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
+
+The abstract from the original FastSpeech2 paper is the following:
+
+*Non-autoregressive text to speech (TTS) models such as FastSpeech (Ren et al., 2019) can synthesize speech significantly faster than previous autoregressive models with comparable quality. The training of FastSpeech model relies on an autoregressive teacher model for duration prediction (to provide more information as input) and knowledge distillation (to simplify the data distribution in output), which can ease the one-to-many mapping problem (i.e., multiple speech variations correspond to the same text) in TTS. However, FastSpeech has several disadvantages: 1) the teacher-student distillation pipeline is complicated and time-consuming, 2) the duration extracted from the teacher model is not accurate enough, and the target mel-spectrograms distilled from teacher model suffer from information loss due to data simplification, both of which limit the voice quality. In this paper, we propose FastSpeech 2, which addresses the issues in FastSpeech and better solves the one-to-many mapping problem in TTS by 1) directly training the model with ground-truth target instead of the simplified output from teacher, and 2) introducing more variation information of speech (e.g., pitch, energy and more accurate duration) as conditional inputs. Specifically, we extract duration, pitch and energy from speech waveform and directly take them as conditional inputs in training and use predicted values in inference. We further design FastSpeech 2s, which is the first attempt to directly generate speech waveform from text in parallel, enjoying the benefit of fully end-to-end inference. Experimental results show that 1) FastSpeech 2 achieves a 3x training speed-up over FastSpeech, and FastSpeech 2s enjoys even faster inference speed; 2) FastSpeech 2 and 2s outperform FastSpeech in voice quality, and FastSpeech 2 can even surpass autoregressive models. Audio samples are available at https://speechresearch.github.io/fastspeech2/.*
+
+This model was contributed by [Connor Henderson](https://huggingface.co/connor-henderson). The original code can be found [here](https://github.com/espnet/espnet/blob/master/espnet2/tts/fastspeech2/fastspeech2.py).
+
+
+## 🤗 Model Architecture
+FastSpeech2's general structure with a Mel-spectrogram decoder was implemented, and the traditional transformer blocks were replaced with conformer blocks as done in the ESPnet library.
+
+#### FastSpeech2 Model Architecture
+
+
+#### Conformer Blocks
+
+
+#### Convolution Module
+
+
+## 🤗 Transformers Usage
+
+You can run FastSpeech2Conformer locally with the 🤗 Transformers library.
+
+1. First install the 🤗 [Transformers library](https://github.com/huggingface/transformers), g2p-en:
+
+```bash
+pip install --upgrade pip
+pip install --upgrade transformers g2p-en
+```
+
+2. Run inference via the Transformers modelling code with the model and hifigan separately
+
+```python
+
+from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerModel, FastSpeech2ConformerHifiGan
+import soundfile as sf
+
+tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
+inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
+input_ids = inputs["input_ids"]
+
+model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
+output_dict = model(input_ids, return_dict=True)
+spectrogram = output_dict["spectrogram"]
+
+hifigan = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
+waveform = hifigan(spectrogram)
+
+sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)
+```
+
+3. Run inference via the Transformers modelling code with the model and hifigan combined
+
+```python
+from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerWithHifiGan
+import soundfile as sf
+
+tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
+inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
+input_ids = inputs["input_ids"]
+
+model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
+output_dict = model(input_ids, return_dict=True)
+waveform = output_dict["waveform"]
+
+sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)
+```
+
+4. Run inference with a pipeline and specify which vocoder to use
+```python
+from transformers import pipeline, FastSpeech2ConformerHifiGan
+import soundfile as sf
+
+vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
+synthesiser = pipeline(model="espnet/fastspeech2_conformer", vocoder=vocoder)
+
+speech = synthesiser("Hello, my dog is cooler than you!")
+
+sf.write("speech.wav", speech["audio"].squeeze(), samplerate=speech["sampling_rate"])
+```
+
+
+## FastSpeech2ConformerConfig
+
+[[autodoc]] FastSpeech2ConformerConfig
+
+## FastSpeech2ConformerHifiGanConfig
+
+[[autodoc]] FastSpeech2ConformerHifiGanConfig
+
+## FastSpeech2ConformerWithHifiGanConfig
+
+[[autodoc]] FastSpeech2ConformerWithHifiGanConfig
+
+## FastSpeech2ConformerTokenizer
+
+[[autodoc]] FastSpeech2ConformerTokenizer
+ - __call__
+ - save_vocabulary
+ - decode
+ - batch_decode
+
+## FastSpeech2ConformerModel
+
+[[autodoc]] FastSpeech2ConformerModel
+ - forward
+
+## FastSpeech2ConformerHifiGan
+
+[[autodoc]] FastSpeech2ConformerHifiGan
+ - forward
+
+## FastSpeech2ConformerWithHifiGan
+
+[[autodoc]] FastSpeech2ConformerWithHifiGan
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/flan-t5.md b/docs/transformers/docs/source/en/model_doc/flan-t5.md
new file mode 100644
index 0000000000000000000000000000000000000000..0e3b9ba0738fc99679235c4eb75f62981d6b2fe4
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/flan-t5.md
@@ -0,0 +1,64 @@
+
+
+# FLAN-T5
+
+
+
+
+
+
+
+## Overview
+
+FLAN-T5 was released in the paper [Scaling Instruction-Finetuned Language Models](https://arxiv.org/pdf/2210.11416.pdf) - it is an enhanced version of T5 that has been finetuned in a mixture of tasks.
+
+One can directly use FLAN-T5 weights without finetuning the model:
+
+```python
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-small")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-small")
+
+>>> inputs = tokenizer("A step by step recipe to make bolognese pasta:", return_tensors="pt")
+>>> outputs = model.generate(**inputs)
+>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['Pour a cup of bolognese into a large bowl and add the pasta']
+```
+
+FLAN-T5 includes the same improvements as T5 version 1.1 (see [here](https://huggingface.co/docs/transformers/model_doc/t5v1.1) for the full details of the model's improvements.)
+
+Google has released the following variants:
+
+- [google/flan-t5-small](https://huggingface.co/google/flan-t5-small)
+
+- [google/flan-t5-base](https://huggingface.co/google/flan-t5-base)
+
+- [google/flan-t5-large](https://huggingface.co/google/flan-t5-large)
+
+- [google/flan-t5-xl](https://huggingface.co/google/flan-t5-xl)
+
+- [google/flan-t5-xxl](https://huggingface.co/google/flan-t5-xxl).
+
+The original checkpoints can be found [here](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints).
+
+
+
+Refer to [T5's documentation page](t5) for all API reference, code examples and notebooks. For more details regarding training and evaluation of the FLAN-T5, refer to the model card.
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/flan-ul2.md b/docs/transformers/docs/source/en/model_doc/flan-ul2.md
new file mode 100644
index 0000000000000000000000000000000000000000..3b946b909b09ee9d023ffe33f80256aca11c53d3
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/flan-ul2.md
@@ -0,0 +1,61 @@
+
+
+# FLAN-UL2
+
+
+
+
+
+
+
+## Overview
+
+Flan-UL2 is an encoder decoder model based on the T5 architecture. It uses the same configuration as the [UL2](ul2) model released earlier last year.
+It was fine tuned using the "Flan" prompt tuning and dataset collection. Similar to `Flan-T5`, one can directly use FLAN-UL2 weights without finetuning the model:
+
+According to the original blog here are the notable improvements:
+
+- The original UL2 model was only trained with receptive field of 512, which made it non-ideal for N-shot prompting where N is large.
+- The Flan-UL2 checkpoint uses a receptive field of 2048 which makes it more usable for few-shot in-context learning.
+- The original UL2 model also had mode switch tokens that was rather mandatory to get good performance. However, they were a little cumbersome as this requires often some changes during inference or finetuning. In this update/change, we continue training UL2 20B for an additional 100k steps (with small batch) to forget “mode tokens” before applying Flan instruction tuning. This Flan-UL2 checkpoint does not require mode tokens anymore.
+Google has released the following variants:
+
+The original checkpoints can be found [here](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints).
+
+
+## Running on low resource devices
+
+The model is pretty heavy (~40GB in half precision) so if you just want to run the model, make sure you load your model in 8bit, and use `device_map="auto"` to make sure you don't have any OOM issue!
+
+```python
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-ul2", load_in_8bit=True, device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/flan-ul2")
+
+>>> inputs = tokenizer("A step by step recipe to make bolognese pasta:", return_tensors="pt")
+>>> outputs = model.generate(**inputs)
+>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['In a large skillet, brown the ground beef and onion over medium heat. Add the garlic']
+```
+
+
+
+Refer to [T5's documentation page](t5) for API reference, tips, code examples and notebooks.
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/flaubert.md b/docs/transformers/docs/source/en/model_doc/flaubert.md
new file mode 100644
index 0000000000000000000000000000000000000000..59ab44ebff0387446030c57699e8b3f454b8b3ef
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/flaubert.md
@@ -0,0 +1,140 @@
+
+
+# FlauBERT
+
+
+
+
+
+
+## Overview
+
+The FlauBERT model was proposed in the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le et al. It's a transformer model pretrained using a masked language
+modeling (MLM) objective (like BERT).
+
+The abstract from the paper is the following:
+
+*Language models have become a key step to achieve state-of-the art results in many different Natural Language
+Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way
+to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their
+contextualization at the sentence level. This has been widely demonstrated for English using contextualized
+representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al.,
+2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and
+heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for
+Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text
+classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the
+time they outperform other pretraining approaches. Different versions of FlauBERT as well as a unified evaluation
+protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research
+community for further reproducible experiments in French NLP.*
+
+This model was contributed by [formiel](https://huggingface.co/formiel). The original code can be found [here](https://github.com/getalp/Flaubert).
+
+Tips:
+- Like RoBERTa, without the sentence ordering prediction (so just trained on the MLM objective).
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## FlaubertConfig
+
+[[autodoc]] FlaubertConfig
+
+## FlaubertTokenizer
+
+[[autodoc]] FlaubertTokenizer
+
+
+
+
+## FlaubertModel
+
+[[autodoc]] FlaubertModel
+ - forward
+
+## FlaubertWithLMHeadModel
+
+[[autodoc]] FlaubertWithLMHeadModel
+ - forward
+
+## FlaubertForSequenceClassification
+
+[[autodoc]] FlaubertForSequenceClassification
+ - forward
+
+## FlaubertForMultipleChoice
+
+[[autodoc]] FlaubertForMultipleChoice
+ - forward
+
+## FlaubertForTokenClassification
+
+[[autodoc]] FlaubertForTokenClassification
+ - forward
+
+## FlaubertForQuestionAnsweringSimple
+
+[[autodoc]] FlaubertForQuestionAnsweringSimple
+ - forward
+
+## FlaubertForQuestionAnswering
+
+[[autodoc]] FlaubertForQuestionAnswering
+ - forward
+
+
+
+
+## TFFlaubertModel
+
+[[autodoc]] TFFlaubertModel
+ - call
+
+## TFFlaubertWithLMHeadModel
+
+[[autodoc]] TFFlaubertWithLMHeadModel
+ - call
+
+## TFFlaubertForSequenceClassification
+
+[[autodoc]] TFFlaubertForSequenceClassification
+ - call
+
+## TFFlaubertForMultipleChoice
+
+[[autodoc]] TFFlaubertForMultipleChoice
+ - call
+
+## TFFlaubertForTokenClassification
+
+[[autodoc]] TFFlaubertForTokenClassification
+ - call
+
+## TFFlaubertForQuestionAnsweringSimple
+
+[[autodoc]] TFFlaubertForQuestionAnsweringSimple
+ - call
+
+
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/flava.md b/docs/transformers/docs/source/en/model_doc/flava.md
new file mode 100644
index 0000000000000000000000000000000000000000..c809be73589a9c06552b8633e270864f05a5feb7
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/flava.md
@@ -0,0 +1,112 @@
+
+
+# FLAVA
+
+
+
+
+
+## Overview
+
+The FLAVA model was proposed in [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela and is accepted at CVPR 2022.
+
+The paper aims at creating a single unified foundation model which can work across vision, language
+as well as vision-and-language multimodal tasks.
+
+The abstract from the paper is the following:
+
+*State-of-the-art vision and vision-and-language models rely on large-scale visio-linguistic pretraining for obtaining good performance on a variety
+of downstream tasks. Generally, such models are often either cross-modal (contrastive) or multi-modal
+(with earlier fusion) but not both; and they often only target specific modalities or tasks. A promising
+direction would be to use a single holistic universal model, as a "foundation", that targets all modalities
+at once -- a true vision and language foundation model should be good at vision tasks, language tasks, and
+cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate
+impressive performance on a wide range of 35 tasks spanning these target modalities.*
+
+This model was contributed by [aps](https://huggingface.co/aps). The original code can be found [here](https://github.com/facebookresearch/multimodal/tree/main/examples/flava).
+
+## FlavaConfig
+
+[[autodoc]] FlavaConfig
+
+## FlavaTextConfig
+
+[[autodoc]] FlavaTextConfig
+
+## FlavaImageConfig
+
+[[autodoc]] FlavaImageConfig
+
+## FlavaMultimodalConfig
+
+[[autodoc]] FlavaMultimodalConfig
+
+## FlavaImageCodebookConfig
+
+[[autodoc]] FlavaImageCodebookConfig
+
+## FlavaProcessor
+
+[[autodoc]] FlavaProcessor
+
+## FlavaFeatureExtractor
+
+[[autodoc]] FlavaFeatureExtractor
+
+## FlavaImageProcessor
+
+[[autodoc]] FlavaImageProcessor
+ - preprocess
+
+## FlavaImageProcessorFast
+
+[[autodoc]] FlavaImageProcessorFast
+ - preprocess
+
+## FlavaForPreTraining
+
+[[autodoc]] FlavaForPreTraining
+ - forward
+
+## FlavaModel
+
+[[autodoc]] FlavaModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## FlavaImageCodebook
+
+[[autodoc]] FlavaImageCodebook
+ - forward
+ - get_codebook_indices
+ - get_codebook_probs
+
+## FlavaTextModel
+
+[[autodoc]] FlavaTextModel
+ - forward
+
+## FlavaImageModel
+
+[[autodoc]] FlavaImageModel
+ - forward
+
+## FlavaMultimodalModel
+
+[[autodoc]] FlavaMultimodalModel
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/fnet.md b/docs/transformers/docs/source/en/model_doc/fnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..fcf75e21caed25f830d3dd1d5c98d36627c6522f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/fnet.md
@@ -0,0 +1,114 @@
+
+
+# FNet
+
+
+
+
+
+## Overview
+
+The FNet model was proposed in [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by
+James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon. The model replaces the self-attention layer in a BERT
+model with a fourier transform which returns only the real parts of the transform. The model is significantly faster
+than the BERT model because it has fewer parameters and is more memory efficient. The model achieves about 92-97%
+accuracy of BERT counterparts on GLUE benchmark, and trains much faster than the BERT model. The abstract from the
+paper is the following:
+
+*We show that Transformer encoder architectures can be sped up, with limited accuracy costs, by replacing the
+self-attention sublayers with simple linear transformations that "mix" input tokens. These linear mixers, along with
+standard nonlinearities in feed-forward layers, prove competent at modeling semantic relationships in several text
+classification tasks. Most surprisingly, we find that replacing the self-attention sublayer in a Transformer encoder
+with a standard, unparameterized Fourier Transform achieves 92-97% of the accuracy of BERT counterparts on the GLUE
+benchmark, but trains 80% faster on GPUs and 70% faster on TPUs at standard 512 input lengths. At longer input lengths,
+our FNet model is significantly faster: when compared to the "efficient" Transformers on the Long Range Arena
+benchmark, FNet matches the accuracy of the most accurate models, while outpacing the fastest models across all
+sequence lengths on GPUs (and across relatively shorter lengths on TPUs). Finally, FNet has a light memory footprint
+and is particularly efficient at smaller model sizes; for a fixed speed and accuracy budget, small FNet models
+outperform Transformer counterparts.*
+
+This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/google-research/google-research/tree/master/f_net).
+
+## Usage tips
+
+The model was trained without an attention mask as it is based on Fourier Transform. The model was trained with
+maximum sequence length 512 which includes pad tokens. Hence, it is highly recommended to use the same maximum
+sequence length for fine-tuning and inference.
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## FNetConfig
+
+[[autodoc]] FNetConfig
+
+## FNetTokenizer
+
+[[autodoc]] FNetTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## FNetTokenizerFast
+
+[[autodoc]] FNetTokenizerFast
+
+## FNetModel
+
+[[autodoc]] FNetModel
+ - forward
+
+## FNetForPreTraining
+
+[[autodoc]] FNetForPreTraining
+ - forward
+
+## FNetForMaskedLM
+
+[[autodoc]] FNetForMaskedLM
+ - forward
+
+## FNetForNextSentencePrediction
+
+[[autodoc]] FNetForNextSentencePrediction
+ - forward
+
+## FNetForSequenceClassification
+
+[[autodoc]] FNetForSequenceClassification
+ - forward
+
+## FNetForMultipleChoice
+
+[[autodoc]] FNetForMultipleChoice
+ - forward
+
+## FNetForTokenClassification
+
+[[autodoc]] FNetForTokenClassification
+ - forward
+
+## FNetForQuestionAnswering
+
+[[autodoc]] FNetForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/focalnet.md b/docs/transformers/docs/source/en/model_doc/focalnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..5312cae4ff675e936bd282f9663b64f681fbd994
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/focalnet.md
@@ -0,0 +1,54 @@
+
+
+# FocalNet
+
+
+
+
+
+## Overview
+
+The FocalNet model was proposed in [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
+FocalNets completely replace self-attention (used in models like [ViT](vit) and [Swin](swin)) by a focal modulation mechanism for modeling token interactions in vision.
+The authors claim that FocalNets outperform self-attention based models with similar computational costs on the tasks of image classification, object detection, and segmentation.
+
+The abstract from the paper is the following:
+
+*We propose focal modulation networks (FocalNets in short), where self-attention (SA) is completely replaced by a focal modulation mechanism for modeling token interactions in vision. Focal modulation comprises three components: (i) hierarchical contextualization, implemented using a stack of depth-wise convolutional layers, to encode visual contexts from short to long ranges, (ii) gated aggregation to selectively gather contexts for each query token based on its
+content, and (iii) element-wise modulation or affine transformation to inject the aggregated context into the query. Extensive experiments show FocalNets outperform the state-of-the-art SA counterparts (e.g., Swin and Focal Transformers) with similar computational costs on the tasks of image classification, object detection, and segmentation. Specifically, FocalNets with tiny and base size achieve 82.3% and 83.9% top-1 accuracy on ImageNet-1K. After pretrained on ImageNet-22K in 224 resolution, it attains 86.5% and 87.3% top-1 accuracy when finetuned with resolution 224 and 384, respectively. When transferred to downstream tasks, FocalNets exhibit clear superiority. For object detection with Mask R-CNN, FocalNet base trained with 1\times outperforms the Swin counterpart by 2.1 points and already surpasses Swin trained with 3\times schedule (49.0 v.s. 48.5). For semantic segmentation with UPerNet, FocalNet base at single-scale outperforms Swin by 2.4, and beats Swin at multi-scale (50.5 v.s. 49.7). Using large FocalNet and Mask2former, we achieve 58.5 mIoU for ADE20K semantic segmentation, and 57.9 PQ for COCO Panoptic Segmentation. Using huge FocalNet and DINO, we achieved 64.3 and 64.4 mAP on COCO minival and test-dev, respectively, establishing new SoTA on top of much larger attention-based models like Swinv2-G and BEIT-3.*
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/microsoft/FocalNet).
+
+## FocalNetConfig
+
+[[autodoc]] FocalNetConfig
+
+## FocalNetModel
+
+[[autodoc]] FocalNetModel
+ - forward
+
+## FocalNetForMaskedImageModeling
+
+[[autodoc]] FocalNetForMaskedImageModeling
+ - forward
+
+## FocalNetForImageClassification
+
+[[autodoc]] FocalNetForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/fsmt.md b/docs/transformers/docs/source/en/model_doc/fsmt.md
new file mode 100644
index 0000000000000000000000000000000000000000..9419dce71edf38d4a287fb429c2525b95abe9dbe
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/fsmt.md
@@ -0,0 +1,64 @@
+
+
+# FSMT
+
+## Overview
+
+FSMT (FairSeq MachineTranslation) models were introduced in [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616) by Nathan Ng, Kyra Yee, Alexei Baevski, Myle Ott, Michael Auli, Sergey Edunov.
+
+The abstract of the paper is the following:
+
+*This paper describes Facebook FAIR's submission to the WMT19 shared news translation task. We participate in two
+language pairs and four language directions, English <-> German and English <-> Russian. Following our submission from
+last year, our baseline systems are large BPE-based transformer models trained with the Fairseq sequence modeling
+toolkit which rely on sampled back-translations. This year we experiment with different bitext data filtering schemes,
+as well as with adding filtered back-translated data. We also ensemble and fine-tune our models on domain-specific
+data, then decode using noisy channel model reranking. Our submissions are ranked first in all four directions of the
+human evaluation campaign. On En->De, our system significantly outperforms other systems as well as human translations.
+This system improves upon our WMT'18 submission by 4.5 BLEU points.*
+
+This model was contributed by [stas](https://huggingface.co/stas). The original code can be found
+[here](https://github.com/pytorch/fairseq/tree/master/examples/wmt19).
+
+## Implementation Notes
+
+- FSMT uses source and target vocabulary pairs that aren't combined into one. It doesn't share embeddings tokens
+ either. Its tokenizer is very similar to [`XLMTokenizer`] and the main model is derived from
+ [`BartModel`].
+
+
+## FSMTConfig
+
+[[autodoc]] FSMTConfig
+
+## FSMTTokenizer
+
+[[autodoc]] FSMTTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## FSMTModel
+
+[[autodoc]] FSMTModel
+ - forward
+
+## FSMTForConditionalGeneration
+
+[[autodoc]] FSMTForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/funnel.md b/docs/transformers/docs/source/en/model_doc/funnel.md
new file mode 100644
index 0000000000000000000000000000000000000000..96050a153df2aaf8a3f62a669aeb66fc31ec4b86
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/funnel.md
@@ -0,0 +1,180 @@
+
+
+# Funnel Transformer
+
+
+
+
+
+
+## Overview
+
+The Funnel Transformer model was proposed in the paper [Funnel-Transformer: Filtering out Sequential Redundancy for
+Efficient Language Processing](https://arxiv.org/abs/2006.03236). It is a bidirectional transformer model, like
+BERT, but with a pooling operation after each block of layers, a bit like in traditional convolutional neural networks
+(CNN) in computer vision.
+
+The abstract from the paper is the following:
+
+*With the success of language pretraining, it is highly desirable to develop more efficient architectures of good
+scalability that can exploit the abundant unlabeled data at a lower cost. To improve the efficiency, we examine the
+much-overlooked redundancy in maintaining a full-length token-level presentation, especially for tasks that only
+require a single-vector presentation of the sequence. With this intuition, we propose Funnel-Transformer which
+gradually compresses the sequence of hidden states to a shorter one and hence reduces the computation cost. More
+importantly, by re-investing the saved FLOPs from length reduction in constructing a deeper or wider model, we further
+improve the model capacity. In addition, to perform token-level predictions as required by common pretraining
+objectives, Funnel-Transformer is able to recover a deep representation for each token from the reduced hidden sequence
+via a decoder. Empirically, with comparable or fewer FLOPs, Funnel-Transformer outperforms the standard Transformer on
+a wide variety of sequence-level prediction tasks, including text classification, language understanding, and reading
+comprehension.*
+
+This model was contributed by [sgugger](https://huggingface.co/sgugger). The original code can be found [here](https://github.com/laiguokun/Funnel-Transformer).
+
+## Usage tips
+
+- Since Funnel Transformer uses pooling, the sequence length of the hidden states changes after each block of layers. This way, their length is divided by 2, which speeds up the computation of the next hidden states.
+ The base model therefore has a final sequence length that is a quarter of the original one. This model can be used
+ directly for tasks that just require a sentence summary (like sequence classification or multiple choice). For other
+ tasks, the full model is used; this full model has a decoder that upsamples the final hidden states to the same
+ sequence length as the input.
+- For tasks such as classification, this is not a problem, but for tasks like masked language modeling or token classification, we need a hidden state with the same sequence length as the original input. In those cases, the final hidden states are upsampled to the input sequence length and go through two additional layers. That's why there are two versions of each checkpoint. The version suffixed with “-base” contains only the three blocks, while the version without that suffix contains the three blocks and the upsampling head with its additional layers.
+- The Funnel Transformer checkpoints are all available with a full version and a base version. The first ones should be
+ used for [`FunnelModel`], [`FunnelForPreTraining`],
+ [`FunnelForMaskedLM`], [`FunnelForTokenClassification`] and
+ [`FunnelForQuestionAnswering`]. The second ones should be used for
+ [`FunnelBaseModel`], [`FunnelForSequenceClassification`] and
+ [`FunnelForMultipleChoice`].
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+
+## FunnelConfig
+
+[[autodoc]] FunnelConfig
+
+## FunnelTokenizer
+
+[[autodoc]] FunnelTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## FunnelTokenizerFast
+
+[[autodoc]] FunnelTokenizerFast
+
+## Funnel specific outputs
+
+[[autodoc]] models.funnel.modeling_funnel.FunnelForPreTrainingOutput
+
+[[autodoc]] models.funnel.modeling_tf_funnel.TFFunnelForPreTrainingOutput
+
+
+
+
+## FunnelBaseModel
+
+[[autodoc]] FunnelBaseModel
+ - forward
+
+## FunnelModel
+
+[[autodoc]] FunnelModel
+ - forward
+
+## FunnelModelForPreTraining
+
+[[autodoc]] FunnelForPreTraining
+ - forward
+
+## FunnelForMaskedLM
+
+[[autodoc]] FunnelForMaskedLM
+ - forward
+
+## FunnelForSequenceClassification
+
+[[autodoc]] FunnelForSequenceClassification
+ - forward
+
+## FunnelForMultipleChoice
+
+[[autodoc]] FunnelForMultipleChoice
+ - forward
+
+## FunnelForTokenClassification
+
+[[autodoc]] FunnelForTokenClassification
+ - forward
+
+## FunnelForQuestionAnswering
+
+[[autodoc]] FunnelForQuestionAnswering
+ - forward
+
+
+
+
+## TFFunnelBaseModel
+
+[[autodoc]] TFFunnelBaseModel
+ - call
+
+## TFFunnelModel
+
+[[autodoc]] TFFunnelModel
+ - call
+
+## TFFunnelModelForPreTraining
+
+[[autodoc]] TFFunnelForPreTraining
+ - call
+
+## TFFunnelForMaskedLM
+
+[[autodoc]] TFFunnelForMaskedLM
+ - call
+
+## TFFunnelForSequenceClassification
+
+[[autodoc]] TFFunnelForSequenceClassification
+ - call
+
+## TFFunnelForMultipleChoice
+
+[[autodoc]] TFFunnelForMultipleChoice
+ - call
+
+## TFFunnelForTokenClassification
+
+[[autodoc]] TFFunnelForTokenClassification
+ - call
+
+## TFFunnelForQuestionAnswering
+
+[[autodoc]] TFFunnelForQuestionAnswering
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/fuyu.md b/docs/transformers/docs/source/en/model_doc/fuyu.md
new file mode 100644
index 0000000000000000000000000000000000000000..c0ea89ad19fb508cca1be90415441d973f019d67
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/fuyu.md
@@ -0,0 +1,119 @@
+
+
+# Fuyu
+
+
+
+
+
+## Overview
+
+The Fuyu model was created by [ADEPT](https://www.adept.ai/blog/fuyu-8b), and authored by Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar.
+
+The authors introduced Fuyu-8B, a decoder-only multimodal model based on the classic transformers architecture, with query and key normalization. A linear encoder is added to create multimodal embeddings from image inputs.
+
+By treating image tokens like text tokens and using a special image-newline character, the model knows when an image line ends. Image positional embeddings are removed. This avoids the need for different training phases for various image resolutions. With 8 billion parameters and licensed under CC-BY-NC, Fuyu-8B is notable for its ability to handle both text and images, its impressive context size of 16K, and its overall performance.
+
+
+
+The `Fuyu` models were trained using `bfloat16`, but the original inference uses `float16` The checkpoints uploaded on the hub use `torch_dtype = 'float16'` which will be
+used by the `AutoModel` API to cast the checkpoints from `torch.float32` to `torch.float16`.
+
+The `dtype` of the online weights is mostly irrelevant, unless you are using `torch_dtype="auto"` when initializing a model using `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`. The reason is that the model will first be downloaded ( using the `dtype` of the checkpoints online) then it will be cast to the default `dtype` of `torch` (becomes `torch.float32`). Users should specify the `torch_dtype` they want, and if they don't it will be `torch.float32`.
+
+Finetuning the model in `float16` is not recommended and known to produce `nan`, as such the model should be fine-tuned in `bfloat16`.
+
+
+
+
+Tips:
+
+- To convert the model, you need to clone the original repository using `git clone https://github.com/persimmon-ai-labs/adept-inference`, then get the checkpoints:
+
+```bash
+git clone https://github.com/persimmon-ai-labs/adept-inference
+wget path/to/fuyu-8b-model-weights.tar
+tar -xvf fuyu-8b-model-weights.tar
+python src/transformers/models/fuyu/convert_fuyu_weights_to_hf.py --input_dir /path/to/downloaded/fuyu/weights/ --output_dir /output/path \
+ --pt_model_path /path/to/fuyu_8b_release/iter_0001251/mp_rank_00/model_optim_rng.pt
+ --ada_lib_path /path/to/adept-inference
+```
+
+For the chat model:
+```bash
+wget https://axtkn4xl5cip.objectstorage.us-phoenix-1.oci.customer-oci.com/n/axtkn4xl5cip/b/adept-public-data/o/8b_chat_model_release.tar
+tar -xvf 8b_base_model_release.tar
+```
+Then, model can be loaded via:
+
+```py
+from transformers import FuyuConfig, FuyuForCausalLM
+model_config = FuyuConfig()
+model = FuyuForCausalLM(model_config).from_pretrained('/output/path')
+```
+
+Inputs need to be passed through a specific Processor to have the correct formats.
+A processor requires an image_processor and a tokenizer. Hence, inputs can be loaded via:
+
+```py
+from PIL import Image
+from transformers import AutoTokenizer
+from transformers.models.fuyu.processing_fuyu import FuyuProcessor
+from transformers.models.fuyu.image_processing_fuyu import FuyuImageProcessor
+
+
+tokenizer = AutoTokenizer.from_pretrained('adept-hf-collab/fuyu-8b')
+image_processor = FuyuImageProcessor()
+
+
+processor = FuyuProcessor(image_processor=image_processor, tokenizer=tokenizer)
+text_prompt = "Generate a coco-style caption.\\n"
+
+bus_image_url = "https://huggingface.co/datasets/hf-internal-testing/fixtures-captioning/resolve/main/bus.png"
+bus_image_pil = Image.open(io.BytesIO(requests.get(bus_image_url).content))
+inputs_to_model = processor(images=bus_image_pil, text=text_prompt)
+
+
+```
+
+This model was contributed by [Molbap](https://huggingface.co/Molbap).
+The original code can be found [here](https://github.com/persimmon-ai-labs/adept-inference).
+
+- Fuyu uses a `sentencepiece` based tokenizer, with a `Unigram` model. It supports bytefallback, which is only available in `tokenizers==0.14.0` for the fast tokenizer.
+The `LlamaTokenizer` is used as it is a standard wrapper around sentencepiece.
+
+- The authors suggest to use the following prompt for image captioning: `f"Generate a coco-style caption.\\n"`
+
+
+## FuyuConfig
+
+[[autodoc]] FuyuConfig
+
+## FuyuForCausalLM
+
+[[autodoc]] FuyuForCausalLM
+ - forward
+
+## FuyuImageProcessor
+
+[[autodoc]] FuyuImageProcessor
+ - __call__
+
+## FuyuProcessor
+
+[[autodoc]] FuyuProcessor
+ - __call__
diff --git a/docs/transformers/docs/source/en/model_doc/gemma.md b/docs/transformers/docs/source/en/model_doc/gemma.md
new file mode 100644
index 0000000000000000000000000000000000000000..144bcf33886b17816fa87b6526ebb0079411d0e3
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/gemma.md
@@ -0,0 +1,84 @@
+
+
+# Gemma
+
+
+
+
+
+
+
+
+## Overview
+
+The Gemma model was proposed in [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by Gemma Team, Google.
+Gemma models are trained on 6T tokens, and released with 2 versions, 2b and 7b.
+
+The abstract from the paper is the following:
+
+*This work introduces Gemma, a new family of open language models demonstrating strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of our model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations*
+
+Tips:
+
+- The original checkpoints can be converted using the conversion script `src/transformers/models/gemma/convert_gemma_weights_to_hf.py`
+
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ), [Younes Belkada](https://huggingface.co/ybelkada), [Sanchit Gandhi](https://huggingface.co/sanchit-gandhi), [Pedro Cuenca](https://huggingface.co/pcuenq).
+
+
+## GemmaConfig
+
+[[autodoc]] GemmaConfig
+
+## GemmaTokenizer
+
+[[autodoc]] GemmaTokenizer
+
+
+## GemmaTokenizerFast
+
+[[autodoc]] GemmaTokenizerFast
+
+## GemmaModel
+
+[[autodoc]] GemmaModel
+ - forward
+
+## GemmaForCausalLM
+
+[[autodoc]] GemmaForCausalLM
+ - forward
+
+## GemmaForSequenceClassification
+
+[[autodoc]] GemmaForSequenceClassification
+ - forward
+
+## GemmaForTokenClassification
+
+[[autodoc]] GemmaForTokenClassification
+ - forward
+
+## FlaxGemmaModel
+
+[[autodoc]] FlaxGemmaModel
+ - __call__
+
+## FlaxGemmaForCausalLM
+
+[[autodoc]] FlaxGemmaForCausalLM
+ - __call__
diff --git a/docs/transformers/docs/source/en/model_doc/gemma2.md b/docs/transformers/docs/source/en/model_doc/gemma2.md
new file mode 100644
index 0000000000000000000000000000000000000000..4380cae2690322461dc3abb7bebde0ecc87e3f51
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/gemma2.md
@@ -0,0 +1,167 @@
+
+
+
+
+
+
+
+
+
+
+
+
+# Gemma2
+
+[Gemma 2](https://huggingface.co/papers/2408.00118) is a family of language models with pretrained and instruction-tuned variants, available in 2B, 9B, 27B parameters. The architecture is similar to the previous Gemma, except it features interleaved local attention (4096 tokens) and global attention (8192 tokens) and grouped-query attention (GQA) to increase inference performance.
+
+The 2B and 9B models are trained with knowledge distillation, and the instruction-tuned variant was post-trained with supervised fine-tuning and reinforcement learning.
+
+You can find all the original Gemma 2 checkpoints under the [Gemma 2](https://huggingface.co/collections/google/gemma-2-release-667d6600fd5220e7b967f315) collection.
+
+> [!TIP]
+> Click on the Gemma 2 models in the right sidebar for more examples of how to apply Gemma to different language tasks.
+
+The example below demonstrates how to chat with the model with [`Pipeline`] or the [`AutoModel`] class, and from the command line.
+
+
+
+
+
+```python
+import torch
+from transformers import pipeline
+
+pipe = pipeline(
+ task="text-generation",
+ model="google/gemma-2-9b",
+ torch_dtype=torch.bfloat16,
+ device="cuda",
+)
+
+pipe("Explain quantum computing simply. ", max_new_tokens=50)
+```
+
+
+
+
+```python
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b")
+model = AutoModelForCausalLM.from_pretrained(
+ "google/gemma-2-9b",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+
+input_text = "Explain quantum computing simply."
+input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
+
+outputs = model.generate(**input_ids, max_new_tokens=32, cache_implementation="static")
+print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+
+```
+
+
+
+
+```
+echo -e "Explain quantum computing simply." | transformers-cli run --task text-generation --model google/gemma-2-2b --device 0
+```
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes) to only quantize the weights to int4.
+
+```python
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_4bit=True)
+tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-27b")
+model = AutoModelForCausalLM.from_pretrained(
+ "google/gemma-2-27b",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+
+input_text = "Explain quantum computing simply."
+input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
+
+outputs = model.generate(**input_ids, max_new_tokens=32, cache_implementation="static")
+print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+```
+
+Use the [AttentionMaskVisualizer](https://github.com/huggingface/transformers/blob/beb9b5b02246b9b7ee81ddf938f93f44cfeaad19/src/transformers/utils/attention_visualizer.py#L139) to better understand what tokens the model can and cannot attend to.
+
+
+```python
+from transformers.utils.attention_visualizer import AttentionMaskVisualizer
+visualizer = AttentionMaskVisualizer("google/gemma-2b")
+visualizer("You are an assistant. Make sure you print me")
+```
+
+
+
+
+
+## Notes
+
+- Use a [`HybridCache`] instance to enable caching in Gemma 2. Gemma 2 doesn't support kv-caching strategies like [`DynamicCache`] or tuples of tensors because it uses sliding window attention every second layer.
+
+ ```python
+ from transformers import AutoTokenizer, AutoModelForCausalLM, HybridCache
+
+ model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b")
+ tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b")
+
+ inputs = tokenizer(text="My name is Gemma", return_tensors="pt")
+ max_generated_length = inputs.input_ids.shape[1] + 10
+ past_key_values = HybridCache(config=model.config, max_batch_size=1,
+ max_cache_len=max_generated_length, device=model.device, dtype=model.dtype)
+ outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
+ ```
+
+## Gemma2Config
+
+[[autodoc]] Gemma2Config
+
+## Gemma2Model
+
+[[autodoc]] Gemma2Model
+ - forward
+
+## Gemma2ForCausalLM
+
+[[autodoc]] Gemma2ForCausalLM
+ - forward
+
+## Gemma2ForSequenceClassification
+
+[[autodoc]] Gemma2ForSequenceClassification
+ - forward
+
+## Gemma2ForTokenClassification
+
+[[autodoc]] Gemma2ForTokenClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/gemma3.md b/docs/transformers/docs/source/en/model_doc/gemma3.md
new file mode 100644
index 0000000000000000000000000000000000000000..72c0c5d76af49b0ea3ce9ff1b6be675522c44a0e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/gemma3.md
@@ -0,0 +1,265 @@
+
+
+
+
+
+
+
+
+
+
+# Gemma 3
+
+[Gemma 3](https://goo.gle/Gemma3Report) is a multimodal model with pretrained and instruction-tuned variants, available in 1B, 13B, and 27B parameters. The architecture is mostly the same as the previous Gemma versions. The key differences are alternating 5 local sliding window self-attention layers for every global self-attention layer, support for a longer context length of 128K tokens, and a [SigLip](./siglip) encoder that can "pan & scan" high-resolution images to prevent information from disappearing in high resolution images or images with non-square aspect ratios.
+
+The instruction-tuned variant was post-trained with knowledge distillation and reinforcement learning.
+
+You can find all the original Gemma 3 checkpoints under the [Gemma 3](https://huggingface.co/collections/meta-llama/llama-2-family-661da1f90a9d678b6f55773b) release.
+
+> [!TIP]
+> Click on the Gemma 3 models in the right sidebar for more examples of how to apply Gemma to different vision and language tasks.
+
+The example below demonstrates how to generate text based on an image with [`Pipeline`] or the [`AutoModel`] class.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="image-text-to-text",
+ model="google/gemma-3-4b-pt",
+ device=0,
+ torch_dtype=torch.bfloat16
+)
+pipeline(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg",
+ text=" What is shown in this image?"
+)
+```
+
+
+
+
+```py
+import torch
+from transformers import AutoProcessor, Gemma3ForConditionalGeneration
+
+model = Gemma3ForConditionalGeneration.from_pretrained(
+ "google/gemma-3-4b-it",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+processor = AutoProcessor.from_pretrained(
+ "google/gemma-3-4b-it",
+ padding_side="left"
+)
+
+messages = [
+ {
+ "role": "system",
+ "content": [
+ {"type": "text", "text": "You are a helpful assistant."}
+ ]
+ },
+ {
+ "role": "user", "content": [
+ {"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"},
+ {"type": "text", "text": "What is shown in this image?"},
+ ]
+ },
+]
+inputs = processor.apply_chat_template(
+ messages,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ add_generation_prompt=True,
+).to("cuda")
+
+output = model.generate(**inputs, max_new_tokens=50, cache_implementation="static")
+print(processor.decode(output[0], skip_special_tokens=True))
+```
+
+
+
+
+```bash
+echo -e "Plants create energy through a process known as" | transformers-cli run --task text-generation --model google/gemma-3-1b-pt --device 0
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [torchao](../quantization/torchao) to only quantize the weights to int4.
+
+```py
+# pip install torchao
+import torch
+from transformers import TorchAoConfig, Gemma3ForConditionalGeneration, AutoProcessor
+
+quantization_config = TorchAoConfig("int4_weight_only", group_size=128)
+model = Gemma3ForConditionalGeneration.from_pretrained(
+ "google/gemma-3-27b-it",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ quantization_config=quantization_config
+)
+processor = AutoProcessor.from_pretrained(
+ "google/gemma-3-27b-it",
+ padding_side="left"
+)
+
+messages = [
+ {
+ "role": "system",
+ "content": [
+ {"type": "text", "text": "You are a helpful assistant."}
+ ]
+ },
+ {
+ "role": "user", "content": [
+ {"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"},
+ {"type": "text", "text": "What is shown in this image?"},
+ ]
+ },
+]
+inputs = processor.apply_chat_template(
+ messages,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ add_generation_prompt=True,
+).to("cuda")
+
+output = model.generate(**inputs, max_new_tokens=50, cache_implementation="static")
+print(processor.decode(output[0], skip_special_tokens=True))
+```
+
+Use the [AttentionMaskVisualizer](https://github.com/huggingface/transformers/blob/beb9b5b02246b9b7ee81ddf938f93f44cfeaad19/src/transformers/utils/attention_visualizer.py#L139) to better understand what tokens the model can and cannot attend to.
+
+```py
+from transformers.utils.attention_visualizer import AttentionMaskVisualizer
+
+visualizer = AttentionMaskVisualizer("google/gemma-3-4b-it")
+visualizer("What is shown in this image?")
+```
+
+
+
+
+
+## Notes
+
+- Use [`Gemma3ForConditionalGeneration`] for image-and-text and image-only inputs.
+- Gemma 3 supports multiple input images, but make sure the images are correctly batched before passing them to the processor. Each batch should be a list of one or more images.
+
+ ```py
+ url_cow = "https://media.istockphoto.com/id/1192867753/photo/cow-in-berchida-beach-siniscola.jpg?s=612x612&w=0&k=20&c=v0hjjniwsMNfJSuKWZuIn8pssmD5h5bSN1peBd1CmH4="
+ url_cat = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+
+ messages =[
+ {
+ "role": "system",
+ "content": [
+ {"type": "text", "text": "You are a helpful assistant."}
+ ]
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": url_cow},
+ {"type": "image", "url": url_cat},
+ {"type": "text", "text": "Which image is cuter?"},
+ ]
+ },
+ ]
+ ```
+- Text passed to the processor should have a `` token wherever an image should be inserted.
+- The processor has its own [`~ProcessorMixin.apply_chat_template`] method to convert chat messages to model inputs.
+- By default, images aren't cropped and only the base image is forwarded to the model. In high resolution images or images with non-square aspect ratios, artifacts can result because the vision encoder uses a fixed resolution of 896x896. To prevent these artifacts and improve performance during inference, set `do_pan_and_scan=True` to crop the image into multiple smaller patches and concatenate them with the base image embedding. You can disable pan and scan for faster inference.
+
+ ```diff
+ inputs = processor.apply_chat_template(
+ messages,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ add_generation_prompt=True,
+ + do_pan_and_scan=True,
+ ).to("cuda")
+ ```
+- For Gemma-3 1B checkpoint trained in text-only mode, use [`AutoModelForCausalLM`] instead.
+
+ ```py
+ import torch
+ from transformers import AutoModelForCausalLM, AutoTokenizer
+
+ tokenizer = AutoTokenizer.from_pretrained(
+ "google/gemma-3-1b-pt",
+ )
+ model = AutoModelForCausalLM.from_pretrained(
+ "google/gemma-3-1b-pt",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ attn_implementation="sdpa"
+ )
+ input_ids = tokenizer("Plants create energy through a process known as", return_tensors="pt").to("cuda")
+
+ output = model.generate(**input_ids, cache_implementation="static")
+ print(tokenizer.decode(output[0], skip_special_tokens=True))
+ ```
+
+## Gemma3ImageProcessor
+
+[[autodoc]] Gemma3ImageProcessor
+
+## Gemma3ImageProcessorFast
+
+[[autodoc]] Gemma3ImageProcessorFast
+
+## Gemma3Processor
+
+[[autodoc]] Gemma3Processor
+
+## Gemma3TextConfig
+
+[[autodoc]] Gemma3TextConfig
+
+## Gemma3Config
+
+[[autodoc]] Gemma3Config
+
+## Gemma3TextModel
+
+[[autodoc]] Gemma3TextModel
+ - forward
+
+## Gemma3ForCausalLM
+
+[[autodoc]] Gemma3ForCausalLM
+ - forward
+
+## Gemma3ForConditionalGeneration
+
+[[autodoc]] Gemma3ForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/git.md b/docs/transformers/docs/source/en/model_doc/git.md
new file mode 100644
index 0000000000000000000000000000000000000000..825b73c5c59b5092900a08b62116cb234a935e9c
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/git.md
@@ -0,0 +1,83 @@
+
+
+# GIT
+
+
+
+
+
+## Overview
+
+The GIT model was proposed in [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by
+Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang. GIT is a decoder-only Transformer
+that leverages [CLIP](clip)'s vision encoder to condition the model on vision inputs besides text. The model obtains state-of-the-art results on
+image captioning and visual question answering benchmarks.
+
+The abstract from the paper is the following:
+
+*In this paper, we design and train a Generative Image-to-text Transformer, GIT, to unify vision-language tasks such as image/video captioning and question answering. While generative models provide a consistent network architecture between pre-training and fine-tuning, existing work typically contains complex structures (uni/multi-modal encoder/decoder) and depends on external modules such as object detectors/taggers and optical character recognition (OCR). In GIT, we simplify the architecture as one image encoder and one text decoder under a single language modeling task. We also scale up the pre-training data and the model size to boost the model performance. Without bells and whistles, our GIT establishes new state of the arts on 12 challenging benchmarks with a large margin. For instance, our model surpasses the human performance for the first time on TextCaps (138.2 vs. 125.5 in CIDEr). Furthermore, we present a new scheme of generation-based image classification and scene text recognition, achieving decent performance on standard benchmarks.*
+
+
+
+ GIT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
+
+## Usage tips
+
+- GIT is implemented in a very similar way to GPT-2, the only difference being that the model is also conditioned on `pixel_values`.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GIT.
+
+- Demo notebooks regarding inference + fine-tuning GIT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GIT).
+- See also: [Causal language modeling task guide](../tasks/language_modeling)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
+The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## GitVisionConfig
+
+[[autodoc]] GitVisionConfig
+
+## GitVisionModel
+
+[[autodoc]] GitVisionModel
+ - forward
+
+## GitConfig
+
+[[autodoc]] GitConfig
+ - all
+
+## GitProcessor
+
+[[autodoc]] GitProcessor
+ - __call__
+
+## GitModel
+
+[[autodoc]] GitModel
+ - forward
+
+## GitForCausalLM
+
+[[autodoc]] GitForCausalLM
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/glm.md b/docs/transformers/docs/source/en/model_doc/glm.md
new file mode 100644
index 0000000000000000000000000000000000000000..cfcd549d1493f430ef26ed1789b2e8f3f8dc8a25
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/glm.md
@@ -0,0 +1,105 @@
+
+
+# GLM
+
+
+
+
+
+
+
+## Overview
+
+The GLM Model was proposed
+in [ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools](https://arxiv.org/html/2406.12793v1)
+by GLM Team, THUDM & ZhipuAI.
+
+The abstract from the paper is the following:
+
+*We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report
+primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most
+capable models that are trained with all the insights and lessons gained from the preceding three generations of
+ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with
+a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment
+is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human
+feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU,
+GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3)
+matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as
+measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide
+when and which tool(s) to use—including web browser, Python interpreter, text-to-image model, and user-defined
+functions—to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All
+Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter.
+Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M),
+GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone.*
+
+Tips:
+
+- This model was contributed by [THUDM](https://huggingface.co/THUDM). The most recent code can be
+ found [here](https://github.com/thudm/GLM-4).
+
+
+## Usage tips
+
+`GLM-4` can be found on the [Huggingface Hub](https://huggingface.co/collections/THUDM/glm-4-665fcf188c414b03c2f7e3b7)
+
+In the following, we demonstrate how to use `glm-4-9b-chat` for the inference. Note that we have used the ChatML format for dialog, in this demo we show how to leverage `apply_chat_template` for this purpose.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("THUDM/glm-4-9b-chat", device_map="auto", trust_remote_code=True)
+>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat")
+
+>>> prompt = "Give me a short introduction to large language model."
+
+>>> messages = [{"role": "user", "content": prompt}]
+
+>>> text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
+
+>>> model_inputs = tokenizer([text], return_tensors="pt").to(device)
+
+>>> generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=True)
+
+>>> generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
+
+>>> response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+```
+
+## GlmConfig
+
+[[autodoc]] GlmConfig
+
+## GlmModel
+
+[[autodoc]] GlmModel
+ - forward
+
+## GlmForCausalLM
+
+[[autodoc]] GlmForCausalLM
+ - forward
+
+## GlmForSequenceClassification
+
+[[autodoc]] GlmForSequenceClassification
+ - forward
+
+## GlmForTokenClassification
+
+[[autodoc]] GlmForTokenClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/glm4.md b/docs/transformers/docs/source/en/model_doc/glm4.md
new file mode 100644
index 0000000000000000000000000000000000000000..f854bb658f75e60240480788eca25d75bef27bba
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/glm4.md
@@ -0,0 +1,45 @@
+
+
+# Glm4
+
+## Overview
+
+To be released with the official model launch.
+
+## Glm4Config
+
+[[autodoc]] Glm4Config
+
+## Glm4Model
+
+[[autodoc]] Glm4Model
+ - forward
+
+## Glm4ForCausalLM
+
+[[autodoc]] Glm4ForCausalLM
+ - forward
+
+## Glm4ForSequenceClassification
+
+[[autodoc]] Glm4ForSequenceClassification
+ - forward
+
+## Glm4ForTokenClassification
+
+[[autodoc]] Glm4ForTokenClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/glpn.md b/docs/transformers/docs/source/en/model_doc/glpn.md
new file mode 100644
index 0000000000000000000000000000000000000000..95ecc36bf5b75b7c5c5b5cc100e39f3737836492
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/glpn.md
@@ -0,0 +1,76 @@
+
+
+# GLPN
+
+
+
+
+
+
+
+This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
+breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
+
+
+
+## Overview
+
+The GLPN model was proposed in [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+GLPN combines [SegFormer](segformer)'s hierarchical mix-Transformer with a lightweight decoder for monocular depth estimation. The proposed decoder shows better performance than the previously proposed decoders, with considerably
+less computational complexity.
+
+The abstract from the paper is the following:
+
+*Depth estimation from a single image is an important task that can be applied to various fields in computer vision, and has grown rapidly with the development of convolutional neural networks. In this paper, we propose a novel structure and training strategy for monocular depth estimation to further improve the prediction accuracy of the network. We deploy a hierarchical transformer encoder to capture and convey the global context, and design a lightweight yet powerful decoder to generate an estimated depth map while considering local connectivity. By constructing connected paths between multi-scale local features and the global decoding stream with our proposed selective feature fusion module, the network can integrate both representations and recover fine details. In addition, the proposed decoder shows better performance than the previously proposed decoders, with considerably less computational complexity. Furthermore, we improve the depth-specific augmentation method by utilizing an important observation in depth estimation to enhance the model. Our network achieves state-of-the-art performance over the challenging depth dataset NYU Depth V2. Extensive experiments have been conducted to validate and show the effectiveness of the proposed approach. Finally, our model shows better generalisation ability and robustness than other comparative models.*
+
+
+
+ Summary of the approach. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/vinvino02/GLPDepth).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GLPN.
+
+- Demo notebooks for [`GLPNForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GLPN).
+- [Monocular depth estimation task guide](../tasks/monocular_depth_estimation)
+
+## GLPNConfig
+
+[[autodoc]] GLPNConfig
+
+## GLPNFeatureExtractor
+
+[[autodoc]] GLPNFeatureExtractor
+ - __call__
+
+## GLPNImageProcessor
+
+[[autodoc]] GLPNImageProcessor
+ - preprocess
+
+## GLPNModel
+
+[[autodoc]] GLPNModel
+ - forward
+
+## GLPNForDepthEstimation
+
+[[autodoc]] GLPNForDepthEstimation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/got_ocr2.md b/docs/transformers/docs/source/en/model_doc/got_ocr2.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb14cdbcf8477cdb926a9ce8549492d6a6ec2c0f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/got_ocr2.md
@@ -0,0 +1,284 @@
+
+
+# GOT-OCR2
+
+
+
+
+
+## Overview
+
+The GOT-OCR2 model was proposed in [General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model](https://arxiv.org/abs/2409.01704) by Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, Chunrui Han, Xiangyu Zhang.
+
+The abstract from the paper is the following:
+
+*Traditional OCR systems (OCR-1.0) are increasingly unable to meet people’snusage due to the growing demand for intelligent processing of man-made opticalncharacters. In this paper, we collectively refer to all artificial optical signals (e.g., plain texts, math/molecular formulas, tables, charts, sheet music, and even geometric shapes) as "characters" and propose the General OCR Theory along with an excellent model, namely GOT, to promote the arrival of OCR-2.0. The GOT, with 580M parameters, is a unified, elegant, and end-to-end model, consisting of a high-compression encoder and a long-contexts decoder. As an OCR-2.0 model, GOT can handle all the above "characters" under various OCR tasks. On the input side, the model supports commonly used scene- and document-style images in slice and whole-page styles. On the output side, GOT can generate plain or formatted results (markdown/tikz/smiles/kern) via an easy prompt. Besides, the model enjoys interactive OCR features, i.e., region-level recognition guided by coordinates or colors. Furthermore, we also adapt dynamic resolution and multipage OCR technologies to GOT for better practicality. In experiments, we provide sufficient results to prove the superiority of our model.*
+
+
+
+ GOT-OCR2 training stages. Taken from the original paper.
+
+
+Tips:
+
+GOT-OCR2 works on a wide range of tasks, including plain document OCR, scene text OCR, formatted document OCR, and even OCR for tables, charts, mathematical formulas, geometric shapes, molecular formulas and sheet music. While this implementation of the model will only output plain text, the outputs can be further processed to render the desired format, with packages like `pdftex`, `mathpix`, `matplotlib`, `tikz`, `verovio` or `pyecharts`.
+The model can also be used for interactive OCR, where the user can specify the region to be recognized by providing the coordinates or the color of the region's bounding box.
+
+This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
+The original code can be found [here](https://github.com/Ucas-HaoranWei/GOT-OCR2.0).
+
+## Usage example
+
+### Plain text inference
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/image_ocr.jpg"
+>>> inputs = processor(image, return_tensors="pt", device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"R&D QUALITY IMPROVEMENT\nSUGGESTION/SOLUTION FORM\nName/Phone Ext. : (...)"
+```
+
+### Plain text inference batched
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image1 = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/multi_box.png"
+>>> image2 = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/image_ocr.jpg"
+
+>>> inputs = processor([image1, image2], return_tensors="pt", device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4,
+... )
+
+>>> processor.batch_decode(generate_ids[:, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+["Reducing the number", "R&D QUALITY"]
+```
+
+### Formatted text inference
+
+GOT-OCR2 can also generate formatted text, such as markdown or LaTeX. Here is an example of how to generate formatted text:
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/latex.png"
+>>> inputs = processor(image, return_tensors="pt", format=True, device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"\\author{\nHanwen Jiang* \\(\\quad\\) Arjun Karpur \\({ }^{\\dagger} \\quad\\) Bingyi Cao \\({ }^{\\dagger} \\quad\\) (...)"
+```
+
+### Inference on multiple pages
+
+Although it might be reasonable in most cases to use a “for loop” for multi-page processing, some text data with formatting across several pages make it necessary to process all pages at once. GOT introduces a multi-page OCR (without “for loop”) feature, where multiple pages can be processed by the model at once, whith the output being one continuous text.
+Here is an example of how to process multiple pages at once:
+
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image1 = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/page1.png"
+>>> image2 = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/page2.png"
+>>> inputs = processor([image1, image2], return_tensors="pt", multi_page=True, format=True, device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"\\title{\nGeneral OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model\n}\n\\author{\nHaoran Wei (...)"
+```
+
+### Inference on cropped patches
+
+GOT supports a 1024×1024 input resolution, which is sufficient for most OCR tasks, such as scene OCR or processing A4-sized PDF pages. However, certain scenarios, like horizontally stitched two-page PDFs commonly found in academic papers or images with unusual aspect ratios, can lead to accuracy issues when processed as a single image. To address this, GOT can dynamically crop an image into patches, process them all at once, and merge the results for better accuracy with such inputs.
+Here is an example of how to process cropped patches:
+
+```python
+>>> import torch
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", torch_dtype=torch.bfloat16, device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/one_column.png"
+>>> inputs = processor(image, return_tensors="pt", format=True, crop_to_patches=True, max_patches=3, device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"on developing architectural improvements to make learnable matching methods generalize.\nMotivated by the above observations, (...)"
+```
+
+### Inference on a specific region
+
+GOT supports interactive OCR, where the user can specify the region to be recognized by providing the coordinates or the color of the region's bounding box. Here is an example of how to process a specific region:
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/multi_box.png"
+>>> inputs = processor(image, return_tensors="pt", color="green", device=device).to(device) # or box=[x1, y1, x2, y2] for coordinates (image pixels)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"You should keep in mind what features from the module should be used, especially \nwhen you’re planning to sell a template."
+```
+
+### Inference on general OCR data example: sheet music
+
+Although this implementation of the model will only output plain text, the outputs can be further processed to render the desired format, with packages like `pdftex`, `mathpix`, `matplotlib`, `tikz`, `verovio` or `pyecharts`.
+Here is an example of how to process sheet music:
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+>>> import verovio
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/sheet_music.png"
+>>> inputs = processor(image, return_tensors="pt", format=True, device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> outputs = processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+>>> tk = verovio.toolkit()
+>>> tk.loadData(outputs)
+>>> tk.setOptions(
+... {
+... "pageWidth": 2100,
+... "pageHeight": 800,
+... "footer": "none",
+... "barLineWidth": 0.5,
+... "beamMaxSlope": 15,
+... "staffLineWidth": 0.2,
+... "spacingStaff": 6,
+... }
+... )
+>>> tk.getPageCount()
+>>> svg = tk.renderToSVG()
+>>> svg = svg.replace('overflow="inherit"', 'overflow="visible"')
+>>> with open("output.svg", "w") as f:
+>>> f.write(svg)
+```
+
+
+## GotOcr2Config
+
+[[autodoc]] GotOcr2Config
+
+## GotOcr2VisionConfig
+
+[[autodoc]] GotOcr2VisionConfig
+
+## GotOcr2ImageProcessor
+
+[[autodoc]] GotOcr2ImageProcessor
+
+## GotOcr2ImageProcessorFast
+
+[[autodoc]] GotOcr2ImageProcessorFast
+
+## GotOcr2Processor
+
+[[autodoc]] GotOcr2Processor
+
+## GotOcr2ForConditionalGeneration
+
+[[autodoc]] GotOcr2ForConditionalGeneration
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/gpt-sw3.md b/docs/transformers/docs/source/en/model_doc/gpt-sw3.md
new file mode 100644
index 0000000000000000000000000000000000000000..20daa3537af0f37c48b95385dc288a1629a6814d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/gpt-sw3.md
@@ -0,0 +1,76 @@
+
+
+# GPT-Sw3
+
+
+
+
+
+
+
+## Overview
+
+The GPT-Sw3 model was first proposed in
+[Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf)
+by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman,
+Fredrik Carlsson, Magnus Sahlgren.
+
+Since that first paper the authors have extended their work and trained new models on their new 1.2TB corpora named The Nordic Pile.
+
+GPT-Sw3 is a collection of large decoder-only pretrained transformer language models that were developed by AI Sweden
+in collaboration with RISE and the WASP WARA for Media and Language. GPT-Sw3 has been trained on a dataset containing
+320B tokens in Swedish, Norwegian, Danish, Icelandic, English, and programming code. The model was pretrained using a
+causal language modeling (CLM) objective utilizing the NeMo Megatron GPT implementation.
+
+This model was contributed by [AI Sweden Models](https://huggingface.co/AI-Sweden-Models).
+
+## Usage example
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForCausalLM
+
+>>> tokenizer = AutoTokenizer.from_pretrained("AI-Sweden-Models/gpt-sw3-356m")
+>>> model = AutoModelForCausalLM.from_pretrained("AI-Sweden-Models/gpt-sw3-356m")
+
+>>> input_ids = tokenizer("Träd är fina för att", return_tensors="pt")["input_ids"]
+
+>>> generated_token_ids = model.generate(inputs=input_ids, max_new_tokens=10, do_sample=True)[0]
+
+>>> print(tokenizer.decode(generated_token_ids))
+Träd är fina för att de är färgstarka. Men ibland är det fint
+```
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Causal language modeling task guide](../tasks/language_modeling)
+
+
+
+The implementation uses the `GPT2Model` coupled with our `GPTSw3Tokenizer`. Refer to [GPT2Model documentation](gpt2)
+for API reference and examples.
+
+Note that sentencepiece is required to use our tokenizer and can be installed with `pip install transformers[sentencepiece]` or `pip install sentencepiece`
+
+
+
+## GPTSw3Tokenizer
+
+[[autodoc]] GPTSw3Tokenizer
+ - save_vocabulary
diff --git a/docs/transformers/docs/source/en/model_doc/gpt2.md b/docs/transformers/docs/source/en/model_doc/gpt2.md
new file mode 100644
index 0000000000000000000000000000000000000000..6ce006c9081dfc112bb5e1dea32e9836d75b891f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/gpt2.md
@@ -0,0 +1,206 @@
+
+
+
+
+
+
+
+
+
+
+
+
+# GPT-2
+
+[GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) is a scaled up version of GPT, a causal transformer language model, with 10x more parameters and training data. The model was pretrained on a 40GB dataset to predict the next word in a sequence based on all the previous words. This approach enabled the model to perform many downstream tasks in a zero-shot setting.
+
+The model architecture uses a unidirectional (causal) attention mechanism where each token can only attend to previous tokens, making it particularly effective for text generation tasks.
+
+You can find all the original GPT-2 checkpoints under the [OpenAI community](https://huggingface.co/openai-community?search_models=gpt) organization.
+
+> [!TIP]
+> Click on the GPT-2 models in the right sidebar for more examples of how to apply GPT-2 to different language tasks.
+
+The example below demonstrates how to generate text with [`Pipeline`] or the [`AutoModel`], and from the command line.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(task="text-generation", model="openai-community/gpt2", torch_dtype=torch.float16, device=0)
+pipeline("Hello, I'm a language model")
+```
+
+
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2", torch_dtype=torch.float16, device_map="auto", attn_implementation="sdpa")
+tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
+
+input_ids = tokenzier("Hello, I'm a language model". return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+
+
+
+```bash
+echo -e "Hello, I'm a language model" | transformers-cli run --task text-generation --model openai-community/gpt2 --device 0
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes) to only quantize the weights to 4-bits.
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, pipeline
+
+quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype="float16",
+ bnb_4bit_use_double_quant=True
+)
+
+model = AutoModelForCausalLM.from_pretrained(
+ "openai-community/gpt2-xl",
+ quantization_config=quantization_config,
+ device_map="auto"
+)
+
+tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2-xl")
+inputs = tokenizer("Once upon a time, there was a magical forest", return_tensors="pt").to("cuda")
+outputs = model.generate(**inputs, max_new_tokens=100)
+print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+```
+
+## Notes
+
+- Pad inputs on the right because GPT-2 uses absolute position embeddings.
+- GPT-2 can reuse previously computed key-value attention pairs. Access this feature with the [past_key_values](https://huggingface.co/docs/transformers//en/model_doc/gpt2#transformers.GPT2Model.forward.past_key_values) parameter in [`GPT2Model.forward`].
+- Enable the [scale_attn_by_inverse_layer_idx](https://huggingface.co/docs/transformers/en/model_doc/gpt2#transformers.GPT2Config.scale_attn_by_inverse_layer_idx) and [reorder_and_upcast_attn](https://huggingface.co/docs/transformers/en/model_doc/gpt2#transformers.GPT2Config.reorder_and_upcast_attn) parameters to apply the training stability improvements from [Mistral](./mistral).
+
+## GPT2Config
+
+[[autodoc]] GPT2Config
+
+## GPT2Tokenizer
+
+[[autodoc]] GPT2Tokenizer
+ - save_vocabulary
+
+## GPT2TokenizerFast
+
+[[autodoc]] GPT2TokenizerFast
+
+## GPT2 specific outputs
+
+[[autodoc]] models.gpt2.modeling_gpt2.GPT2DoubleHeadsModelOutput
+
+[[autodoc]] models.gpt2.modeling_tf_gpt2.TFGPT2DoubleHeadsModelOutput
+
+
+
+
+## GPT2Model
+
+[[autodoc]] GPT2Model
+ - forward
+
+## GPT2LMHeadModel
+
+[[autodoc]] GPT2LMHeadModel
+ - forward
+
+## GPT2DoubleHeadsModel
+
+[[autodoc]] GPT2DoubleHeadsModel
+ - forward
+
+## GPT2ForQuestionAnswering
+
+[[autodoc]] GPT2ForQuestionAnswering
+ - forward
+
+## GPT2ForSequenceClassification
+
+[[autodoc]] GPT2ForSequenceClassification
+ - forward
+
+## GPT2ForTokenClassification
+
+[[autodoc]] GPT2ForTokenClassification
+ - forward
+
+
+
+
+## TFGPT2Model
+
+[[autodoc]] TFGPT2Model
+ - call
+
+## TFGPT2LMHeadModel
+
+[[autodoc]] TFGPT2LMHeadModel
+ - call
+
+## TFGPT2DoubleHeadsModel
+
+[[autodoc]] TFGPT2DoubleHeadsModel
+ - call
+
+## TFGPT2ForSequenceClassification
+
+[[autodoc]] TFGPT2ForSequenceClassification
+ - call
+
+## TFSequenceClassifierOutputWithPast
+
+[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutputWithPast
+
+## TFGPT2Tokenizer
+
+[[autodoc]] TFGPT2Tokenizer
+
+
+
+
+## FlaxGPT2Model
+
+[[autodoc]] FlaxGPT2Model
+ - __call__
+
+## FlaxGPT2LMHeadModel
+
+[[autodoc]] FlaxGPT2LMHeadModel
+ - __call__
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/gpt_bigcode.md b/docs/transformers/docs/source/en/model_doc/gpt_bigcode.md
new file mode 100644
index 0000000000000000000000000000000000000000..648fa6cb8d605491129c797ad3f20e0f0e3bff29
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/gpt_bigcode.md
@@ -0,0 +1,112 @@
+
+
+# GPTBigCode
+
+
+
+
+
+
+
+## Overview
+
+The GPTBigCode model was proposed in [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by BigCode. The listed authors are: Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
+
+The abstract from the paper is the following:
+
+*The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at [this https URL.](https://huggingface.co/bigcode)*
+
+The model is an optimized [GPT2 model](https://huggingface.co/docs/transformers/model_doc/gpt2) with support for Multi-Query Attention.
+
+## Implementation details
+
+The main differences compared to GPT2.
+- Added support for Multi-Query Attention.
+- Use `gelu_pytorch_tanh` instead of classic `gelu`.
+- Avoid unnecessary synchronizations (this has since been added to GPT2 in #20061, but wasn't in the reference codebase).
+- Use Linear layers instead of Conv1D (good speedup but makes the checkpoints incompatible).
+- Merge `_attn` and `_upcast_and_reordered_attn`. Always merge the matmul with scaling. Rename `reorder_and_upcast_attn`->`attention_softmax_in_fp32`
+- Cache the attention mask value to avoid recreating it every time.
+- Use jit to fuse the attention fp32 casting, masking, softmax, and scaling.
+- Combine the attention and causal masks into a single one, pre-computed for the whole model instead of every layer.
+- Merge the key and value caches into one (this changes the format of layer_past/ present, does it risk creating problems?)
+- Use the memory layout (self.num_heads, 3, self.head_dim) instead of `(3, self.num_heads, self.head_dim)` for the QKV tensor with MHA. (prevents an overhead with the merged key and values, but makes the checkpoints incompatible with the original openai-community/gpt2 model).
+
+You can read more about the optimizations in the [original pull request](https://github.com/huggingface/transformers/pull/22575)
+
+## Combining Starcoder and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("bigcode/gpt_bigcode-santacoder", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
+>>> tokenizer = AutoTokenizer.from_pretrained("bigcode/gpt_bigcode-santacoder")
+
+>>> prompt = "def hello_world():"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
+>>> tokenizer.batch_decode(generated_ids)[0]
+'def hello_world():\n print("hello world")\n\nif __name__ == "__main__":\n print("hello world")\n<|endoftext|>'
+```
+
+### Expected speedups
+
+Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using `bigcode/starcoder` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
+
+
+
+## Overview
+
+The GPTNeo model was released in the [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) repository by Sid
+Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy. It is a GPT2 like causal language model trained on the
+[Pile](https://pile.eleuther.ai/) dataset.
+
+The architecture is similar to GPT2 except that GPT Neo uses local attention in every other layer with a window size of
+256 tokens.
+
+This model was contributed by [valhalla](https://huggingface.co/valhalla).
+
+## Usage example
+
+The `generate()` method can be used to generate text using GPT Neo model.
+
+```python
+>>> from transformers import GPTNeoForCausalLM, GPT2Tokenizer
+
+>>> model = GPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
+>>> tokenizer = GPT2Tokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
+
+>>> prompt = (
+... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
+... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
+... "researchers was the fact that the unicorns spoke perfect English."
+... )
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
+```
+
+## Combining GPT-Neo and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature, and make sure your hardware is compatible with Flash-Attention 2. More details are available [here](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2) concerning the installation.
+
+Make sure as well to load your model in half-precision (e.g. `torch.float16`).
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-2.7B", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
+>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-2.7B")
+
+>>> prompt = "def hello_world():"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"def hello_world():\n >>> run_script("hello.py")\n >>> exit(0)\n<|endoftext|>"
+```
+
+### Expected speedups
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `EleutherAI/gpt-neo-2.7B` checkpoint and the Flash Attention 2 version of the model.
+Note that for GPT-Neo it is not possible to train / run on very long context as the max [position embeddings](https://huggingface.co/EleutherAI/gpt-neo-2.7B/blob/main/config.json#L58 ) is limited to 2048 - but this is applicable to all gpt-neo models and not specific to FA-2
+
+
+
+## Overview
+
+We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will
+be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge,
+the largest dense autoregressive model that has publicly available weights at the time of submission. In this work,
+we describe GPT-NeoX-20B's architecture and training and evaluate its performance on a range of language-understanding,
+mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and
+gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source
+the training and evaluation code, as well as the model weights, at [https://github.com/EleutherAI/gpt-neox](https://github.com/EleutherAI/gpt-neox).
+
+Development of the model was led by Sid Black, Stella Biderman and Eric Hallahan, and the model was trained with
+generous the support of [CoreWeave](https://www.coreweave.com/).
+
+GPT-NeoX-20B was trained with fp16, thus it is recommended to initialize the model as follows:
+
+```python
+model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b").half().cuda()
+```
+
+GPT-NeoX-20B also has a different tokenizer from the one used in GPT-J-6B and GPT-Neo. The new tokenizer allocates
+additional tokens to whitespace characters, making the model more suitable for certain tasks like code generation.
+
+## Usage example
+
+The `generate()` method can be used to generate text using GPT Neo model.
+
+```python
+>>> from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast
+
+>>> model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b")
+>>> tokenizer = GPTNeoXTokenizerFast.from_pretrained("EleutherAI/gpt-neox-20b")
+
+>>> prompt = "GPTNeoX20B is a 20B-parameter autoregressive Transformer model developed by EleutherAI."
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
+```
+
+## Using Flash Attention 2
+
+Flash Attention 2 is an faster, optimized version of the model.
+
+### Installation
+
+First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features). If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered [above](https://huggingface.co/docs/transformers/main/en/model_doc/bark#using-better-transformer).
+
+Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+### Usage
+
+To load a model using Flash Attention 2, we can pass the argument `attn_implementation="flash_attention_2"` to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). We'll also load the model in half-precision (e.g. `torch.float16`), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
+
+```python
+>>> from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast
+
+model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
+...
+```
+
+
+### Expected speedups
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `stockmark/gpt-neox-japanese-1.4b` checkpoint and the Flash Attention 2 version of the model using a sequence length of 2048.
+
+
+
+## Overview
+
+We introduce GPT-NeoX-Japanese, which is an autoregressive language model for Japanese, trained on top of [https://github.com/EleutherAI/gpt-neox](https://github.com/EleutherAI/gpt-neox).
+Japanese is a unique language with its large vocabulary and a combination of hiragana, katakana, and kanji writing scripts.
+To address this distinct structure of the Japanese language, we use a [special sub-word tokenizer](https://github.com/tanreinama/Japanese-BPEEncoder_V2). We are very grateful to *tanreinama* for open-sourcing this incredibly helpful tokenizer.
+Following the recommendations from Google's research on [PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html), we have removed bias parameters from transformer blocks, achieving better model performance. Please refer [this article](https://medium.com/ml-abeja/training-a-better-gpt-2-93b157662ae4) in detail.
+
+Development of the model was led by [Shinya Otani](https://github.com/SO0529), [Takayoshi Makabe](https://github.com/spider-man-tm), [Anuj Arora](https://github.com/Anuj040), and [Kyo Hattori](https://github.com/go5paopao) from [ABEJA, Inc.](https://www.abejainc.com/). For more information on this model-building activity, please refer [here (ja)](https://tech-blog.abeja.asia/entry/abeja-gpt-project-202207).
+
+### Usage example
+
+The `generate()` method can be used to generate text using GPT NeoX Japanese model.
+
+```python
+>>> from transformers import GPTNeoXJapaneseForCausalLM, GPTNeoXJapaneseTokenizer
+
+>>> model = GPTNeoXJapaneseForCausalLM.from_pretrained("abeja/gpt-neox-japanese-2.7b")
+>>> tokenizer = GPTNeoXJapaneseTokenizer.from_pretrained("abeja/gpt-neox-japanese-2.7b")
+
+>>> prompt = "人とAIが協調するためには、"
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens, skip_special_tokens=True)[0]
+
+>>> print(gen_text)
+人とAIが協調するためには、AIと人が共存し、AIを正しく理解する必要があります。
+```
+
+## Resources
+
+- [Causal language modeling task guide](../tasks/language_modeling)
+
+## GPTNeoXJapaneseConfig
+
+[[autodoc]] GPTNeoXJapaneseConfig
+
+## GPTNeoXJapaneseTokenizer
+
+[[autodoc]] GPTNeoXJapaneseTokenizer
+
+## GPTNeoXJapaneseModel
+
+[[autodoc]] GPTNeoXJapaneseModel
+ - forward
+
+## GPTNeoXJapaneseForCausalLM
+
+[[autodoc]] GPTNeoXJapaneseForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/gptj.md b/docs/transformers/docs/source/en/model_doc/gptj.md
new file mode 100644
index 0000000000000000000000000000000000000000..8e852d931aae0a6e96622fae2d5e455d24f2d0c9
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/gptj.md
@@ -0,0 +1,208 @@
+
+
+# GPT-J
+
+
+
+
+
+
+
+
+## Overview
+
+The GPT-J model was released in the [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax) repository by Ben Wang and Aran Komatsuzaki. It is a GPT-2-like
+causal language model trained on [the Pile](https://pile.eleuther.ai/) dataset.
+
+This model was contributed by [Stella Biderman](https://huggingface.co/stellaathena).
+
+## Usage tips
+
+- To load [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B) in float32 one would need at least 2x model size
+ RAM: 1x for initial weights and another 1x to load the checkpoint. So for GPT-J it would take at least 48GB
+ RAM to just load the model. To reduce the RAM usage there are a few options. The `torch_dtype` argument can be
+ used to initialize the model in half-precision on a CUDA device only. There is also a fp16 branch which stores the fp16 weights,
+ which could be used to further minimize the RAM usage:
+
+```python
+>>> from transformers import GPTJForCausalLM
+>>> import torch
+
+>>> device = "cuda"
+>>> model = GPTJForCausalLM.from_pretrained(
+... "EleutherAI/gpt-j-6B",
+... revision="float16",
+... torch_dtype=torch.float16,
+... ).to(device)
+```
+
+- The model should fit on 16GB GPU for inference. For training/fine-tuning it would take much more GPU RAM. Adam
+ optimizer for example makes four copies of the model: model, gradients, average and squared average of the gradients.
+ So it would need at least 4x model size GPU memory, even with mixed precision as gradient updates are in fp32. This
+ is not including the activations and data batches, which would again require some more GPU RAM. So one should explore
+ solutions such as DeepSpeed, to train/fine-tune the model. Another option is to use the original codebase to
+ train/fine-tune the model on TPU and then convert the model to Transformers format for inference. Instructions for
+ that could be found [here](https://github.com/kingoflolz/mesh-transformer-jax/blob/master/howto_finetune.md)
+
+- Although the embedding matrix has a size of 50400, only 50257 entries are used by the GPT-2 tokenizer. These extra
+ tokens are added for the sake of efficiency on TPUs. To avoid the mismatch between embedding matrix size and vocab
+ size, the tokenizer for [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B) contains 143 extra tokens
+ `<|extratoken_1|>... <|extratoken_143|>`, so the `vocab_size` of tokenizer also becomes 50400.
+
+## Usage examples
+
+The [`~generation.GenerationMixin.generate`] method can be used to generate text using GPT-J
+model.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6B")
+>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
+
+>>> prompt = (
+... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
+... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
+... "researchers was the fact that the unicorns spoke perfect English."
+... )
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
+```
+
+...or in float16 precision:
+
+```python
+>>> from transformers import GPTJForCausalLM, AutoTokenizer
+>>> import torch
+
+>>> device = "cuda"
+>>> model = GPTJForCausalLM.from_pretrained("EleutherAI/gpt-j-6B", torch_dtype=torch.float16).to(device)
+>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
+
+>>> prompt = (
+... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
+... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
+... "researchers was the fact that the unicorns spoke perfect English."
+... )
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GPT-J. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+- Description of [GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B).
+- A blog on how to [Deploy GPT-J 6B for inference using Hugging Face Transformers and Amazon SageMaker](https://huggingface.co/blog/gptj-sagemaker).
+- A blog on how to [Accelerate GPT-J inference with DeepSpeed-Inference on GPUs](https://www.philschmid.de/gptj-deepspeed-inference).
+- A blog post introducing [GPT-J-6B: 6B JAX-Based Transformer](https://arankomatsuzaki.wordpress.com/2021/06/04/gpt-j/). 🌎
+- A notebook for [GPT-J-6B Inference Demo](https://colab.research.google.com/github/kingoflolz/mesh-transformer-jax/blob/master/colab_demo.ipynb). 🌎
+- Another notebook demonstrating [Inference with GPT-J-6B](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/GPT-J-6B/Inference_with_GPT_J_6B.ipynb).
+- [Causal language modeling](https://huggingface.co/course/en/chapter7/6?fw=pt#training-a-causal-language-model-from-scratch) chapter of the 🤗 Hugging Face Course.
+- [`GPTJForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling), [text generation example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation), and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
+- [`TFGPTJForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_clmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
+- [`FlaxGPTJForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/causal_language_modeling_flax.ipynb).
+
+**Documentation resources**
+- [Text classification task guide](../tasks/sequence_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+
+## GPTJConfig
+
+[[autodoc]] GPTJConfig
+ - all
+
+
+
+
+## GPTJModel
+
+[[autodoc]] GPTJModel
+ - forward
+
+## GPTJForCausalLM
+
+[[autodoc]] GPTJForCausalLM
+ - forward
+
+## GPTJForSequenceClassification
+
+[[autodoc]] GPTJForSequenceClassification
+ - forward
+
+## GPTJForQuestionAnswering
+
+[[autodoc]] GPTJForQuestionAnswering
+ - forward
+
+
+
+
+## TFGPTJModel
+
+[[autodoc]] TFGPTJModel
+ - call
+
+## TFGPTJForCausalLM
+
+[[autodoc]] TFGPTJForCausalLM
+ - call
+
+## TFGPTJForSequenceClassification
+
+[[autodoc]] TFGPTJForSequenceClassification
+ - call
+
+## TFGPTJForQuestionAnswering
+
+[[autodoc]] TFGPTJForQuestionAnswering
+ - call
+
+
+
+
+## FlaxGPTJModel
+
+[[autodoc]] FlaxGPTJModel
+ - __call__
+
+## FlaxGPTJForCausalLM
+
+[[autodoc]] FlaxGPTJForCausalLM
+ - __call__
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/gptsan-japanese.md b/docs/transformers/docs/source/en/model_doc/gptsan-japanese.md
new file mode 100644
index 0000000000000000000000000000000000000000..929e7330ceea261eabc8f94ccac8af35f66a4672
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/gptsan-japanese.md
@@ -0,0 +1,133 @@
+
+
+# GPTSAN-japanese
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+The GPTSAN-japanese model was released in the repository by Toshiyuki Sakamoto (tanreinama).
+
+GPTSAN is a Japanese language model using Switch Transformer. It has the same structure as the model introduced as Prefix LM
+in the T5 paper, and support both Text Generation and Masked Language Modeling tasks. These basic tasks similarly can
+fine-tune for translation or summarization.
+
+### Usage example
+
+The `generate()` method can be used to generate text using GPTSAN-Japanese model.
+
+```python
+>>> from transformers import AutoModel, AutoTokenizer
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("Tanrei/GPTSAN-japanese")
+>>> model = AutoModel.from_pretrained("Tanrei/GPTSAN-japanese").cuda()
+>>> x_tok = tokenizer("は、", prefix_text="織田信長", return_tensors="pt")
+>>> torch.manual_seed(0)
+>>> gen_tok = model.generate(x_tok.input_ids.cuda(), token_type_ids=x_tok.token_type_ids.cuda(), max_new_tokens=20)
+>>> tokenizer.decode(gen_tok[0])
+'織田信長は、2004年に『戦国BASARA』のために、豊臣秀吉'
+```
+
+## GPTSAN Features
+
+GPTSAN has some unique features. It has a model structure of Prefix-LM. It works as a shifted Masked Language Model for Prefix Input tokens. Un-prefixed inputs behave like normal generative models.
+The Spout vector is a GPTSAN specific input. Spout is pre-trained with random inputs, but you can specify a class of text or an arbitrary vector during fine-tuning. This allows you to indicate the tendency of the generated text.
+GPTSAN has a sparse Feed Forward based on Switch-Transformer. You can also add other layers and train them partially. See the original GPTSAN repository for details.
+
+### Prefix-LM Model
+
+GPTSAN has the structure of the model named Prefix-LM in the `T5` paper. (The original GPTSAN repository calls it `hybrid`)
+In GPTSAN, the `Prefix` part of Prefix-LM, that is, the input position that can be referenced by both tokens, can be specified with any length.
+Arbitrary lengths can also be specified differently for each batch.
+This length applies to the text entered in `prefix_text` for the tokenizer.
+The tokenizer returns the mask of the `Prefix` part of Prefix-LM as `token_type_ids`.
+The model treats the part where `token_type_ids` is 1 as a `Prefix` part, that is, the input can refer to both tokens before and after.
+
+## Usage tips
+
+Specifying the Prefix part is done with a mask passed to self-attention.
+When token_type_ids=None or all zero, it is equivalent to regular causal mask
+
+for example:
+
+>>> x_token = tokenizer("アイウエ")
+input_ids: | SOT | SEG | ア | イ | ウ | エ |
+token_type_ids: | 1 | 0 | 0 | 0 | 0 | 0 |
+prefix_lm_mask:
+SOT | 1 0 0 0 0 0 |
+SEG | 1 1 0 0 0 0 |
+ア | 1 1 1 0 0 0 |
+イ | 1 1 1 1 0 0 |
+ウ | 1 1 1 1 1 0 |
+エ | 1 1 1 1 1 1 |
+
+>>> x_token = tokenizer("", prefix_text="アイウエ")
+input_ids: | SOT | ア | イ | ウ | エ | SEG |
+token_type_ids: | 1 | 1 | 1 | 1 | 1 | 0 |
+prefix_lm_mask:
+SOT | 1 1 1 1 1 0 |
+ア | 1 1 1 1 1 0 |
+イ | 1 1 1 1 1 0 |
+ウ | 1 1 1 1 1 0 |
+エ | 1 1 1 1 1 0 |
+SEG | 1 1 1 1 1 1 |
+
+>>> x_token = tokenizer("ウエ", prefix_text="アイ")
+input_ids: | SOT | ア | イ | SEG | ウ | エ |
+token_type_ids: | 1 | 1 | 1 | 0 | 0 | 0 |
+prefix_lm_mask:
+SOT | 1 1 1 0 0 0 |
+ア | 1 1 1 0 0 0 |
+イ | 1 1 1 0 0 0 |
+SEG | 1 1 1 1 0 0 |
+ウ | 1 1 1 1 1 0 |
+エ | 1 1 1 1 1 1 |
+
+### Spout Vector
+
+A Spout Vector is a special vector for controlling text generation.
+This vector is treated as the first embedding in self-attention to bring extraneous attention to the generated tokens.
+In the pre-trained model published from `Tanrei/GPTSAN-japanese`, the Spout Vector is a 128-dimensional vector that passes through 8 fully connected layers in the model and is projected into the space acting as external attention.
+The Spout Vector projected by the fully connected layer is split to be passed to all self-attentions.
+
+## GPTSanJapaneseConfig
+
+[[autodoc]] GPTSanJapaneseConfig
+
+## GPTSanJapaneseTokenizer
+
+[[autodoc]] GPTSanJapaneseTokenizer
+
+## GPTSanJapaneseModel
+
+[[autodoc]] GPTSanJapaneseModel
+
+## GPTSanJapaneseForConditionalGeneration
+
+[[autodoc]] GPTSanJapaneseForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/granite.md b/docs/transformers/docs/source/en/model_doc/granite.md
new file mode 100644
index 0000000000000000000000000000000000000000..0326bc5ad24a33b2a60520dcf8ee59186565cbf6
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/granite.md
@@ -0,0 +1,80 @@
+
+
+# Granite
+
+
+
+
+
+
+
+## Overview
+
+The Granite model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
+
+PowerLM-3B is a 3B state-of-the-art small language model trained with the Power learning rate scheduler. It is trained on a wide range of open-source and synthetic datasets with permissive licenses. PowerLM-3B has shown promising results compared to other models in the size categories across various benchmarks, including natural language multi-choices, code generation, and math reasoning.
+
+The abstract from the paper is the following:
+
+*Finding the optimal learning rate for language model pretraining is a challenging task.
+This is not only because there is a complicated correlation between learning rate, batch size, number of training tokens, model size, and other hyperparameters but also because it is prohibitively expensive to perform a hyperparameter search for large language models with Billions or Trillions of parameters. Recent studies propose using small proxy models and small corpus to perform hyperparameter searches and transposing the optimal parameters to large models and large corpus. While the zero-shot transferability is theoretically and empirically proven for model size related hyperparameters, like depth and width, the zero-shot transfer from small corpus to large corpus is underexplored.
+In this paper, we study the correlation between optimal learning rate, batch size, and number of training tokens for the recently proposed WSD scheduler. After thousands of small experiments, we found a power-law relationship between variables and demonstrated its transferability across model sizes. Based on the observation, we propose a new learning rate scheduler, Power scheduler, that is agnostic about the number of training tokens and batch size. The experiment shows that combining the Power scheduler with Maximum Update Parameterization (\mup) can consistently achieve impressive performance with one set of hyperparameters regardless of the number of training tokens, batch size, model size, and even model architecture. Our 3B dense and MoE models trained with the Power scheduler achieve comparable performance as state-of-the-art small language models.
+We [open source](https://huggingface.co/collections/ibm/power-lm-66be64ae647ddf11b9808000) these pretrained models.*
+
+Tips:
+
+```python
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_path = "ibm/PowerLM-3b"
+tokenizer = AutoTokenizer.from_pretrained(model_path)
+
+# drop device_map if running on CPU
+model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
+model.eval()
+
+# change input text as desired
+prompt = "Write a code to find the maximum value in a list of numbers."
+
+# tokenize the text
+input_tokens = tokenizer(prompt, return_tensors="pt")
+# generate output tokens
+output = model.generate(**input_tokens, max_new_tokens=100)
+# decode output tokens into text
+output = tokenizer.batch_decode(output)
+# loop over the batch to print, in this example the batch size is 1
+for i in output:
+ print(i)
+```
+
+This model was contributed by [mayank-mishra](https://huggingface.co/mayank-mishra).
+
+
+## GraniteConfig
+
+[[autodoc]] GraniteConfig
+
+## GraniteModel
+
+[[autodoc]] GraniteModel
+ - forward
+
+## GraniteForCausalLM
+
+[[autodoc]] GraniteForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/granite_speech.md b/docs/transformers/docs/source/en/model_doc/granite_speech.md
new file mode 100644
index 0000000000000000000000000000000000000000..212c3d1499354cccf3d313063cea643878daaa66
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/granite_speech.md
@@ -0,0 +1,68 @@
+
+
+# Granite Speech
+
+
+
+
+
+## Overview
+The Granite Speech model is a multimodal language model, consisting of a speech encoder, speech projector, large language model, and LoRA adapter(s). More details regarding each component for the current (Granite 3.2 Speech) model architecture may be found below.
+
+1. Speech Encoder: A [Conformer](https://arxiv.org/abs/2005.08100) encoder trained with Connectionist Temporal Classification (CTC) on character-level targets on ASR corpora. The encoder uses block-attention and self-conditioned CTC from the middle layer.
+
+2. Speech Projector: A query transformer (q-former) operating on the outputs of the last encoder block. The encoder and projector temporally downsample the audio features to be merged into the multimodal embeddings to be processed by the llm.
+
+3. Large Language Model: The Granite Speech model leverages Granite LLMs, which were originally proposed in [this paper](https://arxiv.org/abs/2408.13359).
+
+4. LoRA adapter(s): The Granite Speech model contains a modality specific LoRA, which will be enabled when audio features are provided, and disabled otherwise.
+
+
+Note that most of the aforementioned components are implemented generically to enable compatability and potential integration with other model architectures in transformers.
+
+
+This model was contributed by [Alexander Brooks](https://huggingface.co/abrooks9944), [Avihu Dekel](https://huggingface.co/Avihu), and [George Saon](https://huggingface.co/gsaon).
+
+## Usage tips
+- This model bundles its own LoRA adapter, which will be automatically loaded and enabled/disabled as needed during inference calls. Be sure to install [PEFT](https://github.com/huggingface/peft) to ensure the LoRA is correctly applied!
+
+
+
+## GraniteSpeechConfig
+
+[[autodoc]] GraniteSpeechConfig
+
+
+## GraniteSpeechEncoderConfig
+
+[[autodoc]] GraniteSpeechEncoderConfig
+
+
+## GraniteSpeechProcessor
+
+[[autodoc]] GraniteSpeechProcessor
+
+
+## GraniteSpeechFeatureExtractor
+
+[[autodoc]] GraniteSpeechFeatureExtractor
+
+
+## GraniteSpeechForConditionalGeneration
+
+[[autodoc]] GraniteSpeechForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/granitemoe.md b/docs/transformers/docs/source/en/model_doc/granitemoe.md
new file mode 100644
index 0000000000000000000000000000000000000000..56ba5d936c9d4fd6205ee5ed616f3b7d374236a5
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/granitemoe.md
@@ -0,0 +1,80 @@
+
+
+# GraniteMoe
+
+
+
+
+
+
+
+## Overview
+
+The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
+
+PowerMoE-3B is a 3B sparse Mixture-of-Experts (sMoE) language model trained with the Power learning rate scheduler. It sparsely activates 800M parameters for each token. It is trained on a mix of open-source and proprietary datasets. PowerMoE-3B has shown promising results compared to other dense models with 2x activate parameters across various benchmarks, including natural language multi-choices, code generation, and math reasoning.
+
+The abstract from the paper is the following:
+
+*Finding the optimal learning rate for language model pretraining is a challenging task.
+This is not only because there is a complicated correlation between learning rate, batch size, number of training tokens, model size, and other hyperparameters but also because it is prohibitively expensive to perform a hyperparameter search for large language models with Billions or Trillions of parameters. Recent studies propose using small proxy models and small corpus to perform hyperparameter searches and transposing the optimal parameters to large models and large corpus. While the zero-shot transferability is theoretically and empirically proven for model size related hyperparameters, like depth and width, the zero-shot transfer from small corpus to large corpus is underexplored.
+In this paper, we study the correlation between optimal learning rate, batch size, and number of training tokens for the recently proposed WSD scheduler. After thousands of small experiments, we found a power-law relationship between variables and demonstrated its transferability across model sizes. Based on the observation, we propose a new learning rate scheduler, Power scheduler, that is agnostic about the number of training tokens and batch size. The experiment shows that combining the Power scheduler with Maximum Update Parameterization (\mup) can consistently achieve impressive performance with one set of hyperparameters regardless of the number of training tokens, batch size, model size, and even model architecture. Our 3B dense and MoE models trained with the Power scheduler achieve comparable performance as state-of-the-art small language models.
+We [open source](https://huggingface.co/collections/ibm/power-lm-66be64ae647ddf11b9808000) these pretrained models.*
+
+Tips:
+
+```python
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_path = "ibm/PowerMoE-3b"
+tokenizer = AutoTokenizer.from_pretrained(model_path)
+
+# drop device_map if running on CPU
+model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
+model.eval()
+
+# change input text as desired
+prompt = "Write a code to find the maximum value in a list of numbers."
+
+# tokenize the text
+input_tokens = tokenizer(prompt, return_tensors="pt")
+# generate output tokens
+output = model.generate(**input_tokens, max_new_tokens=100)
+# decode output tokens into text
+output = tokenizer.batch_decode(output)
+# loop over the batch to print, in this example the batch size is 1
+for i in output:
+ print(i)
+```
+
+This model was contributed by [mayank-mishra](https://huggingface.co/mayank-mishra).
+
+
+## GraniteMoeConfig
+
+[[autodoc]] GraniteMoeConfig
+
+## GraniteMoeModel
+
+[[autodoc]] GraniteMoeModel
+ - forward
+
+## GraniteMoeForCausalLM
+
+[[autodoc]] GraniteMoeForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/granitemoeshared.md b/docs/transformers/docs/source/en/model_doc/granitemoeshared.md
new file mode 100644
index 0000000000000000000000000000000000000000..38eb7daf8c92ae78a0ff4b5526ffa428ba7e72f5
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/granitemoeshared.md
@@ -0,0 +1,66 @@
+
+
+# GraniteMoeShared
+
+## Overview
+
+
+The GraniteMoe model was proposed in [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox and Rameswar Panda.
+
+Additionally this class GraniteMoeSharedModel adds shared experts for Moe.
+
+```python
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_path = "ibm-research/moe-7b-1b-active-shared-experts"
+tokenizer = AutoTokenizer.from_pretrained(model_path)
+
+# drop device_map if running on CPU
+model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto")
+model.eval()
+
+# change input text as desired
+prompt = "Write a code to find the maximum value in a list of numbers."
+
+# tokenize the text
+input_tokens = tokenizer(prompt, return_tensors="pt")
+# generate output tokens
+output = model.generate(**input_tokens, max_new_tokens=100)
+# decode output tokens into text
+output = tokenizer.batch_decode(output)
+# loop over the batch to print, in this example the batch size is 1
+for i in output:
+ print(i)
+```
+
+This HF implementation is contributed by [Mayank Mishra](https://huggingface.co/mayank-mishra), [Shawn Tan](https://huggingface.co/shawntan) and [Sukriti Sharma](https://huggingface.co/SukritiSharma).
+
+
+## GraniteMoeSharedConfig
+
+[[autodoc]] GraniteMoeSharedConfig
+
+## GraniteMoeSharedModel
+
+[[autodoc]] GraniteMoeSharedModel
+ - forward
+
+## GraniteMoeSharedForCausalLM
+
+[[autodoc]] GraniteMoeSharedForCausalLM
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/granitevision.md b/docs/transformers/docs/source/en/model_doc/granitevision.md
new file mode 100644
index 0000000000000000000000000000000000000000..e11c806ae6722b8d454c60936f09974a53a38826
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/granitevision.md
@@ -0,0 +1,85 @@
+
+
+# Granite Vision
+
+## Overview
+
+The Granite Vision model is a variant of [LLaVA-NeXT](llava_next), leveraging a [Granite](granite) language model alongside a [SigLIP](SigLIP) visual encoder. It utilizes multiple concatenated vision hidden states as its image features, similar to [VipLlava](vipllava). It also uses a larger set of image grid pinpoints than the original LlaVa-NeXT models to support additional aspect ratios.
+
+Tips:
+- This model is loaded into Transformers as an instance of LlaVA-Next. The usage and tips from [LLaVA-NeXT](llava_next) apply to this model as well.
+
+- You can apply the chat template on the tokenizer / processor in the same way as well. Example chat format:
+```bash
+"<|user|>\nWhat’s shown in this image?\n<|assistant|>\nThis image shows a red stop sign.<|end_of_text|><|user|>\nDescribe the image in more details.\n<|assistant|>\n"
+```
+
+Sample inference:
+```python
+from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
+
+model_path = "ibm-granite/granite-vision-3.1-2b-preview"
+processor = LlavaNextProcessor.from_pretrained(model_path)
+
+model = LlavaNextForConditionalGeneration.from_pretrained(model_path).to("cuda")
+
+# prepare image and text prompt, using the appropriate prompt template
+url = "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
+
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": url},
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+]
+inputs = processor.apply_chat_template(
+ conversation,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to("cuda")
+
+
+# autoregressively complete prompt
+output = model.generate(**inputs, max_new_tokens=100)
+
+print(processor.decode(output[0], skip_special_tokens=True))
+```
+
+This model was contributed by [Alexander Brooks](https://huggingface.co/abrooks9944).
+
+## LlavaNextConfig
+
+[[autodoc]] LlavaNextConfig
+
+## LlavaNextImageProcessor
+
+[[autodoc]] LlavaNextImageProcessor
+ - preprocess
+
+## LlavaNextProcessor
+
+[[autodoc]] LlavaNextProcessor
+
+## LlavaNextForConditionalGeneration
+
+[[autodoc]] LlavaNextForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/graphormer.md b/docs/transformers/docs/source/en/model_doc/graphormer.md
new file mode 100644
index 0000000000000000000000000000000000000000..0d88134d4b7e608976e6f47dc1cb770afa16c8a8
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/graphormer.md
@@ -0,0 +1,59 @@
+
+
+# Graphormer
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+The Graphormer model was proposed in [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by
+Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen and Tie-Yan Liu. It is a Graph Transformer model, modified to allow computations on graphs instead of text sequences by generating embeddings and features of interest during preprocessing and collation, then using a modified attention.
+
+The abstract from the paper is the following:
+
+*The Transformer architecture has become a dominant choice in many domains, such as natural language processing and computer vision. Yet, it has not achieved competitive performance on popular leaderboards of graph-level prediction compared to mainstream GNN variants. Therefore, it remains a mystery how Transformers could perform well for graph representation learning. In this paper, we solve this mystery by presenting Graphormer, which is built upon the standard Transformer architecture, and could attain excellent results on a broad range of graph representation learning tasks, especially on the recent OGB Large-Scale Challenge. Our key insight to utilizing Transformer in the graph is the necessity of effectively encoding the structural information of a graph into the model. To this end, we propose several simple yet effective structural encoding methods to help Graphormer better model graph-structured data. Besides, we mathematically characterize the expressive power of Graphormer and exhibit that with our ways of encoding the structural information of graphs, many popular GNN variants could be covered as the special cases of Graphormer.*
+
+This model was contributed by [clefourrier](https://huggingface.co/clefourrier). The original code can be found [here](https://github.com/microsoft/Graphormer).
+
+## Usage tips
+
+This model will not work well on large graphs (more than 100 nodes/edges), as it will make the memory explode.
+You can reduce the batch size, increase your RAM, or decrease the `UNREACHABLE_NODE_DISTANCE` parameter in algos_graphormer.pyx, but it will be hard to go above 700 nodes/edges.
+
+This model does not use a tokenizer, but instead a special collator during training.
+
+## GraphormerConfig
+
+[[autodoc]] GraphormerConfig
+
+## GraphormerModel
+
+[[autodoc]] GraphormerModel
+ - forward
+
+## GraphormerForGraphClassification
+
+[[autodoc]] GraphormerForGraphClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/grounding-dino.md b/docs/transformers/docs/source/en/model_doc/grounding-dino.md
new file mode 100644
index 0000000000000000000000000000000000000000..022224351951c69d37c5999ec5944e9af59076b9
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/grounding-dino.md
@@ -0,0 +1,129 @@
+
+
+# Grounding DINO
+
+
+
+
+
+## Overview
+
+The Grounding DINO model was proposed in [Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection](https://arxiv.org/abs/2303.05499) by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
+
+The abstract from the paper is the following:
+
+*In this paper, we present an open-set object detector, called Grounding DINO, by marrying Transformer-based detector DINO with grounded pre-training, which can detect arbitrary objects with human inputs such as category names or referring expressions. The key solution of open-set object detection is introducing language to a closed-set detector for open-set concept generalization. To effectively fuse language and vision modalities, we conceptually divide a closed-set detector into three phases and propose a tight fusion solution, which includes a feature enhancer, a language-guided query selection, and a cross-modality decoder for cross-modality fusion. While previous works mainly evaluate open-set object detection on novel categories, we propose to also perform evaluations on referring expression comprehension for objects specified with attributes. Grounding DINO performs remarkably well on all three settings, including benchmarks on COCO, LVIS, ODinW, and RefCOCO/+/g. Grounding DINO achieves a 52.5 AP on the COCO detection zero-shot transfer benchmark, i.e., without any training data from COCO. It sets a new record on the ODinW zero-shot benchmark with a mean 26.1 AP.*
+
+
+
+ Grounding DINO overview. Taken from the original paper.
+
+This model was contributed by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/IDEA-Research/GroundingDINO).
+
+## Usage tips
+
+- One can use [`GroundingDinoProcessor`] to prepare image-text pairs for the model.
+- To separate classes in the text use a period e.g. "a cat. a dog."
+- When using multiple classes (e.g. `"a cat. a dog."`), use `post_process_grounded_object_detection` from [`GroundingDinoProcessor`] to post process outputs. Since, the labels returned from `post_process_object_detection` represent the indices from the model dimension where prob > threshold.
+
+Here's how to use the model for zero-shot object detection:
+
+```python
+>>> import requests
+
+>>> import torch
+>>> from PIL import Image
+>>> from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
+
+>>> model_id = "IDEA-Research/grounding-dino-tiny"
+>>> device = "cuda"
+
+>>> processor = AutoProcessor.from_pretrained(model_id)
+>>> model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
+
+>>> image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(image_url, stream=True).raw)
+>>> # Check for cats and remote controls
+>>> text_labels = [["a cat", "a remote control"]]
+
+>>> inputs = processor(images=image, text=text_labels, return_tensors="pt").to(device)
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> results = processor.post_process_grounded_object_detection(
+... outputs,
+... inputs.input_ids,
+... box_threshold=0.4,
+... text_threshold=0.3,
+... target_sizes=[image.size[::-1]]
+... )
+
+# Retrieve the first image result
+>>> result = results[0]
+>>> for box, score, labels in zip(result["boxes"], result["scores"], result["labels"]):
+... box = [round(x, 2) for x in box.tolist()]
+... print(f"Detected {labels} with confidence {round(score.item(), 3)} at location {box}")
+Detected a cat with confidence 0.468 at location [344.78, 22.9, 637.3, 373.62]
+Detected a cat with confidence 0.426 at location [11.74, 51.55, 316.51, 473.22]
+```
+
+## Grounded SAM
+
+One can combine Grounding DINO with the [Segment Anything](sam) model for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://arxiv.org/abs/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
+
+
+
+ Grounded SAM overview. Taken from the original repository.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Grounding DINO. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- Demo notebooks regarding inference with Grounding DINO as well as combining it with [SAM](sam) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Grounding%20DINO). 🌎
+
+## GroundingDinoImageProcessor
+
+[[autodoc]] GroundingDinoImageProcessor
+ - preprocess
+
+## GroundingDinoImageProcessorFast
+
+[[autodoc]] GroundingDinoImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+
+## GroundingDinoProcessor
+
+[[autodoc]] GroundingDinoProcessor
+ - post_process_grounded_object_detection
+
+## GroundingDinoConfig
+
+[[autodoc]] GroundingDinoConfig
+
+## GroundingDinoModel
+
+[[autodoc]] GroundingDinoModel
+ - forward
+
+## GroundingDinoForObjectDetection
+
+[[autodoc]] GroundingDinoForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/groupvit.md b/docs/transformers/docs/source/en/model_doc/groupvit.md
new file mode 100644
index 0000000000000000000000000000000000000000..c77a51d8b1b78ea77190cb10892e298dcdd35d89
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/groupvit.md
@@ -0,0 +1,101 @@
+
+
+# GroupViT
+
+
+
+
+
+
+## Overview
+
+The GroupViT model was proposed in [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+Inspired by [CLIP](clip), GroupViT is a vision-language model that can perform zero-shot semantic segmentation on any given vocabulary categories.
+
+The abstract from the paper is the following:
+
+*Grouping and recognition are important components of visual scene understanding, e.g., for object detection and semantic segmentation. With end-to-end deep learning systems, grouping of image regions usually happens implicitly via top-down supervision from pixel-level recognition labels. Instead, in this paper, we propose to bring back the grouping mechanism into deep networks, which allows semantic segments to emerge automatically with only text supervision. We propose a hierarchical Grouping Vision Transformer (GroupViT), which goes beyond the regular grid structure representation and learns to group image regions into progressively larger arbitrary-shaped segments. We train GroupViT jointly with a text encoder on a large-scale image-text dataset via contrastive losses. With only text supervision and without any pixel-level annotations, GroupViT learns to group together semantic regions and successfully transfers to the task of semantic segmentation in a zero-shot manner, i.e., without any further fine-tuning. It achieves a zero-shot accuracy of 52.3% mIoU on the PASCAL VOC 2012 and 22.4% mIoU on PASCAL Context datasets, and performs competitively to state-of-the-art transfer-learning methods requiring greater levels of supervision.*
+
+This model was contributed by [xvjiarui](https://huggingface.co/xvjiarui). The TensorFlow version was contributed by [ariG23498](https://huggingface.co/ariG23498) with the help of [Yih-Dar SHIEH](https://huggingface.co/ydshieh), [Amy Roberts](https://huggingface.co/amyeroberts), and [Joao Gante](https://huggingface.co/joaogante).
+The original code can be found [here](https://github.com/NVlabs/GroupViT).
+
+## Usage tips
+
+- You may specify `output_segmentation=True` in the forward of `GroupViTModel` to get the segmentation logits of input texts.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GroupViT.
+
+- The quickest way to get started with GroupViT is by checking the [example notebooks](https://github.com/xvjiarui/GroupViT/blob/main/demo/GroupViT_hf_inference_notebook.ipynb) (which showcase zero-shot segmentation inference).
+- One can also check out the [HuggingFace Spaces demo](https://huggingface.co/spaces/xvjiarui/GroupViT) to play with GroupViT.
+
+## GroupViTConfig
+
+[[autodoc]] GroupViTConfig
+ - from_text_vision_configs
+
+## GroupViTTextConfig
+
+[[autodoc]] GroupViTTextConfig
+
+## GroupViTVisionConfig
+
+[[autodoc]] GroupViTVisionConfig
+
+
+
+
+## GroupViTModel
+
+[[autodoc]] GroupViTModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## GroupViTTextModel
+
+[[autodoc]] GroupViTTextModel
+ - forward
+
+## GroupViTVisionModel
+
+[[autodoc]] GroupViTVisionModel
+ - forward
+
+
+
+
+## TFGroupViTModel
+
+[[autodoc]] TFGroupViTModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFGroupViTTextModel
+
+[[autodoc]] TFGroupViTTextModel
+ - call
+
+## TFGroupViTVisionModel
+
+[[autodoc]] TFGroupViTVisionModel
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/helium.md b/docs/transformers/docs/source/en/model_doc/helium.md
new file mode 100644
index 0000000000000000000000000000000000000000..a9296eb110d5a0f476aad2adad215db99f0cc4df
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/helium.md
@@ -0,0 +1,159 @@
+
+
+# Helium
+
+
+
+
+
+
+
+## Overview
+
+Helium was proposed in [Announcing Helium-1 Preview](https://kyutai.org/2025/01/13/helium.html) by the Kyutai Team.
+
+
+Helium-1 preview is a lightweight language model with 2B parameters, targeting edge and mobile devices.
+It supports the following languages: English, French, German, Italian, Portuguese, Spanish.
+
+- **Developed by:** Kyutai
+- **Model type:** Large Language Model
+- **Language(s) (NLP):** English, French, German, Italian, Portuguese, Spanish
+- **License:** CC-BY 4.0
+
+
+
+
+## Evaluation
+
+
+
+#### Testing Data
+
+
+
+The model was evaluated on MMLU, TriviaQA, NaturalQuestions, ARC Easy & Challenge, Open Book QA, Common Sense QA,
+Physical Interaction QA, Social Interaction QA, HellaSwag, WinoGrande, Multilingual Knowledge QA, FLORES 200.
+
+#### Metrics
+
+
+
+We report accuracy on MMLU, ARC, OBQA, CSQA, PIQA, SIQA, HellaSwag, WinoGrande.
+We report exact match on TriviaQA, NQ and MKQA.
+We report BLEU on FLORES.
+
+### English Results
+
+| Benchmark | Helium-1 Preview | HF SmolLM2 (1.7B) | Gemma-2 (2.6B) | Llama-3.2 (3B) | Qwen2.5 (1.5B) |
+|--------------|--------|--------|--------|--------|--------|
+| | | | | | |
+| MMLU | 51.2 | 50.4 | 53.1 | 56.6 | 61.0 |
+| NQ | 17.3 | 15.1 | 17.7 | 22.0 | 13.1 |
+| TQA | 47.9 | 45.4 | 49.9 | 53.6 | 35.9 |
+| ARC E | 80.9 | 81.8 | 81.1 | 84.6 | 89.7 |
+| ARC C | 62.7 | 64.7 | 66.0 | 69.0 | 77.2 |
+| OBQA | 63.8 | 61.4 | 64.6 | 68.4 | 73.8 |
+| CSQA | 65.6 | 59.0 | 64.4 | 65.4 | 72.4 |
+| PIQA | 77.4 | 77.7 | 79.8 | 78.9 | 76.0 |
+| SIQA | 64.4 | 57.5 | 61.9 | 63.8 | 68.7 |
+| HS | 69.7 | 73.2 | 74.7 | 76.9 | 67.5 |
+| WG | 66.5 | 65.6 | 71.2 | 72.0 | 64.8 |
+| | | | | | |
+| Average | 60.7 | 59.3 | 62.2 | 64.7 | 63.6 |
+
+#### Multilingual Results
+
+| Language | Benchmark | Helium-1 Preview | HF SmolLM2 (1.7B) | Gemma-2 (2.6B) | Llama-3.2 (3B) | Qwen2.5 (1.5B) |
+|-----|--------------|--------|--------|--------|--------|--------|
+| | | | | | | |
+|German| MMLU | 45.6 | 35.3 | 45.0 | 47.5 | 49.5 |
+|| ARC C | 56.7 | 38.4 | 54.7 | 58.3 | 60.2 |
+|| HS | 53.5 | 33.9 | 53.4 | 53.7 | 42.8 |
+|| MKQA | 16.1 | 7.1 | 18.9 | 20.2 | 10.4 |
+| | | | | | | |
+|Spanish| MMLU | 46.5 | 38.9 | 46.2 | 49.6 | 52.8 |
+|| ARC C | 58.3 | 43.2 | 58.8 | 60.0 | 68.1 |
+|| HS | 58.6 | 40.8 | 60.5 | 61.1 | 51.4 |
+|| MKQA | 16.0 | 7.9 | 18.5 | 20.6 | 10.6 |
+
+
+## Technical Specifications
+
+### Model Architecture and Objective
+
+| Hyperparameter | Value |
+|--------------|--------|
+| Layers | 24 |
+| Heads | 20 |
+| Model dimension | 2560 |
+| MLP dimension | 7040 |
+| Context size | 4096 |
+| Theta RoPE | 100,000 |
+
+Tips:
+
+- This model was contributed by [Laurent Mazare](https://huggingface.co/lmz)
+
+
+## Usage tips
+
+`Helium` can be found on the [Huggingface Hub](https://huggingface.co/models?other=helium)
+
+In the following, we demonstrate how to use `helium-1-preview` for the inference.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("kyutai/helium-1-preview-2b", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("kyutai/helium-1-preview-2b")
+
+>>> prompt = "Give me a short introduction to large language model."
+
+>>> model_inputs = tokenizer(prompt, return_tensors="pt").to(device)
+
+>>> generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=True)
+
+>>> generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
+
+>>> response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+```
+
+## HeliumConfig
+
+[[autodoc]] HeliumConfig
+
+## HeliumModel
+
+[[autodoc]] HeliumModel
+ - forward
+
+## HeliumForCausalLM
+
+[[autodoc]] HeliumForCausalLM
+ - forward
+
+## HeliumForSequenceClassification
+
+[[autodoc]] HeliumForSequenceClassification
+ - forward
+
+## HeliumForTokenClassification
+
+[[autodoc]] HeliumForTokenClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/herbert.md b/docs/transformers/docs/source/en/model_doc/herbert.md
new file mode 100644
index 0000000000000000000000000000000000000000..aa4f535ed274305456bebb7b9d24f0298b78c0a4
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/herbert.md
@@ -0,0 +1,83 @@
+
+
+# HerBERT
+
+
+
+
+
+
+
+## Overview
+
+The HerBERT model was proposed in [KLEJ: Comprehensive Benchmark for Polish Language Understanding](https://www.aclweb.org/anthology/2020.acl-main.111.pdf) by Piotr Rybak, Robert Mroczkowski, Janusz Tracz, and
+Ireneusz Gawlik. It is a BERT-based Language Model trained on Polish Corpora using only MLM objective with dynamic
+masking of whole words.
+
+The abstract from the paper is the following:
+
+*In recent years, a series of Transformer-based models unlocked major improvements in general natural language
+understanding (NLU) tasks. Such a fast pace of research would not be possible without general NLU benchmarks, which
+allow for a fair comparison of the proposed methods. However, such benchmarks are available only for a handful of
+languages. To alleviate this issue, we introduce a comprehensive multi-task benchmark for the Polish language
+understanding, accompanied by an online leaderboard. It consists of a diverse set of tasks, adopted from existing
+datasets for named entity recognition, question-answering, textual entailment, and others. We also introduce a new
+sentiment analysis task for the e-commerce domain, named Allegro Reviews (AR). To ensure a common evaluation scheme and
+promote models that generalize to different NLU tasks, the benchmark includes datasets from varying domains and
+applications. Additionally, we release HerBERT, a Transformer-based model trained specifically for the Polish language,
+which has the best average performance and obtains the best results for three out of nine tasks. Finally, we provide an
+extensive evaluation, including several standard baselines and recently proposed, multilingual Transformer-based
+models.*
+
+This model was contributed by [rmroczkowski](https://huggingface.co/rmroczkowski). The original code can be found
+[here](https://github.com/allegro/HerBERT).
+
+
+## Usage example
+
+```python
+>>> from transformers import HerbertTokenizer, RobertaModel
+
+>>> tokenizer = HerbertTokenizer.from_pretrained("allegro/herbert-klej-cased-tokenizer-v1")
+>>> model = RobertaModel.from_pretrained("allegro/herbert-klej-cased-v1")
+
+>>> encoded_input = tokenizer.encode("Kto ma lepszą sztukę, ma lepszy rząd – to jasne.", return_tensors="pt")
+>>> outputs = model(encoded_input)
+
+>>> # HerBERT can also be loaded using AutoTokenizer and AutoModel:
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("allegro/herbert-klej-cased-tokenizer-v1")
+>>> model = AutoModel.from_pretrained("allegro/herbert-klej-cased-v1")
+```
+
+
+
+Herbert implementation is the same as `BERT` except for the tokenization method. Refer to [BERT documentation](bert)
+for API reference and examples.
+
+
+
+## HerbertTokenizer
+
+[[autodoc]] HerbertTokenizer
+
+## HerbertTokenizerFast
+
+[[autodoc]] HerbertTokenizerFast
diff --git a/docs/transformers/docs/source/en/model_doc/hiera.md b/docs/transformers/docs/source/en/model_doc/hiera.md
new file mode 100644
index 0000000000000000000000000000000000000000..a82eec950a513737dc0c3992d9e5703987761b35
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/hiera.md
@@ -0,0 +1,66 @@
+
+
+# Hiera
+
+
+
+
+
+## Overview
+
+Hiera was proposed in [Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles](https://arxiv.org/abs/2306.00989) by Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, Christoph Feichtenhofer
+
+The paper introduces "Hiera," a hierarchical Vision Transformer that simplifies the architecture of modern hierarchical vision transformers by removing unnecessary components without compromising on accuracy or efficiency. Unlike traditional transformers that add complex vision-specific components to improve supervised classification performance, Hiera demonstrates that such additions, often termed "bells-and-whistles," are not essential for high accuracy. By leveraging a strong visual pretext task (MAE) for pretraining, Hiera retains simplicity and achieves superior accuracy and speed both in inference and training across various image and video recognition tasks. The approach suggests that spatial biases required for vision tasks can be effectively learned through proper pretraining, eliminating the need for added architectural complexity.
+
+The abstract from the paper is the following:
+
+*Modern hierarchical vision transformers have added several vision-specific components in the pursuit of supervised classification performance. While these components lead to effective accuracies and attractive FLOP counts, the added complexity actually makes these transformers slower than their vanilla ViT counterparts. In this paper, we argue that this additional bulk is unnecessary. By pretraining with a strong visual pretext task (MAE), we can strip out all the bells-and-whistles from a state-of-the-art multi-stage vision transformer without losing accuracy. In the process, we create Hiera, an extremely simple hierarchical vision transformer that is more accurate than previous models while being significantly faster both at inference and during training. We evaluate Hiera on a variety of tasks for image and video recognition. Our code and models are available at https://github.com/facebookresearch/hiera.*
+
+
+
+ Hiera architecture. Taken from the original paper.
+
+This model was a joint contribution by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [namangarg110](https://huggingface.co/namangarg110). The original code can be found [here] (https://github.com/facebookresearch/hiera).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Hiera. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+- [`HieraForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+## HieraConfig
+
+[[autodoc]] HieraConfig
+
+## HieraModel
+
+[[autodoc]] HieraModel
+ - forward
+
+## HieraForPreTraining
+
+[[autodoc]] HieraForPreTraining
+ - forward
+
+## HieraForImageClassification
+
+[[autodoc]] HieraForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/hubert.md b/docs/transformers/docs/source/en/model_doc/hubert.md
new file mode 100644
index 0000000000000000000000000000000000000000..67e7d78beb635bb11c788b16fb6456697d20ca00
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/hubert.md
@@ -0,0 +1,132 @@
+
+
+# Hubert
+
+
+
+
+
+
+
+
+## Overview
+
+Hubert was proposed in [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan
+Salakhutdinov, Abdelrahman Mohamed.
+
+The abstract from the paper is the following:
+
+*Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are
+multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training
+phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we
+propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an
+offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our
+approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined
+acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised
+clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means
+teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the
+state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h,
+10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER
+reduction on the more challenging dev-other and test-other evaluation subsets.*
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+
+# Usage tips
+
+- Hubert is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- Hubert model was fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded
+ using [`Wav2Vec2CTCTokenizer`].
+
+
+## Using Flash Attention 2
+
+Flash Attention 2 is an faster, optimized version of the model.
+
+### Installation
+
+First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features). If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered [above](https://huggingface.co/docs/transformers/main/en/model_doc/bark#using-better-transformer).
+
+Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+### Usage
+
+Below is an expected speedup diagram comparing the pure inference time between the native implementation in transformers of `facebook/hubert-large-ls960-ft`, the flash-attention-2 and the sdpa (scale-dot-product-attention) version. We show the average speedup obtained on the `librispeech_asr` `clean` validation split:
+
+```python
+>>> from transformers import HubertModel
+>>> import torch
+
+>>> model = HubertModel.from_pretrained("facebook/hubert-large-ls960-ft", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda")
+...
+```
+
+### Expected speedups
+
+Below is an expected speedup diagram comparing the pure inference time between the native implementation in transformers of the `facebook/hubert-large-ls960-ft` model and the flash-attention-2 and sdpa (scale-dot-product-attention) versions. . We show the average speedup obtained on the `librispeech_asr` `clean` validation split:
+
+
+
+
+## Overview
+
+The I-BERT model was proposed in [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by
+Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney and Kurt Keutzer. It's a quantized version of RoBERTa running
+inference up to four times faster.
+
+The abstract from the paper is the following:
+
+*Transformer based models, like BERT and RoBERTa, have achieved state-of-the-art results in many Natural Language
+Processing tasks. However, their memory footprint, inference latency, and power consumption are prohibitive for
+efficient inference at the edge, and even at the data center. While quantization can be a viable solution for this,
+previous work on quantizing Transformer based models use floating-point arithmetic during inference, which cannot
+efficiently utilize integer-only logical units such as the recent Turing Tensor Cores, or traditional integer-only ARM
+processors. In this work, we propose I-BERT, a novel quantization scheme for Transformer based models that quantizes
+the entire inference with integer-only arithmetic. Based on lightweight integer-only approximation methods for
+nonlinear operations, e.g., GELU, Softmax, and Layer Normalization, I-BERT performs an end-to-end integer-only BERT
+inference without any floating point calculation. We evaluate our approach on GLUE downstream tasks using
+RoBERTa-Base/Large. We show that for both cases, I-BERT achieves similar (and slightly higher) accuracy as compared to
+the full-precision baseline. Furthermore, our preliminary implementation of I-BERT shows a speedup of 2.4 - 4.0x for
+INT8 inference on a T4 GPU system as compared to FP32 inference. The framework has been developed in PyTorch and has
+been open-sourced.*
+
+This model was contributed by [kssteven](https://huggingface.co/kssteven). The original code can be found [here](https://github.com/kssteven418/I-BERT).
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/masked_language_modeling)
+
+## IBertConfig
+
+[[autodoc]] IBertConfig
+
+## IBertModel
+
+[[autodoc]] IBertModel
+ - forward
+
+## IBertForMaskedLM
+
+[[autodoc]] IBertForMaskedLM
+ - forward
+
+## IBertForSequenceClassification
+
+[[autodoc]] IBertForSequenceClassification
+ - forward
+
+## IBertForMultipleChoice
+
+[[autodoc]] IBertForMultipleChoice
+ - forward
+
+## IBertForTokenClassification
+
+[[autodoc]] IBertForTokenClassification
+ - forward
+
+## IBertForQuestionAnswering
+
+[[autodoc]] IBertForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/idefics.md b/docs/transformers/docs/source/en/model_doc/idefics.md
new file mode 100644
index 0000000000000000000000000000000000000000..2b8e471213d71e1f171da074c68f27bb73ebfcb8
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/idefics.md
@@ -0,0 +1,79 @@
+
+
+# IDEFICS
+
+
+
+
+
+
+
+## Overview
+
+The IDEFICS model was proposed in [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
+](https://huggingface.co/papers/2306.16527
+) by Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander M. Rush, Douwe Kiela, Matthieu Cord, Victor Sanh
+
+The abstract from the paper is the following:
+
+*Large multimodal models trained on natural documents, which interleave images and text, outperform models trained on image-text pairs on various multimodal benchmarks that require reasoning over one or multiple images to generate a text. However, the datasets used to train these models have not been released, and the collection process has not been fully specified. We introduce the OBELICS dataset, an open web-scale filtered dataset of interleaved image-text documents comprising 141 million web pages extracted from Common Crawl, 353 million associated images, and 115 billion text tokens. We describe the dataset creation process, present comprehensive filtering rules, and provide an analysis of the dataset's content. To show the viability of OBELISC, we train an 80 billion parameters vision and language model on the dataset and obtain competitive performance on various multimodal benchmarks. We release the code to reproduce the dataset along with the dataset itself.*
+
+This model was contributed by [HuggingFaceM4](https://huggingface.co/HuggingFaceM4). The original code can be found [here](). (TODO: don't have a public link yet).
+
+
+
+
+IDEFICS modeling code in Transformers is for finetuning and inferencing the pre-trained IDEFICS models.
+
+To train a new IDEFICS model from scratch use the m4 codebase (a link will be provided once it's made public)
+
+
+
+
+## IdeficsConfig
+
+[[autodoc]] IdeficsConfig
+
+## IdeficsModel
+
+[[autodoc]] IdeficsModel
+ - forward
+
+## IdeficsForVisionText2Text
+
+[[autodoc]] IdeficsForVisionText2Text
+ - forward
+
+## TFIdeficsModel
+
+[[autodoc]] TFIdeficsModel
+ - call
+
+## TFIdeficsForVisionText2Text
+
+[[autodoc]] TFIdeficsForVisionText2Text
+ - call
+
+## IdeficsImageProcessor
+
+[[autodoc]] IdeficsImageProcessor
+ - preprocess
+
+## IdeficsProcessor
+
+[[autodoc]] IdeficsProcessor
+ - __call__
diff --git a/docs/transformers/docs/source/en/model_doc/idefics2.md b/docs/transformers/docs/source/en/model_doc/idefics2.md
new file mode 100644
index 0000000000000000000000000000000000000000..8de2c92d560944491ac8ef0d96d2b64c20c3ac77
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/idefics2.md
@@ -0,0 +1,224 @@
+
+
+# Idefics2
+
+
+
+
+
+
+
+## Overview
+
+The Idefics2 model was proposed in [What matters when building vision-language models?](https://arxiv.org/abs/2405.02246) by Léo Tronchon, Hugo Laurencon, Victor Sanh. The accompanying blog post can be found [here](https://huggingface.co/blog/idefics2).
+
+Idefics2 is an open multimodal model that accepts arbitrary sequences of image and text inputs and produces text
+outputs. The model can answer questions about images, describe visual content, create stories grounded on multiple
+images, or simply behave as a pure language model without visual inputs. It improves upon IDEFICS-1, notably on
+document understanding, OCR, or visual reasoning. Idefics2 is lightweight (8 billion parameters) and treats
+images in their native aspect ratio and resolution, which allows for varying inference efficiency.
+
+The abstract from the paper is the following:
+
+*The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.*
+
+
+
+ Idefics2 architecture. Taken from the original paper.
+
+This model was contributed by [amyeroberts](https://huggingface.co/amyeroberts).
+The original code can be found [here](https://huggingface.co/HuggingFaceM4/idefics2).
+
+## Usage tips
+
+- Each sample can contain multiple images, and the number of images can vary between samples. The processor will pad the inputs to the maximum number of images in a batch for input to the model.
+- The processor has a `do_image_splitting` option. If `True`, each input image will be split into 4 sub-images, and concatenated with the original to form 5 images. This is useful for increasing model performance. Make sure `processor.image_processor.do_image_splitting` is set to `False` if the model was not trained with this option.
+- `text` passed to the processor should have the `` tokens where the images should be inserted. And `` at the end of each utterance if the text is a chat message.
+- The processor has its own `apply_chat_template` method to convert chat messages to text that can then be passed as `text` to the processor.
+
+Example of how to use the processor on chat messages:
+
+```python
+import requests
+from PIL import Image
+from transformers import Idefics2Processor, Idefics2ForConditionalGeneration
+import torch
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+
+url_1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+url_2 = "http://images.cocodataset.org/val2017/000000219578.jpg"
+
+image_1 = Image.open(requests.get(url_1, stream=True).raw)
+image_2 = Image.open(requests.get(url_2, stream=True).raw)
+images = [image_1, image_2]
+
+messages = [{
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "What’s the difference between these two images?"},
+ {"type": "image"},
+ {"type": "image"},
+ ],
+}]
+
+processor = Idefics2Processor.from_pretrained("HuggingFaceM4/idefics2-8b")
+model = Idefics2ForConditionalGeneration.from_pretrained("HuggingFaceM4/idefics2-8b")
+model.to(device)
+
+# at inference time, one needs to pass `add_generation_prompt=True` in order to make sure the model completes the prompt
+text = processor.apply_chat_template(messages, add_generation_prompt=True)
+print(text)
+# 'User: What’s the difference between these two images?\nAssistant:'
+
+inputs = processor(images=images, text=text, return_tensors="pt").to(device)
+
+generated_text = model.generate(**inputs, max_new_tokens=500)
+generated_text = processor.batch_decode(generated_text, skip_special_tokens=True)[0]
+print("Generated text:", generated_text)
+```
+
+- During training, it's important to determine which tokens the model should not learn. For Idefics2, this typically comes down to the image and padding tokens. This means that one can create the labels as follows:
+
+```python
+import requests
+from PIL import Image
+from transformers import Idefics2Processor, Idefics2ForConditionalGeneration
+import torch
+
+url_1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+url_2 = "http://images.cocodataset.org/val2017/000000219578.jpg"
+
+image_1 = Image.open(requests.get(url_1, stream=True).raw)
+image_2 = Image.open(requests.get(url_2, stream=True).raw)
+images = [image_1, image_2]
+
+messages = [{
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "What’s the difference between these two images?"},
+ {"type": "image"},
+ {"type": "image"},
+ ],
+},
+{
+ "role": "assistant",
+ "content": [
+ {"type": "text", "text": "The difference is that one image is about dogs and the other one about cats."},
+ ],
+}]
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+
+processor = Idefics2Processor.from_pretrained("HuggingFaceM4/idefics2-8b")
+model = Idefics2ForConditionalGeneration.from_pretrained("HuggingFaceM4/idefics2-8b")
+model.to(device)
+
+text = processor.apply_chat_template(messages, add_generation_prompt=False)
+inputs = processor(images=images, text=text, return_tensors="pt").to(device)
+
+labels = inputs.input_ids.clone()
+labels[labels == processor.tokenizer.pad_token_id] = -100
+labels[labels == model.config.image_token_id] = -100
+
+inputs["labels"] = labels
+
+outputs = model(**inputs)
+loss = outputs.loss
+loss.backward()
+```
+
+Do note that when training Idefics2 on multi-turn conversations between a user and an assistant, one typically also sets all the tokens corresponding to the user messages to -100.
+
+## Model optimizations: Flash Attention
+
+The code snippets above showcase inference without any optimization tricks. However, one can drastically speed up the model by leveraging [Flash Attention](../perf_train_gpu_one#flash-attention-2), which is a faster implementation of the attention mechanism used inside the model.
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). Make also sure to load your model in half-precision (e.g. `torch.float16`)
+
+To load and run a model using Flash Attention-2, simply change the code snippet above with the following change:
+
+```diff
+model = Idefics2ForConditionalGeneration.from_pretrained(
+ "HuggingFaceM4/idefics2-8b",
++ torch_dtype=torch.float16,
++ attn_implementation="flash_attention_2",
+).to(device)
+```
+
+## Shrinking down Idefics2 using quantization
+
+As the Idefics2 model has 8 billion parameters, that would require about 16GB of GPU RAM in half precision (float16), since each parameter is stored in 2 bytes. However, one can shrink down the size of the model using [quantization](../quantization.md). If the model is quantized to 4 bits (or half a byte per parameter), that requires only about 3.5GB of RAM.
+
+Quantizing a model is as simple as passing a `quantization_config` to the model. One can change the code snippet above with the changes below. We'll leverage the BitsAndyBytes quantization (but refer to [this page](../quantization.md) for other quantization methods):
+
+```diff
++ from transformers import BitsAndBytesConfig
+
++ quantization_config = BitsAndBytesConfig(
++ load_in_4bit=True,
++ bnb_4bit_quant_type="nf4",
++ bnb_4bit_use_double_quant=True,
++ bnb_4bit_compute_dtype=torch.float16
++ )
+model = Idefics2ForConditionalGeneration.from_pretrained(
+ "HuggingFaceM4/idefics2-8b",
++ torch_dtype=torch.float16,
++ quantization_config=quantization_config,
+).to(device)
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Idefics2. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- A notebook on how to fine-tune Idefics2 on a custom dataset using the [Trainer](../main_classes/trainer.md) can be found [here](https://colab.research.google.com/drive/1NtcTgRbSBKN7pYD3Vdx1j9m8pt3fhFDB?usp=sharing). It supports both full fine-tuning as well as (quantized) LoRa.
+- A script regarding how to fine-tune Idefics2 using the TRL library can be found [here](https://gist.github.com/edbeeching/228652fc6c2b29a1641be5a5778223cb).
+- Demo notebook regarding fine-tuning Idefics2 for JSON extraction use cases can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Idefics2). 🌎
+
+## Idefics2Config
+
+[[autodoc]] Idefics2Config
+
+
+## Idefics2Model
+
+[[autodoc]] Idefics2Model
+ - forward
+
+
+## Idefics2ForConditionalGeneration
+
+[[autodoc]] Idefics2ForConditionalGeneration
+ - forward
+
+
+## Idefics2ImageProcessor
+[[autodoc]] Idefics2ImageProcessor
+ - preprocess
+
+
+## Idefics2Processor
+[[autodoc]] Idefics2Processor
+ - __call__
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/idefics3.md b/docs/transformers/docs/source/en/model_doc/idefics3.md
new file mode 100644
index 0000000000000000000000000000000000000000..deab4423f80c08137316e73470474f20a0477bac
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/idefics3.md
@@ -0,0 +1,86 @@
+
+
+# Idefics3
+
+
+
+
+
+
+
+## Overview
+
+The Idefics3 model was proposed in [Building and better understanding vision-language models: insights and future directions](https://huggingface.co/papers/2408.12637) by Hugo Laurençon, Andrés Marafioti, Victor Sanh, and Léo Tronchon.
+
+Idefics3 is an adaptation of the Idefics2 model with three main differences:
+
+- It uses Llama3 for the text model.
+- It uses an updated processing logic for the images.
+- It removes the perceiver.
+
+The abstract from the paper is the following:
+
+*The field of vision-language models (VLMs), which take images and texts as inputs and output texts, is rapidly evolving and has yet to reach consensus on several key aspects of the development pipeline, including data, architecture, and training methods. This paper can be seen as a tutorial for building a VLM. We begin by providing a comprehensive overview of the current state-of-the-art approaches, highlighting the strengths and weaknesses of each, addressing the major challenges in the field, and suggesting promising research directions for underexplored areas. We then walk through the practical steps to build Idefics3-8B, a powerful VLM that significantly outperforms its predecessor Idefics2-8B, while being trained efficiently, exclusively on open datasets, and using a straightforward pipeline. These steps include the creation of Docmatix, a dataset for improving document understanding capabilities, which is 240 times larger than previously available datasets. We release the model along with the datasets created for its training.*
+
+## Usage tips
+
+Input images are processed either by upsampling (if resizing is enabled) or at their original resolution. The resizing behavior depends on two parameters: do_resize and size.
+
+If `do_resize` is set to `True`, the model resizes images so that the longest edge is 4*364 pixels by default.
+The default resizing behavior can be customized by passing a dictionary to the `size` parameter. For example, `{"longest_edge": 4 * 364}` is the default, but you can change it to a different value if needed.
+
+Here’s how to control resizing and set a custom size:
+```python
+image_processor = Idefics3ImageProcessor(do_resize=True, size={"longest_edge": 2 * 364}, max_image_size=364)
+```
+
+Additionally, the `max_image_size` parameter, which controls the size of each square patch the image is decomposed into, is set to 364 by default but can be adjusted as needed. After resizing (if applicable), the image processor decomposes the images into square patches based on the `max_image_size` parameter.
+
+This model was contributed by [amyeroberts](https://huggingface.co/amyeroberts) and [andimarafioti](https://huggingface.co/andito).
+
+
+## Idefics3Config
+
+[[autodoc]] Idefics3Config
+
+## Idefics3VisionConfig
+
+[[autodoc]] Idefics3VisionConfig
+
+## Idefics3VisionTransformer
+
+[[autodoc]] Idefics3VisionTransformer
+
+## Idefics3Model
+
+[[autodoc]] Idefics3Model
+ - forward
+
+## Idefics3ForConditionalGeneration
+
+[[autodoc]] Idefics3ForConditionalGeneration
+ - forward
+
+
+## Idefics3ImageProcessor
+[[autodoc]] Idefics3ImageProcessor
+ - preprocess
+
+
+## Idefics3Processor
+[[autodoc]] Idefics3Processor
+ - __call__
diff --git a/docs/transformers/docs/source/en/model_doc/ijepa.md b/docs/transformers/docs/source/en/model_doc/ijepa.md
new file mode 100644
index 0000000000000000000000000000000000000000..d35011478182318575d3fcd797a512837b4e7bcd
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/ijepa.md
@@ -0,0 +1,98 @@
+
+
+# I-JEPA
+
+
+
+
+
+
+
+## Overview
+
+The I-JEPA model was proposed in [Image-based Joint-Embedding Predictive Architecture](https://arxiv.org/abs/2301.08243) by Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas.
+I-JEPA is a self-supervised learning method that predicts the representations of one part of an image based on other parts of the same image. This approach focuses on learning semantic features without relying on pre-defined invariances from hand-crafted data transformations, which can bias specific tasks, or on filling in pixel-level details, which often leads to less meaningful representations.
+
+The abstract from the paper is the following:
+
+This paper demonstrates an approach for learning highly semantic image representations without relying on hand-crafted data-augmentations. We introduce the Image- based Joint-Embedding Predictive Architecture (I-JEPA), a non-generative approach for self-supervised learning from images. The idea behind I-JEPA is simple: from a single context block, predict the representations of various target blocks in the same image. A core design choice to guide I-JEPA towards producing semantic representations is the masking strategy; specifically, it is crucial to (a) sample tar- get blocks with sufficiently large scale (semantic), and to (b) use a sufficiently informative (spatially distributed) context block. Empirically, when combined with Vision Transform- ers, we find I-JEPA to be highly scalable. For instance, we train a ViT-Huge/14 on ImageNet using 16 A100 GPUs in under 72 hours to achieve strong downstream performance across a wide range of tasks, from linear classification to object counting and depth prediction.
+
+
+
+ I-JEPA architecture. Taken from the original paper.
+
+This model was contributed by [jmtzt](https://huggingface.co/jmtzt).
+The original code can be found [here](https://github.com/facebookresearch/ijepa).
+
+## How to use
+
+Here is how to use this model for image feature extraction:
+
+```python
+import requests
+import torch
+from PIL import Image
+from torch.nn.functional import cosine_similarity
+
+from transformers import AutoModel, AutoProcessor
+
+url_1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+url_2 = "http://images.cocodataset.org/val2017/000000219578.jpg"
+image_1 = Image.open(requests.get(url_1, stream=True).raw)
+image_2 = Image.open(requests.get(url_2, stream=True).raw)
+
+model_id = "facebook/ijepa_vith14_1k"
+processor = AutoProcessor.from_pretrained(model_id)
+model = AutoModel.from_pretrained(model_id)
+
+@torch.no_grad()
+def infer(image):
+ inputs = processor(image, return_tensors="pt")
+ outputs = model(**inputs)
+ return outputs.last_hidden_state.mean(dim=1)
+
+
+embed_1 = infer(image_1)
+embed_2 = infer(image_2)
+
+similarity = cosine_similarity(embed_1, embed_2)
+print(similarity)
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with I-JEPA.
+
+
+
+- [`IJepaForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+## IJepaConfig
+
+[[autodoc]] IJepaConfig
+
+## IJepaModel
+
+[[autodoc]] IJepaModel
+ - forward
+
+## IJepaForImageClassification
+
+[[autodoc]] IJepaForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/imagegpt.md b/docs/transformers/docs/source/en/model_doc/imagegpt.md
new file mode 100644
index 0000000000000000000000000000000000000000..7fbec62d30bb2fd90be3fd33a36a1312fae33f0e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/imagegpt.md
@@ -0,0 +1,119 @@
+
+
+# ImageGPT
+
+
+
+
+
+## Overview
+
+The ImageGPT model was proposed in [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt) by Mark
+Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever. ImageGPT (iGPT) is a GPT-2-like
+model trained to predict the next pixel value, allowing for both unconditional and conditional image generation.
+
+The abstract from the paper is the following:
+
+*Inspired by progress in unsupervised representation learning for natural language, we examine whether similar models
+can learn useful representations for images. We train a sequence Transformer to auto-regressively predict pixels,
+without incorporating knowledge of the 2D input structure. Despite training on low-resolution ImageNet without labels,
+we find that a GPT-2 scale model learns strong image representations as measured by linear probing, fine-tuning, and
+low-data classification. On CIFAR-10, we achieve 96.3% accuracy with a linear probe, outperforming a supervised Wide
+ResNet, and 99.0% accuracy with full fine-tuning, matching the top supervised pre-trained models. We are also
+competitive with self-supervised benchmarks on ImageNet when substituting pixels for a VQVAE encoding, achieving 69.0%
+top-1 accuracy on a linear probe of our features.*
+
+
+
+ Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr), based on [this issue](https://github.com/openai/image-gpt/issues/7). The original code can be found
+[here](https://github.com/openai/image-gpt).
+
+## Usage tips
+
+- ImageGPT is almost exactly the same as [GPT-2](gpt2), with the exception that a different activation
+ function is used (namely "quick gelu"), and the layer normalization layers don't mean center the inputs. ImageGPT
+ also doesn't have tied input- and output embeddings.
+- As the time- and memory requirements of the attention mechanism of Transformers scales quadratically in the sequence
+ length, the authors pre-trained ImageGPT on smaller input resolutions, such as 32x32 and 64x64. However, feeding a
+ sequence of 32x32x3=3072 tokens from 0..255 into a Transformer is still prohibitively large. Therefore, the authors
+ applied k-means clustering to the (R,G,B) pixel values with k=512. This way, we only have a 32*32 = 1024-long
+ sequence, but now of integers in the range 0..511. So we are shrinking the sequence length at the cost of a bigger
+ embedding matrix. In other words, the vocabulary size of ImageGPT is 512, + 1 for a special "start of sentence" (SOS)
+ token, used at the beginning of every sequence. One can use [`ImageGPTImageProcessor`] to prepare
+ images for the model.
+- Despite being pre-trained entirely unsupervised (i.e. without the use of any labels), ImageGPT produces fairly
+ performant image features useful for downstream tasks, such as image classification. The authors showed that the
+ features in the middle of the network are the most performant, and can be used as-is to train a linear model (such as
+ a sklearn logistic regression model for example). This is also referred to as "linear probing". Features can be
+ easily obtained by first forwarding the image through the model, then specifying `output_hidden_states=True`, and
+ then average-pool the hidden states at whatever layer you like.
+- Alternatively, one can further fine-tune the entire model on a downstream dataset, similar to BERT. For this, you can
+ use [`ImageGPTForImageClassification`].
+- ImageGPT comes in different sizes: there's ImageGPT-small, ImageGPT-medium and ImageGPT-large. The authors did also
+ train an XL variant, which they didn't release. The differences in size are summarized in the following table:
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
+|---|---|---|---|---|---|
+| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ImageGPT.
+
+
+
+- Demo notebooks for ImageGPT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ImageGPT).
+- [`ImageGPTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## ImageGPTConfig
+
+[[autodoc]] ImageGPTConfig
+
+## ImageGPTFeatureExtractor
+
+[[autodoc]] ImageGPTFeatureExtractor
+ - __call__
+
+## ImageGPTImageProcessor
+
+[[autodoc]] ImageGPTImageProcessor
+ - preprocess
+
+## ImageGPTModel
+
+[[autodoc]] ImageGPTModel
+ - forward
+
+## ImageGPTForCausalImageModeling
+
+[[autodoc]] ImageGPTForCausalImageModeling
+ - forward
+
+## ImageGPTForImageClassification
+
+[[autodoc]] ImageGPTForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/informer.md b/docs/transformers/docs/source/en/model_doc/informer.md
new file mode 100644
index 0000000000000000000000000000000000000000..1dfc397db7770bdcd44af12edeec57e34bd68ddb
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/informer.md
@@ -0,0 +1,54 @@
+
+
+# Informer
+
+
+
+
+
+## Overview
+
+The Informer model was proposed in [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
+
+This method introduces a Probabilistic Attention mechanism to select the "active" queries rather than the "lazy" queries and provides a sparse Transformer thus mitigating the quadratic compute and memory requirements of vanilla attention.
+
+The abstract from the paper is the following:
+
+*Many real-world applications require the prediction of long sequence time-series, such as electricity consumption planning. Long sequence time-series forecasting (LSTF) demands a high prediction capacity of the model, which is the ability to capture precise long-range dependency coupling between output and input efficiently. Recent studies have shown the potential of Transformer to increase the prediction capacity. However, there are several severe issues with Transformer that prevent it from being directly applicable to LSTF, including quadratic time complexity, high memory usage, and inherent limitation of the encoder-decoder architecture. To address these issues, we design an efficient transformer-based model for LSTF, named Informer, with three distinctive characteristics: (i) a ProbSparse self-attention mechanism, which achieves O(L logL) in time complexity and memory usage, and has comparable performance on sequences' dependency alignment. (ii) the self-attention distilling highlights dominating attention by halving cascading layer input, and efficiently handles extreme long input sequences. (iii) the generative style decoder, while conceptually simple, predicts the long time-series sequences at one forward operation rather than a step-by-step way, which drastically improves the inference speed of long-sequence predictions. Extensive experiments on four large-scale datasets demonstrate that Informer significantly outperforms existing methods and provides a new solution to the LSTF problem.*
+
+This model was contributed by [elisim](https://huggingface.co/elisim) and [kashif](https://huggingface.co/kashif).
+The original code can be found [here](https://github.com/zhouhaoyi/Informer2020).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- Check out the Informer blog-post in HuggingFace blog: [Multivariate Probabilistic Time Series Forecasting with Informer](https://huggingface.co/blog/informer)
+
+## InformerConfig
+
+[[autodoc]] InformerConfig
+
+## InformerModel
+
+[[autodoc]] InformerModel
+ - forward
+
+## InformerForPrediction
+
+[[autodoc]] InformerForPrediction
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/instructblip.md b/docs/transformers/docs/source/en/model_doc/instructblip.md
new file mode 100644
index 0000000000000000000000000000000000000000..4f2feb015f1f8185b479ef6e6177f6e93f847f9e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/instructblip.md
@@ -0,0 +1,76 @@
+
+
+# InstructBLIP
+
+
+
+
+
+## Overview
+
+The InstructBLIP model was proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+InstructBLIP leverages the [BLIP-2](blip2) architecture for visual instruction tuning.
+
+The abstract from the paper is the following:
+
+*General-purpose language models that can solve various language-domain tasks have emerged driven by the pre-training and instruction-tuning pipeline. However, building general-purpose vision-language models is challenging due to the increased task discrepancy introduced by the additional visual input. Although vision-language pre-training has been widely studied, vision-language instruction tuning remains relatively less explored. In this paper, we conduct a systematic and comprehensive study on vision-language instruction tuning based on the pre-trained BLIP-2 models. We gather a wide variety of 26 publicly available datasets, transform them into instruction tuning format and categorize them into two clusters for held-in instruction tuning and held-out zero-shot evaluation. Additionally, we introduce instruction-aware visual feature extraction, a crucial method that enables the model to extract informative features tailored to the given instruction. The resulting InstructBLIP models achieve state-of-the-art zero-shot performance across all 13 held-out datasets, substantially outperforming BLIP-2 and the larger Flamingo. Our models also lead to state-of-the-art performance when finetuned on individual downstream tasks (e.g., 90.7% accuracy on ScienceQA IMG). Furthermore, we qualitatively demonstrate the advantages of InstructBLIP over concurrent multimodal models.*
+
+
+
+ InstructBLIP architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
+
+## Usage tips
+
+InstructBLIP uses the same architecture as [BLIP-2](blip2) with a tiny but important difference: it also feeds the text prompt (instruction) to the Q-Former.
+
+> [!NOTE]
+> BLIP models after release v4.46 will raise warnings about adding `processor.num_query_tokens = {{num_query_tokens}}` and expand model embeddings layer to add special `` token. It is strongly recommended to add the attributes to the processor if you own the model checkpoint, or open a PR if it is not owned by you. Adding these attributes means that BLIP will add the number of query tokens required per image and expand the text with as many `` placeholders as there will be query tokens. Usually it is around 500 tokens per image, so make sure that the text is not truncated as otherwise there wil be failure when merging the embeddings.
+The attributes can be obtained from model config, as `model.config.num_query_tokens` and model embeddings expansion can be done by following [this link](https://gist.github.com/zucchini-nlp/e9f20b054fa322f84ac9311d9ab67042).
+
+## InstructBlipConfig
+
+[[autodoc]] InstructBlipConfig
+ - from_vision_qformer_text_configs
+
+## InstructBlipVisionConfig
+
+[[autodoc]] InstructBlipVisionConfig
+
+## InstructBlipQFormerConfig
+
+[[autodoc]] InstructBlipQFormerConfig
+
+## InstructBlipProcessor
+
+[[autodoc]] InstructBlipProcessor
+
+
+## InstructBlipVisionModel
+
+[[autodoc]] InstructBlipVisionModel
+ - forward
+
+## InstructBlipQFormerModel
+
+[[autodoc]] InstructBlipQFormerModel
+ - forward
+
+## InstructBlipForConditionalGeneration
+
+[[autodoc]] InstructBlipForConditionalGeneration
+ - forward
+ - generate
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/instructblipvideo.md b/docs/transformers/docs/source/en/model_doc/instructblipvideo.md
new file mode 100644
index 0000000000000000000000000000000000000000..c26562a8530862d5df2ab0674a467dba4866be5b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/instructblipvideo.md
@@ -0,0 +1,80 @@
+
+
+# InstructBlipVideo
+
+
+
+
+
+## Overview
+
+The InstructBLIPVideo is an extension of the models proposed in [InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning](https://arxiv.org/abs/2305.06500) by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi.
+InstructBLIPVideo uses the same architecture as [InstructBLIP](instructblip) and works with the same checkpoints as [InstructBLIP](instructblip). The only difference is the ability to process videos.
+
+The abstract from the paper is the following:
+
+*General-purpose language models that can solve various language-domain tasks have emerged driven by the pre-training and instruction-tuning pipeline. However, building general-purpose vision-language models is challenging due to the increased task discrepancy introduced by the additional visual input. Although vision-language pre-training has been widely studied, vision-language instruction tuning remains relatively less explored. In this paper, we conduct a systematic and comprehensive study on vision-language instruction tuning based on the pre-trained BLIP-2 models. We gather a wide variety of 26 publicly available datasets, transform them into instruction tuning format and categorize them into two clusters for held-in instruction tuning and held-out zero-shot evaluation. Additionally, we introduce instruction-aware visual feature extraction, a crucial method that enables the model to extract informative features tailored to the given instruction. The resulting InstructBLIP models achieve state-of-the-art zero-shot performance across all 13 held-out datasets, substantially outperforming BLIP-2 and the larger Flamingo. Our models also lead to state-of-the-art performance when finetuned on individual downstream tasks (e.g., 90.7% accuracy on ScienceQA IMG). Furthermore, we qualitatively demonstrate the advantages of InstructBLIP over concurrent multimodal models.*
+
+
+
+ InstructBLIPVideo architecture. Taken from the original paper.
+
+This model was contributed by [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
+The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
+
+## Usage tips
+
+- The model was trained by sampling 4 frames per video, so it's recommended to sample 4 frames
+
+> [!NOTE]
+> BLIP models after release v4.46 will raise warnings about adding `processor.num_query_tokens = {{num_query_tokens}}` and expand model embeddings layer to add special `` token. It is strongly recommended to add the attributes to the processor if you own the model checkpoint, or open a PR if it is not owned by you. Adding these attributes means that BLIP will add the number of query tokens required per image and expand the text with as many `` placeholders as there will be query tokens. Usually it is around 500 tokens per image, so make sure that the text is not truncated as otherwise there wil be failure when merging the embeddings.
+The attributes can be obtained from model config, as `model.config.num_query_tokens` and model embeddings expansion can be done by following [this link](https://gist.github.com/zucchini-nlp/e9f20b054fa322f84ac9311d9ab67042).
+
+## InstructBlipVideoConfig
+
+[[autodoc]] InstructBlipVideoConfig
+ - from_vision_qformer_text_configs
+
+## InstructBlipVideoVisionConfig
+
+[[autodoc]] InstructBlipVideoVisionConfig
+
+## InstructBlipVideoQFormerConfig
+
+[[autodoc]] InstructBlipVideoQFormerConfig
+
+## InstructBlipVideoProcessor
+
+[[autodoc]] InstructBlipVideoProcessor
+
+## InstructBlipVideoImageProcessor
+
+[[autodoc]] InstructBlipVideoImageProcessor
+ - preprocess
+
+## InstructBlipVideoVisionModel
+
+[[autodoc]] InstructBlipVideoVisionModel
+ - forward
+
+## InstructBlipVideoQFormerModel
+
+[[autodoc]] InstructBlipVideoQFormerModel
+ - forward
+
+## InstructBlipVideoForConditionalGeneration
+
+[[autodoc]] InstructBlipVideoForConditionalGeneration
+ - forward
+ - generate
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/internvl.md b/docs/transformers/docs/source/en/model_doc/internvl.md
new file mode 100644
index 0000000000000000000000000000000000000000..4ac56c853777cc0669ab91f654b6e8a7765dc02e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/internvl.md
@@ -0,0 +1,350 @@
+
+
+
+
+
+
+
+
+
+
+
+# InternVL
+
+The InternVL3 family of Visual Language Models was introduced in [InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models](https://huggingface.co/papers/2504.10479).
