![]()
 ## Quickstart
```shell
pip install chandra-ocr
# With vLLM (recommended, easy install)
chandra_vllm
chandra input.pdf ./output
# With HuggingFace (requires torch)
pip install chandra-ocr[hf]
chandra input.pdf ./output --method hf
```
## Usage
### With vLLM (recommended)
```python
from chandra.model import InferenceManager
from chandra.model.schema import BatchInputItem
from PIL import Image
# Start vLLM server first with: chandra_vllm
manager = InferenceManager(method="vllm")
batch = [
BatchInputItem(
image=Image.open("document.png"),
prompt_type="ocr_layout"
)
]
result = manager.generate(batch)[0]
print(result.markdown)
```
### With HuggingFace Transformers
```python
from transformers import AutoModelForImageTextToText, AutoProcessor
from chandra.model.hf import generate_hf
from chandra.model.schema import BatchInputItem
from chandra.output import parse_markdown
from PIL import Image
import torch
model = AutoModelForImageTextToText.from_pretrained(
"datalab-to/chandra-ocr-2",
dtype=torch.bfloat16,
device_map="auto",
)
model.eval()
model.processor = AutoProcessor.from_pretrained("datalab-to/chandra-ocr-2")
model.processor.tokenizer.padding_side = "left"
batch = [
BatchInputItem(
image=Image.open("document.png"),
prompt_type="ocr_layout"
)
]
result = generate_hf(batch, model)[0]
markdown = parse_markdown(result.raw)
print(markdown)
```
## Benchmarks
### olmOCR Benchmark
## Quickstart
```shell
pip install chandra-ocr
# With vLLM (recommended, easy install)
chandra_vllm
chandra input.pdf ./output
# With HuggingFace (requires torch)
pip install chandra-ocr[hf]
chandra input.pdf ./output --method hf
```
## Usage
### With vLLM (recommended)
```python
from chandra.model import InferenceManager
from chandra.model.schema import BatchInputItem
from PIL import Image
# Start vLLM server first with: chandra_vllm
manager = InferenceManager(method="vllm")
batch = [
BatchInputItem(
image=Image.open("document.png"),
prompt_type="ocr_layout"
)
]
result = manager.generate(batch)[0]
print(result.markdown)
```
### With HuggingFace Transformers
```python
from transformers import AutoModelForImageTextToText, AutoProcessor
from chandra.model.hf import generate_hf
from chandra.model.schema import BatchInputItem
from chandra.output import parse_markdown
from PIL import Image
import torch
model = AutoModelForImageTextToText.from_pretrained(
"datalab-to/chandra-ocr-2",
dtype=torch.bfloat16,
device_map="auto",
)
model.eval()
model.processor = AutoProcessor.from_pretrained("datalab-to/chandra-ocr-2")
model.processor.tokenizer.padding_side = "left"
batch = [
BatchInputItem(
image=Image.open("document.png"),
prompt_type="ocr_layout"
)
]
result = generate_hf(batch, model)[0]
markdown = parse_markdown(result.raw)
print(markdown)
```
## Benchmarks
### olmOCR Benchmark
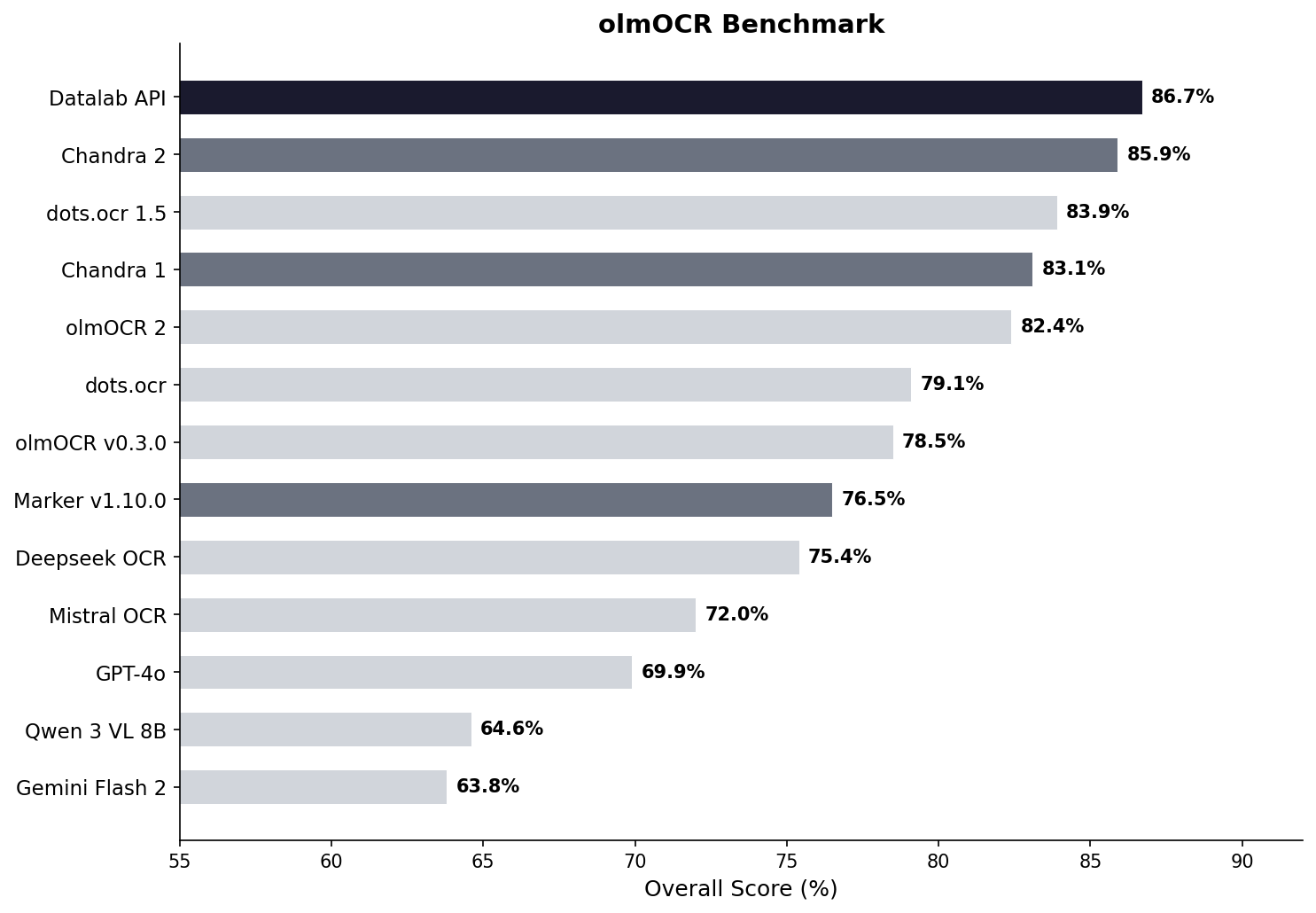 | **Model** | ArXiv | Old Scans Math | Tables | Old Scans | Headers and Footers | Multi column | Long tiny text | Base | Overall | Source |
