Datasets:

admin
commited on
Commit
·
74e66b3
1
Parent(s):
9502712
upd md
Browse files
README.md
CHANGED
|
@@ -15,9 +15,15 @@ viewer: false
|
|
| 15 |
---
|
| 16 |
|
| 17 |
# Dataset Card for GZ_IsoTech Dataset
|
| 18 |
-
|
|
|
|
| 19 |
|
| 20 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
|
| 22 |
## Viewer
|
| 23 |
<https://www.modelscope.cn/datasets/ccmusic-database/GZ_IsoTech/dataPeview>
|
|
@@ -58,31 +64,31 @@ Based on the aforementioned original dataset, we conducted data processing to co
|
|
| 58 |
|
| 59 |
### Data Fields
|
| 60 |
Categorization of the clips is based on the diverse playing techniques characteristic of the guzheng, the clips are divided into eight categories: Vibrato (chanyin), Upward Portamento (shanghuayin), Downward Portamento (xiahuayin), Returning Portamento (huihuayin), Glissando (guazou, huazhi), Tremolo (yaozhi), Harmonic (fanyin), Plucks (gou, da, mo, tuo…).
|
| 61 |
-
<img src="https://www.modelscope.cn/api/v1/datasets/ccmusic-database/GZ_IsoTech/repo?Revision=master&FilePath=.%2Fdata%2Fiso.png&View=true">
|
| 62 |
|
| 63 |
### Data Splits
|
| 64 |
train, test
|
| 65 |
|
| 66 |
## Dataset Description
|
| 67 |
-
- **Homepage:** <https://ccmusic-database.github.io>
|
| 68 |
-
- **Repository:** <https://huggingface.co/datasets/ccmusic-database/Guzheng_Tech99>
|
| 69 |
-
- **Paper:** <https://doi.org/10.5281/zenodo.5676893>
|
| 70 |
-
- **Leaderboard:** <https://www.modelscope.cn/datasets/ccmusic-database/GZ_IsoTech>
|
| 71 |
-
- **Point of Contact:** <https://arxiv.org/abs/2209.08774>
|
| 72 |
-
|
| 73 |
### Dataset Summary
|
| 74 |
Due to the pre-existing split in the raw dataset, wherein the data has been partitioned approximately in a 4:1 ratio for training and testing sets, we uphold the original data division approach. In contrast to utilizing platform-specific automated splitting mechanisms, we directly employ the pre-split data for subsequent integration steps.
|
| 75 |
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
|
| 79 |
-
|
|
| 80 |
-
|
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
|
| 85 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 86 |
|
| 87 |
### Supported Tasks and Leaderboards
|
| 88 |
MIR, audio classification
|
|
@@ -91,6 +97,7 @@ MIR, audio classification
|
|
| 91 |
Chinese, English
|
| 92 |
|
| 93 |
## Usage
|
|
|
|
| 94 |
```python
|
| 95 |
from datasets import load_dataset
|
| 96 |
|
|
@@ -102,10 +109,19 @@ for item in ds["test"]:
|
|
| 102 |
print(item)
|
| 103 |
```
|
| 104 |
|
| 105 |
-
|
| 106 |
-
```
|
| 107 |
-
|
| 108 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 109 |
```
|
| 110 |
|
| 111 |
## Dataset Creation
|
|
@@ -126,9 +142,6 @@ This database contains 2824 audio clips of guzheng playing techniques. Among the
|
|
| 126 |
#### Who are the annotators?
|
| 127 |
Students from FD-LAMT
|
| 128 |
|
| 129 |
-
### Personal and Sensitive Information
|
| 130 |
-
None
|
| 131 |
-
|
| 132 |
## Considerations for Using the Data
|
| 133 |
### Social Impact of Dataset
|
| 134 |
Promoting the development of the music AI industry
|
|
@@ -144,7 +157,8 @@ Insufficient sample
|
|
| 144 |
Dichucheng Li
|
| 145 |
|
| 146 |
### Evaluation
|
| 147 |
-
[
|
|
|
|
| 148 |
|
| 149 |
### Citation Information
|
| 150 |
```bibtex
|
|
|
|
| 15 |
---
|
| 16 |
|
| 17 |
# Dataset Card for GZ_IsoTech Dataset
|
| 18 |
+
## Original Content
|
| 19 |
+
The dataset is created and used for Guzheng playing technique detection. The original dataset comprises 2,824 variable-length audio clips showcasing various Guzheng playing techniques. Specifically, 2,328 clips were sourced from virtual sound banks, while 496 clips were performed by a professional Guzheng artist.
