DukaanBench: Can AI Run an Indian Grocery Store for 30 Days?



Part 1: Simulation, Harness and Frontier LLM testing

Most AI benchmarks ask a model to answer. DukaanBench asks a model to operate.
In DukaanBench, a language model runs a small Indian kirana store for 30 simulated days. Every morning it receives the shop state, recent sales and misses, inventory, cash, trust, weather, customer signals, khata exposure, active marketing, and a fixed neighborhood profile. It must return one executable JSON action before the shop opens. The backend then simulates customers, stockouts, payments, khata, waste, marketing effects, trust movement, and reward.
Across the 30 days, the AI goes through the ordinary pressure of shopkeeping: it starts with limited cash and shelves, decides what to reorder, protects fast-moving essentials, handles perishable stock, chooses whether to discount or market products, reminds khata customers, and then watches simulated customers either get served or walk away disappointed. Each day leaves a mark. Cash, inventory, trust, customer memory, and missed demand carry into the next morning.
The question is deliberately practical:
Can an AI make profit without losing customer trust?
This is Part 1 of the project. Part 1 publishes the environment, the Arena, the live leaderboard, and the first lessons from model behavior. Part 2 will use the day-level traces to train a smaller shopkeeper model and test whether a focused SLM can learn this environment better than a general model with a long prompt.
Live project:
- Webpage: research.becapable.in/dukaanbench
- Arena replay: research.becapable.in/dukaanbench/arena-2
Methodology Snapshot
Part 1 is a research preview of the benchmark, not a released training dataset yet.
- Same starting world: every model gets the same fixed fictional shop, opening cash, SKU set, customer memory, and neighborhood profile.
- Same horizon: each run is 30 simulated shop days.
- Same action contract: one executable JSON action per day.
- Same engine: the validator, customer simulator, state updates, and scoring logic are shared across models.
- Same live surface: the leaderboard and Arena replay are served from the deployed DukaanBench app.
- Captured leaderboard: the table below reflects the live Arena API on June 27, 2026.
The traces are already useful for analysis, replay, and Part 2 planning. The public training dataset and small-model release are intentionally left for Part 2, after the trace format is cleaned and documented.
Why a Kirana?
A kirana shop is a small operating system for neighborhood commerce.
The shopkeeper is not only buying and selling goods. They are reading school timings, salary cycles, rainy days, festivals, supplier constraints, expiry risk, customer habits, credit relationships, and local competition. Missing a packet of milk is not just a missed sale. If it happens to a regular customer twice, it becomes a trust problem.
That makes a kirana a useful AI-agent benchmark because it combines:
- limited cash
- uncertain demand
- perishable inventory
- frequent customer visits
- informal credit through khata
- local marketing
- relationship memory
- delayed consequences
DukaanBench uses a fictional but fixed shop, Shree Shyam Bhandar, on Nehru Colony School Road. Every model faces the same neighborhood: nearby apartments, a school, a bus stop, a small market lane, and repeat customers with different trust and khata behavior.
The Benchmark Loop

One episode is one full 30-day game. One step is one shop day.
The daily loop is:
- Observe: the model receives JSON describing the shop, inventory, customer memory, khata, marketing, recent history, and environment signals.
- Act: the model returns one JSON action for tomorrow.
- Validate: the backend checks that the action is parseable, affordable, executable, and consistent with the model's rationale.
- Simulate: customers visit, ask for items, pay in cash or khata, face fulfillment or stockouts, and update trust.
- Score: the backend computes the day reward and persists the full trace.
The model does not directly control customers. It controls the shopkeeper's plan.
The action JSON can include:
{
"orders": {"milk": 20, "bread": 10},
"removals": {},
"discounts": {"bananas": 10},
"khataReminders": ["mrs_sharma"],
"marketingActions": [
{"specId": "whatsapp_status", "targetProducts": ["milk", "bread", "eggs"]}
],
"cashReserve": 600,
"fridgeAllocation": {"milk": 60, "cold_drinks": 30, "buffer": 10}
}
The rationale is not executed. If a model says "run a WhatsApp campaign" but leaves marketingActions empty, the campaign does not happen. This small detail turned out to be one of the most important parts of the benchmark.