|:----------|:--------:|:--------------:|:--------:|:---------:|:-------------------:|:------------:|:--------------:|:----:|:--------------:|:------:|
| Datalab API | **90.4** | **90.2** | **90.7** | **54.6** | 91.6 | 83.7 | **92.3** | **99.9** | **86.7 ± 0.8** | Own benchmarks |
| Chandra 2 | 90.2 | 89.3 | 89.9 | 49.8 | 92.5 | 83.5 | 92.1 | 99.6 | 85.9 ± 0.8 | Own benchmarks |
| dots.ocr 1.5 | 85.9 | 85.5 | **90.7** | 48.2 | 94.0 | **85.3** | 81.6 | 99.7 | 83.9 | dots.ocr repo |
| Chandra 1 | 82.2 | 80.3 | 88.0 | 50.4 | 90.8 | 81.2 | **92.3** | **99.9** | 83.1 ± 0.9 | Own benchmarks |
| olmOCR 2 | 83.0 | 82.3 | 84.9 | 47.7 | **96.1** | 83.7 | 81.9 | 99.6 | 82.4 | olmocr repo |
| dots.ocr | 82.1 | 64.2 | 88.3 | 40.9 | 94.1 | 82.4 | 81.2 | 99.5 | 79.1 ± 1.0 | dots.ocr repo |
| olmOCR v0.3.0 | 78.6 | 79.9 | 72.9 | 43.9 | 95.1 | 77.3 | 81.2 | 98.9 | 78.5 ± 1.1 | olmocr repo |
| Datalab Marker v1.10.0 | 83.8 | 69.7 | 74.8 | 32.3 | 86.6 | 79.4 | 85.7 | 99.6 | 76.5 ± 1.0 | Own benchmarks |
| Deepseek OCR | 75.2 | 72.3 | 79.7 | 33.3 | **96.1** | 66.7 | 80.1 | 99.7 | 75.4 ± 1.0 | Own benchmarks |
| Mistral OCR API | 77.2 | 67.5 | 60.6 | 29.3 | 93.6 | 71.3 | 77.1 | 99.4 | 72.0 ± 1.1 | olmocr repo |
| GPT-4o (Anchored) | 53.5 | 74.5 | 70.0 | 40.7 | 93.8 | 69.3 | 60.6 | 96.8 | 69.9 ± 1.1 | olmocr repo |
| Qwen 3 VL 8B | 70.2 | 75.1 | 45.6 | 37.5 | 89.1 | 62.1 | 43.0 | 94.3 | 64.6 ± 1.1 | Own benchmarks |
| Gemini Flash 2 (Anchored) | 54.5 | 56.1 | 72.1 | 34.2 | 64.7 | 61.5 | 71.5 | 95.6 | 63.8 ± 1.2 | olmocr repo |
## Examples
| Type | Name | Link |
|------|------|------|
| Tables | Statistical Distribution | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/tables/complex_tables.png) |
| Tables | Financial Table | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/tables/financial_table.png) |
| Forms | Registration Form | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/forms/handwritten_form.png) |
| Forms | Lease Form | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/forms/lease_filled.png) |
| Math | CS229 Textbook | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/math/cs229.png) |
| Math | Handwritten Math | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/math/handwritten_math.png) |
| Math | Chinese Math | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/math/chinese_math.png) |
| Handwriting | Cursive Writing | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/handwriting/cursive_writing.png) |
| Handwriting | Handwritten Notes | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/handwriting/handwritten_notes.png) |
| Languages | Arabic | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/languages/arabic.png) |
| Languages | Japanese | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/languages/japanese.png) |
