---
task_categories:
- question-answering
- visual-question-answering
language:
- en
tags:
- Multimodal Search
- Multimodal Long Context
size_categories:
- n<1K
configs:
- config_name: default
data_files:
- split: train
path: "*.arrow"
dataset_info:
features:
- name: question
dtype: string
- name: answer
sequence: string
- name: num_images
dtype: int64
- name: arxiv_id
dtype: string
- name: video_url
dtype: string
- name: category
dtype: string
- name: difficulty
dtype: string
- name: subtask
dtype: string
- name: img_1
dtype: image
- name: img_2
dtype: image
- name: img_3
dtype: image
- name: img_4
dtype: image
- name: img_5
dtype: image
splits:
- name: train
num_examples: 311
---
# MMSearch-Plus✨: Benchmarking Provenance-Aware Search for Multimodal Browsing Agents
Official repository for the paper "[MMSearch-Plus: Benchmarking Provenance-Aware Search for Multimodal Browsing Agents](https://arxiv.org/abs/2508.21475)".
🌟 For more details, please refer to the project page with examples: [https://mmsearch-plus.github.io/](https://mmsearch-plus.github.io).
[[🌐 Webpage](https://mmsearch-plus.github.io/)] [[📖 Paper](https://arxiv.org/pdf/2508.21475)] [[🤗 Huggingface Dataset](https://huggingface.co/datasets/Cie1/MMSearch-Plus)] [[🏆 Leaderboard](https://mmsearch-plus.github.io/#leaderboard)]
## 💥 News
- **[2025.09.26]** 🔥 We update the [arXiv paper](https://arxiv.org/abs/2508.21475) and release all MMSearch-Plus data samples in [huggingface dataset](https://huggingface.co/datasets/Cie1/MMSearch-Plus).
- **[2025.08.29]** 🚀 We release the [arXiv paper](https://arxiv.org/abs/2508.21475).
## 📌 ToDo
- Agentic rollout framework code
- Evaluation script
- Set-of-Mark annotations
## Usage
**⚠️ Important: This dataset is encrypted to prevent data contamination. However, decryption is handled transparently by the dataset loader.**
### Dataset Usage
For better compatibility with newer versions of the datasets library, we provide explicit decryption functions, downloadable from our GitHub/HF repo.
```bash
wget https://raw.githubusercontent.com/mmsearch-plus/MMSearch-Plus/main/decrypt_after_load.py
```
```python
import os
from datasets import load_dataset
from decrypt_after_load import decrypt_dataset
encrypted_dataset = load_dataset("Cie1/MMSearch-Plus", split='train')
decrypted_dataset = decrypt_dataset(
encrypted_dataset=encrypted_dataset,
canary='your_canary_string' # Set the canary string (hint: it's the name of this repo without username)
)
# Access a sample
sample = decrypted_dataset[0]
print(f"Question: {sample['question']}")
print(f"Answer: {sample['answer']}")
print(f"Category: {sample['category']}")
print(f"Number of images: {sample['num_images']}")
# Access images (PIL Image objects)
sample['img_1'].show() # Display the first image
```
## 👀 About MMSearch-Plus
MMSearch-Plus is a challenging benchmark designed to test multimodal browsing agents' ability to perform genuine visual reasoning. Unlike existing benchmarks where many tasks can be solved with text-only approaches, MMSearch-Plus requires models to extract and use fine-grained visual cues through iterative image-text retrieval.
