File size: 3,021 Bytes
8b8210d 15e1ea1 8b8210d 15e1ea1 8b8210d 15e1ea1 8b8210d 92a4e74 8b8210d 15e1ea1 92a4e74 15e1ea1 92a4e74 15e1ea1 92a4e74 15e1ea1 92a4e74 15e1ea1 8b8210d 15e1ea1 8b8210d 15e1ea1 8b8210d |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
---
license: apache-2.0
---
# GEM_Testing_Arsenal
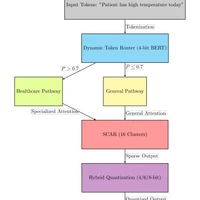
Welcome to ***GEM_Testing_Arsenal***, where groundbreaking research meets practical power! This repository unveils a novel architecture for On-Device Language Models (ODLMs), straight from our paper, ["Fragile Mastery: are domain-specific trade-offs undermining On-Device Language Models?"](./link_to_be_insterted). With just a few lines of code, our custom `gem_trainer.py` script lets you train ODLMs that are more accurate than ever, tracking accuracy and loss as you go.
---
## Highlights:
- **Next-Level ODLMs**: Boosts accuracy with a new architecture from our research.
- **Easy Training**: Call run_gem_pipeline to train on your dataset in minutes.
- **Live Metrics**: Get accuracy and loss results as training unfolds.
- **Flexible Design**: Works with any compatible dataset—plug and play!
---
## Prerequisites:
To dive in, you’ll need:
- **Python** `3.8+`
- Required libraries (go through [quick start](#quick-start) below 👇)
- **Git** *(to clone the repo)*
---
## Quick Start:
1. **Clone the repository:**
```bash
git clone https://huggingface.co/datasets/GEM025/GEM_Arsenal
```
2. **Install Dependencies:**
```pwsh
pip install -r requirements.txt
```
3. **Train Your Model:**
Create a new python file and execute the code like:
```python
from datasets import load_dataset
from gem_trainer import run_gem_pipeline
# Load a dataset (e.g., Banking77) {just replace the dataset here.}
dataset = load_dataset("banking77")
# Train the ODLM
results = run_gem_pipeline(dataset, num_classes=77)
print(results) # See accuracy and loss
```
> ***Boom—your ODLM is training with boosted accuracy!***
---
## Running on Colab/Kaggle?
Well it's pretty similar to the local run.
```python
""" This is very recommended to run for clean ouput during trains...
import warnings
warnings.filterwarnings('ignore')
"""
#@ Step 1: Clone the github repo
! git clone https://huggingface.co/datasets/GEM025/GEM_Arsenal
#@ Step 2: Install all requirements
!pip install -r /content/GEM_Arsenal/requirements.txt #! For colab
"""
@! For kaggle:
!pip install -r /kaggle/working/GEM_Arsenal/requirements.txt
"""
#@ Step 3: Add repo to path
import sys
sys.path.append('/content/GEM_Arsenal') #! Or /kaggle/working/GEM_Arsenal (for kaggle)
#@ Step 4: Import and run function
from gem_trainer import run_gem_pipeline
from datasets import load_dataset
#@ Rest of the code as above
dataset = load_dataset("imdb")
result = run_gem_pipeline(dataset, num_classes=2, num_epochs=2)
print(result)
```
---
## Customizing Training:
`run_gem_pipeline` keeps it simple, but you can tweak it! Dive into [`gem_trainer.py`](./gem_trainer.py) to adjust epochs, batch size, or other settings to fit your needs.
---
## Contributing 💓
Got ideas to make this even better? We’re all ears!
- Fork the repo.
- Branch off (`git checkout -b your-feature`).
- Submit a pull request with your magic.
--- |