Datasets:

admin
commited on
Commit
·
944df66
1
Parent(s):
7335fe4
upd md
Browse files
README.md
CHANGED
|
@@ -88,68 +88,26 @@ This dataset was created and has been utilized for Erhu playing technique detect
|
|
| 88 |
## Integration
|
| 89 |
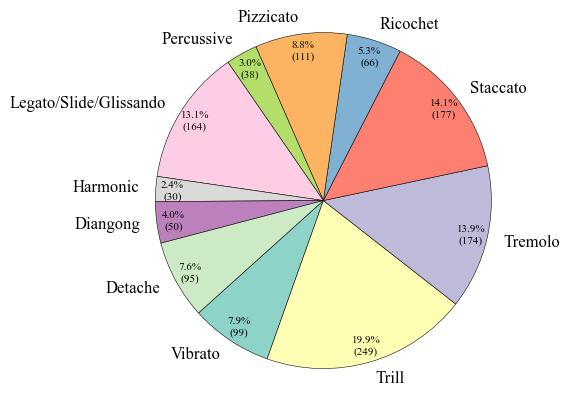
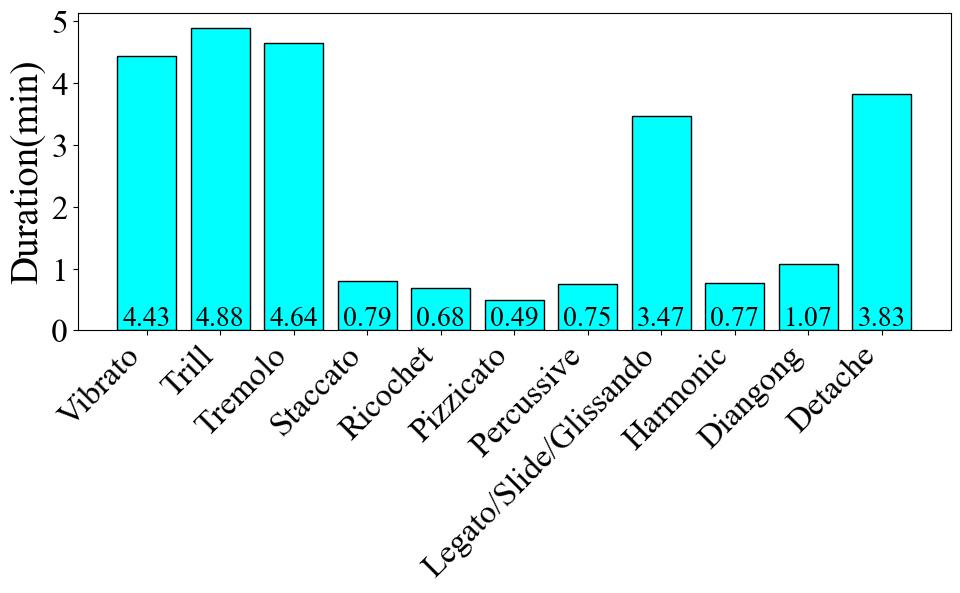
We first perform label cleaning to abandon the labels for the four and seven categories, since there are also missing data problems. This process leaves us with only the labels for the 11 categories. Then, we add Chinese character label and Chinese pinyin label to enhance comprehensibility. The 11 labels are: Detache (分弓), Diangong (垫弓), Harmonic (泛音), Legato\slide\glissando (连弓\滑音\连音), Percussive (击弓), Pizzicato (拨弦), Ricochet (抛弓), Staccato (断弓), Tremolo (震音), Trill (颤音), and Vibrato (揉弦). After integration, the data structure contains six columns: audio (with a sampling rate of 44,100 Hz), mel spectrograms, numeric label, Italian label, Chinese character label, and Chinese pinyin label. The total number of audio clips remains at 1,253, with a total duration of 25.81 minutes. The average duration is 1.24 seconds.
