 +
+
+ OpenMMLab website
+
+
+ HOT
+
+
+
+ OpenMMLab platform
+
+
+ TRY IT OUT
+
+
+
+  +
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmengine.git
+```
+
+After that, you should ddd official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmengine
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmengine.git (fetch)
+origin git@github.com:{username}/mmengine.git (push)
+upstream git@github.com:open-mmlab/mmengine (fetch)
+upstream git@github.com:open-mmlab/mmengine (push)
+```
+
+> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the mmengine directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
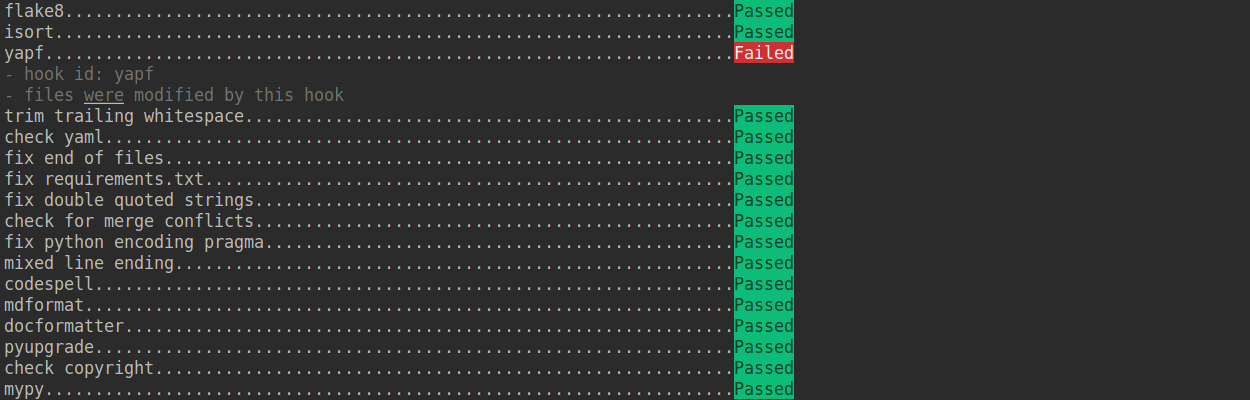
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmengine.git
+```
+
+After that, you should ddd official repository as the upstream repository
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmengine
+```
+
+Check whether remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmengine.git (fetch)
+origin git@github.com:{username}/mmengine.git (push)
+upstream git@github.com:open-mmlab/mmengine (fetch)
+upstream git@github.com:open-mmlab/mmengine (push)
+```
+
+> Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the mmengine directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+ +
+
+
+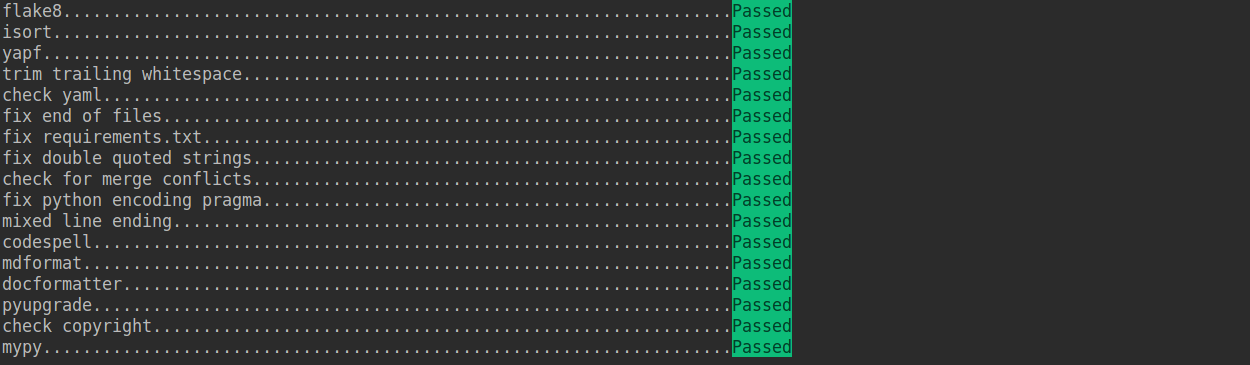 +
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+ +
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMEngine introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time without specifying a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+
+
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMEngine introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time without specifying a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+ +
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+
+
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+ +
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+
+
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+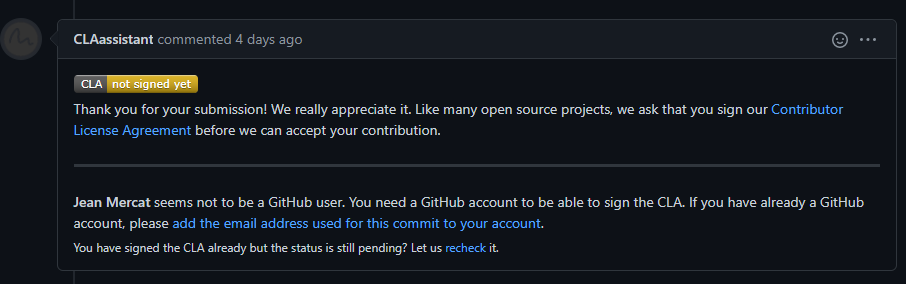 +
+(c) Check whether the Pull Request pass through the CI
+
+
+
+(c) Check whether the Pull Request pass through the CI
+
+ +
+MMEngine will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+
+
+MMEngine will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+ +
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Python Code style
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/testbed/open-mmlab__mmengine/CONTRIBUTING_zh-CN.md b/testbed/open-mmlab__mmengine/CONTRIBUTING_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..357c02d4c6da0a4552708d715e02c7946a0c7844
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/CONTRIBUTING_zh-CN.md
@@ -0,0 +1,255 @@
+## 贡献代码
+
+欢迎加入 MMEngine 社区,我们致力于打造最前沿的深度学习模型训练的基础库,我们欢迎任何类型的贡献,包括但不限于
+
+**修复错误**
+
+修复代码实现错误的步骤如下:
+
+1. 如果提交的代码改动较大,建议先提交 issue,并正确描述 issue 的现象、原因和复现方式,讨论后确认修复方案。
+2. 修复错误并补充相应的单元测试,提交拉取请求。
+
+**新增功能或组件**
+
+1. 如果新功能或模块涉及较大的代码改动,建议先提交 issue,确认功能的必要性。
+2. 实现新增功能并添单元测试,提交拉取请求。
+
+**文档补充**
+
+修复文档可以直接提交拉取请求
+
+添加文档或将文档翻译成其他语言步骤如下
+
+1. 提交 issue,确认添加文档的必要性。
+2. 添加文档,提交拉取请求。
+
+### 拉取请求工作流
+
+如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. 复刻仓库
+
+当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
+
+
+
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmengine.git
+```
+
+添加原代码库为上游代码库
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmengine
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmengine.git (fetch)
+origin git@github.com:{username}/mmengine.git (push)
+upstream git@github.com:open-mmlab/mmengine (fetch)
+upstream git@github.com:open-mmlab/mmengine (push)
+```
+
+> 这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+
+#### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 mmengine 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+> 如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+
+> pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+> pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 master 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 master 分支落后于 upstream 的 master 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream master
+```
+
+#### 4. 提交代码并在本地通过单元测试
+
+- MMEngine 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 runner 为例
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+#### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+#### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+
+
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+
+
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+
+
+MMEngine 会在不同的平台(Linux、Window、Mac),基于不同版本的 Python、PyTorch、CUDA 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+
+
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到主分支。
+
+#### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与主分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+### 指引
+
+#### 单元测试
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Python 代码风格
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
+
+- [flake8](https://github.com/PyCQA/flake8): Python 官方发布的代码规范检查工具,是多个检查工具的封装
+- [isort](https://github.com/timothycrosley/isort): 自动调整模块导入顺序的工具
+- [yapf](https://github.com/google/yapf): Google 发布的代码规范检查工具
+- [codespell](https://github.com/codespell-project/codespell): 检查单词拼写是否有误
+- [mdformat](https://github.com/executablebooks/mdformat): 检查 markdown 文件的工具
+- [docformatter](https://github.com/myint/docformatter): 格式化 docstring 的工具
+
+yapf 和 isort 的配置可以在 [setup.cfg](./setup.cfg) 找到
+
+通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
+pre-commit 钩子的配置可以在 [.pre-commit-config](./.pre-commit-config.yaml) 找到。
+
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
+
+更具体的规范请参考 [OpenMMLab 代码规范](code_style.md)。
+
+### 拉取请求规范
+
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
+
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 MMEngine 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
diff --git a/testbed/open-mmlab__mmengine/LICENSE b/testbed/open-mmlab__mmengine/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..1bfc23e48f92245b229cdd57c77e79bc10a1cc27
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/LICENSE
@@ -0,0 +1,203 @@
+Copyright 2018-2023 OpenMMLab. All rights reserved.
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2018-2023 OpenMMLab.
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/testbed/open-mmlab__mmengine/MANIFEST.in b/testbed/open-mmlab__mmengine/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..8bf078a7572fb583af011ac5d714895694f279cf
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/MANIFEST.in
@@ -0,0 +1 @@
+include mmengine/hub/openmmlab.json mmengine/hub/deprecated.json mmengine/hub/mmcls.json mmengine/hub/torchvision_0.12.json
diff --git a/testbed/open-mmlab__mmengine/README.md b/testbed/open-mmlab__mmengine/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c0bb49df1cb9d83af4ac2c53d8529eaceaba9561
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/README.md
@@ -0,0 +1,306 @@
+
+
+
+
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Python Code style
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/testbed/open-mmlab__mmengine/CONTRIBUTING_zh-CN.md b/testbed/open-mmlab__mmengine/CONTRIBUTING_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..357c02d4c6da0a4552708d715e02c7946a0c7844
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/CONTRIBUTING_zh-CN.md
@@ -0,0 +1,255 @@
+## 贡献代码
+
+欢迎加入 MMEngine 社区,我们致力于打造最前沿的深度学习模型训练的基础库,我们欢迎任何类型的贡献,包括但不限于
+
+**修复错误**
+
+修复代码实现错误的步骤如下:
+
+1. 如果提交的代码改动较大,建议先提交 issue,并正确描述 issue 的现象、原因和复现方式,讨论后确认修复方案。
+2. 修复错误并补充相应的单元测试,提交拉取请求。
+
+**新增功能或组件**
+
+1. 如果新功能或模块涉及较大的代码改动,建议先提交 issue,确认功能的必要性。
+2. 实现新增功能并添单元测试,提交拉取请求。
+
+**文档补充**
+
+修复文档可以直接提交拉取请求
+
+添加文档或将文档翻译成其他语言步骤如下
+
+1. 提交 issue,确认添加文档的必要性。
+2. 添加文档,提交拉取请求。
+
+### 拉取请求工作流
+
+如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+#### 1. 复刻仓库
+
+当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
+
+
+
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmengine.git
+```
+
+添加原代码库为上游代码库
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmengine
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmengine.git (fetch)
+origin git@github.com:{username}/mmengine.git (push)
+upstream git@github.com:open-mmlab/mmengine (fetch)
+upstream git@github.com:open-mmlab/mmengine (push)
+```
+
+> 这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+
+#### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 mmengine 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+> 如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+
+> pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+> pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 master 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 master 分支落后于 upstream 的 master 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream master
+```
+
+#### 4. 提交代码并在本地通过单元测试
+
+- MMEngine 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 runner 为例
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+#### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+#### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+
+
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+
+
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+
+
+MMEngine 会在不同的平台(Linux、Window、Mac),基于不同版本的 Python、PyTorch、CUDA 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+
+
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到主分支。
+
+#### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与主分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+### 指引
+
+#### 单元测试
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Python 代码风格
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
+
+- [flake8](https://github.com/PyCQA/flake8): Python 官方发布的代码规范检查工具,是多个检查工具的封装
+- [isort](https://github.com/timothycrosley/isort): 自动调整模块导入顺序的工具
+- [yapf](https://github.com/google/yapf): Google 发布的代码规范检查工具
+- [codespell](https://github.com/codespell-project/codespell): 检查单词拼写是否有误
+- [mdformat](https://github.com/executablebooks/mdformat): 检查 markdown 文件的工具
+- [docformatter](https://github.com/myint/docformatter): 格式化 docstring 的工具
+
+yapf 和 isort 的配置可以在 [setup.cfg](./setup.cfg) 找到
+
+通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
+pre-commit 钩子的配置可以在 [.pre-commit-config](./.pre-commit-config.yaml) 找到。
+
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
+
+更具体的规范请参考 [OpenMMLab 代码规范](code_style.md)。
+
+### 拉取请求规范
+
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
+
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 MMEngine 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
diff --git a/testbed/open-mmlab__mmengine/LICENSE b/testbed/open-mmlab__mmengine/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..1bfc23e48f92245b229cdd57c77e79bc10a1cc27
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/LICENSE
@@ -0,0 +1,203 @@
+Copyright 2018-2023 OpenMMLab. All rights reserved.
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2018-2023 OpenMMLab.
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/testbed/open-mmlab__mmengine/MANIFEST.in b/testbed/open-mmlab__mmengine/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..8bf078a7572fb583af011ac5d714895694f279cf
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/MANIFEST.in
@@ -0,0 +1 @@
+include mmengine/hub/openmmlab.json mmengine/hub/deprecated.json mmengine/hub/mmcls.json mmengine/hub/torchvision_0.12.json
diff --git a/testbed/open-mmlab__mmengine/README.md b/testbed/open-mmlab__mmengine/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c0bb49df1cb9d83af4ac2c53d8529eaceaba9561
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/README.md
@@ -0,0 +1,306 @@
+
+
+ 

 +
+
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmengine.git
+```
+
+After that, you should add the official repository as the upstream repository.
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmengine
+```
+
+Check whether the remote repository has been added successfully by `git remote -v`.
+
+```bash
+origin git@github.com:{username}/mmengine.git (fetch)
+origin git@github.com:{username}/mmengine.git (push)
+upstream git@github.com:open-mmlab/mmengine (fetch)
+upstream git@github.com:open-mmlab/mmengine (push)
+```
+
+```{note}
+Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+```
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the mmengine directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporary committing**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMEngine introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+
+
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+
+
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+
+
+(c) Check whether the Pull Request pass through the CI
+
+
+
+MMEngine will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+
+
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Python Code style
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/testbed/open-mmlab__mmengine/docs/en/switch_language.md b/testbed/open-mmlab__mmengine/docs/en/switch_language.md
new file mode 100644
index 0000000000000000000000000000000000000000..e47b751e33928f59c4bf1aea94110493214754ea
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/en/switch_language.md
@@ -0,0 +1,3 @@
+## English
+
+## 简体中文
diff --git a/testbed/open-mmlab__mmengine/docs/en/tutorials/dataset.md b/testbed/open-mmlab__mmengine/docs/en/tutorials/dataset.md
new file mode 100644
index 0000000000000000000000000000000000000000..b1a1c8ff945b63e4212e23eb51b000c88ca69e5a
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/en/tutorials/dataset.md
@@ -0,0 +1,200 @@
+# Dataset and DataLoader
+
+```{hint}
+If you have never been exposed to PyTorch's Dataset and DataLoader classes, you are recommended to read through [PyTorch official tutorial](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html) to get familiar with some basic concepts.
+```
+
+Datasets and DataLoaders are necessary components in MMEngine's training pipeline. They are conceptually derived from and consistent with PyTorch. Typically, a dataset defines the quantity, parsing, and pre-processing of the data, while a dataloader iteratively loads data according to settings such as `batch_size`, `shuffle`, `num_workers`, etc. Datasets are encapsulated with dataloaders and they together constitute the data source.
+
+In this tutorial, we will step through their usage in MMEngine runner from the outside (dataloader) to the inside (dataset) and give some practical examples. After reading through this tutorial, you will be able to:
+
+- Master the configuration of dataloaders in MMEngine
+- Learn to use existing datasets (e.g. those from `torchvision`) from config files
+- Know about building and using your own dataset
+
+## Details on dataloader
+
+Dataloaders can be configured in MMEngine's `Runner` with 3 arguments:
+
+- `train_dataloader`: Used in `Runner.train()` to provide training data for models
+- `val_dataloader`: Used in `Runner.val()` or in `Runner.train()` at regular intervals for model evaluation
+- `test_dataloader`: Used in `Runner.test()` for the final test
+
+MMEngine has full support for PyTorch native `DataLoader` objects. Therefore, you can simply pass your valid, already built dataloaders to the runner, as shown in [getting started in 15 minutes](../get_started/15_minutes.md). Meanwhile, thanks to the [Registry Mechanism](../advanced_tutorials/registry.md) of MMEngine, those arguments also accept `dict`s as inputs, as illustrated in the following example (referred to as example 1). The keys in the dictionary correspond to arguments in DataLoader's init function.
+
+```python
+runner = Runner(
+ train_dataloader=dict(
+ batch_size=32,
+ sampler=dict(
+ type='DefaultSampler',
+ shuffle=True),
+ dataset=torchvision.datasets.CIFAR10(...),
+ collate_fn=dict(type='default_collate')
+ )
+)
+```
+
+When passed to the runner in the form of a dict, the dataloader will be lazily built in the runner when actually needed.
+
+```{note}
+For more configurable arguments of the `DataLoader`, please refer to [PyTorch API documentation](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader)
+```
+
+```{note}
+If you are interested in the details of the building procedure, you may refer to [build_dataloader](mmengine.runner.Runner.build_dataloader)
+```
+
+You may find example 1 differs from that in [getting started in 15 minutes](../get_started/15_minutes.md) in some arguments. Indeed, due to some obscure conventions in MMEngine, you can't seamlessly switch it to a dict by simply replacing `DataLoader` with `dict`. We will discuss the differences between our convention and PyTorch's in the following sections, in case you run into trouble when using config files.
+
+### sampler and shuffle
+
+One obvious difference is that we add a `sampler` argument to the dict. This is because we **require `sampler` to be explicitly specified** when using a dict as a dataloader. Meanwhile, `shuffle` is also removed from `DataLoader` arguments, because it conflicts with `sampler` in PyTorch, as referred to in [PyTorch DataLoader API documentation](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader).
+
+```{note}
+In fact, `shuffle` is just a notation for convenience in PyTorch implementation. If `shuffle` is set to `True`, the dataloader will automatically switch to `RandomSampler`
+```
+
+With a `sampler` argument, codes in example 1 is **nearly** equivalent to code block below
+
+```python
+from mmengine.dataset import DefaultSampler
+
+dataset = torchvision.datasets.CIFAR10(...)
+sampler = DefaultSampler(dataset, shuffle=True)
+
+runner = Runner(
+ train_dataloader=DataLoader(
+ batch_size=32,
+ sampler=sampler,
+ dataset=dataset,
+ collate_fn=default_collate
+ )
+)
+```
+
+```{warning}
+The equivalence of the above codes holds only if: 1) you are training with a single process, and 2) no `randomness` argument is passed to the runner. This is due to the fact that `sampler` should be built after distributed environment setup to be correct. The runner will guarantee the correct order and proper random seed by applying lazy initialization techniques, which is only possible for dict inputs. Instead, when building a sampler manually, it requires extra work and is highly error-prone. Therefore, the code block above is just for illustration and definitely not recommended. We **strongly suggest passing `sampler` as a `dict`** to avoid potential problems.
+```
+
+### DefaultSampler
+
+The above example may make you wonder what a `DefaultSampler` is, why use it and whether there are other options. In fact, `DefaultSampler` is a built-in sampler in MMEngine which eliminates the gap between distributed and non-distributed training and thus enabling a seamless conversion between them. If you have the experience of using `DistributedDataParallel` in PyTorch, you may be impressed by having to change the `sampler` argument to make it correct. However, in MMEngine, you don't need to bother with this `DefaultSampler`.
+
+`DefaultSampler` accepts the following arguments:
+
+- `shuffle`: Set to `True` to load data in the dataset in random order
+- `seed`: Random seed used to shuffle the dataset. Typically it doesn't require manual configuration here because the runner will handle it with `randomness` configuration
+- `round_up`: When set this to `True`, this is the same behavior as setting `drop_last=False` in PyTorch `DataLoader`. You should take care of it when doing migration from PyTorch.
