Datasets:

admin
commited on
Commit
·
e366eea
1
Parent(s):
affc9ea
upd md
Browse files
README.md
CHANGED
|
@@ -16,7 +16,7 @@ viewer: false
|
|
| 16 |
|
| 17 |
# Dataset Card for GZ_IsoTech Dataset
|
| 18 |
## Original Content
|
| 19 |
-
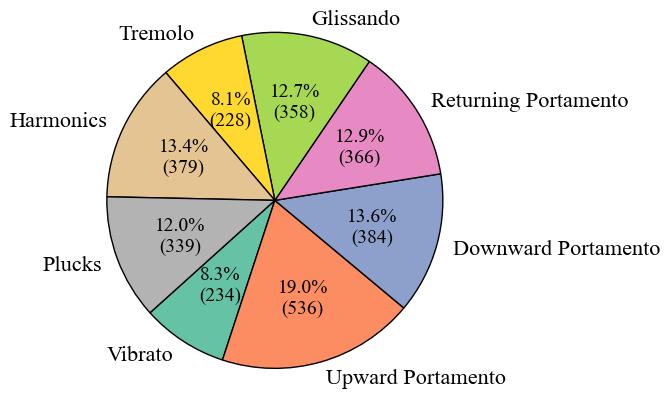
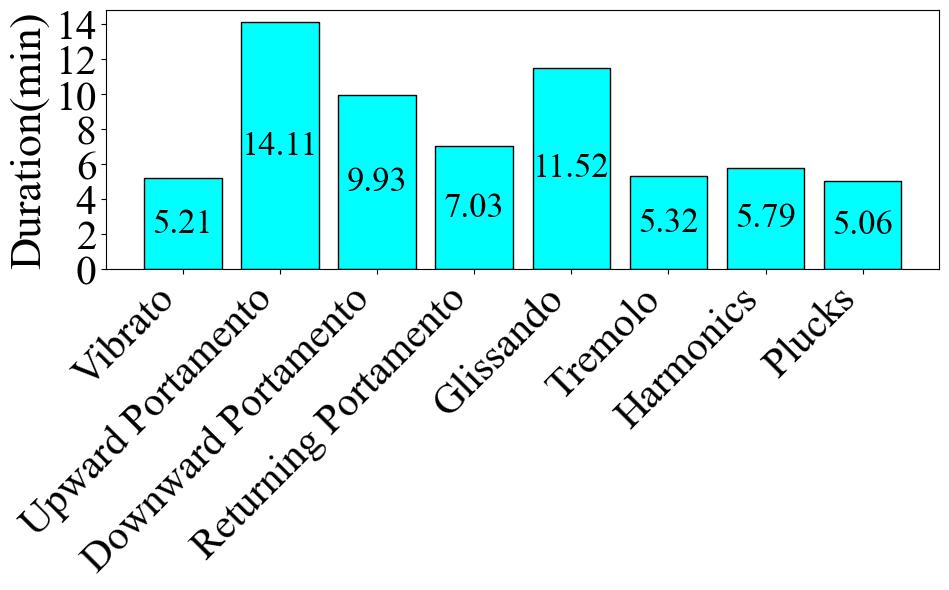
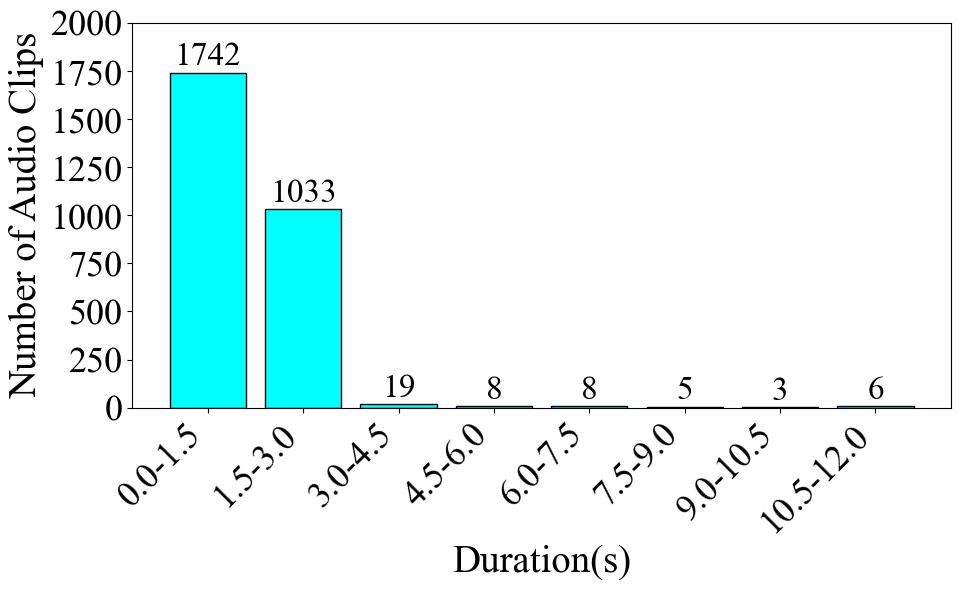
The dataset is created and used for Guzheng playing technique detection. The original dataset comprises 2,824 variable-length audio clips showcasing various Guzheng playing techniques. Specifically, 2,328 clips were sourced from virtual sound banks, while 496 clips were performed by a professional Guzheng artist.
