Datasets:

ArXiv:
License:
Alan Zhao
commited on
Commit
·
c54d2f6
1
Parent(s):
ff81e56
update readme
Browse files
README.md
CHANGED
|
@@ -1,3 +1,67 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
---
|
| 4 |
+
|
| 5 |
+
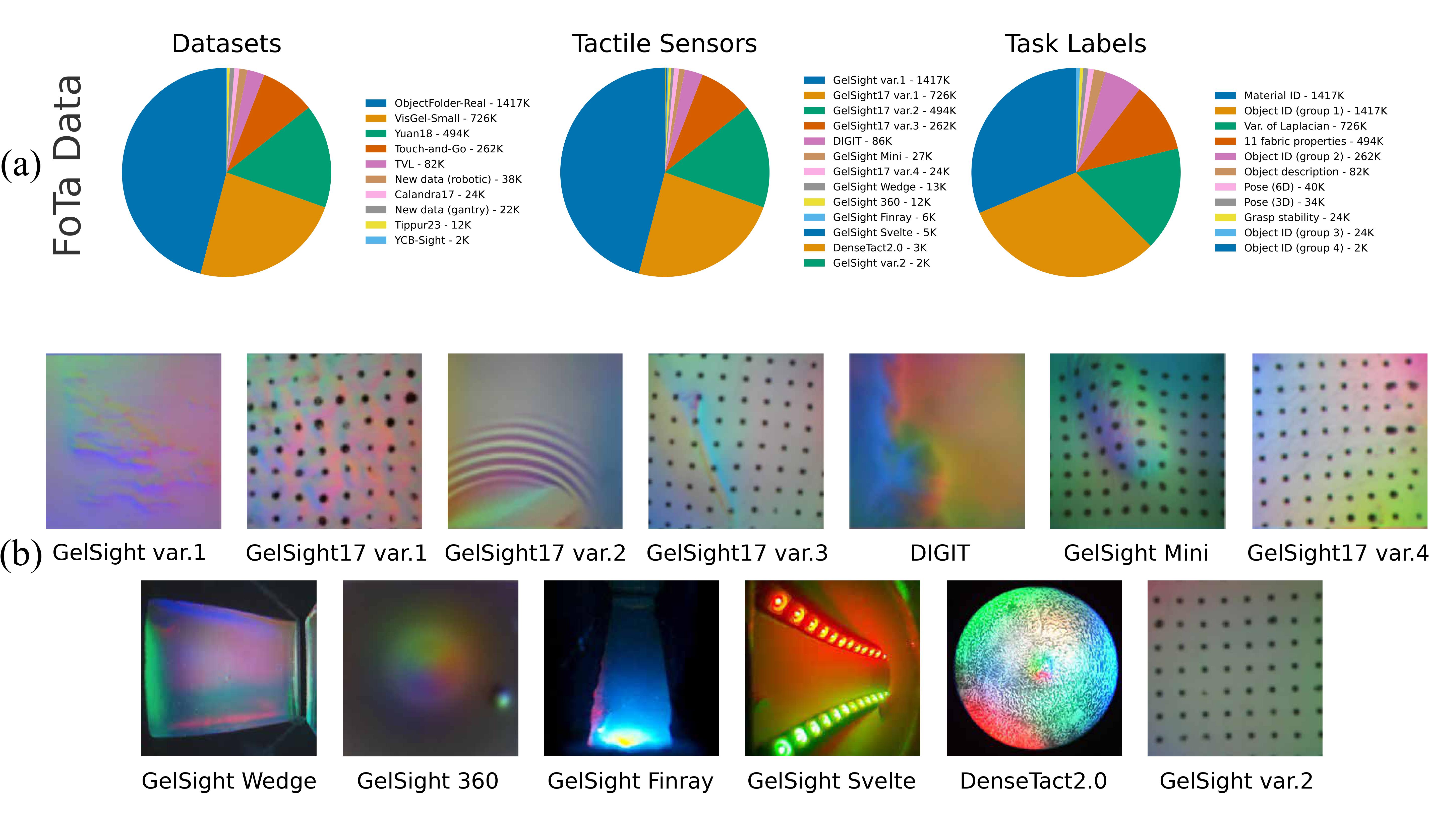
# Foundation Tactile (FoTa) - a multi-sensor multi-task large dataset for tactile sensing
|
| 6 |
+
|
| 7 |
+
[](https://github.com/alanzjl/t3_release)
|
| 8 |
+
[](https://github.com/alanzjl/t3_release)
|
| 9 |
+
[](https://github.com/alanzjl/t3_release)
|
| 10 |
+
|
| 11 |
+
[Jialiang (Alan) Zhao](https://alanz.info/),
|
| 12 |
+
[Yuxiang Ma](https://yuxiang-ma.github.io/),
|
| 13 |
+
[Lirui Wang](https://liruiw.github.io/), and
|
| 14 |
+
[Edward H. Adelson](https://persci.mit.edu/people/adelson/)
|
| 15 |
+
MIT CSAIL
|
| 16 |
+
|
| 17 |
+
[[Project Website]](https://t3.alanz.info/)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
## Overview
|
| 22 |
+
FoTa was released with Transferable Tactile Transformers (T3) as a large dataset for tactile representation learning.
|
| 23 |
+
It aggregates some of the largest open-source tactile datasets, and it is released in a unified [WebDataset](https://webdataset.github.io/webdataset/) format.
|
| 24 |
+
|
| 25 |
+
Fota contains over 3 million tactile images collected from 13 camera-based tactile sensors and 11 tasks.
|
| 26 |
+
|
| 27 |
+
## File structure
|
| 28 |
+
|
| 29 |
+
After downloading and unzipping, the file structure of FoTa looks like:
|
| 30 |
+
|
| 31 |
+
```
|
| 32 |
+
dataset_1
|
| 33 |
+
|---- train
|
| 34 |
+
|---- count.txt
|
| 35 |
+
|---- data_000000.tar
|
| 36 |
+
|---- data_000001.tar
|
| 37 |
+
|---- ...
|
| 38 |
+
|---- val
|
| 39 |
+
|---- count.txt
|
| 40 |
+
|---- data_000000.tar
|
| 41 |
+
|---- ...
|
| 42 |
+
dataset_2
|
| 43 |
+
:
|
| 44 |
+
dataset_n
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
Each `.tar` file is one sharded dataset. At runtime, wds (WebDataset) api automatically loads, shuffles, and unpacks all shards on demand.
|
| 48 |
+
The nicest part of having a `.tar` file, instead of saving all raw data into matrices (e.g. `.npz` for zarr), is that `.tar` is easy to visualize without the need of any code.
|
| 49 |
+
Simply double clip on any `.tar` file to check its content.
|
| 50 |
+
|
| 51 |
+
Although you will never need to unpack a `.tar` manually (wds does that automatically), it helps to understand the logic and file structure.
|
| 52 |
+
|
| 53 |
+
```
|
| 54 |
+
data_000000.tar
|
| 55 |
+
|---- file_name_1.jpg
|
| 56 |
+
|---- file_name_1.json
|
| 57 |
+
:
|
| 58 |
+
|---- file_name_n.jpg
|
| 59 |
+
|---- file_name_n.json
|
| 60 |
+
```
|
| 61 |
+
The `.jpg` files are tactile images, and the `.json` files store task-specific labels.
|
| 62 |
+
|
| 63 |
+
For more details on operations of the paper, checkout our GitHub repository and Colab tutorial.
|
| 64 |
+
|
| 65 |
+
## Citation
|
| 66 |
+
|
| 67 |
+
MIT License.
|