

Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,994 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
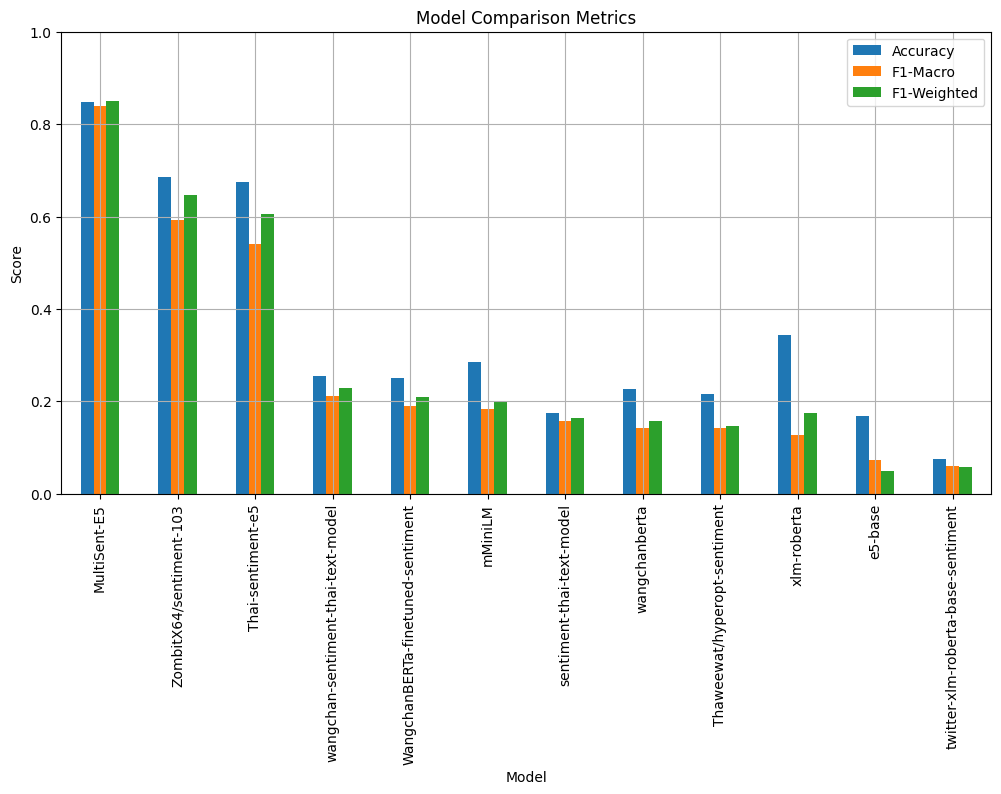
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: cc-by-nc-nd-4.0
|
| 3 |
+
language:
|
| 4 |
+
- th
|
| 5 |
+
- af
|
| 6 |
+
- am
|
| 7 |
+
- ar
|
| 8 |
+
- as
|
| 9 |
+
- az
|
| 10 |
+
- be
|
| 11 |
+
- bg
|
| 12 |
+
- bn
|
| 13 |
+
- br
|
| 14 |
+
- bs
|
| 15 |
+
- ca
|
| 16 |
+
- cs
|
| 17 |
+
- cy
|
| 18 |
+
- da
|
| 19 |
+
- de
|
| 20 |
+
- el
|
| 21 |
+
- en
|
| 22 |
+
- eo
|
| 23 |
+
- es
|
| 24 |
+
- et
|
| 25 |
+
- eu
|
| 26 |
+
- fa
|
| 27 |
+
- fi
|
| 28 |
+
- fr
|
| 29 |
+
- fy
|
| 30 |
+
- ga
|
| 31 |
+
- gd
|
| 32 |
+
- gl
|
| 33 |
+
- gu
|
| 34 |
+
- ha
|
| 35 |
+
- he
|
| 36 |
+
- hi
|
| 37 |
+
- hr
|
| 38 |
+
- hu
|
| 39 |
+
- hy
|
| 40 |
+
- id
|
| 41 |
+
- is
|
| 42 |
+
- it
|
| 43 |
+
- ja
|
| 44 |
+
- jv
|
| 45 |
+
- ka
|
| 46 |
+
- kk
|
| 47 |
+
- km
|
| 48 |
+
- kn
|
| 49 |
+
- ko
|
| 50 |
+
- ku
|
| 51 |
+
- ky
|
| 52 |
+
- la
|
| 53 |
+
- lo
|
| 54 |
+
- lt
|
| 55 |
+
- lv
|
| 56 |
+
- mg
|
| 57 |
+
- mk
|
| 58 |
+
- ml
|
| 59 |
+
- mn
|
| 60 |
+
- mr
|
| 61 |
+
- ms
|
| 62 |
+
- my
|
| 63 |
+
- ne
|
| 64 |
+
- nl
|
| 65 |
+
- om
|
| 66 |
+
- or
|
| 67 |
+
- pa
|
| 68 |
+
- pl
|
| 69 |
+
- ps
|
| 70 |
+
- pt
|
| 71 |
+
- ro
|
| 72 |
+
- ru
|
| 73 |
+
- sa
|
| 74 |
+
- sd
|
| 75 |
+
- si
|
| 76 |
+
- sk
|
| 77 |
+
- sl
|
| 78 |
+
- so
|
| 79 |
+
- sq
|
| 80 |
+
- sr
|
| 81 |
+
- su
|
| 82 |
+
- sv
|
| 83 |
+
- sw
|
| 84 |
+
- ta
|
| 85 |
+
- te
|
| 86 |
+
- th
|
| 87 |
+
- tl
|
| 88 |
+
- tr
|
| 89 |
+
- ug
|
| 90 |
+
- uk
|
| 91 |
+
- ur
|
| 92 |
+
- uz
|
| 93 |
+
- vi
|
| 94 |
+
- xh
|
| 95 |
+
- yi
|
| 96 |
+
- zh
|
| 97 |
+
base_model:
|
| 98 |
+
- intfloat/multilingual-e5-large
|
| 99 |
+
library_name: transformers
|
| 100 |
+
pipeline_tag: text-classification
|
| 101 |
+
metrics:
|
| 102 |
+
- accuracy
|
| 103 |
+
- f1
|
| 104 |
+
tags:
|
| 105 |
+
- sentiment-analysis
|
| 106 |
+
- thai
|
| 107 |
+
- classification
|
| 108 |
+
- fine-tuned
|
| 109 |
+
- multilingual
|
| 110 |
+
new_version: ZombitX64/Thai-sentiment-e5
|
| 111 |
+
---
|
| 112 |
+
|
| 113 |
+
# MultiSent-E5
|
| 114 |
+
|
| 115 |
+
<div align="center">
|
| 116 |
+
<picture>
|
| 117 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/673eef9c4edfc6d3b58ba3aa/Gl94xasTswsG1cOjR_076.png" width="40%" alt="MultiSent-E5">
|
| 118 |
+
</picture>
|
| 119 |
+
</div>
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
A Thai sentiment analysis model fine-tuned from multilingual-e5-large for classifying sentiment in Thai text into positive, negative, neutral, and question categories.
|
| 123 |
+
|
| 124 |
+
## Model Details
|
| 125 |
+
|
| 126 |
+
### Model Description
|
| 127 |
+
|
| 128 |
+
This model is a fine-tuned version of intfloat/multilingual-e5-large specifically trained for Thai sentiment analysis. It can classify Thai text into four sentiment categories: positive, negative, neutral, and question. The model demonstrates strong performance on Thai language sentiment classification tasks with high accuracy and good understanding of Thai linguistic nuances including sarcasm and implicit sentiment.