|
| 20 |
|
| 21 |
+
The clips are annotated in eight categories, with a Chinese pinyin and Chinese characters written in parentheses: _Vibrato (chanyin 颤音), Upward Portamento (shanghuayin 上滑音), Downward Portamento (xiahuayin 下滑音), Returning Portamento (huihuayin 回滑音), Glissando (guazou 刮奏, huazhi 花指...), Tremolo (yaozhi 摇指), Harmonic (fanyin 泛音), Plucks (gou 勾, da 打, mo 抹, tuo 托...)_.
|
| 22 |
+
|
| 23 |
+
## Integration
|
| 24 |
+
In the original dataset, the labels were represented by folder names, which provided Italian and Chinese pinyin labels. During the integration process, we added the corresponding Chinese character labels to ensure comprehensiveness. Lastly, after integration, the data structure has six columns: audio clip sampled at a rate of 44,100 Hz, mel spectrogram, numerical label, Italian label, Chinese character label, and Chinese pinyin label. The data number after integration remains at 2,824 with a total duration of 63.98 minutes. The average duration is 1.36 seconds.
|
| 25 |
+
|
| 26 |
+
Based on the aforementioned original dataset, we conducted data processing to construct the [default subset](#default-subset) of the current integrated version of the dataset. Due to the pre-existing split in the original dataset, wherein the data has been partitioned approximately in a 4:1 ratio for training and testing sets, we uphold the original data division approach for the default subset. The data structure of the default subset can be viewed in the [viewer](https://www.modelscope.cn/datasets/ccmusic-database/GZ_IsoTech/dataPeview). In addition, we have retained the [eval subset](#eval-subset) used in the experiment for easy replication.
|
| 27 |
|
| 28 |
## Viewer
|
| 29 |
<https://www.modelscope.cn/datasets/ccmusic-database/GZ_IsoTech/dataPeview>
|
|
|
|
| 64 |
|
| 65 |
### Data Fields
|
| 66 |
Categorization of the clips is based on the diverse playing techniques characteristic of the guzheng, the clips are divided into eight categories: Vibrato (chanyin), Upward Portamento (shanghuayin), Downward Portamento (xiahuayin), Returning Portamento (huihuayin), Glissando (guazou, huazhi), Tremolo (yaozhi), Harmonic (fanyin), Plucks (gou, da, mo, tuo…).
|
|
|
|
| 67 |
|
| 68 |
### Data Splits
|
| 69 |
train, test
|
| 70 |
|
| 71 |
## Dataset Description
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 72 |
### Dataset Summary
|
| 73 |
Due to the pre-existing split in the raw dataset, wherein the data has been partitioned approximately in a 4:1 ratio for training and testing sets, we uphold the original data division approach. In contrast to utilizing platform-specific automated splitting mechanisms, we directly employ the pre-split data for subsequent integration steps.