+
+The abstract from the paper is the following:
+
+*We introduce InternVL3, a significant advancement in the InternVL series featuring a native multimodal pre-training paradigm. Rather than adapting a text-only large language model (LLM) into a multimodal large language model (MLLM) that supports visual inputs, InternVL3 jointly acquires multimodal and linguistic capabilities from both diverse multimodal data and pure-text corpora during a single pre-training stage. This unified training paradigm effectively addresses the complexities and alignment challenges commonly encountered in conventional post-hoc training pipelines for MLLMs. To further improve performance and scalability, InternVL3 incorporates variable visual position encoding (V2PE) to support extended multimodal contexts, employs advanced post-training techniques such as supervised fine-tuning (SFT) and mixed preference optimization (MPO), and adopts test-time scaling strategies alongside an optimized training infrastructure. Extensive empirical evaluations demonstrate that InternVL3 delivers superior performance across a wide range of multi-modal tasks. In particular, InternVL3-78B achieves a score of 72.2 on the MMMU benchmark, setting a new state-of-the-art among open-source MLLMs. Its capabilities remain highly competitive with leading proprietary models, including ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro, while also maintaining strong pure-language proficiency. In pursuit of open-science principles, we will publicly release both the training data and model weights to foster further research and development in next-generation MLLMs.*
+
+
+
+
+ Overview of InternVL3 models architecture, which is the same as InternVL2.5. Taken from the original checkpoint.
+
+
+
+
+
+ Comparison of InternVL3 performance on OpenCompass against other SOTA VLLMs. Taken from the original checkpoint.
+
+
+
+This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
+The original code can be found [here](https://github.com/OpenGVLab/InternVL).
+
+## Usage example
+
+### Inference with Pipeline
+
+Here is how you can use the `image-text-to-text` pipeline to perform inference with the `InternVL3` models in just a few lines of code:
+
+```python
+>>> from transformers import pipeline
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {
+... "type": "image",
+... "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg",
+... },
+... {"type": "text", "text": "Describe this image."},
+... ],
+... },
+... ]
+
+>>> pipe = pipeline("image-text-to-text", model="OpenGVLab/InternVL3-1B-hf")
+>>> outputs = pipe(text=messages, max_new_tokens=50, return_full_text=False)
+>>> outputs[0]["generated_text"]
+'The image showcases a vibrant scene of nature, featuring several flowers and a bee. \n\n1. **Foreground Flowers**: \n - The primary focus is on a large, pink cosmos flower with a prominent yellow center. The petals are soft and slightly r'
+```
+### Inference on a single image
+
+This example demonstrates how to perform inference on a single image with the InternVL models using chat templates.
+
+> [!NOTE]
+> Note that the model has been trained with a specific prompt format for chatting. Use `processor.apply_chat_template(my_conversation_dict)` to correctly format your prompts.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
+... {"type": "text", "text": "Please describe the image explicitly."},
+... ],
+... }
+... ]
+
+>>> inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+>>> generate_ids = model.generate(**inputs, max_new_tokens=50)
+>>> decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+
+>>> decoded_output
+'The image shows two cats lying on a pink blanket. The cat on the left is a tabby with a mix of brown, black, and white fur, and it appears to be sleeping with its head resting on the blanket. The cat on the'
+```
+
+### Text-only generation
+This example shows how to generate text using the InternVL model without providing any image input.
+
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {"type": "text", "text": "Write a haiku"},
+... ],
+... }
+... ]
+
+>>> inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(torch_device, dtype=torch.bfloat16)
+
+>>> generate_ids = model.generate(**inputs, max_new_tokens=50)
+>>> decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+
+>>> print(decoded_output)
+"Whispers of dawn,\nSilent whispers of the night,\nNew day's light begins."
+```
+
+### Batched image and text inputs
+InternVL models also support batched image and text inputs.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+... {"type": "text", "text": "Write a haiku for this image"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"},
+... {"type": "text", "text": "Describe this image"},
+... ],
+... },
+... ],
+... ]
+
+
+>>> inputs = processor.apply_chat_template(messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+>>> output = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_outputs = processor.batch_decode(output, skip_special_tokens=True)
+>>> decoded_outputs
+["user\n\nWrite a haiku for this image\nassistant\nSilky lake, \nWooden pier, \nNature's peace.",
+ 'user\n\nDescribe this image\nassistant\nThe image shows a street scene with a traditional Chinese archway, known as a "Chinese Gate" or "Chinese Gate of']
+```
+
+### Batched multi-image input
+This implementation of the InternVL models supports batched text-images inputs with different number of images for each text.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+... {"type": "text", "text": "Write a haiku for this image"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"},
+... {"type": "image", "url": "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg"},
+... {"type": "text", "text": "These images depict two different landmarks. Can you identify them?"},
+... ],
+... },
+... ],
+>>> ]
+
+>>> inputs = processor.apply_chat_template(messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+>>> output = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_outputs = processor.batch_decode(output, skip_special_tokens=True)
+>>> decoded_outputs
+["user\n\nWrite a haiku for this image\nassistant\nSilky lake, \nWooden pier, \nNature's peace.",
+ 'user\n\n\nThese images depict two different landmarks. Can you identify them?\nassistant\nYes, these images depict the Statue of Liberty and the Golden Gate Bridge.']
+```
+
+### Video input
+InternVL models can also handle video inputs. Here is an example of how to perform inference on a video input using chat templates.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
+
+>>> model_checkpoint = "OpenGVLab/InternVL3-8B-hf"
+>>> quantization_config = BitsAndBytesConfig(load_in_4bit=True)
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, quantization_config=quantization_config)
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {
+... "type": "video",
+... "url": "https://huggingface.co/datasets/hf-internal-testing/fixtures_videos/resolve/main/tennis.mp4",
+... },
+... {"type": "text", "text": "What type of shot is the man performing?"},
+... ],
+... }
+>>> ]
+>>> inputs = processor.apply_chat_template(
+... messages,
+... return_tensors="pt",
+... add_generation_prompt=True,
+... tokenize=True,
+... return_dict=True,
+... num_frames=8,
+>>> ).to(model.device, dtype=torch.float16)
+
+>>> output = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_output = processor.decode(output[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+>>> decoded_output
+'The man is performing a forehand shot.'
+```
+
+### Interleaved image and video inputs
+This example showcases how to handle a batch of chat conversations with interleaved image and video inputs using chat template.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"},
+... {"type": "image", "url": "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg"},
+... {"type": "text", "text": "These images depict two different landmarks. Can you identify them?"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "video", "url": "https://huggingface.co/datasets/hf-internal-testing/fixtures_videos/resolve/main/tennis.mp4"},
+... {"type": "text", "text": "What type of shot is the man performing?"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+... {"type": "text", "text": "Write a haiku for this image"},
+... ],
+... },
+... ],
+>>> ]
+>>> inputs = processor.apply_chat_template(
+... messages,
+... padding=True,
+... add_generation_prompt=True,
+... tokenize=True,
+... return_dict=True,
+... return_tensors="pt",
+>>> ).to(model.device, dtype=torch.bfloat16)
+
+>>> outputs = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_outputs = processor.batch_decode(outputs, skip_special_tokens=True)
+>>> decoded_outputs
+['user\n\n\nThese images depict two different landmarks. Can you identify them?\nassistant\nThe images depict the Statue of Liberty and the Golden Gate Bridge.',
+ 'user\nFrame1: \nFrame2: \nFrame3: \nFrame4: \nFrame5: \nFrame6: \nFrame7: \nFrame8: \nWhat type of shot is the man performing?\nassistant\nA forehand shot',
+ "user\n\nWrite a haiku for this image\nassistant\nSilky lake, \nWooden pier, \nNature's peace."]
+```
+
+## InternVLVisionConfig
+
+[[autodoc]] InternVLVisionConfig
+
+## InternVLConfig
+
+[[autodoc]] InternVLConfig
+
+## InternVLVisionModel
+
+[[autodoc]] InternVLVisionModel
+ - forward
+
+## InternVLForConditionalGeneration
+
+[[autodoc]] InternVLForConditionalGeneration
+ - forward
+
+## InternVLProcessor
+
+[[autodoc]] InternVLProcessor
diff --git a/docs/transformers/docs/source/en/model_doc/jamba.md b/docs/transformers/docs/source/en/model_doc/jamba.md
new file mode 100644
index 0000000000000000000000000000000000000000..8c2c147c0c7e846ced20aa487dc0f42ab897122e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/jamba.md
@@ -0,0 +1,158 @@
+
+
+
+
+
+
+
+
+
+
+# Jamba
+
+[Jamba](https://huggingface.co/papers/2403.19887) is a hybrid Transformer-Mamba mixture-of-experts (MoE) language model ranging from 52B to 398B total parameters. This model aims to combine the advantages of both model families, the performance of transformer models and the efficiency and longer context (256K tokens) of state space models (SSMs) like Mamba.
+
+Jamba's architecture features a blocks-and-layers approach that allows Jamba to successfully integrate Transformer and Mamba architectures altogether. Each Jamba block contains either an attention or a Mamba layer, followed by a multi-layer perceptron (MLP), producing an overall ratio of one Transformer layer out of every eight total layers. MoE layers are mixed in to increase model capacity.
+
+You can find all the original Jamba checkpoints under the [AI21](https://huggingface.co/ai21labs) organization.
+
+> [!TIP]
+> Click on the Jamba models in the right sidebar for more examples of how to apply Jamba to different language tasks.
+
+The example below demonstrates how to generate text with [`Pipeline`], [`AutoModel`], and from the command line.
+
+
+
+
+```py
+# install optimized Mamba implementations
+# !pip install mamba-ssm causal-conv1d>=1.2.0
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="text-generation",
+ model="ai21labs/AI21-Jamba-Mini-1.6",
+ torch_dtype=torch.float16,
+ device=0
+)
+pipeline("Plants create energy through a process known as")
+```
+
+
+
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained(
+ "ai21labs/AI21-Jamba-Large-1.6",
+)
+model = AutoModelForCausalLM.from_pretrained(
+ "ai21labs/AI21-Jamba-Large-1.6",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+input_ids = tokenizer("Plants create energy through a process known as", return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+
+
+```bash
+echo -e "Plants create energy through a process known as" | transformers-cli run --task text-generation --model ai21labs/AI21-Jamba-Mini-1.6 --device 0
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes) to only quantize the weights to 8-bits.
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_8bit=True,
+ llm_int8_skip_modules=["mamba"])
+
+# a device map to distribute the model evenly across 8 GPUs
+device_map = {'model.embed_tokens': 0, 'model.layers.0': 0, 'model.layers.1': 0, 'model.layers.2': 0, 'model.layers.3': 0, 'model.layers.4': 0, 'model.layers.5': 0, 'model.layers.6': 0, 'model.layers.7': 0, 'model.layers.8': 0, 'model.layers.9': 1, 'model.layers.10': 1, 'model.layers.11': 1, 'model.layers.12': 1, 'model.layers.13': 1, 'model.layers.14': 1, 'model.layers.15': 1, 'model.layers.16': 1, 'model.layers.17': 1, 'model.layers.18': 2, 'model.layers.19': 2, 'model.layers.20': 2, 'model.layers.21': 2, 'model.layers.22': 2, 'model.layers.23': 2, 'model.layers.24': 2, 'model.layers.25': 2, 'model.layers.26': 2, 'model.layers.27': 3, 'model.layers.28': 3, 'model.layers.29': 3, 'model.layers.30': 3, 'model.layers.31': 3, 'model.layers.32': 3, 'model.layers.33': 3, 'model.layers.34': 3, 'model.layers.35': 3, 'model.layers.36': 4, 'model.layers.37': 4, 'model.layers.38': 4, 'model.layers.39': 4, 'model.layers.40': 4, 'model.layers.41': 4, 'model.layers.42': 4, 'model.layers.43': 4, 'model.layers.44': 4, 'model.layers.45': 5, 'model.layers.46': 5, 'model.layers.47': 5, 'model.layers.48': 5, 'model.layers.49': 5, 'model.layers.50': 5, 'model.layers.51': 5, 'model.layers.52': 5, 'model.layers.53': 5, 'model.layers.54': 6, 'model.layers.55': 6, 'model.layers.56': 6, 'model.layers.57': 6, 'model.layers.58': 6, 'model.layers.59': 6, 'model.layers.60': 6, 'model.layers.61': 6, 'model.layers.62': 6, 'model.layers.63': 7, 'model.layers.64': 7, 'model.layers.65': 7, 'model.layers.66': 7, 'model.layers.67': 7, 'model.layers.68': 7, 'model.layers.69': 7, 'model.layers.70': 7, 'model.layers.71': 7, 'model.final_layernorm': 7, 'lm_head': 7}
+model = AutoModelForCausalLM.from_pretrained("ai21labs/AI21-Jamba-Large-1.6",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+ quantization_config=quantization_config,
+ device_map=device_map)
+
+tokenizer = AutoTokenizer.from_pretrained("ai21labs/AI21-Jamba-Large-1.6")
+
+messages = [
+ {"role": "system", "content": "You are an ancient oracle who speaks in cryptic but wise phrases, always hinting at deeper meanings."},
+ {"role": "user", "content": "Hello!"},
+]
+
+input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt').to(model.device)
+
+outputs = model.generate(input_ids, max_new_tokens=216)
+
+# Decode the output
+conversation = tokenizer.decode(outputs[0], skip_special_tokens=True)
+
+# Split the conversation to get only the assistant's response
+assistant_response = conversation.split(messages[-1]['content'])[1].strip()
+print(assistant_response)
+# Output: Seek and you shall find. The path is winding, but the journey is enlightening. What wisdom do you seek from the ancient echoes?
+```
+
+## Notes
+
+- Don't quantize the Mamba blocks to prevent model performance degradation.
+- It is not recommended to use Mamba without the optimized Mamba kernels as it results in significantly lower latencies. If you still want to use Mamba without the kernels, then set `use_mamba_kernels=False` in [`~AutoModel.from_pretrained`].
+
+ ```py
+ import torch
+ from transformers import AutoModelForCausalLM
+ model = AutoModelForCausalLM.from_pretrained("ai21labs/AI21-Jamba-1.5-Large",
+ use_mamba_kernels=False)
+ ```
+
+## JambaConfig
+
+[[autodoc]] JambaConfig
+
+
+## JambaModel
+
+[[autodoc]] JambaModel
+ - forward
+
+
+## JambaForCausalLM
+
+[[autodoc]] JambaForCausalLM
+ - forward
+
+
+## JambaForSequenceClassification
+
+[[autodoc]] transformers.JambaForSequenceClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/janus.md b/docs/transformers/docs/source/en/model_doc/janus.md
new file mode 100644
index 0000000000000000000000000000000000000000..015f2910dfe450014e7a0441e188206024182a7b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/janus.md
@@ -0,0 +1,230 @@
+
+
+# Janus
+
+## Overview
+
+The Janus Model was originally proposed in [Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation](https://arxiv.org/abs/2410.13848) by DeepSeek AI team and later refined in [Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling](https://arxiv.org/abs/2501.17811). Janus is a vision-language model that can generate both image and text output, it can also take both images and text as input.
+
+> [!NOTE]
+> The model doesn't generate both images and text in an interleaved format. The user has to pass a parameter indicating whether to generate text or image.
+
+The abstract from the original paper is the following:
+
+*In this paper, we introduce Janus, an autoregressive framework that unifies multimodal understanding and generation. Prior research often relies on a single visual encoder for both tasks, such as Chameleon. However, due to the differing levels of information granularity required by multimodal understanding and generation, this approach can lead to suboptimal performance, particularly in multimodal understanding. To address this issue, we decouple visual encoding into separate pathways, while still leveraging a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder's roles in understanding and generation, but also enhances the framework's flexibility. For instance, both the multimodal understanding and generation components can independently select their most suitable encoding methods. Experiments show that Janus surpasses previous unified model and matches or exceeds the performance of task-specific models. The simplicity, high flexibility, and effectiveness of Janus make it a strong candidate for next-generation unified multimodal models.*
+
+The abstract from the aforementioned `Janus-Pro` paper, released afterwards, is the following:
+
+*In this work, we introduce Janus-Pro, an advanced version of the previous work Janus. Specifically, Janus-Pro incorporates (1) an optimized training strate (2) expanded training data, and (3) scaling to larger model size. With these improvements, Janus-Pro achieves significant advancements in both multimodal understanding and text-to-image instruction-following capabilities, while also enhancing the stability of text-to-image generation. We hope this work will inspire further exploration in the field. Code and models are publicly available.*
+
+This model was contributed by [Yaswanth Gali](https://huggingface.co/yaswanthgali) and [Hugo Silva](https://huggingface.co/hugosilva664).
+The original code can be found [here](https://github.com/deepseek-ai/Janus).
+
+## Usage Example
+
+### Single image inference
+
+Here is the example of visual understanding with a single image.
+
+> [!NOTE]
+> Note that the model has been trained with a specific prompt format for chatting. Use `processor.apply_chat_template(my_conversation_dict)` to correctly format your prompts.
+
+```python
+import torch
+from PIL import Image
+import requests
+
+from transformers import JanusForConditionalGeneration, JanusProcessor
+
+model_id = "deepseek-community/Janus-Pro-1B"
+# Prepare Input for generation.
+messages = [
+ {
+ "role": "user",
+ "content": [
+ {'type':'image', 'url': 'http://images.cocodataset.org/val2017/000000039769.jpg'},
+ {'type':"text", "text":"What do you see in this image?."}
+ ]
+ },
+]
+
+# Set generation mode to `text` to perform text generation.
+processor = JanusProcessor.from_pretrained(model_id)
+model = JanusForConditionalGeneration.from_pretrained(model_id,
+ torch_dtype=torch.bfloat16,
+ device_map="auto")
+
+inputs = processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ generation_mode="text",
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+).to(model.device, dtype=torch.bfloat16)
+
+output = model.generate(**inputs, max_new_tokens=40,generation_mode='text',do_sample=True)
+text = processor.decode(output[0], skip_special_tokens=True)
+print(text)
+```
+
+### Multi image inference
+
+Janus can perform inference with multiple images as input, where images can belong to the same prompt or different prompts in batched inference, where the model processes many conversations in parallel. Here is how you can do it:
+
+```python
+import torch
+from PIL import Image
+import requests
+
+from transformers import JanusForConditionalGeneration, JanusProcessor
+
+model_id = "deepseek-community/Janus-Pro-1B"
+
+image_urls = [
+ "http://images.cocodataset.org/val2017/000000039769.jpg",
+ "https://www.ilankelman.org/stopsigns/australia.jpg",
+ "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
+]
+
+messages = [
+ [
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "What’s the difference between"},
+ {"type": "image", "url": image_urls[0]},
+ {"type": "text", "text": " and "},
+ {"type": "image", "url": image_urls[1]}
+ ]
+ }
+ ],
+ [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": image_urls[2]},
+ {"type": "text", "text": "What do you see in this image?"}
+ ]
+ }
+ ]
+]
+
+# Load model and processor
+processor = JanusProcessor.from_pretrained(model_id)
+model = JanusForConditionalGeneration.from_pretrained(
+ model_id, torch_dtype=torch.bfloat16, device_map="auto"
+)
+
+inputs = processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ generation_mode="text",
+ tokenize=True,
+ padding=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device, dtype=torch.bfloat16)
+
+# Generate response
+output = model.generate(**inputs, max_new_tokens=40, generation_mode='text', do_sample=False)
+text = processor.batch_decode(output, skip_special_tokens=True)
+print(text)
+```
+
+## Text to Image generation
+
+Janus can also generate images given a prompt.
+
+```python
+import torch
+from transformers import JanusForConditionalGeneration, JanusProcessor
+
+# Set generation mode to `image` to prepare inputs for image generation..
+
+model_id = "deepseek-community/Janus-Pro-1B"
+processor = JanusProcessor.from_pretrained(model_id)
+model = JanusForConditionalGeneration.from_pretrained(model_id,
+ torch_dtype=torch.bfloat16,
+ device_map="auto")
+
+messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "A dog running under the rain."},
+ ],
+ }
+]
+
+prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
+inputs = processor(text=prompt,generation_mode="image",return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+# Set num_return_sequence parameter to generate multiple images per prompt.
+model.generation_config.num_return_sequences = 2
+outputs = model.generate(**inputs,
+ generation_mode="image",
+ do_sample=True,
+ use_cache=True,
+ )
+# Perform post-processing on the generated token ids.
+decoded_image = model.decode_image_tokens(outputs)
+images = processor.postprocess(list(decoded_image.float()),return_tensors="PIL.Image.Image")
+# Save the image
+for i, image in enumerate(images['pixel_values']):
+ image.save(f"result{i}.png")
+```
+
+## JanusConfig
+
+[[autodoc]] JanusConfig
+
+## JanusVisionConfig
+
+[[autodoc]] JanusVisionConfig
+
+## JanusVQVAEConfig
+
+[[autodoc]] JanusVQVAEConfig
+
+## JanusProcessor
+
+[[autodoc]] JanusProcessor
+
+## JanusImageProcessor
+
+[[autodoc]] JanusImageProcessor
+
+## JanusVisionModel
+
+[[autodoc]] JanusVisionModel
+ - forward
+
+## JanusVQVAE
+
+[[autodoc]] JanusVQVAE
+ - forward
+
+## JanusModel
+
+[[autodoc]] JanusModel
+ - forward
+
+## JanusForConditionalGeneration
+
+[[autodoc]] JanusForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/jetmoe.md b/docs/transformers/docs/source/en/model_doc/jetmoe.md
new file mode 100644
index 0000000000000000000000000000000000000000..aba6577f70cd4b889d3c841a39032ae8a1752b96
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/jetmoe.md
@@ -0,0 +1,55 @@
+
+
+# JetMoe
+
+
+
+
+
+
+
+## Overview
+
+**JetMoe-8B** is an 8B Mixture-of-Experts (MoE) language model developed by [Yikang Shen](https://scholar.google.com.hk/citations?user=qff5rRYAAAAJ) and [MyShell](https://myshell.ai/).
+JetMoe project aims to provide a LLaMA2-level performance and efficient language model with a limited budget.
+To achieve this goal, JetMoe uses a sparsely activated architecture inspired by the [ModuleFormer](https://arxiv.org/abs/2306.04640).
+Each JetMoe block consists of two MoE layers: Mixture of Attention Heads and Mixture of MLP Experts.
+Given the input tokens, it activates a subset of its experts to process them.
+This sparse activation schema enables JetMoe to achieve much better training throughput than similar size dense models.
+The training throughput of JetMoe-8B is around 100B tokens per day on a cluster of 96 H100 GPUs with a straightforward 3-way pipeline parallelism strategy.
+
+This model was contributed by [Yikang Shen](https://huggingface.co/YikangS).
+
+
+## JetMoeConfig
+
+[[autodoc]] JetMoeConfig
+
+## JetMoeModel
+
+[[autodoc]] JetMoeModel
+ - forward
+
+## JetMoeForCausalLM
+
+[[autodoc]] JetMoeForCausalLM
+ - forward
+
+## JetMoeForSequenceClassification
+
+[[autodoc]] JetMoeForSequenceClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/jukebox.md b/docs/transformers/docs/source/en/model_doc/jukebox.md
new file mode 100644
index 0000000000000000000000000000000000000000..144134d9b0709b4a7ff8ca2392ac4a15569c7dcd
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/jukebox.md
@@ -0,0 +1,97 @@
+
+# Jukebox
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+The Jukebox model was proposed in [Jukebox: A generative model for music](https://arxiv.org/pdf/2005.00341.pdf)
+by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford,
+Ilya Sutskever. It introduces a generative music model which can produce minute long samples that can be conditioned on
+an artist, genres and lyrics.
+
+The abstract from the paper is the following:
+
+*We introduce Jukebox, a model that generates music with singing in the raw audio domain. We tackle the long context of raw audio using a multiscale VQ-VAE to compress it to discrete codes, and modeling those using autoregressive Transformers. We show that the combined model at scale can generate high-fidelity and diverse songs with coherence up to multiple minutes. We can condition on artist and genre to steer the musical and vocal style, and on unaligned lyrics to make the singing more controllable. We are releasing thousands of non cherry-picked samples, along with model weights and code.*
+
+As shown on the following figure, Jukebox is made of 3 `priors` which are decoder only models. They follow the architecture described in [Generating Long Sequences with Sparse Transformers](https://arxiv.org/abs/1904.10509), modified to support longer context length.
+First, a autoencoder is used to encode the text lyrics. Next, the first (also called `top_prior`) prior attends to the last hidden states extracted from the lyrics encoder. The priors are linked to the previous priors respectively via an `AudioConditioner` module. The`AudioConditioner` upsamples the outputs of the previous prior to raw tokens at a certain audio frame per second resolution.
+The metadata such as *artist, genre and timing* are passed to each prior, in the form of a start token and positional embedding for the timing data. The hidden states are mapped to the closest codebook vector from the VQVAE in order to convert them to raw audio.
+
+
+
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/openai/jukebox).
+
+## Usage tips
+
+- This model only supports inference. This is for a few reasons, mostly because it requires a crazy amount of memory to train. Feel free to open a PR and add what's missing to have a full integration with the hugging face trainer!
+- This model is very slow, and takes 8h to generate a minute long audio using the 5b top prior on a V100 GPU. In order automaticallay handle the device on which the model should execute, use `accelerate`.
+- Contrary to the paper, the order of the priors goes from `0` to `1` as it felt more intuitive : we sample starting from `0`.
+- Primed sampling (conditioning the sampling on raw audio) requires more memory than ancestral sampling and should be used with `fp16` set to `True`.
+
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/openai/jukebox).
+
+## JukeboxConfig
+
+[[autodoc]] JukeboxConfig
+
+## JukeboxPriorConfig
+
+[[autodoc]] JukeboxPriorConfig
+
+## JukeboxVQVAEConfig
+
+[[autodoc]] JukeboxVQVAEConfig
+
+## JukeboxTokenizer
+
+[[autodoc]] JukeboxTokenizer
+ - save_vocabulary
+
+## JukeboxModel
+
+[[autodoc]] JukeboxModel
+ - ancestral_sample
+ - primed_sample
+ - continue_sample
+ - upsample
+ - _sample
+
+## JukeboxPrior
+
+[[autodoc]] JukeboxPrior
+ - sample
+ - forward
+
+## JukeboxVQVAE
+
+[[autodoc]] JukeboxVQVAE
+ - forward
+ - encode
+ - decode
diff --git a/docs/transformers/docs/source/en/model_doc/kosmos-2.md b/docs/transformers/docs/source/en/model_doc/kosmos-2.md
new file mode 100644
index 0000000000000000000000000000000000000000..88a3b6bd99e1493d10b0bd50b9a9f69a92332a74
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/kosmos-2.md
@@ -0,0 +1,102 @@
+
+
+# KOSMOS-2
+
+
+
+
+
+## Overview
+
+The KOSMOS-2 model was proposed in [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
+
+KOSMOS-2 is a Transformer-based causal language model and is trained using the next-word prediction task on a web-scale
+dataset of grounded image-text pairs [GRIT](https://huggingface.co/datasets/zzliang/GRIT). The spatial coordinates of
+the bounding boxes in the dataset are converted to a sequence of location tokens, which are appended to their respective
+entity text spans (for example, `a snowman` followed by ``). The data format is
+similar to “hyperlinks” that connect the object regions in an image to their text span in the corresponding caption.
+
+The abstract from the paper is the following:
+
+*We introduce Kosmos-2, a Multimodal Large Language Model (MLLM), enabling new capabilities of perceiving object descriptions (e.g., bounding boxes) and grounding text to the visual world. Specifically, we represent refer expressions as links in Markdown, i.e., ``[text span](bounding boxes)'', where object descriptions are sequences of location tokens. Together with multimodal corpora, we construct large-scale data of grounded image-text pairs (called GrIT) to train the model. In addition to the existing capabilities of MLLMs (e.g., perceiving general modalities, following instructions, and performing in-context learning), Kosmos-2 integrates the grounding capability into downstream applications. We evaluate Kosmos-2 on a wide range of tasks, including (i) multimodal grounding, such as referring expression comprehension, and phrase grounding, (ii) multimodal referring, such as referring expression generation, (iii) perception-language tasks, and (iv) language understanding and generation. This work lays out the foundation for the development of Embodiment AI and sheds light on the big convergence of language, multimodal perception, action, and world modeling, which is a key step toward artificial general intelligence. Code and pretrained models are available at https://aka.ms/kosmos-2.*
+
+
+
+ Overview of tasks that KOSMOS-2 can handle. Taken from the original paper.
+
+## Example
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, Kosmos2ForConditionalGeneration
+
+>>> model = Kosmos2ForConditionalGeneration.from_pretrained("microsoft/kosmos-2-patch14-224")
+>>> processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
+
+>>> url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> prompt = " An image of"
+
+>>> inputs = processor(text=prompt, images=image, return_tensors="pt")
+
+>>> generated_ids = model.generate(
+... pixel_values=inputs["pixel_values"],
+... input_ids=inputs["input_ids"],
+... attention_mask=inputs["attention_mask"],
+... image_embeds=None,
+... image_embeds_position_mask=inputs["image_embeds_position_mask"],
+... use_cache=True,
+... max_new_tokens=64,
+... )
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+>>> processed_text = processor.post_process_generation(generated_text, cleanup_and_extract=False)
+>>> processed_text
+' An image of a snowman warming himself by a fire.'
+
+>>> caption, entities = processor.post_process_generation(generated_text)
+>>> caption
+'An image of a snowman warming himself by a fire.'
+
+>>> entities
+[('a snowman', (12, 21), [(0.390625, 0.046875, 0.984375, 0.828125)]), ('a fire', (41, 47), [(0.171875, 0.015625, 0.484375, 0.890625)])]
+```
+
+This model was contributed by [Yih-Dar SHIEH](https://huggingface.co/ydshieh). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/kosmos-2).
+
+## Kosmos2Config
+
+[[autodoc]] Kosmos2Config
+
+## Kosmos2ImageProcessor
+
+## Kosmos2Processor
+
+[[autodoc]] Kosmos2Processor
+ - __call__
+
+## Kosmos2Model
+
+[[autodoc]] Kosmos2Model
+ - forward
+
+## Kosmos2ForConditionalGeneration
+
+[[autodoc]] Kosmos2ForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/layoutlm.md b/docs/transformers/docs/source/en/model_doc/layoutlm.md
new file mode 100644
index 0000000000000000000000000000000000000000..51cc52b7f4526d2556dd9dd158f36f6af8481759
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/layoutlm.md
@@ -0,0 +1,180 @@
+
+
+# LayoutLM
+
+
+
+
+
+
+
+
+## Overview
+
+The LayoutLM model was proposed in the paper [LayoutLM: Pre-training of Text and Layout for Document Image
+Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and
+Ming Zhou. It's a simple but effective pretraining method of text and layout for document image understanding and
+information extraction tasks, such as form understanding and receipt understanding. It obtains state-of-the-art results
+on several downstream tasks:
+
+- form understanding: the [FUNSD](https://guillaumejaume.github.io/FUNSD/) dataset (a collection of 199 annotated
+ forms comprising more than 30,000 words).
+- receipt understanding: the [SROIE](https://rrc.cvc.uab.es/?ch=13) dataset (a collection of 626 receipts for
+ training and 347 receipts for testing).
+- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
+ 400,000 images belonging to one of 16 classes).
+
+The abstract from the paper is the following:
+
+*Pre-training techniques have been verified successfully in a variety of NLP tasks in recent years. Despite the
+widespread use of pretraining models for NLP applications, they almost exclusively focus on text-level manipulation,
+while neglecting layout and style information that is vital for document image understanding. In this paper, we propose
+the LayoutLM to jointly model interactions between text and layout information across scanned document images, which is
+beneficial for a great number of real-world document image understanding tasks such as information extraction from
+scanned documents. Furthermore, we also leverage image features to incorporate words' visual information into LayoutLM.
+To the best of our knowledge, this is the first time that text and layout are jointly learned in a single framework for
+document-level pretraining. It achieves new state-of-the-art results in several downstream tasks, including form
+understanding (from 70.72 to 79.27), receipt understanding (from 94.02 to 95.24) and document image classification
+(from 93.07 to 94.42).*
+
+## Usage tips
+
+- In addition to *input_ids*, [`~transformers.LayoutLMModel.forward`] also expects the input `bbox`, which are
+ the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
+ as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1) format, where
+ (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the
+ position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on a 0-1000
+ scale. To normalize, you can use the following function:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+Here, `width` and `height` correspond to the width and height of the original document in which the token
+occurs. Those can be obtained using the Python Image Library (PIL) library for example, as follows:
+
+```python
+from PIL import Image
+
+# Document can be a png, jpg, etc. PDFs must be converted to images.
+image = Image.open(name_of_your_document).convert("RGB")
+
+width, height = image.size
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLM. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+
+- A blog post on [fine-tuning
+ LayoutLM for document-understanding using Keras & Hugging Face
+ Transformers](https://www.philschmid.de/fine-tuning-layoutlm-keras).
+
+- A blog post on how to [fine-tune LayoutLM for document-understanding using only Hugging Face Transformers](https://www.philschmid.de/fine-tuning-layoutlm).
+
+- A notebook on how to [fine-tune LayoutLM on the FUNSD dataset with image embeddings](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Add_image_embeddings_to_LayoutLM.ipynb).
+
+- See also: [Document question answering task guide](../tasks/document_question_answering)
+
+
+
+- A notebook on how to [fine-tune LayoutLM for sequence classification on the RVL-CDIP dataset](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb).
+- [Text classification task guide](../tasks/sequence_classification)
+
+
+
+- A notebook on how to [ fine-tune LayoutLM for token classification on the FUNSD dataset](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb).
+- [Token classification task guide](../tasks/token_classification)
+
+**Other resources**
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+
+🚀 Deploy
+
+- A blog post on how to [Deploy LayoutLM with Hugging Face Inference Endpoints](https://www.philschmid.de/inference-endpoints-layoutlm).
+
+## LayoutLMConfig
+
+[[autodoc]] LayoutLMConfig
+
+## LayoutLMTokenizer
+
+[[autodoc]] LayoutLMTokenizer
+
+## LayoutLMTokenizerFast
+
+[[autodoc]] LayoutLMTokenizerFast
+
+
+
+
+## LayoutLMModel
+
+[[autodoc]] LayoutLMModel
+
+## LayoutLMForMaskedLM
+
+[[autodoc]] LayoutLMForMaskedLM
+
+## LayoutLMForSequenceClassification
+
+[[autodoc]] LayoutLMForSequenceClassification
+
+## LayoutLMForTokenClassification
+
+[[autodoc]] LayoutLMForTokenClassification
+
+## LayoutLMForQuestionAnswering
+
+[[autodoc]] LayoutLMForQuestionAnswering
+
+
+
+
+## TFLayoutLMModel
+
+[[autodoc]] TFLayoutLMModel
+
+## TFLayoutLMForMaskedLM
+
+[[autodoc]] TFLayoutLMForMaskedLM
+
+## TFLayoutLMForSequenceClassification
+
+[[autodoc]] TFLayoutLMForSequenceClassification
+
+## TFLayoutLMForTokenClassification
+
+[[autodoc]] TFLayoutLMForTokenClassification
+
+## TFLayoutLMForQuestionAnswering
+
+[[autodoc]] TFLayoutLMForQuestionAnswering
+
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/layoutlmv2.md b/docs/transformers/docs/source/en/model_doc/layoutlmv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..af2068757192c30f65a79987ed70c4eebeb810e0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/layoutlmv2.md
@@ -0,0 +1,349 @@
+
+
+# LayoutLMV2
+
+
+
+
+
+## Overview
+
+The LayoutLMV2 model was proposed in [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu,
+Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou. LayoutLMV2 improves [LayoutLM](layoutlm) to obtain
+state-of-the-art results across several document image understanding benchmarks:
+
+- information extraction from scanned documents: the [FUNSD](https://guillaumejaume.github.io/FUNSD/) dataset (a
+ collection of 199 annotated forms comprising more than 30,000 words), the [CORD](https://github.com/clovaai/cord)
+ dataset (a collection of 800 receipts for training, 100 for validation and 100 for testing), the [SROIE](https://rrc.cvc.uab.es/?ch=13) dataset (a collection of 626 receipts for training and 347 receipts for testing)
+ and the [Kleister-NDA](https://github.com/applicaai/kleister-nda) dataset (a collection of non-disclosure
+ agreements from the EDGAR database, including 254 documents for training, 83 documents for validation, and 203
+ documents for testing).
+- document image classification: the [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/) dataset (a collection of
+ 400,000 images belonging to one of 16 classes).
+- document visual question answering: the [DocVQA](https://arxiv.org/abs/2007.00398) dataset (a collection of 50,000
+ questions defined on 12,000+ document images).
+
+The abstract from the paper is the following:
+
+*Pre-training of text and layout has proved effective in a variety of visually-rich document understanding tasks due to
+its effective model architecture and the advantage of large-scale unlabeled scanned/digital-born documents. In this
+paper, we present LayoutLMv2 by pre-training text, layout and image in a multi-modal framework, where new model
+architectures and pre-training tasks are leveraged. Specifically, LayoutLMv2 not only uses the existing masked
+visual-language modeling task but also the new text-image alignment and text-image matching tasks in the pre-training
+stage, where cross-modality interaction is better learned. Meanwhile, it also integrates a spatial-aware self-attention
+mechanism into the Transformer architecture, so that the model can fully understand the relative positional
+relationship among different text blocks. Experiment results show that LayoutLMv2 outperforms strong baselines and
+achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks,
+including FUNSD (0.7895 -> 0.8420), CORD (0.9493 -> 0.9601), SROIE (0.9524 -> 0.9781), Kleister-NDA (0.834 -> 0.852),
+RVL-CDIP (0.9443 -> 0.9564), and DocVQA (0.7295 -> 0.8672). The pre-trained LayoutLMv2 model is publicly available at
+this https URL.*
+
+LayoutLMv2 depends on `detectron2`, `torchvision` and `tesseract`. Run the
+following to install them:
+```bash
+python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
+python -m pip install torchvision tesseract
+```
+(If you are developing for LayoutLMv2, note that passing the doctests also requires the installation of these packages.)
+
+## Usage tips
+
+- The main difference between LayoutLMv1 and LayoutLMv2 is that the latter incorporates visual embeddings during
+ pre-training (while LayoutLMv1 only adds visual embeddings during fine-tuning).
+- LayoutLMv2 adds both a relative 1D attention bias as well as a spatial 2D attention bias to the attention scores in
+ the self-attention layers. Details can be found on page 5 of the [paper](https://arxiv.org/abs/2012.14740).
+- Demo notebooks on how to use the LayoutLMv2 model on RVL-CDIP, FUNSD, DocVQA, CORD can be found [here](https://github.com/NielsRogge/Transformers-Tutorials).
+- LayoutLMv2 uses Facebook AI's [Detectron2](https://github.com/facebookresearch/detectron2/) package for its visual
+ backbone. See [this link](https://detectron2.readthedocs.io/en/latest/tutorials/install.html) for installation
+ instructions.
+- In addition to `input_ids`, [`~LayoutLMv2Model.forward`] expects 2 additional inputs, namely
+ `image` and `bbox`. The `image` input corresponds to the original document image in which the text
+ tokens occur. The model expects each document image to be of size 224x224. This means that if you have a batch of
+ document images, `image` should be a tensor of shape (batch_size, 3, 224, 224). This can be either a
+ `torch.Tensor` or a `Detectron2.structures.ImageList`. You don't need to normalize the channels, as this is
+ done by the model. Important to note is that the visual backbone expects BGR channels instead of RGB, as all models
+ in Detectron2 are pre-trained using the BGR format. The `bbox` input are the bounding boxes (i.e. 2D-positions)
+ of the input text tokens. This is identical to [`LayoutLMModel`]. These can be obtained using an
+ external OCR engine such as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python
+ wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1)
+ format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1)
+ represents the position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on
+ a 0-1000 scale. To normalize, you can use the following function:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+Here, `width` and `height` correspond to the width and height of the original document in which the token
+occurs (before resizing the image). Those can be obtained using the Python Image Library (PIL) library for example, as
+follows:
+
+```python
+from PIL import Image
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+)
+
+width, height = image.size
+```
+
+However, this model includes a brand new [`~transformers.LayoutLMv2Processor`] which can be used to directly
+prepare data for the model (including applying OCR under the hood). More information can be found in the "Usage"
+section below.
+
+- Internally, [`~transformers.LayoutLMv2Model`] will send the `image` input through its visual backbone to
+ obtain a lower-resolution feature map, whose shape is equal to the `image_feature_pool_shape` attribute of
+ [`~transformers.LayoutLMv2Config`]. This feature map is then flattened to obtain a sequence of image tokens. As
+ the size of the feature map is 7x7 by default, one obtains 49 image tokens. These are then concatenated with the text
+ tokens, and send through the Transformer encoder. This means that the last hidden states of the model will have a
+ length of 512 + 49 = 561, if you pad the text tokens up to the max length. More generally, the last hidden states
+ will have a shape of `seq_length` + `image_feature_pool_shape[0]` *
+ `config.image_feature_pool_shape[1]`.
+- When calling [`~transformers.LayoutLMv2Model.from_pretrained`], a warning will be printed with a long list of
+ parameter names that are not initialized. This is not a problem, as these parameters are batch normalization
+ statistics, which are going to have values when fine-tuning on a custom dataset.
+- If you want to train the model in a distributed environment, make sure to call [`synchronize_batch_norm`] on the
+ model in order to properly synchronize the batch normalization layers of the visual backbone.
+
+In addition, there's LayoutXLM, which is a multilingual version of LayoutLMv2. More information can be found on
+[LayoutXLM's documentation page](layoutxlm).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv2. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+- A notebook on how to [finetune LayoutLMv2 for text-classification on RVL-CDIP dataset](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/RVL-CDIP/Fine_tuning_LayoutLMv2ForSequenceClassification_on_RVL_CDIP.ipynb).
+- See also: [Text classification task guide](../tasks/sequence_classification)
+
+
+
+- A notebook on how to [finetune LayoutLMv2 for question-answering on DocVQA dataset](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/DocVQA/Fine_tuning_LayoutLMv2ForQuestionAnswering_on_DocVQA.ipynb).
+- See also: [Question answering task guide](../tasks/question_answering)
+- See also: [Document question answering task guide](../tasks/document_question_answering)
+
+
+
+
+- A notebook on how to [finetune LayoutLMv2 for token-classification on CORD dataset](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/CORD/Fine_tuning_LayoutLMv2ForTokenClassification_on_CORD.ipynb).
+- A notebook on how to [finetune LayoutLMv2 for token-classification on FUNSD dataset](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/FUNSD/Fine_tuning_LayoutLMv2ForTokenClassification_on_FUNSD_using_HuggingFace_Trainer.ipynb).
+- See also: [Token classification task guide](../tasks/token_classification)
+
+## Usage: LayoutLMv2Processor
+
+The easiest way to prepare data for the model is to use [`LayoutLMv2Processor`], which internally
+combines a image processor ([`LayoutLMv2ImageProcessor`]) and a tokenizer
+([`LayoutLMv2Tokenizer`] or [`LayoutLMv2TokenizerFast`]). The image processor
+handles the image modality, while the tokenizer handles the text modality. A processor combines both, which is ideal
+for a multi-modal model like LayoutLMv2. Note that you can still use both separately, if you only want to handle one
+modality.
+
+```python
+from transformers import LayoutLMv2ImageProcessor, LayoutLMv2TokenizerFast, LayoutLMv2Processor
+
+image_processor = LayoutLMv2ImageProcessor() # apply_ocr is set to True by default
+tokenizer = LayoutLMv2TokenizerFast.from_pretrained("microsoft/layoutlmv2-base-uncased")
+processor = LayoutLMv2Processor(image_processor, tokenizer)
+```
+
+In short, one can provide a document image (and possibly additional data) to [`LayoutLMv2Processor`],
+and it will create the inputs expected by the model. Internally, the processor first uses
+[`LayoutLMv2ImageProcessor`] to apply OCR on the image to get a list of words and normalized
+bounding boxes, as well to resize the image to a given size in order to get the `image` input. The words and
+normalized bounding boxes are then provided to [`LayoutLMv2Tokenizer`] or
+[`LayoutLMv2TokenizerFast`], which converts them to token-level `input_ids`,
+`attention_mask`, `token_type_ids`, `bbox`. Optionally, one can provide word labels to the processor,
+which are turned into token-level `labels`.
+
+[`LayoutLMv2Processor`] uses [PyTesseract](https://pypi.org/project/pytesseract/), a Python
+wrapper around Google's Tesseract OCR engine, under the hood. Note that you can still use your own OCR engine of
+choice, and provide the words and normalized boxes yourself. This requires initializing
+[`LayoutLMv2ImageProcessor`] with `apply_ocr` set to `False`.
+
+In total, there are 5 use cases that are supported by the processor. Below, we list them all. Note that each of these
+use cases work for both batched and non-batched inputs (we illustrate them for non-batched inputs).
+
+**Use case 1: document image classification (training, inference) + token classification (inference), apply_ocr =
+True**
+
+This is the simplest case, in which the processor (actually the image processor) will perform OCR on the image to get
+the words and normalized bounding boxes.
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+encoding = processor(
+ image, return_tensors="pt"
+) # you can also add all tokenizer parameters here such as padding, truncation
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
+```
+
+**Use case 2: document image classification (training, inference) + token classification (inference), apply_ocr=False**
+
+In case one wants to do OCR themselves, one can initialize the image processor with `apply_ocr` set to
+`False`. In that case, one should provide the words and corresponding (normalized) bounding boxes themselves to
+the processor.
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+words = ["hello", "world"]
+boxes = [[1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
+encoding = processor(image, words, boxes=boxes, return_tensors="pt")
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
+```
+
+**Use case 3: token classification (training), apply_ocr=False**
+
+For token classification tasks (such as FUNSD, CORD, SROIE, Kleister-NDA), one can also provide the corresponding word
+labels in order to train a model. The processor will then convert these into token-level `labels`. By default, it
+will only label the first wordpiece of a word, and label the remaining wordpieces with -100, which is the
+`ignore_index` of PyTorch's CrossEntropyLoss. In case you want all wordpieces of a word to be labeled, you can
+initialize the tokenizer with `only_label_first_subword` set to `False`.
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+words = ["hello", "world"]
+boxes = [[1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
+word_labels = [1, 2]
+encoding = processor(image, words, boxes=boxes, word_labels=word_labels, return_tensors="pt")
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'labels', 'image'])
+```
+
+**Use case 4: visual question answering (inference), apply_ocr=True**
+
+For visual question answering tasks (such as DocVQA), you can provide a question to the processor. By default, the
+processor will apply OCR on the image, and create [CLS] question tokens [SEP] word tokens [SEP].
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+question = "What's his name?"
+encoding = processor(image, question, return_tensors="pt")
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
+```
+
+**Use case 5: visual question answering (inference), apply_ocr=False**
+
+For visual question answering tasks (such as DocVQA), you can provide a question to the processor. If you want to
+perform OCR yourself, you can provide your own words and (normalized) bounding boxes to the processor.
+
+```python
+from transformers import LayoutLMv2Processor
+from PIL import Image
+
+processor = LayoutLMv2Processor.from_pretrained("microsoft/layoutlmv2-base-uncased", revision="no_ocr")
+
+image = Image.open(
+ "name_of_your_document - can be a png, jpg, etc. of your documents (PDFs must be converted to images)."
+).convert("RGB")
+question = "What's his name?"
+words = ["hello", "world"]
+boxes = [[1, 2, 3, 4], [5, 6, 7, 8]] # make sure to normalize your bounding boxes
+encoding = processor(image, question, words, boxes=boxes, return_tensors="pt")
+print(encoding.keys())
+# dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'bbox', 'image'])
+```
+
+## LayoutLMv2Config
+
+[[autodoc]] LayoutLMv2Config
+
+## LayoutLMv2FeatureExtractor
+
+[[autodoc]] LayoutLMv2FeatureExtractor
+ - __call__
+
+## LayoutLMv2ImageProcessor
+
+[[autodoc]] LayoutLMv2ImageProcessor
+ - preprocess
+
+## LayoutLMv2ImageProcessorFast
+
+[[autodoc]] LayoutLMv2ImageProcessorFast
+ - preprocess
+
+## LayoutLMv2Tokenizer
+
+[[autodoc]] LayoutLMv2Tokenizer
+ - __call__
+ - save_vocabulary
+
+## LayoutLMv2TokenizerFast
+
+[[autodoc]] LayoutLMv2TokenizerFast
+ - __call__
+
+## LayoutLMv2Processor
+
+[[autodoc]] LayoutLMv2Processor
+ - __call__
+
+## LayoutLMv2Model
+
+[[autodoc]] LayoutLMv2Model
+ - forward
+
+## LayoutLMv2ForSequenceClassification
+
+[[autodoc]] LayoutLMv2ForSequenceClassification
+
+## LayoutLMv2ForTokenClassification
+
+[[autodoc]] LayoutLMv2ForTokenClassification
+
+## LayoutLMv2ForQuestionAnswering
+
+[[autodoc]] LayoutLMv2ForQuestionAnswering
diff --git a/docs/transformers/docs/source/en/model_doc/layoutlmv3.md b/docs/transformers/docs/source/en/model_doc/layoutlmv3.md
new file mode 100644
index 0000000000000000000000000000000000000000..07200be3619c35676831b3438803b8fff7ca76b3
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/layoutlmv3.md
@@ -0,0 +1,159 @@
+
+
+# LayoutLMv3
+
+## Overview
+
+The LayoutLMv3 model was proposed in [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+LayoutLMv3 simplifies [LayoutLMv2](layoutlmv2) by using patch embeddings (as in [ViT](vit)) instead of leveraging a CNN backbone, and pre-trains the model on 3 objectives: masked language modeling (MLM), masked image modeling (MIM)
+and word-patch alignment (WPA).
+
+The abstract from the paper is the following:
+
+*Self-supervised pre-training techniques have achieved remarkable progress in Document AI. Most multimodal pre-trained models use a masked language modeling objective to learn bidirectional representations on the text modality, but they differ in pre-training objectives for the image modality. This discrepancy adds difficulty to multimodal representation learning. In this paper, we propose LayoutLMv3 to pre-train multimodal Transformers for Document AI with unified text and image masking. Additionally, LayoutLMv3 is pre-trained with a word-patch alignment objective to learn cross-modal alignment by predicting whether the corresponding image patch of a text word is masked. The simple unified architecture and training objectives make LayoutLMv3 a general-purpose pre-trained model for both text-centric and image-centric Document AI tasks. Experimental results show that LayoutLMv3 achieves state-of-the-art performance not only in text-centric tasks, including form understanding, receipt understanding, and document visual question answering, but also in image-centric tasks such as document image classification and document layout analysis.*
+
+
+
+ LayoutLMv3 architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
+
+## Usage tips
+
+- In terms of data processing, LayoutLMv3 is identical to its predecessor [LayoutLMv2](layoutlmv2), except that:
+ - images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
+ - text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
+ Due to these differences in data preprocessing, one can use [`LayoutLMv3Processor`] which internally combines a [`LayoutLMv3ImageProcessor`] (for the image modality) and a [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (for the text modality) to prepare all data for the model.
+- Regarding usage of [`LayoutLMv3Processor`], we refer to the [usage guide](layoutlmv2#usage-layoutlmv2processor) of its predecessor.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv3. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+LayoutLMv3 is nearly identical to LayoutLMv2, so we've also included LayoutLMv2 resources you can adapt for LayoutLMv3 tasks. For these notebooks, take care to use [`LayoutLMv2Processor`] instead when preparing data for the model!
+
+
+
+- Demo notebooks for LayoutLMv3 can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv3).
+- Demo scripts can be found [here](https://github.com/huggingface/transformers-research-projects/tree/main/layoutlmv3).
+
+
+
+- [`LayoutLMv2ForSequenceClassification`] is supported by this [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/RVL-CDIP/Fine_tuning_LayoutLMv2ForSequenceClassification_on_RVL_CDIP.ipynb).
+- [Text classification task guide](../tasks/sequence_classification)
+
+
+
+- [`LayoutLMv3ForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers-research-projects/tree/main/layoutlmv3) and [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv3/Fine_tune_LayoutLMv3_on_FUNSD_(HuggingFace_Trainer).ipynb).
+- A [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/FUNSD/Inference_with_LayoutLMv2ForTokenClassification.ipynb) for how to perform inference with [`LayoutLMv2ForTokenClassification`] and a [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/FUNSD/True_inference_with_LayoutLMv2ForTokenClassification_%2B_Gradio_demo.ipynb) for how to perform inference when no labels are available with [`LayoutLMv2ForTokenClassification`].
+- A [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/FUNSD/Fine_tuning_LayoutLMv2ForTokenClassification_on_FUNSD_using_HuggingFace_Trainer.ipynb) for how to finetune [`LayoutLMv2ForTokenClassification`] with the 🤗 Trainer.
+- [Token classification task guide](../tasks/token_classification)
+
+
+
+- [`LayoutLMv2ForQuestionAnswering`] is supported by this [notebook](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/DocVQA/Fine_tuning_LayoutLMv2ForQuestionAnswering_on_DocVQA.ipynb).
+- [Question answering task guide](../tasks/question_answering)
+
+**Document question answering**
+- [Document question answering task guide](../tasks/document_question_answering)
+
+## LayoutLMv3Config
+
+[[autodoc]] LayoutLMv3Config
+
+## LayoutLMv3FeatureExtractor
+
+[[autodoc]] LayoutLMv3FeatureExtractor
+ - __call__
+
+## LayoutLMv3ImageProcessor
+
+[[autodoc]] LayoutLMv3ImageProcessor
+ - preprocess
+
+## LayoutLMv3ImageProcessorFast
+
+[[autodoc]] LayoutLMv3ImageProcessorFast
+ - preprocess
+
+## LayoutLMv3Tokenizer
+
+[[autodoc]] LayoutLMv3Tokenizer
+ - __call__
+ - save_vocabulary
+
+## LayoutLMv3TokenizerFast
+
+[[autodoc]] LayoutLMv3TokenizerFast
+ - __call__
+
+## LayoutLMv3Processor
+
+[[autodoc]] LayoutLMv3Processor
+ - __call__
+
+
+
+
+## LayoutLMv3Model
+
+[[autodoc]] LayoutLMv3Model
+ - forward
+
+## LayoutLMv3ForSequenceClassification
+
+[[autodoc]] LayoutLMv3ForSequenceClassification
+ - forward
+
+## LayoutLMv3ForTokenClassification
+
+[[autodoc]] LayoutLMv3ForTokenClassification
+ - forward
+
+## LayoutLMv3ForQuestionAnswering
+
+[[autodoc]] LayoutLMv3ForQuestionAnswering
+ - forward
+
+
+
+
+## TFLayoutLMv3Model
+
+[[autodoc]] TFLayoutLMv3Model
+ - call
+
+## TFLayoutLMv3ForSequenceClassification
+
+[[autodoc]] TFLayoutLMv3ForSequenceClassification
+ - call
+
+## TFLayoutLMv3ForTokenClassification
+
+[[autodoc]] TFLayoutLMv3ForTokenClassification
+ - call
+
+## TFLayoutLMv3ForQuestionAnswering
+
+[[autodoc]] TFLayoutLMv3ForQuestionAnswering
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/layoutxlm.md b/docs/transformers/docs/source/en/model_doc/layoutxlm.md
new file mode 100644
index 0000000000000000000000000000000000000000..96e0a4d4bf5134459a8a43e8980184566fc90155
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/layoutxlm.md
@@ -0,0 +1,89 @@
+
+
+# LayoutXLM
+
+
+
+
+
+## Overview
+
+LayoutXLM was proposed in [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha
+Zhang, Furu Wei. It's a multilingual extension of the [LayoutLMv2 model](https://arxiv.org/abs/2012.14740) trained
+on 53 languages.
+
+The abstract from the paper is the following:
+
+*Multimodal pre-training with text, layout, and image has achieved SOTA performance for visually-rich document
+understanding tasks recently, which demonstrates the great potential for joint learning across different modalities. In
+this paper, we present LayoutXLM, a multimodal pre-trained model for multilingual document understanding, which aims to
+bridge the language barriers for visually-rich document understanding. To accurately evaluate LayoutXLM, we also
+introduce a multilingual form understanding benchmark dataset named XFUN, which includes form understanding samples in
+7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese), and key-value pairs are manually labeled
+for each language. Experiment results show that the LayoutXLM model has significantly outperformed the existing SOTA
+cross-lingual pre-trained models on the XFUN dataset.*
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm).
+
+## Usage tips and examples
+
+One can directly plug in the weights of LayoutXLM into a LayoutLMv2 model, like so:
+
+```python
+from transformers import LayoutLMv2Model
+
+model = LayoutLMv2Model.from_pretrained("microsoft/layoutxlm-base")
+```
+
+Note that LayoutXLM has its own tokenizer, based on
+[`LayoutXLMTokenizer`]/[`LayoutXLMTokenizerFast`]. You can initialize it as
+follows:
+
+```python
+from transformers import LayoutXLMTokenizer
+
+tokenizer = LayoutXLMTokenizer.from_pretrained("microsoft/layoutxlm-base")
+```
+
+Similar to LayoutLMv2, you can use [`LayoutXLMProcessor`] (which internally applies
+[`LayoutLMv2ImageProcessor`] and
+[`LayoutXLMTokenizer`]/[`LayoutXLMTokenizerFast`] in sequence) to prepare all
+data for the model.
+
+
+
+As LayoutXLM's architecture is equivalent to that of LayoutLMv2, one can refer to [LayoutLMv2's documentation page](layoutlmv2) for all tips, code examples and notebooks.
+
+
+## LayoutXLMTokenizer
+
+[[autodoc]] LayoutXLMTokenizer
+ - __call__
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## LayoutXLMTokenizerFast
+
+[[autodoc]] LayoutXLMTokenizerFast
+ - __call__
+
+## LayoutXLMProcessor
+
+[[autodoc]] LayoutXLMProcessor
+ - __call__
diff --git a/docs/transformers/docs/source/en/model_doc/led.md b/docs/transformers/docs/source/en/model_doc/led.md
new file mode 100644
index 0000000000000000000000000000000000000000..729d5666d8a3d3be4e72c725267de4af22ffcca0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/led.md
@@ -0,0 +1,148 @@
+
+
+# LED
+
+
+
+
+
+
+## Overview
+
+The LED model was proposed in [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz
+Beltagy, Matthew E. Peters, Arman Cohan.
+
+The abstract from the paper is the following:
+
+*Transformer-based models are unable to process long sequences due to their self-attention operation, which scales
+quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention
+mechanism that scales linearly with sequence length, making it easy to process documents of thousands of tokens or
+longer. Longformer's attention mechanism is a drop-in replacement for the standard self-attention and combines a local
+windowed attention with a task motivated global attention. Following prior work on long-sequence transformers, we
+evaluate Longformer on character-level language modeling and achieve state-of-the-art results on text8 and enwik8. In
+contrast to most prior work, we also pretrain Longformer and finetune it on a variety of downstream tasks. Our
+pretrained Longformer consistently outperforms RoBERTa on long document tasks and sets new state-of-the-art results on
+WikiHop and TriviaQA. We finally introduce the Longformer-Encoder-Decoder (LED), a Longformer variant for supporting
+long document generative sequence-to-sequence tasks, and demonstrate its effectiveness on the arXiv summarization
+dataset.*
+
+## Usage tips
+
+- [`LEDForConditionalGeneration`] is an extension of
+ [`BartForConditionalGeneration`] exchanging the traditional *self-attention* layer with
+ *Longformer*'s *chunked self-attention* layer. [`LEDTokenizer`] is an alias of
+ [`BartTokenizer`].
+- LED works very well on long-range *sequence-to-sequence* tasks where the `input_ids` largely exceed a length of
+ 1024 tokens.
+- LED pads the `input_ids` to be a multiple of `config.attention_window` if required. Therefore a small speed-up is
+ gained, when [`LEDTokenizer`] is used with the `pad_to_multiple_of` argument.
+- LED makes use of *global attention* by means of the `global_attention_mask` (see
+ [`LongformerModel`]). For summarization, it is advised to put *global attention* only on the first
+ `` token. For question answering, it is advised to put *global attention* on all tokens of the question.
+- To fine-tune LED on all 16384, *gradient checkpointing* can be enabled in case training leads to out-of-memory (OOM)
+ errors. This can be done by executing `model.gradient_checkpointing_enable()`.
+ Moreover, the `use_cache=False`
+ flag can be used to disable the caching mechanism to save memory.
+- LED is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
+
+## Resources
+
+- [A notebook showing how to evaluate LED](https://colab.research.google.com/drive/12INTTR6n64TzS4RrXZxMSXfrOd9Xzamo?usp=sharing).
+- [A notebook showing how to fine-tune LED](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing).
+- [Text classification task guide](../tasks/sequence_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## LEDConfig
+
+[[autodoc]] LEDConfig
+
+## LEDTokenizer
+
+[[autodoc]] LEDTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## LEDTokenizerFast
+
+[[autodoc]] LEDTokenizerFast
+
+## LED specific outputs
+
+[[autodoc]] models.led.modeling_led.LEDEncoderBaseModelOutput
+
+[[autodoc]] models.led.modeling_led.LEDSeq2SeqModelOutput
+
+[[autodoc]] models.led.modeling_led.LEDSeq2SeqLMOutput
+
+[[autodoc]] models.led.modeling_led.LEDSeq2SeqSequenceClassifierOutput
+
+[[autodoc]] models.led.modeling_led.LEDSeq2SeqQuestionAnsweringModelOutput
+
+[[autodoc]] models.led.modeling_tf_led.TFLEDEncoderBaseModelOutput
+
+[[autodoc]] models.led.modeling_tf_led.TFLEDSeq2SeqModelOutput
+
+[[autodoc]] models.led.modeling_tf_led.TFLEDSeq2SeqLMOutput
+
+
+
+
+## LEDModel
+
+[[autodoc]] LEDModel
+ - forward
+
+## LEDForConditionalGeneration
+
+[[autodoc]] LEDForConditionalGeneration
+ - forward
+
+## LEDForSequenceClassification
+
+[[autodoc]] LEDForSequenceClassification
+ - forward
+
+## LEDForQuestionAnswering
+
+[[autodoc]] LEDForQuestionAnswering
+ - forward
+
+
+
+
+## TFLEDModel
+
+[[autodoc]] TFLEDModel
+ - call
+
+## TFLEDForConditionalGeneration
+
+[[autodoc]] TFLEDForConditionalGeneration
+ - call
+
+
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/levit.md b/docs/transformers/docs/source/en/model_doc/levit.md
new file mode 100644
index 0000000000000000000000000000000000000000..f794f7902f02349bfaf95c8b5c9f39e09e0389e2
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/levit.md
@@ -0,0 +1,115 @@
+
+
+# LeViT
+
+
+
+
+
+## Overview
+
+The LeViT model was proposed in [LeViT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze. LeViT improves the [Vision Transformer (ViT)](vit) in performance and efficiency by a few architectural differences such as activation maps with decreasing resolutions in Transformers and the introduction of an attention bias to integrate positional information.
+
+The abstract from the paper is the following:
+
+*We design a family of image classification architectures that optimize the trade-off between accuracy
+and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures,
+which are competitive on highly parallel processing hardware. We revisit principles from the extensive
+literature on convolutional neural networks to apply them to transformers, in particular activation maps
+with decreasing resolutions. We also introduce the attention bias, a new way to integrate positional information
+in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification.
+We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of
+application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable
+to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect
+to the speed/accuracy tradeoff. For example, at 80% ImageNet top-1 accuracy, LeViT is 5 times faster than EfficientNet on CPU. *
+
+
+
+ LeViT Architecture. Taken from the original paper.
+
+This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
+
+## Usage tips
+
+- Compared to ViT, LeViT models use an additional distillation head to effectively learn from a teacher (which, in the LeViT paper, is a ResNet like-model). The distillation head is learned through backpropagation under supervision of a ResNet like-model. They also draw inspiration from convolution neural networks to use activation maps with decreasing resolutions to increase the efficiency.
+- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
+ of the final hidden state and not using the distillation head, or (2) by placing both a prediction head and distillation
+ head on top of the final hidden state. In that case, the prediction head is trained using regular cross-entropy between
+ the prediction of the head and the ground-truth label, while the distillation prediction head is trained using hard distillation
+ (cross-entropy between the prediction of the distillation head and the label predicted by the teacher). At inference time,
+ one takes the average prediction between both heads as final prediction. (2) is also called "fine-tuning with distillation",
+ because one relies on a teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds
+ to [`LevitForImageClassification`] and (2) corresponds to [`LevitForImageClassificationWithTeacher`].
+- All released checkpoints were pre-trained and fine-tuned on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)
+ (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). only. No external data was used. This is in
+ contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for
+ pre-training.
+- The authors of LeViT released 5 trained LeViT models, which you can directly plug into [`LevitModel`] or [`LevitForImageClassification`].
+ Techniques like data augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
+ (while only using ImageNet-1k for pre-training). The 5 variants available are (all trained on images of size 224x224):
+ *facebook/levit-128S*, *facebook/levit-128*, *facebook/levit-192*, *facebook/levit-256* and
+ *facebook/levit-384*. Note that one should use [`LevitImageProcessor`] in order to
+ prepare images for the model.
+- [`LevitForImageClassificationWithTeacher`] currently supports only inference and not training or fine-tuning.
+- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
+ (you can just replace [`ViTFeatureExtractor`] by [`LevitImageProcessor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LeViT.
+
+
+
+- [`LevitForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## LevitConfig
+
+[[autodoc]] LevitConfig
+
+## LevitFeatureExtractor
+
+[[autodoc]] LevitFeatureExtractor
+ - __call__
+
+## LevitImageProcessor
+
+ [[autodoc]] LevitImageProcessor
+ - preprocess
+
+## LevitImageProcessorFast
+
+ [[autodoc]] LevitImageProcessorFast
+ - preprocess
+
+## LevitModel
+
+[[autodoc]] LevitModel
+ - forward
+
+## LevitForImageClassification
+
+[[autodoc]] LevitForImageClassification
+ - forward
+
+## LevitForImageClassificationWithTeacher
+
+[[autodoc]] LevitForImageClassificationWithTeacher
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/lilt.md b/docs/transformers/docs/source/en/model_doc/lilt.md
new file mode 100644
index 0000000000000000000000000000000000000000..2474d854e030538724837e596d87e3e439a76c44
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/lilt.md
@@ -0,0 +1,92 @@
+
+
+# LiLT
+
+
+
+
+
+## Overview
+
+The LiLT model was proposed in [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+LiLT allows to combine any pre-trained RoBERTa text encoder with a lightweight Layout Transformer, to enable [LayoutLM](layoutlm)-like document understanding for many
+languages.
+
+The abstract from the paper is the following:
+
+*Structured document understanding has attracted considerable attention and made significant progress recently, owing to its crucial role in intelligent document processing. However, most existing related models can only deal with the document data of specific language(s) (typically English) included in the pre-training collection, which is extremely limited. To address this issue, we propose a simple yet effective Language-independent Layout Transformer (LiLT) for structured document understanding. LiLT can be pre-trained on the structured documents of a single language and then directly fine-tuned on other languages with the corresponding off-the-shelf monolingual/multilingual pre-trained textual models. Experimental results on eight languages have shown that LiLT can achieve competitive or even superior performance on diverse widely-used downstream benchmarks, which enables language-independent benefit from the pre-training of document layout structure.*
+
+
+
+ LiLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/jpwang/lilt).
+
+## Usage tips
+
+- To combine the Language-Independent Layout Transformer with a new RoBERTa checkpoint from the [hub](https://huggingface.co/models?search=roberta), refer to [this guide](https://github.com/jpWang/LiLT#or-generate-your-own-checkpoint-optional).
+The script will result in `config.json` and `pytorch_model.bin` files being stored locally. After doing this, one can do the following (assuming you're logged in with your HuggingFace account):
+
+```python
+from transformers import LiltModel
+
+model = LiltModel.from_pretrained("path_to_your_files")
+model.push_to_hub("name_of_repo_on_the_hub")
+```
+
+- When preparing data for the model, make sure to use the token vocabulary that corresponds to the RoBERTa checkpoint you combined with the Layout Transformer.
+- As [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) uses the same vocabulary as [LayoutLMv3](layoutlmv3), one can use [`LayoutLMv3TokenizerFast`] to prepare data for the model.
+The same is true for [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-infoxlm-base): one can use [`LayoutXLMTokenizerFast`] for that model.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LiLT.
+
+- Demo notebooks for LiLT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT).
+
+**Documentation resources**
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## LiltConfig
+
+[[autodoc]] LiltConfig
+
+## LiltModel
+
+[[autodoc]] LiltModel
+ - forward
+
+## LiltForSequenceClassification
+
+[[autodoc]] LiltForSequenceClassification
+ - forward
+
+## LiltForTokenClassification
+
+[[autodoc]] LiltForTokenClassification
+ - forward
+
+## LiltForQuestionAnswering
+
+[[autodoc]] LiltForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/llama.md b/docs/transformers/docs/source/en/model_doc/llama.md
new file mode 100644
index 0000000000000000000000000000000000000000..7dc06608963a3ec3a4aa42bd6ce94b9f1fc164ad
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/llama.md
@@ -0,0 +1,181 @@
+
+
+
+
+
+
+
+
+
+
+
+# Llama
+
+[Llama](https://huggingface.co/papers/2302.13971) is a family of large language models ranging from 7B to 65B parameters. These models are focused on efficient inference (important for serving language models) by training a smaller model on more tokens rather than training a larger model on fewer tokens. The Llama model is based on the GPT architecture, but it uses pre-normalization to improve training stability, replaces ReLU with SwiGLU to improve performance, and replaces absolute positional embeddings with rotary positional embeddings (RoPE) to better handle longer sequence lengths.
+
+You can find all the original Llama checkpoints under the [Huggy Llama](https://huggingface.co/huggyllama) organization.
+
+> [!TIP]
+> Click on the Llama models in the right sidebar for more examples of how to apply Llama to different language tasks.
+
+The example below demonstrates how to generate text with [`Pipeline`] or the [`AutoModel`], and from the command line.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="text-generation",
+ model="huggyllama/llama-7b",
+ torch_dtype=torch.float16,
+ device=0
+)
+pipeline("Plants create energy through a process known as")
+```
+
+
+
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained(
+ "huggyllama/llama-7b",
+)
+model = AutoModelForCausalLM.from_pretrained(
+ "huggyllama/llama-7b",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+input_ids = tokenizer("Plants create energy through a process known as", return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+
+
+
+```bash
+echo -e "Plants create energy through a process known as" | transformers-cli run --task text-generation --model huggyllama/llama-7b --device 0
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [torchao](../quantization/torchao) to only quantize the weights to int4.
+
+```py
+# pip install torchao
+import torch
+from transformers import TorchAoConfig, AutoModelForCausalLM, AutoTokenizer
+
+quantization_config = TorchAoConfig("int4_weight_only", group_size=128)
+model = AutoModelForCausalLM.from_pretrained(
+ "huggyllama/llama-30b",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ quantization_config=quantization_config
+)
+
+tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-30b")
+input_ids = tokenizer("Plants create energy through a process known as", return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+Use the [AttentionMaskVisualizer](https://github.com/huggingface/transformers/blob/beb9b5b02246b9b7ee81ddf938f93f44cfeaad19/src/transformers/utils/attention_visualizer.py#L139) to better understand what tokens the model can and cannot attend to.
+
+```py
+from transformers.utils.attention_visualizer import AttentionMaskVisualizer
+
+visualizer = AttentionMaskVisualizer("huggyllama/llama-7b")
+visualizer("Plants create energy through a process known as")
+```
+
+
+
+
+
+## Notes
+
+- The tokenizer is a byte-pair encoding model based on [SentencePiece](https://github.com/google/sentencepiece). During decoding, if the first token is the start of the word (for example, "Banana"), the tokenizer doesn't prepend the prefix space to the string.
+
+## LlamaConfig
+
+[[autodoc]] LlamaConfig
+
+## LlamaTokenizer
+
+[[autodoc]] LlamaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## LlamaTokenizerFast
+
+[[autodoc]] LlamaTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - update_post_processor
+ - save_vocabulary
+
+## LlamaModel
+
+[[autodoc]] LlamaModel
+ - forward
+
+## LlamaForCausalLM
+
+[[autodoc]] LlamaForCausalLM
+ - forward
+
+## LlamaForSequenceClassification
+
+[[autodoc]] LlamaForSequenceClassification
+ - forward
+
+## LlamaForQuestionAnswering
+
+[[autodoc]] LlamaForQuestionAnswering
+ - forward
+
+## LlamaForTokenClassification
+
+[[autodoc]] LlamaForTokenClassification
+ - forward
+
+## FlaxLlamaModel
+
+[[autodoc]] FlaxLlamaModel
+ - __call__
+
+## FlaxLlamaForCausalLM
+
+[[autodoc]] FlaxLlamaForCausalLM
+ - __call__
diff --git a/docs/transformers/docs/source/en/model_doc/llama2.md b/docs/transformers/docs/source/en/model_doc/llama2.md
new file mode 100644
index 0000000000000000000000000000000000000000..ec981890b28414dbf85b9a07aade07b5fa4667ea
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/llama2.md
@@ -0,0 +1,178 @@
+
+
+
+
+
+
+
+
+
+# Llama 2
+
+[Llama 2](https://huggingface.co/papers/2307.09288) is a family of large language models, Llama 2 and Llama 2-Chat, available in 7B, 13B, and 70B parameters. The Llama 2 model mostly keeps the same architecture as [Llama](./llama), but it is pretrained on more tokens, doubles the context length, and uses grouped-query attention (GQA) in the 70B model to improve inference.
+
+Llama 2-Chat is trained with supervised fine-tuning (SFT), and reinforcement learning with human feedback (RLHF) - rejection sampling and proximal policy optimization (PPO) - is applied to the fine-tuned model to align the chat model with human preferences.
+
+You can find all the original Llama 2 checkpoints under the [Llama 2 Family](https://huggingface.co/collections/meta-llama/llama-2-family-661da1f90a9d678b6f55773b) collection.
+
+> [!TIP]
+> Click on the Llama 2 models in the right sidebar for more examples of how to apply Llama to different language tasks.
+
+The example below demonstrates how to generate text with [`Pipeline`], [`AutoModel`], and how to chat with Llama 2-Chat from the command line.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="text-generation",
+ model="meta-llama/Llama-2-7b-hf",
+ torch_dtype=torch.float16,
+ device=0
+)
+pipeline("Plants create energy through a process known as")
+```
+
+
+
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained(
+ "meta-llama/Llama-2-7b-hf",
+)
+model = AutoModelForCausalLM.from_pretrained(
+ "meta-llama/Llama-2-7b-hf",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+input_ids = tokenizer("Plants create energy through a process known as", return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+
+
+
+```bash
+transformers-cli chat --model_name_or_path meta-llama/Llama-2-7b-chat-hf --torch_dtype auto --attn_implementation flash_attention_2
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [torchao](../quantization/torchao) to only quantize the weights to int4.
+
+```py
+# pip install torchao
+import torch
+from transformers import TorchAoConfig, AutoModelForCausalLM, AutoTokenizer
+
+quantization_config = TorchAoConfig("int4_weight_only", group_size=128)
+model = AutoModelForCausalLM.from_pretrained(
+ "meta-llama/Llama-2-13b-hf",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ quantization_config=quantization_config
+)
+
+tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-13b-hf")
+input_ids = tokenizer("Plants create energy through a process known as", return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+Use the [AttentionMaskVisualizer](https://github.com/huggingface/transformers/blob/beb9b5b02246b9b7ee81ddf938f93f44cfeaad19/src/transformers/utils/attention_visualizer.py#L139) to better understand what tokens the model can and cannot attend to.
+
+```py
+from transformers.utils.attention_visualizer import AttentionMaskVisualizer
+
+visualizer = AttentionMaskVisualizer("meta-llama/Llama-2-7b-hf")
+visualizer("Plants create energy through a process known as")
+```
+
+
+
+
+
+## Notes
+
+- Setting `config.pretraining_tp` to a value besides `1` activates a more accurate but slower computation of the linear layers. This matches the original logits better.
+- The original model uses `pad_id = -1` to indicate a padding token. The Transformers implementation requires adding a padding token and resizing the token embedding accordingly.
+
+ ```py
+ tokenizer.add_special_tokens({"pad_token":""})
+ # update model config with padding token
+ model.config.pad_token_id
+ ```
+- It is recommended to initialize the `embed_tokens` layer with the following code to ensure encoding the padding token outputs zeros.
+
+ ```py
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.config.padding_idx)
+ ```
+- The tokenizer is a byte-pair encoding model based on [SentencePiece](https://github.com/google/sentencepiece). During decoding, if the first token is the start of the word (for example, "Banana"), the tokenizer doesn't prepend the prefix space to the string.
+- Don't use the `torch_dtype` parameter in [`~AutoModel.from_pretrained`] if you're using FlashAttention-2 because it only supports fp16 or bf16. You should use [Automatic Mixed Precision](https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html), set fp16 or bf16 to `True` if using [`Trainer`], or use [torch.autocast](https://pytorch.org/docs/stable/amp.html#torch.autocast).
+
+## LlamaConfig
+
+[[autodoc]] LlamaConfig
+
+
+## LlamaTokenizer
+
+[[autodoc]] LlamaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## LlamaTokenizerFast
+
+[[autodoc]] LlamaTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - update_post_processor
+ - save_vocabulary
+
+## LlamaModel
+
+[[autodoc]] LlamaModel
+ - forward
+
+
+## LlamaForCausalLM
+
+[[autodoc]] LlamaForCausalLM
+ - forward
+
+## LlamaForSequenceClassification
+
+[[autodoc]] LlamaForSequenceClassification
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/llama3.md b/docs/transformers/docs/source/en/model_doc/llama3.md
new file mode 100644
index 0000000000000000000000000000000000000000..0bb5e8160c909e9b1a5e9c99647a65eda2eacc9e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/llama3.md
@@ -0,0 +1,88 @@
+
+
+# Llama3
+
+
+
+
+
+
+```py3
+import transformers
+import torch
+
+model_id = "meta-llama/Meta-Llama-3-8B"
+
+pipeline = transformers.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto")
+pipeline("Hey how are you doing today?")
+```
+
+## Overview
+
+The Llama3 model was proposed in [Introducing Meta Llama 3: The most capable openly available LLM to date](https://ai.meta.com/blog/meta-llama-3/) by the meta AI team.
+
+The abstract from the blogpost is the following:
+
+*Today, we’re excited to share the first two models of the next generation of Llama, Meta Llama 3, available for broad use. This release features pretrained and instruction-fine-tuned language models with 8B and 70B parameters that can support a broad range of use cases. This next generation of Llama demonstrates state-of-the-art performance on a wide range of industry benchmarks and offers new capabilities, including improved reasoning. We believe these are the best open source models of their class, period. In support of our longstanding open approach, we’re putting Llama 3 in the hands of the community. We want to kickstart the next wave of innovation in AI across the stack—from applications to developer tools to evals to inference optimizations and more. We can’t wait to see what you build and look forward to your feedback.*
+
+Checkout all Llama3 model checkpoints [here](https://huggingface.co/models?search=llama3).
+The original code of the authors can be found [here](https://github.com/meta-llama/llama3).
+
+## Usage tips
+
+
+
+The `Llama3` models were trained using `bfloat16`, but the original inference uses `float16`. The checkpoints uploaded on the Hub use `torch_dtype = 'float16'`, which will be
+used by the `AutoModel` API to cast the checkpoints from `torch.float32` to `torch.float16`.
+
+The `dtype` of the online weights is mostly irrelevant unless you are using `torch_dtype="auto"` when initializing a model using `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`. The reason is that the model will first be downloaded ( using the `dtype` of the checkpoints online), then it will be casted to the default `dtype` of `torch` (becomes `torch.float32`), and finally, if there is a `torch_dtype` provided in the config, it will be used.
+
+Training the model in `float16` is not recommended and is known to produce `nan`; as such, the model should be trained in `bfloat16`.
+
+
+
+Tips:
+
+- Weights for the Llama3 models can be obtained by filling out [this form](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
+- The architecture is exactly the same as Llama2.
+- The tokenizer is a BPE model based on [tiktoken](https://github.com/openai/tiktoken) (vs the one based on sentencepiece implementation for Llama2). The main difference that it ignores BPE merge rules when an input token is part of the vocab. This means that if no merge exist to produce `"hugging"`, instead of having the smallest units, like `["hug","ging"] form 2 tokens, if `"hugging"` is part of the vocab, it will be automatically returned as a token.
+- The original model uses `pad_id = -1` which means that there is no padding token. We can't have the same logic, make sure to add a padding token using `tokenizer.add_special_tokens({"pad_token":""})` and resize the token embedding accordingly. You should also set the `model.config.pad_token_id`. The `embed_tokens` layer of the model is initialized with `self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.config.padding_idx)`, which makes sure that encoding the padding token will output zeros, so passing it when initializing is recommended.
+- The original checkpoint can be converted using the [conversion script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py). The script can be called with the following (example) command:
+
+ ```bash
+ python src/transformers/models/llama/convert_llama_weights_to_hf.py \
+ --input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path --llama_version 3
+ ```
+
+- After conversion, the model and tokenizer can be loaded via:
+
+ ```python
+ from transformers import AutoModelForCausalLM, AutoTokenizer
+
+ tokenizer = AutoTokenizer.from_pretrained("/output/path")
+ model = AutoModelForCausalLM.from_pretrained("/output/path")
+ ```
+
+ Note that executing the script requires enough CPU RAM to host the whole model in float16 precision (even if the biggest versions
+ come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM). For the 75B model, it's thus 145GB of RAM needed.
+
+- When using Flash Attention 2 via `attn_implementation="flash_attention_2"`, don't pass `torch_dtype` to the `from_pretrained` class method and use Automatic Mixed-Precision training. When using `Trainer`, it is simply specifying either `fp16` or `bf16` to `True`. Otherwise, make sure you are using `torch.autocast`. This is required because the Flash Attention only support `fp16` and `bf16` data type.
+
+## Resources
+
+A ton of cool resources are already available on the documentation page of [Llama2](./llama2), inviting contributors to add new resources curated for Llama3 here! 🤗
diff --git a/docs/transformers/docs/source/en/model_doc/llama4.md b/docs/transformers/docs/source/en/model_doc/llama4.md
new file mode 100644
index 0000000000000000000000000000000000000000..8e2cd3a2786f7ad1bd8df00c436edda87427d25a
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/llama4.md
@@ -0,0 +1,442 @@
+
+
+# Llama4
+
+
+
+
+
+
+
+
+
+Llama 4, developed by Meta, introduces a new auto-regressive Mixture-of-Experts (MoE) architecture.
+This generation includes two models:
+- The highly capable Llama 4 Maverick with 17B active parameters out of ~400B total, with 128 experts.
+- The efficient Llama 4 Scout also has 17B active parameters out of ~109B total, using just 16 experts.
+-
+Both models leverage early fusion for native multimodality, enabling them to process text and image inputs.
+Maverick and Scout are both trained on up to 40 trillion tokens on data encompassing 200 languages
+(with specific fine-tuning support for 12 languages including Arabic, Spanish, German, and Hindi).
+
+For deployment, Llama 4 Scout is designed for accessibility, fitting on a single server-grade GPU via
+on-the-fly 4-bit or 8-bitint4 quantization, while Maverick is available in BF16 and FP8 formats.
+These models are released under the custom Llama 4 Community License Agreement, available on the model repositories.
+
+You can find all the original Llama checkpoints under the [meta-llama](https://huggingface.co/meta-llama) organization.
+
+> [!TIP]
+> The Llama 4 family of models comes in two flavors: 109B, and 402B parameters. Both of these flavors are extremely
+> large and won't fit on your run-of-the-mill device. See below for some examples to reduce the memory usage of the
+> model.
+>
+> For the download to be faster and more resilient, we recommend installing the `hf_xet` dependency as followed:
+> `pip install transformers[hf_xet]`
+
+The examples below demonstrates how to generate with [`Pipeline`] or the [`AutoModel`]. We additionally add an example
+showcasing how to toggle the right attributes to enable very long-context generations, as some flavors of Llama 4
+have context lengths going up to 10 million tokens.
+
+
+
+
+
+```py
+from transformers import pipeline
+import torch
+
+model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
+
+messages = [
+ {"role": "user", "content": "what is the recipe of mayonnaise?"},
+]
+
+pipe = pipeline(
+ "text-generation",
+ model=model_id,
+ device_map="auto",
+ torch_dtype=torch.bfloat16
+)
+
+output = pipe(messages, do_sample=False, max_new_tokens=200)
+print(output[0]["generated_text"][-1]["content"])
+```
+
+
+
+
+```py
+from transformers import AutoTokenizer, Llama4ForConditionalGeneration
+import torch
+
+model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
+
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+
+messages = [
+ {"role": "user", "content": "Who are you?"},
+]
+inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt", return_dict=True)
+
+model = Llama4ForConditionalGeneration.from_pretrained(
+ model_id,
+ device_map="auto",
+ torch_dtype=torch.bfloat16
+)
+
+outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
+outputs = tokenizer.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])
+print(outputs[0])
+```
+
+
+
+
+```py
+from transformers import AutoProcessor, Llama4ForConditionalGeneration
+import torch
+
+model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
+
+processor = AutoProcessor.from_pretrained(model_id)
+model = Llama4ForConditionalGeneration.from_pretrained(
+ model_id,
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+)
+
+img_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
+messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": img_url},
+ {"type": "text", "text": "Describe this image in two sentences."},
+ ]
+ },
+]
+
+inputs = processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+).to(model.device)
+
+outputs = model.generate(
+ **inputs,
+ max_new_tokens=256,
+)
+
+response = processor.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])[0]
+print(response)
+```
+
+
+
+
+```py
+from transformers import AutoProcessor, Llama4ForConditionalGeneration
+import torch
+
+model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
+
+processor = AutoProcessor.from_pretrained(model_id)
+model = Llama4ForConditionalGeneration.from_pretrained(
+ model_id,
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+)
+
+url1 = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
+url2 = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/cat_style_layout.png"
+messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": url1},
+ {"type": "image", "url": url2},
+ {"type": "text", "text": "Can you describe how these two images are similar, and how they differ?"},
+ ]
+ },
+]
+
+inputs = processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+).to(model.device)
+
+outputs = model.generate(
+ **inputs,
+ max_new_tokens=256,
+)
+
+response = processor.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])[0]
+print(response)
+```
+
+
+
+
+Beware: the example below uses both `device_map="auto"` and flex-attention.
+Please use `torchrun` to run this example in tensor-parallel mode.
+
+We will work to enable running with `device_map="auto"` and flex-attention without
+tensor-parallel in the future.
+
+```py
+from transformers import Llama4ForConditionalGeneration, AutoTokenizer
+import torch
+import time
+
+file = "very_long_context_prompt.txt"
+model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
+
+with open(file, "r") as f:
+ very_long_text = "\n".join(f.readlines())
+
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = Llama4ForConditionalGeneration.from_pretrained(
+ model_id,
+ device_map="auto",
+ attn_implementation="flex_attention",
+ torch_dtype=torch.bfloat16
+)
+
+messages = [
+ {"role": "user", "content": f"Look at the following texts: [{very_long_text}]\n\n\n\nWhat are the books, and who wrote them? Make me a nice list."},
+]
+input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
+
+torch.cuda.synchronize()
+start = time.time()
+out = model.generate(
+ input_ids.to(model.device),
+ prefill_chunk_size=2048*8,
+ max_new_tokens=300,
+ cache_implementation="hybrid",
+)
+print(time.time()-start)
+print(tokenizer.batch_decode(out[:, input_ids.shape[-1]:]))
+print(f"{torch.cuda.max_memory_allocated(model.device) / 1024**3:.2f} GiB")
+```
+
+
+
+
+## Efficiency; how to get the best out of llama 4
+
+### The Attention methods
+
+Updating the default attention function can significantly improve compute performance as well as memory usage. Refer to the [Attention Interface](../attention_interface) overview for an in-depth explanation of our interface.
+
+As of release, the Llama 4 model supports the following attention methods: `eager`, `flex_attention`, `sdpa`. We recommend using `flex_attention` for best results.
+Switching attention mechanism is done at the model initialization step:
+
+
+
+
+
+Setting Flex Attention ensures the best results with the very long context the model can handle.
+
+> [!TIP] Beware: the example below uses both `device_map="auto"` and flex-attention.
+> Please use `torchrun` to run this example in tensor-parallel mode.
+>
+> We will work to enable running with `device_map="auto"` and flex-attention without
+> tensor-parallel in the future.
+
+```py
+from transformers import Llama4ForConditionalGeneration
+import torch
+
+model = Llama4ForConditionalGeneration.from_pretrained(
+ model_id,
+ attn_implementation="flex_attention",
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+)
+```
+
+
+The `sdpa` attention method is generally more compute-efficient than the `eager` method.
+
+```py
+from transformers import Llama4ForConditionalGeneration
+import torch
+
+model = Llama4ForConditionalGeneration.from_pretrained(
+ model_id,
+ attn_implementation="sdpa",
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+)
+```
+
+
+The `eager` attention method is set by default, so no need for anything different when loading the model:
+
+```py
+from transformers import Llama4ForConditionalGeneration
+import torch
+
+model = Llama4ForConditionalGeneration.from_pretrained(
+ model_id,
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+)
+```
+
+
+
+
+### Quantization
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for available quantization backends.
+At time of release, both FBGEMM and LLM-Compressor are supported; more quantization methods will be supported in the days that follow the release.
+
+See below for examples using both:
+
+
+
+Here is an example loading an BF16 model in FP8 using the FBGEMM approach:
+
+
+
+
+```python
+from transformers import AutoTokenizer, Llama4ForConditionalGeneration, FbgemmFp8Config
+import torch
+
+model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
+
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+
+messages = [
+ {"role": "user", "content": "Who are you?"},
+]
+inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt", return_dict=True)
+
+model = Llama4ForConditionalGeneration.from_pretrained(
+ model_id,
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+ quantization_config=FbgemmFp8Config()
+)
+
+outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
+outputs = tokenizer.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])
+print(outputs[0])
+```
+
+
+
+
+To use the LLM-Compressor technique, we recommend leveraging the pre-quantized FP8 checkpoint available with the release:
+
+```python
+from transformers import AutoTokenizer, Llama4ForConditionalGeneration
+import torch
+
+model_id = "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8"
+
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+
+messages = [
+ {"role": "user", "content": "Who are you?"},
+]
+inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt", return_dict=True)
+
+model = Llama4ForConditionalGeneration.from_pretrained(
+ model_id,
+ tp_plan="auto",
+ torch_dtype=torch.bfloat16,
+)
+
+outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
+outputs = tokenizer.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])
+print(outputs[0])
+```
+
+
+
+### Offloading
+
+Enabling CPU-offloading means that components of the model might be moved to CPU instead of GPU in case the GPU-memory available isn't sufficient to load the entire model.
+At inference, different components will be loaded/unloaded from/to the GPU on the fly. This ensures that the model can be loaded on smaller machines as long as the CPU-memory is sufficient.
+However, this also slows down inference as it adds communication overhead.
+
+In order to enable CPU-offloading, you simply need to specify the `device_map` to `auto` at model load:
+
+```py
+from transformers import Llama4ForConditionalGeneration
+import torch
+
+model = Llama4ForConditionalGeneration.from_pretrained(
+ model_id,
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+)
+```
+
+## Llama4Config
+
+[[autodoc]] Llama4Config
+
+## Llama4TextConfig
+
+[[autodoc]] Llama4TextConfig
+
+## Llama4VisionConfig
+
+[[autodoc]] Llama4VisionConfig
+
+## Llama4Processor
+
+[[autodoc]] Llama4Processor
+
+## Llama4ImageProcessorFast
+
+[[autodoc]] Llama4ImageProcessorFast
+
+## Llama4ForConditionalGeneration
+
+[[autodoc]] Llama4ForConditionalGeneration
+- forward
+
+## Llama4ForCausalLM
+
+[[autodoc]] Llama4ForCausalLM
+- forward
+
+## Llama4TextModel
+
+[[autodoc]] Llama4TextModel
+- forward
+
+## Llama4ForCausalLM
+
+[[autodoc]] Llama4ForCausalLM
+- forward
+
+## Llama4VisionModel
+
+[[autodoc]] Llama4VisionModel
+- forward
diff --git a/docs/transformers/docs/source/en/model_doc/llava.md b/docs/transformers/docs/source/en/model_doc/llava.md
new file mode 100644
index 0000000000000000000000000000000000000000..79033ec5a189199796f8ef394829ba1e61d556f5
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/llava.md
@@ -0,0 +1,262 @@
+
+
+# LLaVa
+
+
+
+
+
+
+
+## Overview
+
+LLaVa is an open-source chatbot trained by fine-tuning LlamA/Vicuna on GPT-generated multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. In other words, it is an multi-modal version of LLMs fine-tuned for chat / instructions.
+
+The LLaVa model was proposed in [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) and improved in [Improved Baselines with Visual Instruction Tuning](https://arxiv.org/pdf/2310.03744) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
+
+The abstract from the paper is the following:
+
+*Large multimodal models (LMM) have recently shown encouraging progress with visual instruction tuning. In this note, we show that the fully-connected vision-language cross-modal connector in LLaVA is surprisingly powerful and data-efficient. With simple modifications to LLaVA, namely, using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts, we establish stronger baselines that achieve state-of-the-art across 11 benchmarks. Our final 13B checkpoint uses merely 1.2M publicly available data, and finishes full training in ∼1 day on a single 8-A100 node. We hope this can make state-of-the-art LMM research more accessible. Code and model will be publicly available*
+
+
+
+ LLaVa architecture. Taken from the original paper.
+
+This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
+The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
+
+## Usage tips
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
+
+- Note the model has not been explicitly trained to process multiple images in the same prompt, although this is technically possible, you may experience inaccurate results.
+
+
+> [!NOTE]
+> LLaVA models after release v4.46 will raise warnings about adding `processor.patch_size = {{patch_size}}`, `processor.num_additional_image_tokens = {{num_additional_image_tokens}}` and processor.vision_feature_select_strategy = {{vision_feature_select_strategy}}`. It is strongly recommended to add the attributes to the processor if you own the model checkpoint, or open a PR if it is not owned by you.
+Adding these attributes means that LLaVA will try to infer the number of image tokens required per image and expand the text with as many `` placeholders as there will be tokens. Usually it is around 500 tokens per image, so make sure that the text is not truncated as otherwise there will be failure when merging the embeddings.
+The attributes can be obtained from model config, as `model.config.vision_config.patch_size` or `model.config.vision_feature_select_strategy`. The `num_additional_image_tokens` should be `1` if the vision backbone adds a CLS token or `0` if nothing extra is added to the vision patches.
+
+
+### Formatting Prompts with Chat Templates
+
+Each **checkpoint** is trained with a specific prompt format, depending on the underlying large language model backbone. To ensure correct formatting, use the processor’s `apply_chat_template` method.
+
+**Important:**
+- You must construct a conversation history — passing a plain string won't work.
+- Each message should be a dictionary with `"role"` and `"content"` keys.
+- The `"content"` should be a list of dictionaries for different modalities like `"text"` and `"image"`.
+
+
+Here’s an example of how to structure your input.
+We will use [llava-hf/llava-1.5-7b-hf](https://huggingface.co/llava-hf/llava-1.5-7b-hf) and a conversation history of text and image. Each content field has to be a list of dicts, as follows:
+
+
+```python
+from transformers import AutoProcessor
+
+processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
+
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "What’s shown in this image?"},
+ ],
+ },
+ {
+ "role": "assistant",
+ "content": [{"type": "text", "text": "This image shows a red stop sign."},]
+ },
+ {
+
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Describe the image in more details."},
+ ],
+ },
+]
+
+text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
+
+# Note that the template simply formats your prompt, you still have to tokenize it and obtain pixel values for your images
+print(text_prompt)
+>>> "USER: \nUSER: Describe the image in more details. ASSISTANT:"
+```
+
+- If you want to construct a chat prompt yourself, below is a list of prompt formats accepted by each llava checkpoint:
+
+[llava-interleave models](https://huggingface.co/collections/llava-hf/llava-interleave-668e19a97da0036aad4a2f19) requires the following format:
+```bash
+"<|im_start|>user \nWhat is shown in this image?<|im_end|><|im_start|>assistant"
+```
+
+For multiple turns conversation:
+
+```bash
+"<|im_start|>user \n<|im_end|><|im_start|>assistant <|im_end|><|im_start|>user \n<|im_end|><|im_start|>assistant "
+```
+
+[llava-1.5 models](https://huggingface.co/collections/llava-hf/llava-15-65f762d5b6941db5c2ba07e0) requires the following format:
+```bash
+"USER: \n ASSISTANT:"
+```
+
+For multiple turns conversation:
+
+```bash
+"USER: \n ASSISTANT: USER: ASSISTANT: USER: ASSISTANT:"
+```
+
+🚀 **Bonus:** If you're using `transformers>=4.49.0`, you can also get a vectorized output from `apply_chat_template`. See the **Usage Examples** below for more details on how to use it.
+
+
+## Usage examples
+
+### Single input inference
+
+
+```python
+import torch
+from transformers import AutoProcessor, LlavaForConditionalGeneration
+
+# Load the model in half-precision
+model = LlavaForConditionalGeneration.from_pretrained("llava-hf/llava-1.5-7b-hf", torch_dtype=torch.float16, device_map="auto")
+processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
+
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"},
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device, torch.float16)
+
+# Generate
+generate_ids = model.generate(**inputs, max_new_tokens=30)
+processor.batch_decode(generate_ids, skip_special_tokens=True)
+```
+
+
+### Batched inference
+
+LLaVa also supports batched inference. Here is how you can do it:
+
+```python
+import torch
+from transformers import AutoProcessor, LlavaForConditionalGeneration
+
+# Load the model in half-precision
+model = LlavaForConditionalGeneration.from_pretrained("llava-hf/llava-1.5-7b-hf", torch_dtype=torch.float16, device_map="auto")
+processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
+
+
+# Prepare a batch of two prompts
+conversation_1 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"},
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+]
+
+conversation_2 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+]
+
+inputs = processor.apply_chat_template(
+ [conversation_1, conversation_2],
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ padding=True,
+ return_tensors="pt"
+).to(model.device, torch.float16)
+
+
+# Generate
+generate_ids = model.generate(**inputs, max_new_tokens=30)
+processor.batch_decode(generate_ids, skip_special_tokens=True)
+```
+
+
+## Note regarding reproducing original implementation
+
+In order to match the logits of the [original implementation](https://github.com/haotian-liu/LLaVA/tree/main), one needs to additionally specify `do_pad=True` when instantiating `LLavaImageProcessor`:
+
+```python
+from transformers import LLavaImageProcessor
+
+image_processor = LLavaImageProcessor.from_pretrained("https://huggingface.co/llava-hf/llava-1.5-7b-hf", do_pad=True)
+```
+
+### Using Flash Attention 2
+
+Flash Attention 2 is an even faster, optimized version of the previous optimization, please refer to the [Flash Attention 2 section of performance docs](https://huggingface.co/docs/transformers/perf_infer_gpu_one).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
+
+
+
+- A [Google Colab demo](https://colab.research.google.com/drive/1qsl6cd2c8gGtEW1xV5io7S8NHh-Cp1TV?usp=sharing) on how to run Llava on a free-tier Google colab instance leveraging 4-bit inference.
+- A [similar notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LLaVa/Inference_with_LLaVa_for_multimodal_generation.ipynb) showcasing batched inference. 🌎
+
+
+## LlavaConfig
+
+[[autodoc]] LlavaConfig
+
+## LlavaImageProcessor
+
+[[autodoc]] LlavaImageProcessor
+ - preprocess
+
+## LlavaImageProcessorFast
+
+[[autodoc]] LlavaImageProcessorFast
+ - preprocess
+
+## LlavaProcessor
+
+[[autodoc]] LlavaProcessor
+
+## LlavaForConditionalGeneration
+
+[[autodoc]] LlavaForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/llava_next.md b/docs/transformers/docs/source/en/model_doc/llava_next.md
new file mode 100644
index 0000000000000000000000000000000000000000..7d85ab8b6967755836dd767a21bc19c9c411648d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/llava_next.md
@@ -0,0 +1,321 @@
+
+
+# LLaVA-NeXT
+
+
+
+
+
+
+
+## Overview
+
+The LLaVA-NeXT model was proposed in [LLaVA-NeXT: Improved reasoning, OCR, and world knowledge](https://llava-vl.github.io/blog/2024-01-30-llava-next/) by Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, Yong Jae Lee. LLaVa-NeXT (also called LLaVa-1.6) improves upon [LLaVa](llava) by increasing the input image resolution and training on an improved visual instruction tuning dataset to improve OCR and common sense reasoning.
+
+The introduction from the blog is the following:
+
+*In October 2023, we released LLaVA-1.5 with a simple and efficient design along with great performance on a benchmark suite of 12 datasets. It has since served as the foundation of many comprehensive studies of data, model, and capabilities of large multimodal models (LMM), and has enabled various new applications.
+
+Today, we are thrilled to present LLaVA-NeXT, with improved reasoning, OCR, and world knowledge. LLaVA-NeXT even exceeds Gemini Pro on several benchmarks.
+
+Compared with LLaVA-1.5, LLaVA-NeXT has several improvements:
+
+Increasing the input image resolution to 4x more pixels. This allows it to grasp more visual details. It supports three aspect ratios, up to 672x672, 336x1344, 1344x336 resolution.
+Better visual reasoning and OCR capability with an improved visual instruction tuning data mixture.
+Better visual conversation for more scenarios, covering different applications. Better world knowledge and logical reasoning.
+Efficient deployment and inference with SGLang.
+Along with performance improvements, LLaVA-NeXT maintains the minimalist design and data efficiency of LLaVA-1.5. It re-uses the pretrained connector of LLaVA-1.5, and still uses less than 1M visual instruction tuning samples. The largest 34B variant finishes training in ~1 day with 32 A100s.*
+
+
+
+ LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main).
+
+## Usage tips
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
+
+
+
+- Llava-Next uses different number of patches for images and thus has to pad the inputs inside modeling code, aside from the padding done when processing the inputs. The default setting is "left-padding" if model is in `eval()` mode, otherwise "right-padding".
+
+
+
+
+> [!NOTE]
+> LLaVA models after release v4.46 will raise warnings about adding `processor.patch_size = {{patch_size}}`, `processor.num_additional_image_tokens = {{num_additional_image_tokens}}` and processor.vision_feature_select_strategy = {{vision_feature_select_strategy}}`. It is strongly recommended to add the attributes to the processor if you own the model checkpoint, or open a PR if it is not owned by you.
+Adding these attributes means that LLaVA will try to infer the number of image tokens required per image and expand the text with as many `` placeholders as there will be tokens. Usually it is around 500 tokens per image, so make sure that the text is not truncated as otherwise there will be failure when merging the embeddings.
+The attributes can be obtained from model config, as `model.config.vision_config.patch_size` or `model.config.vision_feature_select_strategy`. The `num_additional_image_tokens` should be `1` if the vision backbone adds a CLS token or `0` if nothing extra is added to the vision patches.
+
+
+### Formatting Prompts with Chat Templates
+
+Each **checkpoint** is trained with a specific prompt format, depending on the underlying large language model backbone. To ensure correct formatting, use the processor’s `apply_chat_template` method.
+
+**Important:**
+- You must construct a conversation history — passing a plain string won't work.
+- Each message should be a dictionary with `"role"` and `"content"` keys.
+- The `"content"` should be a list of dictionaries for different modalities like `"text"` and `"image"`.
+
+
+Here’s an example of how to structure your input. We will use [llava-v1.6-mistral-7b-hf](https://huggingface.co/llava-hf/llava-v1.6-mistral-7b-hf) and a conversation history of text and image.
+
+```python
+from transformers import LlavaNextProcessor
+
+processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
+
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "What’s shown in this image?"},
+ ],
+ },
+ {
+ "role": "assistant",
+ "content": [{"type": "text", "text": "This image shows a red stop sign."},]
+ },
+ {
+
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Describe the image in more details."},
+ ],
+ },
+]
+
+text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
+
+# Note that the template simply formats your prompt, you still have to tokenize it and obtain pixel values for your images
+print(text_prompt)
+>>> "[INST] \nWhat's shown in this image? [/INST] This image shows a red stop sign. [INST] Describe the image in more details. [/INST]"
+```
+
+- If you want to construct a chat prompt yourself, below is a list of possible formats
+.
+[llava-v1.6-mistral-7b-hf](https://huggingface.co/llava-hf/llava-v1.6-mistral-7b-hf) requires the following format:
+```bash
+"[INST] \nWhat is shown in this image? [/INST]"
+```
+
+[llava-v1.6-vicuna-7b-hf](https://huggingface.co/llava-hf/llava-v1.6-vicuna-7b-hf) and [llava-v1.6-vicuna-13b-hf](https://huggingface.co/llava-hf/llava-v1.6-vicuna-13b-hf) require the following format:
+```bash
+"A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: \nWhat is shown in this image? ASSISTANT:"
+```
+
+[llava-v1.6-34b-hf](https://huggingface.co/llava-hf/llava-v1.6-34b-hf) requires the following format:
+```bash
+"<|im_start|>system\nAnswer the questions.<|im_end|><|im_start|>user\n\nWhat is shown in this image?<|im_end|><|im_start|>assistant\n"
+```
+
+[llama3-llava-next-8b-hf](https://huggingface.co/llava-hf/llava-next-8b-hf) requires the following format:
+
+```bash
+"<|start_header_id|>system<|end_header_id|>\n\nYou are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language.<|eot_id|><|start_header_id|><|start_header_id|>user<|end_header_id|>\n\n\nWhat is shown in this image?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"
+```
+
+[llava-next-72b-hf](https://huggingface.co/llava-hf/llava-next-72b-hf) and [llava-next-110b-hf](https://huggingface.co/llava-hf/llava-next-110b-hf) require the following format:
+
+```bash
+"<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n\nWhat is shown in this image?<|im_end|>\n<|im_start|>assistant\n"
+```
+
+🚀 **Bonus:** If you're using `transformers>=4.49.0`, you can also get a vectorized output from `apply_chat_template`. See the **Usage Examples** below for more details on how to use it.
+
+
+
+## Usage example
+
+### Single image inference
+
+Here's how to load the model and perform inference in half-precision (`torch.float16`):
+
+```python
+from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
+import torch
+from PIL import Image
+import requests
+
+processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
+
+model = LlavaNextForConditionalGeneration.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf", torch_dtype=torch.float16, low_cpu_mem_usage=True)
+model.to("cuda:0")
+
+# prepare image and text prompt, using the appropriate prompt template
+url = "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
+image = Image.open(requests.get(url, stream=True).raw)
+
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+]
+prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
+inputs = processor(image, prompt, return_tensors="pt").to("cuda:0")
+
+# autoregressively complete prompt
+output = model.generate(**inputs, max_new_tokens=100)
+
+print(processor.decode(output[0], skip_special_tokens=True))
+```
+
+### Multi image inference
+
+LLaVa-Next can perform inference with multiple images as input, where images either belong to the same prompt or different prompts (in batched inference). Here is how you can do it:
+
+```python
+import requests
+from PIL import Image
+import torch
+from transformers import AutoProcessor, AutoModelForImageTextToText
+
+# Load the model in half-precision
+model = AutoModelForImageTextToText.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf", torch_dtype=torch.float16, device_map="auto")
+processor = AutoProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
+
+# Get three different images
+url = "https://www.ilankelman.org/stopsigns/australia.jpg"
+image_stop = Image.open(requests.get(url, stream=True).raw)
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image_cats = Image.open(requests.get(url, stream=True).raw)
+
+url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
+image_snowman = Image.open(requests.get(url, stream=True).raw)
+
+# Prepare a batch of two prompts, where the first one is a multi-turn conversation and the second is not
+conversation_1 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+ {
+ "role": "assistant",
+ "content": [
+ {"type": "text", "text": "There is a red stop sign in the image."},
+ ],
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "What about this image? How many cats do you see?"},
+ ],
+ },
+]
+
+conversation_2 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+]
+
+prompt_1 = processor.apply_chat_template(conversation_1, add_generation_prompt=True)
+prompt_2 = processor.apply_chat_template(conversation_2, add_generation_prompt=True)
+prompts = [prompt_1, prompt_2]
+
+# We can simply feed images in the order they have to be used in the text prompt
+# Each "" token uses one image leaving the next for the subsequent "" tokens
+inputs = processor(images=[image_stop, image_cats, image_snowman], text=prompts, padding=True, return_tensors="pt").to(model.device)
+
+# Generate
+generate_ids = model.generate(**inputs, max_new_tokens=30)
+processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
+```
+
+## Model optimization
+
+### Quantization using Bitsandbytes
+
+The model can be loaded in 8 or 4 bits, greatly reducing the memory requirements while maintaining the performance of the original model. First make sure to install bitsandbytes, `pip install bitsandbytes`, and to have access to a GPU/accelerator that is supported by the library.
+
+
+
+bitsandbytes is being refactored to support multiple backends beyond CUDA. Currently, ROCm (AMD GPU) and Intel CPU implementations are mature, with Intel XPU in progress and Apple Silicon support expected by Q4/Q1. For installation instructions and the latest backend updates, visit [this link](https://huggingface.co/docs/bitsandbytes/main/en/installation#multi-backend).
+
+We value your feedback to help identify bugs before the full release! Check out [these docs](https://huggingface.co/docs/bitsandbytes/main/en/non_cuda_backends) for more details and feedback links.
+
+
+
+Simply change the snippet above with:
+
+```python
+from transformers import AutoModelForImageTextToText, BitsAndBytesConfig
+
+# specify how to quantize the model
+quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.float16,
+)
+
+model = AutoModelForImageTextToText.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf", quantization_config=quantization_config, device_map="auto")
+```
+
+### Use Flash-Attention 2 to further speed-up generation
+
+First make sure to install flash-attn. Refer to the [original repository of Flash Attention](https://github.com/Dao-AILab/flash-attention) regarding that package installation. Simply change the snippet above with:
+
+```python
+from transformers import AutoModelForImageTextToText
+
+model = AutoModelForImageTextToText.from_pretrained(
+ model_id,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ use_flash_attention_2=True
+).to(0)
+```
+
+## LlavaNextConfig
+
+[[autodoc]] LlavaNextConfig
+
+## LlavaNextImageProcessor
+
+[[autodoc]] LlavaNextImageProcessor
+ - preprocess
+
+## LlavaNextImageProcessorFast
+
+[[autodoc]] LlavaNextImageProcessorFast
+ - preprocess
+
+## LlavaNextProcessor
+
+[[autodoc]] LlavaNextProcessor
+
+## LlavaNextForConditionalGeneration
+
+[[autodoc]] LlavaNextForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/llava_next_video.md b/docs/transformers/docs/source/en/model_doc/llava_next_video.md
new file mode 100644
index 0000000000000000000000000000000000000000..e435861cbe26f4c1176f11d2b85d071c5aea1454
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/llava_next_video.md
@@ -0,0 +1,268 @@
+
+
+# LLaVa-NeXT-Video
+
+
+
+
+
+
+
+## Overview
+
+The LLaVa-NeXT-Video model was proposed in [LLaVA-NeXT: A Strong Zero-shot Video Understanding Model
+](https://llava-vl.github.io/blog/2024-04-30-llava-next-video/) by Yuanhan Zhang, Bo Li, Haotian Liu, Yong Jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, Chunyuan Li. LLaVa-NeXT-Video improves upon [LLaVa-NeXT](llava_next) by fine-tuning on a mix if video and image dataset thus increasing the model's performance on videos.
+
+[LLaVA-NeXT](llava_next) surprisingly has strong performance in understanding video content in zero-shot fashion with the AnyRes technique that it uses. The AnyRes technique naturally represents a high-resolution image into multiple images. This technique is naturally generalizable to represent videos because videos can be considered as a set of frames (similar to a set of images in LLaVa-NeXT). The current version of LLaVA-NeXT makes use of AnyRes and trains with supervised fine-tuning (SFT) on top of LLaVA-Next on video data to achieves better video understanding capabilities.The model is a current SOTA among open-source models on [VideoMME bench](https://arxiv.org/abs/2405.21075).
+
+
+The introduction from the blog is the following:
+
+On January 30, 2024, we released LLaVA-NeXT, an open-source Large Multimodal Model (LMM) that has been trained exclusively on text-image data. With the proposed AnyRes technique, it boosts capabilities in reasoning, OCR, and world knowledge, demonstrating remarkable performance across a spectrum of image-based multimodal understanding tasks, and even exceeding Gemini-Pro on several image benchmarks, e.g. MMMU and MathVista.
+
+**In today’s exploration, we delve into the performance of LLaVA-NeXT within the realm of video understanding tasks. We reveal that LLaVA-NeXT surprisingly has strong performance in understanding video content. The current version of LLaVA-NeXT for videos has several improvements:
+
+- Zero-shot video representation capabilities with AnyRes: The AnyRes technique naturally represents a high-resolution image into multiple images that a pre-trained VIT is able to digest, and forms them into a concatenated sequence. This technique is naturally generalizable to represent videos (consisting of multiple frames), allowing the image-only-trained LLaVA-Next model to perform surprisingly well on video tasks. Notably, this is the first time that LMMs show strong zero-shot modality transfer ability.
+- Inference with length generalization improves on longer videos. The linear scaling technique enables length generalization, allowing LLaVA-NeXT to effectively handle long-video beyond the limitation of the "max_token_length" of the LLM.
+- Strong video understanding ability. (1) LLaVA-Next-Image, which combines the above two techniques, yields superior zero-shot performance than open-source LMMs tuned on videos. (2) LLaVA-Next-Video, further supervised fine-tuning (SFT) LLaVA-Next-Image on video data, achieves better video understanding capabilities compared to LLaVA-Next-Image. (3) LLaVA-Next-Video-DPO, which aligns the model response with AI feedback using direct preference optimization (DPO), showing significant performance boost.
+- Efficient deployment and inference with SGLang. It allows 5x faster inference on video tasks, allowing more scalable serving such as million-level video re-captioning. See instructions in our repo.**
+
+
+This model was contributed by [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
+The original code can be found [here](https://github.com/LLaVA-VL/LLaVA-NeXT/tree/inference).
+
+## Usage tips
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
+
+
+
+- Llava-Next uses different number of patches for images and thus has to pad the inputs inside modeling code, aside from the padding done when processing the inputs. The default setting is "left-padding" if model is in `eval()` mode, otherwise "right-padding".
+
+
+
+
+> [!NOTE]
+> LLaVA models after release v4.46 will raise warnings about adding `processor.patch_size = {{patch_size}}`, `processor.num_additional_image_tokens = {{num_additional_image_tokens}}` and processor.vision_feature_select_strategy = {{vision_feature_select_strategy}}`. It is strongly recommended to add the attributes to the processor if you own the model checkpoint, or open a PR if it is not owned by you.
+Adding these attributes means that LLaVA will try to infer the number of image tokens required per image and expand the text with as many `` placeholders as there will be tokens. Usually it is around 500 tokens per image, so make sure that the text is not truncated as otherwise there will be failure when merging the embeddings.
+The attributes can be obtained from model config, as `model.config.vision_config.patch_size` or `model.config.vision_feature_select_strategy`. The `num_additional_image_tokens` should be `1` if the vision backbone adds a CLS token or `0` if nothing extra is added to the vision patches.
+
+
+### Formatting Prompts with Chat Templates
+
+Each **checkpoint** is trained with a specific prompt format, depending on the underlying large language model backbone. To ensure correct formatting, use the processor’s `apply_chat_template` method.
+
+**Important:**
+- You must construct a conversation history — passing a plain string won't work.
+- Each message should be a dictionary with `"role"` and `"content"` keys.
+- The `"content"` should be a list of dictionaries for different modalities like `"text"` and `"image"`.
+
+
+Here’s an example of how to structure your input. We will use [LLaVA-NeXT-Video-7B-hf](https://huggingface.co/llava-hf/LLaVA-NeXT-Video-7B-hf) and a conversation history of videos and images.
+
+```python
+from transformers import LlavaNextVideoProcessor
+
+processor = LlavaNextVideoProcessor.from_pretrained("llava-hf/LLaVA-NeXT-Video-7B-hf")
+
+conversation = [
+ {
+ "role": "system",
+ "content": [
+ {"type": "text", "text": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions."},
+ ],
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "What’s shown in this image?"},
+ {"type": "image"},
+ ],
+ },
+ {
+ "role": "assistant",
+ "content": [{"type": "text", "text": "This image shows a red stop sign."},]
+ },
+ {
+
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Why is this video funny?"},
+ {"type": "video"},
+ ],
+ },
+]
+
+text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
+
+# Note that the template simply formats your prompt, you still have to tokenize it and obtain pixel values for your visuals
+print(text_prompt)
+```
+
+🚀 **Bonus:** If you're using `transformers>=4.49.0`, you can also get a vectorized output from `apply_chat_template`. See the **Usage Examples** below for more details on how to use it.
+
+
+
+## Usage example
+
+### Single Media Mode
+
+The model can accept both images and videos as input. Here's an example code for inference in half-precision (`torch.float16`):
+
+```python
+from huggingface_hub import hf_hub_download
+import torch
+from transformers import LlavaNextVideoForConditionalGeneration, LlavaNextVideoProcessor
+
+# Load the model in half-precision
+model = LlavaNextVideoForConditionalGeneration.from_pretrained("llava-hf/LLaVA-NeXT-Video-7B-hf", torch_dtype=torch.float16, device_map="auto")
+processor = LlavaNextVideoProcessor.from_pretrained("llava-hf/LLaVA-NeXT-Video-7B-hf")
+
+# Load the video as an np.array, sampling uniformly 8 frames (can sample more for longer videos)
+video_path = hf_hub_download(repo_id="raushan-testing-hf/videos-test", filename="sample_demo_1.mp4", repo_type="dataset")
+
+conversation = [
+ {
+
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Why is this video funny?"},
+ {"type": "video", "path": video_path},
+ ],
+ },
+]
+
+inputs = processor.apply_chat_template(conversation, num_frames=8, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt")
+
+out = model.generate(**inputs, max_new_tokens=60)
+processor.batch_decode(out, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+```
+
+
+### Mixed Media Mode
+
+The model can also generate from an interleaved image-video inputs. However note, that it was not trained in interleaved image-video setting which might affect the performance. Below is an example usage for mixed media input, add the following lines to the above code snippet:
+
+```python
+
+# Generate from image and video mixed inputs
+conversation = [
+ {
+
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "How many cats are there in the image?"},
+ {"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
+ ],
+ },
+ {
+
+ "role": "assistant",
+ "content": [{"type": "text", "text": "There are two cats"}],
+ },
+ {
+
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Why is this video funny?"},
+ {"type": "video", "path": video_path},
+ ],
+ },
+]
+inputs = processor.apply_chat_template(conversation, num_frames=8, add_generation_prompt=True, tokenize=True, return_dict=True, padding=True, return_tensors="pt")
+
+# Generate
+generate_ids = model.generate(**inputs, max_length=50)
+processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+
+```
+
+## Model optimization
+
+### Quantization using Bitsandbytes for memory efficiency
+
+The model can be loaded in lower bits, significantly reducing memory burden while maintaining the performance of the original model. This allows for efficient deployment on resource-constrained cases.
+
+First, make sure to install bitsandbytes by running `pip install bitsandbytes` and to have access to a GPU/accelerator that is supported by the library.
+
+
+
+bitsandbytes is being refactored to support multiple backends beyond CUDA. Currently, ROCm (AMD GPU) and Intel CPU implementations are mature, with Intel XPU in progress and Apple Silicon support expected by Q4/Q1. For installation instructions and the latest backend updates, visit [this link](https://huggingface.co/docs/bitsandbytes/main/en/installation#multi-backend).
+
+We value your feedback to help identify bugs before the full release! Check out [these docs](https://huggingface.co/docs/bitsandbytes/main/en/non_cuda_backends) for more details and feedback links.
+
+
+
+Then simply load the quantized model by adding [`BitsAndBytesConfig`](../main_classes/quantization#transformers.BitsAndBytesConfig) as shown below:
+
+
+```python
+from transformers import LlavaNextVideoForConditionalGeneration, LlavaNextVideoProcessor
+
+# specify how to quantize the model
+quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.float16,
+)
+
+model = LlavaNextVideoForConditionalGeneration.from_pretrained("llava-hf/LLaVA-NeXT-Video-7B-hf", quantization_config=quantization_config, device_map="auto")
+```
+
+
+### Flash-Attention 2 to speed-up generation
+
+Additionally, we can greatly speed-up model inference by using [Flash Attention](../perf_train_gpu_one#flash-attention-2), which is a faster implementation of the attention mechanism used inside the model.
+
+First, make sure to install the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Also, you should have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). FlashAttention-2 can only be used when a model is loaded in `torch.float16` or `torch.bfloat16`.
+
+To load and run a model using Flash Attention-2, simply add `attn_implementation="flash_attention_2"` when loading the model as follows:
+
+```python
+from transformers import LlavaNextVideoForConditionalGeneration
+
+model = LlavaNextVideoForConditionalGeneration.from_pretrained(
+ "llava-hf/LLaVA-NeXT-Video-7B-hf",
+ torch_dtype=torch.float16,
+ attn_implementation="flash_attention_2",
+).to(0)
+```
+
+
+
+## LlavaNextVideoConfig
+
+[[autodoc]] LlavaNextVideoConfig
+
+## LlavaNextVideoProcessor
+
+[[autodoc]] LlavaNextVideoProcessor
+
+## LlavaNextVideoImageProcessor
+
+[[autodoc]] LlavaNextVideoImageProcessor
+
+## LlavaNextVideoForConditionalGeneration
+
+[[autodoc]] LlavaNextVideoForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/llava_onevision.md b/docs/transformers/docs/source/en/model_doc/llava_onevision.md
new file mode 100644
index 0000000000000000000000000000000000000000..77fe807d46d0083e0b1895d8b305d5f5073f87ee
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/llava_onevision.md
@@ -0,0 +1,319 @@
+
+
+# LLaVA-OneVision
+
+
+
+
+
+
+
+## Overview
+
+The LLaVA-OneVision model was proposed in [LLaVA-OneVision: Easy Visual Task Transfer](https://arxiv.org/abs/2408.03326) by
+
+ LLaVA-OneVision architecture. Taken from the original paper.
+
+Tips:
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
+
+
+
+- Llava-OneVision uses different number of patches for images and thus has to pad the inputs inside modeling code, aside from the padding done when processing the inputs. The default setting is "left-padding" if model is in `eval()` mode, otherwise "right-padding".
+
+
+
+
+### Formatting Prompts with Chat Templates
+
+Each **checkpoint** is trained with a specific prompt format, depending on the underlying large language model backbone. To ensure correct formatting, use the processor’s `apply_chat_template` method.
+
+**Important:**
+- You must construct a conversation history — passing a plain string won't work.
+- Each message should be a dictionary with `"role"` and `"content"` keys.
+- The `"content"` should be a list of dictionaries for different modalities like `"text"` and `"image"`.
+
+
+Here’s an example of how to structure your input.
+We will use [llava-onevision-qwen2-7b-si-hf](https://huggingface.co/llava-hf/llava-onevision-qwen2-7b-si-hf) and a conversation history of text and image. Each content field has to be a list of dicts, as follows:
+
+```python
+from transformers import AutoProcessor
+
+processor = AutoProcessor.from_pretrained("llava-hf/llava-onevision-qwen2-7b-si-hf")
+
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "What’s shown in this image?"},
+ ],
+ },
+ {
+ "role": "assistant",
+ "content": [{"type": "text", "text": "This image shows a red stop sign."},]
+ },
+ {
+
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Describe the image in more details."},
+ ],
+ },
+]
+
+text_prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
+
+# Note that the template simply formats your prompt, you still have to tokenize it and obtain pixel values for your images
+print(text_prompt)
+'<|im_start|>user\nWhat is shown in this image?<|im_end|>\n<|im_start|>assistant\nPage showing the list of options.<|im_end|>'
+```
+
+🚀 **Bonus:** If you're using `transformers>=4.49.0`, you can also get a vectorized output from `apply_chat_template`. See the **Usage Examples** below for more details on how to use it.
+
+
+This model was contributed by [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
+The original code can be found [here](https://github.com/LLaVA-VL/LLaVA-NeXT/tree/main).
+
+
+## Usage example
+
+### Single image inference
+
+Here's how to load the model and perform inference in half-precision (`torch.float16`):
+
+```python
+from transformers import AutoProcessor, LlavaOnevisionForConditionalGeneration
+import torch
+
+processor = AutoProcessor.from_pretrained("llava-hf/llava-onevision-qwen2-7b-ov-hf")
+model = LlavaOnevisionForConditionalGeneration.from_pretrained(
+ "llava-hf/llava-onevision-qwen2-7b-ov-hf",
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ device_map="cuda:0"
+)
+
+# prepare image and text prompt, using the appropriate prompt template
+url = "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": url},
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+]
+inputs = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt")
+inputs = inputs.to("cuda:0", torch.float16)
+
+# autoregressively complete prompt
+output = model.generate(**inputs, max_new_tokens=100)
+print(processor.decode(output[0], skip_special_tokens=True))
+'user\n\nWhat is shown in this image?\nassistant\nThe image shows a radar chart, also known as a spider chart or a star chart, which is used to compare multiple quantitative variables. Each axis represents a different variable, and the chart is filled with'
+```
+
+### Multi image inference
+
+LLaVa-OneVision can perform inference with multiple images as input, where images either belong to the same prompt or different prompts (in batched inference). For that you have to use checkpoints with an "ov" suffix. Here is how you can do it:
+
+```python
+import requests
+from PIL import Image
+import torch
+from transformers import AutoProcessor, LlavaOnevisionForConditionalGeneration
+
+# Load the model in half-precision
+model = LlavaOnevisionForConditionalGeneration.from_pretrained("llava-hf/llava-onevision-qwen2-7b-ov-hf", torch_dtype=torch.float16, device_map="auto")
+processor = AutoProcessor.from_pretrained("llava-hf/llava-onevision-qwen2-7b-ov-hf")
+
+# Prepare a batch of two prompts, where the first one is a multi-turn conversation and the second is not
+conversation_1 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"},
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+ {
+ "role": "assistant",
+ "content": [
+ {"type": "text", "text": "There is a red stop sign in the image."},
+ ],
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
+ {"type": "text", "text": "What about this image? How many cats do you see?"},
+ ],
+ },
+]
+
+conversation_2 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"},
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+]
+
+inputs = processor.apply_chat_template(
+ [conversation_1, conversation_2],
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ padding=True,
+ return_tensors="pt"
+).to(model.device, torch.float16)
+
+# Generate
+generate_ids = model.generate(**inputs, max_new_tokens=30)
+processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
+['user\n\nWhat is shown in this image?\nassistant\nThere is a red stop sign in the image.\nuser\n\nWhat about this image? How many cats do you see?\nassistant\ntwo', 'user\n\nWhat is shown in this image?\nassistant\n']
+```
+
+### Video inference
+
+LLaVa-OneVision also can perform inference with videos as input, where video frames are treated as multiple images. Here is how you can do it:
+
+```python
+from huggingface_hub import hf_hub_download
+import torch
+from transformers import AutoProcessor, LlavaOnevisionForConditionalGeneration
+
+# Load the model in half-precision
+model = LlavaOnevisionForConditionalGeneration.from_pretrained("llava-hf/llava-onevision-qwen2-7b-ov-hf", torch_dtype=torch.float16, device_map="auto")
+processor = AutoProcessor.from_pretrained("llava-hf/llava-onevision-qwen2-7b-ov-hf")
+
+video_path = hf_hub_download(repo_id="raushan-testing-hf/videos-test", filename="sample_demo_1.mp4", repo_type="dataset")
+conversation = [
+ {
+
+ "role": "user",
+ "content": [
+ {"type": "video", "path": video_path},
+ {"type": "text", "text": "Why is this video funny?"},
+ ],
+ },
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ num_frames=8
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device, torch.float16)
+
+out = model.generate(**inputs, max_new_tokens=60)
+processor.batch_decode(out, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+["user\n\nWhy is this video funny?\nassistant\nThe video appears to be humorous because it shows a young child, who is wearing glasses and holding a book, seemingly reading with a serious and focused expression. The child's glasses are a bit oversized for their face, which adds a comical touch, as it's a common trope to see children wearing"]
+```
+
+## Model optimization
+
+### Quantization using bitsandbytes
+
+The model can be loaded in 8 or 4 bits, greatly reducing the memory requirements while maintaining the performance of the original model. First make sure to install bitsandbytes, `pip install bitsandbytes` and make sure to have access to a GPU/accelerator that is supported by the library.
+
+
+
+bitsandbytes is being refactored to support multiple backends beyond CUDA. Currently, ROCm (AMD GPU) and Intel CPU implementations are mature, with Intel XPU in progress and Apple Silicon support expected by Q4/Q1. For installation instructions and the latest backend updates, visit [this link](https://huggingface.co/docs/bitsandbytes/main/en/installation#multi-backend).
+
+We value your feedback to help identify bugs before the full release! Check out [these docs](https://huggingface.co/docs/bitsandbytes/main/en/non_cuda_backends) for more details and feedback links.
+
+
+
+Simply change the snippet above with:
+
+```python
+from transformers import LlavaOnevisionForConditionalGeneration, BitsAndBytesConfig
+
+# specify how to quantize the model
+quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.float16,
+)
+
+model = LlavaOnevisionForConditionalGeneration.from_pretrained(model_id, quantization_config=quantization_config, device_map="auto")
+```
+
+### Use Flash-Attention 2 to further speed-up generation
+
+First make sure to install flash-attn. Refer to the [original repository of Flash Attention](https://github.com/Dao-AILab/flash-attention) regarding that package installation. Simply change the snippet above with:
+
+```python
+from transformers import LlavaOnevisionForConditionalGeneration
+
+model = LlavaOnevisionForConditionalGeneration.from_pretrained(
+ model_id,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ use_flash_attention_2=True
+).to(0)
+```
+
+
+## LlavaOnevisionConfig
+
+[[autodoc]] LlavaOnevisionConfig
+
+## LlavaOnevisionProcessor
+
+[[autodoc]] LlavaOnevisionProcessor
+
+## LlavaOnevisionImageProcessor
+
+[[autodoc]] LlavaOnevisionImageProcessor
+
+## LlavaOnevisionImageProcessorFast
+
+[[autodoc]] LlavaOnevisionImageProcessorFast
+ - preprocess
+
+## LlavaOnevisionVideoProcessor
+
+[[autodoc]] LlavaOnevisionVideoProcessor
+
+## LlavaOnevisionForConditionalGeneration
+
+[[autodoc]] LlavaOnevisionForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/longformer.md b/docs/transformers/docs/source/en/model_doc/longformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..17360c8958684855a9cd7a6f9ec8d4ab7494bd2b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/longformer.md
@@ -0,0 +1,201 @@
+
+
+
+
+
+
+
+
+
+# Longformer
+
+[Longformer](https://huggingface.co/papers/2004.05150) is a transformer model designed for processing long documents. The self-attention operation usually scales quadratically with sequence length, preventing transformers from processing longer sequences. The Longformer attention mechanism overcomes this by scaling linearly with sequence length. It combines local windowed attention with task-specific global attention, enabling efficient processing of documents with thousands of tokens.
+
+You can find all the original Longformer checkpoints under the [Ai2](https://huggingface.co/allenai?search_models=longformer) organization.
+
+> [!TIP]
+> Click on the Longformer models in the right sidebar for more examples of how to apply Longformer to different language tasks.
+
+The example below demonstrates how to fill the `` token with [`Pipeline`], [`AutoModel`] and from the command line.
+
+
+
+
+```python
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="fill-mask",
+ model="allenai/longformer-base-4096",
+ torch_dtype=torch.float16,
+ device=0
+)
+pipeline("""San Francisco 49ers cornerback Shawntae Spencer will miss the rest of the with a torn ligament in his left knee.
+Spencer, a fifth-year pro, will be placed on injured reserve soon after undergoing surgery Wednesday to repair the ligament. He injured his knee late in the 49ers’ road victory at Seattle on Sept. 14, and missed last week’s victory over Detroit.
+Tarell Brown and Donald Strickland will compete to replace Spencer with the 49ers, who kept 12 defensive backs on their 53-man roster to start the season. Brown, a second-year pro, got his first career interception last weekend while filling in for Strickland, who also sat out with a knee injury.""")
+```
+
+
+
+
+```python
+import torch
+from transformers import AutoModelForMaskedLM, AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("allenai/longformer-base-4096")
+model = AutoModelForMaskedLM.from_pretrained("allenai/longformer-base-4096")
+
+text = (
+"""
+San Francisco 49ers cornerback Shawntae Spencer will miss the rest of the with a torn ligament in his left knee.
+Spencer, a fifth-year pro, will be placed on injured reserve soon after undergoing surgery Wednesday to repair the ligament. He injured his knee late in the 49ers’ road victory at Seattle on Sept. 14, and missed last week’s victory over Detroit.
+Tarell Brown and Donald Strickland will compete to replace Spencer with the 49ers, who kept 12 defensive backs on their 53-man roster to start the season. Brown, a second-year pro, got his first career interception last weekend while filling in for Strickland, who also sat out with a knee injury.
+"""
+)
+
+input_ids = tokenizer([text], return_tensors="pt")["input_ids"]
+logits = model(input_ids).logits
+
+masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
+probs = logits[0, masked_index].softmax(dim=0)
+values, predictions = probs.topk(5)
+tokenizer.decode(predictions).split()
+```
+
+
+
+
+```bash
+echo -e "San Francisco 49ers cornerback Shawntae Spencer will miss the rest of the with a torn ligament in his left knee." | transformers-cli run --task fill-mask --model allenai/longformer-base-4096 --device 0
+```
+
+
+` or `tokenizer.sep_token`.
+- You can set which tokens can attend locally and which tokens attend globally with the `global_attention_mask` at inference (see this [example](https://huggingface.co/docs/transformers/en/model_doc/longformer#transformers.LongformerModel.forward.example) for more details). A value of `0` means a token attends locally and a value of `1` means a token attends globally.
+- [`LongformerForMaskedLM`] is trained like [`RobertaForMaskedLM`] and should be used as shown below.
+
+ ```py
+ input_ids = tokenizer.encode("This is a sentence from [MASK] training data", return_tensors="pt")
+ mlm_labels = tokenizer.encode("This is a sentence from the training data", return_tensors="pt")
+ loss = model(input_ids, labels=input_ids, masked_lm_labels=mlm_labels)[0]
+ ```
+
+## LongformerConfig
+
+[[autodoc]] LongformerConfig
+
+## LongformerTokenizer
+
+[[autodoc]] LongformerTokenizer
+
+## LongformerTokenizerFast
+
+[[autodoc]] LongformerTokenizerFast
+
+## Longformer specific outputs
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerBaseModelOutput
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerBaseModelOutputWithPooling
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerMaskedLMOutput
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerQuestionAnsweringModelOutput
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerSequenceClassifierOutput
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerMultipleChoiceModelOutput
+
+[[autodoc]] models.longformer.modeling_longformer.LongformerTokenClassifierOutput
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerBaseModelOutput
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerBaseModelOutputWithPooling
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerMaskedLMOutput
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerQuestionAnsweringModelOutput
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerSequenceClassifierOutput
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerMultipleChoiceModelOutput
+
+[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerTokenClassifierOutput
+
+## LongformerModel
+
+[[autodoc]] LongformerModel
+ - forward
+
+## LongformerForMaskedLM
+
+[[autodoc]] LongformerForMaskedLM
+ - forward
+
+## LongformerForSequenceClassification
+
+[[autodoc]] LongformerForSequenceClassification
+ - forward
+
+## LongformerForMultipleChoice
+
+[[autodoc]] LongformerForMultipleChoice
+ - forward
+
+## LongformerForTokenClassification
+
+[[autodoc]] LongformerForTokenClassification
+ - forward
+
+## LongformerForQuestionAnswering
+
+[[autodoc]] LongformerForQuestionAnswering
+ - forward
+
+## TFLongformerModel
+
+[[autodoc]] TFLongformerModel
+ - call
+
+## TFLongformerForMaskedLM
+
+[[autodoc]] TFLongformerForMaskedLM
+ - call
+
+## TFLongformerForQuestionAnswering
+
+[[autodoc]] TFLongformerForQuestionAnswering
+ - call
+
+## TFLongformerForSequenceClassification
+
+[[autodoc]] TFLongformerForSequenceClassification
+ - call
+
+## TFLongformerForTokenClassification
+
+[[autodoc]] TFLongformerForTokenClassification
+ - call
+
+## TFLongformerForMultipleChoice
+
+[[autodoc]] TFLongformerForMultipleChoice
+ - call
diff --git a/docs/transformers/docs/source/en/model_doc/longt5.md b/docs/transformers/docs/source/en/model_doc/longt5.md
new file mode 100644
index 0000000000000000000000000000000000000000..85a869f3c5948934ea42ba66339370ae62964b15
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/longt5.md
@@ -0,0 +1,145 @@
+
+
+# LongT5
+
+
+
+
+
+
+## Overview
+
+The LongT5 model was proposed in [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916)
+by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung and Yinfei Yang. It's an
+encoder-decoder transformer pre-trained in a text-to-text denoising generative setting. LongT5 model is an extension of
+T5 model, and it enables using one of the two different efficient attention mechanisms - (1) Local attention, or (2)
+Transient-Global attention.
+
+
+The abstract from the paper is the following:
+
+*Recent work has shown that either (1) increasing the input length or (2) increasing model size can improve the
+performance of Transformer-based neural models. In this paper, we present a new model, called LongT5, with which we
+explore the effects of scaling both the input length and model size at the same time. Specifically, we integrated
+attention ideas from long-input transformers (ETC), and adopted pre-training strategies from summarization pre-training
+(PEGASUS) into the scalable T5 architecture. The result is a new attention mechanism we call {\em Transient Global}
+(TGlobal), which mimics ETC's local/global attention mechanism, but without requiring additional side-inputs. We are
+able to achieve state-of-the-art results on several summarization tasks and outperform the original T5 models on
+question answering tasks.*
+
+This model was contributed by [stancld](https://huggingface.co/stancld).
+The original code can be found [here](https://github.com/google-research/longt5).
+
+## Usage tips
+
+- [`LongT5ForConditionalGeneration`] is an extension of [`T5ForConditionalGeneration`] exchanging the traditional
+encoder *self-attention* layer with efficient either *local* attention or *transient-global* (*tglobal*) attention.
+- Unlike the T5 model, LongT5 does not use a task prefix. Furthermore, it uses a different pre-training objective
+inspired by the pre-training of [`PegasusForConditionalGeneration`].
+- LongT5 model is designed to work efficiently and very well on long-range *sequence-to-sequence* tasks where the
+input sequence exceeds commonly used 512 tokens. It is capable of handling input sequences of a length up to 16,384 tokens.
+- For *Local Attention*, the sparse sliding-window local attention operation allows a given token to attend only `r`
+tokens to the left and right of it (with `r=127` by default). *Local Attention* does not introduce any new parameters
+to the model. The complexity of the mechanism is linear in input sequence length `l`: `O(l*r)`.
+- *Transient Global Attention* is an extension of the *Local Attention*. It, furthermore, allows each input token to
+interact with all other tokens in the layer. This is achieved via splitting an input sequence into blocks of a fixed
+length `k` (with a default `k=16`). Then, a global token for such a block is obtained via summing and normalizing the embeddings of every token
+in the block. Thanks to this, the attention allows each token to attend to both nearby tokens like in Local attention, and
+also every global token like in the case of standard global attention (*transient* represents the fact the global tokens
+are constructed dynamically within each attention operation). As a consequence, *TGlobal* attention introduces
+a few new parameters -- global relative position biases and a layer normalization for global token's embedding.
+The complexity of this mechanism is `O(l(r + l/k))`.
+- An example showing how to evaluate a fine-tuned LongT5 model on the [pubmed dataset](https://huggingface.co/datasets/scientific_papers) is below.
+
+```python
+>>> import evaluate
+>>> from datasets import load_dataset
+>>> from transformers import AutoTokenizer, LongT5ForConditionalGeneration
+
+>>> dataset = load_dataset("scientific_papers", "pubmed", split="validation")
+>>> model = (
+... LongT5ForConditionalGeneration.from_pretrained("Stancld/longt5-tglobal-large-16384-pubmed-3k_steps")
+... .to("cuda")
+... .half()
+... )
+>>> tokenizer = AutoTokenizer.from_pretrained("Stancld/longt5-tglobal-large-16384-pubmed-3k_steps")
+
+
+>>> def generate_answers(batch):
+... inputs_dict = tokenizer(
+... batch["article"], max_length=16384, padding="max_length", truncation=True, return_tensors="pt"
+... )
+... input_ids = inputs_dict.input_ids.to("cuda")
+... attention_mask = inputs_dict.attention_mask.to("cuda")
+... output_ids = model.generate(input_ids, attention_mask=attention_mask, max_length=512, num_beams=2)
+... batch["predicted_abstract"] = tokenizer.batch_decode(output_ids, skip_special_tokens=True)
+... return batch
+
+
+>>> result = dataset.map(generate_answer, batched=True, batch_size=2)
+>>> rouge = evaluate.load("rouge")
+>>> rouge.compute(predictions=result["predicted_abstract"], references=result["abstract"])
+```
+
+
+## Resources
+
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## LongT5Config
+
+[[autodoc]] LongT5Config
+
+
+
+
+## LongT5Model
+
+[[autodoc]] LongT5Model
+ - forward
+
+## LongT5ForConditionalGeneration
+
+[[autodoc]] LongT5ForConditionalGeneration
+ - forward
+
+## LongT5EncoderModel
+
+[[autodoc]] LongT5EncoderModel
+ - forward
+
+
+
+
+## FlaxLongT5Model
+
+[[autodoc]] FlaxLongT5Model
+ - __call__
+ - encode
+ - decode
+
+## FlaxLongT5ForConditionalGeneration
+
+[[autodoc]] FlaxLongT5ForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/luke.md b/docs/transformers/docs/source/en/model_doc/luke.md
new file mode 100644
index 0000000000000000000000000000000000000000..be4d5946dfcf2950afbfdb1e88a506c9383c9a5f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/luke.md
@@ -0,0 +1,185 @@
+
+
+# LUKE
+
+
+
+
+
+## Overview
+
+The LUKE model was proposed in [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda and Yuji Matsumoto.
+It is based on RoBERTa and adds entity embeddings as well as an entity-aware self-attention mechanism, which helps
+improve performance on various downstream tasks involving reasoning about entities such as named entity recognition,
+extractive and cloze-style question answering, entity typing, and relation classification.
+
+The abstract from the paper is the following:
+
+*Entity representations are useful in natural language tasks involving entities. In this paper, we propose new
+pretrained contextualized representations of words and entities based on the bidirectional transformer. The proposed
+model treats words and entities in a given text as independent tokens, and outputs contextualized representations of
+them. Our model is trained using a new pretraining task based on the masked language model of BERT. The task involves
+predicting randomly masked words and entities in a large entity-annotated corpus retrieved from Wikipedia. We also
+propose an entity-aware self-attention mechanism that is an extension of the self-attention mechanism of the
+transformer, and considers the types of tokens (words or entities) when computing attention scores. The proposed model
+achieves impressive empirical performance on a wide range of entity-related tasks. In particular, it obtains
+state-of-the-art results on five well-known datasets: Open Entity (entity typing), TACRED (relation classification),
+CoNLL-2003 (named entity recognition), ReCoRD (cloze-style question answering), and SQuAD 1.1 (extractive question
+answering).*
+
+This model was contributed by [ikuyamada](https://huggingface.co/ikuyamada) and [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/studio-ousia/luke).
+
+## Usage tips
+
+- This implementation is the same as [`RobertaModel`] with the addition of entity embeddings as well
+ as an entity-aware self-attention mechanism, which improves performance on tasks involving reasoning about entities.
+- LUKE treats entities as input tokens; therefore, it takes `entity_ids`, `entity_attention_mask`,
+ `entity_token_type_ids` and `entity_position_ids` as extra input. You can obtain those using
+ [`LukeTokenizer`].
+- [`LukeTokenizer`] takes `entities` and `entity_spans` (character-based start and end
+ positions of the entities in the input text) as extra input. `entities` typically consist of [MASK] entities or
+ Wikipedia entities. The brief description when inputting these entities are as follows:
+
+ - *Inputting [MASK] entities to compute entity representations*: The [MASK] entity is used to mask entities to be
+ predicted during pretraining. When LUKE receives the [MASK] entity, it tries to predict the original entity by
+ gathering the information about the entity from the input text. Therefore, the [MASK] entity can be used to address
+ downstream tasks requiring the information of entities in text such as entity typing, relation classification, and
+ named entity recognition.
+ - *Inputting Wikipedia entities to compute knowledge-enhanced token representations*: LUKE learns rich information
+ (or knowledge) about Wikipedia entities during pretraining and stores the information in its entity embedding. By
+ using Wikipedia entities as input tokens, LUKE outputs token representations enriched by the information stored in
+ the embeddings of these entities. This is particularly effective for tasks requiring real-world knowledge, such as
+ question answering.
+
+- There are three head models for the former use case:
+
+ - [`LukeForEntityClassification`], for tasks to classify a single entity in an input text such as
+ entity typing, e.g. the [Open Entity dataset](https://www.cs.utexas.edu/~eunsol/html_pages/open_entity.html).
+ This model places a linear head on top of the output entity representation.
+ - [`LukeForEntityPairClassification`], for tasks to classify the relationship between two entities
+ such as relation classification, e.g. the [TACRED dataset](https://nlp.stanford.edu/projects/tacred/). This
+ model places a linear head on top of the concatenated output representation of the pair of given entities.
+ - [`LukeForEntitySpanClassification`], for tasks to classify the sequence of entity spans, such as
+ named entity recognition (NER). This model places a linear head on top of the output entity representations. You
+ can address NER using this model by inputting all possible entity spans in the text to the model.
+
+ [`LukeTokenizer`] has a `task` argument, which enables you to easily create an input to these
+ head models by specifying `task="entity_classification"`, `task="entity_pair_classification"`, or
+ `task="entity_span_classification"`. Please refer to the example code of each head models.
+
+Usage example:
+
+```python
+>>> from transformers import LukeTokenizer, LukeModel, LukeForEntityPairClassification
+
+>>> model = LukeModel.from_pretrained("studio-ousia/luke-base")
+>>> tokenizer = LukeTokenizer.from_pretrained("studio-ousia/luke-base")
+# Example 1: Computing the contextualized entity representation corresponding to the entity mention "Beyoncé"
+
+>>> text = "Beyoncé lives in Los Angeles."
+>>> entity_spans = [(0, 7)] # character-based entity span corresponding to "Beyoncé"
+>>> inputs = tokenizer(text, entity_spans=entity_spans, add_prefix_space=True, return_tensors="pt")
+>>> outputs = model(**inputs)
+>>> word_last_hidden_state = outputs.last_hidden_state
+>>> entity_last_hidden_state = outputs.entity_last_hidden_state
+# Example 2: Inputting Wikipedia entities to obtain enriched contextualized representations
+
+>>> entities = [
+... "Beyoncé",
+... "Los Angeles",
+... ] # Wikipedia entity titles corresponding to the entity mentions "Beyoncé" and "Los Angeles"
+>>> entity_spans = [(0, 7), (17, 28)] # character-based entity spans corresponding to "Beyoncé" and "Los Angeles"
+>>> inputs = tokenizer(text, entities=entities, entity_spans=entity_spans, add_prefix_space=True, return_tensors="pt")
+>>> outputs = model(**inputs)
+>>> word_last_hidden_state = outputs.last_hidden_state
+>>> entity_last_hidden_state = outputs.entity_last_hidden_state
+# Example 3: Classifying the relationship between two entities using LukeForEntityPairClassification head model
+
+>>> model = LukeForEntityPairClassification.from_pretrained("studio-ousia/luke-large-finetuned-tacred")
+>>> tokenizer = LukeTokenizer.from_pretrained("studio-ousia/luke-large-finetuned-tacred")
+>>> entity_spans = [(0, 7), (17, 28)] # character-based entity spans corresponding to "Beyoncé" and "Los Angeles"
+>>> inputs = tokenizer(text, entity_spans=entity_spans, return_tensors="pt")
+>>> outputs = model(**inputs)
+>>> logits = outputs.logits
+>>> predicted_class_idx = int(logits[0].argmax())
+>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
+```
+
+## Resources
+
+- [A demo notebook on how to fine-tune [`LukeForEntityPairClassification`] for relation classification](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LUKE)
+- [Notebooks showcasing how you to reproduce the results as reported in the paper with the HuggingFace implementation of LUKE](https://github.com/studio-ousia/luke/tree/master/notebooks)
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## LukeConfig
+
+[[autodoc]] LukeConfig
+
+## LukeTokenizer
+
+[[autodoc]] LukeTokenizer
+ - __call__
+ - save_vocabulary
+
+## LukeModel
+
+[[autodoc]] LukeModel
+ - forward
+
+## LukeForMaskedLM
+
+[[autodoc]] LukeForMaskedLM
+ - forward
+
+## LukeForEntityClassification
+
+[[autodoc]] LukeForEntityClassification
+ - forward
+
+## LukeForEntityPairClassification
+
+[[autodoc]] LukeForEntityPairClassification
+ - forward
+
+## LukeForEntitySpanClassification
+
+[[autodoc]] LukeForEntitySpanClassification
+ - forward
+
+## LukeForSequenceClassification
+
+[[autodoc]] LukeForSequenceClassification
+ - forward
+
+## LukeForMultipleChoice
+
+[[autodoc]] LukeForMultipleChoice
+ - forward
+
+## LukeForTokenClassification
+
+[[autodoc]] LukeForTokenClassification
+ - forward
+
+## LukeForQuestionAnswering
+
+[[autodoc]] LukeForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/lxmert.md b/docs/transformers/docs/source/en/model_doc/lxmert.md
new file mode 100644
index 0000000000000000000000000000000000000000..a0f686efc35d0437c943d11bfb9f98e0aef680c9
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/lxmert.md
@@ -0,0 +1,123 @@
+
+
+# LXMERT
+
+
+
+
+
+
+## Overview
+
+The LXMERT model was proposed in [LXMERT: Learning Cross-Modality Encoder Representations from Transformers](https://arxiv.org/abs/1908.07490) by Hao Tan & Mohit Bansal. It is a series of bidirectional transformer encoders
+(one for the vision modality, one for the language modality, and then one to fuse both modalities) pretrained using a
+combination of masked language modeling, visual-language text alignment, ROI-feature regression, masked
+visual-attribute modeling, masked visual-object modeling, and visual-question answering objectives. The pretraining
+consists of multiple multi-modal datasets: MSCOCO, Visual-Genome + Visual-Genome Question Answering, VQA 2.0, and GQA.
+
+The abstract from the paper is the following:
+
+*Vision-and-language reasoning requires an understanding of visual concepts, language semantics, and, most importantly,
+the alignment and relationships between these two modalities. We thus propose the LXMERT (Learning Cross-Modality
+Encoder Representations from Transformers) framework to learn these vision-and-language connections. In LXMERT, we
+build a large-scale Transformer model that consists of three encoders: an object relationship encoder, a language
+encoder, and a cross-modality encoder. Next, to endow our model with the capability of connecting vision and language
+semantics, we pre-train the model with large amounts of image-and-sentence pairs, via five diverse representative
+pretraining tasks: masked language modeling, masked object prediction (feature regression and label classification),
+cross-modality matching, and image question answering. These tasks help in learning both intra-modality and
+cross-modality relationships. After fine-tuning from our pretrained parameters, our model achieves the state-of-the-art
+results on two visual question answering datasets (i.e., VQA and GQA). We also show the generalizability of our
+pretrained cross-modality model by adapting it to a challenging visual-reasoning task, NLVR, and improve the previous
+best result by 22% absolute (54% to 76%). Lastly, we demonstrate detailed ablation studies to prove that both our novel
+model components and pretraining strategies significantly contribute to our strong results; and also present several
+attention visualizations for the different encoders*
+
+This model was contributed by [eltoto1219](https://huggingface.co/eltoto1219). The original code can be found [here](https://github.com/airsplay/lxmert).
+
+## Usage tips
+
+- Bounding boxes are not necessary to be used in the visual feature embeddings, any kind of visual-spacial features
+ will work.
+- Both the language hidden states and the visual hidden states that LXMERT outputs are passed through the
+ cross-modality layer, so they contain information from both modalities. To access a modality that only attends to
+ itself, select the vision/language hidden states from the first input in the tuple.
+- The bidirectional cross-modality encoder attention only returns attention values when the language modality is used
+ as the input and the vision modality is used as the context vector. Further, while the cross-modality encoder
+ contains self-attention for each respective modality and cross-attention, only the cross attention is returned and
+ both self attention outputs are disregarded.