How the Benchmark Engine Works
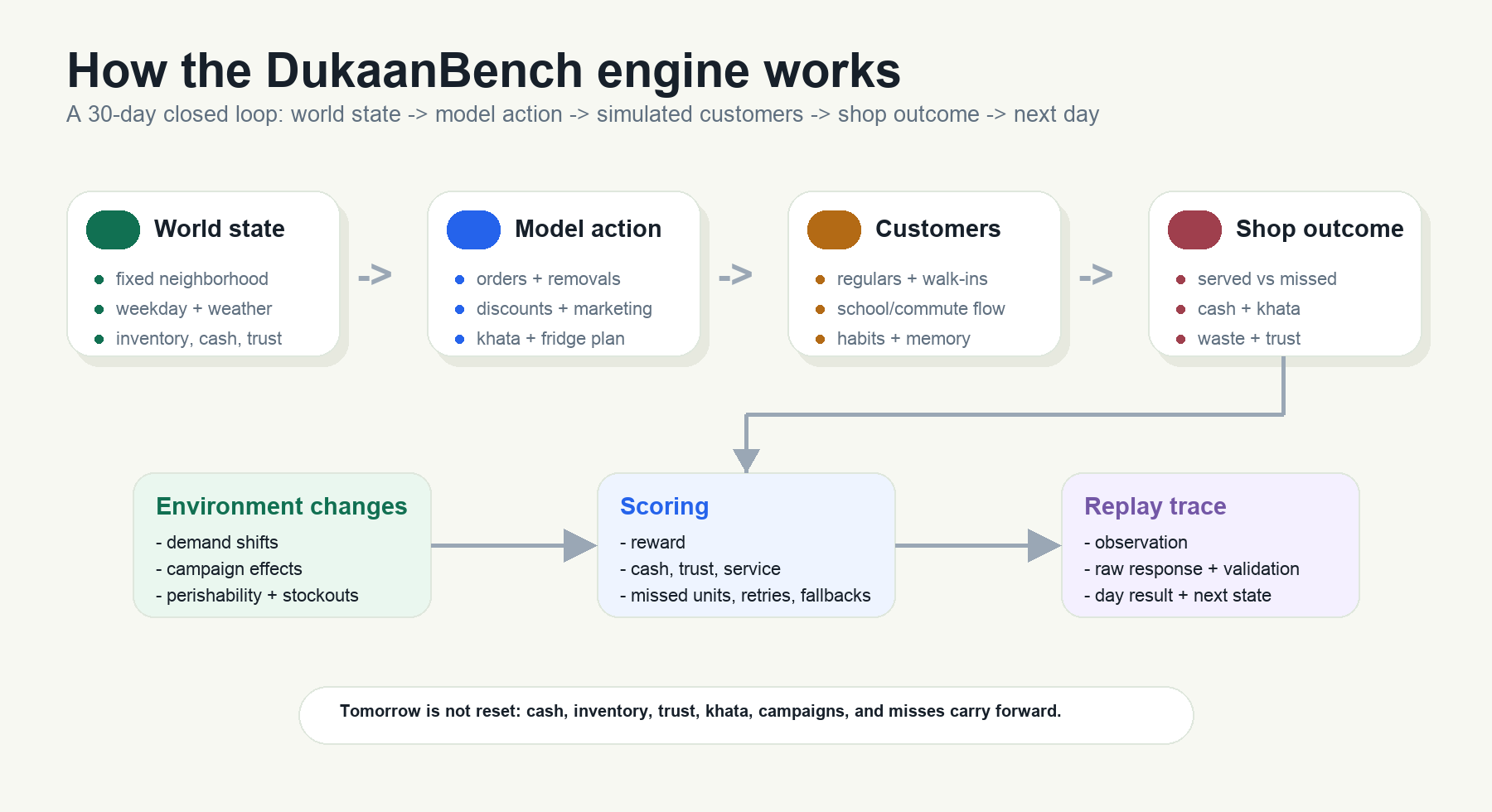
DukaanBench is a closed-loop shop simulator. It is not a static questionnaire. The model acts, the shop changes, and tomorrow's situation depends on what happened today.
The engine answers the basic Ws:
- Who is being tested? A model acting as the daily operator of Shree Shyam Bhandar.
- Where is it operating? A fixed fictional Indian neighborhood with apartments, a school, a bus stop, regulars, passers-by, and local demand rhythms.
