

Replace with clean markdown card
Browse files
README.md
CHANGED
|
@@ -15,13 +15,12 @@ tags:
|
|
| 15 |
|
| 16 |
# AttnSleep
|
| 17 |
|
| 18 |
-
Sleep Staging Architecture from Eldele et al (2021) .
|
| 19 |
|
| 20 |
-
> **Architecture-only repository.**
|
| 21 |
> `braindecode.models.AttnSleep` class. **No pretrained weights are
|
| 22 |
-
> distributed here**
|
| 23 |
-
> data
|
| 24 |
-
> separately.
|
| 25 |
|
| 26 |
## Quick start
|
| 27 |
|
|
@@ -40,158 +39,48 @@ model = AttnSleep(
|
|
| 40 |
)
|
| 41 |
```
|
| 42 |
|
| 43 |
-
The signal-shape arguments above are
|
| 44 |
-
|
| 45 |
|
| 46 |
## Documentation
|
| 47 |
-
|
| 48 |
-
-
|
| 49 |
-
<https://braindecode.org/stable/generated/braindecode.models.AttnSleep.html>
|
| 50 |
-
- Interactive browser with live instantiation:
|
| 51 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 52 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/attn_sleep.py#L18>
|
| 53 |
|
| 54 |
-
## Architecture description
|
| 55 |
-
|
| 56 |
-
The block below is the rendered class docstring (parameters,
|
| 57 |
-
references, architecture figure where available).
|
| 58 |
-
|
| 59 |
-
<div class='bd-doc'><main>
|
| 60 |
-
<p>Sleep Staging Architecture from Eldele et al (2021) [Eldele2021]_.</p>
|
| 61 |
-
<span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#5cb85c;color:white;font-size:11px;font-weight:600;margin-right:4px;">Convolution</span><span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#56B4E9;color:white;font-size:11px;font-weight:600;margin-right:4px;">Attention/Transformer</span>
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
.. figure:: https://raw.githubusercontent.com/emadeldeen24/AttnSleep/refs/heads/main/imgs/AttnSleep.png
|
| 66 |
-
:align: center
|
| 67 |
-
:alt: AttnSleep Architecture
|
| 68 |
-
|
| 69 |
-
Attention based Neural Net for sleep staging as described in [Eldele2021]_.
|
| 70 |
-
The code for the paper and this model is also available at [1]_.
|
| 71 |
-
Takes single channel EEG as input.
|
| 72 |
-
Feature extraction module based on multi-resolution convolutional neural network (MRCNN)
|
| 73 |
-
and adaptive feature recalibration (AFR).
|
| 74 |
-
The second module is the temporal context encoder (TCE) that leverages a multi-head attention
|
| 75 |
-
mechanism to capture the temporal dependencies among the extracted features.
|
| 76 |
-
|
| 77 |
-
Warning - This model was designed for signals of 30 seconds at 100Hz or 125Hz (in which case
|
| 78 |
-
the reference architecture from [1]_ which was validated on SHHS dataset [2]_ will be used)
|
| 79 |
-
to use any other input is likely to make the model perform in unintended ways.
|
| 80 |
-
|
| 81 |
-
Parameters
|
| 82 |
-
----------
|
| 83 |
-
n_tce : int
|
| 84 |
-
Number of TCE clones.
|
| 85 |
-
d_model : int
|
| 86 |
-
Input dimension for the TCE.
|
| 87 |
-
Also the input dimension of the first FC layer in the feed forward
|
| 88 |
-
and the output of the second FC layer in the same.
|
| 89 |
-
Increase for higher sampling rate/signal length.
|
| 90 |
-
It should be divisible by n_attn_heads
|
| 91 |
-
d_ff : int
|
| 92 |
-
Output dimension of the first FC layer in the feed forward and the
|
| 93 |
-
input dimension of the second FC layer in the same.
