

Replace with clean markdown card
Browse files
README.md
CHANGED
|
@@ -14,13 +14,12 @@ tags:
|
|
| 14 |
|
| 15 |
# REVE
|
| 16 |
|
| 17 |
-
**R**\ epresentation for **E**\ EG with **V**\ ersatile **E**\ mbeddings (REVE) from El Ouahidi et al. (2025) .
|
| 18 |
|
| 19 |
-
> **Architecture-only repository.**
|
| 20 |
> `braindecode.models.REVE` class. **No pretrained weights are
|
| 21 |
-
> distributed here**
|
| 22 |
-
> data
|
| 23 |
-
> separately.
|
| 24 |
|
| 25 |
## Quick start
|
| 26 |
|
|
@@ -39,298 +38,46 @@ model = REVE(
|
|
| 39 |
)
|
| 40 |
```
|
| 41 |
|
| 42 |
-
The signal-shape arguments above are
|
| 43 |
-
|
| 44 |
|
| 45 |
## Documentation
|
| 46 |
-
|
| 47 |
-
-
|
| 48 |
-
<https://braindecode.org/stable/generated/braindecode.models.REVE.html>
|
| 49 |
-
- Interactive browser with live instantiation:
|
| 50 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 51 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/reve.py#L35>
|
| 52 |
|
| 53 |
-
## Architecture description
|
| 54 |
|
| 55 |
-
|
| 56 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 57 |
|
| 58 |
-
<div class='bd-doc'><main>
|
| 59 |
-
<p><strong>R</strong>epresentation for <strong>E</strong>EG with <strong>V</strong>ersatile <strong>E</strong>mbeddings (REVE) from El Ouahidi et al. (2025) <a class="citation-reference" href="#reve" id="citation-reference-1" role="doc-biblioref">[reve]</a>.</p>
|
| 60 |
-
<span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#d9534f;color:white;font-size:11px;font-weight:600;margin-right:4px;">Foundation Model</span><span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#56B4E9;color:white;font-size:11px;font-weight:600;margin-right:4px;">Attention/Transformer</span><figure class="align-center">
|
| 61 |
-
<img alt="REVE Training pipeline overview" src="https://brain-bzh.github.io/reve/static/images/architecture.png" style="width: 1000px;" />
|
| 62 |
-
</figure>
|
| 63 |
-
<p>Foundation models have transformed machine learning by reducing reliance on
|
| 64 |
-
task-specific data and induced biases through large-scale pretraining. While
|
| 65 |
-
successful in language and vision, their adoption in EEG has lagged due to the
|
| 66 |
-
heterogeneity of public datasets, which are collected under varying protocols,
|
| 67 |
-
devices, and electrode configurations. Existing EEG foundation models struggle
|
| 68 |
-
to generalize across these variations, often restricting pretraining to a single
|
| 69 |
-
setup and resulting in suboptimal performance, particularly under linear probing.</p>
|
| 70 |
-
<p>REVE is a pretrained model explicitly designed to generalize across diverse EEG signals. It introduces
|
| 71 |
-
a <strong>4D positional encoding</strong> scheme that enables processing signals of arbitrary length and electrode
|
| 72 |
-
arrangement. Using a masked autoencoding objective, REVE was pretrained on over <strong>60,000 hours</strong> of EEG
|
| 73 |
-
data from <strong>92 datasets</strong> spanning <strong>25,000 subjects</strong>, the largest EEG pretraining effort to date.</p>
|
| 74 |
-
<p><strong>Channels Invariant Positional Encoding</strong></p>
|
| 75 |
-
<p>Prior EEG foundation models (:class:`~braindecode.models.Labram`, :class:`~braindecode.models.BIOT`) rely on
|
| 76 |
-
fixed positional embeddings, making direct transfer to unseen electrode layouts infeasible. CBraMod uses
|
| 77 |
-
convolution-based positional encoding that requires fine-tuning when adapting to new configurations.
