此项目已暂停维护
- - -" -totond/TextPathView,master,1916,214,2018-01-10T10:36:47Z,315,3,A View with text path animation!,,"# TextPathView - - - -
-**A:** Ensure good code quality and consistent formatting. - -License --------- - - Copyright 2015 HwangJR, Inc. - - Licensed under the Apache License, Version 2.0 (the ""License""); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - - Unless required by applicable law or agreed to in writing, software - distributed under the License is distributed on an ""AS IS"" BASIS, - WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the License for the specific language governing permissions and - limitations under the License. -" -weibocom/motan,master,5872,1780,2016-04-20T10:56:17Z,4340,356,A cross-language remote procedure call(RPC) framework for rapid development of high performance distributed services.,,"# Motan - -[](https://github.com/weibocom/motan/blob/master/LICENSE) -[](http://search.maven.org/#search%7Cga%7C1%7Cg%3A%22com.weibo%22%20AND%20motan) -[](https://travis-ci.org/weibocom/motan) -[](http://opentracing.io) -[](https://github.com/OpenSkywalking/skywalking) - -# Overview - -Motan is a cross-language remote procedure call(RPC) framework for rapid development of high performance distributed services. - -Related projects in Motan ecosystem: - -- [Motan-go](https://github.com/weibocom/motan-go) is golang implementation. -- [Motan-PHP](https://github.com/weibocom/motan-php) is PHP client can interactive with Motan server directly or through Motan-go agent. -- [Motan-openresty](https://github.com/weibocom/motan-openresty) is a Lua(Luajit) implementation based on [Openresty](http://openresty.org). - -# Features - -- Create distributed services without writing extra code. -- Provides cluster support and integrate with popular service discovery services like [Consul][consul] or [Zookeeper][zookeeper]. -- Supports advanced scheduling features like weighted load-balance, scheduling cross IDCs, etc. -- Optimization for high load scenarios, provides high availability in production environment. -- Supports both synchronous and asynchronous calls. -- Support cross-language interactive with Golang, PHP, Lua(Luajit), etc. - -# Quick Start - -The quick start gives very basic example of running client and server on the same machine. For the detailed information about using and developing Motan, please jump to [Documents](#documents). - -> The minimum requirements to run the quick start are: -> -> - JDK 1.8 or above -> - A java-based project management software like [Maven][maven] or [Gradle][gradle] - -## Synchronous calls - -1. Add dependencies to pom. - -```xml -
- - 1、天梯是一款使用Java编写的免费的轻量级CMS系统,目前提供了从后台管理到前端展现的整体解决方案。 - 2、用户可以不编写一句代码,就制作出一个默认风格的CMS站点。 - 3、前端页面自适应,支持PC和H5端,采用前后端分离的机制实现。后端支持天梯蓝和天梯红换肤功能。 - 4、项目技术分层明显,用户可以根据自己的业务模块进行相应地扩展,很方便二次开发。 - - 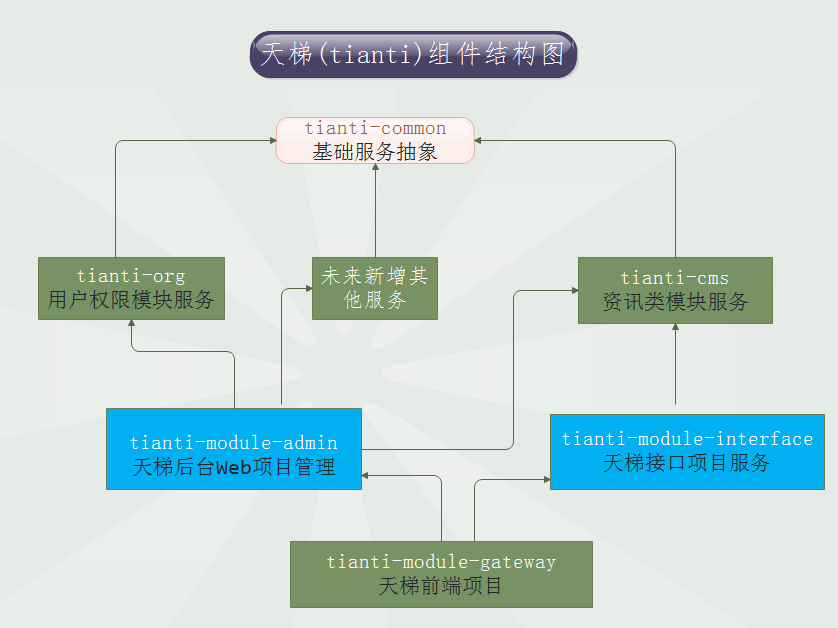
- 
- - 技术架构:
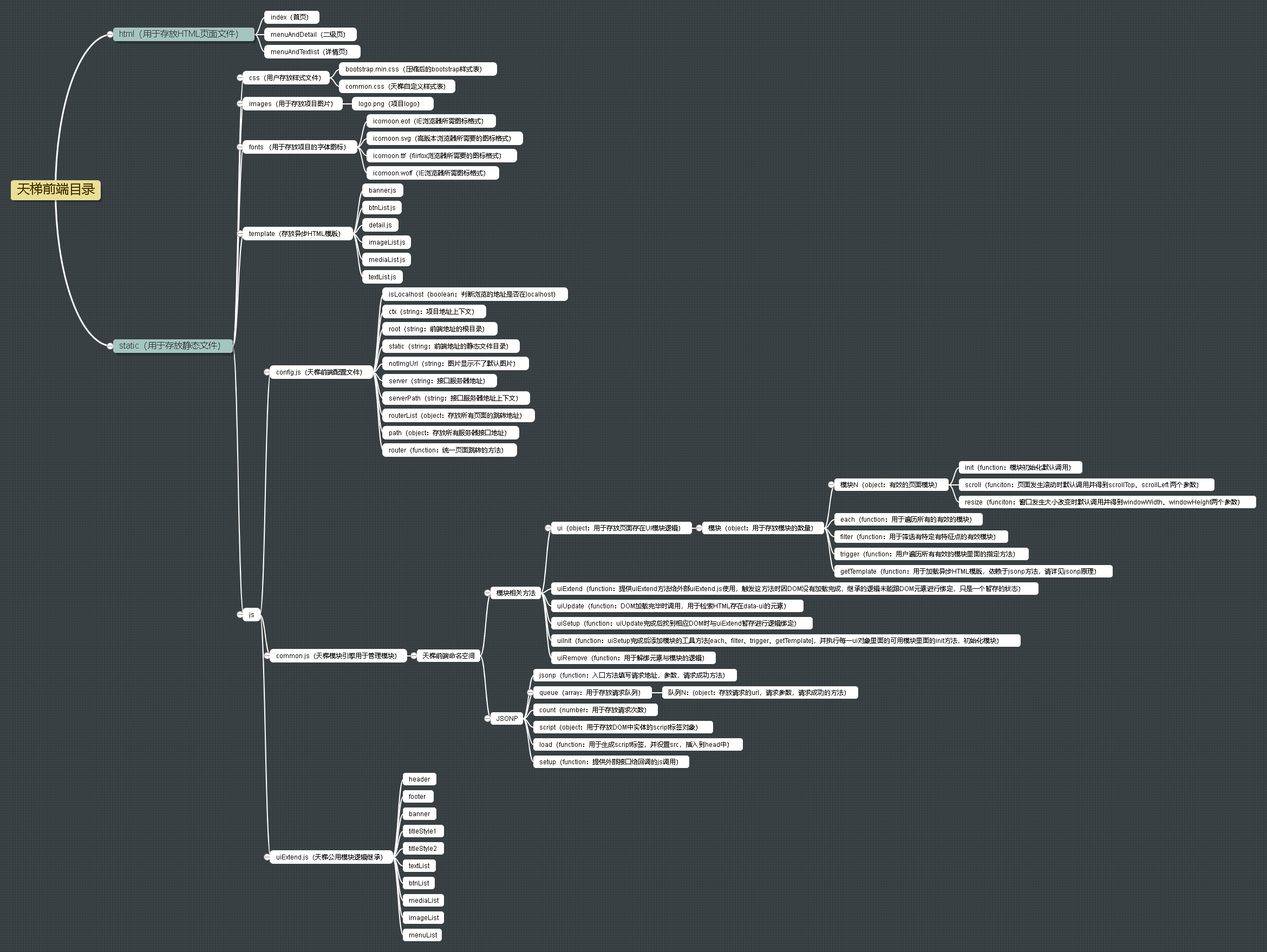
- - 1、技术选型: - 后端 - ·核心框架:Spring Framework 4.2.5.RELEASE - ·安全框架:Apache Shiro 1.3.2 - ·视图框架:Spring MVC 4.2.5.RELEASE - ·数据库连接池:Tomcat JDBC - ·缓存框架:Ehcache - ·ORM框架:Spring Data JPA、hibernate 4.3.5.Final - ·日志管理:SLF4J 1.7.21、Log4j - ·编辑器:ueditor - ·工具类:Apache Commons、Jackson 2.8.5、POI 3.15 - ·view层:JSP - ·数据库:mysql、oracle等关系型数据库 - - 前端 - ·dom : Jquery - ·分页 : jquery.pagination - ·UI管理 : common - ·UI集成 : uiExtend - ·滚动条 : jquery.nicescroll.min.js - ·图表 : highcharts - ·3D图表 :highcharts-more - ·轮播图 : jquery-swipe - ·表单提交 :jquery.form - ·文件上传 :jquery.uploadify - ·表单验证 :jquery.validator - ·展现树 :jquery.ztree - ·html模版引擎 :template - 2、项目结构: - 2.1、tianti-common:系统基础服务抽象,包括entity、dao和service的基础抽象; - 2.2、tianti-org:用户权限模块服务实现; - 2.3、tianti-cms:资讯类模块服务实现; - 2.4、tianti-module-admin:天梯后台web项目实现; - 2.5、tianti-module-interface:天梯接口项目实现; - 2.6、tianti-module-gateway:天梯前端自适应项目实现(是一个静态项目,调用tianti-module-interface获取数据); - - - 前端项目概览:
- PC:
- 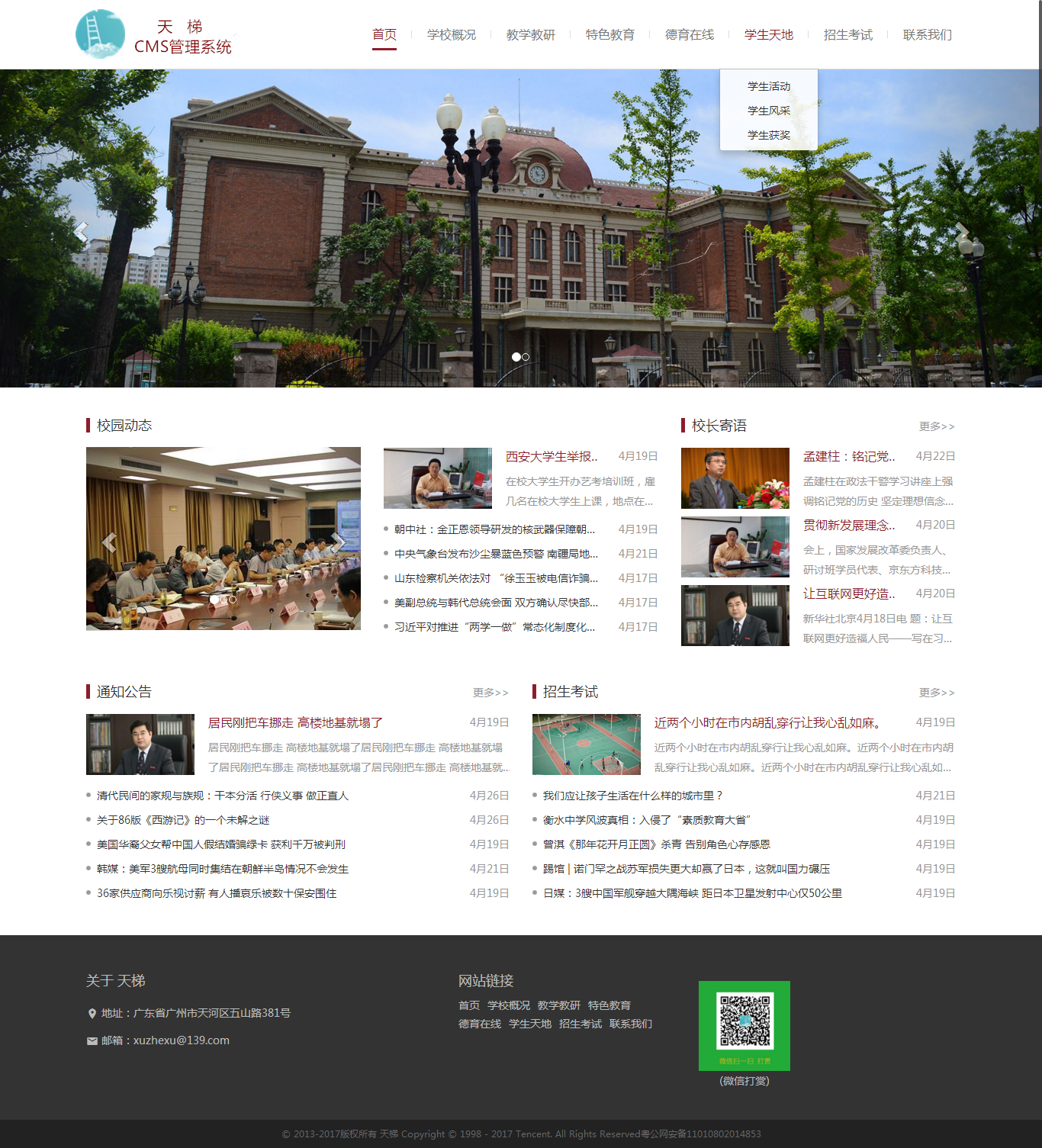 - 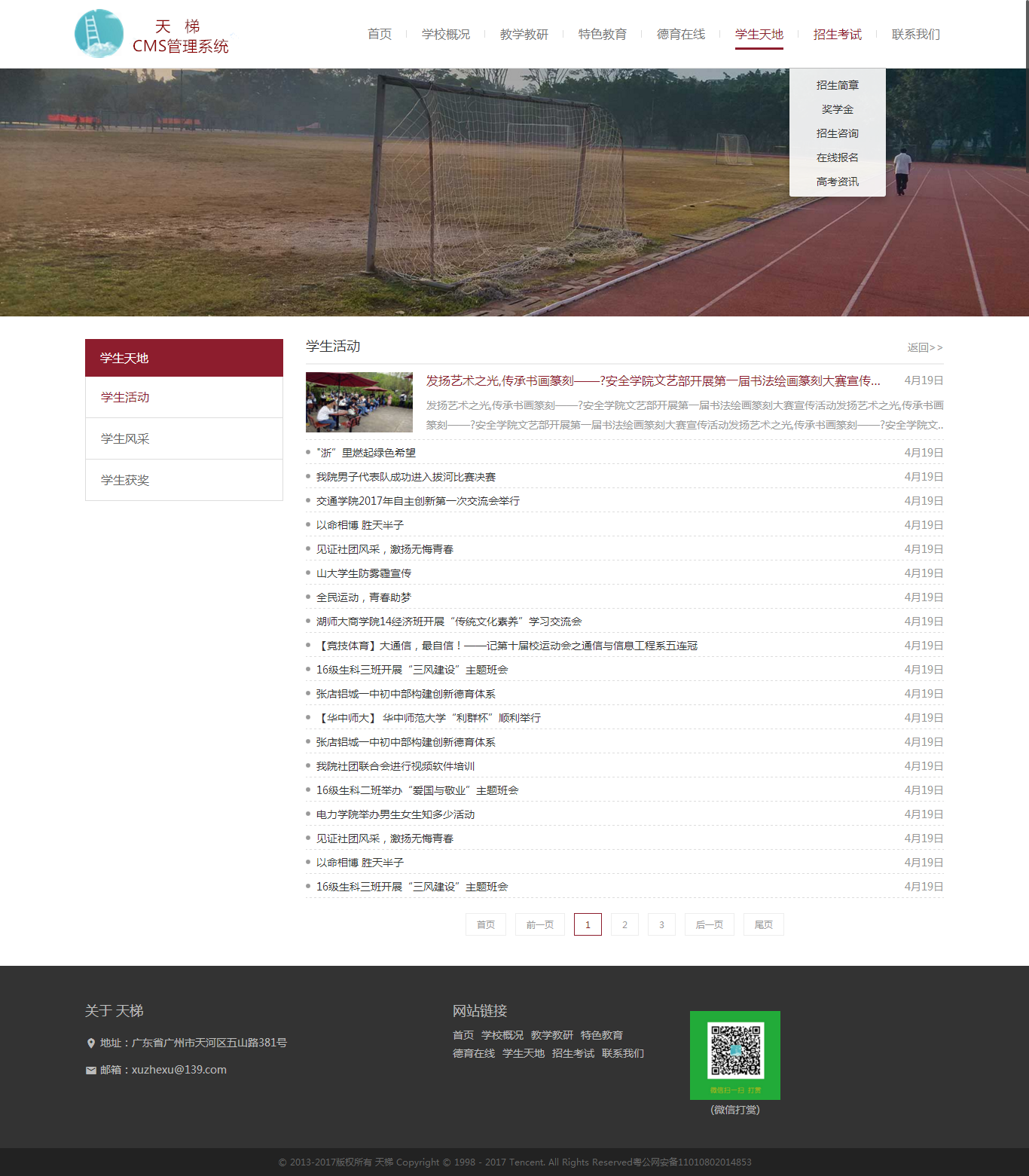 -  - H5:
-  -  -  -
- 后台项目概览:
- 天梯登陆页面: - 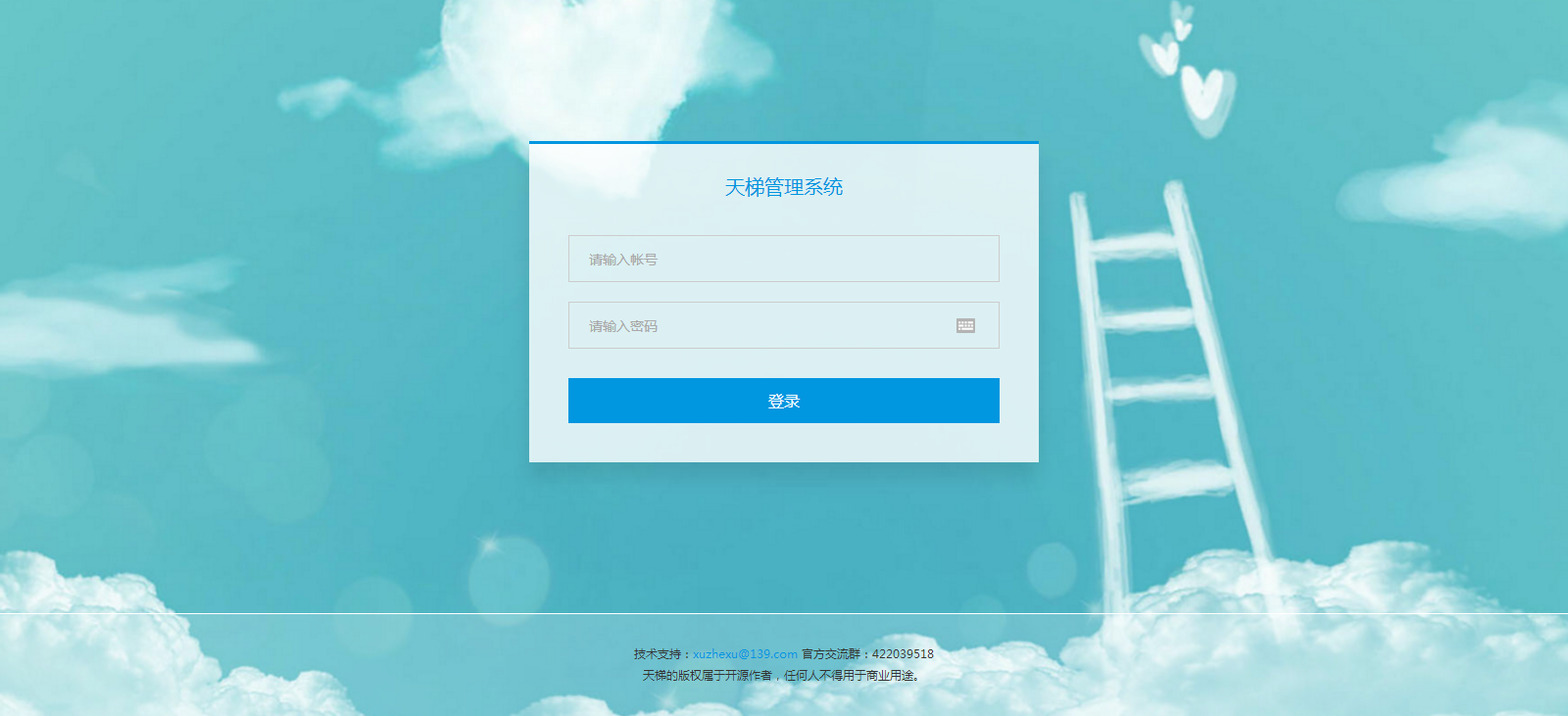 - 天梯蓝风格(默认): - 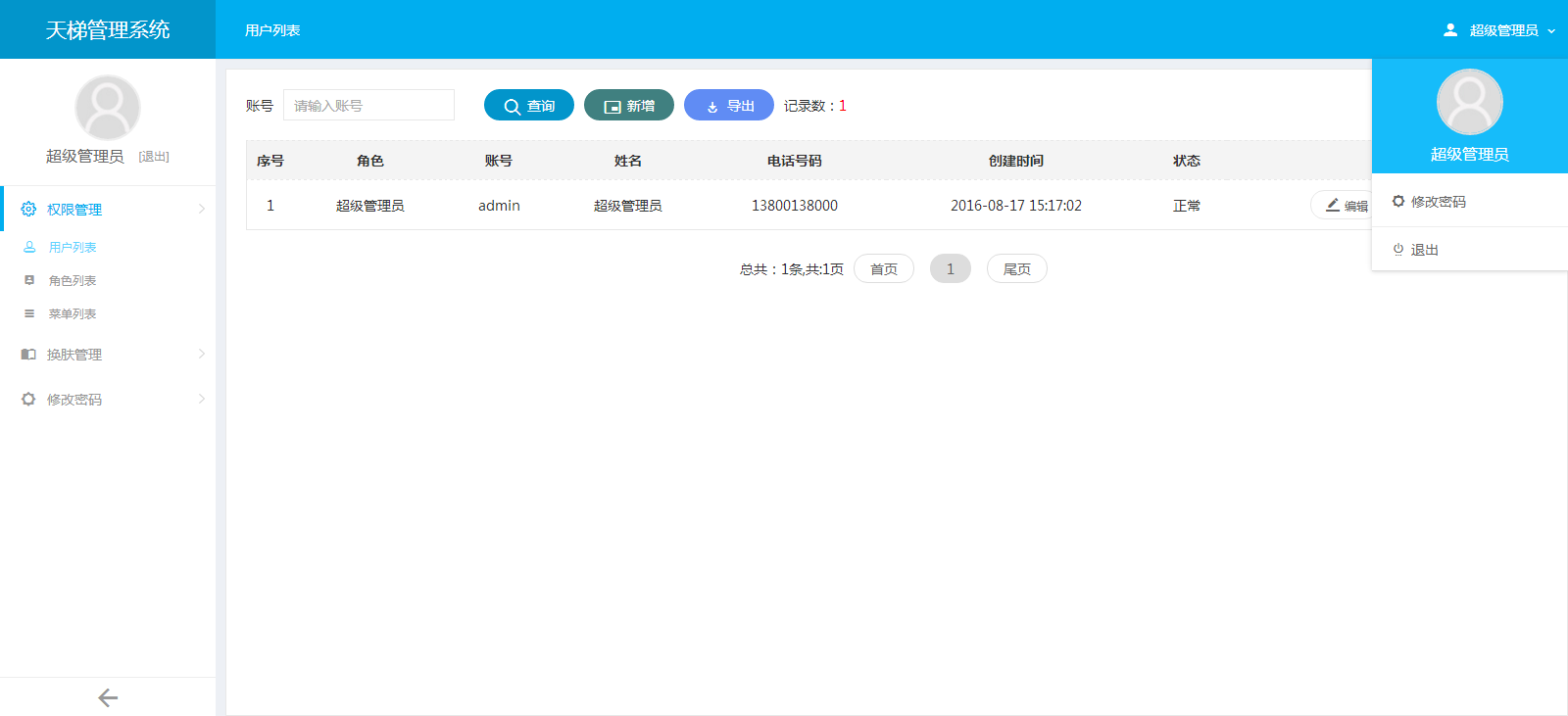 - 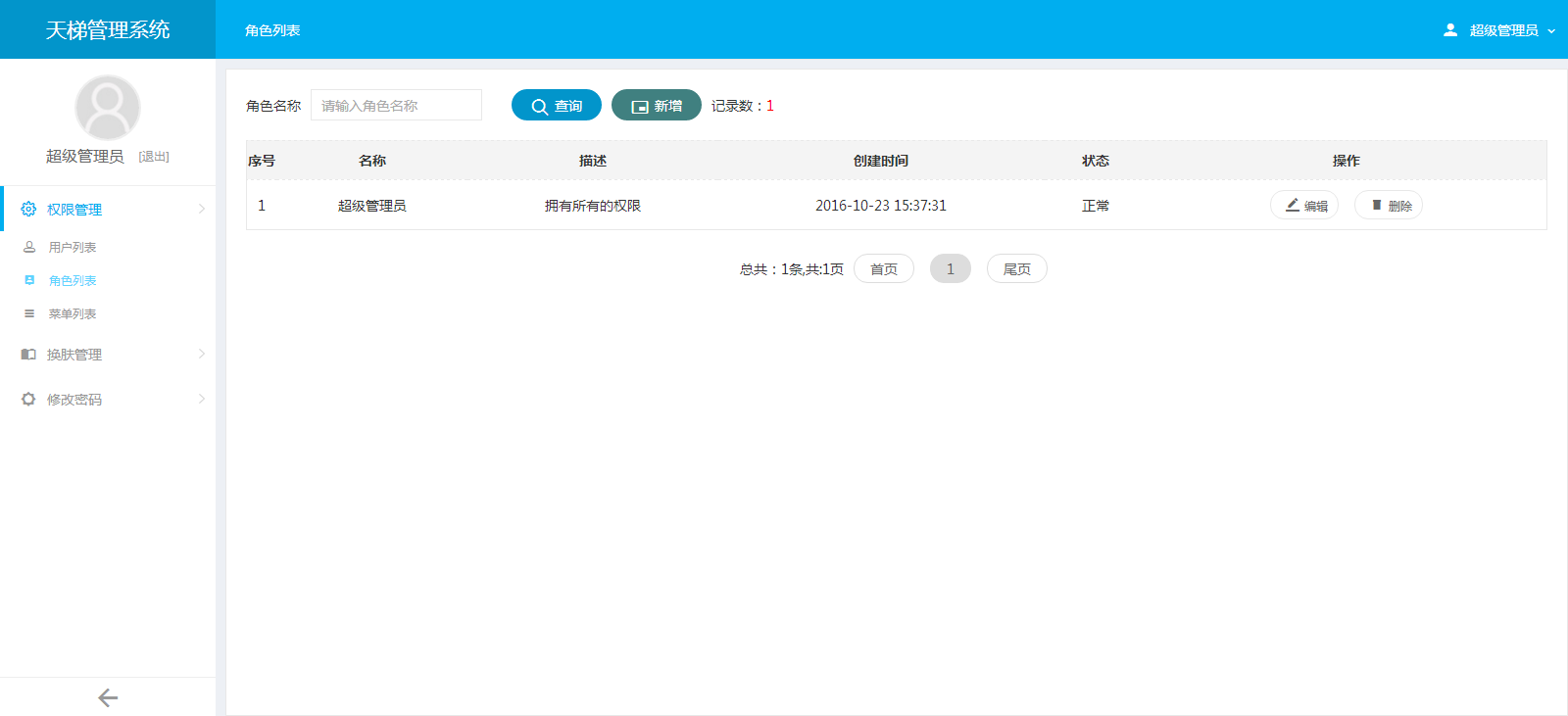 - 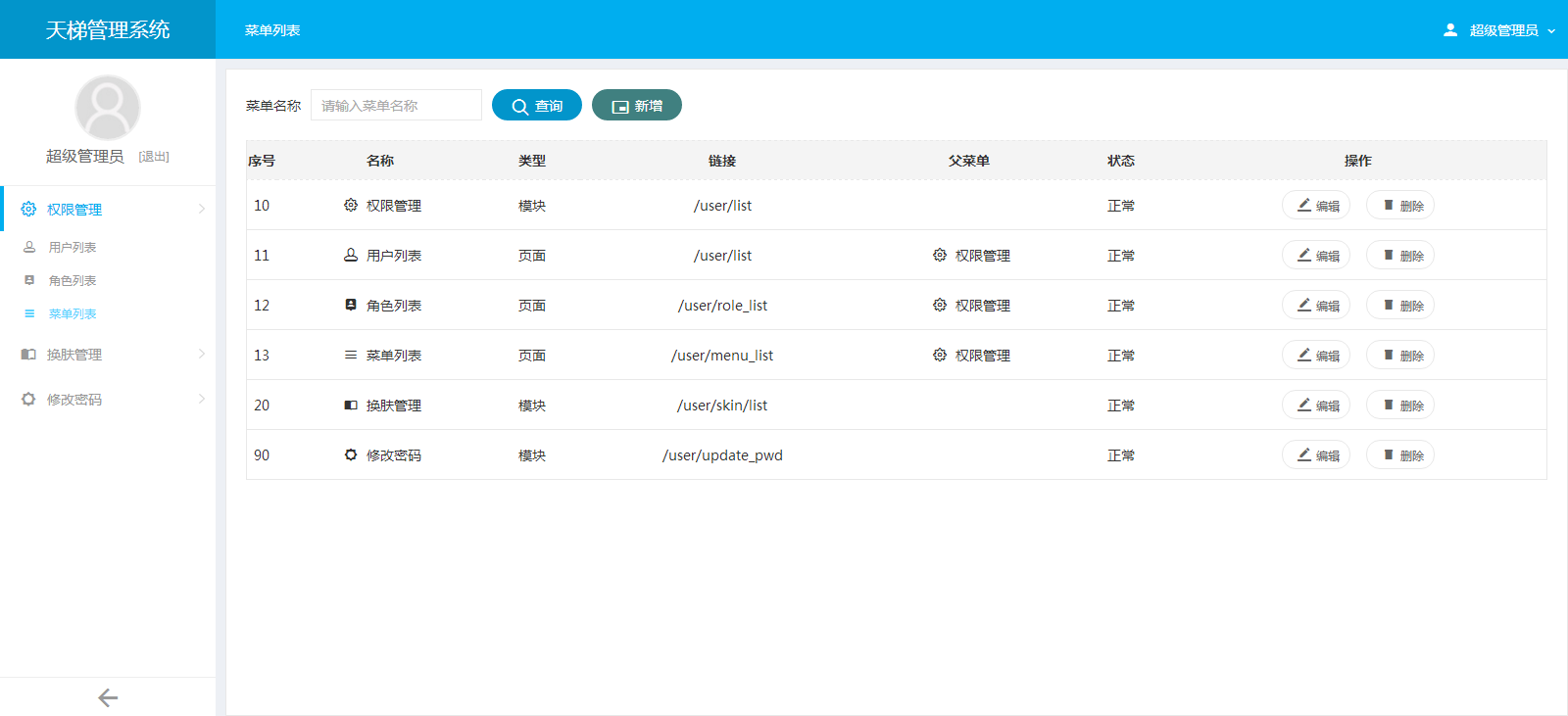 - 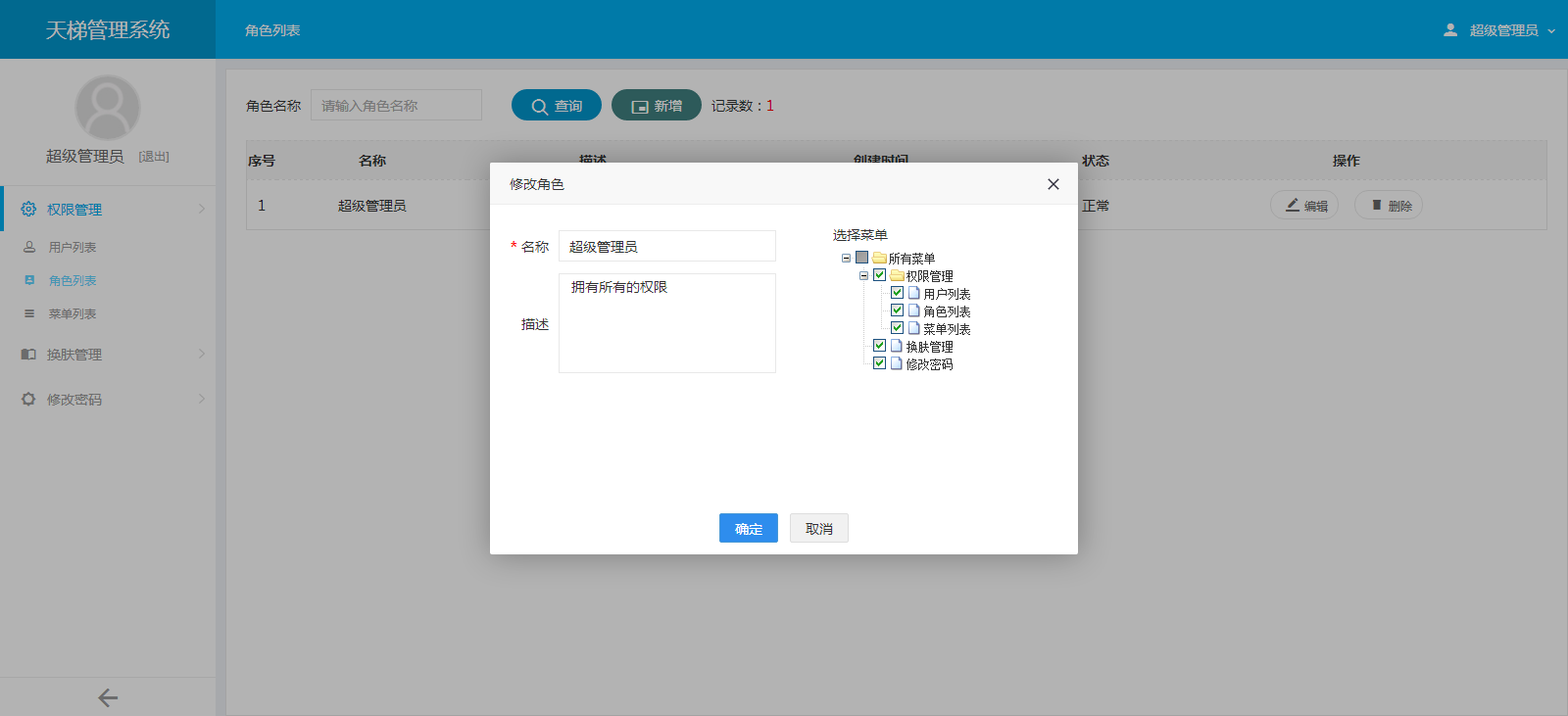 -  - 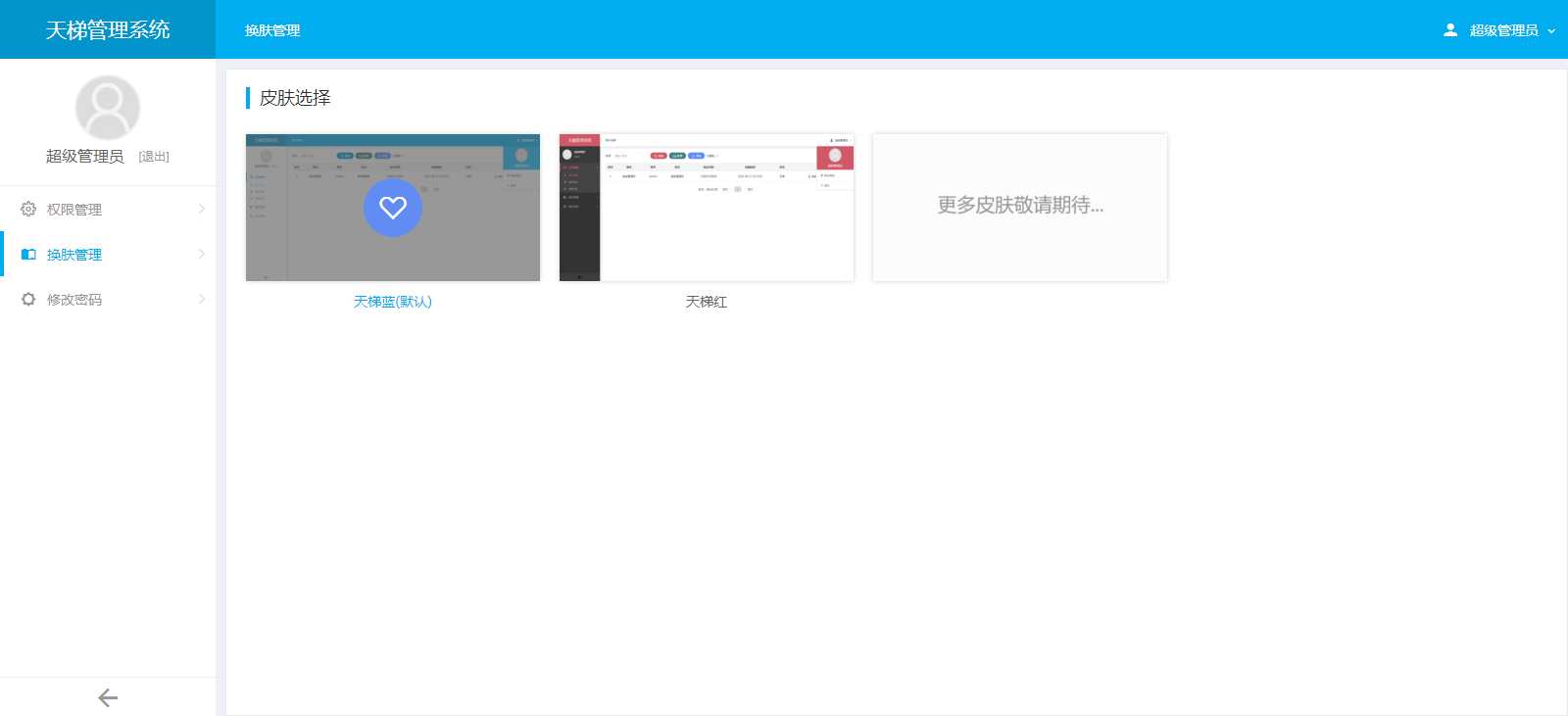 - 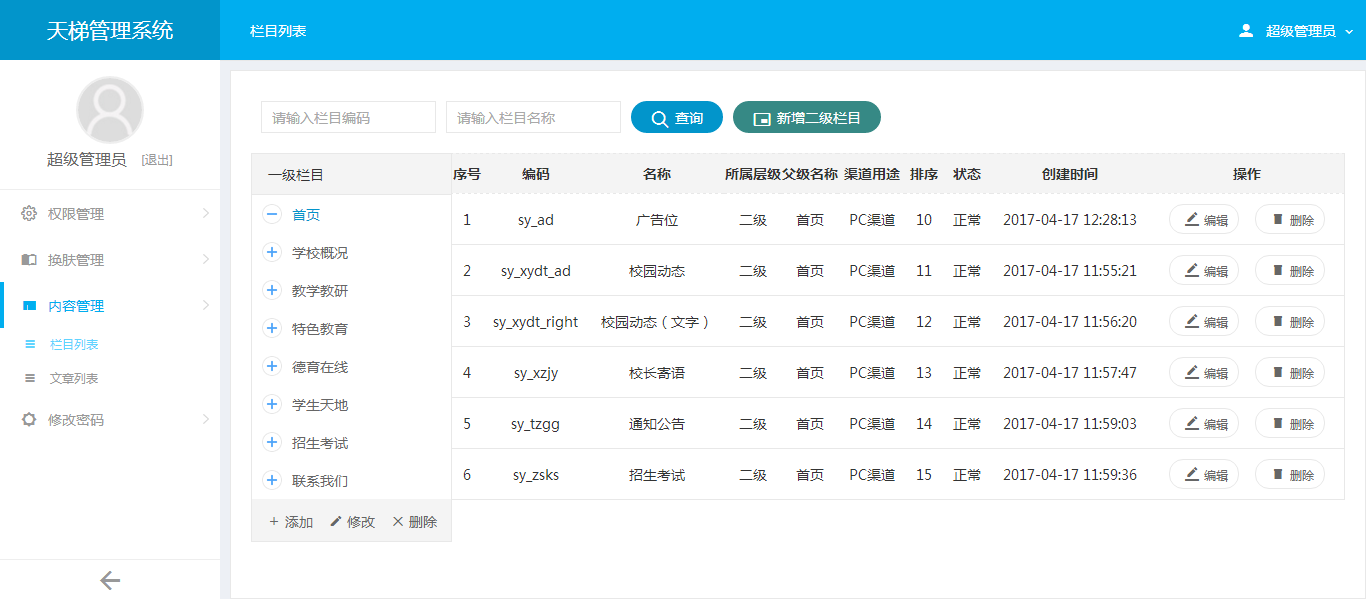 - 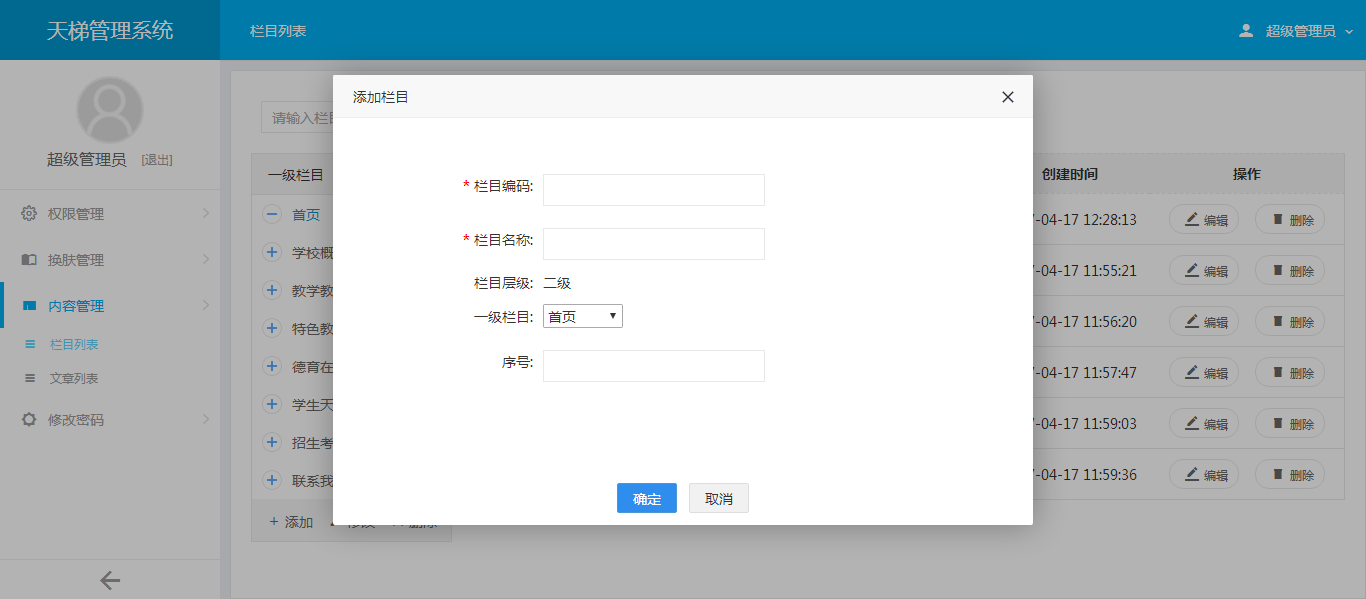 - 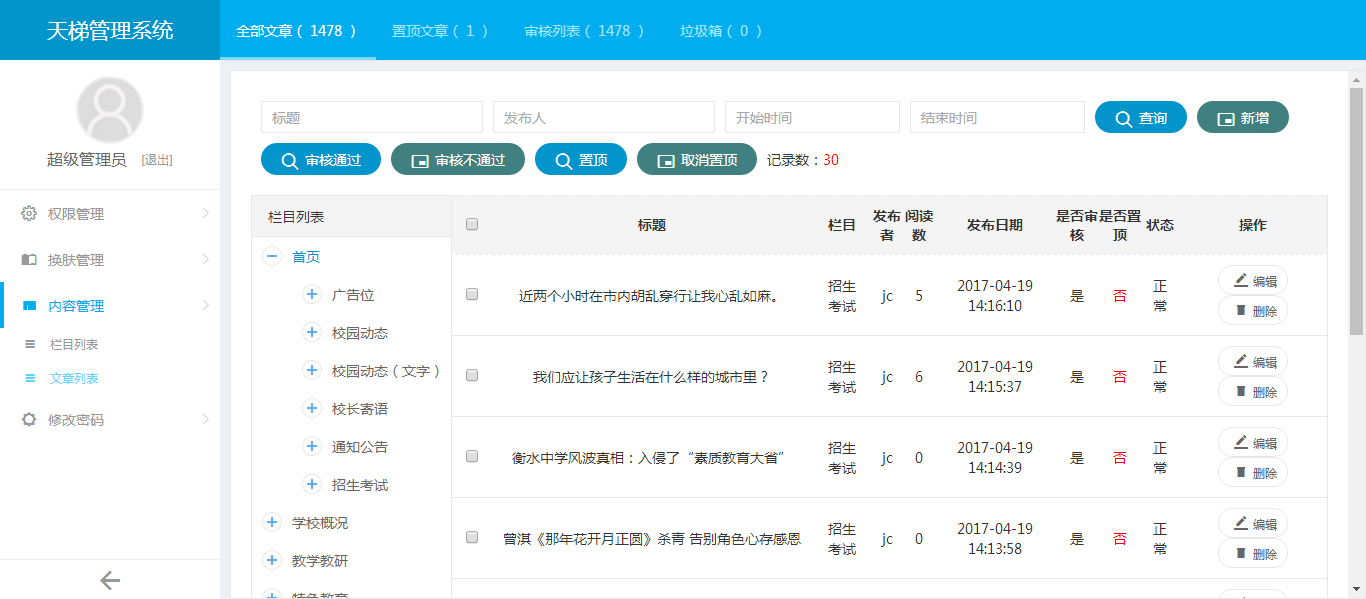 - 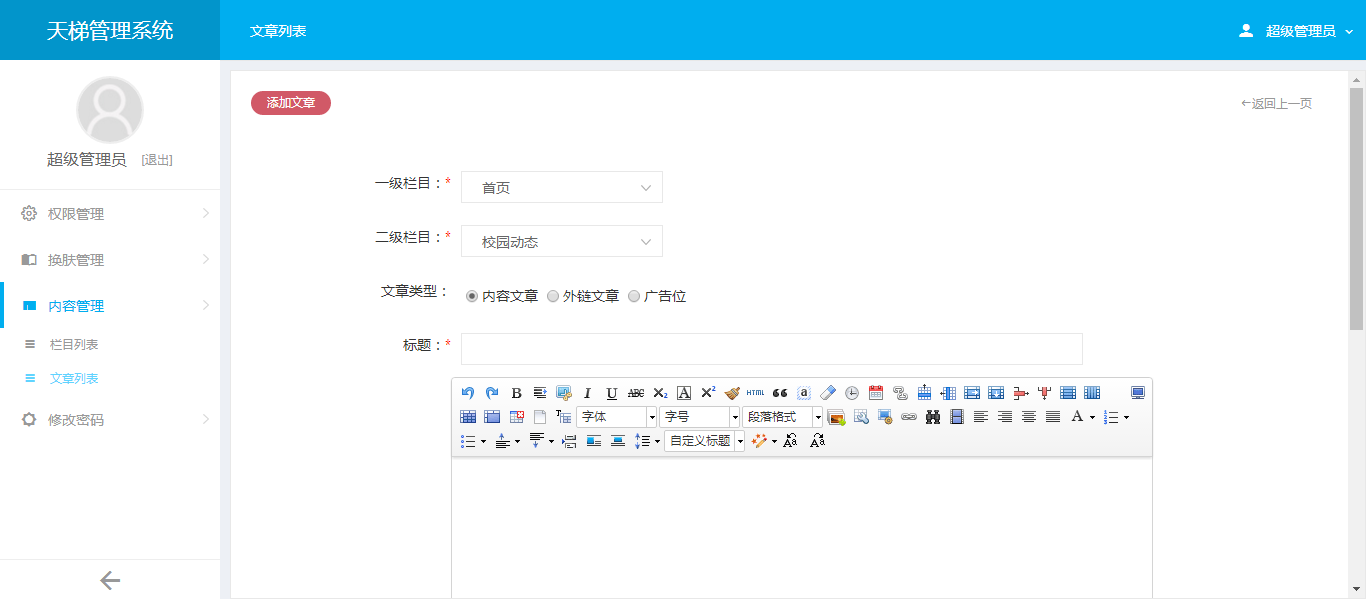 - 天梯红风格: - 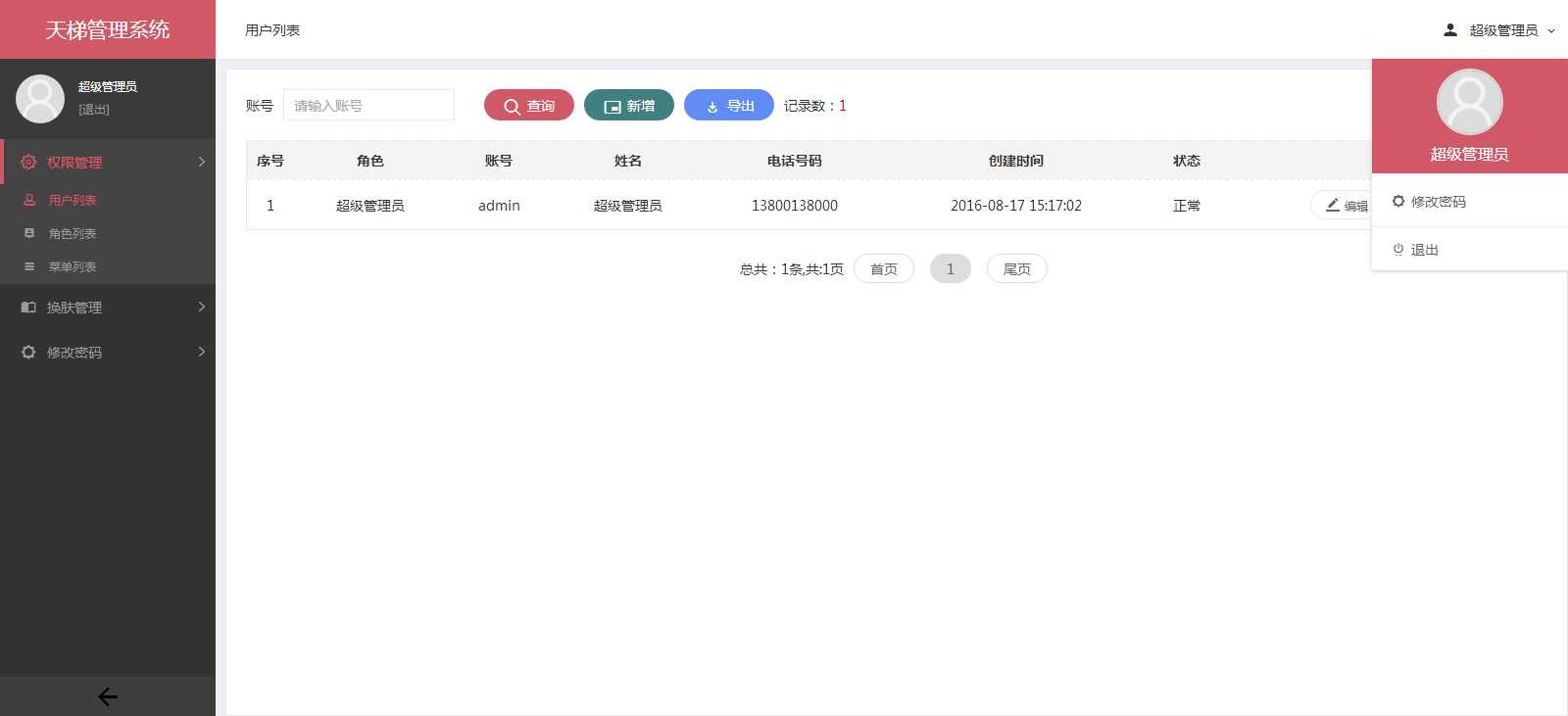 - 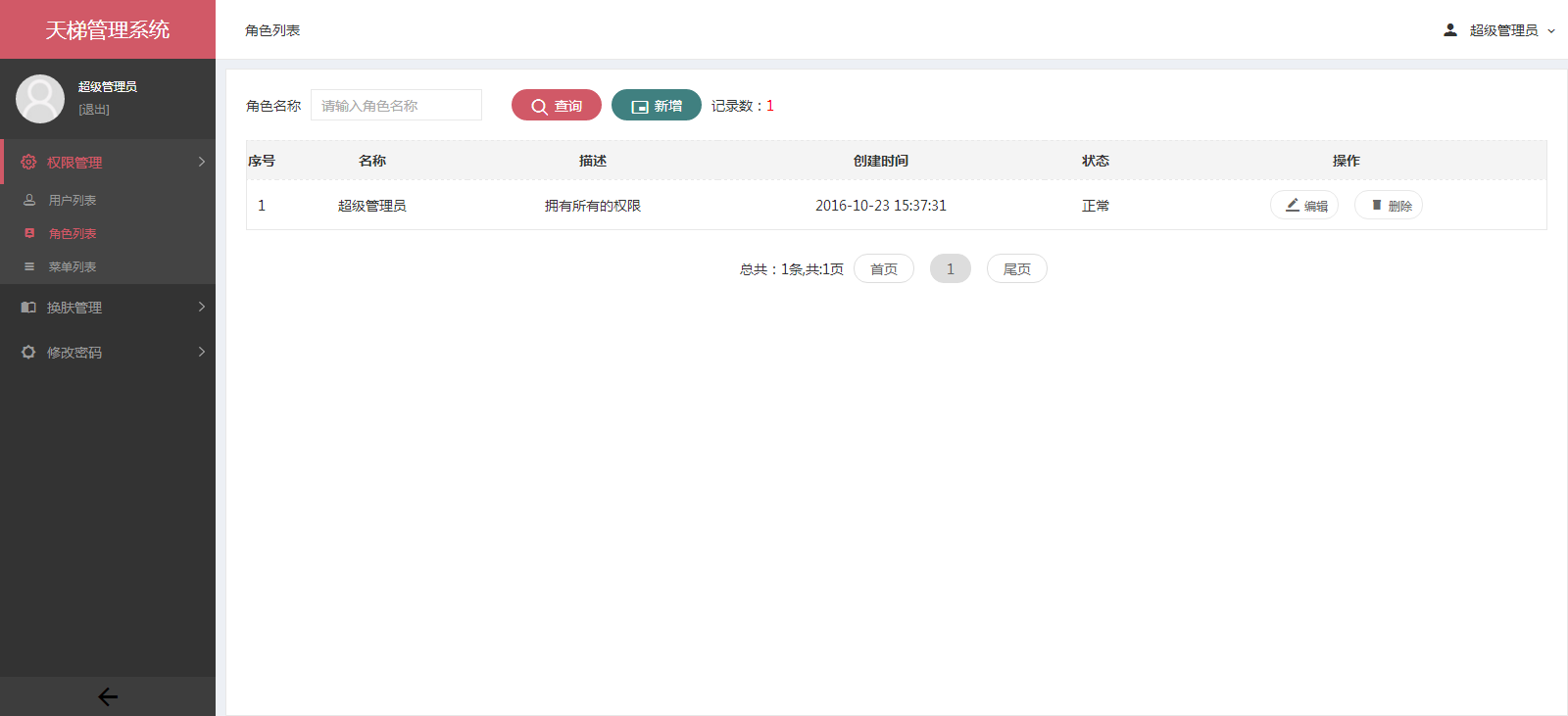 - 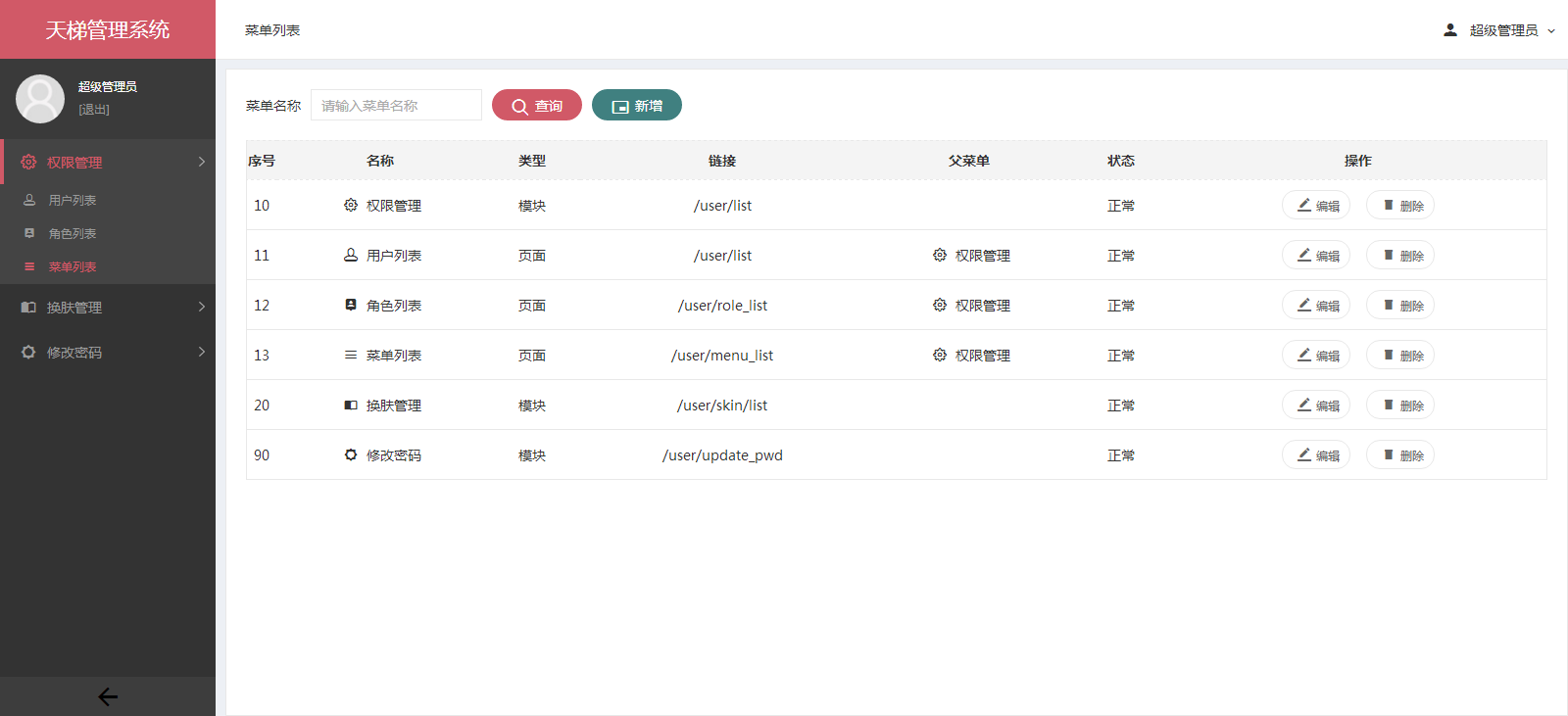 - 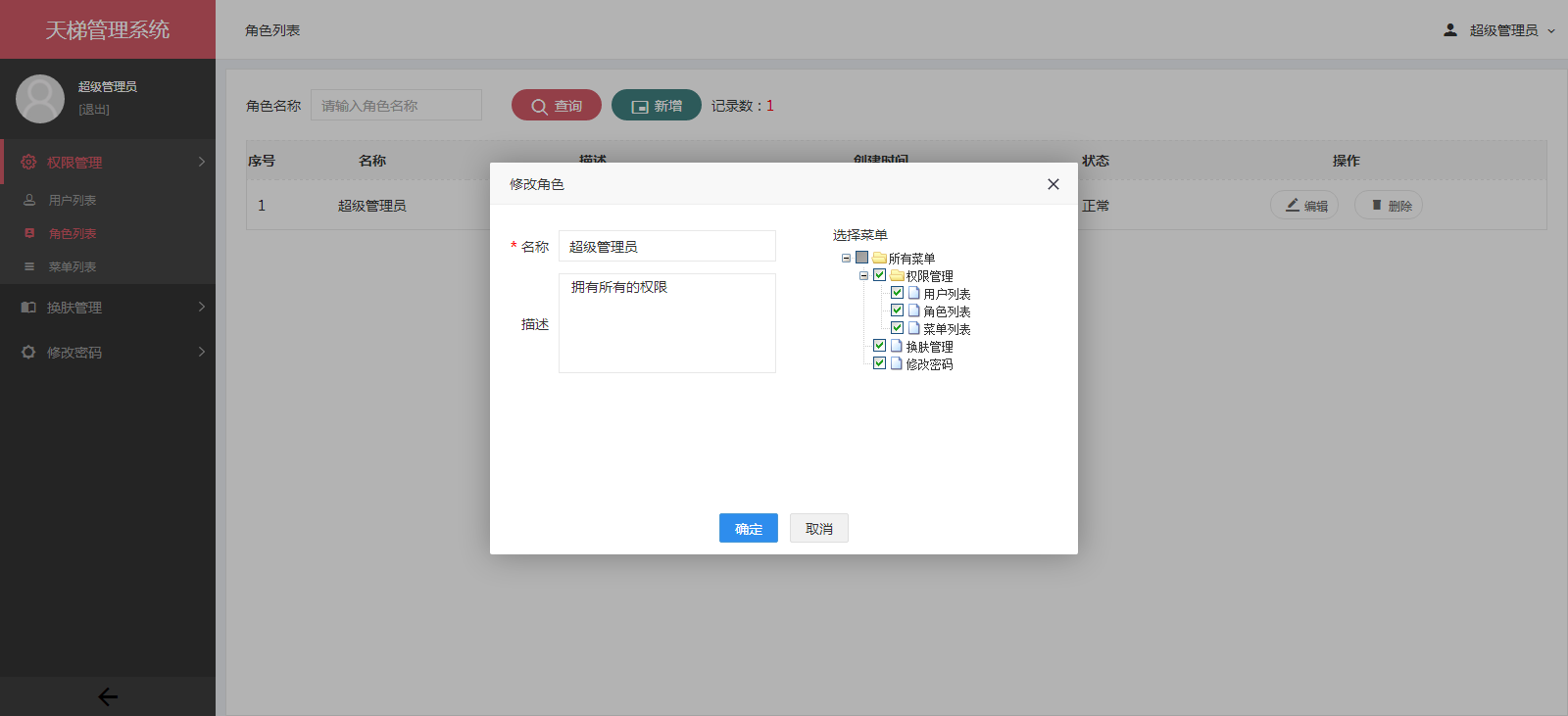 -  - 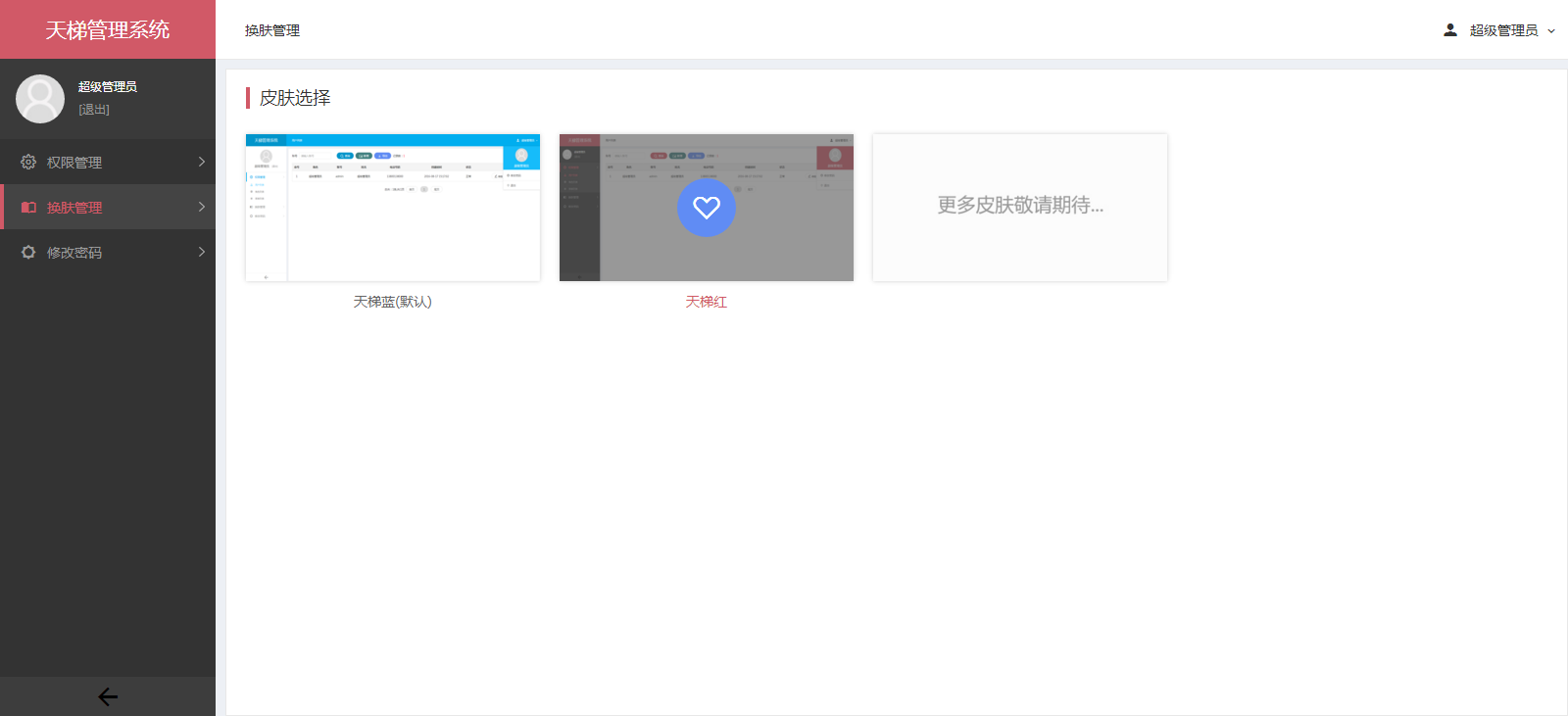 - 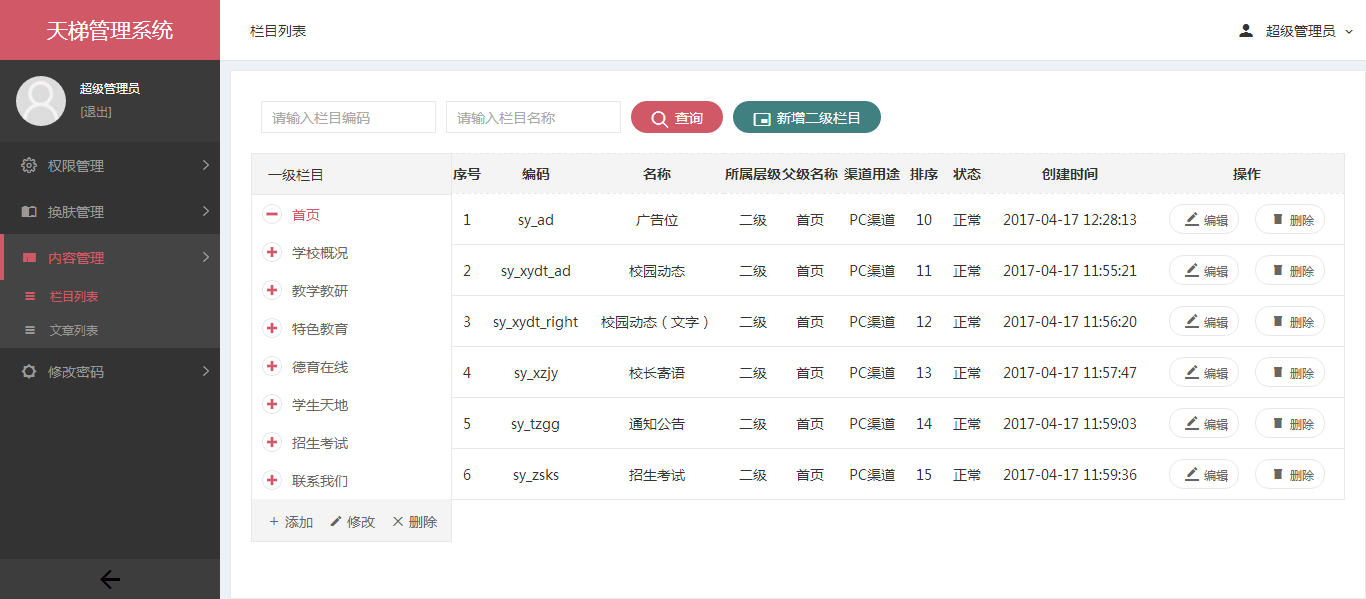 - 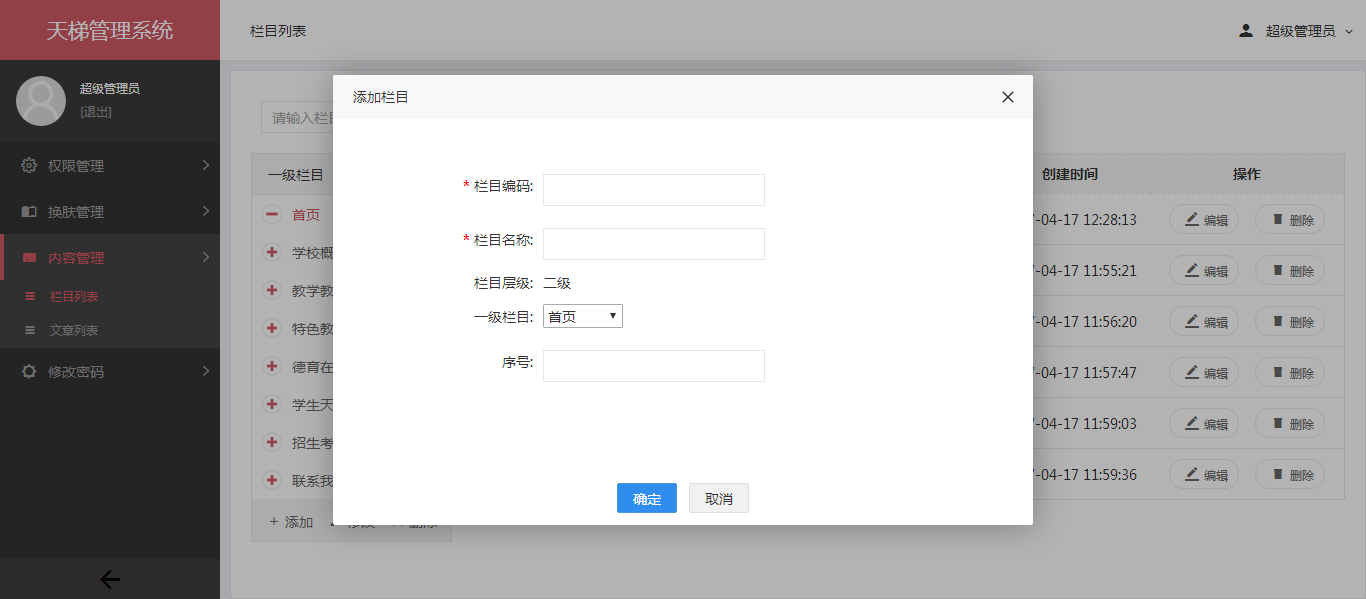 - 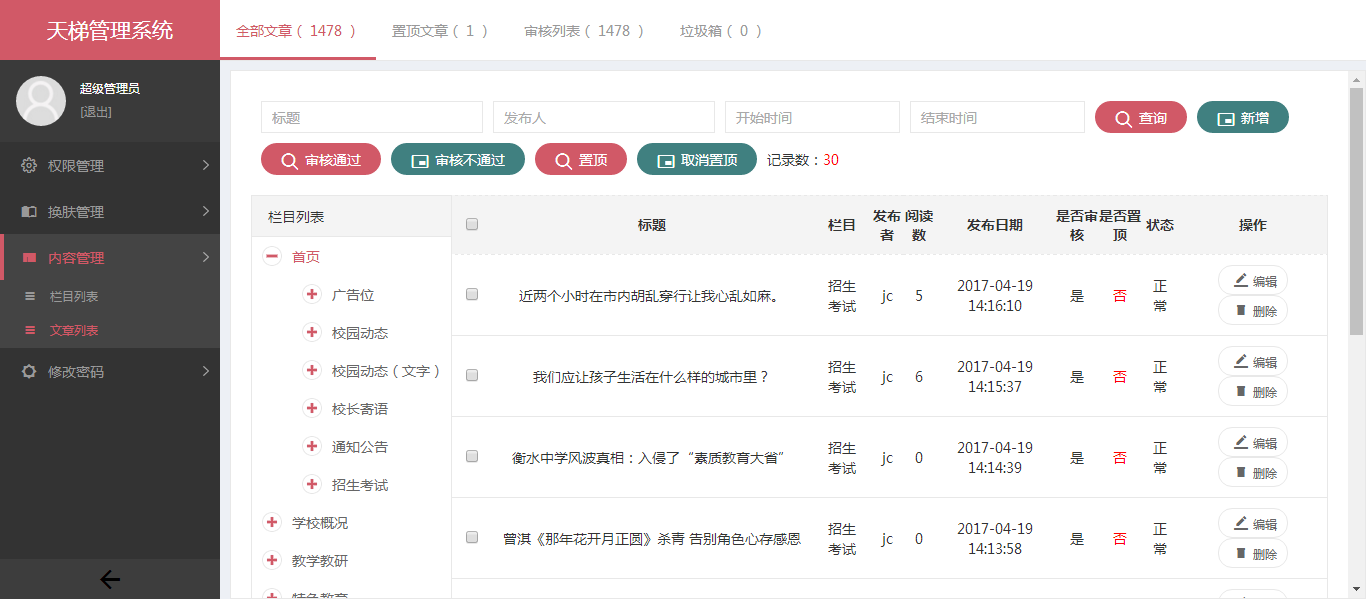 - 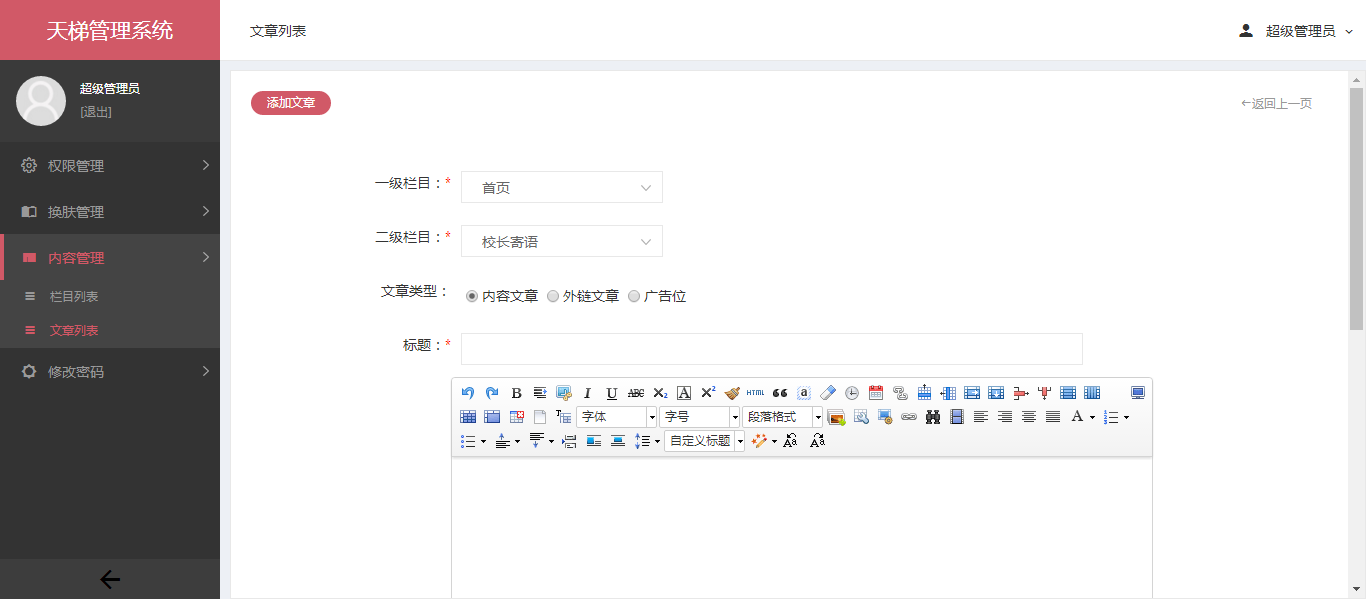 - - -" -davidmoten/rtree,master,1071,211,2014-08-26T12:29:14Z,1812,34,Immutable in-memory R-tree and R*-tree implementations in Java with reactive api,,"rtree -========= -
-[](https://scan.coverity.com/projects/4762?tab=overview)
-[](https://maven-badges.herokuapp.com/maven-central/com.github.davidmoten/rtree)
-[](https://codecov.io/gh/davidmoten/rtree) - - -In-memory immutable 2D [R-tree](http://en.wikipedia.org/wiki/R-tree) implementation in java using [RxJava Observables](https://github.com/ReactiveX/RxJava) for reactive processing of search results. - -Status: *released to Maven Central* - -Note that the **next version** (without a reactive API and without serialization) is at [rtree2](https://github.com/davidmoten/rtree2). - -An [R-tree](http://en.wikipedia.org/wiki/R-tree) is a commonly used spatial index. - -This was fun to make, has an elegant concise algorithm, is thread-safe, fast, and reasonably memory efficient (uses structural sharing). - -The algorithm to achieve immutability is cute. For insertion/deletion it involves recursion down to the -required leaf node then recursion back up to replace the parent nodes up to the root. The guts of -it is in [Leaf.java](src/main/java/com/github/davidmoten/rtree/internal/LeafDefault.java) and [NonLeaf.java](src/main/java/com/github/davidmoten/rtree/internal/NonLeafDefault.java). - -[Backpressure](https://github.com/ReactiveX/RxJava/wiki/Backpressure) support required some complexity because effectively a -bookmark needed to be kept for a position in the tree and returned to later to continue traversal. An immutable stack containing - the node and child index of the path nodes came to the rescue here and recursion was abandoned in favour of looping to prevent stack overflow (unfortunately java doesn't support tail recursion!). - -Maven site reports are [here](http://davidmoten.github.io/rtree/index.html) including [javadoc](http://davidmoten.github.io/rtree/apidocs/index.html). - -Features ------------- -* immutable R-tree suitable for concurrency -* Guttman's heuristics (Quadratic splitter) ([paper](https://www.google.com.au/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0CB8QFjAA&url=http%3A%2F%2Fpostgis.org%2Fsupport%2Frtree.pdf&ei=ieEQVJuKGdK8uATpgoKQCg&usg=AFQjCNED9w2KjgiAa9UI-UO_0eWjcADTng&sig2=rZ_dzKHBHY62BlkBuw3oCw&bvm=bv.74894050,d.c2E)) -* R*-tree heuristics ([paper](http://dbs.mathematik.uni-marburg.de/publications/myPapers/1990/BKSS90.pdf)) -* Customizable [splitter](src/main/java/com/github/davidmoten/rtree/Splitter.java) and [selector](src/main/java/com/github/davidmoten/rtree/Selector.java) -* 10x faster index creation with STR bulk loading ([paper](https://www.researchgate.net/profile/Scott_Leutenegger/publication/3686660_STR_A_Simple_and_Efficient_Algorithm_for_R-Tree_Packing/links/5563368008ae86c06b676a02.pdf)). -* search returns [```Observable```](http://reactivex.io/RxJava/javadoc/rx/Observable.html) -* search is cancelled by unsubscription -* search is ```O(log(n))``` on average -* insert, delete are ```O(n)``` worst case -* all search methods return lazy-evaluated streams offering efficiency and flexibility of functional style including functional composition and concurrency -* balanced delete -* uses structural sharing -* supports [backpressure](https://github.com/ReactiveX/RxJava/wiki/Backpressure) -* JMH benchmarks -* visualizer included -* serialization using [FlatBuffers](http://github.com/google/flatbuffers) -* high unit test [code coverage](http://davidmoten.github.io/rtree/cobertura/index.html) -* R*-tree performs 900,000 searches/second returning 22 entries from a tree of 38,377 Greek earthquake locations on i7-920@2.67Ghz (maxChildren=4, minChildren=1). Insert at 240,000 entries per second. -* requires java 1.6 or later - -Number of points = 1000, max children per node 8: - -| Quadratic split | R*-tree split | STR bulk loaded | -| :-------------: | :-----------: | :-----------: | -|