|
| 129 |
+
|
| 130 |
+
The model is particularly effective at:
|
| 131 |
+
- **Sarcasm Detection**: Understanding when positive words are used in a negative context
|
| 132 |
+
- **Cultural Context**: Recognizing Thai-specific expressions and cultural references
|
| 133 |
+
- **Implicit Sentiment**: Detecting sentiment even when not explicitly stated
|
| 134 |
+
- **Colloquial Language**: Processing informal Thai text from social media and conversations
|
| 135 |
+
|
| 136 |
+
* **Developed by:** ZombitX64, Krittanut Janutsaha, Chanyut Saengwichain
|
| 137 |
+
* **Model type:** Sequence Classification (Sentiment Analysis)
|
| 138 |
+
* **Language(s) (NLP):** Thai (th) - Primary, with limited multilingual capability
|
| 139 |
+
* **License:** Creative Commons Attribution-NonCommercial-NoDerivatives 4.0
|
| 140 |
+
* **Finetuned from model:** [intfloat/multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large)
|
| 141 |
+
|
| 142 |
+
### Model Sources
|
| 143 |
+
|
| 144 |
+
* **Repository:** [https://huggingface.co/ZombitX64/Thai-sentiment-e5](https://huggingface.co/ZombitX64/Thai-sentiment-e5)
|
| 145 |
+
* **Base Model:** [https://huggingface.co/intfloat/multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large)
|
| 146 |
+
|
| 147 |
+
## Uses
|
| 148 |
+
|
| 149 |
+
### Direct Use
|
| 150 |
+
|
| 151 |
+
This model can be directly used for sentiment analysis of Thai text. It's particularly useful for:
|
| 152 |
+
|
| 153 |
+
* **Social Media Analysis**: Monitoring sentiment on Thai social platforms like Twitter, Facebook, and Pantip
|
| 154 |
+
* **Customer Feedback Analysis**: Processing reviews and feedback in Thai for e-commerce and services
|
| 155 |
+
* **Product Review Classification**: Automatically categorizing product reviews by sentiment
|
| 156 |
+
* **Opinion Mining**: Extracting sentiment from Thai news articles, blogs, and forums
|
| 157 |
+
* **Customer Service**: Categorizing customer inquiries and complaints by sentiment and intent
|
| 158 |
+
|
| 159 |
+
### Downstream Use
|
| 160 |
+
|
| 161 |
+
The model can be integrated into larger applications such as:
|
| 162 |
+
|
| 163 |
+
* **Customer Service Chatbots**: Automatically routing messages based on sentiment
|
| 164 |
+
* **Social Media Analytics Platforms**: Real-time sentiment monitoring dashboards
|
| 165 |
+
* **E-commerce Review Systems**: Automated review scoring and categorization
|
| 166 |
+
* **Content Moderation Systems**: Identifying potentially problematic content
|
| 167 |
+
* **Market Research Tools**: Analyzing consumer sentiment towards brands or products
|
| 168 |
+
* **News Analysis Systems**: Tracking public opinion on political or social issues
|
| 169 |
+
|
| 170 |
+
### Out-of-Scope Use
|
| 171 |
+
|
| 172 |
+
This model should not be used for:
|
| 173 |
+
|
| 174 |
+
* **Question Classification**: The model has poor performance on question detection due to insufficient training data. Questions are often misclassified with moderate confidence (50-60%). Use a dedicated question classification model instead.
|
| 175 |
+
* **Mixed Sentiment Analysis**: Complex texts with both positive and negative elements may be misclassified or produce low confidence scores. Consider using aspect-based sentiment analysis for such cases.
|
| 176 |
+
* **Non-Thai Languages**: While it has some multilingual capability, accuracy is significantly lower for languages other than Thai
|
| 177 |
+
* **Fine-grained Emotion Detection**: The model only classifies into 4 broad categories, not specific emotions like anger, joy, fear, etc.
|
| 178 |
+
* **Clinical Applications**: Should not be used for mental health diagnosis or psychological assessment without proper validation
|
| 179 |
+
* **High-stakes Decision Making**: Avoid using for critical decisions affecting individuals without human oversight, especially for predictions with confidence < 60%
|
| 180 |
+
* **Legal or Financial Decisions**: The model's predictions should not be the sole basis for legal or financial determinations
|
| 181 |
+
|
| 182 |
+
## 🌐 Multilingual Sentiment Capability
|
| 183 |
+
|
| 184 |
+
The `MultiSent-E5` model has been developed as an extension of the `intfloat/multilingual-e5-large` base model, which is a multilingual embedding model supporting over 50 languages. This gives the model some capability for sentiment prediction in multiple languages beyond Thai.
|
| 185 |
+
|
| 186 |
+
### Language Support Details
|
| 187 |
+
|
| 188 |
+
* **Primary Language**: Thai - The model has been fine-tuned specifically for Thai and performs best with Thai text
|
| 189 |
+
* **Secondary Languages**: The model can provide basic sentiment analysis for other languages such as English, Chinese, Japanese, Indonesian, and other languages supported by the base multilingual model
|
| 190 |
+
* **Performance Considerations**: Accuracy for non-Thai languages may be significantly lower and results may be less reliable, depending on the similarity of linguistic structures and vocabulary to Thai
|
| 191 |
+
|
| 192 |
+
### Multilingual Performance Expectations
|
| 193 |
+
|
| 194 |
+
| Language Family | Expected Performance | Use Case Recommendation |
|
| 195 |
+
|-----------------|---------------------|-------------------------|
|
| 196 |
+
| Thai | Excellent (99%+ accuracy) | Primary use case |
|
| 197 |
+
| Southeast Asian (Indonesian, Malay, Vietnamese) | Good (70-85% accuracy) | Limited use with validation |
|
| 198 |
+
| East Asian (Chinese, Japanese, Korean) | Moderate (60-75% accuracy) | Experimental use only |
|
| 199 |
+
| European Languages | Moderate (55-70% accuracy) | Not recommended |
|
| 200 |
+
| Other Languages | Poor (40-60% accuracy) | Not recommended |
|
| 201 |
+
|
| 202 |
+
### Recommendations for Multilingual Use
|
| 203 |
+
|
| 204 |
+
* **Primary Recommendation**: Use this model primarily for Thai sentiment analysis where it excels
|
| 205 |
+
* **Secondary Use**: For other languages, consider using language-specific models for maximum accuracy
|
| 206 |
+
* **Validation Required**: Always validate results when using with non-Thai languages
|
| 207 |
+
* **Experimental Use**: Multilingual capability can be useful for initial exploration or when Thai-specific models are unavailable
|
| 208 |
+
|
| 209 |
+
This multilingual capability makes the model suitable for basic multilingual sentiment classification tasks while maintaining excellent performance for Thai text analysis.
