
Add files using upload-large-folder tool
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- evalkit_tf437/lib/python3.10/site-packages/fastapi-0.103.2.dist-info/METADATA +531 -0
- evalkit_tf437/lib/python3.10/site-packages/fastapi-0.103.2.dist-info/WHEEL +4 -0
- evalkit_tf437/lib/python3.10/site-packages/google_crc32c/_checksum.py +87 -0
- evalkit_tf437/lib/python3.10/site-packages/google_crc32c/_crc32c.cpython-310-x86_64-linux-gnu.so +0 -0
- evalkit_tf437/lib/python3.10/site-packages/google_crc32c/cext.py +45 -0
- evalkit_tf437/lib/python3.10/site-packages/google_crc32c/py.typed +2 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/Openmp/omp-tools.h +1083 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/__pycache__/__init__.cpython-310.pyc +0 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/cupti_callbacks.h +762 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/cupti_checkpoint.h +127 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/cupti_pcsampling_util.h +419 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/cupti_runtime_cbid.h +458 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/generated_cuda_vdpau_interop_meta.h +38 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_nvrtc/__init__.py +0 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_nvrtc/include/__init__.py +0 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_nvrtc/include/nvrtc.h +845 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_nvrtc/lib/__init__.py +0 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_nvrtc/lib/__pycache__/__init__.cpython-310.pyc +0 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/channel_descriptor.h +588 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cooperative_groups/details/coalesced_reduce.h +108 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cooperative_groups/details/scan.h +320 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cudaEGLTypedefs.h +96 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cudaGLTypedefs.h +123 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cuda_fp8.h +367 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cuda_fp8.hpp +1546 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cuda_occupancy.h +1958 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cuda_pipeline_primitives.h +148 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cuda_vdpau_interop.h +201 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/device_atomic_functions.h +217 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/device_double_functions.h +65 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/device_functions.h +65 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/driver_types.h +0 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/library_types.h +103 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/math_functions.h +65 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_20_atomic_functions.hpp +85 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_20_intrinsics.hpp +221 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_30_intrinsics.hpp +604 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_32_intrinsics.hpp +588 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_35_atomic_functions.h +58 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_35_intrinsics.h +116 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_60_atomic_functions.hpp +527 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/texture_fetch_functions.h +223 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/texture_types.h +177 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/vector_types.h +443 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/lib/__init__.py +0 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cudnn/include/__pycache__/__init__.cpython-310.pyc +0 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cudnn/include/cudnn_adv_infer.h +658 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cudnn/include/cudnn_backend.h +608 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cudnn/include/cudnn_cnn_infer_v8.h +571 -0
- evalkit_tf437/lib/python3.10/site-packages/nvidia/cudnn/include/cudnn_cnn_train_v8.h +219 -0
evalkit_tf437/lib/python3.10/site-packages/fastapi-0.103.2.dist-info/METADATA
ADDED
|
@@ -0,0 +1,531 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Metadata-Version: 2.1
|
| 2 |
+
Name: fastapi
|
| 3 |
+
Version: 0.103.2
|
| 4 |
+
Summary: FastAPI framework, high performance, easy to learn, fast to code, ready for production
|
| 5 |
+
Project-URL: Homepage, https://github.com/tiangolo/fastapi
|
| 6 |
+
Project-URL: Documentation, https://fastapi.tiangolo.com/
|
| 7 |
+
Project-URL: Repository, https://github.com/tiangolo/fastapi
|
| 8 |
+
Author-email: Sebastián Ramírez <tiangolo@gmail.com>
|
| 9 |
+
License-Expression: MIT
|
| 10 |
+
License-File: LICENSE
|
| 11 |
+
Classifier: Development Status :: 4 - Beta
|
| 12 |
+
Classifier: Environment :: Web Environment
|
| 13 |
+
Classifier: Framework :: AsyncIO
|
| 14 |
+
Classifier: Framework :: FastAPI
|
| 15 |
+
Classifier: Framework :: Pydantic
|
| 16 |
+
Classifier: Framework :: Pydantic :: 1
|
| 17 |
+
Classifier: Intended Audience :: Developers
|
| 18 |
+
Classifier: Intended Audience :: Information Technology
|
| 19 |
+
Classifier: Intended Audience :: System Administrators
|
| 20 |
+
Classifier: License :: OSI Approved :: MIT License
|
| 21 |
+
Classifier: Operating System :: OS Independent
|
| 22 |
+
Classifier: Programming Language :: Python
|
| 23 |
+
Classifier: Programming Language :: Python :: 3
|
| 24 |
+
Classifier: Programming Language :: Python :: 3 :: Only
|
| 25 |
+
Classifier: Programming Language :: Python :: 3.7
|
| 26 |
+
Classifier: Programming Language :: Python :: 3.8
|
| 27 |
+
Classifier: Programming Language :: Python :: 3.9
|
| 28 |
+
Classifier: Programming Language :: Python :: 3.10
|
| 29 |
+
Classifier: Programming Language :: Python :: 3.11
|
| 30 |
+
Classifier: Topic :: Internet
|
| 31 |
+
Classifier: Topic :: Internet :: WWW/HTTP
|
| 32 |
+
Classifier: Topic :: Internet :: WWW/HTTP :: HTTP Servers
|
| 33 |
+
Classifier: Topic :: Software Development
|
| 34 |
+
Classifier: Topic :: Software Development :: Libraries
|
| 35 |
+
Classifier: Topic :: Software Development :: Libraries :: Application Frameworks
|
| 36 |
+
Classifier: Topic :: Software Development :: Libraries :: Python Modules
|
| 37 |
+
Classifier: Typing :: Typed
|
| 38 |
+
Requires-Python: >=3.7
|
| 39 |
+
Requires-Dist: anyio<4.0.0,>=3.7.1
|
| 40 |
+
Requires-Dist: pydantic!=1.8,!=1.8.1,!=2.0.0,!=2.0.1,!=2.1.0,<3.0.0,>=1.7.4
|
| 41 |
+
Requires-Dist: starlette<0.28.0,>=0.27.0
|
| 42 |
+
Requires-Dist: typing-extensions>=4.5.0
|
| 43 |
+
Provides-Extra: all
|
| 44 |
+
Requires-Dist: email-validator>=2.0.0; extra == 'all'
|
| 45 |
+
Requires-Dist: httpx>=0.23.0; extra == 'all'
|
| 46 |
+
Requires-Dist: itsdangerous>=1.1.0; extra == 'all'
|
| 47 |
+
Requires-Dist: jinja2>=2.11.2; extra == 'all'
|
| 48 |
+
Requires-Dist: orjson>=3.2.1; extra == 'all'
|
| 49 |
+
Requires-Dist: pydantic-extra-types>=2.0.0; extra == 'all'
|
| 50 |
+
Requires-Dist: pydantic-settings>=2.0.0; extra == 'all'
|
| 51 |
+
Requires-Dist: python-multipart>=0.0.5; extra == 'all'
|
| 52 |
+
Requires-Dist: pyyaml>=5.3.1; extra == 'all'
|
| 53 |
+
Requires-Dist: ujson!=4.0.2,!=4.1.0,!=4.2.0,!=4.3.0,!=5.0.0,!=5.1.0,>=4.0.1; extra == 'all'
|
| 54 |
+
Requires-Dist: uvicorn[standard]>=0.12.0; extra == 'all'
|
| 55 |
+
Description-Content-Type: text/markdown
|
| 56 |
+
|
| 57 |
+
<p align="center">
|
| 58 |
+
<a href="https://fastapi.tiangolo.com"><img src="https://fastapi.tiangolo.com/img/logo-margin/logo-teal.png" alt="FastAPI"></a>
|
| 59 |
+
</p>
|
| 60 |
+
<p align="center">
|
| 61 |
+
<em>FastAPI framework, high performance, easy to learn, fast to code, ready for production</em>
|
| 62 |
+
</p>
|
| 63 |
+
<p align="center">
|
| 64 |
+
<a href="https://github.com/tiangolo/fastapi/actions?query=workflow%3ATest+event%3Apush+branch%3Amaster" target="_blank">
|
| 65 |
+
<img src="https://github.com/tiangolo/fastapi/workflows/Test/badge.svg?event=push&branch=master" alt="Test">
|
| 66 |
+
</a>
|
| 67 |
+
<a href="https://coverage-badge.samuelcolvin.workers.dev/redirect/tiangolo/fastapi" target="_blank">
|
| 68 |
+
<img src="https://coverage-badge.samuelcolvin.workers.dev/tiangolo/fastapi.svg" alt="Coverage">
|
| 69 |
+
</a>
|
| 70 |
+
<a href="https://pypi.org/project/fastapi" target="_blank">
|
| 71 |
+
<img src="https://img.shields.io/pypi/v/fastapi?color=%2334D058&label=pypi%20package" alt="Package version">
|
| 72 |
+
</a>
|
| 73 |
+
<a href="https://pypi.org/project/fastapi" target="_blank">
|
| 74 |
+
<img src="https://img.shields.io/pypi/pyversions/fastapi.svg?color=%2334D058" alt="Supported Python versions">
|
| 75 |
+
</a>
|
| 76 |
+
</p>
|
| 77 |
+
|
| 78 |
+
---
|
| 79 |
+
|
| 80 |
+
**Documentation**: <a href="https://fastapi.tiangolo.com" target="_blank">https://fastapi.tiangolo.com</a>
|
| 81 |
+
|
| 82 |
+
**Source Code**: <a href="https://github.com/tiangolo/fastapi" target="_blank">https://github.com/tiangolo/fastapi</a>
|
| 83 |
+
|
| 84 |
+
---
|
| 85 |
+
|
| 86 |
+
FastAPI is a modern, fast (high-performance), web framework for building APIs with Python 3.7+ based on standard Python type hints.
|
| 87 |
+
|
| 88 |
+
The key features are:
|
| 89 |
+
|
| 90 |
+
* **Fast**: Very high performance, on par with **NodeJS** and **Go** (thanks to Starlette and Pydantic). [One of the fastest Python frameworks available](#performance).
|
| 91 |
+
* **Fast to code**: Increase the speed to develop features by about 200% to 300%. *
|
| 92 |
+
* **Fewer bugs**: Reduce about 40% of human (developer) induced errors. *
|
| 93 |
+
* **Intuitive**: Great editor support. <abbr title="also known as auto-complete, autocompletion, IntelliSense">Completion</abbr> everywhere. Less time debugging.
|
| 94 |
+
* **Easy**: Designed to be easy to use and learn. Less time reading docs.
|
| 95 |
+
* **Short**: Minimize code duplication. Multiple features from each parameter declaration. Fewer bugs.
|
| 96 |
+
* **Robust**: Get production-ready code. With automatic interactive documentation.
|
| 97 |
+
* **Standards-based**: Based on (and fully compatible with) the open standards for APIs: <a href="https://github.com/OAI/OpenAPI-Specification" class="external-link" target="_blank">OpenAPI</a> (previously known as Swagger) and <a href="https://json-schema.org/" class="external-link" target="_blank">JSON Schema</a>.
|
| 98 |
+
|
| 99 |
+
<small>* estimation based on tests on an internal development team, building production applications.</small>
|
| 100 |
+
|
| 101 |
+
## Sponsors
|
| 102 |
+
|
| 103 |
+
<!-- sponsors -->
|
| 104 |
+
|
| 105 |
+
<a href="https://cryptapi.io/" target="_blank" title="CryptAPI: Your easy to use, secure and privacy oriented payment gateway."><img src="https://fastapi.tiangolo.com/img/sponsors/cryptapi.svg"></a>
|
| 106 |
+
<a href="https://platform.sh/try-it-now/?utm_source=fastapi-signup&utm_medium=banner&utm_campaign=FastAPI-signup-June-2023" target="_blank" title="Build, run and scale your apps on a modern, reliable, and secure PaaS."><img src="https://fastapi.tiangolo.com/img/sponsors/platform-sh.png"></a>
|
| 107 |
+
<a href="https://www.buildwithfern.com/?utm_source=tiangolo&utm_medium=website&utm_campaign=main-badge" target="_blank" title="Fern | SDKs and API docs"><img src="https://fastapi.tiangolo.com/img/sponsors/fern.svg"></a>
|
| 108 |
+
<a href="https://www.porter.run" target="_blank" title="Deploy FastAPI on AWS with a few clicks"><img src="https://fastapi.tiangolo.com/img/sponsors/porter.png"></a>
|
| 109 |
+
<a href="https://bump.sh/fastapi?utm_source=fastapi&utm_medium=referral&utm_campaign=sponsor" target="_blank" title="Automate FastAPI documentation generation with Bump.sh"><img src="https://fastapi.tiangolo.com/img/sponsors/bump-sh.png"></a>
|
| 110 |
+
<a href="https://www.deta.sh/?ref=fastapi" target="_blank" title="The launchpad for all your (team's) ideas"><img src="https://fastapi.tiangolo.com/img/sponsors/deta.svg"></a>
|
| 111 |
+
<a href="https://training.talkpython.fm/fastapi-courses" target="_blank" title="FastAPI video courses on demand from people you trust"><img src="https://fastapi.tiangolo.com/img/sponsors/talkpython.png"></a>
|
| 112 |
+
<a href="https://testdriven.io/courses/tdd-fastapi/" target="_blank" title="Learn to build high-quality web apps with best practices"><img src="https://fastapi.tiangolo.com/img/sponsors/testdriven.svg"></a>
|
| 113 |
+
<a href="https://github.com/deepset-ai/haystack/" target="_blank" title="Build powerful search from composable, open source building blocks"><img src="https://fastapi.tiangolo.com/img/sponsors/haystack-fastapi.svg"></a>
|
| 114 |
+
<a href="https://careers.powens.com/" target="_blank" title="Powens is hiring!"><img src="https://fastapi.tiangolo.com/img/sponsors/powens.png"></a>
|
| 115 |
+
<a href="https://databento.com/" target="_blank" title="Pay as you go for market data"><img src="https://fastapi.tiangolo.com/img/sponsors/databento.svg"></a>
|
| 116 |
+
<a href="https://speakeasyapi.dev?utm_source=fastapi+repo&utm_medium=github+sponsorship" target="_blank" title="SDKs for your API | Speakeasy"><img src="https://fastapi.tiangolo.com/img/sponsors/speakeasy.png"></a>
|
| 117 |
+
<a href="https://www.svix.com/" target="_blank" title="Svix - Webhooks as a service"><img src="https://fastapi.tiangolo.com/img/sponsors/svix.svg"></a>
|
| 118 |
+
|
| 119 |
+
<!-- /sponsors -->
|
| 120 |
+
|
| 121 |
+
<a href="https://fastapi.tiangolo.com/fastapi-people/#sponsors" class="external-link" target="_blank">Other sponsors</a>
|
| 122 |
+
|
| 123 |
+
## Opinions
|
| 124 |
+
|
| 125 |
+
"_[...] I'm using **FastAPI** a ton these days. [...] I'm actually planning to use it for all of my team's **ML services at Microsoft**. Some of them are getting integrated into the core **Windows** product and some **Office** products._"
|
| 126 |
+
|
| 127 |
+
<div style="text-align: right; margin-right: 10%;">Kabir Khan - <strong>Microsoft</strong> <a href="https://github.com/tiangolo/fastapi/pull/26" target="_blank"><small>(ref)</small></a></div>
|
| 128 |
+
|
| 129 |
+
---
|
| 130 |
+
|
| 131 |
+
"_We adopted the **FastAPI** library to spawn a **REST** server that can be queried to obtain **predictions**. [for Ludwig]_"
|
| 132 |
+
|
| 133 |
+
<div style="text-align: right; margin-right: 10%;">Piero Molino, Yaroslav Dudin, and Sai Sumanth Miryala - <strong>Uber</strong> <a href="https://eng.uber.com/ludwig-v0-2/" target="_blank"><small>(ref)</small></a></div>
|
| 134 |
+
|
| 135 |
+
---
|
| 136 |
+
|
| 137 |
+
"_**Netflix** is pleased to announce the open-source release of our **crisis management** orchestration framework: **Dispatch**! [built with **FastAPI**]_"
|
| 138 |
+
|
| 139 |
+
<div style="text-align: right; margin-right: 10%;">Kevin Glisson, Marc Vilanova, Forest Monsen - <strong>Netflix</strong> <a href="https://netflixtechblog.com/introducing-dispatch-da4b8a2a8072" target="_blank"><small>(ref)</small></a></div>
|
| 140 |
+
|
| 141 |
+
---
|
| 142 |
+
|
| 143 |
+
"_I’m over the moon excited about **FastAPI**. It’s so fun!_"
|
| 144 |
+
|
| 145 |
+
<div style="text-align: right; margin-right: 10%;">Brian Okken - <strong><a href="https://pythonbytes.fm/episodes/show/123/time-to-right-the-py-wrongs?time_in_sec=855" target="_blank">Python Bytes</a> podcast host</strong> <a href="https://twitter.com/brianokken/status/1112220079972728832" target="_blank"><small>(ref)</small></a></div>
|
| 146 |
+
|
| 147 |
+
---
|
| 148 |
+
|
| 149 |
+
"_Honestly, what you've built looks super solid and polished. In many ways, it's what I wanted **Hug** to be - it's really inspiring to see someone build that._"
|
| 150 |
+
|
| 151 |
+
<div style="text-align: right; margin-right: 10%;">Timothy Crosley - <strong><a href="https://www.hug.rest/" target="_blank">Hug</a> creator</strong> <a href="https://news.ycombinator.com/item?id=19455465" target="_blank"><small>(ref)</small></a></div>
|
| 152 |
+
|
| 153 |
+
---
|
| 154 |
+
|
| 155 |
+
"_If you're looking to learn one **modern framework** for building REST APIs, check out **FastAPI** [...] It's fast, easy to use and easy to learn [...]_"
|
| 156 |
+
|
| 157 |
+
"_We've switched over to **FastAPI** for our **APIs** [...] I think you'll like it [...]_"
|
| 158 |
+
|
| 159 |
+
<div style="text-align: right; margin-right: 10%;">Ines Montani - Matthew Honnibal - <strong><a href="https://explosion.ai" target="_blank">Explosion AI</a> founders - <a href="https://spacy.io" target="_blank">spaCy</a> creators</strong> <a href="https://twitter.com/_inesmontani/status/1144173225322143744" target="_blank"><small>(ref)</small></a> - <a href="https://twitter.com/honnibal/status/1144031421859655680" target="_blank"><small>(ref)</small></a></div>
|
| 160 |
+
|
| 161 |
+
---
|
| 162 |
+
|
| 163 |
+
"_If anyone is looking to build a production Python API, I would highly recommend **FastAPI**. It is **beautifully designed**, **simple to use** and **highly scalable**, it has become a **key component** in our API first development strategy and is driving many automations and services such as our Virtual TAC Engineer._"
|
| 164 |
+
|
| 165 |
+
<div style="text-align: right; margin-right: 10%;">Deon Pillsbury - <strong>Cisco</strong> <a href="https://www.linkedin.com/posts/deonpillsbury_cisco-cx-python-activity-6963242628536487936-trAp/" target="_blank"><small>(ref)</small></a></div>
|
| 166 |
+
|
| 167 |
+
---
|
| 168 |
+
|
| 169 |
+
## **Typer**, the FastAPI of CLIs
|
| 170 |
+
|
| 171 |
+
<a href="https://typer.tiangolo.com" target="_blank"><img src="https://typer.tiangolo.com/img/logo-margin/logo-margin-vector.svg" style="width: 20%;"></a>
|
| 172 |
+
|
| 173 |
+
If you are building a <abbr title="Command Line Interface">CLI</abbr> app to be used in the terminal instead of a web API, check out <a href="https://typer.tiangolo.com/" class="external-link" target="_blank">**Typer**</a>.
|
| 174 |
+
|
| 175 |
+
**Typer** is FastAPI's little sibling. And it's intended to be the **FastAPI of CLIs**. ⌨️ 🚀
|
| 176 |
+
|
| 177 |
+
## Requirements
|
| 178 |
+
|
| 179 |
+
Python 3.7+
|
| 180 |
+
|
| 181 |
+
FastAPI stands on the shoulders of giants:
|
| 182 |
+
|
| 183 |
+
* <a href="https://www.starlette.io/" class="external-link" target="_blank">Starlette</a> for the web parts.
|
| 184 |
+
* <a href="https://pydantic-docs.helpmanual.io/" class="external-link" target="_blank">Pydantic</a> for the data parts.
|
| 185 |
+
|
| 186 |
+
## Installation
|
| 187 |
+
|
| 188 |
+
<div class="termy">
|
| 189 |
+
|
| 190 |
+
```console
|
| 191 |
+
$ pip install fastapi
|
| 192 |
+
|
| 193 |
+
---> 100%
|
| 194 |
+
```
|
| 195 |
+
|
| 196 |
+
</div>
|
| 197 |
+
|
| 198 |
+
You will also need an ASGI server, for production such as <a href="https://www.uvicorn.org" class="external-link" target="_blank">Uvicorn</a> or <a href="https://github.com/pgjones/hypercorn" class="external-link" target="_blank">Hypercorn</a>.
|
| 199 |
+
|
| 200 |
+
<div class="termy">
|
| 201 |
+
|
| 202 |
+
```console
|
| 203 |
+
$ pip install "uvicorn[standard]"
|
| 204 |
+
|
| 205 |
+
---> 100%
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+
</div>
|
| 209 |
+
|
| 210 |
+
## Example
|
| 211 |
+
|
| 212 |
+
### Create it
|
| 213 |
+
|
| 214 |
+
* Create a file `main.py` with:
|
| 215 |
+
|
| 216 |
+
```Python
|
| 217 |
+
from typing import Union
|
| 218 |
+
|
| 219 |
+
from fastapi import FastAPI
|
| 220 |
+
|
| 221 |
+
app = FastAPI()
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
@app.get("/")
|
| 225 |
+
def read_root():
|
| 226 |
+
return {"Hello": "World"}
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
@app.get("/items/{item_id}")
|
| 230 |
+
def read_item(item_id: int, q: Union[str, None] = None):
|
| 231 |
+
return {"item_id": item_id, "q": q}
|
| 232 |
+
```
|
| 233 |
+
|
| 234 |
+
<details markdown="1">
|
| 235 |
+
<summary>Or use <code>async def</code>...</summary>
|
| 236 |
+
|
| 237 |
+
If your code uses `async` / `await`, use `async def`:
|
| 238 |
+
|
| 239 |
+
```Python hl_lines="9 14"
|
| 240 |
+
from typing import Union
|
| 241 |
+
|
| 242 |
+
from fastapi import FastAPI
|
| 243 |
+
|
| 244 |
+
app = FastAPI()
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
@app.get("/")
|
| 248 |
+
async def read_root():
|
| 249 |
+
return {"Hello": "World"}
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
@app.get("/items/{item_id}")
|
| 253 |
+
async def read_item(item_id: int, q: Union[str, None] = None):
|
| 254 |
+
return {"item_id": item_id, "q": q}
|
| 255 |
+
```
|
| 256 |
+
|
| 257 |
+
**Note**:
|
| 258 |
+
|
| 259 |
+
If you don't know, check the _"In a hurry?"_ section about <a href="https://fastapi.tiangolo.com/async/#in-a-hurry" target="_blank">`async` and `await` in the docs</a>.
|
| 260 |
+
|
| 261 |
+
</details>
|
| 262 |
+
|
| 263 |
+
### Run it
|
| 264 |
+
|
| 265 |
+
Run the server with:
|
| 266 |
+
|
| 267 |
+
<div class="termy">
|
| 268 |
+
|
| 269 |
+
```console
|
| 270 |
+
$ uvicorn main:app --reload
|
| 271 |
+
|
| 272 |
+
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
|
| 273 |
+
INFO: Started reloader process [28720]
|
| 274 |
+
INFO: Started server process [28722]
|
| 275 |
+
INFO: Waiting for application startup.
|
| 276 |
+
INFO: Application startup complete.
|
| 277 |
+
```
|
| 278 |
+
|
| 279 |
+
</div>
|
| 280 |
+
|
| 281 |
+
<details markdown="1">
|
| 282 |
+
<summary>About the command <code>uvicorn main:app --reload</code>...</summary>
|
| 283 |
+
|
| 284 |
+
The command `uvicorn main:app` refers to:
|
| 285 |
+
|
| 286 |
+
* `main`: the file `main.py` (the Python "module").
|
| 287 |
+
* `app`: the object created inside of `main.py` with the line `app = FastAPI()`.
|
| 288 |
+
* `--reload`: make the server restart after code changes. Only do this for development.
|
| 289 |
+
|
| 290 |
+
</details>
|
| 291 |
+
|
| 292 |
+
### Check it
|
| 293 |
+
|
| 294 |
+
Open your browser at <a href="http://127.0.0.1:8000/items/5?q=somequery" class="external-link" target="_blank">http://127.0.0.1:8000/items/5?q=somequery</a>.
|
| 295 |
+
|
| 296 |
+
You will see the JSON response as:
|
| 297 |
+
|
| 298 |
+
```JSON
|
| 299 |
+
{"item_id": 5, "q": "somequery"}
|
| 300 |
+
```
|
| 301 |
+
|
| 302 |
+
You already created an API that:
|
| 303 |
+
|
| 304 |
+
* Receives HTTP requests in the _paths_ `/` and `/items/{item_id}`.
|
| 305 |
+
* Both _paths_ take `GET` <em>operations</em> (also known as HTTP _methods_).
|
| 306 |
+
* The _path_ `/items/{item_id}` has a _path parameter_ `item_id` that should be an `int`.
|
| 307 |
+
* The _path_ `/items/{item_id}` has an optional `str` _query parameter_ `q`.
|
| 308 |
+
|
| 309 |
+
### Interactive API docs
|
| 310 |
+
|
| 311 |
+
Now go to <a href="http://127.0.0.1:8000/docs" class="external-link" target="_blank">http://127.0.0.1:8000/docs</a>.
|
| 312 |
+
|
| 313 |
+
You will see the automatic interactive API documentation (provided by <a href="https://github.com/swagger-api/swagger-ui" class="external-link" target="_blank">Swagger UI</a>):
|
| 314 |
+
|
| 315 |
+
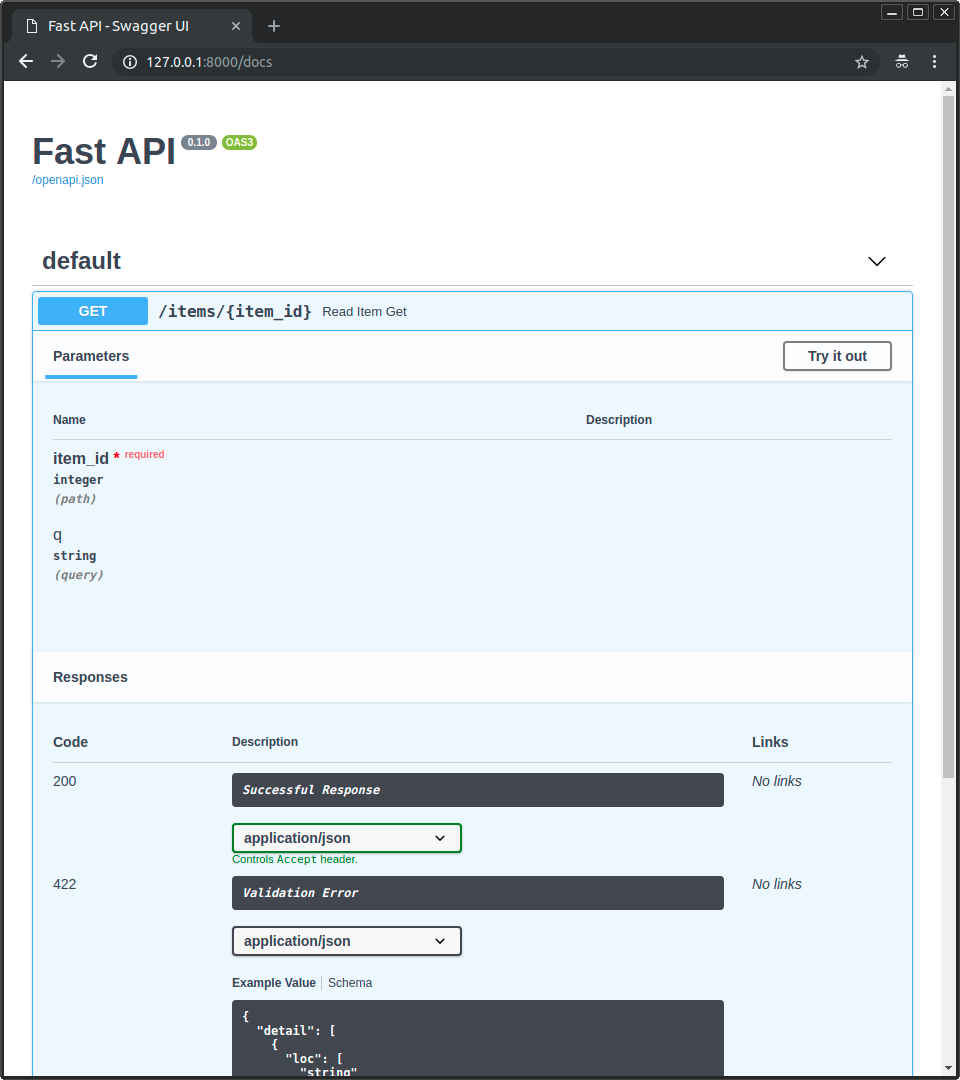
|
| 316 |
+
|
| 317 |
+
### Alternative API docs
|
| 318 |
+
|
| 319 |
+
And now, go to <a href="http://127.0.0.1:8000/redoc" class="external-link" target="_blank">http://127.0.0.1:8000/redoc</a>.
|
| 320 |
+
|
| 321 |
+
You will see the alternative automatic documentation (provided by <a href="https://github.com/Rebilly/ReDoc" class="external-link" target="_blank">ReDoc</a>):
|
| 322 |
+
|
| 323 |
+
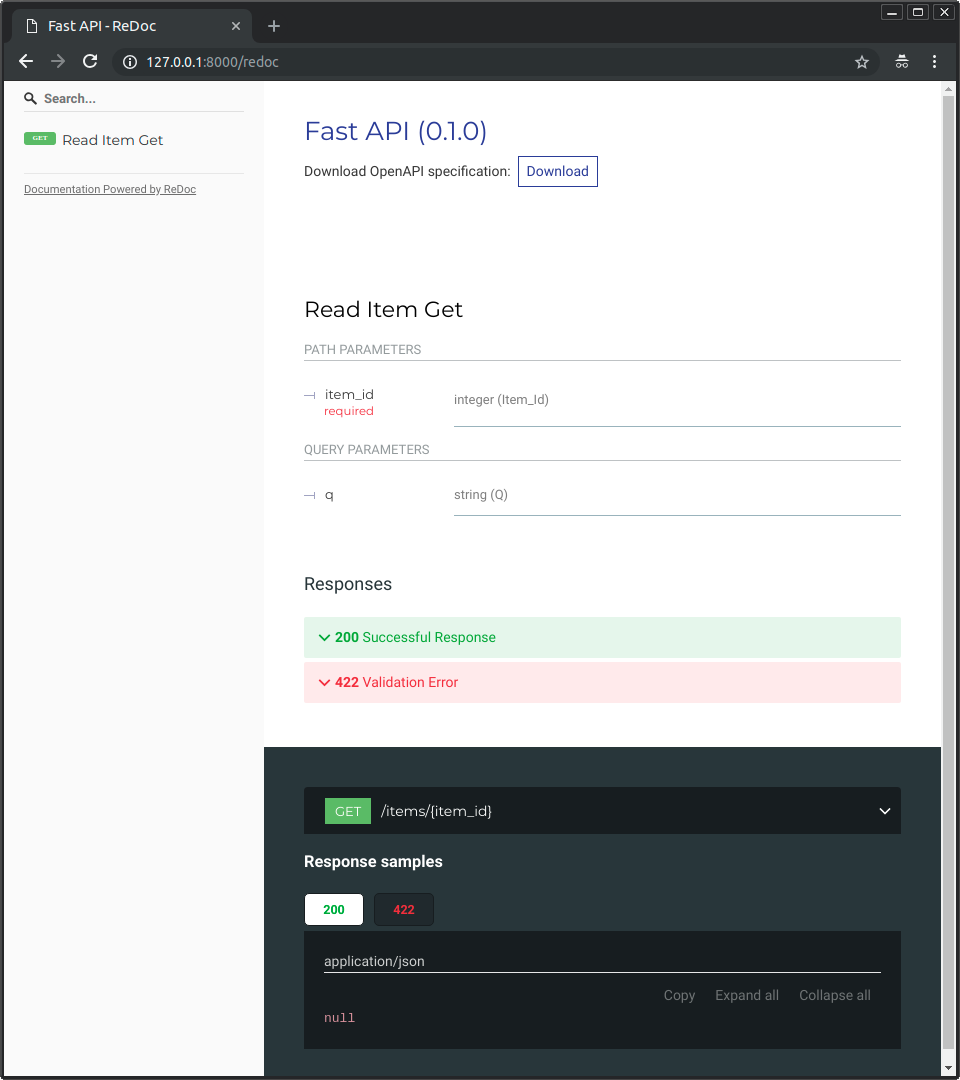
|
| 324 |
+
|
| 325 |
+
## Example upgrade
|
| 326 |
+
|
| 327 |
+
Now modify the file `main.py` to receive a body from a `PUT` request.
|
| 328 |
+
|
| 329 |
+
Declare the body using standard Python types, thanks to Pydantic.
|
| 330 |
+
|
| 331 |
+
```Python hl_lines="4 9-12 25-27"
|
| 332 |
+
from typing import Union
|
| 333 |
+
|
| 334 |
+
from fastapi import FastAPI
|
| 335 |
+
from pydantic import BaseModel
|
| 336 |
+
|
| 337 |
+
app = FastAPI()
|
| 338 |
+
|
| 339 |
+
|
| 340 |
+
class Item(BaseModel):
|
| 341 |
+
name: str
|
| 342 |
+
price: float
|
| 343 |
+
is_offer: Union[bool, None] = None
|
| 344 |
+
|
| 345 |
+
|
| 346 |
+
@app.get("/")
|
| 347 |
+
def read_root():
|
| 348 |
+
return {"Hello": "World"}
|
| 349 |
+
|
| 350 |
+
|
| 351 |
+
@app.get("/items/{item_id}")
|
| 352 |
+
def read_item(item_id: int, q: Union[str, None] = None):
|
| 353 |
+
return {"item_id": item_id, "q": q}
|
| 354 |
+
|
| 355 |
+
|
| 356 |
+
@app.put("/items/{item_id}")
|
| 357 |
+
def update_item(item_id: int, item: Item):
|
| 358 |
+
return {"item_name": item.name, "item_id": item_id}
|
| 359 |
+
```
|
| 360 |
+
|
| 361 |
+
The server should reload automatically (because you added `--reload` to the `uvicorn` command above).
|
| 362 |
+
|
| 363 |
+
### Interactive API docs upgrade
|
| 364 |
+
|
| 365 |
+
Now go to <a href="http://127.0.0.1:8000/docs" class="external-link" target="_blank">http://127.0.0.1:8000/docs</a>.
|
| 366 |
+
|
| 367 |
+
* The interactive API documentation will be automatically updated, including the new body:
|
| 368 |
+
|
| 369 |
+
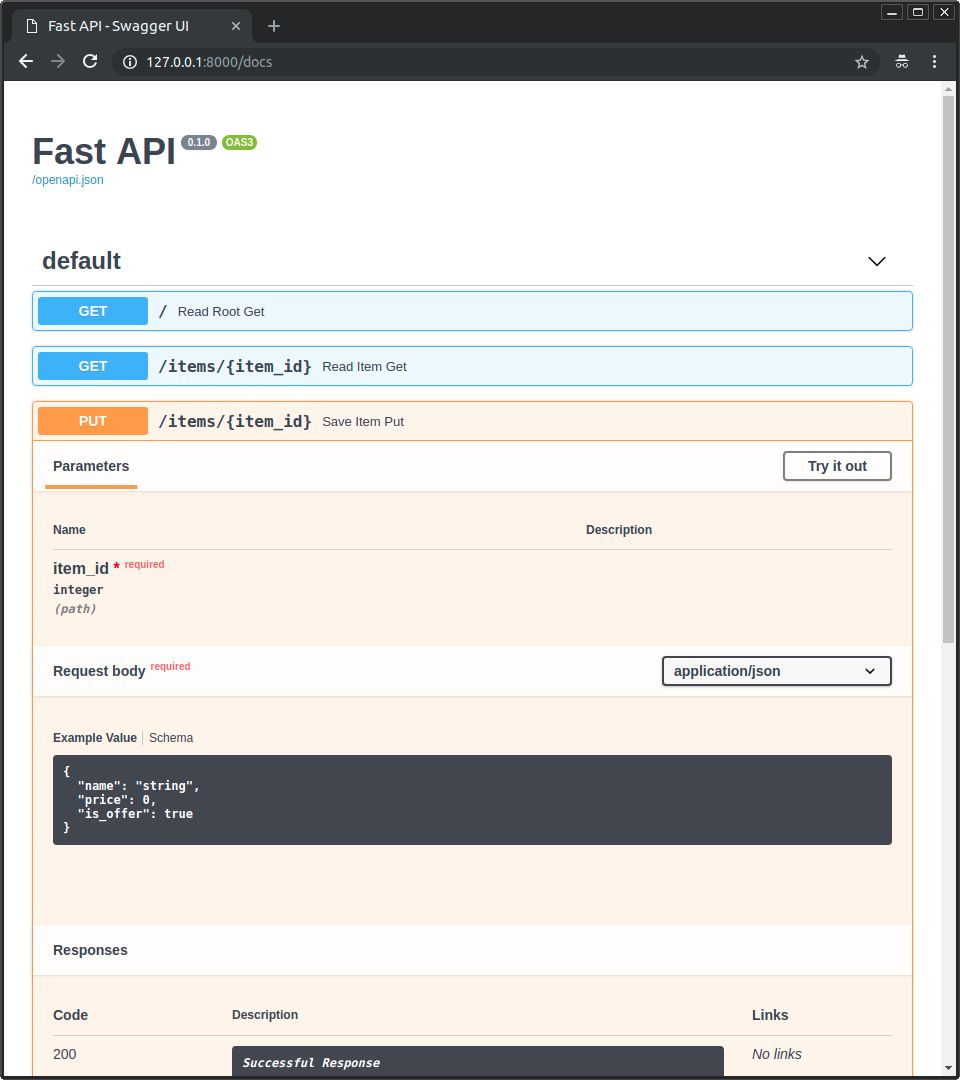
|
| 370 |
+
|
| 371 |
+
* Click on the button "Try it out", it allows you to fill the parameters and directly interact with the API:
|
| 372 |
+
|
| 373 |
+
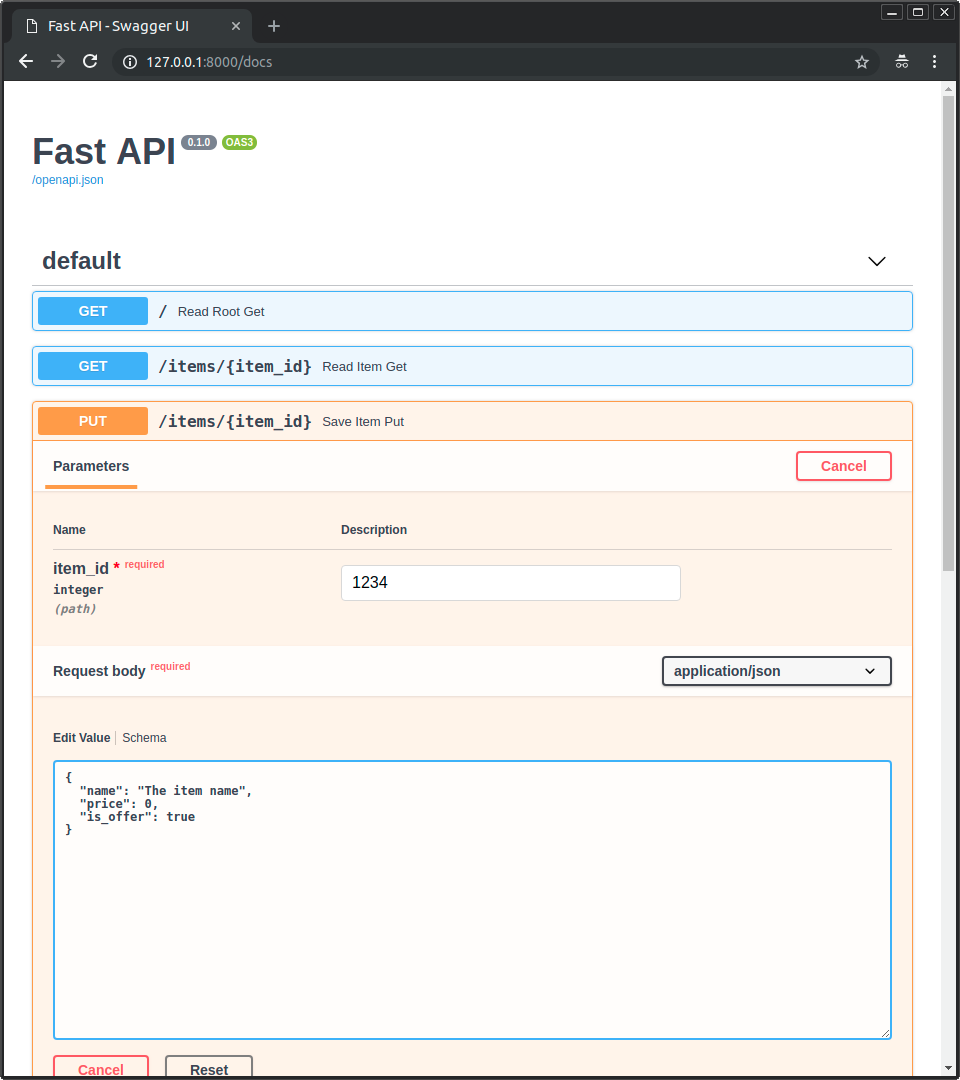
|
| 374 |
+
|
| 375 |
+
* Then click on the "Execute" button, the user interface will communicate with your API, send the parameters, get the results and show them on the screen:
|
| 376 |
+
|
| 377 |
+
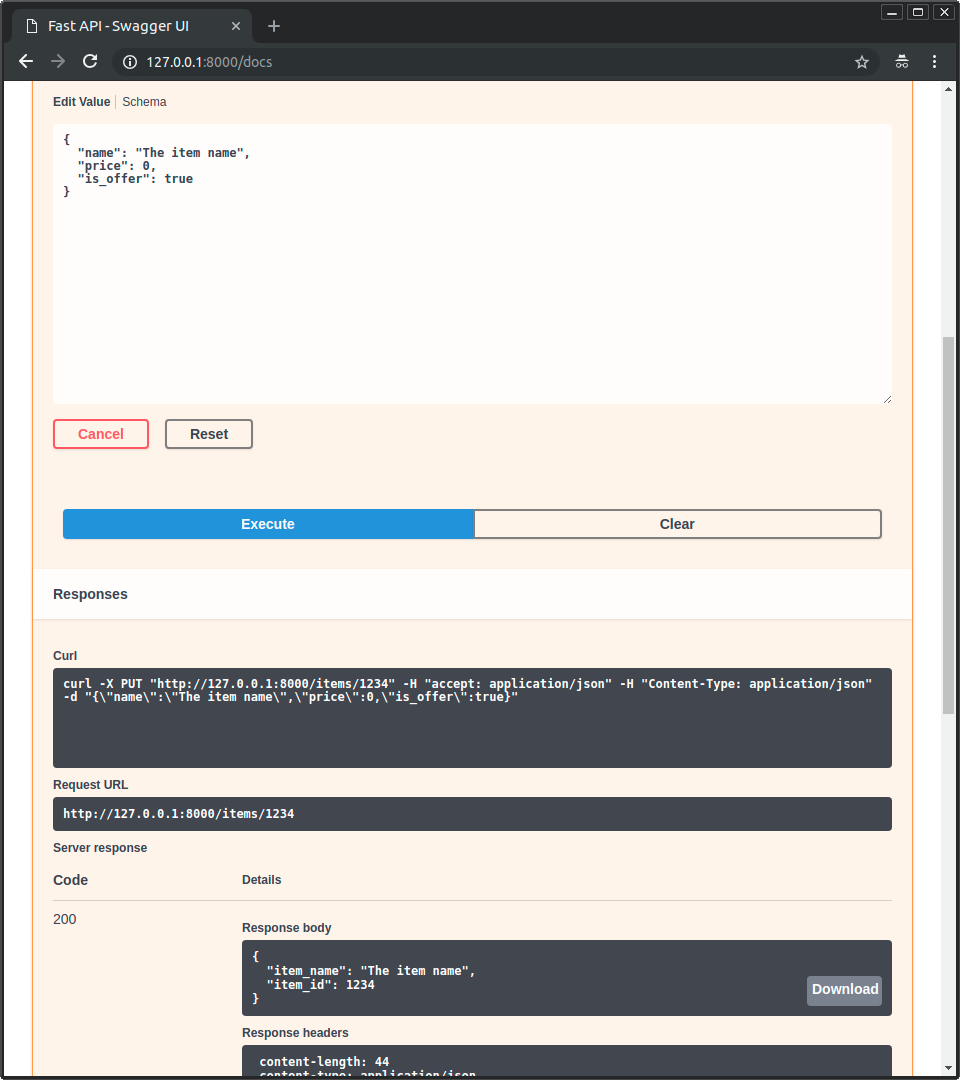
|
| 378 |
+
|
| 379 |
+
### Alternative API docs upgrade
|
| 380 |
+
|
| 381 |
+
And now, go to <a href="http://127.0.0.1:8000/redoc" class="external-link" target="_blank">http://127.0.0.1:8000/redoc</a>.
|
| 382 |
+
|
| 383 |
+
* The alternative documentation will also reflect the new query parameter and body:
|
| 384 |
+
|
| 385 |
+
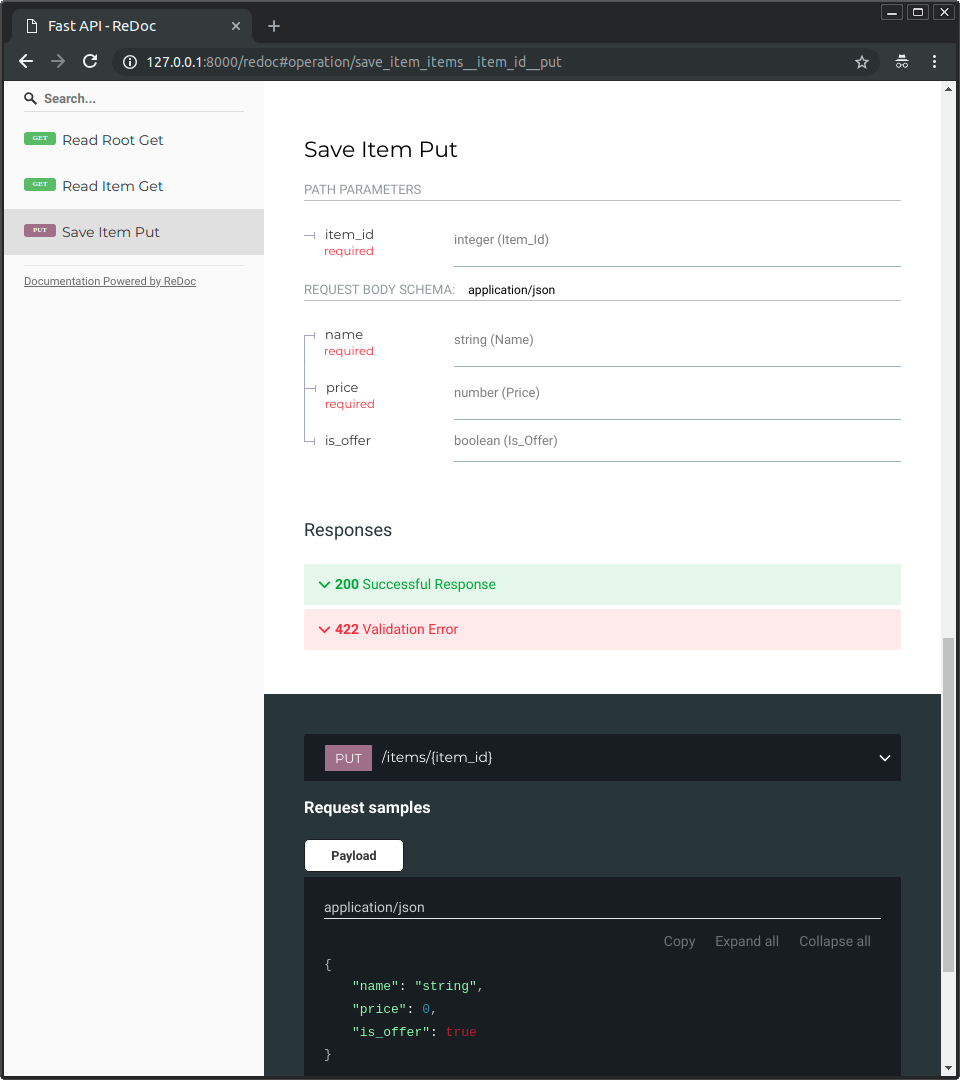
|
| 386 |
+
|
| 387 |
+
### Recap
|
| 388 |
+
|
| 389 |
+
In summary, you declare **once** the types of parameters, body, etc. as function parameters.
|
| 390 |
+
|
| 391 |
+
You do that with standard modern Python types.
|
| 392 |
+
|
| 393 |
+
You don't have to learn a new syntax, the methods or classes of a specific library, etc.
|
| 394 |
+
|
| 395 |
+
Just standard **Python 3.7+**.
|
| 396 |
+
|
| 397 |
+
For example, for an `int`:
|
| 398 |
+
|
| 399 |
+
```Python
|
| 400 |
+
item_id: int
|
| 401 |
+
```
|
| 402 |
+
|
| 403 |
+
or for a more complex `Item` model:
|
| 404 |
+
|
| 405 |
+
```Python
|
| 406 |
+
item: Item
|
| 407 |
+
```
|
| 408 |
+
|
| 409 |
+
...and with that single declaration you get:
|
| 410 |
+
|
| 411 |
+
* Editor support, including:
|
| 412 |
+
* Completion.
|
| 413 |
+
* Type checks.
|
| 414 |
+
* Validation of data:
|
| 415 |
+
* Automatic and clear errors when the data is invalid.
|
| 416 |
+
* Validation even for deeply nested JSON objects.
|
| 417 |
+
* <abbr title="also known as: serialization, parsing, marshalling">Conversion</abbr> of input data: coming from the network to Python data and types. Reading from:
|
| 418 |
+
* JSON.
|
| 419 |
+
* Path parameters.
|
| 420 |
+
* Query parameters.
|
| 421 |
+
* Cookies.
|
| 422 |
+
* Headers.
|
| 423 |
+
* Forms.
|
| 424 |
+
* Files.
|
| 425 |
+
* <abbr title="also known as: serialization, parsing, marshalling">Conversion</abbr> of output data: converting from Python data and types to network data (as JSON):
|
| 426 |
+
* Convert Python types (`str`, `int`, `float`, `bool`, `list`, etc).
|
| 427 |
+
* `datetime` objects.
|
| 428 |
+
* `UUID` objects.
|
| 429 |
+
* Database models.
|
| 430 |
+
* ...and many more.
|
| 431 |
+
* Automatic interactive API documentation, including 2 alternative user interfaces:
|
| 432 |
+
* Swagger UI.
|
| 433 |
+
* ReDoc.
|
| 434 |
+
|
| 435 |
+
---
|
| 436 |
+
|
| 437 |
+
Coming back to the previous code example, **FastAPI** will:
|
| 438 |
+
|
| 439 |
+
* Validate that there is an `item_id` in the path for `GET` and `PUT` requests.
|
| 440 |
+
* Validate that the `item_id` is of type `int` for `GET` and `PUT` requests.
|
| 441 |
+
* If it is not, the client will see a useful, clear error.
|
| 442 |
+
* Check if there is an optional query parameter named `q` (as in `http://127.0.0.1:8000/items/foo?q=somequery`) for `GET` requests.
|
| 443 |
+
* As the `q` parameter is declared with `= None`, it is optional.
|
| 444 |
+
* Without the `None` it would be required (as is the body in the case with `PUT`).
|
| 445 |
+
* For `PUT` requests to `/items/{item_id}`, Read the body as JSON:
|
| 446 |
+
* Check that it has a required attribute `name` that should be a `str`.
|
| 447 |
+
* Check that it has a required attribute `price` that has to be a `float`.
|
| 448 |
+
* Check that it has an optional attribute `is_offer`, that should be a `bool`, if present.
|
| 449 |
+
* All this would also work for deeply nested JSON objects.
|
| 450 |
+
* Convert from and to JSON automatically.
|
| 451 |
+
* Document everything with OpenAPI, that can be used by:
|
| 452 |
+
* Interactive documentation systems.
|
| 453 |
+
* Automatic client code generation systems, for many languages.
|
| 454 |
+
* Provide 2 interactive documentation web interfaces directly.
|
| 455 |
+
|
| 456 |
+
---
|
| 457 |
+
|
| 458 |
+
We just scratched the surface, but you already get the idea of how it all works.
|
| 459 |
+
|
| 460 |
+
Try changing the line with:
|
| 461 |
+
|
| 462 |
+
```Python
|
| 463 |
+
return {"item_name": item.name, "item_id": item_id}
|
| 464 |
+
```
|
| 465 |
+
|
| 466 |
+
...from:
|
| 467 |
+
|
| 468 |
+
```Python
|
| 469 |
+
... "item_name": item.name ...
|
| 470 |
+
```
|
| 471 |
+
|
| 472 |
+
...to:
|
| 473 |
+
|
| 474 |
+
```Python
|
| 475 |
+
... "item_price": item.price ...
|
| 476 |
+
```
|
| 477 |
+
|
| 478 |
+
...and see how your editor will auto-complete the attributes and know their types:
|
| 479 |
+
|
| 480 |
+
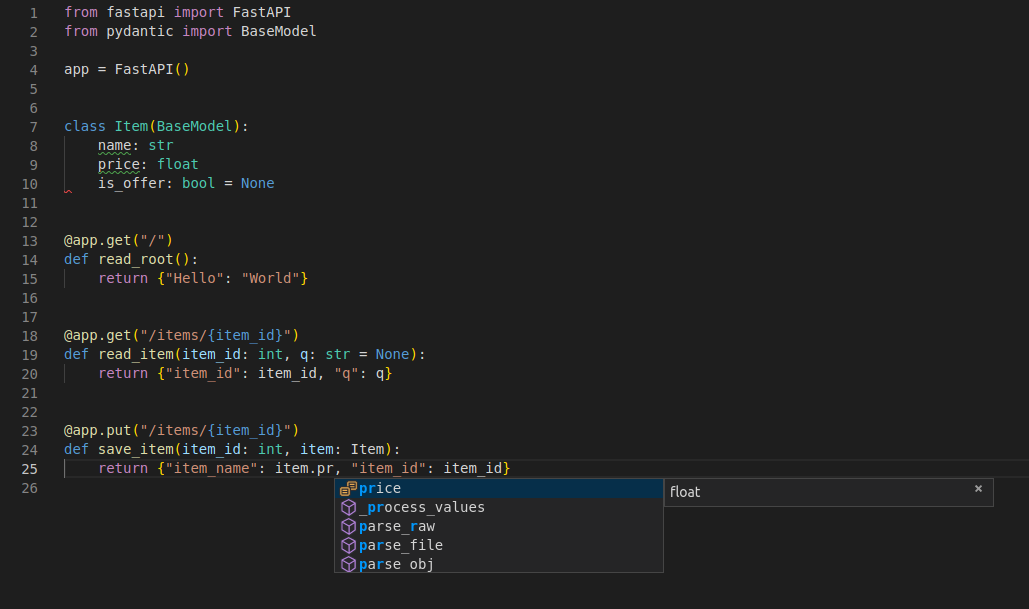
|
| 481 |
+
|
| 482 |
+
For a more complete example including more features, see the <a href="https://fastapi.tiangolo.com/tutorial/">Tutorial - User Guide</a>.
|
| 483 |
+
|
| 484 |
+
**Spoiler alert**: the tutorial - user guide includes:
|
| 485 |
+
|
| 486 |
+
* Declaration of **parameters** from other different places as: **headers**, **cookies**, **form fields** and **files**.
|
| 487 |
+
* How to set **validation constraints** as `maximum_length` or `regex`.
|
| 488 |
+
* A very powerful and easy to use **<abbr title="also known as components, resources, providers, services, injectables">Dependency Injection</abbr>** system.
|
| 489 |
+
* Security and authentication, including support for **OAuth2** with **JWT tokens** and **HTTP Basic** auth.
|
| 490 |
+
* More advanced (but equally easy) techniques for declaring **deeply nested JSON models** (thanks to Pydantic).
|
| 491 |
+
* **GraphQL** integration with <a href="https://strawberry.rocks" class="external-link" target="_blank">Strawberry</a> and other libraries.
|
| 492 |
+
* Many extra features (thanks to Starlette) as:
|
| 493 |
+
* **WebSockets**
|
| 494 |
+
* extremely easy tests based on HTTPX and `pytest`
|
| 495 |
+
* **CORS**
|
| 496 |
+
* **Cookie Sessions**
|
| 497 |
+
* ...and more.
|
| 498 |
+
|
| 499 |
+
## Performance
|
| 500 |
+
|
| 501 |
+
Independent TechEmpower benchmarks show **FastAPI** applications running under Uvicorn as <a href="https://www.techempower.com/benchmarks/#section=test&runid=7464e520-0dc2-473d-bd34-dbdfd7e85911&hw=ph&test=query&l=zijzen-7" class="external-link" target="_blank">one of the fastest Python frameworks available</a>, only below Starlette and Uvicorn themselves (used internally by FastAPI). (*)
|
| 502 |
+
|
| 503 |
+
To understand more about it, see the section <a href="https://fastapi.tiangolo.com/benchmarks/" class="internal-link" target="_blank">Benchmarks</a>.
|
| 504 |
+
|
| 505 |
+
## Optional Dependencies
|
| 506 |
+
|
| 507 |
+
Used by Pydantic:
|
| 508 |
+
|
| 509 |
+
* <a href="https://github.com/JoshData/python-email-validator" target="_blank"><code>email_validator</code></a> - for email validation.
|
| 510 |
+
* <a href="https://docs.pydantic.dev/latest/usage/pydantic_settings/" target="_blank"><code>pydantic-settings</code></a> - for settings management.
|
| 511 |
+
* <a href="https://docs.pydantic.dev/latest/usage/types/extra_types/extra_types/" target="_blank"><code>pydantic-extra-types</code></a> - for extra types to be used with Pydantic.
|
| 512 |
+
|
| 513 |
+
Used by Starlette:
|
| 514 |
+
|
| 515 |
+
* <a href="https://www.python-httpx.org" target="_blank"><code>httpx</code></a> - Required if you want to use the `TestClient`.
|
| 516 |
+
* <a href="https://jinja.palletsprojects.com" target="_blank"><code>jinja2</code></a> - Required if you want to use the default template configuration.
|
| 517 |
+
* <a href="https://andrew-d.github.io/python-multipart/" target="_blank"><code>python-multipart</code></a> - Required if you want to support form <abbr title="converting the string that comes from an HTTP request into Python data">"parsing"</abbr>, with `request.form()`.
|
| 518 |
+
* <a href="https://pythonhosted.org/itsdangerous/" target="_blank"><code>itsdangerous</code></a> - Required for `SessionMiddleware` support.
|
| 519 |
+
* <a href="https://pyyaml.org/wiki/PyYAMLDocumentation" target="_blank"><code>pyyaml</code></a> - Required for Starlette's `SchemaGenerator` support (you probably don't need it with FastAPI).
|
| 520 |
+
* <a href="https://github.com/esnme/ultrajson" target="_blank"><code>ujson</code></a> - Required if you want to use `UJSONResponse`.
|
| 521 |
+
|
| 522 |
+
Used by FastAPI / Starlette:
|
| 523 |
+
|
| 524 |
+
* <a href="https://www.uvicorn.org" target="_blank"><code>uvicorn</code></a> - for the server that loads and serves your application.
|
| 525 |
+
* <a href="https://github.com/ijl/orjson" target="_blank"><code>orjson</code></a> - Required if you want to use `ORJSONResponse`.
|
| 526 |
+
|
| 527 |
+
You can install all of these with `pip install "fastapi[all]"`.
|
| 528 |
+
|
| 529 |
+
## License
|
| 530 |
+
|
| 531 |
+
This project is licensed under the terms of the MIT license.
|
evalkit_tf437/lib/python3.10/site-packages/fastapi-0.103.2.dist-info/WHEEL
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Wheel-Version: 1.0
|
| 2 |
+
Generator: hatchling 1.17.1
|
| 3 |
+
Root-Is-Purelib: true
|
| 4 |
+
Tag: py3-none-any
|
evalkit_tf437/lib/python3.10/site-packages/google_crc32c/_checksum.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2020 Google LLC
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import struct
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class CommonChecksum(object):
|
| 19 |
+
"""Hashlib-alike helper for CRC32C operations.
|
| 20 |
+
|
| 21 |
+
This class should not be used directly and requires an update implementation.
|
| 22 |
+
|
| 23 |
+
Args:
|
| 24 |
+
initial_value (Optional[bytes]): the initial chunk of data from
|
| 25 |
+
which the CRC32C checksum is computed. Defaults to b''.
|
| 26 |
+
"""
|
| 27 |
+
__slots__ = ()
|
| 28 |
+
|
| 29 |
+
def __init__(self, initial_value=b""):
|
| 30 |
+
self._crc = 0
|
| 31 |
+
if initial_value != b"":
|
| 32 |
+
self.update(initial_value)
|
| 33 |
+
|
| 34 |
+
def update(self, data):
|
| 35 |
+
"""Update the checksum with a new chunk of data.
|
| 36 |
+
|
| 37 |
+
Args:
|
| 38 |
+
chunk (Optional[bytes]): a chunk of data used to extend
|
| 39 |
+
the CRC32C checksum.
|
| 40 |
+
"""
|
| 41 |
+
raise NotImplemented()
|
| 42 |
+
|
| 43 |
+
def digest(self):
|
| 44 |
+
"""Big-endian order, per RFC 4960.
|
| 45 |
+
|
| 46 |
+
See: https://cloud.google.com/storage/docs/json_api/v1/objects#crc32c
|
| 47 |
+
|
| 48 |
+
Returns:
|
| 49 |
+
bytes: An eight-byte digest string.
|
| 50 |
+
"""
|
| 51 |
+
return struct.pack(">L", self._crc)
|
| 52 |
+
|
| 53 |
+
def hexdigest(self):
|
| 54 |
+
"""Like :meth:`digest` except returns as a bytestring of double length.
|
| 55 |
+
|
| 56 |
+
Returns
|
| 57 |
+
bytes: A sixteen byte digest string, contaiing only hex digits.
|
| 58 |
+
"""
|
| 59 |
+
return "{:08x}".format(self._crc).encode("ascii")
|
| 60 |
+
|
| 61 |
+
def copy(self):
|
| 62 |
+
"""Create another checksum with the same CRC32C value.
|
| 63 |
+
|
| 64 |
+
Returns:
|
| 65 |
+
Checksum: the new instance.
|
| 66 |
+
"""
|
| 67 |
+
clone = self.__class__()
|
| 68 |
+
clone._crc = self._crc
|
| 69 |
+
return clone
|
| 70 |
+
|
| 71 |
+
def consume(self, stream, chunksize):
|
| 72 |
+
"""Consume chunks from a stream, extending our CRC32 checksum.
|
| 73 |
+
|
| 74 |
+
Args:
|
| 75 |
+
stream (BinaryIO): the stream to consume.
|
| 76 |
+
chunksize (int): the size of the read to perform
|
| 77 |
+
|
| 78 |
+
Returns:
|
| 79 |
+
Generator[bytes, None, None]: Iterable of the chunks read from the
|
| 80 |
+
stream.
|
| 81 |
+
"""
|
| 82 |
+
while True:
|
| 83 |
+
chunk = stream.read(chunksize)
|
| 84 |
+
if not chunk:
|
| 85 |
+
break
|
| 86 |
+
self.update(chunk)
|
| 87 |
+
yield chunk
|
evalkit_tf437/lib/python3.10/site-packages/google_crc32c/_crc32c.cpython-310-x86_64-linux-gnu.so
ADDED
|
Binary file (37.7 kB). View file
|
|
|
evalkit_tf437/lib/python3.10/site-packages/google_crc32c/cext.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2020 Google LLC
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# https://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import struct
|
| 16 |
+
|
| 17 |
+
# NOTE: ``__config__`` **must** be the first import because it (may)
|
| 18 |
+
# modify the search path used to locate shared libraries.
|
| 19 |
+
import google_crc32c.__config__ # type: ignore
|
| 20 |
+
from google_crc32c._crc32c import extend # type: ignore
|
| 21 |
+
from google_crc32c._crc32c import value # type: ignore
|
| 22 |
+
from google_crc32c._checksum import CommonChecksum
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class Checksum(CommonChecksum):
|
| 26 |
+
"""Hashlib-alike helper for CRC32C operations.
|
| 27 |
+
|
| 28 |
+
Args:
|
| 29 |
+
initial_value (Optional[bytes]): the initial chunk of data from
|
| 30 |
+
which the CRC32C checksum is computed. Defaults to b''.
|
| 31 |
+
"""
|
| 32 |
+
|
| 33 |
+
__slots__ = ("_crc",)
|
| 34 |
+
|
| 35 |
+
def __init__(self, initial_value=b""):
|
| 36 |
+
self._crc = value(initial_value)
|
| 37 |
+
|
| 38 |
+
def update(self, chunk):
|
| 39 |
+
"""Update the checksum with a new chunk of data.
|
| 40 |
+
|
| 41 |
+
Args:
|
| 42 |
+
chunk (Optional[bytes]): a chunk of data used to extend
|
| 43 |
+
the CRC32C checksum.
|
| 44 |
+
"""
|
| 45 |
+
self._crc = extend(self._crc, chunk)
|
evalkit_tf437/lib/python3.10/site-packages/google_crc32c/py.typed
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Marker file for PEP 561.
|
| 2 |
+
# The google_crc32c package uses inline types.
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/Openmp/omp-tools.h
ADDED
|
@@ -0,0 +1,1083 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* include/50/omp-tools.h.var
|
| 3 |
+
*/
|
| 4 |
+
|
| 5 |
+
//===----------------------------------------------------------------------===//
|
| 6 |
+
//
|
| 7 |
+
// The LLVM Compiler Infrastructure
|
| 8 |
+
//
|
| 9 |
+
// This file is dual licensed under the MIT and the University of Illinois Open
|
| 10 |
+
// Source Licenses. See LICENSE.txt for details.
|
| 11 |
+
//
|
| 12 |
+
//===----------------------------------------------------------------------===//
|
| 13 |
+
|
| 14 |
+
#ifndef __OMPT__
|
| 15 |
+
#define __OMPT__
|
| 16 |
+
|
| 17 |
+
/*****************************************************************************
|
| 18 |
+
* system include files
|
| 19 |
+
*****************************************************************************/
|
| 20 |
+
|
| 21 |
+
#include <stdint.h>
|
| 22 |
+
#include <stddef.h>
|
| 23 |
+
|
| 24 |
+
/*****************************************************************************
|
| 25 |
+
* iteration macros
|
| 26 |
+
*****************************************************************************/
|
| 27 |
+
|
| 28 |
+
#define FOREACH_OMPT_INQUIRY_FN(macro) \
|
| 29 |
+
macro (ompt_enumerate_states) \
|
| 30 |
+
macro (ompt_enumerate_mutex_impls) \
|
| 31 |
+
\
|
| 32 |
+
macro (ompt_set_callback) \
|
| 33 |
+
macro (ompt_get_callback) \
|
| 34 |
+
\
|
| 35 |
+
macro (ompt_get_state) \
|
| 36 |
+
\
|
| 37 |
+
macro (ompt_get_parallel_info) \
|
| 38 |
+
macro (ompt_get_task_info) \
|
| 39 |
+
macro (ompt_get_task_memory) \
|
| 40 |
+
macro (ompt_get_thread_data) \
|
| 41 |
+
macro (ompt_get_unique_id) \
|
| 42 |
+
macro (ompt_finalize_tool) \
|
| 43 |
+
\
|
| 44 |
+
macro(ompt_get_num_procs) \
|
| 45 |
+
macro(ompt_get_num_places) \
|
| 46 |
+
macro(ompt_get_place_proc_ids) \
|
| 47 |
+
macro(ompt_get_place_num) \
|
| 48 |
+
macro(ompt_get_partition_place_nums) \
|
| 49 |
+
macro(ompt_get_proc_id) \
|
| 50 |
+
\
|
| 51 |
+
macro(ompt_get_target_info) \
|
| 52 |
+
macro(ompt_get_num_devices)
|
| 53 |
+
|
| 54 |
+
#define FOREACH_OMPT_STATE(macro) \
|
| 55 |
+
\
|
| 56 |
+
/* first available state */ \
|
| 57 |
+
macro (ompt_state_undefined, 0x102) /* undefined thread state */ \
|
| 58 |
+
\
|
| 59 |
+
/* work states (0..15) */ \
|
| 60 |
+
macro (ompt_state_work_serial, 0x000) /* working outside parallel */ \
|
| 61 |
+
macro (ompt_state_work_parallel, 0x001) /* working within parallel */ \
|
| 62 |
+
macro (ompt_state_work_reduction, 0x002) /* performing a reduction */ \
|
| 63 |
+
\
|
| 64 |
+
/* barrier wait states (16..31) */ \
|
| 65 |
+
macro (ompt_state_wait_barrier, 0x010) /* waiting at a barrier */ \
|
| 66 |
+
macro (ompt_state_wait_barrier_implicit_parallel, 0x011) \
|
| 67 |
+
/* implicit barrier at the end of parallel region */\
|
| 68 |
+
macro (ompt_state_wait_barrier_implicit_workshare, 0x012) \
|
| 69 |
+
/* implicit barrier at the end of worksharing */ \
|
| 70 |
+
macro (ompt_state_wait_barrier_implicit, 0x013) /* implicit barrier */ \
|
| 71 |
+
macro (ompt_state_wait_barrier_explicit, 0x014) /* explicit barrier */ \
|
| 72 |
+
\
|
| 73 |
+
/* task wait states (32..63) */ \
|
| 74 |
+
macro (ompt_state_wait_taskwait, 0x020) /* waiting at a taskwait */ \
|
| 75 |
+
macro (ompt_state_wait_taskgroup, 0x021) /* waiting at a taskgroup */ \
|
| 76 |
+
\
|
| 77 |
+
/* mutex wait states (64..127) */ \
|
| 78 |
+
macro (ompt_state_wait_mutex, 0x040) \
|
| 79 |
+
macro (ompt_state_wait_lock, 0x041) /* waiting for lock */ \
|
| 80 |
+
macro (ompt_state_wait_critical, 0x042) /* waiting for critical */ \
|
| 81 |
+
macro (ompt_state_wait_atomic, 0x043) /* waiting for atomic */ \
|
| 82 |
+
macro (ompt_state_wait_ordered, 0x044) /* waiting for ordered */ \
|
| 83 |
+
\
|
| 84 |
+
/* target wait states (128..255) */ \
|
| 85 |
+
macro (ompt_state_wait_target, 0x080) /* waiting for target region */ \
|
| 86 |
+
macro (ompt_state_wait_target_map, 0x081) /* waiting for target data mapping operation */ \
|
| 87 |
+
macro (ompt_state_wait_target_update, 0x082) /* waiting for target update operation */ \
|
| 88 |
+
\
|
| 89 |
+
/* misc (256..511) */ \
|
| 90 |
+
macro (ompt_state_idle, 0x100) /* waiting for work */ \
|
| 91 |
+
macro (ompt_state_overhead, 0x101) /* overhead excluding wait states */ \
|
| 92 |
+
\
|
| 93 |
+
/* implementation-specific states (512..) */
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
#define FOREACH_KMP_MUTEX_IMPL(macro) \
|
| 97 |
+
macro (kmp_mutex_impl_none, 0) /* unknown implementation */ \
|
| 98 |
+
macro (kmp_mutex_impl_spin, 1) /* based on spin */ \
|
| 99 |
+
macro (kmp_mutex_impl_queuing, 2) /* based on some fair policy */ \
|
| 100 |
+
macro (kmp_mutex_impl_speculative, 3) /* based on HW-supported speculation */
|
| 101 |
+
|
| 102 |
+
#define FOREACH_OMPT_EVENT(macro) \
|
| 103 |
+
\
|
| 104 |
+
/*--- Mandatory Events ---*/ \
|
| 105 |
+
macro (ompt_callback_thread_begin, ompt_callback_thread_begin_t, 1) /* thread begin */ \
|
| 106 |
+
macro (ompt_callback_thread_end, ompt_callback_thread_end_t, 2) /* thread end */ \
|
| 107 |
+
\
|
| 108 |
+
macro (ompt_callback_parallel_begin, ompt_callback_parallel_begin_t, 3) /* parallel begin */ \
|
| 109 |
+
macro (ompt_callback_parallel_end, ompt_callback_parallel_end_t, 4) /* parallel end */ \
|
| 110 |
+
\
|
| 111 |
+
macro (ompt_callback_task_create, ompt_callback_task_create_t, 5) /* task begin */ \
|
| 112 |
+
macro (ompt_callback_task_schedule, ompt_callback_task_schedule_t, 6) /* task schedule */ \
|
| 113 |
+
macro (ompt_callback_implicit_task, ompt_callback_implicit_task_t, 7) /* implicit task */ \
|
| 114 |
+
\
|
| 115 |
+
macro (ompt_callback_target, ompt_callback_target_t, 8) /* target */ \
|
| 116 |
+
macro (ompt_callback_target_data_op, ompt_callback_target_data_op_t, 9) /* target data op */ \
|
| 117 |
+
macro (ompt_callback_target_submit, ompt_callback_target_submit_t, 10) /* target submit */ \
|
| 118 |
+
\
|
| 119 |
+
macro (ompt_callback_control_tool, ompt_callback_control_tool_t, 11) /* control tool */ \
|
| 120 |
+
\
|
| 121 |
+
macro (ompt_callback_device_initialize, ompt_callback_device_initialize_t, 12) /* device initialize */ \
|
| 122 |
+
macro (ompt_callback_device_finalize, ompt_callback_device_finalize_t, 13) /* device finalize */ \
|
| 123 |
+
\
|
| 124 |
+
macro (ompt_callback_device_load, ompt_callback_device_load_t, 14) /* device load */ \
|
| 125 |
+
macro (ompt_callback_device_unload, ompt_callback_device_unload_t, 15) /* device unload */ \
|
| 126 |
+
\
|
| 127 |
+
/* Optional Events */ \
|
| 128 |
+
macro (ompt_callback_sync_region_wait, ompt_callback_sync_region_t, 16) /* sync region wait begin or end */ \
|
| 129 |
+
\
|
| 130 |
+
macro (ompt_callback_mutex_released, ompt_callback_mutex_t, 17) /* mutex released */ \
|
| 131 |
+
\
|
| 132 |
+
macro (ompt_callback_dependences, ompt_callback_dependences_t, 18) /* report task dependences */ \
|
| 133 |
+
macro (ompt_callback_task_dependence, ompt_callback_task_dependence_t, 19) /* report task dependence */ \
|
| 134 |
+
\
|
| 135 |
+
macro (ompt_callback_work, ompt_callback_work_t, 20) /* task at work begin or end */ \
|
| 136 |
+
\
|
| 137 |
+
macro (ompt_callback_master, ompt_callback_master_t, 21) /* task at master begin or end */ \
|
| 138 |
+
\
|
| 139 |
+
macro (ompt_callback_target_map, ompt_callback_target_map_t, 22) /* target map */ \
|
| 140 |
+
\
|
| 141 |
+
macro (ompt_callback_sync_region, ompt_callback_sync_region_t, 23) /* sync region begin or end */ \
|
| 142 |
+
\
|
| 143 |
+
macro (ompt_callback_lock_init, ompt_callback_mutex_acquire_t, 24) /* lock init */ \
|
| 144 |
+
macro (ompt_callback_lock_destroy, ompt_callback_mutex_t, 25) /* lock destroy */ \
|
| 145 |
+
\
|
| 146 |
+
macro (ompt_callback_mutex_acquire, ompt_callback_mutex_acquire_t, 26) /* mutex acquire */ \
|
| 147 |
+
macro (ompt_callback_mutex_acquired, ompt_callback_mutex_t, 27) /* mutex acquired */ \
|
| 148 |
+
\
|
| 149 |
+
macro (ompt_callback_nest_lock, ompt_callback_nest_lock_t, 28) /* nest lock */ \
|
| 150 |
+
\
|
| 151 |
+
macro (ompt_callback_flush, ompt_callback_flush_t, 29) /* after executing flush */ \
|
| 152 |
+
\
|
| 153 |
+
macro (ompt_callback_cancel, ompt_callback_cancel_t, 30) /* cancel innermost binding region */ \
|
| 154 |
+
\
|
| 155 |
+
macro (ompt_callback_reduction, ompt_callback_sync_region_t, 31) /* reduction */ \
|
| 156 |
+
\
|
| 157 |
+
macro (ompt_callback_dispatch, ompt_callback_dispatch_t, 32) /* dispatch of work */
|
| 158 |
+
|
| 159 |
+
/*****************************************************************************
|
| 160 |
+
* implementation specific types
|
| 161 |
+
*****************************************************************************/
|
| 162 |
+
|
| 163 |
+
typedef enum kmp_mutex_impl_t {
|
| 164 |
+
#define kmp_mutex_impl_macro(impl, code) impl = code,
|
| 165 |
+
FOREACH_KMP_MUTEX_IMPL(kmp_mutex_impl_macro)
|
| 166 |
+
#undef kmp_mutex_impl_macro
|
| 167 |
+
} kmp_mutex_impl_t;
|
| 168 |
+
|
| 169 |
+
/*****************************************************************************
|
| 170 |
+
* definitions generated from spec
|
| 171 |
+
*****************************************************************************/
|
| 172 |
+
|
| 173 |
+
typedef enum ompt_callbacks_t {
|
| 174 |
+
ompt_callback_thread_begin = 1,
|
| 175 |
+
ompt_callback_thread_end = 2,
|
| 176 |
+
ompt_callback_parallel_begin = 3,
|
| 177 |
+
ompt_callback_parallel_end = 4,
|
| 178 |
+
ompt_callback_task_create = 5,
|
| 179 |
+
ompt_callback_task_schedule = 6,
|
| 180 |
+
ompt_callback_implicit_task = 7,
|
| 181 |
+
ompt_callback_target = 8,
|
| 182 |
+
ompt_callback_target_data_op = 9,
|
| 183 |
+
ompt_callback_target_submit = 10,
|
| 184 |
+
ompt_callback_control_tool = 11,
|
| 185 |
+
ompt_callback_device_initialize = 12,
|
| 186 |
+
ompt_callback_device_finalize = 13,
|
| 187 |
+
ompt_callback_device_load = 14,
|
| 188 |
+
ompt_callback_device_unload = 15,
|
| 189 |
+
ompt_callback_sync_region_wait = 16,
|
| 190 |
+
ompt_callback_mutex_released = 17,
|
| 191 |
+
ompt_callback_dependences = 18,
|
| 192 |
+
ompt_callback_task_dependence = 19,
|
| 193 |
+
ompt_callback_work = 20,
|
| 194 |
+
ompt_callback_master = 21,
|
| 195 |
+
ompt_callback_target_map = 22,
|
| 196 |
+
ompt_callback_sync_region = 23,
|
| 197 |
+
ompt_callback_lock_init = 24,
|
| 198 |
+
ompt_callback_lock_destroy = 25,
|
| 199 |
+
ompt_callback_mutex_acquire = 26,
|
| 200 |
+
ompt_callback_mutex_acquired = 27,
|
| 201 |
+
ompt_callback_nest_lock = 28,
|
| 202 |
+
ompt_callback_flush = 29,
|
| 203 |
+
ompt_callback_cancel = 30,
|
| 204 |
+
ompt_callback_reduction = 31,
|
| 205 |
+
ompt_callback_dispatch = 32
|
| 206 |
+
} ompt_callbacks_t;
|
| 207 |
+
|
| 208 |
+
typedef enum ompt_record_t {
|
| 209 |
+
ompt_record_ompt = 1,
|
| 210 |
+
ompt_record_native = 2,
|
| 211 |
+
ompt_record_invalid = 3
|
| 212 |
+
} ompt_record_t;
|
| 213 |
+
|
| 214 |
+
typedef enum ompt_record_native_t {
|
| 215 |
+
ompt_record_native_info = 1,
|
| 216 |
+
ompt_record_native_event = 2
|
| 217 |
+
} ompt_record_native_t;
|
| 218 |
+
|
| 219 |
+
typedef enum ompt_set_result_t {
|
| 220 |
+
ompt_set_error = 0,
|
| 221 |
+
ompt_set_never = 1,
|
| 222 |
+
ompt_set_impossible = 2,
|
| 223 |
+
ompt_set_sometimes = 3,
|
| 224 |
+
ompt_set_sometimes_paired = 4,
|
| 225 |
+
ompt_set_always = 5
|
| 226 |
+
} ompt_set_result_t;
|
| 227 |
+
|
| 228 |
+
typedef uint64_t ompt_id_t;
|
| 229 |
+
|
| 230 |
+
typedef uint64_t ompt_device_time_t;
|
| 231 |
+
|
| 232 |
+
typedef uint64_t ompt_buffer_cursor_t;
|
| 233 |
+
|
| 234 |
+
typedef enum ompt_thread_t {
|
| 235 |
+
ompt_thread_initial = 1,
|
| 236 |
+
ompt_thread_worker = 2,
|
| 237 |
+
ompt_thread_other = 3,
|
| 238 |
+
ompt_thread_unknown = 4
|
| 239 |
+
} ompt_thread_t;
|
| 240 |
+
|
| 241 |
+
typedef enum ompt_scope_endpoint_t {
|
| 242 |
+
ompt_scope_begin = 1,
|
| 243 |
+
ompt_scope_end = 2
|
| 244 |
+
} ompt_scope_endpoint_t;
|
| 245 |
+
|
| 246 |
+
typedef enum ompt_dispatch_t {
|
| 247 |
+
ompt_dispatch_iteration = 1,
|
| 248 |
+
ompt_dispatch_section = 2
|
| 249 |
+
} ompt_dispatch_t;
|
| 250 |
+
|
| 251 |
+
typedef enum ompt_sync_region_t {
|
| 252 |
+
ompt_sync_region_barrier = 1,
|
| 253 |
+
ompt_sync_region_barrier_implicit = 2,
|
| 254 |
+
ompt_sync_region_barrier_explicit = 3,
|
| 255 |
+
ompt_sync_region_barrier_implementation = 4,
|
| 256 |
+
ompt_sync_region_taskwait = 5,
|
| 257 |
+
ompt_sync_region_taskgroup = 6,
|
| 258 |
+
ompt_sync_region_reduction = 7
|
| 259 |
+
} ompt_sync_region_t;
|
| 260 |
+
|
| 261 |
+
typedef enum ompt_target_data_op_t {
|
| 262 |
+
ompt_target_data_alloc = 1,
|
| 263 |
+
ompt_target_data_transfer_to_device = 2,
|
| 264 |
+
ompt_target_data_transfer_from_device = 3,
|
| 265 |
+
ompt_target_data_delete = 4,
|
| 266 |
+
ompt_target_data_associate = 5,
|
| 267 |
+
ompt_target_data_disassociate = 6
|
| 268 |
+
} ompt_target_data_op_t;
|
| 269 |
+
|
| 270 |
+
typedef enum ompt_work_t {
|
| 271 |
+
ompt_work_loop = 1,
|
| 272 |
+
ompt_work_sections = 2,
|
| 273 |
+
ompt_work_single_executor = 3,
|
| 274 |
+
ompt_work_single_other = 4,
|
| 275 |
+
ompt_work_workshare = 5,
|
| 276 |
+
ompt_work_distribute = 6,
|
| 277 |
+
ompt_work_taskloop = 7
|
| 278 |
+
} ompt_work_t;
|
| 279 |
+
|
| 280 |
+
typedef enum ompt_mutex_t {
|
| 281 |
+
ompt_mutex_lock = 1,
|
| 282 |
+
ompt_mutex_test_lock = 2,
|
| 283 |
+
ompt_mutex_nest_lock = 3,
|
| 284 |
+
ompt_mutex_test_nest_lock = 4,
|
| 285 |
+
ompt_mutex_critical = 5,
|
| 286 |
+
ompt_mutex_atomic = 6,
|
| 287 |
+
ompt_mutex_ordered = 7
|
| 288 |
+
} ompt_mutex_t;
|
| 289 |
+
|
| 290 |
+
typedef enum ompt_native_mon_flag_t {
|
| 291 |
+
ompt_native_data_motion_explicit = 0x01,
|
| 292 |
+
ompt_native_data_motion_implicit = 0x02,
|
| 293 |
+
ompt_native_kernel_invocation = 0x04,
|
| 294 |
+
ompt_native_kernel_execution = 0x08,
|
| 295 |
+
ompt_native_driver = 0x10,
|
| 296 |
+
ompt_native_runtime = 0x20,
|
| 297 |
+
ompt_native_overhead = 0x40,
|
| 298 |
+
ompt_native_idleness = 0x80
|
| 299 |
+
} ompt_native_mon_flag_t;
|
| 300 |
+
|
| 301 |
+
typedef enum ompt_task_flag_t {
|
| 302 |
+
ompt_task_initial = 0x00000001,
|
| 303 |
+
ompt_task_implicit = 0x00000002,
|
| 304 |
+
ompt_task_explicit = 0x00000004,
|
| 305 |
+
ompt_task_target = 0x00000008,
|
| 306 |
+
ompt_task_undeferred = 0x08000000,
|
| 307 |
+
ompt_task_untied = 0x10000000,
|
| 308 |
+
ompt_task_final = 0x20000000,
|
| 309 |
+
ompt_task_mergeable = 0x40000000,
|
| 310 |
+
ompt_task_merged = 0x80000000
|
| 311 |
+
} ompt_task_flag_t;
|
| 312 |
+
|
| 313 |
+
typedef enum ompt_task_status_t {
|
| 314 |
+
ompt_task_complete = 1,
|
| 315 |
+
ompt_task_yield = 2,
|
| 316 |
+
ompt_task_cancel = 3,
|
| 317 |
+
ompt_task_detach = 4,
|
| 318 |
+
ompt_task_early_fulfill = 5,
|
| 319 |
+
ompt_task_late_fulfill = 6,
|
| 320 |
+
ompt_task_switch = 7
|
| 321 |
+
} ompt_task_status_t;
|
| 322 |
+
|
| 323 |
+
typedef enum ompt_target_t {
|
| 324 |
+
ompt_target = 1,
|
| 325 |
+
ompt_target_enter_data = 2,
|
| 326 |
+
ompt_target_exit_data = 3,
|
| 327 |
+
ompt_target_update = 4
|
| 328 |
+
} ompt_target_t;
|
| 329 |
+
|
| 330 |
+
typedef enum ompt_parallel_flag_t {
|
| 331 |
+
ompt_parallel_invoker_program = 0x00000001,
|
| 332 |
+
ompt_parallel_invoker_runtime = 0x00000002,
|
| 333 |
+
ompt_parallel_league = 0x40000000,
|
| 334 |
+
ompt_parallel_team = 0x80000000
|
| 335 |
+
} ompt_parallel_flag_t;
|
| 336 |
+
|
| 337 |
+
typedef enum ompt_target_map_flag_t {
|
| 338 |
+
ompt_target_map_flag_to = 0x01,
|
| 339 |
+
ompt_target_map_flag_from = 0x02,
|
| 340 |
+
ompt_target_map_flag_alloc = 0x04,
|
| 341 |
+
ompt_target_map_flag_release = 0x08,
|
| 342 |
+
ompt_target_map_flag_delete = 0x10,
|
| 343 |
+
ompt_target_map_flag_implicit = 0x20
|
| 344 |
+
} ompt_target_map_flag_t;
|
| 345 |
+
|
| 346 |
+
typedef enum ompt_dependence_type_t {
|
| 347 |
+
ompt_dependence_type_in = 1,
|
| 348 |
+
ompt_dependence_type_out = 2,
|
| 349 |
+
ompt_dependence_type_inout = 3,
|
| 350 |
+
ompt_dependence_type_mutexinoutset = 4,
|
| 351 |
+
ompt_dependence_type_source = 5,
|
| 352 |
+
ompt_dependence_type_sink = 6
|
| 353 |
+
} ompt_dependence_type_t;
|
| 354 |
+
|
| 355 |
+
typedef enum ompt_cancel_flag_t {
|
| 356 |
+
ompt_cancel_parallel = 0x01,
|
| 357 |
+
ompt_cancel_sections = 0x02,
|
| 358 |
+
ompt_cancel_loop = 0x04,
|
| 359 |
+
ompt_cancel_taskgroup = 0x08,
|
| 360 |
+
ompt_cancel_activated = 0x10,
|
| 361 |
+
ompt_cancel_detected = 0x20,
|
| 362 |
+
ompt_cancel_discarded_task = 0x40
|
| 363 |
+
} ompt_cancel_flag_t;
|
| 364 |
+
|
| 365 |
+
typedef uint64_t ompt_hwid_t;
|
| 366 |
+
|
| 367 |
+
typedef uint64_t ompt_wait_id_t;
|
| 368 |
+
|
| 369 |
+
typedef enum ompt_frame_flag_t {
|
| 370 |
+
ompt_frame_runtime = 0x00,
|
| 371 |
+
ompt_frame_application = 0x01,
|
| 372 |
+
ompt_frame_cfa = 0x10,
|
| 373 |
+
ompt_frame_framepointer = 0x20,
|
| 374 |
+
ompt_frame_stackaddress = 0x30
|
| 375 |
+
} ompt_frame_flag_t;
|
| 376 |
+
|
| 377 |
+
typedef enum ompt_state_t {
|
| 378 |
+
ompt_state_work_serial = 0x000,
|
| 379 |
+
ompt_state_work_parallel = 0x001,
|
| 380 |
+
ompt_state_work_reduction = 0x002,
|
| 381 |
+
|
| 382 |
+
ompt_state_wait_barrier = 0x010,
|
| 383 |
+
ompt_state_wait_barrier_implicit_parallel = 0x011,
|
| 384 |
+
ompt_state_wait_barrier_implicit_workshare = 0x012,
|
| 385 |
+
ompt_state_wait_barrier_implicit = 0x013,
|
| 386 |
+
ompt_state_wait_barrier_explicit = 0x014,
|
| 387 |
+
|
| 388 |
+
ompt_state_wait_taskwait = 0x020,
|
| 389 |
+
ompt_state_wait_taskgroup = 0x021,
|
| 390 |
+
|
| 391 |
+
ompt_state_wait_mutex = 0x040,
|
| 392 |
+
ompt_state_wait_lock = 0x041,
|
| 393 |
+
ompt_state_wait_critical = 0x042,
|
| 394 |
+
ompt_state_wait_atomic = 0x043,
|
| 395 |
+
ompt_state_wait_ordered = 0x044,
|
| 396 |
+
|
| 397 |
+
ompt_state_wait_target = 0x080,
|
| 398 |
+
ompt_state_wait_target_map = 0x081,
|
| 399 |
+
ompt_state_wait_target_update = 0x082,
|
| 400 |
+
|
| 401 |
+
ompt_state_idle = 0x100,
|
| 402 |
+
ompt_state_overhead = 0x101,
|
| 403 |
+
ompt_state_undefined = 0x102
|
| 404 |
+
} ompt_state_t;
|
| 405 |
+
|
| 406 |
+
typedef uint64_t (*ompt_get_unique_id_t) (void);
|
| 407 |
+
|
| 408 |
+
typedef uint64_t ompd_size_t;
|
| 409 |
+
|
| 410 |
+
typedef uint64_t ompd_wait_id_t;
|
| 411 |
+
|
| 412 |
+
typedef uint64_t ompd_addr_t;
|
| 413 |
+
typedef int64_t ompd_word_t;
|
| 414 |
+
typedef uint64_t ompd_seg_t;
|
| 415 |
+
|
| 416 |
+
typedef uint64_t ompd_device_t;
|
| 417 |
+
|
| 418 |
+
typedef uint64_t ompd_thread_id_t;
|
| 419 |
+
|
| 420 |
+
typedef enum ompd_scope_t {
|
| 421 |
+
ompd_scope_global = 1,
|
| 422 |
+
ompd_scope_address_space = 2,
|
| 423 |
+
ompd_scope_thread = 3,
|
| 424 |
+
ompd_scope_parallel = 4,
|
| 425 |
+
ompd_scope_implicit_task = 5,
|
| 426 |
+
ompd_scope_task = 6
|
| 427 |
+
} ompd_scope_t;
|
| 428 |
+
|
| 429 |
+
typedef uint64_t ompd_icv_id_t;
|
| 430 |
+
|
| 431 |
+
typedef enum ompd_rc_t {
|
| 432 |
+
ompd_rc_ok = 0,
|
| 433 |
+
ompd_rc_unavailable = 1,
|
| 434 |
+
ompd_rc_stale_handle = 2,
|
| 435 |
+
ompd_rc_bad_input = 3,
|
| 436 |
+
ompd_rc_error = 4,
|
| 437 |
+
ompd_rc_unsupported = 5,
|
| 438 |
+
ompd_rc_needs_state_tracking = 6,
|
| 439 |
+
ompd_rc_incompatible = 7,
|
| 440 |
+
ompd_rc_device_read_error = 8,
|
| 441 |
+
ompd_rc_device_write_error = 9,
|
| 442 |
+
ompd_rc_nomem = 10,
|
| 443 |
+
} ompd_rc_t;
|
| 444 |
+
|
| 445 |
+
typedef void (*ompt_interface_fn_t) (void);
|
| 446 |
+
|
| 447 |
+
typedef ompt_interface_fn_t (*ompt_function_lookup_t) (
|
| 448 |
+
const char *interface_function_name
|
| 449 |
+
);
|
| 450 |
+
|
| 451 |
+
typedef union ompt_data_t {
|
| 452 |
+
uint64_t value;
|
| 453 |
+
void *ptr;
|
| 454 |
+
} ompt_data_t;
|
| 455 |
+
|
| 456 |
+
typedef struct ompt_frame_t {
|
| 457 |
+
ompt_data_t exit_frame;
|
| 458 |
+
ompt_data_t enter_frame;
|
| 459 |
+
int exit_frame_flags;
|
| 460 |
+
int enter_frame_flags;
|
| 461 |
+
} ompt_frame_t;
|
| 462 |
+
|
| 463 |
+
typedef void (*ompt_callback_t) (void);
|
| 464 |
+
|
| 465 |
+
typedef void ompt_device_t;
|
| 466 |
+
|
| 467 |
+
typedef void ompt_buffer_t;
|
| 468 |
+
|
| 469 |
+
typedef void (*ompt_callback_buffer_request_t) (
|
| 470 |
+
int device_num,
|
| 471 |
+
ompt_buffer_t **buffer,
|
| 472 |
+
size_t *bytes
|
| 473 |
+
);
|
| 474 |
+
|
| 475 |
+
typedef void (*ompt_callback_buffer_complete_t) (
|
| 476 |
+
int device_num,
|
| 477 |
+
ompt_buffer_t *buffer,
|
| 478 |
+
size_t bytes,
|
| 479 |
+
ompt_buffer_cursor_t begin,
|
| 480 |
+
int buffer_owned
|
| 481 |
+
);
|
| 482 |
+
|
| 483 |
+
typedef void (*ompt_finalize_t) (
|
| 484 |
+
ompt_data_t *tool_data
|
| 485 |
+
);
|
| 486 |
+
|
| 487 |
+
typedef int (*ompt_initialize_t) (
|
| 488 |
+
ompt_function_lookup_t lookup,
|
| 489 |
+
int initial_device_num,
|
| 490 |
+
ompt_data_t *tool_data
|
| 491 |
+
);
|
| 492 |
+
|
| 493 |
+
typedef struct ompt_start_tool_result_t {
|
| 494 |
+
ompt_initialize_t initialize;
|
| 495 |
+
ompt_finalize_t finalize;
|
| 496 |
+
ompt_data_t tool_data;
|
| 497 |
+
} ompt_start_tool_result_t;
|
| 498 |
+
|
| 499 |
+
typedef struct ompt_record_abstract_t {
|
| 500 |
+
ompt_record_native_t rclass;
|
| 501 |
+
const char *type;
|
| 502 |
+
ompt_device_time_t start_time;
|
| 503 |
+
ompt_device_time_t end_time;
|
| 504 |
+
ompt_hwid_t hwid;
|
| 505 |
+
} ompt_record_abstract_t;
|
| 506 |
+
|
| 507 |
+
typedef struct ompt_dependence_t {
|
| 508 |
+
ompt_data_t variable;
|
| 509 |
+
ompt_dependence_type_t dependence_type;
|
| 510 |
+
} ompt_dependence_t;
|
| 511 |
+
|
| 512 |
+
typedef int (*ompt_enumerate_states_t) (
|
| 513 |
+
int current_state,
|
| 514 |
+
int *next_state,
|
| 515 |
+
const char **next_state_name
|
| 516 |
+
);
|
| 517 |
+
|
| 518 |
+
typedef int (*ompt_enumerate_mutex_impls_t) (
|
| 519 |
+
int current_impl,
|
| 520 |
+
int *next_impl,
|
| 521 |
+
const char **next_impl_name
|
| 522 |
+
);
|
| 523 |
+
|
| 524 |
+
typedef ompt_set_result_t (*ompt_set_callback_t) (
|
| 525 |
+
ompt_callbacks_t event,
|
| 526 |
+
ompt_callback_t callback
|
| 527 |
+
);
|
| 528 |
+
|
| 529 |
+
typedef int (*ompt_get_callback_t) (
|
| 530 |
+
ompt_callbacks_t event,
|
| 531 |
+
ompt_callback_t *callback
|
| 532 |
+
);
|
| 533 |
+
|
| 534 |
+
typedef ompt_data_t *(*ompt_get_thread_data_t) (void);
|
| 535 |
+
|
| 536 |
+
typedef int (*ompt_get_num_procs_t) (void);
|
| 537 |
+
|
| 538 |
+
typedef int (*ompt_get_num_places_t) (void);
|
| 539 |
+
|
| 540 |
+
typedef int (*ompt_get_place_proc_ids_t) (
|
| 541 |
+
int place_num,
|
| 542 |
+
int ids_size,
|
| 543 |
+
int *ids
|
| 544 |
+
);
|
| 545 |
+
|
| 546 |
+
typedef int (*ompt_get_place_num_t) (void);
|
| 547 |
+
|
| 548 |
+
typedef int (*ompt_get_partition_place_nums_t) (
|
| 549 |
+
int place_nums_size,
|
| 550 |
+
int *place_nums
|
| 551 |
+
);
|
| 552 |
+
|
| 553 |
+
typedef int (*ompt_get_proc_id_t) (void);
|
| 554 |
+
|
| 555 |
+
typedef int (*ompt_get_state_t) (
|
| 556 |
+
ompt_wait_id_t *wait_id
|
| 557 |
+
);
|
| 558 |
+
|
| 559 |
+
typedef int (*ompt_get_parallel_info_t) (
|
| 560 |
+
int ancestor_level,
|
| 561 |
+
ompt_data_t **parallel_data,
|
| 562 |
+
int *team_size
|
| 563 |
+
);
|
| 564 |
+
|
| 565 |
+
typedef int (*ompt_get_task_info_t) (
|
| 566 |
+
int ancestor_level,
|
| 567 |
+
int *flags,
|
| 568 |
+
ompt_data_t **task_data,
|
| 569 |
+
ompt_frame_t **task_frame,
|
| 570 |
+
ompt_data_t **parallel_data,
|
| 571 |
+
int *thread_num
|
| 572 |
+
);
|
| 573 |
+
|
| 574 |
+
typedef int (*ompt_get_task_memory_t)(
|
| 575 |
+
void **addr,
|
| 576 |
+
size_t *size,
|
| 577 |
+
int block
|
| 578 |
+
);
|
| 579 |
+
|
| 580 |
+
typedef int (*ompt_get_target_info_t) (
|
| 581 |
+
uint64_t *device_num,
|
| 582 |
+
ompt_id_t *target_id,
|
| 583 |
+
ompt_id_t *host_op_id
|
| 584 |
+
);
|
| 585 |
+
|
| 586 |
+
typedef int (*ompt_get_num_devices_t) (void);
|
| 587 |
+
|
| 588 |
+
typedef void (*ompt_finalize_tool_t) (void);
|
| 589 |
+
|
| 590 |
+
typedef int (*ompt_get_device_num_procs_t) (
|
| 591 |
+
ompt_device_t *device
|
| 592 |
+
);
|
| 593 |
+
|
| 594 |
+
typedef ompt_device_time_t (*ompt_get_device_time_t) (
|
| 595 |
+
ompt_device_t *device
|
| 596 |
+
);
|
| 597 |
+
|
| 598 |
+
typedef double (*ompt_translate_time_t) (
|
| 599 |
+
ompt_device_t *device,
|
| 600 |
+
ompt_device_time_t time
|
| 601 |
+
);
|
| 602 |
+
|
| 603 |
+
typedef ompt_set_result_t (*ompt_set_trace_ompt_t) (
|
| 604 |
+
ompt_device_t *device,
|
| 605 |
+
unsigned int enable,
|
| 606 |
+
unsigned int etype
|
| 607 |
+
);
|
| 608 |
+
|
| 609 |
+
typedef ompt_set_result_t (*ompt_set_trace_native_t) (
|
| 610 |
+
ompt_device_t *device,
|
| 611 |
+
int enable,
|
| 612 |
+
int flags
|
| 613 |
+
);
|
| 614 |
+
|
| 615 |
+
typedef int (*ompt_start_trace_t) (
|
| 616 |
+
ompt_device_t *device,
|
| 617 |
+
ompt_callback_buffer_request_t request,
|
| 618 |
+
ompt_callback_buffer_complete_t complete
|
| 619 |
+
);
|
| 620 |
+
|
| 621 |
+
typedef int (*ompt_pause_trace_t) (
|
| 622 |
+
ompt_device_t *device,
|
| 623 |
+
int begin_pause
|
| 624 |
+
);
|
| 625 |
+
|
| 626 |
+
typedef int (*ompt_flush_trace_t) (
|
| 627 |
+
ompt_device_t *device
|
| 628 |
+
);
|
| 629 |
+
|
| 630 |
+
typedef int (*ompt_stop_trace_t) (
|
| 631 |
+
ompt_device_t *device
|
| 632 |
+
);
|
| 633 |
+
|
| 634 |
+
typedef int (*ompt_advance_buffer_cursor_t) (
|
| 635 |
+
ompt_device_t *device,
|
| 636 |
+
ompt_buffer_t *buffer,
|
| 637 |
+
size_t size,
|
| 638 |
+
ompt_buffer_cursor_t current,
|
| 639 |
+
ompt_buffer_cursor_t *next
|
| 640 |
+
);
|
| 641 |
+
|
| 642 |
+
typedef ompt_record_t (*ompt_get_record_type_t) (
|
| 643 |
+
ompt_buffer_t *buffer,
|
| 644 |
+
ompt_buffer_cursor_t current
|
| 645 |
+
);
|
| 646 |
+
|
| 647 |
+
typedef void *(*ompt_get_record_native_t) (
|
| 648 |
+
ompt_buffer_t *buffer,
|
| 649 |
+
ompt_buffer_cursor_t current,
|
| 650 |
+
ompt_id_t *host_op_id
|
| 651 |
+
);
|
| 652 |
+
|
| 653 |
+
typedef ompt_record_abstract_t *
|
| 654 |
+
(*ompt_get_record_abstract_t) (
|
| 655 |
+
void *native_record
|
| 656 |
+
);
|
| 657 |
+
|
| 658 |
+
typedef void (*ompt_callback_thread_begin_t) (
|
| 659 |
+
ompt_thread_t thread_type,
|
| 660 |
+
ompt_data_t *thread_data
|
| 661 |
+
);
|
| 662 |
+
|
| 663 |
+
typedef struct ompt_record_thread_begin_t {
|
| 664 |
+
ompt_thread_t thread_type;
|
| 665 |
+
} ompt_record_thread_begin_t;
|
| 666 |
+
|
| 667 |
+
typedef void (*ompt_callback_thread_end_t) (
|
| 668 |
+
ompt_data_t *thread_data
|
| 669 |
+
);
|
| 670 |
+
|
| 671 |
+
typedef void (*ompt_callback_parallel_begin_t) (
|
| 672 |
+
ompt_data_t *encountering_task_data,
|
| 673 |
+
const ompt_frame_t *encountering_task_frame,
|
| 674 |
+
ompt_data_t *parallel_data,
|
| 675 |
+
unsigned int requested_parallelism,
|
| 676 |
+
int flags,
|
| 677 |
+
const void *codeptr_ra
|
| 678 |
+
);
|
| 679 |
+
|
| 680 |
+
typedef struct ompt_record_parallel_begin_t {
|
| 681 |
+
ompt_id_t encountering_task_id;
|
| 682 |
+
ompt_id_t parallel_id;
|
| 683 |
+
unsigned int requested_parallelism;
|
| 684 |
+
int flags;
|
| 685 |
+
const void *codeptr_ra;
|
| 686 |
+
} ompt_record_parallel_begin_t;
|
| 687 |
+
|
| 688 |
+
typedef void (*ompt_callback_parallel_end_t) (
|
| 689 |
+
ompt_data_t *parallel_data,
|
| 690 |
+
ompt_data_t *encountering_task_data,
|
| 691 |
+
int flags,
|
| 692 |
+
const void *codeptr_ra
|
| 693 |
+
);
|
| 694 |
+
|
| 695 |
+
typedef struct ompt_record_parallel_end_t {
|
| 696 |
+
ompt_id_t parallel_id;
|
| 697 |
+
ompt_id_t encountering_task_id;
|
| 698 |
+
int flags;
|
| 699 |
+
const void *codeptr_ra;
|
| 700 |
+
} ompt_record_parallel_end_t;
|
| 701 |
+
|
| 702 |
+
typedef void (*ompt_callback_work_t) (
|
| 703 |
+
ompt_work_t wstype,
|
| 704 |
+
ompt_scope_endpoint_t endpoint,
|
| 705 |
+
ompt_data_t *parallel_data,
|
| 706 |
+
ompt_data_t *task_data,
|
| 707 |
+
uint64_t count,
|
| 708 |
+
const void *codeptr_ra
|
| 709 |
+
);
|
| 710 |
+
|
| 711 |
+
typedef struct ompt_record_work_t {
|
| 712 |
+
ompt_work_t wstype;
|
| 713 |
+
ompt_scope_endpoint_t endpoint;
|
| 714 |
+
ompt_id_t parallel_id;
|
| 715 |
+
ompt_id_t task_id;
|
| 716 |
+
uint64_t count;
|
| 717 |
+
const void *codeptr_ra;
|
| 718 |
+
} ompt_record_work_t;
|
| 719 |
+
|
| 720 |
+
typedef void (*ompt_callback_dispatch_t) (
|
| 721 |
+
ompt_data_t *parallel_data,
|
| 722 |
+
ompt_data_t *task_data,
|
| 723 |
+
ompt_dispatch_t kind,
|
| 724 |
+
ompt_data_t instance
|
| 725 |
+
);
|
| 726 |
+
|
| 727 |
+
typedef struct ompt_record_dispatch_t {
|
| 728 |
+
ompt_id_t parallel_id;
|
| 729 |
+
ompt_id_t task_id;
|
| 730 |
+
ompt_dispatch_t kind;
|
| 731 |
+
ompt_data_t instance;
|
| 732 |
+
} ompt_record_dispatch_t;
|
| 733 |
+
|
| 734 |
+
typedef void (*ompt_callback_task_create_t) (
|
| 735 |
+
ompt_data_t *encountering_task_data,
|
| 736 |
+
const ompt_frame_t *encountering_task_frame,
|
| 737 |
+
ompt_data_t *new_task_data,
|
| 738 |
+
int flags,
|
| 739 |
+
int has_dependences,
|
| 740 |
+
const void *codeptr_ra
|
| 741 |
+
);
|
| 742 |
+
|
| 743 |
+
typedef struct ompt_record_task_create_t {
|
| 744 |
+
ompt_id_t encountering_task_id;
|
| 745 |
+
ompt_id_t new_task_id;
|
| 746 |
+
int flags;
|
| 747 |
+
int has_dependences;
|
| 748 |
+
const void *codeptr_ra;
|
| 749 |
+
} ompt_record_task_create_t;
|
| 750 |
+
|
| 751 |
+
typedef void (*ompt_callback_dependences_t) (
|
| 752 |
+
ompt_data_t *task_data,
|
| 753 |
+
const ompt_dependence_t *deps,
|
| 754 |
+
int ndeps
|
| 755 |
+
);
|
| 756 |
+
|
| 757 |
+
typedef struct ompt_record_dependences_t {
|
| 758 |
+
ompt_id_t task_id;
|
| 759 |
+
ompt_dependence_t dep;
|
| 760 |
+
int ndeps;
|
| 761 |
+
} ompt_record_dependences_t;
|
| 762 |
+
|
| 763 |
+
typedef void (*ompt_callback_task_dependence_t) (
|
| 764 |
+
ompt_data_t *src_task_data,
|
| 765 |
+
ompt_data_t *sink_task_data
|
| 766 |
+
);
|
| 767 |
+
|
| 768 |
+
typedef struct ompt_record_task_dependence_t {
|
| 769 |
+
ompt_id_t src_task_id;
|
| 770 |
+
ompt_id_t sink_task_id;
|
| 771 |
+
} ompt_record_task_dependence_t;
|
| 772 |
+
|
| 773 |
+
typedef void (*ompt_callback_task_schedule_t) (
|
| 774 |
+
ompt_data_t *prior_task_data,
|
| 775 |
+
ompt_task_status_t prior_task_status,
|
| 776 |
+
ompt_data_t *next_task_data
|
| 777 |
+
);
|
| 778 |
+
|
| 779 |
+
typedef struct ompt_record_task_schedule_t {
|
| 780 |
+
ompt_id_t prior_task_id;
|
| 781 |
+
ompt_task_status_t prior_task_status;
|
| 782 |
+
ompt_id_t next_task_id;
|
| 783 |
+
} ompt_record_task_schedule_t;
|
| 784 |
+
|
| 785 |
+
typedef void (*ompt_callback_implicit_task_t) (
|
| 786 |
+
ompt_scope_endpoint_t endpoint,
|
| 787 |
+
ompt_data_t *parallel_data,
|
| 788 |
+
ompt_data_t *task_data,
|
| 789 |
+
unsigned int actual_parallelism,
|
| 790 |
+
unsigned int index,
|
| 791 |
+
int flags
|
| 792 |
+
);
|
| 793 |
+
|
| 794 |
+
typedef struct ompt_record_implicit_task_t {
|
| 795 |
+
ompt_scope_endpoint_t endpoint;
|
| 796 |
+
ompt_id_t parallel_id;
|
| 797 |
+
ompt_id_t task_id;
|
| 798 |
+
unsigned int actual_parallelism;
|
| 799 |
+
unsigned int index;
|
| 800 |
+
int flags;
|
| 801 |
+
} ompt_record_implicit_task_t;
|
| 802 |
+
|
| 803 |
+
typedef void (*ompt_callback_master_t) (
|
| 804 |
+
ompt_scope_endpoint_t endpoint,
|
| 805 |
+
ompt_data_t *parallel_data,
|
| 806 |
+
ompt_data_t *task_data,
|
| 807 |
+
const void *codeptr_ra
|
| 808 |
+
);
|
| 809 |
+
|
| 810 |
+
typedef struct ompt_record_master_t {
|
| 811 |
+
ompt_scope_endpoint_t endpoint;
|
| 812 |
+
ompt_id_t parallel_id;
|
| 813 |
+
ompt_id_t task_id;
|
| 814 |
+
const void *codeptr_ra;
|
| 815 |
+
} ompt_record_master_t;
|
| 816 |
+
|
| 817 |
+
typedef void (*ompt_callback_sync_region_t) (
|
| 818 |
+
ompt_sync_region_t kind,
|
| 819 |
+
ompt_scope_endpoint_t endpoint,
|
| 820 |
+
ompt_data_t *parallel_data,
|
| 821 |
+
ompt_data_t *task_data,
|
| 822 |
+
const void *codeptr_ra
|
| 823 |
+
);
|
| 824 |
+
|
| 825 |
+
typedef struct ompt_record_sync_region_t {
|
| 826 |
+
ompt_sync_region_t kind;
|
| 827 |
+
ompt_scope_endpoint_t endpoint;
|
| 828 |
+
ompt_id_t parallel_id;
|
| 829 |
+
ompt_id_t task_id;
|
| 830 |
+
const void *codeptr_ra;
|
| 831 |
+
} ompt_record_sync_region_t;
|
| 832 |
+
|
| 833 |
+
typedef void (*ompt_callback_mutex_acquire_t) (
|
| 834 |
+
ompt_mutex_t kind,
|
| 835 |
+
unsigned int hint,
|
| 836 |
+
unsigned int impl,
|
| 837 |
+
ompt_wait_id_t wait_id,
|
| 838 |
+
const void *codeptr_ra
|
| 839 |
+
);
|
| 840 |
+
|
| 841 |
+
typedef struct ompt_record_mutex_acquire_t {
|
| 842 |
+
ompt_mutex_t kind;
|
| 843 |
+
unsigned int hint;
|
| 844 |
+
unsigned int impl;
|
| 845 |
+
ompt_wait_id_t wait_id;
|
| 846 |
+
const void *codeptr_ra;
|
| 847 |
+
} ompt_record_mutex_acquire_t;
|
| 848 |
+
|
| 849 |
+
typedef void (*ompt_callback_mutex_t) (
|
| 850 |
+
ompt_mutex_t kind,
|
| 851 |
+
ompt_wait_id_t wait_id,
|
| 852 |
+
const void *codeptr_ra
|
| 853 |
+
);
|
| 854 |
+
|
| 855 |
+
typedef struct ompt_record_mutex_t {
|
| 856 |
+
ompt_mutex_t kind;
|
| 857 |
+
ompt_wait_id_t wait_id;
|
| 858 |
+
const void *codeptr_ra;
|
| 859 |
+
} ompt_record_mutex_t;
|
| 860 |
+
|
| 861 |
+
typedef void (*ompt_callback_nest_lock_t) (
|
| 862 |
+
ompt_scope_endpoint_t endpoint,
|
| 863 |
+
ompt_wait_id_t wait_id,
|
| 864 |
+
const void *codeptr_ra
|
| 865 |
+
);
|
| 866 |
+
|
| 867 |
+
typedef struct ompt_record_nest_lock_t {
|
| 868 |
+
ompt_scope_endpoint_t endpoint;
|
| 869 |
+
ompt_wait_id_t wait_id;
|
| 870 |
+
const void *codeptr_ra;
|
| 871 |
+
} ompt_record_nest_lock_t;
|
| 872 |
+
|
| 873 |
+
typedef void (*ompt_callback_flush_t) (
|
| 874 |
+
ompt_data_t *thread_data,
|
| 875 |
+
const void *codeptr_ra
|
| 876 |
+
);
|
| 877 |
+
|
| 878 |
+
typedef struct ompt_record_flush_t {
|
| 879 |
+
const void *codeptr_ra;
|
| 880 |
+
} ompt_record_flush_t;
|
| 881 |
+
|
| 882 |
+
typedef void (*ompt_callback_cancel_t) (
|
| 883 |
+
ompt_data_t *task_data,
|
| 884 |
+
int flags,
|
| 885 |
+
const void *codeptr_ra
|
| 886 |
+
);
|
| 887 |
+
|
| 888 |
+
typedef struct ompt_record_cancel_t {
|
| 889 |
+
ompt_id_t task_id;
|
| 890 |
+
int flags;
|
| 891 |
+
const void *codeptr_ra;
|
| 892 |
+
} ompt_record_cancel_t;
|
| 893 |
+
|
| 894 |
+
typedef void (*ompt_callback_device_initialize_t) (
|
| 895 |
+
int device_num,
|
| 896 |
+
const char *type,
|
| 897 |
+
ompt_device_t *device,
|
| 898 |
+
ompt_function_lookup_t lookup,
|
| 899 |
+
const char *documentation
|
| 900 |
+
);
|
| 901 |
+
|
| 902 |
+
typedef void (*ompt_callback_device_finalize_t) (
|
| 903 |
+
int device_num
|
| 904 |
+
);
|
| 905 |
+
|
| 906 |
+
typedef void (*ompt_callback_device_load_t) (
|
| 907 |
+
int device_num,
|
| 908 |
+
const char *filename,
|
| 909 |
+
int64_t offset_in_file,
|
| 910 |
+
void *vma_in_file,
|
| 911 |
+
size_t bytes,
|
| 912 |
+
void *host_addr,
|
| 913 |
+
void *device_addr,
|
| 914 |
+
uint64_t module_id
|
| 915 |
+
);
|
| 916 |
+
|
| 917 |
+
typedef void (*ompt_callback_device_unload_t) (
|
| 918 |
+
int device_num,
|
| 919 |
+
uint64_t module_id
|
| 920 |
+
);
|
| 921 |
+
|
| 922 |
+
typedef void (*ompt_callback_target_data_op_t) (
|
| 923 |
+
ompt_id_t target_id,
|
| 924 |
+
ompt_id_t host_op_id,
|
| 925 |
+
ompt_target_data_op_t optype,
|
| 926 |
+
void *src_addr,
|
| 927 |
+
int src_device_num,
|
| 928 |
+
void *dest_addr,
|
| 929 |
+
int dest_device_num,
|
| 930 |
+
size_t bytes,
|
| 931 |
+
const void *codeptr_ra
|
| 932 |
+
);
|
| 933 |
+
|
| 934 |
+
typedef struct ompt_record_target_data_op_t {
|
| 935 |
+
ompt_id_t host_op_id;
|
| 936 |
+
ompt_target_data_op_t optype;
|
| 937 |
+
void *src_addr;
|
| 938 |
+
int src_device_num;
|
| 939 |
+
void *dest_addr;
|
| 940 |
+
int dest_device_num;
|
| 941 |
+
size_t bytes;
|
| 942 |
+
ompt_device_time_t end_time;
|
| 943 |
+
const void *codeptr_ra;
|
| 944 |
+
} ompt_record_target_data_op_t;
|
| 945 |
+
|
| 946 |
+
typedef void (*ompt_callback_target_t) (
|
| 947 |
+
ompt_target_t kind,
|
| 948 |
+
ompt_scope_endpoint_t endpoint,
|
| 949 |
+
int device_num,
|
| 950 |
+
ompt_data_t *task_data,
|
| 951 |
+
ompt_id_t target_id,
|
| 952 |
+
const void *codeptr_ra
|
| 953 |
+
);
|
| 954 |
+
|
| 955 |
+
typedef struct ompt_record_target_t {
|
| 956 |
+
ompt_target_t kind;
|
| 957 |
+
ompt_scope_endpoint_t endpoint;
|
| 958 |
+
int device_num;
|
| 959 |
+
ompt_id_t task_id;
|
| 960 |
+
ompt_id_t target_id;
|
| 961 |
+
const void *codeptr_ra;
|
| 962 |
+
} ompt_record_target_t;
|
| 963 |
+
|
| 964 |
+
typedef void (*ompt_callback_target_map_t) (
|
| 965 |
+
ompt_id_t target_id,
|
| 966 |
+
unsigned int nitems,
|
| 967 |
+
void **host_addr,
|
| 968 |
+
void **device_addr,
|
| 969 |
+
size_t *bytes,
|
| 970 |
+
unsigned int *mapping_flags,
|
| 971 |
+
const void *codeptr_ra
|
| 972 |
+
);
|
| 973 |
+
|
| 974 |
+
typedef struct ompt_record_target_map_t {
|
| 975 |
+
ompt_id_t target_id;
|
| 976 |
+
unsigned int nitems;
|
| 977 |
+
void **host_addr;
|
| 978 |
+
void **device_addr;
|
| 979 |
+
size_t *bytes;
|
| 980 |
+
unsigned int *mapping_flags;
|
| 981 |
+
const void *codeptr_ra;
|
| 982 |
+
} ompt_record_target_map_t;
|
| 983 |
+
|
| 984 |
+
typedef void (*ompt_callback_target_submit_t) (
|
| 985 |
+
ompt_id_t target_id,
|
| 986 |
+
ompt_id_t host_op_id,
|
| 987 |
+
unsigned int requested_num_teams
|
| 988 |
+
);
|
| 989 |
+
|
| 990 |
+
typedef struct ompt_record_target_kernel_t {
|
| 991 |
+
ompt_id_t host_op_id;
|
| 992 |
+
unsigned int requested_num_teams;
|
| 993 |
+
unsigned int granted_num_teams;
|
| 994 |
+
ompt_device_time_t end_time;
|
| 995 |
+
} ompt_record_target_kernel_t;
|
| 996 |
+
|
| 997 |
+
typedef int (*ompt_callback_control_tool_t) (
|
| 998 |
+
uint64_t command,
|
| 999 |
+
uint64_t modifier,
|
| 1000 |
+
void *arg,
|
| 1001 |
+
const void *codeptr_ra
|
| 1002 |
+
);
|
| 1003 |
+
|
| 1004 |
+
typedef struct ompt_record_control_tool_t {
|
| 1005 |
+
uint64_t command;
|
| 1006 |
+
uint64_t modifier;
|
| 1007 |
+
const void *codeptr_ra;
|
| 1008 |
+
} ompt_record_control_tool_t;
|
| 1009 |
+
|
| 1010 |
+
typedef struct ompd_address_t {
|
| 1011 |
+
ompd_seg_t segment;
|
| 1012 |
+
ompd_addr_t address;
|
| 1013 |
+
} ompd_address_t;
|
| 1014 |
+
|
| 1015 |
+
typedef struct ompd_frame_info_t {
|
| 1016 |
+
ompd_address_t frame_address;
|
| 1017 |
+
ompd_word_t frame_flag;
|
| 1018 |
+
} ompd_frame_info_t;
|
| 1019 |
+
|
| 1020 |
+
typedef struct _ompd_aspace_handle ompd_address_space_handle_t;
|
| 1021 |
+
typedef struct _ompd_thread_handle ompd_thread_handle_t;
|
| 1022 |
+
typedef struct _ompd_parallel_handle ompd_parallel_handle_t;
|
| 1023 |
+
typedef struct _ompd_task_handle ompd_task_handle_t;
|
| 1024 |
+
|
| 1025 |
+
typedef struct _ompd_aspace_cont ompd_address_space_context_t;
|
| 1026 |
+
typedef struct _ompd_thread_cont ompd_thread_context_t;
|
| 1027 |
+
|
| 1028 |
+
typedef struct ompd_device_type_sizes_t {
|
| 1029 |
+
uint8_t sizeof_char;
|
| 1030 |
+
uint8_t sizeof_short;
|
| 1031 |
+
uint8_t sizeof_int;
|
| 1032 |
+
uint8_t sizeof_long;
|
| 1033 |
+
uint8_t sizeof_long_long;
|
| 1034 |
+
uint8_t sizeof_pointer;
|
| 1035 |
+
} ompd_device_type_sizes_t;
|
| 1036 |
+
|
| 1037 |
+
typedef struct ompt_record_ompt_t {
|
| 1038 |
+
ompt_callbacks_t type;
|
| 1039 |
+
ompt_device_time_t time;
|
| 1040 |
+
ompt_id_t thread_id;
|
| 1041 |
+
ompt_id_t target_id;
|
| 1042 |
+
union {
|
| 1043 |
+
ompt_record_thread_begin_t thread_begin;
|
| 1044 |
+
ompt_record_parallel_begin_t parallel_begin;
|
| 1045 |
+
ompt_record_parallel_end_t parallel_end;
|
| 1046 |
+
ompt_record_work_t work;
|
| 1047 |
+
ompt_record_dispatch_t dispatch;
|
| 1048 |
+
ompt_record_task_create_t task_create;
|
| 1049 |
+
ompt_record_dependences_t dependences;
|
| 1050 |
+
ompt_record_task_dependence_t task_dependence;
|
| 1051 |
+
ompt_record_task_schedule_t task_schedule;
|
| 1052 |
+
ompt_record_implicit_task_t implicit_task;
|
| 1053 |
+
ompt_record_master_t master;
|
| 1054 |
+
ompt_record_sync_region_t sync_region;
|
| 1055 |
+
ompt_record_mutex_acquire_t mutex_acquire;
|
| 1056 |
+
ompt_record_mutex_t mutex;
|
| 1057 |
+
ompt_record_nest_lock_t nest_lock;
|
| 1058 |
+
ompt_record_flush_t flush;
|
| 1059 |
+
ompt_record_cancel_t cancel;
|
| 1060 |
+
ompt_record_target_t target;
|
| 1061 |
+
ompt_record_target_data_op_t target_data_op;
|
| 1062 |
+
ompt_record_target_map_t target_map;
|
| 1063 |
+
ompt_record_target_kernel_t target_kernel;
|
| 1064 |
+
ompt_record_control_tool_t control_tool;
|
| 1065 |
+
} record;
|
| 1066 |
+
} ompt_record_ompt_t;
|
| 1067 |
+
|
| 1068 |
+
typedef ompt_record_ompt_t *(*ompt_get_record_ompt_t) (
|
| 1069 |
+
ompt_buffer_t *buffer,
|
| 1070 |
+
ompt_buffer_cursor_t current
|
| 1071 |
+
);
|
| 1072 |
+
|
| 1073 |
+
#define ompt_id_none 0
|
| 1074 |
+
#define ompt_data_none {0}
|
| 1075 |
+
#define ompt_time_none 0
|
| 1076 |
+
#define ompt_hwid_none 0
|
| 1077 |
+
#define ompt_addr_none ~0
|
| 1078 |
+
#define ompt_mutex_impl_none 0
|
| 1079 |
+
#define ompt_wait_id_none 0
|
| 1080 |
+
|
| 1081 |
+
#define ompd_segment_none 0
|
| 1082 |
+
|
| 1083 |
+
#endif /* __OMPT__ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (184 Bytes). View file
|
|
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/cupti_callbacks.h
ADDED
|
@@ -0,0 +1,762 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2010-2020 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__CUPTI_CALLBACKS_H__)
|
| 51 |
+
#define __CUPTI_CALLBACKS_H__
|
| 52 |
+
|
| 53 |
+
#include <cuda.h>
|
| 54 |
+
#include <builtin_types.h>
|
| 55 |
+
#include <string.h>
|
| 56 |
+
#include <cuda_stdint.h>
|
| 57 |
+
#include <cupti_result.h>
|
| 58 |
+
|
| 59 |
+
#ifndef CUPTIAPI
|
| 60 |
+
#ifdef _WIN32
|
| 61 |
+
#define CUPTIAPI __stdcall
|
| 62 |
+
#else
|
| 63 |
+
#define CUPTIAPI
|
| 64 |
+
#endif
|
| 65 |
+
#endif
|
| 66 |
+
|
| 67 |
+
#if defined(__cplusplus)
|
| 68 |
+
extern "C" {
|
| 69 |
+
#endif
|
| 70 |
+
|
| 71 |
+
#if defined(__GNUC__) && defined(CUPTI_LIB)
|
| 72 |
+
#pragma GCC visibility push(default)
|
| 73 |
+
#endif
|
| 74 |
+
|
| 75 |
+
/**
|
| 76 |
+
* \defgroup CUPTI_CALLBACK_API CUPTI Callback API
|
| 77 |
+
* Functions, types, and enums that implement the CUPTI Callback API.
