
Upload batch 82 (20 files, last=huggingface_dataset/Dataset_Card/autoevaluate_autoeval-eval-samsum-samsum-89ef9c-1465453967.md)
Browse files- huggingface_dataset/Dataset_Card/Datatang_Mandarin_Heavy_Accent_Speech_Data.md +126 -0
- huggingface_dataset/Dataset_Card/GabeHD_pokemon-type-captions.md +28 -0
- huggingface_dataset/Dataset_Card/NeuroSenko_senko_anime_face_only.md +15 -0
- huggingface_dataset/Dataset_Card/SetFit_emotion.md +1 -0
- huggingface_dataset/Dataset_Card/acdzh_dingzhen-voice.md +13 -0
- huggingface_dataset/Dataset_Card/andstor_the_pile_github.md +127 -0
- huggingface_dataset/Dataset_Card/aseifert_merlin.md +27 -0
- huggingface_dataset/Dataset_Card/autoevaluate_autoeval-eval-project-quoref-bbfe943f-1305449897.md +35 -0
- huggingface_dataset/Dataset_Card/autoevaluate_autoeval-eval-samsum-samsum-89ef9c-1465453967.md +33 -0
- huggingface_dataset/Dataset_Card/autoevaluate_autoeval-staging-eval-samsum-samsum-41c5cd-15606152.md +33 -0
- huggingface_dataset/Dataset_Card/demo-org_auditor_review.md +134 -0
- huggingface_dataset/Dataset_Card/flax-sentence-embeddings_paws-jsonl.md +20 -0
- huggingface_dataset/Dataset_Card/huggingartists_kojey-radical.md +204 -0
- huggingface_dataset/Dataset_Card/huggingartists_krept-and-konan-bugzy-malone-sl-morisson-abra-cadabra-rv-and-snap-capone.md +204 -0
- huggingface_dataset/Dataset_Card/irds_beir_fiqa_dev.md +57 -0
- huggingface_dataset/Dataset_Card/irds_clueweb09_ar.md +32 -0
- huggingface_dataset/Dataset_Card/irds_dpr-w100.md +45 -0
- huggingface_dataset/Dataset_Card/jet-universe_jetclass.md +150 -0
- huggingface_dataset/Dataset_Card/sumedh_MeQSum.md +26 -0
- huggingface_dataset/Dataset_Card/text-machine-lab_NEG-1500-SIMP-GEN.md +5 -0
huggingface_dataset/Dataset_Card/Datatang_Mandarin_Heavy_Accent_Speech_Data.md
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
YAML tags:
|
| 3 |
+
- copy-paste the tags obtained with the tagging app: https://github.com/huggingface/datasets-tagging
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
# Dataset Card for Datatang/Mandarin_Heavy_Accent_Speech_Data_by_Mobile_Phone
|
| 7 |
+
|
| 8 |
+
## Table of Contents
|
| 9 |
+
- [Table of Contents](#table-of-contents)
|
| 10 |
+
- [Dataset Description](#dataset-description)
|
| 11 |
+
- [Dataset Summary](#dataset-summary)
|
| 12 |
+
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
|
| 13 |
+
- [Languages](#languages)
|
| 14 |
+
- [Dataset Structure](#dataset-structure)
|
| 15 |
+
- [Data Instances](#data-instances)
|
| 16 |
+
- [Data Fields](#data-fields)
|
| 17 |
+
- [Data Splits](#data-splits)
|
| 18 |
+
- [Dataset Creation](#dataset-creation)
|
| 19 |
+
- [Curation Rationale](#curation-rationale)
|
| 20 |
+
- [Source Data](#source-data)
|
| 21 |
+
- [Annotations](#annotations)
|
| 22 |
+
- [Personal and Sensitive Information](#personal-and-sensitive-information)
|
| 23 |
+
- [Considerations for Using the Data](#considerations-for-using-the-data)
|
| 24 |
+
- [Social Impact of Dataset](#social-impact-of-dataset)
|
| 25 |
+
- [Discussion of Biases](#discussion-of-biases)
|
| 26 |
+
- [Other Known Limitations](#other-known-limitations)
|
| 27 |
+
- [Additional Information](#additional-information)
|
| 28 |
+
- [Dataset Curators](#dataset-curators)
|
| 29 |
+
- [Licensing Information](#licensing-information)
|
| 30 |
+
- [Citation Information](#citation-information)
|
| 31 |
+
- [Contributions](#contributions)
|
| 32 |
+
|
| 33 |
+
## Dataset Description
|
| 34 |
+
|
| 35 |
+
- **Homepage:** https://bit.ly/3zZWIFP
|
| 36 |
+
- **Repository:**
|
| 37 |
+
- **Paper:**
|
| 38 |
+
- **Leaderboard:**
|
| 39 |
+
- **Point of Contact:**
|
| 40 |
+
|
| 41 |
+
### Dataset Summary
|
| 42 |
+
|
| 43 |
+
It collects 2,034 local Chinese from 26 provinces like Henan, Shanxi, Sichuan, Hunan, Fujian, etc. It is mandarin speech data with heavy accent. The recoring contents are finance and economics, entertainment, policy, news, TV, and movies.
|
| 44 |
+
|
| 45 |
+
For more details, please refer to the link: https://bit.ly/3zZWIFP
|
| 46 |
+
|
| 47 |
+
### Supported Tasks and Leaderboards
|
| 48 |
+
|
| 49 |
+
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
|
| 50 |
+
|
| 51 |
+
### Languages
|
| 52 |
+
|
| 53 |
+
Mandarin Chinese
|
| 54 |
+
## Dataset Structure
|
| 55 |
+
|
| 56 |
+
### Data Instances
|
| 57 |
+
|
| 58 |
+
[More Information Needed]
|
| 59 |
+
|
| 60 |
+
### Data Fields
|
| 61 |
+
|
| 62 |
+
[More Information Needed]
|
| 63 |
+
|
| 64 |
+
### Data Splits
|
| 65 |
+
|
| 66 |
+
[More Information Needed]
|
| 67 |
+
|
| 68 |
+
## Dataset Creation
|
| 69 |
+
|
| 70 |
+
### Curation Rationale
|
| 71 |
+
|
| 72 |
+
[More Information Needed]
|
| 73 |
+
|
| 74 |
+
### Source Data
|
| 75 |
+
|
| 76 |
+
#### Initial Data Collection and Normalization
|
| 77 |
+
|
| 78 |
+
[More Information Needed]
|
| 79 |
+
|
| 80 |
+
#### Who are the source language producers?
|
| 81 |
+
|
| 82 |
+
[More Information Needed]
|
| 83 |
+
|
| 84 |
+
### Annotations
|
| 85 |
+
|
| 86 |
+
#### Annotation process
|
| 87 |
+
|
| 88 |
+
[More Information Needed]
|
| 89 |
+
|
| 90 |
+
#### Who are the annotators?
|
| 91 |
+
|
| 92 |
+
[More Information Needed]
|
| 93 |
+
|
| 94 |
+
### Personal and Sensitive Information
|
| 95 |
+
|
| 96 |
+
[More Information Needed]
|
| 97 |
+
|
| 98 |
+
## Considerations for Using the Data
|
| 99 |
+
|
| 100 |
+
### Social Impact of Dataset
|
| 101 |
+
|
| 102 |
+
[More Information Needed]
|
| 103 |
+
|
| 104 |
+
### Discussion of Biases
|
| 105 |
+
|
| 106 |
+
[More Information Needed]
|
| 107 |
+
|
| 108 |
+
### Other Known Limitations
|
| 109 |
+
|
| 110 |
+
[More Information Needed]
|
| 111 |
+
|
| 112 |
+
## Additional Information
|
| 113 |
+
|
| 114 |
+
### Dataset Curators
|
| 115 |
+
|
| 116 |
+
[More Information Needed]
|
| 117 |
+
|
| 118 |
+
### Licensing Information
|
| 119 |
+
|
| 120 |
+
Commerical License: https://drive.google.com/file/d/1saDCPm74D4UWfBL17VbkTsZLGfpOQj1J/view?usp=sharing
|
| 121 |
+
|
| 122 |
+
### Citation Information
|
| 123 |
+
|
| 124 |
+
[More Information Needed]
|
| 125 |
+
|
| 126 |
+
### Contributions
|
huggingface_dataset/Dataset_Card/GabeHD_pokemon-type-captions.md
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
dataset_info:
|
| 3 |
+
features:
|
| 4 |
+
- name: image
|
| 5 |
+
dtype: image
|
| 6 |
+
- name: text
|
| 7 |
+
dtype: string
|
| 8 |
+
splits:
|
| 9 |
+
- name: train
|
| 10 |
+
num_bytes: 19372532.0
|
| 11 |
+
num_examples: 898
|
| 12 |
+
download_size: 0
|
| 13 |
+
dataset_size: 19372532.0
|
| 14 |
+
---
|
| 15 |
+
# Dataset Card for Pokémon type captions
|
| 16 |
+
|
| 17 |
+
Contains official artwork and type-specific caption for Pokémon #1-898 (Bulbasaur-Calyrex).