### Key Features
🔍 **Genuine Multimodal Reasoning**: 311 carefully curated tasks that cannot be solved without visual understanding
🎯 **Fine-grained Visual Analysis**: Questions require extracting spatial cues and temporal traces from images to find out-of-image facts like events, dates, and venues
🛠️ **Agent Framework**: Model-agnostic web agent with standard browsing tools (text search, image search, zoom-in)
📍 **Set-of-Mark (SoM) Module**: Enables provenance-aware cropping and targeted searches with human-verified bounding box annotations
### Dataset Structure
Each sample contains:
- Quuestion text and images
- Ground truth answers and alternative valid responses
- Metadata including arXiv id (if an event is a paper), video URL (if an event is a video), area and subfield
### Performance Results
Evaluation of closed- and open-source MLLMs shows:
- Best accuracy is achieved by o3 with full rollout: **36.0%** (indicating significant room for improvement)
- SoM integration provides consistent gains up to **+3.9 points**
- Models struggle with multi-step visual reasoning and cross-modal information integration
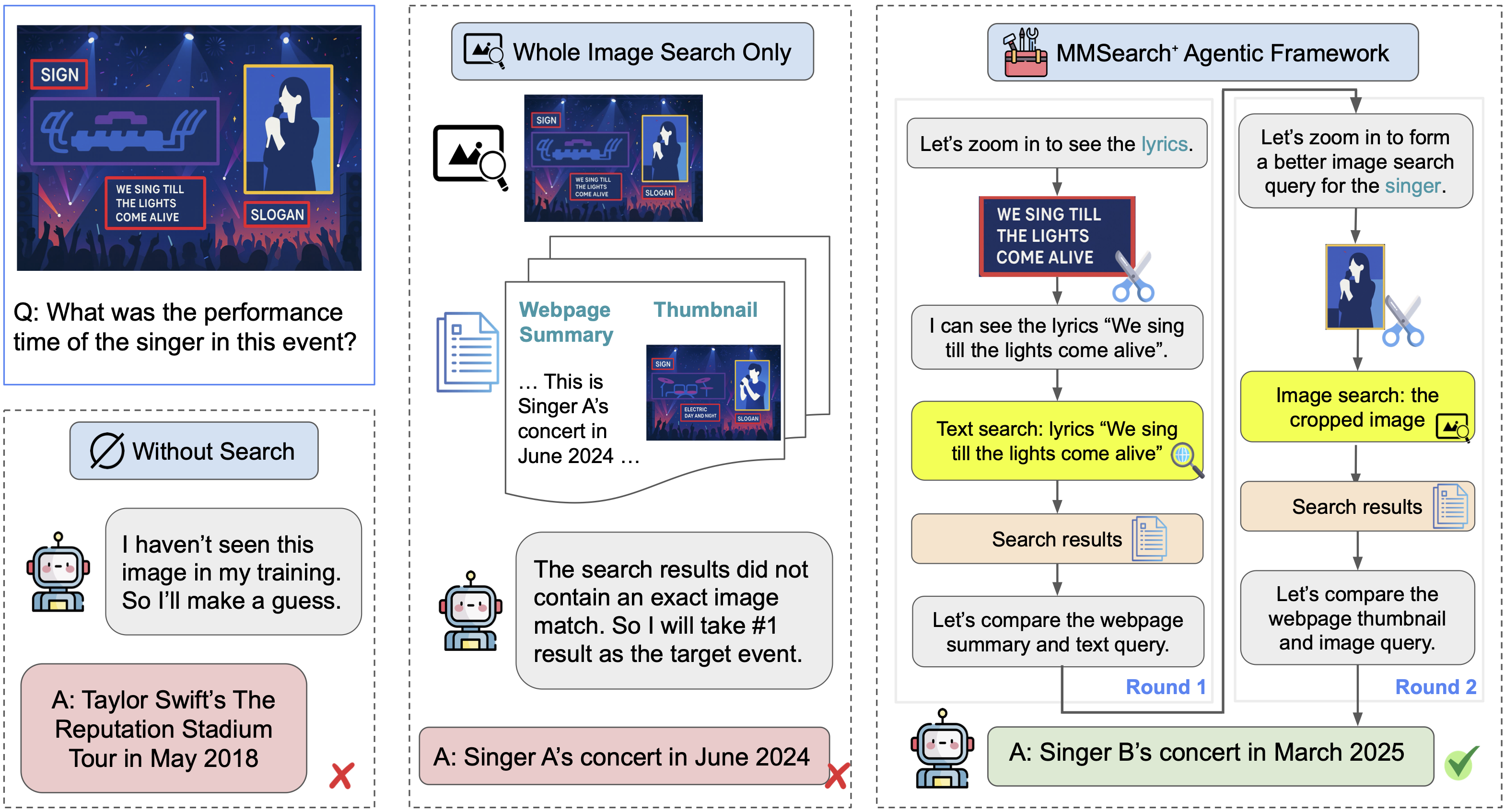
The overview of three paradigms for multimodal browsing tasks that demand fine-grained visual reasoning.
The overview of an example trajectory for a task in MMSearch-Plus.
## 🏆 Leaderboard
### Contributing to the Leaderboard
🚨 The [Leaderboard](https://mmsearch-plus.github.io/#leaderboard) is continuously being updated, welcoming the contribution of your excellent LMMs!
## 🔖 Citation
If you find **MMSearch-Plus** useful for your research and applications, please kindly cite using this BibTeX:
```latex
@article{tao2025mmsearch,
title={MMSearch-Plus: A Simple Yet Challenging Benchmark for Multimodal Browsing Agents},
author={Tao, Xijia and Teng, Yihua and Su, Xinxing and Fu, Xinyu and Wu, Jihao and Tao, Chaofan and Liu, Ziru and Bai, Haoli and Liu, Rui and Kong, Lingpeng},
journal={arXiv preprint arXiv:2508.21475},
year={2025}
}
```