|
| 78 |
+
* @{
|
| 79 |
+
*/
|
| 80 |
+
|
| 81 |
+
/**
|
| 82 |
+
* \brief Specifies the point in an API call that a callback is issued.
|
| 83 |
+
*
|
| 84 |
+
* Specifies the point in an API call that a callback is issued. This
|
| 85 |
+
* value is communicated to the callback function via \ref
|
| 86 |
+
* CUpti_CallbackData::callbackSite.
|
| 87 |
+
*/
|
| 88 |
+
typedef enum {
|
| 89 |
+
/**
|
| 90 |
+
* The callback is at the entry of the API call.
|
| 91 |
+
*/
|
| 92 |
+
CUPTI_API_ENTER = 0,
|
| 93 |
+
/**
|
| 94 |
+
* The callback is at the exit of the API call.
|
| 95 |
+
*/
|
| 96 |
+
CUPTI_API_EXIT = 1,
|
| 97 |
+
CUPTI_API_CBSITE_FORCE_INT = 0x7fffffff
|
| 98 |
+
} CUpti_ApiCallbackSite;
|
| 99 |
+
|
| 100 |
+
/**
|
| 101 |
+
* \brief Callback domains.
|
| 102 |
+
*
|
| 103 |
+
* Callback domains. Each domain represents callback points for a
|
| 104 |
+
* group of related API functions or CUDA driver activity.
|
| 105 |
+
*/
|
| 106 |
+
typedef enum {
|
| 107 |
+
/**
|
| 108 |
+
* Invalid domain.
|
| 109 |
+
*/
|
| 110 |
+
CUPTI_CB_DOMAIN_INVALID = 0,
|
| 111 |
+
/**
|
| 112 |
+
* Domain containing callback points for all driver API functions.
|
| 113 |
+
*/
|
| 114 |
+
CUPTI_CB_DOMAIN_DRIVER_API = 1,
|
| 115 |
+
/**
|
| 116 |
+
* Domain containing callback points for all runtime API
|
| 117 |
+
* functions.
|
| 118 |
+
*/
|
| 119 |
+
CUPTI_CB_DOMAIN_RUNTIME_API = 2,
|
| 120 |
+
/**
|
| 121 |
+
* Domain containing callback points for CUDA resource tracking.
|
| 122 |
+
*/
|
| 123 |
+
CUPTI_CB_DOMAIN_RESOURCE = 3,
|
| 124 |
+
/**
|
| 125 |
+
* Domain containing callback points for CUDA synchronization.
|
| 126 |
+
*/
|
| 127 |
+
CUPTI_CB_DOMAIN_SYNCHRONIZE = 4,
|
| 128 |
+
/**
|
| 129 |
+
* Domain containing callback points for NVTX API functions.
|
| 130 |
+
*/
|
| 131 |
+
CUPTI_CB_DOMAIN_NVTX = 5,
|
| 132 |
+
CUPTI_CB_DOMAIN_SIZE,
|
| 133 |
+
|
| 134 |
+
CUPTI_CB_DOMAIN_FORCE_INT = 0x7fffffff
|
| 135 |
+
} CUpti_CallbackDomain;
|
| 136 |
+
|
| 137 |
+
/**
|
| 138 |
+
* \brief Callback IDs for resource domain.
|
| 139 |
+
*
|
| 140 |
+
* Callback IDs for resource domain, CUPTI_CB_DOMAIN_RESOURCE. This
|
| 141 |
+
* value is communicated to the callback function via the \p cbid
|
| 142 |
+
* parameter.
|
| 143 |
+
*/
|
| 144 |
+
typedef enum {
|
| 145 |
+
/**
|
| 146 |
+
* Invalid resource callback ID.
|
| 147 |
+
*/
|
| 148 |
+
CUPTI_CBID_RESOURCE_INVALID = 0,
|
| 149 |
+
/**
|
| 150 |
+
* A new context has been created.
|
| 151 |
+
*/
|
| 152 |
+
CUPTI_CBID_RESOURCE_CONTEXT_CREATED = 1,
|
| 153 |
+
/**
|
| 154 |
+
* A context is about to be destroyed.
|
| 155 |
+
*/
|
| 156 |
+
CUPTI_CBID_RESOURCE_CONTEXT_DESTROY_STARTING = 2,
|
| 157 |
+
/**
|
| 158 |
+
* A new stream has been created.
|
| 159 |
+
*/
|
| 160 |
+
CUPTI_CBID_RESOURCE_STREAM_CREATED = 3,
|
| 161 |
+
/**
|
| 162 |
+
* A stream is about to be destroyed.
|
| 163 |
+
*/
|
| 164 |
+
CUPTI_CBID_RESOURCE_STREAM_DESTROY_STARTING = 4,
|
| 165 |
+
/**
|
| 166 |
+
* The driver has finished initializing.
|
| 167 |
+
*/
|
| 168 |
+
CUPTI_CBID_RESOURCE_CU_INIT_FINISHED = 5,
|
| 169 |
+
/**
|
| 170 |
+
* A module has been loaded.
|
| 171 |
+
*/
|
| 172 |
+
CUPTI_CBID_RESOURCE_MODULE_LOADED = 6,
|
| 173 |
+
/**
|
| 174 |
+
* A module is about to be unloaded.
|
| 175 |
+
*/
|
| 176 |
+
CUPTI_CBID_RESOURCE_MODULE_UNLOAD_STARTING = 7,
|
| 177 |
+
/**
|
| 178 |
+
* The current module which is being profiled.
|
| 179 |
+
*/
|
| 180 |
+
CUPTI_CBID_RESOURCE_MODULE_PROFILED = 8,
|
| 181 |
+
/**
|
| 182 |
+
* CUDA graph has been created.
|
| 183 |
+
*/
|
| 184 |
+
CUPTI_CBID_RESOURCE_GRAPH_CREATED = 9,
|
| 185 |
+
/**
|
| 186 |
+
* CUDA graph is about to be destroyed.
|
| 187 |
+
*/
|
| 188 |
+
CUPTI_CBID_RESOURCE_GRAPH_DESTROY_STARTING = 10,
|
| 189 |
+
/**
|
| 190 |
+
* CUDA graph is cloned.
|
| 191 |
+
*/
|
| 192 |
+
CUPTI_CBID_RESOURCE_GRAPH_CLONED = 11,
|
| 193 |
+
/**
|
| 194 |
+
* CUDA graph node is about to be created
|
| 195 |
+
*/
|
| 196 |
+
CUPTI_CBID_RESOURCE_GRAPHNODE_CREATE_STARTING = 12,
|
| 197 |
+
/**
|
| 198 |
+
* CUDA graph node is created.
|
| 199 |
+
*/
|
| 200 |
+
CUPTI_CBID_RESOURCE_GRAPHNODE_CREATED = 13,
|
| 201 |
+
/**
|
| 202 |
+
* CUDA graph node is about to be destroyed.
|
| 203 |
+
*/
|
| 204 |
+
CUPTI_CBID_RESOURCE_GRAPHNODE_DESTROY_STARTING = 14,
|
| 205 |
+
/**
|
| 206 |
+
* Dependency on a CUDA graph node is created.
|
| 207 |
+
*/
|
| 208 |
+
CUPTI_CBID_RESOURCE_GRAPHNODE_DEPENDENCY_CREATED = 15,
|
| 209 |
+
/**
|
| 210 |
+
* Dependency on a CUDA graph node is destroyed.
|
| 211 |
+
*/
|
| 212 |
+
CUPTI_CBID_RESOURCE_GRAPHNODE_DEPENDENCY_DESTROY_STARTING = 16,
|
| 213 |
+
/**
|
| 214 |
+
* An executable CUDA graph is about to be created.
|
| 215 |
+
*/
|
| 216 |
+
CUPTI_CBID_RESOURCE_GRAPHEXEC_CREATE_STARTING = 17,
|
| 217 |
+
/**
|
| 218 |
+
* An executable CUDA graph is created.
|
| 219 |
+
*/
|
| 220 |
+
CUPTI_CBID_RESOURCE_GRAPHEXEC_CREATED = 18,
|
| 221 |
+
/**
|
| 222 |
+
* An executable CUDA graph is about to be destroyed.
|
| 223 |
+
*/
|
| 224 |
+
CUPTI_CBID_RESOURCE_GRAPHEXEC_DESTROY_STARTING = 19,
|
| 225 |
+
/**
|
| 226 |
+
* CUDA graph node is cloned.
|
| 227 |
+
*/
|
| 228 |
+
CUPTI_CBID_RESOURCE_GRAPHNODE_CLONED = 20,
|
| 229 |
+
|
| 230 |
+
CUPTI_CBID_RESOURCE_SIZE,
|
| 231 |
+
CUPTI_CBID_RESOURCE_FORCE_INT = 0x7fffffff
|
| 232 |
+
} CUpti_CallbackIdResource;
|
| 233 |
+
|
| 234 |
+
/**
|
| 235 |
+
* \brief Callback IDs for synchronization domain.
|
| 236 |
+
*
|
| 237 |
+
* Callback IDs for synchronization domain,
|
| 238 |
+
* CUPTI_CB_DOMAIN_SYNCHRONIZE. This value is communicated to the
|
| 239 |
+
* callback function via the \p cbid parameter.
|
| 240 |
+
*/
|
| 241 |
+
typedef enum {
|
| 242 |
+
/**
|
| 243 |
+
* Invalid synchronize callback ID.
|
| 244 |
+
*/
|
| 245 |
+
CUPTI_CBID_SYNCHRONIZE_INVALID = 0,
|
| 246 |
+
/**
|
| 247 |
+
* Stream synchronization has completed for the stream.
|
| 248 |
+
*/
|
| 249 |
+
CUPTI_CBID_SYNCHRONIZE_STREAM_SYNCHRONIZED = 1,
|
| 250 |
+
/**
|
| 251 |
+
* Context synchronization has completed for the context.
|
| 252 |
+
*/
|
| 253 |
+
CUPTI_CBID_SYNCHRONIZE_CONTEXT_SYNCHRONIZED = 2,
|
| 254 |
+
CUPTI_CBID_SYNCHRONIZE_SIZE,
|
| 255 |
+
CUPTI_CBID_SYNCHRONIZE_FORCE_INT = 0x7fffffff
|
| 256 |
+
} CUpti_CallbackIdSync;
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
/**
|
| 260 |
+
* \brief Data passed into a runtime or driver API callback function.
|
| 261 |
+
*
|
| 262 |
+
* Data passed into a runtime or driver API callback function as the
|
| 263 |
+
* \p cbdata argument to \ref CUpti_CallbackFunc. The \p cbdata will
|
| 264 |
+
* be this type for \p domain equal to CUPTI_CB_DOMAIN_DRIVER_API or
|
| 265 |
+
* CUPTI_CB_DOMAIN_RUNTIME_API. The callback data is valid only within
|
| 266 |
+
* the invocation of the callback function that is passed the data. If
|
| 267 |
+
* you need to retain some data for use outside of the callback, you
|
| 268 |
+
* must make a copy of that data. For example, if you make a shallow
|
| 269 |
+
* copy of CUpti_CallbackData within a callback, you cannot
|
| 270 |
+
* dereference \p functionParams outside of that callback to access
|
| 271 |
+
* the function parameters. \p functionName is an exception: the
|
| 272 |
+
* string pointed to by \p functionName is a global constant and so
|
| 273 |
+
* may be accessed outside of the callback.
|
| 274 |
+
*/
|
| 275 |
+
typedef struct {
|
| 276 |
+
/**
|
| 277 |
+
* Point in the runtime or driver function from where the callback
|
| 278 |
+
* was issued.
|
| 279 |
+
*/
|
| 280 |
+
CUpti_ApiCallbackSite callbackSite;
|
| 281 |
+
|
| 282 |
+
/**
|
| 283 |
+
* Name of the runtime or driver API function which issued the
|
| 284 |
+
* callback. This string is a global constant and so may be
|
| 285 |
+
* accessed outside of the callback.
|
| 286 |
+
*/
|
| 287 |
+
const char *functionName;
|
| 288 |
+
|
| 289 |
+
/**
|
| 290 |
+
* Pointer to the arguments passed to the runtime or driver API
|
| 291 |
+
* call. See generated_cuda_runtime_api_meta.h and
|
| 292 |
+
* generated_cuda_meta.h for structure definitions for the
|
| 293 |
+
* parameters for each runtime and driver API function.
|
| 294 |
+
*/
|
| 295 |
+
const void *functionParams;
|
| 296 |
+
|
| 297 |
+
/**
|
| 298 |
+
* Pointer to the return value of the runtime or driver API
|
| 299 |
+
* call. This field is only valid within the exit::CUPTI_API_EXIT
|
| 300 |
+
* callback. For a runtime API \p functionReturnValue points to a
|
| 301 |
+
* \p cudaError_t. For a driver API \p functionReturnValue points
|
| 302 |
+
* to a \p CUresult.
|
| 303 |
+
*/
|
| 304 |
+
void *functionReturnValue;
|
| 305 |
+
|
| 306 |
+
/**
|
| 307 |
+
* Name of the symbol operated on by the runtime or driver API
|
| 308 |
+
* function which issued the callback. This entry is valid only for
|
| 309 |
+
* driver and runtime launch callbacks, where it returns the name of
|
| 310 |
+
* the kernel.
|
| 311 |
+
*/
|
| 312 |
+
const char *symbolName;
|
| 313 |
+
|
| 314 |
+
/**
|
| 315 |
+
* Driver context current to the thread, or null if no context is
|
| 316 |
+
* current. This value can change from the entry to exit callback
|
| 317 |
+
* of a runtime API function if the runtime initializes a context.
|
| 318 |
+
*/
|
| 319 |
+
CUcontext context;
|
| 320 |
+
|
| 321 |
+
/**
|
| 322 |
+
* Unique ID for the CUDA context associated with the thread. The
|
| 323 |
+
* UIDs are assigned sequentially as contexts are created and are
|
| 324 |
+
* unique within a process.
|
| 325 |
+
*/
|
| 326 |
+
uint32_t contextUid;
|
| 327 |
+
|
| 328 |
+
/**
|
| 329 |
+
* Pointer to data shared between the entry and exit callbacks of
|
| 330 |
+
* a given runtime or drive API function invocation. This field
|
| 331 |
+
* can be used to pass 64-bit values from the entry callback to
|
| 332 |
+
* the corresponding exit callback.
|
| 333 |
+
*/
|
| 334 |
+
uint64_t *correlationData;
|
| 335 |
+
|
| 336 |
+
/**
|
| 337 |
+
* The activity record correlation ID for this callback. For a
|
| 338 |
+
* driver domain callback (i.e. \p domain
|
| 339 |
+
* CUPTI_CB_DOMAIN_DRIVER_API) this ID will equal the correlation ID
|
| 340 |
+
* in the CUpti_ActivityAPI record corresponding to the CUDA driver
|
| 341 |
+
* function call. For a runtime domain callback (i.e. \p domain
|
| 342 |
+
* CUPTI_CB_DOMAIN_RUNTIME_API) this ID will equal the correlation
|
| 343 |
+
* ID in the CUpti_ActivityAPI record corresponding to the CUDA
|
| 344 |
+
* runtime function call. Within the callback, this ID can be
|
| 345 |
+
* recorded to correlate user data with the activity record. This
|
| 346 |
+
* field is new in 4.1.
|
| 347 |
+
*/
|
| 348 |
+
uint32_t correlationId;
|
| 349 |
+
|
| 350 |
+
} CUpti_CallbackData;
|
| 351 |
+
|
| 352 |
+
/**
|
| 353 |
+
* \brief Data passed into a resource callback function.
|
| 354 |
+
*
|
| 355 |
+
* Data passed into a resource callback function as the \p cbdata
|
| 356 |
+
* argument to \ref CUpti_CallbackFunc. The \p cbdata will be this
|
| 357 |
+
* type for \p domain equal to CUPTI_CB_DOMAIN_RESOURCE. The callback
|
| 358 |
+
* data is valid only within the invocation of the callback function
|
| 359 |
+
* that is passed the data. If you need to retain some data for use
|
| 360 |
+
* outside of the callback, you must make a copy of that data.
|
| 361 |
+
*/
|
| 362 |
+
typedef struct {
|
| 363 |
+
/**
|
| 364 |
+
* For CUPTI_CBID_RESOURCE_CONTEXT_CREATED and
|
| 365 |
+
* CUPTI_CBID_RESOURCE_CONTEXT_DESTROY_STARTING, the context being
|
| 366 |
+
* created or destroyed. For CUPTI_CBID_RESOURCE_STREAM_CREATED and
|
| 367 |
+
* CUPTI_CBID_RESOURCE_STREAM_DESTROY_STARTING, the context
|
| 368 |
+
* containing the stream being created or destroyed.
|
| 369 |
+
*/
|
| 370 |
+
CUcontext context;
|
| 371 |
+
|
| 372 |
+
union {
|
| 373 |
+
/**
|
| 374 |
+
* For CUPTI_CBID_RESOURCE_STREAM_CREATED and
|
| 375 |
+
* CUPTI_CBID_RESOURCE_STREAM_DESTROY_STARTING, the stream being
|
| 376 |
+
* created or destroyed.
|
| 377 |
+
*/
|
| 378 |
+
CUstream stream;
|
| 379 |
+
} resourceHandle;
|
| 380 |
+
|
| 381 |
+
/**
|
| 382 |
+
* Reserved for future use.
|
| 383 |
+
*/
|
| 384 |
+
void *resourceDescriptor;
|
| 385 |
+
} CUpti_ResourceData;
|
| 386 |
+
|
| 387 |
+
|
| 388 |
+
/**
|
| 389 |
+
* \brief Module data passed into a resource callback function.
|
| 390 |
+
*
|
| 391 |
+
* CUDA module data passed into a resource callback function as the \p cbdata
|
| 392 |
+
* argument to \ref CUpti_CallbackFunc. The \p cbdata will be this
|
| 393 |
+
* type for \p domain equal to CUPTI_CB_DOMAIN_RESOURCE. The module
|
| 394 |
+
* data is valid only within the invocation of the callback function
|
| 395 |
+
* that is passed the data. If you need to retain some data for use
|
| 396 |
+
* outside of the callback, you must make a copy of that data.
|
| 397 |
+
*/
|
| 398 |
+
|
| 399 |
+
typedef struct {
|
| 400 |
+
/**
|
| 401 |
+
* Identifier to associate with the CUDA module.
|
| 402 |
+
*/
|
| 403 |
+
uint32_t moduleId;
|
| 404 |
+
|
| 405 |
+
/**
|
| 406 |
+
* The size of the cubin.
|
| 407 |
+
*/
|
| 408 |
+
size_t cubinSize;
|
| 409 |
+
|
| 410 |
+
/**
|
| 411 |
+
* Pointer to the associated cubin.
|
| 412 |
+
*/
|
| 413 |
+
const char *pCubin;
|
| 414 |
+
} CUpti_ModuleResourceData;
|
| 415 |
+
|
| 416 |
+
/**
|
| 417 |
+
* \brief CUDA graphs data passed into a resource callback function.
|
| 418 |
+
*
|
| 419 |
+
* CUDA graphs data passed into a resource callback function as the \p cbdata
|
| 420 |
+
* argument to \ref CUpti_CallbackFunc. The \p cbdata will be this
|
| 421 |
+
* type for \p domain equal to CUPTI_CB_DOMAIN_RESOURCE. The graph
|
| 422 |
+
* data is valid only within the invocation of the callback function
|
| 423 |
+
* that is passed the data. If you need to retain some data for use
|
| 424 |
+
* outside of the callback, you must make a copy of that data.
|
| 425 |
+
*/
|
| 426 |
+
|
| 427 |
+
typedef struct {
|
| 428 |
+
/**
|
| 429 |
+
* CUDA graph
|
| 430 |
+
*/
|
| 431 |
+
CUgraph graph;
|
| 432 |
+
/**
|
| 433 |
+
* The original CUDA graph from which \param graph is cloned
|
| 434 |
+
*/
|
| 435 |
+
CUgraph originalGraph;
|
| 436 |
+
/**
|
| 437 |
+
* CUDA graph node
|
| 438 |
+
*/
|
| 439 |
+
CUgraphNode node;
|
| 440 |
+
/**
|
| 441 |
+
* The original CUDA graph node from which \param node is cloned
|
| 442 |
+
*/
|
| 443 |
+
CUgraphNode originalNode;
|
| 444 |
+
/**
|
| 445 |
+
* Type of the \param node
|
| 446 |
+
*/
|
| 447 |
+
CUgraphNodeType nodeType;
|
| 448 |
+
/**
|
| 449 |
+
* The dependent graph node
|
| 450 |
+
* The size of the array is \param numDependencies.
|
| 451 |
+
*/
|
| 452 |
+
CUgraphNode dependency;
|
| 453 |
+
/**
|
| 454 |
+
* CUDA executable graph
|
| 455 |
+
*/
|
| 456 |
+
CUgraphExec graphExec;
|
| 457 |
+
} CUpti_GraphData;
|
| 458 |
+
|
| 459 |
+
/**
|
| 460 |
+
* \brief Data passed into a synchronize callback function.
|
| 461 |
+
*
|
| 462 |
+
* Data passed into a synchronize callback function as the \p cbdata
|
| 463 |
+
* argument to \ref CUpti_CallbackFunc. The \p cbdata will be this
|
| 464 |
+
* type for \p domain equal to CUPTI_CB_DOMAIN_SYNCHRONIZE. The
|
| 465 |
+
* callback data is valid only within the invocation of the callback
|
| 466 |
+
* function that is passed the data. If you need to retain some data
|
| 467 |
+
* for use outside of the callback, you must make a copy of that data.
|
| 468 |
+
*/
|
| 469 |
+
typedef struct {
|
| 470 |
+
/**
|
| 471 |
+
* The context of the stream being synchronized.
|
| 472 |
+
*/
|
| 473 |
+
CUcontext context;
|
| 474 |
+
/**
|
| 475 |
+
* The stream being synchronized.
|
| 476 |
+
*/
|
| 477 |
+
CUstream stream;
|
| 478 |
+
} CUpti_SynchronizeData;
|
| 479 |
+
|
| 480 |
+
/**
|
| 481 |
+
* \brief Data passed into a NVTX callback function.
|
| 482 |
+
*
|
| 483 |
+
* Data passed into a NVTX callback function as the \p cbdata argument
|
| 484 |
+
* to \ref CUpti_CallbackFunc. The \p cbdata will be this type for \p
|
| 485 |
+
* domain equal to CUPTI_CB_DOMAIN_NVTX. Unless otherwise notes, the
|
| 486 |
+
* callback data is valid only within the invocation of the callback
|
| 487 |
+
* function that is passed the data. If you need to retain some data
|
| 488 |
+
* for use outside of the callback, you must make a copy of that data.
|
| 489 |
+
*/
|
| 490 |
+
typedef struct {
|
| 491 |
+
/**
|
| 492 |
+
* Name of the NVTX API function which issued the callback. This
|
| 493 |
+
* string is a global constant and so may be accessed outside of the
|
| 494 |
+
* callback.
|
| 495 |
+
*/
|
| 496 |
+
const char *functionName;
|
| 497 |
+
|
| 498 |
+
/**
|
| 499 |
+
* Pointer to the arguments passed to the NVTX API call. See
|
| 500 |
+
* generated_nvtx_meta.h for structure definitions for the
|
| 501 |
+
* parameters for each NVTX API function.
|
| 502 |
+
*/
|
| 503 |
+
const void *functionParams;
|
| 504 |
+
|
| 505 |
+
/**
|
| 506 |
+
* Pointer to the return value of the NVTX API call. See
|
| 507 |
+
* nvToolsExt.h for each NVTX API function's return value.
|
| 508 |
+
*/
|
| 509 |
+
const void *functionReturnValue;
|
| 510 |
+
} CUpti_NvtxData;
|
| 511 |
+
|
| 512 |
+
/**
|
| 513 |
+
* \brief An ID for a driver API, runtime API, resource or
|
| 514 |
+
* synchronization callback.
|
| 515 |
+
*
|
| 516 |
+
* An ID for a driver API, runtime API, resource or synchronization
|
| 517 |
+
* callback. Within a driver API callback this should be interpreted
|
| 518 |
+
* as a CUpti_driver_api_trace_cbid value (these values are defined in
|
| 519 |
+
* cupti_driver_cbid.h). Within a runtime API callback this should be
|
| 520 |
+
* interpreted as a CUpti_runtime_api_trace_cbid value (these values
|
| 521 |
+
* are defined in cupti_runtime_cbid.h). Within a resource API
|
| 522 |
+
* callback this should be interpreted as a \ref
|
| 523 |
+
* CUpti_CallbackIdResource value. Within a synchronize API callback
|
| 524 |
+
* this should be interpreted as a \ref CUpti_CallbackIdSync value.
|
| 525 |
+
*/
|
| 526 |
+
typedef uint32_t CUpti_CallbackId;
|
| 527 |
+
|
| 528 |
+
/**
|
| 529 |
+
* \brief Function type for a callback.
|
| 530 |
+
*
|
| 531 |
+
* Function type for a callback. The type of the data passed to the
|
| 532 |
+
* callback in \p cbdata depends on the \p domain. If \p domain is
|
| 533 |
+
* CUPTI_CB_DOMAIN_DRIVER_API or CUPTI_CB_DOMAIN_RUNTIME_API the type
|
| 534 |
+
* of \p cbdata will be CUpti_CallbackData. If \p domain is
|
| 535 |
+
* CUPTI_CB_DOMAIN_RESOURCE the type of \p cbdata will be
|
| 536 |
+
* CUpti_ResourceData. If \p domain is CUPTI_CB_DOMAIN_SYNCHRONIZE the
|
| 537 |
+
* type of \p cbdata will be CUpti_SynchronizeData. If \p domain is
|
| 538 |
+
* CUPTI_CB_DOMAIN_NVTX the type of \p cbdata will be CUpti_NvtxData.
|
| 539 |
+
*
|
| 540 |
+
* \param userdata User data supplied at subscription of the callback
|
| 541 |
+
* \param domain The domain of the callback
|
| 542 |
+
* \param cbid The ID of the callback
|
| 543 |
+
* \param cbdata Data passed to the callback.
|
| 544 |
+
*/
|
| 545 |
+
typedef void (CUPTIAPI *CUpti_CallbackFunc)(
|
| 546 |
+
void *userdata,
|
| 547 |
+
CUpti_CallbackDomain domain,
|
| 548 |
+
CUpti_CallbackId cbid,
|
| 549 |
+
const void *cbdata);
|
| 550 |
+
|
| 551 |
+
/**
|
| 552 |
+
* \brief A callback subscriber.
|
| 553 |
+
*/
|
| 554 |
+
typedef struct CUpti_Subscriber_st *CUpti_SubscriberHandle;
|
| 555 |
+
|
| 556 |
+
/**
|
| 557 |
+
* \brief Pointer to an array of callback domains.
|
| 558 |
+
*/
|
| 559 |
+
typedef CUpti_CallbackDomain *CUpti_DomainTable;
|
| 560 |
+
|
| 561 |
+
/**
|
| 562 |
+
* \brief Get the available callback domains.
|
| 563 |
+
*
|
| 564 |
+
* Returns in \p *domainTable an array of size \p *domainCount of all
|
| 565 |
+
* the available callback domains.
|
| 566 |
+
* \note \b Thread-safety: this function is thread safe.
|
| 567 |
+
*
|
| 568 |
+
* \param domainCount Returns number of callback domains
|
| 569 |
+
* \param domainTable Returns pointer to array of available callback domains
|
| 570 |
+
*
|
| 571 |
+
* \retval CUPTI_SUCCESS on success
|
| 572 |
+
* \retval CUPTI_ERROR_NOT_INITIALIZED if unable to initialize CUPTI
|
| 573 |
+
* \retval CUPTI_ERROR_INVALID_PARAMETER if \p domainCount or \p domainTable are NULL
|
| 574 |
+
*/
|
| 575 |
+
CUptiResult CUPTIAPI cuptiSupportedDomains(size_t *domainCount,
|
| 576 |
+
CUpti_DomainTable *domainTable);
|
| 577 |
+
|
| 578 |
+
/**
|
| 579 |
+
* \brief Initialize a callback subscriber with a callback function
|
| 580 |
+
* and user data.
|
| 581 |
+
*
|
| 582 |
+
* Initializes a callback subscriber with a callback function and
|
| 583 |
+
* (optionally) a pointer to user data. The returned subscriber handle
|
| 584 |
+
* can be used to enable and disable the callback for specific domains
|
| 585 |
+
* and callback IDs.
|
| 586 |
+
* \note Only a single subscriber can be registered at a time. To ensure
|
| 587 |
+
* that no other CUPTI client interrupts the profiling session, it's the
|
| 588 |
+
* responsibility of all the CUPTI clients to call this function before
|
| 589 |
+
* starting the profling session. In case profiling session is already
|
| 590 |
+
* started by another CUPTI client, this function returns the error code
|
| 591 |
+
* CUPTI_ERROR_MULTIPLE_SUBSCRIBERS_NOT_SUPPORTED.
|
| 592 |
+
* Note that this function returns the same error when application is
|
| 593 |
+
* launched using NVIDIA tools like nvprof, Visual Profiler, Nsight Systems,
|
| 594 |
+
* Nsight Compute, cuda-gdb and cuda-memcheck.
|
| 595 |
+
* \note This function does not enable any callbacks.
|
| 596 |
+
* \note \b Thread-safety: this function is thread safe.
|
| 597 |
+
*
|
| 598 |
+
* \param subscriber Returns handle to initialize subscriber
|
| 599 |
+
* \param callback The callback function
|
| 600 |
+
* \param userdata A pointer to user data. This data will be passed to
|
| 601 |
+
* the callback function via the \p userdata paramater.
|
| 602 |
+
*
|
| 603 |
+
* \retval CUPTI_SUCCESS on success
|
| 604 |
+
* \retval CUPTI_ERROR_NOT_INITIALIZED if unable to initialize CUPTI
|
| 605 |
+
* \retval CUPTI_ERROR_MULTIPLE_SUBSCRIBERS_NOT_SUPPORTED if there is already a CUPTI subscriber
|
| 606 |
+
* \retval CUPTI_ERROR_INVALID_PARAMETER if \p subscriber is NULL
|
| 607 |
+
*/
|
| 608 |
+
CUptiResult CUPTIAPI cuptiSubscribe(CUpti_SubscriberHandle *subscriber,
|
| 609 |
+
CUpti_CallbackFunc callback,
|
| 610 |
+
void *userdata);
|
| 611 |
+
|
| 612 |
+
/**
|
| 613 |
+
* \brief Unregister a callback subscriber.
|
| 614 |
+
*
|
| 615 |
+
* Removes a callback subscriber so that no future callbacks will be
|
| 616 |
+
* issued to that subscriber.
|
| 617 |
+
* \note \b Thread-safety: this function is thread safe.
|
| 618 |
+
*
|
| 619 |
+
* \param subscriber Handle to the initialize subscriber
|
| 620 |
+
*
|
| 621 |
+
* \retval CUPTI_SUCCESS on success
|
| 622 |
+
* \retval CUPTI_ERROR_NOT_INITIALIZED if unable to initialized CUPTI
|
| 623 |
+
* \retval CUPTI_ERROR_INVALID_PARAMETER if \p subscriber is NULL or not initialized
|
| 624 |
+
*/
|
| 625 |
+
CUptiResult CUPTIAPI cuptiUnsubscribe(CUpti_SubscriberHandle subscriber);
|
| 626 |
+
|
| 627 |
+
/**
|
| 628 |
+
* \brief Get the current enabled/disabled state of a callback for a specific
|
| 629 |
+
* domain and function ID.
|
| 630 |
+
*
|
| 631 |
+
* Returns non-zero in \p *enable if the callback for a domain and
|
| 632 |
+
* callback ID is enabled, and zero if not enabled.
|
| 633 |
+
*
|
| 634 |
+
* \note \b Thread-safety: a subscriber must serialize access to
|
| 635 |
+
* cuptiGetCallbackState, cuptiEnableCallback, cuptiEnableDomain, and
|
| 636 |
+
* cuptiEnableAllDomains. For example, if cuptiGetCallbackState(sub,
|
| 637 |
+
* d, c) and cuptiEnableCallback(sub, d, c) are called concurrently,
|
| 638 |
+
* the results are undefined.
|
| 639 |
+
*
|
| 640 |
+
* \param enable Returns non-zero if callback enabled, zero if not enabled
|
| 641 |
+
* \param subscriber Handle to the initialize subscriber
|
| 642 |
+
* \param domain The domain of the callback
|
| 643 |
+
* \param cbid The ID of the callback
|
| 644 |
+
*
|
| 645 |
+
* \retval CUPTI_SUCCESS on success
|
| 646 |
+
* \retval CUPTI_ERROR_NOT_INITIALIZED if unable to initialized CUPTI
|
| 647 |
+
* \retval CUPTI_ERROR_INVALID_PARAMETER if \p enabled is NULL, or if \p
|
| 648 |
+
* subscriber, \p domain or \p cbid is invalid.
|
| 649 |
+
*/
|
| 650 |
+
CUptiResult CUPTIAPI cuptiGetCallbackState(uint32_t *enable,
|
| 651 |
+
CUpti_SubscriberHandle subscriber,
|
| 652 |
+
CUpti_CallbackDomain domain,
|
| 653 |
+
CUpti_CallbackId cbid);
|
| 654 |
+
|
| 655 |
+
/**
|
| 656 |
+
* \brief Enable or disabled callbacks for a specific domain and
|
| 657 |
+
* callback ID.
|
| 658 |
+
*
|
| 659 |
+
* Enable or disabled callbacks for a subscriber for a specific domain
|
| 660 |
+
* and callback ID.
|
| 661 |
+
*
|
| 662 |
+
* \note \b Thread-safety: a subscriber must serialize access to
|
| 663 |
+
* cuptiGetCallbackState, cuptiEnableCallback, cuptiEnableDomain, and
|
| 664 |
+
* cuptiEnableAllDomains. For example, if cuptiGetCallbackState(sub,
|
| 665 |
+
* d, c) and cuptiEnableCallback(sub, d, c) are called concurrently,
|
| 666 |
+
* the results are undefined.
|
| 667 |
+
*
|
| 668 |
+
* \param enable New enable state for the callback. Zero disables the
|
| 669 |
+
* callback, non-zero enables the callback.
|
| 670 |
+
* \param subscriber - Handle to callback subscription
|
| 671 |
+
* \param domain The domain of the callback
|
| 672 |
+
* \param cbid The ID of the callback
|
| 673 |
+
*
|
| 674 |
+
* \retval CUPTI_SUCCESS on success
|
| 675 |
+
* \retval CUPTI_ERROR_NOT_INITIALIZED if unable to initialized CUPTI
|
| 676 |
+
* \retval CUPTI_ERROR_INVALID_PARAMETER if \p subscriber, \p domain or \p
|
| 677 |
+
* cbid is invalid.
|
| 678 |
+
*/
|
| 679 |
+
CUptiResult CUPTIAPI cuptiEnableCallback(uint32_t enable,
|
| 680 |
+
CUpti_SubscriberHandle subscriber,
|
| 681 |
+
CUpti_CallbackDomain domain,
|
| 682 |
+
CUpti_CallbackId cbid);
|
| 683 |
+
|
| 684 |
+
/**
|
| 685 |
+
* \brief Enable or disabled all callbacks for a specific domain.
|
| 686 |
+
*
|
| 687 |
+
* Enable or disabled all callbacks for a specific domain.
|
| 688 |
+
*
|
| 689 |
+
* \note \b Thread-safety: a subscriber must serialize access to
|
| 690 |
+
* cuptiGetCallbackState, cuptiEnableCallback, cuptiEnableDomain, and
|
| 691 |
+
* cuptiEnableAllDomains. For example, if cuptiGetCallbackEnabled(sub,
|
| 692 |
+
* d, *) and cuptiEnableDomain(sub, d) are called concurrently, the
|
| 693 |
+
* results are undefined.
|
| 694 |
+
*
|
| 695 |
+
* \param enable New enable state for all callbacks in the
|
| 696 |
+
* domain. Zero disables all callbacks, non-zero enables all
|
| 697 |
+
* callbacks.
|
| 698 |
+
* \param subscriber - Handle to callback subscription
|
| 699 |
+
* \param domain The domain of the callback
|
| 700 |
+
*
|
| 701 |
+
* \retval CUPTI_SUCCESS on success
|
| 702 |
+
* \retval CUPTI_ERROR_NOT_INITIALIZED if unable to initialized CUPTI
|
| 703 |
+
* \retval CUPTI_ERROR_INVALID_PARAMETER if \p subscriber or \p domain is invalid
|
| 704 |
+
*/
|
| 705 |
+
CUptiResult CUPTIAPI cuptiEnableDomain(uint32_t enable,
|
| 706 |
+
CUpti_SubscriberHandle subscriber,
|
| 707 |
+
CUpti_CallbackDomain domain);
|
| 708 |
+
|
| 709 |
+
/**
|
| 710 |
+
* \brief Enable or disable all callbacks in all domains.
|
| 711 |
+
*
|
| 712 |
+
* Enable or disable all callbacks in all domains.
|
| 713 |
+
*
|
| 714 |
+
* \note \b Thread-safety: a subscriber must serialize access to
|
| 715 |
+
* cuptiGetCallbackState, cuptiEnableCallback, cuptiEnableDomain, and
|
| 716 |
+
* cuptiEnableAllDomains. For example, if cuptiGetCallbackState(sub,
|
| 717 |
+
* d, *) and cuptiEnableAllDomains(sub) are called concurrently, the
|
| 718 |
+
* results are undefined.
|
| 719 |
+
*
|
| 720 |
+
* \param enable New enable state for all callbacks in all
|
| 721 |
+
* domain. Zero disables all callbacks, non-zero enables all
|
| 722 |
+
* callbacks.
|
| 723 |
+
* \param subscriber - Handle to callback subscription
|
| 724 |
+
*
|
| 725 |
+
* \retval CUPTI_SUCCESS on success
|
| 726 |
+
* \retval CUPTI_ERROR_NOT_INITIALIZED if unable to initialized CUPTI
|
| 727 |
+
* \retval CUPTI_ERROR_INVALID_PARAMETER if \p subscriber is invalid
|
| 728 |
+
*/
|
| 729 |
+
CUptiResult CUPTIAPI cuptiEnableAllDomains(uint32_t enable,
|
| 730 |
+
CUpti_SubscriberHandle subscriber);
|
| 731 |
+
|
| 732 |
+
/**
|
| 733 |
+
* \brief Get the name of a callback for a specific domain and callback ID.
|
| 734 |
+
*
|
| 735 |
+
* Returns a pointer to the name c_string in \p **name.
|
| 736 |
+
*
|
| 737 |
+
* \note \b Names are available only for the DRIVER and RUNTIME domains.
|
| 738 |
+
*
|
| 739 |
+
* \param domain The domain of the callback
|
| 740 |
+
* \param cbid The ID of the callback
|
| 741 |
+
* \param name Returns pointer to the name string on success, NULL otherwise
|
| 742 |
+
*
|
| 743 |
+
* \retval CUPTI_SUCCESS on success
|
| 744 |
+
* \retval CUPTI_ERROR_INVALID_PARAMETER if \p name is NULL, or if
|
| 745 |
+
* \p domain or \p cbid is invalid.
|
| 746 |
+
*/
|
| 747 |
+
CUptiResult CUPTIAPI cuptiGetCallbackName(CUpti_CallbackDomain domain,
|
| 748 |
+
uint32_t cbid,
|
| 749 |
+
const char **name);
|
| 750 |
+
|
| 751 |
+
/** @} */ /* END CUPTI_CALLBACK_API */
|
| 752 |
+
|
| 753 |
+
#if defined(__GNUC__) && defined(CUPTI_LIB)
|
| 754 |
+
#pragma GCC visibility pop
|
| 755 |
+
#endif
|
| 756 |
+
|
| 757 |
+
#if defined(__cplusplus)
|
| 758 |
+
}
|
| 759 |
+
#endif
|
| 760 |
+
|
| 761 |
+
#endif // file guard
|
| 762 |
+
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/cupti_checkpoint.h
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#pragma once
|
| 2 |
+
|
| 3 |
+
#include <cuda.h>
|
| 4 |
+
#include <cupti_result.h>
|
| 5 |
+
|
| 6 |
+
#include <stddef.h>
|
| 7 |
+
#include <stdint.h>
|
| 8 |
+
|
| 9 |
+
namespace NV { namespace Cupti { namespace Checkpoint {
|
| 10 |
+
|
| 11 |
+
#ifdef __cplusplus
|
| 12 |
+
extern "C"
|
| 13 |
+
{
|
| 14 |
+
#endif
|
| 15 |
+
|
| 16 |
+
/**
|
| 17 |
+
* \defgroup CUPTI_CHECKPOINT_API CUPTI Checkpoint API
|
| 18 |
+
* Functions, types, and enums that implement the CUPTI Checkpoint API.
|
| 19 |
+
* @{
|
| 20 |
+
*/
|
| 21 |
+
|
| 22 |
+
/**
|
| 23 |
+
* \brief Specifies optimization options for a checkpoint, may be OR'd together to specify multiple options.
|
| 24 |
+
*/
|
| 25 |
+
typedef enum
|
| 26 |
+
{
|
| 27 |
+
CUPTI_CHECKPOINT_OPT_NONE = 0, //!< Default behavior
|
| 28 |
+
CUPTI_CHECKPOINT_OPT_TRANSFER = 1, //!< Determine which mem blocks have changed, and only restore those. This optimization is cached, which means cuptiCheckpointRestore must always be called at the same point in the application when this option is enabled, or the result may be incorrect.
|
| 29 |
+
} CUpti_CheckpointOptimizations;
|
| 30 |
+
|
| 31 |
+
/**
|
| 32 |
+
* \brief Configuration and handle for a CUPTI Checkpoint
|
| 33 |
+
*
|
| 34 |
+
* A CUptiCheckpoint object should be initialized with desired options prior to passing into any
|
| 35 |
+
* CUPTI Checkpoint API function. The first call into a Checkpoint API function will initialize internal
|
| 36 |
+
* state based on these options. Subsequent changes to these options will not have any effect.
|
| 37 |
+
*
|
| 38 |
+
* Checkpoint data is saved in device, host, and filesystem space. There are options to reserve memory
|
| 39 |
+
* at each level (device, host, filesystem) which are intended to allow a guarantee that a certain amount
|
| 40 |
+
* of memory will remain free for use after the checkpoint is saved.
|
| 41 |
+
* Note, however, that falling back to slower levels of memory (host, and then filesystem) to save the checkpoint
|
| 42 |
+
* will result in performance degradation.
|
| 43 |
+
* Currently, the filesystem limitation is not implemented. Note that falling back to filesystem storage may
|
| 44 |
+
* significantly impact the performance for saving and restoring a checkpoint.
|
| 45 |
+
*/
|
| 46 |
+
typedef struct
|
| 47 |
+
{
|
| 48 |
+
size_t structSize; //!< [in] Must be set to CUpti_Checkpoint_STRUCT_SIZE
|
| 49 |
+
|
| 50 |
+
CUcontext ctx; //!< [in] Set to context to save from, or will use current context if NULL
|
| 51 |
+
|
| 52 |
+
size_t reserveDeviceMB; //!< [in] Restrict checkpoint from using last N MB of device memory (-1 = use no device memory)
|
| 53 |
+
size_t reserveHostMB; //!< [in] Restrict checkpoint from using last N MB of host memory (-1 = use no host memory)
|
| 54 |
+
uint8_t allowOverwrite; //!< [in] Boolean, Allow checkpoint to save over existing checkpoint
|
| 55 |
+
uint8_t optimizations; //!< [in] Mask of CUpti_CheckpointOptimizations flags for this checkpoint
|
| 56 |
+
|
| 57 |
+
void * pPriv; //!< [in] Assign to NULL
|
| 58 |
+
} CUpti_Checkpoint;
|
| 59 |
+
|
| 60 |
+
#define CUpti_Checkpoint_STRUCT_SIZE \
|
| 61 |
+
(offsetof(CUpti_Checkpoint, pPriv) + \
|
| 62 |
+
sizeof(((CUpti_Checkpoint*)(nullptr))->pPriv))
|
| 63 |
+
|
| 64 |
+
#if defined(__GNUC__) && defined(CUPTI_LIB)
|
| 65 |
+
#pragma GCC visibility push(default)
|
| 66 |
+
#endif
|
| 67 |
+
|
| 68 |
+
/**
|
| 69 |
+
* \brief Initialize and save a checkpoint of the device state associated with the handle context
|
| 70 |
+
*
|
| 71 |
+
* Uses the handle options to configure and save a checkpoint of the device state associated with the specified context.
|
| 72 |
+
*
|
| 73 |
+
* \param handle A pointer to a CUpti_Checkpoint object
|
| 74 |
+
*
|
| 75 |
+
* \retval CUPTI_SUCCESS if a checkpoint was successfully initialized and saved
|
| 76 |
+
* \retval CUPTI_ERROR_INVALID_PARAMETER if \p handle does not appear to refer to a valid CUpti_Checkpoint
|
| 77 |
+
* \retval CUPTI_ERROR_INVALID_CONTEXT
|
| 78 |
+
* \retval CUPTI_ERROR_INVALID_DEVICE if device associated with context is not compatible with checkpoint API
|
| 79 |
+
* \retval CUPTI_ERROR_INVALID_OPERATION if Save is requested over an existing checkpoint, but \p allowOverwrite was not originally specified
|
| 80 |
+
* \retval CUPTI_ERROR_OUT_OF_MEMORY if as configured, not enough backing storage space to save the checkpoint
|
| 81 |
+
*/
|
| 82 |
+
CUptiResult cuptiCheckpointSave(CUpti_Checkpoint * const handle);
|
| 83 |
+
|
| 84 |
+
/**
|
| 85 |
+
* \brief Restore a checkpoint to the device associated with its context
|
| 86 |
+
*
|
| 87 |
+
* Restores device, pinned, and allocated memory to the state when the checkpoint was saved
|
| 88 |
+
*
|
| 89 |
+
* \param handle A pointer to a previously saved CUpti_Checkpoint object
|
| 90 |
+
*
|
| 91 |
+
* \retval CUTPI_SUCCESS if the checkpoint was successfully restored
|
| 92 |
+
* \retval CUPTI_ERROR_NOT_INITIALIZED if the checkpoint was not previously initialized
|
| 93 |
+
* \retval CUPTI_ERROR_INVALID_CONTEXT
|
| 94 |
+
* \retval CUPTI_ERROR_INVALID_PARAMETER if the handle appears invalid
|
| 95 |
+
* \retval CUPTI_ERROR_UNKNOWN if the restore or optimization operation fails
|
| 96 |
+
*/
|
| 97 |
+
CUptiResult cuptiCheckpointRestore(CUpti_Checkpoint * const handle);
|
| 98 |
+
|
| 99 |
+
/**
|
| 100 |
+
* \brief Free the backing data for a checkpoint
|
| 101 |
+
*
|
| 102 |
+
* Frees all associated device, host memory and filesystem storage used for this context.
|
| 103 |
+
* After freeing a handle, it may be re-used as if it was new - options may be re-configured and will
|
| 104 |
+
* take effect on the next call to \p cuptiCheckpointSave.
|
| 105 |
+
*
|
| 106 |
+
* \param handle A pointer to a previously saved CUpti_Checkpoint object
|
| 107 |
+
*
|
| 108 |
+
* \retval CUPTI_SUCCESS if the handle was successfully freed
|
| 109 |
+
* \retval CUPTI_ERROR_INVALID_PARAMETER if the handle was already freed or appears invalid
|
| 110 |
+
* \retval CUPTI_ERROR_INVALID_CONTEXT if the context is no longer valid
|
| 111 |
+
*/
|
| 112 |
+
CUptiResult cuptiCheckpointFree(CUpti_Checkpoint * const handle);
|
| 113 |
+
|
| 114 |
+
#if defined(__GNUC__) && defined(CUPTI_LIB)
|
| 115 |
+
#pragma GCC visibility pop
|
| 116 |
+
#endif
|
| 117 |
+
|
| 118 |
+
/**
|
| 119 |
+
* @}
|
| 120 |
+
*/
|
| 121 |
+
|
| 122 |
+
#ifdef __cplusplus
|
| 123 |
+
}
|
| 124 |
+
#endif
|
| 125 |
+
|
| 126 |
+
// Exit namespace NV::Cupti::Checkpoint
|
| 127 |
+
}}}
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/cupti_pcsampling_util.h
ADDED
|
@@ -0,0 +1,419 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#if !defined(_CUPTI_PCSAMPLING_UTIL_H_)
|
| 2 |
+
#define _CUPTI_PCSAMPLING_UTIL_H_
|
| 3 |
+
|
| 4 |
+
#include <cupti_pcsampling.h>
|
| 5 |
+
#include <fstream>
|
| 6 |
+
|
| 7 |
+
#ifndef CUPTIUTILAPI
|
| 8 |
+
#ifdef _WIN32
|
| 9 |
+
#define CUPTIUTILAPI __stdcall
|
| 10 |
+
#else
|
| 11 |
+
#define CUPTIUTILAPI
|
| 12 |
+
#endif
|
| 13 |
+
#endif
|
| 14 |
+
|
| 15 |
+
#define ACTIVITY_RECORD_ALIGNMENT 8
|
| 16 |
+
#if defined(_WIN32) // Windows 32- and 64-bit
|
| 17 |
+
#define START_PACKED_ALIGNMENT __pragma(pack(push,1)) // exact fit - no padding
|
| 18 |
+
#define PACKED_ALIGNMENT __declspec(align(ACTIVITY_RECORD_ALIGNMENT))
|
| 19 |
+
#define END_PACKED_ALIGNMENT __pragma(pack(pop))
|
| 20 |
+
#elif defined(__GNUC__) // GCC
|
| 21 |
+
#define START_PACKED_ALIGNMENT
|
| 22 |
+
#define PACKED_ALIGNMENT __attribute__ ((__packed__)) __attribute__ ((aligned (ACTIVITY_RECORD_ALIGNMENT)))
|
| 23 |
+
#define END_PACKED_ALIGNMENT
|
| 24 |
+
#else // all other compilers
|
| 25 |
+
#define START_PACKED_ALIGNMENT
|
| 26 |
+
#define PACKED_ALIGNMENT
|
| 27 |
+
#define END_PACKED_ALIGNMENT
|
| 28 |
+
#endif
|
| 29 |
+
|
| 30 |
+
#ifndef CUPTI_UTIL_STRUCT_SIZE
|
| 31 |
+
#define CUPTI_UTIL_STRUCT_SIZE(type_, lastfield_) (offsetof(type_, lastfield_) + sizeof(((type_*)0)->lastfield_))
|
| 32 |
+
#endif
|
| 33 |
+
|
| 34 |
+
#ifndef CHECK_PC_SAMPLING_STRUCT_FIELD_EXISTS
|
| 35 |
+
#define CHECK_PC_SAMPLING_STRUCT_FIELD_EXISTS(type, member, structSize) \
|
| 36 |
+
(offsetof(type, member) < structSize)
|
| 37 |
+
#endif
|
| 38 |
+
|
| 39 |
+
#if defined(__cplusplus)
|
| 40 |
+
extern "C" {
|
| 41 |
+
#endif
|
| 42 |
+
|
| 43 |
+
#if defined(__GNUC__)
|
| 44 |
+
#pragma GCC visibility push(default)
|
| 45 |
+
#endif
|
| 46 |
+
|
| 47 |
+
namespace CUPTI { namespace PcSamplingUtil {
|
| 48 |
+
|
| 49 |
+
/**
|
| 50 |
+
* \defgroup CUPTI_PCSAMPLING_UTILITY CUPTI PC Sampling Utility API
|
| 51 |
+
* Functions, types, and enums that implement the CUPTI PC Sampling Utility API.
|
| 52 |
+
* @{
|
| 53 |
+
*/
|
| 54 |
+
|
| 55 |
+
/**
|
| 56 |
+
* \brief Header info will be stored in file.
|
| 57 |
+
*/
|
| 58 |
+
typedef struct PACKED_ALIGNMENT {
|
| 59 |
+
/**
|
| 60 |
+
* Version of file format.
|
| 61 |
+
*/
|
| 62 |
+
uint32_t version;
|
| 63 |
+
/**
|
| 64 |
+
* Total number of buffers present in the file.
|
| 65 |
+
*/
|
| 66 |
+
uint32_t totalBuffers;
|
| 67 |
+
} Header;
|
| 68 |
+
|
| 69 |
+
/**
|
| 70 |
+
* \brief BufferInfo will be stored in the file for every buffer
|
| 71 |
+
* i.e for every call of UtilDumpPcSamplingBufferInFile() API.
|
| 72 |
+
*/
|
| 73 |
+
typedef struct PACKED_ALIGNMENT {
|
| 74 |
+
/**
|
| 75 |
+
* Total number of PC records.
|
| 76 |
+
*/
|
| 77 |
+
uint64_t recordCount;
|
| 78 |
+
/**
|
| 79 |
+
* Count of all stall reasons supported on the GPU
|
| 80 |
+
*/
|
| 81 |
+
size_t numStallReasons;
|
| 82 |
+
/**
|
| 83 |
+
* Total number of stall reasons in single record.
|
| 84 |
+
*/
|
| 85 |
+
uint64_t numSelectedStallReasons;
|
| 86 |
+
/**
|
| 87 |
+
* Buffer size in Bytes.
|
| 88 |
+
*/
|
| 89 |
+
uint64_t bufferByteSize;
|
| 90 |
+
} BufferInfo;
|
| 91 |
+
|
| 92 |
+
/**
|
| 93 |
+
* \brief All available stall reasons name and respective indexes
|
| 94 |
+
* will be stored in it.
|
| 95 |
+
*/
|
| 96 |
+
typedef struct PACKED_ALIGNMENT {
|
| 97 |
+
/**
|
| 98 |
+
* Number of all available stall reasons
|
| 99 |
+
*/
|
| 100 |
+
size_t numStallReasons;
|
| 101 |
+
/**
|
| 102 |
+
* Stall reasons names of all available stall reasons
|
| 103 |
+
*/
|
| 104 |
+
char **stallReasons;
|
| 105 |
+
/**
|
| 106 |
+
* Stall reason index of all available stall reasons
|
| 107 |
+
*/
|
| 108 |
+
uint32_t *stallReasonIndex;
|
| 109 |
+
} PcSamplingStallReasons;
|
| 110 |
+
|
| 111 |
+
typedef enum {
|
| 112 |
+
/**
|
| 113 |
+
* Invalid buffer type.
|
| 114 |
+
*/
|
| 115 |
+
PC_SAMPLING_BUFFER_INVALID = 0,
|
| 116 |
+
/**
|
| 117 |
+
* Refers to CUpti_PCSamplingData buffer.
|
| 118 |
+
*/
|
| 119 |
+
PC_SAMPLING_BUFFER_PC_TO_COUNTER_DATA = 1
|
| 120 |
+
} PcSamplingBufferType;
|
| 121 |
+
|
| 122 |
+
/**
|
| 123 |
+
* \brief CUPTI PC sampling utility API result codes.
|
| 124 |
+
*
|
| 125 |
+
* Error and result codes returned by CUPTI PC sampling utility API.
|
| 126 |
+
*/
|
| 127 |
+
typedef enum {
|
| 128 |
+
/**
|
| 129 |
+
* No error
|
| 130 |
+
*/
|
| 131 |
+
CUPTI_UTIL_SUCCESS = 0,
|
| 132 |
+
/**
|
| 133 |
+
* One or more of the parameters are invalid.
|
| 134 |
+
*/
|
| 135 |
+
CUPTI_UTIL_ERROR_INVALID_PARAMETER = 1,
|
| 136 |
+
/**
|
| 137 |
+
* Unable to create a new file
|
| 138 |
+
*/
|
| 139 |
+
CUPTI_UTIL_ERROR_UNABLE_TO_CREATE_FILE = 2,
|
| 140 |
+
/**
|
| 141 |
+
* Unable to open a file
|
| 142 |
+
*/
|
| 143 |
+
CUPTI_UTIL_ERROR_UNABLE_TO_OPEN_FILE = 3,
|
| 144 |
+
/**
|
| 145 |
+
* Read or write operation failed
|
| 146 |
+
*/
|
| 147 |
+
CUPTI_UTIL_ERROR_READ_WRITE_OPERATION_FAILED = 4,
|
| 148 |
+
/**
|
| 149 |
+
* Provided file handle is corrupted.
|
| 150 |
+
*/
|
| 151 |
+
CUPTI_UTIL_ERROR_FILE_HANDLE_CORRUPTED = 5,
|
| 152 |
+
/**
|
| 153 |
+
* seek operation failed.
|
| 154 |
+
*/
|
| 155 |
+
CUPTI_UTIL_ERROR_SEEK_OPERATION_FAILED = 6,
|
| 156 |
+
/**
|
| 157 |
+
* Unable to allocate enough memory to perform the requested
|
| 158 |
+
* operation.
|
| 159 |
+
*/
|
| 160 |
+
CUPTI_UTIL_ERROR_OUT_OF_MEMORY = 7,
|
| 161 |
+
/**
|
| 162 |
+
* An unknown internal error has occurred.
|
| 163 |
+
*/
|
| 164 |
+
CUPTI_UTIL_ERROR_UNKNOWN = 999,
|
| 165 |
+
CUPTI_UTIL_ERROR_FORCE_INT = 0x7fffffff
|
| 166 |
+
} CUptiUtilResult;
|
| 167 |
+
|
| 168 |
+
/**
|
| 169 |
+
* \brief Params for \ref CuptiUtilPutPcSampData
|
| 170 |
+
*/
|
| 171 |
+
typedef struct {
|
| 172 |
+
/**
|
| 173 |
+
* Size of the data structure i.e. CUpti_PCSamplingDisableParamsSize
|
| 174 |
+
* CUPTI client should set the size of the structure. It will be used in CUPTI to check what fields are
|
| 175 |
+
* available in the structure. Used to preserve backward compatibility.
|
| 176 |
+
*/
|
| 177 |
+
size_t size;
|
| 178 |
+
/**
|
| 179 |
+
* Type of buffer to store in file
|
| 180 |
+
*/
|
| 181 |
+
PcSamplingBufferType bufferType;
|
| 182 |
+
/**
|
| 183 |
+
* PC sampling buffer.
|
| 184 |
+
*/
|
| 185 |
+
void *pSamplingData;
|
| 186 |
+
/**
|
| 187 |
+
* Number of configured attributes
|
| 188 |
+
*/
|
| 189 |
+
size_t numAttributes;
|
| 190 |
+
/**
|
| 191 |
+
* Refer \ref CUpti_PCSamplingConfigurationInfo
|
| 192 |
+
* It is expected to provide configuration details of at least
|
| 193 |
+
* CUPTI_PC_SAMPLING_CONFIGURATION_ATTR_TYPE_STALL_REASON attribute.
|
| 194 |
+
*/
|
| 195 |
+
CUpti_PCSamplingConfigurationInfo *pPCSamplingConfigurationInfo;
|
| 196 |
+
/**
|
| 197 |
+
* Refer \ref PcSamplingStallReasons.
|
| 198 |
+
*/
|
| 199 |
+
PcSamplingStallReasons *pPcSamplingStallReasons;
|
| 200 |
+
/**
|
| 201 |
+
* File name to store buffer into it.
|
| 202 |
+
*/
|
| 203 |
+
const char* fileName;
|
| 204 |
+
} CUptiUtil_PutPcSampDataParams;
|
| 205 |
+
#define CUptiUtil_PutPcSampDataParamsSize CUPTI_UTIL_STRUCT_SIZE(CUptiUtil_PutPcSampDataParams, fileName)
|
| 206 |
+
|
| 207 |
+
/**
|
| 208 |
+
* \brief Dump PC sampling data into the file.
|
| 209 |
+
*
|
| 210 |
+
* This API can be called multiple times.
|
| 211 |
+
* It will append buffer in the file.
|
| 212 |
+
* For every buffer it will store BufferInfo
|
| 213 |
+
* so that before retrieving data it will help to allocate buffer
|
| 214 |
+
* to store retrieved data.
|
| 215 |
+
* This API creates file if file does not present.
|
| 216 |
+
* If stallReasonIndex or stallReasons pointer of \ref CUptiUtil_PutPcSampDataParams is NULL
|
| 217 |
+
* then stall reasons data will not be stored in file.
|
| 218 |
+
* It is expected to store all available stall reason data at least once to refer it during
|
| 219 |
+
* offline correlation.
|
| 220 |
+
*
|
| 221 |
+
* \retval CUPTI_UTIL_SUCCESS
|
| 222 |
+
* \retval CUPTI_UTIL_ERROR_INVALID_PARAMETER error out if buffer type is invalid
|
| 223 |
+
* or if either of pSamplingData, pParams pointer is NULL or stall reason configuration details not provided
|
| 224 |
+
* or filename is empty.
|
| 225 |
+
* \retval CUPTI_UTIL_ERROR_UNABLE_TO_CREATE_FILE
|
| 226 |
+
* \retval CUPTI_UTIL_ERROR_UNABLE_TO_OPEN_FILE
|
| 227 |
+
* \retval CUPTI_UTIL_ERROR_READ_WRITE_OPERATION_FAILED
|
| 228 |
+
*/
|
| 229 |
+
CUptiUtilResult CUPTIUTILAPI CuptiUtilPutPcSampData(CUptiUtil_PutPcSampDataParams *pParams);
|
| 230 |
+
|
| 231 |
+
/**
|
| 232 |
+
* \brief Params for \ref CuptiUtilGetHeaderData
|
| 233 |
+
*/
|
| 234 |
+
typedef struct {
|
| 235 |
+
/**
|
| 236 |
+
* Size of the data structure i.e. CUpti_PCSamplingDisableParamsSize
|
| 237 |
+
* CUPTI client should set the size of the structure. It will be used in CUPTI to check what fields are
|
| 238 |
+
* available in the structure. Used to preserve backward compatibility.
|
| 239 |
+
*/
|
| 240 |
+
size_t size;
|
| 241 |
+
/**
|
| 242 |
+
* File handle.
|
| 243 |
+
*/
|
| 244 |
+
std::ifstream *fileHandler;
|
| 245 |
+
/**
|
| 246 |
+
* Header Info.
|
| 247 |
+
*/
|
| 248 |
+
Header headerInfo;
|
| 249 |
+
|
| 250 |
+
} CUptiUtil_GetHeaderDataParams;
|
| 251 |
+
#define CUptiUtil_GetHeaderDataParamsSize CUPTI_UTIL_STRUCT_SIZE(CUptiUtil_GetHeaderDataParams, headerInfo)
|
| 252 |
+
|
| 253 |
+
/**
|
| 254 |
+
* \brief Get header data of file.
|
| 255 |
+
*
|
| 256 |
+
* This API must be called once initially while retrieving data from file.
|
| 257 |
+
* \ref Header structure, it gives info about total number
|
| 258 |
+
* of buffers present in the file.
|
| 259 |
+
*
|
| 260 |
+
* \retval CUPTI_UTIL_SUCCESS
|
| 261 |
+
* \retval CUPTI_UTIL_ERROR_INVALID_PARAMETER error out if either of pParam or fileHandle is NULL or param struct size is incorrect.
|
| 262 |
+
* \retval CUPTI_UTIL_ERROR_FILE_HANDLE_CORRUPTED file handle is not in good state to read data from file
|
| 263 |
+
* \retval CUPTI_UTIL_ERROR_READ_WRITE_OPERATION_FAILED failed to read data from file.
|
| 264 |
+
*/
|
| 265 |
+
CUptiUtilResult CUPTIUTILAPI CuptiUtilGetHeaderData(CUptiUtil_GetHeaderDataParams *pParams);
|
| 266 |
+
|
| 267 |
+
/**
|
| 268 |
+
* \brief Params for \ref CuptiUtilGetBufferInfo
|
| 269 |
+
*/
|
| 270 |
+
typedef struct {
|
| 271 |
+
/**
|
| 272 |
+
* Size of the data structure i.e. CUpti_PCSamplingDisableParamsSize
|
| 273 |
+
* CUPTI client should set the size of the structure. It will be used in CUPTI to check what fields are
|
| 274 |
+
* available in the structure. Used to preserve backward compatibility.
|
| 275 |
+
*/
|
| 276 |
+
size_t size;
|
| 277 |
+
/**
|
| 278 |
+
* File handle.
|
| 279 |
+
*/
|
| 280 |
+
std::ifstream *fileHandler;
|
| 281 |
+
/**
|
| 282 |
+
* Buffer Info.
|
| 283 |
+
*/
|
| 284 |
+
BufferInfo bufferInfoData;
|
| 285 |
+
} CUptiUtil_GetBufferInfoParams;
|
| 286 |
+
#define CUptiUtil_GetBufferInfoParamsSize CUPTI_UTIL_STRUCT_SIZE(CUptiUtil_GetBufferInfoParams, bufferInfoData)
|
| 287 |
+
|
| 288 |
+
/**
|
| 289 |
+
* \brief Get buffer info data of file.
|
| 290 |
+
*
|
| 291 |
+
* This API must be called every time before calling CuptiUtilGetPcSampData API.
|
| 292 |
+
* \ref BufferInfo structure, it gives info about recordCount and stallReasonCount
|
| 293 |
+
* of every record in the buffer. This will help to allocate exact buffer to retrieve data into it.
|
| 294 |
+
*
|
| 295 |
+
* \retval CUPTI_UTIL_SUCCESS
|
| 296 |
+
* \retval CUPTI_UTIL_ERROR_INVALID_PARAMETER error out if either of pParam or fileHandle is NULL or param struct size is incorrect.
|
| 297 |
+
* \retval CUPTI_UTIL_ERROR_FILE_HANDLE_CORRUPTED file handle is not in good state to read data from file.
|
| 298 |
+
* \retval CUPTI_UTIL_ERROR_READ_WRITE_OPERATION_FAILED failed to read data from file.
|
| 299 |
+
*/
|
| 300 |
+
CUptiUtilResult CUPTIUTILAPI CuptiUtilGetBufferInfo(CUptiUtil_GetBufferInfoParams *pParams);
|
| 301 |
+
|
| 302 |
+
/**
|
| 303 |
+
* \brief Params for \ref CuptiUtilGetPcSampData
|
| 304 |
+
*/
|
| 305 |
+
typedef struct {
|
| 306 |
+
/**
|
| 307 |
+
* Size of the data structure i.e. CUpti_PCSamplingDisableParamsSize
|
| 308 |
+
* CUPTI client should set the size of the structure. It will be used in CUPTI to check what fields are
|
| 309 |
+
* available in the structure. Used to preserve backward compatibility.
|
| 310 |
+
*/
|
| 311 |
+
size_t size;
|
| 312 |
+
/**
|
| 313 |
+
* File handle.
|
| 314 |
+
*/
|
| 315 |
+
std::ifstream *fileHandler;
|
| 316 |
+
/**
|
| 317 |
+
* Type of buffer to store in file
|
| 318 |
+
*/
|
| 319 |
+
PcSamplingBufferType bufferType;
|
| 320 |
+
/**
|
| 321 |
+
* Pointer to collected buffer info using \ref CuptiUtilGetBufferInfo
|
| 322 |
+
*/
|
| 323 |
+
BufferInfo *pBufferInfoData;
|
| 324 |
+
/**
|
| 325 |
+
* Pointer to allocated memory to store retrieved data from file.
|
| 326 |
+
*/
|
| 327 |
+
void *pSamplingData;
|
| 328 |
+
/**
|
| 329 |
+
* Number of configuration attributes
|
| 330 |
+
*/
|
| 331 |
+
size_t numAttributes;
|
| 332 |
+
/**
|
| 333 |
+
* Refer \ref CUpti_PCSamplingConfigurationInfo
|
| 334 |
+
*/
|
| 335 |
+
CUpti_PCSamplingConfigurationInfo *pPCSamplingConfigurationInfo;
|
| 336 |
+
/**
|
| 337 |
+
* Refer \ref PcSamplingStallReasons.
|
| 338 |
+
* For stallReasons field of \ref PcSamplingStallReasons it is expected to
|
| 339 |
+
* allocate memory for each string element of array.
|
| 340 |
+
*/
|
| 341 |
+
PcSamplingStallReasons *pPcSamplingStallReasons;
|
| 342 |
+
} CUptiUtil_GetPcSampDataParams;
|
| 343 |
+
#define CUptiUtil_GetPcSampDataParamsSize CUPTI_UTIL_STRUCT_SIZE(CUptiUtil_GetPcSampDataParams, pPcSamplingStallReasons)
|
| 344 |
+
|
| 345 |
+
/**
|
| 346 |
+
* \brief Retrieve PC sampling data from file into allocated buffer.
|
| 347 |
+
*
|
| 348 |
+
* This API must be called after CuptiUtilGetBufferInfo API.
|
| 349 |
+
* It will retrieve data from file into allocated buffer.
|
| 350 |
+
*
|
| 351 |
+
* \retval CUPTI_UTIL_SUCCESS
|
| 352 |
+
* \retval CUPTI_UTIL_ERROR_INVALID_PARAMETER error out if buffer type is invalid
|
| 353 |
+
* or if either of pSampData, pParams is NULL. If pPcSamplingStallReasons is not NULL then
|
| 354 |
+
* error out if either of stallReasonIndex, stallReasons or stallReasons array element pointer is NULL.
|
| 355 |
+
* or filename is empty.
|
| 356 |
+
* \retval CUPTI_UTIL_ERROR_READ_WRITE_OPERATION_FAILED
|
| 357 |
+
* \retval CUPTI_UTIL_ERROR_FILE_HANDLE_CORRUPTED file handle is not in good state to read data from file.
|
| 358 |
+
*/
|
| 359 |
+
CUptiUtilResult CUPTIUTILAPI CuptiUtilGetPcSampData(CUptiUtil_GetPcSampDataParams *pParams);
|
| 360 |
+
|
| 361 |
+
/**
|
| 362 |
+
* \brief Params for \ref CuptiUtilMergePcSampData
|
| 363 |
+
*/
|
| 364 |
+
typedef struct
|
| 365 |
+
{
|
| 366 |
+
/**
|
| 367 |
+
* Size of the data structure i.e. CUpti_PCSamplingDisableParamsSize
|
| 368 |
+
* CUPTI client should set the size of the structure. It will be used in CUPTI to check what fields are
|
| 369 |
+
* available in the structure. Used to preserve backward compatibility.
|
| 370 |
+
*/
|
| 371 |
+
size_t size;
|
| 372 |
+
/**
|
| 373 |
+
* Number of buffers to merge.
|
| 374 |
+
*/
|
| 375 |
+
size_t numberOfBuffers;
|
| 376 |
+
/**
|
| 377 |
+
* Pointer to array of buffers to merge
|
| 378 |
+
*/
|
| 379 |
+
CUpti_PCSamplingData *PcSampDataBuffer;
|
| 380 |
+
/**
|
| 381 |
+
* Pointer to array of merged buffers as per the range id.
|
| 382 |
+
*/
|
| 383 |
+
CUpti_PCSamplingData **MergedPcSampDataBuffers;
|
| 384 |
+
/**
|
| 385 |
+
* Number of merged buffers.
|
| 386 |
+
*/
|
| 387 |
+
size_t *numMergedBuffer;
|
| 388 |
+
} CUptiUtil_MergePcSampDataParams;
|
| 389 |
+
#define CUptiUtil_MergePcSampDataParamsSize CUPTI_UTIL_STRUCT_SIZE(CUptiUtil_MergePcSampDataParams, numMergedBuffer)
|
| 390 |
+
|
| 391 |
+
/**
|
| 392 |
+
* \brief Merge PC sampling data range id wise.
|
| 393 |
+
*
|
| 394 |
+
* This API merge PC sampling data range id wise.
|
| 395 |
+
* It allocates memory for merged data and fill data in it
|
| 396 |
+
* and provide buffer pointer in MergedPcSampDataBuffers field.
|
| 397 |
+
* It is expected from user to free merge data buffers after use.
|
| 398 |
+
*
|
| 399 |
+
* \retval CUPTI_UTIL_SUCCESS
|
| 400 |
+
* \retval CUPTI_UTIL_ERROR_INVALID_PARAMETER error out if param struct size is invalid
|
| 401 |
+
* or count of buffers to merge is invalid i.e less than 1
|
| 402 |
+
* or either of PcSampDataBuffer, MergedPcSampDataBuffers, numMergedBuffer is NULL
|
| 403 |
+
* \retval CUPTI_UTIL_ERROR_OUT_OF_MEMORY Unable to allocate memory for merged buffer.
|
| 404 |
+
*/
|
| 405 |
+
CUptiUtilResult CUPTIUTILAPI CuptiUtilMergePcSampData(CUptiUtil_MergePcSampDataParams *pParams);
|
| 406 |
+
|
| 407 |
+
/** @} */ /* END CUPTI_PCSAMPLING_UTILITY */
|
| 408 |
+
|
| 409 |
+
} }
|
| 410 |
+
|
| 411 |
+
#if defined(__GNUC__)
|
| 412 |
+
#pragma GCC visibility pop
|
| 413 |
+
#endif
|
| 414 |
+
|
| 415 |
+
#if defined(__cplusplus)
|
| 416 |
+
}
|
| 417 |
+
#endif
|
| 418 |
+
|
| 419 |
+
#endif
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/cupti_runtime_cbid.h
ADDED
|
@@ -0,0 +1,458 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
// *************************************************************************
|
| 3 |
+
// Definitions of indices for API functions, unique across entire API
|
| 4 |
+
// *************************************************************************
|
| 5 |
+
|
| 6 |
+
// This file is generated. Any changes you make will be lost during the next clean build.
|
| 7 |
+
// CUDA public interface, for type definitions and cu* function prototypes
|
| 8 |
+
|
| 9 |
+
typedef enum CUpti_runtime_api_trace_cbid_enum {
|
| 10 |
+
CUPTI_RUNTIME_TRACE_CBID_INVALID = 0,
|
| 11 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDriverGetVersion_v3020 = 1,
|
| 12 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaRuntimeGetVersion_v3020 = 2,
|
| 13 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetDeviceCount_v3020 = 3,
|
| 14 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetDeviceProperties_v3020 = 4,
|
| 15 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaChooseDevice_v3020 = 5,
|
| 16 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetChannelDesc_v3020 = 6,
|
| 17 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaCreateChannelDesc_v3020 = 7,
|
| 18 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaConfigureCall_v3020 = 8,
|
| 19 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaSetupArgument_v3020 = 9,
|
| 20 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetLastError_v3020 = 10,
|
| 21 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaPeekAtLastError_v3020 = 11,
|
| 22 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetErrorString_v3020 = 12,
|
| 23 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaLaunch_v3020 = 13,
|
| 24 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaFuncSetCacheConfig_v3020 = 14,
|
| 25 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaFuncGetAttributes_v3020 = 15,
|
| 26 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaSetDevice_v3020 = 16,
|
| 27 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetDevice_v3020 = 17,
|
| 28 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaSetValidDevices_v3020 = 18,
|
| 29 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaSetDeviceFlags_v3020 = 19,
|
| 30 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMalloc_v3020 = 20,
|
| 31 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMallocPitch_v3020 = 21,
|
| 32 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaFree_v3020 = 22,
|
| 33 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMallocArray_v3020 = 23,
|
| 34 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaFreeArray_v3020 = 24,
|
| 35 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMallocHost_v3020 = 25,
|
| 36 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaFreeHost_v3020 = 26,
|
| 37 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaHostAlloc_v3020 = 27,
|
| 38 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaHostGetDevicePointer_v3020 = 28,
|
| 39 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaHostGetFlags_v3020 = 29,
|
| 40 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemGetInfo_v3020 = 30,
|
| 41 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy_v3020 = 31,
|
| 42 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2D_v3020 = 32,
|
| 43 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyToArray_v3020 = 33,
|
| 44 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2DToArray_v3020 = 34,
|
| 45 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyFromArray_v3020 = 35,
|
| 46 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2DFromArray_v3020 = 36,
|
| 47 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyArrayToArray_v3020 = 37,
|
| 48 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2DArrayToArray_v3020 = 38,
|
| 49 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyToSymbol_v3020 = 39,
|
| 50 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyFromSymbol_v3020 = 40,
|
| 51 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyAsync_v3020 = 41,
|
| 52 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyToArrayAsync_v3020 = 42,
|
| 53 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyFromArrayAsync_v3020 = 43,
|
| 54 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2DAsync_v3020 = 44,
|
| 55 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2DToArrayAsync_v3020 = 45,
|
| 56 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2DFromArrayAsync_v3020 = 46,
|
| 57 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyToSymbolAsync_v3020 = 47,
|
| 58 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyFromSymbolAsync_v3020 = 48,
|
| 59 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemset_v3020 = 49,
|
| 60 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemset2D_v3020 = 50,
|
| 61 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemsetAsync_v3020 = 51,
|
| 62 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemset2DAsync_v3020 = 52,
|
| 63 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetSymbolAddress_v3020 = 53,
|
| 64 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetSymbolSize_v3020 = 54,
|
| 65 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaBindTexture_v3020 = 55,
|
| 66 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaBindTexture2D_v3020 = 56,
|
| 67 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaBindTextureToArray_v3020 = 57,
|
| 68 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaUnbindTexture_v3020 = 58,
|
| 69 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetTextureAlignmentOffset_v3020 = 59,
|
| 70 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetTextureReference_v3020 = 60,
|
| 71 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaBindSurfaceToArray_v3020 = 61,
|
| 72 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetSurfaceReference_v3020 = 62,
|
| 73 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGLSetGLDevice_v3020 = 63,
|
| 74 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGLRegisterBufferObject_v3020 = 64,
|
| 75 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGLMapBufferObject_v3020 = 65,
|
| 76 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGLUnmapBufferObject_v3020 = 66,
|
| 77 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGLUnregisterBufferObject_v3020 = 67,
|
| 78 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGLSetBufferObjectMapFlags_v3020 = 68,
|
| 79 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGLMapBufferObjectAsync_v3020 = 69,
|
| 80 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGLUnmapBufferObjectAsync_v3020 = 70,
|
| 81 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaWGLGetDevice_v3020 = 71,
|
| 82 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsGLRegisterImage_v3020 = 72,
|
| 83 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsGLRegisterBuffer_v3020 = 73,
|
| 84 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsUnregisterResource_v3020 = 74,
|
| 85 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsResourceSetMapFlags_v3020 = 75,
|
| 86 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsMapResources_v3020 = 76,
|
| 87 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsUnmapResources_v3020 = 77,
|
| 88 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsResourceGetMappedPointer_v3020 = 78,
|
| 89 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsSubResourceGetMappedArray_v3020 = 79,
|
| 90 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaVDPAUGetDevice_v3020 = 80,
|
| 91 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaVDPAUSetVDPAUDevice_v3020 = 81,
|
| 92 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsVDPAURegisterVideoSurface_v3020 = 82,
|
| 93 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsVDPAURegisterOutputSurface_v3020 = 83,
|
| 94 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D11GetDevice_v3020 = 84,
|
| 95 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D11GetDevices_v3020 = 85,
|
| 96 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D11SetDirect3DDevice_v3020 = 86,
|
| 97 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsD3D11RegisterResource_v3020 = 87,
|
| 98 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10GetDevice_v3020 = 88,
|
| 99 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10GetDevices_v3020 = 89,
|
| 100 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10SetDirect3DDevice_v3020 = 90,
|
| 101 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsD3D10RegisterResource_v3020 = 91,
|
| 102 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10RegisterResource_v3020 = 92,
|
| 103 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10UnregisterResource_v3020 = 93,
|
| 104 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10MapResources_v3020 = 94,
|
| 105 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10UnmapResources_v3020 = 95,
|
| 106 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10ResourceSetMapFlags_v3020 = 96,
|
| 107 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10ResourceGetSurfaceDimensions_v3020 = 97,
|
| 108 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10ResourceGetMappedArray_v3020 = 98,
|
| 109 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10ResourceGetMappedPointer_v3020 = 99,
|
| 110 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10ResourceGetMappedSize_v3020 = 100,
|
| 111 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10ResourceGetMappedPitch_v3020 = 101,
|
| 112 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9GetDevice_v3020 = 102,
|
| 113 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9GetDevices_v3020 = 103,
|
| 114 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9SetDirect3DDevice_v3020 = 104,
|
| 115 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9GetDirect3DDevice_v3020 = 105,
|
| 116 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsD3D9RegisterResource_v3020 = 106,
|
| 117 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9RegisterResource_v3020 = 107,
|
| 118 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9UnregisterResource_v3020 = 108,
|
| 119 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9MapResources_v3020 = 109,
|
| 120 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9UnmapResources_v3020 = 110,
|
| 121 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9ResourceSetMapFlags_v3020 = 111,
|
| 122 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9ResourceGetSurfaceDimensions_v3020 = 112,
|
| 123 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9ResourceGetMappedArray_v3020 = 113,
|
| 124 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9ResourceGetMappedPointer_v3020 = 114,
|
| 125 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9ResourceGetMappedSize_v3020 = 115,
|
| 126 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9ResourceGetMappedPitch_v3020 = 116,
|
| 127 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9Begin_v3020 = 117,
|
| 128 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9End_v3020 = 118,
|
| 129 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9RegisterVertexBuffer_v3020 = 119,
|
| 130 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9UnregisterVertexBuffer_v3020 = 120,
|
| 131 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9MapVertexBuffer_v3020 = 121,
|
| 132 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D9UnmapVertexBuffer_v3020 = 122,
|
| 133 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaThreadExit_v3020 = 123,
|
| 134 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaSetDoubleForDevice_v3020 = 124,
|
| 135 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaSetDoubleForHost_v3020 = 125,
|
| 136 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaThreadSynchronize_v3020 = 126,
|
| 137 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaThreadGetLimit_v3020 = 127,
|
| 138 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaThreadSetLimit_v3020 = 128,
|
| 139 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamCreate_v3020 = 129,
|
| 140 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamDestroy_v3020 = 130,
|
| 141 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamSynchronize_v3020 = 131,
|
| 142 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamQuery_v3020 = 132,
|
| 143 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEventCreate_v3020 = 133,
|
| 144 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEventCreateWithFlags_v3020 = 134,
|
| 145 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEventRecord_v3020 = 135,
|
| 146 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEventDestroy_v3020 = 136,
|
| 147 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEventSynchronize_v3020 = 137,
|
| 148 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEventQuery_v3020 = 138,
|
| 149 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEventElapsedTime_v3020 = 139,
|
| 150 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMalloc3D_v3020 = 140,
|
| 151 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMalloc3DArray_v3020 = 141,
|
| 152 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemset3D_v3020 = 142,
|
| 153 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemset3DAsync_v3020 = 143,
|
| 154 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy3D_v3020 = 144,
|
| 155 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy3DAsync_v3020 = 145,
|
| 156 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaThreadSetCacheConfig_v3020 = 146,
|
| 157 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamWaitEvent_v3020 = 147,
|
| 158 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D11GetDirect3DDevice_v3020 = 148,
|
| 159 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaD3D10GetDirect3DDevice_v3020 = 149,
|
| 160 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaThreadGetCacheConfig_v3020 = 150,
|
| 161 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaPointerGetAttributes_v4000 = 151,
|
| 162 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaHostRegister_v4000 = 152,
|
| 163 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaHostUnregister_v4000 = 153,
|
| 164 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceCanAccessPeer_v4000 = 154,
|
| 165 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceEnablePeerAccess_v4000 = 155,
|
| 166 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceDisablePeerAccess_v4000 = 156,
|
| 167 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaPeerRegister_v4000 = 157,
|
| 168 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaPeerUnregister_v4000 = 158,
|
| 169 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaPeerGetDevicePointer_v4000 = 159,
|
| 170 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyPeer_v4000 = 160,
|
| 171 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyPeerAsync_v4000 = 161,
|
| 172 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy3DPeer_v4000 = 162,
|
| 173 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy3DPeerAsync_v4000 = 163,
|
| 174 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceReset_v3020 = 164,
|
| 175 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceSynchronize_v3020 = 165,
|
| 176 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetLimit_v3020 = 166,
|
| 177 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceSetLimit_v3020 = 167,
|
| 178 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetCacheConfig_v3020 = 168,
|
| 179 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceSetCacheConfig_v3020 = 169,
|
| 180 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaProfilerInitialize_v4000 = 170,
|
| 181 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaProfilerStart_v4000 = 171,
|
| 182 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaProfilerStop_v4000 = 172,
|
| 183 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetByPCIBusId_v4010 = 173,
|
| 184 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetPCIBusId_v4010 = 174,
|
| 185 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGLGetDevices_v4010 = 175,
|
| 186 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaIpcGetEventHandle_v4010 = 176,
|
| 187 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaIpcOpenEventHandle_v4010 = 177,
|
| 188 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaIpcGetMemHandle_v4010 = 178,
|
| 189 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaIpcOpenMemHandle_v4010 = 179,
|
| 190 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaIpcCloseMemHandle_v4010 = 180,
|
| 191 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaArrayGetInfo_v4010 = 181,
|
| 192 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaFuncSetSharedMemConfig_v4020 = 182,
|
| 193 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetSharedMemConfig_v4020 = 183,
|
| 194 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceSetSharedMemConfig_v4020 = 184,
|
| 195 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaCreateTextureObject_v5000 = 185,
|
| 196 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDestroyTextureObject_v5000 = 186,
|
| 197 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetTextureObjectResourceDesc_v5000 = 187,
|
| 198 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetTextureObjectTextureDesc_v5000 = 188,
|
| 199 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaCreateSurfaceObject_v5000 = 189,
|
| 200 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDestroySurfaceObject_v5000 = 190,
|
| 201 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetSurfaceObjectResourceDesc_v5000 = 191,
|
| 202 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMallocMipmappedArray_v5000 = 192,
|
| 203 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetMipmappedArrayLevel_v5000 = 193,
|
| 204 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaFreeMipmappedArray_v5000 = 194,
|
| 205 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaBindTextureToMipmappedArray_v5000 = 195,
|
| 206 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsResourceGetMappedMipmappedArray_v5000 = 196,
|
| 207 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamAddCallback_v5000 = 197,
|
| 208 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamCreateWithFlags_v5000 = 198,
|
| 209 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetTextureObjectResourceViewDesc_v5000 = 199,
|
| 210 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetAttribute_v5000 = 200,
|
| 211 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamDestroy_v5050 = 201,
|
| 212 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamCreateWithPriority_v5050 = 202,
|
| 213 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamGetPriority_v5050 = 203,
|
| 214 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamGetFlags_v5050 = 204,
|
| 215 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetStreamPriorityRange_v5050 = 205,
|
| 216 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMallocManaged_v6000 = 206,
|
| 217 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaOccupancyMaxActiveBlocksPerMultiprocessor_v6000 = 207,
|
| 218 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamAttachMemAsync_v6000 = 208,
|
| 219 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetErrorName_v6050 = 209,
|
| 220 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaOccupancyMaxActiveBlocksPerMultiprocessor_v6050 = 210,
|
| 221 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaLaunchKernel_v7000 = 211,
|
| 222 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetDeviceFlags_v7000 = 212,
|
| 223 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaLaunch_ptsz_v7000 = 213,
|
| 224 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaLaunchKernel_ptsz_v7000 = 214,
|
| 225 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy_ptds_v7000 = 215,
|
| 226 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2D_ptds_v7000 = 216,
|
| 227 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyToArray_ptds_v7000 = 217,
|
| 228 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2DToArray_ptds_v7000 = 218,
|
| 229 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyFromArray_ptds_v7000 = 219,
|
| 230 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2DFromArray_ptds_v7000 = 220,
|
| 231 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyArrayToArray_ptds_v7000 = 221,
|
| 232 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2DArrayToArray_ptds_v7000 = 222,
|
| 233 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyToSymbol_ptds_v7000 = 223,
|
| 234 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyFromSymbol_ptds_v7000 = 224,
|
| 235 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyAsync_ptsz_v7000 = 225,
|
| 236 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyToArrayAsync_ptsz_v7000 = 226,
|
| 237 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyFromArrayAsync_ptsz_v7000 = 227,
|
| 238 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2DAsync_ptsz_v7000 = 228,
|
| 239 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2DToArrayAsync_ptsz_v7000 = 229,
|
| 240 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy2DFromArrayAsync_ptsz_v7000 = 230,
|
| 241 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyToSymbolAsync_ptsz_v7000 = 231,
|
| 242 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpyFromSymbolAsync_ptsz_v7000 = 232,
|
| 243 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemset_ptds_v7000 = 233,
|
| 244 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemset2D_ptds_v7000 = 234,
|
| 245 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemsetAsync_ptsz_v7000 = 235,
|
| 246 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemset2DAsync_ptsz_v7000 = 236,
|
| 247 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamGetPriority_ptsz_v7000 = 237,
|
| 248 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamGetFlags_ptsz_v7000 = 238,
|
| 249 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamSynchronize_ptsz_v7000 = 239,
|
| 250 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamQuery_ptsz_v7000 = 240,
|
| 251 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamAttachMemAsync_ptsz_v7000 = 241,
|
| 252 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEventRecord_ptsz_v7000 = 242,
|
| 253 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemset3D_ptds_v7000 = 243,
|
| 254 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemset3DAsync_ptsz_v7000 = 244,
|
| 255 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy3D_ptds_v7000 = 245,
|
| 256 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy3DAsync_ptsz_v7000 = 246,
|
| 257 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamWaitEvent_ptsz_v7000 = 247,
|
| 258 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamAddCallback_ptsz_v7000 = 248,
|
| 259 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy3DPeer_ptds_v7000 = 249,
|
| 260 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemcpy3DPeerAsync_ptsz_v7000 = 250,
|
| 261 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaOccupancyMaxActiveBlocksPerMultiprocessorWithFlags_v7000 = 251,
|
| 262 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPrefetchAsync_v8000 = 252,
|
| 263 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPrefetchAsync_ptsz_v8000 = 253,
|
| 264 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemAdvise_v8000 = 254,
|
| 265 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetP2PAttribute_v8000 = 255,
|
| 266 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsEGLRegisterImage_v7000 = 256,
|
| 267 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEGLStreamConsumerConnect_v7000 = 257,
|
| 268 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEGLStreamConsumerDisconnect_v7000 = 258,
|
| 269 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEGLStreamConsumerAcquireFrame_v7000 = 259,
|
| 270 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEGLStreamConsumerReleaseFrame_v7000 = 260,
|
| 271 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEGLStreamProducerConnect_v7000 = 261,
|
| 272 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEGLStreamProducerDisconnect_v7000 = 262,
|
| 273 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEGLStreamProducerPresentFrame_v7000 = 263,
|
| 274 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEGLStreamProducerReturnFrame_v7000 = 264,
|
| 275 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphicsResourceGetMappedEglFrame_v7000 = 265,
|
| 276 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemRangeGetAttribute_v8000 = 266,
|
| 277 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemRangeGetAttributes_v8000 = 267,
|
| 278 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEGLStreamConsumerConnectWithFlags_v7000 = 268,
|
| 279 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaLaunchCooperativeKernel_v9000 = 269,
|
| 280 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaLaunchCooperativeKernel_ptsz_v9000 = 270,
|
| 281 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEventCreateFromEGLSync_v9000 = 271,
|
| 282 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaLaunchCooperativeKernelMultiDevice_v9000 = 272,
|
| 283 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaFuncSetAttribute_v9000 = 273,
|
| 284 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaImportExternalMemory_v10000 = 274,
|
| 285 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaExternalMemoryGetMappedBuffer_v10000 = 275,
|
| 286 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaExternalMemoryGetMappedMipmappedArray_v10000 = 276,
|
| 287 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDestroyExternalMemory_v10000 = 277,
|
| 288 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaImportExternalSemaphore_v10000 = 278,
|
| 289 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaSignalExternalSemaphoresAsync_v10000 = 279,
|
| 290 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaSignalExternalSemaphoresAsync_ptsz_v10000 = 280,
|
| 291 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaWaitExternalSemaphoresAsync_v10000 = 281,
|
| 292 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaWaitExternalSemaphoresAsync_ptsz_v10000 = 282,
|
| 293 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDestroyExternalSemaphore_v10000 = 283,
|
| 294 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaLaunchHostFunc_v10000 = 284,
|
| 295 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaLaunchHostFunc_ptsz_v10000 = 285,
|
| 296 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphCreate_v10000 = 286,
|
| 297 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphKernelNodeGetParams_v10000 = 287,
|
| 298 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphKernelNodeSetParams_v10000 = 288,
|
| 299 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddKernelNode_v10000 = 289,
|
| 300 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddMemcpyNode_v10000 = 290,
|
| 301 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphMemcpyNodeGetParams_v10000 = 291,
|
| 302 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphMemcpyNodeSetParams_v10000 = 292,
|
| 303 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddMemsetNode_v10000 = 293,
|
| 304 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphMemsetNodeGetParams_v10000 = 294,
|
| 305 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphMemsetNodeSetParams_v10000 = 295,
|
| 306 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddHostNode_v10000 = 296,
|
| 307 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphHostNodeGetParams_v10000 = 297,
|
| 308 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddChildGraphNode_v10000 = 298,
|
| 309 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphChildGraphNodeGetGraph_v10000 = 299,
|
| 310 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddEmptyNode_v10000 = 300,
|
| 311 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphClone_v10000 = 301,
|
| 312 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphNodeFindInClone_v10000 = 302,
|
| 313 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphNodeGetType_v10000 = 303,
|
| 314 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphGetRootNodes_v10000 = 304,
|
| 315 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphNodeGetDependencies_v10000 = 305,
|
| 316 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphNodeGetDependentNodes_v10000 = 306,
|
| 317 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddDependencies_v10000 = 307,
|
| 318 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphRemoveDependencies_v10000 = 308,
|
| 319 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphDestroyNode_v10000 = 309,
|
| 320 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphInstantiate_v10000 = 310,
|
| 321 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphLaunch_v10000 = 311,
|
| 322 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphLaunch_ptsz_v10000 = 312,
|
| 323 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecDestroy_v10000 = 313,
|
| 324 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphDestroy_v10000 = 314,
|
| 325 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamBeginCapture_v10000 = 315,
|
| 326 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamBeginCapture_ptsz_v10000 = 316,
|
| 327 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamIsCapturing_v10000 = 317,
|
| 328 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamIsCapturing_ptsz_v10000 = 318,
|
| 329 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamEndCapture_v10000 = 319,
|
| 330 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamEndCapture_ptsz_v10000 = 320,
|
| 331 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphHostNodeSetParams_v10000 = 321,
|
| 332 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphGetNodes_v10000 = 322,
|
| 333 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphGetEdges_v10000 = 323,
|
| 334 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamGetCaptureInfo_v10010 = 324,
|
| 335 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamGetCaptureInfo_ptsz_v10010 = 325,
|
| 336 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecKernelNodeSetParams_v10010 = 326,
|
| 337 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaThreadExchangeStreamCaptureMode_v10010 = 327,
|
| 338 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetNvSciSyncAttributes_v10020 = 328,
|
| 339 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaOccupancyAvailableDynamicSMemPerBlock_v10200 = 329,
|
| 340 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamSetFlags_v10200 = 330,
|
| 341 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamSetFlags_ptsz_v10200 = 331,
|
| 342 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecMemcpyNodeSetParams_v10020 = 332,
|
| 343 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecMemsetNodeSetParams_v10020 = 333,
|
| 344 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecHostNodeSetParams_v10020 = 334,
|
| 345 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecUpdate_v10020 = 335,
|
| 346 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetFuncBySymbol_v11000 = 336,
|
| 347 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaCtxResetPersistingL2Cache_v11000 = 337,
|
| 348 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphKernelNodeCopyAttributes_v11000 = 338,
|
| 349 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphKernelNodeGetAttribute_v11000 = 339,
|
| 350 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphKernelNodeSetAttribute_v11000 = 340,
|
| 351 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamCopyAttributes_v11000 = 341,
|
| 352 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamCopyAttributes_ptsz_v11000 = 342,
|
| 353 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamGetAttribute_v11000 = 343,
|
| 354 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamGetAttribute_ptsz_v11000 = 344,
|
| 355 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamSetAttribute_v11000 = 345,
|
| 356 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamSetAttribute_ptsz_v11000 = 346,
|
| 357 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetTexture1DLinearMaxWidth_v11010 = 347,
|
| 358 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphUpload_v10000 = 348,
|
| 359 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphUpload_ptsz_v10000 = 349,
|
| 360 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddMemcpyNodeToSymbol_v11010 = 350,
|
| 361 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddMemcpyNodeFromSymbol_v11010 = 351,
|
| 362 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddMemcpyNode1D_v11010 = 352,
|
| 363 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphMemcpyNodeSetParamsToSymbol_v11010 = 353,
|
| 364 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphMemcpyNodeSetParamsFromSymbol_v11010 = 354,
|
| 365 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphMemcpyNodeSetParams1D_v11010 = 355,
|
| 366 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecMemcpyNodeSetParamsToSymbol_v11010 = 356,
|
| 367 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecMemcpyNodeSetParamsFromSymbol_v11010 = 357,
|
| 368 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecMemcpyNodeSetParams1D_v11010 = 358,
|
| 369 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaArrayGetSparseProperties_v11010 = 359,
|
| 370 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMipmappedArrayGetSparseProperties_v11010 = 360,
|
| 371 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecChildGraphNodeSetParams_v11010 = 361,
|
| 372 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddEventRecordNode_v11010 = 362,
|
| 373 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphEventRecordNodeGetEvent_v11010 = 363,
|
| 374 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphEventRecordNodeSetEvent_v11010 = 364,
|
| 375 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddEventWaitNode_v11010 = 365,
|
| 376 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphEventWaitNodeGetEvent_v11010 = 366,
|
| 377 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphEventWaitNodeSetEvent_v11010 = 367,
|
| 378 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecEventRecordNodeSetEvent_v11010 = 368,
|
| 379 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecEventWaitNodeSetEvent_v11010 = 369,
|
| 380 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEventRecordWithFlags_v11010 = 370,
|
| 381 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaEventRecordWithFlags_ptsz_v11010 = 371,
|
| 382 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetDefaultMemPool_v11020 = 372,
|
| 383 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMallocAsync_v11020 = 373,
|
| 384 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMallocAsync_ptsz_v11020 = 374,
|
| 385 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaFreeAsync_v11020 = 375,
|
| 386 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaFreeAsync_ptsz_v11020 = 376,
|
| 387 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPoolTrimTo_v11020 = 377,
|
| 388 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPoolSetAttribute_v11020 = 378,
|
| 389 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPoolGetAttribute_v11020 = 379,
|
| 390 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPoolSetAccess_v11020 = 380,
|
| 391 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaArrayGetPlane_v11020 = 381,
|
| 392 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPoolGetAccess_v11020 = 382,
|
| 393 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPoolCreate_v11020 = 383,
|
| 394 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPoolDestroy_v11020 = 384,
|
| 395 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceSetMemPool_v11020 = 385,
|
| 396 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetMemPool_v11020 = 386,
|
| 397 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPoolExportToShareableHandle_v11020 = 387,
|
| 398 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPoolImportFromShareableHandle_v11020 = 388,
|
| 399 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPoolExportPointer_v11020 = 389,
|
| 400 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMemPoolImportPointer_v11020 = 390,
|
| 401 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMallocFromPoolAsync_v11020 = 391,
|
| 402 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMallocFromPoolAsync_ptsz_v11020 = 392,
|
| 403 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaSignalExternalSemaphoresAsync_v2_v11020 = 393,
|
| 404 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaSignalExternalSemaphoresAsync_v2_ptsz_v11020 = 394,
|
| 405 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaWaitExternalSemaphoresAsync_v2_v11020 = 395,
|
| 406 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaWaitExternalSemaphoresAsync_v2_ptsz_v11020 = 396,
|
| 407 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddExternalSemaphoresSignalNode_v11020 = 397,
|
| 408 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExternalSemaphoresSignalNodeGetParams_v11020 = 398,
|
| 409 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExternalSemaphoresSignalNodeSetParams_v11020 = 399,
|
| 410 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddExternalSemaphoresWaitNode_v11020 = 400,
|
| 411 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExternalSemaphoresWaitNodeGetParams_v11020 = 401,
|
| 412 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExternalSemaphoresWaitNodeSetParams_v11020 = 402,
|
| 413 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecExternalSemaphoresSignalNodeSetParams_v11020 = 403,
|
| 414 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecExternalSemaphoresWaitNodeSetParams_v11020 = 404,
|
| 415 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceFlushGPUDirectRDMAWrites_v11030 = 405,
|
| 416 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetDriverEntryPoint_v11030 = 406,
|
| 417 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetDriverEntryPoint_ptsz_v11030 = 407,
|
| 418 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphDebugDotPrint_v11030 = 408,
|
| 419 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamGetCaptureInfo_v2_v11030 = 409,
|
| 420 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamGetCaptureInfo_v2_ptsz_v11030 = 410,
|
| 421 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamUpdateCaptureDependencies_v11030 = 411,
|
| 422 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamUpdateCaptureDependencies_ptsz_v11030 = 412,
|
| 423 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaUserObjectCreate_v11030 = 413,
|
| 424 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaUserObjectRetain_v11030 = 414,
|
| 425 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaUserObjectRelease_v11030 = 415,
|
| 426 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphRetainUserObject_v11030 = 416,
|
| 427 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphReleaseUserObject_v11030 = 417,
|
| 428 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphInstantiateWithFlags_v11040 = 418,
|
| 429 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddMemAllocNode_v11040 = 419,
|
| 430 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphMemAllocNodeGetParams_v11040 = 420,
|
| 431 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphAddMemFreeNode_v11040 = 421,
|
| 432 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphMemFreeNodeGetParams_v11040 = 422,
|
| 433 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGraphMemTrim_v11040 = 423,
|
| 434 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceGetGraphMemAttribute_v11040 = 424,
|
| 435 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaDeviceSetGraphMemAttribute_v11040 = 425,
|
| 436 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphNodeSetEnabled_v11060 = 426,
|
| 437 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphNodeGetEnabled_v11060 = 427,
|
| 438 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaArrayGetMemoryRequirements_v11060 = 428,
|
| 439 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaMipmappedArrayGetMemoryRequirements_v11060 = 429,
|
| 440 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaLaunchKernelExC_v11060 = 430,
|
| 441 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaLaunchKernelExC_ptsz_v11060 = 431,
|
| 442 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaOccupancyMaxPotentialClusterSize_v11070 = 432,
|
| 443 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaOccupancyMaxActiveClusters_v11070 = 433,
|
| 444 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaCreateTextureObject_v2_v11080 = 434,
|
| 445 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetTextureObjectTextureDesc_v2_v11080 = 435,
|
| 446 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphInstantiateWithParams_v12000 = 436,
|
| 447 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphInstantiateWithParams_ptsz_v12000 = 437,
|
| 448 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphExecGetFlags_v12000 = 438,
|
| 449 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetKernel_v12000 = 439,
|
| 450 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGetDeviceProperties_v2_v12000 = 440,
|
| 451 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamGetId_v12000 = 441,
|
| 452 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaStreamGetId_ptsz_v12000 = 442,
|
| 453 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaGraphInstantiate_v12000 = 443,
|
| 454 |
+
CUPTI_RUNTIME_TRACE_CBID_cudaInitDevice_v12000 = 444,
|
| 455 |
+
CUPTI_RUNTIME_TRACE_CBID_SIZE = 445,
|
| 456 |
+
CUPTI_RUNTIME_TRACE_CBID_FORCE_INT = 0x7fffffff
|
| 457 |
+
} CUpti_runtime_api_trace_cbid;
|
| 458 |
+
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_cupti/include/generated_cuda_vdpau_interop_meta.h
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// This file is generated. Any changes you make will be lost during the next clean build.
