
Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
pipeline_tag: image-text-to-text
|
| 4 |
+
library_name: transformers
|
| 5 |
+
---
|
| 6 |
+
<a href="https://chat.qwenlm.ai/" target="_blank" style="margin: 2px;">
|
| 7 |
+
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
|
| 8 |
+
</a>
|
| 9 |
+
|
| 10 |
+
# Octopus-8B
|
| 11 |
+
|
| 12 |
+
Octopus-8B is built based on Qwen-3-VL-8B-Instruct, featuring self-correction reasoning ability.
|
| 13 |
+
|
| 14 |
+
Paper:
|
| 15 |
+
Project Page: https://dripnowhy.github.io/Octopus/
|
| 16 |
+
Code: https://github.com/DripNowhy/Octopus
|
| 17 |
+
|
| 18 |
+
This is the weight repository for Octopus-8B.
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
---
|
| 22 |
+
|
| 23 |
+
## Model Performance
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
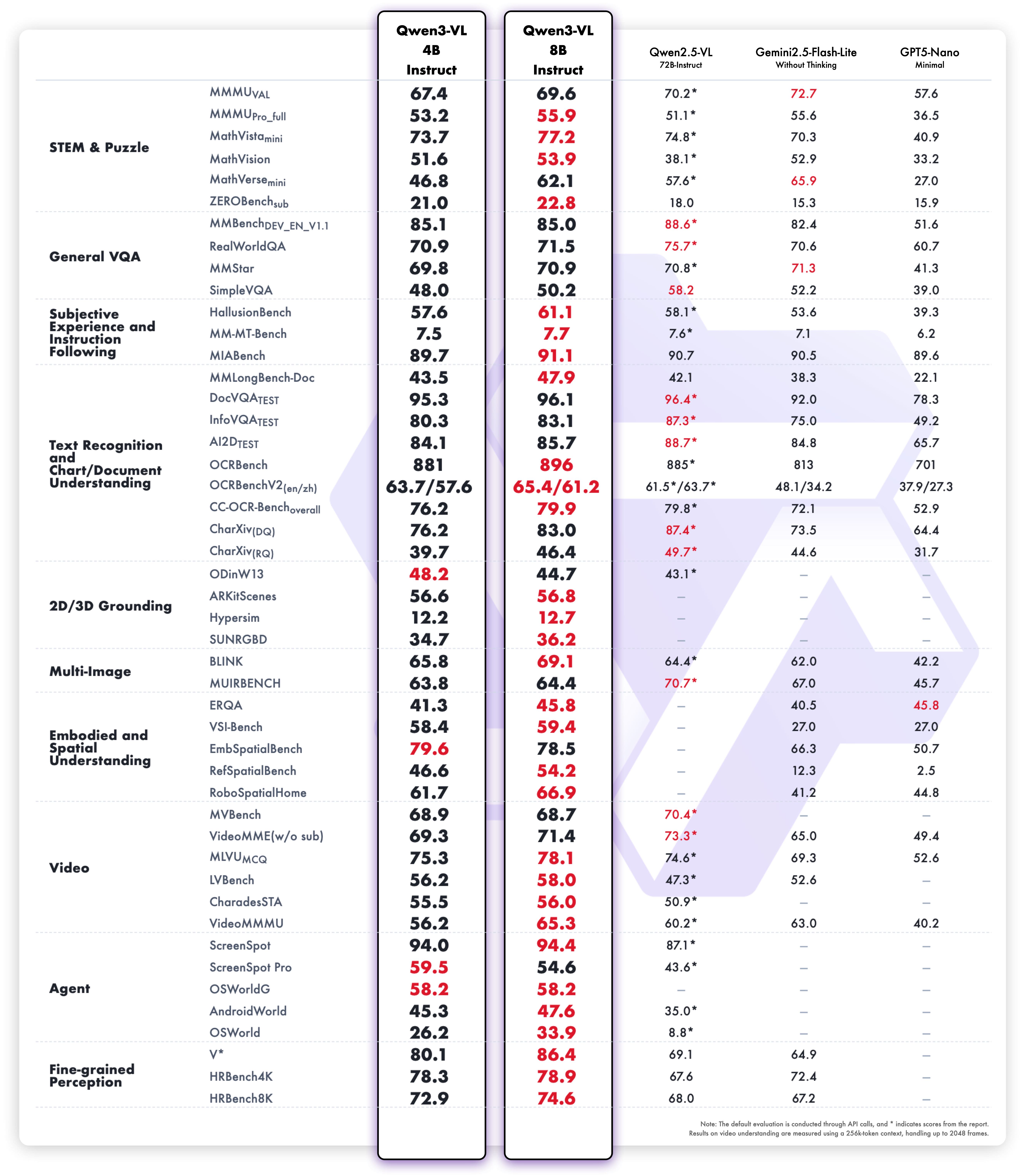
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
## Quickstart
|
| 30 |
+
|
| 31 |
+
Below, we provide simple examples to show how to use $\texttt{Octopus-8B}$ with vLLM and 🤗 Transformers.
