--help), see issue #28 (now using the great jopt-simple library)--once option, terminal will not be cleared anymore (see issue #27)JAVA_HOME environment variable is not present (thanks to Markus Kolb)
-
-
| |
- |
Build your own cloud testing infrastructure
-| Android Experience App | -iOS Experience App | -
|---|---|
| Native SDK - | Download Address - | Integration Guide - | Update Log - |
|---|---|---|---|
| Android | -GitHub (Recommended) | -[Quick Integration] TUIKit Integration (Android) [General Integration] SDK Integration (Android) |
-Update Log (Native) | -
| iOS | -GitHub (Recommended) | -[Quick Integration] TUIKit Integration (iOS) [General Integration] SDK Integration (iOS) |
-|
| Mac | -GitHub (Recommended) | -[General Integration] SDK Integration (Mac) | -|
| Windows | -GitHub (Recommended) | -[General Integration] SDK Integration (Windows) | -|
| HarmonyOS | -GitHub (Recommended) | -[General Integration] SDK Integration (HarmonyOS) | -
| Functional Module | -Platform | -Document Link | -
|---|---|---|
| TUIKit Library | -iOS | -TUIKit-iOS Library | -
| Android | -TUIKit-Android Library | -|
| Quick Integration | -iOS | -TUIKit-iOS Quick Integration | -
| Android | -TUIKit-Android Quick Integration | -|
| Modifying UI Themes | -iOS | -TUIKit-iOS Modifying UI Themes | -
| Android | -TUIKit-Android Modifying UI Themes | -|
| Setting UI Styles | -iOS | -TUIKit-iOS Setting UI Styles | -
| Android | -TUIKit-Android Setting UI Styles | -|
| Adding Custom Messages | -iOS | -TUIKit-iOS Adding Custom Messages | -
| Android | -TUIKit-Android Adding Custom Messages | -|
| Implementing Local Search | -iOS | -TUIKit-iOS Implementing Local Search | -
| Android | -TUIKit-Android Implementing Local Search | -|
| Integrating Offline Push | -iOS | -TUIKit-iOS Integrating Offline Push | -
| Android | -TUIKit-Android Integrating Offline Push | -
| Key | Required | Default Value | -
| jasypt.encryptor.password | True | - | -
| jasypt.encryptor.algorithm | False | PBEWITHHMACSHA512ANDAES_256 | -
| jasypt.encryptor.key-obtention-iterations | False | 1000 | -
| jasypt.encryptor.pool-size | False | 1 | -
| jasypt.encryptor.provider-name | False | SunJCE | -
| jasypt.encryptor.provider-class-name | False | null | -
| jasypt.encryptor.salt-generator-classname | False | org.jasypt.salt.RandomSaltGenerator | -
| jasypt.encryptor.iv-generator-classname | False | org.jasypt.iv.RandomIvGenerator | -
| jasypt.encryptor.string-output-type | False | base64 | -
| jasypt.encryptor.proxy-property-sources | False | false | -
| jasypt.encryptor.skip-property-sources | False | empty list | -
| Key | Default Value | Description | -
| jasypt.encryptor.privateKeyString | null | private key for decryption in String format | -
| jasypt.encryptor.privateKeyLocation | null | location of the private key for decryption in spring resource format | -
| jasypt.encryptor.privateKeyFormat | DER | Key format. DER or PEM | -
 -
-- iPhone X
-
-
-
-- iPhone X
-
- -
-
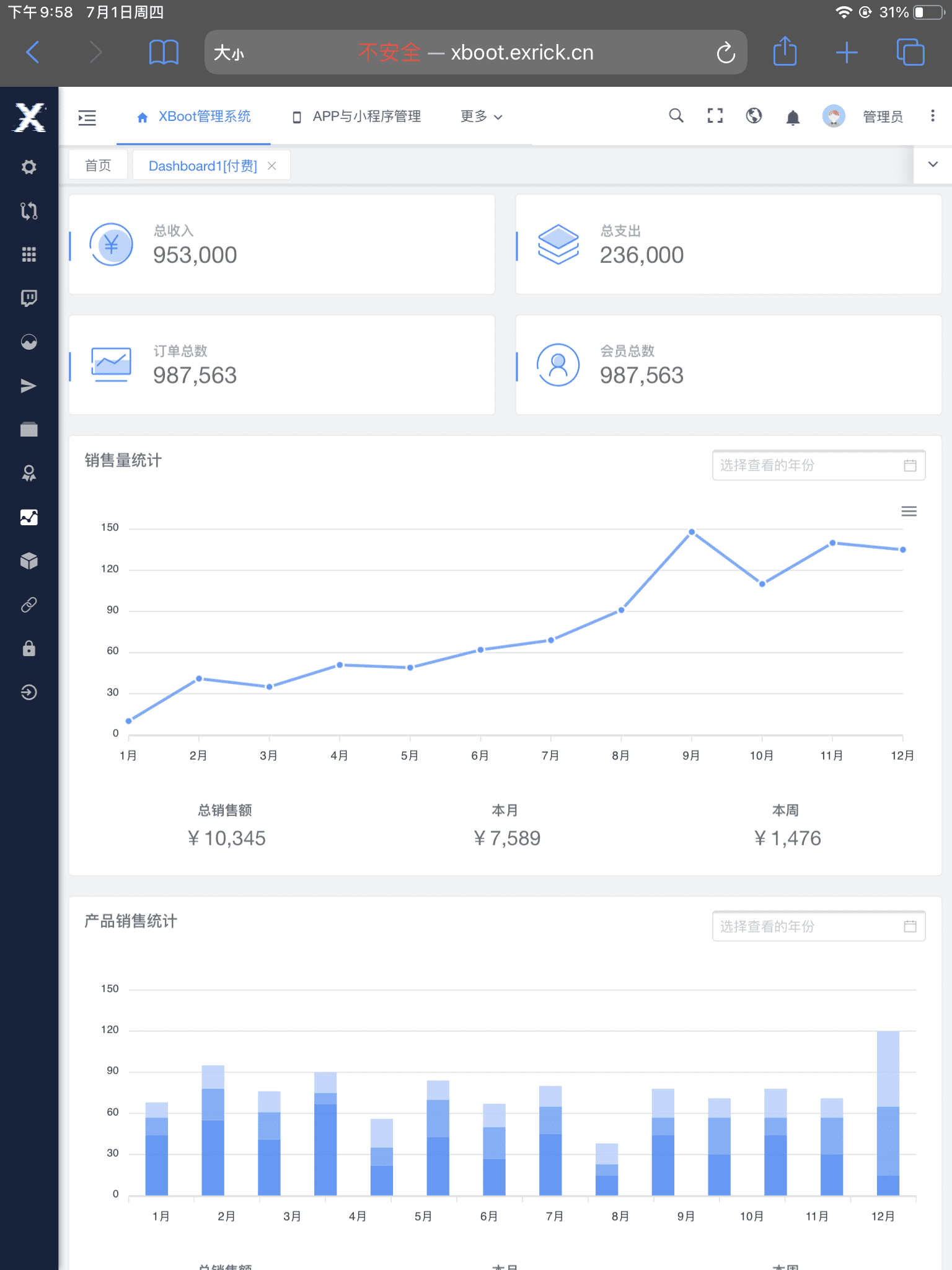
-### [完整版截图细节展示](https://github.com/Exrick/x-boot/wiki/%E5%AE%8C%E6%95%B4%E7%89%88%E6%88%AA%E5%9B%BE%E7%BB%86%E8%8A%82%E5%B1%95%E7%A4%BA)
-
-### 系统架构
-
-
-
-
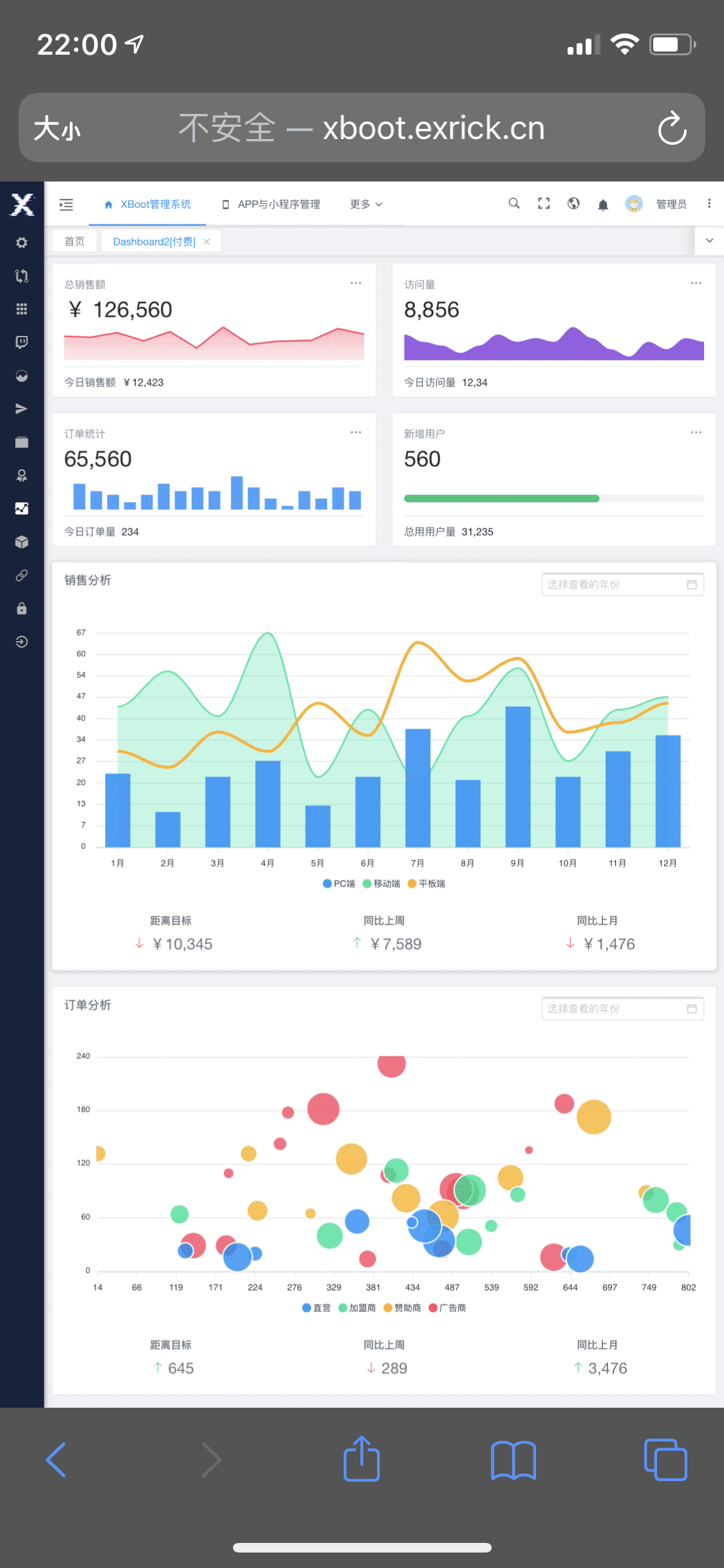
-### [完整版截图细节展示](https://github.com/Exrick/x-boot/wiki/%E5%AE%8C%E6%95%B4%E7%89%88%E6%88%AA%E5%9B%BE%E7%BB%86%E8%8A%82%E5%B1%95%E7%A4%BA)
-
-### 系统架构
-
-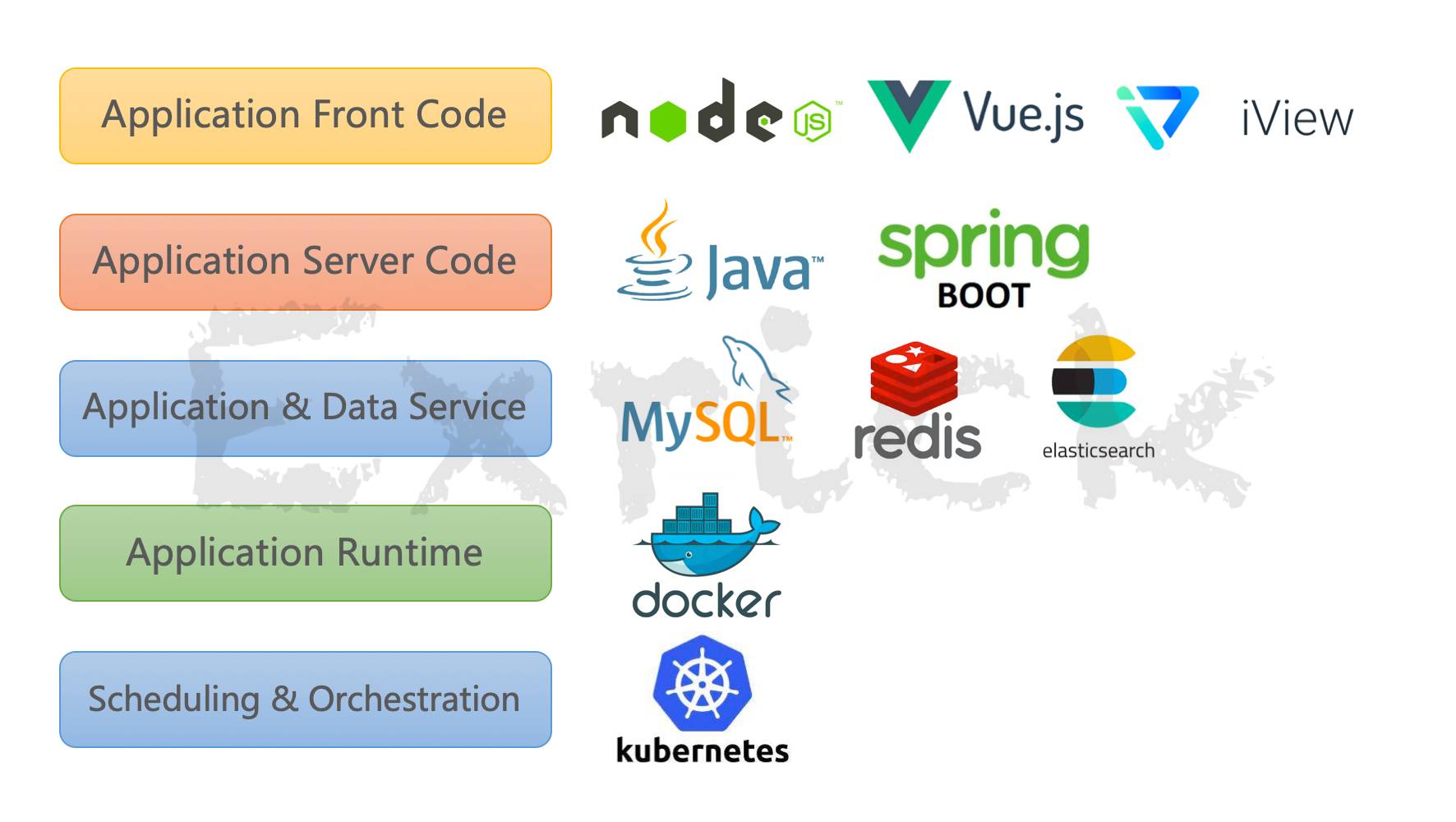 -
-##### 各框架依赖版本皆使用目前最新版本
-- Spring Boot
-- SpringMVC
-- Spring Security
-- [Spring Data JPA](https://docs.spring.io/spring-data/jpa/docs/2.2.2.RELEASE/reference/html/)
-- [MyBatis-Plus](http://mp.baomidou.com):已更新至3.x版本
-- [Redis](https://github.com/Exrick/xmall/blob/master/study/Redis.md)
-- [Elasticsearch](https://github.com/Exrick/xmall/blob/master/study/Elasticsearch.md):基于Lucene分布式搜索引擎
-- [Druid](http://druid.io/):阿里高性能数据库连接池(偏监控 注重性能可使用默认HikariCP) [Druid配置官方中文文档](https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter)
-- [Json Web Token(JWT)](https://jwt.io/)
-- [Quartz](http://www.quartz-scheduler.org):定时任务
-- [Beetl](http://ibeetl.com/guide/#beetl):模版引擎 代码生成使用
-- [Thymeleaf](https://www.thymeleaf.org/):发送模版邮件使用
-- [Hutool](http://hutool.mydoc.io/):Java工具包
-- [Jasypt](https://github.com/ulisesbocchio/jasypt-spring-boot):配置文件加密(thymeleaf作者开发)
-- [Swagger2](https://github.com/Exrick/xmall/blob/master/study/Swagger2.md):Api文档生成
-- MySQL
-- [Nginx](https://github.com/Exrick/xmall/blob/master/study/Nginx.md)
-- [Maven](https://github.com/Exrick/xmall/blob/master/study/Maven.md)
-- 第三方SDK或服务
- - [七牛云文件存储服务](https://developer.qiniu.com/kodo/sdk/1239/java)
- - [腾讯位置服务](https://lbs.qq.com/webservice_v1/guide-ip.html):需申请填入key后免费使用
- - 完整版
- - [Vaptcha人机验证码](https://www.vaptcha.com/)
- - [阿里云短信服务](https://dysms.console.aliyun.com)
-- 其它开发工具
- - [Lombok](https://projectlombok.org/)
- - [JRebel](https://github.com/Exrick/xmall/blob/master/study/JRebel.md):开发秒级热部署
- - [阿里JAVA开发规约插件](https://github.com/alibaba/p3c)
-
-### 最新最全面在线文档
-
-> 第一时间更新,文档永不收费
-
-https://www.kancloud.cn/exrick/xboot/content
-
-### 本地运行部署
-- 安装依赖并启动:[Redis](https://github.com/Exrick/xmall/blob/master/study/Redis.md)、[Elasticsearch](https://github.com/Exrick/xmall/blob/master/study/Elasticsearch.md)(当配置使用ES记录日志时需要)
-- [Maven安装和在IDEA中配置](https://github.com/Exrick/xmall/blob/master/study/Maven.md)
-- 建议使用IDEA([破解/免费注册](http://idea.lanyus.com/)) 安装 `Lombok` 插件后导入该Maven项目 若未自动下载依赖请在根目录下执行 `mvn install` 命令