|
| 78 |
-
As noted in the CBraMod paper: <em>"fixing the pre-trained parameters during training on downstream
|
| 79 |
-
datasets will lead to a very large performance decline."</em></p>
|
| 80 |
-
<p>REVE's 4D positional encoding jointly encodes spatial <math xmlns="http://www.w3.org/1998/Math/MathML">
|
| 81 |
-
<mo stretchy="false">(</mo>
|
| 82 |
-
<mi>x</mi>
|
| 83 |
-
<mo>,</mo>
|
| 84 |
-
<mi>y</mi>
|
| 85 |
-
<mo>,</mo>
|
| 86 |
-
<mi>z</mi>
|
| 87 |
-
<mo stretchy="false">)</mo>
|
| 88 |
-
</math> and temporal <math xmlns="http://www.w3.org/1998/Math/MathML">
|
| 89 |
-
<mo stretchy="false">(</mo>
|
| 90 |
-
<mi>t</mi>
|
| 91 |
-
<mo stretchy="false">)</mo>
|
| 92 |
-
</math> positions
|
| 93 |
-
using Fourier embeddings, enabling true cross-configuration transfer without retraining. The fourier embedding
|
| 94 |
-
have inspiration on brainmodule <a class="citation-reference" href="#brainmodule" id="citation-reference-2" role="doc-biblioref">[brainmodule]</a>, generalized to 4D for EEG with the channel spatial coordinates
|
| 95 |
-
and temporal patch index.</p>
|
| 96 |
-
<p><strong>Linear Probing Performance</strong></p>
|
| 97 |
-
<p>A key advantage of REVE is producing useful latent representation without heavy fine-tuning. Under linear
|
| 98 |
-
probing (frozen encoder), REVE achieves state-of-the-art results on downstream EEG tasks.
|
| 99 |
-
This enables practical deployment in low-data scenarios where extensive fine-tuning is not feasible.</p>
|
| 100 |
-
<p><strong>Architecture</strong></p>
|
| 101 |
-
<p>The model adopts modern Transformer components validated through ablation studies:</p>
|
| 102 |
-
<ul class="simple">
|
| 103 |
-
<li><p><strong>Normalization</strong>: RMSNorm outperforms LayerNorm;</p></li>
|
| 104 |
-
<li><p><strong>Activation</strong>: GEGLU outperforms GELU;</p></li>
|
| 105 |
-
<li><p><strong>Attention</strong>: Flash Attention via PyTorch's SDPA;</p></li>
|
| 106 |
-
<li><p><strong>Masking ratio</strong>: 55% optimal for spatio-temporal block masking</p></li>
|
| 107 |
-
</ul>
|
| 108 |
-
<p>These choices align with best practices from large language models and were empirically validated
|
| 109 |
-
on EEG data.</p>
|
| 110 |
-
<p><strong>Secondary Loss</strong></p>
|
| 111 |
-
<p>A secondary reconstruction objective using attention pooling across layers prevents over-specialization
|
| 112 |
-
in the final layer. This pooling acts as an information bottleneck, forcing the model to distill key
|
| 113 |
-
information from the entire sequence. Ablations show this loss is crucial for linear probing quality:
|
| 114 |
-
removing it drops average performance in 10% under the frozen evaluation.</p>
|
| 115 |
-
<p><strong>Macro Components</strong></p>
|
| 116 |
-
<ul>
|
| 117 |
-
<li><p><span class="docutils literal">REVE.to_patch_embedding</span> <strong>Patch Tokenization</strong></p>
|
| 118 |
-
<p>The EEG signal is split into overlapping patches along the time dimension, generating
|
| 119 |
-
<math xmlns="http://www.w3.org/1998/Math/MathML">
