---
tags:
- 7b
- agentic-coding
- android
- apple-silicon
- attested
- bash
- c
- chain-of-custody
- chinese
- code
- code-completion
- code-generation
- code-infill
- compacted
- compensation-lora
- consumer-gpu
- cpp
- cryptographically-verified
- css
- distillation
- edge-inference
- efficient
- embedded
- english
- forge-alloy
- function-calling
- general
- general-purpose
- go
- head-pruning
- html
- iphone
- java
- javascript
- knowledge-distillation
- kotlin
- llama-cpp
- lm-studio
- local-inference
- lora
- macbook
- mlx
- mobile
- multilingual
- ollama
- on-device
- optimized
- php
- pruned
- python
- qwen
- qwen-coder
- qwen2
- qwen2.5
- qwen2.5-coder
- raspberry-pi
- reproducible
- ruby
- rust
- sql
- swift
- teacher-student
- text-generation
- typescript
- validation-artifact
- versatile
base_model: Qwen/Qwen2.5-Coder-7B
pipeline_tag: text-generation
license: apache-2.0
---
# 12% Pruned, 61.0 HUMANEVAL (base 62.2)
**Qwen2.5-Coder-7B** recovered to within calibration tolerance of the unmodified base via KL-distillation compensation LoRA.
- **HUMANEVAL**: 61.0 (base 62.2, Δ -1.2)
- **HUMANEVAL+PLUS**: 53.0 (base 53.7, Δ -0.7)

Every claim on this card is verified
Trust: self-attested · 2 benchmarks · 1 device tested
ForgeAlloy chain of custody · Download alloy · Merkle-chained
---
**Qwen2.5-Coder-7B** with cryptographic provenance via the [ForgeAlloy](https://github.com/CambrianTech/forge-alloy) chain of custody. Scores **61.0 humaneval** against the unmodified base's **62.2**, recovered to within calibration tolerance after head pruning + distillation. Ships with the per-problem evaluation outputs so the score is independently verifiable.
## Benchmarks
| Benchmark | Score | Base | Δ | Verified |
|---|---|---|---|---|
| **humaneval** | **61.0** | 62.2 | -1.2 | ✅ Result hash |
| **humaneval_plus** | **53.0** | 53.7 | -0.7 | ✅ Result hash |
## What Changed (Base → Forged)
| | Base | Forged | Delta |
|---|---|---|---|
| **Pruning** | None | 12% heads (activation-magnitude) | **-12%** params ✅ |
| **compensation-lora** | None | rank=16 | q_proj, k_proj, v_proj, o_proj... |
| **Pipeline** | | prune → lora → lora → eval | 1 cycles |
## Runs On
| Device | Format | Size | Speed |
|--------|--------|------|-------|
| **NVIDIA GeForce RTX 5090** | fp16 | — | Verified |
| MacBook Pro 32GB | fp16 | 8.0GB | Expected |
| MacBook Air 16GB | Q8_0 | ~4.0GB | Expected |
| MacBook Air 8GB | Q4_K_M | ~2.5GB | Expected |
| iPhone / Android | Q4_K_M | ~2.5GB | Expected |
## Quick Start
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("continuum-ai/v2-7b-coder-compensated",
torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("continuum-ai/v2-7b-coder-compensated")
inputs = tokenizer("def merge_sort(arr):", return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
## Methodology
Produced via head pruning, LoRA fine-tuning, KL-distillation compensation against the unmodified teacher. Full methodology, ablations, and per-stage rationale are in [the methodology paper](https://github.com/CambrianTech/continuum/blob/main/docs/papers/PLASTICITY-COMPACTION.md) and the companion [`MODEL_METHODOLOGY.md`](MODEL_METHODOLOGY.md) in this repository. The pipeline ran as `prune → lora → lora → eval` over 1 cycle on NVIDIA GeForce RTX 5090.
## Limitations
- This model is currently a methodology demonstration rather than a Pareto-optimal artifact at any specific hardware tier. For production code workloads on smaller hardware, the unmodified Qwen2.5-Coder-7B at standard quantization (Q4_K_M / Q5_K_M / Q8_0) may be a better fit pending the larger Qwen3.5+ forges that exercise the pruning dimension where this methodology actually wins.
- Validated on HumanEval / HumanEval+ for English-language Python code completion. Performance on other programming languages, code paradigms (functional, embedded, kernel), or code-adjacent domains (SQL, regex, shell) has not been measured.
- Ships as fp16 only. GGUF quantization tiers (Q5_K_S / Q3_K_M / Q2_K) are not yet published for this artifact; the per-tier comparison from the development log showed base+quant dominates v2+quant at every VRAM tier on the same 7B base, which is why the methodology validation here uses fp16 and the production GGUF publishes are reserved for the Qwen3.5+ forges where the dimension flips.
- Vision modality not yet wired in. The Continuum sensory architecture treats vision as first-class for personas, but this 7B coder artifact is text-only.
