---
license: apache-2.0
language:
- en
base_model:
- Ultralytics/YOLOv8
pipeline_tag: object-detection
tags:
- yolov8
- firearm-detection
- object-detection
- computer-vision
new_version: Subh775/Threat-Detection-RF-DETR
---
# Firearm Detection YOLOv8n
[](https://opensource.org/licenses/Apache-2.0)
[](https://github.com/ultralytics/ultralytics)
[](https://ultralytics.com/)
[](https://www.python.org/)
Try out the more accurate version at: [](https://huggingface.co/Subh775/Threat-Detection-RF-DETR)
A high-performance **YOLOv8-nano** model specifically trained for firearm detection in images and videos. This model achieves exceptional accuracy with 89.0% mAP@0.5 and is optimized for real-time inference applications in security and surveillance systems.
## Model Overview
This model is trained on a comprehensive firearm detection (A custom dataset) containing over 7k high-quality images. The model can detect various types of firearms including pistols, rifles, shotguns, and other weapon types unified under a single "Gun" class for detection of fire-armed weapons
**Key Features:**
- Single-class detection (Gun) for simplified integration.
- High accuracy: 89.0% mAP@0.5, 60.2% mAP@0.5-0.95.
- Optimized for real-time inference.
- Comprehensive training on diverse firearm types.
- Robust performance across different lighting and background conditions.
## Sample Demo
Here is an example output by the model:
## Performance Metrics
The model demonstrates exceptional performance on the validation dataset after 100 epochs of training:
| Metric | Value |
|--------|-------|
| **mAP@0.5** | **0.890** |
| **mAP@0.5-0.95** | **0.602** |
| **Precision** | **0.864** |
| **Recall** | **0.824** |
| **F1-Score** | **0.84** |
## Training Results
### Training and Validation Curves
The training progression over 100 epochs shows consistent improvement across all metrics:

The graphs demonstrate:
- **Loss Reduction**: Steady decrease in box_loss, cls_loss, and dfl_loss
- **Metric Improvement**: Consistent increase in precision, recall, mAP50, and mAP50-95
- **Convergence**: Stable performance indicating optimal training completion
### Dataset Distribution
The dataset contains 6,800 gun instances across 7,068 training images, with balanced spatial distribution and varied object sizes for robust detection capabilities.
## Model Performance Analysis
### Confusion Matrix
**Absolute Counts:**

**Normalized Values:**
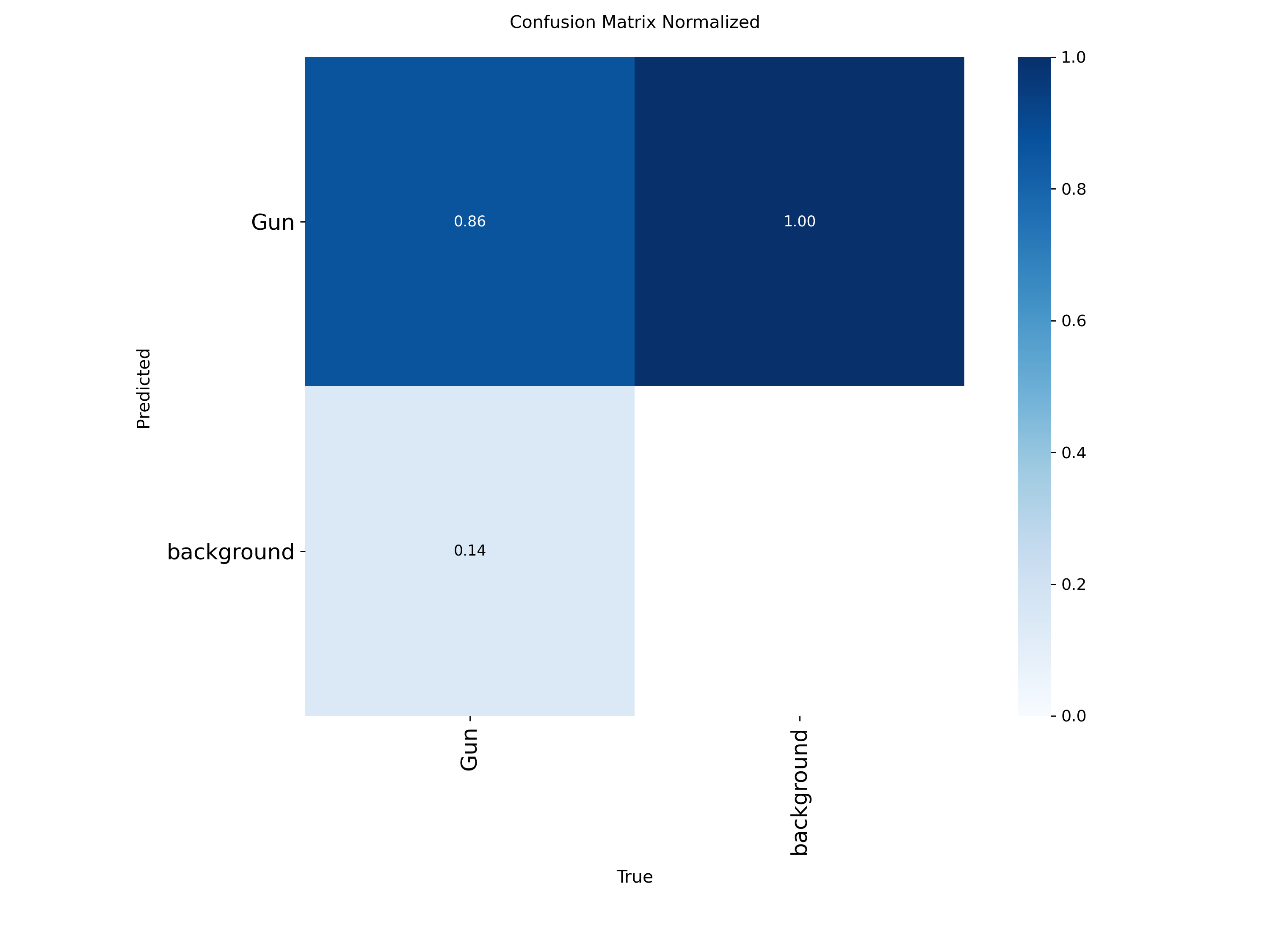
The confusion matrices show:
- **True Positives**: 1,537 correctly identified guns (86% accuracy)
- **False Negatives**: 249 missed detections (14% miss rate)
- **False Positives**: 324 background misclassifications
- **Strong Performance**: High precision with minimal false positive rate
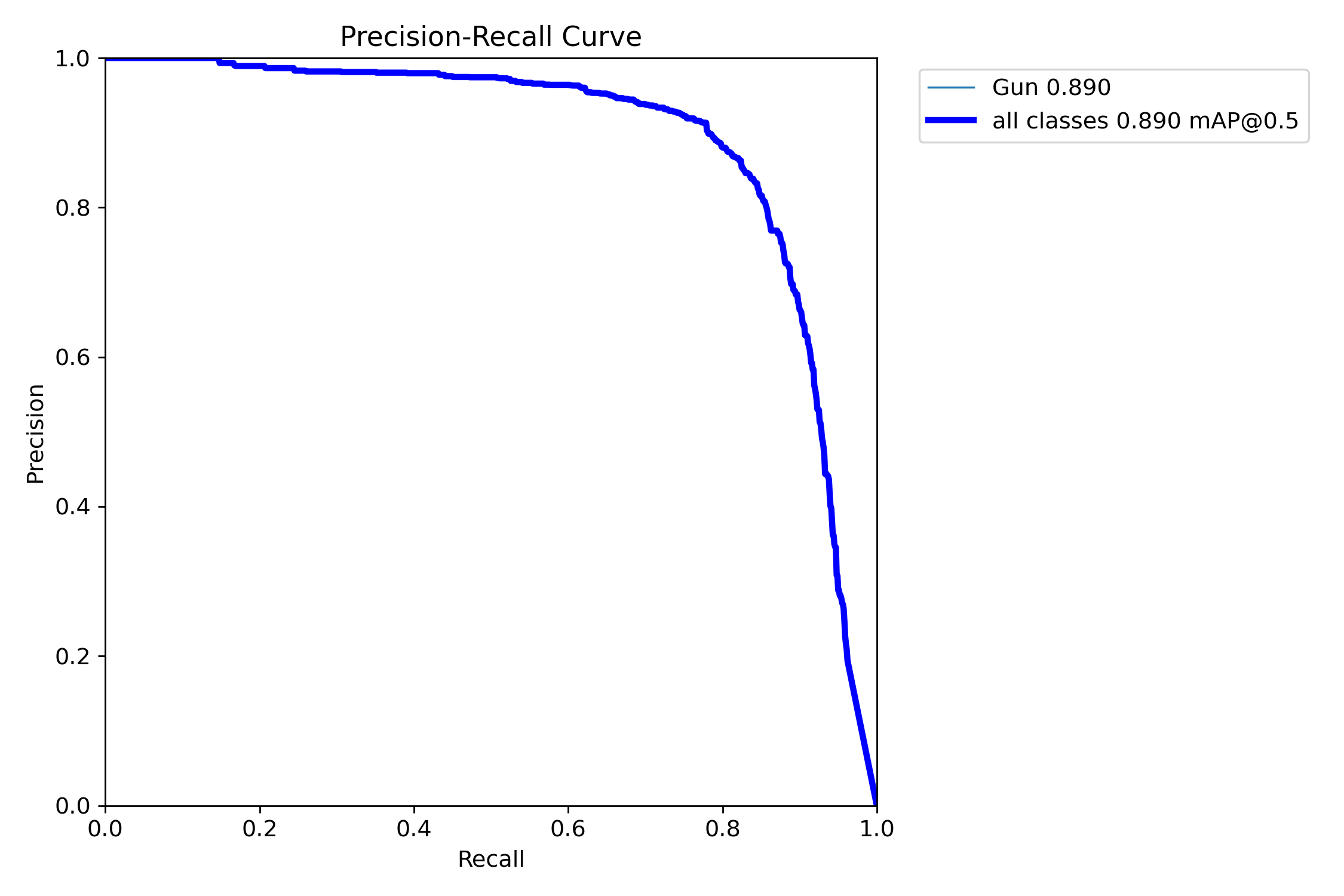
### Performance Curves
Precision-Recall Curve
Precision-Confidence Curve
Recall-Confidence Curve
F1-Confidence Curve
These curves demonstrate optimal performance at confidence threshold 0.4, balancing precision and recall for practical deployment.