|
| 120 |
-
<mi>p</mi>
|
| 121 |
-
<mo>=</mo>
|
| 122 |
-
<mrow>
|
| 123 |
-
<mo>⌈</mo>
|
| 124 |
-
<mfrac>
|
| 125 |
-
<mrow>
|
| 126 |
-
<mi>T</mi>
|
| 127 |
-
<mo>−</mo>
|
| 128 |
-
<mi>w</mi>
|
| 129 |
-
</mrow>
|
| 130 |
-
<mrow>
|
| 131 |
-
<mi>w</mi>
|
| 132 |
-
<mo>−</mo>
|
| 133 |
-
<mi>o</mi>
|
| 134 |
-
</mrow>
|
| 135 |
-
</mfrac>
|
| 136 |
-
<mo>⌉</mo>
|
| 137 |
-
</mrow>
|
| 138 |
-
<mo>+</mo>
|
| 139 |
-
<mn>𝟏</mn>
|
| 140 |
-
<mo stretchy="false">[</mo>
|
| 141 |
-
<mo stretchy="false">(</mo>
|
| 142 |
-
<mi>T</mi>
|
| 143 |
-
<mo>−</mo>
|
| 144 |
-
<mi>w</mi>
|
| 145 |
-
<mo stretchy="false">)</mo>
|
| 146 |
-
<mo lspace="0.278em" rspace="0.278em">mod</mo>
|
| 147 |
-
<mo stretchy="false">(</mo>
|
| 148 |
-
<mi>w</mi>
|
| 149 |
-
<mo>−</mo>
|
| 150 |
-
<mi>o</mi>
|
| 151 |
-
<mo stretchy="false">)</mo>
|
| 152 |
-
<mo>≠</mo>
|
| 153 |
-
<mn>0</mn>
|
| 154 |
-
<mo stretchy="false">]</mo>
|
| 155 |
-
</math>
|
| 156 |
-
patches of size <math xmlns="http://www.w3.org/1998/Math/MathML">
|
| 157 |
-
<mi>w</mi>
|
| 158 |
-
</math> with overlap <math xmlns="http://www.w3.org/1998/Math/MathML">
|
| 159 |
-
<mi>o</mi>
|
| 160 |
-
</math>, where <math xmlns="http://www.w3.org/1998/Math/MathML">
|
| 161 |
-
<mi>T</mi>
|
| 162 |
-
</math> is the signal length.
|
| 163 |
-
Each patch is linearly projected to the embedding dimension.</p>
|
| 164 |
-
</li>
|
| 165 |
-
<li><p><span class="docutils literal">REVE.fourier4d</span> + <span class="docutils literal">REVE.mlp4d</span> <strong>4D Positional Embedding (4DPE)</strong></p>
|
| 166 |
-
<p>The 4DPE encodes each token's 4D coordinates <math xmlns="http://www.w3.org/1998/Math/MathML">
|
| 167 |
-
<mo stretchy="false">(</mo>
|
| 168 |
-
<mi>x</mi>
|
| 169 |
-
<mo>,</mo>
|
| 170 |
-
<mi>y</mi>
|
| 171 |
-
<mo>,</mo>
|
| 172 |
-
<mi>z</mi>
|
| 173 |
-
<mo>,</mo>
|
| 174 |
-
<mi>t</mi>
|
| 175 |
-
<mo stretchy="false">)</mo>
|
| 176 |
-
</math> where <math xmlns="http://www.w3.org/1998/Math/MathML">
|
| 177 |
-
<mo stretchy="false">(</mo>
|
| 178 |
-
<mi>x</mi>
|
| 179 |
-
<mo>,</mo>
|
| 180 |
-
<mi>y</mi>
|
| 181 |
-
<mo>,</mo>
|
| 182 |
-
<mi>z</mi>
|
| 183 |
-
<mo stretchy="false">)</mo>
|
| 184 |
-
</math> are the
|
| 185 |
-
3D spatial coordinates from a standardized electrode position bank, and <math xmlns="http://www.w3.org/1998/Math/MathML">
|
| 186 |
-
<mi>t</mi>
|
| 187 |
-
</math> is the temporal
|
| 188 |
-
patch index. The encoding combines:</p>
|
| 189 |
-
<ol class="arabic simple">
|
| 190 |
-
<li><p><strong>Fourier embedding</strong>: Sinusoidal encoding across multiple frequencies for smooth interpolation
|
| 191 |
-
to unseen positions</p></li>
|
| 192 |
-
<li><p><strong>MLP embedding</strong>: :class:`~torch.nn.Linear` (4 → embed_dim) → :class:`~torch.nn.GELU` → :class:`~torch.nn.LayerNorm` for learnable refinement</p></li>
|
| 193 |
-
</ol>
|
| 194 |
-
<p>Both components are summed and normalized. The 4DPE adds negligible computational overhead,
|
| 195 |
-
scaling linearly with the number of tokens.</p>
|