-- MySQL数据库新建 `xboot` 数据库,配置文件已开启ddl自动生成表结构但无初始数据,请记得运行导入xboot.sql文件(当报错找不到Quartz相关表时请设置数据库忽略大小写或额外重新导入quartz.sql)
-- 修改配置文件 `application.yml` 相应配置,其中有详细注释,所有配置只需在这里修改
-- 编译器中启动运行 `XbootApplication.java` 或根目录下执行命令 `mvn spring-boot:run` 默认端口8888 访问接口文档 `http://localhost:8888/doc.html` 说明启动成功 管理员账密admin|123456
-- 前台页面请启动基于Vue的 [xboot-front](https://github.com/Exrick/xboot-front) 项目,并修改其接口代理配置
-> 温馨提示:若更新代码后报错,请记得更新sql并清空Redis缓存
-### 开发指南及相关技术栈文档
-- [项目基本配置和使用相关技术栈文档【必读】](https://github.com/Exrick/x-boot/wiki/%E9%A1%B9%E7%9B%AE%E5%9F%BA%E6%9C%AC%E9%85%8D%E7%BD%AE%E5%92%8C%E4%BD%BF%E7%94%A8%E7%9B%B8%E5%85%B3%E6%8A%80%E6%9C%AF%E6%A0%88%E6%96%87%E6%A1%A3%E3%80%90%E5%BF%85%E8%AF%BB%E3%80%91)
-- [如何使用XBoot后端在30秒内开发出增删改接口](https://github.com/Exrick/x-boot/wiki/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8XBoot%E5%90%8E%E7%AB%AF%E5%9C%A830%E7%A7%92%E5%86%85%E5%BC%80%E5%8F%91%E5%87%BA%E5%A2%9E%E5%88%A0%E6%94%B9%E6%8E%A5%E5%8F%A3)
-- [具体XBoot增删改文档示例](https://github.com/Exrick/x-boot/wiki/CRUD)
-- 完整版
- - [第三方社交账号登录配置](https://github.com/Exrick/x-boot/wiki/%E7%AC%AC%E4%B8%89%E6%96%B9%E7%A4%BE%E4%BA%A4%E8%B4%A6%E5%8F%B7%E7%99%BB%E5%BD%95%E9%85%8D%E7%BD%AE)
- - [短信登录配置](https://github.com/Exrick/x-boot/wiki/%E7%9F%AD%E4%BF%A1%E7%99%BB%E5%BD%95%E9%85%8D%E7%BD%AE)
- - [Vaptcha人机验证码配置使用](https://github.com/Exrick/x-boot/wiki/vaptcha%E4%BA%BA%E6%9C%BA%E9%AA%8C%E8%AF%81%E7%A0%81%E9%85%8D%E7%BD%AE%E4%BD%BF%E7%94%A8)
- - [Activiti工作流开发说明](https://github.com/Exrick/x-boot/wiki/Activiti%E5%B7%A5%E4%BD%9C%E6%B5%81%E5%BC%80%E5%8F%91%E8%AF%B4%E6%98%8E)
-
-### [分布式扩展](https://github.com/alibaba/dubbo-spring-boot-starter/blob/master/README_zh.md)
-
-### XBoot后端学习分享(更新中)
-1. [Spring Boot 2.x 区别总结](https://github.com/Exrick/x-boot/wiki/SpringBoot2.x%E5%8C%BA%E5%88%AB%E6%80%BB%E7%BB%93)
-
-2. [Spring Security整合JWT](https://github.com/Exrick/x-boot/wiki/SpringSecurity%E6%95%B4%E5%90%88JWT)
-
-3. [Spring Security实现动态数据库权限管理](https://github.com/Exrick/x-boot/wiki/SpringSecurity%E5%8A%A8%E6%80%81%E6%9D%83%E9%99%90%E7%AE%A1%E7%90%86)
-
-4. [Spring Boot 2.x整合Quartz](https://github.com/Exrick/x-boot/wiki/Spring-Boot-2.x%E6%95%B4%E5%90%88Quartz)
-
-5. [基于Websocket实现发送消息后右上角消息图标红点实时显示](https://github.com/Exrick/x-boot/wiki/%E5%9F%BA%E4%BA%8EWebsocket%E5%AE%9E%E7%8E%B0%E5%8F%91%E9%80%81%E6%B6%88%E6%81%AF%E5%90%8E%E5%8F%B3%E4%B8%8A%E8%A7%92%E6%B6%88%E6%81%AF%E5%9B%BE%E6%A0%87%E7%BA%A2%E7%82%B9%E5%AE%9E%E6%97%B6%E6%98%BE%E7%A4%BA)
-
-6. [Spring Boot 2.x整合Activiti工作流以及模型设计器](https://github.com/Exrick/x-boot/wiki/Spring-Boot-2.x%E6%95%B4%E5%90%88Activiti%E5%B7%A5%E4%BD%9C%E6%B5%81%E4%BB%A5%E5%8F%8A%E6%A8%A1%E5%9E%8B%E8%AE%BE%E8%AE%A1%E5%99%A8)
-### Docker下后端集群部署(更新中)
-
-> 前端集群部署请跳转至[xboot-front](https://github.com/Exrick/xboot-front)项目查看
-
-1.[Docker的安装与常用命令](https://github.com/Exrick/x-boot/wiki/Docker%E7%9A%84%E5%AE%89%E8%A3%85%E4%B8%8E%E5%B8%B8%E7%94%A8%E5%91%BD%E4%BB%A4)
-
-2.基于PXC架构Mysql数据库集群搭建
-
-3.Redis集群搭建
-
-4.Elasticsearch集群搭建
-
-5.XBoot后端集群部署
-
-### 商用授权
-- 个人学习使用遵循GPL开源协议
-- 商用需联系作者授权
-
-### 作者其他项目推荐
-- [XMall微信小程序APP前端 现已开源!](https://github.com/Exrick/xmall-weapp)
-
- [](https://www.bilibili.com/video/av70226175)
-
-- [XMall:基于SOA架构的分布式电商购物商城](https://github.com/Exrick/xmall)
-
- 
-
-- [XPay个人免签收款支付系统](https://github.com/Exrick/xpay)
-
-- 机器学习笔记
- - [Machine-Learning](https://github.com/Exrick/Machine-Learning)
-
-### 技术疑问交流
-- QQ交流群 `475743731(付费)`,可获取各项目详细图文文档、疑问解答 [](http://shang.qq.com/wpa/qunwpa?idkey=7b60cec12ba93ebed7568b0a63f22e6e034c0d1df33125ac43ed753342ec6ce7)
-- 免费交流群 `562962309` [](http://shang.qq.com/wpa/qunwpa?idkey=52f6003e230b26addeed0ba6cf343fcf3ba5d97829d17f5b8fa5b151dba7e842)
-- 作者博客:[http://blog.exrick.cn](http://blog.exrick.cn)
-### [捐赠](http://xpay.exrick.cn/pay)",0
-traccar/traccar,Traccar GPS Tracking System,2012-04-16T08:33:49Z,,"# [Traccar](https://www.traccar.org)
-
-## Overview
-
-Traccar is an open source GPS tracking system. This repository contains Java-based back-end service. It supports more than 200 GPS protocols and more than 2000 models of GPS tracking devices. Traccar can be used with any major SQL database system. It also provides easy to use [REST API](https://www.traccar.org/traccar-api/).
-
-Other parts of Traccar solution include:
-
-- [Traccar web app](https://github.com/traccar/traccar-web)
-- [Traccar Manager Android app](https://github.com/traccar/traccar-manager-android)
-- [Traccar Manager iOS app](https://github.com/traccar/traccar-manager-ios)
-
-There is also a set of mobile apps that you can use for tracking mobile devices:
-
-- [Traccar Client Android app](https://github.com/traccar/traccar-client-android)
-- [Traccar Client iOS app](https://github.com/traccar/traccar-client-ios)
-
-## Features
-
-Some of the available features include:
-
-- Real-time GPS tracking
-- Driver behaviour monitoring
-- Detailed and summary reports
-- Geofencing functionality
-- Alarms and notifications
-- Account and device management
-- Email and SMS support
-
-## Build
-
-Please read [build from source documentation](https://www.traccar.org/build/) on the official website.
-
-## Team
-
-- Anton Tananaev ([anton@traccar.org](mailto:anton@traccar.org))
-- Andrey Kunitsyn ([andrey@traccar.org](mailto:andrey@traccar.org))
-
-## License
-
- Apache License, Version 2.0
-
- Licensed under the Apache License, Version 2.0 (the ""License"");
- you may not use this file except in compliance with the License.