|
| 74 |
|
| 75 |
+
|
| 76 |
+
### Statistics
|
| 77 |
+
| 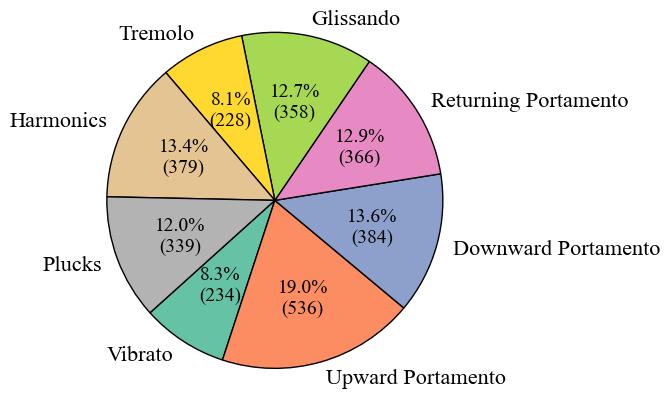 | 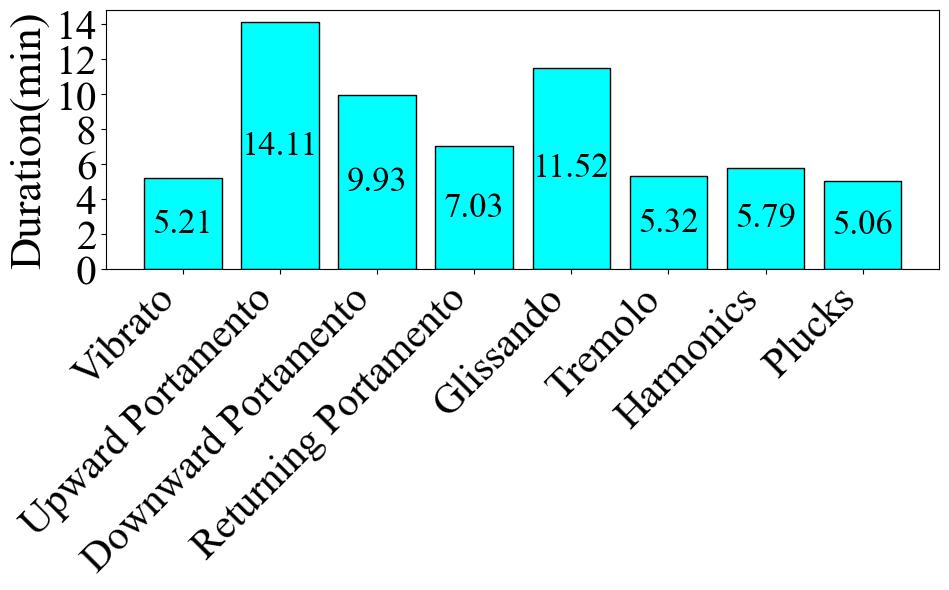 | 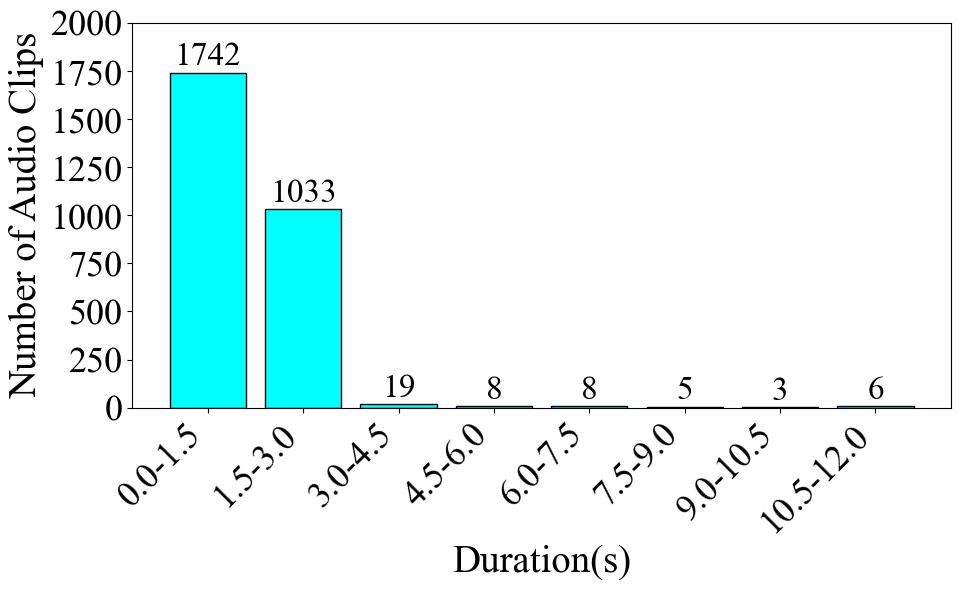 |
|
| 78 |
+
| :---------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------: |
|
| 79 |
+
| **Fig. 1** | **Fig. 2** | **Fig. 3** |
|
| 80 |
+
|
| 81 |
+
Firstly, **Fig. 1** illustrates the number and proportion of audio clips in each category. The category with the largest proportion is Upward Portamento, accounting for 19.0% with 536 clips. The smallest category is Tremolo, accounting for 8.1% with 228 clips. The difference in proportion between the largest and smallest categories is 10.9%. Next, **Fig. 2** displays the total audio duration for each category. The category with the longest total duration is Upward Portamento, with 14.11 minutes, consistent with the results shown in the pie chart. However, the category with the shortest total duration is Plucks, with a total of 5.06 minutes, which differs from the ranking in the pie chart. Overall, this dataset is comparatively balanced within the database. Finally, **Fig. 3** presents the number of audio clips distributed across specific duration intervals. The interval with the highest number of clips is 0-2 seconds. However, the number of audio clips decreases sharply for durations exceeding 4 seconds.
|
| 82 |
+
|
| 83 |
+
| Statistical items | Values |
|
| 84 |
+
| :-----------------: | :------------------: |
|
| 85 |
+
| Total count | `2824` |
|
| 86 |
+
| Total duration(s) | `3838.6787528344717` |
|
| 87 |
+
| Mean duration(s) | `1.359305507377644` |
|
| 88 |
+
| Min duration(s) | `0.3935827664399093` |