| 196 |
-
</li>
|
| 197 |
-
<li><p><span class="docutils literal">REVE.transformer</span> <strong>Transformer Encoder</strong></p>
|
| 198 |
-
<p>Pre-LayerNorm Transformer with multi-head self-attention (:class:`~torch.nn.RMSNorm`), feed-forward networks (GEGLU
|
| 199 |
-
activation), and residual connections. Default configuration: 22 layers, 8 heads, 512 embedding
|
| 200 |
-
dimension (~72M parameters).</p>
|
| 201 |
-
</li>
|
| 202 |
-
<li><p><span class="docutils literal">REVE.final_layer</span> <strong>Classification Head</strong></p>
|
| 203 |
-
<p>Two modes (controlled by the <span class="docutils literal">attention_pooling</span> parameter):</p>
|
| 204 |
-
<ul class="simple">
|
| 205 |
-
<li><p>When <span class="docutils literal">attention_pooling</span> is disabled (e.g., <span class="docutils literal">None</span> or <span class="docutils literal">False</span>): flatten all tokens
|
| 206 |
-
→ :class:`~torch.nn.LayerNorm` → :class:`~torch.nn.Linear`</p></li>
|
| 207 |
-
<li><p>When <span class="docutils literal">attention_pooling</span> is enabled: attention pooling with a learnable query token
|
| 208 |
-
attending to all encoder outputs</p></li>
|
| 209 |
-
</ul>
|
| 210 |
-
</li>
|
| 211 |
-
</ul>
|
| 212 |
-
<p><strong>Known Limitations</strong></p>
|
| 213 |
-
<ul class="simple">
|
| 214 |
-
<li><p><strong>Sparse electrode setups</strong>: Performance degrades with very few channels. On motor imagery,
|
| 215 |
-
accuracy drops from 0.824 (64 channels) to 0.660 (1 channel). For tasks requiring broad
|
| 216 |
-
spatial coverage (e.g., imagined speech), performance with <4 channels approaches chance level.</p></li>
|
| 217 |
-
<li><p><strong>Demographic bias</strong>: The pretraining corpus aggregates publicly available datasets, most
|
| 218 |
-
originating from North America and Europe, resulting in limited demographic diversity,
|
| 219 |
-
more details about the datasets used for pretraining can be found in the REVE paper <a class="citation-reference" href="#reve" id="citation-reference-3" role="doc-biblioref">[reve]</a>.</p></li>
|
| 220 |
-
</ul>
|
| 221 |
-
<p><strong>Pretrained Weights</strong></p>
|
| 222 |
-
<p>Weights are available on <a class="reference external" href="https://huggingface.co/collections/brain-bzh/reve">HuggingFace</a>,
|
| 223 |
-
but you must agree to the data usage terms before downloading:</p>
|
| 224 |
-
<ul class="simple">
|
| 225 |
-
<li><p><span class="docutils literal"><span class="pre">brain-bzh/reve-base</span></span>: 72M parameters, 512 embedding dim, 22 layers (~260 A100 GPU hours)</p></li>
|
| 226 |
-
<li><p><span class="docutils literal"><span class="pre">brain-bzh/reve-large</span></span>: ~400M parameters, 1250 embedding dim</p></li>
|
| 227 |
-
</ul>
|
| 228 |
-
<aside class="admonition important">
|
| 229 |
-
<p class="admonition-title">Important</p>
|
| 230 |
-
<p><strong>Pre-trained Weights Available (Registration Required)</strong></p>
|
| 231 |
-
<p>This model has pre-trained weights available on the Hugging Face Hub.