+
+```{note}
+For more details about `DefaultSampler`, please refer to [its API docs](mmengine.dataset.DefaultSampler)
+```
+
+`DefaultSampler` handles most of the cases. We ensure that error-prone details such as random seeds are handled properly when you are using it in a runner. This prevents you from getting into troubles with distributed training. Apart from `DefaultSampler`, you may also be interested in [InfiniteSampler](mmengine.dataset.InfiniteSampler) for iteration-based training pipelines. If you have more advanced demands, you may want to refer to the codes of these two built-in samplers to implement your own one and register it to `DATA_SAMPLERS` registry.
+
+```python
+@DATA_SAMPLERS.register_module()
+class MySampler(Sampler):
+ pass
+
+runner = Runner(
+ train_dataloader=dict(
+ sampler=dict(type='MySampler'),
+ ...
+ )
+)
+```
+
+### The obscure collate_fn
+
+Among the arguments of PyTorch `DataLoader`, `collate_fn` is often ignored by users, but in MMEngine you must pay special attention to it. When you pass the dataloader argument as a dict, MMEngine will use the built-in [pseudo_collate](mmengine.dataset.pseudo_collate) by default, which is significantly different from that, [default_collate](https://pytorch.org/docs/stable/data.html#torch.utils.data.default_collate), in PyTorch. Therefore, when doing a migration from PyTorch, you have to explicitly specify the `collate_fn` in config files to be consistent in behavior.
+
+```{note}
+MMEngine uses `pseudo_collate` as default value is mainly due to historical compatibility reasons. You don't have to look deeply into it. You can just know about it and avoid potential errors.
+```
+
+MMEngine provides 2 built-in `collate_fn`:
+
+- `pseudo_collate`: Default value in MMEngine. It won't concatenate data through `batch` index. Detailed explanations can be found in [pseudo_collate API doc](mmengine.dataset.pseudo_collate)
+- `default_collate`: It behaves almost identically to PyTorch's `default_collate`. It will transfer data into `Tensor` and concatenate them through `batch` index. More details and slight differences from PyTorch can be found in [default_collate API doc](mmengine.dataset.default_collate)
+
+If you want to use a custom `collate_fn`, you can register it to `COLLATE_FUNCTIONS` registry.
+
+```python
+@COLLATE_FUNCTIONS.register_module()
+def my_collate_func(data_batch: Sequence) -> Any:
+ pass
+
+runner = Runner(
+ train_dataloader=dict(
+ ...
+ collate_fn=dict(type='my_collate_func')
+ )
+)
+```
+
+## Details on dataset
+
+Typically, datasets define the quantity, parsing, and pre-processing of the data. It is encapsulated in dataloader, allowing the latter to load data in batches. Since we fully support PyTorch `DataLoader`, the dataset is also compatible. Meanwhile, thanks to the registry mechanism, when a dataloader is given as a dict, its `dataset` argument can also be given as a dict, which enables lazy initialization in the runner. This mechanism allows for writing config files.
+
+### Use torchvision datasets
+
+`torchvision` provides various open datasets. They can be directly used in MMEngine as shown in [getting started in 15 minutes](../get_started/15_minutes.md), where a `CIFAR10` dataset is used together with torchvision's built-in data transforms.
+
+However, if you want to use the dataset in config files, registration is needed. What's more, if you also require data transforms in torchvision, some more registrations are required. The following example illustrates how to do it.
+
+```python
+import torchvision.transforms as tvt
+from mmengine.registry import DATASETS, TRANSFORMS
+from mmengine.dataset.base_dataset import Compose
+
+# register CIFAR10 dataset in torchvision
+# data transforms should also be built here
+@DATASETS.register_module(name='Cifar10', force=False)
+def build_torchvision_cifar10(transform=None, **kwargs):
+ if isinstance(transform, dict):
+ transform = [transform]
+ if isinstance(transform, (list, tuple)):
+ transform = Compose(transform)
+ return torchvision.datasets.CIFAR10(**kwargs, transform=transform)
+
+# register data transforms in torchvision
+DATA_TRANSFORMS.register_module('RandomCrop', module=tvt.RandomCrop)
+DATA_TRANSFORMS.register_module('RandomHorizontalFlip', module=tvt.RandomHorizontalFlip)
+DATA_TRANSFORMS.register_module('ToTensor', module=tvt.ToTensor)
+DATA_TRANSFORMS.register_module('Normalize', module=tvt.Normalize)
+
+# specify in runner
+runner = Runner(
+ train_dataloader=dict(
+ batch_size=32,
+ sampler=dict(
+ type='DefaultSampler',
+ shuffle=True),
+ dataset=dict(type='Cifar10',
+ root='data/cifar10',
+ train=True,
+ download=True,
+ transform=[
+ dict(type='RandomCrop', size=32, padding=4),
+ dict(type='RandomHorizontalFlip'),
+ dict(type='ToTensor'),
+ dict(type='Normalize', **norm_cfg)])
+ )
+)
+```
+
+```{note}
+The above example makes extensive use of the registry mechanism and borrows the [Compose](mmengine.dataset.Compose) module from MMEngine. If you urge to use torchvision dataset in your config files, you can refer to it and make some slight modifications. However, we recommend you borrow datasets from downstream repos such as [MMDet](https://github.com/open-mmlab/mmdetection), [MMCls](https://github.com/open-mmlab/mmclassification), etc. This may give you a better experience.
+```
+
+### Customize your dataset
+
+You are free to customize your own datasets, as you would with PyTorch. You can also copy existing datasets from your previous PyTorch projects. If you want to learn how to customize your dataset, please refer to [PyTorch official tutorials](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html#creating-a-custom-dataset-for-your-files)
+
+### Use MMEngine BaseDataset
+
+Apart from directly using PyTorch native `Dataset` class, you can also use MMEngine's built-in class `BaseDataset` to customize your own one, as referred to [BaseDataset tutorial](../advanced_tutorials/basedataset.md). It makes some conventions on the format of annotation files, which makes the data interface more unified and multi-task training more convenient. Meanwhile, `BaseDataset` can easily cooperate with built-in [data transforms](../advanced_tutorials/data_element.md) in MMEngine, which releases you from writing one from scratch.
+
+Currently, `BaseDataset` has been widely used in downstream repos of OpenMMLab 2.0 projects.
diff --git a/testbed/open-mmlab__mmengine/docs/en/tutorials/evaluation.md b/testbed/open-mmlab__mmengine/docs/en/tutorials/evaluation.md
new file mode 100644
index 0000000000000000000000000000000000000000..90f09e776ae7d36c6b3ce6831b00bd78ced5d026
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/en/tutorials/evaluation.md
@@ -0,0 +1,3 @@
+# Evaluation
+
+Coming soon. Please refer to [chinese documentation](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/evaluation.html).
diff --git a/testbed/open-mmlab__mmengine/docs/en/tutorials/param_scheduler.md b/testbed/open-mmlab__mmengine/docs/en/tutorials/param_scheduler.md
new file mode 100644
index 0000000000000000000000000000000000000000..06dc047a95e3f0015338572443296b94caf3ddb8
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/en/tutorials/param_scheduler.md
@@ -0,0 +1,229 @@
+# Parameter Scheduler
+
+During neural network training, optimization hyperparameters (e.g. learning rate) are usually adjusted along with the training process.
+One of the simplest and most common learning rate adjustment strategies is multi-step learning rate decay, which reduces the learning rate to a fraction at regular intervals.
+PyTorch provides LRScheduler to implement various learning rate adjustment strategies. In MMEngine, we have extended it and implemented a more general [ParamScheduler](mmengine.optim._ParamScheduler).
+It can adjust optimization hyperparameters such as learning rate and momentum. It also supports the combination of multiple schedulers to create more complex scheduling strategies.
+
+## Usage
+
+We first introduce how to use PyTorch's `torch.optim.lr_scheduler` to adjust learning rate.
+
+
+
+
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmengine.git
+```
+
+After that, you should add the official repository as the upstream repository.
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmengine
+```
+
+Check whether the remote repository has been added successfully by `git remote -v`.
+
+```bash
+origin git@github.com:{username}/mmengine.git (fetch)
+origin git@github.com:{username}/mmengine.git (push)
+upstream git@github.com:open-mmlab/mmengine (fetch)
+upstream git@github.com:open-mmlab/mmengine (push)
+```
+
+```{note}
+Here's a brief introduction to origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+```
+
+#### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the mmengine directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporary committing**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the master branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the master branch of the local repository is behind the master branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream master
+```
+
+#### 4. Commit the code and pass the unit test
+
+- MMEngine introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of runner
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+#### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+#### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+
+
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes
+
+
+
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)
+
+(b) If it is your first contribution, please sign the CLA
+
+
+
+(c) Check whether the Pull Request pass through the CI
+
+
+
+MMEngine will run unit test for the posted Pull Request on different platforms (Linux, Window, Mac), based on different versions of Python, PyTorch, CUDA to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+
+
+#### 7. Resolve conflicts
+
+If your local branch conflicts with the latest master branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are not familiar with `rebase`, then you can use `merge` to resolve conflicts.
+
+### Guidance
+
+#### Unit test
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Python Code style
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](./setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](./.pre-commit-config.yaml).
+
+### PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/testbed/open-mmlab__mmengine/docs/en/switch_language.md b/testbed/open-mmlab__mmengine/docs/en/switch_language.md
new file mode 100644
index 0000000000000000000000000000000000000000..e47b751e33928f59c4bf1aea94110493214754ea
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/en/switch_language.md
@@ -0,0 +1,3 @@
+## English
+
+## 简体中文
diff --git a/testbed/open-mmlab__mmengine/docs/en/tutorials/dataset.md b/testbed/open-mmlab__mmengine/docs/en/tutorials/dataset.md
new file mode 100644
index 0000000000000000000000000000000000000000..b1a1c8ff945b63e4212e23eb51b000c88ca69e5a
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/en/tutorials/dataset.md
@@ -0,0 +1,200 @@
+# Dataset and DataLoader
+
+```{hint}
+If you have never been exposed to PyTorch's Dataset and DataLoader classes, you are recommended to read through [PyTorch official tutorial](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html) to get familiar with some basic concepts.
+```
+
+Datasets and DataLoaders are necessary components in MMEngine's training pipeline. They are conceptually derived from and consistent with PyTorch. Typically, a dataset defines the quantity, parsing, and pre-processing of the data, while a dataloader iteratively loads data according to settings such as `batch_size`, `shuffle`, `num_workers`, etc. Datasets are encapsulated with dataloaders and they together constitute the data source.
+
+In this tutorial, we will step through their usage in MMEngine runner from the outside (dataloader) to the inside (dataset) and give some practical examples. After reading through this tutorial, you will be able to:
+
+- Master the configuration of dataloaders in MMEngine
+- Learn to use existing datasets (e.g. those from `torchvision`) from config files
+- Know about building and using your own dataset
+
+## Details on dataloader
+
+Dataloaders can be configured in MMEngine's `Runner` with 3 arguments:
+
+- `train_dataloader`: Used in `Runner.train()` to provide training data for models
+- `val_dataloader`: Used in `Runner.val()` or in `Runner.train()` at regular intervals for model evaluation
+- `test_dataloader`: Used in `Runner.test()` for the final test
+
+MMEngine has full support for PyTorch native `DataLoader` objects. Therefore, you can simply pass your valid, already built dataloaders to the runner, as shown in [getting started in 15 minutes](../get_started/15_minutes.md). Meanwhile, thanks to the [Registry Mechanism](../advanced_tutorials/registry.md) of MMEngine, those arguments also accept `dict`s as inputs, as illustrated in the following example (referred to as example 1). The keys in the dictionary correspond to arguments in DataLoader's init function.
+
+```python
+runner = Runner(
+ train_dataloader=dict(
+ batch_size=32,
+ sampler=dict(
+ type='DefaultSampler',
+ shuffle=True),
+ dataset=torchvision.datasets.CIFAR10(...),
+ collate_fn=dict(type='default_collate')
+ )
+)
+```
+
+When passed to the runner in the form of a dict, the dataloader will be lazily built in the runner when actually needed.
+
+```{note}
+For more configurable arguments of the `DataLoader`, please refer to [PyTorch API documentation](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader)
+```
+
+```{note}
+If you are interested in the details of the building procedure, you may refer to [build_dataloader](mmengine.runner.Runner.build_dataloader)
+```
+
+You may find example 1 differs from that in [getting started in 15 minutes](../get_started/15_minutes.md) in some arguments. Indeed, due to some obscure conventions in MMEngine, you can't seamlessly switch it to a dict by simply replacing `DataLoader` with `dict`. We will discuss the differences between our convention and PyTorch's in the following sections, in case you run into trouble when using config files.
+
+### sampler and shuffle
+
+One obvious difference is that we add a `sampler` argument to the dict. This is because we **require `sampler` to be explicitly specified** when using a dict as a dataloader. Meanwhile, `shuffle` is also removed from `DataLoader` arguments, because it conflicts with `sampler` in PyTorch, as referred to in [PyTorch DataLoader API documentation](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader).
+
+```{note}
+In fact, `shuffle` is just a notation for convenience in PyTorch implementation. If `shuffle` is set to `True`, the dataloader will automatically switch to `RandomSampler`
+```
+
+With a `sampler` argument, codes in example 1 is **nearly** equivalent to code block below
+
+```python
+from mmengine.dataset import DefaultSampler
+
+dataset = torchvision.datasets.CIFAR10(...)
+sampler = DefaultSampler(dataset, shuffle=True)
+
+runner = Runner(
+ train_dataloader=DataLoader(
+ batch_size=32,
+ sampler=sampler,
+ dataset=dataset,
+ collate_fn=default_collate
+ )
+)
+```
+
+```{warning}
+The equivalence of the above codes holds only if: 1) you are training with a single process, and 2) no `randomness` argument is passed to the runner. This is due to the fact that `sampler` should be built after distributed environment setup to be correct. The runner will guarantee the correct order and proper random seed by applying lazy initialization techniques, which is only possible for dict inputs. Instead, when building a sampler manually, it requires extra work and is highly error-prone. Therefore, the code block above is just for illustration and definitely not recommended. We **strongly suggest passing `sampler` as a `dict`** to avoid potential problems.
+```
+
+### DefaultSampler
+
+The above example may make you wonder what a `DefaultSampler` is, why use it and whether there are other options. In fact, `DefaultSampler` is a built-in sampler in MMEngine which eliminates the gap between distributed and non-distributed training and thus enabling a seamless conversion between them. If you have the experience of using `DistributedDataParallel` in PyTorch, you may be impressed by having to change the `sampler` argument to make it correct. However, in MMEngine, you don't need to bother with this `DefaultSampler`.
+
+`DefaultSampler` accepts the following arguments:
+
+- `shuffle`: Set to `True` to load data in the dataset in random order
+- `seed`: Random seed used to shuffle the dataset. Typically it doesn't require manual configuration here because the runner will handle it with `randomness` configuration
+- `round_up`: When set this to `True`, this is the same behavior as setting `drop_last=False` in PyTorch `DataLoader`. You should take care of it when doing migration from PyTorch.
+
+```{note}
+For more details about `DefaultSampler`, please refer to [its API docs](mmengine.dataset.DefaultSampler)
+```
+
+`DefaultSampler` handles most of the cases. We ensure that error-prone details such as random seeds are handled properly when you are using it in a runner. This prevents you from getting into troubles with distributed training. Apart from `DefaultSampler`, you may also be interested in [InfiniteSampler](mmengine.dataset.InfiniteSampler) for iteration-based training pipelines. If you have more advanced demands, you may want to refer to the codes of these two built-in samplers to implement your own one and register it to `DATA_SAMPLERS` registry.
+
+```python
+@DATA_SAMPLERS.register_module()
+class MySampler(Sampler):
+ pass
+
+runner = Runner(
+ train_dataloader=dict(
+ sampler=dict(type='MySampler'),
+ ...
+ )
+)
+```
+
+### The obscure collate_fn
+
+Among the arguments of PyTorch `DataLoader`, `collate_fn` is often ignored by users, but in MMEngine you must pay special attention to it. When you pass the dataloader argument as a dict, MMEngine will use the built-in [pseudo_collate](mmengine.dataset.pseudo_collate) by default, which is significantly different from that, [default_collate](https://pytorch.org/docs/stable/data.html#torch.utils.data.default_collate), in PyTorch. Therefore, when doing a migration from PyTorch, you have to explicitly specify the `collate_fn` in config files to be consistent in behavior.
+
+```{note}
+MMEngine uses `pseudo_collate` as default value is mainly due to historical compatibility reasons. You don't have to look deeply into it. You can just know about it and avoid potential errors.
+```
+
+MMEngine provides 2 built-in `collate_fn`:
+
+- `pseudo_collate`: Default value in MMEngine. It won't concatenate data through `batch` index. Detailed explanations can be found in [pseudo_collate API doc](mmengine.dataset.pseudo_collate)
+- `default_collate`: It behaves almost identically to PyTorch's `default_collate`. It will transfer data into `Tensor` and concatenate them through `batch` index. More details and slight differences from PyTorch can be found in [default_collate API doc](mmengine.dataset.default_collate)
+
+If you want to use a custom `collate_fn`, you can register it to `COLLATE_FUNCTIONS` registry.
+
+```python
+@COLLATE_FUNCTIONS.register_module()
+def my_collate_func(data_batch: Sequence) -> Any:
+ pass
+
+runner = Runner(
+ train_dataloader=dict(
+ ...
+ collate_fn=dict(type='my_collate_func')
+ )
+)
+```
+
+## Details on dataset
+
+Typically, datasets define the quantity, parsing, and pre-processing of the data. It is encapsulated in dataloader, allowing the latter to load data in batches. Since we fully support PyTorch `DataLoader`, the dataset is also compatible. Meanwhile, thanks to the registry mechanism, when a dataloader is given as a dict, its `dataset` argument can also be given as a dict, which enables lazy initialization in the runner. This mechanism allows for writing config files.
+
+### Use torchvision datasets
+
+`torchvision` provides various open datasets. They can be directly used in MMEngine as shown in [getting started in 15 minutes](../get_started/15_minutes.md), where a `CIFAR10` dataset is used together with torchvision's built-in data transforms.
+
+However, if you want to use the dataset in config files, registration is needed. What's more, if you also require data transforms in torchvision, some more registrations are required. The following example illustrates how to do it.
+
+```python
+import torchvision.transforms as tvt
+from mmengine.registry import DATASETS, TRANSFORMS
+from mmengine.dataset.base_dataset import Compose
+
+# register CIFAR10 dataset in torchvision
+# data transforms should also be built here
+@DATASETS.register_module(name='Cifar10', force=False)
+def build_torchvision_cifar10(transform=None, **kwargs):
+ if isinstance(transform, dict):
+ transform = [transform]
+ if isinstance(transform, (list, tuple)):
+ transform = Compose(transform)
+ return torchvision.datasets.CIFAR10(**kwargs, transform=transform)
+
+# register data transforms in torchvision
+DATA_TRANSFORMS.register_module('RandomCrop', module=tvt.RandomCrop)
+DATA_TRANSFORMS.register_module('RandomHorizontalFlip', module=tvt.RandomHorizontalFlip)
+DATA_TRANSFORMS.register_module('ToTensor', module=tvt.ToTensor)
+DATA_TRANSFORMS.register_module('Normalize', module=tvt.Normalize)
+
+# specify in runner
+runner = Runner(
+ train_dataloader=dict(
+ batch_size=32,
+ sampler=dict(
+ type='DefaultSampler',
+ shuffle=True),
+ dataset=dict(type='Cifar10',
+ root='data/cifar10',
+ train=True,
+ download=True,
+ transform=[
+ dict(type='RandomCrop', size=32, padding=4),
+ dict(type='RandomHorizontalFlip'),
+ dict(type='ToTensor'),
+ dict(type='Normalize', **norm_cfg)])
+ )
+)
+```
+
+```{note}
+The above example makes extensive use of the registry mechanism and borrows the [Compose](mmengine.dataset.Compose) module from MMEngine. If you urge to use torchvision dataset in your config files, you can refer to it and make some slight modifications. However, we recommend you borrow datasets from downstream repos such as [MMDet](https://github.com/open-mmlab/mmdetection), [MMCls](https://github.com/open-mmlab/mmclassification), etc. This may give you a better experience.
