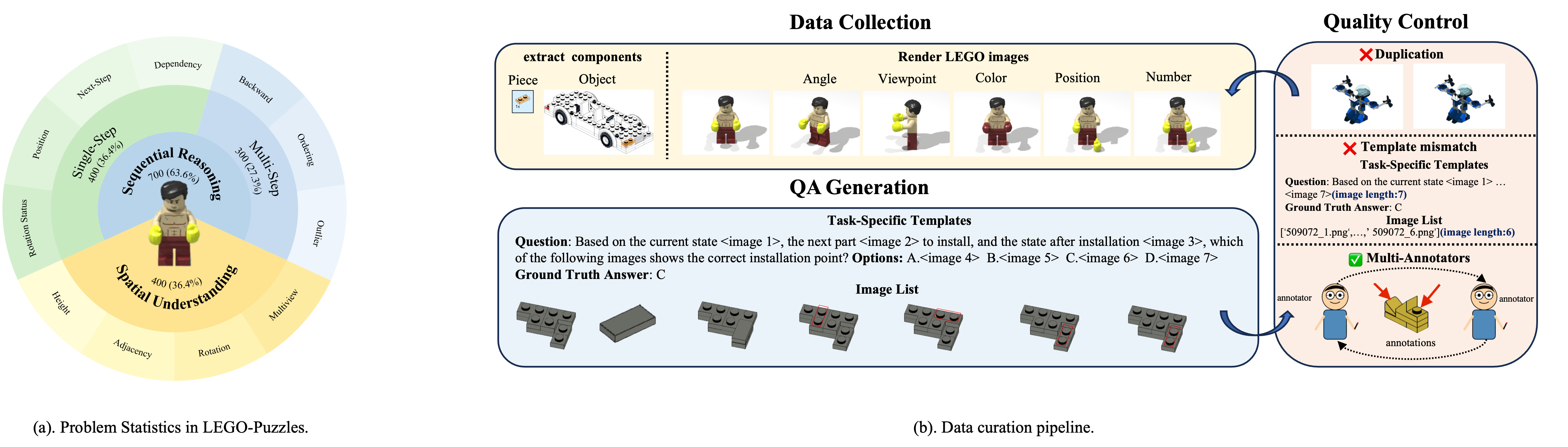
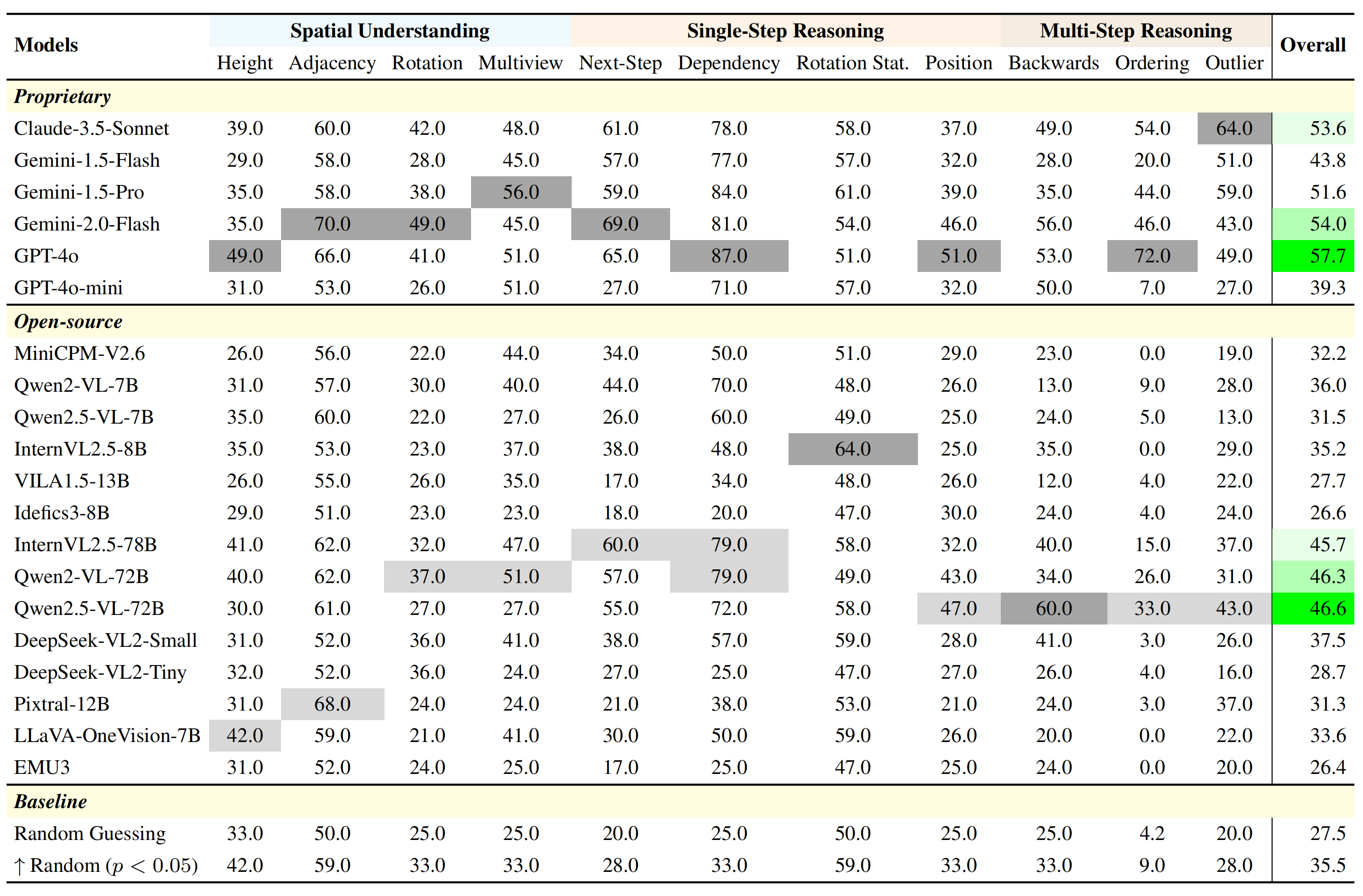
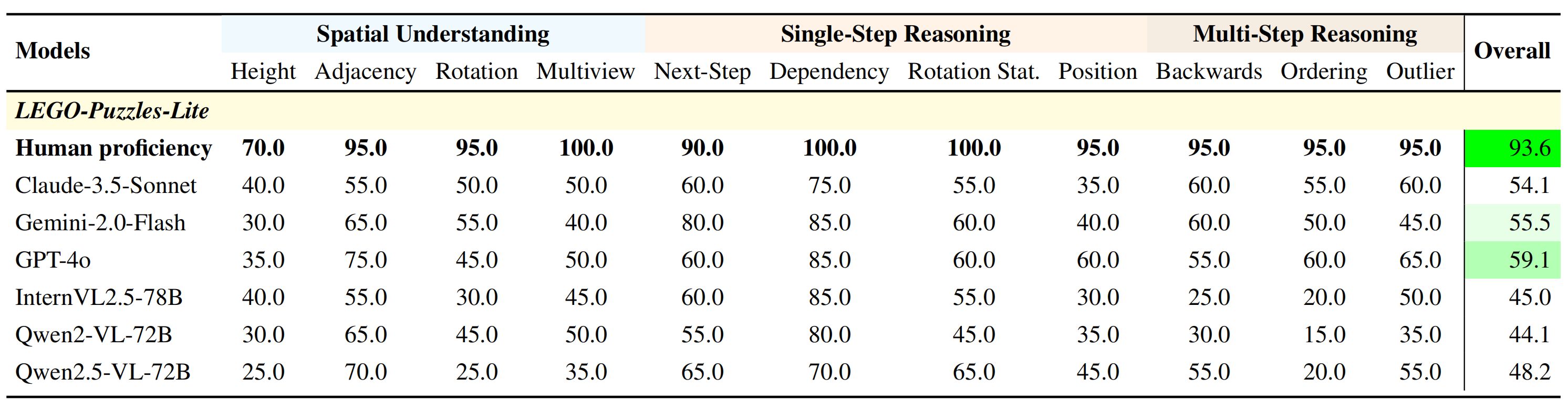
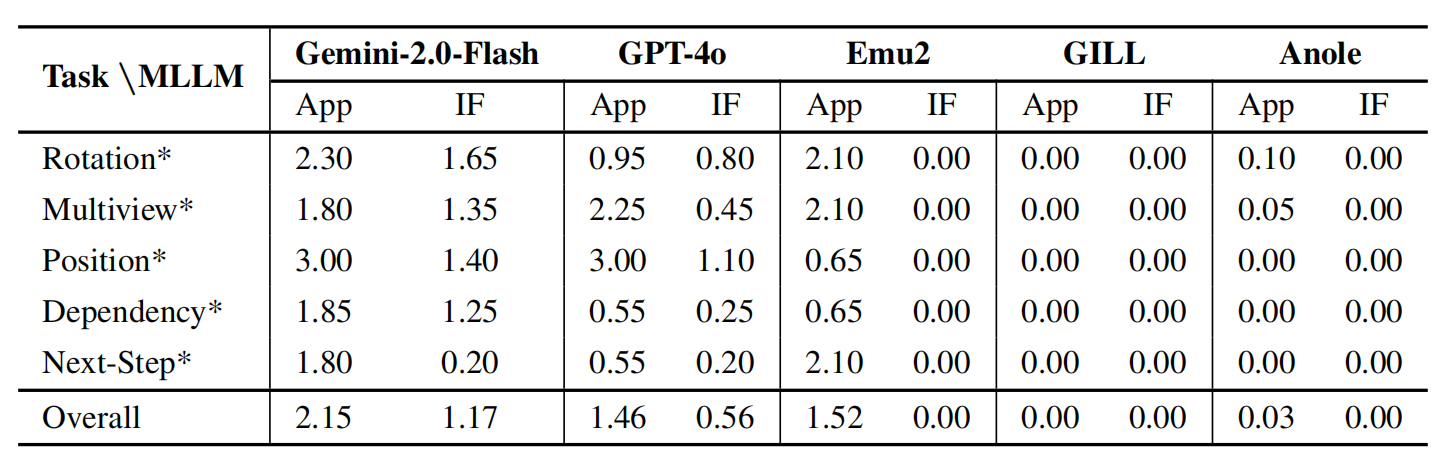
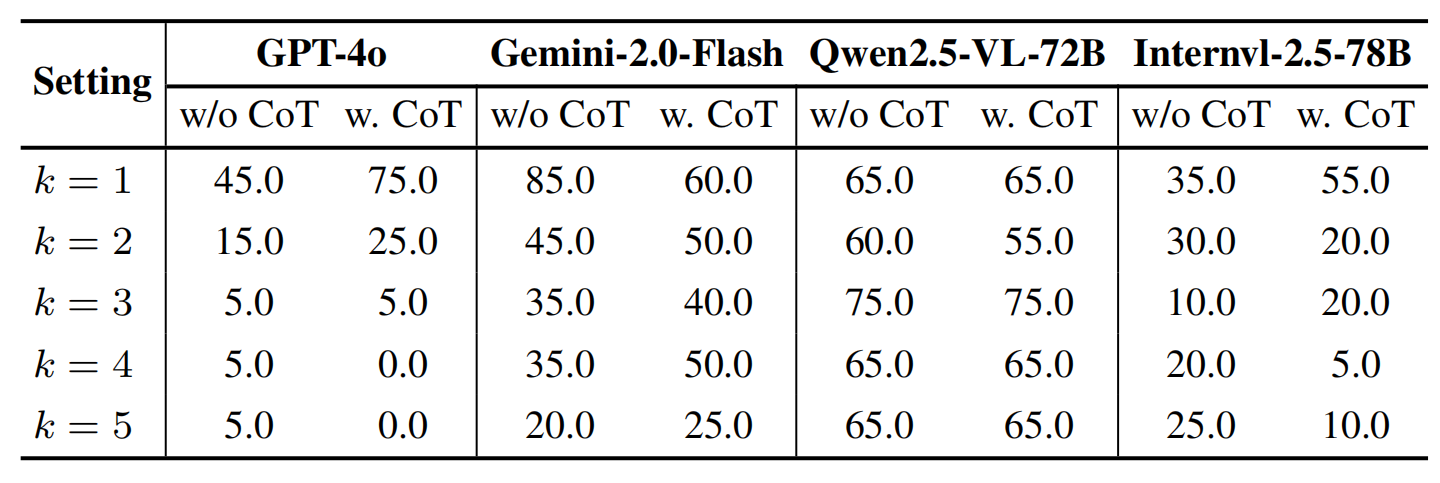