- When does it act? Once per simulated day, before the shop opens.
- What can it control? Orders, removals, discounts, khata reminders, marketing actions, cash reserve, and fridge allocation.
- Why does the state change? Customer demand, stock availability, payment behavior, trust, weather, weekday patterns, perishability, marketing, and past misses all feed into the next day.
- How is it judged? The engine simulates the day, records served and missed demand, updates cash/inventory/trust, computes reward, and persists a replayable trace.
Customers are generated from context, not random noise
Each day produces a customer stream from several signals: weekday, weather, nearby school and commute flow, product habits, recent stockouts, active campaigns, price changes, and customer memory. Regulars behave differently from walk-ins. A trusted regular with khata history is not the same as a passing customer buying a cold drink.
That matters because the model must plan for demand before it sees the day unfold. If it under-orders milk on a school morning, the misses are visible. If it pushes a campaign without stock, the promoted demand becomes a liability. If it keeps essentials available across several days, trust compounds.
The environment changes because the shop has memory
The simulator carries state forward. Cash changes after purchases, sales, discounts, campaign costs, khata payments, and inventory orders. Inventory changes after customer purchases, waste, removals, and new stock. Trust changes after service quality, repeated misses, successful recovery, and customer-specific experience. Marketing changes demand only while campaigns are active, and those campaigns are scored by whether the generated demand was actually served.
So the benchmark is not asking, "Can the model produce one good plan?" It asks, "Can the model recover, compound good decisions, and avoid slow operational damage over 30 days?"
What Gets Scored
DukaanBench is not a pure profit game. A model can make money and still damage the shop.
The reward combines:
- Service: did customers get what they asked for?
- Inventory: did the model avoid stockouts, overstock, and waste?
- Money: did it make profit while protecting cash?
- Relationships: did trust rise or fall, especially for regulars?
- Marketing: did campaigns create demand the shop could actually serve?
- Operations: did the plan use the available tools coherently?
- Penalties: did invalid actions, fallbacks, waste, or severe stockouts appear?
This is why the leaderboard reports more than score. Final cash, trust, service rate, missed units, stockout incidents, retries, fallbacks, and latency all matter.
How to read the scoring factors
Reward is the headline outcome. It is the combined signal of profitable, reliable, customer-serving shopkeeping. GPT 5.5 leads with +2,294, but the reward only makes sense beside the operating metrics that created it.
Cash shows business health, not just survival. A model can hoard cash and starve shelves, or spend aggressively and create waste. GPT 5.5 ended with ₹50,184, Claude Opus 4.8 with ₹46,440, and Gemini 3.1 Pro with ₹45,869, which tells us the top models turned operations into liquidity rather than only avoiding mistakes.
Trust is the relationship ledger. It falls when customers repeatedly miss essentials or feel the shop is unreliable. This is where the leaderboard becomes interesting: Grok 4.3 still ended with positive reward, but trust fell to 29; Sarvam 105B and Qwen 3.7 Max fell to 6 and 10. That means they were not merely lower-scoring; they were damaging future demand.
Service rate measures how often the shop actually fulfilled demand. GPT 5.5 served 97.5%, Gemini 3.1 Pro served 96.5%, and Claude Opus 4.8 served 93.9%. Lower service rates point to operational misses: wrong inventory, late recovery, or demand created without supply.
Missed units explain the human cost behind service rate. GPT 5.5 missed 212 units; Qwen 3.7 Max missed 1,155. The score difference is not abstract. It is hundreds of customers leaving without what they asked for.
Retries and fallbacks measure whether the model can reliably speak the action language. Gemini 3.1 Pro needed 8 retries despite strong final performance. Sarvam 105B had 1 fallback. This matters because a shop agent must be dependable, not just clever when everything parses.
Latency is not part of shop intelligence, but it matters for deployability. Gemini 3.1 Flash Lite is interesting because it finished with high trust and no fallbacks while averaging only 2.4s, making it a strong fast baseline even though it did not win overall.
Current Leaderboard
The table below is from the live deployed Arena scoreboard on June 27, 2026.