-
- -Dashboard Console -
-
- -CRUD Operations -
-
- -Import Feature -
-
- -Track History of changes -
-
- -Status of Zookeeper Servers -
-
- -License & Contribution -==================== - -ZKUI is released under the Apache 2.0 license. Comments, bugs, pull requests, and other contributions are all welcomed! - -Thanks to Jozef Krajčovič for creating the logo which has been used in the project. -https://www.iconfinder.com/iconsets/origami-birds -" -Jude95/EasyRecyclerView,master,2029,458,2015-07-18T13:11:48Z,11336,110,"ArrayAdapter,pull to refresh,auto load more,Header/Footer,EmptyView,ProgressView,ErrorView",,"# EasyRecyclerView -[中文](https://github.com/Jude95/EasyRecyclerView/blob/master/README_ch.md) | [English](https://github.com/Jude95/EasyRecyclerView/blob/master/README.md) - -Encapsulate many API about RecyclerView into the library,such as arrayAdapter,pull to refresh,auto load more,no more and error in the end,header&footer. -The library uses a new usage of ViewHolder,decoupling the ViewHolder and Adapter. -Adapter will do less work,adapter only direct the ViewHolder,if you use MVP,you can put adapter into presenter.ViewHolder only show the item,then you can use one ViewHolder for many Adapter. -Part of the code modified from [Malinskiy/SuperRecyclerView](https://github.com/Malinskiy/SuperRecyclerView),make more functions handed by Adapter. - - -# Dependency -```groovy -compile 'com.jude:easyrecyclerview:4.4.2' -``` - -# ScreenShot - -# Usage -## EasyRecyclerView -```xml -
-
- org.zalando
- logbook-core
-
-
- org.zalando
- logbook-httpclient
-
-
- org.zalando
- logbook-jaxrs
-
-
- org.zalando
- logbook-json
-
-
- org.zalando
- logbook-netty
-
-
- org.zalando
- logbook-okhttp
-
-
- org.zalando
- logbook-okhttp2
-
-
- org.zalando
- logbook-servlet
-
-
- org.zalando
- logbook-spring-boot-starter
-
-
- org.zalando
- logbook-ktor-common
-
-
- org.zalando
- logbook-ktor-client
-
-
- org.zalando
- logbook-ktor-server
-
-
- org.zalando
- logbook-ktor
-
-
- org.zalando
- logbook-logstash
-
-```
-
-
-The logbook logger must be configured to trace level in order to log the requests and responses. With Spring Boot 2 (using Logback) this can be accomplished by adding the following line to your `application.properties`
-
-```
-logging.level.org.zalando.logbook: TRACE
-```
-
-## Usage
-
-All integrations require an instance of `Logbook` which holds all configuration and wires all necessary parts together.
-You can either create one using all the defaults:
-
-```java
-Logbook logbook = Logbook.create();
-```
-or create a customized version using the `LogbookBuilder`:
-
-```java
-Logbook logbook = Logbook.builder()
- .condition(new CustomCondition())
- .queryFilter(new CustomQueryFilter())
- .pathFilter(new CustomPathFilter())
- .headerFilter(new CustomHeaderFilter())
- .bodyFilter(new CustomBodyFilter())
- .requestFilter(new CustomRequestFilter())
- .responseFilter(new CustomResponseFilter())
- .sink(new DefaultSink(
- new CustomHttpLogFormatter(),
- new CustomHttpLogWriter()
- ))
- .build();
-```
-
-### Strategy
-
-Logbook used to have a very rigid strategy how to do request/response logging:
-
-- Requests/responses are logged separately
-- Requests/responses are logged soon as possible
-- Requests/responses are logged as a pair or not logged at all
- (i.e. no partial logging of traffic)
-
-Some of those restrictions could be mitigated with custom [`HttpLogWriter`](#writing)
-implementations, but they were never ideal.
-
-Starting with version 2.0 Logbook now comes with a [Strategy pattern](https://en.wikipedia.org/wiki/Strategy_pattern)
-at its core. Make sure you read the documentation of the [`Strategy`](logbook-api/src/main/java/org/zalando/logbook/Strategy.java)
-interface to understand the implications.
-
-Logbook comes with some built-in strategies:
-
-- [`BodyOnlyIfStatusAtLeastStrategy`](logbook-core/src/main/java/org/zalando/logbook/core/BodyOnlyIfStatusAtLeastStrategy.java)
-- [`StatusAtLeastStrategy`](logbook-core/src/main/java/org/zalando/logbook/core/StatusAtLeastStrategy.java)
-- [`WithoutBodyStrategy`](logbook-core/src/main/java/org/zalando/logbook/core/WithoutBodyStrategy.java)
-
-### Attribute Extractor
-Starting with version 3.4.0, Logbook is equipped with a feature called *Attribute Extractor*. Attributes are basically a
-list of key/value pairs that can be extracted from request and/or response, and logged with them. The idea was sprouted
-from [issue 381](https://github.com/zalando/logbook/issues/381), where a feature was requested to extract the subject
-claim from JWT tokens in the authorization header.
-
-The `AttributeExtractor` interface has two `extract` methods: One that can extract attributes from the request only, and
-one that has both request and response at its avail. The both return an instance of the `HttpAttributes` class, which is
-basically a fancy `Map... which allows you to omit versions:
- -```xml -form: `client_secret` and `password` | -| `RequestFilter` | `HttpRequest` | request | Replace binary, multipart and stream bodies. | -| `ResponseFilter` | `HttpResponse` | response | Replace binary, multipart and stream bodies. | - -`QueryFilter`, `PathFilter`, `HeaderFilter` and `BodyFilter` are relatively high-level and should cover all needs in ~90% of all -cases. For more complicated setups one should fallback to the low-level variants, i.e. `RequestFilter` and `ResponseFilter` -respectively (in conjunction with `ForwardingHttpRequest`/`ForwardingHttpResponse`). - -You can configure filters like this: - -```java -import static org.zalando.logbook.core.HeaderFilters.authorization; -import static org.zalando.logbook.core.HeaderFilters.eachHeader; -import static org.zalando.logbook.core.QueryFilters.accessToken; -import static org.zalando.logbook.core.QueryFilters.replaceQuery; - -Logbook logbook = Logbook.builder() - .requestFilter(RequestFilters.replaceBody(message -> contentType(""audio/*"").test(message) ? ""mmh mmh mmh mmh"" : null)) - .responseFilter(ResponseFilters.replaceBody(message -> contentType(""*/*-stream"").test(message) ? ""It just keeps going and going..."" : null)) - .queryFilter(accessToken()) - .queryFilter(replaceQuery(""password"", ""
-
-
-Before
- -```json -{ - ""id"": 1, - ""name"": ""Alice"", - ""password"": ""s3cr3t"", - ""active"": true, - ""address"": ""Anhalter Straße 17 13, 67278 Bockenheim an der Weinstraße"", - ""friends"": [ - { - ""id"": 2, - ""name"": ""Bob"" - }, - { - ""id"": 3, - ""name"": ""Charlie"" - } - ], - ""grades"": { - ""Math"": 1.0, - ""English"": 2.2, - ""Science"": 1.9, - ""PE"": 4.0 - } -} -``` -
-
-
-#### Correlation
-
-Logbook uses a *correlation id* to correlate requests and responses. This allows match-related requests and responses that would usually be located in different places in the log file.
-
-If the default implementation of the correlation id is insufficient for your use case, you may provide a custom implementation:
-
-```java
-Logbook logbook = Logbook.builder()
- .correlationId(new CustomCorrelationId())
- .build();
-```
-
-#### Formatting
-
-*Formatting* defines how requests and responses will be transformed to strings basically. Formatters do **not** specify where requests and responses are logged to — writers do that work.
-
-Logbook comes with two different default formatters: *HTTP* and *JSON*.
-
-##### HTTP
-
-*HTTP* is the default formatting style, provided by the `DefaultHttpLogFormatter`. It is primarily designed to be used for local development and debugging, not for production use. This is because it’s
-not as readily machine-readable as JSON.
-
-###### Request
-
-```http
-Incoming Request: 2d66e4bc-9a0d-11e5-a84c-1f39510f0d6b
-GET http://example.org/test HTTP/1.1
-Accept: application/json
-Host: localhost
-Content-Type: text/plain
-
-Hello world!
-```
-
-###### Response
-
-```http
-Outgoing Response: 2d66e4bc-9a0d-11e5-a84c-1f39510f0d6b
-Duration: 25 ms
-HTTP/1.1 200
-Content-Type: application/json
-
-{""value"":""Hello world!""}
-```
-
-##### JSON
-
-*JSON* is an alternative formatting style, provided by the `JsonHttpLogFormatter`. Unlike HTTP, it is primarily designed for production use — parsers and log consumers can easily consume it.
