


Commit ·
32ed653
0
Parent(s):
Duplicate from zai-org/GLM-ASR-Nano-2512
Browse filesCo-authored-by: zR <ZHANGYUXUAN-zR@users.noreply.huggingface.co>
- .gitattributes +35 -0
- README.md +125 -0
- chat_template.jinja +32 -0
- config.json +60 -0
- generation_config.json +10 -0
- model.safetensors +3 -0
- processor_config.json +20 -0
- tokenizer.json +0 -0
- tokenizer_config.json +37 -0
.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- zh
|
| 6 |
+
pipeline_tag: automatic-speech-recognition
|
| 7 |
+
library_name: transformers
|
| 8 |
+
---
|
| 9 |
+
# GLM-ASR-Nano-2512
|
| 10 |
+
|
| 11 |
+
<div align="center">
|
| 12 |
+
<img src=https://raw.githubusercontent.com/zai-org/GLM-ASR/refs/heads/main/resources/logo.svg width="20%"/>
|
| 13 |
+
</div>
|
| 14 |
+
<p align="center">
|
| 15 |
+
👋 Join our <a href="https://raw.githubusercontent.com/zai-org/GLM-ASR/refs/heads/main/resources/wechat.png" target="_blank">WeChat</a> community
|
| 16 |
+
</p>
|
| 17 |
+
|
| 18 |
+
## Model Introduction
|
| 19 |
+
|
| 20 |
+
**GLM-ASR-Nano-2512** is a robust, open-source speech recognition model with **1.5B parameters**. Designed for
|
| 21 |
+
real-world complexity, it outperforms OpenAI Whisper V3 on multiple benchmarks while maintaining a compact size.
|
| 22 |
+
|
| 23 |
+
Key capabilities include:
|
| 24 |
+
|
| 25 |
+
* **Exceptional Dialect Support:**
|
| 26 |
+
Beyond standard Mandarin and English, the model is highly optimized for **Cantonese (粤语)** and other dialects,
|
| 27 |
+
effectively bridging the gap in dialectal speech recognition.
|
| 28 |
+
|
| 29 |
+
* **Low-Volume Speech Robustness:**
|
| 30 |
+
Specifically trained for **"Whisper/Quiet Speech"** scenarios. It captures and accurately transcribes extremely
|
| 31 |
+
low-volume audio that traditional models often miss.
|
| 32 |
+
|
| 33 |
+
* **SOTA Performance:**
|
| 34 |
+
Achieves the **lowest average error rate (4.10)** among comparable open-source models, showing significant advantages
|
| 35 |
+
in Chinese benchmarks (Wenet Meeting, Aishell-1, etc..).
|
| 36 |
+
|
| 37 |
+
## Benchmark
|
| 38 |
+
|
| 39 |
+
We evaluated GLM-ASR-Nano against leading open-source and closed-source models. The results demonstrate that *
|
| 40 |
+
*GLM-ASR-Nano (1.5B)** achieves superior performance, particularly in challenging acoustic environments.
