
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- .gitattributes +14 -0
- .gitignore +180 -0
- .hydra/config.yaml +193 -0
- .hydra/hydra.yaml +178 -0
- .hydra/overrides.yaml +16 -0
- .vscode/launch.json +18 -0
- CLAUDE.md +161 -0
- DATASETS.md +78 -0
- LICENSE +21 -0
- MODEL_ZOO.md +46 -0
- MinkowskiEngine/.gitignore +11 -0
- MinkowskiEngine/CHANGELOG.md +319 -0
- MinkowskiEngine/LICENSE +26 -0
- MinkowskiEngine/MANIFEST.in +3 -0
- MinkowskiEngine/Makefile +178 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiBroadcast.py +253 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiChannelwiseConvolution.py +215 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiCommon.py +120 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiConvolution.py +634 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiCoordinateManager.py +498 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiFunctional.py +232 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiInterpolation.py +131 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiKernelGenerator.py +395 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiNetwork.py +57 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiNonlinearity.py +200 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiNormalization.py +399 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiOps.py +497 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiPooling.py +780 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiPruning.py +121 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiSparseTensor.py +783 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiTensor.py +604 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiTensorField.py +506 -0
- MinkowskiEngine/MinkowskiEngine/MinkowskiUnion.py +156 -0
- MinkowskiEngine/MinkowskiEngine/__init__.py +228 -0
- MinkowskiEngine/MinkowskiEngine/diagnostics.py +70 -0
- MinkowskiEngine/MinkowskiEngine/modules/__init__.py +23 -0
- MinkowskiEngine/MinkowskiEngine/modules/resnet_block.py +121 -0
- MinkowskiEngine/MinkowskiEngine/modules/senet_block.py +129 -0
- MinkowskiEngine/MinkowskiEngine/sparse_matrix_functions.py +213 -0
- MinkowskiEngine/MinkowskiEngine/utils/__init__.py +28 -0
- MinkowskiEngine/MinkowskiEngine/utils/collation.py +263 -0
- MinkowskiEngine/MinkowskiEngine/utils/coords.py +63 -0
- MinkowskiEngine/MinkowskiEngine/utils/gradcheck.py +57 -0
- MinkowskiEngine/MinkowskiEngine/utils/init.py +41 -0
- MinkowskiEngine/MinkowskiEngine/utils/quantization.py +363 -0
- MinkowskiEngine/MinkowskiEngine/utils/summary.py +136 -0
- MinkowskiEngine/README.md +396 -0
- MinkowskiEngine/docker/Dockerfile +30 -0
- MinkowskiEngine/docs/.gitignore +3 -0
- MinkowskiEngine/docs/Makefile +19 -0
.gitattributes
CHANGED
|
@@ -1 +1,15 @@
|
|
| 1 |
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
MinkowskiEngine/docs/images/classification_3d_net.png filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
MinkowskiEngine/docs/images/conv_dense.gif filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
MinkowskiEngine/docs/images/conv_generalized.gif filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
MinkowskiEngine/docs/images/conv_sparse.gif filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
MinkowskiEngine/docs/images/conv_sparse_conv.gif filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
MinkowskiEngine/docs/images/detection_3d_net.png filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
MinkowskiEngine/docs/images/generative_3d_results.gif filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
MinkowskiEngine/docs/images/kernel_map.gif filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
MinkowskiEngine/docs/images/segmentation.png filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
MinkowskiEngine/docs/images/segmentation_3d_net.png filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
diff-gaussian-rasterization-modified-main/third_party/glm/doc/manual/frontpage1.png filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
diff-gaussian-rasterization-modified-main/third_party/glm/doc/manual/frontpage2.png filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
diff-gaussian-rasterization-modified-main/third_party/glm/doc/manual.pdf filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
visualization/depth_comparison.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/latest/usage/project/#working-with-version-control
|
| 110 |
+
.pdm.toml
|
| 111 |
+
.pdm-python
|
| 112 |
+
.pdm-build/
|
| 113 |
+
|
| 114 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 115 |
+
__pypackages__/
|
| 116 |
+
|
| 117 |
+
# Celery stuff
|
| 118 |
+
celerybeat-schedule
|
| 119 |
+
celerybeat.pid
|
| 120 |
+
|
| 121 |
+
# SageMath parsed files
|
| 122 |
+
*.sage.py
|
| 123 |
+
|
| 124 |
+
# Environments
|
| 125 |
+
.env
|
| 126 |
+
.venv
|
| 127 |
+
env/
|
| 128 |
+
venv/
|
| 129 |
+
ENV/
|
| 130 |
+
env.bak/
|
| 131 |
+
venv.bak/
|
| 132 |
+
|
| 133 |
+
# Spyder project settings
|
| 134 |
+
.spyderproject
|
| 135 |
+
.spyproject
|
| 136 |
+
|
| 137 |
+
# Rope project settings
|
| 138 |
+
.ropeproject
|
| 139 |
+
|
| 140 |
+
# mkdocs documentation
|
| 141 |
+
/site
|
| 142 |
+
|
| 143 |
+
# mypy
|
| 144 |
+
.mypy_cache/
|
| 145 |
+
.dmypy.json
|
| 146 |
+
dmypy.json
|
| 147 |
+
|
| 148 |
+
# Pyre type checker
|
| 149 |
+
.pyre/
|
| 150 |
+
|
| 151 |
+
# pytype static type analyzer
|
| 152 |
+
.pytype/
|
| 153 |
+
|
| 154 |
+
# Cython debug symbols
|
| 155 |
+
cython_debug/
|
| 156 |
+
|
| 157 |
+
# PyCharm
|
| 158 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 159 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 160 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 161 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 162 |
+
#.idea/
|
| 163 |
+
|
| 164 |
+
output.txt
|
| 165 |
+
checkpoints/*
|
| 166 |
+
outputs/*
|
| 167 |
+
models/*
|
| 168 |
+
datasets/*
|
| 169 |
+
pretrained/*
|
| 170 |
+
.idea/*
|
| 171 |
+
|
| 172 |
+
test.sh
|
| 173 |
+
test.ipynb
|
| 174 |
+
test.py
|
| 175 |
+
# test/
|
| 176 |
+
|
| 177 |
+
*.zip
|
| 178 |
+
final/
|
| 179 |
+
wandb/
|
| 180 |
+
*.mp4
|
.hydra/config.yaml
ADDED
|
@@ -0,0 +1,193 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dataset:
|
| 2 |
+
view_sampler:
|
| 3 |
+
name: boundedv2
|
| 4 |
+
num_target_views: 8
|
| 5 |
+
num_context_views: 6
|
| 6 |
+
min_distance_between_context_views: 20
|
| 7 |
+
max_distance_between_context_views: 50
|
| 8 |
+
max_distance_to_context_views: 0
|
| 9 |
+
context_gap_warm_up_steps: 10000
|
| 10 |
+
target_gap_warm_up_steps: 0
|
| 11 |
+
initial_min_distance_between_context_views: 15
|
| 12 |
+
initial_max_distance_between_context_views: 30
|
| 13 |
+
initial_max_distance_to_context_views: 0
|
| 14 |
+
extra_views_sampling_strategy: farthest_point
|
| 15 |
+
target_views_replace_sample: false
|
| 16 |
+
name: dl3dv
|
| 17 |
+
roots:
|
| 18 |
+
- datasets/dl3dv
|
| 19 |
+
make_baseline_1: false
|
| 20 |
+
augment: true
|
| 21 |
+
image_shape:
|
| 22 |
+
- 270
|
| 23 |
+
- 480
|
| 24 |
+
background_color:
|
| 25 |
+
- 0.0
|
| 26 |
+
- 0.0
|
| 27 |
+
- 0.0
|
| 28 |
+
cameras_are_circular: false
|
| 29 |
+
baseline_epsilon: 0.001
|
| 30 |
+
max_fov: 100.0
|
| 31 |
+
skip_bad_shape: true
|
| 32 |
+
near: 0.5
|
| 33 |
+
far: 200.0
|
| 34 |
+
baseline_scale_bounds: false
|
| 35 |
+
shuffle_val: true
|
| 36 |
+
test_len: -1
|
| 37 |
+
test_chunk_interval: 1
|
| 38 |
+
sort_target_index: true
|
| 39 |
+
sort_context_index: true
|
| 40 |
+
train_times_per_scene: 1
|
| 41 |
+
test_times_per_scene: 1
|
| 42 |
+
ori_image_shape:
|
| 43 |
+
- 270
|
| 44 |
+
- 480
|
| 45 |
+
overfit_max_views: 148
|
| 46 |
+
use_index_to_load_chunk: false
|
| 47 |
+
mix_tartanair: false
|
| 48 |
+
no_mix_test_set: true
|
| 49 |
+
load_depth: false
|
| 50 |
+
overfit_to_scene: null
|
| 51 |
+
min_views: 1
|
| 52 |
+
max_views: 6
|
| 53 |
+
highres: false
|
| 54 |
+
model:
|
| 55 |
+
encoder:
|
| 56 |
+
name: depthsplat
|
| 57 |
+
num_depth_candidates: 128
|
| 58 |
+
num_surfaces: 1
|
| 59 |
+
gaussians_per_pixel: 1
|
| 60 |
+
gaussian_adapter:
|
| 61 |
+
gaussian_scale_min: 1.0e-10
|
| 62 |
+
gaussian_scale_max: 3.0
|
| 63 |
+
sh_degree: 2
|
| 64 |
+
d_feature: 128
|
| 65 |
+
visualizer:
|
| 66 |
+
num_samples: 8
|
| 67 |
+
min_resolution: 256
|
| 68 |
+
export_ply: false
|
| 69 |
+
unimatch_weights_path: pretrained/gmdepth-scale1-resumeflowthings-scannet-5d9d7964.pth
|
| 70 |
+
multiview_trans_attn_split: 2
|
| 71 |
+
costvolume_unet_feat_dim: 128
|
| 72 |
+
costvolume_unet_channel_mult:
|
| 73 |
+
- 1
|
| 74 |
+
- 1
|
| 75 |
+
- 1
|
| 76 |
+
costvolume_unet_attn_res:
|
| 77 |
+
- 4
|
| 78 |
+
depth_unet_feat_dim: 32
|
| 79 |
+
depth_unet_attn_res:
|
| 80 |
+
- 16
|
| 81 |
+
depth_unet_channel_mult:
|
| 82 |
+
- 1
|
| 83 |
+
- 1
|
| 84 |
+
- 1
|
| 85 |
+
- 1
|
| 86 |
+
- 1
|
| 87 |
+
downscale_factor: 4
|
| 88 |
+
shim_patch_size: 16
|
| 89 |
+
local_mv_match: 2
|
| 90 |
+
monodepth_vit_type: vitb
|
| 91 |
+
supervise_intermediate_depth: true
|
| 92 |
+
return_depth: true
|
| 93 |
+
num_scales: 2
|
| 94 |
+
upsample_factor: 4
|
| 95 |
+
lowest_feature_resolution: 8
|
| 96 |
+
depth_unet_channels: 128
|
| 97 |
+
grid_sample_disable_cudnn: false
|
| 98 |
+
large_gaussian_head: false
|
| 99 |
+
color_large_unet: false
|
| 100 |
+
init_sh_input_img: true
|
| 101 |
+
feature_upsampler_channels: 64
|
| 102 |
+
gaussian_regressor_channels: 64
|
| 103 |
+
train_depth_only: false
|
| 104 |
+
decoder:
|
| 105 |
+
name: splatting_cuda
|
| 106 |
+
loss:
|
| 107 |
+
mse:
|
| 108 |
+
weight: 1.0
|
| 109 |
+
lpips:
|
| 110 |
+
weight: 0.05
|
| 111 |
+
apply_after_step: 0
|
| 112 |
+
wandb:
|
| 113 |
+
project: depthsplat
|
| 114 |
+
entity: placeholder
|
| 115 |
+
name: dl3dv
|
| 116 |
+
mode: disabled
|
| 117 |
+
id: null
|
| 118 |
+
tags:
|
| 119 |
+
- dl3dv
|
| 120 |
+
- 270x480
|
| 121 |
+
mode: train
|
| 122 |
+
data_loader:
|
| 123 |
+
train:
|
| 124 |
+
num_workers: 10
|
| 125 |
+
persistent_workers: true
|
| 126 |
+
batch_size: 1
|
| 127 |
+
seed: 1234
|
| 128 |
+
test:
|
| 129 |
+
num_workers: 4
|
| 130 |
+
persistent_workers: false
|
| 131 |
+
batch_size: 1
|
| 132 |
+
seed: 2345
|
| 133 |
+
val:
|
| 134 |
+
num_workers: 1
|
| 135 |
+
persistent_workers: true
|
| 136 |
+
batch_size: 1
|
| 137 |
+
seed: 3456
|
| 138 |
+
optimizer:
|
| 139 |
+
lr: 0.0002
|
| 140 |
+
lr_monodepth: 2.0e-06
|
| 141 |
+
warm_up_steps: 2000
|
| 142 |
+
weight_decay: 0.01
|
| 143 |
+
checkpointing:
|
| 144 |
+
load: null
|
| 145 |
+
every_n_train_steps: 5000
|
| 146 |
+
save_top_k: 5
|
| 147 |
+
pretrained_model: pretrained/depthsplat-gs-base-re10k-256x448-view2-76a0605a.pth
|
| 148 |
+
pretrained_monodepth: null
|
| 149 |
+
pretrained_mvdepth: null
|
| 150 |
+
pretrained_depth: null
|
| 151 |
+
no_strict_load: false
|
| 152 |
+
resume: false
|
| 153 |
+
train:
|
| 154 |
+
depth_mode: null
|
| 155 |
+
extended_visualization: false
|
| 156 |
+
print_log_every_n_steps: 100
|
| 157 |
+
eval_model_every_n_val: 2
|
| 158 |
+
eval_data_length: 999999
|
| 159 |
+
eval_deterministic: false
|
| 160 |
+
eval_time_skip_steps: 3
|
| 161 |
+
eval_save_model: true
|
| 162 |
+
l1_loss: false
|
| 163 |
+
intermediate_loss_weight: 0.9
|
| 164 |
+
no_viz_video: false
|
| 165 |
+
viz_depth: false
|
| 166 |
+
forward_depth_only: false
|
| 167 |
+
train_ignore_large_loss: 0.0
|
| 168 |
+
no_log_projections: false
|
| 169 |
+
test:
|
| 170 |
+
output_path: outputs/test
|
| 171 |
+
compute_scores: true
|
| 172 |
+
eval_time_skip_steps: 0
|
| 173 |
+
save_image: false
|
| 174 |
+
save_video: false
|
| 175 |
+
save_gt_image: false
|
| 176 |
+
save_input_images: false
|
| 177 |
+
save_depth: false
|
| 178 |
+
save_depth_npy: false
|
| 179 |
+
save_depth_concat_img: false
|
| 180 |
+
save_gaussian: false
|
| 181 |
+
render_chunk_size: null
|
| 182 |
+
stablize_camera: false
|
| 183 |
+
stab_camera_kernel: 50
|
| 184 |
+
dec_chunk_size: 30
|
| 185 |
+
seed: 111123
|
| 186 |
+
trainer:
|
| 187 |
+
max_steps: 100000
|
| 188 |
+
val_check_interval: 0.5
|
| 189 |
+
gradient_clip_val: 0.5
|
| 190 |
+
num_sanity_val_steps: 2
|
| 191 |
+
num_nodes: 1
|
| 192 |
+
output_dir: checkpoints/dl3dv-256x448-depthsplat-base-randview2-6
|
| 193 |
+
use_plugins: false
|
.hydra/hydra.yaml
ADDED
|
@@ -0,0 +1,178 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
hydra:
|
| 2 |
+
run:
|
| 3 |
+
dir: /mnt/pfs/users/wangweijie/yeqing/BEV-Splat
|
| 4 |
+
sweep:
|
| 5 |
+
dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 6 |
+
subdir: ${hydra.job.num}
|
| 7 |
+
launcher:
|
| 8 |
+
_target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
|
| 9 |
+
sweeper:
|
| 10 |
+
_target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
|
| 11 |
+
max_batch_size: null
|
| 12 |
+
params: null
|
| 13 |
+
help:
|
| 14 |
+
app_name: ${hydra.job.name}
|
| 15 |
+
header: '${hydra.help.app_name} is powered by Hydra.
|
| 16 |
+
|
| 17 |
+
'
|
| 18 |
+
footer: 'Powered by Hydra (https://hydra.cc)
|
| 19 |
+
|
| 20 |
+
Use --hydra-help to view Hydra specific help
|
| 21 |
+
|
| 22 |
+
'
|
| 23 |
+
template: '${hydra.help.header}
|
| 24 |
+
|
| 25 |
+
== Configuration groups ==
|
| 26 |
+
|
| 27 |
+
Compose your configuration from those groups (group=option)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
$APP_CONFIG_GROUPS
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
== Config ==
|
| 34 |
+
|
| 35 |
+
Override anything in the config (foo.bar=value)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
$CONFIG
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
${hydra.help.footer}
|
| 42 |
+
|
| 43 |
+
'
|
| 44 |
+
hydra_help:
|
| 45 |
+
template: 'Hydra (${hydra.runtime.version})
|
| 46 |
+
|
| 47 |
+
See https://hydra.cc for more info.
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
== Flags ==
|
| 51 |
+
|
| 52 |
+
$FLAGS_HELP
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
== Configuration groups ==
|
| 56 |
+
|
| 57 |
+
Compose your configuration from those groups (For example, append hydra/job_logging=disabled
|
| 58 |
+
to command line)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
$HYDRA_CONFIG_GROUPS
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
Use ''--cfg hydra'' to Show the Hydra config.
|
| 65 |
+
|
| 66 |
+
'
|
| 67 |
+
hydra_help: ???
|
| 68 |
+
hydra_logging:
|
| 69 |
+
version: 1
|
| 70 |
+
formatters:
|
| 71 |
+
simple:
|
| 72 |
+
format: '[%(asctime)s][HYDRA] %(message)s'
|
| 73 |
+
handlers:
|
| 74 |
+
console:
|
| 75 |
+
class: logging.StreamHandler
|
| 76 |
+
formatter: simple
|
| 77 |
+
stream: ext://sys.stdout
|
| 78 |
+
root:
|
| 79 |
+
level: INFO
|
| 80 |
+
handlers:
|
| 81 |
+
- console
|
| 82 |
+
loggers:
|
| 83 |
+
logging_example:
|
| 84 |
+
level: DEBUG
|
| 85 |
+
disable_existing_loggers: false
|
| 86 |
+
job_logging:
|
| 87 |
+
version: 1
|
| 88 |
+
formatters:
|
| 89 |
+
simple:
|
| 90 |
+
format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
|
| 91 |
+
handlers:
|
| 92 |
+
console:
|
| 93 |
+
class: logging.StreamHandler
|
| 94 |
+
formatter: simple
|
| 95 |
+
stream: ext://sys.stdout
|
| 96 |
+
file:
|
| 97 |
+
class: logging.FileHandler
|
| 98 |
+
formatter: simple
|
| 99 |
+
filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
|
| 100 |
+
root:
|
| 101 |
+
level: INFO
|
| 102 |
+
handlers:
|
| 103 |
+
- console
|
| 104 |
+
- file
|
| 105 |
+
disable_existing_loggers: false
|
| 106 |
+
env: {}
|
| 107 |
+
mode: RUN
|
| 108 |
+
searchpath: []
|
| 109 |
+
callbacks: {}
|
| 110 |
+
output_subdir: .hydra
|
| 111 |
+
overrides:
|
| 112 |
+
hydra:
|
| 113 |
+
- hydra.run.dir="/mnt/pfs/users/wangweijie/yeqing/BEV-Splat"
|
| 114 |
+
- hydra.job.name=train_ddp_process_1
|
| 115 |
+
- hydra.mode=RUN
|
| 116 |
+
task:
|
| 117 |
+
- +experiment=dl3dv
|
| 118 |
+
- data_loader.train.batch_size=1
|
| 119 |
+
- dataset.roots=["datasets/dl3dv"]
|
| 120 |
+
- dataset.view_sampler.num_target_views=8
|
| 121 |
+
- dataset.view_sampler.num_context_views=6
|
| 122 |
+
- dataset.min_views=1
|
| 123 |
+
- dataset.max_views=6
|
| 124 |
+
- trainer.max_steps=100000
|
| 125 |
+
- trainer.num_nodes=1
|
| 126 |
+
- model.encoder.num_scales=2
|
| 127 |
+
- model.encoder.upsample_factor=4
|
| 128 |
+
- model.encoder.lowest_feature_resolution=8
|
| 129 |
+
- model.encoder.monodepth_vit_type=vitb
|
| 130 |
+
- checkpointing.pretrained_model=pretrained/depthsplat-gs-base-re10k-256x448-view2-76a0605a.pth
|
| 131 |
+
- wandb.project=depthsplat
|
| 132 |
+
- output_dir=checkpoints/dl3dv-256x448-depthsplat-base-randview2-6
|
| 133 |
+
job:
|
| 134 |
+
name: train_ddp_process_1
|
| 135 |
+
chdir: null
|
| 136 |
+
override_dirname: +experiment=dl3dv,checkpointing.pretrained_model=pretrained/depthsplat-gs-base-re10k-256x448-view2-76a0605a.pth,data_loader.train.batch_size=1,dataset.max_views=6,dataset.min_views=1,dataset.roots=["datasets/dl3dv"],dataset.view_sampler.num_context_views=6,dataset.view_sampler.num_target_views=8,model.encoder.lowest_feature_resolution=8,model.encoder.monodepth_vit_type=vitb,model.encoder.num_scales=2,model.encoder.upsample_factor=4,output_dir=checkpoints/dl3dv-256x448-depthsplat-base-randview2-6,trainer.max_steps=100000,trainer.num_nodes=1,wandb.project=depthsplat
|
| 137 |
+
id: ???
|
| 138 |
+
num: ???
|
| 139 |
+
config_name: main
|
| 140 |
+
env_set: {}
|
| 141 |
+
env_copy: []
|
| 142 |
+
config:
|
| 143 |
+
override_dirname:
|
| 144 |
+
kv_sep: '='
|
| 145 |
+
item_sep: ','
|
| 146 |
+
exclude_keys: []
|
| 147 |
+
runtime:
|
| 148 |
+
version: 1.3.2
|
| 149 |
+
version_base: '1.3'
|
| 150 |
+
cwd: /mnt/pfs/users/wangweijie/yeqing/BEV-Splat
|
| 151 |
+
config_sources:
|
| 152 |
+
- path: hydra.conf
|
| 153 |
+
schema: pkg
|
| 154 |
+
provider: hydra
|
| 155 |
+
- path: /mnt/pfs/users/wangweijie/yeqing/BEV-Splat/config
|
| 156 |
+
schema: file
|
| 157 |
+
provider: main
|
| 158 |
+
- path: ''
|
| 159 |
+
schema: structured
|
| 160 |
+
provider: schema
|
| 161 |
+
output_dir: /mnt/pfs/users/wangweijie/yeqing/BEV-Splat
|
| 162 |
+
choices:
|
| 163 |
+
experiment: dl3dv
|
| 164 |
+
model/decoder: splatting_cuda
|
| 165 |
+
model/encoder: depthsplat
|
| 166 |
+
dataset: dl3dv
|
| 167 |
+
dataset/view_sampler: boundedv2_360
|
| 168 |
+
dataset/view_sampler_dataset_specific_config: boundedv2_360_dl3dv
|
| 169 |
+
hydra/env: default
|
| 170 |
+
hydra/callbacks: null
|
| 171 |
+
hydra/job_logging: default
|
| 172 |
+
hydra/hydra_logging: default
|
| 173 |
+
hydra/hydra_help: default
|
| 174 |
+
hydra/help: default
|
| 175 |
+
hydra/sweeper: basic
|
| 176 |
+
hydra/launcher: basic
|
| 177 |
+
hydra/output: default
|
| 178 |
+
verbose: false
|
.hydra/overrides.yaml
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- +experiment=dl3dv
|
| 2 |
+
- data_loader.train.batch_size=1
|
| 3 |
+
- dataset.roots=["datasets/dl3dv"]
|
| 4 |
+
- dataset.view_sampler.num_target_views=8
|
| 5 |
+
- dataset.view_sampler.num_context_views=6
|
| 6 |
+
- dataset.min_views=1
|
| 7 |
+
- dataset.max_views=6
|
| 8 |
+
- trainer.max_steps=100000
|
| 9 |
+
- trainer.num_nodes=1
|
| 10 |
+
- model.encoder.num_scales=2
|
| 11 |
+
- model.encoder.upsample_factor=4
|
| 12 |
+
- model.encoder.lowest_feature_resolution=8
|
| 13 |
+
- model.encoder.monodepth_vit_type=vitb
|
| 14 |
+
- checkpointing.pretrained_model=pretrained/depthsplat-gs-base-re10k-256x448-view2-76a0605a.pth
|
| 15 |
+
- wandb.project=depthsplat
|
| 16 |
+
- output_dir=checkpoints/dl3dv-256x448-depthsplat-base-randview2-6
|
.vscode/launch.json
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
{
|
| 3 |
+
// 使用 IntelliSense 了解相关属性。
|
| 4 |
+
// 悬停以查看现有属性的描述。
|
| 5 |
+
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
|
| 6 |
+
"version": "0.2.0",
|
| 7 |
+
"configurations": [
|
| 8 |
+
{
|
| 9 |
+
"name": "sh_file_debug",
|
| 10 |
+
"type": "debugpy",
|
| 11 |
+
"request": "attach",
|
| 12 |
+
"connect": {
|
| 13 |
+
"host": "localhost",
|
| 14 |
+
"port": 9326}
|
| 15 |
+
}
|
| 16 |
+
]
|
| 17 |
+
}
|
| 18 |
+
|
CLAUDE.md
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CLAUDE.md
|
| 2 |
+
|
| 3 |
+
This file provides guidance to Claude Code (claude.ai/code) when working with code in this repository.
|
| 4 |
+
|
| 5 |
+
## Project Overview
|
| 6 |
+
|
| 7 |
+
This is BEV-Splat, a 3D computer vision project based on DepthSplat that uses Gaussian splatting for novel view synthesis. The codebase is built with PyTorch Lightning and uses Hydra for configuration management. It incorporates MinkowskiEngine for sparse 3D convolution operations and integrates depth prediction models (Depth Anything V2) with multi-view depth estimation.
|
| 8 |
+
|
| 9 |
+
## Development Environment Setup
|
| 10 |
+
|
| 11 |
+
### Environment Creation
|
| 12 |
+
```bash
|
| 13 |
+
# Create conda environment from environment.yml
|
| 14 |
+
conda env create -f environment.yml
|
| 15 |
+
conda activate scube
|
| 16 |
+
|
| 17 |
+
# Alternative: Use depthsplat environment
|
| 18 |
+
conda activate depthsplat
|
| 19 |
+
conda install -c conda-forge openblas
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
### MinkowskiEngine Installation
|
| 23 |
+
This project requires MinkowskiEngine for sparse 3D convolution. For CUDA versions >11, follow the specific installation guide referenced in the README.md.
|
| 24 |
+
|
| 25 |
+
Test installation:
|
| 26 |
+
```bash
|
| 27 |
+
python -c "import MinkowskiEngine as ME; print(ME.__version__)"
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
## Common Development Commands
|
| 31 |
+
|
| 32 |
+
### Training
|
| 33 |
+
Basic training command structure:
|
| 34 |
+
```bash
|
| 35 |
+
python -m src.main +experiment=<dataset_name> \
|
| 36 |
+
data_loader.train.batch_size=<batch_size> \
|
| 37 |
+
trainer.max_steps=<steps> \
|
| 38 |
+
output_dir=<checkpoint_dir>
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
For DL3DV dataset training:
|
| 42 |
+
```bash
|
| 43 |
+
CUDA_VISIBLE_DEVICES=<gpu_id> python -m src.main +experiment=dl3dv \
|
| 44 |
+
data_loader.train.batch_size=1 \
|
| 45 |
+
'dataset.roots'='["datasets/dl3dv"]' \
|
| 46 |
+
dataset.view_sampler.num_target_views=8 \
|
| 47 |
+
dataset.view_sampler.num_context_views=6 \
|
| 48 |
+
trainer.max_steps=100000 \
|
| 49 |
+
model.encoder.monodepth_vit_type=vitb \
|
| 50 |
+
checkpointing.pretrained_monodepth=pretrained/pretrained_weights/depth_anything_v2_vitb.pth \
|
| 51 |
+
output_dir=checkpoints/<experiment_name>
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
### Testing/Inference
|
| 55 |
+
```bash
|
| 56 |
+
python -m src.main mode=test \
|
| 57 |
+
checkpointing.pretrained_model=<model_path> \
|
| 58 |
+
test.output_path=outputs/test \
|
| 59 |
+
test.save_image=true
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
### Dataset Processing
|
| 63 |
+
Data conversion scripts are located in `src/scripts/`:
|
| 64 |
+
- `convert_dl3dv_test.py` - Convert DL3DV test set
|
| 65 |
+
- `convert_dl3dv_train.py` - Convert DL3DV training set
|
| 66 |
+
- `generate_dl3dv_index.py` - Generate index.json files
|
| 67 |
+
|
| 68 |
+
## Architecture Overview
|
| 69 |
+
|
| 70 |
+
### Core Components
|
| 71 |
+
|
| 72 |
+
**Main Entry Point**: `src/main.py`
|
| 73 |
+
- Hydra-based configuration management
|
| 74 |
+
- PyTorch Lightning trainer setup
|
| 75 |
+
- Multi-GPU DDP support with custom strategy for frozen parameters
|
| 76 |
+
- Pretrained model loading for depth networks
|
| 77 |
+
|
| 78 |
+
**Model Architecture**:
|
| 79 |
+
- **Encoder** (`src/model/encoder/`): DepthSplat encoder with configurable scales and depth prediction
|
| 80 |
+
- **Decoder** (`src/model/decoder/`): CUDA-based Gaussian splatting renderer
|
| 81 |
+
- **ModelWrapper** (`src/model/model_wrapper.py`): Lightning module wrapper handling optimization and training logic
|
| 82 |
+
|
| 83 |
+
**Data Pipeline**:
|
| 84 |
+
- **DataModule** (`src/dataset/data_module.py`): Lightning data module
|
| 85 |
+
- **View Samplers** (`src/dataset/view_sampler/`): Different sampling strategies (bounded, arbitrary, evaluation)
|
| 86 |
+
- **Dataset Classes**: Support for RealEstate10K, DL3DV datasets with torch chunk format
|
| 87 |
+
|
| 88 |
+
### Configuration System
|
| 89 |
+
|
| 90 |
+
Uses Hydra with YAML configs in `config/`:
|
| 91 |
+
- `main.yaml`: Base configuration
|
| 92 |
+
- `experiment/`: Dataset-specific experiment configs
|
| 93 |
+
- `model/encoder/`: Encoder configurations
|
| 94 |
+
- `model/decoder/`: Decoder configurations
|
| 95 |
+
- `dataset/`: Dataset and view sampler configurations
|
| 96 |
+
|
| 97 |
+
Key config sections:
|
| 98 |
+
- `wandb`: Experiment tracking (using SwanLab logger)
|
| 99 |
+
- `optimizer`: Learning rates, warm-up, weight decay
|
| 100 |
+
- `checkpointing`: Model loading/saving, pretrained weights
|
| 101 |
+
- `trainer`: PyTorch Lightning trainer settings
|
| 102 |
+
|
| 103 |
+
### Key Features
|
| 104 |
+
|
| 105 |
+
**Pretrained Model Integration**:
|
| 106 |
+
- Supports loading pretrained depth models (Depth Anything V2)
|
| 107 |
+
- Multi-view depth estimation integration
|
| 108 |
+
- Parameter freezing/unfreezing during training
|
| 109 |
+
- Custom callback for gradual parameter unfreezing
|
| 110 |
+
|
| 111 |
+
**Multi-GPU Training**:
|
| 112 |
+
- DDP strategy with `find_unused_parameters=True` for frozen parameters
|
| 113 |
+
- Global seed management for distributed training
|
| 114 |
+
- Custom parameter update checking
|
| 115 |
+
|
| 116 |
+
**Visualization**:
|
| 117 |
+
- Video rendering capabilities
|
| 118 |
+
- Depth visualization
|
| 119 |
+
- Camera trajectory visualization
|
| 120 |
+
- Integration with visualization tools
|
| 121 |
+
|
| 122 |
+
## Dataset Structure
|
| 123 |
+
|
| 124 |
+
Expected dataset format (torch chunks):
|
| 125 |
+
```
|
| 126 |
+
datasets/
|
| 127 |
+
├── re10k/
|
| 128 |
+
│ ├── train/
|
| 129 |
+
│ │ ├── 000000.torch
|
| 130 |
+
│ │ └── index.json
|
| 131 |
+
│ └── test/
|
| 132 |
+
├── dl3dv/
|
| 133 |
+
│ ├── train/
|
| 134 |
+
│ └── test/
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
Use symbolic links to point to actual dataset locations:
|
| 138 |
+
```bash
|
| 139 |
+
ln -s /path/to/your/datasets datasets
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
## Important Implementation Notes
|
| 143 |
+
|
| 144 |
+
### Camera Conventions
|
| 145 |
+
The codebase uses specific camera coordinate conventions - refer to camera convention documentation when adding new datasets.
|
| 146 |
+
|
| 147 |
+
### Memory Management
|
| 148 |
+
- Batch sizes are typically small (1-4) due to memory constraints
|
| 149 |
+
- Use gradient accumulation for effective larger batch sizes
|
| 150 |
+
- CUDA memory optimization for Gaussian splatting operations
|
| 151 |
+
|
| 152 |
+
### Distributed Training Considerations
|
| 153 |
+
- Custom DDP strategy handles frozen parameters correctly
|
| 154 |
+
- Global seed setting with rank-specific PyTorch seeds
|
| 155 |
+
- Proper barrier synchronization for distributed operations
|
| 156 |
+
|
| 157 |
+
### Logging and Checkpointing
|
| 158 |
+
- Uses SwanLab instead of WandB for experiment tracking
|
| 159 |
+
- Automatic checkpoint saving every N steps
|
| 160 |
+
- Supports resuming from latest checkpoint
|
| 161 |
+
- Model parameter loading reports with detailed statistics
|
DATASETS.md
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Datasets
|
| 2 |
+
|
| 3 |
+
For view synthesis experiments with Gaussian splatting, we mainly use [RealEstate10K](https://google.github.io/realestate10k/index.html) and [DL3DV](https://github.com/DL3DV-10K/Dataset) datasets. We provide the data processing scripts to convert the original datasets to pytorch chunk files which can be directly loaded with this codebase.
|
| 4 |
+
|
| 5 |
+
Expected folder structure:
|
| 6 |
+
|
| 7 |
+
```
|
| 8 |
+
├── datasets
|
| 9 |
+
│ ├── re10k
|
| 10 |
+
│ ├── ├── train
|
| 11 |
+
│ ├── ├── ├── 000000.torch
|
| 12 |
+
│ ├── ├── ├── ...
|
| 13 |
+
│ ├── ├── ├── index.json
|
| 14 |
+
│ ├── ├── test
|
| 15 |
+
│ ├── ├── ├── 000000.torch
|
| 16 |
+
│ ├── ├── ├── ...
|
| 17 |
+
│ ├── ├── ├── index.json
|
| 18 |
+
│ ├── dl3dv
|
| 19 |
+
│ ├── ├── train
|
| 20 |
+
│ ├── ├── ├── 000000.torch
|
| 21 |
+
│ ├── ├── ├── ...
|
| 22 |
+
│ ├── ├── ├── index.json
|
| 23 |
+
│ ├── ├── test
|
| 24 |
+
│ ├── ├── ├── 000000.torch
|
| 25 |
+
│ ├── ├── ├── ...
|
| 26 |
+
│ ├── ├── ├── index.json
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
It's recommended to create a symbolic link from `YOUR_DATASET_PATH` to `datasets` using
|
| 30 |
+
```
|
| 31 |
+
ln -s YOUR_DATASET_PATH datasets
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
Or you can specify your dataset path with `dataset.roots=[YOUR_DATASET_PATH]/re10k` and `dataset.roots=[YOUR_DATASET_PATH]/dl3dv` in the config.
|
| 35 |
+
|
| 36 |
+
We also provide instructions to convert additional datasets to the desired format.
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
## RealEstate10K
|
| 40 |
+
|
| 41 |
+
For experiments on RealEstate10K, we primarily follow [pixelSplat](https://github.com/dcharatan/pixelsplat) and [MVSplat](https://github.com/donydchen/mvsplat) to train and evaluate on the 256x256 resolution.
|
| 42 |
+
|
| 43 |
+
Please refer to [pixelSplat repo](https://github.com/dcharatan/pixelsplat?tab=readme-ov-file#acquiring-datasets) for acquiring the processed 360p (360x640) dataset.
|
| 44 |
+
|
| 45 |
+
If you would like to train and evaluate on the high-resolution RealEstate10K dataset, you will need to download the 720p (720x1280) version. Please refer to [here](https://github.com/yilundu/cross_attention_renderer/tree/master/data_download) for the downloading script. Note that the script by default downloads the 360p videos, you will need to modify the`360p` to `720p` in [this line of code](https://github.com/yilundu/cross_attention_renderer/blob/master/data_download/generate_realestate.py#L137) to download the 720p videos.
|
| 46 |
+
|
| 47 |
+
After downloading the 720p dataset, you can use the scripts [here](https://github.com/dcharatan/real_estate_10k_tools/tree/main/src) to convert the dataset to the desired format in this codebase.
|
| 48 |
+
|
| 49 |
+
Considering the full 720p dataset is quite large and may take time to download and process, we provide a preprocessed subset in `.torch` chunks ([download](https://huggingface.co/datasets/haofeixu/depthsplat/resolve/main/re10k_720p_test_subset.zip)) containing two test scenes to quickly run inference with our model.
|
| 50 |
+
|
| 51 |
+
## DL3DV
|
| 52 |
+
|
| 53 |
+
For experiments on DL3DV, we primarily train and evaluate at a resolution of 256×448. Additionally, we train high-resolution models (448×768) for qualitative results.
|
| 54 |
+
|
| 55 |
+
For the test set, we use the [DL3DV-Benchmark](https://huggingface.co/datasets/DL3DV/DL3DV-Benchmark) split, which contains 140 scenes for evaluation. You can first use the script [src/scripts/convert_dl3dv_test.py](src/scripts/convert_dl3dv_test.py) to convert the test set, and then run [src/scripts/generate_dl3dv_index.py](src/scripts/generate_dl3dv_index.py) to generate the `index.json` file for the test set.
|
| 56 |
+
|
| 57 |
+
For the training set, we use the [DL3DV-480p](https://huggingface.co/datasets/DL3DV/DL3DV-ALL-480P) dataset (270x480 resolution), where the 140 scenes in the test set are excluded during processing the training set. After downloading the [DL3DV-480p](https://huggingface.co/datasets/DL3DV/DL3DV-ALL-480P) dataset, You can first use the script [src/scripts/convert_dl3dv_train.py](src/scripts/convert_dl3dv_train.py) to convert the training set, and then run [src/scripts/generate_dl3dv_index.py](src/scripts/generate_dl3dv_index.py) to generate the `index.json` file for the training set.
|
| 58 |
+
|
| 59 |
+
Please note that you will need to update the dataset paths in the aforementioned processing scripts.
|
| 60 |
+
|
| 61 |
+
If you would like to train and evaluate on the high-resolution DL3DV dataset, you will need to download the [DL3DV-960P](https://huggingface.co/datasets/DL3DV/DL3DV-ALL-960P) version (540x960 resolution). Simply follow the same procedure for data processing, but update the `images_8` folder to `images_4`.
|
| 62 |
+
|
| 63 |
+
Please follow the [DL3DV license](https://github.com/DL3DV-10K/Dataset/blob/main/License.md) if you use this dataset in your project and kindly [reference the DL3DV paper](https://github.com/DL3DV-10K/Dataset?tab=readme-ov-file#bibtex).
|
| 64 |
+
|
| 65 |
+
Considering the full 960p dataset is quite large and may take time to download and process, we provide a preprocessed subset in `.torch` chunks ([download](https://huggingface.co/datasets/haofeixu/depthsplat/resolve/main/dl3dv_960p_test_subset.zip)) containing two test scenes to quickly run inference with our model. Please note that this released subset is intended solely for research purposes. We disclaim any responsibility for the misuse, inappropriate use, or unethical application of the dataset by individuals or entities who download or access it. We kindly ask users to adhere to the [DL3DV license](https://github.com/DL3DV-10K/Dataset/blob/main/License.md).
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
## ACID
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
We also evaluate our generalization on the [ACID](https://infinite-nature.github.io/) dataset. Note that we do not use the training set; you only need to [download the test set](http://schadenfreude.csail.mit.edu:8000/re10k_test_only.zip) (provided by [pixelSplat repo](https://github.com/dcharatan/pixelsplat?tab=readme-ov-file#acquiring-datasets)) for evaluation.
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
## Additional Datasets
|
| 76 |
+
|
| 77 |
+
If you would like to train and/or evaluate on additional datasets, just modify the [data processing scripts](src/scripts) to convert the dataset format. Kindly note the [camera conventions](https://github.com/cvg/depthsplat/tree/main?tab=readme-ov-file#camera-conventions) used in this codebase.
|
| 78 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 Haofei Xu
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
MODEL_ZOO.md
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model Zoo
|
| 2 |
+
|
| 3 |
+
- We provide pre-trained models for view synthesis with 3D Gaussian splatting and scale-consistent depth estimation from multi-view posed images.
|
| 4 |
+
|
| 5 |
+
- We assume that the downloaded weights are stored in the `pretrained` directory. It's recommended to create a symbolic link from `YOUR_MODEL_PATH` to `pretrained` using
|
| 6 |
+
```
|
| 7 |
+
ln -s YOUR_MODEL_PATH pretrained
|
| 8 |
+
```
|
| 9 |
+
|
| 10 |
+
- To verify the integrity of downloaded files, each model on this page includes its [sha256sum](https://sha256sum.com/) prefix in the file name, which can be checked using the command `sha256sum filename`.
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
## Gaussian Splatting
|
| 14 |
+
|
| 15 |
+
- The models are trained on RealEstate10K (re10k) and/or DL3DV (dl3dv) datasets at resolutions of 256x256, 256x448, and 448x768. The number of training views ranges from 2 to 10.
|
| 16 |
+
|
| 17 |
+
- The "→" symbol indicates that the models are trained in two stages. For example, "re10k → (re10k+dl3dv)" means the model is firstly trained on the RealEstate10K dataset and then fine-tuned using a combination of the RealEstate10K and DL3DV datasets.
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
| Model | Training Data | Training Resolution | Training Views | Params (M) | Download |
|
| 21 |
+
| ------------------------------------------------------------ | :------------------------: | :-------------------: | :------------: | :--------: | :----------------------------------------------------------: |
|
| 22 |
+
| depthsplat-gs-small-re10k-256x256-view2-cfeab6b1.pth | re10k | 256x256 | 2 | 37 | [download](https://huggingface.co/haofeixu/depthsplat/resolve/main/depthsplat-gs-small-re10k-256x256-view2-cfeab6b1.pth) |
|
| 23 |
+
| depthsplat-gs-base-re10k-256x256-view2-ca7b6795.pth | re10k | 256x256 | 2 | 117 | [download](https://huggingface.co/haofeixu/depthsplat/resolve/main/depthsplat-gs-base-re10k-256x256-view2-ca7b6795.pth) |
|
| 24 |
+
| depthsplat-gs-large-re10k-256x256-view2-e0f0f27a.pth | re10k | 256x256 | 2 | 360 | [download](https://huggingface.co/haofeixu/depthsplat/resolve/main/depthsplat-gs-large-re10k-256x256-view2-e0f0f27a.pth) |
|
| 25 |
+
| depthsplat-gs-base-re10k-256x448-view2-fea94f65.pth | re10k | 256x448 | 2 | 117 | [download](https://huggingface.co/haofeixu/depthsplat/resolve/main/depthsplat-gs-base-re10k-256x448-view2-fea94f65.pth) |
|
| 26 |
+
| depthsplat-gs-base-dl3dv-256x448-randview2-6-02c7b19d.pth | re10k → dl3dv | 256x448 | 2-6 | 117 | [download](https://huggingface.co/haofeixu/depthsplat/resolve/main/depthsplat-gs-base-dl3dv-256x448-randview2-6-02c7b19d.pth) |
|
| 27 |
+
| depthsplat-gs-small-re10kdl3dv-448x768-randview4-10-c08188db.pth | re10k → (re10k+dl3dv) | 256x448 →448x768 | 4-10 | 37 | [download](https://huggingface.co/haofeixu/depthsplat/resolve/main/depthsplat-gs-small-re10kdl3dv-448x768-randview4-10-c08188db.pth) |
|
| 28 |
+
| depthsplat-gs-base-re10kdl3dv-448x768-randview2-6-f8ddd845.pth | re10k → (re10k+dl3dv) | 256x448 →448x768 | 2-6 | 117 | [download](https://huggingface.co/haofeixu/depthsplat/resolve/main/depthsplat-gs-base-re10kdl3dv-448x768-randview2-6-f8ddd845.pth) |
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
## Depth Prediction
|
| 33 |
+
|
| 34 |
+
- The depth models are trained with the following procedure:
|
| 35 |
+
- Initialize the monocular feature with Depth Anything V2 and the multi-view Transformer with UniMatch.
|
| 36 |
+
- Train the full DepthSplat model end-to-end on the mixed RealEstate10K and DL3DV datasets.
|
| 37 |
+
- Fine-tune the pre-trained depth model on the depth datasets with ground truth depth supervision. The depth datasets used for fine-tuning include ScanNet, TartanAir, and VKITTI2.
|
| 38 |
+
- The depth models are fine-tuned with random numbers (2-8) of input images, and the training image resolution is 352x640.
|
| 39 |
+
- The scale of the predicted depth is aligned with the scale of camera pose's translation.
|
| 40 |
+
|
| 41 |
+
| Model | Training Data | Training Resolution | Training Views | Params (M) | Download |
|
| 42 |
+
| ------------------------------------------------------- | :----------------------------------------------: | :--------------------: | :------------: | :--------: | :----------------------------------------------------------: |
|
| 43 |
+
| depthsplat-depth-small-352x640-randview2-8-e807bd82.pth | (re10k+dl3dv) → (scannet+tartanair+vkitti2) | 448x768 → 352x640 | 2-8 | 36 | [download](https://huggingface.co/haofeixu/depthsplat/resolve/main/depthsplat-depth-small-352x640-randview2-8-e807bd82.pth) |
|
| 44 |
+
| depthsplat-depth-base-352x640-randview2-8-65a892c5.pth | (re10k+dl3dv) → (scannet+tartanair+vkitti2) | 448x768 → 352x640 | 2-8 | 111 | [download](https://huggingface.co/haofeixu/depthsplat/resolve/main/depthsplat-depth-base-352x640-randview2-8-65a892c5.pth) |
|
| 45 |
+
|
| 46 |
+
|
MinkowskiEngine/.gitignore
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.so
|
| 2 |
+
*.[o,d,a]
|
| 3 |
+
*.swo
|
| 4 |
+
*.swp
|
| 5 |
+
*.swn
|
| 6 |
+
*.pyc
|
| 7 |
+
|
| 8 |
+
build/
|
| 9 |
+
objs/
|
| 10 |
+
dist/
|
| 11 |
+
MinkowskiEngine.egg-info/
|
MinkowskiEngine/CHANGELOG.md
ADDED
|
@@ -0,0 +1,319 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Change Log
|
| 2 |
+
|
| 3 |
+
## [0.5.5]
|
| 4 |
+
|
| 5 |
+
- MKL compilation fix (#358)
|
| 6 |
+
- Example updates for `has_bias` (PR #356)
|
| 7 |
+
- Add thrust exception handling (issue #357)
|
| 8 |
+
- `min_coordinate` to device in `dense()`
|
| 9 |
+
- `cpu_kernel_region` `to_gpu` now uses `shared_ptr` allocator for gpu memory
|
| 10 |
+
- Docker installation instruction added
|
| 11 |
+
- Fix for GPU `coo_spmm` when nnz == 0
|
| 12 |
+
- Fix MinkowskiInterpolationGPU for invalid samples (issue #383)
|
| 13 |
+
- gradcheck wrap func 1.9
|
| 14 |
+
- Handles `dense` for an empty tensor (issue #384)
|
| 15 |
+
- Handles an emtpy tensor for convolution (issue #384)
|
| 16 |
+
- When `coordinates` is provided in `MinkowskiToSparseTensor`, `remove_zeros` will be ignored (issue #387)
|
| 17 |
+
- Pybind equality error from the package (issue #414)
|
| 18 |
+
- Fix undefined coordinate merge for multiple coordinate unions
|
| 19 |
+
- Add cross-shaped kernel support (issue #436)
|
| 20 |
+
|
| 21 |
+
## [0.5.4]
|
| 22 |
+
|
| 23 |
+
- Fix `TensorField.sparse()` for no duplicate coordinates
|
| 24 |
+
- Skip unnecessary spmm if `SparseTensor.initialize_coordinates()` has no duplicate coordinates
|
| 25 |
+
- Model summary utility function added
|
| 26 |
+
- TensorField.splat function for splat features to a sparse tensor
|
| 27 |
+
- SparseTensor.interpolate function for extracting interpolated features
|
| 28 |
+
- `coordinate_key` property function for `SparseTensor` and `TensorField`
|
| 29 |
+
- Fix .dense() for GPU tensors. (PR #319)
|
| 30 |
+
|
| 31 |
+
## [0.5.3]
|
| 32 |
+
|
| 33 |
+
- Updated README for pytorch 1.8.1 support
|
| 34 |
+
- Use custom `gpu_storage` instead of thrust vector for faster constructors
|
| 35 |
+
- pytorch installation instruction updates
|
| 36 |
+
- fix transpose kernel map with `kernel_size == stride_size`
|
| 37 |
+
- Update reconstruction and vae examples for v0.5 API
|
| 38 |
+
- `stack_unet.py` example, API updates
|
| 39 |
+
- `MinkowskiToFeature` layer
|
| 40 |
+
|
| 41 |
+
## [0.5.2]
|
| 42 |
+
|
| 43 |
+
- spmm average cuda function
|
| 44 |
+
- SparseTensor list operators (cat, mean, sum, var)
|
| 45 |
+
- MinkowskiStack containers
|
| 46 |
+
- Replace all at::cuda::getCurrentCUDASparseHandle with custom getCurrentCUDASparseHandle (issue #308)
|
| 47 |
+
- fix coordinate manager kernel map python function
|
| 48 |
+
- direct max pool
|
| 49 |
+
- SparseTensorQuantizationMode.MAX_POOL
|
| 50 |
+
- TensorField global max pool
|
| 51 |
+
- origin field
|
| 52 |
+
- origin field map
|
| 53 |
+
- MinkowskiGlobalMaxPool CPU/GPU updates for a field input
|
| 54 |
+
- SparseTensor.dense() raises a value error when a coordinate is negative rather than subtracting the minimum coordinate from a sparse tensor. (issue #316)
|
| 55 |
+
- Added `to_sparse()` that removes zeros. (issue #317)
|
| 56 |
+
- Previous `to_sparse()` was renamed to `to_sparse_all()`
|
| 57 |
+
- `MinkowskiToSparseTensor` takes an optional `remove_zeros` boolean argument.
|
| 58 |
+
- Fix global max pool with batch size 1
|
| 59 |
+
- Use separate memory chunks for in, out map, and kernel indices for `gpu_kernel_map` for gpu memory misaligned error
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
## [0.5.1]
|
| 63 |
+
|
| 64 |
+
- v0.5 documentation updates
|
| 65 |
+
- Nonlinear functionals and modules
|
| 66 |
+
- Warning when using cuda without ME cuda support
|
| 67 |
+
- diagnostics test
|
| 68 |
+
- TensorField slice
|
| 69 |
+
- Cache the unique map and inverse map pair in the coordinate manager
|
| 70 |
+
- generate inverse_mapping on the fly
|
| 71 |
+
- CoordinateManager
|
| 72 |
+
- `field_to_sparse_insert_and_map`
|
| 73 |
+
- `exists_field_to_sparse`
|
| 74 |
+
- `get_field_to_sparse_map`
|
| 75 |
+
- fix `kernel_map` with empty coordinate maps
|
| 76 |
+
- CoordiateFieldMap
|
| 77 |
+
- `quantize_coordinates`
|
| 78 |
+
- TensorField binary ops fix
|
| 79 |
+
- MinkowskiSyncBatchNorm
|
| 80 |
+
- Support tfield
|
| 81 |
+
- conver sync batchnorm updates
|
| 82 |
+
- TensorField to sparse with coordinate map key
|
| 83 |
+
- Sparse matrix multiplication
|
| 84 |
+
- force contiguous matrix
|
| 85 |
+
- Fix AveragePooling cudaErrorMisalignedAddress error for CUDA 10 (#246)
|
| 86 |
+
|
| 87 |
+
## [0.5.0] - 2020-12-24
|
| 88 |
+
|
| 89 |
+
## [0.5.0a] - 2020-08-05
|
| 90 |
+
|
| 91 |
+
### Changed
|
| 92 |
+
|
| 93 |
+
- Remove Makefile for installation as pytorch supports multithreaded compilation
|
| 94 |
+
- GPU coordinate map support
|
| 95 |
+
- Coordinate union
|
| 96 |
+
- Sparse tensor binary operators
|
| 97 |
+
- CUDA 11.1 support
|
| 98 |
+
- quantization function updates
|
| 99 |
+
- Multi GPU examples
|
| 100 |
+
- Pytorch-lightning multi-gpu example
|
| 101 |
+
- Transpose pooling layers
|
| 102 |
+
- TensorField updates
|
| 103 |
+
- Batch-wise decomposition
|
| 104 |
+
- inverse_map when sparse() called (slice)
|
| 105 |
+
- ChannelwiseConvolution
|
| 106 |
+
- TensorField support for non-linearities
|
| 107 |
+
|
| 108 |
+
## [0.4.3] - 2020-05-29
|
| 109 |
+
|
| 110 |
+
### Changed
|
| 111 |
+
|
| 112 |
+
- Use `CPU_ONLY` compile when `torch` fails to detect a GPU (Issue #105)
|
| 113 |
+
- Fix `get_kernel_map` for `CPU_ONLY` (Issue #107)
|
| 114 |
+
- Update `get_union_map` doc (Issue #108)
|
| 115 |
+
- Abstract getattr minkowski backend functions
|
| 116 |
+
- Add `coordinates_and_features_at(batch_index)` function in the SparseTensor class.
|
| 117 |
+
- Add `MinkowskiChannelwiseConvolution` (Issue #92)
|
| 118 |
+
- Update `MinkowskiPruning` to generate an empty sparse tensor as output (Issue #102)
|
| 119 |
+
- Add `return_index` for `sparse_quantize`
|
| 120 |
+
- Templated CoordsManager for coords to int and coords to vector classes
|
| 121 |
+
- Sparse tensor quantization mode
|
| 122 |
+
- Features at duplicated coordinates will be averaged automatically with `quantization_mode=ME.SparseTensorQuantizationMode.UNWEIGHTED_AVERAGE`
|
| 123 |
+
- `SparseTensor.slice()` slicing features on discrete coordinates to continuous coordinates
|
| 124 |
+
- CoordsManager.getKernelMapGPU returns long type tensors (Issue #125)
|
| 125 |
+
- SyncBatchNorm error fix (Issue #129)
|
| 126 |
+
- Sparse Tensor `dense()` doc update (Issue #126)
|
| 127 |
+
- Installation arguments `--cuda_home=<value>`, `--force_cuda`, `--blas_include_dirs=<comma_separated_values>`, and '--blas_library_dirs=<comma_separated_values>`. (Issue #135)
|
| 128 |
+
- SparseTensor query by coordinates `features_at_coords` (Issue #137)
|
| 129 |
+
- Memory manager control. CUDA | Pytorch memory manager for cuda malloc
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
## [0.4.2] - 2020-03-13
|
| 133 |
+
|
| 134 |
+
### Added
|
| 135 |
+
|
| 136 |
+
- Completion and VAE examples
|
| 137 |
+
- GPU version of getKernelMap: getKernelMapGPU
|
| 138 |
+
|
| 139 |
+
### Changed
|
| 140 |
+
|
| 141 |
+
- Fix dtype double to float on the multi-gpu example
|
| 142 |
+
- Remove the dimension input argument on GlobalPooling, Broadcast functions
|
| 143 |
+
- Kernel map generation has tensor stride > 0 check
|
| 144 |
+
- Fix `SparseTensor.set_tensor_stride`
|
| 145 |
+
- Track whether the batch indices are set first when initializing coords, The initial batch indices will be used throughout the lifetime of a sparse tensor
|
| 146 |
+
- Add a memory warning on ModelNet40 training example (Issue #86)
|
| 147 |
+
- Update the readme, definition
|
| 148 |
+
- Fix an error in examples.convolution
|
| 149 |
+
- Changed `features_at`, `coordinates_at` to take a batch index not the index of the unique batch indices. (Issue #100)
|
| 150 |
+
- Fix an error torch.range --> torch.arange in `sparse_quantize` (Issue #101)
|
| 151 |
+
- Fix BLAS installation link error (Issue #94)
|
| 152 |
+
- Fix `MinkowskiBroadcast` and `MinkowskiBroadcastConcatenation` to use arbitrary channel sizes
|
| 153 |
+
- Fix `pointnet.py` example (Issue #103)
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
## [0.4.1] - 2020-01-28
|
| 157 |
+
|
| 158 |
+
### Changed
|
| 159 |
+
|
| 160 |
+
- Kernel maps with region size 1 do not require `Region` class initialization.
|
| 161 |
+
- Faster union map with out map initialization
|
| 162 |
+
- Batch index order hot fix on `dense()`, `sparse()`
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
## [0.4.0] - 2020-01-26
|
| 166 |
+
|
| 167 |
+
### Added
|
| 168 |
+
|
| 169 |
+
- Add `MinkowskiGlobalSumPooling`, `MinkowskiGlobalAvgPooling`
|
| 170 |
+
- Add `examples/convolution.py` to showcase various usages
|
| 171 |
+
- Add `examples/sparse_tensor_basic.py` and a SparseTensor tutorial page
|
| 172 |
+
- Add convolution, kernel map gifs
|
| 173 |
+
- Add batch decomposition functions
|
| 174 |
+
- Add `SparseTensor.decomposed_coordinates`
|
| 175 |
+
- Add `SparseTensor.decomposed_features`
|
| 176 |
+
- Add `SparseTensor.coordinates_at(batch_index)`
|
| 177 |
+
- Add `SparseTensor.features_at(batch_index)`
|
| 178 |
+
- Add `CoordsManager.get_row_indices_at(coords_key, batch_index)`
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
### Changed
|
| 182 |
+
|
| 183 |
+
- `SparseTensor` additional coords.device guard
|
| 184 |
+
- `MinkowskiConvolution`, `Minkowski*Pooling` output coordinates will be equal to the input coordinates if stride == 1. Before this change, they generated output coordinates previously defined for a specific tensor stride.
|
| 185 |
+
- `MinkowskiUnion` and `Ops.cat` will take a variable number of sparse tensors not a list of sparse tensors
|
| 186 |
+
- Namespace cleanup
|
| 187 |
+
- Fix global in out map with uninitialized global map
|
| 188 |
+
- `getKernelMap` now can generate new kernel map if it doesn't exist
|
| 189 |
+
- `MinkowskiPruning` initialization takes no argument
|
| 190 |
+
- Batched coordinates with batch indices prepended before coordinates
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
## [0.3.3] - 2020-01-07
|
| 194 |
+
|
| 195 |
+
### Added
|
| 196 |
+
|
| 197 |
+
- Add `get_coords_map` on `CoordsManager`.
|
| 198 |
+
- Add `get_coords_map` on `MinkowskiEngine.utils`.
|
| 199 |
+
- Sparse Tensor Sparse Tensor binary operations `(+,-,*,/)`
|
| 200 |
+
- Binary operations between sparse tensors or sparse tensor + pytorch tensor
|
| 201 |
+
- Inplace operations for the same coords key
|
| 202 |
+
- Sparse Tensor operation mode
|
| 203 |
+
- Add `set_sparse_tensor_operation_mode` sharing the global coords manager by default
|
| 204 |
+
|
| 205 |
+
### Changed
|
| 206 |
+
|
| 207 |
+
- Minor changes on `setup.py` for torch installation check and system assertions.
|
| 208 |
+
- Update BLAS installation configuration.
|
| 209 |
+
- Update union kernel map and union coords to use reference wrappers.
|
| 210 |
+
- namespace `minkowski` for all cpp, cu files
|
| 211 |
+
- `MinkowskiConvolution` and `MinkowskiConvolutionTranspose` now support output coordinate specification on the function call.
|
| 212 |
+
- `Minkowski[Avg|Max|Sum]Pooling` and `Minkowski[Avg|Max|Sum]PoolingTranspose` now support output coordinate specification on the function call.
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
## [0.3.2] - 2019-12-25
|
| 216 |
+
|
| 217 |
+
### Added
|
| 218 |
+
- Synchronized Batch Norm: `ME.MinkowskiSyncBatchNorm`
|
| 219 |
+
- `ME.MinkowskiSyncBatchNorm.convert_sync_batchnorm` converts a MinkowskiNetwork automatically to use synched batch norm.
|
| 220 |
+
- `examples/multigpu.py` update for `ME.MinkowskiSynchBatchNorm`.
|
| 221 |
+
- Add `MinkowskiUnion`
|
| 222 |
+
- Add CoordsManager functions
|
| 223 |
+
- `get_batch_size`
|
| 224 |
+
- `get_batch_indices`
|
| 225 |
+
- `set_origin_coords_key`
|
| 226 |
+
- Add `quantize_th`, `quantize_label_th`
|
| 227 |
+
- Add MANIFEST
|
| 228 |
+
|
| 229 |
+
### Changed
|
| 230 |
+
|
| 231 |
+
- Update `MinkowskiUnion`, `MinkowskiPruning` docs
|
| 232 |
+
- Update multigpu documentation
|
| 233 |
+
- Update GIL release
|
| 234 |
+
- Use cudaMalloc instead of `at::Tensor` for GPU memory management for illegal memory access, invalid arg.
|
| 235 |
+
- Minor error fixes on `examples/modelnet40.py`
|
| 236 |
+
- CoordsMap size initialization updates
|
| 237 |
+
- Region hypercube iterator with even numbered kernel
|
| 238 |
+
- Fix global reduction in-out map with non contiguous batch indices
|
| 239 |
+
- GlobalPooling with torch reduction
|
| 240 |
+
- Update CoordsManager function `get_row_indices_per_batch` to return a list of `torch.LongTensor` for mapping indices. The corresponding batch indices is accessible by `get_batch_indices`.
|
| 241 |
+
- Update `MinkowskiBroadcast`, `MinkowskiBroadcastConcatenation` to use row indices per batch (`getRowIndicesPerBatch`)
|
| 242 |
+
- Update `SparseTensor`
|
| 243 |
+
- `allow_duplicate_coords` argument support
|
| 244 |
+
- update documentation, add unittest
|
| 245 |
+
- Update the training demo and documentation.
|
| 246 |
+
- Update `MinkowskiInstanceNorm`: no `dimension` argument.
|
| 247 |
+
- Fix CPU only build
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
## [0.3.1] - 2019-12-15
|
| 251 |
+
|
| 252 |
+
- Cache in-out mapping on device
|
| 253 |
+
- Robinhood unordered map for coordinate management
|
| 254 |
+
- hash based quantization to C++ CoordsManager based quantization with label collision
|
| 255 |
+
- CUDA compilation to support older devices (compute_30, 35)
|
| 256 |
+
- OMP_NUM_THREADS to initialize the number of threads
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
## [0.3.0] - 2019-12-08
|
| 260 |
+
|
| 261 |
+
- Change the hash map from google-sparsehash to Threading Building Blocks (TBB) `concurrent_unordered_map`.
|
| 262 |
+
- Optional duplicate coords (CoordsMap.initialize, TODO: make mapping more user-friendly)
|
| 263 |
+
- Explicit coords generation (`CoordsMap.stride`, `CoordsMap.reduce`, `CoordsMap.transposed_stride`)
|
| 264 |
+
- Speed up for pooling with `kernel_size == stride_size`.
|
| 265 |
+
- Faster `SparseTensor.dense` function.
|
| 266 |
+
- Force scratch memory space to be contiguous.
|
| 267 |
+
- CUDA error checks
|
| 268 |
+
- Update Makefile
|
| 269 |
+
- Architecture and sm updates for CUDA > 10.0
|
| 270 |
+
- Optional cblas
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
## [0.2.9] - 2019-11-17
|
| 274 |
+
|
| 275 |
+
- Pytorch 1.3 support
|
| 276 |
+
- Update torch cublas, cusparse handles.
|
| 277 |
+
- Global max pooling layers.
|
| 278 |
+
- Minor error fix in the coordinate manager
|
| 279 |
+
- Fix cases to return `in_coords_key` when stride is identity.
|
| 280 |
+
|
| 281 |
+
|
| 282 |
+
## [0.2.8] - 2019-10-18
|
| 283 |
+
|
| 284 |
+
- ModelNet40 training.
|
| 285 |
+
- open3d v0.8 update.
|
| 286 |
+
- Dynamic coordinate generation.