|
| 32 |
+
|
| 33 |
+
First, Qwen3-VL has been in the latest Hugging Face transformers and we advise you to build from source with command:
|
| 34 |
+
```
|
| 35 |
+
pip install git+https://github.com/huggingface/transformers
|
| 36 |
+
# pip install transformers==4.57.0 # currently, V4.57.0 is not released
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
### Using vLLM to Chat
|
| 40 |
+
|
| 41 |
+
Here we show a code snippet to show how to use the chat model with `vllm`:
|
| 42 |
+
```python
|
| 43 |
+
from vllm import LLM, SamplingParams
|
| 44 |
+
from transformers import AutoProcessor
|
| 45 |
+
from PIL import Image
|
| 46 |
+
|
| 47 |
+
prompt_suffix = """\n\nYou first think through your reasoning process as an internal monologue, enclosed within <think> </think> tags. Then, provide your final answer enclosed within \\boxed{}. If you believe the answer can be further enhanced, generate <self-correction> </self-correction> tags enclosed with no content, and regenerate a new reasoning process and a new answer from scratch after that. The new response should first think through your reasoning process as an internal monologue, enclosed within <think> </think> tags. Then, provide your final answer enclosed within \\boxed{}. All reasoning, answer steps must be included without omission."""
|
| 48 |
+
|
| 49 |
+
MODEL_PATH = "Tuwhy/Octopus-8B"
|
| 50 |
+
|
| 51 |
+
def main():
|
| 52 |
+
# Initialize model
|
| 53 |
+
llm = LLM(
|
| 54 |
+
model=MODEL_PATH,
|
| 55 |
+
tensor_parallel_size=1,
|
| 56 |
+
gpu_memory_utilization=0.9,
|
| 57 |
+
seed=1,
|
| 58 |
+
max_model_len=8192 * 8,
|
| 59 |
+
trust_remote_code=True
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
processor = AutoProcessor.from_pretrained(
|
| 63 |
+
MODEL_PATH,
|
| 64 |
+
max_pixels=1280*28*28,
|
| 65 |
+
min_pixels=256*28*28
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
# Single case
|
| 69 |
+
prompt = "The accuracy gap between the Octopus-8B and the Qwen3-8B-VL-Thinking model is?"
|
| 70 |
+
image_path = "./assets/head.png"
|
| 71 |
+
|
| 72 |
+
sampling_params = SamplingParams(
|
| 73 |
+
temperature=1.0,
|
| 74 |
+
top_p=0.95,
|
| 75 |
+
top_k=-1,
|
| 76 |
+
max_tokens=8192*2
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
# Prepare messages
|
| 80 |
+
messages = [
|
| 81 |
+
{
|
| 82 |
+
"role": "user",
|
| 83 |
+
"content": [
|
| 84 |
+
{"type": "image", "image": image_path},
|
| 85 |
+
{"type": "text", "text": prompt + prompt_suffix}
|
| 86 |
+
]
|
| 87 |
+
}
|
| 88 |
+
]
|
| 89 |
+
|
| 90 |
+
text_prompt = processor.apply_chat_template(
|
| 91 |
+
messages,
|
| 92 |
+
tokenize=False,
|
| 93 |
+
add_generation_prompt=True
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
# Load image
|
| 97 |
+
image = Image.open(image_path).convert("RGB")
|
| 98 |
+
|
| 99 |
+
# Prepare input
|
| 100 |
+
inputs = {
|
| 101 |
+
"prompt": text_prompt,
|
| 102 |
+
"multi_modal_data": {
|
| 103 |
+
"image": image
|
| 104 |
+
}
|
| 105 |
+
}
|
| 106 |
+
|
| 107 |
+
# Generate
|
| 108 |
+
outputs = llm.generate([inputs], sampling_params=sampling_params)
|
| 109 |
+
|
| 110 |
+
# Print result
|
| 111 |
+
generated_text = outputs[0].outputs[0].text
|
| 112 |
+
|
| 113 |
+
print("Generated response:")
|
| 114 |
+
print("=" * 50)
|
| 115 |
+
print(generated_text)
|
| 116 |
+
print("=" * 50)
|
| 117 |
+
|
| 118 |
+
if __name__ == '__main__':
|
| 119 |
+
main()
|
| 120 |
+
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
### Using 🤗 Transformers to Chat
|
| 124 |
+
|
| 125 |
+
Here we show a code snippet to show how to use the chat model with `transformers`:
|
| 126 |
+
|
| 127 |
+
```python
|
| 128 |
+
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
|
| 129 |
+
|
| 130 |
+
prompt_suffix = """\n\nYou first think through your reasoning process as an internal monologue, enclosed within <think> </think> tags. Then, provide your final answer enclosed within \\boxed{}. If you believe the answer can be further enhanced, generate <self-correction> </self-correction> tags enclosed with no content, and regenerate a new reasoning process and a new answer from scratch after that. The new response should first think through your reasoning process as an internal monologue, enclosed within <think> </think> tags. Then, provide your final answer enclosed within \\boxed{}. All reasoning, answer steps must be included without omission."""