- You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an ""AS IS"" BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License.
-",0
-nzymedefense/nzyme,Network Defense System.,2016-11-11T22:06:03Z,,"# nzyme - Network Defense System
-
-[](https://codecov.io/gh/lennartkoopmann/nzyme/)
-[](http://www.mongodb.com/licensing/server-side-public-license)
-
-Learn more at https://www.nzyme.org/.
-
-**Version 2.0.0 of nzyme is currently in development. The previous website for v1.x is archived [here](https://v1.nzyme.org/).**
-
-## Contributing
-
-There are many ways to contribute and all community interaction is absolutely welcome:
-
-* Open an issue for any kind of bug you think you have found.
-* Open an issue for anything that was confusing to you. Bad, missing or confusing documentation is considered a bug.
-* Open a Pull Request for a new feature or a bugfix. It is a good idea to get in contact first to make sure that it fits the roadmap and has a chance to be merged.
-* Write documentation.
-* Write a blog post.
-* Help a user in the issue tracker or the IRC channel (#nzyme on FreeNode.)
-* Get in contact and say how you use it or what would be a cool addition.
-* Tell the world.
-
-Please be aware of the [Code of Conduct](CODE_OF_CONDUCT.md) that will be enforced across all channels and platforms.
-
-## Legal notice
-
-Make sure to comply with local laws, especially with regards to wiretapping, when running nzyme. Note that nzyme is never decrypting any data but only reading unencrypted data.
-",0
-apache/eventmesh,EventMesh is a new generation serverless event middleware for building distributed event-driven applications.,2019-09-16T03:04:56Z,,"
-
-##### 各框架依赖版本皆使用目前最新版本
-- Spring Boot
-- SpringMVC
-- Spring Security
-- [Spring Data JPA](https://docs.spring.io/spring-data/jpa/docs/2.2.2.RELEASE/reference/html/)
-- [MyBatis-Plus](http://mp.baomidou.com):已更新至3.x版本
-- [Redis](https://github.com/Exrick/xmall/blob/master/study/Redis.md)
-- [Elasticsearch](https://github.com/Exrick/xmall/blob/master/study/Elasticsearch.md):基于Lucene分布式搜索引擎
-- [Druid](http://druid.io/):阿里高性能数据库连接池(偏监控 注重性能可使用默认HikariCP) [Druid配置官方中文文档](https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter)
-- [Json Web Token(JWT)](https://jwt.io/)
-- [Quartz](http://www.quartz-scheduler.org):定时任务
-- [Beetl](http://ibeetl.com/guide/#beetl):模版引擎 代码生成使用
-- [Thymeleaf](https://www.thymeleaf.org/):发送模版邮件使用
-- [Hutool](http://hutool.mydoc.io/):Java工具包
-- [Jasypt](https://github.com/ulisesbocchio/jasypt-spring-boot):配置文件加密(thymeleaf作者开发)
-- [Swagger2](https://github.com/Exrick/xmall/blob/master/study/Swagger2.md):Api文档生成
-- MySQL
-- [Nginx](https://github.com/Exrick/xmall/blob/master/study/Nginx.md)
-- [Maven](https://github.com/Exrick/xmall/blob/master/study/Maven.md)
-- 第三方SDK或服务
- - [七牛云文件存储服务](https://developer.qiniu.com/kodo/sdk/1239/java)
- - [腾讯位置服务](https://lbs.qq.com/webservice_v1/guide-ip.html):需申请填入key后免费使用
- - 完整版
- - [Vaptcha人机验证码](https://www.vaptcha.com/)
- - [阿里云短信服务](https://dysms.console.aliyun.com)
-- 其它开发工具
- - [Lombok](https://projectlombok.org/)
- - [JRebel](https://github.com/Exrick/xmall/blob/master/study/JRebel.md):开发秒级热部署
- - [阿里JAVA开发规约插件](https://github.com/alibaba/p3c)
-
-### 最新最全面在线文档
-
-> 第一时间更新,文档永不收费
-
-https://www.kancloud.cn/exrick/xboot/content
-
-### 本地运行部署
-- 安装依赖并启动:[Redis](https://github.com/Exrick/xmall/blob/master/study/Redis.md)、[Elasticsearch](https://github.com/Exrick/xmall/blob/master/study/Elasticsearch.md)(当配置使用ES记录日志时需要)
-- [Maven安装和在IDEA中配置](https://github.com/Exrick/xmall/blob/master/study/Maven.md)
-- 建议使用IDEA([破解/免费注册](http://idea.lanyus.com/)) 安装 `Lombok` 插件后导入该Maven项目 若未自动下载依赖请在根目录下执行 `mvn install` 命令
-- MySQL数据库新建 `xboot` 数据库,配置文件已开启ddl自动生成表结构但无初始数据,请记得运行导入xboot.sql文件(当报错找不到Quartz相关表时请设置数据库忽略大小写或额外重新导入quartz.sql)
-- 修改配置文件 `application.yml` 相应配置,其中有详细注释,所有配置只需在这里修改
-- 编译器中启动运行 `XbootApplication.java` 或根目录下执行命令 `mvn spring-boot:run` 默认端口8888 访问接口文档 `http://localhost:8888/doc.html` 说明启动成功 管理员账密admin|123456
-- 前台页面请启动基于Vue的 [xboot-front](https://github.com/Exrick/xboot-front) 项目,并修改其接口代理配置
-> 温馨提示:若更新代码后报错,请记得更新sql并清空Redis缓存
-### 开发指南及相关技术栈文档
-- [项目基本配置和使用相关技术栈文档【必读】](https://github.com/Exrick/x-boot/wiki/%E9%A1%B9%E7%9B%AE%E5%9F%BA%E6%9C%AC%E9%85%8D%E7%BD%AE%E5%92%8C%E4%BD%BF%E7%94%A8%E7%9B%B8%E5%85%B3%E6%8A%80%E6%9C%AF%E6%A0%88%E6%96%87%E6%A1%A3%E3%80%90%E5%BF%85%E8%AF%BB%E3%80%91)
-- [如何使用XBoot后端在30秒内开发出增删改接口](https://github.com/Exrick/x-boot/wiki/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8XBoot%E5%90%8E%E7%AB%AF%E5%9C%A830%E7%A7%92%E5%86%85%E5%BC%80%E5%8F%91%E5%87%BA%E5%A2%9E%E5%88%A0%E6%94%B9%E6%8E%A5%E5%8F%A3)
-- [具体XBoot增删改文档示例](https://github.com/Exrick/x-boot/wiki/CRUD)
-- 完整版
- - [第三方社交账号登录配置](https://github.com/Exrick/x-boot/wiki/%E7%AC%AC%E4%B8%89%E6%96%B9%E7%A4%BE%E4%BA%A4%E8%B4%A6%E5%8F%B7%E7%99%BB%E5%BD%95%E9%85%8D%E7%BD%AE)
- - [短信登录配置](https://github.com/Exrick/x-boot/wiki/%E7%9F%AD%E4%BF%A1%E7%99%BB%E5%BD%95%E9%85%8D%E7%BD%AE)
- - [Vaptcha人机验证码配置使用](https://github.com/Exrick/x-boot/wiki/vaptcha%E4%BA%BA%E6%9C%BA%E9%AA%8C%E8%AF%81%E7%A0%81%E9%85%8D%E7%BD%AE%E4%BD%BF%E7%94%A8)
- - [Activiti工作流开发说明](https://github.com/Exrick/x-boot/wiki/Activiti%E5%B7%A5%E4%BD%9C%E6%B5%81%E5%BC%80%E5%8F%91%E8%AF%B4%E6%98%8E)
-
-### [分布式扩展](https://github.com/alibaba/dubbo-spring-boot-starter/blob/master/README_zh.md)
-
-### XBoot后端学习分享(更新中)