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
## [0.2.7] - 2019-09-04
|
| 290 |
+
|
| 291 |
+
Use `std::vector` for all internal coordinates to support arbitrary spatial dimensions.
|
| 292 |
+
|
| 293 |
+
- Vectorized coordinates to support arbitrary spatial dimensions.
|
| 294 |
+
- Removed all dimension template instantiation.
|
| 295 |
+
- Use assertion macro for cleaner exception handling.
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
## [0.2.6] - 2019-08-28
|
| 299 |
+
|
| 300 |
+
Use OpenMP for multi-threaded kernel map generation and minor renaming and explicit coordinate management for future upgrades.
|
| 301 |
+
|
| 302 |
+
- Major speed up
|
| 303 |
+
- Suboptimal kernels were introduced, and optimal kernels removed for faulty cleanup in v0.2.5. CUDA kernels were re-introduced and major speed up was restored.
|
| 304 |
+
- Minor name changes in `CoordsManager`.
|
| 305 |
+
- `CoordsManager` saves all coordinates for future updates.
|
| 306 |
+
- `CoordsManager` functions `createInOutPerKernel` and `createInOutPerKernelTranspose` now support multi-threaded kernel map generation by default using OpenMP.
|
| 307 |
+
- Thus, all manual thread functions such as `createInOutPerKernelInThreads`, `initialize_nthreads` removed.
|
| 308 |
+
- Use `export OMP_NUM_THREADS` to control the number of threads.
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
## [0.2.5a0] - 2019-07-12
|
| 312 |
+
|
| 313 |
+
- Added the `MinkowskiBroadcast` and `MinkowskiBroadcastConcatenation` module.
|
| 314 |
+
|
| 315 |
+
|
| 316 |
+
## [0.2.5] - 2019-07-02
|
| 317 |
+
|
| 318 |
+
- Better GPU memory management:
|
| 319 |
+
- GPU Memory management is now delegated to pytorch. Before the change, we need to cleanup the GPU cache that pytorch created to call `cudaMalloc`, which not only is slow but also hampers the long-running training that dies due to Out Of Memory (OOM).
|
MinkowskiEngine/LICENSE
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2020 NVIDIA CORPORATION.
|
| 4 |
+
Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu)
|
| 5 |
+
|
| 6 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 7 |
+
this software and associated documentation files (the "Software"), to deal in
|
| 8 |
+
the Software without restriction, including without limitation the rights to
|
| 9 |
+
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 10 |
+
of the Software, and to permit persons to whom the Software is furnished to do
|
| 11 |
+
so, subject to the following conditions:
|
| 12 |
+
|
| 13 |
+
The above copyright notice and this permission notice shall be included in all
|
| 14 |
+
copies or substantial portions of the Software.
|
| 15 |
+
|
| 16 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 17 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 18 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 19 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 20 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 21 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 22 |
+
SOFTWARE.
|
| 23 |
+
|
| 24 |
+
Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 25 |
+
Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 26 |
+
of the code.
|
MinkowskiEngine/MANIFEST.in
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
include Makefile
|
| 2 |
+
recursive-include src *.hpp *.cpp *.cu *.cuh *.h
|
| 3 |
+
recursive-include pybind *.hpp *.cpp
|
MinkowskiEngine/Makefile
ADDED
|
@@ -0,0 +1,178 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
###############################################################################
|
| 2 |
+
# Uncomment for debugging
|
| 3 |
+
# DEBUG := 1
|
| 4 |
+
# Pretty build
|
| 5 |
+
Q ?= @
|
| 6 |
+
|
| 7 |
+
# Uncomment for CPU only build. From the command line, `python setup.py install --cpu_only`
|
| 8 |
+
# CPU_ONLY := 1
|
| 9 |
+
|
| 10 |
+
CXX ?= g++
|
| 11 |
+
PYTHON ?= python
|
| 12 |
+
|
| 13 |
+
EXTENSION_NAME := minkowski
|
| 14 |
+
|
| 15 |
+
# BLAS choice:
|
| 16 |
+
# atlas for ATLAS
|
| 17 |
+
# blas for default blas
|
| 18 |
+
# mkl for MKL. For conda, conda install -c intel mkl mkl-include
|
| 19 |
+
# openblas for OpenBlas (default)
|
| 20 |
+
BLAS ?= openblas
|
| 21 |
+
CUDA_HOME ?= $(shell $(PYTHON) -c 'from torch.utils.cpp_extension import _find_cuda_home; print(_find_cuda_home())')
|
| 22 |
+
|
| 23 |
+
# Custom (MKL/ATLAS/OpenBLAS) include and lib directories.
|
| 24 |
+
# Leave commented to accept the defaults for your choice of BLAS
|
| 25 |
+
# (which should work)!
|
| 26 |
+
# BLAS_INCLUDE_DIRS ?=
|
| 27 |
+
# BLAS_LIBRARY_DIRS ?=
|
| 28 |
+
|
| 29 |
+
###############################################################################
|
| 30 |
+
# PYTHON Header path
|
| 31 |
+
PYTHON_HEADER_DIR := $(shell $(PYTHON) -c 'from distutils.sysconfig import get_python_inc; print(get_python_inc())')
|
| 32 |
+
PYTORCH_INCLUDES := $(shell $(PYTHON) -c 'from torch.utils.cpp_extension import include_paths; [print(p) for p in include_paths()]')
|
| 33 |
+
PYTORCH_LIBRARIES := $(shell $(PYTHON) -c 'from torch.utils.cpp_extension import library_paths; [print(p) for p in library_paths()]')
|
| 34 |
+
|
| 35 |
+
# HEADER DIR is in pythonX.Xm folder
|
| 36 |
+
INCLUDE_DIRS := $(PYTHON_HEADER_DIR)
|
| 37 |
+
INCLUDE_DIRS += $(PYTHON_HEADER_DIR)/..
|
| 38 |
+
INCLUDE_DIRS += $(PYTORCH_INCLUDES)
|
| 39 |
+
LIBRARY_DIRS := $(PYTORCH_LIBRARIES)
|
| 40 |
+
|
| 41 |
+
# Determine ABI support
|
| 42 |
+
WITH_ABI := $(shell $(PYTHON) -c 'import torch; print(int(torch._C._GLIBCXX_USE_CXX11_ABI))')
|
| 43 |
+
|
| 44 |
+
# Determine platform
|
| 45 |
+
UNAME := $(shell uname -s)
|
| 46 |
+
ifeq ($(UNAME), Linux)
|
| 47 |
+
LINUX := 1
|
| 48 |
+
else ifeq ($(UNAME), Darwin)
|
| 49 |
+
OSX := 1
|
| 50 |
+
OSX_MAJOR_VERSION := $(shell sw_vers -productVersion | cut -f 1 -d .)
|
| 51 |
+
OSX_MINOR_VERSION := $(shell sw_vers -productVersion | cut -f 2 -d .)
|
| 52 |
+
|
| 53 |
+
CXX := /usr/local/opt/llvm/bin/clang
|
| 54 |
+
# brew install llvm libomp
|
| 55 |
+
INCLUDE_DIRS += /usr/local/opt/llvm/include
|
| 56 |
+
LIBRARY_DIRS += /usr/local/opt/llvm/lib
|
| 57 |
+
endif
|
| 58 |
+
|
| 59 |
+
ifneq ($(CPU_ONLY), 1)
|
| 60 |
+
# CUDA ROOT DIR that contains bin/ lib64/ and include/
|
| 61 |
+
# CUDA_HOME := /usr/local/cuda
|
| 62 |
+
|
| 63 |
+
NVCC ?= $(CUDA_HOME)/bin/nvcc
|
| 64 |
+
INCLUDE_DIRS += ./ $(CUDA_HOME)/include
|
| 65 |
+
LIBRARY_DIRS += $(CUDA_HOME)/lib64
|
| 66 |
+
endif
|
| 67 |
+
|
| 68 |
+
SRC_DIR := ./src
|
| 69 |
+
OBJ_DIR := ./objs
|
| 70 |
+
CPP_SRCS := $(wildcard $(SRC_DIR)/*.cpp)
|
| 71 |
+
CU_SRCS := $(wildcard $(SRC_DIR)/*.cu)
|
| 72 |
+
OBJS := $(patsubst $(SRC_DIR)/%.cpp,$(OBJ_DIR)/%.o,$(CPP_SRCS))
|
| 73 |
+
CU_OBJS := $(patsubst $(SRC_DIR)/%.cu,$(OBJ_DIR)/cuda/%.o,$(CU_SRCS))
|
| 74 |
+
STATIC_LIB := $(OBJ_DIR)/lib$(EXTENSION_NAME).a
|
| 75 |
+
|
| 76 |
+
# We will also explicitly add stdc++ to the link target.
|
| 77 |
+
LIBRARIES := stdc++ c10 caffe2 torch torch_python _C
|
| 78 |
+
ifneq ($(CPU_ONLY), 1)
|
| 79 |
+
LIBRARIES += cudart cublas cusparse caffe2_gpu c10_cuda
|
| 80 |
+
CUDA_ARCH := -gencode arch=compute_30,code=sm_30 \
|
| 81 |
+
-gencode arch=compute_35,code=sm_35 \
|
| 82 |
+
-gencode=arch=compute_50,code=sm_50 \
|
| 83 |
+
-gencode=arch=compute_52,code=sm_52 \
|
| 84 |
+
-gencode=arch=compute_60,code=sm_60 \
|
| 85 |
+
-gencode=arch=compute_61,code=sm_61 \
|
| 86 |
+
-gencode=arch=compute_70,code=sm_70 \
|
| 87 |
+
-gencode=arch=compute_75,code=sm_75 \
|
| 88 |
+
-gencode=arch=compute_75,code=compute_75
|
| 89 |
+
endif
|
| 90 |
+
|
| 91 |
+
# BLAS configuration: mkl, atlas, open, blas
|
| 92 |
+
BLAS ?= openblas
|
| 93 |
+
ifeq ($(BLAS), mkl)
|
| 94 |
+
# MKL
|
| 95 |
+
LIBRARIES += mkl_rt
|
| 96 |
+
COMMON_FLAGS += -DUSE_MKL
|
| 97 |
+
MKLROOT ?= /opt/intel/mkl
|
| 98 |
+
BLAS_INCLUDE_DIRS ?= $(MKLROOT)/include
|
| 99 |
+
BLAS_LIBRARY_DIRS ?= $(MKLROOT)/lib $(MKLROOT)/lib/intel64
|
| 100 |
+
else ifeq ($(BLAS), openblas)
|
| 101 |
+
# OpenBLAS
|
| 102 |
+
LIBRARIES += openblas
|
| 103 |
+
else ifeq ($(BLAS), blas)
|
| 104 |
+
# OpenBLAS
|
| 105 |
+
LIBRARIES += blas
|
| 106 |
+
else
|
| 107 |
+
# ATLAS
|
| 108 |
+
LIBRARIES += atlas
|
| 109 |
+
ATLAS_PATH := $(shell $(PYTHON) -c "import numpy.distutils.system_info as si; ai = si.atlas_info(); [print(p) for p in ai.get_lib_dirs()]")
|
| 110 |
+
BLAS_LIBRARY_DIRS += $(ATLAS_PATH)
|
| 111 |
+
endif
|
| 112 |
+
|
| 113 |
+
INCLUDE_DIRS += ./src/3rdparty
|
| 114 |
+
INCLUDE_DIRS += $(BLAS_INCLUDE_DIRS)
|
| 115 |
+
LIBRARY_DIRS += $(BLAS_LIBRARY_DIRS)
|
| 116 |
+
|
| 117 |
+
# Debugging
|
| 118 |
+
ifeq ($(DEBUG), 1)
|
| 119 |
+
COMMON_FLAGS += -DDEBUG -g -O0
|
| 120 |
+
# https://gcoe-dresden.de/reaching-the-shore-with-a-fog-warning-my-eurohack-day-4-morning-session/
|
| 121 |
+
NVCCFLAGS := -g -G # -rdc true
|
| 122 |
+
else
|
| 123 |
+
COMMON_FLAGS += -DNDEBUG -O3
|
| 124 |
+
endif
|
| 125 |
+
|
| 126 |
+
WARNINGS := -Wall -Wcomment -Wno-sign-compare -Wno-deprecated-declarations
|
| 127 |
+
|
| 128 |
+
# Automatic dependency generation (nvcc is handled separately)
|
| 129 |
+
CXXFLAGS += -MMD -MP
|
| 130 |
+
|
| 131 |
+
# Fast math
|
| 132 |
+
CXXFLAGS += -ffast-math -funsafe-math-optimizations -fno-math-errno
|
| 133 |
+
|
| 134 |
+
# BATCH FIRST
|
| 135 |
+
CXXFLAGS += -DBATCH_FIRST=1
|
| 136 |
+
|
| 137 |
+
# Complete build flags.
|
| 138 |
+
COMMON_FLAGS += $(foreach includedir,$(INCLUDE_DIRS),-I$(includedir)) \
|
| 139 |
+
-DTORCH_API_INCLUDE_EXTENSION_H -DTORCH_EXTENSION_NAME=$(EXTENSION_NAME) \
|
| 140 |
+
-D_GLIBCXX_USE_CXX11_ABI=$(WITH_ABI)
|
| 141 |
+
|
| 142 |
+
CXXFLAGS += -fopenmp -fPIC -fwrapv -std=c++14 $(COMMON_FLAGS) $(WARNINGS)
|
| 143 |
+
NVCCFLAGS += -std=c++14 -ccbin=$(CXX) -Xcompiler -fPIC $(COMMON_FLAGS)
|
| 144 |
+
LINKFLAGS += -pthread -fPIC $(WARNINGS) -Wl,-rpath=$(PYTHON_LIB_DIR) -Wl,--no-as-needed -Wl,--sysroot=/
|
| 145 |
+
LDFLAGS += $(foreach librarydir,$(LIBRARY_DIRS),-L$(librarydir)) \
|
| 146 |
+
$(foreach library,$(LIBRARIES),-l$(library))
|
| 147 |
+
|
| 148 |
+
ifeq ($(CPU_ONLY), 1)
|
| 149 |
+
ALL_OBJS := $(OBJS)
|
| 150 |
+
CXXFLAGS += -DCPU_ONLY
|
| 151 |
+
else
|
| 152 |
+
ALL_OBJS := $(OBJS) $(CU_OBJS)
|
| 153 |
+
endif
|
| 154 |
+
|
| 155 |
+
all: $(STATIC_LIB)
|
| 156 |
+
$(RM) -rf build dist
|
| 157 |
+
|
| 158 |
+
$(OBJ_DIR):
|
| 159 |
+
@ mkdir -p $@
|
| 160 |
+
@ mkdir -p $@/cuda
|
| 161 |
+
|
| 162 |
+
$(OBJ_DIR)/%.o: $(SRC_DIR)/%.cpp | $(OBJ_DIR)
|
| 163 |
+
@ echo CXX $<
|
| 164 |
+
$(Q)$(CXX) $< $(CXXFLAGS) -c -o $@
|
| 165 |
+
|
| 166 |
+
$(OBJ_DIR)/cuda/%.o: $(SRC_DIR)/%.cu | $(OBJ_DIR)
|
| 167 |
+
@ echo NVCC $<
|
| 168 |
+
$(Q)$(NVCC) $(NVCCFLAGS) $(CUDA_ARCH) -M $< -o ${@:.o=.d} \
|
| 169 |
+
-odir $(@D)
|
| 170 |
+
$(Q)$(NVCC) $(NVCCFLAGS) $(CUDA_ARCH) -c $< -o $@
|
| 171 |
+
|
| 172 |
+
$(STATIC_LIB): $(ALL_OBJS) | $(OBJ_DIR)
|
| 173 |
+
$(RM) -f $(STATIC_LIB)
|
| 174 |
+
@ echo LD -o $@
|
| 175 |
+
ar rc $(STATIC_LIB) $(ALL_OBJS)
|
| 176 |
+
|
| 177 |
+
clean:
|
| 178 |
+
@- $(RM) -rf $(OBJ_DIR) build dist
|
MinkowskiEngine/MinkowskiEngine/MinkowskiBroadcast.py
ADDED
|
@@ -0,0 +1,253 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
from typing import Union
|
| 26 |
+
|
| 27 |
+
import torch
|
| 28 |
+
from torch.nn import Module
|
| 29 |
+
from torch.autograd import Function
|
| 30 |
+
|
| 31 |
+
from MinkowskiEngineBackend._C import CoordinateMapKey, RegionType, BroadcastMode
|
| 32 |
+
from MinkowskiSparseTensor import SparseTensor, _get_coordinate_map_key
|
| 33 |
+
from MinkowskiCoordinateManager import CoordinateManager
|
| 34 |
+
from MinkowskiCommon import (
|
| 35 |
+
MinkowskiModuleBase,
|
| 36 |
+
get_minkowski_function,
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class MinkowskiBroadcastFunction(Function):
|
| 41 |
+
@staticmethod
|
| 42 |
+
def forward(
|
| 43 |
+
ctx,
|
| 44 |
+
input_features: torch.Tensor,
|
| 45 |
+
input_features_global: torch.Tensor,
|
| 46 |
+
operation_type: BroadcastMode,
|
| 47 |
+
in_coords_key: CoordinateMapKey,
|
| 48 |
+
glob_coords_key: CoordinateMapKey,
|
| 49 |
+
coords_manager: CoordinateManager,
|
| 50 |
+
):
|
| 51 |
+
assert isinstance(operation_type, BroadcastMode)
|
| 52 |
+
|
| 53 |
+
ctx.saved_vars = (
|
| 54 |
+
input_features,
|
| 55 |
+
input_features_global,
|
| 56 |
+
operation_type,
|
| 57 |
+
in_coords_key,
|
| 58 |
+
glob_coords_key,
|
| 59 |
+
coords_manager,
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
fw_fn = get_minkowski_function("BroadcastForward", input_features)
|
| 63 |
+
return fw_fn(
|
| 64 |
+
input_features,
|
| 65 |
+
input_features_global,
|
| 66 |
+
operation_type,
|
| 67 |
+
in_coords_key,
|
| 68 |
+
glob_coords_key,
|
| 69 |
+
coords_manager._manager,
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
@staticmethod
|
| 73 |
+
def backward(ctx, grad_out_feat):
|
| 74 |
+
if not grad_out_feat.is_contiguous():
|
| 75 |
+
grad_out_feat = grad_out_feat.contiguous()
|
| 76 |
+
|
| 77 |
+
(
|
| 78 |
+
input_features,
|
| 79 |
+
input_features_global,
|
| 80 |
+
operation_type,
|
| 81 |
+
in_coords_key,
|
| 82 |
+
glob_coords_key,
|
| 83 |
+
coords_manager,
|
| 84 |
+
) = ctx.saved_vars
|
| 85 |
+
|
| 86 |
+
bw_fn = get_minkowski_function("BroadcastBackward", grad_out_feat)
|
| 87 |
+
grad_in_feat, grad_in_feat_glob = bw_fn(
|
| 88 |
+
input_features,
|
| 89 |
+
input_features_global,
|
| 90 |
+
grad_out_feat,
|
| 91 |
+
operation_type,
|
| 92 |
+
in_coords_key,
|
| 93 |
+
glob_coords_key,
|
| 94 |
+
coords_manager._manager,
|
| 95 |
+
)
|
| 96 |
+
return grad_in_feat, grad_in_feat_glob, None, None, None, None
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class MinkowskiBroadcastBase(MinkowskiModuleBase):
|
| 100 |
+
def __init__(self, operation_type):
|
| 101 |
+
MinkowskiModuleBase.__init__(self)
|
| 102 |
+
assert isinstance(operation_type, BroadcastMode)
|
| 103 |
+
|
| 104 |
+
self.operation_type = operation_type
|
| 105 |
+
|
| 106 |
+
self.broadcast = MinkowskiBroadcastFunction()
|
| 107 |
+
|
| 108 |
+
def forward(self, input: SparseTensor, input_glob: SparseTensor):
|
| 109 |
+
assert isinstance(input, SparseTensor)
|
| 110 |
+
|
| 111 |
+
output = self.broadcast.apply(
|
| 112 |
+
input.F,
|
| 113 |
+
input_glob.F,
|
| 114 |
+
self.operation_type,
|
| 115 |
+
input.coordinate_map_key,
|
| 116 |
+
input_glob.coordinate_map_key,
|
| 117 |
+
input.coordinate_manager,
|
| 118 |
+
)
|
| 119 |
+
return SparseTensor(
|
| 120 |
+
output,
|
| 121 |
+
coordinate_map_key=input.coordinate_map_key,
|
| 122 |
+
coordinate_manager=input.coordinate_manager,
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
def __repr__(self):
|
| 126 |
+
return self.__class__.__name__
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
class MinkowskiBroadcastAddition(MinkowskiBroadcastBase):
|
| 130 |
+
r"""Broadcast the reduced features to all input coordinates.
|
| 131 |
+
|
| 132 |
+
.. math::
|
| 133 |
+
|
| 134 |
+
\mathbf{y}_\mathbf{u} = \mathbf{x}_{1, \mathbf{u}} + \mathbf{x}_2
|
| 135 |
+
\; \text{for} \; \mathbf{u} \in \mathcal{C}^\text{in}
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
For all input :math:`\mathbf{x}_\mathbf{u}`, add :math:`\mathbf{x}_2`. The
|
| 139 |
+
output coordinates will be the same as the input coordinates
|
| 140 |
+
:math:`\mathcal{C}^\text{in} = \mathcal{C}^\text{out}`.
|
| 141 |
+
|
| 142 |
+
.. note::
|
| 143 |
+
The first argument takes a sparse tensor; the second argument takes
|
| 144 |
+
features that are reduced to the origin. This can be typically done with
|
| 145 |
+
the global reduction such as the :attr:`MinkowskiGlobalPooling`.
|
| 146 |
+
|
| 147 |
+
"""
|
| 148 |
+
|
| 149 |
+
def __init__(self):
|
| 150 |
+
MinkowskiBroadcastBase.__init__(self, BroadcastMode.ELEMENTWISE_ADDITON)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class MinkowskiBroadcastMultiplication(MinkowskiBroadcastBase):
|
| 154 |
+
r"""Broadcast reduced features to all input coordinates.
|
| 155 |
+
|
| 156 |
+
.. math::
|
| 157 |
+
|
| 158 |
+
\mathbf{y}_\mathbf{u} = \mathbf{x}_{1, \mathbf{u}} \times \mathbf{x}_2
|
| 159 |
+
\; \text{for} \; \mathbf{u} \in \mathcal{C}^\text{in}
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
For all input :math:`\mathbf{x}_\mathbf{u}`, multiply :math:`\mathbf{x}_2`
|
| 163 |
+
element-wise. The output coordinates will be the same as the input
|
| 164 |
+
coordinates :math:`\mathcal{C}^\text{in} = \mathcal{C}^\text{out}`.
|
| 165 |
+
|
| 166 |
+
.. note::
|
| 167 |
+
The first argument takes a sparse tensor; the second argument takes
|
| 168 |
+
features that are reduced to the origin. This can be typically done with
|
| 169 |
+
the global reduction such as the :attr:`MinkowskiGlobalPooling`.
|
| 170 |
+
|
| 171 |
+
"""
|
| 172 |
+
|
| 173 |
+
def __init__(self):
|
| 174 |
+
MinkowskiBroadcastBase.__init__(self, BroadcastMode.ELEMENTWISE_MULTIPLICATION)
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
class MinkowskiBroadcast(Module):
|
| 178 |
+
r"""Broadcast reduced features to all input coordinates.
|
| 179 |
+
|
| 180 |
+
.. math::
|
| 181 |
+
|
| 182 |
+
\mathbf{y}_\mathbf{u} = \mathbf{x}_2 \; \text{for} \; \mathbf{u} \in
|
| 183 |
+
\mathcal{C}^\text{in}
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
For all input :math:`\mathbf{x}_\mathbf{u}`, copy value :math:`\mathbf{x}_2`
|
| 187 |
+
element-wise. The output coordinates will be the same as the input
|
| 188 |
+
coordinates :math:`\mathcal{C}^\text{in} = \mathcal{C}^\text{out}`. The
|
| 189 |
+
first input :math:`\mathbf{x}_1` is only used for defining the output
|
| 190 |
+
coordinates.
|
| 191 |
+
|
| 192 |
+
.. note::
|
| 193 |
+
The first argument takes a sparse tensor; the second argument takes
|
| 194 |
+
features that are reduced to the origin. This can be typically done with
|
| 195 |
+
the global reduction such as the :attr:`MinkowskiGlobalPooling`.
|
| 196 |
+
|
| 197 |
+
"""
|
| 198 |
+
|
| 199 |
+
def __repr__(self):
|
| 200 |
+
return self.__class__.__name__
|
| 201 |
+
|
| 202 |
+
def forward(self, input: SparseTensor, input_glob: SparseTensor):
|
| 203 |
+
assert isinstance(input, SparseTensor)
|
| 204 |
+
assert isinstance(input_glob, SparseTensor)
|
| 205 |
+
|
| 206 |
+
broadcast_feat = input.F.new(len(input), input_glob.size()[1])
|
| 207 |
+
batch_indices, batch_rows = input.coordinate_manager.origin_map(input.coordinate_map_key)
|
| 208 |
+
for b, rows in zip(batch_indices, batch_rows):
|
| 209 |
+
broadcast_feat[rows] = input_glob.F[b]
|
| 210 |
+
|
| 211 |
+
return SparseTensor(
|
| 212 |
+
broadcast_feat,
|
| 213 |
+
coordinate_map_key=input.coordinate_map_key,
|
| 214 |
+
coordinate_manager=input.coordinate_manager,
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
class MinkowskiBroadcastConcatenation(MinkowskiBroadcast):
|
| 219 |
+
r"""Broadcast reduced features to all input coordinates and concatenate to the input.
|
| 220 |
+
|
| 221 |
+
.. math::
|
| 222 |
+
|
| 223 |
+
\mathbf{y}_\mathbf{u} = [\mathbf{x}_{1,\mathbf{u}}, \mathbf{x}_2] \;
|
| 224 |
+
\text{for} \; \mathbf{u} \in \mathcal{C}^\text{in}
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
For all input :math:`\mathbf{x}_\mathbf{u}`, concatenate vector
|
| 228 |
+
:math:`\mathbf{x}_2`. :math:`[\cdot, \cdot]` is a concatenation operator.
|
| 229 |
+
The output coordinates will be the same as the input coordinates
|
| 230 |
+
:math:`\mathcal{C}^\text{in} = \mathcal{C}^\text{out}`.
|
| 231 |
+
|
| 232 |
+
.. note::
|
| 233 |
+
The first argument takes a sparse tensor; the second argument takes
|
| 234 |
+
features that are reduced to the origin. This can be typically done with
|
| 235 |
+
the global reduction such as the :attr:`MinkowskiGlobalPooling`.
|
| 236 |
+
|
| 237 |
+
"""
|
| 238 |
+
|
| 239 |
+
def forward(self, input: SparseTensor, input_glob: SparseTensor):
|
| 240 |
+
assert isinstance(input, SparseTensor)
|
| 241 |
+
assert isinstance(input_glob, SparseTensor)
|
| 242 |
+
|
| 243 |
+
broadcast_feat = input.F.new(len(input), input_glob.size()[1])
|
| 244 |
+
batch_indices, batch_rows = input.coordinate_manager.origin_map(input.coordinate_map_key)
|
| 245 |
+
for b, row_ind in zip(batch_indices, batch_rows):
|
| 246 |
+
broadcast_feat[row_ind] = input_glob.F[b]
|
| 247 |
+
|
| 248 |
+
broadcast_cat = torch.cat((input.F, broadcast_feat), dim=1)
|
| 249 |
+
return SparseTensor(
|
| 250 |
+
broadcast_cat,
|
| 251 |
+
coordinate_map_key=input.coordinate_map_key,
|
| 252 |
+
coordinate_manager=input.coordinate_manager,
|
| 253 |
+
)
|
MinkowskiEngine/MinkowskiEngine/MinkowskiChannelwiseConvolution.py
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
import math
|
| 26 |
+
from typing import Union
|
| 27 |
+
|
| 28 |
+
import torch
|
| 29 |
+
from torch.nn import Parameter
|
| 30 |
+
|
| 31 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 32 |
+
from MinkowskiEngineBackend._C import CoordinateMapKey, RegionType
|
| 33 |
+
from MinkowskiCommon import MinkowskiModuleBase
|
| 34 |
+
from MinkowskiKernelGenerator import KernelGenerator
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class MinkowskiChannelwiseConvolution(MinkowskiModuleBase):
|
| 38 |
+
|
| 39 |
+
__slots__ = (
|
| 40 |
+
"in_channels",
|
| 41 |
+
"out_channels",
|
| 42 |
+
"kernel_generator",
|
| 43 |
+
"dimension",
|
| 44 |
+
"kernel",
|
| 45 |
+
"bias",
|
| 46 |
+
"conv",
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
r"""Channelwise (Depthwise) Convolution layer for a sparse tensor.
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
.. math::
|
| 53 |
+
|
| 54 |
+
\mathbf{x}_\mathbf{u} = \sum_{\mathbf{i} \in \mathcal{N}^D(\mathbf{u}, K) \cap
|
| 55 |
+
\mathcal{C}^\text{in}} W_\mathbf{i} \odot \mathbf{x}_{\mathbf{i} +
|
| 56 |
+
\mathbf{u}} \;\text{for} \; \mathbf{u} \in \mathcal{C}^\text{out}
|
| 57 |
+
|
| 58 |
+
where :math:`K` is the kernel size and :math:`\mathcal{N}^D(\mathbf{u}, K)
|
| 59 |
+
\cap \mathcal{C}^\text{in}` is the set of offsets that are at most :math:`\left
|
| 60 |
+
\lceil{\frac{1}{2}(K - 1)} \right \rceil` away from :math:`\mathbf{u}`
|
| 61 |
+
defined in :math:`\mathcal{S}^\text{in}`. :math:`\odot` indicates the
|
| 62 |
+
elementwise product.
|
| 63 |
+
|
| 64 |
+
.. note::
|
| 65 |
+
For even :math:`K`, the kernel offset :math:`\mathcal{N}^D`
|
| 66 |
+
implementation is different from the above definition. The offsets
|
| 67 |
+
range from :math:`\mathbf{i} \in [0, K)^D, \; \mathbf{i} \in
|
| 68 |
+
\mathbb{Z}_+^D`.
|
| 69 |
+
|
| 70 |
+
"""
|
| 71 |
+
|
| 72 |
+
def __init__(
|
| 73 |
+
self,
|
| 74 |
+
in_channels,
|
| 75 |
+
kernel_size=-1,
|
| 76 |
+
stride=1,
|
| 77 |
+
dilation=1,
|
| 78 |
+
bias=False,
|
| 79 |
+
kernel_generator=None,
|
| 80 |
+
dimension=-1,
|
| 81 |
+
):
|
| 82 |
+
r"""convolution on a sparse tensor
|
| 83 |
+
|
| 84 |
+
Args:
|
| 85 |
+
:attr:`in_channels` (int): the number of input channels in the
|
| 86 |
+
input tensor.
|
| 87 |
+
|
| 88 |
+
:attr:`kernel_size` (int, optional): the size of the kernel in the
|
| 89 |
+
output tensor. If not provided, :attr:`region_offset` should be
|
| 90 |
+
:attr:`RegionType.CUSTOM` and :attr:`region_offset` should be a 2D
|
| 91 |
+
matrix with size :math:`N\times D` such that it lists all :math:`N`
|
| 92 |
+
offsets in D-dimension.
|
| 93 |
+
|
| 94 |
+
:attr:`stride` (int, or list, optional): stride size of the
|
| 95 |
+
convolution layer. If non-identity is used, the output coordinates
|
| 96 |
+
will be at least :attr:`stride` :math:`\times` :attr:`tensor_stride`
|
| 97 |
+
away. When a list is given, the length must be D; each element will
|
| 98 |
+
be used for stride size for the specific axis.
|
| 99 |
+
|
| 100 |
+
:attr:`dilation` (int, or list, optional): dilation size for the
|
| 101 |
+
convolution kernel. When a list is given, the length must be D and
|
| 102 |
+
each element is an axis specific dilation. All elements must be > 0.
|
| 103 |
+
|
| 104 |
+
:attr:`bias` (bool, optional): if True, the convolution layer
|
| 105 |
+
has a bias.
|
| 106 |
+
|
| 107 |
+
:attr:`kernel_generator` (:attr:`MinkowskiEngine.KernelGenerator`,
|
| 108 |
+
optional): defines the custom kernel shape.
|
| 109 |
+
|
| 110 |
+
:attr:`dimension` (int): the spatial dimension of the space where
|
| 111 |
+
all the inputs and the network are defined. For example, images are
|
| 112 |
+
in a 2D space, meshes and 3D shapes are in a 3D space.
|
| 113 |
+
|
| 114 |
+
"""
|
| 115 |
+
|
| 116 |
+
super(MinkowskiChannelwiseConvolution, self).__init__()
|
| 117 |
+
assert (
|
| 118 |
+
dimension > 0
|
| 119 |
+
), f"Invalid dimension. Please provide a valid dimension argument. dimension={dimension}"
|
| 120 |
+
|
| 121 |
+
if kernel_generator is None:
|
| 122 |
+
kernel_generator = KernelGenerator(
|
| 123 |
+
kernel_size=kernel_size,
|
| 124 |
+
stride=stride,
|
| 125 |
+
dilation=dilation,
|
| 126 |
+
dimension=dimension,
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
self.kernel_generator = kernel_generator
|
| 130 |
+
|
| 131 |
+
self.in_channels = in_channels
|
| 132 |
+
self.dimension = dimension
|
| 133 |
+
|
| 134 |
+
self.kernel_shape = (kernel_generator.kernel_volume, self.in_channels)
|
| 135 |
+
|
| 136 |
+
Tensor = torch.FloatTensor
|
| 137 |
+
self.kernel = Parameter(Tensor(*self.kernel_shape))
|
| 138 |
+
self.bias = Parameter(Tensor(1, in_channels)) if bias else None
|
| 139 |
+
|
| 140 |
+
self.reset_parameters()
|
| 141 |
+
|
| 142 |
+
def forward(
|
| 143 |
+
self,
|
| 144 |
+
input: SparseTensor,
|
| 145 |
+
coords: Union[torch.IntTensor, CoordinateMapKey, SparseTensor] = None,
|
| 146 |
+
):
|
| 147 |
+
r"""
|
| 148 |
+
:attr:`input` (`MinkowskiEngine.SparseTensor`): Input sparse tensor to apply a
|
| 149 |
+
convolution on.
|
| 150 |
+
|
| 151 |
+
:attr:`coords` ((`torch.IntTensor`, `MinkowskiEngine.CoordinateMapKey`,
|
| 152 |
+
`MinkowskiEngine.SparseTensor`), optional): If provided, generate
|
| 153 |
+
results on the provided coordinates. None by default.
|
| 154 |
+
|
| 155 |
+
"""
|
| 156 |
+
assert isinstance(input, SparseTensor)
|
| 157 |
+
assert input.D == self.dimension
|
| 158 |
+
assert (
|
| 159 |
+
self.in_channels == input.shape[1]
|
| 160 |
+
), f"Channel size mismatch {self.in_channels} != {input.shape[1]}"
|
| 161 |
+
|
| 162 |
+
# Create a region_offset
|
| 163 |
+
region_type_, region_offset_, _ = self.kernel_generator.get_kernel(
|
| 164 |
+
input.tensor_stride, False
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
cm = input.coordinate_manager
|
| 168 |
+
in_key = input.coordinate_map_key
|
| 169 |
+
|
| 170 |
+
out_key = cm.stride(in_key, self.kernel_generator.kernel_stride)
|
| 171 |
+
N_out = cm.size(out_key)
|
| 172 |
+
out_F = input._F.new(N_out, self.in_channels).zero_()
|
| 173 |
+
|
| 174 |
+
kernel_map = cm.kernel_map(
|
| 175 |
+
in_key,
|
| 176 |
+
out_key,
|
| 177 |
+
self.kernel_generator.kernel_stride,
|
| 178 |
+
self.kernel_generator.kernel_size,
|
| 179 |
+
self.kernel_generator.kernel_dilation,
|
| 180 |
+
region_type=region_type_,
|
| 181 |
+
region_offset=region_offset_,
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
for k, in_out in kernel_map.items():
|
| 185 |
+
in_out = in_out.long().to(input.device)
|
| 186 |
+
out_F[in_out[1]] += input.F[in_out[0]] * self.kernel[k]
|
| 187 |
+
|
| 188 |
+
if self.bias is not None:
|
| 189 |
+
out_F += self.bias
|
| 190 |
+
|
| 191 |
+
return SparseTensor(out_F, coordinate_map_key=out_key, coordinate_manager=cm)
|
| 192 |
+
|
| 193 |
+
def reset_parameters(self, is_transpose=False):
|
| 194 |
+
with torch.no_grad():
|
| 195 |
+
n = (
|
| 196 |
+
self.out_channels if is_transpose else self.in_channels
|
| 197 |
+
) * self.kernel_generator.kernel_volume
|
| 198 |
+
stdv = 1.0 / math.sqrt(n)
|
| 199 |
+
self.kernel.data.uniform_(-stdv, stdv)
|
| 200 |
+
if self.bias is not None:
|
| 201 |
+
self.bias.data.uniform_(-stdv, stdv)
|
| 202 |
+
|
| 203 |
+
def __repr__(self):
|
| 204 |
+
s = "(in={}, region_type={}, ".format(
|
| 205 |
+
self.in_channels, self.kernel_generator.region_type
|
| 206 |
+
)
|
| 207 |
+
if self.kernel_generator.region_type in [RegionType.CUSTOM]:
|
| 208 |
+
s += "kernel_volume={}, ".format(self.kernel_generator.kernel_volume)
|
| 209 |
+
else:
|
| 210 |
+
s += "kernel_size={}, ".format(self.kernel_generator.kernel_size)
|
| 211 |
+
s += "stride={}, dilation={})".format(
|
| 212 |
+
self.kernel_generator.kernel_stride,
|
| 213 |
+
self.kernel_generator.kernel_dilation,
|
| 214 |
+
)
|
| 215 |
+
return self.__class__.__name__ + s
|
MinkowskiEngine/MinkowskiEngine/MinkowskiCommon.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
from collections.abc import Sequence
|
| 26 |
+
import numpy as np
|
| 27 |
+
from typing import Union
|
| 28 |
+
|
| 29 |
+
import torch
|
| 30 |
+
|
| 31 |
+
from torch.nn import Module
|
| 32 |
+
|
| 33 |
+
import MinkowskiEngineBackend._C as MEB
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
StrideType = Union[int, Sequence, np.ndarray, torch.IntTensor]
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def convert_to_int_list(
|
| 40 |
+
arg: Union[int, Sequence, np.ndarray, torch.Tensor], dimension: int
|
| 41 |
+
):
|
| 42 |
+
if isinstance(arg, list):
|
| 43 |
+
assert len(arg) == dimension
|
| 44 |
+
return arg
|
| 45 |
+
|
| 46 |
+
if isinstance(arg, (Sequence, np.ndarray, torch.Tensor)):
|
| 47 |
+
tmp = [i for i in arg]
|
| 48 |
+
assert len(tmp) == dimension
|
| 49 |
+
elif np.isscalar(arg): # Assume that it is a scalar
|
| 50 |
+
tmp = [int(arg) for i in range(dimension)]
|
| 51 |
+
else:
|
| 52 |
+
raise ValueError("Input must be a scalar or a sequence")
|
| 53 |
+
|
| 54 |
+
return tmp
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def convert_to_int_tensor(
|
| 58 |
+
arg: Union[int, Sequence, np.ndarray, torch.IntTensor], dimension: int
|
| 59 |
+
):
|
| 60 |
+
if isinstance(arg, torch.IntTensor):
|
| 61 |
+
assert arg.numel() == dimension
|
| 62 |
+
return arg
|
| 63 |
+
|
| 64 |
+
if isinstance(arg, (Sequence, np.ndarray)):
|
| 65 |
+
tmp = torch.IntTensor([i for i in arg])
|
| 66 |
+
assert tmp.numel() == dimension
|
| 67 |
+
elif np.isscalar(arg): # Assume that it is a scalar
|
| 68 |
+
tmp = torch.IntTensor([int(arg) for i in range(dimension)])
|
| 69 |
+
else:
|
| 70 |
+
raise ValueError("Input must be a scalar or a sequence")
|
| 71 |
+
|
| 72 |
+
return tmp
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def prep_args(
|
| 76 |
+
tensor_stride: Union[int, Sequence, np.ndarray, torch.IntTensor],
|
| 77 |
+
stride: Union[int, Sequence, np.ndarray, torch.IntTensor],
|
| 78 |
+
kernel_size: Union[int, Sequence, np.ndarray, torch.IntTensor],
|
| 79 |
+
dilation: Union[int, Sequence, np.ndarray, torch.IntTensor],
|
| 80 |
+
region_type: Union[int, MEB.RegionType],
|
| 81 |
+
D=-1,
|
| 82 |
+
):
|
| 83 |
+
assert torch.prod(
|
| 84 |
+
kernel_size > 0
|
| 85 |
+
), f"kernel_size must be a positive integer, provided {kernel_size}"
|
| 86 |
+
assert D > 0, f"dimension must be a positive integer, {D}"
|
| 87 |
+
tensor_stride = convert_to_int_tensor(tensor_stride, D)
|
| 88 |
+
stride = convert_to_int_tensor(stride, D)
|
| 89 |
+
kernel_size = convert_to_int_tensor(kernel_size, D)
|
| 90 |
+
dilation = convert_to_int_tensor(dilation, D)
|
| 91 |
+
region_type = int(region_type)
|
| 92 |
+
return (
|
| 93 |
+
tensor_stride,
|
| 94 |
+
stride,
|
| 95 |
+
kernel_size,
|
| 96 |
+
dilation,
|
| 97 |
+
region_type,
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def get_postfix(tensor: torch.Tensor):
|
| 102 |
+
postfix = "GPU" if tensor.is_cuda else "CPU"
|
| 103 |
+
return postfix
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
class MinkowskiModuleBase(Module):
|
| 107 |
+
pass
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def get_minkowski_function(name, variable):
|
| 111 |
+
fn_name = name + get_postfix(variable)
|
| 112 |
+
if hasattr(MEB, fn_name):
|
| 113 |
+
return getattr(MEB, fn_name)
|
| 114 |
+
else:
|
| 115 |
+
if variable.is_cuda:
|
| 116 |
+
raise ValueError(
|
| 117 |
+
f"Function {fn_name} not available. Please compile MinkowskiEngine with `torch.cuda.is_available()` is `True`."
|
| 118 |
+
)
|
| 119 |
+
else:
|
| 120 |
+
raise ValueError(f"Function {fn_name} not available.")
|
MinkowskiEngine/MinkowskiEngine/MinkowskiConvolution.py
ADDED
|
@@ -0,0 +1,634 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
import math
|
| 26 |
+
from typing import Union
|
| 27 |
+
|
| 28 |
+
import torch
|
| 29 |
+
from torch.autograd import Function
|
| 30 |
+
from torch.nn import Parameter
|
| 31 |
+
|
| 32 |
+
from MinkowskiEngineBackend._C import CoordinateMapKey, RegionType, ConvolutionMode
|
| 33 |
+
from MinkowskiSparseTensor import SparseTensor, _get_coordinate_map_key
|
| 34 |
+
from MinkowskiCommon import (
|
| 35 |
+
MinkowskiModuleBase,
|
| 36 |
+
get_minkowski_function,
|
| 37 |
+
)
|
| 38 |
+
from MinkowskiCoordinateManager import CoordinateManager
|
| 39 |
+
from MinkowskiKernelGenerator import KernelGenerator
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class MinkowskiConvolutionFunction(Function):
|
| 43 |
+
@staticmethod
|
| 44 |
+
def forward(
|
| 45 |
+
ctx,
|
| 46 |
+
input_features: torch.Tensor,
|
| 47 |
+
kernel_weights: torch.Tensor,
|
| 48 |
+
kernel_generator: KernelGenerator,
|
| 49 |
+
convolution_mode: ConvolutionMode,
|
| 50 |
+
in_coordinate_map_key: CoordinateMapKey,
|
| 51 |
+
out_coordinate_map_key: CoordinateMapKey = None,
|
| 52 |
+
coordinate_manager: CoordinateManager = None,
|
| 53 |
+
):
|
| 54 |
+
if out_coordinate_map_key is None:
|
| 55 |
+
out_coordinate_map_key = CoordinateMapKey(
|
| 56 |
+
in_coordinate_map_key.get_coordinate_size()
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
input_features = input_features.contiguous()
|
| 60 |
+
|
| 61 |
+
ctx.input_features = input_features
|
| 62 |
+
ctx.kernel_weights = kernel_weights
|
| 63 |
+
ctx.misc = [
|
| 64 |
+
kernel_generator,
|
| 65 |
+
convolution_mode,
|
| 66 |
+
in_coordinate_map_key,
|
| 67 |
+
out_coordinate_map_key,
|
| 68 |
+
coordinate_manager,
|
| 69 |
+
]
|
| 70 |
+
|
| 71 |
+
fw_fn = get_minkowski_function("ConvolutionForward", input_features)
|
| 72 |
+
return fw_fn(
|
| 73 |
+
ctx.input_features,
|
| 74 |
+
kernel_weights,
|
| 75 |
+
kernel_generator.kernel_size,
|
| 76 |
+
kernel_generator.kernel_stride,
|
| 77 |
+
kernel_generator.kernel_dilation,
|
| 78 |
+
kernel_generator.region_type,
|
| 79 |
+
kernel_generator.region_offsets,
|
| 80 |
+
kernel_generator.expand_coordinates,
|
| 81 |
+
convolution_mode,
|
| 82 |
+
in_coordinate_map_key,
|
| 83 |
+
out_coordinate_map_key,
|
| 84 |
+
coordinate_manager._manager,
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
@staticmethod
|
| 88 |
+
def backward(ctx, grad_out_feat: torch.Tensor):
|
| 89 |
+
grad_out_feat = grad_out_feat.contiguous()
|
| 90 |
+
(
|
| 91 |
+
kernel_generator,
|
| 92 |
+
convolution_mode,
|
| 93 |
+
in_coordinate_map_key,
|
| 94 |
+
out_coordinate_map_key,
|
| 95 |
+
coordinate_manager,
|
| 96 |
+
) = ctx.misc
|
| 97 |
+
|
| 98 |
+
bw_fn = get_minkowski_function("ConvolutionBackward", grad_out_feat)
|
| 99 |
+
grad_in_feat, grad_kernel = bw_fn(
|
| 100 |
+
ctx.input_features,
|
| 101 |
+
grad_out_feat,
|
| 102 |
+
ctx.kernel_weights,
|
| 103 |
+
kernel_generator.kernel_size,
|
| 104 |
+
kernel_generator.kernel_stride,
|
| 105 |
+
kernel_generator.kernel_dilation,
|
| 106 |
+
kernel_generator.region_type,
|
| 107 |
+
kernel_generator.region_offsets,
|
| 108 |
+
convolution_mode,
|
| 109 |
+
in_coordinate_map_key,
|
| 110 |
+
out_coordinate_map_key,
|
| 111 |
+
coordinate_manager._manager,
|
| 112 |
+
)
|
| 113 |
+
return (
|
| 114 |
+
grad_in_feat,
|
| 115 |
+
grad_kernel,
|
| 116 |
+
None,
|
| 117 |
+
None,
|
| 118 |
+
None,
|
| 119 |
+
None,
|
| 120 |
+
None,
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
class MinkowskiConvolutionTransposeFunction(Function):
|
| 125 |
+
@staticmethod
|
| 126 |
+
def forward(
|
| 127 |
+
ctx,
|
| 128 |
+
input_features: torch.Tensor,
|
| 129 |
+
kernel_weights: torch.Tensor,
|
| 130 |
+
kernel_generator: KernelGenerator,
|
| 131 |
+
convolution_mode: ConvolutionMode,
|
| 132 |
+
in_coordinate_map_key: CoordinateMapKey,
|
| 133 |
+
out_coordinate_map_key: CoordinateMapKey = None,
|
| 134 |
+
coordinate_manager: CoordinateManager = None,
|
| 135 |
+
):
|
| 136 |
+
if out_coordinate_map_key is None:
|
| 137 |
+
out_coordinate_map_key = CoordinateMapKey(
|
| 138 |
+
in_coordinate_map_key.get_coordinate_size()
|
| 139 |
+
)
|
| 140 |
+
input_features = input_features.contiguous()
|
| 141 |
+
ctx.input_features = input_features
|
| 142 |
+
ctx.kernel_weights = kernel_weights
|
| 143 |
+
ctx.misc = (
|
| 144 |
+
kernel_generator,
|
| 145 |
+
convolution_mode,
|
| 146 |
+
in_coordinate_map_key,
|
| 147 |
+
out_coordinate_map_key,
|
| 148 |
+
coordinate_manager,
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
fw_fn = get_minkowski_function("ConvolutionTransposeForward", input_features)
|
| 152 |
+
return fw_fn(
|
| 153 |
+
ctx.input_features,
|
| 154 |
+
kernel_weights,
|
| 155 |
+
kernel_generator.kernel_size,
|
| 156 |
+
kernel_generator.kernel_stride,
|
| 157 |
+
kernel_generator.kernel_dilation,
|
| 158 |
+
kernel_generator.region_type,
|
| 159 |
+
kernel_generator.region_offsets,
|
| 160 |
+
kernel_generator.expand_coordinates,
|
| 161 |
+
convolution_mode,
|
| 162 |
+
in_coordinate_map_key,
|
| 163 |
+
out_coordinate_map_key,
|
| 164 |
+
coordinate_manager._manager,
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
@staticmethod
|
| 168 |
+
def backward(ctx, grad_out_feat: torch.Tensor):
|
| 169 |
+
grad_out_feat = grad_out_feat.contiguous()
|
| 170 |
+
(
|
| 171 |
+
kernel_generator,
|
| 172 |
+
convolution_mode,
|
| 173 |
+
in_coordinate_map_key,
|
| 174 |
+
out_coordinate_map_key,
|
| 175 |
+
coordinate_manager,
|
| 176 |
+
) = ctx.misc
|
| 177 |
+
|
| 178 |
+
bw_fn = get_minkowski_function("ConvolutionTransposeBackward", grad_out_feat)
|
| 179 |
+
grad_in_feat, grad_kernel = bw_fn(
|
| 180 |
+
ctx.input_features,
|
| 181 |
+
grad_out_feat,
|
| 182 |
+
ctx.kernel_weights,
|
| 183 |
+
kernel_generator.kernel_size,
|
| 184 |
+
kernel_generator.kernel_stride,
|
| 185 |
+
kernel_generator.kernel_dilation,
|
| 186 |
+
kernel_generator.region_type,
|
| 187 |
+
kernel_generator.region_offsets,
|
| 188 |
+
convolution_mode,
|
| 189 |
+
in_coordinate_map_key,
|
| 190 |
+
out_coordinate_map_key,
|
| 191 |
+
coordinate_manager._manager,
|
| 192 |
+
)
|
| 193 |
+
return (
|
| 194 |
+
grad_in_feat,
|
| 195 |
+
grad_kernel,
|
| 196 |
+
None,
|
| 197 |
+
None,
|
| 198 |
+
None,
|
| 199 |
+
None,
|
| 200 |
+
None,
|
| 201 |
+
)
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
class MinkowskiConvolutionBase(MinkowskiModuleBase):
|
| 205 |
+
|
| 206 |
+
__slots__ = (
|
| 207 |
+
"in_channels",
|
| 208 |
+
"out_channels",
|
| 209 |
+
"is_transpose",
|
| 210 |
+
"kernel_generator",
|
| 211 |
+
"dimension",
|
| 212 |
+
"use_mm",
|
| 213 |
+
"kernel",
|
| 214 |
+
"bias",
|
| 215 |
+
"conv",
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
def __init__(
|
| 219 |
+
self,
|
| 220 |
+
in_channels,
|
| 221 |
+
out_channels,
|
| 222 |
+
kernel_size=-1,
|
| 223 |
+
stride=1,
|
| 224 |
+
dilation=1,
|
| 225 |
+
bias=False,
|
| 226 |
+
kernel_generator=None,
|
| 227 |
+
is_transpose=False, # only the base class has this argument
|
| 228 |
+
expand_coordinates=False,
|
| 229 |
+
convolution_mode=ConvolutionMode.DEFAULT,
|
| 230 |
+
dimension=-1,
|
| 231 |
+
):
|
| 232 |
+
r"""
|
| 233 |
+
|
| 234 |
+
.. note::
|
| 235 |
+
|
| 236 |
+
When the kernel generator is provided, all kernel related arguments
|
| 237 |
+
(kernel_size, stride, dilation) will be ignored.
|
| 238 |
+
|
| 239 |
+
"""
|
| 240 |
+
super(MinkowskiConvolutionBase, self).__init__()
|
| 241 |
+
assert (
|
| 242 |
+
dimension > 0
|
| 243 |
+
), f"Invalid dimension. Please provide a valid dimension argument. dimension={dimension}"
|
| 244 |
+
|
| 245 |
+
if kernel_generator is None:
|
| 246 |
+
kernel_generator = KernelGenerator(
|
| 247 |
+
kernel_size=kernel_size,
|
| 248 |
+
stride=stride,
|
| 249 |
+
dilation=dilation,
|
| 250 |
+
expand_coordinates=expand_coordinates,
|
| 251 |
+
dimension=dimension,
|
| 252 |
+
)
|
| 253 |
+
else:
|
| 254 |
+
kernel_generator.expand_coordinates = expand_coordinates
|
| 255 |
+
|
| 256 |
+
self.is_transpose = is_transpose
|
| 257 |
+
self.in_channels = in_channels
|
| 258 |
+
self.out_channels = out_channels
|
| 259 |
+
|
| 260 |
+
self.kernel_generator = kernel_generator
|
| 261 |
+
self.dimension = dimension
|
| 262 |
+
self.use_mm = False # use matrix multiplication when kernel_volume is 1
|
| 263 |
+
|
| 264 |
+
Tensor = torch.FloatTensor
|
| 265 |
+
if (
|
| 266 |
+
self.kernel_generator.kernel_volume == 1
|
| 267 |
+
and self.kernel_generator.requires_strided_coordinates
|
| 268 |
+
):
|
| 269 |
+
kernel_shape = (self.in_channels, self.out_channels)
|
| 270 |
+
self.use_mm = True
|
| 271 |
+
else:
|
| 272 |
+
kernel_shape = (
|
| 273 |
+
self.kernel_generator.kernel_volume,
|
| 274 |
+
self.in_channels,
|
| 275 |
+
self.out_channels,
|
| 276 |
+
)
|
| 277 |
+
|
| 278 |
+
self.kernel = Parameter(Tensor(*kernel_shape))
|
| 279 |
+
self.bias = Parameter(Tensor(1, out_channels)) if bias else None
|
| 280 |
+
self.convolution_mode = convolution_mode
|
| 281 |
+
self.conv = (
|
| 282 |
+
MinkowskiConvolutionTransposeFunction()
|
| 283 |
+
if is_transpose
|
| 284 |
+
else MinkowskiConvolutionFunction()
|
| 285 |
+
)
|
| 286 |
+
|
| 287 |
+
def forward(
|
| 288 |
+
self,
|
| 289 |
+
input: SparseTensor,
|
| 290 |
+
coordinates: Union[torch.Tensor, CoordinateMapKey, SparseTensor] = None,
|
| 291 |
+
):
|
| 292 |
+
r"""
|
| 293 |
+
:attr:`input` (`MinkowskiEngine.SparseTensor`): Input sparse tensor to apply a
|
| 294 |
+
convolution on.
|
| 295 |
+
|
| 296 |
+
:attr:`coordinates` ((`torch.IntTensor`, `MinkowskiEngine.CoordinateMapKey`,
|
| 297 |
+
`MinkowskiEngine.SparseTensor`), optional): If provided, generate
|
| 298 |
+
results on the provided coordinates. None by default.
|
| 299 |
+
|
| 300 |
+
"""
|
| 301 |
+
assert isinstance(input, SparseTensor)
|
| 302 |
+
assert input.D == self.dimension
|
| 303 |
+
|
| 304 |
+
if self.use_mm:
|
| 305 |
+
# If the kernel_size == 1, the convolution is simply a matrix
|
| 306 |
+
# multiplication
|
| 307 |
+
out_coordinate_map_key = input.coordinate_map_key
|
| 308 |
+
outfeat = input.F.mm(self.kernel)
|
| 309 |
+
else:
|
| 310 |
+
# Get a new coordinate_map_key or extract one from the coords
|
| 311 |
+
out_coordinate_map_key = _get_coordinate_map_key(
|
| 312 |
+
input, coordinates, self.kernel_generator.expand_coordinates
|
| 313 |
+
)
|
| 314 |
+
outfeat = self.conv.apply(
|
| 315 |
+
input.F,
|
| 316 |
+
self.kernel,
|
| 317 |
+
self.kernel_generator,
|
| 318 |
+
self.convolution_mode,
|
| 319 |
+
input.coordinate_map_key,
|
| 320 |
+
out_coordinate_map_key,
|
| 321 |
+
input._manager,
|
| 322 |
+
)
|
| 323 |
+
if self.bias is not None:
|
| 324 |
+
outfeat += self.bias
|
| 325 |
+
|
| 326 |
+
return SparseTensor(
|
| 327 |
+
outfeat,
|
| 328 |
+
coordinate_map_key=out_coordinate_map_key,
|
| 329 |
+
coordinate_manager=input._manager,
|
| 330 |
+
)
|
| 331 |
+
|
| 332 |
+
def reset_parameters(self, is_transpose=False):
|
| 333 |
+
with torch.no_grad():
|
| 334 |
+
n = (
|
| 335 |
+
self.out_channels if is_transpose else self.in_channels
|
| 336 |
+
) * self.kernel_generator.kernel_volume
|
| 337 |
+
stdv = 1.0 / math.sqrt(n)
|
| 338 |
+
self.kernel.data.uniform_(-stdv, stdv)
|
| 339 |
+
if self.bias is not None:
|
| 340 |
+
self.bias.data.uniform_(-stdv, stdv)
|
| 341 |
+
|
| 342 |
+
def __repr__(self):
|
| 343 |
+
s = "(in={}, out={}, ".format(
|
| 344 |
+
self.in_channels,
|
| 345 |
+
self.out_channels,
|
| 346 |
+
)
|
| 347 |
+
if self.kernel_generator.region_type in [RegionType.CUSTOM]:
|
| 348 |
+
s += "region_type={}, kernel_volume={}, ".format(
|
| 349 |
+
self.kernel_generator.region_type, self.kernel_generator.kernel_volume
|
| 350 |
+
)
|
| 351 |
+
else:
|
| 352 |
+
s += "kernel_size={}, ".format(self.kernel_generator.kernel_size)
|
| 353 |
+
s += "stride={}, dilation={})".format(
|
| 354 |
+
self.kernel_generator.kernel_stride,
|
| 355 |
+
self.kernel_generator.kernel_dilation,
|
| 356 |
+
)
|
| 357 |
+
return self.__class__.__name__ + s
|
| 358 |
+
|
| 359 |
+
|
| 360 |
+
class MinkowskiConvolution(MinkowskiConvolutionBase):
|
| 361 |
+
r"""Convolution layer for a sparse tensor.