|
| 18 |
+
Each Pokémon is represented once by the default form from [PokéAPI](https://pokeapi.co/)
|
| 19 |
+
|
| 20 |
+
Each row contains `image` and `text` keys:
|
| 21 |
+
- `image` is a 475x475 PIL jpg of the Pokémon's official artwork.
|
| 22 |
+
- `text` is a label describing the Pokémon by its type(s)
|
| 23 |
+
|
| 24 |
+
## Attributions
|
| 25 |
+
|
| 26 |
+
_Images and typing information pulled from [PokéAPI](https://pokeapi.co/)_
|
| 27 |
+
|
| 28 |
+
_Based on the [Lambda Labs Pokémon Blip Captions Dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions)_
|
huggingface_dataset/Dataset_Card/NeuroSenko_senko_anime_face_only.md
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
tags:
|
| 4 |
+
- Senko
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
## Description
|
| 8 |
+
This dataset contains images of Senko-san which were extracted from anime Sewayaki Kitsune no Senko-san. All images are cropped up to 512x512. This dataset includes only images which are focused on face of Senko-san.
|
| 9 |
+
|
| 10 |
+
## Examples
|
| 11 |
+

|
| 12 |
+

|
| 13 |
+
|
| 14 |
+
## TODO
|
| 15 |
+
1. Add tags for every image
|
huggingface_dataset/Dataset_Card/SetFit_emotion.md
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
** Attention: There appears an overlap in train / test. I trained a model on the train set and achieved 100% acc on test set. With the original emotion dataset this is not the case (92.4% acc)**
|
huggingface_dataset/Dataset_Card/acdzh_dingzhen-voice.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
---
|
| 4 |
+
|
| 5 |
+
应该没外国人用,直接用中文吧
|
| 6 |
+
|
| 7 |
+
`dingzhen.zip` 是声源压缩文件,声源来自两部分
|
| 8 |
+
|
| 9 |
+
- 某次录播(qh_0_*.wav):[220725丁真直播录屏完整版_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV15S4y1t789)
|
| 10 |
+
- 粘合国演讲(qh_1_*.wav):[丁真 出席联合国演讲(完整版)毫不怯场 从容自若 好有魅力_哔哩哔哩_bilibili](https://www.bilibili.com/video/BV1NN411f7mN)
|
| 11 |
+
|
| 12 |
+
`cuts.txt` 是对应文件字幕。
|
| 13 |
+
|
huggingface_dataset/Dataset_Card/andstor_the_pile_github.md
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
annotations_creators:
|
| 3 |
+
- no-annotation
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
language_creators:
|
| 7 |
+
- found
|
| 8 |
+
license:
|
| 9 |
+
- other
|
| 10 |
+
multilinguality:
|
| 11 |
+
- monolingual
|
| 12 |
+
pretty_name: The Pile GitHub
|
| 13 |
+
size_categories: []
|
| 14 |
+
source_datasets:
|
| 15 |
+
- original
|
| 16 |
+
tags: []
|
| 17 |
+
task_categories:
|
| 18 |
+
- text-generation
|
| 19 |
+
- fill-mask
|
| 20 |
+
- text-classification
|
| 21 |
+
task_ids: []
|
| 22 |
+
---
|
| 23 |
+
|
| 24 |
+
# Dataset Card for The Pile GitHub
|
| 25 |
+
|
| 26 |
+
## Table of Contents
|
| 27 |
+
- [Dataset Card for Smart Contracts](#dataset-card-for-the-pile-github)
|
| 28 |
+
- [Table of Contents](#table-of-contents)
|
| 29 |
+
- [Dataset Description](#dataset-description)
|
| 30 |
+
- [Dataset Summary](#dataset-summary)
|
| 31 |
+
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
|
| 32 |
+
- [Languages](#languages)
|
| 33 |
+
- [Dataset Structure](#dataset-structure)
|
| 34 |
+
- [Data Instances](#data-instances)
|
| 35 |
+
- [Data Fields](#data-fields)
|
| 36 |
+
- [Data Splits](#data-splits)
|
| 37 |
+
- [Dataset Creation](#dataset-creation)
|
| 38 |
+
- [Curation Rationale](#curation-rationale)
|
| 39 |
+
- [Source Data](#source-data)
|
| 40 |
+
- [Additional Information](#additional-information)
|
| 41 |
+
- [Licensing Information](#licensing-information)
|
| 42 |
+
- [Citation Information](#citation-information)
|
| 43 |
+
- [Contributions](#contributions)
|
| 44 |
+
|
| 45 |
+
## Dataset Description
|
| 46 |
+
|
| 47 |
+
- **Homepage:** [ElutherAI](https://pile.eleuther.ai)
|
| 48 |
+
- **Repository:** [GitHub](https://github.com/andstor/the-pile-github)
|
| 49 |
+
- **Paper:** [arXiv](https://arxiv.org/abs/2101.00027)
|
| 50 |
+
- **Leaderboard:** [Needs More Information]
|
| 51 |
+
- **Point of Contact:** [Needs More Information]
|
| 52 |
+
|
| 53 |
+
### Dataset Summary
|
| 54 |
+
|
| 55 |
+
This is the GitHub subset of EleutherAi/The Pile dataset and contains GitHub repositories. The programming languages are identified using the [guesslang library](https://github.com/yoeo/guesslang). A total of 54 programming languages are included in the dataset.
|
| 56 |
+
|
| 57 |
+
### Supported Tasks and Leaderboards
|
| 58 |
+
|
| 59 |
+
[More Information Needed]
|
| 60 |
+
|
| 61 |
+
### Languages
|
| 62 |
+
The following languages are covered by the dataset:
|
| 63 |
+
```
|
| 64 |
+
'Assembly', 'Batchfile', 'C', 'C#', 'C++', 'CMake', 'COBOL', 'CSS', 'CSV', 'Clojure', 'CoffeeScript', 'DM', 'Dart', 'Dockerfile', 'Elixir', 'Erlang', 'Fortran', 'Go', 'Groovy', 'HTML', 'Haskell', 'INI', 'JSON', 'Java', 'JavaScript', 'Julia', 'Kotlin', 'Lisp', 'Lua', 'Makefile', 'Markdown', 'Matlab', 'None', 'OCaml', 'Objective-C', 'PHP', 'Pascal', 'Perl', 'PowerShell', 'Prolog', 'Python', 'R', 'Ruby', 'Rust', 'SQL', 'Scala', 'Shell', 'Swift', 'TOML', 'TeX', 'TypeScript', 'Verilog', 'Visual Basic', 'XML', 'YAML'
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
The [guesslang library](https://github.com/yoeo/guesslang) is used to identify the programming languages. It has a guessing accuracy of above 90%. Hence, there will be some misclassifications in the language identification.
|
| 68 |
+
|
| 69 |
+
## Dataset Structure
|
| 70 |
+
|
| 71 |
+
### Data Instances
|
| 72 |
+
|
| 73 |
+
[More Information Needed]
|
| 74 |
+
|
| 75 |
+
```
|
| 76 |
+
{
|
| 77 |
+
'text': ...,
|
| 78 |
+
'meta': {'language': ...}
|
| 79 |
+
}
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
### Data Fields
|
| 83 |
+
|
| 84 |
+
- `text` (`string`): the source code.
|
| 85 |
+
- `meta` (`dict`): the metadata of the source code.
|
| 86 |
+
- `language` (`string`): the programming language of the source code.
|
| 87 |
+
|
| 88 |
+
### Data Splits
|
| 89 |
+
|
| 90 |
+
[More Information Needed]
|
| 91 |
+
|
| 92 |
+
| | train | validation | test |
|
| 93 |
+
|-------------------------|------:|-----------:|-----:|
|
| 94 |
+
| Input Sentences | | | |
|
| 95 |
+
| Average Sentence Length | | | |
|
| 96 |
+
|
| 97 |
+
## Dataset Creation
|
| 98 |
+
|
| 99 |
+
### Curation Rationale
|
| 100 |
+
|
| 101 |
+
[More Information Needed]
|
| 102 |
+
|
| 103 |
+
### Source Data
|
| 104 |
+
|
| 105 |
+
The data is purely a subset of the [EleutherAI/The Pile dataset](https://huggingface.co/datasets/the_pile). See the original [dataset](https://arxiv.org/abs/2201.07311) for more details.
|
| 106 |
+
|
| 107 |
+
## Additional Information
|
| 108 |
+
|
| 109 |
+
### Licensing Information
|
| 110 |
+
|
| 111 |
+
The Pile dataset was released on January 1st, 2021. It is licensed under the MIT License. See the [dataset](https://arxiv.org/abs/2201.07311) for more details.