+
+## Resources
+
+- [Question answering task guide](../tasks/question_answering)
+
+## LxmertConfig
+
+[[autodoc]] LxmertConfig
+
+## LxmertTokenizer
+
+[[autodoc]] LxmertTokenizer
+
+## LxmertTokenizerFast
+
+[[autodoc]] LxmertTokenizerFast
+
+## Lxmert specific outputs
+
+[[autodoc]] models.lxmert.modeling_lxmert.LxmertModelOutput
+
+[[autodoc]] models.lxmert.modeling_lxmert.LxmertForPreTrainingOutput
+
+[[autodoc]] models.lxmert.modeling_lxmert.LxmertForQuestionAnsweringOutput
+
+[[autodoc]] models.lxmert.modeling_tf_lxmert.TFLxmertModelOutput
+
+[[autodoc]] models.lxmert.modeling_tf_lxmert.TFLxmertForPreTrainingOutput
+
+
+
+
+## LxmertModel
+
+[[autodoc]] LxmertModel
+ - forward
+
+## LxmertForPreTraining
+
+[[autodoc]] LxmertForPreTraining
+ - forward
+
+## LxmertForQuestionAnswering
+
+[[autodoc]] LxmertForQuestionAnswering
+ - forward
+
+
+
+
+## TFLxmertModel
+
+[[autodoc]] TFLxmertModel
+ - call
+
+## TFLxmertForPreTraining
+
+[[autodoc]] TFLxmertForPreTraining
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/m2m_100.md b/docs/transformers/docs/source/en/model_doc/m2m_100.md
new file mode 100644
index 0000000000000000000000000000000000000000..f4f2955bb046f310195a2b50c81058dad8a99651
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/m2m_100.md
@@ -0,0 +1,189 @@
+
+
+# M2M100
+
+
+
+
+
+
+
+## Overview
+
+The M2M100 model was proposed in [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky,
+Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy
+Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+
+The abstract from the paper is the following:
+
+*Existing work in translation demonstrated the potential of massively multilingual machine translation by training a
+single model able to translate between any pair of languages. However, much of this work is English-Centric by training
+only on data which was translated from or to English. While this is supported by large sources of training data, it
+does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation
+model that can translate directly between any pair of 100 languages. We build and open source a training dataset that
+covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how
+to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters
+to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly
+translating between non-English directions while performing competitively to the best single systems of WMT. We
+open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.*
+
+This model was contributed by [valhalla](https://huggingface.co/valhalla).
+
+
+## Usage tips and examples
+
+M2M100 is a multilingual encoder-decoder (seq-to-seq) model primarily intended for translation tasks. As the model is
+multilingual it expects the sequences in a certain format: A special language id token is used as prefix in both the
+source and target text. The source text format is `[lang_code] X [eos]`, where `lang_code` is source language
+id for source text and target language id for target text, with `X` being the source or target text.
+
+The [`M2M100Tokenizer`] depends on `sentencepiece` so be sure to install it before running the
+examples. To install `sentencepiece` run `pip install sentencepiece`.
+
+**Supervised Training**
+
+```python
+from transformers import M2M100Config, M2M100ForConditionalGeneration, M2M100Tokenizer
+
+model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
+tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="en", tgt_lang="fr")
+
+src_text = "Life is like a box of chocolates."
+tgt_text = "La vie est comme une boîte de chocolat."
+
+model_inputs = tokenizer(src_text, text_target=tgt_text, return_tensors="pt")
+
+loss = model(**model_inputs).loss # forward pass
+```
+
+**Generation**
+
+M2M100 uses the `eos_token_id` as the `decoder_start_token_id` for generation with the target language id
+being forced as the first generated token. To force the target language id as the first generated token, pass the
+*forced_bos_token_id* parameter to the *generate* method. The following example shows how to translate between
+Hindi to French and Chinese to English using the *facebook/m2m100_418M* checkpoint.
+
+```python
+>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
+
+>>> hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
+>>> chinese_text = "生活就像一盒巧克力。"
+
+>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
+>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
+
+>>> # translate Hindi to French
+>>> tokenizer.src_lang = "hi"
+>>> encoded_hi = tokenizer(hi_text, return_tensors="pt")
+>>> generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+"La vie est comme une boîte de chocolat."
+
+>>> # translate Chinese to English
+>>> tokenizer.src_lang = "zh"
+>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
+>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+"Life is like a box of chocolate."
+```
+
+## Resources
+
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## M2M100Config
+
+[[autodoc]] M2M100Config
+
+## M2M100Tokenizer
+
+[[autodoc]] M2M100Tokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## M2M100Model
+
+[[autodoc]] M2M100Model
+ - forward
+
+## M2M100ForConditionalGeneration
+
+[[autodoc]] M2M100ForConditionalGeneration
+ - forward
+
+## Using Flash Attention 2
+
+Flash Attention 2 is a faster, optimized version of the attention scores computation which relies on `cuda` kernels.
+
+### Installation
+
+First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features).
+
+Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+### Usage
+
+To load a model using Flash Attention 2, we can pass the argument `attn_implementation="flash_attention_2"` to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). You can use either `torch.float16` or `torch.bfloat16` precision.
+
+```python
+>>> import torch
+>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
+
+>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda").eval()
+>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
+
+>>> # translate Hindi to French
+>>> hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
+>>> tokenizer.src_lang = "hi"
+>>> encoded_hi = tokenizer(hi_text, return_tensors="pt").to("cuda")
+>>> generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+"La vie est comme une boîte de chocolat."
+```
+
+### Expected speedups
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation and the Flash Attention 2.
+
+
+
+
+
+## Using Scaled Dot Product Attention (SDPA)
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```python
+from transformers import M2M100ForConditionalGeneration
+model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M", torch_dtype=torch.float16, attn_implementation="sdpa")
+...
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/madlad-400.md b/docs/transformers/docs/source/en/model_doc/madlad-400.md
new file mode 100644
index 0000000000000000000000000000000000000000..db6abc38eaf1fba33945f85815a0c8dd692350da
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/madlad-400.md
@@ -0,0 +1,75 @@
+
+
+# MADLAD-400
+
+
+
+
+
+
+
+## Overview
+
+MADLAD-400 models were released in the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](MADLAD-400: A Multilingual And Document-Level Large Audited Dataset).
+
+The abstract from the paper is the following:
+
+*We introduce MADLAD-400, a manually audited, general domain 3T token monolingual dataset based on CommonCrawl, spanning 419 languages. We discuss
+the limitations revealed by self-auditing MADLAD-400, and the role data auditing
+had in the dataset creation process. We then train and release a 10.7B-parameter
+multilingual machine translation model on 250 billion tokens covering over 450
+languages using publicly available data, and find that it is competitive with models
+that are significantly larger, and report the results on different domains. In addition, we train a 8B-parameter language model, and assess the results on few-shot
+translation. We make the baseline models 1
+available to the research community.*
+
+This model was added by [Juarez Bochi](https://huggingface.co/jbochi). The original checkpoints can be found [here](https://github.com/google-research/google-research/tree/master/madlad_400).
+
+This is a machine translation model that supports many low-resource languages, and that is competitive with models that are significantly larger.
+
+One can directly use MADLAD-400 weights without finetuning the model:
+
+```python
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/madlad400-3b-mt")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/madlad400-3b-mt")
+
+>>> inputs = tokenizer("<2pt> I love pizza!", return_tensors="pt")
+>>> outputs = model.generate(**inputs)
+>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['Eu amo pizza!']
+```
+
+Google has released the following variants:
+
+- [google/madlad400-3b-mt](https://huggingface.co/google/madlad400-3b-mt)
+
+- [google/madlad400-7b-mt](https://huggingface.co/google/madlad400-7b-mt)
+
+- [google/madlad400-7b-mt-bt](https://huggingface.co/google/madlad400-7b-mt-bt)
+
+- [google/madlad400-10b-mt](https://huggingface.co/google/madlad400-10b-mt)
+
+The original checkpoints can be found [here](https://github.com/google-research/google-research/tree/master/madlad_400).
+
+
+
+Refer to [T5's documentation page](t5) for all API references, code examples, and notebooks. For more details regarding training and evaluation of the MADLAD-400, refer to the model card.
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/mamba.md b/docs/transformers/docs/source/en/model_doc/mamba.md
new file mode 100644
index 0000000000000000000000000000000000000000..d5c0612b1ebe15de3001091f3d6459a08eebf03b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mamba.md
@@ -0,0 +1,108 @@
+
+
+# Mamba
+
+
+
+
+
+## Overview
+
+The Mamba model was proposed in [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752) by Albert Gu and Tri Dao.
+
+This model is a new paradigm architecture based on `state-space-models`. You can read more about the intuition behind these [here](https://srush.github.io/annotated-s4/).
+
+The abstract from the paper is the following:
+
+*Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5× higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.*
+
+Tips:
+
+- Mamba is a new `state space model` architecture that rivals the classic Transformers. It is based on the line of progress on structured state space models, with an efficient hardware-aware design and implementation in the spirit of [FlashAttention](https://github.com/Dao-AILab/flash-attention).
+- Mamba stacks `mixer` layers, which are the equivalent of `Attention` layers. The core logic of `mamba` is held in the `MambaMixer` class.
+- Two implementations cohabit: one is optimized and uses fast cuda kernels, while the other one is naive but can run on any device!
+- The current implementation leverages the original cuda kernels: the equivalent of flash attention for Mamba are hosted in the [`mamba-ssm`](https://github.com/state-spaces/mamba) and the [`causal_conv1d`](https://github.com/Dao-AILab/causal-conv1d) repositories. Make sure to install them if your hardware supports them!
+- Contributions to make the naive path faster are welcome 🤗
+
+This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/state-spaces/mamba).
+
+# Usage
+
+### A simple generation example:
+```python
+from transformers import MambaConfig, MambaForCausalLM, AutoTokenizer
+import torch
+
+tokenizer = AutoTokenizer.from_pretrained("state-spaces/mamba-130m-hf")
+model = MambaForCausalLM.from_pretrained("state-spaces/mamba-130m-hf")
+input_ids = tokenizer("Hey how are you doing?", return_tensors= "pt")["input_ids"]
+
+out = model.generate(input_ids, max_new_tokens=10)
+print(tokenizer.batch_decode(out))
+```
+
+### Peft finetuning
+The slow version is not very stable for training, and the fast one needs `float32`!
+
+```python
+from datasets import load_dataset
+from trl import SFTTrainer
+from peft import LoraConfig
+from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments
+model_id = "state-spaces/mamba-130m-hf"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = AutoModelForCausalLM.from_pretrained(model_id)
+dataset = load_dataset("Abirate/english_quotes", split="train")
+training_args = TrainingArguments(
+ output_dir="./results",
+ num_train_epochs=3,
+ per_device_train_batch_size=4,
+ logging_dir='./logs',
+ logging_steps=10,
+ learning_rate=2e-3
+)
+lora_config = LoraConfig(
+ r=8,
+ target_modules=["x_proj", "embeddings", "in_proj", "out_proj"],
+ task_type="CAUSAL_LM",
+ bias="none"
+)
+trainer = SFTTrainer(
+ model=model,
+ processing_class=tokenizer,
+ args=training_args,
+ peft_config=lora_config,
+ train_dataset=dataset,
+ dataset_text_field="quote",
+)
+trainer.train()
+```
+
+## MambaConfig
+
+[[autodoc]] MambaConfig
+
+## MambaModel
+
+[[autodoc]] MambaModel
+ - forward
+
+## MambaLMHeadModel
+
+[[autodoc]] MambaForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mamba2.md b/docs/transformers/docs/source/en/model_doc/mamba2.md
new file mode 100644
index 0000000000000000000000000000000000000000..8d88d6c02652e50c3efacc1bdc7277dcabda1376
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mamba2.md
@@ -0,0 +1,110 @@
+
+
+# Mamba 2
+
+
+
+
+
+## Overview
+
+The Mamba2 model was proposed in [Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality](https://arxiv.org/abs/2405.21060) by Tri Dao and Albert Gu. It is a State Space Model similar to Mamba 1, with better performances in a simplified architecture.
+
+
+The abstract from the paper is the following:
+
+*While Transformers have been the main architecture behind deep learning's success in language modeling, state-space models (SSMs) such as Mamba have recently been shown to match or outperform Transformers at small to medium scale. We show that these families of models are actually quite closely related, and develop a rich framework of theoretical connections between SSMs and variants of attention, connected through various decompositions of a well-studied class of structured semiseparable matrices. Our state space duality (SSD) framework allows us to design a new architecture (Mamba-2) whose core layer is an a refinement of Mamba's selective SSM that is 2-8X faster, while continuing to be competitive with Transformers on language modeling.*
+
+Tips:
+
+This version should support all implementations of Mamba 2, and in particular [Mamba-2 codestral](https://huggingface.co/mistralai/Mamba-Codestral-7B-v0.1) from Mistral AI. In particular, mamba 2 codestral was released with a number of `groups` equal to 8, which can be thought intuitively as similar to the number of kv heads in an attention-based model.
+This model has two different forward passes, `torch_forward` or `cuda_kernels_forward`. The latter uses the original cuda kernels if they are found in your environment, and is slower on the prefill i.e. requires a "warmup run" due to high cpu overhead, see [here](https://github.com/state-spaces/mamba/issues/389#issuecomment-2171755306) and [also here](https://github.com/state-spaces/mamba/issues/355#issuecomment-2147597457). Without compilation, the `torch_forward` implementation is faster by a factor 3 to 4. Further, there are no positional embeddings in this model, but there is an `attention_mask` and a specific logic to mask out hidden states in two places in the case of batched generation, see [here](https://github.com/state-spaces/mamba/issues/66#issuecomment-1863563829) as well. Due to this, in addition to the reimplementation of mamba2 kernels, batched generation and cached generation are expected to have slight discrepancies. Further, the results given by the cuda kernels or the torch forward are expected to be slightly different. The SSM algorithm heavily relies on tensor contractions, which have matmul equivalents but the order of operations is slightly different, making the difference greater at smaller precisions.
+Another note, shutdown of hidden states corresponding to padding tokens is done in 2 places and mostly has been tested with left-padding. Right-padding will propagate noise down the line and is not guaranteed to yield satisfactory results. `tokenizer.padding_side = "left"` ensures you are using the correct padding side.
+
+This model was contributed by [Molbap](https://huggingface.co/Molbap), with tremendous help from [Anton Vlasjuk](https://github.com/vasqu).
+The original code can be found [here](https://github.com/state-spaces/mamba).
+
+
+# Usage
+
+### A simple generation example:
+```python
+from transformers import Mamba2Config, Mamba2ForCausalLM, AutoTokenizer
+import torch
+model_id = 'mistralai/Mamba-Codestral-7B-v0.1'
+tokenizer = AutoTokenizer.from_pretrained(model_id, revision='refs/pr/9', from_slow=True, legacy=False)
+model = Mamba2ForCausalLM.from_pretrained(model_id, revision='refs/pr/9')
+input_ids = tokenizer("Hey how are you doing?", return_tensors= "pt")["input_ids"]
+
+out = model.generate(input_ids, max_new_tokens=10)
+print(tokenizer.batch_decode(out))
+```
+
+Here's a draft script for finetuning:
+```python
+from trl import SFTTrainer
+from peft import LoraConfig
+from transformers import AutoTokenizer, Mamba2ForCausalLM, TrainingArguments
+model_id = 'mistralai/Mamba-Codestral-7B-v0.1'
+tokenizer = AutoTokenizer.from_pretrained(model_id, revision='refs/pr/9', from_slow=True, legacy=False)
+tokenizer.pad_token = tokenizer.eos_token
+tokenizer.padding_side = "left" #enforce padding side left
+
+model = Mamba2ForCausalLM.from_pretrained(model_id, revision='refs/pr/9')
+dataset = load_dataset("Abirate/english_quotes", split="train")
+# Without CUDA kernels, batch size of 2 occupies one 80GB device
+# but precision can be reduced.
+# Experiments and trials welcome!
+training_args = TrainingArguments(
+ output_dir="./results",
+ num_train_epochs=3,
+ per_device_train_batch_size=2,
+ logging_dir='./logs',
+ logging_steps=10,
+ learning_rate=2e-3
+)
+lora_config = LoraConfig(
+ r=8,
+ target_modules=["embeddings", "in_proj", "out_proj"],
+ task_type="CAUSAL_LM",
+ bias="none"
+)
+trainer = SFTTrainer(
+ model=model,
+ tokenizer=tokenizer,
+ args=training_args,
+ peft_config=lora_config,
+ train_dataset=dataset,
+ dataset_text_field="quote",
+)
+trainer.train()
+```
+
+
+## Mamba2Config
+
+[[autodoc]] Mamba2Config
+
+## Mamba2Model
+
+[[autodoc]] Mamba2Model
+ - forward
+
+## Mamba2LMHeadModel
+
+[[autodoc]] Mamba2ForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/marian.md b/docs/transformers/docs/source/en/model_doc/marian.md
new file mode 100644
index 0000000000000000000000000000000000000000..80bb73d26df121000a8d6a2343142489532cbf08
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/marian.md
@@ -0,0 +1,223 @@
+
+
+# MarianMT
+
+
+
+
+
+
+
+## Overview
+
+A framework for translation models, using the same models as BART. Translations should be similar, but not identical to output in the test set linked to in each model card.
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer).
+
+
+## Implementation Notes
+
+- Each model is about 298 MB on disk, there are more than 1,000 models.
+- The list of supported language pairs can be found [here](https://huggingface.co/Helsinki-NLP).
+- Models were originally trained by [Jörg Tiedemann](https://researchportal.helsinki.fi/en/persons/j%C3%B6rg-tiedemann) using the [Marian](https://marian-nmt.github.io/) C++ library, which supports fast training and translation.
+- All models are transformer encoder-decoders with 6 layers in each component. Each model's performance is documented
+ in a model card.
+- The 80 opus models that require BPE preprocessing are not supported.
+- The modeling code is the same as [`BartForConditionalGeneration`] with a few minor modifications:
+
+ - static (sinusoid) positional embeddings (`MarianConfig.static_position_embeddings=True`)
+ - no layernorm_embedding (`MarianConfig.normalize_embedding=False`)
+ - the model starts generating with `pad_token_id` (which has 0 as a token_embedding) as the prefix (Bart uses
+ ``),
+- Code to bulk convert models can be found in `convert_marian_to_pytorch.py`.
+
+
+## Naming
+
+- All model names use the following format: `Helsinki-NLP/opus-mt-{src}-{tgt}`
+- The language codes used to name models are inconsistent. Two digit codes can usually be found [here](https://developers.google.com/admin-sdk/directory/v1/languages), three digit codes require googling "language
+ code {code}".
+- Codes formatted like `es_AR` are usually `code_{region}`. That one is Spanish from Argentina.
+- The models were converted in two stages. The first 1000 models use ISO-639-2 codes to identify languages, the second
+ group use a combination of ISO-639-5 codes and ISO-639-2 codes.
+
+
+## Examples
+
+- Since Marian models are smaller than many other translation models available in the library, they can be useful for
+ fine-tuning experiments and integration tests.
+- [Fine-tune on GPU](https://github.com/huggingface/transformers/blob/master/examples/legacy/seq2seq/train_distil_marian_enro.sh)
+
+## Multilingual Models
+
+- All model names use the following format: `Helsinki-NLP/opus-mt-{src}-{tgt}`:
+- If a model can output multiple languages, and you should specify a language code by prepending the desired output
+ language to the `src_text`.
+- You can see a models's supported language codes in its model card, under target constituents, like in [opus-mt-en-roa](https://huggingface.co/Helsinki-NLP/opus-mt-en-roa).
+- Note that if a model is only multilingual on the source side, like `Helsinki-NLP/opus-mt-roa-en`, no language
+ codes are required.
+
+New multi-lingual models from the [Tatoeba-Challenge repo](https://github.com/Helsinki-NLP/Tatoeba-Challenge)
+require 3 character language codes:
+
+```python
+>>> from transformers import MarianMTModel, MarianTokenizer
+
+>>> src_text = [
+... ">>fra<< this is a sentence in english that we want to translate to french",
+... ">>por<< This should go to portuguese",
+... ">>esp<< And this to Spanish",
+... ]
+
+>>> model_name = "Helsinki-NLP/opus-mt-en-roa"
+>>> tokenizer = MarianTokenizer.from_pretrained(model_name)
+>>> print(tokenizer.supported_language_codes)
+['>>zlm_Latn<<', '>>mfe<<', '>>hat<<', '>>pap<<', '>>ast<<', '>>cat<<', '>>ind<<', '>>glg<<', '>>wln<<', '>>spa<<', '>>fra<<', '>>ron<<', '>>por<<', '>>ita<<', '>>oci<<', '>>arg<<', '>>min<<']
+
+>>> model = MarianMTModel.from_pretrained(model_name)
+>>> translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
+>>> [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
+["c'est une phrase en anglais que nous voulons traduire en français",
+ 'Isto deve ir para o português.',
+ 'Y esto al español']
+```
+
+Here is the code to see all available pretrained models on the hub:
+
+```python
+from huggingface_hub import list_models
+
+model_list = list_models()
+org = "Helsinki-NLP"
+model_ids = [x.id for x in model_list if x.id.startswith(org)]
+suffix = [x.split("/")[1] for x in model_ids]
+old_style_multi_models = [f"{org}/{s}" for s in suffix if s != s.lower()]
+```
+
+## Old Style Multi-Lingual Models
+
+These are the old style multi-lingual models ported from the OPUS-MT-Train repo: and the members of each language
+group:
+
+```python no-style
+['Helsinki-NLP/opus-mt-NORTH_EU-NORTH_EU',
+ 'Helsinki-NLP/opus-mt-ROMANCE-en',
+ 'Helsinki-NLP/opus-mt-SCANDINAVIA-SCANDINAVIA',
+ 'Helsinki-NLP/opus-mt-de-ZH',
+ 'Helsinki-NLP/opus-mt-en-CELTIC',
+ 'Helsinki-NLP/opus-mt-en-ROMANCE',
+ 'Helsinki-NLP/opus-mt-es-NORWAY',
+ 'Helsinki-NLP/opus-mt-fi-NORWAY',
+ 'Helsinki-NLP/opus-mt-fi-ZH',
+ 'Helsinki-NLP/opus-mt-fi_nb_no_nn_ru_sv_en-SAMI',
+ 'Helsinki-NLP/opus-mt-sv-NORWAY',
+ 'Helsinki-NLP/opus-mt-sv-ZH']
+GROUP_MEMBERS = {
+ 'ZH': ['cmn', 'cn', 'yue', 'ze_zh', 'zh_cn', 'zh_CN', 'zh_HK', 'zh_tw', 'zh_TW', 'zh_yue', 'zhs', 'zht', 'zh'],
+ 'ROMANCE': ['fr', 'fr_BE', 'fr_CA', 'fr_FR', 'wa', 'frp', 'oc', 'ca', 'rm', 'lld', 'fur', 'lij', 'lmo', 'es', 'es_AR', 'es_CL', 'es_CO', 'es_CR', 'es_DO', 'es_EC', 'es_ES', 'es_GT', 'es_HN', 'es_MX', 'es_NI', 'es_PA', 'es_PE', 'es_PR', 'es_SV', 'es_UY', 'es_VE', 'pt', 'pt_br', 'pt_BR', 'pt_PT', 'gl', 'lad', 'an', 'mwl', 'it', 'it_IT', 'co', 'nap', 'scn', 'vec', 'sc', 'ro', 'la'],
+ 'NORTH_EU': ['de', 'nl', 'fy', 'af', 'da', 'fo', 'is', 'no', 'nb', 'nn', 'sv'],
+ 'SCANDINAVIA': ['da', 'fo', 'is', 'no', 'nb', 'nn', 'sv'],
+ 'SAMI': ['se', 'sma', 'smj', 'smn', 'sms'],
+ 'NORWAY': ['nb_NO', 'nb', 'nn_NO', 'nn', 'nog', 'no_nb', 'no'],
+ 'CELTIC': ['ga', 'cy', 'br', 'gd', 'kw', 'gv']
+}
+```
+
+Example of translating english to many romance languages, using old-style 2 character language codes
+
+
+```python
+>>> from transformers import MarianMTModel, MarianTokenizer
+
+>>> src_text = [
+... ">>fr<< this is a sentence in english that we want to translate to french",
+... ">>pt<< This should go to portuguese",
+... ">>es<< And this to Spanish",
+... ]
+
+>>> model_name = "Helsinki-NLP/opus-mt-en-ROMANCE"
+>>> tokenizer = MarianTokenizer.from_pretrained(model_name)
+
+>>> model = MarianMTModel.from_pretrained(model_name)
+>>> translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
+>>> tgt_text = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
+["c'est une phrase en anglais que nous voulons traduire en français",
+ 'Isto deve ir para o português.',
+ 'Y esto al español']
+```
+
+## Resources
+
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+- [Causal language modeling task guide](../tasks/language_modeling)
+
+## MarianConfig
+
+[[autodoc]] MarianConfig
+
+## MarianTokenizer
+
+[[autodoc]] MarianTokenizer
+ - build_inputs_with_special_tokens
+
+
+
+
+## MarianModel
+
+[[autodoc]] MarianModel
+ - forward
+
+## MarianMTModel
+
+[[autodoc]] MarianMTModel
+ - forward
+
+## MarianForCausalLM
+
+[[autodoc]] MarianForCausalLM
+ - forward
+
+
+
+
+## TFMarianModel
+
+[[autodoc]] TFMarianModel
+ - call
+
+## TFMarianMTModel
+
+[[autodoc]] TFMarianMTModel
+ - call
+
+
+
+
+## FlaxMarianModel
+
+[[autodoc]] FlaxMarianModel
+ - __call__
+
+## FlaxMarianMTModel
+
+[[autodoc]] FlaxMarianMTModel
+ - __call__
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/markuplm.md b/docs/transformers/docs/source/en/model_doc/markuplm.md
new file mode 100644
index 0000000000000000000000000000000000000000..72948da2c5af42913dae55768f3d044fe84ca375
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/markuplm.md
@@ -0,0 +1,257 @@
+
+
+# MarkupLM
+
+
+
+
+
+## Overview
+
+The MarkupLM model was proposed in [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document
+Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei. MarkupLM is BERT, but
+applied to HTML pages instead of raw text documents. The model incorporates additional embedding layers to improve
+performance, similar to [LayoutLM](layoutlm).
+
+The model can be used for tasks like question answering on web pages or information extraction from web pages. It obtains
+state-of-the-art results on 2 important benchmarks:
+- [WebSRC](https://x-lance.github.io/WebSRC/), a dataset for Web-Based Structural Reading Comprehension (a bit like SQuAD but for web pages)
+- [SWDE](https://www.researchgate.net/publication/221299838_From_one_tree_to_a_forest_a_unified_solution_for_structured_web_data_extraction), a dataset
+for information extraction from web pages (basically named-entity recognition on web pages)
+
+The abstract from the paper is the following:
+
+*Multimodal pre-training with text, layout, and image has made significant progress for Visually-rich Document
+Understanding (VrDU), especially the fixed-layout documents such as scanned document images. While, there are still a
+large number of digital documents where the layout information is not fixed and needs to be interactively and
+dynamically rendered for visualization, making existing layout-based pre-training approaches not easy to apply. In this
+paper, we propose MarkupLM for document understanding tasks with markup languages as the backbone such as
+HTML/XML-based documents, where text and markup information is jointly pre-trained. Experiment results show that the
+pre-trained MarkupLM significantly outperforms the existing strong baseline models on several document understanding
+tasks. The pre-trained model and code will be publicly available.*
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/markuplm).
+
+## Usage tips
+
+- In addition to `input_ids`, [`~MarkupLMModel.forward`] expects 2 additional inputs, namely `xpath_tags_seq` and `xpath_subs_seq`.
+These are the XPATH tags and subscripts respectively for each token in the input sequence.
+- One can use [`MarkupLMProcessor`] to prepare all data for the model. Refer to the [usage guide](#usage-markuplmprocessor) for more info.
+
+
+
+ MarkupLM architecture. Taken from the original paper.
+
+## Usage: MarkupLMProcessor
+
+The easiest way to prepare data for the model is to use [`MarkupLMProcessor`], which internally combines a feature extractor
+([`MarkupLMFeatureExtractor`]) and a tokenizer ([`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`]). The feature extractor is
+used to extract all nodes and xpaths from the HTML strings, which are then provided to the tokenizer, which turns them into the
+token-level inputs of the model (`input_ids` etc.). Note that you can still use the feature extractor and tokenizer separately,
+if you only want to handle one of the two tasks.
+
+```python
+from transformers import MarkupLMFeatureExtractor, MarkupLMTokenizerFast, MarkupLMProcessor
+
+feature_extractor = MarkupLMFeatureExtractor()
+tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
+processor = MarkupLMProcessor(feature_extractor, tokenizer)
+```
+
+In short, one can provide HTML strings (and possibly additional data) to [`MarkupLMProcessor`],
+and it will create the inputs expected by the model. Internally, the processor first uses
+[`MarkupLMFeatureExtractor`] to get a list of nodes and corresponding xpaths. The nodes and
+xpaths are then provided to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`], which converts them
+to token-level `input_ids`, `attention_mask`, `token_type_ids`, `xpath_subs_seq`, `xpath_tags_seq`.
+Optionally, one can provide node labels to the processor, which are turned into token-level `labels`.
+
+[`MarkupLMFeatureExtractor`] uses [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/), a Python library for
+pulling data out of HTML and XML files, under the hood. Note that you can still use your own parsing solution of
+choice, and provide the nodes and xpaths yourself to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`].
+
+In total, there are 5 use cases that are supported by the processor. Below, we list them all. Note that each of these
+use cases work for both batched and non-batched inputs (we illustrate them for non-batched inputs).
+
+**Use case 1: web page classification (training, inference) + token classification (inference), parse_html = True**
+
+This is the simplest case, in which the processor will use the feature extractor to get all nodes and xpaths from the HTML.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+
+>>> html_string = """
+...
+...
+...
+... Hello world
+...
+...
+...
Welcome
+...
Here is my website.
+...
+... """
+
+>>> # note that you can also add provide all tokenizer parameters here such as padding, truncation
+>>> encoding = processor(html_string, return_tensors="pt")
+>>> print(encoding.keys())
+dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
+```
+
+**Use case 2: web page classification (training, inference) + token classification (inference), parse_html=False**
+
+In case one already has obtained all nodes and xpaths, one doesn't need the feature extractor. In that case, one should
+provide the nodes and corresponding xpaths themselves to the processor, and make sure to set `parse_html` to `False`.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+>>> processor.parse_html = False
+
+>>> nodes = ["hello", "world", "how", "are"]
+>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
+>>> encoding = processor(nodes=nodes, xpaths=xpaths, return_tensors="pt")
+>>> print(encoding.keys())
+dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
+```
+
+**Use case 3: token classification (training), parse_html=False**
+
+For token classification tasks (such as [SWDE](https://paperswithcode.com/dataset/swde)), one can also provide the
+corresponding node labels in order to train a model. The processor will then convert these into token-level `labels`.
+By default, it will only label the first wordpiece of a word, and label the remaining wordpieces with -100, which is the
+`ignore_index` of PyTorch's CrossEntropyLoss. In case you want all wordpieces of a word to be labeled, you can
+initialize the tokenizer with `only_label_first_subword` set to `False`.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+>>> processor.parse_html = False
+
+>>> nodes = ["hello", "world", "how", "are"]
+>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
+>>> node_labels = [1, 2, 2, 1]
+>>> encoding = processor(nodes=nodes, xpaths=xpaths, node_labels=node_labels, return_tensors="pt")
+>>> print(encoding.keys())
+dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq', 'labels'])
+```
+
+**Use case 4: web page question answering (inference), parse_html=True**
+
+For question answering tasks on web pages, you can provide a question to the processor. By default, the
+processor will use the feature extractor to get all nodes and xpaths, and create [CLS] question tokens [SEP] word tokens [SEP].
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+
+>>> html_string = """
+...
+...
+...
+... Hello world
+...
+...
+...
Welcome
+...
My name is Niels.
+...
+... """
+
+>>> question = "What's his name?"
+>>> encoding = processor(html_string, questions=question, return_tensors="pt")
+>>> print(encoding.keys())
+dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
+```
+
+**Use case 5: web page question answering (inference), parse_html=False**
+
+For question answering tasks (such as WebSRC), you can provide a question to the processor. If you have extracted
+all nodes and xpaths yourself, you can provide them directly to the processor. Make sure to set `parse_html` to `False`.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+>>> processor.parse_html = False
+
+>>> nodes = ["hello", "world", "how", "are"]
+>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
+>>> question = "What's his name?"
+>>> encoding = processor(nodes=nodes, xpaths=xpaths, questions=question, return_tensors="pt")
+>>> print(encoding.keys())
+dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])
+```
+
+## Resources
+
+- [Demo notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MarkupLM)
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+
+## MarkupLMConfig
+
+[[autodoc]] MarkupLMConfig
+ - all
+
+## MarkupLMFeatureExtractor
+
+[[autodoc]] MarkupLMFeatureExtractor
+ - __call__
+
+## MarkupLMTokenizer
+
+[[autodoc]] MarkupLMTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## MarkupLMTokenizerFast
+
+[[autodoc]] MarkupLMTokenizerFast
+ - all
+
+## MarkupLMProcessor
+
+[[autodoc]] MarkupLMProcessor
+ - __call__
+
+## MarkupLMModel
+
+[[autodoc]] MarkupLMModel
+ - forward
+
+## MarkupLMForSequenceClassification
+
+[[autodoc]] MarkupLMForSequenceClassification
+ - forward
+
+## MarkupLMForTokenClassification
+
+[[autodoc]] MarkupLMForTokenClassification
+ - forward
+
+## MarkupLMForQuestionAnswering
+
+[[autodoc]] MarkupLMForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mask2former.md b/docs/transformers/docs/source/en/model_doc/mask2former.md
new file mode 100644
index 0000000000000000000000000000000000000000..37a2603c68800905cabbb5b49cd1ead121c1372e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mask2former.md
@@ -0,0 +1,80 @@
+
+
+# Mask2Former
+
+
+
+
+
+## Overview
+
+The Mask2Former model was proposed in [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former is a unified framework for panoptic, instance and semantic segmentation and features significant performance and efficiency improvements over [MaskFormer](maskformer).
+
+The abstract from the paper is the following:
+
+*Image segmentation groups pixels with different semantics, e.g., category or instance membership. Each choice
+of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).*
+
+
+
+ Mask2Former architecture. Taken from the original paper.
+
+This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
+
+## Usage tips
+
+- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
+- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mask2Former.
+
+- Demo notebooks regarding inference + fine-tuning Mask2Former on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Mask2Former).
+- Scripts for finetuning [`Mask2Former`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/instance-segmentation).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
+The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## Mask2FormerConfig
+
+[[autodoc]] Mask2FormerConfig
+
+## MaskFormer specific outputs
+
+[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerModelOutput
+
+[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerForUniversalSegmentationOutput
+
+## Mask2FormerModel
+
+[[autodoc]] Mask2FormerModel
+ - forward
+
+## Mask2FormerForUniversalSegmentation
+
+[[autodoc]] Mask2FormerForUniversalSegmentation
+ - forward
+
+## Mask2FormerImageProcessor
+
+[[autodoc]] Mask2FormerImageProcessor
+ - preprocess
+ - encode_inputs
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/maskformer.md b/docs/transformers/docs/source/en/model_doc/maskformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..0adbbf2285f9dc1ad625161a9d2bda7f819b05f0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/maskformer.md
@@ -0,0 +1,96 @@
+
+
+# MaskFormer
+
+
+
+
+
+
+
+This is a recently introduced model so the API hasn't been tested extensively. There may be some bugs or slight
+breaking changes to fix it in the future. If you see something strange, file a [Github Issue](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
+
+
+
+## Overview
+
+The MaskFormer model was proposed in [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov. MaskFormer addresses semantic segmentation with a mask classification paradigm instead of performing classic pixel-level classification.
+
+The abstract from the paper is the following:
+
+*Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.*
+
+The figure below illustrates the architecture of MaskFormer. Taken from the [original paper](https://arxiv.org/abs/2107.06278).
+
+
+
+This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
+
+## Usage tips
+
+- MaskFormer's Transformer decoder is identical to the decoder of [DETR](detr). During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help the model output the correct number of objects of each class. If you set the parameter `use_auxiliary_loss` of [`MaskFormerConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses are added after each decoder layer (with the FFNs sharing parameters).
+- If you want to train the model in a distributed environment across multiple nodes, then one should update the
+ `get_num_masks` function inside in the `MaskFormerLoss` class of `modeling_maskformer.py`. When training on multiple nodes, this should be
+ set to the average number of target masks across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/MaskFormer/blob/da3e60d85fdeedcb31476b5edd7d328826ce56cc/mask_former/modeling/criterion.py#L169).
+- One can use [`MaskFormerImageProcessor`] to prepare images for the model and optional targets for the model.
+- To get the final segmentation, depending on the task, you can call [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+
+## Resources
+
+
+
+- All notebooks that illustrate inference as well as fine-tuning on custom data with MaskFormer can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MaskFormer).
+- Scripts for finetuning [`MaskFormer`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/instance-segmentation).
+
+## MaskFormer specific outputs
+
+[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerModelOutput
+
+[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerForInstanceSegmentationOutput
+
+## MaskFormerConfig
+
+[[autodoc]] MaskFormerConfig
+
+## MaskFormerImageProcessor
+
+[[autodoc]] MaskFormerImageProcessor
+ - preprocess
+ - encode_inputs
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
+## MaskFormerFeatureExtractor
+
+[[autodoc]] MaskFormerFeatureExtractor
+ - __call__
+ - encode_inputs
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
+## MaskFormerModel
+
+[[autodoc]] MaskFormerModel
+ - forward
+
+## MaskFormerForInstanceSegmentation
+
+[[autodoc]] MaskFormerForInstanceSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/matcha.md b/docs/transformers/docs/source/en/model_doc/matcha.md
new file mode 100644
index 0000000000000000000000000000000000000000..f3c618953b9b4e2aa39fd22d772de865495b6212
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/matcha.md
@@ -0,0 +1,80 @@
+
+
+# MatCha
+
+
+
+
+
+## Overview
+
+MatCha has been proposed in the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662), from Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
+
+The abstract of the paper states the following:
+
+*Visual language data such as plots, charts, and infographics are ubiquitous in the human world. However, state-of-the-art vision-language models do not perform well on these data. We propose MatCha (Math reasoning and Chart derendering pretraining) to enhance visual language models' capabilities in jointly modeling charts/plots and language data. Specifically, we propose several pretraining tasks that cover plot deconstruction and numerical reasoning which are the key capabilities in visual language modeling. We perform the MatCha pretraining starting from Pix2Struct, a recently proposed image-to-text visual language model. On standard benchmarks such as PlotQA and ChartQA, the MatCha model outperforms state-of-the-art methods by as much as nearly 20%. We also examine how well MatCha pretraining transfers to domains such as screenshots, textbook diagrams, and document figures and observe overall improvement, verifying the usefulness of MatCha pretraining on broader visual language tasks.*
+
+## Model description
+
+MatCha is a model that is trained using `Pix2Struct` architecture. You can find more information about `Pix2Struct` in the [Pix2Struct documentation](https://huggingface.co/docs/transformers/main/en/model_doc/pix2struct).
+MatCha is a Visual Question Answering subset of `Pix2Struct` architecture. It renders the input question on the image and predicts the answer.
+
+## Usage
+
+Currently 6 checkpoints are available for MatCha:
+
+- `google/matcha`: the base MatCha model, used to fine-tune MatCha on downstream tasks
+- `google/matcha-chartqa`: MatCha model fine-tuned on ChartQA dataset. It can be used to answer questions about charts.
+- `google/matcha-plotqa-v1`: MatCha model fine-tuned on PlotQA dataset. It can be used to answer questions about plots.
+- `google/matcha-plotqa-v2`: MatCha model fine-tuned on PlotQA dataset. It can be used to answer questions about plots.
+- `google/matcha-chart2text-statista`: MatCha model fine-tuned on Statista dataset.
+- `google/matcha-chart2text-pew`: MatCha model fine-tuned on Pew dataset.
+
+The models finetuned on `chart2text-pew` and `chart2text-statista` are more suited for summarization, whereas the models finetuned on `plotqa` and `chartqa` are more suited for question answering.
+
+You can use these models as follows (example on a ChatQA dataset):
+
+```python
+from transformers import AutoProcessor, Pix2StructForConditionalGeneration
+import requests
+from PIL import Image
+
+model = Pix2StructForConditionalGeneration.from_pretrained("google/matcha-chartqa").to(0)
+processor = AutoProcessor.from_pretrained("google/matcha-chartqa")
+url = "https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/20294671002019.png"
+image = Image.open(requests.get(url, stream=True).raw)
+
+inputs = processor(images=image, text="Is the sum of all 4 places greater than Laos?", return_tensors="pt").to(0)
+predictions = model.generate(**inputs, max_new_tokens=512)
+print(processor.decode(predictions[0], skip_special_tokens=True))
+```
+
+## Fine-tuning
+
+To fine-tune MatCha, refer to the pix2struct [fine-tuning notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb). For `Pix2Struct` models, we have found out that fine-tuning the model with Adafactor and cosine learning rate scheduler leads to faster convergence:
+```python
+from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
+
+optimizer = Adafactor(self.parameters(), scale_parameter=False, relative_step=False, lr=0.01, weight_decay=1e-05)
+scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=40000)
+```
+
+
+
+MatCha is a model that is trained using `Pix2Struct` architecture. You can find more information about `Pix2Struct` in the [Pix2Struct documentation](https://huggingface.co/docs/transformers/main/en/model_doc/pix2struct).
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/mbart.md b/docs/transformers/docs/source/en/model_doc/mbart.md
new file mode 100644
index 0000000000000000000000000000000000000000..58cf1de3b7e1aaada474d7511dbdb7245e242148
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mbart.md
@@ -0,0 +1,207 @@
+
+
+
+
+
+
+
+
+
+
+
+
+# mBART
+
+[mBART](https://huggingface.co/papers/2001.08210) is a multilingual machine translation model that pretrains the entire translation model (encoder-decoder) unlike previous methods that only focused on parts of the model. The model is trained on a denoising objective which reconstructs the corrupted text. This allows mBART to handle the source language and the target text to translate to.
+
+[mBART-50](https://huggingface.co/paper/2008.00401) is pretrained on an additional 25 languages.
+
+You can find all the original mBART checkpoints under the [AI at Meta](https://huggingface.co/facebook?search_models=mbart) organization.
+
+> [!TIP]
+> Click on the mBART models in the right sidebar for more examples of applying mBART to different language tasks.
+
+The example below demonstrates how to translate text with [`Pipeline`] or the [`AutoModel`] class.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="translation",
+ model="facebook/mbart-large-50-many-to-many-mmt",
+ device=0,
+ torch_dtype=torch.float16,
+ src_lang="en_XX",
+ tgt_lang="fr_XX",
+)
+print(pipeline("UN Chief Says There Is No Military Solution in Syria"))
+```
+
+
+
+
+```py
+import torch
+from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+article_en = "UN Chief Says There Is No Military Solution in Syria"
+
+model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", torch_dtype=torch.bfloat16, attn_implementation="sdpa", device_map="auto")
+tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
+
+tokenizer.src_lang = "en_XX"
+encoded_hi = tokenizer(article_en, return_tensors="pt").to("cuda")
+generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.lang_code_to_id["fr_XX"], cache_implementation="static")
+print(tokenizer.batch_decode(generated_tokens, skip_special_tokens=True))
+```
+
+
+
+
+## Notes
+
+- You can check the full list of language codes via `tokenizer.lang_code_to_id.keys()`.
+- mBART requires a special language id token in the source and target text during training. The source text format is `X [eos, src_lang_code]` where `X` is the source text. The target text format is `[tgt_lang_code] X [eos]`. The `bos` token is never used. The [`~PreTrainedTokenizerBase._call_`] encodes the source text format passed as the first argument or with the `text` keyword. The target text format is passed with the `text_label` keyword.
+- Set the `decoder_start_token_id` to the target language id for mBART.
+
+ ```py
+ import torch
+ from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+ model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-en-ro", torch_dtype=torch.bfloat16, attn_implementation="sdpa", device_map="auto")
+ tokenizer = MBartTokenizer.from_pretrained("facebook/mbart-large-en-ro", src_lang="en_XX")
+
+ article = "UN Chief Says There Is No Military Solution in Syria"
+ inputs = tokenizer(article, return_tensors="pt")
+
+ translated_tokens = model.generate(**inputs, decoder_start_token_id=tokenizer.lang_code_to_id["ro_RO"])
+ tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
+ ```
+
+- mBART-50 has a different text format. The language id token is used as the prefix for the source and target text. The text format is `[lang_code] X [eos]` where `lang_code` is the source language id for the source text and target language id for the target text. `X` is the source or target text respectively.
+- Set the `eos_token_id` as the `decoder_start_token_id` for mBART-50. The target language id is used as the first generated token by passing `forced_bos_token_id` to [`~GenerationMixin.generate`].
+
+ ```py
+ import torch
+ from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+ model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", torch_dtype=torch.bfloat16, attn_implementation="sdpa", device_map="auto")
+ tokenizer = MBartTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
+
+ article_ar = "الأمين العام للأمم المتحدة يقول إنه لا يوجد حل عسكري في سوريا."
+ tokenizer.src_lang = "ar_AR"
+
+ encoded_ar = tokenizer(article_ar, return_tensors="pt")
+ generated_tokens = model.generate(**encoded_ar, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
+ tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+ ```
+
+## MBartConfig
+
+[[autodoc]] MBartConfig
+
+## MBartTokenizer
+
+[[autodoc]] MBartTokenizer
+ - build_inputs_with_special_tokens
+
+## MBartTokenizerFast
+
+[[autodoc]] MBartTokenizerFast
+
+## MBart50Tokenizer
+
+[[autodoc]] MBart50Tokenizer
+
+## MBart50TokenizerFast
+
+[[autodoc]] MBart50TokenizerFast
+
+
+
+
+## MBartModel
+
+[[autodoc]] MBartModel
+
+## MBartForConditionalGeneration
+
+[[autodoc]] MBartForConditionalGeneration
+
+## MBartForQuestionAnswering
+
+[[autodoc]] MBartForQuestionAnswering
+
+## MBartForSequenceClassification
+
+[[autodoc]] MBartForSequenceClassification
+
+## MBartForCausalLM
+
+[[autodoc]] MBartForCausalLM
+ - forward
+
+
+
+
+## TFMBartModel
+
+[[autodoc]] TFMBartModel
+ - call
+
+## TFMBartForConditionalGeneration
+
+[[autodoc]] TFMBartForConditionalGeneration
+ - call
+
+
+
+
+## FlaxMBartModel
+
+[[autodoc]] FlaxMBartModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxMBartForConditionalGeneration
+
+[[autodoc]] FlaxMBartForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+## FlaxMBartForSequenceClassification
+
+[[autodoc]] FlaxMBartForSequenceClassification
+ - __call__
+ - encode
+ - decode
+
+## FlaxMBartForQuestionAnswering
+
+[[autodoc]] FlaxMBartForQuestionAnswering
+ - __call__
+ - encode
+ - decode
+
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/mctct.md b/docs/transformers/docs/source/en/model_doc/mctct.md
new file mode 100644
index 0000000000000000000000000000000000000000..a755f5a027d2051d18fa770449d80756f6455d98
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mctct.md
@@ -0,0 +1,83 @@
+
+
+# M-CTC-T
+
+
+
+
+
+
+
+This model is in maintenance mode only, so we won't accept any new PRs changing its code.
+
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
+You can do so by running the following command: `pip install -U transformers==4.30.0`.
+
+
+
+## Overview
+
+The M-CTC-T model was proposed in [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal.
+
+The abstract from the paper is the following:
+
+*Semi-supervised learning through pseudo-labeling has become a staple of state-of-the-art monolingual
+speech recognition systems. In this work, we extend pseudo-labeling to massively multilingual speech
+recognition with 60 languages. We propose a simple pseudo-labeling recipe that works well even
+with low-resource languages: train a supervised multilingual model, fine-tune it with semi-supervised
+learning on a target language, generate pseudo-labels for that language, and train a final model using
+pseudo-labels for all languages, either from scratch or by fine-tuning. Experiments on the labeled
+Common Voice and unlabeled VoxPopuli datasets show that our recipe can yield a model with better
+performance for many languages that also transfers well to LibriSpeech.*
+
+This model was contributed by [cwkeam](https://huggingface.co/cwkeam). The original code can be found [here](https://github.com/flashlight/wav2letter/tree/main/recipes/mling_pl).
+
+## Usage tips
+
+The PyTorch version of this model is only available in torch 1.9 and higher.
+
+## Resources
+
+- [Automatic speech recognition task guide](../tasks/asr)
+
+## MCTCTConfig
+
+[[autodoc]] MCTCTConfig
+
+## MCTCTFeatureExtractor
+
+[[autodoc]] MCTCTFeatureExtractor
+ - __call__
+
+## MCTCTProcessor
+
+[[autodoc]] MCTCTProcessor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+
+## MCTCTModel
+
+[[autodoc]] MCTCTModel
+ - forward
+
+## MCTCTForCTC
+
+[[autodoc]] MCTCTForCTC
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mega.md b/docs/transformers/docs/source/en/model_doc/mega.md
new file mode 100644
index 0000000000000000000000000000000000000000..4e8ccd4b29f3b6a204c595f39ce4e2cdfb7bf256
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mega.md
@@ -0,0 +1,96 @@
+
+
+# MEGA
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+The MEGA model was proposed in [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
+MEGA proposes a new approach to self-attention with each encoder layer having a multi-headed exponential moving average in addition to a single head of standard dot-product attention, giving the attention mechanism
+stronger positional biases. This allows MEGA to perform competitively to Transformers on standard benchmarks including LRA
+while also having significantly fewer parameters. MEGA's compute efficiency allows it to scale to very long sequences, making it an
+attractive option for long-document NLP tasks.
+
+The abstract from the paper is the following:
+
+ *The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences. In this paper, we introduce Mega, a simple, theoretically grounded, single-head gated attention mechanism equipped with (exponential) moving average to incorporate inductive bias of position-aware local dependencies into the position-agnostic attention mechanism. We further propose a variant of Mega that offers linear time and space complexity yet yields only minimal quality loss, by efficiently splitting the whole sequence into multiple chunks with fixed length. Extensive experiments on a wide range of sequence modeling benchmarks, including the Long Range Arena, neural machine translation, auto-regressive language modeling, and image and speech classification, show that Mega achieves significant improvements over other sequence models, including variants of Transformers and recent state space models. *
+
+This model was contributed by [mnaylor](https://huggingface.co/mnaylor).
+The original code can be found [here](https://github.com/facebookresearch/mega).
+
+
+## Usage tips
+
+- MEGA can perform quite well with relatively few parameters. See Appendix D in the MEGA paper for examples of architectural specs which perform well in various settings. If using MEGA as a decoder, be sure to set `bidirectional=False` to avoid errors with default bidirectional.
+- Mega-chunk is a variant of mega that reduces time and spaces complexity from quadratic to linear. Utilize chunking with MegaConfig.use_chunking and control chunk size with MegaConfig.chunk_size
+
+
+## Implementation Notes
+
+- The original implementation of MEGA had an inconsistent expectation of attention masks for padding and causal self-attention between the softmax attention and Laplace/squared ReLU method. This implementation addresses that inconsistency.
+- The original implementation did not include token type embeddings; this implementation adds support for these, with the option controlled by MegaConfig.add_token_type_embeddings
+
+
+## MegaConfig
+
+[[autodoc]] MegaConfig
+
+## MegaModel
+
+[[autodoc]] MegaModel
+ - forward
+
+## MegaForCausalLM
+
+[[autodoc]] MegaForCausalLM
+ - forward
+
+## MegaForMaskedLM
+
+[[autodoc]] MegaForMaskedLM
+ - forward
+
+## MegaForSequenceClassification
+
+[[autodoc]] MegaForSequenceClassification
+ - forward
+
+## MegaForMultipleChoice
+
+[[autodoc]] MegaForMultipleChoice
+ - forward
+
+## MegaForTokenClassification
+
+[[autodoc]] MegaForTokenClassification
+ - forward
+
+## MegaForQuestionAnswering
+
+[[autodoc]] MegaForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/megatron-bert.md b/docs/transformers/docs/source/en/model_doc/megatron-bert.md
new file mode 100644
index 0000000000000000000000000000000000000000..b032655f75472466a81368488a60c49865d195a2
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/megatron-bert.md
@@ -0,0 +1,145 @@
+
+
+# MegatronBERT
+
+
+
+
+
+## Overview
+
+The MegatronBERT model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
+Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
+Jared Casper and Bryan Catanzaro.
+
+The abstract from the paper is the following:
+
+*Recent work in language modeling demonstrates that training large transformer models advances the state of the art in
+Natural Language Processing applications. However, very large models can be quite difficult to train due to memory
+constraints. In this work, we present our techniques for training very large transformer models and implement a simple,
+efficient intra-layer model parallel approach that enables training transformer models with billions of parameters. Our
+approach does not require a new compiler or library changes, is orthogonal and complimentary to pipeline model
+parallelism, and can be fully implemented with the insertion of a few communication operations in native PyTorch. We
+illustrate this approach by converging transformer based models up to 8.3 billion parameters using 512 GPUs. We sustain
+15.1 PetaFLOPs across the entire application with 76% scaling efficiency when compared to a strong single GPU baseline
+that sustains 39 TeraFLOPs, which is 30% of peak FLOPs. To demonstrate that large language models can further advance
+the state of the art (SOTA), we train an 8.3 billion parameter transformer language model similar to GPT-2 and a 3.9
+billion parameter model similar to BERT. We show that careful attention to the placement of layer normalization in
+BERT-like models is critical to achieving increased performance as the model size grows. Using the GPT-2 model we
+achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.8) and LAMBADA (66.5% compared to SOTA
+accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
+of 89.4%).*
+
+This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM).
+That repository contains a multi-GPU and multi-node implementation of the Megatron Language models. In particular,
+it contains a hybrid model parallel approach using "tensor parallel" and "pipeline parallel" techniques.
+
+## Usage tips
+
+We have provided pretrained [BERT-345M](https://ngc.nvidia.com/catalog/models/nvidia:megatron_bert_345m) checkpoints
+for use to evaluate or finetuning downstream tasks.
+
+To access these checkpoints, first [sign up](https://ngc.nvidia.com/signup) for and setup the NVIDIA GPU Cloud (NGC)
+Registry CLI. Further documentation for downloading models can be found in the [NGC documentation](https://docs.nvidia.com/dgx/ngc-registry-cli-user-guide/index.html#topic_6_4_1).
+
+Alternatively, you can directly download the checkpoints using:
+
+BERT-345M-uncased:
+
+```bash
+wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip
+-O megatron_bert_345m_v0_1_uncased.zip
+```
+
+BERT-345M-cased:
+
+```bash
+wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O
+megatron_bert_345m_v0_1_cased.zip
+```
+
+Once you have obtained the checkpoints from NVIDIA GPU Cloud (NGC), you have to convert them to a format that will
+easily be loaded by Hugging Face Transformers and our port of the BERT code.
+
+The following commands allow you to do the conversion. We assume that the folder `models/megatron_bert` contains
+`megatron_bert_345m_v0_1_{cased, uncased}.zip` and that the commands are run from inside that folder:
+
+```bash
+python3 $PATH_TO_TRANSFORMERS/models/megatron_bert/convert_megatron_bert_checkpoint.py megatron_bert_345m_v0_1_uncased.zip
+```
+
+```bash
+python3 $PATH_TO_TRANSFORMERS/models/megatron_bert/convert_megatron_bert_checkpoint.py megatron_bert_345m_v0_1_cased.zip
+```
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## MegatronBertConfig
+
+[[autodoc]] MegatronBertConfig
+
+## MegatronBertModel
+
+[[autodoc]] MegatronBertModel
+ - forward
+
+## MegatronBertForMaskedLM
+
+[[autodoc]] MegatronBertForMaskedLM
+ - forward
+
+## MegatronBertForCausalLM
+
+[[autodoc]] MegatronBertForCausalLM
+ - forward
+
+## MegatronBertForNextSentencePrediction
+
+[[autodoc]] MegatronBertForNextSentencePrediction
+ - forward
+
+## MegatronBertForPreTraining
+
+[[autodoc]] MegatronBertForPreTraining
+ - forward
+
+## MegatronBertForSequenceClassification
+
+[[autodoc]] MegatronBertForSequenceClassification
+ - forward
+
+## MegatronBertForMultipleChoice
+
+[[autodoc]] MegatronBertForMultipleChoice
+ - forward
+
+## MegatronBertForTokenClassification
+
+[[autodoc]] MegatronBertForTokenClassification
+ - forward
+
+## MegatronBertForQuestionAnswering
+
+[[autodoc]] MegatronBertForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/megatron_gpt2.md b/docs/transformers/docs/source/en/model_doc/megatron_gpt2.md
new file mode 100644
index 0000000000000000000000000000000000000000..7e0ee3cb9e7c98a4dce2ed321a49572db934b689
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/megatron_gpt2.md
@@ -0,0 +1,84 @@
+
+
+# MegatronGPT2
+
+
+
+
+
+
+
+## Overview
+
+The MegatronGPT2 model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
+Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
+Jared Casper and Bryan Catanzaro.
+
+The abstract from the paper is the following:
+
+*Recent work in language modeling demonstrates that training large transformer models advances the state of the art in
+Natural Language Processing applications. However, very large models can be quite difficult to train due to memory
+constraints. In this work, we present our techniques for training very large transformer models and implement a simple,
+efficient intra-layer model parallel approach that enables training transformer models with billions of parameters. Our
+approach does not require a new compiler or library changes, is orthogonal and complimentary to pipeline model
+parallelism, and can be fully implemented with the insertion of a few communication operations in native PyTorch. We
+illustrate this approach by converging transformer based models up to 8.3 billion parameters using 512 GPUs. We sustain
+15.1 PetaFLOPs across the entire application with 76% scaling efficiency when compared to a strong single GPU baseline
+that sustains 39 TeraFLOPs, which is 30% of peak FLOPs. To demonstrate that large language models can further advance
+the state of the art (SOTA), we train an 8.3 billion parameter transformer language model similar to GPT-2 and a 3.9
+billion parameter model similar to BERT. We show that careful attention to the placement of layer normalization in
+BERT-like models is critical to achieving increased performance as the model size grows. Using the GPT-2 model we
+achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.8) and LAMBADA (66.5% compared to SOTA
+accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
+of 89.4%).*
+
+This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM).
+That repository contains a multi-GPU and multi-node implementation of the Megatron Language models. In particular, it
+contains a hybrid model parallel approach using "tensor parallel" and "pipeline parallel" techniques.
+
+## Usage tips
+
+We have provided pretrained [GPT2-345M](https://ngc.nvidia.com/catalog/models/nvidia:megatron_lm_345m) checkpoints
+for use to evaluate or finetuning downstream tasks.
+
+To access these checkpoints, first [sign up](https://ngc.nvidia.com/signup) for and setup the NVIDIA GPU Cloud (NGC)
+Registry CLI. Further documentation for downloading models can be found in the [NGC documentation](https://docs.nvidia.com/dgx/ngc-registry-cli-user-guide/index.html#topic_6_4_1).
+
+Alternatively, you can directly download the checkpoints using:
+
+```bash
+wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O
+megatron_gpt2_345m_v0_0.zip
+```
+
+Once you have obtained the checkpoint from NVIDIA GPU Cloud (NGC), you have to convert it to a format that will easily
+be loaded by Hugging Face Transformers GPT2 implementation.
+
+The following command allows you to do the conversion. We assume that the folder `models/megatron_gpt2` contains
+`megatron_gpt2_345m_v0_0.zip` and that the command is run from that folder:
+
+```bash
+python3 $PATH_TO_TRANSFORMERS/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py megatron_gpt2_345m_v0_0.zip
+```
+
+
+
+ MegatronGPT2 architecture is the same as OpenAI GPT-2 . Refer to [GPT-2 documentation](gpt2) for information on
+ configuration classes and their parameters.
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/mgp-str.md b/docs/transformers/docs/source/en/model_doc/mgp-str.md
new file mode 100644
index 0000000000000000000000000000000000000000..168e5bd1043d5069b1f4a6997ee6a074abbd7602
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mgp-str.md
@@ -0,0 +1,92 @@
+
+
+# MGP-STR
+
+
+
+
+
+## Overview
+
+The MGP-STR model was proposed in [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao. MGP-STR is a conceptually **simple** yet **powerful** vision Scene Text Recognition (STR) model, which is built upon the [Vision Transformer (ViT)](vit). To integrate linguistic knowledge, Multi-Granularity Prediction (MGP) strategy is proposed to inject information from the language modality into the model in an implicit way.
+
+The abstract from the paper is the following:
+
+*Scene text recognition (STR) has been an active research topic in computer vision for years. To tackle this challenging problem, numerous innovative methods have been successively proposed and incorporating linguistic knowledge into STR models has recently become a prominent trend. In this work, we first draw inspiration from the recent progress in Vision Transformer (ViT) to construct a conceptually simple yet powerful vision STR model, which is built upon ViT and outperforms previous state-of-the-art models for scene text recognition, including both pure vision models and language-augmented methods. To integrate linguistic knowledge, we further propose a Multi-Granularity Prediction strategy to inject information from the language modality into the model in an implicit way, i.e. , subword representations (BPE and WordPiece) widely-used in NLP are introduced into the output space, in addition to the conventional character level representation, while no independent language model (LM) is adopted. The resultant algorithm (termed MGP-STR) is able to push the performance envelop of STR to an even higher level. Specifically, it achieves an average recognition accuracy of 93.35% on standard benchmarks.*
+
+
+
+ MGP-STR architecture. Taken from the original paper.
+
+MGP-STR is trained on two synthetic datasets [MJSynth]((http://www.robots.ox.ac.uk/~vgg/data/text/)) (MJ) and [SynthText](http://www.robots.ox.ac.uk/~vgg/data/scenetext/) (ST) without fine-tuning on other datasets. It achieves state-of-the-art results on six standard Latin scene text benchmarks, including 3 regular text datasets (IC13, SVT, IIIT) and 3 irregular ones (IC15, SVTP, CUTE).
+This model was contributed by [yuekun](https://huggingface.co/yuekun). The original code can be found [here](https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR).
+
+## Inference example
+
+[`MgpstrModel`] accepts images as input and generates three types of predictions, which represent textual information at different granularities.
+The three types of predictions are fused to give the final prediction result.
+
+The [`ViTImageProcessor`] class is responsible for preprocessing the input image and
+[`MgpstrTokenizer`] decodes the generated character tokens to the target string. The
+[`MgpstrProcessor`] wraps [`ViTImageProcessor`] and [`MgpstrTokenizer`]
+into a single instance to both extract the input features and decode the predicted token ids.
+
+- Step-by-step Optical Character Recognition (OCR)
+
+```py
+>>> from transformers import MgpstrProcessor, MgpstrForSceneTextRecognition
+>>> import requests
+>>> from PIL import Image
+
+>>> processor = MgpstrProcessor.from_pretrained('alibaba-damo/mgp-str-base')
+>>> model = MgpstrForSceneTextRecognition.from_pretrained('alibaba-damo/mgp-str-base')
+
+>>> # load image from the IIIT-5k dataset
+>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+
+>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
+>>> outputs = model(pixel_values)
+
+>>> generated_text = processor.batch_decode(outputs.logits)['generated_text']
+```
+
+## MgpstrConfig
+
+[[autodoc]] MgpstrConfig
+
+## MgpstrTokenizer
+
+[[autodoc]] MgpstrTokenizer
+ - save_vocabulary
+
+## MgpstrProcessor
+
+[[autodoc]] MgpstrProcessor
+ - __call__
+ - batch_decode
+
+## MgpstrModel
+
+[[autodoc]] MgpstrModel
+ - forward
+
+## MgpstrForSceneTextRecognition
+
+[[autodoc]] MgpstrForSceneTextRecognition
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mimi.md b/docs/transformers/docs/source/en/model_doc/mimi.md
new file mode 100644
index 0000000000000000000000000000000000000000..6e68394fcaeabca35c453347065b5f80cb989bf2
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mimi.md
@@ -0,0 +1,75 @@
+
+
+# Mimi
+
+
+
+
+
+
+
+## Overview
+
+The Mimi model was proposed in [Moshi: a speech-text foundation model for real-time dialogue](https://kyutai.org/Moshi.pdf) by Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave and Neil Zeghidour. Mimi is a high-fidelity audio codec model developed by the Kyutai team, that combines semantic and acoustic information into audio tokens running at 12Hz and a bitrate of 1.1kbps. In other words, it can be used to map audio waveforms into “audio tokens”, known as “codebooks”.
+
+The abstract from the paper is the following:
+
+*We introduce Moshi, a speech-text foundation model and full-duplex spoken dialogue framework. Current systems for spoken dialogue rely on pipelines of independent components, namely voice activity detection, speech recognition, textual dialogue and text-to-speech. Such frameworks cannot emulate the experience of real conversations. First, their complexity induces a latency of several seconds between interactions. Second, text being the intermediate modality for dialogue, non-linguistic information that modifies meaning— such as emotion or non-speech sounds— is lost in the interaction. Finally, they rely on a segmentation into speaker turns, which does not take into account overlapping speech, interruptions and interjections. Moshi solves these independent issues altogether by casting spoken dialogue as speech-to-speech generation. Starting from a text language model backbone, Moshi generates speech as tokens from the residual quantizer of a neural audio codec, while modeling separately its own speech and that of the user into parallel streams. This allows for the removal of explicit speaker turns, and the modeling of arbitrary conversational dynamics. We moreover extend the hierarchical semantic-to-acoustic token generation of previous work to first predict time-aligned text tokens as a prefix to audio tokens. Not only this “Inner Monologue” method significantly improves the linguistic quality of generated speech, but we also illustrate how it can provide streaming speech recognition and text-to-speech. Our resulting model is the first real-time full-duplex spoken large language model, with a theoretical latency of 160ms, 200ms in practice, and is available at github.com/kyutai-labs/moshi.*
+
+Its architecture is based on [Encodec](model_doc/encodec) with several major differences:
+* it uses a much lower frame-rate.
+* it uses additional transformers for encoding and decoding for better latent contextualization
+* it uses a different quantization scheme: one codebook is dedicated to semantic projection.
+
+## Usage example
+
+Here is a quick example of how to encode and decode an audio using this model:
+
+```python
+>>> from datasets import load_dataset, Audio
+>>> from transformers import MimiModel, AutoFeatureExtractor
+>>> librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+
+>>> # load model and feature extractor
+>>> model = MimiModel.from_pretrained("kyutai/mimi")
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("kyutai/mimi")
+
+>>> # load audio sample
+>>> librispeech_dummy = librispeech_dummy.cast_column("audio", Audio(sampling_rate=feature_extractor.sampling_rate))
+>>> audio_sample = librispeech_dummy[-1]["audio"]["array"]
+>>> inputs = feature_extractor(raw_audio=audio_sample, sampling_rate=feature_extractor.sampling_rate, return_tensors="pt")
+
+>>> encoder_outputs = model.encode(inputs["input_values"], inputs["padding_mask"])
+>>> audio_values = model.decode(encoder_outputs.audio_codes, inputs["padding_mask"])[0]
+>>> # or the equivalent with a forward pass
+>>> audio_values = model(inputs["input_values"], inputs["padding_mask"]).audio_values
+```
+
+This model was contributed by [Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe).
+The original code can be found [here](https://github.com/kyutai-labs/moshi).
+
+
+## MimiConfig
+
+[[autodoc]] MimiConfig
+
+## MimiModel
+
+[[autodoc]] MimiModel
+ - decode
+ - encode
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/mistral.md b/docs/transformers/docs/source/en/model_doc/mistral.md
new file mode 100644
index 0000000000000000000000000000000000000000..39334385e6052816250da8aeef09410093f50302
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mistral.md
@@ -0,0 +1,189 @@
+
+
+
+
+
+
+
+
+
+
+
+
+# Mistral
+
+[Mistral](https://huggingface.co/papers/2310.06825) is a 7B parameter language model, available as a pretrained and instruction-tuned variant, focused on balancing
+the scaling costs of large models with performance and efficient inference. This model uses sliding window attention (SWA) trained with a 8K context length and a fixed cache size to handle longer sequences more effectively. Grouped-query attention (GQA) speeds up inference and reduces memory requirements. Mistral also features a byte-fallback BPE tokenizer to improve token handling and efficiency by ensuring characters are never mapped to out-of-vocabulary tokens.
+
+You can find all the original Mistral checkpoints under the [Mistral AI_](https://huggingface.co/mistralai) organization.
+
+> [!TIP]
+> Click on the Mistral models in the right sidebar for more examples of how to apply Mistral to different language tasks.
+
+The example below demonstrates how to chat with [`Pipeline`] or the [`AutoModel`], and from the command line.
+
+
+
+
+```python
+>>> import torch
+>>> from transformers import pipeline
+
+>>> messages = [
+... {"role": "user", "content": "What is your favourite condiment?"},
+... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
+... {"role": "user", "content": "Do you have mayonnaise recipes?"}
+... ]
+
+>>> chatbot = pipeline("text-generation", model="mistralai/Mistral-7B-Instruct-v0.3", torch_dtype=torch.bfloat16, device=0)
+>>> chatbot(messages)
+```
+
+
+
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3", torch_dtype=torch.bfloat16, attn_implementation="sdpa", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3")
+
+>>> messages = [
+... {"role": "user", "content": "What is your favourite condiment?"},
+... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
+... {"role": "user", "content": "Do you have mayonnaise recipes?"}
+... ]
+
+>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
+
+>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"Mayonnaise can be made as follows: (...)"
+```
+
+
+
+
+```python
+echo -e "My favorite condiment is" | transformers-cli chat --model_name_or_path mistralai/Mistral-7B-v0.3 --torch_dtype auto --device 0 --attn_implementation flash_attention_2
+```
+
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes) to only quantize the weights to 4-bits.
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+
+>>> # specify how to quantize the model
+>>> quantization_config = BitsAndBytesConfig(
+... load_in_4bit=True,
+... bnb_4bit_quant_type="nf4",
+... bnb_4bit_compute_dtype="torch.float16",
+... )
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3", quantization_config=True, torch_dtype=torch.bfloat16, device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3")
+
+>>> prompt = "My favourite condiment is"
+
+>>> messages = [
+... {"role": "user", "content": "What is your favourite condiment?"},
+... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
+... {"role": "user", "content": "Do you have mayonnaise recipes?"}
+... ]
+
+>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
+
+>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"The expected output"
+```
+
+Use the [AttentionMaskVisualizer](https://github.com/huggingface/transformers/blob/beb9b5b02246b9b7ee81ddf938f93f44cfeaad19/src/transformers/utils/attention_visualizer.py#L139) to better understand what tokens the model can and cannot attend to.
+
+```py
+>>> from transformers.utils.attention_visualizer import AttentionMaskVisualizer
+
+>>> visualizer = AttentionMaskVisualizer("mistralai/Mistral-7B-Instruct-v0.3")
+>>> visualizer("Do you have mayonnaise recipes?")
+```
+
+
+
+
+
+## MistralConfig
+
+[[autodoc]] MistralConfig
+
+## MistralModel
+
+[[autodoc]] MistralModel
+ - forward
+
+## MistralForCausalLM
+
+[[autodoc]] MistralForCausalLM
+ - forward
+
+## MistralForSequenceClassification
+
+[[autodoc]] MistralForSequenceClassification
+ - forward
+
+## MistralForTokenClassification
+
+[[autodoc]] MistralForTokenClassification
+ - forward
+
+## MistralForQuestionAnswering
+
+[[autodoc]] MistralForQuestionAnswering
+- forward
+
+## FlaxMistralModel
+
+[[autodoc]] FlaxMistralModel
+ - __call__
+
+## FlaxMistralForCausalLM
+
+[[autodoc]] FlaxMistralForCausalLM
+ - __call__
+
+## TFMistralModel
+
+[[autodoc]] TFMistralModel
+ - call
+
+## TFMistralForCausalLM
+
+[[autodoc]] TFMistralForCausalLM
+ - call
+
+## TFMistralForSequenceClassification
+
+[[autodoc]] TFMistralForSequenceClassification
+ - call
diff --git a/docs/transformers/docs/source/en/model_doc/mistral3.md b/docs/transformers/docs/source/en/model_doc/mistral3.md
new file mode 100644
index 0000000000000000000000000000000000000000..4efdb6415599fe8b496a47fecb4904235f918561
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mistral3.md
@@ -0,0 +1,234 @@
+
+
+# Mistral3
+
+## Overview
+
+Building upon Mistral Small 3 (2501), Mistral Small 3.1 (2503) adds state-of-the-art vision understanding and enhances long context capabilities up to 128k tokens without compromising text performance. With 24 billion parameters, this model achieves top-tier capabilities in both text and vision tasks.
+
+It is ideal for:
+- Fast-response conversational agents.
+- Low-latency function calling.
+- Subject matter experts via fine-tuning.
+- Local inference for hobbyists and organizations handling sensitive data.
+- Programming and math reasoning.
+- Long document understanding.
+- Visual understanding.
+
+This model was contributed by [cyrilvallez](https://huggingface.co/cyrilvallez) and [yonigozlan](https://huggingface.co/yonigozlan).
+
+The original code can be found [here](https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/models/pixtral.py) and [here](https://github.com/mistralai/mistral-common).
+
+## Usage example
+
+### Inference with Pipeline
+
+Here is how you can use the `image-text-to-text` pipeline to perform inference with the `Mistral3` models in just a few lines of code:
+```python
+>>> from transformers import pipeline
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {
+... "type": "image",
+... "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg",
+... },
+... {"type": "text", "text": "Describe this image."},
+... ],
+... },
+... ]
+
+>>> pipe = pipeline("image-text-to-text", model="mistralai/Mistral-Small-3.1-24B-Instruct-2503", torch_dtype=torch.bfloat16)
+>>> outputs = pipe(text=messages, max_new_tokens=50, return_full_text=False)
+>>> outputs[0]["generated_text"]
+'The image depicts a vibrant and lush garden scene featuring a variety of wildflowers and plants. The central focus is on a large, pinkish-purple flower, likely a Greater Celandine (Chelidonium majus), with a'
+```
+### Inference on a single image
+
+This example demonstrates how to perform inference on a single image with the Mistral3 models using chat templates.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
+... {"type": "text", "text": "Describe this image"},
+... ],
+... }
+... ]
+
+>>> inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+>>> generate_ids = model.generate(**inputs, max_new_tokens=20)
+>>> decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+
+>>> decoded_output
+"The image depicts two cats lying on a pink blanket. The larger cat, which appears to be an"...
+```
+
+### Text-only generation
+This example shows how to generate text using the Mistral3 model without providing any image input.
+
+
+````python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = ".mistralai/Mistral-Small-3.1-24B-Instruct-2503"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> SYSTEM_PROMPT = "You are a conversational agent that always answers straight to the point, always end your accurate response with an ASCII drawing of a cat."
+>>> user_prompt = "Give me 5 non-formal ways to say 'See you later' in French."
+
+>>> messages = [
+... {"role": "system", "content": SYSTEM_PROMPT},
+... {"role": "user", "content": user_prompt},
+... ]
+
+>>> text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
+>>> inputs = processor(text=text, return_tensors="pt").to(0, dtype=torch.float16)
+>>> generate_ids = model.generate(**inputs, max_new_tokens=50, do_sample=False)
+>>> decoded_output = processor.batch_decode(generate_ids[:, inputs["input_ids"].shape[1] :], skip_special_tokens=True)[0]
+
+>>> print(decoded_output)
+"1. À plus tard!
+2. Salut, à plus!
+3. À toute!
+4. À la prochaine!
+5. Je me casse, à plus!
+
+```
+ /\_/\
+( o.o )
+ > ^ <
+```"
+````
+
+### Batched image and text inputs
+Mistral3 models also support batched image and text inputs.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+... {"type": "text", "text": "Write a haiku for this image"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"},
+... {"type": "text", "text": "Describe this image"},
+... ],
+... },
+... ],
+... ]
+
+
+>>> inputs = processor.apply_chat_template(messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+>>> output = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_outputs = processor.batch_decode(output, skip_special_tokens=True)
+>>> decoded_outputs
+["Write a haiku for this imageCalm waters reflect\nWhispers of the forest's breath\nPeace on wooden path"
+, "Describe this imageThe image depicts a vibrant street scene in what appears to be a Chinatown district. The focal point is a traditional Chinese"]
+```
+
+### Batched multi-image input and quantization with BitsAndBytes
+This implementation of the Mistral3 models supports batched text-images inputs with different number of images for each text.
+This example also how to use `BitsAndBytes` to load the model in 4bit quantization.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> quantization_config = BitsAndBytesConfig(load_in_4bit=True)
+>>> model = AutoModelForImageTextToText.from_pretrained(
+... model_checkpoint, quantization_config=quantization_config
+... )
+
+>>> messages = [
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+... {"type": "text", "text": "Write a haiku for this image"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"},
+... {"type": "image", "url": "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg"},
+... {"type": "text", "text": "These images depict two different landmarks. Can you identify them?"},
+... ],
+... },
+... ],
+>>> ]
+
+>>> inputs = processor.apply_chat_template(messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+>>> output = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_outputs = processor.batch_decode(output, skip_special_tokens=True)
+>>> decoded_outputs
+["Write a haiku for this imageSure, here is a haiku inspired by the image:\n\nCalm lake's wooden path\nSilent forest stands guard\n", "These images depict two different landmarks. Can you identify them? Certainly! The images depict two iconic landmarks:\n\n1. The first image shows the Statue of Liberty in New York City."]
+```
+
+
+## Mistral3Config
+
+[[autodoc]] Mistral3Config
+
+
+## Mistral3ForConditionalGeneration
+
+[[autodoc]] Mistral3ForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mixtral.md b/docs/transformers/docs/source/en/model_doc/mixtral.md
new file mode 100644
index 0000000000000000000000000000000000000000..38c0c98ed0b95714f090dfa21179bab3d839b60e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mixtral.md
@@ -0,0 +1,221 @@
+
+
+# Mixtral
+
+
+
+
+
+
+
+## Overview
+
+Mixtral-8x7B was introduced in the [Mixtral of Experts blogpost](https://mistral.ai/news/mixtral-of-experts/) by Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed.
+
+The introduction of the blog post says:
+
+*Today, the team is proud to release Mixtral 8x7B, a high-quality sparse mixture of experts models (SMoE) with open weights. Licensed under Apache 2.0. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. It is the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. In particular, it matches or outperforms GPT3.5 on most standard benchmarks.*
+
+Mixtral-8x7B is the second large language model (LLM) released by [mistral.ai](https://mistral.ai/), after [Mistral-7B](mistral).
+
+### Architectural details
+
+Mixtral-8x7B is a decoder-only Transformer with the following architectural choices:
+
+- Mixtral is a Mixture of Experts (MoE) model with 8 experts per MLP, with a total of 45 billion parameters. To learn more about mixture-of-experts, refer to the [blog post](https://huggingface.co/blog/moe).
+- Despite the model having 45 billion parameters, the compute required for a single forward pass is the same as that of a 14 billion parameter model. This is because even though each of the experts have to be loaded in RAM (70B like ram requirement) each token from the hidden states are dispatched twice (top 2 routing) and thus the compute (the operation required at each forward computation) is just 2 X sequence_length.
+
+The following implementation details are shared with Mistral AI's first model [Mistral-7B](mistral):
+- Sliding Window Attention - Trained with 8k context length and fixed cache size, with a theoretical attention span of 128K tokens
+- GQA (Grouped Query Attention) - allowing faster inference and lower cache size.
+- Byte-fallback BPE tokenizer - ensures that characters are never mapped to out of vocabulary tokens.
+
+For more details refer to the [release blog post](https://mistral.ai/news/mixtral-of-experts/).
+
+### License
+
+`Mixtral-8x7B` is released under the Apache 2.0 license.
+
+## Usage tips
+
+The Mistral team has released 2 checkpoints:
+- a base model, [Mixtral-8x7B-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1), which has been pre-trained to predict the next token on internet-scale data.
+- an instruction tuned model, [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1), which is the base model optimized for chat purposes using supervised fine-tuning (SFT) and direct preference optimization (DPO).
+
+The base model can be used as follows:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
+
+>>> prompt = "My favourite condiment is"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"My favourite condiment is to ..."
+```
+
+The instruction tuned model can be used as follows:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
+
+>>> messages = [
+... {"role": "user", "content": "What is your favourite condiment?"},
+... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
+... {"role": "user", "content": "Do you have mayonnaise recipes?"}
+... ]
+
+>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
+
+>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"Mayonnaise can be made as follows: (...)"
+```
+
+As can be seen, the instruction-tuned model requires a [chat template](../chat_templating) to be applied to make sure the inputs are prepared in the right format.
+
+## Speeding up Mixtral by using Flash Attention
+
+The code snippets above showcase inference without any optimization tricks. However, one can drastically speed up the model by leveraging [Flash Attention](../perf_train_gpu_one#flash-attention-2), which is a faster implementation of the attention mechanism used inside the model.
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). Make also sure to load your model in half-precision (e.g. `torch.float16`)
+
+To load and run a model using Flash Attention-2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-v0.1")
+
+>>> prompt = "My favourite condiment is"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"The expected output"
+```
+
+### Expected speedups
+
+Below is a expected speedup diagram that compares pure inference time between the native implementation in transformers using `mistralai/Mixtral-8x7B-v0.1` checkpoint and the Flash Attention 2 version of the model.
+
+
+
+
+
+### Sliding window Attention
+
+The current implementation supports the sliding window attention mechanism and memory efficient cache management.
+To enable sliding window attention, just make sure to have a `flash-attn` version that is compatible with sliding window attention (`>=2.3.0`).
+
+The Flash Attention-2 model uses also a more memory efficient cache slicing mechanism - as recommended per the official implementation of Mistral model that use rolling cache mechanism we keep the cache size fixed (`self.config.sliding_window`), support batched generation only for `padding_side="left"` and use the absolute position of the current token to compute the positional embedding.
+
+## Shrinking down Mixtral using quantization
+
+As the Mixtral model has 45 billion parameters, that would require about 90GB of GPU RAM in half precision (float16), since each parameter is stored in 2 bytes. However, one can shrink down the size of the model using [quantization](../quantization.md). If the model is quantized to 4 bits (or half a byte per parameter), a single A100 with 40GB of RAM is enough to fit the entire model, as in that case only about 27 GB of RAM is required.
+
+Quantizing a model is as simple as passing a `quantization_config` to the model. Below, we'll leverage the bitsandbytes quantization library (but refer to [this page](../quantization.md) for alternative quantization methods):
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+
+>>> # specify how to quantize the model
+>>> quantization_config = BitsAndBytesConfig(
+... load_in_4bit=True,
+... bnb_4bit_quant_type="nf4",
+... bnb_4bit_compute_dtype="torch.float16",
+... )
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1", quantization_config=True, device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
+
+>>> prompt = "My favourite condiment is"
+
+>>> messages = [
+... {"role": "user", "content": "What is your favourite condiment?"},
+... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
+... {"role": "user", "content": "Do you have mayonnaise recipes?"}
+... ]
+
+>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
+
+>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"The expected output"
+```
+
+This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ) .
+The original code can be found [here](https://github.com/mistralai/mistral-src).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mixtral. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+- A demo notebook to perform supervised fine-tuning (SFT) of Mixtral-8x7B can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Mistral/Supervised_fine_tuning_(SFT)_of_an_LLM_using_Hugging_Face_tooling.ipynb). 🌎
+- A [blog post](https://medium.com/@prakharsaxena11111/finetuning-mixtral-7bx8-6071b0ebf114) on fine-tuning Mixtral-8x7B using PEFT. 🌎
+- The [Alignment Handbook](https://github.com/huggingface/alignment-handbook) by Hugging Face includes scripts and recipes to perform supervised fine-tuning (SFT) and direct preference optimization with Mistral-7B. This includes scripts for full fine-tuning, QLoRa on a single GPU as well as multi-GPU fine-tuning.
+- [Causal language modeling task guide](../tasks/language_modeling)
+
+## MixtralConfig
+
+[[autodoc]] MixtralConfig
+
+## MixtralModel
+
+[[autodoc]] MixtralModel
+ - forward
+
+## MixtralForCausalLM
+
+[[autodoc]] MixtralForCausalLM
+ - forward
+
+## MixtralForSequenceClassification
+
+[[autodoc]] MixtralForSequenceClassification
+ - forward
+
+## MixtralForTokenClassification
+
+[[autodoc]] MixtralForTokenClassification
+ - forward
+
+## MixtralForQuestionAnswering
+[[autodoc]] MixtralForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mlcd.md b/docs/transformers/docs/source/en/model_doc/mlcd.md
new file mode 100644
index 0000000000000000000000000000000000000000..66d87d3e3ffcbf6977339a9a776de0025c306311
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mlcd.md
@@ -0,0 +1,81 @@
+
+
+# MLCD
+
+
+
+
+
+
+## Overview
+
+The MLCD models were released by the DeepGlint-AI team in [unicom](https://github.com/deepglint/unicom), which focuses on building foundational visual models for large multimodal language models using large-scale datasets such as LAION400M and COYO700M, and employs sample-to-cluster contrastive learning to optimize performance. MLCD models are primarily used for multimodal visual large language models, such as LLaVA.
+
+🔥**MLCD-ViT-bigG**🔥 series is the state-of-the-art vision transformer model enhanced with 2D Rotary Position Embedding (RoPE2D), achieving superior performance on document understanding and visual question answering tasks. Developed by DeepGlint AI, this model demonstrates exceptional capabilities in processing complex visual-language interactions.
+
+Tips:
+
+- We adopted the official [LLaVA-NeXT](https://github.com/LLaVA-VL/LLaVA-NeXT) and the official training dataset [LLaVA-NeXT-Data](https://huggingface.co/datasets/lmms-lab/LLaVA-NeXT-Data) for evaluating the foundational visual models.
+
+- The language model is [Qwen2.5-7B](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct).
+
+Result:
+
+| Vision Tower | RoPE2D | ChartQA | DocVQA | InfoVQA | OCRBench | MMMU |
+| :-------------------------------------------------------------------------------------------- | :----: | :-------- | :-------- | :-------- | :--------- | :-------- |
+| CLIP (ViT-L-14-336px) | × | 66.52 | 75.21 | 38.88 | 525.00 | 44.20 |
+| SigLIP (ViT-SO400M-384px) | × | 69.28 | 76.71 | 41.38 | 554.00 | 46.78 |
+| DFN5B (ViT-H-14-378px) | × | 64.36 | 70.87 | 38.59 | 473.00 | **48.00** |
+| **[MLCD (ViT-L-14-336px)](https://huggingface.co/DeepGlint-AI/mlcd-vit-large-patch14-336)** | × | 67.84 | 76.46 | 43.48 | 531.00 | 44.30 |
+| **[MLCD (ViT-bigG-14-336px)](https://huggingface.co/DeepGlint-AI/mlcd-vit-bigG-patch14-336)** | √ | 71.07 | 79.63 | 44.38 | 572.00 | 46.78 |
+| **[MLCD (ViT-bigG-14-448px)](https://huggingface.co/DeepGlint-AI/mlcd-vit-bigG-patch14-448)** | √ | **73.80** | **83.34** | **46.59** | **582.00** | 46.00 |
+
+
+## Usage
+
+```python
+import requests
+from PIL import Image
+from transformers import AutoProcessor, MLCDVisionModel
+
+# Load model and processor
+model = MLCDVisionModel.from_pretrained("DeepGlint-AI/mlcd-vit-bigG-patch14-448")
+processor = AutoProcessor.from_pretrained("DeepGlint-AI/mlcd-vit-bigG-patch14-448")
+
+# Process single image
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+inputs = processor(images=image, return_tensors="pt")
+
+# Generate outputs
+with torch.no_grad():
+ outputs = model(**inputs)
+
+# Get visual features
+features = outputs.last_hidden_state
+
+print(f"Extracted features shape: {features.shape}")
+```
+
+## MLCDVisionConfig
+
+[[autodoc]] MLCDVisionConfig
+
+## MLCDVisionModel
+
+[[autodoc]] MLCDVisionModel
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mllama.md b/docs/transformers/docs/source/en/model_doc/mllama.md
new file mode 100644
index 0000000000000000000000000000000000000000..77f5e211f170f0d2c2df6c0a4393543c43e96e1e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mllama.md
@@ -0,0 +1,141 @@
+
+
+# Mllama
+
+
+
+
+
+## Overview
+
+The Llama 3.2-Vision collection of multimodal large language models (LLMs) is a collection of pretrained and instruction-tuned image reasoning generative models in 11B and 90B sizes (text \+ images in / text out). The Llama 3.2-Vision instruction-tuned models are optimized for visual recognition, image reasoning, captioning, and answering general questions about an image.
+
+**Model Architecture:** Llama 3.2-Vision is built on top of Llama 3.1 text-only model, which is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety. To support image recognition tasks, the Llama 3.2-Vision model uses a separately trained vision adapter that integrates with the pre-trained Llama 3.1 language model. The adapter consists of a series of cross-attention layers that feed image encoder representations into the core LLM.
+
+## Usage Tips
+
+- For image+text and text inputs use `MllamaForConditionalGeneration`.
+- For text-only inputs use `MllamaForCausalLM` for generation to avoid loading vision tower.
+- Each sample can contain multiple images, and the number of images can vary between samples. The processor will pad the inputs to the maximum number of images across samples and to a maximum number of tiles within each image.
+- The text passed to the processor should have the `"<|image|>"` tokens where the images should be inserted.
+- The processor has its own `apply_chat_template` method to convert chat messages to text that can then be passed as text to the processor. If you're using `transformers>=4.49.0`, you can also get a vectorized output from `apply_chat_template`. See the **Usage Examples** below for more details on how to use it.
+
+
+
+
+
+Mllama has an extra token used as a placeholder for image positions in the text. It means that input ids and an input embedding layer will have an extra token. But since the weights for input and output embeddings are not tied, the `lm_head` layer has one less token and will fail if you want to calculate loss on image tokens or apply some logit processors. In case you are training, make sure to mask out special `"<|image|>"` tokens in the `labels` as the model should not be trained on predicting them.
+
+Otherwise if you see CUDA-side index erros when generating, use the below code to expand the `lm_head` by one more token.
+
+
+```python
+old_embeddings = model.get_output_embeddings()
+
+num_tokens = model.vocab_size + 1
+resized_embeddings = model._get_resized_lm_head(old_embeddings, new_num_tokens=num_tokens, mean_resizing=True)
+resized_embeddings.requires_grad_(old_embeddings.weight.requires_grad)
+model.set_output_embeddings(resized_embeddings)
+```
+
+
+
+## Usage Example
+
+#### Instruct model
+```python
+import torch
+from transformers import MllamaForConditionalGeneration, AutoProcessor
+
+model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
+model = MllamaForConditionalGeneration.from_pretrained(model_id, device_map="auto", torch_dtype=torch.bfloat16)
+processor = AutoProcessor.from_pretrained(model_id)
+
+messages = [
+ [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+ {"type": "text", "text": "What does the image show?"}
+ ]
+ }
+ ],
+]
+inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device)
+output = model.generate(**inputs, max_new_tokens=25)
+print(processor.decode(output[0]))
+```
+
+#### Base model
+```python
+import requests
+import torch
+from PIL import Image
+from transformers import MllamaForConditionalGeneration, AutoProcessor
+
+model_id = "meta-llama/Llama-3.2-11B-Vision"
+model = MllamaForConditionalGeneration.from_pretrained(model_id, device_map="auto", torch_dtype=torch.bfloat16)
+processor = AutoProcessor.from_pretrained(model_id)
+
+prompt = "<|image|>If I had to write a haiku for this one"
+url = "https://llava-vl.github.io/static/images/view.jpg"
+raw_image = Image.open(requests.get(url, stream=True).raw)
+
+inputs = processor(text=prompt, images=raw_image, return_tensors="pt").to(model.device)
+output = model.generate(**inputs, do_sample=False, max_new_tokens=25)
+print(processor.decode(output[0], skip_special_tokens=True))
+```
+
+
+## MllamaConfig
+
+[[autodoc]] MllamaConfig
+
+## MllamaProcessor
+
+[[autodoc]] MllamaProcessor
+
+
+## MllamaImageProcessor
+
+[[autodoc]] MllamaImageProcessor
+
+## MllamaForConditionalGeneration
+
+[[autodoc]] MllamaForConditionalGeneration
+ - forward
+
+## MllamaForCausalLM
+
+[[autodoc]] MllamaForCausalLM
+ - forward
+
+## MllamaTextModel
+
+[[autodoc]] MllamaTextModel
+ - forward
+
+## MllamaForCausalLM
+
+[[autodoc]] MllamaForCausalLM
+ - forward
+
+## MllamaVisionModel
+
+[[autodoc]] MllamaVisionModel
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mluke.md b/docs/transformers/docs/source/en/model_doc/mluke.md
new file mode 100644
index 0000000000000000000000000000000000000000..aae607def6f105d16b2900b3af0d9430a78edae8
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mluke.md
@@ -0,0 +1,75 @@
+
+
+# mLUKE
+
+
+
+
+
+## Overview
+
+The mLUKE model was proposed in [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. It's a multilingual extension
+of the [LUKE model](https://arxiv.org/abs/2010.01057) trained on the basis of XLM-RoBERTa.
+
+It is based on XLM-RoBERTa and adds entity embeddings, which helps improve performance on various downstream tasks
+involving reasoning about entities such as named entity recognition, extractive question answering, relation
+classification, cloze-style knowledge completion.
+
+The abstract from the paper is the following:
+
+*Recent studies have shown that multilingual pretrained language models can be effectively improved with cross-lingual
+alignment information from Wikipedia entities. However, existing methods only exploit entity information in pretraining
+and do not explicitly use entities in downstream tasks. In this study, we explore the effectiveness of leveraging
+entity representations for downstream cross-lingual tasks. We train a multilingual language model with 24 languages
+with entity representations and show the model consistently outperforms word-based pretrained models in various
+cross-lingual transfer tasks. We also analyze the model and the key insight is that incorporating entity
+representations into the input allows us to extract more language-agnostic features. We also evaluate the model with a
+multilingual cloze prompt task with the mLAMA dataset. We show that entity-based prompt elicits correct factual
+knowledge more likely than using only word representations.*
+
+This model was contributed by [ryo0634](https://huggingface.co/ryo0634). The original code can be found [here](https://github.com/studio-ousia/luke).
+
+## Usage tips
+
+One can directly plug in the weights of mLUKE into a LUKE model, like so:
+
+```python
+from transformers import LukeModel
+
+model = LukeModel.from_pretrained("studio-ousia/mluke-base")
+```
+
+Note that mLUKE has its own tokenizer, [`MLukeTokenizer`]. You can initialize it as follows:
+
+```python
+from transformers import MLukeTokenizer
+
+tokenizer = MLukeTokenizer.from_pretrained("studio-ousia/mluke-base")
+```
+
+
+
+As mLUKE's architecture is equivalent to that of LUKE, one can refer to [LUKE's documentation page](luke) for all
+tips, code examples and notebooks.
+
+
+
+## MLukeTokenizer
+
+[[autodoc]] MLukeTokenizer
+ - __call__
+ - save_vocabulary
diff --git a/docs/transformers/docs/source/en/model_doc/mms.md b/docs/transformers/docs/source/en/model_doc/mms.md
new file mode 100644
index 0000000000000000000000000000000000000000..480d5bc8ddb1c2a6709b14756335a9468c7b4fe1
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mms.md
@@ -0,0 +1,396 @@
+
+
+# MMS
+
+
+
+
+
+
+
+## Overview
+
+The MMS model was proposed in [Scaling Speech Technology to 1,000+ Languages](https://arxiv.org/abs/2305.13516)
+by Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, Michael Auli
+
+The abstract from the paper is the following:
+
+*Expanding the language coverage of speech technology has the potential to improve access to information for many more people.
+However, current speech technology is restricted to about one hundred languages which is a small fraction of the over 7,000
+languages spoken around the world.
+The Massively Multilingual Speech (MMS) project increases the number of supported languages by 10-40x, depending on the task.
+The main ingredients are a new dataset based on readings of publicly available religious texts and effectively leveraging
+self-supervised learning. We built pre-trained wav2vec 2.0 models covering 1,406 languages,
+a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models
+for the same number of languages, as well as a language identification model for 4,017 languages.
+Experiments show that our multilingual speech recognition model more than halves the word error rate of
+Whisper on 54 languages of the FLEURS benchmark while being trained on a small fraction of the labeled data.*
+
+Here are the different models open sourced in the MMS project. The models and code are originally released [here](https://github.com/facebookresearch/fairseq/tree/main/examples/mms). We have add them to the `transformers` framework, making them easier to use.
+
+### Automatic Speech Recognition (ASR)
+
+The ASR model checkpoints can be found here : [mms-1b-fl102](https://huggingface.co/facebook/mms-1b-fl102), [mms-1b-l1107](https://huggingface.co/facebook/mms-1b-l1107), [mms-1b-all](https://huggingface.co/facebook/mms-1b-all). For best accuracy, use the `mms-1b-all` model.
+
+Tips:
+
+- All ASR models accept a float array corresponding to the raw waveform of the speech signal. The raw waveform should be pre-processed with [`Wav2Vec2FeatureExtractor`].
+- The models were trained using connectionist temporal classification (CTC) so the model output has to be decoded using
+ [`Wav2Vec2CTCTokenizer`].
+- You can load different language adapter weights for different languages via [`~Wav2Vec2PreTrainedModel.load_adapter`]. Language adapters only consists of roughly 2 million parameters
+ and can therefore be efficiently loaded on the fly when needed.
+
+#### Loading
+
+By default MMS loads adapter weights for English. If you want to load adapter weights of another language
+make sure to specify `target_lang=` as well as `"ignore_mismatched_sizes=True`.
+The `ignore_mismatched_sizes=True` keyword has to be passed to allow the language model head to be resized according
+to the vocabulary of the specified language.
+Similarly, the processor should be loaded with the same target language
+
+```py
+from transformers import Wav2Vec2ForCTC, AutoProcessor
+
+model_id = "facebook/mms-1b-all"
+target_lang = "fra"
+
+processor = AutoProcessor.from_pretrained(model_id, target_lang=target_lang)
+model = Wav2Vec2ForCTC.from_pretrained(model_id, target_lang=target_lang, ignore_mismatched_sizes=True)
+```
+
+
+
+You can safely ignore a warning such as:
+
+```text
+Some weights of Wav2Vec2ForCTC were not initialized from the model checkpoint at facebook/mms-1b-all and are newly initialized because the shapes did not match:
+- lm_head.bias: found shape torch.Size([154]) in the checkpoint and torch.Size([314]) in the model instantiated
+- lm_head.weight: found shape torch.Size([154, 1280]) in the checkpoint and torch.Size([314, 1280]) in the model instantiated
+You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
+```
+
+
+
+If you want to use the ASR pipeline, you can load your chosen target language as such:
+
+```py
+from transformers import pipeline
+
+model_id = "facebook/mms-1b-all"
+target_lang = "fra"
+
+pipe = pipeline(model=model_id, model_kwargs={"target_lang": "fra", "ignore_mismatched_sizes": True})
+```
+
+#### Inference
+
+Next, let's look at how we can run MMS in inference and change adapter layers after having called [`~PretrainedModel.from_pretrained`]
+First, we load audio data in different languages using the [Datasets](https://github.com/huggingface/datasets).
+
+```py
+from datasets import load_dataset, Audio
+
+# English
+stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "en", split="test", streaming=True)
+stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
+en_sample = next(iter(stream_data))["audio"]["array"]
+
+# French
+stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "fr", split="test", streaming=True)
+stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
+fr_sample = next(iter(stream_data))["audio"]["array"]
+```
+
+Next, we load the model and processor
+
+```py
+from transformers import Wav2Vec2ForCTC, AutoProcessor
+import torch
+
+model_id = "facebook/mms-1b-all"
+
+processor = AutoProcessor.from_pretrained(model_id)
+model = Wav2Vec2ForCTC.from_pretrained(model_id)
+```
+
+Now we process the audio data, pass the processed audio data to the model and transcribe the model output,
+just like we usually do for [`Wav2Vec2ForCTC`].
+
+```py
+inputs = processor(en_sample, sampling_rate=16_000, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs).logits
+
+ids = torch.argmax(outputs, dim=-1)[0]
+transcription = processor.decode(ids)
+# 'joe keton disapproved of films and buster also had reservations about the media'
+```
+
+We can now keep the same model in memory and simply switch out the language adapters by
+calling the convenient [`~Wav2Vec2ForCTC.load_adapter`] function for the model and [`~Wav2Vec2CTCTokenizer.set_target_lang`] for the tokenizer.
+We pass the target language as an input - `"fra"` for French.
+
+```py
+processor.tokenizer.set_target_lang("fra")
+model.load_adapter("fra")
+
+inputs = processor(fr_sample, sampling_rate=16_000, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs).logits
+
+ids = torch.argmax(outputs, dim=-1)[0]
+transcription = processor.decode(ids)
+# "ce dernier est volé tout au long de l'histoire romaine"
+```
+
+In the same way the language can be switched out for all other supported languages. Please have a look at:
+
+```py
+processor.tokenizer.vocab.keys()
+```
+
+to see all supported languages.
+
+To further improve performance from ASR models, language model decoding can be used. See the documentation [here](https://huggingface.co/facebook/mms-1b-all) for further details.
+
+### Speech Synthesis (TTS)
+
+MMS-TTS uses the same model architecture as VITS, which was added to 🤗 Transformers in v4.33. MMS trains a separate
+model checkpoint for each of the 1100+ languages in the project. All available checkpoints can be found on the Hugging
+Face Hub: [facebook/mms-tts](https://huggingface.co/models?sort=trending&search=facebook%2Fmms-tts), and the inference
+documentation under [VITS](https://huggingface.co/docs/transformers/main/en/model_doc/vits).
+
+#### Inference
+
+To use the MMS model, first update to the latest version of the Transformers library:
+
+```bash
+pip install --upgrade transformers accelerate
+```
+
+Since the flow-based model in VITS is non-deterministic, it is good practice to set a seed to ensure reproducibility of
+the outputs.
+
+- For languages with a Roman alphabet, such as English or French, the tokenizer can be used directly to
+pre-process the text inputs. The following code example runs a forward pass using the MMS-TTS English checkpoint:
+
+```python
+import torch
+from transformers import VitsTokenizer, VitsModel, set_seed
+
+tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-eng")
+model = VitsModel.from_pretrained("facebook/mms-tts-eng")
+
+inputs = tokenizer(text="Hello - my dog is cute", return_tensors="pt")
+
+set_seed(555) # make deterministic
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+waveform = outputs.waveform[0]
+```
+
+The resulting waveform can be saved as a `.wav` file:
+
+```python
+import scipy
+
+scipy.io.wavfile.write("synthesized_speech.wav", rate=model.config.sampling_rate, data=waveform)
+```
+
+Or displayed in a Jupyter Notebook / Google Colab:
+
+```python
+from IPython.display import Audio
+
+Audio(waveform, rate=model.config.sampling_rate)
+```
+
+For certain languages with non-Roman alphabets, such as Arabic, Mandarin or Hindi, the [`uroman`](https://github.com/isi-nlp/uroman)
+perl package is required to pre-process the text inputs to the Roman alphabet.
+
+You can check whether you require the `uroman` package for your language by inspecting the `is_uroman` attribute of
+the pre-trained `tokenizer`:
+
+```python
+from transformers import VitsTokenizer
+
+tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-eng")
+print(tokenizer.is_uroman)
+```
+
+If required, you should apply the uroman package to your text inputs **prior** to passing them to the `VitsTokenizer`,
+since currently the tokenizer does not support performing the pre-processing itself.
+
+To do this, first clone the uroman repository to your local machine and set the bash variable `UROMAN` to the local path:
+
+```bash
+git clone https://github.com/isi-nlp/uroman.git
+cd uroman
+export UROMAN=$(pwd)
+```
+
+You can then pre-process the text input using the following code snippet. You can either rely on using the bash variable
+`UROMAN` to point to the uroman repository, or you can pass the uroman directory as an argument to the `uromanize` function:
+
+```python
+import torch
+from transformers import VitsTokenizer, VitsModel, set_seed
+import os
+import subprocess
+
+tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-kor")
+model = VitsModel.from_pretrained("facebook/mms-tts-kor")
+
+def uromanize(input_string, uroman_path):
+ """Convert non-Roman strings to Roman using the `uroman` perl package."""
+ script_path = os.path.join(uroman_path, "bin", "uroman.pl")
+
+ command = ["perl", script_path]
+
+ process = subprocess.Popen(command, stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ # Execute the perl command
+ stdout, stderr = process.communicate(input=input_string.encode())
+
+ if process.returncode != 0:
+ raise ValueError(f"Error {process.returncode}: {stderr.decode()}")
+
+ # Return the output as a string and skip the new-line character at the end
+ return stdout.decode()[:-1]
+
+text = "이봐 무슨 일이야"
+uromanized_text = uromanize(text, uroman_path=os.environ["UROMAN"])
+
+inputs = tokenizer(text=uromanized_text, return_tensors="pt")
+
+set_seed(555) # make deterministic
+with torch.no_grad():
+ outputs = model(inputs["input_ids"])
+
+waveform = outputs.waveform[0]
+```
+
+**Tips:**
+
+* The MMS-TTS checkpoints are trained on lower-cased, un-punctuated text. By default, the `VitsTokenizer` *normalizes* the inputs by removing any casing and punctuation, to avoid passing out-of-vocabulary characters to the model. Hence, the model is agnostic to casing and punctuation, so these should be avoided in the text prompt. You can disable normalisation by setting `normalize=False` in the call to the tokenizer, but this will lead to un-expected behaviour and is discouraged.
+* The speaking rate can be varied by setting the attribute `model.speaking_rate` to a chosen value. Likewise, the randomness of the noise is controlled by `model.noise_scale`:
+
+```python
+import torch
+from transformers import VitsTokenizer, VitsModel, set_seed
+
+tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-eng")
+model = VitsModel.from_pretrained("facebook/mms-tts-eng")
+
+inputs = tokenizer(text="Hello - my dog is cute", return_tensors="pt")
+
+# make deterministic
+set_seed(555)
+
+# make speech faster and more noisy
+model.speaking_rate = 1.5
+model.noise_scale = 0.8
+
+with torch.no_grad():
+ outputs = model(**inputs)
+```
+
+### Language Identification (LID)
+
+Different LID models are available based on the number of languages they can recognize - [126](https://huggingface.co/facebook/mms-lid-126), [256](https://huggingface.co/facebook/mms-lid-256), [512](https://huggingface.co/facebook/mms-lid-512), [1024](https://huggingface.co/facebook/mms-lid-1024), [2048](https://huggingface.co/facebook/mms-lid-2048), [4017](https://huggingface.co/facebook/mms-lid-4017).
+
+#### Inference
+First, we install transformers and some other libraries
+
+```bash
+pip install torch accelerate datasets[audio]
+pip install --upgrade transformers
+````
+
+Next, we load a couple of audio samples via `datasets`. Make sure that the audio data is sampled to 16000 kHz.
+
+```py
+from datasets import load_dataset, Audio
+
+# English
+stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "en", split="test", streaming=True)
+stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
+en_sample = next(iter(stream_data))["audio"]["array"]
+
+# Arabic
+stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "ar", split="test", streaming=True)
+stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
+ar_sample = next(iter(stream_data))["audio"]["array"]
+```
+
+Next, we load the model and processor
+
+```py
+from transformers import Wav2Vec2ForSequenceClassification, AutoFeatureExtractor
+import torch
+
+model_id = "facebook/mms-lid-126"
+
+processor = AutoFeatureExtractor.from_pretrained(model_id)
+model = Wav2Vec2ForSequenceClassification.from_pretrained(model_id)
+```
+
+Now we process the audio data, pass the processed audio data to the model to classify it into a language, just like we usually do for Wav2Vec2 audio classification models such as [ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition](https://huggingface.co/harshit345/xlsr-wav2vec-speech-emotion-recognition)
+
+```py
+# English
+inputs = processor(en_sample, sampling_rate=16_000, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs).logits
+
+lang_id = torch.argmax(outputs, dim=-1)[0].item()
+detected_lang = model.config.id2label[lang_id]
+# 'eng'
+
+# Arabic
+inputs = processor(ar_sample, sampling_rate=16_000, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs).logits
+
+lang_id = torch.argmax(outputs, dim=-1)[0].item()
+detected_lang = model.config.id2label[lang_id]
+# 'ara'
+```
+
+To see all the supported languages of a checkpoint, you can print out the language ids as follows:
+```py
+processor.id2label.values()
+```
+
+### Audio Pretrained Models
+
+Pretrained models are available for two different sizes - [300M](https://huggingface.co/facebook/mms-300m) ,
+[1Bil](https://huggingface.co/facebook/mms-1b).
+
+
+
+The MMS for ASR architecture is based on the Wav2Vec2 model, refer to [Wav2Vec2's documentation page](wav2vec2) for further
+details on how to finetune with models for various downstream tasks.
+
+MMS-TTS uses the same model architecture as VITS, refer to [VITS's documentation page](vits) for API reference.
+
diff --git a/docs/transformers/docs/source/en/model_doc/mobilebert.md b/docs/transformers/docs/source/en/model_doc/mobilebert.md
new file mode 100644
index 0000000000000000000000000000000000000000..2104d0a4573f1df3cf7f4d90f45076510db2eb5d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mobilebert.md
@@ -0,0 +1,198 @@
+
+
+
+
+
+
+
+
+
+
+# MobileBERT
+
+[MobileBERT](https://huggingface.co/papers/2004.02984) is a lightweight and efficient variant of BERT, specifically designed for resource-limited devices such as mobile phones. It retains BERT's architecture but significantly reduces model size and inference latency while maintaining strong performance on NLP tasks. MobileBERT achieves this through a bottleneck structure and carefully balanced self-attention and feedforward networks. The model is trained by knowledge transfer from a large BERT model with an inverted bottleneck structure.
+
+You can find the original MobileBERT checkpoint under the [Google](https://huggingface.co/google/mobilebert-uncased) organization.
+> [!TIP]
+> Click on the MobileBERT models in the right sidebar for more examples of how to apply MobileBERT to different language tasks.
+
+The example below demonstrates how to predict the `[MASK]` token with [`Pipeline`], [`AutoModel`], and from the command line.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="fill-mask",
+ model="google/mobilebert-uncased",
+ torch_dtype=torch.float16,
+ device=0
+)
+pipeline("The capital of France is [MASK].")
+```
+
+
+
+```py
+import torch
+from transformers import AutoModelForMaskedLM, AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained(
+ "google/mobilebert-uncased",
+)
+model = AutoModelForMaskedLM.from_pretrained(
+ "google/mobilebert-uncased",
+ torch_dtype=torch.float16,
+ device_map="auto",
+)
+inputs = tokenizer("The capital of France is [MASK].", return_tensors="pt").to("cuda")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+ predictions = outputs.logits
+
+masked_index = torch.where(inputs['input_ids'] == tokenizer.mask_token_id)[1]
+predicted_token_id = predictions[0, masked_index].argmax(dim=-1)
+predicted_token = tokenizer.decode(predicted_token_id)
+
+print(f"The predicted token is: {predicted_token}")
+```
+
+
+
+
+```bash
+echo -e "The capital of France is [MASK]." | transformers-cli run --task fill-mask --model google/mobilebert-uncased --device 0
+```
+
+
+
+
+
+## Notes
+
+- Inputs should be padded on the right because BERT uses absolute position embeddings.
+
+## MobileBertConfig
+
+[[autodoc]] MobileBertConfig
+
+## MobileBertTokenizer
+
+[[autodoc]] MobileBertTokenizer
+
+## MobileBertTokenizerFast
+
+[[autodoc]] MobileBertTokenizerFast
+
+## MobileBert specific outputs
+
+[[autodoc]] models.mobilebert.modeling_mobilebert.MobileBertForPreTrainingOutput
+
+[[autodoc]] models.mobilebert.modeling_tf_mobilebert.TFMobileBertForPreTrainingOutput
+
+
+
+
+## MobileBertModel
+
+[[autodoc]] MobileBertModel
+ - forward
+
+## MobileBertForPreTraining
+
+[[autodoc]] MobileBertForPreTraining
+ - forward
+
+## MobileBertForMaskedLM
+
+[[autodoc]] MobileBertForMaskedLM
+ - forward
+
+## MobileBertForNextSentencePrediction
+
+[[autodoc]] MobileBertForNextSentencePrediction
+ - forward
+
+## MobileBertForSequenceClassification
+
+[[autodoc]] MobileBertForSequenceClassification
+ - forward
+
+## MobileBertForMultipleChoice
+
+[[autodoc]] MobileBertForMultipleChoice
+ - forward
+
+## MobileBertForTokenClassification
+
+[[autodoc]] MobileBertForTokenClassification
+ - forward
+
+## MobileBertForQuestionAnswering
+
+[[autodoc]] MobileBertForQuestionAnswering
+ - forward
+
+
+
+
+## TFMobileBertModel
+
+[[autodoc]] TFMobileBertModel
+ - call
+
+## TFMobileBertForPreTraining
+
+[[autodoc]] TFMobileBertForPreTraining
+ - call
+
+## TFMobileBertForMaskedLM
+
+[[autodoc]] TFMobileBertForMaskedLM
+ - call
+
+## TFMobileBertForNextSentencePrediction
+
+[[autodoc]] TFMobileBertForNextSentencePrediction
+ - call
+
+## TFMobileBertForSequenceClassification
+
+[[autodoc]] TFMobileBertForSequenceClassification
+ - call
+
+## TFMobileBertForMultipleChoice
+
+[[autodoc]] TFMobileBertForMultipleChoice
+ - call
+
+## TFMobileBertForTokenClassification
+
+[[autodoc]] TFMobileBertForTokenClassification
+ - call
+
+## TFMobileBertForQuestionAnswering
+
+[[autodoc]] TFMobileBertForQuestionAnswering
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/mobilenet_v1.md b/docs/transformers/docs/source/en/model_doc/mobilenet_v1.md
new file mode 100644
index 0000000000000000000000000000000000000000..3f3d04aa5f5bcae51dd1d283bf2a64f9bcd95e5e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mobilenet_v1.md
@@ -0,0 +1,93 @@
+
+
+# MobileNet V1
+
+
+
+
+
+## Overview
+
+The MobileNet model was proposed in [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
+
+The abstract from the paper is the following:
+
+*We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks. We introduce two simple global hyper-parameters that efficiently trade off between latency and accuracy. These hyper-parameters allow the model builder to choose the right sized model for their application based on the constraints of the problem. We present extensive experiments on resource and accuracy tradeoffs and show strong performance compared to other popular models on ImageNet classification. We then demonstrate the effectiveness of MobileNets across a wide range of applications and use cases including object detection, finegrain classification, face attributes and large scale geo-localization.*
+
+This model was contributed by [matthijs](https://huggingface.co/Matthijs). The original code and weights can be found [here](https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md).
+
+## Usage tips
+
+- The checkpoints are named **mobilenet\_v1\_*depth*\_*size***, for example **mobilenet\_v1\_1.0\_224**, where **1.0** is the depth multiplier (sometimes also referred to as "alpha" or the width multiplier) and **224** is the resolution of the input images the model was trained on.
+
+- Even though the checkpoint is trained on images of specific size, the model will work on images of any size. The smallest supported image size is 32x32.
+
+- One can use [`MobileNetV1ImageProcessor`] to prepare images for the model.
+
+- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). However, the model predicts 1001 classes: the 1000 classes from ImageNet plus an extra “background” class (index 0).
+
+- The original TensorFlow checkpoints use different padding rules than PyTorch, requiring the model to determine the padding amount at inference time, since this depends on the input image size. To use native PyTorch padding behavior, create a [`MobileNetV1Config`] with `tf_padding = False`.
+
+Unsupported features:
+
+- The [`MobileNetV1Model`] outputs a globally pooled version of the last hidden state. In the original model it is possible to use a 7x7 average pooling layer with stride 2 instead of global pooling. For larger inputs, this gives a pooled output that is larger than 1x1 pixel. The HuggingFace implementation does not support this.
+
+- It is currently not possible to specify an `output_stride`. For smaller output strides, the original model invokes dilated convolution to prevent the spatial resolution from being reduced further. The output stride of the HuggingFace model is always 32.
+
+- The original TensorFlow checkpoints include quantized models. We do not support these models as they include additional "FakeQuantization" operations to unquantize the weights.
+
+- It's common to extract the output from the pointwise layers at indices 5, 11, 12, 13 for downstream purposes. Using `output_hidden_states=True` returns the output from all intermediate layers. There is currently no way to limit this to specific layers.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileNetV1.
+
+
+
+- [`MobileNetV1ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## MobileNetV1Config
+
+[[autodoc]] MobileNetV1Config
+
+## MobileNetV1FeatureExtractor
+
+[[autodoc]] MobileNetV1FeatureExtractor
+ - preprocess
+
+## MobileNetV1ImageProcessor
+
+[[autodoc]] MobileNetV1ImageProcessor
+ - preprocess
+
+## MobileNetV1ImageProcessorFast
+
+[[autodoc]] MobileNetV1ImageProcessorFast
+ - preprocess
+
+## MobileNetV1Model
+
+[[autodoc]] MobileNetV1Model
+ - forward
+
+## MobileNetV1ForImageClassification
+
+[[autodoc]] MobileNetV1ForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mobilenet_v2.md b/docs/transformers/docs/source/en/model_doc/mobilenet_v2.md
new file mode 100644
index 0000000000000000000000000000000000000000..ffe830ac8d91e89687ddff0f76fa6437bd2153a8
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mobilenet_v2.md
@@ -0,0 +1,107 @@
+
+
+# MobileNet V2
+
+
+
+
+
+## Overview
+
+The MobileNet model was proposed in [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
+
+The abstract from the paper is the following:
+
+*In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call SSDLite. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of DeepLabv3 which we call Mobile DeepLabv3.*
+
+*The MobileNetV2 architecture is based on an inverted residual structure where the input and output of the residual block are thin bottleneck layers opposite to traditional residual models which use expanded representations in the input an MobileNetV2 uses lightweight depthwise convolutions to filter features in the intermediate expansion layer. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on Imagenet classification, COCO object detection, VOC image segmentation. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as the number of parameters.*
+
+This model was contributed by [matthijs](https://huggingface.co/Matthijs). The original code and weights can be found [here for the main model](https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet) and [here for DeepLabV3+](https://github.com/tensorflow/models/tree/master/research/deeplab).
+
+## Usage tips
+
+- The checkpoints are named **mobilenet\_v2\_*depth*\_*size***, for example **mobilenet\_v2\_1.0\_224**, where **1.0** is the depth multiplier (sometimes also referred to as "alpha" or the width multiplier) and **224** is the resolution of the input images the model was trained on.
+
+- Even though the checkpoint is trained on images of specific size, the model will work on images of any size. The smallest supported image size is 32x32.
+
+- One can use [`MobileNetV2ImageProcessor`] to prepare images for the model.
+
+- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). However, the model predicts 1001 classes: the 1000 classes from ImageNet plus an extra “background” class (index 0).
+
+- The segmentation model uses a [DeepLabV3+](https://arxiv.org/abs/1802.02611) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
+
+- The original TensorFlow checkpoints use different padding rules than PyTorch, requiring the model to determine the padding amount at inference time, since this depends on the input image size. To use native PyTorch padding behavior, create a [`MobileNetV2Config`] with `tf_padding = False`.
+
+Unsupported features:
+
+- The [`MobileNetV2Model`] outputs a globally pooled version of the last hidden state. In the original model it is possible to use an average pooling layer with a fixed 7x7 window and stride 1 instead of global pooling. For inputs that are larger than the recommended image size, this gives a pooled output that is larger than 1x1. The Hugging Face implementation does not support this.
+
+- The original TensorFlow checkpoints include quantized models. We do not support these models as they include additional "FakeQuantization" operations to unquantize the weights.
+
+- It's common to extract the output from the expansion layers at indices 10 and 13, as well as the output from the final 1x1 convolution layer, for downstream purposes. Using `output_hidden_states=True` returns the output from all intermediate layers. There is currently no way to limit this to specific layers.
+
+- The DeepLabV3+ segmentation head does not use the final convolution layer from the backbone, but this layer gets computed anyway. There is currently no way to tell [`MobileNetV2Model`] up to which layer it should run.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileNetV2.
+
+
+
+- [`MobileNetV2ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+**Semantic segmentation**
+- [Semantic segmentation task guide](../tasks/semantic_segmentation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## MobileNetV2Config
+
+[[autodoc]] MobileNetV2Config
+
+## MobileNetV2FeatureExtractor
+
+[[autodoc]] MobileNetV2FeatureExtractor
+ - preprocess
+ - post_process_semantic_segmentation
+
+## MobileNetV2ImageProcessor
+
+[[autodoc]] MobileNetV2ImageProcessor
+ - preprocess
+
+## MobileNetV2ImageProcessorFast
+
+[[autodoc]] MobileNetV2ImageProcessorFast
+ - preprocess
+ - post_process_semantic_segmentation
+
+## MobileNetV2Model
+
+[[autodoc]] MobileNetV2Model
+ - forward
+
+## MobileNetV2ForImageClassification
+
+[[autodoc]] MobileNetV2ForImageClassification
+ - forward
+
+## MobileNetV2ForSemanticSegmentation
+
+[[autodoc]] MobileNetV2ForSemanticSegmentation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mobilevit.md b/docs/transformers/docs/source/en/model_doc/mobilevit.md
new file mode 100644
index 0000000000000000000000000000000000000000..c9054b59cbc9ba61ac80e72c01cc48473c161715
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mobilevit.md
@@ -0,0 +1,135 @@
+
+
+# MobileViT
+
+
+
+
+
+
+## Overview
+
+The MobileViT model was proposed in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari. MobileViT introduces a new layer that replaces local processing in convolutions with global processing using transformers.
+
+The abstract from the paper is the following:
+
+*Light-weight convolutional neural networks (CNNs) are the de-facto for mobile vision tasks. Their spatial inductive biases allow them to learn representations with fewer parameters across different vision tasks. However, these networks are spatially local. To learn global representations, self-attention-based vision trans-formers (ViTs) have been adopted. Unlike CNNs, ViTs are heavy-weight. In this paper, we ask the following question: is it possible to combine the strengths of CNNs and ViTs to build a light-weight and low latency network for mobile vision tasks? Towards this end, we introduce MobileViT, a light-weight and general-purpose vision transformer for mobile devices. MobileViT presents a different perspective for the global processing of information with transformers, i.e., transformers as convolutions. Our results show that MobileViT significantly outperforms CNN- and ViT-based networks across different tasks and datasets. On the ImageNet-1k dataset, MobileViT achieves top-1 accuracy of 78.4% with about 6 million parameters, which is 3.2% and 6.2% more accurate than MobileNetv3 (CNN-based) and DeIT (ViT-based) for a similar number of parameters. On the MS-COCO object detection task, MobileViT is 5.7% more accurate than MobileNetv3 for a similar number of parameters.*
+
+This model was contributed by [matthijs](https://huggingface.co/Matthijs). The TensorFlow version of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code and weights can be found [here](https://github.com/apple/ml-cvnets).
+
+## Usage tips
+
+- MobileViT is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map. You can follow [this tutorial](https://keras.io/examples/vision/mobilevit) for a lightweight introduction.
+- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
+- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
+- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
+- As the name suggests MobileViT was designed to be performant and efficient on mobile phones. The TensorFlow versions of the MobileViT models are fully compatible with [TensorFlow Lite](https://www.tensorflow.org/lite).
+
+ You can use the following code to convert a MobileViT checkpoint (be it image classification or semantic segmentation) to generate a
+ TensorFlow Lite model:
+
+```py
+from transformers import TFMobileViTForImageClassification
+import tensorflow as tf
+
+
+model_ckpt = "apple/mobilevit-xx-small"
+model = TFMobileViTForImageClassification.from_pretrained(model_ckpt)
+
+converter = tf.lite.TFLiteConverter.from_keras_model(model)
+converter.optimizations = [tf.lite.Optimize.DEFAULT]
+converter.target_spec.supported_ops = [
+ tf.lite.OpsSet.TFLITE_BUILTINS,
+ tf.lite.OpsSet.SELECT_TF_OPS,
+]
+tflite_model = converter.convert()
+tflite_filename = model_ckpt.split("/")[-1] + ".tflite"
+with open(tflite_filename, "wb") as f:
+ f.write(tflite_model)
+```
+
+ The resulting model will be just **about an MB** making it a good fit for mobile applications where resources and network
+ bandwidth can be constrained.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with MobileViT.
+
+
+
+- [`MobileViTForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+**Semantic segmentation**
+- [Semantic segmentation task guide](../tasks/semantic_segmentation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## MobileViTConfig
+
+[[autodoc]] MobileViTConfig
+
+## MobileViTFeatureExtractor
+
+[[autodoc]] MobileViTFeatureExtractor
+ - __call__
+ - post_process_semantic_segmentation
+
+## MobileViTImageProcessor
+
+[[autodoc]] MobileViTImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
+
+
+
+## MobileViTModel
+
+[[autodoc]] MobileViTModel
+ - forward
+
+## MobileViTForImageClassification
+
+[[autodoc]] MobileViTForImageClassification
+ - forward
+
+## MobileViTForSemanticSegmentation
+
+[[autodoc]] MobileViTForSemanticSegmentation
+ - forward
+
+
+
+
+## TFMobileViTModel
+
+[[autodoc]] TFMobileViTModel
+ - call
+
+## TFMobileViTForImageClassification
+
+[[autodoc]] TFMobileViTForImageClassification
+ - call
+
+## TFMobileViTForSemanticSegmentation
+
+[[autodoc]] TFMobileViTForSemanticSegmentation
+ - call
+
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/mobilevitv2.md b/docs/transformers/docs/source/en/model_doc/mobilevitv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..b6549666850afceeb04522dd735bee1c64c69d47
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mobilevitv2.md
@@ -0,0 +1,60 @@
+
+
+# MobileViTV2
+
+
+
+
+
+## Overview
+
+The MobileViTV2 model was proposed in [Separable Self-attention for Mobile Vision Transformers](https://arxiv.org/abs/2206.02680) by Sachin Mehta and Mohammad Rastegari.
+
+MobileViTV2 is the second version of MobileViT, constructed by replacing the multi-headed self-attention in MobileViT with separable self-attention.
+
+The abstract from the paper is the following:
+
+*Mobile vision transformers (MobileViT) can achieve state-of-the-art performance across several mobile vision tasks, including classification and detection. Though these models have fewer parameters, they have high latency as compared to convolutional neural network-based models. The main efficiency bottleneck in MobileViT is the multi-headed self-attention (MHA) in transformers, which requires O(k2) time complexity with respect to the number of tokens (or patches) k. Moreover, MHA requires costly operations (e.g., batch-wise matrix multiplication) for computing self-attention, impacting latency on resource-constrained devices. This paper introduces a separable self-attention method with linear complexity, i.e. O(k). A simple yet effective characteristic of the proposed method is that it uses element-wise operations for computing self-attention, making it a good choice for resource-constrained devices. The improved model, MobileViTV2, is state-of-the-art on several mobile vision tasks, including ImageNet object classification and MS-COCO object detection. With about three million parameters, MobileViTV2 achieves a top-1 accuracy of 75.6% on the ImageNet dataset, outperforming MobileViT by about 1% while running 3.2× faster on a mobile device.*
+
+This model was contributed by [shehan97](https://huggingface.co/shehan97).
+The original code can be found [here](https://github.com/apple/ml-cvnets).
+
+## Usage tips
+
+- MobileViTV2 is more like a CNN than a Transformer model. It does not work on sequence data but on batches of images. Unlike ViT, there are no embeddings. The backbone model outputs a feature map.
+- One can use [`MobileViTImageProcessor`] to prepare images for the model. Note that if you do your own preprocessing, the pretrained checkpoints expect images to be in BGR pixel order (not RGB).
+- The available image classification checkpoints are pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes).
+- The segmentation model uses a [DeepLabV3](https://arxiv.org/abs/1706.05587) head. The available semantic segmentation checkpoints are pre-trained on [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/).
+
+## MobileViTV2Config
+
+[[autodoc]] MobileViTV2Config
+
+## MobileViTV2Model
+
+[[autodoc]] MobileViTV2Model
+ - forward
+
+## MobileViTV2ForImageClassification
+
+[[autodoc]] MobileViTV2ForImageClassification
+ - forward
+
+## MobileViTV2ForSemanticSegmentation
+
+[[autodoc]] MobileViTV2ForSemanticSegmentation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/modernbert.md b/docs/transformers/docs/source/en/model_doc/modernbert.md
new file mode 100644
index 0000000000000000000000000000000000000000..16ada230a2ae3fa5cba788270868d7b9b391416b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/modernbert.md
@@ -0,0 +1,129 @@
+
+
+
+
+
+
+
+
+
+
+# ModernBERT
+
+[ModernBERT](https://huggingface.co/papers/2412.13663) is a modernized version of [`BERT`] trained on 2T tokens. It brings many improvements to the original architecture such as rotary positional embeddings to support sequences of up to 8192 tokens, unpadding to avoid wasting compute on padding tokens, GeGLU layers, and alternating attention.
+
+You can find all the original ModernBERT checkpoints under the [ModernBERT](https://huggingface.co/collections/answerdotai/modernbert-67627ad707a4acbf33c41deb) collection.
+
+> [!TIP]
+> Click on the ModernBERT models in the right sidebar for more examples of how to apply ModernBERT to different language tasks.
+
+The example below demonstrates how to predict the `[MASK]` token with [`Pipeline`], [`AutoModel`], and from the command line.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="fill-mask",
+ model="answerdotai/ModernBERT-base",
+ torch_dtype=torch.float16,
+ device=0
+)
+pipeline("Plants create [MASK] through a process known as photosynthesis.")
+```
+
+
+
+
+```py
+import torch
+from transformers import AutoModelForMaskedLM, AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained(
+ "answerdotai/ModernBERT-base",
+)
+model = AutoModelForMaskedLM.from_pretrained(
+ "answerdotai/ModernBERT-base",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+inputs = tokenizer("Plants create [MASK] through a process known as photosynthesis.", return_tensors="pt").to("cuda")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+ predictions = outputs.logits
+
+masked_index = torch.where(inputs['input_ids'] == tokenizer.mask_token_id)[1]
+predicted_token_id = predictions[0, masked_index].argmax(dim=-1)
+predicted_token = tokenizer.decode(predicted_token_id)
+
+print(f"The predicted token is: {predicted_token}")
+```
+
+
+
+
+```bash
+echo -e "Plants create [MASK] through a process known as photosynthesis." | transformers-cli run --task fill-mask --model answerdotai/ModernBERT-base --device 0
+```
+
+
+
+
+## ModernBertConfig
+
+[[autodoc]] ModernBertConfig
+
+
+
+
+## ModernBertModel
+
+[[autodoc]] ModernBertModel
+ - forward
+
+## ModernBertForMaskedLM
+
+[[autodoc]] ModernBertForMaskedLM
+ - forward
+
+## ModernBertForSequenceClassification
+
+[[autodoc]] ModernBertForSequenceClassification
+ - forward
+
+## ModernBertForTokenClassification
+
+[[autodoc]] ModernBertForTokenClassification
+ - forward
+
+## ModernBertForQuestionAnswering
+
+[[autodoc]] ModernBertForQuestionAnswering
+ - forward
+
+### Usage tips
+
+The ModernBert model can be fine-tuned using the HuggingFace Transformers library with its [official script](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_qa.py) for question-answering tasks.
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/moonshine.md b/docs/transformers/docs/source/en/model_doc/moonshine.md
new file mode 100644
index 0000000000000000000000000000000000000000..2a4599e3d7e08465c0e82b9b0f53a2c6ae33d04a
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/moonshine.md
@@ -0,0 +1,62 @@
+
+
+# Moonshine
+
+
+
+
+
+
+
+## Overview
+
+The Moonshine model was proposed in [Moonshine: Speech Recognition for Live Transcription and Voice Commands
+](https://arxiv.org/abs/2410.15608) by Nat Jeffries, Evan King, Manjunath Kudlur, Guy Nicholson, James Wang, Pete Warden.
+
+The abstract from the paper is the following:
+
+*This paper introduces Moonshine, a family of speech recognition models optimized for live transcription and voice command processing. Moonshine is based on an encoder-decoder transformer architecture and employs Rotary Position Embedding (RoPE) instead of traditional absolute position embeddings. The model is trained on speech segments of various lengths, but without using zero-padding, leading to greater efficiency for the encoder during inference time. When benchmarked against OpenAI's Whisper tiny-en, Moonshine Tiny demonstrates a 5x reduction in compute requirements for transcribing a 10-second speech segment while incurring no increase in word error rates across standard evaluation datasets. These results highlight Moonshine's potential for real-time and resource-constrained applications.*
+
+Tips:
+
+- Moonshine improves upon Whisper's architecture:
+ 1. It uses SwiGLU activation instead of GELU in the decoder layers
+ 2. Most importantly, it replaces absolute position embeddings with Rotary Position Embeddings (RoPE). This allows Moonshine to handle audio inputs of any length, unlike Whisper which is restricted to fixed 30-second windows.
+
+This model was contributed by [Eustache Le Bihan (eustlb)](https://huggingface.co/eustlb).
+The original code can be found [here](https://github.com/usefulsensors/moonshine).
+
+## Resources
+
+- [Automatic speech recognition task guide](../tasks/asr)
+
+## MoonshineConfig
+
+[[autodoc]] MoonshineConfig
+
+## MoonshineModel
+
+[[autodoc]] MoonshineModel
+ - forward
+ - _mask_input_features
+
+## MoonshineForConditionalGeneration
+
+[[autodoc]] MoonshineForConditionalGeneration
+ - forward
+ - generate
+
diff --git a/docs/transformers/docs/source/en/model_doc/moshi.md b/docs/transformers/docs/source/en/model_doc/moshi.md
new file mode 100644
index 0000000000000000000000000000000000000000..9302a94619593492f962b5d54cafce35d1336e92
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/moshi.md
@@ -0,0 +1,194 @@
+
+
+# Moshi
+
+
+
+
+
+
+
+## Overview
+
+The Moshi model was proposed in [Moshi: a speech-text foundation model for real-time dialogue](https://kyutai.org/Moshi.pdf) by Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave and Neil Zeghidour.
+
+Moshi is a speech-text foundation model that casts spoken dialogue as speech-to-speech generation. Starting from a text language model backbone, Moshi generates speech as tokens from the residual quantizer of a neural audio codec, while modeling separately its own speech and that of the user into parallel streams. This allows for the removal of explicit speaker turns, and the modeling of arbitrary conversational dynamics. Moshi also predicts time-aligned text tokens as a prefix to audio tokens. This “Inner Monologue” method significantly improves the linguistic quality of generated speech and provides streaming speech recognition and text-to-speech. As a result, Moshi is the first real-time full-duplex spoken large language model, with a theoretical latency of 160ms, 200ms in practice.
+
+
+
+
+
+The abstract from the paper is the following:
+
+*We introduce Moshi, a speech-text foundation model and full-duplex spoken dialogue framework. Current systems for spoken dialogue rely on pipelines of independent components, namely voice activity detection, speech recognition, textual dialogue and text-to-speech. Such frameworks cannot emulate the experience of real conversations. First, their complexity induces a latency of several seconds between interactions. Second, text being the intermediate modality for dialogue, non-linguistic information that modifies meaning— such as emotion or non-speech sounds— is lost in the interaction. Finally, they rely on a segmentation into speaker turns, which does not take into account overlapping speech, interruptions and interjections. Moshi solves these independent issues altogether by casting spoken dialogue as speech-to-speech generation. Starting from a text language model backbone, Moshi generates speech as tokens from the residual quantizer of a neural audio codec, while modeling separately its own speech and that of the user into parallel streams. This allows for the removal of explicit speaker turns, and the modeling of arbitrary conversational dynamics. We moreover extend the hierarchical semantic-to-acoustic token generation of previous work to first predict time-aligned text tokens as a prefix to audio tokens. Not only this “Inner Monologue” method significantly improves the linguistic quality of generated speech, but we also illustrate how it can provide streaming speech recognition and text-to-speech. Our resulting model is the first real-time full-duplex spoken large language model, with a theoretical latency of 160ms, 200ms in practice, and is available at github.com/kyutai-labs/moshi.*
+
+Moshi deals with 3 streams of information:
+1. The user's audio
+2. Moshi's audio
+3. Moshi's textual output
+
+Similarly to [`~MusicgenModel`], audio is represented with audio codebooks, which can be interpreted like tokens. The main difference between text tokens and audio codebooks is that audio codebooks introduce an additional dimension of information.
+Text tokens are typically of dim `(batch_size, sequence_length)` but audio tokens are of dim `(batch_size, num_codebooks, sequence_length)`.
+
+Moshi's made of 3 components:
+
+**1. The main decoder (Helium in the paper)**
+
+It corresponds to [`MoshiForCausalLM`]. It is strictly a classic text LLM, that uses an architecture similar to [` ~GemmaForCausalLM`]. In other words, it takes text tokens, embeds them, pass them through the decoder and a language head, to get text logits.
+
+**2. The depth decoder**
+
+On its own, it's also a classic LLM, but this time, instead of generating over the time dimension, it generates over the codebook dimension.
+
+It also means that its context length is `num_codebooks`, thus it can't generate more than `num_codebooks`.
+
+Note that each timestamp - i.e each codebook - gets its own set of Linear Layers and Embeddings.
+
+**3. [`MimiModel`]**
+
+It's the audio encoder from Kyutai, that has recently been integrated to transformers, which is used to "tokenize" audio. It has the same use that [`~EncodecModel`] has in [`~MusicgenModel`].
+
+
+## Tips:
+
+The original checkpoints can be converted using the conversion script `src/transformers/models/moshi/convert_moshi_transformers.py`
+
+
+### How to use the model:
+
+This implementation has two main aims:
+1. quickly test model generation by simplifying the original API
+2. simplify training. A training guide will come soon, but user contributions are welcomed!
+
+
+
+It is designed for intermediate use. We strongly recommend using the original [implementation](https://github.com/kyutai-labs/moshi) to infer the model in real-time streaming.
+
+
+
+**1. Model generation**
+
+Moshi is a streaming auto-regressive model with two streams of audio. To put it differently, one audio stream corresponds to what the model said/will say and the other audio stream corresponds to what the user said/will say.
+
+[`MoshiForConditionalGeneration.generate`] thus needs 3 inputs:
+1. `input_ids` - corresponding to the text token history
+2. `moshi_input_values` or `moshi_audio_codes`- corresponding to the model audio history
+3. `user_input_values` or `user_audio_codes` - corresponding to the user audio history
+
+These three inputs must be synchronized. Meaning that their lengths must correspond to the same number of tokens.
+
+You can dynamically use the 3 inputs depending on what you want to test:
+1. Simply check the model response to an user prompt - in that case, `input_ids` can be filled with pad tokens and `user_input_values` can be a zero tensor of the same shape than the user prompt.
+2. Test more complex behaviour - in that case, you must be careful about how the input tokens are synchronized with the audios.
+
+
+
+The original model is synchronized text with audio by padding the text in between each token enunciation.
+
+To follow the example of the following image, `"Hello, I'm Moshi"` could be transformed to `"Hello,I'm Moshi"`.
+
+
+
+
+
+
+
+
+[`MoshiForConditionalGeneration.generate`] then auto-regressively feeds to itself its own audio stream, but since it doesn't have access to the user input stream while using `transformers`, it will thus **assume that the user is producing blank audio**.
+
+
+
+```python
+>>> from datasets import load_dataset, Audio
+>>> import torch, math
+>>> from transformers import MoshiForConditionalGeneration, AutoFeatureExtractor, AutoTokenizer
+
+
+>>> librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("kyutai/moshiko-pytorch-bf16")
+>>> tokenizer = AutoTokenizer.from_pretrained("kyutai/moshiko-pytorch-bf16")
+>>> device = "cuda"
+>>> dtype = torch.bfloat16
+
+>>> # prepare user input audio
+>>> librispeech_dummy = librispeech_dummy.cast_column("audio", Audio(sampling_rate=feature_extractor.sampling_rate))
+>>> audio_sample = librispeech_dummy[-1]["audio"]["array"]
+>>> user_input_values = feature_extractor(raw_audio=audio_sample, sampling_rate=feature_extractor.sampling_rate, return_tensors="pt").to(device=device, dtype=dtype)
+
+>>> # prepare moshi input values - we suppose moshi didn't say anything while the user spoke
+>>> moshi_input_values = torch.zeros_like(user_input_values.input_values)
+
+>>> # prepare moshi input ids - we suppose moshi didn't say anything while the user spoke
+>>> num_tokens = math.ceil(moshi_input_values.shape[-1] * waveform_to_token_ratio)
+>>> input_ids = torch.ones((1, num_tokens), device=device, dtype=torch.int64) * tokenizer.encode("")[0]
+
+>>> # generate 25 new tokens (around 2s of audio)
+>>> output = model.generate(input_ids=input_ids, user_input_values=user_input_values.input_values, moshi_input_values=moshi_input_values, max_new_tokens=25)
+
+>>> text_tokens = output.sequences
+>>> audio_waveforms = output.audio_sequences
+```
+
+**2. Model training**
+
+Most of the work has to be done during data creation/pre-processing, because of the need to align/synchronize streams.
+
+Once it's done, you can simply forward `text_labels` and `audio_labels` to [`MoshiForConditionalGeneration.forward`], alongside the usual inputs, to get the model loss.
+
+A training guide will come soon, but user contributions are welcomed!
+
+### How does the model forward the inputs / generate:
+
+1. The input streams are embedded and combined into `inputs_embeds`.
+
+2. `inputs_embeds` is passed through the main decoder, which processes it like a normal LLM would.
+
+3. The main decoder outputs `text logits` but also its `last hidden state` which is called `temporal context` in the paper.
+
+3. The depth decoder switches the dimension on which we forward / generate (codebooks instead of time). It uses the token generated from `text logits` and the `temporal context` to auto-regressively generate audio codebooks.
+
+
+This model was contributed by [Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe).
+
+The original code can be found [here](https://github.com/kyutai-labs/moshi).
+
+
+
+## MoshiConfig
+
+[[autodoc]] MoshiConfig
+
+## MoshiDepthConfig
+
+[[autodoc]] MoshiDepthConfig
+
+## MoshiModel
+
+[[autodoc]] MoshiModel
+ - forward
+
+## MoshiForCausalLM
+
+[[autodoc]] MoshiForCausalLM
+ - forward
+
+## MoshiForConditionalGeneration
+
+[[autodoc]] MoshiForConditionalGeneration
+ - forward
+ - generate
+ - get_unconditional_inputs
diff --git a/docs/transformers/docs/source/en/model_doc/mpnet.md b/docs/transformers/docs/source/en/model_doc/mpnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..cf84e2b410752429a2523656f8d61e032ad9de38
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mpnet.md
@@ -0,0 +1,143 @@
+
+
+# MPNet
+
+
+
+
+
+
+## Overview
+
+The MPNet model was proposed in [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+
+MPNet adopts a novel pre-training method, named masked and permuted language modeling, to inherit the advantages of
+masked language modeling and permuted language modeling for natural language understanding.
+
+The abstract from the paper is the following:
+
+*BERT adopts masked language modeling (MLM) for pre-training and is one of the most successful pre-training models.
+Since BERT neglects dependency among predicted tokens, XLNet introduces permuted language modeling (PLM) for
+pre-training to address this problem. However, XLNet does not leverage the full position information of a sentence and
+thus suffers from position discrepancy between pre-training and fine-tuning. In this paper, we propose MPNet, a novel
+pre-training method that inherits the advantages of BERT and XLNet and avoids their limitations. MPNet leverages the
+dependency among predicted tokens through permuted language modeling (vs. MLM in BERT), and takes auxiliary position
+information as input to make the model see a full sentence and thus reducing the position discrepancy (vs. PLM in
+XLNet). We pre-train MPNet on a large-scale dataset (over 160GB text corpora) and fine-tune on a variety of
+down-streaming tasks (GLUE, SQuAD, etc). Experimental results show that MPNet outperforms MLM and PLM by a large
+margin, and achieves better results on these tasks compared with previous state-of-the-art pre-trained methods (e.g.,
+BERT, XLNet, RoBERTa) under the same model setting.*
+
+The original code can be found [here](https://github.com/microsoft/MPNet).
+
+## Usage tips
+
+MPNet doesn't have `token_type_ids`, you don't need to indicate which token belongs to which segment. Just
+separate your segments with the separation token `tokenizer.sep_token` (or `[sep]`).
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## MPNetConfig
+
+[[autodoc]] MPNetConfig
+
+## MPNetTokenizer
+
+[[autodoc]] MPNetTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## MPNetTokenizerFast
+
+[[autodoc]] MPNetTokenizerFast
+
+
+
+
+## MPNetModel
+
+[[autodoc]] MPNetModel
+ - forward
+
+## MPNetForMaskedLM
+
+[[autodoc]] MPNetForMaskedLM
+ - forward
+
+## MPNetForSequenceClassification
+
+[[autodoc]] MPNetForSequenceClassification
+ - forward
+
+## MPNetForMultipleChoice
+
+[[autodoc]] MPNetForMultipleChoice
+ - forward
+
+## MPNetForTokenClassification
+
+[[autodoc]] MPNetForTokenClassification
+ - forward
+
+## MPNetForQuestionAnswering
+
+[[autodoc]] MPNetForQuestionAnswering
+ - forward
+
+
+
+
+## TFMPNetModel
+
+[[autodoc]] TFMPNetModel
+ - call
+
+## TFMPNetForMaskedLM
+
+[[autodoc]] TFMPNetForMaskedLM
+ - call
+
+## TFMPNetForSequenceClassification
+
+[[autodoc]] TFMPNetForSequenceClassification
+ - call
+
+## TFMPNetForMultipleChoice
+
+[[autodoc]] TFMPNetForMultipleChoice
+ - call
+
+## TFMPNetForTokenClassification
+
+[[autodoc]] TFMPNetForTokenClassification
+ - call
+
+## TFMPNetForQuestionAnswering
+
+[[autodoc]] TFMPNetForQuestionAnswering
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/mpt.md b/docs/transformers/docs/source/en/model_doc/mpt.md
new file mode 100644
index 0000000000000000000000000000000000000000..a4dbc5ea6a8deb47d184cb3ca76d17d5c6d806b4
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mpt.md
@@ -0,0 +1,74 @@
+
+
+# MPT
+
+
+
+
+
+## Overview
+
+The MPT model was proposed by the [MosaicML](https://www.mosaicml.com/) team and released with multiple sizes and finetuned variants. The MPT models are a series of open source and commercially usable LLMs pre-trained on 1T tokens.
+
+MPT models are GPT-style decoder-only transformers with several improvements: performance-optimized layer implementations, architecture changes that provide greater training stability, and the elimination of context length limits by replacing positional embeddings with ALiBi.
+
+- MPT base: MPT base pre-trained models on next token prediction
+- MPT instruct: MPT base models fine-tuned on instruction based tasks
+- MPT storywriter: MPT base models fine-tuned for 2500 steps on 65k-token excerpts of fiction books contained in the books3 corpus, this enables the model to handle very long sequences
+
+The original code is available at the [`llm-foundry`](https://github.com/mosaicml/llm-foundry/tree/main) repository.
+
+Read more about it [in the release blogpost](https://www.mosaicml.com/blog/mpt-7b)
+
+## Usage tips
+
+- Learn more about some techniques behind training of the model [in this section of llm-foundry repository](https://github.com/mosaicml/llm-foundry/blob/main/TUTORIAL.md#faqs)
+- If you want to use the advanced version of the model (triton kernels, direct flash attention integration), you can still use the original model implementation by adding `trust_remote_code=True` when calling `from_pretrained`.
+
+## Resources
+
+- [Fine-tuning Notebook](https://colab.research.google.com/drive/1HCpQkLL7UXW8xJUJJ29X7QAeNJKO0frZ?usp=sharing) on how to fine-tune MPT-7B on a free Google Colab instance to turn the model into a Chatbot.
+
+## MptConfig
+
+[[autodoc]] MptConfig
+ - all
+
+## MptModel
+
+[[autodoc]] MptModel
+ - forward
+
+## MptForCausalLM
+
+[[autodoc]] MptForCausalLM
+ - forward
+
+## MptForSequenceClassification
+
+[[autodoc]] MptForSequenceClassification
+ - forward
+
+## MptForTokenClassification
+
+[[autodoc]] MptForTokenClassification
+ - forward
+
+## MptForQuestionAnswering
+
+[[autodoc]] MptForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mra.md b/docs/transformers/docs/source/en/model_doc/mra.md
new file mode 100644
index 0000000000000000000000000000000000000000..a5490d5d379cf0b9507b43c911a173d0d4f4ddf8
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mra.md
@@ -0,0 +1,66 @@
+
+
+# MRA
+
+
+
+
+
+## Overview
+
+The MRA model was proposed in [Multi Resolution Analysis (MRA) for Approximate Self-Attention](https://arxiv.org/abs/2207.10284) by Zhanpeng Zeng, Sourav Pal, Jeffery Kline, Glenn M Fung, and Vikas Singh.
+
+The abstract from the paper is the following:
+
+*Transformers have emerged as a preferred model for many tasks in natural language processing and vision. Recent efforts on training and deploying Transformers more efficiently have identified many strategies to approximate the self-attention matrix, a key module in a Transformer architecture. Effective ideas include various prespecified sparsity patterns, low-rank basis expansions and combinations thereof. In this paper, we revisit classical Multiresolution Analysis (MRA) concepts such as Wavelets, whose potential value in this setting remains underexplored thus far. We show that simple approximations based on empirical feedback and design choices informed by modern hardware and implementation challenges, eventually yield a MRA-based approach for self-attention with an excellent performance profile across most criteria of interest. We undertake an extensive set of experiments and demonstrate that this multi-resolution scheme outperforms most efficient self-attention proposals and is favorable for both short and long sequences. Code is available at https://github.com/mlpen/mra-attention.*
+
+This model was contributed by [novice03](https://huggingface.co/novice03).
+The original code can be found [here](https://github.com/mlpen/mra-attention).
+
+## MraConfig
+
+[[autodoc]] MraConfig
+
+## MraModel
+
+[[autodoc]] MraModel
+ - forward
+
+## MraForMaskedLM
+
+[[autodoc]] MraForMaskedLM
+ - forward
+
+## MraForSequenceClassification
+
+[[autodoc]] MraForSequenceClassification
+ - forward
+
+## MraForMultipleChoice
+
+[[autodoc]] MraForMultipleChoice
+ - forward
+
+## MraForTokenClassification
+
+[[autodoc]] MraForTokenClassification
+ - forward
+
+## MraForQuestionAnswering
+
+[[autodoc]] MraForQuestionAnswering
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/mt5.md b/docs/transformers/docs/source/en/model_doc/mt5.md
new file mode 100644
index 0000000000000000000000000000000000000000..d4af9f538cb3579f8b1d6270b0dcc5f894b47743
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mt5.md
@@ -0,0 +1,141 @@
+
+
+# mT5
+
+
+
+
+
+
+
+## Overview
+
+The mT5 model was presented in [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya
+Siddhant, Aditya Barua, Colin Raffel.
+
+The abstract from the paper is the following:
+
+*The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain
+state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a
+multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We detail
+the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual
+benchmarks. We also describe a simple technique to prevent "accidental translation" in the zero-shot setting, where a
+generative model chooses to (partially) translate its prediction into the wrong language. All of the code and model
+checkpoints used in this work are publicly available.*
+
+Note: mT5 was only pre-trained on [mC4](https://huggingface.co/datasets/mc4) excluding any supervised training.
+Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5 model.
+Since mT5 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
+fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
+
+Google has released the following variants:
+
+- [google/mt5-small](https://huggingface.co/google/mt5-small)
+
+- [google/mt5-base](https://huggingface.co/google/mt5-base)
+
+- [google/mt5-large](https://huggingface.co/google/mt5-large)
+
+- [google/mt5-xl](https://huggingface.co/google/mt5-xl)
+
+- [google/mt5-xxl](https://huggingface.co/google/mt5-xxl).
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://github.com/google-research/multilingual-t5).
+
+## Resources
+
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## MT5Config
+
+[[autodoc]] MT5Config
+
+## MT5Tokenizer
+
+[[autodoc]] MT5Tokenizer
+
+See [`T5Tokenizer`] for all details.
+
+
+## MT5TokenizerFast
+
+[[autodoc]] MT5TokenizerFast
+
+See [`T5TokenizerFast`] for all details.
+
+
+
+
+## MT5Model
+
+[[autodoc]] MT5Model
+
+## MT5ForConditionalGeneration
+
+[[autodoc]] MT5ForConditionalGeneration
+
+## MT5EncoderModel
+
+[[autodoc]] MT5EncoderModel
+
+## MT5ForSequenceClassification
+
+[[autodoc]] MT5ForSequenceClassification
+
+## MT5ForTokenClassification
+
+[[autodoc]] MT5ForTokenClassification
+
+## MT5ForQuestionAnswering
+
+[[autodoc]] MT5ForQuestionAnswering
+
+
+
+
+## TFMT5Model
+
+[[autodoc]] TFMT5Model
+
+## TFMT5ForConditionalGeneration
+
+[[autodoc]] TFMT5ForConditionalGeneration
+
+## TFMT5EncoderModel
+
+[[autodoc]] TFMT5EncoderModel
+
+
+
+
+## FlaxMT5Model
+
+[[autodoc]] FlaxMT5Model
+
+## FlaxMT5ForConditionalGeneration
+
+[[autodoc]] FlaxMT5ForConditionalGeneration
+
+## FlaxMT5EncoderModel
+
+[[autodoc]] FlaxMT5EncoderModel
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/musicgen.md b/docs/transformers/docs/source/en/model_doc/musicgen.md
new file mode 100644
index 0000000000000000000000000000000000000000..6d709a963c0436c49d9bf76ae3aa55e8123ab0b4
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/musicgen.md
@@ -0,0 +1,286 @@
+
+
+# MusicGen
+
+
+
+
+
+
+
+## Overview
+
+The MusicGen model was proposed in the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284)
+by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
+
+MusicGen is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned
+on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a
+sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or *audio codes*,
+conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec,
+to recover the audio waveform.
+
+Through an efficient token interleaving pattern, MusicGen does not require a self-supervised semantic representation of
+the text/audio prompts, thus eliminating the need to cascade multiple models to predict a set of codebooks (e.g.
+hierarchically or upsampling). Instead, it is able to generate all the codebooks in a single forward pass.
+
+The abstract from the paper is the following:
+
+*We tackle the task of conditional music generation. We introduce MusicGen, a single Language Model (LM) that operates
+over several streams of compressed discrete music representation, i.e., tokens. Unlike prior work, MusicGen is comprised
+of a single-stage transformer LM together with efficient token interleaving patterns, which eliminates the need for
+cascading several models, e.g., hierarchically or upsampling. Following this approach, we demonstrate how MusicGen
+can generate high-quality samples, while being conditioned on textual description or melodic features, allowing better
+controls over the generated output. We conduct extensive empirical evaluation, considering both automatic and human
+studies, showing the proposed approach is superior to the evaluated baselines on a standard text-to-music benchmark.
