
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,10 +1,10 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: mit
|
| 3 |
-
task_categories:
|
| 4 |
-
- visual-question-answering
|
| 5 |
-
language:
|
| 6 |
-
- en
|
| 7 |
-
---
|
| 8 |
|
| 9 |
# VLM 3TP Data Processing
|
| 10 |
|
|
@@ -25,9 +25,7 @@ This document outlines the steps for processing VLM 3TP data, focusing on datase
|
|
| 25 |
- [VSI-Bench Task Details](#vsi-bench-task-details)
|
| 26 |
- [3D Fundamental Tasks (VSI-Bench)](#3d-fundamental-tasks-vsi-bench)
|
| 27 |
- [Metric Estimation Tasks (VSI-Bench)](#metric-estimation-tasks-vsi-bench)
|
| 28 |
-
|
| 29 |
-
- [Prerequisites](#prerequisites)
|
| 30 |
-
- [Usage](#usage)
|
| 31 |
|
| 32 |
## Quick Start: Mono3DRefer Preprocessing Workflow
|
| 33 |
|
|
@@ -41,6 +39,9 @@ Follow the instructions from the respective repositories to download the raw dat
|
|
| 41 |
|
| 42 |
- **Mono3DRefer**: Download data to `data/Mono3DRefer`. Follow instructions at [Mono3DVG](https://github.com/ZhanYang-nwpu/Mono3DVG).
|
| 43 |
|
|
|
|
|
|
|
|
|
|
| 44 |
## 2. Data Preprocessing Details
|
| 45 |
|
| 46 |
This section outlines the general pipeline for preprocessing 3D scene data for tasks. The goal is to extract structured metadata from raw inputs, which can then be used to generate diverse question-answering (QA) datasets.
|
|
@@ -145,11 +146,15 @@ This section details the Question-Answering (QA) tasks. Inspired by the VSI-Benc
|
|
| 145 |
| Object 3D BBox | Fundamental | JSON |
|
| 146 |
| Ind Object Detect | Metric Estimation | JSON |
|
| 147 |
| Object 3D Detect | Metric Estimation | JSON |
|
|
|
|
|
|
|
| 148 |
|
| 149 |
#### 3D Fundamental Tasks (VSI-Bench)
|
| 150 |
|
| 151 |
These tasks extend the advenced vision-language models' capabilities to understand basic 3D spatial properties of objects in a scene.
|
| 152 |
|
|
|
|
|
|
|
| 153 |
- **Indicted Object 3D Attributes:** Asks the basic 3D attributes of the indicated object by box range, point coord, or description indicator.
|
| 154 |
- **QA Generation (`get_ind_obj_size_qa.py`, `...depth_qa.py`, `...ry_qa.py`, `...3dBbox_qa.py`):** This task generates multiple-choice questions asking about the 3D size, depth, rotation_y of an indicated object. And asking for the 3D bounding box coordinates of an indicated object in JSON format.
|
| 155 |
- **Indicator Types:** The indicated object is specified using three types, including object's bounding box range, object's center point coordinate, or object's textual description.
|
|
@@ -165,34 +170,23 @@ These tasks require estimating quantitative metrics based on existing 3D Object
|
|
| 165 |
|
| 166 |
- **Indicted Object 3D Detection:** Asks the indicated object's 3D size and position to estimate the 3D grounding performance with 3D BBox IoU metric.
|
| 167 |
- **QA Generation (`get_ind_obj_3dIou_qa.py`):** This task generates questions asking for the 3D size and position of an indicated object in JSON format.
|
| 168 |
-
- **Indicator Types:** The indicated object is specified using
|
| 169 |
- **Answer Types:** The answers are provided in JSON format.
|
| 170 |
- **Ambiguity Filtering:** To ensure clarity, the script excludes cases where the objects are inappropriately spaced (too close or too far) based on occlusion and truncation levels.
|
| 171 |
- **Multiple Objects 3D Detection:** Asks for the all 3D attributes (category, angle, 2D bbox, 3D size, 3D location, rotation_y) of all objects in the scene to evaluate the 3D detection performance with KITTI 3D AP metric.
|
| 172 |
- **QA Generation (`get_obj_3dDetect_qa.py`):** (Implementation in progress)
|
| 173 |
|
| 174 |
-
|
| 175 |
-
|
| 176 |
-
After generating the QA datasets, due to different tasks having different answer formats (multiple-choice, JSON, etc.), we provide a script `upload_datasets.py` to convert these datasets into a conversational format and upload them to the Hugging Face Hub.