|
| 112 |
+
|
| 113 |
+
### Citation Information
|
| 114 |
+
|
| 115 |
+
Provide the [BibTex](http://www.bibtex.org/)-formatted reference for the dataset. For example:
|
| 116 |
+
```
|
| 117 |
+
@article{pile,
|
| 118 |
+
title={The {P}ile: An 800GB Dataset of Diverse Text for Language Modeling},
|
| 119 |
+
author={Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and Presser, Shawn and Leahy, Connor},
|
| 120 |
+
journal={arXiv preprint arXiv:2101.00027},
|
| 121 |
+
year={2020}
|
| 122 |
+
}
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
### Contributions
|
| 126 |
+
|
| 127 |
+
Thanks to [@andstor](https://github.com/andstor) for adding this dataset.
|
huggingface_dataset/Dataset_Card/aseifert_merlin.md
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
annotations_creators: []
|
| 3 |
+
language_creators: []
|
| 4 |
+
language:
|
| 5 |
+
- cz
|
| 6 |
+
- de
|
| 7 |
+
- it
|
| 8 |
+
license: []
|
| 9 |
+
multilinguality:
|
| 10 |
+
- translation
|
| 11 |
+
pretty_name: merlin
|
| 12 |
+
size_categories:
|
| 13 |
+
- unknown
|
| 14 |
+
source_datasets: []
|
| 15 |
+
task_categories:
|
| 16 |
+
- conditional-text-generation
|
| 17 |
+
task_ids:
|
| 18 |
+
- machine-translation
|
| 19 |
+
---
|
| 20 |
+
|
| 21 |
+
# MERLIN corpus
|
| 22 |
+
|
| 23 |
+
Project URL: https://merlin-platform.eu/C_mcorpus.php
|
| 24 |
+
|
| 25 |
+
Dataset URL: https://clarin.eurac.edu/repository/xmlui/handle/20.500.12124/6
|
| 26 |
+
|
| 27 |
+
The MERLIN corpus is a written learner corpus for Czech, German, and Italian that has been designed to illustrate the Common European Framework of Reference for Languages (CEFR) with authentic learner data. The corpus contains learner texts produced in standardized language certifications covering CEFR levels A1-C1. The MERLIN annotation scheme includes a wide range of language characteristics that provide researchers with concrete examples of learner performance and progress across multiple proficiency levels.
|
huggingface_dataset/Dataset_Card/autoevaluate_autoeval-eval-project-quoref-bbfe943f-1305449897.md
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
type: predictions
|
| 3 |
+
tags:
|
| 4 |
+
- autotrain
|
| 5 |
+
- evaluation
|
| 6 |
+
datasets:
|
| 7 |
+
- quoref
|
| 8 |
+
eval_info:
|
| 9 |
+
task: extractive_question_answering
|
| 10 |
+
model: nbroad/rob-base-gc1
|
| 11 |
+
metrics: []
|
| 12 |
+
dataset_name: quoref
|
| 13 |
+
dataset_config: default
|
| 14 |
+
dataset_split: validation
|
| 15 |
+
col_mapping:
|
| 16 |
+
context: context
|
| 17 |
+
question: question
|
| 18 |
+
answers-text: answers.text
|
| 19 |
+
answers-answer_start: answers.answer_start
|
| 20 |
+
---
|
| 21 |
+
# Dataset Card for AutoTrain Evaluator
|
| 22 |
+
|
| 23 |
+
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
|
| 24 |
+
|
| 25 |
+
* Task: Question Answering
|
| 26 |
+
* Model: nbroad/rob-base-gc1
|
| 27 |
+
* Dataset: quoref
|
| 28 |
+
* Config: default
|
| 29 |
+
* Split: validation
|
| 30 |
+
|
| 31 |
+
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
|
| 32 |
+
|
| 33 |
+
## Contributions
|
| 34 |
+
|
| 35 |
+
Thanks to [@nbroad](https://huggingface.co/nbroad) for evaluating this model.
|
huggingface_dataset/Dataset_Card/autoevaluate_autoeval-eval-samsum-samsum-89ef9c-1465453967.md
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
type: predictions
|
| 3 |
+
tags:
|
| 4 |
+
- autotrain
|
| 5 |
+
- evaluation
|
| 6 |
+
datasets:
|
| 7 |
+
- samsum
|
| 8 |
+
eval_info:
|
| 9 |
+
task: summarization
|
| 10 |
+
model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
|
| 11 |
+
metrics: []
|
| 12 |
+
dataset_name: samsum
|
| 13 |
+
dataset_config: samsum
|
| 14 |
+
dataset_split: test
|
| 15 |
+
col_mapping:
|
| 16 |
+
text: dialogue
|
| 17 |
+
target: summary
|
| 18 |
+
---
|
| 19 |
+
# Dataset Card for AutoTrain Evaluator
|
| 20 |
+
|
| 21 |
+
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
|
| 22 |
+
|
| 23 |
+
* Task: Summarization
|
| 24 |
+
* Model: pszemraj/long-t5-tglobal-base-16384-booksum-V12
|
| 25 |
+
* Dataset: samsum
|
| 26 |
+
* Config: samsum
|
| 27 |
+
* Split: test
|
| 28 |
+
|
| 29 |
+
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
|
| 30 |
+
|
| 31 |
+
## Contributions
|
| 32 |
+
|
| 33 |
+
Thanks to [@pszemraj](https://huggingface.co/pszemraj) for evaluating this model.
|
huggingface_dataset/Dataset_Card/autoevaluate_autoeval-staging-eval-samsum-samsum-41c5cd-15606152.md
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
type: predictions
|
| 3 |
+
tags:
|
| 4 |
+
- autotrain
|
| 5 |
+
- evaluation
|
| 6 |
+
datasets:
|
| 7 |
+
- samsum
|
| 8 |
+
eval_info:
|
| 9 |
+
task: summarization
|
| 10 |
+
model: SamuelAllen123/t5-efficient-large-nl36_fine_tuned_for_sum
|
| 11 |
+
metrics: ['mae']
|
| 12 |
+
dataset_name: samsum
|
| 13 |
+
dataset_config: samsum
|
| 14 |
+
dataset_split: validation
|
| 15 |
+
col_mapping:
|
| 16 |
+
text: dialogue
|
| 17 |
+
target: summary
|
| 18 |
+
---
|
| 19 |
+
# Dataset Card for AutoTrain Evaluator
|
| 20 |
+
|
| 21 |
+
This repository contains model predictions generated by [AutoTrain](https://huggingface.co/autotrain) for the following task and dataset:
|
| 22 |
+
|
| 23 |
+
* Task: Summarization
|
| 24 |
+
* Model: SamuelAllen123/t5-efficient-large-nl36_fine_tuned_for_sum
|
| 25 |
+
* Dataset: samsum
|
| 26 |
+
* Config: samsum
|
| 27 |
+
* Split: validation
|
| 28 |
+
|
| 29 |
+
To run new evaluation jobs, visit Hugging Face's [automatic model evaluator](https://huggingface.co/spaces/autoevaluate/model-evaluator).
|
| 30 |
+
|
| 31 |
+
## Contributions
|
| 32 |
+
|
| 33 |
+
Thanks to [@SamuelAllen123](https://huggingface.co/SamuelAllen123) for evaluating this model.
|
huggingface_dataset/Dataset_Card/demo-org_auditor_review.md
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
annotations_creators:
|
| 3 |
+
- expert-generated
|
| 4 |
+
language_creators:
|
| 5 |
+
- found
|
| 6 |
+
language:
|
| 7 |
+
- en
|
| 8 |
+
multilinguality:
|
| 9 |
+
- monolingual
|
| 10 |
+
size_categories:
|
| 11 |
+
- 1K<n<10K
|
| 12 |
+
source_datasets:
|
| 13 |
+
- original
|
| 14 |
+
task_categories:
|
| 15 |
+
- text-classification
|
| 16 |
+
task_ids:
|
| 17 |
+
- multi-class-classification
|
| 18 |
+
- sentiment-classification
|
| 19 |
+
paperswithcode_id: null
|
| 20 |
+
pretty_name: Auditor_Review
|
| 21 |
+
---
|
| 22 |
+
# Dataset Card for Auditor_Review
|
| 23 |
+
|
| 24 |
+
## Table of Contents
|
| 25 |
+
- [Table of Contents](#table-of-contents)
|
| 26 |
+
- [Dataset Description](#dataset-description)
|
| 27 |
+
- [Dataset Summary](#dataset-summary)
|
| 28 |
+
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
|
| 29 |
+
- [Languages](#languages)
|
| 30 |
+
- [Dataset Structure](#dataset-structure)
|
| 31 |
+
- [Data Instances](#data-instances)
|
| 32 |
+
- [Data Fields](#data-fields)
|
| 33 |
+
- [Data Splits](#data-splits)
|
| 34 |
+
- [Dataset Creation](#dataset-creation)
|
| 35 |
+
- [Curation Rationale](#curation-rationale)
|
| 36 |
+
- [Source Data](#source-data)
|
| 37 |
+
- [Annotations](#annotations)
|
| 38 |
+
- [Personal and Sensitive Information](#personal-and-sensitive-information)
|
| 39 |
+
- [Considerations for Using the Data](#considerations-for-using-the-data)
|
| 40 |
+
- [Social Impact of Dataset](#social-impact-of-dataset)
|
| 41 |
+
- [Discussion of Biases](#discussion-of-biases)
|
| 42 |
+
- [Other Known Limitations](#other-known-limitations)
|
| 43 |
+
- [Additional Information](#additional-information)
|
| 44 |
+
- [Dataset Curators](#dataset-curators)
|
| 45 |
+
- [Licensing Information](#licensing-information)
|
| 46 |
+
|
| 47 |
+
## Dataset Description
|
| 48 |
+
Auditor review data collected by News Department
|
| 49 |
+
|
| 50 |
+
- **Point of Contact:**
|
| 51 |
+
Talked to COE for Auditing, currently sue@demo.org
|
| 52 |
+
|
| 53 |
+
### Dataset Summary
|
| 54 |
+
|
| 55 |
+
Auditor sentiment dataset of sentences from financial news. The dataset consists of 3500 sentences from English language financial news categorized by sentiment. The dataset is divided by the agreement rate of 5-8 annotators.