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
.. math::
|
| 365 |
+
|
| 366 |
+
\mathbf{x}_\mathbf{u} = \sum_{\mathbf{i} \in \mathcal{N}^D(\mathbf{u}, K,
|
| 367 |
+
\mathcal{C}^\text{in})} W_\mathbf{i} \mathbf{x}_{\mathbf{i} +
|
| 368 |
+
\mathbf{u}} \;\text{for} \; \mathbf{u} \in \mathcal{C}^\text{out}
|
| 369 |
+
|
| 370 |
+
where :math:`K` is the kernel size and :math:`\mathcal{N}^D(\mathbf{u}, K,
|
| 371 |
+
\mathcal{C}^\text{in})` is the set of offsets that are at most :math:`\left
|
| 372 |
+
\lceil{\frac{1}{2}(K - 1)} \right \rceil` away from :math:`\mathbf{u}`
|
| 373 |
+
definied in :math:`\mathcal{S}^\text{in}`.
|
| 374 |
+
|
| 375 |
+
.. note::
|
| 376 |
+
For even :math:`K`, the kernel offset :math:`\mathcal{N}^D`
|
| 377 |
+
implementation is different from the above definition. The offsets
|
| 378 |
+
range from :math:`\mathbf{i} \in [0, K)^D, \; \mathbf{i} \in
|
| 379 |
+
\mathbb{Z}_+^D`.
|
| 380 |
+
|
| 381 |
+
"""
|
| 382 |
+
|
| 383 |
+
def __init__(
|
| 384 |
+
self,
|
| 385 |
+
in_channels,
|
| 386 |
+
out_channels,
|
| 387 |
+
kernel_size=-1,
|
| 388 |
+
stride=1,
|
| 389 |
+
dilation=1,
|
| 390 |
+
bias=False,
|
| 391 |
+
kernel_generator=None,
|
| 392 |
+
expand_coordinates=False,
|
| 393 |
+
convolution_mode=ConvolutionMode.DEFAULT,
|
| 394 |
+
dimension=None,
|
| 395 |
+
):
|
| 396 |
+
r"""convolution on a sparse tensor
|
| 397 |
+
|
| 398 |
+
Args:
|
| 399 |
+
:attr:`in_channels` (int): the number of input channels in the
|
| 400 |
+
input tensor.
|
| 401 |
+
|
| 402 |
+
:attr:`out_channels` (int): the number of output channels in the
|
| 403 |
+
output tensor.
|
| 404 |
+
|
| 405 |
+
:attr:`kernel_size` (int, optional): the size of the kernel in the
|
| 406 |
+
output tensor. If not provided, :attr:`region_offset` should be
|
| 407 |
+
:attr:`RegionType.CUSTOM` and :attr:`region_offset` should be a 2D
|
| 408 |
+
matrix with size :math:`N\times D` such that it lists all :math:`N`
|
| 409 |
+
offsets in D-dimension.
|
| 410 |
+
|
| 411 |
+
:attr:`stride` (int, or list, optional): stride size of the
|
| 412 |
+
convolution layer. If non-identity is used, the output coordinates
|
| 413 |
+
will be at least :attr:`stride` :math:`\times` :attr:`tensor_stride`
|
| 414 |
+
away. When a list is given, the length must be D; each element will
|
| 415 |
+
be used for stride size for the specific axis.
|
| 416 |
+
|
| 417 |
+
:attr:`dilation` (int, or list, optional): dilation size for the
|
| 418 |
+
convolution kernel. When a list is given, the length must be D and
|
| 419 |
+
each element is an axis specific dilation. All elements must be > 0.
|
| 420 |
+
|
| 421 |
+
:attr:`bias` (bool, optional): if True, the convolution layer
|
| 422 |
+
has a bias.
|
| 423 |
+
|
| 424 |
+
:attr:`kernel_generator` (:attr:`MinkowskiEngine.KernelGenerator`,
|
| 425 |
+
optional): defines custom kernel shape.
|
| 426 |
+
|
| 427 |
+
:attr:`expand_coordinates` (bool, optional): Force generation of
|
| 428 |
+
new coordinates. When True, the output coordinates will be the
|
| 429 |
+
outer product of the kernel shape and the input coordinates.
|
| 430 |
+
`False` by default.
|
| 431 |
+
|
| 432 |
+
:attr:`dimension` (int): the spatial dimension of the space where
|
| 433 |
+
all the inputs and the network are defined. For example, images are
|
| 434 |
+
in a 2D space, meshes and 3D shapes are in a 3D space.
|
| 435 |
+
|
| 436 |
+
"""
|
| 437 |
+
MinkowskiConvolutionBase.__init__(
|
| 438 |
+
self,
|
| 439 |
+
in_channels,
|
| 440 |
+
out_channels,
|
| 441 |
+
kernel_size,
|
| 442 |
+
stride,
|
| 443 |
+
dilation,
|
| 444 |
+
bias,
|
| 445 |
+
kernel_generator,
|
| 446 |
+
is_transpose=False,
|
| 447 |
+
expand_coordinates=expand_coordinates,
|
| 448 |
+
convolution_mode=convolution_mode,
|
| 449 |
+
dimension=dimension,
|
| 450 |
+
)
|
| 451 |
+
self.reset_parameters()
|
| 452 |
+
|
| 453 |
+
|
| 454 |
+
class MinkowskiConvolutionTranspose(MinkowskiConvolutionBase):
|
| 455 |
+
r"""A generalized sparse transposed convolution or deconvolution layer."""
|
| 456 |
+
|
| 457 |
+
def __init__(
|
| 458 |
+
self,
|
| 459 |
+
in_channels,
|
| 460 |
+
out_channels,
|
| 461 |
+
kernel_size=-1,
|
| 462 |
+
stride=1,
|
| 463 |
+
dilation=1,
|
| 464 |
+
bias=False,
|
| 465 |
+
kernel_generator=None,
|
| 466 |
+
expand_coordinates=False,
|
| 467 |
+
convolution_mode=ConvolutionMode.DEFAULT,
|
| 468 |
+
dimension=None,
|
| 469 |
+
):
|
| 470 |
+
r"""a generalized sparse transposed convolution layer.
|
| 471 |
+
|
| 472 |
+
Args:
|
| 473 |
+
:attr:`in_channels` (int): the number of input channels in the
|
| 474 |
+
input tensor.
|
| 475 |
+
|
| 476 |
+
:attr:`out_channels` (int): the number of output channels in the
|
| 477 |
+
output tensor.
|
| 478 |
+
|
| 479 |
+
:attr:`kernel_size` (int, optional): the size of the kernel in the
|
| 480 |
+
output tensor. If not provided, :attr:`region_offset` should be
|
| 481 |
+
:attr:`RegionType.CUSTOM` and :attr:`region_offset` should be a 2D
|
| 482 |
+
matrix with size :math:`N\times D` such that it lists all :math:`N`
|
| 483 |
+
offsets in D-dimension.
|
| 484 |
+
|
| 485 |
+
:attr:`stride` (int, or list, optional): stride size that defines
|
| 486 |
+
upsampling rate. If non-identity is used, the output coordinates
|
| 487 |
+
will be :attr:`tensor_stride` / :attr:`stride` apart. When a list is
|
| 488 |
+
given, the length must be D; each element will be used for stride
|
| 489 |
+
size for the specific axis.
|
| 490 |
+
|
| 491 |
+
:attr:`dilation` (int, or list, optional): dilation size for the
|
| 492 |
+
convolution kernel. When a list is given, the length must be D and
|
| 493 |
+
each element is an axis specific dilation. All elements must be > 0.
|
| 494 |
+
|
| 495 |
+
:attr:`bias` (bool, optional): if True, the convolution layer
|
| 496 |
+
has a bias.
|
| 497 |
+
|
| 498 |
+
:attr:`kernel_generator` (:attr:`MinkowskiEngine.KernelGenerator`,
|
| 499 |
+
optional): defines custom kernel shape.
|
| 500 |
+
|
| 501 |
+
:attr:`expand_coordinates` (bool, optional): Force generation of
|
| 502 |
+
new coordinates. When True, the output coordinates will be the
|
| 503 |
+
outer product of the kernel shape and the input coordinates.
|
| 504 |
+
`False` by default.
|
| 505 |
+
|
| 506 |
+
:attr:`dimension` (int): the spatial dimension of the space where
|
| 507 |
+
all the inputs and the network are defined. For example, images are
|
| 508 |
+
in a 2D space, meshes and 3D shapes are in a 3D space.
|
| 509 |
+
|
| 510 |
+
.. note:
|
| 511 |
+
TODO: support `kernel_size` > `stride`.
|
| 512 |
+
|
| 513 |
+
"""
|
| 514 |
+
if kernel_generator is None:
|
| 515 |
+
kernel_generator = KernelGenerator(
|
| 516 |
+
kernel_size=kernel_size,
|
| 517 |
+
stride=stride,
|
| 518 |
+
dilation=dilation,
|
| 519 |
+
dimension=dimension,
|
| 520 |
+
)
|
| 521 |
+
|
| 522 |
+
MinkowskiConvolutionBase.__init__(
|
| 523 |
+
self,
|
| 524 |
+
in_channels,
|
| 525 |
+
out_channels,
|
| 526 |
+
kernel_size,
|
| 527 |
+
stride,
|
| 528 |
+
dilation,
|
| 529 |
+
bias,
|
| 530 |
+
kernel_generator,
|
| 531 |
+
is_transpose=True,
|
| 532 |
+
expand_coordinates=expand_coordinates,
|
| 533 |
+
convolution_mode=convolution_mode,
|
| 534 |
+
dimension=dimension,
|
| 535 |
+
)
|
| 536 |
+
self.reset_parameters(True)
|
| 537 |
+
|
| 538 |
+
|
| 539 |
+
class MinkowskiGenerativeConvolutionTranspose(MinkowskiConvolutionBase):
|
| 540 |
+
r"""A generalized sparse transposed convolution or deconvolution layer that
|
| 541 |
+
generates new coordinates.
|
| 542 |
+
"""
|
| 543 |
+
|
| 544 |
+
def __init__(
|
| 545 |
+
self,
|
| 546 |
+
in_channels,
|
| 547 |
+
out_channels,
|
| 548 |
+
kernel_size=-1,
|
| 549 |
+
stride=1,
|
| 550 |
+
dilation=1,
|
| 551 |
+
bias=False,
|
| 552 |
+
kernel_generator=None,
|
| 553 |
+
convolution_mode=ConvolutionMode.DEFAULT,
|
| 554 |
+
dimension=None,
|
| 555 |
+
):
|
| 556 |
+
r"""a generalized sparse transposed convolution layer that creates new coordinates.
|
| 557 |
+
|
| 558 |
+
Please refer to `Generative Sparse Detection Networks for 3D Single-shot Object Detection <https://arxiv.org/abs/2006.12356>`_ for more detail. Also, please cite the following paper if you use this function.
|
| 559 |
+
|
| 560 |
+
>> @inproceedings{gwak2020gsdn,
|
| 561 |
+
>> title={Generative Sparse Detection Networks for 3D Single-shot Object Detection},
|
| 562 |
+
>> author={Gwak, JunYoung and Choy, Christopher B and Savarese, Silvio},
|
| 563 |
+
>> booktitle={European conference on computer vision},
|
| 564 |
+
>> year={2020}
|
| 565 |
+
>> }
|
| 566 |
+
|
| 567 |
+
Args:
|
| 568 |
+
:attr:`in_channels` (int): the number of input channels in the
|
| 569 |
+
input tensor.
|
| 570 |
+
|
| 571 |
+
:attr:`out_channels` (int): the number of output channels in the
|
| 572 |
+
output tensor.
|
| 573 |
+
|
| 574 |
+
:attr:`kernel_size` (int, optional): the size of the kernel in the
|
| 575 |
+
output tensor. If not provided, :attr:`region_offset` should be
|
| 576 |
+
:attr:`RegionType.CUSTOM` and :attr:`region_offset` should be a 2D
|
| 577 |
+
matrix with size :math:`N\times D` such that it lists all :math:`N`
|
| 578 |
+
offsets in D-dimension.
|
| 579 |
+
|
| 580 |
+
:attr:`stride` (int, or list, optional): stride size that defines
|
| 581 |
+
upsampling rate. If non-identity is used, the output coordinates
|
| 582 |
+
will be :attr:`tensor_stride` / :attr:`stride` apart. When a list is
|
| 583 |
+
given, the length must be D; each element will be used for stride
|
| 584 |
+
size for the specific axis.
|
| 585 |
+
|
| 586 |
+
:attr:`dilation` (int, or list, optional): dilation size for the
|
| 587 |
+
convolution kernel. When a list is given, the length must be D and
|
| 588 |
+
each element is an axis specific dilation. All elements must be > 0.
|
| 589 |
+
|
| 590 |
+
:attr:`bias` (bool, optional): if True, the convolution layer
|
| 591 |
+
has a bias.
|
| 592 |
+
|
| 593 |
+
:attr:`kernel_generator` (:attr:`MinkowskiEngine.KernelGenerator`,
|
| 594 |
+
optional): defines custom kernel shape.
|
| 595 |
+
|
| 596 |
+
:attr:`expand_coordinates` (bool, optional): Force generation of
|
| 597 |
+
new coordinates. When True, the output coordinates will be the
|
| 598 |
+
outer product of the kernel shape and the input coordinates.
|
| 599 |
+
`False` by defaul.
|
| 600 |
+
|
| 601 |
+
:attr:`dimension` (int): the spatial dimension of the space where
|
| 602 |
+
all the inputs and the network are defined. For example, images are
|
| 603 |
+
in a 2D space, meshes and 3D shapes are in a 3D space.
|
| 604 |
+
|
| 605 |
+
.. note:
|
| 606 |
+
TODO: support `kernel_size` > `stride`.
|
| 607 |
+
|
| 608 |
+
"""
|
| 609 |
+
if kernel_generator is None:
|
| 610 |
+
kernel_generator = KernelGenerator(
|
| 611 |
+
kernel_size=kernel_size,
|
| 612 |
+
stride=stride,
|
| 613 |
+
dilation=dilation,
|
| 614 |
+
expand_coordinates=True,
|
| 615 |
+
dimension=dimension,
|
| 616 |
+
)
|
| 617 |
+
else:
|
| 618 |
+
kernel_generator.expand_coordinates = True
|
| 619 |
+
|
| 620 |
+
MinkowskiConvolutionBase.__init__(
|
| 621 |
+
self,
|
| 622 |
+
in_channels,
|
| 623 |
+
out_channels,
|
| 624 |
+
kernel_size,
|
| 625 |
+
stride,
|
| 626 |
+
dilation,
|
| 627 |
+
bias,
|
| 628 |
+
kernel_generator,
|
| 629 |
+
is_transpose=True,
|
| 630 |
+
expand_coordinates=True,
|
| 631 |
+
convolution_mode=convolution_mode,
|
| 632 |
+
dimension=dimension,
|
| 633 |
+
)
|
| 634 |
+
self.reset_parameters(True)
|
MinkowskiEngine/MinkowskiEngine/MinkowskiCoordinateManager.py
ADDED
|
@@ -0,0 +1,498 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
import os
|
| 26 |
+
import numpy as np
|
| 27 |
+
from collections.abc import Sequence
|
| 28 |
+
from typing import Union, List, Tuple
|
| 29 |
+
import warnings
|
| 30 |
+
|
| 31 |
+
import torch
|
| 32 |
+
from MinkowskiCommon import convert_to_int_list, convert_to_int_tensor
|
| 33 |
+
import MinkowskiEngineBackend._C as _C
|
| 34 |
+
from MinkowskiEngineBackend._C import (
|
| 35 |
+
CoordinateMapKey,
|
| 36 |
+
GPUMemoryAllocatorType,
|
| 37 |
+
CoordinateMapType,
|
| 38 |
+
MinkowskiAlgorithm,
|
| 39 |
+
RegionType,
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
CPU_COUNT = os.cpu_count()
|
| 43 |
+
if "OMP_NUM_THREADS" in os.environ:
|
| 44 |
+
CPU_COUNT = int(os.environ["OMP_NUM_THREADS"])
|
| 45 |
+
|
| 46 |
+
_allocator_type = GPUMemoryAllocatorType.PYTORCH
|
| 47 |
+
_coordinate_map_type = (
|
| 48 |
+
CoordinateMapType.CUDA if _C.is_cuda_available() else CoordinateMapType.CPU
|
| 49 |
+
)
|
| 50 |
+
_minkowski_algorithm = MinkowskiAlgorithm.DEFAULT
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def set_coordinate_map_type(coordinate_map_type: CoordinateMapType):
|
| 54 |
+
r"""Set the default coordinate map type.
|
| 55 |
+
|
| 56 |
+
The MinkowskiEngine automatically set the coordinate_map_type to CUDA if
|
| 57 |
+
a NVIDIA GPU is available. To control the
|
| 58 |
+
"""
|
| 59 |
+
global _coordinate_map_type
|
| 60 |
+
_coordinate_map_type = coordinate_map_type
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def set_gpu_allocator(backend: GPUMemoryAllocatorType):
|
| 64 |
+
r"""Set the GPU memory allocator
|
| 65 |
+
|
| 66 |
+
By default, the Minkowski Engine will use the pytorch memory pool to
|
| 67 |
+
allocate temporary GPU memory slots. This allows the pytorch backend to
|
| 68 |
+
effectively reuse the memory pool shared between the pytorch backend and
|
| 69 |
+
the Minkowski Engine. It tends to allow training with larger batch sizes
|
| 70 |
+
given a fixed GPU memory. However, pytorch memory manager tend to be slower
|
| 71 |
+
than allocating GPU directly using raw CUDA calls.
|
| 72 |
+
|
| 73 |
+
By default, the Minkowski Engine uses
|
| 74 |
+
:attr:`ME.GPUMemoryAllocatorType.PYTORCH` for memory management.
|
| 75 |
+
|
| 76 |
+
Example::
|
| 77 |
+
|
| 78 |
+
>>> import MinkowskiEngine as ME
|
| 79 |
+
>>> # Set the GPU memory manager backend to raw CUDA calls
|
| 80 |
+
>>> ME.set_gpu_allocator(ME.GPUMemoryAllocatorType.CUDA)
|
| 81 |
+
>>> # Set the GPU memory manager backend to the pytorch c10 allocator
|
| 82 |
+
>>> ME.set_gpu_allocator(ME.GPUMemoryAllocatorType.PYTORCH)
|
| 83 |
+
|
| 84 |
+
"""
|
| 85 |
+
assert isinstance(
|
| 86 |
+
backend, GPUMemoryAllocatorType
|
| 87 |
+
), f"Input must be an instance of GPUMemoryAllocatorType not {backend}"
|
| 88 |
+
global _allocator_type
|
| 89 |
+
_allocator_type = backend
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def set_memory_manager_backend(backend: GPUMemoryAllocatorType):
|
| 93 |
+
r"""Alias for set_gpu_allocator. Deprecated and will be removed."""
|
| 94 |
+
warnings.warn(
|
| 95 |
+
"`set_memory_manager_backend` has been deprecated. Use `set_gpu_allocator` instead."
|
| 96 |
+
)
|
| 97 |
+
set_gpu_allocator(backend)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
class CoordsManager:
|
| 101 |
+
def __init__(*args, **kwargs):
|
| 102 |
+
raise DeprecationWarning(
|
| 103 |
+
"`CoordsManager` has been deprecated. Use `CoordinateManager` instead."
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
class CoordinateManager:
|
| 108 |
+
def __init__(
|
| 109 |
+
self,
|
| 110 |
+
D: int = 0,
|
| 111 |
+
num_threads: int = -1,
|
| 112 |
+
coordinate_map_type: CoordinateMapType = None,
|
| 113 |
+
allocator_type: GPUMemoryAllocatorType = None,
|
| 114 |
+
minkowski_algorithm: MinkowskiAlgorithm = None,
|
| 115 |
+
):
|
| 116 |
+
r"""
|
| 117 |
+
|
| 118 |
+
:attr:`D`: The order, or dimension of the coordinates.
|
| 119 |
+
"""
|
| 120 |
+
global _coordinate_map_type, _allocator_type, _minkowski_algorithm
|
| 121 |
+
if D < 1:
|
| 122 |
+
raise ValueError(f"Invalid rank D > 0, D = {D}.")
|
| 123 |
+
if num_threads < 0:
|
| 124 |
+
num_threads = min(CPU_COUNT, 20)
|
| 125 |
+
if coordinate_map_type is None:
|
| 126 |
+
coordinate_map_type = _coordinate_map_type
|
| 127 |
+
if allocator_type is None:
|
| 128 |
+
allocator_type = _allocator_type
|
| 129 |
+
if minkowski_algorithm is None:
|
| 130 |
+
minkowski_algorithm = _minkowski_algorithm
|
| 131 |
+
|
| 132 |
+
postfix = ""
|
| 133 |
+
if coordinate_map_type == CoordinateMapType.CPU:
|
| 134 |
+
postfix = "CPU"
|
| 135 |
+
else:
|
| 136 |
+
assert (
|
| 137 |
+
_C.is_cuda_available()
|
| 138 |
+
), "The MinkowskiEngine was compiled with CPU_ONLY flag. If you want to compile with CUDA support, make sure `torch.cuda.is_available()` is True when you install MinkowskiEngine."
|
| 139 |
+
|
| 140 |
+
postfix = "GPU" + (
|
| 141 |
+
"_default" if allocator_type == GPUMemoryAllocatorType.CUDA else "_c10"
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
self.D = D
|
| 145 |
+
self.minkowski_algorithm = minkowski_algorithm
|
| 146 |
+
self._CoordinateManagerClass = getattr(_C, "CoordinateMapManager" + postfix)
|
| 147 |
+
self._manager = self._CoordinateManagerClass(minkowski_algorithm, num_threads)
|
| 148 |
+
|
| 149 |
+
# TODO: insert without remap, unique_map, inverse_mapa
|
| 150 |
+
#
|
| 151 |
+
# def insert() -> CoordinateMapKey
|
| 152 |
+
|
| 153 |
+
def insert_and_map(
|
| 154 |
+
self,
|
| 155 |
+
coordinates: torch.Tensor,
|
| 156 |
+
tensor_stride: Union[int, Sequence, np.ndarray] = 1,
|
| 157 |
+
string_id: str = "",
|
| 158 |
+
) -> Tuple[CoordinateMapKey, Tuple[torch.IntTensor, torch.IntTensor]]:
|
| 159 |
+
r"""create a new coordinate map and returns (key, (map, inverse_map)).
|
| 160 |
+
|
| 161 |
+
:attr:`coordinates`: `torch.Tensor` (Int tensor. `CUDA` if
|
| 162 |
+
coordinate_map_type == `CoordinateMapType.GPU`) that defines the
|
| 163 |
+
coordinates.
|
| 164 |
+
|
| 165 |
+
:attr:`tensor_stride` (`list`): a list of `D` elements that defines the
|
| 166 |
+
tensor stride for the new order-`D + 1` sparse tensor.
|
| 167 |
+
|
| 168 |
+
Example::
|
| 169 |
+
|
| 170 |
+
>>> manager = CoordinateManager(D=1)
|
| 171 |
+
>>> coordinates = torch.IntTensor([[0, 0], [0, 0], [0, 1], [0, 2]])
|
| 172 |
+
>>> key, (unique_map, inverse_map) = manager.insert(coordinates, [1])
|
| 173 |
+
>>> print(key) # key is tensor_stride, string_id [1]:""
|
| 174 |
+
>>> torch.all(coordinates[unique_map] == manager.get_coordinates(key)) # True
|
| 175 |
+
>>> torch.all(coordinates == coordinates[unique_map][inverse_map]) # True
|
| 176 |
+
|
| 177 |
+
"""
|
| 178 |
+
tensor_stride = convert_to_int_list(tensor_stride, self.D)
|
| 179 |
+
return self._manager.insert_and_map(coordinates, tensor_stride, string_id)
|
| 180 |
+
|
| 181 |
+
def insert_field(
|
| 182 |
+
self,
|
| 183 |
+
coordinates: torch.Tensor,
|
| 184 |
+
tensor_stride: Sequence,
|
| 185 |
+
string_id: str = "",
|
| 186 |
+
) -> Tuple[CoordinateMapKey, Tuple[torch.IntTensor, torch.IntTensor]]:
|
| 187 |
+
r"""create a new coordinate map and returns
|
| 188 |
+
|
| 189 |
+
:attr:`coordinates`: `torch.FloatTensor` (`CUDA` if coordinate_map_type
|
| 190 |
+
== `CoordinateMapType.GPU`) that defines the coordinates.
|
| 191 |
+
|
| 192 |
+
:attr:`tensor_stride` (`list`): a list of `D` elements that defines the
|
| 193 |
+
tensor stride for the new order-`D + 1` sparse tensor.
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
Example::
|
| 197 |
+
|
| 198 |
+
>>> manager = CoordinateManager(D=1)
|
| 199 |
+
>>> coordinates = torch.FloatTensor([[0, 0.1], [0, 2.3], [0, 1.2], [0, 2.4]])
|
| 200 |
+
>>> key, (unique_map, inverse_map) = manager.insert(coordinates, [1])
|
| 201 |
+
>>> print(key) # key is tensor_stride, string_id [1]:""
|
| 202 |
+
>>> torch.all(coordinates[unique_map] == manager.get_coordinates(key)) # True
|
| 203 |
+
>>> torch.all(coordinates == coordinates[unique_map][inverse_map]) # True
|
| 204 |
+
|
| 205 |
+
"""
|
| 206 |
+
return self._manager.insert_field(coordinates, tensor_stride, string_id)
|
| 207 |
+
|
| 208 |
+
def field_to_sparse_insert_and_map(
|
| 209 |
+
self,
|
| 210 |
+
field_map_key: CoordinateMapKey,
|
| 211 |
+
sparse_tensor_stride: Union[int, Sequence, np.ndarray],
|
| 212 |
+
sparse_tensor_string_id: str = "",
|
| 213 |
+
) -> Tuple[CoordinateMapKey, Tuple[torch.IntTensor, torch.IntTensor]]:
|
| 214 |
+
|
| 215 |
+
r"""Create a sparse tensor coordinate map with the tensor stride.
|
| 216 |
+
|
| 217 |
+
:attr:`field_map_key` (`CoordinateMapKey`): field map that a new sparse
|
| 218 |
+
tensor will be created from.
|
| 219 |
+
|
| 220 |
+
:attr:`tensor_stride` (`list`): a list of `D` elements that defines the
|
| 221 |
+
tensor stride for the new order-`D + 1` sparse tensor.
|
| 222 |
+
|
| 223 |
+
:attr:`string_id` (`str`): string id of the new sparse tensor coordinate map key.
|
| 224 |
+
|
| 225 |
+
Example::
|
| 226 |
+
|
| 227 |
+
>>> manager = CoordinateManager(D=1)
|
| 228 |
+
>>> coordinates = torch.FloatTensor([[0, 0.1], [0, 2.3], [0, 1.2], [0, 2.4]])
|
| 229 |
+
>>> key, (unique_map, inverse_map) = manager.insert(coordinates, [1])
|
| 230 |
+
|
| 231 |
+
"""
|
| 232 |
+
return self._manager.field_to_sparse_insert_and_map(
|
| 233 |
+
field_map_key, sparse_tensor_stride, sparse_tensor_string_id
|
| 234 |
+
)
|
| 235 |
+
|
| 236 |
+
def exists_field_to_sparse(
|
| 237 |
+
self, field_map_key: CoordinateMapKey, sparse_map_key: CoordinateMapKey
|
| 238 |
+
):
|
| 239 |
+
return self._manager.exists_field_to_sparse(field_map_key, sparse_map_key)
|
| 240 |
+
|
| 241 |
+
def field_to_sparse_keys(self, field_map_key: CoordinateMapKey):
|
| 242 |
+
return self._manager.field_to_sparse_keys(field_map_key.get_key())
|
| 243 |
+
|
| 244 |
+
def get_field_to_sparse_map(
|
| 245 |
+
self, field_map_key: CoordinateMapKey, sparse_map_key: CoordinateMapKey
|
| 246 |
+
):
|
| 247 |
+
return self._manager.get_field_to_sparse_map(field_map_key, sparse_map_key)
|
| 248 |
+
|
| 249 |
+
def field_to_sparse_map(
|
| 250 |
+
self, field_map_key: CoordinateMapKey, sparse_map_key: CoordinateMapKey
|
| 251 |
+
):
|
| 252 |
+
return self._manager.field_to_sparse_map(field_map_key, sparse_map_key)
|
| 253 |
+
|
| 254 |
+
def stride(
|
| 255 |
+
self,
|
| 256 |
+
coordinate_map_key: CoordinateMapKey,
|
| 257 |
+
stride: Union[int, Sequence, np.ndarray, torch.Tensor],
|
| 258 |
+
string_id: str = "",
|
| 259 |
+
) -> CoordinateMapKey:
|
| 260 |
+
r"""Generate a new coordinate map and returns the key.
|
| 261 |
+
|
| 262 |
+
:attr:`coordinate_map_key` (:attr:`MinkowskiEngine.CoordinateMapKey`):
|
| 263 |
+
input map to generate the strided map from.
|
| 264 |
+
|
| 265 |
+
:attr:`stride`: stride size.
|
| 266 |
+
"""
|
| 267 |
+
stride = convert_to_int_list(stride, self.D)
|
| 268 |
+
return self._manager.stride(coordinate_map_key, stride, string_id)
|
| 269 |
+
|
| 270 |
+
def origin(self) -> CoordinateMapKey:
|
| 271 |
+
return self._manager.origin()
|
| 272 |
+
|
| 273 |
+
def origin_field(self) -> CoordinateMapKey:
|
| 274 |
+
return self._manager.origin_field()
|
| 275 |
+
|
| 276 |
+
def size(self, coordinate_map_key: CoordinateMapKey) -> int:
|
| 277 |
+
return self._manager.size(coordinate_map_key)
|
| 278 |
+
|
| 279 |
+
# def transposed_stride(
|
| 280 |
+
# self,
|
| 281 |
+
# coords_key: CoordsKey,
|
| 282 |
+
# stride: Union[int, Sequence, np.ndarray, torch.Tensor],
|
| 283 |
+
# kernel_size: Union[int, Sequence, np.ndarray, torch.Tensor],
|
| 284 |
+
# dilation: Union[int, Sequence, np.ndarray, torch.Tensor],
|
| 285 |
+
# force_creation: bool = False,
|
| 286 |
+
# ):
|
| 287 |
+
# assert isinstance(coords_key, CoordsKey)
|
| 288 |
+
# stride = convert_to_int_list(stride, self.D)
|
| 289 |
+
# kernel_size = convert_to_int_list(kernel_size, self.D)
|
| 290 |
+
# dilation = convert_to_int_list(dilation, self.D)
|
| 291 |
+
# region_type = 0
|
| 292 |
+
# region_offset = torch.IntTensor()
|
| 293 |
+
|
| 294 |
+
# strided_key = CoordsKey(self.D)
|
| 295 |
+
# tensor_stride = coords_key.getTensorStride()
|
| 296 |
+
# strided_key.setTensorStride([int(t / s) for t, s in zip(tensor_stride, stride)])
|
| 297 |
+
|
| 298 |
+
# strided_key.setKey(
|
| 299 |
+
# self.CPPCoordsManager.createTransposedStridedRegionCoords(
|
| 300 |
+
# coords_key.getKey(),
|
| 301 |
+
# coords_key.getTensorStride(),
|
| 302 |
+
# stride,
|
| 303 |
+
# kernel_size,
|
| 304 |
+
# dilation,
|
| 305 |
+
# region_type,
|
| 306 |
+
# region_offset,
|
| 307 |
+
# force_creation,
|
| 308 |
+
# )
|
| 309 |
+
# )
|
| 310 |
+
# return strided_key
|
| 311 |
+
|
| 312 |
+
def _get_coordinate_map_key(self, key_or_tensor_strides) -> CoordinateMapKey:
|
| 313 |
+
r"""Helper function that retrieves the first coordinate map key for the given tensor stride."""
|
| 314 |
+
assert isinstance(key_or_tensor_strides, CoordinateMapKey) or isinstance(
|
| 315 |
+
key_or_tensor_strides, (Sequence, np.ndarray, torch.IntTensor, int)
|
| 316 |
+
), f"The input must be either a CoordinateMapKey or tensor_stride of type (int, list, tuple, array, Tensor). Invalid: {key_or_tensor_strides}"
|
| 317 |
+
if isinstance(key_or_tensor_strides, CoordinateMapKey):
|
| 318 |
+
# Do nothing and return the input
|
| 319 |
+
return key_or_tensor_strides
|
| 320 |
+
else:
|
| 321 |
+
tensor_strides = convert_to_int_list(key_or_tensor_strides, self.D)
|
| 322 |
+
keys = self._manager.get_coordinate_map_keys(tensor_strides)
|
| 323 |
+
assert len(keys) > 0
|
| 324 |
+
return keys[0]
|
| 325 |
+
|
| 326 |
+
def get_coordinates(self, coords_key_or_tensor_strides) -> torch.Tensor:
|
| 327 |
+
key = self._get_coordinate_map_key(coords_key_or_tensor_strides)
|
| 328 |
+
return self._manager.get_coordinates(key)
|
| 329 |
+
|
| 330 |
+
def get_coordinate_field(self, coords_key_or_tensor_strides) -> torch.Tensor:
|
| 331 |
+
key = self._get_coordinate_map_key(coords_key_or_tensor_strides)
|
| 332 |
+
return self._manager.get_coordinate_field(key)
|
| 333 |
+
|
| 334 |
+
def number_of_unique_batch_indices(self) -> int:
|
| 335 |
+
return self._manager.origin_map_size()
|
| 336 |
+
|
| 337 |
+
def get_unique_coordinate_map_key(
|
| 338 |
+
self, tensor_stride: Union[int, list]
|
| 339 |
+
) -> CoordinateMapKey:
|
| 340 |
+
"""
|
| 341 |
+
Returns a unique coordinate_map_key for a given tensor stride.
|
| 342 |
+
|
| 343 |
+
:attr:`tensor_stride` (`list`): a list of `D` elements that defines the
|
| 344 |
+
tensor stride for the new order-`D + 1` sparse tensor.
|
| 345 |
+
|
| 346 |
+
"""
|
| 347 |
+
return self._manager.get_random_string_id(tensor_stride, "")
|
| 348 |
+
|
| 349 |
+
def get_kernel_map(
|
| 350 |
+
self,
|
| 351 |
+
in_key: CoordinateMapKey,
|
| 352 |
+
out_key: CoordinateMapKey,
|
| 353 |
+
stride=1,
|
| 354 |
+
kernel_size=3,
|
| 355 |
+
dilation=1,
|
| 356 |
+
region_type=RegionType.HYPER_CUBE,
|
| 357 |
+
region_offset=None,
|
| 358 |
+
is_transpose=False,
|
| 359 |
+
is_pool=False,
|
| 360 |
+
) -> dict:
|
| 361 |
+
r"""Alias of :attr:`CoordinateManager.kernel_map`. Will be deprecated in the next version."""
|
| 362 |
+
warnings.warn(
|
| 363 |
+
"`get_kernel_map` will be deprecated. Please use `kernel_map` instead."
|
| 364 |
+
)
|
| 365 |
+
return self.kernel_map(
|
| 366 |
+
in_key,
|
| 367 |
+
out_key,
|
| 368 |
+
stride,
|
| 369 |
+
kernel_size,
|
| 370 |
+
dilation,
|
| 371 |
+
region_type,
|
| 372 |
+
region_offset,
|
| 373 |
+
is_transpose,
|
| 374 |
+
is_pool,
|
| 375 |
+
)
|
| 376 |
+
|
| 377 |
+
def kernel_map(
|
| 378 |
+
self,
|
| 379 |
+
in_key: CoordinateMapKey,
|
| 380 |
+
out_key: CoordinateMapKey,
|
| 381 |
+
stride=1,
|
| 382 |
+
kernel_size=3,
|
| 383 |
+
dilation=1,
|
| 384 |
+
region_type=RegionType.HYPER_CUBE,
|
| 385 |
+
region_offset=None,
|
| 386 |
+
is_transpose=False,
|
| 387 |
+
is_pool=False,
|
| 388 |
+
) -> dict:
|
| 389 |
+
r"""Get kernel in-out maps for the specified coords keys or tensor strides.
|
| 390 |
+
|
| 391 |
+
returns dict{kernel_index: in_out_tensor} where in_out_tensor[0] is the input row indices that correspond to in_out_tensor[1], which is the row indices for output.
|
| 392 |
+
"""
|
| 393 |
+
# region type 1 iteration with kernel_size 1 is invalid
|
| 394 |
+
if isinstance(kernel_size, torch.Tensor):
|
| 395 |
+
assert (kernel_size > 0).all(), f"Invalid kernel size: {kernel_size}"
|
| 396 |
+
if (kernel_size == 1).all() == 1:
|
| 397 |
+
region_type = RegionType.HYPER_CUBE
|
| 398 |
+
elif isinstance(kernel_size, int):
|
| 399 |
+
assert kernel_size > 0, f"Invalid kernel size: {kernel_size}"
|
| 400 |
+
if kernel_size == 1:
|
| 401 |
+
region_type = RegionType.HYPER_CUBE
|
| 402 |
+
|
| 403 |
+
in_key = self._get_coordinate_map_key(in_key)
|
| 404 |
+
out_key = self._get_coordinate_map_key(out_key)
|
| 405 |
+
|
| 406 |
+
if region_offset is None:
|
| 407 |
+
region_offset = torch.IntTensor()
|
| 408 |
+
|
| 409 |
+
kernel_map = self._manager.kernel_map(
|
| 410 |
+
in_key,
|
| 411 |
+
out_key,
|
| 412 |
+
convert_to_int_list(kernel_size, self.D), #
|
| 413 |
+
convert_to_int_list(stride, self.D), #
|
| 414 |
+
convert_to_int_list(dilation, self.D), #
|
| 415 |
+
region_type,
|
| 416 |
+
region_offset,
|
| 417 |
+
is_transpose,
|
| 418 |
+
is_pool,
|
| 419 |
+
)
|
| 420 |
+
|
| 421 |
+
return kernel_map
|
| 422 |
+
|
| 423 |
+
def origin_map(self, key: CoordinateMapKey):
|
| 424 |
+
return self._manager.origin_map(key)
|
| 425 |
+
|
| 426 |
+
def origin_field_map(self, key: CoordinateMapKey):
|
| 427 |
+
return self._manager.origin_field_map(key)
|
| 428 |
+
|
| 429 |
+
def stride_map(self, in_key: CoordinateMapKey, stride_key: CoordinateMapKey):
|
| 430 |
+
return self._manager.stride_map(in_key, stride_key)
|
| 431 |
+
|
| 432 |
+
def union_map(self, in_keys: list, out_key):
|
| 433 |
+
return self._manager.union_map(in_keys, out_key)
|
| 434 |
+
|
| 435 |
+
def interpolation_map_weight(
|
| 436 |
+
self,
|
| 437 |
+
key: CoordinateMapKey,
|
| 438 |
+
samples: torch.Tensor,
|
| 439 |
+
):
|
| 440 |
+
return self._manager.interpolation_map_weight(samples, key)
|
| 441 |
+
|
| 442 |
+
# def get_union_map(self, in_keys: List[CoordsKey], out_key: CoordsKey):
|
| 443 |
+
# r"""Generates a union of coordinate sets and returns the mapping from input sets to the new output coordinates.
|
| 444 |
+
|
| 445 |
+
# Args:
|
| 446 |
+
# :attr:`in_keys` (List[CoordsKey]): A list of coordinate keys to
|
| 447 |
+
# create a union on.
|
| 448 |
+
|
| 449 |
+
# :attr:`out_key` (CoordsKey): the placeholder for the coords key of
|
| 450 |
+
# the generated union coords hash map.
|
| 451 |
+
|
| 452 |
+
# Returns:
|
| 453 |
+
# :attr:`in_maps` (List[Tensor[int]]): A list of long tensors that contain mapping from inputs to the union output. Please see the example for more details.
|
| 454 |
+
# :attr:`out_maps` (List[Tensor[int]]): A list of long tensors that contain a mapping from input to the union output. Please see the example for more details.
|
| 455 |
+
|
| 456 |
+
# Example::
|
| 457 |
+
|
| 458 |
+
# >>> # Adding two sparse tensors: A, B
|
| 459 |
+
# >>> out_key = CoordsKey(coords_man.D)
|
| 460 |
+
# >>> ins, outs = coords_man.get_union_map((A.coords_key, B.coords_key), out_key)
|
| 461 |
+
# >>> N = coords_man.get_coords_size_by_coords_key(out_key)
|
| 462 |
+
# >>> out_F = torch.zeros((N, A.F.size(1)), dtype=A.dtype)
|
| 463 |
+
# >>> out_F[outs[0]] = A.F[ins[0]]
|
| 464 |
+
# >>> out_F[outs[1]] += B.F[ins[1]]
|
| 465 |
+
|
| 466 |
+
# """
|
| 467 |
+
# return self.CPPCoordsManager.getUnionMap(
|
| 468 |
+
# [key.CPPCoordsKey for key in in_keys], out_key.CPPCoordsKey
|
| 469 |
+
# )
|
| 470 |
+
|
| 471 |
+
# def permute_label(
|
| 472 |
+
# self, label, max_label, target_tensor_stride, label_tensor_stride=1
|
| 473 |
+
# ):
|
| 474 |
+
# if target_tensor_stride == label_tensor_stride:
|
| 475 |
+
# return label
|
| 476 |
+
|
| 477 |
+
# label_coords_key = self._get_coordinate_map_key(label_tensor_stride)
|
| 478 |
+
# target_coords_key = self._get_coordinate_map_key(target_tensor_stride)
|
| 479 |
+
|
| 480 |
+
# permutation = self.get_mapping_by_coords_key(
|
| 481 |
+
# label_coords_key, target_coords_key
|
| 482 |
+
# )
|
| 483 |
+
# nrows = self.get_coords_size_by_coords_key(target_coords_key)
|
| 484 |
+
|
| 485 |
+
# label = label.contiguous().numpy()
|
| 486 |
+
# permutation = permutation.numpy()
|
| 487 |
+
|
| 488 |
+
# counter = np.zeros((nrows, max_label), dtype="int32")
|
| 489 |
+
# np.add.at(counter, (permutation, label), 1)
|
| 490 |
+
# return torch.from_numpy(np.argmax(counter, 1))
|
| 491 |
+
|
| 492 |
+
def __repr__(self):
|
| 493 |
+
return (
|
| 494 |
+
self._CoordinateManagerClass.__name__
|
| 495 |
+
+ "(\n"
|
| 496 |
+
+ str(self._manager)
|
| 497 |
+
+ f"\talgorithm={self.minkowski_algorithm}\n )\n"
|
| 498 |
+
)
|
MinkowskiEngine/MinkowskiEngine/MinkowskiFunctional.py
ADDED
|
@@ -0,0 +1,232 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Chris Choy (chrischoy@ai.stanford.edu).
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
import torch.nn.functional as F
|
| 25 |
+
|
| 26 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 27 |
+
from MinkowskiTensorField import TensorField
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def _wrap_tensor(input, F):
|
| 31 |
+
if isinstance(input, TensorField):
|
| 32 |
+
return TensorField(
|
| 33 |
+
F,
|
| 34 |
+
coordinate_field_map_key=input.coordinate_field_map_key,
|
| 35 |
+
coordinate_manager=input.coordinate_manager,
|
| 36 |
+
quantization_mode=input.quantization_mode,
|
| 37 |
+
)
|
| 38 |
+
else:
|
| 39 |
+
return SparseTensor(
|
| 40 |
+
F,
|
| 41 |
+
coordinate_map_key=input.coordinate_map_key,
|
| 42 |
+
coordinate_manager=input.coordinate_manager,
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
# Activations
|
| 47 |
+
def threshold(input, *args, **kwargs):
|
| 48 |
+
return _wrap_tensor(input, F.threshold(input.F, *args, **kwargs))
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def relu(input, *args, **kwargs):
|
| 52 |
+
return _wrap_tensor(input, F.relu(input.F, *args, **kwargs))
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def hardtanh(input, *args, **kwargs):
|
| 56 |
+
return _wrap_tensor(input, F.hardtanh(input.F, *args, **kwargs))
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def hardswish(input, *args, **kwargs):
|
| 60 |
+
return _wrap_tensor(input, F.hardswish(input.F, *args, **kwargs))
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def relu6(input, *args, **kwargs):
|
| 64 |
+
return _wrap_tensor(input, F.relu6(input.F, *args, **kwargs))
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def elu(input, *args, **kwargs):
|
| 68 |
+
return _wrap_tensor(input, F.elu(input.F, *args, **kwargs))
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def selu(input, *args, **kwargs):
|
| 72 |
+
return _wrap_tensor(input, F.selu(input.F, *args, **kwargs))
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def celu(input, *args, **kwargs):
|
| 76 |
+
return _wrap_tensor(input, F.celu(input.F, *args, **kwargs))
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def leaky_relu(input, *args, **kwargs):
|
| 80 |
+
return _wrap_tensor(input, F.leaky_relu(input.F, *args, **kwargs))
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def prelu(input, *args, **kwargs):
|
| 84 |
+
return _wrap_tensor(input, F.prelu(input.F, *args, **kwargs))
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def rrelu(input, *args, **kwargs):
|
| 88 |
+
return _wrap_tensor(input, F.rrelu(input.F, *args, **kwargs))
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def glu(input, *args, **kwargs):
|
| 92 |
+
return _wrap_tensor(input, F.glu(input.F, *args, **kwargs))
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def gelu(input, *args, **kwargs):
|
| 96 |
+
return _wrap_tensor(input, F.gelu(input.F, *args, **kwargs))
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def logsigmoid(input, *args, **kwargs):
|
| 100 |
+
return _wrap_tensor(input, F.logsigmoid(input.F, *args, **kwargs))
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def hardshrink(input, *args, **kwargs):
|
| 104 |
+
return _wrap_tensor(input, F.hardshrink(input.F, *args, **kwargs))
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def tanhshrink(input, *args, **kwargs):
|
| 108 |
+
return _wrap_tensor(input, F.tanhshrink(input.F, *args, **kwargs))
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def softsign(input, *args, **kwargs):
|
| 112 |
+
return _wrap_tensor(input, F.softsign(input.F, *args, **kwargs))
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def softplus(input, *args, **kwargs):
|
| 116 |
+
return _wrap_tensor(input, F.softplus(input.F, *args, **kwargs))
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def softmin(input, *args, **kwargs):
|
| 120 |
+
return _wrap_tensor(input, F.softmin(input.F, *args, **kwargs))
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def softmax(input, *args, **kwargs):
|
| 124 |
+
return _wrap_tensor(input, F.softmax(input.F, *args, **kwargs))
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def softshrink(input, *args, **kwargs):
|
| 128 |
+
return _wrap_tensor(input, F.softshrink(input.F, *args, **kwargs))
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def gumbel_softmax(input, *args, **kwargs):
|
| 132 |
+
return _wrap_tensor(input, F.gumbel_softmax(input.F, *args, **kwargs))
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def log_softmax(input, *args, **kwargs):
|
| 136 |
+
return _wrap_tensor(input, F.log_softmax(input.F, *args, **kwargs))
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def tanh(input, *args, **kwargs):
|
| 140 |
+
return _wrap_tensor(input, F.tanh(input.F, *args, **kwargs))
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
def sigmoid(input, *args, **kwargs):
|
| 144 |
+
return _wrap_tensor(input, F.sigmoid(input.F, *args, **kwargs))
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
def hardsigmoid(input, *args, **kwargs):
|
| 148 |
+
return _wrap_tensor(input, F.hardsigmoid(input.F, *args, **kwargs))
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def silu(input, *args, **kwargs):
|
| 152 |
+
return _wrap_tensor(input, F.silu(input.F, *args, **kwargs))
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
# Normalization
|
| 156 |
+
def batch_norm(input, *args, **kwargs):
|
| 157 |
+
return _wrap_tensor(input, F.batch_norm(input.F, *args, **kwargs))
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
def normalize(input, *args, **kwargs):
|
| 161 |
+
return _wrap_tensor(input, F.normalize(input.F, *args, **kwargs))
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
# Linear
|
| 165 |
+
def linear(input, *args, **kwargs):
|
| 166 |
+
return _wrap_tensor(input, F.linear(input.F, *args, **kwargs))
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
# Dropouts
|
| 170 |
+
def dropout(input, *args, **kwargs):
|
| 171 |
+
return _wrap_tensor(input, F.dropout(input.F, *args, **kwargs))
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def alpha_dropout(input, *args, **kwargs):
|
| 175 |
+
return _wrap_tensor(input, F.alpha_dropout(input.F, *args, **kwargs))
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
# Loss functions
|
| 179 |
+
def binary_cross_entropy(input, target, *args, **kwargs):
|
| 180 |
+
return F.binary_cross_entropy(input.F, target, *args, **kwargs)
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
def binary_cross_entropy_with_logits(input, target, *args, **kwargs):
|
| 184 |
+
return F.binary_cross_entropy_with_logits(input.F, target, *args, **kwargs)
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
def poisson_nll_loss(input, target, *args, **kwargs):
|
| 188 |
+
return F.poisson_nll_loss(input.F, target, *args, **kwargs)
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
def cross_entropy(input, target, *args, **kwargs):
|
| 192 |
+
return F.cross_entropy(input.F, target, *args, **kwargs)
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
def hinge_embedding_loss(input, target, *args, **kwargs):
|
| 196 |
+
return F.hinge_embedding_loss(input.F, target, *args, **kwargs)
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
def kl_div(input, target, *args, **kwargs):
|
| 200 |
+
return F.kl_div(input.F, target, *args, **kwargs)
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def l1_loss(input, target, *args, **kwargs):
|
| 204 |
+
return F.l1_loss(input.F, target, *args, **kwargs)
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def mse_loss(input, target, *args, **kwargs):
|
| 208 |
+
return F.mse_loss(input.F, target, *args, **kwargs)
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
def multilabel_margin_loss(input, target, *args, **kwargs):
|
| 212 |
+
return F.multilabel_margin_loss(input.F, target, *args, **kwargs)
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
def multilabel_soft_margin_loss(input, target, *args, **kwargs):
|
| 216 |
+
return F.multilabel_soft_margin_loss(input.F, target, *args, **kwargs)
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
def multi_margin_loss(input, target, *args, **kwargs):
|
| 220 |
+
return F.multi_margin_loss(input.F, target, *args, **kwargs)
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
def nll_loss(input, target, *args, **kwargs):
|
| 224 |
+
return F.nll_loss(input.F, target, *args, **kwargs)
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
def smooth_l1_loss(input, target, *args, **kwargs):
|
| 228 |
+
return F.smooth_l1_loss(input.F, target, *args, **kwargs)
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
def soft_margin_loss(input, target, *args, **kwargs):
|
| 232 |
+
return F.soft_margin_loss(input.F, target, *args, **kwargs)
|
MinkowskiEngine/MinkowskiEngine/MinkowskiInterpolation.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
from typing import Union
|
| 26 |
+
|
| 27 |
+
import torch
|
| 28 |
+
from torch.autograd import Function
|
| 29 |
+
|
| 30 |
+
from MinkowskiEngineBackend._C import CoordinateMapKey
|
| 31 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 32 |
+
from MinkowskiCoordinateManager import CoordinateManager
|
| 33 |
+
from MinkowskiCommon import (
|
| 34 |
+
MinkowskiModuleBase,
|
| 35 |
+
get_minkowski_function,
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class MinkowskiInterpolationFunction(Function):
|
| 40 |
+
@staticmethod
|
| 41 |
+
def forward(
|
| 42 |
+
ctx,
|
| 43 |
+
input_features: torch.Tensor,
|
| 44 |
+
tfield: torch.Tensor,
|
| 45 |
+
in_coordinate_map_key: CoordinateMapKey,
|
| 46 |
+
coordinate_manager: CoordinateManager = None,
|
| 47 |
+
):
|
| 48 |
+
input_features = input_features.contiguous()
|
| 49 |
+
# in_map, out_map, weights = coordinate_manager.interpolation_map_weight(
|
| 50 |
+
# in_coordinate_map_key, tfield)
|
| 51 |
+
fw_fn = get_minkowski_function("InterpolationForward", input_features)
|
| 52 |
+
out_feat, in_map, out_map, weights = fw_fn(
|
| 53 |
+
input_features,
|
| 54 |
+
tfield,
|
| 55 |
+
in_coordinate_map_key,
|
| 56 |
+
coordinate_manager._manager,
|
| 57 |
+
)
|
| 58 |
+
ctx.save_for_backward(in_map, out_map, weights)
|
| 59 |
+
ctx.inputs = (
|
| 60 |
+
in_coordinate_map_key,
|
| 61 |
+
coordinate_manager,
|
| 62 |
+
)
|
| 63 |
+
return out_feat, in_map, out_map, weights
|
| 64 |
+
|
| 65 |
+
@staticmethod
|
| 66 |
+
def backward(
|
| 67 |
+
ctx, grad_out_feat=None, grad_in_map=None, grad_out_map=None, grad_weights=None
|
| 68 |
+
):
|
| 69 |
+
grad_out_feat = grad_out_feat.contiguous()
|
| 70 |
+
bw_fn = get_minkowski_function("InterpolationBackward", grad_out_feat)
|
| 71 |
+
(
|
| 72 |
+
in_coordinate_map_key,
|
| 73 |
+
coordinate_manager,
|
| 74 |
+
) = ctx.inputs
|
| 75 |
+
in_map, out_map, weights = ctx.saved_tensors
|
| 76 |
+
|
| 77 |
+
grad_in_feat = bw_fn(
|
| 78 |
+
grad_out_feat,
|
| 79 |
+
in_map,
|
| 80 |
+
out_map,
|
| 81 |
+
weights,
|
| 82 |
+
in_coordinate_map_key,
|
| 83 |
+
coordinate_manager._manager,
|
| 84 |
+
)
|
| 85 |
+
return grad_in_feat, None, None, None
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
class MinkowskiInterpolation(MinkowskiModuleBase):
|
| 89 |
+
r"""Sample linearly interpolated features at the provided points."""
|
| 90 |
+
|
| 91 |
+
def __init__(self, return_kernel_map=False, return_weights=False):
|
| 92 |
+
r"""Sample linearly interpolated features at the specified coordinates.
|
| 93 |
+
|
| 94 |
+
Args:
|
| 95 |
+
:attr:`return_kernel_map` (bool): In addition to the sampled
|
| 96 |
+
features, the layer returns the kernel map as a pair of input row
|
| 97 |
+
indices and output row indices. False by default.
|
| 98 |
+
|
| 99 |
+
:attr:`return_weights` (bool): When True, return the linear
|
| 100 |
+
interpolation weights. False by default.
|
| 101 |
+
"""
|
| 102 |
+
MinkowskiModuleBase.__init__(self)
|
| 103 |
+
self.return_kernel_map = return_kernel_map
|
| 104 |
+
self.return_weights = return_weights
|
| 105 |
+
self.interp = MinkowskiInterpolationFunction()
|
| 106 |
+
|
| 107 |
+
def forward(
|
| 108 |
+
self,
|
| 109 |
+
input: SparseTensor,
|
| 110 |
+
tfield: torch.Tensor,
|
| 111 |
+
):
|
| 112 |
+
# Get a new coordinate map key or extract one from the coordinates
|
| 113 |
+
out_feat, in_map, out_map, weights = self.interp.apply(
|
| 114 |
+
input.F,
|
| 115 |
+
tfield,
|
| 116 |
+
input.coordinate_map_key,
|
| 117 |
+
input._manager,
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
return_args = [out_feat]
|
| 121 |
+
if self.return_kernel_map:
|
| 122 |
+
return_args.append((in_map, out_map))
|
| 123 |
+
if self.return_weights:
|
| 124 |
+
return_args.append(weights)
|
| 125 |
+
if len(return_args) > 1:
|
| 126 |
+
return tuple(return_args)
|
| 127 |
+
else:
|
| 128 |
+
return out_feat
|
| 129 |
+
|
| 130 |
+
def __repr__(self):
|
| 131 |
+
return self.__class__.__name__ + "()"
|
MinkowskiEngine/MinkowskiEngine/MinkowskiKernelGenerator.py
ADDED
|
@@ -0,0 +1,395 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
import math
|
| 26 |
+
from collections import namedtuple
|
| 27 |
+
from collections.abc import Sequence
|
| 28 |
+
from functools import reduce
|
| 29 |
+
import numpy as np
|
| 30 |
+
from typing import Union
|
| 31 |
+
|
| 32 |
+
import torch
|
| 33 |
+
from MinkowskiCommon import convert_to_int_list
|
| 34 |
+
from MinkowskiEngineBackend._C import CoordinateMapKey, RegionType
|
| 35 |
+
from MinkowskiCoordinateManager import CoordinateManager
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def get_kernel_volume(region_type, kernel_size, region_offset, axis_types, dimension):
|
| 39 |
+
"""
|
| 40 |
+
when center is True, the custom region_offset will be centered at the
|
| 41 |
+
origin. Currently, for HYPER_CUBE, HYPER_CROSS with odd kernel sizes cannot
|
| 42 |
+
use center=False.
|
| 43 |
+
"""
|
| 44 |
+
if region_type == RegionType.HYPER_CUBE:
|
| 45 |
+
assert reduce(
|
| 46 |
+
lambda k1, k2: k1 > 0 and k2 > 0, kernel_size
|
| 47 |
+
), "kernel_size must be positive"
|
| 48 |
+
assert (
|
| 49 |
+
region_offset is None
|
| 50 |
+
), "Region offset must be None when region_type is given"
|
| 51 |
+
assert axis_types is None, "Axis types must be None when region_type is given"
|
| 52 |
+
# Typical convolution kernel
|
| 53 |
+
|
| 54 |
+
# Convolution kernel with even numbered kernel size not defined.
|
| 55 |
+
kernel_volume = torch.prod(torch.IntTensor(kernel_size)).item()
|
| 56 |
+
|
| 57 |
+
elif region_type == RegionType.HYPER_CROSS:
|
| 58 |
+
assert reduce(
|
| 59 |
+
lambda k1, k2: k1 > 0 and k2 > 0, kernel_size
|
| 60 |
+
), "kernel_size must be positive"
|
| 61 |
+
assert (
|
| 62 |
+
torch.IntTensor(kernel_size) % 2
|
| 63 |
+
).prod().item() == 1, "kernel_size must be odd for region_type HYPER_CROSS"
|
| 64 |
+
# 0th: itself, (1, 2) for 0th dim neighbors, (3, 4) for 1th dim ...
|
| 65 |
+
kernel_volume = (torch.sum(torch.IntTensor(kernel_size) - 1) + 1).item()
|
| 66 |
+
|
| 67 |
+
# elif region_type == RegionType.HYBRID:
|
| 68 |
+
# assert reduce(
|
| 69 |
+
# lambda k1, k2: k1 > 0 and k2 > 0, kernel_size
|
| 70 |
+
# ), "kernel_size must be positive"
|
| 71 |
+
# assert (
|
| 72 |
+
# region_offset is None
|
| 73 |
+
# ), "region_offset must be None when region_type is HYBRID"
|
| 74 |
+
# kernel_size_list = kernel_size.tolist()
|
| 75 |
+
# kernel_volume = 1
|
| 76 |
+
# # First HYPER_CUBE
|
| 77 |
+
# for axis_type, curr_kernel_size, d in zip(
|
| 78 |
+
# axis_types, kernel_size_list, range(dimension)
|
| 79 |
+
# ):
|
| 80 |
+
# if axis_type == RegionType.HYPER_CUBE:
|
| 81 |
+
# kernel_volume *= curr_kernel_size
|
| 82 |
+
|
| 83 |
+
# # Second, HYPER_CROSS
|
| 84 |
+
# for axis_type, curr_kernel_size, d in zip(
|
| 85 |
+
# axis_types, kernel_size_list, range(dimension)
|
| 86 |
+
# ):
|
| 87 |
+
# if axis_type == RegionType.HYPER_CROSS:
|
| 88 |
+
# kernel_volume += curr_kernel_size - 1
|
| 89 |
+
|
| 90 |
+
elif region_type == RegionType.CUSTOM:
|
| 91 |
+
assert (
|
| 92 |
+
region_offset.numel() > 0
|
| 93 |
+
), "region_offset must be non empty when region_type is CUSTOM"
|
| 94 |
+
assert (
|
| 95 |
+
region_offset.size(1) == dimension
|
| 96 |
+
), "region_offset must have the same dimension as the network"
|
| 97 |
+
kernel_volume = int(region_offset.size(0))
|
| 98 |
+
|
| 99 |
+
else:
|
| 100 |
+
raise NotImplementedError()
|
| 101 |
+
|
| 102 |
+
return kernel_volume
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def convert_region_type(
|
| 106 |
+
region_type: RegionType,
|
| 107 |
+
tensor_stride: Union[Sequence, np.ndarray, torch.IntTensor],
|
| 108 |
+
kernel_size: Union[Sequence, np.ndarray, torch.IntTensor],
|
| 109 |
+
up_stride: Union[Sequence, np.ndarray, torch.IntTensor],
|
| 110 |
+
dilation: Union[Sequence, np.ndarray, torch.IntTensor],
|
| 111 |
+
region_offset: Union[Sequence, np.ndarray, torch.IntTensor],
|
| 112 |
+
axis_types: Union[Sequence, np.ndarray, torch.IntTensor],
|
| 113 |
+
dimension: int,
|
| 114 |
+
center: bool = True,
|
| 115 |
+
):
|
| 116 |
+
"""
|
| 117 |
+
when center is True, the custom region_offset will be centered at the
|
| 118 |
+
origin. Currently, for HYPER_CUBE, HYPER_CROSS with odd kernel sizes cannot
|
| 119 |
+
use center=False.
|
| 120 |
+
|
| 121 |
+
up_stride: stride for conv_transpose, otherwise set it as 1
|
| 122 |
+
"""
|
| 123 |
+
if region_type == RegionType.HYPER_CUBE:
|
| 124 |
+
if isinstance(region_offset, torch.Tensor):
|
| 125 |
+
assert (
|
| 126 |
+
region_offset.numel() == 0
|
| 127 |
+
), "Region offset must be empty when region_type is given"
|
| 128 |
+
else:
|
| 129 |
+
assert (
|
| 130 |
+
region_offset is None
|
| 131 |
+
), "Region offset must be None when region_type is given"
|
| 132 |
+
|
| 133 |
+
assert axis_types is None, "Axis types must be None when region_type is given"
|
| 134 |
+
# Typical convolution kernel
|
| 135 |
+
assert reduce(
|
| 136 |
+
lambda k1, k2: k1 > 0 and k2 > 0, kernel_size
|
| 137 |
+
), "kernel_size must be positive"
|
| 138 |
+
# assert torch.unique(dilation).numel() == 1
|
| 139 |
+
kernel_volume = reduce(lambda k1, k2: k1 * k2, kernel_size)
|
| 140 |
+
|
| 141 |
+
elif region_type == RegionType.HYPER_CROSS:
|
| 142 |
+
assert reduce(
|
| 143 |
+
lambda k1, k2: k1 > 0 and k2 > 0, kernel_size
|
| 144 |
+
), "kernel_size must be positive"
|
| 145 |
+
assert (
|
| 146 |
+
kernel_size % 2
|
| 147 |
+
).prod() == 1, "kernel_size must be odd for region_type HYPER_CROSS"
|
| 148 |
+
# 0th: itself, (1, 2) for 0th dim neighbors, (3, 4) for 1th dim ...
|
| 149 |
+
kernel_volume = (
|
| 150 |
+
reduce(lambda k1, k2: k1 + k2, map(lambda k: k - 1, kernel_size)) + 1
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
elif region_type == RegionType.HYBRID:
|
| 154 |
+
assert reduce(
|
| 155 |
+
lambda k1, k2: k1 > 0 and k2 > 0, kernel_size
|
| 156 |
+
), "kernel_size must be positive"
|
| 157 |
+
if isinstance(region_offset, torch.Tensor):
|
| 158 |
+
assert (
|
| 159 |
+
region_offset.numel() == 0
|
| 160 |
+
), "Region offset must be empty when region_type is given"
|
| 161 |
+
else:
|
| 162 |
+
assert (
|
| 163 |
+
region_offset is None
|
| 164 |
+
), "Region offset must be None when region_type is given"
|
| 165 |
+
|
| 166 |
+
region_offset = [
|
| 167 |
+
[
|
| 168 |
+
0,
|
| 169 |
+
]
|
| 170 |
+
* dimension
|
| 171 |
+
]
|
| 172 |
+
kernel_size_list = kernel_size.tolist()
|
| 173 |
+
# First HYPER_CUBE
|
| 174 |
+
for axis_type, curr_kernel_size, d in zip(
|
| 175 |
+
axis_types, kernel_size_list, range(dimension)
|
| 176 |
+
):
|
| 177 |
+
new_offset = []
|
| 178 |
+
if axis_type == RegionType.HYPER_CUBE:
|
| 179 |
+
for offset in region_offset:
|
| 180 |
+
for curr_offset in range(curr_kernel_size):
|
| 181 |
+
off_center = (
|
| 182 |
+
int(math.floor((curr_kernel_size - 1) / 2)) if center else 0
|
| 183 |
+
)
|
| 184 |
+
offset = offset.copy() # Do not modify the original
|
| 185 |
+
# Exclude the coord (0, 0, ..., 0)
|
| 186 |
+
if curr_offset == off_center:
|
| 187 |
+
continue
|
| 188 |
+
offset[d] = (
|
| 189 |
+
(curr_offset - off_center)
|
| 190 |
+
* dilation[d]
|
| 191 |
+
* (tensor_stride[d] / up_stride[d])
|
| 192 |
+
)
|
| 193 |
+
new_offset.append(offset)
|
| 194 |
+
region_offset.extend(new_offset)
|
| 195 |
+
|
| 196 |
+
# Second, HYPER_CROSS
|
| 197 |
+
for axis_type, curr_kernel_size, d in zip(
|
| 198 |
+
axis_types, kernel_size_list, range(dimension)
|
| 199 |
+
):
|
| 200 |
+
new_offset = []
|
| 201 |
+
if axis_type == RegionType.HYPER_CROSS:
|
| 202 |
+
for curr_offset in range(curr_kernel_size):
|
| 203 |
+
off_center = (
|
| 204 |
+
int(math.floor((curr_kernel_size - 1) / 2)) if center else 0
|
| 205 |
+
)
|
| 206 |
+
offset = [
|
| 207 |
+
0,
|
| 208 |
+
] * dimension
|
| 209 |
+
# Exclude the coord (0, 0, ..., 0)
|
| 210 |
+
if curr_offset == off_center:
|
| 211 |
+
continue
|
| 212 |
+
offset[d] = (
|
| 213 |
+
(curr_offset - off_center)
|
| 214 |
+
* dilation[d]
|
| 215 |
+
* (tensor_stride[d] / up_stride[d])
|
| 216 |
+
)
|
| 217 |
+
new_offset.append(offset)
|
| 218 |
+
region_offset.extend(new_offset)
|
| 219 |
+
|
| 220 |
+
# Convert to CUSTOM type
|
| 221 |
+
region_type = RegionType.CUSTOM
|
| 222 |
+
region_offset = torch.IntTensor(region_offset)
|
| 223 |
+
kernel_volume = int(region_offset.size(0))
|
| 224 |
+
|
| 225 |
+
elif region_type == RegionType.CUSTOM:
|
| 226 |
+
assert (
|
| 227 |
+
region_offset.numel() > 0
|
| 228 |
+
), "region_offset must be non empty when region_type is CUSTOM"
|
| 229 |
+
assert (
|
| 230 |
+
region_offset.size(1) == dimension
|
| 231 |
+
), "region_offset must have the same dimension as the network"
|
| 232 |
+
kernel_volume = int(region_offset.size(0))
|
| 233 |
+
assert isinstance(
|
| 234 |
+
region_offset.dtype, torch.IntTensor
|
| 235 |
+
), "region_offset must be a torch.IntTensor."
|
| 236 |
+
else:
|
| 237 |
+
raise NotImplementedError()
|
| 238 |
+
|
| 239 |
+
if region_offset is None:
|
| 240 |
+
region_offset = torch.IntTensor()
|
| 241 |
+
|
| 242 |
+
return region_type, region_offset, kernel_volume
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
class KernelGenerator:
|
| 246 |
+
__slots__ = (
|
| 247 |
+
"cache",
|
| 248 |
+
"kernel_size",
|
| 249 |
+
"kernel_stride",
|
| 250 |
+
"kernel_dilation",
|
| 251 |
+
"region_type",
|
| 252 |
+
"region_offsets",
|
| 253 |
+
"axis_types",
|
| 254 |
+
"dimension",
|
| 255 |
+
"kernel_volume",
|
| 256 |
+
"requires_strided_coordinates",
|
| 257 |
+
"expand_coordinates",
|
| 258 |
+
)
|
| 259 |
+
|
| 260 |
+
def __init__(
|
| 261 |
+
self,
|
| 262 |
+
kernel_size=-1,
|
| 263 |
+
stride=1,
|
| 264 |
+
dilation=1,
|
| 265 |
+
is_transpose: bool = False,
|
| 266 |
+
region_type: RegionType = RegionType.HYPER_CUBE,
|
| 267 |
+
region_offsets: torch.Tensor = None,
|
| 268 |
+
expand_coordinates: bool = False,
|
| 269 |
+
axis_types=None,
|
| 270 |
+
dimension=-1,
|
| 271 |
+
):
|
| 272 |
+
r"""
|
| 273 |
+
:attr:`region_type` (RegionType, optional): defines the kernel
|
| 274 |
+
shape. Please refer to MinkowskiEngine.Comon for details.
|
| 275 |
+
|
| 276 |
+
:attr:`region_offset` (torch.IntTensor, optional): when the
|
| 277 |
+
:attr:`region_type` is :attr:`RegionType.CUSTOM`, the convolution
|
| 278 |
+
kernel uses the provided `region_offset` to define offsets. It
|
| 279 |
+
should be a matrix of size :math:`N \times D` where :math:`N` is
|
| 280 |
+
the number of offsets and :math:`D` is the dimension of the
|
| 281 |
+
space.
|
| 282 |
+
|
| 283 |
+
:attr:`axis_types` (list of RegionType, optional): If given, it
|
| 284 |
+
uses different methods to create a kernel for each axis. e.g., when
|
| 285 |
+
it is `[RegionType.HYPER_CUBE, RegionType.HYPER_CUBE,
|
| 286 |
+
RegionType.HYPER_CROSS]`, the kernel would be rectangular for the
|
| 287 |
+
first two dimensions and cross shaped for the thrid dimension.
|
| 288 |
+
"""
|
| 289 |
+
assert dimension > 0
|
| 290 |
+
assert isinstance(region_type, RegionType)
|
| 291 |
+
|
| 292 |
+
kernel_size = convert_to_int_list(kernel_size, dimension)
|
| 293 |
+
kernel_stride = convert_to_int_list(stride, dimension)
|
| 294 |
+
kernel_dilation = convert_to_int_list(dilation, dimension)
|
| 295 |
+
|
| 296 |
+
self.cache = {}
|
| 297 |
+
self.kernel_size = kernel_size
|
| 298 |
+
self.kernel_stride = kernel_stride
|
| 299 |
+
self.kernel_dilation = kernel_dilation
|
| 300 |
+
self.region_type = region_type
|
| 301 |
+
self.region_offsets = region_offsets if region_offsets else torch.IntTensor()
|
| 302 |
+
self.axis_types = axis_types
|
| 303 |
+
self.dimension = dimension
|
| 304 |
+
self.kernel_volume = get_kernel_volume(
|
| 305 |
+
region_type, kernel_size, region_offsets, axis_types, dimension
|
| 306 |
+
)
|
| 307 |
+
self.requires_strided_coordinates = reduce(
|
| 308 |
+
lambda s1, s2: s1 == 1 and s2 == 1, kernel_stride
|
| 309 |
+
)
|
| 310 |
+
self.expand_coordinates = expand_coordinates
|
| 311 |
+
|
| 312 |
+
def get_kernel(self, tensor_stride, is_transpose):
|
| 313 |
+
assert len(tensor_stride) == self.dimension
|
| 314 |
+
if tuple(tensor_stride) not in self.cache:
|
| 315 |
+
up_stride = (
|
| 316 |
+
self.stride
|
| 317 |
+
if is_transpose
|
| 318 |
+
else torch.Tensor(
|
| 319 |
+
[
|
| 320 |
+
1,
|
| 321 |
+
]
|
| 322 |
+
* self.dimension
|
| 323 |
+
)
|
| 324 |
+
)
|
| 325 |
+
|
| 326 |
+
self.cache[tuple(tensor_stride)] = convert_region_type(
|
| 327 |
+
self.region_type,
|
| 328 |
+
tensor_stride,
|
| 329 |
+
self.kernel_size,
|
| 330 |
+
up_stride,
|
| 331 |
+
self.kernel_dilation,
|
| 332 |
+
self.region_offsets,
|
| 333 |
+
self.axis_types,
|
| 334 |
+
self.dimension,
|
| 335 |
+
)
|
| 336 |
+
|
| 337 |
+
return self.cache[tuple(tensor_stride)]
|
| 338 |
+
|
| 339 |
+
def __repr__(self):
|
| 340 |
+
return (
|
| 341 |
+
self.__class__.__name__
|
| 342 |
+
+ f"(kernel_size={self.kernel_size}, kernel_stride={self.kernel_stride}, kernel_dilation={self.kernel_dilation}, "
|
| 343 |
+
+ f"region_type={self.region_type}, expand_coordinates={self.expand_coordinates}, dimension={self.dimension})"
|
| 344 |
+
)
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
class KernelRegion(
|
| 348 |
+
namedtuple(
|
| 349 |
+
"KernelRegion",
|
| 350 |
+
(
|
| 351 |
+
"kernel_size",
|
| 352 |
+
"kernel_stride",
|
| 353 |
+
"kernel_dilation",
|
| 354 |
+
"region_type",
|
| 355 |
+
"offset",
|
| 356 |
+
"D",
|
| 357 |
+
),
|
| 358 |
+
)
|
| 359 |
+
):
|
| 360 |
+
"""adding functionality to a named tuple"""
|
| 361 |
+
|
| 362 |
+
__slots__ = ()
|
| 363 |
+
|
| 364 |
+
def __init__(
|
| 365 |
+
self,
|
| 366 |
+
kernel_size,
|
| 367 |
+
kernel_stride,
|
| 368 |
+
kernel_dilation,
|
| 369 |
+
region_type,
|
| 370 |
+
offset,
|
| 371 |
+
dimension,
|
| 372 |
+
):
|
| 373 |
+
kernel_size = convert_to_int_list(kernel_size, dimension)
|
| 374 |
+
kernel_stride = convert_to_int_list(kernel_stride, dimension)
|
| 375 |
+
kernel_dilation = convert_to_int_list(kernel_dilation, dimension)
|
| 376 |
+
super(KernelRegion, self).__init__(
|
| 377 |
+
kernel_size, kernel_stride, kernel_dilation, region_type, offset, dimension
|
| 378 |
+
)
|
| 379 |
+
|
| 380 |
+
def __str__(self):
|
| 381 |
+
return "kernel_size:{self.kernel_size}, kernel_stride:{self.kernel_stride}, region_type:{self.region_type}"
|
| 382 |
+
|
| 383 |
+
|
| 384 |
+
def save_ctx(
|
| 385 |
+
ctx, # function object context
|
| 386 |
+
kernel_generator: KernelGenerator,
|
| 387 |
+
in_coords_key: CoordinateMapKey,
|
| 388 |
+
out_coords_key: CoordinateMapKey,
|
| 389 |
+
coordinate_manager: CoordinateManager,
|
| 390 |
+
):
|
| 391 |
+
ctx.kernel_generator = kernel_generator
|
| 392 |
+
ctx.in_coordinate_map_key = in_coords_key
|
| 393 |
+
ctx.out_coordinate_map_key = out_coords_key
|
| 394 |
+
ctx.coordinate_manager = coordinate_manager
|
| 395 |
+
return ctx
|
MinkowskiEngine/MinkowskiEngine/MinkowskiNetwork.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Chris Choy (chrischoy@ai.stanford.edu).