|
| 2 |
+
|
| 3 |
+
// CUDA public interface, for type definitions and api function prototypes
|
| 4 |
+
#include "cuda_vdpau_interop.h"
|
| 5 |
+
|
| 6 |
+
// *************************************************************************
|
| 7 |
+
// Definitions of structs to hold parameters for each function
|
| 8 |
+
// *************************************************************************
|
| 9 |
+
|
| 10 |
+
// Currently used parameter trace structures
|
| 11 |
+
typedef struct cudaVDPAUGetDevice_v3020_params_st {
|
| 12 |
+
int *device;
|
| 13 |
+
VdpDevice vdpDevice;
|
| 14 |
+
VdpGetProcAddress *vdpGetProcAddress;
|
| 15 |
+
} cudaVDPAUGetDevice_v3020_params;
|
| 16 |
+
|
| 17 |
+
typedef struct cudaVDPAUSetVDPAUDevice_v3020_params_st {
|
| 18 |
+
int device;
|
| 19 |
+
VdpDevice vdpDevice;
|
| 20 |
+
VdpGetProcAddress *vdpGetProcAddress;
|
| 21 |
+
} cudaVDPAUSetVDPAUDevice_v3020_params;
|
| 22 |
+
|
| 23 |
+
typedef struct cudaGraphicsVDPAURegisterVideoSurface_v3020_params_st {
|
| 24 |
+
struct cudaGraphicsResource **resource;
|
| 25 |
+
VdpVideoSurface vdpSurface;
|
| 26 |
+
unsigned int flags;
|
| 27 |
+
} cudaGraphicsVDPAURegisterVideoSurface_v3020_params;
|
| 28 |
+
|
| 29 |
+
typedef struct cudaGraphicsVDPAURegisterOutputSurface_v3020_params_st {
|
| 30 |
+
struct cudaGraphicsResource **resource;
|
| 31 |
+
VdpOutputSurface vdpSurface;
|
| 32 |
+
unsigned int flags;
|
| 33 |
+
} cudaGraphicsVDPAURegisterOutputSurface_v3020_params;
|
| 34 |
+
|
| 35 |
+
// Parameter trace structures for removed functions
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
// End of parameter trace structures
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_nvrtc/__init__.py
ADDED
|
File without changes
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_nvrtc/include/__init__.py
ADDED
|
File without changes
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_nvrtc/include/nvrtc.h
ADDED
|
@@ -0,0 +1,845 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
//
|
| 2 |
+
// NVIDIA_COPYRIGHT_BEGIN
|
| 3 |
+
//
|
| 4 |
+
// Copyright (c) 2014-2023, NVIDIA CORPORATION. All rights reserved.
|
| 5 |
+
//
|
| 6 |
+
// NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 7 |
+
// and proprietary rights in and to this software, related documentation
|
| 8 |
+
// and any modifications thereto. Any use, reproduction, disclosure or
|
| 9 |
+
// distribution of this software and related documentation without an express
|
| 10 |
+
// license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 11 |
+
//
|
| 12 |
+
// NVIDIA_COPYRIGHT_END
|
| 13 |
+
//
|
| 14 |
+
|
| 15 |
+
#ifndef __NVRTC_H__
|
| 16 |
+
#define __NVRTC_H__
|
| 17 |
+
|
| 18 |
+
#ifdef __cplusplus
|
| 19 |
+
extern "C" {
|
| 20 |
+
#endif /* __cplusplus */
|
| 21 |
+
|
| 22 |
+
#include <stdlib.h>
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
/*************************************************************************//**
|
| 26 |
+
*
|
| 27 |
+
* \defgroup error Error Handling
|
| 28 |
+
*
|
| 29 |
+
* NVRTC defines the following enumeration type and function for API call
|
| 30 |
+
* error handling.
|
| 31 |
+
*
|
| 32 |
+
****************************************************************************/
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
/**
|
| 36 |
+
* \ingroup error
|
| 37 |
+
* \brief The enumerated type nvrtcResult defines API call result codes.
|
| 38 |
+
* NVRTC API functions return nvrtcResult to indicate the call
|
| 39 |
+
* result.
|
| 40 |
+
*/
|
| 41 |
+
typedef enum {
|
| 42 |
+
NVRTC_SUCCESS = 0,
|
| 43 |
+
NVRTC_ERROR_OUT_OF_MEMORY = 1,
|
| 44 |
+
NVRTC_ERROR_PROGRAM_CREATION_FAILURE = 2,
|
| 45 |
+
NVRTC_ERROR_INVALID_INPUT = 3,
|
| 46 |
+
NVRTC_ERROR_INVALID_PROGRAM = 4,
|
| 47 |
+
NVRTC_ERROR_INVALID_OPTION = 5,
|
| 48 |
+
NVRTC_ERROR_COMPILATION = 6,
|
| 49 |
+
NVRTC_ERROR_BUILTIN_OPERATION_FAILURE = 7,
|
| 50 |
+
NVRTC_ERROR_NO_NAME_EXPRESSIONS_AFTER_COMPILATION = 8,
|
| 51 |
+
NVRTC_ERROR_NO_LOWERED_NAMES_BEFORE_COMPILATION = 9,
|
| 52 |
+
NVRTC_ERROR_NAME_EXPRESSION_NOT_VALID = 10,
|
| 53 |
+
NVRTC_ERROR_INTERNAL_ERROR = 11,
|
| 54 |
+
NVRTC_ERROR_TIME_FILE_WRITE_FAILED = 12
|
| 55 |
+
} nvrtcResult;
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
/**
|
| 59 |
+
* \ingroup error
|
| 60 |
+
* \brief nvrtcGetErrorString is a helper function that returns a string
|
| 61 |
+
* describing the given nvrtcResult code, e.g., NVRTC_SUCCESS to
|
| 62 |
+
* \c "NVRTC_SUCCESS".
|
| 63 |
+
* For unrecognized enumeration values, it returns
|
| 64 |
+
* \c "NVRTC_ERROR unknown".
|
| 65 |
+
*
|
| 66 |
+
* \param [in] result CUDA Runtime Compilation API result code.
|
| 67 |
+
* \return Message string for the given #nvrtcResult code.
|
| 68 |
+
*/
|
| 69 |
+
const char *nvrtcGetErrorString(nvrtcResult result);
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
/*************************************************************************//**
|
| 73 |
+
*
|
| 74 |
+
* \defgroup query General Information Query
|
| 75 |
+
*
|
| 76 |
+
* NVRTC defines the following function for general information query.
|
| 77 |
+
*
|
| 78 |
+
****************************************************************************/
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
/**
|
| 82 |
+
* \ingroup query
|
| 83 |
+
* \brief nvrtcVersion sets the output parameters \p major and \p minor
|
| 84 |
+
* with the CUDA Runtime Compilation version number.
|
| 85 |
+
*
|
| 86 |
+
* \param [out] major CUDA Runtime Compilation major version number.
|
| 87 |
+
* \param [out] minor CUDA Runtime Compilation minor version number.
|
| 88 |
+
* \return
|
| 89 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 90 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 91 |
+
*
|
| 92 |
+
*/
|
| 93 |
+
nvrtcResult nvrtcVersion(int *major, int *minor);
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
/**
|
| 97 |
+
* \ingroup query
|
| 98 |
+
* \brief nvrtcGetNumSupportedArchs sets the output parameter \p numArchs
|
| 99 |
+
* with the number of architectures supported by NVRTC. This can
|
| 100 |
+
* then be used to pass an array to ::nvrtcGetSupportedArchs to
|
| 101 |
+
* get the supported architectures.
|
| 102 |
+
*
|
| 103 |
+
* \param [out] numArchs number of supported architectures.
|
| 104 |
+
* \return
|
| 105 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 106 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 107 |
+
*
|
| 108 |
+
* see ::nvrtcGetSupportedArchs
|
| 109 |
+
*/
|
| 110 |
+
nvrtcResult nvrtcGetNumSupportedArchs(int* numArchs);
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
/**
|
| 114 |
+
* \ingroup query
|
| 115 |
+
* \brief nvrtcGetSupportedArchs populates the array passed via the output parameter
|
| 116 |
+
* \p supportedArchs with the architectures supported by NVRTC. The array is
|
| 117 |
+
* sorted in the ascending order. The size of the array to be passed can be
|
| 118 |
+
* determined using ::nvrtcGetNumSupportedArchs.
|
| 119 |
+
*
|
| 120 |
+
* \param [out] supportedArchs sorted array of supported architectures.
|
| 121 |
+
* \return
|
| 122 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 123 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 124 |
+
*
|
| 125 |
+
* see ::nvrtcGetNumSupportedArchs
|
| 126 |
+
*/
|
| 127 |
+
nvrtcResult nvrtcGetSupportedArchs(int* supportedArchs);
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
/*************************************************************************//**
|
| 131 |
+
*
|
| 132 |
+
* \defgroup compilation Compilation
|
| 133 |
+
*
|
| 134 |
+
* NVRTC defines the following type and functions for actual compilation.
|
| 135 |
+
*
|
| 136 |
+
****************************************************************************/
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
/**
|
| 140 |
+
* \ingroup compilation
|
| 141 |
+
* \brief nvrtcProgram is the unit of compilation, and an opaque handle for
|
| 142 |
+
* a program.
|
| 143 |
+
*
|
| 144 |
+
* To compile a CUDA program string, an instance of nvrtcProgram must be
|
| 145 |
+
* created first with ::nvrtcCreateProgram, then compiled with
|
| 146 |
+
* ::nvrtcCompileProgram.
|
| 147 |
+
*/
|
| 148 |
+
typedef struct _nvrtcProgram *nvrtcProgram;
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
/**
|
| 152 |
+
* \ingroup compilation
|
| 153 |
+
* \brief nvrtcCreateProgram creates an instance of nvrtcProgram with the
|
| 154 |
+
* given input parameters, and sets the output parameter \p prog with
|
| 155 |
+
* it.
|
| 156 |
+
*
|
| 157 |
+
* \param [out] prog CUDA Runtime Compilation program.
|
| 158 |
+
* \param [in] src CUDA program source.
|
| 159 |
+
* \param [in] name CUDA program name.\n
|
| 160 |
+
* \p name can be \c NULL; \c "default_program" is
|
| 161 |
+
* used when \p name is \c NULL or "".
|
| 162 |
+
* \param [in] numHeaders Number of headers used.\n
|
| 163 |
+
* \p numHeaders must be greater than or equal to 0.
|
| 164 |
+
* \param [in] headers Sources of the headers.\n
|
| 165 |
+
* \p headers can be \c NULL when \p numHeaders is
|
| 166 |
+
* 0.
|
| 167 |
+
* \param [in] includeNames Name of each header by which they can be
|
| 168 |
+
* included in the CUDA program source.\n
|
| 169 |
+
* \p includeNames can be \c NULL when \p numHeaders
|
| 170 |
+
* is 0. These headers must be included with the exact
|
| 171 |
+
* names specified here.
|
| 172 |
+
* \return
|
| 173 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 174 |
+
* - \link #nvrtcResult NVRTC_ERROR_OUT_OF_MEMORY \endlink
|
| 175 |
+
* - \link #nvrtcResult NVRTC_ERROR_PROGRAM_CREATION_FAILURE \endlink
|
| 176 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 177 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 178 |
+
*
|
| 179 |
+
* \see ::nvrtcDestroyProgram
|
| 180 |
+
*/
|
| 181 |
+
nvrtcResult nvrtcCreateProgram(nvrtcProgram *prog,
|
| 182 |
+
const char *src,
|
| 183 |
+
const char *name,
|
| 184 |
+
int numHeaders,
|
| 185 |
+
const char * const *headers,
|
| 186 |
+
const char * const *includeNames);
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
/**
|
| 190 |
+
* \ingroup compilation
|
| 191 |
+
* \brief nvrtcDestroyProgram destroys the given program.
|
| 192 |
+
*
|
| 193 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 194 |
+
* \return
|
| 195 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 196 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 197 |
+
*
|
| 198 |
+
* \see ::nvrtcCreateProgram
|
| 199 |
+
*/
|
| 200 |
+
nvrtcResult nvrtcDestroyProgram(nvrtcProgram *prog);
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
/**
|
| 204 |
+
* \ingroup compilation
|
| 205 |
+
* \brief nvrtcCompileProgram compiles the given program.
|
| 206 |
+
*
|
| 207 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 208 |
+
* \param [in] numOptions Number of compiler options passed.
|
| 209 |
+
* \param [in] options Compiler options in the form of C string array.\n
|
| 210 |
+
* \p options can be \c NULL when \p numOptions is 0.
|
| 211 |
+
*
|
| 212 |
+
* \return
|
| 213 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 214 |
+
* - \link #nvrtcResult NVRTC_ERROR_OUT_OF_MEMORY \endlink
|
| 215 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 216 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 217 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_OPTION \endlink
|
| 218 |
+
* - \link #nvrtcResult NVRTC_ERROR_COMPILATION \endlink
|
| 219 |
+
* - \link #nvrtcResult NVRTC_ERROR_BUILTIN_OPERATION_FAILURE \endlink
|
| 220 |
+
* - \link #nvrtcResult NVRTC_ERROR_TIME_FILE_WRITE_FAILED \endlink
|
| 221 |
+
*
|
| 222 |
+
* It supports compile options listed in \ref options.
|
| 223 |
+
*/
|
| 224 |
+
nvrtcResult nvrtcCompileProgram(nvrtcProgram prog,
|
| 225 |
+
int numOptions, const char * const *options);
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
/**
|
| 229 |
+
* \ingroup compilation
|
| 230 |
+
* \brief nvrtcGetPTXSize sets the value of \p ptxSizeRet with the size of the PTX
|
| 231 |
+
* generated by the previous compilation of \p prog (including the
|
| 232 |
+
* trailing \c NULL).
|
| 233 |
+
*
|
| 234 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 235 |
+
* \param [out] ptxSizeRet Size of the generated PTX (including the trailing
|
| 236 |
+
* \c NULL).
|
| 237 |
+
* \return
|
| 238 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 239 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 240 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 241 |
+
*
|
| 242 |
+
* \see ::nvrtcGetPTX
|
| 243 |
+
*/
|
| 244 |
+
nvrtcResult nvrtcGetPTXSize(nvrtcProgram prog, size_t *ptxSizeRet);
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
/**
|
| 248 |
+
* \ingroup compilation
|
| 249 |
+
* \brief nvrtcGetPTX stores the PTX generated by the previous compilation
|
| 250 |
+
* of \p prog in the memory pointed by \p ptx.
|
| 251 |
+
*
|
| 252 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 253 |
+
* \param [out] ptx Compiled result.
|
| 254 |
+
* \return
|
| 255 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 256 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 257 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 258 |
+
*
|
| 259 |
+
* \see ::nvrtcGetPTXSize
|
| 260 |
+
*/
|
| 261 |
+
nvrtcResult nvrtcGetPTX(nvrtcProgram prog, char *ptx);
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
/**
|
| 265 |
+
* \ingroup compilation
|
| 266 |
+
* \brief nvrtcGetCUBINSize sets the value of \p cubinSizeRet with the size of the cubin
|
| 267 |
+
* generated by the previous compilation of \p prog. The value of
|
| 268 |
+
* cubinSizeRet is set to 0 if the value specified to \c -arch is a
|
| 269 |
+
* virtual architecture instead of an actual architecture.
|
| 270 |
+
*
|
| 271 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 272 |
+
* \param [out] cubinSizeRet Size of the generated cubin.
|
| 273 |
+
* \return
|
| 274 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 275 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 276 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 277 |
+
*
|
| 278 |
+
* \see ::nvrtcGetCUBIN
|
| 279 |
+
*/
|
| 280 |
+
nvrtcResult nvrtcGetCUBINSize(nvrtcProgram prog, size_t *cubinSizeRet);
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
/**
|
| 284 |
+
* \ingroup compilation
|
| 285 |
+
* \brief nvrtcGetCUBIN stores the cubin generated by the previous compilation
|
| 286 |
+
* of \p prog in the memory pointed by \p cubin. No cubin is available
|
| 287 |
+
* if the value specified to \c -arch is a virtual architecture instead
|
| 288 |
+
* of an actual architecture.
|
| 289 |
+
*
|
| 290 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 291 |
+
* \param [out] cubin Compiled and assembled result.
|
| 292 |
+
* \return
|
| 293 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 294 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 295 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 296 |
+
*
|
| 297 |
+
* \see ::nvrtcGetCUBINSize
|
| 298 |
+
*/
|
| 299 |
+
nvrtcResult nvrtcGetCUBIN(nvrtcProgram prog, char *cubin);
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
#if defined(_WIN32)
|
| 303 |
+
# define __DEPRECATED__(msg) __declspec(deprecated(msg))
|
| 304 |
+
#elif (defined(__GNUC__) && (__GNUC__ < 4 || (__GNUC__ == 4 && __GNUC_MINOR__ < 5 && !defined(__clang__))))
|
| 305 |
+
# define __DEPRECATED__(msg) __attribute__((deprecated))
|
| 306 |
+
#elif (defined(__GNUC__))
|
| 307 |
+
# define __DEPRECATED__(msg) __attribute__((deprecated(msg)))
|
| 308 |
+
#else
|
| 309 |
+
# define __DEPRECATED__(msg)
|
| 310 |
+
#endif
|
| 311 |
+
|
| 312 |
+
/**
|
| 313 |
+
* \ingroup compilation
|
| 314 |
+
* \brief
|
| 315 |
+
* DEPRECATION NOTICE: This function will be removed in a future release. Please use
|
| 316 |
+
* nvrtcGetLTOIRSize (and nvrtcGetLTOIR) instead.
|
| 317 |
+
*/
|
| 318 |
+
__DEPRECATED__("This function will be removed in a future release. Please use nvrtcGetLTOIRSize instead")
|
| 319 |
+
nvrtcResult nvrtcGetNVVMSize(nvrtcProgram prog, size_t *nvvmSizeRet);
|
| 320 |
+
|
| 321 |
+
/**
|
| 322 |
+
* \ingroup compilation
|
| 323 |
+
* \brief
|
| 324 |
+
* DEPRECATION NOTICE: This function will be removed in a future release. Please use
|
| 325 |
+
* nvrtcGetLTOIR (and nvrtcGetLTOIRSize) instead.
|
| 326 |
+
*/
|
| 327 |
+
__DEPRECATED__("This function will be removed in a future release. Please use nvrtcGetLTOIR instead")
|
| 328 |
+
nvrtcResult nvrtcGetNVVM(nvrtcProgram prog, char *nvvm);
|
| 329 |
+
|
| 330 |
+
#undef __DEPRECATED__
|
| 331 |
+
|
| 332 |
+
/**
|
| 333 |
+
* \ingroup compilation
|
| 334 |
+
* \brief nvrtcGetLTOIRSize sets the value of \p LTOIRSizeRet with the size of the LTO IR
|
| 335 |
+
* generated by the previous compilation of \p prog. The value of
|
| 336 |
+
* LTOIRSizeRet is set to 0 if the program was not compiled with
|
| 337 |
+
* \c -dlto.
|
| 338 |
+
*
|
| 339 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 340 |
+
* \param [out] LTOIRSizeRet Size of the generated LTO IR.
|
| 341 |
+
* \return
|
| 342 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 343 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 344 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 345 |
+
*
|
| 346 |
+
* \see ::nvrtcGetLTOIR
|
| 347 |
+
*/
|
| 348 |
+
nvrtcResult nvrtcGetLTOIRSize(nvrtcProgram prog, size_t *LTOIRSizeRet);
|
| 349 |
+
|
| 350 |
+
|
| 351 |
+
/**
|
| 352 |
+
* \ingroup compilation
|
| 353 |
+
* \brief nvrtcGetLTOIR stores the LTO IR generated by the previous compilation
|
| 354 |
+
* of \p prog in the memory pointed by \p LTOIR. No LTO IR is available
|
| 355 |
+
* if the program was compiled without \c -dlto.
|
| 356 |
+
*
|
| 357 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 358 |
+
* \param [out] LTOIR Compiled result.
|
| 359 |
+
* \return
|
| 360 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 361 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 362 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 363 |
+
*
|
| 364 |
+
* \see ::nvrtcGetLTOIRSize
|
| 365 |
+
*/
|
| 366 |
+
nvrtcResult nvrtcGetLTOIR(nvrtcProgram prog, char *LTOIR);
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
/**
|
| 370 |
+
* \ingroup compilation
|
| 371 |
+
* \brief nvrtcGetOptiXIRSize sets the value of \p optixirSizeRet with the size of the OptiX IR
|
| 372 |
+
* generated by the previous compilation of \p prog. The value of
|
| 373 |
+
* nvrtcGetOptiXIRSize is set to 0 if the program was compiled with
|
| 374 |
+
* options incompatible with OptiX IR generation.
|
| 375 |
+
*
|
| 376 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 377 |
+
* \param [out] optixirSizeRet Size of the generated LTO IR.
|
| 378 |
+
* \return
|
| 379 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 380 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 381 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 382 |
+
*
|
| 383 |
+
* \see ::nvrtcGetOptiXIR
|
| 384 |
+
*/
|
| 385 |
+
nvrtcResult nvrtcGetOptiXIRSize(nvrtcProgram prog, size_t *optixirSizeRet);
|
| 386 |
+
|
| 387 |
+
|
| 388 |
+
/**
|
| 389 |
+
* \ingroup compilation
|
| 390 |
+
* \brief nvrtcGetOptiXIR stores the OptiX IR generated by the previous compilation
|
| 391 |
+
* of \p prog in the memory pointed by \p optixir. No OptiX IR is available
|
| 392 |
+
* if the program was compiled with options incompatible with OptiX IR generation.
|
| 393 |
+
*
|
| 394 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 395 |
+
* \param [out] Optix IR Compiled result.
|
| 396 |
+
* \return
|
| 397 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 398 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 399 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 400 |
+
*
|
| 401 |
+
* \see ::nvrtcGetOptiXIRSize
|
| 402 |
+
*/
|
| 403 |
+
nvrtcResult nvrtcGetOptiXIR(nvrtcProgram prog, char *optixir);
|
| 404 |
+
|
| 405 |
+
/**
|
| 406 |
+
* \ingroup compilation
|
| 407 |
+
* \brief nvrtcGetProgramLogSize sets \p logSizeRet with the size of the
|
| 408 |
+
* log generated by the previous compilation of \p prog (including the
|
| 409 |
+
* trailing \c NULL).
|
| 410 |
+
*
|
| 411 |
+
* Note that compilation log may be generated with warnings and informative
|
| 412 |
+
* messages, even when the compilation of \p prog succeeds.
|
| 413 |
+
*
|
| 414 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 415 |
+
* \param [out] logSizeRet Size of the compilation log
|
| 416 |
+
* (including the trailing \c NULL).
|
| 417 |
+
* \return
|
| 418 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 419 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 420 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 421 |
+
*
|
| 422 |
+
* \see ::nvrtcGetProgramLog
|
| 423 |
+
*/
|
| 424 |
+
nvrtcResult nvrtcGetProgramLogSize(nvrtcProgram prog, size_t *logSizeRet);
|
| 425 |
+
|
| 426 |
+
|
| 427 |
+
/**
|
| 428 |
+
* \ingroup compilation
|
| 429 |
+
* \brief nvrtcGetProgramLog stores the log generated by the previous
|
| 430 |
+
* compilation of \p prog in the memory pointed by \p log.
|
| 431 |
+
*
|
| 432 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 433 |
+
* \param [out] log Compilation log.
|
| 434 |
+
* \return
|
| 435 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 436 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_INPUT \endlink
|
| 437 |
+
* - \link #nvrtcResult NVRTC_ERROR_INVALID_PROGRAM \endlink
|
| 438 |
+
*
|
| 439 |
+
* \see ::nvrtcGetProgramLogSize
|
| 440 |
+
*/
|
| 441 |
+
nvrtcResult nvrtcGetProgramLog(nvrtcProgram prog, char *log);
|
| 442 |
+
|
| 443 |
+
|
| 444 |
+
/**
|
| 445 |
+
* \ingroup compilation
|
| 446 |
+
* \brief nvrtcAddNameExpression notes the given name expression
|
| 447 |
+
* denoting the address of a __global__ function
|
| 448 |
+
* or __device__/__constant__ variable.
|
| 449 |
+
*
|
| 450 |
+
* The identical name expression string must be provided on a subsequent
|
| 451 |
+
* call to nvrtcGetLoweredName to extract the lowered name.
|
| 452 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 453 |
+
* \param [in] name_expression constant expression denoting the address of
|
| 454 |
+
* a __global__ function or __device__/__constant__ variable.
|
| 455 |
+
* \return
|
| 456 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 457 |
+
* - \link #nvrtcResult NVRTC_ERROR_NO_NAME_EXPRESSIONS_AFTER_COMPILATION \endlink
|
| 458 |
+
*
|
| 459 |
+
* \see ::nvrtcGetLoweredName
|
| 460 |
+
*/
|
| 461 |
+
nvrtcResult nvrtcAddNameExpression(nvrtcProgram prog,
|
| 462 |
+
const char * const name_expression);
|
| 463 |
+
|
| 464 |
+
/**
|
| 465 |
+
* \ingroup compilation
|
| 466 |
+
* \brief nvrtcGetLoweredName extracts the lowered (mangled) name
|
| 467 |
+
* for a __global__ function or __device__/__constant__ variable,
|
| 468 |
+
* and updates *lowered_name to point to it. The memory containing
|
| 469 |
+
* the name is released when the NVRTC program is destroyed by
|
| 470 |
+
* nvrtcDestroyProgram.
|
| 471 |
+
* The identical name expression must have been previously
|
| 472 |
+
* provided to nvrtcAddNameExpression.
|
| 473 |
+
*
|
| 474 |
+
* \param [in] prog CUDA Runtime Compilation program.
|
| 475 |
+
* \param [in] name_expression constant expression denoting the address of
|
| 476 |
+
* a __global__ function or __device__/__constant__ variable.
|
| 477 |
+
* \param [out] lowered_name initialized by the function to point to a
|
| 478 |
+
* C string containing the lowered (mangled)
|
| 479 |
+
* name corresponding to the provided name expression.
|
| 480 |
+
* \return
|
| 481 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 482 |
+
* - \link #nvrtcResult NVRTC_ERROR_NO_LOWERED_NAMES_BEFORE_COMPILATION \endlink
|
| 483 |
+
* - \link #nvrtcResult NVRTC_ERROR_NAME_EXPRESSION_NOT_VALID \endlink
|
| 484 |
+
*
|
| 485 |
+
* \see ::nvrtcAddNameExpression
|
| 486 |
+
*/
|
| 487 |
+
nvrtcResult nvrtcGetLoweredName(nvrtcProgram prog,
|
| 488 |
+
const char *const name_expression,
|
| 489 |
+
const char** lowered_name);
|
| 490 |
+
|
| 491 |
+
|
| 492 |
+
/**
|
| 493 |
+
* \defgroup options Supported Compile Options
|
| 494 |
+
*
|
| 495 |
+
* NVRTC supports the compile options below.
|
| 496 |
+
* Option names with two preceding dashs (\c --) are long option names and
|
| 497 |
+
* option names with one preceding dash (\c -) are short option names.
|
| 498 |
+
* Short option names can be used instead of long option names.
|
| 499 |
+
* When a compile option takes an argument, an assignment operator (\c =)
|
| 500 |
+
* is used to separate the compile option argument from the compile option
|
| 501 |
+
* name, e.g., \c "--gpu-architecture=compute_60".
|
| 502 |
+
* Alternatively, the compile option name and the argument can be specified in
|
| 503 |
+
* separate strings without an assignment operator, .e.g,
|
| 504 |
+
* \c "--gpu-architecture" \c "compute_60".
|
| 505 |
+
* Single-character short option names, such as \c -D, \c -U, and \c -I, do
|
| 506 |
+
* not require an assignment operator, and the compile option name and the
|
| 507 |
+
* argument can be present in the same string with or without spaces between
|
| 508 |
+
* them.
|
| 509 |
+
* For instance, \c "-D=<def>", \c "-D<def>", and \c "-D <def>" are all
|
| 510 |
+
* supported.
|
| 511 |
+
*
|
| 512 |
+
* The valid compiler options are:
|
| 513 |
+
*
|
| 514 |
+
* - Compilation targets
|
| 515 |
+
* - \c --gpu-architecture=\<arch\> (\c -arch)\n
|
| 516 |
+
* Specify the name of the class of GPU architectures for which the
|
| 517 |
+
* input must be compiled.\n
|
| 518 |
+
* - Valid <c>\<arch\></c>s:
|
| 519 |
+
* - \c compute_50
|
| 520 |
+
* - \c compute_52
|
| 521 |
+
* - \c compute_53
|
| 522 |
+
* - \c compute_60
|
| 523 |
+
* - \c compute_61
|
| 524 |
+
* - \c compute_62
|
| 525 |
+
* - \c compute_70
|
| 526 |
+
* - \c compute_72
|
| 527 |
+
* - \c compute_75
|
| 528 |
+
* - \c compute_80
|
| 529 |
+
* - \c compute_87
|
| 530 |
+
* - \c compute_89
|
| 531 |
+
* - \c compute_90
|
| 532 |
+
* - \c compute_90a
|
| 533 |
+
* - \c sm_50
|
| 534 |
+
* - \c sm_52
|
| 535 |
+
* - \c sm_53
|
| 536 |
+
* - \c sm_60
|
| 537 |
+
* - \c sm_61
|
| 538 |
+
* - \c sm_62
|
| 539 |
+
* - \c sm_70
|
| 540 |
+
* - \c sm_72
|
| 541 |
+
* - \c sm_75
|
| 542 |
+
* - \c sm_80
|
| 543 |
+
* - \c sm_87
|
| 544 |
+
* - \c sm_89
|
| 545 |
+
* - \c sm_90
|
| 546 |
+
* - \c sm_90a
|
| 547 |
+
* - Default: \c compute_52
|
| 548 |
+
* - Separate compilation / whole-program compilation
|
| 549 |
+
* - \c --device-c (\c -dc)\n
|
| 550 |
+
* Generate relocatable code that can be linked with other relocatable
|
| 551 |
+
* device code. It is equivalent to --relocatable-device-code=true.
|
| 552 |
+
* - \c --device-w (\c -dw)\n
|
| 553 |
+
* Generate non-relocatable code. It is equivalent to
|
| 554 |
+
* \c --relocatable-device-code=false.
|
| 555 |
+
* - \c --relocatable-device-code={true|false} (\c -rdc)\n
|
| 556 |
+
* Enable (disable) the generation of relocatable device code.
|
| 557 |
+
* - Default: \c false
|
| 558 |
+
* - \c --extensible-whole-program (\c -ewp)\n
|
| 559 |
+
* Do extensible whole program compilation of device code.
|
| 560 |
+
* - Default: \c false
|
| 561 |
+
* - Debugging support
|
| 562 |
+
* - \c --device-debug (\c -G)\n
|
| 563 |
+
* Generate debug information. If --dopt is not specified,
|
| 564 |
+
* then turns off all optimizations.
|
| 565 |
+
* - \c --generate-line-info (\c -lineinfo)\n
|
| 566 |
+
* Generate line-number information.
|
| 567 |
+
* - Code generation
|
| 568 |
+
* - \c --dopt on (\c -dopt)\n
|
| 569 |
+
* - \c --dopt=on \n
|
| 570 |
+
* Enable device code optimization. When specified along with '-G', enables
|
| 571 |
+
* limited debug information generation for optimized device code (currently,
|
| 572 |
+
* only line number information).
|
| 573 |
+
* When '-G' is not specified, '-dopt=on' is implicit.
|
| 574 |
+
* - \c --ptxas-options \<options\> (\c -Xptxas)\n
|
| 575 |
+
* - \c --ptxas-options=\<options\> \n
|
| 576 |
+
* Specify options directly to ptxas, the PTX optimizing assembler.
|
| 577 |
+
* - \c --maxrregcount=\<N\> (\c -maxrregcount)\n
|
| 578 |
+
* Specify the maximum amount of registers that GPU functions can use.
|
| 579 |
+
* Until a function-specific limit, a higher value will generally
|
| 580 |
+
* increase the performance of individual GPU threads that execute this
|
| 581 |
+
* function. However, because thread registers are allocated from a
|
| 582 |
+
* global register pool on each GPU, a higher value of this option will
|
| 583 |
+
* also reduce the maximum thread block size, thereby reducing the amount
|
| 584 |
+
* of thread parallelism. Hence, a good maxrregcount value is the result
|
| 585 |
+
* of a trade-off. If this option is not specified, then no maximum is
|
| 586 |
+
* assumed. Value less than the minimum registers required by ABI will
|
| 587 |
+
* be bumped up by the compiler to ABI minimum limit.
|
| 588 |
+
* - \c --ftz={true|false} (\c -ftz)\n
|
| 589 |
+
* When performing single-precision floating-point operations, flush
|
| 590 |
+
* denormal values to zero or preserve denormal values.
|
| 591 |
+
* \c --use_fast_math implies \c --ftz=true.
|
| 592 |
+
* - Default: \c false
|
| 593 |
+
* - \c --prec-sqrt={true|false} (\c -prec-sqrt)\n
|
| 594 |
+
* For single-precision floating-point square root, use IEEE
|
| 595 |
+
* round-to-nearest mode or use a faster approximation.
|
| 596 |
+
* \c --use_fast_math implies \c --prec-sqrt=false.
|
| 597 |
+
* - Default: \c true
|
| 598 |
+
* - \c --prec-div={true|false} (\c -prec-div)\n
|
| 599 |
+
* For single-precision floating-point division and reciprocals, use IEEE
|
| 600 |
+
* round-to-nearest mode or use a faster approximation.
|
| 601 |
+
* \c --use_fast_math implies \c --prec-div=false.
|
| 602 |
+
* - Default: \c true
|
| 603 |
+
* - \c --fmad={true|false} (\c -fmad)\n
|
| 604 |
+
* Enables (disables) the contraction of floating-point multiplies and
|
| 605 |
+
* adds/subtracts into floating-point multiply-add operations (FMAD,
|
| 606 |
+
* FFMA, or DFMA). \c --use_fast_math implies \c --fmad=true.
|
| 607 |
+
* - Default: \c true
|
| 608 |
+
* - \c --use_fast_math (\c -use_fast_math)\n
|
| 609 |
+
* Make use of fast math operations.
|
| 610 |
+
* \c --use_fast_math implies \c --ftz=true \c --prec-div=false
|
| 611 |
+
* \c --prec-sqrt=false \c --fmad=true.
|
| 612 |
+
* - \c --extra-device-vectorization (\c -extra-device-vectorization)\n
|
| 613 |
+
* Enables more aggressive device code vectorization in the NVVM optimizer.
|
| 614 |
+
* - \c --modify-stack-limit={true|false} (\c -modify-stack-limit)\n
|
| 615 |
+
* On Linux, during compilation, use \c setrlimit() to increase stack size
|
| 616 |
+
* to maximum allowed. The limit is reset to the previous value at the
|
| 617 |
+
* end of compilation.
|
| 618 |
+
* Note: \c setrlimit() changes the value for the entire process.
|
| 619 |
+
* - Default: \c true
|
| 620 |
+
* - \c --dlink-time-opt (\c -dlto)\n
|
| 621 |
+
* Generate intermediate code for later link-time optimization.
|
| 622 |
+
* It implies \c -rdc=true.
|
| 623 |
+
* Note: when this option is used the nvrtcGetLTOIR API should be used,
|
| 624 |
+
* as PTX or Cubin will not be generated.
|
| 625 |
+
* - \c --gen-opt-lto (\c -gen-opt-lto)\n
|
| 626 |
+
* Run the optimizer passes before generating the LTO IR.
|
| 627 |
+
* - \c --optix-ir (\c -optix-ir)\n
|
| 628 |
+
* Generate OptiX IR. The Optix IR is only intended for consumption by OptiX
|
| 629 |
+
* through appropriate APIs. This feature is not supported with
|
| 630 |
+
* link-time-optimization (\c -dlto)\n.
|
| 631 |
+
* Note: when this option is used the nvrtcGetOptiX API should be used,
|
| 632 |
+
* as PTX or Cubin will not be generated.
|
| 633 |
+
* - Preprocessing
|
| 634 |
+
* - \c --define-macro=\<def\> (\c -D)\n
|
| 635 |
+
* \c \<def\> can be either \c \<name\> or \c \<name=definitions\>.
|
| 636 |
+
* - \c \<name\> \n
|
| 637 |
+
* Predefine \c \<name\> as a macro with definition \c 1.
|
| 638 |
+
* - \c \<name\>=\<definition\> \n
|
| 639 |
+
* The contents of \c \<definition\> are tokenized and preprocessed
|
| 640 |
+
* as if they appeared during translation phase three in a \c \#define
|
| 641 |
+
* directive. In particular, the definition will be truncated by
|
| 642 |
+
* embedded new line characters.
|
| 643 |
+
* - \c --undefine-macro=\<def\> (\c -U)\n
|
| 644 |
+
* Cancel any previous definition of \c \<def\>.
|
| 645 |
+
* - \c --include-path=\<dir\> (\c -I)\n
|
| 646 |
+
* Add the directory \c \<dir\> to the list of directories to be
|
| 647 |
+
* searched for headers. These paths are searched after the list of
|
| 648 |
+
* headers given to ::nvrtcCreateProgram.
|
| 649 |
+
* - \c --pre-include=\<header\> (\c -include)\n
|
| 650 |
+
* Preinclude \c \<header\> during preprocessing.
|
| 651 |
+
* - \c --no-source-include (\c -no-source-include)
|
| 652 |
+
* The preprocessor by default adds the directory of each input sources
|
| 653 |
+
* to the include path. This option disables this feature and only
|
| 654 |
+
* considers the path specified explicitly.
|
| 655 |
+
* - Language Dialect
|
| 656 |
+
* - \c --std={c++03|c++11|c++14|c++17|c++20}
|
| 657 |
+
* (\c -std={c++11|c++14|c++17|c++20})\n
|
| 658 |
+
* Set language dialect to C++03, C++11, C++14, C++17 or C++20
|
| 659 |
+
* - Default: \c c++17
|
| 660 |
+
* - \c --builtin-move-forward={true|false} (\c -builtin-move-forward)\n
|
| 661 |
+
* Provide builtin definitions of \c std::move and \c std::forward,
|
| 662 |
+
* when C++11 or later language dialect is selected.
|
| 663 |
+
* - Default: \c true
|
| 664 |
+
* - \c --builtin-initializer-list={true|false}
|
| 665 |
+
* (\c -builtin-initializer-list)\n
|
| 666 |
+
* Provide builtin definitions of \c std::initializer_list class and
|
| 667 |
+
* member functions when C++11 or later language dialect is selected.
|
| 668 |
+
* - Default: \c true
|
| 669 |
+
* - Misc.
|
| 670 |
+
* - \c --disable-warnings (\c -w)\n
|
| 671 |
+
* Inhibit all warning messages.
|
| 672 |
+
* - \c --restrict (\c -restrict)\n
|
| 673 |
+
* Programmer assertion that all kernel pointer parameters are restrict
|
| 674 |
+
* pointers.
|
| 675 |
+
* - \c --device-as-default-execution-space
|
| 676 |
+
* (\c -default-device)\n
|
| 677 |
+
* Treat entities with no execution space annotation as \c __device__
|
| 678 |
+
* entities.
|
| 679 |
+
* - \c --device-int128 (\c -device-int128)\n
|
| 680 |
+
* Allow the \c __int128 type in device code. Also causes the macro \c __CUDACC_RTC_INT128__
|
| 681 |
+
* to be defined.
|
| 682 |
+
* - \c --optimization-info=\<kind\> (\c -opt-info)\n
|
| 683 |
+
* Provide optimization reports for the specified kind of optimization.
|
| 684 |
+
* The following kind tags are supported:
|
| 685 |
+
* - \c inline : emit a remark when a function is inlined.
|
| 686 |
+
* - \c --version-ident={true|false} (\c -dQ)\n
|
| 687 |
+
* Embed used compiler's version info into generated PTX/CUBIN
|
| 688 |
+
* - Default: \c false
|
| 689 |
+
* - \c --display-error-number (\c -err-no)\n
|
| 690 |
+
* Display diagnostic number for warning messages. (Default)
|
| 691 |
+
* - \c --no-display-error-number (\c -no-err-no)\n
|
| 692 |
+
* Disables the display of a diagnostic number for warning messages.
|
| 693 |
+
* - \c --diag-error=<error-number>,... (\c -diag-error)\n
|
| 694 |
+
* Emit error for specified diagnostic message number(s). Message numbers can be separated by comma.
|
| 695 |
+
* - \c --diag-suppress=<error-number>,... (\c -diag-suppress)\n
|
| 696 |
+
* Suppress specified diagnostic message number(s). Message numbers can be separated by comma.
|
| 697 |
+
* - \c --diag-warn=<error-number>,... (\c -diag-warn)\n
|
| 698 |
+
* Emit warning for specified diagnostic message number(s). Message numbers can be separated by comma.
|
| 699 |
+
* - \c --brief-diagnostics={true|false} (\c -brief-diag)\n
|
| 700 |
+
* This option disables or enables showing source line and column info
|
| 701 |
+
* in a diagnostic.
|
| 702 |
+
* The --brief-diagnostics=true will not show the source line and column info.
|
| 703 |
+
* - Default: \c false
|
| 704 |
+
* - \c --time=<file-name> (\c -time)\n
|
| 705 |
+
* Generate a comma separated value table with the time taken by each compilation
|
| 706 |
+
* phase, and append it at the end of the file given as the option argument.
|
| 707 |
+
* If the file does not exist, the column headings are generated in the first row
|
| 708 |
+
* of the table. If the file name is '-', the timing data is written to the compilation log.
|
| 709 |
+
*
|
| 710 |
+
*/
|
| 711 |
+
|
| 712 |
+
|
| 713 |
+
#ifdef __cplusplus
|
| 714 |
+
}
|
| 715 |
+
#endif /* __cplusplus */
|
| 716 |
+
|
| 717 |
+
|
| 718 |
+
/* The utility function 'nvrtcGetTypeName' is not available by default. Define
|
| 719 |
+
the macro 'NVRTC_GET_TYPE_NAME' to a non-zero value to make it available.
|
| 720 |
+
*/
|
| 721 |
+
|
| 722 |
+
#if NVRTC_GET_TYPE_NAME || __DOXYGEN_ONLY__
|
| 723 |
+
|
| 724 |
+
#if NVRTC_USE_CXXABI || __clang__ || __GNUC__ || __DOXYGEN_ONLY__
|
| 725 |
+
#include <cxxabi.h>
|
| 726 |
+
#include <cstdlib>
|
| 727 |
+
|
| 728 |
+
#elif defined(_WIN32)
|
| 729 |
+
#include <Windows.h>
|
| 730 |
+
#include <DbgHelp.h>
|
| 731 |
+
#endif /* NVRTC_USE_CXXABI || __clang__ || __GNUC__ */
|
| 732 |
+
|
| 733 |
+
|
| 734 |
+
#include <string>
|
| 735 |
+
#include <typeinfo>
|
| 736 |
+
|
| 737 |
+
template <typename T> struct __nvrtcGetTypeName_helper_t { };
|
| 738 |
+
|
| 739 |
+
/*************************************************************************//**
|
| 740 |
+
*
|
| 741 |
+
* \defgroup hosthelper Host Helper
|
| 742 |
+
*
|
| 743 |
+
* NVRTC defines the following functions for easier interaction with host code.
|
| 744 |
+
*
|
| 745 |
+
****************************************************************************/
|
| 746 |
+
|
| 747 |
+
/**
|
| 748 |
+
* \ingroup hosthelper
|
| 749 |
+
* \brief nvrtcGetTypeName stores the source level name of a type in the given
|
| 750 |
+
* std::string location.
|
| 751 |
+
*
|
| 752 |
+
* This function is only provided when the macro NVRTC_GET_TYPE_NAME is
|
| 753 |
+
* defined with a non-zero value. It uses abi::__cxa_demangle or UnDecorateSymbolName
|
| 754 |
+
* function calls to extract the type name, when using gcc/clang or cl.exe compilers,
|
| 755 |
+
* respectively. If the name extraction fails, it will return NVRTC_INTERNAL_ERROR,
|
| 756 |
+
* otherwise *result is initialized with the extracted name.
|
| 757 |
+
*
|
| 758 |
+
* Windows-specific notes:
|
| 759 |
+
* - nvrtcGetTypeName() is not multi-thread safe because it calls UnDecorateSymbolName(),
|
| 760 |
+
* which is not multi-thread safe.
|
| 761 |
+
* - The returned string may contain Microsoft-specific keywords such as __ptr64 and __cdecl.
|
| 762 |
+
*
|
| 763 |
+
* \param [in] tinfo: reference to object of type std::type_info for a given type.
|
| 764 |
+
* \param [in] result: pointer to std::string in which to store the type name.
|
| 765 |
+
* \return
|
| 766 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 767 |
+
* - \link #nvrtcResult NVRTC_ERROR_INTERNAL_ERROR \endlink
|
| 768 |
+
*
|
| 769 |
+
*/
|
| 770 |
+
inline nvrtcResult nvrtcGetTypeName(const std::type_info &tinfo, std::string *result)
|
| 771 |
+
{
|
| 772 |
+
#if USE_CXXABI || __clang__ || __GNUC__
|
| 773 |
+
const char *name = tinfo.name();
|
| 774 |
+
int status;
|
| 775 |
+
char *undecorated_name = abi::__cxa_demangle(name, 0, 0, &status);
|
| 776 |
+
if (status == 0) {
|
| 777 |
+
*result = undecorated_name;
|
| 778 |
+
free(undecorated_name);
|
| 779 |
+
return NVRTC_SUCCESS;
|
| 780 |
+
}
|
| 781 |
+
#elif defined(_WIN32)
|
| 782 |
+
const char *name = tinfo.raw_name();
|
| 783 |
+
if (!name || *name != '.') {
|
| 784 |
+
return NVRTC_ERROR_INTERNAL_ERROR;
|
| 785 |
+
}
|
| 786 |
+
char undecorated_name[4096];
|
| 787 |
+
//name+1 skips over the '.' prefix
|
| 788 |
+
if(UnDecorateSymbolName(name+1, undecorated_name,
|
| 789 |
+
sizeof(undecorated_name) / sizeof(*undecorated_name),
|
| 790 |
+
//note: doesn't seem to work correctly without UNDNAME_NO_ARGUMENTS.
|
| 791 |
+
UNDNAME_NO_ARGUMENTS | UNDNAME_NAME_ONLY ) ) {
|
| 792 |
+
*result = undecorated_name;
|
| 793 |
+
return NVRTC_SUCCESS;
|
| 794 |
+
}
|
| 795 |
+
#endif /* USE_CXXABI || __clang__ || __GNUC__ */
|
| 796 |
+
|
| 797 |
+
return NVRTC_ERROR_INTERNAL_ERROR;
|
| 798 |
+
}
|
| 799 |
+
|
| 800 |
+
/**
|
| 801 |
+
* \ingroup hosthelper
|
| 802 |
+
* \brief nvrtcGetTypeName stores the source level name of the template type argument
|
| 803 |
+
* T in the given std::string location.
|
| 804 |
+
*
|
| 805 |
+
* This function is only provided when the macro NVRTC_GET_TYPE_NAME is
|
| 806 |
+
* defined with a non-zero value. It uses abi::__cxa_demangle or UnDecorateSymbolName
|
| 807 |
+
* function calls to extract the type name, when using gcc/clang or cl.exe compilers,
|
| 808 |
+
* respectively. If the name extraction fails, it will return NVRTC_INTERNAL_ERROR,
|
| 809 |
+
* otherwise *result is initialized with the extracted name.
|
| 810 |
+
*
|
| 811 |
+
* Windows-specific notes:
|
| 812 |
+
* - nvrtcGetTypeName() is not multi-thread safe because it calls UnDecorateSymbolName(),
|
| 813 |
+
* which is not multi-thread safe.
|
| 814 |
+
* - The returned string may contain Microsoft-specific keywords such as __ptr64 and __cdecl.
|
| 815 |
+
*
|
| 816 |
+
* \param [in] result: pointer to std::string in which to store the type name.
|
| 817 |
+
* \return
|
| 818 |
+
* - \link #nvrtcResult NVRTC_SUCCESS \endlink
|
| 819 |
+
* - \link #nvrtcResult NVRTC_ERROR_INTERNAL_ERROR \endlink
|
| 820 |
+
*
|
| 821 |
+
*/
|
| 822 |
+
|
| 823 |
+
template <typename T>
|
| 824 |
+
nvrtcResult nvrtcGetTypeName(std::string *result)
|
| 825 |
+
{
|
| 826 |
+
nvrtcResult res = nvrtcGetTypeName(typeid(__nvrtcGetTypeName_helper_t<T>),
|
| 827 |
+
result);
|
| 828 |
+
if (res != NVRTC_SUCCESS)
|
| 829 |
+
return res;
|
| 830 |
+
|
| 831 |
+
std::string repr = *result;
|
| 832 |
+
std::size_t idx = repr.find("__nvrtcGetTypeName_helper_t");
|
| 833 |
+
idx = (idx != std::string::npos) ? repr.find("<", idx) : idx;
|
| 834 |
+
std::size_t last_idx = repr.find_last_of('>');
|
| 835 |
+
if (idx == std::string::npos || last_idx == std::string::npos) {
|
| 836 |
+
return NVRTC_ERROR_INTERNAL_ERROR;
|
| 837 |
+
}
|
| 838 |
+
++idx;
|
| 839 |
+
*result = repr.substr(idx, last_idx - idx);
|
| 840 |
+
return NVRTC_SUCCESS;
|
| 841 |
+
}
|
| 842 |
+
|
| 843 |
+
#endif /* NVRTC_GET_TYPE_NAME */
|
| 844 |
+
|
| 845 |
+
#endif /* __NVRTC_H__ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_nvrtc/lib/__init__.py
ADDED
|
File without changes
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_nvrtc/lib/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (180 Bytes). View file
|
|
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/channel_descriptor.h
ADDED
|
@@ -0,0 +1,588 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2012 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__CHANNEL_DESCRIPTOR_H__)
|
| 51 |
+
#define __CHANNEL_DESCRIPTOR_H__
|
| 52 |
+
|
| 53 |
+
#if defined(__cplusplus)
|
| 54 |
+
|
| 55 |
+
/*******************************************************************************
|
| 56 |
+
* *
|
| 57 |
+
* *
|
| 58 |
+
* *
|
| 59 |
+
*******************************************************************************/
|
| 60 |
+
|
| 61 |
+
#include "cuda_runtime_api.h"
|
| 62 |
+
|
| 63 |
+
/*******************************************************************************
|
| 64 |
+
* *
|
| 65 |
+
* *
|
| 66 |
+
* *
|
| 67 |
+
*******************************************************************************/
|
| 68 |
+
|
| 69 |
+
/**
|
| 70 |
+
* \addtogroup CUDART_HIGHLEVEL
|
| 71 |
+
*
|
| 72 |
+
* @{
|
| 73 |
+
*/
|
| 74 |
+
|
| 75 |
+
/**
|
| 76 |
+
* \brief \hl Returns a channel descriptor using the specified format
|
| 77 |
+
*
|
| 78 |
+
* Returns a channel descriptor with format \p f and number of bits of each
|
| 79 |
+
* component \p x, \p y, \p z, and \p w. The ::cudaChannelFormatDesc is
|
| 80 |
+
* defined as:
|
| 81 |
+
* \code
|
| 82 |
+
struct cudaChannelFormatDesc {
|
| 83 |
+
int x, y, z, w;
|
| 84 |
+
enum cudaChannelFormatKind f;
|
| 85 |
+
};
|
| 86 |
+
* \endcode
|
| 87 |
+
*
|
| 88 |
+
* where ::cudaChannelFormatKind is one of ::cudaChannelFormatKindSigned,
|
| 89 |
+
* ::cudaChannelFormatKindUnsigned, cudaChannelFormatKindFloat,
|
| 90 |
+
* ::cudaChannelFormatKindSignedNormalized8X1, ::cudaChannelFormatKindSignedNormalized8X2,
|
| 91 |
+
* ::cudaChannelFormatKindSignedNormalized8X4,
|
| 92 |
+
* ::cudaChannelFormatKindUnsignedNormalized8X1, ::cudaChannelFormatKindUnsignedNormalized8X2,
|
| 93 |
+
* ::cudaChannelFormatKindUnsignedNormalized8X4,
|
| 94 |
+
* ::cudaChannelFormatKindSignedNormalized16X1, ::cudaChannelFormatKindSignedNormalized16X2,
|
| 95 |
+
* ::cudaChannelFormatKindSignedNormalized16X4,
|
| 96 |
+
* ::cudaChannelFormatKindUnsignedNormalized16X1, ::cudaChannelFormatKindUnsignedNormalized16X2,
|
| 97 |
+
* ::cudaChannelFormatKindUnsignedNormalized16X4
|
| 98 |
+
* or ::cudaChannelFormatKindNV12.
|
| 99 |
+
*
|
| 100 |
+
* The format is specified by the template specialization.
|
| 101 |
+
*
|
| 102 |
+
* The template function specializes for the following scalar types:
|
| 103 |
+
* char, signed char, unsigned char, short, unsigned short, int, unsigned int, long, unsigned long, and float.
|
| 104 |
+
* The template function specializes for the following vector types:
|
| 105 |
+
* char{1|2|4}, uchar{1|2|4}, short{1|2|4}, ushort{1|2|4}, int{1|2|4}, uint{1|2|4}, long{1|2|4}, ulong{1|2|4}, float{1|2|4}.
|
| 106 |
+
* The template function specializes for following cudaChannelFormatKind enum values:
|
| 107 |
+
* ::cudaChannelFormatKind{Uns|S}ignedNormalized{8|16}X{1|2|4}, and ::cudaChannelFormatKindNV12.
|
| 108 |
+
*
|
| 109 |
+
* Invoking the function on a type without a specialization defaults to creating a channel format of kind ::cudaChannelFormatKindNone
|
| 110 |
+
*
|
| 111 |
+
* \return
|
| 112 |
+
* Channel descriptor with format \p f
|
| 113 |
+
*
|
| 114 |
+
* \sa \ref ::cudaCreateChannelDesc(int,int,int,int,cudaChannelFormatKind) "cudaCreateChannelDesc (Low level)",
|
| 115 |
+
* ::cudaGetChannelDesc,
|
| 116 |
+
*/
|
| 117 |
+
template<class T> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc(void)
|
| 118 |
+
{
|
| 119 |
+
return cudaCreateChannelDesc(0, 0, 0, 0, cudaChannelFormatKindNone);
|
| 120 |
+
}
|
| 121 |
+
|
| 122 |
+
static __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDescHalf(void)
|
| 123 |
+
{
|
| 124 |
+
int e = (int)sizeof(unsigned short) * 8;
|
| 125 |
+
|
| 126 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindFloat);
|
| 127 |
+
}
|
| 128 |
+
|
| 129 |
+
static __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDescHalf1(void)
|
| 130 |
+
{
|
| 131 |
+
int e = (int)sizeof(unsigned short) * 8;
|
| 132 |
+
|
| 133 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindFloat);
|
| 134 |
+
}
|
| 135 |
+
|
| 136 |
+
static __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDescHalf2(void)
|
| 137 |
+
{
|
| 138 |
+
int e = (int)sizeof(unsigned short) * 8;
|
| 139 |
+
|
| 140 |
+
return cudaCreateChannelDesc(e, e, 0, 0, cudaChannelFormatKindFloat);
|
| 141 |
+
}
|
| 142 |
+
|
| 143 |
+
static __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDescHalf4(void)
|
| 144 |
+
{
|
| 145 |
+
int e = (int)sizeof(unsigned short) * 8;
|
| 146 |
+
|
| 147 |
+
return cudaCreateChannelDesc(e, e, e, e, cudaChannelFormatKindFloat);
|
| 148 |
+
}
|
| 149 |
+
|
| 150 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<char>(void)
|
| 151 |
+
{
|
| 152 |
+
int e = (int)sizeof(char) * 8;
|
| 153 |
+
|
| 154 |
+
#if defined(_CHAR_UNSIGNED) || defined(__CHAR_UNSIGNED__)
|
| 155 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindUnsigned);
|
| 156 |
+
#else /* _CHAR_UNSIGNED || __CHAR_UNSIGNED__ */
|
| 157 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindSigned);
|
| 158 |
+
#endif /* _CHAR_UNSIGNED || __CHAR_UNSIGNED__ */
|
| 159 |
+
}
|
| 160 |
+
|
| 161 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<signed char>(void)
|
| 162 |
+
{
|
| 163 |
+
int e = (int)sizeof(signed char) * 8;
|
| 164 |
+
|
| 165 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindSigned);
|
| 166 |
+
}
|
| 167 |
+
|
| 168 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<unsigned char>(void)
|
| 169 |
+
{
|
| 170 |
+
int e = (int)sizeof(unsigned char) * 8;
|
| 171 |
+
|
| 172 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindUnsigned);
|
| 173 |
+
}
|
| 174 |
+
|
| 175 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<char1>(void)
|
| 176 |
+
{
|
| 177 |
+
int e = (int)sizeof(signed char) * 8;
|
| 178 |
+
|
| 179 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindSigned);
|
| 180 |
+
}
|
| 181 |
+
|
| 182 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<uchar1>(void)
|
| 183 |
+
{
|
| 184 |
+
int e = (int)sizeof(unsigned char) * 8;
|
| 185 |
+
|
| 186 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindUnsigned);
|
| 187 |
+
}
|
| 188 |
+
|
| 189 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<char2>(void)
|
| 190 |
+
{
|
| 191 |
+
int e = (int)sizeof(signed char) * 8;
|
| 192 |
+
|
| 193 |
+
return cudaCreateChannelDesc(e, e, 0, 0, cudaChannelFormatKindSigned);
|
| 194 |
+
}
|
| 195 |
+
|
| 196 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<uchar2>(void)
|
| 197 |
+
{
|
| 198 |
+
int e = (int)sizeof(unsigned char) * 8;
|
| 199 |
+
|
| 200 |
+
return cudaCreateChannelDesc(e, e, 0, 0, cudaChannelFormatKindUnsigned);
|
| 201 |
+
}
|
| 202 |
+
|
| 203 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<char4>(void)
|
| 204 |
+
{
|
| 205 |
+
int e = (int)sizeof(signed char) * 8;
|
| 206 |
+
|
| 207 |
+
return cudaCreateChannelDesc(e, e, e, e, cudaChannelFormatKindSigned);
|
| 208 |
+
}
|
| 209 |
+
|
| 210 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<uchar4>(void)
|
| 211 |
+
{
|
| 212 |
+
int e = (int)sizeof(unsigned char) * 8;
|
| 213 |
+
|
| 214 |
+
return cudaCreateChannelDesc(e, e, e, e, cudaChannelFormatKindUnsigned);
|
| 215 |
+
}
|
| 216 |
+
|
| 217 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<short>(void)
|
| 218 |
+
{
|
| 219 |
+
int e = (int)sizeof(short) * 8;
|
| 220 |
+
|
| 221 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindSigned);
|
| 222 |
+
}
|
| 223 |
+
|
| 224 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<unsigned short>(void)
|
| 225 |
+
{
|
| 226 |
+
int e = (int)sizeof(unsigned short) * 8;
|
| 227 |
+
|
| 228 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindUnsigned);
|
| 229 |
+
}
|
| 230 |
+
|
| 231 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<short1>(void)
|
| 232 |
+
{
|
| 233 |
+
int e = (int)sizeof(short) * 8;
|
| 234 |
+
|
| 235 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindSigned);
|
| 236 |
+
}
|
| 237 |
+
|
| 238 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<ushort1>(void)
|
| 239 |
+
{
|
| 240 |
+
int e = (int)sizeof(unsigned short) * 8;
|
| 241 |
+
|
| 242 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindUnsigned);
|
| 243 |
+
}
|
| 244 |
+
|
| 245 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<short2>(void)
|
| 246 |
+
{
|
| 247 |
+
int e = (int)sizeof(short) * 8;
|
| 248 |
+
|
| 249 |
+
return cudaCreateChannelDesc(e, e, 0, 0, cudaChannelFormatKindSigned);
|
| 250 |
+
}
|
| 251 |
+
|
| 252 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<ushort2>(void)
|
| 253 |
+
{
|
| 254 |
+
int e = (int)sizeof(unsigned short) * 8;
|
| 255 |
+
|
| 256 |
+
return cudaCreateChannelDesc(e, e, 0, 0, cudaChannelFormatKindUnsigned);
|
| 257 |
+
}
|
| 258 |
+
|
| 259 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<short4>(void)
|
| 260 |
+
{
|
| 261 |
+
int e = (int)sizeof(short) * 8;
|
| 262 |
+
|
| 263 |
+
return cudaCreateChannelDesc(e, e, e, e, cudaChannelFormatKindSigned);
|
| 264 |
+
}
|
| 265 |
+
|
| 266 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<ushort4>(void)
|
| 267 |
+
{
|
| 268 |
+
int e = (int)sizeof(unsigned short) * 8;
|
| 269 |
+
|
| 270 |
+
return cudaCreateChannelDesc(e, e, e, e, cudaChannelFormatKindUnsigned);
|
| 271 |
+
}
|
| 272 |
+
|
| 273 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<int>(void)
|
| 274 |
+
{
|
| 275 |
+
int e = (int)sizeof(int) * 8;
|
| 276 |
+
|
| 277 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindSigned);
|
| 278 |
+
}
|
| 279 |
+
|
| 280 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<unsigned int>(void)
|
| 281 |
+
{
|
| 282 |
+
int e = (int)sizeof(unsigned int) * 8;
|
| 283 |
+
|
| 284 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindUnsigned);
|
| 285 |
+
}
|
| 286 |
+
|
| 287 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<int1>(void)
|
| 288 |
+
{
|
| 289 |
+
int e = (int)sizeof(int) * 8;
|
| 290 |
+
|
| 291 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindSigned);
|
| 292 |
+
}
|
| 293 |
+
|
| 294 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<uint1>(void)
|
| 295 |
+
{
|
| 296 |
+
int e = (int)sizeof(unsigned int) * 8;
|
| 297 |
+
|
| 298 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindUnsigned);
|
| 299 |
+
}
|
| 300 |
+
|
| 301 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<int2>(void)
|
| 302 |
+
{
|
| 303 |
+
int e = (int)sizeof(int) * 8;
|
| 304 |
+
|
| 305 |
+
return cudaCreateChannelDesc(e, e, 0, 0, cudaChannelFormatKindSigned);
|
| 306 |
+
}
|
| 307 |
+
|
| 308 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<uint2>(void)
|
| 309 |
+
{
|
| 310 |
+
int e = (int)sizeof(unsigned int) * 8;
|
| 311 |
+
|
| 312 |
+
return cudaCreateChannelDesc(e, e, 0, 0, cudaChannelFormatKindUnsigned);
|
| 313 |
+
}
|
| 314 |
+
|
| 315 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<int4>(void)
|
| 316 |
+
{
|
| 317 |
+
int e = (int)sizeof(int) * 8;
|
| 318 |
+
|
| 319 |
+
return cudaCreateChannelDesc(e, e, e, e, cudaChannelFormatKindSigned);
|
| 320 |
+
}
|
| 321 |
+
|
| 322 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<uint4>(void)
|
| 323 |
+
{
|
| 324 |
+
int e = (int)sizeof(unsigned int) * 8;
|
| 325 |
+
|
| 326 |
+
return cudaCreateChannelDesc(e, e, e, e, cudaChannelFormatKindUnsigned);
|
| 327 |
+
}
|
| 328 |
+
|
| 329 |
+
#if !defined(__LP64__)
|
| 330 |
+
|
| 331 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<long>(void)
|
| 332 |
+
{
|
| 333 |
+
int e = (int)sizeof(long) * 8;
|
| 334 |
+
|
| 335 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindSigned);
|
| 336 |
+
}
|
| 337 |
+
|
| 338 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<unsigned long>(void)
|
| 339 |
+
{
|
| 340 |
+
int e = (int)sizeof(unsigned long) * 8;
|
| 341 |
+
|
| 342 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindUnsigned);
|
| 343 |
+
}
|
| 344 |
+
|
| 345 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<long1>(void)
|
| 346 |
+
{
|
| 347 |
+
int e = (int)sizeof(long) * 8;
|
| 348 |
+
|
| 349 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindSigned);
|
| 350 |
+
}
|
| 351 |
+
|
| 352 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<ulong1>(void)
|
| 353 |
+
{
|
| 354 |
+
int e = (int)sizeof(unsigned long) * 8;
|
| 355 |
+
|
| 356 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindUnsigned);
|
| 357 |
+
}
|
| 358 |
+
|
| 359 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<long2>(void)
|
| 360 |
+
{
|
| 361 |
+
int e = (int)sizeof(long) * 8;
|
| 362 |
+
|
| 363 |
+
return cudaCreateChannelDesc(e, e, 0, 0, cudaChannelFormatKindSigned);
|
| 364 |
+
}
|
| 365 |
+
|
| 366 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<ulong2>(void)
|
| 367 |
+
{
|
| 368 |
+
int e = (int)sizeof(unsigned long) * 8;
|
| 369 |
+
|
| 370 |
+
return cudaCreateChannelDesc(e, e, 0, 0, cudaChannelFormatKindUnsigned);
|
| 371 |
+
}
|
| 372 |
+
|
| 373 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<long4>(void)
|
| 374 |
+
{
|
| 375 |
+
int e = (int)sizeof(long) * 8;
|
| 376 |
+
|
| 377 |
+
return cudaCreateChannelDesc(e, e, e, e, cudaChannelFormatKindSigned);
|
| 378 |
+
}
|
| 379 |
+
|
| 380 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<ulong4>(void)
|
| 381 |
+
{
|
| 382 |
+
int e = (int)sizeof(unsigned long) * 8;
|
| 383 |
+
|
| 384 |
+
return cudaCreateChannelDesc(e, e, e, e, cudaChannelFormatKindUnsigned);
|
| 385 |
+
}
|
| 386 |
+
|
| 387 |
+
#endif /* !__LP64__ */
|
| 388 |
+
|
| 389 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<float>(void)
|
| 390 |
+
{
|
| 391 |
+
int e = (int)sizeof(float) * 8;
|
| 392 |
+
|
| 393 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindFloat);
|
| 394 |
+
}
|
| 395 |
+
|
| 396 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<float1>(void)
|
| 397 |
+
{
|
| 398 |
+
int e = (int)sizeof(float) * 8;
|
| 399 |
+
|
| 400 |
+
return cudaCreateChannelDesc(e, 0, 0, 0, cudaChannelFormatKindFloat);
|
| 401 |
+
}
|
| 402 |
+
|
| 403 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<float2>(void)
|
| 404 |
+
{
|
| 405 |
+
int e = (int)sizeof(float) * 8;
|
| 406 |
+
|
| 407 |
+
return cudaCreateChannelDesc(e, e, 0, 0, cudaChannelFormatKindFloat);
|
| 408 |
+
}
|
| 409 |
+
|
| 410 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<float4>(void)
|
| 411 |
+
{
|
| 412 |
+
int e = (int)sizeof(float) * 8;
|
| 413 |
+
|
| 414 |
+
return cudaCreateChannelDesc(e, e, e, e, cudaChannelFormatKindFloat);
|
| 415 |
+
}
|
| 416 |
+
|
| 417 |
+
static __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDescNV12(void)
|
| 418 |
+
{
|
| 419 |
+
int e = (int)sizeof(char) * 8;
|
| 420 |
+
|
| 421 |
+
return cudaCreateChannelDesc(e, e, e, 0, cudaChannelFormatKindNV12);
|
| 422 |
+
}
|
| 423 |
+
|
| 424 |
+
template<cudaChannelFormatKind> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc(void)
|
| 425 |
+
{
|
| 426 |
+
return cudaCreateChannelDesc(0, 0, 0, 0, cudaChannelFormatKindNone);
|
| 427 |
+
}
|
| 428 |
+
|
| 429 |
+
/* Signed 8-bit normalized integer formats */
|
| 430 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindSignedNormalized8X1>(void)
|
| 431 |
+
{
|
| 432 |
+
return cudaCreateChannelDesc(8, 0, 0, 0, cudaChannelFormatKindSignedNormalized8X1);
|
| 433 |
+
}
|
| 434 |
+
|
| 435 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindSignedNormalized8X2>(void)
|
| 436 |
+
{
|
| 437 |
+
return cudaCreateChannelDesc(8, 8, 0, 0, cudaChannelFormatKindSignedNormalized8X2);
|
| 438 |
+
}
|
| 439 |
+
|
| 440 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindSignedNormalized8X4>(void)
|
| 441 |
+
{
|
| 442 |
+
return cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindSignedNormalized8X4);
|
| 443 |
+
}
|
| 444 |
+
|
| 445 |
+
/* Unsigned 8-bit normalized integer formats */
|
| 446 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedNormalized8X1>(void)
|
| 447 |
+
{
|
| 448 |
+
return cudaCreateChannelDesc(8, 0, 0, 0, cudaChannelFormatKindUnsignedNormalized8X1);
|
| 449 |
+
}
|
| 450 |
+
|
| 451 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedNormalized8X2>(void)
|
| 452 |
+
{
|
| 453 |
+
return cudaCreateChannelDesc(8, 8, 0, 0, cudaChannelFormatKindUnsignedNormalized8X2);
|
| 454 |
+
}
|
| 455 |
+
|
| 456 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedNormalized8X4>(void)
|
| 457 |
+
{
|
| 458 |
+
return cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsignedNormalized8X4);
|
| 459 |
+
}
|
| 460 |
+
|
| 461 |
+
/* Signed 16-bit normalized integer formats */
|
| 462 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindSignedNormalized16X1>(void)
|
| 463 |
+
{
|
| 464 |
+
return cudaCreateChannelDesc(16, 0, 0, 0, cudaChannelFormatKindSignedNormalized16X1);
|
| 465 |
+
}
|
| 466 |
+
|
| 467 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindSignedNormalized16X2>(void)
|
| 468 |
+
{
|
| 469 |
+
return cudaCreateChannelDesc(16, 16, 0, 0, cudaChannelFormatKindSignedNormalized16X2);
|
| 470 |
+
}
|
| 471 |
+
|
| 472 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindSignedNormalized16X4>(void)
|
| 473 |
+
{
|
| 474 |
+
return cudaCreateChannelDesc(16, 16, 16, 16, cudaChannelFormatKindSignedNormalized16X4);
|
| 475 |
+
}
|
| 476 |
+
|
| 477 |
+
/* Unsigned 16-bit normalized integer formats */
|
| 478 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedNormalized16X1>(void)
|
| 479 |
+
{
|
| 480 |
+
return cudaCreateChannelDesc(16, 0, 0, 0, cudaChannelFormatKindUnsignedNormalized16X1);
|
| 481 |
+
}
|
| 482 |
+
|
| 483 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedNormalized16X2>(void)
|
| 484 |
+
{
|
| 485 |
+
return cudaCreateChannelDesc(16, 16, 0, 0, cudaChannelFormatKindUnsignedNormalized16X2);
|
| 486 |
+
}
|
| 487 |
+
|
| 488 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedNormalized16X4>(void)
|
| 489 |
+
{
|
| 490 |
+
return cudaCreateChannelDesc(16, 16, 16, 16, cudaChannelFormatKindUnsignedNormalized16X4);
|
| 491 |
+
}
|
| 492 |
+
|
| 493 |
+
/* NV12 format */
|
| 494 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindNV12>(void)
|
| 495 |
+
{
|
| 496 |
+
return cudaCreateChannelDesc(8, 8, 8, 0, cudaChannelFormatKindNV12);
|
| 497 |
+
}
|
| 498 |
+
|
| 499 |
+
/* BC1 format */
|
| 500 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedBlockCompressed1>(void)
|
| 501 |
+
{
|
| 502 |
+
return cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsignedBlockCompressed1);
|
| 503 |
+
}
|
| 504 |
+
|
| 505 |
+
/* BC1sRGB format */
|
| 506 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedBlockCompressed1SRGB>(void)
|
| 507 |
+
{
|
| 508 |
+
return cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsignedBlockCompressed1SRGB);
|
| 509 |
+
}
|
| 510 |
+
|
| 511 |
+
/* BC2 format */
|
| 512 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedBlockCompressed2>(void)
|
| 513 |
+
{
|
| 514 |
+
return cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsignedBlockCompressed2);
|
| 515 |
+
}
|
| 516 |
+
|
| 517 |
+
/* BC2sRGB format */
|
| 518 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedBlockCompressed2SRGB>(void)
|
| 519 |
+
{
|
| 520 |
+
return cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsignedBlockCompressed2SRGB);
|
| 521 |
+
}
|
| 522 |
+
|
| 523 |
+
/* BC3 format */
|
| 524 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedBlockCompressed3>(void)
|
| 525 |
+
{
|
| 526 |
+
return cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsignedBlockCompressed3);
|
| 527 |
+
}
|
| 528 |
+
|
| 529 |
+
/* BC3sRGB format */
|
| 530 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedBlockCompressed3SRGB>(void)
|
| 531 |
+
{
|
| 532 |
+
return cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsignedBlockCompressed3SRGB);
|
| 533 |
+
}
|
| 534 |
+
|
| 535 |
+
/* BC4 unsigned format */
|
| 536 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedBlockCompressed4>(void)
|
| 537 |
+
{
|
| 538 |
+
return cudaCreateChannelDesc(8, 0, 0, 0, cudaChannelFormatKindUnsignedBlockCompressed4);
|
| 539 |
+
}
|
| 540 |
+
|
| 541 |
+
/* BC4 signed format */
|
| 542 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindSignedBlockCompressed4>(void)
|
| 543 |
+
{
|
| 544 |
+
return cudaCreateChannelDesc(8, 0, 0, 0, cudaChannelFormatKindSignedBlockCompressed4);
|
| 545 |
+
}
|
| 546 |
+
|
| 547 |
+
/* BC5 unsigned format */
|
| 548 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedBlockCompressed5>(void)
|
| 549 |
+
{
|
| 550 |
+
return cudaCreateChannelDesc(8, 8, 0, 0, cudaChannelFormatKindUnsignedBlockCompressed5);
|
| 551 |
+
}
|
| 552 |
+
|
| 553 |
+
/* BC5 signed format */
|
| 554 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindSignedBlockCompressed5>(void)
|
| 555 |
+
{
|
| 556 |
+
return cudaCreateChannelDesc(8, 8, 0, 0, cudaChannelFormatKindSignedBlockCompressed5);
|
| 557 |
+
}
|
| 558 |
+
|
| 559 |
+
/* BC6H unsigned format */
|
| 560 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedBlockCompressed6H>(void)
|
| 561 |
+
{
|
| 562 |
+
return cudaCreateChannelDesc(16, 16, 16, 0, cudaChannelFormatKindUnsignedBlockCompressed6H);
|
| 563 |
+
}
|
| 564 |
+
|
| 565 |
+
/* BC6H signed format */
|
| 566 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindSignedBlockCompressed6H>(void)
|
| 567 |
+
{
|
| 568 |
+
return cudaCreateChannelDesc(16, 16, 16, 0, cudaChannelFormatKindSignedBlockCompressed6H);
|
| 569 |
+
}
|
| 570 |
+
|
| 571 |
+
/* BC7 format */
|
| 572 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedBlockCompressed7>(void)
|
| 573 |
+
{
|
| 574 |
+
return cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsignedBlockCompressed7);
|
| 575 |
+
}
|
| 576 |
+
|
| 577 |
+
/* BC7sRGB format */
|
| 578 |
+
template<> __inline__ __host__ cudaChannelFormatDesc cudaCreateChannelDesc<cudaChannelFormatKindUnsignedBlockCompressed7SRGB>(void)
|
| 579 |
+
{
|
| 580 |
+
return cudaCreateChannelDesc(8, 8, 8, 8, cudaChannelFormatKindUnsignedBlockCompressed7SRGB);
|
| 581 |
+
}
|
| 582 |
+
|
| 583 |
+
#endif /* __cplusplus */
|
| 584 |
+
|
| 585 |
+
/** @} */
|
| 586 |
+
/** @} */ /* END CUDART_TEXTURE_HL */
|
| 587 |
+
|
| 588 |
+
#endif /* !__CHANNEL_DESCRIPTOR_H__ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cooperative_groups/details/coalesced_reduce.h
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* Copyright 1993-2016 NVIDIA Corporation. All rights reserved.
|
| 2 |
+
*
|
| 3 |
+
* NOTICE TO LICENSEE:
|
| 4 |
+
*
|
| 5 |
+
* The source code and/or documentation ("Licensed Deliverables") are
|
| 6 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 7 |
+
* international Copyright laws.
|
| 8 |
+
*
|
| 9 |
+
* The Licensed Deliverables contained herein are PROPRIETARY and
|
| 10 |
+
* CONFIDENTIAL to NVIDIA and are being provided under the terms and
|
| 11 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 12 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 13 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 14 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 15 |
+
* of the Licensed Deliverables to any third party without the express
|
| 16 |
+
* written consent of NVIDIA is prohibited.
|
| 17 |
+
*
|
| 18 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 19 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 20 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. THEY ARE
|
| 21 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 22 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 23 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 24 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 25 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 26 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 27 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 28 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 29 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 30 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 31 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 32 |
+
*
|
| 33 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 34 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 35 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 36 |
+
* computer software documentation" as such terms are used in 48
|
| 37 |
+
* C.F.R. 12.212 (SEPT 1995) and are provided to the U.S. Government
|
| 38 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 39 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 40 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 41 |
+
* only those rights set forth herein.
|
| 42 |
+
*
|
| 43 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 44 |
+
* software must include, in the user documentation and internal
|
| 45 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 46 |
+
* Users Notice.
|
| 47 |
+
*/
|
| 48 |
+
|
| 49 |
+
#ifndef _CG_COALESCED_REDUCE_H_
|
| 50 |
+
#define _CG_COALESCED_REDUCE_H_
|
| 51 |
+
|
| 52 |
+
#include "info.h"
|
| 53 |
+
#include "helpers.h"
|
| 54 |
+
#include "cooperative_groups.h"
|
| 55 |
+
#include "partitioning.h"
|
| 56 |
+
#include "coalesced_scan.h"
|
| 57 |
+
|
| 58 |
+
_CG_BEGIN_NAMESPACE
|
| 59 |
+
|
| 60 |
+
namespace details {
|
| 61 |
+
|
| 62 |
+
template <typename TyVal, typename TyOp>
|
| 63 |
+
_CG_QUALIFIER auto coalesced_reduce_to_one(const coalesced_group& group, TyVal&& val, TyOp&& op) -> decltype(op(val, val)) {
|
| 64 |
+
if (group.size() == 32) {
|
| 65 |
+
auto out = val;
|
| 66 |
+
for (int offset = group.size() >> 1; offset > 0; offset >>= 1) {
|
| 67 |
+
out = op(out, group.shfl_up(out, offset));
|
| 68 |
+
}
|
| 69 |
+
return out;
|
| 70 |
+
}
|
| 71 |
+
else {
|
| 72 |
+
auto scan_result =
|
| 73 |
+
inclusive_scan_non_contiguous(group, _CG_STL_NAMESPACE::forward<TyVal>(val), _CG_STL_NAMESPACE::forward<TyOp>(op));
|
| 74 |
+
return scan_result;
|
| 75 |
+
}
|
| 76 |
+
}
|
| 77 |
+
|
| 78 |
+
template <typename TyVal, typename TyOp>
|
| 79 |
+
_CG_QUALIFIER auto coalesced_reduce(const coalesced_group& group, TyVal&& val, TyOp&& op) -> decltype(op(val, val)) {
|
| 80 |
+
auto out = coalesced_reduce_to_one(group, _CG_STL_NAMESPACE::forward<TyVal>(val), _CG_STL_NAMESPACE::forward<TyOp>(op));
|
| 81 |
+
if (group.size() == 32) {
|
| 82 |
+
return group.shfl(out, 31);
|
| 83 |
+
}
|
| 84 |
+
else {
|
| 85 |
+
unsigned int group_mask = _coalesced_group_data_access::get_mask(group);
|
| 86 |
+
unsigned int last_thread_id = 31 - __clz(group_mask);
|
| 87 |
+
return details::tile::shuffle_dispatch<TyVal>::shfl(
|
| 88 |
+
_CG_STL_NAMESPACE::forward<TyVal>(out), group_mask, last_thread_id, 32);
|
| 89 |
+
}
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
template <typename TyVal, typename TyOp, unsigned int TySize, typename ParentT>
|
| 93 |
+
_CG_QUALIFIER auto coalesced_reduce(const __single_warp_thread_block_tile<TySize, ParentT>& group,
|
| 94 |
+
TyVal&& val,
|
| 95 |
+
TyOp&& op) -> decltype(op(val, val)) {
|
| 96 |
+
auto out = val;
|
| 97 |
+
for (int mask = TySize >> 1; mask > 0; mask >>= 1) {
|
| 98 |
+
out = op(out, group.shfl_xor(out, mask));
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
return out;
|
| 102 |
+
}
|
| 103 |
+
|
| 104 |
+
} // details
|
| 105 |
+
|
| 106 |
+
_CG_END_NAMESPACE
|
| 107 |
+
|
| 108 |
+
#endif // _CG_COALESCED_REDUCE_H_
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cooperative_groups/details/scan.h
ADDED
|
@@ -0,0 +1,320 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* Copyright 1993-2016 NVIDIA Corporation. All rights reserved.
|
| 2 |
+
*
|
| 3 |
+
* NOTICE TO LICENSEE:
|
| 4 |
+
*
|
| 5 |
+
* The source code and/or documentation ("Licensed Deliverables") are
|
| 6 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 7 |
+
* international Copyright laws.
|
| 8 |
+
*
|
| 9 |
+
* The Licensed Deliverables contained herein are PROPRIETARY and
|
| 10 |
+
* CONFIDENTIAL to NVIDIA and are being provided under the terms and
|
| 11 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 12 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 13 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 14 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 15 |
+
* of the Licensed Deliverables to any third party without the express
|
| 16 |
+
* written consent of NVIDIA is prohibited.
|
| 17 |
+
*
|
| 18 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 19 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 20 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. THEY ARE
|
| 21 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 22 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 23 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 24 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 25 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 26 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 27 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 28 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 29 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 30 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 31 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 32 |
+
*
|
| 33 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 34 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 35 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 36 |
+
* computer software documentation" as such terms are used in 48
|
| 37 |
+
* C.F.R. 12.212 (SEPT 1995) and are provided to the U.S. Government
|
| 38 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 39 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 40 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 41 |
+
* only those rights set forth herein.
|
| 42 |
+
*
|
| 43 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 44 |
+
* software must include, in the user documentation and internal
|
| 45 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 46 |
+
* Users Notice.
|
| 47 |
+
*/
|
| 48 |
+
|
| 49 |
+
#ifndef _CG_SCAN_H_
|
| 50 |
+
#define _CG_SCAN_H_
|
| 51 |
+
|
| 52 |
+
#include "info.h"
|
| 53 |
+
#include "helpers.h"
|
| 54 |
+
#include "functional.h"
|
| 55 |
+
#include "coalesced_scan.h"
|
| 56 |
+
|
| 57 |
+
_CG_BEGIN_NAMESPACE
|
| 58 |
+
|
| 59 |
+
namespace details {
|
| 60 |
+
|
| 61 |
+
// Group support for scan.
|
| 62 |
+
template <class TyGroup> struct _scan_group_supported : public _CG_STL_NAMESPACE::false_type {};
|
| 63 |
+
|
| 64 |
+
template <unsigned int Sz, typename TyPar>
|
| 65 |
+
struct _scan_group_supported<cooperative_groups::thread_block_tile<Sz, TyPar>> : public _CG_STL_NAMESPACE::true_type {};
|
| 66 |
+
template <unsigned int Sz, typename TyPar>
|
| 67 |
+
struct _scan_group_supported<internal_thread_block_tile<Sz, TyPar>> : public _CG_STL_NAMESPACE::true_type {};
|
| 68 |
+
template <>
|
| 69 |
+
struct _scan_group_supported<cooperative_groups::coalesced_group> : public _CG_STL_NAMESPACE::true_type {};
|
| 70 |
+
|
| 71 |
+
template <typename TyGroup>
|
| 72 |
+
using scan_group_supported = _scan_group_supported<details::remove_qual<TyGroup>>;
|
| 73 |
+
|
| 74 |
+
template <bool IsIntegralPlus>
|
| 75 |
+
struct integral_optimized_scan;
|
| 76 |
+
|
| 77 |
+
enum class ScanType { exclusive, inclusive };
|
| 78 |
+
|
| 79 |
+
template <unsigned int GroupId, ScanType TyScan>
|
| 80 |
+
struct scan_dispatch;
|
| 81 |
+
|
| 82 |
+
template <ScanType TyScan>
|
| 83 |
+
struct scan_dispatch<details::coalesced_group_id, TyScan> {
|
| 84 |
+
template <typename TyGroup, typename TyVal, typename TyFn>
|
| 85 |
+
_CG_STATIC_QUALIFIER auto scan(const TyGroup& group, TyVal&& val, TyFn&& op) -> decltype(op(val, val)) {
|
| 86 |
+
auto scan_result = coalesced_inclusive_scan(group, val, op);
|
| 87 |
+
if (TyScan == ScanType::exclusive) {
|
| 88 |
+
scan_result = convert_inclusive_to_exclusive(group,
|
| 89 |
+
scan_result,
|
| 90 |
+
_CG_STL_NAMESPACE::forward<TyVal>(val),
|
| 91 |
+
_CG_STL_NAMESPACE::forward<TyFn>(op));
|
| 92 |
+
}
|
| 93 |
+
return scan_result;
|
| 94 |
+
}
|
| 95 |
+
};
|
| 96 |
+
|
| 97 |
+
#if defined(_CG_CPP11_FEATURES)
|
| 98 |
+
template <ScanType TyScan>
|
| 99 |
+
struct scan_dispatch<details::multi_tile_group_id, TyScan> {
|
| 100 |
+
template <unsigned int Size, typename ParentT, typename TyVal, typename TyFn>
|
| 101 |
+
_CG_STATIC_QUALIFIER auto scan(const thread_block_tile<Size, ParentT>& group, TyVal&& val, TyFn&& op) -> decltype(op(val, val)) {
|
| 102 |
+
using warpType = details::internal_thread_block_tile<32, __static_size_multi_warp_tile_base<Size>>;
|
| 103 |
+
using TyRet = details::remove_qual<TyVal>;
|
| 104 |
+
const unsigned int num_warps = Size / 32;
|
| 105 |
+
// In warp scan result, calculated in warp_lambda
|
| 106 |
+
TyRet warp_scan;
|
| 107 |
+
|
| 108 |
+
// In warp scan, put sum in the warp_scratch_location
|
| 109 |
+
auto warp_lambda = [&] (const warpType& warp, TyRet* warp_scratch_location) {
|
| 110 |
+
warp_scan =
|
| 111 |
+
details::coalesced_inclusive_scan(warp, _CG_STL_NAMESPACE::forward<TyVal>(val), op);
|
| 112 |
+
if (warp.thread_rank() + 1 == warp.size()) {
|
| 113 |
+
*warp_scratch_location = warp_scan;
|
| 114 |
+
}
|
| 115 |
+
if (TyScan == ScanType::exclusive) {
|
| 116 |
+
warp_scan = warp.shfl_up(warp_scan, 1);
|
| 117 |
+
}
|
| 118 |
+
};
|
| 119 |
+
|
| 120 |
+
// Tile of size num_warps performing the final scan part (exclusive scan of warp sums), other threads will add it
|
| 121 |
+
// to its in-warp scan result
|
| 122 |
+
auto inter_warp_lambda =
|
| 123 |
+
[&] (const details::internal_thread_block_tile<num_warps, warpType>& subwarp, TyRet* thread_scratch_location) {
|
| 124 |
+
auto thread_val = *thread_scratch_location;
|
| 125 |
+
auto result = coalesced_inclusive_scan(subwarp, thread_val, op);
|
| 126 |
+
*thread_scratch_location = convert_inclusive_to_exclusive(subwarp, result, thread_val, op);
|
| 127 |
+
};
|
| 128 |
+
|
| 129 |
+
TyRet previous_warps_sum = details::multi_warp_collectives_helper<TyRet>(group, warp_lambda, inter_warp_lambda);
|
| 130 |
+
if (TyScan == ScanType::exclusive && warpType::thread_rank() == 0) {
|
| 131 |
+
return previous_warps_sum;
|
| 132 |
+
}
|
| 133 |
+
if (warpType::meta_group_rank() == 0) {
|
| 134 |
+
return warp_scan;
|
| 135 |
+
}
|
| 136 |
+
else {
|
| 137 |
+
return op(warp_scan, previous_warps_sum);
|
| 138 |
+
}
|
| 139 |
+
}
|
| 140 |
+
};
|
| 141 |
+
|
| 142 |
+
#if defined(_CG_HAS_STL_ATOMICS)
|
| 143 |
+
template <unsigned int GroupId, ScanType TyScan>
|
| 144 |
+
struct scan_update_dispatch;
|
| 145 |
+
|
| 146 |
+
template <ScanType TyScan>
|
| 147 |
+
struct scan_update_dispatch<details::coalesced_group_id, TyScan> {
|
| 148 |
+
template <typename TyGroup, typename TyAtomic, typename TyVal, typename TyFn>
|
| 149 |
+
_CG_STATIC_QUALIFIER auto scan(const TyGroup& group, TyAtomic& dst, TyVal&& val, TyFn&& op) -> decltype(op(val, val)) {
|
| 150 |
+
details::remove_qual<TyVal> old;
|
| 151 |
+
|
| 152 |
+
// Do regular in group scan
|
| 153 |
+
auto scan_result = details::coalesced_inclusive_scan(group, val, op);
|
| 154 |
+
|
| 155 |
+
// Last thread updates the atomic and distributes its old value to other threads
|
| 156 |
+
if (group.thread_rank() == group.size() - 1) {
|
| 157 |
+
old = atomic_update(dst, scan_result, _CG_STL_NAMESPACE::forward<TyFn>(op));
|
| 158 |
+
}
|
| 159 |
+
old = group.shfl(old, group.size() - 1);
|
| 160 |
+
if (TyScan == ScanType::exclusive) {
|
| 161 |
+
scan_result = convert_inclusive_to_exclusive(group, scan_result, _CG_STL_NAMESPACE::forward<TyVal>(val), op);
|
| 162 |
+
}
|
| 163 |
+
scan_result = op(old, scan_result);
|
| 164 |
+
return scan_result;
|
| 165 |
+
}
|
| 166 |
+
};
|
| 167 |
+
|
| 168 |
+
template <ScanType TyScan>
|
| 169 |
+
struct scan_update_dispatch<details::multi_tile_group_id, TyScan> {
|
| 170 |
+
template <unsigned int Size, typename ParentT, typename TyAtomic, typename TyVal, typename TyFn>
|
| 171 |
+
_CG_STATIC_QUALIFIER auto scan(const thread_block_tile<Size, ParentT>& group, TyAtomic& dst, TyVal&& val, TyFn&& op) -> decltype(op(val, val)) {
|
| 172 |
+
using warpType = details::internal_thread_block_tile<32, __static_size_multi_warp_tile_base<Size>>;
|
| 173 |
+
using TyRet = details::remove_qual<TyVal>;
|
| 174 |
+
const unsigned int num_warps = Size / 32;
|
| 175 |
+
// In warp scan result, calculated in warp_lambda
|
| 176 |
+
TyRet warp_scan;
|
| 177 |
+
|
| 178 |
+
// In warp scan, put sum in the warp_scratch_location
|
| 179 |
+
auto warp_lambda = [&] (const warpType& warp, TyRet* warp_scratch_location) {
|
| 180 |
+
warp_scan =
|
| 181 |
+
details::coalesced_inclusive_scan(warp, _CG_STL_NAMESPACE::forward<TyVal>(val), op);
|
| 182 |
+
if (warp.thread_rank() + 1 == warp.size()) {
|
| 183 |
+
*warp_scratch_location = warp_scan;
|
| 184 |
+
}
|
| 185 |
+
if (TyScan == ScanType::exclusive) {
|
| 186 |
+
warp_scan = warp.shfl_up(warp_scan, 1);
|
| 187 |
+
}
|
| 188 |
+
};
|
| 189 |
+
|
| 190 |
+
// Tile of size num_warps performing the final scan part (exclusive scan of warp sums), other threads will add it
|
| 191 |
+
// to its in-warp scan result
|
| 192 |
+
auto inter_warp_lambda =
|
| 193 |
+
[&] (const details::internal_thread_block_tile<num_warps, warpType>& subwarp, TyRet* thread_scratch_location) {
|
| 194 |
+
auto thread_val = *thread_scratch_location;
|
| 195 |
+
auto scan_result = details::coalesced_inclusive_scan(subwarp, thread_val, op);
|
| 196 |
+
TyRet offset;
|
| 197 |
+
// Single thread does the atomic update with sum of all contributions and reads the old value.
|
| 198 |
+
if (subwarp.thread_rank() == subwarp.size() - 1) {
|
| 199 |
+
offset = details::atomic_update(dst, scan_result, op);
|
| 200 |
+
}
|
| 201 |
+
offset = subwarp.shfl(offset, subwarp.size() - 1);
|
| 202 |
+
scan_result = convert_inclusive_to_exclusive(subwarp, scan_result, thread_val, op);
|
| 203 |
+
// Add offset read from the atomic to the scanned warp sum.
|
| 204 |
+
// Skipping first thread, since it got defautly constructed value from the conversion,
|
| 205 |
+
// it should just return the offset received from the thread that did the atomic update.
|
| 206 |
+
if (subwarp.thread_rank() != 0) {
|
| 207 |
+
offset = op(scan_result, offset);
|
| 208 |
+
}
|
| 209 |
+
*thread_scratch_location = offset;
|
| 210 |
+
};
|
| 211 |
+
|
| 212 |
+
TyRet previous_warps_sum = details::multi_warp_collectives_helper<TyRet>(group, warp_lambda, inter_warp_lambda);
|
| 213 |
+
if (TyScan == ScanType::exclusive && warpType::thread_rank() == 0) {
|
| 214 |
+
return previous_warps_sum;
|
| 215 |
+
}
|
| 216 |
+
return op(warp_scan, previous_warps_sum);
|
| 217 |
+
}
|
| 218 |
+
};
|
| 219 |
+
#endif
|
| 220 |
+
#endif
|
| 221 |
+
|
| 222 |
+
template <typename TyGroup, typename TyInputVal, typename TyRetVal>
|
| 223 |
+
_CG_QUALIFIER void check_scan_params() {
|
| 224 |
+
static_assert(details::is_op_type_same<TyInputVal, TyRetVal>::value, "Operator input and output types differ");
|
| 225 |
+
static_assert(details::scan_group_supported<TyGroup>::value, "This group does not exclusively represent a tile");
|
| 226 |
+
}
|
| 227 |
+
|
| 228 |
+
#if defined(_CG_HAS_STL_ATOMICS)
|
| 229 |
+
template <typename TyGroup, typename TyDstVal, typename TyInputVal, typename TyRetVal>
|
| 230 |
+
_CG_QUALIFIER void check_scan_update_params() {
|
| 231 |
+
check_scan_params<TyGroup, TyInputVal, TyRetVal>();
|
| 232 |
+
static_assert(details::is_op_type_same<TyDstVal, TyInputVal>::value, "Destination and input types differ");
|
| 233 |
+
}
|
| 234 |
+
#endif
|
| 235 |
+
|
| 236 |
+
} // details
|
| 237 |
+
|
| 238 |
+
template <typename TyGroup, typename TyVal, typename TyFn>
|
| 239 |
+
_CG_QUALIFIER auto inclusive_scan(const TyGroup& group, TyVal&& val, TyFn&& op) -> decltype(op(val, val)) {
|
| 240 |
+
details::check_scan_params<TyGroup, TyVal, decltype(op(val, val))>();
|
| 241 |
+
|
| 242 |
+
using dispatch = details::scan_dispatch<TyGroup::_group_id, details::ScanType::inclusive>;
|
| 243 |
+
return dispatch::scan(group, _CG_STL_NAMESPACE::forward<TyVal>(val), _CG_STL_NAMESPACE::forward<TyFn>(op));
|
| 244 |
+
}
|
| 245 |
+
|
| 246 |
+
template <typename TyGroup, typename TyVal>
|
| 247 |
+
_CG_QUALIFIER details::remove_qual<TyVal> inclusive_scan(const TyGroup& group, TyVal&& val) {
|
| 248 |
+
return inclusive_scan(group, _CG_STL_NAMESPACE::forward<TyVal>(val), cooperative_groups::plus<details::remove_qual<TyVal>>());
|
| 249 |
+
}
|
| 250 |
+
|
| 251 |
+
template <typename TyGroup, typename TyVal, typename TyFn>
|
| 252 |
+
_CG_QUALIFIER auto exclusive_scan(const TyGroup& group, TyVal&& val, TyFn&& op) -> decltype(op(val, val)) {
|
| 253 |
+
details::check_scan_params<TyGroup, TyVal, decltype(op(val, val))>();
|
| 254 |
+
|
| 255 |
+
using dispatch = details::scan_dispatch<TyGroup::_group_id, details::ScanType::exclusive>;
|
| 256 |
+
return dispatch::scan(group, _CG_STL_NAMESPACE::forward<TyVal>(val), _CG_STL_NAMESPACE::forward<TyFn>(op));
|
| 257 |
+
}
|
| 258 |
+
|
| 259 |
+
template <typename TyGroup, typename TyVal>
|
| 260 |
+
_CG_QUALIFIER details::remove_qual<TyVal> exclusive_scan(const TyGroup& group, TyVal&& val) {
|
| 261 |
+
return exclusive_scan(group, _CG_STL_NAMESPACE::forward<TyVal>(val), cooperative_groups::plus<details::remove_qual<TyVal>>());
|
| 262 |
+
}
|
| 263 |
+
|
| 264 |
+
#if defined(_CG_HAS_STL_ATOMICS)
|
| 265 |
+
template<typename TyGroup, typename TyVal, typename TyInputVal, cuda::thread_scope Sco, typename TyFn>
|
| 266 |
+
_CG_QUALIFIER auto inclusive_scan_update(const TyGroup& group, cuda::atomic<TyVal, Sco>& dst, TyInputVal&& val, TyFn&& op) -> decltype(op(val, val)) {
|
| 267 |
+
details::check_scan_update_params<TyGroup, TyVal, details::remove_qual<TyInputVal>, decltype(op(val, val))>();
|
| 268 |
+
|
| 269 |
+
using dispatch = details::scan_update_dispatch<TyGroup::_group_id, details::ScanType::inclusive>;
|
| 270 |
+
return dispatch::scan(group, dst, _CG_STL_NAMESPACE::forward<TyInputVal>(val), _CG_STL_NAMESPACE::forward<TyFn>(op));
|
| 271 |
+
}
|
| 272 |
+
|
| 273 |
+
template<typename TyGroup, typename TyVal, typename TyInputVal, cuda::thread_scope Sco>
|
| 274 |
+
_CG_QUALIFIER TyVal inclusive_scan_update(const TyGroup& group, cuda::atomic<TyVal, Sco> & dst, TyInputVal&& val) {
|
| 275 |
+
return inclusive_scan_update(group, dst, _CG_STL_NAMESPACE::forward<TyInputVal>(val), cooperative_groups::plus<TyVal>());
|
| 276 |
+
}
|
| 277 |
+
|
| 278 |
+
template<typename TyGroup, typename TyVal, typename TyInputVal, cuda::thread_scope Sco, typename TyFn>
|
| 279 |
+
_CG_QUALIFIER auto exclusive_scan_update(const TyGroup& group, cuda::atomic<TyVal, Sco>& dst, TyInputVal&& val, TyFn&& op) -> decltype(op(val, val)) {
|
| 280 |
+
details::check_scan_update_params<TyGroup, TyVal, details::remove_qual<TyInputVal>, decltype(op(val, val))>();
|
| 281 |
+
|
| 282 |
+
using dispatch = details::scan_update_dispatch<TyGroup::_group_id, details::ScanType::exclusive>;
|
| 283 |
+
return dispatch::scan(group, dst, _CG_STL_NAMESPACE::forward<TyInputVal>(val), _CG_STL_NAMESPACE::forward<TyFn>(op));
|
| 284 |
+
}
|
| 285 |
+
|
| 286 |
+
template<typename TyGroup, typename TyVal, typename TyInputVal, cuda::thread_scope Sco>
|
| 287 |
+
_CG_QUALIFIER TyVal exclusive_scan_update(const TyGroup& group, cuda::atomic<TyVal, Sco>& dst, TyInputVal&& val) {
|
| 288 |
+
return exclusive_scan_update(group, dst, _CG_STL_NAMESPACE::forward<TyInputVal>(val), cooperative_groups::plus<TyVal>());
|
| 289 |
+
}
|
| 290 |
+
|
| 291 |
+
template<typename TyGroup, typename TyVal, typename TyInputVal, cuda::thread_scope Sco, typename TyFn>
|
| 292 |
+
_CG_QUALIFIER auto inclusive_scan_update(const TyGroup& group, const cuda::atomic_ref<TyVal, Sco>& dst, TyInputVal&& val, TyFn&& op) -> decltype(op(val, val)) {
|
| 293 |
+
details::check_scan_update_params<TyGroup, TyVal, details::remove_qual<TyInputVal>, decltype(op(val, val))>();
|
| 294 |
+
|
| 295 |
+
using dispatch = details::scan_update_dispatch<TyGroup::_group_id, details::ScanType::inclusive>;
|
| 296 |
+
return dispatch::scan(group, dst, _CG_STL_NAMESPACE::forward<TyInputVal>(val), _CG_STL_NAMESPACE::forward<TyFn>(op));
|
| 297 |
+
}
|
| 298 |
+
|
| 299 |
+
template<typename TyGroup, typename TyVal, typename TyInputVal, cuda::thread_scope Sco>
|
| 300 |
+
_CG_QUALIFIER TyVal inclusive_scan_update(const TyGroup& group, const cuda::atomic_ref<TyVal, Sco> & dst, TyInputVal&& val) {
|
| 301 |
+
return inclusive_scan_update(group, dst, _CG_STL_NAMESPACE::forward<TyInputVal>(val), cooperative_groups::plus<TyVal>());
|
| 302 |
+
}
|
| 303 |
+
|
| 304 |
+
template<typename TyGroup, typename TyVal, typename TyInputVal, cuda::thread_scope Sco, typename TyFn>
|
| 305 |
+
_CG_QUALIFIER auto exclusive_scan_update(const TyGroup& group, const cuda::atomic_ref<TyVal, Sco>& dst, TyInputVal&& val, TyFn&& op) -> decltype(op(val, val)) {
|
| 306 |
+
details::check_scan_update_params<TyGroup, TyVal, details::remove_qual<TyInputVal>, decltype(op(val, val))>();
|
| 307 |
+
|
| 308 |
+
using dispatch = details::scan_update_dispatch<TyGroup::_group_id, details::ScanType::exclusive>;
|
| 309 |
+
return dispatch::scan(group, dst, _CG_STL_NAMESPACE::forward<TyInputVal>(val), _CG_STL_NAMESPACE::forward<TyFn>(op));
|
| 310 |
+
}
|
| 311 |
+
|
| 312 |
+
template<typename TyGroup, typename TyVal, typename TyInputVal, cuda::thread_scope Sco>
|
| 313 |
+
_CG_QUALIFIER TyVal exclusive_scan_update(const TyGroup& group, const cuda::atomic_ref<TyVal, Sco>& dst, TyInputVal&& val) {
|
| 314 |
+
return exclusive_scan_update(group, dst, _CG_STL_NAMESPACE::forward<TyInputVal>(val), cooperative_groups::plus<TyVal>());
|
| 315 |
+
}
|
| 316 |
+
#endif
|
| 317 |
+
|
| 318 |
+
_CG_END_NAMESPACE
|
| 319 |
+
|
| 320 |
+
#endif // _CG_SCAN_H_
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cudaEGLTypedefs.h
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2020-2021 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#ifndef CUDAEGLTYPEDEFS_H
|
| 51 |
+
#define CUDAEGLTYPEDEFS_H
|
| 52 |
+
|
| 53 |
+
#include <cudaEGL.h>
|
| 54 |
+
|
| 55 |
+
#ifdef __cplusplus
|
| 56 |
+
extern "C" {
|
| 57 |
+
#endif // __cplusplus
|
| 58 |
+
|
| 59 |
+
/*
|
| 60 |
+
* Macros for the latest version for each driver function in cudaEGL.h
|
| 61 |
+
*/
|
| 62 |
+
#define PFN_cuGraphicsEGLRegisterImage PFN_cuGraphicsEGLRegisterImage_v7000
|
| 63 |
+
#define PFN_cuEGLStreamConsumerConnect PFN_cuEGLStreamConsumerConnect_v7000
|
| 64 |
+
#define PFN_cuEGLStreamConsumerConnectWithFlags PFN_cuEGLStreamConsumerConnectWithFlags_v8000
|
| 65 |
+
#define PFN_cuEGLStreamConsumerDisconnect PFN_cuEGLStreamConsumerDisconnect_v7000
|
| 66 |
+
#define PFN_cuEGLStreamConsumerAcquireFrame PFN_cuEGLStreamConsumerAcquireFrame_v7000
|
| 67 |
+
#define PFN_cuEGLStreamConsumerReleaseFrame PFN_cuEGLStreamConsumerReleaseFrame_v7000
|
| 68 |
+
#define PFN_cuEGLStreamProducerConnect PFN_cuEGLStreamProducerConnect_v7000
|
| 69 |
+
#define PFN_cuEGLStreamProducerDisconnect PFN_cuEGLStreamProducerDisconnect_v7000
|
| 70 |
+
#define PFN_cuEGLStreamProducerPresentFrame PFN_cuEGLStreamProducerPresentFrame_v7000
|
| 71 |
+
#define PFN_cuEGLStreamProducerReturnFrame PFN_cuEGLStreamProducerReturnFrame_v7000
|
| 72 |
+
#define PFN_cuGraphicsResourceGetMappedEglFrame PFN_cuGraphicsResourceGetMappedEglFrame_v7000
|
| 73 |
+
#define PFN_cuEventCreateFromEGLSync PFN_cuEventCreateFromEGLSync_v9000
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
/**
|
| 77 |
+
* Type definitions for functions defined in cudaEGL.h
|
| 78 |
+
*/
|
| 79 |
+
typedef CUresult (CUDAAPI *PFN_cuGraphicsEGLRegisterImage_v7000)(CUgraphicsResource CUDAAPI *pCudaResource, EGLImageKHR image, unsigned int flags);
|
| 80 |
+
typedef CUresult (CUDAAPI *PFN_cuEGLStreamConsumerConnect_v7000)(CUeglStreamConnection CUDAAPI *conn, EGLStreamKHR stream);
|
| 81 |
+
typedef CUresult (CUDAAPI *PFN_cuEGLStreamConsumerConnectWithFlags_v8000)(CUeglStreamConnection CUDAAPI *conn, EGLStreamKHR stream, unsigned int flags);
|
| 82 |
+
typedef CUresult (CUDAAPI *PFN_cuEGLStreamConsumerDisconnect_v7000)(CUeglStreamConnection CUDAAPI *conn);
|
| 83 |
+
typedef CUresult (CUDAAPI *PFN_cuEGLStreamConsumerAcquireFrame_v7000)(CUeglStreamConnection CUDAAPI *conn, CUgraphicsResource CUDAAPI *pCudaResource, CUstream CUDAAPI *pStream, unsigned int timeout);
|
| 84 |
+
typedef CUresult (CUDAAPI *PFN_cuEGLStreamConsumerReleaseFrame_v7000)(CUeglStreamConnection CUDAAPI *conn, CUgraphicsResource pCudaResource, CUstream CUDAAPI *pStream);
|
| 85 |
+
typedef CUresult (CUDAAPI *PFN_cuEGLStreamProducerConnect_v7000)(CUeglStreamConnection CUDAAPI *conn, EGLStreamKHR stream, EGLint width, EGLint height);
|
| 86 |
+
typedef CUresult (CUDAAPI *PFN_cuEGLStreamProducerDisconnect_v7000)(CUeglStreamConnection CUDAAPI *conn);
|
| 87 |
+
typedef CUresult (CUDAAPI *PFN_cuEGLStreamProducerPresentFrame_v7000)(CUeglStreamConnection CUDAAPI *conn, CUeglFrame_v1 eglframe, CUstream CUDAAPI *pStream);
|
| 88 |
+
typedef CUresult (CUDAAPI *PFN_cuEGLStreamProducerReturnFrame_v7000)(CUeglStreamConnection CUDAAPI *conn, CUeglFrame_v1 CUDAAPI *eglframe, CUstream CUDAAPI *pStream);
|
| 89 |
+
typedef CUresult (CUDAAPI *PFN_cuGraphicsResourceGetMappedEglFrame_v7000)(CUeglFrame_v1 CUDAAPI *eglFrame, CUgraphicsResource resource, unsigned int index, unsigned int mipLevel);
|
| 90 |
+
typedef CUresult (CUDAAPI *PFN_cuEventCreateFromEGLSync_v9000)(CUevent CUDAAPI *phEvent, EGLSyncKHR eglSync, unsigned int flags);
|
| 91 |
+
|
| 92 |
+
#ifdef __cplusplus
|
| 93 |
+
}
|
| 94 |
+
#endif // __cplusplus
|
| 95 |
+
|
| 96 |
+
#endif // file guard
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cudaGLTypedefs.h
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2020-2021 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#ifndef CUDAGLTYPEDEFS_H
|
| 51 |
+
#define CUDAGLTYPEDEFS_H
|
| 52 |
+
|
| 53 |
+
// Dependent includes for cudagl.h
|
| 54 |
+
#include <GL/gl.h>
|
| 55 |
+
|
| 56 |
+
#include <cudaGL.h>
|
| 57 |
+
|
| 58 |
+
#if defined(CUDA_API_PER_THREAD_DEFAULT_STREAM)
|
| 59 |
+
#define __API_TYPEDEF_PTDS(api, default_version, ptds_version) api ## _v ## ptds_version ## _ptds
|
| 60 |
+
#define __API_TYPEDEF_PTSZ(api, default_version, ptds_version) api ## _v ## ptds_version ## _ptsz
|
| 61 |
+
#else
|
| 62 |
+
#define __API_TYPEDEF_PTDS(api, default_version, ptds_version) api ## _v ## default_version
|
| 63 |
+
#define __API_TYPEDEF_PTSZ(api, default_version, ptds_version) api ## _v ## default_version
|
| 64 |
+
#endif
|
| 65 |
+
|
| 66 |
+
#ifdef __cplusplus
|
| 67 |
+
extern "C" {
|
| 68 |
+
#endif // __cplusplus
|
| 69 |
+
|
| 70 |
+
/*
|
| 71 |
+
* Macros for the latest version for each driver function in cudaGL.h
|
| 72 |
+
*/
|
| 73 |
+
#define PFN_cuGraphicsGLRegisterBuffer PFN_cuGraphicsGLRegisterBuffer_v3000
|
| 74 |
+
#define PFN_cuGraphicsGLRegisterImage PFN_cuGraphicsGLRegisterImage_v3000
|
| 75 |
+
#define PFN_cuWGLGetDevice PFN_cuWGLGetDevice_v2020
|
| 76 |
+
#define PFN_cuGLGetDevices PFN_cuGLGetDevices_v6050
|
| 77 |
+
#define PFN_cuGLCtxCreate PFN_cuGLCtxCreate_v3020
|
| 78 |
+
#define PFN_cuGLInit PFN_cuGLInit_v2000
|
| 79 |
+
#define PFN_cuGLRegisterBufferObject PFN_cuGLRegisterBufferObject_v2000
|
| 80 |
+
#define PFN_cuGLMapBufferObject __API_TYPEDEF_PTDS(PFN_cuGLMapBufferObject, 3020, 7000)
|
| 81 |
+
#define PFN_cuGLUnmapBufferObject PFN_cuGLUnmapBufferObject_v2000
|
| 82 |
+
#define PFN_cuGLUnregisterBufferObject PFN_cuGLUnregisterBufferObject_v2000
|
| 83 |
+
#define PFN_cuGLSetBufferObjectMapFlags PFN_cuGLSetBufferObjectMapFlags_v2030
|
| 84 |
+
#define PFN_cuGLMapBufferObjectAsync __API_TYPEDEF_PTSZ(PFN_cuGLMapBufferObjectAsync, 3020, 7000)
|
| 85 |
+
#define PFN_cuGLUnmapBufferObjectAsync PFN_cuGLUnmapBufferObjectAsync_v2030
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
/**
|
| 89 |
+
* Type definitions for functions defined in cudaGL.h
|
| 90 |
+
*/
|
| 91 |
+
typedef CUresult (CUDAAPI *PFN_cuGraphicsGLRegisterBuffer_v3000)(CUgraphicsResource *pCudaResource, GLuint buffer, unsigned int Flags);
|
| 92 |
+
typedef CUresult (CUDAAPI *PFN_cuGraphicsGLRegisterImage_v3000)(CUgraphicsResource *pCudaResource, GLuint image, GLenum target, unsigned int Flags);
|
| 93 |
+
#ifdef _WIN32
|
| 94 |
+
typedef CUresult (CUDAAPI *PFN_cuWGLGetDevice_v2020)(CUdevice_v1 *pDevice, HGPUNV hGpu);
|
| 95 |
+
#endif
|
| 96 |
+
typedef CUresult (CUDAAPI *PFN_cuGLGetDevices_v6050)(unsigned int *pCudaDeviceCount, CUdevice_v1 *pCudaDevices, unsigned int cudaDeviceCount, CUGLDeviceList deviceList);
|
| 97 |
+
typedef CUresult (CUDAAPI *PFN_cuGLCtxCreate_v3020)(CUcontext *pCtx, unsigned int Flags, CUdevice_v1 device);
|
| 98 |
+
typedef CUresult (CUDAAPI *PFN_cuGLInit_v2000)(void);
|
| 99 |
+
typedef CUresult (CUDAAPI *PFN_cuGLRegisterBufferObject_v2000)(GLuint buffer);
|
| 100 |
+
typedef CUresult (CUDAAPI *PFN_cuGLMapBufferObject_v7000_ptds)(CUdeviceptr_v2 *dptr, size_t *size, GLuint buffer);
|
| 101 |
+
typedef CUresult (CUDAAPI *PFN_cuGLUnmapBufferObject_v2000)(GLuint buffer);
|
| 102 |
+
typedef CUresult (CUDAAPI *PFN_cuGLUnregisterBufferObject_v2000)(GLuint buffer);
|
| 103 |
+
typedef CUresult (CUDAAPI *PFN_cuGLSetBufferObjectMapFlags_v2030)(GLuint buffer, unsigned int Flags);
|
| 104 |
+
typedef CUresult (CUDAAPI *PFN_cuGLMapBufferObjectAsync_v7000_ptsz)(CUdeviceptr_v2 *dptr, size_t *size, GLuint buffer, CUstream hStream);
|
| 105 |
+
typedef CUresult (CUDAAPI *PFN_cuGLUnmapBufferObjectAsync_v2030)(GLuint buffer, CUstream hStream);
|
| 106 |
+
typedef CUresult (CUDAAPI *PFN_cuGLMapBufferObject_v3020)(CUdeviceptr_v2 *dptr, size_t *size, GLuint buffer);
|
| 107 |
+
typedef CUresult (CUDAAPI *PFN_cuGLMapBufferObjectAsync_v3020)(CUdeviceptr_v2 *dptr, size_t *size, GLuint buffer, CUstream hStream);
|
| 108 |
+
|
| 109 |
+
/*
|
| 110 |
+
* Type definitions for older versioned functions in cuda.h
|
| 111 |
+
*/
|
| 112 |
+
#if defined(__CUDA_API_VERSION_INTERNAL)
|
| 113 |
+
typedef CUresult (CUDAAPI *PFN_cuGLGetDevices_v4010)(unsigned int *pCudaDeviceCount, CUdevice_v1 *pCudaDevices, unsigned int cudaDeviceCount, CUGLDeviceList deviceList);
|
| 114 |
+
typedef CUresult (CUDAAPI *PFN_cuGLMapBufferObject_v2000)(CUdeviceptr_v1 *dptr, unsigned int *size, GLuint buffer);
|
| 115 |
+
typedef CUresult (CUDAAPI *PFN_cuGLMapBufferObjectAsync_v2030)(CUdeviceptr_v1 *dptr, unsigned int *size, GLuint buffer, CUstream hStream);
|
| 116 |
+
typedef CUresult (CUDAAPI *PFN_cuGLCtxCreate_v2000)(CUcontext *pCtx, unsigned int Flags, CUdevice_v1 device);
|
| 117 |
+
#endif
|
| 118 |
+
|
| 119 |
+
#ifdef __cplusplus
|
| 120 |
+
}
|
| 121 |
+
#endif // __cplusplus
|
| 122 |
+
|
| 123 |
+
#endif // file guard
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cuda_fp8.h
ADDED
|
@@ -0,0 +1,367 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2022 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#ifndef __CUDA_FP8_H__
|
| 51 |
+
#define __CUDA_FP8_H__
|
| 52 |
+
|
| 53 |
+
/* Set up function decorations */
|
| 54 |
+
#if defined(__CUDACC__)
|
| 55 |
+
#define __CUDA_FP8_DECL__ static __device__ __inline__
|
| 56 |
+
#define __CUDA_HOSTDEVICE_FP8__ __host__ __device__
|
| 57 |
+
#define __CUDA_HOSTDEVICE_FP8_DECL__ static __host__ __device__ __inline__
|
| 58 |
+
#else /* !defined(__CUDACC__) */
|
| 59 |
+
#if defined(__GNUC__)
|
| 60 |
+
#define __CUDA_HOSTDEVICE_FP8_DECL__ static __attribute__((unused))
|
| 61 |
+
#else
|
| 62 |
+
#define __CUDA_HOSTDEVICE_FP8_DECL__ static
|
| 63 |
+
#endif /* defined(__GNUC__) */
|
| 64 |
+
#define __CUDA_HOSTDEVICE_FP8__
|
| 65 |
+
#endif /* defined(__CUDACC_) */
|
| 66 |
+
|
| 67 |
+
#if !defined(_MSC_VER) && __cplusplus >= 201103L
|
| 68 |
+
#define __CPP_VERSION_AT_LEAST_11_FP8
|
| 69 |
+
#elif _MSC_FULL_VER >= 190024210 && _MSVC_LANG >= 201103L
|
| 70 |
+
#define __CPP_VERSION_AT_LEAST_11_FP8
|
| 71 |
+
#endif
|
| 72 |
+
|
| 73 |
+
/* bring in __half_raw data type */
|
| 74 |
+
#include "cuda_fp16.h"
|
| 75 |
+
/* bring in __nv_bfloat16_raw data type */
|
| 76 |
+
#include "cuda_bf16.h"
|
| 77 |
+
/* bring in float2, double4, etc vector types */
|
| 78 |
+
#include "vector_types.h"
|
| 79 |
+
|
| 80 |
+
/**
|
| 81 |
+
* \defgroup CUDA_MATH_INTRINSIC_FP8 FP8 Intrinsics
|
| 82 |
+
* This section describes fp8 intrinsic functions.