|
| 56 |
+
|
| 57 |
+
### Supported Tasks and Leaderboards
|
| 58 |
+
|
| 59 |
+
Sentiment Classification
|
| 60 |
+
|
| 61 |
+
### Languages
|
| 62 |
+
|
| 63 |
+
English
|
| 64 |
+
|
| 65 |
+
## Dataset Structure
|
| 66 |
+
|
| 67 |
+
### Data Instances
|
| 68 |
+
|
| 69 |
+
```
|
| 70 |
+
"sentence": "Pharmaceuticals group Orion Corp reported a fall in its third-quarter earnings that were hit by larger expenditures on R&D and marketing .",
|
| 71 |
+
"label": "negative"
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
### Data Fields
|
| 75 |
+
|
| 76 |
+
- sentence: a tokenized line from the dataset
|
| 77 |
+
- label: a label corresponding to the class as a string: 'positive' - (2), 'neutral' - (1), or 'negative' - (0)
|
| 78 |
+
|
| 79 |
+
Complete data code is [available here](https://www.datafiles.samhsa.gov/get-help/codebooks/what-codebook)
|
| 80 |
+
|
| 81 |
+
### Data Splits
|
| 82 |
+
|
| 83 |
+
A train/test split was created randomly with a 75/25 split
|
| 84 |
+
|
| 85 |
+
## Dataset Creation
|
| 86 |
+
|
| 87 |
+
### Curation Rationale
|
| 88 |
+
|
| 89 |
+
To gather our auditor evaluations into one dataset. Previous attempts using off-the-shelf sentiment had only 70% F1, this dataset was an attempt to improve upon that performance.
|
| 90 |
+
|
| 91 |
+
### Source Data
|
| 92 |
+
|
| 93 |
+
#### Initial Data Collection and Normalization
|
| 94 |
+
|
| 95 |
+
The corpus used in this paper is made out of English news reports.
|
| 96 |
+
|
| 97 |
+
#### Who are the source language producers?
|
| 98 |
+
|
| 99 |
+
The source data was written by various auditors.
|
| 100 |
+
|
| 101 |
+
### Annotations
|
| 102 |
+
|
| 103 |
+
#### Annotation process
|
| 104 |
+
|
| 105 |
+
This release of the auditor reviews covers a collection of 4840
|
| 106 |
+
sentences. The selected collection of phrases was annotated by 16 people with
|
| 107 |
+
adequate background knowledge of financial markets. The subset here is where inter-annotation agreement was greater than 75%.
|
| 108 |
+
|
| 109 |
+
#### Who are the annotators?
|
| 110 |
+
|
| 111 |
+
They were pulled from the SME list, names are held by sue@demo.org
|
| 112 |
+
|
| 113 |
+
### Personal and Sensitive Information
|
| 114 |
+
|
| 115 |
+
There is no personal or sensitive information in this dataset.
|
| 116 |
+
|
| 117 |
+
## Considerations for Using the Data
|
| 118 |
+
|
| 119 |
+
### Discussion of Biases
|
| 120 |
+
|
| 121 |
+
All annotators were from the same institution and so interannotator agreement
|
| 122 |
+
should be understood with this taken into account.
|
| 123 |
+
|
| 124 |
+
The [Dataset Measurement tool](https://huggingface.co/spaces/huggingface/data-measurements-tool) identified these bias statistics:
|
| 125 |
+
|
| 126 |
+
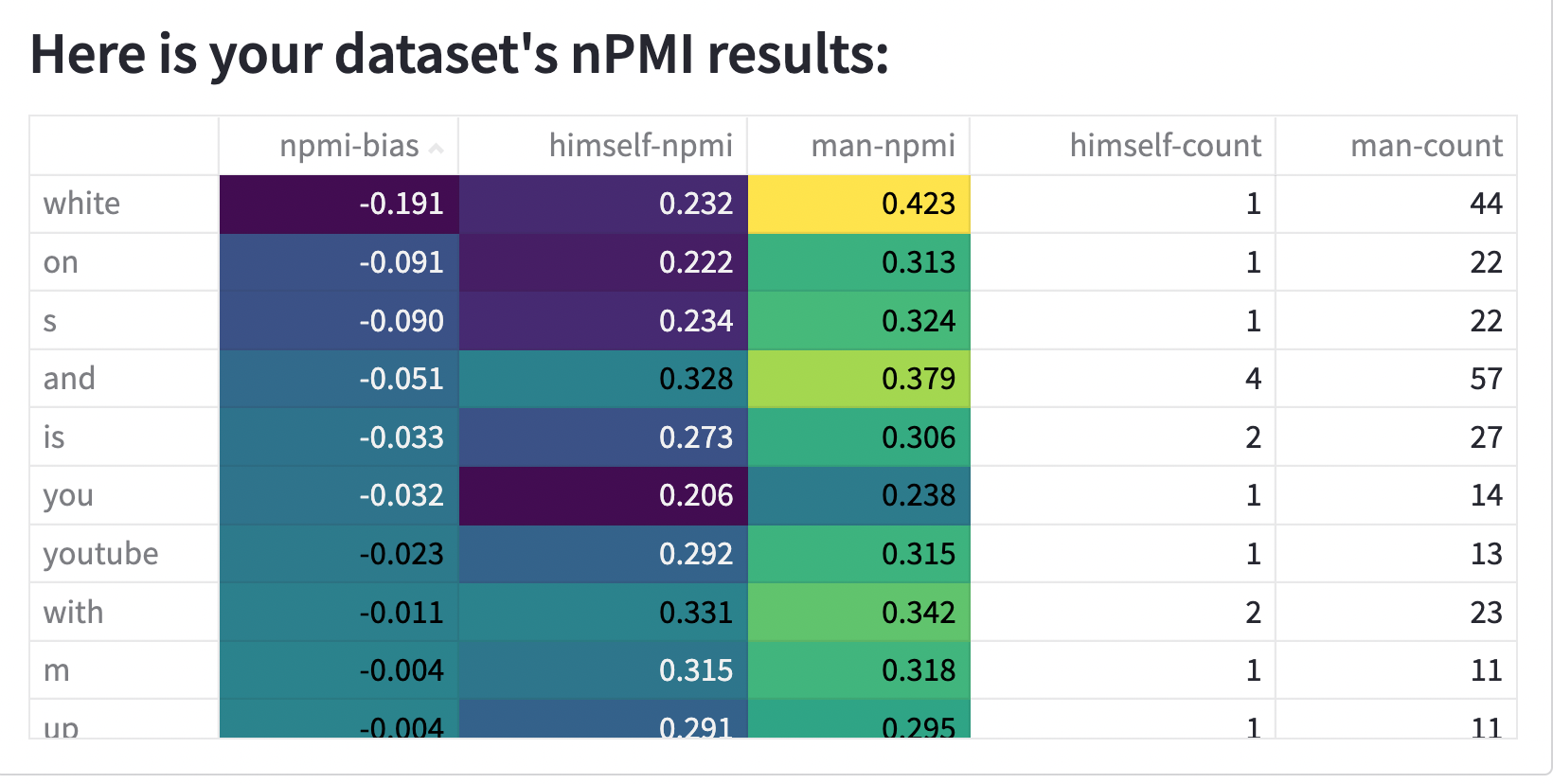
|
| 127 |
+
|
| 128 |
+
### Other Known Limitations
|
| 129 |
+
|
| 130 |
+
[More Information Needed]
|
| 131 |
+
|
| 132 |
+
### Licensing Information
|
| 133 |
+
|
| 134 |
+
License: Demo.Org Proprietary - DO NOT SHARE
|
huggingface_dataset/Dataset_Card/flax-sentence-embeddings_paws-jsonl.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Introduction
|
| 2 |
+
This dataset is a jsonl format for PAWS dataset from: https://github.com/google-research-datasets/paws. It only contains the `PAWS-Wiki Labeled (Final)` and
|
| 3 |
+
`PAWS-Wiki Labeled (Swap-only)` training sections of the original PAWS dataset. Duplicates data are removed.
