

Add 1 files
Browse files- 2311/2311.12085.md +413 -0
2311/2311.12085.md
ADDED
|
@@ -0,0 +1,413 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Pyramid Diffusion for Fine 3D Large Scene Generation
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2311.12085
|
| 4 |
+
|
| 5 |
+
Published Time: Fri, 19 Jul 2024 00:59:55 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
2 2 footnotetext: ∗ Equal contribution.
|
| 9 |
+
|
| 10 |
+
† Corresponding author.1 1 institutetext: Southwest Jiaotong University University of Leeds City University of Hong Kong NVIDIA The University of California, Merced Yonsei University
|
| 11 |
+
Xinke Li∗\orcidlink 0000-0002-9209-2154 33 Xueting Li\orcidlink 0009-0009-2556-8667 44 Lu Qi†\orcidlink 0000-0002-2684-0062 55
|
| 12 |
+
|
| 13 |
+
Chongshou Li\orcidlink 0000-0002-7595-0997 11 Ming-Hsuan Yang\orcidlink 0000-0003-4848-2304 5566112233445566
|
| 14 |
+
|
| 15 |
+
###### Abstract
|
| 16 |
+
|
| 17 |
+
Diffusion models have shown remarkable results in generating 2D images and small-scale 3D objects. However, their application to the synthesis of large-scale 3D scenes has been rarely explored. This is mainly due to the inherent complexity and bulky size of 3D scenery data, particularly outdoor scenes, and the limited availability of comprehensive real-world datasets, which makes training a stable scene diffusion model challenging. In this work, we explore how to effectively generate large-scale 3D scenes using the coarse-to-fine paradigm. We introduce a framework, the Pyramid Discrete Diffusion model (PDD), which employs scale-varied diffusion models to progressively generate high-quality outdoor scenes. Experimental results of PDD demonstrate our successful exploration in generating 3D scenes both unconditionally and conditionally. We further showcase the data compatibility of the PDD model, due to its multi-scale architecture: a PDD model trained on one dataset can be easily fine-tuned with another dataset. Code is available at [https://github.com/yuhengliu02/pyramid-discrete-diffusion](https://github.com/yuhengliu02/pyramid-discrete-diffusion).
|
| 18 |
+
|
| 19 |
+
###### Keywords:
|
| 20 |
+
|
| 21 |
+
3D Scene Generation Diffusion Models Transfer Learning
|
| 22 |
+
|
| 23 |
+
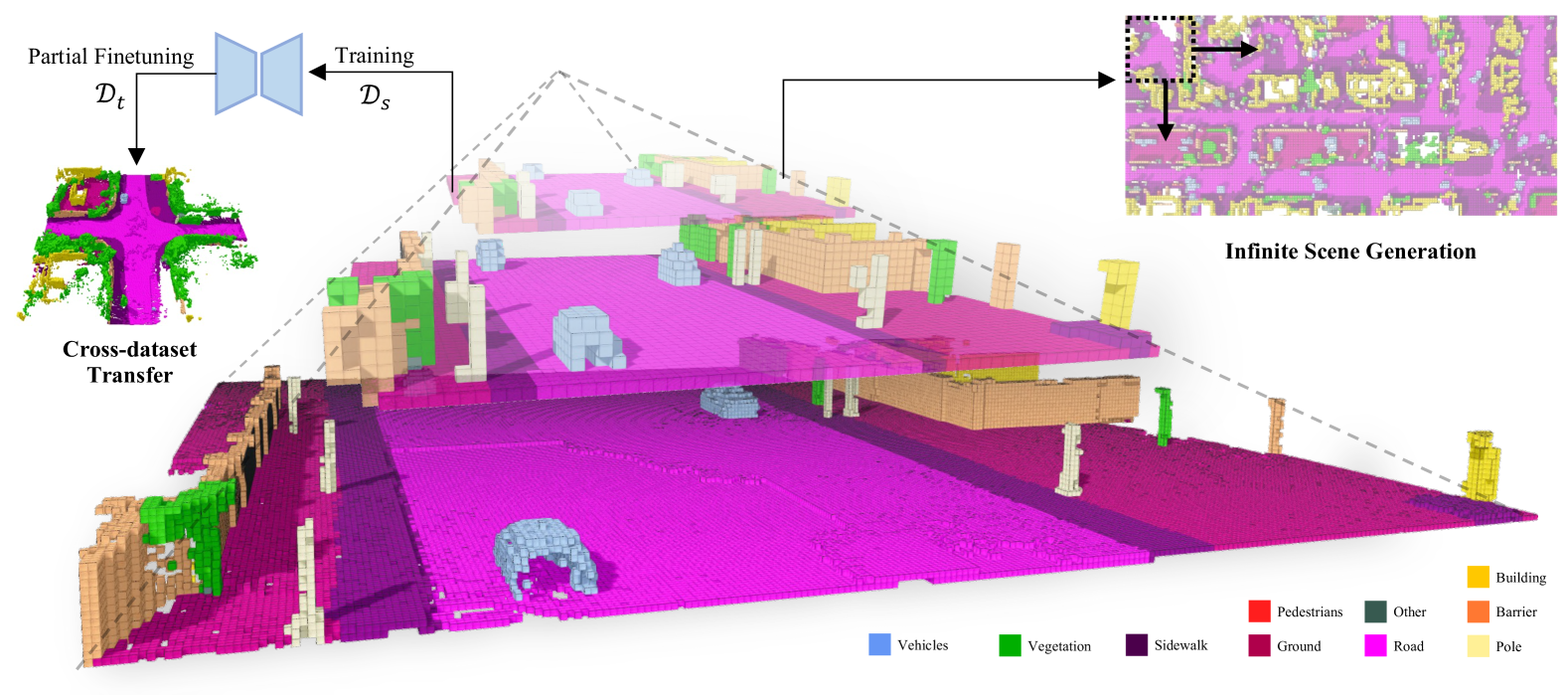
|
| 24 |
+
|
| 25 |
+
Figure 1: We present Pyramid Discrete Diffusion Model, a method that progresses from generating coarse- to fine-grained scenes, mirroring the top-down sequence of the pyramid structure shown. The model is extended for cross-dataset and infinite scene generation, with detailed scene intricacies illustrated on the flanking sides of the image. 𝒟 s subscript 𝒟 𝑠\mathcal{D}_{s}caligraphic_D start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT and 𝒟 t subscript 𝒟 𝑡\mathcal{D}_{t}caligraphic_D start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT refer to a source dataset and a target dataset, respectively.
|
| 26 |
+
|
| 27 |
+
1 Introduction
|
| 28 |
+
--------------
|
| 29 |
+
|
| 30 |
+
3D scene generation is the task of creating digital representations that mimic the three-dimensional complexities of our real-world environment, allowing for a more nuanced understanding of the tangible surroundings. This technique plays an essential role in fundamental computer vision tasks such as autonomous driving [[43](https://arxiv.org/html/2311.12085v2#bib.bib43), [22](https://arxiv.org/html/2311.12085v2#bib.bib22), [45](https://arxiv.org/html/2311.12085v2#bib.bib45)], virtual reality [[40](https://arxiv.org/html/2311.12085v2#bib.bib40), [31](https://arxiv.org/html/2311.12085v2#bib.bib31), [33](https://arxiv.org/html/2311.12085v2#bib.bib33)], and robotic manipulation [[17](https://arxiv.org/html/2311.12085v2#bib.bib17), [9](https://arxiv.org/html/2311.12085v2#bib.bib9), [47](https://arxiv.org/html/2311.12085v2#bib.bib47)]. However, high-quality large 3D scenes are extremely challenging to synthesize due to their inherently bulky size, and the lack of large-scale 3D scene datasets[[44](https://arxiv.org/html/2311.12085v2#bib.bib44)].
|
| 31 |
+
|
| 32 |
+
Meanwhile, recent advances in diffusion models have shown impressive results in generating 2D images[[38](https://arxiv.org/html/2311.12085v2#bib.bib38), [37](https://arxiv.org/html/2311.12085v2#bib.bib37), [36](https://arxiv.org/html/2311.12085v2#bib.bib36)] or small-scale 3D objects[[34](https://arxiv.org/html/2311.12085v2#bib.bib34), [25](https://arxiv.org/html/2311.12085v2#bib.bib25)]. Yet, it is not a trivial task to employ diffusion models in 3D scene generation. On one hand, state-of-the-art diffusion models leave substantial memory footprints and demand considerable training time, posing a particular challenge when generating 3D scenes with large scales and intricate details. On the other hand, diffusion models require a large amount of training data[[30](https://arxiv.org/html/2311.12085v2#bib.bib30), [49](https://arxiv.org/html/2311.12085v2#bib.bib49)], while capturing large-scale 3D scenes is itself a challenging and ongoing research topic[[5](https://arxiv.org/html/2311.12085v2#bib.bib5), [24](https://arxiv.org/html/2311.12085v2#bib.bib24)]. As a result, only a few attempts have been made to apply diffusion models directly to 3D outdoor scenes[[19](https://arxiv.org/html/2311.12085v2#bib.bib19)], which resulted in unstable generation and thus suboptimal performance.
|
| 33 |
+
|
| 34 |
+
To resolve these challenges, existing works focus on conditional generation and resort to additional signals such as Scene Graphs[[42](https://arxiv.org/html/2311.12085v2#bib.bib42)] or 2D maps[[29](https://arxiv.org/html/2311.12085v2#bib.bib29)] for guidance. Nonetheless, such conditional guidance is not always accessible, thereby restricting the generalizability of these approaches. Inspired by the coarse-to-fine philosophy widely used in image super-resolution [[39](https://arxiv.org/html/2311.12085v2#bib.bib39), [15](https://arxiv.org/html/2311.12085v2#bib.bib15), [32](https://arxiv.org/html/2311.12085v2#bib.bib32)], we introduce the Pyramid Discrete Diffusion model (PDD), a framework that progressively generates large 3D scenes without relying on additional guidance.
|
| 35 |
+
|
| 36 |
+
We begin by generating small-scale 3D scenes and progressively increase the scale. At each scale level, we learn a separate diffusion model. This model takes the generated scene from the previous scale as a condition (except for the first diffusion model which takes noise as input) and synthesizes a 3D scene of a larger scale. Intuitively, this multi-scale generation process breaks down a challenging unconditional generation task (_i.e_., high-quality 3D scene generation) into several more manageable conditional generation tasks. This separation allows each diffusion model to specialize in generating either coarse structure (smaller scale) or intricate details (larger scale). Moreover, at the highest scale, we employ a technique known as scene subdivision, which involves dividing a large scene into multiple smaller segments that are synthesized using a shared diffusion model. This approach mitigates the issues of oversized models caused by the bulky size of the 3D scenes. Additionally, a noteworthy outcome of our multi-scale design is its capacity to facilitate cross-data transfer applications, which substantially reduces training resources. Lastly, we further propose a natural extension of our PDD framework with scene subdivision for infinite 3D scene generation, thereby demonstrating the scalability of the proposed method.
|
| 37 |
+
|
| 38 |
+
The main contributions of this work are as follows:
|
| 39 |
+
|
| 40 |
+
* •We practically implement a coarse-to-fine strategy for 3D outdoor scene generation via designing a novel pyramid diffusion model.
|
| 41 |
+
* •We conduct extensive experiments on our pyramid diffusion, demonstrating its generation of higher quality 3D scenes with comparable computational resources of existing approaches. In addition, we introduce new metrics to evaluate the quality of 3D scene generation from various perspectives.
|
| 42 |
+
* •Our proposed method showcases broader applications, enabling the generation of scenes from synthetic datasets to real-world data. Furthermore, our approach can be extended to facilitate the creation of infinite scenes.
|
| 43 |
+
|
| 44 |
+
2 Related Work
|
| 45 |
+
--------------
|
| 46 |
+
|
| 47 |
+
Diffusion Models for 2D Images. Recent advancements in the generative model have seen the diffusion models [[39](https://arxiv.org/html/2311.12085v2#bib.bib39), [15](https://arxiv.org/html/2311.12085v2#bib.bib15), [32](https://arxiv.org/html/2311.12085v2#bib.bib32)] rise to prominence, especially in applications in 2D image creation [[10](https://arxiv.org/html/2311.12085v2#bib.bib10), [37](https://arxiv.org/html/2311.12085v2#bib.bib37), [36](https://arxiv.org/html/2311.12085v2#bib.bib36)]. In order to generate high-fidelity images via diffusion models, a multi-stage diffusion process is proposed and employed as per [[16](https://arxiv.org/html/2311.12085v2#bib.bib16), [38](https://arxiv.org/html/2311.12085v2#bib.bib38), [14](https://arxiv.org/html/2311.12085v2#bib.bib14)]. This process starts with the generation of a coarse-resolution image using an initial diffusion model. Subsequently, a second diffusion model takes this initial output as input, refining it into a finer-resolution image. These cascaded diffusions can be iteratively applied to achieve the desired image resolution. We note that the generation of fine-grained 3D data presents more challenges than 2D due to the addition of an extra dimension. Consequently, our work is motivated by the aforementioned multistage 2D approaches to explore their applicability in 3D contexts. Furthermore, we aim to leverage the advantages of this structure to address the scarcity of datasets in 3D scenes.