|
| 20 |
|
| 21 |
The clips are annotated in eight categories, with a Chinese pinyin and Chinese characters written in parentheses: _Vibrato (chanyin 颤音), Upward Portamento (shanghuayin 上滑音), Downward Portamento (xiahuayin 下滑音), Returning Portamento (huihuayin 回滑音), Glissando (guazou 刮奏, huazhi 花指...), Tremolo (yaozhi 摇指), Harmonic (fanyin 泛音), Plucks (gou 勾, da 打, mo 抹, tuo 托...)_.
|
| 22 |
|
|
@@ -25,7 +25,7 @@ In the original dataset, the labels were represented by folder names, which prov
|
|
| 25 |
|
| 26 |
Based on the aforementioned original dataset, we conducted data processing to construct the [default subset](#default-subset) of the current integrated version of the dataset. Due to the pre-existing split in the original dataset, wherein the data has been partitioned approximately in a 4:1 ratio for training and testing sets, we uphold the original data division approach for the default subset. The data structure of the default subset can be viewed in the [viewer](https://www.modelscope.cn/datasets/ccmusic-database/GZ_IsoTech/dataPeview). In addition, we have retained the [eval subset](#eval-subset) used in the experiment for easy replication.
|
| 27 |
|
| 28 |
-
##
|
| 29 |
<style>
|
| 30 |
.datastructure td {
|
| 31 |
vertical-align: middle !important;
|
|
@@ -60,7 +60,6 @@ Categorization of the clips is based on the diverse playing techniques character
|
|
| 60 |
### Dataset Summary
|
| 61 |
Due to the pre-existing split in the raw dataset, wherein the data has been partitioned approximately in a 4:1 ratio for training and testing sets, we uphold the original data division approach. In contrast to utilizing platform-specific automated splitting mechanisms, we directly employ the pre-split data for subsequent integration steps.
|
| 62 |
|
| 63 |
-
|
| 64 |
### Statistics
|
| 65 |
|  |  |  |
|
| 66 |
| :---------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------: |
|
|
@@ -138,8 +137,8 @@ Insufficient sample
|
|
| 138 |
Dichucheng Li
|
| 139 |
|
| 140 |
### Evaluation
|
| 141 |
-
[1]
|
| 142 |
-
[2]
|
| 143 |
|
| 144 |
### Citation Information
|
| 145 |
```bibtex
|
|
|
|
| 16 |
|
| 17 |
# Dataset Card for GZ_IsoTech Dataset
|
| 18 |
## Original Content
|
| 19 |
+
The dataset is created and used for Guzheng playing technique detection by [[1]](https://archives.ismir.net/ismir2022/paper/000037.pdf). The original dataset comprises 2,824 variable-length audio clips showcasing various Guzheng playing techniques. Specifically, 2,328 clips were sourced from virtual sound banks, while 496 clips were performed by a professional Guzheng artist.
|
| 20 |
|
| 21 |
The clips are annotated in eight categories, with a Chinese pinyin and Chinese characters written in parentheses: _Vibrato (chanyin 颤音), Upward Portamento (shanghuayin 上滑音), Downward Portamento (xiahuayin 下滑音), Returning Portamento (huihuayin 回滑音), Glissando (guazou 刮奏, huazhi 花指...), Tremolo (yaozhi 摇指), Harmonic (fanyin 泛音), Plucks (gou 勾, da 打, mo 抹, tuo 托...)_.
|
| 22 |
|
|
|
|
| 25 |
|
| 26 |
Based on the aforementioned original dataset, we conducted data processing to construct the [default subset](#default-subset) of the current integrated version of the dataset. Due to the pre-existing split in the original dataset, wherein the data has been partitioned approximately in a 4:1 ratio for training and testing sets, we uphold the original data division approach for the default subset. The data structure of the default subset can be viewed in the [viewer](https://www.modelscope.cn/datasets/ccmusic-database/GZ_IsoTech/dataPeview). In addition, we have retained the [eval subset](#eval-subset) used in the experiment for easy replication.
|
| 27 |
|
| 28 |
+
## Default Subset Structure
|
| 29 |
<style>
|
| 30 |
.datastructure td {
|
| 31 |
vertical-align: middle !important;
|
|
|
|
| 60 |
### Dataset Summary
|
| 61 |
Due to the pre-existing split in the raw dataset, wherein the data has been partitioned approximately in a 4:1 ratio for training and testing sets, we uphold the original data division approach. In contrast to utilizing platform-specific automated splitting mechanisms, we directly employ the pre-split data for subsequent integration steps.
|
| 62 |
|
|
|
|
| 63 |
### Statistics
|
| 64 |
|  |  |  |
|
| 65 |
| :---------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------: |
|
|
|
|
| 137 |
Dichucheng Li
|
| 138 |
|
| 139 |
### Evaluation
|
| 140 |
+
[1] [Li, Dichucheng, Yulun Wu, Qinyu Li, Jiahao Zhao, Yi Yu, Fan Xia and Wei Li. “Playing Technique Detection by Fusing Note Onset Information in Guzheng Performance.” International Society for Music Information Retrieval Conference (2022).](https://archives.ismir.net/ismir2022/paper/000037.pdf)<br>
|
| 141 |
+
[2] <https://huggingface.co/ccmusic-database/GZ_IsoTech>
|
| 142 |
|
| 143 |
### Citation Information
|
| 144 |
```bibtex
|