| Languages | Hindi | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/languages/hindi.png) |
| Languages | Russian | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/languages/russian.png) |
| Other | Charts | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/other/charts.png) |
| Other | Chemistry | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/other/chemistry.png) |
### Multilingual Benchmark (43 Languages)
The table below covers the 43 most common languages, benchmarked across multiple models. For a comprehensive evaluation across 90 languages (Chandra 2 vs Gemini 2.5 Flash only), see the [full 90-language benchmark](#full-90-language-benchmark).
| **Model** | ArXiv | Old Scans Math | Tables | Old Scans | Headers and Footers | Multi column | Long tiny text | Base | Overall | Source |
|:----------|:--------:|:--------------:|:--------:|:---------:|:-------------------:|:------------:|:--------------:|:----:|:--------------:|:------:|
| Datalab API | **90.4** | **90.2** | **90.7** | **54.6** | 91.6 | 83.7 | **92.3** | **99.9** | **86.7 ± 0.8** | Own benchmarks |
| Chandra 2 | 90.2 | 89.3 | 89.9 | 49.8 | 92.5 | 83.5 | 92.1 | 99.6 | 85.9 ± 0.8 | Own benchmarks |
| dots.ocr 1.5 | 85.9 | 85.5 | **90.7** | 48.2 | 94.0 | **85.3** | 81.6 | 99.7 | 83.9 | dots.ocr repo |
| Chandra 1 | 82.2 | 80.3 | 88.0 | 50.4 | 90.8 | 81.2 | **92.3** | **99.9** | 83.1 ± 0.9 | Own benchmarks |
| olmOCR 2 | 83.0 | 82.3 | 84.9 | 47.7 | **96.1** | 83.7 | 81.9 | 99.6 | 82.4 | olmocr repo |
| dots.ocr | 82.1 | 64.2 | 88.3 | 40.9 | 94.1 | 82.4 | 81.2 | 99.5 | 79.1 ± 1.0 | dots.ocr repo |
| olmOCR v0.3.0 | 78.6 | 79.9 | 72.9 | 43.9 | 95.1 | 77.3 | 81.2 | 98.9 | 78.5 ± 1.1 | olmocr repo |
| Datalab Marker v1.10.0 | 83.8 | 69.7 | 74.8 | 32.3 | 86.6 | 79.4 | 85.7 | 99.6 | 76.5 ± 1.0 | Own benchmarks |
| Deepseek OCR | 75.2 | 72.3 | 79.7 | 33.3 | **96.1** | 66.7 | 80.1 | 99.7 | 75.4 ± 1.0 | Own benchmarks |
| Mistral OCR API | 77.2 | 67.5 | 60.6 | 29.3 | 93.6 | 71.3 | 77.1 | 99.4 | 72.0 ± 1.1 | olmocr repo |
| GPT-4o (Anchored) | 53.5 | 74.5 | 70.0 | 40.7 | 93.8 | 69.3 | 60.6 | 96.8 | 69.9 ± 1.1 | olmocr repo |
| Qwen 3 VL 8B | 70.2 | 75.1 | 45.6 | 37.5 | 89.1 | 62.1 | 43.0 | 94.3 | 64.6 ± 1.1 | Own benchmarks |
| Gemini Flash 2 (Anchored) | 54.5 | 56.1 | 72.1 | 34.2 | 64.7 | 61.5 | 71.5 | 95.6 | 63.8 ± 1.2 | olmocr repo |
## Examples
| Type | Name | Link |
|------|------|------|
| Tables | Statistical Distribution | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/tables/complex_tables.png) |
| Tables | Financial Table | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/tables/financial_table.png) |
| Forms | Registration Form | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/forms/handwritten_form.png) |
| Forms | Lease Form | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/forms/lease_filled.png) |