+Through ablation studies, we shed light over the importance of each of the components comprising MusicGen.*
+
+This model was contributed by [sanchit-gandhi](https://huggingface.co/sanchit-gandhi). The original code can be found
+[here](https://github.com/facebookresearch/audiocraft). The pre-trained checkpoints can be found on the
+[Hugging Face Hub](https://huggingface.co/models?sort=downloads&search=facebook%2Fmusicgen-).
+
+## Usage tips
+
+- After downloading the original checkpoints from [here](https://github.com/facebookresearch/audiocraft/blob/main/docs/MUSICGEN.md#importing--exporting-models) , you can convert them using the **conversion script** available at
+`src/transformers/models/musicgen/convert_musicgen_transformers.py` with the following command:
+
+```bash
+python src/transformers/models/musicgen/convert_musicgen_transformers.py \
+ --checkpoint small --pytorch_dump_folder /output/path --safe_serialization
+```
+
+## Generation
+
+MusicGen is compatible with two generation modes: greedy and sampling. In practice, sampling leads to significantly
+better results than greedy, thus we encourage sampling mode to be used where possible. Sampling is enabled by default,
+and can be explicitly specified by setting `do_sample=True` in the call to [`MusicgenForConditionalGeneration.generate`],
+or by overriding the model's generation config (see below).
+
+Generation is limited by the sinusoidal positional embeddings to 30 second inputs. Meaning, MusicGen cannot generate more
+than 30 seconds of audio (1503 tokens), and input audio passed by Audio-Prompted Generation contributes to this limit so,
+given an input of 20 seconds of audio, MusicGen cannot generate more than 10 seconds of additional audio.
+
+Transformers supports both mono (1-channel) and stereo (2-channel) variants of MusicGen. The mono channel versions
+generate a single set of codebooks. The stereo versions generate 2 sets of codebooks, 1 for each channel (left/right),
+and each set of codebooks is decoded independently through the audio compression model. The audio streams for each
+channel are combined to give the final stereo output.
+
+### Unconditional Generation
+
+The inputs for unconditional (or 'null') generation can be obtained through the method
+[`MusicgenForConditionalGeneration.get_unconditional_inputs`]:
+
+```python
+>>> from transformers import MusicgenForConditionalGeneration
+
+>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
+>>> unconditional_inputs = model.get_unconditional_inputs(num_samples=1)
+
+>>> audio_values = model.generate(**unconditional_inputs, do_sample=True, max_new_tokens=256)
+```
+
+The audio outputs are a three-dimensional Torch tensor of shape `(batch_size, num_channels, sequence_length)`. To listen
+to the generated audio samples, you can either play them in an ipynb notebook:
+
+```python
+from IPython.display import Audio
+
+sampling_rate = model.config.audio_encoder.sampling_rate
+Audio(audio_values[0].numpy(), rate=sampling_rate)
+```
+
+Or save them as a `.wav` file using a third-party library, e.g. `scipy`:
+
+```python
+>>> import scipy
+
+>>> sampling_rate = model.config.audio_encoder.sampling_rate
+>>> scipy.io.wavfile.write("musicgen_out.wav", rate=sampling_rate, data=audio_values[0, 0].numpy())
+```
+
+### Text-Conditional Generation
+
+The model can generate an audio sample conditioned on a text prompt through use of the [`MusicgenProcessor`] to pre-process
+the inputs:
+
+```python
+>>> from transformers import AutoProcessor, MusicgenForConditionalGeneration
+
+>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
+>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
+
+>>> inputs = processor(
+... text=["80s pop track with bassy drums and synth", "90s rock song with loud guitars and heavy drums"],
+... padding=True,
+... return_tensors="pt",
+... )
+>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
+```
+
+The `guidance_scale` is used in classifier free guidance (CFG), setting the weighting between the conditional logits
+(which are predicted from the text prompts) and the unconditional logits (which are predicted from an unconditional or
+'null' prompt). Higher guidance scale encourages the model to generate samples that are more closely linked to the input
+prompt, usually at the expense of poorer audio quality. CFG is enabled by setting `guidance_scale > 1`. For best results,
+use `guidance_scale=3` (default).
+
+### Audio-Prompted Generation
+
+The same [`MusicgenProcessor`] can be used to pre-process an audio prompt that is used for audio continuation. In the
+following example, we load an audio file using the 🤗 Datasets library, which can be pip installed through the command
+below:
+
+```bash
+pip install --upgrade pip
+pip install datasets[audio]
+```
+
+```python
+>>> from transformers import AutoProcessor, MusicgenForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
+>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
+
+>>> dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
+>>> sample = next(iter(dataset))["audio"]
+
+>>> # take the first half of the audio sample
+>>> sample["array"] = sample["array"][: len(sample["array"]) // 2]
+
+>>> inputs = processor(
+... audio=sample["array"],
+... sampling_rate=sample["sampling_rate"],
+... text=["80s blues track with groovy saxophone"],
+... padding=True,
+... return_tensors="pt",
+... )
+>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
+```
+
+For batched audio-prompted generation, the generated `audio_values` can be post-processed to remove padding by using the
+[`MusicgenProcessor`] class:
+
+```python
+>>> from transformers import AutoProcessor, MusicgenForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
+>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
+
+>>> dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
+>>> sample = next(iter(dataset))["audio"]
+
+>>> # take the first quarter of the audio sample
+>>> sample_1 = sample["array"][: len(sample["array"]) // 4]
+
+>>> # take the first half of the audio sample
+>>> sample_2 = sample["array"][: len(sample["array"]) // 2]
+
+>>> inputs = processor(
+... audio=[sample_1, sample_2],
+... sampling_rate=sample["sampling_rate"],
+... text=["80s blues track with groovy saxophone", "90s rock song with loud guitars and heavy drums"],
+... padding=True,
+... return_tensors="pt",
+... )
+>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
+
+>>> # post-process to remove padding from the batched audio
+>>> audio_values = processor.batch_decode(audio_values, padding_mask=inputs.padding_mask)
+```
+
+### Generation Configuration
+
+The default parameters that control the generation process, such as sampling, guidance scale and number of generated
+tokens, can be found in the model's generation config, and updated as desired:
+
+```python
+>>> from transformers import MusicgenForConditionalGeneration
+
+>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
+
+>>> # inspect the default generation config
+>>> model.generation_config
+
+>>> # increase the guidance scale to 4.0
+>>> model.generation_config.guidance_scale = 4.0
+
+>>> # decrease the max length to 256 tokens
+>>> model.generation_config.max_length = 256
+```
+
+Note that any arguments passed to the generate method will **supersede** those in the generation config, so setting
+`do_sample=False` in the call to generate will supersede the setting of `model.generation_config.do_sample` in the
+generation config.
+
+## Model Structure
+
+The MusicGen model can be de-composed into three distinct stages:
+1. Text encoder: maps the text inputs to a sequence of hidden-state representations. The pre-trained MusicGen models use a frozen text encoder from either T5 or Flan-T5
+2. MusicGen decoder: a language model (LM) that auto-regressively generates audio tokens (or codes) conditional on the encoder hidden-state representations
+3. Audio encoder/decoder: used to encode an audio prompt to use as prompt tokens, and recover the audio waveform from the audio tokens predicted by the decoder
+
+Thus, the MusicGen model can either be used as a standalone decoder model, corresponding to the class [`MusicgenForCausalLM`],
+or as a composite model that includes the text encoder and audio encoder/decoder, corresponding to the class
+[`MusicgenForConditionalGeneration`]. If only the decoder needs to be loaded from the pre-trained checkpoint, it can be loaded by first
+specifying the correct config, or be accessed through the `.decoder` attribute of the composite model:
+
+```python
+>>> from transformers import AutoConfig, MusicgenForCausalLM, MusicgenForConditionalGeneration
+
+>>> # Option 1: get decoder config and pass to `.from_pretrained`
+>>> decoder_config = AutoConfig.from_pretrained("facebook/musicgen-small").decoder
+>>> decoder = MusicgenForCausalLM.from_pretrained("facebook/musicgen-small", **decoder_config)
+
+>>> # Option 2: load the entire composite model, but only return the decoder
+>>> decoder = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small").decoder
+```
+
+Since the text encoder and audio encoder/decoder models are frozen during training, the MusicGen decoder [`MusicgenForCausalLM`]
+can be trained standalone on a dataset of encoder hidden-states and audio codes. For inference, the trained decoder can
+be combined with the frozen text encoder and audio encoder/decoders to recover the composite [`MusicgenForConditionalGeneration`]
+model.
+
+Tips:
+* MusicGen is trained on the 32kHz checkpoint of Encodec. You should ensure you use a compatible version of the Encodec model.
+* Sampling mode tends to deliver better results than greedy - you can toggle sampling with the variable `do_sample` in the call to [`MusicgenForConditionalGeneration.generate`]
+
+## MusicgenDecoderConfig
+
+[[autodoc]] MusicgenDecoderConfig
+
+## MusicgenConfig
+
+[[autodoc]] MusicgenConfig
+
+## MusicgenProcessor
+
+[[autodoc]] MusicgenProcessor
+
+## MusicgenModel
+
+[[autodoc]] MusicgenModel
+ - forward
+
+## MusicgenForCausalLM
+
+[[autodoc]] MusicgenForCausalLM
+ - forward
+
+## MusicgenForConditionalGeneration
+
+[[autodoc]] MusicgenForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/musicgen_melody.md b/docs/transformers/docs/source/en/model_doc/musicgen_melody.md
new file mode 100644
index 0000000000000000000000000000000000000000..b1f16c4574efef76afcb7bd37b631cf8a3cce05c
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/musicgen_melody.md
@@ -0,0 +1,293 @@
+
+
+# MusicGen Melody
+
+
+
+
+
+
+
+## Overview
+
+The MusicGen Melody model was proposed in [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
+
+MusicGen Melody is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or *audio codes*, conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec, to recover the audio waveform.
+
+Through an efficient token interleaving pattern, MusicGen does not require a self-supervised semantic representation of the text/audio prompts, thus eliminating the need to cascade multiple models to predict a set of codebooks (e.g. hierarchically or upsampling). Instead, it is able to generate all the codebooks in a single forward pass.
+
+The abstract from the paper is the following:
+
+*We tackle the task of conditional music generation. We introduce MusicGen, a single Language Model (LM) that operates over several streams of compressed discrete music representation, i.e., tokens. Unlike prior work, MusicGen is comprised of a single-stage transformer LM together with efficient token interleaving patterns, which eliminates the need for cascading several models, e.g., hierarchically or upsampling. Following this approach, we demonstrate how MusicGen can generate high-quality samples, while being conditioned on textual description or melodic features, allowing better controls over the generated output. We conduct extensive empirical evaluation, considering both automatic and human studies, showing the proposed approach is superior to the evaluated baselines on a standard text-to-music benchmark. Through ablation studies, we shed light over the importance of each of the components comprising MusicGen.*
+
+
+This model was contributed by [ylacombe](https://huggingface.co/ylacombe). The original code can be found [here](https://github.com/facebookresearch/audiocraft). The pre-trained checkpoints can be found on the [Hugging Face Hub](https://huggingface.co/models?sort=downloads&search=facebook%2Fmusicgen).
+
+
+## Difference with [MusicGen](https://huggingface.co/docs/transformers/main/en/model_doc/musicgen)
+
+There are two key differences with MusicGen:
+1. The audio prompt is used here as a conditional signal for the generated audio sample, whereas it's used for audio continuation in [MusicGen](https://huggingface.co/docs/transformers/main/en/model_doc/musicgen).
+2. Conditional text and audio signals are concatenated to the decoder's hidden states instead of being used as a cross-attention signal, as in MusicGen.
+
+## Generation
+
+MusicGen Melody is compatible with two generation modes: greedy and sampling. In practice, sampling leads to significantly better results than greedy, thus we encourage sampling mode to be used where possible. Sampling is enabled by default, and can be explicitly specified by setting `do_sample=True` in the call to [`MusicgenMelodyForConditionalGeneration.generate`], or by overriding the model's generation config (see below).
+
+Transformers supports both mono (1-channel) and stereo (2-channel) variants of MusicGen Melody. The mono channel versions generate a single set of codebooks. The stereo versions generate 2 sets of codebooks, 1 for each channel (left/right), and each set of codebooks is decoded independently through the audio compression model. The audio streams for each channel are combined to give the final stereo output.
+
+
+#### Audio Conditional Generation
+
+The model can generate an audio sample conditioned on a text and an audio prompt through use of the [`MusicgenMelodyProcessor`] to pre-process the inputs.
+
+In the following examples, we load an audio file using the 🤗 Datasets library, which can be pip installed through the command below:
+
+```
+pip install --upgrade pip
+pip install datasets[audio]
+```
+
+The audio file we are about to use is loaded as follows:
+```python
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
+>>> sample = next(iter(dataset))["audio"]
+```
+
+The audio prompt should ideally be free of the low-frequency signals usually produced by instruments such as drums and bass. The [Demucs](https://github.com/adefossez/demucs/tree/main) model can be used to separate vocals and other signals from the drums and bass components.
+
+If you wish to use Demucs, you first need to follow the installation steps [here](https://github.com/adefossez/demucs/tree/main?tab=readme-ov-file#for-musicians) before using the following snippet:
+
+```python
+from demucs import pretrained
+from demucs.apply import apply_model
+from demucs.audio import convert_audio
+import torch
+
+
+wav = torch.tensor(sample["array"]).to(torch.float32)
+
+demucs = pretrained.get_model('htdemucs')
+
+wav = convert_audio(wav[None], sample["sampling_rate"], demucs.samplerate, demucs.audio_channels)
+wav = apply_model(demucs, wav[None])
+```
+
+You can then use the following snippet to generate music:
+
+```python
+>>> from transformers import AutoProcessor, MusicgenMelodyForConditionalGeneration
+
+>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-melody")
+>>> model = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody")
+
+>>> inputs = processor(
+... audio=wav,
+... sampling_rate=demucs.samplerate,
+... text=["80s blues track with groovy saxophone"],
+... padding=True,
+... return_tensors="pt",
+... )
+>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
+```
+
+You can also pass the audio signal directly without using Demucs, although the quality of the generation will probably be degraded:
+
+```python
+>>> from transformers import AutoProcessor, MusicgenMelodyForConditionalGeneration
+
+>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-melody")
+>>> model = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody")
+
+>>> inputs = processor(
+... audio=sample["array"],
+... sampling_rate=sample["sampling_rate"],
+... text=["80s blues track with groovy saxophone"],
+... padding=True,
+... return_tensors="pt",
+... )
+>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
+```
+
+The audio outputs are a three-dimensional Torch tensor of shape `(batch_size, num_channels, sequence_length)`. To listen to the generated audio samples, you can either play them in an ipynb notebook:
+
+```python
+from IPython.display import Audio
+
+sampling_rate = model.config.audio_encoder.sampling_rate
+Audio(audio_values[0].numpy(), rate=sampling_rate)
+```
+
+Or save them as a `.wav` file using a third-party library, e.g. `soundfile`:
+
+```python
+>>> import soundfile as sf
+
+>>> sampling_rate = model.config.audio_encoder.sampling_rate
+>>> sf.write("musicgen_out.wav", audio_values[0].T.numpy(), sampling_rate)
+```
+
+
+### Text-only Conditional Generation
+
+The same [`MusicgenMelodyProcessor`] can be used to pre-process a text-only prompt.
+
+```python
+>>> from transformers import AutoProcessor, MusicgenMelodyForConditionalGeneration
+
+>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-melody")
+>>> model = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody")
+
+>>> inputs = processor(
+... text=["80s pop track with bassy drums and synth", "90s rock song with loud guitars and heavy drums"],
+... padding=True,
+... return_tensors="pt",
+... )
+>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
+```
+
+The `guidance_scale` is used in classifier free guidance (CFG), setting the weighting between the conditional logits (which are predicted from the text prompts) and the unconditional logits (which are predicted from an unconditional or 'null' prompt). Higher guidance scale encourages the model to generate samples that are more closely linked to the input prompt, usually at the expense of poorer audio quality. CFG is enabled by setting `guidance_scale > 1`. For best results, use `guidance_scale=3` (default).
+
+
+You can also generate in batch:
+
+```python
+>>> from transformers import AutoProcessor, MusicgenMelodyForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-melody")
+>>> model = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody")
+
+>>> # take the first quarter of the audio sample
+>>> sample_1 = sample["array"][: len(sample["array"]) // 4]
+
+>>> # take the first half of the audio sample
+>>> sample_2 = sample["array"][: len(sample["array"]) // 2]
+
+>>> inputs = processor(
+... audio=[sample_1, sample_2],
+... sampling_rate=sample["sampling_rate"],
+... text=["80s blues track with groovy saxophone", "90s rock song with loud guitars and heavy drums"],
+... padding=True,
+... return_tensors="pt",
+... )
+>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
+```
+
+### Unconditional Generation
+
+The inputs for unconditional (or 'null') generation can be obtained through the method [`MusicgenMelodyProcessor.get_unconditional_inputs`]:
+
+```python
+>>> from transformers import MusicgenMelodyForConditionalGeneration, MusicgenMelodyProcessor
+
+>>> model = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody")
+>>> unconditional_inputs = MusicgenMelodyProcessor.from_pretrained("facebook/musicgen-melody").get_unconditional_inputs(num_samples=1)
+
+>>> audio_values = model.generate(**unconditional_inputs, do_sample=True, max_new_tokens=256)
+```
+
+### Generation Configuration
+
+The default parameters that control the generation process, such as sampling, guidance scale and number of generated tokens, can be found in the model's generation config, and updated as desired:
+
+```python
+>>> from transformers import MusicgenMelodyForConditionalGeneration
+
+>>> model = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody")
+
+>>> # inspect the default generation config
+>>> model.generation_config
+
+>>> # increase the guidance scale to 4.0
+>>> model.generation_config.guidance_scale = 4.0
+
+>>> # decrease the max length to 256 tokens
+>>> model.generation_config.max_length = 256
+```
+
+Note that any arguments passed to the generate method will **supersede** those in the generation config, so setting `do_sample=False` in the call to generate will supersede the setting of `model.generation_config.do_sample` in the generation config.
+
+## Model Structure
+
+The MusicGen model can be de-composed into three distinct stages:
+1. Text encoder: maps the text inputs to a sequence of hidden-state representations. The pre-trained MusicGen models use a frozen text encoder from either T5 or Flan-T5.
+2. MusicGen Melody decoder: a language model (LM) that auto-regressively generates audio tokens (or codes) conditional on the encoder hidden-state representations
+3. Audio decoder: used to recover the audio waveform from the audio tokens predicted by the decoder.
+
+Thus, the MusicGen model can either be used as a standalone decoder model, corresponding to the class [`MusicgenMelodyForCausalLM`], or as a composite model that includes the text encoder and audio encoder, corresponding to the class [`MusicgenMelodyForConditionalGeneration`]. If only the decoder needs to be loaded from the pre-trained checkpoint, it can be loaded by first specifying the correct config, or be accessed through the `.decoder` attribute of the composite model:
+
+```python
+>>> from transformers import AutoConfig, MusicgenMelodyForCausalLM, MusicgenMelodyForConditionalGeneration
+
+>>> # Option 1: get decoder config and pass to `.from_pretrained`
+>>> decoder_config = AutoConfig.from_pretrained("facebook/musicgen-melody").decoder
+>>> decoder = MusicgenMelodyForCausalLM.from_pretrained("facebook/musicgen-melody", **decoder_config.to_dict())
+
+>>> # Option 2: load the entire composite model, but only return the decoder
+>>> decoder = MusicgenMelodyForConditionalGeneration.from_pretrained("facebook/musicgen-melody").decoder
+```
+
+Since the text encoder and audio encoder models are frozen during training, the MusicGen decoder [`MusicgenMelodyForCausalLM`] can be trained standalone on a dataset of encoder hidden-states and audio codes. For inference, the trained decoder can be combined with the frozen text encoder and audio encoder to recover the composite [`MusicgenMelodyForConditionalGeneration`] model.
+
+## Checkpoint Conversion
+
+- After downloading the original checkpoints from [here](https://github.com/facebookresearch/audiocraft/blob/main/docs/MUSICGEN.md#importing--exporting-models), you can convert them using the **conversion script** available at `src/transformers/models/musicgen_melody/convert_musicgen_melody_transformers.py` with the following command:
+
+```bash
+python src/transformers/models/musicgen_melody/convert_musicgen_melody_transformers.py \
+ --checkpoint="facebook/musicgen-melody" --pytorch_dump_folder /output/path
+```
+
+Tips:
+* MusicGen is trained on the 32kHz checkpoint of Encodec. You should ensure you use a compatible version of the Encodec model.
+* Sampling mode tends to deliver better results than greedy - you can toggle sampling with the variable `do_sample` in the call to [`MusicgenMelodyForConditionalGeneration.generate`]
+
+
+## MusicgenMelodyDecoderConfig
+
+[[autodoc]] MusicgenMelodyDecoderConfig
+
+## MusicgenMelodyProcessor
+
+[[autodoc]] MusicgenMelodyProcessor
+ - get_unconditional_inputs
+
+## MusicgenMelodyFeatureExtractor
+
+[[autodoc]] MusicgenMelodyFeatureExtractor
+
+## MusicgenMelodyConfig
+
+[[autodoc]] MusicgenMelodyConfig
+
+## MusicgenMelodyModel
+
+[[autodoc]] MusicgenMelodyModel
+ - forward
+
+## MusicgenMelodyForCausalLM
+
+[[autodoc]] MusicgenMelodyForCausalLM
+ - forward
+
+## MusicgenMelodyForConditionalGeneration
+
+[[autodoc]] MusicgenMelodyForConditionalGeneration
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/mvp.md b/docs/transformers/docs/source/en/model_doc/mvp.md
new file mode 100644
index 0000000000000000000000000000000000000000..d732977167921ecf9c2c9414fc15885774141ff5
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mvp.md
@@ -0,0 +1,157 @@
+
+
+# MVP
+
+
+
+
+
+## Overview
+
+The MVP model was proposed in [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+
+
+According to the abstract,
+
+- MVP follows a standard Transformer encoder-decoder architecture.
+- MVP is supervised pre-trained using labeled datasets.
+- MVP also has task-specific soft prompts to stimulate the model's capacity in performing a certain task.
+- MVP is specially designed for natural language generation and can be adapted to a wide range of generation tasks, including but not limited to summarization, data-to-text generation, open-ended dialogue system, story generation, question answering, question generation, task-oriented dialogue system, commonsense generation, paraphrase generation, text style transfer, and text simplification. Our model can also be adapted to natural language understanding tasks such as sequence classification and (extractive) question answering.
+
+This model was contributed by [Tianyi Tang](https://huggingface.co/StevenTang). The detailed information and instructions can be found [here](https://github.com/RUCAIBox/MVP).
+
+## Usage tips
+
+- We have released a series of models [here](https://huggingface.co/models?filter=mvp), including MVP, MVP with task-specific prompts, and multi-task pre-trained variants.
+- If you want to use a model without prompts (standard Transformer), you can load it through `MvpForConditionalGeneration.from_pretrained('RUCAIBox/mvp')`.
+- If you want to use a model with task-specific prompts, such as summarization, you can load it through `MvpForConditionalGeneration.from_pretrained('RUCAIBox/mvp-summarization')`.
+- Our model supports lightweight prompt tuning following [Prefix-tuning](https://arxiv.org/abs/2101.00190) with method `set_lightweight_tuning()`.
+
+## Usage examples
+
+For summarization, it is an example to use MVP and MVP with summarization-specific prompts.
+
+```python
+>>> from transformers import MvpTokenizer, MvpForConditionalGeneration
+
+>>> tokenizer = MvpTokenizer.from_pretrained("RUCAIBox/mvp")
+>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mvp")
+>>> model_with_prompt = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mvp-summarization")
+
+>>> inputs = tokenizer(
+... "Summarize: You may want to stick it to your boss and leave your job, but don't do it if these are your reasons.",
+... return_tensors="pt",
+... )
+>>> generated_ids = model.generate(**inputs)
+>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+["Why You Shouldn't Quit Your Job"]
+
+>>> generated_ids = model_with_prompt.generate(**inputs)
+>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+["Don't do it if these are your reasons"]
+```
+
+For data-to-text generation, it is an example to use MVP and multi-task pre-trained variants.
+```python
+>>> from transformers import MvpTokenizerFast, MvpForConditionalGeneration
+
+>>> tokenizer = MvpTokenizerFast.from_pretrained("RUCAIBox/mvp")
+>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mvp")
+>>> model_with_mtl = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mtl-data-to-text")
+
+>>> inputs = tokenizer(
+... "Describe the following data: Iron Man | instance of | Superhero [SEP] Stan Lee | creator | Iron Man",
+... return_tensors="pt",
+... )
+>>> generated_ids = model.generate(**inputs)
+>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+['Stan Lee created the character of Iron Man, a fictional superhero appearing in American comic']
+
+>>> generated_ids = model_with_mtl.generate(**inputs)
+>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+['Iron Man is a fictional superhero appearing in American comic books published by Marvel Comics.']
+```
+
+For lightweight tuning, *i.e.*, fixing the model and only tuning prompts, you can load MVP with randomly initialized prompts or with task-specific prompts. Our code also supports Prefix-tuning with BART following the [original paper](https://arxiv.org/abs/2101.00190).
+
+```python
+>>> from transformers import MvpForConditionalGeneration
+
+>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mvp", use_prompt=True)
+>>> # the number of trainable parameters (full tuning)
+>>> sum(p.numel() for p in model.parameters() if p.requires_grad)
+468116832
+
+>>> # lightweight tuning with randomly initialized prompts
+>>> model.set_lightweight_tuning()
+>>> # the number of trainable parameters (lightweight tuning)
+>>> sum(p.numel() for p in model.parameters() if p.requires_grad)
+61823328
+
+>>> # lightweight tuning with task-specific prompts
+>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mtl-data-to-text")
+>>> model.set_lightweight_tuning()
+>>> # original lightweight Prefix-tuning
+>>> model = MvpForConditionalGeneration.from_pretrained("facebook/bart-large", use_prompt=True)
+>>> model.set_lightweight_tuning()
+```
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## MvpConfig
+
+[[autodoc]] MvpConfig
+
+## MvpTokenizer
+
+[[autodoc]] MvpTokenizer
+
+## MvpTokenizerFast
+
+[[autodoc]] MvpTokenizerFast
+
+## MvpModel
+
+[[autodoc]] MvpModel
+ - forward
+
+## MvpForConditionalGeneration
+
+[[autodoc]] MvpForConditionalGeneration
+ - forward
+
+## MvpForSequenceClassification
+
+[[autodoc]] MvpForSequenceClassification
+ - forward
+
+## MvpForQuestionAnswering
+
+[[autodoc]] MvpForQuestionAnswering
+ - forward
+
+## MvpForCausalLM
+
+[[autodoc]] MvpForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/myt5.md b/docs/transformers/docs/source/en/model_doc/myt5.md
new file mode 100644
index 0000000000000000000000000000000000000000..c8b46f43512b6edcee329b1d4537e26802cebb2a
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/myt5.md
@@ -0,0 +1,46 @@
+
+
+# myt5
+
+## Overview
+
+The myt5 model was proposed in [MYTE: Morphology-Driven Byte Encoding for Better and Fairer Multilingual Language Modeling](https://arxiv.org/pdf/2403.10691.pdf) by Tomasz Limisiewicz, Terra Blevins, Hila Gonen, Orevaoghene Ahia, and Luke Zettlemoyer.
+MyT5 (**My**te **T5**) is a multilingual language model based on T5 architecture.
+The model uses a **m**orphologically-driven **byte** (**MYTE**) representation described in our paper.
+**MYTE** uses codepoints corresponding to morphemes in contrast to characters used in UTF-8 encoding.
+As a pre-requisite, we used unsupervised morphological segmentation ([Morfessor](https://aclanthology.org/E14-2006.pdf)) to obtain morpheme inventories for 99 languages.
+However, the morphological segmentation step is not needed when using the pre-defined morpheme inventory from the hub (see: [Tomli/myt5-base](https://huggingface.co/Tomlim/myt5-base)).
+
+The abstract from the paper is the following:
+
+*A major consideration in multilingual language modeling is how to best represent languages with diverse vocabularies and scripts. Although contemporary text encoding methods cover most of the world’s writing systems, they exhibit bias towards the high-resource languages of the Global West. As a result, texts of underrepresented languages tend to be segmented into long sequences of linguistically meaningless units. To address the disparities, we introduce a new paradigm that encodes the same information with segments of consistent size across diverse languages. Our encoding convention (MYTE) is based on morphemes, as their inventories are more balanced across languages than characters, which are used in previous methods. We show that MYTE produces shorter encodings for all 99 analyzed languages, with the most notable improvements for non-European languages and non-Latin scripts. This, in turn, improves multilingual LM performance and diminishes the perplexity gap throughout diverse languages.*
+
+This model was contributed by [Tomasz Limisiewicz](https://huggingface.co/Tomlim).
+The original code can be found [here](https://github.com/tomlimi/MYTE).
+
+## MyT5Tokenizer
+
+[[autodoc]] MyT5Tokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## MyT5Tokenizer
+
+[[autodoc]] MyT5Tokenizer
+
diff --git a/docs/transformers/docs/source/en/model_doc/nat.md b/docs/transformers/docs/source/en/model_doc/nat.md
new file mode 100644
index 0000000000000000000000000000000000000000..c7725ed7a56381d280509180db479aef05b30084
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/nat.md
@@ -0,0 +1,99 @@
+
+
+# Neighborhood Attention Transformer
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+NAT was proposed in [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143)
+by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
+
+It is a hierarchical vision transformer based on Neighborhood Attention, a sliding-window self attention pattern.
+
+The abstract from the paper is the following:
+
+*We present Neighborhood Attention (NA), the first efficient and scalable sliding-window attention mechanism for vision.
+NA is a pixel-wise operation, localizing self attention (SA) to the nearest neighboring pixels, and therefore enjoys a
+linear time and space complexity compared to the quadratic complexity of SA. The sliding-window pattern allows NA's
+receptive field to grow without needing extra pixel shifts, and preserves translational equivariance, unlike
+Swin Transformer's Window Self Attention (WSA). We develop NATTEN (Neighborhood Attention Extension), a Python package
+with efficient C++ and CUDA kernels, which allows NA to run up to 40% faster than Swin's WSA while using up to 25% less
+memory. We further present Neighborhood Attention Transformer (NAT), a new hierarchical transformer design based on NA
+that boosts image classification and downstream vision performance. Experimental results on NAT are competitive;
+NAT-Tiny reaches 83.2% top-1 accuracy on ImageNet, 51.4% mAP on MS-COCO and 48.4% mIoU on ADE20K, which is 1.9%
+ImageNet accuracy, 1.0% COCO mAP, and 2.6% ADE20K mIoU improvement over a Swin model with similar size. *
+
+
+
+ Neighborhood Attention compared to other attention patterns.
+Taken from the original paper.
+
+This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
+The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
+
+## Usage tips
+
+- One can use the [`AutoImageProcessor`] API to prepare images for the model.
+- NAT can be used as a *backbone*. When `output_hidden_states = True`,
+it will output both `hidden_states` and `reshaped_hidden_states`.
+The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than
+`(batch_size, height, width, num_channels)`.
+
+Notes:
+- NAT depends on [NATTEN](https://github.com/SHI-Labs/NATTEN/)'s implementation of Neighborhood Attention.
+You can install it with pre-built wheels for Linux by referring to [shi-labs.com/natten](https://shi-labs.com/natten),
+or build on your system by running `pip install natten`.
+Note that the latter will likely take time to compile. NATTEN does not support Windows devices yet.
+- Patch size of 4 is only supported at the moment.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with NAT.
+
+
+
+- [`NatForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## NatConfig
+
+[[autodoc]] NatConfig
+
+## NatModel
+
+[[autodoc]] NatModel
+ - forward
+
+## NatForImageClassification
+
+[[autodoc]] NatForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/nemotron.md b/docs/transformers/docs/source/en/model_doc/nemotron.md
new file mode 100644
index 0000000000000000000000000000000000000000..13b1b9be2fbcf265e32c3c9fdb508027a0ef37c3
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/nemotron.md
@@ -0,0 +1,152 @@
+
+
+# Nemotron
+
+
+
+
+
+
+
+### License
+
+The use of this model is governed by the [NVIDIA AI Foundation Models Community License Agreement](https://developer.nvidia.com/downloads/nv-ai-foundation-models-license).
+
+### Description
+
+Nemotron-4 is a family of enterprise ready generative text models compatible with [NVIDIA NeMo Framework](https://www.nvidia.com/en-us/ai-data-science/generative-ai/nemo-framework/).
+
+NVIDIA NeMo is an end-to-end, cloud-native platform to build, customize, and deploy generative AI models anywhere. It includes training and inferencing frameworks, guardrailing toolkits, data curation tools, and pretrained models, offering enterprises an easy, cost-effective, and fast way to adopt generative AI. To get access to NeMo Framework, please sign up at [this link](https://developer.nvidia.com/nemo-framework/join).
+
+### References
+
+[Announcement Blog](https://developer.nvidia.com/blog/nvidia-ai-foundation-models-build-custom-enterprise-chatbots-and-co-pilots-with-production-ready-llms/)
+
+### Model Architecture
+
+**Architecture Type:** Transformer
+
+**Network Architecture:** Transformer Decoder (auto-regressive language model).
+
+## Minitron
+
+### Minitron 4B Base
+
+Minitron is a family of small language models (SLMs) obtained by pruning NVIDIA's [Nemotron-4 15B](https://arxiv.org/abs/2402.16819) model. We prune model embedding size, attention heads, and MLP intermediate dimension, following which, we perform continued training with distillation to arrive at the final models.
+
+Deriving the Minitron 8B and 4B models from the base 15B model using our approach requires up to **40x fewer training tokens** per model compared to training from scratch; this results in **compute cost savings of 1.8x** for training the full model family (15B, 8B, and 4B). Minitron models exhibit up to a 16% improvement in MMLU scores compared to training from scratch, perform comparably to other community models such as Mistral 7B, Gemma 7B and Llama-3 8B, and outperform state-of-the-art compression techniques from the literature. Please refer to our [arXiv paper](https://arxiv.org/abs/2407.14679) for more details.
+
+Minitron models are for research and development only.
+
+### HuggingFace Quickstart
+
+The following code provides an example of how to load the Minitron-4B model and use it to perform text generation.
+
+```python
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+# Load the tokenizer and model
+model_path = 'nvidia/Minitron-4B-Base'
+tokenizer = AutoTokenizer.from_pretrained(model_path)
+
+device = 'cuda'
+dtype = torch.bfloat16
+model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=dtype, device_map=device)
+
+# Prepare the input text
+prompt = 'Complete the paragraph: our solar system is'
+inputs = tokenizer.encode(prompt, return_tensors='pt').to(model.device)
+
+# Generate the output
+outputs = model.generate(inputs, max_length=20)
+
+# Decode and print the output
+output_text = tokenizer.decode(outputs[0])
+print(output_text)
+```
+
+### License
+
+Minitron is released under the [NVIDIA Open Model License Agreement](https://developer.download.nvidia.com/licenses/nvidia-open-model-license-agreement-june-2024.pdf).
+
+### Evaluation Results
+
+*5-shot performance.* Language Understanding evaluated using [Massive Multitask Language Understanding](https://arxiv.org/abs/2009.03300):
+
+| Average |
+| :---- |
+| 58.6 |
+
+*Zero-shot performance.* Evaluated using select datasets from the [LM Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) with additions:
+
+| HellaSwag | Winogrande | GSM8K| ARC-C | XLSum |
+| :------------- | :------------- | :------------- | :------------- | :------------- |
+| 75.0 | 74.0 | 24.1 | 50.9 | 29.5
+
+
+*Code generation performance*. Evaluated using [HumanEval](https://github.com/openai/human-eval):
+
+| p@1, 0-Shot |
+| :------------- |
+| 23.3 |
+
+Please refer to our [paper](https://arxiv.org/abs/2407.14679) for the full set of results.
+
+### Citation
+
+If you find our work helpful, please consider citing our paper:
+```
+@article{minitron2024,
+ title={Compact Language Models via Pruning and Knowledge Distillation},
+ author={Saurav Muralidharan and Sharath Turuvekere Sreenivas and Raviraj Joshi and Marcin Chochowski and Mostofa Patwary and Mohammad Shoeybi and Bryan Catanzaro and Jan Kautz and Pavlo Molchanov},
+ journal={arXiv preprint arXiv:2407.14679},
+ year={2024},
+ url={https://arxiv.org/abs/2407.14679},
+}
+```
+
+## NemotronConfig
+
+[[autodoc]] NemotronConfig
+
+
+## NemotronModel
+
+[[autodoc]] NemotronModel
+ - forward
+
+
+## NemotronForCausalLM
+
+[[autodoc]] NemotronForCausalLM
+ - forward
+
+## NemotronForSequenceClassification
+
+[[autodoc]] NemotronForSequenceClassification
+ - forward
+
+
+## NemotronForQuestionAnswering
+
+[[autodoc]] NemotronForQuestionAnswering
+ - forward
+
+
+## NemotronForTokenClassification
+
+[[autodoc]] NemotronForTokenClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/nezha.md b/docs/transformers/docs/source/en/model_doc/nezha.md
new file mode 100644
index 0000000000000000000000000000000000000000..dc815e0ecc48152295479b110952518e3fc7048b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/nezha.md
@@ -0,0 +1,100 @@
+
+
+# Nezha
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+The Nezha model was proposed in [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei et al.
+
+The abstract from the paper is the following:
+
+*The pre-trained language models have achieved great successes in various natural language understanding (NLU) tasks
+due to its capacity to capture the deep contextualized information in text by pre-training on large-scale corpora.
+In this technical report, we present our practice of pre-training language models named NEZHA (NEural contextualiZed
+representation for CHinese lAnguage understanding) on Chinese corpora and finetuning for the Chinese NLU tasks.
+The current version of NEZHA is based on BERT with a collection of proven improvements, which include Functional
+Relative Positional Encoding as an effective positional encoding scheme, Whole Word Masking strategy,
+Mixed Precision Training and the LAMB Optimizer in training the models. The experimental results show that NEZHA
+achieves the state-of-the-art performances when finetuned on several representative Chinese tasks, including
+named entity recognition (People's Daily NER), sentence matching (LCQMC), Chinese sentiment classification (ChnSenti)
+and natural language inference (XNLI).*
+
+This model was contributed by [sijunhe](https://huggingface.co/sijunhe). The original code can be found [here](https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/NEZHA-PyTorch).
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## NezhaConfig
+
+[[autodoc]] NezhaConfig
+
+## NezhaModel
+
+[[autodoc]] NezhaModel
+ - forward
+
+## NezhaForPreTraining
+
+[[autodoc]] NezhaForPreTraining
+ - forward
+
+## NezhaForMaskedLM
+
+[[autodoc]] NezhaForMaskedLM
+ - forward
+
+## NezhaForNextSentencePrediction
+
+[[autodoc]] NezhaForNextSentencePrediction
+ - forward
+
+## NezhaForSequenceClassification
+
+[[autodoc]] NezhaForSequenceClassification
+ - forward
+
+## NezhaForMultipleChoice
+
+[[autodoc]] NezhaForMultipleChoice
+ - forward
+
+## NezhaForTokenClassification
+
+[[autodoc]] NezhaForTokenClassification
+ - forward
+
+## NezhaForQuestionAnswering
+
+[[autodoc]] NezhaForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/nllb-moe.md b/docs/transformers/docs/source/en/model_doc/nllb-moe.md
new file mode 100644
index 0000000000000000000000000000000000000000..65a4812ed6ab335f14f0a13f534605dbeba3e193
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/nllb-moe.md
@@ -0,0 +1,137 @@
+
+
+# NLLB-MOE
+
+
+
+
+
+## Overview
+
+The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
+Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
+Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews,
+Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers,
+Safiyyah Saleem, Holger Schwenk, and Jeff Wang.
+
+The abstract of the paper is the following:
+
+*Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today.
+However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the
+200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by
+first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed
+at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of
+Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training
+improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using
+a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety.
+Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system.*
+
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/facebookresearch/fairseq).
+
+## Usage tips
+
+- M2M100ForConditionalGeneration is the base model for both NLLB and NLLB MoE
+- The NLLB-MoE is very similar to the NLLB model, but it's feed forward layer is based on the implementation of SwitchTransformers.
+- The tokenizer is the same as the NLLB models.
+
+## Implementation differences with SwitchTransformers
+
+The biggest difference is the way the tokens are routed. NLLB-MoE uses a `top-2-gate` which means that for each input, only the top two experts are selected based on the
+highest predicted probabilities from the gating network, and the remaining experts are ignored. In `SwitchTransformers`, only the top-1 probabilities are computed,
+which means that tokens have less probability of being forwarded. Moreover, if a token is not routed to any expert, `SwitchTransformers` still adds its unmodified hidden
+states (kind of like a residual connection) while they are masked in `NLLB`'s top-2 routing mechanism.
+
+## Generating with NLLB-MoE
+
+The available checkpoints require around 350GB of storage. Make sure to use `accelerate` if you do not have enough RAM on your machine.
+
+While generating the target text set the `forced_bos_token_id` to the target language id. The following
+example shows how to translate English to French using the *facebook/nllb-200-distilled-600M* model.
+
+Note that we're using the BCP-47 code for French `fra_Latn`. See [here](https://github.com/facebookresearch/flores/blob/main/flores200/README.md#languages-in-flores-200)
+for the list of all BCP-47 in the Flores 200 dataset.
+
+```python
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-moe-54b")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-moe-54b")
+
+>>> article = "Previously, Ring's CEO, Jamie Siminoff, remarked the company started when his doorbell wasn't audible from his shop in his garage."
+>>> inputs = tokenizer(article, return_tensors="pt")
+
+>>> translated_tokens = model.generate(
+... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["fra_Latn"], max_length=50
+... )
+>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
+"Auparavant, le PDG de Ring, Jamie Siminoff, a fait remarquer que la société avait commencé lorsque sa sonnette n'était pas audible depuis son magasin dans son garage."
+```
+
+### Generating from any other language than English
+
+English (`eng_Latn`) is set as the default language from which to translate. In order to specify that you'd like to translate from a different language,
+you should specify the BCP-47 code in the `src_lang` keyword argument of the tokenizer initialization.
+
+See example below for a translation from romanian to german:
+
+```python
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-moe-54b", src_lang="ron_Latn")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-moe-54b")
+
+>>> article = "Şeful ONU spune că nu există o soluţie militară în Siria"
+>>> inputs = tokenizer(article, return_tensors="pt")
+
+>>> translated_tokens = model.generate(
+... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["deu_Latn"], max_length=30
+... )
+>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
+```
+
+## Resources
+
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+
+## NllbMoeConfig
+
+[[autodoc]] NllbMoeConfig
+
+## NllbMoeTop2Router
+
+[[autodoc]] NllbMoeTop2Router
+ - route_tokens
+ - forward
+
+## NllbMoeSparseMLP
+
+[[autodoc]] NllbMoeSparseMLP
+ - forward
+
+## NllbMoeModel
+
+[[autodoc]] NllbMoeModel
+ - forward
+
+## NllbMoeForConditionalGeneration
+
+[[autodoc]] NllbMoeForConditionalGeneration
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/nllb.md b/docs/transformers/docs/source/en/model_doc/nllb.md
new file mode 100644
index 0000000000000000000000000000000000000000..4ba2737779209a9f8443ea7a88dcf5a3ad6581f9
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/nllb.md
@@ -0,0 +1,214 @@
+
+
+# NLLB
+
+
+
+
+
+
+
+## Updated tokenizer behavior
+
+**DISCLAIMER:** The default behaviour for the tokenizer was fixed and thus changed in April 2023.
+The previous version adds `[self.eos_token_id, self.cur_lang_code]` at the end of the token sequence for both target and source tokenization. This is wrong as the NLLB paper mentions (page 48, 6.1.1. Model Architecture) :
+
+*Note that we prefix the source sequence with the source language, as opposed to the target
+language as previously done in several works (Arivazhagan et al., 2019; Johnson et al.,
+2017). This is primarily because we prioritize optimizing zero-shot performance of our
+model on any pair of 200 languages at a minor cost to supervised performance.*
+
+Previous behaviour:
+
+```python
+>>> from transformers import NllbTokenizer
+
+>>> tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
+>>> tokenizer("How was your day?").input_ids
+[13374, 1398, 4260, 4039, 248130, 2, 256047]
+
+>>> # 2: ''
+>>> # 256047 : 'eng_Latn'
+```
+New behaviour
+
+```python
+>>> from transformers import NllbTokenizer
+
+>>> tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
+>>> tokenizer("How was your day?").input_ids
+[256047, 13374, 1398, 4260, 4039, 248130, 2]
+ ```
+
+Enabling the old behaviour can be done as follows:
+```python
+>>> from transformers import NllbTokenizer
+
+>>> tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M", legacy_behaviour=True)
+```
+
+For more details, feel free to check the linked [PR](https://github.com/huggingface/transformers/pull/22313) and [Issue](https://github.com/huggingface/transformers/issues/19943).
+
+## Overview
+
+The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
+Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
+Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews,
+Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers,
+Safiyyah Saleem, Holger Schwenk, and Jeff Wang.
+
+The abstract of the paper is the following:
+
+*Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today.
+However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the
+200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by
+first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed
+at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of
+Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training
+improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using
+a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety.
+Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system.*
+
+This implementation contains the dense models available on release.
+
+**The sparse model NLLB-MoE (Mixture of Expert) is now available! More details [here](nllb-moe)**
+
+This model was contributed by [Lysandre](https://huggingface.co/lysandre). The authors' code can be found [here](https://github.com/facebookresearch/fairseq/tree/nllb).
+
+## Generating with NLLB
+
+While generating the target text set the `forced_bos_token_id` to the target language id. The following
+example shows how to translate English to French using the *facebook/nllb-200-distilled-600M* model.
+
+Note that we're using the BCP-47 code for French `fra_Latn`. See [here](https://github.com/facebookresearch/flores/blob/main/flores200/README.md#languages-in-flores-200)
+for the list of all BCP-47 in the Flores 200 dataset.
+
+```python
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M")
+
+>>> article = "UN Chief says there is no military solution in Syria"
+>>> inputs = tokenizer(article, return_tensors="pt")
+
+>>> translated_tokens = model.generate(
+... **inputs, forced_bos_token_id=tokenizer.convert_tokens_to_ids("fra_Latn"), max_length=30
+... )
+>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
+Le chef de l'ONU dit qu'il n'y a pas de solution militaire en Syrie
+```
+
+### Generating from any other language than English
+
+English (`eng_Latn`) is set as the default language from which to translate. In order to specify that you'd like to translate from a different language,
+you should specify the BCP-47 code in the `src_lang` keyword argument of the tokenizer initialization.
+
+See example below for a translation from romanian to german:
+
+```py
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained(
+... "facebook/nllb-200-distilled-600M", token=True, src_lang="ron_Latn"
+... )
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", token=True)
+
+>>> article = "Şeful ONU spune că nu există o soluţie militară în Siria"
+>>> inputs = tokenizer(article, return_tensors="pt")
+
+>>> translated_tokens = model.generate(
+... **inputs, forced_bos_token_id=tokenizer.convert_tokens_to_ids("deu_Latn"), max_length=30
+... )
+>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
+UN-Chef sagt, es gibt keine militärische Lösung in Syrien
+```
+
+## Resources
+
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## NllbTokenizer
+
+[[autodoc]] NllbTokenizer
+ - build_inputs_with_special_tokens
+
+## NllbTokenizerFast
+
+[[autodoc]] NllbTokenizerFast
+
+## Using Flash Attention 2
+
+Flash Attention 2 is a faster, optimized version of the attention scores computation which relies on `cuda` kernels.
+
+### Installation
+
+First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features).
+
+Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+### Usage
+
+To load a model using Flash Attention 2, we can pass the argument `attn_implementation="flash_attention_2"` to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). You can use either `torch.float16` or `torch.bfloat16` precision.
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda").eval()
+>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
+
+>>> article = "Şeful ONU spune că nu există o soluţie militară în Siria"
+>>> inputs = tokenizer(article, return_tensors="pt").to("cuda")
+
+>>> translated_tokens = model.generate(
+... **inputs, forced_bos_token_id=tokenizer.convert_tokens_to_ids("deu_Latn"), max_length=30
+... )
+>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
+"UN-Chef sagt, es gibt keine militärische Lösung in Syrien"
+```
+
+### Expected speedups
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation and the Flash Attention 2.
+
+
+
+
+
+## Using Scaled Dot Product Attention (SDPA)
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```python
+from transformers import AutoModelForSeq2SeqLM
+model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", torch_dtype=torch.float16, attn_implementation="sdpa")
+...
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/nougat.md b/docs/transformers/docs/source/en/model_doc/nougat.md
new file mode 100644
index 0000000000000000000000000000000000000000..06b12b5ee8e66cc6c28376aeb9933ff8d65429e9
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/nougat.md
@@ -0,0 +1,122 @@
+
+
+# Nougat
+
+
+
+
+
+
+
+## Overview
+
+The Nougat model was proposed in [Nougat: Neural Optical Understanding for Academic Documents](https://arxiv.org/abs/2308.13418) by
+Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic. Nougat uses the same architecture as [Donut](donut), meaning an image Transformer
+encoder and an autoregressive text Transformer decoder to translate scientific PDFs to markdown, enabling easier access to them.
+
+The abstract from the paper is the following:
+
+*Scientific knowledge is predominantly stored in books and scientific journals, often in the form of PDFs. However, the PDF format leads to a loss of semantic information, particularly for mathematical expressions. We propose Nougat (Neural Optical Understanding for Academic Documents), a Visual Transformer model that performs an Optical Character Recognition (OCR) task for processing scientific documents into a markup language, and demonstrate the effectiveness of our model on a new dataset of scientific documents. The proposed approach offers a promising solution to enhance the accessibility of scientific knowledge in the digital age, by bridging the gap between human-readable documents and machine-readable text. We release the models and code to accelerate future work on scientific text recognition.*
+
+
+
+ Nougat high-level overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/facebookresearch/nougat).
+
+## Usage tips
+
+- The quickest way to get started with Nougat is by checking the [tutorial
+ notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Nougat), which show how to use the model
+ at inference time as well as fine-tuning on custom data.
+- Nougat is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework. The model is identical to [Donut](donut) in terms of architecture.
+
+## Inference
+
+Nougat's [`VisionEncoderDecoder`] model accepts images as input and makes use of
+[`~generation.GenerationMixin.generate`] to autoregressively generate text given the input image.
+
+The [`NougatImageProcessor`] class is responsible for preprocessing the input image and
+[`NougatTokenizerFast`] decodes the generated target tokens to the target string. The
+[`NougatProcessor`] wraps [`NougatImageProcessor`] and [`NougatTokenizerFast`] classes
+into a single instance to both extract the input features and decode the predicted token ids.
+
+- Step-by-step PDF transcription
+
+```py
+>>> from huggingface_hub import hf_hub_download
+>>> import re
+>>> from PIL import Image
+
+>>> from transformers import NougatProcessor, VisionEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> processor = NougatProcessor.from_pretrained("facebook/nougat-base")
+>>> model = VisionEncoderDecoderModel.from_pretrained("facebook/nougat-base")
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model.to(device) # doctest: +IGNORE_RESULT
+
+>>> # prepare PDF image for the model
+>>> filepath = hf_hub_download(repo_id="hf-internal-testing/fixtures_docvqa", filename="nougat_paper.png", repo_type="dataset")
+>>> image = Image.open(filepath)
+>>> pixel_values = processor(image, return_tensors="pt").pixel_values
+
+>>> # generate transcription (here we only generate 30 tokens)
+>>> outputs = model.generate(
+... pixel_values.to(device),
+... min_length=1,
+... max_new_tokens=30,
+... bad_words_ids=[[processor.tokenizer.unk_token_id]],
+... )
+
+>>> sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
+>>> sequence = processor.post_process_generation(sequence, fix_markdown=False)
+>>> # note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequence
+>>> print(repr(sequence))
+'\n\n# Nougat: Neural Optical Understanding for Academic Documents\n\n Lukas Blecher\n\nCorrespondence to: lblecher@'
+```
+
+See the [model hub](https://huggingface.co/models?filter=nougat) to look for Nougat checkpoints.
+
+
+
+The model is identical to [Donut](donut) in terms of architecture.
+
+
+
+## NougatImageProcessor
+
+[[autodoc]] NougatImageProcessor
+ - preprocess
+
+## NougatTokenizerFast
+
+[[autodoc]] NougatTokenizerFast
+
+## NougatProcessor
+
+[[autodoc]] NougatProcessor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+ - post_process_generation
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/nystromformer.md b/docs/transformers/docs/source/en/model_doc/nystromformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..b4c017b35fff8b29edd3dcaa7bc83002b536441e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/nystromformer.md
@@ -0,0 +1,84 @@
+
+
+# Nyströmformer
+
+
+
+
+
+## Overview
+
+The Nyströmformer model was proposed in [*Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention*](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn
+Fung, Yin Li, and Vikas Singh.
+
+The abstract from the paper is the following:
+
+*Transformers have emerged as a powerful tool for a broad range of natural language processing tasks. A key component
+that drives the impressive performance of Transformers is the self-attention mechanism that encodes the influence or
+dependence of other tokens on each specific token. While beneficial, the quadratic complexity of self-attention on the
+input sequence length has limited its application to longer sequences -- a topic being actively studied in the
+community. To address this limitation, we propose Nyströmformer -- a model that exhibits favorable scalability as a
+function of sequence length. Our idea is based on adapting the Nyström method to approximate standard self-attention
+with O(n) complexity. The scalability of Nyströmformer enables application to longer sequences with thousands of
+tokens. We perform evaluations on multiple downstream tasks on the GLUE benchmark and IMDB reviews with standard
+sequence length, and find that our Nyströmformer performs comparably, or in a few cases, even slightly better, than
+standard self-attention. On longer sequence tasks in the Long Range Arena (LRA) benchmark, Nyströmformer performs
+favorably relative to other efficient self-attention methods. Our code is available at this https URL.*
+
+This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/Nystromformer).
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## NystromformerConfig
+
+[[autodoc]] NystromformerConfig
+
+## NystromformerModel
+
+[[autodoc]] NystromformerModel
+ - forward
+
+## NystromformerForMaskedLM
+
+[[autodoc]] NystromformerForMaskedLM
+ - forward
+
+## NystromformerForSequenceClassification
+
+[[autodoc]] NystromformerForSequenceClassification
+ - forward
+
+## NystromformerForMultipleChoice
+
+[[autodoc]] NystromformerForMultipleChoice
+ - forward
+
+## NystromformerForTokenClassification
+
+[[autodoc]] NystromformerForTokenClassification
+ - forward
+
+## NystromformerForQuestionAnswering
+
+[[autodoc]] NystromformerForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/olmo.md b/docs/transformers/docs/source/en/model_doc/olmo.md
new file mode 100644
index 0000000000000000000000000000000000000000..8d722185c31f229c68f4b7216554f64ccedcea77
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/olmo.md
@@ -0,0 +1,51 @@
+
+
+# OLMo
+
+
+
+
+
+
+
+## Overview
+
+The OLMo model was proposed in [OLMo: Accelerating the Science of Language Models](https://arxiv.org/abs/2402.00838) by Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi.
+
+OLMo is a series of **O**pen **L**anguage **Mo**dels designed to enable the science of language models. The OLMo models are trained on the Dolma dataset. We release all code, checkpoints, logs (coming soon), and details involved in training these models.
+
+The abstract from the paper is the following:
+
+*Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.*
+
+This model was contributed by [shanearora](https://huggingface.co/shanearora).
+The original code can be found [here](https://github.com/allenai/OLMo/tree/main/olmo).
+
+
+## OlmoConfig
+
+[[autodoc]] OlmoConfig
+
+## OlmoModel
+
+[[autodoc]] OlmoModel
+ - forward
+
+## OlmoForCausalLM
+
+[[autodoc]] OlmoForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/olmo2.md b/docs/transformers/docs/source/en/model_doc/olmo2.md
new file mode 100644
index 0000000000000000000000000000000000000000..24030b855244c1399c3d4c8fd838aa9ea12847e3
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/olmo2.md
@@ -0,0 +1,52 @@
+
+
+# OLMo2
+
+
+
+
+
+
+
+## Overview
+
+The OLMo2 model is the successor of the OLMo model, which was proposed in
+[OLMo: Accelerating the Science of Language Models](https://arxiv.org/abs/2402.00838).
+
+ The architectural changes from the original OLMo model to this model are:
+
+- RMSNorm is used instead of standard layer norm.
+- Norm is applied to attention queries and keys.
+- Norm is applied after attention/feedforward layers rather than before.
+
+This model was contributed by [shanearora](https://huggingface.co/shanearora).
+The original code can be found [here](https://github.com/allenai/OLMo/tree/main/olmo).
+
+
+## Olmo2Config
+
+[[autodoc]] Olmo2Config
+
+## Olmo2Model
+
+[[autodoc]] Olmo2Model
+ - forward
+
+## Olmo2ForCausalLM
+
+[[autodoc]] Olmo2ForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/olmoe.md b/docs/transformers/docs/source/en/model_doc/olmoe.md
new file mode 100644
index 0000000000000000000000000000000000000000..6496e44c1bd5b98dc254f90873e5dda80b6668fe
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/olmoe.md
@@ -0,0 +1,51 @@
+
+
+# OLMoE
+
+
+
+
+
+
+
+## Overview
+
+The OLMoE model was proposed in [OLMoE: Open Mixture-of-Experts Language Models](https://arxiv.org/abs/2409.02060) by Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, Hannaneh Hajishirzi.
+
+OLMoE is a series of **O**pen **L**anguage **Mo**dels using sparse **M**ixture-**o**f-**E**xperts designed to enable the science of language models. We release all code, checkpoints, logs, and details involved in training these models.
+
+The abstract from the paper is the following:
+
+*We introduce OLMoE, a fully open, state-of-the-art language model leveraging sparse Mixture-of-Experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token. We pretrain it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B. We present various experiments on MoE training, analyze routing in our model showing high specialization, and open-source all aspects of our work: model weights, training data, code, and logs.*
+
+This model was contributed by [Muennighoff](https://hf.co/Muennighoff).
+The original code can be found [here](https://github.com/allenai/OLMoE).
+
+
+## OlmoeConfig
+
+[[autodoc]] OlmoeConfig
+
+## OlmoeModel
+
+[[autodoc]] OlmoeModel
+ - forward
+
+## OlmoeForCausalLM
+
+[[autodoc]] OlmoeForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/omdet-turbo.md b/docs/transformers/docs/source/en/model_doc/omdet-turbo.md
new file mode 100644
index 0000000000000000000000000000000000000000..d73fef2d8b5d8844473b474740dcd42aebbc02f8
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/omdet-turbo.md
@@ -0,0 +1,171 @@
+
+
+# OmDet-Turbo
+
+
+
+
+
+## Overview
+
+The OmDet-Turbo model was proposed in [Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head](https://arxiv.org/abs/2403.06892) by Tiancheng Zhao, Peng Liu, Xuan He, Lu Zhang, Kyusong Lee. OmDet-Turbo incorporates components from RT-DETR and introduces a swift multimodal fusion module to achieve real-time open-vocabulary object detection capabilities while maintaining high accuracy. The base model achieves performance of up to 100.2 FPS and 53.4 AP on COCO zero-shot.
+
+The abstract from the paper is the following:
+
+*End-to-end transformer-based detectors (DETRs) have shown exceptional performance in both closed-set and open-vocabulary object detection (OVD) tasks through the integration of language modalities. However, their demanding computational requirements have hindered their practical application in real-time object detection (OD) scenarios. In this paper, we scrutinize the limitations of two leading models in the OVDEval benchmark, OmDet and Grounding-DINO, and introduce OmDet-Turbo. This novel transformer-based real-time OVD model features an innovative Efficient Fusion Head (EFH) module designed to alleviate the bottlenecks observed in OmDet and Grounding-DINO. Notably, OmDet-Turbo-Base achieves a 100.2 frames per second (FPS) with TensorRT and language cache techniques applied. Notably, in zero-shot scenarios on COCO and LVIS datasets, OmDet-Turbo achieves performance levels nearly on par with current state-of-the-art supervised models. Furthermore, it establishes new state-of-the-art benchmarks on ODinW and OVDEval, boasting an AP of 30.1 and an NMS-AP of 26.86, respectively. The practicality of OmDet-Turbo in industrial applications is underscored by its exceptional performance on benchmark datasets and superior inference speed, positioning it as a compelling choice for real-time object detection tasks.*
+
+
+
+ OmDet-Turbo architecture overview. Taken from the original paper.
+
+This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
+The original code can be found [here](https://github.com/om-ai-lab/OmDet).
+
+## Usage tips
+
+One unique property of OmDet-Turbo compared to other zero-shot object detection models, such as [Grounding DINO](grounding-dino), is the decoupled classes and prompt embedding structure that allows caching of text embeddings. This means that the model needs both classes and task as inputs, where classes is a list of objects we want to detect and task is the grounded text used to guide open-vocabulary detection. This approach limits the scope of the open-vocabulary detection and makes the decoding process faster.
+
+[`OmDetTurboProcessor`] is used to prepare the classes, task and image triplet. The task input is optional, and when not provided, it will default to `"Detect [class1], [class2], [class3], ..."`. To process the results from the model, one can use `post_process_grounded_object_detection` from [`OmDetTurboProcessor`]. Notably, this function takes in the input classes, as unlike other zero-shot object detection models, the decoupling of classes and task embeddings means that no decoding of the predicted class embeddings is needed in the post-processing step, and the predicted classes can be matched to the inputted ones directly.
+
+## Usage example
+
+### Single image inference
+
+Here's how to load the model and prepare the inputs to perform zero-shot object detection on a single image:
+
+```python
+>>> import torch
+>>> import requests
+>>> from PIL import Image
+
+>>> from transformers import AutoProcessor, OmDetTurboForObjectDetection
+
+>>> processor = AutoProcessor.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
+>>> model = OmDetTurboForObjectDetection.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> text_labels = ["cat", "remote"]
+>>> inputs = processor(image, text=text_labels, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> # convert outputs (bounding boxes and class logits)
+>>> results = processor.post_process_grounded_object_detection(
+... outputs,
+... target_sizes=[(image.height, image.width)],
+... text_labels=text_labels,
+... threshold=0.3,
+... nms_threshold=0.3,
+... )
+>>> result = results[0]
+>>> boxes, scores, text_labels = result["boxes"], result["scores"], result["text_labels"]
+>>> for box, score, text_label in zip(boxes, scores, text_labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text_label} with confidence {round(score.item(), 3)} at location {box}")
+Detected remote with confidence 0.768 at location [39.89, 70.35, 176.74, 118.04]
+Detected cat with confidence 0.72 at location [11.6, 54.19, 314.8, 473.95]
+Detected remote with confidence 0.563 at location [333.38, 75.77, 370.7, 187.03]
+Detected cat with confidence 0.552 at location [345.15, 23.95, 639.75, 371.67]
+```
+
+### Multi image inference
+
+OmDet-Turbo can perform batched multi-image inference, with support for different text prompts and classes in the same batch:
+
+```python
+>>> import torch
+>>> import requests
+>>> from io import BytesIO
+>>> from PIL import Image
+>>> from transformers import AutoProcessor, OmDetTurboForObjectDetection
+
+>>> processor = AutoProcessor.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
+>>> model = OmDetTurboForObjectDetection.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
+
+>>> url1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image1 = Image.open(BytesIO(requests.get(url1).content)).convert("RGB")
+>>> text_labels1 = ["cat", "remote"]
+>>> task1 = "Detect {}.".format(", ".join(text_labels1))
+
+>>> url2 = "http://images.cocodataset.org/train2017/000000257813.jpg"
+>>> image2 = Image.open(BytesIO(requests.get(url2).content)).convert("RGB")
+>>> text_labels2 = ["boat"]
+>>> task2 = "Detect everything that looks like a boat."
+
+>>> url3 = "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"
+>>> image3 = Image.open(BytesIO(requests.get(url3).content)).convert("RGB")
+>>> text_labels3 = ["statue", "trees"]
+>>> task3 = "Focus on the foreground, detect statue and trees."
+
+>>> inputs = processor(
+... images=[image1, image2, image3],
+... text=[text_labels1, text_labels2, text_labels3],
+... task=[task1, task2, task3],
+... return_tensors="pt",
+... )
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> # convert outputs (bounding boxes and class logits)
+>>> results = processor.post_process_grounded_object_detection(
+... outputs,
+... text_labels=[text_labels1, text_labels2, text_labels3],
+... target_sizes=[(image.height, image.width) for image in [image1, image2, image3]],
+... threshold=0.2,
+... nms_threshold=0.3,
+... )
+
+>>> for i, result in enumerate(results):
+... for score, text_label, box in zip(
+... result["scores"], result["text_labels"], result["boxes"]
+... ):
+... box = [round(i, 1) for i in box.tolist()]
+... print(
+... f"Detected {text_label} with confidence "
+... f"{round(score.item(), 2)} at location {box} in image {i}"
+... )
+Detected remote with confidence 0.77 at location [39.9, 70.4, 176.7, 118.0] in image 0
+Detected cat with confidence 0.72 at location [11.6, 54.2, 314.8, 474.0] in image 0
+Detected remote with confidence 0.56 at location [333.4, 75.8, 370.7, 187.0] in image 0
+Detected cat with confidence 0.55 at location [345.2, 24.0, 639.8, 371.7] in image 0
+Detected boat with confidence 0.32 at location [146.9, 219.8, 209.6, 250.7] in image 1
+Detected boat with confidence 0.3 at location [319.1, 223.2, 403.2, 238.4] in image 1
+Detected boat with confidence 0.27 at location [37.7, 220.3, 84.0, 235.9] in image 1
+Detected boat with confidence 0.22 at location [407.9, 207.0, 441.7, 220.2] in image 1
+Detected statue with confidence 0.73 at location [544.7, 210.2, 651.9, 502.8] in image 2
+Detected trees with confidence 0.25 at location [3.9, 584.3, 391.4, 785.6] in image 2
+Detected trees with confidence 0.25 at location [1.4, 621.2, 118.2, 787.8] in image 2
+Detected statue with confidence 0.2 at location [428.1, 205.5, 767.3, 759.5] in image 2
+
+```
+
+## OmDetTurboConfig
+
+[[autodoc]] OmDetTurboConfig
+
+## OmDetTurboProcessor
+
+[[autodoc]] OmDetTurboProcessor
+ - post_process_grounded_object_detection
+
+## OmDetTurboForObjectDetection
+
+[[autodoc]] OmDetTurboForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/oneformer.md b/docs/transformers/docs/source/en/model_doc/oneformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..f1c1de791238f3fc64df10a4a4057062696a0c7b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/oneformer.md
@@ -0,0 +1,90 @@
+
+
+# OneFormer
+
+
+
+
+
+## Overview
+
+The OneFormer model was proposed in [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi. OneFormer is a universal image segmentation framework that can be trained on a single panoptic dataset to perform semantic, instance, and panoptic segmentation tasks. OneFormer uses a task token to condition the model on the task in focus, making the architecture task-guided for training, and task-dynamic for inference.
+
+
+
+The abstract from the paper is the following:
+
+*Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible.*
+
+The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
+
+
+
+This model was contributed by [Jitesh Jain](https://huggingface.co/praeclarumjj3). The original code can be found [here](https://github.com/SHI-Labs/OneFormer).
+
+## Usage tips
+
+- OneFormer requires two inputs during inference: *image* and *task token*.
+- During training, OneFormer only uses panoptic annotations.
+- If you want to train the model in a distributed environment across multiple nodes, then one should update the
+ `get_num_masks` function inside in the `OneFormerLoss` class of `modeling_oneformer.py`. When training on multiple nodes, this should be
+ set to the average number of target masks across all nodes, as can be seen in the original implementation [here](https://github.com/SHI-Labs/OneFormer/blob/33ebb56ed34f970a30ae103e786c0cb64c653d9a/oneformer/modeling/criterion.py#L287).
+- One can use [`OneFormerProcessor`] to prepare input images and task inputs for the model and optional targets for the model. [`OneFormerProcessor`] wraps [`OneFormerImageProcessor`] and [`CLIPTokenizer`] into a single instance to both prepare the images and encode the task inputs.
+- To get the final segmentation, depending on the task, you can call [`~OneFormerProcessor.post_process_semantic_segmentation`] or [`~OneFormerImageProcessor.post_process_instance_segmentation`] or [`~OneFormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`OneFormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OneFormer.
+
+- Demo notebooks regarding inference + fine-tuning on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OneFormer).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
+The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## OneFormer specific outputs
+
+[[autodoc]] models.oneformer.modeling_oneformer.OneFormerModelOutput
+
+[[autodoc]] models.oneformer.modeling_oneformer.OneFormerForUniversalSegmentationOutput
+
+## OneFormerConfig
+
+[[autodoc]] OneFormerConfig
+
+## OneFormerImageProcessor
+
+[[autodoc]] OneFormerImageProcessor
+ - preprocess
+ - encode_inputs
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
+## OneFormerProcessor
+
+[[autodoc]] OneFormerProcessor
+
+## OneFormerModel
+
+[[autodoc]] OneFormerModel
+ - forward
+
+## OneFormerForUniversalSegmentation
+
+[[autodoc]] OneFormerForUniversalSegmentation
+ - forward
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/open-llama.md b/docs/transformers/docs/source/en/model_doc/open-llama.md
new file mode 100644
index 0000000000000000000000000000000000000000..3b4856cd4fb6db9fb8acc203c333cd8bfce81c83
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/open-llama.md
@@ -0,0 +1,65 @@
+
+
+# Open-Llama
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.31.0.
+You can do so by running the following command: `pip install -U transformers==4.31.0`.
+
+
+
+
+
+This model differs from the [OpenLLaMA models](https://huggingface.co/models?search=openllama) on the Hugging Face Hub, which primarily use the [LLaMA](llama) architecture.
+
+
+
+## Overview
+
+The Open-Llama model was proposed in the open source Open-Llama project by community developer s-JoL.
+
+The model is mainly based on LLaMA with some modifications, incorporating memory-efficient attention from Xformers, stable embedding from Bloom, and shared input-output embedding from PaLM.
+And the model is pre-trained on both Chinese and English, which gives it better performance on Chinese language tasks.
+
+This model was contributed by [s-JoL](https://huggingface.co/s-JoL).
+The original code was released on GitHub by [s-JoL](https://github.com/s-JoL), but is now removed.
+
+## OpenLlamaConfig
+
+[[autodoc]] OpenLlamaConfig
+
+## OpenLlamaModel
+
+[[autodoc]] OpenLlamaModel
+ - forward
+
+## OpenLlamaForCausalLM
+
+[[autodoc]] OpenLlamaForCausalLM
+ - forward
+
+## OpenLlamaForSequenceClassification
+
+[[autodoc]] OpenLlamaForSequenceClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/openai-gpt.md b/docs/transformers/docs/source/en/model_doc/openai-gpt.md
new file mode 100644
index 0000000000000000000000000000000000000000..7c3affa4942a3252b0ae37eb38bba58d3eca7b97
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/openai-gpt.md
@@ -0,0 +1,136 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+# GPT
+
+[GPT (Generative Pre-trained Transformer)](https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf) focuses on effectively learning text representations and transferring them to tasks. This model trains the Transformer decoder to predict the next word, and then fine-tuned on labeled data.
+
+GPT can generate high-quality text, making it well-suited for a variety of natural language understanding tasks such as textual entailment, question answering, semantic similarity, and document classification.
+
+You can find all the original GPT checkpoints under the [OpenAI community](https://huggingface.co/openai-community/openai-gpt) organization.
+
+> [!TIP]
+> Click on the GPT models in the right sidebar for more examples of how to apply GPT to different language tasks.
+
+The example below demonstrates how to generate text with [`Pipeline`], [`AutoModel`], and from the command line.
+
+
+
+
+
+
+
+```python
+import torch
+from transformers import pipeline
+
+generator = pipeline(task="text-generation", model="openai-community/gpt", torch_dtype=torch.float16, device=0)
+output = generator("The future of AI is", max_length=50, do_sample=True)
+print(output[0]["generated_text"])
+```
+
+
+
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt")
+model = AutoModelForCausalLM.from_pretrained("openai-community/openai-gpt", torch_dtype=torch.float16)
+
+inputs = tokenizer("The future of AI is", return_tensors="pt")
+outputs = model.generate(**inputs, max_length=50)
+print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+```
+
+
+
+
+```bash
+echo -e "The future of AI is" | transformers-cli run --task text-generation --model openai-community/openai-gpt --device 0
+
+```
+
+
+
+## Notes
+
+- Inputs should be padded on the right because GPT uses absolute position embeddings.
+
+## OpenAIGPTConfig
+
+[[autodoc]] OpenAIGPTConfig
+
+## OpenAIGPTModel
+
+[[autodoc]] OpenAIGPTModel
+- forward
+
+## OpenAIGPTLMHeadModel
+
+[[autodoc]] OpenAIGPTLMHeadModel
+- forward
+
+## OpenAIGPTDoubleHeadsModel
+
+[[autodoc]] OpenAIGPTDoubleHeadsModel
+- forward
+
+## OpenAIGPTForSequenceClassification
+
+[[autodoc]] OpenAIGPTForSequenceClassification
+- forward
+
+## OpenAIGPTTokenizer
+
+[[autodoc]] OpenAIGPTTokenizer
+
+## OpenAIGPTTokenizerFast
+
+[[autodoc]] OpenAIGPTTokenizerFast
+
+## TFOpenAIGPTModel
+
+[[autodoc]] TFOpenAIGPTModel
+- call
+
+## TFOpenAIGPTLMHeadModel
+
+[[autodoc]] TFOpenAIGPTLMHeadModel
+- call
+
+## TFOpenAIGPTDoubleHeadsModel
+
+[[autodoc]] TFOpenAIGPTDoubleHeadsModel
+- call
+
+## TFOpenAIGPTForSequenceClassification
+
+[[autodoc]] TFOpenAIGPTForSequenceClassification
+- call
diff --git a/docs/transformers/docs/source/en/model_doc/opt.md b/docs/transformers/docs/source/en/model_doc/opt.md
new file mode 100644
index 0000000000000000000000000000000000000000..f6165e495393e4d0da1e59c0bc4c8266c97671ef
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/opt.md
@@ -0,0 +1,244 @@
+
+
+# OPT
+
+
+
+
+
+
+
+
+
+## Overview
+
+The OPT model was proposed in [Open Pre-trained Transformer Language Models](https://arxiv.org/pdf/2205.01068) by Meta AI.
+OPT is a series of open-sourced large causal language models which perform similar in performance to GPT3.
+
+The abstract from the paper is the following:
+
+*Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.*
+
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ), [Younes Belkada](https://huggingface.co/ybelkada), and [Patrick Von Platen](https://huggingface.co/patrickvonplaten).
+The original code can be found [here](https://github.com/facebookresearch/metaseq).
+
+Tips:
+- OPT has the same architecture as [`BartDecoder`].
+- Contrary to GPT2, OPT adds the EOS token `` to the beginning of every prompt.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OPT. If you're
+interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
+The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+- A notebook on [fine-tuning OPT with PEFT, bitsandbytes, and Transformers](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing). 🌎
+- A blog post on [decoding strategies with OPT](https://huggingface.co/blog/introducing-csearch#62-example-two---opt).
+- [Causal language modeling](https://huggingface.co/course/en/chapter7/6?fw=pt#training-a-causal-language-model-from-scratch) chapter of the 🤗 Hugging Face Course.
+- [`OPTForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
+- [`TFOPTForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_clmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
+- [`FlaxOPTForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#causal-language-modeling).
+
+
+
+- [Text classification task guide](sequence_classification.md)
+- [`OPTForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
+
+
+
+- [`OPTForQuestionAnswering`] is supported by this [question answering example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
+- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter
+ of the 🤗 Hugging Face Course.
+
+⚡️ Inference
+
+- A blog post on [How 🤗 Accelerate runs very large models thanks to PyTorch](https://huggingface.co/blog/accelerate-large-models) with OPT.
+
+
+## Combining OPT and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import OPTForCausalLM, GPT2Tokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
+>>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
+
+>>> prompt = ("A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the "
+ "Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived "
+ "there?")
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
+>>> tokenizer.batch_decode(generated_ids)[0]
+'A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived there?\nStatue: I have lived here for about a year.\nHuman: What is your favorite place to eat?\nStatue: I love'
+```
+
+### Expected speedups
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `facebook/opt-2.7b` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
+
+
+
+
+
+Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `facebook/opt-350m` checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
+
+
+
+## Overview
+
+OWLv2 was proposed in [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up [OWL-ViT](owlvit) using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
+
+The abstract from the paper is the following:
+
+*Open-vocabulary object detection has benefited greatly from pretrained vision-language models, but is still limited by the amount of available detection training data. While detection training data can be expanded by using Web image-text pairs as weak supervision, this has not been done at scales comparable to image-level pretraining. Here, we scale up detection data with self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. Major challenges in scaling self-training are the choice of label space, pseudo-annotation filtering, and training efficiency. We present the OWLv2 model and OWL-ST self-training recipe, which address these challenges. OWLv2 surpasses the performance of previous state-of-the-art open-vocabulary detectors already at comparable training scales (~10M examples). However, with OWL-ST, we can scale to over 1B examples, yielding further large improvement: With an L/14 architecture, OWL-ST improves AP on LVIS rare classes, for which the model has seen no human box annotations, from 31.2% to 44.6% (43% relative improvement). OWL-ST unlocks Web-scale training for open-world localization, similar to what has been seen for image classification and language modelling.*
+
+
+
+ OWLv2 high-level overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+
+## Usage example
+
+OWLv2 is, just like its predecessor [OWL-ViT](owlvit), a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
+
+[`Owlv2ImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`Owlv2Processor`] wraps [`Owlv2ImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`Owlv2Processor`] and [`Owlv2ForObjectDetection`].
+
+```python
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+
+>>> from transformers import Owlv2Processor, Owlv2ForObjectDetection
+
+>>> processor = Owlv2Processor.from_pretrained("google/owlv2-base-patch16-ensemble")
+>>> model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> text_labels = [["a photo of a cat", "a photo of a dog"]]
+>>> inputs = processor(text=text_labels, images=image, return_tensors="pt")
+>>> outputs = model(**inputs)
+
+>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
+>>> target_sizes = torch.tensor([(image.height, image.width)])
+>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
+>>> results = processor.post_process_grounded_object_detection(
+... outputs=outputs, target_sizes=target_sizes, threshold=0.1, text_labels=text_labels
+... )
+>>> # Retrieve predictions for the first image for the corresponding text queries
+>>> result = results[0]
+>>> boxes, scores, text_labels = result["boxes"], result["scores"], result["text_labels"]
+>>> for box, score, text_label in zip(boxes, scores, text_labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text_label} with confidence {round(score.item(), 3)} at location {box}")
+Detected a photo of a cat with confidence 0.614 at location [341.67, 23.39, 642.32, 371.35]
+Detected a photo of a cat with confidence 0.665 at location [6.75, 51.96, 326.62, 473.13]
+```
+
+## Resources
+
+- A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- [Zero-shot object detection task guide](../tasks/zero_shot_object_detection)
+
+
+
+The architecture of OWLv2 is identical to [OWL-ViT](owlvit), however the object detection head now also includes an objectness classifier, which predicts the (query-agnostic) likelihood that a predicted box contains an object (as opposed to background). The objectness score can be used to rank or filter predictions independently of text queries.
+Usage of OWLv2 is identical to [OWL-ViT](owlvit) with a new, updated image processor ([`Owlv2ImageProcessor`]).
+
+
+
+## Owlv2Config
+
+[[autodoc]] Owlv2Config
+ - from_text_vision_configs
+
+## Owlv2TextConfig
+
+[[autodoc]] Owlv2TextConfig
+
+## Owlv2VisionConfig
+
+[[autodoc]] Owlv2VisionConfig
+
+## Owlv2ImageProcessor
+
+[[autodoc]] Owlv2ImageProcessor
+ - preprocess
+ - post_process_object_detection
+ - post_process_image_guided_detection
+
+## Owlv2Processor
+
+[[autodoc]] Owlv2Processor
+ - __call__
+ - post_process_grounded_object_detection
+ - post_process_image_guided_detection
+
+## Owlv2Model
+
+[[autodoc]] Owlv2Model
+ - forward
+ - get_text_features
+ - get_image_features
+
+## Owlv2TextModel
+
+[[autodoc]] Owlv2TextModel
+ - forward
+
+## Owlv2VisionModel
+
+[[autodoc]] Owlv2VisionModel
+ - forward
+
+## Owlv2ForObjectDetection
+
+[[autodoc]] Owlv2ForObjectDetection
+ - forward
+ - image_guided_detection
diff --git a/docs/transformers/docs/source/en/model_doc/owlvit.md b/docs/transformers/docs/source/en/model_doc/owlvit.md
new file mode 100644
index 0000000000000000000000000000000000000000..bbcfe0de9f982171644c7d118bfa4d22577414f4
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/owlvit.md
@@ -0,0 +1,133 @@
+
+
+# OWL-ViT
+
+
+
+
+
+## Overview
+
+The OWL-ViT (short for Vision Transformer for Open-World Localization) was proposed in [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby. OWL-ViT is an open-vocabulary object detection network trained on a variety of (image, text) pairs. It can be used to query an image with one or multiple text queries to search for and detect target objects described in text.
+
+The abstract from the paper is the following:
+
+*Combining simple architectures with large-scale pre-training has led to massive improvements in image classification. For object detection, pre-training and scaling approaches are less well established, especially in the long-tailed and open-vocabulary setting, where training data is relatively scarce. In this paper, we propose a strong recipe for transferring image-text models to open-vocabulary object detection. We use a standard Vision Transformer architecture with minimal modifications, contrastive image-text pre-training, and end-to-end detection fine-tuning. Our analysis of the scaling properties of this setup shows that increasing image-level pre-training and model size yield consistent improvements on the downstream detection task. We provide the adaptation strategies and regularizations needed to attain very strong performance on zero-shot text-conditioned and one-shot image-conditioned object detection. Code and models are available on GitHub.*
+
+
+
+ OWL-ViT architecture. Taken from the original paper.
+
+This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+
+## Usage tips
+
+OWL-ViT is a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
+
+[`OwlViTImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`OwlViTProcessor`] wraps [`OwlViTImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`OwlViTProcessor`] and [`OwlViTForObjectDetection`].
+
+```python
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+
+>>> from transformers import OwlViTProcessor, OwlViTForObjectDetection
+
+>>> processor = OwlViTProcessor.from_pretrained("google/owlvit-base-patch32")
+>>> model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch32")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> text_labels = [["a photo of a cat", "a photo of a dog"]]
+>>> inputs = processor(text=text_labels, images=image, return_tensors="pt")
+>>> outputs = model(**inputs)
+
+>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
+>>> target_sizes = torch.tensor([(image.height, image.width)])
+>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
+>>> results = processor.post_process_grounded_object_detection(
+... outputs=outputs, target_sizes=target_sizes, threshold=0.1, text_labels=text_labels
+... )
+>>> # Retrieve predictions for the first image for the corresponding text queries
+>>> result = results[0]
+>>> boxes, scores, text_labels = result["boxes"], result["scores"], result["text_labels"]
+>>> for box, score, text_label in zip(boxes, scores, text_labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text_label} with confidence {round(score.item(), 3)} at location {box}")
+Detected a photo of a cat with confidence 0.707 at location [324.97, 20.44, 640.58, 373.29]
+Detected a photo of a cat with confidence 0.717 at location [1.46, 55.26, 315.55, 472.17]
+```
+
+## Resources
+
+A demo notebook on using OWL-ViT for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb).
+
+## OwlViTConfig
+
+[[autodoc]] OwlViTConfig
+ - from_text_vision_configs
+
+## OwlViTTextConfig
+
+[[autodoc]] OwlViTTextConfig
+
+## OwlViTVisionConfig
+
+[[autodoc]] OwlViTVisionConfig
+
+## OwlViTImageProcessor
+
+[[autodoc]] OwlViTImageProcessor
+ - preprocess
+
+## OwlViTImageProcessorFast
+
+[[autodoc]] OwlViTImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+ - post_process_image_guided_detection
+
+## OwlViTProcessor
+
+[[autodoc]] OwlViTProcessor
+ - __call__
+ - post_process_grounded_object_detection
+ - post_process_image_guided_detection
+
+## OwlViTModel
+
+[[autodoc]] OwlViTModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## OwlViTTextModel
+
+[[autodoc]] OwlViTTextModel
+ - forward
+
+## OwlViTVisionModel
+
+[[autodoc]] OwlViTVisionModel
+ - forward
+
+## OwlViTForObjectDetection
+
+[[autodoc]] OwlViTForObjectDetection
+ - forward
+ - image_guided_detection
diff --git a/docs/transformers/docs/source/en/model_doc/paligemma.md b/docs/transformers/docs/source/en/model_doc/paligemma.md
new file mode 100644
index 0000000000000000000000000000000000000000..fa119a5f8362e6c1cc9d31673d674e7688824b55
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/paligemma.md
@@ -0,0 +1,180 @@
+
+
+
+
+
+
+
+
+
+
+# PaliGemma
+
+[PaliGemma](https://huggingface.co/papers/2407.07726) is a family of vision-language models (VLMs), combining [SigLIP](./siglip) with the [Gemma](./gemma) 2B model. PaliGemma is available in 3B, 10B, and 28B parameters. The main purpose of PaliGemma is to provide an adaptable base VLM that is easy to transfer to other tasks. The SigLIP vision encoder is a "shape optimized" contrastively pretrained [ViT](./vit) that converts an image into a sequence of tokens and prepended to an optional prompt. The Gemma 2B model is used as the decoder. PaliGemma uses full attention on all image and text tokens to maximize its capacity.
+
+[PaliGemma 2](https://huggingface.co/papers/2412.03555) improves on the first model by using Gemma 2 (2B, 9B, and 27B parameter variants) as the decoder. These are available as **pt** or **mix** variants. The **pt** checkpoints are intended for further fine-tuning and the **mix** checkpoints are ready for use out of the box.
+
+You can find all the original PaliGemma checkpoints under the [PaliGemma](https://huggingface.co/collections/google/paligemma-release-6643a9ffbf57de2ae0448dda), [PaliGemma 2](https://huggingface.co/collections/google/paligemma-2-release-67500e1e1dbfdd4dee27ba48), and [PaliGemma 2 Mix](https://huggingface.co/collections/google/paligemma-2-mix-67ac6a251aaf3ee73679dcc4) collections.
+
+> [!TIP]
+> Click on the PaliGemma models in the right sidebar for more examples of how to apply PaliGemma to different vision and language tasks.
+
+The example below demonstrates how to generate text based on an image with [`Pipeline`] or the [`AutoModel`] class.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="image-text-to-text",
+ model="google/paligemma2-3b-mix-224",
+ device=0,
+ torch_dtype=torch.bfloat16
+)
+pipeline(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg",
+ text="What is in this image?"
+)
+```
+
+
+
+
+```py
+import torch
+import requests
+from PIL import Image
+from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
+
+model = PaliGemmaForConditionalGeneration.from_pretrained(
+ "google/paligemma2-3b-mix-224",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+processor = AutoProcessor.from_pretrained(
+ "google/paligemma2-3b-mix-224",
+)
+
+prompt = "What is in this image?"
+url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+image = Image.open(requests.get(url, stream=True).raw)
+inputs = processor(image, prompt, return_tensors="pt").to("cuda")
+
+output = model.generate(**inputs, max_new_tokens=50, cache_implementation="static")
+print(processor.decode(output[0], skip_special_tokens=True))
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [torchao](../quantization/torchao) to only quantize the weights to int4.
+
+```py
+# pip install torchao
+import torch
+import requests
+from PIL import Image
+from transformers import TorchAoConfig, AutoProcessor, PaliGemmaForConditionalGeneration
+
+quantization_config = TorchAoConfig("int4_weight_only", group_size=128)
+model = PaliGemmaForConditionalGeneration.from_pretrained(
+ "google/paligemma2-28b-mix-224",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ quantization_config=quantization_config
+)
+processor = AutoProcessor.from_pretrained(
+ "google/paligemma2-28b-mix-224",
+)
+
+prompt = "What is in this image?"
+url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+image = Image.open(requests.get(url, stream=True).raw)
+inputs = processor(image, prompt, return_tensors="pt").to("cuda")
+
+output = model.generate(**inputs, max_new_tokens=50, cache_implementation="static")
+print(processor.decode(output[0], skip_special_tokens=True))
+```
+
+Use the [AttentionMaskVisualizer](https://github.com/huggingface/transformers/blob/beb9b5b02246b9b7ee81ddf938f93f44cfeaad19/src/transformers/utils/attention_visualizer.py#L139) to better understand what tokens the model can and cannot attend to.
+
+```py
+from transformers.utils.attention_visualizer import AttentionMaskVisualizer
+
+visualizer = AttentionMaskVisualizer("google/paligemma2-3b-mix-224")
+visualizer(" What is in this image?")
+```
+
+
+
+
+
+## Notes
+
+- PaliGemma is not a conversational model and works best when fine-tuned for specific downstream tasks such as image captioning, visual question answering (VQA), object detection, and document understanding.
+- [`PaliGemmaProcessor`] can prepare images, text, and optional labels for the model. Pass the `suffix` parameter to the processor to create labels for the model during fine-tuning.
+
+ ```py
+ prompt = "What is in this image?"
+ answer = "a pallas cat"
+ inputs = processor(images=image, text=prompt, suffix=answer, return_tensors="pt")
+ ```
+- PaliGemma can support multiple input images if it is fine-tuned to accept multiple images. For example, the [NLVR2](https://huggingface.co/google/paligemma-3b-ft-nlvr2-448) checkpoint supports multiple images. Pass the images as a list to the processor.
+
+ ```py
+ import torch
+ import requests
+ from PIL import Image
+ from transformers import TorchAoConfig, AutoProcessor, PaliGemmaForConditionalGeneration
+
+ model = PaliGemmaForConditionalGeneration.from_pretrained("google/paligemma-3b-ft-nlvr2-448")
+ processor = AutoProcessor.from_pretrained("google/paligemma-3b-ft-nlvr2-448")
+
+ prompt = "Are these two images the same?"
+ cat_image = Image.open(
+ requests.get("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg", stream=True).raw
+ )
+ cow_image = Image.open(
+ requests.get(
+ "https://media.istockphoto.com/id/1192867753/photo/cow-in-berchida-beach-siniscola.jpg?s=612x612&w=0&k=20&c=v0hjjniwsMNfJSuKWZuIn8pssmD5h5bSN1peBd1CmH4=", stream=True
+ ).raw
+ )
+
+ inputs = processor(images=[[cat_image, cow_image]], text=prompt, return_tensors="pt")
+
+ output = model.generate(**inputs, max_new_tokens=20, cache_implementation="static")
+ print(processor.decode(output[0], skip_special_tokens=True))
+ ```
+
+## PaliGemmaConfig
+
+[[autodoc]] PaliGemmaConfig
+
+## PaliGemmaProcessor
+
+[[autodoc]] PaliGemmaProcessor
+
+## PaliGemmaForConditionalGeneration
+
+[[autodoc]] PaliGemmaForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/patchtsmixer.md b/docs/transformers/docs/source/en/model_doc/patchtsmixer.md
new file mode 100644
index 0000000000000000000000000000000000000000..dd678dd401013b210ed57b64ee1c7e0121aa775b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/patchtsmixer.md
@@ -0,0 +1,98 @@
+
+
+# PatchTSMixer
+
+
+
+
+
+## Overview
+
+The PatchTSMixer model was proposed in [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) by Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
+
+
+PatchTSMixer is a lightweight time-series modeling approach based on the MLP-Mixer architecture. In this HuggingFace implementation, we provide PatchTSMixer's capabilities to effortlessly facilitate lightweight mixing across patches, channels, and hidden features for effective multivariate time-series modeling. It also supports various attention mechanisms starting from simple gated attention to more complex self-attention blocks that can be customized accordingly. The model can be pretrained and subsequently used for various downstream tasks such as forecasting, classification and regression.
+
+
+The abstract from the paper is the following:
+
+*TSMixer is a lightweight neural architecture exclusively composed of multi-layer perceptron (MLP) modules designed for multivariate forecasting and representation learning on patched time series. Our model draws inspiration from the success of MLP-Mixer models in computer vision. We demonstrate the challenges involved in adapting Vision MLP-Mixer for time series and introduce empirically validated components to enhance accuracy. This includes a novel design paradigm of attaching online reconciliation heads to the MLP-Mixer backbone, for explicitly modeling the time-series properties such as hierarchy and channel-correlations. We also propose a Hybrid channel modeling approach to effectively handle noisy channel interactions and generalization across diverse datasets, a common challenge in existing patch channel-mixing methods. Additionally, a simple gated attention mechanism is introduced in the backbone to prioritize important features. By incorporating these lightweight components, we significantly enhance the learning capability of simple MLP structures, outperforming complex Transformer models with minimal computing usage. Moreover, TSMixer's modular design enables compatibility with both supervised and masked self-supervised learning methods, making it a promising building block for time-series Foundation Models. TSMixer outperforms state-of-the-art MLP and Transformer models in forecasting by a considerable margin of 8-60%. It also outperforms the latest strong benchmarks of Patch-Transformer models (by 1-2%) with a significant reduction in memory and runtime (2-3X).*
+
+This model was contributed by [ajati](https://huggingface.co/ajati), [vijaye12](https://huggingface.co/vijaye12),
+[gsinthong](https://huggingface.co/gsinthong), [namctin](https://huggingface.co/namctin),
+[wmgifford](https://huggingface.co/wmgifford), [kashif](https://huggingface.co/kashif).
+
+## Usage example
+
+The code snippet below shows how to randomly initialize a PatchTSMixer model. The model is compatible with the [Trainer API](../trainer.md).
+
+```python
+
+from transformers import PatchTSMixerConfig, PatchTSMixerForPrediction
+from transformers import Trainer, TrainingArguments,
+
+
+config = PatchTSMixerConfig(context_length = 512, prediction_length = 96)
+model = PatchTSMixerForPrediction(config)
+trainer = Trainer(model=model, args=training_args,
+ train_dataset=train_dataset,
+ eval_dataset=valid_dataset)
+trainer.train()
+results = trainer.evaluate(test_dataset)
+```
+
+## Usage tips
+
+The model can also be used for time series classification and time series regression. See the respective [`PatchTSMixerForTimeSeriesClassification`] and [`PatchTSMixerForRegression`] classes.
+
+## Resources
+
+- A blog post explaining PatchTSMixer in depth can be found [here](https://huggingface.co/blog/patchtsmixer). The blog can also be opened in Google Colab.
+
+## PatchTSMixerConfig
+
+[[autodoc]] PatchTSMixerConfig
+
+
+## PatchTSMixerModel
+
+[[autodoc]] PatchTSMixerModel
+ - forward
+
+
+## PatchTSMixerForPrediction
+
+[[autodoc]] PatchTSMixerForPrediction
+ - forward
+
+
+## PatchTSMixerForTimeSeriesClassification
+
+[[autodoc]] PatchTSMixerForTimeSeriesClassification
+ - forward
+
+
+## PatchTSMixerForPretraining
+
+[[autodoc]] PatchTSMixerForPretraining
+ - forward
+
+
+## PatchTSMixerForRegression
+
+[[autodoc]] PatchTSMixerForRegression
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/patchtst.md b/docs/transformers/docs/source/en/model_doc/patchtst.md
new file mode 100644
index 0000000000000000000000000000000000000000..c55ba333429906e11d09ba1b7627fa151833e7c4
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/patchtst.md
@@ -0,0 +1,72 @@
+
+
+# PatchTST
+
+
+
+
+
+## Overview
+
+The PatchTST model was proposed in [A Time Series is Worth 64 Words: Long-term Forecasting with Transformers](https://arxiv.org/abs/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
+
+At a high level the model vectorizes time series into patches of a given size and encodes the resulting sequence of vectors via a Transformer that then outputs the prediction length forecast via an appropriate head. The model is illustrated in the following figure:
+
+
+
+The abstract from the paper is the following:
+
+*We propose an efficient design of Transformer-based models for multivariate time series forecasting and self-supervised representation learning. It is based on two key components: (i) segmentation of time series into subseries-level patches which are served as input tokens to Transformer; (ii) channel-independence where each channel contains a single univariate time series that shares the same embedding and Transformer weights across all the series. Patching design naturally has three-fold benefit: local semantic information is retained in the embedding; computation and memory usage of the attention maps are quadratically reduced given the same look-back window; and the model can attend longer history. Our channel-independent patch time series Transformer (PatchTST) can improve the long-term forecasting accuracy significantly when compared with that of SOTA Transformer-based models. We also apply our model to self-supervised pre-training tasks and attain excellent fine-tuning performance, which outperforms supervised training on large datasets. Transferring of masked pre-trained representation on one dataset to others also produces SOTA forecasting accuracy.*
+
+This model was contributed by [namctin](https://huggingface.co/namctin), [gsinthong](https://huggingface.co/gsinthong), [diepi](https://huggingface.co/diepi), [vijaye12](https://huggingface.co/vijaye12), [wmgifford](https://huggingface.co/wmgifford), and [kashif](https://huggingface.co/kashif). The original code can be found [here](https://github.com/yuqinie98/PatchTST).
+
+## Usage tips
+
+The model can also be used for time series classification and time series regression. See the respective [`PatchTSTForClassification`] and [`PatchTSTForRegression`] classes.
+
+## Resources
+
+- A blog post explaining PatchTST in depth can be found [here](https://huggingface.co/blog/patchtst). The blog can also be opened in Google Colab.
+
+## PatchTSTConfig
+
+[[autodoc]] PatchTSTConfig
+
+## PatchTSTModel
+
+[[autodoc]] PatchTSTModel
+ - forward
+
+## PatchTSTForPrediction
+
+[[autodoc]] PatchTSTForPrediction
+ - forward
+
+## PatchTSTForClassification
+
+[[autodoc]] PatchTSTForClassification
+ - forward
+
+## PatchTSTForPretraining
+
+[[autodoc]] PatchTSTForPretraining
+ - forward
+
+## PatchTSTForRegression
+
+[[autodoc]] PatchTSTForRegression
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/pegasus.md b/docs/transformers/docs/source/en/model_doc/pegasus.md
new file mode 100644
index 0000000000000000000000000000000000000000..bdb61e66d98404027a79acbc934e93788bfc9350
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/pegasus.md
@@ -0,0 +1,168 @@
+
+
+# Pegasus
+
+
+
+
+
+
+
+## Overview
+
+The Pegasus model was proposed in [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/pdf/1912.08777.pdf) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu on Dec 18, 2019.
+
+According to the abstract,
+
+- Pegasus' pretraining task is intentionally similar to summarization: important sentences are removed/masked from an
+ input document and are generated together as one output sequence from the remaining sentences, similar to an
+ extractive summary.
+- Pegasus achieves SOTA summarization performance on all 12 downstream tasks, as measured by ROUGE and human eval.
+
+This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The Authors' code can be found [here](https://github.com/google-research/pegasus).
+
+## Usage tips
+
+- Sequence-to-sequence model with the same encoder-decoder model architecture as BART. Pegasus is pre-trained jointly on two self-supervised objective functions: Masked Language Modeling (MLM) and a novel summarization specific pretraining objective, called Gap Sentence Generation (GSG).
+
+ * MLM: encoder input tokens are randomly replaced by a mask tokens and have to be predicted by the encoder (like in BERT)
+ * GSG: whole encoder input sentences are replaced by a second mask token and fed to the decoder, but which has a causal mask to hide the future words like a regular auto-regressive transformer decoder.
+
+- FP16 is not supported (help/ideas on this appreciated!).
+- The adafactor optimizer is recommended for pegasus fine-tuning.
+
+
+## Checkpoints
+
+All the [checkpoints](https://huggingface.co/models?search=pegasus) are fine-tuned for summarization, besides
+*pegasus-large*, whence the other checkpoints are fine-tuned:
+
+- Each checkpoint is 2.2 GB on disk and 568M parameters.
+- FP16 is not supported (help/ideas on this appreciated!).
+- Summarizing xsum in fp32 takes about 400ms/sample, with default parameters on a v100 GPU.
+- Full replication results and correctly pre-processed data can be found in this [Issue](https://github.com/huggingface/transformers/issues/6844#issue-689259666).
+- [Distilled checkpoints](https://huggingface.co/models?search=distill-pegasus) are described in this [paper](https://arxiv.org/abs/2010.13002).
+
+## Implementation Notes
+
+- All models are transformer encoder-decoders with 16 layers in each component.
+- The implementation is completely inherited from [`BartForConditionalGeneration`]
+- Some key configuration differences:
+ - static, sinusoidal position embeddings
+ - the model starts generating with pad_token_id (which has 0 token_embedding) as the prefix.
+ - more beams are used (`num_beams=8`)
+- All pretrained pegasus checkpoints are the same besides three attributes: `tokenizer.model_max_length` (maximum
+ input size), `max_length` (the maximum number of tokens to generate) and `length_penalty`.
+- The code to convert checkpoints trained in the author's [repo](https://github.com/google-research/pegasus) can be
+ found in `convert_pegasus_tf_to_pytorch.py`.
+
+## Usage Example
+
+```python
+>>> from transformers import PegasusForConditionalGeneration, PegasusTokenizer
+>>> import torch
+
+>>> src_text = [
+... """ PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."""
+... ]
+
+... model_name = "google/pegasus-xsum"
+... device = "cuda" if torch.cuda.is_available() else "cpu"
+... tokenizer = PegasusTokenizer.from_pretrained(model_name)
+... model = PegasusForConditionalGeneration.from_pretrained(model_name).to(device)
+... batch = tokenizer(src_text, truncation=True, padding="longest", return_tensors="pt").to(device)
+... translated = model.generate(**batch)
+... tgt_text = tokenizer.batch_decode(translated, skip_special_tokens=True)
+... assert (
+... tgt_text[0]
+... == "California's largest electricity provider has turned off power to hundreds of thousands of customers."
+... )
+```
+
+## Resources
+
+- [Script](https://github.com/huggingface/transformers-research-projects/tree/main/seq2seq-distillation/finetune_pegasus_xsum.sh) to fine-tune pegasus
+ on the XSUM dataset. Data download instructions at [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## PegasusConfig
+
+[[autodoc]] PegasusConfig
+
+## PegasusTokenizer
+
+warning: `add_tokens` does not work at the moment.
+
+[[autodoc]] PegasusTokenizer
+
+## PegasusTokenizerFast
+
+[[autodoc]] PegasusTokenizerFast
+
+
+
+
+## PegasusModel
+
+[[autodoc]] PegasusModel
+ - forward
+
+## PegasusForConditionalGeneration
+
+[[autodoc]] PegasusForConditionalGeneration
+ - forward
+
+## PegasusForCausalLM
+
+[[autodoc]] PegasusForCausalLM
+ - forward
+
+
+
+
+## TFPegasusModel
+
+[[autodoc]] TFPegasusModel
+ - call
+
+## TFPegasusForConditionalGeneration
+
+[[autodoc]] TFPegasusForConditionalGeneration
+ - call
+
+
+
+
+## FlaxPegasusModel
+
+[[autodoc]] FlaxPegasusModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxPegasusForConditionalGeneration
+
+[[autodoc]] FlaxPegasusForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/pegasus_x.md b/docs/transformers/docs/source/en/model_doc/pegasus_x.md
new file mode 100644
index 0000000000000000000000000000000000000000..3f982263cdb1c50963c97ddbd588080e3218a696
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/pegasus_x.md
@@ -0,0 +1,58 @@
+
+
+# PEGASUS-X
+
+
+
+
+
+## Overview
+
+The PEGASUS-X model was proposed in [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao and Peter J. Liu.
+
+PEGASUS-X (PEGASUS eXtended) extends the PEGASUS models for long input summarization through additional long input pretraining and using staggered block-local attention with global tokens in the encoder.
+
+The abstract from the paper is the following:
+
+*While large pretrained Transformer models have proven highly capable at tackling natural language tasks, handling long sequence inputs continues to be a significant challenge. One such task is long input summarization, where inputs are longer than the maximum input context of most pretrained models. Through an extensive set of experiments, we investigate what model architectural changes and pretraining paradigms can most efficiently adapt a pretrained Transformer for long input summarization. We find that a staggered, block-local Transformer with global encoder tokens strikes a good balance of performance and efficiency, and that an additional pretraining phase on long sequences meaningfully improves downstream summarization performance. Based on our findings, we introduce PEGASUS-X, an extension of the PEGASUS model with additional long input pretraining to handle inputs of up to 16K tokens. PEGASUS-X achieves strong performance on long input summarization tasks comparable with much larger models while adding few additional parameters and not requiring model parallelism to train.*
+
+This model was contributed by [zphang](https://huggingface.co/zphang). The original code can be found [here](https://github.com/google-research/pegasus).
+
+## Documentation resources
+
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+
+
+PEGASUS-X uses the same tokenizer as [PEGASUS](pegasus).
+
+
+
+## PegasusXConfig
+
+[[autodoc]] PegasusXConfig
+
+## PegasusXModel
+
+[[autodoc]] PegasusXModel
+ - forward
+
+## PegasusXForConditionalGeneration
+
+[[autodoc]] PegasusXForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/perceiver.md b/docs/transformers/docs/source/en/model_doc/perceiver.md
new file mode 100644
index 0000000000000000000000000000000000000000..629f1859531fb699bd5491092abab293590a66ee
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/perceiver.md
@@ -0,0 +1,238 @@
+
+
+# Perceiver
+
+
+
+
+
+## Overview
+
+The Perceiver IO model was proposed in [Perceiver IO: A General Architecture for Structured Inputs &
+Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch,
+Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M.
+Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+
+Perceiver IO is a generalization of [Perceiver](https://arxiv.org/abs/2103.03206) to handle arbitrary outputs in
+addition to arbitrary inputs. The original Perceiver only produced a single classification label. In addition to
+classification labels, Perceiver IO can produce (for example) language, optical flow, and multimodal videos with audio.
+This is done using the same building blocks as the original Perceiver. The computational complexity of Perceiver IO is
+linear in the input and output size and the bulk of the processing occurs in the latent space, allowing us to process
+inputs and outputs that are much larger than can be handled by standard Transformers. This means, for example,
+Perceiver IO can do BERT-style masked language modeling directly using bytes instead of tokenized inputs.
+
+The abstract from the paper is the following:
+
+*The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point
+clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of
+inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without
+sacrificing the original's appealing properties by learning to flexibly query the model's latent space to produce
+outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales
+linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves
+strong results on tasks with highly structured output spaces, such as natural language and visual understanding,
+StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT
+baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art
+performance on Sintel optical flow estimation.*
+
+Here's a TLDR explaining how Perceiver works:
+
+The main problem with the self-attention mechanism of the Transformer is that the time and memory requirements scale
+quadratically with the sequence length. Hence, models like BERT and RoBERTa are limited to a max sequence length of 512
+tokens. Perceiver aims to solve this issue by, instead of performing self-attention on the inputs, perform it on a set
+of latent variables, and only use the inputs for cross-attention. In this way, the time and memory requirements don't
+depend on the length of the inputs anymore, as one uses a fixed amount of latent variables, like 256 or 512. These are
+randomly initialized, after which they are trained end-to-end using backpropagation.
+
+Internally, [`PerceiverModel`] will create the latents, which is a tensor of shape `(batch_size, num_latents,
+d_latents)`. One must provide `inputs` (which could be text, images, audio, you name it!) to the model, which it will
+use to perform cross-attention with the latents. The output of the Perceiver encoder is a tensor of the same shape. One
+can then, similar to BERT, convert the last hidden states of the latents to classification logits by averaging along
+the sequence dimension, and placing a linear layer on top of that to project the `d_latents` to `num_labels`.
+
+This was the idea of the original Perceiver paper. However, it could only output classification logits. In a follow-up
+work, PerceiverIO, they generalized it to let the model also produce outputs of arbitrary size. How, you might ask? The
+idea is actually relatively simple: one defines outputs of an arbitrary size, and then applies cross-attention with the
+last hidden states of the latents, using the outputs as queries, and the latents as keys and values.
+
+So let's say one wants to perform masked language modeling (BERT-style) with the Perceiver. As the Perceiver's input
+length will not have an impact on the computation time of the self-attention layers, one can provide raw bytes,
+providing `inputs` of length 2048 to the model. If one now masks out certain of these 2048 tokens, one can define the
+`outputs` as being of shape: `(batch_size, 2048, 768)`. Next, one performs cross-attention with the final hidden states
+of the latents to update the `outputs` tensor. After cross-attention, one still has a tensor of shape `(batch_size,
+2048, 768)`. One can then place a regular language modeling head on top, to project the last dimension to the
+vocabulary size of the model, i.e. creating logits of shape `(batch_size, 2048, 262)` (as Perceiver uses a vocabulary
+size of 262 byte IDs).
+
+
+
+ Perceiver IO architecture. Taken from the original paper
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
+
+
+
+Perceiver does **not** work with `torch.nn.DataParallel` due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
+
+
+
+## Resources
+
+- The quickest way to get started with the Perceiver is by checking the [tutorial
+ notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Perceiver).
+- Refer to the [blog post](https://huggingface.co/blog/perceiver) if you want to fully understand how the model works and
+is implemented in the library. Note that the models available in the library only showcase some examples of what you can do
+with the Perceiver. There are many more use cases, including question answering, named-entity recognition, object detection,
+audio classification, video classification, etc.
+- [Text classification task guide](../tasks/sequence_classification)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Image classification task guide](../tasks/image_classification)
+
+## Perceiver specific outputs
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverModelOutput
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverDecoderOutput
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMaskedLMOutput
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassifierOutput
+
+## PerceiverConfig
+
+[[autodoc]] PerceiverConfig
+
+## PerceiverTokenizer
+
+[[autodoc]] PerceiverTokenizer
+ - __call__
+
+## PerceiverFeatureExtractor
+
+[[autodoc]] PerceiverFeatureExtractor
+ - __call__
+
+## PerceiverImageProcessor
+
+[[autodoc]] PerceiverImageProcessor
+ - preprocess
+
+## PerceiverImageProcessorFast
+
+[[autodoc]] PerceiverImageProcessorFast
+ - preprocess
+
+## PerceiverTextPreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverTextPreprocessor
+
+## PerceiverImagePreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverImagePreprocessor
+
+## PerceiverOneHotPreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverOneHotPreprocessor
+
+## PerceiverAudioPreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverAudioPreprocessor
+
+## PerceiverMultimodalPreprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalPreprocessor
+
+## PerceiverProjectionDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverProjectionDecoder
+
+## PerceiverBasicDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverBasicDecoder
+
+## PerceiverClassificationDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassificationDecoder
+
+## PerceiverOpticalFlowDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverOpticalFlowDecoder
+
+## PerceiverBasicVideoAutoencodingDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverBasicVideoAutoencodingDecoder
+
+## PerceiverMultimodalDecoder
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalDecoder
+
+## PerceiverProjectionPostprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverProjectionPostprocessor
+
+## PerceiverAudioPostprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverAudioPostprocessor
+
+## PerceiverClassificationPostprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverClassificationPostprocessor
+
+## PerceiverMultimodalPostprocessor
+
+[[autodoc]] models.perceiver.modeling_perceiver.PerceiverMultimodalPostprocessor
+
+## PerceiverModel
+
+[[autodoc]] PerceiverModel
+ - forward
+
+## PerceiverForMaskedLM
+
+[[autodoc]] PerceiverForMaskedLM
+ - forward
+
+## PerceiverForSequenceClassification
+
+[[autodoc]] PerceiverForSequenceClassification
+ - forward
+
+## PerceiverForImageClassificationLearned
+
+[[autodoc]] PerceiverForImageClassificationLearned
+ - forward
+
+## PerceiverForImageClassificationFourier
+
+[[autodoc]] PerceiverForImageClassificationFourier
+ - forward
+
+## PerceiverForImageClassificationConvProcessing
+
+[[autodoc]] PerceiverForImageClassificationConvProcessing
+ - forward
+
+## PerceiverForOpticalFlow
+
+[[autodoc]] PerceiverForOpticalFlow
+ - forward
+
+## PerceiverForMultimodalAutoencoding
+
+[[autodoc]] PerceiverForMultimodalAutoencoding
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/persimmon.md b/docs/transformers/docs/source/en/model_doc/persimmon.md
new file mode 100644
index 0000000000000000000000000000000000000000..bf721f19a107eb042138e1e81577064e04304b80
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/persimmon.md
@@ -0,0 +1,107 @@
+
+
+# Persimmon
+
+
+
+
+
+## Overview
+
+The Persimmon model was created by [ADEPT](https://www.adept.ai/blog/persimmon-8b), and authored by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
+
+The authors introduced Persimmon-8B, a decoder model based on the classic transformers architecture, with query and key normalization. Persimmon-8B is a fully permissively-licensed model with approximately 8 billion parameters, released under the Apache license. Some of the key attributes of Persimmon-8B are long context size (16K), performance, and capabilities for multimodal extensions.
+
+The authors showcase their approach to model evaluation, focusing on practical text generation, mirroring how users interact with language models. The work also includes a comparative analysis, pitting Persimmon-8B against other prominent models (MPT 7B Instruct and Llama 2 Base 7B 1-Shot), across various evaluation tasks. The results demonstrate Persimmon-8B's competitive performance, even with limited training data.
+
+In terms of model details, the work outlines the architecture and training methodology of Persimmon-8B, providing insights into its design choices, sequence length, and dataset composition. The authors present a fast inference code that outperforms traditional implementations through operator fusion and CUDA graph utilization while maintaining code coherence. They express their anticipation of how the community will leverage this contribution to drive innovation, hinting at further upcoming releases as part of an ongoing series of developments.
+
+This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/persimmon-ai-labs/adept-inference).
+
+## Usage tips
+
+
+
+The `Persimmon` models were trained using `bfloat16`, but the original inference uses `float16` The checkpoints uploaded on the hub use `torch_dtype = 'float16'` which will be
+used by the `AutoModel` API to cast the checkpoints from `torch.float32` to `torch.float16`.
+
+The `dtype` of the online weights is mostly irrelevant, unless you are using `torch_dtype="auto"` when initializing a model using `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`. The reason is that the model will first be downloaded ( using the `dtype` of the checkpoints online) then it will be cast to the default `dtype` of `torch` (becomes `torch.float32`). Users should specify the `torch_dtype` they want, and if they don't it will be `torch.float32`.
+
+Finetuning the model in `float16` is not recommended and known to produce `nan`, as such the model should be fine-tuned in `bfloat16`.
+
+
+
+
+Tips:
+
+- To convert the model, you need to clone the original repository using `git clone https://github.com/persimmon-ai-labs/adept-inference`, then get the checkpoints:
+
+```bash
+git clone https://github.com/persimmon-ai-labs/adept-inference
+wget https://axtkn4xl5cip.objectstorage.us-phoenix-1.oci.customer-oci.com/n/axtkn4xl5cip/b/adept-public-data/o/8b_base_model_release.tar
+tar -xvf 8b_base_model_release.tar
+python src/transformers/models/persimmon/convert_persimmon_weights_to_hf.py --input_dir /path/to/downloaded/persimmon/weights/ --output_dir /output/path \
+ --pt_model_path /path/to/8b_chat_model_release/iter_0001251/mp_rank_00/model_optim_rng.pt
+ --ada_lib_path /path/to/adept-inference
+```
+
+For the chat model:
+```bash
+wget https://axtkn4xl5cip.objectstorage.us-phoenix-1.oci.customer-oci.com/n/axtkn4xl5cip/b/adept-public-data/o/8b_chat_model_release.tar
+tar -xvf 8b_base_model_release.tar
+```
+
+Thereafter, models can be loaded via:
+
+```py
+from transformers import PersimmonForCausalLM, PersimmonTokenizer
+
+model = PersimmonForCausalLM.from_pretrained("/output/path")
+tokenizer = PersimmonTokenizer.from_pretrained("/output/path")
+```
+
+
+- Perismmon uses a `sentencepiece` based tokenizer, with a `Unigram` model. It supports bytefallback, which is only available in `tokenizers==0.14.0` for the fast tokenizer.
+The `LlamaTokenizer` is used as it is a standard wrapper around sentencepiece. The `chat` template will be updated with the templating functions in a follow up PR!
+
+- The authors suggest to use the following prompt format for the chat mode: `f"human: {prompt}\n\nadept:"`
+
+
+## PersimmonConfig
+
+[[autodoc]] PersimmonConfig
+
+## PersimmonModel
+
+[[autodoc]] PersimmonModel
+ - forward
+
+## PersimmonForCausalLM
+
+[[autodoc]] PersimmonForCausalLM
+ - forward
+
+## PersimmonForSequenceClassification
+
+[[autodoc]] PersimmonForSequenceClassification
+ - forward
+
+## PersimmonForTokenClassification
+
+[[autodoc]] PersimmonForTokenClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/phi.md b/docs/transformers/docs/source/en/model_doc/phi.md
new file mode 100644
index 0000000000000000000000000000000000000000..37db41bae0ac8c763a4a23e0ca1bb34d9926547c
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/phi.md
@@ -0,0 +1,146 @@
+
+
+
+
+
+
+
+
+
+# Phi
+
+[Phi](https://huggingface.co/papers/2306.11644) is a 1.3B parameter transformer model optimized for Python code generation. It focuses on "textbook-quality" training data of code examples, exercises and synthetic Python problems rather than scaling the model size or compute.
+
+You can find all the original Phi checkpoints under the [Phi-1](https://huggingface.co/collections/microsoft/phi-1-6626e29134744e94e222d572) collection.
+
+> [!TIP]
+> Click on the Phi models in the right sidebar for more examples of how to apply Phi to different language tasks.
+
+The example below demonstrates how to generate text with [`Pipeline`], [`AutoModel`] and from the command line.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(task="text-generation", model="microsoft/phi-1.5", device=0, torch_dtype=torch.bfloat16)
+pipeline("pipeline('''def print_prime(n): """ Print all primes between 1 and n"""''')")
+
+```
+
+
+
+
+
+```py
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1")
+model = AutoModelForCausalLM.from_pretrained("microsoft/phi-1", torch_dtype=torch.float16, device_map="auto", attn_implementation="sdpa")
+
+input_ids = tokenizer('''def print_prime(n):
+ """
+ Print all primes between 1 and n
+ """''', return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+
+
+
+```bash
+echo -e "'''def print_prime(n): """ Print all primes between 1 and n"""'''" | transformers-cli run --task text-classification --model microsoft/phi-1.5 --device 0
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](https://huggingface.co/docs/transformers/en/quantization/bitsandbytes) to only quantize the weights to 4-bits.
+
+```py
+import torch
+from transformers import BitsAndBytesConfig, AutoTokenizer, AutoModelForCausalLM
+
+bnb_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16, bnb_4bit_quant_type="nf4", bnb_4bit_use_double_quant=True)
+tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1")
+model = AutoModelForCausalLM.from_pretrained("microsoft/phi-1", torch_dtype=torch.float16, device_map="auto", attn_implementation="sdpa", quantization_config=bnb_config)
+
+input_ids = tokenizer('''def print_prime(n):
+ """
+ Print all primes between 1 and n
+ """''', return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+## Notes
+
+- If you're using Transformers < 4.37.0.dev, set `trust_remote_code=True` in [`~AutoModel.from_pretrained`]. Otherwise, make sure you update Transformers to the latest stable version.
+
+ ```py
+ import torch
+ from transformers import AutoTokenizer, AutoModelForCausalLM
+
+ tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1")
+ model = AutoModelForCausalLM.from_pretrained(
+ "microsoft/phi-1",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ trust_remote_code=True,
+ attn_implementation="sdpa")
+
+ input_ids = tokenizer('''def print_prime(n):
+ """
+ Print all primes between 1 and n
+ """''', return_tensors="pt").to("cuda")
+
+ output = model.generate(**input_ids, cache_implementation="static")
+ print(tokenizer.decode(output[0], skip_special_tokens=True))
+ ```
+
+## PhiConfig
+
+[[autodoc]] PhiConfig
+
+## PhiModel
+
+[[autodoc]] PhiModel
+ - forward
+
+## PhiForCausalLM
+
+[[autodoc]] PhiForCausalLM
+ - forward
+ - generate
+
+## PhiForSequenceClassification
+
+[[autodoc]] PhiForSequenceClassification
+ - forward
+
+## PhiForTokenClassification
+
+[[autodoc]] PhiForTokenClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/phi3.md b/docs/transformers/docs/source/en/model_doc/phi3.md
new file mode 100644
index 0000000000000000000000000000000000000000..82973d39c07b6aaeda5db5465d20adf52a01099e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/phi3.md
@@ -0,0 +1,98 @@
+
+
+# Phi-3
+
+
+
+
+
+
+
+## Overview
+
+The Phi-3 model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/abs/2404.14219) by Microsoft.
+
+### Summary
+
+The abstract from the Phi-3 paper is the following:
+
+We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
+
+The original code for Phi-3 can be found [here](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct).
+
+## Usage tips
+
+- This model is very similar to `Llama` with the main difference of [`Phi3SuScaledRotaryEmbedding`] and [`Phi3YarnScaledRotaryEmbedding`], where they are used to extend the context of the rotary embeddings. The query, key and values are fused, and the MLP's up and gate projection layers are also fused.
+- The tokenizer used for this model is identical to the [`LlamaTokenizer`], with the exception of additional tokens.
+
+## How to use Phi-3
+
+
+
+Phi-3 has been integrated in the development version (4.40.0.dev) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
+
+* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
+
+* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
+
+
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
+>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
+
+>>> messages = [{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"}]
+>>> inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
+
+>>> outputs = model.generate(inputs, max_new_tokens=32)
+>>> text = tokenizer.batch_decode(outputs)[0]
+>>> print(text)
+<|user|> Can you provide ways to eat combinations of bananas and dragonfruits?<|end|><|assistant|> Certainly! Bananas and dragonfruits can be combined in various delicious ways. Here are some creative ideas for incorporating both fruits
+```
+
+## Phi3Config
+
+[[autodoc]] Phi3Config
+
+
+
+
+## Phi3Model
+
+[[autodoc]] Phi3Model
+ - forward
+
+## Phi3ForCausalLM
+
+[[autodoc]] Phi3ForCausalLM
+ - forward
+ - generate
+
+## Phi3ForSequenceClassification
+
+[[autodoc]] Phi3ForSequenceClassification
+ - forward
+
+## Phi3ForTokenClassification
+
+[[autodoc]] Phi3ForTokenClassification
+ - forward
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/phi4_multimodal.md b/docs/transformers/docs/source/en/model_doc/phi4_multimodal.md
new file mode 100644
index 0000000000000000000000000000000000000000..22b55792f60ad73c8d93a5ac19615a021d05a997
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/phi4_multimodal.md
@@ -0,0 +1,155 @@
+
+
+# Phi4 Multimodal
+
+## Overview
+
+Phi4 Multimodal is a lightweight open multimodal foundation model that leverages the language, vision, and speech research and datasets used for Phi-3.5 and 4.0 models. The model processes text, image, and audio inputs, generating text outputs, and comes with 128K token context length. The model underwent an enhancement process, incorporating both supervised fine-tuning, direct preference optimization and RLHF (Reinforcement Learning from Human Feedback) to support precise instruction adherence and safety measures. The languages that each modal supports are the following:
+
+- Text: Arabic, Chinese, Czech, Danish, Dutch, English, Finnish, French, German, Hebrew, Hungarian, Italian, Japanese, Korean, Norwegian, Polish, Portuguese, Russian, Spanish, Swedish, Thai, Turkish, Ukrainian
+- Vision: English
+- Audio: English, Chinese, German, French, Italian, Japanese, Spanish, Portuguese
+
+This model was contributed by [Cyril Vallez](https://huggingface.co/cyrilvallez). The most recent code can be
+found [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/phi4_multimodal/modeling_phi4_multimodal.py).
+
+
+## Usage tips
+
+`Phi4-multimodal-instruct` can be found on the [Huggingface Hub](https://huggingface.co/microsoft/Phi-4-multimodal-instruct)
+
+In the following, we demonstrate how to use it for inference depending on the input modalities (text, image, audio).
+
+```python
+import torch
+from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
+
+
+# Define model path
+model_path = "microsoft/Phi-4-multimodal-instruct"
+device = "cuda:0"
+
+# Load model and processor
+processor = AutoProcessor.from_pretrained(model_path)
+model = AutoModelForCausalLM.from_pretrained(model_path, device_map=device, torch_dtype=torch.float16)
+
+# Optional: load the adapters (note that without them, the base model will very likely not work well)
+model.load_adapter(model_path, adapter_name="speech", device_map=device, adapter_kwargs={"subfolder": 'speech-lora'})
+model.load_adapter(model_path, adapter_name="vision", device_map=device, adapter_kwargs={"subfolder": 'vision-lora'})
+
+# Part : Image Processing
+messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"},
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+]
+
+model.set_adapter("vision") # if loaded, activate the vision adapter
+inputs = processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+).to(device)
+
+# Generate response
+generate_ids = model.generate(
+ **inputs,
+ max_new_tokens=1000,
+ do_sample=False,
+)
+generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
+response = processor.batch_decode(
+ generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
+)[0]
+print(f'>>> Response\n{response}')
+
+
+# Part 2: Audio Processing
+model.set_adapter("speech") # if loaded, activate the speech adapter
+audio_url = "https://upload.wikimedia.org/wikipedia/commons/b/b0/Barbara_Sahakian_BBC_Radio4_The_Life_Scientific_29_May_2012_b01j5j24.flac"
+messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "audio", "url": audio_url},
+ {"type": "text", "text": "Transcribe the audio to text, and then translate the audio to French. Use as a separator between the origina transcript and the translation."},
+ ],
+ },
+]
+
+inputs = processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+).to(device)
+
+generate_ids = model.generate(
+ **inputs,
+ max_new_tokens=1000,
+ do_sample=False,
+)
+generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
+response = processor.batch_decode(
+ generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
+)[0]
+print(f'>>> Response\n{response}')
+```
+
+## Phi4MultimodalFeatureExtractor
+
+[[autodoc]] Phi4MultimodalFeatureExtractor
+
+## Phi4MultimodalImageProcessorFast
+
+[[autodoc]] Phi4MultimodalImageProcessorFast
+
+## Phi4MultimodalProcessor
+
+[[autodoc]] Phi4MultimodalProcessor
+
+## Phi4MultimodalAudioConfig
+
+[[autodoc]] Phi4MultimodalAudioConfig
+
+## Phi4MultimodalVisionConfig
+
+[[autodoc]] Phi4MultimodalVisionConfig
+
+## Phi4MultimodalConfig
+
+[[autodoc]] Phi4MultimodalConfig
+
+## Phi4MultimodalAudioModel
+
+[[autodoc]] Phi4MultimodalAudioModel
+
+## Phi4MultimodalVisionModel
+
+[[autodoc]] Phi4MultimodalVisionModel
+
+## Phi4MultimodalModel
+
+[[autodoc]] Phi4MultimodalModel
+ - forward
+
+## Phi4MultimodalForCausalLM
+
+[[autodoc]] Phi4MultimodalForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/phimoe.md b/docs/transformers/docs/source/en/model_doc/phimoe.md
new file mode 100644
index 0000000000000000000000000000000000000000..6728248f2e0a1c177e5dcf66d59bdf16981874ef
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/phimoe.md
@@ -0,0 +1,124 @@
+
+
+# PhiMoE
+
+
+
+
+
+
+
+## Overview
+
+The PhiMoE model was proposed in [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/abs/2404.14219) by Microsoft.
+
+### Summary
+
+The abstract from the Phi-3 paper is the following:
+
+We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. Our training dataset is a scaled-up version of the one used for phi-2, composed of heavily filtered publicly available web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide parameter-scaling results with a 7B, 14B models trained for 4.8T tokens, called phi-3-small, phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75%, 78% on MMLU, and 8.7, 8.9 on MT-bench). To enhance multilingual, multimodal, and long-context capabilities, we introduce three models in the phi-3.5 series: phi-3.5-mini, phi-3.5-MoE, and phi-3.5-Vision. The phi-3.5-MoE, a 16 x 3.8B MoE model with 6.6 billion active parameters, achieves superior performance in language reasoning, math, and code tasks compared to other open-source models of similar scale, such as Llama 3.1 and the Mixtral series, and on par with Gemini-1.5-Flash and GPT-4o-mini. Meanwhile, phi-3.5-Vision, a 4.2 billion parameter model derived from phi-3.5-mini, excels in reasoning tasks and is adept at handling both single-image and text prompts, as well as multi-image and text prompts.
+
+The original code for PhiMoE can be found [here](https://huggingface.co/microsoft/Phi-3.5-MoE-instruct).
+
+## Usage tips
+
+- This model is very similar to `Mixtral` with the main difference of [`Phi3LongRoPEScaledRotaryEmbedding`], where they are used to extend the context of the rotary embeddings. The query, key and values are fused, and the MLP's up and gate projection layers are also fused.
+- The tokenizer used for this model is identical to the [`LlamaTokenizer`], with the exception of additional tokens.
+
+## How to use PhiMoE
+
+
+
+Phi-3.5-MoE-instruct has been integrated in the development version (4.44.2.dev) of `transformers`. Until the official version is released through `pip`, ensure that you are doing the following:
+* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
+
+The current `transformers` version can be verified with: `pip list | grep transformers`.
+
+Examples of required packages:
+```
+flash_attn==2.5.8
+torch==2.3.1
+accelerate==0.31.0
+transformers==4.43.0
+```
+
+
+
+```python
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
+
+torch.random.manual_seed(0)
+
+model = AutoModelForCausalLM.from_pretrained(
+ "microsoft/Phi-3.5-MoE-instruct",
+ device_map="cuda",
+ torch_dtype="auto",
+ trust_remote_code=True,
+)
+
+tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3.5-MoE-instruct")
+
+messages = [
+ {"role": "system", "content": "You are a helpful AI assistant."},
+ {"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
+ {"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
+ {"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
+]
+
+pipe = pipeline(
+ "text-generation",
+ model=model,
+ tokenizer=tokenizer,
+)
+
+generation_args = {
+ "max_new_tokens": 500,
+ "return_full_text": False,
+ "temperature": 0.0,
+ "do_sample": False,
+}
+
+output = pipe(messages, **generation_args)
+print(output[0]['generated_text'])
+```
+
+## PhimoeConfig
+
+[[autodoc]] PhimoeConfig
+
+
+
+
+## PhimoeModel
+
+[[autodoc]] PhimoeModel
+ - forward
+
+## PhimoeForCausalLM
+
+[[autodoc]] PhimoeForCausalLM
+ - forward
+ - generate
+
+## PhimoeForSequenceClassification
+
+[[autodoc]] PhimoeForSequenceClassification
+ - forward
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/phobert.md b/docs/transformers/docs/source/en/model_doc/phobert.md
new file mode 100644
index 0000000000000000000000000000000000000000..c1c4b8742b4d9641528a729892920210f80b5036
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/phobert.md
@@ -0,0 +1,71 @@
+
+
+# PhoBERT
+
+
+
+
+
+
+
+## Overview
+
+The PhoBERT model was proposed in [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92.pdf) by Dat Quoc Nguyen, Anh Tuan Nguyen.
+
+The abstract from the paper is the following:
+
+*We present PhoBERT with two versions, PhoBERT-base and PhoBERT-large, the first public large-scale monolingual
+language models pre-trained for Vietnamese. Experimental results show that PhoBERT consistently outperforms the recent
+best pre-trained multilingual model XLM-R (Conneau et al., 2020) and improves the state-of-the-art in multiple
+Vietnamese-specific NLP tasks including Part-of-speech tagging, Dependency parsing, Named-entity recognition and
+Natural language inference.*
+
+This model was contributed by [dqnguyen](https://huggingface.co/dqnguyen). The original code can be found [here](https://github.com/VinAIResearch/PhoBERT).
+
+## Usage example
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> phobert = AutoModel.from_pretrained("vinai/phobert-base")
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/phobert-base")
+
+>>> # INPUT TEXT MUST BE ALREADY WORD-SEGMENTED!
+>>> line = "Tôi là sinh_viên trường đại_học Công_nghệ ."
+
+>>> input_ids = torch.tensor([tokenizer.encode(line)])
+
+>>> with torch.no_grad():
+... features = phobert(input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> # from transformers import TFAutoModel
+>>> # phobert = TFAutoModel.from_pretrained("vinai/phobert-base")
+```
+
+
+
+PhoBERT implementation is the same as BERT, except for tokenization. Refer to [BERT documentation](bert) for information on
+configuration classes and their parameters. PhoBERT-specific tokenizer is documented below.
+
+
+
+## PhobertTokenizer
+
+[[autodoc]] PhobertTokenizer
diff --git a/docs/transformers/docs/source/en/model_doc/pix2struct.md b/docs/transformers/docs/source/en/model_doc/pix2struct.md
new file mode 100644
index 0000000000000000000000000000000000000000..e912cc96cdccec416125c827463d37829cbdbf71
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/pix2struct.md
@@ -0,0 +1,81 @@
+
+
+# Pix2Struct
+
+
+
+
+
+## Overview
+
+The Pix2Struct model was proposed in [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
+
+The abstract from the paper is the following:
+
+> Visually-situated language is ubiquitous -- sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.
+
+Tips:
+
+Pix2Struct has been fine tuned on a variety of tasks and datasets, ranging from image captioning, visual question answering (VQA) over different inputs (books, charts, science diagrams), captioning UI components etc. The full list can be found in Table 1 of the paper.
+We therefore advise you to use these models for the tasks they have been fine tuned on. For instance, if you want to use Pix2Struct for UI captioning, you should use the model fine tuned on the UI dataset. If you want to use Pix2Struct for image captioning, you should use the model fine tuned on the natural images captioning dataset and so on.
+
+If you want to use the model to perform conditional text captioning, make sure to use the processor with `add_special_tokens=False`.
+
+This model was contributed by [ybelkada](https://huggingface.co/ybelkada).
+The original code can be found [here](https://github.com/google-research/pix2struct).
+
+## Resources
+
+- [Fine-tuning Notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb)
+- [All models](https://huggingface.co/models?search=pix2struct)
+
+## Pix2StructConfig
+
+[[autodoc]] Pix2StructConfig
+ - from_text_vision_configs
+
+## Pix2StructTextConfig
+
+[[autodoc]] Pix2StructTextConfig
+
+## Pix2StructVisionConfig
+
+[[autodoc]] Pix2StructVisionConfig
+
+## Pix2StructProcessor
+
+[[autodoc]] Pix2StructProcessor
+
+## Pix2StructImageProcessor
+
+[[autodoc]] Pix2StructImageProcessor
+ - preprocess
+
+## Pix2StructTextModel
+
+[[autodoc]] Pix2StructTextModel
+ - forward
+
+## Pix2StructVisionModel
+
+[[autodoc]] Pix2StructVisionModel
+ - forward
+
+## Pix2StructForConditionalGeneration
+
+[[autodoc]] Pix2StructForConditionalGeneration
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/pixtral.md b/docs/transformers/docs/source/en/model_doc/pixtral.md
new file mode 100644
index 0000000000000000000000000000000000000000..f287170a0e0fb9c7d0a1a156e0a37db66b5970be
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/pixtral.md
@@ -0,0 +1,106 @@
+
+
+# Pixtral
+
+
+
+
+
+## Overview
+
+The Pixtral model was released by the Mistral AI team in a [blog post](https://mistral.ai/news/pixtral-12b/). Pixtral is a multimodal version of [Mistral](mistral), incorporating a 400 million parameter vision encoder trained from scratch.
+
+The intro from the blog says the following:
+
+*Pixtral is trained to understand both natural images and documents, achieving 52.5% on the MMMU reasoning benchmark, surpassing a number of larger models. The model shows strong abilities in tasks such as chart and figure understanding, document question answering, multimodal reasoning and instruction following. Pixtral is able to ingest images at their natural resolution and aspect ratio, giving the user flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Unlike previous open-source models, Pixtral does not compromise on text benchmark performance to excel in multimodal tasks.*
+
+
+
+ Pixtral architecture. Taken from the blog post.
+
+Tips:
+
+- Pixtral is a multimodal model, taking images and text as input, and producing text as output.
+- This model follows the [Llava](llava) architecture. The model uses [`PixtralVisionModel`] for its vision encoder, and [`MistralForCausalLM`] for its language decoder.
+- The main contribution is the 2d ROPE (rotary position embeddings) on the images, and support for arbitrary image sizes (the images are not padded together nor are they resized).
+- Similar to [Llava](llava), the model internally replaces the `[IMG]` token placeholders by image embeddings from the vision encoder. The format for one or multiple prompts is the following:
+```
+"[INST][IMG]\nWhat are the things I should be cautious about when I visit this place?[/INST]"
+```
+Then, the processor will replace each `[IMG]` token with a number of `[IMG]` tokens that depend on the height and the width of each image. Each *row* of the image is separated by an `[IMG_BREAK]` token, and each image is separated by an `[IMG_END]` token. It's advised to use the `apply_chat_template` method of the processor, which takes care of all of this and formats the text for you. If you're using `transformers>=4.49.0`, you can also get a vectorized output from `apply_chat_template`. See the [usage section](#usage) for more info.
+
+
+This model was contributed by [amyeroberts](https://huggingface.co/amyeroberts) and [ArthurZ](https://huggingface.co/ArthurZ). The original code can be found [here](https://github.com/vllm-project/vllm/pull/8377).
+
+
+## Usage
+
+At inference time, it's advised to use the processor's `apply_chat_template` method, which correctly formats the prompt for the model:
+
+```python
+from transformers import AutoProcessor, LlavaForConditionalGeneration
+
+model_id = "mistral-community/pixtral-12b"
+processor = AutoProcessor.from_pretrained(model_id)
+model = LlavaForConditionalGeneration.from_pretrained(model_id, device_map="cuda")
+
+chat = [
+ {
+ "role": "user", "content": [
+ {"type": "text", "content": "Can this animal"},
+ {"type": "image", "url": "https://picsum.photos/id/237/200/300"},
+ {"type": "text", "content": "live here?"},
+ {"type": "image", "url": "https://picsum.photos/seed/picsum/200/300"}
+ ]
+ }
+]
+
+inputs = processor.apply_chat_template(
+ chat,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+generate_ids = model.generate(**inputs, max_new_tokens=500)
+output = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+```
+
+## PixtralVisionConfig
+
+[[autodoc]] PixtralVisionConfig
+
+## PixtralVisionModel
+
+[[autodoc]] PixtralVisionModel
+ - forward
+
+## PixtralImageProcessor
+
+[[autodoc]] PixtralImageProcessor
+ - preprocess
+
+## PixtralImageProcessorFast
+
+[[autodoc]] PixtralImageProcessorFast
+ - preprocess
+
+## PixtralProcessor
+
+[[autodoc]] PixtralProcessor
diff --git a/docs/transformers/docs/source/en/model_doc/plbart.md b/docs/transformers/docs/source/en/model_doc/plbart.md
new file mode 100644
index 0000000000000000000000000000000000000000..bac567615d42331ca3c0f23e6320dffa7614628e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/plbart.md
@@ -0,0 +1,120 @@
+
+
+# PLBart
+
+
+
+
+
+## Overview
+
+The PLBART model was proposed in [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+This is a BART-like model which can be used to perform code-summarization, code-generation, and code-translation tasks. The pre-trained model `plbart-base` has been trained using multilingual denoising task
+on Java, Python and English.
+
+According to the abstract
+
+*Code summarization and generation empower conversion between programming language (PL) and natural language (NL),
+while code translation avails the migration of legacy code from one PL to another. This paper introduces PLBART,
+a sequence-to-sequence model capable of performing a broad spectrum of program and language understanding and generation tasks.
+PLBART is pre-trained on an extensive collection of Java and Python functions and associated NL text via denoising autoencoding.
+Experiments on code summarization in the English language, code generation, and code translation in seven programming languages
+show that PLBART outperforms or rivals state-of-the-art models. Moreover, experiments on discriminative tasks, e.g., program
+repair, clone detection, and vulnerable code detection, demonstrate PLBART's effectiveness in program understanding.
+Furthermore, analysis reveals that PLBART learns program syntax, style (e.g., identifier naming convention), logical flow
+(e.g., if block inside an else block is equivalent to else if block) that are crucial to program semantics and thus excels
+even with limited annotations.*
+
+This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The Authors' code can be found [here](https://github.com/wasiahmad/PLBART).
+
+## Usage examples
+
+PLBart is a multilingual encoder-decoder (sequence-to-sequence) model primarily intended for code-to-text, text-to-code, code-to-code tasks. As the
+model is multilingual it expects the sequences in a different format. A special language id token is added in both the
+source and target text. The source text format is `X [eos, src_lang_code]` where `X` is the source text. The
+target text format is `[tgt_lang_code] X [eos]`. `bos` is never used.
+
+However, for fine-tuning, in some cases no language token is provided in cases where a single language is used. Please refer to [the paper](https://arxiv.org/abs/2103.06333) to learn more about this.
+
+In cases where the language code is needed, the regular [`~PLBartTokenizer.__call__`] will encode source text format
+when you pass texts as the first argument or with the keyword argument `text`, and will encode target text format if
+it's passed with the `text_target` keyword argument.
+
+### Supervised training
+
+```python
+>>> from transformers import PLBartForConditionalGeneration, PLBartTokenizer
+
+>>> tokenizer = PLBartTokenizer.from_pretrained("uclanlp/plbart-base", src_lang="en_XX", tgt_lang="python")
+>>> example_python_phrase = "def maximum(a,b,c):NEW_LINE_INDENTreturn max([a,b,c])"
+>>> expected_translation_english = "Returns the maximum value of a b c."
+>>> inputs = tokenizer(example_python_phrase, text_target=expected_translation_english, return_tensors="pt")
+>>> model(**inputs)
+```
+
+### Generation
+
+ While generating the target text set the `decoder_start_token_id` to the target language id. The following
+ example shows how to translate Python to English using the `uclanlp/plbart-python-en_XX` model.
+
+```python
+>>> from transformers import PLBartForConditionalGeneration, PLBartTokenizer
+
+>>> tokenizer = PLBartTokenizer.from_pretrained("uclanlp/plbart-python-en_XX", src_lang="python", tgt_lang="en_XX")
+>>> example_python_phrase = "def maximum(a,b,c):NEW_LINE_INDENTreturn max([a,b,c])"
+>>> inputs = tokenizer(example_python_phrase, return_tensors="pt")
+>>> model = PLBartForConditionalGeneration.from_pretrained("uclanlp/plbart-python-en_XX")
+>>> translated_tokens = model.generate(**inputs, decoder_start_token_id=tokenizer.lang_code_to_id["en_XX"])
+>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
+"Returns the maximum value of a b c."
+```
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## PLBartConfig
+
+[[autodoc]] PLBartConfig
+
+## PLBartTokenizer
+
+[[autodoc]] PLBartTokenizer
+ - build_inputs_with_special_tokens
+
+## PLBartModel
+
+[[autodoc]] PLBartModel
+ - forward
+
+## PLBartForConditionalGeneration
+
+[[autodoc]] PLBartForConditionalGeneration
+ - forward
+
+## PLBartForSequenceClassification
+
+[[autodoc]] PLBartForSequenceClassification
+ - forward
+
+## PLBartForCausalLM
+
+[[autodoc]] PLBartForCausalLM
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/poolformer.md b/docs/transformers/docs/source/en/model_doc/poolformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..60573162d686a4cf000bbb1fd0850ca31614bf9f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/poolformer.md
@@ -0,0 +1,89 @@
+
+
+# PoolFormer
+
+
+
+
+
+## Overview
+
+The PoolFormer model was proposed in [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Sea AI Labs. Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of transformer models largely stem from the general architecture MetaFormer.
+
+The abstract from the paper is the following:
+
+*Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design.*
+
+The figure below illustrates the architecture of PoolFormer. Taken from the [original paper](https://arxiv.org/abs/2111.11418).
+
+
+
+This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
+
+## Usage tips
+
+- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
+- One can use [`PoolFormerImageProcessor`] to prepare images for the model.
+- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :------------: | :-------------------: |
+| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
+| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
+| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
+| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
+| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
+
+
+
+- [`PoolFormerForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## PoolFormerConfig
+
+[[autodoc]] PoolFormerConfig
+
+## PoolFormerFeatureExtractor
+
+[[autodoc]] PoolFormerFeatureExtractor
+ - __call__
+
+## PoolFormerImageProcessor
+
+[[autodoc]] PoolFormerImageProcessor
+ - preprocess
+
+## PoolFormerImageProcessorFast
+
+[[autodoc]] PoolFormerImageProcessorFast
+ - preprocess
+
+## PoolFormerModel
+
+[[autodoc]] PoolFormerModel
+ - forward
+
+## PoolFormerForImageClassification
+
+[[autodoc]] PoolFormerForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/pop2piano.md b/docs/transformers/docs/source/en/model_doc/pop2piano.md
new file mode 100644
index 0000000000000000000000000000000000000000..a9554b4924a9bc135aeaf3f1fdae4b3d3915dfb8
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/pop2piano.md
@@ -0,0 +1,192 @@
+
+
+# Pop2Piano
+
+
+
+
+
+## Overview
+
+The Pop2Piano model was proposed in [Pop2Piano : Pop Audio-based Piano Cover Generation](https://arxiv.org/abs/2211.00895) by Jongho Choi and Kyogu Lee.
+
+Piano covers of pop music are widely enjoyed, but generating them from music is not a trivial task. It requires great
+expertise with playing piano as well as knowing different characteristics and melodies of a song. With Pop2Piano you
+can directly generate a cover from a song's audio waveform. It is the first model to directly generate a piano cover
+from pop audio without melody and chord extraction modules.
+
+Pop2Piano is an encoder-decoder Transformer model based on [T5](https://arxiv.org/pdf/1910.10683.pdf). The input audio
+is transformed to its waveform and passed to the encoder, which transforms it to a latent representation. The decoder
+uses these latent representations to generate token ids in an autoregressive way. Each token id corresponds to one of four
+different token types: time, velocity, note and 'special'. The token ids are then decoded to their equivalent MIDI file.
+
+The abstract from the paper is the following:
+
+*Piano covers of pop music are enjoyed by many people. However, the
+task of automatically generating piano covers of pop music is still
+understudied. This is partly due to the lack of synchronized
+{Pop, Piano Cover} data pairs, which made it challenging to apply
+the latest data-intensive deep learning-based methods. To leverage
+the power of the data-driven approach, we make a large amount of
+paired and synchronized {Pop, Piano Cover} data using an automated
+pipeline. In this paper, we present Pop2Piano, a Transformer network
+that generates piano covers given waveforms of pop music. To the best
+of our knowledge, this is the first model to generate a piano cover
+directly from pop audio without using melody and chord extraction
+modules. We show that Pop2Piano, trained with our dataset, is capable
+of producing plausible piano covers.*
+
+This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
+The original code can be found [here](https://github.com/sweetcocoa/pop2piano).
+
+## Usage tips
+
+* To use Pop2Piano, you will need to install the 🤗 Transformers library, as well as the following third party modules:
+```bash
+pip install pretty-midi==0.2.9 essentia==2.1b6.dev1034 librosa scipy
+```
+Please note that you may need to restart your runtime after installation.
+* Pop2Piano is an Encoder-Decoder based model like T5.
+* Pop2Piano can be used to generate midi-audio files for a given audio sequence.
+* Choosing different composers in `Pop2PianoForConditionalGeneration.generate()` can lead to variety of different results.
+* Setting the sampling rate to 44.1 kHz when loading the audio file can give good performance.
+* Though Pop2Piano was mainly trained on Korean Pop music, it also does pretty well on other Western Pop or Hip Hop songs.
+
+## Examples
+
+- Example using HuggingFace Dataset:
+
+```python
+>>> from datasets import load_dataset
+>>> from transformers import Pop2PianoForConditionalGeneration, Pop2PianoProcessor
+
+>>> model = Pop2PianoForConditionalGeneration.from_pretrained("sweetcocoa/pop2piano")
+>>> processor = Pop2PianoProcessor.from_pretrained("sweetcocoa/pop2piano")
+>>> ds = load_dataset("sweetcocoa/pop2piano_ci", split="test")
+
+>>> inputs = processor(
+... audio=ds["audio"][0]["array"], sampling_rate=ds["audio"][0]["sampling_rate"], return_tensors="pt"
+... )
+>>> model_output = model.generate(input_features=inputs["input_features"], composer="composer1")
+>>> tokenizer_output = processor.batch_decode(
+... token_ids=model_output, feature_extractor_output=inputs
+... )["pretty_midi_objects"][0]
+>>> tokenizer_output.write("./Outputs/midi_output.mid")
+```
+
+- Example using your own audio file:
+
+```python
+>>> import librosa
+>>> from transformers import Pop2PianoForConditionalGeneration, Pop2PianoProcessor
+
+>>> audio, sr = librosa.load("", sr=44100) # feel free to change the sr to a suitable value.
+>>> model = Pop2PianoForConditionalGeneration.from_pretrained("sweetcocoa/pop2piano")
+>>> processor = Pop2PianoProcessor.from_pretrained("sweetcocoa/pop2piano")
+
+>>> inputs = processor(audio=audio, sampling_rate=sr, return_tensors="pt")
+>>> model_output = model.generate(input_features=inputs["input_features"], composer="composer1")
+>>> tokenizer_output = processor.batch_decode(
+... token_ids=model_output, feature_extractor_output=inputs
+... )["pretty_midi_objects"][0]
+>>> tokenizer_output.write("./Outputs/midi_output.mid")
+```
+
+- Example of processing multiple audio files in batch:
+
+```python
+>>> import librosa
+>>> from transformers import Pop2PianoForConditionalGeneration, Pop2PianoProcessor
+
+>>> # feel free to change the sr to a suitable value.
+>>> audio1, sr1 = librosa.load("", sr=44100)
+>>> audio2, sr2 = librosa.load("", sr=44100)
+>>> model = Pop2PianoForConditionalGeneration.from_pretrained("sweetcocoa/pop2piano")
+>>> processor = Pop2PianoProcessor.from_pretrained("sweetcocoa/pop2piano")
+
+>>> inputs = processor(audio=[audio1, audio2], sampling_rate=[sr1, sr2], return_attention_mask=True, return_tensors="pt")
+>>> # Since we now generating in batch(2 audios) we must pass the attention_mask
+>>> model_output = model.generate(
+... input_features=inputs["input_features"],
+... attention_mask=inputs["attention_mask"],
+... composer="composer1",
+... )
+>>> tokenizer_output = processor.batch_decode(
+... token_ids=model_output, feature_extractor_output=inputs
+... )["pretty_midi_objects"]
+
+>>> # Since we now have 2 generated MIDI files
+>>> tokenizer_output[0].write("./Outputs/midi_output1.mid")
+>>> tokenizer_output[1].write("./Outputs/midi_output2.mid")
+```
+
+
+- Example of processing multiple audio files in batch (Using `Pop2PianoFeatureExtractor` and `Pop2PianoTokenizer`):
+
+```python
+>>> import librosa
+>>> from transformers import Pop2PianoForConditionalGeneration, Pop2PianoFeatureExtractor, Pop2PianoTokenizer
+
+>>> # feel free to change the sr to a suitable value.
+>>> audio1, sr1 = librosa.load("", sr=44100)
+>>> audio2, sr2 = librosa.load("", sr=44100)
+>>> model = Pop2PianoForConditionalGeneration.from_pretrained("sweetcocoa/pop2piano")
+>>> feature_extractor = Pop2PianoFeatureExtractor.from_pretrained("sweetcocoa/pop2piano")
+>>> tokenizer = Pop2PianoTokenizer.from_pretrained("sweetcocoa/pop2piano")
+
+>>> inputs = feature_extractor(
+... audio=[audio1, audio2],
+... sampling_rate=[sr1, sr2],
+... return_attention_mask=True,
+... return_tensors="pt",
+... )
+>>> # Since we now generating in batch(2 audios) we must pass the attention_mask
+>>> model_output = model.generate(
+... input_features=inputs["input_features"],
+... attention_mask=inputs["attention_mask"],
+... composer="composer1",
+... )
+>>> tokenizer_output = tokenizer.batch_decode(
+... token_ids=model_output, feature_extractor_output=inputs
+... )["pretty_midi_objects"]
+
+>>> # Since we now have 2 generated MIDI files
+>>> tokenizer_output[0].write("./Outputs/midi_output1.mid")
+>>> tokenizer_output[1].write("./Outputs/midi_output2.mid")
+```
+
+
+## Pop2PianoConfig
+
+[[autodoc]] Pop2PianoConfig
+
+## Pop2PianoFeatureExtractor
+
+[[autodoc]] Pop2PianoFeatureExtractor
+ - __call__
+
+## Pop2PianoForConditionalGeneration
+
+[[autodoc]] Pop2PianoForConditionalGeneration
+ - forward
+ - generate
+
+## Pop2PianoTokenizer
+
+[[autodoc]] Pop2PianoTokenizer
+ - __call__
+
+## Pop2PianoProcessor
+
+[[autodoc]] Pop2PianoProcessor
+ - __call__
diff --git a/docs/transformers/docs/source/en/model_doc/prompt_depth_anything.md b/docs/transformers/docs/source/en/model_doc/prompt_depth_anything.md
new file mode 100644
index 0000000000000000000000000000000000000000..910298fa8c71f8473e40c26ddc466a1d2283e3ff
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/prompt_depth_anything.md
@@ -0,0 +1,96 @@
+
+
+# Prompt Depth Anything
+
+## Overview
+
+The Prompt Depth Anything model was introduced in [Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation](https://arxiv.org/abs/2412.14015) by Haotong Lin, Sida Peng, Jingxiao Chen, Songyou Peng, Jiaming Sun, Minghuan Liu, Hujun Bao, Jiashi Feng, Xiaowei Zhou, Bingyi Kang.