|
| 41 |
+
|
| 42 |
+
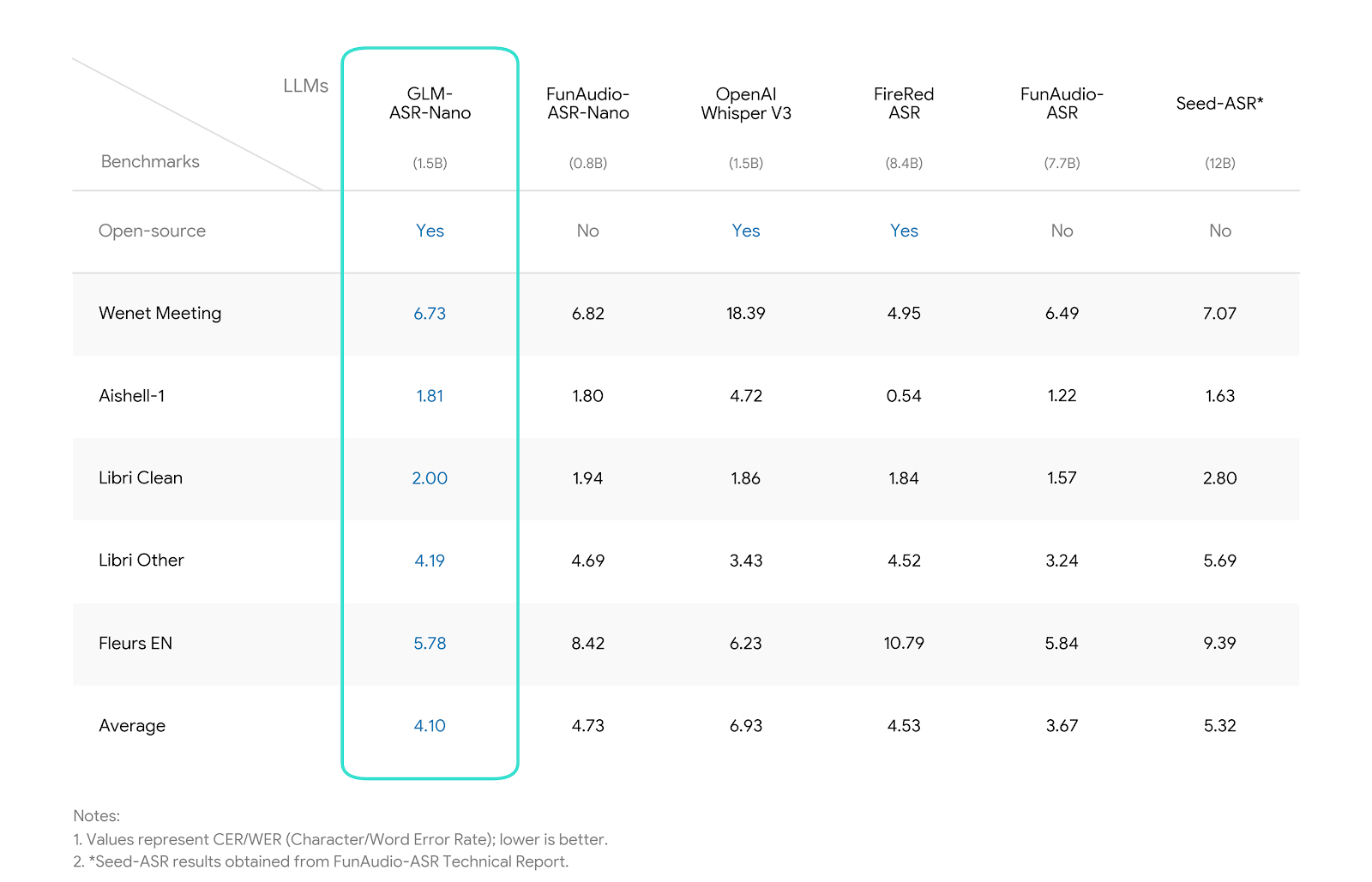
|
| 43 |
+
|
| 44 |
+
Notes:
|
| 45 |
+
|
| 46 |
+
- Wenet Meeting reflects real-world meeting scenarios with noise and overlapping speech.
|
| 47 |
+
- Aishell-1 is a standard Mandarin benchmark.
|
| 48 |
+
|
| 49 |
+
## Inference
|
| 50 |
+
|
| 51 |
+
`GLM-ASR-Nano-2512` can be easily integrated using the `transformers` library.
|
| 52 |
+
We will support `transformers 5.x` as well as inference frameworks such as `vLLM` and `SGLang`.
|
| 53 |
+
you can check more code in [Github](https://github.com/zai-org/GLM-ASR).