| Math | CS229 Textbook | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/math/cs229.png) |
| Math | Handwritten Math | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/math/handwritten_math.png) |
| Math | Chinese Math | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/math/chinese_math.png) |
| Handwriting | Cursive Writing | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/handwriting/cursive_writing.png) |
| Handwriting | Handwritten Notes | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/handwriting/handwritten_notes.png) |
| Languages | Arabic | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/languages/arabic.png) |
| Languages | Japanese | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/languages/japanese.png) |
| Languages | Hindi | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/languages/hindi.png) |
| Languages | Russian | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/languages/russian.png) |
| Other | Charts | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/other/charts.png) |
| Other | Chemistry | [View](https://github.com/datalab-to/chandra/blob/master/assets/examples/other/chemistry.png) |
### Multilingual Benchmark (43 Languages)
The table below covers the 43 most common languages, benchmarked across multiple models. For a comprehensive evaluation across 90 languages (Chandra 2 vs Gemini 2.5 Flash only), see the [full 90-language benchmark](#full-90-language-benchmark).
 | Language | Datalab API | Chandra 2 | Chandra 1 | Gemini 2.5 Flash | GPT-5 Mini |
|---|:---:|:---:|:---:|:---:|:---:|
| ar | 67.6% | 68.4% | 34.0% | 84.4% | 55.6% |
| bn | 85.1% | 72.8% | 45.6% | 55.3% | 23.3% |
| ca | 88.7% | 85.1% | 84.2% | 88.0% | 78.5% |
| cs | 88.2% | 85.3% | 84.7% | 79.1% | 78.8% |
| da | 90.1% | 91.1% | 88.4% | 86.0% | 87.7% |
| de | 93.8% | 94.8% | 83.0% | 88.3% | 93.8% |
| el | 89.9% | 85.6% | 85.5% | 83.5% | 82.4% |
| es | 91.8% | 89.3% | 88.7% | 86.8% | 97.1% |
| fa | 82.2% | 75.1% | 69.6% | 61.8% | 56.4% |
| fi | 85.7% | 83.4% | 78.4% | 86.0% | 84.7% |
| fr | 93.3% | 93.7% | 89.6% | 86.1% | 91.1% |
| gu | 73.8% | 70.8% | 44.6% | 47.6% | 11.5% |
| he | 76.4% | 70.4% | 38.9% | 50.9% | 22.3% |
| hi | 80.5% | 78.4% | 70.2% | 82.7% | 41.0% |
| hr | 93.4% | 90.1% | 85.9% | 88.2% | 81.3% |
| hu | 88.1% | 82.1% | 82.5% | 84.5% | 84.8% |
| id | 91.3% | 91.6% | 86.7% | 88.3% | 89.7% |
| it | 94.4% | 94.1% | 89.1% | 85.7% | 91.6% |
| ja | 87.3% | 86.9% | 85.4% | 80.0% | 76.1% |
| jv | 87.5% | 73.2% | 85.1% | 80.4% | 69.6% |
| kn | 70.0% | 63.2% | 20.6% | 24.5% | 10.1% |
| ko | 89.1% | 81.5% | 82.3% | 84.8% | 78.4% |
| la | 78.0% | 73.8% | 55.9% | 70.5% | 54.6% |
| ml | 72.4% | 64.3% | 18.1% | 23.8% | 11.9% |
| mr | 80.8% | 75.0% | 57.0% | 69.7% | 20.9% |
| nl | 90.0% | 88.6% | 85.3% | 87.5% | 83.8% |
| no | 89.2% | 90.3% | 85.5% | 87.8% | 87.4% |