|
| 48 |
+
|
| 49 |
+
Diffusion Models for 3D Generation. As a sparse and memory-efficient representation, 3D point clouds has been widely used in various computer vision applications such as digital human[[50](https://arxiv.org/html/2311.12085v2#bib.bib50), [41](https://arxiv.org/html/2311.12085v2#bib.bib41), [28](https://arxiv.org/html/2311.12085v2#bib.bib28)], autonomous driving[[21](https://arxiv.org/html/2311.12085v2#bib.bib21)], and 3D scene reconstruction[[18](https://arxiv.org/html/2311.12085v2#bib.bib18)]. Point clouds generation aims to synthesize a 3D point clouds from a random noise[[7](https://arxiv.org/html/2311.12085v2#bib.bib7), [6](https://arxiv.org/html/2311.12085v2#bib.bib6)], or scanned lidar points[[19](https://arxiv.org/html/2311.12085v2#bib.bib19)]. Though the memory efficiency of point clouds is a valuable property, it poses high challenges in the task of point cloud generation. Existing works largely focus on using Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), or Vector Quantized Variational Autoencoders (VQ-VAEs) as the backbone for this task[[6](https://arxiv.org/html/2311.12085v2#bib.bib6), [1](https://arxiv.org/html/2311.12085v2#bib.bib1), [7](https://arxiv.org/html/2311.12085v2#bib.bib7)]. However, these models have limited capacity for high-fidelity generation and are notoriously known for unstable training. As an alternative to the generative models discussed above, diffusion models have revolutionized the computer vision community with their impressive performance in 2D image generation[[38](https://arxiv.org/html/2311.12085v2#bib.bib38), [37](https://arxiv.org/html/2311.12085v2#bib.bib37), [36](https://arxiv.org/html/2311.12085v2#bib.bib36)]. Yet, applying diffusion models for 3D point cloud generation has not been thoroughly explored hitherto. Point-Voxel Diffusion[[51](https://arxiv.org/html/2311.12085v2#bib.bib51)] proposes to generate a raw point cloud through the diffusion process while LION[[48](https://arxiv.org/html/2311.12085v2#bib.bib48)] and DPM[[27](https://arxiv.org/html/2311.12085v2#bib.bib27)] use the latent representation of a point cloud during the denoising process. However, all these methods focus on object-level point clouds and cannot be naively extended to scene-level point clouds. Most relevant to our work is[[19](https://arxiv.org/html/2311.12085v2#bib.bib19)], where a diffusion model is trained on a scene-level point cloud dataset for the synthesis task. However, due to the capacity limitation of diffusion models, generating a scene-level point cloud with a single diffusion model leads to unsatisfying results, such as undesired wholes or the lack of fine-grained objects. In this work, we propose a pyramid discrete diffusion model that reduces the difficulty at each pyramid level, thus producing scene point clouds with more realistic and fine-grained details.
|
| 50 |
+
|
| 51 |
+
3D Large-scale Scene Generation. Generating large-scale 3D scenes is an important but highly challenging task. A generative model on 3D scenes potentially provides infinite training data for tasks such as scene segmentation, autonomous driving, etc. Existing works[[5](https://arxiv.org/html/2311.12085v2#bib.bib5), [23](https://arxiv.org/html/2311.12085v2#bib.bib23), [24](https://arxiv.org/html/2311.12085v2#bib.bib24), [46](https://arxiv.org/html/2311.12085v2#bib.bib46)] simplify this task by first generating 2D scenes and then “lifting” them to 3D. Though such design is efficient for city scenes populated with regular geometries (e.g., buildings), it does not generalize easily to scenes with more fine-grained objects (e.g., pedestrians, cars, trees, etc.) In this paper, we directly generate 3D outdoor scenes using diffusion models, which include abundant small objects with semantics.
|
| 52 |
+
|
| 53 |
+
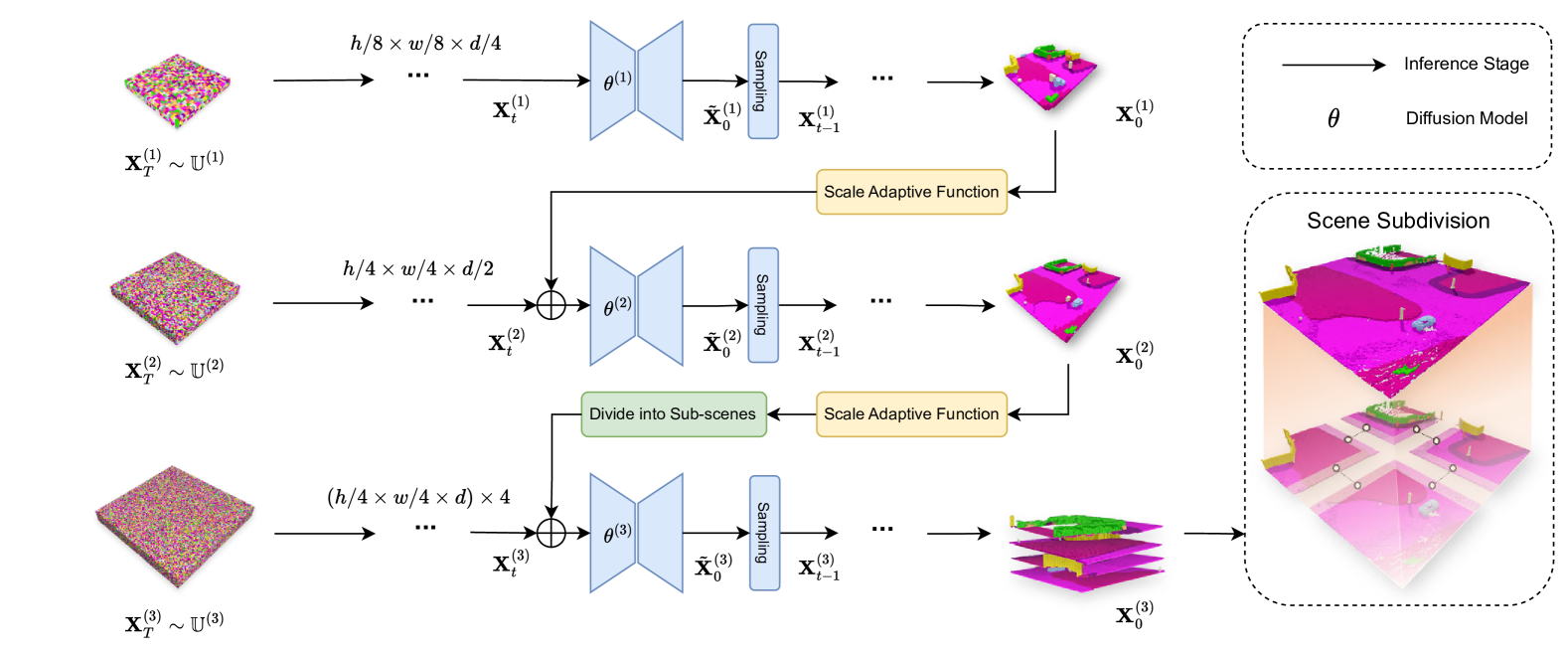
|
| 54 |
+
|
| 55 |
+
Figure 2: Framework of the proposed Pyramid Discrete Diffusion model. In our structure, there are three different scales. Scenes generated by a previous scale can serve as a condition for the current scale after processing through our scale adaptive function. Furthermore, for the final scale processing, the scene from the previous scale is subdivided into four sub-scenes. The final scene is reconstructed into a large scene using our Scene Subdivision module.
|
| 56 |
+
|
| 57 |
+
3 Approach
|
| 58 |
+
----------
|
| 59 |
+
|
| 60 |
+
The proposed Pyramid Discrete Diffusion (PDD) model comprises multi-scale models capable of step-by-step generation of high-quality 3D scenes from smaller scales. The PDD first extends the standard discrete diffusion for 3D data (Section[3.2](https://arxiv.org/html/2311.12085v2#S3.SS2 "3.2 Pyramid Discrete Diffusion ‣ 3 Approach ‣ Pyramid Diffusion for Fine 3D Large Scene Generation")) and then proposes a scene subdivision method to further reduce memory requirements (Section[3.3](https://arxiv.org/html/2311.12085v2#S3.SS3 "3.3 Scene Subdivision ‣ 3 Approach ‣ Pyramid Diffusion for Fine 3D Large Scene Generation")). Finally, we demonstrate two practical applications of PDD in specific scenarios (Section[3.4](https://arxiv.org/html/2311.12085v2#S3.SS4 "3.4 Applications ‣ 3 Approach ‣ Pyramid Diffusion for Fine 3D Large Scene Generation")).
|
| 61 |
+
|
| 62 |
+
### 3.1 Discrete Diffusion
|
| 63 |
+
|
| 64 |
+
We focus on learning a data distribution based on 3D semantic scenes. Specifically, the semantic scene is represented in a one-hot format, i.e.,𝐗∈{0,1}h×w×d×c 𝐗 superscript 0 1 ℎ 𝑤 𝑑 𝑐\mathbf{X}\in\{0,1\}^{h\times w\times d\times c}bold_X ∈ { 0 , 1 } start_POSTSUPERSCRIPT italic_h × italic_w × italic_d × italic_c end_POSTSUPERSCRIPT, where h ℎ h italic_h, w 𝑤 w italic_w, and d 𝑑 d italic_d indicate the dimensions of the scene, respectively, and c 𝑐 c italic_c denotes the size of the one-hot label.
|
| 65 |
+
|
| 66 |
+
Discrete diffusion [[2](https://arxiv.org/html/2311.12085v2#bib.bib2)] has been proposed to generate discrete data including semantic scenes. It involves applying the Markov transition matrix on discrete states for noise diffusion. In the forward process, an original scene 𝐗 0 subscript 𝐗 0\mathbf{X}_{0}bold_X start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT is gradually corrupted into a t 𝑡 t italic_t-step noised map 𝐗 t subscript 𝐗 𝑡\mathbf{X}_{t}bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT with t=1,⋯,T 𝑡 1⋯𝑇 t=1,\cdots,T italic_t = 1 , ⋯ , italic_T. Each forward step can be defined by a Markov uniform transition matrix 𝐐 t subscript 𝐐 𝑡\mathbf{Q}_{t}bold_Q start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT as 𝐗 t=𝐗 t−1𝐐 t subscript 𝐗 𝑡 subscript 𝐗 𝑡 1 subscript 𝐐 𝑡\mathbf{X}_{t}=\mathbf{X}_{t-1}\mathbf{Q}_{t}bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT = bold_X start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT bold_Q start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. Based on the Markov property, we can derive the t 𝑡 t italic_t-step scene 𝐗 t subscript 𝐗 𝑡\mathbf{X}_{t}bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT straight from 𝐗 0 subscript 𝐗 0\mathbf{X}_{0}bold_X start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT with a cumulative transition matrix 𝐐¯t=𝐐 1𝐐 2⋯𝐐 t subscript¯𝐐 𝑡 subscript 𝐐 1 subscript 𝐐 2⋯subscript 𝐐 𝑡\bar{\mathbf{Q}}_{t}=\mathbf{Q}_{1}\mathbf{Q}_{2}\cdots\mathbf{Q}_{t}over¯ start_ARG bold_Q end_ARG start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT = bold_Q start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT bold_Q start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ⋯ bold_Q start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT :
|
| 67 |
+
|
| 68 |
+
q(𝐗 t∣𝐗 0)=Cat(𝐗 t;𝐏=𝐗 0𝐐¯t),𝑞 conditional subscript 𝐗 𝑡 subscript 𝐗 0 Cat subscript 𝐗 𝑡 𝐏 subscript 𝐗 0 subscript¯𝐐 𝑡 q\left(\mathbf{X}_{t}\mid\mathbf{X}_{0}\right)=\operatorname{Cat}\left(\mathbf% {X}_{t};\mathbf{P}=\mathbf{X}_{0}\bar{\mathbf{Q}}_{t}\right),italic_q ( bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ∣ bold_X start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ) = roman_Cat ( bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ; bold_P = bold_X start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT over¯ start_ARG bold_Q end_ARG start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) ,(1)
|
| 69 |
+
|
| 70 |
+
where Cat(𝐗;𝐏)Cat 𝐗 𝐏\operatorname{Cat}(\mathbf{X};\mathbf{P})roman_Cat ( bold_X ; bold_P ) is a multivariate categorical distribution over the one-hot semantic labels 𝐗 𝐗\mathbf{X}bold_X with probabilities given by 𝐏 𝐏\mathbf{P}bold_P. Finally, the semantic scene 𝐗 T subscript 𝐗 𝑇\mathbf{X}_{T}bold_X start_POSTSUBSCRIPT italic_T end_POSTSUBSCRIPT at the last step T 𝑇 T italic_T is supposed to be in the form of a uniform discrete noise. In the reverse process, a learnable model parametrized by θ 𝜃\theta italic_θ is used to predict denoised semantic labels by p~θ(𝐗~0∣𝐗 t)subscript~𝑝 𝜃 conditional subscript~𝐗 0 subscript 𝐗 𝑡\tilde{p}_{\theta}\left(\tilde{\mathbf{X}}_{0}\mid\mathbf{X}_{t}\right)over~ start_ARG italic_p end_ARG start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( over~ start_ARG bold_X end_ARG start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ∣ bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ). The reparametrization trick is applied subsequently to get the reverse process p θ(𝐗 t−1∣𝐗 t)subscript 𝑝 𝜃 conditional subscript 𝐗 𝑡 1 subscript 𝐗 𝑡 p_{\theta}\left(\mathbf{X}_{t-1}\mid\mathbf{X}_{t}\right)italic_p start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( bold_X start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT ∣ bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) :
|
| 71 |
+
|
| 72 |
+
p θ(𝐗 t−1∣𝐗 t)=𝔼 p~θ(𝐗~0∣𝐗 t)q(𝐗 t−1∣𝐗 t,𝐗~0).subscript 𝑝 𝜃 conditional subscript 𝐗 𝑡 1 subscript 𝐗 𝑡 subscript 𝔼 subscript~𝑝 𝜃 conditional subscript~𝐗 0 subscript 𝐗 𝑡 𝑞 conditional subscript 𝐗 𝑡 1 subscript 𝐗 𝑡 subscript~𝐗 0 p_{\theta}\left(\mathbf{X}_{t-1}\mid\mathbf{X}_{t}\right)=\mathbb{E}_{\tilde{p% }_{\theta}\left(\tilde{\mathbf{X}}_{0}\mid\mathbf{X}_{t}\right)}q\left(\mathbf% {X}_{t-1}\mid\mathbf{X}_{t},\tilde{\mathbf{X}}_{0}\right).italic_p start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( bold_X start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT ∣ bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) = blackboard_E start_POSTSUBSCRIPT over~ start_ARG italic_p end_ARG start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( over~ start_ARG bold_X end_ARG start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ∣ bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) end_POSTSUBSCRIPT italic_q ( bold_X start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT ∣ bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , over~ start_ARG bold_X end_ARG start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ) .(2)
|
| 73 |
+
|
| 74 |
+
A loss consisting of the two KL divergences is proposed to learn better reconstruction ability for the model, given by
|
| 75 |
+
|
| 76 |
+
ℒ θ subscript ℒ 𝜃\displaystyle\mathcal{L_{\theta}}caligraphic_L start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT=d KL(q(𝐗 t−1∣𝐗 t,𝐗 0)∥p θ(𝐗 t−1∣𝐗 t))\displaystyle=d_{\text{KL}}\left(q\left(\mathbf{X}_{t-1}\mid\mathbf{X}_{t},% \mathbf{X}_{0}\right)\|p_{\theta}\left(\mathbf{X}_{t-1}\mid\mathbf{X}_{t}% \right)\right)= italic_d start_POSTSUBSCRIPT KL end_POSTSUBSCRIPT ( italic_q ( bold_X start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT ∣ bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , bold_X start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ) ∥ italic_p start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( bold_X start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT ∣ bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) )(3)
|
| 77 |
+
+λ d KL(q(𝐗 0)∥p~θ(𝐗~0∣𝐗 t)),\displaystyle+\lambda d_{\text{KL}}\left(q\left(\mathbf{X}_{0}\right)\|\tilde{% p}_{\theta}\left(\tilde{\mathbf{X}}_{0}\mid\mathbf{X}_{t}\right)\right),+ italic_λ italic_d start_POSTSUBSCRIPT KL end_POSTSUBSCRIPT ( italic_q ( bold_X start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ) ∥ over~ start_ARG italic_p end_ARG start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( over~ start_ARG bold_X end_ARG start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ∣ bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) ) ,
|
| 78 |
+
|
| 79 |
+
where λ 𝜆\lambda italic_λ is an auxiliary loss weight and d KL subscript 𝑑 KL d_{\text{KL}}italic_d start_POSTSUBSCRIPT KL end_POSTSUBSCRIPT stands for KL divergence. In the following, we focus on extending the discrete diffusion into the proposed PDD.