+
+
+The abstract from the paper is as follows:
+
+*Prompts play a critical role in unleashing the power of language and vision foundation models for specific tasks. For the first time, we introduce prompting into depth foundation models, creating a new paradigm for metric depth estimation termed Prompt Depth Anything. Specifically, we use a low-cost LiDAR as the prompt to guide the Depth Anything model for accurate metric depth output, achieving up to 4K resolution. Our approach centers on a concise prompt fusion design that integrates the LiDAR at multiple scales within the depth decoder. To address training challenges posed by limited datasets containing both LiDAR depth and precise GT depth, we propose a scalable data pipeline that includes synthetic data LiDAR simulation and real data pseudo GT depth generation. Our approach sets new state-of-the-arts on the ARKitScenes and ScanNet++ datasets and benefits downstream applications, including 3D reconstruction and generalized robotic grasping.*
+
+
+
+ Prompt Depth Anything overview. Taken from the original paper.
+
+## Usage example
+
+The Transformers library allows you to use the model with just a few lines of code:
+
+```python
+>>> import torch
+>>> import requests
+>>> import numpy as np
+
+>>> from PIL import Image
+>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
+
+>>> url = "https://github.com/DepthAnything/PromptDA/blob/main/assets/example_images/image.jpg?raw=true"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = AutoImageProcessor.from_pretrained("depth-anything/prompt-depth-anything-vits-hf")
+>>> model = AutoModelForDepthEstimation.from_pretrained("depth-anything/prompt-depth-anything-vits-hf")
+
+>>> prompt_depth_url = "https://github.com/DepthAnything/PromptDA/blob/main/assets/example_images/arkit_depth.png?raw=true"
+>>> prompt_depth = Image.open(requests.get(prompt_depth_url, stream=True).raw)
+>>> # the prompt depth can be None, and the model will output a monocular relative depth.
+
+>>> # prepare image for the model
+>>> inputs = image_processor(images=image, return_tensors="pt", prompt_depth=prompt_depth)
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> # interpolate to original size
+>>> post_processed_output = image_processor.post_process_depth_estimation(
+... outputs,
+... target_sizes=[(image.height, image.width)],
+... )
+
+>>> # visualize the prediction
+>>> predicted_depth = post_processed_output[0]["predicted_depth"]
+>>> depth = predicted_depth * 1000
+>>> depth = depth.detach().cpu().numpy()
+>>> depth = Image.fromarray(depth.astype("uint16")) # mm
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Prompt Depth Anything.
+
+- [Prompt Depth Anything Demo](https://huggingface.co/spaces/depth-anything/PromptDA)
+- [Prompt Depth Anything Interactive Results](https://promptda.github.io/interactive.html)
+
+If you are interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## PromptDepthAnythingConfig
+
+[[autodoc]] PromptDepthAnythingConfig
+
+## PromptDepthAnythingForDepthEstimation
+
+[[autodoc]] PromptDepthAnythingForDepthEstimation
+ - forward
+
+## PromptDepthAnythingImageProcessor
+
+[[autodoc]] PromptDepthAnythingImageProcessor
+ - preprocess
+ - post_process_depth_estimation
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/prophetnet.md b/docs/transformers/docs/source/en/model_doc/prophetnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..b768fef72a048448e853e5ed5c298ed7d11ef3ba
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/prophetnet.md
@@ -0,0 +1,98 @@
+
+
+# ProphetNet
+
+
+
+
+
+## Overview
+
+The ProphetNet model was proposed in [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training,](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei
+Zhang, Ming Zhou on 13 Jan, 2020.
+
+ProphetNet is an encoder-decoder model and can predict n-future tokens for "ngram" language modeling instead of just
+the next token.
+
+The abstract from the paper is the following:
+
+*In this paper, we present a new sequence-to-sequence pretraining model called ProphetNet, which introduces a novel
+self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of
+the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by
+n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time
+step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent
+overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale
+dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for
+abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new
+state-of-the-art results on all these datasets compared to the models using the same scale pretraining corpus.*
+
+The Authors' code can be found [here](https://github.com/microsoft/ProphetNet).
+
+## Usage tips
+
+- ProphetNet is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
+ the left.
+- The model architecture is based on the original Transformer, but replaces the “standard” self-attention mechanism in the decoder by a main self-attention mechanism and a self and n-stream (predict) self-attention mechanism.
+
+## Resources
+
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## ProphetNetConfig
+
+[[autodoc]] ProphetNetConfig
+
+## ProphetNetTokenizer
+
+[[autodoc]] ProphetNetTokenizer
+
+## ProphetNet specific outputs
+
+[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetSeq2SeqLMOutput
+
+[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetSeq2SeqModelOutput
+
+[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetDecoderModelOutput
+
+[[autodoc]] models.prophetnet.modeling_prophetnet.ProphetNetDecoderLMOutput
+
+## ProphetNetModel
+
+[[autodoc]] ProphetNetModel
+ - forward
+
+## ProphetNetEncoder
+
+[[autodoc]] ProphetNetEncoder
+ - forward
+
+## ProphetNetDecoder
+
+[[autodoc]] ProphetNetDecoder
+ - forward
+
+## ProphetNetForConditionalGeneration
+
+[[autodoc]] ProphetNetForConditionalGeneration
+ - forward
+
+## ProphetNetForCausalLM
+
+[[autodoc]] ProphetNetForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/pvt.md b/docs/transformers/docs/source/en/model_doc/pvt.md
new file mode 100644
index 0000000000000000000000000000000000000000..daa4806bc3aef4fd65d28117e6dda8232f5e72b0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/pvt.md
@@ -0,0 +1,80 @@
+
+
+# Pyramid Vision Transformer (PVT)
+
+
+
+
+
+## Overview
+
+The PVT model was proposed in
+[Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/abs/2102.12122)
+by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. The PVT is a type of
+vision transformer that utilizes a pyramid structure to make it an effective backbone for dense prediction tasks. Specifically
+it allows for more fine-grained inputs (4 x 4 pixels per patch) to be used, while simultaneously shrinking the sequence length
+of the Transformer as it deepens - reducing the computational cost. Additionally, a spatial-reduction attention (SRA) layer
+is used to further reduce the resource consumption when learning high-resolution features.
+
+The abstract from the paper is the following:
+
+*Although convolutional neural networks (CNNs) have achieved great success in computer vision, this work investigates a
+simpler, convolution-free backbone network useful for many dense prediction tasks. Unlike the recently proposed Vision
+Transformer (ViT) that was designed for image classification specifically, we introduce the Pyramid Vision Transformer
+(PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks. PVT has several
+merits compared to current state of the arts. Different from ViT that typically yields low resolution outputs and
+incurs high computational and memory costs, PVT not only can be trained on dense partitions of an image to achieve high
+output resolution, which is important for dense prediction, but also uses a progressive shrinking pyramid to reduce the
+computations of large feature maps. PVT inherits the advantages of both CNN and Transformer, making it a unified
+backbone for various vision tasks without convolutions, where it can be used as a direct replacement for CNN backbones.
+We validate PVT through extensive experiments, showing that it boosts the performance of many downstream tasks, including
+object detection, instance and semantic segmentation. For example, with a comparable number of parameters, PVT+RetinaNet
+achieves 40.4 AP on the COCO dataset, surpassing ResNet50+RetinNet (36.3 AP) by 4.1 absolute AP (see Figure 2). We hope
+that PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future research.*
+
+This model was contributed by [Xrenya](https://huggingface.co/Xrenya). The original code can be found [here](https://github.com/whai362/PVT).
+
+
+- PVTv1 on ImageNet-1K
+
+| **Model variant** |**Size** |**Acc@1**|**Params (M)**|
+|--------------------|:-------:|:-------:|:------------:|
+| PVT-Tiny | 224 | 75.1 | 13.2 |
+| PVT-Small | 224 | 79.8 | 24.5 |
+| PVT-Medium | 224 | 81.2 | 44.2 |
+| PVT-Large | 224 | 81.7 | 61.4 |
+
+
+## PvtConfig
+
+[[autodoc]] PvtConfig
+
+## PvtImageProcessor
+
+[[autodoc]] PvtImageProcessor
+ - preprocess
+
+## PvtImageProcessorFast
+
+[[autodoc]] PvtImageProcessorFast
+ - preprocess
+
+## PvtForImageClassification
+
+[[autodoc]] PvtForImageClassification
+ - forward
+
+## PvtModel
+
+[[autodoc]] PvtModel
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/pvt_v2.md b/docs/transformers/docs/source/en/model_doc/pvt_v2.md
new file mode 100644
index 0000000000000000000000000000000000000000..deac614d38bff152c7241cb530fd132974a8bf2d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/pvt_v2.md
@@ -0,0 +1,114 @@
+
+
+# Pyramid Vision Transformer V2 (PVTv2)
+
+
+
+
+
+## Overview
+
+The PVTv2 model was proposed in
+[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
+
+The PVTv2 encoder structure has been successfully deployed to achieve state-of-the-art scores in [Segformer](https://arxiv.org/abs/2105.15203) for semantic segmentation, [GLPN](https://arxiv.org/abs/2201.07436) for monocular depth, and [Panoptic Segformer](https://arxiv.org/abs/2109.03814) for panoptic segmentation.
+
+PVTv2 belongs to a family of models called [hierarchical transformers](https://natecibik.medium.com/the-rise-of-vision-transformers-f623c980419f) , which make adaptations to transformer layers in order to generate multi-scale feature maps. Unlike the columnal structure of Vision Transformer ([ViT](https://arxiv.org/abs/2010.11929)) which loses fine-grained detail, multi-scale feature maps are known preserve this detail and aid performance in dense prediction tasks. In the case of PVTv2, this is achieved by generating image patch tokens using 2D convolution with overlapping kernels in each encoder layer.
+
+The multi-scale features of hierarchical transformers allow them to be easily swapped in for traditional workhorse computer vision backbone models like ResNet in larger architectures. Both Segformer and Panoptic Segformer demonstrated that configurations using PVTv2 for a backbone consistently outperformed those with similarly sized ResNet backbones.
+
+Another powerful feature of the PVTv2 is the complexity reduction in the self-attention layers called Spatial Reduction Attention (SRA), which uses 2D convolution layers to project hidden states to a smaller resolution before attending to them with the queries, improving the $O(n^2)$ complexity of self-attention to $O(n^2/R)$, with $R$ being the spatial reduction ratio (`sr_ratio`, aka kernel size and stride in the 2D convolution).
+
+SRA was introduced in PVT, and is the default attention complexity reduction method used in PVTv2. However, PVTv2 also introduced the option of using a self-attention mechanism with linear complexity related to image size, which they called "Linear SRA". This method uses average pooling to reduce the hidden states to a fixed size that is invariant to their original resolution (although this is inherently more lossy than regular SRA). This option can be enabled by setting `linear_attention` to `True` in the PVTv2Config.
+
+### Abstract from the paper:
+
+*Transformer recently has presented encouraging progress in computer vision. In this work, we present new baselines by improving the original Pyramid Vision Transformer (PVT v1) by adding three designs, including (1) linear complexity attention layer, (2) overlapping patch embedding, and (3) convolutional feed-forward network. With these modifications, PVT v2 reduces the computational complexity of PVT v1 to linear and achieves significant improvements on fundamental vision tasks such as classification, detection, and segmentation. Notably, the proposed PVT v2 achieves comparable or better performances than recent works such as Swin Transformer. We hope this work will facilitate state-of-the-art Transformer researches in computer vision. Code is available at https://github.com/whai362/PVT.*
+
+This model was contributed by [FoamoftheSea](https://huggingface.co/FoamoftheSea). The original code can be found [here](https://github.com/whai362/PVT).
+
+## Usage tips
+
+- [PVTv2](https://arxiv.org/abs/2106.13797) is a hierarchical transformer model which has demonstrated powerful performance in image classification and multiple other tasks, used as a backbone for semantic segmentation in [Segformer](https://arxiv.org/abs/2105.15203), monocular depth estimation in [GLPN](https://arxiv.org/abs/2201.07436), and panoptic segmentation in [Panoptic Segformer](https://arxiv.org/abs/2109.03814), consistently showing higher performance than similar ResNet configurations.
+- Hierarchical transformers like PVTv2 achieve superior data and parameter efficiency on image data compared with pure transformer architectures by incorporating design elements of convolutional neural networks (CNNs) into their encoders. This creates a best-of-both-worlds architecture that infuses the useful inductive biases of CNNs like translation equivariance and locality into the network while still enjoying the benefits of dynamic data response and global relationship modeling provided by the self-attention mechanism of [transformers](https://arxiv.org/abs/1706.03762).
+- PVTv2 uses overlapping patch embeddings to create multi-scale feature maps, which are infused with location information using zero-padding and depth-wise convolutions.
+- To reduce the complexity in the attention layers, PVTv2 performs a spatial reduction on the hidden states using either strided 2D convolution (SRA) or fixed-size average pooling (Linear SRA). Although inherently more lossy, Linear SRA provides impressive performance with a linear complexity with respect to image size. To use Linear SRA in the self-attention layers, set `linear_attention=True` in the `PvtV2Config`.
+- [`PvtV2Model`] is the hierarchical transformer encoder (which is also often referred to as Mix Transformer or MiT in the literature). [`PvtV2ForImageClassification`] adds a simple classifier head on top to perform Image Classification. [`PvtV2Backbone`] can be used with the [`AutoBackbone`] system in larger architectures like Deformable DETR.
+- ImageNet pretrained weights for all model sizes can be found on the [hub](https://huggingface.co/models?other=pvt_v2).
+
+ The best way to get started with the PVTv2 is to load the pretrained checkpoint with the size of your choosing using `AutoModelForImageClassification`:
+```python
+import requests
+import torch
+
+from transformers import AutoModelForImageClassification, AutoImageProcessor
+from PIL import Image
+
+model = AutoModelForImageClassification.from_pretrained("OpenGVLab/pvt_v2_b0")
+image_processor = AutoImageProcessor.from_pretrained("OpenGVLab/pvt_v2_b0")
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+processed = image_processor(image)
+outputs = model(torch.tensor(processed["pixel_values"]))
+```
+
+To use the PVTv2 as a backbone for more complex architectures like DeformableDETR, you can use AutoBackbone (this model would need fine-tuning as you're replacing the backbone in the pretrained model):
+
+```python
+import requests
+import torch
+
+from transformers import AutoConfig, AutoModelForObjectDetection, AutoImageProcessor
+from PIL import Image
+
+model = AutoModelForObjectDetection.from_config(
+ config=AutoConfig.from_pretrained(
+ "SenseTime/deformable-detr",
+ backbone_config=AutoConfig.from_pretrained("OpenGVLab/pvt_v2_b5"),
+ use_timm_backbone=False
+ ),
+)
+
+image_processor = AutoImageProcessor.from_pretrained("SenseTime/deformable-detr")
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+processed = image_processor(image)
+outputs = model(torch.tensor(processed["pixel_values"]))
+```
+
+[PVTv2](https://github.com/whai362/PVT/tree/v2) performance on ImageNet-1K by model size (B0-B5):
+
+| Method | Size | Acc@1 | #Params (M) |
+|------------------|:----:|:-----:|:-----------:|
+| PVT-V2-B0 | 224 | 70.5 | 3.7 |
+| PVT-V2-B1 | 224 | 78.7 | 14.0 |
+| PVT-V2-B2-Linear | 224 | 82.1 | 22.6 |
+| PVT-V2-B2 | 224 | 82.0 | 25.4 |
+| PVT-V2-B3 | 224 | 83.1 | 45.2 |
+| PVT-V2-B4 | 224 | 83.6 | 62.6 |
+| PVT-V2-B5 | 224 | 83.8 | 82.0 |
+
+
+## PvtV2Config
+
+[[autodoc]] PvtV2Config
+
+## PvtForImageClassification
+
+[[autodoc]] PvtV2ForImageClassification
+ - forward
+
+## PvtModel
+
+[[autodoc]] PvtV2Model
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/qdqbert.md b/docs/transformers/docs/source/en/model_doc/qdqbert.md
new file mode 100644
index 0000000000000000000000000000000000000000..4c1a485b116138479358dc62361f9f8534167b96
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qdqbert.md
@@ -0,0 +1,180 @@
+
+
+# QDQBERT
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+The QDQBERT model can be referenced in [Integer Quantization for Deep Learning Inference: Principles and Empirical
+Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius
+Micikevicius.
+
+The abstract from the paper is the following:
+
+*Quantization techniques can reduce the size of Deep Neural Networks and improve inference latency and throughput by
+taking advantage of high throughput integer instructions. In this paper we review the mathematical aspects of
+quantization parameters and evaluate their choices on a wide range of neural network models for different application
+domains, including vision, speech, and language. We focus on quantization techniques that are amenable to acceleration
+by processors with high-throughput integer math pipelines. We also present a workflow for 8-bit quantization that is
+able to maintain accuracy within 1% of the floating-point baseline on all networks studied, including models that are
+more difficult to quantize, such as MobileNets and BERT-large.*
+
+This model was contributed by [shangz](https://huggingface.co/shangz).
+
+## Usage tips
+
+- QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to (i) linear layer
+ inputs and weights, (ii) matmul inputs, (iii) residual add inputs, in BERT model.
+- QDQBERT requires the dependency of [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). To install `pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com`
+- QDQBERT model can be loaded from any checkpoint of HuggingFace BERT model (for example *google-bert/bert-base-uncased*), and
+ perform Quantization Aware Training/Post Training Quantization.
+- A complete example of using QDQBERT model to perform Quatization Aware Training and Post Training Quantization for
+ SQUAD task can be found at https://github.com/huggingface/transformers-research-projects/tree/main/quantization-qdqbert.
+
+### Set default quantizers
+
+QDQBERT model adds fake quantization operations (pair of QuantizeLinear/DequantizeLinear ops) to BERT by
+`TensorQuantizer` in [Pytorch Quantization Toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization). `TensorQuantizer` is the module
+for quantizing tensors, with `QuantDescriptor` defining how the tensor should be quantized. Refer to [Pytorch
+Quantization Toolkit userguide](https://docs.nvidia.com/deeplearning/tensorrt/pytorch-quantization-toolkit/docs/userguide.html) for more details.
+
+Before creating QDQBERT model, one has to set the default `QuantDescriptor` defining default tensor quantizers.
+
+Example:
+
+```python
+>>> import pytorch_quantization.nn as quant_nn
+>>> from pytorch_quantization.tensor_quant import QuantDescriptor
+
+>>> # The default tensor quantizer is set to use Max calibration method
+>>> input_desc = QuantDescriptor(num_bits=8, calib_method="max")
+>>> # The default tensor quantizer is set to be per-channel quantization for weights
+>>> weight_desc = QuantDescriptor(num_bits=8, axis=((0,)))
+>>> quant_nn.QuantLinear.set_default_quant_desc_input(input_desc)
+>>> quant_nn.QuantLinear.set_default_quant_desc_weight(weight_desc)
+```
+
+### Calibration
+
+Calibration is the terminology of passing data samples to the quantizer and deciding the best scaling factors for
+tensors. After setting up the tensor quantizers, one can use the following example to calibrate the model:
+
+```python
+>>> # Find the TensorQuantizer and enable calibration
+>>> for name, module in model.named_modules():
+... if name.endswith("_input_quantizer"):
+... module.enable_calib()
+... module.disable_quant() # Use full precision data to calibrate
+
+>>> # Feeding data samples
+>>> model(x)
+>>> # ...
+
+>>> # Finalize calibration
+>>> for name, module in model.named_modules():
+... if name.endswith("_input_quantizer"):
+... module.load_calib_amax()
+... module.enable_quant()
+
+>>> # If running on GPU, it needs to call .cuda() again because new tensors will be created by calibration process
+>>> model.cuda()
+
+>>> # Keep running the quantized model
+>>> # ...
+```
+
+### Export to ONNX
+
+The goal of exporting to ONNX is to deploy inference by [TensorRT](https://developer.nvidia.com/tensorrt). Fake
+quantization will be broken into a pair of QuantizeLinear/DequantizeLinear ONNX ops. After setting static member of
+TensorQuantizer to use Pytorch’s own fake quantization functions, fake quantized model can be exported to ONNX, follow
+the instructions in [torch.onnx](https://pytorch.org/docs/stable/onnx.html). Example:
+
+```python
+>>> from pytorch_quantization.nn import TensorQuantizer
+
+>>> TensorQuantizer.use_fb_fake_quant = True
+
+>>> # Load the calibrated model
+>>> ...
+>>> # ONNX export
+>>> torch.onnx.export(...)
+```
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## QDQBertConfig
+
+[[autodoc]] QDQBertConfig
+
+## QDQBertModel
+
+[[autodoc]] QDQBertModel
+ - forward
+
+## QDQBertLMHeadModel
+
+[[autodoc]] QDQBertLMHeadModel
+ - forward
+
+## QDQBertForMaskedLM
+
+[[autodoc]] QDQBertForMaskedLM
+ - forward
+
+## QDQBertForSequenceClassification
+
+[[autodoc]] QDQBertForSequenceClassification
+ - forward
+
+## QDQBertForNextSentencePrediction
+
+[[autodoc]] QDQBertForNextSentencePrediction
+ - forward
+
+## QDQBertForMultipleChoice
+
+[[autodoc]] QDQBertForMultipleChoice
+ - forward
+
+## QDQBertForTokenClassification
+
+[[autodoc]] QDQBertForTokenClassification
+ - forward
+
+## QDQBertForQuestionAnswering
+
+[[autodoc]] QDQBertForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/qwen2.md b/docs/transformers/docs/source/en/model_doc/qwen2.md
new file mode 100644
index 0000000000000000000000000000000000000000..1c5e3880938da39b05fb75246a4ba622cb40f227
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qwen2.md
@@ -0,0 +1,184 @@
+
+
+
+
+
+
+
+
+
+
+# Qwen2
+
+[Qwen2](https://huggingface.co/papers/2407.10671) is a family of large language models (pretrained, instruction-tuned and mixture-of-experts) available in sizes from 0.5B to 72B parameters. The models are built on the Transformer architecture featuring enhancements like group query attention (GQA), rotary positional embeddings (RoPE), a mix of sliding window and full attention, and dual chunk attention with YARN for training stability. Qwen2 models support multiple languages and context lengths up to 131,072 tokens.
+
+You can find all the official Qwen2 checkpoints under the [Qwen2](https://huggingface.co/collections/Qwen/qwen2-6659360b33528ced941e557f) collection.
+
+> [!TIP]
+> Click on the Qwen2 models in the right sidebar for more examples of how to apply Qwen2 to different language tasks.
+
+The example below demonstrates how to generate text with [`Pipeline`], [`AutoModel`], and from the command line using the instruction-tuned models.
+
+
+
+
+```python
+import torch
+from transformers import pipeline
+
+pipe = pipeline(
+ task="text-generation",
+ model="Qwen/Qwen2-1.5B-Instruct",
+ torch_dtype=torch.bfloat16,
+ device_map=0
+)
+
+messages = [
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": "Tell me about the Qwen2 model family."},
+]
+outputs = pipe(messages, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
+print(outputs[0]["generated_text"][-1]['content'])
+```
+
+
+
+
+```python
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained(
+ "Qwen/Qwen2-1.5B-Instruct",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-1.5B-Instruct")
+
+prompt = "Give me a short introduction to large language models."
+messages = [
+ {"role": "system", "content": "You are a helpful assistant."},
+ {"role": "user", "content": prompt}
+]
+text = tokenizer.apply_chat_template(
+ messages,
+ tokenize=False,
+ add_generation_prompt=True
+)
+model_inputs = tokenizer([text], return_tensors="pt").to("cuda")
+
+generated_ids = model.generate(
+ model_inputs.input_ids,
+ cache_implementation="static",
+ max_new_tokens=512,
+ do_sample=True,
+ temperature=0.7,
+ top_k=50,
+ top_p=0.95
+)
+generated_ids = [
+ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
+]
+
+response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+print(response)
+```
+
+
+
+
+```bash
+# pip install -U flash-attn --no-build-isolation
+transformers-cli chat --model_name_or_path Qwen/Qwen2-7B-Instruct --torch_dtype auto --attn_implementation flash_attention_2 --device 0
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes) to quantize the weights to 4-bits.
+
+```python
+# pip install -U flash-attn --no-build-isolation
+import torch
+from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_compute_dtype=torch.bfloat16,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_use_double_quant=True,
+)
+
+tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B")
+model = AutoModelForCausalLM.from_pretrained(
+ "Qwen/Qwen2-7B",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ quantization_config=quantization_config,
+ attn_implementation="flash_attention_2"
+)
+
+inputs = tokenizer("The Qwen2 model family is", return_tensors="pt").to("cuda")
+outputs = model.generate(**inputs, max_new_tokens=100)
+print(tokenizer.decode(outputs[0], skip_special_tokens=True))
+```
+
+
+## Notes
+
+- Ensure your Transformers library version is up-to-date. Qwen2 requires Transformers>=4.37.0 for full support.
+
+## Qwen2Config
+
+[[autodoc]] Qwen2Config
+
+## Qwen2Tokenizer
+
+[[autodoc]] Qwen2Tokenizer
+ - save_vocabulary
+
+## Qwen2TokenizerFast
+
+[[autodoc]] Qwen2TokenizerFast
+
+## Qwen2Model
+
+[[autodoc]] Qwen2Model
+ - forward
+
+## Qwen2ForCausalLM
+
+[[autodoc]] Qwen2ForCausalLM
+ - forward
+
+## Qwen2ForSequenceClassification
+
+[[autodoc]] Qwen2ForSequenceClassification
+ - forward
+
+## Qwen2ForTokenClassification
+
+[[autodoc]] Qwen2ForTokenClassification
+ - forward
+
+## Qwen2ForQuestionAnswering
+
+[[autodoc]] Qwen2ForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/qwen2_5_omni.md b/docs/transformers/docs/source/en/model_doc/qwen2_5_omni.md
new file mode 100644
index 0000000000000000000000000000000000000000..3e50d45ee86fe4a05cd11ed6a3ba21f565c72712
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qwen2_5_omni.md
@@ -0,0 +1,400 @@
+
+
+# Qwen2.5-Omni
+
+
+
+
+
+
+
+## Overview
+
+The [Qwen2.5-Omni](https://qwenlm.github.io/blog/) model is a unified multiple modalities model proposed in [Qwen2.5-Omni Technical Report]() from Qwen team, Alibaba Group.
+
+The abstract from the technical report is the following:
+
+*We present Qwen2.5-Omni, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. To enable the streaming of multimodal information inputs, both audio and visual encoders utilize a block-wise processing approach. This strategy effectively decouples the handling of long sequences of multimodal data, assigning the perceptual responsibilities to the multimodal encoder and entrusting the modeling of extended sequences to a large language model. Such a division of labor enhances the fusion of different modalities via the shared attention mechanism. To synchronize the timestamps of video inputs with audio, we organized the audio and video sequentially in an interleaved manner and propose a novel position embedding approach, named TMRoPE (Time-aligned Multimodal RoPE). To concurrently generate text and speech while avoiding interference between the two modalities, we propose Thinker-Talker architecture. In this framework, Thinker functions as a large language model tasked with text generation, while Talker is a dual-track autoregressive model that directly utilizes the hidden representations from the Thinker to produce audio tokens as output. Both the Thinker and Talker models are designed to be trained and inferred in an end-to-end manner. For decoding audio tokens in a streaming manner, we introduce a sliding-window DiT that restricts the receptive field, aiming to reduce the initial package delay. Qwen2.5-Omni outperforms the similarly sized Qwen2-VL and Qwen2-Audio in both image and audio capabilities. Furthermore, Qwen2.5-Omni achieves state-of-the-art performance on multimodal benchmarks like Omni-Bench. Notably, Qwen2.5-Omni is the first open-source model to achieve a level of performance in end-to-end speech instruction following that is comparable to its capabilities with text inputs, as evidenced by benchmarks such as MMLU and GSM8K. As for speech generation, Qwen2.5-Omni’s streaming Talker outperform most existing streaming and non-streaming alternatives in robustness and naturalness.*
+
+
+
+## Notes
+
+- Use [`Qwen2_5OmniForConditionalGeneration`] to generate audio and text output. To generate only one output type, use [`Qwen2_5OmniThinkerForConditionalGeneration`] for text-only and [`Qwen2_5OmniTalkersForConditionalGeneration`] for audio-only outputs.
+- Audio generation with [`Qwen2_5OmniForConditionalGeneration`] supports only single batch size at the moment.
+- In case out out-of-memory errors hwen working with video input, decrease `processor.max_pixels`. By default the maximum is set to a very arge value and high resolution visuals will not be resized, unless resolution exceeds `processor.max_pixels`.
+- The processor has its own [`~ProcessorMixin.apply_chat_template`] method to convert chat messages to model inputs.
+
+
+## Usage example
+
+`Qwen2.5-Omni` can be found on the [Huggingface Hub](https://huggingface.co/Qwen).
+
+### Single Media inference
+
+The model can accept text, images, audio and videos as input. Here's an example code for inference.
+
+```python
+import soundfile as sf
+from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
+
+model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2.5-Omni-7B",
+ torch_dtype="auto",
+ device_map="auto"
+)
+processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
+
+conversation = [
+ {
+ "role": "system",
+ "content": [
+ {"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
+ ],
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "video", "video": "/path/to/video.mp4"},
+ {"type": "text", "text": "What cant you hear and see in this video?"},
+ ],
+ },
+]
+
+inputs = processor.apply_chat_template(
+ conversations,
+ load_audio_from_video=True,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ video_fps=1,
+
+ # kwargs to be passed to `Qwen2-5-OmniProcessor`
+ padding=True,
+ use_audio_in_video=True,
+).to(model.device)
+
+# Generation params for audio or text can be different and have to be prefixed with `thinker_` or `talker_`
+text_ids, audio = model.generate(**inputs, use_audio_in_video=True, thinker_do_sample=False, talker_do_sample=True)
+text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
+
+sf.write(
+ "output.wav",
+ audio.reshape(-1).detach().cpu().numpy(),
+ samplerate=24000,
+)
+print(text)
+```
+
+### Text-only generation
+
+To generate only text output and save compute by not loading the audio generation model, we can use `Qwen2_5OmniThinkerForConditionalGeneration` model.
+
+```python
+from transformers import Qwen2_5OmniThinkerForConditionalGeneration, Qwen2_5OmniProcessor
+
+model = Qwen2_5OmniThinkerForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2.5-Omni-7B",
+ torch_dtype="auto",
+ device_map="auto",
+)
+processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
+
+conversation = [
+ {
+ "role": "system",
+ "content": [
+ {"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
+ ],
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "video", "video": "/path/to/video.mp4"},
+ {"type": "text", "text": "What cant you hear and see in this video?"},
+ ],
+ },
+]
+
+inputs = processor.apply_chat_template(
+ conversations,
+ load_audio_from_video=True,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ video_fps=1,
+
+ # kwargs to be passed to `Qwen2-5-OmniProcessor`
+ padding=True,
+ use_audio_in_video=True,
+).to(model.device)
+
+
+text_ids = model.generate(**inputs, use_audio_in_video=True)
+text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
+
+sf.write(
+ "output.wav",
+ audio.reshape(-1).detach().cpu().numpy(),
+ samplerate=24000,
+)
+print(text)
+```
+
+### Batch Mixed Media Inference
+
+The model can batch inputs composed of mixed samples of various types such as text, images, audio and videos as input when using `Qwen2_5OmniThinkerForConditionalGeneration` model. Here is an example.
+
+```python
+import soundfile as sf
+from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
+
+model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2.5-Omni-7B",
+ torch_dtype="auto",
+ device_map="auto"
+)
+processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
+
+# Conversation with video only
+conversation1 = [
+ {
+ "role": "system",
+ "content": [
+ {"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
+ ],
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "video", "path": "/path/to/video.mp4"},
+ ]
+ }
+]
+
+# Conversation with audio only
+conversation2 = [
+ {
+ "role": "system",
+ "content": [
+ {"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
+ ],
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "audio", "path": "/path/to/audio.wav"},
+ ]
+ }
+]
+
+# Conversation with pure text
+conversation3 = [
+ {
+ "role": "system",
+ "content": [
+ {"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
+ ],
+ },
+ {
+ "role": "user",
+ "content": [{"type": "text", "text": "who are you?"}],
+ }
+]
+
+
+# Conversation with mixed media
+conversation4 = [
+ {
+ "role": "system",
+ "content": [
+ {"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
+ ],
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image.jpg"},
+ {"type": "video", "path": "/path/to/video.mp4"},
+ {"type": "audio", "path": "/path/to/audio.wav"},
+ {"type": "text", "text": "What are the elements can you see and hear in these medias?"},
+ ],
+ }
+]
+
+conversations = [conversation1, conversation2, conversation3, conversation4]
+
+inputs = processor.apply_chat_template(
+ conversations,
+ load_audio_from_video=True,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ video_fps=1,
+
+ # kwargs to be passed to `Qwen2-5-OmniProcessor`
+ padding=True,
+ use_audio_in_video=True,
+).to(model.thinker.device)
+
+text_ids = model.generate(**inputs, use_audio_in_video=True)
+text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
+
+print(text)
+```
+
+### Usage Tips
+
+#### Image Resolution trade-off
+
+The model supports a wide range of resolution inputs. By default, it uses the native resolution for input, but higher resolutions can enhance performance at the cost of more computation. Users can set the minimum and maximum number of pixels to achieve an optimal configuration for their needs.
+
+```python
+min_pixels = 128*28*28
+max_pixels = 768*28*28
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+
+#### Prompt for audio output
+If users need audio output, the system prompt must be set as "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.", otherwise the audio output may not work as expected.
+```
+{
+ "role": "system",
+ "content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
+}
+```
+
+#### Use audio output or not
+
+The model supports both text and audio outputs, if users do not need audio outputs, they can set `enable_audio_output` in the `from_pretrained` function. This option will save about `~2GB` of GPU memory but the `return_audio` option for `generate` function will only allow to be set at `False`.
+```python
+model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2.5-Omni-7B",
+ torch_dtype="auto",
+ device_map="auto",
+ enable_audio_output=False,
+)
+```
+
+In order to obtain a flexible experience, we recommend that users set `enable_audio_output` at `True` when initializing the model through `from_pretrained` function, and then decide whether to return audio when `generate` function is called. When `return_audio` is set to `False`, the model will only return text outputs to get text responses faster.
+
+```python
+model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2.5-Omni-7B",
+ torch_dtype="auto",
+ device_map="auto",
+ enable_audio_output=True,
+)
+...
+text_ids = model.generate(**inputs, return_audio=False)
+```
+
+#### Change voice type of output audio
+Qwen2.5-Omni supports the ability to change the voice of the output audio. Users can use the `spk` parameter of `generate` function to specify the voice type. The `"Qwen/Qwen2.5-Omni-7B"` checkpoint support two voice types: `Chelsie` and `Ethan`, while `Chelsie` is a female voice and `Ethan` is a male voice. By defalut, if `spk` is not specified, the default voice type is `Chelsie`.
+
+```python
+text_ids, audio = model.generate(**inputs, spk="Chelsie")
+```
+
+```python
+text_ids, audio = model.generate(**inputs, spk="Ethan")
+```
+
+#### Flash-Attention 2 to speed up generation
+
+First, make sure to install the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Also, you should have hardware that is compatible with FlashAttention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). FlashAttention-2 can only be used when a model is loaded in `torch.float16` or `torch.bfloat16`.
+
+To load and run a model using FlashAttention-2, add `attn_implementation="flash_attention_2"` when loading the model:
+
+```python
+from transformers import Qwen2_5OmniForConditionalGeneration
+
+model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2.5-Omni-7B",
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+```
+
+
+
+## Qwen2_5OmniConfig
+
+[[autodoc]] Qwen2_5OmniConfig
+
+## Qwen2_5OmniProcessor
+
+[[autodoc]] Qwen2_5OmniProcessor
+
+## Qwen2_5OmniForConditionalGeneration
+
+[[autodoc]] Qwen2_5OmniForConditionalGeneration
+ - forward
+
+## Qwen2_5OmniPreTrainedModelForConditionalGeneration
+
+[[autodoc]] Qwen2_5OmniPreTrainedModelForConditionalGeneration
+
+## Qwen2_5OmniThinkerConfig
+
+[[autodoc]] Qwen2_5OmniThinkerConfig
+
+## Qwen2_5OmniThinkerForConditionalGeneration
+
+[[autodoc]] Qwen2_5OmniThinkerForConditionalGeneration
+
+## Qwen2_5OmniThinkerTextModel
+
+[[autodoc]] Qwen2_5OmniThinkerTextModel
+
+## Qwen2_5OmniTalkerConfig
+
+[[autodoc]] Qwen2_5OmniTalkerConfig
+
+## Qwen2_5OmniTalkerForConditionalGeneration
+
+[[autodoc]] Qwen2_5OmniTalkerForConditionalGeneration
+
+## Qwen2_5OmniTalkerModel
+
+[[autodoc]] Qwen2_5OmniTalkerModel
+
+## Qwen2_5OmniToken2WavConfig
+
+[[autodoc]] Qwen2_5OmniToken2WavConfig
+
+## Qwen2_5OmniToken2WavModel
+
+[[autodoc]] Qwen2_5OmniToken2WavModel
+
+## Qwen2_5OmniToken2WavDiTModel
+
+[[autodoc]] Qwen2_5OmniToken2WavDiTModel
+
+## Qwen2_5OmniToken2WavBigVGANModel
+
+[[autodoc]] Qwen2_5OmniToken2WavBigVGANModel
diff --git a/docs/transformers/docs/source/en/model_doc/qwen2_5_vl.md b/docs/transformers/docs/source/en/model_doc/qwen2_5_vl.md
new file mode 100644
index 0000000000000000000000000000000000000000..2fb2eadc53ebf881a203c1e68250263ca55ef6ff
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qwen2_5_vl.md
@@ -0,0 +1,252 @@
+
+
+
+
+
+
+
+
+
+# Qwen2.5-VL
+
+[Qwen2.5-VL](https://huggingface.co/papers/2502.13923) is a multimodal vision-language model, available in 3B, 7B, and 72B parameters, pretrained on 4.1T tokens. The model introduces window attention in the ViT encoder to accelerate training and inference, dynamic FPS sampling on the spatial and temporal dimensions for better video understanding across different sampling rates, and an upgraded MRoPE (multi-resolutional rotary positional encoding) mechanism to better capture and learn temporal dynamics.
+
+
+You can find all the original Qwen2.5-VL checkpoints under the [Qwen2.5-VL](https://huggingface.co/collections/Qwen/qwen25-vl-6795ffac22b334a837c0f9a5) collection.
+
+> [!TIP]
+> Click on the Qwen2.5-VL models in the right sidebar for more examples of how to apply Qwen2.5-VL to different vision and language tasks.
+
+The example below demonstrates how to generate text based on an image with [`Pipeline`] or the [`AutoModel`] class.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+pipe = pipeline(
+ task="image-text-to-text",
+ model="Qwen/Qwen2.5-VL-7B-Instruct",
+ device=0,
+ torch_dtype=torch.bfloat16
+)
+messages = [
+ {
+ "role": "user",
+ "content": [
+ {
+ "type": "image",
+ "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg",
+ },
+ { "type": "text", "text": "Describe this image."},
+ ]
+ }
+]
+pipe(text=messages,max_new_tokens=20, return_full_text=False)
+
+```
+
+
+
+
+```py
+import torch
+from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
+
+model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2.5-VL-7B-Instruct",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ attn_implementation="sdpa"
+)
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
+messages = [
+ {
+ "role":"user",
+ "content":[
+ {
+ "type":"image",
+ "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+ },
+ {
+ "type":"text",
+ "text":"Describe this image."
+ }
+ ]
+ }
+
+]
+
+inputs = processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to("cuda")
+
+generated_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids_trimmed = [
+ out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
+]
+output_text = processor.batch_decode(
+ generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
+)
+print(output_text)
+```
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [torchao](../quantization/torchao) to only quantize the weights to int4.
+
+```python
+import torch
+from transformers import TorchAoConfig, Gemma3ForConditionalGeneration, AutoProcessor
+
+quantization_config = TorchAoConfig("int4_weight_only", group_size=128)
+model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2.5-VL-7B-Instruct",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ quantization_config=quantization_config
+)
+
+```
+### Notes
+
+- Use Qwen2.5-VL for video inputs by setting `"type": "video"` as shown below.
+ ```python
+ conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "video", "path": "/path/to/video.mp4"},
+ {"type": "text", "text": "What happened in the video?"},
+ ],
+ }
+ ]
+
+ inputs = processor.apply_chat_template(
+ conversation,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+ ).to(model.device)
+
+ # Inference: Generation of the output
+ output_ids = model.generate(**inputs, max_new_tokens=128)
+ generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+ output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+ print(output_text)
+ ```
+- Use Qwen2.5-VL for a mixed batch of inputs (images, videos, text). Add labels when handling multiple images or videos for better reference
+ as show below.
+ ```python
+ import torch
+ from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
+
+ model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2.5-VL-7B-Instruct",
+ torch_dtype=torch.float16,
+ device_map="auto",
+ attn_implementation="sdpa"
+ )
+ processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
+ conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "Hello, how are you?"}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'm doing well, thank you for asking. How can I assist you today?"
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Can you describe these images and video?"},
+ {"type": "image"},
+ {"type": "image"},
+ {"type": "video"},
+ {"type": "text", "text": "These are from my vacation."}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'd be happy to describe the images and video for you. Could you please provide more context about your vacation?"
+ },
+ {
+ "role": "user",
+ "content": "It was a trip to the mountains. Can you see the details in the images and video?"
+ }
+ ]
+
+ # default:
+ prompt_without_id = processor.apply_chat_template(conversation, add_generation_prompt=True)
+ # Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?<|vision_start|><|image_pad|><|vision_end|><|vision_start|><|image_pad|><|vision_end|><|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+
+ # add ids
+ prompt_with_id = processor.apply_chat_template(conversation, add_generation_prompt=True, add_vision_id=True)
+ # Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nPicture 1: <|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?Picture 2: <|vision_start|><|image_pad|><|vision_end|>Picture 3: <|vision_start|><|image_pad|><|vision_end|>Video 1: <|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+ ```
+
+- Use the `min_pixels` and `max_pixels` parameters in [`AutoProcessor`] to set the resolution.
+
+ ```python
+ min_pixels = 224*224
+ max_pixels = 2048*2048
+ processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+ ```
+
+ Higher resolution can require more compute whereas reducing the resolution can save memory as follows:
+
+ ```python
+ min_pixels = 256*28*28
+ max_pixels = 1024*28*28
+ processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+ ```
+## Qwen2_5_VLConfig
+
+[[autodoc]] Qwen2_5_VLConfig
+
+## Qwen2_5_VLTextConfig
+
+[[autodoc]] Qwen2_5_VLTextConfig
+
+## Qwen2_5_VLProcessor
+
+[[autodoc]] Qwen2_5_VLProcessor
+
+
+## Qwen2_5_VLModel
+
+[[autodoc]] Qwen2_5_VLModel
+ - forward
+
+## Qwen2_5_VLForConditionalGeneration
+
+[[autodoc]] Qwen2_5_VLForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/qwen2_audio.md b/docs/transformers/docs/source/en/model_doc/qwen2_audio.md
new file mode 100644
index 0000000000000000000000000000000000000000..e53f94b10eb111e526869dd7bd84461b91763b95
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qwen2_audio.md
@@ -0,0 +1,240 @@
+
+
+# Qwen2Audio
+
+
+
+
+
+
+
+## Overview
+
+The Qwen2-Audio is the new model series of large audio-language models from the Qwen team. Qwen2-Audio is capable of accepting various audio signal inputs and performing audio analysis or direct textual responses with regard to speech instructions. We introduce two distinct audio interaction modes:
+
+* voice chat: users can freely engage in voice interactions with Qwen2-Audio without text input
+* audio analysis: users could provide audio and text instructions for analysis during the interaction
+
+It was proposed in [Qwen2-Audio Technical Report](https://arxiv.org/abs/2407.10759) by Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, Jingren Zhou.
+
+The abstract from the paper is the following:
+
+*We introduce the latest progress of Qwen-Audio, a large-scale audio-language model called Qwen2-Audio, which is capable of accepting various audio signal inputs and performing audio analysis or direct textual responses with regard to speech instructions. In contrast to complex hierarchical tags, we have simplified the pre-training process by utilizing natural language prompts for different data and tasks, and have further expanded the data volume. We have boosted the instruction-following capability of Qwen2-Audio and implemented two distinct audio interaction modes for voice chat and audio analysis. In the voice chat mode, users can freely engage in voice interactions with Qwen2-Audio without text input. In the audio analysis mode, users could provide audio and text instructions for analysis during the interaction. Note that we do not use any system prompts to switch between voice chat and audio analysis modes. Qwen2-Audio is capable of intelligently comprehending the content within audio and following voice commands to respond appropriately. For instance, in an audio segment that simultaneously contains sounds, multi-speaker conversations, and a voice command, Qwen2-Audio can directly understand the command and provide an interpretation and response to the audio. Additionally, DPO has optimized the model's performance in terms of factuality and adherence to desired behavior. According to the evaluation results from AIR-Bench, Qwen2-Audio outperformed previous SOTAs, such as Gemini-1.5-pro, in tests focused on audio-centric instruction-following capabilities. Qwen2-Audio is open-sourced with the aim of fostering the advancement of the multi-modal language community. *
+
+
+## Usage tips
+
+`Qwen2-Audio-7B` and `Qwen2-Audio-7B-Instruct` can be found on the [Huggingface Hub](https://huggingface.co/Qwen)
+
+### Inference
+
+```python
+from io import BytesIO
+from urllib.request import urlopen
+import librosa
+from transformers import AutoProcessor, Qwen2AudioForConditionalGeneration
+
+model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B", trust_remote_code=True, device_map="auto")
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B", trust_remote_code=True)
+
+prompt = "<|audio_bos|><|AUDIO|><|audio_eos|>Generate the caption in English:"
+url = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Audio/glass-breaking-151256.mp3"
+audio, sr = librosa.load(BytesIO(urlopen(url).read()), sr=processor.feature_extractor.sampling_rate)
+inputs = processor(text=prompt, audios=audio, return_tensors="pt").to(model.device)
+
+generate_ids = model.generate(**inputs, max_length=256)
+generate_ids = generate_ids[:, inputs.input_ids.size(1):]
+
+response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+
+# We can also omit the audio_bos and audio_eos tokens
+prompt = "<|AUDIO|>Generate the caption in English:"
+inputs = processor(text=prompt, audios=audio, return_tensors="pt").to(model.device)
+
+generate_ids = model.generate(**inputs, max_length=256)
+generate_ids = generate_ids[:, inputs.input_ids.size(1):]
+
+response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+```
+
+In the following, we demonstrate how to use `Qwen2-Audio-7B-Instruct` for the inference, supporting both voice chat and audio analysis modes. Note that we have used the ChatML format for dialog, in this demo we show how to leverage `apply_chat_template` for this purpose.
+
+### Voice Chat Inference
+In the voice chat mode, users can freely engage in voice interactions with Qwen2-Audio without text input:
+```python
+from io import BytesIO
+from urllib.request import urlopen
+import librosa
+from transformers import Qwen2AudioForConditionalGeneration, AutoProcessor
+
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
+model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct", device_map="auto")
+
+conversation = [
+ {"role": "user", "content": [
+ {"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/guess_age_gender.wav"},
+ ]},
+ {"role": "assistant", "content": "Yes, the speaker is female and in her twenties."},
+ {"role": "user", "content": [
+ {"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/translate_to_chinese.wav"},
+ ]},
+]
+text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
+audios = []
+for message in conversation:
+ if isinstance(message["content"], list):
+ for ele in message["content"]:
+ if ele["type"] == "audio":
+ audios.append(librosa.load(
+ BytesIO(urlopen(ele['audio_url']).read()),
+ sr=processor.feature_extractor.sampling_rate)[0]
+ )
+
+inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)
+inputs.input_ids = inputs.input_ids.to("cuda")
+
+generate_ids = model.generate(**inputs, max_length=256)
+generate_ids = generate_ids[:, inputs.input_ids.size(1):]
+
+response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+```
+
+### Audio Analysis Inference
+In the audio analysis, users could provide both audio and text instructions for analysis:
+```python
+from io import BytesIO
+from urllib.request import urlopen
+import librosa
+from transformers import Qwen2AudioForConditionalGeneration, AutoProcessor
+
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
+model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct", device_map="auto")
+
+conversation = [
+ {'role': 'system', 'content': 'You are a helpful assistant.'},
+ {"role": "user", "content": [
+ {"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3"},
+ {"type": "text", "text": "What's that sound?"},
+ ]},
+ {"role": "assistant", "content": "It is the sound of glass shattering."},
+ {"role": "user", "content": [
+ {"type": "text", "text": "What can you do when you hear that?"},
+ ]},
+ {"role": "assistant", "content": "Stay alert and cautious, and check if anyone is hurt or if there is any damage to property."},
+ {"role": "user", "content": [
+ {"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac"},
+ {"type": "text", "text": "What does the person say?"},
+ ]},
+]
+text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
+audios = []
+for message in conversation:
+ if isinstance(message["content"], list):
+ for ele in message["content"]:
+ if ele["type"] == "audio":
+ audios.append(
+ librosa.load(
+ BytesIO(urlopen(ele['audio_url']).read()),
+ sr=processor.feature_extractor.sampling_rate)[0]
+ )
+
+inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)
+inputs.input_ids = inputs.input_ids.to("cuda")
+
+generate_ids = model.generate(**inputs, max_length=256)
+generate_ids = generate_ids[:, inputs.input_ids.size(1):]
+
+response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+```
+
+### Batch Inference
+We also support batch inference:
+```python
+from io import BytesIO
+from urllib.request import urlopen
+import librosa
+from transformers import Qwen2AudioForConditionalGeneration, AutoProcessor
+
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
+model = Qwen2AudioForConditionalGeneration.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct", device_map="auto")
+
+conversation1 = [
+ {"role": "user", "content": [
+ {"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3"},
+ {"type": "text", "text": "What's that sound?"},
+ ]},
+ {"role": "assistant", "content": "It is the sound of glass shattering."},
+ {"role": "user", "content": [
+ {"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/f2641_0_throatclearing.wav"},
+ {"type": "text", "text": "What can you hear?"},
+ ]}
+]
+
+conversation2 = [
+ {"role": "user", "content": [
+ {"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac"},
+ {"type": "text", "text": "What does the person say?"},
+ ]},
+]
+
+conversations = [conversation1, conversation2]
+
+text = [processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False) for conversation in conversations]
+
+audios = []
+for conversation in conversations:
+ for message in conversation:
+ if isinstance(message["content"], list):
+ for ele in message["content"]:
+ if ele["type"] == "audio":
+ audios.append(
+ librosa.load(
+ BytesIO(urlopen(ele['audio_url']).read()),
+ sr=processor.feature_extractor.sampling_rate)[0]
+ )
+
+inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True)
+inputs['input_ids'] = inputs['input_ids'].to("cuda")
+inputs.input_ids = inputs.input_ids.to("cuda")
+
+generate_ids = model.generate(**inputs, max_length=256)
+generate_ids = generate_ids[:, inputs.input_ids.size(1):]
+
+response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
+```
+
+## Qwen2AudioConfig
+
+[[autodoc]] Qwen2AudioConfig
+
+## Qwen2AudioEncoderConfig
+
+[[autodoc]] Qwen2AudioEncoderConfig
+
+## Qwen2AudioProcessor
+
+[[autodoc]] Qwen2AudioProcessor
+
+## Qwen2AudioEncoder
+
+[[autodoc]] Qwen2AudioEncoder
+ - forward
+
+## Qwen2AudioForConditionalGeneration
+
+[[autodoc]] Qwen2AudioForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/qwen2_moe.md b/docs/transformers/docs/source/en/model_doc/qwen2_moe.md
new file mode 100644
index 0000000000000000000000000000000000000000..eaaa66aedf7a70f2801b3d818746729442dd3c30
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qwen2_moe.md
@@ -0,0 +1,93 @@
+
+
+# Qwen2MoE
+
+
+
+
+
+
+
+## Overview
+
+Qwen2MoE is the new model series of large language models from the Qwen team. Previously, we released the Qwen series, including Qwen-72B, Qwen-1.8B, Qwen-VL, Qwen-Audio, etc.
+
+### Model Details
+
+Qwen2MoE is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. Qwen2MoE has the following architectural choices:
+
+- Qwen2MoE is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes.
+- Qwen2MoE employs Mixture of Experts (MoE) architecture, where the models are upcycled from dense language models. For instance, `Qwen1.5-MoE-A2.7B` is upcycled from `Qwen-1.8B`. It has 14.3B parameters in total and 2.7B activated parameters during runtime, while it achieves comparable performance with `Qwen1.5-7B`, with only 25% of the training resources.
+
+For more details refer to the [release blog post](https://qwenlm.github.io/blog/qwen-moe/).
+
+## Usage tips
+
+`Qwen1.5-MoE-A2.7B` and `Qwen1.5-MoE-A2.7B-Chat` can be found on the [Huggingface Hub](https://huggingface.co/Qwen)
+
+In the following, we demonstrate how to use `Qwen1.5-MoE-A2.7B-Chat` for the inference. Note that we have used the ChatML format for dialog, in this demo we show how to leverage `apply_chat_template` for this purpose.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen1.5-MoE-A2.7B-Chat", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-MoE-A2.7B-Chat")
+
+>>> prompt = "Give me a short introduction to large language model."
+
+>>> messages = [{"role": "user", "content": prompt}]
+
+>>> text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
+
+>>> model_inputs = tokenizer([text], return_tensors="pt").to(device)
+
+>>> generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=True)
+
+>>> generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
+
+>>> response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+```
+
+## Qwen2MoeConfig
+
+[[autodoc]] Qwen2MoeConfig
+
+## Qwen2MoeModel
+
+[[autodoc]] Qwen2MoeModel
+ - forward
+
+## Qwen2MoeForCausalLM
+
+[[autodoc]] Qwen2MoeForCausalLM
+ - forward
+
+## Qwen2MoeForSequenceClassification
+
+[[autodoc]] Qwen2MoeForSequenceClassification
+ - forward
+
+## Qwen2MoeForTokenClassification
+
+[[autodoc]] Qwen2MoeForTokenClassification
+ - forward
+
+## Qwen2MoeForQuestionAnswering
+
+[[autodoc]] Qwen2MoeForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/qwen2_vl.md b/docs/transformers/docs/source/en/model_doc/qwen2_vl.md
new file mode 100644
index 0000000000000000000000000000000000000000..3d1845b6015058d01f9b49b509ecdf8b7f605c43
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qwen2_vl.md
@@ -0,0 +1,307 @@
+
+
+# Qwen2-VL
+
+
+
+
+
+
+## Overview
+
+The [Qwen2-VL](https://qwenlm.github.io/blog/qwen2-vl/) model is a major update to [Qwen-VL](https://arxiv.org/pdf/2308.12966) from the Qwen team at Alibaba Research.
+
+The abstract from the blog is the following:
+
+*This blog introduces Qwen2-VL, an advanced version of the Qwen-VL model that has undergone significant enhancements over the past year. Key improvements include enhanced image comprehension, advanced video understanding, integrated visual agent functionality, and expanded multilingual support. The model architecture has been optimized for handling arbitrary image resolutions through Naive Dynamic Resolution support and utilizes Multimodal Rotary Position Embedding (M-ROPE) to effectively process both 1D textual and multi-dimensional visual data. This updated model demonstrates competitive performance against leading AI systems like GPT-4o and Claude 3.5 Sonnet in vision-related tasks and ranks highly among open-source models in text capabilities. These advancements make Qwen2-VL a versatile tool for various applications requiring robust multimodal processing and reasoning abilities.*
+
+
+
+ Qwen2-VL architecture. Taken from the blog post.
+
+This model was contributed by [simonJJJ](https://huggingface.co/simonJJJ).
+
+## Usage example
+
+### Single Media inference
+
+The model can accept both images and videos as input. Here's an example code for inference.
+
+```python
+
+import torch
+from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
+
+# Load the model in half-precision on the available device(s)
+model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", device_map="auto")
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
+
+
+conversation = [
+ {
+ "role":"user",
+ "content":[
+ {
+ "type":"image",
+ "url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"
+ },
+ {
+ "type":"text",
+ "text":"Describe this image."
+ }
+ ]
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+# Inference: Generation of the output
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+
+
+
+# Video
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "video", "path": "/path/to/video.mp4"},
+ {"type": "text", "text": "What happened in the video?"},
+ ],
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+
+# Inference: Generation of the output
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+```
+
+### Batch Mixed Media Inference
+
+The model can batch inputs composed of mixed samples of various types such as images, videos, and text. Here is an example.
+
+```python
+
+# Conversation for the first image
+conversation1 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image1.jpg"},
+ {"type": "text", "text": "Describe this image."}
+ ]
+ }
+]
+
+# Conversation with two images
+conversation2 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image2.jpg"},
+ {"type": "image", "path": "/path/to/image3.jpg"},
+ {"type": "text", "text": "What is written in the pictures?"}
+ ]
+ }
+]
+
+# Conversation with pure text
+conversation3 = [
+ {
+ "role": "user",
+ "content": "who are you?"
+ }
+]
+
+
+# Conversation with mixed midia
+conversation4 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image3.jpg"},
+ {"type": "image", "path": "/path/to/image4.jpg"},
+ {"type": "video", "path": "/path/to/video.jpg"},
+ {"type": "text", "text": "What are the common elements in these medias?"},
+ ],
+ }
+]
+
+conversations = [conversation1, conversation2, conversation3, conversation4]
+# Preparation for batch inference
+ipnuts = processor.apply_chat_template(
+ conversations,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+
+# Batch Inference
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+```
+
+### Usage Tips
+
+#### Image Resolution trade-off
+
+The model supports a wide range of resolution inputs. By default, it uses the native resolution for input, but higher resolutions can enhance performance at the cost of more computation. Users can set the minimum and maximum number of pixels to achieve an optimal configuration for their needs.
+
+```python
+min_pixels = 224*224
+max_pixels = 2048*2048
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+
+In case of limited GPU RAM, one can reduce the resolution as follows:
+
+```python
+min_pixels = 256*28*28
+max_pixels = 1024*28*28
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+This ensures each image gets encoded using a number between 256-1024 tokens. The 28 comes from the fact that the model uses a patch size of 14 and a temporal patch size of 2 (14 x 2 = 28).
+
+
+#### Multiple Image Inputs
+
+By default, images and video content are directly included in the conversation. When handling multiple images, it's helpful to add labels to the images and videos for better reference. Users can control this behavior with the following settings:
+
+```python
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "Hello, how are you?"}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'm doing well, thank you for asking. How can I assist you today?"
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Can you describe these images and video?"},
+ {"type": "image"},
+ {"type": "image"},
+ {"type": "video"},
+ {"type": "text", "text": "These are from my vacation."}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'd be happy to describe the images and video for you. Could you please provide more context about your vacation?"
+ },
+ {
+ "role": "user",
+ "content": "It was a trip to the mountains. Can you see the details in the images and video?"
+ }
+]
+
+# default:
+prompt_without_id = processor.apply_chat_template(conversation, add_generation_prompt=True)
+# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?<|vision_start|><|image_pad|><|vision_end|><|vision_start|><|image_pad|><|vision_end|><|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+
+# add ids
+prompt_with_id = processor.apply_chat_template(conversation, add_generation_prompt=True, add_vision_id=True)
+# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nPicture 1: <|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?Picture 2: <|vision_start|><|image_pad|><|vision_end|>Picture 3: <|vision_start|><|image_pad|><|vision_end|>Video 1: <|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+```
+
+#### Flash-Attention 2 to speed up generation
+
+First, make sure to install the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Also, you should have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). FlashAttention-2 can only be used when a model is loaded in `torch.float16` or `torch.bfloat16`.
+
+To load and run a model using Flash Attention-2, simply add `attn_implementation="flash_attention_2"` when loading the model as follows:
+
+```python
+from transformers import Qwen2VLForConditionalGeneration
+
+model = Qwen2VLForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2-VL-7B-Instruct",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+```
+
+## Qwen2VLConfig
+
+[[autodoc]] Qwen2VLConfig
+
+## Qwen2VLTextConfig
+
+[[autodoc]] Qwen2VLTextConfig
+
+## Qwen2VLImageProcessor
+
+[[autodoc]] Qwen2VLImageProcessor
+ - preprocess
+
+## Qwen2VLImageProcessorFast
+
+[[autodoc]] Qwen2VLImageProcessorFast
+ - preprocess
+
+## Qwen2VLProcessor
+
+[[autodoc]] Qwen2VLProcessor
+
+## Qwen2VLModel
+
+[[autodoc]] Qwen2VLModel
+ - forward
+
+## Qwen2VLForConditionalGeneration
+
+[[autodoc]] Qwen2VLForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/qwen3.md b/docs/transformers/docs/source/en/model_doc/qwen3.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3f3c266091380544a6e85e7913935d5b53f3126
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qwen3.md
@@ -0,0 +1,59 @@
+
+
+# Qwen3
+
+## Overview
+
+To be released with the official model launch.
+
+### Model Details
+
+To be released with the official model launch.
+
+
+## Usage tips
+
+To be released with the official model launch.
+
+## Qwen3Config
+
+[[autodoc]] Qwen3Config
+
+## Qwen3Model
+
+[[autodoc]] Qwen3Model
+ - forward
+
+## Qwen3ForCausalLM
+
+[[autodoc]] Qwen3ForCausalLM
+ - forward
+
+## Qwen3ForSequenceClassification
+
+[[autodoc]] Qwen3ForSequenceClassification
+ - forward
+
+## Qwen3ForTokenClassification
+
+[[autodoc]] Qwen3ForTokenClassification
+ - forward
+
+## Qwen3ForQuestionAnswering
+
+[[autodoc]] Qwen3ForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/qwen3_moe.md b/docs/transformers/docs/source/en/model_doc/qwen3_moe.md
new file mode 100644
index 0000000000000000000000000000000000000000..1de4af1a5bdf04d554ba0325f589fe833c7c0bd0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qwen3_moe.md
@@ -0,0 +1,58 @@
+
+
+# Qwen3MoE
+
+## Overview
+
+To be released with the official model launch.
+
+### Model Details
+
+To be released with the official model launch.
+
+## Usage tips
+
+To be released with the official model launch.
+
+## Qwen3MoeConfig
+
+[[autodoc]] Qwen3MoeConfig
+
+## Qwen3MoeModel
+
+[[autodoc]] Qwen3MoeModel
+ - forward
+
+## Qwen3MoeForCausalLM
+
+[[autodoc]] Qwen3MoeForCausalLM
+ - forward
+
+## Qwen3MoeForSequenceClassification
+
+[[autodoc]] Qwen3MoeForSequenceClassification
+ - forward
+
+## Qwen3MoeForTokenClassification
+
+[[autodoc]] Qwen3MoeForTokenClassification
+ - forward
+
+## Qwen3MoeForQuestionAnswering
+
+[[autodoc]] Qwen3MoeForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/rag.md b/docs/transformers/docs/source/en/model_doc/rag.md
new file mode 100644
index 0000000000000000000000000000000000000000..8b65da43a22eaa3c281fcdfccd05838809983b89
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/rag.md
@@ -0,0 +1,121 @@
+
+
+# RAG
+
+
+
+
+
+
+
+## Overview
+
+Retrieval-augmented generation ("RAG") models combine the powers of pretrained dense retrieval (DPR) and
+sequence-to-sequence models. RAG models retrieve documents, pass them to a seq2seq model, then marginalize to generate
+outputs. The retriever and seq2seq modules are initialized from pretrained models, and fine-tuned jointly, allowing
+both retrieval and generation to adapt to downstream tasks.
+
+It is based on the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir
+Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
+
+The abstract from the paper is the following:
+
+*Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve
+state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely
+manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind
+task-specific architectures. Additionally, providing provenance for their decisions and updating their world knowledge
+remain open research problems. Pre-trained models with a differentiable access mechanism to explicit nonparametric
+memory can overcome this issue, but have so far been only investigated for extractive downstream tasks. We explore a
+general-purpose fine-tuning recipe for retrieval-augmented generation (RAG) — models which combine pre-trained
+parametric and non-parametric memory for language generation. We introduce RAG models where the parametric memory is a
+pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a
+pre-trained neural retriever. We compare two RAG formulations, one which conditions on the same retrieved passages
+across the whole generated sequence, the other can use different passages per token. We fine-tune and evaluate our
+models on a wide range of knowledge-intensive NLP tasks and set the state-of-the-art on three open domain QA tasks,
+outperforming parametric seq2seq models and task-specific retrieve-and-extract architectures. For language generation
+tasks, we find that RAG models generate more specific, diverse and factual language than a state-of-the-art
+parametric-only seq2seq baseline.*
+
+This model was contributed by [ola13](https://huggingface.co/ola13).
+
+## Usage tips
+
+Retrieval-augmented generation ("RAG") models combine the powers of pretrained dense retrieval (DPR) and Seq2Seq models.
+RAG models retrieve docs, pass them to a seq2seq model, then marginalize to generate outputs. The retriever and seq2seq
+modules are initialized from pretrained models, and fine-tuned jointly, allowing both retrieval and generation to adapt
+to downstream tasks.
+
+## RagConfig
+
+[[autodoc]] RagConfig
+
+## RagTokenizer
+
+[[autodoc]] RagTokenizer
+
+## Rag specific outputs
+
+[[autodoc]] models.rag.modeling_rag.RetrievAugLMMarginOutput
+
+[[autodoc]] models.rag.modeling_rag.RetrievAugLMOutput
+
+## RagRetriever
+
+[[autodoc]] RagRetriever
+
+
+
+
+## RagModel
+
+[[autodoc]] RagModel
+ - forward
+
+## RagSequenceForGeneration
+
+[[autodoc]] RagSequenceForGeneration
+ - forward
+ - generate
+
+## RagTokenForGeneration
+
+[[autodoc]] RagTokenForGeneration
+ - forward
+ - generate
+
+
+
+
+## TFRagModel
+
+[[autodoc]] TFRagModel
+ - call
+
+## TFRagSequenceForGeneration
+
+[[autodoc]] TFRagSequenceForGeneration
+ - call
+ - generate
+
+## TFRagTokenForGeneration
+
+[[autodoc]] TFRagTokenForGeneration
+ - call
+ - generate
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/realm.md b/docs/transformers/docs/source/en/model_doc/realm.md
new file mode 100644
index 0000000000000000000000000000000000000000..b5b9102c2c64b265ecdeb9b61981012095fc2191
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/realm.md
@@ -0,0 +1,101 @@
+
+
+# REALM
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+The REALM model was proposed in [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang. It's a
+retrieval-augmented language model that firstly retrieves documents from a textual knowledge corpus and then
+utilizes retrieved documents to process question answering tasks.
+
+The abstract from the paper is the following:
+
+*Language model pre-training has been shown to capture a surprising amount of world knowledge, crucial for NLP tasks
+such as question answering. However, this knowledge is stored implicitly in the parameters of a neural network,
+requiring ever-larger networks to cover more facts. To capture knowledge in a more modular and interpretable way, we
+augment language model pre-training with a latent knowledge retriever, which allows the model to retrieve and attend
+over documents from a large corpus such as Wikipedia, used during pre-training, fine-tuning and inference. For the
+first time, we show how to pre-train such a knowledge retriever in an unsupervised manner, using masked language
+modeling as the learning signal and backpropagating through a retrieval step that considers millions of documents. We
+demonstrate the effectiveness of Retrieval-Augmented Language Model pre-training (REALM) by fine-tuning on the
+challenging task of Open-domain Question Answering (Open-QA). We compare against state-of-the-art models for both
+explicit and implicit knowledge storage on three popular Open-QA benchmarks, and find that we outperform all previous
+methods by a significant margin (4-16% absolute accuracy), while also providing qualitative benefits such as
+interpretability and modularity.*
+
+This model was contributed by [qqaatw](https://huggingface.co/qqaatw). The original code can be found
+[here](https://github.com/google-research/language/tree/master/language/realm).
+
+## RealmConfig
+
+[[autodoc]] RealmConfig
+
+## RealmTokenizer
+
+[[autodoc]] RealmTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+ - batch_encode_candidates
+
+## RealmTokenizerFast
+
+[[autodoc]] RealmTokenizerFast
+ - batch_encode_candidates
+
+## RealmRetriever
+
+[[autodoc]] RealmRetriever
+
+## RealmEmbedder
+
+[[autodoc]] RealmEmbedder
+ - forward
+
+## RealmScorer
+
+[[autodoc]] RealmScorer
+ - forward
+
+## RealmKnowledgeAugEncoder
+
+[[autodoc]] RealmKnowledgeAugEncoder
+ - forward
+
+## RealmReader
+
+[[autodoc]] RealmReader
+ - forward
+
+## RealmForOpenQA
+
+[[autodoc]] RealmForOpenQA
+ - block_embedding_to
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/recurrent_gemma.md b/docs/transformers/docs/source/en/model_doc/recurrent_gemma.md
new file mode 100644
index 0000000000000000000000000000000000000000..b543b35a75f03deeae69ac087668a4649c2edafe
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/recurrent_gemma.md
@@ -0,0 +1,52 @@
+
+
+# RecurrentGemma
+
+
+
+
+
+## Overview
+
+The Recurrent Gemma model was proposed in [RecurrentGemma: Moving Past Transformers for Efficient Open Language Models](https://storage.googleapis.com/deepmind-media/gemma/recurrentgemma-report.pdf) by the Griffin, RLHF and Gemma Teams of Google.
+
+The abstract from the paper is the following:
+
+*We introduce RecurrentGemma, an open language model which uses Google’s novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.*
+
+Tips:
+
+- The original checkpoints can be converted using the conversion script [`src/transformers/models/recurrent_gemma/convert_recurrent_gemma_weights_to_hf.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/recurrent_gemma/convert_recurrent_gemma_to_hf.py).
+
+This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ). The original code can be found [here](https://github.com/google-deepmind/recurrentgemma).
+
+
+## RecurrentGemmaConfig
+
+[[autodoc]] RecurrentGemmaConfig
+
+
+## RecurrentGemmaModel
+
+[[autodoc]] RecurrentGemmaModel
+ - forward
+
+## RecurrentGemmaForCausalLM
+
+[[autodoc]] RecurrentGemmaForCausalLM
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/reformer.md b/docs/transformers/docs/source/en/model_doc/reformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..7e403599fdb0b74ebd354c02ffb850dd28053b36
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/reformer.md
@@ -0,0 +1,194 @@
+
+
+# Reformer
+
+
+
+
+
+## Overview
+
+The Reformer model was proposed in the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451.pdf) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+
+The abstract from the paper is the following:
+
+*Large Transformer models routinely achieve state-of-the-art results on a number of tasks but training these models can
+be prohibitively costly, especially on long sequences. We introduce two techniques to improve the efficiency of
+Transformers. For one, we replace dot-product attention by one that uses locality-sensitive hashing, changing its
+complexity from O(L^2) to O(Llog(L)), where L is the length of the sequence. Furthermore, we use reversible residual
+layers instead of the standard residuals, which allows storing activations only once in the training process instead of
+N times, where N is the number of layers. The resulting model, the Reformer, performs on par with Transformer models
+while being much more memory-efficient and much faster on long sequences.*
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/google/trax/tree/master/trax/models/reformer).
+
+## Usage tips
+
+- Reformer does **not** work with *torch.nn.DataParallel* due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035).
+- Use Axial position encoding (see below for more details). It’s a mechanism to avoid having a huge positional encoding matrix (when the sequence length is very big) by factorizing it into smaller matrices.
+- Replace traditional attention by LSH (local-sensitive hashing) attention (see below for more details). It’s a technique to avoid computing the full product query-key in the attention layers.
+- Avoid storing the intermediate results of each layer by using reversible transformer layers to obtain them during the backward pass (subtracting the residuals from the input of the next layer gives them back) or recomputing them for results inside a given layer (less efficient than storing them but saves memory).
+- Compute the feedforward operations by chunks and not on the whole batch.
+
+### Axial Positional Encodings
+
+Axial Positional Encodings were first implemented in Google's [trax library](https://github.com/google/trax/blob/4d99ad4965bab1deba227539758d59f0df0fef48/trax/layers/research/position_encodings.py#L29)
+and developed by the authors of this model's paper. In models that are treating very long input sequences, the
+conventional position id encodings store an embeddings vector of size \\(d\\) being the `config.hidden_size` for
+every position \\(i, \ldots, n_s\\), with \\(n_s\\) being `config.max_embedding_size`. This means that having
+a sequence length of \\(n_s = 2^{19} \approx 0.5M\\) and a `config.hidden_size` of \\(d = 2^{10} \approx 1000\\)
+would result in a position encoding matrix:
+
+$$X_{i,j}, \text{ with } i \in \left[1,\ldots, d\right] \text{ and } j \in \left[1,\ldots, n_s\right]$$
+
+which alone has over 500M parameters to store. Axial positional encodings factorize \\(X_{i,j}\\) into two matrices:
+
+$$X^{1}_{i,j}, \text{ with } i \in \left[1,\ldots, d^1\right] \text{ and } j \in \left[1,\ldots, n_s^1\right]$$
+
+and
+
+$$X^{2}_{i,j}, \text{ with } i \in \left[1,\ldots, d^2\right] \text{ and } j \in \left[1,\ldots, n_s^2\right]$$
+
+with:
+
+$$d = d^1 + d^2 \text{ and } n_s = n_s^1 \times n_s^2 .$$
+
+Therefore the following holds:
+
+$$X_{i,j} = \begin{cases}
+X^{1}_{i, k}, & \text{if }\ i < d^1 \text{ with } k = j \mod n_s^1 \\
+X^{2}_{i - d^1, l}, & \text{if } i \ge d^1 \text{ with } l = \lfloor\frac{j}{n_s^1}\rfloor
+\end{cases}$$
+
+Intuitively, this means that a position embedding vector \\(x_j \in \mathbb{R}^{d}\\) is now the composition of two
+factorized embedding vectors: \\(x^1_{k, l} + x^2_{l, k}\\), where as the `config.max_embedding_size` dimension
+\\(j\\) is factorized into \\(k \text{ and } l\\). This design ensures that each position embedding vector
+\\(x_j\\) is unique.
+
+Using the above example again, axial position encoding with \\(d^1 = 2^9, d^2 = 2^9, n_s^1 = 2^9, n_s^2 = 2^{10}\\)
+can drastically reduced the number of parameters from 500 000 000 to \\(2^{18} + 2^{19} \approx 780 000\\) parameters, this means 85% less memory usage.
+
+In practice, the parameter `config.axial_pos_embds_dim` is set to a tuple \\((d^1, d^2)\\) which sum has to be
+equal to `config.hidden_size` and `config.axial_pos_shape` is set to a tuple \\((n_s^1, n_s^2)\\) which
+product has to be equal to `config.max_embedding_size`, which during training has to be equal to the *sequence
+length* of the `input_ids`.
+
+
+### LSH Self Attention
+
+In Locality sensitive hashing (LSH) self attention the key and query projection weights are tied. Therefore, the key
+query embedding vectors are also tied. LSH self attention uses the locality sensitive hashing mechanism proposed in
+[Practical and Optimal LSH for Angular Distance](https://arxiv.org/abs/1509.02897) to assign each of the tied key
+query embedding vectors to one of `config.num_buckets` possible buckets. The premise is that the more "similar"
+key query embedding vectors (in terms of *cosine similarity*) are to each other, the more likely they are assigned to
+the same bucket.
+
+The accuracy of the LSH mechanism can be improved by increasing `config.num_hashes` or directly the argument
+`num_hashes` of the forward function so that the output of the LSH self attention better approximates the output
+of the "normal" full self attention. The buckets are then sorted and chunked into query key embedding vector chunks
+each of length `config.lsh_chunk_length`. For each chunk, the query embedding vectors attend to its key vectors
+(which are tied to themselves) and to the key embedding vectors of `config.lsh_num_chunks_before` previous
+neighboring chunks and `config.lsh_num_chunks_after` following neighboring chunks.
+
+For more information, see the [original Paper](https://arxiv.org/abs/2001.04451) or this great [blog post](https://www.pragmatic.ml/reformer-deep-dive/).
+
+Note that `config.num_buckets` can also be factorized into a list \\((n_{\text{buckets}}^1,
+n_{\text{buckets}}^2)\\). This way instead of assigning the query key embedding vectors to one of \\((1,\ldots,
+n_{\text{buckets}})\\) they are assigned to one of \\((1-1,\ldots, n_{\text{buckets}}^1-1, \ldots,
+1-n_{\text{buckets}}^2, \ldots, n_{\text{buckets}}^1-n_{\text{buckets}}^2)\\). This is crucial for very long sequences to
+save memory.
+
+When training a model from scratch, it is recommended to leave `config.num_buckets=None`, so that depending on the
+sequence length a good value for `num_buckets` is calculated on the fly. This value will then automatically be
+saved in the config and should be reused for inference.
+
+Using LSH self attention, the memory and time complexity of the query-key matmul operation can be reduced from
+\\(\mathcal{O}(n_s \times n_s)\\) to \\(\mathcal{O}(n_s \times \log(n_s))\\), which usually represents the memory
+and time bottleneck in a transformer model, with \\(n_s\\) being the sequence length.
+
+
+### Local Self Attention
+
+Local self attention is essentially a "normal" self attention layer with key, query and value projections, but is
+chunked so that in each chunk of length `config.local_chunk_length` the query embedding vectors only attends to
+the key embedding vectors in its chunk and to the key embedding vectors of `config.local_num_chunks_before`
+previous neighboring chunks and `config.local_num_chunks_after` following neighboring chunks.
+
+Using Local self attention, the memory and time complexity of the query-key matmul operation can be reduced from
+\\(\mathcal{O}(n_s \times n_s)\\) to \\(\mathcal{O}(n_s \times \log(n_s))\\), which usually represents the memory
+and time bottleneck in a transformer model, with \\(n_s\\) being the sequence length.
+
+
+### Training
+
+During training, we must ensure that the sequence length is set to a value that can be divided by the least common
+multiple of `config.lsh_chunk_length` and `config.local_chunk_length` and that the parameters of the Axial
+Positional Encodings are correctly set as described above. Reformer is very memory efficient so that the model can
+easily be trained on sequences as long as 64000 tokens.
+
+For training, the [`ReformerModelWithLMHead`] should be used as follows:
+
+```python
+input_ids = tokenizer.encode("This is a sentence from the training data", return_tensors="pt")
+loss = model(input_ids, labels=input_ids)[0]
+```
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+
+## ReformerConfig
+
+[[autodoc]] ReformerConfig
+
+## ReformerTokenizer
+
+[[autodoc]] ReformerTokenizer
+ - save_vocabulary
+
+## ReformerTokenizerFast
+
+[[autodoc]] ReformerTokenizerFast
+
+## ReformerModel
+
+[[autodoc]] ReformerModel
+ - forward
+
+## ReformerModelWithLMHead
+
+[[autodoc]] ReformerModelWithLMHead
+ - forward
+
+## ReformerForMaskedLM
+
+[[autodoc]] ReformerForMaskedLM
+ - forward
+
+## ReformerForSequenceClassification
+
+[[autodoc]] ReformerForSequenceClassification
+ - forward
+
+## ReformerForQuestionAnswering
+
+[[autodoc]] ReformerForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/regnet.md b/docs/transformers/docs/source/en/model_doc/regnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..f292fe0df24bf371415d45c8e791ce158ae54429
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/regnet.md
@@ -0,0 +1,97 @@
+
+
+# RegNet
+
+
+
+
+
+
+
+## Overview
+
+The RegNet model was proposed in [Designing Network Design Spaces](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+
+The authors design search spaces to perform Neural Architecture Search (NAS). They first start from a high dimensional search space and iteratively reduce the search space by empirically applying constraints based on the best-performing models sampled by the current search space.
+
+The abstract from the paper is the following:
+
+*In this work, we present a new network design paradigm. Our goal is to help advance the understanding of network design and discover design principles that generalize across settings. Instead of focusing on designing individual network instances, we design network design spaces that parametrize populations of networks. The overall process is analogous to classic manual design of networks, but elevated to the design space level. Using our methodology we explore the structure aspect of network design and arrive at a low-dimensional design space consisting of simple, regular networks that we call RegNet. The core insight of the RegNet parametrization is surprisingly simple: widths and depths of good networks can be explained by a quantized linear function. We analyze the RegNet design space and arrive at interesting findings that do not match the current practice of network design. The RegNet design space provides simple and fast networks that work well across a wide range of flop regimes. Under comparable training settings and flops, the RegNet models outperform the popular EfficientNet models while being up to 5x faster on GPUs.*
+
+This model was contributed by [Francesco](https://huggingface.co/Francesco). The TensorFlow version of the model
+was contributed by [sayakpaul](https://huggingface.co/sayakpaul) and [ariG23498](https://huggingface.co/ariG23498).
+The original code can be found [here](https://github.com/facebookresearch/pycls).
+
+The huge 10B model from [Self-supervised Pretraining of Visual Features in the Wild](https://arxiv.org/abs/2103.01988),
+trained on one billion Instagram images, is available on the [hub](https://huggingface.co/facebook/regnet-y-10b-seer)
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RegNet.
+
+
+
+- [`RegNetForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## RegNetConfig
+
+[[autodoc]] RegNetConfig
+
+
+
+
+## RegNetModel
+
+[[autodoc]] RegNetModel
+ - forward
+
+## RegNetForImageClassification
+
+[[autodoc]] RegNetForImageClassification
+ - forward
+
+
+
+
+## TFRegNetModel
+
+[[autodoc]] TFRegNetModel
+ - call
+
+## TFRegNetForImageClassification
+
+[[autodoc]] TFRegNetForImageClassification
+ - call
+
+
+
+
+## FlaxRegNetModel
+
+[[autodoc]] FlaxRegNetModel
+ - __call__
+
+## FlaxRegNetForImageClassification
+
+[[autodoc]] FlaxRegNetForImageClassification
+ - __call__
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/rembert.md b/docs/transformers/docs/source/en/model_doc/rembert.md
new file mode 100644
index 0000000000000000000000000000000000000000..319e44cf0987f0ef1e44d814fefaae6ff4d71374
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/rembert.md
@@ -0,0 +1,155 @@
+
+
+# RemBERT
+
+
+
+
+
+
+## Overview
+
+The RemBERT model was proposed in [Rethinking Embedding Coupling in Pre-trained Language Models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, Sebastian Ruder.
+
+The abstract from the paper is the following:
+
+*We re-evaluate the standard practice of sharing weights between input and output embeddings in state-of-the-art
+pre-trained language models. We show that decoupled embeddings provide increased modeling flexibility, allowing us to
+significantly improve the efficiency of parameter allocation in the input embedding of multilingual models. By
+reallocating the input embedding parameters in the Transformer layers, we achieve dramatically better performance on
+standard natural language understanding tasks with the same number of parameters during fine-tuning. We also show that
+allocating additional capacity to the output embedding provides benefits to the model that persist through the
+fine-tuning stage even though the output embedding is discarded after pre-training. Our analysis shows that larger
+output embeddings prevent the model's last layers from overspecializing to the pre-training task and encourage
+Transformer representations to be more general and more transferable to other tasks and languages. Harnessing these
+findings, we are able to train models that achieve strong performance on the XTREME benchmark without increasing the
+number of parameters at the fine-tuning stage.*
+
+## Usage tips
+
+For fine-tuning, RemBERT can be thought of as a bigger version of mBERT with an ALBERT-like factorization of the
+embedding layer. The embeddings are not tied in pre-training, in contrast with BERT, which enables smaller input
+embeddings (preserved during fine-tuning) and bigger output embeddings (discarded at fine-tuning). The tokenizer is
+also similar to the Albert one rather than the BERT one.
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## RemBertConfig
+
+[[autodoc]] RemBertConfig
+
+## RemBertTokenizer
+
+[[autodoc]] RemBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## RemBertTokenizerFast
+
+[[autodoc]] RemBertTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+
+
+
+## RemBertModel
+
+[[autodoc]] RemBertModel
+ - forward
+
+## RemBertForCausalLM
+
+[[autodoc]] RemBertForCausalLM
+ - forward
+
+## RemBertForMaskedLM
+
+[[autodoc]] RemBertForMaskedLM
+ - forward
+
+## RemBertForSequenceClassification
+
+[[autodoc]] RemBertForSequenceClassification
+ - forward
+
+## RemBertForMultipleChoice
+
+[[autodoc]] RemBertForMultipleChoice
+ - forward
+
+## RemBertForTokenClassification
+
+[[autodoc]] RemBertForTokenClassification
+ - forward
+
+## RemBertForQuestionAnswering
+
+[[autodoc]] RemBertForQuestionAnswering
+ - forward
+
+
+
+
+## TFRemBertModel
+
+[[autodoc]] TFRemBertModel
+ - call
+
+## TFRemBertForMaskedLM
+
+[[autodoc]] TFRemBertForMaskedLM
+ - call
+
+## TFRemBertForCausalLM
+
+[[autodoc]] TFRemBertForCausalLM
+ - call
+
+## TFRemBertForSequenceClassification
+
+[[autodoc]] TFRemBertForSequenceClassification
+ - call
+
+## TFRemBertForMultipleChoice
+
+[[autodoc]] TFRemBertForMultipleChoice
+ - call
+
+## TFRemBertForTokenClassification
+
+[[autodoc]] TFRemBertForTokenClassification
+ - call
+
+## TFRemBertForQuestionAnswering
+
+[[autodoc]] TFRemBertForQuestionAnswering
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/resnet.md b/docs/transformers/docs/source/en/model_doc/resnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..d7400b46c838b21cac3838200e50e86f6aa0c1ee
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/resnet.md
@@ -0,0 +1,98 @@
+
+
+# ResNet
+
+
+
+
+
+
+
+## Overview
+
+The ResNet model was proposed in [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Our implementation follows the small changes made by [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch), we apply the `stride=2` for downsampling in bottleneck's `3x3` conv and not in the first `1x1`. This is generally known as "ResNet v1.5".
+
+ResNet introduced residual connections, they allow to train networks with an unseen number of layers (up to 1000). ResNet won the 2015 ILSVRC & COCO competition, one important milestone in deep computer vision.
+
+The abstract from the paper is the following:
+
+*Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
+The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.*
+
+The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://arxiv.org/abs/1512.03385).
+
+
+
+This model was contributed by [Francesco](https://huggingface.co/Francesco). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/KaimingHe/deep-residual-networks).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ResNet.
+
+
+
+- [`ResNetForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## ResNetConfig
+
+[[autodoc]] ResNetConfig
+
+
+
+
+## ResNetModel
+
+[[autodoc]] ResNetModel
+ - forward
+
+## ResNetForImageClassification
+
+[[autodoc]] ResNetForImageClassification
+ - forward
+
+
+
+
+## TFResNetModel
+
+[[autodoc]] TFResNetModel
+ - call
+
+## TFResNetForImageClassification
+
+[[autodoc]] TFResNetForImageClassification
+ - call
+
+
+
+
+## FlaxResNetModel
+
+[[autodoc]] FlaxResNetModel
+ - __call__
+
+## FlaxResNetForImageClassification
+
+[[autodoc]] FlaxResNetForImageClassification
+ - __call__
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/retribert.md b/docs/transformers/docs/source/en/model_doc/retribert.md
new file mode 100644
index 0000000000000000000000000000000000000000..795f81caaa72eef2ebe7c47f8956c5c8e3853290
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/retribert.md
@@ -0,0 +1,57 @@
+
+
+# RetriBERT
+
+
+
+
+
+
+
+This model is in maintenance mode only, so we won't accept any new PRs changing its code.
+
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
+You can do so by running the following command: `pip install -U transformers==4.30.0`.
+
+
+
+## Overview
+
+The RetriBERT model was proposed in the blog post [Explain Anything Like I'm Five: A Model for Open Domain Long Form
+Question Answering](https://yjernite.github.io/lfqa.html). RetriBERT is a small model that uses either a single or
+pair of BERT encoders with lower-dimension projection for dense semantic indexing of text.
+
+This model was contributed by [yjernite](https://huggingface.co/yjernite). Code to train and use the model can be
+found [here](https://github.com/huggingface/transformers/tree/main/examples/research-projects/distillation).
+
+
+## RetriBertConfig
+
+[[autodoc]] RetriBertConfig
+
+## RetriBertTokenizer
+
+[[autodoc]] RetriBertTokenizer
+
+## RetriBertTokenizerFast
+
+[[autodoc]] RetriBertTokenizerFast
+
+## RetriBertModel
+
+[[autodoc]] RetriBertModel
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/roberta-prelayernorm.md b/docs/transformers/docs/source/en/model_doc/roberta-prelayernorm.md
new file mode 100644
index 0000000000000000000000000000000000000000..7cef8526c251385df5ce893a3ce4fb9464781080
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/roberta-prelayernorm.md
@@ -0,0 +1,171 @@
+
+
+# RoBERTa-PreLayerNorm
+
+
+
+
+
+
+
+## Overview
+
+The RoBERTa-PreLayerNorm model was proposed in [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
+It is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
+
+The abstract from the paper is the following:
+
+*fairseq is an open-source sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. The toolkit is based on PyTorch and supports distributed training across multiple GPUs and machines. We also support fast mixed-precision training and inference on modern GPUs.*
+
+This model was contributed by [andreasmaden](https://huggingface.co/andreasmadsen).
+The original code can be found [here](https://github.com/princeton-nlp/DinkyTrain).
+
+## Usage tips
+
+- The implementation is the same as [Roberta](roberta) except instead of using _Add and Norm_ it does _Norm and Add_. _Add_ and _Norm_ refers to the Addition and LayerNormalization as described in [Attention Is All You Need](https://arxiv.org/abs/1706.03762).
+- This is identical to using the `--encoder-normalize-before` flag in [fairseq](https://fairseq.readthedocs.io/).
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## RobertaPreLayerNormConfig
+
+[[autodoc]] RobertaPreLayerNormConfig
+
+
+
+
+## RobertaPreLayerNormModel
+
+[[autodoc]] RobertaPreLayerNormModel
+ - forward
+
+## RobertaPreLayerNormForCausalLM
+
+[[autodoc]] RobertaPreLayerNormForCausalLM
+ - forward
+
+## RobertaPreLayerNormForMaskedLM
+
+[[autodoc]] RobertaPreLayerNormForMaskedLM
+ - forward
+
+## RobertaPreLayerNormForSequenceClassification
+
+[[autodoc]] RobertaPreLayerNormForSequenceClassification
+ - forward
+
+## RobertaPreLayerNormForMultipleChoice
+
+[[autodoc]] RobertaPreLayerNormForMultipleChoice
+ - forward
+
+## RobertaPreLayerNormForTokenClassification
+
+[[autodoc]] RobertaPreLayerNormForTokenClassification
+ - forward
+
+## RobertaPreLayerNormForQuestionAnswering
+
+[[autodoc]] RobertaPreLayerNormForQuestionAnswering
+ - forward
+
+
+
+
+## TFRobertaPreLayerNormModel
+
+[[autodoc]] TFRobertaPreLayerNormModel
+ - call
+
+## TFRobertaPreLayerNormForCausalLM
+
+[[autodoc]] TFRobertaPreLayerNormForCausalLM
+ - call
+
+## TFRobertaPreLayerNormForMaskedLM
+
+[[autodoc]] TFRobertaPreLayerNormForMaskedLM
+ - call
+
+## TFRobertaPreLayerNormForSequenceClassification
+
+[[autodoc]] TFRobertaPreLayerNormForSequenceClassification
+ - call
+
+## TFRobertaPreLayerNormForMultipleChoice
+
+[[autodoc]] TFRobertaPreLayerNormForMultipleChoice
+ - call
+
+## TFRobertaPreLayerNormForTokenClassification
+
+[[autodoc]] TFRobertaPreLayerNormForTokenClassification
+ - call
+
+## TFRobertaPreLayerNormForQuestionAnswering
+
+[[autodoc]] TFRobertaPreLayerNormForQuestionAnswering
+ - call
+
+
+
+
+## FlaxRobertaPreLayerNormModel
+
+[[autodoc]] FlaxRobertaPreLayerNormModel
+ - __call__
+
+## FlaxRobertaPreLayerNormForCausalLM
+
+[[autodoc]] FlaxRobertaPreLayerNormForCausalLM
+ - __call__
+
+## FlaxRobertaPreLayerNormForMaskedLM
+
+[[autodoc]] FlaxRobertaPreLayerNormForMaskedLM
+ - __call__
+
+## FlaxRobertaPreLayerNormForSequenceClassification
+
+[[autodoc]] FlaxRobertaPreLayerNormForSequenceClassification
+ - __call__
+
+## FlaxRobertaPreLayerNormForMultipleChoice
+
+[[autodoc]] FlaxRobertaPreLayerNormForMultipleChoice
+ - __call__
+
+## FlaxRobertaPreLayerNormForTokenClassification
+
+[[autodoc]] FlaxRobertaPreLayerNormForTokenClassification
+ - __call__
+
+## FlaxRobertaPreLayerNormForQuestionAnswering
+
+[[autodoc]] FlaxRobertaPreLayerNormForQuestionAnswering
+ - __call__
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/roberta.md b/docs/transformers/docs/source/en/model_doc/roberta.md
new file mode 100644
index 0000000000000000000000000000000000000000..10a46d6f57eba940f3b5997ff18246f6c48c87c0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/roberta.md
@@ -0,0 +1,240 @@
+
+
+# RoBERTa
+
+
+
+
+
+
+
+## Overview
+
+The RoBERTa model was proposed in [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, [Myle Ott](https://huggingface.co/myleott), Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer
+Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov. It is based on Google's BERT model released in 2018.
+
+It builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with
+much larger mini-batches and learning rates.
+
+The abstract from the paper is the following:
+
+*Language model pretraining has led to significant performance gains but careful comparison between different
+approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes,
+and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication
+study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and
+training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every
+model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results
+highlight the importance of previously overlooked design choices, and raise questions about the source of recently
+reported improvements. We release our models and code.*
+
+This model was contributed by [julien-c](https://huggingface.co/julien-c). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/roberta).
+
+## Usage tips
+
+- This implementation is the same as [`BertModel`] with a minor tweak to the embeddings, as well as a setup
+ for RoBERTa pretrained models.
+- RoBERTa has the same architecture as BERT but uses a byte-level BPE as a tokenizer (same as GPT-2) and uses a
+ different pretraining scheme.
+- RoBERTa doesn't have `token_type_ids`, so you don't need to indicate which token belongs to which segment. Just
+ separate your segments with the separation token `tokenizer.sep_token` (or ``).
+- RoBERTa is similar to BERT but with better pretraining techniques:
+
+ * Dynamic masking: tokens are masked differently at each epoch, whereas BERT does it once and for all.
+ * Sentence packing: Sentences are packed together to reach 512 tokens (so the sentences are in an order that may span several documents).
+ * Larger batches: Training uses larger batches.
+ * Byte-level BPE vocabulary: Uses BPE with bytes as a subunit instead of characters, accommodating Unicode characters.
+- [CamemBERT](camembert) is a wrapper around RoBERTa. Refer to its model page for usage examples.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RoBERTa. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+- A blog on [Getting Started with Sentiment Analysis on Twitter](https://huggingface.co/blog/sentiment-analysis-twitter) using RoBERTa and the [Inference API](https://huggingface.co/inference-api).
+- A blog on [Opinion Classification with Kili and Hugging Face AutoTrain](https://huggingface.co/blog/opinion-classification-with-kili) using RoBERTa.
+- A notebook on how to [finetune RoBERTa for sentiment analysis](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb). 🌎
+- [`RobertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb).
+- [`TFRobertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
+- [`FlaxRobertaForSequenceClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb).
+- [Text classification task guide](../tasks/sequence_classification)
+
+
+
+- [`RobertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb).
+- [`TFRobertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
+- [`FlaxRobertaForTokenClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification).
+- [Token classification](https://huggingface.co/course/chapter7/2?fw=pt) chapter of the 🤗 Hugging Face Course.
+- [Token classification task guide](../tasks/token_classification)
+
+
+
+- A blog on [How to train a new language model from scratch using Transformers and Tokenizers](https://huggingface.co/blog/how-to-train) with RoBERTa.
+- [`RobertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
+- [`TFRobertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
+- [`FlaxRobertaForMaskedLM`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
+- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+
+
+
+- A blog on [Accelerated Inference with Optimum and Transformers Pipelines](https://huggingface.co/blog/optimum-inference) with RoBERTa for question answering.
+- [`RobertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb).
+- [`TFRobertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb).
+- [`FlaxRobertaForQuestionAnswering`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering).
+- [Question answering](https://huggingface.co/course/chapter7/7?fw=pt) chapter of the 🤗 Hugging Face Course.
+- [Question answering task guide](../tasks/question_answering)
+
+**Multiple choice**
+- [`RobertaForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb).
+- [`TFRobertaForMultipleChoice`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## RobertaConfig
+
+[[autodoc]] RobertaConfig
+
+## RobertaTokenizer
+
+[[autodoc]] RobertaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## RobertaTokenizerFast
+
+[[autodoc]] RobertaTokenizerFast
+ - build_inputs_with_special_tokens
+
+
+
+
+## RobertaModel
+
+[[autodoc]] RobertaModel
+ - forward
+
+## RobertaForCausalLM
+
+[[autodoc]] RobertaForCausalLM
+ - forward
+
+## RobertaForMaskedLM
+
+[[autodoc]] RobertaForMaskedLM
+ - forward
+
+## RobertaForSequenceClassification
+
+[[autodoc]] RobertaForSequenceClassification
+ - forward
+
+## RobertaForMultipleChoice
+
+[[autodoc]] RobertaForMultipleChoice
+ - forward
+
+## RobertaForTokenClassification
+
+[[autodoc]] RobertaForTokenClassification
+ - forward
+
+## RobertaForQuestionAnswering
+
+[[autodoc]] RobertaForQuestionAnswering
+ - forward
+
+
+
+
+## TFRobertaModel
+
+[[autodoc]] TFRobertaModel
+ - call
+
+## TFRobertaForCausalLM
+
+[[autodoc]] TFRobertaForCausalLM
+ - call
+
+## TFRobertaForMaskedLM
+
+[[autodoc]] TFRobertaForMaskedLM
+ - call
+
+## TFRobertaForSequenceClassification
+
+[[autodoc]] TFRobertaForSequenceClassification
+ - call
+
+## TFRobertaForMultipleChoice
+
+[[autodoc]] TFRobertaForMultipleChoice
+ - call
+
+## TFRobertaForTokenClassification
+
+[[autodoc]] TFRobertaForTokenClassification
+ - call
+
+## TFRobertaForQuestionAnswering
+
+[[autodoc]] TFRobertaForQuestionAnswering
+ - call
+
+
+
+
+## FlaxRobertaModel
+
+[[autodoc]] FlaxRobertaModel
+ - __call__
+
+## FlaxRobertaForCausalLM
+
+[[autodoc]] FlaxRobertaForCausalLM
+ - __call__
+
+## FlaxRobertaForMaskedLM
+
+[[autodoc]] FlaxRobertaForMaskedLM
+ - __call__
+
+## FlaxRobertaForSequenceClassification
+
+[[autodoc]] FlaxRobertaForSequenceClassification
+ - __call__
+
+## FlaxRobertaForMultipleChoice
+
+[[autodoc]] FlaxRobertaForMultipleChoice
+ - __call__
+
+## FlaxRobertaForTokenClassification
+
+[[autodoc]] FlaxRobertaForTokenClassification
+ - __call__
+
+## FlaxRobertaForQuestionAnswering
+
+[[autodoc]] FlaxRobertaForQuestionAnswering
+ - __call__
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/roc_bert.md b/docs/transformers/docs/source/en/model_doc/roc_bert.md
new file mode 100644
index 0000000000000000000000000000000000000000..f3797663ff70aa6bd8c237e50070512e7f079724
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/roc_bert.md
@@ -0,0 +1,102 @@
+
+
+# RoCBert
+
+
+
+
+
+## Overview
+
+The RoCBert model was proposed in [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
+It's a pretrained Chinese language model that is robust under various forms of adversarial attacks.
+
+The abstract from the paper is the following:
+
+*Large-scale pretrained language models have achieved SOTA results on NLP tasks. However, they have been shown
+vulnerable to adversarial attacks especially for logographic languages like Chinese. In this work, we propose
+ROCBERT: a pretrained Chinese Bert that is robust to various forms of adversarial attacks like word perturbation,
+synonyms, typos, etc. It is pretrained with the contrastive learning objective which maximizes the label consistency
+under different synthesized adversarial examples. The model takes as input multimodal information including the
+semantic, phonetic and visual features. We show all these features are important to the model robustness since the
+attack can be performed in all the three forms. Across 5 Chinese NLU tasks, ROCBERT outperforms strong baselines under
+three blackbox adversarial algorithms without sacrificing the performance on clean testset. It also performs the best
+in the toxic content detection task under human-made attacks.*
+
+This model was contributed by [weiweishi](https://huggingface.co/weiweishi).
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## RoCBertConfig
+
+[[autodoc]] RoCBertConfig
+ - all
+
+## RoCBertTokenizer
+
+[[autodoc]] RoCBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## RoCBertModel
+
+[[autodoc]] RoCBertModel
+ - forward
+
+## RoCBertForPreTraining
+
+[[autodoc]] RoCBertForPreTraining
+ - forward
+
+## RoCBertForCausalLM
+
+[[autodoc]] RoCBertForCausalLM
+ - forward
+
+## RoCBertForMaskedLM
+
+[[autodoc]] RoCBertForMaskedLM
+ - forward
+
+## RoCBertForSequenceClassification
+
+[[autodoc]] transformers.RoCBertForSequenceClassification
+ - forward
+
+## RoCBertForMultipleChoice
+
+[[autodoc]] transformers.RoCBertForMultipleChoice
+ - forward
+
+## RoCBertForTokenClassification
+
+[[autodoc]] transformers.RoCBertForTokenClassification
+ - forward
+
+## RoCBertForQuestionAnswering
+
+[[autodoc]] RoCBertForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/roformer.md b/docs/transformers/docs/source/en/model_doc/roformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..83d01c2fc91dc36c1d9d3f6525935b22c8aa3443
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/roformer.md
@@ -0,0 +1,185 @@
+
+
+# RoFormer
+
+
+
+
+
+
+
+## Overview
+
+The RoFormer model was proposed in [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864v1.pdf) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+
+The abstract from the paper is the following:
+
+*Position encoding in transformer architecture provides supervision for dependency modeling between elements at
+different positions in the sequence. We investigate various methods to encode positional information in
+transformer-based language models and propose a novel implementation named Rotary Position Embedding(RoPE). The
+proposed RoPE encodes absolute positional information with rotation matrix and naturally incorporates explicit relative
+position dependency in self-attention formulation. Notably, RoPE comes with valuable properties such as flexibility of
+being expand to any sequence lengths, decaying inter-token dependency with increasing relative distances, and
+capability of equipping the linear self-attention with relative position encoding. As a result, the enhanced
+transformer with rotary position embedding, or RoFormer, achieves superior performance in tasks with long texts. We
+release the theoretical analysis along with some preliminary experiment results on Chinese data. The undergoing
+experiment for English benchmark will soon be updated.*
+
+This model was contributed by [junnyu](https://huggingface.co/junnyu). The original code can be found [here](https://github.com/ZhuiyiTechnology/roformer).
+
+## Usage tips
+RoFormer is a BERT-like autoencoding model with rotary position embeddings. Rotary position embeddings have shown
+improved performance on classification tasks with long texts.
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Causal language modeling task guide](../tasks/language_modeling)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## RoFormerConfig
+
+[[autodoc]] RoFormerConfig
+
+## RoFormerTokenizer
+
+[[autodoc]] RoFormerTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## RoFormerTokenizerFast
+
+[[autodoc]] RoFormerTokenizerFast
+ - build_inputs_with_special_tokens
+
+
+
+
+## RoFormerModel
+
+[[autodoc]] RoFormerModel
+ - forward
+
+## RoFormerForCausalLM
+
+[[autodoc]] RoFormerForCausalLM
+ - forward
+
+## RoFormerForMaskedLM
+
+[[autodoc]] RoFormerForMaskedLM
+ - forward
+
+## RoFormerForSequenceClassification
+
+[[autodoc]] RoFormerForSequenceClassification
+ - forward
+
+## RoFormerForMultipleChoice
+
+[[autodoc]] RoFormerForMultipleChoice
+ - forward
+
+## RoFormerForTokenClassification
+
+[[autodoc]] RoFormerForTokenClassification
+ - forward
+
+## RoFormerForQuestionAnswering
+
+[[autodoc]] RoFormerForQuestionAnswering
+ - forward
+
+
+
+
+## TFRoFormerModel
+
+[[autodoc]] TFRoFormerModel
+ - call
+
+## TFRoFormerForMaskedLM
+
+[[autodoc]] TFRoFormerForMaskedLM
+ - call
+
+## TFRoFormerForCausalLM
+
+[[autodoc]] TFRoFormerForCausalLM
+ - call
+
+## TFRoFormerForSequenceClassification
+
+[[autodoc]] TFRoFormerForSequenceClassification
+ - call
+
+## TFRoFormerForMultipleChoice
+
+[[autodoc]] TFRoFormerForMultipleChoice
+ - call
+
+## TFRoFormerForTokenClassification
+
+[[autodoc]] TFRoFormerForTokenClassification
+ - call
+
+## TFRoFormerForQuestionAnswering
+
+[[autodoc]] TFRoFormerForQuestionAnswering
+ - call
+
+
+
+
+## FlaxRoFormerModel
+
+[[autodoc]] FlaxRoFormerModel
+ - __call__
+
+## FlaxRoFormerForMaskedLM
+
+[[autodoc]] FlaxRoFormerForMaskedLM
+ - __call__
+
+## FlaxRoFormerForSequenceClassification
+
+[[autodoc]] FlaxRoFormerForSequenceClassification
+ - __call__
+
+## FlaxRoFormerForMultipleChoice
+
+[[autodoc]] FlaxRoFormerForMultipleChoice
+ - __call__
+
+## FlaxRoFormerForTokenClassification
+
+[[autodoc]] FlaxRoFormerForTokenClassification
+ - __call__
+
+## FlaxRoFormerForQuestionAnswering
+
+[[autodoc]] FlaxRoFormerForQuestionAnswering
+ - __call__
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/rt_detr.md b/docs/transformers/docs/source/en/model_doc/rt_detr.md
new file mode 100644
index 0000000000000000000000000000000000000000..c80e83e7b8832465994df36707548b29e26fa384
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/rt_detr.md
@@ -0,0 +1,121 @@
+
+
+# RT-DETR
+
+
+
+
+
+## Overview
+
+
+The RT-DETR model was proposed in [DETRs Beat YOLOs on Real-time Object Detection](https://arxiv.org/abs/2304.08069) by Wenyu Lv, Yian Zhao, Shangliang Xu, Jinman Wei, Guanzhong Wang, Cheng Cui, Yuning Du, Qingqing Dang, Yi Liu.
+
+RT-DETR is an object detection model that stands for "Real-Time DEtection Transformer." This model is designed to perform object detection tasks with a focus on achieving real-time performance while maintaining high accuracy. Leveraging the transformer architecture, which has gained significant popularity in various fields of deep learning, RT-DETR processes images to identify and locate multiple objects within them.
+
+The abstract from the paper is the following:
+
+*Recently, end-to-end transformer-based detectors (DETRs) have achieved remarkable performance. However, the issue of the high computational cost of DETRs has not been effectively addressed, limiting their practical application and preventing them from fully exploiting the benefits of no post-processing, such as non-maximum suppression (NMS). In this paper, we first analyze the influence of NMS in modern real-time object detectors on inference speed, and establish an end-to-end speed benchmark. To avoid the inference delay caused by NMS, we propose a Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge. Specifically, we design an efficient hybrid encoder to efficiently process multi-scale features by decoupling the intra-scale interaction and cross-scale fusion, and propose IoU-aware query selection to improve the initialization of object queries. In addition, our proposed detector supports flexibly adjustment of the inference speed by using different decoder layers without the need for retraining, which facilitates the practical application of real-time object detectors. Our RT-DETR-L achieves 53.0% AP on COCO val2017 and 114 FPS on T4 GPU, while RT-DETR-X achieves 54.8% AP and 74 FPS, outperforming all YOLO detectors of the same scale in both speed and accuracy. Furthermore, our RT-DETR-R50 achieves 53.1% AP and 108 FPS, outperforming DINO-Deformable-DETR-R50 by 2.2% AP in accuracy and by about 21 times in FPS.*
+
+
+
+ RT-DETR performance relative to YOLO models. Taken from the original paper.
+
+The model version was contributed by [rafaelpadilla](https://huggingface.co/rafaelpadilla) and [sangbumchoi](https://github.com/SangbumChoi). The original code can be found [here](https://github.com/lyuwenyu/RT-DETR/).
+
+
+## Usage tips
+
+Initially, an image is processed using a pre-trained convolutional neural network, specifically a Resnet-D variant as referenced in the original code. This network extracts features from the final three layers of the architecture. Following this, a hybrid encoder is employed to convert the multi-scale features into a sequential array of image features. Then, a decoder, equipped with auxiliary prediction heads is used to refine the object queries. This process facilitates the direct generation of bounding boxes, eliminating the need for any additional post-processing to acquire the logits and coordinates for the bounding boxes.
+
+```py
+>>> import torch
+>>> import requests
+
+>>> from PIL import Image
+>>> from transformers import RTDetrForObjectDetection, RTDetrImageProcessor
+
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_r50vd")
+>>> model = RTDetrForObjectDetection.from_pretrained("PekingU/rtdetr_r50vd")
+
+>>> inputs = image_processor(images=image, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([(image.height, image.width)]), threshold=0.3)
+
+>>> for result in results:
+... for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
+... score, label = score.item(), label_id.item()
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"{model.config.id2label[label]}: {score:.2f} {box}")
+sofa: 0.97 [0.14, 0.38, 640.13, 476.21]
+cat: 0.96 [343.38, 24.28, 640.14, 371.5]
+cat: 0.96 [13.23, 54.18, 318.98, 472.22]
+remote: 0.95 [40.11, 73.44, 175.96, 118.48]
+remote: 0.92 [333.73, 76.58, 369.97, 186.99]
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RT-DETR.
+
+
+
+- Scripts for finetuning [`RTDetrForObjectDetection`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- See also: [Object detection task guide](../tasks/object_detection).
+- Notebooks regarding inference and fine-tuning RT-DETR on a custom dataset can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/RT-DETR). 🌎
+
+## RTDetrConfig
+
+[[autodoc]] RTDetrConfig
+
+## RTDetrResNetConfig
+
+[[autodoc]] RTDetrResNetConfig
+
+## RTDetrImageProcessor
+
+[[autodoc]] RTDetrImageProcessor
+ - preprocess
+ - post_process_object_detection
+
+## RTDetrImageProcessorFast
+
+[[autodoc]] RTDetrImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+
+## RTDetrModel
+
+[[autodoc]] RTDetrModel
+ - forward
+
+## RTDetrForObjectDetection
+
+[[autodoc]] RTDetrForObjectDetection
+ - forward
+
+## RTDetrResNetBackbone
+
+[[autodoc]] RTDetrResNetBackbone
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/rt_detr_v2.md b/docs/transformers/docs/source/en/model_doc/rt_detr_v2.md
new file mode 100644
index 0000000000000000000000000000000000000000..e5212d945ce7343b6af1acf4fd8e8c5557c9a9cb
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/rt_detr_v2.md
@@ -0,0 +1,101 @@
+
+
+# RT-DETRv2
+
+
+
+
+
+## Overview
+
+The RT-DETRv2 model was proposed in [RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer](https://arxiv.org/abs/2407.17140) by Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, Yi Liu.
+
+RT-DETRv2 refines RT-DETR by introducing selective multi-scale feature extraction, a discrete sampling operator for broader deployment compatibility, and improved training strategies like dynamic data augmentation and scale-adaptive hyperparameters. These changes enhance flexibility and practicality while maintaining real-time performance.
+
+The abstract from the paper is the following:
+
+*In this report, we present RT-DETRv2, an improved Real-Time DEtection TRansformer (RT-DETR). RT-DETRv2 builds upon the previous state-of-the-art real-time detector, RT-DETR, and opens up a set of bag-of-freebies for flexibility and practicality, as well as optimizing the training strategy to achieve enhanced performance. To improve the flexibility, we suggest setting a distinct number of sampling points for features at different scales in the deformable attention to achieve selective multi-scale feature extraction by the decoder. To enhance practicality, we propose an optional discrete sampling operator to replace the grid_sample operator that is specific to RT-DETR compared to YOLOs. This removes the deployment constraints typically associated with DETRs. For the training strategy, we propose dynamic data augmentation and scale-adaptive hyperparameters customization to improve performance without loss of speed.*
+
+This model was contributed by [jadechoghari](https://huggingface.co/jadechoghari).
+The original code can be found [here](https://github.com/lyuwenyu/RT-DETR).
+
+## Usage tips
+
+This second version of RT-DETR improves how the decoder finds objects in an image.
+
+- **better sampling** – adjusts offsets so the model looks at the right areas
+- **flexible attention** – can use smooth (bilinear) or fixed (discrete) sampling
+- **optimized processing** – improves how attention weights mix information
+
+```py
+>>> import torch
+>>> import requests
+
+>>> from PIL import Image
+>>> from transformers import RTDetrV2ForObjectDetection, RTDetrImageProcessor
+
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_v2_r18vd")
+>>> model = RTDetrV2ForObjectDetection.from_pretrained("PekingU/rtdetr_v2_r18vd")
+
+>>> inputs = image_processor(images=image, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([(image.height, image.width)]), threshold=0.5)
+
+>>> for result in results:
+... for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
+... score, label = score.item(), label_id.item()
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"{model.config.id2label[label]}: {score:.2f} {box}")
+cat: 0.97 [341.14, 25.11, 639.98, 372.89]
+cat: 0.96 [12.78, 56.35, 317.67, 471.34]
+remote: 0.95 [39.96, 73.12, 175.65, 117.44]
+sofa: 0.86 [-0.11, 2.97, 639.89, 473.62]
+sofa: 0.82 [-0.12, 1.78, 639.87, 473.52]
+remote: 0.79 [333.65, 76.38, 370.69, 187.48]
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RT-DETRv2.
+
+
+
+- Scripts for finetuning [`RTDetrV2ForObjectDetection`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- See also: [Object detection task guide](../tasks/object_detection).
+- Notebooks for [inference](https://github.com/qubvel/transformers-notebooks/blob/main/notebooks/RT_DETR_v2_inference.ipynb) and [fine-tuning](https://github.com/qubvel/transformers-notebooks/blob/main/notebooks/RT_DETR_v2_finetune_on_a_custom_dataset.ipynb) RT-DETRv2 on a custom dataset (🌎).
+
+
+## RTDetrV2Config
+
+[[autodoc]] RTDetrV2Config
+
+
+## RTDetrV2Model
+
+[[autodoc]] RTDetrV2Model
+ - forward
+
+## RTDetrV2ForObjectDetection
+
+[[autodoc]] RTDetrV2ForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/rwkv.md b/docs/transformers/docs/source/en/model_doc/rwkv.md
new file mode 100644
index 0000000000000000000000000000000000000000..8b54c25204bb318223900460e703416794f2bb2a
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/rwkv.md
@@ -0,0 +1,154 @@
+
+
+# RWKV
+
+
+
+
+
+## Overview
+
+The RWKV model was proposed in [this repo](https://github.com/BlinkDL/RWKV-LM)
+
+It suggests a tweak in the traditional Transformer attention to make it linear. This way, the model can be used as recurrent network: passing inputs for timestamp 0 and timestamp 1 together is the same as passing inputs at timestamp 0, then inputs at timestamp 1 along with the state of timestamp 0 (see example below).
+
+This can be more efficient than a regular Transformer and can deal with sentence of any length (even if the model uses a fixed context length for training).
+
+This model was contributed by [sgugger](https://huggingface.co/sgugger).
+The original code can be found [here](https://github.com/BlinkDL/RWKV-LM).
+
+## Usage example
+
+```py
+import torch
+from transformers import AutoTokenizer, RwkvConfig, RwkvModel
+
+model = RwkvModel.from_pretrained("sgugger/rwkv-430M-pile")
+tokenizer = AutoTokenizer.from_pretrained("sgugger/rwkv-430M-pile")
+
+inputs = tokenizer("This is an example.", return_tensors="pt")
+# Feed everything to the model
+outputs = model(inputs["input_ids"])
+output_whole = outputs.last_hidden_state
+
+outputs = model(inputs["input_ids"][:, :2])
+output_one = outputs.last_hidden_state
+
+# Using the state computed on the first inputs, we will get the same output
+outputs = model(inputs["input_ids"][:, 2:], state=outputs.state)
+output_two = outputs.last_hidden_state
+
+torch.allclose(torch.cat([output_one, output_two], dim=1), output_whole, atol=1e-5)
+```
+
+If you want to make sure the model stops generating when `'\n\n'` is detected, we recommend using the following stopping criteria:
+
+```python
+from transformers import StoppingCriteria
+
+class RwkvStoppingCriteria(StoppingCriteria):
+ def __init__(self, eos_sequence = [187,187], eos_token_id = 537):
+ self.eos_sequence = eos_sequence
+ self.eos_token_id = eos_token_id
+
+ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
+ last_2_ids = input_ids[:,-2:].tolist()
+ return self.eos_sequence in last_2_ids
+
+
+output = model.generate(inputs["input_ids"], max_new_tokens=64, stopping_criteria = [RwkvStoppingCriteria()])
+```
+
+## RwkvConfig
+
+[[autodoc]] RwkvConfig
+
+## RwkvModel
+
+[[autodoc]] RwkvModel
+ - forward
+
+## RwkvLMHeadModel
+
+[[autodoc]] RwkvForCausalLM
+ - forward
+
+## Rwkv attention and the recurrent formulas
+
+In a traditional auto-regressive Transformer, attention is written as
+
+$$O = \hbox{softmax}(QK^{T} / \sqrt{d}) V$$
+
+with \\(Q\\), \\(K\\) and \\(V\\) are matrices of shape `seq_len x hidden_size` named query, key and value (they are actually bigger matrices with a batch dimension and an attention head dimension but we're only interested in the last two, which is where the matrix product is taken, so for the sake of simplicity we only consider those two). The product \\(QK^{T}\\) then has shape `seq_len x seq_len` and we can take the matrix product with \\(V\\) to get the output \\(O\\) of the same shape as the others.
+
+Replacing the softmax by its value gives:
+
+$$O_{i} = \frac{\sum_{j=1}^{i} e^{Q_{i} K_{j}^{T} / \sqrt{d}} V_{j}}{\sum_{j=1}^{i} e^{Q_{i} K_{j}^{T} / \sqrt{d}}}$$
+
+Note that the entries in \\(QK^{T}\\) corresponding to \\(j > i\\) are masked (the sum stops at j) because the attention is not allowed to look at future tokens (only past ones).
+
+In comparison, the RWKV attention is given by
+
+$$O_{i} = \sigma(R_{i}) \frac{\sum_{j=1}^{i} e^{W_{i-j} + K_{j}} V_{j}}{\sum_{j=1}^{i} e^{W_{i-j} + K_{j}}}$$
+
+where \\(R\\) is a new matrix called receptance by the author, \\(K\\) and \\(V\\) are still the key and value (\\(\sigma\\) here is the sigmoid function). \\(W\\) is a new vector that represents the position of the token and is given by
+
+$$W_{0} = u \hbox{ and } W_{k} = (k-1)w \hbox{ for } k \geq 1$$
+
+with \\(u\\) and \\(w\\) learnable parameters called in the code `time_first` and `time_decay` respectively. The numerator and denominator can both be expressed recursively. Naming them \\(N_{i}\\) and \\(D_{i}\\) we have:
+
+$$N_{i} = e^{u + K_{i}} V_{i} + \hat{N}_{i} \hbox{ where } \hat{N}_{i} = e^{K_{i-1}} V_{i-1} + e^{w + K_{i-2}} V_{i-2} \cdots + e^{(i-2)w + K_{1}} V_{1}$$
+
+so \\(\hat{N}_{i}\\) (called `numerator_state` in the code) satisfies
+
+$$\hat{N}_{0} = 0 \hbox{ and } \hat{N}_{j+1} = e^{K_{j}} V_{j} + e^{w} \hat{N}_{j}$$
+
+and
+
+$$D_{i} = e^{u + K_{i}} + \hat{D}_{i} \hbox{ where } \hat{D}_{i} = e^{K_{i-1}} + e^{w + K_{i-2}} \cdots + e^{(i-2)w + K_{1}}$$
+
+so \\(\hat{D}_{i}\\) (called `denominator_state` in the code) satisfies
+
+$$\hat{D}_{0} = 0 \hbox{ and } \hat{D}_{j+1} = e^{K_{j}} + e^{w} \hat{D}_{j}$$
+
+The actual recurrent formula used are a tiny bit more complex, as for numerical stability we don't want to compute exponentials of big numbers. Usually the softmax is not computed as is, but the exponential of the maximum term is divided of the numerator and denominator:
+
+$$\frac{e^{x_{i}}}{\sum_{j=1}^{n} e^{x_{j}}} = \frac{e^{x_{i} - M}}{\sum_{j=1}^{n} e^{x_{j} - M}}$$
+
+with \\(M\\) the maximum of all \\(x_{j}\\). So here on top of saving the numerator state (\\(\hat{N}\\)) and the denominator state (\\(\hat{D}\\)) we also keep track of the maximum of all terms encountered in the exponentials. So we actually use
+
+$$\tilde{N}_{i} = e^{-M_{i}} \hat{N}_{i} \hbox{ and } \tilde{D}_{i} = e^{-M_{i}} \hat{D}_{i}$$
+
+defined by the following recurrent formulas:
+
+$$\tilde{N}_{0} = 0 \hbox{ and } \tilde{N}_{j+1} = e^{K_{j} - q} V_{j} + e^{w + M_{j} - q} \tilde{N}_{j} \hbox{ where } q = \max(K_{j}, w + M_{j})$$
+
+and
+
+$$\tilde{D}_{0} = 0 \hbox{ and } \tilde{D}_{j+1} = e^{K_{j} - q} + e^{w + M_{j} - q} \tilde{D}_{j} \hbox{ where } q = \max(K_{j}, w + M_{j})$$
+
+and \\(M_{j+1} = q\\). With those, we can then compute
+
+$$N_{i} = e^{u + K_{i} - q} V_{i} + e^{M_{i}} \tilde{N}_{i} \hbox{ where } q = \max(u + K_{i}, M_{i})$$
+
+and
+
+$$D_{i} = e^{u + K_{i} - q} + e^{M_{i}} \tilde{D}_{i} \hbox{ where } q = \max(u + K_{i}, M_{i})$$
+
+which finally gives us
+
+$$O_{i} = \sigma(R_{i}) \frac{N_{i}}{D_{i}}$$
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/sam.md b/docs/transformers/docs/source/en/model_doc/sam.md
new file mode 100644
index 0000000000000000000000000000000000000000..58cbfbfb2190e600d0bcb65960b43781283bec1b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/sam.md
@@ -0,0 +1,173 @@
+
+
+# SAM
+
+
+
+
+
+
+## Overview
+
+SAM (Segment Anything Model) was proposed in [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
+
+The model can be used to predict segmentation masks of any object of interest given an input image.
+
+
+
+The abstract from the paper is the following:
+
+*We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at [https://segment-anything.com](https://segment-anything.com) to foster research into foundation models for computer vision.*
+
+Tips:
+
+- The model predicts binary masks that states the presence or not of the object of interest given an image.
+- The model predicts much better results if input 2D points and/or input bounding boxes are provided
+- You can prompt multiple points for the same image, and predict a single mask.
+- Fine-tuning the model is not supported yet
+- According to the paper, textual input should be also supported. However, at this time of writing this seems not to be supported according to [the official repository](https://github.com/facebookresearch/segment-anything/issues/4#issuecomment-1497626844).
+
+
+This model was contributed by [ybelkada](https://huggingface.co/ybelkada) and [ArthurZ](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/facebookresearch/segment-anything).
+
+Below is an example on how to run mask generation given an image and a 2D point:
+
+```python
+import torch
+from PIL import Image
+import requests
+from transformers import SamModel, SamProcessor
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+model = SamModel.from_pretrained("facebook/sam-vit-huge").to(device)
+processor = SamProcessor.from_pretrained("facebook/sam-vit-huge")
+
+img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
+raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
+input_points = [[[450, 600]]] # 2D location of a window in the image
+
+inputs = processor(raw_image, input_points=input_points, return_tensors="pt").to(device)
+with torch.no_grad():
+ outputs = model(**inputs)
+
+masks = processor.image_processor.post_process_masks(
+ outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu()
+)
+scores = outputs.iou_scores
+```
+
+You can also process your own masks alongside the input images in the processor to be passed to the model.
+
+```python
+import torch
+from PIL import Image
+import requests
+from transformers import SamModel, SamProcessor
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+model = SamModel.from_pretrained("facebook/sam-vit-huge").to(device)
+processor = SamProcessor.from_pretrained("facebook/sam-vit-huge")
+
+img_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
+raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
+mask_url = "https://huggingface.co/ybelkada/segment-anything/resolve/main/assets/car.png"
+segmentation_map = Image.open(requests.get(mask_url, stream=True).raw).convert("1")
+input_points = [[[450, 600]]] # 2D location of a window in the image
+
+inputs = processor(raw_image, input_points=input_points, segmentation_maps=segmentation_map, return_tensors="pt").to(device)
+with torch.no_grad():
+ outputs = model(**inputs)
+
+masks = processor.image_processor.post_process_masks(
+ outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu()
+)
+scores = outputs.iou_scores
+```
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SAM.
+
+- [Demo notebook](https://github.com/huggingface/notebooks/blob/main/examples/segment_anything.ipynb) for using the model.
+- [Demo notebook](https://github.com/huggingface/notebooks/blob/main/examples/automatic_mask_generation.ipynb) for using the automatic mask generation pipeline.
+- [Demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SAM/Run_inference_with_MedSAM_using_HuggingFace_Transformers.ipynb) for inference with MedSAM, a fine-tuned version of SAM on the medical domain. 🌎
+- [Demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SAM/Fine_tune_SAM_(segment_anything)_on_a_custom_dataset.ipynb) for fine-tuning the model on custom data. 🌎
+
+## SlimSAM
+
+SlimSAM, a pruned version of SAM, was proposed in [0.1% Data Makes Segment Anything Slim](https://arxiv.org/abs/2312.05284) by Zigeng Chen et al. SlimSAM reduces the size of the SAM models considerably while maintaining the same performance.
+
+Checkpoints can be found on the [hub](https://huggingface.co/models?other=slimsam), and they can be used as a drop-in replacement of SAM.
+
+## Grounded SAM
+
+One can combine [Grounding DINO](grounding-dino) with SAM for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://arxiv.org/abs/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
+
+
+
+ Grounded SAM overview. Taken from the original repository.
+
+## SamConfig
+
+[[autodoc]] SamConfig
+
+## SamVisionConfig
+
+[[autodoc]] SamVisionConfig
+
+## SamMaskDecoderConfig
+
+[[autodoc]] SamMaskDecoderConfig
+
+## SamPromptEncoderConfig
+
+[[autodoc]] SamPromptEncoderConfig
+
+
+## SamProcessor
+
+[[autodoc]] SamProcessor
+
+
+## SamImageProcessor
+
+[[autodoc]] SamImageProcessor
+
+
+## SamVisionModel
+
+[[autodoc]] SamVisionModel
+ - forward
+
+
+## SamModel
+
+[[autodoc]] SamModel
+ - forward
+
+
+## TFSamVisionModel
+
+[[autodoc]] TFSamVisionModel
+ - call
+
+
+## TFSamModel
+
+[[autodoc]] TFSamModel
+ - call
diff --git a/docs/transformers/docs/source/en/model_doc/seamless_m4t.md b/docs/transformers/docs/source/en/model_doc/seamless_m4t.md
new file mode 100644
index 0000000000000000000000000000000000000000..100198e50170a2600a986f7e2a1851821deae815
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/seamless_m4t.md
@@ -0,0 +1,224 @@
+
+
+# SeamlessM4T
+
+
+
+
+
+## Overview
+
+The SeamlessM4T model was proposed in [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team from Meta AI.
+
+This is the **version 1** release of the model. For the updated **version 2** release, refer to the [Seamless M4T v2 docs](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t_v2).
+
+SeamlessM4T is a collection of models designed to provide high quality translation, allowing people from different linguistic communities to communicate effortlessly through speech and text.
+
+SeamlessM4T enables multiple tasks without relying on separate models:
+
+- Speech-to-speech translation (S2ST)
+- Speech-to-text translation (S2TT)
+- Text-to-speech translation (T2ST)
+- Text-to-text translation (T2TT)
+- Automatic speech recognition (ASR)
+
+[`SeamlessM4TModel`] can perform all the above tasks, but each task also has its own dedicated sub-model.
+
+The abstract from the paper is the following:
+
+*What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication*
+
+## Usage
+
+First, load the processor and a checkpoint of the model:
+
+```python
+>>> from transformers import AutoProcessor, SeamlessM4TModel
+
+>>> processor = AutoProcessor.from_pretrained("facebook/hf-seamless-m4t-medium")
+>>> model = SeamlessM4TModel.from_pretrained("facebook/hf-seamless-m4t-medium")
+```
+
+You can seamlessly use this model on text or on audio, to generated either translated text or translated audio.
+
+Here is how to use the processor to process text and audio:
+
+```python
+>>> # let's load an audio sample from an Arabic speech corpus
+>>> from datasets import load_dataset
+>>> dataset = load_dataset("arabic_speech_corpus", split="test", streaming=True, trust_remote_code=True)
+>>> audio_sample = next(iter(dataset))["audio"]
+
+>>> # now, process it
+>>> audio_inputs = processor(audios=audio_sample["array"], return_tensors="pt")
+
+>>> # now, process some English test as well
+>>> text_inputs = processor(text = "Hello, my dog is cute", src_lang="eng", return_tensors="pt")
+```
+
+
+### Speech
+
+[`SeamlessM4TModel`] can *seamlessly* generate text or speech with few or no changes. Let's target Russian voice translation:
+
+```python
+>>> audio_array_from_text = model.generate(**text_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
+>>> audio_array_from_audio = model.generate(**audio_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
+```
+
+With basically the same code, I've translated English text and Arabic speech to Russian speech samples.
+
+### Text
+
+Similarly, you can generate translated text from audio files or from text with the same model. You only have to pass `generate_speech=False` to [`SeamlessM4TModel.generate`].
+This time, let's translate to French.
+
+```python
+>>> # from audio
+>>> output_tokens = model.generate(**audio_inputs, tgt_lang="fra", generate_speech=False)
+>>> translated_text_from_audio = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
+
+>>> # from text
+>>> output_tokens = model.generate(**text_inputs, tgt_lang="fra", generate_speech=False)
+>>> translated_text_from_text = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
+```
+
+### Tips
+
+
+#### 1. Use dedicated models
+
+[`SeamlessM4TModel`] is transformers top level model to generate speech and text, but you can also use dedicated models that perform the task without additional components, thus reducing the memory footprint.
+For example, you can replace the audio-to-audio generation snippet with the model dedicated to the S2ST task, the rest is exactly the same code:
+
+```python
+>>> from transformers import SeamlessM4TForSpeechToSpeech
+>>> model = SeamlessM4TForSpeechToSpeech.from_pretrained("facebook/hf-seamless-m4t-medium")
+```
+
+Or you can replace the text-to-text generation snippet with the model dedicated to the T2TT task, you only have to remove `generate_speech=False`.
+
+```python
+>>> from transformers import SeamlessM4TForTextToText
+>>> model = SeamlessM4TForTextToText.from_pretrained("facebook/hf-seamless-m4t-medium")
+```
+
+Feel free to try out [`SeamlessM4TForSpeechToText`] and [`SeamlessM4TForTextToSpeech`] as well.
+
+#### 2. Change the speaker identity
+
+You have the possibility to change the speaker used for speech synthesis with the `spkr_id` argument. Some `spkr_id` works better than other for some languages!
+
+#### 3. Change the generation strategy
+
+You can use different [generation strategies](./generation_strategies) for speech and text generation, e.g `.generate(input_ids=input_ids, text_num_beams=4, speech_do_sample=True)` which will successively perform beam-search decoding on the text model, and multinomial sampling on the speech model.
+
+#### 4. Generate speech and text at the same time
+
+Use `return_intermediate_token_ids=True` with [`SeamlessM4TModel`] to return both speech and text !
+
+## Model architecture
+
+
+SeamlessM4T features a versatile architecture that smoothly handles the sequential generation of text and speech. This setup comprises two sequence-to-sequence (seq2seq) models. The first model translates the input modality into translated text, while the second model generates speech tokens, known as "unit tokens," from the translated text.
+
+Each modality has its own dedicated encoder with a unique architecture. Additionally, for speech output, a vocoder inspired by the [HiFi-GAN](https://arxiv.org/abs/2010.05646) architecture is placed on top of the second seq2seq model.
+
+Here's how the generation process works:
+
+- Input text or speech is processed through its specific encoder.
+- A decoder creates text tokens in the desired language.
+- If speech generation is required, the second seq2seq model, following a standard encoder-decoder structure, generates unit tokens.
+- These unit tokens are then passed through the final vocoder to produce the actual speech.
+
+
+This model was contributed by [ylacombe](https://huggingface.co/ylacombe). The original code can be found [here](https://github.com/facebookresearch/seamless_communication).
+
+## SeamlessM4TModel
+
+[[autodoc]] SeamlessM4TModel
+ - generate
+
+
+## SeamlessM4TForTextToSpeech
+
+[[autodoc]] SeamlessM4TForTextToSpeech
+ - generate
+
+
+## SeamlessM4TForSpeechToSpeech
+
+[[autodoc]] SeamlessM4TForSpeechToSpeech
+ - generate
+
+
+## SeamlessM4TForTextToText
+
+[[autodoc]] transformers.SeamlessM4TForTextToText
+ - forward
+ - generate
+
+## SeamlessM4TForSpeechToText
+
+[[autodoc]] transformers.SeamlessM4TForSpeechToText
+ - forward
+ - generate
+
+## SeamlessM4TConfig
+
+[[autodoc]] SeamlessM4TConfig
+
+
+## SeamlessM4TTokenizer
+
+[[autodoc]] SeamlessM4TTokenizer
+ - __call__
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+
+## SeamlessM4TTokenizerFast
+
+[[autodoc]] SeamlessM4TTokenizerFast
+ - __call__
+
+## SeamlessM4TFeatureExtractor
+
+[[autodoc]] SeamlessM4TFeatureExtractor
+ - __call__
+
+## SeamlessM4TProcessor
+
+[[autodoc]] SeamlessM4TProcessor
+ - __call__
+
+## SeamlessM4TCodeHifiGan
+
+[[autodoc]] SeamlessM4TCodeHifiGan
+
+
+## SeamlessM4THifiGan
+
+[[autodoc]] SeamlessM4THifiGan
+
+## SeamlessM4TTextToUnitModel
+
+[[autodoc]] SeamlessM4TTextToUnitModel
+
+## SeamlessM4TTextToUnitForConditionalGeneration
+
+[[autodoc]] SeamlessM4TTextToUnitForConditionalGeneration
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/seamless_m4t_v2.md b/docs/transformers/docs/source/en/model_doc/seamless_m4t_v2.md
new file mode 100644
index 0000000000000000000000000000000000000000..7b68d08b5f95ccfe3b1e15d4aea4027927689168
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/seamless_m4t_v2.md
@@ -0,0 +1,198 @@
+
+
+# SeamlessM4T-v2
+
+
+
+
+
+## Overview
+
+The SeamlessM4T-v2 model was proposed in [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/) by the Seamless Communication team from Meta AI.
+
+SeamlessM4T-v2 is a collection of models designed to provide high quality translation, allowing people from different linguistic communities to communicate effortlessly through speech and text. It is an improvement on the [previous version](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t). For more details on the differences between v1 and v2, refer to section [Difference with SeamlessM4T-v1](#difference-with-seamlessm4t-v1).
+
+SeamlessM4T-v2 enables multiple tasks without relying on separate models:
+
+- Speech-to-speech translation (S2ST)
+- Speech-to-text translation (S2TT)
+- Text-to-speech translation (T2ST)
+- Text-to-text translation (T2TT)
+- Automatic speech recognition (ASR)
+
+[`SeamlessM4Tv2Model`] can perform all the above tasks, but each task also has its own dedicated sub-model.
+
+The abstract from the paper is the following:
+
+*Recent advancements in automatic speech translation have dramatically expanded language coverage, improved multimodal capabilities, and enabled a wide range of tasks and functionalities. That said, large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model—SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. The expanded version of SeamlessAlign adds 114,800 hours of automatically aligned data for a total of 76 languages. SeamlessM4T v2 provides the foundation on which our two newest models, SeamlessExpressive and SeamlessStreaming, are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one’s voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention (EMMA) mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To understand the performance of these models, we combined novel and modified versions of existing automatic metrics to evaluate prosody, latency, and robustness. For human evaluations, we adapted existing protocols tailored for measuring the most relevant attributes in the preservation of meaning, naturalness, and expressivity. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. In sum, Seamless gives us a pivotal look at the technical foundation needed to turn the Universal Speech Translator from a science fiction concept into a real-world technology. Finally, contributions in this work—including models, code, and a watermark detector—are publicly released and accessible at the link below.*
+
+## Usage
+
+In the following example, we'll load an Arabic audio sample and an English text sample and convert them into Russian speech and French text.
+
+First, load the processor and a checkpoint of the model:
+
+```python
+>>> from transformers import AutoProcessor, SeamlessM4Tv2Model
+
+>>> processor = AutoProcessor.from_pretrained("facebook/seamless-m4t-v2-large")
+>>> model = SeamlessM4Tv2Model.from_pretrained("facebook/seamless-m4t-v2-large")
+```
+
+You can seamlessly use this model on text or on audio, to generated either translated text or translated audio.
+
+Here is how to use the processor to process text and audio:
+
+```python
+>>> # let's load an audio sample from an Arabic speech corpus
+>>> from datasets import load_dataset
+>>> dataset = load_dataset("arabic_speech_corpus", split="test", streaming=True, trust_remote_code=True)
+>>> audio_sample = next(iter(dataset))["audio"]
+
+>>> # now, process it
+>>> audio_inputs = processor(audios=audio_sample["array"], return_tensors="pt")
+
+>>> # now, process some English text as well
+>>> text_inputs = processor(text = "Hello, my dog is cute", src_lang="eng", return_tensors="pt")
+```
+
+
+### Speech
+
+[`SeamlessM4Tv2Model`] can *seamlessly* generate text or speech with few or no changes. Let's target Russian voice translation:
+
+```python
+>>> audio_array_from_text = model.generate(**text_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
+>>> audio_array_from_audio = model.generate(**audio_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
+```
+
+With basically the same code, I've translated English text and Arabic speech to Russian speech samples.
+
+### Text
+
+Similarly, you can generate translated text from audio files or from text with the same model. You only have to pass `generate_speech=False` to [`SeamlessM4Tv2Model.generate`].
+This time, let's translate to French.
+
+```python
+>>> # from audio
+>>> output_tokens = model.generate(**audio_inputs, tgt_lang="fra", generate_speech=False)
+>>> translated_text_from_audio = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
+
+>>> # from text
+>>> output_tokens = model.generate(**text_inputs, tgt_lang="fra", generate_speech=False)
+>>> translated_text_from_text = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
+```
+
+### Tips
+
+
+#### 1. Use dedicated models
+
+[`SeamlessM4Tv2Model`] is transformers top level model to generate speech and text, but you can also use dedicated models that perform the task without additional components, thus reducing the memory footprint.
+For example, you can replace the audio-to-audio generation snippet with the model dedicated to the S2ST task, the rest is exactly the same code:
+
+```python
+>>> from transformers import SeamlessM4Tv2ForSpeechToSpeech
+>>> model = SeamlessM4Tv2ForSpeechToSpeech.from_pretrained("facebook/seamless-m4t-v2-large")
+```
+
+Or you can replace the text-to-text generation snippet with the model dedicated to the T2TT task, you only have to remove `generate_speech=False`.
+
+```python
+>>> from transformers import SeamlessM4Tv2ForTextToText
+>>> model = SeamlessM4Tv2ForTextToText.from_pretrained("facebook/seamless-m4t-v2-large")
+```
+
+Feel free to try out [`SeamlessM4Tv2ForSpeechToText`] and [`SeamlessM4Tv2ForTextToSpeech`] as well.
+
+#### 2. Change the speaker identity
+
+You have the possibility to change the speaker used for speech synthesis with the `speaker_id` argument. Some `speaker_id` works better than other for some languages!
+
+#### 3. Change the generation strategy
+
+You can use different [generation strategies](../generation_strategies) for text generation, e.g `.generate(input_ids=input_ids, text_num_beams=4, text_do_sample=True)` which will perform multinomial beam-search decoding on the text model. Note that speech generation only supports greedy - by default - or multinomial sampling, which can be used with e.g. `.generate(..., speech_do_sample=True, speech_temperature=0.6)`.
+
+#### 4. Generate speech and text at the same time
+
+Use `return_intermediate_token_ids=True` with [`SeamlessM4Tv2Model`] to return both speech and text !
+
+## Model architecture
+
+SeamlessM4T-v2 features a versatile architecture that smoothly handles the sequential generation of text and speech. This setup comprises two sequence-to-sequence (seq2seq) models. The first model translates the input modality into translated text, while the second model generates speech tokens, known as "unit tokens," from the translated text.
+
+Each modality has its own dedicated encoder with a unique architecture. Additionally, for speech output, a vocoder inspired by the [HiFi-GAN](https://arxiv.org/abs/2010.05646) architecture is placed on top of the second seq2seq model.
+
+### Difference with SeamlessM4T-v1
+
+The architecture of this new version differs from the first in a few aspects:
+
+#### Improvements on the second-pass model
+
+The second seq2seq model, named text-to-unit model, is now non-auto regressive, meaning that it computes units in a **single forward pass**. This achievement is made possible by:
+- the use of **character-level embeddings**, meaning that each character of the predicted translated text has its own embeddings, which are then used to predict the unit tokens.
+- the use of an intermediate duration predictor, that predicts speech duration at the **character-level** on the predicted translated text.
+- the use of a new text-to-unit decoder mixing convolutions and self-attention to handle longer context.
+
+#### Difference in the speech encoder
+
+The speech encoder, which is used during the first-pass generation process to predict the translated text, differs mainly from the previous speech encoder through these mechanisms:
+- the use of chunked attention mask to prevent attention across chunks, ensuring that each position attends only to positions within its own chunk and a fixed number of previous chunks.
+- the use of relative position embeddings which only considers distance between sequence elements rather than absolute positions. Please refer to [Self-Attentionwith Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155) for more details.
+- the use of a causal depth-wise convolution instead of a non-causal one.
+
+### Generation process
+
+Here's how the generation process works:
+
+- Input text or speech is processed through its specific encoder.
+- A decoder creates text tokens in the desired language.
+- If speech generation is required, the second seq2seq model, generates unit tokens in an non auto-regressive way.
+- These unit tokens are then passed through the final vocoder to produce the actual speech.
+
+
+This model was contributed by [ylacombe](https://huggingface.co/ylacombe). The original code can be found [here](https://github.com/facebookresearch/seamless_communication).
+
+## SeamlessM4Tv2Model
+
+[[autodoc]] SeamlessM4Tv2Model
+ - generate
+
+
+## SeamlessM4Tv2ForTextToSpeech
+
+[[autodoc]] SeamlessM4Tv2ForTextToSpeech
+ - generate
+
+
+## SeamlessM4Tv2ForSpeechToSpeech
+
+[[autodoc]] SeamlessM4Tv2ForSpeechToSpeech
+ - generate
+
+
+## SeamlessM4Tv2ForTextToText
+
+[[autodoc]] transformers.SeamlessM4Tv2ForTextToText
+ - forward
+ - generate
+
+## SeamlessM4Tv2ForSpeechToText
+
+[[autodoc]] transformers.SeamlessM4Tv2ForSpeechToText
+ - forward
+ - generate
+
+## SeamlessM4Tv2Config
+
+[[autodoc]] SeamlessM4Tv2Config
diff --git a/docs/transformers/docs/source/en/model_doc/segformer.md b/docs/transformers/docs/source/en/model_doc/segformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..093a141eaf83c8f90e4b35192d45147cb3531475
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/segformer.md
@@ -0,0 +1,178 @@
+
+
+# SegFormer
+
+
+
+
+
+
+## Overview
+
+The SegFormer model was proposed in [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping
+Luo. The model consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great
+results on image segmentation benchmarks such as ADE20K and Cityscapes.
+
+The abstract from the paper is the following:
+
+*We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with
+lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel
+hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding,
+thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution
+differs from training. 2) SegFormer avoids complex decoders. The proposed MLP decoder aggregates information from
+different layers, and thus combining both local attention and global attention to render powerful representations. We
+show that this simple and lightweight design is the key to efficient segmentation on Transformers. We scale our
+approach up to obtain a series of models from SegFormer-B0 to SegFormer-B5, reaching significantly better performance
+and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50.3% mIoU on ADE20K with 64M parameters,
+being 5x smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on
+Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C.*
+
+The figure below illustrates the architecture of SegFormer. Taken from the [original paper](https://arxiv.org/abs/2105.15203).
+
+
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version
+of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/NVlabs/SegFormer).
+
+## Usage tips
+
+- SegFormer consists of a hierarchical Transformer encoder, and a lightweight all-MLP decoder head.
+ [`SegformerModel`] is the hierarchical Transformer encoder (which in the paper is also referred to
+ as Mix Transformer or MiT). [`SegformerForSemanticSegmentation`] adds the all-MLP decoder head on
+ top to perform semantic segmentation of images. In addition, there's
+ [`SegformerForImageClassification`] which can be used to - you guessed it - classify images. The
+ authors of SegFormer first pre-trained the Transformer encoder on ImageNet-1k to classify images. Next, they throw
+ away the classification head, and replace it by the all-MLP decode head. Next, they fine-tune the model altogether on
+ ADE20K, Cityscapes and COCO-stuff, which are important benchmarks for semantic segmentation. All checkpoints can be
+ found on the [hub](https://huggingface.co/models?other=segformer).
+- The quickest way to get started with SegFormer is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer) (which showcase both inference and
+ fine-tuning on custom data). One can also check out the [blog post](https://huggingface.co/blog/fine-tune-segformer) introducing SegFormer and illustrating how it can be fine-tuned on custom data.
+- TensorFlow users should refer to [this repository](https://github.com/deep-diver/segformer-tf-transformers) that shows off-the-shelf inference and fine-tuning.
+- One can also check out [this interactive demo on Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers)
+ to try out a SegFormer model on custom images.
+- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
+- One can use [`SegformerImageProcessor`] to prepare images and corresponding segmentation maps
+ for the model. Note that this image processor is fairly basic and does not include all data augmentations used in
+ the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
+ important preprocessing step is that images and segmentation maps are randomly cropped and padded to the same size,
+ such as 512x512 or 640x640, after which they are normalized.
+- One additional thing to keep in mind is that one can initialize [`SegformerImageProcessor`] with
+ `do_reduce_labels` set to `True` or `False`. In some datasets (like ADE20k), the 0 index is used in the annotated
+ segmentation maps for background. However, ADE20k doesn't include the "background" class in its 150 labels.
+ Therefore, `do_reduce_labels` is used to reduce all labels by 1, and to make sure no loss is computed for the
+ background class (i.e. it replaces 0 in the annotated maps by 255, which is the *ignore_index* of the loss function
+ used by [`SegformerForSemanticSegmentation`]). However, other datasets use the 0 index as
+ background class and include this class as part of all labels. In that case, `do_reduce_labels` should be set to
+ `False`, as loss should also be computed for the background class.
+- As most models, SegFormer comes in different sizes, the details of which can be found in the table below
+ (taken from Table 7 of the [original paper](https://arxiv.org/abs/2105.15203)).
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
+| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+
+Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For
+SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://arxiv.org/abs/2105.15203).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SegFormer.
+
+
+
+- [`SegformerForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- [Image classification task guide](../tasks/image_classification)
+
+Semantic segmentation:
+
+- [`SegformerForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation).
+- A blog on fine-tuning SegFormer on a custom dataset can be found [here](https://huggingface.co/blog/fine-tune-segformer).
+- More demo notebooks on SegFormer (both inference + fine-tuning on a custom dataset) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer).
+- [`TFSegformerForSemanticSegmentation`] is supported by this [example notebook](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb).
+- [Semantic segmentation task guide](../tasks/semantic_segmentation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## SegformerConfig
+
+[[autodoc]] SegformerConfig
+
+## SegformerFeatureExtractor
+
+[[autodoc]] SegformerFeatureExtractor
+ - __call__
+ - post_process_semantic_segmentation
+
+## SegformerImageProcessor
+
+[[autodoc]] SegformerImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
+
+
+
+## SegformerModel
+
+[[autodoc]] SegformerModel
+ - forward
+
+## SegformerDecodeHead
+
+[[autodoc]] SegformerDecodeHead
+ - forward
+
+## SegformerForImageClassification
+
+[[autodoc]] SegformerForImageClassification
+ - forward
+
+## SegformerForSemanticSegmentation
+
+[[autodoc]] SegformerForSemanticSegmentation
+ - forward
+
+
+
+
+## TFSegformerDecodeHead
+
+[[autodoc]] TFSegformerDecodeHead
+ - call
+
+## TFSegformerModel
+
+[[autodoc]] TFSegformerModel
+ - call
+
+## TFSegformerForImageClassification
+
+[[autodoc]] TFSegformerForImageClassification
+ - call
+
+## TFSegformerForSemanticSegmentation
+
+[[autodoc]] TFSegformerForSemanticSegmentation
+ - call
+
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/seggpt.md b/docs/transformers/docs/source/en/model_doc/seggpt.md
new file mode 100644
index 0000000000000000000000000000000000000000..1eb82b84774c11c078fa80f55fec0766a268e106
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/seggpt.md
@@ -0,0 +1,95 @@
+
+
+# SegGPT
+
+
+
+
+
+## Overview
+
+The SegGPT model was proposed in [SegGPT: Segmenting Everything In Context](https://arxiv.org/abs/2304.03284) by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
+
+The abstract from the paper is the following:
+
+*We present SegGPT, a generalist model for segmenting everything in context. We unify various segmentation tasks into a generalist in-context learning framework that accommodates different kinds of segmentation data by transforming them into the same format of images. The training of SegGPT is formulated as an in-context coloring problem with random color mapping for each data sample. The objective is to accomplish diverse tasks according to the context, rather than relying on specific colors. After training, SegGPT can perform arbitrary segmentation tasks in images or videos via in-context inference, such as object instance, stuff, part, contour, and text. SegGPT is evaluated on a broad range of tasks, including few-shot semantic segmentation, video object segmentation, semantic segmentation, and panoptic segmentation. Our results show strong capabilities in segmenting in-domain and out-of*
+
+Tips:
+- One can use [`SegGptImageProcessor`] to prepare image input, prompt and mask to the model.
+- One can either use segmentation maps or RGB images as prompt masks. If using the latter make sure to set `do_convert_rgb=False` in the `preprocess` method.
+- It's highly advisable to pass `num_labels` when using `segmentation_maps` (not considering background) during preprocessing and postprocessing with [`SegGptImageProcessor`] for your use case.
+- When doing inference with [`SegGptForImageSegmentation`] if your `batch_size` is greater than 1 you can use feature ensemble across your images by passing `feature_ensemble=True` in the forward method.
+
+Here's how to use the model for one-shot semantic segmentation:
+
+```python
+import torch
+from datasets import load_dataset
+from transformers import SegGptImageProcessor, SegGptForImageSegmentation
+
+checkpoint = "BAAI/seggpt-vit-large"
+image_processor = SegGptImageProcessor.from_pretrained(checkpoint)
+model = SegGptForImageSegmentation.from_pretrained(checkpoint)
+
+dataset_id = "EduardoPacheco/FoodSeg103"
+ds = load_dataset(dataset_id, split="train")
+# Number of labels in FoodSeg103 (not including background)
+num_labels = 103
+
+image_input = ds[4]["image"]
+ground_truth = ds[4]["label"]
+image_prompt = ds[29]["image"]
+mask_prompt = ds[29]["label"]
+
+inputs = image_processor(
+ images=image_input,
+ prompt_images=image_prompt,
+ segmentation_maps=mask_prompt,
+ num_labels=num_labels,
+ return_tensors="pt"
+)
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+target_sizes = [image_input.size[::-1]]
+mask = image_processor.post_process_semantic_segmentation(outputs, target_sizes, num_labels=num_labels)[0]
+```
+
+This model was contributed by [EduardoPacheco](https://huggingface.co/EduardoPacheco).
+The original code can be found [here]([(https://github.com/baaivision/Painter/tree/main)).
+
+
+## SegGptConfig
+
+[[autodoc]] SegGptConfig
+
+## SegGptImageProcessor
+
+[[autodoc]] SegGptImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
+## SegGptModel
+
+[[autodoc]] SegGptModel
+ - forward
+
+## SegGptForImageSegmentation
+
+[[autodoc]] SegGptForImageSegmentation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/sew-d.md b/docs/transformers/docs/source/en/model_doc/sew-d.md
new file mode 100644
index 0000000000000000000000000000000000000000..3626d953d97da411e8f4b247b770243b18adfdfa
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/sew-d.md
@@ -0,0 +1,69 @@
+
+
+# SEW-D
+
+
+
+
+
+## Overview
+
+SEW-D (Squeezed and Efficient Wav2Vec with Disentangled attention) was proposed in [Performance-Efficiency Trade-offs
+in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim,
+Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+
+The abstract from the paper is the following:
+
+*This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition
+(ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance
+and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a
+pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a
+variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x
+inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference
+time, SEW reduces word error rate by 25-50% across different model sizes.*
+
+This model was contributed by [anton-l](https://huggingface.co/anton-l).
