---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- bclm
- pytorch
---
# Bellevue College Language Model
# BCLM-1-Small-Preview
We are releasing **BCLM-1 Preview**, an open family of flagship language models that deliver strong, predictable performance across a range of tasks.
**BCLM-1 Preview** is built on a hybrid SSM/attention architecture (Bulldog) for efficient training and inference, tailored for **writing**, **summarization**, and **recall** out of the box.
**Note:** This is a preview model, and may make mistakes or errors not present in future releases.
## Models
| Model | Parameters | Variant | Input | Output | Thinking |
|---|---|---|---|---|---|
| BCLM-1-Small-Preview | 123M | Instruction-tuned | Text-only | Text-only | No |
| BCLM-1-Medium | 720M | Instruction-tuned | Text-only | Text-only | Planned |
## Sample Generations
BCLM-1-Small-Preview generates coherent, actionable text in alignment with prompts.
```
Photosynthesis is a vital process that occurs in plants, algae, and
certain bacteria, allowing them to convert light energy into chemical
energy. This process is essential for life on Earth as it provides the
primary energy source for nearly all ecosystems.
```
```
Prompt: What are the key components of a successful marketing campaign?
* A clear and compelling message that resonates with the target audience.
* Effective use of multiple channels to reach and engage the target
audience effectively.
* Measurable and relevant KPIs to help optimize campaign outcomes.
```
## Example Usage
BCLM-1 is easy to use with our library, `bclm-pytorch`, in Python:
```python
import bclm
model = bclm.load("bclm-1-small-preview")
# Multi-turn chat
chat = model.chat(system_prompt="You are a helpful assistant.")
# Streaming chat (real-time token output)
for chunk in chat.send_stream("Explain the future of AI."):
print(chunk, end="", flush=True)
```
`transformers` support coming soon.
## Training
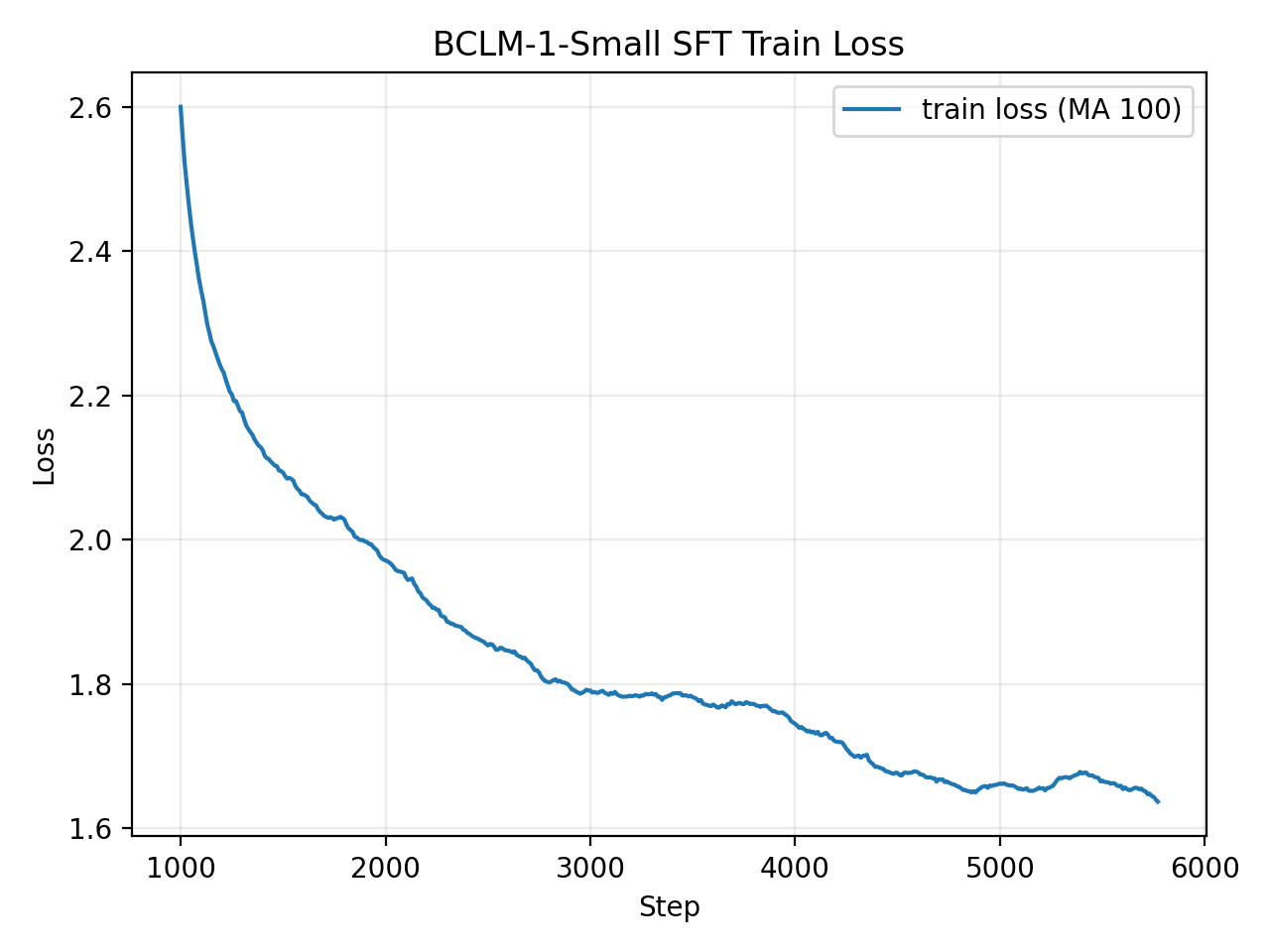 BCLM-1 was trained on NVIDIA H200 GPUs.