|
| 90 |
|
| 91 |
-
We constructed the
|
| 92 |
|
| 93 |
## Statistics
|
| 94 |
-
|  |  |  |
|
| 95 |
-
| :---------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------: |
|
| 96 |
-
| **Fig. 1** | **Fig. 2** | **Fig. 3** |
|
| 97 |
|
| 98 |
-
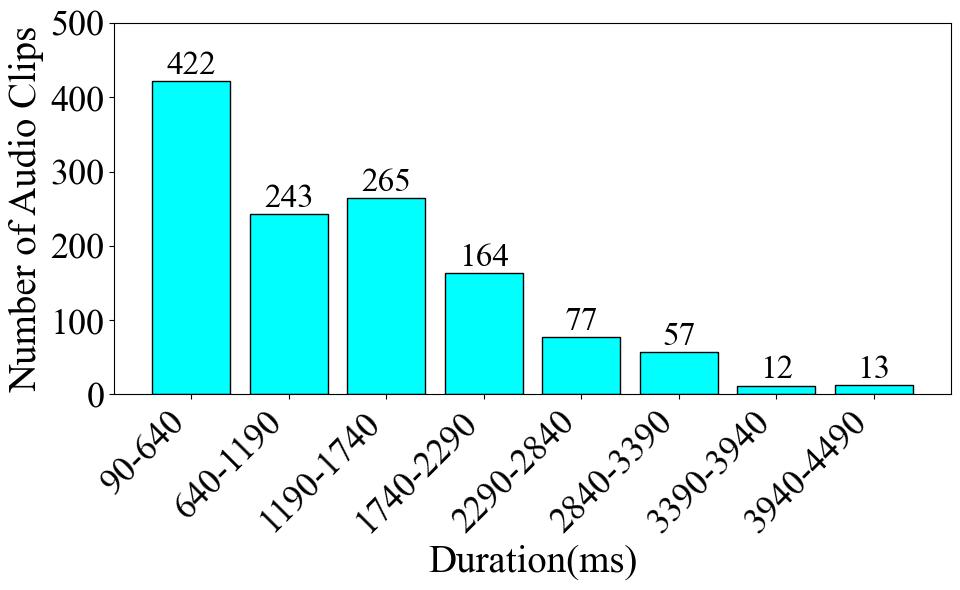
To begin with, **Fig. 1** presents the number of data entries per label. The Trill label has the highest data volume, with 249 instances, which accounts for 19.9% of the total dataset. Conversely, the Harmonic label has the least amount of data, with only 30 instances, representing a meager 2.4% of the total. Turning to the audio duration per category, as illustrated in **Fig. 2**, the audio data associated with the Trill label has the longest cumulative duration, amounting to 4.88 minutes. In contrast, the Percussive label has the shortest audio duration, clocking in at 0.75 minutes. These disparities clearly indicate a class imbalance problem within the dataset. Finally, as shown in **Fig. 3**, we count the frequency of audio occurrences at 550-ms intervals. The quantity of data decreases as the duration lengthens. The most populated duration range is 90-640 ms, with 422 audio clips. The least populated range is 3390-3940 ms, which contains only 12 clips.
|
| 99 |
|
| 100 |
-
### Totals
|
| 101 |
-
| Subset | Total count | Total duration(s) |
|
| 102 |
-
| :-------------------------: | :---------: | :------------------: |
|
| 103 |
-
| Default / 11_classes / Eval | `1253` | `1548.3557823129247` |
|
| 104 |
-
| 7_classes / 4_classes | `635` | `719.8175736961448` |
|
| 105 |
-
|
| 106 |
-
### Range (Default subset)
|
| 107 |
| Statistical items | Values |
|
| 108 |
| :--------------------------------------------: | :------------------: |
|
|
|
|
|
|
|
| 109 |
| Mean duration(ms) | `1235.7189004891661` |
|
| 110 |
| Min duration(ms) | `91.7687074829932` |
|
| 111 |
| Max duration(ms) | `4468.934240362812` |
|
| 112 |
| Classes in the longest audio duartion interval | `Vibrato, Detache` |
|
| 113 |
|
| 114 |
## Dataset Structure
|
| 115 |
-
|
| 116 |
-
<style>
|
| 117 |
-
.erhu td {
|
| 118 |
-
vertical-align: middle !important;
|
| 119 |
-
text-align: center;
|
| 120 |
-
}
|
| 121 |
-
.erhu th {
|
| 122 |
-
text-align: center;
|
| 123 |
-
}
|
| 124 |
-
</style>
|
| 125 |
-
<table class="erhu">
|
| 126 |
-
<tr>
|
| 127 |
-
<th>audio</th>
|
| 128 |
-
<th>mel</th>
|
| 129 |
-
<th>label</th>
|
| 130 |
-
</tr>
|
| 131 |
-
<tr>
|
| 132 |
-
<td>.wav, 44100Hz</td>
|
| 133 |
-
<td>.jpg, 44100Hz</td>
|
| 134 |
-
<td>4/7/11-class</td>
|
| 135 |
-
</tr>
|
| 136 |
-
</table>
|
| 137 |
-
|
| 138 |
-
### Eval Subset Structure
|
| 139 |
-
<table class="erhu">
|
| 140 |
-
<tr>
|
| 141 |
-
<th>mel</th>
|
| 142 |
-
<th>cqt</th>
|
| 143 |
-
<th>chroma</th>
|
| 144 |
-
<th>label</th>
|
| 145 |
-
</tr>
|
| 146 |
-
<tr>
|
| 147 |
-
<td>.jpg, 44100Hz</td>
|
| 148 |
-
<td>.jpg, 44100Hz</td>
|
| 149 |
-
<td>.jpg, 44100Hz</td>
|
| 150 |
-
<td>11-class</td>
|
| 151 |
-
</tr>
|
| 152 |
-
</table>
|
| 153 |
|
| 154 |
### Data Instances
|
| 155 |
.zip(.wav, .jpg)
|
|
|
|
| 88 |
## Integration
|
| 89 |