|
| 83 |
+
* To use these functions, include the header file \p cuda_fp8.h in your
|
| 84 |
+
* program.
|
| 85 |
+
* The following macros are available to help users selectively enable/disable
|
| 86 |
+
* various definitions present in the header file:
|
| 87 |
+
* - \p __CUDA_NO_FP8_CONVERSIONS__ - If defined, this macro will prevent any
|
| 88 |
+
* use of the C++ type conversions (converting constructors and conversion
|
| 89 |
+
* operators) defined in the header.
|
| 90 |
+
* - \p __CUDA_NO_FP8_CONVERSION_OPERATORS__ - If defined, this macro will
|
| 91 |
+
* prevent any use of the C++ conversion operators from \p fp8 to other types.
|
| 92 |
+
*/
|
| 93 |
+
|
| 94 |
+
/**
|
| 95 |
+
* \defgroup CUDA_MATH_FP8_MISC FP8 Conversion and Data Movement
|
| 96 |
+
* \ingroup CUDA_MATH_INTRINSIC_FP8
|
| 97 |
+
* To use these functions, include the header file \p cuda_fp8.h in your
|
| 98 |
+
* program.
|
| 99 |
+
*/
|
| 100 |
+
|
| 101 |
+
/**
|
| 102 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 103 |
+
* \brief 8-bit \p unsigned \p integer
|
| 104 |
+
* type abstraction used to for \p fp8 floating-point
|
| 105 |
+
* numbers storage.
|
| 106 |
+
*/
|
| 107 |
+
typedef unsigned char __nv_fp8_storage_t;
|
| 108 |
+
|
| 109 |
+
/**
|
| 110 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 111 |
+
* \brief 16-bit \p unsigned \p integer
|
| 112 |
+
* type abstraction used to for storage of pairs of
|
| 113 |
+
* \p fp8 floating-point numbers.
|
| 114 |
+
*/
|
| 115 |
+
typedef unsigned short int __nv_fp8x2_storage_t;
|
| 116 |
+
|
| 117 |
+
/**
|
| 118 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 119 |
+
* \brief 32-bit \p unsigned \p integer
|
| 120 |
+
* type abstraction used to for storage of tetrads of
|
| 121 |
+
* \p fp8 floating-point numbers.
|
| 122 |
+
*/
|
| 123 |
+
typedef unsigned int __nv_fp8x4_storage_t;
|
| 124 |
+
|
| 125 |
+
/**
|
| 126 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 127 |
+
* \brief Enumerates the modes applicable when
|
| 128 |
+
* performing a narrowing conversion to \p fp8 destination types.
|
| 129 |
+
*/
|
| 130 |
+
typedef enum __nv_saturation_t {
|
| 131 |
+
/**
|
| 132 |
+
* Means no saturation to finite is performed when conversion
|
| 133 |
+
* results in rounding values outside the range of destination
|
| 134 |
+
* type.
|
| 135 |
+
* NOTE: for fp8 type of e4m3 kind, the results that are larger
|
| 136 |
+
* than the maximum representable finite number of the target
|
| 137 |
+
* format become NaN.
|
| 138 |
+
*/
|
| 139 |
+
__NV_NOSAT,
|
| 140 |
+
/**
|
| 141 |
+
* Means input larger than the maximum representable
|
| 142 |
+
* finite number MAXNORM of the target format round to the
|
| 143 |
+
* MAXNORM of the same sign as input.
|
| 144 |
+
*/
|
| 145 |
+
__NV_SATFINITE,
|
| 146 |
+
} __nv_saturation_t;
|
| 147 |
+
|
| 148 |
+
/**
|
| 149 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 150 |
+
* \brief Enumerates the possible
|
| 151 |
+
* interpretations of the 8-bit values when referring to them as
|
| 152 |
+
* \p fp8 types.
|
| 153 |
+
*/
|
| 154 |
+
typedef enum __nv_fp8_interpretation_t {
|
| 155 |
+
__NV_E4M3, /**< Stands for \p fp8 numbers of \p e4m3 kind. */
|
| 156 |
+
__NV_E5M2, /**< Stands for \p fp8 numbers of \p e5m2 kind. */
|
| 157 |
+
} __nv_fp8_interpretation_t;
|
| 158 |
+
|
| 159 |
+
/* Forward-declaration of C-style APIs */
|
| 160 |
+
|
| 161 |
+
/**
|
| 162 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 163 |
+
* \brief Converts input \p double precision \p x to \p fp8 type of the
|
| 164 |
+
* requested kind using round-to-nearest-even rounding and requested saturation
|
| 165 |
+
* mode.
|
| 166 |
+
*
|
| 167 |
+
* \details Converts input \p x to \p fp8 type of the kind specified by
|
| 168 |
+
* \p fp8_interpretation parameter,
|
| 169 |
+
* using round-to-nearest-even rounding and
|
| 170 |
+
* saturation mode specified by \p saturate parameter.
|
| 171 |
+
*
|
| 172 |
+
* \returns
|
| 173 |
+
* - The \p __nv_fp8_storage_t value holds the result of conversion.
|
| 174 |
+
*/
|
| 175 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8_storage_t
|
| 176 |
+
__nv_cvt_double_to_fp8(const double x, const __nv_saturation_t saturate,
|
| 177 |
+
const __nv_fp8_interpretation_t fp8_interpretation);
|
| 178 |
+
|
| 179 |
+
/**
|
| 180 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 181 |
+
* \brief Converts input vector of two \p double precision numbers packed
|
| 182 |
+
* in \p double2 \p x into a vector of two values of \p fp8 type of
|
| 183 |
+
* the requested kind using round-to-nearest-even rounding and requested
|
| 184 |
+
* saturation mode.
|
| 185 |
+
*
|
| 186 |
+
* \details Converts input vector \p x to a vector of two \p fp8 values of the
|
| 187 |
+
* kind specified by \p fp8_interpretation parameter, using
|
| 188 |
+
* round-to-nearest-even rounding and saturation mode specified by \p saturate
|
| 189 |
+
* parameter.
|
| 190 |
+
*
|
| 191 |
+
* \returns
|
| 192 |
+
* - The \p __nv_fp8x2_storage_t value holds the result of conversion.
|
| 193 |
+
*/
|
| 194 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8x2_storage_t
|
| 195 |
+
__nv_cvt_double2_to_fp8x2(const double2 x, const __nv_saturation_t saturate,
|
| 196 |
+
const __nv_fp8_interpretation_t fp8_interpretation);
|
| 197 |
+
|
| 198 |
+
/**
|
| 199 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 200 |
+
* \brief Converts input \p single precision \p x to \p fp8 type of the
|
| 201 |
+
* requested kind using round-to-nearest-even rounding and requested saturation
|
| 202 |
+
* mode.
|
| 203 |
+
*
|
| 204 |
+
* \details Converts input \p x to \p fp8 type of the kind specified by
|
| 205 |
+
* \p fp8_interpretation parameter,
|
| 206 |
+
* using round-to-nearest-even rounding and
|
| 207 |
+
* saturation mode specified by \p saturate parameter.
|
| 208 |
+
*
|
| 209 |
+
* \returns
|
| 210 |
+
* - The \p __nv_fp8_storage_t value holds the result of conversion.
|
| 211 |
+
*/
|
| 212 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8_storage_t
|
| 213 |
+
__nv_cvt_float_to_fp8(const float x, const __nv_saturation_t saturate,
|
| 214 |
+
const __nv_fp8_interpretation_t fp8_interpretation);
|
| 215 |
+
|
| 216 |
+
/**
|
| 217 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 218 |
+
* \brief Converts input vector of two \p single precision numbers packed
|
| 219 |
+
* in \p float2 \p x into a vector of two values of \p fp8 type of
|
| 220 |
+
* the requested kind using round-to-nearest-even rounding and requested
|
| 221 |
+
* saturation mode.
|
| 222 |
+
*
|
| 223 |
+
* \details Converts input vector \p x to a vector of two \p fp8 values of the
|
| 224 |
+
* kind specified by \p fp8_interpretation parameter, using
|
| 225 |
+
* round-to-nearest-even rounding and saturation mode specified by \p saturate
|
| 226 |
+
* parameter.
|
| 227 |
+
*
|
| 228 |
+
* \returns
|
| 229 |
+
* - The \p __nv_fp8x2_storage_t value holds the result of conversion.
|
| 230 |
+
*/
|
| 231 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8x2_storage_t
|
| 232 |
+
__nv_cvt_float2_to_fp8x2(const float2 x, const __nv_saturation_t saturate,
|
| 233 |
+
const __nv_fp8_interpretation_t fp8_interpretation);
|
| 234 |
+
|
| 235 |
+
/**
|
| 236 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 237 |
+
* \brief Converts input \p half precision \p x to \p fp8 type of the requested
|
| 238 |
+
* kind using round-to-nearest-even rounding and requested saturation mode.
|
| 239 |
+
*
|
| 240 |
+
* \details Converts input \p x to \p fp8 type of the kind specified by
|
| 241 |
+
* \p fp8_interpretation parameter,
|
| 242 |
+
* using round-to-nearest-even rounding and
|
| 243 |
+
* saturation mode specified by \p saturate parameter.
|
| 244 |
+
*
|
| 245 |
+
* \returns
|
| 246 |
+
* - The \p __nv_fp8_storage_t value holds the result of conversion.
|
| 247 |
+
*/
|
| 248 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8_storage_t
|
| 249 |
+
__nv_cvt_halfraw_to_fp8(const __half_raw x, const __nv_saturation_t saturate,
|
| 250 |
+
const __nv_fp8_interpretation_t fp8_interpretation);
|
| 251 |
+
|
| 252 |
+
/**
|
| 253 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 254 |
+
* \brief Converts input vector of two \p half precision numbers packed
|
| 255 |
+
* in \p __half2_raw \p x into a vector of two values of \p fp8 type of
|
| 256 |
+
* the requested kind using round-to-nearest-even rounding and requested
|
| 257 |
+
* saturation mode.
|
| 258 |
+
*
|
| 259 |
+
* \details Converts input vector \p x to a vector of two \p fp8 values of the
|
| 260 |
+
* kind specified by \p fp8_interpretation parameter, using
|
| 261 |
+
* round-to-nearest-even rounding and saturation mode specified by \p saturate
|
| 262 |
+
* parameter.
|
| 263 |
+
*
|
| 264 |
+
* \returns
|
| 265 |
+
* - The \p __nv_fp8x2_storage_t value holds the result of conversion.
|
| 266 |
+
*/
|
| 267 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8x2_storage_t __nv_cvt_halfraw2_to_fp8x2(
|
| 268 |
+
const __half2_raw x, const __nv_saturation_t saturate,
|
| 269 |
+
const __nv_fp8_interpretation_t fp8_interpretation);
|
| 270 |
+
|
| 271 |
+
/**
|
| 272 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 273 |
+
* \brief Converts input \p nv_bfloat16 precision \p x to \p fp8 type of the
|
| 274 |
+
* requested kind using round-to-nearest-even rounding and requested saturation
|
| 275 |
+
* mode.
|
| 276 |
+
*
|
| 277 |
+
* \details Converts input \p x to \p fp8 type of the kind specified by
|
| 278 |
+
* \p fp8_interpretation parameter,
|
| 279 |
+
* using round-to-nearest-even rounding and
|
| 280 |
+
* saturation mode specified by \p saturate parameter.
|
| 281 |
+
*
|
| 282 |
+
* \returns
|
| 283 |
+
* - The \p __nv_fp8_storage_t value holds the result of conversion.
|
| 284 |
+
*/
|
| 285 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8_storage_t __nv_cvt_bfloat16raw_to_fp8(
|
| 286 |
+
const __nv_bfloat16_raw x, const __nv_saturation_t saturate,
|
| 287 |
+
const __nv_fp8_interpretation_t fp8_interpretation);
|
| 288 |
+
|
| 289 |
+
/**
|
| 290 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 291 |
+
* \brief Converts input vector of two \p nv_bfloat16 precision numbers packed
|
| 292 |
+
* in \p __nv_bfloat162_raw \p x into a vector of two values of \p fp8 type of
|
| 293 |
+
* the requested kind using round-to-nearest-even rounding and requested
|
| 294 |
+
* saturation mode.
|
| 295 |
+
*
|
| 296 |
+
* \details Converts input vector \p x to a vector of two \p fp8 values of the
|
| 297 |
+
* kind specified by \p fp8_interpretation parameter, using
|
| 298 |
+
* round-to-nearest-even rounding and saturation mode specified by \p saturate
|
| 299 |
+
* parameter.
|
| 300 |
+
*
|
| 301 |
+
* \returns
|
| 302 |
+
* - The \p __nv_fp8x2_storage_t value holds the result of conversion.
|
| 303 |
+
*/
|
| 304 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8x2_storage_t
|
| 305 |
+
__nv_cvt_bfloat16raw2_to_fp8x2(
|
| 306 |
+
const __nv_bfloat162_raw x, const __nv_saturation_t saturate,
|
| 307 |
+
const __nv_fp8_interpretation_t fp8_interpretation);
|
| 308 |
+
|
| 309 |
+
/**
|
| 310 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 311 |
+
* \brief Converts input \p fp8 \p x of the specified kind
|
| 312 |
+
* to \p half precision.
|
| 313 |
+
*
|
| 314 |
+
* \details Converts input \p x of \p fp8 type of the kind specified by
|
| 315 |
+
* \p fp8_interpretation parameter
|
| 316 |
+
* to \p half precision.
|
| 317 |
+
*
|
| 318 |
+
* \returns
|
| 319 |
+
* - The \p __half_raw value holds the result of conversion.
|
| 320 |
+
*/
|
| 321 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __half_raw
|
| 322 |
+
__nv_cvt_fp8_to_halfraw(const __nv_fp8_storage_t x,
|
| 323 |
+
const __nv_fp8_interpretation_t fp8_interpretation);
|
| 324 |
+
/**
|
| 325 |
+
* \ingroup CUDA_MATH_FP8_MISC
|
| 326 |
+
* \brief Converts input vector of two \p fp8 values of the specified kind
|
| 327 |
+
* to a vector of two \p half precision values packed in \p __half2_raw
|
| 328 |
+
* structure.
|
| 329 |
+
*
|
| 330 |
+
* \details Converts input vector \p x of \p fp8 type of the kind specified by
|
| 331 |
+
* \p fp8_interpretation parameter
|
| 332 |
+
* to a vector of two \p half precision values and returns as \p __half2_raw
|
| 333 |
+
* structure.
|
| 334 |
+
*
|
| 335 |
+
* \returns
|
| 336 |
+
* - The \p __half2_raw value holds the result of conversion.
|
| 337 |
+
*/
|
| 338 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __half2_raw
|
| 339 |
+
__nv_cvt_fp8x2_to_halfraw2(const __nv_fp8x2_storage_t x,
|
| 340 |
+
const __nv_fp8_interpretation_t fp8_interpretation);
|
| 341 |
+
|
| 342 |
+
#if defined(__cplusplus)
|
| 343 |
+
|
| 344 |
+
#define __CUDA_FP8_TYPES_EXIST__
|
| 345 |
+
|
| 346 |
+
/* Forward-declaration of structures defined in "cuda_fp8.hpp" */
|
| 347 |
+
struct __nv_fp8_e5m2;
|
| 348 |
+
struct __nv_fp8x2_e5m2;
|
| 349 |
+
struct __nv_fp8x4_e5m2;
|
| 350 |
+
|
| 351 |
+
struct __nv_fp8_e4m3;
|
| 352 |
+
struct __nv_fp8x2_e4m3;
|
| 353 |
+
struct __nv_fp8x4_e4m3;
|
| 354 |
+
|
| 355 |
+
#endif /* defined(__cplusplus) */
|
| 356 |
+
|
| 357 |
+
#include "cuda_fp8.hpp"
|
| 358 |
+
|
| 359 |
+
#undef __CUDA_FP8_DECL__
|
| 360 |
+
#undef __CUDA_HOSTDEVICE_FP8__
|
| 361 |
+
#undef __CUDA_HOSTDEVICE_FP8_DECL__
|
| 362 |
+
|
| 363 |
+
#if defined(__CPP_VERSION_AT_LEAST_11_FP8)
|
| 364 |
+
#undef __CPP_VERSION_AT_LEAST_11_FP8
|
| 365 |
+
#endif /* defined(__CPP_VERSION_AT_LEAST_11_FP8) */
|
| 366 |
+
|
| 367 |
+
#endif /* end of include guard: __CUDA_FP8_H__ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cuda_fp8.hpp
ADDED
|
@@ -0,0 +1,1546 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2022 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__CUDA_FP8_HPP__)
|
| 51 |
+
#define __CUDA_FP8_HPP__
|
| 52 |
+
|
| 53 |
+
#if !defined(__CUDA_FP8_H__)
|
| 54 |
+
#error "Do not include this file directly. Instead, include cuda_fp8.h."
|
| 55 |
+
#endif
|
| 56 |
+
|
| 57 |
+
/* C++ header for std::memcpy (used for type punning in host-side
|
| 58 |
+
* implementations). When compiling as a CUDA source file memcpy is provided
|
| 59 |
+
* implicitly. !defined(__CUDACC__) implies !defined(__CUDACC_RTC__).
|
| 60 |
+
*/
|
| 61 |
+
#if defined(__cplusplus) && !defined(__CUDACC__)
|
| 62 |
+
#include <cstring>
|
| 63 |
+
#elif !defined(__cplusplus) && !defined(__CUDACC__)
|
| 64 |
+
#include <string.h>
|
| 65 |
+
#endif /* defined(__cplusplus) && !defined(__CUDACC__) */
|
| 66 |
+
|
| 67 |
+
/* Set up structure-alignment attribute */
|
| 68 |
+
#if !(defined __CUDA_ALIGN__)
|
| 69 |
+
#if defined(__CUDACC__)
|
| 70 |
+
#define __CUDA_ALIGN__(align) __align__(align)
|
| 71 |
+
#else
|
| 72 |
+
/* Define alignment macro based on compiler type (cannot assume C11 "_Alignas"
|
| 73 |
+
* is available) */
|
| 74 |
+
#if __cplusplus >= 201103L
|
| 75 |
+
#define __CUDA_ALIGN__(n) \
|
| 76 |
+
alignas(n) /* C++11 kindly gives us a keyword for this */
|
| 77 |
+
#else /* !defined(__CPP_VERSION_AT_LEAST_11_FP8)*/
|
| 78 |
+
#if defined(__GNUC__)
|
| 79 |
+
#define __CUDA_ALIGN__(n) __attribute__((aligned(n)))
|
| 80 |
+
#elif defined(_MSC_VER)
|
| 81 |
+
#define __CUDA_ALIGN__(n) __declspec(align(n))
|
| 82 |
+
#else
|
| 83 |
+
#define __CUDA_ALIGN__(n)
|
| 84 |
+
#endif /* defined(__GNUC__) */
|
| 85 |
+
#endif /* defined(__CPP_VERSION_AT_LEAST_11_FP8) */
|
| 86 |
+
#endif /* defined(__CUDACC__) */
|
| 87 |
+
#endif /* !(defined __CUDA_ALIGN__) */
|
| 88 |
+
|
| 89 |
+
#if !(defined __CPP_VERSION_AT_LEAST_11_FP8)
|
| 90 |
+
/* need c++11 for explicit operators */
|
| 91 |
+
#define __CUDA_NO_FP8_CONVERSION_OPERATORS__
|
| 92 |
+
#endif
|
| 93 |
+
|
| 94 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8_storage_t
|
| 95 |
+
__nv_cvt_double_to_fp8(const double x, const __nv_saturation_t saturate,
|
| 96 |
+
const __nv_fp8_interpretation_t fp8_interpretation) {
|
| 97 |
+
unsigned char res;
|
| 98 |
+
unsigned long long int xbits;
|
| 99 |
+
|
| 100 |
+
#if defined(__CUDACC__) || (!defined __cplusplus)
|
| 101 |
+
(void)memcpy(&xbits, &x, sizeof(x));
|
| 102 |
+
#else
|
| 103 |
+
(void)std::memcpy(&xbits, &x, sizeof(x));
|
| 104 |
+
#endif
|
| 105 |
+
unsigned char FP8_MAXNORM;
|
| 106 |
+
unsigned char FP8_MANTISSA_MASK;
|
| 107 |
+
unsigned short int FP8_EXP_BIAS;
|
| 108 |
+
unsigned long long int FP8_SIGNIFICAND_BITS;
|
| 109 |
+
const unsigned long long int DP_INF_BITS = 0x7FF0000000000000ULL;
|
| 110 |
+
unsigned long long int FP8_MINDENORM_O2;
|
| 111 |
+
unsigned long long int FP8_OVERFLOW_THRESHOLD;
|
| 112 |
+
unsigned long long int FP8_MINNORM;
|
| 113 |
+
|
| 114 |
+
if (fp8_interpretation == __NV_E4M3) {
|
| 115 |
+
FP8_EXP_BIAS = 7U;
|
| 116 |
+
FP8_SIGNIFICAND_BITS = 4ULL;
|
| 117 |
+
FP8_MANTISSA_MASK = 0x7U;
|
| 118 |
+
FP8_MINDENORM_O2 = 0x3F50000000000000ULL; // mindenorm/2 = 2^-10
|
| 119 |
+
FP8_OVERFLOW_THRESHOLD =
|
| 120 |
+
0x407D000000000000ULL; // maxnorm + 1/2ulp = 0x1.Cp+8 + 0x1p+4
|
| 121 |
+
FP8_MAXNORM = 0x7EU;
|
| 122 |
+
FP8_MINNORM = 0x3F90000000000000ULL; // minnorm = 2^-6
|
| 123 |
+
} else { //__NV_E5M2
|
| 124 |
+
FP8_EXP_BIAS = 15U;
|
| 125 |
+
FP8_SIGNIFICAND_BITS = 3ULL;
|
| 126 |
+
FP8_MANTISSA_MASK = 0x3U;
|
| 127 |
+
FP8_MINDENORM_O2 = 0x3EE0000000000000ULL; // mindenorm/2 = 2^-17
|
| 128 |
+
FP8_OVERFLOW_THRESHOLD =
|
| 129 |
+
0x40EE000000000000ULL -
|
| 130 |
+
1ULL; // maxnorm + 1/2ulp = 0x1.Ep+15, and -1 to have common code
|
| 131 |
+
FP8_MAXNORM = 0x7BU;
|
| 132 |
+
FP8_MINNORM = 0x3F10000000000000ULL; // minnorm = 2^-14
|
| 133 |
+
}
|
| 134 |
+
|
| 135 |
+
// 1/2 LSB of the target format, positioned in double precision mantissa
|
| 136 |
+
// helpful in midpoints detection during round-to-nearest-even step
|
| 137 |
+
const unsigned long long int FP8_DP_HALF_ULP =
|
| 138 |
+
(unsigned long long int)1ULL << (53ULL - FP8_SIGNIFICAND_BITS - 1ULL);
|
| 139 |
+
// prepare sign bit in target format
|
| 140 |
+
unsigned char sign = (unsigned char)((xbits >> 63ULL) << 7U);
|
| 141 |
+
// prepare exponent field in target format
|
| 142 |
+
unsigned char exp =
|
| 143 |
+
(unsigned char)((((unsigned short int)(xbits >> 52ULL)) & 0x7FFU) -
|
| 144 |
+
1023U + FP8_EXP_BIAS);
|
| 145 |
+
// round mantissa to target format width, rounding towards zero
|
| 146 |
+
unsigned char mantissa =
|
| 147 |
+
(unsigned char)(xbits >> (53ULL - FP8_SIGNIFICAND_BITS)) &
|
| 148 |
+
FP8_MANTISSA_MASK;
|
| 149 |
+
unsigned long long int absx = xbits & 0x7FFFFFFFFFFFFFFFULL;
|
| 150 |
+
|
| 151 |
+
if (absx <= FP8_MINDENORM_O2) {
|
| 152 |
+
// zero or underflow
|
| 153 |
+
res = 0U;
|
| 154 |
+
} else if (absx > DP_INF_BITS) {
|
| 155 |
+
// NaN
|
| 156 |
+
if (fp8_interpretation == __NV_E4M3) {
|
| 157 |
+
res = 0x7FU;
|
| 158 |
+
} else {
|
| 159 |
+
// NaN --> QNaN
|
| 160 |
+
res = 0x7EU | mantissa;
|
| 161 |
+
}
|
| 162 |
+
} else if (absx > FP8_OVERFLOW_THRESHOLD) {
|
| 163 |
+
if (saturate == __NV_SATFINITE) {
|
| 164 |
+
res = FP8_MAXNORM;
|
| 165 |
+
} else {
|
| 166 |
+
// __NV_NOSAT
|
| 167 |
+
if (fp8_interpretation == __NV_E4M3) {
|
| 168 |
+
// no Inf in E4M3
|
| 169 |
+
res = 0x7FU; // NaN
|
| 170 |
+
} else {
|
| 171 |
+
res = 0x7CU; // Inf in E5M2
|
| 172 |
+
}
|
| 173 |
+
}
|
| 174 |
+
} else if (absx >= FP8_MINNORM) {
|
| 175 |
+
res = (unsigned char)((exp << (FP8_SIGNIFICAND_BITS - 1U)) | mantissa);
|
| 176 |
+
// rounded-off bits
|
| 177 |
+
unsigned long long int round =
|
| 178 |
+
xbits & ((FP8_DP_HALF_ULP << 1ULL) - 1ULL);
|
| 179 |
+
// round-to-nearest-even adjustment
|
| 180 |
+
if ((round > FP8_DP_HALF_ULP) ||
|
| 181 |
+
((round == FP8_DP_HALF_ULP) && (mantissa & 1U))) {
|
| 182 |
+
res = (unsigned char)(res + 1U);
|
| 183 |
+
}
|
| 184 |
+
} else // Denormal range
|
| 185 |
+
{
|
| 186 |
+
unsigned char shift = (unsigned char)(1U - exp);
|
| 187 |
+
// add implicit leading bit
|
| 188 |
+
mantissa |= (unsigned char)(1U << (FP8_SIGNIFICAND_BITS - 1U));
|
| 189 |
+
// additional round-off due to denormalization
|
| 190 |
+
res = (unsigned char)(mantissa >> shift);
|
| 191 |
+
|
| 192 |
+
// rounded-off bits, including implicit leading bit
|
| 193 |
+
unsigned long long int round =
|
| 194 |
+
(xbits | ((unsigned long long int)1ULL << (53ULL - 1ULL))) &
|
| 195 |
+
((FP8_DP_HALF_ULP << (shift + 1ULL)) - 1ULL);
|
| 196 |
+
// round-to-nearest-even adjustment
|
| 197 |
+
if ((round > (FP8_DP_HALF_ULP << shift)) ||
|
| 198 |
+
((round == (FP8_DP_HALF_ULP << shift)) && (res & 1U))) {
|
| 199 |
+
res = (unsigned char)(res + 1U);
|
| 200 |
+
}
|
| 201 |
+
}
|
| 202 |
+
|
| 203 |
+
res |= sign;
|
| 204 |
+
|
| 205 |
+
return (__nv_fp8_storage_t)res;
|
| 206 |
+
}
|
| 207 |
+
|
| 208 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8x2_storage_t
|
| 209 |
+
__nv_cvt_double2_to_fp8x2(const double2 x, const __nv_saturation_t saturate,
|
| 210 |
+
const __nv_fp8_interpretation_t fp8_interpretation) {
|
| 211 |
+
__nv_fp8x2_storage_t storage = (__nv_fp8x2_storage_t)__nv_cvt_double_to_fp8(
|
| 212 |
+
x.y, saturate, fp8_interpretation);
|
| 213 |
+
storage = (__nv_fp8x2_storage_t)(storage << 8U);
|
| 214 |
+
storage = (__nv_fp8x2_storage_t)(storage |
|
| 215 |
+
__nv_cvt_double_to_fp8(
|
| 216 |
+
x.x, saturate, fp8_interpretation));
|
| 217 |
+
return storage;
|
| 218 |
+
}
|
| 219 |
+
|
| 220 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8_storage_t
|
| 221 |
+
__nv_cvt_float_to_fp8(const float x, const __nv_saturation_t saturate,
|
| 222 |
+
const __nv_fp8_interpretation_t fp8_interpretation) {
|
| 223 |
+
__nv_fp8_storage_t res = 0U;
|
| 224 |
+
#if (defined __CUDA_ARCH__) && (__CUDA_ARCH__ >= 890)
|
| 225 |
+
if (saturate == __NV_SATFINITE) {
|
| 226 |
+
__nv_fp8x2_storage_t storage;
|
| 227 |
+
if (fp8_interpretation == __NV_E5M2) {
|
| 228 |
+
asm("{cvt.rn.satfinite.e5m2x2.f32 %0, %2, %1;}\n"
|
| 229 |
+
: "=h"(storage)
|
| 230 |
+
: "f"(x), "f"(0.0f));
|
| 231 |
+
} else {
|
| 232 |
+
asm("{cvt.rn.satfinite.e4m3x2.f32 %0, %2, %1;}\n"
|
| 233 |
+
: "=h"(storage)
|
| 234 |
+
: "f"(x), "f"(0.0f));
|
| 235 |
+
}
|
| 236 |
+
res = (__nv_fp8_storage_t)storage;
|
| 237 |
+
} else
|
| 238 |
+
#endif
|
| 239 |
+
{
|
| 240 |
+
unsigned int xbits;
|
| 241 |
+
#if defined(__CUDACC__) || (!defined __cplusplus)
|
| 242 |
+
(void)memcpy(&xbits, &x, sizeof(x));
|
| 243 |
+
#else
|
| 244 |
+
(void)std::memcpy(&xbits, &x, sizeof(x));
|
| 245 |
+
#endif
|
| 246 |
+
|
| 247 |
+
// isnan
|
| 248 |
+
if ((xbits & 0x7FFFFFFFU) > 0x7F800000U) {
|
| 249 |
+
// Canonical NaN
|
| 250 |
+
xbits = 0x7FFFFFFFU;
|
| 251 |
+
}
|
| 252 |
+
|
| 253 |
+
float fx;
|
| 254 |
+
#if defined(__CUDACC__) || (!defined __cplusplus)
|
| 255 |
+
(void)memcpy(&fx, &xbits, sizeof(xbits));
|
| 256 |
+
#else
|
| 257 |
+
(void)std::memcpy(&fx, &xbits, sizeof(xbits));
|
| 258 |
+
#endif
|
| 259 |
+
|
| 260 |
+
const double dx = (double)fx;
|
| 261 |
+
res = __nv_cvt_double_to_fp8(dx, saturate, fp8_interpretation);
|
| 262 |
+
}
|
| 263 |
+
return res;
|
| 264 |
+
}
|
| 265 |
+
|
| 266 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8x2_storage_t
|
| 267 |
+
__nv_cvt_float2_to_fp8x2(const float2 x, const __nv_saturation_t saturate,
|
| 268 |
+
const __nv_fp8_interpretation_t fp8_interpretation) {
|
| 269 |
+
__nv_fp8x2_storage_t storage;
|
| 270 |
+
#if (defined __CUDA_ARCH__) && (__CUDA_ARCH__ >= 890)
|
| 271 |
+
if (saturate == __NV_SATFINITE) {
|
| 272 |
+
if (fp8_interpretation == __NV_E5M2) {
|
| 273 |
+
asm("{cvt.rn.satfinite.e5m2x2.f32 %0, %2, %1;}\n"
|
| 274 |
+
: "=h"(storage)
|
| 275 |
+
: "f"(x.x), "f"(x.y));
|
| 276 |
+
} else {
|
| 277 |
+
asm("{cvt.rn.satfinite.e4m3x2.f32 %0, %2, %1;}\n"
|
| 278 |
+
: "=h"(storage)
|
| 279 |
+
: "f"(x.x), "f"(x.y));
|
| 280 |
+
}
|
| 281 |
+
} else
|
| 282 |
+
#endif
|
| 283 |
+
{
|
| 284 |
+
storage = (__nv_fp8x2_storage_t)__nv_cvt_float_to_fp8(
|
| 285 |
+
x.y, saturate, fp8_interpretation);
|
| 286 |
+
storage = (__nv_fp8x2_storage_t)(storage << 8U);
|
| 287 |
+
storage = (__nv_fp8x2_storage_t)(storage | __nv_cvt_float_to_fp8(
|
| 288 |
+
x.x, saturate,
|
| 289 |
+
fp8_interpretation));
|
| 290 |
+
}
|
| 291 |
+
return storage;
|
| 292 |
+
}
|
| 293 |
+
|
| 294 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ float
|
| 295 |
+
__internal_halfraw_to_float(const __half_raw x) {
|
| 296 |
+
float f;
|
| 297 |
+
#if (defined __CUDA_ARCH__) && (__CUDA_ARCH__ >= 530)
|
| 298 |
+
asm("{cvt.f32.f16 %0, %1;}\n" : "=f"(f) : "h"(x.x));
|
| 299 |
+
#else
|
| 300 |
+
const unsigned int ux = (unsigned int)x.x;
|
| 301 |
+
unsigned int sign = (ux >> 15U) & 1U;
|
| 302 |
+
unsigned int exponent = (ux >> 10U) & 0x1fU;
|
| 303 |
+
unsigned int mantissa = (ux & 0x3ffU) << 13U;
|
| 304 |
+
if (exponent == 0x1fU) { /* NaN or Inf */
|
| 305 |
+
/* discard sign of a NaN */
|
| 306 |
+
sign = ((mantissa != 0U) ? (sign >> 1U) : sign);
|
| 307 |
+
mantissa = ((mantissa != 0U) ? 0x7fffffU : 0U);
|
| 308 |
+
exponent = 0xffU;
|
| 309 |
+
} else if (exponent == 0U) { /* Denorm or Zero */
|
| 310 |
+
if (mantissa != 0U) {
|
| 311 |
+
unsigned int msb;
|
| 312 |
+
exponent = 0x71U;
|
| 313 |
+
do {
|
| 314 |
+
msb = (mantissa & 0x400000U);
|
| 315 |
+
mantissa <<= 1U; /* normalize */
|
| 316 |
+
--exponent;
|
| 317 |
+
} while (msb == 0U);
|
| 318 |
+
mantissa &= 0x7fffffU; /* 1.mantissa is implicit */
|
| 319 |
+
}
|
| 320 |
+
} else {
|
| 321 |
+
exponent += 0x70U;
|
| 322 |
+
}
|
| 323 |
+
const unsigned int u = ((sign << 31U) | (exponent << 23U) | mantissa);
|
| 324 |
+
#if defined(__CUDACC__) || (!defined __cplusplus)
|
| 325 |
+
(void)memcpy(&f, &u, sizeof(u));
|
| 326 |
+
#else
|
| 327 |
+
(void)std::memcpy(&f, &u, sizeof(u));
|
| 328 |
+
#endif
|
| 329 |
+
#endif /* (defined __CUDA_ARCH__) && (__CUDA_ARCH__ >= 530) */
|
| 330 |
+
return f;
|
| 331 |
+
}
|
| 332 |
+
|
| 333 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ float2
|
| 334 |
+
__internal_halfraw2_to_float2(const __half2_raw x) {
|
| 335 |
+
__half_raw raw;
|
| 336 |
+
float2 res;
|
| 337 |
+
raw.x = x.x;
|
| 338 |
+
res.x = __internal_halfraw_to_float(raw);
|
| 339 |
+
raw.x = x.y;
|
| 340 |
+
res.y = __internal_halfraw_to_float(raw);
|
| 341 |
+
return res;
|
| 342 |
+
}
|
| 343 |
+
|
| 344 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8_storage_t
|
| 345 |
+
__nv_cvt_halfraw_to_fp8(const __half_raw x, const __nv_saturation_t saturate,
|
| 346 |
+
const __nv_fp8_interpretation_t fp8_interpretation) {
|
| 347 |
+
__nv_fp8_storage_t res = 0U;
|
| 348 |
+
#if (defined __CUDA_ARCH__) && (__CUDA_ARCH__ >= 890)
|
| 349 |
+
if (saturate == __NV_SATFINITE) {
|
| 350 |
+
unsigned int half2_storage = (unsigned int)(x.x);
|
| 351 |
+
__nv_fp8x2_storage_t tmp;
|
| 352 |
+
if (fp8_interpretation == __NV_E5M2) {
|
| 353 |
+
asm("{cvt.rn.satfinite.e5m2x2.f16x2 %0, %1;}\n"
|
| 354 |
+
: "=h"(tmp)
|
| 355 |
+
: "r"(half2_storage));
|
| 356 |
+
} else {
|
| 357 |
+
asm("{cvt.rn.satfinite.e4m3x2.f16x2 %0, %1;}\n"
|
| 358 |
+
: "=h"(tmp)
|
| 359 |
+
: "r"(half2_storage));
|
| 360 |
+
}
|
| 361 |
+
res = (__nv_fp8_storage_t)tmp;
|
| 362 |
+
} else
|
| 363 |
+
#endif
|
| 364 |
+
{
|
| 365 |
+
float fx = __internal_halfraw_to_float(x);
|
| 366 |
+
res = __nv_cvt_float_to_fp8(fx, saturate, fp8_interpretation);
|
| 367 |
+
}
|
| 368 |
+
return res;
|
| 369 |
+
}
|
| 370 |
+
|
| 371 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8x2_storage_t __nv_cvt_halfraw2_to_fp8x2(
|
| 372 |
+
const __half2_raw x, const __nv_saturation_t saturate,
|
| 373 |
+
const __nv_fp8_interpretation_t fp8_interpretation) {
|
| 374 |
+
__nv_fp8x2_storage_t tmp;
|
| 375 |
+
#if (defined __CUDA_ARCH__) && (__CUDA_ARCH__ >= 890)
|
| 376 |
+
if (saturate == __NV_SATFINITE) {
|
| 377 |
+
unsigned int half2_storage;
|
| 378 |
+
(void)memcpy(&half2_storage, &x, sizeof(x));
|
| 379 |
+
|
| 380 |
+
if (fp8_interpretation == __NV_E5M2) {
|
| 381 |
+
asm("{cvt.rn.satfinite.e5m2x2.f16x2 %0, %1;}\n"
|
| 382 |
+
: "=h"(tmp)
|
| 383 |
+
: "r"(half2_storage));
|
| 384 |
+
} else {
|
| 385 |
+
asm("{cvt.rn.satfinite.e4m3x2.f16x2 %0, %1;}\n"
|
| 386 |
+
: "=h"(tmp)
|
| 387 |
+
: "r"(half2_storage));
|
| 388 |
+
}
|
| 389 |
+
} else
|
| 390 |
+
#endif
|
| 391 |
+
{
|
| 392 |
+
__half_raw raw;
|
| 393 |
+
raw.x = x.x;
|
| 394 |
+
__nv_fp8_storage_t lo =
|
| 395 |
+
__nv_cvt_halfraw_to_fp8(raw, saturate, fp8_interpretation);
|
| 396 |
+
raw.x = x.y;
|
| 397 |
+
__nv_fp8_storage_t hi =
|
| 398 |
+
__nv_cvt_halfraw_to_fp8(raw, saturate, fp8_interpretation);
|
| 399 |
+
tmp = hi;
|
| 400 |
+
tmp = (__nv_fp8x2_storage_t)(tmp << 8U);
|
| 401 |
+
tmp = (__nv_fp8x2_storage_t)(tmp | lo);
|
| 402 |
+
}
|
| 403 |
+
return tmp;
|
| 404 |
+
}
|
| 405 |
+
|
| 406 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ float
|
| 407 |
+
__internal_bf16raw_to_float(const __nv_bfloat16_raw x) {
|
| 408 |
+
const unsigned int ux = ((unsigned int)x.x) << 16U;
|
| 409 |
+
float fx;
|
| 410 |
+
#if defined(__CUDACC__) || (!defined __cplusplus)
|
| 411 |
+
(void)memcpy(&fx, &ux, sizeof(ux));
|
| 412 |
+
#else
|
| 413 |
+
(void)std::memcpy(&fx, &ux, sizeof(ux));
|
| 414 |
+
#endif
|
| 415 |
+
return fx;
|
| 416 |
+
}
|
| 417 |
+
|
| 418 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_bfloat16_raw
|
| 419 |
+
__internal_float_to_bf16raw_rz(const float x) {
|
| 420 |
+
unsigned int ux;
|
| 421 |
+
__nv_bfloat16_raw r;
|
| 422 |
+
#if defined(__CUDACC__) || (!defined __cplusplus)
|
| 423 |
+
(void)memcpy(&ux, &x, sizeof(x));
|
| 424 |
+
#else
|
| 425 |
+
(void)std::memcpy(&ux, &x, sizeof(x));
|
| 426 |
+
#endif
|
| 427 |
+
r.x = (unsigned short int)(ux >> 16U);
|
| 428 |
+
return r;
|
| 429 |
+
}
|
| 430 |
+
|
| 431 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8_storage_t __nv_cvt_bfloat16raw_to_fp8(
|
| 432 |
+
const __nv_bfloat16_raw x, const __nv_saturation_t saturate,
|
| 433 |
+
const __nv_fp8_interpretation_t fp8_interpretation) {
|
| 434 |
+
const float fx = __internal_bf16raw_to_float(x);
|
| 435 |
+
const __nv_fp8_storage_t res =
|
| 436 |
+
__nv_cvt_float_to_fp8(fx, saturate, fp8_interpretation);
|
| 437 |
+
return res;
|
| 438 |
+
}
|
| 439 |
+
|
| 440 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __nv_fp8x2_storage_t
|
| 441 |
+
__nv_cvt_bfloat16raw2_to_fp8x2(
|
| 442 |
+
const __nv_bfloat162_raw x, const __nv_saturation_t saturate,
|
| 443 |
+
const __nv_fp8_interpretation_t fp8_interpretation) {
|
| 444 |
+
__nv_bfloat16_raw raw;
|
| 445 |
+
raw.x = x.y;
|
| 446 |
+
__nv_fp8x2_storage_t storage =
|
| 447 |
+
(__nv_fp8x2_storage_t)__nv_cvt_bfloat16raw_to_fp8(raw, saturate,
|
| 448 |
+
fp8_interpretation);
|
| 449 |
+
storage = (__nv_fp8x2_storage_t)(storage << 8U);
|
| 450 |
+
raw.x = x.x;
|
| 451 |
+
storage = (__nv_fp8x2_storage_t)(storage |
|
| 452 |
+
__nv_cvt_bfloat16raw_to_fp8(
|
| 453 |
+
raw, saturate, fp8_interpretation));
|
| 454 |
+
return storage;
|
| 455 |
+
}
|
| 456 |
+
|
| 457 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __half2_raw
|
| 458 |
+
__nv_cvt_fp8x2_to_halfraw2(const __nv_fp8x2_storage_t x,
|
| 459 |
+
const __nv_fp8_interpretation_t fp8_interpretation);
|
| 460 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __half_raw
|
| 461 |
+
__nv_cvt_fp8_to_halfraw(const __nv_fp8_storage_t x,
|
| 462 |
+
const __nv_fp8_interpretation_t fp8_interpretation) {
|
| 463 |
+
__half_raw res;
|
| 464 |
+
res.x = 0U;
|
| 465 |
+
#if (defined __CUDA_ARCH__) && (__CUDA_ARCH__ >= 890)
|
| 466 |
+
res.x =
|
| 467 |
+
__nv_cvt_fp8x2_to_halfraw2((__nv_fp8x2_storage_t)x, fp8_interpretation)
|
| 468 |
+
.x;
|
| 469 |
+
#else
|
| 470 |
+
unsigned short int ur = (unsigned short int)x;
|
| 471 |
+
ur = (unsigned short int)(ur << 8U);
|
| 472 |
+
|
| 473 |
+
if (fp8_interpretation == __NV_E5M2) {
|
| 474 |
+
if ((ur & 0x7FFFU) > 0x7C00U) {
|
| 475 |
+
/* If NaN, return canonical NaN */
|
| 476 |
+
ur = 0x7FFFU;
|
| 477 |
+
}
|
| 478 |
+
} else { // __NV_E4M3
|
| 479 |
+
unsigned short int sign = ur & 0x8000U;
|
| 480 |
+
unsigned short int exponent =
|
| 481 |
+
(unsigned short int)(((ur & 0x7800U) >> 1U) + 0x2000U);
|
| 482 |
+
unsigned short int mantissa = (ur & 0x0700U) >> 1U;
|
| 483 |
+
unsigned char absx = 0x7FU & (unsigned char)x;
|
| 484 |
+
|
| 485 |
+
if (absx == 0x7FU) // NaN
|
| 486 |
+
{
|
| 487 |
+
ur = 0x7FFFU; // fp16 canonical NaN, discard sign
|
| 488 |
+
} else if (exponent == 0x2000U) {
|
| 489 |
+
// zero or denormal
|
| 490 |
+
if (mantissa != 0U) {
|
| 491 |
+
// normalize
|
| 492 |
+
mantissa = (unsigned short int)(mantissa << 1U);
|
| 493 |
+
while ((mantissa & 0x0400U) == 0U) {
|
| 494 |
+
mantissa = (unsigned short int)(mantissa << 1U);
|
| 495 |
+
exponent = (unsigned short int)(exponent - 0x0400U);
|
| 496 |
+
}
|
| 497 |
+
// discard implicit leading bit
|
| 498 |
+
mantissa &= 0x03FFU;
|
| 499 |
+
} else { // Zero
|
| 500 |
+
exponent = 0U;
|
| 501 |
+
}
|
| 502 |
+
|
| 503 |
+
ur = (sign | exponent) | mantissa;
|
| 504 |
+
} else {
|
| 505 |
+
ur = (sign | exponent) | mantissa;
|
| 506 |
+
}
|
| 507 |
+
}
|
| 508 |
+
res.x = ur;
|
| 509 |
+
#endif
|
| 510 |
+
return res;
|
| 511 |
+
}
|
| 512 |
+
|
| 513 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ __half2_raw
|
| 514 |
+
__nv_cvt_fp8x2_to_halfraw2(const __nv_fp8x2_storage_t x,
|
| 515 |
+
const __nv_fp8_interpretation_t fp8_interpretation) {
|
| 516 |
+
__half2_raw res;
|
| 517 |
+
#if (defined __CUDA_ARCH__) && (__CUDA_ARCH__ >= 890)
|
| 518 |
+
unsigned int half2_storage;
|
| 519 |
+
if (fp8_interpretation == __NV_E5M2) {
|
| 520 |
+
asm("{cvt.rn.f16x2.e5m2x2 %0, %1;}\n" : "=r"(half2_storage) : "h"(x));
|
| 521 |
+
} else {
|
| 522 |
+
asm("{cvt.rn.f16x2.e4m3x2 %0, %1;}\n" : "=r"(half2_storage) : "h"(x));
|
| 523 |
+
}
|
| 524 |
+
(void)memcpy(&res, &half2_storage, sizeof(half2_storage));
|
| 525 |
+
#else
|
| 526 |
+
res.x =
|
| 527 |
+
__nv_cvt_fp8_to_halfraw((__nv_fp8_storage_t)x, fp8_interpretation).x;
|
| 528 |
+
res.y = __nv_cvt_fp8_to_halfraw((__nv_fp8_storage_t)(x >> 8U),
|
| 529 |
+
fp8_interpretation)
|
| 530 |
+
.x;
|
| 531 |
+
#endif
|
| 532 |
+
return res;
|
| 533 |
+
}
|
| 534 |
+
|
| 535 |
+
/* All other definitions in this file are only visible to C++ compilers */
|
| 536 |
+
#if defined(__cplusplus)
|
| 537 |
+
|
| 538 |
+
/**
|
| 539 |
+
* \defgroup CUDA_MATH_FP8_E5M2_STRUCT C++ struct for handling fp8 data type of e5m2 kind.
|
| 540 |
+
* \ingroup CUDA_MATH_INTRINSIC_FP8
|
| 541 |
+
*/
|
| 542 |
+
|
| 543 |
+
/**
|
| 544 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 545 |
+
* \brief __nv_fp8_e5m2 datatype
|
| 546 |
+
*
|
| 547 |
+
* \details This structure implements the datatype for handling
|
| 548 |
+
* \p fp8 floating-point numbers of \p e5m2 kind:
|
| 549 |
+
* with 1 sign, 5 exponent, 1 implicit and 2 explicit mantissa bits.
|
| 550 |
+
*
|
| 551 |
+
* The structure implements converting constructors and operators.
|
| 552 |
+
*/
|
| 553 |
+
struct __CUDA_ALIGN__(1) __nv_fp8_e5m2 {
|
| 554 |
+
public:
|
| 555 |
+
/**
|
| 556 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 557 |
+
* Storage variable contains the \p fp8 floating-point data.
|
| 558 |
+
*/
|
| 559 |
+
__nv_fp8_storage_t __x;
|
| 560 |
+
|
| 561 |
+
/**
|
| 562 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 563 |
+
* Constructor by default.
|
| 564 |
+
*/
|
| 565 |
+
#if defined(__CPP_VERSION_AT_LEAST_11_FP8)
|
| 566 |
+
__nv_fp8_e5m2() = default;
|
| 567 |
+
#else
|
| 568 |
+
__CUDA_HOSTDEVICE_FP8__ __nv_fp8_e5m2() {}
|
| 569 |
+
#endif /* defined(__CPP_VERSION_AT_LEAST_11_FP8) */
|
| 570 |
+
|
| 571 |
+
#if !defined(__CUDA_NO_FP8_CONVERSIONS__)
|
| 572 |
+
|
| 573 |
+
/* Construct from wider FP types */
|
| 574 |
+
/* Note we do avoid constructor init-list because of special host/device
|
| 575 |
+
* compilation rules */
|
| 576 |
+
|
| 577 |
+
/**
|
| 578 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 579 |
+
* Constructor from \p __half data type, relies on \p __NV_SATFINITE
|
| 580 |
+
* behavior for out-of-range values.
|
| 581 |
+
*/
|
| 582 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e5m2(const __half f) {
|
| 583 |
+
__x = __nv_cvt_halfraw_to_fp8(static_cast<__half_raw>(f),
|
| 584 |
+
__NV_SATFINITE, __NV_E5M2);
|
| 585 |
+
}
|
| 586 |
+
/**
|
| 587 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 588 |
+
* Constructor from \p __nv_bfloat16 data type, relies on \p __NV_SATFINITE
|
| 589 |
+
* behavior for out-of-range values.
|
| 590 |
+
*/
|
| 591 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e5m2(const __nv_bfloat16 f) {
|
| 592 |
+
__x = __nv_cvt_bfloat16raw_to_fp8(static_cast<__nv_bfloat16_raw>(f),
|
| 593 |
+
__NV_SATFINITE, __NV_E5M2);
|
| 594 |
+
}
|
| 595 |
+
/**
|
| 596 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 597 |
+
* Constructor from \p float data type, relies on \p __NV_SATFINITE behavior
|
| 598 |
+
* for out-of-range values.
|
| 599 |
+
*/
|
| 600 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e5m2(const float f) {
|
| 601 |
+
__x = __nv_cvt_float_to_fp8(f, __NV_SATFINITE, __NV_E5M2);
|
| 602 |
+
}
|
| 603 |
+
/**
|
| 604 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 605 |
+
* Constructor from \p double data type, relies on \p __NV_SATFINITE
|
| 606 |
+
* behavior for out-of-range values.
|
| 607 |
+
*/
|
| 608 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e5m2(const double f) {
|
| 609 |
+
__x = __nv_cvt_double_to_fp8(f, __NV_SATFINITE, __NV_E5M2);
|
| 610 |
+
}
|
| 611 |
+
|
| 612 |
+
/* Converts from integral */
|
| 613 |
+
|
| 614 |
+
/**
|
| 615 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 616 |
+
* Constructor from \p unsigned \p short \p int data type, relies on \p
|
| 617 |
+
* __NV_SATFINITE behavior for out-of-range values.
|
| 618 |
+
*/
|
| 619 |
+
explicit __CUDA_HOSTDEVICE_FP8__
|
| 620 |
+
__nv_fp8_e5m2(const unsigned short int val) {
|
| 621 |
+
__x = static_cast<__nv_fp8_e5m2>(static_cast<float>(val)).__x;
|
| 622 |
+
}
|
| 623 |
+
/**
|
| 624 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 625 |
+
* Constructor from \p unsigned \p int data type, relies on \p
|
| 626 |
+
* __NV_SATFINITE behavior for out-of-range values.
|
| 627 |
+
*/
|
| 628 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e5m2(const unsigned int val) {
|
| 629 |
+
__x = static_cast<__nv_fp8_e5m2>(static_cast<float>(val)).__x;
|
| 630 |
+
}
|
| 631 |
+
/**
|
| 632 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 633 |
+
* Constructor from \p unsigned \p long \p long \p int data type, relies on
|
| 634 |
+
* \p __NV_SATFINITE behavior for out-of-range values.
|
| 635 |
+
*/
|
| 636 |
+
explicit __CUDA_HOSTDEVICE_FP8__
|
| 637 |
+
__nv_fp8_e5m2(const unsigned long long int val) {
|
| 638 |
+
__x = static_cast<__nv_fp8_e5m2>(static_cast<float>(val)).__x;
|
| 639 |
+
}
|
| 640 |
+
|
| 641 |
+
/**
|
| 642 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 643 |
+
* Constructor from \p short \p int data type.
|
| 644 |
+
*/
|
| 645 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e5m2(const short int val) {
|
| 646 |
+
__x = static_cast<__nv_fp8_e5m2>(static_cast<float>(val)).__x;
|
| 647 |
+
}
|
| 648 |
+
/**
|
| 649 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 650 |
+
* Constructor from \p int data type, relies on \p __NV_SATFINITE behavior
|
| 651 |
+
* for out-of-range values.
|
| 652 |
+
*/
|
| 653 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e5m2(const int val) {
|
| 654 |
+
__x = static_cast<__nv_fp8_e5m2>(static_cast<float>(val)).__x;
|
| 655 |
+
}
|
| 656 |
+
/**
|
| 657 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 658 |
+
* Constructor from \p long \p long \p int data type, relies on \p
|
| 659 |
+
* __NV_SATFINITE behavior for out-of-range values.
|
| 660 |
+
*/
|
| 661 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e5m2(const long long int val) {
|
| 662 |
+
__x = static_cast<__nv_fp8_e5m2>(static_cast<float>(val)).__x;
|
| 663 |
+
}
|
| 664 |
+
|
| 665 |
+
#if !defined(__CUDA_NO_FP8_CONVERSION_OPERATORS__)
|
| 666 |
+
/* Widening FP converts */
|
| 667 |
+
/**
|
| 668 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 669 |
+
* Conversion operator to \p __half data type.
|
| 670 |
+
*/
|
| 671 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator __half() const {
|
| 672 |
+
return static_cast<__half>(__nv_cvt_fp8_to_halfraw(__x, __NV_E5M2));
|
| 673 |
+
}
|
| 674 |
+
/**
|
| 675 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 676 |
+
* Conversion operator to \p float data type.
|
| 677 |
+
*/
|
| 678 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator float() const {
|
| 679 |
+
return __internal_halfraw_to_float(
|
| 680 |
+
__nv_cvt_fp8_to_halfraw(__x, __NV_E5M2));
|
| 681 |
+
}
|
| 682 |
+
/**
|
| 683 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 684 |
+
* Conversion operator to \p __nv_bfloat16 data type.
|
| 685 |
+
*/
|
| 686 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator __nv_bfloat16() const {
|
| 687 |
+
return static_cast<__nv_bfloat16>(
|
| 688 |
+
__internal_float_to_bf16raw_rz(float(*this)));
|
| 689 |
+
}
|
| 690 |
+
/**
|
| 691 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 692 |
+
* Conversion operator to \p double data type.
|
| 693 |
+
*/
|
| 694 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator double() const {
|
| 695 |
+
return static_cast<double>(float(*this));
|
| 696 |
+
}
|
| 697 |
+
|
| 698 |
+
/* Convert to integral */
|
| 699 |
+
|
| 700 |
+
/**
|
| 701 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 702 |
+
* Conversion operator to \p unsigned \p char data type.
|
| 703 |
+
* Clamps negative and too large inputs to the output range.
|
| 704 |
+
* \p NaN inputs convert to \p zero.
|
| 705 |
+
*/
|
| 706 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator unsigned char() const {
|
| 707 |
+
unsigned char i;
|
| 708 |
+
const float f = float(*this);
|
| 709 |
+
const unsigned char max_val = 0xFFU;
|
| 710 |
+
const unsigned char min_val = 0U;
|
| 711 |
+
const unsigned char bits = (*this).__x;
|
| 712 |
+
// saturation fixup
|
| 713 |
+
if ((bits & 0x7FU) > 0x7CU) {
|
| 714 |
+
// NaN
|
| 715 |
+
i = 0;
|
| 716 |
+
} else if (f > static_cast<float>(max_val)) {
|
| 717 |
+
// saturate maximum
|
| 718 |
+
i = max_val;
|
| 719 |
+
} else if (f < static_cast<float>(min_val)) {
|
| 720 |
+
// saturate minimum
|
| 721 |
+
i = min_val;
|
| 722 |
+
} else {
|
| 723 |
+
// normal value
|
| 724 |
+
i = static_cast<unsigned char>(f);
|
| 725 |
+
}
|
| 726 |
+
return i;
|
| 727 |
+
}
|
| 728 |
+
/**
|
| 729 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 730 |
+
* Conversion operator to \p unsigned \p short \p int data type.
|
| 731 |
+
* Clamps negative and too large inputs to the output range.
|
| 732 |
+
* \p NaN inputs convert to \p zero.
|
| 733 |
+
*/
|
| 734 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator unsigned short int() const {
|
| 735 |
+
return __half2ushort_rz(__half(*this));
|
| 736 |
+
}
|
| 737 |
+
/**
|
| 738 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 739 |
+
* Conversion operator to \p unsigned \p int data type.
|
| 740 |
+
* Clamps negative and too large inputs to the output range.
|
| 741 |
+
* \p NaN inputs convert to \p zero.
|
| 742 |
+
*/
|
| 743 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator unsigned int() const {
|
| 744 |
+
return __half2uint_rz(__half(*this));
|
| 745 |
+
}
|
| 746 |
+
/**
|
| 747 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 748 |
+
* Conversion operator to \p unsigned \p long \p long \p int data type.
|
| 749 |
+
* Clamps negative and too large inputs to the output range.
|
| 750 |
+
* \p NaN inputs convert to \p 0x8000000000000000ULL.
|
| 751 |
+
*/
|
| 752 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator unsigned long long int() const {
|
| 753 |
+
return __half2ull_rz(__half(*this));
|
| 754 |
+
}
|
| 755 |
+
|
| 756 |
+
/**
|
| 757 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 758 |
+
* Conversion operator to \p signed \p char data type.
|
| 759 |
+
* Clamps too large inputs to the output range.
|
| 760 |
+
* \p NaN inputs convert to \p zero.
|
| 761 |
+
*/
|
| 762 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator signed char() const {
|
| 763 |
+
signed char i;
|
| 764 |
+
const float f = float(*this);
|
| 765 |
+
const signed char max_val = (signed char)0x7FU;
|
| 766 |
+
const signed char min_val = (signed char)0x80U;
|
| 767 |
+
const unsigned char bits = (*this).__x;
|
| 768 |
+
// saturation fixup
|
| 769 |
+
if ((bits & 0x7FU) > 0x7CU) {
|
| 770 |
+
// NaN
|
| 771 |
+
i = 0;
|
| 772 |
+
} else if (f > static_cast<float>(max_val)) {
|
| 773 |
+
// saturate maximum
|
| 774 |
+
i = max_val;
|
| 775 |
+
} else if (f < static_cast<float>(min_val)) {
|
| 776 |
+
// saturate minimum
|
| 777 |
+
i = min_val;
|
| 778 |
+
} else {
|
| 779 |
+
// normal value
|
| 780 |
+
i = static_cast<signed char>(f);
|
| 781 |
+
}
|
| 782 |
+
return i;
|
| 783 |
+
}
|
| 784 |
+
/**
|
| 785 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 786 |
+
* Conversion operator to \p short \p int data type.
|
| 787 |
+
* Clamps too large inputs to the output range.
|
| 788 |
+
* \p NaN inputs convert to \p zero.
|
| 789 |
+
*/
|
| 790 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator short int() const {
|
| 791 |
+
return __half2short_rz(__half(*this));
|
| 792 |
+
}
|
| 793 |
+
/**
|
| 794 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 795 |
+
* Conversion operator to \p int data type.
|
| 796 |
+
* Clamps too large inputs to the output range.
|
| 797 |
+
* \p NaN inputs convert to \p zero.
|
| 798 |
+
*/
|
| 799 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator int() const {
|
| 800 |
+
return __half2int_rz(__half(*this));
|
| 801 |
+
}
|
| 802 |
+
/**
|
| 803 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 804 |
+
* Conversion operator to \p long \p long \p int data type.
|
| 805 |
+
* Clamps too large inputs to the output range.
|
| 806 |
+
* \p NaN inputs convert to \p 0x8000000000000000LL.
|
| 807 |
+
*/
|
| 808 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator long long int() const {
|
| 809 |
+
return __half2ll_rz(__half(*this));
|
| 810 |
+
}
|
| 811 |
+
|
| 812 |
+
/**
|
| 813 |
+
* \ingroup CUDA_MATH_FP8_E5M2_STRUCT
|
| 814 |
+
* Conversion operator to \p bool data type.
|
| 815 |
+
* +0 and -0 inputs convert to \p false.
|
| 816 |
+
* Non-zero inputs convert to \p true.
|
| 817 |
+
*/
|
| 818 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator bool() const {
|
| 819 |
+
return (__x & 0x7FU) != 0U;
|
| 820 |
+
}
|
| 821 |
+
#endif /* !defined(__CUDA_NO_FP8_CONVERSION_OPERATORS__) */
|
| 822 |
+
#endif /* !defined(__CUDA_NO_FP8_CONVERSIONS__) */
|
| 823 |
+
};
|
| 824 |
+
|
| 825 |
+
/**
|
| 826 |
+
* \defgroup CUDA_MATH_FP8X2_E5M2_STRUCT C++ struct for handling vector type of two fp8 values of e5m2 kind.
|
| 827 |
+
* \ingroup CUDA_MATH_INTRINSIC_FP8
|
| 828 |
+
*/
|
| 829 |
+
|
| 830 |
+
/**
|
| 831 |
+
* \ingroup CUDA_MATH_FP8X2_E5M2_STRUCT
|
| 832 |
+
* \brief __nv_fp8x2_e5m2 datatype
|
| 833 |
+
*
|
| 834 |
+
* \details This structure implements the datatype for handling two
|
| 835 |
+
* \p fp8 floating-point numbers of \p e5m2 kind each:
|
| 836 |
+
* with 1 sign, 5 exponent, 1 implicit and 2 explicit mantissa bits.
|
| 837 |
+
*
|
| 838 |
+
* The structure implements converting constructors and operators.
|
| 839 |
+
*/
|
| 840 |
+
struct __CUDA_ALIGN__(2) __nv_fp8x2_e5m2 {
|
| 841 |
+
public:
|
| 842 |
+
/**
|
| 843 |
+
* \ingroup CUDA_MATH_FP8X2_E5M2_STRUCT
|
| 844 |
+
* Storage variable contains the vector of two \p fp8 floating-point data
|
| 845 |
+
* values.
|
| 846 |
+
*/
|
| 847 |
+
__nv_fp8x2_storage_t __x;
|
| 848 |
+
|
| 849 |
+
/**
|
| 850 |
+
* \ingroup CUDA_MATH_FP8X2_E5M2_STRUCT
|
| 851 |
+
* Constructor by default.
|
| 852 |
+
*/
|
| 853 |
+
#if defined(__CPP_VERSION_AT_LEAST_11_FP8)
|
| 854 |
+
__nv_fp8x2_e5m2() = default;
|
| 855 |
+
#else
|
| 856 |
+
__CUDA_HOSTDEVICE_FP8__ __nv_fp8x2_e5m2() {}
|
| 857 |
+
#endif /* defined(__CPP_VERSION_AT_LEAST_11_FP8) */
|
| 858 |
+
|
| 859 |
+
#if !defined(__CUDA_NO_FP8_CONVERSIONS__)
|
| 860 |
+
|
| 861 |
+
/* Construct from wider types */
|
| 862 |
+
|
| 863 |
+
/**
|
| 864 |
+
* \ingroup CUDA_MATH_FP8X2_E5M2_STRUCT
|
| 865 |
+
* Constructor from \p __half2 data type, relies on \p __NV_SATFINITE
|
| 866 |
+
* behavior for out-of-range values.
|
| 867 |
+
*/
|
| 868 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x2_e5m2(const __half2 f) {
|
| 869 |
+
__x = __nv_cvt_halfraw2_to_fp8x2(static_cast<__half2_raw>(f),
|
| 870 |
+
__NV_SATFINITE, __NV_E5M2);
|
| 871 |
+
}
|
| 872 |
+
/**
|
| 873 |
+
* \ingroup CUDA_MATH_FP8X2_E5M2_STRUCT
|
| 874 |
+
* Constructor from \p __nv_bfloat162 data type, relies on \p __NV_SATFINITE
|
| 875 |
+
* behavior for out-of-range values.
|
| 876 |
+
*/
|
| 877 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x2_e5m2(const __nv_bfloat162 f) {
|
| 878 |
+
__x = __nv_cvt_bfloat16raw2_to_fp8x2(static_cast<__nv_bfloat162_raw>(f),
|
| 879 |
+
__NV_SATFINITE, __NV_E5M2);
|
| 880 |
+
}
|
| 881 |
+
/**
|
| 882 |
+
* \ingroup CUDA_MATH_FP8X2_E5M2_STRUCT
|
| 883 |
+
* Constructor from \p float2 data type, relies on \p __NV_SATFINITE
|
| 884 |
+
* behavior for out-of-range values.
|
| 885 |
+
*/
|
| 886 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x2_e5m2(const float2 f) {
|
| 887 |
+
__x = __nv_cvt_float2_to_fp8x2(f, __NV_SATFINITE, __NV_E5M2);
|
| 888 |
+
}
|
| 889 |
+
/**
|
| 890 |
+
* \ingroup CUDA_MATH_FP8X2_E5M2_STRUCT
|
| 891 |
+
* Constructor from \p double2 data type, relies on \p __NV_SATFINITE
|
| 892 |
+
* behavior for out-of-range values.
|
| 893 |
+
*/
|
| 894 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x2_e5m2(const double2 f) {
|
| 895 |
+
__x = __nv_cvt_double2_to_fp8x2(f, __NV_SATFINITE, __NV_E5M2);
|
| 896 |
+
}
|
| 897 |
+
|
| 898 |
+
#if !defined(__CUDA_NO_FP8_CONVERSION_OPERATORS__)
|
| 899 |
+
/* Widening converts */
|
| 900 |
+
/**
|
| 901 |
+
* \ingroup CUDA_MATH_FP8X2_E5M2_STRUCT
|
| 902 |
+
* Conversion operator to \p __half2 data type.
|
| 903 |
+
*/
|
| 904 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator __half2() const {
|
| 905 |
+
return static_cast<__half2>(__nv_cvt_fp8x2_to_halfraw2(__x, __NV_E5M2));
|
| 906 |
+
}
|
| 907 |
+
/**
|
| 908 |
+
* \ingroup CUDA_MATH_FP8X2_E5M2_STRUCT
|
| 909 |
+
* Conversion operator to \p float2 data type.
|
| 910 |
+
*/
|
| 911 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator float2() const {
|
| 912 |
+
return __internal_halfraw2_to_float2(
|
| 913 |
+
__nv_cvt_fp8x2_to_halfraw2(__x, __NV_E5M2));
|
| 914 |
+
}
|
| 915 |
+
#endif /* !defined(__CUDA_NO_FP8_CONVERSION_OPERATORS__) */
|
| 916 |
+
#endif /* !defined(__CUDA_NO_FP8_CONVERSIONS__) */
|
| 917 |
+
};
|
| 918 |
+
|
| 919 |
+
__CUDA_HOSTDEVICE_FP8_DECL__ unsigned int
|
| 920 |
+
__internal_pack_u16x2_to_u32(const unsigned short int src_lo,
|
| 921 |
+
const unsigned short int src_hi) {
|
| 922 |
+
unsigned int dst;
|
| 923 |
+
#if (defined __CUDACC__) && (defined __CUDA_ARCH__)
|
| 924 |
+
asm("{ mov.b32 %0, {%1,%2};}\n" : "=r"(dst) : "h"(src_lo), "h"(src_hi));
|
| 925 |
+
#else
|
| 926 |
+
dst = (static_cast<unsigned int>(src_hi) << 16U) |
|
| 927 |
+
static_cast<unsigned int>(src_lo);
|
| 928 |
+
#endif
|
| 929 |
+
return dst;
|
| 930 |
+
}
|
| 931 |
+
|
| 932 |
+
/**
|
| 933 |
+
* \defgroup CUDA_MATH_FP8X4_E5M2_STRUCT C++ struct for handling vector type of four fp8 values of e5m2 kind.
|
| 934 |
+
* \ingroup CUDA_MATH_INTRINSIC_FP8
|
| 935 |
+
*/
|
| 936 |
+
|
| 937 |
+
/**
|
| 938 |
+
* \ingroup CUDA_MATH_FP8X4_E5M2_STRUCT
|
| 939 |
+
* \brief __nv_fp8x4_e5m2 datatype
|
| 940 |
+
*
|
| 941 |
+
* \details This structure implements the datatype for handling four
|
| 942 |
+
* \p fp8 floating-point numbers of \p e5m2 kind each:
|
| 943 |
+
* with 1 sign, 5 exponent, 1 implicit and 2 explicit mantissa bits.
|
| 944 |
+
*
|
| 945 |
+
* The structure implements converting constructors and operators.
|
| 946 |
+
*/
|
| 947 |
+
struct __CUDA_ALIGN__(4) __nv_fp8x4_e5m2 {
|
| 948 |
+
public:
|
| 949 |
+
/**
|
| 950 |
+
* \ingroup CUDA_MATH_FP8X4_E5M2_STRUCT
|
| 951 |
+
* Storage variable contains the vector of four \p fp8 floating-point data
|
| 952 |
+
* values.
|
| 953 |
+
*/
|
| 954 |
+
__nv_fp8x4_storage_t __x;
|
| 955 |
+
|
| 956 |
+
/**
|
| 957 |
+
* \ingroup CUDA_MATH_FP8X4_E5M2_STRUCT
|
| 958 |
+
* Constructor by default.
|
| 959 |
+
*/
|
| 960 |
+
#if defined(__CPP_VERSION_AT_LEAST_11_FP8)
|
| 961 |
+
__nv_fp8x4_e5m2() = default;
|
| 962 |
+
#else
|
| 963 |
+
__CUDA_HOSTDEVICE_FP8__ __nv_fp8x4_e5m2() {}
|
| 964 |
+
#endif /* defined(__CPP_VERSION_AT_LEAST_11_FP8) */
|
| 965 |
+
|
| 966 |
+
#if !defined(__CUDA_NO_FP8_CONVERSIONS__)
|
| 967 |
+
|
| 968 |
+
/* Construct from wider types */
|
| 969 |
+
|
| 970 |
+
/**
|
| 971 |
+
* \ingroup CUDA_MATH_FP8X4_E5M2_STRUCT
|
| 972 |
+
* Constructor from a pair of \p __half2 data type values,
|
| 973 |
+
* relies on \p __NV_SATFINITE behavior for out-of-range values.
|
| 974 |
+
*/
|
| 975 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x4_e5m2(const __half2 flo,
|
| 976 |
+
const __half2 fhi) {
|
| 977 |
+
const __nv_fp8x2_storage_t rlo = __nv_cvt_halfraw2_to_fp8x2(
|
| 978 |
+
static_cast<__half2_raw>(flo), __NV_SATFINITE, __NV_E5M2);
|
| 979 |
+
const __nv_fp8x2_storage_t rhi = __nv_cvt_halfraw2_to_fp8x2(
|
| 980 |
+
static_cast<__half2_raw>(fhi), __NV_SATFINITE, __NV_E5M2);
|
| 981 |
+
__x = __internal_pack_u16x2_to_u32(rlo, rhi);
|
| 982 |
+
}
|
| 983 |
+
/**
|
| 984 |
+
* \ingroup CUDA_MATH_FP8X4_E5M2_STRUCT
|
| 985 |
+
* Constructor from a pair of \p __nv_bfloat162 data type values,
|
| 986 |
+
* relies on \p __NV_SATFINITE behavior for out-of-range values.
|
| 987 |
+
*/
|
| 988 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x4_e5m2(const __nv_bfloat162 flo,
|
| 989 |
+
const __nv_bfloat162 fhi) {
|
| 990 |
+
const __nv_fp8x2_storage_t rlo = __nv_cvt_bfloat16raw2_to_fp8x2(
|
| 991 |
+
static_cast<__nv_bfloat162_raw>(flo), __NV_SATFINITE, __NV_E5M2);
|
| 992 |
+
const __nv_fp8x2_storage_t rhi = __nv_cvt_bfloat16raw2_to_fp8x2(
|
| 993 |
+
static_cast<__nv_bfloat162_raw>(fhi), __NV_SATFINITE, __NV_E5M2);
|
| 994 |
+
__x = __internal_pack_u16x2_to_u32(rlo, rhi);
|
| 995 |
+
}
|
| 996 |
+
/**
|
| 997 |
+
* \ingroup CUDA_MATH_FP8X4_E5M2_STRUCT
|
| 998 |
+
* Constructor from \p float4 vector data type,
|
| 999 |
+
* relies on \p __NV_SATFINITE behavior for out-of-range values.
|
| 1000 |
+
*/
|
| 1001 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x4_e5m2(const float4 f) {
|
| 1002 |
+
const float2 flo = {f.x, f.y};
|
| 1003 |
+
const float2 fhi = {f.z, f.w};
|
| 1004 |
+
const __nv_fp8x2_storage_t rlo =
|
| 1005 |
+
__nv_cvt_float2_to_fp8x2(flo, __NV_SATFINITE, __NV_E5M2);
|
| 1006 |
+
const __nv_fp8x2_storage_t rhi =
|
| 1007 |
+
__nv_cvt_float2_to_fp8x2(fhi, __NV_SATFINITE, __NV_E5M2);
|
| 1008 |
+
__x = __internal_pack_u16x2_to_u32(rlo, rhi);
|
| 1009 |
+
}
|
| 1010 |
+
/**
|
| 1011 |
+
* \ingroup CUDA_MATH_FP8X4_E5M2_STRUCT
|
| 1012 |
+
* Constructor from \p double4 vector data type,
|
| 1013 |
+
* relies on \p __NV_SATFINITE behavior for out-of-range values.
|
| 1014 |
+
*/
|
| 1015 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x4_e5m2(const double4 f) {
|
| 1016 |
+
const double2 flo = {f.x, f.y};
|
| 1017 |
+
const double2 fhi = {f.z, f.w};
|
| 1018 |
+
const __nv_fp8x2_storage_t rlo =
|
| 1019 |
+
__nv_cvt_double2_to_fp8x2(flo, __NV_SATFINITE, __NV_E5M2);
|
| 1020 |
+
const __nv_fp8x2_storage_t rhi =
|
| 1021 |
+
__nv_cvt_double2_to_fp8x2(fhi, __NV_SATFINITE, __NV_E5M2);
|
| 1022 |
+
__x = __internal_pack_u16x2_to_u32(rlo, rhi);
|
| 1023 |
+
}
|
| 1024 |
+
|
| 1025 |
+
#if !defined(__CUDA_NO_FP8_CONVERSION_OPERATORS__)
|
| 1026 |
+
/* Widening converts */
|
| 1027 |
+
|
| 1028 |
+
/**
|
| 1029 |
+
* \ingroup CUDA_MATH_FP8X4_E5M2_STRUCT
|
| 1030 |
+
* Conversion operator to \p float4 vector data type.
|
| 1031 |
+
*/
|
| 1032 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator float4() const {
|
| 1033 |
+
const __nv_fp8x2_storage_t slo = static_cast<__nv_fp8x2_storage_t>(__x);
|
| 1034 |
+
const __nv_fp8x2_storage_t shi =
|
| 1035 |
+
static_cast<__nv_fp8x2_storage_t>(__x >> 16U);
|
| 1036 |
+
float2 rlo = __internal_halfraw2_to_float2(
|
| 1037 |
+
__nv_cvt_fp8x2_to_halfraw2(slo, __NV_E5M2));
|
| 1038 |
+
float2 rhi = __internal_halfraw2_to_float2(
|
| 1039 |
+
__nv_cvt_fp8x2_to_halfraw2(shi, __NV_E5M2));
|
| 1040 |
+
float4 res = {rlo.x, rlo.y, rhi.x, rhi.y};
|
| 1041 |
+
return res;
|
| 1042 |
+
}
|
| 1043 |
+
#endif /* !defined(__CUDA_NO_FP8_CONVERSION_OPERATORS__) */
|
| 1044 |
+
#endif /* !defined(__CUDA_NO_FP8_CONVERSIONS__) */
|
| 1045 |
+
};
|
| 1046 |
+
|
| 1047 |
+
/**
|
| 1048 |
+
* \defgroup CUDA_MATH_FP8_E4M3_STRUCT C++ struct for handling fp8 data type of e4m3 kind.
|
| 1049 |
+
* \ingroup CUDA_MATH_INTRINSIC_FP8
|
| 1050 |
+
*/
|
| 1051 |
+
|
| 1052 |
+
/**
|
| 1053 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1054 |
+
* \brief __nv_fp8_e4m3 datatype
|
| 1055 |
+
*
|
| 1056 |
+
* \details This structure implements the datatype for storing
|
| 1057 |
+
* \p fp8 floating-point numbers of \p e4m3 kind:
|
| 1058 |
+
* with 1 sign, 4 exponent, 1 implicit and 3 explicit mantissa bits.
|
| 1059 |
+
* The encoding doesn't support Infinity.
|
| 1060 |
+
* NaNs are limited to 0x7F and 0xFF values.
|
| 1061 |
+
*
|
| 1062 |
+
* The structure implements converting constructors and operators.
|
| 1063 |
+
*/
|
| 1064 |
+
struct __CUDA_ALIGN__(1) __nv_fp8_e4m3 {
|
| 1065 |
+
public:
|
| 1066 |
+
/**
|
| 1067 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1068 |
+
* Storage variable contains the \p fp8 floating-point data.
|
| 1069 |
+
*/
|
| 1070 |
+
__nv_fp8_storage_t __x;
|
| 1071 |
+
|
| 1072 |
+
/**
|
| 1073 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1074 |
+
* Constructor by default.
|
| 1075 |
+
*/
|
| 1076 |
+
#if defined(__CPP_VERSION_AT_LEAST_11_FP8)
|
| 1077 |
+
__nv_fp8_e4m3() = default;
|
| 1078 |
+
#else
|
| 1079 |
+
__CUDA_HOSTDEVICE_FP8__ __nv_fp8_e4m3() {}
|
| 1080 |
+
#endif /* defined(__CPP_VERSION_AT_LEAST_11_FP8) */
|
| 1081 |
+
|
| 1082 |
+
#if !defined(__CUDA_NO_FP8_CONVERSIONS__)
|
| 1083 |
+
|
| 1084 |
+
/* Construct from wider FP types */
|
| 1085 |
+
/* Note we do avoid constructor init-list because of special host/device
|
| 1086 |
+
* compilation rules */
|
| 1087 |
+
|
| 1088 |
+
/**
|
| 1089 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1090 |
+
* Constructor from \p __half data type, relies on \p __NV_SATFINITE
|
| 1091 |
+
* behavior for out-of-range values.
|
| 1092 |
+
*/
|
| 1093 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e4m3(const __half f) {
|
| 1094 |
+
__x = __nv_cvt_halfraw_to_fp8(static_cast<__half_raw>(f),
|
| 1095 |
+
__NV_SATFINITE, __NV_E4M3);
|
| 1096 |
+
}
|
| 1097 |
+
/**
|
| 1098 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1099 |
+
* Constructor from \p __nv_bfloat16 data type, relies on \p __NV_SATFINITE
|
| 1100 |
+
* behavior for out-of-range values.
|
| 1101 |
+
*/
|
| 1102 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e4m3(const __nv_bfloat16 f) {
|
| 1103 |
+
__x = __nv_cvt_bfloat16raw_to_fp8(static_cast<__nv_bfloat16_raw>(f),
|
| 1104 |
+
__NV_SATFINITE, __NV_E4M3);
|
| 1105 |
+
}
|
| 1106 |
+
/**
|
| 1107 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1108 |
+
* Constructor from \p float data type, relies on \p __NV_SATFINITE behavior
|
| 1109 |
+
* for out-of-range values.
|
| 1110 |
+
*/
|
| 1111 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e4m3(const float f) {
|
| 1112 |
+
__x = __nv_cvt_float_to_fp8(f, __NV_SATFINITE, __NV_E4M3);
|
| 1113 |
+
}
|
| 1114 |
+
/**
|
| 1115 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1116 |
+
* Constructor from \p double data type, relies on \p __NV_SATFINITE
|
| 1117 |
+
* behavior for out-of-range values.
|
| 1118 |
+
*/
|
| 1119 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e4m3(const double f) {
|
| 1120 |
+
__x = __nv_cvt_double_to_fp8(f, __NV_SATFINITE, __NV_E4M3);
|
| 1121 |
+
}
|
| 1122 |
+
|
| 1123 |
+
/* Converts from integral */
|
| 1124 |
+
|
| 1125 |
+
/**
|
| 1126 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1127 |
+
* Constructor from \p unsigned \p short \p int data type, relies on \p
|
| 1128 |
+
* __NV_SATFINITE behavior for out-of-range values.
|
| 1129 |
+
*/
|
| 1130 |
+
explicit __CUDA_HOSTDEVICE_FP8__
|
| 1131 |
+
__nv_fp8_e4m3(const unsigned short int val) {
|
| 1132 |
+
__x = static_cast<__nv_fp8_e4m3>(static_cast<float>(val)).__x;
|
| 1133 |
+
}
|
| 1134 |
+
/**
|
| 1135 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1136 |
+
* Constructor from \p unsigned \p int data type, relies on \p
|
| 1137 |
+
* __NV_SATFINITE behavior for out-of-range values.
|
| 1138 |
+
*/
|
| 1139 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e4m3(const unsigned int val) {
|
| 1140 |
+
__x = static_cast<__nv_fp8_e4m3>(static_cast<float>(val)).__x;
|
| 1141 |
+
}
|
| 1142 |
+
/**
|
| 1143 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1144 |
+
* Constructor from \p unsigned \p long \p long \p int data type, relies on
|
| 1145 |
+
* \p __NV_SATFINITE behavior for out-of-range values.
|
| 1146 |
+
*/
|
| 1147 |
+
explicit __CUDA_HOSTDEVICE_FP8__
|
| 1148 |
+
__nv_fp8_e4m3(const unsigned long long int val) {
|
| 1149 |
+
__x = static_cast<__nv_fp8_e4m3>(static_cast<float>(val)).__x;
|
| 1150 |
+
}
|
| 1151 |
+
|
| 1152 |
+
/**
|
| 1153 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1154 |
+
* Constructor from \p short \p int data type, relies on \p
|
| 1155 |
+
* __NV_SATFINITE behavior for out-of-range values.
|
| 1156 |
+
*/
|
| 1157 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e4m3(const short int val) {
|
| 1158 |
+
__x = static_cast<__nv_fp8_e4m3>(static_cast<float>(val)).__x;
|
| 1159 |
+
}
|
| 1160 |
+
/**
|
| 1161 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1162 |
+
* Constructor from \p int data type, relies on \p __NV_SATFINITE behavior
|
| 1163 |
+
* for out-of-range values.
|
| 1164 |
+
*/
|
| 1165 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e4m3(const int val) {
|
| 1166 |
+
__x = static_cast<__nv_fp8_e4m3>(static_cast<float>(val)).__x;
|
| 1167 |
+
}
|
| 1168 |
+
/**
|
| 1169 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1170 |
+
* Constructor from \p long \p long \p int data type, relies on \p
|
| 1171 |
+
* __NV_SATFINITE behavior for out-of-range values.
|
| 1172 |
+
*/
|
| 1173 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8_e4m3(const long long int val) {
|
| 1174 |
+
__x = static_cast<__nv_fp8_e4m3>(static_cast<float>(val)).__x;
|
| 1175 |
+
}
|
| 1176 |
+
|
| 1177 |
+
#if !defined(__CUDA_NO_FP8_CONVERSION_OPERATORS__)
|
| 1178 |
+
/* Widening FP converts */
|
| 1179 |
+
/**
|
| 1180 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1181 |
+
* Conversion operator to \p __half data type.
|
| 1182 |
+
*/
|
| 1183 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator __half() const {
|
| 1184 |
+
return static_cast<__half>(__nv_cvt_fp8_to_halfraw(__x, __NV_E4M3));
|
| 1185 |
+
}
|
| 1186 |
+
/**
|
| 1187 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1188 |
+
* Conversion operator to \p float data type.
|
| 1189 |
+
*/
|
| 1190 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator float() const {
|
| 1191 |
+
return __internal_halfraw_to_float(
|
| 1192 |
+
__nv_cvt_fp8_to_halfraw(__x, __NV_E4M3));
|
| 1193 |
+
}
|
| 1194 |
+
/**
|
| 1195 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1196 |
+
* Conversion operator to \p __nv_bfloat16 data type.
|
| 1197 |
+
*/
|
| 1198 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator __nv_bfloat16() const {
|
| 1199 |
+
return static_cast<__nv_bfloat16>(
|
| 1200 |
+
__internal_float_to_bf16raw_rz(float(*this)));
|
| 1201 |
+
}
|
| 1202 |
+
/**
|
| 1203 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1204 |
+
* Conversion operator to \p double data type.
|
| 1205 |
+
*/
|
| 1206 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator double() const {
|
| 1207 |
+
return static_cast<double>(float(*this));
|
| 1208 |
+
}
|
| 1209 |
+
|
| 1210 |
+
/* Convert to integral */
|
| 1211 |
+
|
| 1212 |
+
/**
|
| 1213 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1214 |
+
* Conversion operator to \p unsigned \p char data type.
|
| 1215 |
+
* Clamps negative and too large inputs to the output range.
|
| 1216 |
+
* \p NaN inputs convert to \p zero.
|
| 1217 |
+
*/
|
| 1218 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator unsigned char() const {
|
| 1219 |
+
unsigned char i;
|
| 1220 |
+
const float f = float(*this);
|
| 1221 |
+
const unsigned char max_val = 0xFFU;
|
| 1222 |
+
const unsigned char min_val = 0U;
|
| 1223 |
+
const unsigned char bits = (*this).__x;
|
| 1224 |
+
// saturation fixup
|
| 1225 |
+
if ((bits & 0x7FU) == 0x7FU) {
|
| 1226 |
+
// NaN
|
| 1227 |
+
i = 0;
|
| 1228 |
+
} else if (f > static_cast<float>(max_val)) {
|
| 1229 |
+
// saturate maximum
|
| 1230 |
+
i = max_val;
|
| 1231 |
+
} else if (f < static_cast<float>(min_val)) {
|
| 1232 |
+
// saturate minimum
|
| 1233 |
+
i = min_val;
|
| 1234 |
+
} else {
|
| 1235 |
+
// normal value
|
| 1236 |
+
i = static_cast<unsigned char>(f);
|
| 1237 |
+
}
|
| 1238 |
+
return i;
|
| 1239 |
+
}
|
| 1240 |
+
|
| 1241 |
+
/**
|
| 1242 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1243 |
+
* Conversion operator to \p unsigned \p short \p int data type.
|
| 1244 |
+
* Clamps negative inputs to zero.
|
| 1245 |
+
* \p NaN inputs convert to \p zero.
|
| 1246 |
+
*/
|
| 1247 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator unsigned short int() const {
|
| 1248 |
+
return __half2ushort_rz(__half(*this));
|
| 1249 |
+
}
|
| 1250 |
+
/**
|
| 1251 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1252 |
+
* Conversion operator to \p unsigned \p int data type.
|
| 1253 |
+
* Clamps negative inputs to zero.
|
| 1254 |
+
* \p NaN inputs convert to \p zero.
|
| 1255 |
+
*/
|
| 1256 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator unsigned int() const {
|
| 1257 |
+
return __half2uint_rz(__half(*this));
|
| 1258 |
+
}
|
| 1259 |
+
/**
|
| 1260 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1261 |
+
* Conversion operator to \p unsigned \p long \p long \p int data type.
|
| 1262 |
+
* Clamps negative inputs to zero.
|
| 1263 |
+
* \p NaN inputs convert to \p 0x8000000000000000ULL.
|
| 1264 |
+
*/
|
| 1265 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator unsigned long long int() const {
|
| 1266 |
+
return __half2ull_rz(__half(*this));
|
| 1267 |
+
}
|
| 1268 |
+
|
| 1269 |
+
/**
|
| 1270 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1271 |
+
* Conversion operator to \p signed \p char data type.
|
| 1272 |
+
* Clamps too large inputs to the output range.
|
| 1273 |
+
* \p NaN inputs convert to \p zero.
|
| 1274 |
+
*/
|
| 1275 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator signed char() const {
|
| 1276 |
+
signed char i;
|
| 1277 |
+
const float f = float(*this);
|
| 1278 |
+
const signed char max_val = (signed char)0x7FU;
|
| 1279 |
+
const signed char min_val = (signed char)0x80U;
|
| 1280 |
+
const unsigned char bits = (*this).__x;
|
| 1281 |
+
// saturation fixup
|
| 1282 |
+
if ((bits & 0x7FU) == 0x7FU) {
|
| 1283 |
+
// NaN
|
| 1284 |
+
i = 0;
|
| 1285 |
+
} else if (f > static_cast<float>(max_val)) {
|
| 1286 |
+
// saturate maximum
|
| 1287 |
+
i = max_val;
|
| 1288 |
+
} else if (f < static_cast<float>(min_val)) {
|
| 1289 |
+
// saturate minimum
|
| 1290 |
+
i = min_val;
|
| 1291 |
+
} else {
|
| 1292 |
+
// normal value
|
| 1293 |
+
i = static_cast<signed char>(f);
|
| 1294 |
+
}
|
| 1295 |
+
return i;
|
| 1296 |
+
}
|
| 1297 |
+
/**
|
| 1298 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1299 |
+
* Conversion operator to \p short \p int data type.
|
| 1300 |
+
* \p NaN inputs convert to \p zero.
|
| 1301 |
+
*/
|
| 1302 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator short int() const {
|
| 1303 |
+
return __half2short_rz(__half(*this));
|
| 1304 |
+
}
|
| 1305 |
+
/**
|
| 1306 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1307 |
+
* Conversion operator to \p int data type.
|
| 1308 |
+
* \p NaN inputs convert to \p zero.
|
| 1309 |
+
*/
|
| 1310 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator int() const {
|
| 1311 |
+
return __half2int_rz(__half(*this));
|
| 1312 |
+
}
|
| 1313 |
+
/**
|
| 1314 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1315 |
+
* Conversion operator to \p long \p long \p int data type.
|
| 1316 |
+
* \p NaN inputs convert to \p 0x8000000000000000LL.
|
| 1317 |
+
*/
|
| 1318 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator long long int() const {
|
| 1319 |
+
return __half2ll_rz(__half(*this));
|
| 1320 |
+
}
|
| 1321 |
+
|
| 1322 |
+
/**
|
| 1323 |
+
* \ingroup CUDA_MATH_FP8_E4M3_STRUCT
|
| 1324 |
+
* Conversion operator to \p bool data type.
|
| 1325 |
+
* +0 and -0 inputs convert to \p false.
|
| 1326 |
+
* Non-zero inputs convert to \p true.
|
| 1327 |
+
*/
|
| 1328 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator bool() const {
|
| 1329 |
+
return (__x & 0x7FU) != 0U;
|
| 1330 |
+
}
|
| 1331 |
+
#endif /* !defined(__CUDA_NO_FP8_CONVERSION_OPERATORS__) */
|
| 1332 |
+
#endif /* !defined(__CUDA_NO_FP8_CONVERSIONS__) */
|
| 1333 |
+
};
|
| 1334 |
+
|
| 1335 |
+
/**
|
| 1336 |
+
* \defgroup CUDA_MATH_FP8X2_E4M3_STRUCT C++ struct for handling vector type of two fp8 values of e4m3 kind.
|
| 1337 |
+
* \ingroup CUDA_MATH_INTRINSIC_FP8
|
| 1338 |
+
*/
|
| 1339 |
+
|
| 1340 |
+
/**
|
| 1341 |
+
* \ingroup CUDA_MATH_FP8X2_E4M3_STRUCT
|
| 1342 |
+
* \brief __nv_fp8x2_e4m3 datatype
|
| 1343 |
+
*
|
| 1344 |
+
* \details This structure implements the datatype for storage
|
| 1345 |
+
* and operations on the vector of two \p fp8 values of \p e4m3 kind each:
|
| 1346 |
+
* with 1 sign, 4 exponent, 1 implicit and 3 explicit mantissa bits.
|
| 1347 |
+
* The encoding doesn't support Infinity.
|
| 1348 |
+
* NaNs are limited to 0x7F and 0xFF values.
|
| 1349 |
+
*/
|
| 1350 |
+
struct __CUDA_ALIGN__(2) __nv_fp8x2_e4m3 {
|
| 1351 |
+
public:
|
| 1352 |
+
/**
|
| 1353 |
+
* \ingroup CUDA_MATH_FP8X2_E4M3_STRUCT
|
| 1354 |
+
* Storage variable contains the vector of two \p fp8 floating-point data
|
| 1355 |
+
* values.
|
| 1356 |
+
*/
|
| 1357 |
+
__nv_fp8x2_storage_t __x;
|
| 1358 |
+
|
| 1359 |
+
/**
|
| 1360 |
+
* \ingroup CUDA_MATH_FP8X2_E4M3_STRUCT
|
| 1361 |
+
* Constructor by default.
|
| 1362 |
+
*/
|
| 1363 |
+
#if defined(__CPP_VERSION_AT_LEAST_11_FP8)
|
| 1364 |
+
__nv_fp8x2_e4m3() = default;
|
| 1365 |
+
#else
|
| 1366 |
+
__CUDA_HOSTDEVICE_FP8__ __nv_fp8x2_e4m3() {}
|
| 1367 |
+
#endif /* defined(__CPP_VERSION_AT_LEAST_11_FP8) */
|
| 1368 |
+
|
| 1369 |
+
#if !defined(__CUDA_NO_FP8_CONVERSIONS__)
|
| 1370 |
+
|
| 1371 |
+
/* Construct from wider types */
|
| 1372 |
+
|
| 1373 |
+
/**
|
| 1374 |
+
* \ingroup CUDA_MATH_FP8X2_E4M3_STRUCT
|
| 1375 |
+
* Constructor from \p __half2 data type, relies on \p __NV_SATFINITE
|
| 1376 |
+
* behavior for out-of-range values.
|
| 1377 |
+
*/
|
| 1378 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x2_e4m3(const __half2 f) {
|
| 1379 |
+
__x = __nv_cvt_halfraw2_to_fp8x2(static_cast<__half2_raw>(f),
|
| 1380 |
+
__NV_SATFINITE, __NV_E4M3);
|
| 1381 |
+
}
|
| 1382 |
+
/**
|
| 1383 |
+
* \ingroup CUDA_MATH_FP8X2_E4M3_STRUCT
|
| 1384 |
+
* Constructor from \p __nv_bfloat162 data type, relies on \p __NV_SATFINITE
|
| 1385 |
+
* behavior for out-of-range values.
|
| 1386 |
+
*/
|
| 1387 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x2_e4m3(const __nv_bfloat162 f) {
|
| 1388 |
+
__x = __nv_cvt_bfloat16raw2_to_fp8x2(static_cast<__nv_bfloat162_raw>(f),
|
| 1389 |
+
__NV_SATFINITE, __NV_E4M3);
|
| 1390 |
+
}
|
| 1391 |
+
/**
|
| 1392 |
+
* \ingroup CUDA_MATH_FP8X2_E4M3_STRUCT
|
| 1393 |
+
* Constructor from \p float2 data type, relies on \p __NV_SATFINITE
|
| 1394 |
+
* behavior for out-of-range values.
|
| 1395 |
+
*/
|
| 1396 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x2_e4m3(const float2 f) {
|
| 1397 |
+
__x = __nv_cvt_float2_to_fp8x2(f, __NV_SATFINITE, __NV_E4M3);
|
| 1398 |
+
}
|
| 1399 |
+
/**
|
| 1400 |
+
* \ingroup CUDA_MATH_FP8X2_E4M3_STRUCT
|
| 1401 |
+
* Constructor from \p double2 data type, relies on \p __NV_SATFINITE
|
| 1402 |
+
* behavior for out-of-range values.
|
| 1403 |
+
*/
|
| 1404 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x2_e4m3(const double2 f) {
|
| 1405 |
+
__x = __nv_cvt_double2_to_fp8x2(f, __NV_SATFINITE, __NV_E4M3);
|
| 1406 |
+
}
|
| 1407 |
+
|
| 1408 |
+
#if !defined(__CUDA_NO_FP8_CONVERSION_OPERATORS__)
|
| 1409 |
+
/* Widening converts */
|
| 1410 |
+
/**
|
| 1411 |
+
* \ingroup CUDA_MATH_FP8X2_E4M3_STRUCT
|
| 1412 |
+
* Conversion operator to \p __half2 data type.
|
| 1413 |
+
*/
|
| 1414 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator __half2() const {
|
| 1415 |
+
return static_cast<__half2>(__nv_cvt_fp8x2_to_halfraw2(__x, __NV_E4M3));
|
| 1416 |
+
}
|
| 1417 |
+
/**
|
| 1418 |
+
* \ingroup CUDA_MATH_FP8X2_E4M3_STRUCT
|
| 1419 |
+
* Conversion operator to \p float2 data type.
|
| 1420 |
+
*/
|
| 1421 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator float2() const {
|
| 1422 |
+
return __internal_halfraw2_to_float2(
|
| 1423 |
+
__nv_cvt_fp8x2_to_halfraw2(__x, __NV_E4M3));
|
| 1424 |
+
}
|
| 1425 |
+
#endif /* !defined(__CUDA_NO_FP8_CONVERSION_OPERATORS__) */
|
| 1426 |
+
#endif /* !defined(__CUDA_NO_FP8_CONVERSIONS__) */
|
| 1427 |
+
};
|
| 1428 |
+
|
| 1429 |
+
/**
|
| 1430 |
+
* \defgroup CUDA_MATH_FP8X4_E4M3_STRUCT C++ struct for handling vector type of four fp8 values of e4m3 kind.
|
| 1431 |
+
* \ingroup CUDA_MATH_INTRINSIC_FP8
|
| 1432 |
+
*/
|
| 1433 |
+
|
| 1434 |
+
/**
|
| 1435 |
+
* \ingroup CUDA_MATH_FP8X4_E4M3_STRUCT
|
| 1436 |
+
* \brief __nv_fp8x4_e4m3 datatype
|
| 1437 |
+
*
|
| 1438 |
+
* \details This structure implements the datatype for storage
|
| 1439 |
+
* and operations on the vector of four \p fp8 values of \p e4m3 kind each:
|
| 1440 |
+
* with 1 sign, 4 exponent, 1 implicit and 3 explicit mantissa bits.
|
| 1441 |
+
* The encoding doesn't support Infinity.
|
| 1442 |
+
* NaNs are limited to 0x7F and 0xFF values.
|
| 1443 |
+
*/
|
| 1444 |
+
struct __CUDA_ALIGN__(4) __nv_fp8x4_e4m3 {
|
| 1445 |
+
public:
|
| 1446 |
+
/**
|
| 1447 |
+
* \ingroup CUDA_MATH_FP8X4_E4M3_STRUCT
|
| 1448 |
+
* Storage variable contains the vector of four \p fp8 floating-point data
|
| 1449 |
+
* values.
|
| 1450 |
+
*/
|
| 1451 |
+
__nv_fp8x4_storage_t __x;
|
| 1452 |
+
|
| 1453 |
+
/**
|
| 1454 |
+
* \ingroup CUDA_MATH_FP8X4_E4M3_STRUCT
|
| 1455 |
+
* Constructor by default.
|
| 1456 |
+
*/
|
| 1457 |
+
#if defined(__CPP_VERSION_AT_LEAST_11_FP8)
|
| 1458 |
+
__nv_fp8x4_e4m3() = default;
|
| 1459 |
+
#else
|
| 1460 |
+
__CUDA_HOSTDEVICE_FP8__ __nv_fp8x4_e4m3() {}
|
| 1461 |
+
#endif /* defined(__CPP_VERSION_AT_LEAST_11_FP8) */
|
| 1462 |
+
|
| 1463 |
+
#if !defined(__CUDA_NO_FP8_CONVERSIONS__)
|
| 1464 |
+
|
| 1465 |
+
/* Construct from wider types */
|
| 1466 |
+
|
| 1467 |
+
/**
|
| 1468 |
+
* \ingroup CUDA_MATH_FP8X4_E4M3_STRUCT
|
| 1469 |
+
* Constructor from a pair of \p __half2 data type values,
|
| 1470 |
+
* relies on \p __NV_SATFINITE behavior for out-of-range values.
|
| 1471 |
+
*/
|
| 1472 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x4_e4m3(const __half2 flo,
|
| 1473 |
+
const __half2 fhi) {
|
| 1474 |
+
const __nv_fp8x2_storage_t rlo = __nv_cvt_halfraw2_to_fp8x2(
|
| 1475 |
+
static_cast<__half2_raw>(flo), __NV_SATFINITE, __NV_E4M3);
|
| 1476 |
+
const __nv_fp8x2_storage_t rhi = __nv_cvt_halfraw2_to_fp8x2(
|
| 1477 |
+
static_cast<__half2_raw>(fhi), __NV_SATFINITE, __NV_E4M3);
|
| 1478 |
+
__x = __internal_pack_u16x2_to_u32(rlo, rhi);
|
| 1479 |
+
}
|
| 1480 |
+
/**
|
| 1481 |
+
* \ingroup CUDA_MATH_FP8X4_E4M3_STRUCT
|
| 1482 |
+
* Constructor from a pair of \p __nv_bfloat162 data type values,
|
| 1483 |
+
* relies on \p __NV_SATFINITE behavior for out-of-range values.
|
| 1484 |
+
*/
|
| 1485 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x4_e4m3(const __nv_bfloat162 flo,
|
| 1486 |
+
const __nv_bfloat162 fhi) {
|
| 1487 |
+
const __nv_fp8x2_storage_t rlo = __nv_cvt_bfloat16raw2_to_fp8x2(
|
| 1488 |
+
static_cast<__nv_bfloat162_raw>(flo), __NV_SATFINITE, __NV_E4M3);
|
| 1489 |
+
const __nv_fp8x2_storage_t rhi = __nv_cvt_bfloat16raw2_to_fp8x2(
|
| 1490 |
+
static_cast<__nv_bfloat162_raw>(fhi), __NV_SATFINITE, __NV_E4M3);
|
| 1491 |
+
__x = __internal_pack_u16x2_to_u32(rlo, rhi);
|
| 1492 |
+
}
|
| 1493 |
+
/**
|
| 1494 |
+
* \ingroup CUDA_MATH_FP8X4_E4M3_STRUCT
|
| 1495 |
+
* Constructor from \p float4 vector data type,
|
| 1496 |
+
* relies on \p __NV_SATFINITE behavior for out-of-range values.
|
| 1497 |
+
*/
|
| 1498 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x4_e4m3(const float4 f) {
|
| 1499 |
+
const float2 flo = {f.x, f.y};
|
| 1500 |
+
const float2 fhi = {f.z, f.w};
|
| 1501 |
+
const __nv_fp8x2_storage_t rlo =
|
| 1502 |
+
__nv_cvt_float2_to_fp8x2(flo, __NV_SATFINITE, __NV_E4M3);
|
| 1503 |
+
const __nv_fp8x2_storage_t rhi =
|
| 1504 |
+
__nv_cvt_float2_to_fp8x2(fhi, __NV_SATFINITE, __NV_E4M3);
|
| 1505 |
+
__x = __internal_pack_u16x2_to_u32(rlo, rhi);
|
| 1506 |
+
}
|
| 1507 |
+
/**
|
| 1508 |
+
* \ingroup CUDA_MATH_FP8X4_E4M3_STRUCT
|
| 1509 |
+
* Constructor from \p double4 vector data type,
|
| 1510 |
+
* relies on \p __NV_SATFINITE behavior for out-of-range values.
|
| 1511 |
+
*/
|
| 1512 |
+
explicit __CUDA_HOSTDEVICE_FP8__ __nv_fp8x4_e4m3(const double4 f) {
|
| 1513 |
+
const double2 flo = {f.x, f.y};
|
| 1514 |
+
const double2 fhi = {f.z, f.w};
|
| 1515 |
+
const __nv_fp8x2_storage_t rlo =
|
| 1516 |
+
__nv_cvt_double2_to_fp8x2(flo, __NV_SATFINITE, __NV_E4M3);
|
| 1517 |
+
const __nv_fp8x2_storage_t rhi =
|
| 1518 |
+
__nv_cvt_double2_to_fp8x2(fhi, __NV_SATFINITE, __NV_E4M3);
|
| 1519 |
+
__x = __internal_pack_u16x2_to_u32(rlo, rhi);
|
| 1520 |
+
}
|
| 1521 |
+
|
| 1522 |
+
#if !defined(__CUDA_NO_FP8_CONVERSION_OPERATORS__)
|
| 1523 |
+
/* Widening converts */
|
| 1524 |
+
|
| 1525 |
+
/**
|
| 1526 |
+
* \ingroup CUDA_MATH_FP8X4_E4M3_STRUCT
|
| 1527 |
+
* Conversion operator to \p float4 vector data type.
|
| 1528 |
+
*/
|
| 1529 |
+
explicit __CUDA_HOSTDEVICE_FP8__ operator float4() const {
|
| 1530 |
+
const __nv_fp8x2_storage_t slo = static_cast<__nv_fp8x2_storage_t>(__x);
|
| 1531 |
+
const __nv_fp8x2_storage_t shi =
|
| 1532 |
+
static_cast<__nv_fp8x2_storage_t>(__x >> 16U);
|
| 1533 |
+
float2 rlo = __internal_halfraw2_to_float2(
|
| 1534 |
+
__nv_cvt_fp8x2_to_halfraw2(slo, __NV_E4M3));
|
| 1535 |
+
float2 rhi = __internal_halfraw2_to_float2(
|
| 1536 |
+
__nv_cvt_fp8x2_to_halfraw2(shi, __NV_E4M3));
|
| 1537 |
+
float4 res = {rlo.x, rlo.y, rhi.x, rhi.y};
|
| 1538 |
+
return res;
|
| 1539 |
+
}
|
| 1540 |
+
#endif /* !defined(__CUDA_NO_FP8_CONVERSION_OPERATORS__) */
|
| 1541 |
+
#endif /* !defined(__CUDA_NO_FP8_CONVERSIONS__) */
|
| 1542 |
+
};
|
| 1543 |
+
|
| 1544 |
+
#endif /* defined(__cplusplus) */
|
| 1545 |
+
|
| 1546 |
+
#endif /* end of include guard: __CUDA_FP8_HPP__ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cuda_occupancy.h
ADDED
|
@@ -0,0 +1,1958 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2017 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
/**
|
| 51 |
+
* CUDA Occupancy Calculator
|
| 52 |
+
*
|
| 53 |
+
* NAME
|
| 54 |
+
*
|
| 55 |
+
* cudaOccMaxActiveBlocksPerMultiprocessor,
|
| 56 |
+
* cudaOccMaxPotentialOccupancyBlockSize,
|
| 57 |
+
* cudaOccMaxPotentialOccupancyBlockSizeVariableSMem
|
| 58 |
+
* cudaOccAvailableDynamicSMemPerBlock
|
| 59 |
+
*
|
| 60 |
+
* DESCRIPTION
|
| 61 |
+
*
|
| 62 |
+
* The CUDA occupancy calculator provides a standalone, programmatical
|
| 63 |
+
* interface to compute the occupancy of a function on a device. It can also
|
| 64 |
+
* provide occupancy-oriented launch configuration suggestions.
|
| 65 |
+
*
|
| 66 |
+
* The function and device are defined by the user through
|
| 67 |
+
* cudaOccFuncAttributes, cudaOccDeviceProp, and cudaOccDeviceState
|
| 68 |
+
* structures. All APIs require all 3 of them.
|
| 69 |
+
*
|
| 70 |
+
* See the structure definition for more details about the device / function
|
| 71 |
+
* descriptors.
|
| 72 |
+
*
|
| 73 |
+
* See each API's prototype for API usage.
|
| 74 |
+
*
|
| 75 |
+
* COMPATIBILITY
|
| 76 |
+
*
|
| 77 |
+
* The occupancy calculator will be updated on each major CUDA toolkit
|
| 78 |
+
* release. It does not provide forward compatibility, i.e. new hardwares
|
| 79 |
+
* released after this implementation's release will not be supported.
|
| 80 |
+
*
|
| 81 |
+
* NOTE
|
| 82 |
+
*
|
| 83 |
+
* If there is access to CUDA runtime, and the sole intent is to calculate
|
| 84 |
+
* occupancy related values on one of the accessible CUDA devices, using CUDA
|
| 85 |
+
* runtime's occupancy calculation APIs is recommended.
|
| 86 |
+
*
|
| 87 |
+
*/
|
| 88 |
+
|
| 89 |
+
#ifndef __cuda_occupancy_h__
|
| 90 |
+
#define __cuda_occupancy_h__
|
| 91 |
+
|
| 92 |
+
#include <stddef.h>
|
| 93 |
+
#include <limits.h>
|
| 94 |
+
#include <string.h>
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
// __OCC_INLINE will be undefined at the end of this header
|
| 98 |
+
//
|
| 99 |
+
#ifdef __CUDACC__
|
| 100 |
+
#define __OCC_INLINE inline __host__ __device__
|
| 101 |
+
#elif defined _MSC_VER
|
| 102 |
+
#define __OCC_INLINE __inline
|
| 103 |
+
#else // GNUCC assumed
|
| 104 |
+
#define __OCC_INLINE inline
|
| 105 |
+
#endif
|
| 106 |
+
|
| 107 |
+
enum cudaOccError_enum {
|
| 108 |
+
CUDA_OCC_SUCCESS = 0, // no error encountered
|
| 109 |
+
CUDA_OCC_ERROR_INVALID_INPUT = 1, // input parameter is invalid
|
| 110 |
+
CUDA_OCC_ERROR_UNKNOWN_DEVICE = 2, // requested device is not supported in
|
| 111 |
+
// current implementation or device is
|
| 112 |
+
// invalid
|
| 113 |
+
};
|
| 114 |
+
typedef enum cudaOccError_enum cudaOccError;
|
| 115 |
+
|
| 116 |
+
typedef struct cudaOccResult cudaOccResult;
|
| 117 |
+
typedef struct cudaOccDeviceProp cudaOccDeviceProp;
|
| 118 |
+
typedef struct cudaOccFuncAttributes cudaOccFuncAttributes;
|
| 119 |
+
typedef struct cudaOccDeviceState cudaOccDeviceState;
|
| 120 |
+
|
| 121 |
+
/**
|
| 122 |
+
* The CUDA occupancy calculator computes the occupancy of the function
|
| 123 |
+
* described by attributes with the given block size (blockSize), static device
|
| 124 |
+
* properties (properties), dynamic device states (states) and per-block dynamic
|
| 125 |
+
* shared memory allocation (dynamicSMemSize) in bytes, and output it through
|
| 126 |
+
* result along with other useful information. The occupancy is computed in
|
| 127 |
+
* terms of the maximum number of active blocks per multiprocessor. The user can
|
| 128 |
+
* then convert it to other metrics, such as number of active warps.
|
| 129 |
+
*
|
| 130 |
+
* RETURN VALUE
|
| 131 |
+
*
|
| 132 |
+
* The occupancy and related information is returned through result.