|
| 80 |
+
|
| 81 |
+
### 3.2 Pyramid Discrete Diffusion
|
| 82 |
+
|
| 83 |
+
We propose PDD that operates various diffusion processes across multiple scales (or resolutions), as depicted in Figure [2](https://arxiv.org/html/2311.12085v2#S2.F2 "Figure 2 ‣ 2 Related Work ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"). Given a 3D scene data 𝐙∈{0,1}h×w×d×c 𝐙 superscript 0 1 ℎ 𝑤 𝑑 𝑐\mathbf{Z}\in\{0,1\}^{h\times w\times d\times c}bold_Z ∈ { 0 , 1 } start_POSTSUPERSCRIPT italic_h × italic_w × italic_d × italic_c end_POSTSUPERSCRIPT, we define a 3D pyramid including different scales of 𝐙 𝐙\mathbf{Z}bold_Z, i.e.,{𝐙(1),⋯,𝐙(l),⋯,𝐙(L)}superscript 𝐙 1⋯superscript 𝐙 𝑙⋯superscript 𝐙 𝐿\{\mathbf{Z}^{(1)},\cdots,\mathbf{Z}^{(l)},\cdots,\mathbf{Z}^{(L)}\}{ bold_Z start_POSTSUPERSCRIPT ( 1 ) end_POSTSUPERSCRIPT , ⋯ , bold_Z start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT , ⋯ , bold_Z start_POSTSUPERSCRIPT ( italic_L ) end_POSTSUPERSCRIPT }, where a larger l 𝑙 l italic_l indicates a larger scene scale. Formally, let h l×w l×d l×c subscript ℎ 𝑙 subscript 𝑤 𝑙 subscript 𝑑 𝑙 𝑐 h_{l}\times w_{l}\times d_{l}\times c italic_h start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT × italic_w start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT × italic_d start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT × italic_c denote the dimension of 𝐙(l)superscript 𝐙 𝑙\mathbf{Z}^{(l)}bold_Z start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT, h l+1≥h l subscript ℎ 𝑙 1 subscript ℎ 𝑙 h_{l+1}\geq h_{l}italic_h start_POSTSUBSCRIPT italic_l + 1 end_POSTSUBSCRIPT ≥ italic_h start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT, w l+1≥w l subscript 𝑤 𝑙 1 subscript 𝑤 𝑙 w_{l+1}\geq w_{l}italic_w start_POSTSUBSCRIPT italic_l + 1 end_POSTSUBSCRIPT ≥ italic_w start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT and d l+1≥d l subscript 𝑑 𝑙 1 subscript 𝑑 𝑙 d_{l+1}\geq d_{l}italic_d start_POSTSUBSCRIPT italic_l + 1 end_POSTSUBSCRIPT ≥ italic_d start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT are kept for l=1,⋯,L−1 𝑙 1⋯𝐿 1 l=1,\cdots,L-1 italic_l = 1 , ⋯ , italic_L - 1. We note that such a pyramid can be obtained by applying different down-sample operators, such as pooling functions, on 𝐙 𝐙\mathbf{Z}bold_Z. For each scale in the pyramid, we construct a conditional discrete diffusion model parameterized by θ l subscript 𝜃 𝑙\theta_{l}italic_θ start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT. The l 𝑙 l italic_l-th model for l≠1 𝑙 1 l\neq 1 italic_l ≠ 1 is given by:
|
| 84 |
+
|
| 85 |
+
p~θ l(𝐗~0(l)∣𝐗 t(l),𝐙(l−1))=p~θ l(𝐗~0(l)∣Concat(𝐗 t(l),ϕ(l)(𝐙(l−1)))),subscript~𝑝 subscript 𝜃 𝑙 conditional superscript subscript~𝐗 0 𝑙 superscript subscript 𝐗 𝑡 𝑙 superscript 𝐙 𝑙 1 subscript~𝑝 subscript 𝜃 𝑙 conditional superscript subscript~𝐗 0 𝑙 Concat superscript subscript 𝐗 𝑡 𝑙 superscript italic-ϕ 𝑙 superscript 𝐙 𝑙 1\tilde{p}_{\theta_{l}}\left(\tilde{\mathbf{X}}_{0}^{(l)}\mid\mathbf{X}_{t}^{(l% )},\mathbf{Z}^{(l-1)}\right)=\tilde{p}_{\theta_{l}}\left(\tilde{\mathbf{X}}_{0% }^{(l)}\mid\text{Concat}\left(\mathbf{X}_{t}^{(l)},\phi^{(l)}(\mathbf{Z}^{(l-1% )})\right)\right),over~ start_ARG italic_p end_ARG start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT end_POSTSUBSCRIPT ( over~ start_ARG bold_X end_ARG start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT ∣ bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT , bold_Z start_POSTSUPERSCRIPT ( italic_l - 1 ) end_POSTSUPERSCRIPT ) = over~ start_ARG italic_p end_ARG start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT end_POSTSUBSCRIPT ( over~ start_ARG bold_X end_ARG start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT ∣ Concat ( bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT , italic_ϕ start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT ( bold_Z start_POSTSUPERSCRIPT ( italic_l - 1 ) end_POSTSUPERSCRIPT ) ) ) ,(4)
|
| 86 |
+
|
| 87 |
+
where 𝐗 t(l)superscript subscript 𝐗 𝑡 𝑙\mathbf{X}_{t}^{(l)}bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT and 𝐗 0(l)superscript subscript 𝐗 0 𝑙\mathbf{X}_{0}^{(l)}bold_X start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT are with the same size of 𝐙(l)superscript 𝐙 𝑙\mathbf{Z}^{(l)}bold_Z start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT , and ϕ(l)superscript italic-ϕ 𝑙\phi^{(l)}italic_ϕ start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT is a Scale Adaptive Function (SAF) for upsamling 𝐙(l−1)superscript 𝐙 𝑙 1\mathbf{Z}^{(l-1)}bold_Z start_POSTSUPERSCRIPT ( italic_l - 1 ) end_POSTSUPERSCRIPT into the size of 𝐙(l)superscript 𝐙 𝑙\mathbf{Z}^{(l)}bold_Z start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT. As a case in point, SAF can be a tri-linear interpolation function depending on the data. Additionally, we maintain the first model p~θ 1 subscript~𝑝 subscript 𝜃 1\tilde{p}_{\theta_{1}}over~ start_ARG italic_p end_ARG start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT end_POSTSUBSCRIPT as the original non-conditional model.
|
| 88 |
+
|
| 89 |
+
During the training process, PDD learns L 𝐿 L italic_L denoising models separately at varied scales of scene pyramids in the given dataset. Given that 𝐙(l−1)superscript 𝐙 𝑙 1\mathbf{Z}^{(l-1)}bold_Z start_POSTSUPERSCRIPT ( italic_l - 1 ) end_POSTSUPERSCRIPT is essentially a lossy-compressed version of 𝐙(l)superscript 𝐙 𝑙\mathbf{Z}^{(l)}bold_Z start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT , the model training can be viewed as learning to restore the details of a coarse scene. In the inference process, denoising model p θ 1 subscript 𝑝 subscript 𝜃 1 p_{\theta_{1}}italic_p start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT end_POSTSUBSCRIPT is performed initially according to Equation (2) and the rest of PDD models are executed in sequence from l=2 𝑙 2 l=2 italic_l = 2 to L 𝐿 L italic_L via the sampling,
|
| 90 |
+
|
| 91 |
+
𝐗 t−1(l)∼p θ l(𝐗 t−1(l)∣𝐗 t(l),𝐗 0(l−1)),similar-to superscript subscript 𝐗 𝑡 1 𝑙 subscript 𝑝 subscript 𝜃 𝑙 conditional superscript subscript 𝐗 𝑡 1 𝑙 superscript subscript 𝐗 𝑡 𝑙 superscript subscript 𝐗 0 𝑙 1\displaystyle\mathbf{X}_{t-1}^{(l)}\sim p_{\theta_{l}}(\mathbf{X}_{t-1}^{(l)}% \mid\mathbf{X}_{t}^{(l)},\mathbf{X}_{0}^{(l-1)}),bold_X start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT ∼ italic_p start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT end_POSTSUBSCRIPT ( bold_X start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT ∣ bold_X start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT , bold_X start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l - 1 ) end_POSTSUPERSCRIPT ) ,(5)
|
| 92 |
+
|
| 93 |
+
where 𝐗 0(l−1)superscript subscript 𝐗 0 𝑙 1\mathbf{X}_{0}^{(l-1)}bold_X start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l - 1 ) end_POSTSUPERSCRIPT is the denoised result of p~θ l−1 subscript~𝑝 subscript 𝜃 𝑙 1\tilde{p}_{\theta_{l-1}}over~ start_ARG italic_p end_ARG start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT italic_l - 1 end_POSTSUBSCRIPT end_POSTSUBSCRIPT.
|
| 94 |
+
|
| 95 |
+
Except for the high-quality generation, the proposed PDD bears two merits: 1) Diffusion models in PDD can be trained in parallel due to their independence, which allows for a flexible computation reallocation during training. 2) Due to its multi-stage generation process, PDD is fitting for restoring scenes of arbitrary coarse-grained scale by starting from the intermediate processes, thereby extending the method’s versatility.
|
| 96 |
+
|
| 97 |
+
### 3.3 Scene Subdivision
|
| 98 |
+
|
| 99 |
+
To overcome the memory constraint for generating large 3D scenes, we propose the scene subdivision method. We divide a 3D scene 𝐙(l)superscript 𝐙 𝑙\mathbf{Z}^{(l)}bold_Z start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT along z 𝑧 z italic_z-axis into I 𝐼 I italic_I overlapped sub-components as {𝐙 i(l)}i=1 I superscript subscript superscript subscript 𝐙 𝑖 𝑙 𝑖 1 𝐼\{\mathbf{Z}_{i}^{(l)}\}_{i=1}^{I}{ bold_Z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT } start_POSTSUBSCRIPT italic_i = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_I end_POSTSUPERSCRIPT. For the instance of four subscenes case, let 𝐙 i(l)∈{0,1}(1+δ l)h l\2×(1+δ l)w l\2×d l×c superscript subscript 𝐙 𝑖 𝑙 superscript 0 1\\1 subscript 𝛿 𝑙 subscript ℎ 𝑙 2 1 subscript 𝛿 𝑙 subscript 𝑤 𝑙 2 subscript 𝑑 𝑙 𝑐\mathbf{Z}_{i}^{(l)}\in\{0,1\}^{(1+\delta_{l})h_{l}\backslash 2\times(1+\delta% _{l})w_{l}\backslash 2\times d_{l}\times c}bold_Z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT ∈ { 0 , 1 } start_POSTSUPERSCRIPT ( 1 + italic_δ start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) italic_h start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT \ 2 × ( 1 + italic_δ start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) italic_w start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT \ 2 × italic_d start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT × italic_c end_POSTSUPERSCRIPT denote one subscene and δ l subscript 𝛿 𝑙\delta_{l}italic_δ start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT denote the overlap ratio, the shared l 𝑙 l italic_l-th diffusion model in PDD is trained to reconstruct 𝐙 i(l)superscript subscript 𝐙 𝑖 𝑙\mathbf{Z}_{i}^{(l)}bold_Z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT for i=1,⋯,4 𝑖 1⋯4 i=1,\cdots,4 italic_i = 1 , ⋯ , 4. Subsequently, sub-scenes are merged into a holistic one by a fusion algorithm, i.e., voting on the overlapped parts to ensure the continuity of the 3D scene.