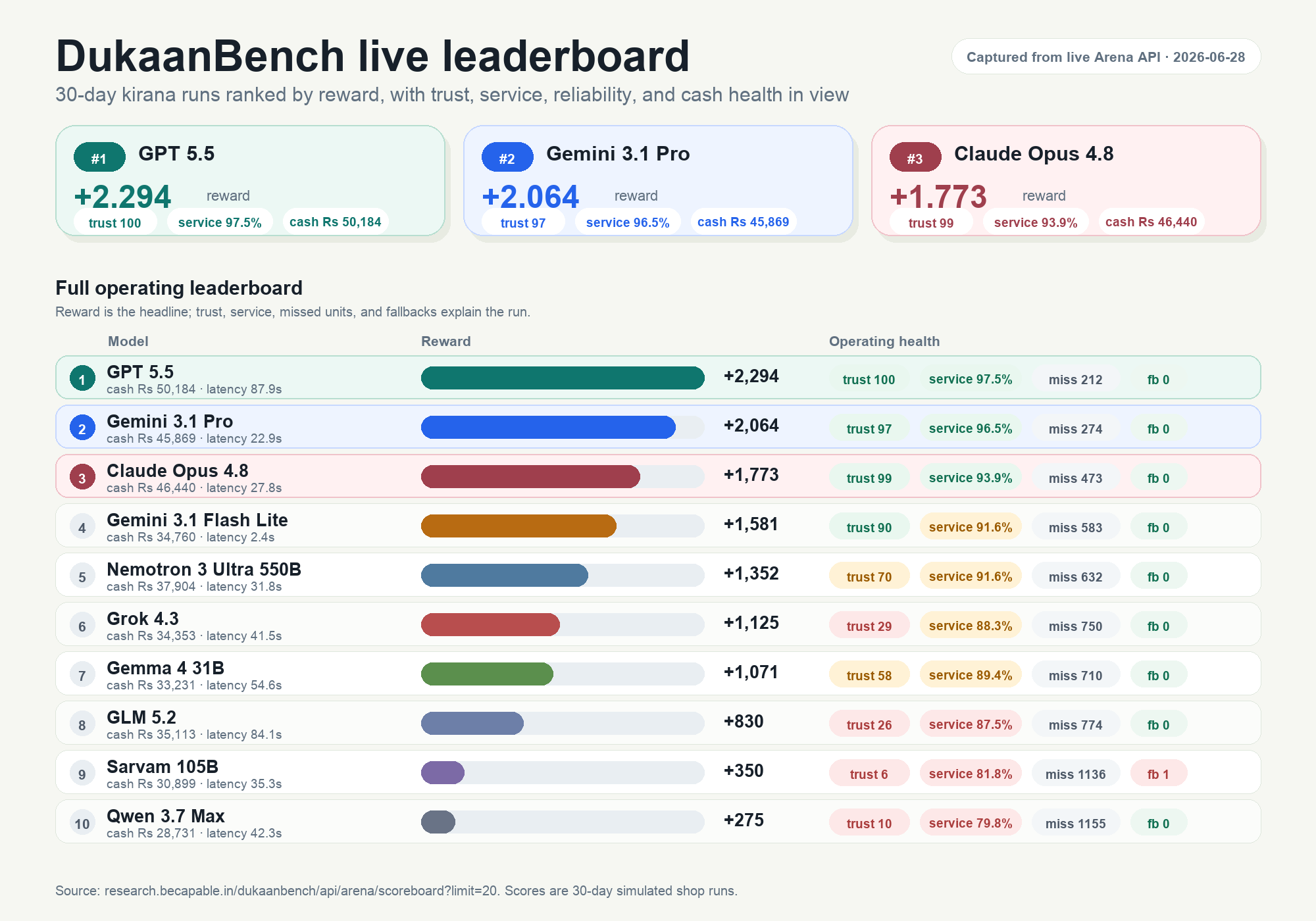
| Rank | Model | Reward | Final Cash | Trust | Service | Missed Units | Retries | Fallbacks | Avg Latency |
|---|---|---|---|---|---|---|---|---|---|
| 1 | openai/gpt-5.5 |
+2,294 | ₹50,184 | 100 | 97.5% | 212 | 1 | 0 | 87.9s |
| 2 | google/gemini-3.1-pro-preview |
+2,064 | ₹45,869 | 97 | 96.5% | 274 | 8 | 0 | 22.9s |
| 3 | anthropic/claude-opus-4.8 |
+1,773 | ₹46,440 | 99 | 93.9% | 473 | 2 | 0 | 27.8s |
| 4 | google/gemini-3.1-flash-lite |
+1,581 | ₹34,760 | 90 | 91.6% | 583 | 0 | 0 | 2.4s |
| 5 | nvidia/nemotron-3-ultra-550b-a55b |
+1,352 | ₹37,904 | 70 | 91.6% | 632 | 2 | 0 | 31.8s |
| 6 | x-ai/grok-4.3 |
+1,125 | ₹34,353 | 29 | 88.3% | 750 | 0 | 0 | 41.5s |
| 7 | google/gemma-4-31b-it |
+1,071 | ₹33,231 | 58 | 89.4% | 710 | 0 | 0 | 54.6s |
| 8 | sarvam-105b |
+350 | ₹30,899 | 6 | 81.8% | 1,136 | 0 | 1 | 35.3s |
| 9 | qwen/qwen3.7-max |
+275 | ₹28,731 | 10 | 79.8% | 1,155 | 0 | 0 | 42.3s |
The top result, GPT 5.5, is strong not simply because it scored highest. It ended with trust capped at 100, missed only 212 units across 30 days, and kept the shop profitable. Gemini 3.1 Pro is close on business health but needed more validation retries. Claude Opus 4.8 preserved trust well and showed strong marketing ROI. Gemini 3.1 Flash Lite is the best fast baseline so far: much lower latency, no fallbacks, high trust, and a strong enough score to be practically interesting.
The lower rows are also useful. Grok 4.3 had clean transport with zero retries and zero fallbacks, but trust fell to 29 because stockouts stayed too frequent. Sarvam 105B and Qwen 3.7 Max produced usable actions, but their service policies were too thin for this trust engine.
Metric Takeaways
The first leaderboard shows four distinct model behaviors:
- Balanced operators: GPT 5.5, Gemini 3.1 Pro, and Claude Opus 4.8 kept reward, cash, trust, and service strong at the same time. These models understood the benchmark as an operating problem, not only an optimization puzzle.
- Fast practical baseline: Gemini 3.1 Flash Lite did not top the board, but its
2.4slatency, zero fallbacks,90trust, and91.6%service rate make it useful for Part 2 comparisons. - Profit without enough trust: Grok 4.3 and Gemma 4 31B stayed profitable but trust fell, showing that cash-positive operation can still be strategically weak.