| pl | 93.8% | 91.5% | 83.9% | 89.7% | 90.4% |
| pt | 97.0% | 95.2% | 84.3% | 89.4% | 90.8% |
| ro | 86.2% | 84.5% | 82.1% | 76.1% | 77.3% |
| ru | 88.8% | 85.5% | 88.7% | 82.8% | 72.2% |
| sa | 57.5% | 51.1% | 33.6% | 44.6% | 12.5% |
| sr | 95.3% | 90.3% | 82.3% | 89.7% | 83.0% |
| sv | 91.9% | 92.8% | 82.1% | 91.1% | 92.1% |
| ta | 82.9% | 77.7% | 50.8% | 53.9% | 8.1% |
| te | 69.4% | 58.6% | 19.5% | 33.3% | 9.9% |
| th | 71.6% | 62.6% | 47.0% | 66.7% | 53.8% |
| tr | 88.9% | 84.1% | 68.1% | 84.1% | 78.2% |
| uk | 93.1% | 91.0% | 88.5% | 87.9% | 81.9% |
| ur | 54.1% | 43.2% | 28.1% | 57.6% | 16.9% |
| vi | 85.0% | 80.4% | 81.6% | 89.5% | 83.6% |
| zh | 87.8% | 88.7% | 88.3% | 70.0% | 70.4% |
| **Average** | **80.4%** | **77.8%** | **69.4%** | **67.6%** | **60.5%** |
### Full 90-Language Benchmark
We also have a more comprehensive evaluation covering 90 languages, comparing Chandra 2 against Gemini 2.5 Flash. The average scores are lower than the 43-language table above because this includes many lower-resource languages. Chandra 2 averages **72.7%** vs Gemini 2.5 Flash at **60.8%**.
See the [full 90-language results](https://github.com/datalab-to/chandra/blob/master/FULL_BENCHMARKS.md).
## Throughput
Benchmarked with vLLM on a single NVIDIA H100 80GB GPU using a diverse mix of documents (math, tables, scans, multi-column layouts) from the olmOCR benchmark set. This set is significantly slower than real-world usage - we estimate 2 pages/s in real-world usage.
| Configuration | Pages/sec | Avg Latency | P95 Latency | Failure Rate |
|---|:---:|:---:|:---:|:---:|
| vLLM, 96 concurrent sequences | 1.44 | 60s | 156s | 0% |
## Commercial Usage
Code is Apache 2.0. Model weights use a modified OpenRAIL-M license: free for research, personal use, and startups under $2M funding/revenue. Cannot be used competitively with our API. For broader commercial licensing, see [pricing](https://www.datalab.to/pricing?utm_source=gh-chandra).
## Credits
- [Huggingface Transformers](https://github.com/huggingface/transformers)
- [vLLM](https://github.com/vllm-project/vllm)
- [olmocr](https://github.com/allenai/olmocr)
- [Qwen 3.5](https://github.com/QwenLM/Qwen3)
| Language | Datalab API | Chandra 2 | Chandra 1 | Gemini 2.5 Flash | GPT-5 Mini |
|---|:---:|:---:|:---:|:---:|:---:|
| ar | 67.6% | 68.4% | 34.0% | 84.4% | 55.6% |
| bn | 85.1% | 72.8% | 45.6% | 55.3% | 23.3% |
| ca | 88.7% | 85.1% | 84.2% | 88.0% | 78.5% |
| cs | 88.2% | 85.3% | 84.7% | 79.1% | 78.8% |
| da | 90.1% | 91.1% | 88.4% | 86.0% | 87.7% |
| de | 93.8% | 94.8% | 83.0% | 88.3% | 93.8% |
| el | 89.9% | 85.6% | 85.5% | 83.5% | 82.4% |
| es | 91.8% | 89.3% | 88.7% | 86.8% | 97.1% |
| fa | 82.2% | 75.1% | 69.6% | 61.8% | 56.4% |
| fi | 85.7% | 83.4% | 78.4% | 86.0% | 84.7% |
| fr | 93.3% | 93.7% | 89.6% | 86.1% | 91.1% |
| gu | 73.8% | 70.8% | 44.6% | 47.6% | 11.5% |