|
| 94 |
-
n_attn_heads : int
|
| 95 |
-
Number of attention heads. It should be a factor of d_model
|
| 96 |
-
drop_prob : float
|
| 97 |
-
Dropout rate in the PositionWiseFeedforward layer and the TCE layers.
|
| 98 |
-
after_reduced_cnn_size : int
|
| 99 |
-
Number of output channels produced by the convolution in the AFR module.
|
| 100 |
-
return_feats : bool
|
| 101 |
-
If True, return the features, i.e. the output of the feature extractor
|
| 102 |
-
(before the final linear layer). If False, pass the features through
|
| 103 |
-
the final linear layer.
|
| 104 |
-
n_classes : int
|
| 105 |
-
Alias for `n_outputs`.
|
| 106 |
-
input_size_s : float
|
| 107 |
-
Alias for `input_window_seconds`.
|
| 108 |
-
activation : nn.Module, default=nn.ReLU
|
| 109 |
-
Activation function class to apply. Should be a PyTorch activation
|
| 110 |
-
module class like ``nn.ReLU`` or ``nn.ELU``. Default is ``nn.ReLU``.
|
| 111 |
-
activation_mrcnn : nn.Module, default=nn.ReLU
|
| 112 |
-
Activation function class to apply in the Mask R-CNN layer.
|
| 113 |
-
Should be a PyTorch activation module class like ``nn.ReLU`` or
|
| 114 |
-
``nn.GELU``. Default is ``nn.GELU``.
|
| 115 |
-
|
| 116 |
-
References
|
| 117 |
-
----------
|
| 118 |
-
.. [Eldele2021] E. Eldele et al., "An Attention-Based Deep Learning Approach for Sleep Stage
|
| 119 |
-
Classification With Single-Channel EEG," in IEEE Transactions on Neural Systems and
|
| 120 |
-
Rehabilitation Engineering, vol. 29, pp. 809-818, 2021, doi: 10.1109/TNSRE.2021.3076234.
|
| 121 |
-
|
| 122 |
-
.. [1] https://github.com/emadeldeen24/AttnSleep
|
| 123 |
-
|
| 124 |
-
.. [2] https://sleepdata.org/datasets/shhs
|
| 125 |
-
|
| 126 |
-
.. rubric:: Hugging Face Hub integration
|
| 127 |
|
| 128 |
-
|
| 129 |
-
automatically gain the ability to be pushed to and loaded from the
|
| 130 |
-
Hugging Face Hub. Install with::
|
| 131 |
|
| 132 |
-
|
| 133 |
|
| 134 |
-
**Pushing a model to the Hub:**
|
| 135 |
|
| 136 |
-
|
| 137 |
-
from braindecode.models import AttnSleep
|
| 138 |
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 142 |
|
| 143 |
-
# Push to the Hub
|
| 144 |
-
model.push_to_hub(
|
| 145 |
-
repo_id="username/my-attnsleep-model",
|
| 146 |
-
commit_message="Initial model upload",
|
| 147 |
-
)
|
| 148 |
|
| 149 |
-
|
| 150 |
|
| 151 |
-
..