|
| 232 |
-
<strong>You must first register and agree to the data usage terms on the authors'
|
| 233 |
-
HuggingFace repository before you can access the weights.</strong>
|
| 234 |
-
<a class="reference external" href="https://huggingface.co/collections/brain-bzh/reve">Link here</a>.</p>
|
| 235 |
-
<p>You can load them using:</p>
|
| 236 |
-
<p>To push your own trained model to the Hub:</p>
|
| 237 |
-
<p>Requires installing <span class="docutils literal">braindecode[hug]</span> for Hub integration.</p>
|
| 238 |
-
</aside>
|
| 239 |
-
<p><strong>Usage</strong></p>
|
| 240 |
-
<aside class="admonition warning">
|
| 241 |
-
<p class="admonition-title">Warning</p>
|
| 242 |
-
<p>Input data must be sampled at <strong>200 Hz</strong> to match pretraining. The model applies
|
| 243 |
-
z-score normalization followed by clipping at 15 standard deviations internally
|
| 244 |
-
during pretraining-users should apply similar preprocessing.</p>
|
| 245 |
-
</aside>
|
| 246 |
-
<section id="parameters">
|
| 247 |
-
<h2>Parameters</h2>
|
| 248 |
-
<dl class="simple">
|
| 249 |
-
<dt>embed_dim<span class="classifier">int, default=512</span></dt>
|
| 250 |
-
<dd><p>Embedding dimension. Use 512 for REVE-Base, 1250 for REVE-Large.</p>
|
| 251 |
-
</dd>
|
| 252 |
-
<dt>depth<span class="classifier">int, default=22</span></dt>
|
| 253 |
-
<dd><p>Number of Transformer layers.</p>
|
| 254 |
-
</dd>
|
| 255 |
-
<dt>heads<span class="classifier">int, default=8</span></dt>
|
| 256 |
-
<dd><p>Number of attention heads.</p>
|
| 257 |
-
</dd>
|
| 258 |
-
<dt>head_dim<span class="classifier">int, default=64</span></dt>
|
| 259 |
-
<dd><p>Dimension per attention head.</p>
|
| 260 |
-
</dd>
|
| 261 |
-
<dt>mlp_dim_ratio<span class="classifier">float, default=2.66</span></dt>
|
| 262 |
-
<dd><p>FFN hidden dimension ratio: <span class="docutils literal">mlp_dim = embed_dim × mlp_dim_ratio</span>.</p>
|
| 263 |
-
</dd>
|
| 264 |
-
<dt>use_geglu<span class="classifier">bool, default=True</span></dt>
|
| 265 |
-
<dd><p>Use GEGLU activation (recommended) or standard GELU.</p>
|
| 266 |
-
</dd>
|
| 267 |
-
<dt>freqs<span class="classifier">int, default=4</span></dt>
|
| 268 |
-
<dd><p>Number of frequencies for Fourier positional embedding.</p>
|
| 269 |
-
</dd>
|
| 270 |
-
<dt>patch_size<span class="classifier">int, default=200</span></dt>
|
| 271 |
-
<dd><p>Temporal patch size in samples (200 samples = 1 second at 200 Hz).</p>
|
| 272 |
-
</dd>
|
| 273 |
-
<dt>patch_overlap<span class="classifier">int, default=20</span></dt>
|
| 274 |
-
<dd><p>Overlap between patches in samples.</p>
|
| 275 |
-
</dd>
|
| 276 |
-
<dt>attention_pooling<span class="classifier">bool, default=False</span></dt>
|
| 277 |
-
<dd><p>Pooling strategy for aggregating transformer outputs before classification.