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
from abc import ABC, abstractmethod
|
| 25 |
+
|
| 26 |
+
import torch.nn as nn
|
| 27 |
+
|
| 28 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class MinkowskiNetwork(nn.Module, ABC):
|
| 32 |
+
"""
|
| 33 |
+
MinkowskiNetwork: an abstract class for sparse convnets.
|
| 34 |
+
|
| 35 |
+
Note: All modules that use the same coordinates must use the same net_metadata
|
| 36 |
+
"""
|
| 37 |
+
|
| 38 |
+
def __init__(self, D):
|
| 39 |
+
super(MinkowskiNetwork, self).__init__()
|
| 40 |
+
self.D = D
|
| 41 |
+
|
| 42 |
+
@abstractmethod
|
| 43 |
+
def forward(self, x):
|
| 44 |
+
pass
|
| 45 |
+
|
| 46 |
+
def init(self, x):
|
| 47 |
+
"""
|
| 48 |
+
Initialize coordinates if it does not exist
|
| 49 |
+
"""
|
| 50 |
+
nrows = self.get_nrows(1)
|
| 51 |
+
if nrows < 0:
|
| 52 |
+
if isinstance(x, SparseTensor):
|
| 53 |
+
self.initialize_coords(x.coords_man)
|
| 54 |
+
else:
|
| 55 |
+
raise ValueError('Initialize input coordinates')
|
| 56 |
+
elif nrows != x.F.size(0):
|
| 57 |
+
raise ValueError('Input size does not match the coordinate size')
|
MinkowskiEngine/MinkowskiEngine/MinkowskiNonlinearity.py
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Chris Choy (chrischoy@ai.stanford.edu).
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
from typing import Union
|
| 25 |
+
|
| 26 |
+
import torch
|
| 27 |
+
import torch.nn as nn
|
| 28 |
+
|
| 29 |
+
from MinkowskiCommon import MinkowskiModuleBase
|
| 30 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 31 |
+
from MinkowskiTensorField import TensorField
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class MinkowskiNonlinearityBase(MinkowskiModuleBase):
|
| 35 |
+
MODULE = None
|
| 36 |
+
|
| 37 |
+
def __init__(self, *args, **kwargs):
|
| 38 |
+
super(MinkowskiNonlinearityBase, self).__init__()
|
| 39 |
+
self.module = self.MODULE(*args, **kwargs)
|
| 40 |
+
|
| 41 |
+
def forward(self, input):
|
| 42 |
+
output = self.module(input.F)
|
| 43 |
+
if isinstance(input, TensorField):
|
| 44 |
+
return TensorField(
|
| 45 |
+
output,
|
| 46 |
+
coordinate_field_map_key=input.coordinate_field_map_key,
|
| 47 |
+
coordinate_manager=input.coordinate_manager,
|
| 48 |
+
quantization_mode=input.quantization_mode,
|
| 49 |
+
)
|
| 50 |
+
else:
|
| 51 |
+
return SparseTensor(
|
| 52 |
+
output,
|
| 53 |
+
coordinate_map_key=input.coordinate_map_key,
|
| 54 |
+
coordinate_manager=input.coordinate_manager,
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
def __repr__(self):
|
| 58 |
+
return self.__class__.__name__ + "()"
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class MinkowskiELU(MinkowskiNonlinearityBase):
|
| 62 |
+
MODULE = torch.nn.ELU
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class MinkowskiHardshrink(MinkowskiNonlinearityBase):
|
| 66 |
+
MODULE = torch.nn.Hardshrink
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class MinkowskiHardsigmoid(MinkowskiNonlinearityBase):
|
| 70 |
+
MODULE = torch.nn.Hardsigmoid
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
class MinkowskiHardtanh(MinkowskiNonlinearityBase):
|
| 74 |
+
MODULE = torch.nn.Hardtanh
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
class MinkowskiHardswish(MinkowskiNonlinearityBase):
|
| 78 |
+
MODULE = torch.nn.Hardswish
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class MinkowskiLeakyReLU(MinkowskiNonlinearityBase):
|
| 82 |
+
MODULE = torch.nn.LeakyReLU
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class MinkowskiLogSigmoid(MinkowskiNonlinearityBase):
|
| 86 |
+
MODULE = torch.nn.LogSigmoid
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
class MinkowskiPReLU(MinkowskiNonlinearityBase):
|
| 90 |
+
MODULE = torch.nn.PReLU
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
class MinkowskiReLU(MinkowskiNonlinearityBase):
|
| 94 |
+
MODULE = torch.nn.ReLU
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class MinkowskiReLU6(MinkowskiNonlinearityBase):
|
| 98 |
+
MODULE = torch.nn.ReLU6
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class MinkowskiRReLU(MinkowskiNonlinearityBase):
|
| 102 |
+
MODULE = torch.nn.RReLU
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
class MinkowskiSELU(MinkowskiNonlinearityBase):
|
| 106 |
+
MODULE = torch.nn.SELU
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class MinkowskiCELU(MinkowskiNonlinearityBase):
|
| 110 |
+
MODULE = torch.nn.CELU
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
class MinkowskiGELU(MinkowskiNonlinearityBase):
|
| 114 |
+
MODULE = torch.nn.GELU
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
class MinkowskiSigmoid(MinkowskiNonlinearityBase):
|
| 118 |
+
MODULE = torch.nn.Sigmoid
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
class MinkowskiSiLU(MinkowskiNonlinearityBase):
|
| 122 |
+
MODULE = torch.nn.SiLU
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
class MinkowskiSoftplus(MinkowskiNonlinearityBase):
|
| 126 |
+
MODULE = torch.nn.Softplus
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
class MinkowskiSoftshrink(MinkowskiNonlinearityBase):
|
| 130 |
+
MODULE = torch.nn.Softshrink
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class MinkowskiSoftsign(MinkowskiNonlinearityBase):
|
| 134 |
+
MODULE = torch.nn.Softsign
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
class MinkowskiTanh(MinkowskiNonlinearityBase):
|
| 138 |
+
MODULE = torch.nn.Tanh
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
class MinkowskiTanhshrink(MinkowskiNonlinearityBase):
|
| 142 |
+
MODULE = torch.nn.Tanhshrink
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
class MinkowskiThreshold(MinkowskiNonlinearityBase):
|
| 146 |
+
MODULE = torch.nn.Threshold
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
# Non-linear Activations (other)
|
| 150 |
+
class MinkowskiSoftmin(MinkowskiNonlinearityBase):
|
| 151 |
+
MODULE = torch.nn.Softmin
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
class MinkowskiSoftmax(MinkowskiNonlinearityBase):
|
| 155 |
+
MODULE = torch.nn.Softmax
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
class MinkowskiLogSoftmax(MinkowskiNonlinearityBase):
|
| 159 |
+
MODULE = torch.nn.LogSoftmax
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class MinkowskiAdaptiveLogSoftmaxWithLoss(MinkowskiNonlinearityBase):
|
| 163 |
+
MODULE = torch.nn.AdaptiveLogSoftmaxWithLoss
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
# Dropouts
|
| 167 |
+
class MinkowskiDropout(MinkowskiNonlinearityBase):
|
| 168 |
+
MODULE = torch.nn.Dropout
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
class MinkowskiAlphaDropout(MinkowskiNonlinearityBase):
|
| 172 |
+
MODULE = torch.nn.AlphaDropout
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
class MinkowskiSinusoidal(MinkowskiModuleBase):
|
| 176 |
+
def __init__(self, in_channel, out_channel):
|
| 177 |
+
MinkowskiModuleBase.__init__(self)
|
| 178 |
+
self.in_channel = in_channel
|
| 179 |
+
self.out_channel = out_channel
|
| 180 |
+
self.kernel = nn.Parameter(torch.rand(in_channel, out_channel))
|
| 181 |
+
self.bias = nn.Parameter(torch.rand(1, out_channel))
|
| 182 |
+
self.coef = nn.Parameter(torch.rand(1, out_channel))
|
| 183 |
+
|
| 184 |
+
def forward(self, input: Union[SparseTensor, TensorField]):
|
| 185 |
+
|
| 186 |
+
out_F = torch.sin(input.F.mm(self.kernel) + self.bias) * self.coef
|
| 187 |
+
|
| 188 |
+
if isinstance(input, TensorField):
|
| 189 |
+
return TensorField(
|
| 190 |
+
out_F,
|
| 191 |
+
coordinate_field_map_key=input.coordinate_field_map_key,
|
| 192 |
+
coordinate_manager=input.coordinate_manager,
|
| 193 |
+
quantization_mode=input.quantization_mode,
|
| 194 |
+
)
|
| 195 |
+
else:
|
| 196 |
+
return SparseTensor(
|
| 197 |
+
out_F,
|
| 198 |
+
coordinate_map_key=input.coordinate_map_key,
|
| 199 |
+
coordinate_manager=input.coordinate_manager,
|
| 200 |
+
)
|
MinkowskiEngine/MinkowskiEngine/MinkowskiNormalization.py
ADDED
|
@@ -0,0 +1,399 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
import torch
|
| 26 |
+
import torch.nn as nn
|
| 27 |
+
from torch.nn import Module
|
| 28 |
+
from torch.autograd import Function
|
| 29 |
+
|
| 30 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 31 |
+
from MinkowskiTensorField import TensorField
|
| 32 |
+
|
| 33 |
+
from MinkowskiPooling import MinkowskiGlobalAvgPooling
|
| 34 |
+
from MinkowskiBroadcast import (
|
| 35 |
+
MinkowskiBroadcastAddition,
|
| 36 |
+
MinkowskiBroadcastMultiplication,
|
| 37 |
+
)
|
| 38 |
+
from MinkowskiEngineBackend._C import (
|
| 39 |
+
CoordinateMapKey,
|
| 40 |
+
BroadcastMode,
|
| 41 |
+
PoolingMode,
|
| 42 |
+
)
|
| 43 |
+
from MinkowskiCoordinateManager import CoordinateManager
|
| 44 |
+
|
| 45 |
+
from MinkowskiCommon import (
|
| 46 |
+
MinkowskiModuleBase,
|
| 47 |
+
get_minkowski_function,
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class MinkowskiBatchNorm(Module):
|
| 52 |
+
r"""A batch normalization layer for a sparse tensor.
|
| 53 |
+
|
| 54 |
+
See the pytorch :attr:`torch.nn.BatchNorm1d` for more details.
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
def __init__(
|
| 58 |
+
self,
|
| 59 |
+
num_features,
|
| 60 |
+
eps=1e-5,
|
| 61 |
+
momentum=0.1,
|
| 62 |
+
affine=True,
|
| 63 |
+
track_running_stats=True,
|
| 64 |
+
):
|
| 65 |
+
super(MinkowskiBatchNorm, self).__init__()
|
| 66 |
+
self.bn = torch.nn.BatchNorm1d(
|
| 67 |
+
num_features,
|
| 68 |
+
eps=eps,
|
| 69 |
+
momentum=momentum,
|
| 70 |
+
affine=affine,
|
| 71 |
+
track_running_stats=track_running_stats,
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
def forward(self, input):
|
| 75 |
+
output = self.bn(input.F)
|
| 76 |
+
if isinstance(input, TensorField):
|
| 77 |
+
return TensorField(
|
| 78 |
+
output,
|
| 79 |
+
coordinate_field_map_key=input.coordinate_field_map_key,
|
| 80 |
+
coordinate_manager=input.coordinate_manager,
|
| 81 |
+
quantization_mode=input.quantization_mode,
|
| 82 |
+
)
|
| 83 |
+
else:
|
| 84 |
+
return SparseTensor(
|
| 85 |
+
output,
|
| 86 |
+
coordinate_map_key=input.coordinate_map_key,
|
| 87 |
+
coordinate_manager=input.coordinate_manager,
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
def __repr__(self):
|
| 91 |
+
s = "({}, eps={}, momentum={}, affine={}, track_running_stats={})".format(
|
| 92 |
+
self.bn.num_features,
|
| 93 |
+
self.bn.eps,
|
| 94 |
+
self.bn.momentum,
|
| 95 |
+
self.bn.affine,
|
| 96 |
+
self.bn.track_running_stats,
|
| 97 |
+
)
|
| 98 |
+
return self.__class__.__name__ + s
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class MinkowskiSyncBatchNorm(MinkowskiBatchNorm):
|
| 102 |
+
r"""A batch normalization layer with multi GPU synchronization."""
|
| 103 |
+
|
| 104 |
+
def __init__(
|
| 105 |
+
self,
|
| 106 |
+
num_features,
|
| 107 |
+
eps=1e-5,
|
| 108 |
+
momentum=0.1,
|
| 109 |
+
affine=True,
|
| 110 |
+
track_running_stats=True,
|
| 111 |
+
process_group=None,
|
| 112 |
+
):
|
| 113 |
+
Module.__init__(self)
|
| 114 |
+
self.bn = torch.nn.SyncBatchNorm(
|
| 115 |
+
num_features,
|
| 116 |
+
eps=eps,
|
| 117 |
+
momentum=momentum,
|
| 118 |
+
affine=affine,
|
| 119 |
+
track_running_stats=track_running_stats,
|
| 120 |
+
process_group=process_group,
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
def forward(self, input):
|
| 124 |
+
output = self.bn(input.F)
|
| 125 |
+
if isinstance(input, TensorField):
|
| 126 |
+
return TensorField(
|
| 127 |
+
output,
|
| 128 |
+
coordinate_field_map_key=input.coordinate_field_map_key,
|
| 129 |
+
coordinate_manager=input.coordinate_manager,
|
| 130 |
+
quantization_mode=input.quantization_mode,
|
| 131 |
+
)
|
| 132 |
+
else:
|
| 133 |
+
return SparseTensor(
|
| 134 |
+
output,
|
| 135 |
+
coordinate_map_key=input.coordinate_map_key,
|
| 136 |
+
coordinate_manager=input.coordinate_manager,
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
@classmethod
|
| 140 |
+
def convert_sync_batchnorm(cls, module, process_group=None):
|
| 141 |
+
r"""Helper function to convert
|
| 142 |
+
:attr:`MinkowskiEngine.MinkowskiBatchNorm` layer in the model to
|
| 143 |
+
:attr:`MinkowskiEngine.MinkowskiSyncBatchNorm` layer.
|
| 144 |
+
|
| 145 |
+
Args:
|
| 146 |
+
module (nn.Module): containing module
|
| 147 |
+
process_group (optional): process group to scope synchronization,
|
| 148 |
+
default is the whole world
|
| 149 |
+
|
| 150 |
+
Returns:
|
| 151 |
+
The original module with the converted
|
| 152 |
+
:attr:`MinkowskiEngine.MinkowskiSyncBatchNorm` layer
|
| 153 |
+
|
| 154 |
+
Example::
|
| 155 |
+
|
| 156 |
+
>>> # Network with MinkowskiBatchNorm layer
|
| 157 |
+
>>> module = torch.nn.Sequential(
|
| 158 |
+
>>> MinkowskiLinear(20, 100),
|
| 159 |
+
>>> MinkowskiBatchNorm1d(100)
|
| 160 |
+
>>> ).cuda()
|
| 161 |
+
>>> # creating process group (optional)
|
| 162 |
+
>>> # process_ids is a list of int identifying rank ids.
|
| 163 |
+
>>> process_group = torch.distributed.new_group(process_ids)
|
| 164 |
+
>>> sync_bn_module = convert_sync_batchnorm(module, process_group)
|
| 165 |
+
|
| 166 |
+
"""
|
| 167 |
+
module_output = module
|
| 168 |
+
if isinstance(module, MinkowskiBatchNorm):
|
| 169 |
+
module_output = MinkowskiSyncBatchNorm(
|
| 170 |
+
module.bn.num_features,
|
| 171 |
+
module.bn.eps,
|
| 172 |
+
module.bn.momentum,
|
| 173 |
+
module.bn.affine,
|
| 174 |
+
module.bn.track_running_stats,
|
| 175 |
+
process_group,
|
| 176 |
+
)
|
| 177 |
+
if module.bn.affine:
|
| 178 |
+
with torch.no_grad():
|
| 179 |
+
module_output.bn.weight = module.bn.weight
|
| 180 |
+
module_output.bn.bias = module.bn.bias
|
| 181 |
+
module_output.bn.running_mean = module.bn.running_mean
|
| 182 |
+
module_output.bn.running_var = module.bn.running_var
|
| 183 |
+
module_output.bn.num_batches_tracked = module.bn.num_batches_tracked
|
| 184 |
+
if hasattr(module, "qconfig"):
|
| 185 |
+
module_output.bn.qconfig = module.bn.qconfig
|
| 186 |
+
for name, child in module.named_children():
|
| 187 |
+
module_output.add_module(
|
| 188 |
+
name, cls.convert_sync_batchnorm(child, process_group)
|
| 189 |
+
)
|
| 190 |
+
del module
|
| 191 |
+
return module_output
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
class MinkowskiInstanceNormFunction(Function):
|
| 195 |
+
@staticmethod
|
| 196 |
+
def forward(
|
| 197 |
+
ctx,
|
| 198 |
+
in_feat: torch.Tensor,
|
| 199 |
+
in_coords_key: CoordinateMapKey,
|
| 200 |
+
glob_coords_key: CoordinateMapKey = None,
|
| 201 |
+
coords_manager: CoordinateManager = None,
|
| 202 |
+
gpooling_mode=PoolingMode.GLOBAL_AVG_POOLING_KERNEL,
|
| 203 |
+
):
|
| 204 |
+
if glob_coords_key is None:
|
| 205 |
+
glob_coords_key = CoordinateMapKey(in_coords_key.get_coordinate_size())
|
| 206 |
+
|
| 207 |
+
gpool_avg_forward = get_minkowski_function("GlobalPoolingForward", in_feat)
|
| 208 |
+
broadcast_forward = get_minkowski_function("BroadcastForward", in_feat)
|
| 209 |
+
|
| 210 |
+
mean, num_nonzero = gpool_avg_forward(
|
| 211 |
+
in_feat,
|
| 212 |
+
gpooling_mode,
|
| 213 |
+
in_coords_key,
|
| 214 |
+
glob_coords_key,
|
| 215 |
+
coords_manager._manager,
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
# X - \mu
|
| 219 |
+
centered_feat = broadcast_forward(
|
| 220 |
+
in_feat,
|
| 221 |
+
-mean,
|
| 222 |
+
BroadcastMode.ELEMENTWISE_ADDITON,
|
| 223 |
+
in_coords_key,
|
| 224 |
+
glob_coords_key,
|
| 225 |
+
coords_manager._manager,
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
# Variance = 1/N \sum (X - \mu) ** 2
|
| 229 |
+
variance, num_nonzero = gpool_avg_forward(
|
| 230 |
+
centered_feat ** 2,
|
| 231 |
+
gpooling_mode,
|
| 232 |
+
in_coords_key,
|
| 233 |
+
glob_coords_key,
|
| 234 |
+
coords_manager._manager,
|
| 235 |
+
)
|
| 236 |
+
|
| 237 |
+
# norm_feat = (X - \mu) / \sigma
|
| 238 |
+
inv_std = 1 / (variance + 1e-8).sqrt()
|
| 239 |
+
norm_feat = broadcast_forward(
|
| 240 |
+
centered_feat,
|
| 241 |
+
inv_std,
|
| 242 |
+
BroadcastMode.ELEMENTWISE_MULTIPLICATION,
|
| 243 |
+
in_coords_key,
|
| 244 |
+
glob_coords_key,
|
| 245 |
+
coords_manager._manager,
|
| 246 |
+
)
|
| 247 |
+
|
| 248 |
+
ctx.saved_vars = (in_coords_key, glob_coords_key, coords_manager, gpooling_mode)
|
| 249 |
+
# For GPU tensors, must use save_for_backward.
|
| 250 |
+
ctx.save_for_backward(inv_std, norm_feat)
|
| 251 |
+
return norm_feat
|
| 252 |
+
|
| 253 |
+
@staticmethod
|
| 254 |
+
def backward(ctx, out_grad):
|
| 255 |
+
# https://kevinzakka.github.io/2016/09/14/batch_normalization/
|
| 256 |
+
in_coords_key, glob_coords_key, coords_manager, gpooling_mode = ctx.saved_vars
|
| 257 |
+
|
| 258 |
+
# To prevent the memory leakage, compute the norm again
|
| 259 |
+
inv_std, norm_feat = ctx.saved_tensors
|
| 260 |
+
|
| 261 |
+
gpool_avg_forward = get_minkowski_function("GlobalPoolingForward", out_grad)
|
| 262 |
+
broadcast_forward = get_minkowski_function("BroadcastForward", out_grad)
|
| 263 |
+
|
| 264 |
+
# 1/N \sum dout
|
| 265 |
+
mean_dout, num_nonzero = gpool_avg_forward(
|
| 266 |
+
out_grad,
|
| 267 |
+
gpooling_mode,
|
| 268 |
+
in_coords_key,
|
| 269 |
+
glob_coords_key,
|
| 270 |
+
coords_manager._manager,
|
| 271 |
+
)
|
| 272 |
+
|
| 273 |
+
# 1/N \sum (dout * out)
|
| 274 |
+
mean_dout_feat, num_nonzero = gpool_avg_forward(
|
| 275 |
+
out_grad * norm_feat,
|
| 276 |
+
gpooling_mode,
|
| 277 |
+
in_coords_key,
|
| 278 |
+
glob_coords_key,
|
| 279 |
+
coords_manager._manager,
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
# out * 1/N \sum (dout * out)
|
| 283 |
+
feat_mean_dout_feat = broadcast_forward(
|
| 284 |
+
norm_feat,
|
| 285 |
+
mean_dout_feat,
|
| 286 |
+
BroadcastMode.ELEMENTWISE_MULTIPLICATION,
|
| 287 |
+
in_coords_key,
|
| 288 |
+
glob_coords_key,
|
| 289 |
+
coords_manager._manager,
|
| 290 |
+
)
|
| 291 |
+
|
| 292 |
+
unnorm_din = broadcast_forward(
|
| 293 |
+
out_grad - feat_mean_dout_feat,
|
| 294 |
+
-mean_dout,
|
| 295 |
+
BroadcastMode.ELEMENTWISE_ADDITON,
|
| 296 |
+
in_coords_key,
|
| 297 |
+
glob_coords_key,
|
| 298 |
+
coords_manager._manager,
|
| 299 |
+
)
|
| 300 |
+
|
| 301 |
+
norm_din = broadcast_forward(
|
| 302 |
+
unnorm_din,
|
| 303 |
+
inv_std,
|
| 304 |
+
BroadcastMode.ELEMENTWISE_MULTIPLICATION,
|
| 305 |
+
in_coords_key,
|
| 306 |
+
glob_coords_key,
|
| 307 |
+
coords_manager._manager,
|
| 308 |
+
)
|
| 309 |
+
|
| 310 |
+
return norm_din, None, None, None, None
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
class MinkowskiStableInstanceNorm(MinkowskiModuleBase):
|
| 314 |
+
def __init__(self, num_features):
|
| 315 |
+
Module.__init__(self)
|
| 316 |
+
self.num_features = num_features
|
| 317 |
+
self.eps = 1e-6
|
| 318 |
+
self.weight = nn.Parameter(torch.ones(1, num_features))
|
| 319 |
+
self.bias = nn.Parameter(torch.zeros(1, num_features))
|
| 320 |
+
|
| 321 |
+
self.mean_in = MinkowskiGlobalAvgPooling()
|
| 322 |
+
self.glob_sum = MinkowskiBroadcastAddition()
|
| 323 |
+
self.glob_sum2 = MinkowskiBroadcastAddition()
|
| 324 |
+
self.glob_mean = MinkowskiGlobalAvgPooling()
|
| 325 |
+
self.glob_times = MinkowskiBroadcastMultiplication()
|
| 326 |
+
self.reset_parameters()
|
| 327 |
+
|
| 328 |
+
def __repr__(self):
|
| 329 |
+
s = f"(nchannels={self.num_features})"
|
| 330 |
+
return self.__class__.__name__ + s
|
| 331 |
+
|
| 332 |
+
def reset_parameters(self):
|
| 333 |
+
self.weight.data.fill_(1)
|
| 334 |
+
self.bias.data.zero_()
|
| 335 |
+
|
| 336 |
+
def forward(self, x):
|
| 337 |
+
neg_mean_in = self.mean_in(
|
| 338 |
+
SparseTensor(-x.F, coords_key=x.coords_key, coords_manager=x.coords_man)
|
| 339 |
+
)
|
| 340 |
+
centered_in = self.glob_sum(x, neg_mean_in)
|
| 341 |
+
temp = SparseTensor(
|
| 342 |
+
centered_in.F ** 2,
|
| 343 |
+
coordinate_map_key=centered_in.coordinate_map_key,
|
| 344 |
+
coordinate_manager=centered_in.coordinate_manager,
|
| 345 |
+
)
|
| 346 |
+
var_in = self.glob_mean(temp)
|
| 347 |
+
instd_in = SparseTensor(
|
| 348 |
+
1 / (var_in.F + self.eps).sqrt(),
|
| 349 |
+
coordinate_map_key=var_in.coordinate_map_key,
|
| 350 |
+
coordinate_manager=var_in.coordinate_manager,
|
| 351 |
+
)
|
| 352 |
+
|
| 353 |
+
x = self.glob_times(self.glob_sum2(x, neg_mean_in), instd_in)
|
| 354 |
+
return SparseTensor(
|
| 355 |
+
x.F * self.weight + self.bias,
|
| 356 |
+
coordinate_map_key=x.coordinate_map_key,
|
| 357 |
+
coordinate_manager=x.coordinate_manager,
|
| 358 |
+
)
|
| 359 |
+
|
| 360 |
+
|
| 361 |
+
class MinkowskiInstanceNorm(MinkowskiModuleBase):
|
| 362 |
+
r"""A instance normalization layer for a sparse tensor."""
|
| 363 |
+
|
| 364 |
+
def __init__(self, num_features):
|
| 365 |
+
r"""
|
| 366 |
+
Args:
|
| 367 |
+
|
| 368 |
+
num_features (int): the dimension of the input feautres.
|
| 369 |
+
|
| 370 |
+
mode (GlobalPoolingModel, optional): The internal global pooling computation mode.
|
| 371 |
+
"""
|
| 372 |
+
Module.__init__(self)
|
| 373 |
+
self.num_features = num_features
|
| 374 |
+
self.weight = nn.Parameter(torch.ones(1, num_features))
|
| 375 |
+
self.bias = nn.Parameter(torch.zeros(1, num_features))
|
| 376 |
+
self.reset_parameters()
|
| 377 |
+
self.inst_norm = MinkowskiInstanceNormFunction()
|
| 378 |
+
|
| 379 |
+
def __repr__(self):
|
| 380 |
+
s = f"(nchannels={self.num_features})"
|
| 381 |
+
return self.__class__.__name__ + s
|
| 382 |
+
|
| 383 |
+
def reset_parameters(self):
|
| 384 |
+
self.weight.data.fill_(1)
|
| 385 |
+
self.bias.data.zero_()
|
| 386 |
+
|
| 387 |
+
def forward(self, input: SparseTensor):
|
| 388 |
+
assert isinstance(input, SparseTensor)
|
| 389 |
+
|
| 390 |
+
output = self.inst_norm.apply(
|
| 391 |
+
input.F, input.coordinate_map_key, None, input.coordinate_manager
|
| 392 |
+
)
|
| 393 |
+
output = output * self.weight + self.bias
|
| 394 |
+
|
| 395 |
+
return SparseTensor(
|
| 396 |
+
output,
|
| 397 |
+
coordinate_map_key=input.coordinate_map_key,
|
| 398 |
+
coordinate_manager=input.coordinate_manager,
|
| 399 |
+
)
|
MinkowskiEngine/MinkowskiEngine/MinkowskiOps.py
ADDED
|
@@ -0,0 +1,497 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
from typing import Union
|
| 26 |
+
import numpy as np
|
| 27 |
+
|
| 28 |
+
import torch
|
| 29 |
+
from torch.nn.modules import Module
|
| 30 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 31 |
+
from MinkowskiTensor import (
|
| 32 |
+
COORDINATE_MANAGER_DIFFERENT_ERROR,
|
| 33 |
+
COORDINATE_KEY_DIFFERENT_ERROR,
|
| 34 |
+
)
|
| 35 |
+
from MinkowskiTensorField import TensorField
|
| 36 |
+
from MinkowskiCommon import MinkowskiModuleBase
|
| 37 |
+
from MinkowskiEngineBackend._C import CoordinateMapKey
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class MinkowskiLinear(Module):
|
| 41 |
+
def __init__(self, in_features, out_features, bias=True):
|
| 42 |
+
super(MinkowskiLinear, self).__init__()
|
| 43 |
+
self.linear = torch.nn.Linear(in_features, out_features, bias=bias)
|
| 44 |
+
|
| 45 |
+
def forward(self, input: Union[SparseTensor, TensorField]):
|
| 46 |
+
output = self.linear(input.F)
|
| 47 |
+
if isinstance(input, TensorField):
|
| 48 |
+
return TensorField(
|
| 49 |
+
output,
|
| 50 |
+
coordinate_field_map_key=input.coordinate_field_map_key,
|
| 51 |
+
coordinate_manager=input.coordinate_manager,
|
| 52 |
+
quantization_mode=input.quantization_mode,
|
| 53 |
+
)
|
| 54 |
+
else:
|
| 55 |
+
return SparseTensor(
|
| 56 |
+
output,
|
| 57 |
+
coordinate_map_key=input.coordinate_map_key,
|
| 58 |
+
coordinate_manager=input.coordinate_manager,
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
def __repr__(self):
|
| 62 |
+
s = "(in_features={}, out_features={}, bias={})".format(
|
| 63 |
+
self.linear.in_features,
|
| 64 |
+
self.linear.out_features,
|
| 65 |
+
self.linear.bias is not None,
|
| 66 |
+
)
|
| 67 |
+
return self.__class__.__name__ + s
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def _tuple_operator(*sparse_tensors, operator):
|
| 71 |
+
if len(sparse_tensors) == 1:
|
| 72 |
+
assert isinstance(sparse_tensors[0], (tuple, list))
|
| 73 |
+
sparse_tensors = sparse_tensors[0]
|
| 74 |
+
|
| 75 |
+
assert (
|
| 76 |
+
len(sparse_tensors) > 1
|
| 77 |
+
), f"Invalid number of inputs. The input must be at least two len(sparse_tensors) > 1"
|
| 78 |
+
|
| 79 |
+
if isinstance(sparse_tensors[0], SparseTensor):
|
| 80 |
+
device = sparse_tensors[0].device
|
| 81 |
+
coordinate_manager = sparse_tensors[0].coordinate_manager
|
| 82 |
+
coordinate_map_key = sparse_tensors[0].coordinate_map_key
|
| 83 |
+
for s in sparse_tensors:
|
| 84 |
+
assert isinstance(
|
| 85 |
+
s, SparseTensor
|
| 86 |
+
), "Inputs must be either SparseTensors or TensorFields."
|
| 87 |
+
assert (
|
| 88 |
+
device == s.device
|
| 89 |
+
), f"Device must be the same. {device} != {s.device}"
|
| 90 |
+
assert (
|
| 91 |
+
coordinate_manager == s.coordinate_manager
|
| 92 |
+
), COORDINATE_MANAGER_DIFFERENT_ERROR
|
| 93 |
+
assert coordinate_map_key == s.coordinate_map_key, (
|
| 94 |
+
COORDINATE_KEY_DIFFERENT_ERROR
|
| 95 |
+
+ str(coordinate_map_key)
|
| 96 |
+
+ " != "
|
| 97 |
+
+ str(s.coordinate_map_key)
|
| 98 |
+
)
|
| 99 |
+
tens = []
|
| 100 |
+
for s in sparse_tensors:
|
| 101 |
+
tens.append(s.F)
|
| 102 |
+
return SparseTensor(
|
| 103 |
+
operator(tens),
|
| 104 |
+
coordinate_map_key=coordinate_map_key,
|
| 105 |
+
coordinate_manager=coordinate_manager,
|
| 106 |
+
)
|
| 107 |
+
elif isinstance(sparse_tensors[0], TensorField):
|
| 108 |
+
device = sparse_tensors[0].device
|
| 109 |
+
coordinate_manager = sparse_tensors[0].coordinate_manager
|
| 110 |
+
coordinate_field_map_key = sparse_tensors[0].coordinate_field_map_key
|
| 111 |
+
for s in sparse_tensors:
|
| 112 |
+
assert isinstance(
|
| 113 |
+
s, TensorField
|
| 114 |
+
), "Inputs must be either SparseTensors or TensorFields."
|
| 115 |
+
assert (
|
| 116 |
+
device == s.device
|
| 117 |
+
), f"Device must be the same. {device} != {s.device}"
|
| 118 |
+
assert (
|
| 119 |
+
coordinate_manager == s.coordinate_manager
|
| 120 |
+
), COORDINATE_MANAGER_DIFFERENT_ERROR
|
| 121 |
+
assert coordinate_field_map_key == s.coordinate_field_map_key, (
|
| 122 |
+
COORDINATE_KEY_DIFFERENT_ERROR
|
| 123 |
+
+ str(coordinate_field_map_key)
|
| 124 |
+
+ " != "
|
| 125 |
+
+ str(s.coordinate_field_map_key)
|
| 126 |
+
)
|
| 127 |
+
tens = []
|
| 128 |
+
for s in sparse_tensors:
|
| 129 |
+
tens.append(s.F)
|
| 130 |
+
return TensorField(
|
| 131 |
+
operator(tens),
|
| 132 |
+
coordinate_field_map_key=coordinate_field_map_key,
|
| 133 |
+
coordinate_manager=coordinate_manager,
|
| 134 |
+
)
|
| 135 |
+
else:
|
| 136 |
+
raise ValueError(
|
| 137 |
+
"Invalid data type. The input must be either a list of sparse tensors or a list of tensor fields."
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def cat(*sparse_tensors):
|
| 142 |
+
r"""Concatenate sparse tensors
|
| 143 |
+
|
| 144 |
+
Concatenate sparse tensor features. All sparse tensors must have the same
|
| 145 |
+
`coordinate_map_key` (the same coordinates). To concatenate sparse tensors
|
| 146 |
+
with different sparsity patterns, use SparseTensor binary operations, or
|
| 147 |
+
:attr:`MinkowskiEngine.MinkowskiUnion`.
|
| 148 |
+
|
| 149 |
+
Example::
|
| 150 |
+
|
| 151 |
+
>>> import MinkowskiEngine as ME
|
| 152 |
+
>>> sin = ME.SparseTensor(feats, coords)
|
| 153 |
+
>>> sin2 = ME.SparseTensor(feats2, coordinate_map_key=sin.coordinate_map_key, coordinate_mananger=sin.coordinate_manager)
|
| 154 |
+
>>> sout = UNet(sin) # Returns an output sparse tensor on the same coordinates
|
| 155 |
+
>>> sout2 = ME.cat(sin, sin2, sout) # Can concatenate multiple sparse tensors
|
| 156 |
+
|
| 157 |
+
"""
|
| 158 |
+
return _tuple_operator(*sparse_tensors, operator=lambda xs: torch.cat(xs, dim=-1))
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
def _sum(*sparse_tensors):
|
| 162 |
+
r"""Compute the sum of sparse tensor features
|
| 163 |
+
|
| 164 |
+
Sum all sparse tensor features. All sparse tensors must have the same
|
| 165 |
+
`coordinate_map_key` (the same coordinates). To sum sparse tensors with
|
| 166 |
+
different sparsity patterns, use SparseTensor binary operations, or
|
| 167 |
+
:attr:`MinkowskiEngine.MinkowskiUnion`.
|
| 168 |
+
|
| 169 |
+
Example::
|
| 170 |
+
|
| 171 |
+
>>> import MinkowskiEngine as ME
|
| 172 |
+
>>> sin = ME.SparseTensor(feats, coords)
|
| 173 |
+
>>> sin2 = ME.SparseTensor(feats2, coordinate_map_key=sin.coordinate_map_key, coordinate_manager=sin.coordinate_manager)
|
| 174 |
+
>>> sout = UNet(sin) # Returns an output sparse tensor on the same coordinates
|
| 175 |
+
>>> sout2 = ME.sum(sin, sin2, sout) # Can concatenate multiple sparse tensors
|
| 176 |
+
|
| 177 |
+
"""
|
| 178 |
+
|
| 179 |
+
def return_sum(xs):
|
| 180 |
+
tmp = xs[0] + xs[1]
|
| 181 |
+
for x in xs[2:]:
|
| 182 |
+
tmp += x
|
| 183 |
+
return tmp
|
| 184 |
+
|
| 185 |
+
return _tuple_operator(*sparse_tensors, operator=lambda xs: return_sum(xs))
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def mean(*sparse_tensors):
|
| 189 |
+
r"""Compute the average of sparse tensor features
|
| 190 |
+
|
| 191 |
+
Sum all sparse tensor features. All sparse tensors must have the same
|
| 192 |
+
`coordinate_map_key` (the same coordinates). To sum sparse tensors with
|
| 193 |
+
different sparsity patterns, use SparseTensor binary operations, or
|
| 194 |
+
:attr:`MinkowskiEngine.MinkowskiUnion`.
|
| 195 |
+
|
| 196 |
+
Example::
|
| 197 |
+
|
| 198 |
+
>>> import MinkowskiEngine as ME
|
| 199 |
+
>>> sin = ME.SparseTensor(feats, coords)
|
| 200 |
+
>>> sin2 = ME.SparseTensor(feats2, coordinate_map_key=sin.coordinate_map_key, coordinate_manager=sin.coordinate_manager)
|
| 201 |
+
>>> sout = UNet(sin) # Returns an output sparse tensor on the same coordinates
|
| 202 |
+
>>> sout2 = ME.mean(sin, sin2, sout) # Can concatenate multiple sparse tensors
|
| 203 |
+
|
| 204 |
+
"""
|
| 205 |
+
|
| 206 |
+
def return_mean(xs):
|
| 207 |
+
tmp = xs[0] + xs[1]
|
| 208 |
+
for x in xs[2:]:
|
| 209 |
+
tmp += x
|
| 210 |
+
return tmp / len(xs)
|
| 211 |
+
|
| 212 |
+
return _tuple_operator(*sparse_tensors, operator=lambda xs: return_mean(xs))
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
def var(*sparse_tensors):
|
| 216 |
+
r"""Compute the variance of sparse tensor features
|
| 217 |
+
|
| 218 |
+
Sum all sparse tensor features. All sparse tensors must have the same
|
| 219 |
+
`coordinate_map_key` (the same coordinates). To sum sparse tensors with
|
| 220 |
+
different sparsity patterns, use SparseTensor binary operations, or
|
| 221 |
+
:attr:`MinkowskiEngine.MinkowskiUnion`.
|
| 222 |
+
|
| 223 |
+
Example::
|
| 224 |
+
|
| 225 |
+
>>> import MinkowskiEngine as ME
|
| 226 |
+
>>> sin = ME.SparseTensor(feats, coords)
|
| 227 |
+
>>> sin2 = ME.SparseTensor(feats2, coordinate_map_key=sin.coordinate_map_key, coordinate_manager=sin.coordinate_manager)
|
| 228 |
+
>>> sout = UNet(sin) # Returns an output sparse tensor on the same coordinates
|
| 229 |
+
>>> sout2 = ME.var(sin, sin2, sout) # Can concatenate multiple sparse tensors
|
| 230 |
+
|
| 231 |
+
"""
|
| 232 |
+
|
| 233 |
+
def return_var(xs):
|
| 234 |
+
tmp = xs[0] + xs[1]
|
| 235 |
+
for x in xs[2:]:
|
| 236 |
+
tmp += x
|
| 237 |
+
mean = tmp / len(xs)
|
| 238 |
+
var = (xs[0] - mean) ** 2
|
| 239 |
+
for x in xs[1:]:
|
| 240 |
+
var += (x - mean) ** 2
|
| 241 |
+
return var / len(xs)
|
| 242 |
+
|
| 243 |
+
return _tuple_operator(*sparse_tensors, operator=lambda xs: return_var(xs))
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
def dense_coordinates(shape: Union[list, torch.Size]):
|
| 247 |
+
"""
|
| 248 |
+
coordinates = dense_coordinates(tensor.shape)
|
| 249 |
+
"""
|
| 250 |
+
r"""
|
| 251 |
+
Assume the input to have BxCxD1xD2x....xDN format.
|
| 252 |
+
|
| 253 |
+
If the shape of the tensor do not change, use
|
| 254 |
+
"""
|
| 255 |
+
spatial_dim = len(shape) - 2
|
| 256 |
+
assert (
|
| 257 |
+
spatial_dim > 0
|
| 258 |
+
), "Invalid shape. Shape must be batch x channel x spatial dimensions."
|
| 259 |
+
|
| 260 |
+
# Generate coordinates
|
| 261 |
+
size = [i for i in shape]
|
| 262 |
+
B = size[0]
|
| 263 |
+
coordinates = torch.from_numpy(
|
| 264 |
+
np.stack(
|
| 265 |
+
[
|
| 266 |
+
s.reshape(-1)
|
| 267 |
+
for s in np.meshgrid(
|
| 268 |
+
np.linspace(0, B - 1, B),
|
| 269 |
+
*(np.linspace(0, s - 1, s) for s in size[2:]),
|
| 270 |
+
indexing="ij",
|
| 271 |
+
)
|
| 272 |
+
],
|
| 273 |
+
1,
|
| 274 |
+
)
|
| 275 |
+
).int()
|
| 276 |
+
return coordinates
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
def to_sparse(x: torch.Tensor, format: str = None, coordinates=None, device=None):
|
| 280 |
+
r"""Convert a batched tensor (dimension 0 is the batch dimension) to a SparseTensor
|
| 281 |
+
|
| 282 |
+
:attr:`x` (:attr:`torch.Tensor`): a batched tensor. The first dimension is the batch dimension.
|
| 283 |
+
|
| 284 |
+
:attr:`format` (:attr:`str`): Format of the tensor. It must include 'B' and 'C' indicating the batch and channel dimension respectively. The rest of the dimensions must be 'X'. .e.g. format="BCXX" if image data with BCHW format is used. If a 3D data with the channel at the last dimension, use format="BXXXC" indicating Batch X Height X Width X Depth X Channel. If not provided, the format will be "BCX...X".
|
| 285 |
+
|
| 286 |
+
:attr:`device`: Device the sparse tensor will be generated on. If not provided, the device of the input tensor will be used.
|
| 287 |
+
|
| 288 |
+
"""
|
| 289 |
+
assert x.ndim > 2, "Input has 0 spatial dimension."
|
| 290 |
+
assert isinstance(x, torch.Tensor)
|
| 291 |
+
if format is None:
|
| 292 |
+
format = [
|
| 293 |
+
"X",
|
| 294 |
+
] * x.ndim
|
| 295 |
+
format[0] = "B"
|
| 296 |
+
format[1] = "C"
|
| 297 |
+
format = "".join(format)
|
| 298 |
+
assert x.ndim == len(format), f"Invalid format: {format}. len(format) != x.ndim"
|
| 299 |
+
assert (
|
| 300 |
+
"B" in format and "B" == format[0] and format.count("B") == 1
|
| 301 |
+
), "The input must have the batch axis and the format must include 'B' indicating the batch axis."
|
| 302 |
+
assert (
|
| 303 |
+
"C" in format and format.count("C") == 1
|
| 304 |
+
), "The format must indicate the channel axis"
|
| 305 |
+
if device is None:
|
| 306 |
+
device = x.device
|
| 307 |
+
ch_dim = format.find("C")
|
| 308 |
+
reduced_x = torch.abs(x).sum(ch_dim)
|
| 309 |
+
bcoords = torch.where(reduced_x != 0)
|
| 310 |
+
stacked_bcoords = torch.stack(bcoords, dim=1).int()
|
| 311 |
+
indexing = [f"bcoords[{i}]" for i in range(len(bcoords))]
|
| 312 |
+
indexing.insert(ch_dim, ":")
|
| 313 |
+
features = torch.zeros(
|
| 314 |
+
(len(stacked_bcoords), x.size(ch_dim)), dtype=x.dtype, device=x.device
|
| 315 |
+
)
|
| 316 |
+
exec("features[:] = x[" + ", ".join(indexing) + "]")
|
| 317 |
+
return SparseTensor(features=features, coordinates=stacked_bcoords, device=device)
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
def to_sparse_all(dense_tensor: torch.Tensor, coordinates: torch.Tensor = None):
|
| 321 |
+
r"""Converts a (differentiable) dense tensor to a sparse tensor with all coordinates.
|
| 322 |
+
|
| 323 |
+
Assume the input to have BxCxD1xD2x....xDN format.
|
| 324 |
+
|
| 325 |
+
If the shape of the tensor do not change, use `dense_coordinates` to cache the coordinates.
|
| 326 |
+
Please refer to tests/python/dense.py for usage
|
| 327 |
+
|
| 328 |
+
Example::
|
| 329 |
+
|
| 330 |
+
>>> dense_tensor = torch.rand(3, 4, 5, 6, 7, 8) # BxCxD1xD2xD3xD4
|
| 331 |
+
>>> dense_tensor.requires_grad = True
|
| 332 |
+
>>> stensor = to_sparse(dense_tensor)
|
| 333 |
+
|
| 334 |
+
"""
|
| 335 |
+
spatial_dim = dense_tensor.ndim - 2
|
| 336 |
+
assert (
|
| 337 |
+
spatial_dim > 0
|
| 338 |
+
), "Invalid shape. Shape must be batch x channel x spatial dimensions."
|
| 339 |
+
|
| 340 |
+
if coordinates is None:
|
| 341 |
+
coordinates = dense_coordinates(dense_tensor.shape)
|
| 342 |
+
|
| 343 |
+
feat_tensor = dense_tensor.permute(0, *(2 + i for i in range(spatial_dim)), 1)
|
| 344 |
+
return SparseTensor(
|
| 345 |
+
feat_tensor.reshape(-1, dense_tensor.size(1)),
|
| 346 |
+
coordinates,
|
| 347 |
+
device=dense_tensor.device,
|
| 348 |
+
)
|
| 349 |
+
|
| 350 |
+
|
| 351 |
+
class MinkowskiToSparseTensor(MinkowskiModuleBase):
|
| 352 |
+
r"""Converts a (differentiable) dense tensor or a :attr:`MinkowskiEngine.TensorField` to a :attr:`MinkowskiEngine.SparseTensor`.
|
| 353 |
+
|
| 354 |
+
For dense tensor, the input must have the BxCxD1xD2x....xDN format.
|
| 355 |
+
|
| 356 |
+
:attr:`remove_zeros` (bool): if True, removes zero valued coordinates. If
|
| 357 |
+
False, use all coordinates to populate a sparse tensor. True by default.
|
| 358 |
+
|
| 359 |
+
:attr:`coordinates` (torch.Tensor): if set, use the provided coordinates
|
| 360 |
+
only for sparse tensor generation. Will ignore `remove_zeros`.
|
| 361 |
+
|
| 362 |
+
If the shape of the tensor do not change, use `dense_coordinates` to cache the coordinates.
|
| 363 |
+
Please refer to tests/python/dense.py for usage.
|
| 364 |
+
|
| 365 |
+
Example::
|
| 366 |
+
|
| 367 |
+
>>> # Differentiable dense torch.Tensor to sparse tensor.
|
| 368 |
+
>>> dense_tensor = torch.rand(3, 4, 11, 11, 11, 11) # BxCxD1xD2x....xDN
|
| 369 |
+
>>> dense_tensor.requires_grad = True
|
| 370 |
+
|
| 371 |
+
>>> # Since the shape is fixed, cache the coordinates for faster inference
|
| 372 |
+
>>> coordinates = dense_coordinates(dense_tensor.shape)
|
| 373 |
+
|
| 374 |
+
>>> network = nn.Sequential(
|
| 375 |
+
>>> # Add layers that can be applied on a regular pytorch tensor
|
| 376 |
+
>>> nn.ReLU(),
|
| 377 |
+
>>> MinkowskiToSparseTensor(coordinates=coordinates),
|
| 378 |
+
>>> MinkowskiConvolution(4, 5, kernel_size=3, dimension=4),
|
| 379 |
+
>>> MinkowskiBatchNorm(5),
|
| 380 |
+
>>> MinkowskiReLU(),
|
| 381 |
+
>>> )
|
| 382 |
+
|
| 383 |
+
>>> for i in range(5):
|
| 384 |
+
>>> print(f"Iteration: {i}")
|
| 385 |
+
>>> soutput = network(dense_tensor)
|
| 386 |
+
>>> soutput.F.sum().backward()
|
| 387 |
+
>>> soutput.dense(shape=dense_tensor.shape)
|
| 388 |
+
|
| 389 |
+
"""
|
| 390 |
+
|
| 391 |
+
def __init__(self, remove_zeros=True, coordinates: torch.Tensor = None):
|
| 392 |
+
MinkowskiModuleBase.__init__(self)
|
| 393 |
+
self.remove_zeros = remove_zeros
|
| 394 |
+
self.coordinates = coordinates
|
| 395 |
+
|
| 396 |
+
def forward(self, input: Union[TensorField, torch.Tensor]):
|
| 397 |
+
if isinstance(input, TensorField):
|
| 398 |
+
return input.sparse()
|
| 399 |
+
elif isinstance(input, torch.Tensor):
|
| 400 |
+
# dense tensor to sparse tensor conversion
|
| 401 |
+
if self.remove_zeros and self.coordinates is not None:
|
| 402 |
+
return to_sparse(input)
|
| 403 |
+
else:
|
| 404 |
+
return to_sparse_all(input, self.coordinates)
|
| 405 |
+
else:
|
| 406 |
+
raise ValueError(
|
| 407 |
+
"Unsupported type. Only TensorField and torch.Tensor are supported"
|
| 408 |
+
)
|
| 409 |
+
|
| 410 |
+
def __repr__(self):
|
| 411 |
+
return self.__class__.__name__ + "()"
|
| 412 |
+
|
| 413 |
+
|
| 414 |
+
class MinkowskiToDenseTensor(MinkowskiModuleBase):
|
| 415 |
+
r"""Converts a (differentiable) sparse tensor to a torch tensor.
|
| 416 |
+
|
| 417 |
+
The return type has the BxCxD1xD2x....xDN format.
|
| 418 |
+
|
| 419 |
+
Example::
|
| 420 |
+
|
| 421 |
+
>>> dense_tensor = torch.rand(3, 4, 11, 11, 11, 11) # BxCxD1xD2x....xDN
|
| 422 |
+
>>> dense_tensor.requires_grad = True
|
| 423 |
+
|
| 424 |
+
>>> # Since the shape is fixed, cache the coordinates for faster inference
|
| 425 |
+
>>> coordinates = dense_coordinates(dense_tensor.shape)
|
| 426 |
+
|
| 427 |
+
>>> network = nn.Sequential(
|
| 428 |
+
>>> # Add layers that can be applied on a regular pytorch tensor
|
| 429 |
+
>>> nn.ReLU(),
|
| 430 |
+
>>> MinkowskiToSparseTensor(coordinates=coordinates),
|
| 431 |
+
>>> MinkowskiConvolution(4, 5, stride=2, kernel_size=3, dimension=4),
|
| 432 |
+
>>> MinkowskiBatchNorm(5),
|
| 433 |
+
>>> MinkowskiReLU(),
|
| 434 |
+
>>> MinkowskiConvolutionTranspose(5, 6, stride=2, kernel_size=3, dimension=4),
|
| 435 |
+
>>> MinkowskiToDenseTensor(
|
| 436 |
+
>>> dense_tensor.shape
|
| 437 |
+
>>> ), # must have the same tensor stride.
|
| 438 |
+
>>> )
|
| 439 |
+
|
| 440 |
+
>>> for i in range(5):
|
| 441 |
+
>>> print(f"Iteration: {i}")
|
| 442 |
+
>>> output = network(dense_tensor) # returns a regular pytorch tensor
|
| 443 |
+
>>> output.sum().backward()
|
| 444 |
+
|
| 445 |
+
"""
|
| 446 |
+
|
| 447 |
+
def __init__(self, shape: torch.Size = None):
|
| 448 |
+
MinkowskiModuleBase.__init__(self)
|
| 449 |
+
self.shape = shape
|
| 450 |
+
|
| 451 |
+
def forward(self, input: SparseTensor):
|
| 452 |
+
# dense tensor to sparse tensor conversion
|
| 453 |
+
dense_tensor, _, _ = input.dense(shape=self.shape)
|
| 454 |
+
return dense_tensor
|
| 455 |
+
|
| 456 |
+
def __repr__(self):
|
| 457 |
+
return self.__class__.__name__ + "()"
|
| 458 |
+
|
| 459 |
+
|
| 460 |
+
class MinkowskiToFeature(MinkowskiModuleBase):
|
| 461 |
+
r"""
|
| 462 |
+
Extract features from a sparse tensor and returns a pytorch tensor.
|
| 463 |
+
|
| 464 |
+
Can be used to to make a network construction simpler.
|
| 465 |
+
|
| 466 |
+
Example::
|
| 467 |
+
|
| 468 |
+
>>> net = nn.Sequential(MinkowskiConvolution(...), MinkowskiGlobalMaxPooling(...), MinkowskiToFeature(), nn.Linear(...))
|
| 469 |
+
>>> torch_tensor = net(sparse_tensor)
|
| 470 |
+
|
| 471 |
+
"""
|
| 472 |
+
|
| 473 |
+
def forward(self, x: SparseTensor):
|
| 474 |
+
assert isinstance(
|
| 475 |
+
x, (SparseTensor, TensorField)
|
| 476 |
+
), "Invalid input type for MinkowskiToFeature"
|
| 477 |
+
return x.F
|
| 478 |
+
|
| 479 |
+
|
| 480 |
+
class MinkowskiStackCat(torch.nn.Sequential):
|
| 481 |
+
def forward(self, x):
|
| 482 |
+
return cat([module(x) for module in self])
|
| 483 |
+
|
| 484 |
+
|
| 485 |
+
class MinkowskiStackSum(torch.nn.Sequential):
|
| 486 |
+
def forward(self, x):
|
| 487 |
+
return _sum([module(x) for module in self])
|
| 488 |
+
|
| 489 |
+
|
| 490 |
+
class MinkowskiStackMean(torch.nn.Sequential):
|
| 491 |
+
def forward(self, x):
|
| 492 |
+
return mean([module(x) for module in self])
|
| 493 |
+
|
| 494 |
+
|
| 495 |
+
class MinkowskiStackVar(torch.nn.Sequential):
|
| 496 |
+
def forward(self, x):
|
| 497 |
+
return var([module(x) for module in self])
|
MinkowskiEngine/MinkowskiEngine/MinkowskiPooling.py
ADDED
|
@@ -0,0 +1,780 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
from typing import Union
|
| 26 |
+
|
| 27 |
+
import torch
|
| 28 |
+
from torch.autograd import Function
|
| 29 |
+
|
| 30 |
+
import MinkowskiEngineBackend._C as _C
|
| 31 |
+
from MinkowskiEngineBackend._C import CoordinateMapKey, PoolingMode
|
| 32 |
+
from MinkowskiSparseTensor import SparseTensor, _get_coordinate_map_key
|
| 33 |
+
from MinkowskiCoordinateManager import CoordinateManager
|
| 34 |
+
from MinkowskiKernelGenerator import KernelGenerator, save_ctx
|
| 35 |
+
from MinkowskiCommon import (
|
| 36 |
+
MinkowskiModuleBase,
|
| 37 |
+
get_minkowski_function,
|
| 38 |
+
)
|
| 39 |
+
import MinkowskiEngine as ME
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class MinkowskiLocalPoolingFunction(Function):
|
| 43 |
+
@staticmethod
|
| 44 |
+
def forward(
|
| 45 |
+
ctx,
|
| 46 |
+
input_features: torch.Tensor,
|
| 47 |
+
pooling_mode: PoolingMode,
|
| 48 |
+
kernel_generator: KernelGenerator,
|
| 49 |
+
in_coordinate_map_key: CoordinateMapKey,
|
| 50 |
+
out_coordinate_map_key: CoordinateMapKey = None,
|
| 51 |
+
coordinate_manager: CoordinateManager = None,
|
| 52 |
+
):
|
| 53 |
+
if out_coordinate_map_key is None:
|
| 54 |
+
out_coordinate_map_key = CoordinateMapKey(
|
| 55 |
+
in_coordinate_map_key.get_coordinate_size()
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
input_features = input_features.contiguous()
|
| 59 |
+
ctx.input_features = input_features
|
| 60 |
+
ctx = save_ctx(
|
| 61 |
+
ctx,
|
| 62 |
+
kernel_generator,
|
| 63 |
+
in_coordinate_map_key,
|
| 64 |
+
out_coordinate_map_key,
|
| 65 |
+
coordinate_manager,
|
| 66 |
+
)
|
| 67 |
+
ctx.pooling_mode = pooling_mode
|
| 68 |
+
|
| 69 |
+
fw_fn = get_minkowski_function("LocalPoolingForward", input_features)
|
| 70 |
+
out_feat, num_nonzero = fw_fn(
|
| 71 |
+
ctx.input_features,
|
| 72 |
+
kernel_generator.kernel_size,
|
| 73 |
+
kernel_generator.kernel_stride,
|
| 74 |
+
kernel_generator.kernel_dilation,
|
| 75 |
+
kernel_generator.region_type,
|
| 76 |
+
kernel_generator.region_offsets,
|
| 77 |
+
pooling_mode,
|
| 78 |
+
ctx.in_coordinate_map_key,
|
| 79 |
+
ctx.out_coordinate_map_key,
|
| 80 |
+
ctx.coordinate_manager._manager,
|
| 81 |
+
)
|
| 82 |
+
ctx.num_nonzero = num_nonzero
|
| 83 |
+
return out_feat
|
| 84 |
+
|
| 85 |
+
@staticmethod
|
| 86 |
+
def backward(ctx, grad_out_feat):
|
| 87 |
+
grad_out_feat = grad_out_feat.contiguous()
|
| 88 |
+
bw_fn = get_minkowski_function("LocalPoolingBackward", grad_out_feat)
|
| 89 |
+
grad_in_feat = bw_fn(
|
| 90 |
+
ctx.input_features,
|
| 91 |
+
grad_out_feat,
|
| 92 |
+
ctx.num_nonzero,
|
| 93 |
+
ctx.kernel_generator.kernel_size,
|
| 94 |
+
ctx.kernel_generator.kernel_stride,
|
| 95 |
+
ctx.kernel_generator.kernel_dilation,
|
| 96 |
+
ctx.kernel_generator.region_type,
|
| 97 |
+
ctx.kernel_generator.region_offsets,
|
| 98 |
+
ctx.pooling_mode,
|
| 99 |
+
ctx.in_coordinate_map_key,
|
| 100 |
+
ctx.out_coordinate_map_key,
|
| 101 |
+
ctx.coordinate_manager._manager,
|
| 102 |
+
)
|
| 103 |
+
return (
|
| 104 |
+
grad_in_feat,
|
| 105 |
+
None,
|
| 106 |
+
None,
|
| 107 |
+
None,
|
| 108 |
+
None,
|
| 109 |
+
None,
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
class MinkowskiPoolingBase(MinkowskiModuleBase):
|
| 114 |
+
|
| 115 |
+
__slots__ = (
|
| 116 |
+
"is_transpose",
|
| 117 |
+
"kernel_generator",
|
| 118 |
+
"pooling_mode",
|
| 119 |
+
"dimension",
|
| 120 |
+
"pooling",
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
def __init__(
|
| 124 |
+
self,
|
| 125 |
+
kernel_size,
|
| 126 |
+
stride=1,
|
| 127 |
+
dilation=1,
|
| 128 |
+
kernel_generator=None,
|
| 129 |
+
is_transpose=False,
|
| 130 |
+
pooling_mode=PoolingMode.LOCAL_AVG_POOLING,
|
| 131 |
+
dimension=-1,
|
| 132 |
+
):
|
| 133 |
+
super(MinkowskiPoolingBase, self).__init__()
|
| 134 |
+
assert (
|
| 135 |
+
dimension > 0
|
| 136 |
+
), f"Invalid dimension. Please provide a valid dimension argument. dimension={dimension}"
|
| 137 |
+
|
| 138 |
+
if kernel_generator is None:
|
| 139 |
+
kernel_generator = KernelGenerator(
|
| 140 |
+
kernel_size=kernel_size,
|
| 141 |
+
stride=stride,
|
| 142 |
+
dilation=dilation,
|
| 143 |
+
dimension=dimension,
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
self.is_transpose = is_transpose
|
| 147 |
+
self.kernel_generator = kernel_generator
|
| 148 |
+
self.pooling_mode = pooling_mode
|
| 149 |
+
self.dimension = dimension
|
| 150 |
+
self.pooling = MinkowskiLocalPoolingFunction()
|
| 151 |
+
|
| 152 |
+
def forward(
|
| 153 |
+
self,
|
| 154 |
+
input: SparseTensor,
|
| 155 |
+
coordinates: Union[torch.IntTensor, CoordinateMapKey, SparseTensor] = None,
|
| 156 |
+
):
|
| 157 |
+
r"""
|
| 158 |
+
:attr:`input` (`MinkowskiEngine.SparseTensor`): Input sparse tensor to apply a
|
| 159 |
+
convolution on.
|
| 160 |
+
|
| 161 |
+
:attr:`coordinates` ((`torch.IntTensor`, `MinkowskiEngine.CoordsKey`,
|
| 162 |
+
`MinkowskiEngine.SparseTensor`), optional): If provided, generate
|
| 163 |
+
results on the provided coordinates. None by default.
|
| 164 |
+
|
| 165 |
+
"""
|
| 166 |
+
assert isinstance(input, SparseTensor)
|
| 167 |
+
assert input.D == self.dimension
|
| 168 |
+
|
| 169 |
+
# Get a new coordinate map key or extract one from the coordinates
|
| 170 |
+
out_coordinate_map_key = _get_coordinate_map_key(input, coordinates)
|
| 171 |
+
outfeat = self.pooling.apply(
|
| 172 |
+
input.F,
|
| 173 |
+
self.pooling_mode,
|
| 174 |
+
self.kernel_generator,
|
| 175 |
+
input.coordinate_map_key,
|
| 176 |
+
out_coordinate_map_key,
|
| 177 |
+
input._manager,
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
return SparseTensor(
|
| 181 |
+
outfeat,
|
| 182 |
+
coordinate_map_key=out_coordinate_map_key,
|
| 183 |
+
coordinate_manager=input.coordinate_manager,
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
def __repr__(self):
|
| 187 |
+
s = "(kernel_size={}, stride={}, dilation={})".format(
|
| 188 |
+
self.kernel_generator.kernel_size,
|
| 189 |
+
self.kernel_generator.kernel_stride,
|
| 190 |
+
self.kernel_generator.kernel_dilation,
|
| 191 |
+
)
|
| 192 |
+
return self.__class__.__name__ + s
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
class MinkowskiAvgPooling(MinkowskiPoolingBase):
|
| 196 |
+
r"""Average input features within a kernel.
|
| 197 |
+
|
| 198 |
+
.. math::
|
| 199 |
+
|
| 200 |
+
\mathbf{y}_\mathbf{u} = \frac{1}{|\mathcal{N}^D(\mathbf{u},
|
| 201 |
+
\mathcal{C}^\text{in})|} \sum_{\mathbf{i} \in \mathcal{N}^D(\mathbf{u},
|
| 202 |
+
\mathcal{C}^\text{in})} \mathbf{x}_{\mathbf{u} + \mathbf{i}}
|
| 203 |
+
\; \text{for} \; \mathbf{u} \in \mathcal{C}^\text{out}
|
| 204 |
+
|
| 205 |
+
For each output :math:`\mathbf{u}` in :math:`\mathcal{C}^\text{out}`,
|
| 206 |
+
average input features.
|
| 207 |
+
|
| 208 |
+
.. note::
|
| 209 |
+
|
| 210 |
+
An average layer first computes the cardinality of the input features,
|
| 211 |
+
the number of input features for each output, and divide the sum of the
|
| 212 |
+
input features by the cardinality. For a dense tensor, the cardinality
|
| 213 |
+
is a constant, the volume of a kernel. However, for a sparse tensor, the
|
| 214 |
+
cardinality varies depending on the number of input features per output.
|
| 215 |
+
Thus, the average pooling for a sparse tensor is not equivalent to the
|
| 216 |
+
conventional average pooling layer for a dense tensor. Please refer to
|
| 217 |
+
the :attr:`MinkowskiSumPooling` for the equivalent layer.
|
| 218 |
+
|
| 219 |
+
.. note::
|
| 220 |
+
|
| 221 |
+
The engine will generate the in-out mapping corresponding to a
|
| 222 |
+
pooling function faster if the kernel sizes is equal to the stride
|
| 223 |
+
sizes, e.g. `kernel_size = [2, 1], stride = [2, 1]`.
|
| 224 |
+
|
| 225 |
+
If you use a U-network architecture, use the transposed version of
|
| 226 |
+
the same function for up-sampling. e.g. `pool =
|
| 227 |
+
MinkowskiSumPooling(kernel_size=2, stride=2, D=D)`, then use the
|
| 228 |
+
`unpool = MinkowskiPoolingTranspose(kernel_size=2, stride=2, D=D)`.
|
| 229 |
+
|
| 230 |
+
"""
|
| 231 |
+
|
| 232 |
+
def __init__(
|
| 233 |
+
self,
|
| 234 |
+
kernel_size=-1,
|
| 235 |
+
stride=1,
|
| 236 |
+
dilation=1,
|
| 237 |
+
kernel_generator=None,
|
| 238 |
+
dimension=None,
|
| 239 |
+
):
|
| 240 |
+
r"""a high-dimensional sparse average pooling layer.
|
| 241 |
+
|
| 242 |
+
Args:
|
| 243 |
+
:attr:`kernel_size` (int, optional): the size of the kernel in the
|
| 244 |
+
output tensor. If not provided, :attr:`region_offset` should be
|
| 245 |
+
:attr:`RegionType.CUSTOM` and :attr:`region_offset` should be a 2D
|
| 246 |
+
matrix with size :math:`N\times D` such that it lists all :math:`N`
|
| 247 |
+
offsets in D-dimension.
|
| 248 |
+
|
| 249 |
+
:attr:`stride` (int, or list, optional): stride size of the
|
| 250 |
+
convolution layer. If non-identity is used, the output coordinates
|
| 251 |
+
will be at least :attr:`stride` :math:`\times` :attr:`tensor_stride`
|
| 252 |
+
away. When a list is given, the length must be D; each element will
|
| 253 |
+
be used for stride size for the specific axis.
|
| 254 |
+
|
| 255 |
+
:attr:`dilation` (int, or list, optional): dilation size for the
|
| 256 |
+
convolution kernel. When a list is given, the length must be D and
|
| 257 |
+
each element is an axis specific dilation. All elements must be > 0.
|
| 258 |
+
|
| 259 |
+
:attr:`kernel_generator` (:attr:`MinkowskiEngine.KernelGenerator`,
|
| 260 |
+
optional): define custom kernel shape.
|
| 261 |
+
|
| 262 |
+
:attr:`dimension` (int): the spatial dimension of the space where
|
| 263 |
+
all the inputs and the network are defined. For example, images are
|
| 264 |
+
in a 2D space, meshes and 3D shapes are in a 3D space.
|
| 265 |
+
|
| 266 |
+
.. warning::
|
| 267 |
+
|
| 268 |
+
Custom kernel shapes are not supported when kernel_size == stride.
|
| 269 |
+
|
| 270 |
+
"""
|
| 271 |
+
is_transpose = False
|
| 272 |
+
MinkowskiPoolingBase.__init__(
|
| 273 |
+
self,
|
| 274 |
+
kernel_size,
|
| 275 |
+
stride,
|
| 276 |
+
dilation,
|
| 277 |
+
kernel_generator,
|
| 278 |
+
is_transpose,
|
| 279 |
+
pooling_mode=PoolingMode.LOCAL_AVG_POOLING,
|
| 280 |
+
dimension=dimension,
|
| 281 |
+
)
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
class MinkowskiSumPooling(MinkowskiPoolingBase):
|
| 285 |
+
r"""Sum all input features within a kernel.
|
| 286 |
+
|
| 287 |
+
.. math::
|
| 288 |
+
|
| 289 |
+
\mathbf{y}_\mathbf{u} = \sum_{\mathbf{i} \in \mathcal{N}^D(\mathbf{u},
|
| 290 |
+
\mathcal{C}^\text{in})} \mathbf{x}_{\mathbf{u} + \mathbf{i}}
|
| 291 |
+
\; \text{for} \; \mathbf{u} \in \mathcal{C}^\text{out}
|
| 292 |
+
|
| 293 |
+
For each output :math:`\mathbf{u}` in :math:`\mathcal{C}^\text{out}`,
|
| 294 |
+
average input features.
|
| 295 |
+
|
| 296 |
+
.. note::
|
| 297 |
+
|
| 298 |
+
An average layer first computes the cardinality of the input features,
|
| 299 |
+
the number of input features for each output, and divide the sum of the
|
| 300 |
+
input features by the cardinality. For a dense tensor, the cardinality
|
| 301 |
+
is a constant, the volume of a kernel. However, for a sparse tensor, the
|
| 302 |
+
cardinality varies depending on the number of input features per output.
|
| 303 |
+
Thus, averaging the input features with the cardinality may not be
|
| 304 |
+
equivalent to the conventional average pooling for a dense tensor.
|
| 305 |
+
This layer provides an alternative that does not divide the sum by the
|
| 306 |
+
cardinality.
|
| 307 |
+
|
| 308 |
+
.. note::
|
| 309 |
+
|
| 310 |
+
The engine will generate the in-out mapping corresponding to a
|
| 311 |
+
pooling function faster if the kernel sizes is equal to the stride
|
| 312 |
+
sizes, e.g. `kernel_size = [2, 1], stride = [2, 1]`.
|
| 313 |
+
|
| 314 |
+
If you use a U-network architecture, use the transposed version of
|
| 315 |
+
the same function for up-sampling. e.g. `pool =
|
| 316 |
+
MinkowskiSumPooling(kernel_size=2, stride=2, D=D)`, then use the
|
| 317 |
+
`unpool = MinkowskiPoolingTranspose(kernel_size=2, stride=2, D=D)`.
