---
license: mit
pipeline_tags:
- Visual Document Retrieval
tags:
- multimodal
- retrieval
- universal
- generative
- cvpr2025
model_name: GENIUS
datasets:
- MSCOCO
- Flickr30k
- VisualNews
- Fashion200K
- WebQA
- EDIS
- NIGHTS
- OVEN
- InfoSeek
- FashionIQ
- CIRR
library_name: transformers
pipeline_tag: visual-document-retrieval
---
# GENIUS
This repo contains the codebase for the CVPR 2025 paper "[GENIUS: A Generative Framework for Universal Multimodal Search](https://arxiv.org/pdf/2503.19868)"
## Introduction
We propose **GENIUS**, a **universal generative retrieval framework** that supports diverse tasks across multiple modalities. By learning discrete, modality‐decoupled IDs via **semantic quantization**, GENIUS encodes multimodal data into compact identifiers and performs constant‐time retrieval with competitive accuracy.

### ✨ Key Advantages
- **Universal Retrieval**
Single model handles various retrieval tasks including image‐to‐image, text‐to‐text, image‐to‐text, text‐to‐image, and their combinations.
- **Fast Retrieval**
Constant‐time lookup via discrete ID matching, independent of candidate pool size.
- **Competitive Accuracy**
Comparable to—and sometimes better than—embedding‐based methods, while significatnly reducing inference cost.
## Overview
GENIUS consists of three key components that work together in a three-stage training pipeline:
1. **Multimodal Encoder (CLIP-SF)**
Extracts joint image/text features using a shared backbone. We leverage **UniIR's score‐fusion CLIP model** to learn cross‐modal relations without extra pretraining, with pretrained checkpoints available on [Hugging Face](https://huggingface.co/TIGER-Lab/UniIR/blob/main/checkpoint/CLIP_SF/clip_sf_large.pth).
2. **Modality-Decoupled Quantizer**
Compresses continuous embeddings into discrete, layered ID codes including modality and semantic information. Through **residual quantization training**, it learns to encode both images and text into layered, discrete IDs:
- First code: **modality indicator** (0 = image, 1 = text, 2 = image‐text)
- Subsequent codes: **semantic features** (objects → attributes → context)

3. **ID Generator**
**Sequence‐to‐sequence decoder** that generates target IDs based on query embeddings. During training, it learns to predict discrete IDs from various input queries (images, text, or pairs with instruction). We employ **query augmentation** (query-target mixing) to improve generalization and incorporate **constrained beam search** during decoding to enforce valid ID sequences.
---
## Installation
Clone the repository and create the Conda environment:
```bash
git clone https://github.com/sung-yeon-kim/GENIUS.git
cd GENIUS
conda env create -f genius_env.yml
```
## Usage
### Download Pretrained CLIP-SF (Stage 0)
We utilize UniIR's score fusion model as a replacement for the encoder pretraining stage.
```bash
mkdir -p checkpoint/CLIP_SF
wget https://huggingface.co/TIGER-Lab/UniIR/resolve/main/checkpoint/CLIP_SF/clip_sf_large.pth -O checkpoint/CLIP_SF/clip_sf_large.pth
```
### Feature Extraction (Preprocessing)
#### - Training Data
Extracts CLIP features for training set → `extracted_embed/CLIP_SF/train`.
```bash
# Navigate to feature extraction directory
cd feature_extraction
# Run feature extraction for training data
bash run_feature_extraction_train.sh
```
#### - Candidate Pool
Extracts CLIP features for the retrieval candidate pool → `extracted_embed/CLIP_SF/cand`.
```bash
# Run feature extraction for candidate pool
bash run_feature_extraction_cand.sh
```
### Residual Quantization (Stage 1)
```bash
cd models/residual_quantization
vim configs_scripts/large/train/inbatch/inbatch.yaml # Edit config like data path, batch size, etc.
bash configs_scripts/large/train/inbatch/run_inbatch.sh
```
### Generator Training (Stage 2)
```bash
cd models/generative_retriever
vim configs_scripts/large/train/inbatch/inbatch.yaml # Edit config like data path, batch size, etc.
bash configs_scripts/large/train/inbatch/run_inbatch.sh
```
### Inference
1. Extract CLIP features for candidate pool (if not already done):
```bash
cd feature_extraction
bash run_feature_extraction_cand.sh
```
2. Compile trie_cpp (recommended for faster inference):
```bash
cd models/generative_retriever/trie_cpp
c++ -O3 -Wall -shared -std=c++17 -fPIC \
$(python3 -m pybind11 --includes) \
trie_cpp.cpp -o trie_cpp$(python3-config --extension-suffix)
```
3. Run evaluation:
```bash
cd models/generative_retriever
bash configs_scripts/large/eval/inbatch/run_eval.sh
```
> For inference, you can choose between three trie implementations: `trie_cpp` (fastest), `trie` (Python), `marisa` (alternative).