+```
+
+### Customize your dataset
+
+You are free to customize your own datasets, as you would with PyTorch. You can also copy existing datasets from your previous PyTorch projects. If you want to learn how to customize your dataset, please refer to [PyTorch official tutorials](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html#creating-a-custom-dataset-for-your-files)
+
+### Use MMEngine BaseDataset
+
+Apart from directly using PyTorch native `Dataset` class, you can also use MMEngine's built-in class `BaseDataset` to customize your own one, as referred to [BaseDataset tutorial](../advanced_tutorials/basedataset.md). It makes some conventions on the format of annotation files, which makes the data interface more unified and multi-task training more convenient. Meanwhile, `BaseDataset` can easily cooperate with built-in [data transforms](../advanced_tutorials/data_element.md) in MMEngine, which releases you from writing one from scratch.
+
+Currently, `BaseDataset` has been widely used in downstream repos of OpenMMLab 2.0 projects.
diff --git a/testbed/open-mmlab__mmengine/docs/en/tutorials/evaluation.md b/testbed/open-mmlab__mmengine/docs/en/tutorials/evaluation.md
new file mode 100644
index 0000000000000000000000000000000000000000..90f09e776ae7d36c6b3ce6831b00bd78ced5d026
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/en/tutorials/evaluation.md
@@ -0,0 +1,3 @@
+# Evaluation
+
+Coming soon. Please refer to [chinese documentation](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/evaluation.html).
diff --git a/testbed/open-mmlab__mmengine/docs/en/tutorials/param_scheduler.md b/testbed/open-mmlab__mmengine/docs/en/tutorials/param_scheduler.md
new file mode 100644
index 0000000000000000000000000000000000000000..06dc047a95e3f0015338572443296b94caf3ddb8
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/en/tutorials/param_scheduler.md
@@ -0,0 +1,229 @@
+# Parameter Scheduler
+
+During neural network training, optimization hyperparameters (e.g. learning rate) are usually adjusted along with the training process.
+One of the simplest and most common learning rate adjustment strategies is multi-step learning rate decay, which reduces the learning rate to a fraction at regular intervals.
+PyTorch provides LRScheduler to implement various learning rate adjustment strategies. In MMEngine, we have extended it and implemented a more general [ParamScheduler](mmengine.optim._ParamScheduler).
+It can adjust optimization hyperparameters such as learning rate and momentum. It also supports the combination of multiple schedulers to create more complex scheduling strategies.
+
+## Usage
+
+We first introduce how to use PyTorch's `torch.optim.lr_scheduler` to adjust learning rate.
+
+ +
+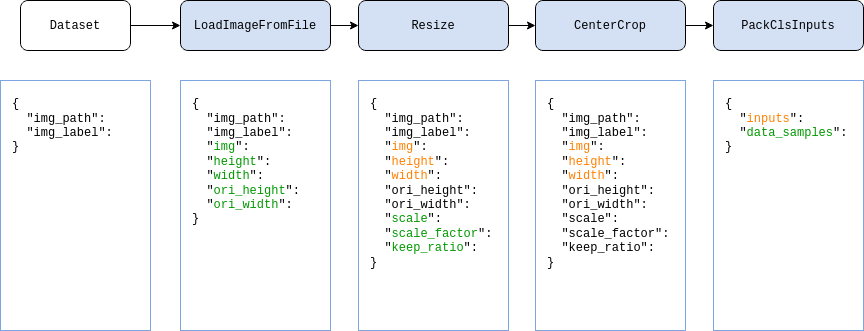 +
+| 统计方法 | +参数 | +功能 | +
|---|---|---|
| mean | +window_size | +统计窗口内日志的均值 | +
| min | +window_size | +统计窗口内日志的最小值 | +
| max | +window_size | +统计窗口内日志的最大值 | +
| current | +/ | +返回最近一次更新的日志 | +
 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+MMEngine 将训练过程中涉及的组件和它们的关系进行了抽象,如上图所示。不同算法库中的同类型组件具有相同的接口定义。
+
+#### 核心模块与相关组件
+
+训练引擎的核心模块是[执行器(Runner)](../tutorials/runner.md)。 执行器负责执行训练、测试和推理任务并管理这些过程中所需要的各个组件。在训练、测试、推理任务执行过程中的特定位置,执行器设置了[钩子(Hook)](../tutorials/hook.md) 来允许用户拓展、插入和执行自定义逻辑。执行器主要调用如下组件来完成训练和推理过程中的循环:
+
+- [数据集(Dataset)](../tutorials/basedataset.md):负责在训练、测试、推理任务中构建数据集,并将数据送给模型。实际使用过程中会被数据加载器(DataLoader)封装一层,数据加载器会启动多个子进程来加载数据。
+- [模型(Model)](../tutorials/model.md):在训练过程中接受数据并输出 loss;在测试、推理任务中接受数据,并进行预测。分布式训练等情况下会被模型的封装器(Model Wrapper,如`MMDistributedDataParallel`)封装一层。
+- [优化器封装(Optimizer)](../tutorials/optim_wrapper.md):优化器封装负责在训练过程中执行反向传播优化模型,并且以统一的接口支持了混合精度训练和梯度累加。
+- [参数调度器(Parameter Scheduler)](../tutorials/param_scheduler.md):训练过程中,对学习率、动量等优化器超参数进行动态调整。
+
+在训练间隙或者测试阶段,[评测指标与评测器(Metrics & Evaluator)](../tutorials/metric_and_evaluator.md)会负责对模型性能进行评测。其中评测器负责基于数据集对模型的预测进行评估。评测器内还有一层抽象是评测指标,负责计算具体的一个或多个评测指标(如召回率、正确率等)。
+
+为了统一接口,OpenMMLab 2.0 中各个算法库的评测器,模型和数据之间交流的接口都使用了[数据元素(Data Element)](../tutorials/data_element.md)来进行封装。
+
+在训练、推理执行过程中,上述各个组件都可以调用日志管理模块和可视化器进行结构化和非结构化日志的存储与展示。[日志管理(Logging Modules)](../tutorials/logging.md):负责管理执行器运行过程中产生的各种日志信息。其中消息枢纽 (MessageHub)负责实现组件与组件、执行器与执行器之间的数据共享,日志处理器(Log Processor)负责对日志信息进行处理,处理后的日志会分别发送给执行器的日志器(Logger)和可视化器(Visualizer)进行日志的管理与展示。[可视化器(Visualizer)](../tutorials/visualization.md):可视化器负责对模型的特征图、预测结果和训练过程中产生的结构化日志进行可视化,支持 Tensorboard 和 WanDB 等多种可视化后端。
+
+#### 公共基础模块
+
+MMEngine 中还实现了各种算法模型执行过程中需要用到的公共基础模块,包括
+
+- [配置类(Config)](../advanced_tutorials/config.md):在 OpenMMLab 算法库中,用户可以通过编写 config 来配置训练、测试过程以及相关的组件。
+- [注册器(Registry)](../advanced_tutorials/registry.md):负责管理算法库中具有相同功能的模块。MMEngine 根据对算法库模块的抽象,定义了一套根注册器,算法库中的注册器可以继承自这套根注册器,实现模块的跨算法库调用。
+- [文件读写(File I/O)](../tutorials/fileio.md):为各个模块的文件读写提供了统一的接口,以统一的形式支持了多种文件读写后端和多种文件格式,并具备扩展性。
+- [分布式通信原语(Distributed Communication Primitives)](../tutorials/distributed.md):负责在程序分布式运行过程中不同进程间的通信。这套接口屏蔽了分布式和非分布式环境的区别,同时也自动处理了数据的设备和通信后端。
+- [其他工具(Utils)](../tutorials/utils.md):还有一些工具性的模块,如 ManagerMixin,它实现了一种全局变量的创建和获取方式,执行器内很多全局可见对象的基类就是 ManagerMixin。
+
+用户可以进一步阅读[教程](<>)来了解这些模块的高级用法,也可以参考[设计文档](<>) 了解它们的设计思路与细节。
diff --git a/testbed/open-mmlab__mmengine/docs/zh_cn/index.rst b/testbed/open-mmlab__mmengine/docs/zh_cn/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..e0a027679c2e43a69a313ac364e863e381edf8b1
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/zh_cn/index.rst
@@ -0,0 +1,111 @@
+欢迎来到 MMEngine 的中文文档!
+=========================================
+您可以在页面左下角切换中英文文档。
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 开始你的第一步
+
+ get_started/introduction.md
+ get_started/installation.md
+ get_started/15_minutes.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 常用功能
+
+ examples/resume_training.md
+ examples/speed_up_training.md
+ examples/save_gpu_memory.md
+ examples/train_a_gan.md
+
+.. toctree::
+ :maxdepth: 3
+ :caption: 入门教程
+
+ tutorials/runner.md
+ tutorials/dataset.md
+ tutorials/model.md
+ tutorials/evaluation.md
+ tutorials/optim_wrapper.md
+ tutorials/param_scheduler.md
+ tutorials/hook.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 进阶教程
+
+ advanced_tutorials/registry.md
+ advanced_tutorials/config.md
+ advanced_tutorials/basedataset.md
+ advanced_tutorials/data_transform.md
+ advanced_tutorials/initialize.md
+ advanced_tutorials/visualization.md
+ advanced_tutorials/data_element.md
+ advanced_tutorials/distributed.md
+ advanced_tutorials/logging.md
+ advanced_tutorials/fileio.md
+ advanced_tutorials/manager_mixin.md
+ advanced_tutorials/cross_library.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 架构设计
+
+ design/hook.md
+ design/runner.md
+ design/evaluation.md
+ design/visualization.md
+ design/logging.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 迁移指南
+
+ migration/runner.md
+ migration/hook.md
+ migration/model.md
+ migration/param_scheduler.md
+ migration/transform.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: API 文档
+
+ mmengine.registry
+
+MMEngine 将训练过程中涉及的组件和它们的关系进行了抽象,如上图所示。不同算法库中的同类型组件具有相同的接口定义。
+
+#### 核心模块与相关组件
+
+训练引擎的核心模块是[执行器(Runner)](../tutorials/runner.md)。 执行器负责执行训练、测试和推理任务并管理这些过程中所需要的各个组件。在训练、测试、推理任务执行过程中的特定位置,执行器设置了[钩子(Hook)](../tutorials/hook.md) 来允许用户拓展、插入和执行自定义逻辑。执行器主要调用如下组件来完成训练和推理过程中的循环:
+
+- [数据集(Dataset)](../tutorials/basedataset.md):负责在训练、测试、推理任务中构建数据集,并将数据送给模型。实际使用过程中会被数据加载器(DataLoader)封装一层,数据加载器会启动多个子进程来加载数据。
+- [模型(Model)](../tutorials/model.md):在训练过程中接受数据并输出 loss;在测试、推理任务中接受数据,并进行预测。分布式训练等情况下会被模型的封装器(Model Wrapper,如`MMDistributedDataParallel`)封装一层。
+- [优化器封装(Optimizer)](../tutorials/optim_wrapper.md):优化器封装负责在训练过程中执行反向传播优化模型,并且以统一的接口支持了混合精度训练和梯度累加。
+- [参数调度器(Parameter Scheduler)](../tutorials/param_scheduler.md):训练过程中,对学习率、动量等优化器超参数进行动态调整。
+
+在训练间隙或者测试阶段,[评测指标与评测器(Metrics & Evaluator)](../tutorials/metric_and_evaluator.md)会负责对模型性能进行评测。其中评测器负责基于数据集对模型的预测进行评估。评测器内还有一层抽象是评测指标,负责计算具体的一个或多个评测指标(如召回率、正确率等)。
+
+为了统一接口,OpenMMLab 2.0 中各个算法库的评测器,模型和数据之间交流的接口都使用了[数据元素(Data Element)](../tutorials/data_element.md)来进行封装。
+
+在训练、推理执行过程中,上述各个组件都可以调用日志管理模块和可视化器进行结构化和非结构化日志的存储与展示。[日志管理(Logging Modules)](../tutorials/logging.md):负责管理执行器运行过程中产生的各种日志信息。其中消息枢纽 (MessageHub)负责实现组件与组件、执行器与执行器之间的数据共享,日志处理器(Log Processor)负责对日志信息进行处理,处理后的日志会分别发送给执行器的日志器(Logger)和可视化器(Visualizer)进行日志的管理与展示。[可视化器(Visualizer)](../tutorials/visualization.md):可视化器负责对模型的特征图、预测结果和训练过程中产生的结构化日志进行可视化,支持 Tensorboard 和 WanDB 等多种可视化后端。
+
+#### 公共基础模块
+
+MMEngine 中还实现了各种算法模型执行过程中需要用到的公共基础模块,包括
+
+- [配置类(Config)](../advanced_tutorials/config.md):在 OpenMMLab 算法库中,用户可以通过编写 config 来配置训练、测试过程以及相关的组件。
+- [注册器(Registry)](../advanced_tutorials/registry.md):负责管理算法库中具有相同功能的模块。MMEngine 根据对算法库模块的抽象,定义了一套根注册器,算法库中的注册器可以继承自这套根注册器,实现模块的跨算法库调用。
+- [文件读写(File I/O)](../tutorials/fileio.md):为各个模块的文件读写提供了统一的接口,以统一的形式支持了多种文件读写后端和多种文件格式,并具备扩展性。
+- [分布式通信原语(Distributed Communication Primitives)](../tutorials/distributed.md):负责在程序分布式运行过程中不同进程间的通信。这套接口屏蔽了分布式和非分布式环境的区别,同时也自动处理了数据的设备和通信后端。
+- [其他工具(Utils)](../tutorials/utils.md):还有一些工具性的模块,如 ManagerMixin,它实现了一种全局变量的创建和获取方式,执行器内很多全局可见对象的基类就是 ManagerMixin。
+
+用户可以进一步阅读[教程](<>)来了解这些模块的高级用法,也可以参考[设计文档](<>) 了解它们的设计思路与细节。
diff --git a/testbed/open-mmlab__mmengine/docs/zh_cn/index.rst b/testbed/open-mmlab__mmengine/docs/zh_cn/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..e0a027679c2e43a69a313ac364e863e381edf8b1
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/zh_cn/index.rst
@@ -0,0 +1,111 @@
+欢迎来到 MMEngine 的中文文档!
+=========================================
+您可以在页面左下角切换中英文文档。
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 开始你的第一步
+
+ get_started/introduction.md
+ get_started/installation.md
+ get_started/15_minutes.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 常用功能
+
+ examples/resume_training.md
+ examples/speed_up_training.md
+ examples/save_gpu_memory.md
+ examples/train_a_gan.md
+
+.. toctree::
+ :maxdepth: 3
+ :caption: 入门教程
+
+ tutorials/runner.md
+ tutorials/dataset.md
+ tutorials/model.md
+ tutorials/evaluation.md
+ tutorials/optim_wrapper.md
+ tutorials/param_scheduler.md
+ tutorials/hook.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 进阶教程
+
+ advanced_tutorials/registry.md
+ advanced_tutorials/config.md
+ advanced_tutorials/basedataset.md
+ advanced_tutorials/data_transform.md
+ advanced_tutorials/initialize.md
+ advanced_tutorials/visualization.md
+ advanced_tutorials/data_element.md
+ advanced_tutorials/distributed.md
+ advanced_tutorials/logging.md
+ advanced_tutorials/fileio.md
+ advanced_tutorials/manager_mixin.md
+ advanced_tutorials/cross_library.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 架构设计
+
+ design/hook.md
+ design/runner.md
+ design/evaluation.md
+ design/visualization.md
+ design/logging.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 迁移指南
+
+ migration/runner.md
+ migration/hook.md
+ migration/model.md
+ migration/param_scheduler.md
+ migration/transform.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: API 文档
+
+ mmengine.registry | + | MMCV | +MMEngine | +
|---|---|---|
| 反向传播以及梯度更新 | +OptimizerHook | +将反向传播以及梯度更新的操作抽象成 OptimWrapper 而不是钩子 | +
| GradientCumulativeOptimizerHook | +||
| 学习率调整 | +LrUpdaterHook | +ParamSchdulerHook 以及 _ParamScheduler 的子类完成优化器超参的调整 | +
| 动量调整 | +MomentumUpdaterHook | +|
| 按指定间隔保存权重 | +CheckpointHook | +CheckpointHook 除了保存权重,还有保存最优权重的功能,而 EvalHook 的模型评估功能则交由 ValLoop 或 TestLoop 完成 | +
| 模型评估并保存最优模型 | +EvalHook | +|
| 打印日志 | +LoggerHook 及其子类实现打印日志、保存日志以及可视化功能 | +LoggerHook | +
| 可视化 | +NaiveVisualizationHook | +|
| 添加运行时信息 | +RuntimeInfoHook | +|
| 模型参数指数滑动平均 | +EMAHook | +EMAHook | +
| 确保分布式 Sampler 的 shuffle 生效 | +DistSamplerSeedHook | +DistSamplerSeedHook | +
| 同步模型的 buffer | +SyncBufferHook | +SyncBufferHook | +
| PyTorch CUDA 缓存清理 | +EmptyCacheHook | +EmptyCacheHook | +
| 统计迭代耗时 | +IterTimerHook | +IterTimerHook | +
| 分析训练时间的瓶颈 | +ProfilerHook | +暂未提供 | +
| 提供注册方法给钩子点位的功能 | +ClosureHook | +暂未提供 | +
| + | MMCV | +MMEngine | +|
|---|---|---|---|
| 全局位点 | +执行前 | +before_run | +before_run | +
| 执行后 | +after_run | +after_run | +|
| Checkpoint 相关 | +加载 checkpoint 后 | +无 | +after_load_checkpoint | +
| 保存 checkpoint 前 | +无 | +before_save_checkpoint | +|
| 训练相关 | +训练前触发 | +无 | +before_train | +
| 训练后触发 | +无 | +after_train | +|
| 每个 epoch 前 | +before_train_epoch | +before_train_epoch | +|
| 每个 epoch 后 | +after_train_epoch | +after_train_epoch | +|
| 每次迭代前 | +before_train_iter | +before_train_iter,新增 batch_idx 和 data_batch 参数 | +|
| 每次迭代后 | +after_train_iter | +after_train_iter,新增 batch_idx、data_batch 和 outputs 参数 | +|
| 验证相关 | +验证前触发 | +无 | +before_val | +
| 验证后触发 | +无 | +after_val | +|
| 每个 epoch 前 | +before_val_epoch | +before_val_epoch | +|
| 每个 epoch 后 | +after_val_epoch | +after_val_epoch | +|
| 每次迭代前 | +before_val_iter | +before_val_iter,新增 batch_idx 和 data_batch 参数 | +|
| 每次迭代后 | +after_val_iter | +after_val_iter,新增 batch_idx、data_batch 和 outputs 参数 | +|
| 测试相关 | +测试前触发 | +无 | +before_test | +
| 测试后触发 | +无 | +after_test | +|
| 每个 epoch 前 | +无 | +before_test_epoch | +|
| 每个 epoch 后 | +无 | +after_test_epoch | +|
| 每次迭代前 | +无 | +before_test_iter,新增 batch_idx 和 data_batch 参数 | +|
| 每次迭代后 | +无 | +after_test_iter,新增 batch_idx、data_batch 和 outputs 参数 | +|
| MMCV 模型 | +MMEngine 模型 | +
|---|---|
+
+```python
+class MMCVToyModel(nn.Module):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.linear = nn.Linear(1, 1)
+
+ def forward(self, img, label, return_loss=False):
+ feat = self.linear(img)
+ loss1 = (feat - label).pow(2)
+ loss2 = (feat - label).abs()
+ loss = (loss1 + loss2).sum()
+ return dict(loss=loss,
+ num_samples=len(img),
+ log_vars=dict(
+ loss1=loss1.sum().item(),
+ loss2=loss2.sum().item()))
+
+ def train_step(self, data, optimizer=None):
+ return self(*data, return_loss=True)
+
+ def val_step(self, data, optimizer=None):
+ return self(*data, return_loss=False)
+```
+
+
+ |
+
+
+```python
+class MMEngineToyModel(BaseModel):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.linear = nn.Linear(1, 1)
+
+ def forward(self, img, label, mode):
+ if mode == 'loss':
+ feat = self.linear(img)
+ loss1 = (feat - label).pow(2)
+ loss2 = (feat - label).abs()
+ return dict(loss1=loss1, loss2=loss2)
+ elif mode == 'predict':
+ return [_feat for _feat in feat]
+ else:
+ pass
+
+ # 模型基类 `train_step` 等效代码
+ # def train_step(self, data, optim_wrapper):
+ # data = self.data_preprocessor(data)
+ # loss_dict = self(*data, mode='loss')
+ # loss_dict['loss1'] = loss_dict['loss1'].sum()
+ # loss_dict['loss2'] = loss_dict['loss2'].sum()
+ # loss = (loss_dict['loss1'] + loss_dict['loss2']).sum()
+ # 调用优化器封装更新模型参数
+ # optim_wrapper.update_params(loss)
+ # return loss_dict
+```
+
+
+ |
+
| Training gan in MMCV | +Training gan in MMEngine | +
|---|---|
+
+```python
+ def train_discriminator(self, inputs, optimizer):
+ real_imgs = inputs['inputs']
+ z = torch.randn(
+ (real_imgs.shape[0], self.noise_size)).type_as(real_imgs)
+ with torch.no_grad():
+ fake_imgs = self.generator(z)
+
+ disc_pred_fake = self.discriminator(fake_imgs)
+ disc_pred_real = self.discriminator(real_imgs)
+
+ parsed_losses, log_vars = self.disc_loss(disc_pred_fake,
+ disc_pred_real)
+ parsed_losses.backward()
+ optimizer.step()
+ optimizer.zero_grad()
+ return log_vars
+
+ def train_generator(self, inputs, optimizer_wrapper):
+ real_imgs = inputs['inputs']
+ z = torch.randn(inputs['inputs'].shape[0], self.noise_size).type_as(
+ real_imgs)
+
+ fake_imgs = self.generator(z)
+
+ disc_pred_fake = self.discriminator(fake_imgs)
+ parsed_loss, log_vars = self.gen_loss(disc_pred_fake)
+
+ parsed_losses.backward()
+ optimizer.step()
+ optimizer.zero_grad()
+ return log_vars
+```
+
+ |
+
+
+
+```python
+ def train_discriminator(self, inputs, optimizer_wrapper):
+ real_imgs = inputs['inputs']
+ z = torch.randn(
+ (real_imgs.shape[0], self.noise_size)).type_as(real_imgs)
+ with torch.no_grad():
+ fake_imgs = self.generator(z)
+
+ disc_pred_fake = self.discriminator(fake_imgs)
+ disc_pred_real = self.discriminator(real_imgs)
+
+ parsed_losses, log_vars = self.disc_loss(disc_pred_fake,
+ disc_pred_real)
+ optimizer_wrapper.update_params(parsed_losses)
+ return log_vars
+
+
+
+ def train_generator(self, inputs, optimizer_wrapper):
+ real_imgs = inputs['inputs']
+ z = torch.randn(real_imgs.shape[0], self.noise_size).type_as(real_imgs)
+
+ fake_imgs = self.generator(z)
+
+ disc_pred_fake = self.discriminator(fake_imgs)
+ parsed_loss, log_vars = self.gen_loss(disc_pred_fake)
+
+ optimizer_wrapper.update_params(parsed_loss)
+ return log_vars
+```
+
+ |
+
+
| MMCV 分布式训练构建模型 | +MMEngine 分布式训练 | +
|---|---|
+
+```python
+model = MMDistributedDataParallel(
+ model,
+ device_ids=[int(os.environ['LOCAL_RANK'])],
+ broadcast_buffers=False,
+ find_unused_parameters=find_unused_parameters)
+...