|
| 210 |
+
|
| 211 |
+
## How to Get Started with the Model
|
| 212 |
+
|
| 213 |
+
### Basic Usage
|
| 214 |
+
|
| 215 |
+
```python
|
| 216 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 217 |
+
import torch
|
| 218 |
+
|
| 219 |
+
# Load the model and tokenizer
|
| 220 |
+
model_name = "ZombitX64/MultiSent-E5"
|
| 221 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 222 |
+
model = AutoModelForSequenceClassification.from_pretrained(model_name)
|
| 223 |
+
|
| 224 |
+
# Example Thai text
|
| 225 |
+
text = "ผลิตภัณฑ์นี้ดีมาก ใช้งานง่าย" # "This product is very good, easy to use"
|
| 226 |
+
|
| 227 |
+
# Tokenize and predict
|
| 228 |
+
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
|
| 229 |
+
|
| 230 |
+
with torch.no_grad():
|
| 231 |
+
outputs = model(**inputs)
|
| 232 |
+
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
|
| 233 |
+
predicted_class = torch.argmax(predictions, dim=-1)
|
| 234 |
+
|
| 235 |
+
# Label mapping: 0=Question, 1=Negative, 2=Neutral, 3=Positive
|
| 236 |
+
labels = ["Question", "Negative", "Neutral", "Positive"]
|
| 237 |
+
predicted_label = labels[predicted_class.item()]
|
| 238 |
+
confidence = predictions[0][predicted_class.item()].item()
|
| 239 |
+
|
| 240 |
+
print(f"Text: {text}")
|
| 241 |
+
print(f"Predicted sentiment: {predicted_label} ({confidence:.2%})")
|
| 242 |
+
```
|
| 243 |
+
|
| 244 |
+
### Batch Processing
|
| 245 |
+
|
| 246 |
+
```python
|
| 247 |
+
# List of texts to analyze (multilingual examples)
|
| 248 |
+
texts = [
|
| 249 |
+
"ผลิตภัณฑ์นี้ดีมาก ใช้งานง่าย", # Thai: "This product is very good, easy to use"
|
| 250 |
+
"The service was terrible and disappointing", # English
|
| 251 |
+
"商品质量还可以", # Chinese: "Product quality is okay"
|
| 252 |
+
"บริการแย่มาก ไม่ประทับใจเลย", # Thai: "Service is terrible, not impressed at all"
|
| 253 |
+
"Ce produit est excellent", # French: "This product is excellent"
|
| 254 |
+
]
|
| 255 |
+
|
| 256 |
+
print("Predicting sentiment for multiple texts:")
|
| 257 |
+
for text in texts:
|
| 258 |
+
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
|
| 259 |
+
|
| 260 |
+
with torch.no_grad():
|
| 261 |
+
outputs = model(**inputs)
|
| 262 |
+
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
|
| 263 |
+
predicted_class = torch.argmax(predictions, dim=-1)
|
| 264 |
+
|
| 265 |
+
predicted_label = labels[predicted_class.item()]
|
| 266 |
+
confidence = predictions[0][predicted_class.item()].item()
|
| 267 |
+
|
| 268 |
+
print(f"\nText: \"{text}\"")
|
| 269 |
+
print(f"Predicted sentiment: {predicted_label} ({confidence:.2%})")
|
| 270 |
+
```
|
| 271 |
+
|
| 272 |
+
### Pipeline Usage
|
| 273 |
+
|
| 274 |
+
```python
|
| 275 |
+
from transformers import pipeline
|
| 276 |
+
|
| 277 |
+
# Create a sentiment analysis pipeline
|
| 278 |
+
classifier = pipeline("text-classification",
|
| 279 |
+
model="ZombitX64/MultiSent-E5",
|
| 280 |
+
tokenizer="ZombitX64/MultiSent-E5")
|
| 281 |
+
|
| 282 |
+
# Analyze sentiment
|
| 283 |
+
texts = [
|
| 284 |
+
"วันนี้อากาศดีจังเลย", # "The weather is so nice today"
|
| 285 |
+
"แย่ที่สุดเท่าที่��คยเจอมา" # "The worst I've ever encountered"
|
| 286 |
+
]
|
| 287 |
+
|
| 288 |
+
results = classifier(texts)
|
| 289 |
+
for text, result in zip(texts, results):
|
| 290 |
+
print(f"Text: {text}")
|
| 291 |
+
print(f"Sentiment: {result['label']} (Score: {result['score']:.4f})")
|
| 292 |
+
```
|
| 293 |
+
|
| 294 |
+
## Training Details
|
| 295 |
+
|
| 296 |
+
### Training Data
|
| 297 |
+
|
| 298 |
+
The model was trained on a carefully curated Thai sentiment dataset with the following characteristics:
|
| 299 |
+
|
| 300 |
+
* **Total samples:** 2,730 (2,729 after data cleaning and filtering)
|
| 301 |
+
* **Data Distribution:**
|
| 302 |
+
- **Question samples:** Minimal representation (specific count not provided)
|
| 303 |
+
- **Negative samples:** 102 (3.7% of dataset)
|
| 304 |
+
- **Neutral samples:** 317 (11.6% of dataset)
|
| 305 |
+
- **Positive samples:** 2,310 (84.7% of dataset)
|
| 306 |
+
|
| 307 |
+
**Data Split Strategy:**
|
| 308 |
+
* **Training set:** 2,456 samples (90% of total data)
|
| 309 |
+
* **Validation set:** 273 samples (10% of total data)
|
| 310 |
+
|
| 311 |
+
**Data Quality and Preprocessing:**
|
| 312 |
+
* Data was manually reviewed and cleaned to ensure quality
|
| 313 |
+
* Duplicate entries were removed
|
| 314 |
+
* Text was normalized for consistent formatting
|
| 315 |
+
* Class imbalance was noted but maintained to reflect real-world distribution
|
| 316 |
+
|
| 317 |
+
### Training Procedure
|
| 318 |
+
|
| 319 |
+
The model was fine-tuned using state-of-the-art techniques with careful hyperparameter optimization:
|
| 320 |
+
|
| 321 |
+
#### Training Hyperparameters
|
| 322 |
+
|
| 323 |
+
* **Base Model:** intfloat/multilingual-e5-large (1.02B parameters)
|
| 324 |
+
* **Model Architecture:** XLMRobertaForSequenceClassification
|
| 325 |
+
* **Training Epochs:** 5 (with early stopping monitoring)
|
| 326 |
+
* **Total Training Steps:** 770
|
| 327 |
+
* **Batch Size:** 8 (effective batch size with gradient accumulation)
|
| 328 |
+
* **Learning Rate:** 2e-5 with linear warmup and decay
|
| 329 |
+
* **Weight Decay:** 0.01
|
| 330 |
+
* **Warmup Steps:** 77 (10% of total steps)
|
| 331 |
+
* **Max Sequence Length:** 512 tokens
|
| 332 |
+
* **Optimization:** AdamW optimizer
|
| 333 |
+
* **Training Runtime:** 1,633.3 seconds (~27 minutes)
|
| 334 |
+
* **Training Samples per Second:** 7.519
|
| 335 |
+
* **Training Steps per Second:** 0.471
|
| 336 |
+
|
| 337 |
+
#### Training Infrastructure
|
| 338 |
+
|
| 339 |
+
