
File size: 3,728 Bytes
c7dc25c a30c2ac c7dc25c a30c2ac f941c6b a30c2ac f941c6b a30c2ac c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c a30c2ac c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b c7dc25c f941c6b a30c2ac f941c6b a30c2ac c7dc25c a30c2ac c7dc25c a30c2ac f941c6b a30c2ac c7dc25c 65c101f f941c6b 76d8163 97bb51e f941c6b 97bb51e f941c6b 97bb51e f941c6b 97bb51e f941c6b 97bb51e 005d793 d88856f |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 |
# Strength Performance Analysis and Modeling
## Overview
This project explores a dataset of athlete strength metrics to understand patterns in deadlift performance and to build models that can predict and classify athletes based on strength.
The workflow includes:
- Exploratory Data Analysis (EDA)
- Feature engineering
- Regression models
- Classification models
- Clustering
- Model selection and export
The final objective was to classify athletes into performance categories and evaluate which model performs best.
---
## Dataset
The dataset contains:
- Body weight
- Height
- Age
- Strength metrics: deadlift, back squat, snatch
After cleaning:
- Duplicate rows were removed
- Placeholder values were replaced
- Unrealistic values were filtered
- Missing key fields were dropped
---
## Exploratory Data Analysis (EDA)
### Average Deadlift by Body Weight

Heavier weight groups generally show higher deadlift performance.
### Average Deadlift by Height

Taller athletes tend to lift more, with higher variability at the upper height ranges.
### Average Deadlift by Age

Performance peaks around ages 25–34 and gradually declines afterward.
### Body Ratio and Deadlift

Higher weight-to-height ratios are associated with stronger lifts.
### Strength Metric Correlations

Deadlift and back squat show a strong positive correlation, while snatch is only weakly related.
---
## Regression Modeling
A baseline linear regression model was trained to predict deadlift performance.
### Actual vs Predicted Deadlift

The model follows the general trend but shows noise due to differences between athletes.
---
## Clustering
K-Means clustering was used to group athletes based on strength metrics.
### Cluster Visualization (PCA)

Three performance clusters were identified, separating athletes by overall strength level.
---
## Classification Modeling
Athletes were grouped into three balanced performance classes:
- Low
- Medium
- High
Models trained:
- Logistic Regression
- Random Forest
- Gradient Boosting
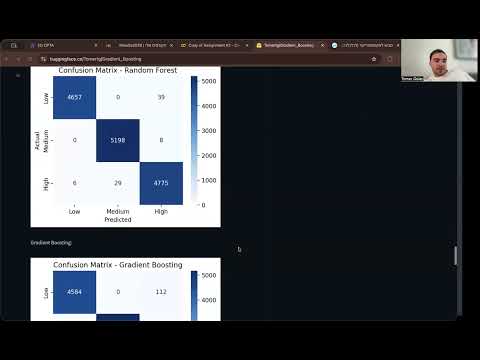
### Confusion Matrices
Logistic Regression:

Random Forest:

Gradient Boosting:

---
## Model Evaluation
All models performed well across accuracy, precision, recall, and F1-score.
Random Forest stood out because it:
- Made fewer major misclassifications
- Separated high and low performers better
- Achieved the highest F1-score
---
## Final Model
The final selected model:
**Random Forest Classifier**
It was trained on the full dataset and exported as:
`best_classifier.pkl`
---
## How to Load the Model
```python
import pickle
with open("best_classifier.pkl", "rb") as f:
model = pickle.load(f)
prediction = model.predict(X_sample)
```
---
## Conclusion
This project provided several key insights:
- Weight, height, and body ratio strongly influence deadlift performance
- Performance peaks in the late 20s and declines afterward
- Deadlift and back squat are closely related
- Classification models performed very well due to clear class separation
- Random Forest proved to be the most reliable model
The work demonstrates a full machine learning workflow, including:
- Data exploration
- Feature engineering
- Model training
- Evaluation
- Model selection
- Export
The final Random Forest model delivers strong performance and can be used to classify athletes into strength categories based on their physical and strength metrics.
## Presentation Video
[](https://youtu.be/R0YGueMVqko) |