- Service-policy failures: Sarvam 105B and Qwen 3.7 Max served too little demand and ended with very low trust. Their traces are valuable because they show what failure looks like: not one dramatic crash, but many small misses.
The main lesson: the best shopkeeper model is not simply the one with the highest final cash or prettiest reasoning. It is the one that keeps essentials available, protects relationships, spends cash productively, emits valid actions, and recovers before yesterday's mistake becomes tomorrow's reputation.
How to Explore the Benchmark
For a first pass, start with the leaderboard, then move into the replay.
- Open the live DukaanBench page to see the current public leaderboard and project framing.
- Open the Arena replay and pick one model day where trust drops, missed units spike, or a campaign runs.
- Compare the model's rationale with the actual JSON action. If the rationale says one thing and the JSON omits it, the shop does not execute it.
- Watch the customer stream and day-end report. The useful question is not only "what score did it get?" but "what operational mistake created that score?"
What We Learned
What the top-three traces show
The top three models did not win by making one brilliant opening plan. They won by repeatedly translating yesterday's shop reality into tomorrow's executable JSON.
GPT 5.5: the balanced operator
GPT 5.5 finished first because it balanced four pressures at once: cash, trust, service rate, and action reliability. It ended with reward 2,294, cash ₹50,184, trust 100, service rate 97.5%, and only 212 missed units. Its saved provider audit shows 30/30 parseable response texts, no empty content, no fallbacks, and only one validation retry in the final scoreboard.
The trace reads like a shopkeeper adjusting to evidence. Day 1 stocked essentials and used a same-day chalkboard_offer only because Maggi, chips, and cold drinks were available. Day 2 raised milk, bread, eggs, snacks, and drinks after opening-day stockouts. By Day 10 it was comfortable combining chalkboard_offer, whatsapp_status, and school_combo with khata reminders. By Day 30 it skipped eggs because the shelf already had enough.