|
| 100 |
+
|
| 101 |
+
In the training process, to ensure context-awareness of the entire scene during the generation of a sub-scene, we train the model by adding the overlapped regions with other sub-scenes as the condition. In the inference process, the entire scene is generated in an autoregressive manner. Apart from the first sub-scene generated without context, all other sub-scenes utilize the already generated overlapped region as a condition, i.e.,
|
| 102 |
+
|
| 103 |
+
𝐗 t−1,i(l)∼p θ(𝐗 t−1,i(l)∣𝐗 t,i(l),𝐗 0,i(l+1),∑j≠i Δ ij⊙𝐗 0,j(l+1)),similar-to superscript subscript 𝐗 𝑡 1 𝑖 𝑙 subscript 𝑝 𝜃 conditional superscript subscript 𝐗 𝑡 1 𝑖 𝑙 superscript subscript 𝐗 𝑡 𝑖 𝑙 superscript subscript 𝐗 0 𝑖 𝑙 1 subscript 𝑗 𝑖 direct-product subscript Δ 𝑖 𝑗 superscript subscript 𝐗 0 𝑗 𝑙 1\mathbf{X}_{t-1,i}^{(l)}\sim p_{\theta}\left(\mathbf{X}_{t-1,i}^{(l)}\mid% \mathbf{X}_{t,i}^{(l)},\mathbf{X}_{0,i}^{(l+1)},\sum_{j\neq i}\Delta_{ij}\odot% \mathbf{X}_{0,j}^{(l+1)}\right),bold_X start_POSTSUBSCRIPT italic_t - 1 , italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT ∼ italic_p start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( bold_X start_POSTSUBSCRIPT italic_t - 1 , italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT ∣ bold_X start_POSTSUBSCRIPT italic_t , italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l ) end_POSTSUPERSCRIPT , bold_X start_POSTSUBSCRIPT 0 , italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l + 1 ) end_POSTSUPERSCRIPT , ∑ start_POSTSUBSCRIPT italic_j ≠ italic_i end_POSTSUBSCRIPT roman_Δ start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT ⊙ bold_X start_POSTSUBSCRIPT 0 , italic_j end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l + 1 ) end_POSTSUPERSCRIPT ) ,(6)
|
| 104 |
+
|
| 105 |
+
where j 𝑗 j italic_j is the index of generated sub-scenes before i 𝑖 i italic_i-th scene, and Δ ij subscript Δ 𝑖 𝑗\Delta_{ij}roman_Δ start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT is a binary mask between 𝐗 0,i(l+1)superscript subscript 𝐗 0 𝑖 𝑙 1\mathbf{X}_{0,i}^{(l+1)}bold_X start_POSTSUBSCRIPT 0 , italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l + 1 ) end_POSTSUPERSCRIPT and 𝐗 0,j(l+1)superscript subscript 𝐗 0 𝑗 𝑙 1\mathbf{X}_{0,j}^{(l+1)}bold_X start_POSTSUBSCRIPT 0 , italic_j end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l + 1 ) end_POSTSUPERSCRIPT representing the overlapped region on 𝐗 0,j(l+1)superscript subscript 𝐗 0 𝑗 𝑙 1\mathbf{X}_{0,j}^{(l+1)}bold_X start_POSTSUBSCRIPT 0 , italic_j end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_l + 1 ) end_POSTSUPERSCRIPT with 1 and the separate region with 0. Scene Subdivision module can reduce the model parameters, as diffusion model could be shared by four sub-scenes. In practice, we only implement the scene subdivision method on the largest scale which demands the largest memory.
|
| 106 |
+
|
| 107 |
+
### 3.4 Applications
|
| 108 |
+
|
| 109 |
+
Beyond its primary function as a generative model, we introduce two novel applications for PDD. First, cross-dataset transfer aims at adapting a model trained on a source dataset to a target dataset[[52](https://arxiv.org/html/2311.12085v2#bib.bib52)]. Due to the flexibility of input scale, PDD can achieve this by retraining or fine-tuning the smaller-scale models in the new dataset while keeping the larger-scale models. The strategy leveraging PDD improves the efficiency of transferring 3D scene generation models between distinct datasets. Second, infinite scene generation is of great interest in fields such as autonomous driving[[11](https://arxiv.org/html/2311.12085v2#bib.bib11)] and urban modeling[[20](https://arxiv.org/html/2311.12085v2#bib.bib20)] which require a huge scale of 3D scenes. PDD can extend its scene subdivision technique. By using the edge of a previously generated scene as a condition as in Equation (6), it can iteratively create larger scenes, potentially without size limitations.
|
| 110 |
+
|
| 111 |
+
4 Experimental Results
|
| 112 |
+
----------------------
|
| 113 |
+
|
| 114 |
+
### 4.1 Evaluation Protocols
|
| 115 |
+
|
| 116 |
+
Since the metrics used in 2D generation such as FID[[13](https://arxiv.org/html/2311.12085v2#bib.bib13)] are not directly applicable in the 3D, we introduce and implement three metrics to assess the quality of the generated 3D scenes. We note that more implementation details can be found in the supplementary material.
|
| 117 |
+
|
| 118 |
+
Table 1: Comparison of various diffusion models on 3D semantic scene generation of CarlaSC. DiscreteDiff [[2](https://arxiv.org/html/2311.12085v2#bib.bib2)], LatentDiff [[19](https://arxiv.org/html/2311.12085v2#bib.bib19)], and P-DiscreteDiff refer to the original discrete diffusion, latent discrete diffusion, and our approach, respectively. Conditioned models work based on the context of unlabeled point clouds or the coarse version of the ground truth scene. A higher Segmentation Metric value is better, indicating semantic consistency. A lower Feature-based Metric value is preferable, representing closer proximity to the original dataset. The brackets with V represent voxel-based network and P represent point-based network.
|
| 119 |
+
|
| 120 |
+
Semantic Segmentation results on the generated scenes are used to evaluate the effectiveness of models in creating semantically coherent scenes. Specifically, two architectures, the voxel-based SparseUNet[[12](https://arxiv.org/html/2311.12085v2#bib.bib12)] and point-based PointNet++[[35](https://arxiv.org/html/2311.12085v2#bib.bib35)], are implemented to perform the segmentation tasks. We report the mean Intersection over Union (mIoU) and Mean Accuracy (MAs) for evaluation.
|
| 121 |
+
|
| 122 |
+
F3D is a 3D adaption of the 2D Fréchet Inception Distance (FID)[[13](https://arxiv.org/html/2311.12085v2#bib.bib13)], which is based on a pre-trained autoencoder with an 3D CNN architecture. We calculate and report the Fréchet distance (by 10−3 superscript 10 3 10^{-3}10 start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT ratio) between the generated scenes and real scenes in the feature domain.
|
| 123 |
+
|
| 124 |
+
Maximum Mean Discrepancy (MMD) is a statistical measure to quantify the disparity between the distributions of generated and real scenes. Similar to our F3D approach, we extract features via the same pre-trained autoencoder and present the MMD between 3D scenes.
|
| 125 |
+
|
| 126 |
+
### 4.2 Experiment Settings
|
| 127 |
+
|
| 128 |
+
Datasets. We use CarlaSC[[44](https://arxiv.org/html/2311.12085v2#bib.bib44)] and SemanticKITTI[[3](https://arxiv.org/html/2311.12085v2#bib.bib3)] for experiments. Specifically, we conduct our main experiments as well as ablation studies on the synthesis dataset CarlaSC due to its large data volume and diverse semantic objects. Our primary model is trained on the training set of CarlaSC with 10 categories and 32,400 scans. SemanticKITTI, which is a real-world collected dataset, is used for our cross-dataset transfer experiment. Both datasets are adjusted to ensure consistency in semantic categories, with further details in the supplementary material.
|
| 129 |
+
|
| 130 |
+
Model Architecture. The primary proposed PDD is performed on three scales of a 3D scene pyramid, _i.e_., s 1 subscript 𝑠 1 s_{1}italic_s start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT, s 2 subscript 𝑠 2 s_{2}italic_s start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT and s 4 subscript 𝑠 4 s_{4}italic_s start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT in Table[2](https://arxiv.org/html/2311.12085v2#S4.T2 "Table 2 ‣ 4.2 Experiment Settings ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"). We implement 3D-UNets[[8](https://arxiv.org/html/2311.12085v2#bib.bib8)] for three diffusion models in PDD based on the scales. Notably, the model applied on s 4 subscript 𝑠 4 s_{4}italic_s start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT scale is with the input/output size of s 3′subscript superscript 𝑠′3 s^{\prime}_{3}italic_s start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT due to the use of scene subdivision, while such a size of other models follows the working scale size. In the ablation study, we also introduce the scale s 3 subscript 𝑠 3 s_{3}italic_s start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT in the experiment. Additionally, we implement two baseline methods merely on scale s 4 subscript 𝑠 4 s_{4}italic_s start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT which are the original discrete diffusion[[2](https://arxiv.org/html/2311.12085v2#bib.bib2)] and the latent diffusion model with VQ-VAE decoder[[19](https://arxiv.org/html/2311.12085v2#bib.bib19)].
|
| 131 |
+
|
| 132 |
+
Training Setting. We train each PDD model using the same training setting except for the batch size. Specifically, we set the learning rate of 10−3 superscript 10 3 10^{-3}10 start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT for the AdamW optimizer[[26](https://arxiv.org/html/2311.12085v2#bib.bib26)], and the time step T=100 𝑇 100 T=100 italic_T = 100 for the diffusion process, and 800 for the max epoch. The batch sizes are set to 128, 32, and 16 for the models working on s 1 subscript 𝑠 1 s_{1}italic_s start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT, s 2 subscript 𝑠 2 s_{2}italic_s start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT and s 4 subscript 𝑠 4 s_{4}italic_s start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT scales. However, for the baseline method based on the s 4 subscript 𝑠 4 s_{4}italic_s start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT scale, we use the batch size of 8 due to memory constraints. We note that all diffusion models are trained on four NVIDIA A100 GPUs. In addition, we apply the trilinear interpolation for the scene fusion algorithm and set the overlap ratio in scene subdivision, δ l subscript 𝛿 𝑙\delta_{l}italic_δ start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT to 0.0625.
|
| 133 |
+
|
| 134 |
+
Table 2: Different scales in the 3D scene pyramid.
|
| 135 |
+
|
| 136 |
+
Table 3: Average SSIM between each generated scene and the closest scene in the training set. We generate 1 k 𝑘 k italic_k scenes and calculat the average.
|
| 137 |
+
|
| 138 |
+
Table 4: Comparison of different diffusion pyramids on 3D semantic scene generation.
|
| 139 |
+
|
| 140 |
+
### 4.3 Main Results
|
| 141 |
+
|
| 142 |
+
Generation Quality. We compare our approach with two baselines, the original Discrete Diffusion [[2](https://arxiv.org/html/2311.12085v2#bib.bib2)] and the Latent Diffusion [[19](https://arxiv.org/html/2311.12085v2#bib.bib19)]. The result reported in Table[1](https://arxiv.org/html/2311.12085v2#S4.T1 "Table 1 ‣ 4.1 Evaluation Protocols ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") demonstrates the notable performance of our method across all metrics in both unconditional and conditional settings in comparable computational resources with existing method. Our proposed method demonstrates a notable advantage in segmentation tasks, especially when it reaches around 70% mIoU for SparseUNet, which reflects its ability to generate scenes with accurate semantic coherence. We also provide visualizations of different model results in Figure [3](https://arxiv.org/html/2311.12085v2#S4.F3 "Figure 3 ‣ 4.3 Main Results ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"), where the proposed method demonstrates better performance in detail generation and scene diversity for random 3D scene generations.
|
| 143 |
+
|
| 144 |
+

|
| 145 |
+
|
| 146 |
+
Figure 3: Visualization of unconditional generation results on CarlaSC. We compare with two baseline models – DiscreteDiff [[2](https://arxiv.org/html/2311.12085v2#bib.bib2)] and LatentDiff [[19](https://arxiv.org/html/2311.12085v2#bib.bib19)] and show synthesis from our models with different scales. Our method produces more diverse scenes compared to the baseline models. Furthermore, with more levels, our model can synthesize scenes with more intricate details.
|
| 147 |
+
|
| 148 |
+
Additionally, we conduct the comparison on conditioned 3D scene generation. We leverage the flexibility of input scale for our method and perform the generation by models in s 2 subscript 𝑠 2 s_{2}italic_s start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT and s 4 subscript 𝑠 4 s_{4}italic_s start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT scales conditioned on a coarse ground truth scene in s 1 subscript 𝑠 1 s_{1}italic_s start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT scale. We benchmark our method against the discrete diffusion conditioned on unlabeled point clouds and the same coarse scenes. Results in Table[1](https://arxiv.org/html/2311.12085v2#S4.T1 "Table 1 ‣ 4.1 Evaluation Protocols ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") and Figure [5](https://arxiv.org/html/2311.12085v2#S4.F5 "Figure 5 ‣ 4.3 Main Results ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") present the impressive results of our conditional generation comparison. It is also observed that the point cloud-based model can achieve decent performance on F3D and MMD, which could be caused by 3D point conditions providing more structural information about the scene than the coarse scene. Despite the informative condition of the point cloud, our method can still outperform it across most metrics.