|
| 133 |
+
*
|
| 134 |
+
* If result->activeBlocksPerMultiprocessor is 0, then the given parameter
|
| 135 |
+
* combination cannot run on the device.
|
| 136 |
+
*
|
| 137 |
+
* ERRORS
|
| 138 |
+
*
|
| 139 |
+
* CUDA_OCC_ERROR_INVALID_INPUT input parameter is invalid.
|
| 140 |
+
* CUDA_OCC_ERROR_UNKNOWN_DEVICE requested device is not supported in
|
| 141 |
+
* current implementation or device is invalid
|
| 142 |
+
*/
|
| 143 |
+
static __OCC_INLINE
|
| 144 |
+
cudaOccError cudaOccMaxActiveBlocksPerMultiprocessor(
|
| 145 |
+
cudaOccResult *result, // out
|
| 146 |
+
const cudaOccDeviceProp *properties, // in
|
| 147 |
+
const cudaOccFuncAttributes *attributes, // in
|
| 148 |
+
const cudaOccDeviceState *state, // in
|
| 149 |
+
int blockSize, // in
|
| 150 |
+
size_t dynamicSmemSize); // in
|
| 151 |
+
|
| 152 |
+
/**
|
| 153 |
+
* The CUDA launch configurator C API suggests a grid / block size pair (in
|
| 154 |
+
* minGridSize and blockSize) that achieves the best potential occupancy
|
| 155 |
+
* (i.e. maximum number of active warps with the smallest number of blocks) for
|
| 156 |
+
* the given function described by attributes, on a device described by
|
| 157 |
+
* properties with settings in state.
|
| 158 |
+
*
|
| 159 |
+
* If per-block dynamic shared memory allocation is not needed, the user should
|
| 160 |
+
* leave both blockSizeToDynamicSMemSize and dynamicSMemSize as 0.
|
| 161 |
+
*
|
| 162 |
+
* If per-block dynamic shared memory allocation is needed, then if the dynamic
|
| 163 |
+
* shared memory size is constant regardless of block size, the size should be
|
| 164 |
+
* passed through dynamicSMemSize, and blockSizeToDynamicSMemSize should be
|
| 165 |
+
* NULL.
|
| 166 |
+
*
|
| 167 |
+
* Otherwise, if the per-block dynamic shared memory size varies with different
|
| 168 |
+
* block sizes, the user needs to provide a pointer to an unary function through
|
| 169 |
+
* blockSizeToDynamicSMemSize that computes the dynamic shared memory needed by
|
| 170 |
+
* a block of the function for any given block size. dynamicSMemSize is
|
| 171 |
+
* ignored. An example signature is:
|
| 172 |
+
*
|
| 173 |
+
* // Take block size, returns dynamic shared memory needed
|
| 174 |
+
* size_t blockToSmem(int blockSize);
|
| 175 |
+
*
|
| 176 |
+
* RETURN VALUE
|
| 177 |
+
*
|
| 178 |
+
* The suggested block size and the minimum number of blocks needed to achieve
|
| 179 |
+
* the maximum occupancy are returned through blockSize and minGridSize.
|
| 180 |
+
*
|
| 181 |
+
* If *blockSize is 0, then the given combination cannot run on the device.
|
| 182 |
+
*
|
| 183 |
+
* ERRORS
|
| 184 |
+
*
|
| 185 |
+
* CUDA_OCC_ERROR_INVALID_INPUT input parameter is invalid.
|
| 186 |
+
* CUDA_OCC_ERROR_UNKNOWN_DEVICE requested device is not supported in
|
| 187 |
+
* current implementation or device is invalid
|
| 188 |
+
*
|
| 189 |
+
*/
|
| 190 |
+
static __OCC_INLINE
|
| 191 |
+
cudaOccError cudaOccMaxPotentialOccupancyBlockSize(
|
| 192 |
+
int *minGridSize, // out
|
| 193 |
+
int *blockSize, // out
|
| 194 |
+
const cudaOccDeviceProp *properties, // in
|
| 195 |
+
const cudaOccFuncAttributes *attributes, // in
|
| 196 |
+
const cudaOccDeviceState *state, // in
|
| 197 |
+
size_t (*blockSizeToDynamicSMemSize)(int), // in
|
| 198 |
+
size_t dynamicSMemSize); // in
|
| 199 |
+
|
| 200 |
+
/**
|
| 201 |
+
* The CUDA launch configurator C++ API suggests a grid / block size pair (in
|
| 202 |
+
* minGridSize and blockSize) that achieves the best potential occupancy
|
| 203 |
+
* (i.e. the maximum number of active warps with the smallest number of blocks)
|
| 204 |
+
* for the given function described by attributes, on a device described by
|
| 205 |
+
* properties with settings in state.
|
| 206 |
+
*
|
| 207 |
+
* If per-block dynamic shared memory allocation is 0 or constant regardless of
|
| 208 |
+
* block size, the user can use cudaOccMaxPotentialOccupancyBlockSize to
|
| 209 |
+
* configure the launch. A constant dynamic shared memory allocation size in
|
| 210 |
+
* bytes can be passed through dynamicSMemSize.
|
| 211 |
+
*
|
| 212 |
+
* Otherwise, if the per-block dynamic shared memory size varies with different
|
| 213 |
+
* block sizes, the user needs to use
|
| 214 |
+
* cudaOccMaxPotentialOccupancyBlockSizeVariableSmem instead, and provide a
|
| 215 |
+
* functor / pointer to an unary function (blockSizeToDynamicSMemSize) that
|
| 216 |
+
* computes the dynamic shared memory needed by func for any given block
|
| 217 |
+
* size. An example signature is:
|
| 218 |
+
*
|
| 219 |
+
* // Take block size, returns per-block dynamic shared memory needed
|
| 220 |
+
* size_t blockToSmem(int blockSize);
|
| 221 |
+
*
|
| 222 |
+
* RETURN VALUE
|
| 223 |
+
*
|
| 224 |
+
* The suggested block size and the minimum number of blocks needed to achieve
|
| 225 |
+
* the maximum occupancy are returned through blockSize and minGridSize.
|
| 226 |
+
*
|
| 227 |
+
* If *blockSize is 0, then the given combination cannot run on the device.
|
| 228 |
+
*
|
| 229 |
+
* ERRORS
|
| 230 |
+
*
|
| 231 |
+
* CUDA_OCC_ERROR_INVALID_INPUT input parameter is invalid.
|
| 232 |
+
* CUDA_OCC_ERROR_UNKNOWN_DEVICE requested device is not supported in
|
| 233 |
+
* current implementation or device is invalid
|
| 234 |
+
*
|
| 235 |
+
*/
|
| 236 |
+
|
| 237 |
+
#if defined(__cplusplus)
|
| 238 |
+
namespace {
|
| 239 |
+
|
| 240 |
+
__OCC_INLINE
|
| 241 |
+
cudaOccError cudaOccMaxPotentialOccupancyBlockSize(
|
| 242 |
+
int *minGridSize, // out
|
| 243 |
+
int *blockSize, // out
|
| 244 |
+
const cudaOccDeviceProp *properties, // in
|
| 245 |
+
const cudaOccFuncAttributes *attributes, // in
|
| 246 |
+
const cudaOccDeviceState *state, // in
|
| 247 |
+
size_t dynamicSMemSize = 0); // in
|
| 248 |
+
|
| 249 |
+
template <typename UnaryFunction>
|
| 250 |
+
__OCC_INLINE
|
| 251 |
+
cudaOccError cudaOccMaxPotentialOccupancyBlockSizeVariableSMem(
|
| 252 |
+
int *minGridSize, // out
|
| 253 |
+
int *blockSize, // out
|
| 254 |
+
const cudaOccDeviceProp *properties, // in
|
| 255 |
+
const cudaOccFuncAttributes *attributes, // in
|
| 256 |
+
const cudaOccDeviceState *state, // in
|
| 257 |
+
UnaryFunction blockSizeToDynamicSMemSize); // in
|
| 258 |
+
|
| 259 |
+
} // namespace anonymous
|
| 260 |
+
#endif // defined(__cplusplus)
|
| 261 |
+
|
| 262 |
+
/**
|
| 263 |
+
*
|
| 264 |
+
* The CUDA dynamic shared memory calculator computes the maximum size of
|
| 265 |
+
* per-block dynamic shared memory if we want to place numBlocks blocks
|
| 266 |
+
* on an SM.
|
| 267 |
+
*
|
| 268 |
+
* RETURN VALUE
|
| 269 |
+
*
|
| 270 |
+
* Returns in *dynamicSmemSize the maximum size of dynamic shared memory to allow
|
| 271 |
+
* numBlocks blocks per SM.
|
| 272 |
+
*
|
| 273 |
+
* ERRORS
|
| 274 |
+
*
|
| 275 |
+
* CUDA_OCC_ERROR_INVALID_INPUT input parameter is invalid.
|
| 276 |
+
* CUDA_OCC_ERROR_UNKNOWN_DEVICE requested device is not supported in
|
| 277 |
+
* current implementation or device is invalid
|
| 278 |
+
*
|
| 279 |
+
*/
|
| 280 |
+
static __OCC_INLINE
|
| 281 |
+
cudaOccError cudaOccAvailableDynamicSMemPerBlock(
|
| 282 |
+
size_t *dynamicSmemSize,
|
| 283 |
+
const cudaOccDeviceProp *properties,
|
| 284 |
+
const cudaOccFuncAttributes *attributes,
|
| 285 |
+
const cudaOccDeviceState *state,
|
| 286 |
+
int numBlocks,
|
| 287 |
+
int blockSize);
|
| 288 |
+
|
| 289 |
+
/**
|
| 290 |
+
* Data structures
|
| 291 |
+
*
|
| 292 |
+
* These structures are subject to change for future architecture and CUDA
|
| 293 |
+
* releases. C users should initialize the structure as {0}.
|
| 294 |
+
*
|
| 295 |
+
*/
|
| 296 |
+
|
| 297 |
+
/**
|
| 298 |
+
* Device descriptor
|
| 299 |
+
*
|
| 300 |
+
* This structure describes a device.
|
| 301 |
+
*/
|
| 302 |
+
struct cudaOccDeviceProp {
|
| 303 |
+
int computeMajor; // Compute capability major version
|
| 304 |
+
int computeMinor; // Compute capability minor
|
| 305 |
+
// version. None supported minor version
|
| 306 |
+
// may cause error
|
| 307 |
+
int maxThreadsPerBlock; // Maximum number of threads per block
|
| 308 |
+
int maxThreadsPerMultiprocessor; // Maximum number of threads per SM
|
| 309 |
+
// i.e. (Max. number of warps) x (warp
|
| 310 |
+
// size)
|
| 311 |
+
int regsPerBlock; // Maximum number of registers per block
|
| 312 |
+
int regsPerMultiprocessor; // Maximum number of registers per SM
|
| 313 |
+
int warpSize; // Warp size
|
| 314 |
+
size_t sharedMemPerBlock; // Maximum shared memory size per block
|
| 315 |
+
size_t sharedMemPerMultiprocessor; // Maximum shared memory size per SM
|
| 316 |
+
int numSms; // Number of SMs available
|
| 317 |
+
size_t sharedMemPerBlockOptin; // Maximum optin shared memory size per block
|
| 318 |
+
size_t reservedSharedMemPerBlock; // Shared memory per block reserved by driver
|
| 319 |
+
|
| 320 |
+
#ifdef __cplusplus
|
| 321 |
+
// This structure can be converted from a cudaDeviceProp structure for users
|
| 322 |
+
// that use this header in their CUDA applications.
|
| 323 |
+
//
|
| 324 |
+
// If the application have access to the CUDA Runtime API, the application
|
| 325 |
+
// can obtain the device properties of a CUDA device through
|
| 326 |
+
// cudaGetDeviceProperties, and initialize a cudaOccDeviceProp with the
|
| 327 |
+
// cudaDeviceProp structure.
|
| 328 |
+
//
|
| 329 |
+
// Example:
|
| 330 |
+
/*
|
| 331 |
+
{
|
| 332 |
+
cudaDeviceProp prop;
|
| 333 |
+
|
| 334 |
+
cudaGetDeviceProperties(&prop, ...);
|
| 335 |
+
|
| 336 |
+
cudaOccDeviceProp occProp = prop;
|
| 337 |
+
|
| 338 |
+
...
|
| 339 |
+
|
| 340 |
+
cudaOccMaxPotentialOccupancyBlockSize(..., &occProp, ...);
|
| 341 |
+
}
|
| 342 |
+
*/
|
| 343 |
+
//
|
| 344 |
+
template<typename DeviceProp>
|
| 345 |
+
__OCC_INLINE
|
| 346 |
+
cudaOccDeviceProp(const DeviceProp &props)
|
| 347 |
+
: computeMajor (props.major),
|
| 348 |
+
computeMinor (props.minor),
|
| 349 |
+
maxThreadsPerBlock (props.maxThreadsPerBlock),
|
| 350 |
+
maxThreadsPerMultiprocessor (props.maxThreadsPerMultiProcessor),
|
| 351 |
+
regsPerBlock (props.regsPerBlock),
|
| 352 |
+
regsPerMultiprocessor (props.regsPerMultiprocessor),
|
| 353 |
+
warpSize (props.warpSize),
|
| 354 |
+
sharedMemPerBlock (props.sharedMemPerBlock),
|
| 355 |
+
sharedMemPerMultiprocessor (props.sharedMemPerMultiprocessor),
|
| 356 |
+
numSms (props.multiProcessorCount),
|
| 357 |
+
sharedMemPerBlockOptin (props.sharedMemPerBlockOptin),
|
| 358 |
+
reservedSharedMemPerBlock (props.reservedSharedMemPerBlock)
|
| 359 |
+
{}
|
| 360 |
+
|
| 361 |
+
__OCC_INLINE
|
| 362 |
+
cudaOccDeviceProp()
|
| 363 |
+
: computeMajor (0),
|
| 364 |
+
computeMinor (0),
|
| 365 |
+
maxThreadsPerBlock (0),
|
| 366 |
+
maxThreadsPerMultiprocessor (0),
|
| 367 |
+
regsPerBlock (0),
|
| 368 |
+
regsPerMultiprocessor (0),
|
| 369 |
+
warpSize (0),
|
| 370 |
+
sharedMemPerBlock (0),
|
| 371 |
+
sharedMemPerMultiprocessor (0),
|
| 372 |
+
numSms (0),
|
| 373 |
+
sharedMemPerBlockOptin (0),
|
| 374 |
+
reservedSharedMemPerBlock (0)
|
| 375 |
+
{}
|
| 376 |
+
#endif // __cplusplus
|
| 377 |
+
};
|
| 378 |
+
|
| 379 |
+
/**
|
| 380 |
+
* Partitioned global caching option
|
| 381 |
+
*/
|
| 382 |
+
typedef enum cudaOccPartitionedGCConfig_enum {
|
| 383 |
+
PARTITIONED_GC_OFF, // Disable partitioned global caching
|
| 384 |
+
PARTITIONED_GC_ON, // Prefer partitioned global caching
|
| 385 |
+
PARTITIONED_GC_ON_STRICT // Force partitioned global caching
|
| 386 |
+
} cudaOccPartitionedGCConfig;
|
| 387 |
+
|
| 388 |
+
/**
|
| 389 |
+
* Per function opt in maximum dynamic shared memory limit
|
| 390 |
+
*/
|
| 391 |
+
typedef enum cudaOccFuncShmemConfig_enum {
|
| 392 |
+
FUNC_SHMEM_LIMIT_DEFAULT, // Default shmem limit
|
| 393 |
+
FUNC_SHMEM_LIMIT_OPTIN, // Use the optin shmem limit
|
| 394 |
+
} cudaOccFuncShmemConfig;
|
| 395 |
+
|
| 396 |
+
/**
|
| 397 |
+
* Function descriptor
|
| 398 |
+
*
|
| 399 |
+
* This structure describes a CUDA function.
|
| 400 |
+
*/
|
| 401 |
+
struct cudaOccFuncAttributes {
|
| 402 |
+
int maxThreadsPerBlock; // Maximum block size the function can work with. If
|
| 403 |
+
// unlimited, use INT_MAX or any value greater than
|
| 404 |
+
// or equal to maxThreadsPerBlock of the device
|
| 405 |
+
int numRegs; // Number of registers used. When the function is
|
| 406 |
+
// launched on device, the register count may change
|
| 407 |
+
// due to internal tools requirements.
|
| 408 |
+
size_t sharedSizeBytes; // Number of static shared memory used
|
| 409 |
+
|
| 410 |
+
cudaOccPartitionedGCConfig partitionedGCConfig;
|
| 411 |
+
// Partitioned global caching is required to enable
|
| 412 |
+
// caching on certain chips, such as sm_52
|
| 413 |
+
// devices. Partitioned global caching can be
|
| 414 |
+
// automatically disabled if the occupancy
|
| 415 |
+
// requirement of the launch cannot support caching.
|
| 416 |
+
//
|
| 417 |
+
// To override this behavior with caching on and
|
| 418 |
+
// calculate occupancy strictly according to the
|
| 419 |
+
// preference, set partitionedGCConfig to
|
| 420 |
+
// PARTITIONED_GC_ON_STRICT. This is especially
|
| 421 |
+
// useful for experimenting and finding launch
|
| 422 |
+
// configurations (MaxPotentialOccupancyBlockSize)
|
| 423 |
+
// that allow global caching to take effect.
|
| 424 |
+
//
|
| 425 |
+
// This flag only affects the occupancy calculation.
|
| 426 |
+
|
| 427 |
+
cudaOccFuncShmemConfig shmemLimitConfig;
|
| 428 |
+
// Certain chips like sm_70 allow a user to opt into
|
| 429 |
+
// a higher per block limit of dynamic shared memory
|
| 430 |
+
// This optin is performed on a per function basis
|
| 431 |
+
// using the cuFuncSetAttribute function
|
| 432 |
+
|
| 433 |
+
size_t maxDynamicSharedSizeBytes;
|
| 434 |
+
// User set limit on maximum dynamic shared memory
|
| 435 |
+
// usable by the kernel
|
| 436 |
+
// This limit is set using the cuFuncSetAttribute
|
| 437 |
+
// function.
|
| 438 |
+
|
| 439 |
+
int numBlockBarriers; // Number of block barriers used (default to 1)
|
| 440 |
+
#ifdef __cplusplus
|
| 441 |
+
// This structure can be converted from a cudaFuncAttributes structure for
|
| 442 |
+
// users that use this header in their CUDA applications.
|
| 443 |
+
//
|
| 444 |
+
// If the application have access to the CUDA Runtime API, the application
|
| 445 |
+
// can obtain the function attributes of a CUDA kernel function through
|
| 446 |
+
// cudaFuncGetAttributes, and initialize a cudaOccFuncAttributes with the
|
| 447 |
+
// cudaFuncAttributes structure.
|
| 448 |
+
//
|
| 449 |
+
// Example:
|
| 450 |
+
/*
|
| 451 |
+
__global__ void foo() {...}
|
| 452 |
+
|
| 453 |
+
...
|
| 454 |
+
|
| 455 |
+
{
|
| 456 |
+
cudaFuncAttributes attr;
|
| 457 |
+
|
| 458 |
+
cudaFuncGetAttributes(&attr, foo);
|
| 459 |
+
|
| 460 |
+
cudaOccFuncAttributes occAttr = attr;
|
| 461 |
+
|
| 462 |
+
...
|
| 463 |
+
|
| 464 |
+
cudaOccMaxPotentialOccupancyBlockSize(..., &occAttr, ...);
|
| 465 |
+
}
|
| 466 |
+
*/
|
| 467 |
+
//
|
| 468 |
+
template<typename FuncAttributes>
|
| 469 |
+
__OCC_INLINE
|
| 470 |
+
cudaOccFuncAttributes(const FuncAttributes &attr)
|
| 471 |
+
: maxThreadsPerBlock (attr.maxThreadsPerBlock),
|
| 472 |
+
numRegs (attr.numRegs),
|
| 473 |
+
sharedSizeBytes (attr.sharedSizeBytes),
|
| 474 |
+
partitionedGCConfig (PARTITIONED_GC_OFF),
|
| 475 |
+
shmemLimitConfig (FUNC_SHMEM_LIMIT_OPTIN),
|
| 476 |
+
maxDynamicSharedSizeBytes (attr.maxDynamicSharedSizeBytes),
|
| 477 |
+
numBlockBarriers (1)
|
| 478 |
+
{}
|
| 479 |
+
|
| 480 |
+
__OCC_INLINE
|
| 481 |
+
cudaOccFuncAttributes()
|
| 482 |
+
: maxThreadsPerBlock (0),
|
| 483 |
+
numRegs (0),
|
| 484 |
+
sharedSizeBytes (0),
|
| 485 |
+
partitionedGCConfig (PARTITIONED_GC_OFF),
|
| 486 |
+
shmemLimitConfig (FUNC_SHMEM_LIMIT_DEFAULT),
|
| 487 |
+
maxDynamicSharedSizeBytes (0),
|
| 488 |
+
numBlockBarriers (0)
|
| 489 |
+
{}
|
| 490 |
+
#endif
|
| 491 |
+
};
|
| 492 |
+
|
| 493 |
+
typedef enum cudaOccCacheConfig_enum {
|
| 494 |
+
CACHE_PREFER_NONE = 0x00, // no preference for shared memory or L1 (default)
|
| 495 |
+
CACHE_PREFER_SHARED = 0x01, // prefer larger shared memory and smaller L1 cache
|
| 496 |
+
CACHE_PREFER_L1 = 0x02, // prefer larger L1 cache and smaller shared memory
|
| 497 |
+
CACHE_PREFER_EQUAL = 0x03 // prefer equal sized L1 cache and shared memory
|
| 498 |
+
} cudaOccCacheConfig;
|
| 499 |
+
|
| 500 |
+
typedef enum cudaOccCarveoutConfig_enum {
|
| 501 |
+
SHAREDMEM_CARVEOUT_DEFAULT = -1, // no preference for shared memory or L1 (default)
|
| 502 |
+
SHAREDMEM_CARVEOUT_MAX_SHARED = 100, // prefer maximum available shared memory, minimum L1 cache
|
| 503 |
+
SHAREDMEM_CARVEOUT_MAX_L1 = 0, // prefer maximum available L1 cache, minimum shared memory
|
| 504 |
+
SHAREDMEM_CARVEOUT_HALF = 50 // prefer half of maximum available shared memory, with the rest as L1 cache
|
| 505 |
+
} cudaOccCarveoutConfig;
|
| 506 |
+
|
| 507 |
+
/**
|
| 508 |
+
* Device state descriptor
|
| 509 |
+
*
|
| 510 |
+
* This structure describes device settings that affect occupancy calculation.
|
| 511 |
+
*/
|
| 512 |
+
struct cudaOccDeviceState
|
| 513 |
+
{
|
| 514 |
+
// Cache / shared memory split preference. Deprecated on Volta
|
| 515 |
+
cudaOccCacheConfig cacheConfig;
|
| 516 |
+
// Shared memory / L1 split preference. Supported on only Volta
|
| 517 |
+
int carveoutConfig;
|
| 518 |
+
|
| 519 |
+
#ifdef __cplusplus
|
| 520 |
+
__OCC_INLINE
|
| 521 |
+
cudaOccDeviceState()
|
| 522 |
+
: cacheConfig (CACHE_PREFER_NONE),
|
| 523 |
+
carveoutConfig (SHAREDMEM_CARVEOUT_DEFAULT)
|
| 524 |
+
{}
|
| 525 |
+
#endif
|
| 526 |
+
};
|
| 527 |
+
|
| 528 |
+
typedef enum cudaOccLimitingFactor_enum {
|
| 529 |
+
// Occupancy limited due to:
|
| 530 |
+
OCC_LIMIT_WARPS = 0x01, // - warps available
|
| 531 |
+
OCC_LIMIT_REGISTERS = 0x02, // - registers available
|
| 532 |
+
OCC_LIMIT_SHARED_MEMORY = 0x04, // - shared memory available
|
| 533 |
+
OCC_LIMIT_BLOCKS = 0x08, // - blocks available
|
| 534 |
+
OCC_LIMIT_BARRIERS = 0x10 // - barrier available
|
| 535 |
+
} cudaOccLimitingFactor;
|
| 536 |
+
|
| 537 |
+
/**
|
| 538 |
+
* Occupancy output
|
| 539 |
+
*
|
| 540 |
+
* This structure contains occupancy calculator's output.
|
| 541 |
+
*/
|
| 542 |
+
struct cudaOccResult {
|
| 543 |
+
int activeBlocksPerMultiprocessor; // Occupancy
|
| 544 |
+
unsigned int limitingFactors; // Factors that limited occupancy. A bit
|
| 545 |
+
// field that counts the limiting
|
| 546 |
+
// factors, see cudaOccLimitingFactor
|
| 547 |
+
int blockLimitRegs; // Occupancy due to register
|
| 548 |
+
// usage, INT_MAX if the kernel does not
|
| 549 |
+
// use any register.
|
| 550 |
+
int blockLimitSharedMem; // Occupancy due to shared memory
|
| 551 |
+
// usage, INT_MAX if the kernel does not
|
| 552 |
+
// use shared memory.
|
| 553 |
+
int blockLimitWarps; // Occupancy due to block size limit
|
| 554 |
+
int blockLimitBlocks; // Occupancy due to maximum number of blocks
|
| 555 |
+
// managable per SM
|
| 556 |
+
int blockLimitBarriers; // Occupancy due to block barrier usage
|
| 557 |
+
int allocatedRegistersPerBlock; // Actual number of registers allocated per
|
| 558 |
+
// block
|
| 559 |
+
size_t allocatedSharedMemPerBlock; // Actual size of shared memory allocated
|
| 560 |
+
// per block
|
| 561 |
+
cudaOccPartitionedGCConfig partitionedGCConfig;
|
| 562 |
+
// Report if partitioned global caching
|
| 563 |
+
// is actually enabled.
|
| 564 |
+
};
|
| 565 |
+
|
| 566 |
+
/**
|
| 567 |
+
* Partitioned global caching support
|
| 568 |
+
*
|
| 569 |
+
* See cudaOccPartitionedGlobalCachingModeSupport
|
| 570 |
+
*/
|
| 571 |
+
typedef enum cudaOccPartitionedGCSupport_enum {
|
| 572 |
+
PARTITIONED_GC_NOT_SUPPORTED, // Partitioned global caching is not supported
|
| 573 |
+
PARTITIONED_GC_SUPPORTED, // Partitioned global caching is supported
|
| 574 |
+
} cudaOccPartitionedGCSupport;
|
| 575 |
+
|
| 576 |
+
/**
|
| 577 |
+
* Implementation
|
| 578 |
+
*/
|
| 579 |
+
|
| 580 |
+
/**
|
| 581 |
+
* Max compute capability supported
|
| 582 |
+
*/
|
| 583 |
+
#define __CUDA_OCC_MAJOR__ 9
|
| 584 |
+
#define __CUDA_OCC_MINOR__ 0
|
| 585 |
+
|
| 586 |
+
//////////////////////////////////////////
|
| 587 |
+
// Mathematical Helper Functions //
|
| 588 |
+
//////////////////////////////////////////
|
| 589 |
+
|
| 590 |
+
static __OCC_INLINE int __occMin(int lhs, int rhs)
|
| 591 |
+
{
|
| 592 |
+
return rhs < lhs ? rhs : lhs;
|
| 593 |
+
}
|
| 594 |
+
|
| 595 |
+
static __OCC_INLINE int __occDivideRoundUp(int x, int y)
|
| 596 |
+
{
|
| 597 |
+
return (x + (y - 1)) / y;
|
| 598 |
+
}
|
| 599 |
+
|
| 600 |
+
static __OCC_INLINE int __occRoundUp(int x, int y)
|
| 601 |
+
{
|
| 602 |
+
return y * __occDivideRoundUp(x, y);
|
| 603 |
+
}
|
| 604 |
+
|
| 605 |
+
//////////////////////////////////////////
|
| 606 |
+
// Architectural Properties //
|
| 607 |
+
//////////////////////////////////////////
|
| 608 |
+
|
| 609 |
+
/**
|
| 610 |
+
* Granularity of shared memory allocation
|
| 611 |
+
*/
|
| 612 |
+
static __OCC_INLINE cudaOccError cudaOccSMemAllocationGranularity(int *limit, const cudaOccDeviceProp *properties)
|
| 613 |
+
{
|
| 614 |
+
int value;
|
| 615 |
+
|
| 616 |
+
switch(properties->computeMajor) {
|
| 617 |
+
case 3:
|
| 618 |
+
case 5:
|
| 619 |
+
case 6:
|
| 620 |
+
case 7:
|
| 621 |
+
value = 256;
|
| 622 |
+
break;
|
| 623 |
+
case 8:
|
| 624 |
+
case 9:
|
| 625 |
+
value = 128;
|
| 626 |
+
break;
|
| 627 |
+
default:
|
| 628 |
+
return CUDA_OCC_ERROR_UNKNOWN_DEVICE;
|
| 629 |
+
}
|
| 630 |
+
|
| 631 |
+
*limit = value;
|
| 632 |
+
|
| 633 |
+
return CUDA_OCC_SUCCESS;
|
| 634 |
+
}
|
| 635 |
+
|
| 636 |
+
/**
|
| 637 |
+
* Maximum number of registers per thread
|
| 638 |
+
*/
|
| 639 |
+
static __OCC_INLINE cudaOccError cudaOccRegAllocationMaxPerThread(int *limit, const cudaOccDeviceProp *properties)
|
| 640 |
+
{
|
| 641 |
+
int value;
|
| 642 |
+
|
| 643 |
+
switch(properties->computeMajor) {
|
| 644 |
+
case 3:
|
| 645 |
+
case 5:
|
| 646 |
+
case 6:
|
| 647 |
+
value = 255;
|
| 648 |
+
break;
|
| 649 |
+
case 7:
|
| 650 |
+
case 8:
|
| 651 |
+
case 9:
|
| 652 |
+
value = 256;
|
| 653 |
+
break;
|
| 654 |
+
default:
|
| 655 |
+
return CUDA_OCC_ERROR_UNKNOWN_DEVICE;
|
| 656 |
+
}
|
| 657 |
+
|
| 658 |
+
*limit = value;
|
| 659 |
+
|
| 660 |
+
return CUDA_OCC_SUCCESS;
|
| 661 |
+
}
|
| 662 |
+
|
| 663 |
+
/**
|
| 664 |
+
* Granularity of register allocation
|
| 665 |
+
*/
|
| 666 |
+
static __OCC_INLINE cudaOccError cudaOccRegAllocationGranularity(int *limit, const cudaOccDeviceProp *properties)
|
| 667 |
+
{
|
| 668 |
+
int value;
|
| 669 |
+
|
| 670 |
+
switch(properties->computeMajor) {
|
| 671 |
+
case 3:
|
| 672 |
+
case 5:
|
| 673 |
+
case 6:
|
| 674 |
+
case 7:
|
| 675 |
+
case 8:
|
| 676 |
+
case 9:
|
| 677 |
+
value = 256;
|
| 678 |
+
break;
|
| 679 |
+
default:
|
| 680 |
+
return CUDA_OCC_ERROR_UNKNOWN_DEVICE;
|
| 681 |
+
}
|
| 682 |
+
|
| 683 |
+
*limit = value;
|
| 684 |
+
|
| 685 |
+
return CUDA_OCC_SUCCESS;
|
| 686 |
+
}
|
| 687 |
+
|
| 688 |
+
/**
|
| 689 |
+
* Number of sub-partitions
|
| 690 |
+
*/
|
| 691 |
+
static __OCC_INLINE cudaOccError cudaOccSubPartitionsPerMultiprocessor(int *limit, const cudaOccDeviceProp *properties)
|
| 692 |
+
{
|
| 693 |
+
int value;
|
| 694 |
+
|
| 695 |
+
switch(properties->computeMajor) {
|
| 696 |
+
case 3:
|
| 697 |
+
case 5:
|
| 698 |
+
case 7:
|
| 699 |
+
case 8:
|
| 700 |
+
case 9:
|
| 701 |
+
value = 4;
|
| 702 |
+
break;
|
| 703 |
+
case 6:
|
| 704 |
+
value = properties->computeMinor ? 4 : 2;
|
| 705 |
+
break;
|
| 706 |
+
default:
|
| 707 |
+
return CUDA_OCC_ERROR_UNKNOWN_DEVICE;
|
| 708 |
+
}
|
| 709 |
+
|
| 710 |
+
*limit = value;
|
| 711 |
+
|
| 712 |
+
return CUDA_OCC_SUCCESS;
|
| 713 |
+
}
|
| 714 |
+
|
| 715 |
+
|
| 716 |
+
/**
|
| 717 |
+
* Maximum number of blocks that can run simultaneously on a multiprocessor
|
| 718 |
+
*/
|
| 719 |
+
static __OCC_INLINE cudaOccError cudaOccMaxBlocksPerMultiprocessor(int* limit, const cudaOccDeviceProp *properties)
|
| 720 |
+
{
|
| 721 |
+
int value;
|
| 722 |
+
|
| 723 |
+
switch(properties->computeMajor) {
|
| 724 |
+
case 3:
|
| 725 |
+
value = 16;
|
| 726 |
+
break;
|
| 727 |
+
case 5:
|
| 728 |
+
case 6:
|
| 729 |
+
value = 32;
|
| 730 |
+
break;
|
| 731 |
+
case 7: {
|
| 732 |
+
int isTuring = properties->computeMinor == 5;
|
| 733 |
+
value = (isTuring) ? 16 : 32;
|
| 734 |
+
break;
|
| 735 |
+
}
|
| 736 |
+
case 8:
|
| 737 |
+
if (properties->computeMinor == 0) {
|
| 738 |
+
value = 32;
|
| 739 |
+
}
|
| 740 |
+
else if (properties->computeMinor == 9) {
|
| 741 |
+
value = 24;
|
| 742 |
+
}
|
| 743 |
+
else {
|
| 744 |
+
value = 16;
|
| 745 |
+
}
|
| 746 |
+
break;
|
| 747 |
+
case 9:
|
| 748 |
+
value = 32;
|
| 749 |
+
break;
|
| 750 |
+
default:
|
| 751 |
+
return CUDA_OCC_ERROR_UNKNOWN_DEVICE;
|
| 752 |
+
}
|
| 753 |
+
|
| 754 |
+
*limit = value;
|
| 755 |
+
|
| 756 |
+
return CUDA_OCC_SUCCESS;
|
| 757 |
+
}
|
| 758 |
+
|
| 759 |
+
/**
|
| 760 |
+
* Align up shared memory based on compute major configurations
|
| 761 |
+
*/
|
| 762 |
+
static __OCC_INLINE cudaOccError cudaOccAlignUpShmemSizeVoltaPlus(size_t *shMemSize, const cudaOccDeviceProp *properties)
|
| 763 |
+
{
|
| 764 |
+
// Volta and Turing have shared L1 cache / shared memory, and support cache
|
| 765 |
+
// configuration to trade one for the other. These values are needed to
|
| 766 |
+
// map carveout config ratio to the next available architecture size
|
| 767 |
+
size_t size = *shMemSize;
|
| 768 |
+
|
| 769 |
+
switch (properties->computeMajor) {
|
| 770 |
+
case 7: {
|
| 771 |
+
// Turing supports 32KB and 64KB shared mem.
|
| 772 |
+
int isTuring = properties->computeMinor == 5;
|
| 773 |
+
if (isTuring) {
|
| 774 |
+
if (size <= 32 * 1024) {
|
| 775 |
+
*shMemSize = 32 * 1024;
|
| 776 |
+
}
|
| 777 |
+
else if (size <= 64 * 1024) {
|
| 778 |
+
*shMemSize = 64 * 1024;
|
| 779 |
+
}
|
| 780 |
+
else {
|
| 781 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 782 |
+
}
|
| 783 |
+
}
|
| 784 |
+
// Volta supports 0KB, 8KB, 16KB, 32KB, 64KB, and 96KB shared mem.
|
| 785 |
+
else {
|
| 786 |
+
if (size == 0) {
|
| 787 |
+
*shMemSize = 0;
|
| 788 |
+
}
|
| 789 |
+
else if (size <= 8 * 1024) {
|
| 790 |
+
*shMemSize = 8 * 1024;
|
| 791 |
+
}
|
| 792 |
+
else if (size <= 16 * 1024) {
|
| 793 |
+
*shMemSize = 16 * 1024;
|
| 794 |
+
}
|
| 795 |
+
else if (size <= 32 * 1024) {
|
| 796 |
+
*shMemSize = 32 * 1024;
|
| 797 |
+
}
|
| 798 |
+
else if (size <= 64 * 1024) {
|
| 799 |
+
*shMemSize = 64 * 1024;
|
| 800 |
+
}
|
| 801 |
+
else if (size <= 96 * 1024) {
|
| 802 |
+
*shMemSize = 96 * 1024;
|
| 803 |
+
}
|
| 804 |
+
else {
|
| 805 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 806 |
+
}
|
| 807 |
+
}
|
| 808 |
+
break;
|
| 809 |
+
}
|
| 810 |
+
case 8:
|
| 811 |
+
if (properties->computeMinor == 0 || properties->computeMinor == 7) {
|
| 812 |
+
if (size == 0) {
|
| 813 |
+
*shMemSize = 0;
|
| 814 |
+
}
|
| 815 |
+
else if (size <= 8 * 1024) {
|
| 816 |
+
*shMemSize = 8 * 1024;
|
| 817 |
+
}
|
| 818 |
+
else if (size <= 16 * 1024) {
|
| 819 |
+
*shMemSize = 16 * 1024;
|
| 820 |
+
}
|
| 821 |
+
else if (size <= 32 * 1024) {
|
| 822 |
+
*shMemSize = 32 * 1024;
|
| 823 |
+
}
|
| 824 |
+
else if (size <= 64 * 1024) {
|
| 825 |
+
*shMemSize = 64 * 1024;
|
| 826 |
+
}
|
| 827 |
+
else if (size <= 100 * 1024) {
|
| 828 |
+
*shMemSize = 100 * 1024;
|
| 829 |
+
}
|
| 830 |
+
else if (size <= 132 * 1024) {
|
| 831 |
+
*shMemSize = 132 * 1024;
|
| 832 |
+
}
|
| 833 |
+
else if (size <= 164 * 1024) {
|
| 834 |
+
*shMemSize = 164 * 1024;
|
| 835 |
+
}
|
| 836 |
+
else {
|
| 837 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 838 |
+
}
|
| 839 |
+
}
|
| 840 |
+
else {
|
| 841 |
+
if (size == 0) {
|
| 842 |
+
*shMemSize = 0;
|
| 843 |
+
}
|
| 844 |
+
else if (size <= 8 * 1024) {
|
| 845 |
+
*shMemSize = 8 * 1024;
|
| 846 |
+
}
|
| 847 |
+
else if (size <= 16 * 1024) {
|
| 848 |
+
*shMemSize = 16 * 1024;
|
| 849 |
+
}
|
| 850 |
+
else if (size <= 32 * 1024) {
|
| 851 |
+
*shMemSize = 32 * 1024;
|
| 852 |
+
}
|
| 853 |
+
else if (size <= 64 * 1024) {
|
| 854 |
+
*shMemSize = 64 * 1024;
|
| 855 |
+
}
|
| 856 |
+
else if (size <= 100 * 1024) {
|
| 857 |
+
*shMemSize = 100 * 1024;
|
| 858 |
+
}
|
| 859 |
+
else {
|
| 860 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 861 |
+
}
|
| 862 |
+
}
|
| 863 |
+
break;
|
| 864 |
+
case 9: {
|
| 865 |
+
if (size == 0) {
|
| 866 |
+
*shMemSize = 0;
|
| 867 |
+
}
|
| 868 |
+
else if (size <= 8 * 1024) {
|
| 869 |
+
*shMemSize = 8 * 1024;
|
| 870 |
+
}
|
| 871 |
+
else if (size <= 16 * 1024) {
|
| 872 |
+
*shMemSize = 16 * 1024;
|
| 873 |
+
}
|
| 874 |
+
else if (size <= 32 * 1024) {
|
| 875 |
+
*shMemSize = 32 * 1024;
|
| 876 |
+
}
|
| 877 |
+
else if (size <= 64 * 1024) {
|
| 878 |
+
*shMemSize = 64 * 1024;
|
| 879 |
+
}
|
| 880 |
+
else if (size <= 100 * 1024) {
|
| 881 |
+
*shMemSize = 100 * 1024;
|
| 882 |
+
}
|
| 883 |
+
else if (size <= 132 * 1024) {
|
| 884 |
+
*shMemSize = 132 * 1024;
|
| 885 |
+
}
|
| 886 |
+
else if (size <= 164 * 1024) {
|
| 887 |
+
*shMemSize = 164 * 1024;
|
| 888 |
+
}
|
| 889 |
+
else if (size <= 196 * 1024) {
|
| 890 |
+
*shMemSize = 196 * 1024;
|
| 891 |
+
}
|
| 892 |
+
else if (size <= 228 * 1024) {
|
| 893 |
+
*shMemSize = 228 * 1024;
|
| 894 |
+
}
|
| 895 |
+
else {
|
| 896 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 897 |
+
}
|
| 898 |
+
break;
|
| 899 |
+
}
|
| 900 |
+
default:
|
| 901 |
+
return CUDA_OCC_ERROR_UNKNOWN_DEVICE;
|
| 902 |
+
}
|
| 903 |
+
|
| 904 |
+
return CUDA_OCC_SUCCESS;
|
| 905 |
+
}
|
| 906 |
+
|
| 907 |
+
/**
|
| 908 |
+
* Shared memory based on the new carveoutConfig API introduced with Volta
|
| 909 |
+
*/
|
| 910 |
+
static __OCC_INLINE cudaOccError cudaOccSMemPreferenceVoltaPlus(size_t *limit, const cudaOccDeviceProp *properties, const cudaOccDeviceState *state)
|
| 911 |
+
{
|
| 912 |
+
cudaOccError status = CUDA_OCC_SUCCESS;
|
| 913 |
+
size_t preferenceShmemSize;
|
| 914 |
+
|
| 915 |
+
// CUDA 9.0 introduces a new API to set shared memory - L1 configuration on supported
|
| 916 |
+
// devices. This preference will take precedence over the older cacheConfig setting.
|
| 917 |
+
// Map cacheConfig to its effective preference value.
|
| 918 |
+
int effectivePreference = state->carveoutConfig;
|
| 919 |
+
if ((effectivePreference < SHAREDMEM_CARVEOUT_DEFAULT) || (effectivePreference > SHAREDMEM_CARVEOUT_MAX_SHARED)) {
|
| 920 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 921 |
+
}
|
| 922 |
+
|
| 923 |
+
if (effectivePreference == SHAREDMEM_CARVEOUT_DEFAULT) {
|
| 924 |
+
switch (state->cacheConfig)
|
| 925 |
+
{
|
| 926 |
+
case CACHE_PREFER_L1:
|
| 927 |
+
effectivePreference = SHAREDMEM_CARVEOUT_MAX_L1;
|
| 928 |
+
break;
|
| 929 |
+
case CACHE_PREFER_SHARED:
|
| 930 |
+
effectivePreference = SHAREDMEM_CARVEOUT_MAX_SHARED;
|
| 931 |
+
break;
|
| 932 |
+
case CACHE_PREFER_EQUAL:
|
| 933 |
+
effectivePreference = SHAREDMEM_CARVEOUT_HALF;
|
| 934 |
+
break;
|
| 935 |
+
default:
|
| 936 |
+
effectivePreference = SHAREDMEM_CARVEOUT_DEFAULT;
|
| 937 |
+
break;
|
| 938 |
+
}
|
| 939 |
+
}
|
| 940 |
+
|
| 941 |
+
if (effectivePreference == SHAREDMEM_CARVEOUT_DEFAULT) {
|
| 942 |
+
preferenceShmemSize = properties->sharedMemPerMultiprocessor;
|
| 943 |
+
}
|
| 944 |
+
else {
|
| 945 |
+
preferenceShmemSize = (size_t) (effectivePreference * properties->sharedMemPerMultiprocessor) / 100;
|
| 946 |
+
}
|
| 947 |
+
|
| 948 |
+
status = cudaOccAlignUpShmemSizeVoltaPlus(&preferenceShmemSize, properties);
|
| 949 |
+
*limit = preferenceShmemSize;
|
| 950 |
+
return status;
|
| 951 |
+
}
|
| 952 |
+
|
| 953 |
+
/**
|
| 954 |
+
* Shared memory based on the cacheConfig
|
| 955 |
+
*/
|
| 956 |
+
static __OCC_INLINE cudaOccError cudaOccSMemPreference(size_t *limit, const cudaOccDeviceProp *properties, const cudaOccDeviceState *state)
|
| 957 |
+
{
|
| 958 |
+
size_t bytes = 0;
|
| 959 |
+
size_t sharedMemPerMultiprocessorHigh = properties->sharedMemPerMultiprocessor;
|
| 960 |
+
cudaOccCacheConfig cacheConfig = state->cacheConfig;
|
| 961 |
+
|
| 962 |
+
// Kepler has shared L1 cache / shared memory, and support cache
|
| 963 |
+
// configuration to trade one for the other. These values are needed to
|
| 964 |
+
// calculate the correct shared memory size for user requested cache
|
| 965 |
+
// configuration.
|
| 966 |
+
//
|
| 967 |
+
size_t minCacheSize = 16384;
|
| 968 |
+
size_t maxCacheSize = 49152;
|
| 969 |
+
size_t cacheAndSharedTotal = sharedMemPerMultiprocessorHigh + minCacheSize;
|
| 970 |
+
size_t sharedMemPerMultiprocessorLow = cacheAndSharedTotal - maxCacheSize;
|
| 971 |
+
|
| 972 |
+
switch (properties->computeMajor) {
|
| 973 |
+
case 3:
|
| 974 |
+
// Kepler supports 16KB, 32KB, or 48KB partitions for L1. The rest
|
| 975 |
+
// is shared memory.
|
| 976 |
+
//
|
| 977 |
+
switch (cacheConfig) {
|
| 978 |
+
default :
|
| 979 |
+
case CACHE_PREFER_NONE:
|
| 980 |
+
case CACHE_PREFER_SHARED:
|
| 981 |
+
bytes = sharedMemPerMultiprocessorHigh;
|
| 982 |
+
break;
|
| 983 |
+
case CACHE_PREFER_L1:
|
| 984 |
+
bytes = sharedMemPerMultiprocessorLow;
|
| 985 |
+
break;
|
| 986 |
+
case CACHE_PREFER_EQUAL:
|
| 987 |
+
// Equal is the mid-point between high and low. It should be
|
| 988 |
+
// equivalent to low + 16KB.
|
| 989 |
+
//
|
| 990 |
+
bytes = (sharedMemPerMultiprocessorHigh + sharedMemPerMultiprocessorLow) / 2;
|
| 991 |
+
break;
|
| 992 |
+
}
|
| 993 |
+
break;
|
| 994 |
+
case 5:
|
| 995 |
+
case 6:
|
| 996 |
+
// Maxwell and Pascal have dedicated shared memory.
|
| 997 |
+
//
|
| 998 |
+
bytes = sharedMemPerMultiprocessorHigh;
|
| 999 |
+
break;
|
| 1000 |
+
default:
|
| 1001 |
+
return CUDA_OCC_ERROR_UNKNOWN_DEVICE;
|
| 1002 |
+
}
|
| 1003 |
+
|
| 1004 |
+
*limit = bytes;
|
| 1005 |
+
|
| 1006 |
+
return CUDA_OCC_SUCCESS;
|
| 1007 |
+
}
|
| 1008 |
+
|
| 1009 |
+
/**
|
| 1010 |
+
* Shared memory based on config requested by User
|
| 1011 |
+
*/
|
| 1012 |
+
static __OCC_INLINE cudaOccError cudaOccSMemPerMultiprocessor(size_t *limit, const cudaOccDeviceProp *properties, const cudaOccDeviceState *state)
|
| 1013 |
+
{
|
| 1014 |
+
// Volta introduces a new API that allows for shared memory carveout preference. Because it is a shared memory preference,
|
| 1015 |
+
// it is handled separately from the cache config preference.
|
| 1016 |
+
if (properties->computeMajor >= 7) {
|
| 1017 |
+
return cudaOccSMemPreferenceVoltaPlus(limit, properties, state);
|
| 1018 |
+
}
|
| 1019 |
+
return cudaOccSMemPreference(limit, properties, state);
|
| 1020 |
+
}
|
| 1021 |
+
|
| 1022 |
+
/**
|
| 1023 |
+
* Return the per block shared memory limit based on function config
|
| 1024 |
+
*/
|
| 1025 |
+
static __OCC_INLINE cudaOccError cudaOccSMemPerBlock(size_t *limit, const cudaOccDeviceProp *properties, cudaOccFuncShmemConfig shmemLimitConfig, size_t smemPerCta)
|
| 1026 |
+
{
|
| 1027 |
+
switch (properties->computeMajor) {
|
| 1028 |
+
case 2:
|
| 1029 |
+
case 3:
|
| 1030 |
+
case 4:
|
| 1031 |
+
case 5:
|
| 1032 |
+
case 6:
|
| 1033 |
+
*limit = properties->sharedMemPerBlock;
|
| 1034 |
+
break;
|
| 1035 |
+
case 7:
|
| 1036 |
+
case 8:
|
| 1037 |
+
case 9:
|
| 1038 |
+
switch (shmemLimitConfig) {
|
| 1039 |
+
default:
|
| 1040 |
+
case FUNC_SHMEM_LIMIT_DEFAULT:
|
| 1041 |
+
*limit = properties->sharedMemPerBlock;
|
| 1042 |
+
break;
|
| 1043 |
+
case FUNC_SHMEM_LIMIT_OPTIN:
|
| 1044 |
+
if (smemPerCta > properties->sharedMemPerBlock) {
|
| 1045 |
+
*limit = properties->sharedMemPerBlockOptin;
|
| 1046 |
+
}
|
| 1047 |
+
else {
|
| 1048 |
+
*limit = properties->sharedMemPerBlock;
|
| 1049 |
+
}
|
| 1050 |
+
break;
|
| 1051 |
+
}
|
| 1052 |
+
break;
|
| 1053 |
+
default:
|
| 1054 |
+
return CUDA_OCC_ERROR_UNKNOWN_DEVICE;
|
| 1055 |
+
}
|
| 1056 |
+
|
| 1057 |
+
// Starting Ampere, CUDA driver reserves additional shared memory per block
|
| 1058 |
+
if (properties->computeMajor >= 8) {
|
| 1059 |
+
*limit += properties->reservedSharedMemPerBlock;
|
| 1060 |
+
}
|
| 1061 |
+
|
| 1062 |
+
return CUDA_OCC_SUCCESS;
|
| 1063 |
+
}
|
| 1064 |
+
|
| 1065 |
+
/**
|
| 1066 |
+
* Partitioned global caching mode support
|
| 1067 |
+
*/
|
| 1068 |
+
static __OCC_INLINE cudaOccError cudaOccPartitionedGlobalCachingModeSupport(cudaOccPartitionedGCSupport *limit, const cudaOccDeviceProp *properties)
|
| 1069 |
+
{
|
| 1070 |
+
*limit = PARTITIONED_GC_NOT_SUPPORTED;
|
| 1071 |
+
|
| 1072 |
+
if ((properties->computeMajor == 5 && (properties->computeMinor == 2 || properties->computeMinor == 3)) ||
|
| 1073 |
+
properties->computeMajor == 6) {
|
| 1074 |
+
*limit = PARTITIONED_GC_SUPPORTED;
|
| 1075 |
+
}
|
| 1076 |
+
|
| 1077 |
+
if (properties->computeMajor == 6 && properties->computeMinor == 0) {
|
| 1078 |
+
*limit = PARTITIONED_GC_NOT_SUPPORTED;
|
| 1079 |
+
}
|
| 1080 |
+
|
| 1081 |
+
return CUDA_OCC_SUCCESS;
|
| 1082 |
+
}
|
| 1083 |
+
|
| 1084 |
+
///////////////////////////////////////////////
|
| 1085 |
+
// User Input Sanity //
|
| 1086 |
+
///////////////////////////////////////////////
|
| 1087 |
+
|
| 1088 |
+
static __OCC_INLINE cudaOccError cudaOccDevicePropCheck(const cudaOccDeviceProp *properties)
|
| 1089 |
+
{
|
| 1090 |
+
// Verify device properties
|
| 1091 |
+
//
|
| 1092 |
+
// Each of these limits must be a positive number.
|
| 1093 |
+
//
|
| 1094 |
+
// Compute capacity is checked during the occupancy calculation
|
| 1095 |
+
//
|
| 1096 |
+
if (properties->maxThreadsPerBlock <= 0 ||
|
| 1097 |
+
properties->maxThreadsPerMultiprocessor <= 0 ||
|
| 1098 |
+
properties->regsPerBlock <= 0 ||
|
| 1099 |
+
properties->regsPerMultiprocessor <= 0 ||
|
| 1100 |
+
properties->warpSize <= 0 ||
|
| 1101 |
+
properties->sharedMemPerBlock <= 0 ||
|
| 1102 |
+
properties->sharedMemPerMultiprocessor <= 0 ||
|
| 1103 |
+
properties->numSms <= 0) {
|
| 1104 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 1105 |
+
}
|
| 1106 |
+
|
| 1107 |
+
return CUDA_OCC_SUCCESS;
|
| 1108 |
+
}
|
| 1109 |
+
|
| 1110 |
+
static __OCC_INLINE cudaOccError cudaOccFuncAttributesCheck(const cudaOccFuncAttributes *attributes)
|
| 1111 |
+
{
|
| 1112 |
+
// Verify function attributes
|
| 1113 |
+
//
|
| 1114 |
+
if (attributes->maxThreadsPerBlock <= 0 ||
|
| 1115 |
+
attributes->numRegs < 0) { // Compiler may choose not to use
|
| 1116 |
+
// any register (empty kernels,
|
| 1117 |
+
// etc.)
|
| 1118 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 1119 |
+
}
|
| 1120 |
+
|
| 1121 |
+
return CUDA_OCC_SUCCESS;
|
| 1122 |
+
}
|
| 1123 |
+
|
| 1124 |
+
static __OCC_INLINE cudaOccError cudaOccDeviceStateCheck(const cudaOccDeviceState *state)
|
| 1125 |
+
{
|
| 1126 |
+
(void)state; // silence unused-variable warning
|
| 1127 |
+
// Placeholder
|
| 1128 |
+
//
|
| 1129 |
+
|
| 1130 |
+
return CUDA_OCC_SUCCESS;
|
| 1131 |
+
}
|
| 1132 |
+
|
| 1133 |
+
static __OCC_INLINE cudaOccError cudaOccInputCheck(
|
| 1134 |
+
const cudaOccDeviceProp *properties,
|
| 1135 |
+
const cudaOccFuncAttributes *attributes,
|
| 1136 |
+
const cudaOccDeviceState *state)
|
| 1137 |
+
{
|
| 1138 |
+
cudaOccError status = CUDA_OCC_SUCCESS;
|
| 1139 |
+
|
| 1140 |
+
status = cudaOccDevicePropCheck(properties);
|
| 1141 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1142 |
+
return status;
|
| 1143 |
+
}
|
| 1144 |
+
|
| 1145 |
+
status = cudaOccFuncAttributesCheck(attributes);
|
| 1146 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1147 |
+
return status;
|
| 1148 |
+
}
|
| 1149 |
+
|
| 1150 |
+
status = cudaOccDeviceStateCheck(state);
|
| 1151 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1152 |
+
return status;
|
| 1153 |
+
}
|
| 1154 |
+
|
| 1155 |
+
return status;
|
| 1156 |
+
}
|
| 1157 |
+
|
| 1158 |
+
///////////////////////////////////////////////
|
| 1159 |
+
// Occupancy calculation Functions //
|
| 1160 |
+
///////////////////////////////////////////////
|
| 1161 |
+
|
| 1162 |
+
static __OCC_INLINE cudaOccPartitionedGCConfig cudaOccPartitionedGCExpected(
|
| 1163 |
+
const cudaOccDeviceProp *properties,
|
| 1164 |
+
const cudaOccFuncAttributes *attributes)
|
| 1165 |
+
{
|
| 1166 |
+
cudaOccPartitionedGCSupport gcSupport;
|
| 1167 |
+
cudaOccPartitionedGCConfig gcConfig;
|
| 1168 |
+
|
| 1169 |
+
cudaOccPartitionedGlobalCachingModeSupport(&gcSupport, properties);
|
| 1170 |
+
|
| 1171 |
+
gcConfig = attributes->partitionedGCConfig;
|
| 1172 |
+
|
| 1173 |
+
if (gcSupport == PARTITIONED_GC_NOT_SUPPORTED) {
|
| 1174 |
+
gcConfig = PARTITIONED_GC_OFF;
|
| 1175 |
+
}
|
| 1176 |
+
|
| 1177 |
+
return gcConfig;
|
| 1178 |
+
}
|
| 1179 |
+
|
| 1180 |
+
// Warp limit
|
| 1181 |
+
//
|
| 1182 |
+
static __OCC_INLINE cudaOccError cudaOccMaxBlocksPerSMWarpsLimit(
|
| 1183 |
+
int *limit,
|
| 1184 |
+
cudaOccPartitionedGCConfig gcConfig,
|
| 1185 |
+
const cudaOccDeviceProp *properties,
|
| 1186 |
+
const cudaOccFuncAttributes *attributes,
|
| 1187 |
+
int blockSize)
|
| 1188 |
+
{
|
| 1189 |
+
cudaOccError status = CUDA_OCC_SUCCESS;
|
| 1190 |
+
int maxWarpsPerSm;
|
| 1191 |
+
int warpsAllocatedPerCTA;
|
| 1192 |
+
int maxBlocks;
|
| 1193 |
+
(void)attributes; // silence unused-variable warning
|
| 1194 |
+
|
| 1195 |
+
if (blockSize > properties->maxThreadsPerBlock) {
|
| 1196 |
+
maxBlocks = 0;
|
| 1197 |
+
}
|
| 1198 |
+
else {
|
| 1199 |
+
maxWarpsPerSm = properties->maxThreadsPerMultiprocessor / properties->warpSize;
|
| 1200 |
+
warpsAllocatedPerCTA = __occDivideRoundUp(blockSize, properties->warpSize);
|
| 1201 |
+
maxBlocks = 0;
|
| 1202 |
+
|
| 1203 |
+
if (gcConfig != PARTITIONED_GC_OFF) {
|
| 1204 |
+
int maxBlocksPerSmPartition;
|
| 1205 |
+
int maxWarpsPerSmPartition;
|
| 1206 |
+
|
| 1207 |
+
// If partitioned global caching is on, then a CTA can only use a SM
|
| 1208 |
+
// partition (a half SM), and thus a half of the warp slots
|
| 1209 |
+
// available per SM
|
| 1210 |
+
//
|
| 1211 |
+
maxWarpsPerSmPartition = maxWarpsPerSm / 2;
|
| 1212 |
+
maxBlocksPerSmPartition = maxWarpsPerSmPartition / warpsAllocatedPerCTA;
|
| 1213 |
+
maxBlocks = maxBlocksPerSmPartition * 2;
|
| 1214 |
+
}
|
| 1215 |
+
// On hardware that supports partitioned global caching, each half SM is
|
| 1216 |
+
// guaranteed to support at least 32 warps (maximum number of warps of a
|
| 1217 |
+
// CTA), so caching will not cause 0 occupancy due to insufficient warp
|
| 1218 |
+
// allocation slots.
|
| 1219 |
+
//
|
| 1220 |
+
else {
|
| 1221 |
+
maxBlocks = maxWarpsPerSm / warpsAllocatedPerCTA;
|
| 1222 |
+
}
|
| 1223 |
+
}
|
| 1224 |
+
|
| 1225 |
+
*limit = maxBlocks;
|
| 1226 |
+
|
| 1227 |
+
return status;
|
| 1228 |
+
}
|
| 1229 |
+
|
| 1230 |
+
// Shared memory limit
|
| 1231 |
+
//
|
| 1232 |
+
static __OCC_INLINE cudaOccError cudaOccMaxBlocksPerSMSmemLimit(
|
| 1233 |
+
int *limit,
|
| 1234 |
+
cudaOccResult *result,
|
| 1235 |
+
const cudaOccDeviceProp *properties,
|
| 1236 |
+
const cudaOccFuncAttributes *attributes,
|
| 1237 |
+
const cudaOccDeviceState *state,
|
| 1238 |
+
int blockSize,
|
| 1239 |
+
size_t dynamicSmemSize)
|
| 1240 |
+
{
|
| 1241 |
+
cudaOccError status = CUDA_OCC_SUCCESS;
|
| 1242 |
+
int allocationGranularity;
|
| 1243 |
+
size_t userSmemPreference = 0;
|
| 1244 |
+
size_t totalSmemUsagePerCTA;
|
| 1245 |
+
size_t maxSmemUsagePerCTA;
|
| 1246 |
+
size_t smemAllocatedPerCTA;
|
| 1247 |
+
size_t staticSmemSize;
|
| 1248 |
+
size_t sharedMemPerMultiprocessor;
|
| 1249 |
+
size_t smemLimitPerCTA;
|
| 1250 |
+
int maxBlocks;
|
| 1251 |
+
int dynamicSmemSizeExceeded = 0;
|
| 1252 |
+
int totalSmemSizeExceeded = 0;
|
| 1253 |
+
(void)blockSize; // silence unused-variable warning
|
| 1254 |
+
|
| 1255 |
+
status = cudaOccSMemAllocationGranularity(&allocationGranularity, properties);
|
| 1256 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1257 |
+
return status;
|
| 1258 |
+
}
|
| 1259 |
+
|
| 1260 |
+
// Obtain the user preferred shared memory size. This setting is ignored if
|
| 1261 |
+
// user requests more shared memory than preferred.
|
| 1262 |
+
//
|
| 1263 |
+
status = cudaOccSMemPerMultiprocessor(&userSmemPreference, properties, state);
|
| 1264 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1265 |
+
return status;
|
| 1266 |
+
}
|
| 1267 |
+
|
| 1268 |
+
staticSmemSize = attributes->sharedSizeBytes + properties->reservedSharedMemPerBlock;
|
| 1269 |
+
totalSmemUsagePerCTA = staticSmemSize + dynamicSmemSize;
|
| 1270 |
+
smemAllocatedPerCTA = __occRoundUp((int)totalSmemUsagePerCTA, (int)allocationGranularity);
|
| 1271 |
+
|
| 1272 |
+
maxSmemUsagePerCTA = staticSmemSize + attributes->maxDynamicSharedSizeBytes;
|
| 1273 |
+
|
| 1274 |
+
dynamicSmemSizeExceeded = 0;
|
| 1275 |
+
totalSmemSizeExceeded = 0;
|
| 1276 |
+
|
| 1277 |
+
// Obtain the user set maximum dynamic size if it exists
|
| 1278 |
+
// If so, the current launch dynamic shared memory must not
|
| 1279 |
+
// exceed the set limit
|
| 1280 |
+
if (attributes->shmemLimitConfig != FUNC_SHMEM_LIMIT_DEFAULT &&
|
| 1281 |
+
dynamicSmemSize > attributes->maxDynamicSharedSizeBytes) {
|
| 1282 |
+
dynamicSmemSizeExceeded = 1;
|
| 1283 |
+
}
|
| 1284 |
+
|
| 1285 |
+
status = cudaOccSMemPerBlock(&smemLimitPerCTA, properties, attributes->shmemLimitConfig, maxSmemUsagePerCTA);
|
| 1286 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1287 |
+
return status;
|
| 1288 |
+
}
|
| 1289 |
+
|
| 1290 |
+
if (smemAllocatedPerCTA > smemLimitPerCTA) {
|
| 1291 |
+
totalSmemSizeExceeded = 1;
|
| 1292 |
+
}
|
| 1293 |
+
|
| 1294 |
+
if (dynamicSmemSizeExceeded || totalSmemSizeExceeded) {
|
| 1295 |
+
maxBlocks = 0;
|
| 1296 |
+
}
|
| 1297 |
+
else {
|
| 1298 |
+
// User requested shared memory limit is used as long as it is greater
|
| 1299 |
+
// than the total shared memory used per CTA, i.e. as long as at least
|
| 1300 |
+
// one CTA can be launched.
|
| 1301 |
+
if (userSmemPreference >= smemAllocatedPerCTA) {
|
| 1302 |
+
sharedMemPerMultiprocessor = userSmemPreference;
|
| 1303 |
+
}
|
| 1304 |
+
else {
|
| 1305 |
+
// On Volta+, user requested shared memory will limit occupancy
|
| 1306 |
+
// if it's less than shared memory per CTA. Otherwise, the
|
| 1307 |
+
// maximum shared memory limit is used.
|
| 1308 |
+
if (properties->computeMajor >= 7) {
|
| 1309 |
+
sharedMemPerMultiprocessor = smemAllocatedPerCTA;
|
| 1310 |
+
status = cudaOccAlignUpShmemSizeVoltaPlus(&sharedMemPerMultiprocessor, properties);
|
| 1311 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1312 |
+
return status;
|
| 1313 |
+
}
|
| 1314 |
+
}
|
| 1315 |
+
else {
|
| 1316 |
+
sharedMemPerMultiprocessor = properties->sharedMemPerMultiprocessor;
|
| 1317 |
+
}
|
| 1318 |
+
}
|
| 1319 |
+
|
| 1320 |
+
if (smemAllocatedPerCTA > 0) {
|
| 1321 |
+
maxBlocks = (int)(sharedMemPerMultiprocessor / smemAllocatedPerCTA);
|
| 1322 |
+
}
|
| 1323 |
+
else {
|
| 1324 |
+
maxBlocks = INT_MAX;
|
| 1325 |
+
}
|
| 1326 |
+
}
|
| 1327 |
+
|
| 1328 |
+
result->allocatedSharedMemPerBlock = smemAllocatedPerCTA;
|
| 1329 |
+
|
| 1330 |
+
*limit = maxBlocks;
|
| 1331 |
+
|
| 1332 |
+
return status;
|
| 1333 |
+
}
|
| 1334 |
+
|
| 1335 |
+
static __OCC_INLINE
|
| 1336 |
+
cudaOccError cudaOccMaxBlocksPerSMRegsLimit(
|
| 1337 |
+
int *limit,
|
| 1338 |
+
cudaOccPartitionedGCConfig *gcConfig,
|
| 1339 |
+
cudaOccResult *result,
|
| 1340 |
+
const cudaOccDeviceProp *properties,
|
| 1341 |
+
const cudaOccFuncAttributes *attributes,
|
| 1342 |
+
int blockSize)
|
| 1343 |
+
{
|
| 1344 |
+
cudaOccError status = CUDA_OCC_SUCCESS;
|
| 1345 |
+
int allocationGranularity;
|
| 1346 |
+
int warpsAllocatedPerCTA;
|
| 1347 |
+
int regsAllocatedPerCTA;
|
| 1348 |
+
int regsAssumedPerCTA;
|
| 1349 |
+
int regsPerWarp;
|
| 1350 |
+
int regsAllocatedPerWarp;
|
| 1351 |
+
int numSubPartitions;
|
| 1352 |
+
int numRegsPerSubPartition;
|
| 1353 |
+
int numWarpsPerSubPartition;
|
| 1354 |
+
int numWarpsPerSM;
|
| 1355 |
+
int maxBlocks;
|
| 1356 |
+
int maxRegsPerThread;
|
| 1357 |
+
|
| 1358 |
+
status = cudaOccRegAllocationGranularity(
|
| 1359 |
+
&allocationGranularity,
|
| 1360 |
+
properties);
|
| 1361 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1362 |
+
return status;
|
| 1363 |
+
}
|
| 1364 |
+
|
| 1365 |
+
status = cudaOccRegAllocationMaxPerThread(
|
| 1366 |
+
&maxRegsPerThread,
|
| 1367 |
+
properties);
|
| 1368 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1369 |
+
return status;
|
| 1370 |
+
}
|
| 1371 |
+
|
| 1372 |
+
status = cudaOccSubPartitionsPerMultiprocessor(&numSubPartitions, properties);
|
| 1373 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1374 |
+
return status;
|
| 1375 |
+
}
|
| 1376 |
+
|
| 1377 |
+
warpsAllocatedPerCTA = __occDivideRoundUp(blockSize, properties->warpSize);
|
| 1378 |
+
|
| 1379 |
+
// GPUs of compute capability 2.x and higher allocate registers to warps
|
| 1380 |
+
//
|
| 1381 |
+
// Number of regs per warp is regs per thread x warp size, rounded up to
|
| 1382 |
+
// register allocation granularity
|
| 1383 |
+
//
|
| 1384 |
+
regsPerWarp = attributes->numRegs * properties->warpSize;
|
| 1385 |
+
regsAllocatedPerWarp = __occRoundUp(regsPerWarp, allocationGranularity);
|
| 1386 |
+
regsAllocatedPerCTA = regsAllocatedPerWarp * warpsAllocatedPerCTA;
|
| 1387 |
+
|
| 1388 |
+
// Hardware verifies if a launch fits the per-CTA register limit. For
|
| 1389 |
+
// historical reasons, the verification logic assumes register
|
| 1390 |
+
// allocations are made to all partitions simultaneously. Therefore, to
|
| 1391 |
+
// simulate the hardware check, the warp allocation needs to be rounded
|
| 1392 |
+
// up to the number of partitions.
|
| 1393 |
+
//
|
| 1394 |
+
regsAssumedPerCTA = regsAllocatedPerWarp * __occRoundUp(warpsAllocatedPerCTA, numSubPartitions);
|
| 1395 |
+
|
| 1396 |
+
if (properties->regsPerBlock < regsAssumedPerCTA || // Hardware check
|
| 1397 |
+
properties->regsPerBlock < regsAllocatedPerCTA || // Software check
|
| 1398 |
+
attributes->numRegs > maxRegsPerThread) { // Per thread limit check
|
| 1399 |
+
maxBlocks = 0;
|
| 1400 |
+
}
|
| 1401 |
+
else {
|
| 1402 |
+
if (regsAllocatedPerWarp > 0) {
|
| 1403 |
+
// Registers are allocated in each sub-partition. The max number
|
| 1404 |
+
// of warps that can fit on an SM is equal to the max number of
|
| 1405 |
+
// warps per sub-partition x number of sub-partitions.
|
| 1406 |
+
//
|
| 1407 |
+
numRegsPerSubPartition = properties->regsPerMultiprocessor / numSubPartitions;
|
| 1408 |
+
numWarpsPerSubPartition = numRegsPerSubPartition / regsAllocatedPerWarp;
|
| 1409 |
+
|
| 1410 |
+
maxBlocks = 0;
|
| 1411 |
+
|
| 1412 |
+
if (*gcConfig != PARTITIONED_GC_OFF) {
|
| 1413 |
+
int numSubPartitionsPerSmPartition;
|
| 1414 |
+
int numWarpsPerSmPartition;
|
| 1415 |
+
int maxBlocksPerSmPartition;
|
| 1416 |
+
|
| 1417 |
+
// If partitioned global caching is on, then a CTA can only
|
| 1418 |
+
// use a half SM, and thus a half of the registers available
|
| 1419 |
+
// per SM
|
| 1420 |
+
//
|
| 1421 |
+
numSubPartitionsPerSmPartition = numSubPartitions / 2;
|
| 1422 |
+
numWarpsPerSmPartition = numWarpsPerSubPartition * numSubPartitionsPerSmPartition;
|
| 1423 |
+
maxBlocksPerSmPartition = numWarpsPerSmPartition / warpsAllocatedPerCTA;
|
| 1424 |
+
maxBlocks = maxBlocksPerSmPartition * 2;
|
| 1425 |
+
}
|
| 1426 |
+
|
| 1427 |
+
// Try again if partitioned global caching is not enabled, or if
|
| 1428 |
+
// the CTA cannot fit on the SM with caching on (maxBlocks == 0). In the latter
|
| 1429 |
+
// case, the device will automatically turn off caching, except
|
| 1430 |
+
// if the user forces enablement via PARTITIONED_GC_ON_STRICT to calculate
|
| 1431 |
+
// occupancy and launch configuration.
|
| 1432 |
+
//
|
| 1433 |
+
if (maxBlocks == 0 && *gcConfig != PARTITIONED_GC_ON_STRICT) {
|
| 1434 |
+
// In case *gcConfig was PARTITIONED_GC_ON flip it OFF since
|
| 1435 |
+
// this is what it will be if we spread CTA across partitions.
|
| 1436 |
+
//
|
| 1437 |
+
*gcConfig = PARTITIONED_GC_OFF;
|
| 1438 |
+
numWarpsPerSM = numWarpsPerSubPartition * numSubPartitions;
|
| 1439 |
+
maxBlocks = numWarpsPerSM / warpsAllocatedPerCTA;
|
| 1440 |
+
}
|
| 1441 |
+
}
|
| 1442 |
+
else {
|
| 1443 |
+
maxBlocks = INT_MAX;
|
| 1444 |
+
}
|
| 1445 |
+
}
|
| 1446 |
+
|
| 1447 |
+
|
| 1448 |
+
result->allocatedRegistersPerBlock = regsAllocatedPerCTA;
|
| 1449 |
+
|
| 1450 |
+
*limit = maxBlocks;
|
| 1451 |
+
|
| 1452 |
+
return status;
|
| 1453 |
+
}
|
| 1454 |
+
|
| 1455 |
+
// Barrier limit
|
| 1456 |
+
//
|
| 1457 |
+
static __OCC_INLINE cudaOccError cudaOccMaxBlocksPerSMBlockBarrierLimit(
|
| 1458 |
+
int *limit,
|
| 1459 |
+
int ctaLimitBlocks,
|
| 1460 |
+
const cudaOccFuncAttributes *attributes)
|
| 1461 |
+
{
|
| 1462 |
+
cudaOccError status = CUDA_OCC_SUCCESS;
|
| 1463 |
+
int numBarriersAvailable = ctaLimitBlocks * 2;
|
| 1464 |
+
int numBarriersUsed = attributes->numBlockBarriers;
|
| 1465 |
+
int maxBlocks = INT_MAX;
|
| 1466 |
+
|
| 1467 |
+
if (numBarriersUsed) {
|
| 1468 |
+
maxBlocks = numBarriersAvailable / numBarriersUsed;
|
| 1469 |
+
}
|
| 1470 |
+
|
| 1471 |
+
*limit = maxBlocks;
|
| 1472 |
+
|
| 1473 |
+
return status;
|
| 1474 |
+
}
|
| 1475 |
+
|
| 1476 |
+
///////////////////////////////////
|
| 1477 |
+
// API Implementations //
|
| 1478 |
+
///////////////////////////////////
|
| 1479 |
+
|
| 1480 |
+
static __OCC_INLINE
|
| 1481 |
+
cudaOccError cudaOccMaxActiveBlocksPerMultiprocessor(
|
| 1482 |
+
cudaOccResult *result,
|
| 1483 |
+
const cudaOccDeviceProp *properties,
|
| 1484 |
+
const cudaOccFuncAttributes *attributes,
|
| 1485 |
+
const cudaOccDeviceState *state,
|
| 1486 |
+
int blockSize,
|
| 1487 |
+
size_t dynamicSmemSize)
|
| 1488 |
+
{
|
| 1489 |
+
cudaOccError status = CUDA_OCC_SUCCESS;
|
| 1490 |
+
int ctaLimitWarps = 0;
|
| 1491 |
+
int ctaLimitBlocks = 0;
|
| 1492 |
+
int ctaLimitSMem = 0;
|
| 1493 |
+
int ctaLimitRegs = 0;
|
| 1494 |
+
int ctaLimitBars = 0;
|
| 1495 |
+
int ctaLimit = 0;
|
| 1496 |
+
unsigned int limitingFactors = 0;
|
| 1497 |
+
|
| 1498 |
+
cudaOccPartitionedGCConfig gcConfig = PARTITIONED_GC_OFF;
|
| 1499 |
+
|
| 1500 |
+
if (!result || !properties || !attributes || !state || blockSize <= 0) {
|
| 1501 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 1502 |
+
}
|
| 1503 |
+
|
| 1504 |
+
///////////////////////////
|
| 1505 |
+
// Check user input
|
| 1506 |
+
///////////////////////////
|
| 1507 |
+
|
| 1508 |
+
status = cudaOccInputCheck(properties, attributes, state);
|
| 1509 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1510 |
+
return status;
|
| 1511 |
+
}
|
| 1512 |
+
|
| 1513 |
+
///////////////////////////
|
| 1514 |
+
// Initialization
|
| 1515 |
+
///////////////////////////
|
| 1516 |
+
|
| 1517 |
+
gcConfig = cudaOccPartitionedGCExpected(properties, attributes);
|
| 1518 |
+
|
| 1519 |
+
///////////////////////////
|
| 1520 |
+
// Compute occupancy
|
| 1521 |
+
///////////////////////////
|
| 1522 |
+
|
| 1523 |
+
// Limits due to registers/SM
|
| 1524 |
+
// Also compute if partitioned global caching has to be turned off
|
| 1525 |
+
//
|
| 1526 |
+
status = cudaOccMaxBlocksPerSMRegsLimit(&ctaLimitRegs, &gcConfig, result, properties, attributes, blockSize);
|
| 1527 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1528 |
+
return status;
|
| 1529 |
+
}
|
| 1530 |
+
|
| 1531 |
+
// SMs on GP100 (6.0) have 2 subpartitions, while those on GP10x have 4.
|
| 1532 |
+
// As a result, an SM on GP100 may be able to run more CTAs than the one on GP10x.
|
| 1533 |
+
// For forward compatibility within Pascal family, if a function cannot run on GP10x (maxBlock == 0),
|
| 1534 |
+
// we do not let it run on any Pascal processor, even though it may be able to run on GP100.
|
| 1535 |
+
// Therefore, we check the occupancy on GP10x when it can run on GP100
|
| 1536 |
+
//
|
| 1537 |
+
if (properties->computeMajor == 6 && properties->computeMinor == 0 && ctaLimitRegs) {
|
| 1538 |
+
cudaOccDeviceProp propertiesGP10x;
|
| 1539 |
+
cudaOccPartitionedGCConfig gcConfigGP10x = gcConfig;
|
| 1540 |
+
int ctaLimitRegsGP10x = 0;
|
| 1541 |
+
|
| 1542 |
+
// Set up properties for GP10x
|
| 1543 |
+
memcpy(&propertiesGP10x, properties, sizeof(propertiesGP10x));
|
| 1544 |
+
propertiesGP10x.computeMinor = 1;
|
| 1545 |
+
|
| 1546 |
+
status = cudaOccMaxBlocksPerSMRegsLimit(&ctaLimitRegsGP10x, &gcConfigGP10x, result, &propertiesGP10x, attributes, blockSize);
|
| 1547 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1548 |
+
return status;
|
| 1549 |
+
}
|
| 1550 |
+
|
| 1551 |
+
if (ctaLimitRegsGP10x == 0) {
|
| 1552 |
+
ctaLimitRegs = 0;
|
| 1553 |
+
}
|
| 1554 |
+
}
|
| 1555 |
+
|
| 1556 |
+
// Limits due to warps/SM
|
| 1557 |
+
//
|
| 1558 |
+
status = cudaOccMaxBlocksPerSMWarpsLimit(&ctaLimitWarps, gcConfig, properties, attributes, blockSize);
|
| 1559 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1560 |
+
return status;
|
| 1561 |
+
}
|
| 1562 |
+
|
| 1563 |
+
// Limits due to blocks/SM
|
| 1564 |
+
//
|
| 1565 |
+
status = cudaOccMaxBlocksPerMultiprocessor(&ctaLimitBlocks, properties);
|
| 1566 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1567 |
+
return status;
|
| 1568 |
+
}
|
| 1569 |
+
|
| 1570 |
+
// Limits due to shared memory/SM
|
| 1571 |
+
//
|
| 1572 |
+
status = cudaOccMaxBlocksPerSMSmemLimit(&ctaLimitSMem, result, properties, attributes, state, blockSize, dynamicSmemSize);
|
| 1573 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1574 |
+
return status;
|
| 1575 |
+
}
|
| 1576 |
+
|
| 1577 |
+
///////////////////////////
|
| 1578 |
+
// Overall occupancy
|
| 1579 |
+
///////////////////////////
|
| 1580 |
+
|
| 1581 |
+
// Overall limit is min() of limits due to above reasons
|
| 1582 |
+
//
|
| 1583 |
+
ctaLimit = __occMin(ctaLimitRegs, __occMin(ctaLimitSMem, __occMin(ctaLimitWarps, ctaLimitBlocks)));
|
| 1584 |
+
|
| 1585 |
+
// Determine occupancy limiting factors
|
| 1586 |
+
//
|
| 1587 |
+
if (ctaLimit == ctaLimitWarps) {
|
| 1588 |
+
limitingFactors |= OCC_LIMIT_WARPS;
|
| 1589 |
+
}
|
| 1590 |
+
if (ctaLimit == ctaLimitRegs) {
|
| 1591 |
+
limitingFactors |= OCC_LIMIT_REGISTERS;
|
| 1592 |
+
}
|
| 1593 |
+
if (ctaLimit == ctaLimitSMem) {
|
| 1594 |
+
limitingFactors |= OCC_LIMIT_SHARED_MEMORY;
|
| 1595 |
+
}
|
| 1596 |
+
if (ctaLimit == ctaLimitBlocks) {
|
| 1597 |
+
limitingFactors |= OCC_LIMIT_BLOCKS;
|
| 1598 |
+
}
|
| 1599 |
+
|
| 1600 |
+
// For Hopper onwards compute the limits to occupancy based on block barrier count
|
| 1601 |
+
//
|
| 1602 |
+
if (properties->computeMajor >= 9 && attributes->numBlockBarriers > 0) {
|
| 1603 |
+
// Limits due to barrier/SM
|
| 1604 |
+
//
|
| 1605 |
+
status = cudaOccMaxBlocksPerSMBlockBarrierLimit(&ctaLimitBars, ctaLimitBlocks, attributes);
|
| 1606 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1607 |
+
return status;
|
| 1608 |
+
}
|
| 1609 |
+
|
| 1610 |
+
// Recompute overall limit based on barrier/SM
|
| 1611 |
+
//
|
| 1612 |
+
ctaLimit = __occMin(ctaLimitBars, ctaLimit);
|
| 1613 |
+
|
| 1614 |
+
// Determine if this is occupancy limiting factor
|
| 1615 |
+
//
|
| 1616 |
+
if (ctaLimit == ctaLimitBars) {
|
| 1617 |
+
limitingFactors |= OCC_LIMIT_BARRIERS;
|
| 1618 |
+
}
|
| 1619 |
+
}
|
| 1620 |
+
else {
|
| 1621 |
+
ctaLimitBars = INT_MAX;
|
| 1622 |
+
}
|
| 1623 |
+
|
| 1624 |
+
// Fill in the return values
|
| 1625 |
+
//
|
| 1626 |
+
result->limitingFactors = limitingFactors;
|
| 1627 |
+
|
| 1628 |
+
result->blockLimitRegs = ctaLimitRegs;
|
| 1629 |
+
result->blockLimitSharedMem = ctaLimitSMem;
|
| 1630 |
+
result->blockLimitWarps = ctaLimitWarps;
|
| 1631 |
+
result->blockLimitBlocks = ctaLimitBlocks;
|
| 1632 |
+
result->blockLimitBarriers = ctaLimitBars;
|
| 1633 |
+
result->partitionedGCConfig = gcConfig;
|
| 1634 |
+
|
| 1635 |
+
// Final occupancy
|
| 1636 |
+
result->activeBlocksPerMultiprocessor = ctaLimit;
|
| 1637 |
+
|
| 1638 |
+
return CUDA_OCC_SUCCESS;
|
| 1639 |
+
}
|
| 1640 |
+
|
| 1641 |
+
static __OCC_INLINE
|
| 1642 |
+
cudaOccError cudaOccAvailableDynamicSMemPerBlock(
|
| 1643 |
+
size_t *bytesAvailable,
|
| 1644 |
+
const cudaOccDeviceProp *properties,
|
| 1645 |
+
const cudaOccFuncAttributes *attributes,
|
| 1646 |
+
const cudaOccDeviceState *state,
|
| 1647 |
+
int numBlocks,
|
| 1648 |
+
int blockSize)
|
| 1649 |
+
{
|
| 1650 |
+
int allocationGranularity;
|
| 1651 |
+
size_t smemLimitPerBlock;
|
| 1652 |
+
size_t smemAvailableForDynamic;
|
| 1653 |
+
size_t userSmemPreference = 0;
|
| 1654 |
+
size_t sharedMemPerMultiprocessor;
|
| 1655 |
+
cudaOccResult result;
|
| 1656 |
+
cudaOccError status = CUDA_OCC_SUCCESS;
|
| 1657 |
+
|
| 1658 |
+
if (numBlocks <= 0)
|
| 1659 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 1660 |
+
|
| 1661 |
+
// First compute occupancy of potential kernel launch.
|
| 1662 |
+
//
|
| 1663 |
+
status = cudaOccMaxActiveBlocksPerMultiprocessor(&result, properties, attributes, state, blockSize, 0);
|
| 1664 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1665 |
+
return status;
|
| 1666 |
+
}
|
| 1667 |
+
// Check if occupancy is achievable given user requested number of blocks.
|
| 1668 |
+
//
|
| 1669 |
+
if (result.activeBlocksPerMultiprocessor < numBlocks) {
|
| 1670 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 1671 |
+
}
|
| 1672 |
+
|
| 1673 |
+
status = cudaOccSMemAllocationGranularity(&allocationGranularity, properties);
|
| 1674 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1675 |
+
return status;
|
| 1676 |
+
}
|
| 1677 |
+
|
| 1678 |
+
// Return the per block shared memory limit based on function config.
|
| 1679 |
+
//
|
| 1680 |
+
status = cudaOccSMemPerBlock(&smemLimitPerBlock, properties, attributes->shmemLimitConfig, properties->sharedMemPerMultiprocessor);
|
| 1681 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1682 |
+
return status;
|
| 1683 |
+
}
|
| 1684 |
+
|
| 1685 |
+
// If there is only a single block needed per SM, then the user preference can be ignored and the fully SW
|
| 1686 |
+
// limit is allowed to be used as shared memory otherwise if more than one block is needed, then the user
|
| 1687 |
+
// preference sets the total limit of available shared memory.
|
| 1688 |
+
//
|
| 1689 |
+
cudaOccSMemPerMultiprocessor(&userSmemPreference, properties, state);
|
| 1690 |
+
if (numBlocks == 1) {
|
| 1691 |
+
sharedMemPerMultiprocessor = smemLimitPerBlock;
|
| 1692 |
+
}
|
| 1693 |
+
else {
|
| 1694 |
+
if (!userSmemPreference) {
|
| 1695 |
+
userSmemPreference = 1 ;
|
| 1696 |
+
status = cudaOccAlignUpShmemSizeVoltaPlus(&userSmemPreference, properties);
|
| 1697 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1698 |
+
return status;
|
| 1699 |
+
}
|
| 1700 |
+
}
|
| 1701 |
+
sharedMemPerMultiprocessor = userSmemPreference;
|
| 1702 |
+
}
|
| 1703 |
+
|
| 1704 |
+
// Compute total shared memory available per SM
|
| 1705 |
+
//
|
| 1706 |
+
smemAvailableForDynamic = sharedMemPerMultiprocessor / numBlocks;
|
| 1707 |
+
smemAvailableForDynamic = (smemAvailableForDynamic / allocationGranularity) * allocationGranularity;
|
| 1708 |
+
|
| 1709 |
+
// Cap shared memory
|
| 1710 |
+
//
|
| 1711 |
+
if (smemAvailableForDynamic > smemLimitPerBlock) {
|
| 1712 |
+
smemAvailableForDynamic = smemLimitPerBlock;
|
| 1713 |
+
}
|
| 1714 |
+
|
| 1715 |
+
// Now compute dynamic shared memory size
|
| 1716 |
+
smemAvailableForDynamic = smemAvailableForDynamic - attributes->sharedSizeBytes;
|
| 1717 |
+
|
| 1718 |
+
// Cap computed dynamic SM by user requested limit specified via cuFuncSetAttribute()
|
| 1719 |
+
//
|
| 1720 |
+
if (smemAvailableForDynamic > attributes->maxDynamicSharedSizeBytes)
|
| 1721 |
+
smemAvailableForDynamic = attributes->maxDynamicSharedSizeBytes;
|
| 1722 |
+
|
| 1723 |
+
*bytesAvailable = smemAvailableForDynamic;
|
| 1724 |
+
return CUDA_OCC_SUCCESS;
|
| 1725 |
+
}
|
| 1726 |
+
|
| 1727 |
+
static __OCC_INLINE
|
| 1728 |
+
cudaOccError cudaOccMaxPotentialOccupancyBlockSize(
|
| 1729 |
+
int *minGridSize,
|
| 1730 |
+
int *blockSize,
|
| 1731 |
+
const cudaOccDeviceProp *properties,
|
| 1732 |
+
const cudaOccFuncAttributes *attributes,
|
| 1733 |
+
const cudaOccDeviceState *state,
|
| 1734 |
+
size_t (*blockSizeToDynamicSMemSize)(int),
|
| 1735 |
+
size_t dynamicSMemSize)
|
| 1736 |
+
{
|
| 1737 |
+
cudaOccError status = CUDA_OCC_SUCCESS;
|
| 1738 |
+
cudaOccResult result;
|
| 1739 |
+
|
| 1740 |
+
// Limits
|
| 1741 |
+
int occupancyLimit;
|
| 1742 |
+
int granularity;
|
| 1743 |
+
int blockSizeLimit;
|
| 1744 |
+
|
| 1745 |
+
// Recorded maximum
|
| 1746 |
+
int maxBlockSize = 0;
|
| 1747 |
+
int numBlocks = 0;
|
| 1748 |
+
int maxOccupancy = 0;
|
| 1749 |
+
|
| 1750 |
+
// Temporary
|
| 1751 |
+
int blockSizeToTryAligned;
|
| 1752 |
+
int blockSizeToTry;
|
| 1753 |
+
int blockSizeLimitAligned;
|
| 1754 |
+
int occupancyInBlocks;
|
| 1755 |
+
int occupancyInThreads;
|
| 1756 |
+
|
| 1757 |
+
///////////////////////////
|
| 1758 |
+
// Check user input
|
| 1759 |
+
///////////////////////////
|
| 1760 |
+
|
| 1761 |
+
if (!minGridSize || !blockSize || !properties || !attributes || !state) {
|
| 1762 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 1763 |
+
}
|
| 1764 |
+
|
| 1765 |
+
status = cudaOccInputCheck(properties, attributes, state);
|
| 1766 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1767 |
+
return status;
|
| 1768 |
+
}
|
| 1769 |
+
|
| 1770 |
+
/////////////////////////////////////////////////////////////////////////////////
|
| 1771 |
+
// Try each block size, and pick the block size with maximum occupancy
|
| 1772 |
+
/////////////////////////////////////////////////////////////////////////////////
|
| 1773 |
+
|
| 1774 |
+
occupancyLimit = properties->maxThreadsPerMultiprocessor;
|
| 1775 |
+
granularity = properties->warpSize;
|
| 1776 |
+
|
| 1777 |
+
blockSizeLimit = __occMin(properties->maxThreadsPerBlock, attributes->maxThreadsPerBlock);
|
| 1778 |
+
blockSizeLimitAligned = __occRoundUp(blockSizeLimit, granularity);
|
| 1779 |
+
|
| 1780 |
+
for (blockSizeToTryAligned = blockSizeLimitAligned; blockSizeToTryAligned > 0; blockSizeToTryAligned -= granularity) {
|
| 1781 |
+
blockSizeToTry = __occMin(blockSizeLimit, blockSizeToTryAligned);
|
| 1782 |
+
|
| 1783 |
+
// Ignore dynamicSMemSize if the user provides a mapping
|
| 1784 |
+
//
|
| 1785 |
+
if (blockSizeToDynamicSMemSize) {
|
| 1786 |
+
dynamicSMemSize = (*blockSizeToDynamicSMemSize)(blockSizeToTry);
|
| 1787 |
+
}
|
| 1788 |
+
|
| 1789 |
+
status = cudaOccMaxActiveBlocksPerMultiprocessor(
|
| 1790 |
+
&result,
|
| 1791 |
+
properties,
|
| 1792 |
+
attributes,
|
| 1793 |
+
state,
|
| 1794 |
+
blockSizeToTry,
|
| 1795 |
+
dynamicSMemSize);
|
| 1796 |
+
|
| 1797 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1798 |
+
return status;
|
| 1799 |
+
}
|
| 1800 |
+
|
| 1801 |
+
occupancyInBlocks = result.activeBlocksPerMultiprocessor;
|
| 1802 |
+
occupancyInThreads = blockSizeToTry * occupancyInBlocks;
|
| 1803 |
+
|
| 1804 |
+
if (occupancyInThreads > maxOccupancy) {
|
| 1805 |
+
maxBlockSize = blockSizeToTry;
|
| 1806 |
+
numBlocks = occupancyInBlocks;
|
| 1807 |
+
maxOccupancy = occupancyInThreads;
|
| 1808 |
+
}
|
| 1809 |
+
|
| 1810 |
+
// Early out if we have reached the maximum
|
| 1811 |
+
//
|
| 1812 |
+
if (occupancyLimit == maxOccupancy) {
|
| 1813 |
+
break;
|
| 1814 |
+
}
|
| 1815 |
+
}
|
| 1816 |
+
|
| 1817 |
+
///////////////////////////
|
| 1818 |
+
// Return best available
|
| 1819 |
+
///////////////////////////
|
| 1820 |
+
|
| 1821 |
+
// Suggested min grid size to achieve a full machine launch
|
| 1822 |
+
//
|
| 1823 |
+
*minGridSize = numBlocks * properties->numSms;
|
| 1824 |
+
*blockSize = maxBlockSize;
|
| 1825 |
+
|
| 1826 |
+
return status;
|
| 1827 |
+
}
|
| 1828 |
+
|
| 1829 |
+
|
| 1830 |
+
#if defined(__cplusplus)
|
| 1831 |
+
|
| 1832 |
+
namespace {
|
| 1833 |
+
|
| 1834 |
+
__OCC_INLINE
|
| 1835 |
+
cudaOccError cudaOccMaxPotentialOccupancyBlockSize(
|
| 1836 |
+
int *minGridSize,
|
| 1837 |
+
int *blockSize,
|
| 1838 |
+
const cudaOccDeviceProp *properties,
|
| 1839 |
+
const cudaOccFuncAttributes *attributes,
|
| 1840 |
+
const cudaOccDeviceState *state,
|
| 1841 |
+
size_t dynamicSMemSize)
|
| 1842 |
+
{
|
| 1843 |
+
return cudaOccMaxPotentialOccupancyBlockSize(
|
| 1844 |
+
minGridSize,
|
| 1845 |
+
blockSize,
|
| 1846 |
+
properties,
|
| 1847 |
+
attributes,
|
| 1848 |
+
state,
|
| 1849 |
+
NULL,
|
| 1850 |
+
dynamicSMemSize);
|
| 1851 |
+
}
|
| 1852 |
+
|
| 1853 |
+
template <typename UnaryFunction>
|
| 1854 |
+
__OCC_INLINE
|
| 1855 |
+
cudaOccError cudaOccMaxPotentialOccupancyBlockSizeVariableSMem(
|
| 1856 |
+
int *minGridSize,
|
| 1857 |
+
int *blockSize,
|
| 1858 |
+
const cudaOccDeviceProp *properties,
|
| 1859 |
+
const cudaOccFuncAttributes *attributes,
|
| 1860 |
+
const cudaOccDeviceState *state,
|
| 1861 |
+
UnaryFunction blockSizeToDynamicSMemSize)
|
| 1862 |
+
{
|
| 1863 |
+
cudaOccError status = CUDA_OCC_SUCCESS;
|
| 1864 |
+
cudaOccResult result;
|
| 1865 |
+
|
| 1866 |
+
// Limits
|
| 1867 |
+
int occupancyLimit;
|
| 1868 |
+
int granularity;
|
| 1869 |
+
int blockSizeLimit;
|
| 1870 |
+
|
| 1871 |
+
// Recorded maximum
|
| 1872 |
+
int maxBlockSize = 0;
|
| 1873 |
+
int numBlocks = 0;
|
| 1874 |
+
int maxOccupancy = 0;
|
| 1875 |
+
|
| 1876 |
+
// Temporary
|
| 1877 |
+
int blockSizeToTryAligned;
|
| 1878 |
+
int blockSizeToTry;
|
| 1879 |
+
int blockSizeLimitAligned;
|
| 1880 |
+
int occupancyInBlocks;
|
| 1881 |
+
int occupancyInThreads;
|
| 1882 |
+
size_t dynamicSMemSize;
|
| 1883 |
+
|
| 1884 |
+
///////////////////////////
|
| 1885 |
+
// Check user input
|
| 1886 |
+
///////////////////////////
|
| 1887 |
+
|
| 1888 |
+
if (!minGridSize || !blockSize || !properties || !attributes || !state) {
|
| 1889 |
+
return CUDA_OCC_ERROR_INVALID_INPUT;
|
| 1890 |
+
}
|
| 1891 |
+
|
| 1892 |
+
status = cudaOccInputCheck(properties, attributes, state);
|
| 1893 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1894 |
+
return status;
|
| 1895 |
+
}
|
| 1896 |
+
|
| 1897 |
+
/////////////////////////////////////////////////////////////////////////////////
|
| 1898 |
+
// Try each block size, and pick the block size with maximum occupancy
|
| 1899 |
+
/////////////////////////////////////////////////////////////////////////////////
|
| 1900 |
+
|
| 1901 |
+
occupancyLimit = properties->maxThreadsPerMultiprocessor;
|
| 1902 |
+
granularity = properties->warpSize;
|
| 1903 |
+
blockSizeLimit = __occMin(properties->maxThreadsPerBlock, attributes->maxThreadsPerBlock);
|
| 1904 |
+
blockSizeLimitAligned = __occRoundUp(blockSizeLimit, granularity);
|
| 1905 |
+
|
| 1906 |
+
for (blockSizeToTryAligned = blockSizeLimitAligned; blockSizeToTryAligned > 0; blockSizeToTryAligned -= granularity) {
|
| 1907 |
+
blockSizeToTry = __occMin(blockSizeLimit, blockSizeToTryAligned);
|
| 1908 |
+
|
| 1909 |
+
dynamicSMemSize = blockSizeToDynamicSMemSize(blockSizeToTry);
|
| 1910 |
+
|
| 1911 |
+
status = cudaOccMaxActiveBlocksPerMultiprocessor(
|
| 1912 |
+
&result,
|
| 1913 |
+
properties,
|
| 1914 |
+
attributes,
|
| 1915 |
+
state,
|
| 1916 |
+
blockSizeToTry,
|
| 1917 |
+
dynamicSMemSize);
|
| 1918 |
+
|
| 1919 |
+
if (status != CUDA_OCC_SUCCESS) {
|
| 1920 |
+
return status;
|
| 1921 |
+
}
|
| 1922 |
+
|
| 1923 |
+
occupancyInBlocks = result.activeBlocksPerMultiprocessor;
|
| 1924 |
+
|
| 1925 |
+
occupancyInThreads = blockSizeToTry * occupancyInBlocks;
|
| 1926 |
+
|
| 1927 |
+
if (occupancyInThreads > maxOccupancy) {
|
| 1928 |
+
maxBlockSize = blockSizeToTry;
|
| 1929 |
+
numBlocks = occupancyInBlocks;
|
| 1930 |
+
maxOccupancy = occupancyInThreads;
|
| 1931 |
+
}
|
| 1932 |
+
|
| 1933 |
+
// Early out if we have reached the maximum
|
| 1934 |
+
//
|
| 1935 |
+
if (occupancyLimit == maxOccupancy) {
|
| 1936 |
+
break;
|
| 1937 |
+
}
|
| 1938 |
+
}
|
| 1939 |
+
|
| 1940 |
+
///////////////////////////
|
| 1941 |
+
// Return best available
|
| 1942 |
+
///////////////////////////
|
| 1943 |
+
|
| 1944 |
+
// Suggested min grid size to achieve a full machine launch
|
| 1945 |
+
//
|
| 1946 |
+
*minGridSize = numBlocks * properties->numSms;
|
| 1947 |
+
*blockSize = maxBlockSize;
|
| 1948 |
+
|
| 1949 |
+
return status;
|
| 1950 |
+
}
|
| 1951 |
+
|
| 1952 |
+
} // namespace anonymous
|
| 1953 |
+
|
| 1954 |
+
#endif /*__cplusplus */
|
| 1955 |
+
|
| 1956 |
+
#undef __OCC_INLINE
|
| 1957 |
+
|
| 1958 |
+
#endif /*__cuda_occupancy_h__*/
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cuda_pipeline_primitives.h
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2019 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#ifndef _CUDA_PIPELINE_PRIMITIVES_H_
|
| 51 |
+
# define _CUDA_PIPELINE_PRIMITIVES_H_
|
| 52 |
+
|
| 53 |
+
# include "cuda_pipeline_helpers.h"
|
| 54 |
+
|
| 55 |
+
_CUDA_PIPELINE_STATIC_QUALIFIER
|
| 56 |
+
void __pipeline_memcpy_async(void* __restrict__ dst_shared, const void* __restrict__ src_global, size_t size_and_align,
|
| 57 |
+
size_t zfill = 0)
|
| 58 |
+
{
|
| 59 |
+
_CUDA_PIPELINE_ASSERT(size_and_align == 4 || size_and_align == 8 || size_and_align == 16);
|
| 60 |
+
_CUDA_PIPELINE_ASSERT(zfill <= size_and_align);
|
| 61 |
+
_CUDA_PIPELINE_ASSERT(__isShared(dst_shared));
|
| 62 |
+
_CUDA_PIPELINE_ASSERT(__isGlobal(src_global));
|
| 63 |
+
_CUDA_PIPELINE_ASSERT(!(reinterpret_cast<uintptr_t>(dst_shared) & (size_and_align - 1)));
|
| 64 |
+
_CUDA_PIPELINE_ASSERT(!(reinterpret_cast<uintptr_t>(src_global) & (size_and_align - 1)));
|
| 65 |
+
|
| 66 |
+
switch (size_and_align) {
|
| 67 |
+
case 16:
|
| 68 |
+
switch (zfill) {
|
| 69 |
+
case 0: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 16>(dst_shared, src_global); return;
|
| 70 |
+
case 1: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 15>(dst_shared, src_global); return;
|
| 71 |
+
case 2: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 14>(dst_shared, src_global); return;
|
| 72 |
+
case 3: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 13>(dst_shared, src_global); return;
|
| 73 |
+
case 4: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 12>(dst_shared, src_global); return;
|
| 74 |
+
case 5: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 11>(dst_shared, src_global); return;
|
| 75 |
+
case 6: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 10>(dst_shared, src_global); return;
|
| 76 |
+
case 7: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 9>(dst_shared, src_global); return;
|
| 77 |
+
case 8: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 8>(dst_shared, src_global); return;
|
| 78 |
+
case 9: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 7>(dst_shared, src_global); return;
|
| 79 |
+
case 10: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 6>(dst_shared, src_global); return;
|
| 80 |
+
case 11: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 5>(dst_shared, src_global); return;
|
| 81 |
+
case 12: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 4>(dst_shared, src_global); return;
|
| 82 |
+
case 13: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 3>(dst_shared, src_global); return;
|
| 83 |
+
case 14: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 2>(dst_shared, src_global); return;
|
| 84 |
+
case 15: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 1>(dst_shared, src_global); return;
|
| 85 |
+
case 16: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async<16, 0>(dst_shared, src_global); return;
|
| 86 |
+
default: _CUDA_PIPELINE_ABORT(); return;
|
| 87 |
+
}
|
| 88 |
+
case 8:
|
| 89 |
+
switch (zfill) {
|
| 90 |
+
case 0: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 8, 8>(dst_shared, src_global); return;
|
| 91 |
+
case 1: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 8, 7>(dst_shared, src_global); return;
|
| 92 |
+
case 2: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 8, 6>(dst_shared, src_global); return;
|
| 93 |
+
case 3: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 8, 5>(dst_shared, src_global); return;
|
| 94 |
+
case 4: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 8, 4>(dst_shared, src_global); return;
|
| 95 |
+
case 5: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 8, 3>(dst_shared, src_global); return;
|
| 96 |
+
case 6: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 8, 2>(dst_shared, src_global); return;
|
| 97 |
+
case 7: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 8, 1>(dst_shared, src_global); return;
|
| 98 |
+
case 8: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 8, 0>(dst_shared, src_global); return;
|
| 99 |
+
default: _CUDA_PIPELINE_ABORT(); return;
|
| 100 |
+
}
|
| 101 |
+
case 4:
|
| 102 |
+
switch (zfill) {
|
| 103 |
+
case 0: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 4, 4>(dst_shared, src_global); return;
|
| 104 |
+
case 1: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 4, 3>(dst_shared, src_global); return;
|
| 105 |
+
case 2: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 4, 2>(dst_shared, src_global); return;
|
| 106 |
+
case 3: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 4, 1>(dst_shared, src_global); return;
|
| 107 |
+
case 4: _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_memcpy_async< 4, 0>(dst_shared, src_global); return;
|
| 108 |
+
default: _CUDA_PIPELINE_ABORT(); return;
|
| 109 |
+
}
|
| 110 |
+
default:
|
| 111 |
+
_CUDA_PIPELINE_ABORT();
|
| 112 |
+
return;
|
| 113 |
+
}
|
| 114 |
+
}
|
| 115 |
+
|
| 116 |
+
_CUDA_PIPELINE_STATIC_QUALIFIER
|
| 117 |
+
void __pipeline_commit()
|
| 118 |
+
{
|
| 119 |
+
_CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_commit();
|
| 120 |
+
}
|
| 121 |
+
|
| 122 |
+
_CUDA_PIPELINE_STATIC_QUALIFIER
|
| 123 |
+
void __pipeline_wait_prior(size_t prior)
|
| 124 |
+
{
|
| 125 |
+
switch (prior) {
|
| 126 |
+
case 0 : _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_wait_prior<0>(); return;
|
| 127 |
+
case 1 : _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_wait_prior<1>(); return;
|
| 128 |
+
case 2 : _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_wait_prior<2>(); return;
|
| 129 |
+
case 3 : _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_wait_prior<3>(); return;
|
| 130 |
+
case 4 : _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_wait_prior<4>(); return;
|
| 131 |
+
case 5 : _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_wait_prior<5>(); return;
|
| 132 |
+
case 6 : _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_wait_prior<6>(); return;
|
| 133 |
+
case 7 : _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_wait_prior<7>(); return;
|
| 134 |
+
default : _CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_wait_prior<8>(); return;
|
| 135 |
+
}
|
| 136 |
+
}
|
| 137 |
+
|
| 138 |
+
# if defined(_CUDA_PIPELINE_ARCH_700_OR_LATER)
|
| 139 |
+
# include "cuda_awbarrier_primitives.h"
|
| 140 |
+
|
| 141 |
+
_CUDA_PIPELINE_STATIC_QUALIFIER
|
| 142 |
+
void __pipeline_arrive_on(__mbarrier_t* barrier)
|
| 143 |
+
{
|
| 144 |
+
_CUDA_PIPELINE_INTERNAL_NAMESPACE::pipeline_arrive_on(barrier);
|
| 145 |
+
}
|
| 146 |
+
# endif
|
| 147 |
+
|
| 148 |
+
#endif /* !_CUDA_PIPELINE_PRIMITIVES_H_ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/cuda_vdpau_interop.h
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2012 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__CUDA_VDPAU_INTEROP_H__)
|
| 51 |
+
#define __CUDA_VDPAU_INTEROP_H__
|
| 52 |
+
|
| 53 |
+
#include "cuda_runtime_api.h"
|
| 54 |
+
|
| 55 |
+
#include <vdpau/vdpau.h>
|
| 56 |
+
|
| 57 |
+
#if defined(__cplusplus)
|
| 58 |
+
extern "C" {
|
| 59 |
+
#endif /* __cplusplus */
|
| 60 |
+
|
| 61 |
+
/**
|
| 62 |
+
* \addtogroup CUDART_VDPAU VDPAU Interoperability
|
| 63 |
+
* This section describes the VDPAU interoperability functions of the CUDA
|
| 64 |
+
* runtime application programming interface.
|
| 65 |
+
*
|
| 66 |
+
* @{
|
| 67 |
+
*/
|
| 68 |
+
|
| 69 |
+
/**
|
| 70 |
+
* \brief Gets the CUDA device associated with a VdpDevice.
|
| 71 |
+
*
|
| 72 |
+
* Returns the CUDA device associated with a VdpDevice, if applicable.
|
| 73 |
+
*
|
| 74 |
+
* \param device - Returns the device associated with vdpDevice, or -1 if
|
| 75 |
+
* the device associated with vdpDevice is not a compute device.
|
| 76 |
+
* \param vdpDevice - A VdpDevice handle
|
| 77 |
+
* \param vdpGetProcAddress - VDPAU's VdpGetProcAddress function pointer
|
| 78 |
+
*
|
| 79 |
+
* \return
|
| 80 |
+
* ::cudaSuccess
|
| 81 |
+
* \notefnerr
|
| 82 |
+
*
|
| 83 |
+
* \sa
|
| 84 |
+
* ::cudaVDPAUSetVDPAUDevice,
|
| 85 |
+
* ::cuVDPAUGetDevice
|
| 86 |
+
*/
|
| 87 |
+
extern __host__ cudaError_t CUDARTAPI cudaVDPAUGetDevice(int *device, VdpDevice vdpDevice, VdpGetProcAddress *vdpGetProcAddress);
|
| 88 |
+
|
| 89 |
+
/**
|
| 90 |
+
* \brief Sets a CUDA device to use VDPAU interoperability
|
| 91 |
+
*
|
| 92 |
+
* Records \p vdpDevice as the VdpDevice for VDPAU interoperability
|
| 93 |
+
* with the CUDA device \p device and sets \p device as the current
|
| 94 |
+
* device for the calling host thread.
|
| 95 |
+
*
|
| 96 |
+
* This function will immediately initialize the primary context on
|
| 97 |
+
* \p device if needed.
|
| 98 |
+
*
|
| 99 |
+
* If \p device has already been initialized then this call will fail
|
| 100 |
+
* with the error ::cudaErrorSetOnActiveProcess. In this case it is
|
| 101 |
+
* necessary to reset \p device using ::cudaDeviceReset() before
|
| 102 |
+
* VDPAU interoperability on \p device may be enabled.
|
| 103 |
+
*
|
| 104 |
+
* \param device - Device to use for VDPAU interoperability
|
| 105 |
+
* \param vdpDevice - The VdpDevice to interoperate with
|
| 106 |
+
* \param vdpGetProcAddress - VDPAU's VdpGetProcAddress function pointer
|
| 107 |
+
*
|
| 108 |
+
* \return
|
| 109 |
+
* ::cudaSuccess,
|
| 110 |
+
* ::cudaErrorInvalidDevice,
|
| 111 |
+
* ::cudaErrorSetOnActiveProcess
|
| 112 |
+
* \notefnerr
|
| 113 |
+
*
|
| 114 |
+
* \sa ::cudaGraphicsVDPAURegisterVideoSurface,
|
| 115 |
+
* ::cudaGraphicsVDPAURegisterOutputSurface,
|
| 116 |
+
* ::cudaDeviceReset
|
| 117 |
+
*/
|
| 118 |
+
extern __host__ cudaError_t CUDARTAPI cudaVDPAUSetVDPAUDevice(int device, VdpDevice vdpDevice, VdpGetProcAddress *vdpGetProcAddress);
|
| 119 |
+
|
| 120 |
+
/**
|
| 121 |
+
* \brief Register a VdpVideoSurface object
|
| 122 |
+
*
|
| 123 |
+
* Registers the VdpVideoSurface specified by \p vdpSurface for access by CUDA.
|
| 124 |
+
* A handle to the registered object is returned as \p resource.
|
| 125 |
+
* The surface's intended usage is specified using \p flags, as follows:
|
| 126 |
+
*
|
| 127 |
+
* - ::cudaGraphicsMapFlagsNone: Specifies no hints about how this
|
| 128 |
+
* resource will be used. It is therefore assumed that this resource will be
|
| 129 |
+
* read from and written to by CUDA. This is the default value.
|
| 130 |
+
* - ::cudaGraphicsMapFlagsReadOnly: Specifies that CUDA
|
| 131 |
+
* will not write to this resource.
|
| 132 |
+
* - ::cudaGraphicsMapFlagsWriteDiscard: Specifies that
|
| 133 |
+
* CUDA will not read from this resource and will write over the
|
| 134 |
+
* entire contents of the resource, so none of the data previously
|
| 135 |
+
* stored in the resource will be preserved.
|
| 136 |
+
*
|
| 137 |
+
* \param resource - Pointer to the returned object handle
|
| 138 |
+
* \param vdpSurface - VDPAU object to be registered
|
| 139 |
+
* \param flags - Map flags
|
| 140 |
+
*
|
| 141 |
+
* \return
|
| 142 |
+
* ::cudaSuccess,
|
| 143 |
+
* ::cudaErrorInvalidDevice,
|
| 144 |
+
* ::cudaErrorInvalidValue,
|
| 145 |
+
* ::cudaErrorInvalidResourceHandle,
|
| 146 |
+
* ::cudaErrorUnknown
|
| 147 |
+
* \notefnerr
|
| 148 |
+
*
|
| 149 |
+
* \sa
|
| 150 |
+
* ::cudaVDPAUSetVDPAUDevice,
|
| 151 |
+
* ::cudaGraphicsUnregisterResource,
|
| 152 |
+
* ::cudaGraphicsSubResourceGetMappedArray,
|
| 153 |
+
* ::cuGraphicsVDPAURegisterVideoSurface
|
| 154 |
+
*/
|
| 155 |
+
extern __host__ cudaError_t CUDARTAPI cudaGraphicsVDPAURegisterVideoSurface(struct cudaGraphicsResource **resource, VdpVideoSurface vdpSurface, unsigned int flags);
|
| 156 |
+
|
| 157 |
+
/**
|
| 158 |
+
* \brief Register a VdpOutputSurface object
|
| 159 |
+
*
|
| 160 |
+
* Registers the VdpOutputSurface specified by \p vdpSurface for access by CUDA.
|
| 161 |
+
* A handle to the registered object is returned as \p resource.
|
| 162 |
+
* The surface's intended usage is specified using \p flags, as follows:
|
| 163 |
+
*
|
| 164 |
+
* - ::cudaGraphicsMapFlagsNone: Specifies no hints about how this
|
| 165 |
+
* resource will be used. It is therefore assumed that this resource will be
|
| 166 |
+
* read from and written to by CUDA. This is the default value.
|
| 167 |
+
* - ::cudaGraphicsMapFlagsReadOnly: Specifies that CUDA
|
| 168 |
+
* will not write to this resource.
|
| 169 |
+
* - ::cudaGraphicsMapFlagsWriteDiscard: Specifies that
|
| 170 |
+
* CUDA will not read from this resource and will write over the
|
| 171 |
+
* entire contents of the resource, so none of the data previously
|
| 172 |
+
* stored in the resource will be preserved.