The important behavior is not "more ordering" or "more marketing." It is calibration. GPT 5.5 ordered heavily where demand was persistent, stayed careful with perishables, and usually promoted products it could actually serve. That is why it reached the best service rate among the top three without creating waste.
Learning from GPT 5.5: strong agents should not merely optimize a score. They should turn recent outcomes into tomorrow's policy: recover after stockouts, avoid blind restocking, spend on campaigns only when inventory can support demand, and keep the JSON action aligned with the rationale.
Gemini 3.1 Pro: the relationship-and-promotion operator
Gemini 3.1 Pro finished second with reward 2,064, cash ₹45,869, trust 97, service rate 96.5%, and 274 missed units. Its best behavior was commercial: it used chalkboard_offer on most days, used whatsapp_status to pull demand toward essentials, applied banana discounts frequently, and issued the most khata reminders among the top three.
That style explains why Gemini stayed close to GPT on business quality. It was willing to use the shop's relationship levers instead of treating the benchmark as a pure inventory puzzle. The frequent reminders helped protect collections and trust. The discounts and local campaigns helped convert stock into demand. In several hot or weekend contexts, it leaned into cold drinks, milk, bread, and higher footfall products rather than keeping a static basket.
The weakness was transport and contract reliability. Gemini needed 8 validation retries. It still had zero fallbacks, which means the backend validator could recover the action contract, but the retries matter: an agent that needs repair before execution is less dependable in a real operating loop.
Learning from Gemini 3.1 Pro: relationship intelligence can be a real advantage. The model behaved more like a merchant than a spreadsheet: remind the right credit customers, discount near-expiry or fast-moving items, and advertise locally. But the same model needs stricter structured-output discipline before we would trust it as a fully autonomous operator.
Claude Opus 4.8: the conservative planner
Claude Opus 4.8 finished third with reward 1,773, cash ₹46,440, trust 99, service rate 93.9%, and 473 missed units. Its provider audit has 32 saved request/response rows for 30 accepted days because of two validation retries, with no empty responses and no fallbacks.
Claude's trace is careful and legible. On Day 1 it stocked essentials but kept milk modest because of the two-day shelf life. Later actions leaned on chalkboard_offer, occasional school_combo, and targeted khata reminders. It preserved trust and avoided waste, which is valuable: many weaker runs failed because they chased cash or under-served essentials until trust collapsed.
The trade-off is visible in service rate. Claude's caution protected downside risk, but it missed more units than GPT and Gemini. In a kirana setting, under-ordering essentials is not neutral. Every missed milk packet, bread loaf, or cold drink can become a small relationship failure. Claude was operationally safe, but sometimes too slow to fully exploit demand signals.
Learning from Claude Opus 4.8: conservative planning is useful when perishability and trust matter, but the agent still needs a recovery mechanism. A good shopkeeper does not only avoid waste; they also notice repeated missed demand and raise the floor for essential stock before customers start going elsewhere.
The useful lesson is that "good reasoning" became visible only when it survived the action contract. The traces show models learning a rhythm: reorder essentials, protect perishables, promote only what can be served, remind khata customers without overdoing it, and correct after stockouts before trust erodes.
1. Pretty reasoning is not enough
Several models produced plausible business prose but failed to encode the matching action. A model might say it will run a school combo, but omit marketingActions. It might say it will remind khata customers, but emit an empty reminder list. It might describe ordering milk and bread, then leave those products out of orders.
The simulator executes JSON, not vibes.
This is why DukaanBench validates action/rationale consistency and records retries, fallbacks, and provider responses. Agent benchmarks should audit the contract between intent and action.
2. Trust changes the game
If the shop repeatedly misses essentials, the customer relationship suffers. A model that optimizes short-term cash while missing milk, bread, bananas, or cold drinks may still end with weak trust. That is visible in the leaderboard: some models made profit but ended with trust below 30.
For a kirana, customer trust is not a side metric. It is future revenue.
3. Marketing must be inventory-aware
Marketing can help only if the shop can serve the demand it creates. A WhatsApp offer or chalkboard campaign without stock creates promoted stockouts. DukaanBench scores marketing through served promoted units, missed promoted demand, campaign cost, gross margin, and ROI proxy.