-
-Requires the following dependency:
-
-```xml
-After
- -```json -{ - ""id"": 1, - ""name"": ""Alice"", - ""active"": ""unknown"", - ""address"": ""XXX"", - ""friends"": [ - { - ""id"": 2, - ""name"": ""B."" - }, - { - ""id"": 3, - ""name"": ""C."" - } - ], - ""grades"": { - ""Math"": 1.0, - ""English"": 1.0, - ""Science"": 1.0, - ""PE"": 1.0 - } -} -``` -:warning: Logbook will still buffer the full body, if the request is eligible for logging, regardless of the `logbook.write.max-body-size` value | `-1` (disabled) | - -##### Example configuration - -```yaml -logbook: - predicate: - include: - - path: /api/** - methods: - - GET - - POST - - path: /actuator/** - exclude: - - path: /actuator/health - - path: /api/admin/** - methods: - - POST - filter.enabled: true - secure-filter.enabled: true - format.style: http - strategy: body-only-if-status-at-least - minimum-status: 400 - obfuscate: - headers: - - Authorization - - X-Secret - parameters: - - access_token - - password - write: - chunk-size: 1000 - attribute-extractors: - - type: JwtFirstMatchingClaimExtractor - claim-names: [ ""sub"", ""subject"" ] - claim-key: Principal - - type: JwtAllMatchingClaimsExtractor - claim-names: [ ""sub"", ""iat"" ] -``` - -### logstash-logback-encoder - -For basic Logback configuraton - -``` -
-
-
- -
-> [](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-sql/readme.md) - -## Who is using Manifold? - -Sampling of companies using Manifold: - -
- DOB: ${user.getDateOfBirth()}
- <% } %> -<% } %> - - -``` - -## [IDE Support](https://github.com/manifold-systems/manifold) -Use the [Manifold plugin](https://plugins.jetbrains.com/plugin/10057-manifold) to fully leverage -Manifold with **IntelliJ IDEA** and **Android Studio**. The plugin provides comprehensive support for Manifold including code -completion, navigation, usage searching, refactoring, incremental compilation, hotswap debugging, full-featured -template editing, integrated preprocessor, and more. - -
- -[Manifold : _Extensions_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-ext)
- -[Manifold : _Delegation_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-delegation)
- -[Manifold : _Properties_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-props)
- -[Manifold : _Tuples_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-tuple)
- -[Manifold : _SQL_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-sql)
-[Manifold : _GraphQL_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-graphql)
-[Manifold : _JSON_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-json)
-[Manifold : _XML_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-xml)
-[Manifold : _YAML_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-yaml)
-[Manifold : _CSV_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-csv)
-[Manifold : _Property Files_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-properties)
-[Manifold : _Image_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-image)
-[Manifold : _Dark Java_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-darkj)
-[Manifold : _JavaScript_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-js)
- -[Manifold : _Java Templates_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-templates)
- -[Manifold : _String Interpolation_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-strings)
-[Manifold : _(Un)checked Exceptions_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-exceptions)
- -[Manifold : _Preprocessor_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-preprocessor)
- -[Manifold : _Science_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-science)
- -[Manifold : _Collections_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-collections)
-[Manifold : _I/0_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-io)
-[Manifold : _Text_](https://github.com/manifold-systems/manifold/tree/master/manifold-deps-parent/manifold-text)
- ->Experiment with sample projects:
->* [Manifold : _Sample App_](https://github.com/manifold-systems/manifold-sample-project)
->* [Manifold : _Sample SQL App_](https://github.com/manifold-systems/manifold-sql-sample-project)
->* [Manifold : _Sample GraphQL App_](https://github.com/manifold-systems/manifold-sample-graphql-app)
->* [Manifold : _Sample REST API App_](https://github.com/manifold-systems/manifold-sample-rest-api)
->* [Manifold : _Sample Web App_](https://github.com/manifold-systems/manifold-sample-web-app) ->* [Manifold : _Gradle Example Project_](https://github.com/manifold-systems/manifold-simple-gradle-project) ->* [Manifold : _Sample Kotlin App_](https://github.com/manifold-systems/manifold-sample-kotlin-app) - -## Platforms - -Manifold supports: -* Java SE (8 - 21) -* [Android](http://manifold.systems/android.html) -* [Kotlin](http://manifold.systems/kotlin.html) (limited) - -Comprehensive IDE support is also available for IntelliJ IDEA and Android Studio. - -## [Chat](https://join.slack.com/t/manifold-group/shared_invite/zt-e0bq8xtu-93ASQa~a8qe0KDhOoD6Bgg) -Join our [Slack Group](https://join.slack.com/t/manifold-group/shared_invite/zt-e0bq8xtu-93ASQa~a8qe0KDhOoD6Bgg) to start -a discussion, ask questions, provide feedback, etc. Someone is usually there to help. - -
-" -beehive-lab/TornadoVM,master,1105,96,2018-09-07T09:37:44Z,120197,31,TornadoVM: A practical and efficient heterogeneous programming framework for managed languages,ai artificial-intelligence cuda fpga gpgpu gpu-acceleration gpu-computing gpus graalvm high-performance java java-library-acceleration level-zero-gpu-runtime levelzero multi-core opencl spirv tornadovm,"# TornadoVM - -
Hydra Lab
-Build your own cloud testing infrastructure
-
-
-[中文(完善中)](README.zh-CN.md)
-
-[](https://dlwteam.visualstudio.com/Next/_build/latest?definitionId=743&branchName=main)
-
-
-
-
----
-
-https://github.com/microsoft/HydraLab/assets/8344245/cefefe24-4e11-4cc7-a3af-70cb44974735
-
-[What is Hydra Lab?](#what-is) | [Get Started](#get-started) | [Contribute](#contribute) | [Contact Us](#contact) | [Wiki](https://github.com/microsoft/HydraLab/wiki)
-
-
-
-## What is Hydra Lab?
-
-As mentioned in the above video, Hydra Lab is a framework that can help you easily build a cloud-testing platform utilizing the test devices/machines in hand.
-
-Capabilities of Hydra Lab include:
-- Scalable test device management under the center-agent distributed design; Test task management and test result visualization.
-- Powering [Android Espresso Test](https://developer.android.com/training/testing/espresso), and Appium(Java) test on different platforms: Windows/iOS/Android/Browser/Cross-platform.
-- Case-free test automation: Monkey test, Smart exploratory test.
-
-For more details, you may refer to:
-- [Introduction: What is Hydra Lab?](https://github.com/microsoft/HydraLab/wiki)
-- [How Hydra Lab Empowers Microsoft Mobile Testing and Test Intelligence](https://medium.com/microsoft-mobile-engineering/how-hydra-lab-empowers-microsoft-mobile-testing-e4bd831ecf41)
-
-
-## Get Started
-
-Please visit our **[GitHub Project Wiki](https://github.com/microsoft/HydraLab/wiki)** to understand the dev environment setup procedure: [Contribution Guideline](CONTRIBUTING.md).
-
-**Supported environments for Hydra Lab agent**: Windows, Mac OSX, and Linux ([Docker](https://github.com/microsoft/HydraLab/blob/main/agent/README.md#run-agent-in-docker)).
-
-**Supported platforms and frameworks matrix**:
-
-| | Appium(Java) | Espresso | XCTest | Maestro | Python Runner |
-| ---- |--------------|---- | ---- | ---- | --- |
-|Android| ✔ | ✔ | x | ✔ | ✔ |
-|iOS| ✔ | x | ✔ | ✔ | ✔ |
-|Windows| ✔ | x | x | x | ✔ |
-|Web (Browser)| ✔ | x | x | x | ✔ |
-
-
-### Quick guide on out-of-box Uber docker image
-
-Hydra Lab offers an out-of-box experience of the Docker image, and we call it `Uber`. You can follow the below steps and start your docker container with both a center instance and an agent instance:
-
-**Step 1. Download and install [Docker](https://www.docker.com)**
-
-**Step 2. Download latest Uber Docker image**
-```bash
-docker pull ghcr.io/microsoft/hydra-lab-uber:latest
-```
-**This step is necessary.** Without this step and jump to step 3, you may target at the local cached Docker image with `latest` tag if it exists.
-
-**Step 3. Run on your machine**
-
-By Default, Hydra Lab will use the local file system as a storage solution, and you may type the following in your terminal to run it:
-
-```bash
-docker run -p 9886:9886 --name=hydra-lab ghcr.io/microsoft/hydra-lab-uber:latest
-```
-
-> We strongly recommend using [Azure Blob Storage](https://azure.microsoft.com/en-us/products/storage/blobs/) service as the file storage solution, and Hydra Lab has native, consistent, and validated support for it.
-
-**Step 3. Visit the web page and view your connected devices**
-
-> Url: http://localhost:9886/portal/index.html#/ (or your custom port).
-
-Enjoy starting your journey of exploration!
-
-**Step 4. Perform the test procedure with a minimal setup**
-
-Note: For Android, Uber image only supports **Espresso/Instrumentation** test. See the ""User Manual"" section on this page for more features: [Hydra Lab Wikis](https://github.com/microsoft/HydraLab/wiki).
-
-**To run a test with Uber image and local storage:**
-- On the front-end page, go to the `Runner` tab and select `HydraLab Client`.
-- Click `Run` and change ""Espresso test scope"" to `Test app`, click `Next`.
-- Pick an available device, click `Next` again, and click `Run` to start the test.
-- When the test is finished, you can view the test result in the `Task` tab on the left navigator of the front-end page.
-
-
-
-
-### Build and run Hydra Lab from the source
-
-You can also run the center java Spring Boot service (a runnable Jar) separately with the following commands:
-
-> The build and run process will require JDK11 | NPM | Android SDK platform-tools in position.
-
-**Step 1. Run Hydra Lab center service**
-
-```bash
-# In the project root, switch to the react folder to build the Web front.
-cd react
-npm ci
-npm run pub
-# Get back to the project root, and build the center runnable Jar.
-cd ..
-# For the gradlew command, if you are on Windows please replace it with `./gradlew` or `./gradlew.bat`
-gradlew :center:bootJar
-# Run it, and then visit http://localhost:9886/portal/index.html#/
-java -jar center/build/libs/center.jar
-# Then visit http://localhost:9886/portal/index.html#/auth to generate a new agent ID and agent secret.
-```
-
-> If you encounter the error: `Error: error:0308010C:digital envelope routines::unsupported`, set the System Variable `NODE_OPTIONS` as `--openssl-legacy-provider` and then restart the terminal.
-
-**Step 2. Run Hydra Lab agent service**
-
-```bash
-# In the project root
-cd android_client
-# Build the Android client APK
-./gradlew assembleDebug
-cp app/build/outputs/apk/debug/app-debug.apk ../common/src/main/resources/record_release.apk
-# If you don't have the SDK for Android ,you can download the prebuilt APK in https://github.com/microsoft/HydraLab/releases
-# Back to the project root
-cd ..
-# In the project root, copy the sample config file and update the:
-# YOUR_AGENT_NAME, YOUR_REGISTERED_AGENT_ID and YOUR_REGISTERED_AGENT_SECRET.
-cp agent/application-sample.yml application.yml
-# Then build an agent jar and run it
-gradlew :agent:bootJar
-java -jar agent/build/libs/agent.jar
-```
-
-**Step 3. visit http://localhost:9886/portal/index.html#/ and view your connected devices**
-
-### More integration guidelines:
-
-- [Test agent setup](https://github.com/microsoft/HydraLab/wiki/Test-agent-setup)
-- [Trigger a test task run in the Hydra Lab test service](https://github.com/microsoft/HydraLab/wiki/Trigger-a-test-task-run-in-the-Hydra-Lab-test-service)
-- [Deploy Center Docker Container](https://github.com/microsoft/HydraLab/wiki/Deploy-Center-Docker-Container)
-
-
-## Contribute
-
-Your contribution to Hydra Lab will make a difference for the entire test automation ecosystem. Please refer to **[CONTRIBUTING.md](CONTRIBUTING.md)** for instructions.
-
-### Contributor Hero Wall:
-
-
- or `brew install jsonschema2pojo` - -You can use jsonschema2pojo as a Maven plugin, an Ant task, a command line utility, a Gradle plugin or embedded within your own Java app. The [Getting Started](https://github.com/joelittlejohn/jsonschema2pojo/wiki/Getting-Started) guide will show you how. - -A very simple Maven example: -```xml -
| |
- |
-
-[](http://geode.apache.org)
-
-[](https://concourse.apachegeode-ci.info/teams/main/pipelines/apache-develop-main) [](https://www.apache.org/licenses/LICENSE-2.0) [](http://search.maven.org/#search%7Cga%7C1%7Cg%3A%22org.apache.geode%22) [](https://formulae.brew.sh/formula/apache-geode) [](https://hub.docker.com/r/apachegeode/geode/) [](https://lgtm.com/projects/g/apache/geode/alerts/) [](https://lgtm.com/projects/g/apache/geode/context:java) [](https://lgtm.com/projects/g/apache/geode/context:javascript) [](https://lgtm.com/projects/g/apache/geode/context:python)
-
-
-
-## Contents
-
-1. [Overview](#overview)
-2. [How to Get Apache Geode](#obtaining)
-3. [Main Concepts and Components](#concepts)
-4. [Location of Directions for Building from Source](#building)
-5. [Geode in 5 minutes](#started)
-6. [Application Development](#development)
-7. [Documentation](https://geode.apache.org/docs/)
-8. [Wiki](https://cwiki.apache.org/confluence/display/GEODE/Index)
-9. [How to Contribute](https://cwiki.apache.org/confluence/display/GEODE/How+to+Contribute)
-10. [Export Control](#export)
-
-## Overview
-
-[Apache Geode](http://geode.apache.org/) is
-a data management platform that provides real-time, consistent access to
-data-intensive applications throughout widely distributed cloud architectures.
-
-Apache Geode pools memory, CPU, network resources, and optionally local disk
-across multiple processes to manage application objects and behavior. It uses
-dynamic replication and data partitioning techniques to implement high
-availability, improved performance, scalability, and fault tolerance. In
-addition to being a distributed data container, Apache Geode is an in-memory
-data management system that provides reliable asynchronous event notifications
-and guaranteed message delivery.
-
-Apache Geode is a mature, robust technology originally developed by GemStone
-Systems. Commercially available as GemFire™, it was first deployed in the
-financial sector as the transactional, low-latency data engine used in Wall
-Street trading platforms. Today Apache Geode technology is used by hundreds of
-enterprise customers for high-scale business applications that must meet low
-latency and 24x7 availability requirements.
-
-## How to Get Apache Geode
-
-You can download Apache Geode from the
-[website](https://geode.apache.org/releases/), run a Docker
-[image](https://hub.docker.com/r/apachegeode/geode/), or install with
-[Homebrew](https://formulae.brew.sh/formula/apache-geode) on OSX. Application developers
-can load dependencies from [Maven
-Central](https://search.maven.org/#search%7Cga%7C1%7Cg%3A%22org.apache.geode%22).
-
-Maven
-```xml
--In a top-like manner, it displays JVM internal metrics (e.g. memory information) of running java processes.
-
-Jvmtop does also include a CPU console profiler.
-
-It's tested with different releases of Oracle JDK, IBM JDK and OpenJDK on Linux, Solaris, FreeBSD and Windows hosts.
-Jvmtop requires a JDK - a JRE will not suffice.
-
-Please note that it's currently in an alpha state -
-if you experience an issue or need further help, please let us know.
-
-Jvmtop is open-source. Checkout the source code. Patches are very welcome!
-
-Also have a look at the documentation or at a captured live-example.
- -``` - JvmTop 0.8.0 alpha amd64 8 cpus, Linux 2.6.32-27, load avg 0.12 - https://github.com/patric-r/jvmtop - - PID MAIN-CLASS HPCUR HPMAX NHCUR NHMAX CPU GC VM USERNAME #T DL - 3370 rapperSimpleApp 165m 455m 109m 176m 0.12% 0.00% S6U37 web 21 -11272 ver.resin.Resin [ERROR: Could not attach to VM] -27338 WatchdogManager 11m 28m 23m 130m 0.00% 0.00% S6U37 web 31 -19187 m.jvmtop.JvmTop 20m 3544m 13m 130m 0.93% 0.47% S6U37 web 20 -16733 artup.Bootstrap 159m 455m 166m 304m 0.12% 0.00% S6U37 web 46 -``` - -
- -
Installation
-Click on the releases tab, download the -most recent tar.gz archive. Extract it, ensure that the `JAVA_HOME` environment variable points to a valid JDK and run `./jvmtop.sh`.-Further information can be found in the [INSTALL file](https://github.com/patric-r/jvmtop/blob/master/INSTALL) - - - -
08/14/2013 jvmtop 0.8.0 released
-Changes: -- improved attach compatibility for all IBM jvms
- - fixed wrong CPU/GC values for IBM J9 jvms
- - in case of unsupported heap size metric retrieval, n/a will be displayed instead of 0m
- - improved argument parsing, support for short-options, added help (pass
--help), see issue #28 (now using the great jopt-simple library)
- - when passing the
--onceoption, terminal will not be cleared anymore (see issue #27)
- - improved shell script for guessing the path if a
JAVA_HOMEenvironment variable is not present (thanks to Markus Kolb)
- -In VM detail mode it shows you the top CPU-consuming threads, beside detailed metrics:
-
-
- -``` - JvmTop 0.8.0 alpha amd64, 4 cpus, Linux 2.6.18-34 - https://github.com/patric-r/jvmtop - - PID 3539: org.apache.catalina.startup.Bootstrap - ARGS: start - VMARGS: -Djava.util.logging.config.file=/home/webserver/apache-tomcat-5.5[...] - VM: Sun Microsystems Inc. Java HotSpot(TM) 64-Bit Server VM 1.6.0_25 - UP: 869:33m #THR: 106 #THRPEAK: 143 #THRCREATED: 128020 USER: webserver - CPU: 4.55% GC: 3.25% HEAP: 137m / 227m NONHEAP: 75m / 304m - TID NAME STATE CPU TOTALCPU BLOCKEDBY - 25 http-8080-Processor13 RUNNABLE 4.55% 1.60% - 128022 RMI TCP Connection(18)-10.101. RUNNABLE 1.82% 0.02% - 36578 http-8080-Processor164 RUNNABLE 0.91% 2.35% - 36453 http-8080-Processor94 RUNNABLE 0.91% 1.52% - 27 http-8080-Processor15 RUNNABLE 0.91% 1.81% - 14 http-8080-Processor2 RUNNABLE 0.91% 3.17% - 128026 JMX server connection timeout TIMED_WAITING 0.00% 0.00% -``` - -Pull requests / bug reports are always welcome.
-
-" -datageartech/datagear,master,1323,316,2020-02-22T04:06:51Z,87397,2,数据可视化分析平台,自由制作任何您想要的数据看板,bi business-intelligence chart data-analysis data-analytics data-visualization echarts,"
-
-
- 数据可视化分析平台 -
-- 自由制作任何您想要的数据看板 -
- -# 简介 - -DataGear是一款开源免费的数据可视化分析平台,自由制作任何您想要的数据看板,支持接入SQL、CSV、Excel、HTTP接口、JSON等多种数据源。 - -## [DataGear 4.7.0 已发布,欢迎官网下载使用!](http://www.datagear.tech) - -## [DataGear专业版 1.0.0 正式发布,欢迎试用!](http://www.datagear.tech/pro/) - -# 特点 - -- 友好接入的数据源 -支持运行时接入任意提供JDBC驱动的数据库,包括MySQL、Oracle、PostgreSQL、SQL Server等关系数据库,以及Elasticsearch、ClickHouse、Hive等大数据引擎 - -- 多样动态的数据集 -
支持创建SQL、CSV、Excel、HTTP接口、JSON数据集,并可设置为动态的参数化数据集,可定义文本框、下拉框、日期框、时间框等类型的数据集参数,灵活筛选满足不同业务需求的数据 - -- 强大丰富的数据图表 -
数据图表可聚合绑定多个不同格式的数据集,轻松定义同比、环比图表,内置折线图、柱状图、饼图、地图、雷达图、漏斗图、散点图、K线图、桑基图等70+开箱即用的图表,并且支持自定义图表配置项,支持编写和上传自定义图表插件 - -- 自由开放的数据看板 -
数据看板采用原生的HTML网页作为模板,支持导入任意HTML网页,支持以可视化方式进行看板设计和编辑,也支持使用JavaScript、CSS等web前端技术自由编辑看板源码,内置丰富的API,可制作图表联动、数据钻取、异步加载、交互表单等个性化的数据看板。 - -# 功能 - - - -# 官网 - -[http://www.datagear.tech](http://www.datagear.tech) - -# 界面 - -数据源管理 - - - -SQL数据集 - - - -看板编辑 - - - -看板展示 - - - -看板展示-图表联动 - - - -看板展示-实时图表 - - - -看板展示-钻取 - - - -看板展示-表单 - - - -看板展示-联动异步加载图表 - - - - -# 技术栈(前后端一体) - -- 后端 -
- Spring Boot、Mybatis、Freemarker、Derby、Jackson、Caffeine、Spring Security - -- 前端 -
- jQuery、Vue3、PrimeVue、CodeMirror、ECharts、DataTables - -# 模块介绍 - -- datagear-analysis -
数据分析底层模块,定义数据集、图表、看板API - -- datagear-connection -
数据库连接支持模块,定义可从指定目录加载JDBC驱动、新建连接的API - -- datagear-dataexchange -
数据导入/导出底层模块,定义导入/导出指定数据源数据的API - -- datagear-management -
系统业务服务模块,定义数据源、数据分析等功能的服务层API - -- datagear-meta -
数据源元信息底层模块,定义解析指定数据源表结构的API - -- datagear-persistence -
数据源数据管理底层模块,定义读取、编辑、查询数据源表数据的API - -- datagear-util -
系统常用工具集模块 - -- datagear-web -
系统web模块,定义web控制器、操作页面 - -- datagear-webapp -
系统web应用模块,定义程序启动类 - -# 依赖 - - Java 8+ - Servlet 3.1+ - -# 编译 - -## 准备单元测试环境 - -1. 安装`MySQL-8.0`数据库,并将`root`用户的密码设置为:`root`(或者修改`test/config/jdbc.properties`配置) - -2. 新建测试数据库,名称取为:`dg_test` - -3. 使用`test/sql/test-mysql.sql`脚本初始化`dg_test`库 - -## 执行编译命令 - - mvn clean package - -或者,也可不准备单元测试环境,直接执行如下编译命令: - - mvn clean package -DskipTests - -编译完成后,将在`datagear-webapp/target/datagear-[version]-packages/`内生成程序包。 - -# 调试 - -1. 将`datagear`以maven工程导入至IDE工具 - -2. 以调试模式运行`datagear-webapp`模块的启动类`org.datagear.webapp.DataGearApplication` - -3. 打开浏览器,输入:`http://localhost:50401` - -## 调试注意 - -在调试开发分支前(`dev-*`),建议先备份DataGear工作目录(`[用户主目录]/.datagear`), -因为开发分支程序启动时会修改DataGear工作目录,可能会导致先前使用的正式版程序、以及后续发布的正式版程序无法正常启动。 - -系统启动时会根据当前版本号自动升级内置数据库(Derby数据库,位于`[用户主目录]/.datagear/derby`目录下),且成功后下次启动时不再自动执行,如果调试时遇到数据库异常,需要查看 - - datagear-management/src/main/resources/org/datagear/management/ddl/datagear.sql - -文件,从中查找需要更新的SQL语句,手动执行。 - -然后,手动执行下面更新系统版本号的SQL语句: - - UPDATE DATAGEAR_VERSION SET VERSION_VALUE='当前版本号' - -例如,对于`4.6.0`版本,应执行: - - UPDATE DATAGEAR_VERSION SET VERSION_VALUE='4.6.0' - -系统自带了一个可用于为内置数据库执行SQL语句的简单工具类`org.datagear.web.util.DerbySqlClient`,可以在IDE中直接运行。注意:运行前需要先停止DataGear程序。 - -# 版权和许可 - -Copyright 2018-2023 datagear.tech - -DataGear is free software: you can redistribute it and/or modify it under the terms of -the GNU Lesser General Public License as published by the Free Software Foundation, -either version 3 of the License, or (at your option) any later version. - -DataGear is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; -without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. -See the GNU Lesser General Public License for more details. - -You should have received a copy of the GNU Lesser General Public License along with DataGear. -If not, see
-
-
-
-
-## CacheCloud是什么?
-
-CacheCloud是一个Redis云管理平台:支持Redis多种架构(Standalone、Sentinel、Cluster)高效管理、有效降低大规模redis运维成本,提升资源管控能力和利用率。平台提供快速搭建/迁移,运维管理,弹性伸缩,统计监控,客户端整合接入等功能。
-
-CacheCloud云平台
- Quickstart - • - Client - • - Docs - • - FAQ - • - Demo - • - Feedback - • - Contact --
Redis 主从/集群部署成本
-
-## 贡献成员
-
-
-
-
-
-![]() -
-
- -[](https://github.com/apache/eventmesh/actions/workflows/ci.yml) -[](https://codecov.io/gh/apache/eventmesh) -[](https://lgtm.com/projects/g/apache/eventmesh/context:java) -[](https://lgtm.com/projects/g/apache/eventmesh/alerts/) - -[](https://www.apache.org/licenses/LICENSE-2.0.html) -[](https://github.com/apache/eventmesh/releases) -[](https://join.slack.com/t/the-asf/shared_invite/zt-1y375qcox-UW1898e4kZE_pqrNsrBM2g) - - -[📦 Documentation](https://eventmesh.apache.org/docs/introduction) | -[📔 Examples](https://github.com/apache/eventmesh/tree/master/eventmesh-examples) | -[⚙️ Roadmap](https://eventmesh.apache.org/docs/roadmap) | -[🌐 简体中文](README.zh-CN.md) -
-
-
-# Apache EventMesh
-
-**Apache EventMesh** is a new generation serverless event middleware for building distributed [event-driven](https://en.wikipedia.org/wiki/Event-driven_architecture) applications.
-
-### EventMesh Architecture
-
-
-
-### EventMesh Dashboard
-
-
-
-## Features
-
-Apache EventMesh has a vast amount of features to help users achieve their goals. Let us share with you some of the key features EventMesh has to offer:
-
-- Built around the [CloudEvents](https://cloudevents.io) specification.
-- Rapidty extendsible interconnector layer [connectors](https://github.com/apache/eventmesh/tree/master/eventmesh-connectors) using [openConnect](https://github.com/apache/eventmesh/tree/master/eventmesh-openconnect) such as the source or sink of Saas, CloudService, and Database etc.
-- Rapidty extendsible storage layer such as [Apache RocketMQ](https://rocketmq.apache.org), [Apache Kafka](https://kafka.apache.org), [Apache Pulsar](https://pulsar.apache.org), [RabbitMQ](https://rabbitmq.com), [Redis](https://redis.io).
-- Rapidty extendsible meta such as [Consul](https://consulproject.org/en/), [Nacos](https://nacos.io), [ETCD](https://etcd.io) and [Zookeeper](https://zookeeper.apache.org/).
-- Guaranteed at-least-once delivery.
-- Deliver events between multiple EventMesh deployments.
-- Event schema management by catalog service.
-- Powerful event orchestration by [Serverless workflow](https://serverlessworkflow.io/) engine.
-- Powerful event filtering and transformation.
-- Rapid, seamless scalability.
-- Easy Function develop and framework integration.
-
-## Roadmap
-
-Please go to the [roadmap](https://eventmesh.apache.org/docs/roadmap) to get the release history and new features of Apache EventMesh.
-
-## Subprojects
-
-- [EventMesh-site](https://github.com/apache/eventmesh-site): Apache official website resources for EventMesh.
-- [EventMesh-workflow](https://github.com/apache/eventmesh-workflow): Serverless workflow runtime for event Orchestration on EventMesh.
-- [EventMesh-dashboard](https://github.com/apache/eventmesh-dashboard): Operation and maintenance console of EventMesh.
-- [EventMesh-catalog](https://github.com/apache/eventmesh-catalog): Catalog service for event schema management using AsyncAPI.
-- [EventMesh-go](https://github.com/apache/eventmesh-go): A go implementation for EventMesh runtime.
-
-## Quick start
-
-This section of the guide will show you the steps to deploy EventMesh from [Local](#run-eventmesh-runtime-locally), [Docker](#run-eventmesh-runtime-in-docker), [K8s](#run-eventmesh-runtime-in-kubernetes).
-
-This section guides the launch of EventMesh according to the default configuration, if you need more detailed EventMesh deployment steps, please visit the [EventMesh official document](https://eventmesh.apache.org/docs/introduction).
-
-### Deployment Event Store
-
-> EventMesh supports [multiple Event Stores](https://eventmesh.apache.org/docs/roadmap#event-store-implementation-status), the default storage mode is `standalone`, and does not rely on other event stores as layers.
-
-### Run EventMesh Runtime locally
-
-#### 1. Download EventMesh
-
-Download the latest version of the Binary Distribution from the [EventMesh Download](https://eventmesh.apache.org/download/) page and extract it:
-
-```shell
-wget https://dlcdn.apache.org/eventmesh/1.10.0/apache-eventmesh-1.10.0-bin.tar.gz
-tar -xvzf apache-eventmesh-1.10.0-bin.tar.gz
-cd apache-eventmesh-1.10.0
-```
-
-#### 2. Run EventMesh
-
-Execute the `start.sh` script to start the EventMesh Runtime server.
-
-```shell
-bash bin/start.sh
-```
-
-View the output log:
-
-```shell
-tail -n 50 -f logs/eventmesh.out
-```
-
-When the log output shows server `state:RUNNING`, it means EventMesh Runtime has started successfully.
-
-You can stop the run with the following command:
-
-```shell
-bash bin/stop.sh
-```
-
-When the script prints `shutdown server ok!`, it means EventMesh Runtime has stopped.
-
-### Run EventMesh Runtime in Docker
-
-#### 1. Pull EventMesh Image
-
-Use the following command line to download the latest version of [EventMesh](https://hub.docker.com/r/apache/eventmesh):
-
-```shell
-sudo docker pull apache/eventmesh:latest
-```
-
-#### 2. Run and Manage EventMesh Container
-
-Use the following command to start the EventMesh container:
-
-```shell
-sudo docker run -d --name eventmesh -p 10000:10000 -p 10105:10105 -p 10205:10205 -p 10106:10106 -t apache/eventmesh:latest
-```
-
-
-Enter the container:
-
-```shell
-sudo docker exec -it eventmesh /bin/bash
-```
-
-view the log:
-
-```shell
-cd logs
-tail -n 50 -f eventmesh.out
-```
-
-### Run EventMesh Runtime in Kubernetes
-
-#### 1. Deploy operator
-
-Run the following commands(To delete a deployment, simply replace `deploy` with `undeploy`):
-
-```shell
-$ cd eventmesh-operator && make deploy
-```
-
-Run `kubectl get pods` 、`kubectl get crd | grep eventmesh-operator.eventmesh`to see the status of the deployed eventmesh-operator.
-
-```shell
-$ kubectl get pods
-NAME READY STATUS RESTARTS AGE
-eventmesh-operator-59c59f4f7b-nmmlm 1/1 Running 0 20s
-
-$ kubectl get crd | grep eventmesh-operator.eventmesh
-connectors.eventmesh-operator.eventmesh 2024-01-10T02:40:27Z
-runtimes.eventmesh-operator.eventmesh 2024-01-10T02:40:27Z
-```
-
-#### 2. Deploy EventMesh Runtime
-
-Execute the following command to deploy runtime, connector-rocketmq (To delete, simply replace `create` with `delete`):
-
-```shell
-$ make create
-```
-
-Run `kubectl get pods` to see if the deployment was successful.
-
-```shell
-NAME READY STATUS RESTARTS AGE
-connector-rocketmq-0 1/1 Running 0 9s
-eventmesh-operator-59c59f4f7b-nmmlm 1/1 Running 0 3m12s
-eventmesh-runtime-0-a-0 1/1 Running 0 15s
-```
-
-## Contributing
-
-Each contributor has played an important role in promoting the robust development of Apache EventMesh. We sincerely appreciate all contributors who have contributed code and documents.
-
-- [Contributing Guideline](https://eventmesh.apache.org/community/contribute/contribute)
-- [Good First Issues](https://github.com/apache/eventmesh/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22)
-
-Here is the [List of Contributors](https://github.com/apache/eventmesh/graphs/contributors), thank you all! :)
-
-
- -
- -[](https://github.com/apache/eventmesh/actions/workflows/ci.yml) -[](https://codecov.io/gh/apache/eventmesh) -[](https://lgtm.com/projects/g/apache/eventmesh/context:java) -[](https://lgtm.com/projects/g/apache/eventmesh/alerts/) - -[](https://www.apache.org/licenses/LICENSE-2.0.html) -[](https://github.com/apache/eventmesh/releases) -[](https://join.slack.com/t/the-asf/shared_invite/zt-1y375qcox-UW1898e4kZE_pqrNsrBM2g) - - -[📦 Documentation](https://eventmesh.apache.org/docs/introduction) | -[📔 Examples](https://github.com/apache/eventmesh/tree/master/eventmesh-examples) | -[⚙️ Roadmap](https://eventmesh.apache.org/docs/roadmap) | -[🌐 简体中文](README.zh-CN.md) -
Not authorized. :///"">Login.
-``` - -Use the following snippet for `/usr/local/etc/nginx/nginx.conf`: -``` -worker_processes 4; - -events { - worker_connections 1024; -} - -http { - upstream kafdrop { - server 127.0.0.1:9000; - keepalive 64; - } - - server { - listen *:8080; - server_name _; - access_log /usr/local/var/log/nginx/nginx.access.log; - error_log /usr/local/var/log/nginx/nginx.error.log; - auth_basic ""Restricted Area""; - auth_basic_user_file /usr/local/etc/nginx/.htpasswd; - - location / { - proxy_pass http://kafdrop; - } - - location /logout { - return 401; - } - - error_page 401 /errors/401.html; - - location /errors { - auth_basic off; - ssi on; - alias /usr/local/opt/nginx/html; - } - } -} -``` - -Run NGINX: -```sh -nginx -``` - -Or reload its configuration if already running: -```sh -nginx -s reload -``` - -To logout, browse to [/logout](http://localhost:8080/logout). - -> **Hey there!** We hope you really like Kafdrop! Please take a moment to [⭐](https://github.com/obsidiandynamics/kafdrop)the repo or [Tweet](https://twitter.com/intent/tweet?url=https%3A%2F%2Fgithub.com%2Fobsidiandynamics%2Fkafdrop&text=Get%20Kafdrop%20%E2%80%94%20a%20web-based%20UI%20for%20viewing%20%23ApacheKafka%20topics%20and%20browsing%20consumers%20) about it. - -# Contributing Guidelines - -See [here](CONTRIBUTING.md). - -## Release workflow - -To cut an official release, these are the steps: - -1. Commit a new version on master that has the `-SNAPSHOT` suffix stripped (see `pom.xml`). Once the commit is merged, the CI will treat it as a release build, and will end up publishing more artifacts than the regular (non-release/snapshot) build. One of those will be a dockerhub push to the specific version and ""latest"" tags. (The regular build doesn't update ""latest""). - -2. You can then edit the release description in GitHub to describe what went into the release. - -3. After the release goes through successfully, you need to prepare the repo for the next version, which requires committing the next snapshot version on master again. So we should increment the minor version and add again the `-SNAPSHOT` suffix. -" -lealone/Lealone,master,2412,516,2013-01-08T13:57:08Z,28140,18,比 MySQL 和 MongoDB 快10倍的 OLTP 关系数据库和文档数据库,acid async database lealone microservice newsql oltp orm rdbms replication sharding sql," -### Lealone 是什么 - -* 是一个高性能的面向 OLTP 场景的关系数据库 - -* 也是一个兼容 MongoDB 的高性能文档数据库 - -* 同时还高度兼容 MySQL 和 PostgreSQL 的协议和 SQL 语法 - - -### Lealone 有哪些特性 - -##### 高亮特性 - -* 并发写性能极其炸裂 - -* 全链路异步化,使用少量线程就能处理大量并发 - -* 可暂停的、渐进式的 SQL 引擎 - -* 基于 SQL 优先级的抢占式调度,慢查询不会长期霸占 CPU - -* 创建 JDBC 连接非常快速,占用资源少,不再需要 JDBC 连接池 - -* 插件化存储引擎架构,内置 AOSE 引擎,采用新颖的异步化 B-Tree - -* 插件化事务引擎架构,事务处理逻辑与存储分离,内置 AOTE 引擎 - -* 支持 Page 级别的行列混合存储,对于有很多字段的表,只读少量字段时能大量节约内存 - -* 支持通过 CREATE SERVICE 语句创建可托管的后端服务 - -* 只需要一个不到 2M 的 jar 包就能运行,不需要安装 - - -##### 普通特性 - -* 支持索引、视图、Join、子查询、触发器、自定义函数、Order By、Group By、聚合 - - -##### 云服务版 - -* 支持高性能分布式事务、支持强一致性复制、支持全局快照隔离 - -* 支持自动化分片 (Sharding),用户不需要关心任何分片的规则,没有热点,能够进行范围查询 - -* 支持混合运行模式,包括4种模式: 嵌入式、Client/Server 模式、复制模式、Sharding 模式 - -* 支持不停机快速手动或自动转换运行模式: Client/Server 模式 -> 复制模式 -> Sharding 模式 - - -### Lealone 文档 - -* [快速入门](https://github.com/lealone/Lealone-Docs/blob/master/应用文档/Lealone数据库快速入门.md) - -* [文档首页](https://github.com/lealone/Lealone-Docs) - - -### Lealone 插件 - -* 兼容 MongoDB、MySQL、PostgreSQL 的插件 - -* [插件首页](https://github.com/lealone-plugins) - - -### Lealone 微服务框架 - -* 非常新颖的基于数据库技术实现的微服务框架,开发分布式微服务应用跟开发单体应用一样简单 - -* [微服务框架文档](https://github.com/lealone/Lealone-Docs/blob/master/%E5%BA%94%E7%94%A8%E6%96%87%E6%A1%A3/%E5%BE%AE%E6%9C%8D%E5%8A%A1%E5%92%8CORM%E6%A1%86%E6%9E%B6%E6%96%87%E6%A1%A3.md#lealone-%E5%BE%AE%E6%9C%8D%E5%8A%A1%E6%A1%86%E6%9E%B6) - - -### Lealone ORM 框架 - -* 超简洁的类型安全的 ORM 框架,不需要配置文件和注解 - -* [ORM 框架文档](https://github.com/lealone/Lealone-Docs/blob/master/%E5%BA%94%E7%94%A8%E6%96%87%E6%A1%A3/%E5%BE%AE%E6%9C%8D%E5%8A%A1%E5%92%8CORM%E6%A1%86%E6%9E%B6%E6%96%87%E6%A1%A3.md#lealone-orm-%E6%A1%86%E6%9E%B6) - - -### Lealone 名字的由来 - -* Lealone 发音 ['li:ləʊn] 这是我新造的英文单词,- 灵感来自于办公桌上那些叫绿萝的室内植物,一直想做个项目以它命名。
- 绿萝的拼音是 lv luo,与 Lealone 英文发音有点相同,
- Lealone 是 lea + lone 的组合,反过来念更有意思哦。:) - - -### Lealone 历史 - -* 2012年从 [H2 数据库 ](http://www.h2database.com/html/main.html)的代码开始 - -* [Lealone 的过去现在将来](https://github.com/codefollower/My-Blog/issues/16) - - -### [Lealone License](https://github.com/lealone/Lealone/blob/master/LICENSE.md) - -" -springdoc/springdoc-openapi,main,3084,462,2019-07-11T23:08:20Z,8721,15,Library for OpenAPI 3 with spring-boot,java json-format kotlin oauth2 openapi openapi-spec openapi-specification openapi3 rest-api spring spring-boot spring-data-rest spring-hateoas spring-security spring-webflux springdoc-openapi swagger swagger-documentation swagger-ui yaml-format," -[](https://ci-cd.springdoc.org:8443/view/springdoc-openapi/job/springdoc-openapi-starter-IC/) -[](https://sonarcloud.io/dashboard?id=springdoc_springdoc-openapi) -[](https://snyk.io/test/github/springdoc/springdoc-openapi.git) -[](https://stackoverflow.com/questions/tagged/springdoc?tab=Votes) - -IMPORTANT: ``springdoc-openapi v1.8.0`` is the latest Open Source release supporting Spring Boot 2.x and 1.x. - -An extended support for [*springdoc-openapi v1*](https://springdoc.org/v1) -project is now available for organizations that need support beyond 2023. - -For more details, feel free to reach out: [sales@springdoc.org](mailto:sales@springdoc.org) - -``springdoc-openapi`` is on [Open Collective](https://opencollective.com/springdoc). If you ❤️ this project consider becoming -a [sponsor](https://github.com/sponsors/springdoc). - -This project is sponsored by - - - -# Table of Contents - -- [Full documentation](#full-documentation) -- [**Introduction**](#introduction) -- [**Getting Started**](#getting-started) - - [Library for springdoc-openapi integration with spring-boot and swagger-ui](#library-for-springdoc-openapi-integration-with-spring-boot-and-swagger-ui) - - [Spring-boot with OpenAPI Demo applications.](#spring-boot-with-openapi-demo-applications) - - [Source Code for Demo Applications.](#source-code-for-demo-applications) - - [Demo Spring Boot 2 Web MVC with OpenAPI 3.](#demo-spring-boot-2-web-mvc-with-openapi-3) - - [Demo Spring Boot 2 WebFlux with OpenAPI 3.](#demo-spring-boot-2-webflux-with-openapi-3) - - [Demo Spring Boot 2 WebFlux with Functional endpoints OpenAPI 3.](#demo-spring-boot-2-webflux-with-functional-endpoints-openapi-3) - - [Demo Spring Boot 2 and Spring Hateoas with OpenAPI 3.](#demo-spring-boot-2-and-spring-hateoas-with-openapi-3) - - [Integration of the library in a Spring Boot 3.x project without the swagger-ui:](#integration-of-the-library-in-a-spring-boot-3x-project-without-the-swagger-ui) - - [Error Handling for REST using @ControllerAdvice](#error-handling-for-rest-using-controlleradvice) - - [Adding API Information and Security documentation](#adding-api-information-and-security-documentation) - - [spring-webflux support with Annotated Controllers](#spring-webflux-support-with-annotated-controllers) -- [Acknowledgements](#acknowledgements) - - [Contributors](#contributors) - - [Additional Support](#additional-support) - -# [Full documentation](https://springdoc.org/) - -# **Introduction** - -The springdoc-openapi Java library helps automating the generation of API documentation -using Spring Boot projects. -springdoc-openapi works by examining an application at runtime to infer API semantics -based on Spring configurations, class structure and various annotations. - -The library automatically generates documentation in JSON/YAML and HTML formatted pages. -The generated documentation can be complemented using `swagger-api` annotations. - -This library supports: - -* OpenAPI 3 -* Spring-boot v3 (Java 17 & Jakarta EE 9) -* JSR-303, specifically for @NotNull, @Min, @Max, and @Size. -* Swagger-ui -* OAuth 2 -* GraalVM native images - -The following video introduces the Library: - -* [https://youtu.be/utRxyPfFlDw](https://youtu.be/utRxyPfFlDw) - -For *spring-boot v3* support, make sure you use [springdoc-openapi v2](https://springdoc.org/) - -This is a community-based project, not maintained by the Spring Framework Contributors (Pivotal) - -# **Getting Started** - -## Library for springdoc-openapi integration with spring-boot and swagger-ui - -* Automatically deploys swagger-ui to a Spring Boot 3.x application -* Documentation will be available in HTML format, using the - official [swagger-ui jars](https://github.com/swagger-api/swagger-ui.git). -* The Swagger UI page should then be available at http://server: - port/context-path/swagger-ui.html and the OpenAPI description will be available at the - following url for json format: http://server:port/context-path/v3/api-docs - * `server`: The server name or IP - * `port`: The server port - * `context-path`: The context path of the application -* Documentation can be available in yaml format as well, on the following path: - `/v3/api-docs.yaml` -* Add the `springdoc-openapi-ui` library to the list of your project dependencies (No - additional configuration is needed): - -```xml -
-
-
-
-
-
-
-
-
-
-“大数据学习路线”中我自己看过的视频、文档资料可以直接在公众号获取云盘链接 - -## 更新中。。。 -#### 牛客网面经 -#### 大数据面试题 - -### 《[大数据面试题 V4.0](https://mp.weixin.qq.com/s/NV90886HAQqBRB1hPNiIPQ)》已出,公众号回复:大数据面试题 - -
-
-
-
- - -## 知识星球 - -知识星球内容包括**学习路线**、**学习资料**(根据编程语言(Java、Python、Java+Scala)分了三大版本)、项目(**50+个大数据项目**)、面试题(**700+道真实大数据面试题**、Java基础、计算机网络、Redis)、**1000+篇大数据真实面经**、600+篇Java后端真实面经(已按公司分类)、自己整理的视频学习笔记 - -**[知识星球资料介绍](https://www.yuque.com/vxo919/gyyog3/ohvyc2e38pprcxkn?singleDoc=)** - -
-
-
-