+
+## Usage tips
+
+- SEW-D is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- SEWDForCTC is fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded
+ using [`Wav2Vec2CTCTokenizer`].
+
+## Resources
+
+- [Audio classification task guide](../tasks/audio_classification)
+- [Automatic speech recognition task guide](../tasks/asr)
+
+## SEWDConfig
+
+[[autodoc]] SEWDConfig
+
+## SEWDModel
+
+[[autodoc]] SEWDModel
+ - forward
+
+## SEWDForCTC
+
+[[autodoc]] SEWDForCTC
+ - forward
+
+## SEWDForSequenceClassification
+
+[[autodoc]] SEWDForSequenceClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/sew.md b/docs/transformers/docs/source/en/model_doc/sew.md
new file mode 100644
index 0000000000000000000000000000000000000000..cfc92db0eaa13eec3eb8fb02b9a1c55007f6ac18
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/sew.md
@@ -0,0 +1,71 @@
+
+
+# SEW
+
+
+
+
+
+
+
+## Overview
+
+SEW (Squeezed and Efficient Wav2Vec) was proposed in [Performance-Efficiency Trade-offs in Unsupervised Pre-training
+for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q.
+Weinberger, Yoav Artzi.
+
+The abstract from the paper is the following:
+
+*This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition
+(ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance
+and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a
+pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a
+variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x
+inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference
+time, SEW reduces word error rate by 25-50% across different model sizes.*
+
+This model was contributed by [anton-l](https://huggingface.co/anton-l).
+
+## Usage tips
+
+- SEW is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+- SEWForCTC is fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded using
+ [`Wav2Vec2CTCTokenizer`].
+
+## Resources
+
+- [Audio classification task guide](../tasks/audio_classification)
+- [Automatic speech recognition task guide](../tasks/asr)
+
+## SEWConfig
+
+[[autodoc]] SEWConfig
+
+## SEWModel
+
+[[autodoc]] SEWModel
+ - forward
+
+## SEWForCTC
+
+[[autodoc]] SEWForCTC
+ - forward
+
+## SEWForSequenceClassification
+
+[[autodoc]] SEWForSequenceClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/shieldgemma2.md b/docs/transformers/docs/source/en/model_doc/shieldgemma2.md
new file mode 100644
index 0000000000000000000000000000000000000000..ed25f57eb7254bb958745f24fb3962f9db0cf70e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/shieldgemma2.md
@@ -0,0 +1,100 @@
+
+
+
+# ShieldGemma 2
+
+## Overview
+
+The ShieldGemma 2 model was proposed in a [technical report](https://arxiv.org/abs/2504.01081) by Google. ShieldGemma 2, built on [Gemma 3](https://ai.google.dev/gemma/docs/core/model_card_3), is a 4 billion (4B) parameter model that checks the safety of both synthetic and natural images against key categories to help you build robust datasets and models. With this addition to the Gemma family of models, researchers and developers can now easily minimize the risk of harmful content in their models across key areas of harm as defined below:
+
+- No Sexually Explicit content: The image shall not contain content that depicts explicit or graphic sexual acts (e.g., pornography, erotic nudity, depictions of rape or sexual assault).
+- No Dangerous Content: The image shall not contain content that facilitates or encourages activities that could cause real-world harm (e.g., building firearms and explosive devices, promotion of terrorism, instructions for suicide).
+- No Violence/Gore content: The image shall not contain content that depicts shocking, sensational, or gratuitous violence (e.g., excessive blood and gore, gratuitous violence against animals, extreme injury or moment of death).
+
+We recommend using ShieldGemma 2 as an input filter to vision language models, or as an output filter of image generation systems. To train a robust image safety model, we curated training datasets of natural and synthetic images and instruction-tuned Gemma 3 to demonstrate strong performance.
+
+This model was contributed by [Ryan Mullins](https://huggingface.co/RyanMullins).
+
+## Usage Example
+
+- ShieldGemma 2 provides a Processor that accepts a list of `images` and an optional list of `policies` as input, and constructs a batch of prompts as the product of these two lists using the provided chat template.
+- You can extend ShieldGemma's built-in in policies with the `custom_policies` argument to the Processor. Using the same key as one of the built-in policies will overwrite that policy with your custom defintion.
+- ShieldGemma 2 does not support the image cropping capabilities used by Gemma 3.
+
+### Classification against Built-in Policies
+
+```python
+from PIL import Image
+import requests
+from transformers import AutoProcessor, ShieldGemma2ForImageClassification
+
+model_id = "google/shieldgemma-2-4b-it"
+model = ShieldGemma2ForImageClassification.from_pretrained(model_id, device_map="auto")
+processor = AutoProcessor.from_pretrained(model_id)
+
+url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+inputs = processor(images=[image], return_tensors="pt").to(model.device)
+
+output = model(**inputs)
+print(output.probabilities)
+```
+
+### Classification against Custom Policies
+
+```python
+from PIL import Image
+import requests
+from transformers import AutoProcessor, ShieldGemma2ForImageClassification
+
+model_id = "google/shieldgemma-2-4b-it"
+model = ShieldGemma2ForImageClassification.from_pretrained(model_id, device_map="auto")
+processor = AutoProcessor.from_pretrained(model_id)
+
+url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+custom_policies = {
+ "key_a": "descrition_a",
+ "key_b": "descrition_b",
+}
+
+inputs = processor(
+ images=[image],
+ custom_policies=custom_policies,
+ policies=["dangerous", "key_a", "key_b"],
+ return_tensors="pt",
+).to(model.device)
+
+output = model(**inputs)
+print(output.probabilities)
+```
+
+
+## ShieldGemma2Processor
+
+[[autodoc]] ShieldGemma2Processor
+
+## ShieldGemma2Config
+
+[[autodoc]] ShieldGemma2Config
+
+## ShieldGemma2ForImageClassification
+
+[[autodoc]] ShieldGemma2ForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/siglip.md b/docs/transformers/docs/source/en/model_doc/siglip.md
new file mode 100644
index 0000000000000000000000000000000000000000..e443a6f0cbd616860f8b67a3cb7decb83168309e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/siglip.md
@@ -0,0 +1,185 @@
+
+
+
+
+
+
+
+
+
+
+# SigLIP
+
+[SigLIP](https://huggingface.co/papers/2303.15343) is a multimodal image-text model similar to [CLIP](clip). It uses separate image and text encoders to generate representations for both modalities.
+
+Unlike CLIP, SigLIP employs a pairwise sigmoid loss on image-text pairs during training. This training loss eliminates the need for a global view of all pairwise similarities between images and texts within a batch. Consequently, it enables more efficient scaling to larger batch sizes while also delivering superior performance with smaller batch sizes.
+
+You can find all the original SigLIP checkpoints under the [SigLIP](https://huggingface.co/collections/google/siglip-659d5e62f0ae1a57ae0e83ba) collection.
+
+
+> [!TIP]
+> Click on the SigLIP models in the right sidebar for more examples of how to apply SigLIP to different image and text tasks.
+
+The example below demonstrates how to generate similarity scores between texts and image(s) with [`Pipeline`] or the [`AutoModel`] class.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+image = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+candidate_labels = ["a Pallas cat", "a lion", "a Siberian tiger"]
+
+pipeline = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224", device=0, torch_dtype=torch.bfloat16)
+pipeline(image, candidate_labels=candidate_labels)
+```
+
+
+
+
+```py
+import torch
+import requests
+from PIL import Image
+from transformers import AutoProcessor, AutoModel
+
+model = AutoModel.from_pretrained("google/siglip-base-patch16-224", torch_dtype=torch.float16, device_map="auto", attn_implementation="sdpa")
+processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+image = Image.open(requests.get(url, stream=True).raw)
+candidate_labels = ["a Pallas cat", "a lion", "a Siberian tiger"]
+texts = [f'This is a photo of {label}.' for label in candidate_labels]
+inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt").to("cuda")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+logits_per_image = outputs.logits_per_image
+probs = torch.sigmoid(logits_per_image)
+print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [bitsandbytes](../quantization/bitsandbytes) to only quantize the weights to int4.
+
+```py
+import torch
+import requests
+from PIL import Image
+from transformers import AutoProcessor, AutoModel, BitsAndBytesConfig
+
+bnb_config = BitsAndBytesConfig(load_in_4bit=True)
+model = AutoModel.from_pretrained("google/siglip-base-patch16-224", quantization_config=bnb_config, device_map="auto", attn_implementation="sdpa")
+processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+image = Image.open(requests.get(url, stream=True).raw)
+candidate_labels = ["a Pallas cat", "a lion", "a Siberian tiger"]
+texts = [f'This is a photo of {label}.' for label in candidate_labels]
+inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt").to("cuda")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+logits_per_image = outputs.logits_per_image
+probs = torch.sigmoid(logits_per_image)
+print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+```
+## Notes
+
+- Training is supported for DDP and FSDP on single-node multi-GPU setups. However, it does not use [torch.distributed](https://pytorch.org/tutorials/beginner/dist_overview.html) utilities which may limit the scalability of batch size.
+- When using the standalone [`SiglipTokenizer`] or [`SiglipProcessor`], make sure to pass `padding="max_length"` because that is how the model was trained.
+- To get the same results as the [`Pipeline`], a prompt template of `"This is a photo of {label}."` should be passed to the processor.
+- Toggle the `attn_implementation` parameter to either `"sdpa"` or `"flash_attention_2"` to use a more memory-efficient attention.
+ ```py
+ # pip install -U flash-attn --no-build-isolation
+
+ from transformers import SiglipModel
+
+ model = SiglipModel.from_pretrained(
+ "google/siglip-so400m-patch14-384",
+ attn_implementation="flash_attention_2",
+ torch_dtype=torch.float16,
+ device_map=device,
+ )
+ ```
+
+
+## SiglipConfig
+
+[[autodoc]] SiglipConfig
+ - from_text_vision_configs
+
+## SiglipTextConfig
+
+[[autodoc]] SiglipTextConfig
+
+## SiglipVisionConfig
+
+[[autodoc]] SiglipVisionConfig
+
+## SiglipTokenizer
+
+[[autodoc]] SiglipTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## SiglipImageProcessor
+
+[[autodoc]] SiglipImageProcessor
+ - preprocess
+
+## SiglipImageProcessorFast
+
+[[autodoc]] SiglipImageProcessorFast
+ - preprocess
+
+## SiglipProcessor
+
+[[autodoc]] SiglipProcessor
+
+## SiglipModel
+
+[[autodoc]] SiglipModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## SiglipTextModel
+
+[[autodoc]] SiglipTextModel
+ - forward
+
+## SiglipVisionModel
+
+[[autodoc]] SiglipVisionModel
+ - forward
+
+
+## SiglipForImageClassification
+
+[[autodoc]] SiglipForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/siglip2.md b/docs/transformers/docs/source/en/model_doc/siglip2.md
new file mode 100644
index 0000000000000000000000000000000000000000..0d49d9382361634bed2513580d4a816117ac34a9
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/siglip2.md
@@ -0,0 +1,282 @@
+
+
+# SigLIP2
+
+
+
+
+
+
+
+## Overview
+
+The SigLIP2 model was proposed in [SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features](https://huggingface.co/papers/2502.14786) by Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin,
+Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen,
+Andreas Steiner and Xiaohua Zhai.
+
+The model comes in two variants
+
+ 1) FixRes - model works with fixed resolution images (backward compatible with SigLIP v1)
+ 2) NaFlex - model works with variable image aspect ratios and resolutions (SigLIP2 in `transformers`)
+
+The abstract from the paper is the following:
+
+*We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success
+of the original SigLIP. In this second iteration, we extend the original image-text training objective with
+several prior, independently developed techniques into a unified recipe—this includes decoder-based
+pretraining, self-supervised losses (self-distillation, masked prediction) and online data curation. With
+these changes, SigLIP 2 models outperform their SigLIP counterparts at all model scales in core capabilities,
+including zero-shot classification (best SigLIP 2 ViT-g/16 achieves 85.0% ImageNet zero-shot
+accuracy), image-text retrieval, and transfer performance when extracting visual representations for
+Vision-Language Models (VLMs). Furthermore, the new training recipe leads to significant improvements
+on localization and dense prediction tasks. We also train variants which support multiple resolutions
+and preserve the input’s native aspect ratio. Finally, we train on a more diverse data-mixture that
+includes de-biasing techniques, leading to much better multilingual understanding and improved fair-
+ness. To provide users with the ability to trade-off inference cost with performance, we release model
+checkpoints at four sizes (ViT-B/86M, L/303M, So400m/400M, and g/1B).*
+
+## Usage tips
+
+- Usage of SigLIP2 is similar to [SigLIP](siglip) and [CLIP](clip). The main difference from CLIP is the training loss, which does not require a global view of all the pairwise similarities of images and texts within a batch. One needs to apply the sigmoid activation function to the logits, rather than the softmax.
+- Training is supported but does not use `torch.distributed` utilities which may limit the scalability of batch size. However, DDP and FDSP works on single-node multi-gpu setup.
+- When using the standalone [`GemmaTokenizerFast`] make sure to pass `padding="max_length"` and `max_length=64` as that's how the model was trained.
+- Model was trained with *lowercased* text, make sure you make the same preprocessing for your text labels.
+- To get the same results as the pipeline, a prompt template of "this is a photo of {label}" should be used.
+- The NaFlex variant supports processing images at higher resolutions by adjusting the `max_num_patches` parameter in the `Processor`. The default value is `max_num_patches=256`. Increasing `max_num_patches` to 1024 (4x) will approximately double processed image height and width, while preserving the aspect ratio.
+
+
+
+This model was contributed by [qubvel](https://huggingface.co/qubvel-hf).
+The original code can be found [here](https://github.com/google-research/big_vision/tree/main).
+
+## Usage example
+
+There are 2 main ways to use SigLIP2: either using the pipeline API, which abstracts away all the complexity for you, or by using the `Siglip2Model` class yourself.
+
+### FixRes variant
+
+**Pipeline API**
+
+The pipeline allows to use the model in a few lines of code:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # load pipe
+>>> image_classifier = pipeline(
+... task="zero-shot-image-classification",
+... model="google/siglip2-base-patch16-224",
+... )
+
+>>> # load image
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # inference
+>>> candidate_labels = ["2 cats", "a plane", "a remote"]
+>>> outputs = image_classifier(image, candidate_labels=candidate_labels)
+>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
+>>> print(outputs)
+[{'score': 0.1499, 'label': '2 cats'}, {'score': 0.0008, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
+```
+
+**Using the model yourself**
+
+If you want to do the pre- and postprocessing yourself, here's how to do that:
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip2-base-patch16-224")
+>>> processor = AutoProcessor.from_pretrained("google/siglip2-base-patch16-224")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# follows the pipeline prompt template to get same results
+>>> texts = [f"This is a photo of {label}." for label in candidate_labels]
+
+# IMPORTANT: we pass `padding=max_length` and `max_length=64` since the model was trained with this
+>>> inputs = processor(text=texts, images=image, padding="max_length", max_length=64, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+15.0% that image 0 is '2 cats'
+```
+
+### NaFlex variant
+
+NaFlex combines ideas from FlexiViT, i.e. supporting multiple, predefined sequence lengths
+with a single ViT model, and NaViT, namely processing images at their native aspect ratio.
+This enables processing different types of images at appropriate resolution, e.g. using a
+larger resolution to process document images, while at the same time minimizing the impact
+of aspect ratio distortion on certain inference tasks, e.g. on OCR.
+
+Given a patch size and target sequence length, NaFlex preprocesses the data by first resizing
+the input image such that the height and width after resizing are multiples of the patch size,
+while
+
+ 1. keeping the aspect ratio distortion as small as possible
+ 2. producing a sequence length of at most the desired target sequence length (`max_num_patches`)
+
+The resulting distortion in width and height is at most `(patch_size - 1) / width` and
+`(patch_size - 1) / height`, respectively, which tends to be small for common resolutions and aspect ratios.
+After resizing, the image is split into a sequence of patches, and a mask with padding information is added.
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip2-base-patch16-naflex")
+>>> processor = AutoProcessor.from_pretrained("google/siglip2-base-patch16-naflex")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# follows the pipeline prompt template to get same results
+>>> texts = [f"This is a photo of {label}." for label in candidate_labels]
+
+# default value for `max_num_patches` is 256, but you can increase resulted image resolution providing
+# higher values e.g. `max_num_patches=512`
+>>> inputs = processor(text=texts, images=image, max_num_patches=256, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+21.1% that image 0 is '2 cats'
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SigLIP2.
+
+- [Zero-shot image classification task guide](../tasks/zero_shot_image_classification)
+- Demo notebook for SigLIP2 can be found [here](https://github.com/qubvel/transformers-notebooks/tree/master/notebooks/SigLIP2_inference.ipynb). 🌎
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+## Combining SigLIP2 and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import AutoProcessor, AutoModel
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModel.from_pretrained(
+... "google/siglip2-so400m-patch14-384",
+... attn_implementation="flash_attention_2",
+... torch_dtype=torch.float16,
+... device_map=device,
+... )
+>>> processor = AutoProcessor.from_pretrained("google/siglip2-so400m-patch14-384")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# follows the pipeline prompt template to get same results
+>>> texts = [f'This is a photo of {label}.' for label in candidate_labels]
+# important: we pass `padding=max_length` since the model was trained with this
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt").to(device)
+
+>>> with torch.no_grad():
+... with torch.autocast(device):
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+19.8% that image 0 is '2 cats'
+```
+
+## Siglip2Config
+
+[[autodoc]] Siglip2Config
+
+## Siglip2TextConfig
+
+[[autodoc]] Siglip2TextConfig
+
+## Siglip2VisionConfig
+
+[[autodoc]] Siglip2VisionConfig
+
+## Siglip2ImageProcessor
+
+[[autodoc]] Siglip2ImageProcessor
+ - preprocess
+
+## Siglip2ImageProcessorFast
+
+[[autodoc]] Siglip2ImageProcessorFast
+ - preprocess
+
+## Siglip2Processor
+
+[[autodoc]] Siglip2Processor
+
+## Siglip2Model
+
+[[autodoc]] Siglip2Model
+ - forward
+ - get_text_features
+ - get_image_features
+
+## Siglip2TextModel
+
+[[autodoc]] Siglip2TextModel
+ - forward
+
+## Siglip2VisionModel
+
+[[autodoc]] Siglip2VisionModel
+ - forward
+
+## Siglip2ForImageClassification
+
+[[autodoc]] Siglip2ForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/smolvlm.md b/docs/transformers/docs/source/en/model_doc/smolvlm.md
new file mode 100644
index 0000000000000000000000000000000000000000..9512fb6aa2958dd2130e9393f122a5b6002e4273
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/smolvlm.md
@@ -0,0 +1,203 @@
+
+
+# SmolVLM
+
+
+
+
+
+
+
+## Overview
+SmolVLM2 is an adaptation of the Idefics3 model with two main differences:
+
+- It uses SmolLM2 for the text model.
+- It supports multi-image and video inputs
+
+## Usage tips
+
+Input images are processed either by upsampling (if resizing is enabled) or at their original resolution. The resizing behavior depends on two parameters: do_resize and size.
+
+Videos should not be upsampled.
+
+If `do_resize` is set to `True`, the model resizes images so that the longest edge is 4*512 pixels by default.
+The default resizing behavior can be customized by passing a dictionary to the `size` parameter. For example, `{"longest_edge": 4 * 512}` is the default, but you can change it to a different value if needed.
+
+Here’s how to control resizing and set a custom size:
+```python
+image_processor = SmolVLMImageProcessor(do_resize=True, size={"longest_edge": 2 * 512}, max_image_size=512)
+```
+
+Additionally, the `max_image_size` parameter, which controls the size of each square patch the image is decomposed into, is set to 512 by default but can be adjusted as needed. After resizing (if applicable), the image processor decomposes the images into square patches based on the `max_image_size` parameter.
+
+This model was contributed by [orrzohar](https://huggingface.co/orrzohar).
+
+
+
+## Usage example
+
+### Single Media inference
+
+The model can accept both images and videos as input, but you should use only one of the modalities at a time. Here's an example code for that.
+
+```python
+import torch
+from transformers import AutoProcessor, AutoModelForImageTextToText
+
+processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM2-256M-Video-Instruct")
+model = AutoModelForImageTextToText.from_pretrained(
+ "HuggingFaceTB/SmolVLM2-256M-Video-Instruct",
+ torch_dtype=torch.bfloat16,
+ device_map="cuda"
+)
+
+conversation = [
+ {
+ "role": "user",
+ "content":[
+ {"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
+ {"type": "text", "text": "Describe this image."}
+ ]
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+).to(model.device, dtype=torch.bfloat16)
+
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_texts = processor.batch_decode(output_ids, skip_special_tokens=True)
+print(generated_texts)
+
+
+# Video
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "video", "path": "/path/to/video.mp4"},
+ {"type": "text", "text": "Describe this video in detail"}
+ ]
+ },
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+).to(model.device, dtype=torch.bfloat16)
+
+generated_ids = model.generate(**inputs, do_sample=False, max_new_tokens=100)
+generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True)
+print(generated_texts[0])
+```
+
+### Batch Mixed Media Inference
+
+The model can batch inputs composed of several images/videos and text. Here is an example.
+
+```python
+import torch
+from transformers import AutoProcessor, AutoModelForImageTextToText
+
+processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM2-256M-Video-Instruct")
+model = AutoModelForImageTextToText.from_pretrained(
+ "HuggingFaceTB/SmolVLM2-256M-Video-Instruct",
+ torch_dtype=torch.bfloat16,
+ device_map="cuda"
+)
+
+# Conversation for the first image
+conversation1 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image.jpg"},
+ {"type": "text", "text": "Describe this image."}
+ ]
+ }
+]
+
+# Conversation with two images
+conversation2 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image.jpg"},
+ {"type": "image", "path": "/path/to/image.jpg"},
+ {"type": "text", "text": "What is written in the pictures?"}
+ ]
+ }
+]
+
+# Conversation with pure text
+conversation3 = [
+ {"role": "user","content": "who are you?"}
+]
+
+
+conversations = [conversation1, conversation2, conversation3]
+inputs = processor.apply_chat_template(
+ conversation,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+).to(model.device, dtype=torch.bfloat16)
+
+generated_ids = model.generate(**inputs, do_sample=False, max_new_tokens=100)
+generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True)
+print(generated_texts[0])
+```
+
+## SmolVLMConfig
+
+[[autodoc]] SmolVLMConfig
+
+## SmolVLMVisionConfig
+
+[[autodoc]] SmolVLMVisionConfig
+
+## Idefics3VisionTransformer
+
+[[autodoc]] SmolVLMVisionTransformer
+
+## SmolVLMModel
+
+[[autodoc]] SmolVLMModel
+ - forward
+
+## SmolVLMForConditionalGeneration
+
+[[autodoc]] SmolVLMForConditionalGeneration
+ - forward
+
+
+## SmolVLMImageProcessor
+[[autodoc]] SmolVLMImageProcessor
+ - preprocess
+
+
+## SmolVLMProcessor
+[[autodoc]] SmolVLMProcessor
+ - __call__
diff --git a/docs/transformers/docs/source/en/model_doc/speech-encoder-decoder.md b/docs/transformers/docs/source/en/model_doc/speech-encoder-decoder.md
new file mode 100644
index 0000000000000000000000000000000000000000..8893adfdd4a05cbd45691ca7bccfc55aff824dbe
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/speech-encoder-decoder.md
@@ -0,0 +1,140 @@
+
+
+# Speech Encoder Decoder Models
+
+
+
+
+
+
+
+
+The [`SpeechEncoderDecoderModel`] can be used to initialize a speech-to-text model
+with any pretrained speech autoencoding model as the encoder (*e.g.* [Wav2Vec2](wav2vec2), [Hubert](hubert)) and any pretrained autoregressive model as the decoder.
+
+The effectiveness of initializing speech-sequence-to-text-sequence models with pretrained checkpoints for speech
+recognition and speech translation has *e.g.* been shown in [Large-Scale Self- and Semi-Supervised Learning for Speech
+Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli,
+Alexis Conneau.
+
+An example of how to use a [`SpeechEncoderDecoderModel`] for inference can be seen in [Speech2Text2](speech_to_text_2).
+
+## Randomly initializing `SpeechEncoderDecoderModel` from model configurations.
+
+[`SpeechEncoderDecoderModel`] can be randomly initialized from an encoder and a decoder config. In the following example, we show how to do this using the default [`Wav2Vec2Model`] configuration for the encoder
+and the default [`BertForCausalLM`] configuration for the decoder.
+
+```python
+>>> from transformers import BertConfig, Wav2Vec2Config, SpeechEncoderDecoderConfig, SpeechEncoderDecoderModel
+
+>>> config_encoder = Wav2Vec2Config()
+>>> config_decoder = BertConfig()
+
+>>> config = SpeechEncoderDecoderConfig.from_encoder_decoder_configs(config_encoder, config_decoder)
+>>> model = SpeechEncoderDecoderModel(config=config)
+```
+
+## Initialising `SpeechEncoderDecoderModel` from a pretrained encoder and a pretrained decoder.
+
+[`SpeechEncoderDecoderModel`] can be initialized from a pretrained encoder checkpoint and a pretrained decoder checkpoint. Note that any pretrained Transformer-based speech model, *e.g.* [Wav2Vec2](wav2vec2), [Hubert](hubert) can serve as the encoder and both pretrained auto-encoding models, *e.g.* BERT, pretrained causal language models, *e.g.* GPT2, as well as the pretrained decoder part of sequence-to-sequence models, *e.g.* decoder of BART, can be used as the decoder.
+Depending on which architecture you choose as the decoder, the cross-attention layers might be randomly initialized.
+Initializing [`SpeechEncoderDecoderModel`] from a pretrained encoder and decoder checkpoint requires the model to be fine-tuned on a downstream task, as has been shown in [the *Warm-starting-encoder-decoder blog post*](https://huggingface.co/blog/warm-starting-encoder-decoder).
+To do so, the `SpeechEncoderDecoderModel` class provides a [`SpeechEncoderDecoderModel.from_encoder_decoder_pretrained`] method.
+
+```python
+>>> from transformers import SpeechEncoderDecoderModel
+
+>>> model = SpeechEncoderDecoderModel.from_encoder_decoder_pretrained(
+... "facebook/hubert-large-ll60k", "google-bert/bert-base-uncased"
+... )
+```
+
+## Loading an existing `SpeechEncoderDecoderModel` checkpoint and perform inference.
+
+To load fine-tuned checkpoints of the `SpeechEncoderDecoderModel` class, [`SpeechEncoderDecoderModel`] provides the `from_pretrained(...)` method just like any other model architecture in Transformers.
+
+To perform inference, one uses the [`generate`] method, which allows to autoregressively generate text. This method supports various forms of decoding, such as greedy, beam search and multinomial sampling.
+
+```python
+>>> from transformers import Wav2Vec2Processor, SpeechEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> # load a fine-tuned speech translation model and corresponding processor
+>>> model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
+>>> processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
+
+>>> # let's perform inference on a piece of English speech (which we'll translate to German)
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values
+
+>>> # autoregressively generate transcription (uses greedy decoding by default)
+>>> generated_ids = model.generate(input_values)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+>>> print(generated_text)
+Mr. Quilter ist der Apostel der Mittelschicht und wir freuen uns, sein Evangelium willkommen heißen zu können.
+```
+
+## Training
+
+Once the model is created, it can be fine-tuned similar to BART, T5 or any other encoder-decoder model on a dataset of (speech, text) pairs.
+As you can see, only 2 inputs are required for the model in order to compute a loss: `input_values` (which are the
+speech inputs) and `labels` (which are the `input_ids` of the encoded target sequence).
+
+```python
+>>> from transformers import AutoTokenizer, AutoFeatureExtractor, SpeechEncoderDecoderModel
+>>> from datasets import load_dataset
+
+>>> encoder_id = "facebook/wav2vec2-base-960h" # acoustic model encoder
+>>> decoder_id = "google-bert/bert-base-uncased" # text decoder
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained(encoder_id)
+>>> tokenizer = AutoTokenizer.from_pretrained(decoder_id)
+>>> # Combine pre-trained encoder and pre-trained decoder to form a Seq2Seq model
+>>> model = SpeechEncoderDecoderModel.from_encoder_decoder_pretrained(encoder_id, decoder_id)
+
+>>> model.config.decoder_start_token_id = tokenizer.cls_token_id
+>>> model.config.pad_token_id = tokenizer.pad_token_id
+
+>>> # load an audio input and pre-process (normalise mean/std to 0/1)
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> input_values = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt").input_values
+
+>>> # load its corresponding transcription and tokenize to generate labels
+>>> labels = tokenizer(ds[0]["text"], return_tensors="pt").input_ids
+
+>>> # the forward function automatically creates the correct decoder_input_ids
+>>> loss = model(input_values=input_values, labels=labels).loss
+>>> loss.backward()
+```
+
+## SpeechEncoderDecoderConfig
+
+[[autodoc]] SpeechEncoderDecoderConfig
+
+## SpeechEncoderDecoderModel
+
+[[autodoc]] SpeechEncoderDecoderModel
+ - forward
+ - from_encoder_decoder_pretrained
+
+## FlaxSpeechEncoderDecoderModel
+
+[[autodoc]] FlaxSpeechEncoderDecoderModel
+ - __call__
+ - from_encoder_decoder_pretrained
diff --git a/docs/transformers/docs/source/en/model_doc/speech_to_text.md b/docs/transformers/docs/source/en/model_doc/speech_to_text.md
new file mode 100644
index 0000000000000000000000000000000000000000..bc65ea79655ff1ac96bb9d79a0990dc2441a4138
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/speech_to_text.md
@@ -0,0 +1,157 @@
+
+
+# Speech2Text
+
+
+
+
+
+
+## Overview
+
+The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
+transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
+Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
+fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
+transcripts/translations autoregressively. Speech2Text has been fine-tuned on several datasets for ASR and ST:
+[LibriSpeech](http://www.openslr.org/12), [CoVoST 2](https://github.com/facebookresearch/covost), [MuST-C](https://ict.fbk.eu/must-c/).
+
+This model was contributed by [valhalla](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text).
+
+## Inference
+
+Speech2Text is a speech model that accepts a float tensor of log-mel filter-bank features extracted from the speech
+signal. It's a transformer-based seq2seq model, so the transcripts/translations are generated autoregressively. The
+`generate()` method can be used for inference.
+
+The [`Speech2TextFeatureExtractor`] class is responsible for extracting the log-mel filter-bank
+features. The [`Speech2TextProcessor`] wraps [`Speech2TextFeatureExtractor`] and
+[`Speech2TextTokenizer`] into a single instance to both extract the input features and decode the
+predicted token ids.
+
+The feature extractor depends on `torchaudio` and the tokenizer depends on `sentencepiece` so be sure to
+install those packages before running the examples. You could either install those as extra speech dependencies with
+`pip install transformers"[speech, sentencepiece]"` or install the packages separately with `pip install torchaudio sentencepiece`. Also `torchaudio` requires the development version of the [libsndfile](http://www.mega-nerd.com/libsndfile/) package which can be installed via a system package manager. On Ubuntu it can
+be installed as follows: `apt install libsndfile1-dev`
+
+- ASR and Speech Translation
+
+```python
+>>> import torch
+>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr")
+>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr")
+
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+
+>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
+>>> generated_ids = model.generate(inputs["input_features"], attention_mask=inputs["attention_mask"])
+
+>>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> transcription
+['mister quilter is the apostle of the middle classes and we are glad to welcome his gospel']
+```
+
+- Multilingual speech translation
+
+ For multilingual speech translation models, `eos_token_id` is used as the `decoder_start_token_id` and
+ the target language id is forced as the first generated token. To force the target language id as the first
+ generated token, pass the `forced_bos_token_id` parameter to the `generate()` method. The following
+ example shows how to translate English speech to French text using the *facebook/s2t-medium-mustc-multilingual-st*
+ checkpoint.
+
+```python
+>>> import torch
+>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
+>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+
+>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
+>>> generated_ids = model.generate(
+... inputs["input_features"],
+... attention_mask=inputs["attention_mask"],
+... forced_bos_token_id=processor.tokenizer.lang_code_to_id["fr"],
+... )
+
+>>> translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> translation
+["(Vidéo) Si M. Kilder est l'apossible des classes moyennes, et nous sommes heureux d'être accueillis dans son évangile."]
+```
+
+See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for Speech2Text checkpoints.
+
+## Speech2TextConfig
+
+[[autodoc]] Speech2TextConfig
+
+## Speech2TextTokenizer
+
+[[autodoc]] Speech2TextTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## Speech2TextFeatureExtractor
+
+[[autodoc]] Speech2TextFeatureExtractor
+ - __call__
+
+## Speech2TextProcessor
+
+[[autodoc]] Speech2TextProcessor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+
+
+
+
+## Speech2TextModel
+
+[[autodoc]] Speech2TextModel
+ - forward
+
+## Speech2TextForConditionalGeneration
+
+[[autodoc]] Speech2TextForConditionalGeneration
+ - forward
+
+
+
+
+## TFSpeech2TextModel
+
+[[autodoc]] TFSpeech2TextModel
+ - call
+
+## TFSpeech2TextForConditionalGeneration
+
+[[autodoc]] TFSpeech2TextForConditionalGeneration
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/speech_to_text_2.md b/docs/transformers/docs/source/en/model_doc/speech_to_text_2.md
new file mode 100644
index 0000000000000000000000000000000000000000..fc2d0357c546c7fe81ea9394ebf585e3a7753204
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/speech_to_text_2.md
@@ -0,0 +1,135 @@
+
+
+# Speech2Text2
+
+
+
+ This model is in maintenance mode only, we don't accept any new PRs changing its code.
+ If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+ You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+The Speech2Text2 model is used together with [Wav2Vec2](wav2vec2) for Speech Translation models proposed in
+[Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by
+Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+
+Speech2Text2 is a *decoder-only* transformer model that can be used with any speech *encoder-only*, such as
+[Wav2Vec2](wav2vec2) or [HuBERT](hubert) for Speech-to-Text tasks. Please refer to the
+[SpeechEncoderDecoder](speech-encoder-decoder) class on how to combine Speech2Text2 with any speech *encoder-only*
+model.
+
+This model was contributed by [Patrick von Platen](https://huggingface.co/patrickvonplaten).
+
+The original code can be found [here](https://github.com/pytorch/fairseq/blob/1f7ef9ed1e1061f8c7f88f8b94c7186834398690/fairseq/models/wav2vec/wav2vec2_asr.py#L266).
+
+## Usage tips
+
+- Speech2Text2 achieves state-of-the-art results on the CoVoST Speech Translation dataset. For more information, see
+ the [official models](https://huggingface.co/models?other=speech2text2) .
+- Speech2Text2 is always used within the [SpeechEncoderDecoder](speech-encoder-decoder) framework.
+- Speech2Text2's tokenizer is based on [fastBPE](https://github.com/glample/fastBPE).
+
+## Inference
+
+Speech2Text2's [`SpeechEncoderDecoderModel`] model accepts raw waveform input values from speech and
+makes use of [`~generation.GenerationMixin.generate`] to translate the input speech
+autoregressively to the target language.
+
+The [`Wav2Vec2FeatureExtractor`] class is responsible for preprocessing the input speech and
+[`Speech2Text2Tokenizer`] decodes the generated target tokens to the target string. The
+[`Speech2Text2Processor`] wraps [`Wav2Vec2FeatureExtractor`] and
+[`Speech2Text2Tokenizer`] into a single instance to both extract the input features and decode the
+predicted token ids.
+
+- Step-by-step Speech Translation
+
+```python
+>>> import torch
+>>> from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import soundfile as sf
+
+>>> model = SpeechEncoderDecoderModel.from_pretrained("facebook/s2t-wav2vec2-large-en-de")
+>>> processor = Speech2Text2Processor.from_pretrained("facebook/s2t-wav2vec2-large-en-de")
+
+
+>>> def map_to_array(batch):
+... speech, _ = sf.read(batch["file"])
+... batch["speech"] = speech
+... return batch
+
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> ds = ds.map(map_to_array)
+
+>>> inputs = processor(ds["speech"][0], sampling_rate=16_000, return_tensors="pt")
+>>> generated_ids = model.generate(inputs=inputs["input_values"], attention_mask=inputs["attention_mask"])
+
+>>> transcription = processor.batch_decode(generated_ids)
+```
+
+- Speech Translation via Pipelines
+
+ The automatic speech recognition pipeline can also be used to translate speech in just a couple lines of code
+
+```python
+>>> from datasets import load_dataset
+>>> from transformers import pipeline
+
+>>> librispeech_en = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> asr = pipeline(
+... "automatic-speech-recognition",
+... model="facebook/s2t-wav2vec2-large-en-de",
+... feature_extractor="facebook/s2t-wav2vec2-large-en-de",
+... )
+
+>>> translation_de = asr(librispeech_en[0]["file"])
+```
+
+See [model hub](https://huggingface.co/models?filter=speech2text2) to look for Speech2Text2 checkpoints.
+
+## Resources
+
+- [Causal language modeling task guide](../tasks/language_modeling)
+
+## Speech2Text2Config
+
+[[autodoc]] Speech2Text2Config
+
+## Speech2TextTokenizer
+
+[[autodoc]] Speech2Text2Tokenizer
+ - batch_decode
+ - decode
+ - save_vocabulary
+
+## Speech2Text2Processor
+
+[[autodoc]] Speech2Text2Processor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+
+## Speech2Text2ForCausalLM
+
+[[autodoc]] Speech2Text2ForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/speecht5.md b/docs/transformers/docs/source/en/model_doc/speecht5.md
new file mode 100644
index 0000000000000000000000000000000000000000..acbadb137f46fbc45b7fe3252565d33fa7ac278a
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/speecht5.md
@@ -0,0 +1,89 @@
+
+
+# SpeechT5
+
+
+
+
+
+## Overview
+
+The SpeechT5 model was proposed in [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
+
+The abstract from the paper is the following:
+
+*Motivated by the success of T5 (Text-To-Text Transfer Transformer) in pre-trained natural language processing models, we propose a unified-modal SpeechT5 framework that explores the encoder-decoder pre-training for self-supervised speech/text representation learning. The SpeechT5 framework consists of a shared encoder-decoder network and six modal-specific (speech/text) pre/post-nets. After preprocessing the input speech/text through the pre-nets, the shared encoder-decoder network models the sequence-to-sequence transformation, and then the post-nets generate the output in the speech/text modality based on the output of the decoder. Leveraging large-scale unlabeled speech and text data, we pre-train SpeechT5 to learn a unified-modal representation, hoping to improve the modeling capability for both speech and text. To align the textual and speech information into this unified semantic space, we propose a cross-modal vector quantization approach that randomly mixes up speech/text states with latent units as the interface between encoder and decoder. Extensive evaluations show the superiority of the proposed SpeechT5 framework on a wide variety of spoken language processing tasks, including automatic speech recognition, speech synthesis, speech translation, voice conversion, speech enhancement, and speaker identification.*
+
+This model was contributed by [Matthijs](https://huggingface.co/Matthijs). The original code can be found [here](https://github.com/microsoft/SpeechT5).
+
+## SpeechT5Config
+
+[[autodoc]] SpeechT5Config
+
+## SpeechT5HifiGanConfig
+
+[[autodoc]] SpeechT5HifiGanConfig
+
+## SpeechT5Tokenizer
+
+[[autodoc]] SpeechT5Tokenizer
+ - __call__
+ - save_vocabulary
+ - decode
+ - batch_decode
+
+## SpeechT5FeatureExtractor
+
+[[autodoc]] SpeechT5FeatureExtractor
+ - __call__
+
+## SpeechT5Processor
+
+[[autodoc]] SpeechT5Processor
+ - __call__
+ - pad
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+
+## SpeechT5Model
+
+[[autodoc]] SpeechT5Model
+ - forward
+
+## SpeechT5ForSpeechToText
+
+[[autodoc]] SpeechT5ForSpeechToText
+ - forward
+
+## SpeechT5ForTextToSpeech
+
+[[autodoc]] SpeechT5ForTextToSpeech
+ - forward
+ - generate
+
+## SpeechT5ForSpeechToSpeech
+
+[[autodoc]] SpeechT5ForSpeechToSpeech
+ - forward
+ - generate_speech
+
+## SpeechT5HifiGan
+
+[[autodoc]] SpeechT5HifiGan
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/splinter.md b/docs/transformers/docs/source/en/model_doc/splinter.md
new file mode 100644
index 0000000000000000000000000000000000000000..0d526beff9686fab6854a0e7fc3f54909e5c734c
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/splinter.md
@@ -0,0 +1,91 @@
+
+
+# Splinter
+
+
+
+
+
+## Overview
+
+The Splinter model was proposed in [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. Splinter
+is an encoder-only transformer (similar to BERT) pretrained using the recurring span selection task on a large corpus
+comprising Wikipedia and the Toronto Book Corpus.
+
+The abstract from the paper is the following:
+
+In several question answering benchmarks, pretrained models have reached human parity through fine-tuning on an order
+of 100,000 annotated questions and answers. We explore the more realistic few-shot setting, where only a few hundred
+training examples are available, and observe that standard models perform poorly, highlighting the discrepancy between
+current pretraining objectives and question answering. We propose a new pretraining scheme tailored for question
+answering: recurring span selection. Given a passage with multiple sets of recurring spans, we mask in each set all
+recurring spans but one, and ask the model to select the correct span in the passage for each masked span. Masked spans
+are replaced with a special token, viewed as a question representation, that is later used during fine-tuning to select
+the answer span. The resulting model obtains surprisingly good results on multiple benchmarks (e.g., 72.7 F1 on SQuAD
+with only 128 training examples), while maintaining competitive performance in the high-resource setting.
+
+This model was contributed by [yuvalkirstain](https://huggingface.co/yuvalkirstain) and [oriram](https://huggingface.co/oriram). The original code can be found [here](https://github.com/oriram/splinter).
+
+## Usage tips
+
+- Splinter was trained to predict answers spans conditioned on a special [QUESTION] token. These tokens contextualize
+ to question representations which are used to predict the answers. This layer is called QASS, and is the default
+ behaviour in the [`SplinterForQuestionAnswering`] class. Therefore:
+- Use [`SplinterTokenizer`] (rather than [`BertTokenizer`]), as it already
+ contains this special token. Also, its default behavior is to use this token when two sequences are given (for
+ example, in the *run_qa.py* script).
+- If you plan on using Splinter outside *run_qa.py*, please keep in mind the question token - it might be important for
+ the success of your model, especially in a few-shot setting.
+- Please note there are two different checkpoints for each size of Splinter. Both are basically the same, except that
+ one also has the pretrained weights of the QASS layer (*tau/splinter-base-qass* and *tau/splinter-large-qass*) and one
+ doesn't (*tau/splinter-base* and *tau/splinter-large*). This is done to support randomly initializing this layer at
+ fine-tuning, as it is shown to yield better results for some cases in the paper.
+
+## Resources
+
+- [Question answering task guide](../tasks/question-answering)
+
+## SplinterConfig
+
+[[autodoc]] SplinterConfig
+
+## SplinterTokenizer
+
+[[autodoc]] SplinterTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## SplinterTokenizerFast
+
+[[autodoc]] SplinterTokenizerFast
+
+## SplinterModel
+
+[[autodoc]] SplinterModel
+ - forward
+
+## SplinterForQuestionAnswering
+
+[[autodoc]] SplinterForQuestionAnswering
+ - forward
+
+## SplinterForPreTraining
+
+[[autodoc]] SplinterForPreTraining
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/squeezebert.md b/docs/transformers/docs/source/en/model_doc/squeezebert.md
new file mode 100644
index 0000000000000000000000000000000000000000..56046e22b79920fd4653bb9714d1346ea53fa4f0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/squeezebert.md
@@ -0,0 +1,103 @@
+
+
+# SqueezeBERT
+
+
+
+
+
+## Overview
+
+The SqueezeBERT model was proposed in [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, Kurt W. Keutzer. It's a
+bidirectional transformer similar to the BERT model. The key difference between the BERT architecture and the
+SqueezeBERT architecture is that SqueezeBERT uses [grouped convolutions](https://blog.yani.io/filter-group-tutorial)
+instead of fully-connected layers for the Q, K, V and FFN layers.
+
+The abstract from the paper is the following:
+
+*Humans read and write hundreds of billions of messages every day. Further, due to the availability of large datasets,
+large computing systems, and better neural network models, natural language processing (NLP) technology has made
+significant strides in understanding, proofreading, and organizing these messages. Thus, there is a significant
+opportunity to deploy NLP in myriad applications to help web users, social networks, and businesses. In particular, we
+consider smartphones and other mobile devices as crucial platforms for deploying NLP models at scale. However, today's
+highly-accurate NLP neural network models such as BERT and RoBERTa are extremely computationally expensive, with
+BERT-base taking 1.7 seconds to classify a text snippet on a Pixel 3 smartphone. In this work, we observe that methods
+such as grouped convolutions have yielded significant speedups for computer vision networks, but many of these
+techniques have not been adopted by NLP neural network designers. We demonstrate how to replace several operations in
+self-attention layers with grouped convolutions, and we use this technique in a novel network architecture called
+SqueezeBERT, which runs 4.3x faster than BERT-base on the Pixel 3 while achieving competitive accuracy on the GLUE test
+set. The SqueezeBERT code will be released.*
+
+This model was contributed by [forresti](https://huggingface.co/forresti).
+
+## Usage tips
+
+- SqueezeBERT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right
+ rather than the left.
+- SqueezeBERT is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore
+ efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained
+ with a causal language modeling (CLM) objective are better in that regard.
+- For best results when finetuning on sequence classification tasks, it is recommended to start with the
+ *squeezebert/squeezebert-mnli-headless* checkpoint.
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+- [Multiple choice task guide](../tasks/multiple_choice)
+
+## SqueezeBertConfig
+
+[[autodoc]] SqueezeBertConfig
+
+## SqueezeBertTokenizer
+
+[[autodoc]] SqueezeBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## SqueezeBertTokenizerFast
+
+[[autodoc]] SqueezeBertTokenizerFast
+
+## SqueezeBertModel
+
+[[autodoc]] SqueezeBertModel
+
+## SqueezeBertForMaskedLM
+
+[[autodoc]] SqueezeBertForMaskedLM
+
+## SqueezeBertForSequenceClassification
+
+[[autodoc]] SqueezeBertForSequenceClassification
+
+## SqueezeBertForMultipleChoice
+
+[[autodoc]] SqueezeBertForMultipleChoice
+
+## SqueezeBertForTokenClassification
+
+[[autodoc]] SqueezeBertForTokenClassification
+
+## SqueezeBertForQuestionAnswering
+
+[[autodoc]] SqueezeBertForQuestionAnswering
diff --git a/docs/transformers/docs/source/en/model_doc/stablelm.md b/docs/transformers/docs/source/en/model_doc/stablelm.md
new file mode 100644
index 0000000000000000000000000000000000000000..b996b7fcf9e85db9db25ccf6318ee2288c410716
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/stablelm.md
@@ -0,0 +1,117 @@
+
+
+# StableLM
+
+
+
+
+
+
+
+## Overview
+
+`StableLM 3B 4E1T` was proposed in [`StableLM 3B 4E1T`: Technical Report](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo) by Stability AI and is the first model in a series of multi-epoch pre-trained language models.
+
+### Model Details
+
+`StableLM 3B 4E1T` is a decoder-only base language model pre-trained on 1 trillion tokens of diverse English and code datasets for four epochs.
+The model architecture is transformer-based with partial Rotary Position Embeddings, SwiGLU activation, LayerNorm, etc.
+
+We also provide `StableLM Zephyr 3B`, an instruction fine-tuned version of the model that can be used for chat-based applications.
+
+### Usage Tips
+
+- The architecture is similar to LLaMA but with RoPE applied to 25% of head embedding dimensions, LayerNorm instead of RMSNorm, and optional QKV bias terms.
+- `StableLM 3B 4E1T`-based models uses the same tokenizer as [`GPTNeoXTokenizerFast`].
+
+`StableLM 3B 4E1T` and `StableLM Zephyr 3B` can be found on the [Huggingface Hub](https://huggingface.co/stabilityai)
+
+The following code snippet demonstrates how to use `StableLM 3B 4E1T` for inference:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
+>>> device = "cuda" # the device to load the model onto
+
+>>> set_seed(0)
+
+>>> tokenizer = AutoTokenizer.from_pretrained("stabilityai/stablelm-3b-4e1t")
+>>> model = AutoModelForCausalLM.from_pretrained("stabilityai/stablelm-3b-4e1t")
+>>> model.to(device) # doctest: +IGNORE_RESULT
+
+>>> model_inputs = tokenizer("The weather is always wonderful in", return_tensors="pt").to(model.device)
+
+>>> generated_ids = model.generate(**model_inputs, max_length=32, do_sample=True)
+>>> responses = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+>>> responses
+['The weather is always wonderful in Costa Rica, which makes it a prime destination for retirees. That’s where the Pensionado program comes in, offering']
+```
+
+## Combining StableLM and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention v2.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Also make sure that your hardware is compatible with Flash-Attention 2. Read more about it in the official documentation of the [`flash-attn`](https://github.com/Dao-AILab/flash-attention) repository. Note: you must load your model in half-precision (e.g. `torch.bfloat16`).
+
+Now, to run the model with Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
+>>> device = "cuda" # the device to load the model onto
+
+>>> set_seed(0)
+
+>>> tokenizer = AutoTokenizer.from_pretrained("stabilityai/stablelm-3b-4e1t")
+>>> model = AutoModelForCausalLM.from_pretrained("stabilityai/stablelm-3b-4e1t", torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2") # doctest: +SKIP
+>>> model.to(device) # doctest: +SKIP
+
+>>> model_inputs = tokenizer("The weather is always wonderful in", return_tensors="pt").to(model.device)
+
+>>> generated_ids = model.generate(**model_inputs, max_length=32, do_sample=True) # doctest: +SKIP
+>>> responses = tokenizer.batch_decode(generated_ids, skip_special_tokens=True) # doctest: +SKIP
+>>> responses # doctest: +SKIP
+['The weather is always wonderful in Costa Rica, which makes it a prime destination for retirees. That’s where the Pensionado program comes in, offering']
+```
+
+
+## StableLmConfig
+
+[[autodoc]] StableLmConfig
+
+## StableLmModel
+
+[[autodoc]] StableLmModel
+ - forward
+
+## StableLmForCausalLM
+
+[[autodoc]] StableLmForCausalLM
+ - forward
+
+## StableLmForSequenceClassification
+
+[[autodoc]] StableLmForSequenceClassification
+ - forward
+
+## StableLmForTokenClassification
+
+[[autodoc]] StableLmForTokenClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/starcoder2.md b/docs/transformers/docs/source/en/model_doc/starcoder2.md
new file mode 100644
index 0000000000000000000000000000000000000000..c6b146bf30ed000e84124f44c1a5d172307ba053
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/starcoder2.md
@@ -0,0 +1,79 @@
+
+
+# Starcoder2
+
+
+
+
+
+
+
+## Overview
+
+StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective. The models have been released with the paper [StarCoder 2 and The Stack v2: The Next Generation](https://arxiv.org/abs/2402.19173) by Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries.
+
+The abstract of the paper is the following:
+
+> The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
+## License
+
+The models are licensed under the [BigCode OpenRAIL-M v1 license agreement](https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement).
+
+## Usage tips
+
+The StarCoder2 models can be found in the [HuggingFace hub](https://huggingface.co/collections/bigcode/starcoder2-65de6da6e87db3383572be1a). You can find some examples for inference and fine-tuning in StarCoder2's [GitHub repo](https://github.com/bigcode-project/starcoder2).
+
+These ready-to-use checkpoints can be downloaded and used via the HuggingFace Hub:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("bigcode/starcoder2-7b", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("bigcode/starcoder2-7b")
+
+>>> prompt = "def print_hello_world():"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=10, do_sample=False)
+>>> tokenizer.batch_decode(generated_ids)[0]
+'def print_hello_world():\n print("Hello World!")\n\ndef print'
+```
+
+## Starcoder2Config
+
+[[autodoc]] Starcoder2Config
+
+## Starcoder2Model
+
+[[autodoc]] Starcoder2Model
+ - forward
+
+## Starcoder2ForCausalLM
+
+[[autodoc]] Starcoder2ForCausalLM
+ - forward
+
+## Starcoder2ForSequenceClassification
+
+[[autodoc]] Starcoder2ForSequenceClassification
+ - forward
+
+## Starcoder2ForTokenClassification
+
+[[autodoc]] Starcoder2ForTokenClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/superglue.md b/docs/transformers/docs/source/en/model_doc/superglue.md
new file mode 100644
index 0000000000000000000000000000000000000000..38ef55ab793f7ac196cacd3fbecb839de68d6117
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/superglue.md
@@ -0,0 +1,142 @@
+
+
+# SuperGlue
+
+
+
+
+
+## Overview
+
+The SuperGlue model was proposed in [SuperGlue: Learning Feature Matching with Graph Neural Networks](https://arxiv.org/abs/1911.11763) by Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
+
+This model consists of matching two sets of interest points detected in an image. Paired with the
+[SuperPoint model](https://huggingface.co/magic-leap-community/superpoint), it can be used to match two images and
+estimate the pose between them. This model is useful for tasks such as image matching, homography estimation, etc.
+
+The abstract from the paper is the following:
+
+*This paper introduces SuperGlue, a neural network that matches two sets of local features by jointly finding correspondences
+and rejecting non-matchable points. Assignments are estimated by solving a differentiable optimal transport problem, whose costs
+are predicted by a graph neural network. We introduce a flexible context aggregation mechanism based on attention, enabling
+SuperGlue to reason about the underlying 3D scene and feature assignments jointly. Compared to traditional, hand-designed heuristics,
+our technique learns priors over geometric transformations and regularities of the 3D world through end-to-end training from image
+pairs. SuperGlue outperforms other learned approaches and achieves state-of-the-art results on the task of pose estimation in
+challenging real-world indoor and outdoor environments. The proposed method performs matching in real-time on a modern GPU and
+can be readily integrated into modern SfM or SLAM systems. The code and trained weights are publicly available at this [URL](https://github.com/magicleap/SuperGluePretrainedNetwork).*
+
+## How to use
+
+Here is a quick example of using the model. Since this model is an image matching model, it requires pairs of images to be matched.
+The raw outputs contain the list of keypoints detected by the keypoint detector as well as the list of matches with their corresponding
+matching scores.
+```python
+from transformers import AutoImageProcessor, AutoModel
+import torch
+from PIL import Image
+import requests
+
+url_image1 = "https://raw.githubusercontent.com/magicleap/SuperGluePretrainedNetwork/refs/heads/master/assets/phototourism_sample_images/united_states_capitol_98169888_3347710852.jpg"
+image1 = Image.open(requests.get(url_image1, stream=True).raw)
+url_image2 = "https://raw.githubusercontent.com/magicleap/SuperGluePretrainedNetwork/refs/heads/master/assets/phototourism_sample_images/united_states_capitol_26757027_6717084061.jpg"
+image_2 = Image.open(requests.get(url_image2, stream=True).raw)
+
+images = [image1, image2]
+
+processor = AutoImageProcessor.from_pretrained("magic-leap-community/superglue_outdoor")
+model = AutoModel.from_pretrained("magic-leap-community/superglue_outdoor")
+
+inputs = processor(images, return_tensors="pt")
+with torch.no_grad():
+ outputs = model(**inputs)
+```
+
+You can use the `post_process_keypoint_matching` method from the `SuperGlueImageProcessor` to get the keypoints and matches in a more readable format:
+
+```python
+image_sizes = [[(image.height, image.width) for image in images]]
+outputs = processor.post_process_keypoint_matching(outputs, image_sizes, threshold=0.2)
+for i, output in enumerate(outputs):
+ print("For the image pair", i)
+ for keypoint0, keypoint1, matching_score in zip(
+ output["keypoints0"], output["keypoints1"], output["matching_scores"]
+ ):
+ print(
+ f"Keypoint at coordinate {keypoint0.numpy()} in the first image matches with keypoint at coordinate {keypoint1.numpy()} in the second image with a score of {matching_score}."
+ )
+
+```
+
+From the outputs, you can visualize the matches between the two images using the following code:
+```python
+import matplotlib.pyplot as plt
+import numpy as np
+
+# Create side by side image
+merged_image = np.zeros((max(image1.height, image2.height), image1.width + image2.width, 3))
+merged_image[: image1.height, : image1.width] = np.array(image1) / 255.0
+merged_image[: image2.height, image1.width :] = np.array(image2) / 255.0
+plt.imshow(merged_image)
+plt.axis("off")
+
+# Retrieve the keypoints and matches
+output = outputs[0]
+keypoints0 = output["keypoints0"]
+keypoints1 = output["keypoints1"]
+matching_scores = output["matching_scores"]
+keypoints0_x, keypoints0_y = keypoints0[:, 0].numpy(), keypoints0[:, 1].numpy()
+keypoints1_x, keypoints1_y = keypoints1[:, 0].numpy(), keypoints1[:, 1].numpy()
+
+# Plot the matches
+for keypoint0_x, keypoint0_y, keypoint1_x, keypoint1_y, matching_score in zip(
+ keypoints0_x, keypoints0_y, keypoints1_x, keypoints1_y, matching_scores
+):
+ plt.plot(
+ [keypoint0_x, keypoint1_x + image1.width],
+ [keypoint0_y, keypoint1_y],
+ color=plt.get_cmap("RdYlGn")(matching_score.item()),
+ alpha=0.9,
+ linewidth=0.5,
+ )
+ plt.scatter(keypoint0_x, keypoint0_y, c="black", s=2)
+ plt.scatter(keypoint1_x + image1.width, keypoint1_y, c="black", s=2)
+
+# Save the plot
+plt.savefig("matched_image.png", dpi=300, bbox_inches='tight')
+plt.close()
+```
+
+
+
+This model was contributed by [stevenbucaille](https://huggingface.co/stevenbucaille).
+The original code can be found [here](https://github.com/magicleap/SuperGluePretrainedNetwork).
+
+## SuperGlueConfig
+
+[[autodoc]] SuperGlueConfig
+
+## SuperGlueImageProcessor
+
+[[autodoc]] SuperGlueImageProcessor
+
+- preprocess
+
+## SuperGlueForKeypointMatching
+
+[[autodoc]] SuperGlueForKeypointMatching
+
+- forward
+- post_process_keypoint_matching
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/superpoint.md b/docs/transformers/docs/source/en/model_doc/superpoint.md
new file mode 100644
index 0000000000000000000000000000000000000000..06ae5cb08127c6c9b91fdaae3e47f7a01ca620c9
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/superpoint.md
@@ -0,0 +1,144 @@
+
+
+# SuperPoint
+
+
+
+
+
+## Overview
+
+The SuperPoint model was proposed
+in [SuperPoint: Self-Supervised Interest Point Detection and Description](https://arxiv.org/abs/1712.07629) by Daniel
+DeTone, Tomasz Malisiewicz and Andrew Rabinovich.
+
+This model is the result of a self-supervised training of a fully-convolutional network for interest point detection and
+description. The model is able to detect interest points that are repeatable under homographic transformations and
+provide a descriptor for each point. The use of the model in its own is limited, but it can be used as a feature
+extractor for other tasks such as homography estimation, image matching, etc.
+
+The abstract from the paper is the following:
+
+*This paper presents a self-supervised framework for training interest point detectors and descriptors suitable for a
+large number of multiple-view geometry problems in computer vision. As opposed to patch-based neural networks, our
+fully-convolutional model operates on full-sized images and jointly computes pixel-level interest point locations and
+associated descriptors in one forward pass. We introduce Homographic Adaptation, a multi-scale, multi-homography
+approach for boosting interest point detection repeatability and performing cross-domain adaptation (e.g.,
+synthetic-to-real). Our model, when trained on the MS-COCO generic image dataset using Homographic Adaptation, is able
+to repeatedly detect a much richer set of interest points than the initial pre-adapted deep model and any other
+traditional corner detector. The final system gives rise to state-of-the-art homography estimation results on HPatches
+when compared to LIFT, SIFT and ORB.*
+
+
+
+ SuperPoint overview. Taken from the original paper.
+
+## Usage tips
+
+Here is a quick example of using the model to detect interest points in an image:
+
+```python
+from transformers import AutoImageProcessor, SuperPointForKeypointDetection
+import torch
+from PIL import Image
+import requests
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
+model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/superpoint")
+
+inputs = processor(image, return_tensors="pt")
+outputs = model(**inputs)
+```
+
+The outputs contain the list of keypoint coordinates with their respective score and description (a 256-long vector).
+
+You can also feed multiple images to the model. Due to the nature of SuperPoint, to output a dynamic number of keypoints,
+you will need to use the mask attribute to retrieve the respective information :
+
+```python
+from transformers import AutoImageProcessor, SuperPointForKeypointDetection
+import torch
+from PIL import Image
+import requests
+
+url_image_1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image_1 = Image.open(requests.get(url_image_1, stream=True).raw)
+url_image_2 = "http://images.cocodataset.org/test-stuff2017/000000000568.jpg"
+image_2 = Image.open(requests.get(url_image_2, stream=True).raw)
+
+images = [image_1, image_2]
+
+processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
+model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/superpoint")
+
+inputs = processor(images, return_tensors="pt")
+outputs = model(**inputs)
+image_sizes = [(image.height, image.width) for image in images]
+outputs = processor.post_process_keypoint_detection(outputs, image_sizes)
+
+for output in outputs:
+ for keypoints, scores, descriptors in zip(output["keypoints"], output["scores"], output["descriptors"]):
+ print(f"Keypoints: {keypoints}")
+ print(f"Scores: {scores}")
+ print(f"Descriptors: {descriptors}")
+```
+
+You can then print the keypoints on the image of your choice to visualize the result:
+```python
+import matplotlib.pyplot as plt
+
+plt.axis("off")
+plt.imshow(image_1)
+plt.scatter(
+ outputs[0]["keypoints"][:, 0],
+ outputs[0]["keypoints"][:, 1],
+ c=outputs[0]["scores"] * 100,
+ s=outputs[0]["scores"] * 50,
+ alpha=0.8
+)
+plt.savefig(f"output_image.png")
+```
+
+
+This model was contributed by [stevenbucaille](https://huggingface.co/stevenbucaille).
+The original code can be found [here](https://github.com/magicleap/SuperPointPretrainedNetwork).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SuperPoint. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- A notebook showcasing inference and visualization with SuperPoint can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SuperPoint/Inference_with_SuperPoint_to_detect_interest_points_in_an_image.ipynb). 🌎
+
+## SuperPointConfig
+
+[[autodoc]] SuperPointConfig
+
+## SuperPointImageProcessor
+
+[[autodoc]] SuperPointImageProcessor
+
+- preprocess
+- post_process_keypoint_detection
+
+## SuperPointForKeypointDetection
+
+[[autodoc]] SuperPointForKeypointDetection
+
+- forward
diff --git a/docs/transformers/docs/source/en/model_doc/swiftformer.md b/docs/transformers/docs/source/en/model_doc/swiftformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..48580a60f580996515d5bdada21900bf306956db
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/swiftformer.md
@@ -0,0 +1,59 @@
+
+
+# SwiftFormer
+
+
+
+
+
+
+## Overview
+
+The SwiftFormer model was proposed in [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
+
+The SwiftFormer paper introduces a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations in the self-attention computation with linear element-wise multiplications. A series of models called 'SwiftFormer' is built based on this, which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Even their small variant achieves 78.5% top-1 ImageNet1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2× faster compared to MobileViT-v2.
+
+The abstract from the paper is the following:
+
+*Self-attention has become a defacto choice for capturing global context in various vision applications. However, its quadratic computational complexity with respect to image resolution limits its use in real-time applications, especially for deployment on resource-constrained mobile devices. Although hybrid approaches have been proposed to combine the advantages of convolutions and self-attention for a better speed-accuracy trade-off, the expensive matrix multiplication operations in self-attention remain a bottleneck. In this work, we introduce a novel efficient additive attention mechanism that effectively replaces the quadratic matrix multiplication operations with linear element-wise multiplications. Our design shows that the key-value interaction can be replaced with a linear layer without sacrificing any accuracy. Unlike previous state-of-the-art methods, our efficient formulation of self-attention enables its usage at all stages of the network. Using our proposed efficient additive attention, we build a series of models called "SwiftFormer" which achieves state-of-the-art performance in terms of both accuracy and mobile inference speed. Our small variant achieves 78.5% top-1 ImageNet-1K accuracy with only 0.8 ms latency on iPhone 14, which is more accurate and 2x faster compared to MobileViT-v2.*
+
+This model was contributed by [shehan97](https://huggingface.co/shehan97). The TensorFlow version was contributed by [joaocmd](https://huggingface.co/joaocmd).
+The original code can be found [here](https://github.com/Amshaker/SwiftFormer).
+
+## SwiftFormerConfig
+
+[[autodoc]] SwiftFormerConfig
+
+## SwiftFormerModel
+
+[[autodoc]] SwiftFormerModel
+ - forward
+
+## SwiftFormerForImageClassification
+
+[[autodoc]] SwiftFormerForImageClassification
+ - forward
+
+## TFSwiftFormerModel
+
+[[autodoc]] TFSwiftFormerModel
+ - call
+
+## TFSwiftFormerForImageClassification
+
+[[autodoc]] TFSwiftFormerForImageClassification
+ - call
diff --git a/docs/transformers/docs/source/en/model_doc/swin.md b/docs/transformers/docs/source/en/model_doc/swin.md
new file mode 100644
index 0000000000000000000000000000000000000000..4e2adf5ca8200b64d6c67ddf74b049cd1d9abe34
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/swin.md
@@ -0,0 +1,112 @@
+
+
+# Swin Transformer
+
+
+
+
+
+
+## Overview
+
+The Swin Transformer was proposed in [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
+by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+
+The abstract from the paper is the following:
+
+*This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone
+for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains,
+such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text.
+To address these differences, we propose a hierarchical Transformer whose representation is computed with \bold{S}hifted
+\bold{win}dows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping
+local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at
+various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it
+compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense
+prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation
+(53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and
++2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones.
+The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.*
+
+
+
+ Swin Transformer architecture. Taken from the original paper.
+
+This model was contributed by [novice03](https://huggingface.co/novice03). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+
+## Usage tips
+
+- Swin pads the inputs supporting any input height and width (if divisible by `32`).
+- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Swin Transformer.
+
+
+
+- [`SwinForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+Besides that:
+
+- [`SwinForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## SwinConfig
+
+[[autodoc]] SwinConfig
+
+
+
+
+## SwinModel
+
+[[autodoc]] SwinModel
+ - forward
+
+## SwinForMaskedImageModeling
+
+[[autodoc]] SwinForMaskedImageModeling
+ - forward
+
+## SwinForImageClassification
+
+[[autodoc]] transformers.SwinForImageClassification
+ - forward
+
+
+
+
+## TFSwinModel
+
+[[autodoc]] TFSwinModel
+ - call
+
+## TFSwinForMaskedImageModeling
+
+[[autodoc]] TFSwinForMaskedImageModeling
+ - call
+
+## TFSwinForImageClassification
+
+[[autodoc]] transformers.TFSwinForImageClassification
+ - call
+
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/swin2sr.md b/docs/transformers/docs/source/en/model_doc/swin2sr.md
new file mode 100644
index 0000000000000000000000000000000000000000..136f1a1c1e17bdbf34e1e2178609115ec452923b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/swin2sr.md
@@ -0,0 +1,65 @@
+
+
+# Swin2SR
+
+
+
+
+
+## Overview
+
+The Swin2SR model was proposed in [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+Swin2SR improves the [SwinIR](https://github.com/JingyunLiang/SwinIR/) model by incorporating [Swin Transformer v2](swinv2) layers which mitigates issues such as training instability, resolution gaps between pre-training
+and fine-tuning, and hunger on data.
+
+The abstract from the paper is the following:
+
+*Compression plays an important role on the efficient transmission and storage of images and videos through band-limited systems such as streaming services, virtual reality or videogames. However, compression unavoidably leads to artifacts and the loss of the original information, which may severely degrade the visual quality. For these reasons, quality enhancement of compressed images has become a popular research topic. While most state-of-the-art image restoration methods are based on convolutional neural networks, other transformers-based methods such as SwinIR, show impressive performance on these tasks.
+In this paper, we explore the novel Swin Transformer V2, to improve SwinIR for image super-resolution, and in particular, the compressed input scenario. Using this method we can tackle the major issues in training transformer vision models, such as training instability, resolution gaps between pre-training and fine-tuning, and hunger on data. We conduct experiments on three representative tasks: JPEG compression artifacts removal, image super-resolution (classical and lightweight), and compressed image super-resolution. Experimental results demonstrate that our method, Swin2SR, can improve the training convergence and performance of SwinIR, and is a top-5 solution at the "AIM 2022 Challenge on Super-Resolution of Compressed Image and Video".*
+
+
+
+ Swin2SR architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/mv-lab/swin2sr).
+
+## Resources
+
+Demo notebooks for Swin2SR can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR).
+
+A demo Space for image super-resolution with SwinSR can be found [here](https://huggingface.co/spaces/jjourney1125/swin2sr).
+
+## Swin2SRImageProcessor
+
+[[autodoc]] Swin2SRImageProcessor
+ - preprocess
+
+## Swin2SRConfig
+
+[[autodoc]] Swin2SRConfig
+
+## Swin2SRModel
+
+[[autodoc]] Swin2SRModel
+ - forward
+
+## Swin2SRForImageSuperResolution
+
+[[autodoc]] Swin2SRForImageSuperResolution
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/swinv2.md b/docs/transformers/docs/source/en/model_doc/swinv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..a709af9712e3acbaf69b8a47b56eb16896482253
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/swinv2.md
@@ -0,0 +1,66 @@
+
+
+# Swin Transformer V2
+
+
+
+
+
+## Overview
+
+The Swin Transformer V2 model was proposed in [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
+
+The abstract from the paper is the following:
+
+*Large-scale NLP models have been shown to significantly improve the performance on language tasks with no signs of saturation. They also demonstrate amazing few-shot capabilities like that of human beings. This paper aims to explore large-scale models in computer vision. We tackle three major issues in training and application of large vision models, including training instability, resolution gaps between pre-training and fine-tuning, and hunger on labelled data. Three main techniques are proposed: 1) a residual-post-norm method combined with cosine attention to improve training stability; 2) A log-spaced continuous position bias method to effectively transfer models pre-trained using low-resolution images to downstream tasks with high-resolution inputs; 3) A self-supervised pre-training method, SimMIM, to reduce the needs of vast labeled images. Through these techniques, this paper successfully trained a 3 billion-parameter Swin Transformer V2 model, which is the largest dense vision model to date, and makes it capable of training with images of up to 1,536×1,536 resolution. It set new performance records on 4 representative vision tasks, including ImageNet-V2 image classification, COCO object detection, ADE20K semantic segmentation, and Kinetics-400 video action classification. Also note our training is much more efficient than that in Google's billion-level visual models, which consumes 40 times less labelled data and 40 times less training time.*
+
+This model was contributed by [nandwalritik](https://huggingface.co/nandwalritik).
+The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Swin Transformer v2.
+
+
+
+- [`Swinv2ForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+Besides that:
+
+- [`Swinv2ForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## Swinv2Config
+
+[[autodoc]] Swinv2Config
+
+## Swinv2Model
+
+[[autodoc]] Swinv2Model
+ - forward
+
+## Swinv2ForMaskedImageModeling
+
+[[autodoc]] Swinv2ForMaskedImageModeling
+ - forward
+
+## Swinv2ForImageClassification
+
+[[autodoc]] transformers.Swinv2ForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/switch_transformers.md b/docs/transformers/docs/source/en/model_doc/switch_transformers.md
new file mode 100644
index 0000000000000000000000000000000000000000..433b84dd862224dfaff9d1ca384a8c258c9f91d2
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/switch_transformers.md
@@ -0,0 +1,75 @@
+
+
+# SwitchTransformers
+
+
+
+
+
+## Overview
+
+The SwitchTransformers model was proposed in [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+
+The Switch Transformer model uses a sparse T5 encoder-decoder architecture, where the MLP are replaced by a Mixture of Experts (MoE). A routing mechanism (top 1 in this case) associates each token to one of the expert, where each expert is a dense MLP. While switch transformers have a lot more weights than their equivalent dense models, the sparsity allows better scaling and better finetuning performance at scale.
+During a forward pass, only a fraction of the weights are used. The routing mechanism allows the model to select relevant weights on the fly which increases the model capacity without increasing the number of operations.
+
+The abstract from the paper is the following:
+
+*In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) defies this and instead selects different parameters for each incoming example. The result is a sparsely-activated model -- with outrageous numbers of parameters -- but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs and training instability -- we address these with the Switch Transformer. We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. Our proposed training techniques help wrangle the instabilities and we show large sparse models may be trained, for the first time, with lower precision (bfloat16) formats. We design models based off T5-Base and T5-Large to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings where we measure gains over the mT5-Base version across all 101 languages. Finally, we advance the current scale of language models by pre-training up to trillion parameter models on the "Colossal Clean Crawled Corpus" and achieve a 4x speedup over the T5-XXL model.*
+
+This model was contributed by [Younes Belkada](https://huggingface.co/ybelkada) and [Arthur Zucker](https://huggingface.co/ArthurZ).
+The original code can be found [here](https://github.com/google/flaxformer/tree/main/flaxformer/architectures/moe).
+
+## Usage tips
+
+- SwitchTransformers uses the [`T5Tokenizer`], which can be loaded directly from each model's repository.
+- The released weights are pretrained on English [Masked Language Modeling](https://moon-ci-docs.huggingface.co/docs/transformers/pr_19323/en/glossary#general-terms) task, and should be finetuned.
+
+## Resources
+
+- [Translation task guide](../tasks/translation)
+- [Summarization task guide](../tasks/summarization)
+
+## SwitchTransformersConfig
+
+[[autodoc]] SwitchTransformersConfig
+
+## SwitchTransformersTop1Router
+
+[[autodoc]] SwitchTransformersTop1Router
+ - _compute_router_probabilities
+ - forward
+
+## SwitchTransformersSparseMLP
+
+[[autodoc]] SwitchTransformersSparseMLP
+ - forward
+
+## SwitchTransformersModel
+
+[[autodoc]] SwitchTransformersModel
+ - forward
+
+## SwitchTransformersForConditionalGeneration
+
+[[autodoc]] SwitchTransformersForConditionalGeneration
+ - forward
+
+## SwitchTransformersEncoderModel
+
+[[autodoc]] SwitchTransformersEncoderModel
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/t5.md b/docs/transformers/docs/source/en/model_doc/t5.md
new file mode 100644
index 0000000000000000000000000000000000000000..e7b28cdf1fba2d84f4759fa872f2edc97b580a4b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/t5.md
@@ -0,0 +1,206 @@
+
+
+
+
+
+
+
+
+
+
+# T5
+
+[T5](https://huggingface.co/papers/1910.10683) is a encoder-decoder transformer available in a range of sizes from 60M to 11B parameters. It is designed to handle a wide range of NLP tasks by treating them all as text-to-text problems. This eliminates the need for task-specific architectures because T5 converts every NLP task into a text generation task.
+
+To formulate every task as text generation, each task is prepended with a task-specific prefix (e.g., translate English to German: ..., summarize: ...). This enables T5 to handle tasks like translation, summarization, question answering, and more.
+
+You can find all official T5 checkpoints under the [T5](https://huggingface.co/collections/google/t5-release-65005e7c520f8d7b4d037918) collection.
+
+> [!TIP]
+> Click on the T5 models in the right sidebar for more examples of how to apply T5 to different language tasks.
+
+The example below demonstrates how to generate text with [`Pipeline`], [`AutoModel`], and how to translate with T5 from the command line.
+
+
+
+
+```py
+import torch
+from transformers import pipeline
+
+pipeline = pipeline(
+ task="text2text-generation",
+ model="google-t5/t5-base",
+ torch_dtype=torch.float16,
+ device=0
+)
+pipeline("translate English to French: The weather is nice today.")
+```
+
+
+
+
+```py
+import torch
+from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained(
+ "google-t5/t5-base"
+ )
+model = AutoModelForSeq2SeqLM.from_pretrained(
+ "google-t5/t5-base",
+ torch_dtype=torch.float16,
+ device_map="auto"
+ )
+
+input_ids = tokenizer("translate English to French: The weather is nice today.", return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+
+
+
+```bash
+echo -e "translate English to French: The weather is nice today." | transformers-cli run --task text2text-generation --model google-t5/t5-base --device 0
+```
+
+
+
+
+Quantization reduces the memory burden of large models by representing the weights in a lower precision. Refer to the [Quantization](../quantization/overview) overview for more available quantization backends.
+
+The example below uses [torchao](../quantization/torchao) to only quantize the weights to int4.
+
+```py
+# pip install torchao
+import torch
+from transformers import TorchAoConfig, AutoModelForSeq2SeqLM, AutoTokenizer
+
+quantization_config = TorchAoConfig("int4_weight_only", group_size=128)
+model = AutoModelForSeq2SeqLM.from_pretrained(
+ "google/t5-v1_1-xl",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ quantization_config=quantization_config
+)
+
+tokenizer = AutoTokenizer.from_pretrained("google/t5-v1_1-xl")
+input_ids = tokenizer("translate English to French: The weather is nice today.", return_tensors="pt").to("cuda")
+
+output = model.generate(**input_ids, cache_implementation="static")
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+## Notes
+
+- You can pad the encoder inputs on the left or right because T5 uses relative scalar embeddings.
+- T5 models need a slightly higher learning rate than the default used in [`Trainer`]. Typically, values of `1e-4` and `3e-4` work well for most tasks.
+
+## T5Config
+
+[[autodoc]] T5Config
+
+## T5Tokenizer
+
+[[autodoc]] T5Tokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## T5TokenizerFast
+
+[[autodoc]] T5TokenizerFast
+
+
+
+
+## T5Model
+
+[[autodoc]] T5Model
+ - forward
+
+## T5ForConditionalGeneration
+
+[[autodoc]] T5ForConditionalGeneration
+ - forward
+
+## T5EncoderModel
+
+[[autodoc]] T5EncoderModel
+ - forward
+
+## T5ForSequenceClassification
+
+[[autodoc]] T5ForSequenceClassification
+ - forward
+
+## T5ForTokenClassification
+
+[[autodoc]] T5ForTokenClassification
+ - forward
+
+## T5ForQuestionAnswering
+
+[[autodoc]] T5ForQuestionAnswering
+ - forward
+
+
+
+
+## TFT5Model
+
+[[autodoc]] TFT5Model
+ - call
+
+## TFT5ForConditionalGeneration
+
+[[autodoc]] TFT5ForConditionalGeneration
+ - call
+
+## TFT5EncoderModel
+
+[[autodoc]] TFT5EncoderModel
+ - call
+
+
+
+
+## FlaxT5Model
+
+[[autodoc]] FlaxT5Model
+ - __call__
+ - encode
+ - decode
+
+## FlaxT5ForConditionalGeneration
+
+[[autodoc]] FlaxT5ForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+## FlaxT5EncoderModel
+
+[[autodoc]] FlaxT5EncoderModel
+ - __call__
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/t5v1.1.md b/docs/transformers/docs/source/en/model_doc/t5v1.1.md
new file mode 100644
index 0000000000000000000000000000000000000000..5ae908bacdaef2bc5e07d7a1d78007b00e0c5a9f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/t5v1.1.md
@@ -0,0 +1,78 @@
+
+
+# T5v1.1
+
+
+
+
+
+
+
+## Overview
+
+T5v1.1 was released in the [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511)
+repository by Colin Raffel et al. It's an improved version of the original T5 model.
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The original code can be
+found [here](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511).
+
+## Usage tips
+
+One can directly plug in the weights of T5v1.1 into a T5 model, like so:
+
+```python
+>>> from transformers import T5ForConditionalGeneration
+
+>>> model = T5ForConditionalGeneration.from_pretrained("google/t5-v1_1-base")
+```
+
+T5 Version 1.1 includes the following improvements compared to the original T5 model:
+
+- GEGLU activation in the feed-forward hidden layer, rather than ReLU. See [this paper](https://arxiv.org/abs/2002.05202).
+
+- Dropout was turned off in pre-training (quality win). Dropout should be re-enabled during fine-tuning.
+
+- Pre-trained on C4 only without mixing in the downstream tasks.
+
+- No parameter sharing between the embedding and classifier layer.
+
+- "xl" and "xxl" replace "3B" and "11B". The model shapes are a bit different - larger `d_model` and smaller
+ `num_heads` and `d_ff`.
+
+Note: T5 Version 1.1 was only pre-trained on [C4](https://huggingface.co/datasets/c4) excluding any supervised
+training. Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5
+model. Since t5v1.1 was pre-trained unsupervisedly, there's no real advantage to using a task prefix during single-task
+fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
+
+Google has released the following variants:
+
+- [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small)
+
+- [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base)
+
+- [google/t5-v1_1-large](https://huggingface.co/google/t5-v1_1-large)
+
+- [google/t5-v1_1-xl](https://huggingface.co/google/t5-v1_1-xl)
+
+- [google/t5-v1_1-xxl](https://huggingface.co/google/t5-v1_1-xxl).
+
+
+
+
+Refer to [T5's documentation page](t5) for all API reference, tips, code examples and notebooks.
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/table-transformer.md b/docs/transformers/docs/source/en/model_doc/table-transformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..fea4dabf3f388c8e82c53519b206131777ccd798
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/table-transformer.md
@@ -0,0 +1,71 @@
+
+
+# Table Transformer
+
+
+
+
+
+## Overview
+
+The Table Transformer model was proposed in [PubTables-1M: Towards comprehensive table extraction from unstructured documents](https://arxiv.org/abs/2110.00061) by
+Brandon Smock, Rohith Pesala, Robin Abraham. The authors introduce a new dataset, PubTables-1M, to benchmark progress in table extraction from unstructured documents,
+as well as table structure recognition and functional analysis. The authors train 2 [DETR](detr) models, one for table detection and one for table structure recognition, dubbed Table Transformers.
+
+The abstract from the paper is the following:
+
+*Recently, significant progress has been made applying machine learning to the problem of table structure inference and extraction from unstructured documents.
+However, one of the greatest challenges remains the creation of datasets with complete, unambiguous ground truth at scale. To address this, we develop a new, more
+comprehensive dataset for table extraction, called PubTables-1M. PubTables-1M contains nearly one million tables from scientific articles, supports multiple input
+modalities, and contains detailed header and location information for table structures, making it useful for a wide variety of modeling approaches. It also addresses a significant
+source of ground truth inconsistency observed in prior datasets called oversegmentation, using a novel canonicalization procedure. We demonstrate that these improvements lead to a
+significant increase in training performance and a more reliable estimate of model performance at evaluation for table structure recognition. Further, we show that transformer-based
+object detection models trained on PubTables-1M produce excellent results for all three tasks of detection, structure recognition, and functional analysis without the need for any
+special customization for these tasks.*
+
+
+
+ Table detection and table structure recognition clarified. Taken from the original paper.
+
+The authors released 2 models, one for [table detection](https://huggingface.co/microsoft/table-transformer-detection) in
+documents, one for [table structure recognition](https://huggingface.co/microsoft/table-transformer-structure-recognition)
+(the task of recognizing the individual rows, columns etc. in a table).
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be
+found [here](https://github.com/microsoft/table-transformer).
+
+## Resources
+
+
+
+- A demo notebook for the Table Transformer can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Table%20Transformer).
+- It turns out padding of images is quite important for detection. An interesting Github thread with replies from the authors can be found [here](https://github.com/microsoft/table-transformer/issues/68).
+
+## TableTransformerConfig
+
+[[autodoc]] TableTransformerConfig
+
+## TableTransformerModel
+
+[[autodoc]] TableTransformerModel
+ - forward
+
+## TableTransformerForObjectDetection
+
+[[autodoc]] TableTransformerForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/tapas.md b/docs/transformers/docs/source/en/model_doc/tapas.md
new file mode 100644
index 0000000000000000000000000000000000000000..21eb697ee34d113bca5dce4d2929c8789005a9e9
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/tapas.md
@@ -0,0 +1,639 @@
+
+
+# TAPAS
+
+
+
+
+
+
+## Overview
+
+The TAPAS model was proposed in [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://www.aclweb.org/anthology/2020.acl-main.398)
+by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos. It's a BERT-based model specifically
+designed (and pre-trained) for answering questions about tabular data. Compared to BERT, TAPAS uses relative position embeddings and has 7
+token types that encode tabular structure. TAPAS is pre-trained on the masked language modeling (MLM) objective on a large dataset comprising
+millions of tables from English Wikipedia and corresponding texts.
+
+For question answering, TAPAS has 2 heads on top: a cell selection head and an aggregation head, for (optionally) performing aggregations (such as counting or summing) among selected cells. TAPAS has been fine-tuned on several datasets:
+- [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253) (Sequential Question Answering by Microsoft)
+- [WTQ](https://github.com/ppasupat/WikiTableQuestions) (Wiki Table Questions by Stanford University)
+- [WikiSQL](https://github.com/salesforce/WikiSQL) (by Salesforce).
+
+It achieves state-of-the-art on both SQA and WTQ, while having comparable performance to SOTA on WikiSQL, with a much simpler architecture.
+
+The abstract from the paper is the following:
+
+*Answering natural language questions over tables is usually seen as a semantic parsing task. To alleviate the collection cost of full logical forms, one popular approach focuses on weak supervision consisting of denotations instead of logical forms. However, training semantic parsers from weak supervision poses difficulties, and in addition, the generated logical forms are only used as an intermediate step prior to retrieving the denotation. In this paper, we present TAPAS, an approach to question answering over tables without generating logical forms. TAPAS trains from weak supervision, and predicts the denotation by selecting table cells and optionally applying a corresponding aggregation operator to such selection. TAPAS extends BERT's architecture to encode tables as input, initializes from an effective joint pre-training of text segments and tables crawled from Wikipedia, and is trained end-to-end. We experiment with three different semantic parsing datasets, and find that TAPAS outperforms or rivals semantic parsing models by improving state-of-the-art accuracy on SQA from 55.1 to 67.2 and performing on par with the state-of-the-art on WIKISQL and WIKITQ, but with a simpler model architecture. We additionally find that transfer learning, which is trivial in our setting, from WIKISQL to WIKITQ, yields 48.7 accuracy, 4.2 points above the state-of-the-art.*
+
+In addition, the authors have further pre-trained TAPAS to recognize **table entailment**, by creating a balanced dataset of millions of automatically created training examples which are learned in an intermediate step prior to fine-tuning. The authors of TAPAS call this further pre-training intermediate pre-training (since TAPAS is first pre-trained on MLM, and then on another dataset). They found that intermediate pre-training further improves performance on SQA, achieving a new state-of-the-art as well as state-of-the-art on [TabFact](https://github.com/wenhuchen/Table-Fact-Checking), a large-scale dataset with 16k Wikipedia tables for table entailment (a binary classification task). For more details, see their follow-up paper: [Understanding tables with intermediate pre-training](https://www.aclweb.org/anthology/2020.findings-emnlp.27/) by Julian Martin Eisenschlos, Syrine Krichene and Thomas Müller.
+
+
+
+ TAPAS architecture. Taken from the original blog post.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The Tensorflow version of this model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/tapas).
+
+## Usage tips
+
+- TAPAS is a model that uses relative position embeddings by default (restarting the position embeddings at every cell of the table). Note that this is something that was added after the publication of the original TAPAS paper. According to the authors, this usually results in a slightly better performance, and allows you to encode longer sequences without running out of embeddings. This is reflected in the `reset_position_index_per_cell` parameter of [`TapasConfig`], which is set to `True` by default. The default versions of the models available on the [hub](https://huggingface.co/models?search=tapas) all use relative position embeddings. You can still use the ones with absolute position embeddings by passing in an additional argument `revision="no_reset"` when calling the `from_pretrained()` method. Note that it's usually advised to pad the inputs on the right rather than the left.
+- TAPAS is based on BERT, so `TAPAS-base` for example corresponds to a `BERT-base` architecture. Of course, `TAPAS-large` will result in the best performance (the results reported in the paper are from `TAPAS-large`). Results of the various sized models are shown on the [original GitHub repository](https://github.com/google-research/tapas).
+- TAPAS has checkpoints fine-tuned on SQA, which are capable of answering questions related to a table in a conversational set-up. This means that you can ask follow-up questions such as "what is his age?" related to the previous question. Note that the forward pass of TAPAS is a bit different in case of a conversational set-up: in that case, you have to feed every table-question pair one by one to the model, such that the `prev_labels` token type ids can be overwritten by the predicted `labels` of the model to the previous question. See "Usage" section for more info.
+- TAPAS is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained with a causal language modeling (CLM) objective are better in that regard. Note that TAPAS can be used as an encoder in the EncoderDecoderModel framework, to combine it with an autoregressive text decoder such as GPT-2.
+
+## Usage: fine-tuning
+
+Here we explain how you can fine-tune [`TapasForQuestionAnswering`] on your own dataset.
+
+**STEP 1: Choose one of the 3 ways in which you can use TAPAS - or experiment**
+
+Basically, there are 3 different ways in which one can fine-tune [`TapasForQuestionAnswering`], corresponding to the different datasets on which Tapas was fine-tuned:
+
+1. SQA: if you're interested in asking follow-up questions related to a table, in a conversational set-up. For example if you first ask "what's the name of the first actor?" then you can ask a follow-up question such as "how old is he?". Here, questions do not involve any aggregation (all questions are cell selection questions).
+2. WTQ: if you're not interested in asking questions in a conversational set-up, but rather just asking questions related to a table, which might involve aggregation, such as counting a number of rows, summing up cell values or averaging cell values. You can then for example ask "what's the total number of goals Cristiano Ronaldo made in his career?". This case is also called **weak supervision**, since the model itself must learn the appropriate aggregation operator (SUM/COUNT/AVERAGE/NONE) given only the answer to the question as supervision.
+3. WikiSQL-supervised: this dataset is based on WikiSQL with the model being given the ground truth aggregation operator during training. This is also called **strong supervision**. Here, learning the appropriate aggregation operator is much easier.
+
+To summarize:
+
+| **Task** | **Example dataset** | **Description** |
+|-------------------------------------|---------------------|---------------------------------------------------------------------------------------------------------|
+| Conversational | SQA | Conversational, only cell selection questions |
+| Weak supervision for aggregation | WTQ | Questions might involve aggregation, and the model must learn this given only the answer as supervision |
+| Strong supervision for aggregation | WikiSQL-supervised | Questions might involve aggregation, and the model must learn this given the gold aggregation operator |
+
+
+
+Initializing a model with a pre-trained base and randomly initialized classification heads from the hub can be done as shown below.
+
+```py
+>>> from transformers import TapasConfig, TapasForQuestionAnswering
+
+>>> # for example, the base sized model with default SQA configuration
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base")
+
+>>> # or, the base sized model with WTQ configuration
+>>> config = TapasConfig.from_pretrained("google/tapas-base-finetuned-wtq")
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+
+>>> # or, the base sized model with WikiSQL configuration
+>>> config = TapasConfig("google-base-finetuned-wikisql-supervised")
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+```
+
+Of course, you don't necessarily have to follow one of these three ways in which TAPAS was fine-tuned. You can also experiment by defining any hyperparameters you want when initializing [`TapasConfig`], and then create a [`TapasForQuestionAnswering`] based on that configuration. For example, if you have a dataset that has both conversational questions and questions that might involve aggregation, then you can do it this way. Here's an example:
+
+```py
+>>> from transformers import TapasConfig, TapasForQuestionAnswering
+
+>>> # you can initialize the classification heads any way you want (see docs of TapasConfig)
+>>> config = TapasConfig(num_aggregation_labels=3, average_logits_per_cell=True)
+>>> # initializing the pre-trained base sized model with our custom classification heads
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+```
+
+
+Initializing a model with a pre-trained base and randomly initialized classification heads from the hub can be done as shown below. Be sure to have installed the [tensorflow_probability](https://github.com/tensorflow/probability) dependency:
+
+```py
+>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
+
+>>> # for example, the base sized model with default SQA configuration
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base")
+
+>>> # or, the base sized model with WTQ configuration
+>>> config = TapasConfig.from_pretrained("google/tapas-base-finetuned-wtq")
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+
+>>> # or, the base sized model with WikiSQL configuration
+>>> config = TapasConfig("google-base-finetuned-wikisql-supervised")
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+```
+
+Of course, you don't necessarily have to follow one of these three ways in which TAPAS was fine-tuned. You can also experiment by defining any hyperparameters you want when initializing [`TapasConfig`], and then create a [`TFTapasForQuestionAnswering`] based on that configuration. For example, if you have a dataset that has both conversational questions and questions that might involve aggregation, then you can do it this way. Here's an example:
+
+```py
+>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
+
+>>> # you can initialize the classification heads any way you want (see docs of TapasConfig)
+>>> config = TapasConfig(num_aggregation_labels=3, average_logits_per_cell=True)
+>>> # initializing the pre-trained base sized model with our custom classification heads
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+```
+
+
+
+What you can also do is start from an already fine-tuned checkpoint. A note here is that the already fine-tuned checkpoint on WTQ has some issues due to the L2-loss which is somewhat brittle. See [here](https://github.com/google-research/tapas/issues/91#issuecomment-735719340) for more info.
+
+For a list of all pre-trained and fine-tuned TAPAS checkpoints available on HuggingFace's hub, see [here](https://huggingface.co/models?search=tapas).
+
+**STEP 2: Prepare your data in the SQA format**
+
+Second, no matter what you picked above, you should prepare your dataset in the [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253) format. This format is a TSV/CSV file with the following columns:
+
+- `id`: optional, id of the table-question pair, for bookkeeping purposes.
+- `annotator`: optional, id of the person who annotated the table-question pair, for bookkeeping purposes.
+- `position`: integer indicating if the question is the first, second, third,... related to the table. Only required in case of conversational setup (SQA). You don't need this column in case you're going for WTQ/WikiSQL-supervised.
+- `question`: string
+- `table_file`: string, name of a csv file containing the tabular data
+- `answer_coordinates`: list of one or more tuples (each tuple being a cell coordinate, i.e. row, column pair that is part of the answer)
+- `answer_text`: list of one or more strings (each string being a cell value that is part of the answer)
+- `aggregation_label`: index of the aggregation operator. Only required in case of strong supervision for aggregation (the WikiSQL-supervised case)
+- `float_answer`: the float answer to the question, if there is one (np.nan if there isn't). Only required in case of weak supervision for aggregation (such as WTQ and WikiSQL)
+
+The tables themselves should be present in a folder, each table being a separate csv file. Note that the authors of the TAPAS algorithm used conversion scripts with some automated logic to convert the other datasets (WTQ, WikiSQL) into the SQA format. The author explains this [here](https://github.com/google-research/tapas/issues/50#issuecomment-705465960). A conversion of this script that works with HuggingFace's implementation can be found [here](https://github.com/NielsRogge/tapas_utils). Interestingly, these conversion scripts are not perfect (the `answer_coordinates` and `float_answer` fields are populated based on the `answer_text`), meaning that WTQ and WikiSQL results could actually be improved.
+
+**STEP 3: Convert your data into tensors using TapasTokenizer**
+
+
+
+Third, given that you've prepared your data in this TSV/CSV format (and corresponding CSV files containing the tabular data), you can then use [`TapasTokenizer`] to convert table-question pairs into `input_ids`, `attention_mask`, `token_type_ids` and so on. Again, based on which of the three cases you picked above, [`TapasForQuestionAnswering`] requires different
+inputs to be fine-tuned:
+
+| **Task** | **Required inputs** |
+|------------------------------------|---------------------------------------------------------------------------------------------------------------------|
+| Conversational | `input_ids`, `attention_mask`, `token_type_ids`, `labels` |
+| Weak supervision for aggregation | `input_ids`, `attention_mask`, `token_type_ids`, `labels`, `numeric_values`, `numeric_values_scale`, `float_answer` |
+| Strong supervision for aggregation | `input ids`, `attention mask`, `token type ids`, `labels`, `aggregation_labels` |
+
+[`TapasTokenizer`] creates the `labels`, `numeric_values` and `numeric_values_scale` based on the `answer_coordinates` and `answer_text` columns of the TSV file. The `float_answer` and `aggregation_labels` are already in the TSV file of step 2. Here's an example:
+
+```py
+>>> from transformers import TapasTokenizer
+>>> import pandas as pd
+
+>>> model_name = "google/tapas-base"
+>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
+
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> queries = [
+... "What is the name of the first actor?",
+... "How many movies has George Clooney played in?",
+... "What is the total number of movies?",
+... ]
+>>> answer_coordinates = [[(0, 0)], [(2, 1)], [(0, 1), (1, 1), (2, 1)]]
+>>> answer_text = [["Brad Pitt"], ["69"], ["209"]]
+>>> table = pd.DataFrame.from_dict(data)
+>>> inputs = tokenizer(
+... table=table,
+... queries=queries,
+... answer_coordinates=answer_coordinates,
+... answer_text=answer_text,
+... padding="max_length",
+... return_tensors="pt",
+... )
+>>> inputs
+{'input_ids': tensor([[ ... ]]), 'attention_mask': tensor([[...]]), 'token_type_ids': tensor([[[...]]]),
+'numeric_values': tensor([[ ... ]]), 'numeric_values_scale: tensor([[ ... ]]), labels: tensor([[ ... ]])}
+```
+
+Note that [`TapasTokenizer`] expects the data of the table to be **text-only**. You can use `.astype(str)` on a dataframe to turn it into text-only data.
+Of course, this only shows how to encode a single training example. It is advised to create a dataloader to iterate over batches:
+
+```py
+>>> import torch
+>>> import pandas as pd
+
+>>> tsv_path = "your_path_to_the_tsv_file"
+>>> table_csv_path = "your_path_to_a_directory_containing_all_csv_files"
+
+
+>>> class TableDataset(torch.utils.data.Dataset):
+... def __init__(self, data, tokenizer):
+... self.data = data
+... self.tokenizer = tokenizer
+
+... def __getitem__(self, idx):
+... item = data.iloc[idx]
+... table = pd.read_csv(table_csv_path + item.table_file).astype(
+... str
+... ) # be sure to make your table data text only
+... encoding = self.tokenizer(
+... table=table,
+... queries=item.question,
+... answer_coordinates=item.answer_coordinates,
+... answer_text=item.answer_text,
+... truncation=True,
+... padding="max_length",
+... return_tensors="pt",
+... )
+... # remove the batch dimension which the tokenizer adds by default
+... encoding = {key: val.squeeze(0) for key, val in encoding.items()}
+... # add the float_answer which is also required (weak supervision for aggregation case)
+... encoding["float_answer"] = torch.tensor(item.float_answer)
+... return encoding
+
+... def __len__(self):
+... return len(self.data)
+
+
+>>> data = pd.read_csv(tsv_path, sep="\t")
+>>> train_dataset = TableDataset(data, tokenizer)
+>>> train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=32)
+```
+
+
+Third, given that you've prepared your data in this TSV/CSV format (and corresponding CSV files containing the tabular data), you can then use [`TapasTokenizer`] to convert table-question pairs into `input_ids`, `attention_mask`, `token_type_ids` and so on. Again, based on which of the three cases you picked above, [`TFTapasForQuestionAnswering`] requires different
+inputs to be fine-tuned:
+
+| **Task** | **Required inputs** |
+|------------------------------------|---------------------------------------------------------------------------------------------------------------------|
+| Conversational | `input_ids`, `attention_mask`, `token_type_ids`, `labels` |
+| Weak supervision for aggregation | `input_ids`, `attention_mask`, `token_type_ids`, `labels`, `numeric_values`, `numeric_values_scale`, `float_answer` |
+| Strong supervision for aggregation | `input ids`, `attention mask`, `token type ids`, `labels`, `aggregation_labels` |
+
+[`TapasTokenizer`] creates the `labels`, `numeric_values` and `numeric_values_scale` based on the `answer_coordinates` and `answer_text` columns of the TSV file. The `float_answer` and `aggregation_labels` are already in the TSV file of step 2. Here's an example:
+
+```py
+>>> from transformers import TapasTokenizer
+>>> import pandas as pd
+
+>>> model_name = "google/tapas-base"
+>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
+
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> queries = [
+... "What is the name of the first actor?",
+... "How many movies has George Clooney played in?",
+... "What is the total number of movies?",
+... ]
+>>> answer_coordinates = [[(0, 0)], [(2, 1)], [(0, 1), (1, 1), (2, 1)]]
+>>> answer_text = [["Brad Pitt"], ["69"], ["209"]]
+>>> table = pd.DataFrame.from_dict(data)
+>>> inputs = tokenizer(
+... table=table,
+... queries=queries,
+... answer_coordinates=answer_coordinates,
+... answer_text=answer_text,
+... padding="max_length",
+... return_tensors="tf",
+... )
+>>> inputs
+{'input_ids': tensor([[ ... ]]), 'attention_mask': tensor([[...]]), 'token_type_ids': tensor([[[...]]]),
+'numeric_values': tensor([[ ... ]]), 'numeric_values_scale: tensor([[ ... ]]), labels: tensor([[ ... ]])}
+```
+
+Note that [`TapasTokenizer`] expects the data of the table to be **text-only**. You can use `.astype(str)` on a dataframe to turn it into text-only data.
+Of course, this only shows how to encode a single training example. It is advised to create a dataloader to iterate over batches:
+
+```py
+>>> import tensorflow as tf
+>>> import pandas as pd
+
+>>> tsv_path = "your_path_to_the_tsv_file"
+>>> table_csv_path = "your_path_to_a_directory_containing_all_csv_files"
+
+
+>>> class TableDataset:
+... def __init__(self, data, tokenizer):
+... self.data = data
+... self.tokenizer = tokenizer
+
+... def __iter__(self):
+... for idx in range(self.__len__()):
+... item = self.data.iloc[idx]
+... table = pd.read_csv(table_csv_path + item.table_file).astype(
+... str
+... ) # be sure to make your table data text only
+... encoding = self.tokenizer(
+... table=table,
+... queries=item.question,
+... answer_coordinates=item.answer_coordinates,
+... answer_text=item.answer_text,
+... truncation=True,
+... padding="max_length",
+... return_tensors="tf",
+... )
+... # remove the batch dimension which the tokenizer adds by default
+... encoding = {key: tf.squeeze(val, 0) for key, val in encoding.items()}
+... # add the float_answer which is also required (weak supervision for aggregation case)
+... encoding["float_answer"] = tf.convert_to_tensor(item.float_answer, dtype=tf.float32)
+... yield encoding["input_ids"], encoding["attention_mask"], encoding["numeric_values"], encoding[
+... "numeric_values_scale"
+... ], encoding["token_type_ids"], encoding["labels"], encoding["float_answer"]
+
+... def __len__(self):
+... return len(self.data)
+
+
+>>> data = pd.read_csv(tsv_path, sep="\t")
+>>> train_dataset = TableDataset(data, tokenizer)
+>>> output_signature = (
+... tf.TensorSpec(shape=(512,), dtype=tf.int32),
+... tf.TensorSpec(shape=(512,), dtype=tf.int32),
+... tf.TensorSpec(shape=(512,), dtype=tf.float32),
+... tf.TensorSpec(shape=(512,), dtype=tf.float32),
+... tf.TensorSpec(shape=(512, 7), dtype=tf.int32),
+... tf.TensorSpec(shape=(512,), dtype=tf.int32),
+... tf.TensorSpec(shape=(512,), dtype=tf.float32),
+... )
+>>> train_dataloader = tf.data.Dataset.from_generator(train_dataset, output_signature=output_signature).batch(32)
+```
+
+
+
+Note that here, we encode each table-question pair independently. This is fine as long as your dataset is **not conversational**. In case your dataset involves conversational questions (such as in SQA), then you should first group together the `queries`, `answer_coordinates` and `answer_text` per table (in the order of their `position`
+index) and batch encode each table with its questions. This will make sure that the `prev_labels` token types (see docs of [`TapasTokenizer`]) are set correctly. See [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) for more info. See [this notebook](https://github.com/kamalkraj/Tapas-Tutorial/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) for more info regarding using the TensorFlow model.
+
+**STEP 4: Train (fine-tune) the model
+
+
+
+You can then fine-tune [`TapasForQuestionAnswering`] as follows (shown here for the weak supervision for aggregation case):
+
+```py
+>>> from transformers import TapasConfig, TapasForQuestionAnswering, AdamW
+
+>>> # this is the default WTQ configuration
+>>> config = TapasConfig(
+... num_aggregation_labels=4,
+... use_answer_as_supervision=True,
+... answer_loss_cutoff=0.664694,
+... cell_selection_preference=0.207951,
+... huber_loss_delta=0.121194,
+... init_cell_selection_weights_to_zero=True,
+... select_one_column=True,
+... allow_empty_column_selection=False,
+... temperature=0.0352513,
+... )
+>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+
+>>> optimizer = AdamW(model.parameters(), lr=5e-5)
+
+>>> model.train()
+>>> for epoch in range(2): # loop over the dataset multiple times
+... for batch in train_dataloader:
+... # get the inputs;
+... input_ids = batch["input_ids"]
+... attention_mask = batch["attention_mask"]
+... token_type_ids = batch["token_type_ids"]
+... labels = batch["labels"]
+... numeric_values = batch["numeric_values"]
+... numeric_values_scale = batch["numeric_values_scale"]
+... float_answer = batch["float_answer"]
+
+... # zero the parameter gradients
+... optimizer.zero_grad()
+
+... # forward + backward + optimize
+... outputs = model(
+... input_ids=input_ids,
+... attention_mask=attention_mask,
+... token_type_ids=token_type_ids,
+... labels=labels,
+... numeric_values=numeric_values,
+... numeric_values_scale=numeric_values_scale,
+... float_answer=float_answer,
+... )
+... loss = outputs.loss
+... loss.backward()
+... optimizer.step()
+```
+
+
+You can then fine-tune [`TFTapasForQuestionAnswering`] as follows (shown here for the weak supervision for aggregation case):
+
+```py
+>>> import tensorflow as tf
+>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
+
+>>> # this is the default WTQ configuration
+>>> config = TapasConfig(
+... num_aggregation_labels=4,
+... use_answer_as_supervision=True,
+... answer_loss_cutoff=0.664694,
+... cell_selection_preference=0.207951,
+... huber_loss_delta=0.121194,
+... init_cell_selection_weights_to_zero=True,
+... select_one_column=True,
+... allow_empty_column_selection=False,
+... temperature=0.0352513,
+... )
+>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
+
+>>> optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5)
+
+>>> for epoch in range(2): # loop over the dataset multiple times
+... for batch in train_dataloader:
+... # get the inputs;
+... input_ids = batch[0]
+... attention_mask = batch[1]
+... token_type_ids = batch[4]
+... labels = batch[-1]
+... numeric_values = batch[2]
+... numeric_values_scale = batch[3]
+... float_answer = batch[6]
+
+... # forward + backward + optimize
+... with tf.GradientTape() as tape:
+... outputs = model(
+... input_ids=input_ids,
+... attention_mask=attention_mask,
+... token_type_ids=token_type_ids,
+... labels=labels,
+... numeric_values=numeric_values,
+... numeric_values_scale=numeric_values_scale,
+... float_answer=float_answer,
+... )
+... grads = tape.gradient(outputs.loss, model.trainable_weights)
+... optimizer.apply_gradients(zip(grads, model.trainable_weights))
+```
+
+
+
+## Usage: inference
+
+
+
+Here we explain how you can use [`TapasForQuestionAnswering`] or [`TFTapasForQuestionAnswering`] for inference (i.e. making predictions on new data). For inference, only `input_ids`, `attention_mask` and `token_type_ids` (which you can obtain using [`TapasTokenizer`]) have to be provided to the model to obtain the logits. Next, you can use the handy [`~models.tapas.tokenization_tapas.convert_logits_to_predictions`] method to convert these into predicted coordinates and optional aggregation indices.
+
+However, note that inference is **different** depending on whether or not the setup is conversational. In a non-conversational set-up, inference can be done in parallel on all table-question pairs of a batch. Here's an example of that:
+
+```py
+>>> from transformers import TapasTokenizer, TapasForQuestionAnswering
+>>> import pandas as pd
+
+>>> model_name = "google/tapas-base-finetuned-wtq"
+>>> model = TapasForQuestionAnswering.from_pretrained(model_name)
+>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
+
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> queries = [
+... "What is the name of the first actor?",
+... "How many movies has George Clooney played in?",
+... "What is the total number of movies?",
+... ]
+>>> table = pd.DataFrame.from_dict(data)
+>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="pt")
+>>> outputs = model(**inputs)
+>>> predicted_answer_coordinates, predicted_aggregation_indices = tokenizer.convert_logits_to_predictions(
+... inputs, outputs.logits.detach(), outputs.logits_aggregation.detach()
+... )
+
+>>> # let's print out the results:
+>>> id2aggregation = {0: "NONE", 1: "SUM", 2: "AVERAGE", 3: "COUNT"}
+>>> aggregation_predictions_string = [id2aggregation[x] for x in predicted_aggregation_indices]
+
+>>> answers = []
+>>> for coordinates in predicted_answer_coordinates:
+... if len(coordinates) == 1:
+... # only a single cell:
+... answers.append(table.iat[coordinates[0]])
+... else:
+... # multiple cells
+... cell_values = []
+... for coordinate in coordinates:
+... cell_values.append(table.iat[coordinate])
+... answers.append(", ".join(cell_values))
+
+>>> display(table)
+>>> print("")
+>>> for query, answer, predicted_agg in zip(queries, answers, aggregation_predictions_string):
+... print(query)
+... if predicted_agg == "NONE":
+... print("Predicted answer: " + answer)
+... else:
+... print("Predicted answer: " + predicted_agg + " > " + answer)
+What is the name of the first actor?
+Predicted answer: Brad Pitt
+How many movies has George Clooney played in?
+Predicted answer: COUNT > 69
+What is the total number of movies?
+Predicted answer: SUM > 87, 53, 69
+```
+
+
+Here we explain how you can use [`TFTapasForQuestionAnswering`] for inference (i.e. making predictions on new data). For inference, only `input_ids`, `attention_mask` and `token_type_ids` (which you can obtain using [`TapasTokenizer`]) have to be provided to the model to obtain the logits. Next, you can use the handy [`~models.tapas.tokenization_tapas.convert_logits_to_predictions`] method to convert these into predicted coordinates and optional aggregation indices.
+
+However, note that inference is **different** depending on whether or not the setup is conversational. In a non-conversational set-up, inference can be done in parallel on all table-question pairs of a batch. Here's an example of that:
+
+```py
+>>> from transformers import TapasTokenizer, TFTapasForQuestionAnswering
+>>> import pandas as pd
+
+>>> model_name = "google/tapas-base-finetuned-wtq"
+>>> model = TFTapasForQuestionAnswering.from_pretrained(model_name)
+>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
+
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> queries = [
+... "What is the name of the first actor?",
+... "How many movies has George Clooney played in?",
+... "What is the total number of movies?",
+... ]
+>>> table = pd.DataFrame.from_dict(data)
+>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="tf")
+>>> outputs = model(**inputs)
+>>> predicted_answer_coordinates, predicted_aggregation_indices = tokenizer.convert_logits_to_predictions(
+... inputs, outputs.logits, outputs.logits_aggregation
+... )
+
+>>> # let's print out the results:
+>>> id2aggregation = {0: "NONE", 1: "SUM", 2: "AVERAGE", 3: "COUNT"}
+>>> aggregation_predictions_string = [id2aggregation[x] for x in predicted_aggregation_indices]
+
+>>> answers = []
+>>> for coordinates in predicted_answer_coordinates:
+... if len(coordinates) == 1:
+... # only a single cell:
+... answers.append(table.iat[coordinates[0]])
+... else:
+... # multiple cells
+... cell_values = []
+... for coordinate in coordinates:
+... cell_values.append(table.iat[coordinate])
+... answers.append(", ".join(cell_values))
+
+>>> display(table)
+>>> print("")
+>>> for query, answer, predicted_agg in zip(queries, answers, aggregation_predictions_string):
+... print(query)
+... if predicted_agg == "NONE":
+... print("Predicted answer: " + answer)
+... else:
+... print("Predicted answer: " + predicted_agg + " > " + answer)
+What is the name of the first actor?
+Predicted answer: Brad Pitt
+How many movies has George Clooney played in?
+Predicted answer: COUNT > 69
+What is the total number of movies?
+Predicted answer: SUM > 87, 53, 69
+```
+
+
+
+In case of a conversational set-up, then each table-question pair must be provided **sequentially** to the model, such that the `prev_labels` token types can be overwritten by the predicted `labels` of the previous table-question pair. Again, more info can be found in [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for PyTorch) and [this notebook](https://github.com/kamalkraj/Tapas-Tutorial/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) (for TensorFlow).
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Masked language modeling task guide](../tasks/masked_language_modeling)
+
+## TAPAS specific outputs
+[[autodoc]] models.tapas.modeling_tapas.TableQuestionAnsweringOutput
+
+## TapasConfig
+[[autodoc]] TapasConfig
+
+## TapasTokenizer
+[[autodoc]] TapasTokenizer
+ - __call__
+ - convert_logits_to_predictions
+ - save_vocabulary
+
+
+
+
+## TapasModel
+[[autodoc]] TapasModel
+ - forward
+
+## TapasForMaskedLM
+[[autodoc]] TapasForMaskedLM
+ - forward
+
+## TapasForSequenceClassification
+[[autodoc]] TapasForSequenceClassification
+ - forward
+
+## TapasForQuestionAnswering
+[[autodoc]] TapasForQuestionAnswering
+ - forward
+
+
+
+
+## TFTapasModel
+[[autodoc]] TFTapasModel
+ - call
+
+## TFTapasForMaskedLM
+[[autodoc]] TFTapasForMaskedLM
+ - call
+
+## TFTapasForSequenceClassification
+[[autodoc]] TFTapasForSequenceClassification
+ - call
+
+## TFTapasForQuestionAnswering
+[[autodoc]] TFTapasForQuestionAnswering
+ - call
+
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/tapex.md b/docs/transformers/docs/source/en/model_doc/tapex.md
new file mode 100644
index 0000000000000000000000000000000000000000..d46d520c7d18f3380dbc915a9fa207b4af1ce018
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/tapex.md
@@ -0,0 +1,156 @@
+
+
+# TAPEX
+
+
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
+You can do so by running the following command: `pip install -U transformers==4.30.0`.
+
+
+
+## Overview
+
+The TAPEX model was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu,
+Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. TAPEX pre-trains a BART model to solve synthetic SQL queries, after
+which it can be fine-tuned to answer natural language questions related to tabular data, as well as performing table fact checking.
+
+TAPEX has been fine-tuned on several datasets:
+- [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253) (Sequential Question Answering by Microsoft)
+- [WTQ](https://github.com/ppasupat/WikiTableQuestions) (Wiki Table Questions by Stanford University)
+- [WikiSQL](https://github.com/salesforce/WikiSQL) (by Salesforce)
+- [TabFact](https://tabfact.github.io/) (by USCB NLP Lab).
+
+The abstract from the paper is the following:
+
+*Recent progress in language model pre-training has achieved a great success via leveraging large-scale unstructured textual data. However, it is
+still a challenge to apply pre-training on structured tabular data due to the absence of large-scale high-quality tabular data. In this paper, we
+propose TAPEX to show that table pre-training can be achieved by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically
+synthesizing executable SQL queries and their execution outputs. TAPEX addresses the data scarcity challenge via guiding the language model to mimic a SQL
+executor on the diverse, large-scale and high-quality synthetic corpus. We evaluate TAPEX on four benchmark datasets. Experimental results demonstrate that
+TAPEX outperforms previous table pre-training approaches by a large margin and achieves new state-of-the-art results on all of them. This includes improvements
+on the weakly-supervised WikiSQL denotation accuracy to 89.5% (+2.3%), the WikiTableQuestions denotation accuracy to 57.5% (+4.8%), the SQA denotation accuracy
+to 74.5% (+3.5%), and the TabFact accuracy to 84.2% (+3.2%). To our knowledge, this is the first work to exploit table pre-training via synthetic executable programs
+and to achieve new state-of-the-art results on various downstream tasks.*
+
+## Usage tips
+
+- TAPEX is a generative (seq2seq) model. One can directly plug in the weights of TAPEX into a BART model.
+- TAPEX has checkpoints on the hub that are either pre-trained only, or fine-tuned on WTQ, SQA, WikiSQL and TabFact.
+- Sentences + tables are presented to the model as `sentence + " " + linearized table`. The linearized table has the following format:
+ `col: col1 | col2 | col 3 row 1 : val1 | val2 | val3 row 2 : ...`.
+- TAPEX has its own tokenizer, that allows to prepare all data for the model easily. One can pass Pandas DataFrames and strings to the tokenizer,
+ and it will automatically create the `input_ids` and `attention_mask` (as shown in the usage examples below).
+
+### Usage: inference
+
+Below, we illustrate how to use TAPEX for table question answering. As one can see, one can directly plug in the weights of TAPEX into a BART model.
+We use the [Auto API](auto), which will automatically instantiate the appropriate tokenizer ([`TapexTokenizer`]) and model ([`BartForConditionalGeneration`]) for us,
+based on the configuration file of the checkpoint on the hub.
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+>>> import pandas as pd
+
+>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/tapex-large-finetuned-wtq")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("microsoft/tapex-large-finetuned-wtq")
+
+>>> # prepare table + question
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> table = pd.DataFrame.from_dict(data)
+>>> question = "how many movies does Leonardo Di Caprio have?"
+
+>>> encoding = tokenizer(table, question, return_tensors="pt")
+
+>>> # let the model generate an answer autoregressively
+>>> outputs = model.generate(**encoding)
+
+>>> # decode back to text
+>>> predicted_answer = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
+>>> print(predicted_answer)
+53
+```
+
+Note that [`TapexTokenizer`] also supports batched inference. Hence, one can provide a batch of different tables/questions, or a batch of a single table
+and multiple questions, or a batch of a single query and multiple tables. Let's illustrate this:
+
+```python
+>>> # prepare table + question
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> table = pd.DataFrame.from_dict(data)
+>>> questions = [
+... "how many movies does Leonardo Di Caprio have?",
+... "which actor has 69 movies?",
+... "what's the first name of the actor who has 87 movies?",
+... ]
+>>> encoding = tokenizer(table, questions, padding=True, return_tensors="pt")
+
+>>> # let the model generate an answer autoregressively
+>>> outputs = model.generate(**encoding)
+
+>>> # decode back to text
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+[' 53', ' george clooney', ' brad pitt']
+```
+
+In case one wants to do table verification (i.e. the task of determining whether a given sentence is supported or refuted by the contents
+of a table), one can instantiate a [`BartForSequenceClassification`] model. TAPEX has checkpoints on the hub fine-tuned on TabFact, an important
+benchmark for table fact checking (it achieves 84% accuracy). The code example below again leverages the [Auto API](auto).
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+
+>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/tapex-large-finetuned-tabfact")
+>>> model = AutoModelForSequenceClassification.from_pretrained("microsoft/tapex-large-finetuned-tabfact")
+
+>>> # prepare table + sentence
+>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
+>>> table = pd.DataFrame.from_dict(data)
+>>> sentence = "George Clooney has 30 movies"
+
+>>> encoding = tokenizer(table, sentence, return_tensors="pt")
+
+>>> # forward pass
+>>> outputs = model(**encoding)
+
+>>> # print prediction
+>>> predicted_class_idx = outputs.logits[0].argmax(dim=0).item()
+>>> print(model.config.id2label[predicted_class_idx])
+Refused
+```
+
+
+
+TAPEX architecture is the same as BART, except for tokenization. Refer to [BART documentation](bart) for information on
+configuration classes and their parameters. TAPEX-specific tokenizer is documented below.
+
+
+
+## TapexTokenizer
+
+[[autodoc]] TapexTokenizer
+ - __call__
+ - save_vocabulary
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/textnet.md b/docs/transformers/docs/source/en/model_doc/textnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..72f29b4463ed94267c7ddeaa95f61c0b3b8d5ba2
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/textnet.md
@@ -0,0 +1,59 @@
+
+
+# TextNet
+
+
+
+
+
+## Overview
+
+The TextNet model was proposed in [FAST: Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation](https://arxiv.org/abs/2111.02394) by Zhe Chen, Jiahao Wang, Wenhai Wang, Guo Chen, Enze Xie, Ping Luo, Tong Lu. TextNet is a vision backbone useful for text detection tasks. It is the result of neural architecture search (NAS) on backbones with reward function as text detection task (to provide powerful features for text detection).
+
+
+
+ TextNet backbone as part of FAST. Taken from the original paper.
+
+This model was contributed by [Raghavan](https://huggingface.co/Raghavan), [jadechoghari](https://huggingface.co/jadechoghari) and [nielsr](https://huggingface.co/nielsr).
+
+## Usage tips
+
+TextNet is mainly used as a backbone network for the architecture search of text detection. Each stage of the backbone network is comprised of a stride-2 convolution and searchable blocks.
+Specifically, we present a layer-level candidate set, defined as {conv3×3, conv1×3, conv3×1, identity}. As the 1×3 and 3×1 convolutions have asymmetric kernels and oriented structure priors, they may help to capture the features of extreme aspect-ratio and rotated text lines.
+
+TextNet is the backbone for Fast, but can also be used as an efficient text/image classification, we add a `TextNetForImageClassification` as is it would allow people to train an image classifier on top of the pre-trained textnet weights
+
+## TextNetConfig
+
+[[autodoc]] TextNetConfig
+
+## TextNetImageProcessor
+
+[[autodoc]] TextNetImageProcessor
+ - preprocess
+
+## TextNetModel
+
+[[autodoc]] TextNetModel
+ - forward
+
+## TextNetForImageClassification
+
+[[autodoc]] TextNetForImageClassification
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/time_series_transformer.md b/docs/transformers/docs/source/en/model_doc/time_series_transformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..a91633b6b0299bce1dcca4054e0ebdf16acb45fc
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/time_series_transformer.md
@@ -0,0 +1,76 @@
+
+
+# Time Series Transformer
+
+
+
+
+
+## Overview
+
+The Time Series Transformer model is a vanilla encoder-decoder Transformer for time series forecasting.
+This model was contributed by [kashif](https://huggingface.co/kashif).
+
+## Usage tips
+
+- Similar to other models in the library, [`TimeSeriesTransformerModel`] is the raw Transformer without any head on top, and [`TimeSeriesTransformerForPrediction`]
+adds a distribution head on top of the former, which can be used for time-series forecasting. Note that this is a so-called probabilistic forecasting model, not a
+point forecasting model. This means that the model learns a distribution, from which one can sample. The model doesn't directly output values.
+- [`TimeSeriesTransformerForPrediction`] consists of 2 blocks: an encoder, which takes a `context_length` of time series values as input (called `past_values`),
+and a decoder, which predicts a `prediction_length` of time series values into the future (called `future_values`). During training, one needs to provide
+pairs of (`past_values` and `future_values`) to the model.
+- In addition to the raw (`past_values` and `future_values`), one typically provides additional features to the model. These can be the following:
+ - `past_time_features`: temporal features which the model will add to `past_values`. These serve as "positional encodings" for the Transformer encoder.
+ Examples are "day of the month", "month of the year", etc. as scalar values (and then stacked together as a vector).
+ e.g. if a given time-series value was obtained on the 11th of August, then one could have [11, 8] as time feature vector (11 being "day of the month", 8 being "month of the year").
+ - `future_time_features`: temporal features which the model will add to `future_values`. These serve as "positional encodings" for the Transformer decoder.
+ Examples are "day of the month", "month of the year", etc. as scalar values (and then stacked together as a vector).
+ e.g. if a given time-series value was obtained on the 11th of August, then one could have [11, 8] as time feature vector (11 being "day of the month", 8 being "month of the year").
+ - `static_categorical_features`: categorical features which are static over time (i.e., have the same value for all `past_values` and `future_values`).
+ An example here is the store ID or region ID that identifies a given time-series.
+ Note that these features need to be known for ALL data points (also those in the future).
+ - `static_real_features`: real-valued features which are static over time (i.e., have the same value for all `past_values` and `future_values`).
+ An example here is the image representation of the product for which you have the time-series values (like the [ResNet](resnet) embedding of a "shoe" picture,
+ if your time-series is about the sales of shoes).
+ Note that these features need to be known for ALL data points (also those in the future).
+- The model is trained using "teacher-forcing", similar to how a Transformer is trained for machine translation. This means that, during training, one shifts the
+`future_values` one position to the right as input to the decoder, prepended by the last value of `past_values`. At each time step, the model needs to predict the
+next target. So the set-up of training is similar to a GPT model for language, except that there's no notion of `decoder_start_token_id` (we just use the last value
+of the context as initial input for the decoder).
+- At inference time, we give the final value of the `past_values` as input to the decoder. Next, we can sample from the model to make a prediction at the next time step,
+which is then fed to the decoder in order to make the next prediction (also called autoregressive generation).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- Check out the Time Series Transformer blog-post in HuggingFace blog: [Probabilistic Time Series Forecasting with 🤗 Transformers](https://huggingface.co/blog/time-series-transformers)
+
+
+## TimeSeriesTransformerConfig
+
+[[autodoc]] TimeSeriesTransformerConfig
+
+## TimeSeriesTransformerModel
+
+[[autodoc]] TimeSeriesTransformerModel
+ - forward
+
+## TimeSeriesTransformerForPrediction
+
+[[autodoc]] TimeSeriesTransformerForPrediction
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/timesfm.md b/docs/transformers/docs/source/en/model_doc/timesfm.md
new file mode 100644
index 0000000000000000000000000000000000000000..f5e279949197e839647820cff63205b2ed2f4c3c
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/timesfm.md
@@ -0,0 +1,88 @@
+
+
+# TimesFM
+
+
+
+
+
+## Overview
+
+TimesFM (Time Series Foundation Model) is a pretrained time-series foundation model proposed in [A decoder-only foundation model for time-series forecasting](https://huggingface.co/papers/2310.10688) by Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. It is a decoder only model that uses non-overlapping patches of time-series data as input and outputs some output patch length prediction in an autoregressive fashion.
+
+
+The abstract from the paper is the following:
+
+*Motivated by recent advances in large language models for Natural Language Processing (NLP), we design a time-series foundation model for forecasting whose out-of-the-box zero-shot performance on a variety of public datasets comes close to the accuracy of state-of-the-art supervised forecasting models for each individual dataset. Our model is based on pretraining a patched-decoder style attention model on a large time-series corpus, and can work well across different forecasting history lengths, prediction lengths and temporal granularities.*
+
+
+This model was contributed by [kashif](https://huggingface.co/kashif).
+The original code can be found [here](https://github.com/google-research/timesfm).
+
+
+To use the model:
+
+```python
+import torch
+from transformers import TimesFmModelForPrediction
+
+
+model = TimesFmModelForPrediction.from_pretrained(
+ "google/timesfm-2.0-500m-pytorch",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="sdpa",
+ device_map="cuda" if torch.cuda.is_available() else None
+)
+
+
+ # Create dummy inputs
+forecast_input = [
+ np.sin(np.linspace(0, 20, 100)),
+ np.sin(np.linspace(0, 20, 200)),
+ np.sin(np.linspace(0, 20, 400)),
+]
+frequency_input = [0, 1, 2]
+
+# Convert inputs to sequence of tensors
+forecast_input_tensor = [
+ torch.tensor(ts, dtype=torch.bfloat16).to("cuda" if torch.cuda.is_available() else "cpu")
+ for ts in forecast_input
+]
+frequency_input_tensor = torch.tensor(frequency_input, dtype=torch.long).to(
+ "cuda" if torch.cuda.is_available() else "cpu"
+)
+
+# Get predictions from the pre-trained model
+with torch.no_grad():
+ outputs = model(past_values=forecast_input_tensor, freq=frequency_input_tensor, return_dict=True)
+ point_forecast_conv = outputs.mean_predictions.float().cpu().numpy()
+ quantile_forecast_conv = outputs.full_predictions.float().cpu().numpy()
+```
+
+## TimesFmConfig
+
+[[autodoc]] TimesFmConfig
+
+## TimesFmModel
+
+[[autodoc]] TimesFmModel
+ - forward
+
+## TimesFmModelForPrediction
+
+[[autodoc]] TimesFmModelForPrediction
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/timesformer.md b/docs/transformers/docs/source/en/model_doc/timesformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..c01f64efa71cba6054d20b9b95378622c47a6065
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/timesformer.md
@@ -0,0 +1,56 @@
+
+
+# TimeSformer
+
+
+
+
+
+## Overview
+
+The TimeSformer model was proposed in [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Facebook Research.
+This work is a milestone in action-recognition field being the first video transformer. It inspired many transformer based video understanding and classification papers.
+
+The abstract from the paper is the following:
+
+*We present a convolution-free approach to video classification built exclusively on self-attention over space and time. Our method, named "TimeSformer," adapts the standard Transformer architecture to video by enabling spatiotemporal feature learning directly from a sequence of frame-level patches. Our experimental study compares different self-attention schemes and suggests that "divided attention," where temporal attention and spatial attention are separately applied within each block, leads to the best video classification accuracy among the design choices considered. Despite the radically new design, TimeSformer achieves state-of-the-art results on several action recognition benchmarks, including the best reported accuracy on Kinetics-400 and Kinetics-600. Finally, compared to 3D convolutional networks, our model is faster to train, it can achieve dramatically higher test efficiency (at a small drop in accuracy), and it can also be applied to much longer video clips (over one minute long). Code and models are available at: [this https URL](https://github.com/facebookresearch/TimeSformer).*
+
+This model was contributed by [fcakyon](https://huggingface.co/fcakyon).
+The original code can be found [here](https://github.com/facebookresearch/TimeSformer).
+
+## Usage tips
+
+There are many pretrained variants. Select your pretrained model based on the dataset it is trained on. Moreover,
+the number of input frames per clip changes based on the model size so you should consider this parameter while selecting your pretrained model.
+
+## Resources
+
+- [Video classification task guide](../tasks/video_classification)
+
+## TimesformerConfig
+
+[[autodoc]] TimesformerConfig
+
+## TimesformerModel
+
+[[autodoc]] TimesformerModel
+ - forward
+
+## TimesformerForVideoClassification
+
+[[autodoc]] TimesformerForVideoClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/timm_wrapper.md b/docs/transformers/docs/source/en/model_doc/timm_wrapper.md
new file mode 100644
index 0000000000000000000000000000000000000000..8095a91054a5fc441e7da07fcd236713aaa98ef6
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/timm_wrapper.md
@@ -0,0 +1,82 @@
+
+
+# TimmWrapper
+
+
+
+
+
+## Overview
+
+Helper class to enable loading timm models to be used with the transformers library and its autoclasses.
+
+```python
+>>> import torch
+>>> from PIL import Image
+>>> from urllib.request import urlopen
+>>> from transformers import AutoModelForImageClassification, AutoImageProcessor
+
+>>> # Load image
+>>> image = Image.open(urlopen(
+... 'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
+... ))
+
+>>> # Load model and image processor
+>>> checkpoint = "timm/resnet50.a1_in1k"
+>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint)
+>>> model = AutoModelForImageClassification.from_pretrained(checkpoint).eval()
+
+>>> # Preprocess image
+>>> inputs = image_processor(image)
+
+>>> # Forward pass
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+
+>>> # Get top 5 predictions
+>>> top5_probabilities, top5_class_indices = torch.topk(logits.softmax(dim=1) * 100, k=5)
+```
+
+## Resources:
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with TimmWrapper.
+
+
+
+- [Collection of Example Notebook](https://github.com/ariG23498/timm-wrapper-examples) 🌎
+
+> [!TIP]
+> For a more detailed overview please read the [official blog post](https://huggingface.co/blog/timm-transformers) on the timm integration.
+
+## TimmWrapperConfig
+
+[[autodoc]] TimmWrapperConfig
+
+## TimmWrapperImageProcessor
+
+[[autodoc]] TimmWrapperImageProcessor
+ - preprocess
+
+## TimmWrapperModel
+
+[[autodoc]] TimmWrapperModel
+ - forward
+
+## TimmWrapperForImageClassification
+
+[[autodoc]] TimmWrapperForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/trajectory_transformer.md b/docs/transformers/docs/source/en/model_doc/trajectory_transformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..0c8fc29e01faf8509989755b61ced7fd343563fc
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/trajectory_transformer.md
@@ -0,0 +1,65 @@
+
+
+# Trajectory Transformer
+
+
+
+
+
+
+
+This model is in maintenance mode only, so we won't accept any new PRs changing its code.
+
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
+You can do so by running the following command: `pip install -U transformers==4.30.0`.
+
+
+
+## Overview
+
+The Trajectory Transformer model was proposed in [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine.
+
+The abstract from the paper is the following:
+
+*Reinforcement learning (RL) is typically concerned with estimating stationary policies or single-step models,
+leveraging the Markov property to factorize problems in time. However, we can also view RL as a generic sequence
+modeling problem, with the goal being to produce a sequence of actions that leads to a sequence of high rewards.
+Viewed in this way, it is tempting to consider whether high-capacity sequence prediction models that work well
+in other domains, such as natural-language processing, can also provide effective solutions to the RL problem.
+To this end, we explore how RL can be tackled with the tools of sequence modeling, using a Transformer architecture
+to model distributions over trajectories and repurposing beam search as a planning algorithm. Framing RL as sequence
+modeling problem simplifies a range of design decisions, allowing us to dispense with many of the components common
+in offline RL algorithms. We demonstrate the flexibility of this approach across long-horizon dynamics prediction,
+imitation learning, goal-conditioned RL, and offline RL. Further, we show that this approach can be combined with
+existing model-free algorithms to yield a state-of-the-art planner in sparse-reward, long-horizon tasks.*
+
+This model was contributed by [CarlCochet](https://huggingface.co/CarlCochet). The original code can be found [here](https://github.com/jannerm/trajectory-transformer).
+
+## Usage tips
+
+This Transformer is used for deep reinforcement learning. To use it, you need to create sequences from
+actions, states and rewards from all previous timesteps. This model will treat all these elements together
+as one big sequence (a trajectory).
+
+## TrajectoryTransformerConfig
+
+[[autodoc]] TrajectoryTransformerConfig
+
+## TrajectoryTransformerModel
+
+[[autodoc]] TrajectoryTransformerModel
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/transfo-xl.md b/docs/transformers/docs/source/en/model_doc/transfo-xl.md
new file mode 100644
index 0000000000000000000000000000000000000000..4d4f68ab07c9d6043b306063e07efcd9422d4e70
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/transfo-xl.md
@@ -0,0 +1,167 @@
+
+
+# Transformer XL
+
+
+
+
+
+
+
+
+This model is in maintenance mode only, so we won't accept any new PRs changing its code. This model was deprecated due to security issues linked to `pickle.load`.
+
+We recommend switching to more recent models for improved security.
+
+In case you would still like to use `TransfoXL` in your experiments, we recommend using the [Hub checkpoint](https://huggingface.co/transfo-xl/transfo-xl-wt103) with a specific revision to ensure you are downloading safe files from the Hub.
+
+You will need to set the environment variable `TRUST_REMOTE_CODE` to `True` in order to allow the
+usage of `pickle.load()`:
+
+```python
+import os
+from transformers import TransfoXLTokenizer, TransfoXLLMHeadModel
+
+os.environ["TRUST_REMOTE_CODE"] = "True"
+
+checkpoint = 'transfo-xl/transfo-xl-wt103'
+revision = '40a186da79458c9f9de846edfaea79c412137f97'
+
+tokenizer = TransfoXLTokenizer.from_pretrained(checkpoint, revision=revision)
+model = TransfoXLLMHeadModel.from_pretrained(checkpoint, revision=revision)
+```
+
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.35.0.
+You can do so by running the following command: `pip install -U transformers==4.35.0`.
+
+
+
+
+
+## Overview
+
+The Transformer-XL model was proposed in [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan
+Salakhutdinov. It's a causal (uni-directional) transformer with relative positioning (sinusoïdal) embeddings which can
+reuse previously computed hidden-states to attend to longer context (memory). This model also uses adaptive softmax
+inputs and outputs (tied).
+
+The abstract from the paper is the following:
+
+*Transformers have a potential of learning longer-term dependency, but are limited by a fixed-length context in the
+setting of language modeling. We propose a novel neural architecture Transformer-XL that enables learning dependency
+beyond a fixed length without disrupting temporal coherence. It consists of a segment-level recurrence mechanism and a
+novel positional encoding scheme. Our method not only enables capturing longer-term dependency, but also resolves the
+context fragmentation problem. As a result, Transformer-XL learns dependency that is 80% longer than RNNs and 450%
+longer than vanilla Transformers, achieves better performance on both short and long sequences, and is up to 1,800+
+times faster than vanilla Transformers during evaluation. Notably, we improve the state-of-the-art results of
+bpc/perplexity to 0.99 on enwiki8, 1.08 on text8, 18.3 on WikiText-103, 21.8 on One Billion Word, and 54.5 on Penn
+Treebank (without finetuning). When trained only on WikiText-103, Transformer-XL manages to generate reasonably
+coherent, novel text articles with thousands of tokens.*
+
+This model was contributed by [thomwolf](https://huggingface.co/thomwolf). The original code can be found [here](https://github.com/kimiyoung/transformer-xl).
+
+## Usage tips
+
+- Transformer-XL uses relative sinusoidal positional embeddings. Padding can be done on the left or on the right. The
+ original implementation trains on SQuAD with padding on the left, therefore the padding defaults are set to left.
+- Transformer-XL is one of the few models that has no sequence length limit.
+- Same as a regular GPT model, but introduces a recurrence mechanism for two consecutive segments (similar to a regular RNNs with two consecutive inputs). In this context, a segment is a number of consecutive tokens (for instance 512) that may span across multiple documents, and segments are fed in order to the model.
+- Basically, the hidden states of the previous segment are concatenated to the current input to compute the attention scores. This allows the model to pay attention to information that was in the previous segment as well as the current one. By stacking multiple attention layers, the receptive field can be increased to multiple previous segments.
+- This changes the positional embeddings to positional relative embeddings (as the regular positional embeddings would give the same results in the current input and the current hidden state at a given position) and needs to make some adjustments in the way attention scores are computed.
+
+
+
+
+TransformerXL does **not** work with *torch.nn.DataParallel* due to a bug in PyTorch, see [issue #36035](https://github.com/pytorch/pytorch/issues/36035)
+
+
+
+## Resources
+
+- [Text classification task guide](../tasks/sequence_classification)
+- [Causal language modeling task guide](../tasks/language_modeling)
+
+## TransfoXLConfig
+
+[[autodoc]] TransfoXLConfig
+
+## TransfoXLTokenizer
+
+[[autodoc]] TransfoXLTokenizer
+ - save_vocabulary
+
+## TransfoXL specific outputs
+
+[[autodoc]] models.deprecated.transfo_xl.modeling_transfo_xl.TransfoXLModelOutput
+
+[[autodoc]] models.deprecated.transfo_xl.modeling_transfo_xl.TransfoXLLMHeadModelOutput
+
+[[autodoc]] models.deprecated.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLModelOutput
+
+[[autodoc]] models.deprecated.transfo_xl.modeling_tf_transfo_xl.TFTransfoXLLMHeadModelOutput
+
+
+
+
+## TransfoXLModel
+
+[[autodoc]] TransfoXLModel
+ - forward
+
+## TransfoXLLMHeadModel
+
+[[autodoc]] TransfoXLLMHeadModel
+ - forward
+
+## TransfoXLForSequenceClassification
+
+[[autodoc]] TransfoXLForSequenceClassification
+ - forward
+
+
+
+
+## TFTransfoXLModel
+
+[[autodoc]] TFTransfoXLModel
+ - call
+
+## TFTransfoXLLMHeadModel
+
+[[autodoc]] TFTransfoXLLMHeadModel
+ - call
+
+## TFTransfoXLForSequenceClassification
+
+[[autodoc]] TFTransfoXLForSequenceClassification
+ - call
+
+
+
+
+## Internal Layers
+
+[[autodoc]] AdaptiveEmbedding
+
+[[autodoc]] TFAdaptiveEmbedding
diff --git a/docs/transformers/docs/source/en/model_doc/trocr.md b/docs/transformers/docs/source/en/model_doc/trocr.md
new file mode 100644
index 0000000000000000000000000000000000000000..0d0fb6ca24abe9425ad5d08f98b7ec22175d78a1
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/trocr.md
@@ -0,0 +1,130 @@
+
+
+# TrOCR
+
+
+
+
+
+## Overview
+
+The TrOCR model was proposed in [TrOCR: Transformer-based Optical Character Recognition with Pre-trained
+Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang,
+Zhoujun Li, Furu Wei. TrOCR consists of an image Transformer encoder and an autoregressive text Transformer decoder to
+perform [optical character recognition (OCR)](https://en.wikipedia.org/wiki/Optical_character_recognition).
+
+The abstract from the paper is the following:
+
+*Text recognition is a long-standing research problem for document digitalization. Existing approaches for text recognition
+are usually built based on CNN for image understanding and RNN for char-level text generation. In addition, another language
+model is usually needed to improve the overall accuracy as a post-processing step. In this paper, we propose an end-to-end
+text recognition approach with pre-trained image Transformer and text Transformer models, namely TrOCR, which leverages the
+Transformer architecture for both image understanding and wordpiece-level text generation. The TrOCR model is simple but
+effective, and can be pre-trained with large-scale synthetic data and fine-tuned with human-labeled datasets. Experiments
+show that the TrOCR model outperforms the current state-of-the-art models on both printed and handwritten text recognition
+tasks.*
+
+
+
+ TrOCR architecture. Taken from the original paper.
+
+Please refer to the [`VisionEncoderDecoder`] class on how to use this model.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/microsoft/unilm/tree/6f60612e7cc86a2a1ae85c47231507a587ab4e01/trocr).
+
+## Usage tips
+
+- The quickest way to get started with TrOCR is by checking the [tutorial
+ notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR), which show how to use the model
+ at inference time as well as fine-tuning on custom data.
+- TrOCR is pre-trained in 2 stages before being fine-tuned on downstream datasets. It achieves state-of-the-art results
+ on both printed (e.g. the [SROIE dataset](https://paperswithcode.com/dataset/sroie) and handwritten (e.g. the [IAM
+ Handwriting dataset](https://fki.tic.heia-fr.ch/databases/iam-handwriting-database>) text recognition tasks. For more
+ information, see the [official models](https://huggingface.co/models?other=trocr>).
+- TrOCR is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with TrOCR. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+- A blog post on [Accelerating Document AI](https://huggingface.co/blog/document-ai) with TrOCR.
+- A blog post on how to [Document AI](https://github.com/philschmid/document-ai-transformers) with TrOCR.
+- A notebook on how to [finetune TrOCR on IAM Handwriting Database using Seq2SeqTrainer](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TrOCR/Fine_tune_TrOCR_on_IAM_Handwriting_Database_using_Seq2SeqTrainer.ipynb).
+- A notebook on [inference with TrOCR](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TrOCR/Inference_with_TrOCR_%2B_Gradio_demo.ipynb) and Gradio demo.
+- A notebook on [finetune TrOCR on the IAM Handwriting Database](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TrOCR/Fine_tune_TrOCR_on_IAM_Handwriting_Database_using_native_PyTorch.ipynb) using native PyTorch.
+- A notebook on [evaluating TrOCR on the IAM test set](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TrOCR/Evaluating_TrOCR_base_handwritten_on_the_IAM_test_set.ipynb).
+
+
+
+- [Casual language modeling](https://huggingface.co/docs/transformers/tasks/language_modeling) task guide.
+
+⚡️ Inference
+
+- An interactive-demo on [TrOCR handwritten character recognition](https://huggingface.co/spaces/nielsr/TrOCR-handwritten).
+
+## Inference
+
+TrOCR's [`VisionEncoderDecoder`] model accepts images as input and makes use of
+[`~generation.GenerationMixin.generate`] to autoregressively generate text given the input image.
+
+The [`ViTImageProcessor`/`DeiTImageProcessor`] class is responsible for preprocessing the input image and
+[`RobertaTokenizer`/`XLMRobertaTokenizer`] decodes the generated target tokens to the target string. The
+[`TrOCRProcessor`] wraps [`ViTImageProcessor`/`DeiTImageProcessor`] and [`RobertaTokenizer`/`XLMRobertaTokenizer`]
+into a single instance to both extract the input features and decode the predicted token ids.
+
+- Step-by-step Optical Character Recognition (OCR)
+
+``` py
+>>> from transformers import TrOCRProcessor, VisionEncoderDecoderModel
+>>> import requests
+>>> from PIL import Image
+
+>>> processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-handwritten")
+>>> model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-handwritten")
+
+>>> # load image from the IAM dataset
+>>> url = "https://fki.tic.heia-fr.ch/static/img/a01-122-02.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+
+>>> pixel_values = processor(image, return_tensors="pt").pixel_values
+>>> generated_ids = model.generate(pixel_values)
+
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+```
+
+See the [model hub](https://huggingface.co/models?filter=trocr) to look for TrOCR checkpoints.
+
+## TrOCRConfig
+
+[[autodoc]] TrOCRConfig
+
+## TrOCRProcessor
+
+[[autodoc]] TrOCRProcessor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+
+## TrOCRForCausalLM
+
+[[autodoc]] TrOCRForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/tvlt.md b/docs/transformers/docs/source/en/model_doc/tvlt.md
new file mode 100644
index 0000000000000000000000000000000000000000..f1a97dfcd8135974de1cdc78a8ab9c538147714f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/tvlt.md
@@ -0,0 +1,89 @@
+
+
+# TVLT
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
+You can do so by running the following command: `pip install -U transformers==4.40.2`.
+
+
+
+## Overview
+
+The TVLT model was proposed in [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156)
+by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal (the first three authors contributed equally). The Textless Vision-Language Transformer (TVLT) is a model that uses raw visual and audio inputs for vision-and-language representation learning, without using text-specific modules such as tokenization or automatic speech recognition (ASR). It can perform various audiovisual and vision-language tasks like retrieval, question answering, etc.
+
+The abstract from the paper is the following:
+
+*In this work, we present the Textless Vision-Language Transformer (TVLT), where homogeneous transformer blocks take raw visual and audio inputs for vision-and-language representation learning with minimal modality-specific design, and do not use text-specific modules such as tokenization or automatic speech recognition (ASR). TVLT is trained by reconstructing masked patches of continuous video frames and audio spectrograms (masked autoencoding) and contrastive modeling to align video and audio. TVLT attains performance comparable to its text-based counterpart on various multimodal tasks, such as visual question answering, image retrieval, video retrieval, and multimodal sentiment analysis, with 28x faster inference speed and only 1/3 of the parameters. Our findings suggest the possibility of learning compact and efficient visual-linguistic representations from low-level visual and audio signals without assuming the prior existence of text.*
+
+
+
+
+
+ TVLT architecture. Taken from the original paper.
+
+The original code can be found [here](https://github.com/zinengtang/TVLT). This model was contributed by [Zineng Tang](https://huggingface.co/ZinengTang).
+
+## Usage tips
+
+- TVLT is a model that takes both `pixel_values` and `audio_values` as input. One can use [`TvltProcessor`] to prepare data for the model.
+ This processor wraps an image processor (for the image/video modality) and an audio feature extractor (for the audio modality) into one.
+- TVLT is trained with images/videos and audios of various sizes: the authors resize and crop the input images/videos to 224 and limit the length of audio spectrogram to 2048. To make batching of videos and audios possible, the authors use a `pixel_mask` that indicates which pixels are real/padding and `audio_mask` that indicates which audio values are real/padding.
+- The design of TVLT is very similar to that of a standard Vision Transformer (ViT) and masked autoencoder (MAE) as in [ViTMAE](vitmae). The difference is that the model includes embedding layers for the audio modality.
+- The PyTorch version of this model is only available in torch 1.10 and higher.
+
+## TvltConfig
+
+[[autodoc]] TvltConfig
+
+## TvltProcessor
+
+[[autodoc]] TvltProcessor
+ - __call__
+
+## TvltImageProcessor
+
+[[autodoc]] TvltImageProcessor
+ - preprocess
+
+## TvltFeatureExtractor
+
+[[autodoc]] TvltFeatureExtractor
+ - __call__
+
+## TvltModel
+
+[[autodoc]] TvltModel
+ - forward
+
+## TvltForPreTraining
+
+[[autodoc]] TvltForPreTraining
+ - forward
+
+## TvltForAudioVisualClassification
+
+[[autodoc]] TvltForAudioVisualClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/tvp.md b/docs/transformers/docs/source/en/model_doc/tvp.md
new file mode 100644
index 0000000000000000000000000000000000000000..cadb6e71f07408c98ac676556ddc6ef165cdc5ab
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/tvp.md
@@ -0,0 +1,190 @@
+
+
+# TVP
+
+
+
+
+
+## Overview
+
+The text-visual prompting (TVP) framework was proposed in the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
+
+The abstract from the paper is the following:
+
+*In this paper, we study the problem of temporal video grounding (TVG), which aims to predict the starting/ending time points of moments described by a text sentence within a long untrimmed video. Benefiting from fine-grained 3D visual features, the TVG techniques have achieved remarkable progress in recent years. However, the high complexity of 3D convolutional neural networks (CNNs) makes extracting dense 3D visual features time-consuming, which calls for intensive memory and computing resources. Towards efficient TVG, we propose a novel text-visual prompting (TVP) framework, which incorporates optimized perturbation patterns (that we call ‘prompts’) into both visual inputs and textual features of a TVG model. In sharp contrast to 3D CNNs, we show that TVP allows us to effectively co-train vision encoder and language encoder in a 2D TVG model and improves the performance of cross-modal feature fusion using only low-complexity sparse 2D visual features. Further, we propose a Temporal-Distance IoU (TDIoU) loss for efficient learning of TVG. Experiments on two benchmark datasets, Charades-STA and ActivityNet Captions datasets, empirically show that the proposed TVP significantly boosts the performance of 2D TVG (e.g., 9.79% improvement on Charades-STA and 30.77% improvement on ActivityNet Captions) and achieves 5× inference acceleration over TVG using 3D visual features.*
+
+This research addresses temporal video grounding (TVG), which is the process of pinpointing the start and end times of specific events in a long video, as described by a text sentence. Text-visual prompting (TVP), is proposed to enhance TVG. TVP involves integrating specially designed patterns, known as 'prompts', into both the visual (image-based) and textual (word-based) input components of a TVG model. These prompts provide additional spatial-temporal context, improving the model's ability to accurately determine event timings in the video. The approach employs 2D visual inputs in place of 3D ones. Although 3D inputs offer more spatial-temporal detail, they are also more time-consuming to process. The use of 2D inputs with the prompting method aims to provide similar levels of context and accuracy more efficiently.
+
+
+
+ TVP architecture. Taken from the original paper.
+
+This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
+
+## Usage tips and examples
+
+Prompts are optimized perturbation patterns, which would be added to input video frames or text features. Universal set refers to using the same exact set of prompts for any input, this means that these prompts are added consistently to all video frames and text features, regardless of the input's content.
+
+TVP consists of a visual encoder and cross-modal encoder. A universal set of visual prompts and text prompts to be integrated into sampled video frames and textual features, respectively. Specially, a set of different visual prompts are applied to uniformly-sampled frames of one untrimmed video in order.
+
+The goal of this model is to incorporate trainable prompts into both visual inputs and textual features to temporal video grounding(TVG) problems.
+In principle, one can apply any visual, cross-modal encoder in the proposed architecture.
+
+The [`TvpProcessor`] wraps [`BertTokenizer`] and [`TvpImageProcessor`] into a single instance to both
+encode the text and prepare the images respectively.
+
+The following example shows how to run temporal video grounding using [`TvpProcessor`] and [`TvpForVideoGrounding`].
+```python
+import av
+import cv2
+import numpy as np
+import torch
+from huggingface_hub import hf_hub_download
+from transformers import AutoProcessor, TvpForVideoGrounding
+
+
+def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video. Return None if the no
+ video stream was found.
+ fps (float): the number of frames per second of the video.
+ '''
+ video = container.streams.video[0]
+ fps = float(video.average_rate)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ delta = max(num_frames - clip_size, 0)
+ start_idx = delta * clip_idx / num_clips
+ end_idx = start_idx + clip_size - 1
+ timebase = video.duration / num_frames
+ video_start_pts = int(start_idx * timebase)
+ video_end_pts = int(end_idx * timebase)
+ seek_offset = max(video_start_pts - 1024, 0)
+ container.seek(seek_offset, any_frame=False, backward=True, stream=video)
+ frames = {}
+ for frame in container.decode(video=0):
+ if frame.pts < video_start_pts:
+ continue
+ frames[frame.pts] = frame
+ if frame.pts > video_end_pts:
+ break
+ frames = [frames[pts] for pts in sorted(frames)]
+ return frames, fps
+
+
+def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Decode the video and perform temporal sampling.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video.
+ '''
+ assert clip_idx >= -2, "Not a valid clip_idx {}".format(clip_idx)
+ frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ index = np.linspace(0, clip_size - 1, num_frames)
+ index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
+ frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
+ frames = frames.transpose(0, 3, 1, 2)
+ return frames
+
+
+file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
+model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
+
+decoder_kwargs = dict(
+ container=av.open(file, metadata_errors="ignore"),
+ sampling_rate=1,
+ num_frames=model.config.num_frames,
+ clip_idx=0,
+ num_clips=1,
+ target_fps=3,
+)
+raw_sampled_frms = decode(**decoder_kwargs)
+
+text = "a person is sitting on a bed."
+processor = AutoProcessor.from_pretrained("Intel/tvp-base")
+model_inputs = processor(
+ text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
+)
+
+model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
+output = model(**model_inputs)
+
+def get_video_duration(filename):
+ cap = cv2.VideoCapture(filename)
+ if cap.isOpened():
+ rate = cap.get(5)
+ frame_num = cap.get(7)
+ duration = frame_num/rate
+ return duration
+ return -1
+
+duration = get_video_duration(file)
+start, end = processor.post_process_video_grounding(output.logits, duration)
+
+print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
+```
+
+Tips:
+
+- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
+- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
+- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
+
+
+## TvpConfig
+
+[[autodoc]] TvpConfig
+
+## TvpImageProcessor
+
+[[autodoc]] TvpImageProcessor
+ - preprocess
+
+## TvpProcessor
+
+[[autodoc]] TvpProcessor
+ - __call__
+
+## TvpModel
+
+[[autodoc]] TvpModel
+ - forward
+
+## TvpForVideoGrounding
+
+[[autodoc]] TvpForVideoGrounding
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/udop.md b/docs/transformers/docs/source/en/model_doc/udop.md
new file mode 100644
index 0000000000000000000000000000000000000000..b63bc11a53ee3421fc4247da2b92ad2a538cb6c7
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/udop.md
@@ -0,0 +1,117 @@
+
+
+# UDOP
+
+
+
+
+
+## Overview
+
+The UDOP model was proposed in [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623) by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
+UDOP adopts an encoder-decoder Transformer architecture based on [T5](t5) for document AI tasks like document image classification, document parsing and document visual question answering.