|
| 278 |
-
If <span class="docutils literal">False</span> (default), all tokens are flattened into a single vector of size
|
| 279 |
-
<span class="docutils literal">(n_chans x n_patches x embed_dim)</span>, which is then passed through LayerNorm
|
| 280 |
-
and a linear classifier. If <span class="docutils literal">True</span>, uses attention-based pooling with a
|
| 281 |
-
learnable query token that attends to all encoder outputs, producing a single
|
| 282 |
-
embedding of size <span class="docutils literal">embed_dim</span>. Attention pooling is more parameter-efficient
|
| 283 |
-
for long sequences and variable-length inputs.</p>
|
| 284 |
-
</dd>
|
| 285 |
-
</dl>
|
| 286 |
-
</section>
|
| 287 |
-
<section id="references">
|
| 288 |
-
<h2>References</h2>
|
| 289 |
-
<div role="list" class="citation-list">
|
| 290 |
-
<div class="citation" id="reve" role="doc-biblioentry">
|
| 291 |
-
<span class="label"><span class="fn-bracket">[</span>reve<span class="fn-bracket">]</span></span>
|
| 292 |
-
<span class="backrefs">(<a role="doc-backlink" href="#citation-reference-1">1</a>,<a role="doc-backlink" href="#citation-reference-3">2</a>)</span>
|
| 293 |
-
<p>El Ouahidi, Y., Lys, J., Thölke, P., Farrugia, N., Pasdeloup, B.,
|
| 294 |
-
Gripon, V., Jerbi, K. & Lioi, G. (2025). REVE: A Foundation Model for EEG -
|
| 295 |
-
Adapting to Any Setup with Large-Scale Pretraining on 25,000 Subjects.
|
| 296 |
-
The Thirty-Ninth Annual Conference on Neural Information Processing Systems.
|
| 297 |
-
<a class="reference external" href="https://openreview.net/forum?id=ZeFMtRBy4Z">https://openreview.net/forum?id=ZeFMtRBy4Z</a></p>
|
| 298 |
-
</div>
|
| 299 |
-
<div class="citation" id="brainmodule" role="doc-biblioentry">
|
| 300 |
-
<span class="label"><span class="fn-bracket">[</span><a role="doc-backlink" href="#citation-reference-2">brainmodule</a><span class="fn-bracket">]</span></span>
|
| 301 |
-
<p>Défossez, A., Caucheteux, C., Rapin, J., Kabeli, O., & King, J. R.
|
| 302 |
-
(2023). Decoding speech perception from non-invasive brain recordings. Nature
|
| 303 |
-
Machine Intelligence, 5(10), 1097-1107.</p>
|
| 304 |
-
</div>
|
| 305 |
-
</div>
|
| 306 |
-
</section>
|
| 307 |
-
<section id="notes">
|
| 308 |
-
<h2>Notes</h2>
|
| 309 |
-
<p>The position bank is downloaded from HuggingFace on first initialization, mapping
|
| 310 |
-
standard 10-20/10-10/10-05 electrode names to 3D coordinates. This enables the
|
| 311 |
-
4D positional encoding to generalize across electrode configurations without
|
| 312 |
-
requiring matched layouts between pretraining and downstream tasks.</p>
|
| 313 |
-
<p><strong>Hugging Face Hub integration</strong></p>
|
| 314 |
-
<p>When the optional <span class="docutils literal">huggingface_hub</span> package is installed, all models
|
| 315 |
-
automatically gain the ability to be pushed to and loaded from the
|
| 316 |
-
Hugging Face Hub. Install with:</p>
|
| 317 |
-
<pre class="literal-block">pip install braindecode[hub]</pre>
|
| 318 |
-
<p><strong>Pushing a model to the Hub:</strong></p>
|
| 319 |
-
<p><strong>Loading a model from the Hub:</strong></p>
|
| 320 |
-
<p><strong>Extracting features and replacing the head:</strong></p>
|
| 321 |
-
<p><strong>Saving and restoring full configuration:</strong></p>
|
| 322 |
-
<p>All model parameters (both EEG-specific and model-specific such as
|
| 323 |
-
dropout rates, activation functions, number of filters) are automatically
|
| 324 |
-
saved to the Hub and restored when loading.</p>
|
| 325 |
-
<p>See :ref:`load-pretrained-models` for a complete tutorial.</p>
|
| 326 |
-
</section>
|
| 327 |
-
</main>
|
| 328 |
-
</div>
|
| 329 |
|
| 330 |
## Citation
|
| 331 |
|
| 332 |
-
|
| 333 |
-
*References* section above) and braindecode:
|
| 334 |
|
| 335 |
```bibtex
|
| 336 |
@article{aristimunha2025braindecode,
|
|
|
|
| 14 |
|
| 15 |
# REVE
|
| 16 |
|
| 17 |
+
**R**\ epresentation for **E**\ EG with **V**\ ersatile **E**\ mbeddings (REVE) from El Ouahidi et al. (2025) [reve].
|
| 18 |
|
| 19 |
+
> **Architecture-only repository.** Documents the
|
| 20 |
> `braindecode.models.REVE` class. **No pretrained weights are
|
| 21 |
+
> distributed here.** Instantiate the model and train it on your own
|
| 22 |
+
> data.
|
|
|
|
| 23 |
|
| 24 |
## Quick start
|
| 25 |
|
|
|
|
| 38 |
)
|
| 39 |
```
|
| 40 |
|
| 41 |
+
The signal-shape arguments above are illustrative defaults — adjust to
|
| 42 |
+
match your recording.
|
| 43 |
|
| 44 |
## Documentation
|
| 45 |
+
- Full API reference: <https://braindecode.org/stable/generated/braindecode.models.REVE.html>
|
| 46 |
+
- Interactive browser (live instantiation, parameter counts):
|
|
|
|
|
|
|
| 47 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 48 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/reve.py#L35>
|
| 49 |
|
|
|
|
| 50 |
|
| 51 |
+
## Architecture
|
| 52 |
+
|
| 53 |
+
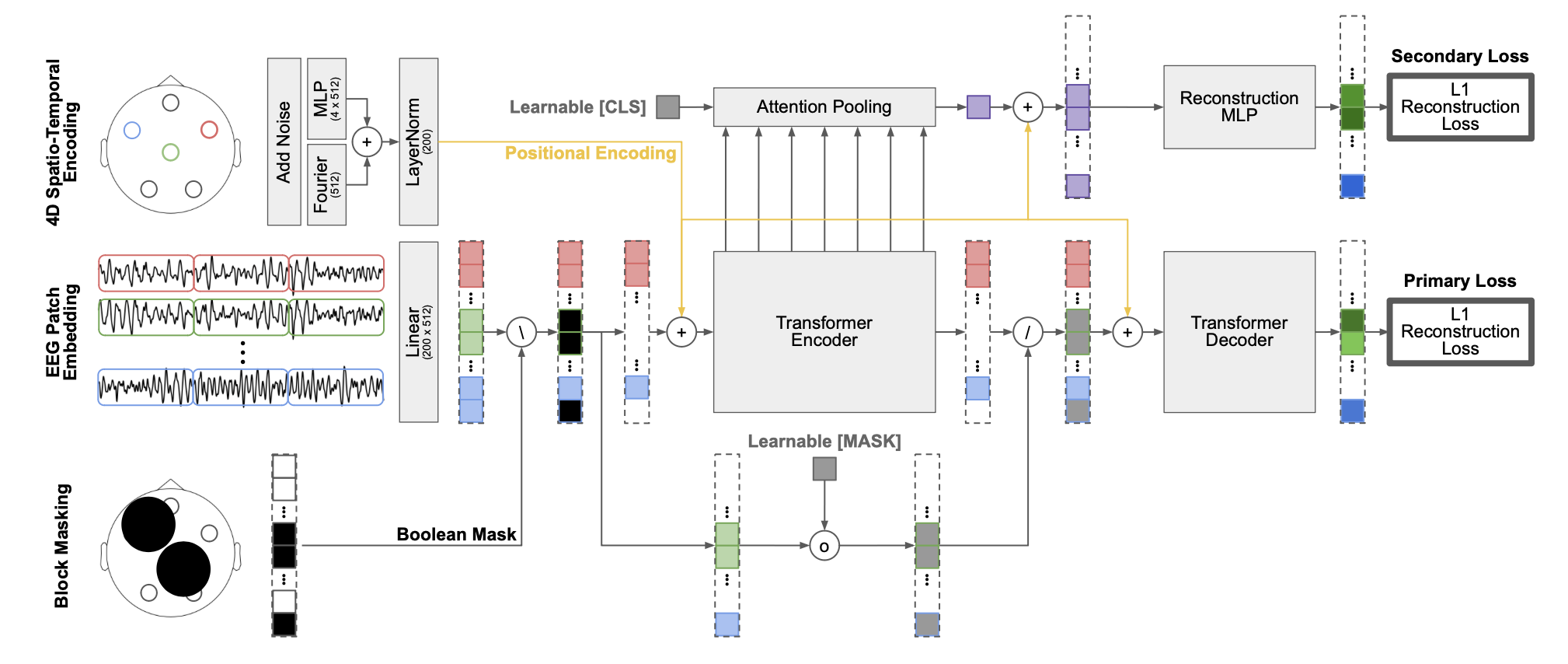
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
## Parameters
|
| 57 |
+
|
| 58 |
+
| Parameter | Type | Description |
|
| 59 |
+
|---|---|---|
|
| 60 |
+
| `embed_dim` | int, default=512 | Embedding dimension. Use 512 for REVE-Base, 1250 for REVE-Large. |
|
| 61 |
+
| `depth` | int, default=22 | Number of Transformer layers. |
|
| 62 |
+
| `heads` | int, default=8 | Number of attention heads. |
|
| 63 |
+
| `head_dim` | int, default=64 | Dimension per attention head. |
|
| 64 |
+
| `mlp_dim_ratio` | float, default=2.66 | FFN hidden dimension ratio: `mlp_dim = embed_dim × mlp_dim_ratio`. |
|
| 65 |
+