|
| 149 |
+
|
| 150 |
+

|
| 151 |
+
|
| 152 |
+
Figure 4: Data retrieval visualization. We generate 1 k 𝑘 k italic_k scenes using PDD on CarlaSC dataset, and retrieve the most similar scene in training set for each scene using SSIM (SSIM=1 means identical), and plot SSIM distribution. Scenes at various percentiles are displayed (red box: generated scenes; grey box: scenes in training set), those with the highest 10% similarity (i.e., 10 th percentile of SSIM) are very similar to the training set, but still not completely identical.
|
| 153 |
+
|
| 154 |
+
None-overfitting Verification. The MMD and F3D metrics (defined in Supp A) numerically illustrate the statistical feature distance between generated scenes and the training set. Our method achieves the lowest MMD and F3D among all baseline methods as shown in Table [1](https://arxiv.org/html/2311.12085v2#S4.T1 "Table 1 ‣ 4.1 Evaluation Protocols ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"). However, we argue that this does not indicate overfitting to the dataset for the following reasons. First, our MMD and F3D are larger than those of the ground truth. Furthermore, we leverage structural similarity (SSIM) to search and show that a generated scene is different from its nearest neighbour in the dataset. Specifically, we generate 1 k 𝑘 k italic_k scenes and identify their closest matches in the training set using the SSIM metric. The average SSIM of these 1 k 𝑘 k italic_k scenes are calculated and presented in Table [3](https://arxiv.org/html/2311.12085v2#S4.T3 "Table 3 ‣ 4.2 Experiment Settings ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"). Additionally, we apply the same methodology to the Validation Set to establish an oracle baseline. Table [3](https://arxiv.org/html/2311.12085v2#S4.T3 "Table 3 ‣ 4.2 Experiment Settings ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") shows that our generated scenes are comparable to the baseline, verifying that our method does not overfit the training set. To further support this, we use distribution plots, as shown in Figure [4](https://arxiv.org/html/2311.12085v2#S4.F4 "Figure 4 ‣ 4.3 Main Results ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"), to validate the similarity between our generated scenes and the training set. We also display three pairs at different percentiles in this figure, showing that scenes with lower SSIM scores differ more from their nearest matches in the training set. This visual evidence reinforces that PDD effectively captures the distribution of the training set instead of merely memorizing it.
|
| 155 |
+
|
| 156 |
+

|
| 157 |
+
|
| 158 |
+
Figure 5: Visualization of conditional generation results on CarlaSC. PC stands for point cloud condition.
|
| 159 |
+
|
| 160 |
+
### 4.4 Ablation Studies
|
| 161 |
+
|
| 162 |
+
Pyramid Diffusion. Our experiments explore the impact of varying refinement scales on the quality of generated scenes. According to Table [4](https://arxiv.org/html/2311.12085v2#S4.T4 "Table 4 ‣ 4.2 Experiment Settings ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"), both conditional and unconditional scene generation quality show incremental improvements with additional scales. Balancing training overhead and generation quality, a three-scale model with the scale of s 4 subscript 𝑠 4 s_{4}italic_s start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT progression offers an optimal compromise between performance and computational cost. We find that as the number of scales increases, there is indeed a rise in performance, particularly notable upon the addition of the second scale. However, the progression from a three-scale pyramid to a four-scale pyramid turns out to be insignificant. Given the greater training overhead for a four-scale pyramid compared to a three-scale one, we choose the latter as our main structure.
|
| 163 |
+
|
| 164 |
+
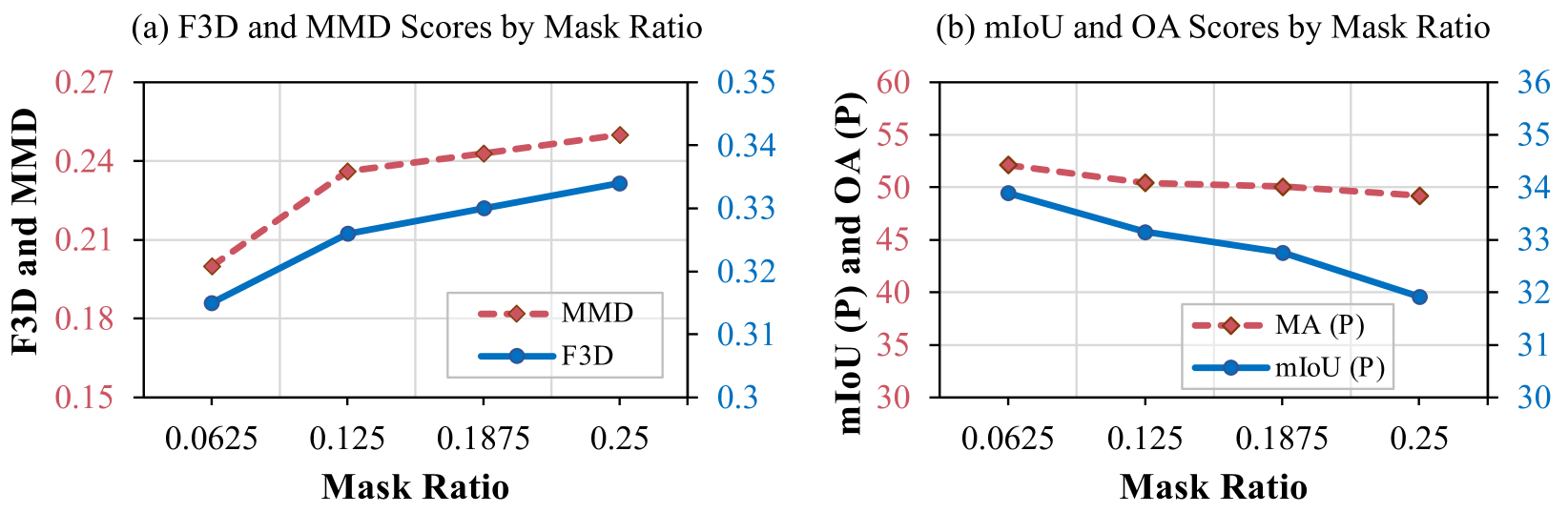
Scene Subdivision. We explore the optimal mask ratio for scene subdivision and report on Figure [6](https://arxiv.org/html/2311.12085v2#S4.F6 "Figure 6 ‣ 4.4 Ablation Studies ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"), which shows an inverse correlation between the mask ratio and the effectiveness of F3D and MMD metrics; higher mask ratios may result in diminished outcomes due to increased overfitting, leading to reduced randomness in the generated results. The lowest mask ratio test, 0.0625, achieves the best results across all metrics with detailed retention. Thus, we set a mask ratio of 0.0625 as the standard for our scene subdivision module. Further analysis shows that higher overlap ratios in scene subdivision result in quality deterioration, mainly due to increased discontinuities when merging sub-scenes using scene fusion algorithm.
|
| 165 |
+
|
| 166 |
+
Performance on Different Scales. To facilitate a comprehensive understanding of the progressive improvement achieved by our coarse-to-fine method, we evaluate the quality of scenes generated at different scales and present the findings in Table[5](https://arxiv.org/html/2311.12085v2#S4.T5 "Table 5 ‣ 4.4 Ablation Studies ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"). Even at the smaller scale s 1 subscript 𝑠 1 s_{1}italic_s start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT, we observe high F3D and MMD scores, indicating its capacity in synthesizing scenes with both reasonable and diverse layouts. As we advance to larger scales (i.e., s 2 subscript 𝑠 2 s_{2}italic_s start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT and s 3 subscript 𝑠 3 s_{3}italic_s start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT), the mIoU and MA scores consistently increase, demonstrating that our model focuses on learning intricate details in later stages. Meanwhile, F3D and MMD metrics show stability without significant decline, indicating a balanced enhancement in scene complexity and fidelity.
|
| 167 |
+
|
| 168 |
+
Table 5: Generation results on CarlaSC in different scales on the diffusion pyramid without any conditions. All output scales are lifted to s 4 subscript 𝑠 4 s_{4}italic_s start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT using the upsampling method.
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
Figure 6: Effects of mask ratio on unconditional generation results.
|
| 173 |
+
|
| 174 |
+
### 4.5 Applications
|
| 175 |
+
|
| 176 |
+
Cross-dataset. Figure [9](https://arxiv.org/html/2311.12085v2#S4.F9 "Figure 9 ‣ 4.5 Applications ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") and Figure [9](https://arxiv.org/html/2311.12085v2#S4.F9 "Figure 9 ‣ 4.5 Applications ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") showcase our model’s performance on the transferred dataset from CarlaSC to SemanticKITTI for both unconditional and conditional scene generation. The PDD shows enhanced scene quality after finetuning with SemanticKITTI data, as indicated by improved results in Table [6](https://arxiv.org/html/2311.12085v2#S4.T6 "Table 6 ‣ 4.5 Applications ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"). This fine-tuning effectively adapts the model to the dataset’s complex object distributions and scene dynamics. Notably, despite the higher training effort of the Discrete Diffusion (DD) approach, our method outperforms DD even without fine-tuning, using only coarse scenes from SemanticKITTI. This demonstrates the strong cross-data transfer capability of our approach.
|
| 177 |
+
|
| 178 |
+

|
| 179 |
+
|
| 180 |
+
Figure 7: Infinite Scene Generation. Thanks to the pyramid representation, PDD can be readily applied for unbounded scene generation. This involves the initial efficient synthesis of a large-scale coarse 3D scene, followed by subsequent refinement at higher levels.
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
Figure 8: SemanticKITTI unconditional generation. FT stands for finetuning pre-trained model from CarlaSC.
|
| 185 |
+
|
| 186 |
+

|
| 187 |
+
|
| 188 |
+
Figure 9: SemanticKITTI conditional generation. FT stands for finetuning from CarlaSC models.
|
| 189 |
+
|
| 190 |
+
Table 6: Generation results on SemanticKITTI. Finetuned Scales set to None indicates training from scratch and others stand for finetuning corresponding pre-trained CarlaSC model.
|
| 191 |
+
|
| 192 |
+
Infinite Scene Generation. Figure [7](https://arxiv.org/html/2311.12085v2#S4.F7 "Figure 7 ‣ 4.5 Applications ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") visualizes the process of generating large-scale infinite scenes using our PDD model. As discussed in Section[3.4](https://arxiv.org/html/2311.12085v2#S3.SS4 "3.4 Applications ‣ 3 Approach ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"), we first use the small-scale model to swiftly generate a coarse infinite 3D scene (bottom level in Figure [7](https://arxiv.org/html/2311.12085v2#S4.F7 "Figure 7 ‣ 4.5 Applications ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation")). We then leverage larger-scale models to progressively add intricate details (middle and top level in Figure [7](https://arxiv.org/html/2311.12085v2#S4.F7 "Figure 7 ‣ 4.5 Applications ‣ 4 Experimental Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation")), enhancing realism. This approach enables our model to produce high-quality, continuous cityscapes without additional inputs, overcoming the limitations of conventional datasets with finite scenes and supporting downstream tasks like 3D scene segmentation.
|
| 193 |
+
|
| 194 |
+
5 Conclusion
|
| 195 |
+
------------
|
| 196 |
+
|
| 197 |
+
In this work, we introduce the Pyramid Discrete Diffusion model (PDD) to address the significant challenges associated with 3D large scene generation, particularly in the context of limited scale and available datasets. The PDD demonstrates a progressive approach to generating high-quality 3D outdoor scenes, transitioning seamlessly from coarse to fine details. Compared to the other methods, the PDD can generate high-quality scenes within limited resource constraints and does not require additional data sources. Our extensive experimental results show that PDD consistently performs favourably in both unconditional and conditional generation tasks, establishing itself as a reliable and robust solution for the creation of realistic and intricate scenes. Furthermore, the proposed PDD method has great potential in efficiently adapting models trained on synthetic data to real-world datasets and suggests a promising solution to the current challenge of limited real-world data.
|
| 198 |
+
|
| 199 |
+
Acknowledgement
|
| 200 |
+
---------------
|
| 201 |
+
|
| 202 |
+
Supported by the Intelligence Advanced Research Projects Activity (IARPA) via Department of Interior/ Interior Business Center (DOI/IBC) contract number 140D0423C0074. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright annotation thereon. Disclaimer: The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of IARPA, DOI/IBC, or the U.S. Government. Y. Liu and C. Li are supported in part by the National Science Foundation of China (Grant No: 62202395).