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
"""
|
| 321 |
+
|
| 322 |
+
def __init__(
|
| 323 |
+
self, kernel_size, stride=1, dilation=1, kernel_generator=None, dimension=None
|
| 324 |
+
):
|
| 325 |
+
r"""a high-dimensional sum pooling layer
|
| 326 |
+
|
| 327 |
+
Args:
|
| 328 |
+
:attr:`kernel_size` (int, optional): the size of the kernel in the
|
| 329 |
+
output tensor. If not provided, :attr:`region_offset` should be
|
| 330 |
+
:attr:`RegionType.CUSTOM` and :attr:`region_offset` should be a 2D
|
| 331 |
+
matrix with size :math:`N\times D` such that it lists all :math:`N`
|
| 332 |
+
offsets in D-dimension.
|
| 333 |
+
|
| 334 |
+
:attr:`stride` (int, or list, optional): stride size of the
|
| 335 |
+
convolution layer. If non-identity is used, the output coordinates
|
| 336 |
+
will be at least :attr:`stride` :math:`\times` :attr:`tensor_stride`
|
| 337 |
+
away. When a list is given, the length must be D; each element will
|
| 338 |
+
be used for stride size for the specific axis.
|
| 339 |
+
|
| 340 |
+
:attr:`dilation` (int, or list, optional): dilation size for the
|
| 341 |
+
convolution kernel. When a list is given, the length must be D and
|
| 342 |
+
each element is an axis specific dilation. All elements must be > 0.
|
| 343 |
+
|
| 344 |
+
:attr:`kernel_generator` (:attr:`MinkowskiEngine.KernelGenerator`,
|
| 345 |
+
optional): define custom kernel shape.
|
| 346 |
+
|
| 347 |
+
:attr:`dimension` (int): the spatial dimension of the space where
|
| 348 |
+
all the inputs and the network are defined. For example, images are
|
| 349 |
+
in a 2D space, meshes and 3D shapes are in a 3D space.
|
| 350 |
+
|
| 351 |
+
.. warning::
|
| 352 |
+
|
| 353 |
+
Custom kernel shapes are not supported when kernel_size == stride.
|
| 354 |
+
|
| 355 |
+
"""
|
| 356 |
+
is_transpose = False
|
| 357 |
+
MinkowskiPoolingBase.__init__(
|
| 358 |
+
self,
|
| 359 |
+
kernel_size,
|
| 360 |
+
stride,
|
| 361 |
+
dilation,
|
| 362 |
+
kernel_generator,
|
| 363 |
+
is_transpose,
|
| 364 |
+
pooling_mode=PoolingMode.LOCAL_SUM_POOLING,
|
| 365 |
+
dimension=dimension,
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
class MinkowskiMaxPooling(MinkowskiPoolingBase):
|
| 370 |
+
r"""A max pooling layer for a sparse tensor.
|
| 371 |
+
|
| 372 |
+
.. math::
|
| 373 |
+
|
| 374 |
+
y^c_\mathbf{u} = \max_{\mathbf{i} \in \mathcal{N}^D(\mathbf{u},
|
| 375 |
+
\mathcal{C}^\text{in})} x^c_{\mathbf{u} + \mathbf{i}} \; \text{for} \;
|
| 376 |
+
\mathbf{u} \in \mathcal{C}^\text{out}
|
| 377 |
+
|
| 378 |
+
where :math:`y^c_\mathbf{u}` is a feature at channel :math:`c` and a
|
| 379 |
+
coordinate :math:`\mathbf{u}`.
|
| 380 |
+
|
| 381 |
+
.. note::
|
| 382 |
+
|
| 383 |
+
The engine will generate the in-out mapping corresponding to a
|
| 384 |
+
pooling function faster if the kernel sizes is equal to the stride
|
| 385 |
+
sizes, e.g. `kernel_size = [2, 1], stride = [2, 1]`.
|
| 386 |
+
|
| 387 |
+
If you use a U-network architecture, use the transposed version of
|
| 388 |
+
the same function for up-sampling. e.g. `pool =
|
| 389 |
+
MinkowskiSumPooling(kernel_size=2, stride=2, D=D)`, then use the
|
| 390 |
+
`unpool = MinkowskiPoolingTranspose(kernel_size=2, stride=2, D=D)`.
|
| 391 |
+
|
| 392 |
+
"""
|
| 393 |
+
|
| 394 |
+
def __init__(
|
| 395 |
+
self, kernel_size, stride=1, dilation=1, kernel_generator=None, dimension=None
|
| 396 |
+
):
|
| 397 |
+
r"""a high-dimensional max pooling layer for sparse tensors.
|
| 398 |
+
|
| 399 |
+
Args:
|
| 400 |
+
:attr:`kernel_size` (int, optional): the size of the kernel in the
|
| 401 |
+
output tensor. If not provided, :attr:`region_offset` should be
|
| 402 |
+
:attr:`RegionType.CUSTOM` and :attr:`region_offset` should be a 2D
|
| 403 |
+
matrix with size :math:`N\times D` such that it lists all :math:`N`
|
| 404 |
+
offsets in D-dimension.
|
| 405 |
+
|
| 406 |
+
:attr:`stride` (int, or list, optional): stride size of the
|
| 407 |
+
convolution layer. If non-identity is used, the output coordinates
|
| 408 |
+
will be at least :attr:`stride` :math:`\times` :attr:`tensor_stride`
|
| 409 |
+
away. When a list is given, the length must be D; each element will
|
| 410 |
+
be used for stride size for the specific axis.
|
| 411 |
+
|
| 412 |
+
:attr:`dilation` (int, or list, optional): dilation size for the
|
| 413 |
+
convolution kernel. When a list is given, the length must be D and
|
| 414 |
+
each element is an axis specific dilation. All elements must be > 0.
|
| 415 |
+
|
| 416 |
+
:attr:`kernel_generator` (:attr:`MinkowskiEngine.KernelGenerator`,
|
| 417 |
+
optional): define custom kernel shape.
|
| 418 |
+
|
| 419 |
+
:attr:`dimension` (int): the spatial dimension of the space where
|
| 420 |
+
all the inputs and the network are defined. For example, images are
|
| 421 |
+
in a 2D space, meshes and 3D shapes are in a 3D space.
|
| 422 |
+
|
| 423 |
+
.. warning::
|
| 424 |
+
|
| 425 |
+
Custom kernel shapes are not supported when kernel_size == stride.
|
| 426 |
+
|
| 427 |
+
"""
|
| 428 |
+
|
| 429 |
+
MinkowskiPoolingBase.__init__(
|
| 430 |
+
self,
|
| 431 |
+
kernel_size,
|
| 432 |
+
stride,
|
| 433 |
+
dilation,
|
| 434 |
+
kernel_generator,
|
| 435 |
+
is_transpose=False,
|
| 436 |
+
pooling_mode=PoolingMode.LOCAL_MAX_POOLING,
|
| 437 |
+
dimension=dimension,
|
| 438 |
+
)
|
| 439 |
+
|
| 440 |
+
|
| 441 |
+
class MinkowskiLocalPoolingTransposeFunction(Function):
|
| 442 |
+
@staticmethod
|
| 443 |
+
def forward(
|
| 444 |
+
ctx,
|
| 445 |
+
input_features: torch.Tensor,
|
| 446 |
+
pooling_mode: PoolingMode,
|
| 447 |
+
kernel_generator: KernelGenerator,
|
| 448 |
+
in_coordinate_map_key: CoordinateMapKey,
|
| 449 |
+
out_coordinate_map_key: CoordinateMapKey = None,
|
| 450 |
+
coordinate_manager: CoordinateManager = None,
|
| 451 |
+
):
|
| 452 |
+
if out_coordinate_map_key is None:
|
| 453 |
+
out_coordinate_map_key = CoordinateMapKey(
|
| 454 |
+
in_coordinate_map_key.get_coordinate_size()
|
| 455 |
+
)
|
| 456 |
+
|
| 457 |
+
input_features = input_features.contiguous()
|
| 458 |
+
ctx.input_features = input_features
|
| 459 |
+
ctx = save_ctx(
|
| 460 |
+
ctx,
|
| 461 |
+
kernel_generator,
|
| 462 |
+
in_coordinate_map_key,
|
| 463 |
+
out_coordinate_map_key,
|
| 464 |
+
coordinate_manager,
|
| 465 |
+
)
|
| 466 |
+
ctx.pooling_mode = pooling_mode
|
| 467 |
+
|
| 468 |
+
fw_fn = get_minkowski_function("LocalPoolingTransposeForward", input_features)
|
| 469 |
+
out_feat, num_nonzero = fw_fn(
|
| 470 |
+
ctx.input_features,
|
| 471 |
+
kernel_generator.kernel_size,
|
| 472 |
+
kernel_generator.kernel_stride,
|
| 473 |
+
kernel_generator.kernel_dilation,
|
| 474 |
+
kernel_generator.region_type,
|
| 475 |
+
kernel_generator.region_offsets,
|
| 476 |
+
kernel_generator.expand_coordinates,
|
| 477 |
+
pooling_mode,
|
| 478 |
+
ctx.in_coordinate_map_key,
|
| 479 |
+
ctx.out_coordinate_map_key,
|
| 480 |
+
ctx.coordinate_manager._manager,
|
| 481 |
+
)
|
| 482 |
+
ctx.num_nonzero = num_nonzero
|
| 483 |
+
return out_feat
|
| 484 |
+
|
| 485 |
+
@staticmethod
|
| 486 |
+
def backward(ctx, grad_out_feat):
|
| 487 |
+
grad_out_feat = grad_out_feat.contiguous()
|
| 488 |
+
bw_fn = get_minkowski_function("LocalPoolingTransposeBackward", grad_out_feat)
|
| 489 |
+
grad_in_feat = bw_fn(
|
| 490 |
+
ctx.input_features,
|
| 491 |
+
grad_out_feat,
|
| 492 |
+
ctx.num_nonzero,
|
| 493 |
+
ctx.kernel_generator.kernel_size,
|
| 494 |
+
ctx.kernel_generator.kernel_stride,
|
| 495 |
+
ctx.kernel_generator.kernel_dilation,
|
| 496 |
+
ctx.kernel_generator.region_type,
|
| 497 |
+
ctx.kernel_generator.region_offsets,
|
| 498 |
+
ctx.pooling_mode,
|
| 499 |
+
ctx.in_coordinate_map_key,
|
| 500 |
+
ctx.out_coordinate_map_key,
|
| 501 |
+
ctx.coordinate_manager._manager,
|
| 502 |
+
)
|
| 503 |
+
return (
|
| 504 |
+
grad_in_feat,
|
| 505 |
+
None,
|
| 506 |
+
None,
|
| 507 |
+
None,
|
| 508 |
+
None,
|
| 509 |
+
None,
|
| 510 |
+
)
|
| 511 |
+
|
| 512 |
+
|
| 513 |
+
class MinkowskiPoolingTranspose(MinkowskiPoolingBase):
|
| 514 |
+
r"""A pooling transpose layer for a sparse tensor.
|
| 515 |
+
|
| 516 |
+
Unpool the features and divide it by the number of non zero elements that
|
| 517 |
+
contributed.
|
| 518 |
+
"""
|
| 519 |
+
|
| 520 |
+
def __init__(
|
| 521 |
+
self,
|
| 522 |
+
kernel_size,
|
| 523 |
+
stride,
|
| 524 |
+
dilation=1,
|
| 525 |
+
kernel_generator=None,
|
| 526 |
+
expand_coordinates=False,
|
| 527 |
+
dimension=None,
|
| 528 |
+
):
|
| 529 |
+
r"""a high-dimensional unpooling layer for sparse tensors.
|
| 530 |
+
|
| 531 |
+
Args:
|
| 532 |
+
:attr:`kernel_size` (int, optional): the size of the kernel in the
|
| 533 |
+
output tensor. If not provided, :attr:`region_offset` should be
|
| 534 |
+
:attr:`RegionType.CUSTOM` and :attr:`region_offset` should be a 2D
|
| 535 |
+
matrix with size :math:`N\times D` such that it lists all :math:`N`
|
| 536 |
+
offsets in D-dimension.
|
| 537 |
+
|
| 538 |
+
:attr:`stride` (int, or list, optional): stride size of the
|
| 539 |
+
convolution layer. If non-identity is used, the output coordinates
|
| 540 |
+
will be at least :attr:`stride` :math:`\times` :attr:`tensor_stride`
|
| 541 |
+
away. When a list is given, the length must be D; each element will
|
| 542 |
+
be used for stride size for the specific axis.
|
| 543 |
+
|
| 544 |
+
:attr:`dilation` (int, or list, optional): dilation size for the
|
| 545 |
+
convolution kernel. When a list is given, the length must be D and
|
| 546 |
+
each element is an axis specific dilation. All elements must be > 0.
|
| 547 |
+
|
| 548 |
+
:attr:`kernel_generator` (:attr:`MinkowskiEngine.KernelGenerator`,
|
| 549 |
+
optional): define custom kernel shape.
|
| 550 |
+
|
| 551 |
+
:attr:`expand_coordinates` (bool, optional): Force generation of
|
| 552 |
+
new coordinates. When True, the output coordinates will be the
|
| 553 |
+
outer product of the kernel shape and the input coordinates.
|
| 554 |
+
`False` by default.
|
| 555 |
+
|
| 556 |
+
:attr:`dimension` (int): the spatial dimension of the space where
|
| 557 |
+
all the inputs and the network are defined. For example, images are
|
| 558 |
+
in a 2D space, meshes and 3D shapes are in a 3D space.
|
| 559 |
+
|
| 560 |
+
"""
|
| 561 |
+
is_transpose = True
|
| 562 |
+
if kernel_generator is None:
|
| 563 |
+
kernel_generator = KernelGenerator(
|
| 564 |
+
kernel_size=kernel_size,
|
| 565 |
+
stride=stride,
|
| 566 |
+
dilation=dilation,
|
| 567 |
+
expand_coordinates=expand_coordinates,
|
| 568 |
+
dimension=dimension,
|
| 569 |
+
)
|
| 570 |
+
|
| 571 |
+
MinkowskiPoolingBase.__init__(
|
| 572 |
+
self,
|
| 573 |
+
kernel_size,
|
| 574 |
+
stride,
|
| 575 |
+
dilation,
|
| 576 |
+
kernel_generator,
|
| 577 |
+
is_transpose,
|
| 578 |
+
dimension=dimension,
|
| 579 |
+
)
|
| 580 |
+
self.pooling = MinkowskiLocalPoolingTransposeFunction()
|
| 581 |
+
|
| 582 |
+
|
| 583 |
+
class MinkowskiGlobalPoolingFunction(Function):
|
| 584 |
+
@staticmethod
|
| 585 |
+
def forward(
|
| 586 |
+
ctx,
|
| 587 |
+
input_features: torch.Tensor,
|
| 588 |
+
pooling_mode: PoolingMode,
|
| 589 |
+
in_coordinate_map_key: CoordinateMapKey,
|
| 590 |
+
out_coordinate_map_key: CoordinateMapKey = None,
|
| 591 |
+
coordinate_manager: CoordinateManager = None,
|
| 592 |
+
):
|
| 593 |
+
if out_coordinate_map_key is None:
|
| 594 |
+
out_coordinate_map_key = CoordinateMapKey(
|
| 595 |
+
in_coordinate_map_key.get_coordinate_size()
|
| 596 |
+
)
|
| 597 |
+
input_features = input_features.contiguous()
|
| 598 |
+
|
| 599 |
+
ctx.input_features = input_features
|
| 600 |
+
ctx.in_coords_key = in_coordinate_map_key
|
| 601 |
+
ctx.out_coords_key = out_coordinate_map_key
|
| 602 |
+
ctx.coordinate_manager = coordinate_manager
|
| 603 |
+
ctx.pooling_mode = pooling_mode
|
| 604 |
+
|
| 605 |
+
fw_fn = get_minkowski_function("GlobalPoolingForward", input_features)
|
| 606 |
+
out_feat, num_nonzero = fw_fn(
|
| 607 |
+
input_features,
|
| 608 |
+
pooling_mode,
|
| 609 |
+
ctx.in_coords_key,
|
| 610 |
+
ctx.out_coords_key,
|
| 611 |
+
ctx.coordinate_manager._manager,
|
| 612 |
+
)
|
| 613 |
+
ctx.num_nonzero = num_nonzero
|
| 614 |
+
return out_feat
|
| 615 |
+
|
| 616 |
+
@staticmethod
|
| 617 |
+
def backward(ctx, grad_out_feat):
|
| 618 |
+
grad_out_feat = grad_out_feat.contiguous()
|
| 619 |
+
bw_fn = get_minkowski_function("GlobalPoolingBackward", grad_out_feat)
|
| 620 |
+
grad_in_feat = bw_fn(
|
| 621 |
+
ctx.input_features,
|
| 622 |
+
grad_out_feat,
|
| 623 |
+
ctx.num_nonzero,
|
| 624 |
+
ctx.pooling_mode,
|
| 625 |
+
ctx.in_coords_key,
|
| 626 |
+
ctx.out_coords_key,
|
| 627 |
+
ctx.coordinate_manager._manager,
|
| 628 |
+
)
|
| 629 |
+
return grad_in_feat, None, None, None, None, None
|
| 630 |
+
|
| 631 |
+
|
| 632 |
+
class MinkowskiGlobalPooling(MinkowskiModuleBase):
|
| 633 |
+
r"""Pool all input features to one output."""
|
| 634 |
+
|
| 635 |
+
def __init__(
|
| 636 |
+
self, mode: PoolingMode = PoolingMode.GLOBAL_AVG_POOLING_PYTORCH_INDEX
|
| 637 |
+
):
|
| 638 |
+
r"""Reduces sparse coords into points at origin, i.e. reduce each point
|
| 639 |
+
cloud into a point at the origin, returning batch_size number of points
|
| 640 |
+
[[0, 0, ..., 0], [0, 0, ..., 1],, [0, 0, ..., 2]] where the last elem
|
| 641 |
+
of the coords is the batch index. The reduction function should be
|
| 642 |
+
provided as the mode.
|
| 643 |
+
|
| 644 |
+
Args:
|
| 645 |
+
:attr:`mode` (PoolingMode): Reduction function mode. E.g.
|
| 646 |
+
`PoolingMode.GLOBAL_SUM_POOLING_DEFAULT`
|
| 647 |
+
|
| 648 |
+
"""
|
| 649 |
+
super(MinkowskiGlobalPooling, self).__init__()
|
| 650 |
+
assert isinstance(
|
| 651 |
+
mode, PoolingMode
|
| 652 |
+
), f"Mode must be an instance of PoolingMode. mode={mode}"
|
| 653 |
+
|
| 654 |
+
self.pooling_mode = mode
|
| 655 |
+
self.pooling = MinkowskiGlobalPoolingFunction()
|
| 656 |
+
|
| 657 |
+
def forward(
|
| 658 |
+
self,
|
| 659 |
+
input: SparseTensor,
|
| 660 |
+
coordinates: Union[torch.IntTensor, CoordinateMapKey, SparseTensor] = None,
|
| 661 |
+
):
|
| 662 |
+
# Get a new coordinate map key or extract one from the coordinates
|
| 663 |
+
out_coordinate_map_key = _get_coordinate_map_key(input, coordinates)
|
| 664 |
+
output = self.pooling.apply(
|
| 665 |
+
input.F,
|
| 666 |
+
self.pooling_mode,
|
| 667 |
+
input.coordinate_map_key,
|
| 668 |
+
out_coordinate_map_key,
|
| 669 |
+
input._manager,
|
| 670 |
+
)
|
| 671 |
+
|
| 672 |
+
return SparseTensor(
|
| 673 |
+
output,
|
| 674 |
+
coordinate_map_key=out_coordinate_map_key,
|
| 675 |
+
coordinate_manager=input.coordinate_manager,
|
| 676 |
+
)
|
| 677 |
+
|
| 678 |
+
def __repr__(self):
|
| 679 |
+
return self.__class__.__name__ + f"(mode={str(self.pooling_mode)})"
|
| 680 |
+
|
| 681 |
+
|
| 682 |
+
class MinkowskiGlobalSumPooling(MinkowskiGlobalPooling):
|
| 683 |
+
def __init__(self, mode=PoolingMode.GLOBAL_SUM_POOLING_PYTORCH_INDEX):
|
| 684 |
+
r"""Reduces sparse coords into points at origin, i.e. reduce each point
|
| 685 |
+
cloud into a point at the origin, returning batch_size number of points
|
| 686 |
+
[[0, 0, ..., 0], [0, 0, ..., 1],, [0, 0, ..., 2]] where the last elem
|
| 687 |
+
of the coords is the batch index.
|
| 688 |
+
|
| 689 |
+
"""
|
| 690 |
+
MinkowskiGlobalPooling.__init__(self, mode=mode)
|
| 691 |
+
|
| 692 |
+
|
| 693 |
+
class MinkowskiGlobalAvgPooling(MinkowskiGlobalPooling):
|
| 694 |
+
def __init__(self, mode=PoolingMode.GLOBAL_AVG_POOLING_PYTORCH_INDEX):
|
| 695 |
+
r"""Reduces sparse coords into points at origin, i.e. reduce each point
|
| 696 |
+
cloud into a point at the origin, returning batch_size number of points
|
| 697 |
+
[[0, 0, ..., 0], [0, 0, ..., 1],, [0, 0, ..., 2]] where the last elem
|
| 698 |
+
of the coords is the batch index.
|
| 699 |
+
|
| 700 |
+
"""
|
| 701 |
+
MinkowskiGlobalPooling.__init__(self, mode=mode)
|
| 702 |
+
|
| 703 |
+
|
| 704 |
+
class MinkowskiGlobalMaxPooling(MinkowskiGlobalPooling):
|
| 705 |
+
r"""Max pool all input features to one output feature at the origin.
|
| 706 |
+
|
| 707 |
+
.. math::
|
| 708 |
+
|
| 709 |
+
\mathbf{y} = \max_{\mathbf{i} \in
|
| 710 |
+
\mathcal{C}^\text{in}} \mathbf{x}_{\mathbf{i}}
|
| 711 |
+
|
| 712 |
+
"""
|
| 713 |
+
|
| 714 |
+
def __init__(self, mode=PoolingMode.GLOBAL_MAX_POOLING_PYTORCH_INDEX):
|
| 715 |
+
r"""Reduces sparse coords into points at origin, i.e. reduce each point
|
| 716 |
+
cloud into a point at the origin, returning batch_size number of points
|
| 717 |
+
[[0, 0, ..., 0], [0, 0, ..., 1],, [0, 0, ..., 2]] where the last elem
|
| 718 |
+
of the coords is the batch index.
|
| 719 |
+
|
| 720 |
+
"""
|
| 721 |
+
MinkowskiGlobalPooling.__init__(self, mode=mode)
|
| 722 |
+
|
| 723 |
+
def forward(
|
| 724 |
+
self,
|
| 725 |
+
input,
|
| 726 |
+
coordinates: Union[torch.IntTensor, CoordinateMapKey, SparseTensor] = None,
|
| 727 |
+
):
|
| 728 |
+
# Get a new coordinate map key or extract one from the coordinates
|
| 729 |
+
if isinstance(input, ME.TensorField):
|
| 730 |
+
in_coordinate_map_key = input.coordinate_field_map_key
|
| 731 |
+
out_coordinate_map_key = CoordinateMapKey(
|
| 732 |
+
input.coordinate_field_map_key.get_coordinate_size()
|
| 733 |
+
)
|
| 734 |
+
else:
|
| 735 |
+
in_coordinate_map_key = input.coordinate_map_key
|
| 736 |
+
out_coordinate_map_key = _get_coordinate_map_key(input, coordinates)
|
| 737 |
+
output = self.pooling.apply(
|
| 738 |
+
input.F,
|
| 739 |
+
self.pooling_mode,
|
| 740 |
+
in_coordinate_map_key,
|
| 741 |
+
out_coordinate_map_key,
|
| 742 |
+
input._manager,
|
| 743 |
+
)
|
| 744 |
+
|
| 745 |
+
return SparseTensor(
|
| 746 |
+
output,
|
| 747 |
+
coordinate_map_key=out_coordinate_map_key,
|
| 748 |
+
coordinate_manager=input.coordinate_manager,
|
| 749 |
+
)
|
| 750 |
+
|
| 751 |
+
|
| 752 |
+
class MinkowskiDirectMaxPoolingFunction(Function):
|
| 753 |
+
@staticmethod
|
| 754 |
+
def forward(
|
| 755 |
+
ctx,
|
| 756 |
+
in_map: torch.Tensor,
|
| 757 |
+
out_map: torch.Tensor,
|
| 758 |
+
in_feat: torch.Tensor,
|
| 759 |
+
out_nrows: int,
|
| 760 |
+
is_sorted: bool = False,
|
| 761 |
+
):
|
| 762 |
+
out_feat, max_mask = _C.direct_max_pool_fw(
|
| 763 |
+
in_map, out_map, in_feat, out_nrows, is_sorted
|
| 764 |
+
)
|
| 765 |
+
ctx.in_nrows = in_feat.size(0)
|
| 766 |
+
ctx.save_for_backward(max_mask)
|
| 767 |
+
return out_feat
|
| 768 |
+
|
| 769 |
+
@staticmethod
|
| 770 |
+
def backward(ctx, grad_out_feat):
|
| 771 |
+
grad_out_feat = grad_out_feat.contiguous()
|
| 772 |
+
max_mask = ctx.saved_tensors[0]
|
| 773 |
+
grad = _C.direct_max_pool_bw(grad_out_feat, max_mask, ctx.in_nrows)
|
| 774 |
+
return (
|
| 775 |
+
None,
|
| 776 |
+
None,
|
| 777 |
+
grad,
|
| 778 |
+
None,
|
| 779 |
+
None,
|
| 780 |
+
)
|
MinkowskiEngine/MinkowskiEngine/MinkowskiPruning.py
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
import torch
|
| 26 |
+
from torch.nn import Module
|
| 27 |
+
from torch.autograd import Function
|
| 28 |
+
|
| 29 |
+
from MinkowskiEngineBackend._C import CoordinateMapKey
|
| 30 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 31 |
+
from MinkowskiCommon import (
|
| 32 |
+
MinkowskiModuleBase,
|
| 33 |
+
get_minkowski_function,
|
| 34 |
+
)
|
| 35 |
+
from MinkowskiCoordinateManager import CoordinateManager
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class MinkowskiPruningFunction(Function):
|
| 39 |
+
@staticmethod
|
| 40 |
+
def forward(
|
| 41 |
+
ctx,
|
| 42 |
+
in_feat: torch.Tensor,
|
| 43 |
+
mask: torch.Tensor,
|
| 44 |
+
in_coords_key: CoordinateMapKey,
|
| 45 |
+
out_coords_key: CoordinateMapKey = None,
|
| 46 |
+
coords_manager: CoordinateManager = None,
|
| 47 |
+
):
|
| 48 |
+
ctx.in_coords_key = in_coords_key
|
| 49 |
+
ctx.out_coords_key = out_coords_key
|
| 50 |
+
ctx.coords_manager = coords_manager
|
| 51 |
+
|
| 52 |
+
in_feat = in_feat.contiguous()
|
| 53 |
+
fw_fn = get_minkowski_function("PruningForward", in_feat)
|
| 54 |
+
return fw_fn(
|
| 55 |
+
in_feat,
|
| 56 |
+
mask,
|
| 57 |
+
ctx.in_coords_key,
|
| 58 |
+
ctx.out_coords_key,
|
| 59 |
+
ctx.coords_manager._manager,
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
@staticmethod
|
| 63 |
+
def backward(ctx, grad_out_feat: torch.Tensor):
|
| 64 |
+
grad_out_feat = grad_out_feat.contiguous()
|
| 65 |
+
bw_fn = get_minkowski_function("PruningBackward", grad_out_feat)
|
| 66 |
+
grad_in_feat = bw_fn(
|
| 67 |
+
grad_out_feat,
|
| 68 |
+
ctx.in_coords_key,
|
| 69 |
+
ctx.out_coords_key,
|
| 70 |
+
ctx.coords_manager._manager,
|
| 71 |
+
)
|
| 72 |
+
return grad_in_feat, None, None, None, None
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class MinkowskiPruning(MinkowskiModuleBase):
|
| 76 |
+
r"""Remove specified coordinates from a :attr:`MinkowskiEngine.SparseTensor`.
|
| 77 |
+
|
| 78 |
+
"""
|
| 79 |
+
|
| 80 |
+
def __init__(self):
|
| 81 |
+
super(MinkowskiPruning, self).__init__()
|
| 82 |
+
self.pruning = MinkowskiPruningFunction()
|
| 83 |
+
|
| 84 |
+
def forward(self, input: SparseTensor, mask: torch.Tensor):
|
| 85 |
+
r"""
|
| 86 |
+
Args:
|
| 87 |
+
:attr:`input` (:attr:`MinkowskiEnigne.SparseTensor`): a sparse tensor
|
| 88 |
+
to remove coordinates from.
|
| 89 |
+
|
| 90 |
+
:attr:`mask` (:attr:`torch.BoolTensor`): mask vector that specifies
|
| 91 |
+
which one to keep. Coordinates with False will be removed.
|
| 92 |
+
|
| 93 |
+
Returns:
|
| 94 |
+
A :attr:`MinkowskiEngine.SparseTensor` with C = coordinates
|
| 95 |
+
corresponding to `mask == True` F = copy of the features from `mask ==
|
| 96 |
+
True`.
|
| 97 |
+
|
| 98 |
+
Example::
|
| 99 |
+
|
| 100 |
+
>>> # Define inputs
|
| 101 |
+
>>> input = SparseTensor(feats, coords=coords)
|
| 102 |
+
>>> # Any boolean tensor can be used as the filter
|
| 103 |
+
>>> mask = torch.rand(feats.size(0)) < 0.5
|
| 104 |
+
>>> pruning = MinkowskiPruning()
|
| 105 |
+
>>> output = pruning(input, mask)
|
| 106 |
+
|
| 107 |
+
"""
|
| 108 |
+
assert isinstance(input, SparseTensor)
|
| 109 |
+
|
| 110 |
+
out_coords_key = CoordinateMapKey(
|
| 111 |
+
input.coordinate_map_key.get_coordinate_size()
|
| 112 |
+
)
|
| 113 |
+
output = self.pruning.apply(
|
| 114 |
+
input.F, mask, input.coordinate_map_key, out_coords_key, input._manager
|
| 115 |
+
)
|
| 116 |
+
return SparseTensor(
|
| 117 |
+
output, coordinate_map_key=out_coords_key, coordinate_manager=input._manager
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
def __repr__(self):
|
| 121 |
+
return self.__class__.__name__ + "()"
|
MinkowskiEngine/MinkowskiEngine/MinkowskiSparseTensor.py
ADDED
|
@@ -0,0 +1,783 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
import os
|
| 26 |
+
import torch
|
| 27 |
+
import warnings
|
| 28 |
+
|
| 29 |
+
from MinkowskiCommon import convert_to_int_list, StrideType
|
| 30 |
+
from MinkowskiEngineBackend._C import (
|
| 31 |
+
CoordinateMapKey,
|
| 32 |
+
CoordinateMapType,
|
| 33 |
+
GPUMemoryAllocatorType,
|
| 34 |
+
MinkowskiAlgorithm,
|
| 35 |
+
)
|
| 36 |
+
from MinkowskiTensor import (
|
| 37 |
+
SparseTensorQuantizationMode,
|
| 38 |
+
SparseTensorOperationMode,
|
| 39 |
+
Tensor,
|
| 40 |
+
sparse_tensor_operation_mode,
|
| 41 |
+
global_coordinate_manager,
|
| 42 |
+
set_global_coordinate_manager,
|
| 43 |
+
)
|
| 44 |
+
from MinkowskiCoordinateManager import CoordinateManager
|
| 45 |
+
from sparse_matrix_functions import MinkowskiSPMMFunction, MinkowskiSPMMAverageFunction
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class SparseTensor(Tensor):
|
| 49 |
+
r"""A sparse tensor class. Can be accessed via
|
| 50 |
+
:attr:`MinkowskiEngine.SparseTensor`.
|
| 51 |
+
|
| 52 |
+
The :attr:`SparseTensor` class is the basic tensor in MinkowskiEngine. For
|
| 53 |
+
the definition of a sparse tensor, please visit `the terminology page
|
| 54 |
+
<https://nvidia.github.io/MinkowskiEngine/terminology.html#sparse-tensor>`_.
|
| 55 |
+
We use the COOrdinate (COO) format to save a sparse tensor `[1]
|
| 56 |
+
<http://groups.csail.mit.edu/commit/papers/2016/parker-thesis.pdf>`_. This
|
| 57 |
+
representation is simply a concatenation of coordinates in a matrix
|
| 58 |
+
:math:`C` and associated features :math:`F`.
|
| 59 |
+
|
| 60 |
+
.. math::
|
| 61 |
+
|
| 62 |
+
\mathbf{C} = \begin{bmatrix}
|
| 63 |
+
b_1 & x_1^1 & x_1^2 & \cdots & x_1^D \\
|
| 64 |
+
\vdots & \vdots & \vdots & \ddots & \vdots \\
|
| 65 |
+
b_N & x_N^1 & x_N^2 & \cdots & x_N^D
|
| 66 |
+
\end{bmatrix}, \; \mathbf{F} = \begin{bmatrix}
|
| 67 |
+
\mathbf{f}_1^T\\
|
| 68 |
+
\vdots\\
|
| 69 |
+
\mathbf{f}_N^T
|
| 70 |
+
\end{bmatrix}
|
| 71 |
+
|
| 72 |
+
where :math:`\mathbf{x}_i \in \mathcal{Z}^D` is a :math:`D`-dimensional
|
| 73 |
+
coordinate and :math:`b_i \in \mathcal{Z}_+` denotes the corresponding
|
| 74 |
+
batch index. :math:`N` is the number of non-zero elements in the sparse
|
| 75 |
+
tensor, each with the coordinate :math:`(b_i, x_i^1, x_i^1, \cdots,
|
| 76 |
+
x_i^D)`, and the associated feature :math:`\mathbf{f}_i`. Internally, we
|
| 77 |
+
handle the batch index as an additional spatial dimension.
|
| 78 |
+
|
| 79 |
+
Example::
|
| 80 |
+
|
| 81 |
+
>>> coords, feats = ME.utils.sparse_collate([coords_batch0, coords_batch1], [feats_batch0, feats_batch1])
|
| 82 |
+
>>> A = ME.SparseTensor(features=feats, coordinates=coords)
|
| 83 |
+
>>> B = ME.SparseTensor(features=feats, coordinate_map_key=A.coordiante_map_key, coordinate_manager=A.coordinate_manager)
|
| 84 |
+
>>> C = ME.SparseTensor(features=feats, coordinates=coords, quantization_mode=ME.SparseTensorQuantizationMode.UNWEIGHTED_AVERAGE)
|
| 85 |
+
>>> D = ME.SparseTensor(features=feats, coordinates=coords, quantization_mode=ME.SparseTensorQuantizationMode.RANDOM_SUBSAMPLE)
|
| 86 |
+
>>> E = ME.SparseTensor(features=feats, coordinates=coords, tensor_stride=2)
|
| 87 |
+
|
| 88 |
+
.. warning::
|
| 89 |
+
|
| 90 |
+
To use the GPU-backend for coordinate management, the
|
| 91 |
+
:attr:`coordinates` must be a torch tensor on GPU. Applying `to(device)`
|
| 92 |
+
after :attr:`MinkowskiEngine.SparseTensor` initialization with a CPU
|
| 93 |
+
`coordinates` will waste time and computation on creating an unnecessary
|
| 94 |
+
CPU CoordinateMap since the GPU CoordinateMap will be created from
|
| 95 |
+
scratch as well.
|
| 96 |
+
|
| 97 |
+
.. warning::
|
| 98 |
+
|
| 99 |
+
Before MinkowskiEngine version 0.4, we put the batch indices on the last
|
| 100 |
+
column. Thus, direct manipulation of coordinates will be incompatible
|
| 101 |
+
with the latest versions. Instead, please use
|
| 102 |
+
:attr:`MinkowskiEngine.utils.batched_coordinates` or
|
| 103 |
+
:attr:`MinkowskiEngine.utils.sparse_collate` to create batched
|
| 104 |
+
coordinates.
|
| 105 |
+
|
| 106 |
+
Also, to access coordinates or features batch-wise, use the functions
|
| 107 |
+
:attr:`coordinates_at(batch_index : int)`, :attr:`features_at(batch_index : int)` of
|
| 108 |
+
a sparse tensor. Or to access all batch-wise coordinates and features,
|
| 109 |
+
`decomposed_coordinates`, `decomposed_features`,
|
| 110 |
+
`decomposed_coordinates_and_features` of a sparse tensor.
|
| 111 |
+
|
| 112 |
+
Example::
|
| 113 |
+
|
| 114 |
+
>>> coords, feats = ME.utils.sparse_collate([coords_batch0, coords_batch1], [feats_batch0, feats_batch1])
|
| 115 |
+
>>> A = ME.SparseTensor(features=feats, coordinates=coords)
|
| 116 |
+
>>> coords_batch0 = A.coordinates_at(batch_index=0)
|
| 117 |
+
>>> feats_batch1 = A.features_at(batch_index=1)
|
| 118 |
+
>>> list_of_coords, list_of_featurs = A.decomposed_coordinates_and_features
|
| 119 |
+
|
| 120 |
+
"""
|
| 121 |
+
|
| 122 |
+
def __init__(
|
| 123 |
+
self,
|
| 124 |
+
features: torch.Tensor,
|
| 125 |
+
coordinates: torch.Tensor = None,
|
| 126 |
+
# optional coordinate related arguments
|
| 127 |
+
tensor_stride: StrideType = 1,
|
| 128 |
+
coordinate_map_key: CoordinateMapKey = None,
|
| 129 |
+
coordinate_manager: CoordinateManager = None,
|
| 130 |
+
quantization_mode: SparseTensorQuantizationMode = SparseTensorQuantizationMode.RANDOM_SUBSAMPLE,
|
| 131 |
+
# optional manager related arguments
|
| 132 |
+
allocator_type: GPUMemoryAllocatorType = None,
|
| 133 |
+
minkowski_algorithm: MinkowskiAlgorithm = None,
|
| 134 |
+
requires_grad=None,
|
| 135 |
+
device=None,
|
| 136 |
+
):
|
| 137 |
+
r"""
|
| 138 |
+
|
| 139 |
+
Args:
|
| 140 |
+
:attr:`features` (:attr:`torch.FloatTensor`,
|
| 141 |
+
:attr:`torch.DoubleTensor`, :attr:`torch.cuda.FloatTensor`, or
|
| 142 |
+
:attr:`torch.cuda.DoubleTensor`): The features of a sparse
|
| 143 |
+
tensor.
|
| 144 |
+
|
| 145 |
+
:attr:`coordinates` (:attr:`torch.IntTensor`): The coordinates
|
| 146 |
+
associated to the features. If not provided, :attr:`coordinate_map_key`
|
| 147 |
+
must be provided.
|
| 148 |
+
|
| 149 |
+
:attr:`tensor_stride` (:attr:`int`, :attr:`list`,
|
| 150 |
+
:attr:`numpy.array`, or :attr:`tensor.Tensor`): The tensor stride
|
| 151 |
+
of the current sparse tensor. By default, it is 1.
|
| 152 |
+
|
| 153 |
+
:attr:`coordinate_map_key`
|
| 154 |
+
(:attr:`MinkowskiEngine.CoordinateMapKey`): When the coordinates
|
| 155 |
+
are already cached in the MinkowskiEngine, we could reuse the same
|
| 156 |
+
coordinate map by simply providing the coordinate map key. In most
|
| 157 |
+
case, this process is done automatically. When you provide a
|
| 158 |
+
`coordinate_map_key`, `coordinates` will be be ignored.
|
| 159 |
+
|
| 160 |
+
:attr:`coordinate_manager`
|
| 161 |
+
(:attr:`MinkowskiEngine.CoordinateManager`): The MinkowskiEngine
|
| 162 |
+
manages all coordinate maps using the `_C.CoordinateMapManager`. If
|
| 163 |
+
not provided, the MinkowskiEngine will create a new computation
|
| 164 |
+
graph. In most cases, this process is handled automatically and you
|
| 165 |
+
do not need to use this.
|
| 166 |
+
|
| 167 |
+
:attr:`quantization_mode`
|
| 168 |
+
(:attr:`MinkowskiEngine.SparseTensorQuantizationMode`): Defines how
|
| 169 |
+
continuous coordinates will be quantized to define a sparse tensor.
|
| 170 |
+
Please refer to :attr:`SparseTensorQuantizationMode` for details.
|
| 171 |
+
|
| 172 |
+
:attr:`allocator_type`
|
| 173 |
+
(:attr:`MinkowskiEngine.GPUMemoryAllocatorType`): Defines the GPU
|
| 174 |
+
memory allocator type. By default, it uses the c10 allocator.
|
| 175 |
+
|
| 176 |
+
:attr:`minkowski_algorithm`
|
| 177 |
+
(:attr:`MinkowskiEngine.MinkowskiAlgorithm`): Controls the mode the
|
| 178 |
+
minkowski engine runs, Use
|
| 179 |
+
:attr:`MinkowskiAlgorithm.MEMORY_EFFICIENT` if you want to reduce
|
| 180 |
+
the memory footprint. Or use
|
| 181 |
+
:attr:`MinkowskiAlgorithm.SPEED_OPTIMIZED` if you want to make it
|
| 182 |
+
run fasterat the cost of more memory.
|
| 183 |
+
|
| 184 |
+
:attr:`requires_grad` (:attr:`bool`): Set the requires_grad flag.
|
| 185 |
+
|
| 186 |
+
:attr:`device` (:attr:`torch.device`): Set the device the sparse
|
| 187 |
+
tensor is defined.
|
| 188 |
+
|
| 189 |
+
"""
|
| 190 |
+
# Type checks
|
| 191 |
+
assert isinstance(features, torch.Tensor), "Features must be a torch.Tensor"
|
| 192 |
+
assert (
|
| 193 |
+
features.ndim == 2
|
| 194 |
+
), f"The feature should be a matrix, The input feature is an order-{features.ndim} tensor."
|
| 195 |
+
assert isinstance(quantization_mode, SparseTensorQuantizationMode)
|
| 196 |
+
self.quantization_mode = quantization_mode
|
| 197 |
+
|
| 198 |
+
if coordinates is not None:
|
| 199 |
+
assert isinstance(coordinates, torch.Tensor)
|
| 200 |
+
if coordinate_map_key is not None:
|
| 201 |
+
assert isinstance(coordinate_map_key, CoordinateMapKey)
|
| 202 |
+
assert (
|
| 203 |
+
coordinate_manager is not None
|
| 204 |
+
), "Must provide coordinate_manager if coordinate_map_key is provided"
|
| 205 |
+
assert (
|
| 206 |
+
coordinates is None
|
| 207 |
+
), "Must not provide coordinates if coordinate_map_key is provided"
|
| 208 |
+
if coordinate_manager is not None:
|
| 209 |
+
assert isinstance(coordinate_manager, CoordinateManager)
|
| 210 |
+
if coordinates is None and (
|
| 211 |
+
coordinate_map_key is None or coordinate_manager is None
|
| 212 |
+
):
|
| 213 |
+
raise ValueError(
|
| 214 |
+
"Either coordinates or (coordinate_map_key, coordinate_manager) pair must be provided."
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
Tensor.__init__(self)
|
| 218 |
+
|
| 219 |
+
# To device
|
| 220 |
+
if device is not None:
|
| 221 |
+
features = features.to(device)
|
| 222 |
+
if coordinates is not None:
|
| 223 |
+
# assertion check for the map key done later
|
| 224 |
+
coordinates = coordinates.to(device)
|
| 225 |
+
|
| 226 |
+
self._D = (
|
| 227 |
+
coordinates.size(1) - 1 if coordinates is not None else coordinate_manager.D
|
| 228 |
+
)
|
| 229 |
+
##########################
|
| 230 |
+
# Setup CoordsManager
|
| 231 |
+
##########################
|
| 232 |
+
if coordinate_manager is None:
|
| 233 |
+
# If set to share the coords man, use the global coords man
|
| 234 |
+
if (
|
| 235 |
+
sparse_tensor_operation_mode()
|
| 236 |
+
== SparseTensorOperationMode.SHARE_COORDINATE_MANAGER
|
| 237 |
+
):
|
| 238 |
+
coordinate_manager = global_coordinate_manager()
|
| 239 |
+
if coordinate_manager is None:
|
| 240 |
+
coordinate_manager = CoordinateManager(
|
| 241 |
+
D=self._D,
|
| 242 |
+
coordinate_map_type=CoordinateMapType.CUDA
|
| 243 |
+
if coordinates.is_cuda
|
| 244 |
+
else CoordinateMapType.CPU,
|
| 245 |
+
allocator_type=allocator_type,
|
| 246 |
+
minkowski_algorithm=minkowski_algorithm,
|
| 247 |
+
)
|
| 248 |
+
set_global_coordinate_manager(coordinate_manager)
|
| 249 |
+
else:
|
| 250 |
+
coordinate_manager = CoordinateManager(
|
| 251 |
+
D=coordinates.size(1) - 1,
|
| 252 |
+
coordinate_map_type=CoordinateMapType.CUDA
|
| 253 |
+
if coordinates.is_cuda
|
| 254 |
+
else CoordinateMapType.CPU,
|
| 255 |
+
allocator_type=allocator_type,
|
| 256 |
+
minkowski_algorithm=minkowski_algorithm,
|
| 257 |
+
)
|
| 258 |
+
self._manager = coordinate_manager
|
| 259 |
+
|
| 260 |
+
##########################
|
| 261 |
+
# Initialize coords
|
| 262 |
+
##########################
|
| 263 |
+
if coordinates is not None:
|
| 264 |
+
assert (
|
| 265 |
+
features.shape[0] == coordinates.shape[0]
|
| 266 |
+
), "The number of rows in features and coordinates must match."
|
| 267 |
+
|
| 268 |
+
assert (
|
| 269 |
+
features.is_cuda == coordinates.is_cuda
|
| 270 |
+
), "Features and coordinates must have the same backend."
|
| 271 |
+
|
| 272 |
+
coordinate_map_key = CoordinateMapKey(
|
| 273 |
+
convert_to_int_list(tensor_stride, self._D), ""
|
| 274 |
+
)
|
| 275 |
+
coordinates, features, coordinate_map_key = self.initialize_coordinates(
|
| 276 |
+
coordinates, features, coordinate_map_key
|
| 277 |
+
)
|
| 278 |
+
else: # coordinate_map_key is not None:
|
| 279 |
+
assert coordinate_map_key.is_key_set(), "The coordinate key must be valid."
|
| 280 |
+
|
| 281 |
+
if requires_grad is not None:
|
| 282 |
+
features.requires_grad_(requires_grad)
|
| 283 |
+
|
| 284 |
+
self._F = features
|
| 285 |
+
self._C = coordinates
|
| 286 |
+
self.coordinate_map_key = coordinate_map_key
|
| 287 |
+
self._batch_rows = None
|
| 288 |
+
|
| 289 |
+
@property
|
| 290 |
+
def coordinate_key(self):
|
| 291 |
+
return self.coordinate_map_key
|
| 292 |
+
|
| 293 |
+
def initialize_coordinates(self, coordinates, features, coordinate_map_key):
|
| 294 |
+
if not isinstance(coordinates, (torch.IntTensor, torch.cuda.IntTensor)):
|
| 295 |
+
warnings.warn(
|
| 296 |
+
"coordinates implicitly converted to torch.IntTensor. "
|
| 297 |
+
+ "To remove this warning, use `.int()` to convert the "
|
| 298 |
+
+ "coords into an torch.IntTensor"
|
| 299 |
+
)
|
| 300 |
+
coordinates = torch.floor(coordinates).int()
|
| 301 |
+
(
|
| 302 |
+
coordinate_map_key,
|
| 303 |
+
(unique_index, inverse_mapping),
|
| 304 |
+
) = self._manager.insert_and_map(coordinates, *coordinate_map_key.get_key())
|
| 305 |
+
self.unique_index = unique_index.long()
|
| 306 |
+
coordinates = coordinates[self.unique_index]
|
| 307 |
+
|
| 308 |
+
if len(inverse_mapping) == 0:
|
| 309 |
+
# When the input has the same shape as the output
|
| 310 |
+
self.inverse_mapping = torch.arange(
|
| 311 |
+
len(features),
|
| 312 |
+
dtype=inverse_mapping.dtype,
|
| 313 |
+
device=inverse_mapping.device,
|
| 314 |
+
)
|
| 315 |
+
return coordinates, features, coordinate_map_key
|
| 316 |
+
|
| 317 |
+
self.inverse_mapping = inverse_mapping
|
| 318 |
+
if self.quantization_mode == SparseTensorQuantizationMode.UNWEIGHTED_SUM:
|
| 319 |
+
spmm = MinkowskiSPMMFunction()
|
| 320 |
+
N = len(features)
|
| 321 |
+
cols = torch.arange(
|
| 322 |
+
N,
|
| 323 |
+
dtype=self.inverse_mapping.dtype,
|
| 324 |
+
device=self.inverse_mapping.device,
|
| 325 |
+
)
|
| 326 |
+
vals = torch.ones(N, dtype=features.dtype, device=features.device)
|
| 327 |
+
size = torch.Size([len(self.unique_index), len(self.inverse_mapping)])
|
| 328 |
+
features = spmm.apply(self.inverse_mapping, cols, vals, size, features)
|
| 329 |
+
elif self.quantization_mode == SparseTensorQuantizationMode.UNWEIGHTED_AVERAGE:
|
| 330 |
+
spmm_avg = MinkowskiSPMMAverageFunction()
|
| 331 |
+
N = len(features)
|
| 332 |
+
cols = torch.arange(
|
| 333 |
+
N,
|
| 334 |
+
dtype=self.inverse_mapping.dtype,
|
| 335 |
+
device=self.inverse_mapping.device,
|
| 336 |
+
)
|
| 337 |
+
size = torch.Size([len(self.unique_index), len(self.inverse_mapping)])
|
| 338 |
+
features = spmm_avg.apply(self.inverse_mapping, cols, size, features)
|
| 339 |
+
elif self.quantization_mode == SparseTensorQuantizationMode.RANDOM_SUBSAMPLE:
|
| 340 |
+
features = features[self.unique_index]
|
| 341 |
+
else:
|
| 342 |
+
# No quantization
|
| 343 |
+
pass
|
| 344 |
+
|
| 345 |
+
return coordinates, features, coordinate_map_key
|
| 346 |
+
|
| 347 |
+
# Conversion functions
|
| 348 |
+
def sparse(self, min_coords=None, max_coords=None, contract_coords=True):
|
| 349 |
+
r"""Convert the :attr:`MinkowskiEngine.SparseTensor` to a torch sparse
|
| 350 |
+
tensor.
|
| 351 |
+
|
| 352 |
+
Args:
|
| 353 |
+
:attr:`min_coords` (torch.IntTensor, optional): The min
|
| 354 |
+
coordinates of the output sparse tensor. Must be divisible by the
|
| 355 |
+
current :attr:`tensor_stride`.
|
| 356 |
+
|
| 357 |
+
:attr:`max_coords` (torch.IntTensor, optional): The max coordinates
|
| 358 |
+
of the output sparse tensor (inclusive). Must be divisible by the
|
| 359 |
+
current :attr:`tensor_stride`.
|
| 360 |
+
|
| 361 |
+
:attr:`contract_coords` (bool, optional): Given True, the output
|
| 362 |
+
coordinates will be divided by the tensor stride to make features
|
| 363 |
+
contiguous.
|
| 364 |
+
|
| 365 |
+
Returns:
|
| 366 |
+
:attr:`spare_tensor` (torch.sparse.Tensor): the torch sparse tensor
|
| 367 |
+
representation of the self in `[Batch Dim, Spatial Dims..., Feature
|
| 368 |
+
Dim]`. The coordinate of each feature can be accessed via
|
| 369 |
+
`min_coord + tensor_stride * [the coordinate of the dense tensor]`.
|
| 370 |
+
|
| 371 |
+
:attr:`min_coords` (torch.IntTensor): the D-dimensional vector
|
| 372 |
+
defining the minimum coordinate of the output sparse tensor. If
|
| 373 |
+
:attr:`contract_coords` is True, the :attr:`min_coords` will also
|
| 374 |
+
be contracted.
|
| 375 |
+
|
| 376 |
+
:attr:`tensor_stride` (torch.IntTensor): the D-dimensional vector
|
| 377 |
+
defining the stride between tensor elements.
|
| 378 |
+
|
| 379 |
+
"""
|
| 380 |
+
|
| 381 |
+
if min_coords is not None:
|
| 382 |
+
assert isinstance(min_coords, torch.IntTensor)
|
| 383 |
+
assert min_coords.numel() == self._D
|
| 384 |
+
if max_coords is not None:
|
| 385 |
+
assert isinstance(max_coords, torch.IntTensor)
|
| 386 |
+
assert min_coords.numel() == self._D
|
| 387 |
+
|
| 388 |
+
def torch_sparse_Tensor(coords, feats, size=None):
|
| 389 |
+
if size is None:
|
| 390 |
+
if feats.dtype == torch.float64:
|
| 391 |
+
return torch.sparse.DoubleTensor(coords, feats)
|
| 392 |
+
elif feats.dtype == torch.float32:
|
| 393 |
+
return torch.sparse.FloatTensor(coords, feats)
|
| 394 |
+
else:
|
| 395 |
+
raise ValueError("Feature type not supported.")
|
| 396 |
+
else:
|
| 397 |
+
if feats.dtype == torch.float64:
|
| 398 |
+
return torch.sparse.DoubleTensor(coords, feats, size)
|
| 399 |
+
elif feats.dtype == torch.float32:
|
| 400 |
+
return torch.sparse.FloatTensor(coords, feats, size)
|
| 401 |
+
else:
|
| 402 |
+
raise ValueError("Feature type not supported.")
|
| 403 |
+
|
| 404 |
+
# Use int tensor for all operations
|
| 405 |
+
tensor_stride = torch.IntTensor(self.tensor_stride)
|
| 406 |
+
|
| 407 |
+
# New coordinates
|
| 408 |
+
coords = self.C
|
| 409 |
+
coords, batch_indices = coords[:, 1:], coords[:, 0]
|
| 410 |
+
|
| 411 |
+
if min_coords is None:
|
| 412 |
+
min_coords, _ = coords.min(0, keepdim=True)
|
| 413 |
+
elif min_coords.ndim == 1:
|
| 414 |
+
min_coords = min_coords.unsqueeze(0)
|
| 415 |
+
|
| 416 |
+
assert (
|
| 417 |
+
min_coords % tensor_stride
|
| 418 |
+
).sum() == 0, "The minimum coordinates must be divisible by the tensor stride."
|
| 419 |
+
|
| 420 |
+
if max_coords is not None:
|
| 421 |
+
if max_coords.ndim == 1:
|
| 422 |
+
max_coords = max_coords.unsqueeze(0)
|
| 423 |
+
assert (
|
| 424 |
+
max_coords % tensor_stride
|
| 425 |
+
).sum() == 0, (
|
| 426 |
+
"The maximum coordinates must be divisible by the tensor stride."
|
| 427 |
+
)
|
| 428 |
+
|
| 429 |
+
coords -= min_coords
|
| 430 |
+
|
| 431 |
+
if coords.ndim == 1:
|
| 432 |
+
coords = coords.unsqueeze(1)
|
| 433 |
+
if batch_indices.ndim == 1:
|
| 434 |
+
batch_indices = batch_indices.unsqueeze(1)
|
| 435 |
+
|
| 436 |
+
# return the contracted tensor
|
| 437 |
+
if contract_coords:
|
| 438 |
+
coords = coords // tensor_stride
|
| 439 |
+
if max_coords is not None:
|
| 440 |
+
max_coords = max_coords // tensor_stride
|
| 441 |
+
min_coords = min_coords // tensor_stride
|
| 442 |
+
|
| 443 |
+
new_coords = torch.cat((batch_indices, coords), dim=1).long()
|
| 444 |
+
|
| 445 |
+
size = None
|
| 446 |
+
if max_coords is not None:
|
| 447 |
+
size = max_coords - min_coords + 1 # inclusive
|
| 448 |
+
# Squeeze to make the size one-dimensional
|
| 449 |
+
size = size.squeeze()
|
| 450 |
+
|
| 451 |
+
max_batch = max(self._manager.get_batch_indices())
|
| 452 |
+
size = torch.Size([max_batch + 1, *size, self.F.size(1)])
|
| 453 |
+
|
| 454 |
+
sparse_tensor = torch_sparse_Tensor(
|
| 455 |
+
new_coords.t().to(self.F.device), self.F, size
|
| 456 |
+
)
|
| 457 |
+
tensor_stride = torch.IntTensor(self.tensor_stride)
|
| 458 |
+
return sparse_tensor, min_coords, tensor_stride
|
| 459 |
+
|
| 460 |
+
def dense(self, shape=None, min_coordinate=None, contract_stride=True):
|
| 461 |
+
r"""Convert the :attr:`MinkowskiEngine.SparseTensor` to a torch dense
|
| 462 |
+
tensor.
