Datasets:

admin commited on
Commit ·
a27e072
1
Parent(s): aa42ddf
upd md
Browse files- .gitignore +0 -1
- README.md +9 -20
.gitignore
CHANGED
|
@@ -1,3 +1,2 @@
|
|
| 1 |
-
rename.sh
|
| 2 |
test.*
|
| 3 |
*__pycache__*
|
|
|
|
|
|
|
| 1 |
test.*
|
| 2 |
*__pycache__*
|
README.md
CHANGED
|
@@ -523,7 +523,7 @@ In the original dataset, the Chinese character label for each instrument was rep
|
|
| 523 |
During integration, we add Chinese pinyin label to make the dataset more accessible to researchers who are not familiar in Chinese.
|
| 524 |
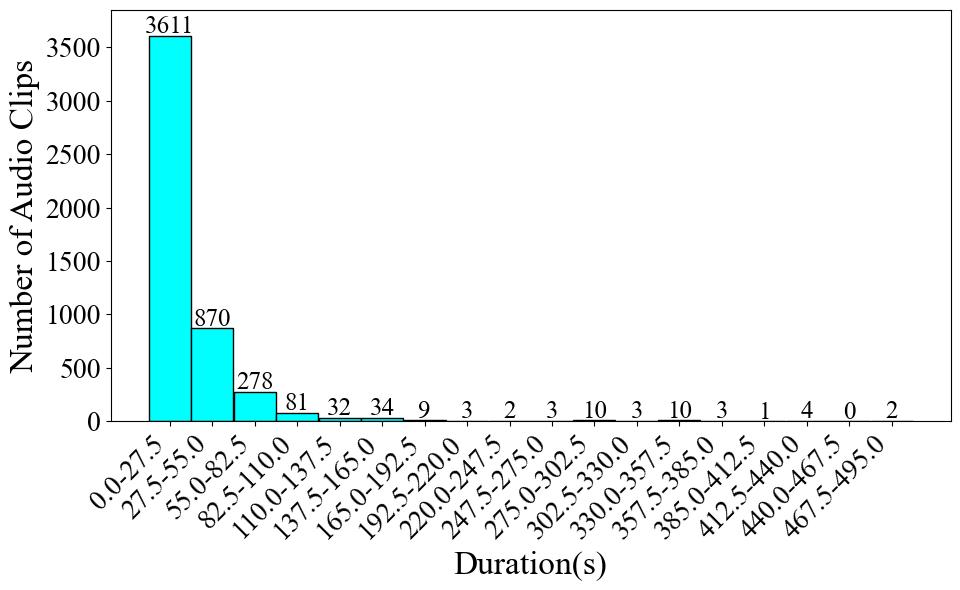
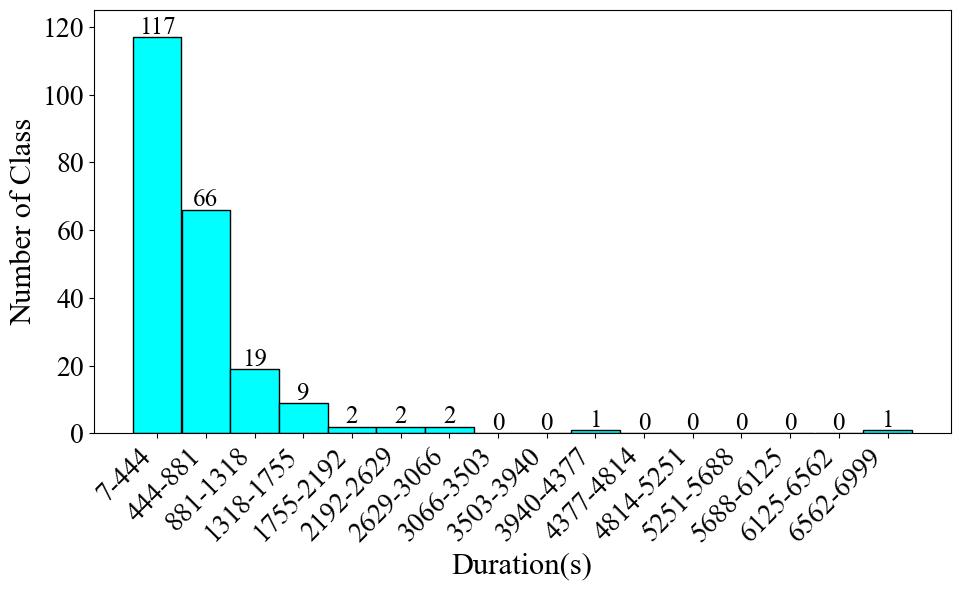
Then, we've reorganized the data into a dictionary with five columns, which includes: audio with a sampling rate of 44,100 Hz, pre-processed mel spectrogram, numerical label, instrument name in Chinese, and instrument name in Chinese pinyin. The provision of mel spectrograms primarily serves to enhance the visualization of the audio in the [viewer](https://huggingface.co/datasets/ccmusic-database/CTIS/viewer). For the remaining datasets, these mel spectrograms will also be included in the integrated data structure. The total data number is 4,956, with a duration of 32.63 hours. The average duration of the recordings is 23.7 seconds.
