Datasets:

license: apache-2.0
language:
- en
task_categories:
- visual-question-answering
- question-answering
tags:
- vision-language-model
- video-question-answering
- 3d-vision
- spatial-understanding
- streaming-video
- multimodal
- online-3d
size_categories:
- 1M<n<10M
📦 Stream3D-1M-Dataset
Stream3D-1M-Dataset is a large-scale online spatio-temporal 3D question-answering dataset for training vision-language models to understand streaming RGB-D video. It is introduced with Stream3D-VLM: Online 3D Spatial Understanding with Incremental Geometry Priors.
The dataset contains over 1M online 3D QA pairs generated from RGB-D video streams. It is designed to support real-time 3D spatial understanding, temporal memory, and interactive reasoning in streaming environments, where models must process observations incrementally instead of relying on complete offline scene inputs.
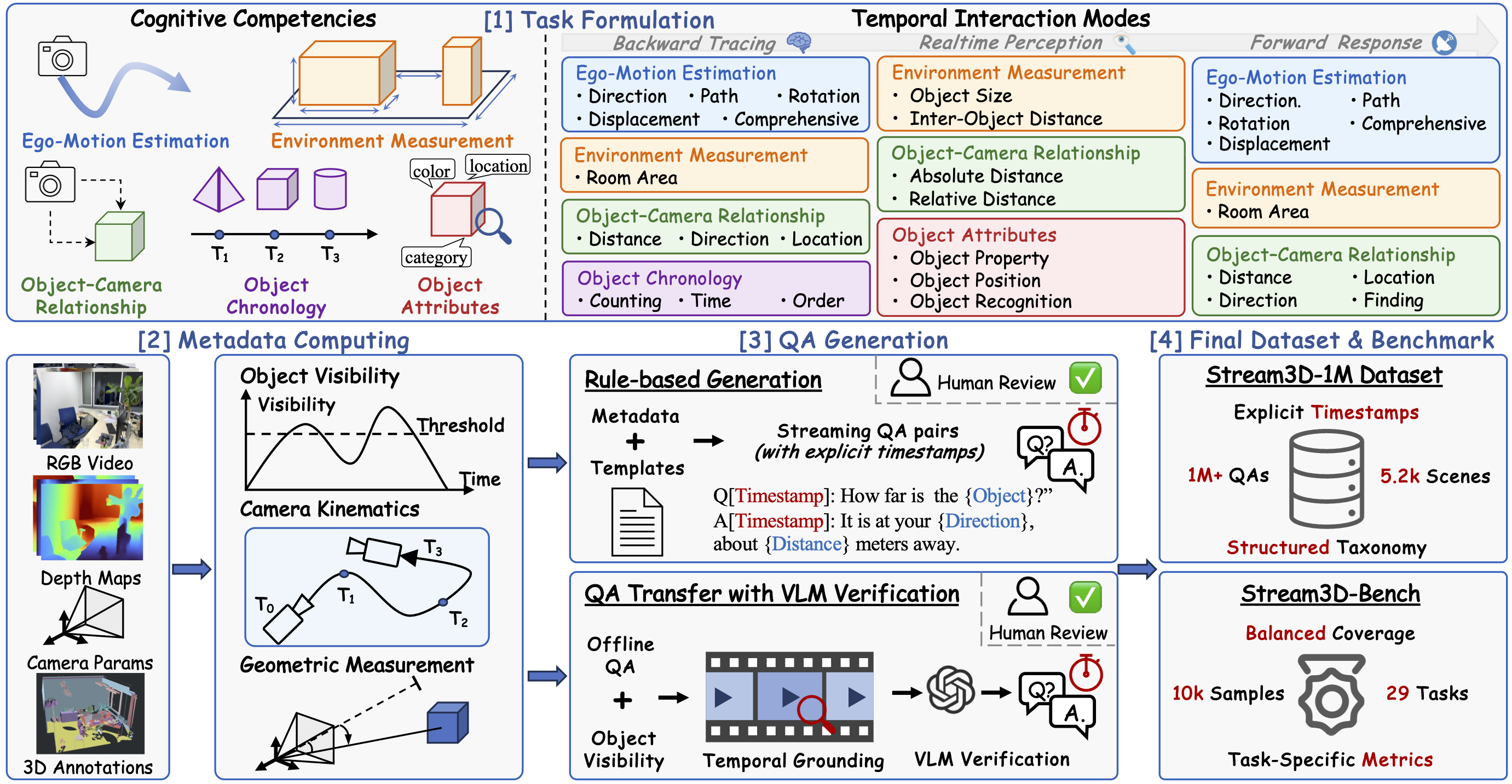
🌟 Features
- Over 1M online spatio-temporal 3D QA pairs
- Built from RGB-D video streams with detailed spatial and temporal metadata
- Covers 5 cognitive competencies and 3 temporal interaction modes
- Supports training models for online 3D spatial understanding from streaming video
- Includes diverse question formats for spatial perception, reasoning, monitoring, and memory
- Designed as the training data for compatible 3D vision-language models
🧠 Task Coverage
Stream3D-1M follows the same task taxonomy as Stream3D-Bench. The tasks are organized around 5 cognitive competencies:
- Ego-Motion Estimation
- Environment Measurement
- Object-Camera Relationship
- Object Attributes
- Object Chronology
The dataset further spans 3 temporal interaction modes:
- Forward Response (Monitoring): tasks that require monitoring future events in the stream
- Realtime Perception (Observation): tasks that require understanding the current frame and immediate surroundings
- Backward Tracing (Memory): tasks that require recalling and reasoning about past observations
📊 Dataset Statistics
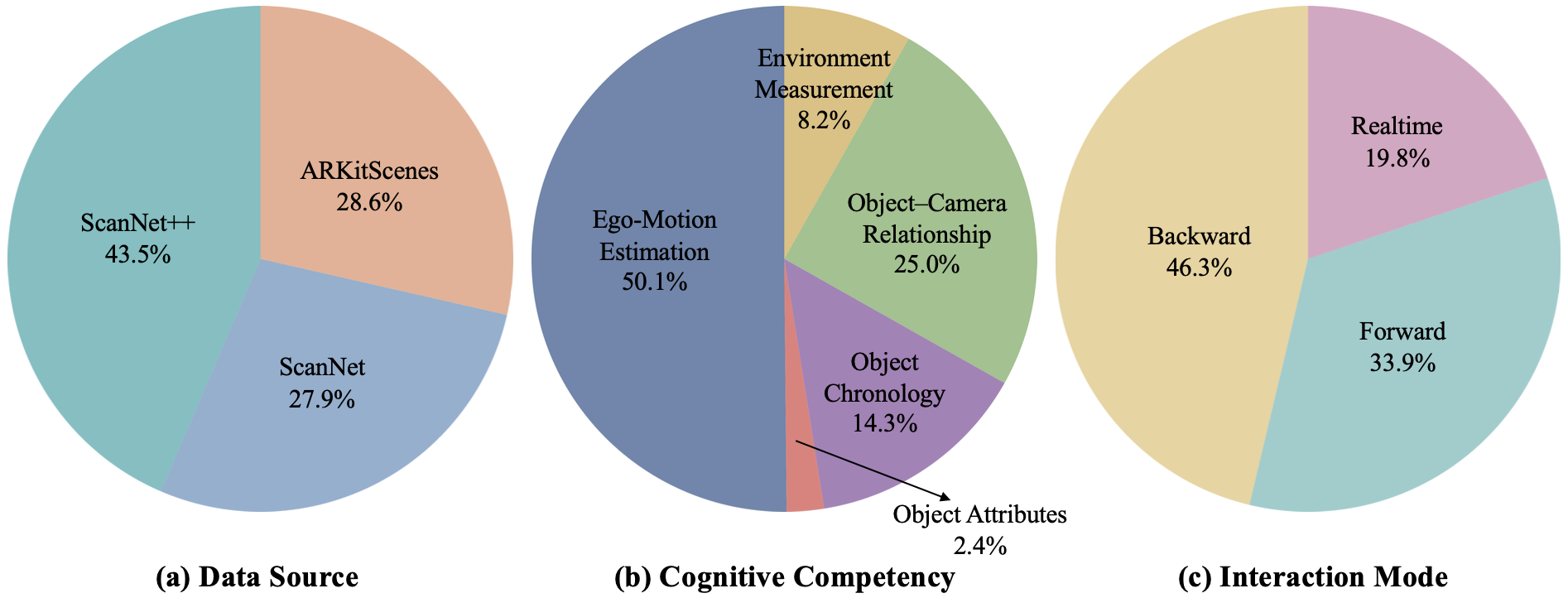
The dataset distribution is analyzed across data source, task category, and interaction mode. ScanNet++ contributes the largest portion of QA pairs due to its dense annotations. Camera Motion tasks account for a major portion of the dataset, and the interaction modes emphasize long-term memory and active monitoring.
🚀 Usage
Please refer to the official repository for:
- Data format details
- Data preprocessing
- Training scripts
- Evaluation examples
- Visualization tools
Repository: https://github.com/hanxunyu/Stream3D-VLM
📝 Citation
If you find Stream3D-1M-Dataset useful for your research or applications, please consider citing our work:
@article{yu2026stream3d,
title={Stream3D-VLM: Online 3D Spatial Understanding with Incremental Geometry Priors},
author={Hanxun Yu and Xuan Qu and Lei Ke and Boqiang Zhang and Yuxin Wang and Jianke Zhu and Dong Yu},
journal={arXiv preprint arXiv:2606.06891},
year={2026}
}