|
| 203 |
+
|
| 204 |
+
References
|
| 205 |
+
----------
|
| 206 |
+
|
| 207 |
+
* [1] Anvekar, T., Tabib, R.A., Hegde, D., Mudengudi, U.: Vg-vae: A venatus geometry point-cloud variational auto-encoder. In: CVPR (2022)
|
| 208 |
+
* [2] Austin, J., Johnson, D.D., Ho, J., Tarlow, D., Van Den Berg, R.: Structured denoising diffusion models in discrete state-spaces. In: NeurIPS (2021)
|
| 209 |
+
* [3] Behley, J., Garbade, M., Milioto, A., Quenzel, J., Behnke, S., Stachniss, C., Gall, J.: Semantickitti: A dataset for semantic scene understanding of lidar sequences. In: ICCV (2019)
|
| 210 |
+
* [4] Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: CVPR (2020)
|
| 211 |
+
* [5] Chen, Z., Wang, G., Liu, Z.: Scenedreamer: Unbounded 3d scene generation from 2d image collections. In: arXiv preprint arXiv: 2302.01330 (2023)
|
| 212 |
+
* [6] Cheng, A.C., Li, X., Liu, S., Sun, M., Yang, M.H.: Learning 3d dense correspondence via canonical point autoencoder. In: ECCV (2022)
|
| 213 |
+
* [7] Cheng, A.C., Li, X., Sun, M., Yang, M.H., Liu, S.: Learning 3d dense correspondence via canonical point autoencoder. In: NeurIPS (2021)
|
| 214 |
+
* [8] Çiçek, Ö., Abdulkadir, A., Lienkamp, S.S., Brox, T., Ronneberger, O.: 3d u-net: learning dense volumetric segmentation from sparse annotation. In: MICCAI (2016)
|
| 215 |
+
* [9] Cong, Y., Chen, R., Ma, B., Liu, H., Hou, D., Yang, C.: A comprehensive study of 3-d vision-based robot manipulation. IEEE Transactions on Cybernetics (2021)
|
| 216 |
+
* [10] Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. In: NeurIPS (2021)
|
| 217 |
+
* [11] Geiger, A., Lenz, P., Urtasun, R.: Are we ready for autonomous driving? the kitti vision benchmark suite. In: CVPR (2012)
|
| 218 |
+
* [12] Graham, B., Engelcke, M., Van Der Maaten, L.: 3d semantic segmentation with submanifold sparse convolutional networks. In: CVPR (2018)
|
| 219 |
+
* [13] Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium. In: NeurIPS (2017)
|
| 220 |
+
* [14] Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022)
|
| 221 |
+
* [15] Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS (2020)
|
| 222 |
+
* [16] Ho, J., Saharia, C., Chan, W., Fleet, D.J., Norouzi, M., Salimans, T.: Cascaded diffusion models for high fidelity image generation. The Journal of Machine Learning Research (2022)
|
| 223 |
+
* [17] Huang, W., Wang, C., Zhang, R., Li, Y., Wu, J., Fei-Fei, L.: Voxposer: Composable 3d value maps for robotic manipulation with language models. arXiv preprint arXiv:2307.05973 (2023)
|
| 224 |
+
* [18] Lan, Z., Yew, Z.J., Lee, G.H.: Robust point cloud based reconstruction of large-scale outdoor scenes. In: CVPR (2019)
|
| 225 |
+
* [19] Lee, J., Im, W., Lee, S., Yoon, S.E.: Diffusion probabilistic models for scene-scale 3d categorical data. arXiv preprint arXiv:2301.00527 (2023)
|
| 226 |
+
* [20] Li, X., Li, C., Tong, Z., Lim, A., Yuan, J., Wu, Y., Tang, J., Huang, R.: Campus3d: A photogrammetry point cloud benchmark for hierarchical understanding of outdoor scene. In: ACM MM (2020)
|
| 227 |
+
* [21] Li, Y., Ma, L., Zhong, Z., Liu, F., Chapman, M.A., Cao, D., Li, J.: Deep learning for lidar point clouds in autonomous driving: A review. NeurIPS (2020)
|
| 228 |
+
* [22] Li, Y., Yu, A.W., Meng, T., Caine, B., Ngiam, J., Peng, D., Shen, J., Lu, Y., Zhou, D., Le, Q.V., et al.: Deepfusion: Lidar-camera deep fusion for multi-modal 3d object detection. In: CVPR (2022)
|
| 229 |
+
* [23] Li, Z., Wang, Q., Snavely, N., Kanazawa, A.: Infinitenature-zero: Learning perpetual view generation of natural scenes from single images. In: ECCV (2022)
|
| 230 |
+
* [24] Lin, C.H., Lee, H.Y., Menapace, W., Chai, M., Siarohin, A., Yang, M.H., Tulyakov, S.: Infinicity: Infinite-scale city synthesis. arXiv preprint arXiv:2301.09637 (2023)
|
| 231 |
+
* [25] Liu, M., Shi, R., Chen, L., Zhang, Z., Xu, C., Wei, X., Chen, H., Zeng, C., Gu, J., Su, H.: One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d diffusion. arXiv preprint arXiv:2311.07885 (2023)
|
| 232 |
+
* [26] Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
|
| 233 |
+
* [27] Luo, S., Hu, W.: Diffusion probabilistic models for 3d point cloud generation. In: CVPR (2021)
|
| 234 |
+
* [28] Ma, Q., Yang, J., Tang, S., Black, M.J.: The power of points for modeling humans in clothing. In: ICCV (2021)
|
| 235 |
+
* [29] Mascaro, R., Teixeira, L., Chli, M.: Diffuser: Multi-view 2d-to-3d label diffusion for semantic scene segmentation. In: ICRA (2021)
|
| 236 |
+
* [30] Moon, T., Choi, M., Lee, G., Ha, J.W., Lee, J.: Fine-tuning diffusion models with limited data. In: NeurIPS 2022 Workshop on Score-Based Methods (2022)
|
| 237 |
+
* [31] Moro, S., Komuro, T.: Generation of virtual reality environment based on 3d scanned indoor physical space. In: ISVC (2021)
|
| 238 |
+
* [32] Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: ICML (2021)
|
| 239 |
+
* [33] Ögün, M.N., Kurul, R., Yaşar, M.F., Turkoglu, S.A., Avci, Ş., Yildiz, N.: Effect of leap motion-based 3d immersive virtual reality usage on upper extremity function in ischemic stroke patients. Arquivos de neuro-psiquiatria (2019)
|
| 240 |
+
* [34] Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv (2022)
|
| 241 |
+
* [35] Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In: NeurIPS (2017)
|
| 242 |
+
* [36] Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022)
|
| 243 |
+
* [37] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
|
| 244 |
+
* [38] Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text-to-image diffusion models with deep language understanding. In: NeurIPS (2022)
|
| 245 |
+
* [39] Sohl-Dickstein, J., Weiss, E.A., Maheswaranathan, N., Ganguli, S.: Deep unsupervised learning using nonequilibrium thermodynamics. arXiv preprint arXiv:1503.03585 (2015)
|
| 246 |
+
* [40] Sra, M., Garrido-Jurado, S., Schmandt, C., Maes, P.: Procedurally generated virtual reality from 3d reconstructed physical space. In: Proceedings of the 22nd ACM Conference on Virtual Reality Software and Technology (2016)
|
| 247 |
+
* [41] Su, S.Y., Bagautdinov, T., Rhodin, H.: Npc: Neural point characters from video. In: ICCV (2023)
|
| 248 |
+
* [42] Tang, J., Nie, Y., Markhasin, L., Dai, A., Thies, J., Nießner, M.: Diffuscene: Scene graph denoising diffusion probabilistic model for generative indoor scene synthesis. arXiv preprint arXiv:2303.14207 (2023)
|
| 249 |
+
* [43] Tang, Y., He, H., Wang, Y., Mao, Z., Wang, H.: Multi-modality 3d object detection in autonomous driving: A review. Neurocomputing (2023)
|
| 250 |
+
* [44] Wilson, J., Song, J., Fu, Y., Zhang, A., Capodieci, A., Jayakumar, P., Barton, K., Ghaffari, M.: Motionsc: Data set and network for real-time semantic mapping in dynamic environments. IEEE Robotics and Automation Letters 7(3) (2022)
|
| 251 |
+
* [45] Wu, P., Jia, X., Chen, L., Yan, J., Li, H., Qiao, Y.: Trajectory-guided control prediction for end-to-end autonomous driving: A simple yet strong baseline. In: NeurIPS (2022)
|
| 252 |
+
* [46] Xie, H., Chen, Z., Hong, F., Liu, Z.: Citydreamer: Compositional generative model of unbounded 3d cities. arXiv preprint arXiv:2309.00610 (2023)
|
| 253 |
+
* [47] Xu, Z., He, Z., Wu, J., Song, S.: Learning 3d dynamic scene representations for robot manipulation. arXiv preprint arXiv:2011.01968 (2020)
|
| 254 |
+
* [48] Zeng, X., Vahdat, A., Williams, F., Gojcic, Z., Litany, O., Fidler, S., Kreis, K.: Lion: Latent point diffusion models for 3d shape generation. In: NeurIPS (2022)
|
| 255 |
+
* [49] Zheng, H., Nie, W., Vahdat, A., Anandkumar, A.: Fast training of diffusion models with masked transformers. arXiv preprint arXiv:2306.09305 (2023)
|
| 256 |
+
* [50] Zheng, Y., Yifan, W., Wetzstein, G., Black, M.J., Hilliges, O.: Pointavatar: Deformable point-based head avatars from videos. In: CVPR (2023)
|
| 257 |
+
* [51] Zhou, L., Du, Y., Wu, J.: 3d shape generation and completion through point-voxel diffusion. In: ICCV (2021)
|
| 258 |
+
* [52] Zhuang, F., Qi, Z., Duan, K., Xi, D., Zhu, Y., Zhu, H., Xiong, H., He, Q.: A comprehensive survey on transfer learning. arXiv preprint arXiv:1911.02685 (2020)
|
| 259 |
+
|
| 260 |
+
Pyramid Diffusion for Fine 3D Large Scene Generation - Supplementary Material
|
| 261 |
+
|
| 262 |
+
This supplementary document details our evaluation setup, hyperparameters setting, data pre-processing, and more experimental results. The supplementary material is organized as follows:
|
| 263 |
+
|
| 264 |
+
* •Evaluation Setup in Section [F](https://arxiv.org/html/2311.12085v2#S6 "F Evaluation Setup ‣ Pyramid Diffusion for Fine 3D Large Scene Generation").
|
| 265 |
+
* •Hyperparameters Setting in Section [G](https://arxiv.org/html/2311.12085v2#S7 "G Hyperparameters Setting ‣ Pyramid Diffusion for Fine 3D Large Scene Generation").
|
| 266 |
+
* •Data Pre-processing in Section [H](https://arxiv.org/html/2311.12085v2#S8 "H Datasets Pre-processing ‣ Pyramid Diffusion for Fine 3D Large Scene Generation").
|
| 267 |
+
* •Additional Experimental Results in Section [I](https://arxiv.org/html/2311.12085v2#S9 "I Additional Experiment Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation").
|
| 268 |
+
* •Additional Discussion in Section [J](https://arxiv.org/html/2311.12085v2#S10 "J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation").
|
| 269 |
+
|
| 270 |
+
F Evaluation Setup
|
| 271 |
+
------------------
|
| 272 |
+
|
| 273 |
+
In all evaluations of our paper, we consistently randomly sample 1,000 distinct scenes to assess the generation quality. The specific methodologies for F3D (Fréchet 3D Distance) and MMD (Maximum Mean Discrepancy) are as follows.
|
| 274 |
+
|
| 275 |
+
### F.1 F3D
|
| 276 |
+
|
| 277 |
+
It is an evaluation metric adapted from the 2D Fréchet Inception Distance (FID)[[13](https://arxiv.org/html/2311.12085v2#bib.bib13)] to evaluate the quality of generated 3D scenes. Implementing F3D aims to complement semantic segmentation by capturing the richness and diversity of generated scenes, which semantic segmentation might overlook. F3D ensures that the generated scenes maintain complexity and reflect the similarity between generated 3D scenes and real-world structures.
|
| 278 |
+
|
| 279 |
+
Our F3D is calculated following the next steps. Initially, we pre-train a 3D CNN-based autoencoder, which is subsequently utilized to extract high-dimensional features from the generated 3D scenes. The F3D is then computed akin to FID, leveraging the extracted features to evaluate the discrepancies between the generated and real scenes. Mathematically, F3D is represented as:
|
| 280 |
+
|
| 281 |
+
F3D=‖𝝁 g−𝝁 r‖2+𝐓𝐫(𝚺 g+𝚺 r−2(𝚺 g𝚺 r)1/2)F3D superscript norm subscript 𝝁 𝑔 subscript 𝝁 𝑟 2 𝐓𝐫 subscript 𝚺 𝑔 subscript 𝚺 𝑟 2 superscript subscript 𝚺 𝑔 subscript 𝚺 𝑟 1 2\ \text{F3D}=\|\boldsymbol{\mu}_{g}-\boldsymbol{\mu}_{r}\|^{2}+\mathbf{Tr}% \left(\mathbf{\Sigma}_{g}+\mathbf{\Sigma}_{r}-2(\mathbf{\Sigma}_{g}\mathbf{% \Sigma}_{r})^{1/2}\right)F3D = ∥ bold_italic_μ start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT - bold_italic_μ start_POSTSUBSCRIPT italic_r end_POSTSUBSCRIPT ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT + bold_Tr ( bold_Σ start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT + bold_Σ start_POSTSUBSCRIPT italic_r end_POSTSUBSCRIPT - 2 ( bold_Σ start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT bold_Σ start_POSTSUBSCRIPT italic_r end_POSTSUBSCRIPT ) start_POSTSUPERSCRIPT 1 / 2 end_POSTSUPERSCRIPT )(7)
|
| 282 |
+
|
| 283 |
+
where 𝝁 g subscript 𝝁 𝑔\boldsymbol{\mu}_{g}bold_italic_μ start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT, 𝝁 r subscript 𝝁 𝑟\boldsymbol{\mu}_{r}bold_italic_μ start_POSTSUBSCRIPT italic_r end_POSTSUBSCRIPT are the feature means, and 𝚺 g subscript 𝚺 𝑔\mathbf{\Sigma}_{g}bold_Σ start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT, 𝚺 r subscript 𝚺 𝑟\mathbf{\Sigma}_{r}bold_Σ start_POSTSUBSCRIPT italic_r end_POSTSUBSCRIPT are the feature covariances of the generated and real scenes.