|
| 177 |
-
|
| 178 |
-
### Prerequisites
|
| 179 |
|
| 180 |
-
|
| 181 |
-
|
| 182 |
-
```bash
|
| 183 |
-
pip install huggingface_hub
|
| 184 |
-
```
|
| 185 |
-
|
| 186 |
-
### Usage
|
| 187 |
-
|
| 188 |
-
- Just covert the generated QA JSON files to conversational format, and save them to a specified output directory.
|
| 189 |
-
|
| 190 |
-
```bash
|
| 191 |
-
python upload_datasets.py --input_dir data/qa_output --split_type val --output_dir data/vlm_3tp_data
|
| 192 |
-
```
|
| 193 |
|
| 194 |
-
|
| 195 |
|
| 196 |
-
|
| 197 |
-
|
| 198 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
task_categories:
|
| 4 |
+
- visual-question-answering
|
| 5 |
+
language:
|
| 6 |
+
- en
|
| 7 |
+
---
|
| 8 |
|
| 9 |
# VLM 3TP Data Processing
|
| 10 |
|
|
|
|
| 25 |
- [VSI-Bench Task Details](#vsi-bench-task-details)
|
| 26 |
- [3D Fundamental Tasks (VSI-Bench)](#3d-fundamental-tasks-vsi-bench)
|
| 27 |
- [Metric Estimation Tasks (VSI-Bench)](#metric-estimation-tasks-vsi-bench)
|
| 28 |
+
- [Measurement Tasks (VSI-Bench)](#measurement-tasks-vsi-bench)
|
|
|
|
|
|
|
| 29 |
|
| 30 |
## Quick Start: Mono3DRefer Preprocessing Workflow
|
| 31 |
|
|
|
|
| 39 |
|
| 40 |
- **Mono3DRefer**: Download data to `data/Mono3DRefer`. Follow instructions at [Mono3DVG](https://github.com/ZhanYang-nwpu/Mono3DVG).
|
| 41 |
|
| 42 |
+
The basic 2D visual knowledge is essential for the 3D spatial understanding. The general 2D visual grounding looks like this:
|
| 43 |
+

|
| 44 |
+
|
| 45 |
## 2. Data Preprocessing Details
|
| 46 |
|
| 47 |
This section outlines the general pipeline for preprocessing 3D scene data for tasks. The goal is to extract structured metadata from raw inputs, which can then be used to generate diverse question-answering (QA) datasets.
|
|
|
|
| 146 |
| Object 3D BBox | Fundamental | JSON |
|
| 147 |
| Ind Object Detect | Metric Estimation | JSON |
|
| 148 |
| Object 3D Detect | Metric Estimation | JSON |
|
| 149 |
+
| Object Center Dist | Measurement | Multiple Choice |
|
| 150 |
+
| Object Min Dist | Measurement | Multiple Choice |
|
| 151 |
|
| 152 |
#### 3D Fundamental Tasks (VSI-Bench)
|
| 153 |
|
| 154 |
These tasks extend the advenced vision-language models' capabilities to understand basic 3D spatial properties of objects in a scene.
|
| 155 |
|
| 156 |
+

|
| 157 |
+
|
| 158 |
- **Indicted Object 3D Attributes:** Asks the basic 3D attributes of the indicated object by box range, point coord, or description indicator.
|
| 159 |
- **QA Generation (`get_ind_obj_size_qa.py`, `...depth_qa.py`, `...ry_qa.py`, `...3dBbox_qa.py`):** This task generates multiple-choice questions asking about the 3D size, depth, rotation_y of an indicated object. And asking for the 3D bounding box coordinates of an indicated object in JSON format.
|
| 160 |
- **Indicator Types:** The indicated object is specified using three types, including object's bounding box range, object's center point coordinate, or object's textual description.
|
|
|
|
| 170 |
|
| 171 |
- **Indicted Object 3D Detection:** Asks the indicated object's 3D size and position to estimate the 3D grounding performance with 3D BBox IoU metric.
|
| 172 |
- **QA Generation (`get_ind_obj_3dIou_qa.py`):** This task generates questions asking for the 3D size and position of an indicated object in JSON format.
|
| 173 |
+
- **Indicator Types:** The indicated object is specified using by object's textual description. For each object, there are multiple descriptions available to choose from. We keep all generated QA pairs with different descriptions for the same object to enhance the diversity of the dataset.
|
| 174 |
- **Answer Types:** The answers are provided in JSON format.
|
| 175 |
- **Ambiguity Filtering:** To ensure clarity, the script excludes cases where the objects are inappropriately spaced (too close or too far) based on occlusion and truncation levels.