-1. [Spring Boot 2.x 区别总结](https://github.com/Exrick/x-boot/wiki/SpringBoot2.x%E5%8C%BA%E5%88%AB%E6%80%BB%E7%BB%93)
-
-2. [Spring Security整合JWT](https://github.com/Exrick/x-boot/wiki/SpringSecurity%E6%95%B4%E5%90%88JWT)
-
-3. [Spring Security实现动态数据库权限管理](https://github.com/Exrick/x-boot/wiki/SpringSecurity%E5%8A%A8%E6%80%81%E6%9D%83%E9%99%90%E7%AE%A1%E7%90%86)
-
-4. [Spring Boot 2.x整合Quartz](https://github.com/Exrick/x-boot/wiki/Spring-Boot-2.x%E6%95%B4%E5%90%88Quartz)
-
-5. [基于Websocket实现发送消息后右上角消息图标红点实时显示](https://github.com/Exrick/x-boot/wiki/%E5%9F%BA%E4%BA%8EWebsocket%E5%AE%9E%E7%8E%B0%E5%8F%91%E9%80%81%E6%B6%88%E6%81%AF%E5%90%8E%E5%8F%B3%E4%B8%8A%E8%A7%92%E6%B6%88%E6%81%AF%E5%9B%BE%E6%A0%87%E7%BA%A2%E7%82%B9%E5%AE%9E%E6%97%B6%E6%98%BE%E7%A4%BA)
-
-6. [Spring Boot 2.x整合Activiti工作流以及模型设计器](https://github.com/Exrick/x-boot/wiki/Spring-Boot-2.x%E6%95%B4%E5%90%88Activiti%E5%B7%A5%E4%BD%9C%E6%B5%81%E4%BB%A5%E5%8F%8A%E6%A8%A1%E5%9E%8B%E8%AE%BE%E8%AE%A1%E5%99%A8)
-### Docker下后端集群部署(更新中)
-
-> 前端集群部署请跳转至[xboot-front](https://github.com/Exrick/xboot-front)项目查看
-
-1.[Docker的安装与常用命令](https://github.com/Exrick/x-boot/wiki/Docker%E7%9A%84%E5%AE%89%E8%A3%85%E4%B8%8E%E5%B8%B8%E7%94%A8%E5%91%BD%E4%BB%A4)
-
-2.基于PXC架构Mysql数据库集群搭建
-
-3.Redis集群搭建
-
-4.Elasticsearch集群搭建
-
-5.XBoot后端集群部署
-
-### 商用授权
-- 个人学习使用遵循GPL开源协议
-- 商用需联系作者授权
-
-### 作者其他项目推荐
-- [XMall微信小程序APP前端 现已开源!](https://github.com/Exrick/xmall-weapp)
-
- [](https://www.bilibili.com/video/av70226175)
-
-- [XMall:基于SOA架构的分布式电商购物商城](https://github.com/Exrick/xmall)
-
- 
-
-- [XPay个人免签收款支付系统](https://github.com/Exrick/xpay)
-
-- 机器学习笔记
- - [Machine-Learning](https://github.com/Exrick/Machine-Learning)
-
-### 技术疑问交流
-- QQ交流群 `475743731(付费)`,可获取各项目详细图文文档、疑问解答 [](http://shang.qq.com/wpa/qunwpa?idkey=7b60cec12ba93ebed7568b0a63f22e6e034c0d1df33125ac43ed753342ec6ce7)
-- 免费交流群 `562962309` [](http://shang.qq.com/wpa/qunwpa?idkey=52f6003e230b26addeed0ba6cf343fcf3ba5d97829d17f5b8fa5b151dba7e842)
-- 作者博客:[http://blog.exrick.cn](http://blog.exrick.cn)
-### [捐赠](http://xpay.exrick.cn/pay)",0
-traccar/traccar,Traccar GPS Tracking System,2012-04-16T08:33:49Z,,"# [Traccar](https://www.traccar.org)
-
-## Overview
-
-Traccar is an open source GPS tracking system. This repository contains Java-based back-end service. It supports more than 200 GPS protocols and more than 2000 models of GPS tracking devices. Traccar can be used with any major SQL database system. It also provides easy to use [REST API](https://www.traccar.org/traccar-api/).
-
-Other parts of Traccar solution include:
-
-- [Traccar web app](https://github.com/traccar/traccar-web)
-- [Traccar Manager Android app](https://github.com/traccar/traccar-manager-android)
-- [Traccar Manager iOS app](https://github.com/traccar/traccar-manager-ios)
-
-There is also a set of mobile apps that you can use for tracking mobile devices:
-
-- [Traccar Client Android app](https://github.com/traccar/traccar-client-android)
-- [Traccar Client iOS app](https://github.com/traccar/traccar-client-ios)
-
-## Features
-
-Some of the available features include:
-
-- Real-time GPS tracking
-- Driver behaviour monitoring
-- Detailed and summary reports
-- Geofencing functionality
-- Alarms and notifications
-- Account and device management
-- Email and SMS support
-
-## Build
-
-Please read [build from source documentation](https://www.traccar.org/build/) on the official website.
-
-## Team
-
-- Anton Tananaev ([anton@traccar.org](mailto:anton@traccar.org))
-- Andrey Kunitsyn ([andrey@traccar.org](mailto:andrey@traccar.org))
-
-## License
-
- Apache License, Version 2.0
-
- Licensed under the Apache License, Version 2.0 (the ""License"");
- you may not use this file except in compliance with the License.
- You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
- Unless required by applicable law or agreed to in writing, software
- distributed under the License is distributed on an ""AS IS"" BASIS,
- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- See the License for the specific language governing permissions and
- limitations under the License.
-",0
-nzymedefense/nzyme,Network Defense System.,2016-11-11T22:06:03Z,,"# nzyme - Network Defense System
-
-[](https://codecov.io/gh/lennartkoopmann/nzyme/)
-[](http://www.mongodb.com/licensing/server-side-public-license)
-
-Learn more at https://www.nzyme.org/.
-
-**Version 2.0.0 of nzyme is currently in development. The previous website for v1.x is archived [here](https://v1.nzyme.org/).**
-
-## Contributing
-
-There are many ways to contribute and all community interaction is absolutely welcome:
-
-* Open an issue for any kind of bug you think you have found.
-* Open an issue for anything that was confusing to you. Bad, missing or confusing documentation is considered a bug.
-* Open a Pull Request for a new feature or a bugfix. It is a good idea to get in contact first to make sure that it fits the roadmap and has a chance to be merged.
-* Write documentation.
-* Write a blog post.
-* Help a user in the issue tracker or the IRC channel (#nzyme on FreeNode.)
-* Get in contact and say how you use it or what would be a cool addition.
-* Tell the world.
-
-Please be aware of the [Code of Conduct](CODE_OF_CONDUCT.md) that will be enforced across all channels and platforms.
-
-## Legal notice
-
-Make sure to comply with local laws, especially with regards to wiretapping, when running nzyme. Note that nzyme is never decrypting any data but only reading unencrypted data.