- - -概述 ---- -[大数据简介](https://github.com/Dr11ft/BigDataGuide/blob/master/Docs/%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%AE%80%E4%BB%8B.md) - -[大数据相关岗位介绍](https://github.com/Dr11ft/BigDataGuide/blob/master/Docs/%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%9B%B8%E5%85%B3%E5%B2%97%E4%BD%8D%E4%BB%8B%E7%BB%8D.md) - -大数据学习路线 ---- -学习路线中的视频、文档资料可以关注公众号:旧时光大数据,回复相应关键字获取云盘链接 - -[大数据学习路线(包含自己看过的视频链接)](https://github.com/Dr11ft/BigDataGuide/blob/master/Docs/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%AD%A6%E4%B9%A0%E8%B7%AF%E7%BA%BF.md) - -编程语言 ---- -编程语言部分建议先JavaSE,Spark和Flink之前学习Scala,如果时间紧迫,就找个Java版的Spark或Flink教程,Python看个人或工作,不过有Java基础,Python会快很多(别问我怎么学,问就是使劲拼命学 [ 吃瓜.jpg ]) -### 一、JavaSE(二选一) -[刘意2019版](https://www.bilibili.com/video/BV1gb411F76B?from=search&seid=16116797084076868427) - -[尚硅谷宋红康版](https://www.bilibili.com/video/BV1Kb411W75N?from=search&seid=9321658006825735818) - -### 二、Scala(二选一) -如果时间短,建议直接看配套Spark的那种三五天的,可以���速了解 - -[韩顺平老师版](https://www.bilibili.com/video/BV1Mp4y1e7B5?from=search&seid=5450215228532207134) - -[清华硕士武晟然老师版](https://www.bilibili.com/video/BV1Mp4y1e7B5?from=search&seid=5450215228532207134) - -### 三、Python -推荐黑马的Python视频,通俗易懂,而且文档比较齐全,有Java基础再看Python的话,上手很快 - -[黑马Python版视频](https://www.bilibili.com/video/BV1C4411A7ej?from=search&seid=11669436417044703145) - -[Python文档and笔记](https://github.com/MoRan1607/BigDataGuide/blob/master/Python/Python%E6%96%87%E6%A1%A3.md) - -Linux ---- -[完全分布式集群搭建文档](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/%E5%88%86%E5%B8%83%E5%BC%8F%E9%9B%86%E7%BE%A4%E6%90%AD%E5%BB%BA.md) - -关于VM、远程登录工具的安装暂时可以参考我的博客,找到相应步骤进行操作即可 - -[集群搭建](https://blog.csdn.net/qq_41544550/category_9458240.html) - -大数据框架组件 ---- -### 一、Hadoop - - 1. [Hadoop——分布式文件管理系统HDFS](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/HDFS.md) - 2. [Hadoop——HDFS的Shell操作](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/HDFS%E7%9A%84Shell%E6%93%8D%E4%BD%9C.md) - 3. [Hadoop——HDFS的Java API操作](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/HDFS%E7%9A%84Java%20API%E6%93%8D%E4%BD%9C.md) - 4. [Hadoop——分布式计算框架MapReduce](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/MapReduce.md) - 5. [Hadoop——MapReduce案例](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/MapReduce%E6%A1%88%E4%BE%8B.md) - 6. [Hadoop——资源调度器YARN](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/YARN.md) - 7. [Hadoop——Hadoop数据压缩](https://github.com/Dr11ft/BigDataGuide/blob/master/Hadoop/Hadoop%E6%95%B0%E6%8D%AE%E5%8E%8B%E7%BC%A9.md) - -### 二、Zookeeper - 1.[Zookeeper——Zookeeper概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E4%B8%80%EF%BC%89.md) - 2.[Zookeeper——Zookeeper单机和分布式安装](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E4%BA%8C%EF%BC%89.md) - 3.[Zookeeper——Zookeeper客户端命令](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E4%B8%89%EF%BC%89.md) - 4.[Zookeeper——Zookeeper内部原理](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E5%9B%9B%EF%BC%89.md) - 5.[Zookeeper——Zookeeper实战](https://github.com/Dr11ft/BigDataGuide/blob/master/Zookeeper/Zookeeper%EF%BC%88%E4%BA%94%EF%BC%89.md) - -### 三、Hive - 1.[Hive——Hive概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/1%E3%80%81Hive%E6%A6%82%E8%BF%B0.md) - 2.[Hive——Hive数据类型](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/2%E3%80%81Hive%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B.md) - 3.[Hive——Hive DDL数据定义](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/3%E3%80%81Hive%20DDL%E6%95%B0%E6%8D%AE.md) - 4.[Hive——Hive DML数据操作](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/4%E3%80%81Hive%20DML%E6%95%B0%E6%8D%AE%E6%93%8D%E4%BD%9C.md) - 5.[Hive——Hive查询](https://github.com/Dr11ft/BigDataGuide/blob/master/Hive/5%E3%80%81Hive%E6%9F%A5%E8%AF%A2.md) - 6.[Hive——Hive函数](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/6%E3%80%81Hive%E5%87%BD%E6%95%B0.md) - 7.[Hive——Hive压缩和存储](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/7%E3%80%81Hive%E5%8E%8B%E7%BC%A9%E5%92%8C%E5%AD%98%E5%82%A8.md) - 8.[Hive——Hive实战:统计影音视频网站的常规指标](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/8%E3%80%81Hive%E5%AE%9E%E6%88%98%EF%BC%9A%E7%BB%9F%E8%AE%A1%E5%BD%B1%E9%9F%B3%E8%A7%86%E9%A2%91%E7%BD%91%E7%AB%99%E7%9A%84%E5%B8%B8%E8%A7%84%E6%8C%87%E6%A0%87.md) - 9.[Hive——Hive分区表和分桶表](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/9%E3%80%81%E5%88%86%E5%8C%BA%E8%A1%A8%E5%92%8C%E5%88%86%E6%A1%B6%E8%A1%A8.md) - 10.[Hive——Hive调优](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/10%E3%80%81Hive%E4%BC%81%E4%B8%9A%E7%BA%A7%E8%B0%83%E4%BC%98.md) - -### 四、Flume - 1.[Flume——Flume概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Flume/1%E3%80%81Flume%E6%A6%82%E8%BF%B0.md) - 2.[Flume——Flume实践操作](https://github.com/Dr11ft/BigDataGuide/blob/master/Flume/2%E3%80%81Flume%E5%AE%9E%E8%B7%B5%E6%93%8D%E4%BD%9C.md) - 3.[Flume——Flume案例](https://github.com/Dr11ft/BigDataGuide/blob/master/Flume/3%E3%80%81Flume%E6%A1%88%E4%BE%8B.md) - -### 五、Kafka - 1.[Kafka——Kafka概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Kafka/1%E3%80%81Kafka%E6%A6%82%E8%BF%B0.md) - 2.[Kafka——Kafka深入解析](https://github.com/Dr11ft/BigDataGuide/blob/master/Kafka/2%E3%80%81Kafka%E6%B7%B1%E5%85%A5%E8%A7%A3%E6%9E%90.md) - 3.[Kafka——Kafka API操作实践](https://github.com/Dr11ft/BigDataGuide/blob/master/Kafka/3%E3%80%81Kafka%20API%E6%93%8D%E4%BD%9C%E5%AE%9E%E8%B7%B5.md) - 3.[Kafka——Kafka对接Flume实践](https://github.com/Dr11ft/BigDataGuide/blob/master/Kafka/4%E3%80%81Flume%E5%AF%B9%E6%8E%A5Kafka%E5%AE%9E%E8%B7%B5%E6%93%8D%E4%BD%9C.md) - -### 六、HBase - 1.[HBase——HBase概述](https://github.com/Dr11ft/BigDataGuide/blob/master/HBase/1%E3%80%81HBase%E6%A6%82%E8%BF%B0.md) - 2.[HBase——HBase数据结构](https://github.com/Dr11ft/BigDataGuide/blob/master/HBase/2%E3%80%81HBase%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84.md) - 3.[HBase——HBase Shell操作](https://github.com/Dr11ft/BigDataGuide/blob/master/HBase/3%E3%80%81HBase%20Shell%E6%93%8D%E4%BD%9C.md) - 4.[HBase——HBase API实践操作](https://github.com/Dr11ft/BigDataGuide/blob/master/HBase/4%E3%80%81HBase%20API%E5%AE%9E%E8%B7%B5%E6%93%8D%E4%BD%9C.md) - -### 七、Spark -#### Spark基础 - 1.[Spark基础——Spark的诞生](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/1%E3%80%81Spark%E7%9A%84%E8%AF%9E%E7%94%9F.md) - 2.[Spark基础——Spark概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/2%E3%80%81Spark%E6%A6%82%E8%BF%B0.md) - 3.[Spark基础——Spark运行模式](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/3%E3%80%81Spark%E8%BF%90%E8%A1%8C%E6%A8%A1%E5%BC%8F.md) - 4.[Spark基础——案例实践](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/2%E3%80%81Spark%E6%A6%82%E8%BF%B0.md) -#### Spark Core - 1.[Spark Core——RDD概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/1%E3%80%81RDD%E6%A6%82%E8%BF%B0.md) - 2.[Spark Core——RDD编程(一)](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/2%E3%80%81RDD%E7%BC%96%E7%A8%8B%EF%BC%88%E4%B8%80%EF%BC%89.md) - 3.[Spark Core——RDD编程(二)](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/3%E3%80%81RDD%E7%BC%96%E7%A8%8B%EF%BC%882%EF%BC%89.md) - 4.[Spark Core——键值对RDD数据分区器](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/4%E3%80%81%E9%94%AE%E5%80%BC%E5%AF%B9RDD%E6%95%B0%E6%8D%AE%E5%88%86%E5%8C%BA%E5%99%A8.md) - 5.[Spark Core——数据读取与保存](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Core/5%E3%80%81%E6%95%B0%E6%8D%AE%E8%AF%BB%E5%8F%96%E4%B8%8E%E4%BF%9D%E5%AD%98.md) -#### Spark SQL - 1.[Spark SQL——Spaek SQL概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20SQL/1%E3%80%81Spark%20SQL%E6%A6%82%E8%BF%B0.md) - 2.[Spark SQL——Spaek SQL编程](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20SQL/2%E3%80%81Spark%20SQL%E7%BC%96%E7%A8%8B.md) - 3.[Spark SQL——Spaek SQL数据的加载与保存](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20SQL/3%E3%80%81Spark%20SQL%E6%95%B0%E6%8D%AE%E7%9A%84%E5%8A%A0%E8%BD%BD%E4%B8%8E%E4%BF%9D%E5%AD%98.md) - 4.[Spark SQL——Spaek SQL实战](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20SQL/4%E3%80%81Spark%20SQL%E5%AE%9E%E6%88%98.md) -#### Spark Streaming - 1.[Spark Streaming——Spark Streaming概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Streaming/1%E3%80%81Spark%20Streaming%E6%A6%82%E8%BF%B0.md) - 2.[Spark Streaming——Dstream基础](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Streaming/2%E3%80%81Dstream%E5%9F%BA%E7%A1%80.md) - 3.[Spark Streaming——Dstream的转换&输出](https://github.com/Dr11ft/BigDataGuide/blob/master/Spark/Spark%20Streaming/3%E3%80%81Dstream%E7%9A%84%E8%BD%AC%E6%8D%A2%26%E8%BE%93%E5%87%BA.md) - -### 八、Flink - 1.[Flink——Flink核心概述](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/1%E3%80%81Flink%E6%A6%82%E8%BF%B0.md) - 2.[Flink——Flink部署](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/2%E3%80%81Flink%E9%83%A8%E7%BD%B2.md) - 3.[Flink——Flink运行架构](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/3、Flink运行架构.md) - 4.[Flink——Flink流处理API](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/4%E3%80%81Flink%E6%B5%81%E5%A4%84%E7%90%86API.md) - 5.[Flink——Flink中的Window](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/5%E3%80%81Flink%E4%B8%AD%E7%9A%84Window.md) - 6.[Flink——时间语义与Wartermark](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/6、时间语义与Wartermark.md) - 7.[Flink——ProcessFunction API(底层API)](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/7%E3%80%81ProcessFunction%20API%EF%BC%88%E5%BA%95%E5%B1%82API%EF%BC%89.md) - 8.[Flink——状态编程和容错机制](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/8%E3%80%81%E7%8A%B6%E6%80%81%E7%BC%96%E7%A8%8B%E5%92%8C%E5%AE%B9%E9%94%99%E6%9C%BA%E5%88%B6.md) - 9.[Flink——Table API 与SQL](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/9%E3%80%81Table%20API%20%E4%B8%8ESQL.md) - 10.[Flink——Flink CEP](https://github.com/Dr11ft/BigDataGuide/blob/master/Flink/10%E3%80%81Flink%20CEP.md) - -数据仓库 ---- - [数据仓库总结](https://zhuanlan.zhihu.com/p/371365562) - -大数据项目 ---- - **基本上选择三到四个即可,B站直接搜索项目名字,都有视频** - **详细说明公众号(旧时光大数据)回复“大数据项目”即可** - -读书笔记 ---- -#### 《阿里大数据之路》读书笔记 -[第一章 总述](https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/%E3%80%8A%E9%98%BF%E9%87%8C%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B9%8B%E8%B7%AF%E3%80%8B%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0%EF%BC%9A%E7%AC%AC%E4%B8%80%E7%AB%A0%20%E6%80%BB%E8%BF%B0.md) - -[第二章 日志采集](https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/%E7%AC%AC%E4%BA%8C%E7%AB%A0%EF%BC%9A%E6%97%A5%E5%BF%97%E9%87%87%E9%9B%86.pdf) - -[第三章 数据同步](https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/PDF/%E7%AC%AC%E4%B8%89%E7%AB%A0%EF%BC%9A%E6%95%B0%E6%8D%AE%E5%90%8C%E6%AD%A5.pdf) - -[第四章 离线数据开发](https://github.com/MoRan1607/BigDataGuide/blob/master/Docs/PDF/%E7%AC%AC%E5%9B%9B%E7%AB%A0%EF%BC%9A%E7%A6%BB%E7%BA%BF%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91.pdf) - -面试题 ---- -> #### 陆续更新中。。。。。全量面试题(700+道牛客网面经原题)见知识星球 -### [大数据面试题 V1.0](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E8%AF%95%E9%A2%98%20V1.0.md) -### [大数据面试题 V3.0](https://mp.weixin.qq.com/s/hMcuDEkzH49rfSmGWy_GRg) -### [大数据面试题 V4.0](https://mp.weixin.qq.com/s/NV90886HAQqBRB1hPNiIPQ) -#### 一、Hadoop -##### 1、Hadoop基础 -[介绍下Hadoop](https://blog.csdn.net/qq_41544550/article/details/123031348) -[Hadoop小文件处理问题](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Hadoop%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93/Hadoop/Hadoop%E5%B0%8F%E6%96%87%E4%BB%B6%E5%A4%84%E7%90%86%E9%97%AE%E9%A2%98.md) -[Hadoop中的几个进程和作用](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop%E4%B8%AD%E7%9A%84%E5%87%A0%E4%B8%AA%E8%BF%9B%E7%A8%8B%E5%92%8C%E4%BD%9C%E7%94%A8.pdf) -[Hadoop的mapper和reducer的个数如何确定?reducer的个数依据是什么?](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop%E7%9A%84mapper%E5%92%8Creducer%E7%9A%84%E4%B8%AA%E6%95%B0%E5%A6%82%E4%BD%95%E7%A1%AE%E5%AE%9A%EF%BC%9Freducer%E7%9A%84%E4%B8%AA%E6%95%B0%E4%BE%9D%E6%8D%AE%E6%98%AF%E4%BB%80%E4%B9%88%EF%BC%9F.md) - -##### 2、HDFS -[HDFS读写流程](https://blog.csdn.net/qq_41544550/article/details/103113335) -[HDFS的block为什么是128M?增大或减小有什么影响?](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/HDFS%E7%9A%84block%E4%B8%BA%E4%BB%80%E4%B9%88%E6%98%AF128M%EF%BC%9F%E5%A2%9E%E5%A4%A7%E6%88%96%E5%87%8F%E5%B0%8F%E6%9C%89%E4%BB%80%E4%B9%88%E5%BD%B1%E5%93%8D%EF%BC%9F/HDFS%E7%9A%84block%E4%B8%BA%E4%BB%80%E4%B9%88%E6%98%AF128M%EF%BC%9F%E5%A2%9E%E5%A4%A7%E6%88%96%E5%87%8F%E5%B0%8F%E6%9C%89%E4%BB%80%E4%B9%88%E5%BD%B1%E5%93%8D.md) - -##### 3、MapReduce -[介绍下MapReduce](https://blog.csdn.net/qq_41544550/article/details/123674103) -[MapReduce优缺点](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Hadoop%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93/Hadoop/MapReduce%E4%BC%98%E7%BC%BA%E7%82%B9.md) -[MapReduce工作原理(流程)](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/MapReduce%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%EF%BC%88%E6%B5%81%E7%A8%8B%EF%BC%89.pdf) -[MapReduce压缩方式](https://github.com/MoRan1607/BigDataGuide/blob/master/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/Hadoop/%E9%9D%A2%E8%AF%95%E9%A2%98/MapReduce%E5%8E%8B%E7%BC%A9%E6%96%B9%E5%BC%8F.pdf) - -##### 4、YARN -[介绍下YARN](https://blog.csdn.net/qq_41544550/article/details/123826496?spm=1001.2014.3001.5501) - -#### 二、Zookeeper -[介绍下Zookeeper是什么?](https://blog.csdn.net/qq_41544550/article/details/123148663) -[Zookeeper有什么作用?优缺点?有什么应用场景?](https://blog.csdn.net/qq_41544550/article/details/123148688) -[Zookeeper架构](https://github.com/MoRan1607/BigDataGuide/blob/master/Zookeeper/%E9%9D%A2%E8%AF%95%E9%A2%98/Zookeeper%E6%9E%B6%E6%9E%84.pdf) - -#### 三、Hive -[说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么?](https://blog.csdn.net/qq_41544550/article/details/123333839) -[Hive的用户自定义函数实现步骤与流程](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/%E9%9D%A2%E8%AF%95%E9%A2%98/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B.md) -[Hive分区和分桶的区别](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/%E9%9D%A2%E8%AF%95%E9%A2%98/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B/Hive%E5%88%86%E5%8C%BA%E5%92%8C%E5%88%86%E6%A1%B6%E7%9A%84%E5%8C%BA%E5%88%AB.md) -[Hive的cluster by 、sort by、distribute by 、order by 区别?](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/%E9%9D%A2%E8%AF%95%E9%A2%98/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B/Hive%E7%9A%84cluster%20by%20%E3%80%81sort%20by%E3%80%81distribute%20by%20%E3%80%81order%20by%20%E5%8C%BA%E5%88%AB%EF%BC%9F.pdf) -[Hive count(distinct)有几个reduce,海量数据会有什么问题?](https://github.com/MoRan1607/BigDataGuide/blob/master/Hive/%E9%9D%A2%E8%AF%95%E9%A2%98/Hive%E7%9A%84%E7%94%A8%E6%88%B7%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0%E5%AE%9E%E7%8E%B0%E6%AD%A5%E9%AA%A4%E4%B8%8E%E6%B5%81%E7%A8%8B/Hive%20count(distinct)%E6%9C%89%E5%87%A0%E4%B8%AAreduce%EF%BC%8C%E6%B5%B7%E9%87%8F%E6%95%B0%E6%8D%AE%E4%BC%9A%E6%9C%89%E4%BB%80%E4%B9%88%E9%97%AE%E9%A2%98%EF%BC%9F.pdf) - -#### 四、Flume -[介绍下Flume](https://blog.csdn.net/qq_41544550/article/details/123451528?spm=1001.2014.3001.5501) -[Flume结构](https://github.com/MoRan1607/BigDataGuide/blob/master/Flume/%E9%9D%A2%E8%AF%95%E9%A2%98/Flume%E6%9E%B6%E6%9E%84/Flume%E6%9E%B6%E6%9E%84.md) - -#### 五、Kafka -[介绍下Kafka,Kafka的作用?Kafka的组件?适用场景?](https://blog.csdn.net/qq_41544550/article/details/123534948) -[Kafka实现高吞吐的原理?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E5%AE%9E%E7%8E%B0%E9%AB%98%E5%90%9E%E5%90%90%E7%9A%84%E5%8E%9F%E7%90%86.pdf) -[Kafka的一条message中包含了哪些信息?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E7%9A%84%E4%B8%80%E6%9D%A1message%E4%B8%AD%E5%8C%85%E5%90%AB%E4%BA%86%E5%93%AA%E4%BA%9B%E4%BF%A1%E6%81%AF%EF%BC%9F.pdf) -[Kafka的消费者和消费者组有什么区别?为什么需要消费者组?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E7%9A%84%E6%B6%88%E8%B4%B9%E8%80%85%E5%92%8C%E6%B6%88%E8%B4%B9%E8%80%85%E7%BB%84%E6%9C%89%E4%BB%80%E4%B9%88%E5%8C%BA%E5%88%AB%EF%BC%9F%E4%B8%BA%E4%BB%80%E4%B9%88%E9%9C%80%E8%A6%81%E6%B6%88%E8%B4%B9%E8%80%85%E7%BB%84%EF%BC%9F.pdf) -[Kafka的ISR、OSR和ACK介绍,ACK分别有几种值?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E7%9A%84ISR%E3%80%81OSR%E5%92%8CACK%E4%BB%8B%E7%BB%8D%EF%BC%8CACK%E5%88%86%E5%88%AB%E6%9C%89%E5%87%A0%E7%A7%8D%E5%80%BC%EF%BC%9F.pdf) -[Kafka怎么保证数据不丢失,不重复?](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E6%80%8E%E4%B9%88%E4%BF%9D%E8%AF%81%E6%95%B0%E6%8D%AE%E4%B8%8D%E4%B8%A2%E5%A4%B1%EF%BC%8C%E4%B8%8D%E9%87%8D%E5%A4%8D%EF%BC%9F.pdf) -[Kafka的单播和多播](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/Kafka%E7%9A%84%E5%8D%95%E6%92%AD%E5%92%8C%E5%A4%9A%E6%92%AD.pdf) -[说下Kafka的ISR机制](https://github.com/MoRan1607/BigDataGuide/blob/master/Kafka/%E9%9D%A2%E8%AF%95%E9%A2%98/%E8%AF%B4%E4%B8%8BKafka%E7%9A%84ISR%E6%9C%BA%E5%88%B6.pdf) - -#### 六、HBase -[介绍下HBase架构](https://blog.csdn.net/qq_41544550/article/details/123583361) -[HBase为什么查询快](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E4%B8%BA%E4%BB%80%E4%B9%88%E6%9F%A5%E8%AF%A2%E5%BF%AB.pdf) -[HBase的大合并、小合并是什么?](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84%E5%A4%A7%E5%90%88%E5%B9%B6%E3%80%81%E5%B0%8F%E5%90%88%E5%B9%B6%E6%98%AF%E4%BB%80%E4%B9%88%EF%BC%9F.pdf) -[HBase的rowkey设计原则](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84rowkey%E8%AE%BE%E8%AE%A1%E5%8E%9F%E5%88%99.pdf) -[HBase的一个region由哪些东西组成?](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84%E4%B8%80%E4%B8%AAregion%E7%94%B1%E5%93%AA%E4%BA%9B%E4%B8%9C%E8%A5%BF%E7%BB%84%E6%88%90%EF%BC%9F.pdf) -[HBase读写数据流程](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E8%AF%BB%E5%86%99%E6%95%B0%E6%8D%AE%E6%B5%81%E7%A8%8B.pdf) -[HBase的RegionServer宕机以后怎么恢复的?](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84RegionServer%E5%AE%95%E6%9C%BA%E4%BB%A5%E5%90%8E%E6%80%8E%E4%B9%88%E6%81%A2%E5%A4%8D%E7%9A%84%EF%BC%9F.pdf) -[HBase的读写缓存](https://github.com/MoRan1607/BigDataGuide/blob/master/HBase/%E9%9D%A2%E8%AF%95%E9%A2%98/HBase%E7%9A%84%E8%AF%BB%E5%86%99%E7%BC%93%E5%AD%98.pdf) - -#### 七、Spark - -[说下对RDD的理解?RDD特点、算子?](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Spark%E9%9D%A2%E8%AF%95%E9%A2%98%E6%95%B4%E7%90%86/Spark/Pics/%E8%AF%B4%E4%B8%8B%E5%AF%B9RDD%E7%9A%84%E7%90%86%E8%A7%A3%EF%BC%9FRDD%E7%89%B9%E7%82%B9%E3%80%81%E7%AE%97%E5%AD%90/%E8%AF%B4%E4%B8%8B%E5%AF%B9RDD%E7%9A%84%E7%90%86%E8%A7%A3%EF%BC%9FRDD%E7%89%B9%E7%82%B9%E3%80%81%E7%AE%97%E5%AD%90.md) -[Spark小文件问题](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Spark%E9%9D%A2%E8%AF%95%E9%A2%98%E6%95%B4%E7%90%86/Spark/Spark%E5%B0%8F%E6%96%87%E4%BB%B6%E9%97%AE%E9%A2%98/Spark%E5%B0%8F%E6%96%87%E4%BB%B6%E9%97%AE%E9%A2%98.md) -[Spark的内存模型](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B.md) -[Spark的Job、Stage、Task分别介绍下,如何划分?](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/Spark%E7%9A%84Job%E3%80%81Stage%E3%80%81Task%E5%88%86%E5%88%AB%E4%BB%8B%E7%BB%8D%E4%B8%8B%EF%BC%8C%E5%A6%82%E4%BD%95%E5%88%92%E5%88%86.md) -[Spark的RDD、DataFrame、DataSet、DataStream区别?](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/Spark%E7%9A%84RDD%E3%80%81DataFrame%E3%80%81DataSet%E3%80%81DataStream%E5%8C%BA%E5%88%AB%EF%BC%9F.pdf) -[RDD的容错](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/RDD%E7%9A%84%E5%AE%B9%E9%94%99.pdf) -[说下Spark中的Transform和Action,为什么Spark要把操作分为Transform和Action?](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/%E8%AF%B4%E4%B8%8BSpark%E4%B8%AD%E7%9A%84Transform%E5%92%8CAction%EF%BC%8C%E4%B8%BA%E4%BB%80%E4%B9%88Spark%E8%A6%81%E6%8A%8A%E6%93%8D%E4%BD%9C%E5%88%86%E4%B8%BATransform%E5%92%8CAction%EF%BC%9F.pdf) -[Spark的任务执行流程](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/Spark%E9%9D%A2%E8%AF%95%E9%A2%98%E6%95%B4%E7%90%86/Spark%E7%9A%84%E4%BB%BB%E5%8A%A1%E6%89%A7%E8%A1%8C%E6%B5%81%E7%A8%8B.pdf) -[Spark的架构](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E6%9E%B6%E6%9E%84.pdf) - - -#### 八、Flink - -[介绍下Flink](https://github.com/MoRan1607/BigDataGuide/blob/master/Flink/%E4%BB%8B%E7%BB%8D%E4%B8%8BFlink) -[Flink架构](https://github.com/MoRan1607/BigDataGuide/blob/master/Flink/%E9%9D%A2%E8%AF%95%E9%A2%98/Flink%E6%9E%B6%E6%9E%84.pdf) - -#### 九、数仓面试题 -[数据仓库和数据中台区别](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E6%95%B0%E4%BB%93/%E6%95%B0%E6%8D%AE%E4%BB%93%E5%BA%93%E5%92%8C%E6%95%B0%E6%8D%AE%E4%B8%AD%E5%8F%B0%E5%8C%BA%E5%88%AB.pdf) - -#### 十、综合面试题 -[Spark和MapReduce之间的区别?各自优缺点?](https://github.com/MoRan1607/BigDataGuide/blob/master/Spark/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E7%9A%84%E5%86%85%E5%AD%98%E6%A8%A1%E5%9E%8B/Spark%E5%92%8CMapReduce%E4%B9%8B%E9%97%B4%E7%9A%84%E5%8C%BA%E5%88%AB%EF%BC%9F%E5%90%84%E8%87%AA%E4%BC%98%E7%BC%BA%E7%82%B9%EF%BC%9F.pdf) -[Spark和Flink的区别](https://github.com/MoRan1607/BigDataGuide/blob/master/Flink/%E9%9D%A2%E8%AF%95%E9%A2%98/Spark%E5%92%8CFlink%E7%9A%84%E5%8C%BA%E5%88%AB.pdf) - - -牛客网面经 ---- -### 大数据面经 -#### 阿里面经 -[阿里巴巴 二面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4%20%E4%BA%8C%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) -[阿里云大数据平台三面+HR面【已OC】](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C%E4%BA%91%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%B9%B3%E5%8F%B0%E4%B8%89%E9%9D%A2%2BHR%E9%9D%A2%E3%80%90%E5%B7%B2OC%E3%80%91.pdf) -[阿里-数据研发-1面2面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-%E6%95%B0%E6%8D%AE%E7%A0%94%E5%8F%91-1%E9%9D%A22%E9%9D%A2.pdf) -[4.23阿里数开一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/4.23%E9%98%BF%E9%87%8C%E6%95%B0%E5%BC%80%E4%B8%80%E9%9D%A2.pdf) -[分享一个大数据的面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E5%88%86%E4%BA%AB%E4%B8%80%E4%B8%AA%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%9A%84%E9%9D%A2%E7%BB%8F.pdf) -[十余家公司大数据开发面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E5%8D%81%E4%BD%99%E5%AE%B6%E5%85%AC%E5%8F%B8%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E9%9D%A2%E7%BB%8F.pdf) -[大数据面经好少啊,我来写点](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F%E5%A5%BD%E5%B0%91%E5%95%8A%EF%BC%8C%E6%88%91%E6%9D%A5%E5%86%99%E7%82%B9.pdf) -[提前批面经(Java_大数据)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E6%8F%90%E5%89%8D%E6%89%B9%E9%9D%A2%E7%BB%8F(Java_%E5%A4%A7%E6%95%B0%E6%8D%AE).pdf) -[阿里-数据技术与产品部(两次简历面)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E9%98%BF%E9%87%8C-%E6%95%B0%E6%8D%AE%E6%8A%80%E6%9C%AF%E4%B8%8E%E4%BA%A7%E5%93%81%E9%83%A8%EF%BC%88%E4%B8%A4%E6%AC%A1%E7%AE%80%E5%8E%86%E9%9D%A2%EF%BC%89.pdf) -[阿里云一二三面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E9%98%BF%E9%87%8C%E4%BA%91%E4%B8%80%E4%BA%8C%E4%B8%89%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) -[阿里巴巴淘系大数据研发工程师三面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4%E6%B7%98%E7%B3%BB%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%A0%94%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88%E4%B8%89%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[阿里集团大淘宝一面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C-01/%E9%98%BF%E9%87%8C%E9%9B%86%E5%9B%A2%E5%A4%A7%E6%B7%98%E5%AE%9D%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) -[阿里巴巴 二面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4%20%E4%BA%8C%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) - -#### 腾讯面经 -[2022暑假实习 数据开发 字节 腾讯](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/2022%E6%9A%91%E5%81%87%E5%AE%9E%E4%B9%A0%20%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%20%E5%AD%97%E8%8A%82%20%E8%85%BE%E8%AE%AF%EF%BC%88%E5%B7%B2offer.pdf) -[4.13 腾讯音乐数据工程笔试](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/4.13%20%E8%85%BE%E8%AE%AF%E9%9F%B3%E4%B9%90%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%E7%AC%94%E8%AF%95.pdf) -[2024届秋招总结](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/2024%E5%B1%8A%E7%A7%8B%E6%8B%9B%E6%80%BB%E7%BB%93.pdf) -[5.30腾讯数据开发一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/5.30%E8%85%BE%E8%AE%AF%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[9.20-腾讯云智-数据-二面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/9.20-%E8%85%BE%E8%AE%AF%E4%BA%91%E6%99%BA-%E6%95%B0%E6%8D%AE-%E4%BA%8C%E9%9D%A2.pdf) -[【腾讯】后端开发暑期实习面经(已offer)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E3%80%90%E8%85%BE%E8%AE%AF%E3%80%91%E5%90%8E%E7%AB%AF%E5%BC%80%E5%8F%91%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%E9%9D%A2%E7%BB%8F%EF%BC%88%E5%B7%B2offer%EF%BC%89.pdf) -[一面凉经-腾讯技术研究-数据科学](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F-%E8%85%BE%E8%AE%AF%E6%8A%80%E6%9C%AF%E7%A0%94%E7%A9%B6-%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6.pdf) -[大数据开发实习面经(阿里、360、腾讯)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0%E9%9D%A2%E7%BB%8F%EF%BC%88%E9%98%BF%E9%87%8C%E3%80%81360%E3%80%81%E8%85%BE%E8%AE%AF%EF%BC%89.pdf) -[奇怪的csig数据工程timeline](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E5%A5%87%E6%80%AA%E7%9A%84csig%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8Btimeline.pdf) -[字节腾讯大数据凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E5%AD%97%E8%8A%82%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%87%89%E7%BB%8F.pdf) -[百度腾讯提前批阿里校招面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E7%99%BE%E5%BA%A6%E8%85%BE%E8%AE%AF%E6%8F%90%E5%89%8D%E6%89%B9%E9%98%BF%E9%87%8C%E6%A0%A1%E6%8B%9B%E9%9D%A2%E7%BB%8F.pdf) -[腾讯 TEG 后台开发 大数据方向 一面总结](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20TEG%20%E5%90%8E%E5%8F%B0%E5%BC%80%E5%8F%91%20%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%96%B9%E5%90%91%20%E4%B8%80%E9%9D%A2%E6%80%BB%E7%BB%93.pdf) -[腾讯 偏大数据开发三面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20%E5%81%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%89%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯 偏大数据开发二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20%E5%81%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%20%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯 偏大数据开发一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20%E5%81%8F%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯 数据科学暑期实习 一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%20%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%20%E4%B8%80%E9%9D%A2.pdf) -[腾讯-数据科学(IEG)+数据工程](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF-%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%EF%BC%88IEG%EF%BC%89%2B%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B.pdf) -[腾讯CSIG后台开发一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFCSIG%E5%90%8E%E5%8F%B0%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯CSIG大数据一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFCSIG%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯IEG数据中心实习面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFIEG%E6%95%B0%E6%8D%AE%E4%B8%AD%E5%BF%83%E5%AE%9E%E4%B9%A0%E9%9D%A2%E7%BB%8F.pdf) -[腾讯PCG数据研发暑期实习一面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFPCG%E6%95%B0%E6%8D%AE%E7%A0%94%E5%8F%91%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) -[腾讯TEG-数据平台部-大数据开发实习-一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFTEG-%E6%95%B0%E6%8D%AE%E5%B9%B3%E5%8F%B0%E9%83%A8-%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0-%E4%B8%80%E9%9D%A2.pdf) -[腾讯TEG-数据平台部-大数据开发实习-二面(等凉)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFTEG-%E6%95%B0%E6%8D%AE%E5%B9%B3%E5%8F%B0%E9%83%A8-%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0-%E4%BA%8C%E9%9D%A2%EF%BC%88%E7%AD%89%E5%87%89%EF%BC%89.pdf) -[腾讯TEG大数据一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFTEG%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯teg大数据 凉](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AFteg%E5%A4%A7%E6%95%B0%E6%8D%AE%20%E5%87%89.pdf) -[腾讯云智 数据工程 面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E4%BA%91%E6%99%BA%20%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%20%E9%9D%A2%E7%BB%8F.pdf) -[腾讯云智暑期实习-数据工程 一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E4%BA%91%E6%99%BA%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0-%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%20%E4%B8%80%E9%9D%A2.pdf) -[腾讯大数据开发一面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) -[腾讯大数据开发实习](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0.pdf) -[腾讯微保实习一面(数据开发工程师)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%BE%AE%E4%BF%9D%E5%AE%9E%E4%B9%A0%E4%B8%80%E9%9D%A2%EF%BC%88%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88%EF%BC%89.pdf) -[腾讯微保实习二面(数据开发工程师)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%BE%AE%E4%BF%9D%E5%AE%9E%E4%B9%A0%E4%BA%8C%E9%9D%A2%EF%BC%88%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88%EF%BC%89.pdf) -[腾讯微信读书 数据科学 暑期实习 一面【放弃笔试但被捞】](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E5%BE%AE%E4%BF%A1%E8%AF%BB%E4%B9%A6%20%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%20%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%20%E4%B8%80%E9%9D%A2%E3%80%90%E6%94%BE%E5%BC%83%E7%AC%94%E8%AF%95%E4%BD%86%E8%A2%AB%E6%8D%9E%E3%80%91.pdf) -[腾讯数开面筋-全程无八股](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%95%B0%E5%BC%80%E9%9D%A2%E7%AD%8B-%E5%85%A8%E7%A8%8B%E6%97%A0%E5%85%AB%E8%82%A1.pdf) -[腾讯数据工程凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%E5%87%89%E7%BB%8F.pdf) -[腾讯数据工程面经(1)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%E9%9D%A2%E7%BB%8F%EF%BC%881%EF%BC%89.pdf) -[腾讯数据工程面经(2)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%95%B0%E6%8D%AE%E5%B7%A5%E7%A8%8B%E9%9D%A2%E7%BB%8F%EF%BC%882%EF%BC%89.pdf) -[腾讯暑期实习 数据科学一面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E6%9A%91%E6%9C%9F%E5%AE%9E%E4%B9%A0%20%E6%95%B0%E6%8D%AE%E7%A7%91%E5%AD%A6%E4%B8%80%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[腾讯秋招大数据运维开发一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E8%85%BE%E8%AE%AF%E7%A7%8B%E6%8B%9B%E5%A4%A7%E6%95%B0%E6%8D%AE%E8%BF%90%E7%BB%B4%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2.pdf) -[阿里、腾讯大数据提前批面经(已拿offer)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E9%98%BF%E9%87%8C%E3%80%81%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%8F%90%E5%89%8D%E6%89%B9%E9%9D%A2%E7%BB%8F(%E5%B7%B2%E6%8B%BFoffer).pdf) -[面试复盘|腾讯-腾讯大数据 一面凉经!!!](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E8%85%BE%E8%AE%AF/%E8%85%BE%E8%AE%AF-2023%E5%B9%B411%E6%9C%8812%E6%97%A5/%E9%9D%A2%E8%AF%95%E5%A4%8D%E7%9B%98%EF%BD%9C%E8%85%BE%E8%AE%AF-%E8%85%BE%E8%AE%AF%E5%A4%A7%E6%95%B0%E6%8D%AE%20%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F%EF%BC%81%EF%BC%81%EF%BC%81.pdf) - - -#### 小米面经 -[2023-3-27 小米-汽车-大数据开发](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/2023-3-27%20%E5%B0%8F%E7%B1%B3-%E6%B1%BD%E8%BD%A6-%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91-1.pdf) -[小米 大数据 一面 二面(凉经)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%20%E5%A4%A7%E6%95%B0%E6%8D%AE%20%E4%B8%80%E9%9D%A2%20%E4%BA%8C%E9%9D%A2%EF%BC%88%E5%87%89%E7%BB%8F%EF%BC%89.pdf) -[小米 大数据开发 一面视频面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%20%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%20%E4%B8%80%E9%9D%A2%E8%A7%86%E9%A2%91%E9%9D%A2.pdf) -[小米 大数据开发 已oc](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%20%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%20%E5%B7%B2oc.pdf) -[小米、头条、知乎面试题总结](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E3%80%81%E5%A4%B4%E6%9D%A1%E3%80%81%E7%9F%A5%E4%B9%8E%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93_%E4%B8%8D%E6%B8%85%E4%B8%8D%E6%85%8E%E7%9A%84%E5%8D%9A%E5%AE%A2-CSDN%E5%8D%9A%E5%AE%A2.pdf) -[小米凉面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%87%89%E9%9D%A2.pdf) -[小米大数据一二面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E4%BA%8C%E9%9D%A2.pdf) -[小米大数据一二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据一二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E4%B8%80%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F02.pdf) -[小米大数据开发一面](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2.pdf) -[小米大数据开发一面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%B8%80%E9%9D%A2%E5%87%89%E7%BB%8F.pdf) -[小米大数据开发二面凉经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据开发实习面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%AE%9E%E4%B9%A0%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据开发岗一面、二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B2%97%E4%B8%80%E9%9D%A2%E3%80%81%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据开发工程师(base北京)已OC](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88%EF%BC%88base%E5%8C%97%E4%BA%AC%EF%BC%89%E5%B7%B2OC.pdf) -[小米大数据开发面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据提前批一面二面面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%8F%90%E5%89%8D%E6%89%B9%E4%B8%80%E9%9D%A2%E4%BA%8C%E9%9D%A2%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据日常实习一二三面(已oc)](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%97%A5%E5%B8%B8%E5%AE%9E%E4%B9%A0%E4%B8%80%E4%BA%8C%E4%B8%89%E9%9D%A2%EF%BC%88%E5%B7%B2oc%EF%BC%89.pdf) -[小米大数据日常面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%97%A5%E5%B8%B8%E9%9D%A2%E7%BB%8F.pdf) -[小米大数据研发(已OC)timeline](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E7%A0%94%E5%8F%91%EF%BC%88%E5%B7%B2OC%EF%BC%89timeline.pdf) -[小米大数据面经](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F.pdf) -[小米面经,二面等通知中](https://github.com/MoRan1607/BigDataGuide/blob/master/%E9%9D%A2%E8%AF%95/%E9%9D%A2%E7%BB%8F/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9D%A2%E7%BB%8F/%E5%B0%8F%E7%B1%B3/%E5%B0%8F%E7%B1%B3%E9%9D%A2%E7%BB%8F%EF%BC%8C%E4%BA%8C%E9%9D%A2%E7%AD%89%E9%80%9A%E7%9F%A5%E4%B8%AD%E3%80%82.pdf) - - - - - - - -大数据&后端书籍 ---- -PDF书籍(含Hadoop、Spark、Flink等大数据书籍)在公众号回复关键字“大数据书籍”或“Java书籍”自行进百度云盘群保存即可 - -## 交流群 -交流群建好了,进群的小伙伴可以加我微信:**MoRan1607,备注:GitHub** -
-
-
-
- - -" -qiurunze123/miaosha,master,26041,6646,2018-09-14T04:36:24Z,65690,1,⭐⭐⭐⭐秒杀系统设计与实现.互联网工程师进阶与分析🙋🐓,," - -> 朋友们,感谢大家对我文章的支持。时间过得很快, -这部分内容还是我几年前刚毕业时写的,而且也只是个人项目,被公众号文章给我一顿喷,博主内容我也看了,晚上回到家就简单的回复下, -想了一下,因为确实没精力维护,对于小白会造成误导,决定下线这个项目,这是我的第一个项目,就让他成回忆吧!以免对自己造成困扰! -大家以后还是可以微信交流其它问题,有时间也会为大家解答! - ->1.理性看待 - -我本意是将一些自己的思路和方向表达出来,因为star的激增,我也就做了最初的一版规划,那时候刚毕业没多久,很荣幸这个项目从一个小项目扩张成了大项目,但也都是一些当时不成熟的想法 ,项目没有完全完成, -也只是自己练手的入门级项目,旨在学习更多的知识,所有大家在看到这个项目的时候要有更多自己的思考和过滤,不要一味的照搬照抄!最后那些不理性的同学,给大家推荐俩本书 《我就是你啊》和《非暴力沟通》没准可以让你进化! -" -Kong/unirest-java,main,2563,591,2011-04-11T21:19:53Z,3793,5,"Unirest in Java: Simplified, lightweight HTTP client library.",,"# Unirest for Java - -[](https://github.com/kong/unirest-java/actions) -[](https://maven-badges.herokuapp.com/maven-central/com.kong/unirest-java) -[](http://www.javadoc.io/doc/com.konghq/unirest-java) - - -## Unirest 4 -Unirest 4 is build on modern Java standards, and as such requires at least Java 11. - -Unirest 4's dependencies are fully modular, and have been moved to new Maven coordinates to avoid conflicts with the previous versions. -You can use a maven bom to manage the modules: - -### Install With Maven - -```xml --There are 3 ways to integrate `jasypt-spring-boot` in your project: - -- Simply adding the starter jar `jasypt-spring-boot-starter` to your classpath if using `@SpringBootApplication` or `@EnableAutoConfiguration` will enable encryptable properties across the entire Spring Environment -- Adding `jasypt-spring-boot` to your classpath and adding `@EnableEncryptableProperties` to your main Configuration class to enable encryptable properties across the entire Spring Environment -- Adding `jasypt-spring-boot` to your classpath and declaring individual encryptable property sources with `@EncrytablePropertySource` -## What's new? -### Go to [Releases](https://github.com/ulisesbocchio/jasypt-spring-boot/releases) -## What to do First? -Use one of the following 3 methods (briefly explained above): - -1. Simply add the starter jar dependency to your project if your Spring Boot application uses `@SpringBootApplication` or `@EnableAutoConfiguration` and encryptable properties will be enabled across the entire Spring Environment (This means any system property, environment property, command line argument, application.properties, application-*.properties, yaml properties, and any other property sources can contain encrypted properties): - - ```xml -
-When using METHOD 3 (`@EncryptablePropertySource`) then you can access the encrypted properties the same way, the only difference is that you must put the properties in the resource that was declared within the `@EncryptablePropertySource` annotation so that the properties can be decrypted properly. - -## Password-based Encryption Configuration -Jasypt uses an `StringEncryptor` to decrypt properties. For all 3 methods, if no custom `StringEncryptor` (see the [Custom Encryptor](#customEncryptor) section for details) is found in the Spring Context, one is created automatically that can be configured through the following properties (System, properties file, command line arguments, environment variable, etc.): - -
| Key | Required | Default Value | -
| jasypt.encryptor.password | True | - | -
| jasypt.encryptor.algorithm | False | PBEWITHHMACSHA512ANDAES_256 | -
| jasypt.encryptor.key-obtention-iterations | False | 1000 | -
| jasypt.encryptor.pool-size | False | 1 | -
| jasypt.encryptor.provider-name | False | SunJCE | -
| jasypt.encryptor.provider-class-name | False | null | -
| jasypt.encryptor.salt-generator-classname | False | org.jasypt.salt.RandomSaltGenerator | -
| jasypt.encryptor.iv-generator-classname | False | org.jasypt.iv.RandomIvGenerator | -
| jasypt.encryptor.string-output-type | False | base64 | -
| jasypt.encryptor.proxy-property-sources | False | false | -
| jasypt.encryptor.skip-property-sources | False | empty list | -