+runner = Runner(model=model, ...)
+```
+
+
+ |
+
+
+```python
+runner = Runner(
+ model=model,
+ launcher='pytorch', #开启分布式训练
+ ..., # 其他参数
+)
+```
+
+
+ |
+
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + warmup='constant', + warmup_ratio=0.1, + warmup_iters=500, + warmup_by_epoch=False +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='ConstantLR', + factor=0.1, + begin=0, + end=500, + by_epoch=False), + dict(...) # 主学习率调度器配置 +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + warmup='linear', + warmup_ratio=0.1, + warmup_iters=500, + warmup_by_epoch=False +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='LinearLR', + start_factor=0.1, + begin=0, + end=500, + by_epoch=False), + dict(...) # 主学习率调度器配置 +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + warmup='exp', + warmup_ratio=0.1, + warmup_iters=500, + warmup_by_epoch=False +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='ExponentialLR', + gamma=0.1, + begin=0, + end=500, + by_epoch=False), + dict(...) # 主学习率调度器配置 +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict(policy='fixed') +``` + + | ++ +```python +param_scheduler = [ + dict(type='ConstantLR', factor=1) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='step', + step=[8, 11], + gamma=0.1, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='MultiStepLR', + milestone=[8, 11], + gamma=0.1, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='poly', + power=0.7, + min_lr=0.001, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='PolyLR', + power=0.7, + eta_min=0.001, + begin=0, + end=num_epochs, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='exp', + power=0.5, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='ExponentialLR', + gamma=0.5, + begin=0, + end=num_epochs, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='CosineAnnealing', + min_lr=0.5, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='CosineAnnealingLR', + eta_min=0.5, + T_max=num_epochs, + begin=0, + end=num_epochs, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='FlatCosineAnnealing', + start_percent=0.5, + min_lr=0.005, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='ConstantLR', factor=1, begin=0, end=num_epochs * 0.75) + dict(type='CosineAnnealingLR', + eta_min=0.005, + begin=num_epochs * 0.75, + end=num_epochs, + T_max=num_epochs * 0.25, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict(policy='CosineRestart', + periods=[5, 10, 15], + restart_weights=[1, 0.7, 0.3], + min_lr=0.001, + by_epoch=True) +``` + + | ++ +```python +param_scheduler = [ + dict(type='CosineRestartLR', + periods=[5, 10, 15], + restart_weights=[1, 0.7, 0.3], + eta_min=0.001, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict(policy='OneCycle', + max_lr=0.02, + total_steps=90000, + pct_start=0.3, + anneal_strategy='cos', + div_factor=25, + final_div_factor=1e4, + three_phase=True, + by_epoch=False) +``` + + | ++ +```python +param_scheduler = [ + dict(type='OneCycleLR', + eta_max=0.02, + total_steps=90000, + pct_start=0.3, + anneal_strategy='cos', + div_factor=25, + final_div_factor=1e4, + three_phase=True, + by_epoch=False) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='LinearAnnealing', + min_lr_ratio=0.01, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + dict(type='LinearLR', + start_factor=1, + end_factor=0.01, + begin=0, + end=num_epochs, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict(...) +momentum_config = dict( + policy='CosineAnnealing', + min_momentum=0.1, + by_epoch=True +) +``` + + | ++ +```python +param_scheduler = [ + # 学习率调度器配置 + dict(...), + # 动量调度器配置 + dict(type='CosineAnnealingMomentum', + eta_min=0.1, + T_max=num_epochs, + begin=0, + end=num_epochs, + by_epoch=True) +] +``` + + | +
| MMCV-1.x | +MMEngine | +
|---|---|
| + +```python +lr_config = dict( + policy='CosineAnnealing', + min_lr=0.5, + by_epoch=False +) +``` + + | ++ +```python +param_scheduler = [ + dict( + type='CosineAnnealingLR', + eta_min=0.5, + T_max=num_epochs, + by_epoch=True, # 注意,by_epoch 需要设置为 True + convert_to_iter_based=True # 转换为按 iter 更新参数 + ) +] +``` + + | +
| 基于 MMCV 执行器的配置文件概览 | +基于 MMEngine 执行器的配置文件概览 | +
|---|---|
+
+```python
+# default_runtime.py
+checkpoint_config = dict(interval=1)
+# yapf:disable
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+# yapf:enable
+custom_hooks = [dict(type='NumClassCheckHook')]
+
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+
+
+opencv_num_threads = 0
+mp_start_method = 'fork'
+auto_scale_lr = dict(enable=False, base_batch_size=16)
+```
+
+
+ |
+
+
+```python
+# default_runtime.py
+default_scope = 'mmdet'
+
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'),
+ logger=dict(type='LoggerHook', interval=50),
+ param_scheduler=dict(type='ParamSchedulerHook'),
+ checkpoint=dict(type='CheckpointHook', interval=1),
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+ visualization=dict(type='DetVisualizationHook'))
+
+env_cfg = dict(
+ cudnn_benchmark=False,
+ mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
+ dist_cfg=dict(backend='nccl'),
+)
+
+vis_backends = [dict(type='LocalVisBackend')]
+visualizer = dict(
+ type='DetLocalVisualizer', vis_backends=vis_backends, name='visualizer')
+log_processor = dict(type='LogProcessor', window_size=50, by_epoch=True)
+
+log_level = 'INFO'
+load_from = None
+resume = False
+```
+
+
+ |
+
+
+```python
+# schedule.py
+
+# optimizer
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[8, 11])
+runner = dict(type='EpochBasedRunner', max_epochs=12)
+```
+
+
+ |
+
+
+```python
+# scheduler.py
+
+# training schedule for 1x
+train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=12, val_interval=1)
+val_cfg = dict(type='ValLoop')
+test_cfg = dict(type='TestLoop')
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=12,
+ by_epoch=True,
+ milestones=[8, 11],
+ gamma=0.1)
+]
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001))
+
+# Default setting for scaling LR automatically
+# - `enable` means enable scaling LR automatically
+# or not by default.
+# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
+auto_scale_lr = dict(enable=False, base_batch_size=16)
+```
+
+
+ |
+
+
+```python
+# coco_detection.py
+
+# dataset settings
+dataset_type = 'CocoDataset'
+data_root = 'data/coco/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_train2017.json',
+ img_prefix=data_root + 'train2017/',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ pipeline=test_pipeline))
+evaluation = dict(interval=1, metric='bbox')
+```
+
+
+ |
+
+
+```python
+# coco_detection.py
+
+# dataset settings
+dataset_type = 'CocoDataset'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', file_client_args=file_client_args),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', prob=0.5),
+ dict(type='PackDetInputs')
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile', file_client_args=file_client_args),
+ dict(type='Resize', scale=(1333, 800), keep_ratio=True),
+ # If you don't have a gt annotation, delete the pipeline
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+train_dataloader = dict(
+ batch_size=2,
+ num_workers=2,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline))
+val_dataloader = dict(
+ batch_size=1,
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_val2017.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=test_pipeline))
+test_dataloader = val_dataloader
+
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ metric='bbox',
+ format_only=False)
+test_evaluator = val_evaluator
+```
+
+
+ |
+
+
| 基于 MMCV 执行器的训练启动脚本 | +基于 MMEngine 执行器的训练启动脚本 | +
|---|---|
+
+```python
+# tools/train.py
+
+args = parse_args()
+
+cfg = Config.fromfile(args.config)
+
+# replace the ${key} with the value of cfg.key
+cfg = replace_cfg_vals(cfg)
+
+# update data root according to MMDET_DATASETS
+update_data_root(cfg)
+
+if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+if args.auto_scale_lr:
+ if 'auto_scale_lr' in cfg and \
+ 'enable' in cfg.auto_scale_lr and \
+ 'base_batch_size' in cfg.auto_scale_lr:
+ cfg.auto_scale_lr.enable = True
+ else:
+ warnings.warn('Can not find "auto_scale_lr" or '
+ '"auto_scale_lr.enable" or '
+ '"auto_scale_lr.base_batch_size" in your'
+ ' configuration file. Please update all the '
+ 'configuration files to mmdet >= 2.24.1.')
+
+# set multi-process settings
+setup_multi_processes(cfg)
+
+# set cudnn_benchmark
+if cfg.get('cudnn_benchmark', False):
+ torch.backends.cudnn.benchmark = True
+
+# work_dir is determined in this priority: CLI > segment in file > filename
+if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+if args.resume_from is not None:
+ cfg.resume_from = args.resume_from
+cfg.auto_resume = args.auto_resume
+if args.gpus is not None:
+ cfg.gpu_ids = range(1)
+ warnings.warn('`--gpus` is deprecated because we only support '
+ 'single GPU mode in non-distributed training. '
+ 'Use `gpus=1` now.')
+if args.gpu_ids is not None:
+ cfg.gpu_ids = args.gpu_ids[0:1]
+ warnings.warn('`--gpu-ids` is deprecated, please use `--gpu-id`. '
+ 'Because we only support single GPU mode in '
+ 'non-distributed training. Use the first GPU '
+ 'in `gpu_ids` now.')
+if args.gpus is None and args.gpu_ids is None:
+ cfg.gpu_ids = [args.gpu_id]
+
+# init distributed env first, since logger depends on the dist info.
+if args.launcher == 'none':
+ distributed = False
+else:
+ distributed = True
+ init_dist(args.launcher, **cfg.dist_params)
+ # re-set gpu_ids with distributed training mode
+ _, world_size = get_dist_info()
+ cfg.gpu_ids = range(world_size)
+
+# create work_dir
+mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
+# dump config
+cfg.dump(osp.join(cfg.work_dir, osp.basename(args.config)))
+# init the logger before other steps
+timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
+log_file = osp.join(cfg.work_dir, f'{timestamp}.log')
+logger = get_root_logger(log_file=log_file, log_level=cfg.log_level)
+
+# init the meta dict to record some important information such as
+# environment info and seed, which will be logged
+meta = dict()
+# log env info
+env_info_dict = collect_env()
+env_info = '\n'.join([(f'{k}: {v}') for k, v in env_info_dict.items()])
+dash_line = '-' * 60 + '\n'
+logger.info('Environment info:\n' + dash_line + env_info + '\n' +
+ dash_line)
+meta['env_info'] = env_info
+meta['config'] = cfg.pretty_text
+# log some basic info
+logger.info(f'Distributed training: {distributed}')
+logger.info(f'Config:\n{cfg.pretty_text}')
+
+cfg.device = get_device()
+# set random seeds
+seed = init_random_seed(args.seed, device=cfg.device)
+seed = seed + dist.get_rank() if args.diff_seed else seed
+logger.info(f'Set random seed to {seed}, '
+ f'deterministic: {args.deterministic}')
+set_random_seed(seed, deterministic=args.deterministic)
+cfg.seed = seed
+meta['seed'] = seed
+meta['exp_name'] = osp.basename(args.config)
+
+model = build_detector(
+ cfg.model,
+ train_cfg=cfg.get('train_cfg'),
+ test_cfg=cfg.get('test_cfg'))
+model.init_weights()
+
+datasets = []
+train_detector(
+ model,
+ datasets,
+ cfg,
+ distributed=distributed,
+ validate=(not args.no_validate),
+ timestamp=timestamp,
+ meta=meta)
+```
+
+
+ |
+
+
+```python
+# tools/train.py
+
+args = parse_args()
+
+# register all modules in mmdet into the registries
+# do not init the default scope here because it will be init in the runner
+register_all_modules(init_default_scope=False)
+
+# load config
+cfg = Config.fromfile(args.config)
+cfg.launcher = args.launcher
+if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+# work_dir is determined in this priority: CLI > segment in file > filename
+if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+# enable automatic-mixed-precision training
+if args.amp is True:
+ optim_wrapper = cfg.optim_wrapper.type
+ if optim_wrapper == 'AmpOptimWrapper':
+ print_log(
+ 'AMP training is already enabled in your config.',
+ logger='current',
+ level=logging.WARNING)
+ else:
+ assert optim_wrapper == 'OptimWrapper', (
+ '`--amp` is only supported when the optimizer wrapper type is '
+ f'`OptimWrapper` but got {optim_wrapper}.')
+ cfg.optim_wrapper.type = 'AmpOptimWrapper'
+ cfg.optim_wrapper.loss_scale = 'dynamic'
+
+# enable automatically scaling LR
+if args.auto_scale_lr:
+ if 'auto_scale_lr' in cfg and \
+ 'enable' in cfg.auto_scale_lr and \
+ 'base_batch_size' in cfg.auto_scale_lr:
+ cfg.auto_scale_lr.enable = True
+ else:
+ raise RuntimeError('Can not find "auto_scale_lr" or '
+ '"auto_scale_lr.enable" or '
+ '"auto_scale_lr.base_batch_size" in your'
+ ' configuration file.')
+
+cfg.resume = args.resume
+
+# build the runner from config
+if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+# start training
+runner.train()
+```
+
+
+ |
+
+
+```python
+def init_random_seed(...):
+ ...
+
+def set_random_seed(...):
+ ...
+
+# define function tools.
+...
+
+
+def train_detector(model,
+ dataset,
+ cfg,
+ distributed=False,
+ validate=False,
+ timestamp=None,
+ meta=None):
+
+ cfg = compat_cfg(cfg)
+ logger = get_root_logger(log_level=cfg.log_level)
+
+ # put model on gpus
+ if distributed:
+ find_unused_parameters = cfg.get('find_unused_parameters', False)
+ # Sets the `find_unused_parameters` parameter in
+ # torch.nn.parallel.DistributedDataParallel
+ model = build_ddp(
+ model,
+ cfg.device,
+ device_ids=[int(os.environ['LOCAL_RANK'])],
+ broadcast_buffers=False,
+ find_unused_parameters=find_unused_parameters)
+ else:
+ model = build_dp(model, cfg.device, device_ids=cfg.gpu_ids)
+
+ # build optimizer
+ auto_scale_lr(cfg, distributed, logger)
+ optimizer = build_optimizer(model, cfg.optimizer)
+
+ runner = build_runner(
+ cfg.runner,
+ default_args=dict(
+ model=model,
+ optimizer=optimizer,
+ work_dir=cfg.work_dir,
+ logger=logger,
+ meta=meta))
+
+ # an ugly workaround to make .log and .log.json filenames the same
+ runner.timestamp = timestamp
+
+ # fp16 setting
+ fp16_cfg = cfg.get('fp16', None)
+ if fp16_cfg is not None:
+ optimizer_config = Fp16OptimizerHook(
+ **cfg.optimizer_config, **fp16_cfg, distributed=distributed)
+ elif distributed and 'type' not in cfg.optimizer_config:
+ optimizer_config = OptimizerHook(**cfg.optimizer_config)
+ else:
+ optimizer_config = cfg.optimizer_config
+
+ # register hooks
+ runner.register_training_hooks(
+ cfg.lr_config,
+ optimizer_config,
+ cfg.checkpoint_config,
+ cfg.log_config,
+ cfg.get('momentum_config', None),
+ custom_hooks_config=cfg.get('custom_hooks', None))
+
+ if distributed:
+ if isinstance(runner, EpochBasedRunner):
+ runner.register_hook(DistSamplerSeedHook())
+
+ # register eval hooks
+ if validate:
+ val_dataloader_default_args = dict(
+ samples_per_gpu=1,
+ workers_per_gpu=2,
+ dist=distributed,
+ shuffle=False,
+ persistent_workers=False)
+
+ val_dataloader_args = {
+ **val_dataloader_default_args,
+ **cfg.data.get('val_dataloader', {})
+ }
+ # Support batch_size > 1 in validation
+
+ if val_dataloader_args['samples_per_gpu'] > 1:
+ # Replace 'ImageToTensor' to 'DefaultFormatBundle'
+ cfg.data.val.pipeline = replace_ImageToTensor(
+ cfg.data.val.pipeline)
+ val_dataset = build_dataset(cfg.data.val, dict(test_mode=True))
+
+ val_dataloader = build_dataloader(val_dataset, **val_dataloader_args)
+ eval_cfg = cfg.get('evaluation', {})
+ eval_cfg['by_epoch'] = cfg.runner['type'] != 'IterBasedRunner'
+ eval_hook = DistEvalHook if distributed else EvalHook
+ # In this PR (https://github.com/open-mmlab/mmcv/pull/1193), the
+ # priority of IterTimerHook has been modified from 'NORMAL' to 'LOW'.