|
| 176 |
- **Multiple Objects 3D Detection:** Asks for the all 3D attributes (category, angle, 2D bbox, 3D size, 3D location, rotation_y) of all objects in the scene to evaluate the 3D detection performance with KITTI 3D AP metric.
|
| 177 |
- **QA Generation (`get_obj_3dDetect_qa.py`):** (Implementation in progress)
|
| 178 |
|
| 179 |
+
#### Measurement Tasks (VSI-Bench)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 180 |
|
| 181 |
+
These tasks involve measuring spatial relationships between objects in the scene.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 182 |
|
| 183 |
+
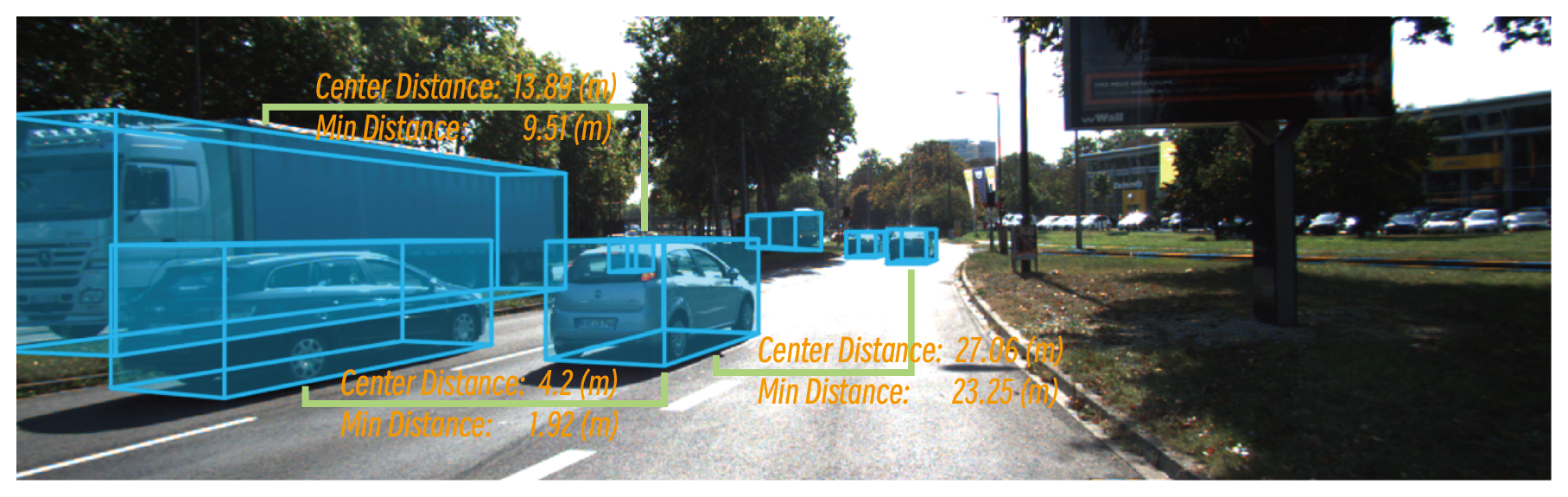
|
| 184 |
|
| 185 |
+
- **Object Center Distance:** Asks for the distance between the centers of two specified objects.
|
| 186 |
+
- **QA Generation (`get_obj_center_distance_qa.py`):** This task generates multiple-choice questions asking for the distance between the centers of two specified objects. The correct answer is calculated using the Euclidean distance formula based on the 3D coordinates of the object centers. The other three distractor options are generated by adding small, random offsets to the correct answer, creating a four-choice question.
|
| 187 |
+
- **Indicator Types:** The two objects are specified using their object's textual description.
|
| 188 |
+
- **Answer Types:** The answers are provided in multiple-choice format.
|
| 189 |
+
- **Object Minimum Distance:** Asks for the minimum distance between the bounding boxes of two specified objects.
|
| 190 |
+
- **QA Generation (`get_obj_min_distance_qa.py`):** This task generates multiple-choice questions asking for the minimum distance between the bounding boxes of two specified objects. The correct answer is calculated using a specialized function that computes the minimum distance between two 3D bounding boxes, considering their dimensions and orientations. The other three distractor options are generated by adding small, random offsets to the correct answer, creating a four-choice question.
|
| 191 |
+
- **Indicator Types:** The two objects are specified using their object's textual description.
|
| 192 |
+
- **Answer Types:** The answers are provided in multiple-choice format.
|