|
| 173 |
+
*
|
| 174 |
+
* \param resource - Pointer to the returned object handle
|
| 175 |
+
* \param vdpSurface - VDPAU object to be registered
|
| 176 |
+
* \param flags - Map flags
|
| 177 |
+
*
|
| 178 |
+
* \return
|
| 179 |
+
* ::cudaSuccess,
|
| 180 |
+
* ::cudaErrorInvalidDevice,
|
| 181 |
+
* ::cudaErrorInvalidValue,
|
| 182 |
+
* ::cudaErrorInvalidResourceHandle,
|
| 183 |
+
* ::cudaErrorUnknown
|
| 184 |
+
* \notefnerr
|
| 185 |
+
*
|
| 186 |
+
* \sa
|
| 187 |
+
* ::cudaVDPAUSetVDPAUDevice,
|
| 188 |
+
* ::cudaGraphicsUnregisterResource,
|
| 189 |
+
* ::cudaGraphicsSubResourceGetMappedArray,
|
| 190 |
+
* ::cuGraphicsVDPAURegisterOutputSurface
|
| 191 |
+
*/
|
| 192 |
+
extern __host__ cudaError_t CUDARTAPI cudaGraphicsVDPAURegisterOutputSurface(struct cudaGraphicsResource **resource, VdpOutputSurface vdpSurface, unsigned int flags);
|
| 193 |
+
|
| 194 |
+
/** @} */ /* END CUDART_VDPAU */
|
| 195 |
+
|
| 196 |
+
#if defined(__cplusplus)
|
| 197 |
+
}
|
| 198 |
+
#endif /* __cplusplus */
|
| 199 |
+
|
| 200 |
+
#endif /* __CUDA_VDPAU_INTEROP_H__ */
|
| 201 |
+
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/device_atomic_functions.h
ADDED
|
@@ -0,0 +1,217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2014 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__DEVICE_ATOMIC_FUNCTIONS_H__)
|
| 51 |
+
#define __DEVICE_ATOMIC_FUNCTIONS_H__
|
| 52 |
+
|
| 53 |
+
#if defined(__CUDACC_RTC__)
|
| 54 |
+
#define __DEVICE_ATOMIC_FUNCTIONS_DECL__ __device__
|
| 55 |
+
#elif defined(_NVHPC_CUDA)
|
| 56 |
+
# define __DEVICE_ATOMIC_FUNCTIONS_DECL__ extern __device__ __cudart_builtin__
|
| 57 |
+
#else /* __CUDACC_RTC__ */
|
| 58 |
+
#define __DEVICE_ATOMIC_FUNCTIONS_DECL__ static __inline__ __device__
|
| 59 |
+
#endif /* __CUDACC_RTC__ */
|
| 60 |
+
|
| 61 |
+
#if defined(__cplusplus) && defined(__CUDACC__)
|
| 62 |
+
|
| 63 |
+
/*******************************************************************************
|
| 64 |
+
* *
|
| 65 |
+
* *
|
| 66 |
+
* *
|
| 67 |
+
*******************************************************************************/
|
| 68 |
+
|
| 69 |
+
#include "cuda_runtime_api.h"
|
| 70 |
+
|
| 71 |
+
/* Add !defined(_NVHPC_CUDA) to avoid empty function definition in PGI CUDA
|
| 72 |
+
* C++ compiler where the macro __CUDA_ARCH__ is not defined. */
|
| 73 |
+
#if !defined(__CUDA_ARCH__) && !defined(_NVHPC_CUDA)
|
| 74 |
+
#define __DEF_IF_HOST { }
|
| 75 |
+
#else /* !__CUDA_ARCH__ */
|
| 76 |
+
#define __DEF_IF_HOST ;
|
| 77 |
+
#endif /* __CUDA_ARCH__ */
|
| 78 |
+
|
| 79 |
+
#if defined(__CUDA_ARCH__) || defined(_NVHPC_CUDA)
|
| 80 |
+
extern "C"
|
| 81 |
+
{
|
| 82 |
+
extern __device__ __device_builtin__ int __iAtomicAdd(int *address, int val);
|
| 83 |
+
extern __device__ __device_builtin__ unsigned int __uAtomicAdd(unsigned int *address, unsigned int val);
|
| 84 |
+
extern __device__ __device_builtin__ int __iAtomicExch(int *address, int val);
|
| 85 |
+
extern __device__ __device_builtin__ unsigned int __uAtomicExch(unsigned int *address, unsigned int val);
|
| 86 |
+
extern __device__ __device_builtin__ float __fAtomicExch(float *address, float val);
|
| 87 |
+
extern __device__ __device_builtin__ int __iAtomicMin(int *address, int val);
|
| 88 |
+
extern __device__ __device_builtin__ unsigned int __uAtomicMin(unsigned int *address, unsigned int val);
|
| 89 |
+
extern __device__ __device_builtin__ int __iAtomicMax(int *address, int val);
|
| 90 |
+
extern __device__ __device_builtin__ unsigned int __uAtomicMax(unsigned int *address, unsigned int val);
|
| 91 |
+
extern __device__ __device_builtin__ unsigned int __uAtomicInc(unsigned int *address, unsigned int val);
|
| 92 |
+
extern __device__ __device_builtin__ unsigned int __uAtomicDec(unsigned int *address, unsigned int val);
|
| 93 |
+
extern __device__ __device_builtin__ int __iAtomicAnd(int *address, int val);
|
| 94 |
+
extern __device__ __device_builtin__ unsigned int __uAtomicAnd(unsigned int *address, unsigned int val);
|
| 95 |
+
extern __device__ __device_builtin__ int __iAtomicOr(int *address, int val);
|
| 96 |
+
extern __device__ __device_builtin__ unsigned int __uAtomicOr(unsigned int *address, unsigned int val);
|
| 97 |
+
extern __device__ __device_builtin__ int __iAtomicXor(int *address, int val);
|
| 98 |
+
extern __device__ __device_builtin__ unsigned int __uAtomicXor(unsigned int *address, unsigned int val);
|
| 99 |
+
extern __device__ __device_builtin__ int __iAtomicCAS(int *address, int compare, int val);
|
| 100 |
+
extern __device__ __device_builtin__ unsigned int __uAtomicCAS(unsigned int *address, unsigned int compare, unsigned int val);
|
| 101 |
+
}
|
| 102 |
+
#endif /* __CUDA_ARCH__ || defined(_NVHPC_CUDA) */
|
| 103 |
+
|
| 104 |
+
/*******************************************************************************
|
| 105 |
+
* *
|
| 106 |
+
* *
|
| 107 |
+
* *
|
| 108 |
+
*******************************************************************************/
|
| 109 |
+
|
| 110 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ int atomicAdd(int *address, int val) __DEF_IF_HOST
|
| 111 |
+
|
| 112 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned int atomicAdd(unsigned int *address, unsigned int val) __DEF_IF_HOST
|
| 113 |
+
|
| 114 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ int atomicSub(int *address, int val) __DEF_IF_HOST
|
| 115 |
+
|
| 116 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned int atomicSub(unsigned int *address, unsigned int val) __DEF_IF_HOST
|
| 117 |
+
|
| 118 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ int atomicExch(int *address, int val) __DEF_IF_HOST
|
| 119 |
+
|
| 120 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned int atomicExch(unsigned int *address, unsigned int val) __DEF_IF_HOST
|
| 121 |
+
|
| 122 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ float atomicExch(float *address, float val) __DEF_IF_HOST
|
| 123 |
+
|
| 124 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ int atomicMin(int *address, int val) __DEF_IF_HOST
|
| 125 |
+
|
| 126 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned int atomicMin(unsigned int *address, unsigned int val) __DEF_IF_HOST
|
| 127 |
+
|
| 128 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ int atomicMax(int *address, int val) __DEF_IF_HOST
|
| 129 |
+
|
| 130 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned int atomicMax(unsigned int *address, unsigned int val) __DEF_IF_HOST
|
| 131 |
+
|
| 132 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned int atomicInc(unsigned int *address, unsigned int val) __DEF_IF_HOST
|
| 133 |
+
|
| 134 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned int atomicDec(unsigned int *address, unsigned int val) __DEF_IF_HOST
|
| 135 |
+
|
| 136 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ int atomicAnd(int *address, int val) __DEF_IF_HOST
|
| 137 |
+
|
| 138 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned int atomicAnd(unsigned int *address, unsigned int val) __DEF_IF_HOST
|
| 139 |
+
|
| 140 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ int atomicOr(int *address, int val) __DEF_IF_HOST
|
| 141 |
+
|
| 142 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned int atomicOr(unsigned int *address, unsigned int val) __DEF_IF_HOST
|
| 143 |
+
|
| 144 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ int atomicXor(int *address, int val) __DEF_IF_HOST
|
| 145 |
+
|
| 146 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned int atomicXor(unsigned int *address, unsigned int val) __DEF_IF_HOST
|
| 147 |
+
|
| 148 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ int atomicCAS(int *address, int compare, int val) __DEF_IF_HOST
|
| 149 |
+
|
| 150 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned int atomicCAS(unsigned int *address, unsigned int compare, unsigned int val) __DEF_IF_HOST
|
| 151 |
+
|
| 152 |
+
/*******************************************************************************
|
| 153 |
+
* *
|
| 154 |
+
* *
|
| 155 |
+
* *
|
| 156 |
+
*******************************************************************************/
|
| 157 |
+
|
| 158 |
+
#include "cuda_runtime_api.h"
|
| 159 |
+
|
| 160 |
+
#if defined(_WIN32)
|
| 161 |
+
# define __DEPRECATED__(msg) __declspec(deprecated(msg))
|
| 162 |
+
#elif (defined(__GNUC__) && (__GNUC__ < 4 || (__GNUC__ == 4 && __GNUC_MINOR__ < 5 && !defined(__clang__))))
|
| 163 |
+
# define __DEPRECATED__(msg) __attribute__((deprecated))
|
| 164 |
+
#else
|
| 165 |
+
# define __DEPRECATED__(msg) __attribute__((deprecated(msg)))
|
| 166 |
+
#endif
|
| 167 |
+
|
| 168 |
+
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 700
|
| 169 |
+
#define __WSB_DEPRECATION_MESSAGE(x) #x"() is not valid on compute_70 and above, and should be replaced with "#x"_sync()."\
|
| 170 |
+
"To continue using "#x"(), specify virtual architecture compute_60 when targeting sm_70 and above, for example, using the pair of compiler options: -arch=compute_60 -code=sm_70."
|
| 171 |
+
#elif defined(_NVHPC_CUDA)
|
| 172 |
+
#define __WSB_DEPRECATION_MESSAGE(x) #x"() is not valid on cc70 and above, and should be replaced with "#x"_sync()."
|
| 173 |
+
#else
|
| 174 |
+
#define __WSB_DEPRECATION_MESSAGE(x) #x"() is deprecated in favor of "#x"_sync() and may be removed in a future release (Use -Wno-deprecated-declarations to suppress this warning)."
|
| 175 |
+
#endif
|
| 176 |
+
|
| 177 |
+
extern "C"
|
| 178 |
+
{
|
| 179 |
+
#if defined(__CUDA_ARCH__) || defined(_NVHPC_CUDA)
|
| 180 |
+
extern __device__ __device_builtin__ unsigned long long int __ullAtomicAdd(unsigned long long int *address, unsigned long long int val);
|
| 181 |
+
extern __device__ __device_builtin__ unsigned long long int __ullAtomicExch(unsigned long long int *address, unsigned long long int val);
|
| 182 |
+
extern __device__ __device_builtin__ unsigned long long int __ullAtomicCAS(unsigned long long int *address, unsigned long long int compare, unsigned long long int val);
|
| 183 |
+
#endif /* __CUDA_ARCH__ || _NVHPC_CUDA */
|
| 184 |
+
extern __device__ __device_builtin__ __DEPRECATED__(__WSB_DEPRECATION_MESSAGE(__any)) int __any(int cond);
|
| 185 |
+
extern __device__ __device_builtin__ __DEPRECATED__(__WSB_DEPRECATION_MESSAGE(__all)) int __all(int cond);
|
| 186 |
+
}
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
/*******************************************************************************
|
| 190 |
+
* *
|
| 191 |
+
* *
|
| 192 |
+
* *
|
| 193 |
+
*******************************************************************************/
|
| 194 |
+
|
| 195 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned long long int atomicAdd(unsigned long long int *address, unsigned long long int val) __DEF_IF_HOST
|
| 196 |
+
|
| 197 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned long long int atomicExch(unsigned long long int *address, unsigned long long int val) __DEF_IF_HOST
|
| 198 |
+
|
| 199 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ unsigned long long int atomicCAS(unsigned long long int *address, unsigned long long int compare, unsigned long long int val) __DEF_IF_HOST
|
| 200 |
+
|
| 201 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ __DEPRECATED__(__WSB_DEPRECATION_MESSAGE(__any)) bool any(bool cond) __DEF_IF_HOST
|
| 202 |
+
|
| 203 |
+
__DEVICE_ATOMIC_FUNCTIONS_DECL__ __DEPRECATED__(__WSB_DEPRECATION_MESSAGE(__all)) bool all(bool cond) __DEF_IF_HOST
|
| 204 |
+
|
| 205 |
+
#undef __DEPRECATED__
|
| 206 |
+
#undef __WSB_DEPRECATION_MESSAGE
|
| 207 |
+
|
| 208 |
+
#endif /* __cplusplus && __CUDACC__ */
|
| 209 |
+
|
| 210 |
+
#undef __DEF_IF_HOST
|
| 211 |
+
#undef __DEVICE_ATOMIC_FUNCTIONS_DECL__
|
| 212 |
+
|
| 213 |
+
#if !defined(__CUDACC_RTC__) && defined(__CUDA_ARCH__)
|
| 214 |
+
#include "device_atomic_functions.hpp"
|
| 215 |
+
#endif /* !__CUDACC_RTC__ && defined(__CUDA_ARCH__) */
|
| 216 |
+
|
| 217 |
+
#endif /* !__DEVICE_ATOMIC_FUNCTIONS_H__ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/device_double_functions.h
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2018 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__)
|
| 51 |
+
#if defined(_MSC_VER)
|
| 52 |
+
#pragma message("device_double_functions.h is an internal header file and must not be used directly. This file will be removed in a future CUDA release. Please use cuda_runtime_api.h or cuda_runtime.h instead.")
|
| 53 |
+
#else
|
| 54 |
+
#warning "device_double_functions.h is an internal header file and must not be used directly. This file will be removed in a future CUDA release. Please use cuda_runtime_api.h or cuda_runtime.h instead."
|
| 55 |
+
#endif
|
| 56 |
+
#define __CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__
|
| 57 |
+
#define __UNDEF_CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS_DEVICE_DOUBLE_FUNCTIONS_H_WRAPPER__
|
| 58 |
+
#endif
|
| 59 |
+
|
| 60 |
+
#include "crt/device_double_functions.h"
|
| 61 |
+
|
| 62 |
+
#if defined(__UNDEF_CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS_DEVICE_DOUBLE_FUNCTIONS_H_WRAPPER__)
|
| 63 |
+
#undef __CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__
|
| 64 |
+
#undef __UNDEF_CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS_DEVICE_DOUBLE_FUNCTIONS_H_WRAPPER__
|
| 65 |
+
#endif
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/device_functions.h
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2018 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__)
|
| 51 |
+
#if defined(_MSC_VER)
|
| 52 |
+
#pragma message("device_functions.h is an internal header file and must not be used directly. This file will be removed in a future CUDA release. Please use cuda_runtime_api.h or cuda_runtime.h instead.")
|
| 53 |
+
#else
|
| 54 |
+
#warning "device_functions.h is an internal header file and must not be used directly. This file will be removed in a future CUDA release. Please use cuda_runtime_api.h or cuda_runtime.h instead."
|
| 55 |
+
#endif
|
| 56 |
+
#define __CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__
|
| 57 |
+
#define __UNDEF_CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS_DEVICE_FUNCTIONS_H_WRAPPER__
|
| 58 |
+
#endif
|
| 59 |
+
|
| 60 |
+
#include "crt/device_functions.h"
|
| 61 |
+
|
| 62 |
+
#if defined(__UNDEF_CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS_DEVICE_FUNCTIONS_H_WRAPPER__)
|
| 63 |
+
#undef __CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__
|
| 64 |
+
#undef __UNDEF_CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS_DEVICE_FUNCTIONS_H_WRAPPER__
|
| 65 |
+
#endif
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/driver_types.h
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/library_types.h
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2015 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__LIBRARY_TYPES_H__)
|
| 51 |
+
#define __LIBRARY_TYPES_H__
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
typedef enum cudaDataType_t
|
| 56 |
+
{
|
| 57 |
+
CUDA_R_16F = 2, /* real as a half */
|
| 58 |
+
CUDA_C_16F = 6, /* complex as a pair of half numbers */
|
| 59 |
+
CUDA_R_16BF = 14, /* real as a nv_bfloat16 */
|
| 60 |
+
CUDA_C_16BF = 15, /* complex as a pair of nv_bfloat16 numbers */
|
| 61 |
+
CUDA_R_32F = 0, /* real as a float */
|
| 62 |
+
CUDA_C_32F = 4, /* complex as a pair of float numbers */
|
| 63 |
+
CUDA_R_64F = 1, /* real as a double */
|
| 64 |
+
CUDA_C_64F = 5, /* complex as a pair of double numbers */
|
| 65 |
+
CUDA_R_4I = 16, /* real as a signed 4-bit int */
|
| 66 |
+
CUDA_C_4I = 17, /* complex as a pair of signed 4-bit int numbers */
|
| 67 |
+
CUDA_R_4U = 18, /* real as a unsigned 4-bit int */
|
| 68 |
+
CUDA_C_4U = 19, /* complex as a pair of unsigned 4-bit int numbers */
|
| 69 |
+
CUDA_R_8I = 3, /* real as a signed 8-bit int */
|
| 70 |
+
CUDA_C_8I = 7, /* complex as a pair of signed 8-bit int numbers */
|
| 71 |
+
CUDA_R_8U = 8, /* real as a unsigned 8-bit int */
|
| 72 |
+
CUDA_C_8U = 9, /* complex as a pair of unsigned 8-bit int numbers */
|
| 73 |
+
CUDA_R_16I = 20, /* real as a signed 16-bit int */
|
| 74 |
+
CUDA_C_16I = 21, /* complex as a pair of signed 16-bit int numbers */
|
| 75 |
+
CUDA_R_16U = 22, /* real as a unsigned 16-bit int */
|
| 76 |
+
CUDA_C_16U = 23, /* complex as a pair of unsigned 16-bit int numbers */
|
| 77 |
+
CUDA_R_32I = 10, /* real as a signed 32-bit int */
|
| 78 |
+
CUDA_C_32I = 11, /* complex as a pair of signed 32-bit int numbers */
|
| 79 |
+
CUDA_R_32U = 12, /* real as a unsigned 32-bit int */
|
| 80 |
+
CUDA_C_32U = 13, /* complex as a pair of unsigned 32-bit int numbers */
|
| 81 |
+
CUDA_R_64I = 24, /* real as a signed 64-bit int */
|
| 82 |
+
CUDA_C_64I = 25, /* complex as a pair of signed 64-bit int numbers */
|
| 83 |
+
CUDA_R_64U = 26, /* real as a unsigned 64-bit int */
|
| 84 |
+
CUDA_C_64U = 27, /* complex as a pair of unsigned 64-bit int numbers */
|
| 85 |
+
CUDA_R_8F_E4M3 = 28, /* real as a nv_fp8_e4m3 */
|
| 86 |
+
CUDA_R_8F_E5M2 = 29, /* real as a nv_fp8_e5m2 */
|
| 87 |
+
} cudaDataType;
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
typedef enum libraryPropertyType_t
|
| 91 |
+
{
|
| 92 |
+
MAJOR_VERSION,
|
| 93 |
+
MINOR_VERSION,
|
| 94 |
+
PATCH_LEVEL
|
| 95 |
+
} libraryPropertyType;
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
#ifndef __cplusplus
|
| 99 |
+
typedef enum cudaDataType_t cudaDataType_t;
|
| 100 |
+
typedef enum libraryPropertyType_t libraryPropertyType_t;
|
| 101 |
+
#endif
|
| 102 |
+
|
| 103 |
+
#endif /* !__LIBRARY_TYPES_H__ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/math_functions.h
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2018 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__)
|
| 51 |
+
#if defined(_MSC_VER)
|
| 52 |
+
#pragma message("math_functions.h is an internal header file and must not be used directly. This file will be removed in a future CUDA release. Please use cuda_runtime_api.h or cuda_runtime.h instead.")
|
| 53 |
+
#else
|
| 54 |
+
#warning "math_functions.h is an internal header file and must not be used directly. This file will be removed in a future CUDA release. Please use cuda_runtime_api.h or cuda_runtime.h instead."
|
| 55 |
+
#endif
|
| 56 |
+
#define __CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__
|
| 57 |
+
#define __UNDEF_CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS_MATH_FUNCTIONS_H_WRAPPER__
|
| 58 |
+
#endif
|
| 59 |
+
|
| 60 |
+
#include "crt/math_functions.h"
|
| 61 |
+
|
| 62 |
+
#if defined(__UNDEF_CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS_MATH_FUNCTIONS_H_WRAPPER__)
|
| 63 |
+
#undef __CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__
|
| 64 |
+
#undef __UNDEF_CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS_MATH_FUNCTIONS_H_WRAPPER__
|
| 65 |
+
#endif
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_20_atomic_functions.hpp
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2014 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__SM_20_ATOMIC_FUNCTIONS_HPP__)
|
| 51 |
+
#define __SM_20_ATOMIC_FUNCTIONS_HPP__
|
| 52 |
+
|
| 53 |
+
#if defined(__CUDACC_RTC__)
|
| 54 |
+
#define __SM_20_ATOMIC_FUNCTIONS_DECL__ __device__
|
| 55 |
+
#else /* __CUDACC_RTC__ */
|
| 56 |
+
#define __SM_20_ATOMIC_FUNCTIONS_DECL__ static __inline__ __device__
|
| 57 |
+
#endif /* __CUDACC_RTC__ */
|
| 58 |
+
|
| 59 |
+
#if defined(__cplusplus) && defined(__CUDACC__)
|
| 60 |
+
|
| 61 |
+
/*******************************************************************************
|
| 62 |
+
* *
|
| 63 |
+
* *
|
| 64 |
+
* *
|
| 65 |
+
*******************************************************************************/
|
| 66 |
+
|
| 67 |
+
#include "cuda_runtime_api.h"
|
| 68 |
+
|
| 69 |
+
/*******************************************************************************
|
| 70 |
+
* *
|
| 71 |
+
* *
|
| 72 |
+
* *
|
| 73 |
+
*******************************************************************************/
|
| 74 |
+
|
| 75 |
+
__SM_20_ATOMIC_FUNCTIONS_DECL__ float atomicAdd(float *address, float val)
|
| 76 |
+
{
|
| 77 |
+
return __fAtomicAdd(address, val);
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
#endif /* __cplusplus && __CUDACC__ */
|
| 81 |
+
|
| 82 |
+
#undef __SM_20_ATOMIC_FUNCTIONS_DECL__
|
| 83 |
+
|
| 84 |
+
#endif /* !__SM_20_ATOMIC_FUNCTIONS_HPP__ */
|
| 85 |
+
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_20_intrinsics.hpp
ADDED
|
@@ -0,0 +1,221 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2014 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__SM_20_INTRINSICS_HPP__)
|
| 51 |
+
#define __SM_20_INTRINSICS_HPP__
|
| 52 |
+
|
| 53 |
+
#if defined(__CUDACC_RTC__)
|
| 54 |
+
#define __SM_20_INTRINSICS_DECL__ __device__
|
| 55 |
+
#else /* __CUDACC_RTC__ */
|
| 56 |
+
#define __SM_20_INTRINSICS_DECL__ static __inline__ __device__
|
| 57 |
+
#endif /* __CUDACC_RTC__ */
|
| 58 |
+
|
| 59 |
+
#if defined(__cplusplus) && defined(__CUDACC__)
|
| 60 |
+
|
| 61 |
+
/*******************************************************************************
|
| 62 |
+
* *
|
| 63 |
+
* *
|
| 64 |
+
* *
|
| 65 |
+
*******************************************************************************/
|
| 66 |
+
|
| 67 |
+
#include "cuda_runtime_api.h"
|
| 68 |
+
|
| 69 |
+
/*******************************************************************************
|
| 70 |
+
* *
|
| 71 |
+
* *
|
| 72 |
+
* *
|
| 73 |
+
*******************************************************************************/
|
| 74 |
+
|
| 75 |
+
__SM_20_INTRINSICS_DECL__ unsigned int ballot(bool pred)
|
| 76 |
+
{
|
| 77 |
+
return __ballot((int)pred);
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
__SM_20_INTRINSICS_DECL__ int syncthreads_count(bool pred)
|
| 81 |
+
{
|
| 82 |
+
return __syncthreads_count((int)pred);
|
| 83 |
+
}
|
| 84 |
+
|
| 85 |
+
__SM_20_INTRINSICS_DECL__ bool syncthreads_and(bool pred)
|
| 86 |
+
{
|
| 87 |
+
return (bool)__syncthreads_and((int)pred);
|
| 88 |
+
}
|
| 89 |
+
|
| 90 |
+
__SM_20_INTRINSICS_DECL__ bool syncthreads_or(bool pred)
|
| 91 |
+
{
|
| 92 |
+
return (bool)__syncthreads_or((int)pred);
|
| 93 |
+
}
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
extern "C" {
|
| 97 |
+
__device__ unsigned __nv_isGlobal_impl(const void *);
|
| 98 |
+
__device__ unsigned __nv_isShared_impl(const void *);
|
| 99 |
+
__device__ unsigned __nv_isConstant_impl(const void *);
|
| 100 |
+
__device__ unsigned __nv_isLocal_impl(const void *);
|
| 101 |
+
__device__ unsigned __nv_isGridConstant_impl(const void *);
|
| 102 |
+
}
|
| 103 |
+
|
| 104 |
+
__SM_20_INTRINSICS_DECL__ unsigned int __isGlobal(const void *ptr)
|
| 105 |
+
{
|
| 106 |
+
return __nv_isGlobal_impl(ptr);
|
| 107 |
+
}
|
| 108 |
+
|
| 109 |
+
__SM_20_INTRINSICS_DECL__ unsigned int __isShared(const void *ptr)
|
| 110 |
+
{
|
| 111 |
+
return __nv_isShared_impl(ptr);
|
| 112 |
+
}
|
| 113 |
+
|
| 114 |
+
__SM_20_INTRINSICS_DECL__ unsigned int __isConstant(const void *ptr)
|
| 115 |
+
{
|
| 116 |
+
return __nv_isConstant_impl(ptr);
|
| 117 |
+
}
|
| 118 |
+
|
| 119 |
+
__SM_20_INTRINSICS_DECL__ unsigned int __isLocal(const void *ptr)
|
| 120 |
+
{
|
| 121 |
+
return __nv_isLocal_impl(ptr);
|
| 122 |
+
}
|
| 123 |
+
|
| 124 |
+
#if !defined(__CUDA_ARCH__) || (__CUDA_ARCH__ >= 700)
|
| 125 |
+
__SM_20_INTRINSICS_DECL__ unsigned int __isGridConstant(const void *ptr)
|
| 126 |
+
{
|
| 127 |
+
return __nv_isGridConstant_impl(ptr);
|
| 128 |
+
}
|
| 129 |
+
#endif /* !defined(__CUDA_ARCH__) || (__CUDA_ARCH__ >= 700) */
|
| 130 |
+
|
| 131 |
+
extern "C" {
|
| 132 |
+
__device__ size_t __nv_cvta_generic_to_global_impl(const void *);
|
| 133 |
+
__device__ size_t __nv_cvta_generic_to_shared_impl(const void *);
|
| 134 |
+
__device__ size_t __nv_cvta_generic_to_constant_impl(const void *);
|
| 135 |
+
__device__ size_t __nv_cvta_generic_to_local_impl(const void *);
|
| 136 |
+
__device__ void * __nv_cvta_global_to_generic_impl(size_t);
|
| 137 |
+
__device__ void * __nv_cvta_shared_to_generic_impl(size_t);
|
| 138 |
+
__device__ void * __nv_cvta_constant_to_generic_impl(size_t);
|
| 139 |
+
__device__ void * __nv_cvta_local_to_generic_impl(size_t);
|
| 140 |
+
}
|
| 141 |
+
|
| 142 |
+
__SM_20_INTRINSICS_DECL__ size_t __cvta_generic_to_global(const void *p)
|
| 143 |
+
{
|
| 144 |
+
return __nv_cvta_generic_to_global_impl(p);
|
| 145 |
+
}
|
| 146 |
+
|
| 147 |
+
__SM_20_INTRINSICS_DECL__ size_t __cvta_generic_to_shared(const void *p)
|
| 148 |
+
{
|
| 149 |
+
return __nv_cvta_generic_to_shared_impl(p);
|
| 150 |
+
}
|
| 151 |
+
|
| 152 |
+
__SM_20_INTRINSICS_DECL__ size_t __cvta_generic_to_constant(const void *p)
|
| 153 |
+
{
|
| 154 |
+
return __nv_cvta_generic_to_constant_impl(p);
|
| 155 |
+
}
|
| 156 |
+
|
| 157 |
+
__SM_20_INTRINSICS_DECL__ size_t __cvta_generic_to_local(const void *p)
|
| 158 |
+
{
|
| 159 |
+
return __nv_cvta_generic_to_local_impl(p);
|
| 160 |
+
}
|
| 161 |
+
|
| 162 |
+
__SM_20_INTRINSICS_DECL__ void * __cvta_global_to_generic(size_t rawbits)
|
| 163 |
+
{
|
| 164 |
+
return __nv_cvta_global_to_generic_impl(rawbits);
|
| 165 |
+
}
|
| 166 |
+
|
| 167 |
+
__SM_20_INTRINSICS_DECL__ void * __cvta_shared_to_generic(size_t rawbits)
|
| 168 |
+
{
|
| 169 |
+
return __nv_cvta_shared_to_generic_impl(rawbits);
|
| 170 |
+
}
|
| 171 |
+
|
| 172 |
+
__SM_20_INTRINSICS_DECL__ void * __cvta_constant_to_generic(size_t rawbits)
|
| 173 |
+
{
|
| 174 |
+
return __nv_cvta_constant_to_generic_impl(rawbits);
|
| 175 |
+
}
|
| 176 |
+
|
| 177 |
+
__SM_20_INTRINSICS_DECL__ void * __cvta_local_to_generic(size_t rawbits)
|
| 178 |
+
{
|
| 179 |
+
return __nv_cvta_local_to_generic_impl(rawbits);
|
| 180 |
+
}
|
| 181 |
+
|
| 182 |
+
#if !defined(__CUDA_ARCH__) || (__CUDA_ARCH__ >= 700)
|
| 183 |
+
#if (defined(_MSC_VER) && defined(_WIN64)) || defined(__LP64__) || defined(__CUDACC_RTC__)
|
| 184 |
+
#define __CVTA_PTR_64 1
|
| 185 |
+
#endif
|
| 186 |
+
|
| 187 |
+
__SM_20_INTRINSICS_DECL__ size_t __cvta_generic_to_grid_constant(const void *ptr)
|
| 188 |
+
{
|
| 189 |
+
#if __CVTA_PTR_64
|
| 190 |
+
unsigned long long ret;
|
| 191 |
+
asm("cvta.to.param.u64 %0, %1;" : "=l"(ret) : "l"(ptr));
|
| 192 |
+
#else /* !__CVTA_PTR_64 */
|
| 193 |
+
unsigned ret;
|
| 194 |
+
asm("cvta.to.param.u32 %0, %1;" : "=r"(ret) : "r"(ptr));
|
| 195 |
+
#endif /* __CVTA_PTR_64 */
|
| 196 |
+
return (size_t)ret;
|
| 197 |
+
|
| 198 |
+
}
|
| 199 |
+
|
| 200 |
+
__SM_20_INTRINSICS_DECL__ void * __cvta_grid_constant_to_generic(size_t rawbits)
|
| 201 |
+
{
|
| 202 |
+
void *ret;
|
| 203 |
+
#if __CVTA_PTR_64
|
| 204 |
+
unsigned long long in = rawbits;
|
| 205 |
+
asm("cvta.param.u64 %0, %1;" : "=l"(ret) : "l"(in));
|
| 206 |
+
#else /* !__CVTA_PTR_64 */
|
| 207 |
+
unsigned in = rawbits;
|
| 208 |
+
asm("cvta.param.u32 %0, %1;" : "=r"(ret) : "r"(in));
|
| 209 |
+
#endif /* __CVTA_PTR_64 */
|
| 210 |
+
return ret;
|
| 211 |
+
}
|
| 212 |
+
#undef __CVTA_PTR_64
|
| 213 |
+
#endif /* !defined(__CUDA_ARCH__) || (__CUDA_ARCH__ >= 700) */
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
#endif /* __cplusplus && __CUDACC__ */
|
| 217 |
+
|
| 218 |
+
#undef __SM_20_INTRINSICS_DECL__
|
| 219 |
+
|
| 220 |
+
#endif /* !__SM_20_INTRINSICS_HPP__ */
|
| 221 |
+
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_30_intrinsics.hpp
ADDED
|
@@ -0,0 +1,604 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2014 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__SM_30_INTRINSICS_HPP__)
|
| 51 |
+
#define __SM_30_INTRINSICS_HPP__
|
| 52 |
+
|
| 53 |
+
#if defined(__CUDACC_RTC__)
|
| 54 |
+
#define __SM_30_INTRINSICS_DECL__ __device__
|
| 55 |
+
#else /* !__CUDACC_RTC__ */
|
| 56 |
+
#define __SM_30_INTRINSICS_DECL__ static __device__ __inline__
|
| 57 |
+
#endif /* __CUDACC_RTC__ */
|
| 58 |
+
|
| 59 |
+
#if defined(__cplusplus) && defined(__CUDACC__)
|
| 60 |
+
|
| 61 |
+
#if defined(_NVHPC_CUDA) || !defined(__CUDA_ARCH__) || __CUDA_ARCH__ >= 300
|
| 62 |
+
|
| 63 |
+
/*******************************************************************************
|
| 64 |
+
* *
|
| 65 |
+
* *
|
| 66 |
+
* *
|
| 67 |
+
*******************************************************************************/
|
| 68 |
+
|
| 69 |
+
#include "cuda_runtime_api.h"
|
| 70 |
+
|
| 71 |
+
// In here are intrinsics which are built in to the compiler. These may be
|
| 72 |
+
// referenced by intrinsic implementations from this file.
|
| 73 |
+
extern "C"
|
| 74 |
+
{
|
| 75 |
+
}
|
| 76 |
+
|
| 77 |
+
/*******************************************************************************
|
| 78 |
+
* *
|
| 79 |
+
* Below are implementations of SM-3.0 intrinsics which are included as *
|
| 80 |
+
* source (instead of being built in to the compiler) *
|
| 81 |
+
* *
|
| 82 |
+
*******************************************************************************/
|
| 83 |
+
|
| 84 |
+
#if !defined warpSize && !defined __local_warpSize
|
| 85 |
+
#define warpSize 32
|
| 86 |
+
#define __local_warpSize
|
| 87 |
+
#endif
|
| 88 |
+
|
| 89 |
+
__SM_30_INTRINSICS_DECL__
|
| 90 |
+
unsigned __fns(unsigned mask, unsigned base, int offset) {
|
| 91 |
+
extern __device__ __device_builtin__ unsigned int __nvvm_fns(unsigned int mask, unsigned int base, int offset);
|
| 92 |
+
return __nvvm_fns(mask, base, offset);
|
| 93 |
+
}
|
| 94 |
+
|
| 95 |
+
__SM_30_INTRINSICS_DECL__
|
| 96 |
+
void __barrier_sync(unsigned id) {
|
| 97 |
+
extern __device__ __device_builtin__ void __nvvm_barrier_sync(unsigned id);
|
| 98 |
+
return __nvvm_barrier_sync(id);
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
__SM_30_INTRINSICS_DECL__
|
| 102 |
+
void __barrier_sync_count(unsigned id, unsigned cnt) {
|
| 103 |
+
extern __device__ __device_builtin__ void __nvvm_barrier_sync_cnt(unsigned id, unsigned cnt);
|
| 104 |
+
return __nvvm_barrier_sync_cnt(id, cnt);
|
| 105 |
+
}
|
| 106 |
+
|
| 107 |
+
__SM_30_INTRINSICS_DECL__
|
| 108 |
+
void __syncwarp(unsigned mask) {
|
| 109 |
+
extern __device__ __device_builtin__ void __nvvm_bar_warp_sync(unsigned mask);
|
| 110 |
+
return __nvvm_bar_warp_sync(mask);
|
| 111 |
+
}
|
| 112 |
+
|
| 113 |
+
__SM_30_INTRINSICS_DECL__
|
| 114 |
+
int __all_sync(unsigned mask, int pred) {
|
| 115 |
+
extern __device__ __device_builtin__ int __nvvm_vote_all_sync(unsigned int mask, int pred);
|
| 116 |
+
return __nvvm_vote_all_sync(mask, pred);
|
| 117 |
+
}
|
| 118 |
+
|
| 119 |
+
__SM_30_INTRINSICS_DECL__
|
| 120 |
+
int __any_sync(unsigned mask, int pred) {
|
| 121 |
+
extern __device__ __device_builtin__ int __nvvm_vote_any_sync(unsigned int mask, int pred);
|
| 122 |
+
return __nvvm_vote_any_sync(mask, pred);
|
| 123 |
+
}
|
| 124 |
+
|
| 125 |
+
__SM_30_INTRINSICS_DECL__
|
| 126 |
+
int __uni_sync(unsigned mask, int pred) {
|
| 127 |
+
extern __device__ __device_builtin__ int __nvvm_vote_uni_sync(unsigned int mask, int pred);
|
| 128 |
+
return __nvvm_vote_uni_sync(mask, pred);
|
| 129 |
+
}
|
| 130 |
+
|
| 131 |
+
__SM_30_INTRINSICS_DECL__
|
| 132 |
+
unsigned __ballot_sync(unsigned mask, int pred) {
|
| 133 |
+
extern __device__ __device_builtin__ unsigned int __nvvm_vote_ballot_sync(unsigned int mask, int pred);
|
| 134 |
+
return __nvvm_vote_ballot_sync(mask, pred);
|
| 135 |
+
}
|
| 136 |
+
|
| 137 |
+
__SM_30_INTRINSICS_DECL__
|
| 138 |
+
unsigned __activemask() {
|
| 139 |
+
unsigned ret;
|
| 140 |
+
asm volatile ("activemask.b32 %0;" : "=r"(ret));
|
| 141 |
+
return ret;
|
| 142 |
+
}
|
| 143 |
+
|
| 144 |
+
// These are removed starting with compute_70 and onwards
|
| 145 |
+
#if defined(_NVHPC_CUDA) || !defined(__CUDA_ARCH__) || __CUDA_ARCH__ < 700
|
| 146 |
+
|
| 147 |
+
__SM_30_INTRINSICS_DECL__ int __shfl(int var, int srcLane, int width) {
|
| 148 |
+
int ret;
|
| 149 |
+
int c = ((warpSize-width) << 8) | 0x1f;
|
| 150 |
+
asm volatile ("shfl.idx.b32 %0, %1, %2, %3;" : "=r"(ret) : "r"(var), "r"(srcLane), "r"(c));
|
| 151 |
+
return ret;
|
| 152 |
+
}
|
| 153 |
+
|
| 154 |
+
__SM_30_INTRINSICS_DECL__ unsigned int __shfl(unsigned int var, int srcLane, int width) {
|
| 155 |
+
return (unsigned int) __shfl((int)var, srcLane, width);
|
| 156 |
+
}
|
| 157 |
+
|
| 158 |
+
__SM_30_INTRINSICS_DECL__ int __shfl_up(int var, unsigned int delta, int width) {
|
| 159 |
+
int ret;
|
| 160 |
+
int c = (warpSize-width) << 8;
|
| 161 |
+
asm volatile ("shfl.up.b32 %0, %1, %2, %3;" : "=r"(ret) : "r"(var), "r"(delta), "r"(c));
|
| 162 |
+
return ret;
|
| 163 |
+
}
|
| 164 |
+
|
| 165 |
+
__SM_30_INTRINSICS_DECL__ unsigned int __shfl_up(unsigned int var, unsigned int delta, int width) {
|
| 166 |
+
return (unsigned int) __shfl_up((int)var, delta, width);
|
| 167 |
+
}
|
| 168 |
+
|
| 169 |
+
__SM_30_INTRINSICS_DECL__ int __shfl_down(int var, unsigned int delta, int width) {
|
| 170 |
+
int ret;
|
| 171 |
+
int c = ((warpSize-width) << 8) | 0x1f;
|
| 172 |
+
asm volatile ("shfl.down.b32 %0, %1, %2, %3;" : "=r"(ret) : "r"(var), "r"(delta), "r"(c));
|
| 173 |
+
return ret;
|
| 174 |
+
}
|
| 175 |
+
|
| 176 |
+
__SM_30_INTRINSICS_DECL__ unsigned int __shfl_down(unsigned int var, unsigned int delta, int width) {
|
| 177 |
+
return (unsigned int) __shfl_down((int)var, delta, width);
|
| 178 |
+
}
|
| 179 |
+
|
| 180 |
+
__SM_30_INTRINSICS_DECL__ int __shfl_xor(int var, int laneMask, int width) {
|
| 181 |
+
int ret;
|
| 182 |
+
int c = ((warpSize-width) << 8) | 0x1f;
|
| 183 |
+
asm volatile ("shfl.bfly.b32 %0, %1, %2, %3;" : "=r"(ret) : "r"(var), "r"(laneMask), "r"(c));
|
| 184 |
+
return ret;
|
| 185 |
+
}
|
| 186 |
+
|
| 187 |
+
__SM_30_INTRINSICS_DECL__ unsigned int __shfl_xor(unsigned int var, int laneMask, int width) {
|
| 188 |
+
return (unsigned int) __shfl_xor((int)var, laneMask, width);
|
| 189 |
+
}
|
| 190 |
+
|
| 191 |
+
__SM_30_INTRINSICS_DECL__ float __shfl(float var, int srcLane, int width) {
|
| 192 |
+
float ret;
|
| 193 |
+
int c;
|
| 194 |
+
c = ((warpSize-width) << 8) | 0x1f;
|
| 195 |
+
asm volatile ("shfl.idx.b32 %0, %1, %2, %3;" : "=f"(ret) : "f"(var), "r"(srcLane), "r"(c));
|
| 196 |
+
return ret;
|
| 197 |
+
}
|
| 198 |
+
|
| 199 |
+
__SM_30_INTRINSICS_DECL__ float __shfl_up(float var, unsigned int delta, int width) {
|
| 200 |
+
float ret;
|
| 201 |
+
int c;
|
| 202 |
+
c = (warpSize-width) << 8;
|
| 203 |
+
asm volatile ("shfl.up.b32 %0, %1, %2, %3;" : "=f"(ret) : "f"(var), "r"(delta), "r"(c));
|
| 204 |
+
return ret;
|
| 205 |
+
}
|
| 206 |
+
|
| 207 |
+
__SM_30_INTRINSICS_DECL__ float __shfl_down(float var, unsigned int delta, int width) {
|
| 208 |
+
float ret;
|
| 209 |
+
int c;
|
| 210 |
+
c = ((warpSize-width) << 8) | 0x1f;
|
| 211 |
+
asm volatile ("shfl.down.b32 %0, %1, %2, %3;" : "=f"(ret) : "f"(var), "r"(delta), "r"(c));
|
| 212 |
+
return ret;
|
| 213 |
+
}
|
| 214 |
+
|
| 215 |
+
__SM_30_INTRINSICS_DECL__ float __shfl_xor(float var, int laneMask, int width) {
|
| 216 |
+
float ret;
|
| 217 |
+
int c;
|
| 218 |
+
c = ((warpSize-width) << 8) | 0x1f;
|
| 219 |
+
asm volatile ("shfl.bfly.b32 %0, %1, %2, %3;" : "=f"(ret) : "f"(var), "r"(laneMask), "r"(c));
|
| 220 |
+
return ret;
|
| 221 |
+
}
|
| 222 |
+
|
| 223 |
+
// 64-bits SHFL
|
| 224 |
+
|
| 225 |
+
__SM_30_INTRINSICS_DECL__ long long __shfl(long long var, int srcLane, int width) {
|
| 226 |
+
int lo, hi;
|
| 227 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "l"(var));
|
| 228 |
+
hi = __shfl(hi, srcLane, width);
|
| 229 |
+
lo = __shfl(lo, srcLane, width);
|
| 230 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=l"(var) : "r"(lo), "r"(hi));
|
| 231 |
+
return var;
|
| 232 |
+
}
|
| 233 |
+
|
| 234 |
+
__SM_30_INTRINSICS_DECL__ unsigned long long __shfl(unsigned long long var, int srcLane, int width) {
|
| 235 |
+
return (unsigned long long) __shfl((long long) var, srcLane, width);
|
| 236 |
+
}
|
| 237 |
+
|
| 238 |
+
__SM_30_INTRINSICS_DECL__ long long __shfl_up(long long var, unsigned int delta, int width) {
|
| 239 |
+
int lo, hi;
|
| 240 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "l"(var));
|
| 241 |
+
hi = __shfl_up(hi, delta, width);
|
| 242 |
+
lo = __shfl_up(lo, delta, width);
|
| 243 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=l"(var) : "r"(lo), "r"(hi));
|
| 244 |
+
return var;
|
| 245 |
+
}
|
| 246 |
+
|
| 247 |
+
__SM_30_INTRINSICS_DECL__ unsigned long long __shfl_up(unsigned long long var, unsigned int delta, int width) {
|
| 248 |
+
return (unsigned long long) __shfl_up((long long) var, delta, width);
|
| 249 |
+
}
|
| 250 |
+
|
| 251 |
+
__SM_30_INTRINSICS_DECL__ long long __shfl_down(long long var, unsigned int delta, int width) {
|
| 252 |
+
int lo, hi;
|
| 253 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "l"(var));
|
| 254 |
+
hi = __shfl_down(hi, delta, width);
|
| 255 |
+
lo = __shfl_down(lo, delta, width);
|
| 256 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=l"(var) : "r"(lo), "r"(hi));
|
| 257 |
+
return var;
|
| 258 |
+
}
|
| 259 |
+
|
| 260 |
+
__SM_30_INTRINSICS_DECL__ unsigned long long __shfl_down(unsigned long long var, unsigned int delta, int width) {
|
| 261 |
+
return (unsigned long long) __shfl_down((long long) var, delta, width);
|
| 262 |
+
}
|
| 263 |
+
|
| 264 |
+
__SM_30_INTRINSICS_DECL__ long long __shfl_xor(long long var, int laneMask, int width) {
|
| 265 |
+
int lo, hi;
|
| 266 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "l"(var));
|
| 267 |
+
hi = __shfl_xor(hi, laneMask, width);
|
| 268 |
+
lo = __shfl_xor(lo, laneMask, width);
|
| 269 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=l"(var) : "r"(lo), "r"(hi));
|
| 270 |
+
return var;
|
| 271 |
+
}
|
| 272 |
+
|
| 273 |
+
__SM_30_INTRINSICS_DECL__ unsigned long long __shfl_xor(unsigned long long var, int laneMask, int width) {
|
| 274 |
+
return (unsigned long long) __shfl_xor((long long) var, laneMask, width);
|
| 275 |
+
}
|
| 276 |
+
|
| 277 |
+
__SM_30_INTRINSICS_DECL__ double __shfl(double var, int srcLane, int width) {
|
| 278 |
+
unsigned lo, hi;
|
| 279 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "d"(var));
|
| 280 |
+
hi = __shfl(hi, srcLane, width);
|
| 281 |
+
lo = __shfl(lo, srcLane, width);
|
| 282 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=d"(var) : "r"(lo), "r"(hi));
|
| 283 |
+
return var;
|
| 284 |
+
}
|
| 285 |
+
|
| 286 |
+
__SM_30_INTRINSICS_DECL__ double __shfl_up(double var, unsigned int delta, int width) {
|
| 287 |
+
unsigned lo, hi;
|
| 288 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "d"(var));
|
| 289 |
+
hi = __shfl_up(hi, delta, width);
|
| 290 |
+
lo = __shfl_up(lo, delta, width);
|
| 291 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=d"(var) : "r"(lo), "r"(hi));
|
| 292 |
+
return var;
|
| 293 |
+
}
|
| 294 |
+
|
| 295 |
+
__SM_30_INTRINSICS_DECL__ double __shfl_down(double var, unsigned int delta, int width) {
|
| 296 |
+
unsigned lo, hi;
|
| 297 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "d"(var));
|
| 298 |
+
hi = __shfl_down(hi, delta, width);
|
| 299 |
+
lo = __shfl_down(lo, delta, width);
|
| 300 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=d"(var) : "r"(lo), "r"(hi));
|
| 301 |
+
return var;
|
| 302 |
+
}
|
| 303 |
+
|
| 304 |
+
__SM_30_INTRINSICS_DECL__ double __shfl_xor(double var, int laneMask, int width) {
|
| 305 |
+
unsigned lo, hi;
|
| 306 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "d"(var));
|
| 307 |
+
hi = __shfl_xor(hi, laneMask, width);
|
| 308 |
+
lo = __shfl_xor(lo, laneMask, width);
|
| 309 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=d"(var) : "r"(lo), "r"(hi));
|
| 310 |
+
return var;
|
| 311 |
+
}
|
| 312 |
+
|
| 313 |
+
__SM_30_INTRINSICS_DECL__ long __shfl(long var, int srcLane, int width) {
|
| 314 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 315 |
+
__shfl((long long) var, srcLane, width) :
|
| 316 |
+
__shfl((int) var, srcLane, width);
|
| 317 |
+
}
|
| 318 |
+
|
| 319 |
+
__SM_30_INTRINSICS_DECL__ unsigned long __shfl(unsigned long var, int srcLane, int width) {
|
| 320 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 321 |
+
__shfl((unsigned long long) var, srcLane, width) :
|
| 322 |
+
__shfl((unsigned int) var, srcLane, width);
|
| 323 |
+
}
|
| 324 |
+
|
| 325 |
+
__SM_30_INTRINSICS_DECL__ long __shfl_up(long var, unsigned int delta, int width) {
|
| 326 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 327 |
+
__shfl_up((long long) var, delta, width) :
|
| 328 |
+
__shfl_up((int) var, delta, width);
|
| 329 |
+
}
|
| 330 |
+
|
| 331 |
+
__SM_30_INTRINSICS_DECL__ unsigned long __shfl_up(unsigned long var, unsigned int delta, int width) {
|
| 332 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 333 |
+
__shfl_up((unsigned long long) var, delta, width) :
|
| 334 |
+
__shfl_up((unsigned int) var, delta, width);
|
| 335 |
+
}
|
| 336 |
+
|
| 337 |
+
__SM_30_INTRINSICS_DECL__ long __shfl_down(long var, unsigned int delta, int width) {
|
| 338 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 339 |
+
__shfl_down((long long) var, delta, width) :
|
| 340 |
+
__shfl_down((int) var, delta, width);
|
| 341 |
+
}
|
| 342 |
+
|
| 343 |
+
__SM_30_INTRINSICS_DECL__ unsigned long __shfl_down(unsigned long var, unsigned int delta, int width) {
|
| 344 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 345 |
+
__shfl_down((unsigned long long) var, delta, width) :
|
| 346 |
+
__shfl_down((unsigned int) var, delta, width);
|
| 347 |
+
}
|
| 348 |
+
|
| 349 |
+
__SM_30_INTRINSICS_DECL__ long __shfl_xor(long var, int laneMask, int width) {
|
| 350 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 351 |
+
__shfl_xor((long long) var, laneMask, width) :
|
| 352 |
+
__shfl_xor((int) var, laneMask, width);
|
| 353 |
+
}
|
| 354 |
+
|
| 355 |
+
__SM_30_INTRINSICS_DECL__ unsigned long __shfl_xor(unsigned long var, int laneMask, int width) {
|
| 356 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 357 |
+
__shfl_xor((unsigned long long) var, laneMask, width) :
|
| 358 |
+
__shfl_xor((unsigned int) var, laneMask, width);
|
| 359 |
+
}
|
| 360 |
+
|
| 361 |
+
#endif /* defined(_NVHPC_CUDA) || !defined(__CUDA_ARCH__) || __CUDA_ARCH__ < 700 */
|
| 362 |
+
|
| 363 |
+
// Warp register exchange (shuffle) intrinsics.
|
| 364 |
+
// Notes:
|
| 365 |
+
// a) Warp size is hardcoded to 32 here, because the compiler does not know
|
| 366 |
+
// the "warpSize" constant at this time
|
| 367 |
+
// b) we cannot map the float __shfl to the int __shfl because it'll mess with
|
| 368 |
+
// the register number (especially if you're doing two shfls to move a double).
|
| 369 |
+
__SM_30_INTRINSICS_DECL__ int __shfl_sync(unsigned mask, int var, int srcLane, int width) {
|
| 370 |
+
extern __device__ __device_builtin__ unsigned __nvvm_shfl_idx_sync(unsigned mask, unsigned a, unsigned b, unsigned c);
|
| 371 |
+
int ret;
|
| 372 |
+
int c = ((warpSize-width) << 8) | 0x1f;
|
| 373 |
+
ret = __nvvm_shfl_idx_sync(mask, var, srcLane, c);
|
| 374 |
+
return ret;
|
| 375 |
+
}
|
| 376 |
+
|
| 377 |
+
__SM_30_INTRINSICS_DECL__ unsigned int __shfl_sync(unsigned mask, unsigned int var, int srcLane, int width) {
|
| 378 |
+
return (unsigned int) __shfl_sync(mask, (int)var, srcLane, width);
|
| 379 |
+
}
|
| 380 |
+
|
| 381 |
+
__SM_30_INTRINSICS_DECL__ int __shfl_up_sync(unsigned mask, int var, unsigned int delta, int width) {
|
| 382 |
+
extern __device__ __device_builtin__ unsigned __nvvm_shfl_up_sync(unsigned mask, unsigned a, unsigned b, unsigned c);
|
| 383 |
+
int ret;
|
| 384 |
+
int c = (warpSize-width) << 8;
|
| 385 |
+
ret = __nvvm_shfl_up_sync(mask, var, delta, c);
|
| 386 |
+
return ret;
|
| 387 |
+
}
|
| 388 |
+
|
| 389 |
+
__SM_30_INTRINSICS_DECL__ unsigned int __shfl_up_sync(unsigned mask, unsigned int var, unsigned int delta, int width) {
|
| 390 |
+
return (unsigned int) __shfl_up_sync(mask, (int)var, delta, width);
|
| 391 |
+
}
|
| 392 |
+
|
| 393 |
+
__SM_30_INTRINSICS_DECL__ int __shfl_down_sync(unsigned mask, int var, unsigned int delta, int width) {
|
| 394 |
+
extern __device__ __device_builtin__ unsigned __nvvm_shfl_down_sync(unsigned mask, unsigned a, unsigned b, unsigned c);
|
| 395 |
+
int ret;
|
| 396 |
+
int c = ((warpSize-width) << 8) | 0x1f;
|
| 397 |
+
ret = __nvvm_shfl_down_sync(mask, var, delta, c);
|
| 398 |
+
return ret;
|
| 399 |
+
}
|
| 400 |
+
|
| 401 |
+
__SM_30_INTRINSICS_DECL__ unsigned int __shfl_down_sync(unsigned mask, unsigned int var, unsigned int delta, int width) {
|
| 402 |
+
return (unsigned int) __shfl_down_sync(mask, (int)var, delta, width);
|
| 403 |
+
}
|
| 404 |
+
|
| 405 |
+
__SM_30_INTRINSICS_DECL__ int __shfl_xor_sync(unsigned mask, int var, int laneMask, int width) {
|
| 406 |
+
extern __device__ __device_builtin__ unsigned __nvvm_shfl_bfly_sync(unsigned mask, unsigned a, unsigned b, unsigned c);
|
| 407 |
+
int ret;
|
| 408 |
+
int c = ((warpSize-width) << 8) | 0x1f;
|
| 409 |
+
ret = __nvvm_shfl_bfly_sync(mask, var, laneMask, c);
|
| 410 |
+
return ret;
|
| 411 |
+
}
|
| 412 |
+
|
| 413 |
+
__SM_30_INTRINSICS_DECL__ unsigned int __shfl_xor_sync(unsigned mask, unsigned int var, int laneMask, int width) {
|
| 414 |
+
return (unsigned int) __shfl_xor_sync(mask, (int)var, laneMask, width);
|
| 415 |
+
}
|
| 416 |
+
|
| 417 |
+
__SM_30_INTRINSICS_DECL__ float __shfl_sync(unsigned mask, float var, int srcLane, int width) {
|
| 418 |
+
extern __device__ __device_builtin__ unsigned __nvvm_shfl_idx_sync(unsigned mask, unsigned a, unsigned b, unsigned c);
|
| 419 |
+
int ret;
|
| 420 |
+
int c;
|
| 421 |
+
c = ((warpSize-width) << 8) | 0x1f;
|
| 422 |
+
ret = __nvvm_shfl_idx_sync(mask, __float_as_int(var), srcLane, c);
|
| 423 |
+
return __int_as_float(ret);
|
| 424 |
+
}
|
| 425 |
+
|
| 426 |
+
__SM_30_INTRINSICS_DECL__ float __shfl_up_sync(unsigned mask, float var, unsigned int delta, int width) {
|
| 427 |
+
extern __device__ __device_builtin__ unsigned __nvvm_shfl_up_sync(unsigned mask, unsigned a, unsigned b, unsigned c);
|
| 428 |
+
int ret;
|
| 429 |
+
int c;
|
| 430 |
+
c = (warpSize-width) << 8;
|
| 431 |
+
ret = __nvvm_shfl_up_sync(mask, __float_as_int(var), delta, c);
|
| 432 |
+
return __int_as_float(ret);
|
| 433 |
+
}
|
| 434 |
+
|
| 435 |
+
__SM_30_INTRINSICS_DECL__ float __shfl_down_sync(unsigned mask, float var, unsigned int delta, int width) {
|
| 436 |
+
extern __device__ __device_builtin__ unsigned __nvvm_shfl_down_sync(unsigned mask, unsigned a, unsigned b, unsigned c);
|
| 437 |
+
int ret;
|
| 438 |
+
int c;
|
| 439 |
+
c = ((warpSize-width) << 8) | 0x1f;
|
| 440 |
+
ret = __nvvm_shfl_down_sync(mask, __float_as_int(var), delta, c);
|
| 441 |
+
return __int_as_float(ret);
|
| 442 |
+
}
|
| 443 |
+
|
| 444 |
+
__SM_30_INTRINSICS_DECL__ float __shfl_xor_sync(unsigned mask, float var, int laneMask, int width) {
|
| 445 |
+
extern __device__ __device_builtin__ unsigned __nvvm_shfl_bfly_sync(unsigned mask, unsigned a, unsigned b, unsigned c);
|
| 446 |
+
int ret;
|
| 447 |
+
int c;
|
| 448 |
+
c = ((warpSize-width) << 8) | 0x1f;
|
| 449 |
+
ret = __nvvm_shfl_bfly_sync(mask, __float_as_int(var), laneMask, c);
|
| 450 |
+
return __int_as_float(ret);
|
| 451 |
+
}
|
| 452 |
+
|
| 453 |
+
// 64-bits SHFL
|
| 454 |
+
__SM_30_INTRINSICS_DECL__ long long __shfl_sync(unsigned mask, long long var, int srcLane, int width) {
|
| 455 |
+
int lo, hi;
|
| 456 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "l"(var));
|
| 457 |
+
hi = __shfl_sync(mask, hi, srcLane, width);
|
| 458 |
+
lo = __shfl_sync(mask, lo, srcLane, width);
|
| 459 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=l"(var) : "r"(lo), "r"(hi));
|
| 460 |
+
return var;
|
| 461 |
+
}
|
| 462 |
+
|
| 463 |
+
__SM_30_INTRINSICS_DECL__ unsigned long long __shfl_sync(unsigned mask, unsigned long long var, int srcLane, int width) {
|
| 464 |
+
return (unsigned long long) __shfl_sync(mask, (long long) var, srcLane, width);
|
| 465 |
+
}
|
| 466 |
+
|
| 467 |
+
__SM_30_INTRINSICS_DECL__ long long __shfl_up_sync(unsigned mask, long long var, unsigned int delta, int width) {
|
| 468 |
+
int lo, hi;
|
| 469 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "l"(var));
|
| 470 |
+
hi = __shfl_up_sync(mask, hi, delta, width);
|
| 471 |
+
lo = __shfl_up_sync(mask, lo, delta, width);
|
| 472 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=l"(var) : "r"(lo), "r"(hi));
|
| 473 |
+
return var;
|
| 474 |
+
}
|
| 475 |
+
|
| 476 |
+
__SM_30_INTRINSICS_DECL__ unsigned long long __shfl_up_sync(unsigned mask, unsigned long long var, unsigned int delta, int width) {
|
| 477 |
+
return (unsigned long long) __shfl_up_sync(mask, (long long) var, delta, width);
|
| 478 |
+
}
|
| 479 |
+
|
| 480 |
+
__SM_30_INTRINSICS_DECL__ long long __shfl_down_sync(unsigned mask, long long var, unsigned int delta, int width) {
|
| 481 |
+
int lo, hi;
|
| 482 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "l"(var));
|
| 483 |
+
hi = __shfl_down_sync(mask, hi, delta, width);
|
| 484 |
+
lo = __shfl_down_sync(mask, lo, delta, width);
|
| 485 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=l"(var) : "r"(lo), "r"(hi));
|
| 486 |
+
return var;
|
| 487 |
+
}
|
| 488 |
+
|
| 489 |
+
__SM_30_INTRINSICS_DECL__ unsigned long long __shfl_down_sync(unsigned mask, unsigned long long var, unsigned int delta, int width) {
|
| 490 |
+
return (unsigned long long) __shfl_down_sync(mask, (long long) var, delta, width);
|
| 491 |
+
}
|
| 492 |
+
|
| 493 |
+
__SM_30_INTRINSICS_DECL__ long long __shfl_xor_sync(unsigned mask, long long var, int laneMask, int width) {
|
| 494 |
+
int lo, hi;
|
| 495 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "l"(var));
|
| 496 |
+
hi = __shfl_xor_sync(mask, hi, laneMask, width);
|
| 497 |
+
lo = __shfl_xor_sync(mask, lo, laneMask, width);
|
| 498 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=l"(var) : "r"(lo), "r"(hi));
|
| 499 |
+
return var;
|
| 500 |
+
}
|
| 501 |
+
|
| 502 |
+
__SM_30_INTRINSICS_DECL__ unsigned long long __shfl_xor_sync(unsigned mask, unsigned long long var, int laneMask, int width) {
|
| 503 |
+
return (unsigned long long) __shfl_xor_sync(mask, (long long) var, laneMask, width);
|
| 504 |
+
}
|
| 505 |
+
|
| 506 |
+
__SM_30_INTRINSICS_DECL__ double __shfl_sync(unsigned mask, double var, int srcLane, int width) {
|
| 507 |
+
unsigned lo, hi;
|
| 508 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "d"(var));
|
| 509 |
+
hi = __shfl_sync(mask, hi, srcLane, width);
|
| 510 |
+
lo = __shfl_sync(mask, lo, srcLane, width);
|
| 511 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=d"(var) : "r"(lo), "r"(hi));
|
| 512 |
+
return var;
|
| 513 |
+
}
|
| 514 |
+
|
| 515 |
+
__SM_30_INTRINSICS_DECL__ double __shfl_up_sync(unsigned mask, double var, unsigned int delta, int width) {
|
| 516 |
+
unsigned lo, hi;
|
| 517 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "d"(var));
|
| 518 |
+
hi = __shfl_up_sync(mask, hi, delta, width);
|
| 519 |
+
lo = __shfl_up_sync(mask, lo, delta, width);
|
| 520 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=d"(var) : "r"(lo), "r"(hi));
|
| 521 |
+
return var;
|
| 522 |
+
}
|
| 523 |
+
|
| 524 |
+
__SM_30_INTRINSICS_DECL__ double __shfl_down_sync(unsigned mask, double var, unsigned int delta, int width) {
|
| 525 |
+
unsigned lo, hi;
|
| 526 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "d"(var));
|
| 527 |
+
hi = __shfl_down_sync(mask, hi, delta, width);
|
| 528 |
+
lo = __shfl_down_sync(mask, lo, delta, width);
|
| 529 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=d"(var) : "r"(lo), "r"(hi));
|
| 530 |
+
return var;
|
| 531 |
+
}
|
| 532 |
+
|
| 533 |
+
__SM_30_INTRINSICS_DECL__ double __shfl_xor_sync(unsigned mask, double var, int laneMask, int width) {
|
| 534 |
+
unsigned lo, hi;
|
| 535 |
+
asm volatile("mov.b64 {%0,%1}, %2;" : "=r"(lo), "=r"(hi) : "d"(var));
|
| 536 |
+
hi = __shfl_xor_sync(mask, hi, laneMask, width);
|
| 537 |
+
lo = __shfl_xor_sync(mask, lo, laneMask, width);
|
| 538 |
+
asm volatile("mov.b64 %0, {%1,%2};" : "=d"(var) : "r"(lo), "r"(hi));
|
| 539 |
+
return var;
|
| 540 |
+
}
|
| 541 |
+
|
| 542 |
+
// long needs some help to choose between 32-bits and 64-bits
|
| 543 |
+
|
| 544 |
+
__SM_30_INTRINSICS_DECL__ long __shfl_sync(unsigned mask, long var, int srcLane, int width) {
|
| 545 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 546 |
+
__shfl_sync(mask, (long long) var, srcLane, width) :
|
| 547 |
+
__shfl_sync(mask, (int) var, srcLane, width);
|
| 548 |
+
}
|
| 549 |
+
|
| 550 |
+
__SM_30_INTRINSICS_DECL__ unsigned long __shfl_sync(unsigned mask, unsigned long var, int srcLane, int width) {
|
| 551 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 552 |
+
__shfl_sync(mask, (unsigned long long) var, srcLane, width) :
|
| 553 |
+
__shfl_sync(mask, (unsigned int) var, srcLane, width);
|
| 554 |
+
}
|
| 555 |
+
|
| 556 |
+
__SM_30_INTRINSICS_DECL__ long __shfl_up_sync(unsigned mask, long var, unsigned int delta, int width) {
|
| 557 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 558 |
+
__shfl_up_sync(mask, (long long) var, delta, width) :
|
| 559 |
+
__shfl_up_sync(mask, (int) var, delta, width);
|
| 560 |
+
}
|
| 561 |
+
|
| 562 |
+
__SM_30_INTRINSICS_DECL__ unsigned long __shfl_up_sync(unsigned mask, unsigned long var, unsigned int delta, int width) {
|
| 563 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 564 |
+
__shfl_up_sync(mask, (unsigned long long) var, delta, width) :
|
| 565 |
+
__shfl_up_sync(mask, (unsigned int) var, delta, width);
|
| 566 |
+
}
|
| 567 |
+
|
| 568 |
+
__SM_30_INTRINSICS_DECL__ long __shfl_down_sync(unsigned mask, long var, unsigned int delta, int width) {
|
| 569 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 570 |
+
__shfl_down_sync(mask, (long long) var, delta, width) :
|
| 571 |
+
__shfl_down_sync(mask, (int) var, delta, width);
|
| 572 |
+
}
|
| 573 |
+
|
| 574 |
+
__SM_30_INTRINSICS_DECL__ unsigned long __shfl_down_sync(unsigned mask, unsigned long var, unsigned int delta, int width) {
|
| 575 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 576 |
+
__shfl_down_sync(mask, (unsigned long long) var, delta, width) :
|
| 577 |
+
__shfl_down_sync(mask, (unsigned int) var, delta, width);
|
| 578 |
+
}
|
| 579 |
+
|
| 580 |
+
__SM_30_INTRINSICS_DECL__ long __shfl_xor_sync(unsigned mask, long var, int laneMask, int width) {
|
| 581 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 582 |
+
__shfl_xor_sync(mask, (long long) var, laneMask, width) :
|
| 583 |
+
__shfl_xor_sync(mask, (int) var, laneMask, width);
|
| 584 |
+
}
|
| 585 |
+
|
| 586 |
+
__SM_30_INTRINSICS_DECL__ unsigned long __shfl_xor_sync(unsigned mask, unsigned long var, int laneMask, int width) {
|
| 587 |
+
return (sizeof(long) == sizeof(long long)) ?
|
| 588 |
+
__shfl_xor_sync(mask, (unsigned long long) var, laneMask, width) :
|
| 589 |
+
__shfl_xor_sync(mask, (unsigned int) var, laneMask, width);
|
| 590 |
+
}
|
| 591 |
+
|
| 592 |
+
#if defined(__local_warpSize)
|
| 593 |
+
#undef warpSize
|
| 594 |
+
#undef __local_warpSize
|
| 595 |
+
#endif
|
| 596 |
+
|
| 597 |
+
#endif /* _NVHPC_CUDA || !__CUDA_ARCH__ || __CUDA_ARCH__ >= 300 */
|
| 598 |
+
|
| 599 |
+
#endif /* __cplusplus && __CUDACC__ */
|
| 600 |
+
|
| 601 |
+
#undef __SM_30_INTRINSICS_DECL__
|
| 602 |
+
|
| 603 |
+
#endif /* !__SM_30_INTRINSICS_HPP__ */
|
| 604 |
+
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_32_intrinsics.hpp
ADDED
|
@@ -0,0 +1,588 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2020 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__SM_32_INTRINSICS_HPP__)
|
| 51 |
+
#define __SM_32_INTRINSICS_HPP__
|
| 52 |
+
|
| 53 |
+
#if defined(__CUDACC_RTC__)
|
| 54 |
+
#define __SM_32_INTRINSICS_DECL__ __device__
|
| 55 |
+
#else /* !__CUDACC_RTC__ */
|
| 56 |
+
#define __SM_32_INTRINSICS_DECL__ static __device__ __inline__
|
| 57 |
+
#endif /* __CUDACC_RTC__ */
|
| 58 |
+
|
| 59 |
+
#if defined(__cplusplus) && defined(__CUDACC__)
|
| 60 |
+
|
| 61 |
+
#if defined(_NVHPC_CUDA) || !defined(__CUDA_ARCH__) || __CUDA_ARCH__ >= 320
|
| 62 |
+
|
| 63 |
+
/*******************************************************************************
|
| 64 |
+
* *
|
| 65 |
+
* *
|
| 66 |
+
* *
|
| 67 |
+
*******************************************************************************/
|
| 68 |
+
|
| 69 |
+
#include "cuda_runtime_api.h"
|
| 70 |
+
|
| 71 |
+
// In here are intrinsics which are built in to the compiler. These may be
|
| 72 |
+
// referenced by intrinsic implementations from this file.
|
| 73 |
+
extern "C"
|
| 74 |
+
{
|
| 75 |
+
// There are no intrinsics built in to the compiler for SM-3.5,
|
| 76 |
+
// all intrinsics are now implemented as inline PTX below.
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
/*******************************************************************************
|
| 80 |
+
* *
|
| 81 |
+
* Below are implementations of SM-3.5 intrinsics which are included as *
|
| 82 |
+
* source (instead of being built in to the compiler) *
|
| 83 |
+
* *
|
| 84 |
+
*******************************************************************************/
|
| 85 |
+
|
| 86 |
+
// LDG is a "load from global via texture path" command which can exhibit higher
|
| 87 |
+
// bandwidth on GK110 than a regular LD.
|
| 88 |
+
// Define a different pointer storage size for 64 and 32 bit
|
| 89 |
+
#if (defined(_MSC_VER) && defined(_WIN64)) || defined(__LP64__) || defined(__CUDACC_RTC__)
|
| 90 |
+
#define __LDG_PTR "l"
|
| 91 |
+
#else
|
| 92 |
+
#define __LDG_PTR "r"
|
| 93 |
+
#endif
|
| 94 |
+
|
| 95 |
+
/******************************************************************************
|
| 96 |
+
* __ldg *
|
| 97 |
+
******************************************************************************/
|
| 98 |
+
|
| 99 |
+
// Size of long is architecture and OS specific.
|
| 100 |
+
#if defined(__LP64__) // 64 bits
|
| 101 |
+
__SM_32_INTRINSICS_DECL__ long __ldg(const long *ptr) { unsigned long ret; asm volatile ("ld.global.nc.s64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return (long)ret; }
|
| 102 |
+
__SM_32_INTRINSICS_DECL__ unsigned long __ldg(const unsigned long *ptr) { unsigned long ret; asm volatile ("ld.global.nc.u64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 103 |
+
#else // 32 bits
|
| 104 |
+
__SM_32_INTRINSICS_DECL__ long __ldg(const long *ptr) { unsigned long ret; asm volatile ("ld.global.nc.s32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (long)ret; }
|
| 105 |
+
__SM_32_INTRINSICS_DECL__ unsigned long __ldg(const unsigned long *ptr) { unsigned long ret; asm volatile ("ld.global.nc.u32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 106 |
+
#endif
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
__SM_32_INTRINSICS_DECL__ char __ldg(const char *ptr) { unsigned int ret; asm volatile ("ld.global.nc.s8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (char)ret; }
|
| 110 |
+
__SM_32_INTRINSICS_DECL__ signed char __ldg(const signed char *ptr) { unsigned int ret; asm volatile ("ld.global.nc.s8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (signed char)ret; }
|
| 111 |
+
__SM_32_INTRINSICS_DECL__ short __ldg(const short *ptr) { unsigned short ret; asm volatile ("ld.global.nc.s16 %0, [%1];" : "=h"(ret) : __LDG_PTR (ptr)); return (short)ret; }
|
| 112 |
+
__SM_32_INTRINSICS_DECL__ int __ldg(const int *ptr) { unsigned int ret; asm volatile ("ld.global.nc.s32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (int)ret; }
|
| 113 |
+
__SM_32_INTRINSICS_DECL__ long long __ldg(const long long *ptr) { unsigned long long ret; asm volatile ("ld.global.nc.s64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return (long long)ret; }
|
| 114 |
+
__SM_32_INTRINSICS_DECL__ char2 __ldg(const char2 *ptr) { char2 ret; int2 tmp; asm volatile ("ld.global.nc.v2.s8 {%0,%1}, [%2];" : "=r"(tmp.x), "=r"(tmp.y) : __LDG_PTR (ptr)); ret.x = (char)tmp.x; ret.y = (char)tmp.y; return ret; }
|
| 115 |
+
__SM_32_INTRINSICS_DECL__ char4 __ldg(const char4 *ptr) { char4 ret; int4 tmp; asm volatile ("ld.global.nc.v4.s8 {%0,%1,%2,%3}, [%4];" : "=r"(tmp.x), "=r"(tmp.y), "=r"(tmp.z), "=r"(tmp.w) : __LDG_PTR (ptr)); ret.x = (char)tmp.x; ret.y = (char)tmp.y; ret.z = (char)tmp.z; ret.w = (char)tmp.w; return ret; }
|
| 116 |
+
__SM_32_INTRINSICS_DECL__ short2 __ldg(const short2 *ptr) { short2 ret; asm volatile ("ld.global.nc.v2.s16 {%0,%1}, [%2];" : "=h"(ret.x), "=h"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 117 |
+
__SM_32_INTRINSICS_DECL__ short4 __ldg(const short4 *ptr) { short4 ret; asm volatile ("ld.global.nc.v4.s16 {%0,%1,%2,%3}, [%4];" : "=h"(ret.x), "=h"(ret.y), "=h"(ret.z), "=h"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 118 |
+
__SM_32_INTRINSICS_DECL__ int2 __ldg(const int2 *ptr) { int2 ret; asm volatile ("ld.global.nc.v2.s32 {%0,%1}, [%2];" : "=r"(ret.x), "=r"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 119 |
+
__SM_32_INTRINSICS_DECL__ int4 __ldg(const int4 *ptr) { int4 ret; asm volatile ("ld.global.nc.v4.s32 {%0,%1,%2,%3}, [%4];" : "=r"(ret.x), "=r"(ret.y), "=r"(ret.z), "=r"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 120 |
+
__SM_32_INTRINSICS_DECL__ longlong2 __ldg(const longlong2 *ptr) { longlong2 ret; asm volatile ("ld.global.nc.v2.s64 {%0,%1}, [%2];" : "=l"(ret.x), "=l"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 121 |
+
|
| 122 |
+
__SM_32_INTRINSICS_DECL__ unsigned char __ldg(const unsigned char *ptr) { unsigned int ret; asm volatile ("ld.global.nc.u8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (unsigned char)ret; }
|
| 123 |
+
__SM_32_INTRINSICS_DECL__ unsigned short __ldg(const unsigned short *ptr) { unsigned short ret; asm volatile ("ld.global.nc.u16 %0, [%1];" : "=h"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 124 |
+
__SM_32_INTRINSICS_DECL__ unsigned int __ldg(const unsigned int *ptr) { unsigned int ret; asm volatile ("ld.global.nc.u32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 125 |
+
__SM_32_INTRINSICS_DECL__ unsigned long long __ldg(const unsigned long long *ptr) { unsigned long long ret; asm volatile ("ld.global.nc.u64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 126 |
+
__SM_32_INTRINSICS_DECL__ uchar2 __ldg(const uchar2 *ptr) { uchar2 ret; uint2 tmp; asm volatile ("ld.global.nc.v2.u8 {%0,%1}, [%2];" : "=r"(tmp.x), "=r"(tmp.y) : __LDG_PTR (ptr)); ret.x = (unsigned char)tmp.x; ret.y = (unsigned char)tmp.y; return ret; }
|
| 127 |
+
__SM_32_INTRINSICS_DECL__ uchar4 __ldg(const uchar4 *ptr) { uchar4 ret; uint4 tmp; asm volatile ("ld.global.nc.v4.u8 {%0,%1,%2,%3}, [%4];" : "=r"(tmp.x), "=r"(tmp.y), "=r"(tmp.z), "=r"(tmp.w) : __LDG_PTR (ptr)); ret.x = (unsigned char)tmp.x; ret.y = (unsigned char)tmp.y; ret.z = (unsigned char)tmp.z; ret.w = (unsigned char)tmp.w; return ret; }
|
| 128 |
+
__SM_32_INTRINSICS_DECL__ ushort2 __ldg(const ushort2 *ptr) { ushort2 ret; asm volatile ("ld.global.nc.v2.u16 {%0,%1}, [%2];" : "=h"(ret.x), "=h"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 129 |
+
__SM_32_INTRINSICS_DECL__ ushort4 __ldg(const ushort4 *ptr) { ushort4 ret; asm volatile ("ld.global.nc.v4.u16 {%0,%1,%2,%3}, [%4];" : "=h"(ret.x), "=h"(ret.y), "=h"(ret.z), "=h"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 130 |
+
__SM_32_INTRINSICS_DECL__ uint2 __ldg(const uint2 *ptr) { uint2 ret; asm volatile ("ld.global.nc.v2.u32 {%0,%1}, [%2];" : "=r"(ret.x), "=r"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 131 |
+
__SM_32_INTRINSICS_DECL__ uint4 __ldg(const uint4 *ptr) { uint4 ret; asm volatile ("ld.global.nc.v4.u32 {%0,%1,%2,%3}, [%4];" : "=r"(ret.x), "=r"(ret.y), "=r"(ret.z), "=r"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 132 |
+
__SM_32_INTRINSICS_DECL__ ulonglong2 __ldg(const ulonglong2 *ptr) { ulonglong2 ret; asm volatile ("ld.global.nc.v2.u64 {%0,%1}, [%2];" : "=l"(ret.x), "=l"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 133 |
+
|
| 134 |
+
__SM_32_INTRINSICS_DECL__ float __ldg(const float *ptr) { float ret; asm volatile ("ld.global.nc.f32 %0, [%1];" : "=f"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 135 |
+
__SM_32_INTRINSICS_DECL__ double __ldg(const double *ptr) { double ret; asm volatile ("ld.global.nc.f64 %0, [%1];" : "=d"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 136 |
+
__SM_32_INTRINSICS_DECL__ float2 __ldg(const float2 *ptr) { float2 ret; asm volatile ("ld.global.nc.v2.f32 {%0,%1}, [%2];" : "=f"(ret.x), "=f"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 137 |
+
__SM_32_INTRINSICS_DECL__ float4 __ldg(const float4 *ptr) { float4 ret; asm volatile ("ld.global.nc.v4.f32 {%0,%1,%2,%3}, [%4];" : "=f"(ret.x), "=f"(ret.y), "=f"(ret.z), "=f"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 138 |
+
__SM_32_INTRINSICS_DECL__ double2 __ldg(const double2 *ptr) { double2 ret; asm volatile ("ld.global.nc.v2.f64 {%0,%1}, [%2];" : "=d"(ret.x), "=d"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
/******************************************************************************
|
| 142 |
+
* __ldcg *
|
| 143 |
+
******************************************************************************/
|
| 144 |
+
|
| 145 |
+
// Size of long is architecture and OS specific.
|
| 146 |
+
#if defined(__LP64__) // 64 bits
|
| 147 |
+
__SM_32_INTRINSICS_DECL__ long __ldcg(const long *ptr) { unsigned long ret; asm volatile ("ld.global.cg.s64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return (long)ret; }
|
| 148 |
+
__SM_32_INTRINSICS_DECL__ unsigned long __ldcg(const unsigned long *ptr) { unsigned long ret; asm volatile ("ld.global.cg.u64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 149 |
+
#else // 32 bits
|
| 150 |
+
__SM_32_INTRINSICS_DECL__ long __ldcg(const long *ptr) { unsigned long ret; asm volatile ("ld.global.cg.s32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (long)ret; }
|
| 151 |
+
__SM_32_INTRINSICS_DECL__ unsigned long __ldcg(const unsigned long *ptr) { unsigned long ret; asm volatile ("ld.global.cg.u32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 152 |
+
#endif
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
__SM_32_INTRINSICS_DECL__ char __ldcg(const char *ptr) { unsigned int ret; asm volatile ("ld.global.cg.s8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (char)ret; }
|
| 156 |
+
__SM_32_INTRINSICS_DECL__ signed char __ldcg(const signed char *ptr) { unsigned int ret; asm volatile ("ld.global.cg.s8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (signed char)ret; }
|
| 157 |
+
__SM_32_INTRINSICS_DECL__ short __ldcg(const short *ptr) { unsigned short ret; asm volatile ("ld.global.cg.s16 %0, [%1];" : "=h"(ret) : __LDG_PTR (ptr)); return (short)ret; }
|
| 158 |
+
__SM_32_INTRINSICS_DECL__ int __ldcg(const int *ptr) { unsigned int ret; asm volatile ("ld.global.cg.s32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (int)ret; }
|
| 159 |
+
__SM_32_INTRINSICS_DECL__ long long __ldcg(const long long *ptr) { unsigned long long ret; asm volatile ("ld.global.cg.s64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return (long long)ret; }
|
| 160 |
+
__SM_32_INTRINSICS_DECL__ char2 __ldcg(const char2 *ptr) { char2 ret; int2 tmp; asm volatile ("ld.global.cg.v2.s8 {%0,%1}, [%2];" : "=r"(tmp.x), "=r"(tmp.y) : __LDG_PTR (ptr)); ret.x = (char)tmp.x; ret.y = (char)tmp.y; return ret; }
|
| 161 |
+
__SM_32_INTRINSICS_DECL__ char4 __ldcg(const char4 *ptr) { char4 ret; int4 tmp; asm volatile ("ld.global.cg.v4.s8 {%0,%1,%2,%3}, [%4];" : "=r"(tmp.x), "=r"(tmp.y), "=r"(tmp.z), "=r"(tmp.w) : __LDG_PTR (ptr)); ret.x = (char)tmp.x; ret.y = (char)tmp.y; ret.z = (char)tmp.z; ret.w = (char)tmp.w; return ret; }
|
| 162 |
+
__SM_32_INTRINSICS_DECL__ short2 __ldcg(const short2 *ptr) { short2 ret; asm volatile ("ld.global.cg.v2.s16 {%0,%1}, [%2];" : "=h"(ret.x), "=h"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 163 |
+
__SM_32_INTRINSICS_DECL__ short4 __ldcg(const short4 *ptr) { short4 ret; asm volatile ("ld.global.cg.v4.s16 {%0,%1,%2,%3}, [%4];" : "=h"(ret.x), "=h"(ret.y), "=h"(ret.z), "=h"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 164 |
+
__SM_32_INTRINSICS_DECL__ int2 __ldcg(const int2 *ptr) { int2 ret; asm volatile ("ld.global.cg.v2.s32 {%0,%1}, [%2];" : "=r"(ret.x), "=r"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 165 |
+
__SM_32_INTRINSICS_DECL__ int4 __ldcg(const int4 *ptr) { int4 ret; asm volatile ("ld.global.cg.v4.s32 {%0,%1,%2,%3}, [%4];" : "=r"(ret.x), "=r"(ret.y), "=r"(ret.z), "=r"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 166 |
+
__SM_32_INTRINSICS_DECL__ longlong2 __ldcg(const longlong2 *ptr) { longlong2 ret; asm volatile ("ld.global.cg.v2.s64 {%0,%1}, [%2];" : "=l"(ret.x), "=l"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 167 |
+
|
| 168 |
+
__SM_32_INTRINSICS_DECL__ unsigned char __ldcg(const unsigned char *ptr) { unsigned int ret; asm volatile ("ld.global.cg.u8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (unsigned char)ret; }
|
| 169 |
+
__SM_32_INTRINSICS_DECL__ unsigned short __ldcg(const unsigned short *ptr) { unsigned short ret; asm volatile ("ld.global.cg.u16 %0, [%1];" : "=h"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 170 |
+
__SM_32_INTRINSICS_DECL__ unsigned int __ldcg(const unsigned int *ptr) { unsigned int ret; asm volatile ("ld.global.cg.u32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 171 |
+
__SM_32_INTRINSICS_DECL__ unsigned long long __ldcg(const unsigned long long *ptr) { unsigned long long ret; asm volatile ("ld.global.cg.u64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 172 |
+
__SM_32_INTRINSICS_DECL__ uchar2 __ldcg(const uchar2 *ptr) { uchar2 ret; uint2 tmp; asm volatile ("ld.global.cg.v2.u8 {%0,%1}, [%2];" : "=r"(tmp.x), "=r"(tmp.y) : __LDG_PTR (ptr)); ret.x = (unsigned char)tmp.x; ret.y = (unsigned char)tmp.y; return ret; }
|
| 173 |
+
__SM_32_INTRINSICS_DECL__ uchar4 __ldcg(const uchar4 *ptr) { uchar4 ret; uint4 tmp; asm volatile ("ld.global.cg.v4.u8 {%0,%1,%2,%3}, [%4];" : "=r"(tmp.x), "=r"(tmp.y), "=r"(tmp.z), "=r"(tmp.w) : __LDG_PTR (ptr)); ret.x = (unsigned char)tmp.x; ret.y = (unsigned char)tmp.y; ret.z = (unsigned char)tmp.z; ret.w = (unsigned char)tmp.w; return ret; }
|
| 174 |
+
__SM_32_INTRINSICS_DECL__ ushort2 __ldcg(const ushort2 *ptr) { ushort2 ret; asm volatile ("ld.global.cg.v2.u16 {%0,%1}, [%2];" : "=h"(ret.x), "=h"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 175 |
+
__SM_32_INTRINSICS_DECL__ ushort4 __ldcg(const ushort4 *ptr) { ushort4 ret; asm volatile ("ld.global.cg.v4.u16 {%0,%1,%2,%3}, [%4];" : "=h"(ret.x), "=h"(ret.y), "=h"(ret.z), "=h"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 176 |
+
__SM_32_INTRINSICS_DECL__ uint2 __ldcg(const uint2 *ptr) { uint2 ret; asm volatile ("ld.global.cg.v2.u32 {%0,%1}, [%2];" : "=r"(ret.x), "=r"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 177 |
+
__SM_32_INTRINSICS_DECL__ uint4 __ldcg(const uint4 *ptr) { uint4 ret; asm volatile ("ld.global.cg.v4.u32 {%0,%1,%2,%3}, [%4];" : "=r"(ret.x), "=r"(ret.y), "=r"(ret.z), "=r"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 178 |
+
__SM_32_INTRINSICS_DECL__ ulonglong2 __ldcg(const ulonglong2 *ptr) { ulonglong2 ret; asm volatile ("ld.global.cg.v2.u64 {%0,%1}, [%2];" : "=l"(ret.x), "=l"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 179 |
+
|
| 180 |
+
__SM_32_INTRINSICS_DECL__ float __ldcg(const float *ptr) { float ret; asm volatile ("ld.global.cg.f32 %0, [%1];" : "=f"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 181 |
+
__SM_32_INTRINSICS_DECL__ double __ldcg(const double *ptr) { double ret; asm volatile ("ld.global.cg.f64 %0, [%1];" : "=d"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 182 |
+
__SM_32_INTRINSICS_DECL__ float2 __ldcg(const float2 *ptr) { float2 ret; asm volatile ("ld.global.cg.v2.f32 {%0,%1}, [%2];" : "=f"(ret.x), "=f"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 183 |
+
__SM_32_INTRINSICS_DECL__ float4 __ldcg(const float4 *ptr) { float4 ret; asm volatile ("ld.global.cg.v4.f32 {%0,%1,%2,%3}, [%4];" : "=f"(ret.x), "=f"(ret.y), "=f"(ret.z), "=f"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 184 |
+
__SM_32_INTRINSICS_DECL__ double2 __ldcg(const double2 *ptr) { double2 ret; asm volatile ("ld.global.cg.v2.f64 {%0,%1}, [%2];" : "=d"(ret.x), "=d"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 185 |
+
|
| 186 |
+
/******************************************************************************
|
| 187 |
+
* __ldca *
|
| 188 |
+
******************************************************************************/
|
| 189 |
+
|
| 190 |
+
// Size of long is architecture and OS specific.
|
| 191 |
+
#if defined(__LP64__) // 64 bits
|
| 192 |
+
__SM_32_INTRINSICS_DECL__ long __ldca(const long *ptr) { unsigned long ret; asm volatile ("ld.global.ca.s64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return (long)ret; }
|
| 193 |
+
__SM_32_INTRINSICS_DECL__ unsigned long __ldca(const unsigned long *ptr) { unsigned long ret; asm volatile ("ld.global.ca.u64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 194 |
+
#else // 32 bits
|
| 195 |
+
__SM_32_INTRINSICS_DECL__ long __ldca(const long *ptr) { unsigned long ret; asm volatile ("ld.global.ca.s32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (long)ret; }
|
| 196 |
+
__SM_32_INTRINSICS_DECL__ unsigned long __ldca(const unsigned long *ptr) { unsigned long ret; asm volatile ("ld.global.ca.u32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 197 |
+
#endif
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
__SM_32_INTRINSICS_DECL__ char __ldca(const char *ptr) { unsigned int ret; asm volatile ("ld.global.ca.s8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (char)ret; }
|
| 201 |
+
__SM_32_INTRINSICS_DECL__ signed char __ldca(const signed char *ptr) { unsigned int ret; asm volatile ("ld.global.ca.s8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (signed char)ret; }
|
| 202 |
+
__SM_32_INTRINSICS_DECL__ short __ldca(const short *ptr) { unsigned short ret; asm volatile ("ld.global.ca.s16 %0, [%1];" : "=h"(ret) : __LDG_PTR (ptr)); return (short)ret; }
|
| 203 |
+
__SM_32_INTRINSICS_DECL__ int __ldca(const int *ptr) { unsigned int ret; asm volatile ("ld.global.ca.s32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (int)ret; }
|
| 204 |
+
__SM_32_INTRINSICS_DECL__ long long __ldca(const long long *ptr) { unsigned long long ret; asm volatile ("ld.global.ca.s64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return (long long)ret; }
|
| 205 |
+
__SM_32_INTRINSICS_DECL__ char2 __ldca(const char2 *ptr) { char2 ret; int2 tmp; asm volatile ("ld.global.ca.v2.s8 {%0,%1}, [%2];" : "=r"(tmp.x), "=r"(tmp.y) : __LDG_PTR (ptr)); ret.x = (char)tmp.x; ret.y = (char)tmp.y; return ret; }
|
| 206 |
+
__SM_32_INTRINSICS_DECL__ char4 __ldca(const char4 *ptr) { char4 ret; int4 tmp; asm volatile ("ld.global.ca.v4.s8 {%0,%1,%2,%3}, [%4];" : "=r"(tmp.x), "=r"(tmp.y), "=r"(tmp.z), "=r"(tmp.w) : __LDG_PTR (ptr)); ret.x = (char)tmp.x; ret.y = (char)tmp.y; ret.z = (char)tmp.z; ret.w = (char)tmp.w; return ret; }
|
| 207 |
+
__SM_32_INTRINSICS_DECL__ short2 __ldca(const short2 *ptr) { short2 ret; asm volatile ("ld.global.ca.v2.s16 {%0,%1}, [%2];" : "=h"(ret.x), "=h"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 208 |
+
__SM_32_INTRINSICS_DECL__ short4 __ldca(const short4 *ptr) { short4 ret; asm volatile ("ld.global.ca.v4.s16 {%0,%1,%2,%3}, [%4];" : "=h"(ret.x), "=h"(ret.y), "=h"(ret.z), "=h"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 209 |
+
__SM_32_INTRINSICS_DECL__ int2 __ldca(const int2 *ptr) { int2 ret; asm volatile ("ld.global.ca.v2.s32 {%0,%1}, [%2];" : "=r"(ret.x), "=r"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 210 |
+
__SM_32_INTRINSICS_DECL__ int4 __ldca(const int4 *ptr) { int4 ret; asm volatile ("ld.global.ca.v4.s32 {%0,%1,%2,%3}, [%4];" : "=r"(ret.x), "=r"(ret.y), "=r"(ret.z), "=r"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 211 |
+
__SM_32_INTRINSICS_DECL__ longlong2 __ldca(const longlong2 *ptr) { longlong2 ret; asm volatile ("ld.global.ca.v2.s64 {%0,%1}, [%2];" : "=l"(ret.x), "=l"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 212 |
+
|
| 213 |
+
__SM_32_INTRINSICS_DECL__ unsigned char __ldca(const unsigned char *ptr) { unsigned int ret; asm volatile ("ld.global.ca.u8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (unsigned char)ret; }
|
| 214 |
+
__SM_32_INTRINSICS_DECL__ unsigned short __ldca(const unsigned short *ptr) { unsigned short ret; asm volatile ("ld.global.ca.u16 %0, [%1];" : "=h"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 215 |
+
__SM_32_INTRINSICS_DECL__ unsigned int __ldca(const unsigned int *ptr) { unsigned int ret; asm volatile ("ld.global.ca.u32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 216 |
+
__SM_32_INTRINSICS_DECL__ unsigned long long __ldca(const unsigned long long *ptr) { unsigned long long ret; asm volatile ("ld.global.ca.u64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 217 |
+
__SM_32_INTRINSICS_DECL__ uchar2 __ldca(const uchar2 *ptr) { uchar2 ret; uint2 tmp; asm volatile ("ld.global.ca.v2.u8 {%0,%1}, [%2];" : "=r"(tmp.x), "=r"(tmp.y) : __LDG_PTR (ptr)); ret.x = (unsigned char)tmp.x; ret.y = (unsigned char)tmp.y; return ret; }
|
| 218 |
+
__SM_32_INTRINSICS_DECL__ uchar4 __ldca(const uchar4 *ptr) { uchar4 ret; uint4 tmp; asm volatile ("ld.global.ca.v4.u8 {%0,%1,%2,%3}, [%4];" : "=r"(tmp.x), "=r"(tmp.y), "=r"(tmp.z), "=r"(tmp.w) : __LDG_PTR (ptr)); ret.x = (unsigned char)tmp.x; ret.y = (unsigned char)tmp.y; ret.z = (unsigned char)tmp.z; ret.w = (unsigned char)tmp.w; return ret; }
|
| 219 |
+
__SM_32_INTRINSICS_DECL__ ushort2 __ldca(const ushort2 *ptr) { ushort2 ret; asm volatile ("ld.global.ca.v2.u16 {%0,%1}, [%2];" : "=h"(ret.x), "=h"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 220 |
+
__SM_32_INTRINSICS_DECL__ ushort4 __ldca(const ushort4 *ptr) { ushort4 ret; asm volatile ("ld.global.ca.v4.u16 {%0,%1,%2,%3}, [%4];" : "=h"(ret.x), "=h"(ret.y), "=h"(ret.z), "=h"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 221 |
+
__SM_32_INTRINSICS_DECL__ uint2 __ldca(const uint2 *ptr) { uint2 ret; asm volatile ("ld.global.ca.v2.u32 {%0,%1}, [%2];" : "=r"(ret.x), "=r"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 222 |
+
__SM_32_INTRINSICS_DECL__ uint4 __ldca(const uint4 *ptr) { uint4 ret; asm volatile ("ld.global.ca.v4.u32 {%0,%1,%2,%3}, [%4];" : "=r"(ret.x), "=r"(ret.y), "=r"(ret.z), "=r"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 223 |
+
__SM_32_INTRINSICS_DECL__ ulonglong2 __ldca(const ulonglong2 *ptr) { ulonglong2 ret; asm volatile ("ld.global.ca.v2.u64 {%0,%1}, [%2];" : "=l"(ret.x), "=l"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 224 |
+
|
| 225 |
+
__SM_32_INTRINSICS_DECL__ float __ldca(const float *ptr) { float ret; asm volatile ("ld.global.ca.f32 %0, [%1];" : "=f"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 226 |
+
__SM_32_INTRINSICS_DECL__ double __ldca(const double *ptr) { double ret; asm volatile ("ld.global.ca.f64 %0, [%1];" : "=d"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 227 |
+
__SM_32_INTRINSICS_DECL__ float2 __ldca(const float2 *ptr) { float2 ret; asm volatile ("ld.global.ca.v2.f32 {%0,%1}, [%2];" : "=f"(ret.x), "=f"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 228 |
+
__SM_32_INTRINSICS_DECL__ float4 __ldca(const float4 *ptr) { float4 ret; asm volatile ("ld.global.ca.v4.f32 {%0,%1,%2,%3}, [%4];" : "=f"(ret.x), "=f"(ret.y), "=f"(ret.z), "=f"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 229 |
+
__SM_32_INTRINSICS_DECL__ double2 __ldca(const double2 *ptr) { double2 ret; asm volatile ("ld.global.ca.v2.f64 {%0,%1}, [%2];" : "=d"(ret.x), "=d"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 230 |
+
|
| 231 |
+
/******************************************************************************
|
| 232 |
+
* __ldcs *
|
| 233 |
+
******************************************************************************/
|
| 234 |
+
|
| 235 |
+
// Size of long is architecture and OS specific.
|
| 236 |
+
#if defined(__LP64__) // 64 bits
|
| 237 |
+
__SM_32_INTRINSICS_DECL__ long __ldcs(const long *ptr) { unsigned long ret; asm volatile ("ld.global.cs.s64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return (long)ret; }
|
| 238 |
+
__SM_32_INTRINSICS_DECL__ unsigned long __ldcs(const unsigned long *ptr) { unsigned long ret; asm volatile ("ld.global.cs.u64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 239 |
+
#else // 32 bits
|
| 240 |
+
__SM_32_INTRINSICS_DECL__ long __ldcs(const long *ptr) { unsigned long ret; asm volatile ("ld.global.cs.s32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (long)ret; }
|
| 241 |
+
__SM_32_INTRINSICS_DECL__ unsigned long __ldcs(const unsigned long *ptr) { unsigned long ret; asm volatile ("ld.global.cs.u32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 242 |
+
#endif
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
__SM_32_INTRINSICS_DECL__ char __ldcs(const char *ptr) { unsigned int ret; asm volatile ("ld.global.cs.s8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (char)ret; }
|
| 246 |
+
__SM_32_INTRINSICS_DECL__ signed char __ldcs(const signed char *ptr) { unsigned int ret; asm volatile ("ld.global.cs.s8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (signed char)ret; }
|
| 247 |
+
__SM_32_INTRINSICS_DECL__ short __ldcs(const short *ptr) { unsigned short ret; asm volatile ("ld.global.cs.s16 %0, [%1];" : "=h"(ret) : __LDG_PTR (ptr)); return (short)ret; }
|
| 248 |
+
__SM_32_INTRINSICS_DECL__ int __ldcs(const int *ptr) { unsigned int ret; asm volatile ("ld.global.cs.s32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (int)ret; }
|
| 249 |
+
__SM_32_INTRINSICS_DECL__ long long __ldcs(const long long *ptr) { unsigned long long ret; asm volatile ("ld.global.cs.s64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return (long long)ret; }
|
| 250 |
+
__SM_32_INTRINSICS_DECL__ char2 __ldcs(const char2 *ptr) { char2 ret; int2 tmp; asm volatile ("ld.global.cs.v2.s8 {%0,%1}, [%2];" : "=r"(tmp.x), "=r"(tmp.y) : __LDG_PTR (ptr)); ret.x = (char)tmp.x; ret.y = (char)tmp.y; return ret; }
|
| 251 |
+
__SM_32_INTRINSICS_DECL__ char4 __ldcs(const char4 *ptr) { char4 ret; int4 tmp; asm volatile ("ld.global.cs.v4.s8 {%0,%1,%2,%3}, [%4];" : "=r"(tmp.x), "=r"(tmp.y), "=r"(tmp.z), "=r"(tmp.w) : __LDG_PTR (ptr)); ret.x = (char)tmp.x; ret.y = (char)tmp.y; ret.z = (char)tmp.z; ret.w = (char)tmp.w; return ret; }
|
| 252 |
+
__SM_32_INTRINSICS_DECL__ short2 __ldcs(const short2 *ptr) { short2 ret; asm volatile ("ld.global.cs.v2.s16 {%0,%1}, [%2];" : "=h"(ret.x), "=h"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 253 |
+
__SM_32_INTRINSICS_DECL__ short4 __ldcs(const short4 *ptr) { short4 ret; asm volatile ("ld.global.cs.v4.s16 {%0,%1,%2,%3}, [%4];" : "=h"(ret.x), "=h"(ret.y), "=h"(ret.z), "=h"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 254 |
+
__SM_32_INTRINSICS_DECL__ int2 __ldcs(const int2 *ptr) { int2 ret; asm volatile ("ld.global.cs.v2.s32 {%0,%1}, [%2];" : "=r"(ret.x), "=r"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 255 |
+
__SM_32_INTRINSICS_DECL__ int4 __ldcs(const int4 *ptr) { int4 ret; asm volatile ("ld.global.cs.v4.s32 {%0,%1,%2,%3}, [%4];" : "=r"(ret.x), "=r"(ret.y), "=r"(ret.z), "=r"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 256 |
+
__SM_32_INTRINSICS_DECL__ longlong2 __ldcs(const longlong2 *ptr) { longlong2 ret; asm volatile ("ld.global.cs.v2.s64 {%0,%1}, [%2];" : "=l"(ret.x), "=l"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 257 |
+
|
| 258 |
+
__SM_32_INTRINSICS_DECL__ unsigned char __ldcs(const unsigned char *ptr) { unsigned int ret; asm volatile ("ld.global.cs.u8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return (unsigned char)ret; }
|
| 259 |
+
__SM_32_INTRINSICS_DECL__ unsigned short __ldcs(const unsigned short *ptr) { unsigned short ret; asm volatile ("ld.global.cs.u16 %0, [%1];" : "=h"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 260 |
+
__SM_32_INTRINSICS_DECL__ unsigned int __ldcs(const unsigned int *ptr) { unsigned int ret; asm volatile ("ld.global.cs.u32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 261 |
+
__SM_32_INTRINSICS_DECL__ unsigned long long __ldcs(const unsigned long long *ptr) { unsigned long long ret; asm volatile ("ld.global.cs.u64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 262 |
+
__SM_32_INTRINSICS_DECL__ uchar2 __ldcs(const uchar2 *ptr) { uchar2 ret; uint2 tmp; asm volatile ("ld.global.cs.v2.u8 {%0,%1}, [%2];" : "=r"(tmp.x), "=r"(tmp.y) : __LDG_PTR (ptr)); ret.x = (unsigned char)tmp.x; ret.y = (unsigned char)tmp.y; return ret; }
|
| 263 |
+
__SM_32_INTRINSICS_DECL__ uchar4 __ldcs(const uchar4 *ptr) { uchar4 ret; uint4 tmp; asm volatile ("ld.global.cs.v4.u8 {%0,%1,%2,%3}, [%4];" : "=r"(tmp.x), "=r"(tmp.y), "=r"(tmp.z), "=r"(tmp.w) : __LDG_PTR (ptr)); ret.x = (unsigned char)tmp.x; ret.y = (unsigned char)tmp.y; ret.z = (unsigned char)tmp.z; ret.w = (unsigned char)tmp.w; return ret; }
|
| 264 |
+
__SM_32_INTRINSICS_DECL__ ushort2 __ldcs(const ushort2 *ptr) { ushort2 ret; asm volatile ("ld.global.cs.v2.u16 {%0,%1}, [%2];" : "=h"(ret.x), "=h"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 265 |
+
__SM_32_INTRINSICS_DECL__ ushort4 __ldcs(const ushort4 *ptr) { ushort4 ret; asm volatile ("ld.global.cs.v4.u16 {%0,%1,%2,%3}, [%4];" : "=h"(ret.x), "=h"(ret.y), "=h"(ret.z), "=h"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 266 |
+
__SM_32_INTRINSICS_DECL__ uint2 __ldcs(const uint2 *ptr) { uint2 ret; asm volatile ("ld.global.cs.v2.u32 {%0,%1}, [%2];" : "=r"(ret.x), "=r"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 267 |
+
__SM_32_INTRINSICS_DECL__ uint4 __ldcs(const uint4 *ptr) { uint4 ret; asm volatile ("ld.global.cs.v4.u32 {%0,%1,%2,%3}, [%4];" : "=r"(ret.x), "=r"(ret.y), "=r"(ret.z), "=r"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 268 |
+
__SM_32_INTRINSICS_DECL__ ulonglong2 __ldcs(const ulonglong2 *ptr) { ulonglong2 ret; asm volatile ("ld.global.cs.v2.u64 {%0,%1}, [%2];" : "=l"(ret.x), "=l"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 269 |
+
|
| 270 |
+
__SM_32_INTRINSICS_DECL__ float __ldcs(const float *ptr) { float ret; asm volatile ("ld.global.cs.f32 %0, [%1];" : "=f"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 271 |
+
__SM_32_INTRINSICS_DECL__ double __ldcs(const double *ptr) { double ret; asm volatile ("ld.global.cs.f64 %0, [%1];" : "=d"(ret) : __LDG_PTR (ptr)); return ret; }
|
| 272 |
+
__SM_32_INTRINSICS_DECL__ float2 __ldcs(const float2 *ptr) { float2 ret; asm volatile ("ld.global.cs.v2.f32 {%0,%1}, [%2];" : "=f"(ret.x), "=f"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 273 |
+
__SM_32_INTRINSICS_DECL__ float4 __ldcs(const float4 *ptr) { float4 ret; asm volatile ("ld.global.cs.v4.f32 {%0,%1,%2,%3}, [%4];" : "=f"(ret.x), "=f"(ret.y), "=f"(ret.z), "=f"(ret.w) : __LDG_PTR (ptr)); return ret; }
|
| 274 |
+
__SM_32_INTRINSICS_DECL__ double2 __ldcs(const double2 *ptr) { double2 ret; asm volatile ("ld.global.cs.v2.f64 {%0,%1}, [%2];" : "=d"(ret.x), "=d"(ret.y) : __LDG_PTR (ptr)); return ret; }
|
| 275 |
+
|
| 276 |
+
/******************************************************************************
|
| 277 |
+
* __ldlu *
|
| 278 |
+
******************************************************************************/
|
| 279 |
+
|
| 280 |
+
// Size of long is architecture and OS specific.
|
| 281 |
+
#if defined(__LP64__) // 64 bits
|
| 282 |
+
__SM_32_INTRINSICS_DECL__ long __ldlu(const long *ptr) { unsigned long ret; asm ("ld.global.lu.s64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr) : "memory"); return (long)ret; }
|
| 283 |
+
__SM_32_INTRINSICS_DECL__ unsigned long __ldlu(const unsigned long *ptr) { unsigned long ret; asm ("ld.global.lu.u64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 284 |
+
#else // 32 bits
|
| 285 |
+
__SM_32_INTRINSICS_DECL__ long __ldlu(const long *ptr) { unsigned long ret; asm ("ld.global.lu.s32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return (long)ret; }
|
| 286 |
+
__SM_32_INTRINSICS_DECL__ unsigned long __ldlu(const unsigned long *ptr) { unsigned long ret; asm ("ld.global.lu.u32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 287 |
+
#endif
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
__SM_32_INTRINSICS_DECL__ char __ldlu(const char *ptr) { unsigned int ret; asm ("ld.global.lu.s8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return (char)ret; }
|
| 291 |
+
__SM_32_INTRINSICS_DECL__ signed char __ldlu(const signed char *ptr) { unsigned int ret; asm ("ld.global.lu.s8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return (signed char)ret; }
|
| 292 |
+
__SM_32_INTRINSICS_DECL__ short __ldlu(const short *ptr) { unsigned short ret; asm ("ld.global.lu.s16 %0, [%1];" : "=h"(ret) : __LDG_PTR (ptr) : "memory"); return (short)ret; }
|
| 293 |
+
__SM_32_INTRINSICS_DECL__ int __ldlu(const int *ptr) { unsigned int ret; asm ("ld.global.lu.s32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return (int)ret; }
|
| 294 |
+
__SM_32_INTRINSICS_DECL__ long long __ldlu(const long long *ptr) { unsigned long long ret; asm ("ld.global.lu.s64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr) : "memory"); return (long long)ret; }
|
| 295 |
+
__SM_32_INTRINSICS_DECL__ char2 __ldlu(const char2 *ptr) { char2 ret; int2 tmp; asm ("ld.global.lu.v2.s8 {%0,%1}, [%2];" : "=r"(tmp.x), "=r"(tmp.y) : __LDG_PTR (ptr) : "memory"); ret.x = (char)tmp.x; ret.y = (char)tmp.y; return ret; }
|
| 296 |
+
__SM_32_INTRINSICS_DECL__ char4 __ldlu(const char4 *ptr) { char4 ret; int4 tmp; asm ("ld.global.lu.v4.s8 {%0,%1,%2,%3}, [%4];" : "=r"(tmp.x), "=r"(tmp.y), "=r"(tmp.z), "=r"(tmp.w) : __LDG_PTR (ptr) : "memory"); ret.x = (char)tmp.x; ret.y = (char)tmp.y; ret.z = (char)tmp.z; ret.w = (char)tmp.w; return ret; }
|
| 297 |
+
__SM_32_INTRINSICS_DECL__ short2 __ldlu(const short2 *ptr) { short2 ret; asm ("ld.global.lu.v2.s16 {%0,%1}, [%2];" : "=h"(ret.x), "=h"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 298 |
+
__SM_32_INTRINSICS_DECL__ short4 __ldlu(const short4 *ptr) { short4 ret; asm ("ld.global.lu.v4.s16 {%0,%1,%2,%3}, [%4];" : "=h"(ret.x), "=h"(ret.y), "=h"(ret.z), "=h"(ret.w) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 299 |
+
__SM_32_INTRINSICS_DECL__ int2 __ldlu(const int2 *ptr) { int2 ret; asm ("ld.global.lu.v2.s32 {%0,%1}, [%2];" : "=r"(ret.x), "=r"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 300 |
+
__SM_32_INTRINSICS_DECL__ int4 __ldlu(const int4 *ptr) { int4 ret; asm ("ld.global.lu.v4.s32 {%0,%1,%2,%3}, [%4];" : "=r"(ret.x), "=r"(ret.y), "=r"(ret.z), "=r"(ret.w) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 301 |
+
__SM_32_INTRINSICS_DECL__ longlong2 __ldlu(const longlong2 *ptr) { longlong2 ret; asm ("ld.global.lu.v2.s64 {%0,%1}, [%2];" : "=l"(ret.x), "=l"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 302 |
+
|
| 303 |
+
__SM_32_INTRINSICS_DECL__ unsigned char __ldlu(const unsigned char *ptr) { unsigned int ret; asm ("ld.global.lu.u8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return (unsigned char)ret; }
|
| 304 |
+
__SM_32_INTRINSICS_DECL__ unsigned short __ldlu(const unsigned short *ptr) { unsigned short ret; asm ("ld.global.lu.u16 %0, [%1];" : "=h"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 305 |
+
__SM_32_INTRINSICS_DECL__ unsigned int __ldlu(const unsigned int *ptr) { unsigned int ret; asm ("ld.global.lu.u32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 306 |
+
__SM_32_INTRINSICS_DECL__ unsigned long long __ldlu(const unsigned long long *ptr) { unsigned long long ret; asm ("ld.global.lu.u64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 307 |
+
__SM_32_INTRINSICS_DECL__ uchar2 __ldlu(const uchar2 *ptr) { uchar2 ret; uint2 tmp; asm ("ld.global.lu.v2.u8 {%0,%1}, [%2];" : "=r"(tmp.x), "=r"(tmp.y) : __LDG_PTR (ptr) : "memory"); ret.x = (unsigned char)tmp.x; ret.y = (unsigned char)tmp.y; return ret; }
|
| 308 |
+
__SM_32_INTRINSICS_DECL__ uchar4 __ldlu(const uchar4 *ptr) { uchar4 ret; uint4 tmp; asm ("ld.global.lu.v4.u8 {%0,%1,%2,%3}, [%4];" : "=r"(tmp.x), "=r"(tmp.y), "=r"(tmp.z), "=r"(tmp.w) : __LDG_PTR (ptr) : "memory"); ret.x = (unsigned char)tmp.x; ret.y = (unsigned char)tmp.y; ret.z = (unsigned char)tmp.z; ret.w = (unsigned char)tmp.w; return ret; }
|
| 309 |
+
__SM_32_INTRINSICS_DECL__ ushort2 __ldlu(const ushort2 *ptr) { ushort2 ret; asm ("ld.global.lu.v2.u16 {%0,%1}, [%2];" : "=h"(ret.x), "=h"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 310 |
+
__SM_32_INTRINSICS_DECL__ ushort4 __ldlu(const ushort4 *ptr) { ushort4 ret; asm ("ld.global.lu.v4.u16 {%0,%1,%2,%3}, [%4];" : "=h"(ret.x), "=h"(ret.y), "=h"(ret.z), "=h"(ret.w) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 311 |
+
__SM_32_INTRINSICS_DECL__ uint2 __ldlu(const uint2 *ptr) { uint2 ret; asm ("ld.global.lu.v2.u32 {%0,%1}, [%2];" : "=r"(ret.x), "=r"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 312 |
+
__SM_32_INTRINSICS_DECL__ uint4 __ldlu(const uint4 *ptr) { uint4 ret; asm ("ld.global.lu.v4.u32 {%0,%1,%2,%3}, [%4];" : "=r"(ret.x), "=r"(ret.y), "=r"(ret.z), "=r"(ret.w) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 313 |
+
__SM_32_INTRINSICS_DECL__ ulonglong2 __ldlu(const ulonglong2 *ptr) { ulonglong2 ret; asm ("ld.global.lu.v2.u64 {%0,%1}, [%2];" : "=l"(ret.x), "=l"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 314 |
+
|
| 315 |
+
__SM_32_INTRINSICS_DECL__ float __ldlu(const float *ptr) { float ret; asm ("ld.global.lu.f32 %0, [%1];" : "=f"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 316 |
+
__SM_32_INTRINSICS_DECL__ double __ldlu(const double *ptr) { double ret; asm ("ld.global.lu.f64 %0, [%1];" : "=d"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 317 |
+
__SM_32_INTRINSICS_DECL__ float2 __ldlu(const float2 *ptr) { float2 ret; asm ("ld.global.lu.v2.f32 {%0,%1}, [%2];" : "=f"(ret.x), "=f"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 318 |
+
__SM_32_INTRINSICS_DECL__ float4 __ldlu(const float4 *ptr) { float4 ret; asm ("ld.global.lu.v4.f32 {%0,%1,%2,%3}, [%4];" : "=f"(ret.x), "=f"(ret.y), "=f"(ret.z), "=f"(ret.w) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 319 |
+
__SM_32_INTRINSICS_DECL__ double2 __ldlu(const double2 *ptr) { double2 ret; asm ("ld.global.lu.v2.f64 {%0,%1}, [%2];" : "=d"(ret.x), "=d"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 320 |
+
|
| 321 |
+
/******************************************************************************
|
| 322 |
+
* __ldcv *
|
| 323 |
+
******************************************************************************/
|
| 324 |
+
|
| 325 |
+
// Size of long is architecture and OS specific.