| he | 76.4% | 70.4% | 38.9% | 50.9% | 22.3% |
| hi | 80.5% | 78.4% | 70.2% | 82.7% | 41.0% |
| hr | 93.4% | 90.1% | 85.9% | 88.2% | 81.3% |
| hu | 88.1% | 82.1% | 82.5% | 84.5% | 84.8% |
| id | 91.3% | 91.6% | 86.7% | 88.3% | 89.7% |
| it | 94.4% | 94.1% | 89.1% | 85.7% | 91.6% |
| ja | 87.3% | 86.9% | 85.4% | 80.0% | 76.1% |
| jv | 87.5% | 73.2% | 85.1% | 80.4% | 69.6% |
| kn | 70.0% | 63.2% | 20.6% | 24.5% | 10.1% |
| ko | 89.1% | 81.5% | 82.3% | 84.8% | 78.4% |
| la | 78.0% | 73.8% | 55.9% | 70.5% | 54.6% |
| ml | 72.4% | 64.3% | 18.1% | 23.8% | 11.9% |
| mr | 80.8% | 75.0% | 57.0% | 69.7% | 20.9% |
| nl | 90.0% | 88.6% | 85.3% | 87.5% | 83.8% |
| no | 89.2% | 90.3% | 85.5% | 87.8% | 87.4% |
| pl | 93.8% | 91.5% | 83.9% | 89.7% | 90.4% |
| pt | 97.0% | 95.2% | 84.3% | 89.4% | 90.8% |
| ro | 86.2% | 84.5% | 82.1% | 76.1% | 77.3% |
| ru | 88.8% | 85.5% | 88.7% | 82.8% | 72.2% |
| sa | 57.5% | 51.1% | 33.6% | 44.6% | 12.5% |
| sr | 95.3% | 90.3% | 82.3% | 89.7% | 83.0% |
| sv | 91.9% | 92.8% | 82.1% | 91.1% | 92.1% |
| ta | 82.9% | 77.7% | 50.8% | 53.9% | 8.1% |
| te | 69.4% | 58.6% | 19.5% | 33.3% | 9.9% |
| th | 71.6% | 62.6% | 47.0% | 66.7% | 53.8% |
| tr | 88.9% | 84.1% | 68.1% | 84.1% | 78.2% |
| uk | 93.1% | 91.0% | 88.5% | 87.9% | 81.9% |
| ur | 54.1% | 43.2% | 28.1% | 57.6% | 16.9% |
| vi | 85.0% | 80.4% | 81.6% | 89.5% | 83.6% |
| zh | 87.8% | 88.7% | 88.3% | 70.0% | 70.4% |
| **Average** | **80.4%** | **77.8%** | **69.4%** | **67.6%** | **60.5%** |
### Full 90-Language Benchmark
We also have a more comprehensive evaluation covering 90 languages, comparing Chandra 2 against Gemini 2.5 Flash. The average scores are lower than the 43-language table above because this includes many lower-resource languages. Chandra 2 averages **72.7%** vs Gemini 2.5 Flash at **60.8%**.
See the [full 90-language results](https://github.com/datalab-to/chandra/blob/master/FULL_BENCHMARKS.md).
## Throughput
Benchmarked with vLLM on a single NVIDIA H100 80GB GPU using a diverse mix of documents (math, tables, scans, multi-column layouts) from the olmOCR benchmark set. This set is significantly slower than real-world usage - we estimate 2 pages/s in real-world usage.
| Configuration | Pages/sec | Avg Latency | P95 Latency | Failure Rate |
|---|:---:|:---:|:---:|:---:|
| vLLM, 96 concurrent sequences | 1.44 | 60s | 156s | 0% |
## Commercial Usage
Code is Apache 2.0. Model weights use a modified OpenRAIL-M license: free for research, personal use, and startups under $2M funding/revenue. Cannot be used competitively with our API. For broader commercial licensing, see [pricing](https://www.datalab.to/pricing?utm_source=gh-chandra).
## Credits
- [Huggingface Transformers](https://github.com/huggingface/transformers)
- [vLLM](https://github.com/vllm-project/vllm)
- [olmocr](https://github.com/allenai/olmocr)
- [Qwen 3.5](https://github.com/QwenLM/Qwen3)