+ runner.register_hook(
+ eval_hook(val_dataloader, **eval_cfg), priority='LOW')
+
+ resume_from = None
+ if cfg.resume_from is None and cfg.get('auto_resume'):
+ resume_from = find_latest_checkpoint(cfg.work_dir)
+ if resume_from is not None:
+ cfg.resume_from = resume_from
+
+ if cfg.resume_from:
+ runner.resume(cfg.resume_from)
+ elif cfg.load_from:
+ runner.load_checkpoint(cfg.load_from)
+ runner.run(data_loaders, cfg.workflow)
+```
+
+
+ |
+ + +```python +# `apis/train.py` is removed in `mmengine` +``` + + | +
| MMCV 配置 | +MMEngine 配置 | +
|---|---|
+
+```python
+seed = 1
+deterministic=False
+diff_seed=False
+```
+
+
+ |
+
+
+```python
+randomness=dict(seed=1,
+ deterministic=True,
+ diff_rank_seed=False)
+```
+
+
+ |
+
| MMCV 配置 | +MMEngine 配置 | +
|---|---|
+
+```python
+launcher = 'pytorch' # 开启分布式训练
+dist_params = dict(backend='nccl') # 选择多进程通信后端
+```
+
+
+ |
+
+
+```python
+launcher = 'pytorch'
+env_cfg = dict(dist_cfg=dict(backend='nccl'))
+```
+
+
+ |
+
| MMCV 配置 | +MMEngine 配置 | +
|---|---|
+
+```python
+data = dict(
+ samples_per_gpu=2, # 单卡 batch_size
+ workers_per_gpu=2, # Dataloader 采样进程数
+ train=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_train2017.json',
+ img_prefix=data_root + 'train2017/',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ pipeline=test_pipeline))
+```
+
+
+ |
+
+
+```python
+train_dataloader = dict(
+ batch_size=2, # samples_per_gpu -> batch_size,
+ num_workers=2,
+ # 遍历完 DataLoader 后,是否重启多进程采样
+ persistent_workers=True,
+ # 可配置的 sampler
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ # 可配置的 batch_sampler
+ batch_sampler=dict(type='AspectRatioBatchSampler'),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ filter_cfg=dict(filter_empty_gt=True, min_size=32),
+ pipeline=train_pipeline))
+
+val_dataloader = dict(
+ batch_size=1, # 验证阶段的 batch_size
+ num_workers=2,
+ persistent_workers=True,
+ drop_last=False, # 是否丢弃最后一个 batch
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ ann_file='annotations/instances_val2017.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=test_pipeline))
+
+test_dataloader = val_dataloader
+```
+
+
+ |
+
| MMCV 配置 | +MMEngine 配置 | +
|---|---|
+
+```python
+optimizer = dict(
+ constructor='CustomConstructor',
+ type='AdamW', # 优化器配置为一级字段
+ lr=0.0001, # 优化器配置为一级字段
+ betas=(0.9, 0.999), # 优化器配置为一级字段
+ weight_decay=0.05, # 优化器配置为一级字段
+ paramwise_cfg={ # constructor 的参数
+ 'decay_rate': 0.95,
+ 'decay_type': 'layer_wise',
+ 'num_layers': 6
+ })
+# MMCV 还需要配置 `optim_config`
+# 来构建优化器钩子,而 MMEngine 不需要
+optimizer_config = dict(grad_clip=None)
+```
+
+
+ |
+
+
+```python
+optim_wrapper = dict(
+ constructor='CustomConstructor',
+ type='OptimWrapper', # 指定优化器封装类型
+ optimizer=dict( # 将优化器配置集中在 optimizer 内
+ type='AdamW',
+ lr=0.0001,
+ betas=(0.9, 0.999),
+ weight_decay=0.05)
+ paramwise_cfg={
+ 'decay_rate': 0.95,
+ 'decay_type': 'layer_wise',
+ 'num_layers': 6
+ })
+```
+
+
+ |
+
| MMCV 常用训练钩子 | +MMEngine 默认钩子 | +
|---|---|
+
+```python
+# MMCV 零散的配置训练钩子
+# 配置 LrUpdaterHook,相当于 MMEngine 的参数调度器
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[8, 11])
+
+# 配置 OptimizerHook,MMEngine 不需要
+optimizer_config = dict(grad_clip=None)
+
+# 配置 LoggerHook
+log_config = dict( # LoggerHook
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+
+# 配置 CheckPointHook
+checkpoint_config = dict(interval=1) # CheckPointHook
+```
+
+
+ |
+
+
+```python
+# 配置参数调度器
+param_scheduler = [
+ dict(
+ type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),
+ dict(
+ type='MultiStepLR',
+ begin=0,
+ end=12,
+ by_epoch=True,
+ milestones=[8, 11],
+ gamma=0.1)
+]
+
+# MMEngine 集中配置默认钩子
+default_hooks = dict(
+ timer=dict(type='IterTimerHook'),
+ logger=dict(type='LoggerHook', interval=50),
+ param_scheduler=dict(type='ParamSchedulerHook'),
+ checkpoint=dict(type='CheckpointHook', interval=1),
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+ visualization=dict(type='DetVisualizationHook'))
+```
+
+
+ |
+
| MMCV 配置验证流程 | +MMEngine 配置验证流程 | +
|---|---|
+
+```python
+eval_cfg = cfg.get('evaluation', {})
+eval_cfg['by_epoch'] = cfg.runner['type'] != 'IterBasedRunner'
+eval_hook = DistEvalHook if distributed else EvalHook # 配置 EvalHook
+runner.register_hook(
+ eval_hook(val_dataloader, **eval_cfg), priority='LOW') # 注册 EvalHook
+```
+
+
+ |
+
+
+```python
+val_dataloader = val_dataloader # 配置验证数据
+val_evaluator = dict(type='ToyAccuracyMetric') # 配置评测器
+val_cfg = dict(type='ValLoop') # 配置验证循环控制器
+```
+
+
+ |
+
| MMCV 加载检查点配置 | +MMEngine 加载检查点配置 | +
|---|---|
+
+```python
+load_from = 'path/to/ckpt'
+```
+
+
+ |
+
+
+```python
+load_from = 'path/to/ckpt'
+resume = False
+```
+
+
+ |
+
+
+```python
+resume_from = 'path/to/ckpt'
+```
+
+
+ |
+
+
+```python
+load_from = 'path/to/ckpt'
+resume = True
+```
+
+
+ |
+
| + | MMClassification (旧) | +MMDetection (旧) | +MMCV (新) | +
|---|---|---|---|
LoadImageFromFile |
+ 从 'img_prefix' 和 'img_info.filename' 字段组合获得文件路径并读取 | +从 'img_prefix' 和 'img_info.filename' 字段组合获得文件路径并读取,支持指定通道顺序 | +从 'img_path' 获得文件路径并读取,支持指定加载失败不报错,支持指定解码后端 | +
LoadAnnotations |
+ 无 | +支持读取 bbox,label,mask(包括多边形样式),seg map,转换 bbox 坐标系 | +支持读取 bbox,label,mask(不包括多边形样式),seg map | +
Pad |
+ 填充 "img_fields" 中所有字段,不支持指定填充至整数倍 | +填充 "img_fields" 中所有字段,支持指定填充至整数倍 | +填充 "img" 字段,支持指定填充至整数倍 | +
CenterCrop |
+ 裁切 "img_fields" 中所有字段,支持以 EfficientNet 方式进行裁切 | +无 | +裁切 "img" 字段的图像,"gt_bboxes" 字段的 bbox,"gt_seg_map" 字段的分割图,"gt_keypoints" 字段的关键点,支持自动填充裁切边缘 | +
Normalize |
+ 图像归一化 | +无差异 | +无差异,但 MMEngine 推荐在数据预处理器中进行归一化 | +
Resize |
+ 缩放 "img_fields" 中所有字段,允许指定根据某边长等比例缩放 | +功能由 Resize 实现。需要 ratio_range 为 None,img_scale 仅指定一个尺寸,且 multiscale_mode 为 "value" 。 |
+ 缩放 "img" 字段的图像,"gt_bboxes" 字段的 bbox,"gt_seg_map" 字段的分割图,"gt_keypoints" 字段的关键点,支持指定缩放比例,支持等比例缩放图像至指定尺寸内 | +
RandomResize |
+ 无 | +功能由 Resize 实现。需要 ratio_range 为 None,img_scale指定两个尺寸,且 multiscale_mode 为 "range",或 ratio_range 不为 None。
+ Resize( + img_sacle=[(640, 480), (960, 720)], + mode="range", +)+ |
+ 缩放功能同 Resize,支持从指定尺寸范围或指定比例范围随机采样缩放尺寸。
+ RandomResize(scale=[(640, 480), (960, 720)])+ |
+
RandomChoiceResize |
+ 无 | +功能由 Resize 实现。需要 ratio_range 为 None,img_scale 指定多个尺寸,且 multiscale_mode 为 "value"。
+ Resize( + img_sacle=[(640, 480), (960, 720)], + mode="value", +)+ |
+ 缩放功能同 Resize,支持从若干指定尺寸中随机选择缩放尺寸。
+ RandomChoiceResize(scales=[(640, 480), (960, 720)])+ |
+
RandomGrayscale |
+ 灰度化 "img_fields" 中所有字段,灰度化后保持通道数。 | +无 | +灰度化 "img" 字段,支持指定灰度化权重,支持指定是否在灰度化后保持通道数(默认不保持)。 | +
RandomFlip |
+ 翻转 "img_fields" 中所有字段,支持指定水平或垂直翻转。 | +翻转 "img_fields", "bbox_fields", "mask_fields", "seg_fields" 中所有字段,支持指定水平、垂直或对角翻转,支持指定各类翻转概率。 | +翻转 "img", "gt_bboxes", "gt_seg_map", "gt_keypoints" 字段,支持指定水平、垂直或对角翻转,支持指定各类翻转概率。 | +
MultiScaleFlipAug |
+ 无 | +用于测试时增强 | +使用 TestTimeAug |
+
ToTensor |
+ 将指定字段转换为 torch.Tensor |
+ 无差异 | +无差异 | +
ImageToTensor |
+ 将指定字段转换为 torch.Tensor,并调整通道顺序至 CHW。 |
+ 无差异 | +无差异 | +
+
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmengine.git
+```
+
+添加原代码库为上游代码库
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmengine
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmengine.git (fetch)
+origin git@github.com:{username}/mmengine.git (push)
+upstream git@github.com:open-mmlab/mmengine (fetch)
+upstream git@github.com:open-mmlab/mmengine (push)
+```
+
+```{note}
+这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+```
+
+#### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 mmengine 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+```{note}
+如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 master 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 master 分支落后于 upstream 的 master 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream master
+```
+
+#### 4. 提交代码并在本地通过单元测试
+
+- MMEngine 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 runner 为例
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+#### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+#### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+
+
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+
+
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+
+
+MMEngine 会在不同的平台(Linux、Window、Mac),基于不同版本的 Python、PyTorch、CUDA 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+
+
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到主分支。
+
+#### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与主分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+### 指引
+
+#### 单元测试
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### Python 代码风格
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
+
+- [flake8](https://github.com/PyCQA/flake8): Python 官方发布的代码规范检查工具,是多个检查工具的封装
+- [isort](https://github.com/timothycrosley/isort): 自动调整模块导入顺序的工具
+- [yapf](https://github.com/google/yapf): Google 发布的代码规范检查工具
+- [codespell](https://github.com/codespell-project/codespell): 检查单词拼写是否有误
+- [mdformat](https://github.com/executablebooks/mdformat): 检查 markdown 文件的工具
+- [docformatter](https://github.com/myint/docformatter): 格式化 docstring 的工具
+
+yapf 和 isort 的配置可以在 [setup.cfg](./setup.cfg) 找到
+
+通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
+pre-commit 钩子的配置可以在 [.pre-commit-config](./.pre-commit-config.yaml) 找到。
+
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
+
+更具体的规范请参考 [OpenMMLab 代码规范](code_style.md)。
+
+### 拉取请求规范
+
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
+
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 MMEngine 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
diff --git a/testbed/open-mmlab__mmengine/docs/zh_cn/switch_language.md b/testbed/open-mmlab__mmengine/docs/zh_cn/switch_language.md
new file mode 100644
index 0000000000000000000000000000000000000000..e47b751e33928f59c4bf1aea94110493214754ea
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/zh_cn/switch_language.md
@@ -0,0 +1,3 @@
+## English
+
+## 简体中文
diff --git a/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/dataset.md b/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/dataset.md
new file mode 100644
index 0000000000000000000000000000000000000000..18e086f500046b44395fec6b2775f8c834094844
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/dataset.md
@@ -0,0 +1,198 @@
+# 数据集(Dataset)与数据加载器(DataLoader)
+
+```{hint}
+如果你没有接触过 PyTorch 的数据集与数据加载器,我们推荐先浏览 [PyTorch 官方教程](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html)以了解一些基本概念
+```
+
+数据集与数据加载器是 MMEngine 中训练流程的必要组件,它们的概念来源于 PyTorch,并且在含义上与 PyTorch 保持一致。通常来说,数据集定义了数据的总体数量、读取方式以及预处理,而数据加载器则在不同的设置下迭代地加载数据,如批次大小(`batch_size`)、随机乱序(`shuffle`)、并行(`num_workers`)等。数据集经过数据加载器封装后构成了数据源。在本篇教程中,我们将按照从外(数据加载器)到内(数据集)的顺序,逐步介绍它们在 MMEngine 执行器中的用法,并给出一些常用示例。读完本篇教程,你将会:
+
+- 掌握如何在 MMEngine 的执行器中配置数据加载器
+- 学会在配置文件中使用已有(如 `torchvision`)数据集
+- 了解如何使用自己的数据集
+
+## 数据加载器详解
+
+在执行器(`Runner`)中,你可以分别配置以下 3 个参数来指定对应的数据加载器
+
+- `train_dataloader`:在 `Runner.train()` 中被使用,为模型提供训练数据
+- `val_dataloader`:在 `Runner.val()` 中被使用,也会在 `Runner.train()` 中每间隔一段时间被使用,用于模型的验证评测
+- `test_dataloader`:在 `Runner.test()` 中被使用,用于模型的测试
+
+MMEngine 完全支持 PyTorch 的原生 `DataLoader`,因此上述 3 个参数均可以直接传入构建好的 `DataLoader`,如[15分钟上手](../get_started/15_minutes.md)中的例子所示。同时,借助 MMEngine 的[注册机制](../advanced_tutorials/registry.md),以上参数也可以传入 `dict`,如下面代码(以下简称例 1)所示。字典中的键值与 `DataLoader` 的构造参数一一对应。
+
+```python
+runner = Runner(
+ train_dataloader=dict(
+ batch_size=32,
+ sampler=dict(
+ type='DefaultSampler',
+ shuffle=True),
+ dataset=torchvision.datasets.CIFAR10(...),
+ collate_fn=dict(type='default_collate')
+ )
+)
+```
+
+在这种情况下,数据加载器会在实际被用到时,在执行器内部被构建。
+
+```{note}
+关于 `DataLoader` 的更多可配置参数,你可以参考 [PyTorch API 文档](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader)
+```
+
+```{note}
+如果你对于构建的具体细节感兴趣,你可以参考 [build_dataloader](mmengine.runner.Runner.build_dataloader)
+```
+
+细心的你可能会发现,例 1 **并非**直接由[15分钟上手](../get_started/15_minutes.md)中的示例代码简单修改而来。你可能本以为将 `DataLoader` 简单替换为 `dict` 就可以无缝切换,但遗憾的是,基于注册机制构建时 MMEngine 会有一些隐式的转换和约定。我们将介绍其中的不同点,以避免你使用配置文件时产生不必要的疑惑。
+
+### sampler 与 shuffle
+
+与 15 分钟上手明显不同,例 1 中我们添加了 `sampler` 参数,这是由于在 MMEngine 中我们要求通过 `dict` 传入的数据加载器的配置**必须包含 `sampler` 参数**。同时,`shuffle` 参数也从 `DataLoader` 中移除,这是由于在 PyTorch 中 **`sampler` 与 `shuffle` 参数是互斥的**,见 [PyTorch API 文档](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader)。
+
+```{note}
+事实上,在 PyTorch 的实现中,`shuffle` 只是一个便利记号。当设置为 `True` 时 `DataLoader` 会自动在内部使用 `RandomSampler`
+```
+
+当考虑 `sampler` 时,例 1 代码**基本**可以认为等价于下面的代码块
+
+```python
+from mmengine.dataset import DefaultSampler
+
+dataset = torchvision.datasets.CIFAR10(...)
+sampler = DefaultSampler(dataset, shuffle=True)
+
+runner = Runner(
+ train_dataloader=DataLoader(
+ batch_size=32,
+ sampler=sampler,
+ dataset=dataset,
+ collate_fn=default_collate
+ )
+)
+```
+
+```{warning}
+上述代码的等价性只有在:1)使用单进程训练,以及 2)没有配置执行器的 `randomness` 参数时成立。这是由于使用 `dict` 传入 `sampler` 时,执行器会保证它在分布式训练环境设置完成后才被惰性构造,并接收到正确的随机种子。这两点在手动构造时需要额外工作且极易出错。因此,上述的写法只是一个示意而非推荐写法。我们**强烈建议 `sampler` 以 `dict` 的形式传入**,让执行器处理构造顺序,以避免出现问题。
+```
+
+### DefaultSampler
+
+上面例子可能会让你好奇:`DefaultSampler` 是什么,为什么要使用它,是否有其他选项?事实上,`DefaultSampler` 是 MMEngine 内置的一种采样器,它屏蔽了单进程训练与多进程训练的细节差异,使得单卡与多卡训练可以无缝切换。如果你有过使用 PyTorch `DistributedDataParallel` 的经验,你一定会对其中更换数据加载器的 `sampler` 参数有所印象。但在 MMEngine 中,这一细节通过 `DefaultSampler` 而被屏蔽。
+
+除了 `Dataset` 本身之外,`DefaultSampler` 还支持以下参数配置:
+
+- `shuffle` 设置为 `True` 时会打乱数据集的读取顺序
+- `seed` 打乱数据集所用的随机种子,通常不需要在此手动设置,会从 `Runner` 的 `randomness` 入参中读取
+- `round_up` 设置为 `True` 时,与 PyTorch `DataLoader` 中设置 `drop_last=False` 行为一致。如果你在迁移 PyTorch 的项目,你可能需要注意这一点。
+
+```{note}
+更多关于 `DefaultSampler` 的内容可以参考 [API 文档](mmengine.dataset.DefaultSampler)
+```
+
+`DefaultSampler` 适用于绝大部分情况,并且我们保证在执行器中使用它时,随机数等容易出错的细节都被正确地处理,防止你陷入多进程训练的常见陷阱。如果你想要使用基于迭代次数 (iteration-based) 的训练流程,你也许会对 [InfiniteSampler](mmengine.dataset.InfiniteSampler) 感兴趣。如果你有更多的进阶需求,你可能会想要参考上述两个内置 `sampler` 的代码,实现一个自定义的 `sampler` 并注册到 `DATA_SAMPLERS` 根注册器中。
+
+```python
+@DATA_SAMPLERS.register_module()
+class MySampler(Sampler):
+ pass
+
+runner = Runner(
+ train_dataloader=dict(
+ sampler=dict(type='MySampler'),
+ ...
+ )
+)
+```
+
+### 不起眼的 collate_fn
+
+PyTorch 的 `DataLoader` 中,`collate_fn` 这一参数常常被使用者忽略,但在 MMEngine 中你需要额外注意:当你传入 `dict` 来构造数据加载器时,MMEngine 会默认使用内置的 [pseudo_collate](mmengine.dataset.pseudo_collate),这一点明显区别于 PyTorch 默认的 [default_collate](https://pytorch.org/docs/stable/data.html#torch.utils.data.default_collate)。因此,当你迁移 PyTorch 项目时,需要在配置文件中手动指明 `collate_fn` 以保持行为一致。
+
+```{note}
+MMEngine 中使用 `pseudo_collate` 作为默认值,主要是由于历史兼容性原因,你可以不必过于深究,只需了解并避免错误使用即可。
+```
+
+MMengine 中提供了 2 种内置的 `collate_fn`:
+
+- `pseudo_collate`,缺省时的默认参数。它不会将数据沿着 `batch` 的维度合并。详细说明可以参考 [pseudo_collate](mmengine.dataset.pseudo_collate)
+- `default_collate`,与 PyTorch 中的 `default_collate` 行为几乎完全一致,会将数据转化为 `Tensor` 并沿着 `batch` 维度合并。一些细微不同和详细说明可以参考 [default_collate](mmengine.dataset.default_collate)
+
+如果你想要使用自定义的 `collate_fn`,你也可以将它注册到 `COLLATE_FUNCTIONS` 根注册器中来使用
+
+```python
+@COLLATE_FUNCTIONS.register_module()
+def my_collate_func(data_batch: Sequence) -> Any:
+ pass
+
+runner = Runner(
+ train_dataloader=dict(
+ ...