## Dataset Information
**Training Dataset Composition:**
- **Total Images**: 7,068 (after quality filtering)
- **Training Set**: 5,642 images
- **Validation Set**: 1,426 images
- **Total Instances**: 6,800 gun annotations
- **Split Ratio**: 80/20 train/validation
**Source Datasets:**
- Roboflow: 3,822 images (rifles, shotguns, heavy weapons)
- Kaggle: 1,946 images (mixed firearms including pistols)
- Additional curated sources: 1,444 images
**Quality Assurance:**
- Duplicate removal: 711 images filtered
- Low-quality filtering: 434 images removed
- Manual verification and annotation correction
---
## Inferencing instructions
```bash
pip install ultralytics huggingface_hub
```
### Basic Inference
```python
from ultralytics import YOLO
from huggingface_hub import hf_hub_download
# Download model from Hugging Face Hub
model_path = hf_hub_download(
repo_id="Subh775/Firearm_Detection_Yolov8n",
filename="weights/best.pt"
)
# Load model
model = YOLO(model_path)
# Run inference
results = model("path/to/your/image.jpg")
# Display results
for box in results[0].boxes:
class_name = model.names[int(box.cls[0])]
confidence = box.conf[0]
print(f"Detected: {class_name} (Confidence: {confidence:.3f})")
# Show annotated image
results[0].show()
```
### Batch Processing for Videos
```python
import cv2
from ultralytics import YOLO
from huggingface_hub import hf_hub_download
import torch
from tqdm import tqdm
# Configuration
MODEL_REPO = "Subh775/Firearm_Detection_Yolov8n"
INPUT_VIDEO = "input_video.mp4"
OUTPUT_VIDEO = "output_video.mp4"
CONFIDENCE_THRESHOLD = 0.4
BATCH_SIZE = 32 # Adjust based on GPU memory
# Setup device
device = 0 if torch.cuda.is_available() else "cpu"
print(f"Using device: {'GPU' if device == 0 else 'CPU'}")
# Load model
model_path = hf_hub_download(repo_id=MODEL_REPO, filename="weights/best.pt")
model = YOLO(model_path)
# Process video
cap = cv2.VideoCapture(INPUT_VIDEO)
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(cap.get(cv2.CAP_PROP_FPS))
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(OUTPUT_VIDEO, fourcc, fps, (frame_width, frame_height))
frames_batch = []
with tqdm(total=total_frames, desc="Processing video") as pbar:
while cap.isOpened():
success, frame = cap.read()
if success:
frames_batch.append(frame)
if len(frames_batch) == BATCH_SIZE:
# Batch inference
results = model(frames_batch, conf=CONFIDENCE_THRESHOLD,
device=device, verbose=False)
# Write annotated frames
for result in results:
annotated_frame = result.plot()
out.write(annotated_frame)
pbar.update(len(frames_batch))
frames_batch = []
else:
break
# Process remaining frames
if frames_batch:
results = model(frames_batch, conf=CONFIDENCE_THRESHOLD,
device=device, verbose=False)
for result in results:
annotated_frame = result.plot()
out.write(annotated_frame)
pbar.update(len(frames_batch))
cap.release()
out.release()
print(f"Processed video saved to: {OUTPUT_VIDEO}")
```
## Model Architecture
- **Base Model**: YOLOv8-nano (yolov8n.pt)
- **Input Size**: 640x640 pixels
- **Classes**: 1 (Gun)
- **Parameters**: ~3.2M
- **Model Size**: ~6.2MB
- **Inference Speed**: ~4ms per image (GPU)
## Training Configuration
- **Epochs**: 100
- **Batch Size**: 16
- **Image Size**: 640x640
- **Optimizer**: AdamW
- **Learning Rate**: 0.01 (initial)
## Limitations and Considerations
**Technical Limitations:**
- Performance may vary with image quality, lighting, and occlusion
- Optimized for common firearm types; may require retraining for specialized weapons
- False positives possible with objects resembling firearms (toys, tools)
**Recommended Usage:**
- Use appropriate confidence thresholds based on application requirements
- Implement human review processes for critical decisions
- Regular model evaluation and updates for optimal performance
- Proper training for operators using the system
## License
This model is released under the Apache 2.0 License. See the LICENSE file for details.
**Disclaimer**: This model is provided for research purposes only. The predictions can not be used to solve real world problems.