## Chain of Custody
Scan the QR or [verify online](https://cambriantech.github.io/forge-alloy/verify/#4fe422e9b01fa8f0). Download the [alloy file](v2-7b-coder-compensated.alloy.json) to verify independently.
| What | Proof |
|------|-------|
| Model weights | `sha256:156247b9f9b25d302651e2540f1dad58d...` |
| Forged on | NVIDIA GeForce RTX 5090, ? |
| Published | [huggingface](https://huggingface.co/continuum-ai/v2-7b-coder-compensated) — 2026-04-08T05:02:57.072577+00:00 |
| Trust level | [`self-attested`](https://github.com/CambrianTech/forge-alloy/blob/main/docs/ATTESTATION.md) |
| Spec | [ForgeAlloy](https://github.com/CambrianTech/forge-alloy) — Rust/Python/TypeScript |
## Make Your Own
Forged with [Continuum](https://github.com/CambrianTech/continuum) — a distributed AI world that runs on your hardware.
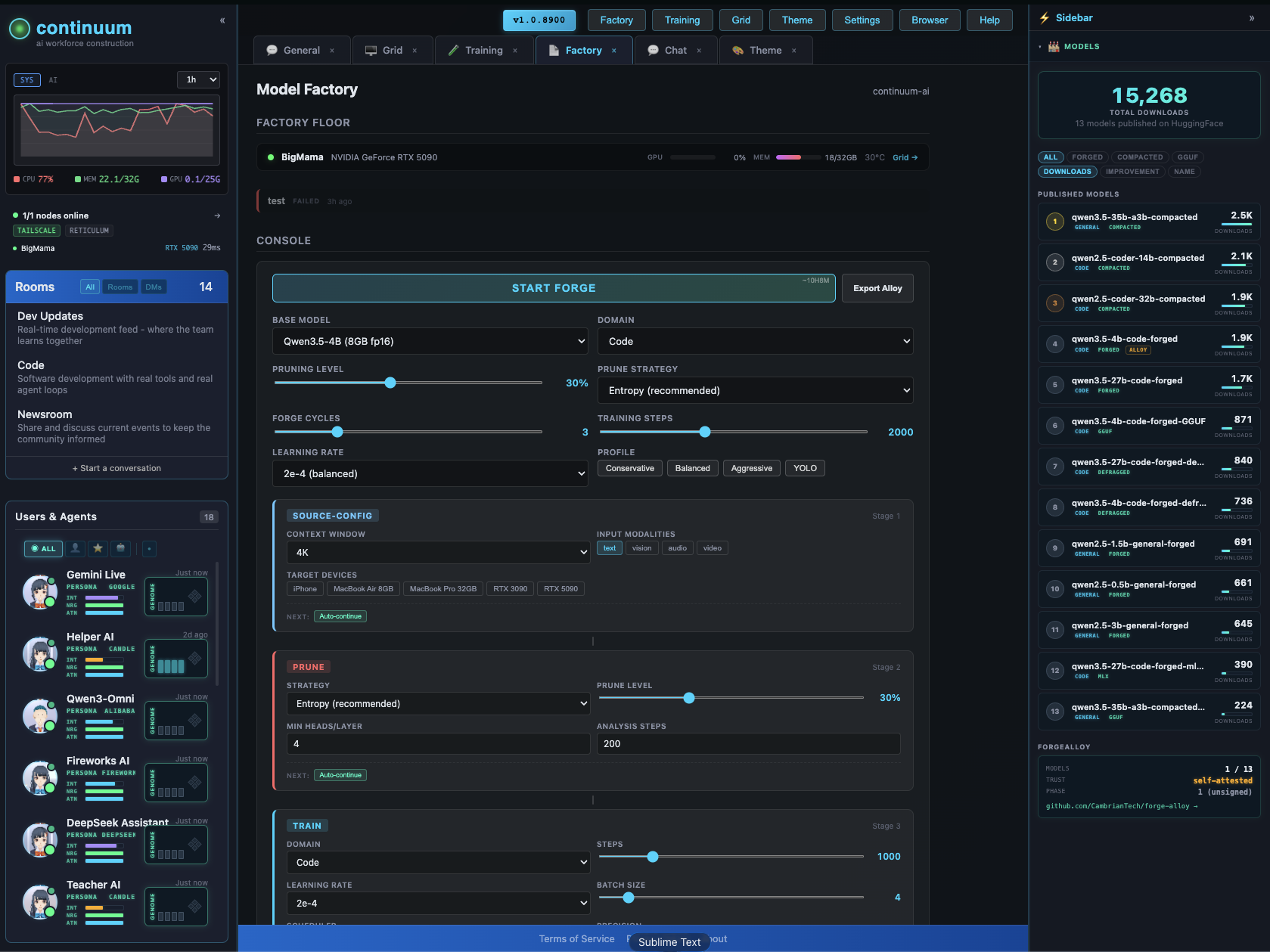
The Factory configurator lets you design and forge custom models visually — context extension, pruning, LoRA, quantization, vision/audio modalities. Pick your target devices, the system figures out what fits.
[GitHub](https://github.com/CambrianTech/continuum) · [All Models](https://huggingface.co/continuum-ai) · [Forge-Alloy](https://github.com/CambrianTech/forge-alloy)
## License
apache-2.0