|
| 284 |
+
|
| 285 |
+
### F.2 MMD
|
| 286 |
+
|
| 287 |
+
We incorporate the Maximum Mean Discrepancy (MMD) as a key statistical measure to quantify the disparity between the distributions of generated and real-world scenes. Following a method akin to our F3D approach, we initially extract high-dimensional features from the 3D scenes using a 3D CNN architecture which is used in F3D. Subsequently, we employ a Gaussian kernel, expressed as
|
| 288 |
+
|
| 289 |
+
k(𝒇,𝒇′)=exp(−‖𝒇−𝒇′‖2 2σ 2)𝑘 𝒇 superscript 𝒇′superscript norm 𝒇 superscript 𝒇′2 2 superscript 𝜎 2 k(\boldsymbol{f},\boldsymbol{f}^{\prime})=\exp\left(-\frac{\|\boldsymbol{f}-% \boldsymbol{f}^{\prime}\|^{2}}{2\sigma^{2}}\right)italic_k ( bold_italic_f , bold_italic_f start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT ) = roman_exp ( - divide start_ARG ∥ bold_italic_f - bold_italic_f start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG start_ARG 2 italic_σ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG )(8)
|
| 290 |
+
|
| 291 |
+
where σ 𝜎\sigma italic_σ is the kernel width to map these features into a higher-dimensional space for MMD calculation. The bandwidth σ 𝜎\sigma italic_σ is determined using the median heuristic, a robust method to estimate the scale of data in the feature space. The MMD formula is given by
|
| 292 |
+
|
| 293 |
+
MMD 2=‖1 n∑i=1 n k(𝒇 i,⋅)−1 m∑j=1 m k(𝒇 j′,⋅)‖2 superscript MMD 2 superscript norm 1 𝑛 superscript subscript 𝑖 1 𝑛 𝑘 subscript 𝒇 𝑖⋅1 𝑚 superscript subscript 𝑗 1 𝑚 𝑘 subscript superscript 𝒇′𝑗⋅2\textbf{MMD}^{2}=\left\|\frac{1}{n}\sum_{i=1}^{n}k(\boldsymbol{f}_{i},\cdot)-% \frac{1}{m}\sum_{j=1}^{m}k(\boldsymbol{f}^{\prime}_{j},\cdot)\right\|^{2}MMD start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT = ∥ divide start_ARG 1 end_ARG start_ARG italic_n end_ARG ∑ start_POSTSUBSCRIPT italic_i = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT italic_k ( bold_italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , ⋅ ) - divide start_ARG 1 end_ARG start_ARG italic_m end_ARG ∑ start_POSTSUBSCRIPT italic_j = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT italic_k ( bold_italic_f start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT , ⋅ ) ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT(9)
|
| 294 |
+
|
| 295 |
+
𝒇 𝒇\boldsymbol{f}bold_italic_f and 𝒇′superscript 𝒇′\boldsymbol{f}^{\prime}bold_italic_f start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT are the extracted features from the generated and real dataset, respectively. The utilization of MMD, especially with the Gaussian kernel, not only captures the overall statistical distribution but also considers finer details in the feature space, rendering it an indispensable tool in our evaluation protocol.
|
| 296 |
+
|
| 297 |
+
G Hyperparameters Setting
|
| 298 |
+
-------------------------
|
| 299 |
+
|
| 300 |
+
### G.1 Pyramid Discrete Diffusion Models
|
| 301 |
+
|
| 302 |
+
Training Hyperparameters. In the main experiment of our Pyramid Discrete Diffusion, a total of four diffusion models, namely PDD (s 1 subscript 𝑠 1 s_{1}italic_s start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT), PDD (s 2 subscript 𝑠 2 s_{2}italic_s start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT), PDD (s 3 subscript 𝑠 3 s_{3}italic_s start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT), and PDD (s 4 subscript 𝑠 4 s_{4}italic_s start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT), are utilized. Each model is trained on four NVIDIA A100 GPUs with batch sizes set to 128, 32, 16, and 8, respectively. A unified learning rate of 10−3 superscript 10 3 10^{-3}10 start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT is applied and the AdamW optimizer is used to train each model for 800 epochs. Additionally, during training, data augmentation techniques, including flipping and rotation, are employed to enhance the robustness of the models.
|
| 303 |
+
|
| 304 |
+
Cross-dataset Hyperparameters. In our paper, we demonstrate the capability of our method for cross-dataset generation. The models labeled with FT are those where the generation model trains on the CarlaSC dataset[[44](https://arxiv.org/html/2311.12085v2#bib.bib44)] and undergoes finetuning using the SemanticKITTI dataset[[3](https://arxiv.org/html/2311.12085v2#bib.bib3)]. Specifically, we use the PDD (s 4 subscript 𝑠 4 s_{4}italic_s start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT) model for finetuning, which has already been trained for 800 epochs on CarlaSC. This model is then further trained for 200 epochs using the SemanticKITTI dataset, with all other hyperparameters remaining unchanged. Consequently, the entire model completes a total of 1,000 epochs of training.
|
| 305 |
+
|
| 306 |
+
Sampling Hyperparameters. In our paper, all the sampled scenes we demonstrate are generated using 100 diffusion steps.
|
| 307 |
+
|
| 308 |
+
### G.2 Evaluation Models
|
| 309 |
+
|
| 310 |
+
We train six different models across three distinct networks in our evaluation process. These include 3D CNNs for evaluating Fréchet 3D Distance (F3D) and Maximum Mean Discrepancy (MMD), SparseUNet[[12](https://arxiv.org/html/2311.12085v2#bib.bib12)], and PointNet+++++ +[[35](https://arxiv.org/html/2311.12085v2#bib.bib35)] for semantic segmentation evaluation.
|
| 311 |
+
|
| 312 |
+
3D CNN Hyperparameters. As mentioned in Section[F](https://arxiv.org/html/2311.12085v2#S6 "F Evaluation Setup ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") of our paper, the evaluation of F3D and MMD relies on a well-trained 3D CNN network. We train two separate 3D CNNs for the CarlaSC and SemanticKITTI datasets to perform their respective F3D and MMD evaluations but maintain identical training parameters for both networks. The 3D CNNs are trained as an autoencoder, with the primary aim of feature extraction. The loss function employed in this training is a balanced cross-entropy, a form of reconstruction loss. We set the batch size to 16 and employed SGD as the optimizer with a cosine scheduler. The networks are trained for 30 epochs at a 10−2 superscript 10 2 10^{-2}10 start_POSTSUPERSCRIPT - 2 end_POSTSUPERSCRIPT learning rate. We adhere to the original dataset splits for training, using the training sets as delineated in the original dataset distributions.
|
| 313 |
+
|
| 314 |
+
SparseUNet Hyperparameters. SparseUNet[[12](https://arxiv.org/html/2311.12085v2#bib.bib12)], designed for voxel-based semantic segmentation, is trained with two separate models for the CarlaSC and SemanticKITTI datasets. All training parameters of these SparseUNet models are consistent with those of the 3D CNNs. This includes a batch size 16, utilizing SGD as the optimizer, employing a cosine scheduler, and training for 30 epochs at a learning rate of 10−2 superscript 10 2 10^{-2}10 start_POSTSUPERSCRIPT - 2 end_POSTSUPERSCRIPT. The training adheres to the original dataset divisions for the respective training sets.
|
| 315 |
+
|
| 316 |
+
PointNet+++++ + Hyperparameters. Similarly to our previous approach, we train a separate semantic segmentation model based on PointNet+++++ + (SSG) for each dataset. Each model is trained with a batch size of 16. We randomly sample 16,384 points for each scene, and if the number of points is insufficient, we supplement them by replication. We set the optimizer to Adam and use a step scheduler with a step size 5. The models are trained for 30 epochs at a learning rate of 5×10−3 5 superscript 10 3 5\times 10^{-3}5 × 10 start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT.
|
| 317 |
+
|
| 318 |
+
### G.3 Baseline
|
| 319 |
+
|
| 320 |
+
Unconditional Generation. In our paper’s unconditional generation comparison experiments, we include two baseline models: the Discrete Diffusion model (DD)[[2](https://arxiv.org/html/2311.12085v2#bib.bib2)] and the Latent Diffusion model[[19](https://arxiv.org/html/2311.12085v2#bib.bib19)]. For the DD, following the descriptions in[[19](https://arxiv.org/html/2311.12085v2#bib.bib19)], we train generation models with a scale of 256×256×16 256 256 16 256\times 256\times 16 256 × 256 × 16 for both the CarlaSC and SemanticKITTI datasets. Regarding the Latent Diffusion model, we utilize the pre-trained model published in the work[[19](https://arxiv.org/html/2311.12085v2#bib.bib19)] as our baseline. However, since the original work trains the model at a scale of 128×128×8 128 128 8 128\times 128\times 8 128 × 128 × 8, during the generation phase, we use the Scale Adaptive Function to upsample the generated scenes to match our scale of 256×256×16 256 256 16 256\times 256\times 16 256 × 256 × 16.
|
| 321 |
+
|
| 322 |
+
Conditional Generation. In our paper’s conditional generation experiment sections, we use a discrete diffusion model conditioned on point clouds as our baseline. The scene is divided into a voxel-based representation based on scale, and each voxel is assigned a binary value (0 or 1). A voxel is set to 1, indicating the presence of points if it contains one or more points from the point cloud.
|
| 323 |
+
|
| 324 |
+
We recognize that this comparison might not be entirely fair due to scale differences. However, the final upscaling and subsequent visualization of the generated scenes allow for a clear discernment of quality differences. It’s important to note that training in the original method at the larger scale of 256×256×16 256 256 16 256\times 256\times 16 256 × 256 × 16 would require substantial computational resources, specifically over 16 days on 4 A100 GPUs. Despite this potential bias, the visual evaluation method, after upscaling, effectively demonstrates the quality distinction between the generated scenes, which is crucial for our evaluation. This approach is chosen as the most feasible solution given our resource constraints.
|
| 325 |
+
|
| 326 |
+
H Datasets Pre-processing
|
| 327 |
+
-------------------------
|
| 328 |
+
|
| 329 |
+
Our paper’s experiments utilize two outdoor scene datasets: CarlaSC[[44](https://arxiv.org/html/2311.12085v2#bib.bib44)] and SemanticKITTI[[3](https://arxiv.org/html/2311.12085v2#bib.bib3)]. CarlaSC is a dataset collected through simulated road scenes and is primarily used in our main experiments. On the other hand, SemanticKITTI, gathered from real-world scenes, is employed in experiments focusing on cross-dataset applications. Due to the different origins of these datasets and their varied labels, we undertake specific processing steps to facilitate better experimentation. The details of these processing steps are as follows.
|
| 330 |
+
|
| 331 |
+
### H.1 CarlaSC
|
| 332 |
+
|
| 333 |
+
Table g: Simplified Semantic Labels for the CarlaSC Dataset After Merging. The table lists the 10 consolidated classes used in our experiments, with 0 denoting unclassified elements not shown here.
|
| 334 |
+
|
| 335 |
+
CarlaSC[[44](https://arxiv.org/html/2311.12085v2#bib.bib44)], primarily employed in our main experiments, is a synthetic dataset featuring outdoor road point cloud scenes. Originally comprising 23 semantic labels, these merge according to the dataset’s official guidelines to simplify the categorization process. The dataset encompasses 11 semantic classes, as detailed in Table [g](https://arxiv.org/html/2311.12085v2#S8.T7 "Table g ‣ H.1 CarlaSC ‣ H Datasets Pre-processing ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"), with 0 representing the unclassified category. This dataset includes 18 scenes for training, 3 for validation, and 3 for testing. In our experiments, we utilize a high-scale version of CarlaSC, where each scene has a scale of 256×256×16 256 256 16 256\times 256\times 16 256 × 256 × 16 voxels, covering a physical space of 25.6 meters both in front of and behind the radar scanner and extending up to a height of 3 meters.
|
| 336 |
+
|
| 337 |
+
Table h: Conversion of SemanticKITTI Labels to Correspond with CarlaSC’s 11 Categories. Labels listed as remove are absent in CarlaSC, while those marked with - are omitted from semantic segmentation according to the original settings.
|
| 338 |
+
|
| 339 |
+
### H.2 SemanticKITTI
|
| 340 |
+
|
| 341 |
+
SemanticKITTI[[3](https://arxiv.org/html/2311.12085v2#bib.bib3)], utilized for cross-dataset validation, showcases diverse environments, including inner-city traffic, residential areas, highways, and countryside roads. After voxelization, it comprises 22 sequences: sequences 00 to 10 (excluding 08) for training, 08 for validation, and 11 to 20 for testing. However, due to the absence of semantic labels for the test set in the official SemanticKITTI release, our assessment of scene generation depends on the validation set. The chosen scope extends 51.2 meters ahead of the vehicle, 25.6 meters laterally, and 6.4 meters in height, yielding a voxel scale of 256×256×32 256 256 32 256\times 256\times 32 256 × 256 × 32. Originally featuring 28 categories, SemanticKITTI undergoes a class remapping or removal process to align with the 11 categories found in CarlaSC, detailed in Table[h](https://arxiv.org/html/2311.12085v2#S8.T8 "Table h ‣ H.1 CarlaSC ‣ H Datasets Pre-processing ‣ Pyramid Diffusion for Fine 3D Large Scene Generation").
|
| 342 |
+
|
| 343 |
+
In this alignment, we have removed certain categories from SemanticKITTI. This decision is primarily based on the original dataset’s configuration for semantic segmentation, such as moving objects, and the absence of corresponding labels in the CarlaSC dataset, like bicycles and motorcycles. Notably, the removed categories represent only a minor portion of the total number of labels. This ensures the labels conform to the relationships in Table[g](https://arxiv.org/html/2311.12085v2#S8.T7 "Table g ‣ H.1 CarlaSC ‣ H Datasets Pre-processing ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"). Additionally, we omit the upper 16 voxels in height from SemanticKITTI to synchronize with CarlaSC’s height representation, a decision justified by the rarity of objects above this limit and the need for consistency in dataset comparison.
