
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,3 +1,33 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: cc-by-nc-nd-4.0
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: cc-by-nc-nd-4.0
|
| 3 |
+
task_categories:
|
| 4 |
+
- automatic-speech-recognition
|
| 5 |
+
- audio-classification
|
| 6 |
+
tags:
|
| 7 |
+
- speech recognition
|
| 8 |
+
- machine learning
|
| 9 |
+
- NLP
|
| 10 |
+
- ASR
|
| 11 |
+
- audio
|
| 12 |
+
- speech
|
| 13 |
+
size_categories:
|
| 14 |
+
- 1K<n<10K
|
| 15 |
+
---
|
| 16 |
+
# Hindi Speech Dataset for recognition task
|
| 17 |
+
Dataset comprises **760** hours of telephone dialogues in Hindi, collected from **1,000+** native speakers across various topics and domains. This dataset boasts an impressive **95%** sentence accuracy rate, making it a valuable resource for advancing **speech recognition technology**.
|
| 18 |
+
|
| 19 |
+
By utilizing this dataset, researchers and developers can advance their understanding and capabilities in **automatic speech recognition** (ASR) systems, **transcribing audio**, and **natural language processing** (NLP). - **[Get the data](https://unidata.pro/datasets/hindi-speech-recognition-dataset/?utm_source=huggingface&utm_medium=cpc&utm_campaign=hindi-speech-recognition-dataset)**
|
| 20 |
+
|
| 21 |
+
The dataset includes high-quality audio recordings with text transcriptions, making it ideal for training and evaluating speech recognition models.
|
| 22 |
+
# 💵 Buy the Dataset: This is a limited preview of the data. To access the full dataset, please contact us at [https://unidata.pro](https://unidata.pro/datasets/hindi-speech-recognition-dataset/?utm_source=huggingface&utm_medium=cpc&utm_campaign=hindi-speech-recognition-dataset) to discuss your requirements and pricing options.
|
| 23 |
+
|
| 24 |
+
## Metadata for the dataset
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
- **Audio files:** High-quality recordings in **WAV** format
|
| 28 |
+
- **Text transcriptions:** Accurate and detailed **transcripts** for each audio segment
|
| 29 |
+
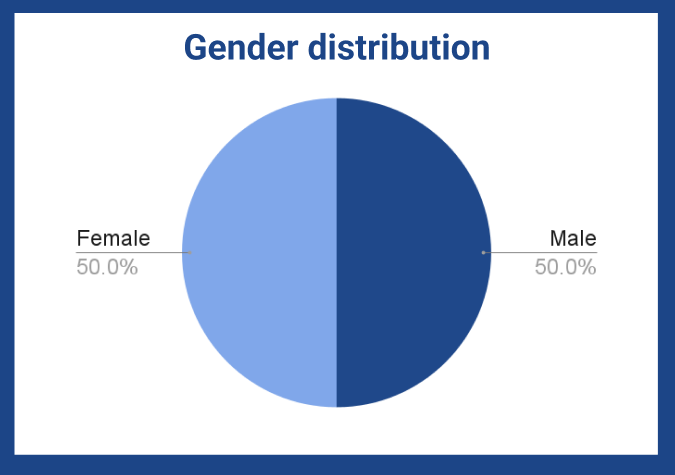
- **Speaker information:** Metadata on **native speakers**, including **gender** and etc
|
| 30 |
+
- **Topics:** Diverse domains such as **general conversations**, **business** and etc
|
| 31 |
+
|
| 32 |
+
This dataset is essential for anyone looking to improve speech recognition technology and develop more effective automatic speech systems.
|
| 33 |
+
# 🌐 [UniData](https://unidata.pro/datasets/hindi-speech-recognition-dataset/?utm_source=huggingface&utm_medium=cpc&utm_campaign=hindi-speech-recognition-dataset) provides high-quality datasets, content moderation, data collection and annotation for your AI/ML projects
|