| Stage | Steps | Loss | Perplexity (ppl) |
|---|---|---|---|
| Pretraining | 24,000 | 2.11 | 8.25 |
| SFT | 6,000 | 1.85 | 6.36 |
## Notes
BCLM-1-Small-Preview is trained for general language tasks only. Math and code generation will be supported in future releases.
## Tokenizer and Supported Languages
BCLM-1 uses the `tokenmonster` tokenizer with a vocabulary of 32,000 tokens.
Only English is supported in this release. Additional languages will follow.
## Context Length
BCLM-1-Small-Preview was trained with a maximum context length of 2,048 tokens. Extended context support is planned for the next release.
## Architecture Information
| Architecture | BCLM-1 |
|---|---|
| Parameters | 123.14M (77.55M non-embedding) |
| Embedding dim | 384 |
| Layers | 12 |
| Attention heads | 6 (KV heads: 2) |
| Vocab size | 32,768 |
| SSM Layers | 12 |
| SSM State Size | 156,672 |
| Local Attn. Layers | 6 |
| Global Attn. Layers | 2 |
| Max sequence length | 16,384 |
| Local Window Size | 1,024 |
| Training Precision | BF16 |
| Weights Precision | F32 (can be changed) |
| Weights format | `safetensors` |
Learn more about the Bulldog architecture: GitHub
## Limitations
Like all generative models, BCLM-1 can produce incorrect, incomplete, or fabricated information. Outputs should not be treated as factual without verification. We are not responsible for any misuse, harm, or consequences arising from the use of this model's outputs.
## Citation
```bibtex
@software{bclm1,
title = {BCLM-1},
author = {BCML Labs},
url = {https://github.com/bcml-labs/bclm-pytorch},
year = {2026}
}
```
BCLM-1 was trained on NVIDIA H200 GPUs.
| Stage | Steps | Loss | Perplexity (ppl) |
|---|---|---|---|
| Pretraining | 24,000 | 2.11 | 8.25 |
| SFT | 6,000 | 1.85 | 6.36 |
## Notes
BCLM-1-Small-Preview is trained for general language tasks only. Math and code generation will be supported in future releases.
## Tokenizer and Supported Languages
BCLM-1 uses the `tokenmonster` tokenizer with a vocabulary of 32,000 tokens.
Only English is supported in this release. Additional languages will follow.
## Context Length
BCLM-1-Small-Preview was trained with a maximum context length of 2,048 tokens. Extended context support is planned for the next release.
## Architecture Information
| Architecture | BCLM-1 |
|---|---|
| Parameters | 123.14M (77.55M non-embedding) |
| Embedding dim | 384 |
| Layers | 12 |
| Attention heads | 6 (KV heads: 2) |
| Vocab size | 32,768 |
| SSM Layers | 12 |
| SSM State Size | 156,672 |
| Local Attn. Layers | 6 |
| Global Attn. Layers | 2 |
| Max sequence length | 16,384 |
| Local Window Size | 1,024 |
| Training Precision | BF16 |
| Weights Precision | F32 (can be changed) |
| Weights format | `safetensors` |
Learn more about the Bulldog architecture: GitHub
## Limitations
Like all generative models, BCLM-1 can produce incorrect, incomplete, or fabricated information. Outputs should not be treated as factual without verification. We are not responsible for any misuse, harm, or consequences arising from the use of this model's outputs.
## Citation
```bibtex
@software{bclm1,
title = {BCLM-1},
author = {BCML Labs},
url = {https://github.com/bcml-labs/bclm-pytorch},
year = {2026}
}
```