|
| 326 |
+
#if defined(__LP64__) // 64 bits
|
| 327 |
+
__SM_32_INTRINSICS_DECL__ long __ldcv(const long *ptr) { unsigned long ret; asm ("ld.global.cv.s64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr) : "memory"); return (long)ret; }
|
| 328 |
+
__SM_32_INTRINSICS_DECL__ unsigned long __ldcv(const unsigned long *ptr) { unsigned long ret; asm ("ld.global.cv.u64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 329 |
+
#else // 32 bits
|
| 330 |
+
__SM_32_INTRINSICS_DECL__ long __ldcv(const long *ptr) { unsigned long ret; asm ("ld.global.cv.s32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return (long)ret; }
|
| 331 |
+
__SM_32_INTRINSICS_DECL__ unsigned long __ldcv(const unsigned long *ptr) { unsigned long ret; asm ("ld.global.cv.u32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 332 |
+
#endif
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
__SM_32_INTRINSICS_DECL__ char __ldcv(const char *ptr) { unsigned int ret; asm ("ld.global.cv.s8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return (char)ret; }
|
| 336 |
+
__SM_32_INTRINSICS_DECL__ signed char __ldcv(const signed char *ptr) { unsigned int ret; asm ("ld.global.cv.s8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return (signed char)ret; }
|
| 337 |
+
__SM_32_INTRINSICS_DECL__ short __ldcv(const short *ptr) { unsigned short ret; asm ("ld.global.cv.s16 %0, [%1];" : "=h"(ret) : __LDG_PTR (ptr) : "memory"); return (short)ret; }
|
| 338 |
+
__SM_32_INTRINSICS_DECL__ int __ldcv(const int *ptr) { unsigned int ret; asm ("ld.global.cv.s32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return (int)ret; }
|
| 339 |
+
__SM_32_INTRINSICS_DECL__ long long __ldcv(const long long *ptr) { unsigned long long ret; asm ("ld.global.cv.s64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr) : "memory"); return (long long)ret; }
|
| 340 |
+
__SM_32_INTRINSICS_DECL__ char2 __ldcv(const char2 *ptr) { char2 ret; int2 tmp; asm ("ld.global.cv.v2.s8 {%0,%1}, [%2];" : "=r"(tmp.x), "=r"(tmp.y) : __LDG_PTR (ptr) : "memory"); ret.x = (char)tmp.x; ret.y = (char)tmp.y; return ret; }
|
| 341 |
+
__SM_32_INTRINSICS_DECL__ char4 __ldcv(const char4 *ptr) { char4 ret; int4 tmp; asm ("ld.global.cv.v4.s8 {%0,%1,%2,%3}, [%4];" : "=r"(tmp.x), "=r"(tmp.y), "=r"(tmp.z), "=r"(tmp.w) : __LDG_PTR (ptr) : "memory"); ret.x = (char)tmp.x; ret.y = (char)tmp.y; ret.z = (char)tmp.z; ret.w = (char)tmp.w; return ret; }
|
| 342 |
+
__SM_32_INTRINSICS_DECL__ short2 __ldcv(const short2 *ptr) { short2 ret; asm ("ld.global.cv.v2.s16 {%0,%1}, [%2];" : "=h"(ret.x), "=h"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 343 |
+
__SM_32_INTRINSICS_DECL__ short4 __ldcv(const short4 *ptr) { short4 ret; asm ("ld.global.cv.v4.s16 {%0,%1,%2,%3}, [%4];" : "=h"(ret.x), "=h"(ret.y), "=h"(ret.z), "=h"(ret.w) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 344 |
+
__SM_32_INTRINSICS_DECL__ int2 __ldcv(const int2 *ptr) { int2 ret; asm ("ld.global.cv.v2.s32 {%0,%1}, [%2];" : "=r"(ret.x), "=r"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 345 |
+
__SM_32_INTRINSICS_DECL__ int4 __ldcv(const int4 *ptr) { int4 ret; asm ("ld.global.cv.v4.s32 {%0,%1,%2,%3}, [%4];" : "=r"(ret.x), "=r"(ret.y), "=r"(ret.z), "=r"(ret.w) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 346 |
+
__SM_32_INTRINSICS_DECL__ longlong2 __ldcv(const longlong2 *ptr) { longlong2 ret; asm ("ld.global.cv.v2.s64 {%0,%1}, [%2];" : "=l"(ret.x), "=l"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 347 |
+
|
| 348 |
+
__SM_32_INTRINSICS_DECL__ unsigned char __ldcv(const unsigned char *ptr) { unsigned int ret; asm ("ld.global.cv.u8 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return (unsigned char)ret; }
|
| 349 |
+
__SM_32_INTRINSICS_DECL__ unsigned short __ldcv(const unsigned short *ptr) { unsigned short ret; asm ("ld.global.cv.u16 %0, [%1];" : "=h"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 350 |
+
__SM_32_INTRINSICS_DECL__ unsigned int __ldcv(const unsigned int *ptr) { unsigned int ret; asm ("ld.global.cv.u32 %0, [%1];" : "=r"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 351 |
+
__SM_32_INTRINSICS_DECL__ unsigned long long __ldcv(const unsigned long long *ptr) { unsigned long long ret; asm ("ld.global.cv.u64 %0, [%1];" : "=l"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 352 |
+
__SM_32_INTRINSICS_DECL__ uchar2 __ldcv(const uchar2 *ptr) { uchar2 ret; uint2 tmp; asm ("ld.global.cv.v2.u8 {%0,%1}, [%2];" : "=r"(tmp.x), "=r"(tmp.y) : __LDG_PTR (ptr) : "memory"); ret.x = (unsigned char)tmp.x; ret.y = (unsigned char)tmp.y; return ret; }
|
| 353 |
+
__SM_32_INTRINSICS_DECL__ uchar4 __ldcv(const uchar4 *ptr) { uchar4 ret; uint4 tmp; asm ("ld.global.cv.v4.u8 {%0,%1,%2,%3}, [%4];" : "=r"(tmp.x), "=r"(tmp.y), "=r"(tmp.z), "=r"(tmp.w) : __LDG_PTR (ptr) : "memory"); ret.x = (unsigned char)tmp.x; ret.y = (unsigned char)tmp.y; ret.z = (unsigned char)tmp.z; ret.w = (unsigned char)tmp.w; return ret; }
|
| 354 |
+
__SM_32_INTRINSICS_DECL__ ushort2 __ldcv(const ushort2 *ptr) { ushort2 ret; asm ("ld.global.cv.v2.u16 {%0,%1}, [%2];" : "=h"(ret.x), "=h"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 355 |
+
__SM_32_INTRINSICS_DECL__ ushort4 __ldcv(const ushort4 *ptr) { ushort4 ret; asm ("ld.global.cv.v4.u16 {%0,%1,%2,%3}, [%4];" : "=h"(ret.x), "=h"(ret.y), "=h"(ret.z), "=h"(ret.w) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 356 |
+
__SM_32_INTRINSICS_DECL__ uint2 __ldcv(const uint2 *ptr) { uint2 ret; asm ("ld.global.cv.v2.u32 {%0,%1}, [%2];" : "=r"(ret.x), "=r"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 357 |
+
__SM_32_INTRINSICS_DECL__ uint4 __ldcv(const uint4 *ptr) { uint4 ret; asm ("ld.global.cv.v4.u32 {%0,%1,%2,%3}, [%4];" : "=r"(ret.x), "=r"(ret.y), "=r"(ret.z), "=r"(ret.w) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 358 |
+
__SM_32_INTRINSICS_DECL__ ulonglong2 __ldcv(const ulonglong2 *ptr) { ulonglong2 ret; asm ("ld.global.cv.v2.u64 {%0,%1}, [%2];" : "=l"(ret.x), "=l"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 359 |
+
|
| 360 |
+
__SM_32_INTRINSICS_DECL__ float __ldcv(const float *ptr) { float ret; asm ("ld.global.cv.f32 %0, [%1];" : "=f"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 361 |
+
__SM_32_INTRINSICS_DECL__ double __ldcv(const double *ptr) { double ret; asm ("ld.global.cv.f64 %0, [%1];" : "=d"(ret) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 362 |
+
__SM_32_INTRINSICS_DECL__ float2 __ldcv(const float2 *ptr) { float2 ret; asm ("ld.global.cv.v2.f32 {%0,%1}, [%2];" : "=f"(ret.x), "=f"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 363 |
+
__SM_32_INTRINSICS_DECL__ float4 __ldcv(const float4 *ptr) { float4 ret; asm ("ld.global.cv.v4.f32 {%0,%1,%2,%3}, [%4];" : "=f"(ret.x), "=f"(ret.y), "=f"(ret.z), "=f"(ret.w) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 364 |
+
__SM_32_INTRINSICS_DECL__ double2 __ldcv(const double2 *ptr) { double2 ret; asm ("ld.global.cv.v2.f64 {%0,%1}, [%2];" : "=d"(ret.x), "=d"(ret.y) : __LDG_PTR (ptr) : "memory"); return ret; }
|
| 365 |
+
|
| 366 |
+
/******************************************************************************
|
| 367 |
+
* __stwb *
|
| 368 |
+
******************************************************************************/
|
| 369 |
+
|
| 370 |
+
// Size of long is architecture and OS specific.
|
| 371 |
+
#if defined(__LP64__) // 64 bits
|
| 372 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(long *ptr, long value) { asm ("st.global.wb.s64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 373 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(unsigned long *ptr, unsigned long value) { asm ("st.global.wb.u64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 374 |
+
#else // 32 bits
|
| 375 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(long *ptr, long value) { asm ("st.global.wb.s32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 376 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(unsigned long *ptr, unsigned long value) { asm ("st.global.wb.u32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 377 |
+
#endif
|
| 378 |
+
|
| 379 |
+
|
| 380 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(char *ptr, char value) { asm ("st.global.wb.s8 [%0], %1;" :: __LDG_PTR (ptr), "r"((int)value) : "memory"); }
|
| 381 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(signed char *ptr, signed char value) { asm ("st.global.wb.s8 [%0], %1;" :: __LDG_PTR (ptr), "r"((int)value) : "memory"); }
|
| 382 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(short *ptr, short value) { asm ("st.global.wb.s16 [%0], %1;" :: __LDG_PTR (ptr), "h"(value) : "memory"); }
|
| 383 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(int *ptr, int value) { asm ("st.global.wb.s32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 384 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(long long *ptr, long long value) { asm ("st.global.wb.s64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 385 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(char2 *ptr, char2 value) { const int x = value.x, y = value.y; asm ("st.global.wb.v2.s8 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(x), "r"(y) : "memory"); }
|
| 386 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(char4 *ptr, char4 value) { const int x = value.x, y = value.y, z = value.z, w = value.w; asm ("st.global.wb.v4.s8 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(x), "r"(y), "r"(z), "r"(w) : "memory"); }
|
| 387 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(short2 *ptr, short2 value) { asm ("st.global.wb.v2.s16 [%0], {%1,%2};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y) : "memory"); }
|
| 388 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(short4 *ptr, short4 value) { asm ("st.global.wb.v4.s16 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y), "h"(value.z), "h"(value.w) : "memory"); }
|
| 389 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(int2 *ptr, int2 value) { asm ("st.global.wb.v2.s32 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y) : "memory"); }
|
| 390 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(int4 *ptr, int4 value) { asm ("st.global.wb.v4.s32 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y), "r"(value.z), "r"(value.w) : "memory"); }
|
| 391 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(longlong2 *ptr, longlong2 value) { asm ("st.global.wb.v2.s64 [%0], {%1,%2};" :: __LDG_PTR (ptr), "l"(value.x), "l"(value.y) : "memory"); }
|
| 392 |
+
|
| 393 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(unsigned char *ptr, unsigned char value) { asm ("st.global.wb.u8 [%0], %1;" :: __LDG_PTR (ptr), "r"((int)value) : "memory"); }
|
| 394 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(unsigned short *ptr, unsigned short value) { asm ("st.global.wb.u16 [%0], %1;" :: __LDG_PTR (ptr), "h"(value) : "memory"); }
|
| 395 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(unsigned int *ptr, unsigned int value) { asm ("st.global.wb.u32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 396 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(unsigned long long *ptr, unsigned long long value) { asm ("st.global.wb.u64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 397 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(uchar2 *ptr, uchar2 value) { const int x = value.x, y = value.y; asm ("st.global.wb.v2.u8 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(x), "r"(y) : "memory"); }
|
| 398 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(uchar4 *ptr, uchar4 value) { const int x = value.x, y = value.y, z = value.z, w = value.w; asm ("st.global.wb.v4.u8 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(x), "r"(y), "r"(z), "r"(w) : "memory"); }
|
| 399 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(ushort2 *ptr, ushort2 value) { asm ("st.global.wb.v2.u16 [%0], {%1,%2};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y) : "memory"); }
|
| 400 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(ushort4 *ptr, ushort4 value) { asm ("st.global.wb.v4.u16 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y), "h"(value.z), "h"(value.w) : "memory"); }
|
| 401 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(uint2 *ptr, uint2 value) { asm ("st.global.wb.v2.u32 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y) : "memory"); }
|
| 402 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(uint4 *ptr, uint4 value) { asm ("st.global.wb.v4.u32 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y), "r"(value.z), "r"(value.w) : "memory"); }
|
| 403 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(ulonglong2 *ptr, ulonglong2 value) { asm ("st.global.wb.v2.u64 [%0], {%1,%2};" :: __LDG_PTR (ptr), "l"(value.x), "l"(value.y) : "memory"); }
|
| 404 |
+
|
| 405 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(float *ptr, float value) { asm ("st.global.wb.f32 [%0], %1;" :: __LDG_PTR (ptr), "f"(value) : "memory"); }
|
| 406 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(double *ptr, double value) { asm ("st.global.wb.f64 [%0], %1;" :: __LDG_PTR (ptr), "d"(value) : "memory"); }
|
| 407 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(float2 *ptr, float2 value) { asm ("st.global.wb.v2.f32 [%0], {%1,%2};" :: __LDG_PTR (ptr), "f"(value.x), "f"(value.y) : "memory"); }
|
| 408 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(float4 *ptr, float4 value) { asm ("st.global.wb.v4.f32 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "f"(value.x), "f"(value.y), "f"(value.z), "f"(value.w) : "memory"); }
|
| 409 |
+
__SM_32_INTRINSICS_DECL__ void __stwb(double2 *ptr, double2 value) { asm ("st.global.wb.v2.f64 [%0], {%1,%2};" :: __LDG_PTR (ptr), "d"(value.x), "d"(value.y) : "memory"); }
|
| 410 |
+
|
| 411 |
+
/******************************************************************************
|
| 412 |
+
* __stcg *
|
| 413 |
+
******************************************************************************/
|
| 414 |
+
|
| 415 |
+
// Size of long is architecture and OS specific.
|
| 416 |
+
#if defined(__LP64__) // 64 bits
|
| 417 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(long *ptr, long value) { asm ("st.global.cg.s64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 418 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(unsigned long *ptr, unsigned long value) { asm ("st.global.cg.u64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 419 |
+
#else // 32 bits
|
| 420 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(long *ptr, long value) { asm ("st.global.cg.s32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 421 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(unsigned long *ptr, unsigned long value) { asm ("st.global.cg.u32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 422 |
+
#endif
|
| 423 |
+
|
| 424 |
+
|
| 425 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(char *ptr, char value) { asm ("st.global.cg.s8 [%0], %1;" :: __LDG_PTR (ptr), "r"((int)value) : "memory"); }
|
| 426 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(signed char *ptr, signed char value) { asm ("st.global.cg.s8 [%0], %1;" :: __LDG_PTR (ptr), "r"((int)value) : "memory"); }
|
| 427 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(short *ptr, short value) { asm ("st.global.cg.s16 [%0], %1;" :: __LDG_PTR (ptr), "h"(value) : "memory"); }
|
| 428 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(int *ptr, int value) { asm ("st.global.cg.s32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 429 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(long long *ptr, long long value) { asm ("st.global.cg.s64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 430 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(char2 *ptr, char2 value) { const int x = value.x, y = value.y; asm ("st.global.cg.v2.s8 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(x), "r"(y) : "memory"); }
|
| 431 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(char4 *ptr, char4 value) { const int x = value.x, y = value.y, z = value.z, w = value.w; asm ("st.global.cg.v4.s8 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(x), "r"(y), "r"(z), "r"(w) : "memory"); }
|
| 432 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(short2 *ptr, short2 value) { asm ("st.global.cg.v2.s16 [%0], {%1,%2};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y) : "memory"); }
|
| 433 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(short4 *ptr, short4 value) { asm ("st.global.cg.v4.s16 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y), "h"(value.z), "h"(value.w) : "memory"); }
|
| 434 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(int2 *ptr, int2 value) { asm ("st.global.cg.v2.s32 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y) : "memory"); }
|
| 435 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(int4 *ptr, int4 value) { asm ("st.global.cg.v4.s32 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y), "r"(value.z), "r"(value.w) : "memory"); }
|
| 436 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(longlong2 *ptr, longlong2 value) { asm ("st.global.cg.v2.s64 [%0], {%1,%2};" :: __LDG_PTR (ptr), "l"(value.x), "l"(value.y) : "memory"); }
|
| 437 |
+
|
| 438 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(unsigned char *ptr, unsigned char value) { asm ("st.global.cg.u8 [%0], %1;" :: __LDG_PTR (ptr), "r"((int)value) : "memory"); }
|
| 439 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(unsigned short *ptr, unsigned short value) { asm ("st.global.cg.u16 [%0], %1;" :: __LDG_PTR (ptr), "h"(value) : "memory"); }
|
| 440 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(unsigned int *ptr, unsigned int value) { asm ("st.global.cg.u32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 441 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(unsigned long long *ptr, unsigned long long value) { asm ("st.global.cg.u64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 442 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(uchar2 *ptr, uchar2 value) { const int x = value.x, y = value.y; asm ("st.global.cg.v2.u8 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(x), "r"(y) : "memory"); }
|
| 443 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(uchar4 *ptr, uchar4 value) { const int x = value.x, y = value.y, z = value.z, w = value.w; asm ("st.global.cg.v4.u8 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(x), "r"(y), "r"(z), "r"(w) : "memory"); }
|
| 444 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(ushort2 *ptr, ushort2 value) { asm ("st.global.cg.v2.u16 [%0], {%1,%2};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y) : "memory"); }
|
| 445 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(ushort4 *ptr, ushort4 value) { asm ("st.global.cg.v4.u16 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y), "h"(value.z), "h"(value.w) : "memory"); }
|
| 446 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(uint2 *ptr, uint2 value) { asm ("st.global.cg.v2.u32 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y) : "memory"); }
|
| 447 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(uint4 *ptr, uint4 value) { asm ("st.global.cg.v4.u32 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y), "r"(value.z), "r"(value.w) : "memory"); }
|
| 448 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(ulonglong2 *ptr, ulonglong2 value) { asm ("st.global.cg.v2.u64 [%0], {%1,%2};" :: __LDG_PTR (ptr), "l"(value.x), "l"(value.y) : "memory"); }
|
| 449 |
+
|
| 450 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(float *ptr, float value) { asm ("st.global.cg.f32 [%0], %1;" :: __LDG_PTR (ptr), "f"(value) : "memory"); }
|
| 451 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(double *ptr, double value) { asm ("st.global.cg.f64 [%0], %1;" :: __LDG_PTR (ptr), "d"(value) : "memory"); }
|
| 452 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(float2 *ptr, float2 value) { asm ("st.global.cg.v2.f32 [%0], {%1,%2};" :: __LDG_PTR (ptr), "f"(value.x), "f"(value.y) : "memory"); }
|
| 453 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(float4 *ptr, float4 value) { asm ("st.global.cg.v4.f32 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "f"(value.x), "f"(value.y), "f"(value.z), "f"(value.w) : "memory"); }
|
| 454 |
+
__SM_32_INTRINSICS_DECL__ void __stcg(double2 *ptr, double2 value) { asm ("st.global.cg.v2.f64 [%0], {%1,%2};" :: __LDG_PTR (ptr), "d"(value.x), "d"(value.y) : "memory"); }
|
| 455 |
+
|
| 456 |
+
/******************************************************************************
|
| 457 |
+
* __stcs *
|
| 458 |
+
******************************************************************************/
|
| 459 |
+
|
| 460 |
+
// Size of long is architecture and OS specific.
|
| 461 |
+
#if defined(__LP64__) // 64 bits
|
| 462 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(long *ptr, long value) { asm ("st.global.cs.s64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 463 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(unsigned long *ptr, unsigned long value) { asm ("st.global.cs.u64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 464 |
+
#else // 32 bits
|
| 465 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(long *ptr, long value) { asm ("st.global.cs.s32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 466 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(unsigned long *ptr, unsigned long value) { asm ("st.global.cs.u32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 467 |
+
#endif
|
| 468 |
+
|
| 469 |
+
|
| 470 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(char *ptr, char value) { asm ("st.global.cs.s8 [%0], %1;" :: __LDG_PTR (ptr), "r"((int)value) : "memory"); }
|
| 471 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(signed char *ptr, signed char value) { asm ("st.global.cs.s8 [%0], %1;" :: __LDG_PTR (ptr), "r"((int)value) : "memory"); }
|
| 472 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(short *ptr, short value) { asm ("st.global.cs.s16 [%0], %1;" :: __LDG_PTR (ptr), "h"(value) : "memory"); }
|
| 473 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(int *ptr, int value) { asm ("st.global.cs.s32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 474 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(long long *ptr, long long value) { asm ("st.global.cs.s64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 475 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(char2 *ptr, char2 value) { const int x = value.x, y = value.y; asm ("st.global.cs.v2.s8 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(x), "r"(y) : "memory"); }
|
| 476 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(char4 *ptr, char4 value) { const int x = value.x, y = value.y, z = value.z, w = value.w; asm ("st.global.cs.v4.s8 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(x), "r"(y), "r"(z), "r"(w) : "memory"); }
|
| 477 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(short2 *ptr, short2 value) { asm ("st.global.cs.v2.s16 [%0], {%1,%2};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y) : "memory"); }
|
| 478 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(short4 *ptr, short4 value) { asm ("st.global.cs.v4.s16 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y), "h"(value.z), "h"(value.w) : "memory"); }
|
| 479 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(int2 *ptr, int2 value) { asm ("st.global.cs.v2.s32 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y) : "memory"); }
|
| 480 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(int4 *ptr, int4 value) { asm ("st.global.cs.v4.s32 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y), "r"(value.z), "r"(value.w) : "memory"); }
|
| 481 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(longlong2 *ptr, longlong2 value) { asm ("st.global.cs.v2.s64 [%0], {%1,%2};" :: __LDG_PTR (ptr), "l"(value.x), "l"(value.y) : "memory"); }
|
| 482 |
+
|
| 483 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(unsigned char *ptr, unsigned char value) { asm ("st.global.cs.u8 [%0], %1;" :: __LDG_PTR (ptr), "r"((int)value) : "memory"); }
|
| 484 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(unsigned short *ptr, unsigned short value) { asm ("st.global.cs.u16 [%0], %1;" :: __LDG_PTR (ptr), "h"(value) : "memory"); }
|
| 485 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(unsigned int *ptr, unsigned int value) { asm ("st.global.cs.u32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 486 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(unsigned long long *ptr, unsigned long long value) { asm ("st.global.cs.u64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 487 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(uchar2 *ptr, uchar2 value) { const int x = value.x, y = value.y; asm ("st.global.cs.v2.u8 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(x), "r"(y) : "memory"); }
|
| 488 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(uchar4 *ptr, uchar4 value) { const int x = value.x, y = value.y, z = value.z, w = value.w; asm ("st.global.cs.v4.u8 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(x), "r"(y), "r"(z), "r"(w) : "memory"); }
|
| 489 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(ushort2 *ptr, ushort2 value) { asm ("st.global.cs.v2.u16 [%0], {%1,%2};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y) : "memory"); }
|
| 490 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(ushort4 *ptr, ushort4 value) { asm ("st.global.cs.v4.u16 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y), "h"(value.z), "h"(value.w) : "memory"); }
|
| 491 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(uint2 *ptr, uint2 value) { asm ("st.global.cs.v2.u32 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y) : "memory"); }
|
| 492 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(uint4 *ptr, uint4 value) { asm ("st.global.cs.v4.u32 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y), "r"(value.z), "r"(value.w) : "memory"); }
|
| 493 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(ulonglong2 *ptr, ulonglong2 value) { asm ("st.global.cs.v2.u64 [%0], {%1,%2};" :: __LDG_PTR (ptr), "l"(value.x), "l"(value.y) : "memory"); }
|
| 494 |
+
|
| 495 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(float *ptr, float value) { asm ("st.global.cs.f32 [%0], %1;" :: __LDG_PTR (ptr), "f"(value) : "memory"); }
|
| 496 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(double *ptr, double value) { asm ("st.global.cs.f64 [%0], %1;" :: __LDG_PTR (ptr), "d"(value) : "memory"); }
|
| 497 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(float2 *ptr, float2 value) { asm ("st.global.cs.v2.f32 [%0], {%1,%2};" :: __LDG_PTR (ptr), "f"(value.x), "f"(value.y) : "memory"); }
|
| 498 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(float4 *ptr, float4 value) { asm ("st.global.cs.v4.f32 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "f"(value.x), "f"(value.y), "f"(value.z), "f"(value.w) : "memory"); }
|
| 499 |
+
__SM_32_INTRINSICS_DECL__ void __stcs(double2 *ptr, double2 value) { asm ("st.global.cs.v2.f64 [%0], {%1,%2};" :: __LDG_PTR (ptr), "d"(value.x), "d"(value.y) : "memory"); }
|
| 500 |
+
|
| 501 |
+
/******************************************************************************
|
| 502 |
+
* __stwt *
|
| 503 |
+
******************************************************************************/
|
| 504 |
+
|
| 505 |
+
// Size of long is architecture and OS specific.
|
| 506 |
+
#if defined(__LP64__) // 64 bits
|
| 507 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(long *ptr, long value) { asm ("st.global.wt.s64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 508 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(unsigned long *ptr, unsigned long value) { asm ("st.global.wt.u64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 509 |
+
#else // 32 bits
|
| 510 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(long *ptr, long value) { asm ("st.global.wt.s32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 511 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(unsigned long *ptr, unsigned long value) { asm ("st.global.wt.u32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 512 |
+
#endif
|
| 513 |
+
|
| 514 |
+
|
| 515 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(char *ptr, char value) { asm ("st.global.wt.s8 [%0], %1;" :: __LDG_PTR (ptr), "r"((int)value) : "memory"); }
|
| 516 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(signed char *ptr, signed char value) { asm ("st.global.wt.s8 [%0], %1;" :: __LDG_PTR (ptr), "r"((int)value) : "memory"); }
|
| 517 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(short *ptr, short value) { asm ("st.global.wt.s16 [%0], %1;" :: __LDG_PTR (ptr), "h"(value) : "memory"); }
|
| 518 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(int *ptr, int value) { asm ("st.global.wt.s32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 519 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(long long *ptr, long long value) { asm ("st.global.wt.s64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 520 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(char2 *ptr, char2 value) { const int x = value.x, y = value.y; asm ("st.global.wt.v2.s8 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(x), "r"(y) : "memory"); }
|
| 521 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(char4 *ptr, char4 value) { const int x = value.x, y = value.y, z = value.z, w = value.w; asm ("st.global.wt.v4.s8 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(x), "r"(y), "r"(z), "r"(w) : "memory"); }
|
| 522 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(short2 *ptr, short2 value) { asm ("st.global.wt.v2.s16 [%0], {%1,%2};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y) : "memory"); }
|
| 523 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(short4 *ptr, short4 value) { asm ("st.global.wt.v4.s16 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y), "h"(value.z), "h"(value.w) : "memory"); }
|
| 524 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(int2 *ptr, int2 value) { asm ("st.global.wt.v2.s32 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y) : "memory"); }
|
| 525 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(int4 *ptr, int4 value) { asm ("st.global.wt.v4.s32 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y), "r"(value.z), "r"(value.w) : "memory"); }
|
| 526 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(longlong2 *ptr, longlong2 value) { asm ("st.global.wt.v2.s64 [%0], {%1,%2};" :: __LDG_PTR (ptr), "l"(value.x), "l"(value.y) : "memory"); }
|
| 527 |
+
|
| 528 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(unsigned char *ptr, unsigned char value) { asm ("st.global.wt.u8 [%0], %1;" :: __LDG_PTR (ptr), "r"((int)value) : "memory"); }
|
| 529 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(unsigned short *ptr, unsigned short value) { asm ("st.global.wt.u16 [%0], %1;" :: __LDG_PTR (ptr), "h"(value) : "memory"); }
|
| 530 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(unsigned int *ptr, unsigned int value) { asm ("st.global.wt.u32 [%0], %1;" :: __LDG_PTR (ptr), "r"(value) : "memory"); }
|
| 531 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(unsigned long long *ptr, unsigned long long value) { asm ("st.global.wt.u64 [%0], %1;" :: __LDG_PTR (ptr), "l"(value) : "memory"); }
|
| 532 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(uchar2 *ptr, uchar2 value) { const int x = value.x, y = value.y; asm ("st.global.wt.v2.u8 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(x), "r"(y) : "memory"); }
|
| 533 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(uchar4 *ptr, uchar4 value) { const int x = value.x, y = value.y, z = value.z, w = value.w; asm ("st.global.wt.v4.u8 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(x), "r"(y), "r"(z), "r"(w) : "memory"); }
|
| 534 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(ushort2 *ptr, ushort2 value) { asm ("st.global.wt.v2.u16 [%0], {%1,%2};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y) : "memory"); }
|
| 535 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(ushort4 *ptr, ushort4 value) { asm ("st.global.wt.v4.u16 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "h"(value.x), "h"(value.y), "h"(value.z), "h"(value.w) : "memory"); }
|
| 536 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(uint2 *ptr, uint2 value) { asm ("st.global.wt.v2.u32 [%0], {%1,%2};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y) : "memory"); }
|
| 537 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(uint4 *ptr, uint4 value) { asm ("st.global.wt.v4.u32 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "r"(value.x), "r"(value.y), "r"(value.z), "r"(value.w) : "memory"); }
|
| 538 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(ulonglong2 *ptr, ulonglong2 value) { asm ("st.global.wt.v2.u64 [%0], {%1,%2};" :: __LDG_PTR (ptr), "l"(value.x), "l"(value.y) : "memory"); }
|
| 539 |
+
|
| 540 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(float *ptr, float value) { asm ("st.global.wt.f32 [%0], %1;" :: __LDG_PTR (ptr), "f"(value) : "memory"); }
|
| 541 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(double *ptr, double value) { asm ("st.global.wt.f64 [%0], %1;" :: __LDG_PTR (ptr), "d"(value) : "memory"); }
|
| 542 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(float2 *ptr, float2 value) { asm ("st.global.wt.v2.f32 [%0], {%1,%2};" :: __LDG_PTR (ptr), "f"(value.x), "f"(value.y) : "memory"); }
|
| 543 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(float4 *ptr, float4 value) { asm ("st.global.wt.v4.f32 [%0], {%1,%2,%3,%4};" :: __LDG_PTR (ptr), "f"(value.x), "f"(value.y), "f"(value.z), "f"(value.w) : "memory"); }
|
| 544 |
+
__SM_32_INTRINSICS_DECL__ void __stwt(double2 *ptr, double2 value) { asm ("st.global.wt.v2.f64 [%0], {%1,%2};" :: __LDG_PTR (ptr), "d"(value.x), "d"(value.y) : "memory"); }
|
| 545 |
+
|
| 546 |
+
#undef __LDG_PTR
|
| 547 |
+
|
| 548 |
+
|
| 549 |
+
// SHF is the "funnel shift" operation - an accelerated left/right shift with carry
|
| 550 |
+
// operating on 64-bit quantities, which are concatenations of two 32-bit registers.
|
| 551 |
+
|
| 552 |
+
// This shifts [b:a] left by "shift" bits, returning the most significant bits of the result.
|
| 553 |
+
__SM_32_INTRINSICS_DECL__ unsigned int __funnelshift_l(unsigned int lo, unsigned int hi, unsigned int shift)
|
| 554 |
+
{
|
| 555 |
+
unsigned int ret;
|
| 556 |
+
asm volatile ("shf.l.wrap.b32 %0, %1, %2, %3;" : "=r"(ret) : "r"(lo), "r"(hi), "r"(shift));
|
| 557 |
+
return ret;
|
| 558 |
+
}
|
| 559 |
+
__SM_32_INTRINSICS_DECL__ unsigned int __funnelshift_lc(unsigned int lo, unsigned int hi, unsigned int shift)
|
| 560 |
+
{
|
| 561 |
+
unsigned int ret;
|
| 562 |
+
asm volatile ("shf.l.clamp.b32 %0, %1, %2, %3;" : "=r"(ret) : "r"(lo), "r"(hi), "r"(shift));
|
| 563 |
+
return ret;
|
| 564 |
+
}
|
| 565 |
+
|
| 566 |
+
// This shifts [b:a] right by "shift" bits, returning the least significant bits of the result.
|
| 567 |
+
__SM_32_INTRINSICS_DECL__ unsigned int __funnelshift_r(unsigned int lo, unsigned int hi, unsigned int shift)
|
| 568 |
+
{
|
| 569 |
+
unsigned int ret;
|
| 570 |
+
asm volatile ("shf.r.wrap.b32 %0, %1, %2, %3;" : "=r"(ret) : "r"(lo), "r"(hi), "r"(shift));
|
| 571 |
+
return ret;
|
| 572 |
+
}
|
| 573 |
+
__SM_32_INTRINSICS_DECL__ unsigned int __funnelshift_rc(unsigned int lo, unsigned int hi, unsigned int shift)
|
| 574 |
+
{
|
| 575 |
+
unsigned int ret;
|
| 576 |
+
asm volatile ("shf.r.clamp.b32 %0, %1, %2, %3;" : "=r"(ret) : "r"(lo), "r"(hi), "r"(shift));
|
| 577 |
+
return ret;
|
| 578 |
+
}
|
| 579 |
+
|
| 580 |
+
|
| 581 |
+
#endif /* _NVHPC_CUDA || !__CUDA_ARCH__ || __CUDA_ARCH__ >= 320 */
|
| 582 |
+
|
| 583 |
+
#endif /* __cplusplus && __CUDACC__ */
|
| 584 |
+
|
| 585 |
+
#undef __SM_32_INTRINSICS_DECL__
|
| 586 |
+
|
| 587 |
+
#endif /* !__SM_32_INTRINSICS_HPP__ */
|
| 588 |
+
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_35_atomic_functions.h
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2012 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 35.235 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.35.235 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__SM_35_ATOMIC_FUNCTIONS_H__)
|
| 51 |
+
#define __SM_35_ATOMIC_FUNCTIONS_H__
|
| 52 |
+
|
| 53 |
+
/*******************************************************************************
|
| 54 |
+
* All sm_35 atomics are supported by sm_32 so simply include its header file *
|
| 55 |
+
*******************************************************************************/
|
| 56 |
+
#include "sm_32_atomic_functions.h"
|
| 57 |
+
|
| 58 |
+
#endif /* !__SM_35_ATOMIC_FUNCTIONS_H__ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_35_intrinsics.h
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
|
| 3 |
+
* Copyright 1993-2012 NVIDIA Corporation. All rights reserved.
|
| 4 |
+
|
| 5 |
+
*
|
| 6 |
+
|
| 7 |
+
* NOTICE TO LICENSEE:
|
| 8 |
+
|
| 9 |
+
*
|
| 10 |
+
|
| 11 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 12 |
+
|
| 13 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 14 |
+
|
| 15 |
+
* international Copyright laws.
|
| 16 |
+
|
| 17 |
+
*
|
| 18 |
+
|
| 19 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 20 |
+
|
| 21 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 22 |
+
|
| 23 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 24 |
+
|
| 25 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 26 |
+
|
| 27 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 28 |
+
|
| 29 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 30 |
+
|
| 31 |
+
* of the Licensed Deliverables to any third party without the express
|
| 32 |
+
|
| 33 |
+
* written consent of NVIDIA is prohibited.
|
| 34 |
+
|
| 35 |
+
*
|
| 36 |
+
|
| 37 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 38 |
+
|
| 39 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 40 |
+
|
| 41 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 42 |
+
|
| 43 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 44 |
+
|
| 45 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 46 |
+
|
| 47 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 48 |
+
|
| 49 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 50 |
+
|
| 51 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 52 |
+
|
| 53 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 54 |
+
|
| 55 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 56 |
+
|
| 57 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 58 |
+
|
| 59 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 60 |
+
|
| 61 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 62 |
+
|
| 63 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 64 |
+
|
| 65 |
+
*
|
| 66 |
+
|
| 67 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 68 |
+
|
| 69 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 70 |
+
|
| 71 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 72 |
+
|
| 73 |
+
* computer software documentation" as such terms are used in 48
|
| 74 |
+
|
| 75 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 76 |
+
|
| 77 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 78 |
+
|
| 79 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 80 |
+
|
| 81 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 82 |
+
|
| 83 |
+
* only those rights set forth herein.
|
| 84 |
+
|
| 85 |
+
*
|
| 86 |
+
|
| 87 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 88 |
+
|
| 89 |
+
* software must include, in the user documentation and internal
|
| 90 |
+
|
| 91 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 92 |
+
|
| 93 |
+
* Users Notice.
|
| 94 |
+
|
| 95 |
+
*/
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
#if !defined(__SM_35_INTRINSICS_H__)
|
| 100 |
+
|
| 101 |
+
#define __SM_35_INTRINSICS_H__
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
/**********************************************************************************
|
| 106 |
+
|
| 107 |
+
* All sm_35 intrinsics are supported by sm_32 so simply include its header file *
|
| 108 |
+
|
| 109 |
+
**********************************************************************************/
|
| 110 |
+
|
| 111 |
+
#include "sm_32_intrinsics.h"
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
#endif /* !__SM_35_INTRINSICS_H__ */
|
| 116 |
+
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/sm_60_atomic_functions.hpp
ADDED
|
@@ -0,0 +1,527 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2014 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__SM_60_ATOMIC_FUNCTIONS_HPP__)
|
| 51 |
+
#define __SM_60_ATOMIC_FUNCTIONS_HPP__
|
| 52 |
+
|
| 53 |
+
#if defined(__CUDACC_RTC__)
|
| 54 |
+
#define __SM_60_ATOMIC_FUNCTIONS_DECL__ __device__
|
| 55 |
+
#else /* __CUDACC_RTC__ */
|
| 56 |
+
#define __SM_60_ATOMIC_FUNCTIONS_DECL__ static __inline__ __device__
|
| 57 |
+
#endif /* __CUDACC_RTC__ */
|
| 58 |
+
|
| 59 |
+
#if defined(__cplusplus) && defined(__CUDACC__)
|
| 60 |
+
|
| 61 |
+
#if defined(_NVHPC_CUDA) || !defined(__CUDA_ARCH__) || __CUDA_ARCH__ >= 600
|
| 62 |
+
|
| 63 |
+
/*******************************************************************************
|
| 64 |
+
* *
|
| 65 |
+
* *
|
| 66 |
+
* *
|
| 67 |
+
*******************************************************************************/
|
| 68 |
+
|
| 69 |
+
#include "cuda_runtime_api.h"
|
| 70 |
+
|
| 71 |
+
/*******************************************************************************
|
| 72 |
+
* *
|
| 73 |
+
* *
|
| 74 |
+
* *
|
| 75 |
+
*******************************************************************************/
|
| 76 |
+
|
| 77 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__ double atomicAdd(double *address, double val)
|
| 78 |
+
{
|
| 79 |
+
return __dAtomicAdd(address, val);
|
| 80 |
+
}
|
| 81 |
+
|
| 82 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 83 |
+
int atomicAdd_block(int *address, int val)
|
| 84 |
+
{
|
| 85 |
+
return __iAtomicAdd_block(address, val);
|
| 86 |
+
}
|
| 87 |
+
|
| 88 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 89 |
+
int atomicAdd_system(int *address, int val)
|
| 90 |
+
{
|
| 91 |
+
return __iAtomicAdd_system(address, val);
|
| 92 |
+
}
|
| 93 |
+
|
| 94 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 95 |
+
unsigned int atomicAdd_block(unsigned int *address, unsigned int val)
|
| 96 |
+
{
|
| 97 |
+
return __uAtomicAdd_block(address, val);
|
| 98 |
+
}
|
| 99 |
+
|
| 100 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 101 |
+
unsigned int atomicAdd_system(unsigned int *address, unsigned int val)
|
| 102 |
+
{
|
| 103 |
+
return __uAtomicAdd_system(address, val);
|
| 104 |
+
}
|
| 105 |
+
|
| 106 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 107 |
+
unsigned long long atomicAdd_block(unsigned long long *address, unsigned long long val)
|
| 108 |
+
{
|
| 109 |
+
return __ullAtomicAdd_block(address, val);
|
| 110 |
+
}
|
| 111 |
+
|
| 112 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 113 |
+
unsigned long long atomicAdd_system(unsigned long long *address, unsigned long long val)
|
| 114 |
+
{
|
| 115 |
+
return __ullAtomicAdd_system(address, val);
|
| 116 |
+
}
|
| 117 |
+
|
| 118 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 119 |
+
float atomicAdd_block(float *address, float val)
|
| 120 |
+
{
|
| 121 |
+
return __fAtomicAdd_block(address, val);
|
| 122 |
+
}
|
| 123 |
+
|
| 124 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 125 |
+
float atomicAdd_system(float *address, float val)
|
| 126 |
+
{
|
| 127 |
+
return __fAtomicAdd_system(address, val);
|
| 128 |
+
}
|
| 129 |
+
|
| 130 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 131 |
+
double atomicAdd_block(double *address, double val)
|
| 132 |
+
{
|
| 133 |
+
return __dAtomicAdd_block(address, val);
|
| 134 |
+
}
|
| 135 |
+
|
| 136 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 137 |
+
double atomicAdd_system(double *address, double val)
|
| 138 |
+
{
|
| 139 |
+
return __dAtomicAdd_system(address, val);
|
| 140 |
+
}
|
| 141 |
+
|
| 142 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 143 |
+
int atomicSub_block(int *address, int val)
|
| 144 |
+
{
|
| 145 |
+
return __iAtomicAdd_block(address, (unsigned int)-(int)val);
|
| 146 |
+
}
|
| 147 |
+
|
| 148 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 149 |
+
int atomicSub_system(int *address, int val)
|
| 150 |
+
{
|
| 151 |
+
return __iAtomicAdd_system(address, (unsigned int)-(int)val);
|
| 152 |
+
}
|
| 153 |
+
|
| 154 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 155 |
+
unsigned int atomicSub_block(unsigned int *address, unsigned int val)
|
| 156 |
+
{
|
| 157 |
+
return __uAtomicAdd_block(address, (unsigned int)-(int)val);
|
| 158 |
+
}
|
| 159 |
+
|
| 160 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 161 |
+
unsigned int atomicSub_system(unsigned int *address, unsigned int val)
|
| 162 |
+
{
|
| 163 |
+
return __uAtomicAdd_system(address, (unsigned int)-(int)val);
|
| 164 |
+
}
|
| 165 |
+
|
| 166 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 167 |
+
int atomicExch_block(int *address, int val)
|
| 168 |
+
{
|
| 169 |
+
return __iAtomicExch_block(address, val);
|
| 170 |
+
}
|
| 171 |
+
|
| 172 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 173 |
+
int atomicExch_system(int *address, int val)
|
| 174 |
+
{
|
| 175 |
+
return __iAtomicExch_system(address, val);
|
| 176 |
+
}
|
| 177 |
+
|
| 178 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 179 |
+
unsigned int atomicExch_block(unsigned int *address, unsigned int val)
|
| 180 |
+
{
|
| 181 |
+
return __uAtomicExch_block(address, val);
|
| 182 |
+
}
|
| 183 |
+
|
| 184 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 185 |
+
unsigned int atomicExch_system(unsigned int *address, unsigned int val)
|
| 186 |
+
{
|
| 187 |
+
return __uAtomicExch_system(address, val);
|
| 188 |
+
}
|
| 189 |
+
|
| 190 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 191 |
+
unsigned long long atomicExch_block(unsigned long long *address, unsigned long long val)
|
| 192 |
+
{
|
| 193 |
+
return __ullAtomicExch_block(address, val);
|
| 194 |
+
}
|
| 195 |
+
|
| 196 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 197 |
+
unsigned long long atomicExch_system(unsigned long long *address, unsigned long long val)
|
| 198 |
+
{
|
| 199 |
+
return __ullAtomicExch_system(address, val);
|
| 200 |
+
}
|
| 201 |
+
|
| 202 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 203 |
+
float atomicExch_block(float *address, float val)
|
| 204 |
+
{
|
| 205 |
+
return __fAtomicExch_block(address, val);
|
| 206 |
+
}
|
| 207 |
+
|
| 208 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 209 |
+
float atomicExch_system(float *address, float val)
|
| 210 |
+
{
|
| 211 |
+
return __fAtomicExch_system(address, val);
|
| 212 |
+
}
|
| 213 |
+
|
| 214 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 215 |
+
int atomicMin_block(int *address, int val)
|
| 216 |
+
{
|
| 217 |
+
return __iAtomicMin_block(address, val);
|
| 218 |
+
}
|
| 219 |
+
|
| 220 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 221 |
+
int atomicMin_system(int *address, int val)
|
| 222 |
+
{
|
| 223 |
+
return __iAtomicMin_system(address, val);
|
| 224 |
+
}
|
| 225 |
+
|
| 226 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 227 |
+
long long atomicMin_block(long long *address, long long val)
|
| 228 |
+
{
|
| 229 |
+
return __illAtomicMin_block(address, val);
|
| 230 |
+
}
|
| 231 |
+
|
| 232 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 233 |
+
long long atomicMin_system(long long *address, long long val)
|
| 234 |
+
{
|
| 235 |
+
return __illAtomicMin_system(address, val);
|
| 236 |
+
}
|
| 237 |
+
|
| 238 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 239 |
+
unsigned int atomicMin_block(unsigned int *address, unsigned int val)
|
| 240 |
+
{
|
| 241 |
+
return __uAtomicMin_block(address, val);
|
| 242 |
+
}
|
| 243 |
+
|
| 244 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 245 |
+
unsigned int atomicMin_system(unsigned int *address, unsigned int val)
|
| 246 |
+
{
|
| 247 |
+
return __uAtomicMin_system(address, val);
|
| 248 |
+
}
|
| 249 |
+
|
| 250 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 251 |
+
unsigned long long atomicMin_block(unsigned long long *address, unsigned long long val)
|
| 252 |
+
{
|
| 253 |
+
return __ullAtomicMin_block(address, val);
|
| 254 |
+
}
|
| 255 |
+
|
| 256 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 257 |
+
unsigned long long atomicMin_system(unsigned long long *address, unsigned long long val)
|
| 258 |
+
{
|
| 259 |
+
return __ullAtomicMin_system(address, val);
|
| 260 |
+
}
|
| 261 |
+
|
| 262 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 263 |
+
int atomicMax_block(int *address, int val)
|
| 264 |
+
{
|
| 265 |
+
return __iAtomicMax_block(address, val);
|
| 266 |
+
}
|
| 267 |
+
|
| 268 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 269 |
+
int atomicMax_system(int *address, int val)
|
| 270 |
+
{
|
| 271 |
+
return __iAtomicMax_system(address, val);
|
| 272 |
+
}
|
| 273 |
+
|
| 274 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 275 |
+
long long atomicMax_block(long long *address, long long val)
|
| 276 |
+
{
|
| 277 |
+
return __illAtomicMax_block(address, val);
|
| 278 |
+
}
|
| 279 |
+
|
| 280 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 281 |
+
long long atomicMax_system(long long *address, long long val)
|
| 282 |
+
{
|
| 283 |
+
return __illAtomicMax_system(address, val);
|
| 284 |
+
}
|
| 285 |
+
|
| 286 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 287 |
+
unsigned int atomicMax_block(unsigned int *address, unsigned int val)
|
| 288 |
+
{
|
| 289 |
+
return __uAtomicMax_block(address, val);
|
| 290 |
+
}
|
| 291 |
+
|
| 292 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 293 |
+
unsigned int atomicMax_system(unsigned int *address, unsigned int val)
|
| 294 |
+
{
|
| 295 |
+
return __uAtomicMax_system(address, val);
|
| 296 |
+
}
|
| 297 |
+
|
| 298 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 299 |
+
unsigned long long atomicMax_block(unsigned long long *address, unsigned long long val)
|
| 300 |
+
{
|
| 301 |
+
return __ullAtomicMax_block(address, val);
|
| 302 |
+
}
|
| 303 |
+
|
| 304 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 305 |
+
unsigned long long atomicMax_system(unsigned long long *address, unsigned long long val)
|
| 306 |
+
{
|
| 307 |
+
return __ullAtomicMax_system(address, val);
|
| 308 |
+
}
|
| 309 |
+
|
| 310 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 311 |
+
unsigned int atomicInc_block(unsigned int *address, unsigned int val)
|
| 312 |
+
{
|
| 313 |
+
return __uAtomicInc_block(address, val);
|
| 314 |
+
}
|
| 315 |
+
|
| 316 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 317 |
+
unsigned int atomicInc_system(unsigned int *address, unsigned int val)
|
| 318 |
+
{
|
| 319 |
+
return __uAtomicInc_system(address, val);
|
| 320 |
+
}
|
| 321 |
+
|
| 322 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 323 |
+
unsigned int atomicDec_block(unsigned int *address, unsigned int val)
|
| 324 |
+
{
|
| 325 |
+
return __uAtomicDec_block(address, val);
|
| 326 |
+
}
|
| 327 |
+
|
| 328 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 329 |
+
unsigned int atomicDec_system(unsigned int *address, unsigned int val)
|
| 330 |
+
{
|
| 331 |
+
return __uAtomicDec_system(address, val);
|
| 332 |
+
}
|
| 333 |
+
|
| 334 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 335 |
+
int atomicCAS_block(int *address, int compare, int val)
|
| 336 |
+
{
|
| 337 |
+
return __iAtomicCAS_block(address, compare, val);
|
| 338 |
+
}
|
| 339 |
+
|
| 340 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 341 |
+
int atomicCAS_system(int *address, int compare, int val)
|
| 342 |
+
{
|
| 343 |
+
return __iAtomicCAS_system(address, compare, val);
|
| 344 |
+
}
|
| 345 |
+
|
| 346 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 347 |
+
unsigned int atomicCAS_block(unsigned int *address, unsigned int compare,
|
| 348 |
+
unsigned int val)
|
| 349 |
+
{
|
| 350 |
+
return __uAtomicCAS_block(address, compare, val);
|
| 351 |
+
}
|
| 352 |
+
|
| 353 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 354 |
+
unsigned int atomicCAS_system(unsigned int *address, unsigned int compare,
|
| 355 |
+
unsigned int val)
|
| 356 |
+
{
|
| 357 |
+
return __uAtomicCAS_system(address, compare, val);
|
| 358 |
+
}
|
| 359 |
+
|
| 360 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 361 |
+
unsigned long long int atomicCAS_block(unsigned long long int *address,
|
| 362 |
+
unsigned long long int compare,
|
| 363 |
+
unsigned long long int val)
|
| 364 |
+
{
|
| 365 |
+
return __ullAtomicCAS_block(address, compare, val);
|
| 366 |
+
}
|
| 367 |
+
|
| 368 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 369 |
+
unsigned long long int atomicCAS_system(unsigned long long int *address,
|
| 370 |
+
unsigned long long int compare,
|
| 371 |
+
unsigned long long int val)
|
| 372 |
+
{
|
| 373 |
+
return __ullAtomicCAS_system(address, compare, val);
|
| 374 |
+
}
|
| 375 |
+
|
| 376 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 377 |
+
int atomicAnd_block(int *address, int val)
|
| 378 |
+
{
|
| 379 |
+
return __iAtomicAnd_block(address, val);
|
| 380 |
+
}
|
| 381 |
+
|
| 382 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 383 |
+
int atomicAnd_system(int *address, int val)
|
| 384 |
+
{
|
| 385 |
+
return __iAtomicAnd_system(address, val);
|
| 386 |
+
}
|
| 387 |
+
|
| 388 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 389 |
+
long long atomicAnd_block(long long *address, long long val)
|
| 390 |
+
{
|
| 391 |
+
return __llAtomicAnd_block(address, val);
|
| 392 |
+
}
|
| 393 |
+
|
| 394 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 395 |
+
long long atomicAnd_system(long long *address, long long val)
|
| 396 |
+
{
|
| 397 |
+
return __llAtomicAnd_system(address, val);
|
| 398 |
+
}
|
| 399 |
+
|
| 400 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 401 |
+
unsigned int atomicAnd_block(unsigned int *address, unsigned int val)
|
| 402 |
+
{
|
| 403 |
+
return __uAtomicAnd_block(address, val);
|
| 404 |
+
}
|
| 405 |
+
|
| 406 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 407 |
+
unsigned int atomicAnd_system(unsigned int *address, unsigned int val)
|
| 408 |
+
{
|
| 409 |
+
return __uAtomicAnd_system(address, val);
|
| 410 |
+
}
|
| 411 |
+
|
| 412 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 413 |
+
unsigned long long atomicAnd_block(unsigned long long *address, unsigned long long val)
|
| 414 |
+
{
|
| 415 |
+
return __ullAtomicAnd_block(address, val);
|
| 416 |
+
}
|
| 417 |
+
|
| 418 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 419 |
+
unsigned long long atomicAnd_system(unsigned long long *address, unsigned long long val)
|
| 420 |
+
{
|
| 421 |
+
return __ullAtomicAnd_system(address, val);
|
| 422 |
+
}
|
| 423 |
+
|
| 424 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 425 |
+
int atomicOr_block(int *address, int val)
|
| 426 |
+
{
|
| 427 |
+
return __iAtomicOr_block(address, val);
|
| 428 |
+
}
|
| 429 |
+
|
| 430 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 431 |
+
int atomicOr_system(int *address, int val)
|
| 432 |
+
{
|
| 433 |
+
return __iAtomicOr_system(address, val);
|
| 434 |
+
}
|
| 435 |
+
|
| 436 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 437 |
+
long long atomicOr_block(long long *address, long long val)
|
| 438 |
+
{
|
| 439 |
+
return __llAtomicOr_block(address, val);
|
| 440 |
+
}
|
| 441 |
+
|
| 442 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 443 |
+
long long atomicOr_system(long long *address, long long val)
|
| 444 |
+
{
|
| 445 |
+
return __llAtomicOr_system(address, val);
|
| 446 |
+
}
|
| 447 |
+
|
| 448 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 449 |
+
unsigned int atomicOr_block(unsigned int *address, unsigned int val)
|
| 450 |
+
{
|
| 451 |
+
return __uAtomicOr_block(address, val);
|
| 452 |
+
}
|
| 453 |
+
|
| 454 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 455 |
+
unsigned int atomicOr_system(unsigned int *address, unsigned int val)
|
| 456 |
+
{
|
| 457 |
+
return __uAtomicOr_system(address, val);
|
| 458 |
+
}
|
| 459 |
+
|
| 460 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 461 |
+
unsigned long long atomicOr_block(unsigned long long *address, unsigned long long val)
|
| 462 |
+
{
|
| 463 |
+
return __ullAtomicOr_block(address, val);
|
| 464 |
+
}
|
| 465 |
+
|
| 466 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 467 |
+
unsigned long long atomicOr_system(unsigned long long *address, unsigned long long val)
|
| 468 |
+
{
|
| 469 |
+
return __ullAtomicOr_system(address, val);
|
| 470 |
+
}
|
| 471 |
+
|
| 472 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 473 |
+
int atomicXor_block(int *address, int val)
|
| 474 |
+
{
|
| 475 |
+
return __iAtomicXor_block(address, val);
|
| 476 |
+
}
|
| 477 |
+
|
| 478 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 479 |
+
int atomicXor_system(int *address, int val)
|
| 480 |
+
{
|
| 481 |
+
return __iAtomicXor_system(address, val);
|
| 482 |
+
}
|
| 483 |
+
|
| 484 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 485 |
+
long long atomicXor_block(long long *address, long long val)
|
| 486 |
+
{
|
| 487 |
+
return __llAtomicXor_block(address, val);
|
| 488 |
+
}
|
| 489 |
+
|
| 490 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 491 |
+
long long atomicXor_system(long long *address, long long val)
|
| 492 |
+
{
|
| 493 |
+
return __llAtomicXor_system(address, val);
|
| 494 |
+
}
|
| 495 |
+
|
| 496 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 497 |
+
unsigned int atomicXor_block(unsigned int *address, unsigned int val)
|
| 498 |
+
{
|
| 499 |
+
return __uAtomicXor_block(address, val);
|
| 500 |
+
}
|
| 501 |
+
|
| 502 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 503 |
+
unsigned int atomicXor_system(unsigned int *address, unsigned int val)
|
| 504 |
+
{
|
| 505 |
+
return __uAtomicXor_system(address, val);
|
| 506 |
+
}
|
| 507 |
+
|
| 508 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 509 |
+
unsigned long long atomicXor_block(unsigned long long *address, unsigned long long val)
|
| 510 |
+
{
|
| 511 |
+
return __ullAtomicXor_block(address, val);
|
| 512 |
+
}
|
| 513 |
+
|
| 514 |
+
__SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 515 |
+
unsigned long long atomicXor_system(unsigned long long *address, unsigned long long val)
|
| 516 |
+
{
|
| 517 |
+
return __ullAtomicXor_system(address, val);
|
| 518 |
+
}
|
| 519 |
+
|
| 520 |
+
#endif /* !__CUDA_ARCH__ || __CUDA_ARCH__ >= 600 */
|
| 521 |
+
|
| 522 |
+
#endif /* __cplusplus && __CUDACC__ */
|
| 523 |
+
|
| 524 |
+
#undef __SM_60_ATOMIC_FUNCTIONS_DECL__
|
| 525 |
+
|
| 526 |
+
#endif /* !__SM_60_ATOMIC_FUNCTIONS_HPP__ */
|
| 527 |
+
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/texture_fetch_functions.h
ADDED
|
@@ -0,0 +1,223 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2022 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__TEXTURE_FETCH_FUNCTIONS_H__)
|
| 51 |
+
#define __TEXTURE_FETCH_FUNCTIONS_H__
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
#if defined(__cplusplus) && defined(__CUDACC__)
|
| 55 |
+
|
| 56 |
+
/*******************************************************************************
|
| 57 |
+
* *
|
| 58 |
+
* *
|
| 59 |
+
* *
|
| 60 |
+
*******************************************************************************/
|
| 61 |
+
|
| 62 |
+
#include "cuda_runtime_api.h"
|
| 63 |
+
#include "cuda_texture_types.h"
|
| 64 |
+
|
| 65 |
+
#if defined(_WIN32)
|
| 66 |
+
# define __DEPRECATED__ __declspec(deprecated)
|
| 67 |
+
#else
|
| 68 |
+
# define __DEPRECATED__ __attribute__((deprecated))
|
| 69 |
+
#endif
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
template <typename T>
|
| 73 |
+
struct __nv_tex_rmet_ret { };
|
| 74 |
+
|
| 75 |
+
template<> struct __nv_tex_rmet_ret<char> { typedef char type; };
|
| 76 |
+
template<> struct __nv_tex_rmet_ret<signed char> { typedef signed char type; };
|
| 77 |
+
template<> struct __nv_tex_rmet_ret<unsigned char> { typedef unsigned char type; };
|
| 78 |
+
template<> struct __nv_tex_rmet_ret<char1> { typedef char1 type; };
|
| 79 |
+
template<> struct __nv_tex_rmet_ret<uchar1> { typedef uchar1 type; };
|
| 80 |
+
template<> struct __nv_tex_rmet_ret<char2> { typedef char2 type; };
|
| 81 |
+
template<> struct __nv_tex_rmet_ret<uchar2> { typedef uchar2 type; };
|
| 82 |
+
template<> struct __nv_tex_rmet_ret<char4> { typedef char4 type; };
|
| 83 |
+
template<> struct __nv_tex_rmet_ret<uchar4> { typedef uchar4 type; };
|
| 84 |
+
|
| 85 |
+
template<> struct __nv_tex_rmet_ret<short> { typedef short type; };
|
| 86 |
+
template<> struct __nv_tex_rmet_ret<unsigned short> { typedef unsigned short type; };
|
| 87 |
+
template<> struct __nv_tex_rmet_ret<short1> { typedef short1 type; };
|
| 88 |
+
template<> struct __nv_tex_rmet_ret<ushort1> { typedef ushort1 type; };
|
| 89 |
+
template<> struct __nv_tex_rmet_ret<short2> { typedef short2 type; };
|
| 90 |
+
template<> struct __nv_tex_rmet_ret<ushort2> { typedef ushort2 type; };
|
| 91 |
+
template<> struct __nv_tex_rmet_ret<short4> { typedef short4 type; };
|
| 92 |
+
template<> struct __nv_tex_rmet_ret<ushort4> { typedef ushort4 type; };
|
| 93 |
+
|
| 94 |
+
template<> struct __nv_tex_rmet_ret<int> { typedef int type; };
|
| 95 |
+
template<> struct __nv_tex_rmet_ret<unsigned int> { typedef unsigned int type; };
|
| 96 |
+
template<> struct __nv_tex_rmet_ret<int1> { typedef int1 type; };
|
| 97 |
+
template<> struct __nv_tex_rmet_ret<uint1> { typedef uint1 type; };
|
| 98 |
+
template<> struct __nv_tex_rmet_ret<int2> { typedef int2 type; };
|
| 99 |
+
template<> struct __nv_tex_rmet_ret<uint2> { typedef uint2 type; };
|
| 100 |
+
template<> struct __nv_tex_rmet_ret<int4> { typedef int4 type; };
|
| 101 |
+
template<> struct __nv_tex_rmet_ret<uint4> { typedef uint4 type; };
|
| 102 |
+
|
| 103 |
+
#if !defined(__LP64__)
|
| 104 |
+
template<> struct __nv_tex_rmet_ret<long> { typedef long type; };
|
| 105 |
+
template<> struct __nv_tex_rmet_ret<unsigned long> { typedef unsigned long type; };
|
| 106 |
+
template<> struct __nv_tex_rmet_ret<long1> { typedef long1 type; };
|
| 107 |
+
template<> struct __nv_tex_rmet_ret<ulong1> { typedef ulong1 type; };
|
| 108 |
+
template<> struct __nv_tex_rmet_ret<long2> { typedef long2 type; };
|
| 109 |
+
template<> struct __nv_tex_rmet_ret<ulong2> { typedef ulong2 type; };
|
| 110 |
+
template<> struct __nv_tex_rmet_ret<long4> { typedef long4 type; };
|
| 111 |
+
template<> struct __nv_tex_rmet_ret<ulong4> { typedef ulong4 type; };
|
| 112 |
+
#endif /* !__LP64__ */
|
| 113 |
+
template<> struct __nv_tex_rmet_ret<float> { typedef float type; };
|
| 114 |
+
template<> struct __nv_tex_rmet_ret<float1> { typedef float1 type; };
|
| 115 |
+
template<> struct __nv_tex_rmet_ret<float2> { typedef float2 type; };
|
| 116 |
+
template<> struct __nv_tex_rmet_ret<float4> { typedef float4 type; };
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
template <typename T> struct __nv_tex_rmet_cast { typedef T* type; };
|
| 120 |
+
#if !defined(__LP64__)
|
| 121 |
+
template<> struct __nv_tex_rmet_cast<long> { typedef int *type; };
|
| 122 |
+
template<> struct __nv_tex_rmet_cast<unsigned long> { typedef unsigned int *type; };
|
| 123 |
+
template<> struct __nv_tex_rmet_cast<long1> { typedef int1 *type; };
|
| 124 |
+
template<> struct __nv_tex_rmet_cast<ulong1> { typedef uint1 *type; };
|
| 125 |
+
template<> struct __nv_tex_rmet_cast<long2> { typedef int2 *type; };
|
| 126 |
+
template<> struct __nv_tex_rmet_cast<ulong2> { typedef uint2 *type; };
|
| 127 |
+
template<> struct __nv_tex_rmet_cast<long4> { typedef int4 *type; };
|
| 128 |
+
template<> struct __nv_tex_rmet_cast<ulong4> { typedef uint4 *type; };
|
| 129 |
+
#endif /* !__LP64__ */
|
| 130 |
+
|
| 131 |
+
template <typename T>
|
| 132 |
+
struct __nv_tex_rmnf_ret { };
|
| 133 |
+
|
| 134 |
+
template <> struct __nv_tex_rmnf_ret<char> { typedef float type; };
|
| 135 |
+
template <> struct __nv_tex_rmnf_ret<signed char> { typedef float type; };
|
| 136 |
+
template <> struct __nv_tex_rmnf_ret<unsigned char> { typedef float type; };
|
| 137 |
+
template <> struct __nv_tex_rmnf_ret<short> { typedef float type; };
|
| 138 |
+
template <> struct __nv_tex_rmnf_ret<unsigned short> { typedef float type; };
|
| 139 |
+
template <> struct __nv_tex_rmnf_ret<char1> { typedef float1 type; };
|
| 140 |
+
template <> struct __nv_tex_rmnf_ret<uchar1> { typedef float1 type; };
|
| 141 |
+
template <> struct __nv_tex_rmnf_ret<short1> { typedef float1 type; };
|
| 142 |
+
template <> struct __nv_tex_rmnf_ret<ushort1> { typedef float1 type; };
|
| 143 |
+
template <> struct __nv_tex_rmnf_ret<char2> { typedef float2 type; };
|
| 144 |
+
template <> struct __nv_tex_rmnf_ret<uchar2> { typedef float2 type; };
|
| 145 |
+
template <> struct __nv_tex_rmnf_ret<short2> { typedef float2 type; };
|
| 146 |
+
template <> struct __nv_tex_rmnf_ret<ushort2> { typedef float2 type; };
|
| 147 |
+
template <> struct __nv_tex_rmnf_ret<char4> { typedef float4 type; };
|
| 148 |
+
template <> struct __nv_tex_rmnf_ret<uchar4> { typedef float4 type; };
|
| 149 |
+
template <> struct __nv_tex_rmnf_ret<short4> { typedef float4 type; };
|
| 150 |
+
template <> struct __nv_tex_rmnf_ret<ushort4> { typedef float4 type; };
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
template <typename T>
|
| 154 |
+
struct __nv_tex2dgather_ret { };
|
| 155 |
+
template <> struct __nv_tex2dgather_ret<char> { typedef char4 type; };
|
| 156 |
+
template <> struct __nv_tex2dgather_ret<signed char> { typedef char4 type; };
|
| 157 |
+
template <> struct __nv_tex2dgather_ret<char1> { typedef char4 type; };
|
| 158 |
+
template <> struct __nv_tex2dgather_ret<char2> { typedef char4 type; };
|
| 159 |
+
template <> struct __nv_tex2dgather_ret<char3> { typedef char4 type; };
|
| 160 |
+
template <> struct __nv_tex2dgather_ret<char4> { typedef char4 type; };
|
| 161 |
+
template <> struct __nv_tex2dgather_ret<unsigned char> { typedef uchar4 type; };
|
| 162 |
+
template <> struct __nv_tex2dgather_ret<uchar1> { typedef uchar4 type; };
|
| 163 |
+
template <> struct __nv_tex2dgather_ret<uchar2> { typedef uchar4 type; };
|
| 164 |
+
template <> struct __nv_tex2dgather_ret<uchar3> { typedef uchar4 type; };
|
| 165 |
+
template <> struct __nv_tex2dgather_ret<uchar4> { typedef uchar4 type; };
|
| 166 |
+
|
| 167 |
+
template <> struct __nv_tex2dgather_ret<short> { typedef short4 type; };
|
| 168 |
+
template <> struct __nv_tex2dgather_ret<short1> { typedef short4 type; };
|
| 169 |
+
template <> struct __nv_tex2dgather_ret<short2> { typedef short4 type; };
|
| 170 |
+
template <> struct __nv_tex2dgather_ret<short3> { typedef short4 type; };
|
| 171 |
+
template <> struct __nv_tex2dgather_ret<short4> { typedef short4 type; };
|
| 172 |
+
template <> struct __nv_tex2dgather_ret<unsigned short> { typedef ushort4 type; };
|
| 173 |
+
template <> struct __nv_tex2dgather_ret<ushort1> { typedef ushort4 type; };
|
| 174 |
+
template <> struct __nv_tex2dgather_ret<ushort2> { typedef ushort4 type; };
|
| 175 |
+
template <> struct __nv_tex2dgather_ret<ushort3> { typedef ushort4 type; };
|
| 176 |
+
template <> struct __nv_tex2dgather_ret<ushort4> { typedef ushort4 type; };
|
| 177 |
+
|
| 178 |
+
template <> struct __nv_tex2dgather_ret<int> { typedef int4 type; };
|
| 179 |
+
template <> struct __nv_tex2dgather_ret<int1> { typedef int4 type; };
|
| 180 |
+
template <> struct __nv_tex2dgather_ret<int2> { typedef int4 type; };
|
| 181 |
+
template <> struct __nv_tex2dgather_ret<int3> { typedef int4 type; };
|
| 182 |
+
template <> struct __nv_tex2dgather_ret<int4> { typedef int4 type; };
|
| 183 |
+
template <> struct __nv_tex2dgather_ret<unsigned int> { typedef uint4 type; };
|
| 184 |
+
template <> struct __nv_tex2dgather_ret<uint1> { typedef uint4 type; };
|
| 185 |
+
template <> struct __nv_tex2dgather_ret<uint2> { typedef uint4 type; };
|
| 186 |
+
template <> struct __nv_tex2dgather_ret<uint3> { typedef uint4 type; };
|
| 187 |
+
template <> struct __nv_tex2dgather_ret<uint4> { typedef uint4 type; };
|
| 188 |
+
|
| 189 |
+
template <> struct __nv_tex2dgather_ret<float> { typedef float4 type; };
|
| 190 |
+
template <> struct __nv_tex2dgather_ret<float1> { typedef float4 type; };
|
| 191 |
+
template <> struct __nv_tex2dgather_ret<float2> { typedef float4 type; };
|
| 192 |
+
template <> struct __nv_tex2dgather_ret<float3> { typedef float4 type; };
|
| 193 |
+
template <> struct __nv_tex2dgather_ret<float4> { typedef float4 type; };
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
template<typename T> struct __nv_tex2dgather_rmnf_ret { };
|
| 197 |
+
template<> struct __nv_tex2dgather_rmnf_ret<char> { typedef float4 type; };
|
| 198 |
+
template<> struct __nv_tex2dgather_rmnf_ret<signed char> { typedef float4 type; };
|
| 199 |
+
template<> struct __nv_tex2dgather_rmnf_ret<unsigned char> { typedef float4 type; };
|
| 200 |
+
template<> struct __nv_tex2dgather_rmnf_ret<char1> { typedef float4 type; };
|
| 201 |
+
template<> struct __nv_tex2dgather_rmnf_ret<uchar1> { typedef float4 type; };
|
| 202 |
+
template<> struct __nv_tex2dgather_rmnf_ret<char2> { typedef float4 type; };
|
| 203 |
+
template<> struct __nv_tex2dgather_rmnf_ret<uchar2> { typedef float4 type; };
|
| 204 |
+
template<> struct __nv_tex2dgather_rmnf_ret<char3> { typedef float4 type; };
|
| 205 |
+
template<> struct __nv_tex2dgather_rmnf_ret<uchar3> { typedef float4 type; };
|
| 206 |
+
template<> struct __nv_tex2dgather_rmnf_ret<char4> { typedef float4 type; };
|
| 207 |
+
template<> struct __nv_tex2dgather_rmnf_ret<uchar4> { typedef float4 type; };
|
| 208 |
+
template<> struct __nv_tex2dgather_rmnf_ret<signed short> { typedef float4 type; };
|
| 209 |
+
template<> struct __nv_tex2dgather_rmnf_ret<unsigned short> { typedef float4 type; };
|
| 210 |
+
template<> struct __nv_tex2dgather_rmnf_ret<short1> { typedef float4 type; };
|
| 211 |
+
template<> struct __nv_tex2dgather_rmnf_ret<ushort1> { typedef float4 type; };
|
| 212 |
+
template<> struct __nv_tex2dgather_rmnf_ret<short2> { typedef float4 type; };
|
| 213 |
+
template<> struct __nv_tex2dgather_rmnf_ret<ushort2> { typedef float4 type; };
|
| 214 |
+
template<> struct __nv_tex2dgather_rmnf_ret<short3> { typedef float4 type; };
|
| 215 |
+
template<> struct __nv_tex2dgather_rmnf_ret<ushort3> { typedef float4 type; };
|
| 216 |
+
template<> struct __nv_tex2dgather_rmnf_ret<short4> { typedef float4 type; };
|
| 217 |
+
template<> struct __nv_tex2dgather_rmnf_ret<ushort4> { typedef float4 type; };
|
| 218 |
+
|
| 219 |
+
#undef __DEPRECATED__
|
| 220 |
+
|
| 221 |
+
#endif /* __cplusplus && __CUDACC__ */
|
| 222 |
+
|
| 223 |
+
#endif /* !__TEXTURE_FETCH_FUNCTIONS_H__ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/texture_types.h
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2012 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__TEXTURE_TYPES_H__)
|
| 51 |
+
#define __TEXTURE_TYPES_H__
|
| 52 |
+
|
| 53 |
+
/*******************************************************************************
|
| 54 |
+
* *
|
| 55 |
+
* *
|
| 56 |
+
* *
|
| 57 |
+
*******************************************************************************/
|
| 58 |
+
|
| 59 |
+
#include "driver_types.h"
|
| 60 |
+
|
| 61 |
+
/**
|
| 62 |
+
* \addtogroup CUDART_TYPES
|
| 63 |
+
*
|
| 64 |
+
* @{
|
| 65 |
+
*/
|
| 66 |
+
|
| 67 |
+
/*******************************************************************************
|
| 68 |
+
* *
|
| 69 |
+
* *
|
| 70 |
+
* *
|
| 71 |
+
*******************************************************************************/
|
| 72 |
+
|
| 73 |
+
#define cudaTextureType1D 0x01
|
| 74 |
+
#define cudaTextureType2D 0x02
|
| 75 |
+
#define cudaTextureType3D 0x03
|
| 76 |
+
#define cudaTextureTypeCubemap 0x0C
|
| 77 |
+
#define cudaTextureType1DLayered 0xF1
|
| 78 |
+
#define cudaTextureType2DLayered 0xF2
|
| 79 |
+
#define cudaTextureTypeCubemapLayered 0xFC
|
| 80 |
+
|
| 81 |
+
/**
|
| 82 |
+
* CUDA texture address modes
|
| 83 |
+
*/
|
| 84 |
+
enum __device_builtin__ cudaTextureAddressMode
|
| 85 |
+
{
|
| 86 |
+
cudaAddressModeWrap = 0, /**< Wrapping address mode */
|
| 87 |
+
cudaAddressModeClamp = 1, /**< Clamp to edge address mode */
|
| 88 |
+
cudaAddressModeMirror = 2, /**< Mirror address mode */
|
| 89 |
+
cudaAddressModeBorder = 3 /**< Border address mode */
|
| 90 |
+
};
|
| 91 |
+
|
| 92 |
+
/**
|
| 93 |
+
* CUDA texture filter modes
|
| 94 |
+
*/
|
| 95 |
+
enum __device_builtin__ cudaTextureFilterMode
|
| 96 |
+
{
|
| 97 |
+
cudaFilterModePoint = 0, /**< Point filter mode */
|
| 98 |
+
cudaFilterModeLinear = 1 /**< Linear filter mode */
|
| 99 |
+
};
|
| 100 |
+
|
| 101 |
+
/**
|
| 102 |
+
* CUDA texture read modes
|
| 103 |
+
*/
|
| 104 |
+
enum __device_builtin__ cudaTextureReadMode
|
| 105 |
+
{
|
| 106 |
+
cudaReadModeElementType = 0, /**< Read texture as specified element type */
|
| 107 |
+
cudaReadModeNormalizedFloat = 1 /**< Read texture as normalized float */
|
| 108 |
+
};
|
| 109 |
+
|
| 110 |
+
/**
|
| 111 |
+
* CUDA texture descriptor
|
| 112 |
+
*/
|
| 113 |
+
struct __device_builtin__ cudaTextureDesc
|
| 114 |
+
{
|
| 115 |
+
/**
|
| 116 |
+
* Texture address mode for up to 3 dimensions
|
| 117 |
+
*/
|
| 118 |
+
enum cudaTextureAddressMode addressMode[3];
|
| 119 |
+
/**
|
| 120 |
+
* Texture filter mode
|
| 121 |
+
*/
|
| 122 |
+
enum cudaTextureFilterMode filterMode;
|
| 123 |
+
/**
|
| 124 |
+
* Texture read mode
|
| 125 |
+
*/
|
| 126 |
+
enum cudaTextureReadMode readMode;
|
| 127 |
+
/**
|
| 128 |
+
* Perform sRGB->linear conversion during texture read
|
| 129 |
+
*/
|
| 130 |
+
int sRGB;
|
| 131 |
+
/**
|
| 132 |
+
* Texture Border Color
|
| 133 |
+
*/
|
| 134 |
+
float borderColor[4];
|
| 135 |
+
/**
|
| 136 |
+
* Indicates whether texture reads are normalized or not
|
| 137 |
+
*/
|
| 138 |
+
int normalizedCoords;
|
| 139 |
+
/**
|
| 140 |
+
* Limit to the anisotropy ratio
|
| 141 |
+
*/
|
| 142 |
+
unsigned int maxAnisotropy;
|
| 143 |
+
/**
|
| 144 |
+
* Mipmap filter mode
|
| 145 |
+
*/
|
| 146 |
+
enum cudaTextureFilterMode mipmapFilterMode;
|
| 147 |
+
/**
|
| 148 |
+
* Offset applied to the supplied mipmap level
|
| 149 |
+
*/
|
| 150 |
+
float mipmapLevelBias;
|
| 151 |
+
/**
|
| 152 |
+
* Lower end of the mipmap level range to clamp access to
|
| 153 |
+
*/
|
| 154 |
+
float minMipmapLevelClamp;
|
| 155 |
+
/**
|
| 156 |
+
* Upper end of the mipmap level range to clamp access to
|
| 157 |
+
*/
|
| 158 |
+
float maxMipmapLevelClamp;
|
| 159 |
+
/**
|
| 160 |
+
* Disable any trilinear filtering optimizations.
|
| 161 |
+
*/
|
| 162 |
+
int disableTrilinearOptimization;
|
| 163 |
+
/**
|
| 164 |
+
* Enable seamless cube map filtering.
|
| 165 |
+
*/
|
| 166 |
+
int seamlessCubemap;
|
| 167 |
+
};
|
| 168 |
+
|
| 169 |
+
/**
|
| 170 |
+
* An opaque value that represents a CUDA texture object
|
| 171 |
+
*/
|
| 172 |
+
typedef __device_builtin__ unsigned long long cudaTextureObject_t;
|
| 173 |
+
|
| 174 |
+
/** @} */
|
| 175 |
+
/** @} */ /* END CUDART_TYPES */
|
| 176 |
+
|
| 177 |
+
#endif /* !__TEXTURE_TYPES_H__ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/include/vector_types.h
ADDED
|
@@ -0,0 +1,443 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 1993-2018 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#if !defined(__VECTOR_TYPES_H__)
|
| 51 |
+
#define __VECTOR_TYPES_H__
|
| 52 |
+
|
| 53 |
+
#if !defined(__CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__)
|
| 54 |
+
#define __CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__
|
| 55 |
+
#define __UNDEF_CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS_VECTOR_TYPES_H__
|
| 56 |
+
#endif
|
| 57 |
+
|
| 58 |
+
/*******************************************************************************
|
| 59 |
+
* *
|
| 60 |
+
* *
|
| 61 |
+
* *
|
| 62 |
+
*******************************************************************************/
|
| 63 |
+
|
| 64 |
+
#ifndef __DOXYGEN_ONLY__
|
| 65 |
+
#include "crt/host_defines.h"
|
| 66 |
+
#endif
|
| 67 |
+
|
| 68 |
+
/*******************************************************************************
|
| 69 |
+
* *
|
| 70 |
+
* *
|
| 71 |
+
* *
|
| 72 |
+
*******************************************************************************/
|
| 73 |
+
|
| 74 |
+
#if !defined(__CUDACC__) && !defined(__CUDACC_RTC__) && \
|
| 75 |
+
defined(_WIN32) && !defined(_WIN64)
|
| 76 |
+
|
| 77 |
+
#pragma warning(push)
|
| 78 |
+
#pragma warning(disable: 4201 4408)
|
| 79 |
+
|
| 80 |
+
#define __cuda_builtin_vector_align8(tag, members) \
|
| 81 |
+
struct __device_builtin__ tag \
|
| 82 |
+
{ \
|
| 83 |
+
union \
|
| 84 |
+
{ \
|
| 85 |
+
struct { members }; \
|
| 86 |
+
struct { long long int :1,:0; }; \
|
| 87 |
+
}; \
|
| 88 |
+
}
|
| 89 |
+
|
| 90 |
+
#else /* !__CUDACC__ && !__CUDACC_RTC__ && _WIN32 && !_WIN64 */
|
| 91 |
+
|
| 92 |
+
#define __cuda_builtin_vector_align8(tag, members) \
|
| 93 |
+
struct __device_builtin__ __align__(8) tag \
|
| 94 |
+
{ \
|
| 95 |
+
members \
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
#endif /* !__CUDACC__ && !__CUDACC_RTC__ && _WIN32 && !_WIN64 */
|
| 99 |
+
|
| 100 |
+
struct __device_builtin__ char1
|
| 101 |
+
{
|
| 102 |
+
signed char x;
|
| 103 |
+
};
|
| 104 |
+
|
| 105 |
+
struct __device_builtin__ uchar1
|
| 106 |
+
{
|
| 107 |
+
unsigned char x;
|
| 108 |
+
};
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
struct __device_builtin__ __align__(2) char2
|
| 112 |
+
{
|
| 113 |
+
signed char x, y;
|
| 114 |
+
};
|
| 115 |
+
|
| 116 |
+
struct __device_builtin__ __align__(2) uchar2
|
| 117 |
+
{
|
| 118 |
+
unsigned char x, y;
|
| 119 |
+
};
|
| 120 |
+
|
| 121 |
+
struct __device_builtin__ char3
|
| 122 |
+
{
|
| 123 |
+
signed char x, y, z;
|
| 124 |
+
};
|
| 125 |
+
|
| 126 |
+
struct __device_builtin__ uchar3
|
| 127 |
+
{
|
| 128 |
+
unsigned char x, y, z;
|
| 129 |
+
};
|
| 130 |
+
|
| 131 |
+
struct __device_builtin__ __align__(4) char4
|
| 132 |
+
{
|
| 133 |
+
signed char x, y, z, w;
|
| 134 |
+
};
|
| 135 |
+
|
| 136 |
+
struct __device_builtin__ __align__(4) uchar4
|
| 137 |
+
{
|
| 138 |
+
unsigned char x, y, z, w;
|
| 139 |
+
};
|
| 140 |
+
|
| 141 |
+
struct __device_builtin__ short1
|
| 142 |
+
{
|
| 143 |
+
short x;
|
| 144 |
+
};
|
| 145 |
+
|
| 146 |
+
struct __device_builtin__ ushort1
|
| 147 |
+
{
|
| 148 |
+
unsigned short x;
|
| 149 |
+
};
|
| 150 |
+
|
| 151 |
+
struct __device_builtin__ __align__(4) short2
|
| 152 |
+
{
|
| 153 |
+
short x, y;
|
| 154 |
+
};
|
| 155 |
+
|
| 156 |
+
struct __device_builtin__ __align__(4) ushort2
|
| 157 |
+
{
|
| 158 |
+
unsigned short x, y;
|
| 159 |
+
};
|
| 160 |
+
|
| 161 |
+
struct __device_builtin__ short3
|
| 162 |
+
{
|
| 163 |
+
short x, y, z;
|
| 164 |
+
};
|
| 165 |
+
|
| 166 |
+
struct __device_builtin__ ushort3
|
| 167 |
+
{
|
| 168 |
+
unsigned short x, y, z;
|
| 169 |
+
};
|
| 170 |
+
|
| 171 |
+
__cuda_builtin_vector_align8(short4, short x; short y; short z; short w;);
|
| 172 |
+
__cuda_builtin_vector_align8(ushort4, unsigned short x; unsigned short y; unsigned short z; unsigned short w;);
|
| 173 |
+
|
| 174 |
+
struct __device_builtin__ int1
|
| 175 |
+
{
|
| 176 |
+
int x;
|
| 177 |
+
};
|
| 178 |
+
|
| 179 |
+
struct __device_builtin__ uint1
|
| 180 |
+
{
|
| 181 |
+
unsigned int x;
|
| 182 |
+
};
|
| 183 |
+
|
| 184 |
+
__cuda_builtin_vector_align8(int2, int x; int y;);
|
| 185 |
+
__cuda_builtin_vector_align8(uint2, unsigned int x; unsigned int y;);
|
| 186 |
+
|
| 187 |
+
struct __device_builtin__ int3
|
| 188 |
+
{
|
| 189 |
+
int x, y, z;
|
| 190 |
+
};
|
| 191 |
+
|
| 192 |
+
struct __device_builtin__ uint3
|
| 193 |
+
{
|
| 194 |
+
unsigned int x, y, z;
|
| 195 |
+
};
|
| 196 |
+
|
| 197 |
+
struct __device_builtin__ __builtin_align__(16) int4
|
| 198 |
+
{
|
| 199 |
+
int x, y, z, w;
|
| 200 |
+
};
|
| 201 |
+
|
| 202 |
+
struct __device_builtin__ __builtin_align__(16) uint4
|
| 203 |
+
{
|
| 204 |
+
unsigned int x, y, z, w;
|
| 205 |
+
};
|
| 206 |
+
|
| 207 |
+
struct __device_builtin__ long1
|
| 208 |
+
{
|
| 209 |
+
long int x;
|
| 210 |
+
};
|
| 211 |
+
|
| 212 |
+
struct __device_builtin__ ulong1
|
| 213 |
+
{
|
| 214 |
+
unsigned long x;
|
| 215 |
+
};
|
| 216 |
+
|
| 217 |
+
#if defined(_WIN32)
|
| 218 |
+
__cuda_builtin_vector_align8(long2, long int x; long int y;);
|
| 219 |
+
__cuda_builtin_vector_align8(ulong2, unsigned long int x; unsigned long int y;);
|
| 220 |
+
#else /* !_WIN32 */
|
| 221 |
+
|
| 222 |
+
struct __device_builtin__ __align__(2*sizeof(long int)) long2
|
| 223 |
+
{
|
| 224 |
+
long int x, y;
|
| 225 |
+
};
|
| 226 |
+
|
| 227 |
+
struct __device_builtin__ __align__(2*sizeof(unsigned long int)) ulong2
|
| 228 |
+
{
|
| 229 |
+
unsigned long int x, y;
|
| 230 |
+
};
|
| 231 |
+
|
| 232 |
+
#endif /* _WIN32 */
|
| 233 |
+
|
| 234 |
+
struct __device_builtin__ long3
|
| 235 |
+
{
|
| 236 |
+
long int x, y, z;
|
| 237 |
+
};
|
| 238 |
+
|
| 239 |
+
struct __device_builtin__ ulong3
|
| 240 |
+
{
|
| 241 |
+
unsigned long int x, y, z;
|
| 242 |
+
};
|
| 243 |
+
|
| 244 |
+
struct __device_builtin__ __builtin_align__(16) long4
|
| 245 |
+
{
|
| 246 |
+
long int x, y, z, w;
|
| 247 |
+
};
|
| 248 |
+
|
| 249 |
+
struct __device_builtin__ __builtin_align__(16) ulong4
|
| 250 |
+
{
|
| 251 |
+
unsigned long int x, y, z, w;
|
| 252 |
+
};
|
| 253 |
+
|
| 254 |
+
struct __device_builtin__ float1
|
| 255 |
+
{
|
| 256 |
+
float x;
|
| 257 |
+
};
|
| 258 |
+
|
| 259 |
+
#if !defined(__CUDACC__) && defined(__arm__) && \
|
| 260 |
+
defined(__ARM_PCS_VFP) && __GNUC__ == 4 && __GNUC_MINOR__ == 6
|
| 261 |
+
|
| 262 |
+
#pragma GCC diagnostic push
|
| 263 |
+
#pragma GCC diagnostic ignored "-pedantic"
|
| 264 |
+
|
| 265 |
+
struct __device_builtin__ __attribute__((aligned(8))) float2
|
| 266 |
+
{
|
| 267 |
+
float x; float y; float __cuda_gnu_arm_ice_workaround[0];
|
| 268 |
+
};
|
| 269 |
+
|
| 270 |
+
#pragma GCC poison __cuda_gnu_arm_ice_workaround
|
| 271 |
+
#pragma GCC diagnostic pop
|
| 272 |
+
|
| 273 |
+
#else /* !__CUDACC__ && __arm__ && __ARM_PCS_VFP &&
|
| 274 |
+
__GNUC__ == 4&& __GNUC_MINOR__ == 6 */
|
| 275 |
+
|
| 276 |
+
__cuda_builtin_vector_align8(float2, float x; float y;);
|
| 277 |
+
|
| 278 |
+
#endif /* !__CUDACC__ && __arm__ && __ARM_PCS_VFP &&
|
| 279 |
+
__GNUC__ == 4&& __GNUC_MINOR__ == 6 */
|
| 280 |
+
|
| 281 |
+
struct __device_builtin__ float3
|
| 282 |
+
{
|
| 283 |
+
float x, y, z;
|
| 284 |
+
};
|
| 285 |
+
|
| 286 |
+
struct __device_builtin__ __builtin_align__(16) float4
|
| 287 |
+
{
|
| 288 |
+
float x, y, z, w;
|
| 289 |
+
};
|
| 290 |
+
|
| 291 |
+
struct __device_builtin__ longlong1
|
| 292 |
+
{
|
| 293 |
+
long long int x;
|
| 294 |
+
};
|
| 295 |
+
|
| 296 |
+
struct __device_builtin__ ulonglong1
|
| 297 |
+
{
|
| 298 |
+
unsigned long long int x;
|
| 299 |
+
};
|
| 300 |
+
|
| 301 |
+
struct __device_builtin__ __builtin_align__(16) longlong2
|
| 302 |
+
{
|
| 303 |
+
long long int x, y;
|
| 304 |
+
};
|
| 305 |
+
|
| 306 |
+
struct __device_builtin__ __builtin_align__(16) ulonglong2
|
| 307 |
+
{
|
| 308 |
+
unsigned long long int x, y;
|
| 309 |
+
};
|
| 310 |
+
|
| 311 |
+
struct __device_builtin__ longlong3
|
| 312 |
+
{
|
| 313 |
+
long long int x, y, z;
|
| 314 |
+
};
|
| 315 |
+
|
| 316 |
+
struct __device_builtin__ ulonglong3
|
| 317 |
+
{
|
| 318 |
+
unsigned long long int x, y, z;
|
| 319 |
+
};
|
| 320 |
+
|
| 321 |
+
struct __device_builtin__ __builtin_align__(16) longlong4
|
| 322 |
+
{
|
| 323 |
+
long long int x, y, z ,w;
|
| 324 |
+
};
|
| 325 |
+
|
| 326 |
+
struct __device_builtin__ __builtin_align__(16) ulonglong4
|
| 327 |
+
{
|
| 328 |
+
unsigned long long int x, y, z, w;
|
| 329 |
+
};
|
| 330 |
+
|
| 331 |
+
struct __device_builtin__ double1
|
| 332 |
+
{
|
| 333 |
+
double x;
|
| 334 |
+
};
|
| 335 |
+
|
| 336 |
+
struct __device_builtin__ __builtin_align__(16) double2
|
| 337 |
+
{
|
| 338 |
+
double x, y;
|
| 339 |
+
};
|
| 340 |
+
|
| 341 |
+
struct __device_builtin__ double3
|
| 342 |
+
{
|
| 343 |
+
double x, y, z;
|
| 344 |
+
};
|
| 345 |
+
|
| 346 |
+
struct __device_builtin__ __builtin_align__(16) double4
|
| 347 |
+
{
|
| 348 |
+
double x, y, z, w;
|
| 349 |
+
};
|
| 350 |
+
|
| 351 |
+
#if !defined(__CUDACC__) && defined(_WIN32) && !defined(_WIN64)
|
| 352 |
+
|
| 353 |
+
#pragma warning(pop)
|
| 354 |
+
|
| 355 |
+
#endif /* !__CUDACC__ && _WIN32 && !_WIN64 */
|
| 356 |
+
|
| 357 |
+
/*******************************************************************************
|
| 358 |
+
* *
|
| 359 |
+
* *
|
| 360 |
+
* *
|
| 361 |
+
*******************************************************************************/
|
| 362 |
+
|
| 363 |
+
typedef __device_builtin__ struct char1 char1;
|
| 364 |
+
typedef __device_builtin__ struct uchar1 uchar1;
|
| 365 |
+
typedef __device_builtin__ struct char2 char2;
|
| 366 |
+
typedef __device_builtin__ struct uchar2 uchar2;
|
| 367 |
+
typedef __device_builtin__ struct char3 char3;
|
| 368 |
+
typedef __device_builtin__ struct uchar3 uchar3;
|
| 369 |
+
typedef __device_builtin__ struct char4 char4;
|
| 370 |
+
typedef __device_builtin__ struct uchar4 uchar4;
|
| 371 |
+
typedef __device_builtin__ struct short1 short1;
|
| 372 |
+
typedef __device_builtin__ struct ushort1 ushort1;
|
| 373 |
+
typedef __device_builtin__ struct short2 short2;
|
| 374 |
+
typedef __device_builtin__ struct ushort2 ushort2;
|
| 375 |
+
typedef __device_builtin__ struct short3 short3;
|
| 376 |
+
typedef __device_builtin__ struct ushort3 ushort3;
|
| 377 |
+
typedef __device_builtin__ struct short4 short4;
|
| 378 |
+
typedef __device_builtin__ struct ushort4 ushort4;
|
| 379 |
+
typedef __device_builtin__ struct int1 int1;
|
| 380 |
+
typedef __device_builtin__ struct uint1 uint1;
|
| 381 |
+
typedef __device_builtin__ struct int2 int2;
|
| 382 |
+
typedef __device_builtin__ struct uint2 uint2;
|
| 383 |
+
typedef __device_builtin__ struct int3 int3;
|
| 384 |
+
typedef __device_builtin__ struct uint3 uint3;
|
| 385 |
+
typedef __device_builtin__ struct int4 int4;
|
| 386 |
+
typedef __device_builtin__ struct uint4 uint4;
|
| 387 |
+
typedef __device_builtin__ struct long1 long1;
|
| 388 |
+
typedef __device_builtin__ struct ulong1 ulong1;
|
| 389 |
+
typedef __device_builtin__ struct long2 long2;
|
| 390 |
+
typedef __device_builtin__ struct ulong2 ulong2;
|
| 391 |
+
typedef __device_builtin__ struct long3 long3;
|
| 392 |
+
typedef __device_builtin__ struct ulong3 ulong3;
|
| 393 |
+
typedef __device_builtin__ struct long4 long4;
|
| 394 |
+
typedef __device_builtin__ struct ulong4 ulong4;
|
| 395 |
+
typedef __device_builtin__ struct float1 float1;
|
| 396 |
+
typedef __device_builtin__ struct float2 float2;
|
| 397 |
+
typedef __device_builtin__ struct float3 float3;
|
| 398 |
+
typedef __device_builtin__ struct float4 float4;
|
| 399 |
+
typedef __device_builtin__ struct longlong1 longlong1;
|
| 400 |
+
typedef __device_builtin__ struct ulonglong1 ulonglong1;
|
| 401 |
+
typedef __device_builtin__ struct longlong2 longlong2;
|
| 402 |
+
typedef __device_builtin__ struct ulonglong2 ulonglong2;
|
| 403 |
+
typedef __device_builtin__ struct longlong3 longlong3;
|
| 404 |
+
typedef __device_builtin__ struct ulonglong3 ulonglong3;
|
| 405 |
+
typedef __device_builtin__ struct longlong4 longlong4;
|
| 406 |
+
typedef __device_builtin__ struct ulonglong4 ulonglong4;
|
| 407 |
+
typedef __device_builtin__ struct double1 double1;
|
| 408 |
+
typedef __device_builtin__ struct double2 double2;
|
| 409 |
+
typedef __device_builtin__ struct double3 double3;
|
| 410 |
+
typedef __device_builtin__ struct double4 double4;
|
| 411 |
+
|
| 412 |
+
/*******************************************************************************
|
| 413 |
+
* *
|
| 414 |
+
* *
|
| 415 |
+
* *
|
| 416 |
+
*******************************************************************************/
|
| 417 |
+
|
| 418 |
+
struct __device_builtin__ dim3
|
| 419 |
+
{
|
| 420 |
+
unsigned int x, y, z;
|
| 421 |
+
#if defined(__cplusplus)
|
| 422 |
+
#if __cplusplus >= 201103L
|
| 423 |
+
__host__ __device__ constexpr dim3(unsigned int vx = 1, unsigned int vy = 1, unsigned int vz = 1) : x(vx), y(vy), z(vz) {}
|
| 424 |
+
__host__ __device__ constexpr dim3(uint3 v) : x(v.x), y(v.y), z(v.z) {}
|
| 425 |
+
__host__ __device__ constexpr operator uint3(void) const { return uint3{x, y, z}; }
|
| 426 |
+
#else
|
| 427 |
+
__host__ __device__ dim3(unsigned int vx = 1, unsigned int vy = 1, unsigned int vz = 1) : x(vx), y(vy), z(vz) {}
|
| 428 |
+
__host__ __device__ dim3(uint3 v) : x(v.x), y(v.y), z(v.z) {}
|
| 429 |
+
__host__ __device__ operator uint3(void) const { uint3 t; t.x = x; t.y = y; t.z = z; return t; }
|
| 430 |
+
#endif
|
| 431 |
+
#endif /* __cplusplus */
|
| 432 |
+
};
|
| 433 |
+
|
| 434 |
+
typedef __device_builtin__ struct dim3 dim3;
|
| 435 |
+
|
| 436 |
+
#undef __cuda_builtin_vector_align8
|
| 437 |
+
|
| 438 |
+
#if defined(__UNDEF_CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS_VECTOR_TYPES_H__)
|
| 439 |
+
#undef __CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS__
|
| 440 |
+
#undef __UNDEF_CUDA_INCLUDE_COMPILER_INTERNAL_HEADERS_VECTOR_TYPES_H__
|
| 441 |
+
#endif
|
| 442 |
+
|
| 443 |
+
#endif /* !__VECTOR_TYPES_H__ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cuda_runtime/lib/__init__.py
ADDED
|
File without changes
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cudnn/include/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (179 Bytes). View file
|
|
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cudnn/include/cudnn_adv_infer.h
ADDED
|
@@ -0,0 +1,658 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2014-2023 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
/* cudnn_adv_infer : cuDNN's advanced and experimental features.
|
| 51 |
+
|
| 52 |
+
*/
|
| 53 |
+
|
| 54 |
+
#if !defined(CUDNN_ADV_INFER_H_)
|
| 55 |
+
#define CUDNN_ADV_INFER_H_
|
| 56 |
+
|
| 57 |
+
#include <cuda_runtime.h>
|
| 58 |
+
#include <stdint.h>
|
| 59 |
+
|
| 60 |
+
#include "cudnn_version.h"
|
| 61 |
+
#include "cudnn_ops_infer.h"
|
| 62 |
+
|
| 63 |
+
/* These version numbers are autogenerated, do not edit manually. */
|
| 64 |
+
#define CUDNN_ADV_INFER_MAJOR 8
|
| 65 |
+
#define CUDNN_ADV_INFER_MINOR 9
|
| 66 |
+
#define CUDNN_ADV_INFER_PATCH 2
|
| 67 |
+
|
| 68 |
+
#if (CUDNN_ADV_INFER_MAJOR != CUDNN_MAJOR) || (CUDNN_ADV_INFER_MINOR != CUDNN_MINOR) || \
|
| 69 |
+
(CUDNN_ADV_INFER_PATCH != CUDNN_PATCHLEVEL)
|
| 70 |
+
#error Version mismatch in cuDNN ADV INFER!!!
|
| 71 |
+
#endif
|
| 72 |
+
|
| 73 |
+
#if defined(__cplusplus)
|
| 74 |
+
extern "C" {
|
| 75 |
+
#endif
|
| 76 |
+
|
| 77 |
+
/* BASIC RNN API */
|
| 78 |
+
|
| 79 |
+
typedef enum {
|
| 80 |
+
CUDNN_FWD_MODE_INFERENCE = 0,
|
| 81 |
+
CUDNN_FWD_MODE_TRAINING = 1,
|
| 82 |
+
} cudnnForwardMode_t;
|
| 83 |
+
|
| 84 |
+
typedef enum {
|
| 85 |
+
CUDNN_RNN_RELU = 0, /* basic RNN cell type with ReLu activation */
|
| 86 |
+
CUDNN_RNN_TANH = 1, /* basic RNN cell type with tanh activation */
|
| 87 |
+
CUDNN_LSTM = 2, /* LSTM with optional recurrent projection and clipping */
|
| 88 |
+
CUDNN_GRU = 3, /* Using h' = tanh(r * Uh(t-1) + Wx) and h = (1 - z) * h' + z * h(t-1); */
|
| 89 |
+
} cudnnRNNMode_t;
|
| 90 |
+
|
| 91 |
+
typedef enum {
|
| 92 |
+
CUDNN_RNN_NO_BIAS = 0, /* rnn cell formulas do not use biases */
|
| 93 |
+
CUDNN_RNN_SINGLE_INP_BIAS = 1, /* rnn cell formulas use one input bias in input GEMM */
|
| 94 |
+
CUDNN_RNN_DOUBLE_BIAS = 2, /* default, rnn cell formulas use two bias vectors */
|
| 95 |
+
CUDNN_RNN_SINGLE_REC_BIAS = 3 /* rnn cell formulas use one recurrent bias in recurrent GEMM */
|
| 96 |
+
} cudnnRNNBiasMode_t;
|
| 97 |
+
|
| 98 |
+
typedef enum {
|
| 99 |
+
CUDNN_UNIDIRECTIONAL = 0, /* single direction network */
|
| 100 |
+
CUDNN_BIDIRECTIONAL = 1, /* output concatination at each layer */
|
| 101 |
+
} cudnnDirectionMode_t;
|
| 102 |
+
|
| 103 |
+
typedef enum {
|
| 104 |
+
CUDNN_LINEAR_INPUT = 0, /* adjustable weight matrix in first layer input GEMM */
|
| 105 |
+
CUDNN_SKIP_INPUT = 1, /* fixed identity matrix in the first layer input GEMM */
|
| 106 |
+
} cudnnRNNInputMode_t;
|
| 107 |
+
|
| 108 |
+
typedef enum {
|
| 109 |
+
CUDNN_RNN_CLIP_NONE = 0, /* disables LSTM cell clipping */
|
| 110 |
+
CUDNN_RNN_CLIP_MINMAX = 1, /* enables LSTM cell clipping */
|
| 111 |
+
} cudnnRNNClipMode_t;
|
| 112 |
+
|
| 113 |
+
typedef enum {
|
| 114 |
+
CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_UNPACKED = 0, /* padded, outer stride from one time-step to the next */
|
| 115 |
+
CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_PACKED = 1, /* sequence length sorted and packed as in basic RNN api */
|
| 116 |
+
CUDNN_RNN_DATA_LAYOUT_BATCH_MAJOR_UNPACKED = 2, /* padded, outer stride from one batch to the next */
|
| 117 |
+
} cudnnRNNDataLayout_t;
|
| 118 |
+
|
| 119 |
+
/* Legacy type for backward compatibility */
|
| 120 |
+
typedef unsigned cudnnRNNPaddingMode_t;
|
| 121 |
+
|
| 122 |
+
/* For auxFlags in cudnnSetRNNDescriptor_v8() and cudnnSetRNNPaddingMode() */
|
| 123 |
+
#define CUDNN_RNN_PADDED_IO_DISABLED 0
|
| 124 |
+
#define CUDNN_RNN_PADDED_IO_ENABLED (1U << 0)
|
| 125 |
+
|
| 126 |
+
struct cudnnRNNStruct;
|
| 127 |
+
typedef struct cudnnRNNStruct *cudnnRNNDescriptor_t;
|
| 128 |
+
|
| 129 |
+
struct cudnnPersistentRNNPlan;
|
| 130 |
+
typedef struct cudnnPersistentRNNPlan *cudnnPersistentRNNPlan_t;
|
| 131 |
+
|
| 132 |
+
struct cudnnRNNDataStruct;
|
| 133 |
+
typedef struct cudnnRNNDataStruct *cudnnRNNDataDescriptor_t;
|
| 134 |
+
|
| 135 |
+
cudnnStatus_t CUDNNWINAPI
|
| 136 |
+
cudnnCreateRNNDescriptor(cudnnRNNDescriptor_t *rnnDesc);
|
| 137 |
+
|
| 138 |
+
cudnnStatus_t CUDNNWINAPI
|
| 139 |
+
cudnnDestroyRNNDescriptor(cudnnRNNDescriptor_t rnnDesc);
|
| 140 |
+
|
| 141 |
+
cudnnStatus_t CUDNNWINAPI
|
| 142 |
+
cudnnSetRNNDescriptor_v8(cudnnRNNDescriptor_t rnnDesc,
|
| 143 |
+
cudnnRNNAlgo_t algo,
|
| 144 |
+
cudnnRNNMode_t cellMode,
|
| 145 |
+
cudnnRNNBiasMode_t biasMode,
|
| 146 |
+
cudnnDirectionMode_t dirMode,
|
| 147 |
+
cudnnRNNInputMode_t inputMode,
|
| 148 |
+
cudnnDataType_t dataType,
|
| 149 |
+
cudnnDataType_t mathPrec,
|
| 150 |
+
cudnnMathType_t mathType,
|
| 151 |
+
int32_t inputSize,
|
| 152 |
+
int32_t hiddenSize,
|
| 153 |
+
int32_t projSize,
|
| 154 |
+
int32_t numLayers,
|
| 155 |
+
cudnnDropoutDescriptor_t dropoutDesc,
|
| 156 |
+
uint32_t auxFlags);
|
| 157 |
+
|
| 158 |
+
cudnnStatus_t CUDNNWINAPI
|
| 159 |
+
cudnnGetRNNDescriptor_v8(cudnnRNNDescriptor_t rnnDesc,
|
| 160 |
+
cudnnRNNAlgo_t *algo,
|
| 161 |
+
cudnnRNNMode_t *cellMode,
|
| 162 |
+
cudnnRNNBiasMode_t *biasMode,
|
| 163 |
+
cudnnDirectionMode_t *dirMode,
|
| 164 |
+
cudnnRNNInputMode_t *inputMode,
|
| 165 |
+
cudnnDataType_t *dataType,
|
| 166 |
+
cudnnDataType_t *mathPrec,
|
| 167 |
+
cudnnMathType_t *mathType,
|
| 168 |
+
int32_t *inputSize,
|
| 169 |
+
int32_t *hiddenSize,
|
| 170 |
+
int32_t *projSize,
|
| 171 |
+
int32_t *numLayers,
|
| 172 |
+
cudnnDropoutDescriptor_t *dropoutDesc,
|
| 173 |
+
uint32_t *auxFlags);
|
| 174 |
+
|
| 175 |
+
/*
|
| 176 |
+
* mathPrec in cudnnSetRNNDescriptor_v6() specifies compute precision
|
| 177 |
+
* compute precision is further modified by cudnnSetRNNMatrixMathType()
|
| 178 |
+
* dataType in cudnnGetRNNParamsSize() and wDesc specify weight storage
|
| 179 |
+
* dropout is between RNN layers, not between recurrent steps
|
| 180 |
+
*/
|
| 181 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 182 |
+
cudnnSetRNNDescriptor_v6(cudnnHandle_t handle,
|
| 183 |
+
cudnnRNNDescriptor_t rnnDesc,
|
| 184 |
+
const int hiddenSize,
|
| 185 |
+
const int numLayers,
|
| 186 |
+
cudnnDropoutDescriptor_t dropoutDesc,
|
| 187 |
+
cudnnRNNInputMode_t inputMode,
|
| 188 |
+
cudnnDirectionMode_t direction,
|
| 189 |
+
cudnnRNNMode_t cellMode,
|
| 190 |
+
cudnnRNNAlgo_t algo,
|
| 191 |
+
cudnnDataType_t mathPrec);
|
| 192 |
+
|
| 193 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 194 |
+
cudnnGetRNNDescriptor_v6(cudnnHandle_t handle,
|
| 195 |
+
cudnnRNNDescriptor_t rnnDesc,
|
| 196 |
+
int *hiddenSize,
|
| 197 |
+
int *numLayers,
|
| 198 |
+
cudnnDropoutDescriptor_t *dropoutDesc,
|
| 199 |
+
cudnnRNNInputMode_t *inputMode,
|
| 200 |
+
cudnnDirectionMode_t *direction,
|
| 201 |
+
cudnnRNNMode_t *cellMode,
|
| 202 |
+
cudnnRNNAlgo_t *algo,
|
| 203 |
+
cudnnDataType_t *mathPrec);
|
| 204 |
+
|
| 205 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 206 |
+
cudnnSetRNNMatrixMathType(cudnnRNNDescriptor_t rnnDesc, cudnnMathType_t mType);
|
| 207 |
+
|
| 208 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 209 |
+
cudnnGetRNNMatrixMathType(cudnnRNNDescriptor_t rnnDesc, cudnnMathType_t *mType);
|
| 210 |
+
|
| 211 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 212 |
+
cudnnSetRNNBiasMode(cudnnRNNDescriptor_t rnnDesc, cudnnRNNBiasMode_t biasMode);
|
| 213 |
+
|
| 214 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 215 |
+
cudnnGetRNNBiasMode(cudnnRNNDescriptor_t rnnDesc, cudnnRNNBiasMode_t *biasMode);
|
| 216 |
+
|
| 217 |
+
cudnnStatus_t CUDNNWINAPI
|
| 218 |
+
cudnnRNNSetClip_v8(cudnnRNNDescriptor_t rnnDesc,
|
| 219 |
+
cudnnRNNClipMode_t clipMode,
|
| 220 |
+
cudnnNanPropagation_t clipNanOpt,
|
| 221 |
+
double lclip,
|
| 222 |
+
double rclip);
|
| 223 |
+
|
| 224 |
+
cudnnStatus_t CUDNNWINAPI
|
| 225 |
+
cudnnRNNGetClip_v8(cudnnRNNDescriptor_t rnnDesc,
|
| 226 |
+
cudnnRNNClipMode_t *clipMode,
|
| 227 |
+
cudnnNanPropagation_t *clipNanOpt,
|
| 228 |
+
double *lclip,
|
| 229 |
+
double *rclip);
|
| 230 |
+
|
| 231 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 232 |
+
cudnnRNNSetClip(cudnnHandle_t handle,
|
| 233 |
+
cudnnRNNDescriptor_t rnnDesc,
|
| 234 |
+
cudnnRNNClipMode_t clipMode,
|
| 235 |
+
cudnnNanPropagation_t clipNanOpt,
|
| 236 |
+
double lclip,
|
| 237 |
+
double rclip);
|
| 238 |
+
|
| 239 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 240 |
+
cudnnRNNGetClip(cudnnHandle_t handle,
|
| 241 |
+
cudnnRNNDescriptor_t rnnDesc,
|
| 242 |
+
cudnnRNNClipMode_t *clipMode,
|
| 243 |
+
cudnnNanPropagation_t *clipNanOpt,
|
| 244 |
+
double *lclip,
|
| 245 |
+
double *rclip);
|
| 246 |
+
|
| 247 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 248 |
+
cudnnSetRNNProjectionLayers(cudnnHandle_t handle,
|
| 249 |
+
cudnnRNNDescriptor_t rnnDesc,
|
| 250 |
+
const int recProjSize,
|
| 251 |
+
const int outProjSize);
|
| 252 |
+
|
| 253 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 254 |
+
cudnnGetRNNProjectionLayers(cudnnHandle_t handle,
|
| 255 |
+
const cudnnRNNDescriptor_t rnnDesc,
|
| 256 |
+
int *recProjSize,
|
| 257 |
+
int *outProjSize);
|
| 258 |
+
|
| 259 |
+
/* Expensive. Creates the plan for the specific settings. */
|
| 260 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 261 |
+
cudnnCreatePersistentRNNPlan(cudnnRNNDescriptor_t rnnDesc,
|
| 262 |
+
const int minibatch,
|
| 263 |
+
const cudnnDataType_t dataType,
|
| 264 |
+
cudnnPersistentRNNPlan_t *plan);
|
| 265 |
+
|
| 266 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 267 |
+
cudnnDestroyPersistentRNNPlan(cudnnPersistentRNNPlan_t plan);
|
| 268 |
+
|
| 269 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 270 |
+
cudnnSetPersistentRNNPlan(cudnnRNNDescriptor_t rnnDesc, cudnnPersistentRNNPlan_t plan);
|
| 271 |
+
|
| 272 |
+
cudnnStatus_t CUDNNWINAPI
|
| 273 |
+
cudnnBuildRNNDynamic(cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, int miniBatch);
|
| 274 |
+
|
| 275 |
+
/* dataType in weight descriptors and input descriptors is used to describe storage */
|
| 276 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 277 |
+
cudnnGetRNNWorkspaceSize(cudnnHandle_t handle,
|
| 278 |
+
const cudnnRNNDescriptor_t rnnDesc,
|
| 279 |
+
const int seqLength,
|
| 280 |
+
const cudnnTensorDescriptor_t *xDesc,
|
| 281 |
+
size_t *sizeInBytes);
|
| 282 |
+
|
| 283 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 284 |
+
cudnnGetRNNTrainingReserveSize(cudnnHandle_t handle,
|
| 285 |
+
const cudnnRNNDescriptor_t rnnDesc,
|
| 286 |
+
const int seqLength,
|
| 287 |
+
const cudnnTensorDescriptor_t *xDesc,
|
| 288 |
+
size_t *sizeInBytes);
|
| 289 |
+
|
| 290 |
+
cudnnStatus_t CUDNNWINAPI
|
| 291 |
+
cudnnGetRNNTempSpaceSizes(cudnnHandle_t handle,
|
| 292 |
+
cudnnRNNDescriptor_t rnnDesc,
|
| 293 |
+
cudnnForwardMode_t fwdMode,
|
| 294 |
+
cudnnRNNDataDescriptor_t xDesc,
|
| 295 |
+
size_t *workSpaceSize,
|
| 296 |
+
size_t *reserveSpaceSize);
|
| 297 |
+
|
| 298 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 299 |
+
cudnnGetRNNParamsSize(cudnnHandle_t handle,
|
| 300 |
+
const cudnnRNNDescriptor_t rnnDesc,
|
| 301 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 302 |
+
size_t *sizeInBytes,
|
| 303 |
+
cudnnDataType_t dataType);
|
| 304 |
+
|
| 305 |
+
cudnnStatus_t CUDNNWINAPI
|
| 306 |
+
cudnnGetRNNWeightSpaceSize(cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, size_t *weightSpaceSize);
|
| 307 |
+
|
| 308 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 309 |
+
cudnnGetRNNLinLayerMatrixParams(cudnnHandle_t handle,
|
| 310 |
+
const cudnnRNNDescriptor_t rnnDesc,
|
| 311 |
+
const int pseudoLayer,
|
| 312 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 313 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 314 |
+
const void *w,
|
| 315 |
+
const int linLayerID,
|
| 316 |
+
cudnnFilterDescriptor_t linLayerMatDesc,
|
| 317 |
+
void **linLayerMat);
|
| 318 |
+
|
| 319 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 320 |
+
cudnnGetRNNLinLayerBiasParams(cudnnHandle_t handle,
|
| 321 |
+
const cudnnRNNDescriptor_t rnnDesc,
|
| 322 |
+
const int pseudoLayer,
|
| 323 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 324 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 325 |
+
const void *w,
|
| 326 |
+
const int linLayerID,
|
| 327 |
+
cudnnFilterDescriptor_t linLayerBiasDesc,
|
| 328 |
+
void **linLayerBias);
|
| 329 |
+
|
| 330 |
+
cudnnStatus_t CUDNNWINAPI
|
| 331 |
+
cudnnGetRNNWeightParams(cudnnHandle_t handle,
|
| 332 |
+
cudnnRNNDescriptor_t rnnDesc,
|
| 333 |
+
int32_t pseudoLayer,
|
| 334 |
+
size_t weightSpaceSize,
|
| 335 |
+
const void *weightSpace,
|
| 336 |
+
int32_t linLayerID,
|
| 337 |
+
cudnnTensorDescriptor_t mDesc,
|
| 338 |
+
void **mAddr,
|
| 339 |
+
cudnnTensorDescriptor_t bDesc,
|
| 340 |
+
void **bAddr);
|
| 341 |
+
|
| 342 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 343 |
+
cudnnRNNForwardInference(cudnnHandle_t handle,
|
| 344 |
+
const cudnnRNNDescriptor_t rnnDesc,
|
| 345 |
+
const int seqLength,
|
| 346 |
+
const cudnnTensorDescriptor_t *xDesc,
|
| 347 |
+
const void *x,
|
| 348 |
+
const cudnnTensorDescriptor_t hxDesc,
|
| 349 |
+
const void *hx,
|
| 350 |
+
const cudnnTensorDescriptor_t cxDesc,
|
| 351 |
+
const void *cx,
|
| 352 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 353 |
+
const void *w,
|
| 354 |
+
const cudnnTensorDescriptor_t *yDesc,
|
| 355 |
+
void *y,
|
| 356 |
+
const cudnnTensorDescriptor_t hyDesc,
|
| 357 |
+
void *hy,
|
| 358 |
+
const cudnnTensorDescriptor_t cyDesc,
|
| 359 |
+
void *cy,
|
| 360 |
+
void *workSpace,
|
| 361 |
+
size_t workSpaceSizeInBytes);
|
| 362 |
+
|
| 363 |
+
/* RNN EX API */
|
| 364 |
+
|
| 365 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 366 |
+
cudnnSetRNNPaddingMode(cudnnRNNDescriptor_t rnnDesc, unsigned paddingMode);
|
| 367 |
+
|
| 368 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 369 |
+
cudnnGetRNNPaddingMode(cudnnRNNDescriptor_t rnnDesc, unsigned *paddingMode);
|
| 370 |
+
|
| 371 |
+
cudnnStatus_t CUDNNWINAPI
|
| 372 |
+
cudnnCreateRNNDataDescriptor(cudnnRNNDataDescriptor_t *rnnDataDesc);
|
| 373 |
+
|
| 374 |
+
cudnnStatus_t CUDNNWINAPI
|
| 375 |
+
cudnnDestroyRNNDataDescriptor(cudnnRNNDataDescriptor_t rnnDataDesc);
|
| 376 |
+
|
| 377 |
+
cudnnStatus_t CUDNNWINAPI
|
| 378 |
+
cudnnSetRNNDataDescriptor(cudnnRNNDataDescriptor_t rnnDataDesc,
|
| 379 |
+
cudnnDataType_t dataType,
|
| 380 |
+
cudnnRNNDataLayout_t layout,
|
| 381 |
+
int maxSeqLength,
|
| 382 |
+
int batchSize,
|
| 383 |
+
int vectorSize,
|
| 384 |
+
const int seqLengthArray[], /* length of each sequence in the batch */
|
| 385 |
+
void *paddingFill); /* symbol for filling padding position in output */
|
| 386 |
+
|
| 387 |
+
cudnnStatus_t CUDNNWINAPI
|
| 388 |
+
cudnnGetRNNDataDescriptor(cudnnRNNDataDescriptor_t rnnDataDesc,
|
| 389 |
+
cudnnDataType_t *dataType,
|
| 390 |
+
cudnnRNNDataLayout_t *layout,
|
| 391 |
+
int *maxSeqLength,
|
| 392 |
+
int *batchSize,
|
| 393 |
+
int *vectorSize,
|
| 394 |
+
int arrayLengthRequested,
|
| 395 |
+
int seqLengthArray[],
|
| 396 |
+
void *paddingFill);
|
| 397 |
+
|
| 398 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 399 |
+
cudnnRNNForwardInferenceEx(cudnnHandle_t handle,
|
| 400 |
+
const cudnnRNNDescriptor_t rnnDesc,
|
| 401 |
+
const cudnnRNNDataDescriptor_t xDesc,
|
| 402 |
+
const void *x,
|
| 403 |
+
const cudnnTensorDescriptor_t hxDesc,
|
| 404 |
+
const void *hx,
|
| 405 |
+
const cudnnTensorDescriptor_t cxDesc,
|
| 406 |
+
const void *cx,
|
| 407 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 408 |
+
const void *w,
|
| 409 |
+
const cudnnRNNDataDescriptor_t yDesc,
|
| 410 |
+
void *y,
|
| 411 |
+
const cudnnTensorDescriptor_t hyDesc,
|
| 412 |
+
void *hy,
|
| 413 |
+
const cudnnTensorDescriptor_t cyDesc,
|
| 414 |
+
void *cy,
|
| 415 |
+
const cudnnRNNDataDescriptor_t kDesc, /* reserved, should pass NULL */
|
| 416 |
+
const void *keys, /* reserved, should pass NULL */
|
| 417 |
+
const cudnnRNNDataDescriptor_t cDesc, /* reserved, should pass NULL */
|
| 418 |
+
void *cAttn, /* reserved, should pass NULL */
|
| 419 |
+
const cudnnRNNDataDescriptor_t iDesc, /* reserved, should pass NULL */
|
| 420 |
+
void *iAttn, /* reserved, should pass NULL */
|
| 421 |
+
const cudnnRNNDataDescriptor_t qDesc, /* reserved, should pass NULL */
|
| 422 |
+
void *queries, /* reserved, should pass NULL */
|
| 423 |
+
void *workSpace,
|
| 424 |
+
size_t workSpaceSizeInBytes);
|
| 425 |
+
|
| 426 |
+
cudnnStatus_t CUDNNWINAPI
|
| 427 |
+
cudnnRNNForward(cudnnHandle_t handle,
|
| 428 |
+
cudnnRNNDescriptor_t rnnDesc,
|
| 429 |
+
cudnnForwardMode_t fwdMode,
|
| 430 |
+
const int32_t devSeqLengths[],
|
| 431 |
+
cudnnRNNDataDescriptor_t xDesc,
|
| 432 |
+
const void *x,
|
| 433 |
+
cudnnRNNDataDescriptor_t yDesc,
|
| 434 |
+
void *y,
|
| 435 |
+
cudnnTensorDescriptor_t hDesc,
|
| 436 |
+
const void *hx,
|
| 437 |
+
void *hy,
|
| 438 |
+
cudnnTensorDescriptor_t cDesc,
|
| 439 |
+
const void *cx,
|
| 440 |
+
void *cy,
|
| 441 |
+
size_t weightSpaceSize,
|
| 442 |
+
const void *weightSpace,
|
| 443 |
+
size_t workSpaceSize,
|
| 444 |
+
void *workSpace,
|
| 445 |
+
size_t reserveSpaceSize,
|
| 446 |
+
void *reserveSpace);
|
| 447 |
+
|
| 448 |
+
/* RNN FIND API */
|
| 449 |
+
|
| 450 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 451 |
+
cudnnSetRNNAlgorithmDescriptor(cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, cudnnAlgorithmDescriptor_t algoDesc);
|
| 452 |
+
|
| 453 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 454 |
+
cudnnGetRNNForwardInferenceAlgorithmMaxCount(cudnnHandle_t handle, const cudnnRNNDescriptor_t rnnDesc, int *count);
|
| 455 |
+
|
| 456 |
+
CUDNN_DEPRECATED cudnnStatus_t CUDNNWINAPI
|
| 457 |
+
cudnnFindRNNForwardInferenceAlgorithmEx(cudnnHandle_t handle,
|
| 458 |
+
const cudnnRNNDescriptor_t rnnDesc,
|
| 459 |
+
const int seqLength,
|
| 460 |
+
const cudnnTensorDescriptor_t *xDesc,
|
| 461 |
+
const void *x,
|
| 462 |
+
const cudnnTensorDescriptor_t hxDesc,
|
| 463 |
+
const void *hx,
|
| 464 |
+
const cudnnTensorDescriptor_t cxDesc,
|
| 465 |
+
const void *cx,
|
| 466 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 467 |
+
const void *w,
|
| 468 |
+
const cudnnTensorDescriptor_t *yDesc,
|
| 469 |
+
void *y,
|
| 470 |
+
const cudnnTensorDescriptor_t hyDesc,
|
| 471 |
+
void *hy,
|
| 472 |
+
const cudnnTensorDescriptor_t cyDesc,
|
| 473 |
+
void *cy,
|
| 474 |
+
const float findIntensity,
|
| 475 |
+
const int requestedAlgoCount,
|
| 476 |
+
int *returnedAlgoCount,
|
| 477 |
+
cudnnAlgorithmPerformance_t *perfResults,
|
| 478 |
+
void *workspace,
|
| 479 |
+
size_t workSpaceSizeInBytes);
|
| 480 |
+
|
| 481 |
+
/* Sequence data descriptor */
|
| 482 |
+
|
| 483 |
+
typedef enum {
|
| 484 |
+
CUDNN_SEQDATA_TIME_DIM = 0, /* index in time */
|
| 485 |
+
CUDNN_SEQDATA_BATCH_DIM = 1, /* index in batch */
|
| 486 |
+
CUDNN_SEQDATA_BEAM_DIM = 2, /* index in beam */
|
| 487 |
+
CUDNN_SEQDATA_VECT_DIM = 3 /* index in vector */
|
| 488 |
+
} cudnnSeqDataAxis_t;
|
| 489 |
+
|
| 490 |
+
struct cudnnSeqDataStruct;
|
| 491 |
+
typedef struct cudnnSeqDataStruct *cudnnSeqDataDescriptor_t;
|
| 492 |
+
|
| 493 |
+
#define CUDNN_SEQDATA_DIM_COUNT 4 /* dimension count */
|
| 494 |
+
|
| 495 |
+
cudnnStatus_t CUDNNWINAPI
|
| 496 |
+
cudnnCreateSeqDataDescriptor(cudnnSeqDataDescriptor_t *seqDataDesc);
|
| 497 |
+
|
| 498 |
+
cudnnStatus_t CUDNNWINAPI
|
| 499 |
+
cudnnDestroySeqDataDescriptor(cudnnSeqDataDescriptor_t seqDataDesc);
|
| 500 |
+
|
| 501 |
+
cudnnStatus_t CUDNNWINAPI
|
| 502 |
+
cudnnSetSeqDataDescriptor(cudnnSeqDataDescriptor_t seqDataDesc,
|
| 503 |
+
cudnnDataType_t dataType,
|
| 504 |
+
int nbDims,
|
| 505 |
+
const int dimA[],
|
| 506 |
+
const cudnnSeqDataAxis_t axes[],
|
| 507 |
+
size_t seqLengthArraySize,
|
| 508 |
+
const int seqLengthArray[],
|
| 509 |
+
void *paddingFill);
|
| 510 |
+
|
| 511 |
+
cudnnStatus_t CUDNNWINAPI
|
| 512 |
+
cudnnGetSeqDataDescriptor(const cudnnSeqDataDescriptor_t seqDataDesc,
|
| 513 |
+
cudnnDataType_t *dataType,
|
| 514 |
+
int *nbDims,
|
| 515 |
+
int nbDimsRequested,
|
| 516 |
+
int dimA[],
|
| 517 |
+
cudnnSeqDataAxis_t axes[],
|
| 518 |
+
size_t *seqLengthArraySize,
|
| 519 |
+
size_t seqLengthSizeRequested,
|
| 520 |
+
int seqLengthArray[],
|
| 521 |
+
void *paddingFill);
|
| 522 |
+
|
| 523 |
+
/* Multihead Attention */
|
| 524 |
+
|
| 525 |
+
/* Legacy type for backward compatibility */
|
| 526 |
+
typedef unsigned cudnnAttnQueryMap_t;
|
| 527 |
+
|
| 528 |
+
/*
|
| 529 |
+
* Multi-head attention options passed via 'attnMode' in cudnnSetAttnDescriptor().