|
| 525 |
|
| 526 |
-
We have constructed the [default subset](#
|
| 527 |
|
| 528 |
## Statistics
|
| 529 |
|  |  |
|
|
@@ -568,28 +568,17 @@ MIR, audio classification
|
|
| 568 |
Chinese, English
|
| 569 |
|
| 570 |
## Usage
|
| 571 |
-
### Default Subset
|
| 572 |
```python
|
| 573 |
from datasets import load_dataset
|
| 574 |
|
| 575 |
-
|
| 576 |
-
|
| 577 |
-
|
| 578 |
-
|
| 579 |
-
|
| 580 |
-
|
| 581 |
-
|
| 582 |
-
|
| 583 |
-
|
| 584 |
-
dataset = load_dataset("ccmusic-database/CTIS", name="eval")
|
| 585 |
-
for item in ds["train"]:
|
| 586 |
-
print(item)
|
| 587 |
-
|
| 588 |
-
for item in ds["validation"]:
|
| 589 |
-
print(item)
|
| 590 |
-
|
| 591 |
-
for item in ds["test"]:
|
| 592 |
-
print(item)
|
| 593 |
```
|
| 594 |
|
| 595 |
## Maintenance
|
|
|
|
| 523 |
During integration, we add Chinese pinyin label to make the dataset more accessible to researchers who are not familiar in Chinese.
|
| 524 |
Then, we've reorganized the data into a dictionary with five columns, which includes: audio with a sampling rate of 44,100 Hz, pre-processed mel spectrogram, numerical label, instrument name in Chinese, and instrument name in Chinese pinyin. The provision of mel spectrograms primarily serves to enhance the visualization of the audio in the [viewer](https://huggingface.co/datasets/ccmusic-database/CTIS/viewer). For the remaining datasets, these mel spectrograms will also be included in the integrated data structure. The total data number is 4,956, with a duration of 32.63 hours. The average duration of the recordings is 23.7 seconds.
|
| 525 |
|
| 526 |
+
We have constructed the [default subset](#usage) of the current integrated version of the dataset. Building on the default subset, we applied silence removal with a threshold of top_db=40 to the audio files, converting them into mel, CQT, and chroma spectrograms. The audio was then segmented into 2-second clips, with segments shorter than 2 seconds padded using circular padding. This process resulted in the construction of the [eval subset](#usage) for dataset evaluation experiments.
|
| 527 |
|
| 528 |
## Statistics
|
| 529 |
|  |  |
|
|
|
|
| 568 |
Chinese, English
|
| 569 |
|
| 570 |
## Usage
|
|
|
|
| 571 |
```python
|
| 572 |
from datasets import load_dataset
|
| 573 |
|
| 574 |
+
ds = load_dataset(
|
| 575 |
+
"ccmusic-database/CTIS",
|
| 576 |
+
name="default", # default / eval
|
| 577 |
+
split="train", # train / validation / test (default only has train)
|
| 578 |
+
cache_dir="./__pycache__",
|
| 579 |
+
)
|
| 580 |
+
for i in ds:
|
| 581 |
+
print(i)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 582 |
```
|
| 583 |
|
| 584 |
## Maintenance
|