+ collate_fn=dict(type='my_collate_func')
+ )
+)
+```
+
+## 数据集详解
+
+数据集通常定义了数据的数量、读取方式与预处理,并作为参数传递给数据加载器供后者分批次加载。由于我们使用了 PyTorch 的 `DataLoader`,因此数据集也自然与 PyTorch `Dataset` 完全兼容。同时得益于注册机制,当数据加载器使用 `dict` 在执行器内部构建时,`dataset` 参数也可以使用 `dict` 传入并在内部被构建。这一点使得编写配置文件成为可能。
+
+### 使用 torchvision 数据集
+
+`torchvision` 中提供了丰富的公开数据集,它们都可以在 MMEngine 中直接使用,例如 [15 分钟上手](../get_started/15_minutes.md)中的示例代码就使用了其中的 `Cifar10` 数据集,并且使用了 `torchvision` 中内置的数据预处理模块。
+
+但是,当需要将上述示例转换为配置文件时,你需要对 `torchvision` 中的数据集进行额外的注册。如果你同时用到了 `torchvision` 中的数据预处理模块,那么你也需要编写额外代码来对它们进行注册和构建。下面我们将给出一个等效的例子来展示如何做到这一点。
+
+```python
+import torchvision.transforms as tvt
+from mmengine.registry import DATASETS, TRANSFORMS
+from mmengine.dataset.base_dataset import Compose
+
+# 注册 torchvision 的 CIFAR10 数据集
+# 数据预处理也需要在此一起构建
+@DATASETS.register_module(name='Cifar10', force=False)
+def build_torchvision_cifar10(transform=None, **kwargs):
+ if isinstance(transform, dict):
+ transform = [transform]
+ if isinstance(transform, (list, tuple)):
+ transform = Compose(transform)
+ return torchvision.datasets.CIFAR10(**kwargs, transform=transform)
+
+# 注册 torchvision 中用到的数据预处理模块
+DATA_TRANSFORMS.register_module('RandomCrop', module=tvt.RandomCrop)
+DATA_TRANSFORMS.register_module('RandomHorizontalFlip', module=tvt.RandomHorizontalFlip)
+DATA_TRANSFORMS.register_module('ToTensor', module=tvt.ToTensor)
+DATA_TRANSFORMS.register_module('Normalize', module=tvt.Normalize)
+
+# 在 Runner 中使用
+runner = Runner(
+ train_dataloader=dict(
+ batch_size=32,
+ sampler=dict(
+ type='DefaultSampler',
+ shuffle=True),
+ dataset=dict(type='Cifar10',
+ root='data/cifar10',
+ train=True,
+ download=True,
+ transform=[
+ dict(type='RandomCrop', size=32, padding=4),
+ dict(type='RandomHorizontalFlip'),
+ dict(type='ToTensor'),
+ dict(type='Normalize', **norm_cfg)])
+ )
+)
+```
+
+```{note}
+上述例子中大量使用了[注册机制](../advanced_tutorials/registry.md),并且用到了 MMEngine 中的 [Compose](mmengine.dataset.Compose)。如果你急需在配置文件中使用 `torchvision` 数据集,你可以参考上述代码并略作修改。但我们更加推荐你有需要时在下游库(如 [MMDet](https://github.com/open-mmlab/mmdetection) 和 [MMCls](https://github.com/open-mmlab/mmclassification) 等)中寻找对应的数据集实现,从而获得更好的使用体验。
+```
+
+### 自定义数据集
+
+你可以像使用 PyTorch 一样,自由地定义自己的数据集,或将之前 PyTorch 项目中的数据集拷贝过来。如果你想要了解如何自定义数据集,可以参考 [PyTorch 官方教程](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html#creating-a-custom-dataset-for-your-files)
+
+### 使用 MMEngine 的数据集基类
+
+除了直接使用 PyTorch 的 `Dataset` 来自定义数据集之外,你也可以使用 MMEngine 内置的 `BaseDataset`,参考[数据集基类](../advanced_tutorials/basedataset.md)文档。它对标注文件的格式做了一些约定,使得数据接口更加统一、多任务训练更加便捷。同时,数据集基类也可以轻松地搭配内置的[数据变换](../advanced_tutorials/data_transform.md)使用,减轻你从头搭建训练流程的工作量。
+
+目前,`BaseDataset` 已经在 OpenMMLab 2.0 系列的下游仓库中被广泛使用。
diff --git a/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/evaluation.md b/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/evaluation.md
new file mode 100644
index 0000000000000000000000000000000000000000..552fa032a9f0c865b97e55cbf65e6d5edbfeea27
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/evaluation.md
@@ -0,0 +1,136 @@
+# 模型精度评测(Evaluation)
+
+在模型验证和模型测试中,通常需要对模型精度做定量评测。我们可以通过在配置文件中指定评测指标(Metric)来实现这一功能。
+
+## 在模型训练或测试中进行评测
+
+### 使用单个评测指标
+
+在基于 MMEngine 进行模型训练或测试时,用户只需要在配置文件中通过 `val_evaluator` 和 `test_evaluator` 2 个字段分别指定模型验证和测试阶段的评测指标即可。例如,用户在使用 [MMClassification](https://github.com/open-mmlab/mmclassification) 训练分类模型时,希望在模型验证阶段评测 top-1 和 top-5 分类正确率,可以按以下方式配置:
+
+```python
+val_evaluator = dict(type='Accuracy', top_k=(1, 5)) # 使用分类正确率评测指标
+```
+
+关于具体评测指标的参数设置,用户可以查阅相关算法库的文档。如上例中的 [Accuracy 文档](https://mmclassification.readthedocs.io/en/1.x/api/generated/mmcls.evaluation.Accuracy.html#mmcls.evaluation.Accuracy)。
+
+### 使用多个评测指标
+
+如果需要同时评测多个指标,也可以将 `val_evaluator` 或 `test_evaluator` 设置为一个列表,其中每一项为一个评测指标的配置信息。例如,在使用 [MMDetection](https://github.com/open-mmlab/mmdetection) 训练全景分割模型时,希望在模型测试阶段同时评测模型的目标检测(COCO AP/AR)和全景分割精度,可以按以下方式配置:
+
+```python
+test_evaluator = [
+ # 目标检测指标
+ dict(
+ type='CocoMetric',
+ metric=['bbox', 'segm'],
+ ann_file='annotations/instances_val2017.json',
+ ),
+ # 全景分割指标
+ dict(
+ type='CocoPanopticMetric',
+ ann_file='annotations/panoptic_val2017.json',
+ seg_prefix='annotations/panoptic_val2017',
+ )
+]
+```
+
+### 自定义评测指标
+
+如果算法库中提供的常用评测指标无法满足需求,用户也可以增加自定义的评测指标。我们以简化的分类正确率为例,介绍实现自定义评测指标的方法:
+
+1. 在定义新的评测指标类时,需要继承基类 [`BaseMetric`](mmengine.evaluator.BaseMetric)(关于该基类的介绍,可以参考[设计文档](../design/evaluation.md))。此外,评测指标类需要用注册器 `METRICS` 进行注册(关于注册器的说明请参考 [Registry 文档](./registry.md))。
+
+2. 实现 `process()` 方法。该方法有 2 个输入参数,分别是一个批次的测试数据样本 `data_batch` 和模型预测结果 `data_samples`。我们从中分别取出样本类别标签和分类预测结果,并存放在 `self.results` 中。
+
+3. 实现 `compute_metrics()` 方法。该方法有 1 个输入参数 `results`,里面存放了所有批次测试数据经过 `process()` 方法处理后得到的结果。从中取出样本类别标签和分类预测结果,即可计算得到分类正确率 `acc`。最终,将计算得到的评测指标以字典的形式返回。
+
+4. (可选)可以为类属性 `default_prefix` 赋值。该属性会自动作为输出的评测指标名前缀(如 `defaut_prefix='my_metric'`,则实际输出的评测指标名为 `'my_metric/acc'`),用以进一步区分不同的评测指标。该前缀也可以在配置文件中通过 `prefix` 参数改写。我们建议在 docstring 中说明该评测指标类的 `default_prefix` 值以及所有的返回指标名称。
+
+具体实现如下:
+
+```python
+from mmengine.evaluator import BaseMetric
+from mmengine.registry import METRICS
+
+import numpy as np
+
+
+@METRICS.register_module() # 将 Accuracy 类注册到 METRICS 注册器
+class SimpleAccuracy(BaseMetric):
+ """ Accuracy Evaluator
+
+ Default prefix: ACC
+
+ Metrics:
+ - accuracy (float): classification accuracy
+ """
+
+ default_prefix = 'ACC' # 设置 default_prefix
+
+ def process(self, data_batch: Sequence[dict], data_samples: Sequence[dict]):
+ """Process one batch of data and predictions. The processed
+ Results should be stored in `self.results`, which will be used
+ to compute the metrics when all batches have been processed.
+
+ Args:
+ data_batch (Sequence[Tuple[Any, dict]]): A batch of data
+ from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from
+ the model.
+ """
+
+ # 取出分类预测结果和类别标签
+ result = {
+ 'pred': data_samples['pred_label'],
+ 'gt': data_samples['data_sample']['gt_label']
+ }
+
+ # 将当前 batch 的结果存进 self.results
+ self.results.append(result)
+
+ def compute_metrics(self, results: List):
+ """Compute the metrics from processed results.
+
+ Args:
+ results (dict): The processed results of each batch.
+
+ Returns:
+ Dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+
+ # 汇总所有样本的分类预测结果和类别标签
+ preds = np.concatenate([res['pred'] for res in results])
+ gts = np.concatenate([res['gt'] for res in results])
+
+ # 计算分类正确率
+ acc = (preds == gts).sum() / preds.size
+
+ # 返回评测指标结果
+ return {'accuracy': acc}
+```
+
+## 使用离线结果进行评测
+
+另一种常见的模型评测方式,是利用提前保存在文件中的模型预测结果进行离线评测。此时,用户需要手动构建**评测器**,并调用评测器的相应接口完成评测。关于离线评测的详细说明,以及评测器和评测指标的关系,可以参考[设计文档](/docs/zh_cn/design/evaluation.md)。我们仅在此给出一个离线评测示例:
+
+```python
+from mmengine.evaluator import Evaluator
+from mmengine.fileio import load
+
+# 构建评测器。参数 `metrics` 为评测指标配置
+evaluator = Evaluator(metrics=dict(type='Accuracy', top_k=(1, 5)))
+
+# 从文件中读取测试数据。数据格式需要参考具使用的 metric。
+data = load('test_data.pkl')
+
+# 从文件中读取模型预测结果。该结果由待评测算法在测试数据集上推理得到。
+# 数据格式需要参考具使用的 metric。
+data_samples = load('prediction.pkl')
+
+# 调用评测器离线评测接口,得到评测结果
+# chunk_size 表示每次处理的样本数量,可根据内存大小调整
+results = evaluator.offline_evaluate(data, data_samples, chunk_size=128)
+
+```
diff --git a/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/hook.md b/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/hook.md
new file mode 100644
index 0000000000000000000000000000000000000000..dab8c55f229905051e5dfe71c30926ea201956e6
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/hook.md
@@ -0,0 +1,265 @@
+# 钩子(Hook)
+
+钩子编程是一种编程模式,是指在程序的一个或者多个位置设置位点(挂载点),当程序运行至某个位点时,会自动调用运行时注册到位点的所有方法。钩子编程可以提高程序的灵活性和拓展性,用户将自定义的方法注册到位点便可被调用而无需修改程序中的代码。
+
+## 内置钩子
+
+MMEngine 提供了很多内置的钩子,将钩子分为两类,分别是默认钩子以及自定义钩子,前者表示会默认往执行器注册,后者表示需要用户自己注册。
+
+每个钩子都有对应的优先级,在同一位点,钩子的优先级越高,越早被执行器调用,如果优先级一样,被调用的顺序和钩子注册的顺序一致。优先级列表如下:
+
+- HIGHEST (0)
+- VERY_HIGH (10)
+- HIGH (30)
+- ABOVE_NORMAL (40)
+- NORMAL (50)
+- BELOW_NORMAL (60)
+- LOW (70)
+- VERY_LOW (90)
+- LOWEST (100)
+
+**默认钩子**
+
+| 名称 | 用途 | 优先级 |
+| :-----------------------------------------: | :--------------------------------: | :---------------: |
+| [RuntimeInfoHook](#runtimeinfohook) | 往 message hub 更新运行时信息 | VERY_HIGH (10) |
+| [IterTimerHook](#itertimerhook) | 统计迭代耗时 | NORMAL (50) |
+| [DistSamplerSeedHook](#distsamplerseedhook) | 确保分布式 Sampler 的 shuffle 生效 | NORMAL (50) |
+| [LoggerHook](#loggerhook) | 打印日志 | BELOW_NORMAL (60) |
+| [ParamSchedulerHook](#paramschedulerhook) | 调用 ParamScheduler 的 step 方法 | LOW (70) |
+| [CheckpointHook](#checkpointhook) | 按指定间隔保存权重 | VERY_LOW (90) |
+
+**自定义钩子**
+
+| 名称 | 用途 | 优先级 |
+| :---------------------------------: | :-------------------: | :---------: |
+| [EMAHook](#emahook) | 模型参数指数滑动平均 | NORMAL (50) |
+| [EmptyCacheHook](#emptycachehook) | PyTorch CUDA 缓存清理 | NORMAL (50) |
+| [SyncBuffersHook](#syncbuffershook) | 同步模型的 buffer | NORMAL (50) |
+
+```{note}
+不建议修改默认钩子的优先级,因为优先级低的钩子可能会依赖优先级高的钩子。例如 CheckpointHook 的优先级需要比 ParamSchedulerHook 低,这样保存的优化器状态才是正确的状态。另外,自定义钩子的优先级默认为 `NORMAL (50)`。
+```
+
+两种钩子在执行器中的设置不同,默认钩子的配置传给执行器的 `default_hooks` 参数,自定义钩子的配置传给 `custom_hooks` 参数,如下所示:
+
+```python
+from mmengine.runner import Runner
+
+default_hooks = dict(
+ runtime_info=dict(type='RuntimeInfoHook'),
+ timer=dict(type='IterTimerHook'),
+ sampler_seed=dict(type='DistSamplerSeedHook'),
+ logger=dict(type='LoggerHook'),
+ param_scheduler=dict(type='ParamSchedulerHook'),
+ checkpoint=dict(type='CheckpointHook', interval=1),
+)
+
+custom_hooks = [dict(type='EmptyCacheHook')]
+
+runner = Runner(default_hooks=default_hooks, custom_hooks=custom_hooks, ...)
+runner.train()
+```
+
+下面逐一介绍 MMEngine 中内置钩子的用法。
+
+### CheckpointHook
+
+[CheckpointHook](mmengine.hooks.CheckpointHook) 按照给定间隔保存模型的权重,如果是分布式多卡训练,则只有主(master)进程会保存权重。`CheckpointHook` 的主要功能如下:
+
+- 按照间隔保存权重,支持按 epoch 数或者 iteration 数保存权重
+- 保存最新的多个权重
+- 保存最优权重
+- 指定保存权重的路径
+
+如需了解其他功能,请阅读 [CheckpointHook API 文档](mmengine.hooks.CheckpointHook)。
+
+下面介绍上面提到的 4 个功能。
+
+- 按照间隔保存权重,支持按 epoch 数或者 iteration 数保存权重
+
+ 假设我们一共训练 20 个 epoch 并希望每隔 5 个 epoch 保存一次权重,下面的配置即可帮我们实现该需求。
+
+ ```python
+ # by_epoch 的默认值为 True
+ default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=5, by_epoch=True))
+ ```
+
+ 如果想以迭代次数作为保存间隔,则可以将 `by_epoch` 设为 False,`interval=5` 则表示每迭代 5 次保存一次权重。
+
+ ```python
+ default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=5, by_epoch=False))
+ ```
+
+- 保存最新的多个权重
+
+ 如果只想保存一定数量的权重,可以通过设置 `max_keep_ckpts` 参数实现最多保存 `max_keep_ckpts` 个权重,当保存的权重数超过 `max_keep_ckpts` 时,前面的权重会被删除。
+
+ ```python
+ default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=5, max_keep_ckpts=2))
+ ```
+
+ 上述例子表示,假如一共训练 20 个 epoch,那么会在第 5, 10, 15, 20 个 epoch 保存模型,但是在第 15 个 epoch 的时候会删除第 5 个 epoch 保存的权重,在第 20 个 epoch 的时候会删除第 10 个 epoch 的权重,最终只有第 15 和第 20 个 epoch 的权重才会被保存。
+
+- 保存最优权重
+
+ 如果想要保存训练过程验证集的最优权重,可以设置 `save_best` 参数,如果设置为 `'auto'`,则会根据验证集的第一个评价指标(验证集返回的评价指标是一个有序字典)判断当前权重是否最优。
+
+ ```python
+ default_hooks = dict(checkpoint=dict(type='CheckpointHook', save_best='auto'))
+ ```
+
+ 也可以直接指定 `save_best` 的值为评价指标,例如在分类任务中,可以指定为 `save_best='top-1'`,则会根据 `'top-1'` 的值判断当前权重是否最优。
+
+ 除了 `save_best` 参数,和保存最优权重相关的参数还有 `rule`,`greater_keys` 和 `less_keys`,这三者用来判断 `save_best` 的值是越大越好还是越小越好。例如指定了 `save_best='top-1'`,可以指定 `rule='greater'`,则表示该值越大表示权重越好。
+
+- 指定保存权重的路径
+
+ 权重默认保存在工作目录(work_dir),但可以通过设置 `out_dir` 改变保存路径。
+
+ ```python
+ default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=5, out_dir='/path/of/directory'))
+ ```
+
+### LoggerHook
+
+[LoggerHook](mmengine.hooks.LoggerHook) 负责收集日志并把日志输出到终端或者输出到文件、TensorBoard 等后端。
+
+如果我们希望每迭代 20 次就输出(或保存)一次日志,我们可以设置 `interval` 参数,配置如下:
+
+```python
+default_hooks = dict(logger=dict(type='LoggerHook', interval=20))
+```
+
+如果你对日志的管理感兴趣,可以阅读[记录日志(logging)](logging.md)。
+
+### ParamSchedulerHook
+
+[ParamSchedulerHook](mmengine.hooks.ParamSchedulerHook) 遍历执行器的所有优化器参数调整策略(Parameter Scheduler)并逐个调用 step 方法更新优化器的参数。如需了解优化器参数调整策略的用法请阅读[文档](../tutorials/param_scheduler.md)。`ParamSchedulerHook` 默认注册到执行器并且没有可配置的参数,所以无需对其做任何配置。
+
+### IterTimerHook
+
+[IterTimerHook](mmengine.hooks.IterTimerHook) 用于记录加载数据的时间以及迭代一次耗费的时间。`IterTimerHook` 默认注册到执行器并且没有可配置的参数,所以无需对其做任何配置。
+
+### DistSamplerSeedHook
+
+[DistSamplerSeedHook](mmengine.hooks.DistSamplerSeedHook) 在分布式训练时调用 Sampler 的 step 方法以确保 shuffle 参数生效。`DistSamplerSeedHook` 默认注册到执行器并且没有可配置的参数,所以无需对其做任何配置。
+
+### RuntimeInfoHook
+
+[RuntimeInfoHook](mmengine.hooks.RuntimeInfoHook) 会在执行器的不同钩子位点将当前的运行时信息(如 epoch、iter、max_epochs、max_iters、lr、metrics等)更新至 message hub 中,以便其他无法访问执行器的模块能够获取到这些信息。`RuntimeInfoHook` 默认注册到执行器并且没有可配置的参数,所以无需对其做任何配置。
+
+### EMAHook
+
+[EMAHook](mmengine.hooks.EMAHook) 在训练过程中对模型执行指数滑动平均操作,目的是提高模型的鲁棒性。注意:指数滑动平均生成的模型只用于验证和测试,不影响训练。
+
+```python
+custom_hooks = [dict(type='EMAHook')]
+runner = Runner(custom_hooks=custom_hooks, ...)
+runner.train()
+```
+
+`EMAHook` 默认使用 `ExponentialMovingAverage`,可选值还有 `StochasticWeightAverage` 和 `MomentumAnnealingEMA`。可以通过设置 `ema_type` 使用其他的平均策略。
+
+```python
+custom_hooks = [dict(type='EMAHook', ema_type='StochasticWeightAverage')]
+```
+
+更多用法请阅读 [EMAHook API 文档](mmengine.hooks.EMAHook)。
+
+### EmptyCacheHook
+
+[EmptyCacheHook](mmengine.hooks.EmptyCacheHook) 调用 `torch.cuda.empty_cache()` 释放未被使用的显存。可以通过设置 `before_epoch`, `after_iter` 以及 `after_epoch` 参数控制释显存的时机,第一个参数表示在每个 epoch 开始之前,第二参数表示在每次迭代之后,第三个参数表示在每个 epoch 之后。
+
+```python
+# 每一个 epoch 结束都会执行释放操作
+custom_hooks = [dict(type='EmptyCacheHook', after_epoch=True)]
+runner = Runner(custom_hooks=custom_hooks, ...)