|
| 463 |
+
|
| 464 |
+
Args:
|
| 465 |
+
:attr:`shape` (torch.Size, optional): The size of the output tensor.
|
| 466 |
+
|
| 467 |
+
:attr:`min_coordinate` (torch.IntTensor, optional): The min
|
| 468 |
+
coordinates of the output sparse tensor. Must be divisible by the
|
| 469 |
+
current :attr:`tensor_stride`. If 0 is given, it will use the origin for the min coordinate.
|
| 470 |
+
|
| 471 |
+
:attr:`contract_stride` (bool, optional): The output coordinates
|
| 472 |
+
will be divided by the tensor stride to make features spatially
|
| 473 |
+
contiguous. True by default.
|
| 474 |
+
|
| 475 |
+
Returns:
|
| 476 |
+
:attr:`tensor` (torch.Tensor): the torch tensor with size `[Batch
|
| 477 |
+
Dim, Feature Dim, Spatial Dim..., Spatial Dim]`. The coordinate of
|
| 478 |
+
each feature can be accessed via `min_coordinate + tensor_stride *
|
| 479 |
+
[the coordinate of the dense tensor]`.
|
| 480 |
+
|
| 481 |
+
:attr:`min_coordinate` (torch.IntTensor): the D-dimensional vector
|
| 482 |
+
defining the minimum coordinate of the output tensor.
|
| 483 |
+
|
| 484 |
+
:attr:`tensor_stride` (torch.IntTensor): the D-dimensional vector
|
| 485 |
+
defining the stride between tensor elements.
|
| 486 |
+
|
| 487 |
+
"""
|
| 488 |
+
if min_coordinate is not None:
|
| 489 |
+
assert isinstance(min_coordinate, torch.IntTensor)
|
| 490 |
+
assert min_coordinate.numel() == self._D
|
| 491 |
+
if shape is not None:
|
| 492 |
+
assert isinstance(shape, torch.Size)
|
| 493 |
+
assert len(shape) == self._D + 2 # batch and channel
|
| 494 |
+
if shape[1] != self._F.size(1):
|
| 495 |
+
shape = torch.Size([shape[0], self._F.size(1), *[s for s in shape[2:]]])
|
| 496 |
+
|
| 497 |
+
# Exception handling for empty tensor
|
| 498 |
+
if self.__len__() == 0:
|
| 499 |
+
assert shape is not None, "shape is required to densify an empty tensor"
|
| 500 |
+
return (
|
| 501 |
+
torch.zeros(shape, dtype=self.dtype, device=self.device),
|
| 502 |
+
torch.zeros(self._D, dtype=torch.int32, device=self.device),
|
| 503 |
+
self.tensor_stride,
|
| 504 |
+
)
|
| 505 |
+
|
| 506 |
+
# Use int tensor for all operations
|
| 507 |
+
tensor_stride = torch.IntTensor(self.tensor_stride).to(self.device)
|
| 508 |
+
|
| 509 |
+
# New coordinates
|
| 510 |
+
batch_indices = self.C[:, 0]
|
| 511 |
+
|
| 512 |
+
if min_coordinate is None:
|
| 513 |
+
min_coordinate, _ = self.C.min(0, keepdim=True)
|
| 514 |
+
min_coordinate = min_coordinate[:, 1:]
|
| 515 |
+
if not torch.all(min_coordinate >= 0):
|
| 516 |
+
raise ValueError(
|
| 517 |
+
f"Coordinate has a negative value: {min_coordinate}. Please provide min_coordinate argument"
|
| 518 |
+
)
|
| 519 |
+
coords = self.C[:, 1:]
|
| 520 |
+
elif isinstance(min_coordinate, int) and min_coordinate == 0:
|
| 521 |
+
coords = self.C[:, 1:]
|
| 522 |
+
else:
|
| 523 |
+
min_coordinate = min_coordinate.to(self.device)
|
| 524 |
+
if min_coordinate.ndim == 1:
|
| 525 |
+
min_coordinate = min_coordinate.unsqueeze(0)
|
| 526 |
+
coords = self.C[:, 1:] - min_coordinate
|
| 527 |
+
|
| 528 |
+
assert (
|
| 529 |
+
min_coordinate % tensor_stride
|
| 530 |
+
).sum() == 0, "The minimum coordinates must be divisible by the tensor stride."
|
| 531 |
+
|
| 532 |
+
if coords.ndim == 1:
|
| 533 |
+
coords = coords.unsqueeze(1)
|
| 534 |
+
|
| 535 |
+
# return the contracted tensor
|
| 536 |
+
if contract_stride:
|
| 537 |
+
coords = coords // tensor_stride
|
| 538 |
+
|
| 539 |
+
nchannels = self.F.size(1)
|
| 540 |
+
if shape is None:
|
| 541 |
+
size = coords.max(0)[0] + 1
|
| 542 |
+
shape = torch.Size(
|
| 543 |
+
[batch_indices.max() + 1, nchannels, *size.cpu().numpy()]
|
| 544 |
+
)
|
| 545 |
+
|
| 546 |
+
dense_F = torch.zeros(shape, dtype=self.dtype, device=self.device)
|
| 547 |
+
|
| 548 |
+
tcoords = coords.t().long()
|
| 549 |
+
batch_indices = batch_indices.long()
|
| 550 |
+
exec(
|
| 551 |
+
"dense_F[batch_indices, :, "
|
| 552 |
+
+ ", ".join([f"tcoords[{i}]" for i in range(len(tcoords))])
|
| 553 |
+
+ "] = self.F"
|
| 554 |
+
)
|
| 555 |
+
|
| 556 |
+
tensor_stride = torch.IntTensor(self.tensor_stride)
|
| 557 |
+
return dense_F, min_coordinate, tensor_stride
|
| 558 |
+
|
| 559 |
+
def interpolate(self, X):
|
| 560 |
+
from MinkowskiTensorField import TensorField
|
| 561 |
+
|
| 562 |
+
assert isinstance(X, TensorField)
|
| 563 |
+
if self.coordinate_map_key in X._splat:
|
| 564 |
+
tensor_map, field_map, weights, size = X._splat[self.coordinate_map_key]
|
| 565 |
+
size = torch.Size([size[1], size[0]]) # transpose
|
| 566 |
+
features = MinkowskiSPMMFunction().apply(
|
| 567 |
+
field_map, tensor_map, weights, size, self._F
|
| 568 |
+
)
|
| 569 |
+
else:
|
| 570 |
+
features = self.features_at_coordinates(X.C)
|
| 571 |
+
return TensorField(
|
| 572 |
+
features=features,
|
| 573 |
+
coordinate_field_map_key=X.coordinate_field_map_key,
|
| 574 |
+
coordinate_manager=X.coordinate_manager,
|
| 575 |
+
)
|
| 576 |
+
|
| 577 |
+
def slice(self, X):
|
| 578 |
+
r"""
|
| 579 |
+
|
| 580 |
+
Args:
|
| 581 |
+
:attr:`X` (:attr:`MinkowskiEngine.SparseTensor`): a sparse tensor
|
| 582 |
+
that discretized the original input.
|
| 583 |
+
|
| 584 |
+
Returns:
|
| 585 |
+
:attr:`tensor_field` (:attr:`MinkowskiEngine.TensorField`): the
|
| 586 |
+
resulting tensor field contains features on the continuous
|
| 587 |
+
coordinates that generated the input X.
|
| 588 |
+
|
| 589 |
+
Example::
|
| 590 |
+
|
| 591 |
+
>>> # coords, feats from a data loader
|
| 592 |
+
>>> print(len(coords)) # 227742
|
| 593 |
+
>>> tfield = ME.TensorField(coordinates=coords, features=feats, quantization_mode=SparseTensorQuantizationMode.UNWEIGHTED_AVERAGE)
|
| 594 |
+
>>> print(len(tfield)) # 227742
|
| 595 |
+
>>> sinput = tfield.sparse() # 161890 quantization results in fewer voxels
|
| 596 |
+
>>> soutput = MinkUNet(sinput)
|
| 597 |
+
>>> print(len(soutput)) # 161890 Output with the same resolution
|
| 598 |
+
>>> ofield = soutput.slice(tfield)
|
| 599 |
+
>>> assert isinstance(ofield, ME.TensorField)
|
| 600 |
+
>>> len(ofield) == len(coords) # recovers the original ordering and length
|
| 601 |
+
>>> assert isinstance(ofield.F, torch.Tensor) # .F returns the features
|
| 602 |
+
"""
|
| 603 |
+
# Currently only supports unweighted slice.
|
| 604 |
+
assert X.quantization_mode in [
|
| 605 |
+
SparseTensorQuantizationMode.RANDOM_SUBSAMPLE,
|
| 606 |
+
SparseTensorQuantizationMode.UNWEIGHTED_AVERAGE,
|
| 607 |
+
], "slice only available for sparse tensors with quantization RANDOM_SUBSAMPLE or UNWEIGHTED_AVERAGE"
|
| 608 |
+
|
| 609 |
+
from MinkowskiTensorField import TensorField
|
| 610 |
+
|
| 611 |
+
if isinstance(X, TensorField):
|
| 612 |
+
return TensorField(
|
| 613 |
+
self.F[X.inverse_mapping(self.coordinate_map_key).long()],
|
| 614 |
+
coordinate_field_map_key=X.coordinate_field_map_key,
|
| 615 |
+
coordinate_manager=X.coordinate_manager,
|
| 616 |
+
quantization_mode=X.quantization_mode,
|
| 617 |
+
)
|
| 618 |
+
elif isinstance(X, SparseTensor):
|
| 619 |
+
inv_map = X.inverse_mapping
|
| 620 |
+
assert (
|
| 621 |
+
X.coordinate_map_key == self.coordinate_map_key
|
| 622 |
+
), "Slice can only be applied on the same coordinates (coordinate_map_key)"
|
| 623 |
+
return TensorField(
|
| 624 |
+
self.F[inv_map],
|
| 625 |
+
coordinates=self.C[inv_map],
|
| 626 |
+
coordinate_manager=self.coordinate_manager,
|
| 627 |
+
quantization_mode=self.quantization_mode,
|
| 628 |
+
)
|
| 629 |
+
else:
|
| 630 |
+
raise ValueError(
|
| 631 |
+
"Invalid input. The input must be an instance of TensorField or SparseTensor."
|
| 632 |
+
)
|
| 633 |
+
|
| 634 |
+
def cat_slice(self, X):
|
| 635 |
+
r"""
|
| 636 |
+
|
| 637 |
+
Args:
|
| 638 |
+
:attr:`X` (:attr:`MinkowskiEngine.SparseTensor`): a sparse tensor
|
| 639 |
+
that discretized the original input.
|
| 640 |
+
|
| 641 |
+
Returns:
|
| 642 |
+
:attr:`tensor_field` (:attr:`MinkowskiEngine.TensorField`): the
|
| 643 |
+
resulting tensor field contains the concatenation of features on the
|
| 644 |
+
original continuous coordinates that generated the input X and the
|
| 645 |
+
self.
|
| 646 |
+
|
| 647 |
+
Example::
|
| 648 |
+
|
| 649 |
+
>>> # coords, feats from a data loader
|
| 650 |
+
>>> print(len(coords)) # 227742
|
| 651 |
+
>>> sinput = ME.SparseTensor(coordinates=coords, features=feats, quantization_mode=SparseTensorQuantizationMode.UNWEIGHTED_AVERAGE)
|
| 652 |
+
>>> print(len(sinput)) # 161890 quantization results in fewer voxels
|
| 653 |
+
>>> soutput = network(sinput)
|
| 654 |
+
>>> print(len(soutput)) # 161890 Output with the same resolution
|
| 655 |
+
>>> ofield = soutput.cat_slice(sinput)
|
| 656 |
+
>>> assert soutput.F.size(1) + sinput.F.size(1) == ofield.F.size(1) # concatenation of features
|
| 657 |
+
"""
|
| 658 |
+
# Currently only supports unweighted slice.
|
| 659 |
+
assert X.quantization_mode in [
|
| 660 |
+
SparseTensorQuantizationMode.RANDOM_SUBSAMPLE,
|
| 661 |
+
SparseTensorQuantizationMode.UNWEIGHTED_AVERAGE,
|
| 662 |
+
], "slice only available for sparse tensors with quantization RANDOM_SUBSAMPLE or UNWEIGHTED_AVERAGE"
|
| 663 |
+
|
| 664 |
+
from MinkowskiTensorField import TensorField
|
| 665 |
+
|
| 666 |
+
inv_map = X.inverse_mapping(self.coordinate_map_key)
|
| 667 |
+
features = torch.cat((self.F[inv_map], X.F), dim=1)
|
| 668 |
+
if isinstance(X, TensorField):
|
| 669 |
+
return TensorField(
|
| 670 |
+
features,
|
| 671 |
+
coordinate_field_map_key=X.coordinate_field_map_key,
|
| 672 |
+
coordinate_manager=X.coordinate_manager,
|
| 673 |
+
quantization_mode=X.quantization_mode,
|
| 674 |
+
)
|
| 675 |
+
elif isinstance(X, SparseTensor):
|
| 676 |
+
assert (
|
| 677 |
+
X.coordinate_map_key == self.coordinate_map_key
|
| 678 |
+
), "Slice can only be applied on the same coordinates (coordinate_map_key)"
|
| 679 |
+
return TensorField(
|
| 680 |
+
features,
|
| 681 |
+
coordinates=self.C[inv_map],
|
| 682 |
+
coordinate_manager=self.coordinate_manager,
|
| 683 |
+
quantization_mode=self.quantization_mode,
|
| 684 |
+
)
|
| 685 |
+
else:
|
| 686 |
+
raise ValueError(
|
| 687 |
+
"Invalid input. The input must be an instance of TensorField or SparseTensor."
|
| 688 |
+
)
|
| 689 |
+
|
| 690 |
+
def features_at_coordinates(self, query_coordinates: torch.Tensor):
|
| 691 |
+
r"""Extract features at the specified continuous coordinate matrix.
|
| 692 |
+
|
| 693 |
+
Args:
|
| 694 |
+
:attr:`query_coordinates` (:attr:`torch.FloatTensor`): a coordinate
|
| 695 |
+
matrix of size :math:`N \times (D + 1)` where :math:`D` is the size
|
| 696 |
+
of the spatial dimension.
|
| 697 |
+
|
| 698 |
+
Returns:
|
| 699 |
+
:attr:`queried_features` (:attr:`torch.Tensor`): a feature matrix of
|
| 700 |
+
size :math:`N \times D_F` where :math:`D_F` is the number of
|
| 701 |
+
channels in the feature. For coordinates not present in the current
|
| 702 |
+
sparse tensor, corresponding feature rows will be zeros.
|
| 703 |
+
"""
|
| 704 |
+
from MinkowskiInterpolation import MinkowskiInterpolationFunction
|
| 705 |
+
|
| 706 |
+
assert (
|
| 707 |
+
self.dtype == query_coordinates.dtype
|
| 708 |
+
), "Invalid query_coordinates dtype. use {self.dtype}"
|
| 709 |
+
|
| 710 |
+
assert (
|
| 711 |
+
query_coordinates.device == self.device
|
| 712 |
+
), "query coordinates device ({query_coordinates.device}) does not match the sparse tensor device ({self.device})."
|
| 713 |
+
return MinkowskiInterpolationFunction().apply(
|
| 714 |
+
self._F,
|
| 715 |
+
query_coordinates,
|
| 716 |
+
self.coordinate_map_key,
|
| 717 |
+
self.coordinate_manager,
|
| 718 |
+
)[0]
|
| 719 |
+
|
| 720 |
+
def __repr__(self):
|
| 721 |
+
return (
|
| 722 |
+
self.__class__.__name__
|
| 723 |
+
+ "("
|
| 724 |
+
+ os.linesep
|
| 725 |
+
+ " coordinates="
|
| 726 |
+
+ str(self.C)
|
| 727 |
+
+ os.linesep
|
| 728 |
+
+ " features="
|
| 729 |
+
+ str(self.F)
|
| 730 |
+
+ os.linesep
|
| 731 |
+
+ " coordinate_map_key="
|
| 732 |
+
+ str(self.coordinate_map_key)
|
| 733 |
+
+ os.linesep
|
| 734 |
+
+ " coordinate_manager="
|
| 735 |
+
+ str(self._manager)
|
| 736 |
+
+ " spatial dimension="
|
| 737 |
+
+ str(self._D)
|
| 738 |
+
+ ")"
|
| 739 |
+
)
|
| 740 |
+
|
| 741 |
+
__slots__ = (
|
| 742 |
+
"_C",
|
| 743 |
+
"_F",
|
| 744 |
+
"_D",
|
| 745 |
+
"coordinate_map_key",
|
| 746 |
+
"_manager",
|
| 747 |
+
"unique_index",
|
| 748 |
+
"inverse_mapping",
|
| 749 |
+
"quantization_mode",
|
| 750 |
+
"_batch_rows",
|
| 751 |
+
)
|
| 752 |
+
|
| 753 |
+
|
| 754 |
+
def _get_coordinate_map_key(
|
| 755 |
+
input: SparseTensor,
|
| 756 |
+
coordinates: torch.Tensor = None,
|
| 757 |
+
tensor_stride: StrideType = 1,
|
| 758 |
+
expand_coordinates: bool = False,
|
| 759 |
+
):
|
| 760 |
+
r"""Returns the coordinates map key."""
|
| 761 |
+
if coordinates is not None and not expand_coordinates:
|
| 762 |
+
assert isinstance(coordinates, (CoordinateMapKey, torch.Tensor, SparseTensor))
|
| 763 |
+
if isinstance(coordinates, torch.Tensor):
|
| 764 |
+
assert coordinates.ndim == 2
|
| 765 |
+
coordinate_map_key = CoordinateMapKey(
|
| 766 |
+
convert_to_int_list(tensor_stride, coordinates.size(1) - 1), ""
|
| 767 |
+
)
|
| 768 |
+
|
| 769 |
+
(
|
| 770 |
+
coordinate_map_key,
|
| 771 |
+
(unique_index, inverse_mapping),
|
| 772 |
+
) = input._manager.insert_and_map(
|
| 773 |
+
coordinates, *coordinate_map_key.get_key()
|
| 774 |
+
)
|
| 775 |
+
elif isinstance(coordinates, SparseTensor):
|
| 776 |
+
coordinate_map_key = coordinates.coordinate_map_key
|
| 777 |
+
else: # CoordinateMapKey type due to the previous assertion
|
| 778 |
+
coordinate_map_key = coordinates
|
| 779 |
+
else: # coordinates is None
|
| 780 |
+
coordinate_map_key = CoordinateMapKey(
|
| 781 |
+
input.coordinate_map_key.get_coordinate_size()
|
| 782 |
+
)
|
| 783 |
+
return coordinate_map_key
|
MinkowskiEngine/MinkowskiEngine/MinkowskiTensor.py
ADDED
|
@@ -0,0 +1,604 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
import os
|
| 26 |
+
import torch
|
| 27 |
+
import copy
|
| 28 |
+
from enum import Enum
|
| 29 |
+
|
| 30 |
+
from MinkowskiEngineBackend._C import CoordinateMapKey
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class SparseTensorOperationMode(Enum):
|
| 34 |
+
r"""Enum class for SparseTensor internal instantiation modes.
|
| 35 |
+
|
| 36 |
+
:attr:`SEPARATE_COORDINATE_MANAGER`: always create a new coordinate manager.
|
| 37 |
+
|
| 38 |
+
:attr:`SHARE_COORDINATE_MANAGER`: always use the globally defined coordinate
|
| 39 |
+
manager. Must clear the coordinate manager manually by
|
| 40 |
+
:attr:`MinkowskiEngine.SparseTensor.clear_global_coordinate_manager`.
|
| 41 |
+
|
| 42 |
+
"""
|
| 43 |
+
SEPARATE_COORDINATE_MANAGER = 0
|
| 44 |
+
SHARE_COORDINATE_MANAGER = 1
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class SparseTensorQuantizationMode(Enum):
|
| 48 |
+
r"""
|
| 49 |
+
`RANDOM_SUBSAMPLE`: Subsample one coordinate per each quantization block randomly.
|
| 50 |
+
`UNWEIGHTED_AVERAGE`: average all features within a quantization block equally.
|
| 51 |
+
`UNWEIGHTED_SUM`: sum all features within a quantization block equally.
|
| 52 |
+
`NO_QUANTIZATION`: No quantization is applied. Should not be used for normal operation.
|
| 53 |
+
`MAX_POOL`: Voxel-wise max pooling is applied.
|
| 54 |
+
`SPLAT_LINEAR_INTERPOLATION`: Splat features using N-dimensional linear interpolation to 2^N neighbors.
|
| 55 |
+
"""
|
| 56 |
+
RANDOM_SUBSAMPLE = 0
|
| 57 |
+
UNWEIGHTED_AVERAGE = 1
|
| 58 |
+
UNWEIGHTED_SUM = 2
|
| 59 |
+
NO_QUANTIZATION = 3
|
| 60 |
+
MAX_POOL = 4
|
| 61 |
+
SPLAT_LINEAR_INTERPOLATION = 5
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
_sparse_tensor_operation_mode = SparseTensorOperationMode.SEPARATE_COORDINATE_MANAGER
|
| 65 |
+
_global_coordinate_manager = None
|
| 66 |
+
|
| 67 |
+
COORDINATE_MANAGER_DIFFERENT_ERROR = "SparseTensors must share the same coordinate manager for this operation. Please refer to the SparseTensor creation API (https://nvidia.github.io/MinkowskiEngine/sparse_tensor.html) to share the coordinate manager, or set the sparse tensor operation mode with `set_sparse_tensor_operation_mode` to share it by default."
|
| 68 |
+
COORDINATE_KEY_DIFFERENT_ERROR = "SparseTensors must have the same coordinate_map_key."
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def set_sparse_tensor_operation_mode(operation_mode: SparseTensorOperationMode):
|
| 72 |
+
r"""Define the sparse tensor coordinate manager operation mode.
|
| 73 |
+
|
| 74 |
+
By default, a :attr:`MinkowskiEngine.SparseTensor.SparseTensor`
|
| 75 |
+
instantiation creates a new coordinate manager that is not shared with
|
| 76 |
+
other sparse tensors. By setting this function with
|
| 77 |
+
:attr:`MinkowskiEngine.SparseTensorOperationMode.SHARE_COORDINATE_MANAGER`, you
|
| 78 |
+
can share the coordinate manager globally with other sparse tensors.
|
| 79 |
+
However, you must explicitly clear the coordinate manger after use. Please
|
| 80 |
+
refer to :attr:`MinkowskiEngine.clear_global_coordinate_manager`.
|
| 81 |
+
|
| 82 |
+
Args:
|
| 83 |
+
:attr:`operation_mode`
|
| 84 |
+
(:attr:`MinkowskiEngine.SparseTensorOperationMode`): The operation mode
|
| 85 |
+
for the sparse tensor coordinate manager. By default
|
| 86 |
+
:attr:`MinkowskiEngine.SparseTensorOperationMode.SEPARATE_COORDINATE_MANAGER`.
|
| 87 |
+
|
| 88 |
+
Example:
|
| 89 |
+
|
| 90 |
+
>>> import MinkowskiEngine as ME
|
| 91 |
+
>>> ME.set_sparse_tensor_operation_mode(ME.SparseTensorOperationMode.SHARE_COORDINATE_MANAGER)
|
| 92 |
+
>>> ...
|
| 93 |
+
>>> a = ME.SparseTensor(...)
|
| 94 |
+
>>> b = ME.SparseTensor(...) # coords_man shared
|
| 95 |
+
>>> ... # one feed forward and backward
|
| 96 |
+
>>> ME.clear_global_coordinate_manager() # Must use to clear the coordinates after one forward/backward
|
| 97 |
+
|
| 98 |
+
"""
|
| 99 |
+
assert isinstance(
|
| 100 |
+
operation_mode, SparseTensorOperationMode
|
| 101 |
+
), f"Input must be an instance of SparseTensorOperationMode not {operation_mode}"
|
| 102 |
+
global _sparse_tensor_operation_mode
|
| 103 |
+
_sparse_tensor_operation_mode = operation_mode
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def sparse_tensor_operation_mode() -> SparseTensorOperationMode:
|
| 107 |
+
r"""Return the current sparse tensor operation mode."""
|
| 108 |
+
global _sparse_tensor_operation_mode
|
| 109 |
+
return copy.deepcopy(_sparse_tensor_operation_mode)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def global_coordinate_manager():
|
| 113 |
+
r"""Return the current global coordinate manager"""
|
| 114 |
+
global _global_coordinate_manager
|
| 115 |
+
return _global_coordinate_manager
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def set_global_coordinate_manager(coordinate_manager):
|
| 119 |
+
r"""Set the global coordinate manager.
|
| 120 |
+
|
| 121 |
+
:attr:`MinkowskiEngine.CoordinateManager` The coordinate manager which will
|
| 122 |
+
be set to the global coordinate manager.
|
| 123 |
+
"""
|
| 124 |
+
global _global_coordinate_manager
|
| 125 |
+
_global_coordinate_manager = coordinate_manager
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def clear_global_coordinate_manager():
|
| 129 |
+
r"""Clear the global coordinate manager cache.
|
| 130 |
+
|
| 131 |
+
When you use the operation mode:
|
| 132 |
+
:attr:`MinkowskiEngine.SparseTensor.SparseTensorOperationMode.SHARE_COORDINATE_MANAGER`,
|
| 133 |
+
you must explicitly clear the coordinate manager after each feed forward/backward.
|
| 134 |
+
"""
|
| 135 |
+
global _global_coordinate_manager
|
| 136 |
+
_global_coordinate_manager = None
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
class Tensor:
|
| 140 |
+
r"""A sparse tensor class. Can be accessed via
|
| 141 |
+
:attr:`MinkowskiEngine.SparseTensor`.
|
| 142 |
+
|
| 143 |
+
The :attr:`SparseTensor` class is the basic tensor in MinkowskiEngine. For
|
| 144 |
+
the definition of a sparse tensor, please visit `the terminology page
|
| 145 |
+
<https://nvidia.github.io/MinkowskiEngine/terminology.html#sparse-tensor>`_.
|
| 146 |
+
We use the COOrdinate (COO) format to save a sparse tensor `[1]
|
| 147 |
+
<http://groups.csail.mit.edu/commit/papers/2016/parker-thesis.pdf>`_. This
|
| 148 |
+
representation is simply a concatenation of coordinates in a matrix
|
| 149 |
+
:math:`C` and associated features :math:`F`.
|
| 150 |
+
|
| 151 |
+
.. math::
|
| 152 |
+
|
| 153 |
+
\mathbf{C} = \begin{bmatrix}
|
| 154 |
+
b_1 & x_1^1 & x_1^2 & \cdots & x_1^D \\
|
| 155 |
+
\vdots & \vdots & \vdots & \ddots & \vdots \\
|
| 156 |
+
b_N & x_N^1 & x_N^2 & \cdots & x_N^D
|
| 157 |
+
\end{bmatrix}, \; \mathbf{F} = \begin{bmatrix}
|
| 158 |
+
\mathbf{f}_1^T\\
|
| 159 |
+
\vdots\\
|
| 160 |
+
\mathbf{f}_N^T
|
| 161 |
+
\end{bmatrix}
|
| 162 |
+
|
| 163 |
+
where :math:`\mathbf{x}_i \in \mathcal{Z}^D` is a :math:`D`-dimensional
|
| 164 |
+
coordinate and :math:`b_i \in \mathcal{Z}_+` denotes the corresponding
|
| 165 |
+
batch index. :math:`N` is the number of non-zero elements in the sparse
|
| 166 |
+
tensor, each with the coordinate :math:`(b_i, x_i^1, x_i^1, \cdots,
|
| 167 |
+
x_i^D)`, and the associated feature :math:`\mathbf{f}_i`. Internally, we
|
| 168 |
+
handle the batch index as an additional spatial dimension.
|
| 169 |
+
|
| 170 |
+
Example::
|
| 171 |
+
|
| 172 |
+
>>> coords, feats = ME.utils.sparse_collate([coords_batch0, coords_batch1], [feats_batch0, feats_batch1])
|
| 173 |
+
>>> A = ME.SparseTensor(features=feats, coordinates=coords)
|
| 174 |
+
>>> B = ME.SparseTensor(features=feats, coordinate_map_key=A.coordiante_map_key, coordinate_manager=A.coordinate_manager)
|
| 175 |
+
>>> C = ME.SparseTensor(features=feats, coordinates=coords, quantization_mode=ME.SparseTensorQuantizationMode.UNWEIGHTED_AVERAGE)
|
| 176 |
+
>>> D = ME.SparseTensor(features=feats, coordinates=coords, tensor_stride=2)
|
| 177 |
+
|
| 178 |
+
.. warning::
|
| 179 |
+
|
| 180 |
+
To use the GPU-backend for coordinate management, the
|
| 181 |
+
:attr:`coordinates` must be a torch tensor on GPU. Applying `to(device)`
|
| 182 |
+
after a :attr:`MinkowskiEngine.SparseTensor` initialization with a CPU
|
| 183 |
+
`coordinates` will waste time and computation for creating a CPU
|
| 184 |
+
CoordinateMap since GPU CoordinateMap will be created from scratch.
|
| 185 |
+
|
| 186 |
+
.. warning::
|
| 187 |
+
|
| 188 |
+
Before MinkowskiEngine version 0.4, we put the batch indices on the last
|
| 189 |
+
column. Thus, direct manipulation of coordinates will be incompatible
|
| 190 |
+
with the latest versions. Instead, please use
|
| 191 |
+
:attr:`MinkowskiEngine.utils.batched_coordinates` or
|
| 192 |
+
:attr:`MinkowskiEngine.utils.sparse_collate` to create batched
|
| 193 |
+
coordinates.
|
| 194 |
+
|
| 195 |
+
Also, to access coordinates or features batch-wise, use the functions
|
| 196 |
+
:attr:`coordinates_at(batch_index : int)`, :attr:`features_at(batch_index : int)` of
|
| 197 |
+
a sparse tensor. Or to access all batch-wise coordinates and features,
|
| 198 |
+
`decomposed_coordinates`, `decomposed_features`,
|
| 199 |
+
`decomposed_coordinates_and_features` of a sparse tensor.
|
| 200 |
+
|
| 201 |
+
Example::
|
| 202 |
+
|
| 203 |
+
>>> coords, feats = ME.utils.sparse_collate([coords_batch0, coords_batch1], [feats_batch0, feats_batch1])
|
| 204 |
+
>>> A = ME.SparseTensor(features=feats, coordinates=coords)
|
| 205 |
+
>>> coords_batch0 = A.coordinates_at(batch_index=0)
|
| 206 |
+
>>> feats_batch1 = A.features_at(batch_index=1)
|
| 207 |
+
>>> list_of_coords, list_of_featurs = A.decomposed_coordinates_and_features
|
| 208 |
+
|
| 209 |
+
"""
|
| 210 |
+
|
| 211 |
+
@property
|
| 212 |
+
def coordinate_manager(self):
|
| 213 |
+
return self._manager
|
| 214 |
+
|
| 215 |
+
@property
|
| 216 |
+
def tensor_stride(self):
|
| 217 |
+
return self.coordinate_map_key.get_tensor_stride()
|
| 218 |
+
|
| 219 |
+
@tensor_stride.setter
|
| 220 |
+
def tensor_stride(self, p):
|
| 221 |
+
r"""
|
| 222 |
+
This function is not recommended to be used directly.
|
| 223 |
+
"""
|
| 224 |
+
raise SyntaxError("Direct modification of tensor_stride is not permitted")
|
| 225 |
+
|
| 226 |
+
def _get_coordinates(self):
|
| 227 |
+
return self._manager.get_coordinates(self.coordinate_map_key)
|
| 228 |
+
|
| 229 |
+
@property
|
| 230 |
+
def C(self):
|
| 231 |
+
r"""The alias of :attr:`coords`."""
|
| 232 |
+
return self.coordinates
|
| 233 |
+
|
| 234 |
+
@property
|
| 235 |
+
def coordinates(self):
|
| 236 |
+
r"""
|
| 237 |
+
The coordinates of the current sparse tensor. The coordinates are
|
| 238 |
+
represented as a :math:`N \times (D + 1)` dimensional matrix where
|
| 239 |
+
:math:`N` is the number of points in the space and :math:`D` is the
|
| 240 |
+
dimension of the space (e.g. 3 for 3D, 4 for 3D + Time). Additional
|
| 241 |
+
dimension of the column of the matrix C is for batch indices which is
|
| 242 |
+
internally treated as an additional spatial dimension to disassociate
|
| 243 |
+
different instances in a batch.
|
| 244 |
+
"""
|
| 245 |
+
if self._C is None:
|
| 246 |
+
self._C = self._get_coordinates()
|
| 247 |
+
return self._C
|
| 248 |
+
|
| 249 |
+
@property
|
| 250 |
+
def coordinate_key(self):
|
| 251 |
+
raise NotImplementedError("Tensor interface does not have coordinate_key")
|
| 252 |
+
|
| 253 |
+
@C.setter
|
| 254 |
+
def C(self):
|
| 255 |
+
raise SyntaxError("Direct modification of coordinates is not permitted")
|
| 256 |
+
|
| 257 |
+
@coordinates.setter
|
| 258 |
+
def coordinates(self):
|
| 259 |
+
raise SyntaxError("Direct modification of coordinates is not permitted")
|
| 260 |
+
|
| 261 |
+
@property
|
| 262 |
+
def F(self):
|
| 263 |
+
r"""The alias of :attr:`feats`."""
|
| 264 |
+
return self._F
|
| 265 |
+
|
| 266 |
+
@property
|
| 267 |
+
def features(self):
|
| 268 |
+
r"""
|
| 269 |
+
The features of the current sparse tensor. The features are :math:`N
|
| 270 |
+
\times D_F` where :math:`N` is the number of points in the space and
|
| 271 |
+
:math:`D_F` is the dimension of each feature vector. Please refer to
|
| 272 |
+
:attr:`coords` to access the associated coordinates.
|
| 273 |
+
"""
|
| 274 |
+
return self._F
|
| 275 |
+
|
| 276 |
+
@property
|
| 277 |
+
def _batchwise_row_indices(self):
|
| 278 |
+
if self._batch_rows is None:
|
| 279 |
+
_, self._batch_rows = self._manager.origin_map(self.coordinate_map_key)
|
| 280 |
+
return self._batch_rows
|
| 281 |
+
|
| 282 |
+
@property
|
| 283 |
+
def _sorted_batchwise_row_indices(self):
|
| 284 |
+
if self._sorted_batch_rows is None:
|
| 285 |
+
batch_rows = self._batchwise_row_indices
|
| 286 |
+
with torch.no_grad():
|
| 287 |
+
self._sorted_batch_rows = [t.sort()[0] for t in batch_rows]
|
| 288 |
+
return self._sorted_batch_rows
|
| 289 |
+
|
| 290 |
+
@property
|
| 291 |
+
def decomposition_permutations(self):
|
| 292 |
+
r"""Returns a list of indices per batch that where indices defines the permutation of the batch-wise decomposition.
|
| 293 |
+
|
| 294 |
+
Example::
|
| 295 |
+
|
| 296 |
+
>>> # coords, feats, labels are given. All follow the same order
|
| 297 |
+
>>> stensor = ME.SparseTensor(feats, coords)
|
| 298 |
+
>>> conv = ME.MinkowskiConvolution(in_channels=3, out_nchannel=3, kernel_size=3, dimension=3)
|
| 299 |
+
>>> list_of_featurs = stensor.decomposed_features
|
| 300 |
+
>>> list_of_permutations = stensor.decomposition_permutations
|
| 301 |
+
>>> # list_of_features == [feats[inds] for inds in list_of_permutations]
|
| 302 |
+
>>> list_of_decomposed_labels = [labels[inds] for inds in list_of_permutations]
|
| 303 |
+
>>> for curr_feats, curr_labels in zip(list_of_features, list_of_decomposed_labels):
|
| 304 |
+
>>> loss += torch.functional.mse_loss(curr_feats, curr_labels)
|
| 305 |
+
"""
|
| 306 |
+
return self._batchwise_row_indices
|
| 307 |
+
|
| 308 |
+
@property
|
| 309 |
+
def decomposed_coordinates(self):
|
| 310 |
+
r"""Returns a list of coordinates per batch.
|
| 311 |
+
|
| 312 |
+
Returns a list of torch.IntTensor :math:`C \in \mathcal{R}^{N_i
|
| 313 |
+
\times D}` coordinates per batch where :math:`N_i` is the number of non
|
| 314 |
+
zero elements in the :math:`i`th batch index in :math:`D` dimensional
|
| 315 |
+
space.
|
| 316 |
+
|
| 317 |
+
.. note::
|
| 318 |
+
|
| 319 |
+
The order of coordinates is non-deterministic within each batch. Use
|
| 320 |
+
:attr:`decomposed_coordinates_and_features` to retrieve both
|
| 321 |
+
coordinates features with the same order. To retrieve the order the
|
| 322 |
+
decomposed coordinates is generated, use
|
| 323 |
+
:attr:`decomposition_permutations`.
|
| 324 |
+
|
| 325 |
+
"""
|
| 326 |
+
return [self.C[row_inds, 1:] for row_inds in self._batchwise_row_indices]
|
| 327 |
+
|
| 328 |
+
def coordinates_at(self, batch_index):
|
| 329 |
+
r"""Return coordinates at the specified batch index.
|
| 330 |
+
|
| 331 |
+
Returns a torch.IntTensor :math:`C \in \mathcal{R}^{N_i
|
| 332 |
+
\times D}` coordinates at the specified batch index where :math:`N_i`
|
| 333 |
+
is the number of non zero elements in the :math:`i`th batch index in
|
| 334 |
+
:math:`D` dimensional space.
|
| 335 |
+
|
| 336 |
+
.. note::
|
| 337 |
+
|
| 338 |
+
The order of coordinates is non-deterministic within each batch. Use
|
| 339 |
+
:attr:`decomposed_coordinates_and_features` to retrieve both
|
| 340 |
+
coordinates features with the same order. To retrieve the order the
|
| 341 |
+
decomposed coordinates is generated, use
|
| 342 |
+
:attr:`decomposition_permutations`.
|
| 343 |
+
|
| 344 |
+
"""
|
| 345 |
+
return self.C[self._batchwise_row_indices[batch_index], 1:]
|
| 346 |
+
|
| 347 |
+
@property
|
| 348 |
+
def decomposed_features(self):
|
| 349 |
+
r"""Returns a list of features per batch.
|
| 350 |
+
|
| 351 |
+
Returns a list of torch.Tensor :math:`C \in \mathcal{R}^{N_i
|
| 352 |
+
\times N_F}` features per batch where :math:`N_i` is the number of non
|
| 353 |
+
zero elements in the :math:`i`th batch index in :math:`D` dimensional
|
| 354 |
+
space.
|
| 355 |
+
|
| 356 |
+
.. note::
|
| 357 |
+
|
| 358 |
+
The order of features is non-deterministic within each batch. Use
|
| 359 |
+
:attr:`decomposed_coordinates_and_features` to retrieve both
|
| 360 |
+
coordinates features with the same order. To retrieve the order the
|
| 361 |
+
decomposed features is generated, use
|
| 362 |
+
:attr:`decomposition_permutations`.
|
| 363 |
+
|
| 364 |
+
"""
|
| 365 |
+
return [self._F[row_inds] for row_inds in self._batchwise_row_indices]
|
| 366 |
+
|
| 367 |
+
def features_at(self, batch_index):
|
| 368 |
+
r"""Returns a feature matrix at the specified batch index.
|
| 369 |
+
|
| 370 |
+
Returns a torch.Tensor :math:`C \in \mathcal{R}^{N
|
| 371 |
+
\times N_F}` feature matrix :math:`N` is the number of non
|
| 372 |
+
zero elements in the specified batch index and :math:`N_F` is the
|
| 373 |
+
number of channels.
|
| 374 |
+
|
| 375 |
+
.. note::
|
| 376 |
+
|
| 377 |
+
The order of features is non-deterministic within each batch. Use
|
| 378 |
+
:attr:`decomposed_coordinates_and_features` to retrieve both
|
| 379 |
+
coordinates features with the same order. To retrieve the order the
|
| 380 |
+
decomposed features is generated, use
|
| 381 |
+
:attr:`decomposition_permutations`.
|
| 382 |
+
|
| 383 |
+
"""
|
| 384 |
+
return self._F[self._batchwise_row_indices[batch_index]]
|
| 385 |
+
|
| 386 |
+
def coordinates_and_features_at(self, batch_index):
|
| 387 |
+
r"""Returns a coordinate and feature matrix at the specified batch index.
|
| 388 |
+
|
| 389 |
+
Returns a coordinate and feature matrix at the specified `batch_index`.
|
| 390 |
+
The coordinate matrix is a torch.IntTensor :math:`C \in \mathcal{R}^{N
|
| 391 |
+
\times D}` where :math:`N` is the number of non zero elements in the
|
| 392 |
+
specified batch index in :math:`D` dimensional space. The feature
|
| 393 |
+
matrix is a torch.Tensor :math:`C \in \mathcal{R}^{N \times N_F}`
|
| 394 |
+
matrix :math:`N` is the number of non zero elements in the specified
|
| 395 |
+
batch index and :math:`N_F` is the number of channels.
|
| 396 |
+
|
| 397 |
+
.. note::
|
| 398 |
+
|
| 399 |
+
The order of features is non-deterministic within each batch. To
|
| 400 |
+
retrieve the order the decomposed features is generated, use
|
| 401 |
+
:attr:`decomposition_permutations`.
|
| 402 |
+
|
| 403 |
+
"""
|
| 404 |
+
row_inds = self._batchwise_row_indices[batch_index]
|
| 405 |
+
return self.C[row_inds, 1:], self._F[row_inds]
|
| 406 |
+
|
| 407 |
+
@property
|
| 408 |
+
def decomposed_coordinates_and_features(self):
|
| 409 |
+
r"""Returns a list of coordinates and a list of features per batch.abs
|
| 410 |
+
|
| 411 |
+
.. note::
|
| 412 |
+
|
| 413 |
+
The order of decomposed coordinates and features is
|
| 414 |
+
non-deterministic within each batch. To retrieve the order the
|
| 415 |
+
decomposed features is generated, use
|
| 416 |
+
:attr:`decomposition_permutations`.
|
| 417 |
+
|
| 418 |
+
"""
|
| 419 |
+
row_inds_list = self._batchwise_row_indices
|
| 420 |
+
return (
|
| 421 |
+
[self.C[row_inds, 1:] for row_inds in row_inds_list],
|
| 422 |
+
[self._F[row_inds] for row_inds in row_inds_list],
|
| 423 |
+
)
|
| 424 |
+
|
| 425 |
+
@property
|
| 426 |
+
def dimension(self):
|
| 427 |
+
r"""Alias of attr:`D`"""
|
| 428 |
+
return self._D
|
| 429 |
+
|
| 430 |
+
@dimension.setter
|
| 431 |
+
def dimension(self):
|
| 432 |
+
raise SyntaxError("Direct modification not permitted")
|
| 433 |
+
|
| 434 |
+
@property
|
| 435 |
+
def D(self):
|
| 436 |
+
r"""Alias of attr:`D`"""
|
| 437 |
+
return self._D
|
| 438 |
+
|
| 439 |
+
@D.setter
|
| 440 |
+
def D(self):
|
| 441 |
+
raise SyntaxError("Direct modification not permitted")
|
| 442 |
+
|
| 443 |
+
@property
|
| 444 |
+
def requires_grad(self):
|
| 445 |
+
return self._F.requires_grad
|
| 446 |
+
|
| 447 |
+
def requires_grad_(self, requires_grad: bool = True):
|
| 448 |
+
self._F.requires_grad_(requires_grad)
|
| 449 |
+
|
| 450 |
+
def float(self):
|
| 451 |
+
self._F = self._F.float()
|
| 452 |
+
return self
|
| 453 |
+
|
| 454 |
+
def double(self):
|
| 455 |
+
self._F = self._F.double()
|
| 456 |
+
return self
|
| 457 |
+
|
| 458 |
+
def __len__(self):
|
| 459 |
+
return len(self._F)
|
| 460 |
+
|
| 461 |
+
def size(self):
|
| 462 |
+
return self._F.size()
|
| 463 |
+
|
| 464 |
+
@property
|
| 465 |
+
def shape(self):
|
| 466 |
+
return self._F.shape
|
| 467 |
+
|
| 468 |
+
@property
|
| 469 |
+
def device(self):
|
| 470 |
+
return self._F.device
|
| 471 |
+
|
| 472 |
+
@property
|
| 473 |
+
def dtype(self):
|
| 474 |
+
return self._F.dtype
|
| 475 |
+
|
| 476 |
+
def detach(self):
|
| 477 |
+
self._F = self._F.detach()
|
| 478 |
+
return self
|
| 479 |
+
|
| 480 |
+
def get_device(self):
|
| 481 |
+
return self._F.get_device()
|
| 482 |
+
|
| 483 |
+
def _is_same_key(self, other):
|
| 484 |
+
assert isinstance(other, self.__class__)
|
| 485 |
+
assert self._manager == other._manager, COORDINATE_MANAGER_DIFFERENT_ERROR
|
| 486 |
+
assert (
|
| 487 |
+
self.coordinate_map_key == other.coordinate_map_key
|
| 488 |
+
), COORDINATE_KEY_DIFFERENT_ERROR
|
| 489 |
+
|
| 490 |
+
# Operation overloading
|
| 491 |
+
def __iadd__(self, other):
|
| 492 |
+
self._is_same_key(other)
|
| 493 |
+
self._F += other.F
|
| 494 |
+
return self
|
| 495 |
+
|
| 496 |
+
def __isub__(self, other):
|
| 497 |
+
self._is_same_key(other)
|
| 498 |
+
self._F -= other.F
|
| 499 |
+
return self
|
| 500 |
+
|
| 501 |
+
def __imul__(self, other):
|
| 502 |
+
self._is_same_key(other)
|
| 503 |
+
self._F *= other.F
|
| 504 |
+
return self
|
| 505 |
+
|
| 506 |
+
def __idiv__(self, other):
|
| 507 |
+
self._is_same_key(other)
|
| 508 |
+
self._F /= other.F
|
| 509 |
+
return self
|
| 510 |
+
|
| 511 |
+
def _binary_functor(self, other, binary_fn):
|
| 512 |
+
assert isinstance(other, (self.__class__, torch.Tensor))
|
| 513 |
+
if isinstance(other, self.__class__):
|
| 514 |
+
assert self._manager == other._manager, COORDINATE_MANAGER_DIFFERENT_ERROR
|
| 515 |
+
|
| 516 |
+
if self.coordinate_map_key == other.coordinate_map_key:
|
| 517 |
+
return self.__class__(
|
| 518 |
+
binary_fn(self._F, other.F),
|
| 519 |
+
coordinate_map_key=self.coordinate_map_key,
|
| 520 |
+
coordinate_manager=self._manager,
|
| 521 |
+
)
|
| 522 |
+
else:
|
| 523 |
+
# Generate union maps
|
| 524 |
+
out_key = CoordinateMapKey(
|
| 525 |
+
self.coordinate_map_key.get_coordinate_size()
|
| 526 |
+
)
|
| 527 |
+
union_maps = self.coordinate_manager.union_map(
|
| 528 |
+
[self.coordinate_map_key, other.coordinate_map_key], out_key
|
| 529 |
+
)
|
| 530 |
+
N_out = self.coordinate_manager.size(out_key)
|
| 531 |
+
out_F = torch.zeros(
|
| 532 |
+
(N_out, self._F.size(1)), dtype=self.dtype, device=self.device
|
| 533 |
+
)
|
| 534 |
+
out_F[union_maps[0][1]] = self._F[union_maps[0][0]]
|
| 535 |
+
out_F[union_maps[1][1]] = binary_fn(
|
| 536 |
+
out_F[union_maps[1][1]], other._F[union_maps[1][0]]
|
| 537 |
+
)
|
| 538 |
+
return self.__class__(
|
| 539 |
+
out_F, coordinate_map_key=out_key, coordinate_manager=self._manager
|
| 540 |
+
)
|
| 541 |
+
else: # when it is a torch.Tensor
|
| 542 |
+
return self.__class__(
|
| 543 |
+
binary_fn(self._F, other),
|
| 544 |
+
coordinate_map_key=self.coordinate_map_key,
|
| 545 |
+
coordinate_manager=self._manager,
|
| 546 |
+
)
|
| 547 |
+
|
| 548 |
+
def __add__(self, other):
|
| 549 |
+
r"""
|
| 550 |
+
Add its feature with the corresponding feature of the other
|
| 551 |
+
:attr:`MinkowskiEngine.SparseTensor` or a :attr:`torch.Tensor`
|
| 552 |
+
element-wise. For coordinates that exist on one sparse tensor but not
|
| 553 |
+
on the other, features of the counterpart that do not exist will be set
|
| 554 |
+
to 0.
|
| 555 |
+
"""
|
| 556 |
+
return self._binary_functor(other, lambda x, y: x + y)
|
| 557 |
+
|
| 558 |
+
def __sub__(self, other):
|
| 559 |
+
r"""
|
| 560 |
+
Subtract the feature of the other :attr:`MinkowskiEngine.SparseTensor`
|
| 561 |
+
or a :attr:`torch.Tensor` from its corresponding feature element-wise.
|
| 562 |
+
For coordinates that exist on one sparse tensor but not on the other,
|
| 563 |
+
features of the counterpart that do not exist will be set to 0.
|
| 564 |
+
"""
|
| 565 |
+
return self._binary_functor(other, lambda x, y: x - y)
|
| 566 |
+
|
| 567 |
+
def __mul__(self, other):
|
| 568 |
+
r"""
|
| 569 |
+
Multiply its feature of with the corresponding feature of the other
|
| 570 |
+
:attr:`MinkowskiEngine.SparseTensor` or a :attr:`torch.Tensor`
|
| 571 |
+
element-wise. For coordinates that exist on one sparse tensor but not
|
| 572 |
+
on the other, features of the counterpart that do not exist will be set
|
| 573 |
+
to 0.
|
| 574 |
+
"""
|
| 575 |
+
return self._binary_functor(other, lambda x, y: x * y)
|
| 576 |
+
|
| 577 |
+
def __truediv__(self, other):
|
| 578 |
+
r"""
|
| 579 |
+
Divide its feature by the corresponding feature of the other
|
| 580 |
+
:attr:`MinkowskiEngine.SparseTensor` or a :attr:`torch.Tensor`
|
| 581 |
+
element-wise. For coordinates that exist on one sparse tensor but not
|
| 582 |
+
on the other, features of the counterpart that do not exist will be set
|
| 583 |
+
to 0.
|
| 584 |
+
"""
|
| 585 |
+
return self._binary_functor(other, lambda x, y: x / y)
|
| 586 |
+
|
| 587 |
+
def __power__(self, power):
|
| 588 |
+
return self.__class__(
|
| 589 |
+
self._F ** power,
|
| 590 |
+
coordinate_map_key=self.coordinate_map_key,
|
| 591 |
+
coordinate_manager=self._manager,
|
| 592 |
+
)
|
| 593 |
+
|
| 594 |
+
__slots__ = (
|
| 595 |
+
"_C",
|
| 596 |
+
"_F",
|
| 597 |
+
"_D",
|
| 598 |
+
"coordinate_map_key",
|
| 599 |
+
"_manager",
|
| 600 |
+
"unique_index",
|
| 601 |
+
"inverse_mapping",
|
| 602 |
+
"quantization_mode",
|
| 603 |
+
"_batch_rows",
|
| 604 |
+
)
|
MinkowskiEngine/MinkowskiEngine/MinkowskiTensorField.py
ADDED
|
@@ -0,0 +1,506 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
import os
|
| 25 |
+
import numpy as np
|
| 26 |
+
from collections.abc import Sequence
|
| 27 |
+
from typing import Union, List, Tuple
|
| 28 |
+
|
| 29 |
+
import torch
|
| 30 |
+
from MinkowskiCommon import convert_to_int_list, StrideType
|
| 31 |
+
from MinkowskiEngineBackend._C import (
|
| 32 |
+
GPUMemoryAllocatorType,
|
| 33 |
+
MinkowskiAlgorithm,
|
| 34 |
+
CoordinateMapKey,
|
| 35 |
+
CoordinateMapType,
|
| 36 |
+
)
|
| 37 |
+
from MinkowskiCoordinateManager import CoordinateManager
|
| 38 |
+
from MinkowskiTensor import (
|
| 39 |
+
SparseTensorOperationMode,
|
| 40 |
+
SparseTensorQuantizationMode,
|
| 41 |
+
Tensor,
|
| 42 |
+
sparse_tensor_operation_mode,
|
| 43 |
+
global_coordinate_manager,
|
| 44 |
+
set_global_coordinate_manager,
|
| 45 |
+
COORDINATE_MANAGER_DIFFERENT_ERROR,
|
| 46 |
+
COORDINATE_KEY_DIFFERENT_ERROR,
|
| 47 |
+
)
|
| 48 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 49 |
+
from sparse_matrix_functions import MinkowskiSPMMFunction, MinkowskiSPMMAverageFunction
|
| 50 |
+
from MinkowskiPooling import MinkowskiDirectMaxPoolingFunction
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def create_splat_coordinates(coordinates: torch.Tensor) -> torch.Tensor:
|
| 54 |
+
r"""Create splat coordinates. splat coordinates could have duplicate coordinates."""
|
| 55 |
+
dimension = coordinates.shape[1] - 1
|
| 56 |
+
region_offset = [
|
| 57 |
+
[
|
| 58 |
+
0,
|
| 59 |
+
]
|
| 60 |
+
* (dimension + 1)
|
| 61 |
+
]
|
| 62 |
+
for d in reversed(range(1, dimension + 1)):
|
| 63 |
+
new_offset = []
|
| 64 |
+
for offset in region_offset:
|
| 65 |
+
offset = offset.copy() # Do not modify the original
|
| 66 |
+
offset[d] = 1
|
| 67 |
+
new_offset.append(offset)
|
| 68 |
+
region_offset.extend(new_offset)
|
| 69 |
+
region_offset = torch.IntTensor(region_offset).to(coordinates.device)
|
| 70 |
+
coordinates = torch.floor(coordinates).int().unsqueeze(1) + region_offset.unsqueeze(
|
| 71 |
+
0
|
| 72 |
+
)
|
| 73 |
+
return coordinates.reshape(-1, dimension + 1)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class TensorField(Tensor):
|
| 77 |
+
def __init__(
|
| 78 |
+
self,
|
| 79 |
+
features: torch.Tensor,
|
| 80 |
+
coordinates: torch.Tensor = None,
|
| 81 |
+
# optional coordinate related arguments
|
| 82 |
+
tensor_stride: StrideType = 1,
|
| 83 |
+
coordinate_field_map_key: CoordinateMapKey = None,
|
| 84 |
+
coordinate_manager: CoordinateManager = None,
|
| 85 |
+
quantization_mode: SparseTensorQuantizationMode = SparseTensorQuantizationMode.UNWEIGHTED_AVERAGE,
|
| 86 |
+
# optional manager related arguments
|
| 87 |
+
allocator_type: GPUMemoryAllocatorType = None,
|
| 88 |
+
minkowski_algorithm: MinkowskiAlgorithm = None,
|
| 89 |
+
requires_grad=None,
|
| 90 |
+
device=None,
|
| 91 |
+
):
|
| 92 |
+
r"""
|
| 93 |
+
|
| 94 |
+
Args:
|
| 95 |
+
:attr:`features` (:attr:`torch.FloatTensor`,
|
| 96 |
+
:attr:`torch.DoubleTensor`, :attr:`torch.cuda.FloatTensor`, or
|
| 97 |
+
:attr:`torch.cuda.DoubleTensor`): The features of a sparse
|
| 98 |
+
tensor.
|
| 99 |
+
|
| 100 |
+
:attr:`coordinates` (:attr:`torch.IntTensor`): The coordinates
|
| 101 |
+
associated to the features. If not provided, :attr:`coordinate_map_key`
|
| 102 |
+
must be provided.
|
| 103 |
+
|
| 104 |
+
:attr:`tensor_stride` (:attr:`int`, :attr:`list`,
|
| 105 |
+
:attr:`numpy.array`, or :attr:`tensor.Tensor`): The tensor stride
|
| 106 |
+
of the current sparse tensor. By default, it is 1.
|
| 107 |
+
|
| 108 |
+
:attr:`coordinate_field_map_key`
|
| 109 |
+
(:attr:`MinkowskiEngine.CoordinateMapKey`): When the coordinates
|
| 110 |
+
are already cached in the MinkowskiEngine, we could reuse the same
|
| 111 |
+
coordinate map by simply providing the coordinate map key. In most
|
| 112 |
+
case, this process is done automatically. When you provide a
|
| 113 |
+
`coordinate_field_map_key`, `coordinates` will be be ignored.
|
| 114 |
+
|
| 115 |
+
:attr:`coordinate_manager`
|
| 116 |
+
(:attr:`MinkowskiEngine.CoordinateManager`): The MinkowskiEngine
|
| 117 |
+
manages all coordinate maps using the `_C.CoordinateMapManager`. If
|
| 118 |
+
not provided, the MinkowskiEngine will create a new computation
|
| 119 |
+
graph. In most cases, this process is handled automatically and you
|
| 120 |
+
do not need to use this.
|
| 121 |
+
|
| 122 |
+
:attr:`quantization_mode`
|
| 123 |
+
(:attr:`MinkowskiEngine.SparseTensorQuantizationMode`): Defines how
|
| 124 |
+
continuous coordinates will be quantized to define a sparse tensor.
|
| 125 |
+
Please refer to :attr:`SparseTensorQuantizationMode` for details.
|
| 126 |
+
|
| 127 |
+
:attr:`allocator_type`
|
| 128 |
+
(:attr:`MinkowskiEngine.GPUMemoryAllocatorType`): Defines the GPU
|
| 129 |
+
memory allocator type. By default, it uses the c10 allocator.
|
| 130 |
+
|
| 131 |
+
:attr:`minkowski_algorithm`
|
| 132 |
+
(:attr:`MinkowskiEngine.MinkowskiAlgorithm`): Controls the mode the
|
| 133 |
+
minkowski engine runs, Use
|
| 134 |
+
:attr:`MinkowskiAlgorithm.MEMORY_EFFICIENT` if you want to reduce
|
| 135 |
+
the memory footprint. Or use
|
| 136 |
+
:attr:`MinkowskiAlgorithm.SPEED_OPTIMIZED` if you want to make it
|
| 137 |
+
run fasterat the cost of more memory.
|
| 138 |
+
|
| 139 |
+
:attr:`requires_grad` (:attr:`bool`): Set the requires_grad flag.
|
| 140 |
+
|
| 141 |
+
:attr:`device` (:attr:`torch.device`): Set the device the sparse
|
| 142 |
+
tensor is defined.
|
| 143 |
+
"""
|
| 144 |
+
# Type checks
|
| 145 |
+
assert isinstance(features, torch.Tensor), "Features must be a torch.Tensor"
|
| 146 |
+
assert (
|
| 147 |
+
features.ndim == 2
|
| 148 |
+
), f"The feature should be a matrix, The input feature is an order-{features.ndim} tensor."
|
| 149 |
+
assert isinstance(quantization_mode, SparseTensorQuantizationMode)
|
| 150 |
+
assert quantization_mode in [
|
| 151 |
+
SparseTensorQuantizationMode.UNWEIGHTED_AVERAGE,
|
| 152 |
+
SparseTensorQuantizationMode.UNWEIGHTED_SUM,
|
| 153 |
+
SparseTensorQuantizationMode.RANDOM_SUBSAMPLE,
|
| 154 |
+
SparseTensorQuantizationMode.MAX_POOL,
|
| 155 |
+
], "invalid quantization mode"
|
| 156 |
+
|
| 157 |
+
self.quantization_mode = quantization_mode
|
| 158 |
+
|
| 159 |
+
if coordinates is not None:
|
| 160 |
+
assert isinstance(coordinates, torch.Tensor)
|
| 161 |
+
if coordinate_field_map_key is not None:
|
| 162 |
+
assert isinstance(coordinate_field_map_key, CoordinateMapKey)
|
| 163 |
+
assert coordinate_manager is not None, "Must provide coordinate_manager if coordinate_field_map_key is provided"
|
| 164 |
+
assert coordinates is None, "Must not provide coordinates if coordinate_field_map_key is provided"
|
| 165 |
+
if coordinate_manager is not None:
|
| 166 |
+
assert isinstance(coordinate_manager, CoordinateManager)
|
| 167 |
+
if coordinates is None and (
|
| 168 |
+
coordinate_field_map_key is None or coordinate_manager is None
|
| 169 |
+
):
|
| 170 |
+
raise ValueError(
|
| 171 |
+
"Either coordinates or (coordinate_field_map_key, coordinate_manager) pair must be provided."