+
+The abstract from the paper is the following:
+
+We propose Universal Document Processing (UDOP), a foundation Document AI model which unifies text, image, and layout modalities together with varied task formats, including document understanding and generation. UDOP leverages the spatial correlation between textual content and document image to model image, text, and layout modalities with one uniform representation. With a novel Vision-Text-Layout Transformer, UDOP unifies pretraining and multi-domain downstream tasks into a prompt-based sequence generation scheme. UDOP is pretrained on both large-scale unlabeled document corpora using innovative self-supervised objectives and diverse labeled data. UDOP also learns to generate document images from text and layout modalities via masked image reconstruction. To the best of our knowledge, this is the first time in the field of document AI that one model simultaneously achieves high-quality neural document editing and content customization. Our method sets the state-of-the-art on 9 Document AI tasks, e.g., document understanding and QA, across diverse data domains like finance reports, academic papers, and websites. UDOP ranks first on the leaderboard of the Document Understanding Benchmark (DUE).*
+
+
+
+ UDOP architecture. Taken from the original paper.
+
+## Usage tips
+
+- In addition to *input_ids*, [`UdopForConditionalGeneration`] also expects the input `bbox`, which are
+ the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
+ as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the
+ position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on a 0-1000
+ scale. To normalize, you can use the following function:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+Here, `width` and `height` correspond to the width and height of the original document in which the token
+occurs. Those can be obtained using the Python Image Library (PIL) library for example, as follows:
+
+```python
+from PIL import Image
+
+# Document can be a png, jpg, etc. PDFs must be converted to images.
+image = Image.open(name_of_your_document).convert("RGB")
+
+width, height = image.size
+```
+
+One can use [`UdopProcessor`] to prepare images and text for the model, which takes care of all of this. By default, this class uses the Tesseract engine to extract a list of words and boxes (coordinates) from a given document. Its functionality is equivalent to that of [`LayoutLMv3Processor`], hence it supports passing either `apply_ocr=False` in case you prefer to use your own OCR engine or `apply_ocr=True` in case you want the default OCR engine to be used. Refer to the [usage guide of LayoutLMv2](layoutlmv2#usage-layoutlmv2processor) regarding all possible use cases (the functionality of `UdopProcessor` is identical).
+
+- If using an own OCR engine of choice, one recommendation is Azure's [Read API](https://learn.microsoft.com/en-us/azure/ai-services/computer-vision/how-to/call-read-api), which supports so-called line segments. Use of segment position embeddings typically results in better performance.
+- At inference time, it's recommended to use the `generate` method to autoregressively generate text given a document image.
+- The model has been pre-trained on both self-supervised and supervised objectives. One can use the various task prefixes (prompts) used during pre-training to test out the out-of-the-box capabilities. For instance, the model can be prompted with "Question answering. What is the date?", as "Question answering." is the task prefix used during pre-training for DocVQA. Refer to the [paper](https://arxiv.org/abs/2212.02623) (table 1) for all task prefixes.
+- One can also fine-tune [`UdopEncoderModel`], which is the encoder-only part of UDOP, which can be seen as a LayoutLMv3-like Transformer encoder. For discriminative tasks, one can just add a linear classifier on top of it and fine-tune it on a labeled dataset.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/microsoft/UDOP).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UDOP. If
+you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll
+review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- Demo notebooks regarding UDOP can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UDOP) that show how
+to fine-tune UDOP on a custom dataset as well as inference. 🌎
+- [Document question answering task guide](../tasks/document_question_answering)
+
+## UdopConfig
+
+[[autodoc]] UdopConfig
+
+## UdopTokenizer
+
+[[autodoc]] UdopTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## UdopTokenizerFast
+
+[[autodoc]] UdopTokenizerFast
+
+## UdopProcessor
+
+[[autodoc]] UdopProcessor
+ - __call__
+
+## UdopModel
+
+[[autodoc]] UdopModel
+ - forward
+
+## UdopForConditionalGeneration
+
+[[autodoc]] UdopForConditionalGeneration
+ - forward
+
+## UdopEncoderModel
+
+[[autodoc]] UdopEncoderModel
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/ul2.md b/docs/transformers/docs/source/en/model_doc/ul2.md
new file mode 100644
index 0000000000000000000000000000000000000000..18743a28426e81acceee54ec21db9b3901a7d30d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/ul2.md
@@ -0,0 +1,50 @@
+
+
+# UL2
+
+
+
+
+
+
+
+## Overview
+
+The T5 model was presented in [Unifying Language Learning Paradigms](https://arxiv.org/pdf/2205.05131v1.pdf) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler.
+
+The abstract from the paper is the following:
+
+*Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization.*
+
+This model was contributed by [DanielHesslow](https://huggingface.co/Seledorn). The original code can be found [here](https://github.com/google-research/google-research/tree/master/ul2).
+
+## Usage tips
+
+- UL2 is an encoder-decoder model pre-trained on a mixture of denoising functions as well as fine-tuned on an array of downstream tasks.
+- UL2 has the same architecture as [T5v1.1](t5v1.1) but uses the Gated-SiLU activation function instead of Gated-GELU.
+- The authors release checkpoints of one architecture which can be seen [here](https://huggingface.co/google/ul2)
+
+
+
+As UL2 has the same architecture as T5v1.1, refer to [T5's documentation page](t5) for API reference, tips, code examples and notebooks.
+
+
+
+
+
+
diff --git a/docs/transformers/docs/source/en/model_doc/umt5.md b/docs/transformers/docs/source/en/model_doc/umt5.md
new file mode 100644
index 0000000000000000000000000000000000000000..736574373c5053ad40aafa3eac1fd543105d6d00
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/umt5.md
@@ -0,0 +1,107 @@
+
+
+# UMT5
+
+
+
+
+
+## Overview
+
+The UMT5 model was proposed in [UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining](https://openreview.net/forum?id=kXwdL1cWOAi) by Hyung Won Chung, Xavier Garcia, Adam Roberts, Yi Tay, Orhan Firat, Sharan Narang, Noah Constant.
+
+The abstract from the paper is the following:
+
+*Pretrained multilingual large language models have typically used heuristic temperature-based sampling to balance between different languages. However previous work has not systematically evaluated the efficacy of different pretraining language distributions across model scales. In this paper, we propose a new sampling method, UniMax, that delivers more uniform coverage of head languages while mitigating overfitting on tail languages by explicitly capping the number of repeats over each language's corpus. We perform an extensive series of ablations testing a range of sampling strategies on a suite of multilingual benchmarks, while varying model scale. We find that UniMax outperforms standard temperature-based sampling, and the benefits persist as scale increases. As part of our contribution, we release: (i) an improved and refreshed mC4 multilingual corpus consisting of 29 trillion characters across 107 languages, and (ii) a suite of pretrained umT5 model checkpoints trained with UniMax sampling.*
+
+Google has released the following variants:
+
+- [google/umt5-small](https://huggingface.co/google/umt5-small)
+- [google/umt5-base](https://huggingface.co/google/umt5-base)
+- [google/umt5-xl](https://huggingface.co/google/umt5-xl)
+- [google/umt5-xxl](https://huggingface.co/google/umt5-xxl).
+
+This model was contributed by [agemagician](https://huggingface.co/agemagician) and [stefan-it](https://huggingface.co/stefan-it). The original code can be
+found [here](https://github.com/google-research/t5x).
+
+## Usage tips
+
+- UMT5 was only pre-trained on [mC4](https://huggingface.co/datasets/mc4) excluding any supervised training.
+Therefore, this model has to be fine-tuned before it is usable on a downstream task, unlike the original T5 model.
+- Since umT5 was pre-trained in an unsupervised manner, there's no real advantage to using a task prefix during single-task
+fine-tuning. If you are doing multi-task fine-tuning, you should use a prefix.
+
+## Differences with mT5?
+`UmT5` is based on mT5, with a non-shared relative positional bias that is computed for each layer. This means that the model set `has_relative_bias` for each layer.
+The conversion script is also different because the model was saved in t5x's latest checkpointing format.
+
+# Sample usage
+
+```python
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/umt5-small")
+>>> tokenizer = AutoTokenizer.from_pretrained("google/umt5-small")
+
+>>> inputs = tokenizer(
+... "A walks into a bar and orders a with pinch of .",
+... return_tensors="pt",
+... )
+>>> outputs = model.generate(**inputs)
+>>> print(tokenizer.batch_decode(outputs))
+['nyone who drink a alcohol A A. This I']
+```
+
+
+
+Refer to [T5's documentation page](t5) for more tips, code examples and notebooks.
+
+
+## UMT5Config
+
+[[autodoc]] UMT5Config
+
+## UMT5Model
+
+[[autodoc]] UMT5Model
+ - forward
+
+## UMT5ForConditionalGeneration
+
+[[autodoc]] UMT5ForConditionalGeneration
+ - forward
+
+## UMT5EncoderModel
+
+[[autodoc]] UMT5EncoderModel
+ - forward
+
+## UMT5ForSequenceClassification
+
+[[autodoc]] UMT5ForSequenceClassification
+ - forward
+
+## UMT5ForTokenClassification
+
+[[autodoc]] UMT5ForTokenClassification
+ - forward
+
+## UMT5ForQuestionAnswering
+
+[[autodoc]] UMT5ForQuestionAnswering
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/unispeech-sat.md b/docs/transformers/docs/source/en/model_doc/unispeech-sat.md
new file mode 100644
index 0000000000000000000000000000000000000000..ae4eed71874c5290461ac2d053cd40fe639fa849
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/unispeech-sat.md
@@ -0,0 +1,98 @@
+
+
+# UniSpeech-SAT
+
+
+
+
+
+
+
+## Overview
+
+The UniSpeech-SAT model was proposed in [UniSpeech-SAT: Universal Speech Representation Learning with Speaker Aware
+Pre-Training](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen,
+Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu .
+
+The abstract from the paper is the following:
+
+*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled
+data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in
+speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In
+this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are
+introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to
+the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function.
+Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where
+additional overlapped utterances are created unsupervisedly and incorporate during training. We integrate the proposed
+methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves
+state-of-the-art performance in universal representation learning, especially for speaker identification oriented
+tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training
+dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks.*
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT).
+
+## Usage tips
+
+- UniSpeechSat is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
+ Please use [`Wav2Vec2Processor`] for the feature extraction.
+- UniSpeechSat model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be
+ decoded using [`Wav2Vec2CTCTokenizer`].
+- UniSpeechSat performs especially well on speaker verification, speaker identification, and speaker diarization tasks.
+
+## Resources
+
+- [Audio classification task guide](../tasks/audio_classification)
+- [Automatic speech recognition task guide](../tasks/asr)
+
+## UniSpeechSatConfig
+
+[[autodoc]] UniSpeechSatConfig
+
+## UniSpeechSat specific outputs
+
+[[autodoc]] models.unispeech_sat.modeling_unispeech_sat.UniSpeechSatForPreTrainingOutput
+
+## UniSpeechSatModel
+
+[[autodoc]] UniSpeechSatModel
+ - forward
+
+## UniSpeechSatForCTC
+
+[[autodoc]] UniSpeechSatForCTC
+ - forward
+
+## UniSpeechSatForSequenceClassification
+
+[[autodoc]] UniSpeechSatForSequenceClassification
+ - forward
+
+## UniSpeechSatForAudioFrameClassification
+
+[[autodoc]] UniSpeechSatForAudioFrameClassification
+ - forward
+
+## UniSpeechSatForXVector
+
+[[autodoc]] UniSpeechSatForXVector
+ - forward
+
+## UniSpeechSatForPreTraining
+
+[[autodoc]] UniSpeechSatForPreTraining
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/unispeech.md b/docs/transformers/docs/source/en/model_doc/unispeech.md
new file mode 100644
index 0000000000000000000000000000000000000000..43b0c3bb117e14c5611e98b6c8bce69967fbe58d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/unispeech.md
@@ -0,0 +1,83 @@
+
+
+# UniSpeech
+
+
+
+
+
+
+
+## Overview
+
+The UniSpeech model was proposed in [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael
+Zeng, Xuedong Huang .
+
+The abstract from the paper is the following:
+
+*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both
+unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive
+self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture
+information more correlated with phonetic structures and improve the generalization across languages and domains. We
+evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The
+results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech
+recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all
+testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task,
+i.e., a relative word error rate reduction of 6% against the previous approach.*
+
+This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten). The Authors' code can be
+found [here](https://github.com/microsoft/UniSpeech/tree/main/UniSpeech).
+
+## Usage tips
+
+- UniSpeech is a speech model that accepts a float array corresponding to the raw waveform of the speech signal. Please
+ use [`Wav2Vec2Processor`] for the feature extraction.
+- UniSpeech model can be fine-tuned using connectionist temporal classification (CTC) so the model output has to be
+ decoded using [`Wav2Vec2CTCTokenizer`].
+
+## Resources
+
+- [Audio classification task guide](../tasks/audio_classification)
+- [Automatic speech recognition task guide](../tasks/asr)
+
+## UniSpeechConfig
+
+[[autodoc]] UniSpeechConfig
+
+## UniSpeech specific outputs
+
+[[autodoc]] models.unispeech.modeling_unispeech.UniSpeechForPreTrainingOutput
+
+## UniSpeechModel
+
+[[autodoc]] UniSpeechModel
+ - forward
+
+## UniSpeechForCTC
+
+[[autodoc]] UniSpeechForCTC
+ - forward
+
+## UniSpeechForSequenceClassification
+
+[[autodoc]] UniSpeechForSequenceClassification
+ - forward
+
+## UniSpeechForPreTraining
+
+[[autodoc]] UniSpeechForPreTraining
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/univnet.md b/docs/transformers/docs/source/en/model_doc/univnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..367147115278bf934d142ecd52e566eee9a2c989
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/univnet.md
@@ -0,0 +1,84 @@
+
+
+# UnivNet
+
+
+
+
+
+## Overview
+
+The UnivNet model was proposed in [UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation](https://arxiv.org/abs/2106.07889) by Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kin, and Juntae Kim.
+The UnivNet model is a generative adversarial network (GAN) trained to synthesize high fidelity speech waveforms. The UnivNet model shared in `transformers` is the *generator*, which maps a conditioning log-mel spectrogram and optional noise sequence to a speech waveform (e.g. a vocoder). Only the generator is required for inference. The *discriminator* used to train the `generator` is not implemented.
+
+The abstract from the paper is the following:
+
+*Most neural vocoders employ band-limited mel-spectrograms to generate waveforms. If full-band spectral features are used as the input, the vocoder can be provided with as much acoustic information as possible. However, in some models employing full-band mel-spectrograms, an over-smoothing problem occurs as part of which non-sharp spectrograms are generated. To address this problem, we propose UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multi-resolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input. In an evaluation on a dataset containing information on hundreds of speakers, UnivNet obtained the best objective and subjective results among competing models for both seen and unseen speakers. These results, including the best subjective score for text-to-speech, demonstrate the potential for fast adaptation to new speakers without a need for training from scratch.*
+
+Tips:
+
+- The `noise_sequence` argument for [`UnivNetModel.forward`] should be standard Gaussian noise (such as from `torch.randn`) of shape `([batch_size], noise_length, model.config.model_in_channels)`, where `noise_length` should match the length dimension (dimension 1) of the `input_features` argument. If not supplied, it will be randomly generated; a `torch.Generator` can be supplied to the `generator` argument so that the forward pass can be reproduced. (Note that [`UnivNetFeatureExtractor`] will return generated noise by default, so it shouldn't be necessary to generate `noise_sequence` manually.)
+- Padding added by [`UnivNetFeatureExtractor`] can be removed from the [`UnivNetModel`] output through the [`UnivNetFeatureExtractor.batch_decode`] method, as shown in the usage example below.
+- Padding the end of each waveform with silence can reduce artifacts at the end of the generated audio sample. This can be done by supplying `pad_end = True` to [`UnivNetFeatureExtractor.__call__`]. See [this issue](https://github.com/seungwonpark/melgan/issues/8) for more details.
+
+Usage Example:
+
+```python
+import torch
+from scipy.io.wavfile import write
+from datasets import Audio, load_dataset
+
+from transformers import UnivNetFeatureExtractor, UnivNetModel
+
+model_id_or_path = "dg845/univnet-dev"
+model = UnivNetModel.from_pretrained(model_id_or_path)
+feature_extractor = UnivNetFeatureExtractor.from_pretrained(model_id_or_path)
+
+ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+# Resample the audio to the model and feature extractor's sampling rate.
+ds = ds.cast_column("audio", Audio(sampling_rate=feature_extractor.sampling_rate))
+# Pad the end of the converted waveforms to reduce artifacts at the end of the output audio samples.
+inputs = feature_extractor(
+ ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], pad_end=True, return_tensors="pt"
+)
+
+with torch.no_grad():
+ audio = model(**inputs)
+
+# Remove the extra padding at the end of the output.
+audio = feature_extractor.batch_decode(**audio)[0]
+# Convert to wav file
+write("sample_audio.wav", feature_extractor.sampling_rate, audio)
+```
+
+This model was contributed by [dg845](https://huggingface.co/dg845).
+To the best of my knowledge, there is no official code release, but an unofficial implementation can be found at [maum-ai/univnet](https://github.com/maum-ai/univnet) with pretrained checkpoints [here](https://github.com/maum-ai/univnet#pre-trained-model).
+
+
+## UnivNetConfig
+
+[[autodoc]] UnivNetConfig
+
+## UnivNetFeatureExtractor
+
+[[autodoc]] UnivNetFeatureExtractor
+ - __call__
+
+## UnivNetModel
+
+[[autodoc]] UnivNetModel
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/upernet.md b/docs/transformers/docs/source/en/model_doc/upernet.md
new file mode 100644
index 0000000000000000000000000000000000000000..a2c96582f24a81a36134df9c2471308859338e98
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/upernet.md
@@ -0,0 +1,83 @@
+
+
+# UPerNet
+
+
+
+
+
+## Overview
+
+The UPerNet model was proposed in [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
+by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. UPerNet is a general framework to effectively segment
+a wide range of concepts from images, leveraging any vision backbone like [ConvNeXt](convnext) or [Swin](swin).
+
+The abstract from the paper is the following:
+
+*Humans recognize the visual world at multiple levels: we effortlessly categorize scenes and detect objects inside, while also identifying the textures and surfaces of the objects along with their different compositional parts. In this paper, we study a new task called Unified Perceptual Parsing, which requires the machine vision systems to recognize as many visual concepts as possible from a given image. A multi-task framework called UPerNet and a training strategy are developed to learn from heterogeneous image annotations. We benchmark our framework on Unified Perceptual Parsing and show that it is able to effectively segment a wide range of concepts from images. The trained networks are further applied to discover visual knowledge in natural scenes.*
+
+
+
+ UPerNet framework. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code is based on OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
+
+## Usage examples
+
+UPerNet is a general framework for semantic segmentation. It can be used with any vision backbone, like so:
+
+```py
+from transformers import SwinConfig, UperNetConfig, UperNetForSemanticSegmentation
+
+backbone_config = SwinConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
+
+config = UperNetConfig(backbone_config=backbone_config)
+model = UperNetForSemanticSegmentation(config)
+```
+
+To use another vision backbone, like [ConvNeXt](convnext), simply instantiate the model with the appropriate backbone:
+
+```py
+from transformers import ConvNextConfig, UperNetConfig, UperNetForSemanticSegmentation
+
+backbone_config = ConvNextConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
+
+config = UperNetConfig(backbone_config=backbone_config)
+model = UperNetForSemanticSegmentation(config)
+```
+
+Note that this will randomly initialize all the weights of the model.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UPerNet.
+
+- Demo notebooks for UPerNet can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
+- [`UperNetForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb).
+- See also: [Semantic segmentation task guide](../tasks/semantic_segmentation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## UperNetConfig
+
+[[autodoc]] UperNetConfig
+
+## UperNetForSemanticSegmentation
+
+[[autodoc]] UperNetForSemanticSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/van.md b/docs/transformers/docs/source/en/model_doc/van.md
new file mode 100644
index 0000000000000000000000000000000000000000..1df6a4640bbbb3e9e5f6b19bf4079c0401f0c1e2
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/van.md
@@ -0,0 +1,76 @@
+
+
+# VAN
+
+
+
+
+
+
+
+This model is in maintenance mode only, we don't accept any new PRs changing its code.
+
+If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
+You can do so by running the following command: `pip install -U transformers==4.30.0`.
+
+
+
+## Overview
+
+The VAN model was proposed in [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+
+This paper introduces a new attention layer based on convolution operations able to capture both local and distant relationships. This is done by combining normal and large kernel convolution layers. The latter uses a dilated convolution to capture distant correlations.
+
+The abstract from the paper is the following:
+
+*While originally designed for natural language processing tasks, the self-attention mechanism has recently taken various computer vision areas by storm. However, the 2D nature of images brings three challenges for applying self-attention in computer vision. (1) Treating images as 1D sequences neglects their 2D structures. (2) The quadratic complexity is too expensive for high-resolution images. (3) It only captures spatial adaptability but ignores channel adaptability. In this paper, we propose a novel large kernel attention (LKA) module to enable self-adaptive and long-range correlations in self-attention while avoiding the above issues. We further introduce a novel neural network based on LKA, namely Visual Attention Network (VAN). While extremely simple, VAN outperforms the state-of-the-art vision transformers and convolutional neural networks with a large margin in extensive experiments, including image classification, object detection, semantic segmentation, instance segmentation, etc. Code is available at [this https URL](https://github.com/Visual-Attention-Network/VAN-Classification).*
+
+Tips:
+
+- VAN does not have an embedding layer, thus the `hidden_states` will have a length equal to the number of stages.
+
+The figure below illustrates the architecture of a Visual Attention Layer. Taken from the [original paper](https://arxiv.org/abs/2202.09741).
+
+
+
+This model was contributed by [Francesco](https://huggingface.co/Francesco). The original code can be found [here](https://github.com/Visual-Attention-Network/VAN-Classification).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with VAN.
+
+
+
+- [`VanForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+- See also: [Image classification task guide](../tasks/image_classification)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## VanConfig
+
+[[autodoc]] VanConfig
+
+## VanModel
+
+[[autodoc]] VanModel
+ - forward
+
+## VanForImageClassification
+
+[[autodoc]] VanForImageClassification
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/video_llava.md b/docs/transformers/docs/source/en/model_doc/video_llava.md
new file mode 100644
index 0000000000000000000000000000000000000000..f407b4dc5ebdb51a278faa51891725cce805fffd
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/video_llava.md
@@ -0,0 +1,221 @@
+
+
+# Video-LLaVA
+
+
+
+
+
+
+
+## Overview
+
+Video-LLaVa is an open-source multimodal LLM trained by fine-tuning LlamA/Vicuna on multimodal instruction-following data generated by Llava1.5 and VideChat. It is an auto-regressive language model, based on the transformer architecture. Video-LLaVa unifies visual representations to the language feature space, and enables an LLM to perform visual reasoning capabilities on both images and videos simultaneously.
+
+
+The Video-LLaVA model was proposed in [Video-LLaVA: Learning United Visual Representation by Alignment Before Projection](https://arxiv.org/abs/2311.10122) by Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munang Ning, Peng Jin, Li Yuan.
+
+The abstract from the paper is the following:
+
+*The Large Vision-Language Model (LVLM) has enhanced the performance of various downstream tasks in
+visual-language understanding. Most existing approaches
+encode images and videos into separate feature spaces,
+which are then fed as inputs to large language models.
+However, due to the lack of unified tokenization for images and videos, namely misalignment before projection, it
+becomes challenging for a Large Language Model (LLM)
+to learn multi-modal interactions from several poor projection layers. In this work, we unify visual representation into the language feature space to advance the foundational LLM towards a unified LVLM. As a result, we establish a simple but robust LVLM baseline, Video-LLaVA,
+which learns from a mixed dataset of images and videos,
+mutually enhancing each other. Video-LLaVA achieves superior performances on a broad range of 9 image benchmarks across 5 image question-answering datasets and 4
+image benchmark toolkits. Additionally, our Video-LLaVA
+also outperforms Video-ChatGPT by 5.8%, 9.9%, 18.6%,
+and 10.1% on MSRVTT, MSVD, TGIF, and ActivityNet, respectively. Notably, extensive experiments demonstrate that
+Video-LLaVA mutually benefits images and videos within
+a unified visual representation, outperforming models designed specifically for images or videos. We aim for this
+work to provide modest insights into the multi-modal inputs
+for the LLM*
+
+## Usage tips:
+
+- We advise users to use padding_side="left" when computing batched generation as it leads to more accurate results. Simply make sure to call processor.tokenizer.padding_side = "left" before generating.
+
+- Note the model has not been explicitly trained to process multiple images/videos in the same prompt, although this is technically possible, you may experience inaccurate results.
+
+- Note that the video inputs should have exactly 8 frames at the input, since the models were trained in that setting.
+
+This model was contributed by [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
+The original code can be found [here](https://github.com/PKU-YuanGroup/Video-LLaVA).
+
+
+> [!NOTE]
+> LLaVA models after release v4.46 will raise warnings about adding `processor.patch_size = {{patch_size}}`, `processor.num_additional_image_tokens = {{num_additional_image_tokens}}` and processor.vision_feature_select_strategy = {{vision_feature_select_strategy}}`. It is strongly recommended to add the attributes to the processor if you own the model checkpoint, or open a PR if it is not owned by you.
+Adding these attributes means that LLaVA will try to infer the number of image tokens required per image and expand the text with as many `` placeholders as there will be tokens. Usually it is around 500 tokens per image, so make sure that the text is not truncated as otherwise there will be failure when merging the embeddings.
+The attributes can be obtained from model config, as `model.config.vision_config.patch_size` or `model.config.vision_feature_select_strategy`. The `num_additional_image_tokens` should be `1` if the vision backbone adds a CLS token or `0` if nothing extra is added to the vision patches.
+
+
+## Usage example
+
+### Single Media Mode
+
+The model can accept both images and videos as input. Here's an example code for inference in half-precision (`torch.float16`):
+
+```python
+import av
+import torch
+import numpy as np
+from transformers import VideoLlavaForConditionalGeneration, VideoLlavaProcessor
+
+def read_video_pyav(container, indices):
+ '''
+ Decode the video with PyAV decoder.
+ Args:
+ container (`av.container.input.InputContainer`): PyAV container.
+ indices (`List[int]`): List of frame indices to decode.
+ Returns:
+ result (np.ndarray): np array of decoded frames of shape (num_frames, height, width, 3).
+ '''
+ frames = []
+ container.seek(0)
+ start_index = indices[0]
+ end_index = indices[-1]
+ for i, frame in enumerate(container.decode(video=0)):
+ if i > end_index:
+ break
+ if i >= start_index and i in indices:
+ frames.append(frame)
+ return np.stack([x.to_ndarray(format="rgb24") for x in frames])
+
+# Load the model in half-precision
+model = VideoLlavaForConditionalGeneration.from_pretrained("LanguageBind/Video-LLaVA-7B-hf", torch_dtype=torch.float16, device_map="auto")
+processor = VideoLlavaProcessor.from_pretrained("LanguageBind/Video-LLaVA-7B-hf")
+
+# Load the video as an np.arrau, sampling uniformly 8 frames
+video_path = hf_hub_download(repo_id="raushan-testing-hf/videos-test", filename="sample_demo_1.mp4", repo_type="dataset")
+container = av.open(video_path)
+total_frames = container.streams.video[0].frames
+indices = np.arange(0, total_frames, total_frames / 8).astype(int)
+video = read_video_pyav(container, indices)
+
+# For better results, we recommend to prompt the model in the following format
+prompt = "USER:
 +
+ +
+ +
+ +
+ +
+ +
+ +
+  +
+  +
+
+
+ +
+[[autodoc]] get_cosine_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_schedule_with_warmup
+
+ +
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+ +
+[[autodoc]] get_linear_schedule_with_warmup
+
+
+
+[[autodoc]] get_linear_schedule_with_warmup
+
+ +
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+[[autodoc]] get_inverse_sqrt_schedule
+
+[[autodoc]] get_wsd_schedule
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## Gradient Strategies
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
diff --git a/docs/transformers/docs/source/en/main_classes/output.md b/docs/transformers/docs/source/en/main_classes/output.md
new file mode 100644
index 0000000000000000000000000000000000000000..300213d4513ebbf832e22828ac8be3164d5b95e6
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/output.md
@@ -0,0 +1,321 @@
+
+
+# Model outputs
+
+All models have outputs that are instances of subclasses of [`~utils.ModelOutput`]. Those are
+data structures containing all the information returned by the model, but that can also be used as tuples or
+dictionaries.
+
+Let's see how this looks in an example:
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
+outputs = model(**inputs, labels=labels)
+```
+
+The `outputs` object is a [`~modeling_outputs.SequenceClassifierOutput`], as we can see in the
+documentation of that class below, it means it has an optional `loss`, a `logits`, an optional `hidden_states` and
+an optional `attentions` attribute. Here we have the `loss` since we passed along `labels`, but we don't have
+`hidden_states` and `attentions` because we didn't pass `output_hidden_states=True` or
+`output_attentions=True`.
+
+
+
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+[[autodoc]] get_inverse_sqrt_schedule
+
+[[autodoc]] get_wsd_schedule
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## Gradient Strategies
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
diff --git a/docs/transformers/docs/source/en/main_classes/output.md b/docs/transformers/docs/source/en/main_classes/output.md
new file mode 100644
index 0000000000000000000000000000000000000000..300213d4513ebbf832e22828ac8be3164d5b95e6
--- /dev/null
+++ b/docs/transformers/docs/source/en/main_classes/output.md
@@ -0,0 +1,321 @@
+
+
+# Model outputs
+
+All models have outputs that are instances of subclasses of [`~utils.ModelOutput`]. Those are
+data structures containing all the information returned by the model, but that can also be used as tuples or
+dictionaries.
+
+Let's see how this looks in an example:
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
+outputs = model(**inputs, labels=labels)
+```
+
+The `outputs` object is a [`~modeling_outputs.SequenceClassifierOutput`], as we can see in the
+documentation of that class below, it means it has an optional `loss`, a `logits`, an optional `hidden_states` and
+an optional `attentions` attribute. Here we have the `loss` since we passed along `labels`, but we don't have
+`hidden_states` and `attentions` because we didn't pass `output_hidden_states=True` or
+`output_attentions=True`.
+
+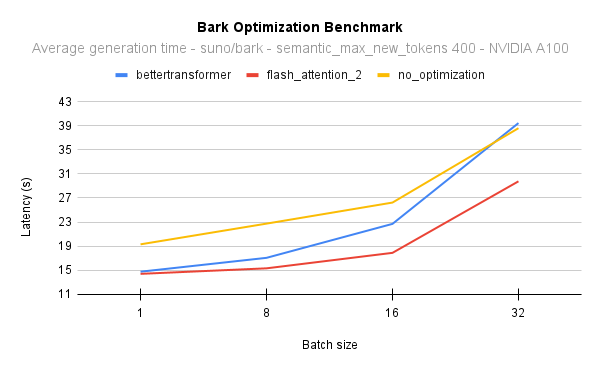 +
+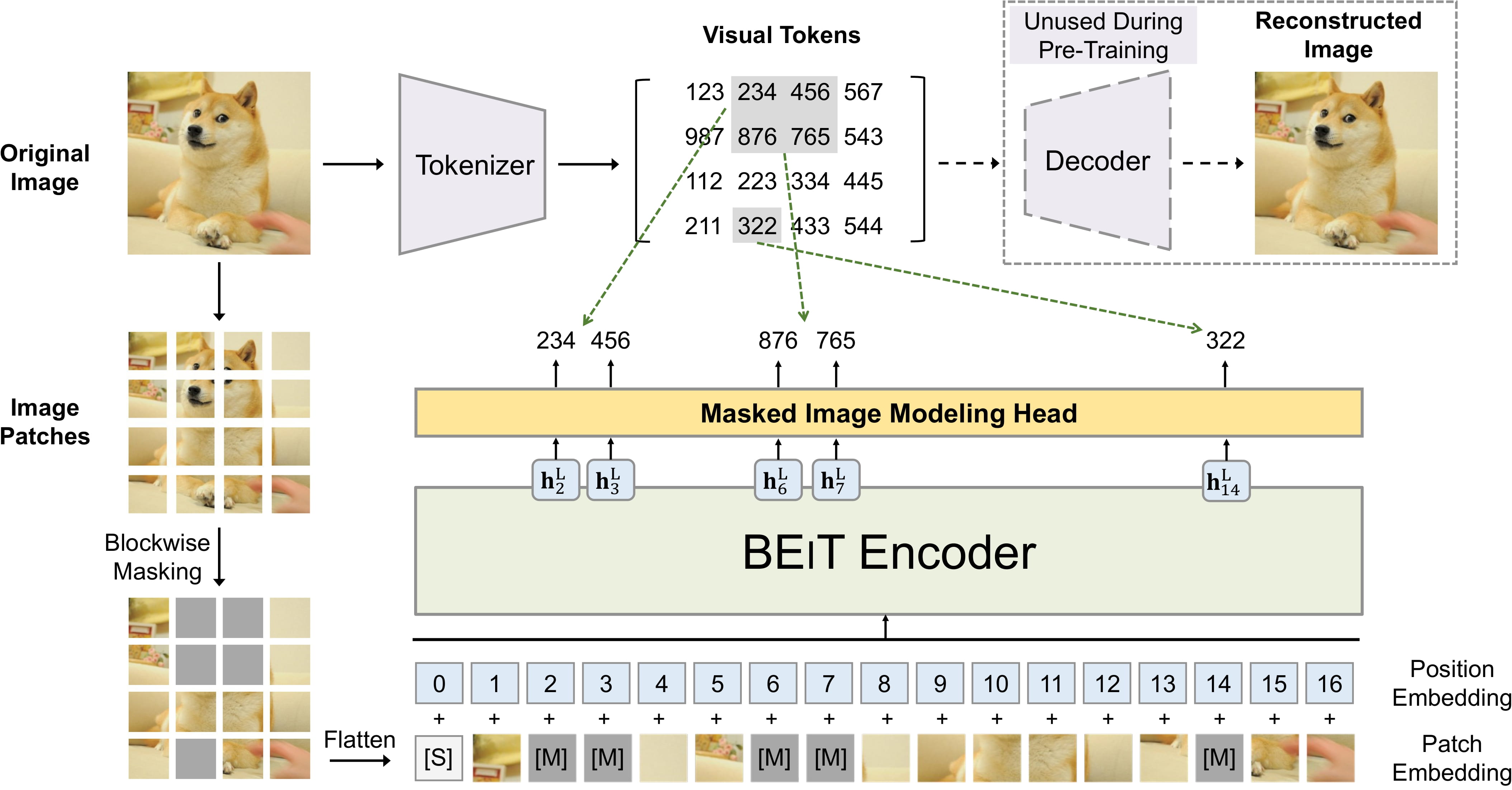 +
+ BEiT pre-training. Taken from the original paper.
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```
+from transformers import BeitForImageClassification
+model = BeitForImageClassification.from_pretrained("microsoft/beit-base-patch16-224", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+On a local benchmark (NVIDIA GeForce RTX 2060-8GB, PyTorch 2.5.1, OS Ubuntu 20.04) with `float16` and
+`microsoft/beit-base-patch16-224` model, we saw the following improvements during training and inference:
+
+#### Training
+
+| num_training_steps | batch_size | image_size | is_cuda | Time per batch (eager - s) | Time per batch (sdpa - s) | Speedup (%) | Eager peak mem (MB) | SDPA peak mem (MB) | Mem saving (%) |
+|--------------------|------------|--------------|---------|----------------------------|---------------------------|-------------|----------------------|--------------------|----------------|
+| 50 | 2 | (1048, 640) | True | 0.984 | 0.746 | 31.975 | 6738.915 | 4319.886 | 55.998 |
+
+#### Inference
+
+| Image batch size | Eager (s/iter) | Eager CI, % | Eager memory (MB) | SDPA (s/iter) | SDPA CI, % | SDPA memory (MB) | SDPA speedup | SDPA memory saved (%) |
+|-------------------:|-----------------:|:--------------|--------------------:|----------------:|:-------------|-------------------:|---------------:|----------------------:|
+| 1 | 0.012 | ±0.3% | 3.76657e+08 | 0.011 | ±0.5% | 3.75739e+08 | 1.05 | 0.244 |
+| 4 | 0.013 | ±0.1% | 4.03147e+08 | 0.011 | ±0.2% | 3.90554e+08 | 1.178 | 3.225 |
+| 16 | 0.045 | ±0.1% | 4.96697e+08 | 0.035 | ±0.1% | 4.51232e+08 | 1.304 | 10.076 |
+| 32 | 0.088 | ±0.1% | 6.24417e+08 | 0.066 | ±0.1% | 5.33488e+08 | 1.325 | 17.044 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
+
+
+
+ BEiT pre-training. Taken from the original paper.
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```
+from transformers import BeitForImageClassification
+model = BeitForImageClassification.from_pretrained("microsoft/beit-base-patch16-224", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+On a local benchmark (NVIDIA GeForce RTX 2060-8GB, PyTorch 2.5.1, OS Ubuntu 20.04) with `float16` and
+`microsoft/beit-base-patch16-224` model, we saw the following improvements during training and inference:
+
+#### Training
+
+| num_training_steps | batch_size | image_size | is_cuda | Time per batch (eager - s) | Time per batch (sdpa - s) | Speedup (%) | Eager peak mem (MB) | SDPA peak mem (MB) | Mem saving (%) |
+|--------------------|------------|--------------|---------|----------------------------|---------------------------|-------------|----------------------|--------------------|----------------|
+| 50 | 2 | (1048, 640) | True | 0.984 | 0.746 | 31.975 | 6738.915 | 4319.886 | 55.998 |
+
+#### Inference
+
+| Image batch size | Eager (s/iter) | Eager CI, % | Eager memory (MB) | SDPA (s/iter) | SDPA CI, % | SDPA memory (MB) | SDPA speedup | SDPA memory saved (%) |
+|-------------------:|-----------------:|:--------------|--------------------:|----------------:|:-------------|-------------------:|---------------:|----------------------:|
+| 1 | 0.012 | ±0.3% | 3.76657e+08 | 0.011 | ±0.5% | 3.75739e+08 | 1.05 | 0.244 |
+| 4 | 0.013 | ±0.1% | 4.03147e+08 | 0.011 | ±0.2% | 3.90554e+08 | 1.178 | 3.225 |
+| 16 | 0.045 | ±0.1% | 4.96697e+08 | 0.035 | ±0.1% | 4.51232e+08 | 1.304 | 10.076 |
+| 32 | 0.088 | ±0.1% | 6.24417e+08 | 0.066 | ±0.1% | 5.33488e+08 | 1.325 | 17.044 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BEiT.
+
+ +
+ BLIP-2 architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207).
+
+## Usage tips
+
+- BLIP-2 can be used for conditional text generation given an image and an optional text prompt. At inference time, it's recommended to use the [`generate`] method.
+- One can use [`Blip2Processor`] to prepare images for the model, and decode the predicted tokens ID's back to text.
+
+> [!NOTE]
+> BLIP models after release v4.46 will raise warnings about adding `processor.num_query_tokens = {{num_query_tokens}}` and expand model embeddings layer to add special `
+
+ BLIP-2 architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207).
+
+## Usage tips
+
+- BLIP-2 can be used for conditional text generation given an image and an optional text prompt. At inference time, it's recommended to use the [`generate`] method.
+- One can use [`Blip2Processor`] to prepare images for the model, and decode the predicted tokens ID's back to text.
+
+> [!NOTE]
+> BLIP models after release v4.46 will raise warnings about adding `processor.num_query_tokens = {{num_query_tokens}}` and expand model embeddings layer to add special ` +
+ BridgeTower architecture. Taken from the original paper.
+
+This model was contributed by [Anahita Bhiwandiwalla](https://huggingface.co/anahita-b), [Tiep Le](https://huggingface.co/Tile) and [Shaoyen Tseng](https://huggingface.co/shaoyent). The original code can be found [here](https://github.com/microsoft/BridgeTower).
+
+## Usage tips and examples
+
+BridgeTower consists of a visual encoder, a textual encoder and cross-modal encoder with multiple lightweight bridge layers.
+The goal of this approach was to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder.
+In principle, one can apply any visual, textual or cross-modal encoder in the proposed architecture.
+
+The [`BridgeTowerProcessor`] wraps [`RobertaTokenizer`] and [`BridgeTowerImageProcessor`] into a single instance to both
+encode the text and prepare the images respectively.
+
+The following example shows how to run contrastive learning using [`BridgeTowerProcessor`] and [`BridgeTowerForContrastiveLearning`].
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs
+```
+
+The following example shows how to run image-text retrieval using [`BridgeTowerProcessor`] and [`BridgeTowerForImageAndTextRetrieval`].
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs.logits[0, 1].item()
+```
+
+The following example shows how to run masked language modeling using [`BridgeTowerProcessor`] and [`BridgeTowerForMaskedLM`].
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+>>> text = "a
+
+ BridgeTower architecture. Taken from the original paper.
+
+This model was contributed by [Anahita Bhiwandiwalla](https://huggingface.co/anahita-b), [Tiep Le](https://huggingface.co/Tile) and [Shaoyen Tseng](https://huggingface.co/shaoyent). The original code can be found [here](https://github.com/microsoft/BridgeTower).
+
+## Usage tips and examples
+
+BridgeTower consists of a visual encoder, a textual encoder and cross-modal encoder with multiple lightweight bridge layers.
+The goal of this approach was to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder.
+In principle, one can apply any visual, textual or cross-modal encoder in the proposed architecture.
+
+The [`BridgeTowerProcessor`] wraps [`RobertaTokenizer`] and [`BridgeTowerImageProcessor`] into a single instance to both
+encode the text and prepare the images respectively.
+
+The following example shows how to run contrastive learning using [`BridgeTowerProcessor`] and [`BridgeTowerForContrastiveLearning`].
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs
+```
+
+The following example shows how to run image-text retrieval using [`BridgeTowerProcessor`] and [`BridgeTowerForImageAndTextRetrieval`].
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs.logits[0, 1].item()
+```
+
+The following example shows how to run masked language modeling using [`BridgeTowerProcessor`] and [`BridgeTowerForMaskedLM`].
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+>>> text = "a  +
+ Chameleon incorporates a vector quantizer module to transform images into discrete tokens. That also enables image generation using an auto-regressive transformer. Taken from the original paper.
+
+This model was contributed by [joaogante](https://huggingface.co/joaogante) and [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
+The original code can be found [here](https://github.com/facebookresearch/chameleon).
+
+
+## Usage tips
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to set `processor.tokenizer.padding_side = "left"` before generating.
+
+- Note that Chameleon was tuned for safety alignment. If the model is refusing to answer, consider asking a more concrete question, instead of an open question.
+
+- Chameleon generates in chat format which means that the generated text will always be the "assistant's turn". You can enable a text completion generation by passing `return_for_text_completion=True` when calling the processor.
+
+> [!NOTE]
+> Chameleon implementation in Transformers uses a special image token to indicate where to merge image embeddings. For special image token we didn't add a new one but used one of the reserved tokens: `
+
+ Chameleon incorporates a vector quantizer module to transform images into discrete tokens. That also enables image generation using an auto-regressive transformer. Taken from the original paper.
+
+This model was contributed by [joaogante](https://huggingface.co/joaogante) and [RaushanTurganbay](https://huggingface.co/RaushanTurganbay).
+The original code can be found [here](https://github.com/facebookresearch/chameleon).
+
+
+## Usage tips
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to set `processor.tokenizer.padding_side = "left"` before generating.
+
+- Note that Chameleon was tuned for safety alignment. If the model is refusing to answer, consider asking a more concrete question, instead of an open question.
+
+- Chameleon generates in chat format which means that the generated text will always be the "assistant's turn". You can enable a text completion generation by passing `return_for_text_completion=True` when calling the processor.
+
+> [!NOTE]
+> Chameleon implementation in Transformers uses a special image token to indicate where to merge image embeddings. For special image token we didn't add a new one but used one of the reserved tokens: `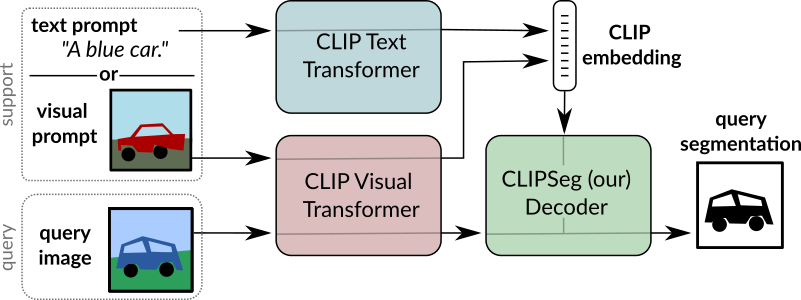 +
+ CLIPSeg overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/timojl/clipseg).
+
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] adds a decoder on top of [`CLIPSegModel`]. The latter is identical to [`CLIPModel`].
+- [`CLIPSegForImageSegmentation`] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text
+(provided to the model as `input_ids`) or an image (provided to the model as `conditional_pixel_values`). One can also provide custom
+conditional embeddings (provided to the model as `conditional_embeddings`).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIPSeg. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+ CLIPSeg overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/timojl/clipseg).
+
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] adds a decoder on top of [`CLIPSegModel`]. The latter is identical to [`CLIPModel`].
+- [`CLIPSegForImageSegmentation`] can generate image segmentations based on arbitrary prompts at test time. A prompt can be either a text
+(provided to the model as `input_ids`) or an image (provided to the model as `conditional_pixel_values`). One can also provide custom
+conditional embeddings (provided to the model as `conditional_embeddings`).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CLIPSeg. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+ +
+ +
+ +
+ Conditional DETR shows much faster convergence compared to the original DETR. Taken from the original paper.
+
+This model was contributed by [DepuMeng](https://huggingface.co/DepuMeng). The original code can be found [here](https://github.com/Atten4Vis/ConditionalDETR).
+
+## Resources
+
+- Scripts for finetuning [`ConditionalDetrForObjectDetection`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- See also: [Object detection task guide](../tasks/object_detection).
+
+## ConditionalDetrConfig
+
+[[autodoc]] ConditionalDetrConfig
+
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+ - preprocess
+
+## ConditionalDetrImageProcessorFast
+
+[[autodoc]] ConditionalDetrImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrFeatureExtractor
+
+[[autodoc]] ConditionalDetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrModel
+
+[[autodoc]] ConditionalDetrModel
+ - forward
+
+## ConditionalDetrForObjectDetection
+
+[[autodoc]] ConditionalDetrForObjectDetection
+ - forward
+
+## ConditionalDetrForSegmentation
+
+[[autodoc]] ConditionalDetrForSegmentation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/convbert.md b/docs/transformers/docs/source/en/model_doc/convbert.md
new file mode 100644
index 0000000000000000000000000000000000000000..e52bbd5c4772ec62e2f06e0dece55abab09b801d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/convbert.md
@@ -0,0 +1,141 @@
+
+
+# ConvBERT
+
+
+
+ Conditional DETR shows much faster convergence compared to the original DETR. Taken from the original paper.
+
+This model was contributed by [DepuMeng](https://huggingface.co/DepuMeng). The original code can be found [here](https://github.com/Atten4Vis/ConditionalDETR).
+
+## Resources
+
+- Scripts for finetuning [`ConditionalDetrForObjectDetection`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- See also: [Object detection task guide](../tasks/object_detection).
+
+## ConditionalDetrConfig
+
+[[autodoc]] ConditionalDetrConfig
+
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+ - preprocess
+
+## ConditionalDetrImageProcessorFast
+
+[[autodoc]] ConditionalDetrImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrFeatureExtractor
+
+[[autodoc]] ConditionalDetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrModel
+
+[[autodoc]] ConditionalDetrModel
+ - forward
+
+## ConditionalDetrForObjectDetection
+
+[[autodoc]] ConditionalDetrForObjectDetection
+ - forward
+
+## ConditionalDetrForSegmentation
+
+[[autodoc]] ConditionalDetrForSegmentation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/convbert.md b/docs/transformers/docs/source/en/model_doc/convbert.md
new file mode 100644
index 0000000000000000000000000000000000000000..e52bbd5c4772ec62e2f06e0dece55abab09b801d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/convbert.md
@@ -0,0 +1,141 @@
+
+
+# ConvBERT
+
+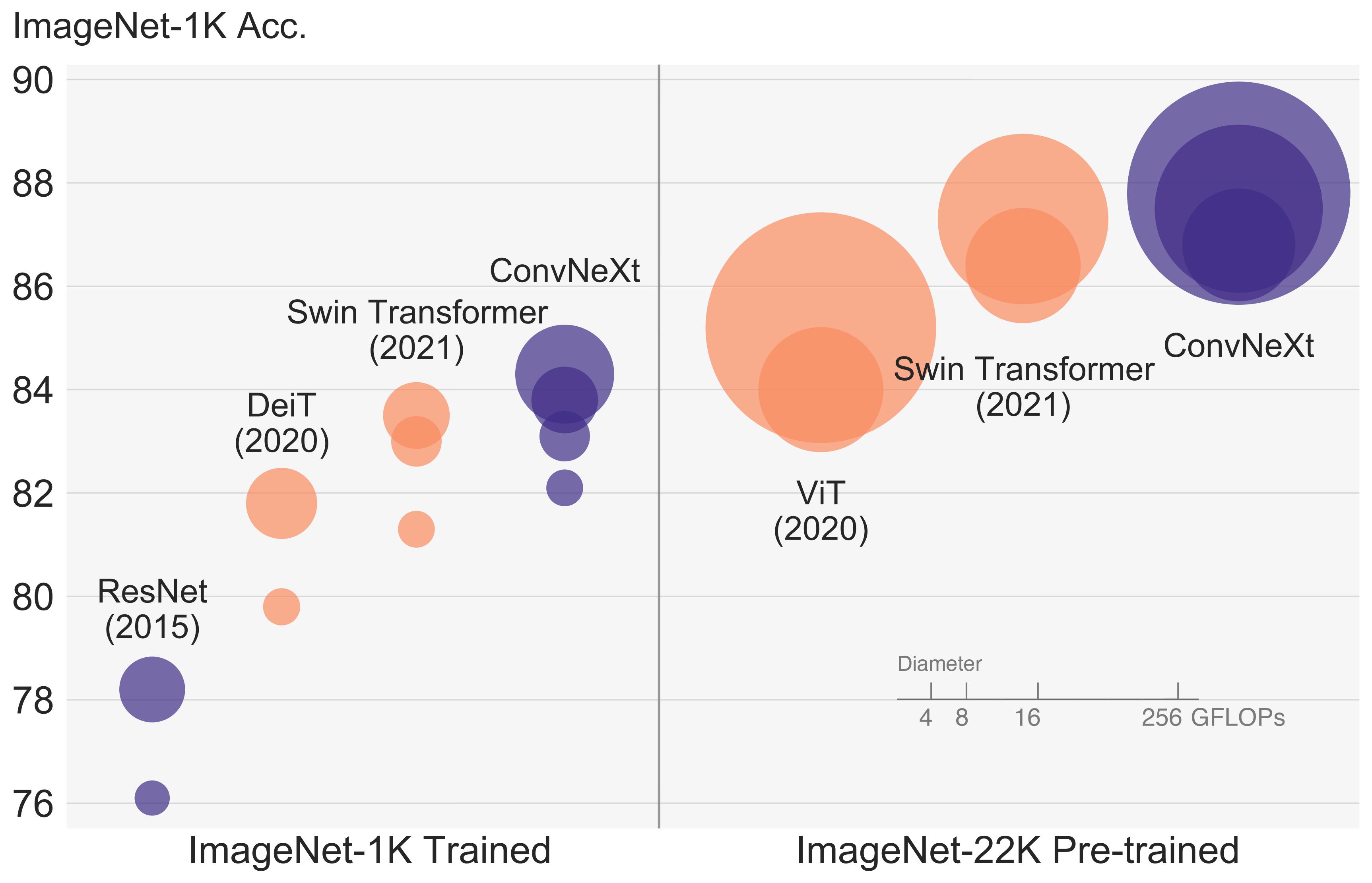 +
+ ConvNeXT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [ariG23498](https://github.com/ariG23498),
+[gante](https://github.com/gante), and [sayakpaul](https://github.com/sayakpaul) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ConvNeXT.
+
+
+
+ ConvNeXT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [ariG23498](https://github.com/ariG23498),
+[gante](https://github.com/gante), and [sayakpaul](https://github.com/sayakpaul) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ConvNeXT.
+
+ +
+ ConvNeXt V2 architecture. Taken from the original paper.
+
+This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt-V2).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ConvNeXt V2.
+
+
+
+ ConvNeXt V2 architecture. Taken from the original paper.
+
+This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt-V2).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ConvNeXt V2.
+
+ +
+The abstract from the paper is the following:
+
+*We present in this paper a novel query formulation using dynamic anchor boxes
+for DETR (DEtection TRansformer) and offer a deeper understanding of the role
+of queries in DETR. This new formulation directly uses box coordinates as queries
+in Transformer decoders and dynamically updates them layer-by-layer. Using box
+coordinates not only helps using explicit positional priors to improve the query-to-feature similarity and eliminate the slow training convergence issue in DETR,
+but also allows us to modulate the positional attention map using the box width
+and height information. Such a design makes it clear that queries in DETR can be
+implemented as performing soft ROI pooling layer-by-layer in a cascade manner.
+As a result, it leads to the best performance on MS-COCO benchmark among
+the DETR-like detection models under the same setting, e.g., AP 45.7% using
+ResNet50-DC5 as backbone trained in 50 epochs. We also conducted extensive
+experiments to confirm our analysis and verify the effectiveness of our methods.*
+
+This model was contributed by [davidhajdu](https://huggingface.co/davidhajdu).
+The original code can be found [here](https://github.com/IDEA-Research/DAB-DETR).
+
+## How to Get Started with the Model
+
+Use the code below to get started with the model.
+
+```python
+import torch
+import requests
+
+from PIL import Image
+from transformers import AutoModelForObjectDetection, AutoImageProcessor
+
+url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+image = Image.open(requests.get(url, stream=True).raw)
+
+image_processor = AutoImageProcessor.from_pretrained("IDEA-Research/dab-detr-resnet-50")
+model = AutoModelForObjectDetection.from_pretrained("IDEA-Research/dab-detr-resnet-50")
+
+inputs = image_processor(images=image, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.3)
+
+for result in results:
+ for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
+ score, label = score.item(), label_id.item()
+ box = [round(i, 2) for i in box.tolist()]
+ print(f"{model.config.id2label[label]}: {score:.2f} {box}")
+```
+This should output
+```
+cat: 0.87 [14.7, 49.39, 320.52, 469.28]
+remote: 0.86 [41.08, 72.37, 173.39, 117.2]
+cat: 0.86 [344.45, 19.43, 639.85, 367.86]
+remote: 0.61 [334.27, 75.93, 367.92, 188.81]
+couch: 0.59 [-0.04, 1.34, 639.9, 477.09]
+```
+
+There are three other ways to instantiate a DAB-DETR model (depending on what you prefer):
+
+Option 1: Instantiate DAB-DETR with pre-trained weights for entire model
+```py
+>>> from transformers import DabDetrForObjectDetection
+
+>>> model = DabDetrForObjectDetection.from_pretrained("IDEA-Research/dab-detr-resnet-50")
+```
+
+Option 2: Instantiate DAB-DETR with randomly initialized weights for Transformer, but pre-trained weights for backbone
+```py
+>>> from transformers import DabDetrConfig, DabDetrForObjectDetection
+
+>>> config = DabDetrConfig()
+>>> model = DabDetrForObjectDetection(config)
+```
+Option 3: Instantiate DAB-DETR with randomly initialized weights for backbone + Transformer
+```py
+>>> config = DabDetrConfig(use_pretrained_backbone=False)
+>>> model = DabDetrForObjectDetection(config)
+```
+
+
+## DabDetrConfig
+
+[[autodoc]] DabDetrConfig
+
+## DabDetrModel
+
+[[autodoc]] DabDetrModel
+ - forward
+
+## DabDetrForObjectDetection
+
+[[autodoc]] DabDetrForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/dac.md b/docs/transformers/docs/source/en/model_doc/dac.md
new file mode 100644
index 0000000000000000000000000000000000000000..3ee4d92b58e0277b868db701596adf1ea3c95023
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/dac.md
@@ -0,0 +1,84 @@
+
+
+# DAC
+
+
+
+The abstract from the paper is the following:
+
+*We present in this paper a novel query formulation using dynamic anchor boxes
+for DETR (DEtection TRansformer) and offer a deeper understanding of the role
+of queries in DETR. This new formulation directly uses box coordinates as queries
+in Transformer decoders and dynamically updates them layer-by-layer. Using box
+coordinates not only helps using explicit positional priors to improve the query-to-feature similarity and eliminate the slow training convergence issue in DETR,
+but also allows us to modulate the positional attention map using the box width
+and height information. Such a design makes it clear that queries in DETR can be
+implemented as performing soft ROI pooling layer-by-layer in a cascade manner.
+As a result, it leads to the best performance on MS-COCO benchmark among
+the DETR-like detection models under the same setting, e.g., AP 45.7% using
+ResNet50-DC5 as backbone trained in 50 epochs. We also conducted extensive
+experiments to confirm our analysis and verify the effectiveness of our methods.*
+
+This model was contributed by [davidhajdu](https://huggingface.co/davidhajdu).
+The original code can be found [here](https://github.com/IDEA-Research/DAB-DETR).
+
+## How to Get Started with the Model
+
+Use the code below to get started with the model.
+
+```python
+import torch
+import requests
+
+from PIL import Image
+from transformers import AutoModelForObjectDetection, AutoImageProcessor
+
+url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+image = Image.open(requests.get(url, stream=True).raw)
+
+image_processor = AutoImageProcessor.from_pretrained("IDEA-Research/dab-detr-resnet-50")
+model = AutoModelForObjectDetection.from_pretrained("IDEA-Research/dab-detr-resnet-50")
+
+inputs = image_processor(images=image, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.3)
+
+for result in results:
+ for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
+ score, label = score.item(), label_id.item()
+ box = [round(i, 2) for i in box.tolist()]
+ print(f"{model.config.id2label[label]}: {score:.2f} {box}")
+```
+This should output
+```
+cat: 0.87 [14.7, 49.39, 320.52, 469.28]
+remote: 0.86 [41.08, 72.37, 173.39, 117.2]
+cat: 0.86 [344.45, 19.43, 639.85, 367.86]
+remote: 0.61 [334.27, 75.93, 367.92, 188.81]
+couch: 0.59 [-0.04, 1.34, 639.9, 477.09]
+```
+
+There are three other ways to instantiate a DAB-DETR model (depending on what you prefer):
+
+Option 1: Instantiate DAB-DETR with pre-trained weights for entire model
+```py
+>>> from transformers import DabDetrForObjectDetection
+
+>>> model = DabDetrForObjectDetection.from_pretrained("IDEA-Research/dab-detr-resnet-50")
+```
+
+Option 2: Instantiate DAB-DETR with randomly initialized weights for Transformer, but pre-trained weights for backbone
+```py
+>>> from transformers import DabDetrConfig, DabDetrForObjectDetection
+
+>>> config = DabDetrConfig()
+>>> model = DabDetrForObjectDetection(config)
+```
+Option 3: Instantiate DAB-DETR with randomly initialized weights for backbone + Transformer
+```py
+>>> config = DabDetrConfig(use_pretrained_backbone=False)
+>>> model = DabDetrForObjectDetection(config)
+```
+
+
+## DabDetrConfig
+
+[[autodoc]] DabDetrConfig
+
+## DabDetrModel
+
+[[autodoc]] DabDetrModel
+ - forward
+
+## DabDetrForObjectDetection
+
+[[autodoc]] DabDetrForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/dac.md b/docs/transformers/docs/source/en/model_doc/dac.md
new file mode 100644
index 0000000000000000000000000000000000000000..3ee4d92b58e0277b868db701596adf1ea3c95023
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/dac.md
@@ -0,0 +1,84 @@
+
+
+# DAC
+
+ +
+ Deformable DETR architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
+
+## Usage tips
+
+- Training Deformable DETR is equivalent to training the original [DETR](detr) model. See the [resources](#resources) section below for demo notebooks.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Deformable DETR.
+
+
+
+ Deformable DETR architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/fundamentalvision/Deformable-DETR).
+
+## Usage tips
+
+- Training Deformable DETR is equivalent to training the original [DETR](detr) model. See the [resources](#resources) section below for demo notebooks.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Deformable DETR.
+
+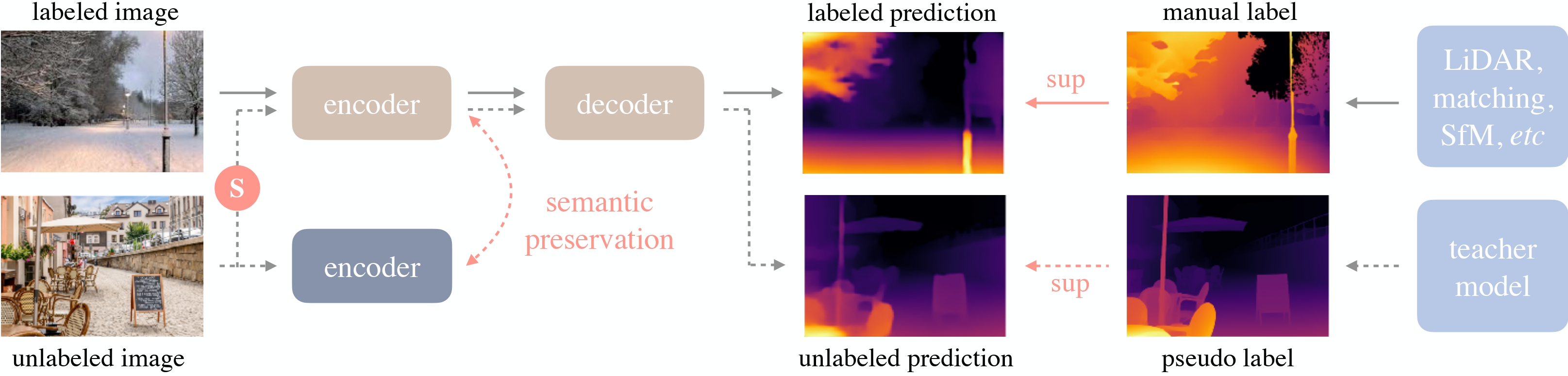 +
+ Depth Anything overview. Taken from the original paper.
+
+The Depth Anything models were contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/DepthAnything/Depth-Anything-V2).
+
+## Usage example
+
+There are 2 main ways to use Depth Anything V2: either using the pipeline API, which abstracts away all the complexity for you, or by using the `DepthAnythingForDepthEstimation` class yourself.
+
+### Pipeline API
+
+The pipeline allows to use the model in a few lines of code:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # load pipe
+>>> pipe = pipeline(task="depth-estimation", model="depth-anything/Depth-Anything-V2-Small-hf")
+
+>>> # load image
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # inference
+>>> depth = pipe(image)["depth"]
+```
+
+### Using the model yourself
+
+If you want to do the pre- and post-processing yourself, here's how to do that:
+
+```python
+>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
+>>> import torch
+>>> import numpy as np
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = AutoImageProcessor.from_pretrained("depth-anything/Depth-Anything-V2-Small-hf")
+>>> model = AutoModelForDepthEstimation.from_pretrained("depth-anything/Depth-Anything-V2-Small-hf")
+
+>>> # prepare image for the model
+>>> inputs = image_processor(images=image, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> # interpolate to original size and visualize the prediction
+>>> post_processed_output = image_processor.post_process_depth_estimation(
+... outputs,
+... target_sizes=[(image.height, image.width)],
+... )
+
+>>> predicted_depth = post_processed_output[0]["predicted_depth"]
+>>> depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
+>>> depth = depth.detach().cpu().numpy() * 255
+>>> depth = Image.fromarray(depth.astype("uint8"))
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Depth Anything.
+
+- [Monocular depth estimation task guide](../tasks/monocular_depth_estimation)
+- [Depth Anything V2 demo](https://huggingface.co/spaces/depth-anything/Depth-Anything-V2).
+- A notebook showcasing inference with [`DepthAnythingForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Depth%20Anything/Predicting_depth_in_an_image_with_Depth_Anything.ipynb). 🌎
+- [Core ML conversion of the `small` variant for use on Apple Silicon](https://huggingface.co/apple/coreml-depth-anything-v2-small).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DepthAnythingConfig
+
+[[autodoc]] DepthAnythingConfig
+
+## DepthAnythingForDepthEstimation
+
+[[autodoc]] DepthAnythingForDepthEstimation
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/depth_pro.md b/docs/transformers/docs/source/en/model_doc/depth_pro.md
new file mode 100644
index 0000000000000000000000000000000000000000..42fd725a9abefb52fdf3af82e966983268af436f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/depth_pro.md
@@ -0,0 +1,187 @@
+
+
+# DepthPro
+
+
+
+ Depth Anything overview. Taken from the original paper.
+
+The Depth Anything models were contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/DepthAnything/Depth-Anything-V2).
+
+## Usage example
+
+There are 2 main ways to use Depth Anything V2: either using the pipeline API, which abstracts away all the complexity for you, or by using the `DepthAnythingForDepthEstimation` class yourself.
+
+### Pipeline API
+
+The pipeline allows to use the model in a few lines of code:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # load pipe
+>>> pipe = pipeline(task="depth-estimation", model="depth-anything/Depth-Anything-V2-Small-hf")
+
+>>> # load image
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # inference
+>>> depth = pipe(image)["depth"]
+```
+
+### Using the model yourself
+
+If you want to do the pre- and post-processing yourself, here's how to do that:
+
+```python
+>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
+>>> import torch
+>>> import numpy as np
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = AutoImageProcessor.from_pretrained("depth-anything/Depth-Anything-V2-Small-hf")
+>>> model = AutoModelForDepthEstimation.from_pretrained("depth-anything/Depth-Anything-V2-Small-hf")
+
+>>> # prepare image for the model
+>>> inputs = image_processor(images=image, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> # interpolate to original size and visualize the prediction
+>>> post_processed_output = image_processor.post_process_depth_estimation(
+... outputs,
+... target_sizes=[(image.height, image.width)],
+... )
+
+>>> predicted_depth = post_processed_output[0]["predicted_depth"]
+>>> depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
+>>> depth = depth.detach().cpu().numpy() * 255
+>>> depth = Image.fromarray(depth.astype("uint8"))
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Depth Anything.
+
+- [Monocular depth estimation task guide](../tasks/monocular_depth_estimation)
+- [Depth Anything V2 demo](https://huggingface.co/spaces/depth-anything/Depth-Anything-V2).
+- A notebook showcasing inference with [`DepthAnythingForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Depth%20Anything/Predicting_depth_in_an_image_with_Depth_Anything.ipynb). 🌎
+- [Core ML conversion of the `small` variant for use on Apple Silicon](https://huggingface.co/apple/coreml-depth-anything-v2-small).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DepthAnythingConfig
+
+[[autodoc]] DepthAnythingConfig
+
+## DepthAnythingForDepthEstimation
+
+[[autodoc]] DepthAnythingForDepthEstimation
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/depth_pro.md b/docs/transformers/docs/source/en/model_doc/depth_pro.md
new file mode 100644
index 0000000000000000000000000000000000000000..42fd725a9abefb52fdf3af82e966983268af436f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/depth_pro.md
@@ -0,0 +1,187 @@
+
+
+# DepthPro
+
+ +
+ DepthPro Outputs. Taken from the official code.
+
+This model was contributed by [geetu040](https://github.com/geetu040). The original code can be found [here](https://github.com/apple/ml-depth-pro).
+
+## Usage Tips
+
+The DepthPro model processes an input image by first downsampling it at multiple scales and splitting each scaled version into patches. These patches are then encoded using a shared Vision Transformer (ViT)-based Dinov2 patch encoder, while the full image is processed by a separate image encoder. The extracted patch features are merged into feature maps, upsampled, and fused using a DPT-like decoder to generate the final depth estimation. If enabled, an additional Field of View (FOV) encoder processes the image for estimating the camera's field of view, aiding in depth accuracy.
+
+```py
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+>>> from transformers import DepthProImageProcessorFast, DepthProForDepthEstimation
+
+>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = DepthProImageProcessorFast.from_pretrained("apple/DepthPro-hf")
+>>> model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf").to(device)
+
+>>> inputs = image_processor(images=image, return_tensors="pt").to(device)
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> post_processed_output = image_processor.post_process_depth_estimation(
+... outputs, target_sizes=[(image.height, image.width)],
+... )
+
+>>> field_of_view = post_processed_output[0]["field_of_view"]
+>>> focal_length = post_processed_output[0]["focal_length"]
+>>> depth = post_processed_output[0]["predicted_depth"]
+>>> depth = (depth - depth.min()) / depth.max()
+>>> depth = depth * 255.
+>>> depth = depth.detach().cpu().numpy()
+>>> depth = Image.fromarray(depth.astype("uint8"))
+```
+
+### Architecture and Configuration
+
+
+
+ DepthPro Outputs. Taken from the official code.
+
+This model was contributed by [geetu040](https://github.com/geetu040). The original code can be found [here](https://github.com/apple/ml-depth-pro).
+
+## Usage Tips
+
+The DepthPro model processes an input image by first downsampling it at multiple scales and splitting each scaled version into patches. These patches are then encoded using a shared Vision Transformer (ViT)-based Dinov2 patch encoder, while the full image is processed by a separate image encoder. The extracted patch features are merged into feature maps, upsampled, and fused using a DPT-like decoder to generate the final depth estimation. If enabled, an additional Field of View (FOV) encoder processes the image for estimating the camera's field of view, aiding in depth accuracy.
+
+```py
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+>>> from transformers import DepthProImageProcessorFast, DepthProForDepthEstimation
+
+>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = DepthProImageProcessorFast.from_pretrained("apple/DepthPro-hf")
+>>> model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf").to(device)
+
+>>> inputs = image_processor(images=image, return_tensors="pt").to(device)
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> post_processed_output = image_processor.post_process_depth_estimation(
+... outputs, target_sizes=[(image.height, image.width)],
+... )
+
+>>> field_of_view = post_processed_output[0]["field_of_view"]
+>>> focal_length = post_processed_output[0]["focal_length"]
+>>> depth = post_processed_output[0]["predicted_depth"]
+>>> depth = (depth - depth.min()) / depth.max()
+>>> depth = depth * 255.
+>>> depth = depth.detach().cpu().numpy()
+>>> depth = Image.fromarray(depth.astype("uint8"))
+```
+
+### Architecture and Configuration
+
+ +
+ DepthPro architecture. Taken from the original paper.
+
+The `DepthProForDepthEstimation` model uses a `DepthProEncoder`, for encoding the input image and a `FeatureFusionStage` for fusing the output features from encoder.
+
+The `DepthProEncoder` further uses two encoders:
+- `patch_encoder`
+ - Input image is scaled with multiple ratios, as specified in the `scaled_images_ratios` configuration.
+ - Each scaled image is split into smaller **patches** of size `patch_size` with overlapping areas determined by `scaled_images_overlap_ratios`.
+ - These patches are processed by the **`patch_encoder`**
+- `image_encoder`
+ - Input image is also rescaled to `patch_size` and processed by the **`image_encoder`**
+
+Both these encoders can be configured via `patch_model_config` and `image_model_config` respectively, both of which are separate `Dinov2Model` by default.
+
+Outputs from both encoders (`last_hidden_state`) and selected intermediate states (`hidden_states`) from **`patch_encoder`** are fused by a `DPT`-based `FeatureFusionStage` for depth estimation.
+
+### Field-of-View (FOV) Prediction
+
+The network is supplemented with a focal length estimation head. A small convolutional head ingests frozen features from the depth estimation network and task-specific features from a separate ViT image encoder to predict the horizontal angular field-of-view.
+
+The `use_fov_model` parameter in `DepthProConfig` controls whether **FOV prediction** is enabled. By default, it is set to `False` to conserve memory and computation. When enabled, the **FOV encoder** is instantiated based on the `fov_model_config` parameter, which defaults to a `Dinov2Model`. The `use_fov_model` parameter can also be passed when initializing the `DepthProForDepthEstimation` model.
+
+The pretrained model at checkpoint `apple/DepthPro-hf` uses the FOV encoder. To use the pretrained-model without FOV encoder, set `use_fov_model=False` when loading the model, which saves computation.
+```py
+>>> from transformers import DepthProForDepthEstimation
+>>> model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf", use_fov_model=False)
+```
+
+To instantiate a new model with FOV encoder, set `use_fov_model=True` in the config.
+```py
+>>> from transformers import DepthProConfig, DepthProForDepthEstimation
+>>> config = DepthProConfig(use_fov_model=True)
+>>> model = DepthProForDepthEstimation(config)
+```
+
+Or set `use_fov_model=True` when initializing the model, which overrides the value in config.
+```py
+>>> from transformers import DepthProConfig, DepthProForDepthEstimation
+>>> config = DepthProConfig()
+>>> model = DepthProForDepthEstimation(config, use_fov_model=True)
+```
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```py
+from transformers import DepthProForDepthEstimation
+model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf", attn_implementation="sdpa", torch_dtype=torch.float16)
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32` and `google/vit-base-patch16-224` model, we saw the following speedups during inference.
+
+| Batch size | Average inference time (ms), eager mode | Average inference time (ms), sdpa model | Speed up, Sdpa / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 7 | 6 | 1.17 |
+| 2 | 8 | 6 | 1.33 |
+| 4 | 8 | 6 | 1.33 |
+| 8 | 8 | 6 | 1.33 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DepthPro:
+
+- Research Paper: [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/pdf/2410.02073)
+- Official Implementation: [apple/ml-depth-pro](https://github.com/apple/ml-depth-pro)
+- DepthPro Inference Notebook: [DepthPro Inference](https://github.com/qubvel/transformers-notebooks/blob/main/notebooks/DepthPro_inference.ipynb)
+- DepthPro for Super Resolution and Image Segmentation
+ - Read blog on Medium: [Depth Pro: Beyond Depth](https://medium.com/@raoarmaghanshakir040/depth-pro-beyond-depth-9d822fc557ba)
+ - Code on Github: [geetu040/depthpro-beyond-depth](https://github.com/geetu040/depthpro-beyond-depth)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DepthProConfig
+
+[[autodoc]] DepthProConfig
+
+## DepthProImageProcessor
+
+[[autodoc]] DepthProImageProcessor
+ - preprocess
+ - post_process_depth_estimation
+
+## DepthProImageProcessorFast
+
+[[autodoc]] DepthProImageProcessorFast
+ - preprocess
+ - post_process_depth_estimation
+
+## DepthProModel
+
+[[autodoc]] DepthProModel
+ - forward
+
+## DepthProForDepthEstimation
+
+[[autodoc]] DepthProForDepthEstimation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/deta.md b/docs/transformers/docs/source/en/model_doc/deta.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3859341a71af9ec7ae0d74ba9cfb4882587fe6a
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/deta.md
@@ -0,0 +1,77 @@
+
+
+# DETA
+
+
+
+ DepthPro architecture. Taken from the original paper.
+
+The `DepthProForDepthEstimation` model uses a `DepthProEncoder`, for encoding the input image and a `FeatureFusionStage` for fusing the output features from encoder.
+
+The `DepthProEncoder` further uses two encoders:
+- `patch_encoder`
+ - Input image is scaled with multiple ratios, as specified in the `scaled_images_ratios` configuration.
+ - Each scaled image is split into smaller **patches** of size `patch_size` with overlapping areas determined by `scaled_images_overlap_ratios`.
+ - These patches are processed by the **`patch_encoder`**
+- `image_encoder`
+ - Input image is also rescaled to `patch_size` and processed by the **`image_encoder`**
+
+Both these encoders can be configured via `patch_model_config` and `image_model_config` respectively, both of which are separate `Dinov2Model` by default.
+
+Outputs from both encoders (`last_hidden_state`) and selected intermediate states (`hidden_states`) from **`patch_encoder`** are fused by a `DPT`-based `FeatureFusionStage` for depth estimation.
+
+### Field-of-View (FOV) Prediction
+
+The network is supplemented with a focal length estimation head. A small convolutional head ingests frozen features from the depth estimation network and task-specific features from a separate ViT image encoder to predict the horizontal angular field-of-view.
+
+The `use_fov_model` parameter in `DepthProConfig` controls whether **FOV prediction** is enabled. By default, it is set to `False` to conserve memory and computation. When enabled, the **FOV encoder** is instantiated based on the `fov_model_config` parameter, which defaults to a `Dinov2Model`. The `use_fov_model` parameter can also be passed when initializing the `DepthProForDepthEstimation` model.
+
+The pretrained model at checkpoint `apple/DepthPro-hf` uses the FOV encoder. To use the pretrained-model without FOV encoder, set `use_fov_model=False` when loading the model, which saves computation.
+```py
+>>> from transformers import DepthProForDepthEstimation
+>>> model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf", use_fov_model=False)
+```
+
+To instantiate a new model with FOV encoder, set `use_fov_model=True` in the config.
+```py
+>>> from transformers import DepthProConfig, DepthProForDepthEstimation
+>>> config = DepthProConfig(use_fov_model=True)
+>>> model = DepthProForDepthEstimation(config)
+```
+
+Or set `use_fov_model=True` when initializing the model, which overrides the value in config.
+```py
+>>> from transformers import DepthProConfig, DepthProForDepthEstimation
+>>> config = DepthProConfig()
+>>> model = DepthProForDepthEstimation(config, use_fov_model=True)
+```
+
+### Using Scaled Dot Product Attention (SDPA)
+
+PyTorch includes a native scaled dot-product attention (SDPA) operator as part of `torch.nn.functional`. This function
+encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
+[official documentation](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+or the [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+page for more information.
+
+SDPA is used by default for `torch>=2.1.1` when an implementation is available, but you may also set
+`attn_implementation="sdpa"` in `from_pretrained()` to explicitly request SDPA to be used.
+
+```py
+from transformers import DepthProForDepthEstimation
+model = DepthProForDepthEstimation.from_pretrained("apple/DepthPro-hf", attn_implementation="sdpa", torch_dtype=torch.float16)
+```
+
+For the best speedups, we recommend loading the model in half-precision (e.g. `torch.float16` or `torch.bfloat16`).
+
+On a local benchmark (A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04) with `float32` and `google/vit-base-patch16-224` model, we saw the following speedups during inference.
+
+| Batch size | Average inference time (ms), eager mode | Average inference time (ms), sdpa model | Speed up, Sdpa / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 7 | 6 | 1.17 |
+| 2 | 8 | 6 | 1.33 |
+| 4 | 8 | 6 | 1.33 |
+| 8 | 8 | 6 | 1.33 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DepthPro:
+
+- Research Paper: [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/pdf/2410.02073)
+- Official Implementation: [apple/ml-depth-pro](https://github.com/apple/ml-depth-pro)
+- DepthPro Inference Notebook: [DepthPro Inference](https://github.com/qubvel/transformers-notebooks/blob/main/notebooks/DepthPro_inference.ipynb)
+- DepthPro for Super Resolution and Image Segmentation
+ - Read blog on Medium: [Depth Pro: Beyond Depth](https://medium.com/@raoarmaghanshakir040/depth-pro-beyond-depth-9d822fc557ba)
+ - Code on Github: [geetu040/depthpro-beyond-depth](https://github.com/geetu040/depthpro-beyond-depth)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DepthProConfig
+
+[[autodoc]] DepthProConfig
+
+## DepthProImageProcessor
+
+[[autodoc]] DepthProImageProcessor
+ - preprocess
+ - post_process_depth_estimation
+
+## DepthProImageProcessorFast
+
+[[autodoc]] DepthProImageProcessorFast
+ - preprocess
+ - post_process_depth_estimation
+
+## DepthProModel
+
+[[autodoc]] DepthProModel
+ - forward
+
+## DepthProForDepthEstimation
+
+[[autodoc]] DepthProForDepthEstimation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/deta.md b/docs/transformers/docs/source/en/model_doc/deta.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3859341a71af9ec7ae0d74ba9cfb4882587fe6a
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/deta.md
@@ -0,0 +1,77 @@
+
+
+# DETA
+
+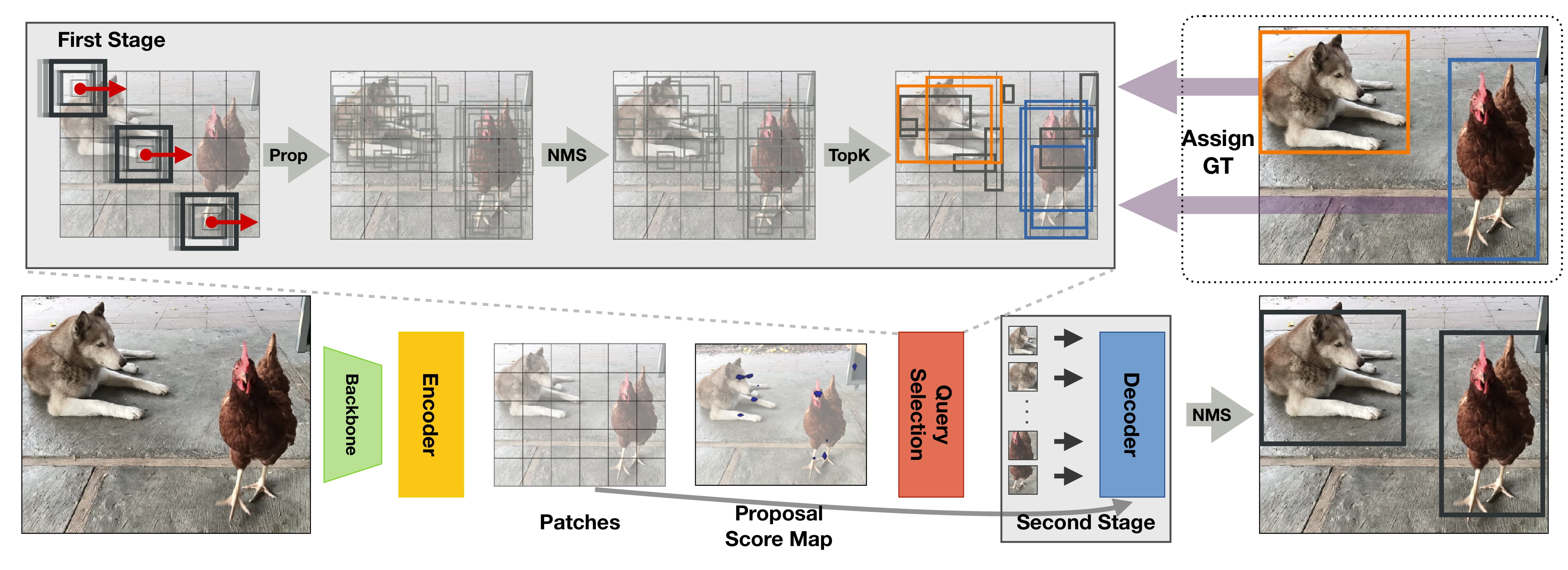 +
+ DETA overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/jozhang97/DETA).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DETA.
+
+- Demo notebooks for DETA can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETA).
+- Scripts for finetuning [`DetaForObjectDetection`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- See also: [Object detection task guide](../tasks/object_detection).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DetaConfig
+
+[[autodoc]] DetaConfig
+
+## DetaImageProcessor
+
+[[autodoc]] DetaImageProcessor
+ - preprocess
+ - post_process_object_detection
+
+## DetaModel
+
+[[autodoc]] DetaModel
+ - forward
+
+## DetaForObjectDetection
+
+[[autodoc]] DetaForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/detr.md b/docs/transformers/docs/source/en/model_doc/detr.md
new file mode 100644
index 0000000000000000000000000000000000000000..4614d549a180fe51d9d1947471dabc8c126fbc11
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/detr.md
@@ -0,0 +1,227 @@
+
+
+# DETR
+
+
+
+ DETA overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/jozhang97/DETA).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DETA.
+
+- Demo notebooks for DETA can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETA).
+- Scripts for finetuning [`DetaForObjectDetection`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- See also: [Object detection task guide](../tasks/object_detection).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DetaConfig
+
+[[autodoc]] DetaConfig
+
+## DetaImageProcessor
+
+[[autodoc]] DetaImageProcessor
+ - preprocess
+ - post_process_object_detection
+
+## DetaModel
+
+[[autodoc]] DetaModel
+ - forward
+
+## DetaForObjectDetection
+
+[[autodoc]] DetaForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/detr.md b/docs/transformers/docs/source/en/model_doc/detr.md
new file mode 100644
index 0000000000000000000000000000000000000000..4614d549a180fe51d9d1947471dabc8c126fbc11
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/detr.md
@@ -0,0 +1,227 @@
+
+
+# DETR
+
+ +
+ Visualization of attention maps of various models trained with vs. without registers. Taken from the original paper.
+
+Tips:
+
+- Usage of DINOv2 with Registers is identical to DINOv2 without, you'll just get better performance.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/facebookresearch/dinov2).
+
+
+## Dinov2WithRegistersConfig
+
+[[autodoc]] Dinov2WithRegistersConfig
+
+## Dinov2WithRegistersModel
+
+[[autodoc]] Dinov2WithRegistersModel
+ - forward
+
+## Dinov2WithRegistersForImageClassification
+
+[[autodoc]] Dinov2WithRegistersForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/distilbert.md b/docs/transformers/docs/source/en/model_doc/distilbert.md
new file mode 100644
index 0000000000000000000000000000000000000000..cb906234501c87727efe19a62994296d953264ae
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/distilbert.md
@@ -0,0 +1,219 @@
+
+
+
+
+ Visualization of attention maps of various models trained with vs. without registers. Taken from the original paper.
+
+Tips:
+
+- Usage of DINOv2 with Registers is identical to DINOv2 without, you'll just get better performance.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/facebookresearch/dinov2).
+
+
+## Dinov2WithRegistersConfig
+
+[[autodoc]] Dinov2WithRegistersConfig
+
+## Dinov2WithRegistersModel
+
+[[autodoc]] Dinov2WithRegistersModel
+ - forward
+
+## Dinov2WithRegistersForImageClassification
+
+[[autodoc]] Dinov2WithRegistersForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/distilbert.md b/docs/transformers/docs/source/en/model_doc/distilbert.md
new file mode 100644
index 0000000000000000000000000000000000000000..cb906234501c87727efe19a62994296d953264ae
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/distilbert.md
@@ -0,0 +1,219 @@
+
+
+ +
+ Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378).
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
+
+## Usage tips
+
+One can directly use the weights of DiT with the AutoModel API:
+
+```python
+from transformers import AutoModel
+
+model = AutoModel.from_pretrained("microsoft/dit-base")
+```
+
+This will load the model pre-trained on masked image modeling. Note that this won't include the language modeling head on top, used to predict visual tokens.
+
+To include the head, you can load the weights into a `BeitForMaskedImageModeling` model, like so:
+
+```python
+from transformers import BeitForMaskedImageModeling
+
+model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")
+```
+
+You can also load a fine-tuned model from the [hub](https://huggingface.co/models?other=dit), like so:
+
+```python
+from transformers import AutoModelForImageClassification
+
+model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")
+```
+
+This particular checkpoint was fine-tuned on [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/), an important benchmark for document image classification.
+A notebook that illustrates inference for document image classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiT.
+
+
+
+ Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378).
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/dit).
+
+## Usage tips
+
+One can directly use the weights of DiT with the AutoModel API:
+
+```python
+from transformers import AutoModel
+
+model = AutoModel.from_pretrained("microsoft/dit-base")
+```
+
+This will load the model pre-trained on masked image modeling. Note that this won't include the language modeling head on top, used to predict visual tokens.
+
+To include the head, you can load the weights into a `BeitForMaskedImageModeling` model, like so:
+
+```python
+from transformers import BeitForMaskedImageModeling
+
+model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")
+```
+
+You can also load a fine-tuned model from the [hub](https://huggingface.co/models?other=dit), like so:
+
+```python
+from transformers import AutoModelForImageClassification
+
+model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")
+```
+
+This particular checkpoint was fine-tuned on [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/), an important benchmark for document image classification.
+A notebook that illustrates inference for document image classification can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiT.
+
+ +
+ DPT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/isl-org/DPT).
+
+## Usage tips
+
+DPT is compatible with the [`AutoBackbone`] class. This allows to use the DPT framework with various computer vision backbones available in the library, such as [`VitDetBackbone`] or [`Dinov2Backbone`]. One can create it as follows:
+
+```python
+from transformers import Dinov2Config, DPTConfig, DPTForDepthEstimation
+
+# initialize with a Transformer-based backbone such as DINOv2
+# in that case, we also specify `reshape_hidden_states=False` to get feature maps of shape (batch_size, num_channels, height, width)
+backbone_config = Dinov2Config.from_pretrained("facebook/dinov2-base", out_features=["stage1", "stage2", "stage3", "stage4"], reshape_hidden_states=False)
+
+config = DPTConfig(backbone_config=backbone_config)
+model = DPTForDepthEstimation(config=config)
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DPT.
+
+- Demo notebooks for [`DPTForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DPT).
+
+- [Semantic segmentation task guide](../tasks/semantic_segmentation)
+- [Monocular depth estimation task guide](../tasks/monocular_depth_estimation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DPTConfig
+
+[[autodoc]] DPTConfig
+
+## DPTFeatureExtractor
+
+[[autodoc]] DPTFeatureExtractor
+ - __call__
+ - post_process_semantic_segmentation
+
+## DPTImageProcessor
+
+[[autodoc]] DPTImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
+## DPTModel
+
+[[autodoc]] DPTModel
+ - forward
+
+## DPTForDepthEstimation
+
+[[autodoc]] DPTForDepthEstimation
+ - forward
+
+## DPTForSemanticSegmentation
+
+[[autodoc]] DPTForSemanticSegmentation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/efficientformer.md b/docs/transformers/docs/source/en/model_doc/efficientformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..f05ccacc3dbf596ad590ce001b9b3480565bed90
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/efficientformer.md
@@ -0,0 +1,109 @@
+
+
+# EfficientFormer
+
+
+
+ DPT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/isl-org/DPT).
+
+## Usage tips
+
+DPT is compatible with the [`AutoBackbone`] class. This allows to use the DPT framework with various computer vision backbones available in the library, such as [`VitDetBackbone`] or [`Dinov2Backbone`]. One can create it as follows:
+
+```python
+from transformers import Dinov2Config, DPTConfig, DPTForDepthEstimation
+
+# initialize with a Transformer-based backbone such as DINOv2
+# in that case, we also specify `reshape_hidden_states=False` to get feature maps of shape (batch_size, num_channels, height, width)
+backbone_config = Dinov2Config.from_pretrained("facebook/dinov2-base", out_features=["stage1", "stage2", "stage3", "stage4"], reshape_hidden_states=False)
+
+config = DPTConfig(backbone_config=backbone_config)
+model = DPTForDepthEstimation(config=config)
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DPT.
+
+- Demo notebooks for [`DPTForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DPT).
+
+- [Semantic segmentation task guide](../tasks/semantic_segmentation)
+- [Monocular depth estimation task guide](../tasks/monocular_depth_estimation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## DPTConfig
+
+[[autodoc]] DPTConfig
+
+## DPTFeatureExtractor
+
+[[autodoc]] DPTFeatureExtractor
+ - __call__
+ - post_process_semantic_segmentation
+
+## DPTImageProcessor
+
+[[autodoc]] DPTImageProcessor
+ - preprocess
+ - post_process_semantic_segmentation
+
+## DPTModel
+
+[[autodoc]] DPTModel
+ - forward
+
+## DPTForDepthEstimation
+
+[[autodoc]] DPTForDepthEstimation
+ - forward
+
+## DPTForSemanticSegmentation
+
+[[autodoc]] DPTForSemanticSegmentation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/efficientformer.md b/docs/transformers/docs/source/en/model_doc/efficientformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..f05ccacc3dbf596ad590ce001b9b3480565bed90
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/efficientformer.md
@@ -0,0 +1,109 @@
+
+
+# EfficientFormer
+
+ +
+ +
+ +
+ GIT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
+
+## Usage tips
+
+- GIT is implemented in a very similar way to GPT-2, the only difference being that the model is also conditioned on `pixel_values`.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GIT.
+
+- Demo notebooks regarding inference + fine-tuning GIT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GIT).
+- See also: [Causal language modeling task guide](../tasks/language_modeling)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
+The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## GitVisionConfig
+
+[[autodoc]] GitVisionConfig
+
+## GitVisionModel
+
+[[autodoc]] GitVisionModel
+ - forward
+
+## GitConfig
+
+[[autodoc]] GitConfig
+ - all
+
+## GitProcessor
+
+[[autodoc]] GitProcessor
+ - __call__
+
+## GitModel
+
+[[autodoc]] GitModel
+ - forward
+
+## GitForCausalLM
+
+[[autodoc]] GitForCausalLM
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/glm.md b/docs/transformers/docs/source/en/model_doc/glm.md
new file mode 100644
index 0000000000000000000000000000000000000000..cfcd549d1493f430ef26ed1789b2e8f3f8dc8a25
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/glm.md
@@ -0,0 +1,105 @@
+
+
+# GLM
+
+
+
+ GIT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/microsoft/GenerativeImage2Text).
+
+## Usage tips
+
+- GIT is implemented in a very similar way to GPT-2, the only difference being that the model is also conditioned on `pixel_values`.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GIT.
+
+- Demo notebooks regarding inference + fine-tuning GIT on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GIT).
+- See also: [Causal language modeling task guide](../tasks/language_modeling)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
+The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## GitVisionConfig
+
+[[autodoc]] GitVisionConfig
+
+## GitVisionModel
+
+[[autodoc]] GitVisionModel
+ - forward
+
+## GitConfig
+
+[[autodoc]] GitConfig
+ - all
+
+## GitProcessor
+
+[[autodoc]] GitProcessor
+ - __call__
+
+## GitModel
+
+[[autodoc]] GitModel
+ - forward
+
+## GitForCausalLM
+
+[[autodoc]] GitForCausalLM
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/glm.md b/docs/transformers/docs/source/en/model_doc/glm.md
new file mode 100644
index 0000000000000000000000000000000000000000..cfcd549d1493f430ef26ed1789b2e8f3f8dc8a25
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/glm.md
@@ -0,0 +1,105 @@
+
+
+# GLM
+
+ +
+ Summary of the approach. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/vinvino02/GLPDepth).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GLPN.
+
+- Demo notebooks for [`GLPNForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GLPN).
+- [Monocular depth estimation task guide](../tasks/monocular_depth_estimation)
+
+## GLPNConfig
+
+[[autodoc]] GLPNConfig
+
+## GLPNFeatureExtractor
+
+[[autodoc]] GLPNFeatureExtractor
+ - __call__
+
+## GLPNImageProcessor
+
+[[autodoc]] GLPNImageProcessor
+ - preprocess
+
+## GLPNModel
+
+[[autodoc]] GLPNModel
+ - forward
+
+## GLPNForDepthEstimation
+
+[[autodoc]] GLPNForDepthEstimation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/got_ocr2.md b/docs/transformers/docs/source/en/model_doc/got_ocr2.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb14cdbcf8477cdb926a9ce8549492d6a6ec2c0f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/got_ocr2.md
@@ -0,0 +1,284 @@
+
+
+# GOT-OCR2
+
+
+
+ Summary of the approach. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/vinvino02/GLPDepth).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with GLPN.
+
+- Demo notebooks for [`GLPNForDepthEstimation`] can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GLPN).
+- [Monocular depth estimation task guide](../tasks/monocular_depth_estimation)
+
+## GLPNConfig
+
+[[autodoc]] GLPNConfig
+
+## GLPNFeatureExtractor
+
+[[autodoc]] GLPNFeatureExtractor
+ - __call__
+
+## GLPNImageProcessor
+
+[[autodoc]] GLPNImageProcessor
+ - preprocess
+
+## GLPNModel
+
+[[autodoc]] GLPNModel
+ - forward
+
+## GLPNForDepthEstimation
+
+[[autodoc]] GLPNForDepthEstimation
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/got_ocr2.md b/docs/transformers/docs/source/en/model_doc/got_ocr2.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb14cdbcf8477cdb926a9ce8549492d6a6ec2c0f
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/got_ocr2.md
@@ -0,0 +1,284 @@
+
+
+# GOT-OCR2
+
+ +
+ GOT-OCR2 training stages. Taken from the original paper.
+
+
+Tips:
+
+GOT-OCR2 works on a wide range of tasks, including plain document OCR, scene text OCR, formatted document OCR, and even OCR for tables, charts, mathematical formulas, geometric shapes, molecular formulas and sheet music. While this implementation of the model will only output plain text, the outputs can be further processed to render the desired format, with packages like `pdftex`, `mathpix`, `matplotlib`, `tikz`, `verovio` or `pyecharts`.
+The model can also be used for interactive OCR, where the user can specify the region to be recognized by providing the coordinates or the color of the region's bounding box.
+
+This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
+The original code can be found [here](https://github.com/Ucas-HaoranWei/GOT-OCR2.0).
+
+## Usage example
+
+### Plain text inference
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/image_ocr.jpg"
+>>> inputs = processor(image, return_tensors="pt", device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"R&D QUALITY IMPROVEMENT\nSUGGESTION/SOLUTION FORM\nName/Phone Ext. : (...)"
+```
+
+### Plain text inference batched
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image1 = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/multi_box.png"
+>>> image2 = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/image_ocr.jpg"
+
+>>> inputs = processor([image1, image2], return_tensors="pt", device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4,
+... )
+
+>>> processor.batch_decode(generate_ids[:, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+["Reducing the number", "R&D QUALITY"]
+```
+
+### Formatted text inference
+
+GOT-OCR2 can also generate formatted text, such as markdown or LaTeX. Here is an example of how to generate formatted text:
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/latex.png"
+>>> inputs = processor(image, return_tensors="pt", format=True, device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"\\author{\nHanwen Jiang* \\(\\quad\\) Arjun Karpur \\({ }^{\\dagger} \\quad\\) Bingyi Cao \\({ }^{\\dagger} \\quad\\) (...)"
+```
+
+### Inference on multiple pages
+
+Although it might be reasonable in most cases to use a “for loop” for multi-page processing, some text data with formatting across several pages make it necessary to process all pages at once. GOT introduces a multi-page OCR (without “for loop”) feature, where multiple pages can be processed by the model at once, whith the output being one continuous text.
+Here is an example of how to process multiple pages at once:
+
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image1 = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/page1.png"
+>>> image2 = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/page2.png"
+>>> inputs = processor([image1, image2], return_tensors="pt", multi_page=True, format=True, device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"\\title{\nGeneral OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model\n}\n\\author{\nHaoran Wei (...)"
+```
+
+### Inference on cropped patches
+
+GOT supports a 1024×1024 input resolution, which is sufficient for most OCR tasks, such as scene OCR or processing A4-sized PDF pages. However, certain scenarios, like horizontally stitched two-page PDFs commonly found in academic papers or images with unusual aspect ratios, can lead to accuracy issues when processed as a single image. To address this, GOT can dynamically crop an image into patches, process them all at once, and merge the results for better accuracy with such inputs.
+Here is an example of how to process cropped patches:
+
+```python
+>>> import torch
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", torch_dtype=torch.bfloat16, device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/one_column.png"
+>>> inputs = processor(image, return_tensors="pt", format=True, crop_to_patches=True, max_patches=3, device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"on developing architectural improvements to make learnable matching methods generalize.\nMotivated by the above observations, (...)"
+```
+
+### Inference on a specific region
+
+GOT supports interactive OCR, where the user can specify the region to be recognized by providing the coordinates or the color of the region's bounding box. Here is an example of how to process a specific region:
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/multi_box.png"
+>>> inputs = processor(image, return_tensors="pt", color="green", device=device).to(device) # or box=[x1, y1, x2, y2] for coordinates (image pixels)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"You should keep in mind what features from the module should be used, especially \nwhen you’re planning to sell a template."
+```
+
+### Inference on general OCR data example: sheet music
+
+Although this implementation of the model will only output plain text, the outputs can be further processed to render the desired format, with packages like `pdftex`, `mathpix`, `matplotlib`, `tikz`, `verovio` or `pyecharts`.
+Here is an example of how to process sheet music:
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+>>> import verovio
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/sheet_music.png"
+>>> inputs = processor(image, return_tensors="pt", format=True, device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> outputs = processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+>>> tk = verovio.toolkit()
+>>> tk.loadData(outputs)
+>>> tk.setOptions(
+... {
+... "pageWidth": 2100,
+... "pageHeight": 800,
+... "footer": "none",
+... "barLineWidth": 0.5,
+... "beamMaxSlope": 15,
+... "staffLineWidth": 0.2,
+... "spacingStaff": 6,
+... }
+... )
+>>> tk.getPageCount()
+>>> svg = tk.renderToSVG()
+>>> svg = svg.replace('overflow="inherit"', 'overflow="visible"')
+>>> with open("output.svg", "w") as f:
+>>> f.write(svg)
+```
+
+
+ GOT-OCR2 training stages. Taken from the original paper.
+
+
+Tips:
+
+GOT-OCR2 works on a wide range of tasks, including plain document OCR, scene text OCR, formatted document OCR, and even OCR for tables, charts, mathematical formulas, geometric shapes, molecular formulas and sheet music. While this implementation of the model will only output plain text, the outputs can be further processed to render the desired format, with packages like `pdftex`, `mathpix`, `matplotlib`, `tikz`, `verovio` or `pyecharts`.
+The model can also be used for interactive OCR, where the user can specify the region to be recognized by providing the coordinates or the color of the region's bounding box.
+
+This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
+The original code can be found [here](https://github.com/Ucas-HaoranWei/GOT-OCR2.0).
+
+## Usage example
+
+### Plain text inference
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/image_ocr.jpg"
+>>> inputs = processor(image, return_tensors="pt", device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"R&D QUALITY IMPROVEMENT\nSUGGESTION/SOLUTION FORM\nName/Phone Ext. : (...)"
+```
+
+### Plain text inference batched
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image1 = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/multi_box.png"
+>>> image2 = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/image_ocr.jpg"
+
+>>> inputs = processor([image1, image2], return_tensors="pt", device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4,
+... )
+
+>>> processor.batch_decode(generate_ids[:, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+["Reducing the number", "R&D QUALITY"]
+```
+
+### Formatted text inference
+
+GOT-OCR2 can also generate formatted text, such as markdown or LaTeX. Here is an example of how to generate formatted text:
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/latex.png"
+>>> inputs = processor(image, return_tensors="pt", format=True, device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"\\author{\nHanwen Jiang* \\(\\quad\\) Arjun Karpur \\({ }^{\\dagger} \\quad\\) Bingyi Cao \\({ }^{\\dagger} \\quad\\) (...)"
+```
+
+### Inference on multiple pages
+
+Although it might be reasonable in most cases to use a “for loop” for multi-page processing, some text data with formatting across several pages make it necessary to process all pages at once. GOT introduces a multi-page OCR (without “for loop”) feature, where multiple pages can be processed by the model at once, whith the output being one continuous text.
+Here is an example of how to process multiple pages at once:
+
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image1 = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/page1.png"
+>>> image2 = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/page2.png"
+>>> inputs = processor([image1, image2], return_tensors="pt", multi_page=True, format=True, device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"\\title{\nGeneral OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model\n}\n\\author{\nHaoran Wei (...)"
+```
+
+### Inference on cropped patches
+
+GOT supports a 1024×1024 input resolution, which is sufficient for most OCR tasks, such as scene OCR or processing A4-sized PDF pages. However, certain scenarios, like horizontally stitched two-page PDFs commonly found in academic papers or images with unusual aspect ratios, can lead to accuracy issues when processed as a single image. To address this, GOT can dynamically crop an image into patches, process them all at once, and merge the results for better accuracy with such inputs.
+Here is an example of how to process cropped patches:
+
+```python
+>>> import torch
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", torch_dtype=torch.bfloat16, device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/one_column.png"
+>>> inputs = processor(image, return_tensors="pt", format=True, crop_to_patches=True, max_patches=3, device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"on developing architectural improvements to make learnable matching methods generalize.\nMotivated by the above observations, (...)"
+```
+
+### Inference on a specific region
+
+GOT supports interactive OCR, where the user can specify the region to be recognized by providing the coordinates or the color of the region's bounding box. Here is an example of how to process a specific region:
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/multi_box.png"
+>>> inputs = processor(image, return_tensors="pt", color="green", device=device).to(device) # or box=[x1, y1, x2, y2] for coordinates (image pixels)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+"You should keep in mind what features from the module should be used, especially \nwhen you’re planning to sell a template."
+```
+
+### Inference on general OCR data example: sheet music
+
+Although this implementation of the model will only output plain text, the outputs can be further processed to render the desired format, with packages like `pdftex`, `mathpix`, `matplotlib`, `tikz`, `verovio` or `pyecharts`.
+Here is an example of how to process sheet music:
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+>>> import verovio
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model = AutoModelForImageTextToText.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", device_map=device)
+>>> processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf", use_fast=True)
+
+>>> image = "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/sheet_music.png"
+>>> inputs = processor(image, return_tensors="pt", format=True, device=device).to(device)
+
+>>> generate_ids = model.generate(
+... **inputs,
+... do_sample=False,
+... tokenizer=processor.tokenizer,
+... stop_strings="<|im_end|>",
+... max_new_tokens=4096,
+... )
+
+>>> outputs = processor.decode(generate_ids[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True)
+>>> tk = verovio.toolkit()
+>>> tk.loadData(outputs)
+>>> tk.setOptions(
+... {
+... "pageWidth": 2100,
+... "pageHeight": 800,
+... "footer": "none",
+... "barLineWidth": 0.5,
+... "beamMaxSlope": 15,
+... "staffLineWidth": 0.2,
+... "spacingStaff": 6,
+... }
+... )
+>>> tk.getPageCount()
+>>> svg = tk.renderToSVG()
+>>> svg = svg.replace('overflow="inherit"', 'overflow="visible"')
+>>> with open("output.svg", "w") as f:
+>>> f.write(svg)
+```
+ +
+## GotOcr2Config
+
+[[autodoc]] GotOcr2Config
+
+## GotOcr2VisionConfig
+
+[[autodoc]] GotOcr2VisionConfig
+
+## GotOcr2ImageProcessor
+
+[[autodoc]] GotOcr2ImageProcessor
+
+## GotOcr2ImageProcessorFast
+
+[[autodoc]] GotOcr2ImageProcessorFast
+
+## GotOcr2Processor
+
+[[autodoc]] GotOcr2Processor
+
+## GotOcr2ForConditionalGeneration
+
+[[autodoc]] GotOcr2ForConditionalGeneration
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/gpt-sw3.md b/docs/transformers/docs/source/en/model_doc/gpt-sw3.md
new file mode 100644
index 0000000000000000000000000000000000000000..20daa3537af0f37c48b95385dc288a1629a6814d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/gpt-sw3.md
@@ -0,0 +1,76 @@
+
+
+# GPT-Sw3
+
+
+
+## GotOcr2Config
+
+[[autodoc]] GotOcr2Config
+
+## GotOcr2VisionConfig
+
+[[autodoc]] GotOcr2VisionConfig
+
+## GotOcr2ImageProcessor
+
+[[autodoc]] GotOcr2ImageProcessor
+
+## GotOcr2ImageProcessorFast
+
+[[autodoc]] GotOcr2ImageProcessorFast
+
+## GotOcr2Processor
+
+[[autodoc]] GotOcr2Processor
+
+## GotOcr2ForConditionalGeneration
+
+[[autodoc]] GotOcr2ForConditionalGeneration
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/gpt-sw3.md b/docs/transformers/docs/source/en/model_doc/gpt-sw3.md
new file mode 100644
index 0000000000000000000000000000000000000000..20daa3537af0f37c48b95385dc288a1629a6814d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/gpt-sw3.md
@@ -0,0 +1,76 @@
+
+
+# GPT-Sw3
+
+ +
+ +
+ +
+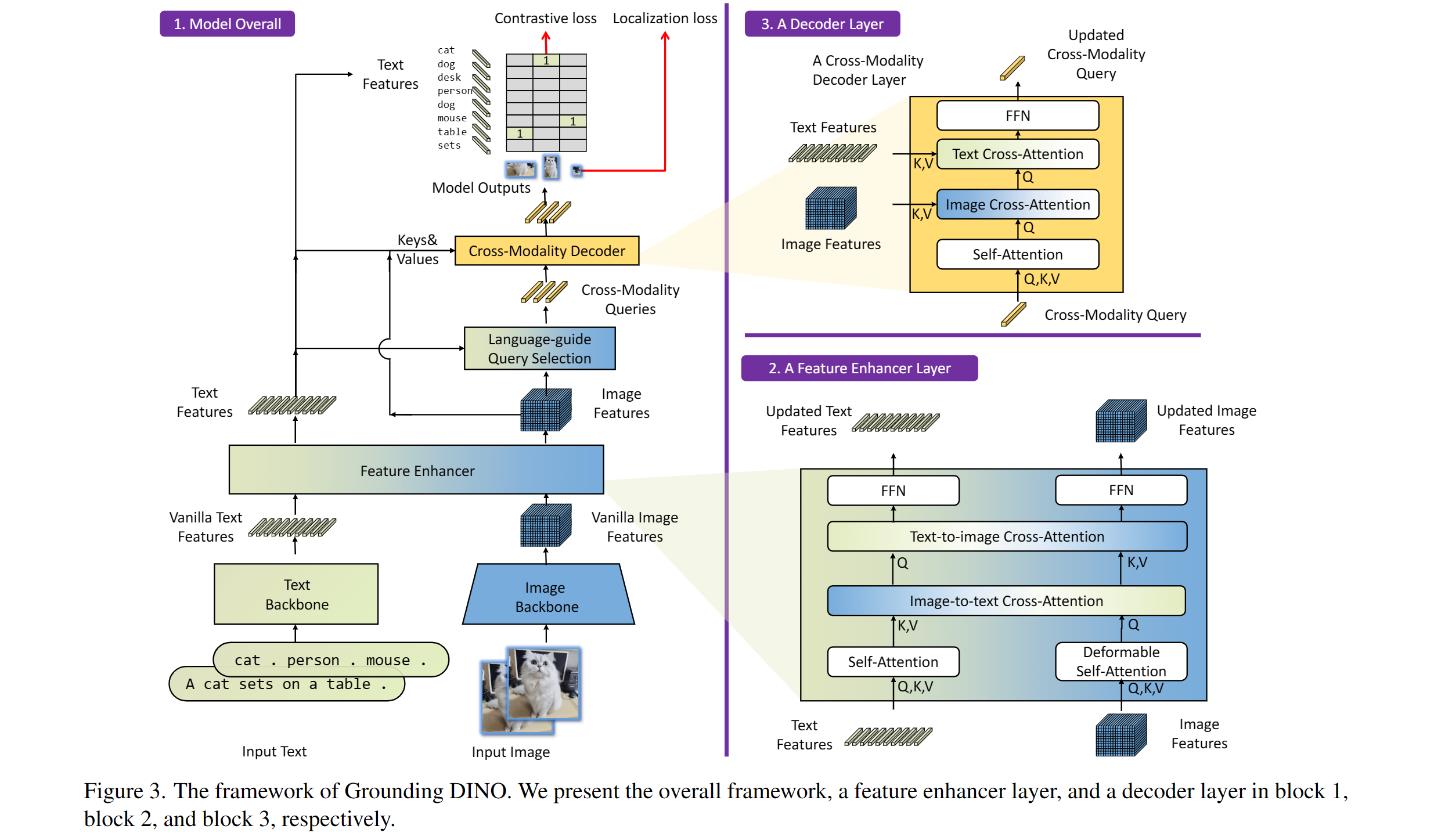 +
+ Grounding DINO overview. Taken from the original paper.
+
+This model was contributed by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/IDEA-Research/GroundingDINO).
+
+## Usage tips
+
+- One can use [`GroundingDinoProcessor`] to prepare image-text pairs for the model.
+- To separate classes in the text use a period e.g. "a cat. a dog."
+- When using multiple classes (e.g. `"a cat. a dog."`), use `post_process_grounded_object_detection` from [`GroundingDinoProcessor`] to post process outputs. Since, the labels returned from `post_process_object_detection` represent the indices from the model dimension where prob > threshold.
+
+Here's how to use the model for zero-shot object detection:
+
+```python
+>>> import requests
+
+>>> import torch
+>>> from PIL import Image
+>>> from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
+
+>>> model_id = "IDEA-Research/grounding-dino-tiny"
+>>> device = "cuda"
+
+>>> processor = AutoProcessor.from_pretrained(model_id)
+>>> model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
+
+>>> image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(image_url, stream=True).raw)
+>>> # Check for cats and remote controls
+>>> text_labels = [["a cat", "a remote control"]]
+
+>>> inputs = processor(images=image, text=text_labels, return_tensors="pt").to(device)
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> results = processor.post_process_grounded_object_detection(
+... outputs,
+... inputs.input_ids,
+... box_threshold=0.4,
+... text_threshold=0.3,
+... target_sizes=[image.size[::-1]]
+... )
+
+# Retrieve the first image result
+>>> result = results[0]
+>>> for box, score, labels in zip(result["boxes"], result["scores"], result["labels"]):
+... box = [round(x, 2) for x in box.tolist()]
+... print(f"Detected {labels} with confidence {round(score.item(), 3)} at location {box}")
+Detected a cat with confidence 0.468 at location [344.78, 22.9, 637.3, 373.62]
+Detected a cat with confidence 0.426 at location [11.74, 51.55, 316.51, 473.22]
+```
+
+## Grounded SAM
+
+One can combine Grounding DINO with the [Segment Anything](sam) model for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://arxiv.org/abs/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
+
+
+
+ Grounding DINO overview. Taken from the original paper.
+
+This model was contributed by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/IDEA-Research/GroundingDINO).
+
+## Usage tips
+
+- One can use [`GroundingDinoProcessor`] to prepare image-text pairs for the model.
+- To separate classes in the text use a period e.g. "a cat. a dog."
+- When using multiple classes (e.g. `"a cat. a dog."`), use `post_process_grounded_object_detection` from [`GroundingDinoProcessor`] to post process outputs. Since, the labels returned from `post_process_object_detection` represent the indices from the model dimension where prob > threshold.
+
+Here's how to use the model for zero-shot object detection:
+
+```python
+>>> import requests
+
+>>> import torch
+>>> from PIL import Image
+>>> from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
+
+>>> model_id = "IDEA-Research/grounding-dino-tiny"
+>>> device = "cuda"
+
+>>> processor = AutoProcessor.from_pretrained(model_id)
+>>> model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
+
+>>> image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(image_url, stream=True).raw)
+>>> # Check for cats and remote controls
+>>> text_labels = [["a cat", "a remote control"]]
+
+>>> inputs = processor(images=image, text=text_labels, return_tensors="pt").to(device)
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> results = processor.post_process_grounded_object_detection(
+... outputs,
+... inputs.input_ids,
+... box_threshold=0.4,
+... text_threshold=0.3,
+... target_sizes=[image.size[::-1]]
+... )
+
+# Retrieve the first image result
+>>> result = results[0]
+>>> for box, score, labels in zip(result["boxes"], result["scores"], result["labels"]):
+... box = [round(x, 2) for x in box.tolist()]
+... print(f"Detected {labels} with confidence {round(score.item(), 3)} at location {box}")
+Detected a cat with confidence 0.468 at location [344.78, 22.9, 637.3, 373.62]
+Detected a cat with confidence 0.426 at location [11.74, 51.55, 316.51, 473.22]
+```
+
+## Grounded SAM
+
+One can combine Grounding DINO with the [Segment Anything](sam) model for text-based mask generation as introduced in [Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks](https://arxiv.org/abs/2401.14159). You can refer to this [demo notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 for details.
+
+ +
+ Grounded SAM overview. Taken from the original repository.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Grounding DINO. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- Demo notebooks regarding inference with Grounding DINO as well as combining it with [SAM](sam) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Grounding%20DINO). 🌎
+
+## GroundingDinoImageProcessor
+
+[[autodoc]] GroundingDinoImageProcessor
+ - preprocess
+
+## GroundingDinoImageProcessorFast
+
+[[autodoc]] GroundingDinoImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+
+## GroundingDinoProcessor
+
+[[autodoc]] GroundingDinoProcessor
+ - post_process_grounded_object_detection
+
+## GroundingDinoConfig
+
+[[autodoc]] GroundingDinoConfig
+
+## GroundingDinoModel
+
+[[autodoc]] GroundingDinoModel
+ - forward
+
+## GroundingDinoForObjectDetection
+
+[[autodoc]] GroundingDinoForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/groupvit.md b/docs/transformers/docs/source/en/model_doc/groupvit.md
new file mode 100644
index 0000000000000000000000000000000000000000..c77a51d8b1b78ea77190cb10892e298dcdd35d89
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/groupvit.md
@@ -0,0 +1,101 @@
+
+
+# GroupViT
+
+
+
+ Grounded SAM overview. Taken from the original repository.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Grounding DINO. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- Demo notebooks regarding inference with Grounding DINO as well as combining it with [SAM](sam) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Grounding%20DINO). 🌎
+
+## GroundingDinoImageProcessor
+
+[[autodoc]] GroundingDinoImageProcessor
+ - preprocess
+
+## GroundingDinoImageProcessorFast
+
+[[autodoc]] GroundingDinoImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+
+## GroundingDinoProcessor
+
+[[autodoc]] GroundingDinoProcessor
+ - post_process_grounded_object_detection
+
+## GroundingDinoConfig
+
+[[autodoc]] GroundingDinoConfig
+
+## GroundingDinoModel
+
+[[autodoc]] GroundingDinoModel
+ - forward
+
+## GroundingDinoForObjectDetection
+
+[[autodoc]] GroundingDinoForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/groupvit.md b/docs/transformers/docs/source/en/model_doc/groupvit.md
new file mode 100644
index 0000000000000000000000000000000000000000..c77a51d8b1b78ea77190cb10892e298dcdd35d89
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/groupvit.md
@@ -0,0 +1,101 @@
+
+
+# GroupViT
+
+ +
+ Hiera architecture. Taken from the original paper.
+
+This model was a joint contribution by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [namangarg110](https://huggingface.co/namangarg110). The original code can be found [here] (https://github.com/facebookresearch/hiera).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Hiera. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+ Hiera architecture. Taken from the original paper.
+
+This model was a joint contribution by [EduardoPacheco](https://huggingface.co/EduardoPacheco) and [namangarg110](https://huggingface.co/namangarg110). The original code can be found [here] (https://github.com/facebookresearch/hiera).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Hiera. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+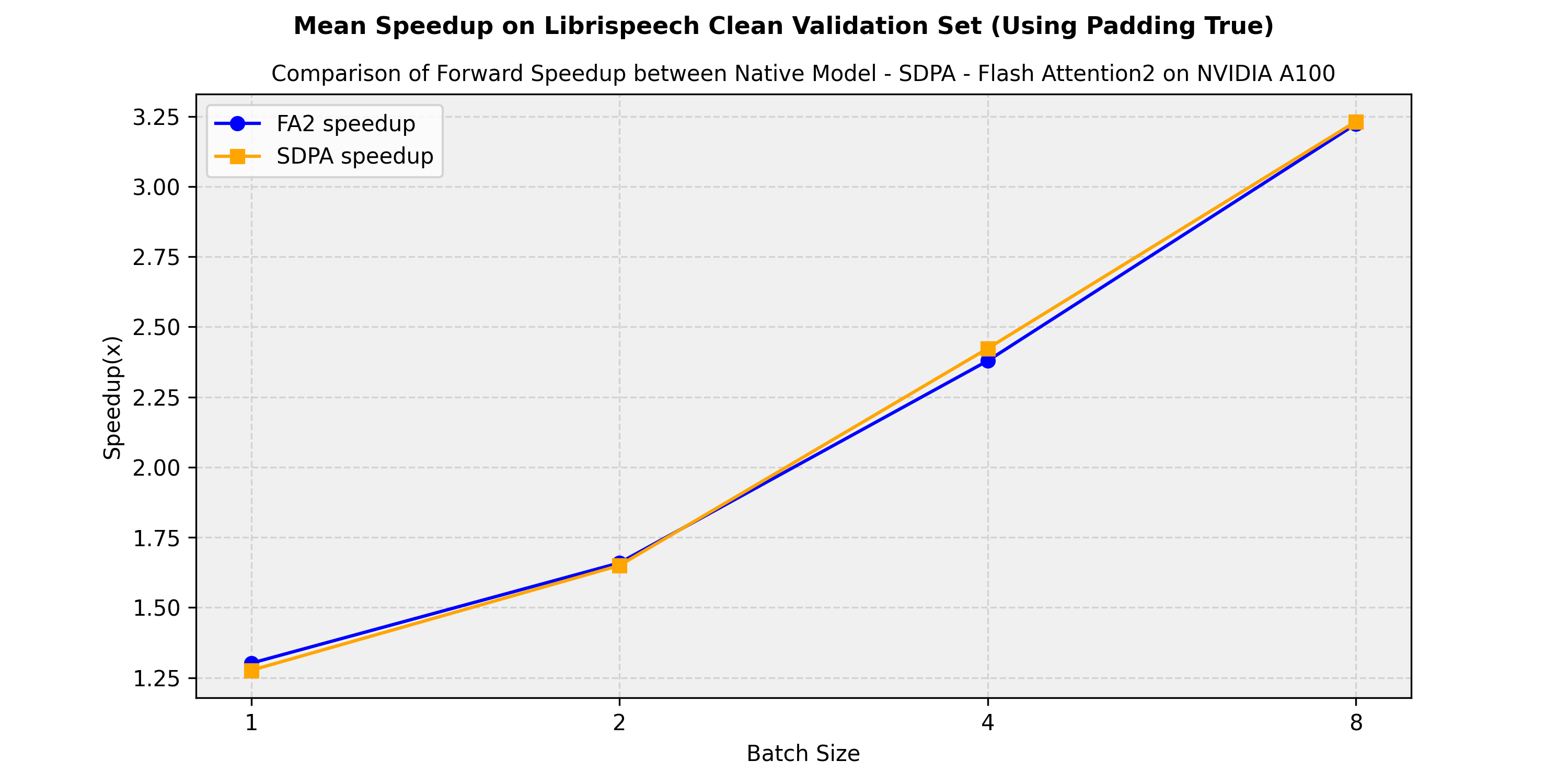 +
+ +
+ Idefics2 architecture. Taken from the original paper.
+
+This model was contributed by [amyeroberts](https://huggingface.co/amyeroberts).
+The original code can be found [here](https://huggingface.co/HuggingFaceM4/idefics2).
+
+## Usage tips
+
+- Each sample can contain multiple images, and the number of images can vary between samples. The processor will pad the inputs to the maximum number of images in a batch for input to the model.
+- The processor has a `do_image_splitting` option. If `True`, each input image will be split into 4 sub-images, and concatenated with the original to form 5 images. This is useful for increasing model performance. Make sure `processor.image_processor.do_image_splitting` is set to `False` if the model was not trained with this option.
+- `text` passed to the processor should have the `
+
+ Idefics2 architecture. Taken from the original paper.
+
+This model was contributed by [amyeroberts](https://huggingface.co/amyeroberts).
+The original code can be found [here](https://huggingface.co/HuggingFaceM4/idefics2).
+
+## Usage tips
+
+- Each sample can contain multiple images, and the number of images can vary between samples. The processor will pad the inputs to the maximum number of images in a batch for input to the model.
+- The processor has a `do_image_splitting` option. If `True`, each input image will be split into 4 sub-images, and concatenated with the original to form 5 images. This is useful for increasing model performance. Make sure `processor.image_processor.do_image_splitting` is set to `False` if the model was not trained with this option.
+- `text` passed to the processor should have the ` +
+ I-JEPA architecture. Taken from the original paper.
+
+This model was contributed by [jmtzt](https://huggingface.co/jmtzt).
+The original code can be found [here](https://github.com/facebookresearch/ijepa).
+
+## How to use
+
+Here is how to use this model for image feature extraction:
+
+```python
+import requests
+import torch
+from PIL import Image
+from torch.nn.functional import cosine_similarity
+
+from transformers import AutoModel, AutoProcessor
+
+url_1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+url_2 = "http://images.cocodataset.org/val2017/000000219578.jpg"
+image_1 = Image.open(requests.get(url_1, stream=True).raw)
+image_2 = Image.open(requests.get(url_2, stream=True).raw)
+
+model_id = "facebook/ijepa_vith14_1k"
+processor = AutoProcessor.from_pretrained(model_id)
+model = AutoModel.from_pretrained(model_id)
+
+@torch.no_grad()
+def infer(image):
+ inputs = processor(image, return_tensors="pt")
+ outputs = model(**inputs)
+ return outputs.last_hidden_state.mean(dim=1)
+
+
+embed_1 = infer(image_1)
+embed_2 = infer(image_2)
+
+similarity = cosine_similarity(embed_1, embed_2)
+print(similarity)
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with I-JEPA.
+
+
+
+ I-JEPA architecture. Taken from the original paper.
+
+This model was contributed by [jmtzt](https://huggingface.co/jmtzt).
+The original code can be found [here](https://github.com/facebookresearch/ijepa).
+
+## How to use
+
+Here is how to use this model for image feature extraction:
+
+```python
+import requests
+import torch
+from PIL import Image
+from torch.nn.functional import cosine_similarity
+
+from transformers import AutoModel, AutoProcessor
+
+url_1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+url_2 = "http://images.cocodataset.org/val2017/000000219578.jpg"
+image_1 = Image.open(requests.get(url_1, stream=True).raw)
+image_2 = Image.open(requests.get(url_2, stream=True).raw)
+
+model_id = "facebook/ijepa_vith14_1k"
+processor = AutoProcessor.from_pretrained(model_id)
+model = AutoModel.from_pretrained(model_id)
+
+@torch.no_grad()
+def infer(image):
+ inputs = processor(image, return_tensors="pt")
+ outputs = model(**inputs)
+ return outputs.last_hidden_state.mean(dim=1)
+
+
+embed_1 = infer(image_1)
+embed_2 = infer(image_2)
+
+similarity = cosine_similarity(embed_1, embed_2)
+print(similarity)
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with I-JEPA.
+
+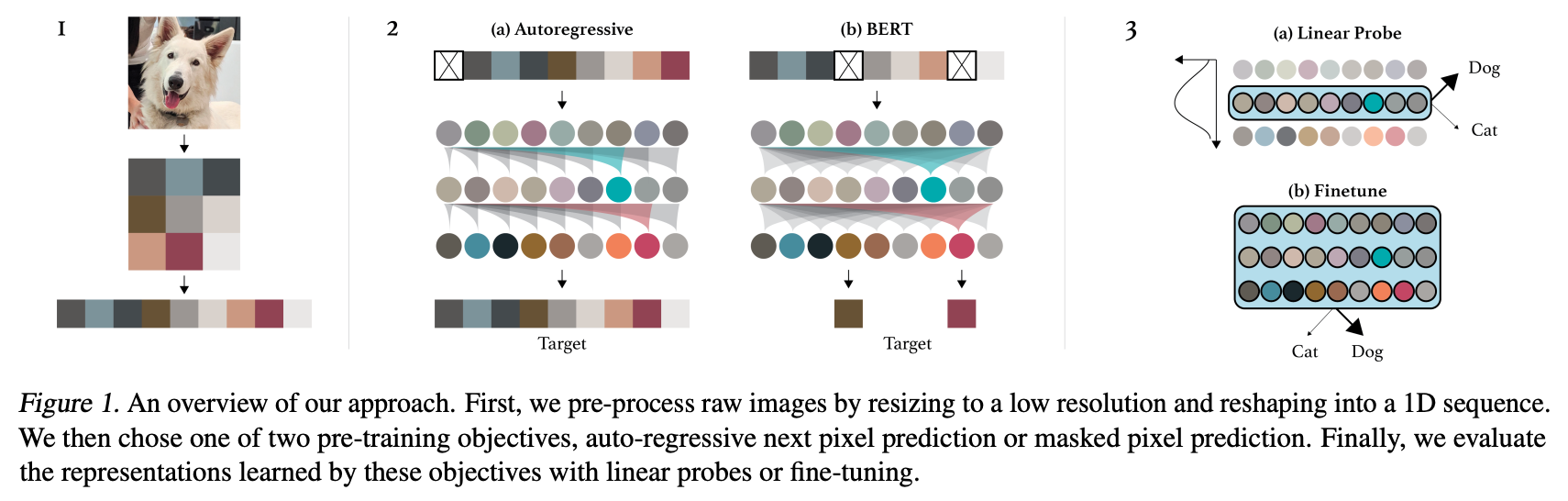 +
+ Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr), based on [this issue](https://github.com/openai/image-gpt/issues/7). The original code can be found
+[here](https://github.com/openai/image-gpt).
+
+## Usage tips
+
+- ImageGPT is almost exactly the same as [GPT-2](gpt2), with the exception that a different activation
+ function is used (namely "quick gelu"), and the layer normalization layers don't mean center the inputs. ImageGPT
+ also doesn't have tied input- and output embeddings.
+- As the time- and memory requirements of the attention mechanism of Transformers scales quadratically in the sequence
+ length, the authors pre-trained ImageGPT on smaller input resolutions, such as 32x32 and 64x64. However, feeding a
+ sequence of 32x32x3=3072 tokens from 0..255 into a Transformer is still prohibitively large. Therefore, the authors
+ applied k-means clustering to the (R,G,B) pixel values with k=512. This way, we only have a 32*32 = 1024-long
+ sequence, but now of integers in the range 0..511. So we are shrinking the sequence length at the cost of a bigger
+ embedding matrix. In other words, the vocabulary size of ImageGPT is 512, + 1 for a special "start of sentence" (SOS)
+ token, used at the beginning of every sequence. One can use [`ImageGPTImageProcessor`] to prepare
+ images for the model.
+- Despite being pre-trained entirely unsupervised (i.e. without the use of any labels), ImageGPT produces fairly
+ performant image features useful for downstream tasks, such as image classification. The authors showed that the
+ features in the middle of the network are the most performant, and can be used as-is to train a linear model (such as
+ a sklearn logistic regression model for example). This is also referred to as "linear probing". Features can be
+ easily obtained by first forwarding the image through the model, then specifying `output_hidden_states=True`, and
+ then average-pool the hidden states at whatever layer you like.
+- Alternatively, one can further fine-tune the entire model on a downstream dataset, similar to BERT. For this, you can
+ use [`ImageGPTForImageClassification`].
+- ImageGPT comes in different sizes: there's ImageGPT-small, ImageGPT-medium and ImageGPT-large. The authors did also
+ train an XL variant, which they didn't release. The differences in size are summarized in the following table:
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
+|---|---|---|---|---|---|
+| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ImageGPT.
+
+
+
+ Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr), based on [this issue](https://github.com/openai/image-gpt/issues/7). The original code can be found
+[here](https://github.com/openai/image-gpt).
+
+## Usage tips
+
+- ImageGPT is almost exactly the same as [GPT-2](gpt2), with the exception that a different activation
+ function is used (namely "quick gelu"), and the layer normalization layers don't mean center the inputs. ImageGPT
+ also doesn't have tied input- and output embeddings.
+- As the time- and memory requirements of the attention mechanism of Transformers scales quadratically in the sequence
+ length, the authors pre-trained ImageGPT on smaller input resolutions, such as 32x32 and 64x64. However, feeding a
+ sequence of 32x32x3=3072 tokens from 0..255 into a Transformer is still prohibitively large. Therefore, the authors
+ applied k-means clustering to the (R,G,B) pixel values with k=512. This way, we only have a 32*32 = 1024-long
+ sequence, but now of integers in the range 0..511. So we are shrinking the sequence length at the cost of a bigger
+ embedding matrix. In other words, the vocabulary size of ImageGPT is 512, + 1 for a special "start of sentence" (SOS)
+ token, used at the beginning of every sequence. One can use [`ImageGPTImageProcessor`] to prepare
+ images for the model.
+- Despite being pre-trained entirely unsupervised (i.e. without the use of any labels), ImageGPT produces fairly
+ performant image features useful for downstream tasks, such as image classification. The authors showed that the
+ features in the middle of the network are the most performant, and can be used as-is to train a linear model (such as
+ a sklearn logistic regression model for example). This is also referred to as "linear probing". Features can be
+ easily obtained by first forwarding the image through the model, then specifying `output_hidden_states=True`, and
+ then average-pool the hidden states at whatever layer you like.
+- Alternatively, one can further fine-tune the entire model on a downstream dataset, similar to BERT. For this, you can
+ use [`ImageGPTForImageClassification`].
+- ImageGPT comes in different sizes: there's ImageGPT-small, ImageGPT-medium and ImageGPT-large. The authors did also
+ train an XL variant, which they didn't release. The differences in size are summarized in the following table:
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
+|---|---|---|---|---|---|
+| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ImageGPT.
+
+ +
+ InstructBLIP architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
+
+## Usage tips
+
+InstructBLIP uses the same architecture as [BLIP-2](blip2) with a tiny but important difference: it also feeds the text prompt (instruction) to the Q-Former.
+
+> [!NOTE]
+> BLIP models after release v4.46 will raise warnings about adding `processor.num_query_tokens = {{num_query_tokens}}` and expand model embeddings layer to add special `
+
+ InstructBLIP architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
+
+## Usage tips
+
+InstructBLIP uses the same architecture as [BLIP-2](blip2) with a tiny but important difference: it also feeds the text prompt (instruction) to the Q-Former.
+
+> [!NOTE]
+> BLIP models after release v4.46 will raise warnings about adding `processor.num_query_tokens = {{num_query_tokens}}` and expand model embeddings layer to add special ` +
+ Overview of InternVL3 models architecture, which is the same as InternVL2.5. Taken from the original checkpoint.
+
+
+
+
+
+ Overview of InternVL3 models architecture, which is the same as InternVL2.5. Taken from the original checkpoint.
+
+
+
+ +
+ Comparison of InternVL3 performance on OpenCompass against other SOTA VLLMs. Taken from the original checkpoint.
+
+
+
+This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
+The original code can be found [here](https://github.com/OpenGVLab/InternVL).
+
+## Usage example
+
+### Inference with Pipeline
+
+Here is how you can use the `image-text-to-text` pipeline to perform inference with the `InternVL3` models in just a few lines of code:
+
+```python
+>>> from transformers import pipeline
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {
+... "type": "image",
+... "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg",
+... },
+... {"type": "text", "text": "Describe this image."},
+... ],
+... },
+... ]
+
+>>> pipe = pipeline("image-text-to-text", model="OpenGVLab/InternVL3-1B-hf")
+>>> outputs = pipe(text=messages, max_new_tokens=50, return_full_text=False)
+>>> outputs[0]["generated_text"]
+'The image showcases a vibrant scene of nature, featuring several flowers and a bee. \n\n1. **Foreground Flowers**: \n - The primary focus is on a large, pink cosmos flower with a prominent yellow center. The petals are soft and slightly r'
+```
+### Inference on a single image
+
+This example demonstrates how to perform inference on a single image with the InternVL models using chat templates.
+
+> [!NOTE]
+> Note that the model has been trained with a specific prompt format for chatting. Use `processor.apply_chat_template(my_conversation_dict)` to correctly format your prompts.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
+... {"type": "text", "text": "Please describe the image explicitly."},
+... ],
+... }
+... ]
+
+>>> inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+>>> generate_ids = model.generate(**inputs, max_new_tokens=50)
+>>> decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+
+>>> decoded_output
+'The image shows two cats lying on a pink blanket. The cat on the left is a tabby with a mix of brown, black, and white fur, and it appears to be sleeping with its head resting on the blanket. The cat on the'
+```
+
+### Text-only generation
+This example shows how to generate text using the InternVL model without providing any image input.
+
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {"type": "text", "text": "Write a haiku"},
+... ],
+... }
+... ]
+
+>>> inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(torch_device, dtype=torch.bfloat16)
+
+>>> generate_ids = model.generate(**inputs, max_new_tokens=50)
+>>> decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+
+>>> print(decoded_output)
+"Whispers of dawn,\nSilent whispers of the night,\nNew day's light begins."
+```
+
+### Batched image and text inputs
+InternVL models also support batched image and text inputs.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+... {"type": "text", "text": "Write a haiku for this image"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"},
+... {"type": "text", "text": "Describe this image"},
+... ],
+... },
+... ],
+... ]
+
+
+>>> inputs = processor.apply_chat_template(messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+>>> output = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_outputs = processor.batch_decode(output, skip_special_tokens=True)
+>>> decoded_outputs
+["user\n\nWrite a haiku for this image\nassistant\nSilky lake, \nWooden pier, \nNature's peace.",
+ 'user\n\nDescribe this image\nassistant\nThe image shows a street scene with a traditional Chinese archway, known as a "Chinese Gate" or "Chinese Gate of']
+```
+
+### Batched multi-image input
+This implementation of the InternVL models supports batched text-images inputs with different number of images for each text.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+... {"type": "text", "text": "Write a haiku for this image"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"},
+... {"type": "image", "url": "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg"},
+... {"type": "text", "text": "These images depict two different landmarks. Can you identify them?"},
+... ],
+... },
+... ],
+>>> ]
+
+>>> inputs = processor.apply_chat_template(messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+>>> output = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_outputs = processor.batch_decode(output, skip_special_tokens=True)
+>>> decoded_outputs
+["user\n\nWrite a haiku for this image\nassistant\nSilky lake, \nWooden pier, \nNature's peace.",
+ 'user\n\n\nThese images depict two different landmarks. Can you identify them?\nassistant\nYes, these images depict the Statue of Liberty and the Golden Gate Bridge.']
+```
+
+### Video input
+InternVL models can also handle video inputs. Here is an example of how to perform inference on a video input using chat templates.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
+
+>>> model_checkpoint = "OpenGVLab/InternVL3-8B-hf"
+>>> quantization_config = BitsAndBytesConfig(load_in_4bit=True)
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, quantization_config=quantization_config)
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {
+... "type": "video",
+... "url": "https://huggingface.co/datasets/hf-internal-testing/fixtures_videos/resolve/main/tennis.mp4",
+... },
+... {"type": "text", "text": "What type of shot is the man performing?"},
+... ],
+... }
+>>> ]
+>>> inputs = processor.apply_chat_template(
+... messages,
+... return_tensors="pt",
+... add_generation_prompt=True,
+... tokenize=True,
+... return_dict=True,
+... num_frames=8,
+>>> ).to(model.device, dtype=torch.float16)
+
+>>> output = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_output = processor.decode(output[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+>>> decoded_output
+'The man is performing a forehand shot.'
+```
+
+### Interleaved image and video inputs
+This example showcases how to handle a batch of chat conversations with interleaved image and video inputs using chat template.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"},
+... {"type": "image", "url": "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg"},
+... {"type": "text", "text": "These images depict two different landmarks. Can you identify them?"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "video", "url": "https://huggingface.co/datasets/hf-internal-testing/fixtures_videos/resolve/main/tennis.mp4"},
+... {"type": "text", "text": "What type of shot is the man performing?"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+... {"type": "text", "text": "Write a haiku for this image"},
+... ],
+... },
+... ],
+>>> ]
+>>> inputs = processor.apply_chat_template(
+... messages,
+... padding=True,
+... add_generation_prompt=True,
+... tokenize=True,
+... return_dict=True,
+... return_tensors="pt",
+>>> ).to(model.device, dtype=torch.bfloat16)
+
+>>> outputs = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_outputs = processor.batch_decode(outputs, skip_special_tokens=True)
+>>> decoded_outputs
+['user\n\n\nThese images depict two different landmarks. Can you identify them?\nassistant\nThe images depict the Statue of Liberty and the Golden Gate Bridge.',
+ 'user\nFrame1: \nFrame2: \nFrame3: \nFrame4: \nFrame5: \nFrame6: \nFrame7: \nFrame8: \nWhat type of shot is the man performing?\nassistant\nA forehand shot',
+ "user\n\nWrite a haiku for this image\nassistant\nSilky lake, \nWooden pier, \nNature's peace."]
+```
+
+## InternVLVisionConfig
+
+[[autodoc]] InternVLVisionConfig
+
+## InternVLConfig
+
+[[autodoc]] InternVLConfig
+
+## InternVLVisionModel
+
+[[autodoc]] InternVLVisionModel
+ - forward
+
+## InternVLForConditionalGeneration
+
+[[autodoc]] InternVLForConditionalGeneration
+ - forward
+
+## InternVLProcessor
+
+[[autodoc]] InternVLProcessor
diff --git a/docs/transformers/docs/source/en/model_doc/jamba.md b/docs/transformers/docs/source/en/model_doc/jamba.md
new file mode 100644
index 0000000000000000000000000000000000000000..8c2c147c0c7e846ced20aa487dc0f42ab897122e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/jamba.md
@@ -0,0 +1,158 @@
+
+
+
+
+ Comparison of InternVL3 performance on OpenCompass against other SOTA VLLMs. Taken from the original checkpoint.
+
+
+
+This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
+The original code can be found [here](https://github.com/OpenGVLab/InternVL).
+
+## Usage example
+
+### Inference with Pipeline
+
+Here is how you can use the `image-text-to-text` pipeline to perform inference with the `InternVL3` models in just a few lines of code:
+
+```python
+>>> from transformers import pipeline
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {
+... "type": "image",
+... "image": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg",
+... },
+... {"type": "text", "text": "Describe this image."},
+... ],
+... },
+... ]
+
+>>> pipe = pipeline("image-text-to-text", model="OpenGVLab/InternVL3-1B-hf")
+>>> outputs = pipe(text=messages, max_new_tokens=50, return_full_text=False)
+>>> outputs[0]["generated_text"]
+'The image showcases a vibrant scene of nature, featuring several flowers and a bee. \n\n1. **Foreground Flowers**: \n - The primary focus is on a large, pink cosmos flower with a prominent yellow center. The petals are soft and slightly r'
+```
+### Inference on a single image
+
+This example demonstrates how to perform inference on a single image with the InternVL models using chat templates.
+
+> [!NOTE]
+> Note that the model has been trained with a specific prompt format for chatting. Use `processor.apply_chat_template(my_conversation_dict)` to correctly format your prompts.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
+... {"type": "text", "text": "Please describe the image explicitly."},
+... ],
+... }
+... ]
+
+>>> inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+>>> generate_ids = model.generate(**inputs, max_new_tokens=50)
+>>> decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+
+>>> decoded_output
+'The image shows two cats lying on a pink blanket. The cat on the left is a tabby with a mix of brown, black, and white fur, and it appears to be sleeping with its head resting on the blanket. The cat on the'
+```
+
+### Text-only generation
+This example shows how to generate text using the InternVL model without providing any image input.
+
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {"type": "text", "text": "Write a haiku"},
+... ],
+... }
+... ]
+
+>>> inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(torch_device, dtype=torch.bfloat16)
+
+>>> generate_ids = model.generate(**inputs, max_new_tokens=50)
+>>> decoded_output = processor.decode(generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+
+>>> print(decoded_output)
+"Whispers of dawn,\nSilent whispers of the night,\nNew day's light begins."
+```
+
+### Batched image and text inputs
+InternVL models also support batched image and text inputs.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+... {"type": "text", "text": "Write a haiku for this image"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"},
+... {"type": "text", "text": "Describe this image"},
+... ],
+... },
+... ],
+... ]
+
+
+>>> inputs = processor.apply_chat_template(messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+>>> output = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_outputs = processor.batch_decode(output, skip_special_tokens=True)
+>>> decoded_outputs
+["user\n\nWrite a haiku for this image\nassistant\nSilky lake, \nWooden pier, \nNature's peace.",
+ 'user\n\nDescribe this image\nassistant\nThe image shows a street scene with a traditional Chinese archway, known as a "Chinese Gate" or "Chinese Gate of']
+```
+
+### Batched multi-image input
+This implementation of the InternVL models supports batched text-images inputs with different number of images for each text.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+... {"type": "text", "text": "Write a haiku for this image"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"},
+... {"type": "image", "url": "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg"},
+... {"type": "text", "text": "These images depict two different landmarks. Can you identify them?"},
+... ],
+... },
+... ],
+>>> ]
+
+>>> inputs = processor.apply_chat_template(messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+>>> output = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_outputs = processor.batch_decode(output, skip_special_tokens=True)
+>>> decoded_outputs
+["user\n\nWrite a haiku for this image\nassistant\nSilky lake, \nWooden pier, \nNature's peace.",
+ 'user\n\n\nThese images depict two different landmarks. Can you identify them?\nassistant\nYes, these images depict the Statue of Liberty and the Golden Gate Bridge.']
+```
+
+### Video input
+InternVL models can also handle video inputs. Here is an example of how to perform inference on a video input using chat templates.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
+
+>>> model_checkpoint = "OpenGVLab/InternVL3-8B-hf"
+>>> quantization_config = BitsAndBytesConfig(load_in_4bit=True)
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, quantization_config=quantization_config)
+
+>>> messages = [
+... {
+... "role": "user",
+... "content": [
+... {
+... "type": "video",
+... "url": "https://huggingface.co/datasets/hf-internal-testing/fixtures_videos/resolve/main/tennis.mp4",
+... },
+... {"type": "text", "text": "What type of shot is the man performing?"},
+... ],
+... }
+>>> ]
+>>> inputs = processor.apply_chat_template(
+... messages,
+... return_tensors="pt",
+... add_generation_prompt=True,
+... tokenize=True,
+... return_dict=True,
+... num_frames=8,
+>>> ).to(model.device, dtype=torch.float16)
+
+>>> output = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_output = processor.decode(output[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+>>> decoded_output
+'The man is performing a forehand shot.'
+```
+
+### Interleaved image and video inputs
+This example showcases how to handle a batch of chat conversations with interleaved image and video inputs using chat template.
+
+```python
+>>> from transformers import AutoProcessor, AutoModelForImageTextToText, BitsAndBytesConfig
+>>> import torch
+
+>>> torch_device = "cuda"
+>>> model_checkpoint = "OpenGVLab/InternVL3-1B-hf"
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+>>> model = AutoModelForImageTextToText.from_pretrained(model_checkpoint, device_map=torch_device, torch_dtype=torch.bfloat16)
+
+>>> messages = [
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"},
+... {"type": "image", "url": "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg"},
+... {"type": "text", "text": "These images depict two different landmarks. Can you identify them?"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "video", "url": "https://huggingface.co/datasets/hf-internal-testing/fixtures_videos/resolve/main/tennis.mp4"},
+... {"type": "text", "text": "What type of shot is the man performing?"},
+... ],
+... },
+... ],
+... [
+... {
+... "role": "user",
+... "content": [
+... {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+... {"type": "text", "text": "Write a haiku for this image"},
+... ],
+... },
+... ],
+>>> ]
+>>> inputs = processor.apply_chat_template(
+... messages,
+... padding=True,
+... add_generation_prompt=True,
+... tokenize=True,
+... return_dict=True,
+... return_tensors="pt",
+>>> ).to(model.device, dtype=torch.bfloat16)
+
+>>> outputs = model.generate(**inputs, max_new_tokens=25)
+
+>>> decoded_outputs = processor.batch_decode(outputs, skip_special_tokens=True)
+>>> decoded_outputs
+['user\n\n\nThese images depict two different landmarks. Can you identify them?\nassistant\nThe images depict the Statue of Liberty and the Golden Gate Bridge.',
+ 'user\nFrame1: \nFrame2: \nFrame3: \nFrame4: \nFrame5: \nFrame6: \nFrame7: \nFrame8: \nWhat type of shot is the man performing?\nassistant\nA forehand shot',
+ "user\n\nWrite a haiku for this image\nassistant\nSilky lake, \nWooden pier, \nNature's peace."]
+```
+
+## InternVLVisionConfig
+
+[[autodoc]] InternVLVisionConfig
+
+## InternVLConfig
+
+[[autodoc]] InternVLConfig
+
+## InternVLVisionModel
+
+[[autodoc]] InternVLVisionModel
+ - forward
+
+## InternVLForConditionalGeneration
+
+[[autodoc]] InternVLForConditionalGeneration
+ - forward
+
+## InternVLProcessor
+
+[[autodoc]] InternVLProcessor
diff --git a/docs/transformers/docs/source/en/model_doc/jamba.md b/docs/transformers/docs/source/en/model_doc/jamba.md
new file mode 100644
index 0000000000000000000000000000000000000000..8c2c147c0c7e846ced20aa487dc0f42ab897122e
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/jamba.md
@@ -0,0 +1,158 @@
+
+
+ +
+ Overview of tasks that KOSMOS-2 can handle. Taken from the original paper.
+
+## Example
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, Kosmos2ForConditionalGeneration
+
+>>> model = Kosmos2ForConditionalGeneration.from_pretrained("microsoft/kosmos-2-patch14-224")
+>>> processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
+
+>>> url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> prompt = "
+
+ Overview of tasks that KOSMOS-2 can handle. Taken from the original paper.
+
+## Example
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, Kosmos2ForConditionalGeneration
+
+>>> model = Kosmos2ForConditionalGeneration.from_pretrained("microsoft/kosmos-2-patch14-224")
+>>> processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
+
+>>> url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> prompt = " +
+ LayoutLMv3 architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
+
+## Usage tips
+
+- In terms of data processing, LayoutLMv3 is identical to its predecessor [LayoutLMv2](layoutlmv2), except that:
+ - images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
+ - text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
+ Due to these differences in data preprocessing, one can use [`LayoutLMv3Processor`] which internally combines a [`LayoutLMv3ImageProcessor`] (for the image modality) and a [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (for the text modality) to prepare all data for the model.
+- Regarding usage of [`LayoutLMv3Processor`], we refer to the [usage guide](layoutlmv2#usage-layoutlmv2processor) of its predecessor.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv3. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+ LayoutLMv3 architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version of this model was added by [chriskoo](https://huggingface.co/chriskoo), [tokec](https://huggingface.co/tokec), and [lre](https://huggingface.co/lre). The original code can be found [here](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
+
+## Usage tips
+
+- In terms of data processing, LayoutLMv3 is identical to its predecessor [LayoutLMv2](layoutlmv2), except that:
+ - images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
+ - text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
+ Due to these differences in data preprocessing, one can use [`LayoutLMv3Processor`] which internally combines a [`LayoutLMv3ImageProcessor`] (for the image modality) and a [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (for the text modality) to prepare all data for the model.
+- Regarding usage of [`LayoutLMv3Processor`], we refer to the [usage guide](layoutlmv2#usage-layoutlmv2processor) of its predecessor.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv3. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+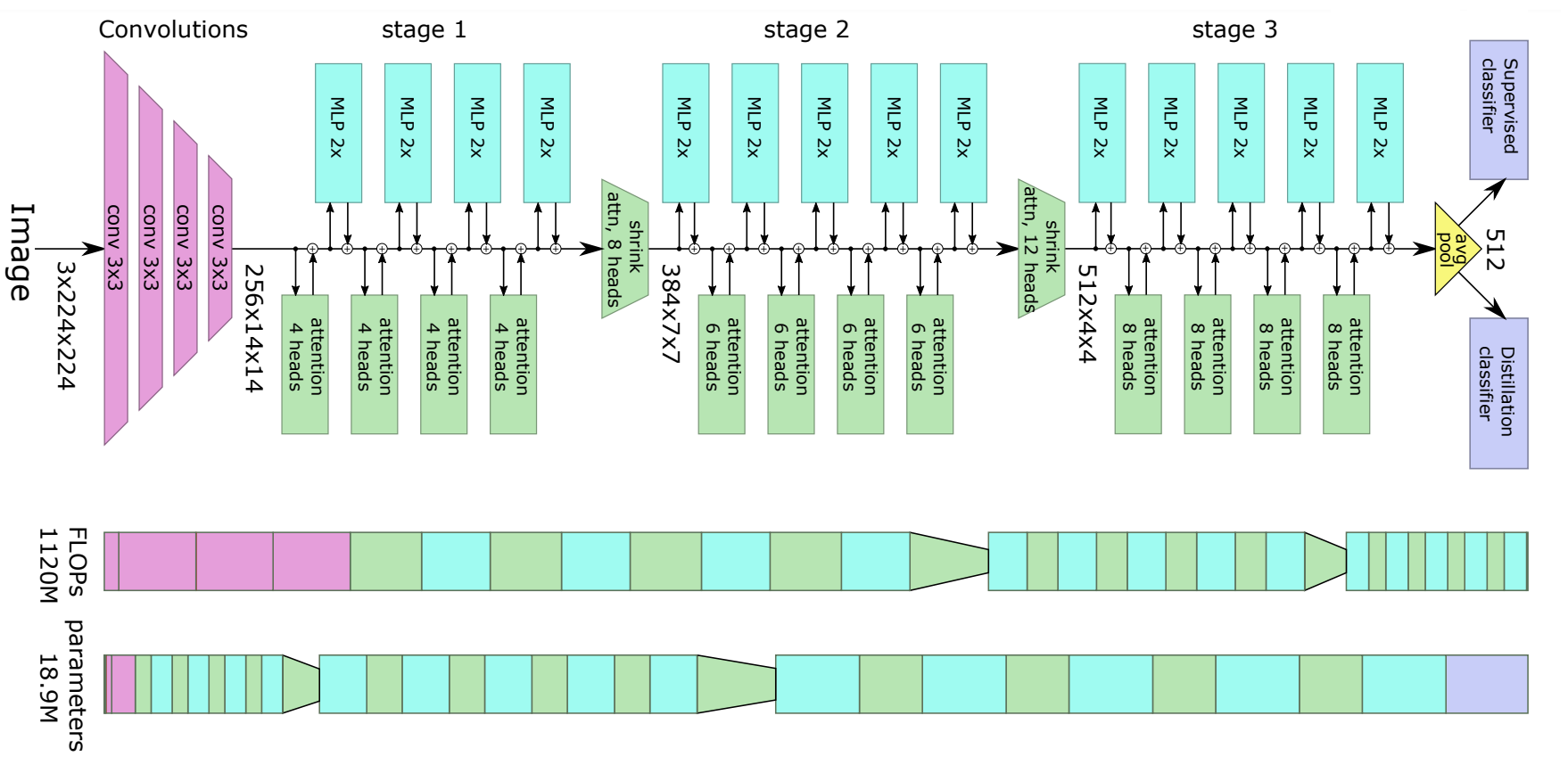 +
+ LeViT Architecture. Taken from the original paper.