|
| 54 |
+
|
| 55 |
+
### Transformers 🤗
|
| 56 |
+
|
| 57 |
+
Install `transformers` from source:
|
| 58 |
+
```bash
|
| 59 |
+
pip install git+https://github.com/huggingface/transformers
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
#### Basic Usage
|
| 63 |
+
|
| 64 |
+
```python
|
| 65 |
+
from transformers import AutoModelForSeq2SeqLM, AutoProcessor
|
| 66 |
+
|
| 67 |
+
processor = AutoProcessor.from_pretrained("zai-org/GLM-ASR-Nano-2512")
|
| 68 |
+
model = AutoModelForSeq2SeqLM.from_pretrained("zai-org/GLM-ASR-Nano-2512", dtype="auto", device_map="auto")
|
| 69 |
+
|
| 70 |
+
inputs = processor.apply_transcription_request("https://huggingface.co/datasets/hf-internal-testing/dummy-audio-samples/resolve/main/bcn_weather.mp3")
|
| 71 |
+
|
| 72 |
+
inputs = inputs.to(model.device, dtype=model.dtype)
|
| 73 |
+
outputs = model.generate(**inputs, do_sample=False, max_new_tokens=500)
|
| 74 |
+
|
| 75 |
+
decoded_outputs = processor.batch_decode(outputs[:, inputs.input_ids.shape[1] :], skip_special_tokens=True)
|
| 76 |
+
print(decoded_outputs)
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
#### Using Audio Arrays Directly
|
| 80 |
+
|
| 81 |
+
You can also use audio arrays directly:
|
| 82 |
+
|
| 83 |
+
```python
|
| 84 |
+
from transformers import GlmAsrForConditionalGeneration, AutoProcessor
|
| 85 |
+
from datasets import load_dataset
|
| 86 |
+
from datasets import Audio
|
| 87 |
+
|
| 88 |
+
processor = AutoProcessor.from_pretrained("zai-org/GLM-ASR-Nano-2512")
|
| 89 |
+
model = GlmAsrForConditionalGeneration.from_pretrained("zai-org/GLM-ASR-Nano-2512", dtype="auto", device_map="auto")
|
| 90 |
+
|
| 91 |
+
# loading audio directly from dataset
|
| 92 |
+
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
|
| 93 |
+
ds = ds.cast_column("audio", Audio(sampling_rate=processor.feature_extractor.sampling_rate))
|
| 94 |
+
audio_array = ds[0]["audio"]["array"]
|
| 95 |
+
|
| 96 |
+
inputs = processor.apply_transcription_request(audio_array)
|
| 97 |
+
|
| 98 |
+
inputs = inputs.to(model.device, dtype=model.dtype)
|
| 99 |
+
outputs = model.generate(**inputs, do_sample=False, max_new_tokens=500)
|
| 100 |
+
|
| 101 |
+
decoded_outputs = processor.batch_decode(outputs[:, inputs.input_ids.shape[1] :], skip_special_tokens=True)
|
| 102 |
+
print(decoded_outputs)
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
#### Batched Inference
|
| 106 |
+
|
| 107 |
+
You can process multiple audio files at once:
|
| 108 |
+
|
| 109 |
+
```python
|
| 110 |
+
from transformers import GlmAsrForConditionalGeneration, AutoProcessor
|
| 111 |
+
|
| 112 |
+
processor = AutoProcessor.from_pretrained("zai-org/GLM-ASR-Nano-2512")
|
| 113 |
+
model = GlmAsrForConditionalGeneration.from_pretrained("zai-org/GLM-ASR-Nano-2512", dtype="auto", device_map="auto")
|
| 114 |
+
|
| 115 |
+
inputs = processor.apply_transcription_request([
|
| 116 |
+