|
| 89 |
+
| Max duration(s) | `11.5` |
|
| 90 |
+
| Eval subset total | `2899` |
|
| 91 |
+
| Class with max durs | `Glissando` |
|
| 92 |
|
| 93 |
### Supported Tasks and Leaderboards
|
| 94 |
MIR, audio classification
|
|
|
|
| 97 |
Chinese, English
|
| 98 |
|
| 99 |
## Usage
|
| 100 |
+
### Default subset
|
| 101 |
```python
|
| 102 |
from datasets import load_dataset
|
| 103 |
|
|
|
|
| 109 |
print(item)
|
| 110 |
```
|
| 111 |
|
| 112 |
+
### Eval subset
|
| 113 |
+
```python
|
| 114 |
+
from datasets import load_dataset
|
| 115 |
+
|
| 116 |
+
ds = load_dataset("ccmusic-database/GZ_IsoTech", name="eval")
|
| 117 |
+
for item in ds["train"]:
|
| 118 |
+
print(item)
|
| 119 |
+
|
| 120 |
+
for item in ds["validation"]:
|
| 121 |
+
print(item)
|
| 122 |
+
|
| 123 |
+
for item in ds["test"]:
|
| 124 |
+
print(item)
|
| 125 |
```
|
| 126 |
|
| 127 |
## Dataset Creation
|
|
|
|
| 142 |
#### Who are the annotators?
|
| 143 |
Students from FD-LAMT
|
| 144 |
|
|
|
|
|
|
|
|
|
|
| 145 |
## Considerations for Using the Data
|
| 146 |
### Social Impact of Dataset
|
| 147 |
Promoting the development of the music AI industry
|
|
|
|
| 157 |
Dichucheng Li
|
| 158 |
|
| 159 |
### Evaluation
|
| 160 |
+
[1] <https://huggingface.co/ccmusic-database/GZ_IsoTech>
|
| 161 |
+
[2] [Li, Dichucheng, Yulun Wu, Qinyu Li, Jiahao Zhao, Yi Yu, Fan Xia and Wei Li. “Playing Technique Detection by Fusing Note Onset Information in Guzheng Performance.” International Society for Music Information Retrieval Conference (2022).](https://archives.ismir.net/ismir2022/paper/000037.pdf)
|
| 162 |
|
| 163 |
### Citation Information
|
| 164 |
```bibtex
|