## Model Checkpoints
We provide model checkpoints for GENIUS in the 🤗 [Hugging Face](https://huggingface.co/Sungyeon/GENIUS):
### How to Download
```bash
# Download the CLIP-SF model (Stage 0)
wget https://huggingface.co/TIGER-Lab/UniIR/resolve/main/checkpoint/CLIP_SF/clip_sf_large.pth -O checkpoint/CLIP_SF/clip_sf_large.pth
# Clone the GENIUS checkpoints (Stage 1 and 2)
git clone https://huggingface.co/Sungyeon/GENIUS
```
### Each Component Checkpoints
- **CLIP-SF Model** (Stage 0): [`clip_sf_large.pth`](https://huggingface.co/TIGER-Lab/UniIR/blob/main/checkpoint/CLIP_SF/clip_sf_large.pth)
- **Residual Quantization Model** (Stage 1): [`rq_clip_large.pth`](https://huggingface.co/Sungyeon/GENIUS/blob/main/checkpoint/rq_clip_large.pth)
- **Generator Model** (Stage 2): [`GENIUS_t5small.pth`](https://huggingface.co/Sungyeon/GENIUS/blob/main/checkpoint/GENIUS_t5small.pth)
> Note: All three models are required for full functionality.
>
## 📈 Performance
> The results in parentheses denote scores from our reimplemented checkpoints, as the originals were lost during server migration. While close to the paper, slight variations may occur due to retraining randomness.
### Universal Information Retrieval
| Task | Dataset | CLIP_SF | BLIP_FF | GENIUS (checkpoint) | GENIUSᴿ (checkpoint) |
|:-----|:--------|:-------:|:-------:|:------:|:-------:|
| **T→I** | VisualNews | 42.6 | 23.0 | 18.5 (18.5) | 27.3 (27.3)|
| | MSCOCO | 77.9 | 75.6 | 55.1 (55.3) | 68.0 (68.0) |
| | Fashion200K | 17.8 | 25.4 | 13.7 (14.0) | 16.2 (15.9)|
| **T→T** | WebQA | 84.7 | 79.5 | 31.1 (31.9) | 42.9 (43.6)|
| **T→(I,T)** | EDIS | 59.4 | 50.3 | 36.6 (37.0) | 44.1 (44.1)|
| | WebQA | 78.8 | 79.7 | 49.0 (49.0) | 59.7 (59.3) |
| **I→T** | VisualNews | 42.8 | 21.1 | 18.4 (18.2) | 26.8 (26.8)|
| | MSCOCO | 92.3 | 88.8 | 82.7 (83.0) | 90.6 (90.7) |
| | Fashion200K | 17.9 | 27.6 | 12.8 (12.9) | 16.2 (16.6) |
| **I→I** | NIGHTS | 33.4 | 33.0 | 8.1 (8.1) | 30.2 (30.0) |
| | OVEN | 39.2 | 34.7 | 34.6 (34.5) | 38.0 (38.0) |
| **(I,T)→T** | InfoSeek | 24.0 | 19.7 | 10.4 (10.5) | 18.0 (18.0) |
| **(I,T)→I** | FashionIQ | 26.2 | 28.5 | 13.1 (13.1) | 19.2 (19.3) |
| | CIRR | 43.0 | 51.4 | 20.1 (20.1) | 38.3 (38.1)|
| **(I,T)→(I,T)** | OVEN | 60.2 | 57.8 | 36.5 (36.6) | 48.6 (48.3)|
| | InfoSeek | 44.6 | 27.7 | 14.2 (14.3) | 28.6 (28.7) |
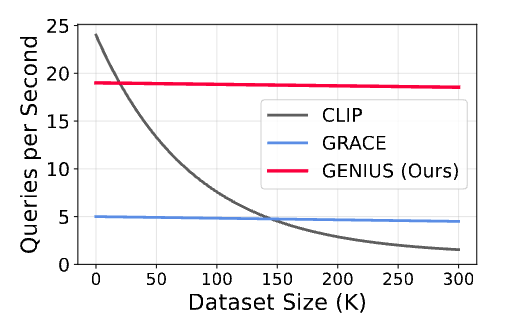
### ⚡ Efficiency
When the candidate pool grows, embedding‐based retrieval (e.g., CLIP + nearest neighbors) slows down dramatically. In contrast, GENIUS's discrete ID generation is **nearly constant time**. Empirically, GENIUS is roughly **4× faster** than competing generative methods like GRACE.
## Citation
If you find this work useful, please cite:
```bibtex
@inproceedings{kim2024genius,
title={GENIUS: A Generative Framework for Universal Multimodal Search},
author={Kim, Sungyeon and Zhu, Xinliang and Lin, Xiaofan and Bastan, Muhammet and Gray, Douglas and Kwak, Suha},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2025}
}
```
## License
This project is licensed under the MIT License - see the [LICENSE](https://github.com/sung-yeon-kim/GENIUS-CVPR25/blob/main/LICENSE) file for details.