We first perform label cleaning to abandon the labels for the four and seven categories, since there are also missing data problems. This process leaves us with only the labels for the 11 categories. Then, we add Chinese character label and Chinese pinyin label to enhance comprehensibility. The 11 labels are: Detache (分弓), Diangong (垫弓), Harmonic (泛音), Legato\slide\glissando (连弓\滑音\连音), Percussive (击弓), Pizzicato (拨弦), Ricochet (抛弓), Staccato (断弓), Tremolo (震音), Trill (颤音), and Vibrato (揉弦). After integration, the data structure contains six columns: audio (with a sampling rate of 44,100 Hz), mel spectrograms, numeric label, Italian label, Chinese character label, and Chinese pinyin label. The total number of audio clips remains at 1,253, with a total duration of 25.81 minutes. The average duration is 1.24 seconds.
|
| 90 |
|
| 91 |
+
We constructed the [default subset](#default-subset) of the current integrated version dataset based on its 11 classification data and optimized the names of the 11 categories. The data structure can be seen in the [viewer](https://huggingface.co/datasets/ccmusic-database/erhu_playing_tech/viewer). Although the original dataset has been cited in some articles, the experiments in those articles lack reproducibility. In order to demonstrate the effectiveness of the default subset, we further processed the data and constructed the [eval subset](#eval-subset) to supplement the evaluation of this integrated version dataset. The results of the evaluation can be viewed in [[2]](https://huggingface.co/ccmusic-database/erhu_playing_tech).
|
| 92 |
|
| 93 |
## Statistics
|
| 94 |
+
|  |  |  |
|
| 95 |
+
| :---------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------: |
|
| 96 |
+
| **Fig. 1** | **Fig. 2** | **Fig. 3** |
|
| 97 |
|
| 98 |
+
To begin with, **Fig. 1** presents the number of data entries per label. The Trill label has the highest data volume, with 249 instances, which accounts for 19.9% of the total dataset. Conversely, the Harmonic label has the least amount of data, with only 30 instances, representing a meager 2.4% of the total. Turning to the audio duration per category, as illustrated in **Fig. 2**, the audio data associated with the Trill label has the longest cumulative duration, amounting to 4.88 minutes. In contrast, the Percussive label has the shortest audio duration, clocking in at 0.75 minutes. These disparities clearly indicate a class imbalance problem within the dataset. Finally, as shown in **Fig. 3**, we count the frequency of audio occurrences at 550-ms intervals. The quantity of data decreases as the duration lengthens. The most populated duration range is 90-640 ms, with 422 audio clips. The least populated range is 3390-3940 ms, which contains only 12 clips.
|
| 99 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 100 |
| Statistical items | Values |
|
| 101 |
| :--------------------------------------------: | :------------------: |
|
| 102 |
+
| Total count | `1253` |
|
| 103 |
+
| Total duration(s) | `1548.3557823129247` |
|
| 104 |
| Mean duration(ms) | `1235.7189004891661` |
|
| 105 |
| Min duration(ms) | `91.7687074829932` |
|
| 106 |
| Max duration(ms) | `4468.934240362812` |
|
| 107 |
| Classes in the longest audio duartion interval | `Vibrato, Detache` |
|
| 108 |
|
| 109 |
## Dataset Structure
|
| 110 |
+
<https://huggingface.co/datasets/ccmusic-database/erhu_playing_tech/viewer>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 111 |
|
| 112 |
### Data Instances
|
| 113 |
.zip(.wav, .jpg)
|