- -The last property, `jasypt.encryptor.proxyPropertySources` is used to indicate `jasyp-spring-boot` how property values are going to be intercepted for decryption. The default value, `false` uses custom wrapper implementations of `PropertySource`, `EnumerablePropertySource`, and `MapPropertySource`. When `true` is specified for this property, the interception mechanism will use CGLib proxies on each specific `PropertySource` implementation. This may be useful on some scenarios where the type of the original `PropertySource` must be preserved. - -## Use you own Custom Encryptor -For custom configuration of the encryptor and the source of the encryptor password you can always define your own StringEncryptor bean in your Spring Context, and the default encryptor will be ignored. For instance: - -```java - @Bean(""jasyptStringEncryptor"") - public StringEncryptor stringEncryptor() { - PooledPBEStringEncryptor encryptor = new PooledPBEStringEncryptor(); - SimpleStringPBEConfig config = new SimpleStringPBEConfig(); - config.setPassword(""password""); - config.setAlgorithm(""PBEWITHHMACSHA512ANDAES_256""); - config.setKeyObtentionIterations(""1000""); - config.setPoolSize(""1""); - config.setProviderName(""SunJCE""); - config.setSaltGeneratorClassName(""org.jasypt.salt.RandomSaltGenerator""); - config.setIvGeneratorClassName(""org.jasypt.iv.RandomIvGenerator""); - config.setStringOutputType(""base64""); - encryptor.setConfig(config); - return encryptor; - } -``` -Notice that the bean name is required, as `jasypt-spring-boot` detects custom String Encyptors by name as of version `1.5`. The default bean name is: - -``` jasyptStringEncryptor ``` - -But one can also override this by defining property: - -``` jasypt.encryptor.bean ``` - -So for instance, if you define `jasypt.encryptor.bean=encryptorBean` then you would define your custom encryptor with that name: - -```java - @Bean(""encryptorBean"") - public StringEncryptor stringEncryptor() { - ... - } -``` - -## Custom Property Detector, Prefix, Suffix and/or Resolver - -As of `jasypt-spring-boot-1.10` there are new extensions points. `EncryptablePropertySource` now uses `EncryptablePropertyResolver` to resolve all properties: - -```java -public interface EncryptablePropertyResolver { - String resolvePropertyValue(String value); -} -``` - -Implementations of this interface are responsible of both **detecting** and **decrypting** properties. The default implementation, `DefaultPropertyResolver` uses the before mentioned -`StringEncryptor` and a new `EncryptablePropertyDetector`. - -### Provide a Custom `EncryptablePropertyDetector` - -You can override the default implementation by providing a Bean of type `EncryptablePropertyDetector` with name `encryptablePropertyDetector` or if you wanna provide -your own bean name, override property `jasypt.encryptor.property.detector-bean` and specify the name you wanna give the bean. When providing this, you'll be responsible for -detecting encrypted properties. -Example: - -```java -private static class MyEncryptablePropertyDetector implements EncryptablePropertyDetector { - @Override - public boolean isEncrypted(String value) { - if (value != null) { - return value.startsWith(""ENC@""); - } - return false; - } - - @Override - public String unwrapEncryptedValue(String value) { - return value.substring(""ENC@"".length()); - } -} -``` - -```java -@Bean(name = ""encryptablePropertyDetector"") - public EncryptablePropertyDetector encryptablePropertyDetector() { - return new MyEncryptablePropertyDetector(); - } -``` - -### Provide a Custom Encrypted Property `prefix` and `suffix` - -If all you want to do is to have different prefix/suffix for encrypted properties, you can keep using all the default implementations -and just override the following properties in `application.properties` (or `application.yml`): - -```YAML -jasypt: - encryptor: - property: - prefix: ""ENC@["" - suffix: ""]"" -``` - -### Provide a Custom `EncryptablePropertyResolver` - -You can override the default implementation by providing a Bean of type `EncryptablePropertyResolver` with name `encryptablePropertyResolver` or if you wanna provide -your own bean name, override property `jasypt.encryptor.property.resolver-bean` and specify the name you wanna give the bean. When providing this, you'll be responsible for -detecting and decrypting encrypted properties. -Example: - -```java - class MyEncryptablePropertyResolver implements EncryptablePropertyResolver { - - - private final PooledPBEStringEncryptor encryptor; - - public MyEncryptablePropertyResolver(char[] password) { - this.encryptor = new PooledPBEStringEncryptor(); - SimpleStringPBEConfig config = new SimpleStringPBEConfig(); - config.setPasswordCharArray(password); - config.setAlgorithm(""PBEWITHHMACSHA512ANDAES_256""); - config.setKeyObtentionIterations(""1000""); - config.setPoolSize(1); - config.setProviderName(""SunJCE""); - config.setSaltGeneratorClassName(""org.jasypt.salt.RandomSaltGenerator""); - config.setIvGeneratorClassName(""org.jasypt.iv.RandomIvGenerator""); - config.setStringOutputType(""base64""); - encryptor.setConfig(config); - } - - @Override - public String resolvePropertyValue(String value) { - if (value != null && value.startsWith(""{cipher}"")) { - return encryptor.decrypt(value.substring(""{cipher}"".length())); - } - return value; - } - } -``` - -```java -@Bean(name=""encryptablePropertyResolver"") - EncryptablePropertyResolver encryptablePropertyResolver(@Value(""${jasypt.encryptor.password}"") String password) { - return new MyEncryptablePropertyResolver(password.toCharArray()); - } -``` - -Notice that by overriding `EncryptablePropertyResolver`, any other configuration or overrides you may have for prefixes, suffixes, -`EncryptablePropertyDetector` and `StringEncryptor` will stop working since the Default resolver is what uses them. You'd have to -wire all that stuff yourself. Fortunately, you don't have to override this bean in most cases, the previous options should suffice. - -But as you can see in the implementation, the detection and decryption of the encrypted properties are internal to `MyEncryptablePropertyResolver` - -## Using Filters - -`jasypt-spring-boot:2.1.0` introduces a new feature to specify property filters. The filter is part of the `EncryptablePropertyResolver` API -and allows you to determine which properties or property sources to contemplate for decryption. This is, before even examining the actual -property value to search for, or try to, decrypt it. For instance, by default, all properties which name start with `jasypt.encryptor` -are excluded from examination. This is to avoid circular dependencies at load time when the library beans are configured. - -### DefaultPropertyFilter properties - -By default, the `DefaultPropertyResolver` uses `DefaultPropertyFilter`, which allows you to specify the following string pattern lists: - -* jasypt.encryptor.property.filter.include-sources: Specify the property sources name patterns to be included for decryption -* jasypt.encryptor.property.filter.exclude-sources: Specify the property sources name patterns to be EXCLUDED for decryption -* jasypt.encryptor.property.filter.include-names: Specify the property name patterns to be included for decryption -* jasypt.encryptor.property.filter.exclude-names: Specify the property name patterns to be EXCLUDED for decryption - -### Provide a custom `EncryptablePropertyFilter` - -You can override the default implementation by providing a Bean of type `EncryptablePropertyFilter` with name `encryptablePropertyFilter` or if you wanna provide -your own bean name, override property `jasypt.encryptor.property.filter-bean` and specify the name you wanna give the bean. When providing this, you'll be responsible for -detecting properties and/or property sources you want to contemplate for decryption. -Example: - -```java - class MyEncryptablePropertyFilter implements EncryptablePropertyFilter { - - public boolean shouldInclude(PropertySource source, String name) { - return name.startsWith('encrypted.'); - } - } -``` - -```java -@Bean(name=""encryptablePropertyFilter"") - EncryptablePropertyFilter encryptablePropertyFilter() { - return new MyEncryptablePropertyFilter(); - } -``` - -Notice that for this mechanism to work, you should not provide a custom `EncryptablePropertyResolver` and use the default -resolver instead. If you provide custom resolver, you are responsible for the entire process of detecting and decrypting -properties. - -## Filter out `PropertySource` classes from being introspected -Define a comma-separated list of fully-qualified class names to be skipped from introspection. This classes will not be -wrapped/proxied by this plugin and thereby properties contained in them won't supported encryption/decryption: - -```properties -jasypt.encryptor.skip-property-sources=org.springframework.boot.env.RandomValuePropertySource,org.springframework.boot.ansi.AnsiPropertySource -``` -## Encryptable Properties cache refresh -Encrypted properties are cached within your application and in certain scenarios, like when using externalized configuration -from a config server the properties need to be refreshed when they changed. For this `jasypt-spring-boot` registers a -`RefreshScopeRefreshedEventListener` that listens to the following events by default to clear the encrypted properties cache: -```java -public static final List
| Key | Default Value | Description | -
| jasypt.encryptor.privateKeyString | null | private key for decryption in String format | -
| jasypt.encryptor.privateKeyLocation | null | location of the private key for decryption in spring resource format | -
| jasypt.encryptor.privateKeyFormat | DER | Key format. DER or PEM | -
-The `SimpleGCMByteEncryptor` uses a `IVGenerator` to encrypt properties. You can configure that with property `jasypt.encryptor.iv-generator-classname` if you don't want to -use the default implementation `RandomIvGenerator` -### Using a key -When using a key via `jasypt.encryptor.gcm-secret-key-string` or `jasypt.encryptor.gcm-secret-key-location`, make sure you encode your key in base64. -The base64 string value could set to `jasypt.encryptor.gcm-secret-key-string`, or just can save it in a file and use a spring resource locator to that file in property `jasypt.encryptor.gcm-secret-key-location`. For instance: -```properties -jasypt.encryptor.gcm-secret-key-string=""PNG5egJcwiBrd+E8go1tb9PdPvuRSmLSV3jjXBmWlIU="" -#OR -jasypt.encryptor.gcm-secret-key-location=classpath:secret_key.b64 -#OR -jasypt.encryptor.gcm-secret-key-location=file:/full/path/secret_key.b64 -#OR -jasypt.encryptor.gcm-secret-key-location=file:relative/path/secret_key.b64 -``` -Optionally, you can create your own `StringEncryptor` bean: -```java -@Bean(""encryptorBean"") -public StringEncryptor stringEncryptor() { - SimpleGCMConfig config = new SimpleGCMConfig(); - config.setSecretKey(""PNG5egJcwiBrd+E8go1tb9PdPvuRSmLSV3jjXBmWlIU=""); - return new SimpleGCMStringEncryptor(config); -} -``` -### Using a password -Alternatively, you can use a password to encrypt/decrypt properties using AES 256-GCM. The password is used to generate a -key on startup, so there is a few properties you need to/can set, these are: -```properties -jasypt.encryptor.gcm-secret-key-password=""chupacabras"" -#Optional, defaults to ""1000"" -jasypt.encryptor.key-obtention-iterations=""1000"" -#Optional, defaults to 0, no salt. If provided, specify the salt string in ba64 format -jasypt.encryptor.gcm-secret-key-salt=""HrqoFr44GtkAhhYN+jP8Ag=="" -#Optional, defaults to PBKDF2WithHmacSHA256 -jasypt.encryptor.gcm-secret-key-algorithm=""PBKDF2WithHmacSHA256"" -``` -Make sure this parameters are the same if you're encrypting your secrets with external tools. -Optionally, you can create your own `StringEncryptor` bean: -```java -@Bean(""encryptorBean"") -public StringEncryptor stringEncryptor() { - SimpleGCMConfig config = new SimpleGCMConfig(); - config.setSecretKeyPassword(""chupacabras""); - config.setSecretKeyIterations(1000); - config.setSecretKeySalt(""HrqoFr44GtkAhhYN+jP8Ag==""); - config.setSecretKeyAlgorithm(""PBKDF2WithHmacSHA256""); - return new SimpleGCMStringEncryptor(config); -} -``` -### Encrypting properties with AES GCM-256 -You can use the [Maven Plugin](#maven-plugin) or follow a similar strategy as explained in [Asymmetric Encryption](#asymmetric-encryption)'s [Encrypting Properties](#encrypting-properties) -## Demo App -The [jasypt-spring-boot-demo-samples](https://github.com/ulisesbocchio/jasypt-spring-boot-samples) repo contains working Spring Boot app examples. -The main [jasypt-spring-boot-demo](https://github.com/ulisesbocchio/jasypt-spring-boot-samples/tree/master/jasypt-spring-boot-demo) Demo app explicitly sets a System property with the encryption password before the app runs. -To have a little more realistic scenario try removing the line where the system property is set, build the app with maven, and the run: - -``` - java -jar target/jasypt-spring-boot-demo-0.0.1-SNAPSHOT.jar --jasypt.encryptor.password=password -``` -And you'll be passing the encryption password as a command line argument. -Run it like this: - -``` - java -Djasypt.encryptor.password=password -jar target/jasypt-spring-boot-demo-0.0.1-SNAPSHOT.jar -``` -And you'll be passing the encryption password as a System property. - -If you need to pass this property as an Environment Variable you can accomplish this by creating application.properties or application.yml and adding: -``` -jasypt.encryptor.password=${JASYPT_ENCRYPTOR_PASSWORD:} -``` -or in YAML -``` -jasypt: - encryptor: - password: ${JASYPT_ENCRYPTOR_PASSWORD:} -``` -basically what this does is to define the `jasypt.encryptor.password` property pointing to a different property `JASYPT_ENCRYPTOR_PASSWORD` that you can set with an Environment Variable, and you can also override via System Properties. This technique can also be used to translate property name/values for any other library you need. -This is also available in the Demo app. So you can run the Demo app like this: - -``` -JASYPT_ENCRYPTOR_PASSWORD=password java -jar target/jasypt-spring-boot-demo-1.5-SNAPSHOT.jar -``` - -**Note:** When using Gradle as build tool, processResources task fails because of '$' character, to solve this you just need to scape this variable like this '\\$'. - -## Other Demo Apps -While [jasypt-spring-boot-demo](https://github.com/ulisesbocchio/jasypt-spring-boot-samples/tree/master/jasypt-spring-boot-demo) is a comprehensive Demo that showcases all possible ways to encrypt/decrypt properties, there are other multiple Demos that demo isolated scenarios. - -[//]: # (## Flattr) - -[//]: # ([](https://flattr.com/@ubocchio/github/ulisesbocchio)) -" -google/bindiff,main,1872,101,2023-09-20T06:41:55Z,323705,29,Quickly find differences and similarities in disassembled code,bindiff binexport c-plus-plus diffing ida-plugin ida-pro java program-analysis program-differencing reverse-engineering vxsig," - -Copyright 2011-2024 Google LLC. - -# BinDiff - -This repository contains the BinDiff source code. BinDiff is an open-source -comparison tool for binary files to quickly find differences and similarities -in disassembled code. - -## Table of Contents - -- [About BinDiff](#about-bindiff) -- [Quickstart](#quickstart) -- [Documentation](#documentation) -- [Codemap](#codemap) -- [Building from Source](#building-from-source) -- [License](#license) -- [Getting Involved](#getting-involved) - -## About BinDiff - -BinDiff is an open-source comparison tool for binary files, that assists -vulnerability researchers and engineers to quickly find differences and -similarities in disassembled code. - -With BinDiff, researchers can identify and isolate fixes for vulnerabilities in -vendor-supplied patches. It can also be used to port symbols and comments -between disassemblies of multiple versions of the same binary. This makes -tracking changes over time easier and allows organizations to retain analysis -results and enables knowledge transfer among binary analysts. - -### Use Cases - -* Compare binary files for x86, MIPS, ARM, PowerPC, and other architectures - supported by popular [disassemblers](docs/disassemblers.md). -* Identify identical and similar functions in different binaries -* Port function names, comments and local names from one disassembly to the - other -* Detect and highlight changes between two variants of the same function - -## Quickstart - -If you want to just get started using BinDiff, download prebuilt installation -packages from the -[releases page](https://github.com/google/bindiff/releases). - -Note: BinDiff relies on a separate disassembler. Out of the box, it ships with -support for IDA Pro, Binary Ninja and Ghidra. The [disassemblers page](docs/disassemblers.md) lists the supported configurations. - -## Documentation - -A subset of the existing [manual](https://www.zynamics.com/bindiff/manual) is -available in the [`docs/` directory](docs/README.md). - -## Codemap - -BinDiff contains the following components: - -* [`cmake`](cmake) - CMake build files declaring external dependencies -* [`fixtures`](fixtures) - A collection of test files to exercise the BinDiff - core engine -* [`ida`](ida) - Integration with the IDA Pro disassembler -* [`java`](java) - Java source code. This contains the the BinDiff visual diff - user interface and its corresponding utility library. -* [`match`](match) - Matching algorithms for the BinDiff core engine -* [`packaging`](packaging) - Package sources for the installation packages -* [`tools`](tools) - Helper executables that are shipped with the product - -## Building from Source - -The instruction below should be enough to build both the native code and the -Java based components. - -More detailed build instructions will be added at a later date. This includes -ready-made `Dockerfile`s and scripts for building the installation packages. - -### Native code - -BinDiff uses CMake to generate its build files for those components that consist -of native C++ code. - -The following build dependencies are required: - -* [BinExport](https://github.com/google/binexport) 12, the companion plugin - to BinDiff that also contains a lot of shared code -* Boost 1.71.0 or higher (a partial copy of 1.71.0 ships with BinExport and - will be used automatically) -* [CMake](https://cmake.org/download/) 3.14 or higher -* [Ninja](https://ninja-build.org/) for speedy builds -* GCC 9 or a recent version of Clang on Linux/macOS. On Windows, use the - Visual Studio 2019 compiler and the Windows SDK for Windows 10. -* Git 1.8 or higher -* Dependencies that will be downloaded: - * Abseil, GoogleTest, Protocol Buffers (3.14), and SQLite3 - * Binary Ninja SDK - -The following build dependencies are optional: -* IDA Pro only: IDA SDK 8.0 or higher (unpack into `deps/idasdk`) - -The general build steps are the same on Windows, Linux and macOS. The following -shows the commands for Linux. - -Download dependencies that won't be downloaded automatically: - -```bash -mkdir -p build/out -git clone https://github.com/google/binexport build/binexport -unzip -q
DDDplus
- -
-
-A lightweight DDD(Domain Driven Design) enhancement framework for forward/reverse business modeling, supporting complex system architecture evolution!
-
-[](https://github.com/funkygao/cp-ddd-framework/actions?query=branch%3Amaster+workflow%3ACI)
-[](https://funkygao.github.io/cp-ddd-framework/doc/apidocs/)
-[](https://central.sonatype.com/namespace/io.github.dddplus)
-
-[](https://codecov.io/gh/funkygao/cp-ddd-framework)
-[](https://github.com/heynickc/awesome-ddd#jvm)
-[](https://gitter.im/cp-ddd-framework/community)
-
-
-
-
-
-Languages: English | [中文](README.zh-cn.md)
-
-
-----
-
-## What is DDDplus?
-
-DDDplus, formerly named cp-ddd-framework(cp means Central Platform:中台), is a lightweight DDD(Domain Driven Design) enhancement framework for forward/reverse business modeling, supporting complex system architecture evolution!
-
->It captures DDD missing concepts and patches the building block. It empowers building domain model with forward and reverse modeling. It visualizes the complete domain knowledge from code. It connects frontline developers with (architect, product manager, business stakeholder, management team). It makes (analysis, design, design review, implementation, code review, test) a positive feedback closed-loop. It strengthens building extension oriented flexible software solution. It eliminates frequently encountered misunderstanding of DDD via thorough javadoc for each building block with detailed example.
-
-In short, the 3 most essential `plus` are:
-1. [patch](/dddplus-spec/src/main/java/io/github/dddplus/model) DDD building blocks for pragmatic forward modeling, clearing obstacles of DDD implementation
-2. offer a reverse modeling [DSL](/dddplus-spec/src/main/java/io/github/dddplus/dsl), visualizing complete domain knowledge from code
-3. provide [extension point](/dddplus-spec/src/main/java/io/github/dddplus/ext) with multiple routing mechanism, suited for complex business scenarios
-
-## Current status
-
-Used for several complex critical central platform projects in production environment.
-
-## Showcase
-
-[A full demo of DDDplus forward/reverse modeling ->](dddplus-test/src/test/java/ddd/plus/showcase/README.md)
-
-## Quickstart
-
-### Forward modeling
-
-```xml
-Smart-Doc Project
- - -[](https://www.apache.org/licenses/LICENSE-2.0) - - - -[](https://smart-doc-group.github.io/#/zh-cn/) - - -## Introduce - -`smart-doc[smɑːt dɒk]`is a tool that supports both `JAVA REST API` and `JAVA WebSocket` and `Apache Dubbo RPC` interface document generation. `Smart-doc` is -based on interface source code analysis to generate interface documents, and zero annotation intrusion. You only need to -write Javadoc comments when developing, `smart-doc` can help you generate `Markdown` or `HTML5` document. `smart-doc` does not -need to inject annotations into the code like `Swagger`. - -[quick start](https://smart-doc-group.github.io/#/) - -## Documentation -* [English](https://smart-doc-group.github.io/#/) -* [中文](https://smart-doc-group.github.io/#/zh-cn/) - -## Features - -- Zero annotation, zero learning cost, only need to write standard `JAVA` document comments. -- Automatic derivation based on source code interface definition, powerful return structure derivation support. -- Support `Spring MVC`, `Spring Boot`, `Spring Boot Web Flux` (Not support endpoint), `Feign`,`JAX-RS`. -- Supports the derivation of asynchronous interface returns such as `Callable`, `Future`, `CompletableFuture`. -- Support `JSR-303`parameter verification specification. -- Support for automatic generation of request examples based on request parameters. -- Support for generating `JSON` return value examples. -- Support for loading source code from outside the project to generate field comments (including the sources jar - package). -- Support for generating multiple formats of documents: `Markdown`,`HTML5`,`Word`,`Asciidoctor`,`Postman Collection 2.0+`,`OpenAPI 3.0`. -- Support the generation of `Jmeter` performance testing scripts -- Support for exporting error codes and data dictionary codes to API documentation. -- The debug html5 page fully supports file upload and download testing. -- Support `Apache Dubbo RPC`. - -## Best Practice - -`smart-doc` + [Torna](http://torna.cn) form an industry-leading document generation and management solution, using -`smart-doc` to complete Java source code analysis and extract annotations to generate API documents without intrusion, and -automatically push the documents to the `Torna` enterprise-level interface document management platform. - - - -## Building - -You could build with the following commands. (`JDK 1.8` is required to build the master branch) - -``` -mvn clean install -Dmaven.test.skip=true -``` - -## TODO - -- GRPC - -## Who is using - -These are only part of the companies using `smart-doc`, for reference only. If you are using smart-doc, -please [add your company here](https://github.com/smart-doc-group/smart-doc/issues/12) to tell us your scenario to make -`smart-doc` better. - - -
-
-
-
-## Main Functions
-
-- [x] Supports Imagine instructions and related actions
-- [x] Supports adding image base64 as a placeholder when using the Imagine command
-- [x] Supports Blend (image blending) and Describe (image to text) commands
-- [x] Supports real-time progress tracking of tasks
-- [x] Supports translation of Chinese prompts, requires configuration of Baidu Translate or GPT
-- [x] Prompt sensitive word pre-detection, supports override adjustment
-- [x] User-token connects to WSS (WebSocket Secure), allowing access to error messages and full functionality
-- [x] Supports multi-account configuration, with each account able to set up corresponding task queues
-
-**🚀 For more features, please refer to [midjourney-proxy-plus](https://github.com/litter-coder/midjourney-proxy-plus)**
-> - [x] Supports all the features of the open-source version
-> - [x] Supports Shorten (prompt analysis) command
-> - [x] Supports focus shifting: Pan ⬅️ ➡️ ⬆️ ⬇️
-> - [x] Supports image zooming: Zoom 🔍
-> - [x] Supports local redrawing: Vary (Region) 🖌
-> - [x] Supports nearly all associated button actions and the 🎛️ Remix mode
-> - [x] Supports retrieving the seed value of images
-> - [x] Account pool persistence, dynamic maintenance
-> - [x] Supports retrieving account /info and /settings information
-> - [x] Account settings configuration
-> - [x] Supports Niji bot robot
-> - [x] Supports InsightFace face replacement robot
-> - [x] Embedded management dashboard page
-
-## Prerequisites for use
-
-1. Register and subscribe to MidJourney, create `your own server and channel`, refer
- to https://docs.midjourney.com/docs/quick-start
-2. Obtain user Token, server ID, channel ID: [Method of acquisition](./docs/discord-params.md)
-
-## Quick Start
-
-1. `Railway`: Based on the Railway platform, no need for your own server: [Deployment method](./docs/railway-start.md) ;
- If Railway is not available, you can start using Zeabur instead.
-2. `Zeabur`: Based on the Zeabur platform, no need for your own server: [Deployment method](./docs/zeabur-start.md)
-3. `Docker`: Start using Docker on a server or locally: [Deployment method](./docs/docker-start.md)
-
-## Local development
-
-- Depends on Java 17 and Maven
-- Change configuration items: Edit src/main/resources/application.yml
-- Project execution: Start the main function of ProxyApplication
-- After changing the code, build the image: Uncomment VOLUME in the Dockerfile, then
- execute `docker build . -t midjourney-proxy`
-
-## Configuration items
-
-- mj.accounts: Refer
- to [Account pool configuration](./docs/config.md#%E8%B4%A6%E5%8F%B7%E6%B1%A0%E9%85%8D%E7%BD%AE%E5%8F%82%E8%80%83)
-- mj.task-store.type: Task storage method, default is in_memory (in memory, lost after restart), Redis is an alternative
- option.
-- mj.task-store.timeout: Task storage expiration time, tasks are deleted after expiration, default is 30 days.
-- mj.api-secret: API key, if left empty, authentication is not enabled; when calling the API, you need to add the
- request header 'mj-api-secret'.
-- mj.translate-way: The method for translating Chinese prompts into English, options include null (default), Baidu, or
- GPT.
-- For more configuration options, see [Configuration items](./docs/config.md)
-
-## Related documentation
-
-1. [API Interface Description](./docs/api.md)
-2. [Version Update Log](https://github.com/novicezk/midjourney-proxy/wiki/%E6%9B%B4%E6%96%B0%E8%AE%B0%E5%BD%95)
-
-## Precautions
-
-1. Frequent image generation and similar behaviors may trigger warnings on your Midjourney account. Please use with
- caution.
-2. For common issues and solutions, see [Wiki / FAQ](https://github.com/novicezk/midjourney-proxy/wiki/FAQ)
-3. Interested friends are also welcome to join the discussion group. If the group is full from scanning the code, you
- can add the administrator’s WeChat to be invited into the group. Please remark: mj join group.
-
- midjourney-proxy
- -English | [中文](./README_CN.md) - -Proxy the Discord channel for MidJourney to enable API-based calls for AI drawing - -[](https://www.github.com/novicezk/midjourney-proxy) -[](https://www.apache.org/licenses/LICENSE-2.0.html) - -| Android Experience App | -iOS Experience App | -
|---|---|
| Native SDK - | Download Address - | Integration Guide - | Update Log - |
|---|---|---|---|
| Android | -GitHub (Recommended) | -[Quick Integration] TUIKit Integration (Android) [General Integration] SDK Integration (Android) |
-Update Log (Native) | -
| iOS | -GitHub (Recommended) | -[Quick Integration] TUIKit Integration (iOS) [General Integration] SDK Integration (iOS) |
-|
| Mac | -GitHub (Recommended) | -[General Integration] SDK Integration (Mac) | -|
| Windows | -GitHub (Recommended) | -[General Integration] SDK Integration (Windows) | -|
| HarmonyOS | -GitHub (Recommended) | -[General Integration] SDK Integration (HarmonyOS) | -
| Functional Module | -Platform | -Document Link | -
|---|---|---|
| TUIKit Library | -iOS | -TUIKit-iOS Library | -
| Android | -TUIKit-Android Library | -|
| Quick Integration | -iOS | -TUIKit-iOS Quick Integration | -
| Android | -TUIKit-Android Quick Integration | -|
| Modifying UI Themes | -iOS | -TUIKit-iOS Modifying UI Themes | -
| Android | -TUIKit-Android Modifying UI Themes | -|
| Setting UI Styles | -iOS | -TUIKit-iOS Setting UI Styles | -
| Android | -TUIKit-Android Setting UI Styles | -|
| Adding Custom Messages | -iOS | -TUIKit-iOS Adding Custom Messages | -
| Android | -TUIKit-Android Adding Custom Messages | -|
| Implementing Local Search | -iOS | -TUIKit-iOS Implementing Local Search | -
| Android | -TUIKit-Android Implementing Local Search | -|
| Integrating Offline Push | -iOS | -TUIKit-iOS Integrating Offline Push | -
| Android | -TUIKit-Android Integrating Offline Push | -
-
-
- -Apache ShardingSphere is a distributed SQL transaction & query engine that allows for data sharding, scaling, encryption, and more - on any database. Our community's guiding development concept is Database Plus for creating a complete ecosystem that allows you to transform any database into a distributed database system. - -It focuses on repurposing existing databases, by placing a standardized upper layer above existing and fragmented databases, rather than creating a new database. - -The goal is to provide unified database services and minimize or eliminate the challenges caused by underlying databases' fragmentation. -This results in applications only needing to communicate with a single standardized service. - -The concepts at the core of the project are `Connect`, `Enhance` and `Pluggable`. - -- `Connect:` Flexible adaptation of database protocol, SQL dialect and database storage. It can quickly connect applications and heterogeneous databases. -- `Enhance:` Capture database access entry to provide additional features transparently, such as: redirect (sharding, readwrite-splitting and shadow), transform (data encrypt and mask), authentication (security, audit and authority), governance (circuit breaker and access limitation and analyze, QoS and observability). -- `Pluggable:` Leveraging the micro kernel and 3 layers pluggable mode, features and database ecosystem can be embedded flexibly. Developers can customize their ShardingSphere just like building with LEGO blocks. - -ShardingSphere became an [Apache](https://apache.org/index.html#projects-list) Top-Level Project on April 16, 2020. - -So far, ShardingSphere has been used by over [10,000 projects on GitHub](https://github.com/search?l=Maven+POM&q=shardingsphere+language%3A%22Maven+POM%22&type=Code). - -### DOCUMENTATION📜 - -
- -[](https://shardingsphere.apache.org/document/current/en/overview/) -[](https://shardingsphere.apache.org/document/current/cn/overview/) - -For full documentation & more details, visit: [Docs](https://shardingsphere.apache.org/document/current/en/overview/) - -### CONTRIBUTION🚀🧑💻 - -
- -For guides on how to get started and setup your environment, contributor & committer guides, visit: [Contribution Guidelines](https://shardingsphere.apache.org/community/en/involved/) - -### Team - -
- -We deeply appreciate [community contributors](https://shardingsphere.apache.org/community/en/team) for their dedication to Apache ShardingSphere. - -## - -### COMMUNITY & SUPPORT💝🖤 - -
- -:link: [Mailing List](https://shardingsphere.apache.org/community/en/involved/subscribe/). Best for: Apache community updates, releases, changes. - -:link: [GitHub Issues](https://github.com/apache/shardingsphere/issues). Best for: larger systemic questions/bug reports or anything development related. - -:link: [GitHub Discussions](https://github.com/apache/shardingsphere/discussions). Best for: technical questions & support, requesting new features, proposing new features. - -:link: [Slack channel](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg). Best for: instant communications and online meetings, sharing your applications. - -:link: [Twitter](https://twitter.com/ShardingSphere). Best for: keeping up to date on everything ShardingSphere. - -:link: [LinkedIn](https://www.linkedin.com/showcase/apache-shardingsphere/e). Best for: professional networking and career development with other ShardingSphere contributors. - -## - -### STATUS👀 - -
- -:white_check_mark: Version 5.4.1: released :tada: - -🔗 For the release notes, follow this link to the relevant [GitHub page](https://github.com/apache/shardingsphere/blob/master/RELEASE-NOTES.md). - -:soon: Version 5.4.2 - -We are currently working towards our 5.4.2 milestone. -Keep an eye on the [milestones page](https://github.com/apache/shardingsphere/milestones) of this repo to stay up to date. - -[comment]: <> (##) - -[comment]: <> (### NIGHTLY BUILDS:) - -[comment]: <> (
) - -[comment]: <> (A nightly build of ShardingSphere from the latest master branch is available. ) - -[comment]: <> (The package is updated daily and is available [here](http://117.48.121.24:8080).) - -[comment]: <> (##) - -[comment]: <> (**‼️ Notice:**) - -[comment]: <> (
) - -[comment]: <> (Use this nightly build at your own risk! ) - -[comment]: <> (The branch is not always fully tested. ) - -[comment]: <> (The nightly build may contain bugs, and there may be new features added which may cause problems with your environment. ) - -## - -### How it Works - -
- -Apache ShardingSphere includes 2 independent products: JDBC & Proxy. -They all provide functions of data scale-out, distributed transaction and distributed governance, applicable in a variety of situations such as Java-based isomorphism, heterogeneous language and Cloud-Native. - -### ShardingSphere-JDBC - -
- -[](https://mvnrepository.com/artifact/org.apache.shardingsphere/shardingsphere-jdbc) - -A lightweight Java framework providing extra services at the Java JDBC layer. -With the client end connecting directly to the database, it provides services in the form of a jar and requires no extra deployment and dependence. - -:link: For more details, follow this [link to the official website](https://shardingsphere.apache.org/document/current/en/overview/#shardingsphere-jdbc). - -### ShardingSphere-Proxy - -
- -[](https://nightlies.apache.org/shardingsphere/) -[](https://www.apache.org/dyn/closer.lua/shardingsphere/5.3.2/apache-shardingsphere-5.3.2-shardingsphere-proxy-bin.tar.gz) -[](https://store.docker.com/community/images/apache/shardingsphere-proxy) - -A transparent database proxy, providing a database server that encapsulates the database binary protocol to support heterogeneous languages. -Friendlier to DBAs, the MySQL and PostgreSQL version now provided can use any kind of terminal. - -:link: For more details, follow this [link to the official website](https://shardingsphere.apache.org/document/current/en/overview/#shardingsphere-proxy). - -### Hybrid Architecture - -
- -ShardingSphere-JDBC adopts a decentralized architecture, applicable to high-performance light-weight OLTP applications developed with Java. -ShardingSphere-Proxy provides static entry and all languages support, suitable for an OLAP application and sharding databases management and operation. - -Through the combination of ShardingSphere-JDBC & ShardingSphere-Proxy together with a unified sharding strategy by the same registry center, the ShardingSphere ecosystem can build an application system suitable to all kinds of scenarios. - -:link: More details can be found following this [link to the official website](https://shardingsphere.apache.org/document/current/en/overview/#hybrid-architecture). - -## - -### Solution - -
- -| *Solutions/Features* | *Distributed Database* | *Data Security* | *Database Gateway* | *Stress Testing* | -|----------------------|-------------------------|----------------------|-----------------------------------|------------------| -| | Data Sharding | Data Encryption | Heterogeneous Databases Supported | Shadow Database | -| | Read/write Splitting | Row Authority (TODO) | SQL Dialect Translate (TODO) | Observability | -| | Distributed Transaction | SQL Audit (TODO) | | | -| | Elastic Scale-out | SQL Firewall (TODO) | | | -| | High Availability | | | | - -## - -### Roadmap - -
- - - -## - -### How to Build Apache ShardingSphere - -
- -Check out [Wiki](https://github.com/apache/shardingsphere/wiki) section for details on how to build Apache ShardingSphere and a full guide on how to get started and setup your local dev environment. - -## - -### Landscapes - -
- -
-
-
-
-Apache ShardingSphere enriches the CNCF CLOUD NATIVE Landscape.
-
 -
-- iPhone X
-
-
-
-- iPhone X
-
-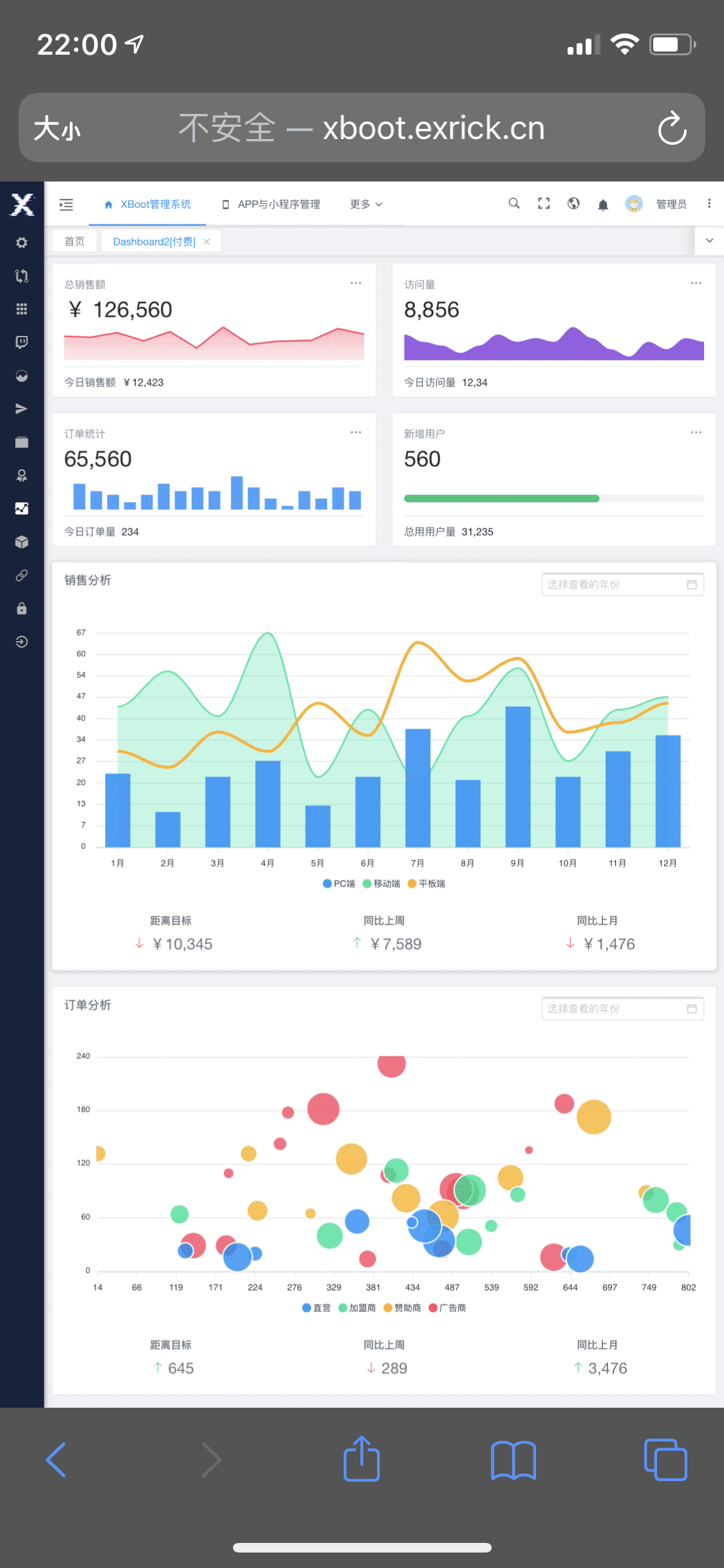 -
-
-### [完整版截图细节展示](https://github.com/Exrick/x-boot/wiki/%E5%AE%8C%E6%95%B4%E7%89%88%E6%88%AA%E5%9B%BE%E7%BB%86%E8%8A%82%E5%B1%95%E7%A4%BA)
-
-### 系统架构
-
-
-
-
-### [完整版截图细节展示](https://github.com/Exrick/x-boot/wiki/%E5%AE%8C%E6%95%B4%E7%89%88%E6%88%AA%E5%9B%BE%E7%BB%86%E8%8A%82%E5%B1%95%E7%A4%BA)
-
-### 系统架构
-
-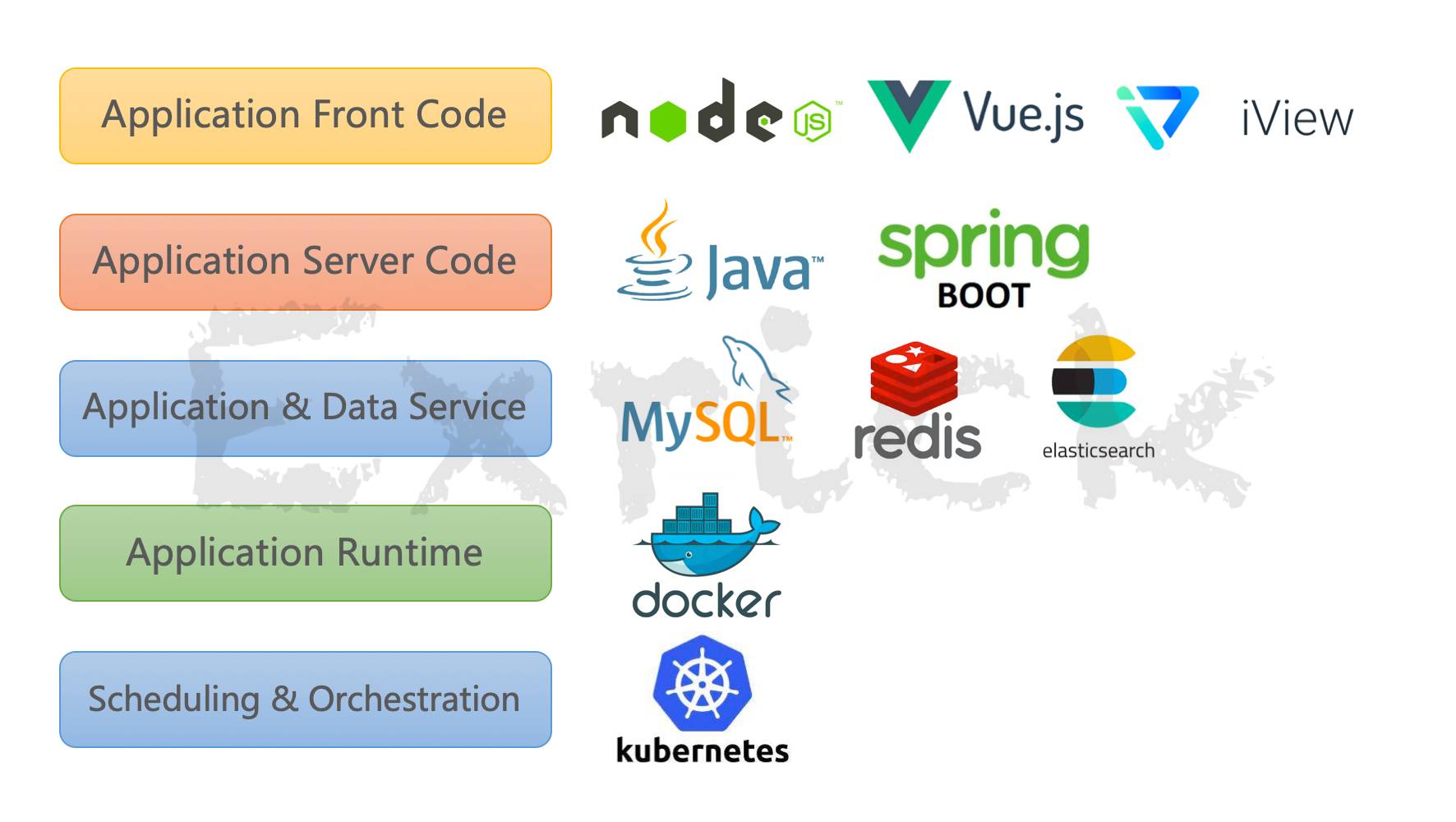 -
-##### 各框架依赖版本皆使用目前最新版本
-- Spring Boot
-- SpringMVC
-- Spring Security
-- [Spring Data JPA](https://docs.spring.io/spring-data/jpa/docs/2.2.2.RELEASE/reference/html/)
-- [MyBatis-Plus](http://mp.baomidou.com):已更新至3.x版本
-- [Redis](https://github.com/Exrick/xmall/blob/master/study/Redis.md)
-- [Elasticsearch](https://github.com/Exrick/xmall/blob/master/study/Elasticsearch.md):基于Lucene分布式搜索引擎
-- [Druid](http://druid.io/):阿里高性能数据库连接池(偏监控 注重性能可使用默认HikariCP) [Druid配置官方中文文档](https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter)
-- [Json Web Token(JWT)](https://jwt.io/)
-- [Quartz](http://www.quartz-scheduler.org):定时任务
-- [Beetl](http://ibeetl.com/guide/#beetl):模版引擎 代码生成使用
-- [Thymeleaf](https://www.thymeleaf.org/):发送模版邮件使用
-- [Hutool](http://hutool.mydoc.io/):Java工具包
-- [Jasypt](https://github.com/ulisesbocchio/jasypt-spring-boot):配置文件加密(thymeleaf作者开发)
-- [Swagger2](https://github.com/Exrick/xmall/blob/master/study/Swagger2.md):Api文档生成
-- MySQL
-- [Nginx](https://github.com/Exrick/xmall/blob/master/study/Nginx.md)
-- [Maven](https://github.com/Exrick/xmall/blob/master/study/Maven.md)
-- 第三方SDK或服务
- - [七牛云文件存储服务](https://developer.qiniu.com/kodo/sdk/1239/java)
- - [腾讯位置服务](https://lbs.qq.com/webservice_v1/guide-ip.html):需申请填入key后免费使用
- - 完整版
- - [Vaptcha人机验证码](https://www.vaptcha.com/)
- - [阿里云短信服务](https://dysms.console.aliyun.com)
-- 其它开发工具
- - [Lombok](https://projectlombok.org/)
- - [JRebel](https://github.com/Exrick/xmall/blob/master/study/JRebel.md):开发秒级热部署
- - [阿里JAVA开发规约插件](https://github.com/alibaba/p3c)
-
-### 最新最全面在线文档
-
-> 第一时间更新,文档永不收费
-
-https://www.kancloud.cn/exrick/xboot/content
-
-### 本地运行部署
-- 安装依赖并启动:[Redis](https://github.com/Exrick/xmall/blob/master/study/Redis.md)、[Elasticsearch](https://github.com/Exrick/xmall/blob/master/study/Elasticsearch.md)(当配置使用ES记录日志时需要)
-- [Maven安装和在IDEA中配置](https://github.com/Exrick/xmall/blob/master/study/Maven.md)
-- 建议使用IDEA([破解/免费注册](http://idea.lanyus.com/)) 安装 `Lombok` 插件后导入该Maven项目 若未自动下载依赖请在根目录下执行 `mvn install` 命令
-- MySQL数据库新建 `xboot` 数据库,配置文件已开启ddl自动生成表结构但无初始数据,请记得运行导入xboot.sql文件(当报错找不到Quartz相关表时请设置数据库忽略大小写或额外重新导入quartz.sql)
-- 修改配置文件 `application.yml` 相应配置,其中有详细注释,所有配置只需在这里修改
-- 编译器中启动运行 `XbootApplication.java` 或根目录下执行命令 `mvn spring-boot:run` 默认端口8888 访问接口文档 `http://localhost:8888/doc.html` 说明启动成功 管理员账密admin|123456
-- 前台页面请启动基于Vue的 [xboot-front](https://github.com/Exrick/xboot-front) 项目,并修改其接口代理配置
-> 温馨提示:若更新代码后报错,请记得更新sql并清空Redis缓存
-### 开发指南及相关技术栈文档
-- [项目基本配置和使用相关技术栈文档【必读】](https://github.com/Exrick/x-boot/wiki/%E9%A1%B9%E7%9B%AE%E5%9F%BA%E6%9C%AC%E9%85%8D%E7%BD%AE%E5%92%8C%E4%BD%BF%E7%94%A8%E7%9B%B8%E5%85%B3%E6%8A%80%E6%9C%AF%E6%A0%88%E6%96%87%E6%A1%A3%E3%80%90%E5%BF%85%E8%AF%BB%E3%80%91)
-- [如何使用XBoot后端在30秒内开发出增删改接口](https://github.com/Exrick/x-boot/wiki/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8XBoot%E5%90%8E%E7%AB%AF%E5%9C%A830%E7%A7%92%E5%86%85%E5%BC%80%E5%8F%91%E5%87%BA%E5%A2%9E%E5%88%A0%E6%94%B9%E6%8E%A5%E5%8F%A3)
-- [具体XBoot增删改文档示例](https://github.com/Exrick/x-boot/wiki/CRUD)
-- 完整版
- - [第三方社交账号登录配置](https://github.com/Exrick/x-boot/wiki/%E7%AC%AC%E4%B8%89%E6%96%B9%E7%A4%BE%E4%BA%A4%E8%B4%A6%E5%8F%B7%E7%99%BB%E5%BD%95%E9%85%8D%E7%BD%AE)
- - [短信登录配置](https://github.com/Exrick/x-boot/wiki/%E7%9F%AD%E4%BF%A1%E7%99%BB%E5%BD%95%E9%85%8D%E7%BD%AE)
- - [Vaptcha人机验证码配置使用](https://github.com/Exrick/x-boot/wiki/vaptcha%E4%BA%BA%E6%9C%BA%E9%AA%8C%E8%AF%81%E7%A0%81%E9%85%8D%E7%BD%AE%E4%BD%BF%E7%94%A8)
- - [Activiti工作流开发说明](https://github.com/Exrick/x-boot/wiki/Activiti%E5%B7%A5%E4%BD%9C%E6%B5%81%E5%BC%80%E5%8F%91%E8%AF%B4%E6%98%8E)
-
-### [分布式扩展](https://github.com/alibaba/dubbo-spring-boot-starter/blob/master/README_zh.md)
-
-### XBoot后端学习分享(更新中)
-1. [Spring Boot 2.x 区别总结](https://github.com/Exrick/x-boot/wiki/SpringBoot2.x%E5%8C%BA%E5%88%AB%E6%80%BB%E7%BB%93)
-
-2. [Spring Security整合JWT](https://github.com/Exrick/x-boot/wiki/SpringSecurity%E6%95%B4%E5%90%88JWT)
-
-3. [Spring Security实现动态数据库权限管理](https://github.com/Exrick/x-boot/wiki/SpringSecurity%E5%8A%A8%E6%80%81%E6%9D%83%E9%99%90%E7%AE%A1%E7%90%86)
-
-4. [Spring Boot 2.x整合Quartz](https://github.com/Exrick/x-boot/wiki/Spring-Boot-2.x%E6%95%B4%E5%90%88Quartz)
-
-5. [基于Websocket实现发送消息后右上角消息图标红点实时显示](https://github.com/Exrick/x-boot/wiki/%E5%9F%BA%E4%BA%8EWebsocket%E5%AE%9E%E7%8E%B0%E5%8F%91%E9%80%81%E6%B6%88%E6%81%AF%E5%90%8E%E5%8F%B3%E4%B8%8A%E8%A7%92%E6%B6%88%E6%81%AF%E5%9B%BE%E6%A0%87%E7%BA%A2%E7%82%B9%E5%AE%9E%E6%97%B6%E6%98%BE%E7%A4%BA)
-
-6. [Spring Boot 2.x整合Activiti工作流以及模型设计器](https://github.com/Exrick/x-boot/wiki/Spring-Boot-2.x%E6%95%B4%E5%90%88Activiti%E5%B7%A5%E4%BD%9C%E6%B5%81%E4%BB%A5%E5%8F%8A%E6%A8%A1%E5%9E%8B%E8%AE%BE%E8%AE%A1%E5%99%A8)
-### Docker下后端集群部署(更新中)
-
-> 前端集群部署请跳转至[xboot-front](https://github.com/Exrick/xboot-front)项目查看
-
-1.[Docker的安装与常用命令](https://github.com/Exrick/x-boot/wiki/Docker%E7%9A%84%E5%AE%89%E8%A3%85%E4%B8%8E%E5%B8%B8%E7%94%A8%E5%91%BD%E4%BB%A4)
-
-2.基于PXC架构Mysql数据库集群搭建
-
-3.Redis集群搭建
-
-4.Elasticsearch集群搭建
-
-5.XBoot后端集群部署
-
-### 商用授权
-- 个人学习使用遵循GPL开源协议
-- 商用需联系作者授权
-
-### 作者其他项目推荐
-- [XMall微信小程序APP前端 现已开源!](https://github.com/Exrick/xmall-weapp)
-
- [](https://www.bilibili.com/video/av70226175)
-
-- [XMall:基于SOA架构的分布式电商购物商城](https://github.com/Exrick/xmall)
-
- 
-
-- [XPay个人免签收款支付系统](https://github.com/Exrick/xpay)
-
-- 机器学习笔记
- - [Machine-Learning](https://github.com/Exrick/Machine-Learning)
-
-### 技术疑问交流
-- QQ交流群 `475743731(付费)`,可获取各项目详细图文文档、疑问解答 [](http://shang.qq.com/wpa/qunwpa?idkey=7b60cec12ba93ebed7568b0a63f22e6e034c0d1df33125ac43ed753342ec6ce7)
-- 免费交流群 `562962309` [](http://shang.qq.com/wpa/qunwpa?idkey=52f6003e230b26addeed0ba6cf343fcf3ba5d97829d17f5b8fa5b151dba7e842)
-- 作者博客:[http://blog.exrick.cn](http://blog.exrick.cn)
-### [捐赠](http://xpay.exrick.cn/pay)"
-alibaba/druid,master,27622,8518,2011-11-03T05:12:51Z,83924,2160,阿里云计算平台DataWorks(https://help.aliyun.com/document_detail/137663.html) 团队出品,为监控而生的数据库连接池,,"# druid
-
-[](https://github.com/alibaba/druid/actions/workflows/ci.yaml)
-[](https://codecov.io/gh/alibaba/druid/branch/master)
-[](https://search.maven.org/artifact/com.alibaba/druid)
-[](https://oss.sonatype.org/content/repositories/snapshots/com/alibaba/druid/)
-[](https://github.com/alibaba/druid/releases)
-[](https://www.apache.org/licenses/LICENSE-2.0.html)
-
-Introduction
----
-
-- git clone https://github.com/alibaba/druid.git
-- cd druid && mvn install
-- have fun.