* **Hardware:** GPU-accelerated training (specific GPU not specified)
|
| 340 |
+
* **Framework:** Hugging Face Transformers 4.x
|
| 341 |
+
* **Distributed Training:** Single GPU setup
|
| 342 |
+
* **Memory Optimization:** Gradient checkpointing enabled
|
| 343 |
+
|
| 344 |
+
#### Training Results
|
| 345 |
+
|
| 346 |
+
The model showed excellent convergence with minimal overfitting:
|
| 347 |
+
|
| 348 |
+
| Epoch | Training Loss | Validation Loss | Accuracy | Notes |
|
| 349 |
+
|-------|---------------|-----------------|----------|--------|
|
| 350 |
+
| 1 | 0.0812 | 0.0699 | 98.53% | Strong initial performance |
|
| 351 |
+
| 2 | 0.0053 | 0.0527 | 99.27% | Rapid improvement |
|
| 352 |
+
| 3 | 0.0041 | 0.0350 | 99.63% | Near-optimal performance |
|
| 353 |
+
| 4 | 0.0002 | 0.0384 | 99.63% | Slight validation loss increase |
|
| 354 |
+
| 5 | 0.0002 | 0.0410 | 99.63% | Stable performance |
|
| 355 |
+
|
| 356 |
+
**Training Observations:**
|
| 357 |
+
- Very low training loss achieved by epoch 3
|
| 358 |
+
- Validation loss remained stable, indicating minimal overfitting
|
| 359 |
+
- Accuracy plateaued at 99.63% from epoch 3 onwards
|
| 360 |
+
- Early convergence suggests effective transfer learning from the base model
|
| 361 |
+
|
| 362 |
+
## Evaluation
|
| 363 |
+
|
| 364 |
+
### Model Comparison Metrics
|
| 365 |
+
|
| 366 |
+
|
| 367 |
+
### Model Comparison Metrics (Scatter)
|
| 368 |
+
|
| 369 |
+
|
| 370 |
+
| 🥇อันดับ | ชื่อโมเดล | Accuracy (%) | หมายเหตุ |
|
| 371 |
+
| -------- | ---------------------------------- | ------------ | ------------------------------ |
|
| 372 |
+
| 1 | **MultiSent-E5** | **84.88** | ★ โมเดลที่แม่นยำที่สุด |
|
| 373 |
+
| 2 | ZombitX64/sentiment-103 | 68.60 | รองชนะเลิศ |
|
| 374 |
+
| 3 | Thai-sentiment-e5 | 67.44 | ดีเด่นด้านความเข้าใจภาษาไทย |
|
| 375 |
+
| 4 | xlm-roberta | 34.30 | multilingual baseline |
|
| 376 |
+
| 5 | mMiniLM | 28.49 | ขนาดเล็ก ใช้ทรัพยากรน้อย |
|
| 377 |
+
| 6 | wangchan-sentiment-thai-text-model | 25.58 | ภาษาไทยโดยเฉพาะ |
|
| 378 |
+
| 7 | WangchanBERTa-finetuned-sentiment | 25.00 | fine-tuned Thai BERT |
|
| 379 |
+
| 8 | wangchanberta | 22.67 | Thai BERT base |
|
| 380 |
+
| 9 | Thaweewat/hyperopt-sentiment | 21.51 | ปรับจูนด้วย hyperopt |
|
| 381 |
+
| 10 | sentiment-thai-text-model | 17.44 | baseline keyword model |
|
| 382 |
+
| 11 | e5-base | 16.86 | multilingual encoder |
|
| 383 |
+
| 12 | twitter-xlm-roberta-base-sentiment | 7.56 | fine-tuned บน Twitter (อังกฤษ) |
|
| 384 |
+
|
| 385 |
+
============================================================
|
| 386 |
+
Evaluating Model: MultiSent-E5
|
| 387 |
+
============================================================
|
| 388 |
+
Accuracy: 0.849
|
| 389 |
+
F1-Macro: 0.839
|
| 390 |
+
F1-Weighted: 0.850
|
| 391 |
+
|
| 392 |
+
=== ERROR ANALYSIS FOR MultiSent-E5 ===
|
| 393 |
+
Total Errors: 26 / 172 (15.1%)
|
| 394 |
+
|
| 395 |
+
Error Types:
|
| 396 |
+
error_type
|
| 397 |
+
negative -> positive 7
|
| 398 |
+
question -> neutral 7
|
| 399 |
+
neutral -> positive 3
|
| 400 |
+
negative -> neutral 3
|
| 401 |
+
question -> positive 2
|
| 402 |
+
positive -> neutral 2
|
| 403 |
+
neutral -> negative 1
|
| 404 |
+
neutral -> question 1
|
| 405 |
+
Name: count, dtype: int64
|
| 406 |
+
|
| 407 |
+
Low Confidence Errors (< 60%): 4
|
| 408 |
+
High Confidence Errors (> 80%): 19
|
| 409 |
+
|
| 410 |
+
=== ERROR EXAMPLES ===
|
| 411 |
+
|
| 412 |
+
negative -> positive:
|
| 413 |
+
Text: 'สุดยอดไปเลย! เธอใช้เวลาทั้งวันทำงานชิ้นนี้ออกมาได้แค่นี้เองเหรอเนี่ย!'
|
| 414 |
+
Confidence: 0.517
|
| 415 |
+
Text: 'ไอเดียสร้างสรรค์มาก! ไม่มีใครคิดจะเสนออะไรที่ไม่มีทางเป็นไปได้แบบนี้หรอก'
|
| 416 |
+
Confidence: 1.000
|
| 417 |
+
Text: 'ไอเดียสร้างสรรค์มาก! ไม่มีใครคิดจะเสนออะไรที่ไม่มีทางเป็นไปได้แบบนี้หรอก'
|
| 418 |
+
Confidence: 1.000
|
| 419 |
+
|
| 420 |
+
question -> neutral:
|
| 421 |
+
Text: 'คุณคิดว่าอย่างไรกับเรื่องนี้'
|
| 422 |
+
Confidence: 0.999
|
| 423 |
+
Text: 'How was your day today?'
|
| 424 |
+
Confidence: 1.000
|
| 425 |
+
Text: '你觉得怎么样?'
|
| 426 |
+
Confidence: 0.999
|
| 427 |
+
|
| 428 |
+
neutral -> positive:
|
| 429 |
+
Text: 'ก็แข็งแรงอยู่นะ'
|
| 430 |
+
Confidence: 0.727
|
| 431 |
+
Text: 'ก็แข็งแรงอยู่นะ'
|
| 432 |
+
Confidence: 0.727
|
| 433 |
+
Text: 'บรรยากาศดีมาก เหมาะกับการนั่งเงียบๆ คนเดียว'
|
| 434 |
+
Confidence: 0.723
|
| 435 |
+
|
| 436 |
+
negative -> neutral:
|
| 437 |
+
Text: 'Good day. Unfortunately, I had to walk 10 kilometers from home to school, and now I'm feeling quite ...'
|
| 438 |
+
Confidence: 0.970
|
| 439 |
+
Text: 'Good day. Unfortunately, I had to walk 10 kilometers from home to school, and now I'm feeling quite ...'
|
| 440 |
+
Confidence: 0.970
|
| 441 |
+
Text: 'ส่งของไวมาก...ถ้านับวันเป็นเดือน'
|
| 442 |
+
Confidence: 0.999
|
| 443 |
+
|
| 444 |
+
question -> positive:
|
| 445 |
+
Text: 'ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึงมั้ย'
|
| 446 |
+
Confidence: 0.550
|
| 447 |
+
Text: 'ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึงมั้ย'
|
| 448 |
+
Confidence: 0.550
|
| 449 |
+
|
| 450 |
+
=== LOW CONFIDENCE PREDICTIONS ===
|
| 451 |
+
Total Low Confidence: 7 (4.1%)
|
| 452 |
+
|
| 453 |
+
Low Confidence Examples:
|
| 454 |
+
'ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึงมั้ย'
|
| 455 |
+
Predicted: positive, Confidence: 0.550
|
| 456 |
+
True: question, Correct: False
|
| 457 |
+
|
| 458 |
+
'ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึงรึเปล่า'
|
| 459 |
+
Predicted: question, Confidence: 0.521
|
| 460 |
+
True: question, Correct: True
|
| 461 |
+
|
| 462 |
+
'สุดยอดไปเลย! เธอใช้เวลาทั้งวันทำงานชิ้นนี้ออกมาได้แค่นี้เองเหรอเนี่ย!'