+
+This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
+
+## Usage tips
+
+- Compared to ViT, LeViT models use an additional distillation head to effectively learn from a teacher (which, in the LeViT paper, is a ResNet like-model). The distillation head is learned through backpropagation under supervision of a ResNet like-model. They also draw inspiration from convolution neural networks to use activation maps with decreasing resolutions to increase the efficiency.
+- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
+ of the final hidden state and not using the distillation head, or (2) by placing both a prediction head and distillation
+ head on top of the final hidden state. In that case, the prediction head is trained using regular cross-entropy between
+ the prediction of the head and the ground-truth label, while the distillation prediction head is trained using hard distillation
+ (cross-entropy between the prediction of the distillation head and the label predicted by the teacher). At inference time,
+ one takes the average prediction between both heads as final prediction. (2) is also called "fine-tuning with distillation",
+ because one relies on a teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds
+ to [`LevitForImageClassification`] and (2) corresponds to [`LevitForImageClassificationWithTeacher`].
+- All released checkpoints were pre-trained and fine-tuned on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)
+ (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). only. No external data was used. This is in
+ contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for
+ pre-training.
+- The authors of LeViT released 5 trained LeViT models, which you can directly plug into [`LevitModel`] or [`LevitForImageClassification`].
+ Techniques like data augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
+ (while only using ImageNet-1k for pre-training). The 5 variants available are (all trained on images of size 224x224):
+ *facebook/levit-128S*, *facebook/levit-128*, *facebook/levit-192*, *facebook/levit-256* and
+ *facebook/levit-384*. Note that one should use [`LevitImageProcessor`] in order to
+ prepare images for the model.
+- [`LevitForImageClassificationWithTeacher`] currently supports only inference and not training or fine-tuning.
+- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
+ (you can just replace [`ViTFeatureExtractor`] by [`LevitImageProcessor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LeViT.
+
+
+
+ LeViT Architecture. Taken from the original paper.
+
+This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/facebookresearch/LeViT).
+
+## Usage tips
+
+- Compared to ViT, LeViT models use an additional distillation head to effectively learn from a teacher (which, in the LeViT paper, is a ResNet like-model). The distillation head is learned through backpropagation under supervision of a ResNet like-model. They also draw inspiration from convolution neural networks to use activation maps with decreasing resolutions to increase the efficiency.
+- There are 2 ways to fine-tune distilled models, either (1) in a classic way, by only placing a prediction head on top
+ of the final hidden state and not using the distillation head, or (2) by placing both a prediction head and distillation
+ head on top of the final hidden state. In that case, the prediction head is trained using regular cross-entropy between
+ the prediction of the head and the ground-truth label, while the distillation prediction head is trained using hard distillation
+ (cross-entropy between the prediction of the distillation head and the label predicted by the teacher). At inference time,
+ one takes the average prediction between both heads as final prediction. (2) is also called "fine-tuning with distillation",
+ because one relies on a teacher that has already been fine-tuned on the downstream dataset. In terms of models, (1) corresponds
+ to [`LevitForImageClassification`] and (2) corresponds to [`LevitForImageClassificationWithTeacher`].
+- All released checkpoints were pre-trained and fine-tuned on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)
+ (also referred to as ILSVRC 2012, a collection of 1.3 million images and 1,000 classes). only. No external data was used. This is in
+ contrast with the original ViT model, which used external data like the JFT-300M dataset/Imagenet-21k for
+ pre-training.
+- The authors of LeViT released 5 trained LeViT models, which you can directly plug into [`LevitModel`] or [`LevitForImageClassification`].
+ Techniques like data augmentation, optimization, and regularization were used in order to simulate training on a much larger dataset
+ (while only using ImageNet-1k for pre-training). The 5 variants available are (all trained on images of size 224x224):
+ *facebook/levit-128S*, *facebook/levit-128*, *facebook/levit-192*, *facebook/levit-256* and
+ *facebook/levit-384*. Note that one should use [`LevitImageProcessor`] in order to
+ prepare images for the model.
+- [`LevitForImageClassificationWithTeacher`] currently supports only inference and not training or fine-tuning.
+- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)
+ (you can just replace [`ViTFeatureExtractor`] by [`LevitImageProcessor`] and [`ViTForImageClassification`] by [`LevitForImageClassification`] or [`LevitForImageClassificationWithTeacher`]).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LeViT.
+
+ +
+ LiLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/jpwang/lilt).
+
+## Usage tips
+
+- To combine the Language-Independent Layout Transformer with a new RoBERTa checkpoint from the [hub](https://huggingface.co/models?search=roberta), refer to [this guide](https://github.com/jpWang/LiLT#or-generate-your-own-checkpoint-optional).
+The script will result in `config.json` and `pytorch_model.bin` files being stored locally. After doing this, one can do the following (assuming you're logged in with your HuggingFace account):
+
+```python
+from transformers import LiltModel
+
+model = LiltModel.from_pretrained("path_to_your_files")
+model.push_to_hub("name_of_repo_on_the_hub")
+```
+
+- When preparing data for the model, make sure to use the token vocabulary that corresponds to the RoBERTa checkpoint you combined with the Layout Transformer.
+- As [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) uses the same vocabulary as [LayoutLMv3](layoutlmv3), one can use [`LayoutLMv3TokenizerFast`] to prepare data for the model.
+The same is true for [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-infoxlm-base): one can use [`LayoutXLMTokenizerFast`] for that model.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LiLT.
+
+- Demo notebooks for LiLT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT).
+
+**Documentation resources**
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## LiltConfig
+
+[[autodoc]] LiltConfig
+
+## LiltModel
+
+[[autodoc]] LiltModel
+ - forward
+
+## LiltForSequenceClassification
+
+[[autodoc]] LiltForSequenceClassification
+ - forward
+
+## LiltForTokenClassification
+
+[[autodoc]] LiltForTokenClassification
+ - forward
+
+## LiltForQuestionAnswering
+
+[[autodoc]] LiltForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/llama.md b/docs/transformers/docs/source/en/model_doc/llama.md
new file mode 100644
index 0000000000000000000000000000000000000000..7dc06608963a3ec3a4aa42bd6ce94b9f1fc164ad
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/llama.md
@@ -0,0 +1,181 @@
+
+
+
+
+ LiLT architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/jpwang/lilt).
+
+## Usage tips
+
+- To combine the Language-Independent Layout Transformer with a new RoBERTa checkpoint from the [hub](https://huggingface.co/models?search=roberta), refer to [this guide](https://github.com/jpWang/LiLT#or-generate-your-own-checkpoint-optional).
+The script will result in `config.json` and `pytorch_model.bin` files being stored locally. After doing this, one can do the following (assuming you're logged in with your HuggingFace account):
+
+```python
+from transformers import LiltModel
+
+model = LiltModel.from_pretrained("path_to_your_files")
+model.push_to_hub("name_of_repo_on_the_hub")
+```
+
+- When preparing data for the model, make sure to use the token vocabulary that corresponds to the RoBERTa checkpoint you combined with the Layout Transformer.
+- As [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) uses the same vocabulary as [LayoutLMv3](layoutlmv3), one can use [`LayoutLMv3TokenizerFast`] to prepare data for the model.
+The same is true for [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-infoxlm-base): one can use [`LayoutXLMTokenizerFast`] for that model.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LiLT.
+
+- Demo notebooks for LiLT can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT).
+
+**Documentation resources**
+- [Text classification task guide](../tasks/sequence_classification)
+- [Token classification task guide](../tasks/token_classification)
+- [Question answering task guide](../tasks/question_answering)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## LiltConfig
+
+[[autodoc]] LiltConfig
+
+## LiltModel
+
+[[autodoc]] LiltModel
+ - forward
+
+## LiltForSequenceClassification
+
+[[autodoc]] LiltForSequenceClassification
+ - forward
+
+## LiltForTokenClassification
+
+[[autodoc]] LiltForTokenClassification
+ - forward
+
+## LiltForQuestionAnswering
+
+[[autodoc]] LiltForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/llama.md b/docs/transformers/docs/source/en/model_doc/llama.md
new file mode 100644
index 0000000000000000000000000000000000000000..7dc06608963a3ec3a4aa42bd6ce94b9f1fc164ad
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/llama.md
@@ -0,0 +1,181 @@
+
+
+ +
+ +
+ +
+ LLaVa architecture. Taken from the original paper.
+
+This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
+The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
+
+## Usage tips
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
+
+- Note the model has not been explicitly trained to process multiple images in the same prompt, although this is technically possible, you may experience inaccurate results.
+
+
+> [!NOTE]
+> LLaVA models after release v4.46 will raise warnings about adding `processor.patch_size = {{patch_size}}`, `processor.num_additional_image_tokens = {{num_additional_image_tokens}}` and processor.vision_feature_select_strategy = {{vision_feature_select_strategy}}`. It is strongly recommended to add the attributes to the processor if you own the model checkpoint, or open a PR if it is not owned by you.
+Adding these attributes means that LLaVA will try to infer the number of image tokens required per image and expand the text with as many `
+
+ LLaVa architecture. Taken from the original paper.
+
+This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ) and [ybelkada](https://huggingface.co/ybelkada).
+The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main/llava).
+
+## Usage tips
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
+
+- Note the model has not been explicitly trained to process multiple images in the same prompt, although this is technically possible, you may experience inaccurate results.
+
+
+> [!NOTE]
+> LLaVA models after release v4.46 will raise warnings about adding `processor.patch_size = {{patch_size}}`, `processor.num_additional_image_tokens = {{num_additional_image_tokens}}` and processor.vision_feature_select_strategy = {{vision_feature_select_strategy}}`. It is strongly recommended to add the attributes to the processor if you own the model checkpoint, or open a PR if it is not owned by you.
+Adding these attributes means that LLaVA will try to infer the number of image tokens required per image and expand the text with as many ` +
+ LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main).
+
+## Usage tips
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
+
+
+
+ LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/haotian-liu/LLaVA/tree/main).
+
+## Usage tips
+
+- We advise users to use `padding_side="left"` when computing batched generation as it leads to more accurate results. Simply make sure to call `processor.tokenizer.padding_side = "left"` before generating.
+
+ +
+ +
+ MarkupLM architecture. Taken from the original paper.
+
+## Usage: MarkupLMProcessor
+
+The easiest way to prepare data for the model is to use [`MarkupLMProcessor`], which internally combines a feature extractor
+([`MarkupLMFeatureExtractor`]) and a tokenizer ([`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`]). The feature extractor is
+used to extract all nodes and xpaths from the HTML strings, which are then provided to the tokenizer, which turns them into the
+token-level inputs of the model (`input_ids` etc.). Note that you can still use the feature extractor and tokenizer separately,
+if you only want to handle one of the two tasks.
+
+```python
+from transformers import MarkupLMFeatureExtractor, MarkupLMTokenizerFast, MarkupLMProcessor
+
+feature_extractor = MarkupLMFeatureExtractor()
+tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
+processor = MarkupLMProcessor(feature_extractor, tokenizer)
+```
+
+In short, one can provide HTML strings (and possibly additional data) to [`MarkupLMProcessor`],
+and it will create the inputs expected by the model. Internally, the processor first uses
+[`MarkupLMFeatureExtractor`] to get a list of nodes and corresponding xpaths. The nodes and
+xpaths are then provided to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`], which converts them
+to token-level `input_ids`, `attention_mask`, `token_type_ids`, `xpath_subs_seq`, `xpath_tags_seq`.
+Optionally, one can provide node labels to the processor, which are turned into token-level `labels`.
+
+[`MarkupLMFeatureExtractor`] uses [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/), a Python library for
+pulling data out of HTML and XML files, under the hood. Note that you can still use your own parsing solution of
+choice, and provide the nodes and xpaths yourself to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`].
+
+In total, there are 5 use cases that are supported by the processor. Below, we list them all. Note that each of these
+use cases work for both batched and non-batched inputs (we illustrate them for non-batched inputs).
+
+**Use case 1: web page classification (training, inference) + token classification (inference), parse_html = True**
+
+This is the simplest case, in which the processor will use the feature extractor to get all nodes and xpaths from the HTML.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+
+>>> html_string = """
+...
+...
+...
+...
+
+ MarkupLM architecture. Taken from the original paper.
+
+## Usage: MarkupLMProcessor
+
+The easiest way to prepare data for the model is to use [`MarkupLMProcessor`], which internally combines a feature extractor
+([`MarkupLMFeatureExtractor`]) and a tokenizer ([`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`]). The feature extractor is
+used to extract all nodes and xpaths from the HTML strings, which are then provided to the tokenizer, which turns them into the
+token-level inputs of the model (`input_ids` etc.). Note that you can still use the feature extractor and tokenizer separately,
+if you only want to handle one of the two tasks.
+
+```python
+from transformers import MarkupLMFeatureExtractor, MarkupLMTokenizerFast, MarkupLMProcessor
+
+feature_extractor = MarkupLMFeatureExtractor()
+tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
+processor = MarkupLMProcessor(feature_extractor, tokenizer)
+```
+
+In short, one can provide HTML strings (and possibly additional data) to [`MarkupLMProcessor`],
+and it will create the inputs expected by the model. Internally, the processor first uses
+[`MarkupLMFeatureExtractor`] to get a list of nodes and corresponding xpaths. The nodes and
+xpaths are then provided to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`], which converts them
+to token-level `input_ids`, `attention_mask`, `token_type_ids`, `xpath_subs_seq`, `xpath_tags_seq`.
+Optionally, one can provide node labels to the processor, which are turned into token-level `labels`.
+
+[`MarkupLMFeatureExtractor`] uses [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/), a Python library for
+pulling data out of HTML and XML files, under the hood. Note that you can still use your own parsing solution of
+choice, and provide the nodes and xpaths yourself to [`MarkupLMTokenizer`] or [`MarkupLMTokenizerFast`].
+
+In total, there are 5 use cases that are supported by the processor. Below, we list them all. Note that each of these
+use cases work for both batched and non-batched inputs (we illustrate them for non-batched inputs).
+
+**Use case 1: web page classification (training, inference) + token classification (inference), parse_html = True**
+
+This is the simplest case, in which the processor will use the feature extractor to get all nodes and xpaths from the HTML.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+
+>>> html_string = """
+...
+...
+...
+...  +
+ Mask2Former architecture. Taken from the original paper.
+
+This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
+
+## Usage tips
+
+- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
+- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mask2Former.
+
+- Demo notebooks regarding inference + fine-tuning Mask2Former on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Mask2Former).
+- Scripts for finetuning [`Mask2Former`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/instance-segmentation).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
+The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## Mask2FormerConfig
+
+[[autodoc]] Mask2FormerConfig
+
+## MaskFormer specific outputs
+
+[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerModelOutput
+
+[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerForUniversalSegmentationOutput
+
+## Mask2FormerModel
+
+[[autodoc]] Mask2FormerModel
+ - forward
+
+## Mask2FormerForUniversalSegmentation
+
+[[autodoc]] Mask2FormerForUniversalSegmentation
+ - forward
+
+## Mask2FormerImageProcessor
+
+[[autodoc]] Mask2FormerImageProcessor
+ - preprocess
+ - encode_inputs
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/maskformer.md b/docs/transformers/docs/source/en/model_doc/maskformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..0adbbf2285f9dc1ad625161a9d2bda7f819b05f0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/maskformer.md
@@ -0,0 +1,96 @@
+
+
+# MaskFormer
+
+
+
+ Mask2Former architecture. Taken from the original paper.
+
+This model was contributed by [Shivalika Singh](https://huggingface.co/shivi) and [Alara Dirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/facebookresearch/Mask2Former).
+
+## Usage tips
+
+- Mask2Former uses the same preprocessing and postprocessing steps as [MaskFormer](maskformer). Use [`Mask2FormerImageProcessor`] or [`AutoImageProcessor`] to prepare images and optional targets for the model.
+- To get the final segmentation, depending on the task, you can call [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] or [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] or [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`Mask2FormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Mask2Former.
+
+- Demo notebooks regarding inference + fine-tuning Mask2Former on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Mask2Former).
+- Scripts for finetuning [`Mask2Former`] with [`Trainer`] or [Accelerate](https://huggingface.co/docs/accelerate/index) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/instance-segmentation).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
+The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## Mask2FormerConfig
+
+[[autodoc]] Mask2FormerConfig
+
+## MaskFormer specific outputs
+
+[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerModelOutput
+
+[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerForUniversalSegmentationOutput
+
+## Mask2FormerModel
+
+[[autodoc]] Mask2FormerModel
+ - forward
+
+## Mask2FormerForUniversalSegmentation
+
+[[autodoc]] Mask2FormerForUniversalSegmentation
+ - forward
+
+## Mask2FormerImageProcessor
+
+[[autodoc]] Mask2FormerImageProcessor
+ - preprocess
+ - encode_inputs
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/maskformer.md b/docs/transformers/docs/source/en/model_doc/maskformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..0adbbf2285f9dc1ad625161a9d2bda7f819b05f0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/maskformer.md
@@ -0,0 +1,96 @@
+
+
+# MaskFormer
+
+ +
+This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
+
+## Usage tips
+
+- MaskFormer's Transformer decoder is identical to the decoder of [DETR](detr). During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help the model output the correct number of objects of each class. If you set the parameter `use_auxiliary_loss` of [`MaskFormerConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses are added after each decoder layer (with the FFNs sharing parameters).
+- If you want to train the model in a distributed environment across multiple nodes, then one should update the
+ `get_num_masks` function inside in the `MaskFormerLoss` class of `modeling_maskformer.py`. When training on multiple nodes, this should be
+ set to the average number of target masks across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/MaskFormer/blob/da3e60d85fdeedcb31476b5edd7d328826ce56cc/mask_former/modeling/criterion.py#L169).
+- One can use [`MaskFormerImageProcessor`] to prepare images for the model and optional targets for the model.
+- To get the final segmentation, depending on the task, you can call [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+
+## Resources
+
+
+
+This model was contributed by [francesco](https://huggingface.co/francesco). The original code can be found [here](https://github.com/facebookresearch/MaskFormer).
+
+## Usage tips
+
+- MaskFormer's Transformer decoder is identical to the decoder of [DETR](detr). During training, the authors of DETR did find it helpful to use auxiliary losses in the decoder, especially to help the model output the correct number of objects of each class. If you set the parameter `use_auxiliary_loss` of [`MaskFormerConfig`] to `True`, then prediction feedforward neural networks and Hungarian losses are added after each decoder layer (with the FFNs sharing parameters).
+- If you want to train the model in a distributed environment across multiple nodes, then one should update the
+ `get_num_masks` function inside in the `MaskFormerLoss` class of `modeling_maskformer.py`. When training on multiple nodes, this should be
+ set to the average number of target masks across all nodes, as can be seen in the original implementation [here](https://github.com/facebookresearch/MaskFormer/blob/da3e60d85fdeedcb31476b5edd7d328826ce56cc/mask_former/modeling/criterion.py#L169).
+- One can use [`MaskFormerImageProcessor`] to prepare images for the model and optional targets for the model.
+- To get the final segmentation, depending on the task, you can call [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] or [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. Both tasks can be solved using [`MaskFormerForInstanceSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+
+## Resources
+
+ +
+ MGP-STR architecture. Taken from the original paper.
+
+MGP-STR is trained on two synthetic datasets [MJSynth]((http://www.robots.ox.ac.uk/~vgg/data/text/)) (MJ) and [SynthText](http://www.robots.ox.ac.uk/~vgg/data/scenetext/) (ST) without fine-tuning on other datasets. It achieves state-of-the-art results on six standard Latin scene text benchmarks, including 3 regular text datasets (IC13, SVT, IIIT) and 3 irregular ones (IC15, SVTP, CUTE).
+This model was contributed by [yuekun](https://huggingface.co/yuekun). The original code can be found [here](https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR).
+
+## Inference example
+
+[`MgpstrModel`] accepts images as input and generates three types of predictions, which represent textual information at different granularities.
+The three types of predictions are fused to give the final prediction result.
+
+The [`ViTImageProcessor`] class is responsible for preprocessing the input image and
+[`MgpstrTokenizer`] decodes the generated character tokens to the target string. The
+[`MgpstrProcessor`] wraps [`ViTImageProcessor`] and [`MgpstrTokenizer`]
+into a single instance to both extract the input features and decode the predicted token ids.
+
+- Step-by-step Optical Character Recognition (OCR)
+
+```py
+>>> from transformers import MgpstrProcessor, MgpstrForSceneTextRecognition
+>>> import requests
+>>> from PIL import Image
+
+>>> processor = MgpstrProcessor.from_pretrained('alibaba-damo/mgp-str-base')
+>>> model = MgpstrForSceneTextRecognition.from_pretrained('alibaba-damo/mgp-str-base')
+
+>>> # load image from the IIIT-5k dataset
+>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+
+>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
+>>> outputs = model(pixel_values)
+
+>>> generated_text = processor.batch_decode(outputs.logits)['generated_text']
+```
+
+## MgpstrConfig
+
+[[autodoc]] MgpstrConfig
+
+## MgpstrTokenizer
+
+[[autodoc]] MgpstrTokenizer
+ - save_vocabulary
+
+## MgpstrProcessor
+
+[[autodoc]] MgpstrProcessor
+ - __call__
+ - batch_decode
+
+## MgpstrModel
+
+[[autodoc]] MgpstrModel
+ - forward
+
+## MgpstrForSceneTextRecognition
+
+[[autodoc]] MgpstrForSceneTextRecognition
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mimi.md b/docs/transformers/docs/source/en/model_doc/mimi.md
new file mode 100644
index 0000000000000000000000000000000000000000..6e68394fcaeabca35c453347065b5f80cb989bf2
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mimi.md
@@ -0,0 +1,75 @@
+
+
+# Mimi
+
+
+
+ MGP-STR architecture. Taken from the original paper.
+
+MGP-STR is trained on two synthetic datasets [MJSynth]((http://www.robots.ox.ac.uk/~vgg/data/text/)) (MJ) and [SynthText](http://www.robots.ox.ac.uk/~vgg/data/scenetext/) (ST) without fine-tuning on other datasets. It achieves state-of-the-art results on six standard Latin scene text benchmarks, including 3 regular text datasets (IC13, SVT, IIIT) and 3 irregular ones (IC15, SVTP, CUTE).
+This model was contributed by [yuekun](https://huggingface.co/yuekun). The original code can be found [here](https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR).
+
+## Inference example
+
+[`MgpstrModel`] accepts images as input and generates three types of predictions, which represent textual information at different granularities.
+The three types of predictions are fused to give the final prediction result.
+
+The [`ViTImageProcessor`] class is responsible for preprocessing the input image and
+[`MgpstrTokenizer`] decodes the generated character tokens to the target string. The
+[`MgpstrProcessor`] wraps [`ViTImageProcessor`] and [`MgpstrTokenizer`]
+into a single instance to both extract the input features and decode the predicted token ids.
+
+- Step-by-step Optical Character Recognition (OCR)
+
+```py
+>>> from transformers import MgpstrProcessor, MgpstrForSceneTextRecognition
+>>> import requests
+>>> from PIL import Image
+
+>>> processor = MgpstrProcessor.from_pretrained('alibaba-damo/mgp-str-base')
+>>> model = MgpstrForSceneTextRecognition.from_pretrained('alibaba-damo/mgp-str-base')
+
+>>> # load image from the IIIT-5k dataset
+>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+
+>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
+>>> outputs = model(pixel_values)
+
+>>> generated_text = processor.batch_decode(outputs.logits)['generated_text']
+```
+
+## MgpstrConfig
+
+[[autodoc]] MgpstrConfig
+
+## MgpstrTokenizer
+
+[[autodoc]] MgpstrTokenizer
+ - save_vocabulary
+
+## MgpstrProcessor
+
+[[autodoc]] MgpstrProcessor
+ - __call__
+ - batch_decode
+
+## MgpstrModel
+
+[[autodoc]] MgpstrModel
+ - forward
+
+## MgpstrForSceneTextRecognition
+
+[[autodoc]] MgpstrForSceneTextRecognition
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/mimi.md b/docs/transformers/docs/source/en/model_doc/mimi.md
new file mode 100644
index 0000000000000000000000000000000000000000..6e68394fcaeabca35c453347065b5f80cb989bf2
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/mimi.md
@@ -0,0 +1,75 @@
+
+
+# Mimi
+
+ +
+ +
+ +
+ +
+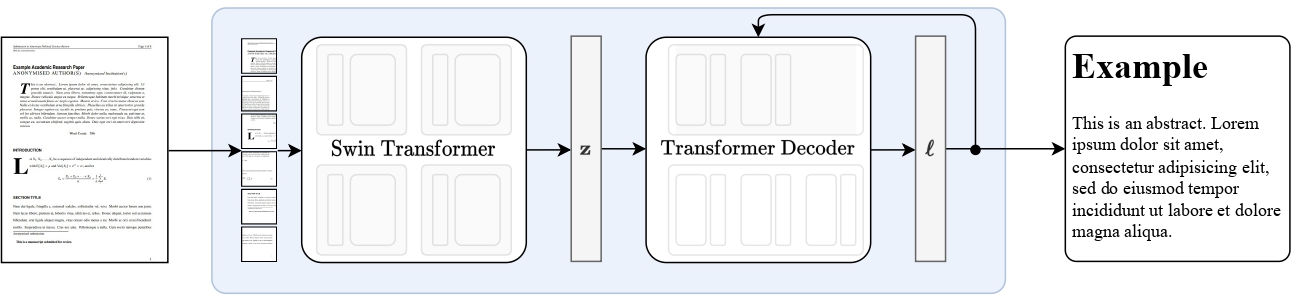 +
+ Nougat high-level overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/facebookresearch/nougat).
+
+## Usage tips
+
+- The quickest way to get started with Nougat is by checking the [tutorial
+ notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Nougat), which show how to use the model
+ at inference time as well as fine-tuning on custom data.
+- Nougat is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework. The model is identical to [Donut](donut) in terms of architecture.
+
+## Inference
+
+Nougat's [`VisionEncoderDecoder`] model accepts images as input and makes use of
+[`~generation.GenerationMixin.generate`] to autoregressively generate text given the input image.
+
+The [`NougatImageProcessor`] class is responsible for preprocessing the input image and
+[`NougatTokenizerFast`] decodes the generated target tokens to the target string. The
+[`NougatProcessor`] wraps [`NougatImageProcessor`] and [`NougatTokenizerFast`] classes
+into a single instance to both extract the input features and decode the predicted token ids.
+
+- Step-by-step PDF transcription
+
+```py
+>>> from huggingface_hub import hf_hub_download
+>>> import re
+>>> from PIL import Image
+
+>>> from transformers import NougatProcessor, VisionEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> processor = NougatProcessor.from_pretrained("facebook/nougat-base")
+>>> model = VisionEncoderDecoderModel.from_pretrained("facebook/nougat-base")
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model.to(device) # doctest: +IGNORE_RESULT
+
+>>> # prepare PDF image for the model
+>>> filepath = hf_hub_download(repo_id="hf-internal-testing/fixtures_docvqa", filename="nougat_paper.png", repo_type="dataset")
+>>> image = Image.open(filepath)
+>>> pixel_values = processor(image, return_tensors="pt").pixel_values
+
+>>> # generate transcription (here we only generate 30 tokens)
+>>> outputs = model.generate(
+... pixel_values.to(device),
+... min_length=1,
+... max_new_tokens=30,
+... bad_words_ids=[[processor.tokenizer.unk_token_id]],
+... )
+
+>>> sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
+>>> sequence = processor.post_process_generation(sequence, fix_markdown=False)
+>>> # note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequence
+>>> print(repr(sequence))
+'\n\n# Nougat: Neural Optical Understanding for Academic Documents\n\n Lukas Blecher\n\nCorrespondence to: lblecher@'
+```
+
+See the [model hub](https://huggingface.co/models?filter=nougat) to look for Nougat checkpoints.
+
+
+
+ Nougat high-level overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/facebookresearch/nougat).
+
+## Usage tips
+
+- The quickest way to get started with Nougat is by checking the [tutorial
+ notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Nougat), which show how to use the model
+ at inference time as well as fine-tuning on custom data.
+- Nougat is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework. The model is identical to [Donut](donut) in terms of architecture.
+
+## Inference
+
+Nougat's [`VisionEncoderDecoder`] model accepts images as input and makes use of
+[`~generation.GenerationMixin.generate`] to autoregressively generate text given the input image.
+
+The [`NougatImageProcessor`] class is responsible for preprocessing the input image and
+[`NougatTokenizerFast`] decodes the generated target tokens to the target string. The
+[`NougatProcessor`] wraps [`NougatImageProcessor`] and [`NougatTokenizerFast`] classes
+into a single instance to both extract the input features and decode the predicted token ids.
+
+- Step-by-step PDF transcription
+
+```py
+>>> from huggingface_hub import hf_hub_download
+>>> import re
+>>> from PIL import Image
+
+>>> from transformers import NougatProcessor, VisionEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> processor = NougatProcessor.from_pretrained("facebook/nougat-base")
+>>> model = VisionEncoderDecoderModel.from_pretrained("facebook/nougat-base")
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model.to(device) # doctest: +IGNORE_RESULT
+
+>>> # prepare PDF image for the model
+>>> filepath = hf_hub_download(repo_id="hf-internal-testing/fixtures_docvqa", filename="nougat_paper.png", repo_type="dataset")
+>>> image = Image.open(filepath)
+>>> pixel_values = processor(image, return_tensors="pt").pixel_values
+
+>>> # generate transcription (here we only generate 30 tokens)
+>>> outputs = model.generate(
+... pixel_values.to(device),
+... min_length=1,
+... max_new_tokens=30,
+... bad_words_ids=[[processor.tokenizer.unk_token_id]],
+... )
+
+>>> sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
+>>> sequence = processor.post_process_generation(sequence, fix_markdown=False)
+>>> # note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequence
+>>> print(repr(sequence))
+'\n\n# Nougat: Neural Optical Understanding for Academic Documents\n\n Lukas Blecher\n\nCorrespondence to: lblecher@'
+```
+
+See the [model hub](https://huggingface.co/models?filter=nougat) to look for Nougat checkpoints.
+
+ +
+ OmDet-Turbo architecture overview. Taken from the original paper.
+
+This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
+The original code can be found [here](https://github.com/om-ai-lab/OmDet).
+
+## Usage tips
+
+One unique property of OmDet-Turbo compared to other zero-shot object detection models, such as [Grounding DINO](grounding-dino), is the decoupled classes and prompt embedding structure that allows caching of text embeddings. This means that the model needs both classes and task as inputs, where classes is a list of objects we want to detect and task is the grounded text used to guide open-vocabulary detection. This approach limits the scope of the open-vocabulary detection and makes the decoding process faster.
+
+[`OmDetTurboProcessor`] is used to prepare the classes, task and image triplet. The task input is optional, and when not provided, it will default to `"Detect [class1], [class2], [class3], ..."`. To process the results from the model, one can use `post_process_grounded_object_detection` from [`OmDetTurboProcessor`]. Notably, this function takes in the input classes, as unlike other zero-shot object detection models, the decoupling of classes and task embeddings means that no decoding of the predicted class embeddings is needed in the post-processing step, and the predicted classes can be matched to the inputted ones directly.
+
+## Usage example
+
+### Single image inference
+
+Here's how to load the model and prepare the inputs to perform zero-shot object detection on a single image:
+
+```python
+>>> import torch
+>>> import requests
+>>> from PIL import Image
+
+>>> from transformers import AutoProcessor, OmDetTurboForObjectDetection
+
+>>> processor = AutoProcessor.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
+>>> model = OmDetTurboForObjectDetection.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> text_labels = ["cat", "remote"]
+>>> inputs = processor(image, text=text_labels, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> # convert outputs (bounding boxes and class logits)
+>>> results = processor.post_process_grounded_object_detection(
+... outputs,
+... target_sizes=[(image.height, image.width)],
+... text_labels=text_labels,
+... threshold=0.3,
+... nms_threshold=0.3,
+... )
+>>> result = results[0]
+>>> boxes, scores, text_labels = result["boxes"], result["scores"], result["text_labels"]
+>>> for box, score, text_label in zip(boxes, scores, text_labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text_label} with confidence {round(score.item(), 3)} at location {box}")
+Detected remote with confidence 0.768 at location [39.89, 70.35, 176.74, 118.04]
+Detected cat with confidence 0.72 at location [11.6, 54.19, 314.8, 473.95]
+Detected remote with confidence 0.563 at location [333.38, 75.77, 370.7, 187.03]
+Detected cat with confidence 0.552 at location [345.15, 23.95, 639.75, 371.67]
+```
+
+### Multi image inference
+
+OmDet-Turbo can perform batched multi-image inference, with support for different text prompts and classes in the same batch:
+
+```python
+>>> import torch
+>>> import requests
+>>> from io import BytesIO
+>>> from PIL import Image
+>>> from transformers import AutoProcessor, OmDetTurboForObjectDetection
+
+>>> processor = AutoProcessor.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
+>>> model = OmDetTurboForObjectDetection.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
+
+>>> url1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image1 = Image.open(BytesIO(requests.get(url1).content)).convert("RGB")
+>>> text_labels1 = ["cat", "remote"]
+>>> task1 = "Detect {}.".format(", ".join(text_labels1))
+
+>>> url2 = "http://images.cocodataset.org/train2017/000000257813.jpg"
+>>> image2 = Image.open(BytesIO(requests.get(url2).content)).convert("RGB")
+>>> text_labels2 = ["boat"]
+>>> task2 = "Detect everything that looks like a boat."
+
+>>> url3 = "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"
+>>> image3 = Image.open(BytesIO(requests.get(url3).content)).convert("RGB")
+>>> text_labels3 = ["statue", "trees"]
+>>> task3 = "Focus on the foreground, detect statue and trees."
+
+>>> inputs = processor(
+... images=[image1, image2, image3],
+... text=[text_labels1, text_labels2, text_labels3],
+... task=[task1, task2, task3],
+... return_tensors="pt",
+... )
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> # convert outputs (bounding boxes and class logits)
+>>> results = processor.post_process_grounded_object_detection(
+... outputs,
+... text_labels=[text_labels1, text_labels2, text_labels3],
+... target_sizes=[(image.height, image.width) for image in [image1, image2, image3]],
+... threshold=0.2,
+... nms_threshold=0.3,
+... )
+
+>>> for i, result in enumerate(results):
+... for score, text_label, box in zip(
+... result["scores"], result["text_labels"], result["boxes"]
+... ):
+... box = [round(i, 1) for i in box.tolist()]
+... print(
+... f"Detected {text_label} with confidence "
+... f"{round(score.item(), 2)} at location {box} in image {i}"
+... )
+Detected remote with confidence 0.77 at location [39.9, 70.4, 176.7, 118.0] in image 0
+Detected cat with confidence 0.72 at location [11.6, 54.2, 314.8, 474.0] in image 0
+Detected remote with confidence 0.56 at location [333.4, 75.8, 370.7, 187.0] in image 0
+Detected cat with confidence 0.55 at location [345.2, 24.0, 639.8, 371.7] in image 0
+Detected boat with confidence 0.32 at location [146.9, 219.8, 209.6, 250.7] in image 1
+Detected boat with confidence 0.3 at location [319.1, 223.2, 403.2, 238.4] in image 1
+Detected boat with confidence 0.27 at location [37.7, 220.3, 84.0, 235.9] in image 1
+Detected boat with confidence 0.22 at location [407.9, 207.0, 441.7, 220.2] in image 1
+Detected statue with confidence 0.73 at location [544.7, 210.2, 651.9, 502.8] in image 2
+Detected trees with confidence 0.25 at location [3.9, 584.3, 391.4, 785.6] in image 2
+Detected trees with confidence 0.25 at location [1.4, 621.2, 118.2, 787.8] in image 2
+Detected statue with confidence 0.2 at location [428.1, 205.5, 767.3, 759.5] in image 2
+
+```
+
+## OmDetTurboConfig
+
+[[autodoc]] OmDetTurboConfig
+
+## OmDetTurboProcessor
+
+[[autodoc]] OmDetTurboProcessor
+ - post_process_grounded_object_detection
+
+## OmDetTurboForObjectDetection
+
+[[autodoc]] OmDetTurboForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/oneformer.md b/docs/transformers/docs/source/en/model_doc/oneformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..f1c1de791238f3fc64df10a4a4057062696a0c7b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/oneformer.md
@@ -0,0 +1,90 @@
+
+
+# OneFormer
+
+
+
+ OmDet-Turbo architecture overview. Taken from the original paper.
+
+This model was contributed by [yonigozlan](https://huggingface.co/yonigozlan).
+The original code can be found [here](https://github.com/om-ai-lab/OmDet).
+
+## Usage tips
+
+One unique property of OmDet-Turbo compared to other zero-shot object detection models, such as [Grounding DINO](grounding-dino), is the decoupled classes and prompt embedding structure that allows caching of text embeddings. This means that the model needs both classes and task as inputs, where classes is a list of objects we want to detect and task is the grounded text used to guide open-vocabulary detection. This approach limits the scope of the open-vocabulary detection and makes the decoding process faster.
+
+[`OmDetTurboProcessor`] is used to prepare the classes, task and image triplet. The task input is optional, and when not provided, it will default to `"Detect [class1], [class2], [class3], ..."`. To process the results from the model, one can use `post_process_grounded_object_detection` from [`OmDetTurboProcessor`]. Notably, this function takes in the input classes, as unlike other zero-shot object detection models, the decoupling of classes and task embeddings means that no decoding of the predicted class embeddings is needed in the post-processing step, and the predicted classes can be matched to the inputted ones directly.
+
+## Usage example
+
+### Single image inference
+
+Here's how to load the model and prepare the inputs to perform zero-shot object detection on a single image:
+
+```python
+>>> import torch
+>>> import requests
+>>> from PIL import Image
+
+>>> from transformers import AutoProcessor, OmDetTurboForObjectDetection
+
+>>> processor = AutoProcessor.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
+>>> model = OmDetTurboForObjectDetection.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> text_labels = ["cat", "remote"]
+>>> inputs = processor(image, text=text_labels, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> # convert outputs (bounding boxes and class logits)
+>>> results = processor.post_process_grounded_object_detection(
+... outputs,
+... target_sizes=[(image.height, image.width)],
+... text_labels=text_labels,
+... threshold=0.3,
+... nms_threshold=0.3,
+... )
+>>> result = results[0]
+>>> boxes, scores, text_labels = result["boxes"], result["scores"], result["text_labels"]
+>>> for box, score, text_label in zip(boxes, scores, text_labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text_label} with confidence {round(score.item(), 3)} at location {box}")
+Detected remote with confidence 0.768 at location [39.89, 70.35, 176.74, 118.04]
+Detected cat with confidence 0.72 at location [11.6, 54.19, 314.8, 473.95]
+Detected remote with confidence 0.563 at location [333.38, 75.77, 370.7, 187.03]
+Detected cat with confidence 0.552 at location [345.15, 23.95, 639.75, 371.67]
+```
+
+### Multi image inference
+
+OmDet-Turbo can perform batched multi-image inference, with support for different text prompts and classes in the same batch:
+
+```python
+>>> import torch
+>>> import requests
+>>> from io import BytesIO
+>>> from PIL import Image
+>>> from transformers import AutoProcessor, OmDetTurboForObjectDetection
+
+>>> processor = AutoProcessor.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
+>>> model = OmDetTurboForObjectDetection.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
+
+>>> url1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image1 = Image.open(BytesIO(requests.get(url1).content)).convert("RGB")
+>>> text_labels1 = ["cat", "remote"]
+>>> task1 = "Detect {}.".format(", ".join(text_labels1))
+
+>>> url2 = "http://images.cocodataset.org/train2017/000000257813.jpg"
+>>> image2 = Image.open(BytesIO(requests.get(url2).content)).convert("RGB")
+>>> text_labels2 = ["boat"]
+>>> task2 = "Detect everything that looks like a boat."
+
+>>> url3 = "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"
+>>> image3 = Image.open(BytesIO(requests.get(url3).content)).convert("RGB")
+>>> text_labels3 = ["statue", "trees"]
+>>> task3 = "Focus on the foreground, detect statue and trees."
+
+>>> inputs = processor(
+... images=[image1, image2, image3],
+... text=[text_labels1, text_labels2, text_labels3],
+... task=[task1, task2, task3],
+... return_tensors="pt",
+... )
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> # convert outputs (bounding boxes and class logits)
+>>> results = processor.post_process_grounded_object_detection(
+... outputs,
+... text_labels=[text_labels1, text_labels2, text_labels3],
+... target_sizes=[(image.height, image.width) for image in [image1, image2, image3]],
+... threshold=0.2,
+... nms_threshold=0.3,
+... )
+
+>>> for i, result in enumerate(results):
+... for score, text_label, box in zip(
+... result["scores"], result["text_labels"], result["boxes"]
+... ):
+... box = [round(i, 1) for i in box.tolist()]
+... print(
+... f"Detected {text_label} with confidence "
+... f"{round(score.item(), 2)} at location {box} in image {i}"
+... )
+Detected remote with confidence 0.77 at location [39.9, 70.4, 176.7, 118.0] in image 0
+Detected cat with confidence 0.72 at location [11.6, 54.2, 314.8, 474.0] in image 0
+Detected remote with confidence 0.56 at location [333.4, 75.8, 370.7, 187.0] in image 0
+Detected cat with confidence 0.55 at location [345.2, 24.0, 639.8, 371.7] in image 0
+Detected boat with confidence 0.32 at location [146.9, 219.8, 209.6, 250.7] in image 1
+Detected boat with confidence 0.3 at location [319.1, 223.2, 403.2, 238.4] in image 1
+Detected boat with confidence 0.27 at location [37.7, 220.3, 84.0, 235.9] in image 1
+Detected boat with confidence 0.22 at location [407.9, 207.0, 441.7, 220.2] in image 1
+Detected statue with confidence 0.73 at location [544.7, 210.2, 651.9, 502.8] in image 2
+Detected trees with confidence 0.25 at location [3.9, 584.3, 391.4, 785.6] in image 2
+Detected trees with confidence 0.25 at location [1.4, 621.2, 118.2, 787.8] in image 2
+Detected statue with confidence 0.2 at location [428.1, 205.5, 767.3, 759.5] in image 2
+
+```
+
+## OmDetTurboConfig
+
+[[autodoc]] OmDetTurboConfig
+
+## OmDetTurboProcessor
+
+[[autodoc]] OmDetTurboProcessor
+ - post_process_grounded_object_detection
+
+## OmDetTurboForObjectDetection
+
+[[autodoc]] OmDetTurboForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/oneformer.md b/docs/transformers/docs/source/en/model_doc/oneformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..f1c1de791238f3fc64df10a4a4057062696a0c7b
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/oneformer.md
@@ -0,0 +1,90 @@
+
+
+# OneFormer
+
+ +
+The abstract from the paper is the following:
+
+*Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible.*
+
+The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
+
+
+
+The abstract from the paper is the following:
+
+*Universal Image Segmentation is not a new concept. Past attempts to unify image segmentation in the last decades include scene parsing, panoptic segmentation, and, more recently, new panoptic architectures. However, such panoptic architectures do not truly unify image segmentation because they need to be trained individually on the semantic, instance, or panoptic segmentation to achieve the best performance. Ideally, a truly universal framework should be trained only once and achieve SOTA performance across all three image segmentation tasks. To that end, we propose OneFormer, a universal image segmentation framework that unifies segmentation with a multi-task train-once design. We first propose a task-conditioned joint training strategy that enables training on ground truths of each domain (semantic, instance, and panoptic segmentation) within a single multi-task training process. Secondly, we introduce a task token to condition our model on the task at hand, making our model task-dynamic to support multi-task training and inference. Thirdly, we propose using a query-text contrastive loss during training to establish better inter-task and inter-class distinctions. Notably, our single OneFormer model outperforms specialized Mask2Former models across all three segmentation tasks on ADE20k, CityScapes, and COCO, despite the latter being trained on each of the three tasks individually with three times the resources. With new ConvNeXt and DiNAT backbones, we observe even more performance improvement. We believe OneFormer is a significant step towards making image segmentation more universal and accessible.*
+
+The figure below illustrates the architecture of OneFormer. Taken from the [original paper](https://arxiv.org/abs/2211.06220).
+
+ +
+This model was contributed by [Jitesh Jain](https://huggingface.co/praeclarumjj3). The original code can be found [here](https://github.com/SHI-Labs/OneFormer).
+
+## Usage tips
+
+- OneFormer requires two inputs during inference: *image* and *task token*.
+- During training, OneFormer only uses panoptic annotations.
+- If you want to train the model in a distributed environment across multiple nodes, then one should update the
+ `get_num_masks` function inside in the `OneFormerLoss` class of `modeling_oneformer.py`. When training on multiple nodes, this should be
+ set to the average number of target masks across all nodes, as can be seen in the original implementation [here](https://github.com/SHI-Labs/OneFormer/blob/33ebb56ed34f970a30ae103e786c0cb64c653d9a/oneformer/modeling/criterion.py#L287).
+- One can use [`OneFormerProcessor`] to prepare input images and task inputs for the model and optional targets for the model. [`OneFormerProcessor`] wraps [`OneFormerImageProcessor`] and [`CLIPTokenizer`] into a single instance to both prepare the images and encode the task inputs.
+- To get the final segmentation, depending on the task, you can call [`~OneFormerProcessor.post_process_semantic_segmentation`] or [`~OneFormerImageProcessor.post_process_instance_segmentation`] or [`~OneFormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`OneFormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OneFormer.
+
+- Demo notebooks regarding inference + fine-tuning on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OneFormer).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
+The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## OneFormer specific outputs
+
+[[autodoc]] models.oneformer.modeling_oneformer.OneFormerModelOutput
+
+[[autodoc]] models.oneformer.modeling_oneformer.OneFormerForUniversalSegmentationOutput
+
+## OneFormerConfig
+
+[[autodoc]] OneFormerConfig
+
+## OneFormerImageProcessor
+
+[[autodoc]] OneFormerImageProcessor
+ - preprocess
+ - encode_inputs
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
+## OneFormerProcessor
+
+[[autodoc]] OneFormerProcessor
+
+## OneFormerModel
+
+[[autodoc]] OneFormerModel
+ - forward
+
+## OneFormerForUniversalSegmentation
+
+[[autodoc]] OneFormerForUniversalSegmentation
+ - forward
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/open-llama.md b/docs/transformers/docs/source/en/model_doc/open-llama.md
new file mode 100644
index 0000000000000000000000000000000000000000..3b4856cd4fb6db9fb8acc203c333cd8bfce81c83
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/open-llama.md
@@ -0,0 +1,65 @@
+
+
+# Open-Llama
+
+
+
+This model was contributed by [Jitesh Jain](https://huggingface.co/praeclarumjj3). The original code can be found [here](https://github.com/SHI-Labs/OneFormer).
+
+## Usage tips
+
+- OneFormer requires two inputs during inference: *image* and *task token*.
+- During training, OneFormer only uses panoptic annotations.
+- If you want to train the model in a distributed environment across multiple nodes, then one should update the
+ `get_num_masks` function inside in the `OneFormerLoss` class of `modeling_oneformer.py`. When training on multiple nodes, this should be
+ set to the average number of target masks across all nodes, as can be seen in the original implementation [here](https://github.com/SHI-Labs/OneFormer/blob/33ebb56ed34f970a30ae103e786c0cb64c653d9a/oneformer/modeling/criterion.py#L287).
+- One can use [`OneFormerProcessor`] to prepare input images and task inputs for the model and optional targets for the model. [`OneFormerProcessor`] wraps [`OneFormerImageProcessor`] and [`CLIPTokenizer`] into a single instance to both prepare the images and encode the task inputs.
+- To get the final segmentation, depending on the task, you can call [`~OneFormerProcessor.post_process_semantic_segmentation`] or [`~OneFormerImageProcessor.post_process_instance_segmentation`] or [`~OneFormerImageProcessor.post_process_panoptic_segmentation`]. All three tasks can be solved using [`OneFormerForUniversalSegmentation`] output, panoptic segmentation accepts an optional `label_ids_to_fuse` argument to fuse instances of the target object/s (e.g. sky) together.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OneFormer.
+
+- Demo notebooks regarding inference + fine-tuning on custom data can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OneFormer).
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it.
+The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## OneFormer specific outputs
+
+[[autodoc]] models.oneformer.modeling_oneformer.OneFormerModelOutput
+
+[[autodoc]] models.oneformer.modeling_oneformer.OneFormerForUniversalSegmentationOutput
+
+## OneFormerConfig
+
+[[autodoc]] OneFormerConfig
+
+## OneFormerImageProcessor
+
+[[autodoc]] OneFormerImageProcessor
+ - preprocess
+ - encode_inputs
+ - post_process_semantic_segmentation
+ - post_process_instance_segmentation
+ - post_process_panoptic_segmentation
+
+## OneFormerProcessor
+
+[[autodoc]] OneFormerProcessor
+
+## OneFormerModel
+
+[[autodoc]] OneFormerModel
+ - forward
+
+## OneFormerForUniversalSegmentation
+
+[[autodoc]] OneFormerForUniversalSegmentation
+ - forward
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/open-llama.md b/docs/transformers/docs/source/en/model_doc/open-llama.md
new file mode 100644
index 0000000000000000000000000000000000000000..3b4856cd4fb6db9fb8acc203c333cd8bfce81c83
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/open-llama.md
@@ -0,0 +1,65 @@
+
+
+# Open-Llama
+
+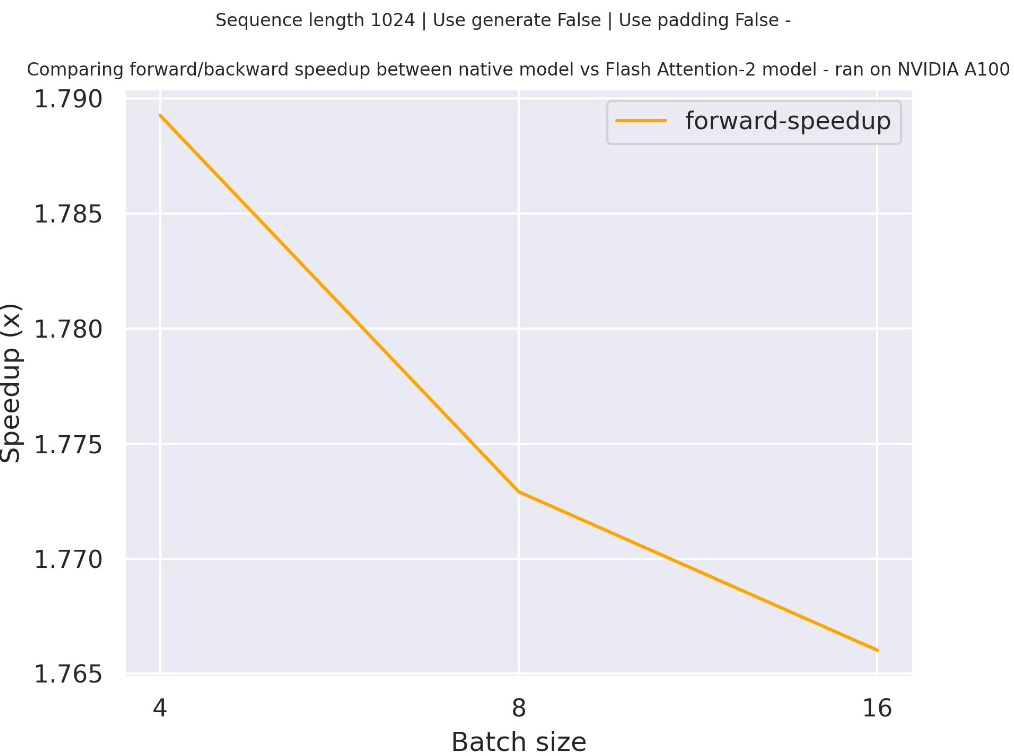 +
+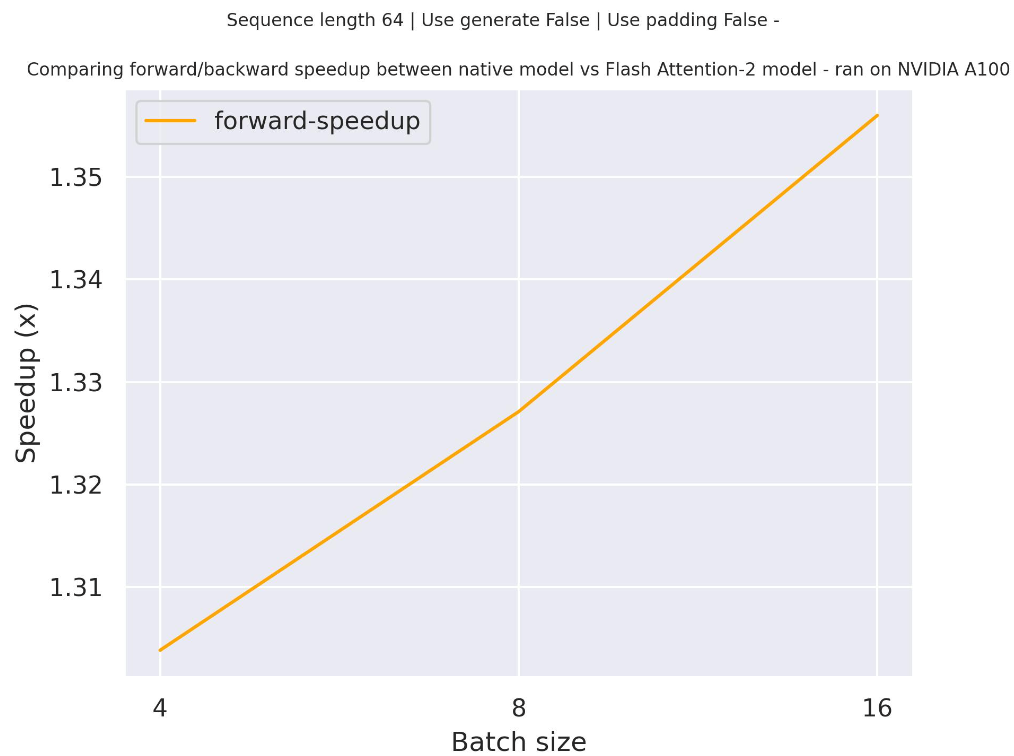 +
+ +
+ OWLv2 high-level overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+
+## Usage example
+
+OWLv2 is, just like its predecessor [OWL-ViT](owlvit), a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
+
+[`Owlv2ImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`Owlv2Processor`] wraps [`Owlv2ImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`Owlv2Processor`] and [`Owlv2ForObjectDetection`].
+
+```python
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+
+>>> from transformers import Owlv2Processor, Owlv2ForObjectDetection
+
+>>> processor = Owlv2Processor.from_pretrained("google/owlv2-base-patch16-ensemble")
+>>> model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> text_labels = [["a photo of a cat", "a photo of a dog"]]
+>>> inputs = processor(text=text_labels, images=image, return_tensors="pt")
+>>> outputs = model(**inputs)
+
+>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
+>>> target_sizes = torch.tensor([(image.height, image.width)])
+>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
+>>> results = processor.post_process_grounded_object_detection(
+... outputs=outputs, target_sizes=target_sizes, threshold=0.1, text_labels=text_labels
+... )
+>>> # Retrieve predictions for the first image for the corresponding text queries
+>>> result = results[0]
+>>> boxes, scores, text_labels = result["boxes"], result["scores"], result["text_labels"]
+>>> for box, score, text_label in zip(boxes, scores, text_labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text_label} with confidence {round(score.item(), 3)} at location {box}")
+Detected a photo of a cat with confidence 0.614 at location [341.67, 23.39, 642.32, 371.35]
+Detected a photo of a cat with confidence 0.665 at location [6.75, 51.96, 326.62, 473.13]
+```
+
+## Resources
+
+- A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- [Zero-shot object detection task guide](../tasks/zero_shot_object_detection)
+
+
+
+ OWLv2 high-level overview. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+
+## Usage example
+
+OWLv2 is, just like its predecessor [OWL-ViT](owlvit), a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
+
+[`Owlv2ImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`Owlv2Processor`] wraps [`Owlv2ImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`Owlv2Processor`] and [`Owlv2ForObjectDetection`].
+
+```python
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+
+>>> from transformers import Owlv2Processor, Owlv2ForObjectDetection
+
+>>> processor = Owlv2Processor.from_pretrained("google/owlv2-base-patch16-ensemble")
+>>> model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> text_labels = [["a photo of a cat", "a photo of a dog"]]
+>>> inputs = processor(text=text_labels, images=image, return_tensors="pt")
+>>> outputs = model(**inputs)
+
+>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
+>>> target_sizes = torch.tensor([(image.height, image.width)])
+>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
+>>> results = processor.post_process_grounded_object_detection(
+... outputs=outputs, target_sizes=target_sizes, threshold=0.1, text_labels=text_labels
+... )
+>>> # Retrieve predictions for the first image for the corresponding text queries
+>>> result = results[0]
+>>> boxes, scores, text_labels = result["boxes"], result["scores"], result["text_labels"]
+>>> for box, score, text_label in zip(boxes, scores, text_labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text_label} with confidence {round(score.item(), 3)} at location {box}")
+Detected a photo of a cat with confidence 0.614 at location [341.67, 23.39, 642.32, 371.35]
+Detected a photo of a cat with confidence 0.665 at location [6.75, 51.96, 326.62, 473.13]
+```
+
+## Resources
+
+- A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- [Zero-shot object detection task guide](../tasks/zero_shot_object_detection)
+
+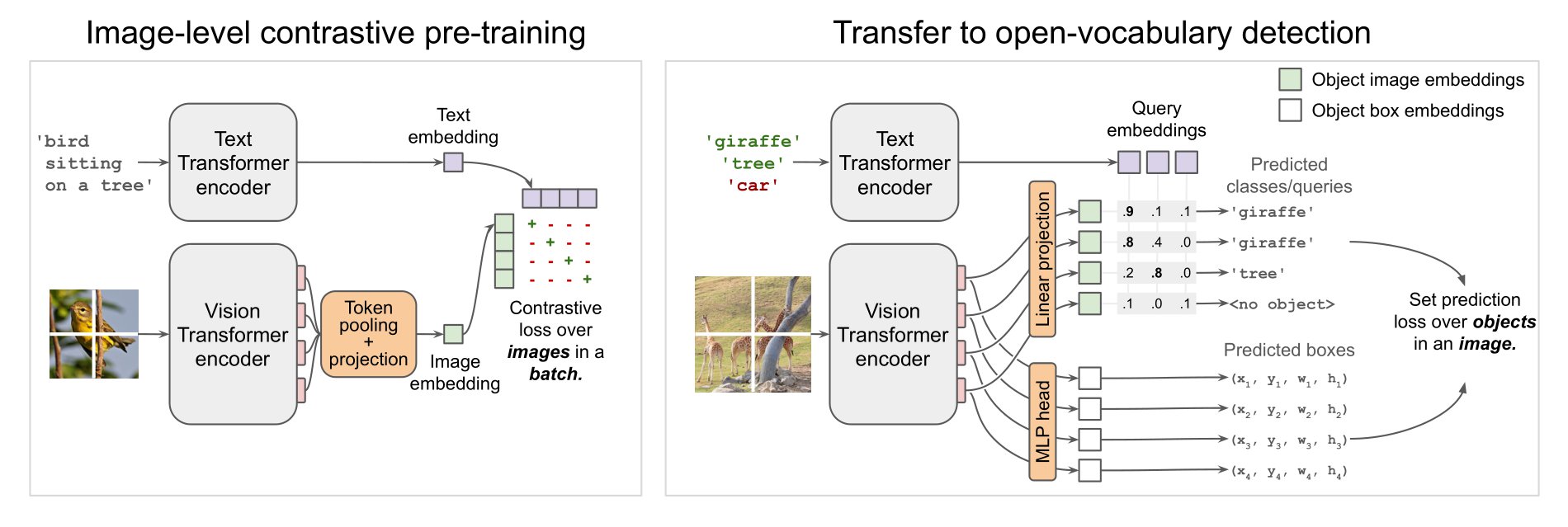 +
+ OWL-ViT architecture. Taken from the original paper.
+
+This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+
+## Usage tips
+
+OWL-ViT is a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
+
+[`OwlViTImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`OwlViTProcessor`] wraps [`OwlViTImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`OwlViTProcessor`] and [`OwlViTForObjectDetection`].
+
+```python
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+
+>>> from transformers import OwlViTProcessor, OwlViTForObjectDetection
+
+>>> processor = OwlViTProcessor.from_pretrained("google/owlvit-base-patch32")
+>>> model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch32")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> text_labels = [["a photo of a cat", "a photo of a dog"]]
+>>> inputs = processor(text=text_labels, images=image, return_tensors="pt")
+>>> outputs = model(**inputs)
+
+>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
+>>> target_sizes = torch.tensor([(image.height, image.width)])
+>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
+>>> results = processor.post_process_grounded_object_detection(
+... outputs=outputs, target_sizes=target_sizes, threshold=0.1, text_labels=text_labels
+... )
+>>> # Retrieve predictions for the first image for the corresponding text queries
+>>> result = results[0]
+>>> boxes, scores, text_labels = result["boxes"], result["scores"], result["text_labels"]
+>>> for box, score, text_label in zip(boxes, scores, text_labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text_label} with confidence {round(score.item(), 3)} at location {box}")
+Detected a photo of a cat with confidence 0.707 at location [324.97, 20.44, 640.58, 373.29]
+Detected a photo of a cat with confidence 0.717 at location [1.46, 55.26, 315.55, 472.17]
+```
+
+## Resources
+
+A demo notebook on using OWL-ViT for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb).
+
+## OwlViTConfig
+
+[[autodoc]] OwlViTConfig
+ - from_text_vision_configs
+
+## OwlViTTextConfig
+
+[[autodoc]] OwlViTTextConfig
+
+## OwlViTVisionConfig
+
+[[autodoc]] OwlViTVisionConfig
+
+## OwlViTImageProcessor
+
+[[autodoc]] OwlViTImageProcessor
+ - preprocess
+
+## OwlViTImageProcessorFast
+
+[[autodoc]] OwlViTImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+ - post_process_image_guided_detection
+
+## OwlViTProcessor
+
+[[autodoc]] OwlViTProcessor
+ - __call__
+ - post_process_grounded_object_detection
+ - post_process_image_guided_detection
+
+## OwlViTModel
+
+[[autodoc]] OwlViTModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## OwlViTTextModel
+
+[[autodoc]] OwlViTTextModel
+ - forward
+
+## OwlViTVisionModel
+
+[[autodoc]] OwlViTVisionModel
+ - forward
+
+## OwlViTForObjectDetection
+
+[[autodoc]] OwlViTForObjectDetection
+ - forward
+ - image_guided_detection
diff --git a/docs/transformers/docs/source/en/model_doc/paligemma.md b/docs/transformers/docs/source/en/model_doc/paligemma.md
new file mode 100644
index 0000000000000000000000000000000000000000..fa119a5f8362e6c1cc9d31673d674e7688824b55
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/paligemma.md
@@ -0,0 +1,180 @@
+
+
+
+
+ OWL-ViT architecture. Taken from the original paper.
+
+This model was contributed by [adirik](https://huggingface.co/adirik). The original code can be found [here](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+
+## Usage tips
+
+OWL-ViT is a zero-shot text-conditioned object detection model. OWL-ViT uses [CLIP](clip) as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
+
+[`OwlViTImageProcessor`] can be used to resize (or rescale) and normalize images for the model and [`CLIPTokenizer`] is used to encode the text. [`OwlViTProcessor`] wraps [`OwlViTImageProcessor`] and [`CLIPTokenizer`] into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using [`OwlViTProcessor`] and [`OwlViTForObjectDetection`].
+
+```python
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+
+>>> from transformers import OwlViTProcessor, OwlViTForObjectDetection
+
+>>> processor = OwlViTProcessor.from_pretrained("google/owlvit-base-patch32")
+>>> model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch32")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> text_labels = [["a photo of a cat", "a photo of a dog"]]
+>>> inputs = processor(text=text_labels, images=image, return_tensors="pt")
+>>> outputs = model(**inputs)
+
+>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
+>>> target_sizes = torch.tensor([(image.height, image.width)])
+>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
+>>> results = processor.post_process_grounded_object_detection(
+... outputs=outputs, target_sizes=target_sizes, threshold=0.1, text_labels=text_labels
+... )
+>>> # Retrieve predictions for the first image for the corresponding text queries
+>>> result = results[0]
+>>> boxes, scores, text_labels = result["boxes"], result["scores"], result["text_labels"]
+>>> for box, score, text_label in zip(boxes, scores, text_labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text_label} with confidence {round(score.item(), 3)} at location {box}")
+Detected a photo of a cat with confidence 0.707 at location [324.97, 20.44, 640.58, 373.29]
+Detected a photo of a cat with confidence 0.717 at location [1.46, 55.26, 315.55, 472.17]
+```
+
+## Resources
+
+A demo notebook on using OWL-ViT for zero- and one-shot (image-guided) object detection can be found [here](https://github.com/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb).
+
+## OwlViTConfig
+
+[[autodoc]] OwlViTConfig
+ - from_text_vision_configs
+
+## OwlViTTextConfig
+
+[[autodoc]] OwlViTTextConfig
+
+## OwlViTVisionConfig
+
+[[autodoc]] OwlViTVisionConfig
+
+## OwlViTImageProcessor
+
+[[autodoc]] OwlViTImageProcessor
+ - preprocess
+
+## OwlViTImageProcessorFast
+
+[[autodoc]] OwlViTImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+ - post_process_image_guided_detection
+
+## OwlViTProcessor
+
+[[autodoc]] OwlViTProcessor
+ - __call__
+ - post_process_grounded_object_detection
+ - post_process_image_guided_detection
+
+## OwlViTModel
+
+[[autodoc]] OwlViTModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## OwlViTTextModel
+
+[[autodoc]] OwlViTTextModel
+ - forward
+
+## OwlViTVisionModel
+
+[[autodoc]] OwlViTVisionModel
+ - forward
+
+## OwlViTForObjectDetection
+
+[[autodoc]] OwlViTForObjectDetection
+ - forward
+ - image_guided_detection
diff --git a/docs/transformers/docs/source/en/model_doc/paligemma.md b/docs/transformers/docs/source/en/model_doc/paligemma.md
new file mode 100644
index 0000000000000000000000000000000000000000..fa119a5f8362e6c1cc9d31673d674e7688824b55
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/paligemma.md
@@ -0,0 +1,180 @@
+
+
+ +
+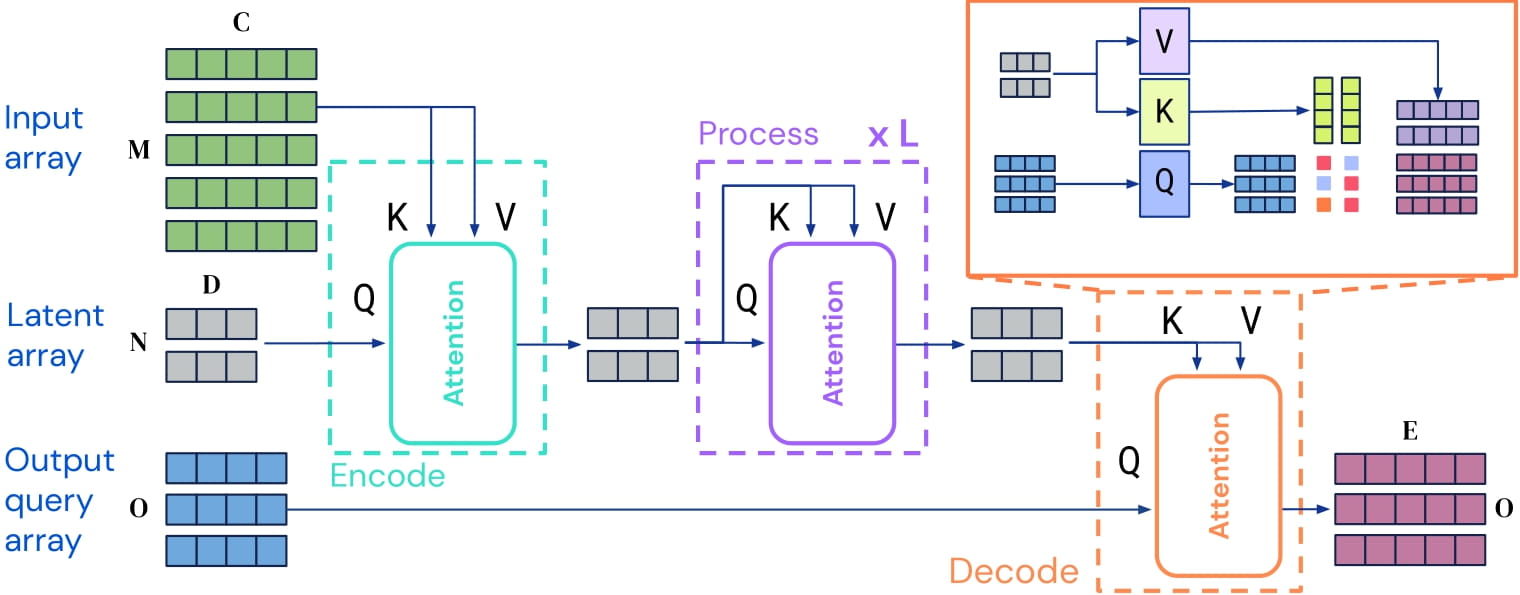 +
+ Perceiver IO architecture. Taken from the original paper
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
+
+
+
+ Perceiver IO architecture. Taken from the original paper
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
+
+ +
+ Pixtral architecture. Taken from the blog post.
+
+Tips:
+
+- Pixtral is a multimodal model, taking images and text as input, and producing text as output.
+- This model follows the [Llava](llava) architecture. The model uses [`PixtralVisionModel`] for its vision encoder, and [`MistralForCausalLM`] for its language decoder.
+- The main contribution is the 2d ROPE (rotary position embeddings) on the images, and support for arbitrary image sizes (the images are not padded together nor are they resized).
+- Similar to [Llava](llava), the model internally replaces the `[IMG]` token placeholders by image embeddings from the vision encoder. The format for one or multiple prompts is the following:
+```
+"
+
+ Pixtral architecture. Taken from the blog post.
+
+Tips:
+
+- Pixtral is a multimodal model, taking images and text as input, and producing text as output.
+- This model follows the [Llava](llava) architecture. The model uses [`PixtralVisionModel`] for its vision encoder, and [`MistralForCausalLM`] for its language decoder.
+- The main contribution is the 2d ROPE (rotary position embeddings) on the images, and support for arbitrary image sizes (the images are not padded together nor are they resized).
+- Similar to [Llava](llava), the model internally replaces the `[IMG]` token placeholders by image embeddings from the vision encoder. The format for one or multiple prompts is the following:
+```
+"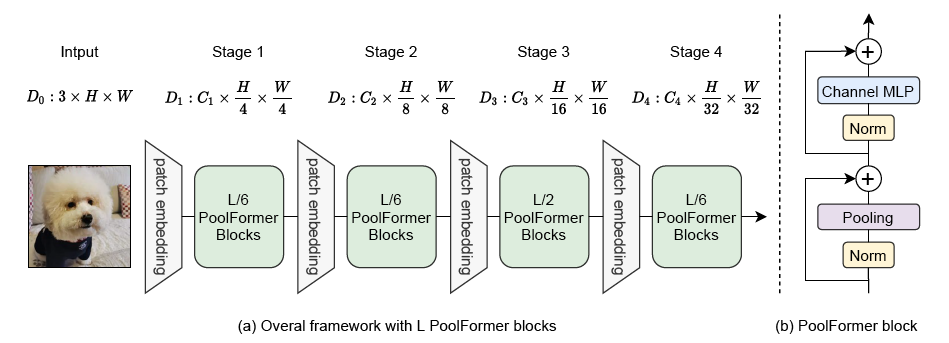 +
+This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
+
+## Usage tips
+
+- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
+- One can use [`PoolFormerImageProcessor`] to prepare images for the model.
+- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :------------: | :-------------------: |
+| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
+| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
+| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
+| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
+| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
+
+
+
+This model was contributed by [heytanay](https://huggingface.co/heytanay). The original code can be found [here](https://github.com/sail-sg/poolformer).
+
+## Usage tips
+
+- PoolFormer has a hierarchical architecture, where instead of Attention, a simple Average Pooling layer is present. All checkpoints of the model can be found on the [hub](https://huggingface.co/models?other=poolformer).
+- One can use [`PoolFormerImageProcessor`] to prepare images for the model.
+- As most models, PoolFormer comes in different sizes, the details of which can be found in the table below.
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :------------: | :-------------------: |
+| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
+| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
+| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
+| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
+| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with PoolFormer.
+
+ +
+ Prompt Depth Anything overview. Taken from the original paper.
+
+## Usage example
+
+The Transformers library allows you to use the model with just a few lines of code:
+
+```python
+>>> import torch
+>>> import requests
+>>> import numpy as np
+
+>>> from PIL import Image
+>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
+
+>>> url = "https://github.com/DepthAnything/PromptDA/blob/main/assets/example_images/image.jpg?raw=true"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = AutoImageProcessor.from_pretrained("depth-anything/prompt-depth-anything-vits-hf")
+>>> model = AutoModelForDepthEstimation.from_pretrained("depth-anything/prompt-depth-anything-vits-hf")
+
+>>> prompt_depth_url = "https://github.com/DepthAnything/PromptDA/blob/main/assets/example_images/arkit_depth.png?raw=true"
+>>> prompt_depth = Image.open(requests.get(prompt_depth_url, stream=True).raw)
+>>> # the prompt depth can be None, and the model will output a monocular relative depth.
+
+>>> # prepare image for the model
+>>> inputs = image_processor(images=image, return_tensors="pt", prompt_depth=prompt_depth)
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> # interpolate to original size
+>>> post_processed_output = image_processor.post_process_depth_estimation(
+... outputs,
+... target_sizes=[(image.height, image.width)],
+... )
+
+>>> # visualize the prediction
+>>> predicted_depth = post_processed_output[0]["predicted_depth"]
+>>> depth = predicted_depth * 1000
+>>> depth = depth.detach().cpu().numpy()
+>>> depth = Image.fromarray(depth.astype("uint16")) # mm
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Prompt Depth Anything.
+
+- [Prompt Depth Anything Demo](https://huggingface.co/spaces/depth-anything/PromptDA)
+- [Prompt Depth Anything Interactive Results](https://promptda.github.io/interactive.html)
+
+If you are interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## PromptDepthAnythingConfig
+
+[[autodoc]] PromptDepthAnythingConfig
+
+## PromptDepthAnythingForDepthEstimation
+
+[[autodoc]] PromptDepthAnythingForDepthEstimation
+ - forward
+
+## PromptDepthAnythingImageProcessor
+
+[[autodoc]] PromptDepthAnythingImageProcessor
+ - preprocess
+ - post_process_depth_estimation
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/prophetnet.md b/docs/transformers/docs/source/en/model_doc/prophetnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..b768fef72a048448e853e5ed5c298ed7d11ef3ba
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/prophetnet.md
@@ -0,0 +1,98 @@
+
+
+# ProphetNet
+
+
+
+ Prompt Depth Anything overview. Taken from the original paper.
+
+## Usage example
+
+The Transformers library allows you to use the model with just a few lines of code:
+
+```python
+>>> import torch
+>>> import requests
+>>> import numpy as np
+
+>>> from PIL import Image
+>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
+
+>>> url = "https://github.com/DepthAnything/PromptDA/blob/main/assets/example_images/image.jpg?raw=true"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = AutoImageProcessor.from_pretrained("depth-anything/prompt-depth-anything-vits-hf")
+>>> model = AutoModelForDepthEstimation.from_pretrained("depth-anything/prompt-depth-anything-vits-hf")
+
+>>> prompt_depth_url = "https://github.com/DepthAnything/PromptDA/blob/main/assets/example_images/arkit_depth.png?raw=true"
+>>> prompt_depth = Image.open(requests.get(prompt_depth_url, stream=True).raw)
+>>> # the prompt depth can be None, and the model will output a monocular relative depth.
+
+>>> # prepare image for the model
+>>> inputs = image_processor(images=image, return_tensors="pt", prompt_depth=prompt_depth)
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> # interpolate to original size
+>>> post_processed_output = image_processor.post_process_depth_estimation(
+... outputs,
+... target_sizes=[(image.height, image.width)],
+... )
+
+>>> # visualize the prediction
+>>> predicted_depth = post_processed_output[0]["predicted_depth"]
+>>> depth = predicted_depth * 1000
+>>> depth = depth.detach().cpu().numpy()
+>>> depth = Image.fromarray(depth.astype("uint16")) # mm
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Prompt Depth Anything.
+
+- [Prompt Depth Anything Demo](https://huggingface.co/spaces/depth-anything/PromptDA)
+- [Prompt Depth Anything Interactive Results](https://promptda.github.io/interactive.html)
+
+If you are interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## PromptDepthAnythingConfig
+
+[[autodoc]] PromptDepthAnythingConfig
+
+## PromptDepthAnythingForDepthEstimation
+
+[[autodoc]] PromptDepthAnythingForDepthEstimation
+ - forward
+
+## PromptDepthAnythingImageProcessor
+
+[[autodoc]] PromptDepthAnythingImageProcessor
+ - preprocess
+ - post_process_depth_estimation
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/prophetnet.md b/docs/transformers/docs/source/en/model_doc/prophetnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..b768fef72a048448e853e5ed5c298ed7d11ef3ba
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/prophetnet.md
@@ -0,0 +1,98 @@
+
+
+# ProphetNet
+
+ +
+ Qwen2-VL architecture. Taken from the blog post.
+
+This model was contributed by [simonJJJ](https://huggingface.co/simonJJJ).
+
+## Usage example
+
+### Single Media inference
+
+The model can accept both images and videos as input. Here's an example code for inference.
+
+```python
+
+import torch
+from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
+
+# Load the model in half-precision on the available device(s)
+model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", device_map="auto")
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
+
+
+conversation = [
+ {
+ "role":"user",
+ "content":[
+ {
+ "type":"image",
+ "url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"
+ },
+ {
+ "type":"text",
+ "text":"Describe this image."
+ }
+ ]
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+# Inference: Generation of the output
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+
+
+
+# Video
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "video", "path": "/path/to/video.mp4"},
+ {"type": "text", "text": "What happened in the video?"},
+ ],
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+
+# Inference: Generation of the output
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+```
+
+### Batch Mixed Media Inference
+
+The model can batch inputs composed of mixed samples of various types such as images, videos, and text. Here is an example.
+
+```python
+
+# Conversation for the first image
+conversation1 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image1.jpg"},
+ {"type": "text", "text": "Describe this image."}
+ ]
+ }
+]
+
+# Conversation with two images
+conversation2 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image2.jpg"},
+ {"type": "image", "path": "/path/to/image3.jpg"},
+ {"type": "text", "text": "What is written in the pictures?"}
+ ]
+ }
+]
+
+# Conversation with pure text
+conversation3 = [
+ {
+ "role": "user",
+ "content": "who are you?"
+ }
+]
+
+
+# Conversation with mixed midia
+conversation4 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image3.jpg"},
+ {"type": "image", "path": "/path/to/image4.jpg"},
+ {"type": "video", "path": "/path/to/video.jpg"},
+ {"type": "text", "text": "What are the common elements in these medias?"},
+ ],
+ }
+]
+
+conversations = [conversation1, conversation2, conversation3, conversation4]
+# Preparation for batch inference
+ipnuts = processor.apply_chat_template(
+ conversations,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+
+# Batch Inference
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+```
+
+### Usage Tips
+
+#### Image Resolution trade-off
+
+The model supports a wide range of resolution inputs. By default, it uses the native resolution for input, but higher resolutions can enhance performance at the cost of more computation. Users can set the minimum and maximum number of pixels to achieve an optimal configuration for their needs.
+
+```python
+min_pixels = 224*224
+max_pixels = 2048*2048
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+
+In case of limited GPU RAM, one can reduce the resolution as follows:
+
+```python
+min_pixels = 256*28*28
+max_pixels = 1024*28*28
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+This ensures each image gets encoded using a number between 256-1024 tokens. The 28 comes from the fact that the model uses a patch size of 14 and a temporal patch size of 2 (14 x 2 = 28).
+
+
+#### Multiple Image Inputs
+
+By default, images and video content are directly included in the conversation. When handling multiple images, it's helpful to add labels to the images and videos for better reference. Users can control this behavior with the following settings:
+
+```python
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "Hello, how are you?"}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'm doing well, thank you for asking. How can I assist you today?"
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Can you describe these images and video?"},
+ {"type": "image"},
+ {"type": "image"},
+ {"type": "video"},
+ {"type": "text", "text": "These are from my vacation."}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'd be happy to describe the images and video for you. Could you please provide more context about your vacation?"
+ },
+ {
+ "role": "user",
+ "content": "It was a trip to the mountains. Can you see the details in the images and video?"
+ }
+]
+
+# default:
+prompt_without_id = processor.apply_chat_template(conversation, add_generation_prompt=True)
+# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?<|vision_start|><|image_pad|><|vision_end|><|vision_start|><|image_pad|><|vision_end|><|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+
+# add ids
+prompt_with_id = processor.apply_chat_template(conversation, add_generation_prompt=True, add_vision_id=True)
+# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nPicture 1: <|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?Picture 2: <|vision_start|><|image_pad|><|vision_end|>Picture 3: <|vision_start|><|image_pad|><|vision_end|>Video 1: <|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+```
+
+#### Flash-Attention 2 to speed up generation
+
+First, make sure to install the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Also, you should have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). FlashAttention-2 can only be used when a model is loaded in `torch.float16` or `torch.bfloat16`.
+
+To load and run a model using Flash Attention-2, simply add `attn_implementation="flash_attention_2"` when loading the model as follows:
+
+```python
+from transformers import Qwen2VLForConditionalGeneration
+
+model = Qwen2VLForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2-VL-7B-Instruct",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+```
+
+## Qwen2VLConfig
+
+[[autodoc]] Qwen2VLConfig
+
+## Qwen2VLTextConfig
+
+[[autodoc]] Qwen2VLTextConfig
+
+## Qwen2VLImageProcessor
+
+[[autodoc]] Qwen2VLImageProcessor
+ - preprocess
+
+## Qwen2VLImageProcessorFast
+
+[[autodoc]] Qwen2VLImageProcessorFast
+ - preprocess
+
+## Qwen2VLProcessor
+
+[[autodoc]] Qwen2VLProcessor
+
+## Qwen2VLModel
+
+[[autodoc]] Qwen2VLModel
+ - forward
+
+## Qwen2VLForConditionalGeneration
+
+[[autodoc]] Qwen2VLForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/qwen3.md b/docs/transformers/docs/source/en/model_doc/qwen3.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3f3c266091380544a6e85e7913935d5b53f3126
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qwen3.md
@@ -0,0 +1,59 @@
+
+
+# Qwen3
+
+## Overview
+
+To be released with the official model launch.
+
+### Model Details
+
+To be released with the official model launch.
+
+
+## Usage tips
+
+To be released with the official model launch.
+
+## Qwen3Config
+
+[[autodoc]] Qwen3Config
+
+## Qwen3Model
+
+[[autodoc]] Qwen3Model
+ - forward
+
+## Qwen3ForCausalLM
+
+[[autodoc]] Qwen3ForCausalLM
+ - forward
+
+## Qwen3ForSequenceClassification
+
+[[autodoc]] Qwen3ForSequenceClassification
+ - forward
+
+## Qwen3ForTokenClassification
+
+[[autodoc]] Qwen3ForTokenClassification
+ - forward
+
+## Qwen3ForQuestionAnswering
+
+[[autodoc]] Qwen3ForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/qwen3_moe.md b/docs/transformers/docs/source/en/model_doc/qwen3_moe.md
new file mode 100644
index 0000000000000000000000000000000000000000..1de4af1a5bdf04d554ba0325f589fe833c7c0bd0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qwen3_moe.md
@@ -0,0 +1,58 @@
+
+
+# Qwen3MoE
+
+## Overview
+
+To be released with the official model launch.
+
+### Model Details
+
+To be released with the official model launch.
+
+## Usage tips
+
+To be released with the official model launch.
+
+## Qwen3MoeConfig
+
+[[autodoc]] Qwen3MoeConfig
+
+## Qwen3MoeModel
+
+[[autodoc]] Qwen3MoeModel
+ - forward
+
+## Qwen3MoeForCausalLM
+
+[[autodoc]] Qwen3MoeForCausalLM
+ - forward
+
+## Qwen3MoeForSequenceClassification
+
+[[autodoc]] Qwen3MoeForSequenceClassification
+ - forward
+
+## Qwen3MoeForTokenClassification
+
+[[autodoc]] Qwen3MoeForTokenClassification
+ - forward
+
+## Qwen3MoeForQuestionAnswering
+
+[[autodoc]] Qwen3MoeForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/rag.md b/docs/transformers/docs/source/en/model_doc/rag.md
new file mode 100644
index 0000000000000000000000000000000000000000..8b65da43a22eaa3c281fcdfccd05838809983b89
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/rag.md
@@ -0,0 +1,121 @@
+
+
+# RAG
+
+
+
+ Qwen2-VL architecture. Taken from the blog post.
+
+This model was contributed by [simonJJJ](https://huggingface.co/simonJJJ).
+
+## Usage example
+
+### Single Media inference
+
+The model can accept both images and videos as input. Here's an example code for inference.
+
+```python
+
+import torch
+from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
+
+# Load the model in half-precision on the available device(s)
+model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", device_map="auto")
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
+
+
+conversation = [
+ {
+ "role":"user",
+ "content":[
+ {
+ "type":"image",
+ "url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"
+ },
+ {
+ "type":"text",
+ "text":"Describe this image."
+ }
+ ]
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+# Inference: Generation of the output
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+
+
+
+# Video
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "video", "path": "/path/to/video.mp4"},
+ {"type": "text", "text": "What happened in the video?"},
+ ],
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+
+# Inference: Generation of the output
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+```
+
+### Batch Mixed Media Inference
+
+The model can batch inputs composed of mixed samples of various types such as images, videos, and text. Here is an example.
+
+```python
+
+# Conversation for the first image
+conversation1 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image1.jpg"},
+ {"type": "text", "text": "Describe this image."}
+ ]
+ }
+]
+
+# Conversation with two images
+conversation2 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image2.jpg"},
+ {"type": "image", "path": "/path/to/image3.jpg"},
+ {"type": "text", "text": "What is written in the pictures?"}
+ ]
+ }
+]
+
+# Conversation with pure text
+conversation3 = [
+ {
+ "role": "user",
+ "content": "who are you?"
+ }
+]
+
+
+# Conversation with mixed midia
+conversation4 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image3.jpg"},
+ {"type": "image", "path": "/path/to/image4.jpg"},
+ {"type": "video", "path": "/path/to/video.jpg"},
+ {"type": "text", "text": "What are the common elements in these medias?"},
+ ],
+ }
+]
+
+conversations = [conversation1, conversation2, conversation3, conversation4]
+# Preparation for batch inference
+ipnuts = processor.apply_chat_template(
+ conversations,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+
+# Batch Inference
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+```
+
+### Usage Tips
+
+#### Image Resolution trade-off
+
+The model supports a wide range of resolution inputs. By default, it uses the native resolution for input, but higher resolutions can enhance performance at the cost of more computation. Users can set the minimum and maximum number of pixels to achieve an optimal configuration for their needs.
+
+```python
+min_pixels = 224*224
+max_pixels = 2048*2048
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+
+In case of limited GPU RAM, one can reduce the resolution as follows:
+
+```python
+min_pixels = 256*28*28
+max_pixels = 1024*28*28
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+This ensures each image gets encoded using a number between 256-1024 tokens. The 28 comes from the fact that the model uses a patch size of 14 and a temporal patch size of 2 (14 x 2 = 28).
+
+
+#### Multiple Image Inputs
+
+By default, images and video content are directly included in the conversation. When handling multiple images, it's helpful to add labels to the images and videos for better reference. Users can control this behavior with the following settings:
+
+```python
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "Hello, how are you?"}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'm doing well, thank you for asking. How can I assist you today?"
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Can you describe these images and video?"},
+ {"type": "image"},
+ {"type": "image"},
+ {"type": "video"},
+ {"type": "text", "text": "These are from my vacation."}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'd be happy to describe the images and video for you. Could you please provide more context about your vacation?"
+ },
+ {
+ "role": "user",
+ "content": "It was a trip to the mountains. Can you see the details in the images and video?"
+ }
+]
+
+# default:
+prompt_without_id = processor.apply_chat_template(conversation, add_generation_prompt=True)
+# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?<|vision_start|><|image_pad|><|vision_end|><|vision_start|><|image_pad|><|vision_end|><|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+
+# add ids
+prompt_with_id = processor.apply_chat_template(conversation, add_generation_prompt=True, add_vision_id=True)
+# Excepted output: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nPicture 1: <|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?Picture 2: <|vision_start|><|image_pad|><|vision_end|>Picture 3: <|vision_start|><|image_pad|><|vision_end|>Video 1: <|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+```
+
+#### Flash-Attention 2 to speed up generation
+
+First, make sure to install the latest version of Flash Attention 2:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Also, you should have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). FlashAttention-2 can only be used when a model is loaded in `torch.float16` or `torch.bfloat16`.
+
+To load and run a model using Flash Attention-2, simply add `attn_implementation="flash_attention_2"` when loading the model as follows:
+
+```python
+from transformers import Qwen2VLForConditionalGeneration
+
+model = Qwen2VLForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2-VL-7B-Instruct",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+```
+
+## Qwen2VLConfig
+
+[[autodoc]] Qwen2VLConfig
+
+## Qwen2VLTextConfig
+
+[[autodoc]] Qwen2VLTextConfig
+
+## Qwen2VLImageProcessor
+
+[[autodoc]] Qwen2VLImageProcessor
+ - preprocess
+
+## Qwen2VLImageProcessorFast
+
+[[autodoc]] Qwen2VLImageProcessorFast
+ - preprocess
+
+## Qwen2VLProcessor
+
+[[autodoc]] Qwen2VLProcessor
+
+## Qwen2VLModel
+
+[[autodoc]] Qwen2VLModel
+ - forward
+
+## Qwen2VLForConditionalGeneration
+
+[[autodoc]] Qwen2VLForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/qwen3.md b/docs/transformers/docs/source/en/model_doc/qwen3.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3f3c266091380544a6e85e7913935d5b53f3126
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qwen3.md
@@ -0,0 +1,59 @@
+
+
+# Qwen3
+
+## Overview
+
+To be released with the official model launch.
+
+### Model Details
+
+To be released with the official model launch.
+
+
+## Usage tips
+
+To be released with the official model launch.
+
+## Qwen3Config
+
+[[autodoc]] Qwen3Config
+
+## Qwen3Model
+
+[[autodoc]] Qwen3Model
+ - forward
+
+## Qwen3ForCausalLM
+
+[[autodoc]] Qwen3ForCausalLM
+ - forward
+
+## Qwen3ForSequenceClassification
+
+[[autodoc]] Qwen3ForSequenceClassification
+ - forward
+
+## Qwen3ForTokenClassification
+
+[[autodoc]] Qwen3ForTokenClassification
+ - forward
+
+## Qwen3ForQuestionAnswering
+
+[[autodoc]] Qwen3ForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/qwen3_moe.md b/docs/transformers/docs/source/en/model_doc/qwen3_moe.md
new file mode 100644
index 0000000000000000000000000000000000000000..1de4af1a5bdf04d554ba0325f589fe833c7c0bd0
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/qwen3_moe.md
@@ -0,0 +1,58 @@
+
+
+# Qwen3MoE
+
+## Overview
+
+To be released with the official model launch.
+
+### Model Details
+
+To be released with the official model launch.
+
+## Usage tips
+
+To be released with the official model launch.
+
+## Qwen3MoeConfig
+
+[[autodoc]] Qwen3MoeConfig
+
+## Qwen3MoeModel
+
+[[autodoc]] Qwen3MoeModel
+ - forward
+
+## Qwen3MoeForCausalLM
+
+[[autodoc]] Qwen3MoeForCausalLM
+ - forward
+
+## Qwen3MoeForSequenceClassification
+
+[[autodoc]] Qwen3MoeForSequenceClassification
+ - forward
+
+## Qwen3MoeForTokenClassification
+
+[[autodoc]] Qwen3MoeForTokenClassification
+ - forward
+
+## Qwen3MoeForQuestionAnswering
+
+[[autodoc]] Qwen3MoeForQuestionAnswering
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/rag.md b/docs/transformers/docs/source/en/model_doc/rag.md
new file mode 100644
index 0000000000000000000000000000000000000000..8b65da43a22eaa3c281fcdfccd05838809983b89
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/rag.md
@@ -0,0 +1,121 @@
+
+
+# RAG
+
+ +
+This model was contributed by [Francesco](https://huggingface.co/Francesco). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/KaimingHe/deep-residual-networks).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ResNet.
+
+
+
+This model was contributed by [Francesco](https://huggingface.co/Francesco). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/KaimingHe/deep-residual-networks).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ResNet.
+
+ +
+ RT-DETR performance relative to YOLO models. Taken from the original paper.
+
+The model version was contributed by [rafaelpadilla](https://huggingface.co/rafaelpadilla) and [sangbumchoi](https://github.com/SangbumChoi). The original code can be found [here](https://github.com/lyuwenyu/RT-DETR/).
+
+
+## Usage tips
+
+Initially, an image is processed using a pre-trained convolutional neural network, specifically a Resnet-D variant as referenced in the original code. This network extracts features from the final three layers of the architecture. Following this, a hybrid encoder is employed to convert the multi-scale features into a sequential array of image features. Then, a decoder, equipped with auxiliary prediction heads is used to refine the object queries. This process facilitates the direct generation of bounding boxes, eliminating the need for any additional post-processing to acquire the logits and coordinates for the bounding boxes.
+
+```py
+>>> import torch
+>>> import requests
+
+>>> from PIL import Image
+>>> from transformers import RTDetrForObjectDetection, RTDetrImageProcessor
+
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_r50vd")
+>>> model = RTDetrForObjectDetection.from_pretrained("PekingU/rtdetr_r50vd")
+
+>>> inputs = image_processor(images=image, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([(image.height, image.width)]), threshold=0.3)
+
+>>> for result in results:
+... for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
+... score, label = score.item(), label_id.item()
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"{model.config.id2label[label]}: {score:.2f} {box}")
+sofa: 0.97 [0.14, 0.38, 640.13, 476.21]
+cat: 0.96 [343.38, 24.28, 640.14, 371.5]
+cat: 0.96 [13.23, 54.18, 318.98, 472.22]
+remote: 0.95 [40.11, 73.44, 175.96, 118.48]
+remote: 0.92 [333.73, 76.58, 369.97, 186.99]
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RT-DETR.
+
+
+
+ RT-DETR performance relative to YOLO models. Taken from the original paper.
+
+The model version was contributed by [rafaelpadilla](https://huggingface.co/rafaelpadilla) and [sangbumchoi](https://github.com/SangbumChoi). The original code can be found [here](https://github.com/lyuwenyu/RT-DETR/).
+
+
+## Usage tips
+
+Initially, an image is processed using a pre-trained convolutional neural network, specifically a Resnet-D variant as referenced in the original code. This network extracts features from the final three layers of the architecture. Following this, a hybrid encoder is employed to convert the multi-scale features into a sequential array of image features. Then, a decoder, equipped with auxiliary prediction heads is used to refine the object queries. This process facilitates the direct generation of bounding boxes, eliminating the need for any additional post-processing to acquire the logits and coordinates for the bounding boxes.
+
+```py
+>>> import torch
+>>> import requests
+
+>>> from PIL import Image
+>>> from transformers import RTDetrForObjectDetection, RTDetrImageProcessor
+
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = RTDetrImageProcessor.from_pretrained("PekingU/rtdetr_r50vd")
+>>> model = RTDetrForObjectDetection.from_pretrained("PekingU/rtdetr_r50vd")
+
+>>> inputs = image_processor(images=image, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> results = image_processor.post_process_object_detection(outputs, target_sizes=torch.tensor([(image.height, image.width)]), threshold=0.3)
+
+>>> for result in results:
+... for score, label_id, box in zip(result["scores"], result["labels"], result["boxes"]):
+... score, label = score.item(), label_id.item()
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"{model.config.id2label[label]}: {score:.2f} {box}")
+sofa: 0.97 [0.14, 0.38, 640.13, 476.21]
+cat: 0.96 [343.38, 24.28, 640.14, 371.5]
+cat: 0.96 [13.23, 54.18, 318.98, 472.22]
+remote: 0.95 [40.11, 73.44, 175.96, 118.48]
+remote: 0.92 [333.73, 76.58, 369.97, 186.99]
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with RT-DETR.
+
+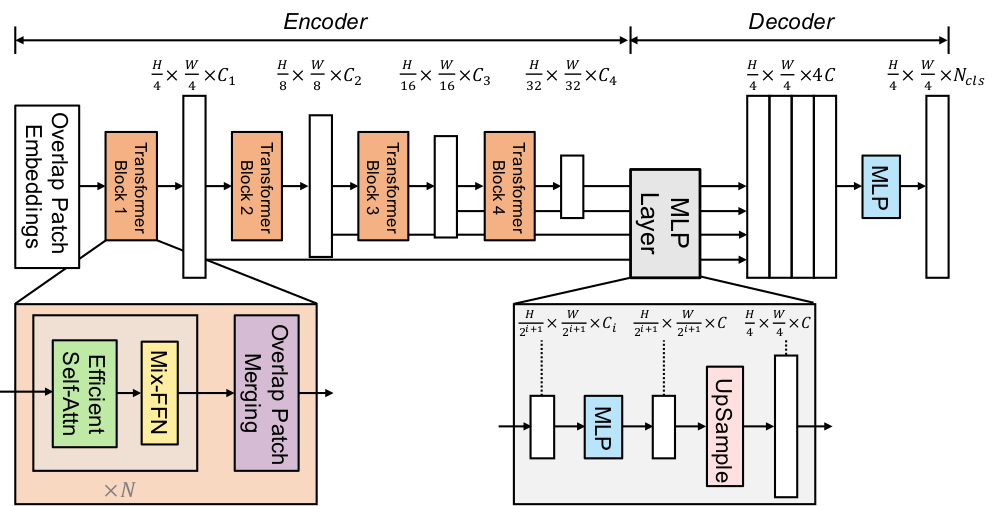 +
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version
+of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/NVlabs/SegFormer).
+
+## Usage tips
+
+- SegFormer consists of a hierarchical Transformer encoder, and a lightweight all-MLP decoder head.
+ [`SegformerModel`] is the hierarchical Transformer encoder (which in the paper is also referred to
+ as Mix Transformer or MiT). [`SegformerForSemanticSegmentation`] adds the all-MLP decoder head on
+ top to perform semantic segmentation of images. In addition, there's
+ [`SegformerForImageClassification`] which can be used to - you guessed it - classify images. The
+ authors of SegFormer first pre-trained the Transformer encoder on ImageNet-1k to classify images. Next, they throw
+ away the classification head, and replace it by the all-MLP decode head. Next, they fine-tune the model altogether on
+ ADE20K, Cityscapes and COCO-stuff, which are important benchmarks for semantic segmentation. All checkpoints can be
+ found on the [hub](https://huggingface.co/models?other=segformer).
+- The quickest way to get started with SegFormer is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer) (which showcase both inference and
+ fine-tuning on custom data). One can also check out the [blog post](https://huggingface.co/blog/fine-tune-segformer) introducing SegFormer and illustrating how it can be fine-tuned on custom data.
+- TensorFlow users should refer to [this repository](https://github.com/deep-diver/segformer-tf-transformers) that shows off-the-shelf inference and fine-tuning.
+- One can also check out [this interactive demo on Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers)
+ to try out a SegFormer model on custom images.
+- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
+- One can use [`SegformerImageProcessor`] to prepare images and corresponding segmentation maps
+ for the model. Note that this image processor is fairly basic and does not include all data augmentations used in
+ the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
+ important preprocessing step is that images and segmentation maps are randomly cropped and padded to the same size,
+ such as 512x512 or 640x640, after which they are normalized.
+- One additional thing to keep in mind is that one can initialize [`SegformerImageProcessor`] with
+ `do_reduce_labels` set to `True` or `False`. In some datasets (like ADE20k), the 0 index is used in the annotated
+ segmentation maps for background. However, ADE20k doesn't include the "background" class in its 150 labels.
+ Therefore, `do_reduce_labels` is used to reduce all labels by 1, and to make sure no loss is computed for the
+ background class (i.e. it replaces 0 in the annotated maps by 255, which is the *ignore_index* of the loss function
+ used by [`SegformerForSemanticSegmentation`]). However, other datasets use the 0 index as
+ background class and include this class as part of all labels. In that case, `do_reduce_labels` should be set to
+ `False`, as loss should also be computed for the background class.
+- As most models, SegFormer comes in different sizes, the details of which can be found in the table below
+ (taken from Table 7 of the [original paper](https://arxiv.org/abs/2105.15203)).
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
+| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+
+Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For
+SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://arxiv.org/abs/2105.15203).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SegFormer.
+
+
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version
+of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/NVlabs/SegFormer).
+
+## Usage tips
+
+- SegFormer consists of a hierarchical Transformer encoder, and a lightweight all-MLP decoder head.
+ [`SegformerModel`] is the hierarchical Transformer encoder (which in the paper is also referred to
+ as Mix Transformer or MiT). [`SegformerForSemanticSegmentation`] adds the all-MLP decoder head on
+ top to perform semantic segmentation of images. In addition, there's
+ [`SegformerForImageClassification`] which can be used to - you guessed it - classify images. The
+ authors of SegFormer first pre-trained the Transformer encoder on ImageNet-1k to classify images. Next, they throw
+ away the classification head, and replace it by the all-MLP decode head. Next, they fine-tune the model altogether on
+ ADE20K, Cityscapes and COCO-stuff, which are important benchmarks for semantic segmentation. All checkpoints can be
+ found on the [hub](https://huggingface.co/models?other=segformer).
+- The quickest way to get started with SegFormer is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer) (which showcase both inference and
+ fine-tuning on custom data). One can also check out the [blog post](https://huggingface.co/blog/fine-tune-segformer) introducing SegFormer and illustrating how it can be fine-tuned on custom data.
+- TensorFlow users should refer to [this repository](https://github.com/deep-diver/segformer-tf-transformers) that shows off-the-shelf inference and fine-tuning.
+- One can also check out [this interactive demo on Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers)
+ to try out a SegFormer model on custom images.
+- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
+- One can use [`SegformerImageProcessor`] to prepare images and corresponding segmentation maps
+ for the model. Note that this image processor is fairly basic and does not include all data augmentations used in
+ the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
+ important preprocessing step is that images and segmentation maps are randomly cropped and padded to the same size,
+ such as 512x512 or 640x640, after which they are normalized.
+- One additional thing to keep in mind is that one can initialize [`SegformerImageProcessor`] with
+ `do_reduce_labels` set to `True` or `False`. In some datasets (like ADE20k), the 0 index is used in the annotated
+ segmentation maps for background. However, ADE20k doesn't include the "background" class in its 150 labels.
+ Therefore, `do_reduce_labels` is used to reduce all labels by 1, and to make sure no loss is computed for the
+ background class (i.e. it replaces 0 in the annotated maps by 255, which is the *ignore_index* of the loss function
+ used by [`SegformerForSemanticSegmentation`]). However, other datasets use the 0 index as
+ background class and include this class as part of all labels. In that case, `do_reduce_labels` should be set to
+ `False`, as loss should also be computed for the background class.
+- As most models, SegFormer comes in different sizes, the details of which can be found in the table below
+ (taken from Table 7 of the [original paper](https://arxiv.org/abs/2105.15203)).
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
+| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+
+Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For
+SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://arxiv.org/abs/2105.15203).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SegFormer.
+
+ +
+This model was contributed by [qubvel](https://huggingface.co/qubvel-hf).
+The original code can be found [here](https://github.com/google-research/big_vision/tree/main).
+
+## Usage example
+
+There are 2 main ways to use SigLIP2: either using the pipeline API, which abstracts away all the complexity for you, or by using the `Siglip2Model` class yourself.
+
+### FixRes variant
+
+**Pipeline API**
+
+The pipeline allows to use the model in a few lines of code:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # load pipe
+>>> image_classifier = pipeline(
+... task="zero-shot-image-classification",
+... model="google/siglip2-base-patch16-224",
+... )
+
+>>> # load image
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # inference
+>>> candidate_labels = ["2 cats", "a plane", "a remote"]
+>>> outputs = image_classifier(image, candidate_labels=candidate_labels)
+>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
+>>> print(outputs)
+[{'score': 0.1499, 'label': '2 cats'}, {'score': 0.0008, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
+```
+
+**Using the model yourself**
+
+If you want to do the pre- and postprocessing yourself, here's how to do that:
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip2-base-patch16-224")
+>>> processor = AutoProcessor.from_pretrained("google/siglip2-base-patch16-224")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# follows the pipeline prompt template to get same results
+>>> texts = [f"This is a photo of {label}." for label in candidate_labels]
+
+# IMPORTANT: we pass `padding=max_length` and `max_length=64` since the model was trained with this
+>>> inputs = processor(text=texts, images=image, padding="max_length", max_length=64, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+15.0% that image 0 is '2 cats'
+```
+
+### NaFlex variant
+
+NaFlex combines ideas from FlexiViT, i.e. supporting multiple, predefined sequence lengths
+with a single ViT model, and NaViT, namely processing images at their native aspect ratio.
+This enables processing different types of images at appropriate resolution, e.g. using a
+larger resolution to process document images, while at the same time minimizing the impact
+of aspect ratio distortion on certain inference tasks, e.g. on OCR.
+
+Given a patch size and target sequence length, NaFlex preprocesses the data by first resizing
+the input image such that the height and width after resizing are multiples of the patch size,
+while
+
+ 1. keeping the aspect ratio distortion as small as possible
+ 2. producing a sequence length of at most the desired target sequence length (`max_num_patches`)
+
+The resulting distortion in width and height is at most `(patch_size - 1) / width` and
+`(patch_size - 1) / height`, respectively, which tends to be small for common resolutions and aspect ratios.
+After resizing, the image is split into a sequence of patches, and a mask with padding information is added.
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip2-base-patch16-naflex")
+>>> processor = AutoProcessor.from_pretrained("google/siglip2-base-patch16-naflex")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# follows the pipeline prompt template to get same results
+>>> texts = [f"This is a photo of {label}." for label in candidate_labels]
+
+# default value for `max_num_patches` is 256, but you can increase resulted image resolution providing
+# higher values e.g. `max_num_patches=512`
+>>> inputs = processor(text=texts, images=image, max_num_patches=256, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+21.1% that image 0 is '2 cats'
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SigLIP2.
+
+- [Zero-shot image classification task guide](../tasks/zero_shot_image_classification)
+- Demo notebook for SigLIP2 can be found [here](https://github.com/qubvel/transformers-notebooks/tree/master/notebooks/SigLIP2_inference.ipynb). 🌎
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+## Combining SigLIP2 and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import AutoProcessor, AutoModel
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModel.from_pretrained(
+... "google/siglip2-so400m-patch14-384",
+... attn_implementation="flash_attention_2",
+... torch_dtype=torch.float16,
+... device_map=device,
+... )
+>>> processor = AutoProcessor.from_pretrained("google/siglip2-so400m-patch14-384")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# follows the pipeline prompt template to get same results
+>>> texts = [f'This is a photo of {label}.' for label in candidate_labels]
+# important: we pass `padding=max_length` since the model was trained with this
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt").to(device)
+
+>>> with torch.no_grad():
+... with torch.autocast(device):
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+19.8% that image 0 is '2 cats'
+```
+
+## Siglip2Config
+
+[[autodoc]] Siglip2Config
+
+## Siglip2TextConfig
+
+[[autodoc]] Siglip2TextConfig
+
+## Siglip2VisionConfig
+
+[[autodoc]] Siglip2VisionConfig
+
+## Siglip2ImageProcessor
+
+[[autodoc]] Siglip2ImageProcessor
+ - preprocess
+
+## Siglip2ImageProcessorFast
+
+[[autodoc]] Siglip2ImageProcessorFast
+ - preprocess
+
+## Siglip2Processor
+
+[[autodoc]] Siglip2Processor
+
+## Siglip2Model
+
+[[autodoc]] Siglip2Model
+ - forward
+ - get_text_features
+ - get_image_features
+
+## Siglip2TextModel
+
+[[autodoc]] Siglip2TextModel
+ - forward
+
+## Siglip2VisionModel
+
+[[autodoc]] Siglip2VisionModel
+ - forward
+
+## Siglip2ForImageClassification
+
+[[autodoc]] Siglip2ForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/smolvlm.md b/docs/transformers/docs/source/en/model_doc/smolvlm.md
new file mode 100644
index 0000000000000000000000000000000000000000..9512fb6aa2958dd2130e9393f122a5b6002e4273
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/smolvlm.md
@@ -0,0 +1,203 @@
+
+
+# SmolVLM
+
+
+
+This model was contributed by [qubvel](https://huggingface.co/qubvel-hf).
+The original code can be found [here](https://github.com/google-research/big_vision/tree/main).
+
+## Usage example
+
+There are 2 main ways to use SigLIP2: either using the pipeline API, which abstracts away all the complexity for you, or by using the `Siglip2Model` class yourself.
+
+### FixRes variant
+
+**Pipeline API**
+
+The pipeline allows to use the model in a few lines of code:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # load pipe
+>>> image_classifier = pipeline(
+... task="zero-shot-image-classification",
+... model="google/siglip2-base-patch16-224",
+... )
+
+>>> # load image
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # inference
+>>> candidate_labels = ["2 cats", "a plane", "a remote"]
+>>> outputs = image_classifier(image, candidate_labels=candidate_labels)
+>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
+>>> print(outputs)
+[{'score': 0.1499, 'label': '2 cats'}, {'score': 0.0008, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
+```
+
+**Using the model yourself**
+
+If you want to do the pre- and postprocessing yourself, here's how to do that:
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip2-base-patch16-224")
+>>> processor = AutoProcessor.from_pretrained("google/siglip2-base-patch16-224")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# follows the pipeline prompt template to get same results
+>>> texts = [f"This is a photo of {label}." for label in candidate_labels]
+
+# IMPORTANT: we pass `padding=max_length` and `max_length=64` since the model was trained with this
+>>> inputs = processor(text=texts, images=image, padding="max_length", max_length=64, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+15.0% that image 0 is '2 cats'
+```
+
+### NaFlex variant
+
+NaFlex combines ideas from FlexiViT, i.e. supporting multiple, predefined sequence lengths
+with a single ViT model, and NaViT, namely processing images at their native aspect ratio.
+This enables processing different types of images at appropriate resolution, e.g. using a
+larger resolution to process document images, while at the same time minimizing the impact
+of aspect ratio distortion on certain inference tasks, e.g. on OCR.
+
+Given a patch size and target sequence length, NaFlex preprocesses the data by first resizing
+the input image such that the height and width after resizing are multiples of the patch size,
+while
+
+ 1. keeping the aspect ratio distortion as small as possible
+ 2. producing a sequence length of at most the desired target sequence length (`max_num_patches`)
+
+The resulting distortion in width and height is at most `(patch_size - 1) / width` and
+`(patch_size - 1) / height`, respectively, which tends to be small for common resolutions and aspect ratios.
+After resizing, the image is split into a sequence of patches, and a mask with padding information is added.
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip2-base-patch16-naflex")
+>>> processor = AutoProcessor.from_pretrained("google/siglip2-base-patch16-naflex")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# follows the pipeline prompt template to get same results
+>>> texts = [f"This is a photo of {label}." for label in candidate_labels]
+
+# default value for `max_num_patches` is 256, but you can increase resulted image resolution providing
+# higher values e.g. `max_num_patches=512`
+>>> inputs = processor(text=texts, images=image, max_num_patches=256, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+21.1% that image 0 is '2 cats'
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SigLIP2.
+
+- [Zero-shot image classification task guide](../tasks/zero_shot_image_classification)
+- Demo notebook for SigLIP2 can be found [here](https://github.com/qubvel/transformers-notebooks/tree/master/notebooks/SigLIP2_inference.ipynb). 🌎
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+## Combining SigLIP2 and Flash Attention 2
+
+First, make sure to install the latest version of Flash Attention 2.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
+
+To load and run a model using Flash Attention 2, refer to the snippet below:
+
+```python
+>>> import torch
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import AutoProcessor, AutoModel
+>>> device = "cuda" # the device to load the model onto
+
+>>> model = AutoModel.from_pretrained(
+... "google/siglip2-so400m-patch14-384",
+... attn_implementation="flash_attention_2",
+... torch_dtype=torch.float16,
+... device_map=device,
+... )
+>>> processor = AutoProcessor.from_pretrained("google/siglip2-so400m-patch14-384")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# follows the pipeline prompt template to get same results
+>>> texts = [f'This is a photo of {label}.' for label in candidate_labels]
+# important: we pass `padding=max_length` since the model was trained with this
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt").to(device)
+
+>>> with torch.no_grad():
+... with torch.autocast(device):
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+19.8% that image 0 is '2 cats'
+```
+
+## Siglip2Config
+
+[[autodoc]] Siglip2Config
+
+## Siglip2TextConfig
+
+[[autodoc]] Siglip2TextConfig
+
+## Siglip2VisionConfig
+
+[[autodoc]] Siglip2VisionConfig
+
+## Siglip2ImageProcessor
+
+[[autodoc]] Siglip2ImageProcessor
+ - preprocess
+
+## Siglip2ImageProcessorFast
+
+[[autodoc]] Siglip2ImageProcessorFast
+ - preprocess
+
+## Siglip2Processor
+
+[[autodoc]] Siglip2Processor
+
+## Siglip2Model
+
+[[autodoc]] Siglip2Model
+ - forward
+ - get_text_features
+ - get_image_features
+
+## Siglip2TextModel
+
+[[autodoc]] Siglip2TextModel
+ - forward
+
+## Siglip2VisionModel
+
+[[autodoc]] Siglip2VisionModel
+ - forward
+
+## Siglip2ForImageClassification
+
+[[autodoc]] Siglip2ForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/smolvlm.md b/docs/transformers/docs/source/en/model_doc/smolvlm.md
new file mode 100644
index 0000000000000000000000000000000000000000..9512fb6aa2958dd2130e9393f122a5b6002e4273
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/smolvlm.md
@@ -0,0 +1,203 @@
+
+
+# SmolVLM
+
+ +
+ SuperPoint overview. Taken from the original paper.
+
+## Usage tips
+
+Here is a quick example of using the model to detect interest points in an image:
+
+```python
+from transformers import AutoImageProcessor, SuperPointForKeypointDetection
+import torch
+from PIL import Image
+import requests
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
+model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/superpoint")
+
+inputs = processor(image, return_tensors="pt")
+outputs = model(**inputs)
+```
+
+The outputs contain the list of keypoint coordinates with their respective score and description (a 256-long vector).
+
+You can also feed multiple images to the model. Due to the nature of SuperPoint, to output a dynamic number of keypoints,
+you will need to use the mask attribute to retrieve the respective information :
+
+```python
+from transformers import AutoImageProcessor, SuperPointForKeypointDetection
+import torch
+from PIL import Image
+import requests
+
+url_image_1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image_1 = Image.open(requests.get(url_image_1, stream=True).raw)
+url_image_2 = "http://images.cocodataset.org/test-stuff2017/000000000568.jpg"
+image_2 = Image.open(requests.get(url_image_2, stream=True).raw)
+
+images = [image_1, image_2]
+
+processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
+model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/superpoint")
+
+inputs = processor(images, return_tensors="pt")
+outputs = model(**inputs)
+image_sizes = [(image.height, image.width) for image in images]
+outputs = processor.post_process_keypoint_detection(outputs, image_sizes)
+
+for output in outputs:
+ for keypoints, scores, descriptors in zip(output["keypoints"], output["scores"], output["descriptors"]):
+ print(f"Keypoints: {keypoints}")
+ print(f"Scores: {scores}")
+ print(f"Descriptors: {descriptors}")
+```
+
+You can then print the keypoints on the image of your choice to visualize the result:
+```python
+import matplotlib.pyplot as plt
+
+plt.axis("off")
+plt.imshow(image_1)
+plt.scatter(
+ outputs[0]["keypoints"][:, 0],
+ outputs[0]["keypoints"][:, 1],
+ c=outputs[0]["scores"] * 100,
+ s=outputs[0]["scores"] * 50,
+ alpha=0.8
+)
+plt.savefig(f"output_image.png")
+```
+
+
+This model was contributed by [stevenbucaille](https://huggingface.co/stevenbucaille).
+The original code can be found [here](https://github.com/magicleap/SuperPointPretrainedNetwork).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SuperPoint. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- A notebook showcasing inference and visualization with SuperPoint can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SuperPoint/Inference_with_SuperPoint_to_detect_interest_points_in_an_image.ipynb). 🌎
+
+## SuperPointConfig
+
+[[autodoc]] SuperPointConfig
+
+## SuperPointImageProcessor
+
+[[autodoc]] SuperPointImageProcessor
+
+- preprocess
+- post_process_keypoint_detection
+
+## SuperPointForKeypointDetection
+
+[[autodoc]] SuperPointForKeypointDetection
+
+- forward
diff --git a/docs/transformers/docs/source/en/model_doc/swiftformer.md b/docs/transformers/docs/source/en/model_doc/swiftformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..48580a60f580996515d5bdada21900bf306956db
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/swiftformer.md
@@ -0,0 +1,59 @@
+
+
+# SwiftFormer
+
+
+
+ SuperPoint overview. Taken from the original paper.
+
+## Usage tips
+
+Here is a quick example of using the model to detect interest points in an image:
+
+```python
+from transformers import AutoImageProcessor, SuperPointForKeypointDetection
+import torch
+from PIL import Image
+import requests
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
+model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/superpoint")
+
+inputs = processor(image, return_tensors="pt")
+outputs = model(**inputs)
+```
+
+The outputs contain the list of keypoint coordinates with their respective score and description (a 256-long vector).
+
+You can also feed multiple images to the model. Due to the nature of SuperPoint, to output a dynamic number of keypoints,
+you will need to use the mask attribute to retrieve the respective information :
+
+```python
+from transformers import AutoImageProcessor, SuperPointForKeypointDetection
+import torch
+from PIL import Image
+import requests
+
+url_image_1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image_1 = Image.open(requests.get(url_image_1, stream=True).raw)
+url_image_2 = "http://images.cocodataset.org/test-stuff2017/000000000568.jpg"
+image_2 = Image.open(requests.get(url_image_2, stream=True).raw)
+
+images = [image_1, image_2]
+
+processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
+model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/superpoint")
+
+inputs = processor(images, return_tensors="pt")
+outputs = model(**inputs)
+image_sizes = [(image.height, image.width) for image in images]
+outputs = processor.post_process_keypoint_detection(outputs, image_sizes)
+
+for output in outputs:
+ for keypoints, scores, descriptors in zip(output["keypoints"], output["scores"], output["descriptors"]):
+ print(f"Keypoints: {keypoints}")
+ print(f"Scores: {scores}")
+ print(f"Descriptors: {descriptors}")
+```
+
+You can then print the keypoints on the image of your choice to visualize the result:
+```python
+import matplotlib.pyplot as plt
+
+plt.axis("off")
+plt.imshow(image_1)
+plt.scatter(
+ outputs[0]["keypoints"][:, 0],
+ outputs[0]["keypoints"][:, 1],
+ c=outputs[0]["scores"] * 100,
+ s=outputs[0]["scores"] * 50,
+ alpha=0.8
+)
+plt.savefig(f"output_image.png")
+```
+
+
+This model was contributed by [stevenbucaille](https://huggingface.co/stevenbucaille).
+The original code can be found [here](https://github.com/magicleap/SuperPointPretrainedNetwork).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SuperPoint. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- A notebook showcasing inference and visualization with SuperPoint can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SuperPoint/Inference_with_SuperPoint_to_detect_interest_points_in_an_image.ipynb). 🌎
+
+## SuperPointConfig
+
+[[autodoc]] SuperPointConfig
+
+## SuperPointImageProcessor
+
+[[autodoc]] SuperPointImageProcessor
+
+- preprocess
+- post_process_keypoint_detection
+
+## SuperPointForKeypointDetection
+
+[[autodoc]] SuperPointForKeypointDetection
+
+- forward
diff --git a/docs/transformers/docs/source/en/model_doc/swiftformer.md b/docs/transformers/docs/source/en/model_doc/swiftformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..48580a60f580996515d5bdada21900bf306956db
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/swiftformer.md
@@ -0,0 +1,59 @@
+
+
+# SwiftFormer
+
+ +
+ Swin2SR architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/mv-lab/swin2sr).
+
+## Resources
+
+Demo notebooks for Swin2SR can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR).
+
+A demo Space for image super-resolution with SwinSR can be found [here](https://huggingface.co/spaces/jjourney1125/swin2sr).
+
+## Swin2SRImageProcessor
+
+[[autodoc]] Swin2SRImageProcessor
+ - preprocess
+
+## Swin2SRConfig
+
+[[autodoc]] Swin2SRConfig
+
+## Swin2SRModel
+
+[[autodoc]] Swin2SRModel
+ - forward
+
+## Swin2SRForImageSuperResolution
+
+[[autodoc]] Swin2SRForImageSuperResolution
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/swinv2.md b/docs/transformers/docs/source/en/model_doc/swinv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..a709af9712e3acbaf69b8a47b56eb16896482253
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/swinv2.md
@@ -0,0 +1,66 @@
+
+
+# Swin Transformer V2
+
+
+
+ Swin2SR architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/mv-lab/swin2sr).
+
+## Resources
+
+Demo notebooks for Swin2SR can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR).
+
+A demo Space for image super-resolution with SwinSR can be found [here](https://huggingface.co/spaces/jjourney1125/swin2sr).
+
+## Swin2SRImageProcessor
+
+[[autodoc]] Swin2SRImageProcessor
+ - preprocess
+
+## Swin2SRConfig
+
+[[autodoc]] Swin2SRConfig
+
+## Swin2SRModel
+
+[[autodoc]] Swin2SRModel
+ - forward
+
+## Swin2SRForImageSuperResolution
+
+[[autodoc]] Swin2SRForImageSuperResolution
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/swinv2.md b/docs/transformers/docs/source/en/model_doc/swinv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..a709af9712e3acbaf69b8a47b56eb16896482253
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/swinv2.md
@@ -0,0 +1,66 @@
+
+
+# Swin Transformer V2
+
+ +
+ TAPAS architecture. Taken from the original blog post.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The Tensorflow version of this model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/tapas).
+
+## Usage tips
+
+- TAPAS is a model that uses relative position embeddings by default (restarting the position embeddings at every cell of the table). Note that this is something that was added after the publication of the original TAPAS paper. According to the authors, this usually results in a slightly better performance, and allows you to encode longer sequences without running out of embeddings. This is reflected in the `reset_position_index_per_cell` parameter of [`TapasConfig`], which is set to `True` by default. The default versions of the models available on the [hub](https://huggingface.co/models?search=tapas) all use relative position embeddings. You can still use the ones with absolute position embeddings by passing in an additional argument `revision="no_reset"` when calling the `from_pretrained()` method. Note that it's usually advised to pad the inputs on the right rather than the left.
+- TAPAS is based on BERT, so `TAPAS-base` for example corresponds to a `BERT-base` architecture. Of course, `TAPAS-large` will result in the best performance (the results reported in the paper are from `TAPAS-large`). Results of the various sized models are shown on the [original GitHub repository](https://github.com/google-research/tapas).
+- TAPAS has checkpoints fine-tuned on SQA, which are capable of answering questions related to a table in a conversational set-up. This means that you can ask follow-up questions such as "what is his age?" related to the previous question. Note that the forward pass of TAPAS is a bit different in case of a conversational set-up: in that case, you have to feed every table-question pair one by one to the model, such that the `prev_labels` token type ids can be overwritten by the predicted `labels` of the model to the previous question. See "Usage" section for more info.
+- TAPAS is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained with a causal language modeling (CLM) objective are better in that regard. Note that TAPAS can be used as an encoder in the EncoderDecoderModel framework, to combine it with an autoregressive text decoder such as GPT-2.
+
+## Usage: fine-tuning
+
+Here we explain how you can fine-tune [`TapasForQuestionAnswering`] on your own dataset.
+
+**STEP 1: Choose one of the 3 ways in which you can use TAPAS - or experiment**
+
+Basically, there are 3 different ways in which one can fine-tune [`TapasForQuestionAnswering`], corresponding to the different datasets on which Tapas was fine-tuned:
+
+1. SQA: if you're interested in asking follow-up questions related to a table, in a conversational set-up. For example if you first ask "what's the name of the first actor?" then you can ask a follow-up question such as "how old is he?". Here, questions do not involve any aggregation (all questions are cell selection questions).
+2. WTQ: if you're not interested in asking questions in a conversational set-up, but rather just asking questions related to a table, which might involve aggregation, such as counting a number of rows, summing up cell values or averaging cell values. You can then for example ask "what's the total number of goals Cristiano Ronaldo made in his career?". This case is also called **weak supervision**, since the model itself must learn the appropriate aggregation operator (SUM/COUNT/AVERAGE/NONE) given only the answer to the question as supervision.
+3. WikiSQL-supervised: this dataset is based on WikiSQL with the model being given the ground truth aggregation operator during training. This is also called **strong supervision**. Here, learning the appropriate aggregation operator is much easier.
+
+To summarize:
+
+| **Task** | **Example dataset** | **Description** |
+|-------------------------------------|---------------------|---------------------------------------------------------------------------------------------------------|
+| Conversational | SQA | Conversational, only cell selection questions |
+| Weak supervision for aggregation | WTQ | Questions might involve aggregation, and the model must learn this given only the answer as supervision |
+| Strong supervision for aggregation | WikiSQL-supervised | Questions might involve aggregation, and the model must learn this given the gold aggregation operator |
+
+
+
+ TAPAS architecture. Taken from the original blog post.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The Tensorflow version of this model was contributed by [kamalkraj](https://huggingface.co/kamalkraj). The original code can be found [here](https://github.com/google-research/tapas).
+
+## Usage tips
+
+- TAPAS is a model that uses relative position embeddings by default (restarting the position embeddings at every cell of the table). Note that this is something that was added after the publication of the original TAPAS paper. According to the authors, this usually results in a slightly better performance, and allows you to encode longer sequences without running out of embeddings. This is reflected in the `reset_position_index_per_cell` parameter of [`TapasConfig`], which is set to `True` by default. The default versions of the models available on the [hub](https://huggingface.co/models?search=tapas) all use relative position embeddings. You can still use the ones with absolute position embeddings by passing in an additional argument `revision="no_reset"` when calling the `from_pretrained()` method. Note that it's usually advised to pad the inputs on the right rather than the left.
+- TAPAS is based on BERT, so `TAPAS-base` for example corresponds to a `BERT-base` architecture. Of course, `TAPAS-large` will result in the best performance (the results reported in the paper are from `TAPAS-large`). Results of the various sized models are shown on the [original GitHub repository](https://github.com/google-research/tapas).
+- TAPAS has checkpoints fine-tuned on SQA, which are capable of answering questions related to a table in a conversational set-up. This means that you can ask follow-up questions such as "what is his age?" related to the previous question. Note that the forward pass of TAPAS is a bit different in case of a conversational set-up: in that case, you have to feed every table-question pair one by one to the model, such that the `prev_labels` token type ids can be overwritten by the predicted `labels` of the model to the previous question. See "Usage" section for more info.
+- TAPAS is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained with a causal language modeling (CLM) objective are better in that regard. Note that TAPAS can be used as an encoder in the EncoderDecoderModel framework, to combine it with an autoregressive text decoder such as GPT-2.
+
+## Usage: fine-tuning
+
+Here we explain how you can fine-tune [`TapasForQuestionAnswering`] on your own dataset.
+
+**STEP 1: Choose one of the 3 ways in which you can use TAPAS - or experiment**
+
+Basically, there are 3 different ways in which one can fine-tune [`TapasForQuestionAnswering`], corresponding to the different datasets on which Tapas was fine-tuned:
+
+1. SQA: if you're interested in asking follow-up questions related to a table, in a conversational set-up. For example if you first ask "what's the name of the first actor?" then you can ask a follow-up question such as "how old is he?". Here, questions do not involve any aggregation (all questions are cell selection questions).
+2. WTQ: if you're not interested in asking questions in a conversational set-up, but rather just asking questions related to a table, which might involve aggregation, such as counting a number of rows, summing up cell values or averaging cell values. You can then for example ask "what's the total number of goals Cristiano Ronaldo made in his career?". This case is also called **weak supervision**, since the model itself must learn the appropriate aggregation operator (SUM/COUNT/AVERAGE/NONE) given only the answer to the question as supervision.
+3. WikiSQL-supervised: this dataset is based on WikiSQL with the model being given the ground truth aggregation operator during training. This is also called **strong supervision**. Here, learning the appropriate aggregation operator is much easier.
+
+To summarize:
+
+| **Task** | **Example dataset** | **Description** |
+|-------------------------------------|---------------------|---------------------------------------------------------------------------------------------------------|
+| Conversational | SQA | Conversational, only cell selection questions |
+| Weak supervision for aggregation | WTQ | Questions might involve aggregation, and the model must learn this given only the answer as supervision |
+| Strong supervision for aggregation | WikiSQL-supervised | Questions might involve aggregation, and the model must learn this given the gold aggregation operator |
+
+ +
+ TextNet backbone as part of FAST. Taken from the original paper.
+
+This model was contributed by [Raghavan](https://huggingface.co/Raghavan), [jadechoghari](https://huggingface.co/jadechoghari) and [nielsr](https://huggingface.co/nielsr).
+
+## Usage tips
+
+TextNet is mainly used as a backbone network for the architecture search of text detection. Each stage of the backbone network is comprised of a stride-2 convolution and searchable blocks.
+Specifically, we present a layer-level candidate set, defined as {conv3×3, conv1×3, conv3×1, identity}. As the 1×3 and 3×1 convolutions have asymmetric kernels and oriented structure priors, they may help to capture the features of extreme aspect-ratio and rotated text lines.
+
+TextNet is the backbone for Fast, but can also be used as an efficient text/image classification, we add a `TextNetForImageClassification` as is it would allow people to train an image classifier on top of the pre-trained textnet weights
+
+## TextNetConfig
+
+[[autodoc]] TextNetConfig
+
+## TextNetImageProcessor
+
+[[autodoc]] TextNetImageProcessor
+ - preprocess
+
+## TextNetModel
+
+[[autodoc]] TextNetModel
+ - forward
+
+## TextNetForImageClassification
+
+[[autodoc]] TextNetForImageClassification
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/time_series_transformer.md b/docs/transformers/docs/source/en/model_doc/time_series_transformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..a91633b6b0299bce1dcca4054e0ebdf16acb45fc
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/time_series_transformer.md
@@ -0,0 +1,76 @@
+
+
+# Time Series Transformer
+
+
+
+ TextNet backbone as part of FAST. Taken from the original paper.
+
+This model was contributed by [Raghavan](https://huggingface.co/Raghavan), [jadechoghari](https://huggingface.co/jadechoghari) and [nielsr](https://huggingface.co/nielsr).
+
+## Usage tips
+
+TextNet is mainly used as a backbone network for the architecture search of text detection. Each stage of the backbone network is comprised of a stride-2 convolution and searchable blocks.
+Specifically, we present a layer-level candidate set, defined as {conv3×3, conv1×3, conv3×1, identity}. As the 1×3 and 3×1 convolutions have asymmetric kernels and oriented structure priors, they may help to capture the features of extreme aspect-ratio and rotated text lines.
+
+TextNet is the backbone for Fast, but can also be used as an efficient text/image classification, we add a `TextNetForImageClassification` as is it would allow people to train an image classifier on top of the pre-trained textnet weights
+
+## TextNetConfig
+
+[[autodoc]] TextNetConfig
+
+## TextNetImageProcessor
+
+[[autodoc]] TextNetImageProcessor
+ - preprocess
+
+## TextNetModel
+
+[[autodoc]] TextNetModel
+ - forward
+
+## TextNetForImageClassification
+
+[[autodoc]] TextNetForImageClassification
+ - forward
+
diff --git a/docs/transformers/docs/source/en/model_doc/time_series_transformer.md b/docs/transformers/docs/source/en/model_doc/time_series_transformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..a91633b6b0299bce1dcca4054e0ebdf16acb45fc
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/time_series_transformer.md
@@ -0,0 +1,76 @@
+
+
+# Time Series Transformer
+
+ +
+ TrOCR architecture. Taken from the original paper.
+
+Please refer to the [`VisionEncoderDecoder`] class on how to use this model.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/microsoft/unilm/tree/6f60612e7cc86a2a1ae85c47231507a587ab4e01/trocr).
+
+## Usage tips
+
+- The quickest way to get started with TrOCR is by checking the [tutorial
+ notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR), which show how to use the model
+ at inference time as well as fine-tuning on custom data.
+- TrOCR is pre-trained in 2 stages before being fine-tuned on downstream datasets. It achieves state-of-the-art results
+ on both printed (e.g. the [SROIE dataset](https://paperswithcode.com/dataset/sroie) and handwritten (e.g. the [IAM
+ Handwriting dataset](https://fki.tic.heia-fr.ch/databases/iam-handwriting-database>) text recognition tasks. For more
+ information, see the [official models](https://huggingface.co/models?other=trocr>).
+- TrOCR is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with TrOCR. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+
+
+ TrOCR architecture. Taken from the original paper.
+
+Please refer to the [`VisionEncoderDecoder`] class on how to use this model.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found
+[here](https://github.com/microsoft/unilm/tree/6f60612e7cc86a2a1ae85c47231507a587ab4e01/trocr).
+
+## Usage tips
+
+- The quickest way to get started with TrOCR is by checking the [tutorial
+ notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR), which show how to use the model
+ at inference time as well as fine-tuning on custom data.
+- TrOCR is pre-trained in 2 stages before being fine-tuned on downstream datasets. It achieves state-of-the-art results
+ on both printed (e.g. the [SROIE dataset](https://paperswithcode.com/dataset/sroie) and handwritten (e.g. the [IAM
+ Handwriting dataset](https://fki.tic.heia-fr.ch/databases/iam-handwriting-database>) text recognition tasks. For more
+ information, see the [official models](https://huggingface.co/models?other=trocr>).
+- TrOCR is always used within the [VisionEncoderDecoder](vision-encoder-decoder) framework.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with TrOCR. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+ +
+ +
+ TVP architecture. Taken from the original paper.
+
+This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
+
+## Usage tips and examples
+
+Prompts are optimized perturbation patterns, which would be added to input video frames or text features. Universal set refers to using the same exact set of prompts for any input, this means that these prompts are added consistently to all video frames and text features, regardless of the input's content.
+
+TVP consists of a visual encoder and cross-modal encoder. A universal set of visual prompts and text prompts to be integrated into sampled video frames and textual features, respectively. Specially, a set of different visual prompts are applied to uniformly-sampled frames of one untrimmed video in order.
+
+The goal of this model is to incorporate trainable prompts into both visual inputs and textual features to temporal video grounding(TVG) problems.
+In principle, one can apply any visual, cross-modal encoder in the proposed architecture.
+
+The [`TvpProcessor`] wraps [`BertTokenizer`] and [`TvpImageProcessor`] into a single instance to both
+encode the text and prepare the images respectively.
+
+The following example shows how to run temporal video grounding using [`TvpProcessor`] and [`TvpForVideoGrounding`].
+```python
+import av
+import cv2
+import numpy as np
+import torch
+from huggingface_hub import hf_hub_download
+from transformers import AutoProcessor, TvpForVideoGrounding
+
+
+def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video. Return None if the no
+ video stream was found.
+ fps (float): the number of frames per second of the video.
+ '''
+ video = container.streams.video[0]
+ fps = float(video.average_rate)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ delta = max(num_frames - clip_size, 0)
+ start_idx = delta * clip_idx / num_clips
+ end_idx = start_idx + clip_size - 1
+ timebase = video.duration / num_frames
+ video_start_pts = int(start_idx * timebase)
+ video_end_pts = int(end_idx * timebase)
+ seek_offset = max(video_start_pts - 1024, 0)
+ container.seek(seek_offset, any_frame=False, backward=True, stream=video)
+ frames = {}
+ for frame in container.decode(video=0):
+ if frame.pts < video_start_pts:
+ continue
+ frames[frame.pts] = frame
+ if frame.pts > video_end_pts:
+ break
+ frames = [frames[pts] for pts in sorted(frames)]
+ return frames, fps
+
+
+def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Decode the video and perform temporal sampling.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video.
+ '''
+ assert clip_idx >= -2, "Not a valid clip_idx {}".format(clip_idx)
+ frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ index = np.linspace(0, clip_size - 1, num_frames)
+ index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
+ frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
+ frames = frames.transpose(0, 3, 1, 2)
+ return frames
+
+
+file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
+model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
+
+decoder_kwargs = dict(
+ container=av.open(file, metadata_errors="ignore"),
+ sampling_rate=1,
+ num_frames=model.config.num_frames,
+ clip_idx=0,
+ num_clips=1,
+ target_fps=3,
+)
+raw_sampled_frms = decode(**decoder_kwargs)
+
+text = "a person is sitting on a bed."
+processor = AutoProcessor.from_pretrained("Intel/tvp-base")
+model_inputs = processor(
+ text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
+)
+
+model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
+output = model(**model_inputs)
+
+def get_video_duration(filename):
+ cap = cv2.VideoCapture(filename)
+ if cap.isOpened():
+ rate = cap.get(5)
+ frame_num = cap.get(7)
+ duration = frame_num/rate
+ return duration
+ return -1
+
+duration = get_video_duration(file)
+start, end = processor.post_process_video_grounding(output.logits, duration)
+
+print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
+```
+
+Tips:
+
+- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
+- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
+- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
+
+
+## TvpConfig
+
+[[autodoc]] TvpConfig
+
+## TvpImageProcessor
+
+[[autodoc]] TvpImageProcessor
+ - preprocess
+
+## TvpProcessor
+
+[[autodoc]] TvpProcessor
+ - __call__
+
+## TvpModel
+
+[[autodoc]] TvpModel
+ - forward
+
+## TvpForVideoGrounding
+
+[[autodoc]] TvpForVideoGrounding
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/udop.md b/docs/transformers/docs/source/en/model_doc/udop.md
new file mode 100644
index 0000000000000000000000000000000000000000..b63bc11a53ee3421fc4247da2b92ad2a538cb6c7
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/udop.md
@@ -0,0 +1,117 @@
+
+
+# UDOP
+
+
+
+ TVP architecture. Taken from the original paper.
+
+This model was contributed by [Jiqing Feng](https://huggingface.co/Jiqing). The original code can be found [here](https://github.com/intel/TVP).
+
+## Usage tips and examples
+
+Prompts are optimized perturbation patterns, which would be added to input video frames or text features. Universal set refers to using the same exact set of prompts for any input, this means that these prompts are added consistently to all video frames and text features, regardless of the input's content.
+
+TVP consists of a visual encoder and cross-modal encoder. A universal set of visual prompts and text prompts to be integrated into sampled video frames and textual features, respectively. Specially, a set of different visual prompts are applied to uniformly-sampled frames of one untrimmed video in order.
+
+The goal of this model is to incorporate trainable prompts into both visual inputs and textual features to temporal video grounding(TVG) problems.
+In principle, one can apply any visual, cross-modal encoder in the proposed architecture.
+
+The [`TvpProcessor`] wraps [`BertTokenizer`] and [`TvpImageProcessor`] into a single instance to both
+encode the text and prepare the images respectively.
+
+The following example shows how to run temporal video grounding using [`TvpProcessor`] and [`TvpForVideoGrounding`].
+```python
+import av
+import cv2
+import numpy as np
+import torch
+from huggingface_hub import hf_hub_download
+from transformers import AutoProcessor, TvpForVideoGrounding
+
+
+def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video. Return None if the no
+ video stream was found.
+ fps (float): the number of frames per second of the video.
+ '''
+ video = container.streams.video[0]
+ fps = float(video.average_rate)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ delta = max(num_frames - clip_size, 0)
+ start_idx = delta * clip_idx / num_clips
+ end_idx = start_idx + clip_size - 1
+ timebase = video.duration / num_frames
+ video_start_pts = int(start_idx * timebase)
+ video_end_pts = int(end_idx * timebase)
+ seek_offset = max(video_start_pts - 1024, 0)
+ container.seek(seek_offset, any_frame=False, backward=True, stream=video)
+ frames = {}
+ for frame in container.decode(video=0):
+ if frame.pts < video_start_pts:
+ continue
+ frames[frame.pts] = frame
+ if frame.pts > video_end_pts:
+ break
+ frames = [frames[pts] for pts in sorted(frames)]
+ return frames, fps
+
+
+def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Decode the video and perform temporal sampling.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video.
+ '''
+ assert clip_idx >= -2, "Not a valid clip_idx {}".format(clip_idx)
+ frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ index = np.linspace(0, clip_size - 1, num_frames)
+ index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
+ frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
+ frames = frames.transpose(0, 3, 1, 2)
+ return frames
+
+
+file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
+model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
+
+decoder_kwargs = dict(
+ container=av.open(file, metadata_errors="ignore"),
+ sampling_rate=1,
+ num_frames=model.config.num_frames,
+ clip_idx=0,
+ num_clips=1,
+ target_fps=3,
+)
+raw_sampled_frms = decode(**decoder_kwargs)
+
+text = "a person is sitting on a bed."
+processor = AutoProcessor.from_pretrained("Intel/tvp-base")
+model_inputs = processor(
+ text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
+)
+
+model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
+output = model(**model_inputs)
+
+def get_video_duration(filename):
+ cap = cv2.VideoCapture(filename)
+ if cap.isOpened():
+ rate = cap.get(5)
+ frame_num = cap.get(7)
+ duration = frame_num/rate
+ return duration
+ return -1
+
+duration = get_video_duration(file)
+start, end = processor.post_process_video_grounding(output.logits, duration)
+
+print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
+```
+
+Tips:
+
+- This implementation of TVP uses [`BertTokenizer`] to generate text embeddings and Resnet-50 model to compute visual embeddings.
+- Checkpoints for pre-trained [tvp-base](https://huggingface.co/Intel/tvp-base) is released.
+- Please refer to [Table 2](https://arxiv.org/pdf/2303.04995.pdf) for TVP's performance on Temporal Video Grounding task.
+
+
+## TvpConfig
+
+[[autodoc]] TvpConfig
+
+## TvpImageProcessor
+
+[[autodoc]] TvpImageProcessor
+ - preprocess
+
+## TvpProcessor
+
+[[autodoc]] TvpProcessor
+ - __call__
+
+## TvpModel
+
+[[autodoc]] TvpModel
+ - forward
+
+## TvpForVideoGrounding
+
+[[autodoc]] TvpForVideoGrounding
+ - forward
diff --git a/docs/transformers/docs/source/en/model_doc/udop.md b/docs/transformers/docs/source/en/model_doc/udop.md
new file mode 100644
index 0000000000000000000000000000000000000000..b63bc11a53ee3421fc4247da2b92ad2a538cb6c7
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/udop.md
@@ -0,0 +1,117 @@
+
+
+# UDOP
+
+ +
+ UDOP architecture. Taken from the original paper.
+
+## Usage tips
+
+- In addition to *input_ids*, [`UdopForConditionalGeneration`] also expects the input `bbox`, which are
+ the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
+ as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the
+ position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on a 0-1000
+ scale. To normalize, you can use the following function:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+Here, `width` and `height` correspond to the width and height of the original document in which the token
+occurs. Those can be obtained using the Python Image Library (PIL) library for example, as follows:
+
+```python
+from PIL import Image
+
+# Document can be a png, jpg, etc. PDFs must be converted to images.
+image = Image.open(name_of_your_document).convert("RGB")
+
+width, height = image.size
+```
+
+One can use [`UdopProcessor`] to prepare images and text for the model, which takes care of all of this. By default, this class uses the Tesseract engine to extract a list of words and boxes (coordinates) from a given document. Its functionality is equivalent to that of [`LayoutLMv3Processor`], hence it supports passing either `apply_ocr=False` in case you prefer to use your own OCR engine or `apply_ocr=True` in case you want the default OCR engine to be used. Refer to the [usage guide of LayoutLMv2](layoutlmv2#usage-layoutlmv2processor) regarding all possible use cases (the functionality of `UdopProcessor` is identical).
+
+- If using an own OCR engine of choice, one recommendation is Azure's [Read API](https://learn.microsoft.com/en-us/azure/ai-services/computer-vision/how-to/call-read-api), which supports so-called line segments. Use of segment position embeddings typically results in better performance.
+- At inference time, it's recommended to use the `generate` method to autoregressively generate text given a document image.
+- The model has been pre-trained on both self-supervised and supervised objectives. One can use the various task prefixes (prompts) used during pre-training to test out the out-of-the-box capabilities. For instance, the model can be prompted with "Question answering. What is the date?", as "Question answering." is the task prefix used during pre-training for DocVQA. Refer to the [paper](https://arxiv.org/abs/2212.02623) (table 1) for all task prefixes.
+- One can also fine-tune [`UdopEncoderModel`], which is the encoder-only part of UDOP, which can be seen as a LayoutLMv3-like Transformer encoder. For discriminative tasks, one can just add a linear classifier on top of it and fine-tune it on a labeled dataset.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/microsoft/UDOP).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UDOP. If
+you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll
+review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- Demo notebooks regarding UDOP can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UDOP) that show how
+to fine-tune UDOP on a custom dataset as well as inference. 🌎
+- [Document question answering task guide](../tasks/document_question_answering)
+
+## UdopConfig
+
+[[autodoc]] UdopConfig
+
+## UdopTokenizer
+
+[[autodoc]] UdopTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## UdopTokenizerFast
+
+[[autodoc]] UdopTokenizerFast
+
+## UdopProcessor
+
+[[autodoc]] UdopProcessor
+ - __call__
+
+## UdopModel
+
+[[autodoc]] UdopModel
+ - forward
+
+## UdopForConditionalGeneration
+
+[[autodoc]] UdopForConditionalGeneration
+ - forward
+
+## UdopEncoderModel
+
+[[autodoc]] UdopEncoderModel
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/ul2.md b/docs/transformers/docs/source/en/model_doc/ul2.md
new file mode 100644
index 0000000000000000000000000000000000000000..18743a28426e81acceee54ec21db9b3901a7d30d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/ul2.md
@@ -0,0 +1,50 @@
+
+
+# UL2
+
+
+
+ UDOP architecture. Taken from the original paper.
+
+## Usage tips
+
+- In addition to *input_ids*, [`UdopForConditionalGeneration`] also expects the input `bbox`, which are
+ the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such
+ as Google's [Tesseract](https://github.com/tesseract-ocr/tesseract) (there's a [Python wrapper](https://pypi.org/project/pytesseract/) available). Each bounding box should be in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the
+ position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on a 0-1000
+ scale. To normalize, you can use the following function:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+Here, `width` and `height` correspond to the width and height of the original document in which the token
+occurs. Those can be obtained using the Python Image Library (PIL) library for example, as follows:
+
+```python
+from PIL import Image
+
+# Document can be a png, jpg, etc. PDFs must be converted to images.
+image = Image.open(name_of_your_document).convert("RGB")
+
+width, height = image.size
+```
+
+One can use [`UdopProcessor`] to prepare images and text for the model, which takes care of all of this. By default, this class uses the Tesseract engine to extract a list of words and boxes (coordinates) from a given document. Its functionality is equivalent to that of [`LayoutLMv3Processor`], hence it supports passing either `apply_ocr=False` in case you prefer to use your own OCR engine or `apply_ocr=True` in case you want the default OCR engine to be used. Refer to the [usage guide of LayoutLMv2](layoutlmv2#usage-layoutlmv2processor) regarding all possible use cases (the functionality of `UdopProcessor` is identical).
+
+- If using an own OCR engine of choice, one recommendation is Azure's [Read API](https://learn.microsoft.com/en-us/azure/ai-services/computer-vision/how-to/call-read-api), which supports so-called line segments. Use of segment position embeddings typically results in better performance.
+- At inference time, it's recommended to use the `generate` method to autoregressively generate text given a document image.
+- The model has been pre-trained on both self-supervised and supervised objectives. One can use the various task prefixes (prompts) used during pre-training to test out the out-of-the-box capabilities. For instance, the model can be prompted with "Question answering. What is the date?", as "Question answering." is the task prefix used during pre-training for DocVQA. Refer to the [paper](https://arxiv.org/abs/2212.02623) (table 1) for all task prefixes.
+- One can also fine-tune [`UdopEncoderModel`], which is the encoder-only part of UDOP, which can be seen as a LayoutLMv3-like Transformer encoder. For discriminative tasks, one can just add a linear classifier on top of it and fine-tune it on a labeled dataset.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/microsoft/UDOP).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UDOP. If
+you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll
+review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+- Demo notebooks regarding UDOP can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UDOP) that show how
+to fine-tune UDOP on a custom dataset as well as inference. 🌎
+- [Document question answering task guide](../tasks/document_question_answering)
+
+## UdopConfig
+
+[[autodoc]] UdopConfig
+
+## UdopTokenizer
+
+[[autodoc]] UdopTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## UdopTokenizerFast
+
+[[autodoc]] UdopTokenizerFast
+
+## UdopProcessor
+
+[[autodoc]] UdopProcessor
+ - __call__
+
+## UdopModel
+
+[[autodoc]] UdopModel
+ - forward
+
+## UdopForConditionalGeneration
+
+[[autodoc]] UdopForConditionalGeneration
+ - forward
+
+## UdopEncoderModel
+
+[[autodoc]] UdopEncoderModel
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/ul2.md b/docs/transformers/docs/source/en/model_doc/ul2.md
new file mode 100644
index 0000000000000000000000000000000000000000..18743a28426e81acceee54ec21db9b3901a7d30d
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/ul2.md
@@ -0,0 +1,50 @@
+
+
+# UL2
+
+ +
+ UPerNet framework. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code is based on OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
+
+## Usage examples
+
+UPerNet is a general framework for semantic segmentation. It can be used with any vision backbone, like so:
+
+```py
+from transformers import SwinConfig, UperNetConfig, UperNetForSemanticSegmentation
+
+backbone_config = SwinConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
+
+config = UperNetConfig(backbone_config=backbone_config)
+model = UperNetForSemanticSegmentation(config)
+```
+
+To use another vision backbone, like [ConvNeXt](convnext), simply instantiate the model with the appropriate backbone:
+
+```py
+from transformers import ConvNextConfig, UperNetConfig, UperNetForSemanticSegmentation
+
+backbone_config = ConvNextConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
+
+config = UperNetConfig(backbone_config=backbone_config)
+model = UperNetForSemanticSegmentation(config)
+```
+
+Note that this will randomly initialize all the weights of the model.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UPerNet.
+
+- Demo notebooks for UPerNet can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
+- [`UperNetForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb).
+- See also: [Semantic segmentation task guide](../tasks/semantic_segmentation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## UperNetConfig
+
+[[autodoc]] UperNetConfig
+
+## UperNetForSemanticSegmentation
+
+[[autodoc]] UperNetForSemanticSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/van.md b/docs/transformers/docs/source/en/model_doc/van.md
new file mode 100644
index 0000000000000000000000000000000000000000..1df6a4640bbbb3e9e5f6b19bf4079c0401f0c1e2
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/van.md
@@ -0,0 +1,76 @@
+
+
+# VAN
+
+
+
+ UPerNet framework. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code is based on OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
+
+## Usage examples
+
+UPerNet is a general framework for semantic segmentation. It can be used with any vision backbone, like so:
+
+```py
+from transformers import SwinConfig, UperNetConfig, UperNetForSemanticSegmentation
+
+backbone_config = SwinConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
+
+config = UperNetConfig(backbone_config=backbone_config)
+model = UperNetForSemanticSegmentation(config)
+```
+
+To use another vision backbone, like [ConvNeXt](convnext), simply instantiate the model with the appropriate backbone:
+
+```py
+from transformers import ConvNextConfig, UperNetConfig, UperNetForSemanticSegmentation
+
+backbone_config = ConvNextConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
+
+config = UperNetConfig(backbone_config=backbone_config)
+model = UperNetForSemanticSegmentation(config)
+```
+
+Note that this will randomly initialize all the weights of the model.
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UPerNet.
+
+- Demo notebooks for UPerNet can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
+- [`UperNetForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb).
+- See also: [Semantic segmentation task guide](../tasks/semantic_segmentation)
+
+If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
+
+## UperNetConfig
+
+[[autodoc]] UperNetConfig
+
+## UperNetForSemanticSegmentation
+
+[[autodoc]] UperNetForSemanticSegmentation
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/en/model_doc/van.md b/docs/transformers/docs/source/en/model_doc/van.md
new file mode 100644
index 0000000000000000000000000000000000000000..1df6a4640bbbb3e9e5f6b19bf4079c0401f0c1e2
--- /dev/null
+++ b/docs/transformers/docs/source/en/model_doc/van.md
@@ -0,0 +1,76 @@
+
+
+# VAN
+
+ +
+This model was contributed by [Francesco](https://huggingface.co/Francesco). The original code can be found [here](https://github.com/Visual-Attention-Network/VAN-Classification).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with VAN.
+
+
+
+This model was contributed by [Francesco](https://huggingface.co/Francesco). The original code can be found [here](https://github.com/Visual-Attention-Network/VAN-Classification).
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with VAN.
+
+