
File size: 2,887 Bytes
1afd1cf 7abb7e9 1afd1cf 7abb7e9 1afd1cf 7abb7e9 1afd1cf 7abb7e9 ae33429 bfc01ab 1dbc168 bfc01ab 1dbc168 bfc01ab 3f9b2c3 1dbc168 bfc01ab 3f9b2c3 bfc01ab 1dbc168 a46d514 bfc01ab 1dbc168 bfc01ab 1dbc168 bfc01ab 1dbc168 bfc01ab 1dbc168 bfc01ab 1dbc168 bfc01ab 1dbc168 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | ---
license: unlicense
tags:
- flux2
- flux
- image-to-image
- image-upscaling
- latent-upscaling
- super-resolution
- diffusion
- flow-matching
- rectified-flow
- generative-models
- image-generation
- pytorch
library_name: pytorch
base_model:
- black-forest-labs/FLUX.2-klein-4B
pipeline_tag: image-to-image
---
# Flow Upscaler
**Flow Upscaler** is a fast latent upscaler model that works in the [Flux.2](https://bfl.ai/models/flux-2) latent space.
Under the hood, it is a lightweight **Rectified Flow** model with **59M** parameters that generates upscaled latents in a single denoising step.
**[ComfyUI Node](https://github.com/TensorForger/comfyui-flow-upscaler)**
Features:
* Upscaling from **512x512** to **1024x1024** takes **8ms***
* The model is trained for **2X** upscaling, but multiple passes can be chained to reach up to **8K** resolution
* A full pipeline with Flux generation, upscaling to **8K**, and decoding runs in just **25 seconds** (on RTX 5090)
* The training process uses **Flow Distillation** with Flux.2 as a teacher, forcing the model to learn strong image semantics
*On RTX 5090, in latent space, without decoding, see benchmark [here](https://github.com/tensorforger/CTGMWorkshop).
Here is one **4X** upscaled image (two passes):

## How it works
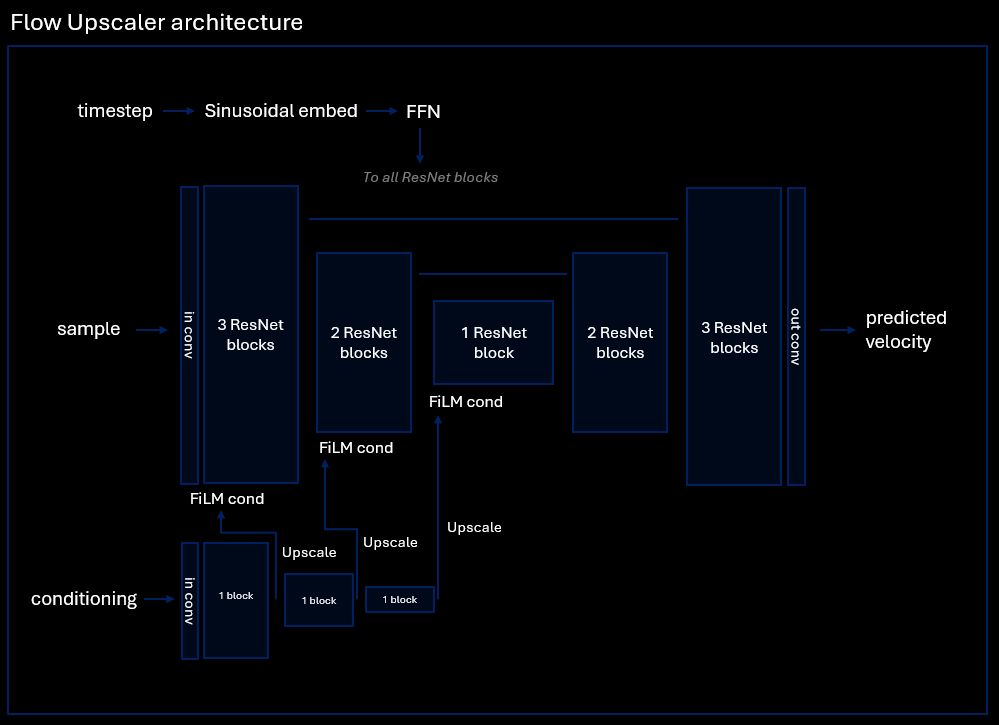
Architecturally, Flow Upscaler is a U-Net with SDXL-style ResNet blocks. It takes a noisy sample as input and predicts velocity as output. The generation process happens directly in high-resolution latent space.
The low-resolution latents are passed through a separate conditioning encoder that produces control signals, which are injected into the main U-Net encoder using FiLM conditioning.
No attention layers are used, so compute scales linearly with image area. This makes generation at **8K** resolution possible.
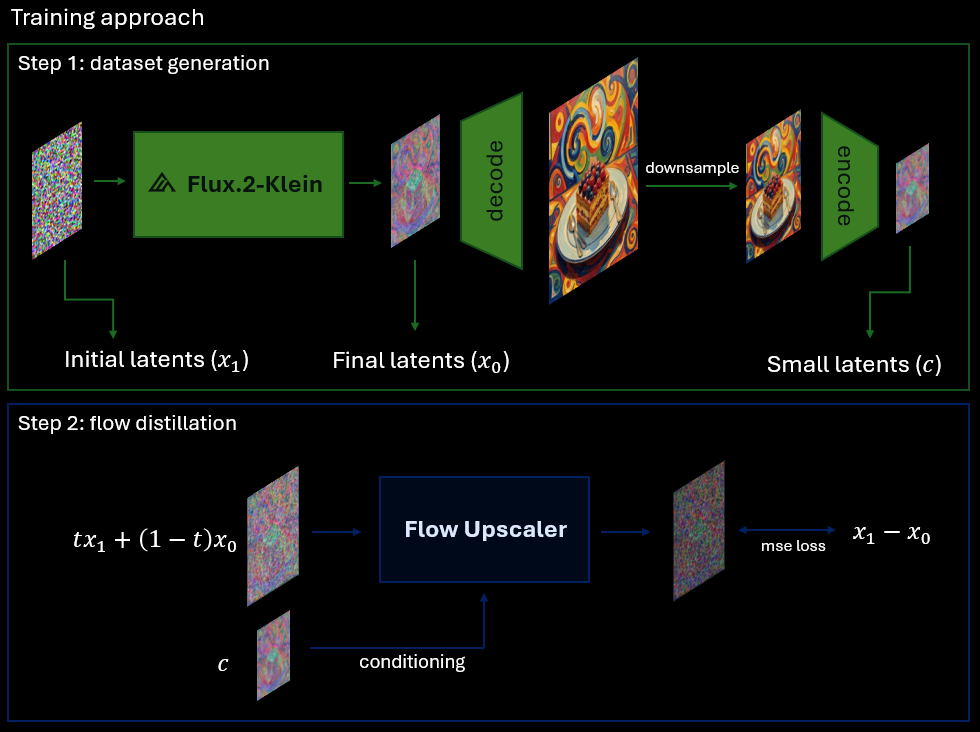
The model is trained using **Flow Distillation** with Flux.2-klein-4B as a teacher. We generated **20K** diverse images with Flux, storing the initial noise, generated latents, and downscaled latents used for conditioning.
The downscaled latents are created by decoding high-resolution latents, downscaling them in pixel space, and encoding them back into latents. Direct latent downscaling introduces artifacts and breaks latent patterns, resulting in blurry decoded images.
## Training code
If you want to explore the training code or use the model outside ComfyUI, see:
`notebooks/flow_upscaler` in [https://github.com/tensorforger/CTGMWorkshop](https://github.com/tensorforger/CTGMWorkshop) |