-",0
-apache/eventmesh,EventMesh is a new generation serverless event middleware for building distributed event-driven applications.,2019-09-16T03:04:56Z,,"
-
-
-
- - -## 知识星球 - -知识星球内容包括**学习路线**、**学习资料**(根据编程语言(Java、Python、Java+Scala)分了三大版本)、项目(**50+个大数据项目**)、面试题(**700+道真实大数据面试题**、Java基础、计算机网络、Redis)、**1000+篇大数据真实面经**、600+篇Java后端真实面经(已按公司分类)、自己整理的视频学习笔记 - -**[知识星球资料介绍](https://www.yuque.com/vxo919/gyyog3/ohvyc2e38pprcxkn?singleDoc=)** - -
-
-
-
- - -概述 ---- -[大数据简介](https://github.com/Dr11ft/BigDataGuide/blob/master/Docs/%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%AE%80%E4%BB%8B.md) - -[大数据相关岗位介绍](https://github.com/Dr11ft/BigDataGuide/blob/master/Docs/%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%9B%B8%E5%85%B3%E5%B2%97%E4%BD%8D%E4%BB%8B%E7%BB%8D.md) - -大数据学习路线 ---- -学习路线中的视频、文档资料可以关注公众号:旧时光大数据,回复相应关键字获取云盘链接 - -[大数据学习路线(包含自己看过的视频链接)](https://github.com/Dr11ft/BigDataGuide/blob/master/Docs/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%AD%A6%E4%B9%A0%E8%B7%AF%E7%BA%BF.md) - -编程语言 ---- -编程语言部分建议先JavaSE,Spark和Flink之前学习Scala,如果时间紧迫,就找个Java版的Spark或Flink教程,Python看个人或工作,不过有Java基础,Python会快很多(别问我怎么学,问就是使劲拼命学 [ 吃瓜.jpg ]) -### 一、JavaSE(二选一) -[刘意2019版](https://www.bilibili.com/video/BV1gb411F76B?from=search&seid=16116797084076868427) - -[尚硅谷宋红康版](https://www.bilibili.com/video/BV1Kb411W75N?from=search&seid=9321658006825735818) - -### 二、Scala(二选一) -如果时间短,建议直接看配套Spark的那种三五天的,可以快速了解 - -[韩顺平老师版](https://www.bilibili.com/video/BV1Mp4y1e7B5?from=search&seid=5450215228532207134) - -[清华硕士武晟然老师版](https://www.bilibili.com/video/BV1Mp4y1e7B5?from=search&seid=5450215228532207134) - -### 三、Python -推荐黑马的Python视频,通俗易懂,而且文档比较齐全,有Java基础再看Python的话,上手很快 - -[黑马Python版视频](https://www.bilibili.com/video/BV1C4411A7ej?from=search&seid=11669436417044703145) - -[Python文档and笔记](https://github.com/MoRan1607/BigDataGuide/blob/master/Python/Python%E6%96%87%E6%A1%A3.md) - -Linux ---- -[完全分布式集群搭建文档](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/%E5%88%86%E5%B8%83%E5%BC%8F%E9%9B%86%E7%BE%A4%E6%90%AD%E5%BB%BA.md) - -关于VM、远程登录工具的安装暂时可以参考我的博客,找到相应步骤进行操作即可 - -[集群搭建](https://blog.csdn.net/qq_41544550/category_9458240.html) - -大数据框架组件 ---- -### 一、Hadoop - - 1. [Hadoop——分布式文件管理系统HDFS](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/HDFS.md) - 2. [Hadoop——HDFS的Shell操作](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/HDFS%E7%9A%84Shell%E6%93%8D%E4%BD%9C.md) - 3. [Hadoop——HDFS的Java API操作](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/HDFS%E7%9A%84Java%20API%E6%93%8D%E4%BD%9C.md) - 4. [Hadoop——分布式计算框架MapReduce](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/MapReduce.md) - 5. [Hadoop——MapReduce案例](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/MapReduce%E6%A1%88%E4%BE%8B.md) - 6. [Hadoop——资源调度器YARN](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/YARN.md) - 7. [Hadoop——Hadoop数据压缩](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/Hadoop%E6%95%B0%E6%8D%AE%E5%8E%8B%E7%BC%A9.md) - -### 二、Zookeeper - 1.[Zookeeper——Zookeeper概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E4%B8%80%EF%BC%89.md) - 2.[Zookeeper——Zookeeper单机和分布式安装](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E4%BA%8C%EF%BC%89.md) - 3.[Zookeeper——Zookeeper客户端命令](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E4%B8%89%EF%BC%89.md) - 4.[Zookeeper——Zookeeper内部原理](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E5%9B%9B%EF%BC%89.md) - 5.[Zookeeper——Zookeeper实战](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E4%BA%94%EF%BC%89.md) - -### 三、Hive - 1.[Hive——Hive概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/1%E3%80%81Hive%E6%A6%82%E8%BF%B0.md) - 2.[Hive——Hive数据类型](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/2%E3%80%81Hive%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B.md) - 3.[Hive——Hive DDL数据定义](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/3%E3%80%81Hive%20DDL%E6%95%B0%E6%8D%AE.md) - 4.[Hive——Hive DML数据操作](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/4%E3%80%81Hive%20DML%E6%95%B0%E6%8D%AE%E6%93%8D%E4%BD%9C.md) - 5.[Hive——Hive查询](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/5%E3%80%81Hive%E6%9F%A5%E8%AF%A2.md) - 6.[Hive——Hive函数](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/6%E3%80%81Hive%E5%87%BD%E6%95%B0.md) - 7.[Hive——Hive压缩和存储](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/7%E3%80%81Hive%E5%8E%8B%E7%BC%A9%E5%92%8C%E5%AD%98%E5%82%A8.md) - 8.[Hive——Hive实战:统计影音视频网站的常规指标](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/8%E3%80%81Hive%E5%AE%9E%E6%88%98%EF%BC%9A%E7%BB%9F%E8%AE%A1%E5%BD%B1%E9%9F%B3%E8%A7%86%E9%A2%91%E7%BD%91%E7%AB%99%E7%9A%84%E5%B8%B8%E8%A7%84%E6%8C%87%E6%A0%87.md) - 9.[Hive——Hive分区表和分桶表](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/9%E3%80%81%E5%88%86%E5%8C%BA%E8%A1%A8%E5%92%8C%E5%88%86%E6%A1%B6%E8%A1%A8.md) - 10.[Hive——Hive调优](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/10%E3%80%81Hive%E4%BC%81%E4%B8%9A%E7%BA%A7%E8%B0%83%E4%BC%98.md) - -### 四、Flume - 1.[Flume——Flume概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Flume/1%E3%80%81Flume%E6%A6%82%E8%BF%B0.md) - 2.[Flume——Flume实践操作](https://github.com/Dr11ft/BigDataGuide/blob/master/Flume/2%E3%80%81Flume%E5%AE%9E%E8%B7%B5%E6%93%8D%E4%BD%9C.md) - 3.[Flume——Flume案例](https://github.com/Dr11ft/BigDataGuide/blob/master/Flume/3%E3%80%81Flume%E6%A1%88%E4%BE%8B.md) - -### 五、Kafka - 1.[Kafka——Kafka概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Kafka/1%E3%80%81Kafka%E6%A6%82%E8%BF%B0.md) - 2.[Kafka——Kafka深入解析](https://github.com/Dr11ft/BigDataGuide/blob/master/Kafka/2%E3%80%81Kafka%E6%B7%B1%E5%85%A5%E8%A7%A3%E6%9E%90.md) - 3.[Kafka——Kafka API操作实践](https://github.com/Dr11ft/BigDataGuide/blob/master/Kafka/3%E3%80%81Kafka%20API%E6%93%8D%E4%BD%9C%E5%AE%9E%E8%B7%B5.md) - 3.[Kafka——Kafka对接Flume实践](https://github.com/Dr11ft/BigDataGuide/blob/master/Kafka/4%E3%80%81Flume%E5%AF%B9%E6%8E%A5Kafka%E5%AE%9E%E8%B7%B5%E6%93%8D%E4%BD%9C.md) - -### 六、HBase - 1.[HBase——HBase概述](https://github.com/Dr11ft/BigDataGuide/blob/master/HBase/1%E3%80%81HBase%E6%A6%82%E8%BF%B0.md) - 2.[HBase——HBase数据结构](https://github.com/Dr11ft/BigDataGuide/blob/master/HBase/2%E3%80%81HBase%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84.md) - 3.[HBase——HBase Shell操作](https://github.com/Dr11ft/BigDataGuide/blob/master/HBase/3%E3%80%81HBase%20Shell%E6%93%8D%E4%BD%9C.md) - 4.[HBase——HBase API实践操作](https://github.com/Dr11ft/BigDataGuide/blob/master/HBase/4%E3%80%81HBase%20API%E5%AE%9E%E8%B7%B5%E6%93%8D%E4%BD%9C.md) - -### 七、Spark -#### Spark基础 - 1.[Spark基础——Spark的诞生](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/1%E3%80%81Spark%E7%9A%84%E8%AF%9E%E7%94%9F.md) - 2.[Spark基础——Spark概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/2%E3%80%81Spark%E6%A6%82%E8%BF%B0.md) - 3.[Spark基础——Spark运行模式](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/3%E3%80%81Spark%E8%BF%90%E8%A1%8C%E6%A8%A1%E5%BC%8F.md) - 4.[Spark基础——案例实践](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/2%E3%80%81Spark%E6%A6%82%E8%BF%B0.md) -#### Spark Core - 1.[Spark Core——RDD概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/1%E3%80%81RDD%E6%A6%82%E8%BF%B0.md) - 2.[Spark Core——RDD编程(一)](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/2%E3%80%81RDD%E7%BC%96%E7%A8%8B%EF%BC%88%E4%B8%80%EF%BC%89.md) - 3.[Spark Core——RDD编程(二)](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/3%E3%80%81RDD%E7%BC%96%E7%A8%8B%EF%BC%882%EF%BC%89.md) - 4.[Spark Core——键值对RDD数据分区器](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/4%E3%80%81%E9%94%AE%E5%80%BC%E5%AF%B9RDD%E6%95%B0%E6%8D%AE%E5%88%86%E5%8C%BA%E5%99%A8.md) - 5.[Spark Core——数据读取与保存](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/5%E3%80%81%E6%95%B0%E6%8D%AE%E8%AF%BB%E5%8F%96%E4%B8%8E%E4%BF%9D%E5%AD%98.md) -#### Spark SQL - 1.[Spark SQL——Spaek SQL概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20SQL/1%E3%80%81Spark%20SQL%E6%A6%82%E8%BF%B0.md) - 2.[Spark SQL——Spaek SQL编程](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20SQL/2%E3%80%81Spark%20SQL%E7%BC%96%E7%A8%8B.md) - 3.[Spark SQL——Spaek SQL数据的加载与保存](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20SQL/3%E3%80%81Spark%20SQL%E6%95%B0%E6%8D%AE%E7%9A%84%E5%8A%A0%E8%BD%BD%E4%B8%8E%E4%BF%9D%E5%AD%98.md) - 4.[Spark SQL——Spaek SQL实战](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20SQL/4%E3%80%81Spark%20SQL%E5%AE%9E%E6%88%98.md) -#### Spark Streaming - 1.[Spark Streaming——Spark Streaming概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Streaming/1%E3%80%81Spark%20Streaming%E6%A6%82%E8%BF%B0.md) - 2.[Spark Streaming——Dstream基础](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Streaming/2%E3%80%81Dstream%E5%9F%BA%E7%A1%80.md) - 3.[Spark Streaming——Dstream的转换&输出](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Streaming/3%E3%80%81Dstream%E7%9A%84%E8%BD%AC%E6%8D%A2%26%E8%BE%93%E5%87%BA.md) - -### 八、Flink - 1.[Flink——Flink核心概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/1%E3%80%81Flink%E6%A6%82%E8%BF%B0.md) - 2.