+runner.train()
+```
+
+### SyncBuffersHook
+
+[SyncBuffersHook](mmengine.hooks.SyncBuffersHook) 在分布式训练每一轮(epoch)结束时同步模型的 buffer,例如 BN 层的 `running_mean` 以及 `running_var`。
+
+```python
+custom_hooks = [dict(type='SyncBuffersHook')]
+runner = Runner(custom_hooks=custom_hooks, ...)
+runner.train()
+```
+
+## 自定义钩子
+
+如果 MMEngine 提供的默认钩子不能满足需求,用户可以自定义钩子,只需继承钩子基类并重写相应的位点方法。
+
+例如,如果希望在训练的过程中判断损失值是否有效,如果值为无穷大则无效,我们可以在每次迭代后判断损失值是否无穷大,因此只需重写 `after_train_iter` 位点。
+
+```python
+import torch
+
+from mmengine.registry import HOOKS
+from mmengine.hooks import Hook
+
+
+@HOOKS.register_module()
+class CheckInvalidLossHook(Hook):
+ """Check invalid loss hook.
+
+ This hook will regularly check whether the loss is valid
+ during training.
+
+ Args:
+ interval (int): Checking interval (every k iterations).
+ Defaults to 50.
+ """
+
+ def __init__(self, interval=50):
+ self.interval = interval
+
+ def after_train_iter(self, runner, batch_idx, data_batch=None, outputs=None):
+ """All subclasses should override this method, if they need any
+ operations after each training iteration.
+
+ Args:
+ runner (Runner): The runner of the training process.
+ batch_idx (int): The index of the current batch in the train loop.
+ data_batch (dict or tuple or list, optional): Data from dataloader.
+ outputs (dict, optional): Outputs from model.
+ """
+ if self.every_n_train_iters(runner, self.interval):
+ assert torch.isfinite(outputs['loss']),\
+ runner.logger.info('loss become infinite or NaN!')
+```
+
+我们只需将钩子的配置传给执行器的 `custom_hooks` 的参数,执行器初始化的时候会注册钩子,
+
+```python
+from mmengine.runner import Runner
+
+custom_hooks = dict(
+ dict(type='CheckInvalidLossHook', interval=50)
+)
+runner = Runner(custom_hooks=custom_hooks, ...) # 实例化执行器,主要完成环境的初始化以及各种模块的构建
+runner.train() # 执行器开始训练
+```
+
+便会在每次模型前向计算后检查损失值。
+
+注意,自定义钩子的优先级默认为 `NORMAL (50)`,如果想改变钩子的优先级,则可以在配置中设置 priority 字段。
+
+```python
+custom_hooks = dict(
+ dict(type='CheckInvalidLossHook', interval=50, priority='ABOVE_NORMAL')
+)
+```
+
+也可以在定义类时给定优先级
+
+```python
+@HOOKS.register_module()
+class CheckInvalidLossHook(Hook):
+
+ priority = 'ABOVE_NORMAL'
+```
+
+你可能还想阅读[钩子的设计](../design/hook.md)或者[钩子的 API 文档](mmengine.hooks)。
diff --git a/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/model.md b/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/model.md
new file mode 100644
index 0000000000000000000000000000000000000000..94474de1b5d7f065ca878eadce850c26aff138be
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/model.md
@@ -0,0 +1,197 @@
+# 模型(Model)
+
+## Runner 与 model
+
+在 [Runner 教程的基本数据流](./runner.md#基本数据流)中我们提到,DataLoader、model 和 evaluator 之间的数据流通遵循了一些规则,我们先来回顾一下基本数据流的伪代码:
+
+```python
+# 训练过程
+for data_batch in train_dataloader:
+ data_batch = model.data_preprocessor(data_batch, training=True)
+ if isinstance(data_batch, dict):
+ losses = model(**data_batch, mode='loss')
+ elif isinstance(data_batch, (list, tuple)):
+ losses = model(*data_batch, mode='loss')
+ else:
+ raise TypeError()
+# 验证过程
+for data_batch in val_dataloader:
+ data_batch = model.data_preprocessor(data_batch, training=False)
+ if isinstance(data_batch, dict):
+ outputs = model(**data_batch, mode='predict')
+ elif isinstance(data_batch, (list, tuple)):
+ outputs = model(**data_batch, mode='predict')
+ else:
+ raise TypeError()
+ evaluator.process(data_samples=outputs, data_batch=data_batch)
+metrics = evaluator.evaluate(len(val_dataloader.dataset))
+```
+
+在 Runner 的教程中,我们简单介绍了模型和前后组件之间的数据流通关系,提到了 `data_preprocessor` 的概念,对 model 有了一定的了解。然而在 Runner 实际运行的过程中,模型的功能和调用关系,其复杂程度远超上述伪代码。为了让你能够不感知模型和外部组件的复杂关系,进而聚焦精力到算法本身,我们设计了 [BaseModel](mmengine.model.BaseModel)。大多数情况下你只需要让 model 继承 `BaseModel`,并按照要求实现 `forward` 接口,就能完成训练、测试、验证的逻辑。
+
+在继续阅读模型教程之前,我们先抛出两个问题,希望你在阅读完 model 教程后能够找到相应的答案:
+
+1. 我们在什么位置更新模型参数?如果我有一些非常复杂的参数更新逻辑,又该如何实现?
+2. 为什么要有 data_preprocessor 的概念?它又可以实现哪些功能?
+
+## 接口约定
+
+在训练深度学习任务时,我们通常需要定义一个模型来实现算法的主体。在基于 MMEngine 开发时,定义的模型由执行器管理,且需要实现 `train_step`、`val_step` 和 `test_step` 方法。
+对于检测、识别、分割一类的深度学习任务,上述方法通常为标准的流程,例如在 `train_step` 里更新参数,返回损失;`val_step` 和 `test_step` 返回预测结果。因此 MMEngine 抽象出模型基类 [BaseModel](mmengine.model.BaseModel),实现了上述接口的标准流程。
+
+得益于 `BaseModel` 我们只需要让模型继承自模型基类,并按照一定的规范实现 `forward`,就能让模型在执行器中运行起来。
+
+```{note}
+模型基类继承自[模块基类](../advanced_tutorials/initialize.md),能够通过配置 `init_cfg` 灵活地选择初始化方式。
+```
+
+[**forward**](mmengine.model.BaseModel.forward): `forward` 的入参需通常需要和 [DataLoader](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html) 的输出保持一致 (自定义[数据预处理器](#数据预处理器datapreprocessor)除外),如果 `DataLoader` 返回元组类型的数据 `data`,`forward` 需要能够接受 `*data` 的解包后的参数;如果返回字典类型的数据 `data`,`forward` 需要能够接受 `**data` 解包后的参数。 `mode` 参数用于控制 forward 的返回结果:
+
+- `mode='loss'`:`loss` 模式通常在训练阶段启用,并返回一个损失字典。损失字典的 key-value 分别为损失名和可微的 `torch.Tensor`。字典中记录的损失会被用于更新参数和记录日志。模型基类会在 `train_step` 方法中调用该模式的 `forward`。
+- `mode='predict'`: `predict` 模式通常在验证、测试阶段启用,并返回列表/元组形式的预测结果,预测结果需要和 [process](mmengine.evaluator.Evaluator.process) 接口的参数相匹配。OpenMMLab 系列算法对 `predict` 模式的输出有着更加严格的约定,需要输出列表形式的[数据元素](../advanced_tutorials/data_element.md)。模型基类会在 `val_step`,`test_step` 方法中调用该模式的 `forward`。
+- `mode='tensor'`:`tensor` 和 `predict` 模式均返回模型的前向推理结果,区别在于 `tensor` 模式下,`forward` 会返回未经后处理的张量,例如返回未经非极大值抑制(nms)处理的检测结果,返回未经 `argmax` 处理的分类结果。我们可以基于 `tensor` 模式的结果进行自定义的后处理。
+
+[**train_step**](mmengine.model.BaseModel.train_step): 执行 `forward` 方法的 `loss` 分支,得到损失字典。模型基类基于[优化器封装](./optim_wrapper.md) 实现了标准的梯度计算、参数更新、梯度清零流程。其等效伪代码如下:
+
+```python
+def train_step(self, data, optim_wrapper):
+ data = self.data_preprocessor(data, training=True) # 按下不表,详见数据与处理器一节
+ loss = self(**data, mode='loss') # loss 模式,返回损失字典,假设 data 是字典,使用 ** 进行解析。事实上 train_step 兼容 tuple 和 dict 类型的输入。
+ parsed_losses, log_vars = self.parse_losses() # 解析损失字典,返回可以 backward 的损失以及可以被日志记录的损失
+ optim_wrapper.update_params(parsed_losses) # 更新参数
+ return log_vars
+```
+
+[**val_step**](mmengine.model.BaseModel.val_step): 执行 `forward` 方法的 `predict` 分支,返回预测结果:
+
+```python
+def val_step(self, data, optim_wrapper):
+ data = self.data_preprocessor(data, training=False)
+ outputs = self(**data, mode='predict') # 预测模式,返回预测结果
+ return outputs
+```
+
+[**test_step**](mmengine.model.BaseModel.test_step): 同 `val_step`
+
+看到这我们就可以给出一份 **基本数据流伪代码 plus**:
+
+```python
+# 训练过程
+for data_batch in train_dataloader:
+ loss_dict = model.train_step(data_batch)
+# 验证过程
+for data_batch in val_dataloader:
+ preds = model.test_step(data_batch)
+ evaluator.process(data_samples=outputs, data_batch=data_batch)
+metrics = evaluator.evaluate(len(val_dataloader.dataset))
+```
+
+没错,抛开 Hook 不谈,[loop](mmengine.runner.loop) 调用 model 的过程和上述代码一模一样!看到这,我们再回过头去看 [15 分钟上手 MMEngine](../get_started/15_minutes.md) 里的模型定义部分,就有一种看山不是山的感觉:
+
+```python
+import torch.nn.functional as F
+import torchvision
+from mmengine.model import BaseModel
+
+class MMResNet50(BaseModel):
+ def __init__(self):
+ super().__init__()
+ self.resnet = torchvision.models.resnet50()
+
+ def forward(self, imgs, labels, mode):
+ x = self.resnet(imgs)
+ if mode == 'loss':
+ return {'loss': F.cross_entropy(x, labels)}
+ elif mode == 'predict':
+ return x, labels
+
+ # 下面的 3 个方法已在 BaseModel 实现,这里列出是为了
+ # 解释调用过程
+ def train_step(self, data, optim_wrapper):
+ data = self.data_preprocessor(data)
+ loss = self(*data, mode='loss') # CIFAR10 返回 tuple,因此用 * 解包
+ parsed_losses, log_vars = self.parse_losses()
+ optim_wrapper.update_params(parsed_losses)
+ return log_vars
+
+ def val_step(self, data, optim_wrapper):
+ data = self.data_preprocessor(data)
+ outputs = self(*data, mode='predict')
+ return outputs
+
+ def test_step(self, data, optim_wrapper):
+ data = self.data_preprocessor(data)
+ outputs = self(*data, mode='predict')
+ return outputs
+```
+
+看到这里,相信你对数据流有了更加深刻的理解,也能够回答 [Runner 与 model](#runner-与-model) 里提到的第一个问题:
+
+`BaseModel.train_step` 里实现了默认的参数更新逻辑,如果我们想实现自定义的参数更新流程,可以重写 `train_step` 方法。但是需要注意的是,我们需要保证 `train_step` 最后能够返回损失字典。
+
+## 数据预处理器(DataPreprocessor)
+
+如果你的电脑配有 GPU(或其他能够加速训练的硬件,如 MPS、IPU 等),并且运行了 [15 分钟上手 MMEngine](../get_started/15_minutes.md) 的代码示例,你会发现程序是在 GPU 上运行的,那么 `MMEngine` 是在何时把数据和模型从 CPU 搬运到 GPU 的呢?
+
+事实上,执行器会在构造阶段将模型搬运到指定设备,而数据则会在上一节提到的 `self.data_preprocessor` 这一行搬运到指定设备,进一步将处理好的数据传给模型。看到这里相信你会疑惑:
+
+1. `MMResNet50` 并没有配置 `data_preprocessor`,为什么却可以访问到 `data_preprocessor`,并且把数据搬运到 GPU?
+
+2. 为什么不直接在模型里调用 `data.to(device)` 搬运数据,而需要有 `data_preprocessor` 这一层抽象?它又能实现哪些功能?
+
+首先回答第一个问题:`MMResNet50` 继承了 `BaseModel`。在执行 `super().__init__` 时,如果不传入任何参数,会构造一个默认的 `BaseDataPreprocessor`,其等效简易实现如下:
+
+```python
+class BaseDataPreprocessor(nn.Module):
+ def forward(self, data, training=True): # 先忽略 training 参数
+ # 假设 data 是 CIFAR10 返回的 tuple 类型数据,事实上
+ # BaseDataPreprocessor 可以处理任意类型的数
+ # BaseDataPreprocessor 同样可以把数据搬运到多种设备,这边方便
+ # 起见写成 .cuda()
+ return tuple(_data.cuda() for _data in data)
+```
+
+`BaseDataPreprocessor` 会在训练过程中,将各种类型的数据搬运到指定设备。
+
+在回答第二个问题之前,我们不妨先再思考几个问题
+
+1. 数据归一化操作应该在哪里进行,[transform](../advanced_tutorials/data_transform.md) 还是 model?
+
+ 听上去好像都挺合理,放在 transform 里可以利用 Dataloader 的多进程加速,放在 model 里可以搬运到 GPU 上,利用GPU 资源加速归一化。然而在我们纠结 CPU 归一化快还是 GPU 归一化快的时候,CPU 到 GPU 的数据搬运耗时相较于前者,可算的上是“降维打击”。
+ 事实上对于归一化这类计算量较低的操作,其耗时会远低于数据搬运,因此优化数据搬运的效率就显得更加重要。设想一下,如果我能够在数据仍处于 uint8 时、归一化之前将其搬运到指定设备上(归一化后的 float 型数据大小是 unit8 的 4 倍),就能降低带宽,大大提升数据搬运的效率。这种“滞后”归一化的行为,也是我们设计数据预处理器(data preprocessor) 的主要原因之一。数据预处理器会先搬运数据,再做归一化,提升数据搬运的效率。
+
+2. 我们应该如何实现 MixUp、Mosaic 一类的数据增强?
+
+ 尽管看上去 MixUp 和 Mosaic 只是一种特殊的数据变换,按理说应该在 transform 里实现。考虑到这两种增强会涉及到“将多张图片融合成一张图片”的操作,在 transform 里实现他们的难度就会很大,因为目前 transform 的范式是对一张图片做各种增强,我们很难在一个 transform 里去额外读取其他图片(transform 里无法访问到 dataset)。然而如果基于 Dataloader 采样得到的 `batch_data` 去实现 Mosaic 或者 Mixup,事情就会变得非常简单,因为这个时候我们能够同时访问多张图片,可以轻而易举的完成图片融合的操作:
+
+ ```python
+ class MixUpDataPreprocessor(nn.Module):
+ def __init__(self, num_class, alpha):
+ self.alpha = alpha
+
+ def forward(self, data, training=True):
+ data = tuple(_data.cuda() for _data in data)
+ # 验证阶段无需进行 MixUp 数据增强
+ if not training:
+ return data
+
+ label = F.one_hot(label) # label 转 onehot 编码
+ batch_size = len(label)
+ index = torch.randperm(batch_size) # 计算用于叠加的图片数
+ img, label = data
+ lam = np.random.beta(self.alpha, self.alpha) # 融合因子
+
+ # 原图和标签的 MixUp.
+ img = lam * img + (1 - lam) * img[index, :]
+ label = lam * batch_scores + (1 - lam) * batch_scores[index, :]
+ # 由于此时返回的是 onehot 编码的 label,model 的 forward 也需要做相应调整
+ return tuple(img, label)
+ ```
+
+ 因此,除了数据搬运和归一化,`data_preprocessor` 另一大功能就是数据批增强(BatchAugmentation)。数据预处理器的模块化也能帮助我们实现算法和数据增强之间的自由组合。
+
+3. 如果 DataLoader 的输出和模型的输入类型不匹配怎么办,是修改 DataLoader 还是修改模型接口?