|
| 131 |
+
|
| 132 |
+
# default: Load the model on the available device(s)
|
| 133 |
+
model = Qwen3VLForConditionalGeneration.from_pretrained(
|
| 134 |
+
"Tuwhy/Octopus-8B", dtype="auto", device_map="auto"
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
|
| 138 |
+
# model = Qwen3VLForConditionalGeneration.from_pretrained(
|
| 139 |
+
# "Qwen/Qwen3-VL-8B-Instruct",
|
| 140 |
+
# dtype=torch.bfloat16,
|
| 141 |
+
# attn_implementation="flash_attention_2",
|
| 142 |
+
# device_map="auto",
|
| 143 |
+
# )
|
| 144 |
+
|
| 145 |
+
processor = AutoProcessor.from_pretrained("Tuwhy/Octopus-8B")
|
| 146 |
+
|
| 147 |
+
messages = [
|
| 148 |
+
{
|
| 149 |
+
"role": "user",
|
| 150 |
+
"content": [
|
| 151 |
+
{
|
| 152 |
+
"type": "image",
|
| 153 |
+
"image": "./assets/head.png",
|
| 154 |
+
},
|
| 155 |
+
{"type": "text", "text": "The accuracy gap between the Octopus-8B and the Qwen3-8B-VL-Thinking model is?" + prompt_suffix},
|
| 156 |
+
],
|
| 157 |
+
}
|
| 158 |
+
]
|
| 159 |
+
|
| 160 |
+
# Preparation for inference
|
| 161 |
+
inputs = processor.apply_chat_template(
|
| 162 |
+
messages,
|
| 163 |
+
tokenize=True,
|
| 164 |
+
add_generation_prompt=True,
|
| 165 |
+
return_dict=True,
|
| 166 |
+
return_tensors="pt"
|
| 167 |
+
)
|
| 168 |
+
inputs = inputs.to(model.device)
|
| 169 |
+
|
| 170 |
+
# Inference: Generation of the output
|
| 171 |
+
generated_ids = model.generate(**inputs, max_new_tokens=8192*2)
|
| 172 |
+
generated_ids_trimmed = [
|
| 173 |
+
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
| 174 |
+
]
|
| 175 |
+
output_text = processor.batch_decode(
|
| 176 |
+
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 177 |
+
)
|
| 178 |
+
print(output_text)
|
| 179 |
+
```
|
| 180 |
+
|
| 181 |
+
### Generation Hyperparameters
|
| 182 |
+
#### VL
|
| 183 |
+
```bash
|
| 184 |
+
export greedy='false'
|
| 185 |
+
export top_p=0.95
|
| 186 |
+
export top_k=-1
|
| 187 |
+
export temperature=0.6
|
| 188 |
+
export out_seq_length=16384
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
## Citation
|
| 192 |
+
|
| 193 |
+
If you find our work helpful, feel free to give us a cite.
|
| 194 |
+
|
| 195 |
+
```bibtex
|
| 196 |
+
@article{ding2025sherlock,
|
| 197 |
+
title={Sherlock: Self-Correcting Reasoning in Vision-Language Models},
|
| 198 |
+
author={Ding, Yi and Zhang, Ruqi},
|
| 199 |
+
journal={arXiv preprint arXiv:2505.22651},
|
| 200 |
+
year={2025}
|
| 201 |
+
}
|
| 202 |
+
```
|