"https://huggingface.co/datasets/hf-internal-testing/dummy-audio-samples/resolve/main/bcn_weather.mp3",
|
| 117 |
+
"https://huggingface.co/datasets/hf-internal-testing/dummy-audio-samples/resolve/main/obama.mp3",
|
| 118 |
+
])
|
| 119 |
+
|
| 120 |
+
inputs = inputs.to(model.device, dtype=model.dtype)
|
| 121 |
+
outputs = model.generate(**inputs, do_sample=False, max_new_tokens=500)
|
| 122 |
+
|
| 123 |
+
decoded_outputs = processor.batch_decode(outputs[:, inputs.input_ids.shape[1] :], skip_special_tokens=True)
|
| 124 |
+
print(decoded_outputs)
|
| 125 |
+
```
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{%- macro to_text(content) -%}
|
| 2 |
+
{%- if content is string -%}
|
| 3 |
+
{{- content -}}
|
| 4 |
+
{%- elif content is iterable and content is not mapping -%}
|
| 5 |
+
{%- for item in content -%}
|
| 6 |
+
{%- if item is mapping and item.type == 'text' and item.text is defined -%}
|
| 7 |
+
{{- item.text -}}
|
| 8 |
+
{%- elif item is mapping and (item.type == 'audio' or 'audio' in item) -%}
|
| 9 |
+
<|begin_of_audio|><|pad|><|end_of_audio|><|user|>
|
| 10 |
+
{% elif item is string -%}
|
| 11 |
+
{{- item -}}
|
| 12 |
+
{%- endif -%}
|
| 13 |
+
{%- endfor -%}
|
| 14 |
+
{%- else -%}
|
| 15 |
+
{{- content -}}
|
| 16 |
+
{%- endif -%}
|
| 17 |
+
{%- endmacro -%}
|
| 18 |
+
{%- for m in messages -%}
|
| 19 |
+
{%- if m.role == 'system' -%}
|
| 20 |
+
<|system|>
|
| 21 |
+
{{ to_text(m.content) | trim }}
|
| 22 |
+
{%- elif m.role == 'user' -%}
|
| 23 |
+
<|user|>
|
| 24 |
+
{{ to_text(m.content) | trim }}
|
| 25 |
+
{%- elif m.role == 'assistant' -%}
|
| 26 |
+
<|assistant|>
|
| 27 |
+
{{ to_text(m.content) | trim }}
|
| 28 |
+
{%- endif -%}
|
| 29 |
+
{%- endfor -%}
|
| 30 |
+
{%- if add_generation_prompt -%}
|
| 31 |
+
<|assistant|>
|
| 32 |
+
{% endif -%}
|
config.json
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"GlmAsrForConditionalGeneration"
|
| 4 |
+
],
|
| 5 |
+
"audio_config": {
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"head_dim": 64,
|
| 8 |
+
"hidden_act": "gelu",
|
| 9 |
+
"hidden_size": 1280,
|
| 10 |
+
"initializer_range": 0.02,
|
| 11 |
+
"intermediate_size": 5120,
|
| 12 |
+
"max_position_embeddings": 1500,
|
| 13 |
+
"model_type": "glmasr_encoder",
|
| 14 |
+
"num_attention_heads": 20,
|
| 15 |
+
"num_hidden_layers": 32,
|
| 16 |
+
"num_key_value_heads": 20,
|
| 17 |
+
"num_mel_bins": 128,
|
| 18 |
+
"partial_rotary_factor": 0.5,
|
| 19 |
+
"rope_parameters": {
|
| 20 |
+
"partial_rotary_factor": 0.5,
|
| 21 |
+
"rope_theta": 10000.0,
|
| 22 |
+
"rope_type": "default"
|
| 23 |
+
}
|
| 24 |
+
},
|
| 25 |
+
"audio_token_id": 59260,
|
| 26 |
+
"dtype": "bfloat16",
|
| 27 |
+
"hidden_size": 2048,
|
| 28 |
+
"model_type": "glmasr",
|
| 29 |
+
"projector_hidden_act": "gelu",
|
| 30 |
+
"text_config": {
|
| 31 |
+
"attention_bias": false,
|
| 32 |
+
"attention_dropout": 0.0,
|
| 33 |
+
"eos_token_id": [
|
| 34 |
+
59246,
|
| 35 |
+
59253,
|
| 36 |
+
59255
|