+
+ 答案是都不合适。理想的解决方案是我们能够在不破坏模型和数据已有接口的情况下完成适配。这个时候数据预处理器也能承担类型转换的工作,例如将传入的 data 从 `tuple` 转换成指定字段的 `dict`。
+
+看到这里,相信你已经能够理解数据预处理器存在的合理性,并且也能够自信地回答教程最初提出的两个问题!但是你可能还会疑惑 `train_step` 接口中传入的 `optim_wrapper` 又是什么,`test_step` 和 `val_step` 返回的结果和 evaluator 又有怎样的关系,这些问题会在[模型精度评测教程](./evaluation.md)和[优化器封装](./optim_wrapper.md)得到解答。
diff --git a/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/optim_wrapper.md b/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/optim_wrapper.md
new file mode 100644
index 0000000000000000000000000000000000000000..20fb968473d39e1939e02cd8e0feee9fe617bcc2
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/optim_wrapper.md
@@ -0,0 +1,502 @@
+# 优化器封装(OptimWrapper)
+
+在[执行器教程](./runner.md)和[模型教程](./model.md)中,我们或多或少地提到了优化器封装(OptimWrapper)的概念,但是却没有介绍为什么我们需要优化器封装,相比于 Pytorch 原生的优化器,优化器封装又有怎样的优势,这些问题会在本教程中得到一一解答。我们将通过对比的方式帮助大家理解,优化器封装的优势,以及如何使用它。
+
+优化器封装顾名思义,是 Pytorch 原生优化器(Optimizer)高级抽象,它在增加了更多功能的同时,提供了一套统一的接口。优化器封装支持不同的训练策略,包括混合精度训练、梯度累加和梯度截断。我们可以根据需求选择合适的训练策略。优化器封装还定义了一套标准的参数更新流程,用户可以基于这一套流程,实现同一套代码,不同训练策略的切换。
+
+## 优化器封装 vs 优化器
+
+这里我们分别基于 Pytorch 内置的优化器和 MMEngine 的优化器封装进行单精度训练、混合精度训练和梯度累加,对比二者实现上的区别。
+
+### 训练模型
+
+**1.1 基于 Pytorch 的 SGD 优化器实现单精度训练**
+
+```python
+import torch
+from torch.optim import SGD
+import torch.nn as nn
+import torch.nn.functional as F
+
+inputs = [torch.zeros(10, 1, 1)] * 10
+targets = [torch.ones(10, 1, 1)] * 10
+model = nn.Linear(1, 1)
+optimizer = SGD(model.parameters(), lr=0.01)
+optimizer.zero_grad()
+
+for input, target in zip(inputs, targets):
+ output = model(input)
+ loss = F.l1_loss(output, target)
+ loss.backward()
+ optimizer.step()
+ optimizer.zero_grad()
+```
+
+**1.2 使用 MMEngine 的优化器封装实现单精度训练**
+
+```python
+from mmengine.optim import OptimWrapper
+
+optim_wrapper = OptimWrapper(optimizer=optimizer)
+
+for input, target in zip(inputs, targets):
+ output = model(input)
+ loss = F.l1_loss(output, target)
+ optim_wrapper.update_params(loss)
+```
+
+
+
+优化器封装的 `update_params` 实现了标准的梯度计算、参数更新和梯度清零流程,可以直接用来更新模型参数。
+
+**2.1 基于 Pytorch 的 SGD 优化器实现混合精度训练**
+
+```python
+from torch.cuda.amp import autocast
+
+model = model.cuda()
+inputs = [torch.zeros(10, 1, 1, 1)] * 10
+targets = [torch.ones(10, 1, 1, 1)] * 10
+
+for input, target in zip(inputs, targets):
+ with autocast():
+ output = model(input.cuda())
+ loss = F.l1_loss(output, target.cuda())
+ loss.backward()
+ optimizer.step()
+ optimizer.zero_grad()
+```
+
+**2.2 基于 MMEngine 的 优化器封装实现混合精度训练**
+
+```python
+from mmengine.optim import AmpOptimWrapper
+
+optim_wrapper = AmpOptimWrapper(optimizer=optimizer)
+
+for input, target in zip(inputs, targets):
+ with optim_wrapper.optim_context(model):
+ output = model(input.cuda())
+ loss = F.l1_loss(output, target.cuda())
+ optim_wrapper.update_params(loss)
+```
+
+
+
+开启混合精度训练需要使用 `AmpOptimWrapper`,他的 optim_context 接口类似 `autocast`,会开启混合精度训练的上下文。除此之外他还能加速分布式训练时的梯度累加,这个我们会在下一个示例中介绍。
+
+**3.1 基于 Pytorch 的 SGD 优化器实现混合精度训练和梯度累加**
+
+```python
+for idx, (input, target) in enumerate(zip(inputs, targets)):
+ with autocast():
+ output = model(input.cuda())
+ loss = F.l1_loss(output, target.cuda())
+ loss.backward()
+ if idx % 2 == 0:
+ optimizer.step()
+ optimizer.zero_grad()
+```
+
+**3.2 基于 MMEngine 的优化器封装实现混合精度训练和梯度累加**
+
+```python
+optim_wrapper = AmpOptimWrapper(optimizer=optimizer, accumulative_counts=2)
+
+for input, target in zip(inputs, targets):
+ with optim_wrapper.optim_context(model):
+ output = model(input.cuda())
+ loss = F.l1_loss(output, target.cuda())
+ optim_wrapper.update_params(loss)
+```
+
+
+
+我们只需要配置 `accumulative_counts` 参数,并调用 `update_params` 接口就能实现梯度累加的功能。除此之外,分布式训练情况下,如果我们配置梯度累加的同时开启了 `optim_wrapper` 上下文,可以避免梯度累加阶段不必要的梯度同步。
+
+优化器封装同样提供了更细粒度的接口,方便用户实现一些自定义的参数更新逻辑:
+
+- `backward`:传入损失,用于计算参数梯度。
+- `step`:同 `optimizer.step`,用于更新参数。
+- `zero_grad`:同 `optimizer.zero_grad`,用于参数的梯度。
+
+我们可以使用上述接口实现和 Pytorch 优化器相同的参数更新逻辑:
+
+```python
+for idx, (input, target) in enumerate(zip(inputs, targets)):
+ optimizer.zero_grad()
+ with optim_wrapper.optim_context(model):
+ output = model(input.cuda())
+ loss = F.l1_loss(output, target.cuda())
+ optim_wrapper.backward(loss)
+ if idx % 2 == 0:
+ optim_wrapper.step()
+ optim_wrapper.zero_grad()
+```
+
+我们同样可以为优化器封装配置梯度裁减策略:
+
+```python
+# 基于 torch.nn.utils.clip_grad_norm_ 对梯度进行裁减
+optim_wrapper = AmpOptimWrapper(
+ optimizer=optimizer, clip_grad=dict(max_norm=1))
+
+# 基于 torch.nn.utils.clip_grad_value_ 对梯度进行裁减
+optim_wrapper = AmpOptimWrapper(
+ optimizer=optimizer, clip_grad=dict(clip_value=0.2))
+```
+
+### 获取学习率/动量
+
+优化器封装提供了 `get_lr` 和 `get_momentum` 接口用于获取优化器的一个参数组的学习率:
+
+```python
+import torch.nn as nn
+from torch.optim import SGD
+
+from mmengine.optim import OptimWrapper
+
+model = nn.Linear(1, 1)
+optimizer = SGD(model.parameters(), lr=0.01)
+optim_wrapper = OptimWrapper(optimizer)
+
+print(optimizer.param_groups[0]['lr']) # 0.01
+print(optimizer.param_groups[0]['momentum']) # 0
+print(optim_wrapper.get_lr()) # {'lr': [0.01]}
+print(optim_wrapper.get_momentum()) # {'momentum': [0]}
+```
+
+```
+0.01
+0
+{'lr': [0.01]}
+{'momentum': [0]}
+```
+
+### 导出/加载状态字典
+
+优化器封装和优化器一样,提供了 `state_dict` 和 `load_state_dict` 接口,用于导出/加载优化器状态,对于 `AmpOptimWrapper`,优化器封装还会额外导出混合精度训练相关的参数:
+
+```python
+import torch.nn as nn
+from torch.optim import SGD
+from mmengine.optim import OptimWrapper, AmpOptimWrapper
+
+model = nn.Linear(1, 1)
+optimizer = SGD(model.parameters(), lr=0.01)
+
+optim_wrapper = OptimWrapper(optimizer=optimizer)
+amp_optim_wrapper = AmpOptimWrapper(optimizer=optimizer)
+
+# 导出状态字典
+optim_state_dict = optim_wrapper.state_dict()
+amp_optim_state_dict = amp_optim_wrapper.state_dict()
+
+print(optim_state_dict)
+print(amp_optim_state_dict)
+optim_wrapper_new = OptimWrapper(optimizer=optimizer)
+amp_optim_wrapper_new = AmpOptimWrapper(optimizer=optimizer)
+
+# 加载状态字典
+amp_optim_wrapper_new.load_state_dict(amp_optim_state_dict)
+optim_wrapper_new.load_state_dict(optim_state_dict)
+```
+
+```
+{'state': {}, 'param_groups': [{'lr': 0.01, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'maximize': False, 'foreach': None, 'params': [0, 1]}]}
+{'state': {}, 'param_groups': [{'lr': 0.01, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'maximize': False, 'foreach': None, 'params': [0, 1]}], 'loss_scaler': {'scale': 65536.0, 'growth_factor': 2.0, 'backoff_factor': 0.5, 'growth_interval': 2000, '_growth_tracker': 0}}
+```
+
+### 使用多个优化器
+
+考虑到生成对抗网络之类的算法通常需要使用多个优化器来训练生成器和判别器,因此优化器封装提供了优化器封装的容器类:`OptimWrapperDict` 来管理多个优化器封装。`OptimWrapperDict` 以字典的形式存储优化器封装,并允许用户像字典一样访问、遍历其中的元素,即优化器封装实例。
+
+与普通的优化器封装不同,`OptimWrapperDict` 没有实现 `update_params`、 `optim_context`, `backward`、`step` 等方法,无法被直接用于训练模型。我们建议直接访问 `OptimWrapperDict` 管理的优化器实例,来实现参数更新逻辑。
+
+你或许会好奇,既然 `OptimWrapperDict` 没有训练的功能,那为什么不直接使用 `dict` 来管理多个优化器?事实上,`OptimWrapperDict` 的核心功能是支持批量导出/加载所有优化器封装的状态字典;支持获取多个优化器封装的学习率、动量。如果没有 `OptimWrapperDict`,`MMEngine` 就需要在很多位置对优化器封装的类型做 `if else` 判断,以获取所有优化器封装的状态。
+
+```python
+from torch.optim import SGD
+import torch.nn as nn
+
+from mmengine.optim import OptimWrapper, OptimWrapperDict
+
+gen = nn.Linear(1, 1)
+disc = nn.Linear(1, 1)
+optimizer_gen = SGD(gen.parameters(), lr=0.01)
+optimizer_disc = SGD(disc.parameters(), lr=0.01)
+
+optim_wapper_gen = OptimWrapper(optimizer=optimizer_gen)
+optim_wapper_disc = OptimWrapper(optimizer=optimizer_disc)
+optim_dict = OptimWrapperDict(gen=optim_wapper_gen, disc=optim_wapper_disc)
+
+print(optim_dict.get_lr()) # {'gen.lr': [0.01], 'disc.lr': [0.01]}
+print(optim_dict.get_momentum()) # {'gen.momentum': [0], 'disc.momentum': [0]}
+```
+
+```
+{'gen.lr': [0.01], 'disc.lr': [0.01]}
+{'gen.momentum': [0], 'disc.momentum': [0]}
+```
+
+如上例所示,`OptimWrapperDict` 可以非常方便的导出所有优化器封装的学习率和动量,同样的,优化器封装也能够导出/加载所有优化器封装的状态字典。
+
+### 在[执行器](./runner.md)中配置优化器封装
+
+优化器封装需要接受 `optimizer` 参数,因此我们首先需要为优化器封装配置 `optimizer`。MMEngine 会自动将 PyTorch 中的所有优化器都添加进 `OPTIMIZERS` 注册表中,用户可以用字典的形式来指定优化器,所有支持的优化器见 [PyTorch 优化器列表](https://pytorch.org/docs/stable/optim.html#algorithms)。
+
+以配置一个 SGD 优化器封装为例:
+
+```python
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
+optim_wrapper = dict(type='OptimWrapper', optimizer=optimizer)
+```
+
+这样我们就配置好了一个优化器类型为 SGD 的优化器封装,学习率、动量等参数如配置所示。考虑到 `OptimWrapper` 为标准的单精度训练,因此我们也可以不配置 `type` 字段:
+
+```python
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
+optim_wrapper = dict(optimizer=optimizer)
+```
+
+要想开启混合精度训练和梯度累加,需要将 `type` 切换成 `AmpOptimWrapper`,并指定 `accumulative_counts` 参数:
+
+```python
+optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
+optim_wrapper = dict(type='AmpOptimWrapper', optimizer=optimizer, accumulative_counts=2)
+```
+
+```{note}
+如果你是第一次阅读 MMEngine 的教程文档,并且尚未了解[配置类](../advanced_tutorials/config.md)、[注册器](../advanced_tutorials/registry.md) 等概念,建议可以先跳过以下进阶教程,先去阅读其他文档。当然了,如果你已经具备了这些储备知识,我们强烈建议阅读进阶教程,在进阶教程中,我们将学会:
+
+1. 如何在配置文件中定制化地在优化器中配置模型参数的学习率、衰减系数等。
+2. 如何自定义一个优化器构造策略,实现真正意义上的“优化器配置自由”。
+
+除了配置类和注册器等前置知识,我们建议在开始进阶教程之前,先深入了解 Pytorch 原生优化器构造时的 params 参数。
+```
+
+## 进阶配置
+
+PyTorch 的优化器支持对模型中的不同参数设置不同的超参数,例如对一个分类模型的骨干(backbone)和分类头(head)设置不同的学习率:
+
+```python
+from torch.optim import SGD
+import torch.nn as nn
+
+model = nn.ModuleDict(dict(backbone=nn.Linear(1, 1), head=nn.Linear(1, 1)))
+optimizer = SGD([{'params': model.backbone.parameters()},
+ {'params': model.head.parameters(), 'lr': 1e-3}],
+ lr=0.01,
+ momentum=0.9)
+```
+
+上面的例子中,模型的骨干部分使用了 0.01 学习率,而模型的头部则使用了 1e-3 学习率。用户可以将模型的不同部分参数和对应的超参组成一个字典的列表传给优化器,来实现对模型优化的细粒度调整。
+
+在 MMEngine 中,我们通过优化器封装构造器(optimizer wrapper constructor),让用户能够直接通过设置优化器封装配置文件中的 `paramwise_cfg` 字段而非修改代码来实现对模型的不同部分设置不同的超参。
+
+### 为不同类型的参数设置不同的超参系数
+
+MMEngine 提供的默认优化器封装构造器支持对模型中不同类型的参数设置不同的超参系数。例如,我们可以在 `paramwise_cfg` 中设置 `norm_decay_mult=0`,从而将正则化层(normalization layer)的权重(weight)和偏置(bias)的权值衰减系数(weight decay)设置为 0,来实现 [Bag of Tricks](https://arxiv.org/abs/1812.01187) 论文中提到的不对正则化层进行权值衰减的技巧。
+
+具体示例如下,我们将 `ToyModel` 中所有正则化层(`head.bn`)的权重衰减系数设置为 0:
+
+```python
+from mmengine.optim import build_optim_wrapper
+from collections import OrderedDict
+
+class ToyModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.backbone = nn.ModuleDict(
+ dict(layer0=nn.Linear(1, 1), layer1=nn.Linear(1, 1)))
+ self.head = nn.Sequential(
+ OrderedDict(
+ linear=nn.Linear(1, 1),
+ bn=nn.BatchNorm1d(1)))
+
+
+optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001),
+ paramwise_cfg=dict(norm_decay_mult=0))
+optimizer = build_optim_wrapper(ToyModel(), optim_wrapper)
+```
+
+```
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.bias:lr=0.01
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.bias:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.bias:lr=0.01
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.bias:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.bias:lr=0.01
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.bias:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.weight:weight_decay=0.0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.bias:weight_decay=0.0
+```
+
+除了可以对正则化层的权重衰减进行配置外,MMEngine 的默认优化器封装构造器的 `paramwise_cfg` 还支持对更多不同类型的参数设置超参系数,支持的配置如下:
+
+`lr_mult`:所有参数的学习率系数
+
+`decay_mult`:所有参数的衰减系数
+
+`bias_lr_mult`:偏置的学习率系数(不包括正则化层的偏置以及可变形卷积的 offset)
+
+`bias_decay_mult`:偏置的权值衰减系数(不包括正则化层的偏置以及可变形卷积的 offset)
+
+`norm_decay_mult`:正则化层权重和偏置的权值衰减系数
+
+`flat_decay_mult`:一维参数的权值衰减系数
+
+`dwconv_decay_mult`:Depth-wise 卷积的权值衰减系数
+
+`bypass_duplicate`:是否跳过重复的参数,默认为 `False`
+
+`dcn_offset_lr_mult`:可变形卷积(Deformable Convolution)的学习率系数
+
+### 为模型不同部分的参数设置不同的超参系数
+
+此外,与上文 PyTorch 的示例一样,在 MMEngine 中我们也同样可以对模型中的任意模块设置不同的超参,只需要在 `paramwise_cfg` 中设置 `custom_keys` 即可。
+
+例如我们想将 `backbone.layer0` 所有参数的学习率设置为 0,衰减系数设置为 0,`backbone` 其余子模块的学习率设置为 0.01;`head` 所有参数的学习率设置为 0.001,可以这样配置:
+
+```python
+optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001),
+ paramwise_cfg=dict(
+ custom_keys={
+ 'backbone.layer0': dict(lr_mult=0, decay_mult=0),
+ 'backbone': dict(lr_mult=1),
+ 'head': dict(lr_mult=0.1)
+ }))
+optimizer = build_optim_wrapper(ToyModel(), optim_wrapper)
+```
+
+```
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.weight:lr=0.0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.weight:weight_decay=0.0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.weight:lr_mult=0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.weight:decay_mult=0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.bias:lr=0.0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.bias:weight_decay=0.0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.bias:lr_mult=0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer0.bias:decay_mult=0
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.weight:lr=0.01
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.weight:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.weight:lr_mult=1
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.bias:lr=0.01
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.bias:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- backbone.layer1.bias:lr_mult=1
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.weight:lr=0.001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.weight:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.weight:lr_mult=0.1
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.bias:lr=0.001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.bias:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.linear.bias:lr_mult=0.1
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.weight:lr=0.001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.weight:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.weight:lr_mult=0.1
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.bias:lr=0.001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.bias:weight_decay=0.0001
+08/23 22:02:43 - mmengine - INFO - paramwise_options -- head.bn.bias:lr_mult=0.1
+```
+
+上例中,模型的状态字典的 `key` 如下:
+
+```python
+for name, val in ToyModel().named_parameters():
+ print(name)
+```
+
+```
+backbone.layer0.weight
+backbone.layer0.bias
+backbone.layer1.weight
+backbone.layer1.bias
+head.linear.weight
+head.linear.bias
+head.bn.weight
+head.bn.bias
+```
+
+custom_keys 中每一个字段的含义如下:
+
+1. `'backbone': dict(lr_mult=1)`:将名字前缀为 `backbone` 的参数的学习率系数设置为 1
+2. `'backbone.layer0': dict(lr_mult=0, decay_mult=0)`:将名字前缀为 `backbone.layer0` 的参数学习率系数设置为 0,衰减系数设置为 0,该配置优先级比第一条高
+3. `'head': dict(lr_mult=0.1)`:将名字前缀为 `head` 的参数的学习率系数设置为 0.1
+
+### 自定义优化器构造策略
+
+与 MMEngine 中的其他模块一样,优化器封装构造器也同样由[注册表](../advanced_tutorial/registry.md)管理。我们可以通过实现自定义的优化器封装构造器来实现自定义的超参设置策略。
+
+例如,我们想实现一个叫做 `LayerDecayOptimWrapperConstructor` 的优化器封装构造器,能够对模型不同深度的层自动设置递减的学习率:
+
+```python
+from mmengine.optim import DefaultOptimWrapperConstructor
+from mmengine.registry import OPTIM_WRAPPER_CONSTRUCTORS
+from mmengine.logging import print_log
+
+
+@OPTIM_WRAPPER_CONSTRUCTORS.register_module(force=True)
+class LayerDecayOptimWrapperConstructor(DefaultOptimWrapperConstructor):
+
+ def __init__(self, optim_wrapper_cfg, paramwise_cfg=None):
+ super().__init__(optim_wrapper_cfg, paramwise_cfg=None)
+ self.decay_factor = paramwise_cfg.get('decay_factor', 0.5)
+
+ super().__init__(optim_wrapper_cfg, paramwise_cfg)
+
+ def add_params(self, params, module, prefix='' ,lr=None):
+ if lr is None:
+ lr = self.base_lr
+
+ for name, param in module.named_parameters(recurse=False):
+ param_group = dict()
+ param_group['params'] = [param]
+ param_group['lr'] = lr
+ params.append(param_group)
+ full_name = f'{prefix}.{name}' if prefix else name
+ print_log(f'{full_name} : lr={lr}', logger='current')
+
+ for name, module in module.named_children():
+ chiled_prefix = f'{prefix}.{name}' if prefix else name
+ self.add_params(
+ params, module, chiled_prefix, lr=lr * self.decay_factor)
+
+
+class ToyModel(nn.Module):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.layer = nn.ModuleDict(dict(linear=nn.Linear(1, 1)))
+ self.linear = nn.Linear(1, 1)
+
+
+model = ToyModel()
+
+optim_wrapper = dict(
+ optimizer=dict(type='SGD', lr=0.01, weight_decay=0.0001),
+ paramwise_cfg=dict(decay_factor=0.5),
+ constructor='LayerDecayOptimWrapperConstructor')
+
+optimizer = build_optim_wrapper(model, optim_wrapper)
+```
+
+```
+08/23 22:20:26 - mmengine - INFO - layer.linear.weight : lr=0.0025
+08/23 22:20:26 - mmengine - INFO - layer.linear.bias : lr=0.0025
+08/23 22:20:26 - mmengine - INFO - linear.weight : lr=0.005
+08/23 22:20:26 - mmengine - INFO - linear.bias : lr=0.005
+```
+
+`add_params` 被第一次调用时,`params` 参数为空列表(`list`),`module` 为模型(`model`)。详细的重载规则参考[优化器封装构造器文档](mmengine.optim.DefaultOptimWrapperConstructor)。
+
+类似地,如果想构造多个优化器,也需要实现自定义的构造器:
+
+```python
+@OPTIM_WRAPPER_CONSTRUCTORS.register_module()
+class MultipleOptimiWrapperConstructor:
+ ...
+```
+
+### 在训练过程中调整超参
+
+优化器中的超参数在构造时只能设置为一个定值,仅仅使用优化器封装,并不能在训练过程中调整学习率等参数。在 MMEngine 中,我们实现了参数调度器(Parameter Scheduler),以便能够在训练过程中调整参数。关于参数调度器的用法请见[优化器参数调整策略](./param_scheduler.md)
diff --git a/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/param_scheduler.md b/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/param_scheduler.md
new file mode 100644
index 0000000000000000000000000000000000000000..e18cb6aa4610f074c16e851c4d9eaa466230d773
--- /dev/null
+++ b/testbed/open-mmlab__mmengine/docs/zh_cn/tutorials/param_scheduler.md
@@ -0,0 +1,214 @@
+# 优化器参数调整策略(Parameter Scheduler)
+
+在模型训练过程中,我们往往不是采用固定的优化参数,例如学习率等,会随着训练轮数的增加进行调整。最简单常见的学习率调整策略就是阶梯式下降,例如每隔一段时间将学习率降低为原来的几分之一。PyTorch 中有学习率调度器 LRScheduler 来对各种不同的学习率调整方式进行抽象,但支持仍然比较有限,在 MMEngine 中,我们对其进行了拓展,实现了更通用的[参数调度器](mmengine.optim._ParamScheduler),可以对学习率、动量等优化器相关的参数进行调整,并且支持多个调度器进行组合,应用更复杂的调度策略。
+
+## 参数调度器的使用
+
+我们先简单介绍一下如何使用 PyTorch 内置的学习率调度器来进行学习率的调整:
+
+