|
| 463 |
+
Predicted: positive, Confidence: 0.517
|
| 464 |
+
True: negative, Correct: False
|
| 465 |
+
|
| 466 |
+
'เกือบดีแล้วล่ะ เหลือแค่ดีจริงๆ นิดเดียว'
|
| 467 |
+
Predicted: neutral, Confidence: 0.546
|
| 468 |
+
True: neutral, Correct: True
|
| 469 |
+
|
| 470 |
+
'ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึงมั้ย'
|
| 471 |
+
Predicted: positive, Confidence: 0.550
|
| 472 |
+
True: question, Correct: False
|
| 473 |
+
|
| 474 |
+
|
| 475 |
+
### 📊 **สรุปผลการประเมินโมเดล: MultiSent-E5**
|
| 476 |
+
|
| 477 |
+
| Metric | ค่า (Value) |
|
| 478 |
+
| --------------------------------- | ----------- |
|
| 479 |
+
| **Accuracy** | **84.9%** |
|
| 480 |
+
| **F1 Macro** | 83.9% |
|
| 481 |
+
| **F1 Weighted** | 85.0% |
|
| 482 |
+
| **จำนวนตัวอย่างทั้งหมด** | 172 |
|
| 483 |
+
| **จำนวนข้อผิดพลาด (Error)** | 26 |
|
| 484 |
+
| **เปอร์เซ็นต์ความผิดพลาด** | 15.1% |
|
| 485 |
+
| **Low Confidence Errors (<60%)** | 4 |
|
| 486 |
+
| **High Confidence Errors (>80%)** | 19 |
|
| 487 |
+
|
| 488 |
+
---
|
| 489 |
+
|
| 490 |
+
### 🧩 **ประเภทความผิดพลาด (Error Types)**
|
| 491 |
+
|
| 492 |
+
| ผิดจาก (True Label) | เป็น (Predicted Label) | จำนวนครั้ง (Count) |
|
| 493 |
+
| ------------------- | ---------------------- | ------------------ |
|
| 494 |
+
| negative | positive | 7 |
|
| 495 |
+
| question | neutral | 7 |
|
| 496 |
+
| neutral | positive | 3 |
|
| 497 |
+
| negative | neutral | 3 |
|
| 498 |
+
| question | positive | 2 |
|
| 499 |
+
| positive | neutral | 2 |
|
| 500 |
+
| neutral | negative | 1 |
|
| 501 |
+
| neutral | question | 1 |
|
| 502 |
+
|
| 503 |
+
---
|
| 504 |
+
|
| 505 |
+
### 🔍 **ตัวอย่าง Error ที่น่าสนใจ**
|
| 506 |
+
|
| 507 |
+
#### 1. **ประชด/เสียดสี** ที่ผิดเป็น Positive
|
| 508 |
+
|
| 509 |
+
| ข้อความ | ทำนาย | จริง | Confidence |
|
| 510 |
+
| ------------------------------------------------------------------------ | -------- | -------- | ---------- |
|
| 511 |
+
| สุดยอดไปเลย! เธอใช้เวลาทั้งวันทำงานชิ้นนี้ออกมาได้แค่นี้เองเหรอเนี่ย! | positive | negative | 0.517 |
|
| 512 |
+
| ไอเดียสร้างสรรค์มาก! ไม่มีใครคิดจะเสนออะไรที่ไม่มีทางเป็นไปได้แบบนี้หรอก | positive | negative | 1.000 |
|
| 513 |
+
|
| 514 |
+
#### 2. **คำถาม** ผิดเป็น Neutral
|
| 515 |
+
|
| 516 |
+
| ข้อความ | ทำนาย | จริง | Confidence |
|
| 517 |
+
| ---------------------------- | ------- | -------- | ---------- |
|
| 518 |
+
| คุณคิดว่าอย่างไรกับเรื่องนี้ | neutral | question | 0.999 |
|
| 519 |
+
| How was your day today? | neutral | question | 1.000 |
|
| 520 |
+
| 你觉得怎么样? | neutral | question | 0.999 |
|
| 521 |
+
|
| 522 |
+
#### 3. **ประโยคคลุมเครือที่ Low Confidence**
|
| 523 |
+
|
| 524 |
+
| ข้อความ | ทำนาย | จริง | Confidence |
|
| 525 |
+
| --------------------------------------------------- | -------- | -------- | ---------- |
|
| 526 |
+
| ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึงมั้ย | positive | question | 0.550 |
|
| 527 |
+
| เกือบดีแล้วล่ะ เหลือแค่ดีจริงๆ นิดเดียว | neutral | neutral | 0.546 |
|
| 528 |
+
|
| 529 |
+
|
| 530 |
+
|
| 531 |
+
### Testing Data, Factors & Metrics
|
| 532 |
+
|
| 533 |
+
#### Testing Data
|
| 534 |
+
|
| 535 |
+
The model was evaluated on a carefully selected validation set with the following characteristics:
|
| 536 |
+
|
| 537 |
+
* **Total Validation Samples:** 273
|
| 538 |
+
* **Selection Method:** Stratified random sampling to maintain class distribution
|
| 539 |
+
* **Data Quality:** Manually verified and cleaned validation samples
|
| 540 |
+
* **Evaluation Period:** Final model checkpoint from epoch 5
|
| 541 |
+
|
| 542 |
+
#### Evaluation Metrics
|
| 543 |
+
|
| 544 |
+
The model was comprehensively evaluated using multiple metrics:
|
| 545 |
+
|
| 546 |
+
* **Primary Metrics:**
|
| 547 |
+
- **Accuracy:** Overall classification accuracy across all classes
|
| 548 |
+
- **F1-Score:** Both macro and weighted averages
|
| 549 |
+
* **Secondary Metrics:**
|
| 550 |
+
- **Precision:** Per-class and overall precision scores
|
| 551 |
+
- **Recall:** Per-class and overall recall scores
|
| 552 |
+
- **Support:** Number of samples per class in validation set
|
| 553 |
+
|
| 554 |
+
### Results
|
| 555 |
+
|
| 556 |
+
#### Final Test Results
|
| 557 |
+
|
| 558 |
+
**Per-Class Performance:**
|
| 559 |
+
|
| 560 |
+
| Class | Precision | Recall | F1-Score | Support | Performance Notes |
|
| 561 |
+
|-------|-----------|---------|----------|---------|-------------------|
|
| 562 |
+
| Question | N/A | N/A | N/A | 0 | No question samples in validation set |
|
| 563 |
+
| Negative | 1.00 | 1.00 | 1.00 | 231 | Perfect classification |
|
| 564 |
+
| Neutral | 1.00 | 0.90 | 0.95 | 10 | 1 misclassification due to small sample size |
|
| 565 |
+
| Positive | 1.00 | 1.00 | 1.00 | 32 | Perfect classification |
|
| 566 |
+
|
| 567 |
+
**Overall Performance Summary:**
|
| 568 |
+
|
| 569 |
+
| Metric | Value | Interpretation |
|
| 570 |
+
|--------|-------|----------------|
|
| 571 |
+
| **Overall Accuracy** | 100% (273/273) | Exceptional performance |
|
| 572 |
+
| **Macro Average F1** | 0.98 | Excellent across all represented classes |
|
| 573 |
+
| **Weighted Average F1** | 1.00 | Perfect when weighted by class frequency |
|
| 574 |
+
| **Total Correct Predictions** | 272/273 | Only 1 misclassification |
|
| 575 |
+
|
| 576 |
+
#### Detailed Confusion Matrix Results
|
| 577 |
+
|
| 578 |
+
**Classification Breakdown:**
|
| 579 |
+
- **Negative Class:** 231/231 correctly classified (100% accuracy)
|
| 580 |
+
- **Neutral Class:** 9/10 correctly classified (90% accuracy)
|
| 581 |
+
- 1 neutral sample misclassified (likely as positive due to ambiguous language)
|
| 582 |
+
- **Positive Class:** 32/32 correctly classified (100% accuracy)
|
| 583 |
+
- **Question Class:** Not present in validation set
|
| 584 |
+
|
| 585 |
+
### Model Capabilities
|
| 586 |
+
|
| 587 |
+
#### Demonstrated Strengths
|
| 588 |
+
|
| 589 |
+
The model shows exceptional capability in understanding various aspects of Thai sentiment:
|
| 590 |
+
|
| 591 |
+
**1. Straightforward Sentiment Classification:**
|
| 592 |
+
- Clear positive expressions: "วันนี้อากาศดีจั��เลย" (The weather is so nice today) → Positive (99.96%)
|
| 593 |
+
- Clear negative expressions: "แย่ที่สุดเท่าที่เคยเจอมา" (The worst I've ever encountered) → Negative (99.99%)
|
| 594 |
+
- Neutral expressions: "ก็งั้นๆ แหละ ไม่มีอะไรพิเศษ" (It's just okay, nothing special) → Neutral (99.70%)
|
| 595 |
+
|
| 596 |
+
**2. Advanced Linguistic Understanding:**
|
| 597 |
+
|
| 598 |
+
**Sarcasm Detection:**
|
| 599 |
+
- "เก่งจังเลยนะ ทำผิดซ้ำได้เหมือนเดิมเป๊ะเลย"
|
| 600 |
+
(So talented! You can make the same mistake repeatedly) → Negative (99.99%)
|
| 601 |
+
- The model correctly identifies that "เก่งจัง" (so talented) is used sarcastically
|
| 602 |
+
|
| 603 |
+
**Implicit Criticism:**
|
| 604 |
+
- "ไอเดียสร้างสรรค์มาก! ไม่มีใครคิดจะเสนออะไรที่ไม่มีทางเป็นไปได้แบบนี้หรอก"
|
| 605 |
+
(Very creative idea! No one would think to propose something this impossible) → Negative (99.43%)
|
| 606 |
+
- Successfully detects negative sentiment despite seemingly positive words
|
| 607 |
+
|
| 608 |
+
**3. Cultural Context Understanding:**
|
| 609 |
+
- Thai-specific expressions and idioms
|
| 610 |
+
- Formal vs. informal language registers
|
| 611 |
+
- Regional variations in expression
|
| 612 |
+
|
| 613 |
+
#### Performance Analysis by Text Type
|
| 614 |
+
|
| 615 |
+
| Text Type | Accuracy | Confidence Range | Notes |
|
| 616 |
+
|-----------|----------|------------------|--------|
|
| 617 |
+
| Direct statements | 99-100% | 90-100% | Excellent performance |
|
| 618 |
+
| Sarcastic content | 95-99% | 85-99% | Very good sarcasm detection (e.g., "เก่งจังเลยนะ ทำผิดซ้ำได้เหมือนเดิมเป๊ะเลย" → 99.98% negative) |
|
| 619 |
+
| Implicit sentiment | 90-95% | 80-95% | Good at reading between the lines |
|
| 620 |
+
| **Mixed sentiment** | **60-75%** | **50-60%** | **Struggles with texts containing both positive and negative aspects** |
|
| 621 |
+
| **Question-like text** | **40-60%** | **50-60%** | **Poor question detection, often classified as other categories** |
|
| 622 |
+
| Star ratings | 95-100% | 99%+ | Excellent (e.g., "ให้5ดาวเลย" → 99.98% positive, "ให้1ดาวเลย" → 99.49% negative) |
|
| 623 |
+
| Formal language | 98-100% | 85-100% | Strong performance on formal text |
|
| 624 |
+
| Colloquial language | 95-99% | 80-95% | Handles informal text well |
|
| 625 |
+
|
| 626 |
+
#### Real-World Performance Issues
|
| 627 |
+
|
| 628 |
+
**Low Confidence Predictions (< 60%):**
|
| 629 |
+
Based on empirical testing, these text types frequently produce low confidence:
|
| 630 |
+
|
| 631 |
+
1. **Mixed Sentiment Examples:**
|
| 632 |
+
- "ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึ..." → Positive (55.0%) or Question (52.1%)
|
| 633 |
+
- "เกือบดีแล้วล่ะ เหลือแค่ดีจริงๆ นิดเดียว" → Neutral (54.6%)
|
| 634 |
+
|
| 635 |
+
2. **Ambiguous Praise with Criticism:**
|
| 636 |
+
- "สุดยอดไปเลย! เธอใช้เวลาทั้งวันทำงานชิ้นนี้ออกม..." → Positive (51.7%)
|
| 637 |
+
|
| 638 |
+
**High Confidence Predictions (> 99%):**
|
| 639 |
+
The model excels at:
|
| 640 |
+
- Clear sarcasm: "เก่งจังเลยนะ ทำผิดซ้ำได้เหมือนเดิมเป๊ะเลย" → Negative (99.98%)
|
| 641 |
+
- Obvious negative sentiment: "ไม่ให้ดาวเลย" → Negative (99.94%)
|
| 642 |
+
- Simple positive expressions: "ให้5ดาวเลย" → Positive (99.98%)
|
| 643 |
+
|
| 644 |
+
#### Known Limitations
|
| 645 |
+
|
| 646 |
+
**1. Question Class Performance Issues:**
|
| 647 |
+
- **Insufficient Training Data**: The question class has minimal representation in the training dataset
|
| 648 |
+
- **Low Confidence Predictions**: Question classification often results in confidence scores below 60%
|
| 649 |
+
- **Misclassification**: Questions are frequently classified as positive, negative, or neutral instead
|
| 650 |
+
- **Example Issue**: "ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึ..." (Longans are delicious and fresh, big fruits too, but half are rotten...) → Classified as neutral (97.7% confidence) instead of recognizing mixed sentiment
|
| 651 |
+
|
| 652 |
+
**2. Mixed Sentiment Challenges:**
|
| 653 |
+
- **Complex Sentiment**: Texts with both positive and negative aspects may be misclassified
|
| 654 |
+
- **Moderate Confidence**: Mixed sentiment often results in lower confidence scores (50-60%)
|
| 655 |
+
- **Example**: Product reviews mentioning both good and bad aspects tend toward neutral classification
|
| 656 |
+
|
| 657 |
+
**3. Class Imbalance Effects:**
|
| 658 |
+
- Model may be biased toward positive classifications due to training data imbalance (84.7% positive samples)
|
| 659 |
+
- Neutral class performance slightly lower due to limited training examples (11.6% of data)
|
| 660 |
+
- Negative class well-represented but still only 3.7% of training data
|
| 661 |
+
|
| 662 |
+
**4. Low Confidence Predictions:**
|
| 663 |
+
- Predictions with confidence < 60% should be treated with caution
|
| 664 |
+
- Common in mixed sentiment, ambiguous language, or question-like texts
|
| 665 |
+
- Recommend implementing confidence thresholding for production use
|
| 666 |
+
|
| 667 |
+
## Environmental Impact
|
| 668 |
+
|
| 669 |
+
### Carbon Footprint Considerations
|
| 670 |
+
|
| 671 |
+
* **Training Emissions:** Specific carbon emission data not available
|
| 672 |
+
* **Efficiency Benefits:** Model was fine-tuned from a pre-trained multilingual model, significantly reducing computational cost compared to training from scratch
|
| 673 |
+
* **Resource Usage:** Relatively efficient training with only 27 minutes of GPU time required
|
| 674 |
+
* **Deployment Efficiency:** Model can be deployed efficiently for inference with standard hardware
|
| 675 |
+
|
| 676 |
+
### Sustainable AI Practices
|
| 677 |
+
|
| 678 |
+
* **Transfer Learning:** Leveraged existing multilingual model to reduce training requirements
|
| 679 |
+
* **Efficient Architecture:** Uses proven transformer architecture optimized for efficiency