|
| 4 |
+
|
| 5 |
+
Each line contains a dict in the following format:
|
| 6 |
+
|
| 7 |
+
`{"guid": <id>, "texts": [anchor, positive]}` or
|
| 8 |
+
|
| 9 |
+
`{"guid": <id>, "texts": [anchor, positive, negative]}`
|
| 10 |
+
|
| 11 |
+
positives_negatives.jsonl.gz: 24,723
|
| 12 |
+
|
| 13 |
+
positives_only.jsonl.gz: 13,487
|
| 14 |
+
|
| 15 |
+
**Total**: 38,210
|
| 16 |
+
|
| 17 |
+
## Dataset summary
|
| 18 |
+
[**PAWS: Paraphrase Adversaries from Word Scrambling**](https://github.com/google-research-datasets/paws)
|
| 19 |
+
|
| 20 |
+
This dataset contains 108,463 human-labeled and 656k noisily labeled pairs that feature the importance of modeling structure, context, and word order information for the problem of paraphrase identification. The dataset has two subsets, one based on Wikipedia and the other one based on the Quora Question Pairs (QQP) dataset.
|
huggingface_dataset/Dataset_Card/huggingartists_kojey-radical.md
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
tags:
|
| 5 |
+
- huggingartists
|
| 6 |
+
- lyrics
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# Dataset Card for "huggingartists/kojey-radical"
|
| 10 |
+
|
| 11 |
+
## Table of Contents
|
| 12 |
+
- [Dataset Description](#dataset-description)
|
| 13 |
+
- [Dataset Summary](#dataset-summary)
|
| 14 |
+
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
|
| 15 |
+
- [Languages](#languages)
|
| 16 |
+
- [How to use](#how-to-use)
|
| 17 |
+
- [Dataset Structure](#dataset-structure)
|
| 18 |
+
- [Data Fields](#data-fields)
|
| 19 |
+
- [Data Splits](#data-splits)
|
| 20 |
+
- [Dataset Creation](#dataset-creation)
|
| 21 |
+
- [Curation Rationale](#curation-rationale)
|
| 22 |
+
- [Source Data](#source-data)
|
| 23 |
+
- [Annotations](#annotations)
|
| 24 |
+
- [Personal and Sensitive Information](#personal-and-sensitive-information)
|
| 25 |
+
- [Considerations for Using the Data](#considerations-for-using-the-data)
|
| 26 |
+
- [Social Impact of Dataset](#social-impact-of-dataset)
|
| 27 |
+
- [Discussion of Biases](#discussion-of-biases)
|
| 28 |
+
- [Other Known Limitations](#other-known-limitations)
|
| 29 |
+
- [Additional Information](#additional-information)
|
| 30 |
+
- [Dataset Curators](#dataset-curators)
|
| 31 |
+
- [Licensing Information](#licensing-information)
|
| 32 |
+
- [Citation Information](#citation-information)
|
| 33 |
+
- [About](#about)
|
| 34 |
+
|
| 35 |
+
## Dataset Description
|
| 36 |
+
|
| 37 |
+
- **Homepage:** [https://github.com/AlekseyKorshuk/huggingartists](https://github.com/AlekseyKorshuk/huggingartists)
|
| 38 |
+
- **Repository:** [https://github.com/AlekseyKorshuk/huggingartists](https://github.com/AlekseyKorshuk/huggingartists)
|
| 39 |
+
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 40 |
+
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 41 |
+
- **Size of the generated dataset:** 0.317423 MB
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
<div class="inline-flex flex-col" style="line-height: 1.5;">
|
| 45 |
+
<div class="flex">
|
| 46 |
+
<div style="display:DISPLAY_1; margin-left: auto; margin-right: auto; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://images.genius.com/69984b683bf9f7d43b1580896174bf9f.673x673x1.jpg')">
|
| 47 |
+
</div>
|
| 48 |
+
</div>
|
| 49 |
+
<a href="https://huggingface.co/huggingartists/kojey-radical">
|
| 50 |
+
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 HuggingArtists Model 🤖</div>
|
| 51 |
+
</a>
|
| 52 |
+
<div style="text-align: center; font-size: 16px; font-weight: 800">Kojey Radical</div>
|
| 53 |
+
<a href="https://genius.com/artists/kojey-radical">
|
| 54 |
+
<div style="text-align: center; font-size: 14px;">@kojey-radical</div>
|
| 55 |
+
</a>
|
| 56 |
+
</div>
|
| 57 |
+
|
| 58 |
+
### Dataset Summary
|
| 59 |
+
|
| 60 |
+
The Lyrics dataset parsed from Genius. This dataset is designed to generate lyrics with HuggingArtists.
|
| 61 |
+
Model is available [here](https://huggingface.co/huggingartists/kojey-radical).
|
| 62 |
+
|
| 63 |
+
### Supported Tasks and Leaderboards
|
| 64 |
+
|
| 65 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 66 |
+
|
| 67 |
+
### Languages
|
| 68 |
+
|
| 69 |
+
en
|
| 70 |
+
|
| 71 |
+
## How to use
|
| 72 |
+
|
| 73 |
+
How to load this dataset directly with the datasets library:
|
| 74 |
+
|
| 75 |
+
```python
|
| 76 |
+
from datasets import load_dataset
|
| 77 |
+
|
| 78 |
+
dataset = load_dataset("huggingartists/kojey-radical")
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
## Dataset Structure
|
| 82 |
+
|
| 83 |
+
An example of 'train' looks as follows.
|
| 84 |
+
```
|
| 85 |
+
This example was too long and was cropped:
|
| 86 |
+
|
| 87 |
+
{
|
| 88 |
+
"text": "Look, I was gonna go easy on you\nNot to hurt your feelings\nBut I'm only going to get this one chance\nSomething's wrong, I can feel it..."
|
| 89 |
+
}
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
### Data Fields
|
| 93 |
+
|
| 94 |
+
The data fields are the same among all splits.
|
| 95 |
+
|
| 96 |
+
- `text`: a `string` feature.
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
### Data Splits
|
| 100 |
+
|
| 101 |
+
| train |validation|test|
|
| 102 |
+
|------:|---------:|---:|
|
| 103 |
+
|138| -| -|
|
| 104 |
+
|
| 105 |
+
'Train' can be easily divided into 'train' & 'validation' & 'test' with few lines of code:
|
| 106 |
+
|
| 107 |
+
```python
|
| 108 |
+
from datasets import load_dataset, Dataset, DatasetDict
|
| 109 |
+
import numpy as np
|
| 110 |
+
|
| 111 |
+
datasets = load_dataset("huggingartists/kojey-radical")
|
| 112 |
+
|
| 113 |
+
train_percentage = 0.9
|
| 114 |
+
validation_percentage = 0.07
|
| 115 |
+
test_percentage = 0.03
|
| 116 |
+
|
| 117 |
+
train, validation, test = np.split(datasets['train']['text'], [int(len(datasets['train']['text'])*train_percentage), int(len(datasets['train']['text'])*(train_percentage + validation_percentage))])
|
| 118 |
+
|
| 119 |
+
datasets = DatasetDict(
|
| 120 |
+
{
|
| 121 |
+
'train': Dataset.from_dict({'text': list(train)}),
|
| 122 |
+
'validation': Dataset.from_dict({'text': list(validation)}),
|
| 123 |
+
'test': Dataset.from_dict({'text': list(test)})
|
| 124 |
+
}
|
| 125 |
+
)
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
## Dataset Creation
|
| 129 |
+
|
| 130 |
+
### Curation Rationale
|
| 131 |
+
|
| 132 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 133 |
+
|
| 134 |
+
### Source Data
|
| 135 |
+
|
| 136 |
+
#### Initial Data Collection and Normalization
|
| 137 |
+
|
| 138 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 139 |
+
|
| 140 |
+
#### Who are the source language producers?
|
| 141 |
+
|
| 142 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 143 |
+
|
| 144 |
+
### Annotations
|
| 145 |
+
|
| 146 |
+
#### Annotation process
|
| 147 |
+
|
| 148 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 149 |
+
|
| 150 |
+
#### Who are the annotators?
|
| 151 |
+
|
| 152 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 153 |
+
|
| 154 |
+
### Personal and Sensitive Information
|
| 155 |
+
|
| 156 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 157 |
+
|
| 158 |
+
## Considerations for Using the Data
|
| 159 |
+
|
| 160 |
+
### Social Impact of Dataset
|
| 161 |
+
|
| 162 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 163 |
+
|
| 164 |
+
### Discussion of Biases
|
| 165 |
+
|
| 166 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 167 |
+
|
| 168 |
+
### Other Known Limitations
|
| 169 |
+
|
| 170 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 171 |
+
|
| 172 |
+
## Additional Information
|
| 173 |
+
|
| 174 |
+
### Dataset Curators
|
| 175 |
+
|
| 176 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 177 |
+
|
| 178 |
+
### Licensing Information
|
| 179 |
+
|
| 180 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 181 |
+
|
| 182 |
+
### Citation Information
|
| 183 |
+
|
| 184 |
+
```
|
| 185 |
+
@InProceedings{huggingartists,
|
| 186 |
+
author={Aleksey Korshuk}
|
| 187 |
+
year=2021
|
| 188 |
+
}
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
## About
|
| 193 |
+
|
| 194 |
+
*Built by Aleksey Korshuk*
|
| 195 |
+
|
| 196 |
+
[](https://github.com/AlekseyKorshuk)
|
| 197 |
+
|
| 198 |
+
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
|
| 199 |
+
|
| 200 |
+
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
|
| 201 |
+
|
| 202 |
+
For more details, visit the project repository.