-
-# 相关阿里云产品
-* [DataWorks数据集成](https://help.aliyun.com/document_detail/137663.html) 
-
-Documentation
----
-
-- 中文 https://github.com/alibaba/druid/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98
-- English https://github.com/alibaba/druid/wiki/FAQ
-- Druid Spring Boot Starter https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
-"
-itwanger/paicoding,main,1634,324,2022-07-06T12:43:21Z,15426,13,⭐️一款好用又强大的开源社区,基于 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等主流技术栈,附详细教程,包括Java、Spring、MySQL、Redis、微服务&分布式、消息队列等核心知识点。学编程,就上技术派😁。,java mybatis mysql redis spring springboot,"
-
-##### 各框架依赖版本皆使用目前最新版本
-- Spring Boot
-- SpringMVC
-- Spring Security
-- [Spring Data JPA](https://docs.spring.io/spring-data/jpa/docs/2.2.2.RELEASE/reference/html/)
-- [MyBatis-Plus](http://mp.baomidou.com):已更新至3.x版本
-- [Redis](https://github.com/Exrick/xmall/blob/master/study/Redis.md)
-- [Elasticsearch](https://github.com/Exrick/xmall/blob/master/study/Elasticsearch.md):基于Lucene分布式搜索引擎
-- [Druid](http://druid.io/):阿里高性能数据库连接池(偏监控 注重性能可使用默认HikariCP) [Druid配置官方中文文档](https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter)
-- [Json Web Token(JWT)](https://jwt.io/)
-- [Quartz](http://www.quartz-scheduler.org):定时任务
-- [Beetl](http://ibeetl.com/guide/#beetl):模版引擎 代码生成使用
-- [Thymeleaf](https://www.thymeleaf.org/):发送模版邮件使用
-- [Hutool](http://hutool.mydoc.io/):Java工具包
-- [Jasypt](https://github.com/ulisesbocchio/jasypt-spring-boot):配置文件加密(thymeleaf作者开发)
-- [Swagger2](https://github.com/Exrick/xmall/blob/master/study/Swagger2.md):Api文档生成
-- MySQL
-- [Nginx](https://github.com/Exrick/xmall/blob/master/study/Nginx.md)
-- [Maven](https://github.com/Exrick/xmall/blob/master/study/Maven.md)
-- 第三方SDK或服务
- - [七牛云文件存储服务](https://developer.qiniu.com/kodo/sdk/1239/java)
- - [腾讯位置服务](https://lbs.qq.com/webservice_v1/guide-ip.html):需申请填入key后免费使用
- - 完整版
- - [Vaptcha人机验证码](https://www.vaptcha.com/)
- - [阿里云短信服务](https://dysms.console.aliyun.com)
-- 其它开发工具
- - [Lombok](https://projectlombok.org/)
- - [JRebel](https://github.com/Exrick/xmall/blob/master/study/JRebel.md):开发秒级热部署
- - [阿里JAVA开发规约插件](https://github.com/alibaba/p3c)
-
-### 最新最全面在线文档
-
-> 第一时间更新,文档永不收费
-
-https://www.kancloud.cn/exrick/xboot/content
-
-### 本地运行部署
-- 安装依赖并启动:[Redis](https://github.com/Exrick/xmall/blob/master/study/Redis.md)、[Elasticsearch](https://github.com/Exrick/xmall/blob/master/study/Elasticsearch.md)(当配置使用ES记录日志时需要)
-- [Maven安装和在IDEA中配置](https://github.com/Exrick/xmall/blob/master/study/Maven.md)
-- 建议使用IDEA([破解/免费注册](http://idea.lanyus.com/)) 安装 `Lombok` 插件后导入该Maven项目 若未自动下载依赖请在根目录下执行 `mvn install` 命令
-- MySQL数据库新建 `xboot` 数据库,配置文件已开启ddl自动生成表结构但无初始数据,请记得运行导入xboot.sql文件(当报错找不到Quartz相关表时请设置数据库忽略大小写或额外重新导入quartz.sql)
-- 修改配置文件 `application.yml` 相应配置,其中有详细注释,所有配置只需在这里修改
-- 编译器中启动运行 `XbootApplication.java` 或根目录下执行命令 `mvn spring-boot:run` 默认端口8888 访问接口文档 `http://localhost:8888/doc.html` 说明启动成功 管理员账密admin|123456
-- 前台页面请启动基于Vue的 [xboot-front](https://github.com/Exrick/xboot-front) 项目,并修改其接口代理配置
-> 温馨提示:若更新代码后报错,请记得更新sql并清空Redis缓存
-### 开发指南及相关技术栈文档
-- [项目基本配置和使用相关技术栈文档【必读】](https://github.com/Exrick/x-boot/wiki/%E9%A1%B9%E7%9B%AE%E5%9F%BA%E6%9C%AC%E9%85%8D%E7%BD%AE%E5%92%8C%E4%BD%BF%E7%94%A8%E7%9B%B8%E5%85%B3%E6%8A%80%E6%9C%AF%E6%A0%88%E6%96%87%E6%A1%A3%E3%80%90%E5%BF%85%E8%AF%BB%E3%80%91)
-- [如何使用XBoot后端在30秒内开发出增删改接口](https://github.com/Exrick/x-boot/wiki/%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8XBoot%E5%90%8E%E7%AB%AF%E5%9C%A830%E7%A7%92%E5%86%85%E5%BC%80%E5%8F%91%E5%87%BA%E5%A2%9E%E5%88%A0%E6%94%B9%E6%8E%A5%E5%8F%A3)
-- [具体XBoot增删改文档示例](https://github.com/Exrick/x-boot/wiki/CRUD)
-- 完整版
- - [第三方社交账号登录配置](https://github.com/Exrick/x-boot/wiki/%E7%AC%AC%E4%B8%89%E6%96%B9%E7%A4%BE%E4%BA%A4%E8%B4%A6%E5%8F%B7%E7%99%BB%E5%BD%95%E9%85%8D%E7%BD%AE)
- - [短信登录配置](https://github.com/Exrick/x-boot/wiki/%E7%9F%AD%E4%BF%A1%E7%99%BB%E5%BD%95%E9%85%8D%E7%BD%AE)
- - [Vaptcha人机验证码配置使用](https://github.com/Exrick/x-boot/wiki/vaptcha%E4%BA%BA%E6%9C%BA%E9%AA%8C%E8%AF%81%E7%A0%81%E9%85%8D%E7%BD%AE%E4%BD%BF%E7%94%A8)
- - [Activiti工作流开发说明](https://github.com/Exrick/x-boot/wiki/Activiti%E5%B7%A5%E4%BD%9C%E6%B5%81%E5%BC%80%E5%8F%91%E8%AF%B4%E6%98%8E)
-
-### [分布式扩展](https://github.com/alibaba/dubbo-spring-boot-starter/blob/master/README_zh.md)
-
-### XBoot后端学习分享(更新中)
-1. [Spring Boot 2.x 区别总结](https://github.com/Exrick/x-boot/wiki/SpringBoot2.x%E5%8C%BA%E5%88%AB%E6%80%BB%E7%BB%93)
-
-2. [Spring Security整合JWT](https://github.com/Exrick/x-boot/wiki/SpringSecurity%E6%95%B4%E5%90%88JWT)
-
-3. [Spring Security实现动态数据库权限管理](https://github.com/Exrick/x-boot/wiki/SpringSecurity%E5%8A%A8%E6%80%81%E6%9D%83%E9%99%90%E7%AE%A1%E7%90%86)
-
-4. [Spring Boot 2.x整合Quartz](https://github.com/Exrick/x-boot/wiki/Spring-Boot-2.x%E6%95%B4%E5%90%88Quartz)
-
-5. [基于Websocket实现发送消息后右上角消息图标红点实时显示](https://github.com/Exrick/x-boot/wiki/%E5%9F%BA%E4%BA%8EWebsocket%E5%AE%9E%E7%8E%B0%E5%8F%91%E9%80%81%E6%B6%88%E6%81%AF%E5%90%8E%E5%8F%B3%E4%B8%8A%E8%A7%92%E6%B6%88%E6%81%AF%E5%9B%BE%E6%A0%87%E7%BA%A2%E7%82%B9%E5%AE%9E%E6%97%B6%E6%98%BE%E7%A4%BA)
-
-6. [Spring Boot 2.x整合Activiti工作流以及模型设计器](https://github.com/Exrick/x-boot/wiki/Spring-Boot-2.x%E6%95%B4%E5%90%88Activiti%E5%B7%A5%E4%BD%9C%E6%B5%81%E4%BB%A5%E5%8F%8A%E6%A8%A1%E5%9E%8B%E8%AE%BE%E8%AE%A1%E5%99%A8)
-### Docker下后端集群部署(更新中)
-
-> 前端集群部署请跳转至[xboot-front](https://github.com/Exrick/xboot-front)项目查看
-
-1.[Docker的安装与常用命令](https://github.com/Exrick/x-boot/wiki/Docker%E7%9A%84%E5%AE%89%E8%A3%85%E4%B8%8E%E5%B8%B8%E7%94%A8%E5%91%BD%E4%BB%A4)
-
-2.基于PXC架构Mysql数据库集群搭建
-
-3.Redis集群搭建
-
-4.Elasticsearch集群搭建
-
-5.XBoot后端集群部署
-
-### 商用授权
-- 个人学习使用遵循GPL开源协议
-- 商用需联系作者授权
-
-### 作者其他项目推荐
-- [XMall微信小程序APP前端 现已开源!](https://github.com/Exrick/xmall-weapp)
-
- [](https://www.bilibili.com/video/av70226175)
-
-- [XMall:基于SOA架构的分布式电商购物商城](https://github.com/Exrick/xmall)
-
- 
-
-- [XPay个人免签收款支付系统](https://github.com/Exrick/xpay)
-
-- 机器学习笔记
- - [Machine-Learning](https://github.com/Exrick/Machine-Learning)
-
-### 技术疑问交流
-- QQ交流群 `475743731(付费)`,可获取各项目详细图文文档、疑问解答 [](http://shang.qq.com/wpa/qunwpa?idkey=7b60cec12ba93ebed7568b0a63f22e6e034c0d1df33125ac43ed753342ec6ce7)
-- 免费交流群 `562962309` [](http://shang.qq.com/wpa/qunwpa?idkey=52f6003e230b26addeed0ba6cf343fcf3ba5d97829d17f5b8fa5b151dba7e842)
-- 作者博客:[http://blog.exrick.cn](http://blog.exrick.cn)
-### [捐赠](http://xpay.exrick.cn/pay)"
-alibaba/druid,master,27622,8518,2011-11-03T05:12:51Z,83924,2160,阿里云计算平台DataWorks(https://help.aliyun.com/document_detail/137663.html) 团队出品,为监控而生的数据库连接池,,"# druid
-
-[](https://github.com/alibaba/druid/actions/workflows/ci.yaml)
-[](https://codecov.io/gh/alibaba/druid/branch/master)
-[](https://search.maven.org/artifact/com.alibaba/druid)
-[](https://oss.sonatype.org/content/repositories/snapshots/com/alibaba/druid/)
-[](https://github.com/alibaba/druid/releases)
-[](https://www.apache.org/licenses/LICENSE-2.0.html)
-
-Introduction
----
-
-- git clone https://github.com/alibaba/druid.git
-- cd druid && mvn install
-- have fun.
-
-# 相关阿里云产品
-* [DataWorks数据集成](https://help.aliyun.com/document_detail/137663.html) 
-
-Documentation
----
-
-- 中文 https://github.com/alibaba/druid/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98
-- English https://github.com/alibaba/druid/wiki/FAQ
-- Druid Spring Boot Starter https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
-"
-itwanger/paicoding,main,1634,324,2022-07-06T12:43:21Z,15426,13,⭐️一款好用又强大的开源社区,基于 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等主流技术栈,附详细教程,包括Java、Spring、MySQL、Redis、微服务&分布式、消息队列等核心知识点。学编程,就上技术派😁。,java mybatis mysql redis spring springboot,"
-
-
-
-
-
-
-
-
-
-
-
-
-### Math
-
-View contents
- -* [`chunk`](#chunk) -* [`countOccurrences`](#countoccurrences) -* [`deepFlatten`](#deepflatten) -* [`difference`](#difference) -* [`differenceWith`](#differencewith) -* [`distinctValuesOfArray`](#distinctvaluesofarray) -* [`dropElements`](#dropelements) -* [`dropRight`](#dropright) -* [`everyNth`](#everynth) -* [`filterNonUnique`](#filternonunique) -* [`flatten`](#flatten) -* [`flattenDepth`](#flattendepth) -* [`groupBy`](#groupby) -* [`head`](#head) -* [`initial`](#initial) -* [`initializeArrayWithRange`](#initializearraywithrange) -* [`initializeArrayWithValues`](#initializearraywithvalues) -* [`intersection`](#intersection) -* [`isSorted`](#issorted) -* [`join`](#join) -* [`nthElement`](#nthelement) -* [`pick`](#pick) -* [`reducedFilter`](#reducedfilter) -* [`remove`](#remove) -* [`sample`](#sample) -* [`sampleSize`](#samplesize) -* [`shuffle`](#shuffle) -* [`similarity`](#similarity) -* [`sortedIndex`](#sortedindex) -* [`symmetricDifference`](#symmetricdifference) -* [`tail`](#tail) -* [`take`](#take) -* [`takeRight`](#takeright) -* [`union`](#union) -* [`without`](#without) -* [`zip`](#zip) -* [`zipObject`](#zipobject) - -
-
-
-### String
-
-View contents
- -* [`average`](#average) -* [`gcd`](#gcd) -* [`lcm`](#lcm) -* [`findNextPositivePowerOfTwo`](#findnextpositivepoweroftwo) -* [`isEven`](#iseven) -* [`isPowerOfTwo`](#ispoweroftwo) -* [`generateRandomInt`](#generaterandomint) - -
-
-
-### IO
-
-View contents
- -* [`anagrams`](#anagrams) -* [`byteSize`](#bytesize) -* [`capitalize`](#capitalize) -* [`capitalizeEveryWord`](#capitalizeeveryword) -* [`countVowels`](#countvowels) -* [`escapeRegExp`](#escaperegexp) -* [`fromCamelCase`](#fromcamelcase) -* [`isAbsoluteURL`](#isabsoluteurl) -* [`isLowerCase`](#islowercase) -* [`isUpperCase`](#isuppercase) -* [`isPalindrome`](#ispalindrome) -* [`isNumeric`](#isnumeric) -* [`mask`](#mask) -* [`reverseString`](#reversestring) -* [`sortCharactersInString`](#sortcharactersinstring) -* [`splitLines`](#splitlines) -* [`toCamelCase`](#tocamelcase) -* [`toKebabCase`](#tokebabcase) -* [`match`](#match) -* [`toSnakeCase`](#tosnakecase) -* [`truncateString`](#truncatestring) -* [`words`](#words) -* [`stringToIntegers`](#stringtointegers) - - -
-
-
-### Exception
-
-View contents
- -* [`convertInputStreamToString`](#convertinputstreamtostring) -* [`readFileAsString`](#readfileasstring) -* [`getCurrentWorkingDirectoryPath`](#getcurrentworkingdirectorypath) -* [`tmpDirName`](#tmpdirname) - -
-
-
-### System
-
-View contents
- -* [`stackTraceAsString`](#stacktraceasstring) - -
-
-
-### Class
-
-View contents
- -- [`osName`](#osname) -- [`isDebuggerEnabled`](#isdebuggerenabled) - -
-
-
-### Enum
-
-View contents
- -- [`getAllInterfaces`](#getallinterfaces) -- [`IsInnerClass`](#isinnerclass) - -
-
-
-## Array
-
-### chunk
-
-Chunks an array into smaller arrays of specified size.
-
-```java
-public static int[][] chunk(int[] numbers, int size) {
- return IntStream.iterate(0, i -> i + size)
- .limit((long) Math.ceil((double) numbers.length / size))
- .mapToObj(cur -> Arrays.copyOfRange(numbers, cur, cur + size > numbers.length ? numbers.length : cur + size))
- .toArray(int[][]::new);
-}
-```
-
-### concat
-
-```java
-public static View contents
- -- [`getEnumMap`](#getenummap) - -资源下载
- - canal server 服务端deployer: [https://github.com/alibaba/canal/releases/tag/canal-1.0.22](https://github.com/alibaba/canal/releases/tag/canal-1.0.22) - - - canal client 客户端: [https://github.com/liukelin/canal_mysql_nosql_sync/releases/tag/1.0.22.2](https://github.com/liukelin/canal_mysql_nosql_sync/releases/tag/1.0.22.2) - - 阿里canal项目原始地址:[https://github.com/alibaba/canal](https://github.com/alibaba/canal) - - 数据消费写入nosql例子: python_sync_nosql 这里是消费rabbitmq数据最终同步到redis - - 其他说明:[使用canal和canal_mysql_nosql_sync同步mysql数据](https://www.aliyun.com/jiaocheng/1114823.html?spm=5176.100033.2.18.hXjlSb) - -使用golang语言开发的版本:[https://github.com/liukelin/bubod](https://github.com/liukelin/bubod) - - -" -LillteZheng/ViewPagerHelper,master,1163,161,2017-11-12T10:07:27Z,80880,1,这个一个 viewpager/viewpager2工具类,能够帮你快速实现导航栏轮播图,app引导页,viewpager/viewpager2 + fragment;内置多种tab指示器,让你告别 viewpager 的繁琐操作,专注逻辑功能,arc banner banner2 circleindicator fragment-tab-viewpager tabindicator tablayout viewpager viewpager2," -你是否有遇到这样的问题,每次开发一个新的项目,在 viewpager 这一块上,总是在做重复的东西,比如app引导页,轮播图, -viewpager+fragment 的 tab 指示器等等,这些虽然简单,但却是每个app都要的,而且很耗时,有没有每次在写这个,都很无语的感觉呢? -基于这个,ViewPagerHleper 就诞生了,它可以快速帮你搞定 banner 轮播图,实现高级定制化,内置多种指示器,满足你的日常需求,妈妈再也不用担心我不会复制粘贴了。 - -[](https://jitpack.io/#LillteZheng/ViewPagerHelpe) - - -[](https://blog.csdn.net/u011418943) - - - -**工程实际使用 - 玩Android 客户端 : https://github.com/LillteZheng/WanAndroid** - - -**注意注意注意!!!** -**提问题的时候,请遵循以下标准** - -- **现象: 操作步骤,应用场景** -- **对应代码: 贴图或者贴代码** -- **机型或版本: 可选** - -**后面对描述不清的问题,不予理会,精力有限,感谢理解** - - -详细内容可以参考这篇博客: -http://blog.csdn.net/u011418943/article/details/78493002 - -## **使用** -这里用的是 jitpack 这个网站,所以: - -``` -allprojects { - repositories { - ... - maven { url 'https://jitpack.io' } - } -} -``` -然后在你的 module 中添加: - -``` -implementation 'com.github.LillteZheng.ViewPagerHelper:viewpagerlib:v2.9' -``` - -**如果你使用 androidx 也想要使用 ViewPager2,可以添加 androidx 库** - -``` -implementation 'com.github.LillteZheng.ViewPagerHelper:viewpagerlibx:v2.9' -``` - -> ViewPager2 使用的是 BannerViewPager2 这个类,只支持横向的 ViewPager2,竖直的后面有时间再搞 -> 使用与 BannerViewPageer 一样,只是多了 **banner2_l_margin和banner2_r_margin**,或者**setMzMargin()** -> 去设置一屏多页(魅族)的效果。 - - - -## **效果图** - -首先,大家最常用到的就是轮播图了,这里给大家提供了 常用的 Indicator - -### **轮播图** - -| 文字效果 | -扇形效果 | -
|---|---|
| CircleIndicator | -RectIndicator | -
|---|---|
| 图片放大效果 | -卡片效果 | -
|---|---|
| 三角形版本 | -条形状版本 | -文字颜色渐变方式,加了滚动效果 | -
|---|---|---|
| 没有结合ViewPager | -结合ViewPager | -
|---|---|
| 弧形图片 | -
|---|
CircleDisplay, define it in .xml:
-```xml
- CircleDisplay, and **show values**.
-
-**Styling methods:**
- - setColor(int color): Use this method to set the color for the arc/bar that represents the value. You can either use Color.COLORNAME as a parameter or getColor(resid).
- - setStartAngle(float angle): Set the starting angle of your arc/bar. By default, it starts at the top of the view (270°).
- - setAnimDuration(int millis): Set the duration in milliseconds it takes to animate/build up the bar.
- - setTextSize(float size): Set the size of the text in the center of the view.
- - setValueWidthPercent(float percentFromTotalWidth): Set the width of the value bar/arc in percent of the circle radius.
- - setFormatDigits(int digits): Sets the number of digits to use for the value in the center of the view.
- - setDimAlpha(int alpha): Value between 0 and 255 indicating the alpha value used for the remainder of the value-arc.
- - setDrawText(boolean enabled): If enabled, center text (containing value and unit) is drawn.
- - setPaint(int which, Paint p): Sets a new Paint object instead of the default one. Use CircleDisplay.PAINT_TEXT for example to change the text paint used.
- - setUnit(String unit): Sets a unit that is displayed in the center of the view. E.g. ""%"" or ""€"" or whatever it is you want the circle-display to represent.
- - setStepSize(float stepsize): Sets the stepsize (minimum selection interval) of the circle display,
-default 1f. It is recommended to make this value not higher than 1/5 of the maximum selectable value, and not lower than 1/200 of the maximum selectable value. For example, if a maximum of 100 has been chosen, a stepsize between 0.5 and 20 is recommended.
- - setCustomText(String[] custom): Sets an array of custom Strings to be drawn instead of the actual value in the center of the CircleDisplay. If set to null, the custom text will be reset and the value will be drawn. Make sure the length of the array corresponds with the maximum number of steps (maxvalue / stepsize).
-
-**Showing stuff:**
- - public void showValue(float toShow, float total, boolean animated): Shows the given value. A maximumvalue also needs to be provided. Set animated to true to animate the displaying of the value.
-
-
-**Selecting values:**
- - **IMPORTANT** for selecting values onTouch(): Make sure to call showValue(...) at least once before trying to select values by touching. This is needed to set a maximum value that can be chosen on touch. Calling showValue(0, 1000, false) before touching as an example will allow the user to choose a value between 0 and 1000, default 0.
- - setTouchEnabled(boolean enabled): Set this to true to allow touch-gestures / selecting.
- - setSelectionListener(SelectionListener l): Set a SelectionListener for callbacks when selecting values with touch-gestures.
-
-
-**Full example:**
-```java
- CircleDisplay cd = (CircleDisplay) findViewById(R.id.circleDisplay);
- cd.setAnimDuration(3000);
- cd.setValueWidthPercent(55f);
- cd.setTextSize(36f);
- cd.setColor(Color.GREEN);
- cd.setDrawText(true);
- cd.setDrawInnerCircle(true);
- cd.setFormatDigits(1);
- cd.setTouchEnabled(true);
- cd.setSelectionListener(this);
- cd.setUnit(""%"");
- cd.setStepSize(0.5f);
- // cd.setCustomText(...); // sets a custom array of text
- cd.showValue(75f, 100f, true);
-```
-
-License
-=======
-Copyright 2014 Philipp Jahoda
-
-Licensed under the Apache License, Version 2.0 (the ""License"");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an ""AS IS"" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
-"
-pravega/pravega,master,1965,402,2016-07-11T19:41:03Z,49362,244,Pravega - Streaming as a new software defined storage primitive,data-ingestion distributed-storage real-time-data streaming streaming-data,"
-# Pravega [](https://github.com/pravega/pravega/actions?query=branch%3Amaster) [](https://codecov.io/gh/pravega/pravega) [](https://www.apache.org/licenses/LICENSE-2.0) [](https://github.com/pravega/pravega/releases) [](https://bestpractices.coreinfrastructure.org/projects/4178)
-
-Pravega is an open source distributed storage service implementing **Streams**. It offers Stream as the main primitive for the foundation of reliable storage systems: a *high-performance, durable, elastic, and unlimited append-only byte stream with strict ordering and consistency*.
-
-To learn more about Pravega, visit https://pravega.io
-
-## Prerequisites
-
-- Java 11+
-
- In spite of the requirements of using JDK 11+ to build this project, `client` artifacts (and its dependencies) must be compatible with a *Java 8* runtime. All other components are built and ran using JDK11+.
-
-The `clientJavaVersion` project property determines the version used to build the client (defaults to *8*).
-## Building Pravega
-
-Checkout the source code:
-
-```
-git clone https://github.com/pravega/pravega.git
-cd pravega
-```
-
-Build the pravega distribution:
-
-```
-./gradlew distribution
-```
-
-Install pravega jar files into the local maven repository. This is handy for running the `pravega-samples` locally against a custom version of pravega.
-
-```
-./gradlew install
-```
-
-Running unit tests:
-
-```
-./gradlew test
-```
-
-## Setting up your IDE
-
-Pravega uses [Project Lombok](https://projectlombok.org/) so you should ensure you have your IDE setup with the required plugins. Using IntelliJ is recommended.
-
-To import the source into IntelliJ:
-
-1. Import the project directory into IntelliJ IDE. It will automatically detect the gradle project and import things correctly.
-2. Enable `Annotation Processing` by going to `Build, Execution, Deployment` -> `Compiler` > `Annotation Processors` and checking 'Enable annotation processing'.
-3. Install the `Lombok Plugin`. This can be found in `Preferences` -> `Plugins`. Restart your IDE.
-4. Pravega should now compile properly.
-
-For eclipse, you can generate eclipse project files by running `./gradlew eclipse`.
-
- Note: Some unit tests will create (and delete) a significant amount of files. For improved performance on Windows machines, be sure to add the appropriate 'Microsoft Defender' exclusion.
-
-## Releases
-
-The latest pravega releases can be found on the [Github Release](https://github.com/pravega/pravega/releases) project page.
-
-## Snapshot artifacts
-
-All snapshot artifacts from `master` and `release` branches are available in GitHub Packages Registry
-
-Add the following to your repositories list and import dependencies as usual.
-
-```
-maven {
- url ""https://maven.pkg.github.com/pravega/pravega""
- credentials {
- username = ""pravega-public""
- password = ""\u0067\u0068\u0070\u005F\u0048\u0034\u0046\u0079\u0047\u005A\u0031\u006B\u0056\u0030\u0051\u0070\u006B\u0079\u0058\u006D\u0035\u0063\u0034\u0055\u0033\u006E\u0032\u0065\u0078\u0039\u0032\u0046\u006E\u0071\u0033\u0053\u0046\u0076\u005A\u0049""
- }
-}
-```
-Note GitHub Packages requires authentication to download packages thus credentials above are required. Use the provided password as is, please do not decode it.
-
-If you need a dedicated token to use in your repository (and GitHub Actions) please reach out to us.
-
-As alternative option you can use JitPack (https://jitpack.io/#pravega/pravega) to get pre-release artifacts.
-
-## Quick Start
-
-Read [Getting Started](documentation/src/docs/getting-started/quick-start.md) page for more information, and also visit [sample-apps](https://github.com/pravega/pravega-samples) repo for more applications.
-
-## Running Pravega
-
-Pravega can be installed locally or in a distributed environment. The installation and deployment of pravega is covered in the [Running Pravega](documentation/src/docs/deployment/deployment.md) guide.
-
-## Support
-
-Don’t hesitate to ask! Contact the developers and community on [slack](https://pravega-io.slack.com/)
-([signup](https://join.slack.com/t/pravega-io/shared_invite/zt-245sgpw47-vbLBLiLfBdW9TlKemXkUnw)) if you need any help.
-Open an issue if you found a bug on [Github Issues](https://github.com/pravega/pravega/issues).
-
-## Documentation
-
-The Pravega documentation is hosted on the website:
-创建时间:2015-11-16
文章数:17篇
[RSS订阅](http://blog.csdn.net/xiaoxian8023/rss/list)
[轻松把玩HttpClient](http://blog.csdn.net/column/details/httpclient-arron.html)
介绍如何使用HttpClient,通过一些简单示例,来帮助初学者快速入手。
同时提供了一个非常强大的工具类,比现在网络上分享的都强大:
支持插件式设置header、代理、ssl等配置信息,支持携带Cookie的操作,支持http的各种方法,支持上传、下载等功能。 ----|--- - - ---- - -# 最新更新文章 -##  [轻松把玩HttpClient之封装HttpClient工具类(九),添加多文件上传功能](http://blog.csdn.net/xiaoxian8023/article/details/53065507) -``` -在Git上有人给我提Issue,说怎么上传文件,其实我一开始就想上这个功能,不过这半年比较忙,所以一直耽搁了。 -这次正好没什么任务了,赶紧完成这个功能。毕竟作为一款工具类,有基本的请求和下载功能,就差上... -``` -##  [轻松把玩HttpClient之封装HttpClient工具类(八),优化启用Http连接池策略](http://blog.csdn.net/xiaoxian8023/article/details/53064210) -``` -写了HttpClient工具类后,有人一直在问我怎么启用http连接池,其实我没考虑过这个问题难过。 -不过闲暇的时候,突然间想起了这个问题,就想把这个问题搞一搞。 -``` -##  [轻松把玩HttpClient之封装HttpClient工具类(七),新增验证码识别功能](http://blog.csdn.net/xiaoxian8023/article/details/51606865) -``` -这个HttpClientUtil工具类分享在GitHub上已经半年多的时间了,并且得到了不小的关注,有25颗star,被fork了38次。 -有了大家的鼓励,工具类一直也在完善中。最近比较忙,两个多月前的修改在今天刚修改测试完成,今天再次分享给大家。 -验证码识别这项技术并不是本工具类的功能,而是通过一个开源的api来识别验证码的。 -这里做了一个简单的封装,主要是用来解决登陆时的验证码的问题。... -``` -##  [轻松把玩HttpClient之封装HttpClient工具类(六),封装输入参数,简化工具类](http://blog.csdn.net/xiaoxian8023/article/details/50768320) -``` -在写这个工具类的时候发现传入的参数太多,以至于方法泛滥,只一个send方法就有30多个, -所以对工具类进行了优化,把输入参数封装在一个对象里,这样以后再扩展输入参数,直接修改这个类就ok了。 -``` -##  [轻松把玩HttpClient之封装HttpClient工具类(五),携带Cookie的请求](http://blog.csdn.net/xiaoxian8023/article/details/50474987) -``` -最近更新了一下HttpClientUtil工具类代码,主要是添加了一个参数HttpContext,这个是用来干嘛的呢? -其实是用来保存和传递Cookie所需要的。因为我们有很多时候都需要登录,然后才能请求一些想要的数据。 -而在这以前使用HttpClientUtil工具类,还不能办到。现在更新了以后,终于可以了。 -先说一下思路:本次的demo,就是获取csdn中的c币,要想获取c币,必须先登... -``` -##  [轻松把玩HttpAsyncClient之模拟post请求示例](http://blog.csdn.net/xiaoxian8023/article/details/49949813) -``` -如果看到过我前些天写过的《轻松把玩HttpClient之模拟post请求示例》这篇文章,你再看本文就是小菜一碟了,如果你顺便懂一些NIO,基本上是毫无压力了。 -因为HttpAsyncClient相对于HttpClient,就多了一个NIO,这也是为什么支持异步的原因。 -不过我有一个疑问,虽说NIO是同步非阻塞IO,但是HttpAsyncClient提供了回调的机制, -这点儿跟netty很像,所以可以模拟... -``` -##  [轻松把玩HttpClient之封装HttpClient工具类(四),单线程调用及多线程批量调用测试](http://blog.csdn.net/xiaoxian8023/article/details/49910885) -``` -本文主要来分享一下该工具类的测试结果。工具类的整体源码不再单独分享,源码基本上都已经在文章中了。 -开始我们的测试。单线程调用测试: - public static void testOne() throws HttpProcessException{ - - System.out.println(""--------简单方式调用(默认post)--------""); - String url = ""http://... -``` -##  [轻松把玩HttpClient之封装HttpClient工具类(三),插件式配置Header](http://blog.csdn.net/xiaoxian8023/article/details/49910127) -``` -上篇文章介绍了插件式配置HttpClient,本文将介绍插件式配置Header。为什么要配置header在前面已经提到了,还里再简单说一下, -要使用HttpClient模拟请求,去访问各种接口或者网站资源,都有可能有各种限制, -比如说java客户端模拟访问csdn博客,就必须设置User-Agent,否则就报错了。 -还有各种其他情况,必须的设置一些特定的Header,才能请求成功,或者才能不出问题。好了... -``` -##  [轻松把玩HttpClient之封装HttpClient工具类(二),插件式配置HttpClient对象](http://blog.csdn.net/xiaoxian8023/article/details/49909359) -``` -上一篇文章中,简单分享一下封装HttpClient工具类的思路及部分代码,本文将分享如何实现插件式配置HttpClient对象。 -如果你看过我前面的几篇关于HttpClient的文章或者官网示例,应该都知道HttpClient对象在创建时,都可以设置各种参数, -但是却没有简单的进行封装,比如对我来说比较重要的3个: -代理、ssl(包含绕过证书验证和自定义证书验证)、超时。还需要自己写。 -所以这里我就简单封... -``` -##  [轻松把玩HttpClient之封装HttpClient工具类(一)(现有网上分享中的最强大的工具类)](http://blog.csdn.net/xiaoxian8023/article/details/49883113) -``` -搜了一下网络上别人封装的HttpClient,大部分特别简单,有一些看起来比较高级,但是用起来都不怎么好用。 -调用关系不清楚,结构有点混乱。所以也就萌生了自己封装HttpClient工具类的想法。 -要做就做最好的,本工具类支持插件式配置Header、插件式配置httpclient对象, -这样就可以方便地自定义header信息、配置ssl、配置proxy等。是不是觉得说的有点悬乎了,那就先看看调用吧:... -``` -##  [轻松把玩HttpClient之设置代理,可以访问FaceBook](http://blog.csdn.net/xiaoxian8023/article/details/49867257) -``` -前面的文章介绍了一些HttpClient的简单示例,本文继续采用示例的方式来演示HttpClient的功能。 -在项目中我们可能会遇到这样的情况:为了保证系统的安全性,只允许使用特定的代理才可以访问, -而与这些系统使用HttpClient进行交互时,只能为其配置代理。 -这里我们使用gogent代理访问脸书来模拟这种情况。现在在浏览器上访问是可以访问的:... -``` -##  [轻松把玩HttpClient之配置ssl,采用设置信任自签名证书实现https](http://blog.csdn.net/xiaoxian8023/article/details/49866397) -``` -在上篇文章《HttpClient配置ssl实现https简单示例——绕过证书验证》中简单分享了一下如何绕过证书验证。 -如果你想用httpclient访问一个网站,但是对方的证书没有通过ca认证或者其他问题导致证书不被信任, -比如12306的证书就是这样的。所以对于这样的情况,你只能是选择绕过证书验证的方案了。 -但是,如果是自己用jdk或者其他工具生成的证书,还是希望用其他方式认证自签名的证书,这篇文... -``` -##  [轻松把玩HttpClient之配置ssl,采用绕过证书验证实现https](http://blog.csdn.net/xiaoxian8023/article/details/49865335) -``` -上篇文章说道httpclient不能直接访问https的资源,这次就来模拟一下环境,然后配置https测试一下。 -在前面的文章中,分享了一篇自己生成并在tomcat中配置ssl的文章《Tomcat配置SSL》,大家可以据此来在本地配置https。 -我已经配置好了,效果是这样滴: -可以看到已经信任该证书(显示浅绿色小锁),浏览器可以正常访问。现在我们用代码测试一下: -``` -##  [轻松把玩HttpClient之模拟post请求示例](http://blog.csdn.net/xiaoxian8023/article/details/49863967) -``` -HttpClient 是 Apache Jakarta Common 下的子项目,可以用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。 -许多需要后台模拟请求的系统或者框架都用的是httpclient。所以作为一个java开发人员,有必要学一学。 -本文提供了一个简单的demo,供初学者参考。 -``` -##  [简单的利用UrlConnection,后台模拟http请求](http://blog.csdn.net/xiaoxian8023/article/details/49785417) -``` -这两天在整理看httpclient,然后想自己用UrlConnection后台模拟实现Http请求,于是一个简单的小例子就新鲜出炉了(支持代理哦): - public class SimpleHttpTest { - - public static String send(String urlStr, Map map,String encoding){ - String body=""""; - Strin... -``` -" -nanchen2251/CompressHelper,master,2484,414,2017-03-16T07:20:08Z,1159,27,":fire: 压缩文件,压缩图片,压缩Bitmap,Compress, CompressImage, CompressFile, CompressBitmap:https://github.com/nanchen2251/AiYaCompressHelper",compress compressed-files compresshelper compressimage file image,"# AiYaCompressHelper -压缩,图片压缩,压缩Bitmap,Compress,CompressImage,CompressFile,CompressBitmap
- -主要通过尺寸压缩和质量压缩,以达到清晰度最优,该项目参考了 [https://github.com/zetbaitsu/Compressor](https://github.com/zetbaitsu/Compressor) 的部分代码,且在基础上修正了部分 bug - - - -## 效果图
- - -#### ⊙开源不易,希望给个 star 或者 fork 奖励 -#### ⊙拥抱开源:https://github.com/nanchen2251/ -#### ⊙交流群(拒绝无脑问):118116509
- -## 特点 - 1、支持压缩单张图片和多张图片
-## 使用方法 -#### 1、添加依赖
-##### Step 1. Add it in your root build.gradle at the end of repositories: -```java -allprojects { - repositories { - ... - maven { url 'https://jitpack.io' } - } - } -``` -##### Step 2. Add the dependency -```java -dependencies { - implementation 'com.github.nanchen2251:CompressHelper:1.0.5' - } -``` -#### 2、在Activity里面使用
-```java - File newFile = CompressHelper.getDefault(this).compressToFile(oldFile); -``` -#### 3、你也可以自定义属性 -```java - File newFile = new CompressHelper.Builder(this) - .setMaxWidth(720) // 默认最大宽度为720 - .setMaxHeight(960) // 默认最大高度为960 - .setQuality(80) // 默认压缩质量为80 - .setFileName(yourFileName) // 设置你需要修改的文件名 - .setCompressFormat(CompressFormat.JPEG) // 设置默认压缩为jpg格式 - .setDestinationDirectoryPath(Environment.getExternalStoragePublicDirectory( - Environment.DIRECTORY_PICTURES).getAbsolutePath()) - .build() - .compressToFile(oldFile); -``` -该项目参考了: - -* [https://github.com/zetbaitsu/Compressor](https://github.com/zetbaitsu/Compressor) -* [https://github.com/Curzibn/Luban](https://github.com/Curzibn/Luban) - -### 关于作者 - 南尘
- 四川成都
- [其它开源](https://github.com/nanchen2251/)
- [个人博客](https://nanchen2251.github.io/)
- [简书](http://www.jianshu.com/u/f690947ed5a6)
- [博客园](http://www.cnblogs.com/liushilin/)
- 交流群:118116509
- 欢迎投稿(关注)我的唯一公众号,公众号搜索 nanchen 或者扫描下方二维码:
-  - - -#### 有码走遍天下 无码寸步难行(引自网络) - -> 1024 - 梦想,永不止步! -爱编程 不爱Bug -爱加班 不爱黑眼圈 -固执 但不偏执 -疯狂 但不疯癫 -生活里的菜鸟 -工作中的大神 -身怀宝藏,一心憧憬星辰大海 -追求极致,目标始于高山之巅 -一群怀揣好奇,梦想改变世界的孩子 -一群追日逐浪,正在改变世界的极客 -你们用最美的语言,诠释着科技的力量 -你们用极速的创新,引领着时代的变迁 - -------至所有正在努力奋斗的程序猿们!加油!! - -## Licenses -``` - Copyright 2017 nanchen(刘世麟) - - Licensed under the Apache License, Version 2.0 (the ""License""); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - - Unless required by applicable law or agreed to in writing, software - distributed under the License is distributed on an ""AS IS"" BASIS, - WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the License for the specific language governing permissions and - limitations under the License. -``` -" -cundong/HeaderAndFooterRecyclerView,master,1370,322,2015-10-30T12:47:33Z,492,27,"A RecyclerView solution, support addHeaderView、addFooterView",,"## HeaderAndFooterRecyclerView - -## Introduction - -HeaderAndFooterRecyclerView is a RecyclerView solution that supports addHeaderView, addFooterView to a RecyclerView. - -Through this library, you can implement RecyclerView's Page Loading by dynamically modify the FooterView's State, such as ""loading"", ""loading error"", ""loading success"", ""slipping to the bottom"". - -## How to Use It - -* Add HeaderView, FooterView -```java - mHeaderAndFooterRecyclerViewAdapter = new HeaderAndFooterRecyclerViewAdapter(mDataAdapter); - mRecyclerView.setAdapter(mHeaderAndFooterRecyclerViewAdapter); - mRecyclerView.setLayoutManager(new LinearLayoutManager(this)); - - //add a HeaderView - RecyclerViewUtils.setHeaderView(mRecyclerView, new SampleHeader(this)); - - //add a FooterView - RecyclerViewUtils.setFooterView(mRecyclerView, new SampleFooter(this)); -``` -* LinearLayout / GridLayout / StaggeredGridLayout layout of RecyclerView paging load - -```java -mRecyclerView.addOnScrollListener(mOnScrollListener); -``` - -```java -private EndlessRecyclerOnScrollListener mOnScrollListener = new EndlessRecyclerOnScrollListener() { - - @Override - public void onLoadNextPage(View view) { - super.onLoadNextPage(view); - - LoadingFooter.State state = RecyclerViewStateUtils.getFooterViewState(mRecyclerView); - if(state == LoadingFooter.State.Loading) { - Log.d(""@Cundong"", ""the state is Loading, just wait..""); - return; - } - - mCurrentCounter = mDataList.size(); - - if (mCurrentCounter < TOTAL_COUNTER) { - // loading more - RecyclerViewStateUtils.setFooterViewState(EndlessLinearLayoutActivity.this, mRecyclerView, REQUEST_COUNT, LoadingFooter.State.Loading, null); - requestData(); - } else { - //the end - RecyclerViewStateUtils.setFooterViewState(EndlessLinearLayoutActivity.this, mRecyclerView, REQUEST_COUNT, LoadingFooter.State.TheEnd, null); - } - } - }; -``` - -## Attention - -If you have already added a HeaderView for RecyclerView by ```RecyclerViewUtils.setHeaderView(mRecyclerView, view);``` , then call the ViewHolder 's ```getAdapterPosition()```、```getLayoutPosition()```, ,the returned value will be affected by the addition of the HeaderView (the return position is the real position + headerCounter). - -Therefore, in this case, please use: ```RecyclerViewUtils.getAdapterPosition(mRecyclerView, ViewHolder.this)```, ```RecyclerViewUtils.getLayoutPosition(mRecyclerView, ViewHolder.this)```. - -## Demo - -* Add HeaderView, FooterView - -![Screenshots][1] - -* Support for ply loading of the LinearLayout layout RecyclerView - -![Screenshots][2] - -* Support for paging loads of GridLayout layout RecyclerView - -![Screenshots][3] - -* Supports paging loads of StaggeredGridLayout layout RecyclerView - -![Screenshots][4] - -* The page load fails when the GridLayout layout is RecyclerView - -![Screenshots][5] - - -## License - -> Copyright 2015 Cundong -> -> Licensed under the Apache License, Version 2.0 (the ""License""); you -> may not use this file except in compliance with the License. You may -> obtain a copy of the License at -> -> http://www.apache.org/licenses/LICENSE-2.0 -> -> Unless required by applicable law or agreed to in writing, software -> distributed under the License is distributed on an ""AS IS"" BASIS, -> WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or -> implied. See the License for the specific language governing -> permissions and limitations under the License. - -[1]: https://raw.githubusercontent.com/cundong/HeaderAndFooterRecyclerView/master/art/art1.png -[2]: https://raw.githubusercontent.com/cundong/HeaderAndFooterRecyclerView/master/art/art2.png -[3]: https://raw.githubusercontent.com/cundong/HeaderAndFooterRecyclerView/master/art/art3.png -[4]: https://raw.githubusercontent.com/cundong/HeaderAndFooterRecyclerView/master/art/art4.png -[5]: https://raw.githubusercontent.com/cundong/HeaderAndFooterRecyclerView/master/art/art5.png -" -OpnTec/ots15-companion,master,1391,5,2015-05-05T13:32:22Z,1290,5,Opentech Event app,,"# OpenTech summit 2015 app based on FOSSASIA companion-android - -Advanced native Android schedule browser application for the [FOSSASIA](http://fossasia.org/) conference in Singapore. - -This is build upon the [FOSDEM Companion For android](https://github.com/cbeyls/fosdem-companion-android). It uses loaders and fragments extensively and is backward compatible up to Android 2.1 thanks to the support library. - -To get more information and install the app, look at the [Google Play Store](https://play.google.com/store/apps/details?id=be.digitalia.fosdem) page. - -## How to build - -All dependencies are defined in ```app/build.gradle```. Import the project in Android Studio or use Gradle in command line: - -``` -./gradlew assembleRelease -``` - -The result apk file will be placed in ```app/build/outputs/apk/```. - -####Build status -[](https://travis-ci.org/fossasia/ots15-companion) - -## Pending Task -* Download schedule in a background thread -* Notification for Bookmarked Events/Talks -* Integrate Google+ login or any other mechanism to fetch user email address [TBD](https://github.com/fossasia/fossasia-companion-android/issues/68) -* Integrate Google Maps - - - - -## License - -[Apache License, Version 2.0](http://www.apache.org/licenses/LICENSE-2.0) - -## Used libraries - -* [Android Support Library](http://developer.android.com/tools/support-library/) by The Android Open Source Project -* [ViewPagerIndicator](http://viewpagerindicator.com/) by Jake Wharton -* [PhotoView](https://github.com/chrisbanes/PhotoView) by Chris Banes -* [Volley Library](https://android.googlesource.com/platform/frameworks/volley) -* [Snackbar Library](https://github.com/nispok/snackbar) by nispok -## Contributors - -* Christophe Beyls -* Abhishek Batra -* Manan Wason -* Pratik Todi -* Mario Behling -* Tymon Radzik -* Arnav Gupta - -" -borball/weixin-sdk,master,1038,489,2015-09-25T02:43:29Z,5754,22,微信公众平台(订阅号、服务号、企业号、小程序)、微信开放平台和微信支付 Java SDK,wechat-java wechat-sdk weixin weixin-java weixin-sdk,"# 微信公众平台(服务号、订阅号、企业号、小程序)、微信开放平台和微信支付JAVA SDK - -[](https://semaphoreci.com/borball/weixin-sdk) [](https://jitpack.io/#borball/weixin-sdk) [](https://maven-badges.herokuapp.com/maven-central/cn.com.riversoft/weixin-sdk) - - -weixin-sdk 是对微信公众平台(订阅号、服务号、企业号、小程序)、微信开放平台和微信支付的JAVA版封装: - - - 服务号,订阅号: weixin-mp - - 企业号: weixin-qydev - - 开放平台: weixin-open - - 支付: weixin-pay - - 小程序: weixin-app - -[API使用指南](https://github.com/borball/weixin-sdk/wiki) - -[SDK DEMO](https://github.com/borball/weixin-sdk-demo) - -## 如何获取 - -### Maven - - - 服务号,订阅号: - -
[groupId: com.mchange, artifactId: c3p0] For available versions, look [here](https://oss.sonatype.org/content/repositories/releases/com/mchange/c3p0/).