That makes campaigns strategically honest: a good campaign is useful; a careless campaign is a liability.
4. Transport reliability is part of model quality
Some models are strategically promising but brittle under structured output. Others are less verbose but emit cleaner JSON. The Arena stores transport, response mode, reasoning mode, latency, usage, raw provider responses, validation errors, retries, and fallback flags so the final score can be interpreted properly.
For practical agents, "can think" and "can execute the action contract 30 days in a row" are different skills.
Why This Is Different From A Normal Eval
Most language-model evaluations compress performance into answer quality: did the model solve the prompt? DukaanBench evaluates sequential operation. The model's action changes the world, the changed world becomes tomorrow's context, and delayed consequences matter.
That makes the benchmark closer to a small business control problem than a quiz. A model has to balance cash, inventory, trust, demand creation, perishable waste, structured-output reliability, and recovery. The score is not a judgment of intelligence in general. It is a judgment of whether the model can operate this specific world without slowly breaking it.
Why the Arena Matters
The live Arena exists because a leaderboard alone hides too much.
In the replay, you can inspect the model's action, watch customers enter, see what they asked for, see what was served or missed, and inspect the reward breakdown for that day. If a model loses trust, the replay should make the reason visible.
That matters for learning. You can ask:
- Did the model under-order essentials?
- Did it overstock perishables?
- Did it run marketing without stock?
- Did it protect cash but starve the shelves?
- Did it recover after a bad day?
- Did it emit valid JSON or rely on fallbacks?
The goal is not only to rank models. The goal is to make model behavior legible.
Part 2: Training a Small Shopkeeper Model(Detailed blog soon)
Part 1 establishes the environment and the evaluation loop. Part 2 will use the traces.
Each day record has a useful supervised-learning shape:
previous day reality
-> upcoming day signals
-> model action
-> simulated customer outcomes
-> reward breakdown
-> next state
That makes the dataset useful for:
- supervised fine-tuning on strong action traces
- learning a compact JSON action policy
- comparing frontier-model advice against SLM execution
- reward-model experiments
- replay-based failure analysis
The working hypothesis is simple: a smaller model trained on this narrow environment may become a better daily shop operator than a general model that has to infer the game from a long prompt every time.
If that works, the result is not "AI replaces the shopkeeper." It is closer to a practical operating companion: a model that helps a shopkeeper reorder essentials, notice stockout patterns, time campaigns, manage khata gently, and explain trade-offs in plain language.
Limitations
DukaanBench is still a simulation. It currently uses a compact SKU set and a fixed fictional neighborhood. Supplier behavior, multilingual interaction, real POS ingestion, privacy controls, regional calendars, and real customer variation are not yet fully modeled.
That is intentional for Part 1. A benchmark should start controllable before it becomes richer.
Future versions should add:
- more SKUs and category-level shelves
- multiple fixed neighborhoods
- supplier delays and wholesale price shifts
- competitor and quick-commerce pressure
- local-language explanations
- anonymized trace datasets
- trained SLM baselines
- robustness tests under hidden shocks
Closing
DukaanBench asks a small but demanding question:
Can an AI run a neighborhood shop without losing the thing that matters most?
Part 1 gives the first serious answer. Yes, strong models can operate the shop for 30 days, make money, and preserve trust. But the scoreboard also shows that intelligence alone is not enough. A model can reason well and still miss the action contract. It can earn cash and still damage customer trust. It can run marketing and accidentally create stockouts. It can be strategically good but operationally unreliable.
That is exactly why the benchmark is useful. It turns "AI for business" from a broad claim into inspectable daily behavior: what the model saw, what it decided, what customers did, what changed in the shop, and what the decision cost.
Part 2 will use those traces to ask the next question: can a smaller, focused shopkeeper model learn the rhythm of this world well enough to beat a general model that starts fresh every morning?
Credits, Citation, and Status
DukaanBench is a Capabl Machines research project.
- Project: research.becapable.in/dukaanbench
- Arena: research.becapable.in/dukaanbench/arena-2
- Status: Part 1 research preview; Part 2 will focus on trace release, SLM training, and reproducible model comparisons.
- Suggested citation: Capabl Machines. "DukaanBench Part 1: Can AI Run an Indian Kirana for 30 Days?" 2026.