|
| 203 |
+
|
| 204 |
+
[](https://github.com/AlekseyKorshuk/huggingartists)
|
huggingface_dataset/Dataset_Card/huggingartists_krept-and-konan-bugzy-malone-sl-morisson-abra-cadabra-rv-and-snap-capone.md
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
tags:
|
| 5 |
+
- huggingartists
|
| 6 |
+
- lyrics
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# Dataset Card for "huggingartists/krept-and-konan-bugzy-malone-sl-morisson-abra-cadabra-rv-and-snap-capone"
|
| 10 |
+
|
| 11 |
+
## Table of Contents
|
| 12 |
+
- [Dataset Description](#dataset-description)
|
| 13 |
+
- [Dataset Summary](#dataset-summary)
|
| 14 |
+
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
|
| 15 |
+
- [Languages](#languages)
|
| 16 |
+
- [How to use](#how-to-use)
|
| 17 |
+
- [Dataset Structure](#dataset-structure)
|
| 18 |
+
- [Data Fields](#data-fields)
|
| 19 |
+
- [Data Splits](#data-splits)
|
| 20 |
+
- [Dataset Creation](#dataset-creation)
|
| 21 |
+
- [Curation Rationale](#curation-rationale)
|
| 22 |
+
- [Source Data](#source-data)
|
| 23 |
+
- [Annotations](#annotations)
|
| 24 |
+
- [Personal and Sensitive Information](#personal-and-sensitive-information)
|
| 25 |
+
- [Considerations for Using the Data](#considerations-for-using-the-data)
|
| 26 |
+
- [Social Impact of Dataset](#social-impact-of-dataset)
|
| 27 |
+
- [Discussion of Biases](#discussion-of-biases)
|
| 28 |
+
- [Other Known Limitations](#other-known-limitations)
|
| 29 |
+
- [Additional Information](#additional-information)
|
| 30 |
+
- [Dataset Curators](#dataset-curators)
|
| 31 |
+
- [Licensing Information](#licensing-information)
|
| 32 |
+
- [Citation Information](#citation-information)
|
| 33 |
+
- [About](#about)
|
| 34 |
+
|
| 35 |
+
## Dataset Description
|
| 36 |
+
|
| 37 |
+
- **Homepage:** [https://github.com/AlekseyKorshuk/huggingartists](https://github.com/AlekseyKorshuk/huggingartists)
|
| 38 |
+
- **Repository:** [https://github.com/AlekseyKorshuk/huggingartists](https://github.com/AlekseyKorshuk/huggingartists)
|
| 39 |
+
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 40 |
+
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 41 |
+
- **Size of the generated dataset:** 0.032823 MB
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
<div class="inline-flex flex-col" style="line-height: 1.5;">
|
| 45 |
+
<div class="flex">
|
| 46 |
+
<div style="display:DISPLAY_1; margin-left: auto; margin-right: auto; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://assets.genius.com/images/default_avatar_300.png?1631203230')">
|
| 47 |
+
</div>
|
| 48 |
+
</div>
|
| 49 |
+
<a href="https://huggingface.co/huggingartists/krept-and-konan-bugzy-malone-sl-morisson-abra-cadabra-rv-and-snap-capone">
|
| 50 |
+
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 HuggingArtists Model 🤖</div>
|
| 51 |
+
</a>
|
| 52 |
+
<div style="text-align: center; font-size: 16px; font-weight: 800">Krept & Konan, Bugzy Malone, SL, Morisson, Abra Cadabra, RV & Snap Capone</div>
|
| 53 |
+
<a href="https://genius.com/artists/krept-and-konan-bugzy-malone-sl-morisson-abra-cadabra-rv-and-snap-capone">
|
| 54 |
+
<div style="text-align: center; font-size: 14px;">@krept-and-konan-bugzy-malone-sl-morisson-abra-cadabra-rv-and-snap-capone</div>
|
| 55 |
+
</a>
|
| 56 |
+
</div>
|
| 57 |
+
|
| 58 |
+
### Dataset Summary
|
| 59 |
+
|
| 60 |
+
The Lyrics dataset parsed from Genius. This dataset is designed to generate lyrics with HuggingArtists.
|
| 61 |
+
Model is available [here](https://huggingface.co/huggingartists/krept-and-konan-bugzy-malone-sl-morisson-abra-cadabra-rv-and-snap-capone).
|
| 62 |
+
|
| 63 |
+
### Supported Tasks and Leaderboards
|
| 64 |
+
|
| 65 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 66 |
+
|
| 67 |
+
### Languages
|
| 68 |
+
|
| 69 |
+
en
|
| 70 |
+
|
| 71 |
+
## How to use
|
| 72 |
+
|
| 73 |
+
How to load this dataset directly with the datasets library:
|
| 74 |
+
|
| 75 |
+
```python
|
| 76 |
+
from datasets import load_dataset
|
| 77 |
+
|
| 78 |
+
dataset = load_dataset("huggingartists/krept-and-konan-bugzy-malone-sl-morisson-abra-cadabra-rv-and-snap-capone")
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
## Dataset Structure
|
| 82 |
+
|
| 83 |
+
An example of 'train' looks as follows.
|
| 84 |
+
```
|
| 85 |
+
This example was too long and was cropped:
|
| 86 |
+
|
| 87 |
+
{
|
| 88 |
+
"text": "Look, I was gonna go easy on you\nNot to hurt your feelings\nBut I'm only going to get this one chance\nSomething's wrong, I can feel it..."
|
| 89 |
+
}
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
### Data Fields
|
| 93 |
+
|
| 94 |
+
The data fields are the same among all splits.
|
| 95 |
+
|
| 96 |
+
- `text`: a `string` feature.
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
### Data Splits
|
| 100 |
+
|
| 101 |
+
| train |validation|test|
|
| 102 |
+
|------:|---------:|---:|
|
| 103 |
+
|1| -| -|
|
| 104 |
+
|
| 105 |
+
'Train' can be easily divided into 'train' & 'validation' & 'test' with few lines of code:
|
| 106 |
+
|
| 107 |
+
```python
|
| 108 |
+
from datasets import load_dataset, Dataset, DatasetDict
|
| 109 |
+
import numpy as np
|
| 110 |
+
|
| 111 |
+
datasets = load_dataset("huggingartists/krept-and-konan-bugzy-malone-sl-morisson-abra-cadabra-rv-and-snap-capone")
|
| 112 |
+
|
| 113 |
+
train_percentage = 0.9
|
| 114 |
+
validation_percentage = 0.07
|
| 115 |
+
test_percentage = 0.03
|
| 116 |
+
|
| 117 |
+
train, validation, test = np.split(datasets['train']['text'], [int(len(datasets['train']['text'])*train_percentage), int(len(datasets['train']['text'])*(train_percentage + validation_percentage))])
|
| 118 |
+
|
| 119 |
+
datasets = DatasetDict(
|
| 120 |
+
{
|
| 121 |
+
'train': Dataset.from_dict({'text': list(train)}),
|
| 122 |
+
'validation': Dataset.from_dict({'text': list(validation)}),
|
| 123 |
+
'test': Dataset.from_dict({'text': list(test)})
|
| 124 |
+
}
|
| 125 |
+
)
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
## Dataset Creation
|
| 129 |
+
|
| 130 |
+
### Curation Rationale
|
| 131 |
+
|
| 132 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 133 |
+
|
| 134 |
+
### Source Data
|
| 135 |
+
|
| 136 |
+
#### Initial Data Collection and Normalization
|
| 137 |
+
|
| 138 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 139 |
+
|
| 140 |
+
#### Who are the source language producers?
|
| 141 |
+
|
| 142 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 143 |
+
|
| 144 |
+
### Annotations
|
| 145 |
+
|
| 146 |
+
#### Annotation process
|
| 147 |
+
|
| 148 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 149 |
+
|
| 150 |
+
#### Who are the annotators?
|
| 151 |
+
|
| 152 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 153 |
+
|
| 154 |
+
### Personal and Sensitive Information
|
| 155 |
+
|
| 156 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 157 |
+
|
| 158 |
+
## Considerations for Using the Data
|
| 159 |
+
|
| 160 |
+
### Social Impact of Dataset
|
| 161 |
+
|
| 162 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 163 |
+
|
| 164 |
+
### Discussion of Biases
|
| 165 |
+
|
| 166 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 167 |
+
|
| 168 |
+
### Other Known Limitations
|
| 169 |
+
|
| 170 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 171 |
+
|
| 172 |
+
## Additional Information
|
| 173 |
+
|
| 174 |
+
### Dataset Curators
|
| 175 |
+
|
| 176 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 177 |
+
|
| 178 |
+
### Licensing Information
|
| 179 |
+
|
| 180 |
+
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
| 181 |
+
|
| 182 |
+
### Citation Information
|
| 183 |
+
|
| 184 |
+
```
|
| 185 |
+
@InProceedings{huggingartists,
|
| 186 |
+
author={Aleksey Korshuk}
|
| 187 |
+
year=2021
|
| 188 |
+
}
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
## About
|
| 193 |
+
|
| 194 |
+
*Built by Aleksey Korshuk*
|
| 195 |
+
|
| 196 |
+
[](https://github.com/AlekseyKorshuk)
|
| 197 |
+
|
| 198 |
+
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
|
| 199 |
+
|
| 200 |
+
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
|
| 201 |
+
|
| 202 |
+
For more details, visit the project repository.