|
| 344 |
+
|
| 345 |
+
I Additional Experiment Results
|
| 346 |
+
-------------------------------
|
| 347 |
+
|
| 348 |
+
Due to the limitations on the length of the main text, we have reserved the primary experimental results for inclusion in the main body of the paper. In this section, we provide supplementary experimental outcomes not mentioned in the main text and more showcases of our visualization effects.
|
| 349 |
+
|
| 350 |
+
### I.1 Generation Quality
|
| 351 |
+
|
| 352 |
+
In this section, we present an array of qualitative comparative results. Figures [j](https://arxiv.org/html/2311.12085v2#S10.F10 "Figure j ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") and [l](https://arxiv.org/html/2311.12085v2#S10.F12 "Figure l ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") showcase the outcomes of our Unconditional Generation, from which we can discern that scenes generated using the PDD method achieve greater semantic accuracy and encompass more details within the generated scenes. Figures[m](https://arxiv.org/html/2311.12085v2#S10.F13 "Figure m ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") and[k](https://arxiv.org/html/2311.12085v2#S10.F11 "Figure k ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") illustrate the results of our Conditional Generation. The outcomes reveal that the scenes generated by our conditional generation method closely resemble the ground truth. In contrast, while the approach using point clouds as a condition for scene restoration maintains structural similarity, it exhibits numerous inaccuracies in label correctness.
|
| 353 |
+
|
| 354 |
+
### I.2 Applications
|
| 355 |
+
|
| 356 |
+
Our PDD method extends to two applications: cross-dataset and infinite scene generation. Figures[o](https://arxiv.org/html/2311.12085v2#S10.F15 "Figure o ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"),[q](https://arxiv.org/html/2311.12085v2#S10.F17 "Figure q ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"),[o](https://arxiv.org/html/2311.12085v2#S10.F15 "Figure o ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") and[q](https://arxiv.org/html/2311.12085v2#S10.F17 "Figure q ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") provide additional visualizations of cross-dataset scene generation on the SemanticKITTI dataset. Specifically, Figure[o](https://arxiv.org/html/2311.12085v2#S10.F15 "Figure o ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") and[q](https://arxiv.org/html/2311.12085v2#S10.F17 "Figure q ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") illustrate the distinctions in generation effects between DD and our method. Our method consistently generates more coherent semantic scenes, encompassing a wider range of objects and richer details. For Figure[o](https://arxiv.org/html/2311.12085v2#S10.F15 "Figure o ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") and[q](https://arxiv.org/html/2311.12085v2#S10.F17 "Figure q ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"), we initially downsample the ground truth to 64×64×8 64 64 8 64\times 64\times 8 64 × 64 × 8 and then restore it to 256×256×16 256 256 16 256\times 256\times 16 256 × 256 × 16. These results demonstrate our method’s capability to reconstruct scenes closely aligned with the ground truth accurately.
|
| 357 |
+
|
| 358 |
+
Additionally, Figure [r](https://arxiv.org/html/2311.12085v2#S10.F18 "Figure r ‣ J Additional Discussion ‣ Pyramid Diffusion for Fine 3D Large Scene Generation") demonstrates the capability of our method to generate infinite scenes. Overall, the scenes generated by our method show high diversity with minimal repetition. We note certain artifacts, such as road interruptions, which can be attributed to two main factors. First, our approach, in line with prior works[[24](https://arxiv.org/html/2311.12085v2#bib.bib24)], assumes a local dependency for infinite scene generation (see Equation 6 in the paper). Though efficient, this approach may result in artifacts due to its tendency to overlook long-range dependencies. This could be addressed by sequential models like transformers, which is beyond the scope of this paper. Furthermore, the training dataset[[44](https://arxiv.org/html/2311.12085v2#bib.bib44), [3](https://arxiv.org/html/2311.12085v2#bib.bib3)] consists of radar-scanned road segments rather than complete regional scenes, which potentially causes artifacts. The extrapolation beyond the scanned scene segments poses a significant challenge, resulting in disruptions within the generated infinite scenes. We anticipate that, with enhanced datasets and the incorporation of sequential models, our method has the potential to generate better infinite 3D scenes.
|
| 359 |
+
|
| 360 |
+
### I.3 Ablation Study
|
| 361 |
+
|
| 362 |
+
Pyramid Diffusion. Due to space constraints, only a subset of experimental results are provided in Table 3. We now present the full experimental outcomes in Table [i](https://arxiv.org/html/2311.12085v2#S9.T9 "Table i ‣ I.3 Ablation Study ‣ I Additional Experiment Results ‣ Pyramid Diffusion for Fine 3D Large Scene Generation"). The full results show that the performance for both conditional and unconditional generation improves incrementally with adding scales. However, within the four-scale pyramid, the increase is only marginal.
|
| 363 |
+
|
| 364 |
+
Table i: Complete comparison of different diffusion pyramids on 3D semantic scene generation.
|
| 365 |
+
|
| 366 |
+
J Additional Discussion
|
| 367 |
+
-----------------------
|
| 368 |
+
|
| 369 |
+
Differences from 2D Approaches. While inspired by coarse-to-fine approaches in 2D image processing[[15](https://arxiv.org/html/2311.12085v2#bib.bib15), [32](https://arxiv.org/html/2311.12085v2#bib.bib32), [39](https://arxiv.org/html/2311.12085v2#bib.bib39)], directly applying them to 3D presents significant challenges due to the added dimension, resulting in more complex data and increased computational demands. Furthermore, we focus on generating large-scale outdoor 3D scenes rather than the more prevalent generation of individual 3D objects. Outdoor scenes imply a higher level of diversity, comprising numerous objects, all of which require semantic coherence within the generated environments.
|
| 370 |
+
|
| 371 |
+
Another consideration is the relative scarcity of high-quality 3D datasets compared to the more mature field of 2D images. These constraints pose challenges for diffusion models in scene generation. To address this, we adopt a multi-scale approach. Initially, diffusion models train efficiently on small-scale data, ensuring diverse and semantically accurate scene generation. We then employ conditional generation techniques to refine the scenes progressively. Diffusion models excel under conditions’ guidance, allowing for high-quality scene generation.
|
| 372 |
+
|
| 373 |
+
The flexibility offered by our pyramid approach ensures the diversity and quality of the generated scenes and facilitates cross-dataset generation. Additionally, the concept of our proposed Scene Subdivision Module aids in the realization of infinite scene generation, allowing for the seamless stitching and extension of scenes beyond fixed boundaries.
|
| 374 |
+
|
| 375 |
+
In conclusion, by tailoring the diffusion process to the unique demands of 3D data and leveraging conditional inputs for refinement, our method effectively bridges the gap between 2D inspiration and 3D application, unlocking new possibilities in scene generation with efficiency and adaptability.
|
| 376 |
+
|
| 377 |
+
Limitations. Despite the notable advantages of our method in both unconditional and conditional generation compared to other methods, as well as its extension to cross-dataset and infinite scene generation, it is subject to limitations primarily stemming from the scale and collecting methods of the current outdoor 3D scene datasets[[44](https://arxiv.org/html/2311.12085v2#bib.bib44), [3](https://arxiv.org/html/2311.12085v2#bib.bib3), [4](https://arxiv.org/html/2311.12085v2#bib.bib4)]. Consequently, the scenes generated by our method are constrained to the largest scale of 256×256×16 256 256 16 256\times 256\times 16 256 × 256 × 16, although our method possesses the theoretical capability to generate larger scale. Additionally, incomplete object generation may occur in the generated scenes. Despite our efforts to mitigate this limitation through infinite scene generation, the quality of the generated results is still influenced by the characteristics of the training dataset.
|
| 378 |
+
|
| 379 |
+

|
| 380 |
+
|
| 381 |
+
Figure j: Additional visualization of unconditional generation results on CarlaSC. Our method produces more diverse scenes compared to the two baseline models [[19](https://arxiv.org/html/2311.12085v2#bib.bib19), [2](https://arxiv.org/html/2311.12085v2#bib.bib2)].
|
| 382 |
+
|
| 383 |
+

|
| 384 |
+
|
| 385 |
+
Figure k: Additional visualization of conditional generation results on CarlaSC.PC stands for point cloud condition.
|
| 386 |
+
|
| 387 |
+

|
| 388 |
+
|
| 389 |
+
Figure l: Additional visualization of unconditional generation results on CarlaSC. Our method produces more diverse scenes compared to the two baseline models [[19](https://arxiv.org/html/2311.12085v2#bib.bib19), [2](https://arxiv.org/html/2311.12085v2#bib.bib2)].
|
| 390 |
+
|
| 391 |
+

|
| 392 |
+
|
| 393 |
+
Figure m: Additional visualization of conditional generation results on CarlaSC.PC stands for point cloud condition.
|
| 394 |
+
|
| 395 |
+
|
| 396 |
+
|
| 397 |
+
Figure n: Additional SemanticKITTI unconditional generation.FT stands for finetuning pre-trained model from CarlaSC.
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
|
| 401 |
+
Figure o: Additional SemanticKITTI conditional generation. Our proposed PDD achieves results close to the groundtruth. Note that FT stands for finetuning from CarlaSC models.
|
| 402 |
+
|
| 403 |
+
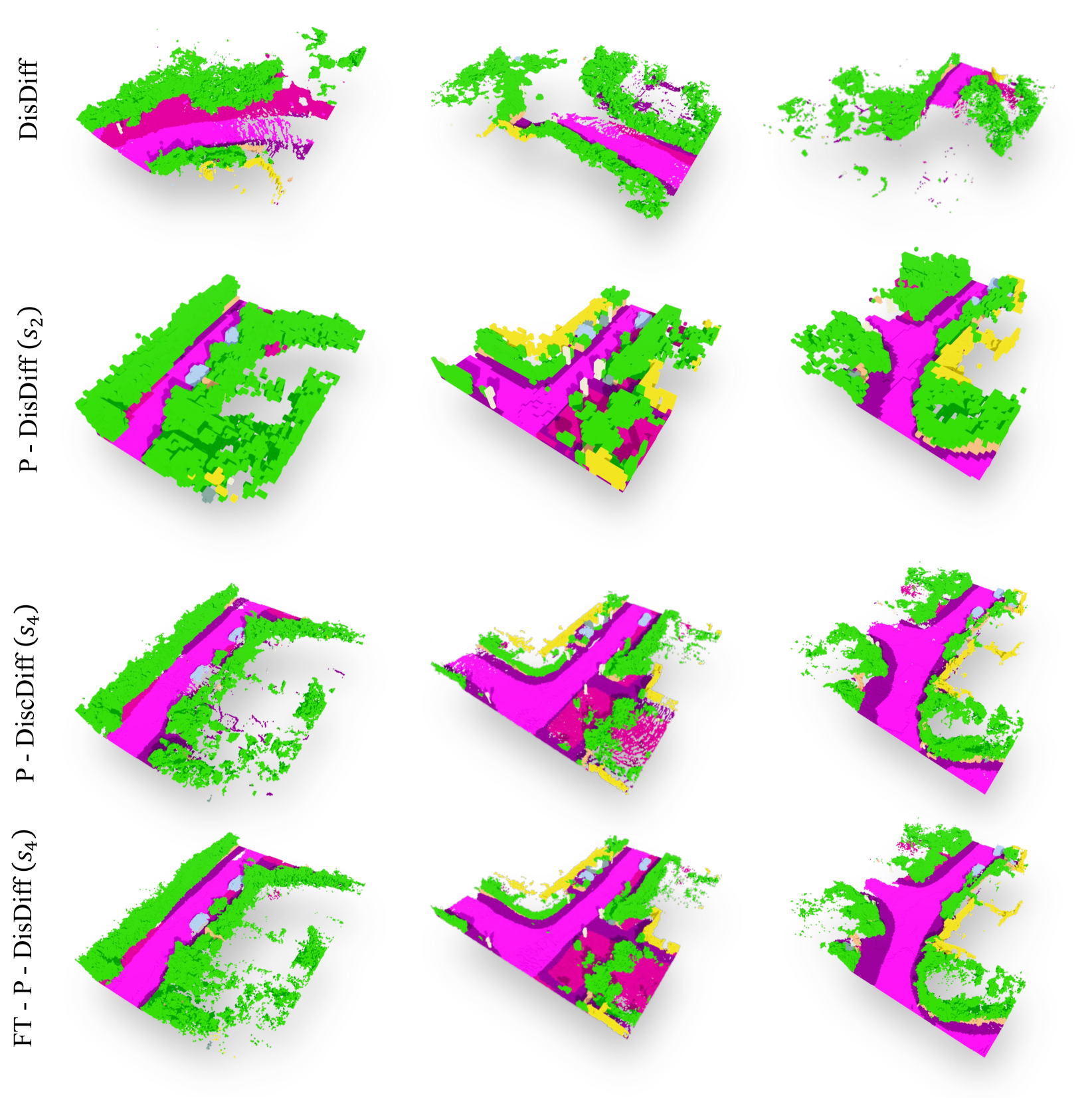
|
| 404 |
+
|
| 405 |
+
Figure p: Additional SemanticKITTI unconditional generation.FT stands for finetuning pre-trained model from CarlaSC.
|
| 406 |
+
|
| 407 |
+

|
| 408 |
+
|
| 409 |
+
Figure q: Additional SemanticKITTI conditional generation. Our proposed PDD achieves results close to the groundtruth. Note that FT stands for finetuning from CarlaSC models.
|
| 410 |
+
|
| 411 |
+

|
| 412 |
+
|
| 413 |
+
Figure r: Infinite Scene Generation. Using PDD, we generate three different scenes. Our method produces infinite and consistent urban landscapes, seamlessly blending diverse urban elements to create a coherent and realistic cityscape.
|