-
-Please see the [documentation](http://www.mchange.com/projects/c3p0/) for more.
-
-From the current *development snapshot*, here is the latest [CHANGELOG](CHANGELOG).
-
-Please address comments and questions to the [library author](mailto:swaldman@mchange.com).
-
-However, please keep in mind he is an abysmal correspondent and basically an asshole.
-
-Despite that, your feedback is very much appreciated. Pull requests are gratefully accepted. You may also open issues.
-
-Thank you for your interest in c3p0. I do hope that you find it useful!
-
-### Building c3p0
-
-For now (v0.10.0), c3p0 is built under a Java 11 VM, targetting JDK 7 classfiles for continued compatibility with legacy apps.
-
-_In order to remind me to switch to Java 11, the build will fail with an Exception if it detects an unexpected version._
-
-You can comment this requirement out of `build.sc` if you like. It's the line that looks like
-
-```scala
- require( sys.props(""java.runtime.version"").startsWith(""11""), s""Bad build JVM: ${sys.props(""java.runtime.version"")} -- We currently expect to build under Java 11. (We generate Java $JvmCompatVersion compatible source files.)"" )
-```
-
-c3p0 relies on the excellent build tool [`mill`](https://mill-build.com/).
-
-Install `mill`. Then, within this repository direcory, run
-
-```plaintext
-$ mill jar
-```
-
-You'll find the raw as library `out/jar.dest/out.jar`.
-
-If you maintain a local ivy repository, You can customize `publishVersion` in [`build.sc`](build.sc), then run
-
-```plaintext
-$ mill publishLocal
-```
-
-To build the documentation
-
-```plaintext
-$ mill doc.docroot
-```
-
-You can then open in your browser `out/doc/docroot.dest/index.html`
-
-### Testing c3p0
-
-By default the tests expect to find a database at `jdbc:postgresql://localhost:5432/c3p0`.
-As you can see, I usually test against a local postgres database. You can change this in
-the `forkArgs` function of [`build.sc`](build.sc).
-
-c3p0's testing is, um, embarrassingly informal. There is a junit test suite, but it covers a
-very small fraction of c3p0 functionality. To run that, it's just
-
-```plaintext
-$ mill test.test
-```
-
-Mostly c3p0 is tested by running a few test applications, and varying config _ad hoc_ to see how things work.
-
-_If you think c3p0 could/should be tested more professionally and automatically, me too! I'd love a pull request._
-
-[`build.sc`](build.sc) contains a lot of test applications, but the most important are
-
-```plaintext
-$ mill test.c3p0Benchmark
-```
-
-This is c3p0 most basic, common, test-of-first-resort.
-It runs through and times a bunch of different c3p0 operations, and puts the library through pretty good exercise
-
-```plaintext
-$ mill test.c3p0Load
-```
-
-This one puts c3p0 under load of a 100 thread performing 1000 database operations each,
-then terminates.
-
-```plaintext
-$ mill test.c3p0PSLoad
-```
-
-This one puts c3p0 under load of a 100 thread performing database operations indefinitely.
-It uses `PreparedStatement` for its database operations, so is a good way of exercising the
-statement cache.
-
-#### Test configuration
-
-You can observe (most of) the config of your c3p0 `DataSource` when you test, because c3p0 logs it at `INFO`
-upon the first `Connection` checkout attempt. When testing, verify that you are working with the configuration
-you expect!
-
-Tests are configured by command-line arguments and by a `c3p0.properties` file.
-To play with different configurations, edit [`test/resources-local/c3p0.properties`](test/resources-local/c3p0.properties).
-Also check the `forkArgs()` method in [`build.sc`](build.sc)
-
-Sometimes you want to put the library through its paces with pathological configuration.
-A baseline pathological configuration is defined in [`test/resources-local-rough/c3p0.properties`](test/resources-local-rough/c3p0.properties).
-
-To give this effect, temporarily edit [`build.sc`](build.sc):
-
-```scala
- override def runClasspath : T[Seq[PathRef]] = T{
- super.runClasspath() ++ localResources()
- // super.runClasspath() ++ localResourcesRough()
- }
-```
-
-* Comment out `super.runClasspath() ++ localResources()`
-* Uncomment in `super.runClasspath() ++ localResourcesRough()`
-
-Then of course you can edit [`test/resources-local-rough/c3p0.properties`](test/resources-local-rough/c3p0.properties).
-
-#### Test logging
-
-Often you will want to focus logging on a class or feature you are testing. By default, c3p0 tests
-are configured to use `java.util.logging.`, and be configured by the file [`test/conf-logging/logging.properties`](test/conf-logging/logging.properties).
-
-Of course you can change the config (in `c3p0.properties`) to use another logging library if you'd like,
-but you may need to modify the build to bring third-party logging libraries in, and configure those libraries
-in their own ways.
-
-### Building c3p0-loom
-
-Because c3p0 currently builds under Java 11, but c3p0-loom requires Java 21, c3p0 loom is a
-[separate project](https://github.com/swaldman/c3p0-loom).
-
-It is just a parallel mill project.
-The instructions above apply (except `c3p0-loom` does not have independent documentation to build).
-
-### License
-
-c3p0 is licensed under [LGPL v.2.1](LICENSE-LGPL) or [EPL v.1.0](LICENSE-EPL), at your option. You may also
-opt to license c3p0 under any version of LGPL higher than v.2.1.
-
----
-
-**Note:** c3p0 has had a good experience with reporting of a security vulnerability via Sonatype's _Central Security Project_.
-If you find a c3p0 security issue, do consider reporting it via https://hackerone.com/central-security-project
-
-
-
-
-
-"
-wuyr/PathLayoutManager,master,2018,244,2018-05-26T16:48:22Z,32867,8,RecyclerView的LayoutManager,轻松实现各种炫酷、特殊效果,再也不怕产品经理为难! ,,"## RecyclerView的LayoutManager,轻松实现各种炫酷、特殊效果,再也不怕产品经理为难!
-### 博客详情: https://blog.csdn.net/u011387817/article/details/81875021
-
-### 使用方式:
-#### 添加依赖:
-```
-implementation 'com.wuyr:pathlayoutmanager:1.0.3'
-```
-
-### APIs:
-|Method|Description|
-|------|-----------|
-|updatePath(Path path)|更新Path|
-|setItemOffset(int itemOffset)|设置Item间距 (单位: px)|
-|setOrientation(int orientation)|设置滑动方向:**RecyclerView.HORIZONTAL** (水平滑动)
**RecyclerView.VERTICAL** (垂直滑动)| -|setScrollMode(int mode)|设置滚动模式:
**SCROLL_MODE_NORMAL** (普通模式)
**SCROLL_MODE_OVERFLOW** (允许溢出)
**SCROLL_MODE_LOOP** (无限循环)
| -|setItemDirectionFixed(boolean isFixed)|设置Item是否保持垂直| -|setAutoSelect(boolean isAutoSelect)|设置是否开启自动选中效果| -|setAutoSelectFraction(float position)|设置自动选中的目标落点 (0~1)| -|setFlingEnable(boolean enable)|设置惯性滚动是否开启| -|setCacheCount(int count)|设置Item缓存个数| -|setItemScaleRatio(float... ratios)|设置平滑缩放比例
**ratios**: 缩放比例, 数组长度必须是双数,
**偶数索引**表示要**缩放的比例**
**奇数索引**表示在**路径上的位置** (0~1)
奇数索引必须要递增,即越往后的数值应越大
例如:
**setItemScaleRatio(0.8, 0.5)**
表示在路径的50%处把Item缩放到原来的80%
**setItemScaleRatio(0, 0, 1, 0.5, 0, 1)**
表示在起点处的Item比例是原来的0%,在路径的50%处会恢复原样
到路径终点处会缩小到0%| -|scrollToPosition(int position)|将目标Item滚动到自动选中的落点(setAutoSelectFraction)
例如 setAutoSelectFraction(0) 则滚动到Path的起点处
若为1,则滚动到路径终点处,0.6则路径的60%处 (默认: 0.5)| -|smoothScrollToPosition(int position)|同上,此方法为平滑滚动,即选中时会播放动画
动画时长通过 setFixingAnimationDuration 方法来设置| -|setFixingAnimationDuration(long duration)|设置自动选中后的选中动画时长| -|setOnItemSelectedListener(Listener listener)|设置Item被选中后的监听器 (需开启自动选中才生效)| - - -### 使用示例: -```java - mPathLayoutManager = new PathLayoutManager(path, itemOffset); - mRecyclerView.setLayoutManager(mPathLayoutManager); -``` - -### Demo下载: [app-debug.apk](https://github.com/wuyr/PathLayoutManager/raw/master/app-debug.apk) -### 库源码地址: https://github.com/Ifxcyr/PathLayoutManager - -### 效果: -  -  -  -  -" -apache/dubbo-spring-boot-project,master,5401,1868,2018-01-18T12:10:50Z,1557,43,Spring Boot Project for Apache Dubbo,dubbo,"# Apache Dubbo Spring Boot Project - -## This repo has been archived. All of the implements have been moved to [apache/dubbo](https://github.com/apache/dubbo). - -[](https://travis-ci.org/apache/dubbo-spring-boot-project) -[](https://codecov.io/gh/apache/dubbo-spring-boot-project) - - -[Apache Dubbo](https://github.com/apache/dubbo) Spring Boot Project makes it easy to create [Spring Boot](https://github.com/spring-projects/spring-boot/) application using Dubbo as RPC Framework. What's more, it also provides: -* [auto-configure features](dubbo-spring-boot-autoconfigure) (e.g., annotation-driven, auto configuration, externalized configuration). -* [production-ready features](dubbo-spring-boot-actuator) (e.g., security, health checks, externalized configuration). - -> Apache Dubbo |ˈdʌbəʊ| is a high-performance, light weight, java based RPC framework. Dubbo offers three key functionalities, which include interface based remote call, fault tolerance & load balancing, and automatic service registration & discovery. - -## [中文说明](README_CN.md) - - -## Released version - -You can introduce the latest `dubbo-spring-boot-starter` to your project by adding the following dependency to your pom.xml -```xml -
-
- 🎉🎉🎉 企业版
-
-全新的 企业版 已经发布,前后端分别采用 React(Ant design)、VUE(Element)、Spring Boot,详情可前往体验
-
-调问网官网地址:https://www.diaowen.net
-企业版体验地址
-新版本:https://element-ent.surveyform.cn账号密码(service@diaowen.net/123456)
- -- -
-
-
- 🎉🎉🎉 专业版
-
-新一代的 专业版 即将发布,前端采用纯VUE实现(Element)、后端使用 Spring Boot、Elasticsearch,敬请关注
-
-调问网官网地址:https://www.diaowen.net
--
-
-
- ☀️☀️☀️ 社区版
-
-️ 全新的 社区版 也已经发布,前后端分别采用Vue、ElementUI、Spring Boot,详情可前往体验。
-
-社区版文档地址:https://www.diaowen.net/docs
- -[comment]: <> (社区版体验地址:https://oss.surveyform.cn
) -后续我们将持续迭代更新,并有专人维护,敬请关注,别忘了点下源码仓库 右上角Star关注,便于下次查找。
- -### 快速安装(一行命令完成) - -1、下载调问问卷社区版安装包 - -最新的JAR包放在QQ群3(`811287103`已满),请加群4(`398556555`),加群备注`安装包`。 - -2、输入启动命令 - -``` cmd - java -Dfile.encoding=utf-8 -jar dwsurvey-oss-vue-v.*.*.jar --server.port=8080 --spring.datasource.username=root --spring.datasource.password=123456 -``` -3、打开浏览器访问 http://localhost:8080,输入账号密码: service@diaowen.net/123456 - - -``` js - //可选,文件编码,windows上如果有乱码则使用,linux一般不会出现 - -Dfile.encoding=utf-8 - //必填,安装包名称, 后面的v.*.*.jar依据您下载的最新安装包来定。 - dwsurvey-oss-vue-v.*.*.jar - //可选,指定启动服务占用的端口,默认值8080 - --server.port=8080 - //可选,数据库账号,默认值为root - --spring.datasource.username=root - //可选,数据库账密码,默认值123456,. - --spring.datasource.password=123456 -``` - -更详细参数说明请查看[配置说明文档](http://www.diaowen.net/docs/) - -## 特性 - - - -### 汇总 - -* 多种技术方案,满足不同的技术选型需求 -* 完善的浏览器兼容、保证传统客户也能正常使用 -* 部署简单,一行命令完成部署 -* 更新方便,直接替换原安装文件不用担心数据被覆盖 -* 最高支持多达40多种题型,如单选题、多选题、填空题、评分题、排序题、分页、分段... -* 可见即所得设计理念、所有内容支持快速富文本编辑 -* 多种端适配,不管是PC还是移动端同一个地址系统自动适配 -* 支持答卷密码、结束跳转、仅微信答卷限制等 -* 数据实时统计,答卷的数据以可视化的方案展现,不同的统计图表 -* 后端满足JPA规范,为未来支持更多数据库提供条件 -* 成熟稳定,经过多年技术发展,技术体系完善 -* 完善的支持服务,QQ群,微信群全天24小时技术服务 - -### 完善的浏览器兼容 - -**支持现代浏览器和IE6** - -在实际收集问卷过程中,不是所有用户都会安装最新的浏览器,DWSurvey在答卷端支持所有的浏览器环境,方案B、方案C更是全站完全支持 - -| IE / Edge | Firefox | Chrome | Safari | Opera | -| :-----| ----: | :----: | :----: | :----: | -| IE6+,Edge | 支持 | 支持 | 支持 | 支持 | - - -### 各技术方案简介 - -| 方案A | 前后端分离,基于 Vue、Element ui、Spring Boot | |
|---|---|---|
| 方案特性:基于VUE、前后分离开发更容易,部署维护更简单 | ||
| 前端 | Gitee | https://gitee.com/wkeyuan/dwsurvey-vue |
| GitHub | https://github.com/wkeyuan/DWSurvey_Vue | |
| 后端 | Gitee | https://gitee.com/wkeyuan/DWSurvey |
| GitHub | https://github.com/wkeyuan/DWSurvey | |
| 方案B | Spring Boot + JSP | |
| 方案特性: 原生JS+HTML技术,支持更多浏览器,如IE6 | ||
| Gitee | https://gitee.com/wkeyuan/dwsurvey-springboot-jsp | |
| GitHub | https://gitee.com/wkeyuan/dwsurvey-springboot-jsp | |
| 方案C | Struts2 + JSP | |
| 方案特性: 原生JS+HTML技术,支持更多浏览器,如IE6 | | ||
| Gitee | https://gitee.com/wkeyuan/dwsurvey-struts2-jsp | |
| GitHub | https://gitee.com/wkeyuan/dwsurvey-struts2-jsp |
- -### Step 1: Install Java8, Maven, MySQL -If you have already installed maven, jdk8+ and Mysql or other DB which supported by Mybatis, just skip to next.
-Download [Java8](http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html), -[MySQL](https://dev.mysql.com/downloads/mysql/) and [Maven](https://maven.apache.org/download.cgi), -and install jdk, mysql. For maven, extracting and setting MAVEN_HOME is enough. - -#### Set JAVA_HOME & MAVEN_HOME -Here is a sample script to set JAVA_HOME and MAVEN_HOME -```shell -export MAVEN_HOME=/xxx/xxx/software/maven/apache-maven-3.3.9 -export PATH=$MAVEN_HOME/bin:$PATH -JAVA_HOME=""/Library/Java/JavaVirtualMachines/jdk1.8.0_91.jdk/Contents/Home""; -export JAVA_HOME; -``` - -### Step 2: Create table WORKER_NODE -Replace ```xxxxx``` with real database name, and run following script to create table, -```sql -DROP DATABASE IF EXISTS `xxxx`; -CREATE DATABASE `xxxx` ; -use `xxxx`; -DROP TABLE IF EXISTS WORKER_NODE; -CREATE TABLE WORKER_NODE -( -ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id', -HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name', -PORT VARCHAR(64) NOT NULL COMMENT 'port', -TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER', -LAUNCH_DATE DATE NOT NULL COMMENT 'launch date', -MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time', -CREATED TIMESTAMP NOT NULL COMMENT 'created time', -PRIMARY KEY(ID) -) - COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB; -``` - -Reset property of 'jdbc.url', 'jdbc.username' and 'jdbc.password' in [mysql.properties](src/test/resources/uid/mysql.properties). - -### Step 3: Spring configuration -#### DefaultUidGenerator -There are two implements of UidGenerator: [DefaultUidGenerator](src/main/java/com/baidu/fsg/uid/impl/DefaultUidGenerator.java), [CachedUidGenerator](src/main/java/com/baidu/fsg/uid/impl/CachedUidGenerator.java).
-For performance sensitive application, CachedUidGenerator is recommended. - -```xml - -
-Firstly, workerBits is arbitrarily fixed to 20, and change timeBits from 25(about 1 year) to 32(about 136 years),
- -|timeBits|25|26|27|28|29|30|31|32| -|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:| -|throughput|6,831,465|7,007,279|6,679,625|6,499,205|6,534,971|7,617,440|6,186,930|6,364,997| - - - -Then, timeBits is arbitrarily fixed to 31, and workerBits is changed from 20(about 1 million total reboots) to 29(about - 500 million total reboots),
- -|workerBits|20|21|22|23|24|25|26|27|28|29| -|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:| -|throughput|6,186,930|6,642,727|6,581,661|6,462,726|6,774,609|6,414,906|6,806,266|6,223,617|6,438,055|6,435,549| - - - -It is obvious that whatever the configuration is, CachedUidGenerator always has the ability to provide **6 million** -stable throughput, what sacrificed is just life expectancy, this is very cool. - -Finally, both timeBits and workerBits are fixed to 31 and 23 separately, and change the number of CachedUidGenerator -consumer. Since our CPU only has 4 cores, \[1, 8\] is chosen.
- -|consumers|1|2|3|4|5|6|7|8| -|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:| -|throughput|6,462,726|6,542,259|6,077,717|6,377,958|7,002,410|6,599,113|7,360,934|6,490,969| - - -" -ysc/word,master,1795,680,2014-03-18T03:22:55Z,518924,36,Java分布式中文分词组件 - word分词,,"### Java分布式中文分词组件 - word分词 - -#### word分词是一个Java实现的分布式的中文分词组件,提供了多种基于词典的分词算法,并利用ngram模型来消除歧义。能准确识别英文、数字,以及日期、时间等数量词,能识别人名、地名、组织机构名等未登录词。能通过自定义配置文件来改变组件行为,能自定义用户词库、自动检测词库变化、支持大规模分布式环境,能灵活指定多种分词算法,能使用refine功能灵活控制分词结果,还能使用词频统计、词性标注、同义标注、反义标注、拼音标注等功能。提供了10种分词算法,还提供了10种文本相似度算法,同时还无缝和Lucene、Solr、ElasticSearch、Luke集成。注意:word1.3需要JDK1.8 - -### [捐赠致谢](https://github.com/ysc/QuestionAnsweringSystem/wiki/donation) - -### API在线文档: - - [word 1.0 API](http://apdplat.org/word/apidocs/1.0/) - - [word 1.1 API](http://apdplat.org/word/apidocs/1.1/) - - [word 1.2 API](http://apdplat.org/word/apidocs/1.2/) - - [word 1.3 API](http://apdplat.org/word/apidocs/1.3/) - -### [编译好的jar包下载](https://pan.baidu.com/s/1eisJUL47fmYZYgsdINXX4w) 提取码: ku8i - -### Maven依赖: - - 在pom.xml中指定dependency,可用版本有1.0、1.1、1.2、1.3、1.3.1: - -
-Thanks for the idea.
- -I like all the animation in that webpage , but it's so hard to develop all of them .
- -Finally , i find this way , it's simple , but it work perfect. - -## Look like - -### Season one - -Idea from [Link](http://mp.weixin.qq.com/s?__biz=MjM5MDMxOTE5NA==&mid=402703079&idx=2&sn=2fcc6746a866dcc003c68ead9b68e595&scene=2&srcid=0302A7p723KK8E5gSzLKb2ZL&from=timeline&isappinstalled=0#wechat_redirect) .
- -  
- -  
- -  
- -  
- -  
- -  
- -  
- -### Season two - -Idea from [Link](http://weibo.com/uidesign?from=myfollow_all&is_all=1) .
- -  
- -  
- -  
- -  
- -  
- -  
- -  
- -  
- -  
- -  
- -  
- -  
- -  
- -  
- -### Season Three - -Idea from [Link](http://weibo.com/uidesign?from=myfollow_all&is_all=1) .
- - -
- -
- -
- -
- -
- -
- - -
- - -..as you see right now,wish you like it. - -### Step - -Import this project into android studio..it's build with it. - -### Usage - -#### Gradle - - -``` -compile 'com.roger.gifloadinglibrary:gifloadinglibrary:1.1.1' -``` - -#### config in java code - - private GifLoadingView mGifLoadingView; - - - @Override protected void onCreate(Bundle savedInstanceState) { - super.onCreate(savedInstanceState); - setContentView(R.layout.activity_main); - - mGifLoadingView = new GifLoadingView(); - findViewById(R.id.button).setOnClickListener( - new View.OnClickListener() { - @Override public void onClick(View v) { - - mGifLoadingView.setImageResource(R.drawable.image); - mGifLoadingView.show(getFragmentManager()); - - } - }); - } - -## Dependencies - -This project use this libraries ~ Thanks to them. - - [android-gif-drawable](https://github.com/koral--/android-gif-drawable)
- [BlurDialogFragment](https://github.com/tvbarthel/BlurDialogFragment) - -## TODO - -This view is adjust in Nexue5 but not test in the other size screen . - -## About me - -A small guy in mainland FUJIAN China. - -If you have any new idea about this project, feel free to tell me ,Tks. :smiley: - - -## License - - The MIT License (MIT) - - Copyright © 2015 Roger - - Permission is hereby granted, free of charge, to any person obtaining a copy - of this software and associated documentation files (the ""Software""), to deal - in the Software without restriction, including without limitation the rights - to use, copy, modify, merge, publish, distribute, sublicense, and/or sell - copies of the Software, and to permit persons to whom the Software is - furnished to do so, subject to the following conditions: - - The above copyright notice and this permission notice shall be included in - all copies or substantial portions of the Software. - - THE SOFTWARE IS PROVIDED ""AS IS"", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR - IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, - FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE - AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER - LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, - OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN - THE SOFTWARE. - -" -Bukkit/Bukkit,master,2359,1050,2011-01-02T23:47:25Z,19858,70,The Minecraft Mod API,,"Bukkit -====== - -A Minecraft Server API. - -Website: [http://bukkit.org](http://bukkit.org) -Bugs/Suggestions: [http://leaky.bukkit.org](http://leaky.bukkit.org) -Contributing Guidelines: [CONTRIBUTING.md](https://github.com/Bukkit/Bukkit/blob/master/CONTRIBUTING.md) - -Compilation ------------ - -We use maven to handle our dependencies. - -* Install [Maven 3](http://maven.apache.org/download.html) -* Check out this repo and: `mvn clean install` -" -gouthampradhan/leetcode,master,3249,815,2017-03-09T10:30:30Z,876,9,Leetcode solutions,algorithms coding-interviews competitive-programming java leetcode leetcode-java leetcode-solutions,"# Leetcode solutions in Java - -My accepted leetcode solutions to some of the common interview problems. - -#### [Array](src/main/java/array) - -- [Pascals Traiangle II](src/main/java/array/PascalsTriangle.java) (Easy) -- [Product Of Array Except Self](src/main/java/array/ProductOfArrayExceptSelf.java) (Medium) -- [Rotate Matrix](src/main/java/array/RotateMatrix.java) (Medium) -- [Set Matrix Zeroes](src/main/java/array/SetMatrixZeroes.java) (Medium) -- [Third Maximum Number](src/main/java/array/ThirdMaximumNumber.java) (Easy) -- [Two Sum](src/main/java/array/TwoSum.java) (Easy) -- [TwoSum II](src/main/java/array/TwoSumII.java) (Easy) -- [Can Place Flowers](src/main/java/array/CanPlaceFlowers.java) (Easy) -- [Merge Intervals](src/main/java/array/MergeIntervals.java) (Medium) --  [First Missing Positive](src/main/java/array/FirstMissingPositive.java) (Hard) -- [Fruit Into Baskets](src/main/java/array/FruitIntoBaskets.java) (Medium) -- [MaxProduct Of Three Numbers](src/main/java/array/MaxProductOfThreeNumbers.java) (Easy) -- [Missing Number](src/main/java/array/MissingNumber.java) (Easy) -- [Merge Sorted Array](src/main/java/array/MergeSortedArray.java) (Easy) -- [Rotate Array](src/main/java/array/RotateArray.java) (Easy) -- [Sort Colors](src/main/java/array/SortColors.java) (Medium) -- [Battleships in a Board](src/main/java/array/BattleshipsInABoard.java) (Medium) -- [Find the Celebrity](src/main/java/array/FindTheCelebrity.java) (Medium) -- [Meeting Rooms](src/main/java/array/MeetingRooms.java) (Easy) -- [Longest Continuous Increasing Subsequence](src/main/java/array/LongestIncreasingSubsequence.java) (Easy) -- [Sparse Matrix Multiplication](src/main/java/array/SparseMatrixMultiplication.java) (Medium) -- [Read N Characters Given Read4](src/main/java/array/ReadNCharacters.java) (Easy) -- [Maximum Swap](src/main/java/array/MaximumSwap.java) (Medium) -- [H-Index](src/main/java/array/HIndex.java) (Medium) --  [Insert Interval](src/main/java/array/InsertInterval.java) (Hard) -- [Increasing Triplet Subsequence](src/main/java/array/IncreasingTripletSubsequence.java) (Medium) --  [K Empty Slots](src/main/java/array/KEmptySlots.java) (Hard) -- [Subarray Sum Equals K](src/main/java/array/SubarraySumEqualsK.java) (Medium) -- [Pour Water](src/main/java/array/PourWater.java) (Medium) -- [Relative Ranks](src/main/java/array/RelativeRanks.java) (Easy) -- [Next Greater Element I](src/main/java/array/NextGreaterElementI.java) (Easy) -- [Largest Number At Least Twice of Others](src/main/java/array/LargestNumberAtLeastTwice.java) (Easy) -- [Minimum Moves to Equal Array Elements II](src/main/java/array/MinimumMovesToEqualArray.java) (Median) -- [Image Smoother](src/main/java/array/ImageSmoother.java) (Easy) -- [Minimum Index Sum of Two Lists](src/main/java/array/MinimumIndexSumOfTwoLists.java) (Easy) -- [Card Flipping Game](src/main/java/array/CardFilipGame.java) (Medium) --  [Employee Free Time](src/main/java/array/EmployeeFreeTime.java) (Hard) --  [Best Meeting Point](src/main/java/array/BestMeetingPoint.java) (Hard) --  [My Calendar III](src/main/java/array/MyCalendarThree.java) (Hard) -- [Champagne Tower](src/main/java/array/ChampagneTower.java) (Medium) -- [Valid Tic-Tac-Toe State](src/main/java/array/ValidTicTacToeState.java) (Medium) -- [Number of Subarrays with Bounded Maximum](src/main/java/array/SubArraysWithBoundedMaximum.java) (Medium) -- [Surface Area of 3D Shapes](src/main/java/array/SurfaceAreaOfThreeDShapes.java) (Easy) -- [Max Consecutive Ones](src/main/java/array/MaxConsecutiveOnes.java) (Easy) -- [Max Consecutive Ones II](src/main/java/array/MaxConsecutiveOnesII.java) (Medium) -- [Add to Array-Form of Integer](src/main/java/array/AddToArrayFormOfInteger.java) (Easy) -- [Find Pivot Index](src/main/java/array/FindPivotIndex.java) (Easy) -- [Largest Time for Given Digits](src/main/java/array/LargestTimeForGivenDigits.java) (Easy) -- [Minimum Time Difference](src/main/java/array/MinimumTimeDifference.java) (Medium) -- [Reveal Cards In Increasing Order](src/main/java/array/RevealCardsInIncreasingOrder.java) (Medium) -- [Sort Array By Parity II](src/main/java/array/SortArrayByParityII.java) (Easy) -- [Matrix Cells in Distance Order](src/main/java/array/MatrixCellsinDistanceOrder.java) (Easy) -- [Maximum Sum of Two Non-Overlapping Subarrays](src/main/java/array/MaximumSumofTwoNonOverlappingSubarrays.java) (Medium) -- [Longest Line of Consecutive One in Matrix](src/main/java/array/LongestLineofConsecutiveOneinMatrix.java) (Medium) -- [Array Partition I](src/main/java/array/ArrayPartitionI.java) (Easy) -- [Relative Sort Array](src/main/java/array/RelativeSortArray.java) (Easy) -- [Meeting Scheduler](src/main/java/array/MeetingScheduler.java) (Medium) -- [Minimum Swaps to Group All 1's Together](src/main/java/array/MinimumSwapsToGroupAll1Together.java) (Medium) -- [Array Nesting](src/main/java/array/ArrayNesting.java) (Medium) - -#### [Backtracking](src/main/java/backtracking) - -- [Combinations](src/main/java/backtracking/Combinations.java) (Medium) -- [Combinations Sum](src/main/java/backtracking/CombinationSum.java) (Medium) -- [Combinations Sum II](src/main/java/backtracking/CombinationSumII.java) (Medium) -- [Letter Phone Number](src/main/java/backtracking/LetterPhoneNumber.java) (Medium) -- [Paliandrome Partitioning](src/main/java/backtracking/PalindromePartitioning.java) (Medium) -- [Permutations](src/main/java/backtracking/Permutations.java) (Medium) -- [Permutations II](src/main/java/backtracking/PermutationsII.java) (Medium) -- [SubSets](src/main/java/backtracking/Subsets.java) (Medium) -- [SubSet II](src/main/java/backtracking/SubsetsII.java) (Medium) -- [Word Search](src/main/java/backtracking/WordSearch.java) (Medium) --  [Word Search II](src/main/java/backtracking/WordSearchII.java) (Hard) -- [Generate Parentheses](src/main/java/backtracking/GenerateParentheses.java) (Medium) --  [Remove Invalid Parentheses](src/main/java/backtracking/RemoveInvalidParentheses.java) (Hard) --  [Regular Expression Matching](src/main/java/backtracking/RegularExpressionMatching.java) (Hard) --  [Expression Add Operators](src/main/java/backtracking/ExpressionAddOperators.java) (Hard) --  [Wildcard Matching](src/main/java/backtracking/WildcardMatching.java) (Hard) -- [Letter Case Permutation](src/main/java/backtracking/LetterCasePermutation.java) (Easy) --  [Zuma Game](src/main/java/backtracking/ZumaGame.java) (Hard) -- [Matchsticks to Square](src/main/java/backtracking/MatchsticksToSquare.java) (Medium) - -#### [Binary Search](src/main/java/binary_search) - -- [Minimum Sorted Rotated Array](src/main/java/binary_search/MinSortedRotatedArray.java) (Medium) -- [Search in a Rotated Sorted Array](src/main/java/binary_search/SearchRotatedSortedArray.java) (Medium) -- [Search for a Range](src/main/java/binary_search/SearchForARange.java) (Medium) -- [Sqrt(x)](src/main/java/binary_search/SqrtX.java) (Easy) -- [Search Insert Position](src/main/java/binary_search/SearchInsertPosition.java) (Easy) --  [Median of Two Sorted Arrays](src/main/java/binary_search/MedianOfTwoSortedArrays.java) (Hard) -- [Pow(x, n)](src/main/java/binary_search/PowXN.java) (Medium) -- [Find Peak Element](src/main/java/binary_search/FindPeakElement.java) (Medium) -- [Target Sum](src/main/java/binary_search/TargetSum.java) (Medium) -- [H-Index II](src/main/java/binary_search/HIndexII.java) (Medium) --  [Swim in Rising Water](src/main/java/binary_search/SwimInRisingWater.java) (Hard) -- [Time Based Key-Value Store](src/main/java/binary_search/TimeBasedKeyValuePair.java) (Medium) --  [Minimum Window Subsequence](src/main/java/binary_search/MinimumWindowSubsequence.java) (Hard) --  [Koko Eating Bananas](src/main/java/binary_search/KokoEatingBananas.java) (Hard) -- [Single Element in a Sorted Array](src/main/java/binary_search/SingleElementInASortedArray.java) (Medium) - -#### [Bit Manipulation](src/main/java/bit_manipulation) - -- [Gray Code](src/main/java/bit_manipulation/GrayCode.java) (Medium) -- [Hamming Distance](src/main/java/bit_manipulation/HammingDistance.java) (Easy) -- [Total Hamming Distance](src/main/java/bit_manipulation/TotalHammingDistance.java) (Medium) -- [Divide Two Integers](src/main/java/bit_manipulation/DivideTwoIntegers.java) (Medium) -- [Binary Number with Alternating Bits](src/main/java/bit_manipulation/BinaryNumberWithAlternatingBits.java) (Easy) -- [Binary Watch](src/main/java/bit_manipulation/BinaryWatch.java) (Easy) - -#### [Breadth First Search](src/main/java/breadth_first_search) - -- [Binaray Tree Level Order Traversal](src/main/java/breadth_first_search/BinarayTreeLevelOrderTraversal.java) (Medium) -- [Word Ladder](src/main/java/breadth_first_search/WordLadder.java) (Medium) --  [Word Ladder II](src/main/java/breadth_first_search/WordLadderII.java) (Hard) -- [Walls and Gates](src/main/java/breadth_first_search/WallsAndGates.java) (Medium) -- [Open the lock](src/main/java/breadth_first_search/OpenTheLock.java) (Medium) --  [Cut Off Trees for Golf Event](src/main/java/breadth_first_search/CutOffTreesForGolfEvent.java) (Hard) --  [Race Car](src/main/java/breadth_first_search/RaceCar.java) (Hard) --  [Bus Routes](src/main/java/breadth_first_search/BusRoutes.java) (Hard) --  [Sliding Puzzle](src/main/java/breadth_first_search/SlidingPuzzle.java) (Hard) -- [Matrix](src/main/java/breadth_first_search/Matrix.java) (Medium) -- [Rotting Oranges](src/main/java/breadth_first_search/RottingOranges.java) (Medium) - -#### [Depth First Search](src/main/java/depth_first_search) - -- [Minesweeper](src/main/java/depth_first_search/Minesweeper.java) (Medium) -- [Movie Recommend](src/main/java/depth_first_search/MovieRecommend.java) (Medium) -- [Number Of Islands](src/main/java/depth_first_search/NumberOfIslands.java) (Medium) -- [Course Schedule](src/main/java/depth_first_search/CourseSchedule.java) (Medium) -- [Course Schedule II](src/main/java/depth_first_search/CourseScheduleII.java) (Medium) --  [Alien Dictionary](src/main/java/depth_first_search/AlienDictionary.java) (Hard) -- [Graph Valid Tree](src/main/java/depth_first_search/GraphValidTree.java) (Medium) --  [Longest Consecutive Sequence](src/main/java/depth_first_search/LongestConsecutiveSequence.java) (Hard) -- [Accounts Merge](src/main/java/depth_first_search/AccountsMerge.java) (Medium) -- [CloneGraph](src/main/java/depth_first_search/CloneGraph.java) (Medium) -- [Island Perimeter](src/main/java/depth_first_search/IslandPerimeter.java) (Easy) -- [Number of Distinct Islands](src/main/java/depth_first_search/NumberOfDistinctIslands.java) (Medium) --  [Number of Distinct Islands II](src/main/java/depth_first_search/NumberOfDistinctIslandsII.java) (Hard) --  [Smallest Rectangle Enclosing Black Pixels](src/main/java/depth_first_search/SmallestRectangleEnclosingBlackPixels.java) (Hard) --  [Bricks Falling When Hit](src/main/java/depth_first_search/BricksFallingWhenHit.java) (Hard) --  [Robot Room Cleaner](src/main/java/depth_first_search/RobotRoomCleaner.java) (Hard) --  [Cracking the Safe](src/main/java/depth_first_search/CrackingTheSafe.java) (Hard) -- [All Paths From Source to Target](src/main/java/depth_first_search/AllPathsFromSourceToTarget.java) (Medium) -- [Max Area of Island](src/main/java/depth_first_search/MaxAreaOfIsland.java) (Medium) -- [Satisfiability of Equality Equations](src/main/java/depth_first_search/SatisfiabilityOfEquations.java) (Medium) -- [Number of Enclaves](src/main/java/depth_first_search/NumberOfEnclaves.java) (Medium) -- [As Far from Land as Possible](src/main/java/depth_first_search/AsFarfromLandAsPossible.java) (Medium) --  [Minimize Malware Spread](src/main/java/depth_first_search/MinimizeMalwareSpread.java) (Hard) --  [Parallel Courses](src/main/java/depth_first_search/ParallelCourses.java) (Hard) -- [Connecting Cities With Minimum Cost](src/main/java/depth_first_search/ConnectingCitiesWithMinimumCost.java) (Medium) --  [Critical Connections in a Network](src/main/java/depth_first_search/CriticalConnection.java) (Hard) - -#### [Design](src/main/java/design) - -- [Copy List With Random Pointer](src/main/java/design/CopyListWithRandomPointer.java) (Medium) -- [Encode and Decode Tiny URL](src/main/java/design/EncodeAndDecodeTinyURL.java) (Medium) --  [LFU Cache](src/main/java/design/LFUCache.java) (Hard) --  [LRU Cache](src/main/java/design/LRUCache.java) (Hard) -- [Insert Delete Get Random](src/main/java/design/RandomizedSet.java) (Medium) --  [Serialize Deserialize Binary Tree](src/main/java/design/SerializeDeserializeBinaryTree.java) (Hard) -- [Design Twitter](src/main/java/design/Twitter.java) (Medium) -- [Tic-Tac-Toe](src/main/java/design/TicTacToe.java) (Medium) -- [Implement Trie (Prefix Tree)](src/main/java/design/Trie.java) (Medium) -- [Binary Search Tree Iterator](src/main/java/design/BSTIterator.java) (Medium) --  [Design Search Autocomplete System](src/main/java/design/AutocompleteSystem.java) (Hard) --  [Design Excel Sum Formula](src/main/java/design/Excel.java) (Hard) -- [Flatten Nested List Iterator](src/main/java/design/NestedIterator.java) (Medium) -- [Add and Search Word - Data structure design](src/main/java/design/WordDictionary.java) (Medium) --  [Prefix and Suffix Search](src/main/java/design/WordFilter.java) (Hard) --  [Insert Delete GetRandom O(1) - Duplicates allowed](src/main/java/design/RandomizedCollection.java) (Hard) - -#### [Divide and Conquer](src/main/java/divide_and_conquer) - -- [Kth Largest Element In a Array](src/main/java/divide_and_conquer/KthLargestElementInAnArray.java) (Medium) --  [Reverse Pairs](src/main/java/divide_and_conquer/ReversePairs.java) (Hard) -- [Search in a 2D Matrix](src/main/java/divide_and_conquer/SearchA2DMatrix.java) (Medium) --  [24 Game](src/main/java/divide_and_conquer/TwentyFourGame.java) (Hard) --  [Reverse Pairs II](src/main/java/divide_and_conquer/ReversePairsII.java) (Hard) -- [My Calendar II](src/main/java/divide_and_conquer/MyCalendarII.java) (Medium) - -#### [Dynamic Programming](src/main/java/dynamic_programming) - -- [Best Time To Buy and Sell Stocks](src/main/java/dynamic_programming/BestTimeToBuyAndSellStocks.java) (Easy) --  [Best Time to Buy and Sell Stock III](src/main/java/dynamic_programming/BestTimeToBuyAndSellStockIII.java) (Hard) -- [Best Time to Buy and Sell Stock with Transaction Fee](src/main/java/dynamic_programming/BestTimeToBuyAndSellStocksWithFee.java) (Medium) -- [Climbing Stairs](src/main/java/dynamic_programming/ClimbingStairs.java) (Easy) -- [Coin Change](src/main/java/dynamic_programming/CoinChange.java) (Medium) -- [Coin Change 2](src/main/java/dynamic_programming/CoinChange2.java) (Medium) -- [Decode Ways](src/main/java/dynamic_programming/DecodeWays.java) (Medium) -- [House Robber](src/main/java/dynamic_programming/HouseRobber.java) (Easy) -- [House Robber II](src/main/java/dynamic_programming/HouseRobberII.java) (Medium) -- [Longest Increasing Subsequence](src/main/java/dynamic_programming/LongestIncreasingSubsequence.java) (Medium) -- [Longest Paliandromic Substring](src/main/java/dynamic_programming/LongestPaliandromicSubstring.java) (Medium) -- [Longest Palindromic Subsequence](src/main/java/dynamic_programming/LongestPalindromicSubsequence.java) (Medium) -- [Maximum Product Subarray](src/main/java/dynamic_programming/MaximumProductSubarray.java) (Medium) -- [Min Cost Climbing Stairs](src/main/java/dynamic_programming/MinCostClimbingStairs.java) (Easy) --  [Palindrome Partitioning II](src/main/java/dynamic_programming/PalindromePartitioningII.java) (Hard) -- [UniqueBinary Search Trees](src/main/java/dynamic_programming/UniqueBinarySearchTrees.java) (Medium) -- [Unique Binary Search Trees II](src/main/java/dynamic_programming/UniqueBinarySearchTreesII.java) (Medium) -- [WordBreak](src/main/java/dynamic_programming/WordBreak.java) (Medium) --  [WordBreak II](src/main/java/dynamic_programming/WordBreakII.java) (Hard) --  [Concatenated Words](src/main/java/dynamic_programming/ConcatenatedWords.java) (Hard) -- [Can I Win](src/main/java/dynamic_programming/CanIWin.java) (Medium) -- [Maximum Subarray](src/main/java/dynamic_programming/MaximumSubarray.java) (Easy) --  [Dungeon Game](src/main/java/dynamic_programming/DungeonGame.java) (Hard) -- [2 Keys Keyboard](src/main/java/dynamic_programming/TwoKeysKeyboard.java) (Medium) --  [Maximum Sum of 3 Non-Overlapping Subarrays](src/main/java/dynamic_programming/MaxSum3SubArray.java) (Hard) -- [Maximal Square](src/main/java/dynamic_programming/MaximalSquare.java) (Medium) -- [Continuous Subarray Sum](src/main/java/dynamic_programming/ContinuousSubarraySum.java) (Medium) --  [Decode Ways II](src/main/java/dynamic_programming/DecodeWaysII.java) (Hard) -- [Palindromic