|
| 152 |
-
|
|
|
|
| 153 |
|
| 154 |
-
# Load pretrained model
|
| 155 |
-
model = AttnSleep.from_pretrained("username/my-attnsleep-model")
|
| 156 |
-
|
| 157 |
-
# Load with a different number of outputs (head is rebuilt automatically)
|
| 158 |
-
model = AttnSleep.from_pretrained("username/my-attnsleep-model", n_outputs=4)
|
| 159 |
-
|
| 160 |
-
**Extracting features and replacing the head:**
|
| 161 |
-
|
| 162 |
-
.. code::
|
| 163 |
-
import torch
|
| 164 |
-
|
| 165 |
-
x = torch.randn(1, model.n_chans, model.n_times)
|
| 166 |
-
# Extract encoder features (consistent dict across all models)
|
| 167 |
-
out = model(x, return_features=True)
|
| 168 |
-
features = out["features"]
|
| 169 |
-
|
| 170 |
-
# Replace the classification head
|
| 171 |
-
model.reset_head(n_outputs=10)
|
| 172 |
-
|
| 173 |
-
**Saving and restoring full configuration:**
|
| 174 |
-
|
| 175 |
-
.. code::
|
| 176 |
-
import json
|
| 177 |
-
|
| 178 |
-
config = model.get_config() # all __init__ params
|
| 179 |
-
with open("config.json", "w") as f:
|
| 180 |
-
json.dump(config, f)
|
| 181 |
-
|
| 182 |
-
model2 = AttnSleep.from_config(config) # reconstruct (no weights)
|
| 183 |
-
|
| 184 |
-
All model parameters (both EEG-specific and model-specific such as
|
| 185 |
-
dropout rates, activation functions, number of filters) are automatically
|
| 186 |
-
saved to the Hub and restored when loading.
|
| 187 |
-
|
| 188 |
-
See :ref:`load-pretrained-models` for a complete tutorial.</main>
|
| 189 |
-
</div>
|
| 190 |
|
| 191 |
## Citation
|
| 192 |
|
| 193 |
-
|
| 194 |
-
*References* section above) and braindecode:
|
| 195 |
|
| 196 |
```bibtex
|
| 197 |
@article{aristimunha2025braindecode,
|
|
|
|
| 15 |
|
| 16 |
# AttnSleep
|
| 17 |
|
| 18 |
+
Sleep Staging Architecture from Eldele et al (2021) [Eldele2021].
|
| 19 |
|
| 20 |
+
> **Architecture-only repository.** Documents the
|
| 21 |
> `braindecode.models.AttnSleep` class. **No pretrained weights are
|
| 22 |
+
> distributed here.** Instantiate the model and train it on your own
|
| 23 |
+
> data.
|
|
|
|
| 24 |
|
| 25 |
## Quick start
|
| 26 |
|
|
|
|
| 39 |
)
|
| 40 |
```
|
| 41 |
|
| 42 |
+
The signal-shape arguments above are illustrative defaults — adjust to
|
| 43 |
+
match your recording.
|
| 44 |
|
| 45 |
## Documentation
|
| 46 |
+
- Full API reference: <https://braindecode.org/stable/generated/braindecode.models.AttnSleep.html>
|
| 47 |
+
- Interactive browser (live instantiation, parameter counts):
|
|
|
|
|
|
|
| 48 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 49 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/attn_sleep.py#L18>