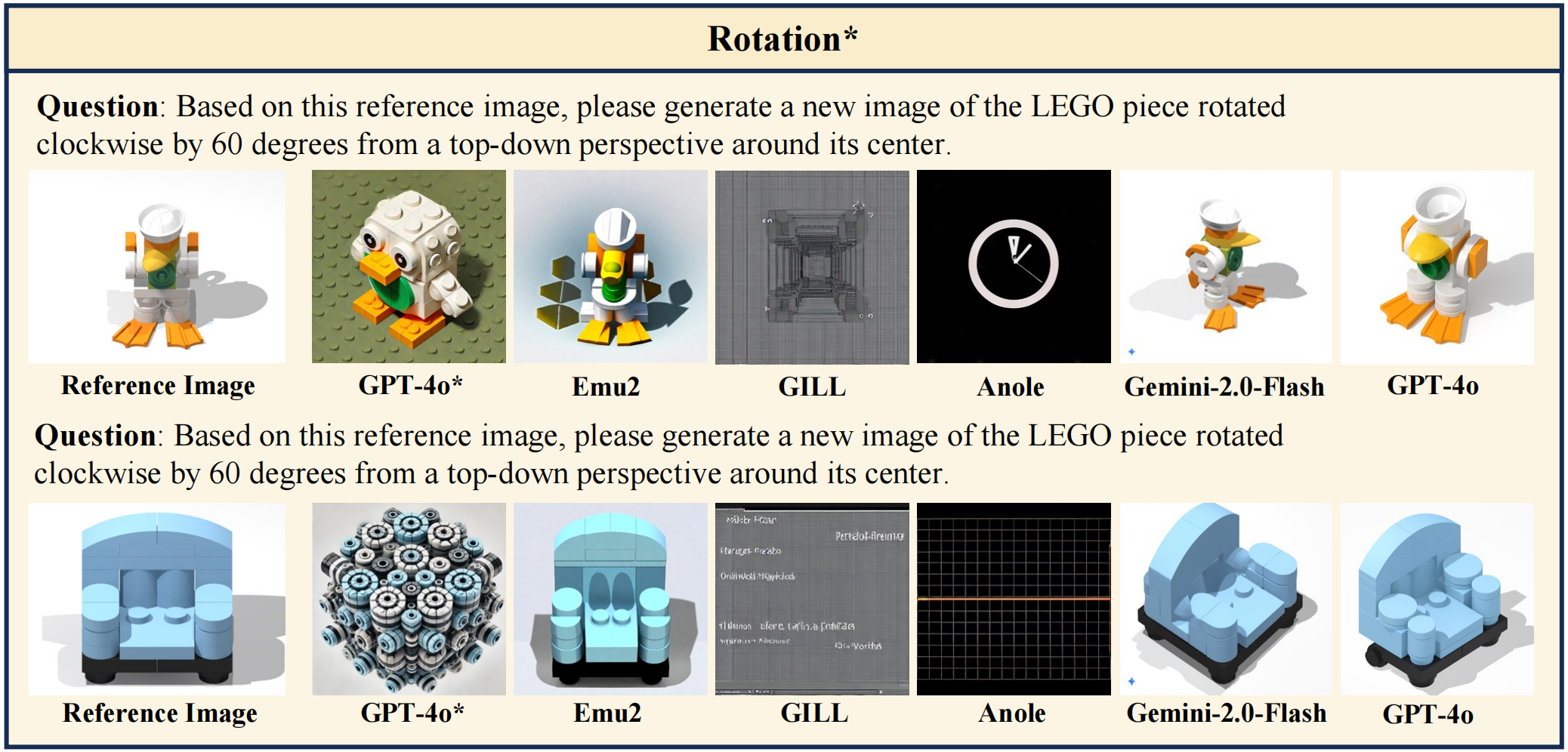
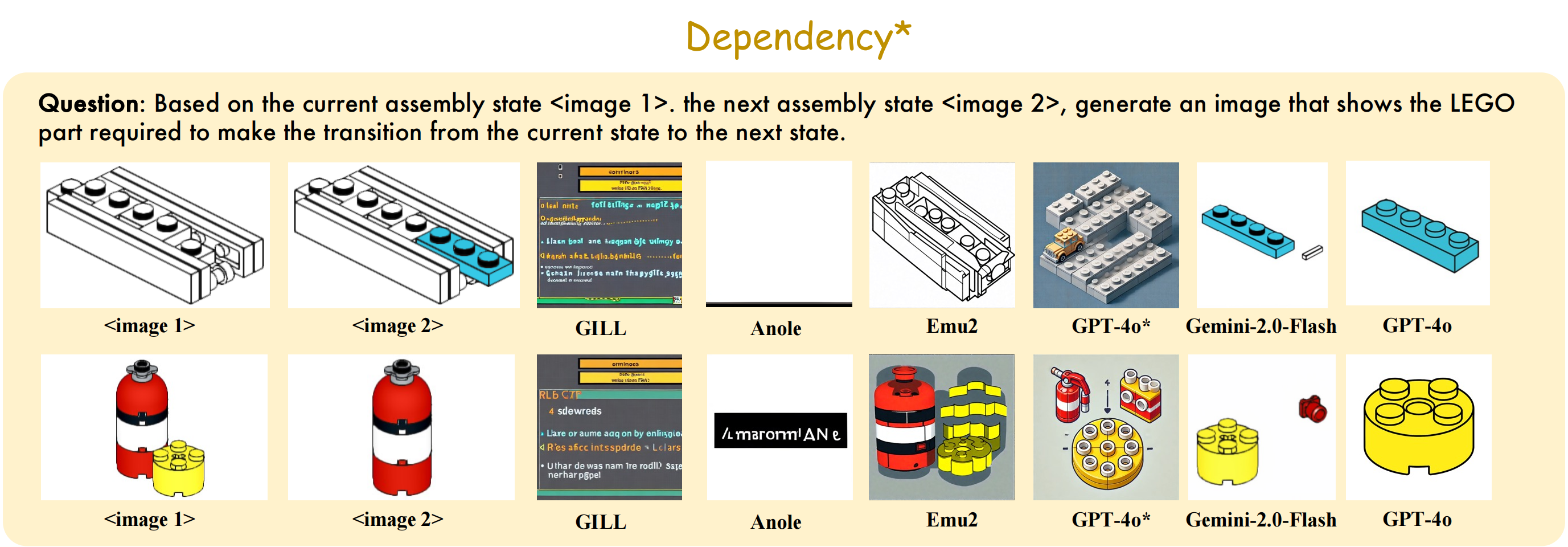
# LEGO-Puzzles: How Good Are MLLMs at Multi-Step Spatial Reasoning?
[Kexian Tang](https://scholar.google.com/citations?user=cXjomd8AAAAJ&hl=zh-CN&oi=ao)
1,2\*,
[Junyao Gao](https://jeoyal.github.io/home/)
1,2\*,
[Yanhong Zeng](https://zengyh1900.github.io)
1†,
[Haodong Duan](https://kennymckormick.github.io/)
1†,
[Yanan Sun](https://scholar.google.com/citations?user=6TA1oPkAAAAJ&hl=zh-CN&oi=ao)
1,
[Zhening Xing](https://scholar.google.com/citations?hl=zh-CN&user=sVYO0GYAAAAJ)
1,
[Wenran Liu](https://scholar.google.com/citations?hl=zh-CN&user=fwKOaD8AAAAJ)
1,
[Kaifeng Lyu](https://kaifeng.ac/cn/)
3‡,
[Kai Chen](https://chenkai.site/)
1‡
1Shanghai AI Laboratory 2Tongji University 3Tsinghua University
\*Equal contribution. †Project Leads. ‡Corresponding Authors.