| `use_geglu` | bool, default=True | Use GEGLU activation (recommended) or standard GELU. |
|
| 66 |
+
| `freqs` | int, default=4 | Number of frequencies for Fourier positional embedding. |
|
| 67 |
+
| `patch_size` | int, default=200 | Temporal patch size in samples (200 samples = 1 second at 200 Hz). |
|
| 68 |
+
| `patch_overlap` | int, default=20 | Overlap between patches in samples. |
|
| 69 |
+
| `attention_pooling` | bool, default=False | Pooling strategy for aggregating transformer outputs before classification. If `False` (default), all tokens are flattened into a single vector of size `(n_chans x n_patches x embed_dim)`, which is then passed through LayerNorm and a linear classifier. If `True`, uses attention-based pooling with a learnable query token that attends to all encoder outputs, producing a single embedding of size `embed_dim`. Attention pooling is more parameter-efficient for long sequences and variable-length inputs. |
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
## References
|
| 73 |
+
|
| 74 |
+
1. El Ouahidi, Y., Lys, J., Thölke, P., Farrugia, N., Pasdeloup, B., Gripon, V., Jerbi, K. & Lioi, G. (2025). REVE: A Foundation Model for EEG - Adapting to Any Setup with Large-Scale Pretraining on 25,000 Subjects. The Thirty-Ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=ZeFMtRBy4Z
|
| 75 |
+
2. Défossez, A., Caucheteux, C., Rapin, J., Kabeli, O., & King, J. R. (2023). Decoding speech perception from non-invasive brain recordings. Nature Machine Intelligence, 5(10), 1097-1107.
|
| 76 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 77 |
|
| 78 |
## Citation
|
| 79 |
|
| 80 |
+
Cite the original architecture paper (see *References* above) and braindecode:
|
|
|
|
| 81 |
|
| 82 |
```bibtex
|
| 83 |
@article{aristimunha2025braindecode,
|