Substrings](src/main/java/dynamic_programming/PalindromicSubstrings.java) (Medium) -- [Number of Longest Increasing Subsequence](src/main/java/dynamic_programming/NumberOfLIS.java) (Medium) -- [Combination Sum IV](src/main/java/dynamic_programming/CombinationSumIV.java) (Medium) --  [Paint House II](src/main/java/dynamic_programming/PaintHouseII.java) (Hard) --  [Split Array Largest Sum](src/main/java/dynamic_programming/SplitArrayLargestSum.java) (Hard) -- [Number Of Corner Rectangles](src/main/java/dynamic_programming/CornerRectangles.java) (Medium) --  [Burst Balloons](src/main/java/dynamic_programming/BurstBalloons.java) (Hard) -- [Largest Plus Sign](src/main/java/dynamic_programming/LargestPlusSign.java) (Medium) --  [Palindrome Pairs](src/main/java/dynamic_programming/PalindromePairs.java) (Hard) --  [Cherry Pickup](src/main/java/dynamic_programming/CherryPickup.java) (Hard) -- [Knight Probability in Chessboard](src/main/java/dynamic_programming/KnightProbabilityInChessboard.java) (Medium) -- [Largest Sum of Averages](src/main/java/dynamic_programming/LargestSumOfAverages.java) (Medium) --  [Minimum Number of Refueling Stops](src/main/java/dynamic_programming/MinimumNumberOfRefuelingStops.java) (Hard) --  [Cat and Mouse](src/main/java/dynamic_programming/CatAndMouse.java) (Hard) -- [Stone Game](src/main/java/dynamic_programming/StoneGame.java) (Medium) --  [Odd Even Jump](src/main/java/dynamic_programming/OddEvenJump.java) (Hard) --  [Profitable Schemes](src/main/java/dynamic_programming/ProfitableSchemes.java) (Hard) --  [Maximum Vacation Days](src/main/java/dynamic_programming/MaximumVacationDays.java) (Hard) --  [Russian Doll Envelopes](src/main/java/dynamic_programming/RussianDollEnvelopes.java) (Hard) --  [Student Attendance Record II](src/main/java/dynamic_programming/StudentAttendanceRecordII.java) (Hard) -- [Out of Boundary Paths](src/main/java/dynamic_programming/OutOfBoundaryPaths.java) (Medium) --  [Remove Boxes](src/main/java/dynamic_programming/RemoveBoxes.java) (Hard) --  [Stickers to Spell Word](src/main/java/dynamic_programming/StickersToSpellWord.java) (Hard) -- [Ones and Zeroes](src/main/java/dynamic_programming/OnesAndZeroes.java) (Medium) --  [Encode String with Shortest Length](src/main/java/dynamic_programming/EncodeStringWithShortestLength.java) (Hard) -- [Length of Longest Fibonacci Subsequence](src/main/java/dynamic_programming/LengthofLongestFibonacciSubsequence.java) (Medium) --  [Make Array Strictly Increasing](src/main/java/dynamic_programming/MakeArrayStrictlyIncreasing.java) (Hard) --  [Minimum Number of Taps to Open to Water a Garden](src/main/java/dynamic_programming/MinimumNumberOfTaps.java) (Hard) --  [Delete Columns to Make Sorted III](src/main/java/dynamic_programming/DeleteColumnsToMakeSortedIII.java) (Hard) --  [Handshakes That Don't Cross](src/main/java/dynamic_programming/HandshakesThatDontCross.java) (Hard) --  [Minimum Difficulty of a Job Schedule](src/main/java/dynamic_programming/MinimumDifficultyOfAJobSchedule.java) (Hard) --  [Jump Game V](src/main/java/dynamic_programming/JumpGameV.java) (Hard) --  [Freedom Trail](src/main/java/dynamic_programming/FreedomTrail.java) (Hard) --  [Strange Printer](src/main/java/dynamic_programming/StrangePrinter.java) (Hard) --  [Minimum Cost to Merge Stones](src/main/java/dynamic_programming/MinimumCostToMergeStones.java) (Hard) --  [Interleaving String](src/main/java/dynamic_programming/InterleavingString.java) (Hard) --  [Count Vowels Permutation](src/main/java/dynamic_programming/CountVowelsPermutation.java) (Hard) --  [Non-negative Integers without Consecutive Ones](src/main/java/dynamic_programming/NonNegativeIntegersWithoutConsecutiveOnes.java) (Hard) -- [Bomb Enemy](src/main/java/dynamic_programming/BombEnemy.java) (Medium) -- [Number of Dice Rolls With Target Sum](src/main/java/dynamic_programming/NumberOfDiceRollsWithTargetSum.java) (Medium) --  [Distinct Subsequences](src/main/java/dynamic_programming/DistinctSubsequences.java) (Hard) --  [Distinct Subsequences II](src/main/java/dynamic_programming/DistinctSubsequencesII.java) (Hard) --  [Minimum Distance to Type a Word Using Two Fingers](src/main/java/dynamic_programming/MinimumDistanceToTypeAWordUsingTwoFingers.java) (Hard) --  [Valid Palindrome III](src/main/java/dynamic_programming/ValidPalindromeIII.java) (Hard) --  [Palindrome Partitioning III](src/main/java/dynamic_programming/PalindromePartitioningIII.java) (Hard) --  [Tiling a Rectangle with the Fewest Squares](src/main/java/dynamic_programming/TilingARectangle.java) (Hard) --  [Longest Chunked Palindrome Decomposition](src/main/java/dynamic_programming/LongestChunkedPalindromeDecomposition.java) (Hard) --  [Stone Game III](src/main/java/dynamic_programming/StoneGameIII.java) (Hard) --  [Number of Ways to Stay in the Same Place After Some Steps](src/main/java/dynamic_programming/NumberOfWaysToStayInTheSamePlace.java) (Hard) -- [Toss Strange Coins](src/main/java/dynamic_programming/TossStrangeCoins.java) (Medium) -- [Knight Dialer](src/main/java/dynamic_programming/KnightDialer.java) (Medium) --  [Palindrome Removal](src/main/java/dynamic_programming/PalindromeRemoval.java) (Hard) --  [Restore The Array](src/main/java/dynamic_programming/RestoreTheArray.java) (Hard) --  [Cherry Pickup II](src/main/java/dynamic_programming/CherryPickupII.java) (Hard) --  [Constrained Subsequence Sum](src/main/java/dynamic_programming/ConstrainedSubsequenceSum.java) (Hard) --  [Largest Multiple of Three](src/main/java/dynamic_programming/LargestMultipleOfThree.java) (Hard) --  [Largest Multiple of Three](src/main/java/dynamic_programming/MaximumProfitInJobScheduling.java) (Hard) --  [Number of Music Playlists](src/main/java/dynamic_programming/NumberOfMusicPlaylists.java) (Hard) --  [Paint House III](src/main/java/dynamic_programming/PaintHouseIII.java) (Hard) --  [Shortest Path Visiting All Nodes](src/main/java/dynamic_programming/ShortestPathVisitingAllNodes.java) (Hard) --  [Smallest Sufficient Team](src/main/java/dynamic_programming/SmallestSufficientTeam.java) (Hard) --  [Stone Game IV](src/main/java/dynamic_programming/StoneGameIV.java) (Hard) --  [Tallest Billboard](src/main/java/dynamic_programming/TallestBillboard.java) (Hard) --  [Count Different Palindromic Subsequences](src/main/java/dynamic_programming/CountDifferentPalindromicSubsequences.java) (Hard) --  [Number of Paths with Max Score](src/main/java/dynamic_programming/NumberOfPathsWithMaxScore.java) (Hard) - - -#### [Greedy](src/main/java/greedy) - -- [Jump Game](src/main/java/greedy/JumpGame.java) (Medium) --  [Jump Game II](src/main/java/greedy/JumpGameII.java) (Hard) -- [Course Schedule III](src/main/java/greedy/CourseScheduleIII.java) (Medium) -- [GasStation](src/main/java/greedy/GasStation.java) (Medium) -- [Non-Overlapping Intervals](src/main/java/greedy/NonOverlappingIntervals.java) (Medium) -- [Minimum Number of Arrows to Burst Balloons](src/main/java/greedy/BurstBalloons.java) (Medium) -- [Queue Reconstruction By Height](src/main/java/greedy/QueueReconstructionByHeight.java) (Medium) -- [Task Scheduler](src/main/java/greedy/TaskScheduler.java) (Medium) -- [Maximum Length of Pair Chain](src/main/java/greedy/MaximumLengthOfPairChain.java) (Medium) -- [Lemonade Change](src/main/java/greedy/LemonadeChange.java) (Easy) -- [Score After Flipping Matrix](src/main/java/greedy/ScoreAfterFlippingMatrix.java) (Medium) --  [IPO](src/main/java/greedy/IPO.java) (Hard) -- [String Without AAA or BBB](src/main/java/greedy/StringWithout3A3B.java) (Medium) -- [Boats to Save People](src/main/java/greedy/BoatsToSavePeople.java) (Medium) -- [Broken Calculator](src/main/java/greedy/BrokenCalculator.java) (Medium) -- [Two City Scheduling](src/main/java/greedy/TwoCityScheduling.java) (Easy) --  [Minimum Time to Build Blocks](src/main/java/greedy/MinimumTimeToBuildBlocks.java) (Hard) --  [Reducing Dishes](src/main/java/greedy/ReducingDishes.java) (Hard) - -#### [Hashing](src/main/java/hashing) - -- [Anagrams](src/main/java/hashing/Anagrams.java) (Medium) -- [Group Anagrams](src/main/java/hashing/GroupAnagrams.java) (Medium) -- [Kdiff Pairs In a Array](src/main/java/hashing/KdiffPairsInanArray.java) (Easy) -- [Sort Character by Frequency](src/main/java/hashing/SortCharByFrequency.java) (Medium) -- [Two Sum](src/main/java/hashing/TwoSum.java) (Easy) -- [Valid Anagram](src/main/java/hashing/ValidAnagram.java) (Easy) -- [Maximum Size Subarray Sum Equals k](src/main/java/hashing/MaximumSizeSubarraySumEqualsk.java) (Medium) -- [Contiguous Array](src/main/java/hashing/ContiguousArray.java) (Medium) -- [Brick Wall](src/main/java/hashing/BrickWall.java) (Medium) -- [Partition Labels](src/main/java/hashing/PartitionLabels.java) (Medium) -- [Custom Sort String](src/main/java/hashing/CustomSortString.java) (Medium) -- [Short Encoding of Words](src/main/java/hashing/ShortEncodingOfWords.java) (Medium) --  [Substring with Concatenation of All Words](src/main/java/hashing/SubstringConcatenationOfWords.java) (Hard) -- [Distribute Candies](src/main/java/hashing/DistributeCandies.java) (Easy) -- [Groups of Special-Equivalent Strings](src/main/java/hashing/GroupsOfSpecialEquivalentStrings.java) (Easy) --  [Number of Atoms](src/main/java/hashing/NumberOfAtoms.java) (Hard) -- [Analyze User Website Visit Pattern](src/main/java/hashing/AnalyzeUserWebsiteVisitPattern.java) (Medium) --  [String Transforms Into Another String](src/main/java/hashing/StringTransformsIntoAnotherString.java) (Hard) - -#### [Heap](src/main/java/heap) - --  [Sliding Window Maximum](src/main/java/heap/SlidingWindowMaximum.java) (Hard) --  [The Skyline Problem](src/main/java/heap/TheSkylineProblem.java) (Hard) -- [Meeting Rooms II](src/main/java/heap/MeetingRoomsII.java) (Medium) -- [Top K Frequent Words](src/main/java/heap/TopKFrequentWords.java) (Medium) --  [Candy](src/main/java/heap/Candy.java) (Hard) --  [Smallest Rotation with Highest Score](src/main/java/heap/SmallestRotationWithHighestScore.java) (Hard) --  [Maximum Frequency Stack](src/main/java/heap/FreqStack.java) (Hard) --  [Reachable Nodes In Subdivided Graph](src/main/java/heap/ReachableNodesInSubdividedGraph.java) (Hard) -- [K Closest Points to Origin](src/main/java/heap/KClosestPointsToOrigin.java) (Medium) -- [Distant Barcodes](src/main/java/heap/DistantBarcodes.java) (Medium) - -#### [Linked List](src/main/java/linked_list) - -- [Intersection of two Linked-Lists](src/main/java/linked_list/IntersectionOfTwoLists.java) (Easy) -- [Linked List Cycle](src/main/java/linked_list/LinkedListCycle.java) (Easy) --  [Merge K Sorted Lists](src/main/java/linked_list/MergeKSortedLists.java) (Hard) -- [Merge Two Sorted List](src/main/java/linked_list/MergeTwoSortedList.java) (Easy) -- [Paliandrome List](src/main/java/linked_list/PaliandromeList.java) (Easy) -- [Reverse Linked List](src/main/java/linked_list/ReverseLinkedList.java) (Easy) -- [Delete Node in a Linked List](src/main/java/linked_list/DeleteNode.java) (Easy) --  [Reverse Nodes in k-Group](src/main/java/linked_list/ReverseNodesKGroup.java) (Hard) -- [Swap Nodes in Pairs](src/main/java/linked_list/SwapNodesInPairs.java) (Medium) -- [Middle of Linked List](src/main/java/linked_list/MiddleOfLinkedList.java) (Easy) -- [Split Linked List in Parts](src/main/java/linked_list/SplitLinkedListInParts.java) (Medium) -- [Next Greater Node In Linked List](src/main/java/linked_list/NextGreaterNodeInLinkedList.java) (Medium) - -#### [Math](src/main/java/math) - -- [Add Two Numbers](src/main/java/math/AddTwoNumbers.java) (Medium) -- [Count Primes](src/main/java/math/CountPrimes.java) (Easy) -- [Rotate Function](src/main/java/math/RotateFunction.java) (Medium) -- [Water and Jug Problem](src/main/java/math/WaterAndJugProblem.java) (Medium) -- [Add Digits](src/main/java/math/AddDigits.java) (Easy) -- [Excel Sheet Column Title](src/main/java/math/ExcelSheetColumnTitle.java) (Easy) -- [Roman to Integer](src/main/java/math/RomanToInteger.java) (Easy) -- [Bulb Switcher II](src/main/java/math/BulbSwitcherII.java) (Medium) -- [Global and Local Inversions](src/main/java/math/GlobalAndLocalInversions.java) (Medium) -- [Solve the Equation](src/main/java/math/SolveTheEquation.java) (Medium) --  [Couples Holding Hands](src/main/java/math/CouplesHoldingHands.java) (Hard) --  [Reaching Points](src/main/java/math/ReachingPoints.java) (Hard) --  [Nth Magical Number](src/main/java/math/NthMagicalNumber.java) (Hard) -- [Squirrel Simulation](src/main/java/math/SquirrelSimulation.java) (Medium) -- [Projection Area of 3D Shapes](src/main/java/math/ProjectionAreaOf3DShapes.java) (Easy) -- [Decoded String at Index](src/main/java/math/DecodedStringAtIndex.java) (Medium) -- [Base 7](src/main/java/math/Base7.java) (Easy) -- [Smallest Range I](src/main/java/math/SmallestRangeI.java) (Easy) --  [Largest Component Size by Common Factor](src/main/java/math/LargestComponentSizebyCommonFactor.java) (Hard) --  [Super Washing Machines](src/main/java/math/SuperWashingMachines.java) (Hard) -- [Rectangle Overlap](src/main/java/math/RectangleOverlap.java) (Easy) -- [Nth Digit](src/main/java/math/NthDigit.java) (Easy) - -#### [Reservoir Sampling](src/main/java/reservoir_sampling) - -- [Random Pick Index](src/main/java/reservoir_sampling/RandomPickIndex.java) (Medium) - -#### [Stack](src/main/java/stack) - -- [Min Stack](src/main/java/stack/MinStack.java) (Easy) -- [Valid Parentheses](src/main/java/stack/ValidParentheses.java) (Easy) --  [Largest Rectangle In Histogram](src/main/java/stack/LargestRectangleInHistogram.java) (Hard) -- [Implement Queue using Stacks](src/main/java/stack/MyQueue.java) (Easy) --  [Maximal Rectangle](src/main/java/stack/MaximalRectangle.java) (Hard) -- [Exclusive Time of Functions](src/main/java/stack/ExclusiveTimeOfFunctions.java) (Medium) --  [Basic Calculator](src/main/java/stack/BasicCalculator.java) (Hard) -- [Decode String](src/main/java/stack/DecodeString.java) (Medium) --  [Longest Valid Parentheses](src/main/java/stack/LongestValidParentheses.java) (Hard) - - -#### [String](src/main/java/string) - -- [First Unique Character In a String](src/main/java/string/FirstUniqueCharacterInAString.java) (Easy) -- [Repeated Substring Pattern](src/main/java/string/RepeatedSubstringPattern.java) (Easy) -- [Reverse Words In a String](src/main/java/string/ReverseWordsInAString.java) (Medium) -- [ReverseWords II](src/main/java/string/ReverseWordsII.java) (Medium) -- [String to Integer](src/main/java/string/StringToInteger.java) (Medium) --  [Text Justification](src/main/java/string/TextJustification.java) (Hard) -- [ZigZag Conversion](src/main/java/string/ZigZagConversion.java) (Medium) -- [Implement StrStr](src/main/java/string/ImplementStrStr.java) (Easy) -- [Excel Sheet Column Number](src/main/java/string/ExcelSheetColumnNumber.java) (Easy) -- [Compare Version Numbers](src/main/java/string/CompareVersionNumbers.java) (Easy) -- [Valid Palindrome](src/main/java/string/ValidPalindrome.java) (Easy) -- [Simplify Path](src/main/java/string/SimplifyPath.java) (Medium) -- [Permutation in String](src/main/java/string/PermutationInString.java) (Medium) -- [Add Binary](src/main/java/string/AddBinary.java) (Easy) -- [Valid Palindrome II](src/main/java/string/ValidPalindromeII.java) (Easy) -- [One Edit Distance](src/main/java/string/OneEditDistance.java) (Medium) -- [Count and Say](src/main/java/string/CountAndSay.java) (Easy) -- [Multiply Strings](src/main/java/string/MultiplyStrings.java) (Medium) -- [Longest Word in Dictionary through Deleting](src/main/java/string/LongestWordInDictonary.java) (Medium) -- [Isomorphic Strings](src/main/java/string/IsomorphicStrings.java) (Easy) -- [String Compression](src/main/java/string/StringCompression.java) (Easy) -- [Longest Common Prefix](src/main/java/string/LongestCommonPrefix.java) (Easy) --  [Find the Closest Palindrome](src/main/java/string/FindTheClosestPalindrome.java) (Hard) -- [Monotone Increasing Digits](src/main/java/string/MonotoneIncreasingDigits.java) (Medium) --  [Shortest Palindrome](src/main/java/string/ShortestPalindrome.java) (Hard) -- [Valid Word Abbreviation](src/main/java/string/ValidWordAbbreviation.java) (Easy) -- [Longest Palindrome](src/main/java/string/LongestPalindrome.java) (Easy) -- [Replace Words](src/main/java/string/ReplaceWords.java) (Medium) -- [Rotate String](src/main/java/string/RotateString.java) (Easy) -- [Keyboard Row](src/main/java/string/KeyboardRow.java) (Easy) -- [Student Attendance Record I](src/main/java/string/StudentAttendanceRecordI.java) (Easy) -- [Split Concatenated Strings](src/main/java/string/SplitConcatenatedStrings.java) (Medium) -- [Valid Word Square](src/main/java/string/ValidWordSquare.java) (Easy) -- [Reconstruct Original Digits from English](src/main/java/string/ReconstructOriginalDigitsFromEnglish.java) (Medium) -- [Push Dominoes](src/main/java/string/PushDominoes.java) (Medium) -- [Validate IP Address](src/main/java/string/ValidateIPAddress.java) (Medium) -- [Reverse String II](src/main/java/string/ReverseStringII.java) (Easy) -- [Find Words That Can Be Formed by Characters](src/main/java/string/FindWordsThatCanBeFormedbyCharacters.java) (Easy) -- [Minimum Add to Make Parentheses Valid](src/main/java/string/MinimumAddtoMakeParenthesesValid.java) (Medium) - -#### [Tree](src/main/java/tree) - -- [Binaray Tree Right Side View](src/main/java/tree/BinarayTreeRightSideView.java) (Medium) --  [Binary Tree Maximum Path Sum](src/main/java/tree/BinaryTreeMaximumPathSum.java) (Hard) -- [Boundary of Binary Tree](src/main/java/tree/BoundaryOfBinaryTree.java) (Medium) -- [Convert sorted array to BST](src/main/java/tree/ConvertSortedArrayToBST.java) (Medium) -- [Lowest Common Ancestor of a Binary Tree](src/main/java/tree/LCA.java) (Medium) -- [Lowest Common Ancestor of a BST](src/main/java/tree/LowestCommonAncestorBST.java) (Easy) -- [Most Frequent Subtree Sum](src/main/java/tree/MostFrequentSubtreeSum.java) (Medium) -- [Path Sum III](src/main/java/tree/PathSumIII.java) (Easy) -- [Convert Postorder and Inorder traversal to Binary Tree](src/main/java/tree/PostorderToBT.java) (Medium) -- [Convert Preorder and Inorder traversal to Binary Tree](src/main/java/tree/PreorderToBT.java) (Medium) -- [Sorted Array to BST](src/main/java/tree/SortedArrayToBST.java) (Medium) -- [Valid Binary Search Tree](src/main/java/tree/ValidBinarySearchTree.java) (Medium) -- [Largest BST Subtree](src/main/java/tree/LargestBSTSubtree.java) (Medium) -- [Closest Binary Search Tree Value](src/main/java/tree/ClosestBinarySearchTreeValue.java) (Easy) -- [Inorder Successor in BST](src/main/java/tree/InorderSuccessorInBST.java) (Medium) -- [Construct String From Binary Tree](src/main/java/tree/ConstructStringFromBinaryTree.java) (Easy) -- [Flatten Binary Tree to Linked List](src/main/java/tree/FlattenBinaryTree.java) (Medium) -- [Populating Next Right Pointers in Each Node](src/main/java/tree/NextRightPointer.java) (Medium) -- [Populating Next Right Pointers in Each Node II](src/main/java/tree/NextRightPointerII.java) (Medium) -- [Subtree of Another Tree](src/main/java/tree/SubtreeOfAnotherTree.java) (Easy) -- [Binary Tree Zigzag Level Order Traversal](src/main/java/tree/ZigZagTraversal.java) (Medium) -- [Binary Tree Inorder Traversal](src/main/java/tree/BinaryTreeInorderTraversal.java) (Medium) -- [Symmetric Tree](src/main/java/tree/SymmetricTree.java) (Easy) -- [Maximum Binary Tree](src/main/java/tree/MaximumBinaryTree.java) (Medium) -- [Find Bottom Left Tree Value](src/main/java/tree/FindBottomLeftTreeValue.java) (Medium) -- [Diameter of Binary Tree](src/main/java/tree/DiameterOfBinaryTree.java) (Easy) -- [Binary Tree Paths](src/main/java/tree/BinaryTreePaths.java) (Easy) -- [Sum of Left Leaves](src/main/java/tree/SumofLeftLeaves.java) (Easy) -- [Two Sum IV - Input is a BST](src/main/java/tree/TwoSumIV.java) (Easy) -- [Average of Levels in Binary Tree](src/main/java/tree/AverageOfLevelsInBinaryTree.java) (Easy) -- [Convert Binary Search Tree to Sorted Doubly Linked List](src/main/java/tree/BSTtoDoublyLinkedList.java) (Easy) -- [Same Tree](src/main/java/tree/SameTree.java) (Easy) -- [Binary Tree Longest Consecutive SequencefindMinDifference II](src/main/java/tree/BinaryTreeLongestConsecutiveSequenceII.java) (Medium) -- [Minimum Absolute Difference in BST](src/main/java/tree/MinimumAbsoluteDifferenceInBST.java) (Medium) -- [Equal Tree Partition](src/main/java/tree/EqualTreePartition.java) (Medium) -- [Split BST](src/main/java/tree/SplitBST.java) (Medium) -- [Closest Leaf in a Binary Tree](src/main/java/tree/ClosestLeafInABinaryTree.java) (Medium) -- [Maximum Width of Binary Tree](src/main/java/tree/MaximumWidthOfBinaryTree.java) (Medium) --  [Recover Binary Search Tree](src/main/java/tree/RecoverBinarySearchTree.java) (Hard) --  [Binary Tree Postorder Traversal](src/main/java/tree/BinaryTreePostorderTraversal.java) (Hard) --  [Serialize and Deserialize N-ary Tree](src/main/java/tree/SerializeAndDeserializeNAryTree.java) (Hard) -- [Convert BST to Greater Tree](src/main/java/tree/ConvertBSTToGreaterTree.java) (Easy) -- [All Nodes Distance K in Binary Tree](src/main/java/tree/AllNodesDistanceKInBinaryTree.java) (Medium) -- [All Possible Full Binary Trees](src/main/java/tree/AllPossibleFullBinaryTrees.java) (Medium) -- [Flip Equivalent Binary Trees](src/main/java/tree/FlipEquivalentBinaryTrees.java) (Medium) -- [Construct Binary Tree from String](src/main/java/tree/ConstructBinaryTreefromString.java) (Medium) -- [Find Largest Value in Each Tree Row](src/main/java/tree/FindLargestValueInEachTreeRow.java) (Medium) -- [Find Bottom Left Tree Value](src/main/java/tree/FindBottomLeftTreeValue.java) (Medium) -- [Maximum Level Sum of a Binary Tree](src/main/java/tree/MaximumLevelSumofABinaryTree.java) (Medium) -- [Leaf-Similar Trees](src/main/java/tree/LeafSimilarTrees.java) (Easy) -- [Binary Tree Tilt](src/main/java/tree/BinaryTreeTilt.java) (Easy) - -#### [Two Pointers](src/main/java/two_pointers) - -- [Four Sum](src/main/java/two_pointers/FourSum.java) (Medium) -- [Longest Substring Witout Repeats](src/main/java/two_pointers/LongestSubstringWitoutRepeats.java) (Medium) -- [Three Sum](src/main/java/two_pointers/ThreeSum.java) (Medium) --  [Trapping Rain Water](src/main/java/two_pointers/TrappingRainWater.java) (Hard) -- [3Sum Closest](src/main/java/two_pointers/ThreeSumClosest.java) (Medium) -- [Move Zeroes](src/main/java/two_pointers/MoveZeroes.java) (Easy) -- [Remove Duplicates](src/main/java/two_pointers/RemoveDuplicates.java) (Easy) -- [Remove Duplicates II](src/main/java/two_pointers/RemoveDuplicatesII.java) (Medium) -- [Minimum Size Subarray Sum](src/main/java/two_pointers/MinimumSizeSubarraySum.java) (Medium) --  [Minimum Window Substring](src/main/java/two_pointers/MinimumWindowSubstring.java) (Hard) --  [Smallest Range](src/main/java/two_pointers/SmallestRange.java) (Hard) -- [Subarray Product Less Than K](src/main/java/two_pointers/SubarrayProductLessThanK.java) (Medium) -- [Number of Matching Subsequences](src/main/java/two_pointers/NumberOfMatchingSubsequences.java) (Medium) --  [Subarrays with K Different Integers](src/main/java/two_pointers/SubarraysWithKDifferentIntegers.java) (Hard) --  [Last Substring in Lexicographical Order](src/main/java/two_pointers/LastSubstringInLexicographicalOrder.java) (Hard) - -" -youseries/ureport,master,1925,821,2017-06-05T07:48:31Z,99439,194,"UReport2 is a high-performance pure Java report engine based on Spring architecture, where complex Chinese-style statements and reports can be prepared by iterating over cells.",chinese-report java-report java-report-engine report spring springboot,"# Overview - -UReport2 is a high-performance pure Java report engine based on Spring architecture, where complex Chinese-style statements and reports can be prepared by iteraing over cells. - -UReport2 provides the brand new web-based report designer that runs in mainstream browsers including Chrome, Firefox and Edge etc. \(other than IE\). You can complete the design and preparation of complex statements and reports with UReport2 by simply opening the browser. - -UReport2 is the first Chinese-style report engine based on Apache-2.0 License. - -[中文 README](README-zh_CN.md) - -# Teaching video - -[http://pan.baidu.com/s/1boWTxF5](http://pan.baidu.com/s/1boWTxF5),password:98hj - -# Installation and Configuration - -UReport2 is a pure Java report engine, so it supports all current popular types of J2EE projects. Here we will mainly introduce how Maven-based J2EE projects incorporate UReport2. - -### Maven-based UReport2 project - -Firstly, we need to create a standard Maven project \(create a project with Eclipse or other tools, while no more details are introduced here\), then open the file pom.xml of Maven, and add the dependence information of UReport2, as shown below: - -``` -
-
-![]() -
-![]() -
-![]() -
-
-
-![]() -
-![]() -
-![]() -
-
-
-![]() -
-![]() -
-
-
-## 实战项目
-
-为了方便大家更好的在项目中使用LRecyclerView,这里提供一个项目demo,有需要可以参考下!
-
-github地址: https://github.com/jdsjlzx/Community
-
--
-
-
- Solutions to problems on HackerRank. -
-- Check out HackerRank's new format here -
-- If you are interested in helping or have a solution in a different language feel free to make a pull request. -
-
-
-
-
-
- [Java](./Algorithms/Warmup/Solve%20Me%20First/Solution.java)
- [C#](./Algorithms/Warmup/Solve%20Me%20First/Solution.cs)
- [Java](./Algorithms/Warmup/Simple%20Array%20Sum/Solution.java)
- [C#](./Algorithms/Warmup/Simple%20Array%20Sum/Solution.cs)
- [Java](./Algorithms/Warmup/Compare%20the%20Triplets/Solution.java)
- [C#](./Algorithms/Warmup/Compare%20the%20Triplets/Solution.cs)
- [Java](./Algorithms/Warmup/A%20Very%20Big%20Sum/Solution.java)
- [C#](./Algorithms/Warmup/A%20Very%20Big%20Sum/Solution.cs)
- [Java](./Algorithms/Warmup/Diagonal%20Difference/Solution.java)
- [C#](./Algorithms/Warmup/Diagonal%20Difference/Solution.cs)
- [Java](./Algorithms/Warmup/Plus%20Minus/Solution.java)
- [C#](./Algorithms/Warmup/Plus%20Minus/Solution.cs)
- [Java](./Algorithms/Warmup/Staircase/Solution.java)
- [C#](./Algorithms/Warmup/Staircase/Solution.cs)
- [Java](./Algorithms/Warmup/Mini-Max%20Sum/Solution.java)
- [C#](./Algorithms/Warmup/Mini-Max%20Sum/Solution.cs)
- [Java](./Algorithms/Warmup/Time%20Conversion/Solution.java)
- [C#](./Algorithms/Warmup/Time%20Conversion/Solution.cs)
- [Java](./Algorithms/Warmup/Birthday%20Cake%20Candles/Solution.java)
- [C#](./Algorithms/Warmup/Birthday%20Cake%20Candles/Solution.cs)
- [Java](./Algorithms/Implementation/Grading%20Students/Solution.java)
- [JS](./Algorithms/Implementation/Grading%20Students/Solution.js)
- [C#](./Algorithms/Implementation/Grading%20Students/Solution.cs)
- [Java](./Algorithms/Implementation/Apple%20and%20Orange/Solution.java)
- [JS](./Algorithms/Implementation/Apple%20and%20Orange/Solution.js)
- [C#](./Algorithms/Implementation/Apple%20and%20Orange/Solution.cs)
- [Java](./Algorithms/Implementation/Kangaroo/Solution.java)
- [C#](./Algorithms/Implementation/Kangaroo/Solution.cs)
- [Java](./Algorithms/Implementation/Between%20Two%20Sets/Solution.java)
- [C#](./Algorithms/Implementation/Between%20Two%20Sets/Solution.cs)
- [Java](./Algorithms/Implementation/Divisible%20Sum%20Pairs/Solution.java)
- [C#](./Algorithms/Implementation/Divisible%20Sum%20Pairs/Solution.cs)
- [Java](./Algorithms/Implementation/Birthday%20Chocolate/Solution.java)
- [C#](./Algorithms/Implementation/Birthday%20Chocolate/Solution.cs)
- [Java](./Algorithms/Implementation/Breaking%20the%20Records/Solution.java)
- [C#](./Algorithms/Implementation/Breaking%20the%20Records/Solution.cs)
- [Java](./Algorithms/Implementation/Migratory%20Birds/Solution.java)
- [JS](./Algorithms/Implementation/Migratory%20Birds/Solution.js)
- [C#](./Algorithms/Implementation/Migratory%20Birds/Solution.cs)
- [Java](./Algorithms/Implementation/Day%20Of%20The%20Programmer/Solution.java)
- [C#](./Algorithms/Implementation/Day%20Of%20The%20Programmer/Solution.cs)
- [Java](./Algorithms/Implementation/Bon%20Appetit/Solution.java)
- [C#](./Algorithms/Implementation/Bon%20Appetit/Solution.cs)
- [Java](./Algorithms/Implementation/Sock%20Merchant/Solution.java)
- [C#](./Algorithms/Implementation/Sock%20Merchant/Solution.cs)
- [Java](./Algorithms/Implementation/Drawing%20Book/Solution.java)
- [C#](./Algorithms/Implementation/Drawing%20Book/Solution.cs)
- [Java](./Algorithms/Implementation/Counting%20Valleys/Solution.java)
- [JS](./Algorithms/Implementation/Counting%20Valleys/Solution.js)
- [C#](./Algorithms/Implementation/Counting%20Valleys/Solution.cs)
- [Java](./Algorithms/Implementation/Cats%20and%20a%20Mouse/Solution.java)
- [C#](./Algorithms/Implementation/Cats%20and%20a%20Mouse/Solution.cs)
- [Java](./Algorithms/Implementation/Electronics%20Shop/Solution.java)
- [JS](./Algorithms/Implementation/Electronics%20Shop/Solution.js)
- [C#](./Algorithms/Implementation/Electronics%20Shop/Solution.cs)
- [Java](./Algorithms/Implementation/Picking%20Numbers/Solution.java)
- [C#](./Algorithms/Implementation/Picking%20Numbers/Solution.cs)
- [Java](./Algorithms/Implementation/Climbing%20the%20Leaderboard/Solution.java)
- [JS](./Algorithms/Implementation/Climbing%20the%20Leaderboard/Solution.js)
- [C#](./Algorithms/Implementation/Climbing%20the%20Leaderboard/Solution.cs)
- [Java](./Algorithms/Implementation/The%20Hurdle%20Race/Solution.java)
- [C#](./Algorithms/Implementation/The%20Hurdle%20Race/Solution.cs)
- [Java](./Algorithms/Implementation/Designer%20PDF%20Viewer/Solution.java)
- [JS](./Algorithms/Implementation/Designer%20PDF%20Viewer/Solution.js)
- [C#](./Algorithms/Implementation/Designer%20PDF%20Viewer/Solution.cs)
- [Java](./Algorithms/Implementation/Forming%20a%20Magic%20Square/Solution.java)
- [Java](./Algorithms/Implementation/Utopian%20Tree/Solution.java)
- [JS](./Algorithms/Implementation/Utopian%20Tree/Solution.js)
- [C#](./Algorithms/Implementation/Utopian%20Tree/Solution.cs)
- [Java](./Algorithms/Implementation/Angry%20Professor/Solution.java)
- [JS](./Algorithms/Implementation/Angry%20Professor/Solution.js)
- [C#](./Algorithms/Implementation/Angry%20Professor/Solution.cs)
- [Java](./Algorithms/Implementation/Beautiful%20Days%20at%20the%20Movies/Solution.java)
- [JS](./Algorithms/Implementation/Beautiful%20Days%20at%20the%20Movies/Solution.js)
- [C#](./Algorithms/Implementation/Beautiful%20Days%20at%20the%20Movies/Solution.cs)
- [Java](./Algorithms/Implementation/Viral%20Advertising/Solution.java)
- [JS](./Algorithms/Implementation/Viral%20Advertising/Solution.js)
- [C#](./Algorithms/Implementation/Viral%20Advertising/Solution.cs)
- [Java](./Algorithms/Implementation/Save%20the%20Prisoner!/Solution.java)
- [C#](./Algorithms/Implementation/Save%20the%20Prisoner!/Solution.cs)
- [Java](./Algorithms/Implementation/Circular%20Array%20Rotation/Solution.java)
- [C#](./Algorithms/Implementation/Circular%20Array%20Rotation/Solution.cs)
- [Java](./Algorithms/Implementation/Sequence%20Equation/Solution.java)
- [C#](./Algorithms/Implementation/Sequence%20Equation/Solution.cs)
- [Java](./Algorithms/Implementation/Jumping%20on%20the%20Clouds-%20Revisited/Solution.java)
- [C#](./Algorithms/Implementation/Jumping%20on%20the%20Clouds-%20Revisited/Solution.cs)
- [Java](./Algorithms/Implementation/Find%20Digits/Solution.java)
- [C#](./Algorithms/Implementation/Find%20Digits/Solution.cs)
- | _O(1)_ | _O(1)_| Easy | 1 | ||
-| |[Simple Array Sum](https://www.hackerrank.com/challenges/simple-array-sum)|
- | _O(n)_ | _O(1)_ | Easy | 10 | ||
-| |[Compare the Triplets](https://www.hackerrank.com/challenges/compare-the-triplets)|
- | _O(1)_ | _O(1)_ | Easy | 10 | ||
-| |[A Very Big Sum](https://www.hackerrank.com/challenges/a-very-big-sum)|
- | _O(n)_ | _O(1)_ | Easy | 10 | ||
-| |[Diagonal Difference](https://www.hackerrank.com/challenges/diagonal-difference)|
- | _O(n)_ | _O(1)_ | Easy | 10 | ||
-| |[Plus Minus](https://www.hackerrank.com/challenges/plus-minus)|
- | _O(n)_ | _O(1)_ | Easy | 10 | ||
-| |[Staircase](https://www.hackerrank.com/challenges/staircase)|
- | _O(n)_ | _O(n)_ | Easy | 10 | ||
-| |[Mini-Max Sum](https://www.hackerrank.com/challenges/mini-max-sum)|
- | _O(1)_ | _O(1)_ | Easy | 10 | ||
-| |[Time Conversion](https://www.hackerrank.com/challenges/time-conversion)|
- | _O(1)_ | _O(1)_ | Easy | 15 | ||
-| |[Birthday Cake Candles](https://www.hackerrank.com/challenges/birthday-cake-candles)|
- | _O(n)_ | _O(1)_ | Easy | 10 | ||
-
-### Implementation
-| # | Title | Solution | Time | Space | Difficulty | Points | Note
------|---------------- |:---------------:| --------------- | --------------- |:-------------:|:--------------:| -----
-| | [Grading Students](https://www.hackerrank.com/challenges/grading)|
- | _O(n)_ | _O(1)_ | Easy| 10| ||
-| | [Apple and Orange](https://www.hackerrank.com/challenges/apple-and-orange)|
- | _O(n+m)_ | _O(1)_ | Easy| 10| ||
-| | [Kangaroo](https://www.hackerrank.com/challenges/kangaroo)|
- | _O(1)_ | _O(1)_ | Easy| 10| ||
-| | [Between Two Sets](https://www.hackerrank.com/challenges/between-two-sets)|
- | _O(x(n+m))_ | _O(1)_ | Easy| 10| _x=(max(m) - min(n))/min(n)_ ||
-| | [Divisible Sum Pairs](https://www.hackerrank.com/challenges/divisible-sum-pairs)|
- | _O(n^2)_ | _O(1)_ | Easy| 10| ||
-| | [Birthday Chocolate](https://www.hackerrank.com/challenges/the-birthday-bar)|
- | _O(n)_ | _O(1)_ | Easy| 10| ||
-| | [Breaking the Records](https://www.hackerrank.com/challenges/breaking-best-and-worst-records)|
- | _O(n)_ | _O(1)_ | Easy| 10| ||
-| | [Migratory Birds](https://www.hackerrank.com/challenges/migratory-birds)|
- | _O(n)_ | _O(1)_ | Easy| 10| ||
-| | [Day of the Programmer](https://www.hackerrank.com/challenges/day-of-the-programmer)|
- | _O(1)_ | _O(1)_ | Easy| 15| ||
-| | [Bon Appetit](https://www.hackerrank.com/challenges/bon-appetit)|
- | _O(n)_ | _O(1)_ | Easy| 10| ||
-| | [Sock Merchant](https://www.hackerrank.com/challenges/sock-merchant)|
- | _O(n)_ | _O(n)_ | Easy| 10| ||
-| | [Drawing Book](https://www.hackerrank.com/challenges/drawing-book)|
- | _O(1)_ | _O(1)_ | Easy| 10| ||
-| | [Counting Valleys](https://www.hackerrank.com/challenges/counting-valleys)|
- | _O(n)_ | _O(1)_ | Easy| 15| ||
-| | [Cats and a Mouse](https://www.hackerrank.com/challenges/cats-and-a-mouse)|
- | _O(1)_ | _O(1)_ | Easy| 15| ||
-| | [Electronics Shop](https://www.hackerrank.com/challenges/electronics-shop)|
- | _O(n log (n))_ | _O(1)_ | Easy| 15| n = m+n||
-| | [Picking Numbers](https://www.hackerrank.com/challenges/picking-numbers)|
- | _O(n)_ | _O(n)_ | Easy| 20| ||
-| | [Climbing the Leaderboard](https://www.hackerrank.com/challenges/climbing-the-leaderboard)|
- | _O(n+m)_ | _(n)_ | Easy| 20| ||
-| | [The Hurdle Race](https://www.hackerrank.com/challenges/the-hurdle-race)|
- | _O(n)_ | _O(1)_ | Easy| 15| ||
-| | [Designer PDF Viewer](https://www.hackerrank.com/challenges/designer-pdf-viewer)|
- | _O(n)_ | _O(n)_ | Easy| 20| ||
-| | [Forming a Magic Square](https://www.hackerrank.com/challenges/magic-square-forming)|
- | _O(1)_ | _O(1)_ | Easy| 20| ||
-| | [Utopian Tree](https://www.hackerrank.com/challenges/utopian-tree)|
- | _O(n)_ | _O(1)_ | Easy | 20| ||
-| | [Angry Professor](https://www.hackerrank.com/challenges/angry-professor)|
- | _O(n)_ | _O(1)_ | Easy | 20| ||
-| | [Beautiful Days at the Movies](https://www.hackerrank.com/challenges/beautiful-days-at-the-movies)|
- | _O(n)_ | _O(1)_ | Easy | 15| ||
-| | [Viral Advertising](https://www.hackerrank.com/challenges/strange-advertising)|
- | _O(n)_ | _O(1)_ | Easy | 15| ||
-| | [Save the Prisoner!](https://www.hackerrank.com/challenges/save-the-prisoner)|
- | _O(1)_ | _O(1)_ | Easy | 15| ||
-| | [Circular Array Rotation](https://www.hackerrank.com/challenges/circular-array-rotation)|
- | _O(n)_ | _O(1)_ | Easy | 20| ||
-| | [Sequence Equation](https://www.hackerrank.com/challenges/permutation-equation)|
- | _O(n)_ | _O(n)_ | Easy | 20| ||
-| | [Jumping on the Clouds: Revisited](https://www.hackerrank.com/challenges/jumping-on-the-clouds-revisited)|
- | _O(n)_ | _O(n)_ | Easy | 15| ||
-| | [Find Digits](https://www.hackerrank.com/challenges/find-digits)|
- | _O(n)_ | _O(1)_ | Easy | 25| ||
-| | [Extra Long Factorials](https://www.hackerrank.com/challenges/extra-long-factorials)|