
Update README.md
Browse files
README.md
CHANGED
|
@@ -31,17 +31,22 @@ inference:
|
|
| 31 |
|
| 32 |
# SEGA-large model
|
| 33 |
|
| 34 |
-
**SEGA: SkEtch-based Generative Augmentation**
|
|
|
|
| 35 |
|
| 36 |
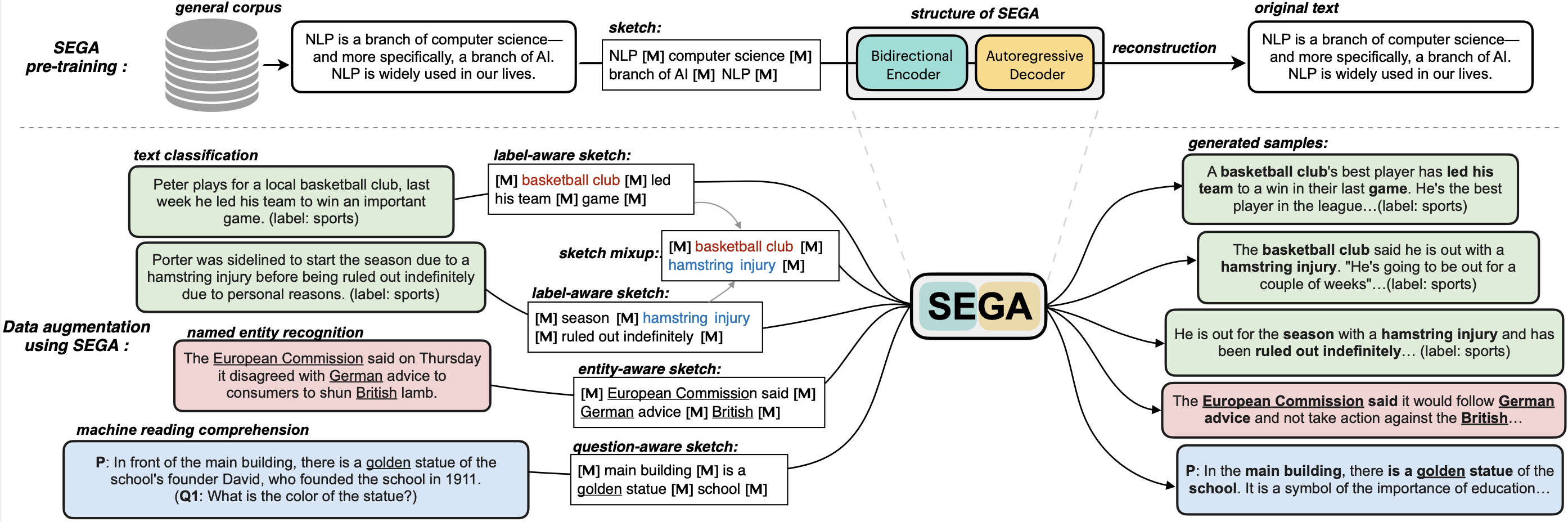
**SEGA** is a **general text augmentation model** that can be used for data augmentation for **various NLP tasks** (including sentiment analysis, topic classification, NER, and QA). SEGA uses an encoder-decoder structure (based on the BART architecture) and is pre-trained on the `C4-realnewslike` corpus.
|
| 37 |
|
| 38 |
|
| 39 |
|
| 40 |
|
| 41 |
-
- Paper: [
|
| 42 |
-
-
|
| 43 |
-
|
| 44 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
|
| 46 |
### How to use
|
| 47 |
```python
|
|
@@ -65,11 +70,11 @@ Output:
|
|
| 65 |
| Model | #params | Language |
|
| 66 |
|------------------------|--------------------------------|-------|
|
| 67 |
| [`sega-large`]() | xM | English |
|
| 68 |
-
| [`sega-base`]() | xM | English |
|
| 69 |
-
| [`sega-small`]() | xM | English |
|
| 70 |
-
| [`sega-large-chinese`]() | xM | Chinese |
|
| 71 |
-
| [`sega-base-chinese`]() | xM | Chinese |
|
| 72 |
-
| [`sega-small-chinese`]() | xM | Chinese |
|
| 73 |
|
| 74 |
|
| 75 |
## Data Augmentation for Text Classification Tasks:
|
|
|
|
| 31 |
|
| 32 |
# SEGA-large model
|
| 33 |
|
| 34 |
+
**SEGA: SkEtch-based Generative Augmentation** \
|
| 35 |
+
**基于草稿的生成式增强模型**
|
| 36 |
|
| 37 |
**SEGA** is a **general text augmentation model** that can be used for data augmentation for **various NLP tasks** (including sentiment analysis, topic classification, NER, and QA). SEGA uses an encoder-decoder structure (based on the BART architecture) and is pre-trained on the `C4-realnewslike` corpus.
|
| 38 |
|
| 39 |
|
| 40 |

|
| 41 |
|
| 42 |
+
- Paper: [coming soon](to_be_added)
|
| 43 |
+
- GitHub: [coming soon](to_be_added).
|
|
|
|
| 44 |
|
| 45 |
+
**SEGA** is able to write complete paragraphs given a sketch (or framework), which can be composed of:
|
| 46 |
+
- keywords /key-phrases, like [NLP | AI | computer science]
|
| 47 |
+
- spans, like [Conference on Empirical Methods | submission of research papers]
|
| 48 |
+
- sentences, like [I really like machine learning | I work at Google since last year]
|
| 49 |
+
- all mixup~
|
| 50 |
|
| 51 |
### How to use
|
| 52 |
```python
|
|
|
|
| 70 |
| Model | #params | Language |
|
| 71 |
|------------------------|--------------------------------|-------|
|
| 72 |
| [`sega-large`]() | xM | English |
|
| 73 |
+
| [`sega-base`(coming soon)]() | xM | English |
|
| 74 |
+
| [`sega-small`(coming soon)]() | xM | English |
|
| 75 |
+
| [`sega-large-chinese`(coming soon)]() | xM | Chinese |
|
| 76 |
+
| [`sega-base-chinese`(coming soon)]() | xM | Chinese |
|
| 77 |
+
| [`sega-small-chinese`(coming soon)]() | xM | Chinese |
|
| 78 |
|
| 79 |
|
| 80 |
## Data Augmentation for Text Classification Tasks:
|