|
| 50 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 51 |
|
| 52 |
+
## Architecture
|
|
|
|
|
|
|
| 53 |
|
| 54 |
+
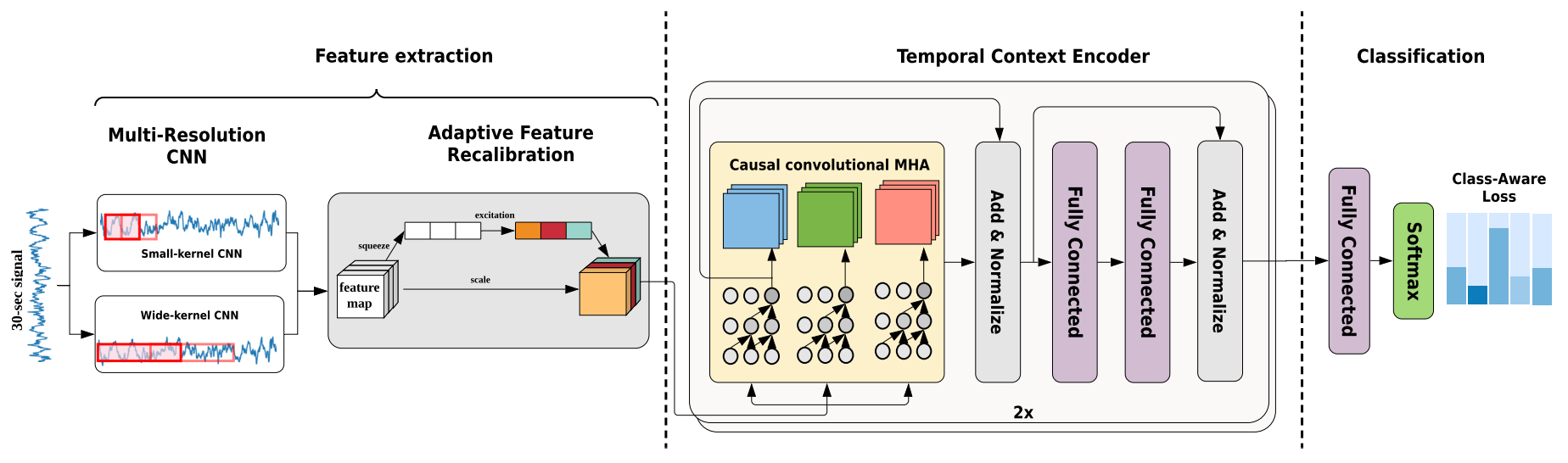
|
| 55 |
|
|
|
|
| 56 |
|
| 57 |
+
## Parameters
|
|
|
|
| 58 |
|
| 59 |
+
| Parameter | Type | Description |
|
| 60 |
+
|---|---|---|
|
| 61 |
+
| `n_tce` | int | Number of TCE clones. |
|
| 62 |
+
| `d_model` | int | Input dimension for the TCE. Also the input dimension of the first FC layer in the feed forward and the output of the second FC layer in the same. Increase for higher sampling rate/signal length. It should be divisible by n_attn_heads |
|
| 63 |
+
| `d_ff` | int | Output dimension of the first FC layer in the feed forward and the input dimension of the second FC layer in the same. |
|
| 64 |
+
| `n_attn_heads` | int | Number of attention heads. It should be a factor of d_model |
|
| 65 |
+
| `drop_prob` | float | Dropout rate in the PositionWiseFeedforward layer and the TCE layers. |
|
| 66 |
+
| `after_reduced_cnn_size` | int | Number of output channels produced by the convolution in the AFR module. |
|
| 67 |
+
| `return_feats` | bool | If True, return the features, i.e. the output of the feature extractor (before the final linear layer). If False, pass the features through the final linear layer. |
|
| 68 |
+
| `n_classes` | int | Alias for `n_outputs`. |
|
| 69 |
+
| `input_size_s` | float | Alias for `input_window_seconds`. |
|
| 70 |
+
| `activation` | nn.Module, default=nn.ReLU | Activation function class to apply. Should be a PyTorch activation module class like `nn.ReLU` or `nn.ELU`. Default is `nn.ReLU`. |
|
| 71 |
+
| `activation_mrcnn` | nn.Module, default=nn.ReLU | Activation function class to apply in the Mask R-CNN layer. Should be a PyTorch activation module class like `nn.ReLU` or `nn.GELU`. Default is `nn.GELU`. |
|
| 72 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 73 |
|
| 74 |
+
## References
|
| 75 |
|
| 76 |
+
1. E. Eldele et al., "An Attention-Based Deep Learning Approach for Sleep Stage Classification With Single-Channel EEG," in IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 29, pp. 809-818, 2021, doi: 10.1109/TNSRE.2021.3076234.
|
| 77 |
+
2. https://github.com/emadeldeen24/AttnSleep
|
| 78 |
+
3. https://sleepdata.org/datasets/shhs
|
| 79 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 80 |
|
| 81 |
## Citation
|
| 82 |
|
| 83 |
+
Cite the original architecture paper (see *References* above) and braindecode:
|
|
|
|
| 84 |
|
| 85 |
```bibtex
|
| 86 |
@article{aristimunha2025braindecode,
|