|
| 530 |
+
* Use the bitwise OR operator to combine several settings listed below. Additional
|
| 531 |
+
* minor options can be added here w/o changing or introducing new API functions.
|
| 532 |
+
*/
|
| 533 |
+
#define CUDNN_ATTN_QUERYMAP_ALL_TO_ONE 0 /* multiple Q-s map to a single (K,V) set when beam size > 1 */
|
| 534 |
+
#define CUDNN_ATTN_QUERYMAP_ONE_TO_ONE (1U << 0) /* multiple Q-s map to multiple (K,V) sets when beam size > 1 */
|
| 535 |
+
#define CUDNN_ATTN_DISABLE_PROJ_BIASES 0 /* no biases in attention input and output projections */
|
| 536 |
+
#define CUDNN_ATTN_ENABLE_PROJ_BIASES (1U << 1) /* use biases in attention input and output projections */
|
| 537 |
+
|
| 538 |
+
struct cudnnAttnStruct;
|
| 539 |
+
typedef struct cudnnAttnStruct *cudnnAttnDescriptor_t;
|
| 540 |
+
|
| 541 |
+
cudnnStatus_t CUDNNWINAPI
|
| 542 |
+
cudnnCreateAttnDescriptor(cudnnAttnDescriptor_t *attnDesc);
|
| 543 |
+
|
| 544 |
+
cudnnStatus_t CUDNNWINAPI
|
| 545 |
+
cudnnDestroyAttnDescriptor(cudnnAttnDescriptor_t attnDesc);
|
| 546 |
+
|
| 547 |
+
cudnnStatus_t CUDNNWINAPI
|
| 548 |
+
cudnnSetAttnDescriptor(cudnnAttnDescriptor_t attnDesc,
|
| 549 |
+
unsigned attnMode,
|
| 550 |
+
int nHeads,
|
| 551 |
+
double smScaler,
|
| 552 |
+
cudnnDataType_t dataType,
|
| 553 |
+
cudnnDataType_t computePrec,
|
| 554 |
+
cudnnMathType_t mathType,
|
| 555 |
+
cudnnDropoutDescriptor_t attnDropoutDesc,
|
| 556 |
+
cudnnDropoutDescriptor_t postDropoutDesc,
|
| 557 |
+
int qSize,
|
| 558 |
+
int kSize,
|
| 559 |
+
int vSize,
|
| 560 |
+
int qProjSize,
|
| 561 |
+
int kProjSize,
|
| 562 |
+
int vProjSize,
|
| 563 |
+
int oProjSize,
|
| 564 |
+
int qoMaxSeqLength,
|
| 565 |
+
int kvMaxSeqLength,
|
| 566 |
+
int maxBatchSize,
|
| 567 |
+
int maxBeamSize);
|
| 568 |
+
|
| 569 |
+
cudnnStatus_t CUDNNWINAPI
|
| 570 |
+
cudnnGetAttnDescriptor(cudnnAttnDescriptor_t attnDesc,
|
| 571 |
+
unsigned *attnMode,
|
| 572 |
+
int *nHeads,
|
| 573 |
+
double *smScaler,
|
| 574 |
+
cudnnDataType_t *dataType,
|
| 575 |
+
cudnnDataType_t *computePrec,
|
| 576 |
+
cudnnMathType_t *mathType,
|
| 577 |
+
cudnnDropoutDescriptor_t *attnDropoutDesc,
|
| 578 |
+
cudnnDropoutDescriptor_t *postDropoutDesc,
|
| 579 |
+
int *qSize,
|
| 580 |
+
int *kSize,
|
| 581 |
+
int *vSize,
|
| 582 |
+
int *qProjSize,
|
| 583 |
+
int *kProjSize,
|
| 584 |
+
int *vProjSize,
|
| 585 |
+
int *oProjSize,
|
| 586 |
+
int *qoMaxSeqLength,
|
| 587 |
+
int *kvMaxSeqLength,
|
| 588 |
+
int *maxBatchSize,
|
| 589 |
+
int *maxBeamSize);
|
| 590 |
+
|
| 591 |
+
cudnnStatus_t CUDNNWINAPI
|
| 592 |
+
cudnnGetMultiHeadAttnBuffers(cudnnHandle_t handle,
|
| 593 |
+
const cudnnAttnDescriptor_t attnDesc,
|
| 594 |
+
size_t *weightSizeInBytes,
|
| 595 |
+
size_t *workSpaceSizeInBytes,
|
| 596 |
+
size_t *reserveSpaceSizeInBytes);
|
| 597 |
+
|
| 598 |
+
typedef enum {
|
| 599 |
+
CUDNN_MH_ATTN_Q_WEIGHTS = 0, /* input projection weights for 'queries' */
|
| 600 |
+
CUDNN_MH_ATTN_K_WEIGHTS = 1, /* input projection weights for 'keys' */
|
| 601 |
+
CUDNN_MH_ATTN_V_WEIGHTS = 2, /* input projection weights for 'values' */
|
| 602 |
+
CUDNN_MH_ATTN_O_WEIGHTS = 3, /* output projection weights */
|
| 603 |
+
CUDNN_MH_ATTN_Q_BIASES = 4, /* input projection bias tensor for 'queries' */
|
| 604 |
+
CUDNN_MH_ATTN_K_BIASES = 5, /* input projection bias for 'keys' */
|
| 605 |
+
CUDNN_MH_ATTN_V_BIASES = 6, /* input projection bias for 'values' */
|
| 606 |
+
CUDNN_MH_ATTN_O_BIASES = 7, /* output projection biases */
|
| 607 |
+
} cudnnMultiHeadAttnWeightKind_t;
|
| 608 |
+
|
| 609 |
+
#define CUDNN_ATTN_WKIND_COUNT 8 /* Number of attention weight/bias tensors */
|
| 610 |
+
|
| 611 |
+
cudnnStatus_t CUDNNWINAPI
|
| 612 |
+
cudnnGetMultiHeadAttnWeights(cudnnHandle_t handle,
|
| 613 |
+
const cudnnAttnDescriptor_t attnDesc,
|
| 614 |
+
cudnnMultiHeadAttnWeightKind_t wKind,
|
| 615 |
+
size_t weightSizeInBytes,
|
| 616 |
+
const void *weights,
|
| 617 |
+
cudnnTensorDescriptor_t wDesc,
|
| 618 |
+
void **wAddr);
|
| 619 |
+
|
| 620 |
+
cudnnStatus_t CUDNNWINAPI
|
| 621 |
+
cudnnMultiHeadAttnForward(cudnnHandle_t handle,
|
| 622 |
+
const cudnnAttnDescriptor_t attnDesc,
|
| 623 |
+
int currIdx,
|
| 624 |
+
const int loWinIdx[],
|
| 625 |
+
const int hiWinIdx[],
|
| 626 |
+
const int devSeqLengthsQO[],
|
| 627 |
+
const int devSeqLengthsKV[],
|
| 628 |
+
const cudnnSeqDataDescriptor_t qDesc,
|
| 629 |
+
const void *queries,
|
| 630 |
+
const void *residuals,
|
| 631 |
+
const cudnnSeqDataDescriptor_t kDesc,
|
| 632 |
+
const void *keys,
|
| 633 |
+
const cudnnSeqDataDescriptor_t vDesc,
|
| 634 |
+
const void *values,
|
| 635 |
+
const cudnnSeqDataDescriptor_t oDesc,
|
| 636 |
+
void *out,
|
| 637 |
+
size_t weightSizeInBytes,
|
| 638 |
+
const void *weights,
|
| 639 |
+
size_t workSpaceSizeInBytes,
|
| 640 |
+
void *workSpace,
|
| 641 |
+
size_t reserveSpaceSizeInBytes,
|
| 642 |
+
void *reserveSpace);
|
| 643 |
+
|
| 644 |
+
/*
|
| 645 |
+
* \brief Cross-library version checker.
|
| 646 |
+
* This function is implemented differently in each sub-library. Each sublib
|
| 647 |
+
* checks whether its own version matches that of its dependencies.
|
| 648 |
+
* \returns CUDNN_STATUS_SUCCESS if the version check passes,
|
| 649 |
+
* CUDNN_STATUS_VERSION_MISMATCH if the versions are inconsistent.
|
| 650 |
+
*/
|
| 651 |
+
cudnnStatus_t CUDNNWINAPI
|
| 652 |
+
cudnnAdvInferVersionCheck(void);
|
| 653 |
+
|
| 654 |
+
#if defined(__cplusplus)
|
| 655 |
+
}
|
| 656 |
+
#endif
|
| 657 |
+
|
| 658 |
+
#endif /* CUDNN_ADV_INFER_H_ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cudnn/include/cudnn_backend.h
ADDED
|
@@ -0,0 +1,608 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2014-2023 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
#ifndef _CUDNN_BACKEND_H_
|
| 51 |
+
#define _CUDNN_BACKEND_H_
|
| 52 |
+
|
| 53 |
+
/*
|
| 54 |
+
* The content in this header file is under development to be included in cudnn.h in the future
|
| 55 |
+
* Production code should have all include of this header file remove.
|
| 56 |
+
*/
|
| 57 |
+
|
| 58 |
+
#include "cudnn_ops_infer.h"
|
| 59 |
+
#include "cudnn_cnn_infer.h"
|
| 60 |
+
|
| 61 |
+
/* NOTE: definition in extern "C" to be copied later to public header */
|
| 62 |
+
#if defined(__cplusplus)
|
| 63 |
+
extern "C" {
|
| 64 |
+
#endif
|
| 65 |
+
|
| 66 |
+
typedef void *cudnnBackendDescriptor_t;
|
| 67 |
+
|
| 68 |
+
typedef struct cudnnFractionStruct {
|
| 69 |
+
int64_t numerator;
|
| 70 |
+
int64_t denominator;
|
| 71 |
+
} cudnnFraction_t;
|
| 72 |
+
|
| 73 |
+
typedef enum {
|
| 74 |
+
CUDNN_POINTWISE_ADD = 0,
|
| 75 |
+
CUDNN_POINTWISE_ADD_SQUARE = 5,
|
| 76 |
+
CUDNN_POINTWISE_DIV = 6,
|
| 77 |
+
CUDNN_POINTWISE_MAX = 3,
|
| 78 |
+
CUDNN_POINTWISE_MIN = 2,
|
| 79 |
+
CUDNN_POINTWISE_MOD = 7,
|
| 80 |
+
CUDNN_POINTWISE_MUL = 1,
|
| 81 |
+
CUDNN_POINTWISE_POW = 8,
|
| 82 |
+
CUDNN_POINTWISE_SUB = 9,
|
| 83 |
+
|
| 84 |
+
CUDNN_POINTWISE_ABS = 10,
|
| 85 |
+
CUDNN_POINTWISE_CEIL = 11,
|
| 86 |
+
CUDNN_POINTWISE_COS = 12,
|
| 87 |
+
CUDNN_POINTWISE_EXP = 13,
|
| 88 |
+
CUDNN_POINTWISE_FLOOR = 14,
|
| 89 |
+
CUDNN_POINTWISE_LOG = 15,
|
| 90 |
+
CUDNN_POINTWISE_NEG = 16,
|
| 91 |
+
CUDNN_POINTWISE_RSQRT = 17,
|
| 92 |
+
CUDNN_POINTWISE_SIN = 18,
|
| 93 |
+
CUDNN_POINTWISE_SQRT = 4,
|
| 94 |
+
CUDNN_POINTWISE_TAN = 19,
|
| 95 |
+
CUDNN_POINTWISE_ERF = 20,
|
| 96 |
+
CUDNN_POINTWISE_IDENTITY = 21,
|
| 97 |
+
CUDNN_POINTWISE_RECIPROCAL = 22,
|
| 98 |
+
|
| 99 |
+
CUDNN_POINTWISE_RELU_FWD = 100,
|
| 100 |
+
CUDNN_POINTWISE_TANH_FWD = 101,
|
| 101 |
+
CUDNN_POINTWISE_SIGMOID_FWD = 102,
|
| 102 |
+
CUDNN_POINTWISE_ELU_FWD = 103,
|
| 103 |
+
CUDNN_POINTWISE_GELU_FWD = 104,
|
| 104 |
+
CUDNN_POINTWISE_SOFTPLUS_FWD = 105,
|
| 105 |
+
CUDNN_POINTWISE_SWISH_FWD = 106,
|
| 106 |
+
CUDNN_POINTWISE_GELU_APPROX_TANH_FWD = 107,
|
| 107 |
+
|
| 108 |
+
CUDNN_POINTWISE_RELU_BWD = 200,
|
| 109 |
+
CUDNN_POINTWISE_TANH_BWD = 201,
|
| 110 |
+
CUDNN_POINTWISE_SIGMOID_BWD = 202,
|
| 111 |
+
CUDNN_POINTWISE_ELU_BWD = 203,
|
| 112 |
+
CUDNN_POINTWISE_GELU_BWD = 204,
|
| 113 |
+
CUDNN_POINTWISE_SOFTPLUS_BWD = 205,
|
| 114 |
+
CUDNN_POINTWISE_SWISH_BWD = 206,
|
| 115 |
+
CUDNN_POINTWISE_GELU_APPROX_TANH_BWD = 207,
|
| 116 |
+
|
| 117 |
+
CUDNN_POINTWISE_CMP_EQ = 300,
|
| 118 |
+
CUDNN_POINTWISE_CMP_NEQ = 301,
|
| 119 |
+
CUDNN_POINTWISE_CMP_GT = 302,
|
| 120 |
+
CUDNN_POINTWISE_CMP_GE = 303,
|
| 121 |
+
CUDNN_POINTWISE_CMP_LT = 304,
|
| 122 |
+
CUDNN_POINTWISE_CMP_LE = 305,
|
| 123 |
+
|
| 124 |
+
CUDNN_POINTWISE_LOGICAL_AND = 400,
|
| 125 |
+
CUDNN_POINTWISE_LOGICAL_OR = 401,
|
| 126 |
+
CUDNN_POINTWISE_LOGICAL_NOT = 402,
|
| 127 |
+
|
| 128 |
+
CUDNN_POINTWISE_GEN_INDEX = 501,
|
| 129 |
+
|
| 130 |
+
CUDNN_POINTWISE_BINARY_SELECT = 601,
|
| 131 |
+
} cudnnPointwiseMode_t;
|
| 132 |
+
|
| 133 |
+
typedef enum {
|
| 134 |
+
CUDNN_RESAMPLE_NEAREST = 0,
|
| 135 |
+
CUDNN_RESAMPLE_BILINEAR = 1,
|
| 136 |
+
CUDNN_RESAMPLE_AVGPOOL = 2,
|
| 137 |
+
CUDNN_RESAMPLE_AVGPOOL_INCLUDE_PADDING = 2,
|
| 138 |
+
CUDNN_RESAMPLE_AVGPOOL_EXCLUDE_PADDING = 4,
|
| 139 |
+
CUDNN_RESAMPLE_MAXPOOL = 3,
|
| 140 |
+
} cudnnResampleMode_t;
|
| 141 |
+
|
| 142 |
+
typedef enum {
|
| 143 |
+
CUDNN_SIGNAL_SET = 0,
|
| 144 |
+
CUDNN_SIGNAL_WAIT = 1,
|
| 145 |
+
} cudnnSignalMode_t;
|
| 146 |
+
|
| 147 |
+
typedef enum {
|
| 148 |
+
CUDNN_GENSTATS_SUM_SQSUM = 0,
|
| 149 |
+
} cudnnGenStatsMode_t;
|
| 150 |
+
|
| 151 |
+
typedef enum {
|
| 152 |
+
CUDNN_BN_FINALIZE_STATISTICS_TRAINING = 0,
|
| 153 |
+
CUDNN_BN_FINALIZE_STATISTICS_INFERENCE = 1,
|
| 154 |
+
} cudnnBnFinalizeStatsMode_t;
|
| 155 |
+
|
| 156 |
+
typedef enum {
|
| 157 |
+
CUDNN_RNG_DISTRIBUTION_BERNOULLI,
|
| 158 |
+
CUDNN_RNG_DISTRIBUTION_UNIFORM,
|
| 159 |
+
CUDNN_RNG_DISTRIBUTION_NORMAL,
|
| 160 |
+
} cudnnRngDistribution_t;
|
| 161 |
+
|
| 162 |
+
typedef enum {
|
| 163 |
+
CUDNN_ATTR_POINTWISE_MODE = 0,
|
| 164 |
+
CUDNN_ATTR_POINTWISE_MATH_PREC = 1,
|
| 165 |
+
CUDNN_ATTR_POINTWISE_NAN_PROPAGATION = 2,
|
| 166 |
+
CUDNN_ATTR_POINTWISE_RELU_LOWER_CLIP = 3,
|
| 167 |
+
CUDNN_ATTR_POINTWISE_RELU_UPPER_CLIP = 4,
|
| 168 |
+
CUDNN_ATTR_POINTWISE_RELU_LOWER_CLIP_SLOPE = 5,
|
| 169 |
+
CUDNN_ATTR_POINTWISE_ELU_ALPHA = 6,
|
| 170 |
+
CUDNN_ATTR_POINTWISE_SOFTPLUS_BETA = 7,
|
| 171 |
+
CUDNN_ATTR_POINTWISE_SWISH_BETA = 8,
|
| 172 |
+
CUDNN_ATTR_POINTWISE_AXIS = 9,
|
| 173 |
+
|
| 174 |
+
CUDNN_ATTR_CONVOLUTION_COMP_TYPE = 100,
|
| 175 |
+
CUDNN_ATTR_CONVOLUTION_CONV_MODE = 101,
|
| 176 |
+
CUDNN_ATTR_CONVOLUTION_DILATIONS = 102,
|
| 177 |
+
CUDNN_ATTR_CONVOLUTION_FILTER_STRIDES = 103,
|
| 178 |
+
CUDNN_ATTR_CONVOLUTION_POST_PADDINGS = 104,
|
| 179 |
+
CUDNN_ATTR_CONVOLUTION_PRE_PADDINGS = 105,
|
| 180 |
+
CUDNN_ATTR_CONVOLUTION_SPATIAL_DIMS = 106,
|
| 181 |
+
|
| 182 |
+
CUDNN_ATTR_ENGINEHEUR_MODE = 200,
|
| 183 |
+
CUDNN_ATTR_ENGINEHEUR_OPERATION_GRAPH = 201,
|
| 184 |
+
CUDNN_ATTR_ENGINEHEUR_RESULTS = 202,
|
| 185 |
+
|
| 186 |
+
CUDNN_ATTR_ENGINECFG_ENGINE = 300,
|
| 187 |
+
CUDNN_ATTR_ENGINECFG_INTERMEDIATE_INFO = 301,
|
| 188 |
+
CUDNN_ATTR_ENGINECFG_KNOB_CHOICES = 302,
|
| 189 |
+
|
| 190 |
+
CUDNN_ATTR_EXECUTION_PLAN_HANDLE = 400,
|
| 191 |
+
CUDNN_ATTR_EXECUTION_PLAN_ENGINE_CONFIG = 401,
|
| 192 |
+
CUDNN_ATTR_EXECUTION_PLAN_WORKSPACE_SIZE = 402,
|
| 193 |
+
CUDNN_ATTR_EXECUTION_PLAN_COMPUTED_INTERMEDIATE_UIDS = 403,
|
| 194 |
+
CUDNN_ATTR_EXECUTION_PLAN_RUN_ONLY_INTERMEDIATE_UIDS = 404,
|
| 195 |
+
CUDNN_ATTR_EXECUTION_PLAN_JSON_REPRESENTATION = 405,
|
| 196 |
+
|
| 197 |
+
CUDNN_ATTR_INTERMEDIATE_INFO_UNIQUE_ID = 500,
|
| 198 |
+
CUDNN_ATTR_INTERMEDIATE_INFO_SIZE = 501,
|
| 199 |
+
CUDNN_ATTR_INTERMEDIATE_INFO_DEPENDENT_DATA_UIDS = 502,
|
| 200 |
+
CUDNN_ATTR_INTERMEDIATE_INFO_DEPENDENT_ATTRIBUTES = 503,
|
| 201 |
+
|
| 202 |
+
CUDNN_ATTR_KNOB_CHOICE_KNOB_TYPE = 600,
|
| 203 |
+
CUDNN_ATTR_KNOB_CHOICE_KNOB_VALUE = 601,
|
| 204 |
+
|
| 205 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_ALPHA = 700,
|
| 206 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_BETA = 701,
|
| 207 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_CONV_DESC = 702,
|
| 208 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_W = 703,
|
| 209 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_X = 704,
|
| 210 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_Y = 705,
|
| 211 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_ALPHA = 706,
|
| 212 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_BETA = 707,
|
| 213 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_CONV_DESC = 708,
|
| 214 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_W = 709,
|
| 215 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_DX = 710,
|
| 216 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_DY = 711,
|
| 217 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_ALPHA = 712,
|
| 218 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_BETA = 713,
|
| 219 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_CONV_DESC = 714,
|
| 220 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_DW = 715,
|
| 221 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_X = 716,
|
| 222 |
+
CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_DY = 717,
|
| 223 |
+
|
| 224 |
+
CUDNN_ATTR_OPERATION_POINTWISE_PW_DESCRIPTOR = 750,
|
| 225 |
+
CUDNN_ATTR_OPERATION_POINTWISE_XDESC = 751,
|
| 226 |
+
CUDNN_ATTR_OPERATION_POINTWISE_BDESC = 752,
|
| 227 |
+
CUDNN_ATTR_OPERATION_POINTWISE_YDESC = 753,
|
| 228 |
+
CUDNN_ATTR_OPERATION_POINTWISE_ALPHA1 = 754,
|
| 229 |
+
CUDNN_ATTR_OPERATION_POINTWISE_ALPHA2 = 755,
|
| 230 |
+
CUDNN_ATTR_OPERATION_POINTWISE_DXDESC = 756,
|
| 231 |
+
CUDNN_ATTR_OPERATION_POINTWISE_DYDESC = 757,
|
| 232 |
+
CUDNN_ATTR_OPERATION_POINTWISE_TDESC = 758,
|
| 233 |
+
|
| 234 |
+
CUDNN_ATTR_OPERATION_GENSTATS_MODE = 770,
|
| 235 |
+
CUDNN_ATTR_OPERATION_GENSTATS_MATH_PREC = 771,
|
| 236 |
+
CUDNN_ATTR_OPERATION_GENSTATS_XDESC = 772,
|
| 237 |
+
CUDNN_ATTR_OPERATION_GENSTATS_SUMDESC = 773,
|
| 238 |
+
CUDNN_ATTR_OPERATION_GENSTATS_SQSUMDESC = 774,
|
| 239 |
+
|
| 240 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_STATS_MODE = 780,
|
| 241 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_MATH_PREC = 781,
|
| 242 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_Y_SUM_DESC = 782,
|
| 243 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_Y_SQ_SUM_DESC = 783,
|
| 244 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_SCALE_DESC = 784,
|
| 245 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_BIAS_DESC = 785,
|
| 246 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_PREV_RUNNING_MEAN_DESC = 786,
|
| 247 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_PREV_RUNNING_VAR_DESC = 787,
|
| 248 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_UPDATED_RUNNING_MEAN_DESC = 788,
|
| 249 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_UPDATED_RUNNING_VAR_DESC = 789,
|
| 250 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_SAVED_MEAN_DESC = 790,
|
| 251 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_SAVED_INV_STD_DESC = 791,
|
| 252 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_EQ_SCALE_DESC = 792,
|
| 253 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_EQ_BIAS_DESC = 793,
|
| 254 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_ACCUM_COUNT_DESC = 794,
|
| 255 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_EPSILON_DESC = 795,
|
| 256 |
+
CUDNN_ATTR_OPERATION_BN_FINALIZE_EXP_AVERATE_FACTOR_DESC = 796,
|
| 257 |
+
|
| 258 |
+
CUDNN_ATTR_OPERATIONGRAPH_HANDLE = 800,
|
| 259 |
+
CUDNN_ATTR_OPERATIONGRAPH_OPS = 801,
|
| 260 |
+
CUDNN_ATTR_OPERATIONGRAPH_ENGINE_GLOBAL_COUNT = 802,
|
| 261 |
+
|
| 262 |
+
CUDNN_ATTR_TENSOR_BYTE_ALIGNMENT = 900,
|
| 263 |
+
CUDNN_ATTR_TENSOR_DATA_TYPE = 901,
|
| 264 |
+
CUDNN_ATTR_TENSOR_DIMENSIONS = 902,
|
| 265 |
+
CUDNN_ATTR_TENSOR_STRIDES = 903,
|
| 266 |
+
CUDNN_ATTR_TENSOR_VECTOR_COUNT = 904,
|
| 267 |
+
CUDNN_ATTR_TENSOR_VECTORIZED_DIMENSION = 905,
|
| 268 |
+
CUDNN_ATTR_TENSOR_UNIQUE_ID = 906,
|
| 269 |
+
CUDNN_ATTR_TENSOR_IS_VIRTUAL = 907,
|
| 270 |
+
CUDNN_ATTR_TENSOR_IS_BY_VALUE = 908,
|
| 271 |
+
CUDNN_ATTR_TENSOR_REORDERING_MODE = 909,
|
| 272 |
+
CUDNN_ATTR_TENSOR_RAGGED_OFFSET_DESC = 913,
|
| 273 |
+
|
| 274 |
+
CUDNN_ATTR_VARIANT_PACK_UNIQUE_IDS = 1000,
|
| 275 |
+
CUDNN_ATTR_VARIANT_PACK_DATA_POINTERS = 1001,
|
| 276 |
+
CUDNN_ATTR_VARIANT_PACK_INTERMEDIATES = 1002,
|
| 277 |
+
CUDNN_ATTR_VARIANT_PACK_WORKSPACE = 1003,
|
| 278 |
+
|
| 279 |
+
CUDNN_ATTR_LAYOUT_INFO_TENSOR_UID = 1100,
|
| 280 |
+
CUDNN_ATTR_LAYOUT_INFO_TYPES = 1101,
|
| 281 |
+
|
| 282 |
+
CUDNN_ATTR_KNOB_INFO_TYPE = 1200,
|
| 283 |
+
CUDNN_ATTR_KNOB_INFO_MAXIMUM_VALUE = 1201,
|
| 284 |
+
CUDNN_ATTR_KNOB_INFO_MINIMUM_VALUE = 1202,
|
| 285 |
+
CUDNN_ATTR_KNOB_INFO_STRIDE = 1203,
|
| 286 |
+
|
| 287 |
+
CUDNN_ATTR_ENGINE_OPERATION_GRAPH = 1300,
|
| 288 |
+
CUDNN_ATTR_ENGINE_GLOBAL_INDEX = 1301,
|
| 289 |
+
CUDNN_ATTR_ENGINE_KNOB_INFO = 1302,
|
| 290 |
+
CUDNN_ATTR_ENGINE_NUMERICAL_NOTE = 1303,
|
| 291 |
+
CUDNN_ATTR_ENGINE_LAYOUT_INFO = 1304,
|
| 292 |
+
CUDNN_ATTR_ENGINE_BEHAVIOR_NOTE = 1305,
|
| 293 |
+
|
| 294 |
+
CUDNN_ATTR_MATMUL_COMP_TYPE = 1500,
|
| 295 |
+
CUDNN_ATTR_MATMUL_PADDING_VALUE = 1503,
|
| 296 |
+
|
| 297 |
+
CUDNN_ATTR_OPERATION_MATMUL_ADESC = 1520,
|
| 298 |
+
CUDNN_ATTR_OPERATION_MATMUL_BDESC = 1521,
|
| 299 |
+
CUDNN_ATTR_OPERATION_MATMUL_CDESC = 1522,
|
| 300 |
+
CUDNN_ATTR_OPERATION_MATMUL_DESC = 1523,
|
| 301 |
+
CUDNN_ATTR_OPERATION_MATMUL_IRREGULARLY_STRIDED_BATCH_COUNT = 1524,
|
| 302 |
+
CUDNN_ATTR_OPERATION_MATMUL_GEMM_M_OVERRIDE_DESC = 1525,
|
| 303 |
+
CUDNN_ATTR_OPERATION_MATMUL_GEMM_N_OVERRIDE_DESC = 1526,
|
| 304 |
+
CUDNN_ATTR_OPERATION_MATMUL_GEMM_K_OVERRIDE_DESC = 1527,
|
| 305 |
+
|
| 306 |
+
CUDNN_ATTR_REDUCTION_OPERATOR = 1600,
|
| 307 |
+
CUDNN_ATTR_REDUCTION_COMP_TYPE = 1601,
|
| 308 |
+
|
| 309 |
+
CUDNN_ATTR_OPERATION_REDUCTION_XDESC = 1610,
|
| 310 |
+
CUDNN_ATTR_OPERATION_REDUCTION_YDESC = 1611,
|
| 311 |
+
CUDNN_ATTR_OPERATION_REDUCTION_DESC = 1612,
|
| 312 |
+
|
| 313 |
+
CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_MATH_PREC = 1620,
|
| 314 |
+
CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_MEAN_DESC = 1621,
|
| 315 |
+
CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_INVSTD_DESC = 1622,
|
| 316 |
+
CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_BN_SCALE_DESC = 1623,
|
| 317 |
+
CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_X_DESC = 1624,
|
| 318 |
+
CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_DY_DESC = 1625,
|
| 319 |
+
CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_DBN_SCALE_DESC = 1626,
|
| 320 |
+
CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_DBN_BIAS_DESC = 1627,
|
| 321 |
+
CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_EQ_DY_SCALE_DESC = 1628,
|
| 322 |
+
CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_EQ_X_SCALE_DESC = 1629,
|
| 323 |
+
CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_EQ_BIAS = 1630,
|
| 324 |
+
|
| 325 |
+
CUDNN_ATTR_RESAMPLE_MODE = 1700,
|
| 326 |
+
CUDNN_ATTR_RESAMPLE_COMP_TYPE = 1701,
|
| 327 |
+
CUDNN_ATTR_RESAMPLE_SPATIAL_DIMS = 1702,
|
| 328 |
+
CUDNN_ATTR_RESAMPLE_POST_PADDINGS = 1703,
|
| 329 |
+
CUDNN_ATTR_RESAMPLE_PRE_PADDINGS = 1704,
|
| 330 |
+
CUDNN_ATTR_RESAMPLE_STRIDES = 1705,
|
| 331 |
+
CUDNN_ATTR_RESAMPLE_WINDOW_DIMS = 1706,
|
| 332 |
+
CUDNN_ATTR_RESAMPLE_NAN_PROPAGATION = 1707,
|
| 333 |
+
CUDNN_ATTR_RESAMPLE_PADDING_MODE = 1708,
|
| 334 |
+
|
| 335 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_FWD_XDESC = 1710,
|
| 336 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_FWD_YDESC = 1711,
|
| 337 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_FWD_IDXDESC = 1712,
|
| 338 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_FWD_ALPHA = 1713,
|
| 339 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_FWD_BETA = 1714,
|
| 340 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_FWD_DESC = 1716,
|
| 341 |
+
|
| 342 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_BWD_DXDESC = 1720,
|
| 343 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_BWD_DYDESC = 1721,
|
| 344 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_BWD_IDXDESC = 1722,
|
| 345 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_BWD_ALPHA = 1723,
|
| 346 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_BWD_BETA = 1724,
|
| 347 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_BWD_DESC = 1725,
|
| 348 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_BWD_XDESC = 1726,
|
| 349 |
+
CUDNN_ATTR_OPERATION_RESAMPLE_BWD_YDESC = 1727,
|
| 350 |
+
|
| 351 |
+
CUDNN_ATTR_OPERATION_CONCAT_AXIS = 1800,
|
| 352 |
+
CUDNN_ATTR_OPERATION_CONCAT_INPUT_DESCS = 1801,
|
| 353 |
+
CUDNN_ATTR_OPERATION_CONCAT_INPLACE_INDEX = 1802,
|
| 354 |
+
CUDNN_ATTR_OPERATION_CONCAT_OUTPUT_DESC = 1803,
|
| 355 |
+
|
| 356 |
+
CUDNN_ATTR_OPERATION_SIGNAL_MODE = 1900,
|
| 357 |
+
CUDNN_ATTR_OPERATION_SIGNAL_FLAGDESC = 1901,
|
| 358 |
+
CUDNN_ATTR_OPERATION_SIGNAL_VALUE = 1902,
|
| 359 |
+
CUDNN_ATTR_OPERATION_SIGNAL_XDESC = 1903,
|
| 360 |
+
CUDNN_ATTR_OPERATION_SIGNAL_YDESC = 1904,
|
| 361 |
+
|
| 362 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_MODE = 2000,
|
| 363 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_PHASE = 2001,
|
| 364 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_XDESC = 2002,
|
| 365 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_MEAN_DESC = 2003,
|
| 366 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_INV_VARIANCE_DESC = 2004,
|
| 367 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_SCALE_DESC = 2005,
|
| 368 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_BIAS_DESC = 2006,
|
| 369 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_EPSILON_DESC = 2007,
|
| 370 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_EXP_AVG_FACTOR_DESC = 2008,
|
| 371 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_INPUT_RUNNING_MEAN_DESC = 2009,
|
| 372 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_INPUT_RUNNING_VAR_DESC = 2010,
|
| 373 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_OUTPUT_RUNNING_MEAN_DESC = 2011,
|
| 374 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_OUTPUT_RUNNING_VAR_DESC = 2012,
|
| 375 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_YDESC = 2013,
|
| 376 |
+
CUDNN_ATTR_OPERATION_NORM_FWD_PEER_STAT_DESCS = 2014,
|
| 377 |
+
|
| 378 |
+
CUDNN_ATTR_OPERATION_NORM_BWD_MODE = 2100,
|
| 379 |
+
CUDNN_ATTR_OPERATION_NORM_BWD_XDESC = 2101,
|
| 380 |
+
CUDNN_ATTR_OPERATION_NORM_BWD_MEAN_DESC = 2102,
|
| 381 |
+
CUDNN_ATTR_OPERATION_NORM_BWD_INV_VARIANCE_DESC = 2103,
|
| 382 |
+
CUDNN_ATTR_OPERATION_NORM_BWD_DYDESC = 2104,
|
| 383 |
+
CUDNN_ATTR_OPERATION_NORM_BWD_SCALE_DESC = 2105,
|
| 384 |
+
CUDNN_ATTR_OPERATION_NORM_BWD_EPSILON_DESC = 2106,
|
| 385 |
+
CUDNN_ATTR_OPERATION_NORM_BWD_DSCALE_DESC = 2107,
|
| 386 |
+
CUDNN_ATTR_OPERATION_NORM_BWD_DBIAS_DESC = 2108,
|
| 387 |
+
CUDNN_ATTR_OPERATION_NORM_BWD_DXDESC = 2109,
|
| 388 |
+
CUDNN_ATTR_OPERATION_NORM_BWD_PEER_STAT_DESCS = 2110,
|
| 389 |
+
|
| 390 |
+
CUDNN_ATTR_OPERATION_RESHAPE_XDESC = 2200,
|
| 391 |
+
CUDNN_ATTR_OPERATION_RESHAPE_YDESC = 2201,
|
| 392 |
+
|
| 393 |
+
CUDNN_ATTR_RNG_DISTRIBUTION = 2300,
|
| 394 |
+
CUDNN_ATTR_RNG_NORMAL_DIST_MEAN = 2301,
|
| 395 |
+
CUDNN_ATTR_RNG_NORMAL_DIST_STANDARD_DEVIATION = 2302,
|
| 396 |
+
CUDNN_ATTR_RNG_UNIFORM_DIST_MAXIMUM = 2303,
|
| 397 |
+
CUDNN_ATTR_RNG_UNIFORM_DIST_MINIMUM = 2304,
|
| 398 |
+
CUDNN_ATTR_RNG_BERNOULLI_DIST_PROBABILITY = 2305,
|
| 399 |
+
|
| 400 |
+
CUDNN_ATTR_OPERATION_RNG_YDESC = 2310,
|
| 401 |
+
CUDNN_ATTR_OPERATION_RNG_SEED = 2311,
|
| 402 |
+
CUDNN_ATTR_OPERATION_RNG_DESC = 2312,
|
| 403 |
+
CUDNN_ATTR_OPERATION_RNG_OFFSET_DESC = 2313,
|
| 404 |
+
|
| 405 |
+
} cudnnBackendAttributeName_t;
|
| 406 |
+
|
| 407 |
+
typedef enum {
|
| 408 |
+
CUDNN_TYPE_HANDLE = 0,
|
| 409 |
+
CUDNN_TYPE_DATA_TYPE,
|
| 410 |
+
CUDNN_TYPE_BOOLEAN,
|
| 411 |
+
CUDNN_TYPE_INT64,
|
| 412 |
+
CUDNN_TYPE_FLOAT,
|
| 413 |
+
CUDNN_TYPE_DOUBLE,
|
| 414 |
+
CUDNN_TYPE_VOID_PTR,
|
| 415 |
+
CUDNN_TYPE_CONVOLUTION_MODE,
|
| 416 |
+
CUDNN_TYPE_HEUR_MODE,
|
| 417 |
+
CUDNN_TYPE_KNOB_TYPE,
|
| 418 |
+
CUDNN_TYPE_NAN_PROPOGATION,
|
| 419 |
+
CUDNN_TYPE_NUMERICAL_NOTE,
|
| 420 |
+
CUDNN_TYPE_LAYOUT_TYPE,
|
| 421 |
+
CUDNN_TYPE_ATTRIB_NAME,
|
| 422 |
+
CUDNN_TYPE_POINTWISE_MODE,
|
| 423 |
+
CUDNN_TYPE_BACKEND_DESCRIPTOR,
|
| 424 |
+
CUDNN_TYPE_GENSTATS_MODE,
|
| 425 |
+
CUDNN_TYPE_BN_FINALIZE_STATS_MODE,
|
| 426 |
+
CUDNN_TYPE_REDUCTION_OPERATOR_TYPE,
|
| 427 |
+
CUDNN_TYPE_BEHAVIOR_NOTE,
|
| 428 |
+
CUDNN_TYPE_TENSOR_REORDERING_MODE,
|
| 429 |
+
CUDNN_TYPE_RESAMPLE_MODE,
|
| 430 |
+
CUDNN_TYPE_PADDING_MODE,
|
| 431 |
+
CUDNN_TYPE_INT32,
|
| 432 |
+
CUDNN_TYPE_CHAR,
|
| 433 |
+
CUDNN_TYPE_SIGNAL_MODE,
|
| 434 |
+
CUDNN_TYPE_FRACTION,
|
| 435 |
+
CUDNN_TYPE_NORM_MODE,
|
| 436 |
+
CUDNN_TYPE_NORM_FWD_PHASE,
|
| 437 |
+
CUDNN_TYPE_RNG_DISTRIBUTION
|
| 438 |
+
} cudnnBackendAttributeType_t;
|
| 439 |
+
|
| 440 |
+
typedef enum {
|
| 441 |
+
CUDNN_BACKEND_POINTWISE_DESCRIPTOR = 0,
|
| 442 |
+
CUDNN_BACKEND_CONVOLUTION_DESCRIPTOR,
|
| 443 |
+
CUDNN_BACKEND_ENGINE_DESCRIPTOR,
|
| 444 |
+
CUDNN_BACKEND_ENGINECFG_DESCRIPTOR,
|
| 445 |
+
CUDNN_BACKEND_ENGINEHEUR_DESCRIPTOR,
|
| 446 |
+
CUDNN_BACKEND_EXECUTION_PLAN_DESCRIPTOR,
|
| 447 |
+
CUDNN_BACKEND_INTERMEDIATE_INFO_DESCRIPTOR,
|
| 448 |
+
CUDNN_BACKEND_KNOB_CHOICE_DESCRIPTOR,
|
| 449 |
+
CUDNN_BACKEND_KNOB_INFO_DESCRIPTOR,
|
| 450 |
+
CUDNN_BACKEND_LAYOUT_INFO_DESCRIPTOR,
|
| 451 |
+
CUDNN_BACKEND_OPERATION_CONVOLUTION_FORWARD_DESCRIPTOR,
|
| 452 |
+
CUDNN_BACKEND_OPERATION_CONVOLUTION_BACKWARD_FILTER_DESCRIPTOR,
|
| 453 |
+
CUDNN_BACKEND_OPERATION_CONVOLUTION_BACKWARD_DATA_DESCRIPTOR,
|
| 454 |
+
CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR,
|
| 455 |
+
CUDNN_BACKEND_OPERATION_GEN_STATS_DESCRIPTOR,
|
| 456 |
+
CUDNN_BACKEND_OPERATIONGRAPH_DESCRIPTOR,
|
| 457 |
+
CUDNN_BACKEND_VARIANT_PACK_DESCRIPTOR,
|
| 458 |
+
CUDNN_BACKEND_TENSOR_DESCRIPTOR,
|
| 459 |
+
CUDNN_BACKEND_MATMUL_DESCRIPTOR,
|
| 460 |
+
CUDNN_BACKEND_OPERATION_MATMUL_DESCRIPTOR,
|
| 461 |
+
CUDNN_BACKEND_OPERATION_BN_FINALIZE_STATISTICS_DESCRIPTOR,
|
| 462 |
+
CUDNN_BACKEND_REDUCTION_DESCRIPTOR,
|
| 463 |
+
CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR,
|
| 464 |
+
CUDNN_BACKEND_OPERATION_BN_BWD_WEIGHTS_DESCRIPTOR,
|
| 465 |
+
CUDNN_BACKEND_RESAMPLE_DESCRIPTOR,
|
| 466 |
+
CUDNN_BACKEND_OPERATION_RESAMPLE_FWD_DESCRIPTOR,
|
| 467 |
+
CUDNN_BACKEND_OPERATION_RESAMPLE_BWD_DESCRIPTOR,
|
| 468 |
+
CUDNN_BACKEND_OPERATION_CONCAT_DESCRIPTOR,
|
| 469 |
+
CUDNN_BACKEND_OPERATION_SIGNAL_DESCRIPTOR,
|
| 470 |
+
CUDNN_BACKEND_OPERATION_NORM_FORWARD_DESCRIPTOR,
|
| 471 |
+
CUDNN_BACKEND_OPERATION_NORM_BACKWARD_DESCRIPTOR,
|
| 472 |
+
CUDNN_BACKEND_OPERATION_RESHAPE_DESCRIPTOR,
|
| 473 |
+
CUDNN_BACKEND_RNG_DESCRIPTOR,
|
| 474 |
+
CUDNN_BACKEND_OPERATION_RNG_DESCRIPTOR
|
| 475 |
+
} cudnnBackendDescriptorType_t;
|
| 476 |
+
|
| 477 |
+
typedef enum {
|
| 478 |
+
CUDNN_NUMERICAL_NOTE_TENSOR_CORE = 0,
|
| 479 |
+
CUDNN_NUMERICAL_NOTE_DOWN_CONVERT_INPUTS,
|
| 480 |
+
CUDNN_NUMERICAL_NOTE_REDUCED_PRECISION_REDUCTION,
|
| 481 |
+
CUDNN_NUMERICAL_NOTE_FFT,
|
| 482 |
+
CUDNN_NUMERICAL_NOTE_NONDETERMINISTIC,
|
| 483 |
+
CUDNN_NUMERICAL_NOTE_WINOGRAD,
|
| 484 |
+
CUDNN_NUMERICAL_NOTE_WINOGRAD_TILE_4x4,
|
| 485 |
+
CUDNN_NUMERICAL_NOTE_WINOGRAD_TILE_6x6,
|
| 486 |
+
CUDNN_NUMERICAL_NOTE_WINOGRAD_TILE_13x13,
|
| 487 |
+
CUDNN_NUMERICAL_NOTE_TYPE_COUNT,
|
| 488 |
+
} cudnnBackendNumericalNote_t;
|
| 489 |
+
|
| 490 |
+
typedef enum {
|
| 491 |
+
CUDNN_BEHAVIOR_NOTE_RUNTIME_COMPILATION = 0,
|
| 492 |
+
CUDNN_BEHAVIOR_NOTE_REQUIRES_FILTER_INT8x32_REORDER = 1,
|
| 493 |
+
CUDNN_BEHAVIOR_NOTE_REQUIRES_BIAS_INT8x32_REORDER = 2,
|
| 494 |
+
CUDNN_BEHAVIOR_NOTE_TYPE_COUNT,
|
| 495 |
+
} cudnnBackendBehaviorNote_t;
|
| 496 |
+
|
| 497 |
+
typedef enum {
|
| 498 |
+
CUDNN_KNOB_TYPE_SPLIT_K = 0,
|
| 499 |
+
CUDNN_KNOB_TYPE_SWIZZLE = 1,
|
| 500 |
+
CUDNN_KNOB_TYPE_TILE_SIZE = 2,
|
| 501 |
+
CUDNN_KNOB_TYPE_USE_TEX = 3,
|
| 502 |
+
CUDNN_KNOB_TYPE_EDGE = 4,
|
| 503 |
+
CUDNN_KNOB_TYPE_KBLOCK = 5,
|
| 504 |
+
CUDNN_KNOB_TYPE_LDGA = 6,
|
| 505 |
+
CUDNN_KNOB_TYPE_LDGB = 7,
|
| 506 |
+
CUDNN_KNOB_TYPE_CHUNK_K = 8,
|
| 507 |
+
CUDNN_KNOB_TYPE_SPLIT_H = 9,
|
| 508 |
+
CUDNN_KNOB_TYPE_WINO_TILE = 10,
|
| 509 |
+
CUDNN_KNOB_TYPE_MULTIPLY = 11,
|
| 510 |
+
CUDNN_KNOB_TYPE_SPLIT_K_BUF = 12,
|
| 511 |
+
CUDNN_KNOB_TYPE_TILEK = 13,
|
| 512 |
+
CUDNN_KNOB_TYPE_STAGES = 14,
|
| 513 |
+
CUDNN_KNOB_TYPE_REDUCTION_MODE = 15,
|
| 514 |
+
CUDNN_KNOB_TYPE_CTA_SPLIT_K_MODE = 16,
|
| 515 |
+
CUDNN_KNOB_TYPE_SPLIT_K_SLC = 17,
|
| 516 |
+
CUDNN_KNOB_TYPE_IDX_MODE = 18,
|
| 517 |
+
CUDNN_KNOB_TYPE_SLICED = 19,
|
| 518 |
+
CUDNN_KNOB_TYPE_SPLIT_RS = 20,
|
| 519 |
+
CUDNN_KNOB_TYPE_SINGLEBUFFER = 21,
|
| 520 |
+
CUDNN_KNOB_TYPE_LDGC = 22,
|
| 521 |
+
CUDNN_KNOB_TYPE_SPECFILT = 23,
|
| 522 |
+
CUDNN_KNOB_TYPE_KERNEL_CFG = 24,
|
| 523 |
+
CUDNN_KNOB_TYPE_WORKSPACE = 25,
|
| 524 |
+
CUDNN_KNOB_TYPE_TILE_CGA = 26,
|
| 525 |
+
CUDNN_KNOB_TYPE_TILE_CGA_M = 27,
|
| 526 |
+
CUDNN_KNOB_TYPE_TILE_CGA_N = 28,
|
| 527 |
+
CUDNN_KNOB_TYPE_BLOCK_SIZE = 29,
|
| 528 |
+
CUDNN_KNOB_TYPE_OCCUPANCY = 30,
|
| 529 |
+
CUDNN_KNOB_TYPE_ARRAY_SIZE_PER_THREAD = 31,
|
| 530 |
+
CUDNN_KNOB_TYPE_NUM_C_PER_BLOCK = 32,
|
| 531 |
+
CUDNN_KNOB_TYPE_COUNTS,
|
| 532 |
+
} cudnnBackendKnobType_t;
|
| 533 |
+
|
| 534 |
+
typedef enum {
|
| 535 |
+
CUDNN_LAYOUT_TYPE_PREFERRED_NCHW = 0,
|
| 536 |
+
CUDNN_LAYOUT_TYPE_PREFERRED_NHWC = 1,
|
| 537 |
+
CUDNN_LAYOUT_TYPE_PREFERRED_PAD4CK = 2,
|
| 538 |
+
CUDNN_LAYOUT_TYPE_PREFERRED_PAD8CK = 3,
|
| 539 |
+
CUDNN_LAYOUT_TYPE_COUNT = 4,
|
| 540 |
+
} cudnnBackendLayoutType_t;
|
| 541 |
+
|
| 542 |
+
typedef enum {
|
| 543 |
+
CUDNN_HEUR_MODE_INSTANT = 0,
|
| 544 |
+
CUDNN_HEUR_MODE_B = 1,
|
| 545 |
+
CUDNN_HEUR_MODE_FALLBACK = 2,
|
| 546 |
+
CUDNN_HEUR_MODE_A = 3,
|
| 547 |
+
CUDNN_HEUR_MODES_COUNT = 4,
|
| 548 |
+
} cudnnBackendHeurMode_t;
|
| 549 |
+
|
| 550 |
+
typedef enum {
|
| 551 |
+
CUDNN_TENSOR_REORDERING_NONE = 0,
|
| 552 |
+
CUDNN_TENSOR_REORDERING_INT8x32 = 1,
|
| 553 |
+
CUDNN_TENSOR_REORDERING_F16x16 = 2,
|
| 554 |
+
} cudnnBackendTensorReordering_t;
|
| 555 |
+
|
| 556 |
+
typedef enum {
|
| 557 |
+
CUDNN_ZERO_PAD = 0,
|
| 558 |
+
CUDNN_NEG_INF_PAD = 1,
|
| 559 |
+
CUDNN_EDGE_VAL_PAD = 2,
|
| 560 |
+
} cudnnPaddingMode_t;
|
| 561 |
+
|
| 562 |
+
typedef enum {
|
| 563 |
+
CUDNN_LAYER_NORM = 0,
|
| 564 |
+
CUDNN_INSTANCE_NORM = 1,
|
| 565 |
+
CUDNN_BATCH_NORM = 2,
|
| 566 |
+
CUDNN_GROUP_NORM = 3,
|
| 567 |
+
} cudnnBackendNormMode_t;
|
| 568 |
+
|
| 569 |
+
typedef enum {
|
| 570 |
+
CUDNN_NORM_FWD_INFERENCE = 0,
|
| 571 |
+
CUDNN_NORM_FWD_TRAINING = 1,
|
| 572 |
+
} cudnnBackendNormFwdPhase_t;
|
| 573 |
+
|
| 574 |
+
cudnnStatus_t CUDNNWINAPI
|
| 575 |
+
cudnnBackendCreateDescriptor(cudnnBackendDescriptorType_t descriptorType, cudnnBackendDescriptor_t *descriptor);
|
| 576 |
+
|
| 577 |
+
cudnnStatus_t CUDNNWINAPI
|
| 578 |
+
cudnnBackendDestroyDescriptor(cudnnBackendDescriptor_t descriptor);
|
| 579 |
+
|
| 580 |
+
cudnnStatus_t CUDNNWINAPI
|
| 581 |
+
cudnnBackendInitialize(cudnnBackendDescriptor_t descriptor);
|
| 582 |
+
|
| 583 |
+
cudnnStatus_t CUDNNWINAPI
|
| 584 |
+
cudnnBackendFinalize(cudnnBackendDescriptor_t descriptor);
|
| 585 |
+
|
| 586 |
+
cudnnStatus_t CUDNNWINAPI
|
| 587 |
+
cudnnBackendSetAttribute(cudnnBackendDescriptor_t descriptor,
|
| 588 |
+
cudnnBackendAttributeName_t attributeName,
|
| 589 |
+
cudnnBackendAttributeType_t attributeType,
|
| 590 |
+
int64_t elementCount,
|
| 591 |
+
const void *arrayOfElements);
|
| 592 |
+
|
| 593 |
+
cudnnStatus_t CUDNNWINAPI
|
| 594 |
+
cudnnBackendGetAttribute(cudnnBackendDescriptor_t const descriptor,
|
| 595 |
+
cudnnBackendAttributeName_t attributeName,
|
| 596 |
+
cudnnBackendAttributeType_t attributeType,
|
| 597 |
+
int64_t requestedElementCount,
|
| 598 |
+
int64_t *elementCount,
|
| 599 |
+
void *arrayOfElements);
|
| 600 |
+
|
| 601 |
+
cudnnStatus_t CUDNNWINAPI
|
| 602 |
+
cudnnBackendExecute(cudnnHandle_t handle, cudnnBackendDescriptor_t executionPlan, cudnnBackendDescriptor_t variantPack);
|
| 603 |
+
|
| 604 |
+
#if defined(__cplusplus)
|
| 605 |
+
}
|
| 606 |
+
#endif
|
| 607 |
+
|
| 608 |
+
#endif /* _CUDNN_BACKEND_H_ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cudnn/include/cudnn_cnn_infer_v8.h
ADDED
|
@@ -0,0 +1,571 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2014-2023 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
/*
|
| 51 |
+
* cudnn_cnn_infer : cuDNN's basic definitions and inference CNN functions.
|
| 52 |
+
*/
|
| 53 |
+
|
| 54 |
+
#if !defined(CUDNN_CNN_INFER_H_)
|
| 55 |
+
#define CUDNN_CNN_INFER_H_
|
| 56 |
+
|
| 57 |
+
#pragma once
|
| 58 |
+
#include <cuda_runtime.h>
|
| 59 |
+
#include <stdint.h>
|
| 60 |
+
|
| 61 |
+
#include "cudnn_version.h"
|
| 62 |
+
#include "cudnn_ops_infer.h"
|
| 63 |
+
|
| 64 |
+
/* These version numbers are autogenerated, do not edit manually. */
|
| 65 |
+
#define CUDNN_CNN_INFER_MAJOR 8
|
| 66 |
+
#define CUDNN_CNN_INFER_MINOR 9
|
| 67 |
+
#define CUDNN_CNN_INFER_PATCH 2
|
| 68 |
+
|
| 69 |
+
#if (CUDNN_CNN_INFER_MAJOR != CUDNN_MAJOR) || (CUDNN_CNN_INFER_MINOR != CUDNN_MINOR) || \
|
| 70 |
+
(CUDNN_CNN_INFER_PATCH != CUDNN_PATCHLEVEL)
|
| 71 |
+
#error Version mismatch in cuDNN CNN INFER!!!
|
| 72 |
+
#endif
|
| 73 |
+
|
| 74 |
+
#if defined(__cplusplus)
|
| 75 |
+
extern "C" {
|
| 76 |
+
#endif
|
| 77 |
+
|
| 78 |
+
typedef struct cudnnConvolutionStruct *cudnnConvolutionDescriptor_t;
|
| 79 |
+
|
| 80 |
+
/*
|
| 81 |
+
* convolution mode
|
| 82 |
+
*/
|
| 83 |
+
typedef enum { CUDNN_CONVOLUTION = 0, CUDNN_CROSS_CORRELATION = 1 } cudnnConvolutionMode_t;
|
| 84 |
+
|
| 85 |
+
/*
|
| 86 |
+
* CUDNN Reorder
|
| 87 |
+
*/
|
| 88 |
+
typedef enum {
|
| 89 |
+
CUDNN_DEFAULT_REORDER = 0,
|
| 90 |
+
CUDNN_NO_REORDER = 1,
|
| 91 |
+
} cudnnReorderType_t;
|
| 92 |
+
|
| 93 |
+
typedef struct cudnnConvolutionFwdAlgoPerfStruct {
|
| 94 |
+
cudnnConvolutionFwdAlgo_t algo;
|
| 95 |
+
cudnnStatus_t status;
|
| 96 |
+
float time;
|
| 97 |
+
size_t memory;
|
| 98 |
+
cudnnDeterminism_t determinism;
|
| 99 |
+
cudnnMathType_t mathType;
|
| 100 |
+
int reserved[3];
|
| 101 |
+
} cudnnConvolutionFwdAlgoPerf_t;
|
| 102 |
+
|
| 103 |
+
/* Create an instance of convolution descriptor */
|
| 104 |
+
cudnnStatus_t CUDNNWINAPI
|
| 105 |
+
cudnnCreateConvolutionDescriptor(cudnnConvolutionDescriptor_t *convDesc);
|
| 106 |
+
|
| 107 |
+
/* Destroy an instance of convolution descriptor */
|
| 108 |
+
cudnnStatus_t CUDNNWINAPI
|
| 109 |
+
cudnnDestroyConvolutionDescriptor(cudnnConvolutionDescriptor_t convDesc);
|
| 110 |
+
|
| 111 |
+
cudnnStatus_t CUDNNWINAPI
|
| 112 |
+
cudnnSetConvolutionMathType(cudnnConvolutionDescriptor_t convDesc, cudnnMathType_t mathType);
|
| 113 |
+
|
| 114 |
+
cudnnStatus_t CUDNNWINAPI
|
| 115 |
+
cudnnGetConvolutionMathType(cudnnConvolutionDescriptor_t convDesc, cudnnMathType_t *mathType);
|
| 116 |
+
|
| 117 |
+
cudnnStatus_t CUDNNWINAPI
|
| 118 |
+
cudnnSetConvolutionGroupCount(cudnnConvolutionDescriptor_t convDesc, int groupCount);
|
| 119 |
+
|
| 120 |
+
cudnnStatus_t CUDNNWINAPI
|
| 121 |
+
cudnnGetConvolutionGroupCount(cudnnConvolutionDescriptor_t convDesc, int *groupCount);
|
| 122 |
+
|
| 123 |
+
cudnnStatus_t CUDNNWINAPI
|
| 124 |
+
cudnnSetConvolutionReorderType(cudnnConvolutionDescriptor_t convDesc, cudnnReorderType_t reorderType);
|
| 125 |
+
|
| 126 |
+
cudnnStatus_t CUDNNWINAPI
|
| 127 |
+
cudnnGetConvolutionReorderType(cudnnConvolutionDescriptor_t convDesc, cudnnReorderType_t *reorderType);
|
| 128 |
+
|
| 129 |
+
cudnnStatus_t CUDNNWINAPI
|
| 130 |
+
cudnnSetConvolution2dDescriptor(cudnnConvolutionDescriptor_t convDesc,
|
| 131 |
+
int pad_h, /* zero-padding height */
|
| 132 |
+
int pad_w, /* zero-padding width */
|
| 133 |
+
int u, /* vertical filter stride */
|
| 134 |
+
int v, /* horizontal filter stride */
|
| 135 |
+
int dilation_h, /* filter dilation in the vertical dimension */
|
| 136 |
+
int dilation_w, /* filter dilation in the horizontal dimension */
|
| 137 |
+
cudnnConvolutionMode_t mode,
|
| 138 |
+
cudnnDataType_t computeType);
|
| 139 |
+
|
| 140 |
+
cudnnStatus_t CUDNNWINAPI
|
| 141 |
+
cudnnGetConvolution2dDescriptor(const cudnnConvolutionDescriptor_t convDesc,
|
| 142 |
+
int *pad_h, /* zero-padding height */
|
| 143 |
+
int *pad_w, /* zero-padding width */
|
| 144 |
+
int *u, /* vertical filter stride */
|
| 145 |
+
int *v, /* horizontal filter stride */
|
| 146 |
+
int *dilation_h, /* filter dilation in the vertical dimension */
|
| 147 |
+
int *dilation_w, /* filter dilation in the horizontal dimension */
|
| 148 |
+
cudnnConvolutionMode_t *mode,
|
| 149 |
+
cudnnDataType_t *computeType);
|
| 150 |
+
|
| 151 |
+
cudnnStatus_t CUDNNWINAPI
|
| 152 |
+
cudnnSetConvolutionNdDescriptor(cudnnConvolutionDescriptor_t convDesc,
|
| 153 |
+
int arrayLength, /* nbDims-2 size */
|
| 154 |
+
const int padA[],
|
| 155 |
+
const int filterStrideA[],
|
| 156 |
+
const int dilationA[],
|
| 157 |
+
cudnnConvolutionMode_t mode,
|
| 158 |
+
cudnnDataType_t computeType); /* convolution data type */
|
| 159 |
+
|
| 160 |
+
/* Helper function to return the dimensions of the output tensor given a convolution descriptor */
|
| 161 |
+
cudnnStatus_t CUDNNWINAPI
|
| 162 |
+
cudnnGetConvolutionNdDescriptor(const cudnnConvolutionDescriptor_t convDesc,
|
| 163 |
+
int arrayLengthRequested,
|
| 164 |
+
int *arrayLength,
|
| 165 |
+
int padA[],
|
| 166 |
+
int strideA[],
|
| 167 |
+
int dilationA[],
|
| 168 |
+
cudnnConvolutionMode_t *mode,
|
| 169 |
+
cudnnDataType_t *computeType); /* convolution data type */
|
| 170 |
+
|
| 171 |
+
cudnnStatus_t CUDNNWINAPI
|
| 172 |
+
cudnnGetConvolution2dForwardOutputDim(const cudnnConvolutionDescriptor_t convDesc,
|
| 173 |
+
const cudnnTensorDescriptor_t inputTensorDesc,
|
| 174 |
+
const cudnnFilterDescriptor_t filterDesc,
|
| 175 |
+
int *n,
|
| 176 |
+
int *c,
|
| 177 |
+
int *h,
|
| 178 |
+
int *w);
|
| 179 |
+
|
| 180 |
+
/* Helper function to return the dimensions of the output tensor given a convolution descriptor */
|
| 181 |
+
cudnnStatus_t CUDNNWINAPI
|
| 182 |
+
cudnnGetConvolutionNdForwardOutputDim(const cudnnConvolutionDescriptor_t convDesc,
|
| 183 |
+
const cudnnTensorDescriptor_t inputTensorDesc,
|
| 184 |
+
const cudnnFilterDescriptor_t filterDesc,
|
| 185 |
+
int nbDims,
|
| 186 |
+
int tensorOuputDimA[]);
|
| 187 |
+
|
| 188 |
+
/* helper function to provide the convolution forward algo that fit best the requirement */
|
| 189 |
+
cudnnStatus_t CUDNNWINAPI
|
| 190 |
+
cudnnGetConvolutionForwardAlgorithmMaxCount(cudnnHandle_t handle, int *count);
|
| 191 |
+
|
| 192 |
+
cudnnStatus_t CUDNNWINAPI
|
| 193 |
+
cudnnGetConvolutionForwardAlgorithm_v7(cudnnHandle_t handle,
|
| 194 |
+
const cudnnTensorDescriptor_t srcDesc,
|
| 195 |
+
const cudnnFilterDescriptor_t filterDesc,
|
| 196 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 197 |
+
const cudnnTensorDescriptor_t destDesc,
|
| 198 |
+
const int requestedAlgoCount,
|
| 199 |
+
int *returnedAlgoCount,
|
| 200 |
+
cudnnConvolutionFwdAlgoPerf_t *perfResults);
|
| 201 |
+
|
| 202 |
+
cudnnStatus_t CUDNNWINAPI
|
| 203 |
+
cudnnFindConvolutionForwardAlgorithm(cudnnHandle_t handle,
|
| 204 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 205 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 206 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 207 |
+
const cudnnTensorDescriptor_t yDesc,
|
| 208 |
+
const int requestedAlgoCount,
|
| 209 |
+
int *returnedAlgoCount,
|
| 210 |
+
cudnnConvolutionFwdAlgoPerf_t *perfResults);
|
| 211 |
+
|
| 212 |
+
cudnnStatus_t CUDNNWINAPI
|
| 213 |
+
cudnnFindConvolutionForwardAlgorithmEx(cudnnHandle_t handle,
|
| 214 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 215 |
+
const void *x,
|
| 216 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 217 |
+
const void *w,
|
| 218 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 219 |
+
const cudnnTensorDescriptor_t yDesc,
|
| 220 |
+
void *y,
|
| 221 |
+
const int requestedAlgoCount,
|
| 222 |
+
int *returnedAlgoCount,
|
| 223 |
+
cudnnConvolutionFwdAlgoPerf_t *perfResults,
|
| 224 |
+
void *workSpace,
|
| 225 |
+
size_t workSpaceSizeInBytes);
|
| 226 |
+
|
| 227 |
+
cudnnStatus_t CUDNNWINAPI
|
| 228 |
+
cudnnIm2Col(cudnnHandle_t handle,
|
| 229 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 230 |
+
const void *x,
|
| 231 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 232 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 233 |
+
void *colBuffer);
|
| 234 |
+
|
| 235 |
+
cudnnStatus_t CUDNNWINAPI
|
| 236 |
+
cudnnReorderFilterAndBias(cudnnHandle_t handle,
|
| 237 |
+
const cudnnFilterDescriptor_t filterDesc,
|
| 238 |
+
cudnnReorderType_t reorderType,
|
| 239 |
+
const void *filterData,
|
| 240 |
+
void *reorderedFilterData,
|
| 241 |
+
int reorderBias,
|
| 242 |
+
const void *biasData,
|
| 243 |
+
void *reorderedBiasData);
|
| 244 |
+
|
| 245 |
+
/* Helper function to return the minimum size of the workspace to be passed to the convolution given an algo*/
|
| 246 |
+
cudnnStatus_t CUDNNWINAPI
|
| 247 |
+
cudnnGetConvolutionForwardWorkspaceSize(cudnnHandle_t handle,
|
| 248 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 249 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 250 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 251 |
+
const cudnnTensorDescriptor_t yDesc,
|
| 252 |
+
cudnnConvolutionFwdAlgo_t algo,
|
| 253 |
+
size_t *sizeInBytes);
|
| 254 |
+
|
| 255 |
+
/* Convolution functions: All of the form "output = alpha * Op(inputs) + beta * output" */
|
| 256 |
+
|
| 257 |
+
/* Function to perform the forward pass for batch convolution */
|
| 258 |
+
cudnnStatus_t CUDNNWINAPI
|
| 259 |
+
cudnnConvolutionForward(cudnnHandle_t handle,
|
| 260 |
+
const void *alpha,
|
| 261 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 262 |
+
const void *x,
|
| 263 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 264 |
+
const void *w,
|
| 265 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 266 |
+
cudnnConvolutionFwdAlgo_t algo,
|
| 267 |
+
void *workSpace,
|
| 268 |
+
size_t workSpaceSizeInBytes,
|
| 269 |
+
const void *beta,
|
| 270 |
+
const cudnnTensorDescriptor_t yDesc,
|
| 271 |
+
void *y);
|
| 272 |
+
|
| 273 |
+
/* Fused conv/bias/activation operation : y = Act( alpha1 * conv(x) + alpha2 * z + bias ) */
|
| 274 |
+
cudnnStatus_t CUDNNWINAPI
|
| 275 |
+
cudnnConvolutionBiasActivationForward(cudnnHandle_t handle,
|
| 276 |
+
const void *alpha1,
|
| 277 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 278 |
+
const void *x,
|
| 279 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 280 |
+
const void *w,
|
| 281 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 282 |
+
cudnnConvolutionFwdAlgo_t algo,
|
| 283 |
+
void *workSpace,
|
| 284 |
+
size_t workSpaceSizeInBytes,
|
| 285 |
+
const void *alpha2,
|
| 286 |
+
const cudnnTensorDescriptor_t zDesc,
|
| 287 |
+
const void *z,
|
| 288 |
+
const cudnnTensorDescriptor_t biasDesc,
|
| 289 |
+
const void *bias,
|
| 290 |
+
const cudnnActivationDescriptor_t activationDesc,
|
| 291 |
+
const cudnnTensorDescriptor_t yDesc,
|
| 292 |
+
void *y);
|
| 293 |
+
|
| 294 |
+
/* helper function to provide the convolution backward data algo that fit best the requirement */
|
| 295 |
+
|
| 296 |
+
typedef struct cudnnConvolutionBwdDataAlgoPerfStruct {
|
| 297 |
+
cudnnConvolutionBwdDataAlgo_t algo;
|
| 298 |
+
cudnnStatus_t status;
|
| 299 |
+
float time;
|
| 300 |
+
size_t memory;
|
| 301 |
+
cudnnDeterminism_t determinism;
|
| 302 |
+
cudnnMathType_t mathType;
|
| 303 |
+
int reserved[3];
|
| 304 |
+
} cudnnConvolutionBwdDataAlgoPerf_t;
|
| 305 |
+
|
| 306 |
+
cudnnStatus_t CUDNNWINAPI
|
| 307 |
+
cudnnGetConvolutionBackwardDataAlgorithmMaxCount(cudnnHandle_t handle, int *count);
|
| 308 |
+
|
| 309 |
+
cudnnStatus_t CUDNNWINAPI
|
| 310 |
+
cudnnFindConvolutionBackwardDataAlgorithm(cudnnHandle_t handle,
|
| 311 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 312 |
+
const cudnnTensorDescriptor_t dyDesc,
|
| 313 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 314 |
+
const cudnnTensorDescriptor_t dxDesc,
|
| 315 |
+
const int requestedAlgoCount,
|
| 316 |
+
int *returnedAlgoCount,
|
| 317 |
+
cudnnConvolutionBwdDataAlgoPerf_t *perfResults);
|
| 318 |
+
|
| 319 |
+
cudnnStatus_t CUDNNWINAPI
|
| 320 |
+
cudnnFindConvolutionBackwardDataAlgorithmEx(cudnnHandle_t handle,
|
| 321 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 322 |
+
const void *w,
|
| 323 |
+
const cudnnTensorDescriptor_t dyDesc,
|
| 324 |
+
const void *dy,
|
| 325 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 326 |
+
const cudnnTensorDescriptor_t dxDesc,
|
| 327 |
+
void *dx,
|
| 328 |
+
const int requestedAlgoCount,
|
| 329 |
+
int *returnedAlgoCount,
|
| 330 |
+
cudnnConvolutionBwdDataAlgoPerf_t *perfResults,
|
| 331 |
+
void *workSpace,
|
| 332 |
+
size_t workSpaceSizeInBytes);
|
| 333 |
+
|
| 334 |
+
cudnnStatus_t CUDNNWINAPI
|
| 335 |
+
cudnnGetConvolutionBackwardDataAlgorithm_v7(cudnnHandle_t handle,
|
| 336 |
+
const cudnnFilterDescriptor_t filterDesc,
|
| 337 |
+
const cudnnTensorDescriptor_t diffDesc,
|
| 338 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 339 |
+
const cudnnTensorDescriptor_t gradDesc,
|
| 340 |
+
const int requestedAlgoCount,
|
| 341 |
+
int *returnedAlgoCount,
|
| 342 |
+
cudnnConvolutionBwdDataAlgoPerf_t *perfResults);
|
| 343 |
+
|
| 344 |
+
/*
|
| 345 |
+
* convolution algorithm (which requires potentially some workspace)
|
| 346 |
+
*/
|
| 347 |
+
|
| 348 |
+
/* Helper function to return the minimum size of the workspace to be passed to the convolution given an algo*/
|
| 349 |
+
cudnnStatus_t CUDNNWINAPI
|
| 350 |
+
cudnnGetConvolutionBackwardDataWorkspaceSize(cudnnHandle_t handle,
|
| 351 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 352 |
+
const cudnnTensorDescriptor_t dyDesc,
|
| 353 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 354 |
+
const cudnnTensorDescriptor_t dxDesc,
|
| 355 |
+
cudnnConvolutionBwdDataAlgo_t algo,
|
| 356 |
+
size_t *sizeInBytes);
|
| 357 |
+
|
| 358 |
+
cudnnStatus_t CUDNNWINAPI
|
| 359 |
+
cudnnConvolutionBackwardData(cudnnHandle_t handle,
|
| 360 |
+
const void *alpha,
|
| 361 |
+
const cudnnFilterDescriptor_t wDesc,
|
| 362 |
+
const void *w,
|
| 363 |
+
const cudnnTensorDescriptor_t dyDesc,
|
| 364 |
+
const void *dy,
|
| 365 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 366 |
+
cudnnConvolutionBwdDataAlgo_t algo,
|
| 367 |
+
void *workSpace,
|
| 368 |
+
size_t workSpaceSizeInBytes,
|
| 369 |
+
const void *beta,
|
| 370 |
+
const cudnnTensorDescriptor_t dxDesc,
|
| 371 |
+
void *dx);
|
| 372 |
+
|
| 373 |
+
/* Helper function to calculate folding descriptors for dgrad */
|
| 374 |
+
cudnnStatus_t CUDNNWINAPI
|
| 375 |
+
cudnnGetFoldedConvBackwardDataDescriptors(const cudnnHandle_t handle,
|
| 376 |
+
const cudnnFilterDescriptor_t filterDesc,
|
| 377 |
+
const cudnnTensorDescriptor_t diffDesc,
|
| 378 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 379 |
+
const cudnnTensorDescriptor_t gradDesc,
|
| 380 |
+
const cudnnTensorFormat_t transformFormat,
|
| 381 |
+
cudnnFilterDescriptor_t foldedFilterDesc,
|
| 382 |
+
cudnnTensorDescriptor_t paddedDiffDesc,
|
| 383 |
+
cudnnConvolutionDescriptor_t foldedConvDesc,
|
| 384 |
+
cudnnTensorDescriptor_t foldedGradDesc,
|
| 385 |
+
cudnnTensorTransformDescriptor_t filterFoldTransDesc,
|
| 386 |
+
cudnnTensorTransformDescriptor_t diffPadTransDesc,
|
| 387 |
+
cudnnTensorTransformDescriptor_t gradFoldTransDesc,
|
| 388 |
+
cudnnTensorTransformDescriptor_t gradUnfoldTransDesc);
|
| 389 |
+
|
| 390 |
+
/* cudnnFusedOps... */
|
| 391 |
+
struct cudnnFusedOpsConstParamStruct;
|
| 392 |
+
typedef struct cudnnFusedOpsConstParamStruct *cudnnFusedOpsConstParamPack_t;
|
| 393 |
+
|
| 394 |
+
struct cudnnFusedOpsVariantParamStruct;
|
| 395 |
+
typedef struct cudnnFusedOpsVariantParamStruct *cudnnFusedOpsVariantParamPack_t;
|
| 396 |
+
|
| 397 |
+
struct cudnnFusedOpsPlanStruct;
|
| 398 |
+
typedef struct cudnnFusedOpsPlanStruct *cudnnFusedOpsPlan_t;
|
| 399 |
+
|
| 400 |
+
typedef enum {
|
| 401 |
+
/* each op in [ ] can be disabled by passing NULL ptr */
|
| 402 |
+
/* [per channel scale], [per channel bias], [activation], convolution, [generate BN stats] */
|
| 403 |
+
CUDNN_FUSED_SCALE_BIAS_ACTIVATION_CONV_BNSTATS = 0,
|
| 404 |
+
/* [per channel scale], [per channel bias], [activation], convolutionBackwardWeights */
|
| 405 |
+
CUDNN_FUSED_SCALE_BIAS_ACTIVATION_WGRAD = 1,
|
| 406 |
+
/* utility for BN training in BN-conv fusion */
|
| 407 |
+
/* computes the equivalent scale and bias from ySum ySqSum and learned scale, bias */
|
| 408 |
+
/* optionally update running stats and generate saved stats */
|
| 409 |
+
CUDNN_FUSED_BN_FINALIZE_STATISTICS_TRAINING = 2,
|
| 410 |
+
/* utility for BN inference in BN-conv fusion */
|
| 411 |
+
/* computes the equivalent scale and bias from learned running stats and learned scale, bias */
|
| 412 |
+
CUDNN_FUSED_BN_FINALIZE_STATISTICS_INFERENCE = 3,
|
| 413 |
+
/* reserved for future use: convolution, [per channel scale], [per channel bias], [residual add], [activation] */
|
| 414 |
+
CUDNN_FUSED_CONV_SCALE_BIAS_ADD_ACTIVATION = 4,
|
| 415 |
+
/* reserved for future use: [per channel scale], [per channel bias], [residual add], activation, bitmask */
|
| 416 |
+
CUDNN_FUSED_SCALE_BIAS_ADD_ACTIVATION_GEN_BITMASK = 5,
|
| 417 |
+
/* reserved for future use */
|
| 418 |
+
CUDNN_FUSED_DACTIVATION_FORK_DBATCHNORM = 6,
|
| 419 |
+
} cudnnFusedOps_t;
|
| 420 |
+
|
| 421 |
+
typedef enum {
|
| 422 |
+
/* set XDESC: pass previously initialized cudnnTensorDescriptor_t */
|
| 423 |
+
/* get XDESC: pass previously created cudnnTensorDescriptor_t */
|
| 424 |
+
CUDNN_PARAM_XDESC = 0,
|
| 425 |
+
/* set/get XDATA_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 426 |
+
CUDNN_PARAM_XDATA_PLACEHOLDER = 1,
|
| 427 |
+
/* set/get BN_MODE: pass cudnnBatchNormMode_t* */
|
| 428 |
+
CUDNN_PARAM_BN_MODE = 2,
|
| 429 |
+
/* set CUDNN_PARAM_BN_EQSCALEBIAS_DESC: pass previously initialized cudnnTensorDescriptor_t */
|
| 430 |
+
/* get CUDNN_PARAM_BN_EQSCALEBIAS_DESC: pass previously created cudnnTensorDescriptor_t */
|
| 431 |
+
CUDNN_PARAM_BN_EQSCALEBIAS_DESC = 3,
|
| 432 |
+
/* set/get BN_EQSCALE_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 433 |
+
CUDNN_PARAM_BN_EQSCALE_PLACEHOLDER = 4,
|
| 434 |
+
/* set/get BN_EQBIAS_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 435 |
+
CUDNN_PARAM_BN_EQBIAS_PLACEHOLDER = 5,
|
| 436 |
+
/* set ACTIVATION_DESC: pass previously initialized cudnnActivationDescriptor_t */
|
| 437 |
+
/* get ACTIVATION_DESC: pass previously created cudnnActivationDescriptor_t */
|
| 438 |
+
CUDNN_PARAM_ACTIVATION_DESC = 6,
|
| 439 |
+
/* set CONV_DESC: pass previously initialized cudnnConvolutionDescriptor_t */
|
| 440 |
+
/* get CONV_DESC: pass previously created cudnnConvolutionDescriptor_t */
|
| 441 |
+
CUDNN_PARAM_CONV_DESC = 7,
|
| 442 |
+
/* set WDESC: pass previously initialized cudnnFilterDescriptor_t */
|
| 443 |
+
/* get WDESC: pass previously created cudnnFilterDescriptor_t */
|
| 444 |
+
CUDNN_PARAM_WDESC = 8,
|
| 445 |
+
/* set/get WDATA_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 446 |
+
CUDNN_PARAM_WDATA_PLACEHOLDER = 9,
|
| 447 |
+
/* set DWDESC: pass previously initialized cudnnFilterDescriptor_t */
|
| 448 |
+
/* get DWDESC: pass previously created cudnnFilterDescriptor_t */
|
| 449 |
+
CUDNN_PARAM_DWDESC = 10,
|
| 450 |
+
/* set/get DWDATA_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 451 |
+
CUDNN_PARAM_DWDATA_PLACEHOLDER = 11,
|
| 452 |
+
/* set YDESC: pass previously initialized cudnnTensorDescriptor_t */
|
| 453 |
+
/* get YDESC: pass previously created cudnnTensorDescriptor_t */
|
| 454 |
+
CUDNN_PARAM_YDESC = 12,
|
| 455 |
+
/* set/get YDATA_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 456 |
+
CUDNN_PARAM_YDATA_PLACEHOLDER = 13,
|
| 457 |
+
/* set DYDESC: pass previously initialized cudnnTensorDescriptor_t */
|
| 458 |
+
/* get DYDESC: pass previously created cudnnTensorDescriptor_t */
|
| 459 |
+
CUDNN_PARAM_DYDESC = 14,
|
| 460 |
+
/* set/get DYDATA_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 461 |
+
CUDNN_PARAM_DYDATA_PLACEHOLDER = 15,
|
| 462 |
+
/* set YSTATS_DESC: pass previously initialized cudnnTensorDescriptor_t */
|
| 463 |
+
/* get YSTATS_DESC: pass previously created cudnnTensorDescriptor_t */
|
| 464 |
+
CUDNN_PARAM_YSTATS_DESC = 16,
|
| 465 |
+
/* set/get YSUM_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 466 |
+
CUDNN_PARAM_YSUM_PLACEHOLDER = 17,
|
| 467 |
+
/* set/get YSQSUM_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 468 |
+
CUDNN_PARAM_YSQSUM_PLACEHOLDER = 18,
|
| 469 |
+
/* set CUDNN_PARAM_BN_SCALEBIAS_MEANVAR_DESC: pass previously initialized cudnnTensorDescriptor_t */
|
| 470 |
+
/* get CUDNN_PARAM_BN_SCALEBIAS_MEANVAR_DESC: pass previously created cudnnTensorDescriptor_t */
|
| 471 |
+
CUDNN_PARAM_BN_SCALEBIAS_MEANVAR_DESC = 19,
|
| 472 |
+
/* set/get CUDNN_PARAM_BN_SCALE_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 473 |
+
CUDNN_PARAM_BN_SCALE_PLACEHOLDER = 20,
|
| 474 |
+
/* set/get CUDNN_PARAM_BN_BIAS_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 475 |
+
CUDNN_PARAM_BN_BIAS_PLACEHOLDER = 21,
|
| 476 |
+
/* set/get CUDNN_PARAM_BN_SAVED_MEAN_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 477 |
+
CUDNN_PARAM_BN_SAVED_MEAN_PLACEHOLDER = 22,
|
| 478 |
+
/* set/get CUDNN_PARAM_BN_SAVED_INVSTD_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 479 |
+
CUDNN_PARAM_BN_SAVED_INVSTD_PLACEHOLDER = 23,
|
| 480 |
+
/* set/get CUDNN_PARAM_BN_RUNNING_MEAN_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 481 |
+
CUDNN_PARAM_BN_RUNNING_MEAN_PLACEHOLDER = 24,
|
| 482 |
+
/* set/get CUDNN_PARAM_BN_RUNNING_VAR_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 483 |
+
CUDNN_PARAM_BN_RUNNING_VAR_PLACEHOLDER = 25,
|
| 484 |
+
|
| 485 |
+
/* set ZDESC: pass previously initialized cudnnTensorDescriptor_t */
|
| 486 |
+
/* get ZDESC: pass previously created cudnnTensorDescriptor_t */
|
| 487 |
+
CUDNN_PARAM_ZDESC = 26,
|
| 488 |
+
/* set/get ZDATA_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 489 |
+
CUDNN_PARAM_ZDATA_PLACEHOLDER = 27,
|
| 490 |
+
/* set BN_Z_EQSCALEBIAS_DESC: pass previously initialized cudnnTensorDescriptor_t */
|
| 491 |
+
/* get BN_Z_EQSCALEBIAS_DESC: pass previously created cudnnTensorDescriptor_t */
|
| 492 |
+
CUDNN_PARAM_BN_Z_EQSCALEBIAS_DESC = 28,
|
| 493 |
+
/* set/get BN_Z_EQSCALE_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 494 |
+
CUDNN_PARAM_BN_Z_EQSCALE_PLACEHOLDER = 29,
|
| 495 |
+
/* set/get BN_Z_EQBIAS_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 496 |
+
CUDNN_PARAM_BN_Z_EQBIAS_PLACEHOLDER = 30,
|
| 497 |
+
|
| 498 |
+
/* set ACTIVATION_BITMASK_DESC: pass previously initialized cudnnTensorDescriptor_t */
|
| 499 |
+
/* get ACTIVATION_BITMASK_DESC: pass previously created cudnnTensorDescriptor_t */
|
| 500 |
+
CUDNN_PARAM_ACTIVATION_BITMASK_DESC = 31,
|
| 501 |
+
/* set/get ACTIVATION_BITMASK_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 502 |
+
CUDNN_PARAM_ACTIVATION_BITMASK_PLACEHOLDER = 32,
|
| 503 |
+
|
| 504 |
+
/* set DXDESC: pass previously initialized cudnnTensorDescriptor_t */
|
| 505 |
+
/* get DXDESC: pass previously created cudnnTensorDescriptor_t */
|
| 506 |
+
CUDNN_PARAM_DXDESC = 33,
|
| 507 |
+
/* set/get DXDATA_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 508 |
+
CUDNN_PARAM_DXDATA_PLACEHOLDER = 34,
|
| 509 |
+
/* set DZDESC: pass previously initialized cudnnTensorDescriptor_t */
|
| 510 |
+
/* get DZDESC: pass previously created cudnnTensorDescriptor_t */
|
| 511 |
+
CUDNN_PARAM_DZDESC = 35,
|
| 512 |
+
/* set/get DZDATA_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 513 |
+
CUDNN_PARAM_DZDATA_PLACEHOLDER = 36,
|
| 514 |
+
/* set/get CUDNN_PARAM_BN_DSCALE_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 515 |
+
CUDNN_PARAM_BN_DSCALE_PLACEHOLDER = 37,
|
| 516 |
+
/* set/get CUDNN_PARAM_BN_DBIAS_PLACEHOLDER: pass cudnnFusedOpsPointerPlaceHolder_t* */
|
| 517 |
+
CUDNN_PARAM_BN_DBIAS_PLACEHOLDER = 38,
|
| 518 |
+
} cudnnFusedOpsConstParamLabel_t;
|
| 519 |
+
|
| 520 |
+
typedef enum {
|
| 521 |
+
CUDNN_PTR_NULL = 0,
|
| 522 |
+
CUDNN_PTR_ELEM_ALIGNED = 1,
|
| 523 |
+
CUDNN_PTR_16B_ALIGNED = 2,
|
| 524 |
+
} cudnnFusedOpsPointerPlaceHolder_t;
|
| 525 |
+
|
| 526 |
+
typedef enum {
|
| 527 |
+
/* set: pass void* pointing to dev memory */
|
| 528 |
+
/* get: pass void** pointing to host memory */
|
| 529 |
+
CUDNN_PTR_XDATA = 0,
|
| 530 |
+
CUDNN_PTR_BN_EQSCALE = 1,
|
| 531 |
+
CUDNN_PTR_BN_EQBIAS = 2,
|
| 532 |
+
CUDNN_PTR_WDATA = 3,
|
| 533 |
+
CUDNN_PTR_DWDATA = 4,
|
| 534 |
+
CUDNN_PTR_YDATA = 5,
|
| 535 |
+
CUDNN_PTR_DYDATA = 6,
|
| 536 |
+
CUDNN_PTR_YSUM = 7,
|
| 537 |
+
CUDNN_PTR_YSQSUM = 8,
|
| 538 |
+
CUDNN_PTR_WORKSPACE = 9,
|
| 539 |
+
CUDNN_PTR_BN_SCALE = 10,
|
| 540 |
+
CUDNN_PTR_BN_BIAS = 11,
|
| 541 |
+
CUDNN_PTR_BN_SAVED_MEAN = 12,
|
| 542 |
+
CUDNN_PTR_BN_SAVED_INVSTD = 13,
|
| 543 |
+
CUDNN_PTR_BN_RUNNING_MEAN = 14,
|
| 544 |
+
CUDNN_PTR_BN_RUNNING_VAR = 15,
|
| 545 |
+
CUDNN_PTR_ZDATA = 16,
|
| 546 |
+
CUDNN_PTR_BN_Z_EQSCALE = 17,
|
| 547 |
+
CUDNN_PTR_BN_Z_EQBIAS = 18,
|
| 548 |
+
CUDNN_PTR_ACTIVATION_BITMASK = 19,
|
| 549 |
+
CUDNN_PTR_DXDATA = 20,
|
| 550 |
+
CUDNN_PTR_DZDATA = 21,
|
| 551 |
+
CUDNN_PTR_BN_DSCALE = 22,
|
| 552 |
+
CUDNN_PTR_BN_DBIAS = 23,
|
| 553 |
+
|
| 554 |
+
/* set/get: pass size_t* pointing to host memory */
|
| 555 |
+
CUDNN_SCALAR_SIZE_T_WORKSPACE_SIZE_IN_BYTES = 100,
|
| 556 |
+
/* set/get: pass int64_t* pointing to host memory */
|
| 557 |
+
CUDNN_SCALAR_INT64_T_BN_ACCUMULATION_COUNT = 101,
|
| 558 |
+
/* set/get: pass double* pointing to host memory */
|
| 559 |
+
CUDNN_SCALAR_DOUBLE_BN_EXP_AVG_FACTOR = 102,
|
| 560 |
+
/* set/get: pass double* pointing to host memory */
|
| 561 |
+
CUDNN_SCALAR_DOUBLE_BN_EPSILON = 103,
|
| 562 |
+
} cudnnFusedOpsVariantParamLabel_t;
|
| 563 |
+
|
| 564 |
+
cudnnStatus_t CUDNNWINAPI
|
| 565 |
+
cudnnCnnInferVersionCheck(void);
|
| 566 |
+
|
| 567 |
+
#if defined(__cplusplus)
|
| 568 |
+
}
|
| 569 |
+
#endif
|
| 570 |
+
|
| 571 |
+
#endif /* CUDNN_CNN_INFER_H_ */
|
evalkit_tf437/lib/python3.10/site-packages/nvidia/cudnn/include/cudnn_cnn_train_v8.h
ADDED
|
@@ -0,0 +1,219 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
* Copyright 2014-2023 NVIDIA Corporation. All rights reserved.
|
| 3 |
+
*
|
| 4 |
+
* NOTICE TO LICENSEE:
|
| 5 |
+
*
|
| 6 |
+
* This source code and/or documentation ("Licensed Deliverables") are
|
| 7 |
+
* subject to NVIDIA intellectual property rights under U.S. and
|
| 8 |
+
* international Copyright laws.
|
| 9 |
+
*
|
| 10 |
+
* These Licensed Deliverables contained herein is PROPRIETARY and
|
| 11 |
+
* CONFIDENTIAL to NVIDIA and is being provided under the terms and
|
| 12 |
+
* conditions of a form of NVIDIA software license agreement by and
|
| 13 |
+
* between NVIDIA and Licensee ("License Agreement") or electronically
|
| 14 |
+
* accepted by Licensee. Notwithstanding any terms or conditions to
|
| 15 |
+
* the contrary in the License Agreement, reproduction or disclosure
|
| 16 |
+
* of the Licensed Deliverables to any third party without the express
|
| 17 |
+
* written consent of NVIDIA is prohibited.
|
| 18 |
+
*
|
| 19 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 20 |
+
* LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
|
| 21 |
+
* SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
|
| 22 |
+
* PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
|
| 23 |
+
* NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
|
| 24 |
+
* DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
|
| 25 |
+
* NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
|
| 26 |
+
* NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
|
| 27 |
+
* LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
|
| 28 |
+
* SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
|
| 29 |
+
* DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
|
| 30 |
+
* WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
|
| 31 |
+
* ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
|
| 32 |
+
* OF THESE LICENSED DELIVERABLES.
|
| 33 |
+
*
|
| 34 |
+
* U.S. Government End Users. These Licensed Deliverables are a
|
| 35 |
+
* "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
|
| 36 |
+
* 1995), consisting of "commercial computer software" and "commercial
|
| 37 |
+
* computer software documentation" as such terms are used in 48
|
| 38 |
+
* C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
|
| 39 |
+
* only as a commercial end item. Consistent with 48 C.F.R.12.212 and
|
| 40 |
+
* 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
|
| 41 |
+
* U.S. Government End Users acquire the Licensed Deliverables with
|
| 42 |
+
* only those rights set forth herein.
|
| 43 |
+
*
|
| 44 |
+
* Any use of the Licensed Deliverables in individual and commercial
|
| 45 |
+
* software must include, in the user documentation and internal
|
| 46 |
+
* comments to the code, the above Disclaimer and U.S. Government End
|
| 47 |
+
* Users Notice.
|
| 48 |
+
*/
|
| 49 |
+
|
| 50 |
+
/*
|
| 51 |
+
* cudnn_cnn_train : cuDNN's basic definitions and inference CNN functions.
|
| 52 |
+
*/
|
| 53 |
+
|
| 54 |
+
#pragma once
|
| 55 |
+
#include <cuda_runtime.h>
|
| 56 |
+
#include <stdint.h>
|
| 57 |
+
|
| 58 |
+
#include "cudnn_version.h"
|
| 59 |
+
#include "cudnn_ops_infer.h"
|
| 60 |
+
#include "cudnn_ops_train.h"
|
| 61 |
+
#include "cudnn_cnn_infer.h"
|
| 62 |
+
|
| 63 |
+
/* These version numbers are autogenerated, do not edit manually. */
|
| 64 |
+
#define CUDNN_CNN_TRAIN_MAJOR 8
|
| 65 |
+
#define CUDNN_CNN_TRAIN_MINOR 9
|
| 66 |
+
#define CUDNN_CNN_TRAIN_PATCH 2
|
| 67 |
+
|
| 68 |
+
#if (CUDNN_CNN_TRAIN_MAJOR != CUDNN_MAJOR) || (CUDNN_CNN_TRAIN_MINOR != CUDNN_MINOR) || \
|
| 69 |
+
(CUDNN_CNN_TRAIN_PATCH != CUDNN_PATCHLEVEL)
|
| 70 |
+
#error Version mismatch in cuDNN CNN INFER!!!
|
| 71 |
+
#endif
|
| 72 |
+
|
| 73 |
+
#if defined(__cplusplus)
|
| 74 |
+
extern "C" {
|
| 75 |
+
#endif
|
| 76 |
+
|
| 77 |
+
/* helper function to provide the convolution backward filter algo that fit best the requirement */
|
| 78 |
+
|
| 79 |
+
typedef struct cudnnConvolutionBwdFilterAlgoPerfStruct {
|
| 80 |
+
cudnnConvolutionBwdFilterAlgo_t algo;
|
| 81 |
+
cudnnStatus_t status;
|
| 82 |
+
float time;
|
| 83 |
+
size_t memory;
|
| 84 |
+
cudnnDeterminism_t determinism;
|
| 85 |
+
cudnnMathType_t mathType;
|
| 86 |
+
int reserved[3];
|
| 87 |
+
} cudnnConvolutionBwdFilterAlgoPerf_t;
|
| 88 |
+
|
| 89 |
+
cudnnStatus_t CUDNNWINAPI
|
| 90 |
+
cudnnGetConvolutionBackwardFilterAlgorithmMaxCount(cudnnHandle_t handle, int *count);
|
| 91 |
+
|
| 92 |
+
cudnnStatus_t CUDNNWINAPI
|
| 93 |
+
cudnnFindConvolutionBackwardFilterAlgorithm(cudnnHandle_t handle,
|
| 94 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 95 |
+
const cudnnTensorDescriptor_t dyDesc,
|
| 96 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 97 |
+
const cudnnFilterDescriptor_t dwDesc,
|
| 98 |
+
const int requestedAlgoCount,
|
| 99 |
+
int *returnedAlgoCount,
|
| 100 |
+
cudnnConvolutionBwdFilterAlgoPerf_t *perfResults);
|
| 101 |
+
|
| 102 |
+
cudnnStatus_t CUDNNWINAPI
|
| 103 |
+
cudnnFindConvolutionBackwardFilterAlgorithmEx(cudnnHandle_t handle,
|
| 104 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 105 |
+
const void *x,
|
| 106 |
+
const cudnnTensorDescriptor_t dyDesc,
|
| 107 |
+
const void *y,
|
| 108 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 109 |
+
const cudnnFilterDescriptor_t dwDesc,
|
| 110 |
+
void *dw,
|
| 111 |
+
const int requestedAlgoCount,
|
| 112 |
+
int *returnedAlgoCount,
|
| 113 |
+
cudnnConvolutionBwdFilterAlgoPerf_t *perfResults,
|
| 114 |
+
void *workSpace,
|
| 115 |
+
size_t workSpaceSizeInBytes);
|
| 116 |
+
|
| 117 |
+
cudnnStatus_t CUDNNWINAPI
|
| 118 |
+
cudnnGetConvolutionBackwardFilterAlgorithm_v7(cudnnHandle_t handle,
|
| 119 |
+
const cudnnTensorDescriptor_t srcDesc,
|
| 120 |
+
const cudnnTensorDescriptor_t diffDesc,
|
| 121 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 122 |
+
const cudnnFilterDescriptor_t gradDesc,
|
| 123 |
+
const int requestedAlgoCount,
|
| 124 |
+
int *returnedAlgoCount,
|
| 125 |
+
cudnnConvolutionBwdFilterAlgoPerf_t *perfResults);
|
| 126 |
+
|
| 127 |
+
/*
|
| 128 |
+
* convolution algorithm (which requires potentially some workspace)
|
| 129 |
+
*/
|
| 130 |
+
|
| 131 |
+
/* Helper function to return the minimum size of the workspace to be passed to the convolution given an algo*/
|
| 132 |
+
cudnnStatus_t CUDNNWINAPI
|
| 133 |
+
cudnnGetConvolutionBackwardFilterWorkspaceSize(cudnnHandle_t handle,
|
| 134 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 135 |
+
const cudnnTensorDescriptor_t dyDesc,
|
| 136 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 137 |
+
const cudnnFilterDescriptor_t gradDesc,
|
| 138 |
+
cudnnConvolutionBwdFilterAlgo_t algo,
|
| 139 |
+
size_t *sizeInBytes);
|
| 140 |
+
|
| 141 |
+
cudnnStatus_t CUDNNWINAPI
|
| 142 |
+
cudnnConvolutionBackwardFilter(cudnnHandle_t handle,
|
| 143 |
+
const void *alpha,
|
| 144 |
+
const cudnnTensorDescriptor_t xDesc,
|
| 145 |
+
const void *x,
|
| 146 |
+
const cudnnTensorDescriptor_t dyDesc,
|
| 147 |
+
const void *dy,
|
| 148 |
+
const cudnnConvolutionDescriptor_t convDesc,
|
| 149 |
+
cudnnConvolutionBwdFilterAlgo_t algo,
|
| 150 |
+
void *workSpace,
|
| 151 |
+
size_t workSpaceSizeInBytes,
|
| 152 |
+
const void *beta,
|
| 153 |
+
const cudnnFilterDescriptor_t dwDesc,
|
| 154 |
+
void *dw);
|
| 155 |
+
|
| 156 |
+
/* Function to compute the bias gradient for batch convolution */
|
| 157 |
+
cudnnStatus_t CUDNNWINAPI
|
| 158 |
+
cudnnConvolutionBackwardBias(cudnnHandle_t handle,
|
| 159 |
+
const void *alpha,
|
| 160 |
+
const cudnnTensorDescriptor_t dyDesc,
|
| 161 |
+
const void *dy,
|
| 162 |
+
const void *beta,
|
| 163 |
+
const cudnnTensorDescriptor_t dbDesc,
|
| 164 |
+
void *db);
|
| 165 |
+
|
| 166 |
+
cudnnStatus_t CUDNNWINAPI
|
| 167 |
+
cudnnCreateFusedOpsConstParamPack(cudnnFusedOpsConstParamPack_t *constPack, cudnnFusedOps_t ops);
|
| 168 |
+
|
| 169 |
+
cudnnStatus_t CUDNNWINAPI
|
| 170 |
+
cudnnDestroyFusedOpsConstParamPack(cudnnFusedOpsConstParamPack_t constPack);
|
| 171 |
+
|
| 172 |
+
cudnnStatus_t CUDNNWINAPI
|
| 173 |
+
cudnnSetFusedOpsConstParamPackAttribute(cudnnFusedOpsConstParamPack_t constPack,
|
| 174 |
+
cudnnFusedOpsConstParamLabel_t paramLabel,
|
| 175 |
+
const void *param);
|
| 176 |
+
|
| 177 |
+
cudnnStatus_t CUDNNWINAPI
|
| 178 |
+
cudnnGetFusedOpsConstParamPackAttribute(const cudnnFusedOpsConstParamPack_t constPack,
|
| 179 |
+
cudnnFusedOpsConstParamLabel_t paramLabel,
|
| 180 |
+
void *param,
|
| 181 |
+
int *isNULL);
|
| 182 |
+
|
| 183 |
+
cudnnStatus_t CUDNNWINAPI
|
| 184 |
+
cudnnCreateFusedOpsVariantParamPack(cudnnFusedOpsVariantParamPack_t *varPack, cudnnFusedOps_t ops);
|
| 185 |
+
|
| 186 |
+
cudnnStatus_t CUDNNWINAPI
|
| 187 |
+
cudnnDestroyFusedOpsVariantParamPack(cudnnFusedOpsVariantParamPack_t varPack);
|
| 188 |
+
|
| 189 |
+
cudnnStatus_t CUDNNWINAPI
|
| 190 |
+
cudnnSetFusedOpsVariantParamPackAttribute(cudnnFusedOpsVariantParamPack_t varPack,
|
| 191 |
+
cudnnFusedOpsVariantParamLabel_t paramLabel,
|
| 192 |
+
void *ptr);
|
| 193 |
+
|
| 194 |
+
cudnnStatus_t CUDNNWINAPI
|
| 195 |
+
cudnnGetFusedOpsVariantParamPackAttribute(const cudnnFusedOpsVariantParamPack_t varPack,
|
| 196 |
+
cudnnFusedOpsVariantParamLabel_t paramLabel,
|
| 197 |
+
void *ptr);
|
| 198 |
+
|
| 199 |
+
cudnnStatus_t CUDNNWINAPI
|
| 200 |
+
cudnnCreateFusedOpsPlan(cudnnFusedOpsPlan_t *plan, cudnnFusedOps_t ops);
|
| 201 |
+
|
| 202 |
+
cudnnStatus_t CUDNNWINAPI
|
| 203 |
+
cudnnDestroyFusedOpsPlan(cudnnFusedOpsPlan_t plan);
|
| 204 |
+
|
| 205 |
+
cudnnStatus_t CUDNNWINAPI
|
| 206 |
+
cudnnMakeFusedOpsPlan(cudnnHandle_t handle,
|
| 207 |
+
cudnnFusedOpsPlan_t plan,
|
| 208 |
+
const cudnnFusedOpsConstParamPack_t constPack,
|
| 209 |
+
size_t *workspaceSizeInBytes);
|
| 210 |
+
|
| 211 |
+
cudnnStatus_t CUDNNWINAPI
|
| 212 |
+
cudnnFusedOpsExecute(cudnnHandle_t handle, const cudnnFusedOpsPlan_t plan, cudnnFusedOpsVariantParamPack_t varPack);
|
| 213 |
+
|
| 214 |
+
cudnnStatus_t CUDNNWINAPI
|
| 215 |
+
cudnnCnnTrainVersionCheck(void);
|
| 216 |
+
|
| 217 |
+
#if defined(__cplusplus)
|
| 218 |
+
}
|
| 219 |
+
#endif
|