| 37 |
+
],
|
| 38 |
+
"head_dim": 128,
|
| 39 |
+
"hidden_act": "silu",
|
| 40 |
+
"hidden_size": 2048,
|
| 41 |
+
"initializer_range": 0.02,
|
| 42 |
+
"intermediate_size": 6144,
|
| 43 |
+
"max_position_embeddings": 8192,
|
| 44 |
+
"mlp_bias": false,
|
| 45 |
+
"model_type": "llama",
|
| 46 |
+
"num_attention_heads": 16,
|
| 47 |
+
"num_hidden_layers": 28,
|
| 48 |
+
"num_key_value_heads": 4,
|
| 49 |
+
"pretraining_tp": 1,
|
| 50 |
+
"rms_norm_eps": 1e-05,
|
| 51 |
+
"rope_parameters": {
|
| 52 |
+
"rope_theta": 10000.0,
|
| 53 |
+
"rope_type": "default"
|
| 54 |
+
},
|
| 55 |
+
"use_cache": true,
|
| 56 |
+
"vocab_size": 59264
|
| 57 |
+
},
|
| 58 |
+
"transformers_version": "5.0.0.dev0",
|
| 59 |
+
"vocab_size": 59264
|
| 60 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": [
|
| 5 |
+
59246,
|
| 6 |
+
59253,
|
| 7 |
+
59255
|
| 8 |
+
],
|
| 9 |
+
"transformers_version": "5.0.0.dev0"
|
| 10 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b8af83ccf6b34dfc7921cedcc46d4a6dc6aaffa661b8f71b44e3a2ff60a90a91
|
| 3 |
+
size 4515776712
|
processor_config.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"audio_token": "<|pad|>",
|
| 3 |
+
"default_transcription_prompt": "Please transcribe this audio into text",
|
| 4 |
+
"feature_extractor": {
|
| 5 |
+
"chunk_length": 30,
|
| 6 |
+
"dither": 0.0,
|
| 7 |
+
"feature_extractor_type": "WhisperFeatureExtractor",
|
| 8 |
+
"feature_size": 128,
|
| 9 |
+
"hop_length": 160,
|
| 10 |
+
"n_fft": 400,
|
| 11 |
+
"n_samples": 480000,
|
| 12 |
+
"nb_max_frames": 3000,
|
| 13 |
+
"padding_side": "right",
|
| 14 |
+
"padding_value": 0.0,
|
| 15 |
+
"return_attention_mask": false,
|
| 16 |
+
"sampling_rate": 16000
|
| 17 |
+
},
|
| 18 |
+
"max_audio_len": 655,
|
| 19 |
+
"processor_class": "GlmAsrProcessor"
|
| 20 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"backend": "tokenizers",
|
| 3 |
+
"clean_up_tokenization_spaces": false,
|
| 4 |
+
"do_lower_case": false,
|
| 5 |
+
"eos_token": "<|endoftext|>",
|
| 6 |
+
"extra_special_tokens": [
|
| 7 |
+
"<|endoftext|>",
|
| 8 |
+
"[MASK]",
|
| 9 |
+
"[gMASK]",
|
| 10 |
+
"[sMASK]",
|
| 11 |
+
"<sop>",
|
| 12 |
+
"<eop>",
|
| 13 |
+
"<|system|>",
|
| 14 |
+
"<|user|>",
|
| 15 |
+
"<|assistant|>",
|
| 16 |
+
"<|observation|>",
|
| 17 |
+
"<|begin_of_image|>",
|
| 18 |
+
"<|end_of_image|>",
|
| 19 |
+
"<|begin_of_video|>",
|
| 20 |
+
"<|end_of_video|>",
|
| 21 |
+
"<|pad|>",
|
| 22 |
+
"<|begin_of_audio|>",
|
| 23 |
+
"<|end_of_audio|>"
|
| 24 |
+
],
|
| 25 |
+
"is_local": false,
|
| 26 |
+
"model_input_names": [
|
| 27 |
+
"input_ids",
|
| 28 |
+
"attention_mask"
|
| 29 |
+
],
|
| 30 |
+
"model_max_length": 65536,
|
| 31 |
+
"model_specific_special_tokens": {},
|
| 32 |
+
"pad_token": "<|endoftext|>",
|
| 33 |
+
"padding_side": "left",
|
| 34 |
+
"processor_class": "GlmAsrProcessor",
|
| 35 |
+
"remove_space": false,
|
| 36 |
+
"tokenizer_class": "TokenizersBackend"
|
| 37 |
+
}
|