[Flink——Flink部署](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/2%E3%80%81Flink%E9%83%A8%E7%BD%B2.md) - 3.[Flink——Flink运行架构](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/3、Flink运行架构.md) - 4.[Flink——Flink流处理API](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/4%E3%80%81Flink%E6%B5%81%E5%A4%84%E7%90%86API.md) - 5.[Flink——Flink中的Window](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/5%E3%80%81Flink%E4%B8%AD%E7%9A%84Window.md) - 6.[Flink——时间语义与Wartermark](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/6、时间语义与Wartermark.md) - 7.[Flink——ProcessFunction API(底层API)](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/7%E3%80%81ProcessFunction%20API%EF%BC%88%E5%BA%95%E5%B1%82API%EF%BC%89.md) - 8.[Flink——状态编程和容错机制](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/8%E3%80%81%E7%8A%B6%E6%80%81%E7%BC%96%E7%A8%8B%E5%92%8C%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6.md) - 9.[Flink——Table API 与SQL](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/9%E3%80%81Table%20API%20%E4%B8%8ESQL.md) - 10.[Flink——Flink CEP](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/10%E3%80%81Flink%20CEP.md) - -数据仓库 ---- - [数据仓库总结](https://zhuanlan.zhihu.com/p/371365562) - -大数据项目 ---- - **基本上选择三到四个即可,B站直接搜索项目名字,都有视频** - **详细说明公众号(旧时光大数据)回复“大数据项目”即可** - -读书笔记 ---- -#### 《阿里大数据之路》读书笔记 -[第一章 总述](https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/%E3%80%8A%E9%98%BF%E9%87%8C%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B9%8B%E8%B7%AF%E3%80%8B%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0%EF%BC%9A%E7%AC%AC%E4%B8%80%E7%AB%A0%20%E6%80%BB%E8%BF%B0.md) - -[第二章 日志采集](https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/%E7%AC%AC%E4%BA%8C%E7%AB%A0%EF%BC%9A%E6%97%A5%E5%BF%97%E9%87%87%E9%9B%86.pdf) - -[第三章 数据同步](https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/PDF/%E7%AC%AC%E4%B8%89%E7%AB%A0%EF%BC%9A%E6%95%B0%E6%8D%AE%E5%90%8C%E6%AD%A5.pdf) - -[第四章 离线数据开发](https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/PDF/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E7%A6%BB%E7%BA%BF%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91.pdf) - -面试题 ---- -> #### 陆续更新中。。。。。全量面试题(700+道牛客网面经原题)见知识星球 -### [大数据面试题 V1.0](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E8%AF%95%E9%A2%98%20V1.0.md) -### [大数据面试题 V3.0](https://mp.weixin.qq.com/s/hMcuDEkzH49rfSmGWy_GRg) -### [大数据面试题 V4.0](https://mp.weixin.qq.com/s/NV90886HAQqBRB1hPNiIPQ) -#### 一、Hadoop -##### 1、Hadoop基础 -[介绍下Hadoop](https://blog.csdn.net/qq_41544550/article/details/123031348) -[Hadoop小文件处理问题](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Hadoop%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93/Hadoop/Hadoop%E5%B0%8F%E6%96%87%E4%BB%B6%E5%A4%84%E7%90%86%E9%97%AE%E9%A2%98.md) -[Hadoop中的几个进程和作用](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop%E4%B8%AD%E7%9A%84%E5%87%A0%E4%B8%AA%E8%BF%9B%E7%A8%8B%E5%92%8C%E4%BD%9C%E7%94%A8.pdf) -[Hadoop的mapper和reducer的个数如何确定?reducer的个数依据是什么?](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop%E7%9A%84mapper%E5%92%8Creducer%E7%9A%84%E4%B8%AA%E6%95%B0%E5%A6%82%E4%BD%95%E7%A1%AE%E5%AE%9A%EF%BC%9Freducer%E7%9A%84%E4%B8%AA%E6%95%B0%E4%BE%9D%E6%8D%AE%E6%98%AF%E4%BB%80%E4%B9%88%EF%BC%9F.md) - -##### 2、HDFS -[HDFS读写流程](https://blog.csdn.net/qq_41544550/article/details/103113335) -[HDFS的block为什么是128M?增大或减小有什么影响?](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/HDFS%E7%9A%84block%E4%B8%BA%E4%BB%80%E4%B9%88%E6%98%AF128M%EF%BC%9F%E5%A2%9E%E5%A4%A7%E6%88%96%E5%87%8F%E5%B0%8F%E6%9C%89%E4%BB%80%E4%B9%88%E5%BD%B1%E5%93%8D%EF%BC%9F/HDFS%E7%9A%84block%E4%B8%BA%E4%BB%80%E4%B9%88%E6%98%AF128M%EF%BC%9F%E5%A2%9E%E5%A4%A7%E6%88%96%E5%87%8F%E5%B0%8F%E6%9C%89%E4%BB%80%E4%B9%88%E5%BD%B1%E5%93%8D.md) - -##### 3、MapReduce -[介绍下MapReduce](https://blog.csdn.net/qq_41544550/article/details/123674103) -[MapReduce优缺点](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Hadoop%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93/Hadoop/MapReduce%E4%BC%98%E7%BC%BA%E7%82%B9.md) -[MapReduce工作原理(流程)](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/MapReduce%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%EF%BC%88%E6%B5%81%E7%A8%8B%EF%BC%89.pdf) -[MapReduce压缩方式](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/MapReduce%E5%8E%8B%E7%BC%A9%E6%96%B9%E5%BC%8F.pdf) - -##### 4、YARN -[介绍下YARN](https://blog.csdn.net/qq_41544550/article/details/123826496?spm=1001.2014.3001.5501) - -#### 二、Zookeeper -[介绍下Zookeeper是什么?](https://blog.csdn.net/qq_41544550/article/details/123148663) -[Zookeeper有什么作用?优缺点?有什么应用场景?](https://blog.csdn.net/qq_41544550/article/details/123148688) -[Zookeeper架构](https://github.com/MoRan1607/BigDataGuide/blob/master/Zookeeper/%E9%9D%A2%E8%AF%95%E9%A2%98/Zookeeper%E6%9E%B6%E6%9E%84.pdf) - -#### 三、Hive -[说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么?](https://blog.csdn.net/qq_41544550/article/details/123333839) -[Hive的用户自定义函数实现步骤与流程](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/%E9%9D%A2%E8%AF%95%E9%A2%98/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B.md) -[Hive分区和分桶的区别](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/%E9%9D%A2%E8%AF%95%E9%A2%98/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B/Hive%E5%88%86%E5%8C%BA%E5%92%8C%E5%88%86%E6%A1%B6%E7%9A%84%E5%8C%BA%E5%88%AB.md) -[Hive的cluster by 、sort by、distribute by 、order by 区别?](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/%E9%9D%A2%E8%AF%95%E9%A2%98/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B/Hive%E7%9A%84cluster%20by%20%E3%80%81sort%20by%E3%80%81distribute%20by%20%E3%80%81order%20by%20%E5%8C%BA%E5%88%AB%EF%BC%9F.pdf) -[Hive count(distinct)有几个reduce,海量数据会有什么问题?](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/%E9%9D%A2%E8%AF%95%E9%A2%98/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B/Hive%20count(distinct)%E6%9C%89%E5%87%A0%E4%B8%AAreduce%EF%BC%8C%E6%B5%B7%E9%87%8F%E6%95%B0%E6%8D%AE%E4%BC%9A%E6%9C%89%E4%BB%80%E4%B9%88%E9%97%AE%E9%A2%98%EF%BC%9F.pdf) - -#### 四、Flume -[介绍下Flume](https://blog.csdn.net/qq_41544550/article/details/123451528?spm=1001.2014.3001.5501) -[Flume结构](https://github.com/MoRan1607/BigDataGuide/blob/master/Flume/%E9%9D%A2%E8%AF%95%E9%A2%98/Flume%E6%9E%B6%E6%9E%84/Flume%E6%9E%B6%E6%9E%84.md) - -#### 五、Kafka -[介绍下Kafka,Kafka的作用?Kafka的组件?适用场景?](https://blog.csdn.net/qq_41544550/article/details/123534948) -[Kafka实现高吞吐的原理?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E5%AE%9E%E7%8E%B0%E9%AB%98%E5%90%9E%E5%90%90%E7%9A%84%E5%8E%9F%E7%90%86.pdf) -[Kafka的一条message中包含了哪些信息?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E7%9A%84%E4%B8%80%E6%9D%A1message%E4%B8%AD%E5%8C%85%E5%90%AB%E4%BA%86%E5%93%AA%E4%BA%9B%E4%BF%A1%E6%81%AF%EF%BC%9F.pdf) -[Kafka的消费者和消费者组有什么区别?为什么需要消费者组?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E7%9A%84%E6%B6%88%E8%B4%B9%E8%80%85%E5%92%8C%E6%B6%88%E8%B4%B9%E8%80%85%E7%BB%84%E6%9C%89%E4%BB%80%E4%B9%88%E5%8C%BA%E5%88%AB%EF%BC%9F%E4%B8%BA%E4%BB%80%E4%B9%88%E9%9C%80%E8%A6%81%E6%B6%88%E8%B4%B9%E8%80%85%E7%BB%84%EF%BC%9F.pdf) -[Kafka的ISR、OSR和ACK介绍,ACK分别有几种值?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E7%9A%84ISR%E3%80%81OSR%E5%92%8CACK%E4%BB%8B%E7%BB%8D%EF%BC%8CACK%E5%88%86%E5%88%AB%E6%9C%89%E5%87%A0%E7%A7%8D%E5%80%BC%EF%BC%9F.pdf) -[Kafka怎么保证数据不丢失,不重复?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E6%80%8E%E4%B9%88%E4%BF%9D%E8%AF%81%E6%95%B0%E6%8D%AE%E4%B8%8D%E4%B8%A2%E5%A4%B1%EF%BC%8C%E4%B8%8D%E9%87%8D%E5%A4%8D%EF%BC%9F.pdf) -[Kafka的单播和多播](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E7%9A%84%E5%8D%95%E6%92%AD%E5%92%8C%E5%A4%9A%E6%92%AD.pdf) -[说下Kafka的ISR机制](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/%E8%AF%B4%E4%B8%8BKafka%E7%9A%84ISR%E6%9C%BA%E5%88%B6.pdf) - -#### 六、HBase -[介绍下HBase架构](https://blog.csdn.net/qq_41544550/article/details/123583361) -[HBase为什么查询快](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E4%B8%BA%E4%BB%80%E4%B9%88%E6%9F%A5%E8%AF%A2%E5%BF%AB.pdf) -[HBase的大合并、小合并是什么?](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84%E5%A4%A7%E5%90%88%E5%B9%B6%E3%80%81%E5%B0%8F%E5%90%88%E5%B9%B6%E6%98%AF%E4%BB%80%E4%B9%88%EF%BC%9F.pdf) -[HBase的rowkey设计原则](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84rowkey%E8%AE%BE%E8%AE%A1%E5%8E%9F%E5%88%99.pdf) -[HBase的一个region由哪些东西组成?](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84%E4%B8%80%E4%B8%AAregion%E7%94%B1%E5%93%AA%E4%BA%9B%E4%B8%9C%E8%A5%BF%E7%BB%84%E6%88%90%EF%BC%9F.pdf) -[HBase读写数据流程](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E8%AF%BB%E5%86%99%E6%95%B0%E6%8D%AE%E6%B5%81%E7%A8%8B.pdf) -[HBase的RegionServer宕机以后怎么恢复的?](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84RegionServer%E5%AE%95%E6%9C%BA%E4%BB%A5%E5%90%8E%E6%80%8E%E4%B9%88%E6%81%A2%E5%A4%8D%E7%9A%84%EF%BC%9F.pdf) -[HBase的读写缓存](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84%E8%AF%BB%E5%86%99%E7%BC%93%E5%AD%98.pdf) - -#### 七、Spark - -[说下对RDD的理解?RDD特点、算子?](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Spark%E9%9D%A2%E8%AF%95%E9%A2%98%E6%95%B4%E7%90%86/Spark/Pics/%E8%AF%B4%E4%B8%8B%E5%AF%B9RDD%E7%9A%84%E7%90%86%E8%A7%A3%EF%BC%9FRDD%E7%89%B9%E7%82%B9%E3%80%81%E7%AE%97%E5%AD%90/%E8%AF%B4%E4%B8%8B%E5%AF%B9RDD%E7%9A%84%E7%90%86%E8%A7%A3%EF%BC%9FRDD%E7%89%B9%E7%82%B9%E3%80%81%E7%AE%97%E5%AD%90.md) -[Spark小文件问题](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Spark%E9%9D%A2%E8%AF%95%E9%A2%98%E6%95%B4%E7%90%86/Spark/Spark%E5%B0%8F%E6%96%87%E4%BB%B6%E9%97%AE%E9%A2%98/Spark%E5%B0%8F%E6%96%87%E4%BB%B6%E9%97%AE%E9%A2%98.md) -[Spark的内存模型](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B.md) -[Spark的Job、Stage、Task分别介绍下,如何划分?](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/Spark%E7%9A%84Job%E3%80%81Stage%E3%80%81Task%E5%88%86%E5%88%AB%E4%BB%8B%E7%BB%8D%E4%B8%8B%EF%BC%8C%E5%A6%82%E4%BD%95%E5%88%92%E5%88%86.md) -[Spark的RDD、DataFrame、DataSet、DataStream区别?](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/Spark%E7%9A%84RDD%E3%80%81DataFrame%E3%80%81DataSet%E3%80%81DataStream%E5%8C%BA%E5%88%AB%EF%BC%9F.pdf) -[RDD的容错](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/RDD%E7%9A%84%E5%AE%B9%E9%94%99.pdf) -[说下Spark中的Transform和Action,为什么Spark要把操作分为Transform和Action?](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/%E8%AF%B4%E4%B8%8BSpark%E4%B8%AD%E7%9A%84Transform%E5%92%8CAction%EF%BC%8C%E4%B8%BA%E4%BB%80%E4%B9%88Spark%E8%A6%81%E6%8A%8A%E6%93%8D%E4%BD%9C%E5%88%86%E4%B8%BATransform%E5%92%8CAction%EF%BC%9F.pdf) -[Spark的任务执行流程](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Spark%E9%9D%A2%E8%AF%95%E9%A2%98%E6%95%B4%E7%90%86/Spark%E7%9A%84%E4%BB%BB%E5%8A%A1%E6%89%A7%E8%A1%8C%E6%B5%81%E7%A8%8B.pdf) -[Spark的架构](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E6%9E%B6%E6%9E%84.pdf) - - -#### 八、Flink - -[介绍下Flink](https://github.com/MoRan1607/BigDataGuide/blob/master/Flink/%E4%BB%8B%E7%BB%8D%E4%B8%8BFlink) -[Flink架构](https://github.com/MoRan1607/BigDataGuide/blob/master/Flink/%E9%9D%A2%E8%AF%95%E9%A2%98/Flink%E6%9E%B6%E6%9E%84.pdf) - -#### 九、数仓面试题 -[数据仓库和数据中台区别](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E6%95%B0%E4%BB%93/%E6%95%B0%E6%8D%AE%E4%BB%93%E5%BA%93%E5%92%8C%E6%95%B0%E6%8D%AE%E4%B8%AD%E5%8F%B0%E5%8C%BA%E5%88%AB.pdf) - -#### 十、综合面试题 -[Spark和MapReduce之间的区别?各自优缺点?](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/Spark%E5%92%8CMapReduce%E4%B9%8B%E9%97%B4%E7%9A%84%E5%8C%BA%E5%88%AB%EF%BC%9F%E5%90%84%E8%87%AA%E4%BC%98%E7%BC%BA%E7%82%B9%EF%BC%9F.pdf) -[Spark和Flink的区别](https://github.com/MoRan1607/BigDataGuide/blob/master/Flink/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E5%92%8CFlink%E7%9A%84%E5%8C%BA%E5%88%AB.pdf) - - -牛客网面经 ---- -### 大数据面经 -#### 阿里面经 -[阿里巴巴 二面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4%20%E4%BA%8C%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) -[阿里云大数据平台三面+HR面【已OC】](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C%E4%BA%91%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%B9%B3%E5%8F%B0%E4%B8%89%E9%9D%A2%2BHR%E9%9D%A2%E3%80%90%E5%B7%B2OC%E3%80%91.pdf) -[阿里-数据研发-1面2面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-%E6%95%B0%E6%8D%AE%E7%A0%94%E5%8F%91-1%E9%9D%A22%E9%9D%A2.pdf) -[4.23阿里数开一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/4.23%E9%98%BF%E9%87%8C%E6%95%B0%E5%BC%80%E4%B8%80%E9%9D%A2.pdf) -[分享一个大数据的面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E5%88%86%E4%BA%AB%E4%B8%80%E4%B8%AA%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%9A%84%E9%9D%A2%E7%BB%8F.pdf) -[十余家公司大数据开发面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E5%8D%81%E4%BD%99%E5%AE%B6%E5%85%AC%E5%8F%B8%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E9%9D%A2%E7%BB%8F.pdf) -[大数据面经好少啊,我来写点](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F%E5%A5%BD%E5%B0%91%E5%95%8A%EF%BC%8C%E6%88%91%E6%9D%A5%E5%86%99%E7%82%B9.pdf) -[提前批面经(Java_大数据)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E6%8F%90%E5%89%8D%E6%89%B9%E9%9D%A2%E7%BB%8F(Java_%E5%A4%A7%E6%95%B0%E6%8D%AE).pdf) -[阿里-数据技术与产品部(两次简历面)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E9%98%BF%E9%87%8C-%E6%95%B0%E6%8D%AE%E6%8A%80%E6%9C%AF%E4%B8%8E%E4%BA%A7%E5%93%81%E9%83%A8%EF%BC%88%E4%B8%A4%E6%AC%A1%E7%AE%80%E5%8E%86%E9%9D%A2%EF%BC%89.pdf) -[阿里云一二三面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E9%98%BF%E9%87%8C%E4%BA%91%E4%B8%80%E4%BA%8C%E4%B8%89%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) -[阿里巴巴淘系大数据研发工程师三面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4%E6%B7%98%E7%B3%BB%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%A0%94%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88%E4%B8%89%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[阿里集团大淘宝一面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E9%98%BF%E9%87%8C%E9%9B%86%E5%9B%A2%E5%A4%A7%E6%B7%98%E5%AE%9D%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) -[阿里巴巴 二面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4%20%E4%BA%8C%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) - -#### 腾讯面经 -[2022暑假实习 数据开发 字节 腾讯](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/2022%E6%9A%91%E5%81%87%E5%AE%9E%E4%B9%A0%20%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%20%E5%AD%97%E8%8A%82%20%E8%85%BE%E8%AE%AF%EF%BC%88%E5%B7%B2offer.pdf) -[4.13 腾讯音乐数据工程笔试](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/4.13%20%E8%85%BE%E8%AE%AF%E9%9F%B3%E4%B9%90%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%E7%AC%94%E8%AF%95.pdf) -[2024届秋招总结](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/2024%E5%B1%8A%E7%A7%8B%E6%8B%9B%E6%80%BB%E7%BB%93.pdf) -[5.30腾讯数据开发一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/5.30%E8%85%BE%E8%AE%AF%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[9.20-腾讯云智-数据-二面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/9.20-%E8%85%BE%E8%AE%AF%E4%BA%91%E6%99%BA-%E6%95%B0%E6%8D%AE-%E4%BA%8C%E9%9D%A2.pdf) -[【腾讯】后端开发暑期实习面经(已offer)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E3%80%90%E8%85%BE%E8%AE%AF%E3%80%91%E5%90%8E%E7%AB%AF%E5%BC%80%E5%8F%91%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%E9%9D%A2%E7%BB%8F%EF%BC%88%E5%B7%B2offer%EF%BC%89.pdf) -[一面凉经-腾讯技术研究-数据科学](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F-%E8%85%BE%E8%AE%AF%E6%8A%80%E6%9C%AF%E7%A0%94%E7%A9%B6-%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6.pdf) -[大数据开发实习面经(阿里、360、腾讯)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0%E9%9D%A2%E7%BB%8F%EF%BC%88%E9%98%BF%E9%87%8C%E3%80%81360%E3%80%81%E8%85%BE%E8%AE%AF%EF%BC%89.pdf) -[奇怪的csig数据工程timeline](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E5%A5%87%E6%80%AA%E7%9A%84csig%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8Btimeline.pdf) -[字节腾讯大数据凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E5%AD%97%E8%8A%82%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%87%89%E7%BB%8F.pdf) -[百度腾讯提前批阿里校招面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E7%99%BE%E5%BA%A6%E8%85%BE%E8%AE%AF%E6%8F%90%E5%89%8D%E6%89%B9%E9%98%BF%E9%87%8C%E6%A0%A1%E6%8B%9B%E9%9D%A2%E7%BB%8F.pdf) -[腾讯 TEG 后台开发 大数据方向 一面总结](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20TEG%20%E5%90%8E%E5%8F%B0%E5%BC%80%E5%8F%91%20%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%96%B9%E5%90%91%20%E4%B8%80%E9%9D%A2%E6%80%BB%E7%BB%93.pdf) -[腾讯 偏大数据开发三面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20%E5%81%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%89%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯 偏大数据开发二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20%E5%81%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%20%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯 偏大数据开发一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20%E5%81%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯 数据科学暑期实习 一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%20%E4%B8%80%E9%9D%A2.pdf) -[腾讯-数据科学(IEG)+数据工程](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF-%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%EF%BC%88IEG%EF%BC%89%2B%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B.pdf) -[腾讯CSIG后台开发一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFCSIG%E5%90%8E%E5%8F%B0%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯CSIG大数据一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFCSIG%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯IEG数据中心实习面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFIEG%E6%95%B0%E6%8D%AE%E4%B8%AD%E5%BF%83%E5%AE%9E%E4%B9%A0%E9%9D%A2%E7%BB%8F.pdf) -[腾讯PCG数据研发暑期实习一���凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFPCG%E6%95%B0%E6%8D%AE%E7%A0%94%E5%8F%91%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) -[腾讯TEG-数据平台部-大数据开发实习-一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFTEG-%E6%95%B0%E6%8D%AE%E5%B9%B3%E5%8F%B0%E9%83%A8-%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0-%E4%B8%80%E9%9D%A2.pdf) -[腾讯TEG-数据平台部-大数据开发实习-二面(等凉)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFTEG-%E6%95%B0%E6%8D%AE%E5%B9%B3%E5%8F%B0%E9%83%A8-%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0-%E4%BA%8C%E9%9D%A2%EF%BC%88%E7%AD%89%E5%87%89%EF%BC%89.pdf) -[腾讯TEG大数据一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFTEG%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯teg大数据 凉](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFteg%E5%A4%A7%E6%95%B0%E6%8D%AE%20%E5%87%89.pdf) -[腾讯云智 数据工程 面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E4%BA%91%E6%99%BA%20%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%20%E9%9D%A2%E7%BB%8F.pdf) -[腾讯云智暑期实习-数据工程 一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E4%BA%91%E6%99%BA%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0-%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%20%E4%B8%80%E9%9D%A2.pdf) -[腾讯大数据开发一面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) -[腾讯大数据开发实习](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0.pdf) -[腾讯微保实习一面(数据开发工程师)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%BE%AE%E4%BF%9D%E5%AE%9E%E4%B9%A0%E4%B8%80%E9%9D%A2%EF%BC%88%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88%EF%BC%89.pdf) -[腾讯微保实习二面(数据开发工程师)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%BE%AE%E4%BF%9D%E5%AE%9E%E4%B9%A0%E4%BA%8C%E9%9D%A2%EF%BC%88%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88%EF%BC%89.pdf) -[腾讯微信读书 数据科学 暑期实习 一面【放弃笔试但被捞】](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%BE%AE%E4%BF%A1%E8%AF%BB%E4%B9%A6%20%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%20%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%20%E4%B8%80%E9%9D%A2%E3%80%90%E6%94%BE%E5%BC%83%E7%AC%94%E8%AF%95%E4%BD%86%E8%A2%AB%E6%8D%9E%E3%80%91.pdf) -[腾讯数开面筋-全程无八股](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%95%B0%E5%BC%80%E9%9D%A2%E7%AD%8B-%E5%85%A8%E7%A8%8B%E6%97%A0%E5%85%AB%E8%82%A1.pdf) -[腾讯数据工程凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%E5%87%89%E7%BB%8F.pdf) -[腾讯数据工程面经(1)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%E9%9D%A2%E7%BB%8F%EF%BC%881%EF%BC%89.pdf) -[腾讯数据工程面经(2)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%E9%9D%A2%E7%BB%8F%EF%BC%882%EF%BC%89.pdf) -[腾讯暑期实习 数据科学一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%20%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯秋招大数据运维开发一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E7%A7%8B%E6%8B%9B%E5%A4%A7%E6%95%B0%E6%8D%AE%E8%BF%90%E7%BB%B4%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2.pdf) -[阿里、腾讯大数据提前批面经(已拿offer)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E9%98%BF%E9%87%8C%E3%80%81%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%8F%90%E5%89%8D%E6%89%B9%E9%9D%A2%E7%BB%8F(%E5%B7%B2%E6%8B%BFoffer).pdf) -[面试复盘|腾讯-腾讯大数据 一面凉经!!!](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E9%9D%A2%E8%AF%95%E5%A4%8D%E7%9B%98%EF%BD%9C%E8%85%BE%E8%AE%AF-%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%20%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F%EF%BC%81%EF%BC%81%EF%BC%81.pdf) - - -#### 小米面经 -[2023-3-27 小米-汽车-大数据开发](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/2023-3-27%20%E5%B0%8F%E7%B1%B3-%E6%B1%BD%E8%BD%A6-%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91-1.pdf) -[小米 大数据 一面 二面(凉经)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%20%E5%A4%A7%E6%95%B0%E6%8D%AE%20%E4%B8%80%E9%9D%A2%20%E4%BA%8C%E9%9D%A2%EF%BC%88%E5%87%89%E7%BB%8F%EF%BC%89.pdf) -[小米 大数据开发 一面视频面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%20%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%20%E4%B8%80%E9%9D%A2%E8%A7%86%E9%A2%91%E9%9D%A2.pdf) -[小米 大数据开发 已oc](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%20%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%20%E5%B7%B2oc.pdf) -[小米、头条、知乎面试题总结](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E3%80%81%E5%A4%B4%E6%9D%A1%E3%80%81%E7%9F%A5%E4%B9%8E%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93_%E4%B8%8D%E6%B8%85%E4%B8%8D%E6%85%8E%E7%9A%84%E5%8D%9A%E5%AE%A2-CSDN%E5%8D%9A%E5%AE%A2.pdf) -[小米凉面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%87%89%E9%9D%A2.pdf) -[小米大数据一二面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E4%BA%8C%E9%9D%A2.pdf) -[小米大数据一二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据一二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F02.pdf) -[小米大数据开发一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2.pdf) -[小米大数据开发一面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) -[小米大数据开发二面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据开发实习面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据开发岗一面、二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B2%97%E4%B8%80%E9%9D%A2%E3%80%81%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据开发工程师(base北京)已OC](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88%EF%BC%88base%E5%8C%97%E4%BA%AC%EF%BC%89%E5%B7%B2OC.pdf) -[小米大数据开发面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据提前批一面二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%8F%90%E5%89%8D%E6%89%B9%E4%B8%80%E9%9D%A2%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据日常实习一二三面(已oc)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%97%A5%E5%B8%B8%E5%AE%9E%E4%B9%A0%E4%B8%80%E4%BA%8C%E4%B8%89%E9%9D%A2%EF%BC%88%E5%B7%B2oc%EF%BC%89.pdf) -[小米大数据日常面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%97%A5%E5%B8%B8%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据研发(已OC)timeline](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%A0%94%E5%8F%91%EF%BC%88%E5%B7%B2OC%EF%BC%89timeline.pdf) -[小米大数据面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F.pdf) -[小米面经,二面等通知中](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E9%9D%A2%E7%BB%8F%EF%BC%8C%E4%BA%8C%E9%9D%A2%E7%AD%89%E9%80%9A%E7%9F%A5%E4%B8%AD%E3%80%82.pdf) - - - - - - - -大数据&后端书籍 ---- -PDF书籍(含Hadoop、Spark、Flink等大数据书籍)在公众号回复关键字“大数据书籍”或“Java书籍”自行进百度云盘群保存即可 - -## 交流群 -交流群建好了,进群的小伙伴可以加我微信:**MoRan1607,备注:GitHub** -
-
-
-
- - -",0 -manifold-systems/manifold,"Manifold is a Java compiler plugin, its features include Metaprogramming, Properties, Extension Methods, Operator Overloading, Templates, a Preprocessor, and more.",2017-06-07T02:37:23Z,,"
-
-
-
-
-
-
-
-
-
-
-
Not authorized. :///"">Login.
-``` - -Use the following snippet for `/usr/local/etc/nginx/nginx.conf`: -``` -worker_processes 4; - -events { - worker_connections 1024; -} - -http { - upstream kafdrop { - server 127.0.0.1:9000; - keepalive 64; - } - - server { - listen *:8080; - server_name _; - access_log /usr/local/var/log/nginx/nginx.access.log; - error_log /usr/local/var/log/nginx/nginx.error.log; - auth_basic ""Restricted Area""; - auth_basic_user_file /usr/local/etc/nginx/.htpasswd; - - location / { - proxy_pass http://kafdrop; - } - - location /logout { - return 401; - } - - error_page 401 /errors/401.html; - - location /errors { - auth_basic off; - ssi on; - alias /usr/local/opt/nginx/html; - } - } -} -``` - -Run NGINX: -```sh -nginx -``` - -Or reload its configuration if already running: -```sh -nginx -s reload -``` - -To logout, browse to [/logout](http://localhost:8080/logout). - -> **Hey there!** We hope you really like Kafdrop! Please take a moment to [⭐](https://github.com/obsidiandynamics/kafdrop)the repo or [Tweet](https://twitter.com/intent/tweet?url=https%3A%2F%2Fgithub.com%2Fobsidiandynamics%2Fkafdrop&text=Get%20Kafdrop%20%E2%80%94%20a%20web-based%20UI%20for%20viewing%20%23ApacheKafka%20topics%20and%20browsing%20consumers%20) about it. - -# Contributing Guidelines - -See [here](CONTRIBUTING.md). - -## Release workflow - -To cut an official release, these are the steps: - -1. Commit a new version on master that has the `-SNAPSHOT` suffix stripped (see `pom.xml`). Once the commit is merged, the CI will treat it as a release build, and will end up publishing more artifacts than the regular (non-release/snapshot) build. One of those will be a dockerhub push to the specific version and ""latest"" tags. (The regular build doesn't update ""latest""). - -2. You can then edit the release description in GitHub to describe what went into the release. - -3. After the release goes through successfully, you need to prepare the repo for the next version, which requires committing the next snapshot version on master again. So we should increment the minor version and add again the `-SNAPSHOT` suffix. -",0 -kermitt2/grobid,A machine learning software for extracting information from scholarly documents,2012-09-13T15:48:54Z,,,0 -beehive-lab/TornadoVM,TornadoVM: A practical and efficient heterogeneous programming framework for managed languages,2018-09-07T09:37:44Z,,"# TornadoVM - -
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-Apache ShardingSphere enriches the CNCF CLOUD NATIVE Landscape.
-
| 文字效果 | -扇形效果 | -
|---|---|
| CircleIndicator | -RectIndicator | -
|---|---|
| 图片放大效果 | -卡片效果 | -
|---|---|
| 三角形版本 | -条形状版本 | -文字颜色渐变方式,加了滚动效果 | -
|---|---|---|
| 没有结合ViewPager | -结合ViewPager | -
|---|---|
| 弧形图片 | -
|---|
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-