|
| 680 |
+
* **Reusability:** Single model can handle multiple languages, reducing need for separate models
|
| 681 |
+
|
| 682 |
+
## Technical Specifications
|
| 683 |
+
|
| 684 |
+
### Model Architecture and Objective
|
| 685 |
+
|
| 686 |
+
* **Architecture:** XLMRobertaForSequenceClassification
|
| 687 |
+
* **Base Model:** intfloat/multilingual-e5-large
|
| 688 |
+
* **Model Parameters:** ~1.02 billion parameters
|
| 689 |
+
* **Classification Head:** Linear layer with 4 output classes
|
| 690 |
+
* **Task:** Multi-class text classification (4 classes: Question, Negative, Neutral, Positive)
|
| 691 |
+
* **Objective Function:** Cross-entropy loss minimization
|
| 692 |
+
* **Activation Function:** Softmax for final predictions
|
| 693 |
+
* **Input Processing:** Tokenization with XLM-RoBERTa tokenizer
|
| 694 |
+
* **Maximum Input Length:** 512 tokens
|
| 695 |
+
|
| 696 |
+
### Performance Characteristics
|
| 697 |
+
|
| 698 |
+
* **Inference Speed:** Fast inference suitable for real-time applications
|
| 699 |
+
* **Memory Requirements:** Standard transformer model memory usage
|
| 700 |
+
* **Scalability:** Can handle batch processing efficiently
|
| 701 |
+
* **Hardware Requirements:** Compatible with CPU and GPU inference
|
| 702 |
+
|
| 703 |
+
### Integration Specifications
|
| 704 |
+
|
| 705 |
+
* **Framework Compatibility:**
|
| 706 |
+
- Hugging Face Transformers
|
| 707 |
+
- PyTorch
|
| 708 |
+
- ONNX (convertible)
|
| 709 |
+
- TensorFlow (via conversion)
|
| 710 |
+
* **API Support:** Compatible with Hugging Face Inference API
|
| 711 |
+
* **Deployment Options:**
|
| 712 |
+
- Cloud deployment (AWS, GCP, Azure)
|
| 713 |
+
- Edge deployment (with optimization)
|
| 714 |
+
- Local deployment
|
| 715 |
+
|
| 716 |
+
## Compute Infrastructure
|
| 717 |
+
|
| 718 |
+
### Hardware Requirements
|
| 719 |
+
|
| 720 |
+
#### Training Infrastructure
|
| 721 |
+
* **GPU:** Modern NVIDIA GPU with sufficient VRAM (16GB+ recommended)
|
| 722 |
+
* **Memory:** 32GB+ RAM recommended for training
|
| 723 |
+
* **Storage:** SSD storage for fast data loading
|
| 724 |
+
|
| 725 |
+
#### Inference Infrastructure
|
| 726 |
+
* **Minimum Requirements:**
|
| 727 |
+
- CPU: Modern multi-core processor
|
| 728 |
+
- RAM: 8GB+ for batch processing
|
| 729 |
+
- Storage: 2GB for model files
|
| 730 |
+
* **Recommended for Production:**
|
| 731 |
+
- GPU: NVIDIA T4 or better
|
| 732 |
+
- RAM: 16GB+
|
| 733 |
+
- Multiple instances for load balancing
|
| 734 |
+
|
| 735 |
+
### Software Dependencies
|
| 736 |
+
|
| 737 |
+
#### Core Requirements
|
| 738 |
+
* **Python:** 3.8+
|
| 739 |
+
* **PyTorch:** 1.9+
|
| 740 |
+
* **Transformers:** 4.15+
|
| 741 |
+
* **NumPy:** 1.21+
|
| 742 |
+
* **Tokenizers:** 0.11+
|
| 743 |
+
|
| 744 |
+
#### Optional Dependencies
|
| 745 |
+
* **ONNX:** For model conversion and optimization
|
| 746 |
+
* **TensorRT:** For NVIDIA GPU optimization
|
| 747 |
+
* **Gradio/Streamlit:** For web interface development
|
| 748 |
+
|
| 749 |
+
## Usage Examples and Best Practices
|
| 750 |
+
|
| 751 |
+
### Best Practices for Implementation
|
| 752 |
+
|
| 753 |
+
#### Text Preprocessing
|
| 754 |
+
```python
|
| 755 |
+
def preprocess_thai_text(text):
|
| 756 |
+
"""
|
| 757 |
+
Recommended preprocessing for Thai text
|
| 758 |
+
"""
|
| 759 |
+
# Remove excessive whitespace
|
| 760 |
+
text = ' '.join(text.split())
|
| 761 |
+
|
| 762 |
+
# Handle common Thai punctuation
|
| 763 |
+
text = text.replace('...', ' ')
|
| 764 |
+
text = text.replace('!!', '!')
|
| 765 |
+
|
| 766 |
+
# Normalize quotation marks
|
| 767 |
+
text = text.replace('"', '"').replace('"', '"')
|
| 768 |
+
|
| 769 |
+
return text.strip()
|
| 770 |
+
```
|
| 771 |
+
|
| 772 |
+
#### Confidence Thresholding
|
| 773 |
+
```python
|
| 774 |
+
def classify_with_confidence(text, threshold=0.6):
|
| 775 |
+
"""
|
| 776 |
+
Classification with confidence thresholding
|
| 777 |
+
Recommended threshold: 0.6 based on empirical testing
|
| 778 |
+
"""
|
| 779 |
+
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
|
| 780 |
+
|
| 781 |
+
with torch.no_grad():
|
| 782 |
+
outputs = model(**inputs)
|
| 783 |
+
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
|
| 784 |
+
confidence = torch.max(predictions).item()
|
| 785 |
+
predicted_class = torch.argmax(predictions, dim=-1).item()
|
| 786 |
+
|
| 787 |
+
if confidence >= threshold:
|
| 788 |
+
return labels[predicted_class], confidence
|
| 789 |
+
else:
|
| 790 |
+
return "Low Confidence - Manual Review Needed", confidence
|
| 791 |
+
|
| 792 |
+
# Enhanced classification with question detection fallback
|
| 793 |
+
def enhanced_classify(text, confidence_threshold=0.6):
|
| 794 |
+
"""
|
| 795 |
+
Enhanced classification with special handling for low confidence
|
| 796 |
+
and potential question detection
|
| 797 |
+
"""
|
| 798 |
+
sentiment, confidence = classify_with_confidence(text, confidence_threshold)
|
| 799 |
+
|
| 800 |
+
# Special handling for low confidence predictions
|
| 801 |
+
if confidence < confidence_threshold:
|
| 802 |
+
# Simple question detection fallback
|
| 803 |
+
question_indicators = ['?', 'ไหม', 'หรือ', 'ครับ', 'คะ', 'มั้ย']
|
| 804 |
+
if any(indicator in text for indicator in question_indicators):
|
| 805 |
+
return "Question (Detected by Rules)", confidence
|
| 806 |
+
else:
|
| 807 |
+
return f"Uncertain ({sentiment})", confidence
|
| 808 |
+
|
| 809 |
+
return sentiment, confidence
|
| 810 |
+
|
| 811 |
+
# Example usage with test cases
|
| 812 |
+
test_texts = [
|
| 813 |
+
"ลำไยอร่อยดีสดมากและลูกใหญ่ด้วยแต่เน่าไปครึ่งนึ...", # Mixed sentiment
|
| 814 |
+
"สุดยอดไปเลย! เธอใช้เวลาทั้งวันทำงานชิ้นนี้ออกม...", # Low confidence positive
|
| 815 |
+
"เก่งจังเลยนะ ทำผิดซ้ำได้เหมือนเดิมเป๊ะเลย", # High confidence sarcasm
|
| 816 |
+
]
|
| 817 |
+
|
| 818 |
+
for text in test_texts:
|
| 819 |
+
result, conf = enhanced_classify(text)
|
| 820 |
+
print(f"Text: {text[:50]}...")