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
Tensor.__init__(self)
|
| 175 |
+
|
| 176 |
+
# To device
|
| 177 |
+
if device is not None:
|
| 178 |
+
features = features.to(device)
|
| 179 |
+
if coordinates is not None:
|
| 180 |
+
# assertion check for the map key done later
|
| 181 |
+
coordinates = coordinates.to(device)
|
| 182 |
+
|
| 183 |
+
self._D = (
|
| 184 |
+
coordinates.size(1) - 1 if coordinates is not None else coordinate_manager.D
|
| 185 |
+
)
|
| 186 |
+
##########################
|
| 187 |
+
# Setup CoordsManager
|
| 188 |
+
##########################
|
| 189 |
+
if coordinate_manager is None:
|
| 190 |
+
# If set to share the coords man, use the global coords man
|
| 191 |
+
if (
|
| 192 |
+
sparse_tensor_operation_mode()
|
| 193 |
+
== SparseTensorOperationMode.SHARE_COORDINATE_MANAGER
|
| 194 |
+
):
|
| 195 |
+
coordinate_manager = global_coordinate_manager()
|
| 196 |
+
if coordinate_manager is None:
|
| 197 |
+
coordinate_manager = CoordinateManager(
|
| 198 |
+
D=self._D,
|
| 199 |
+
coordinate_map_type=CoordinateMapType.CUDA
|
| 200 |
+
if coordinates.is_cuda
|
| 201 |
+
else CoordinateMapType.CPU,
|
| 202 |
+
allocator_type=allocator_type,
|
| 203 |
+
minkowski_algorithm=minkowski_algorithm,
|
| 204 |
+
)
|
| 205 |
+
set_global_coordinate_manager(coordinate_manager)
|
| 206 |
+
else:
|
| 207 |
+
coordinate_manager = CoordinateManager(
|
| 208 |
+
D=coordinates.size(1) - 1,
|
| 209 |
+
coordinate_map_type=CoordinateMapType.CUDA
|
| 210 |
+
if coordinates.is_cuda
|
| 211 |
+
else CoordinateMapType.CPU,
|
| 212 |
+
allocator_type=allocator_type,
|
| 213 |
+
minkowski_algorithm=minkowski_algorithm,
|
| 214 |
+
)
|
| 215 |
+
self._manager = coordinate_manager
|
| 216 |
+
|
| 217 |
+
##########################
|
| 218 |
+
# Initialize coords
|
| 219 |
+
##########################
|
| 220 |
+
# Coordinate Management
|
| 221 |
+
if coordinates is not None:
|
| 222 |
+
assert (
|
| 223 |
+
features.shape[0] == coordinates.shape[0]
|
| 224 |
+
), "The number of rows in features and coordinates must match."
|
| 225 |
+
|
| 226 |
+
assert (
|
| 227 |
+
features.is_cuda == coordinates.is_cuda
|
| 228 |
+
), "Features and coordinates must have the same backend."
|
| 229 |
+
|
| 230 |
+
coordinate_field_map_key = CoordinateMapKey(
|
| 231 |
+
convert_to_int_list(tensor_stride, self._D), ""
|
| 232 |
+
)
|
| 233 |
+
coordinate_field_map_key = self._manager.insert_field(
|
| 234 |
+
coordinates.float(), convert_to_int_list(tensor_stride, self._D), ""
|
| 235 |
+
)
|
| 236 |
+
else:
|
| 237 |
+
assert (
|
| 238 |
+
coordinate_field_map_key.is_key_set()
|
| 239 |
+
), "The coordinate field map key must be valid."
|
| 240 |
+
|
| 241 |
+
if requires_grad is not None:
|
| 242 |
+
features.requires_grad_(requires_grad)
|
| 243 |
+
|
| 244 |
+
self._F = features
|
| 245 |
+
self._C = coordinates
|
| 246 |
+
self.coordinate_field_map_key = coordinate_field_map_key
|
| 247 |
+
self._batch_rows = None
|
| 248 |
+
self._inverse_mapping = {}
|
| 249 |
+
self._splat = {}
|
| 250 |
+
|
| 251 |
+
@property
|
| 252 |
+
def coordinate_key(self):
|
| 253 |
+
return self.coordinate_field_map_key
|
| 254 |
+
|
| 255 |
+
@property
|
| 256 |
+
def C(self):
|
| 257 |
+
r"""The alias of :attr:`coords`."""
|
| 258 |
+
return self.coordinates
|
| 259 |
+
|
| 260 |
+
@property
|
| 261 |
+
def coordinates(self):
|
| 262 |
+
r"""
|
| 263 |
+
The coordinates of the current sparse tensor. The coordinates are
|
| 264 |
+
represented as a :math:`N \times (D + 1)` dimensional matrix where
|
| 265 |
+
:math:`N` is the number of points in the space and :math:`D` is the
|
| 266 |
+
dimension of the space (e.g. 3 for 3D, 4 for 3D + Time). Additional
|
| 267 |
+
dimension of the column of the matrix C is for batch indices which is
|
| 268 |
+
internally treated as an additional spatial dimension to disassociate
|
| 269 |
+
different instances in a batch.
|
| 270 |
+
"""
|
| 271 |
+
if self._C is None:
|
| 272 |
+
self._C = self._get_coordinate_field()
|
| 273 |
+
return self._C
|
| 274 |
+
|
| 275 |
+
@property
|
| 276 |
+
def _batchwise_row_indices(self):
|
| 277 |
+
if self._batch_rows is None:
|
| 278 |
+
_, self._batch_rows = self._manager.origin_field_map(
|
| 279 |
+
self.coordinate_field_map_key
|
| 280 |
+
)
|
| 281 |
+
return self._batch_rows
|
| 282 |
+
|
| 283 |
+
def _get_coordinate_field(self):
|
| 284 |
+
return self._manager.get_coordinate_field(self.coordinate_field_map_key)
|
| 285 |
+
|
| 286 |
+
def sparse(
|
| 287 |
+
self,
|
| 288 |
+
tensor_stride: Union[int, Sequence, np.array] = 1,
|
| 289 |
+
coordinate_map_key: CoordinateMapKey = None,
|
| 290 |
+
quantization_mode: SparseTensorQuantizationMode = None,
|
| 291 |
+
):
|
| 292 |
+
r"""Converts the current sparse tensor field to a sparse tensor."""
|
| 293 |
+
if quantization_mode is None:
|
| 294 |
+
quantization_mode = self.quantization_mode
|
| 295 |
+
assert (
|
| 296 |
+
quantization_mode != SparseTensorQuantizationMode.SPLAT_LINEAR_INTERPOLATION
|
| 297 |
+
), "Please use .splat() for splat quantization."
|
| 298 |
+
|
| 299 |
+
if coordinate_map_key is None:
|
| 300 |
+
tensor_stride = convert_to_int_list(tensor_stride, self.D)
|
| 301 |
+
|
| 302 |
+
coordinate_map_key, (
|
| 303 |
+
unique_index,
|
| 304 |
+
inverse_mapping,
|
| 305 |
+
) = self._manager.field_to_sparse_insert_and_map(
|
| 306 |
+
self.coordinate_field_map_key,
|
| 307 |
+
tensor_stride,
|
| 308 |
+
)
|
| 309 |
+
N_rows = len(unique_index)
|
| 310 |
+
else:
|
| 311 |
+
# sparse index, field index
|
| 312 |
+
inverse_mapping, unique_index = self._manager.field_to_sparse_map(
|
| 313 |
+
self.coordinate_field_map_key,
|
| 314 |
+
coordinate_map_key,
|
| 315 |
+
)
|
| 316 |
+
N_rows = self._manager.size(coordinate_map_key)
|
| 317 |
+
|
| 318 |
+
assert N_rows > 0, f"Invalid out coordinate map key. Found {N_row} elements."
|
| 319 |
+
|
| 320 |
+
if len(inverse_mapping) == 0:
|
| 321 |
+
# When the input has the same shape as the output
|
| 322 |
+
self._inverse_mapping[coordinate_map_key] = torch.arange(
|
| 323 |
+
len(self._F),
|
| 324 |
+
dtype=inverse_mapping.dtype,
|
| 325 |
+
device=inverse_mapping.device,
|
| 326 |
+
)
|
| 327 |
+
return SparseTensor(
|
| 328 |
+
self._F,
|
| 329 |
+
coordinate_map_key=coordinate_map_key,
|
| 330 |
+
coordinate_manager=self._manager,
|
| 331 |
+
)
|
| 332 |
+
|
| 333 |
+
# Create features
|
| 334 |
+
if quantization_mode == SparseTensorQuantizationMode.UNWEIGHTED_SUM:
|
| 335 |
+
N = len(self._F)
|
| 336 |
+
cols = torch.arange(
|
| 337 |
+
N,
|
| 338 |
+
dtype=inverse_mapping.dtype,
|
| 339 |
+
device=inverse_mapping.device,
|
| 340 |
+
)
|
| 341 |
+
vals = torch.ones(N, dtype=self._F.dtype, device=self._F.device)
|
| 342 |
+
size = torch.Size([N_rows, len(inverse_mapping)])
|
| 343 |
+
features = MinkowskiSPMMFunction().apply(
|
| 344 |
+
inverse_mapping, cols, vals, size, self._F
|
| 345 |
+
)
|
| 346 |
+
elif quantization_mode == SparseTensorQuantizationMode.UNWEIGHTED_AVERAGE:
|
| 347 |
+
N = len(self._F)
|
| 348 |
+
cols = torch.arange(
|
| 349 |
+
N,
|
| 350 |
+
dtype=inverse_mapping.dtype,
|
| 351 |
+
device=inverse_mapping.device,
|
| 352 |
+
)
|
| 353 |
+
size = torch.Size([N_rows, len(inverse_mapping)])
|
| 354 |
+
features = MinkowskiSPMMAverageFunction().apply(
|
| 355 |
+
inverse_mapping, cols, size, self._F
|
| 356 |
+
)
|
| 357 |
+
elif quantization_mode == SparseTensorQuantizationMode.RANDOM_SUBSAMPLE:
|
| 358 |
+
features = self._F[unique_index]
|
| 359 |
+
elif quantization_mode == SparseTensorQuantizationMode.MAX_POOL:
|
| 360 |
+
N = len(self._F)
|
| 361 |
+
in_map = torch.arange(
|
| 362 |
+
N,
|
| 363 |
+
dtype=inverse_mapping.dtype,
|
| 364 |
+
device=inverse_mapping.device,
|
| 365 |
+
)
|
| 366 |
+
features = MinkowskiDirectMaxPoolingFunction().apply(
|
| 367 |
+
in_map, inverse_mapping, self._F, N_rows
|
| 368 |
+
)
|
| 369 |
+
else:
|
| 370 |
+
# No quantization
|
| 371 |
+
raise ValueError("Invalid quantization mode")
|
| 372 |
+
|
| 373 |
+
self._inverse_mapping[coordinate_map_key] = inverse_mapping
|
| 374 |
+
|
| 375 |
+
return SparseTensor(
|
| 376 |
+
features,
|
| 377 |
+
coordinate_map_key=coordinate_map_key,
|
| 378 |
+
coordinate_manager=self._manager,
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
def splat(self):
|
| 382 |
+
r"""
|
| 383 |
+
For slice, use Y.slice(X) where X is the tensor field and Y is the
|
| 384 |
+
resulting sparse tensor.
|
| 385 |
+
"""
|
| 386 |
+
splat_coordinates = create_splat_coordinates(self.C)
|
| 387 |
+
(coordinate_map_key, _) = self._manager.insert_and_map(splat_coordinates)
|
| 388 |
+
N_rows = self._manager.size(coordinate_map_key)
|
| 389 |
+
|
| 390 |
+
tensor_map, field_map, weights = self._manager.interpolation_map_weight(
|
| 391 |
+
coordinate_map_key, self._C
|
| 392 |
+
)
|
| 393 |
+
# features
|
| 394 |
+
N = len(self._F)
|
| 395 |
+
assert weights.dtype == self._F.dtype
|
| 396 |
+
size = torch.Size([N_rows, N])
|
| 397 |
+
# Save the results for slice
|
| 398 |
+
self._splat[coordinate_map_key] = (tensor_map, field_map, weights, size)
|
| 399 |
+
features = MinkowskiSPMMFunction().apply(
|
| 400 |
+
tensor_map, field_map, weights, size, self._F
|
| 401 |
+
)
|
| 402 |
+
return SparseTensor(
|
| 403 |
+
features,
|
| 404 |
+
coordinate_map_key=coordinate_map_key,
|
| 405 |
+
coordinate_manager=self._manager,
|
| 406 |
+
)
|
| 407 |
+
|
| 408 |
+
def inverse_mapping(self, sparse_tensor_map_key: CoordinateMapKey):
|
| 409 |
+
if sparse_tensor_map_key not in self._inverse_mapping:
|
| 410 |
+
if not self._manager.exists_field_to_sparse(
|
| 411 |
+
self.coordinate_field_map_key, sparse_tensor_map_key
|
| 412 |
+
):
|
| 413 |
+
sparse_keys = self.coordinate_manager.field_to_sparse_keys(
|
| 414 |
+
self.coordinate_field_map_key
|
| 415 |
+
)
|
| 416 |
+
one_key = None
|
| 417 |
+
if len(sparse_keys) > 0:
|
| 418 |
+
for key in sparse_keys:
|
| 419 |
+
if np.prod(key.get_tensor_stride()) == 1:
|
| 420 |
+
one_key = key
|
| 421 |
+
else:
|
| 422 |
+
one_key = CoordinateMapKey(
|
| 423 |
+
[
|
| 424 |
+
1,
|
| 425 |
+
]
|
| 426 |
+
* self.D,
|
| 427 |
+
"",
|
| 428 |
+
)
|
| 429 |
+
|
| 430 |
+
if one_key not in self._inverse_mapping:
|
| 431 |
+
(
|
| 432 |
+
_,
|
| 433 |
+
self._inverse_mapping[one_key],
|
| 434 |
+
) = self._manager.get_field_to_sparse_map(
|
| 435 |
+
self.coordinate_field_map_key, one_key
|
| 436 |
+
)
|
| 437 |
+
_, stride_map = self.coordinate_manager.stride_map(
|
| 438 |
+
one_key, sparse_tensor_map_key
|
| 439 |
+
)
|
| 440 |
+
field_map = self._inverse_mapping[one_key]
|
| 441 |
+
self._inverse_mapping[sparse_tensor_map_key] = stride_map[field_map]
|
| 442 |
+
else:
|
| 443 |
+
# Extract the mapping
|
| 444 |
+
(
|
| 445 |
+
_,
|
| 446 |
+
self._inverse_mapping[sparse_tensor_map_key],
|
| 447 |
+
) = self._manager.get_field_to_sparse_map(
|
| 448 |
+
self.coordinate_field_map_key, sparse_tensor_map_key
|
| 449 |
+
)
|
| 450 |
+
return self._inverse_mapping[sparse_tensor_map_key]
|
| 451 |
+
|
| 452 |
+
def _is_same_key(self, other):
|
| 453 |
+
assert isinstance(other, self.__class__)
|
| 454 |
+
assert self._manager == other._manager, COORDINATE_MANAGER_DIFFERENT_ERROR
|
| 455 |
+
assert (
|
| 456 |
+
self.coordinate_field_map_key == other.coordinate_field_map_key
|
| 457 |
+
), COORDINATE_KEY_DIFFERENT_ERROR
|
| 458 |
+
|
| 459 |
+
def _binary_functor(self, other, binary_fn):
|
| 460 |
+
assert isinstance(other, (self.__class__, torch.Tensor))
|
| 461 |
+
if isinstance(other, self.__class__):
|
| 462 |
+
self._is_same_key(other)
|
| 463 |
+
return self.__class__(
|
| 464 |
+
binary_fn(self._F, other.F),
|
| 465 |
+
coordinate_map_key=self.coordinate_map_key,
|
| 466 |
+
coordinate_manager=self._manager,
|
| 467 |
+
)
|
| 468 |
+
else: # when it is a torch.Tensor
|
| 469 |
+
return self.__class__(
|
| 470 |
+
binary_fn(self._F, other),
|
| 471 |
+
coordinate_field_map_key=self.coordinate_map_key,
|
| 472 |
+
coordinate_manager=self._manager,
|
| 473 |
+
)
|
| 474 |
+
|
| 475 |
+
def __repr__(self):
|
| 476 |
+
return (
|
| 477 |
+
self.__class__.__name__
|
| 478 |
+
+ "("
|
| 479 |
+
+ os.linesep
|
| 480 |
+
+ " coordinates="
|
| 481 |
+
+ str(self.C)
|
| 482 |
+
+ os.linesep
|
| 483 |
+
+ " features="
|
| 484 |
+
+ str(self.F)
|
| 485 |
+
+ os.linesep
|
| 486 |
+
+ " coordinate_field_map_key="
|
| 487 |
+
+ str(self.coordinate_field_map_key)
|
| 488 |
+
+ os.linesep
|
| 489 |
+
+ " coordinate_manager="
|
| 490 |
+
+ str(self._manager)
|
| 491 |
+
+ " spatial dimension="
|
| 492 |
+
+ str(self._D)
|
| 493 |
+
+ ")"
|
| 494 |
+
)
|
| 495 |
+
|
| 496 |
+
__slots__ = (
|
| 497 |
+
"_C",
|
| 498 |
+
"_F",
|
| 499 |
+
"_D",
|
| 500 |
+
"coordinate_field_map_key",
|
| 501 |
+
"_manager",
|
| 502 |
+
"quantization_mode",
|
| 503 |
+
"_inverse_mapping",
|
| 504 |
+
"_batch_rows",
|
| 505 |
+
"_splat",
|
| 506 |
+
)
|
MinkowskiEngine/MinkowskiEngine/MinkowskiUnion.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Chris Choy (chrischoy@ai.stanford.edu).
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
import torch
|
| 25 |
+
from torch.nn import Module
|
| 26 |
+
from torch.autograd import Function
|
| 27 |
+
|
| 28 |
+
from MinkowskiEngineBackend._C import CoordinateMapKey
|
| 29 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 30 |
+
from MinkowskiCoordinateManager import CoordinateManager
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class MinkowskiUnionFunction(Function):
|
| 34 |
+
@staticmethod
|
| 35 |
+
def forward(
|
| 36 |
+
ctx,
|
| 37 |
+
in_coords_keys: list,
|
| 38 |
+
out_coords_key: CoordinateMapKey,
|
| 39 |
+
coordinate_manager: CoordinateManager,
|
| 40 |
+
*in_feats,
|
| 41 |
+
):
|
| 42 |
+
assert isinstance(
|
| 43 |
+
in_feats, (list, tuple)
|
| 44 |
+
), "Input must be a collection of Tensors"
|
| 45 |
+
assert len(in_feats) > 1, "input must be a set with at least 2 Tensors"
|
| 46 |
+
assert len(in_feats) == len(
|
| 47 |
+
in_coords_keys
|
| 48 |
+
), "The input features and keys must have the same length"
|
| 49 |
+
|
| 50 |
+
union_maps = coordinate_manager.union_map(in_coords_keys, out_coords_key)
|
| 51 |
+
out_feat = torch.zeros(
|
| 52 |
+
(coordinate_manager.size(out_coords_key), in_feats[0].shape[1]),
|
| 53 |
+
dtype=in_feats[0].dtype,
|
| 54 |
+
device=in_feats[0].device,
|
| 55 |
+
)
|
| 56 |
+
for in_feat, union_map in zip(in_feats, union_maps):
|
| 57 |
+
out_feat[union_map[1]] += in_feat[union_map[0]]
|
| 58 |
+
ctx.keys = (in_coords_keys, coordinate_manager)
|
| 59 |
+
ctx.save_for_backward(*union_maps)
|
| 60 |
+
return out_feat
|
| 61 |
+
|
| 62 |
+
@staticmethod
|
| 63 |
+
def backward(ctx, grad_out_feat):
|
| 64 |
+
if not grad_out_feat.is_contiguous():
|
| 65 |
+
grad_out_feat = grad_out_feat.contiguous()
|
| 66 |
+
|
| 67 |
+
union_maps = ctx.saved_tensors
|
| 68 |
+
in_coords_keys, coordinate_manager = ctx.keys
|
| 69 |
+
num_ch, dtype, device = (
|
| 70 |
+
grad_out_feat.shape[1],
|
| 71 |
+
grad_out_feat.dtype,
|
| 72 |
+
grad_out_feat.device,
|
| 73 |
+
)
|
| 74 |
+
grad_in_feats = []
|
| 75 |
+
for in_coords_key, union_map in zip(in_coords_keys, union_maps):
|
| 76 |
+
grad_in_feat = torch.zeros(
|
| 77 |
+
(coordinate_manager.size(in_coords_key), num_ch),
|
| 78 |
+
dtype=dtype,
|
| 79 |
+
device=device,
|
| 80 |
+
)
|
| 81 |
+
grad_in_feat[union_map[0]] = grad_out_feat[union_map[1]]
|
| 82 |
+
grad_in_feats.append(grad_in_feat)
|
| 83 |
+
return (None, None, None, *grad_in_feats)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
class MinkowskiUnion(Module):
|
| 87 |
+
r"""Create a union of all sparse tensors and add overlapping features.
|
| 88 |
+
|
| 89 |
+
Args:
|
| 90 |
+
None
|
| 91 |
+
|
| 92 |
+
.. warning::
|
| 93 |
+
This function is experimental and the usage can be changed in the future updates.
|
| 94 |
+
|
| 95 |
+
"""
|
| 96 |
+
|
| 97 |
+
def __init__(self):
|
| 98 |
+
super(MinkowskiUnion, self).__init__()
|
| 99 |
+
self.union = MinkowskiUnionFunction()
|
| 100 |
+
|
| 101 |
+
def forward(self, *inputs):
|
| 102 |
+
r"""
|
| 103 |
+
Args:
|
| 104 |
+
A variable number of :attr:`MinkowskiEngine.SparseTensor`'s.
|
| 105 |
+
|
| 106 |
+
Returns:
|
| 107 |
+
A :attr:`MinkowskiEngine.SparseTensor` with coordinates = union of all
|
| 108 |
+
input coordinates, and features = sum of all features corresponding to the
|
| 109 |
+
coordinate.
|
| 110 |
+
|
| 111 |
+
Example::
|
| 112 |
+
|
| 113 |
+
>>> # Define inputs
|
| 114 |
+
>>> input1 = SparseTensor(
|
| 115 |
+
>>> torch.rand(N, in_channels, dtype=torch.double), coords=coords)
|
| 116 |
+
>>> # All inputs must share the same coordinate manager
|
| 117 |
+
>>> input2 = SparseTensor(
|
| 118 |
+
>>> torch.rand(N, in_channels, dtype=torch.double),
|
| 119 |
+
>>> coords=coords + 1,
|
| 120 |
+
>>> coords_manager=input1.coordinate_manager, # Must use same coords manager
|
| 121 |
+
>>> force_creation=True # The tensor stride [1, 1] already exists.
|
| 122 |
+
>>> )
|
| 123 |
+
>>> union = MinkowskiUnion()
|
| 124 |
+
>>> output = union(input1, iput2)
|
| 125 |
+
|
| 126 |
+
"""
|
| 127 |
+
assert isinstance(inputs, (list, tuple)), "The input must be a list or tuple"
|
| 128 |
+
for s in inputs:
|
| 129 |
+
assert isinstance(s, SparseTensor), "Inputs must be sparse tensors."
|
| 130 |
+
assert len(inputs) > 1, "input must be a set with at least 2 SparseTensors"
|
| 131 |
+
# Assert the same coordinate manager
|
| 132 |
+
ref_coordinate_manager = inputs[0].coordinate_manager
|
| 133 |
+
for s in inputs:
|
| 134 |
+
assert (
|
| 135 |
+
ref_coordinate_manager == s.coordinate_manager
|
| 136 |
+
), "Invalid coordinate manager. All inputs must have the same coordinate manager."
|
| 137 |
+
|
| 138 |
+
in_coordinate_map_key = inputs[0].coordinate_map_key
|
| 139 |
+
coordinate_manager = inputs[0].coordinate_manager
|
| 140 |
+
out_coordinate_map_key = CoordinateMapKey(
|
| 141 |
+
in_coordinate_map_key.get_coordinate_size()
|
| 142 |
+
)
|
| 143 |
+
output = self.union.apply(
|
| 144 |
+
[input.coordinate_map_key for input in inputs],
|
| 145 |
+
out_coordinate_map_key,
|
| 146 |
+
coordinate_manager,
|
| 147 |
+
*[input.F for input in inputs],
|
| 148 |
+
)
|
| 149 |
+
return SparseTensor(
|
| 150 |
+
output,
|
| 151 |
+
coordinate_map_key=out_coordinate_map_key,
|
| 152 |
+
coordinate_manager=coordinate_manager,
|
| 153 |
+
)
|
| 154 |
+
|
| 155 |
+
def __repr__(self):
|
| 156 |
+
return self.__class__.__name__ + "()"
|
MinkowskiEngine/MinkowskiEngine/__init__.py
ADDED
|
@@ -0,0 +1,228 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
# Copyright (c) 2018-2020 Chris Choy (chrischoy@ai.stanford.edu).
|
| 3 |
+
#
|
| 4 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 5 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 6 |
+
# the Software without restriction, including without limitation the rights to
|
| 7 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 8 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 9 |
+
# so, subject to the following conditions:
|
| 10 |
+
#
|
| 11 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 12 |
+
# copies or substantial portions of the Software.
|
| 13 |
+
#
|
| 14 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 20 |
+
# SOFTWARE.
|
| 21 |
+
#
|
| 22 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 23 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 24 |
+
# of the code.
|
| 25 |
+
__version__ = "0.5.4"
|
| 26 |
+
|
| 27 |
+
import os
|
| 28 |
+
import sys
|
| 29 |
+
import warnings
|
| 30 |
+
|
| 31 |
+
file_dir = os.path.dirname(__file__)
|
| 32 |
+
sys.path.append(file_dir)
|
| 33 |
+
|
| 34 |
+
# Force OMP_NUM_THREADS setup
|
| 35 |
+
if os.cpu_count() > 16 and "OMP_NUM_THREADS" not in os.environ:
|
| 36 |
+
warnings.warn(
|
| 37 |
+
" ".join(
|
| 38 |
+
[
|
| 39 |
+
"The environment variable `OMP_NUM_THREADS` not set. MinkowskiEngine will automatically set `OMP_NUM_THREADS=16`.",
|
| 40 |
+
"If you want to set `OMP_NUM_THREADS` manually, please export it on the command line before running a python script.",
|
| 41 |
+
"e.g. `export OMP_NUM_THREADS=12; python your_program.py`.",
|
| 42 |
+
"It is recommended to set it below 24.",
|
| 43 |
+
]
|
| 44 |
+
)
|
| 45 |
+
)
|
| 46 |
+
os.environ["OMP_NUM_THREADS"] = str(16)
|
| 47 |
+
|
| 48 |
+
# Must be imported first to load all required shared libs
|
| 49 |
+
import torch
|
| 50 |
+
|
| 51 |
+
from diagnostics import print_diagnostics
|
| 52 |
+
|
| 53 |
+
from MinkowskiEngineBackend._C import (
|
| 54 |
+
MinkowskiAlgorithm,
|
| 55 |
+
CoordinateMapKey,
|
| 56 |
+
GPUMemoryAllocatorType,
|
| 57 |
+
CoordinateMapType,
|
| 58 |
+
RegionType,
|
| 59 |
+
PoolingMode,
|
| 60 |
+
BroadcastMode,
|
| 61 |
+
is_cuda_available,
|
| 62 |
+
cuda_version,
|
| 63 |
+
cudart_version,
|
| 64 |
+
get_gpu_memory_info,
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
from MinkowskiKernelGenerator import (
|
| 68 |
+
KernelRegion,
|
| 69 |
+
KernelGenerator,
|
| 70 |
+
convert_region_type,
|
| 71 |
+
get_kernel_volume,
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
from MinkowskiTensor import (
|
| 75 |
+
SparseTensorOperationMode,
|
| 76 |
+
SparseTensorQuantizationMode,
|
| 77 |
+
set_sparse_tensor_operation_mode,
|
| 78 |
+
sparse_tensor_operation_mode,
|
| 79 |
+
global_coordinate_manager,
|
| 80 |
+
set_global_coordinate_manager,
|
| 81 |
+
clear_global_coordinate_manager,
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 85 |
+
|
| 86 |
+
from MinkowskiTensorField import TensorField
|
| 87 |
+
|
| 88 |
+
from MinkowskiCommon import (
|
| 89 |
+
convert_to_int_tensor,
|
| 90 |
+
MinkowskiModuleBase,
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
from MinkowskiCoordinateManager import (
|
| 94 |
+
set_memory_manager_backend,
|
| 95 |
+
set_gpu_allocator,
|
| 96 |
+
CoordsManager,
|
| 97 |
+
CoordinateManager,
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
from MinkowskiConvolution import (
|
| 101 |
+
MinkowskiConvolutionFunction,
|
| 102 |
+
MinkowskiConvolution,
|
| 103 |
+
MinkowskiConvolutionTransposeFunction,
|
| 104 |
+
MinkowskiConvolutionTranspose,
|
| 105 |
+
MinkowskiGenerativeConvolutionTranspose,
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
from MinkowskiChannelwiseConvolution import MinkowskiChannelwiseConvolution
|
| 110 |
+
|
| 111 |
+
from MinkowskiPooling import (
|
| 112 |
+
MinkowskiLocalPoolingFunction,
|
| 113 |
+
MinkowskiSumPooling,
|
| 114 |
+
MinkowskiAvgPooling,
|
| 115 |
+
MinkowskiMaxPooling,
|
| 116 |
+
MinkowskiLocalPoolingTransposeFunction,
|
| 117 |
+
MinkowskiPoolingTranspose,
|
| 118 |
+
MinkowskiGlobalPoolingFunction,
|
| 119 |
+
MinkowskiGlobalPooling,
|
| 120 |
+
MinkowskiGlobalSumPooling,
|
| 121 |
+
MinkowskiGlobalAvgPooling,
|
| 122 |
+
MinkowskiGlobalMaxPooling,
|
| 123 |
+
MinkowskiDirectMaxPoolingFunction,
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
from MinkowskiBroadcast import (
|
| 127 |
+
MinkowskiBroadcastFunction,
|
| 128 |
+
MinkowskiBroadcastAddition,
|
| 129 |
+
MinkowskiBroadcastMultiplication,
|
| 130 |
+
MinkowskiBroadcast,
|
| 131 |
+
MinkowskiBroadcastConcatenation,
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
from MinkowskiNonlinearity import (
|
| 135 |
+
MinkowskiELU,
|
| 136 |
+
MinkowskiHardshrink,
|
| 137 |
+
MinkowskiHardsigmoid,
|
| 138 |
+
MinkowskiHardtanh,
|
| 139 |
+
MinkowskiHardswish,
|
| 140 |
+
MinkowskiLeakyReLU,
|
| 141 |
+
MinkowskiLogSigmoid,
|
| 142 |
+
MinkowskiPReLU,
|
| 143 |
+
MinkowskiReLU,
|
| 144 |
+
MinkowskiReLU6,
|
| 145 |
+
MinkowskiRReLU,
|
| 146 |
+
MinkowskiSELU,
|
| 147 |
+
MinkowskiCELU,
|
| 148 |
+
MinkowskiGELU,
|
| 149 |
+
MinkowskiSigmoid,
|
| 150 |
+
MinkowskiSiLU,
|
| 151 |
+
MinkowskiSoftplus,
|
| 152 |
+
MinkowskiSoftshrink,
|
| 153 |
+
MinkowskiSoftsign,
|
| 154 |
+
MinkowskiTanh,
|
| 155 |
+
MinkowskiTanhshrink,
|
| 156 |
+
MinkowskiThreshold,
|
| 157 |
+
MinkowskiSoftmin,
|
| 158 |
+
MinkowskiSoftmax,
|
| 159 |
+
MinkowskiLogSoftmax,
|
| 160 |
+
MinkowskiAdaptiveLogSoftmaxWithLoss,
|
| 161 |
+
MinkowskiDropout,
|
| 162 |
+
MinkowskiAlphaDropout,
|
| 163 |
+
MinkowskiSinusoidal,
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
from MinkowskiNormalization import (
|
| 167 |
+
MinkowskiBatchNorm,
|
| 168 |
+
MinkowskiSyncBatchNorm,
|
| 169 |
+
MinkowskiInstanceNorm,
|
| 170 |
+
MinkowskiInstanceNormFunction,
|
| 171 |
+
MinkowskiStableInstanceNorm,
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
from MinkowskiPruning import MinkowskiPruning, MinkowskiPruningFunction
|
| 176 |
+
|
| 177 |
+
from MinkowskiUnion import MinkowskiUnion, MinkowskiUnionFunction
|
| 178 |
+
|
| 179 |
+
from MinkowskiInterpolation import (
|
| 180 |
+
MinkowskiInterpolation,
|
| 181 |
+
MinkowskiInterpolationFunction,
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
from MinkowskiNetwork import MinkowskiNetwork
|
| 185 |
+
|
| 186 |
+
import MinkowskiOps
|
| 187 |
+
|
| 188 |
+
from MinkowskiOps import (
|
| 189 |
+
MinkowskiLinear,
|
| 190 |
+
MinkowskiToSparseTensor,
|
| 191 |
+
MinkowskiToDenseTensor,
|
| 192 |
+
MinkowskiToFeature,
|
| 193 |
+
MinkowskiStackCat,
|
| 194 |
+
MinkowskiStackSum,
|
| 195 |
+
MinkowskiStackMean,
|
| 196 |
+
MinkowskiStackVar,
|
| 197 |
+
cat,
|
| 198 |
+
mean,
|
| 199 |
+
var,
|
| 200 |
+
to_sparse,
|
| 201 |
+
to_sparse_all,
|
| 202 |
+
dense_coordinates,
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
from MinkowskiOps import _sum as sum
|
| 206 |
+
|
| 207 |
+
import MinkowskiFunctional
|
| 208 |
+
|
| 209 |
+
import MinkowskiEngine.utils as utils
|
| 210 |
+
|
| 211 |
+
import MinkowskiEngine.modules as modules
|
| 212 |
+
|
| 213 |
+
from sparse_matrix_functions import (
|
| 214 |
+
spmm,
|
| 215 |
+
MinkowskiSPMMFunction,
|
| 216 |
+
MinkowskiSPMMAverageFunction,
|
| 217 |
+
)
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
if not is_cuda_available():
|
| 221 |
+
warnings.warn(
|
| 222 |
+
" ".join(
|
| 223 |
+
[
|
| 224 |
+
"The MinkowskiEngine was compiled with CPU_ONLY flag.",
|
| 225 |
+
"If you want to compile with CUDA support, make sure `torch.cuda.is_available()` is True when you install MinkowskiEngine.",
|
| 226 |
+
]
|
| 227 |
+
)
|
| 228 |
+
)
|
MinkowskiEngine/MinkowskiEngine/diagnostics.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import os
|
| 3 |
+
import platform
|
| 4 |
+
import subprocess
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def parse_nvidia_smi():
|
| 8 |
+
sp = subprocess.Popen(
|
| 9 |
+
["nvidia-smi", "-q"], stdout=subprocess.PIPE, stderr=subprocess.PIPE
|
| 10 |
+
)
|
| 11 |
+
out_dict = dict()
|
| 12 |
+
for item in sp.communicate()[0].decode("utf-8").split("\n"):
|
| 13 |
+
if item.count(":") == 1:
|
| 14 |
+
key, val = [i.strip() for i in item.split(":")]
|
| 15 |
+
out_dict[key] = val
|
| 16 |
+
return out_dict
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def print_diagnostics():
|
| 20 |
+
print("==========System==========")
|
| 21 |
+
print(platform.platform())
|
| 22 |
+
os.system("cat /etc/lsb-release")
|
| 23 |
+
print(sys.version)
|
| 24 |
+
|
| 25 |
+
print("==========Pytorch==========")
|
| 26 |
+
try:
|
| 27 |
+
import torch
|
| 28 |
+
|
| 29 |
+
print(torch.__version__)
|
| 30 |
+
print(f"torch.cuda.is_available(): {torch.cuda.is_available()}")
|
| 31 |
+
except ImportError:
|
| 32 |
+
print("torch not installed")
|
| 33 |
+
|
| 34 |
+
print("==========NVIDIA-SMI==========")
|
| 35 |
+
os.system("which nvidia-smi")
|
| 36 |
+
for k, v in parse_nvidia_smi().items():
|
| 37 |
+
if "version" in k.lower():
|
| 38 |
+
print(k, v)
|
| 39 |
+
|
| 40 |
+
print("==========NVCC==========")
|
| 41 |
+
os.system("which nvcc")
|
| 42 |
+
os.system("nvcc --version")
|
| 43 |
+
|
| 44 |
+
print("==========CC==========")
|
| 45 |
+
CC = "c++"
|
| 46 |
+
if "CC" in os.environ or "CXX" in os.environ:
|
| 47 |
+
# distutils only checks CC not CXX
|
| 48 |
+
if "CXX" in os.environ:
|
| 49 |
+
os.environ["CC"] = os.environ["CXX"]
|
| 50 |
+
CC = os.environ["CXX"]
|
| 51 |
+
else:
|
| 52 |
+
CC = os.environ["CC"]
|
| 53 |
+
print(f"CC={CC}")
|
| 54 |
+
os.system(f"which {CC}")
|
| 55 |
+
os.system(f"{CC} --version")
|
| 56 |
+
|
| 57 |
+
print("==========MinkowskiEngine==========")
|
| 58 |
+
try:
|
| 59 |
+
import MinkowskiEngine as ME
|
| 60 |
+
|
| 61 |
+
print(ME.__version__)
|
| 62 |
+
print(f"MinkowskiEngine compiled with CUDA Support: {ME.is_cuda_available()}")
|
| 63 |
+
print(f"NVCC version MinkowskiEngine is compiled: {ME.cuda_version()}")
|
| 64 |
+
print(f"CUDART version MinkowskiEngine is compiled: {ME.cudart_version()}")
|
| 65 |
+
except ImportError:
|
| 66 |
+
print("MinkowskiEngine not installed")
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
if __name__ == "__main__":
|
| 70 |
+
print_diagnostics()
|
MinkowskiEngine/MinkowskiEngine/modules/__init__.py
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Chris Choy (chrischoy@ai.stanford.edu).
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
MinkowskiEngine/MinkowskiEngine/modules/resnet_block.py
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Chris Choy (chrischoy@ai.stanford.edu).
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
import torch.nn as nn
|
| 25 |
+
|
| 26 |
+
import MinkowskiEngine as ME
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class BasicBlock(nn.Module):
|
| 30 |
+
expansion = 1
|
| 31 |
+
|
| 32 |
+
def __init__(self,
|
| 33 |
+
inplanes,
|
| 34 |
+
planes,
|
| 35 |
+
stride=1,
|
| 36 |
+
dilation=1,
|
| 37 |
+
downsample=None,
|
| 38 |
+
bn_momentum=0.1,
|
| 39 |
+
dimension=-1):
|
| 40 |
+
super(BasicBlock, self).__init__()
|
| 41 |
+
assert dimension > 0
|
| 42 |
+
|
| 43 |
+
self.conv1 = ME.MinkowskiConvolution(
|
| 44 |
+
inplanes, planes, kernel_size=3, stride=stride, dilation=dilation, dimension=dimension)
|
| 45 |
+
self.norm1 = ME.MinkowskiBatchNorm(planes, momentum=bn_momentum)
|
| 46 |
+
self.conv2 = ME.MinkowskiConvolution(
|
| 47 |
+
planes, planes, kernel_size=3, stride=1, dilation=dilation, dimension=dimension)
|
| 48 |
+
self.norm2 = ME.MinkowskiBatchNorm(planes, momentum=bn_momentum)
|
| 49 |
+
self.relu = ME.MinkowskiReLU(inplace=True)
|
| 50 |
+
self.downsample = downsample
|
| 51 |
+
|
| 52 |
+
def forward(self, x):
|
| 53 |
+
residual = x
|
| 54 |
+
|
| 55 |
+
out = self.conv1(x)
|
| 56 |
+
out = self.norm1(out)
|
| 57 |
+
out = self.relu(out)
|
| 58 |
+
|
| 59 |
+
out = self.conv2(out)
|
| 60 |
+
out = self.norm2(out)
|
| 61 |
+
|
| 62 |
+
if self.downsample is not None:
|
| 63 |
+
residual = self.downsample(x)
|
| 64 |
+
|
| 65 |
+
out += residual
|
| 66 |
+
out = self.relu(out)
|
| 67 |
+
|
| 68 |
+
return out
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
class Bottleneck(nn.Module):
|
| 72 |
+
expansion = 4
|
| 73 |
+
|
| 74 |
+
def __init__(self,
|
| 75 |
+
inplanes,
|
| 76 |
+
planes,
|
| 77 |
+
stride=1,
|
| 78 |
+
dilation=1,
|
| 79 |
+
downsample=None,
|
| 80 |
+
bn_momentum=0.1,
|
| 81 |
+
dimension=-1):
|
| 82 |
+
super(Bottleneck, self).__init__()
|
| 83 |
+
assert dimension > 0
|
| 84 |
+
|
| 85 |
+
self.conv1 = ME.MinkowskiConvolution(
|
| 86 |
+
inplanes, planes, kernel_size=1, dimension=dimension)
|
| 87 |
+
self.norm1 = ME.MinkowskiBatchNorm(planes, momentum=bn_momentum)
|
| 88 |
+
|
| 89 |
+
self.conv2 = ME.MinkowskiConvolution(
|
| 90 |
+
planes, planes, kernel_size=3, stride=stride, dilation=dilation, dimension=dimension)
|
| 91 |
+
self.norm2 = ME.MinkowskiBatchNorm(planes, momentum=bn_momentum)
|
| 92 |
+
|
| 93 |
+
self.conv3 = ME.MinkowskiConvolution(
|
| 94 |
+
planes, planes * self.expansion, kernel_size=1, dimension=dimension)
|
| 95 |
+
self.norm3 = ME.MinkowskiBatchNorm(
|
| 96 |
+
planes * self.expansion, momentum=bn_momentum)
|
| 97 |
+
|
| 98 |
+
self.relu = ME.MinkowskiReLU(inplace=True)
|
| 99 |
+
self.downsample = downsample
|
| 100 |
+
|
| 101 |
+
def forward(self, x):
|
| 102 |
+
residual = x
|
| 103 |
+
|
| 104 |
+
out = self.conv1(x)
|
| 105 |
+
out = self.norm1(out)
|
| 106 |
+
out = self.relu(out)
|
| 107 |
+
|
| 108 |
+
out = self.conv2(out)
|
| 109 |
+
out = self.norm2(out)
|
| 110 |
+
out = self.relu(out)
|
| 111 |
+
|
| 112 |
+
out = self.conv3(out)
|
| 113 |
+
out = self.norm3(out)
|
| 114 |
+
|
| 115 |
+
if self.downsample is not None:
|
| 116 |
+
residual = self.downsample(x)
|
| 117 |
+
|
| 118 |
+
out += residual
|
| 119 |
+
out = self.relu(out)
|
| 120 |
+
|
| 121 |
+
return out
|
MinkowskiEngine/MinkowskiEngine/modules/senet_block.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Chris Choy (chrischoy@ai.stanford.edu).
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
import torch.nn as nn
|
| 25 |
+
|
| 26 |
+
import MinkowskiEngine as ME
|
| 27 |
+
|
| 28 |
+
from MinkowskiEngine.modules.resnet_block import BasicBlock, Bottleneck
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class SELayer(nn.Module):
|
| 32 |
+
|
| 33 |
+
def __init__(self, channel, reduction=16, D=-1):
|
| 34 |
+
# Global coords does not require coords_key
|
| 35 |
+
super(SELayer, self).__init__()
|
| 36 |
+
self.fc = nn.Sequential(
|
| 37 |
+
ME.MinkowskiLinear(channel, channel // reduction),
|
| 38 |
+
ME.MinkowskiReLU(inplace=True),
|
| 39 |
+
ME.MinkowskiLinear(channel // reduction, channel),
|
| 40 |
+
ME.MinkowskiSigmoid())
|
| 41 |
+
self.pooling = ME.MinkowskiGlobalPooling()
|
| 42 |
+
self.broadcast_mul = ME.MinkowskiBroadcastMultiplication()
|
| 43 |
+
|
| 44 |
+
def forward(self, x):
|
| 45 |
+
y = self.pooling(x)
|
| 46 |
+
y = self.fc(y)
|
| 47 |
+
return self.broadcast_mul(x, y)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class SEBasicBlock(BasicBlock):
|
| 51 |
+
|
| 52 |
+
def __init__(self,
|
| 53 |
+
inplanes,
|
| 54 |
+
planes,
|
| 55 |
+
stride=1,
|
| 56 |
+
dilation=1,
|
| 57 |
+
downsample=None,
|
| 58 |
+
reduction=16,
|
| 59 |
+
D=-1):
|
| 60 |
+
super(SEBasicBlock, self).__init__(
|
| 61 |
+
inplanes,
|
| 62 |
+
planes,
|
| 63 |
+
stride=stride,
|
| 64 |
+
dilation=dilation,
|
| 65 |
+
downsample=downsample,
|
| 66 |
+
D=D)
|
| 67 |
+
self.se = SELayer(planes, reduction=reduction, D=D)
|
| 68 |
+
|
| 69 |
+
def forward(self, x):
|
| 70 |
+
residual = x
|
| 71 |
+
|
| 72 |
+
out = self.conv1(x)
|
| 73 |
+
out = self.norm1(out)
|
| 74 |
+
out = self.relu(out)
|
| 75 |
+
|
| 76 |
+
out = self.conv2(out)
|
| 77 |
+
out = self.norm2(out)
|
| 78 |
+
out = self.se(out)
|
| 79 |
+
|
| 80 |
+
if self.downsample is not None:
|
| 81 |
+
residual = self.downsample(x)
|
| 82 |
+
|
| 83 |
+
out += residual
|
| 84 |
+
out = self.relu(out)
|
| 85 |
+
|
| 86 |
+
return out
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
class SEBottleneck(Bottleneck):
|
| 90 |
+
|
| 91 |
+
def __init__(self,
|
| 92 |
+
inplanes,
|
| 93 |
+
planes,
|
| 94 |
+
stride=1,
|
| 95 |
+
dilation=1,
|
| 96 |
+
downsample=None,
|
| 97 |
+
D=3,
|
| 98 |
+
reduction=16):
|
| 99 |
+
super(SEBottleneck, self).__init__(
|
| 100 |
+
inplanes,
|
| 101 |
+
planes,
|
| 102 |
+
stride=stride,
|
| 103 |
+
dilation=dilation,
|
| 104 |
+
downsample=downsample,
|
| 105 |
+
D=D)
|
| 106 |
+
self.se = SELayer(planes * self.expansion, reduction=reduction, D=D)
|
| 107 |
+
|
| 108 |
+
def forward(self, x):
|
| 109 |
+
residual = x
|
| 110 |
+
|
| 111 |
+
out = self.conv1(x)
|
| 112 |
+
out = self.norm1(out)
|
| 113 |
+
out = self.relu(out)
|
| 114 |
+
|
| 115 |
+
out = self.conv2(out)
|
| 116 |
+
out = self.norm2(out)
|
| 117 |
+
out = self.relu(out)
|
| 118 |
+
|
| 119 |
+
out = self.conv3(out)
|
| 120 |
+
out = self.norm3(out)
|
| 121 |
+
out = self.se(out)
|
| 122 |
+
|
| 123 |
+
if self.downsample is not None:
|
| 124 |
+
residual = self.downsample(x)
|
| 125 |
+
|
| 126 |
+
out += residual
|
| 127 |
+
out = self.relu(out)
|
| 128 |
+
|
| 129 |
+
return out
|
MinkowskiEngine/MinkowskiEngine/sparse_matrix_functions.py
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2020 NVIDIA CORPORATION.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
import torch
|
| 25 |
+
from torch.autograd import Function
|
| 26 |
+
|
| 27 |
+
import MinkowskiEngineBackend._C as MEB
|
| 28 |
+
|
| 29 |
+
EPS = 1e-10
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def spmm(
|
| 33 |
+
rows: torch.Tensor,
|
| 34 |
+
cols: torch.Tensor,
|
| 35 |
+
vals: torch.Tensor,
|
| 36 |
+
size: torch.Size,
|
| 37 |
+
mat: torch.Tensor,
|
| 38 |
+
is_sorted: bool = False,
|
| 39 |
+
cuda_spmm_alg: int = 1,
|
| 40 |
+
) -> torch.Tensor:
|
| 41 |
+
|
| 42 |
+
assert len(rows) == len(cols), "Invalid length"
|
| 43 |
+
assert len(rows) == len(vals), "Invalid length"
|
| 44 |
+
assert vals.dtype == mat.dtype, "dtype mismatch"
|
| 45 |
+
assert vals.device == mat.device, "device mismatch"
|
| 46 |
+
if mat.is_cuda:
|
| 47 |
+
assert (
|
| 48 |
+
rows.is_cuda and cols.is_cuda and vals.is_cuda
|
| 49 |
+
), "All inputs must be on cuda"
|
| 50 |
+
rows = rows.int()
|
| 51 |
+
cols = cols.int()
|
| 52 |
+
result = MEB.coo_spmm_int32(
|
| 53 |
+
rows, cols, vals, size[0], size[1], mat, cuda_spmm_alg, is_sorted
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
# WARNING: TODO: not sorting the vals. Should not be used for generic SPMM
|
| 57 |
+
# coosort only supports int32
|
| 58 |
+
# return MEB.coo_spmm_int64(
|
| 59 |
+
# rows, cols, vals, size[0], size[1], mat, cuda_spmm_alg
|
| 60 |
+
# )
|
| 61 |
+
else:
|
| 62 |
+
COO = torch.stack(
|
| 63 |
+
(rows, cols),
|
| 64 |
+
0,
|
| 65 |
+
).long()
|
| 66 |
+
torchSparseTensor = None
|
| 67 |
+
if vals.dtype == torch.float64:
|
| 68 |
+
torchSparseTensor = torch.sparse.DoubleTensor
|
| 69 |
+
elif vals.dtype == torch.float32:
|
| 70 |
+
torchSparseTensor = torch.sparse.FloatTensor
|
| 71 |
+
else:
|
| 72 |
+
raise ValueError(f"Unsupported data type: {vals.dtype}")
|
| 73 |
+
|
| 74 |
+
sp = torchSparseTensor(COO, vals, size)
|
| 75 |
+
result = sp.matmul(mat)
|
| 76 |
+
|
| 77 |
+
return result
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def spmm_average(
|
| 81 |
+
rows: torch.Tensor,
|
| 82 |
+
cols: torch.Tensor,
|
| 83 |
+
size: torch.Size,
|
| 84 |
+
mat: torch.Tensor,
|
| 85 |
+
cuda_spmm_alg: int = 1,
|
| 86 |
+
) -> (torch.Tensor, torch.Tensor, torch.Tensor):
|
| 87 |
+
|
| 88 |
+
assert len(rows) == len(cols), "Invalid length"
|
| 89 |
+
if mat.is_cuda:
|
| 90 |
+
assert rows.is_cuda and cols.is_cuda, "All inputs must be on cuda"
|
| 91 |
+
rows = rows.int()
|
| 92 |
+
cols = cols.int()
|
| 93 |
+
result, COO, vals = MEB.coo_spmm_average_int32(
|
| 94 |
+
rows, cols, size[0], size[1], mat, cuda_spmm_alg
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
# WARNING: TODO: not sorting the vals. Should not be used for generic SPMM
|
| 98 |
+
# coosort only supports int32
|
| 99 |
+
# return MEB.coo_spmm_int64(
|
| 100 |
+
# rows, cols, vals, size[0], size[1], mat, cuda_spmm_alg
|
| 101 |
+
# )
|
| 102 |
+
else:
|
| 103 |
+
# fmt: off
|
| 104 |
+
rows, sort_ind = torch.sort(rows)
|
| 105 |
+
cols = cols[sort_ind]
|
| 106 |
+
COO = torch.stack((rows, cols), 0,).long()
|
| 107 |
+
# Vals
|
| 108 |
+
_, inverse_ind, counts = torch.unique(rows, return_counts=True, return_inverse=True)
|
| 109 |
+
vals = (1 / counts[inverse_ind]).to(mat.dtype)
|
| 110 |
+
# fmt: on
|
| 111 |
+
torchSparseTensor = None
|
| 112 |
+
if mat.dtype == torch.float64:
|
| 113 |
+
torchSparseTensor = torch.sparse.DoubleTensor
|
| 114 |
+
elif mat.dtype == torch.float32:
|
| 115 |
+
torchSparseTensor = torch.sparse.FloatTensor
|
| 116 |
+
else:
|
| 117 |
+
raise ValueError(f"Unsupported data type: {mat.dtype}")
|
| 118 |
+
sp = torchSparseTensor(COO, vals, size)
|
| 119 |
+
result = sp.matmul(mat)
|
| 120 |
+
|
| 121 |
+
return result, COO, vals
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
class MinkowskiSPMMFunction(Function):
|
| 125 |
+
@staticmethod
|
| 126 |
+
def forward(
|
| 127 |
+
ctx,
|
| 128 |
+
rows: torch.Tensor,
|
| 129 |
+
cols: torch.Tensor,
|
| 130 |
+
vals: torch.Tensor,
|
| 131 |
+
size: torch.Size,
|
| 132 |
+
mat: torch.Tensor,
|
| 133 |
+
cuda_spmm_alg: int = 1,
|
| 134 |
+
):
|
| 135 |
+
ctx.misc_args = size, cuda_spmm_alg
|
| 136 |
+
ctx.save_for_backward(rows, cols, vals)
|
| 137 |
+
result = spmm(
|
| 138 |
+
rows,
|
| 139 |
+
cols,
|
| 140 |
+
vals,
|
| 141 |
+
size,
|
| 142 |
+
mat,
|
| 143 |
+
is_sorted=False,
|
| 144 |
+
cuda_spmm_alg=cuda_spmm_alg,
|
| 145 |
+
)
|
| 146 |
+
return result
|
| 147 |
+
|
| 148 |
+
@staticmethod
|
| 149 |
+
def backward(ctx, grad: torch.Tensor):
|
| 150 |
+
size, cuda_spmm_alg = ctx.misc_args
|
| 151 |
+
rows, cols, vals = ctx.saved_tensors
|
| 152 |
+
new_size = torch.Size([size[1], size[0]])
|
| 153 |
+
grad = spmm(
|
| 154 |
+
cols,
|
| 155 |
+
rows,
|
| 156 |
+
vals,
|
| 157 |
+
new_size,
|
| 158 |
+
grad,
|
| 159 |
+
is_sorted=False,
|
| 160 |
+
cuda_spmm_alg=cuda_spmm_alg,
|
| 161 |
+
)
|
| 162 |
+
return (
|
| 163 |
+
None,
|
| 164 |
+
None,
|
| 165 |
+
None,
|
| 166 |
+
None,
|
| 167 |
+
grad,
|
| 168 |
+
None,
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
class MinkowskiSPMMAverageFunction(Function):
|
| 173 |
+
@staticmethod
|
| 174 |
+
def forward(
|
| 175 |
+
ctx,
|
| 176 |
+
rows: torch.Tensor,
|
| 177 |
+
cols: torch.Tensor,
|
| 178 |
+
size: torch.Size,
|
| 179 |
+
mat: torch.Tensor,
|
| 180 |
+
cuda_spmm_alg: int = 1,
|
| 181 |
+
):
|
| 182 |
+
ctx.misc_args = size, cuda_spmm_alg
|
| 183 |
+
result, COO, vals = spmm_average(
|
| 184 |
+
rows,
|
| 185 |
+
cols,
|
| 186 |
+
size,
|
| 187 |
+
mat,
|
| 188 |
+
cuda_spmm_alg=cuda_spmm_alg,
|
| 189 |
+
)
|
| 190 |
+
ctx.save_for_backward(COO, vals)
|
| 191 |
+
return result
|
| 192 |
+
|
| 193 |
+
@staticmethod
|
| 194 |
+
def backward(ctx, grad: torch.Tensor):
|
| 195 |
+
size, cuda_spmm_alg = ctx.misc_args
|
| 196 |
+
COO, vals = ctx.saved_tensors
|
| 197 |
+
new_size = torch.Size([size[1], size[0]])
|
| 198 |
+
grad = spmm(
|
| 199 |
+
COO[1],
|
| 200 |
+
COO[0],
|
| 201 |
+
vals,
|
| 202 |
+
new_size,
|
| 203 |
+
grad,
|
| 204 |
+
is_sorted=False,
|
| 205 |
+
cuda_spmm_alg=cuda_spmm_alg,
|
| 206 |
+
)
|
| 207 |
+
return (
|
| 208 |
+
None,
|
| 209 |
+
None,
|
| 210 |
+
None,
|
| 211 |
+
grad,
|
| 212 |
+
None,
|
| 213 |
+
)
|
MinkowskiEngine/MinkowskiEngine/utils/__init__.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Chris Choy (chrischoy@ai.stanford.edu).
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
from .quantization import sparse_quantize, ravel_hash_vec, fnv_hash_vec, unique_coordinate_map
|
| 25 |
+
from .collation import SparseCollation, batched_coordinates, sparse_collate, batch_sparse_collate
|
| 26 |
+
# from .coords import get_coords_map
|
| 27 |
+
from .init import kaiming_normal_
|
| 28 |
+
from .summary import summary
|
MinkowskiEngine/MinkowskiEngine/utils/collation.py
ADDED
|
@@ -0,0 +1,263 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Chris Choy (chrischoy@ai.stanford.edu).
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
import numpy as np
|
| 25 |
+
import torch
|
| 26 |
+
import logging
|
| 27 |
+
import collections.abc
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def batched_coordinates(coords, dtype=torch.int32, device=None):
|
| 31 |
+
r"""Create a `ME.SparseTensor` coordinates from a sequence of coordinates
|
| 32 |
+
|
| 33 |
+
Given a list of either numpy or pytorch tensor coordinates, return the
|
| 34 |
+
batched coordinates suitable for `ME.SparseTensor`.
|
| 35 |
+
|
| 36 |
+
Args:
|
| 37 |
+
:attr:`coords` (a sequence of `torch.Tensor` or `numpy.ndarray`): a
|
| 38 |
+
list of coordinates.
|
| 39 |
+
|
| 40 |
+
:attr:`dtype`: torch data type of the return tensor. torch.int32 by default.
|
| 41 |
+
|
| 42 |
+
Returns:
|
| 43 |
+
:attr:`batched_coordindates` (`torch.Tensor`): a batched coordinates.
|
| 44 |
+
|
| 45 |
+
.. warning::
|
| 46 |
+
|
| 47 |
+
From v0.4, the batch index will be prepended before all coordinates.
|
| 48 |
+
|
| 49 |
+
"""
|
| 50 |
+
assert isinstance(
|
| 51 |
+
coords, collections.abc.Sequence
|
| 52 |
+
), "The coordinates must be a sequence."
|
| 53 |
+
assert np.array(
|
| 54 |
+
[cs.ndim == 2 for cs in coords]
|
| 55 |
+
).all(), "All coordinates must be in a 2D array."
|
| 56 |
+
D = np.unique(np.array([cs.shape[1] for cs in coords]))
|
| 57 |
+
assert len(D) == 1, f"Dimension of the array mismatch. All dimensions: {D}"
|
| 58 |
+
D = D[0]
|
| 59 |
+
if device is None:
|
| 60 |
+
if isinstance(coords, torch.Tensor):
|
| 61 |
+
device = coords[0].device
|
| 62 |
+
else:
|
| 63 |
+
device = "cpu"
|
| 64 |
+
assert dtype in [
|
| 65 |
+
torch.int32,
|
| 66 |
+
torch.float32,
|
| 67 |
+
], "Only torch.int32, torch.float32 supported for coordinates."
|
| 68 |
+
|
| 69 |
+
# Create a batched coordinates
|
| 70 |
+
N = np.array([len(cs) for cs in coords]).sum()
|
| 71 |
+
bcoords = torch.zeros((N, D + 1), dtype=dtype, device=device) # uninitialized
|
| 72 |
+
|
| 73 |
+
s = 0
|
| 74 |
+
for b, cs in enumerate(coords):
|
| 75 |
+
if dtype == torch.int32:
|
| 76 |
+
if isinstance(cs, np.ndarray):
|
| 77 |
+
cs = torch.from_numpy(np.floor(cs))
|
| 78 |
+
elif not (
|
| 79 |
+
isinstance(cs, torch.IntTensor) or isinstance(cs, torch.LongTensor)
|
| 80 |
+
):
|
| 81 |
+
cs = cs.floor()
|
| 82 |
+
|
| 83 |
+
cs = cs.int()
|
| 84 |
+
else:
|
| 85 |
+
if isinstance(cs, np.ndarray):
|
| 86 |
+
cs = torch.from_numpy(cs)
|
| 87 |
+
|
| 88 |
+
cn = len(cs)
|
| 89 |
+
# BATCH_FIRST:
|
| 90 |
+
bcoords[s : s + cn, 1:] = cs
|
| 91 |
+
bcoords[s : s + cn, 0] = b
|
| 92 |
+
s += cn
|
| 93 |
+
return bcoords
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def sparse_collate(coords, feats, labels=None, dtype=torch.int32, device=None):
|
| 97 |
+
r"""Create input arguments for a sparse tensor `the documentation
|
| 98 |
+
<https://nvidia.github.io/MinkowskiEngine/sparse_tensor.html>`_.
|
| 99 |
+
|
| 100 |
+
Convert a set of coordinates and features into the batch coordinates and
|
| 101 |
+
batch features.
|
| 102 |
+
|
| 103 |
+
Args:
|
| 104 |
+
:attr:`coords` (set of `torch.Tensor` or `numpy.ndarray`): a set of coordinates.
|
| 105 |
+
|
| 106 |
+
:attr:`feats` (set of `torch.Tensor` or `numpy.ndarray`): a set of features.
|
| 107 |
+
|
| 108 |
+
:attr:`labels` (set of `torch.Tensor` or `numpy.ndarray`): a set of labels
|
| 109 |
+
associated to the inputs.
|
| 110 |
+
|
| 111 |
+
"""
|
| 112 |
+
use_label = False if labels is None else True
|
| 113 |
+
feats_batch, labels_batch = [], []
|
| 114 |
+
assert isinstance(
|
| 115 |
+
coords, collections.abc.Sequence
|
| 116 |
+
), "The coordinates must be a sequence of arrays or tensors."
|
| 117 |
+
assert isinstance(
|
| 118 |
+
feats, collections.abc.Sequence
|
| 119 |
+
), "The features must be a sequence of arrays or tensors."
|
| 120 |
+
D = np.unique(np.array([cs.shape[1] for cs in coords]))
|
| 121 |
+
assert len(D) == 1, f"Dimension of the array mismatch. All dimensions: {D}"
|
| 122 |
+
D = D[0]
|
| 123 |
+
if device is None:
|
| 124 |
+
if isinstance(coords[0], torch.Tensor):
|
| 125 |
+
device = coords[0].device
|
| 126 |
+
else:
|
| 127 |
+
device = "cpu"
|
| 128 |
+
assert dtype in [
|
| 129 |
+
torch.int32,
|
| 130 |
+
torch.float32,
|
| 131 |
+
], "Only torch.int32, torch.float32 supported for coordinates."
|
| 132 |
+
|
| 133 |
+
if use_label:
|
| 134 |
+
assert isinstance(
|
| 135 |
+
labels, collections.abc.Sequence
|
| 136 |
+
), "The labels must be a sequence of arrays or tensors."
|
| 137 |
+
|
| 138 |
+
N = np.array([len(cs) for cs in coords]).sum()
|
| 139 |
+
Nf = np.array([len(fs) for fs in feats]).sum()
|
| 140 |
+
assert N == Nf, f"Coordinate length {N} != Feature length {Nf}"
|
| 141 |
+
|
| 142 |
+
batch_id = 0
|
| 143 |
+
s = 0 # start index
|
| 144 |
+
bcoords = torch.zeros((N, D + 1), dtype=dtype, device=device) # uninitialized
|
| 145 |
+
for coord, feat in zip(coords, feats):
|
| 146 |
+
if isinstance(coord, np.ndarray):
|
| 147 |
+
coord = torch.from_numpy(coord)
|
| 148 |
+
else:
|
| 149 |
+
assert isinstance(
|
| 150 |
+
coord, torch.Tensor
|
| 151 |
+
), "Coords must be of type numpy.ndarray or torch.Tensor"
|
| 152 |
+
if dtype == torch.int32 and coord.dtype in [torch.float32, torch.float64]:
|
| 153 |
+
coord = coord.floor()
|
| 154 |
+
|
| 155 |
+
if isinstance(feat, np.ndarray):
|
| 156 |
+
feat = torch.from_numpy(feat)
|
| 157 |
+
else:
|
| 158 |
+
assert isinstance(
|
| 159 |
+
feat, torch.Tensor
|
| 160 |
+
), "Features must be of type numpy.ndarray or torch.Tensor"
|
| 161 |
+
|
| 162 |
+
# Labels
|
| 163 |
+
if use_label:
|
| 164 |
+
label = labels[batch_id]
|
| 165 |
+
if isinstance(label, np.ndarray):
|
| 166 |
+
label = torch.from_numpy(label)
|
| 167 |
+
labels_batch.append(label)
|
| 168 |
+
|
| 169 |
+
cn = coord.shape[0]
|
| 170 |
+
# Batched coords
|
| 171 |
+
bcoords[s : s + cn, 1:] = coord
|
| 172 |
+
bcoords[s : s + cn, 0] = batch_id
|
| 173 |
+
|
| 174 |
+
# Features
|
| 175 |
+
feats_batch.append(feat)
|
| 176 |
+
|
| 177 |
+
# Post processing steps
|
| 178 |
+
batch_id += 1
|
| 179 |
+
s += cn
|
| 180 |
+
|
| 181 |
+
# Concatenate all lists
|
| 182 |
+
feats_batch = torch.cat(feats_batch, 0)
|
| 183 |
+
if use_label:
|
| 184 |
+
if isinstance(labels_batch[0], torch.Tensor):
|
| 185 |
+
labels_batch = torch.cat(labels_batch, 0)
|
| 186 |
+
return bcoords, feats_batch, labels_batch
|
| 187 |
+
else:
|
| 188 |
+
return bcoords, feats_batch
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
def batch_sparse_collate(data, dtype=torch.int32, device=None):
|
| 192 |
+
r"""The wrapper function that can be used in in conjunction with
|
| 193 |
+
`torch.utils.data.DataLoader` to generate inputs for a sparse tensor.
|
| 194 |
+
|
| 195 |
+
Please refer to `the training example
|
| 196 |
+
<https://nvidia.github.io/MinkowskiEngine/demo/training.html>`_ for the
|
| 197 |
+
usage.
|
| 198 |
+
|
| 199 |
+
Args:
|
| 200 |
+
:attr:`data`: list of (coordinates, features, labels) tuples.
|
| 201 |
+
|
| 202 |
+
"""
|
| 203 |
+
return sparse_collate(*list(zip(*data)), dtype=dtype, device=device)
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
class SparseCollation:
|
| 207 |
+
r"""Generates collate function for coords, feats, labels.
|
| 208 |
+
|
| 209 |
+
Please refer to `the training example
|
| 210 |
+
<https://nvidia.github.io/MinkowskiEngine/demo/training.html>`_ for the
|
| 211 |
+
usage.
|
| 212 |
+
|
| 213 |
+
Args:
|
| 214 |
+
:attr:`limit_numpoints` (int): If positive integer, limits batch size
|
| 215 |
+
so that the number of input coordinates is below limit_numpoints. If 0
|
| 216 |
+
or False, concatenate all points. -1 by default.
|
| 217 |
+
|
| 218 |
+
Example::
|
| 219 |
+
|
| 220 |
+
>>> data_loader = torch.utils.data.DataLoader(
|
| 221 |
+
>>> dataset,
|
| 222 |
+
>>> ...,
|
| 223 |
+
>>> collate_fn=SparseCollation())
|
| 224 |
+
>>> for d in iter(data_loader):
|
| 225 |
+
>>> print(d)
|
| 226 |
+
|
| 227 |
+
"""
|
| 228 |
+
|
| 229 |
+
def __init__(self, limit_numpoints=-1, dtype=torch.int32, device=None):
|
| 230 |
+
self.limit_numpoints = limit_numpoints
|
| 231 |
+
self.dtype = dtype
|
| 232 |
+
self.device = device
|
| 233 |
+
|
| 234 |
+
def __call__(self, list_data):
|
| 235 |
+
coords, feats, labels = list(zip(*list_data))
|
| 236 |
+
coords_batch, feats_batch, labels_batch = [], [], []
|
| 237 |
+
|
| 238 |
+
batch_num_points = 0
|
| 239 |
+
for batch_id, _ in enumerate(coords):
|
| 240 |
+
num_points = coords[batch_id].shape[0]
|
| 241 |
+
batch_num_points += num_points
|
| 242 |
+
if self.limit_numpoints > 0 and batch_num_points > self.limit_numpoints:
|
| 243 |
+
num_full_points = sum(len(c) for c in coords)
|
| 244 |
+
num_full_batch_size = len(coords)
|
| 245 |
+
logging.warning(
|
| 246 |
+
f"\tCannot fit {num_full_points} points into"
|
| 247 |
+
" {self.limit_numpoints} points limit. Truncating batch "
|
| 248 |
+
f"size at {batch_id} out of {num_full_batch_size} with "
|
| 249 |
+
f"{batch_num_points - num_points}."
|
| 250 |
+
)
|
| 251 |
+
break
|
| 252 |
+
coords_batch.append(coords[batch_id])
|
| 253 |
+
feats_batch.append(feats[batch_id])
|
| 254 |
+
labels_batch.append(labels[batch_id])
|
| 255 |
+
|
| 256 |
+
# Concatenate all lists
|
| 257 |
+
return sparse_collate(
|
| 258 |
+
coords_batch,
|
| 259 |
+
feats_batch,
|
| 260 |
+
labels_batch,
|
| 261 |
+
dtype=self.dtype,
|
| 262 |
+
device=self.device,
|
| 263 |
+
)
|
MinkowskiEngine/MinkowskiEngine/utils/coords.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Chris Choy (chrischoy@ai.stanford.edu).