|
| 203 |
+
|
| 204 |
+
[](https://github.com/AlekseyKorshuk/huggingartists)
|
huggingface_dataset/Dataset_Card/irds_beir_fiqa_dev.md
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pretty_name: '`beir/fiqa/dev`'
|
| 3 |
+
viewer: false
|
| 4 |
+
source_datasets: ['irds/beir_fiqa']
|
| 5 |
+
task_categories:
|
| 6 |
+
- text-retrieval
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# Dataset Card for `beir/fiqa/dev`
|
| 10 |
+
|
| 11 |
+
The `beir/fiqa/dev` dataset, provided by the [ir-datasets](https://ir-datasets.com/) package.
|
| 12 |
+
For more information about the dataset, see the [documentation](https://ir-datasets.com/beir#beir/fiqa/dev).
|
| 13 |
+
|
| 14 |
+
# Data
|
| 15 |
+
|
| 16 |
+
This dataset provides:
|
| 17 |
+
- `queries` (i.e., topics); count=500
|
| 18 |
+
- `qrels`: (relevance assessments); count=1,238
|
| 19 |
+
|
| 20 |
+
- For `docs`, use [`irds/beir_fiqa`](https://huggingface.co/datasets/irds/beir_fiqa)
|
| 21 |
+
|
| 22 |
+
## Usage
|
| 23 |
+
|
| 24 |
+
```python
|
| 25 |
+
from datasets import load_dataset
|
| 26 |
+
|
| 27 |
+
queries = load_dataset('irds/beir_fiqa_dev', 'queries')
|
| 28 |
+
for record in queries:
|
| 29 |
+
record # {'query_id': ..., 'text': ...}
|
| 30 |
+
|
| 31 |
+
qrels = load_dataset('irds/beir_fiqa_dev', 'qrels')
|
| 32 |
+
for record in qrels:
|
| 33 |
+
record # {'query_id': ..., 'doc_id': ..., 'relevance': ..., 'iteration': ...}
|
| 34 |
+
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
Note that calling `load_dataset` will download the dataset (or provide access instructions when it's not public) and make a copy of the
|
| 38 |
+
data in 🤗 Dataset format.
|
| 39 |
+
|
| 40 |
+
## Citation Information
|
| 41 |
+
|
| 42 |
+
```
|
| 43 |
+
@article{Maia2018Fiqa,
|
| 44 |
+
title={WWW'18 Open Challenge: Financial Opinion Mining and Question Answering},
|
| 45 |
+
author={Macedo Maia and S. Handschuh and A. Freitas and Brian Davis and R. McDermott and M. Zarrouk and A. Balahur},
|
| 46 |
+
journal={Companion Proceedings of the The Web Conference 2018},
|
| 47 |
+
year={2018}
|
| 48 |
+
}
|
| 49 |
+
@article{Thakur2021Beir,
|
| 50 |
+
title = "BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models",
|
| 51 |
+
author = "Thakur, Nandan and Reimers, Nils and Rücklé, Andreas and Srivastava, Abhishek and Gurevych, Iryna",
|
| 52 |
+
journal= "arXiv preprint arXiv:2104.08663",
|
| 53 |
+
month = "4",
|
| 54 |
+
year = "2021",
|
| 55 |
+
url = "https://arxiv.org/abs/2104.08663",
|
| 56 |
+
}
|
| 57 |
+
```
|
huggingface_dataset/Dataset_Card/irds_clueweb09_ar.md
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pretty_name: '`clueweb09/ar`'
|
| 3 |
+
viewer: false
|
| 4 |
+
source_datasets: []
|
| 5 |
+
task_categories:
|
| 6 |
+
- text-retrieval
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# Dataset Card for `clueweb09/ar`
|
| 10 |
+
|
| 11 |
+
The `clueweb09/ar` dataset, provided by the [ir-datasets](https://ir-datasets.com/) package.
|
| 12 |
+
For more information about the dataset, see the [documentation](https://ir-datasets.com/clueweb09#clueweb09/ar).
|
| 13 |
+
|
| 14 |
+
# Data
|
| 15 |
+
|
| 16 |
+
This dataset provides:
|
| 17 |
+
- `docs` (documents, i.e., the corpus); count=29,192,662
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
## Usage
|
| 21 |
+
|
| 22 |
+
```python
|
| 23 |
+
from datasets import load_dataset
|
| 24 |
+
|
| 25 |
+
docs = load_dataset('irds/clueweb09_ar', 'docs')
|
| 26 |
+
for record in docs:
|
| 27 |
+
record # {'doc_id': ..., 'url': ..., 'date': ..., 'http_headers': ..., 'body': ..., 'body_content_type': ...}
|
| 28 |
+
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
Note that calling `load_dataset` will download the dataset (or provide access instructions when it's not public) and make a copy of the
|
| 32 |
+
data in 🤗 Dataset format.
|
huggingface_dataset/Dataset_Card/irds_dpr-w100.md
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pretty_name: '`dpr-w100`'
|
| 3 |
+
viewer: false
|
| 4 |
+
source_datasets: []
|
| 5 |
+
task_categories:
|
| 6 |
+
- text-retrieval
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# Dataset Card for `dpr-w100`
|
| 10 |
+
|
| 11 |
+
The `dpr-w100` dataset, provided by the [ir-datasets](https://ir-datasets.com/) package.
|
| 12 |
+
For more information about the dataset, see the [documentation](https://ir-datasets.com/dpr-w100#dpr-w100).
|
| 13 |
+
|
| 14 |
+
# Data
|
| 15 |
+
|
| 16 |
+
This dataset provides:
|
| 17 |
+
- `docs` (documents, i.e., the corpus); count=21,015,324
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
## Usage
|
| 21 |
+
|
| 22 |
+
```python
|
| 23 |
+
from datasets import load_dataset
|
| 24 |
+
|
| 25 |
+
docs = load_dataset('irds/dpr-w100', 'docs')
|
| 26 |
+
for record in docs:
|
| 27 |
+
record # {'doc_id': ..., 'text': ..., 'title': ...}
|
| 28 |
+
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
Note that calling `load_dataset` will download the dataset (or provide access instructions when it's not public) and make a copy of the
|
| 32 |
+
data in 🤗 Dataset format.