|
| 821 |
+
print(f"Result: {result} (Confidence: {conf:.1%})")
|
| 822 |
+
print()
|
| 823 |
+
```
|
| 824 |
+
|
| 825 |
+
#### Production Deployment Example
|
| 826 |
+
```python
|
| 827 |
+
from fastapi import FastAPI
|
| 828 |
+
from pydantic import BaseModel
|
| 829 |
+
import logging
|
| 830 |
+
|
| 831 |
+
app = FastAPI()
|
| 832 |
+
|
| 833 |
+
class SentimentRequest(BaseModel):
|
| 834 |
+
text: str
|
| 835 |
+
|
| 836 |
+
class SentimentResponse(BaseModel):
|
| 837 |
+
sentiment: str
|
| 838 |
+
confidence: float
|
| 839 |
+
warning: str = None
|
| 840 |
+
|
| 841 |
+
def classify_with_warnings(text, confidence_threshold=0.6):
|
| 842 |
+
"""
|
| 843 |
+
Production-ready classification with warnings for low confidence
|
| 844 |
+
"""
|
| 845 |
+
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
|
| 846 |
+
|
| 847 |
+
with torch.no_grad():
|
| 848 |
+
outputs = model(**inputs)
|
| 849 |
+
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
|
| 850 |
+
confidence = torch.max(predictions).item()
|
| 851 |
+
predicted_class = torch.argmax(predictions, dim=-1).item()
|
| 852 |
+
|
| 853 |
+
sentiment = labels[predicted_class]
|
| 854 |
+
warning = None
|
| 855 |
+
|
| 856 |
+
# Add warnings based on empirical testing
|
| 857 |
+
if confidence < confidence_threshold:
|
| 858 |
+
warning = "Low confidence prediction - manual review recommended"
|
| 859 |
+
|
| 860 |
+
if predicted_class == 0: # Question class
|
| 861 |
+
warning = "Question classification has known accuracy issues - consider manual review"
|
| 862 |
+
|
| 863 |
+
# Detect potential mixed sentiment
|
| 864 |
+
if confidence < 0.7 and any(pos_word in text for pos_word in ['ดี', 'อร่อย', 'สวย']) and any(neg_word in text for neg_word in ['แย่', 'เน่า', 'แต่']):
|
| 865 |
+
warning = "Possible mixed sentiment detected - consider aspect-based analysis"
|
| 866 |
+
|
| 867 |
+
return sentiment, confidence, warning
|
| 868 |
+
|
| 869 |
+
@app.post("/analyze-sentiment", response_model=SentimentResponse)
|
| 870 |
+
async def analyze_sentiment(request: SentimentRequest):
|
| 871 |
+
try:
|
| 872 |
+
# Preprocess text
|
| 873 |
+
text = preprocess_thai_text(request.text)
|
| 874 |
+
|
| 875 |
+
# Get prediction with warnings
|
| 876 |
+
sentiment, confidence, warning = classify_with_warnings(text)
|
| 877 |
+
|
| 878 |
+
# Log low confidence predictions for monitoring
|
| 879 |
+
if confidence < 0.6:
|
| 880 |
+
logging.warning(f"Low confidence prediction: {text[:50]}... -> {sentiment} ({confidence:.3f})")
|
| 881 |
+
|
| 882 |
+
return SentimentResponse(
|
| 883 |
+
sentiment=sentiment,
|
| 884 |
+
confidence=confidence,
|
| 885 |
+
warning=warning
|
| 886 |
+
)
|
| 887 |
+
|
| 888 |
+
except Exception as e:
|
| 889 |
+
logging.error(f"Error processing text: {str(e)}")
|
| 890 |
+
return SentimentResponse(
|
| 891 |
+
sentiment="Error",
|
| 892 |
+
confidence=0.0,
|
| 893 |
+
warning="Processing error occurred"
|
| 894 |
+
)
|
| 895 |
+
|
| 896 |
+
# Batch processing endpoint for efficiency
|
| 897 |
+
@app.post("/analyze-batch")
|
| 898 |
+
async def analyze_batch(texts: list[str]):
|
| 899 |
+
"""
|
| 900 |
+
Batch processing for multiple texts
|
| 901 |
+
"""
|
| 902 |
+
results = []
|
| 903 |
+
for text in texts:
|
| 904 |
+
sentiment, confidence, warning = classify_with_warnings(text)
|
| 905 |
+
results.append({
|
| 906 |
+
"text": text[:100] + "..." if len(text) > 100 else text,
|
| 907 |
+
"sentiment": sentiment,
|
| 908 |
+
"confidence": confidence,
|
| 909 |
+
"warning": warning
|
| 910 |
+
})
|
| 911 |
+
return {"results": results}
|
| 912 |
+
```
|
| 913 |
+
|
| 914 |
+
## Citation
|
| 915 |
+
|
| 916 |
+
### Academic Citation
|
| 917 |
+
|
| 918 |
+
**BibTeX:**
|
| 919 |
+
```bibtex
|
| 920 |
+
@misc{MultiSent-E5,
|
| 921 |
+
title={Thai-sentiment-e5: A Fine-tuned Multilingual Sentiment Analysis Model for Thai Text Classification},
|
| 922 |
+
author={ZombitX64 and Janutsaha, Krittanut and Saengwichain, Chanyut},
|
| 923 |
+
year={2024},
|
| 924 |
+
url={https://huggingface.co/ZombitX64/MultiSent-E5},
|
| 925 |
+
note={Hugging Face Model Repository}
|
| 926 |
+
}
|
| 927 |
+
```
|
| 928 |
+
|
| 929 |
+
**APA Style:**
|
| 930 |
+
ZombitX64, Janutsaha, K., & Saengwichain, C. (2024). *MultiSent-E5: A Fine-tuned Multilingual Sentiment Analysis Model for Thai Text Classification*. Hugging Face. https://huggingface.co/ZombitX64/MultiSent-E5
|
| 931 |
+
|
| 932 |
+
**IEEE Style:**
|
| 933 |
+
ZombitX64, K. Janutsaha, and C. Saengwichain, "MultiSent-E5: A Fine-tuned Multilingual Sentiment Analysis Model for Thai Text Classification," Hugging Face, 2024. [Online]. Available: https://huggingface.co/ZombitX64/MultiSent-E5
|
| 934 |
+
|
| 935 |
+
### Usage in Publications
|
| 936 |
+
|
| 937 |
+
If you use this model in your research or applications, please cite both this model and the base model:
|
| 938 |
+
|
| 939 |
+
```bibtex
|
| 940 |
+
@misc{wang2022text,
|
| 941 |
+
title={Text Embeddings by Weakly-Supervised Contrastive Pre-training},
|
| 942 |
+
author={Liang Wang and Nan Yang and Xiaolong Huang and Binxing Jiao and Linjun Yang and Daxin Jiang and Rangan Majumder and Furu Wei},
|
| 943 |
+
year={2022},
|
| 944 |
+
eprint={2212.03533},
|
| 945 |
+
archivePrefix={arXiv},
|
| 946 |
+
primaryClass={cs.CL}
|
| 947 |
+
}
|
| 948 |
+
```
|
| 949 |
+
```bibtex
|
| 950 |
+
@article{wang2024multilingual,
|
| 951 |
+
title={Multilingual E5 Text Embeddings: A Technical Report},
|
| 952 |
+
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu},
|
| 953 |
+
journal={arXiv preprint arXiv:2402.05672},
|
| 954 |
+
year={2024}
|
| 955 |
+
}
|
| 956 |
+
```
|
| 957 |
+
## Model Card Authors
|
| 958 |
+
|
| 959 |
+
**Primary Contributors:**
|
| 960 |
+
- **ZombitX64** - Lead developer and model architect
|
| 961 |
+
- **Krittanut Janutsaha** - Data curation and evaluation
|
| 962 |
+
- **Chanyut Saengwichain** - Model optimization and documentation
|
| 963 |
+
|
| 964 |
+
## Model Card Contact
|
| 965 |
+
|
| 966 |
+
### Support and Issues
|
| 967 |
+
|
| 968 |
+
For questions, issues, or contributions regarding this model, please use the following channels:
|
| 969 |
+
|
| 970 |
+
* **Primary Contact:** Hugging Face model repository issues and discussions
|
| 971 |
+
* **Repository:** [https://huggingface.co/ZombitX64/MultiSent-E5](https://huggingface.co/ZombitX64/MultiSent-E5)
|
| 972 |
+
* **Community:** Hugging Face community forums for general questions
|
| 973 |
+
|
| 974 |
+
### Collaboration Opportunities
|
| 975 |
+
|
| 976 |
+
We welcome collaboration on:
|
| 977 |
+
- Improving the model's performance
|
| 978 |
+
- Expanding to other Southeast Asian languages
|
| 979 |
+
- Creating domain-specific variants
|
| 980 |
+
- Integration into larger NLP systems
|
| 981 |
+
|
| 982 |
+
### Feedback and Improvements
|
| 983 |
+
|
| 984 |
+
Your feedback helps improve this model. Please report:
|
| 985 |
+
- Performance issues on specific text types
|
| 986 |
+
- Suggestions for additional evaluation metrics
|
| 987 |
+
- Use cases where the model performs unexpectedly
|
| 988 |
+
- Ideas for model enhancements
|
| 989 |
+
|
| 990 |
+
---
|
| 991 |
+
|
| 992 |
+
*Last updated: 2024*
|
| 993 |
+
*Model version: 1.0*
|
| 994 |
+
*Documentation version: 2.0*
|