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
import torch
|
| 25 |
+
|
| 26 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def get_coords_map(x, y):
|
| 30 |
+
r"""Get mapping between sparse tensor 1 and sparse tensor 2.
|
| 31 |
+
|
| 32 |
+
Args:
|
| 33 |
+
:attr:`x` (:attr:`MinkowskiEngine.SparseTensor`): a sparse tensor with
|
| 34 |
+
`x.tensor_stride` <= `y.tensor_stride`.
|
| 35 |
+
|
| 36 |
+
:attr:`y` (:attr:`MinkowskiEngine.SparseTensor`): a sparse tensor with
|
| 37 |
+
`x.tensor_stride` <= `y.tensor_stride`.
|
| 38 |
+
|
| 39 |
+
Returns:
|
| 40 |
+
:attr:`x_indices` (:attr:`torch.LongTensor`): the indices of x that
|
| 41 |
+
corresponds to the returned indices of y.
|
| 42 |
+
|
| 43 |
+
:attr:`x_indices` (:attr:`torch.LongTensor`): the indices of y that
|
| 44 |
+
corresponds to the returned indices of x.
|
| 45 |
+
|
| 46 |
+
Example::
|
| 47 |
+
|
| 48 |
+
.. code-block:: python
|
| 49 |
+
|
| 50 |
+
sp_tensor = ME.SparseTensor(features, coordinates=coordinates)
|
| 51 |
+
out_sp_tensor = stride_2_conv(sp_tensor)
|
| 52 |
+
|
| 53 |
+
ins, outs = get_coords_map(sp_tensor, out_sp_tensor)
|
| 54 |
+
for i, o in zip(ins, outs):
|
| 55 |
+
print(f"{i} -> {o}")
|
| 56 |
+
|
| 57 |
+
"""
|
| 58 |
+
assert isinstance(x, SparseTensor)
|
| 59 |
+
assert isinstance(y, SparseTensor)
|
| 60 |
+
assert (
|
| 61 |
+
x.coords_man == y.coords_man
|
| 62 |
+
), "X and Y are using different CoordinateManagers. Y must be derived from X through strided conv/pool/etc."
|
| 63 |
+
return x.coords_man.get_coords_map(x.coords_key, y.coords_key)
|
MinkowskiEngine/MinkowskiEngine/utils/gradcheck.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Chris Choy (chrischoy@ai.stanford.edu).
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
import torch
|
| 25 |
+
|
| 26 |
+
assert torch.__version__ >= "1.7.0", "Gradcheck requires pytorch 1.7 or higher"
|
| 27 |
+
|
| 28 |
+
from torch.types import _TensorOrTensors
|
| 29 |
+
from typing import Callable, Union, Optional
|
| 30 |
+
|
| 31 |
+
from torch.autograd.gradcheck import gradcheck as _gradcheck
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def gradcheck(
|
| 35 |
+
func: Callable[..., Union[_TensorOrTensors]], # See Note [VarArg of Tensors]
|
| 36 |
+
inputs: _TensorOrTensors,
|
| 37 |
+
eps: float = 1e-6,
|
| 38 |
+
atol: float = 1e-5,
|
| 39 |
+
rtol: float = 1e-3,
|
| 40 |
+
raise_exception: bool = True,
|
| 41 |
+
check_sparse_nnz: bool = False,
|
| 42 |
+
nondet_tol: float = 0.0,
|
| 43 |
+
check_undefined_grad: bool = True,
|
| 44 |
+
check_grad_dtypes: bool = False,
|
| 45 |
+
) -> bool:
|
| 46 |
+
return _gradcheck(
|
| 47 |
+
lambda *x: func.apply(*x),
|
| 48 |
+
inputs,
|
| 49 |
+
eps=eps,
|
| 50 |
+
atol=atol,
|
| 51 |
+
rtol=rtol,
|
| 52 |
+
raise_exception=raise_exception,
|
| 53 |
+
check_sparse_nnz=check_sparse_nnz,
|
| 54 |
+
nondet_tol=nondet_tol,
|
| 55 |
+
check_undefined_grad=check_undefined_grad,
|
| 56 |
+
check_grad_dtypes=check_grad_dtypes,
|
| 57 |
+
)
|
MinkowskiEngine/MinkowskiEngine/utils/init.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def _calculate_fan_in_and_fan_out(tensor):
|
| 6 |
+
dimensions = tensor.dim()
|
| 7 |
+
if dimensions < 2:
|
| 8 |
+
raise ValueError(
|
| 9 |
+
"Fan in and fan out can not be computed for tensor with fewer than 2 dimensions"
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
if dimensions == 2: # Linear
|
| 13 |
+
fan_in = tensor.size(1)
|
| 14 |
+
fan_out = tensor.size(0)
|
| 15 |
+
else:
|
| 16 |
+
num_input_fmaps = tensor.size(1)
|
| 17 |
+
num_output_fmaps = tensor.size(2)
|
| 18 |
+
receptive_field_size = tensor.size(0)
|
| 19 |
+
fan_in = num_input_fmaps * receptive_field_size
|
| 20 |
+
fan_out = num_output_fmaps * receptive_field_size
|
| 21 |
+
|
| 22 |
+
return fan_in, fan_out
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def _calculate_correct_fan(tensor, mode):
|
| 26 |
+
mode = mode.lower()
|
| 27 |
+
valid_modes = ['fan_in', 'fan_out']
|
| 28 |
+
if mode not in valid_modes:
|
| 29 |
+
raise ValueError("Mode {} not supported, please use one of {}".format(
|
| 30 |
+
mode, valid_modes))
|
| 31 |
+
|
| 32 |
+
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
|
| 33 |
+
return fan_in if mode == 'fan_in' else fan_out
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu'):
|
| 37 |
+
fan = _calculate_correct_fan(tensor, mode)
|
| 38 |
+
gain = torch.nn.init.calculate_gain(nonlinearity, a)
|
| 39 |
+
std = gain / math.sqrt(fan)
|
| 40 |
+
with torch.no_grad():
|
| 41 |
+
return tensor.normal_(0, std)
|
MinkowskiEngine/MinkowskiEngine/utils/quantization.py
ADDED
|
@@ -0,0 +1,363 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Chris Choy (chrischoy@ai.stanford.edu).
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
| 7 |
+
# of the Software, and to permit persons to whom the Software is furnished to do
|
| 8 |
+
# so, subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
# SOFTWARE.
|
| 20 |
+
#
|
| 21 |
+
# Please cite "4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural
|
| 22 |
+
# Networks", CVPR'19 (https://arxiv.org/abs/1904.08755) if you use any part
|
| 23 |
+
# of the code.
|
| 24 |
+
import torch
|
| 25 |
+
import numpy as np
|
| 26 |
+
from collections.abc import Sequence
|
| 27 |
+
import MinkowskiEngineBackend._C as MEB
|
| 28 |
+
from typing import Union, Tuple
|
| 29 |
+
from MinkowskiCommon import convert_to_int_list
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def fnv_hash_vec(arr):
|
| 33 |
+
"""
|
| 34 |
+
FNV64-1A
|
| 35 |
+
"""
|
| 36 |
+
assert arr.ndim == 2
|
| 37 |
+
# Floor first for negative coordinates
|
| 38 |
+
arr = arr.copy()
|
| 39 |
+
arr = arr.astype(np.uint64, copy=False)
|
| 40 |
+
hashed_arr = np.uint64(14695981039346656037) * np.ones(
|
| 41 |
+
arr.shape[0], dtype=np.uint64
|
| 42 |
+
)
|
| 43 |
+
for j in range(arr.shape[1]):
|
| 44 |
+
hashed_arr *= np.uint64(1099511628211)
|
| 45 |
+
hashed_arr = np.bitwise_xor(hashed_arr, arr[:, j])
|
| 46 |
+
return hashed_arr
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def ravel_hash_vec(arr):
|
| 50 |
+
"""
|
| 51 |
+
Ravel the coordinates after subtracting the min coordinates.
|
| 52 |
+
"""
|
| 53 |
+
assert arr.ndim == 2
|
| 54 |
+
arr = arr.copy()
|
| 55 |
+
arr -= arr.min(0)
|
| 56 |
+
arr = arr.astype(np.uint64, copy=False)
|
| 57 |
+
arr_max = arr.max(0).astype(np.uint64) + 1
|
| 58 |
+
|
| 59 |
+
keys = np.zeros(arr.shape[0], dtype=np.uint64)
|
| 60 |
+
# Fortran style indexing
|
| 61 |
+
for j in range(arr.shape[1] - 1):
|
| 62 |
+
keys += arr[:, j]
|
| 63 |
+
keys *= arr_max[j + 1]
|
| 64 |
+
keys += arr[:, -1]
|
| 65 |
+
return keys
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def quantize(coords):
|
| 69 |
+
r"""Returns a unique index map and an inverse index map.
|
| 70 |
+
|
| 71 |
+
Args:
|
| 72 |
+
:attr:`coords` (:attr:`numpy.ndarray` or :attr:`torch.Tensor`): a
|
| 73 |
+
matrix of size :math:`N \times D` where :math:`N` is the number of
|
| 74 |
+
points in the :math:`D` dimensional space.
|
| 75 |
+
|
| 76 |
+
Returns:
|
| 77 |
+
:attr:`unique_map` (:attr:`numpy.ndarray` or :attr:`torch.Tensor`): a
|
| 78 |
+
list of indices that defines unique coordinates.
|
| 79 |
+
:attr:`coords[unique_map]` is the unique coordinates.
|
| 80 |
+
|
| 81 |
+
:attr:`inverse_map` (:attr:`numpy.ndarray` or :attr:`torch.Tensor`): a
|
| 82 |
+
list of indices that defines the inverse map that recovers the original
|
| 83 |
+
coordinates. :attr:`coords[unique_map[inverse_map]] == coords`
|
| 84 |
+
|
| 85 |
+
Example::
|
| 86 |
+
|
| 87 |
+
>>> unique_map, inverse_map = quantize(coords)
|
| 88 |
+
>>> unique_coords = coords[unique_map]
|
| 89 |
+
>>> print(unique_coords[inverse_map] == coords) # True, ..., True
|
| 90 |
+
>>> print(coords[unique_map[inverse_map]] == coords) # True, ..., True
|
| 91 |
+
|
| 92 |
+
"""
|
| 93 |
+
assert isinstance(coords, np.ndarray) or isinstance(
|
| 94 |
+
coords, torch.Tensor
|
| 95 |
+
), "Invalid coords type"
|
| 96 |
+
if isinstance(coords, np.ndarray):
|
| 97 |
+
assert (
|
| 98 |
+
coords.dtype == np.int32
|
| 99 |
+
), f"Invalid coords type {coords.dtype} != np.int32"
|
| 100 |
+
return MEB.quantize_np(coords.astype(np.int32))
|
| 101 |
+
else:
|
| 102 |
+
# Type check done inside
|
| 103 |
+
return MEB.quantize_th(coords.int())
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def quantize_label(coords, labels, ignore_label):
|
| 107 |
+
assert isinstance(coords, np.ndarray) or isinstance(
|
| 108 |
+
coords, torch.Tensor
|
| 109 |
+
), "Invalid coords type"
|
| 110 |
+
if isinstance(coords, np.ndarray):
|
| 111 |
+
assert isinstance(labels, np.ndarray)
|
| 112 |
+
assert (
|
| 113 |
+
coords.dtype == np.int32
|
| 114 |
+
), f"Invalid coords type {coords.dtype} != np.int32"
|
| 115 |
+
assert (
|
| 116 |
+
labels.dtype == np.int32
|
| 117 |
+
), f"Invalid label type {labels.dtype} != np.int32"
|
| 118 |
+
return MEB.quantize_label_np(coords, labels, ignore_label)
|
| 119 |
+
else:
|
| 120 |
+
assert isinstance(labels, torch.Tensor)
|
| 121 |
+
# Type check done inside
|
| 122 |
+
return MEB.quantize_label_th(coords, labels.int(), ignore_label)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def _auto_floor(array):
|
| 126 |
+
assert isinstance(
|
| 127 |
+
array, (np.ndarray, torch.Tensor)
|
| 128 |
+
), "array must be either np.array or torch.Tensor."
|
| 129 |
+
|
| 130 |
+
if isinstance(array, np.ndarray):
|
| 131 |
+
return np.floor(array)
|
| 132 |
+
else:
|
| 133 |
+
return torch.floor(array)
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def sparse_quantize(
|
| 137 |
+
coordinates,
|
| 138 |
+
features=None,
|
| 139 |
+
labels=None,
|
| 140 |
+
ignore_label=-100,
|
| 141 |
+
return_index=False,
|
| 142 |
+
return_inverse=False,
|
| 143 |
+
return_maps_only=False,
|
| 144 |
+
quantization_size=None,
|
| 145 |
+
device="cpu",
|
| 146 |
+
):
|
| 147 |
+
r"""Given coordinates, and features (optionally labels), the function
|
| 148 |
+
generates quantized (voxelized) coordinates.
|
| 149 |
+
|
| 150 |
+
Args:
|
| 151 |
+
:attr:`coordinates` (:attr:`numpy.ndarray` or :attr:`torch.Tensor`): a
|
| 152 |
+
matrix of size :math:`N \times D` where :math:`N` is the number of
|
| 153 |
+
points in the :math:`D` dimensional space.
|
| 154 |
+
|
| 155 |
+
:attr:`features` (:attr:`numpy.ndarray` or :attr:`torch.Tensor`, optional): a
|
| 156 |
+
matrix of size :math:`N \times D_F` where :math:`N` is the number of
|
| 157 |
+
points and :math:`D_F` is the dimension of the features. Must have the
|
| 158 |
+
same container as `coords` (i.e. if `coords` is a torch.Tensor, `feats`
|
| 159 |
+
must also be a torch.Tensor).
|
| 160 |
+
|
| 161 |
+
:attr:`labels` (:attr:`numpy.ndarray` or :attr:`torch.IntTensor`,
|
| 162 |
+
optional): integer labels associated to eah coordinates. Must have the
|
| 163 |
+
same container as `coords` (i.e. if `coords` is a torch.Tensor,
|
| 164 |
+
`labels` must also be a torch.Tensor). For classification where a set
|
| 165 |
+
of points are mapped to one label, do not feed the labels.
|
| 166 |
+
|
| 167 |
+
:attr:`ignore_label` (:attr:`int`, optional): the int value of the
|
| 168 |
+
IGNORE LABEL.
|
| 169 |
+
:attr:`torch.nn.CrossEntropyLoss(ignore_index=ignore_label)`
|
| 170 |
+
|
| 171 |
+
:attr:`return_index` (:attr:`bool`, optional): set True if you want the
|
| 172 |
+
indices of the quantized coordinates. False by default.
|
| 173 |
+
|
| 174 |
+
:attr:`return_inverse` (:attr:`bool`, optional): set True if you want
|
| 175 |
+
the indices that can recover the discretized original coordinates.
|
| 176 |
+
False by default. `return_index` must be True when `return_reverse` is True.
|
| 177 |
+
|
| 178 |
+
:attr:`return_maps_only` (:attr:`bool`, optional): if set, return the
|
| 179 |
+
unique_map or optionally inverse map, but not the coordinates. Can be
|
| 180 |
+
used if you don't care about final coordinates or if you use
|
| 181 |
+
device==cuda and you don't need coordinates on GPU. This returns either
|
| 182 |
+
unique_map alone or (unique_map, inverse_map) if return_inverse is set.
|
| 183 |
+
|
| 184 |
+
:attr:`quantization_size` (attr:`float`, optional): if set, will use
|
| 185 |
+
the quanziation size to define the smallest distance between
|
| 186 |
+
coordinates.
|
| 187 |
+
|
| 188 |
+
:attr:`device` (attr:`str`, optional): Either 'cpu' or 'cuda'.
|
| 189 |
+
|
| 190 |
+
Example::
|
| 191 |
+
|
| 192 |
+
>>> unique_map, inverse_map = sparse_quantize(discrete_coords, return_index=True, return_inverse=True)
|
| 193 |
+
>>> unique_coords = discrete_coords[unique_map]
|
| 194 |
+
>>> print(unique_coords[inverse_map] == discrete_coords) # True
|
| 195 |
+
|
| 196 |
+
:attr:`quantization_size` (:attr:`float`, :attr:`list`, or
|
| 197 |
+
:attr:`numpy.ndarray`, optional): the length of the each side of the
|
| 198 |
+
hyperrectangle of of the grid cell.
|
| 199 |
+
|
| 200 |
+
Example::
|
| 201 |
+
|
| 202 |
+
>>> # Segmentation
|
| 203 |
+
>>> criterion = torch.nn.CrossEntropyLoss(ignore_index=-100)
|
| 204 |
+
>>> coords, feats, labels = MinkowskiEngine.utils.sparse_quantize(
|
| 205 |
+
>>> coords, feats, labels, ignore_label=-100, quantization_size=0.1)
|
| 206 |
+
>>> output = net(MinkowskiEngine.SparseTensor(feats, coords))
|
| 207 |
+
>>> loss = criterion(output.F, labels.long())
|
| 208 |
+
>>>
|
| 209 |
+
>>> # Classification
|
| 210 |
+
>>> criterion = torch.nn.CrossEntropyLoss(ignore_index=-100)
|
| 211 |
+
>>> coords, feats = MinkowskiEngine.utils.sparse_quantize(coords, feats)
|
| 212 |
+
>>> output = net(MinkowskiEngine.SparseTensor(feats, coords))
|
| 213 |
+
>>> loss = criterion(output.F, labels.long())
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
"""
|
| 217 |
+
assert isinstance(
|
| 218 |
+
coordinates, (np.ndarray, torch.Tensor)
|
| 219 |
+
), "Coords must be either np.array or torch.Tensor."
|
| 220 |
+
|
| 221 |
+
use_label = labels is not None
|
| 222 |
+
use_feat = features is not None
|
| 223 |
+
|
| 224 |
+
assert (
|
| 225 |
+
coordinates.ndim == 2
|
| 226 |
+
), "The coordinates must be a 2D matrix. The shape of the input is " + str(
|
| 227 |
+
coordinates.shape
|
| 228 |
+
)
|
| 229 |
+
|
| 230 |
+
if return_inverse:
|
| 231 |
+
assert return_index, "return_reverse must be set with return_index"
|
| 232 |
+
|
| 233 |
+
if use_feat:
|
| 234 |
+
assert features.ndim == 2
|
| 235 |
+
assert coordinates.shape[0] == features.shape[0]
|
| 236 |
+
|
| 237 |
+
if use_label:
|
| 238 |
+
assert coordinates.shape[0] == len(labels)
|
| 239 |
+
|
| 240 |
+
dimension = coordinates.shape[1]
|
| 241 |
+
# Quantize the coordinates
|
| 242 |
+
if quantization_size is not None:
|
| 243 |
+
if isinstance(quantization_size, (Sequence, np.ndarray, torch.Tensor)):
|
| 244 |
+
assert (
|
| 245 |
+
len(quantization_size) == dimension
|
| 246 |
+
), "Quantization size and coordinates size mismatch."
|
| 247 |
+
if isinstance(coordinates, np.ndarray):
|
| 248 |
+
quantization_size = np.array([i for i in quantization_size])
|
| 249 |
+
else:
|
| 250 |
+
quantization_size = torch.Tensor([i for i in quantization_size])
|
| 251 |
+
discrete_coordinates = _auto_floor(coordinates / quantization_size)
|
| 252 |
+
|
| 253 |
+
elif np.isscalar(quantization_size): # Assume that it is a scalar
|
| 254 |
+
|
| 255 |
+
if quantization_size == 1:
|
| 256 |
+
discrete_coordinates = _auto_floor(coordinates)
|
| 257 |
+
else:
|
| 258 |
+
discrete_coordinates = _auto_floor(coordinates / quantization_size)
|
| 259 |
+
else:
|
| 260 |
+
raise ValueError("Not supported type for quantization_size.")
|
| 261 |
+
else:
|
| 262 |
+
discrete_coordinates = _auto_floor(coordinates)
|
| 263 |
+
|
| 264 |
+
if isinstance(coordinates, np.ndarray):
|
| 265 |
+
discrete_coordinates = discrete_coordinates.astype(np.int32)
|
| 266 |
+
else:
|
| 267 |
+
discrete_coordinates = discrete_coordinates.int()
|
| 268 |
+
|
| 269 |
+
if (type(device) == str and device == "cpu") or (type(device) == torch.device and device.type == "cpu"):
|
| 270 |
+
manager = MEB.CoordinateMapManagerCPU()
|
| 271 |
+
elif (type(device) == str and "cuda" in device) or (type(device) == torch.device and device.type == "cuda"):
|
| 272 |
+
manager = MEB.CoordinateMapManagerGPU_c10()
|
| 273 |
+
else:
|
| 274 |
+
raise ValueError("Invalid device. Only `cpu`, `cuda` or torch.device supported.")
|
| 275 |
+
|
| 276 |
+
# Return values accordingly
|
| 277 |
+
if use_label:
|
| 278 |
+
if isinstance(coordinates, np.ndarray):
|
| 279 |
+
unique_map, inverse_map, colabels = MEB.quantize_label_np(
|
| 280 |
+
discrete_coordinates, labels, ignore_label
|
| 281 |
+
)
|
| 282 |
+
else:
|
| 283 |
+
assert (
|
| 284 |
+
not discrete_coordinates.is_cuda
|
| 285 |
+
), "Quantization with label requires cpu tensors."
|
| 286 |
+
assert not labels.is_cuda, "Quantization with label requires cpu tensors."
|
| 287 |
+
unique_map, inverse_map, colabels = MEB.quantize_label_th(
|
| 288 |
+
discrete_coordinates, labels, ignore_label
|
| 289 |
+
)
|
| 290 |
+
return_args = [discrete_coordinates[unique_map]]
|
| 291 |
+
if use_feat:
|
| 292 |
+
return_args.append(features[unique_map])
|
| 293 |
+
# Labels
|
| 294 |
+
return_args.append(colabels)
|
| 295 |
+
# Additional return args
|
| 296 |
+
if return_index:
|
| 297 |
+
return_args.append(unique_map)
|
| 298 |
+
if return_inverse:
|
| 299 |
+
return_args.append(inverse_map)
|
| 300 |
+
|
| 301 |
+
if len(return_args) == 1:
|
| 302 |
+
return return_args[0]
|
| 303 |
+
else:
|
| 304 |
+
return tuple(return_args)
|
| 305 |
+
else:
|
| 306 |
+
tensor_stride = [1 for i in range(discrete_coordinates.shape[1] - 1)]
|
| 307 |
+
discrete_coordinates = (
|
| 308 |
+
discrete_coordinates.to(device)
|
| 309 |
+
if isinstance(discrete_coordinates, torch.Tensor)
|
| 310 |
+
else torch.from_numpy(discrete_coordinates).to(device)
|
| 311 |
+
)
|
| 312 |
+
_, (unique_map, inverse_map) = manager.insert_and_map(
|
| 313 |
+
discrete_coordinates, tensor_stride, ""
|
| 314 |
+
)
|
| 315 |
+
if return_maps_only:
|
| 316 |
+
if return_inverse:
|
| 317 |
+
return unique_map, inverse_map
|
| 318 |
+
else:
|
| 319 |
+
return unique_map
|
| 320 |
+
|
| 321 |
+
return_args = [discrete_coordinates[unique_map]]
|
| 322 |
+
if use_feat:
|
| 323 |
+
return_args.append(features[unique_map])
|
| 324 |
+
if return_index:
|
| 325 |
+
return_args.append(unique_map)
|
| 326 |
+
if return_inverse:
|
| 327 |
+
return_args.append(inverse_map)
|
| 328 |
+
|
| 329 |
+
if len(return_args) == 1:
|
| 330 |
+
return return_args[0]
|
| 331 |
+
else:
|
| 332 |
+
return tuple(return_args)
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
def unique_coordinate_map(
|
| 336 |
+
coordinates: torch.Tensor,
|
| 337 |
+
tensor_stride: Union[int, Sequence, np.ndarray] = 1,
|
| 338 |
+
) -> Tuple[torch.IntTensor, torch.IntTensor]:
|
| 339 |
+
r"""Returns the unique indices and the inverse indices of the coordinates.
|
| 340 |
+
|
| 341 |
+
:attr:`coordinates`: `torch.Tensor` (Int tensor. `CUDA` if
|
| 342 |
+
coordinate_map_type == `CoordinateMapType.GPU`) that defines the
|
| 343 |
+
coordinates.
|
| 344 |
+
|
| 345 |
+
Example::
|
| 346 |
+
|
| 347 |
+
>>> coordinates = torch.IntTensor([[0, 0], [0, 0], [0, 1], [0, 2]])
|
| 348 |
+
>>> unique_map, inverse_map = unique_coordinates_map(coordinates)
|
| 349 |
+
>>> coordinates[unique_map] # unique coordinates
|
| 350 |
+
>>> torch.all(coordinates == coordinates[unique_map][inverse_map]) # True
|
| 351 |
+
|
| 352 |
+
"""
|
| 353 |
+
assert coordinates.ndim == 2, "Coordinates must be a matrix"
|
| 354 |
+
assert isinstance(coordinates, torch.Tensor)
|
| 355 |
+
if not coordinates.is_cuda:
|
| 356 |
+
manager = MEB.CoordinateMapManagerCPU()
|
| 357 |
+
else:
|
| 358 |
+
manager = MEB.CoordinateMapManagerGPU_c10()
|
| 359 |
+
tensor_stride = convert_to_int_list(tensor_stride, coordinates.shape[-1] - 1)
|
| 360 |
+
key, (unique_map, inverse_map) = manager.insert_and_map(
|
| 361 |
+
coordinates, tensor_stride, ""
|
| 362 |
+
)
|
| 363 |
+
return unique_map, inverse_map
|
MinkowskiEngine/MinkowskiEngine/utils/summary.py
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from torch.autograd import Variable
|
| 4 |
+
|
| 5 |
+
from collections import OrderedDict
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
import MinkowskiEngine as ME
|
| 9 |
+
from MinkowskiSparseTensor import SparseTensor
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def summary(model, summary_input):
|
| 13 |
+
result, params_info = minkowski_summary_string(model, summary_input)
|
| 14 |
+
print(result)
|
| 15 |
+
return params_info
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def pruned_weight_sparsity_string(module) -> float:
|
| 19 |
+
r"""
|
| 20 |
+
returns the sparsity ratio of weights.
|
| 21 |
+
"""
|
| 22 |
+
for k in dir(module):
|
| 23 |
+
if '_mask' in k:
|
| 24 |
+
return (getattr(module, k.replace('_mask', '')) == 0).float().mean().item()
|
| 25 |
+
else:
|
| 26 |
+
return 0.0;
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def size2list(size: torch.Size) -> list:
|
| 30 |
+
return [i for i in size]
|
| 31 |
+
|
| 32 |
+
def get_hash_occupancy_ratio(minkowski_tensor):
|
| 33 |
+
alg = minkowski_tensor.coordinate_manager.minkowski_algorithm
|
| 34 |
+
if alg == ME.MinkowskiAlgorithm.SPEED_OPTIMIZED:
|
| 35 |
+
return 25;
|
| 36 |
+
else:
|
| 37 |
+
return 50;
|
| 38 |
+
|
| 39 |
+
def minkowski_summary_string(model, summary_input):
|
| 40 |
+
summary_str = ''
|
| 41 |
+
|
| 42 |
+
def register_hook(module):
|
| 43 |
+
def hook(module, input, output):
|
| 44 |
+
class_name = str(module.__class__).split(".")[-1].split("'")[0]
|
| 45 |
+
module_idx = len(summary)
|
| 46 |
+
|
| 47 |
+
m_key = "%s-%i" % (class_name, module_idx + 1)
|
| 48 |
+
summary[m_key] = OrderedDict()
|
| 49 |
+
|
| 50 |
+
# for the weight pruned model, print the sparsity information
|
| 51 |
+
summary[m_key]['sparsity_ratio'] = pruned_weight_sparsity_string(module)
|
| 52 |
+
|
| 53 |
+
# save only the size of NNZ
|
| 54 |
+
summary[m_key]["input_shape"] = input[0].shape
|
| 55 |
+
if isinstance(output, (list, tuple)):
|
| 56 |
+
summary[m_key]["output_shape"] = [size2list(o.shape) for o in output]
|
| 57 |
+
else:
|
| 58 |
+
summary[m_key]["output_shape"] = size2list(output.shape)
|
| 59 |
+
|
| 60 |
+
params = 0
|
| 61 |
+
if hasattr(module, "weight") and hasattr(module.weight, "size"):
|
| 62 |
+
params += module.weight.numel()
|
| 63 |
+
summary[m_key]["trainable"] = module.weight.requires_grad
|
| 64 |
+
if hasattr(module, "kernel") and hasattr(module.kernel, "size"):
|
| 65 |
+
params += module.kernel.numel()
|
| 66 |
+
summary[m_key]["trainable"] = module.kernel.requires_grad
|
| 67 |
+
if hasattr(module, "bias") and hasattr(module.bias, "size"):
|
| 68 |
+
params += module.bias.numel()
|
| 69 |
+
summary[m_key]["nb_params"] = params
|
| 70 |
+
|
| 71 |
+
if (
|
| 72 |
+
not isinstance(module, nn.Sequential)
|
| 73 |
+
and not isinstance(module, nn.ModuleList)
|
| 74 |
+
):
|
| 75 |
+
hooks.append(module.register_forward_hook(hook))
|
| 76 |
+
|
| 77 |
+
# create properties
|
| 78 |
+
summary = OrderedDict()
|
| 79 |
+
hooks = []
|
| 80 |
+
|
| 81 |
+
# register hook
|
| 82 |
+
model.apply(register_hook)
|
| 83 |
+
|
| 84 |
+
# make a forward pass
|
| 85 |
+
# print(x.shape)
|
| 86 |
+
model(summary_input)
|
| 87 |
+
|
| 88 |
+
# remove these hooks
|
| 89 |
+
for h in hooks:
|
| 90 |
+
h.remove()
|
| 91 |
+
|
| 92 |
+
summary_str += "----------------------------------------------------------------" + "\n"
|
| 93 |
+
line_new = "{:>20} {:>25} {:>15}".format(
|
| 94 |
+
"Layer (type)", "Output Shape", "Param #")
|
| 95 |
+
summary_str += line_new + "\n"
|
| 96 |
+
summary_str += "================================================================" + "\n"
|
| 97 |
+
total_params = 0
|
| 98 |
+
total_output = 0
|
| 99 |
+
trainable_params = 0
|
| 100 |
+
for layer in summary:
|
| 101 |
+
# input_shape, output_shape, trainable, nb_params
|
| 102 |
+
line_new = "{:>20} {:>25} {:>15}".format(
|
| 103 |
+
layer,
|
| 104 |
+
str(summary[layer]["output_shape"]),
|
| 105 |
+
"{0:,}".format(summary[layer]["nb_params"]),
|
| 106 |
+
)
|
| 107 |
+
total_params += summary[layer]["nb_params"]
|
| 108 |
+
|
| 109 |
+
total_output += np.prod(summary[layer]["output_shape"])
|
| 110 |
+
if "trainable" in summary[layer]:
|
| 111 |
+
if summary[layer]["trainable"] == True:
|
| 112 |
+
trainable_params += summary[layer]["nb_params"]
|
| 113 |
+
summary_str += line_new + "\n"
|
| 114 |
+
|
| 115 |
+
# assume 4 bytes/number (float on cuda).
|
| 116 |
+
total_input_size = (len(summary_input) * summary_input.shape[1] # feature size
|
| 117 |
+
+ len(summary_input) * (1 + summary_input.D) * (100 / get_hash_occupancy_ratio(summary_input)) # coordinate size
|
| 118 |
+
) * 4. / (1024 ** 2.)
|
| 119 |
+
total_output_size = abs(2. * total_output * 4. /
|
| 120 |
+
(1024 ** 2.)) # x2 for gradients
|
| 121 |
+
total_params_size = abs(total_params * 4. / (1024 ** 2.))
|
| 122 |
+
total_size = total_params_size + total_output_size + total_input_size
|
| 123 |
+
|
| 124 |
+
summary_str += "================================================================" + "\n"
|
| 125 |
+
summary_str += "Total params: {0:,}".format(total_params) + "\n"
|
| 126 |
+
summary_str += "Trainable params: {0:,}".format(trainable_params) + "\n"
|
| 127 |
+
summary_str += "Non-trainable params: {0:,}".format(total_params -
|
| 128 |
+
trainable_params) + "\n"
|
| 129 |
+
summary_str += "----------------------------------------------------------------" + "\n"
|
| 130 |
+
summary_str += "Input size (MB): %0.2f" % total_input_size + "\n"
|
| 131 |
+
summary_str += "Forward/backward pass size (MB): %0.2f" % total_output_size + "\n"
|
| 132 |
+
summary_str += "Params size (MB): %0.2f" % total_params_size + "\n"
|
| 133 |
+
summary_str += "Estimated Total Size (MB): %0.2f" % total_size + "\n"
|
| 134 |
+
summary_str += "----------------------------------------------------------------" + "\n"
|
| 135 |
+
# return summary
|
| 136 |
+
return summary_str, (total_params, trainable_params)
|
MinkowskiEngine/README.md
ADDED
|
@@ -0,0 +1,396 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[pypi-image]: https://badge.fury.io/py/MinkowskiEngine.svg
|
| 2 |
+
[pypi-url]: https://pypi.org/project/MinkowskiEngine/
|
| 3 |
+
[pypi-download]: https://img.shields.io/pypi/dm/MinkowskiEngine
|
| 4 |
+
[slack-badge]: https://img.shields.io/badge/slack-join%20chats-brightgreen
|
| 5 |
+
[slack-url]: https://join.slack.com/t/minkowskiengine/shared_invite/zt-piq2x02a-31dOPocLt6bRqOGY3U_9Sw
|
| 6 |
+
|
| 7 |
+
# Minkowski Engine
|
| 8 |
+
|
| 9 |
+
[![PyPI Version][pypi-image]][pypi-url] [![pypi monthly download][pypi-download]][pypi-url] [![slack chat][slack-badge]][slack-url]
|
| 10 |
+
|
| 11 |
+
The Minkowski Engine is an auto-differentiation library for sparse tensors. It supports all standard neural network layers such as convolution, pooling, unpooling, and broadcasting operations for sparse tensors. For more information, please visit [the documentation page](http://nvidia.github.io/MinkowskiEngine/overview.html).
|
| 12 |
+
|
| 13 |
+
## News
|
| 14 |
+
|
| 15 |
+
- 2021-08-11 Docker installation instruction added
|
| 16 |
+
- 2021-08-06 All installation errors with pytorch 1.8 and 1.9 have been resolved.
|
| 17 |
+
- 2021-04-08 Due to recent errors in [pytorch 1.8 + CUDA 11](https://github.com/NVIDIA/MinkowskiEngine/issues/330), it is recommended to use [anaconda for installation](#anaconda).
|
| 18 |
+
- 2020-12-24 v0.5 is now available! The new version provides CUDA accelerations for all coordinate management functions.
|
| 19 |
+
|
| 20 |
+
## Example Networks
|
| 21 |
+
|
| 22 |
+
The Minkowski Engine supports various functions that can be built on a sparse tensor. We list a few popular network architectures and applications here. To run the examples, please install the package and run the command in the package root directory.
|
| 23 |
+
|
| 24 |
+
| Examples | Networks and Commands |
|
| 25 |
+
|:---------------------:|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
|
| 26 |
+
| Semantic Segmentation | <img src="https://nvidia.github.io/MinkowskiEngine/_images/segmentation_3d_net.png"> <br /> <img src="https://nvidia.github.io/MinkowskiEngine/_images/segmentation.png" width="256"> <br /> `python -m examples.indoor` |
|
| 27 |
+
| Classification | 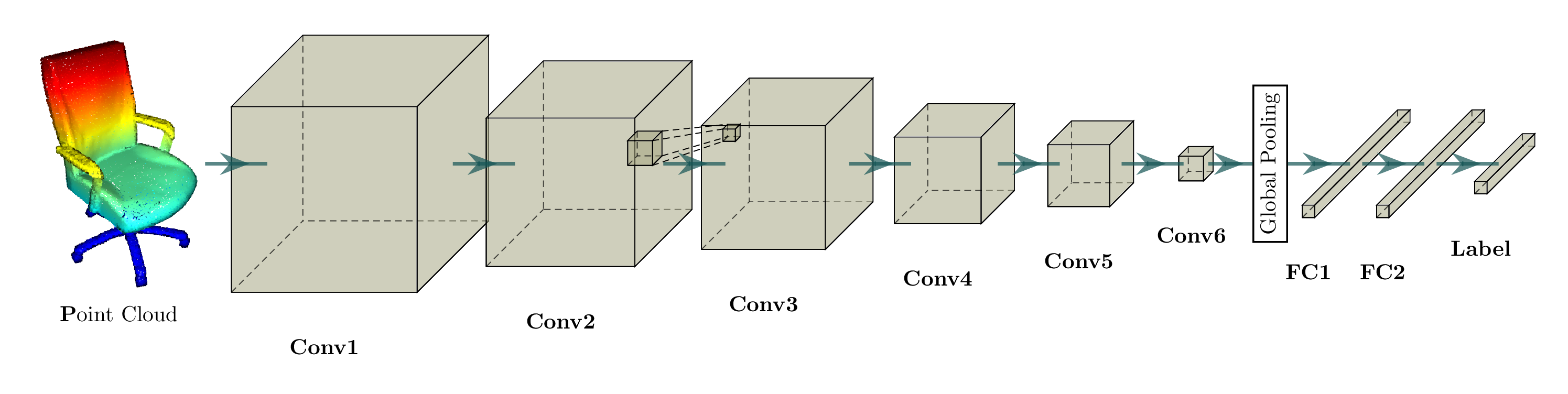 <br /> `python -m examples.classification_modelnet40` |
|
| 28 |
+
| Reconstruction | <img src="https://nvidia.github.io/MinkowskiEngine/_images/generative_3d_net.png"> <br /> <img src="https://nvidia.github.io/MinkowskiEngine/_images/generative_3d_results.gif" width="256"> <br /> `python -m examples.reconstruction` |
|
| 29 |
+
| Completion | <img src="https://nvidia.github.io/MinkowskiEngine/_images/completion_3d_net.png"> <br /> `python -m examples.completion` |
|
| 30 |
+
| Detection | <img src="https://nvidia.github.io/MinkowskiEngine/_images/detection_3d_net.png"> |
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## Sparse Tensor Networks: Neural Networks for Spatially Sparse Tensors
|
| 34 |
+
|
| 35 |
+
Compressing a neural network to speedup inference and minimize memory footprint has been studied widely. One of the popular techniques for model compression is pruning the weights in convnets, is also known as [*sparse convolutional networks*](https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Liu_Sparse_Convolutional_Neural_2015_CVPR_paper.pdf). Such parameter-space sparsity used for model compression compresses networks that operate on dense tensors and all intermediate activations of these networks are also dense tensors.
|
| 36 |
+
|
| 37 |
+
However, in this work, we focus on [*spatially* sparse data](https://arxiv.org/abs/1409.6070), in particular, spatially sparse high-dimensional inputs and 3D data and convolution on the surface of 3D objects, first proposed in [Siggraph'17](https://wang-ps.github.io/O-CNN.html). We can also represent these data as sparse tensors, and these sparse tensors are commonplace in high-dimensional problems such as 3D perception, registration, and statistical data. We define neural networks specialized for these inputs as *sparse tensor networks* and these sparse tensor networks process and generate sparse tensors as outputs. To construct a sparse tensor network, we build all standard neural network layers such as MLPs, non-linearities, convolution, normalizations, pooling operations as the same way we define them on a dense tensor and implemented in the Minkowski Engine.
|
| 38 |
+
|
| 39 |
+
We visualized a sparse tensor network operation on a sparse tensor, convolution, below. The convolution layer on a sparse tensor works similarly to that on a dense tensor. However, on a sparse tensor, we compute convolution outputs on a few specified points which we can control in the [generalized convolution](https://nvidia.github.io/MinkowskiEngine/sparse_tensor_network.html). For more information, please visit [the documentation page on sparse tensor networks](https://nvidia.github.io/MinkowskiEngine/sparse_tensor_network.html) and [the terminology page](https://nvidia.github.io/MinkowskiEngine/terminology.html).
|
| 40 |
+
|
| 41 |
+
| Dense Tensor | Sparse Tensor |
|
| 42 |
+
|:---------------------------------------------------------------------------:|:----------------------------------------------------------------------------:|
|
| 43 |
+
| <img src="https://nvidia.github.io/MinkowskiEngine/_images/conv_dense.gif"> | <img src="https://nvidia.github.io/MinkowskiEngine/_images/conv_sparse.gif"> |
|
| 44 |
+
|
| 45 |
+
--------------------------------------------------------------------------------
|
| 46 |
+
|
| 47 |
+
## Features
|
| 48 |
+
|
| 49 |
+
- Unlimited high-dimensional sparse tensor support
|
| 50 |
+
- All standard neural network layers (Convolution, Pooling, Broadcast, etc.)
|
| 51 |
+
- Dynamic computation graph
|
| 52 |
+
- Custom kernel shapes
|
| 53 |
+
- Multi-GPU training
|
| 54 |
+
- Multi-threaded kernel map
|
| 55 |
+
- Multi-threaded compilation
|
| 56 |
+
- Highly-optimized GPU kernels
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
## Requirements
|
| 60 |
+
|
| 61 |
+
- Ubuntu >= 14.04
|
| 62 |
+
- CUDA >= 10.1.243 and **the same CUDA version used for pytorch** (e.g. if you use conda cudatoolkit=11.1, use CUDA=11.1 for MinkowskiEngine compilation)
|
| 63 |
+
- pytorch >= 1.7 To specify CUDA version, please use conda for installation. You must match the CUDA version pytorch uses and CUDA version used for Minkowski Engine installation. `conda install -y -c nvidia -c pytorch pytorch=1.8.1 cudatoolkit=10.2`)
|
| 64 |
+
- python >= 3.6
|
| 65 |
+
- ninja (for installation)
|
| 66 |
+
- GCC >= 7.4.0
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
## Installation
|
| 70 |
+
|
| 71 |
+
You can install the Minkowski Engine with `pip`, with anaconda, or on the system directly. If you experience issues installing the package, please checkout the [the installation wiki page](https://github.com/NVIDIA/MinkowskiEngine/wiki/Installation).
|
| 72 |
+
If you cannot find a relevant problem, please report the issue on [the github issue page](https://github.com/NVIDIA/MinkowskiEngine/issues).
|
| 73 |
+
|
| 74 |
+
- [PIP](https://github.com/NVIDIA/MinkowskiEngine#pip) installation
|
| 75 |
+
- [Conda](https://github.com/NVIDIA/MinkowskiEngine#anaconda) installation
|
| 76 |
+
- [Python](https://github.com/NVIDIA/MinkowskiEngine#system-python) installation
|
| 77 |
+
- [Docker](https://github.com/NVIDIA/MinkowskiEngine#docker) installation
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
### Pip
|
| 81 |
+
|
| 82 |
+
The MinkowskiEngine is distributed via [PyPI MinkowskiEngine][pypi-url] which can be installed simply with `pip`.
|
| 83 |
+
First, install pytorch following the [instruction](https://pytorch.org). Next, install `openblas`.
|
| 84 |
+
|
| 85 |
+
```
|
| 86 |
+
sudo apt install build-essential python3-dev libopenblas-dev
|
| 87 |
+
pip install torch ninja
|
| 88 |
+
pip install -U MinkowskiEngine --install-option="--blas=openblas" -v --no-deps
|
| 89 |
+
|
| 90 |
+
# For pip installation from the latest source
|
| 91 |
+
# pip install -U git+https://github.com/NVIDIA/MinkowskiEngine --no-deps
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
If you want to specify arguments for the setup script, please refer to the following command.
|
| 95 |
+
|
| 96 |
+
```
|
| 97 |
+
# Uncomment some options if things don't work
|
| 98 |
+
# export CXX=c++; # set this if you want to use a different C++ compiler
|
| 99 |
+
# export CUDA_HOME=/usr/local/cuda-11.1; # or select the correct cuda version on your system.
|
| 100 |
+
pip install -U git+https://github.com/NVIDIA/MinkowskiEngine -v --no-deps \
|
| 101 |
+
# \ # uncomment the following line if you want to force cuda installation
|
| 102 |
+
# --install-option="--force_cuda" \
|
| 103 |
+
# \ # uncomment the following line if you want to force no cuda installation. force_cuda supercedes cpu_only
|
| 104 |
+
# --install-option="--cpu_only" \
|
| 105 |
+
# \ # uncomment the following line to override to openblas, atlas, mkl, blas
|
| 106 |
+
# --install-option="--blas=openblas" \
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
### Anaconda
|
| 110 |
+
|
| 111 |
+
MinkowskiEngine supports both CUDA 10.2 and cuda 11.1, which work for most of latest pytorch versions.
|
| 112 |
+
#### CUDA 10.2
|
| 113 |
+
|
| 114 |
+
We recommend `python>=3.6` for installation.
|
| 115 |
+
First, follow [the anaconda documentation](https://docs.anaconda.com/anaconda/install/) to install anaconda on your computer.
|
| 116 |
+
|
| 117 |
+
```
|
| 118 |
+
sudo apt install g++-7 # For CUDA 10.2, must use GCC < 8
|
| 119 |
+
# Make sure `g++-7 --version` is at least 7.4.0
|
| 120 |
+
conda create -n py3-mink python=3.8
|
| 121 |
+
conda activate py3-mink
|
| 122 |
+
|
| 123 |
+
conda install openblas-devel -c anaconda
|
| 124 |
+
conda install pytorch=1.9.0 torchvision cudatoolkit=10.2 -c pytorch -c nvidia
|
| 125 |
+
|
| 126 |
+
# Install MinkowskiEngine
|
| 127 |
+
export CXX=g++-7
|
| 128 |
+
# Uncomment the following line to specify the cuda home. Make sure `$CUDA_HOME/nvcc --version` is 10.2
|
| 129 |
+
# export CUDA_HOME=/usr/local/cuda-10.2
|
| 130 |
+
pip install -U git+https://github.com/NVIDIA/MinkowskiEngine -v --no-deps --install-option="--blas_include_dirs=${CONDA_PREFIX}/include" --install-option="--blas=openblas"
|
| 131 |
+
|
| 132 |
+
# Or if you want local MinkowskiEngine
|
| 133 |
+
git clone https://github.com/NVIDIA/MinkowskiEngine.git
|
| 134 |
+
cd MinkowskiEngine
|
| 135 |
+
export CXX=g++-7
|
| 136 |
+
python setup.py install --blas_include_dirs=${CONDA_PREFIX}/include --blas=openblas
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
#### CUDA 11.X
|
| 140 |
+
|
| 141 |
+
We recommend `python>=3.6` for installation.
|
| 142 |
+
First, follow [the anaconda documentation](https://docs.anaconda.com/anaconda/install/) to install anaconda on your computer.
|
| 143 |
+
|
| 144 |
+
```
|
| 145 |
+
conda create -n py3-mink python=3.8
|
| 146 |
+
conda activate py3-mink
|
| 147 |
+
|
| 148 |
+
conda install openblas-devel -c anaconda
|
| 149 |
+
conda install pytorch=1.9.0 torchvision cudatoolkit=11.1 -c pytorch -c nvidia
|
| 150 |
+
|
| 151 |
+
# Install MinkowskiEngine
|
| 152 |
+
|
| 153 |
+
# Uncomment the following line to specify the cuda home. Make sure `$CUDA_HOME/nvcc --version` is 11.X
|
| 154 |
+
# export CUDA_HOME=/usr/local/cuda-11.1
|
| 155 |
+
pip install -U git+https://github.com/NVIDIA/MinkowskiEngine -v --no-deps --install-option="--blas_include_dirs=${CONDA_PREFIX}/include" --install-option="--blas=openblas"
|
| 156 |
+
|
| 157 |
+
# Or if you want local MinkowskiEngine
|
| 158 |
+
git clone https://github.com/NVIDIA/MinkowskiEngine.git
|
| 159 |
+
cd MinkowskiEngine
|
| 160 |
+
python setup.py install --blas_include_dirs=${CONDA_PREFIX}/include --blas=openblas
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
### System Python
|
| 164 |
+
|
| 165 |
+
Like the anaconda installation, make sure that you install pytorch with the same CUDA version that `nvcc` uses.
|
| 166 |
+
|
| 167 |
+
```
|
| 168 |
+
# install system requirements
|
| 169 |
+
sudo apt install build-essential python3-dev libopenblas-dev
|
| 170 |
+
|
| 171 |
+
# Skip if you already have pip installed on your python3
|
| 172 |
+
curl https://bootstrap.pypa.io/get-pip.py | python3
|
| 173 |
+
|
| 174 |
+
# Get pip and install python requirements
|
| 175 |
+
python3 -m pip install torch numpy ninja
|
| 176 |
+
|
| 177 |
+
git clone https://github.com/NVIDIA/MinkowskiEngine.git
|
| 178 |
+
|
| 179 |
+
cd MinkowskiEngine
|
| 180 |
+
|
| 181 |
+
python setup.py install
|
| 182 |
+
# To specify blas, CXX, CUDA_HOME and force CUDA installation, use the following command
|
| 183 |
+
# export CXX=c++; export CUDA_HOME=/usr/local/cuda-11.1; python setup.py install --blas=openblas --force_cuda
|
| 184 |
+
```
|
| 185 |
+
|
| 186 |
+
### Docker
|
| 187 |
+
|
| 188 |
+
```
|
| 189 |
+
git clone https://github.com/NVIDIA/MinkowskiEngine
|
| 190 |
+
cd MinkowskiEngine
|
| 191 |
+
docker build -t minkowski_engine docker
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
Once the docker is built, check it loads MinkowskiEngine correctly.
|
| 195 |
+
|
| 196 |
+
```
|
| 197 |
+
docker run MinkowskiEngine python3 -c "import MinkowskiEngine; print(MinkowskiEngine.__version__)"
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
## CPU only build and BLAS configuration (MKL)
|
| 201 |
+
|
| 202 |
+
The Minkowski Engine supports CPU only build on other platforms that do not have NVidia GPUs. Please refer to [quick start](https://nvidia.github.io/MinkowskiEngine/quick_start.html) for more details.
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
## Quick Start
|
| 206 |
+
|
| 207 |
+
To use the Minkowski Engine, you first would need to import the engine.
|
| 208 |
+
Then, you would need to define the network. If the data you have is not
|
| 209 |
+
quantized, you would need to voxelize or quantize the (spatial) data into a
|
| 210 |
+
sparse tensor. Fortunately, the Minkowski Engine provides the quantization
|
| 211 |
+
function (`MinkowskiEngine.utils.sparse_quantize`).
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
### Creating a Network
|
| 215 |
+
|
| 216 |
+
```python
|
| 217 |
+
import torch.nn as nn
|
| 218 |
+
import MinkowskiEngine as ME
|
| 219 |
+
|
| 220 |
+
class ExampleNetwork(ME.MinkowskiNetwork):
|
| 221 |
+
|
| 222 |
+
def __init__(self, in_feat, out_feat, D):
|
| 223 |
+
super(ExampleNetwork, self).__init__(D)
|
| 224 |
+
self.conv1 = nn.Sequential(
|
| 225 |
+
ME.MinkowskiConvolution(
|
| 226 |
+
in_channels=in_feat,
|
| 227 |
+
out_channels=64,
|
| 228 |
+
kernel_size=3,
|
| 229 |
+
stride=2,
|
| 230 |
+
dilation=1,
|
| 231 |
+
bias=False,
|
| 232 |
+
dimension=D),
|
| 233 |
+
ME.MinkowskiBatchNorm(64),
|
| 234 |
+
ME.MinkowskiReLU())
|
| 235 |
+
self.conv2 = nn.Sequential(
|
| 236 |
+
ME.MinkowskiConvolution(
|
| 237 |
+
in_channels=64,
|
| 238 |
+
out_channels=128,
|
| 239 |
+
kernel_size=3,
|
| 240 |
+
stride=2,
|
| 241 |
+
dimension=D),
|
| 242 |
+
ME.MinkowskiBatchNorm(128),
|
| 243 |
+
ME.MinkowskiReLU())
|
| 244 |
+
self.pooling = ME.MinkowskiGlobalPooling()
|
| 245 |
+
self.linear = ME.MinkowskiLinear(128, out_feat)
|
| 246 |
+
|
| 247 |
+
def forward(self, x):
|
| 248 |
+
out = self.conv1(x)
|
| 249 |
+
out = self.conv2(out)
|
| 250 |
+
out = self.pooling(out)
|
| 251 |
+
return self.linear(out)
|
| 252 |
+
```
|
| 253 |
+
|
| 254 |
+
### Forward and backward using the custom network
|
| 255 |
+
|
| 256 |
+
```python
|
| 257 |
+
# loss and network
|
| 258 |
+
criterion = nn.CrossEntropyLoss()
|
| 259 |
+
net = ExampleNetwork(in_feat=3, out_feat=5, D=2)
|
| 260 |
+
print(net)
|
| 261 |
+
|
| 262 |
+
# a data loader must return a tuple of coords, features, and labels.
|
| 263 |
+
coords, feat, label = data_loader()
|
| 264 |
+
input = ME.SparseTensor(feat, coordinates=coords)
|
| 265 |
+
# Forward
|
| 266 |
+
output = net(input)
|
| 267 |
+
|
| 268 |
+
# Loss
|
| 269 |
+
loss = criterion(output.F, label)
|
| 270 |
+
```
|
| 271 |
+
|
| 272 |
+
## Discussion and Documentation
|
| 273 |
+
|
| 274 |
+
For discussion and questions, please use `minkowskiengine@googlegroups.com`.
|
| 275 |
+
For API and general usage, please refer to the [MinkowskiEngine documentation
|
| 276 |
+
page](http://nvidia.github.io/MinkowskiEngine/) for more detail.
|
| 277 |
+
|
| 278 |
+
For issues not listed on the API and feature requests, feel free to submit
|
| 279 |
+
an issue on the [github issue
|
| 280 |
+
page](https://github.com/NVIDIA/MinkowskiEngine/issues).
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
## Known Issues
|
| 284 |
+
|
| 285 |
+
### Specifying CUDA architecture list
|
| 286 |
+
|
| 287 |
+
In some cases, you need to explicitly specify which compute capability your GPU uses. The default list might not contain your architecture.
|
| 288 |
+
|
| 289 |
+
```bash
|
| 290 |
+
export TORCH_CUDA_ARCH_LIST="5.2 6.0 6.1 7.0 7.5 8.0 8.6+PTX"; python setup.py install --force_cuda
|
| 291 |
+
```
|
| 292 |
+
|
| 293 |
+
### Unhandled Out-Of-Memory thrust::system exception
|
| 294 |
+
|
| 295 |
+
There is [a known issue](https://github.com/NVIDIA/thrust/issues/1448) in thrust with CUDA 10 that leads to an unhandled thrust exception. Please refer to the [issue](https://github.com/NVIDIA/MinkowskiEngine/issues/357) for detail.
|
| 296 |
+
|
| 297 |
+
### Too much GPU memory usage or Frequent Out of Memory
|
| 298 |
+
|
| 299 |
+
There are a few causes for this error.
|
| 300 |
+
|
| 301 |
+
1. Out of memory during a long running training
|
| 302 |
+
|
| 303 |
+
MinkowskiEngine is a specialized library that can handle different number of points or different number of non-zero elements at every iteration during training, which is common in point cloud data.
|
| 304 |
+
However, pytorch is implemented assuming that the number of point, or size of the activations do not change at every iteration. Thus, the GPU memory caching used by pytorch can result in unnecessarily large memory consumption.
|
| 305 |
+
|
| 306 |
+
Specifically, pytorch caches chunks of memory spaces to speed up allocation used in every tensor creation. If it fails to find the memory space, it splits an existing cached memory or allocate new space if there's no cached memory large enough for the requested size. Thus, every time we use different number of point (number of non-zero elements) with pytorch, it either split existing cache or reserve new memory. If the cache is too fragmented and allocated all GPU space, it will raise out of memory error.
|
| 307 |
+
|
| 308 |
+
**To prevent this, you must clear the cache at regular interval with `torch.cuda.empty_cache()`.**
|
| 309 |
+
|
| 310 |
+
### CUDA 11.1 Installation
|
| 311 |
+
|
| 312 |
+
```
|
| 313 |
+
wget https://developer.download.nvidia.com/compute/cuda/11.1.1/local_installers/cuda_11.1.1_455.32.00_linux.run
|
| 314 |
+
sudo sh cuda_11.1.1_455.32.00_linux.run --toolkit --silent --override
|
| 315 |
+
|
| 316 |
+
# Install MinkowskiEngine with CUDA 11.1
|
| 317 |
+
export CUDA_HOME=/usr/local/cuda-11.1; pip install MinkowskiEngine -v --no-deps
|
| 318 |
+
```
|
| 319 |
+
|
| 320 |
+
### Running the MinkowskiEngine on nodes with a large number of CPUs
|
| 321 |
+
|
| 322 |
+
The MinkowskiEngine uses OpenMP to parallelize the kernel map generation. However, when the number of threads used for parallelization is too large (e.g. OMP_NUM_THREADS=80), the efficiency drops rapidly as all threads simply wait for multithread locks to be released.
|
| 323 |
+
In such cases, set the number of threads used for OpenMP. Usually, any number below 24 would be fine, but search for the optimal setup on your system.
|
| 324 |
+
|
| 325 |
+
```
|
| 326 |
+
export OMP_NUM_THREADS=<number of threads to use>; python <your_program.py>
|
| 327 |
+
```
|
| 328 |
+
|
| 329 |
+
## Citing Minkowski Engine
|
| 330 |
+
|
| 331 |
+
If you use the Minkowski Engine, please cite:
|
| 332 |
+
|
| 333 |
+
- [4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks, CVPR'19](https://arxiv.org/abs/1904.08755), [[pdf]](https://arxiv.org/pdf/1904.08755.pdf)
|
| 334 |
+
|
| 335 |
+
```
|
| 336 |
+
@inproceedings{choy20194d,
|
| 337 |
+
title={4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks},
|
| 338 |
+
author={Choy, Christopher and Gwak, JunYoung and Savarese, Silvio},
|
| 339 |
+
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
|
| 340 |
+
pages={3075--3084},
|
| 341 |
+
year={2019}
|
| 342 |
+
}
|
| 343 |
+
```
|
| 344 |
+
|
| 345 |
+
For multi-threaded kernel map generation, please cite:
|
| 346 |
+
|
| 347 |
+
```
|
| 348 |
+
@inproceedings{choy2019fully,
|
| 349 |
+
title={Fully Convolutional Geometric Features},
|
| 350 |
+
author={Choy, Christopher and Park, Jaesik and Koltun, Vladlen},
|
| 351 |
+
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
|
| 352 |
+
pages={8958--8966},
|
| 353 |
+
year={2019}
|
| 354 |
+
}
|
| 355 |
+
```
|
| 356 |
+
|
| 357 |
+
For strided pooling layers for high-dimensional convolutions, please cite:
|
| 358 |
+
|
| 359 |
+
```
|
| 360 |
+
@inproceedings{choy2020high,
|
| 361 |
+
title={High-dimensional Convolutional Networks for Geometric Pattern Recognition},
|
| 362 |
+
author={Choy, Christopher and Lee, Junha and Ranftl, Rene and Park, Jaesik and Koltun, Vladlen},
|
| 363 |
+
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
|
| 364 |
+
year={2020}
|
| 365 |
+
}
|
| 366 |
+
```
|
| 367 |
+
|
| 368 |
+
For generative transposed convolution, please cite:
|
| 369 |
+
|
| 370 |
+
```
|
| 371 |
+
@inproceedings{gwak2020gsdn,
|
| 372 |
+
title={Generative Sparse Detection Networks for 3D Single-shot Object Detection},
|
| 373 |
+
author={Gwak, JunYoung and Choy, Christopher B and Savarese, Silvio},
|
| 374 |
+
booktitle={European conference on computer vision},
|
| 375 |
+
year={2020}
|
| 376 |
+
}
|
| 377 |
+
```
|
| 378 |
+
|
| 379 |
+
|
| 380 |
+
## Unittest
|
| 381 |
+
|
| 382 |
+
For unittests and gradcheck, use torch >= 1.7
|
| 383 |
+
|
| 384 |
+
## Projects using Minkowski Engine
|
| 385 |
+
|
| 386 |
+
Please feel free to update [the wiki page](https://github.com/NVIDIA/MinkowskiEngine/wiki/Usage) to add your projects!
|
| 387 |
+
|
| 388 |
+
- [Projects using MinkowskiEngine](https://github.com/NVIDIA/MinkowskiEngine/wiki/Usage)
|
| 389 |
+
|
| 390 |
+
- Segmentation: [3D and 4D Spatio-Temporal Semantic Segmentation, CVPR'19](https://github.com/chrischoy/SpatioTemporalSegmentation)
|
| 391 |
+
- Representation Learning: [Fully Convolutional Geometric Features, ICCV'19](https://github.com/chrischoy/FCGF)
|
| 392 |
+
- 3D Registration: [Learning multiview 3D point cloud registration, CVPR'20](https://arxiv.org/abs/2001.05119)
|
| 393 |
+
- 3D Registration: [Deep Global Registration, CVPR'20](https://arxiv.org/abs/2004.11540)
|
| 394 |
+
- Pattern Recognition: [High-Dimensional Convolutional Networks for Geometric Pattern Recognition, CVPR'20](https://arxiv.org/abs/2005.08144)
|
| 395 |
+
- Detection: [Generative Sparse Detection Networks for 3D Single-shot Object Detection, ECCV'20](https://arxiv.org/abs/2006.12356)
|
| 396 |
+
- Image matching: [Sparse Neighbourhood Consensus Networks, ECCV'20](https://www.di.ens.fr/willow/research/sparse-ncnet/)
|
MinkowskiEngine/docker/Dockerfile
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Use use previous versions, modify these variables
|
| 2 |
+
# ARG PYTORCH="1.9.0"
|
| 3 |
+
# ARG CUDA="11.1"
|
| 4 |
+
|
| 5 |
+
ARG PYTORCH="1.12.0"
|
| 6 |
+
ARG CUDA="11.3"
|
| 7 |
+
ARG CUDNN="8"
|
| 8 |
+
|
| 9 |
+
FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
|
| 10 |
+
|
| 11 |
+
##############################################
|
| 12 |
+
# You should modify this to match your GPU compute capability
|
| 13 |
+
# ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0+PTX"
|
| 14 |
+
ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 6.2 7.0 7.2 7.5 8.0 8.6"
|
| 15 |
+
##############################################
|
| 16 |
+
|
| 17 |
+
ENV TORCH_NVCC_FLAGS="-Xfatbin -compress-all"
|
| 18 |
+
|
| 19 |
+
# Install dependencies
|
| 20 |
+
RUN apt-get update
|
| 21 |
+
RUN apt-get install -y git ninja-build cmake build-essential libopenblas-dev \
|
| 22 |
+
xterm xauth openssh-server tmux wget mate-desktop-environment-core
|
| 23 |
+
|
| 24 |
+
RUN apt-get clean
|
| 25 |
+
RUN rm -rf /var/lib/apt/lists/*
|
| 26 |
+
|
| 27 |
+
# For faster build, use more jobs.
|
| 28 |
+
ENV MAX_JOBS=4
|
| 29 |
+
RUN git clone --recursive "https://github.com/NVIDIA/MinkowskiEngine"
|
| 30 |
+
RUN cd MinkowskiEngine; python setup.py install --force_cuda --blas=openblas
|
MinkowskiEngine/docs/.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
source
|
| 2 |
+
_build
|
| 3 |
+
_static
|
MinkowskiEngine/docs/Makefile
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Minimal makefile for Sphinx documentation
|
| 2 |
+
#
|
| 3 |
+
|
| 4 |
+
# You can set these variables from the command line.
|
| 5 |
+
SPHINXOPTS =
|
| 6 |
+
SPHINXBUILD = sphinx-build
|
| 7 |
+
SOURCEDIR = .
|
| 8 |
+
BUILDDIR = _build
|
| 9 |
+
|
| 10 |
+
# Put it first so that "make" without argument is like "make help".
|
| 11 |
+
help:
|
| 12 |
+
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
| 13 |
+
|
| 14 |
+
.PHONY: help Makefile
|
| 15 |
+
|
| 16 |
+
# Catch-all target: route all unknown targets to Sphinx using the new
|
| 17 |
+
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
| 18 |
+
%: Makefile
|
| 19 |
+
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|