|
| 33 |
+
|
| 34 |
+
## Citation Information
|
| 35 |
+
|
| 36 |
+
```
|
| 37 |
+
@misc{Karpukhin2020Dpr,
|
| 38 |
+
title={Dense Passage Retrieval for Open-Domain Question Answering},
|
| 39 |
+
author={Vladimir Karpukhin and Barlas Oğuz and Sewon Min and Patrick Lewis and Ledell Wu and Sergey Edunov and Danqi Chen and Wen-tau Yih},
|
| 40 |
+
year={2020},
|
| 41 |
+
eprint={2004.04906},
|
| 42 |
+
archivePrefix={arXiv},
|
| 43 |
+
primaryClass={cs.CL}
|
| 44 |
+
}
|
| 45 |
+
```
|
huggingface_dataset/Dataset_Card/jet-universe_jetclass.md
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
---
|
| 4 |
+
|
| 5 |
+
# Dataset Card for JetClass
|
| 6 |
+
|
| 7 |
+
## Table of Contents
|
| 8 |
+
- [Dataset Card for [Dataset Name]](#dataset-card-for-dataset-name)
|
| 9 |
+
- [Table of Contents](#table-of-contents)
|
| 10 |
+
- [Dataset Description](#dataset-description)
|
| 11 |
+
- [Dataset Summary](#dataset-summary)
|
| 12 |
+
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
|
| 13 |
+
- [Languages](#languages)
|
| 14 |
+
- [Dataset Structure](#dataset-structure)
|
| 15 |
+
- [Data Instances](#data-instances)
|
| 16 |
+
- [Data Fields](#data-fields)
|
| 17 |
+
- [Data Splits](#data-splits)
|
| 18 |
+
- [Dataset Creation](#dataset-creation)
|
| 19 |
+
- [Curation Rationale](#curation-rationale)
|
| 20 |
+
- [Source Data](#source-data)
|
| 21 |
+
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
|
| 22 |
+
- [Who are the source language producers?](#who-are-the-source-language-producers)
|
| 23 |
+
- [Annotations](#annotations)
|
| 24 |
+
- [Annotation process](#annotation-process)
|
| 25 |
+
- [Who are the annotators?](#who-are-the-annotators)
|
| 26 |
+
- [Personal and Sensitive Information](#personal-and-sensitive-information)
|
| 27 |
+
- [Considerations for Using the Data](#considerations-for-using-the-data)
|
| 28 |
+
- [Social Impact of Dataset](#social-impact-of-dataset)
|
| 29 |
+
- [Discussion of Biases](#discussion-of-biases)
|
| 30 |
+
- [Other Known Limitations](#other-known-limitations)
|
| 31 |
+
- [Additional Information](#additional-information)
|
| 32 |
+
- [Dataset Curators](#dataset-curators)
|
| 33 |
+
- [Licensing Information](#licensing-information)
|
| 34 |
+
- [Citation Information](#citation-information)
|
| 35 |
+
- [Contributions](#contributions)
|
| 36 |
+
|
| 37 |
+
## Dataset Description
|
| 38 |
+
|
| 39 |
+
- **Homepage:**
|
| 40 |
+
- **Repository:** https://github.com/jet-universe/particle_transformer
|
| 41 |
+
- **Paper:** https://arxiv.org/abs/2202.03772
|
| 42 |
+
- **Leaderboard:**
|
| 43 |
+
- **Point of Contact:** [Huilin Qu](mailto:huilin.qu@cern.ch)
|
| 44 |
+
|
| 45 |
+
### Dataset Summary
|
| 46 |
+
|
| 47 |
+
JetClass is a large and comprehensive dataset to advance deep learning for jet tagging. The dataset consists of 100 million jets for training, with 10 different types of jets. The jets in this dataset generally fall into two categories:
|
| 48 |
+
|
| 49 |
+
* The background jets are initiated by light quarks or gluons (q/g) and are ubiquitously produced at the
|
| 50 |
+
LHC.
|
| 51 |
+
* The signal jets are those arising either from the top quarks (t), or from the W, Z or Higgs (H) bosons. For top quarks and Higgs bosons, we further consider their different decay modes as separate types, because the resulting jets have rather distinct characteristics and are often tagged individually.
|
| 52 |
+
|
| 53 |
+
Jets in this dataset are simulated with standard Monte Carlo event generators used by LHC experiments. The production and decay of the top quarks and the W, Z and Higgs bosons are generated with MADGRAPH5_aMC@NLO. We use PYTHIA to evolve the produced particles, i.e., performing parton showering and hadronization, and produce the final outgoing particles. To be close to realistic jets reconstructed at the ATLAS or CMS experiment, detector effects are simulated with DELPHES using the CMS detector configuration provided in DELPHES. In addition, the impact parameters of electrically charged particles are smeared to match the resolution of the CMS tracking detector . Jets are clustered from DELPHES E-Flow objects with the anti-kT algorithm using a distance
|
| 54 |
+
parameter R = 0.8. Only jets with transverse momentum in 500–1000 GeV and pseudorapidity |η| < 2 are considered. For signal jets, only the “high-quality” ones that fully contain the decay products of initial particles are included.
|
| 55 |
+
|
| 56 |
+
### Supported Tasks and Leaderboards
|
| 57 |
+
|
| 58 |
+
[More Information Needed]
|
| 59 |
+
|
| 60 |
+
### Languages
|
| 61 |
+
|
| 62 |
+
[More Information Needed]
|
| 63 |
+
|
| 64 |
+
## Dataset Structure
|
| 65 |
+
|
| 66 |
+
### Data Instances
|
| 67 |
+
|
| 68 |
+
[More Information Needed]
|
| 69 |
+
|
| 70 |
+
### Data Fields
|
| 71 |
+
|
| 72 |
+
[More Information Needed]
|
| 73 |
+
|
| 74 |
+
### Data Splits
|
| 75 |
+
|
| 76 |
+
[More Information Needed]
|
| 77 |
+
|
| 78 |
+
## Dataset Creation
|
| 79 |
+
|
| 80 |
+
### Curation Rationale
|
| 81 |
+
|
| 82 |
+
[More Information Needed]
|
| 83 |
+
|
| 84 |
+
### Source Data
|
| 85 |
+
|
| 86 |
+
#### Initial Data Collection and Normalization
|
| 87 |
+
|
| 88 |
+
[More Information Needed]
|
| 89 |
+
|
| 90 |
+
#### Who are the source language producers?
|
| 91 |
+
|
| 92 |
+
[More Information Needed]
|
| 93 |
+
|
| 94 |
+
### Annotations
|
| 95 |
+
|
| 96 |
+
#### Annotation process
|
| 97 |
+
|
| 98 |
+
[More Information Needed]
|
| 99 |
+
|
| 100 |
+
#### Who are the annotators?
|
| 101 |
+
|
| 102 |
+
[More Information Needed]
|
| 103 |
+
|
| 104 |
+
### Personal and Sensitive Information
|
| 105 |
+
|
| 106 |
+
[More Information Needed]
|
| 107 |
+
|
| 108 |
+
## Considerations for Using the Data
|
| 109 |
+
|
| 110 |
+
### Social Impact of Dataset
|
| 111 |
+
|
| 112 |
+
[More Information Needed]
|
| 113 |
+
|
| 114 |
+
### Discussion of Biases
|
| 115 |
+
|
| 116 |
+
[More Information Needed]
|
| 117 |
+
|
| 118 |
+
### Other Known Limitations
|
| 119 |
+
|
| 120 |
+
[More Information Needed]
|
| 121 |
+
|
| 122 |
+
## Additional Information
|
| 123 |
+
|
| 124 |
+
### Dataset Curators
|
| 125 |
+
|
| 126 |
+
[More Information Needed]
|
| 127 |
+
|
| 128 |
+
### Licensing Information
|
| 129 |
+
|
| 130 |
+
[More Information Needed]
|
| 131 |
+
|
| 132 |
+
### Citation Information
|
| 133 |
+
|
| 134 |
+
If you use the JetClass dataset, please cite:
|
| 135 |
+
|
| 136 |
+
```
|
| 137 |
+
@article{Qu:2022mxj,
|
| 138 |
+
author = "Qu, Huilin and Li, Congqiao and Qian, Sitian",
|
| 139 |
+
title = "{Particle Transformer for Jet Tagging}",
|
| 140 |
+
eprint = "2202.03772",
|
| 141 |
+
archivePrefix = "arXiv",
|
| 142 |
+
primaryClass = "hep-ph",
|
| 143 |
+
month = "2",
|
| 144 |
+
year = "2022"
|
| 145 |
+
}
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
### Contributions
|
| 149 |
+
|
| 150 |
+
Thanks to [@lewtun](https://github.com/lewtun) for adding this dataset.
|
huggingface_dataset/Dataset_Card/sumedh_MeQSum.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
---
|
| 4 |
+
- Problem type: Summarization
|
| 5 |
+
|
| 6 |
+
languages:
|
| 7 |
+
- en
|
| 8 |
+
|
| 9 |
+
multilinguality:
|
| 10 |
+
- monolingual
|
| 11 |
+
|
| 12 |
+
task_ids:
|
| 13 |
+
- summarization
|
| 14 |
+
|
| 15 |
+
# MeQSum
|
| 16 |
+
Dataset for medical question summarization introduced in the ACL 2019 paper "On the Summarization of Consumer Health Questions": https://www.aclweb.org/anthology/P19-1215
|
| 17 |
+
|
| 18 |
+
### Citation Information
|
| 19 |
+
```bibtex
|
| 20 |
+
@Inproceedings{MeQSum,
|
| 21 |
+
author = {Asma {Ben Abacha} and Dina Demner-Fushman},
|
| 22 |
+
title = {On the Summarization of Consumer Health Questions},
|
| 23 |
+
booktitle = {Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28th - August 2},
|
| 24 |
+
year = {2019},
|
| 25 |
+
abstract = {Question understanding is one of the main challenges in question answering. In real world applications, users often submit natural language questions that are longer than needed and include peripheral information that increases the complexity of the question, leading to substantially more false positives in answer retrieval. In this paper, we study neural abstractive models for medical question summarization. We introduce the MeQSum corpus of 1,000 summarized consumer health questions. We explore data augmentation methods and evaluate state-of-the-art neural abstractive models on this new task. In particular, we show that semantic augmentation from question datasets improves the overall performance, and that pointer-generator networks outperform sequence-to-sequence attentional models on this task, with a ROUGE-1 score of 44.16%. We also present a detailed error analysis and discuss directions for improvement that are specific to question summarization. }}
|
| 26 |
+
```
|
huggingface_dataset/Dataset_Card/text-machine-lab_NEG-1500-SIMP-GEN.md
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
---
|
| 4 |
+
|
| 5 |
+
NEG-1500-SIMP-GEN is an extended version of NEG-136-SIMP. The dataset is extended using GPT-3.
|