

Add 1 files
Browse files- 2505/2505.14990.md +336 -0
2505/2505.14990.md
ADDED
|
@@ -0,0 +1,336 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
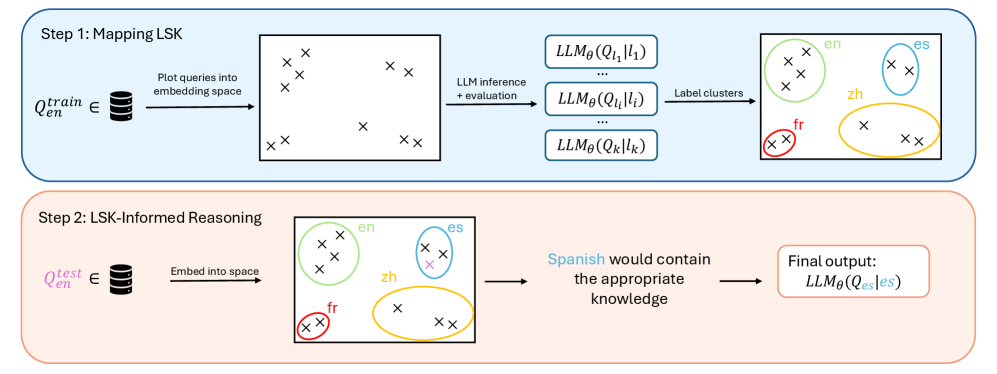
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
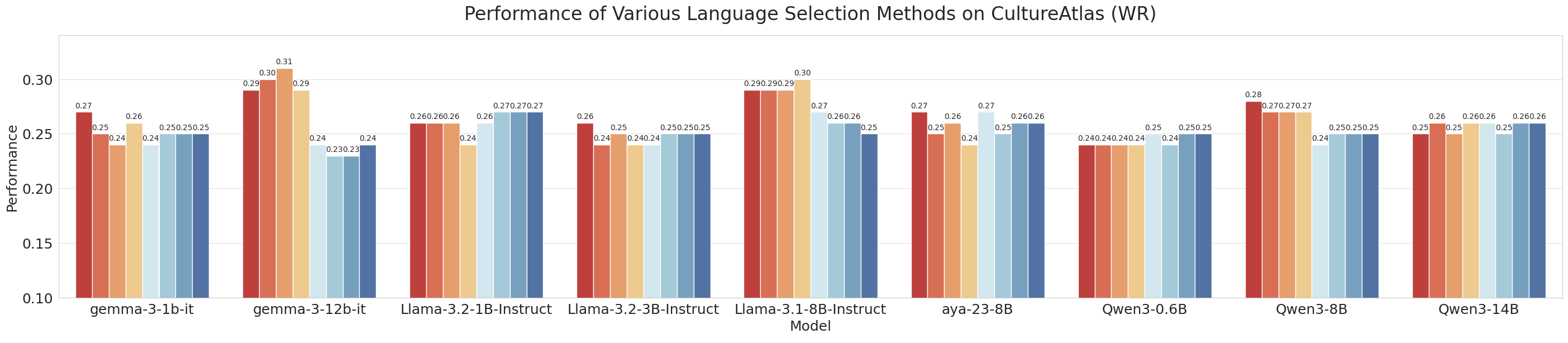
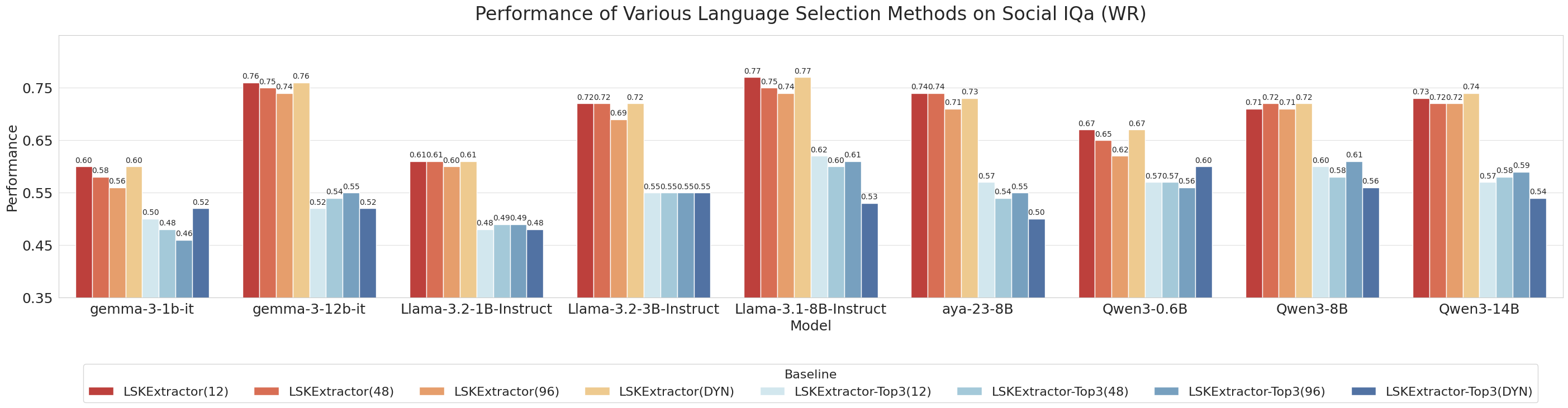
|
|
|
|
|
|
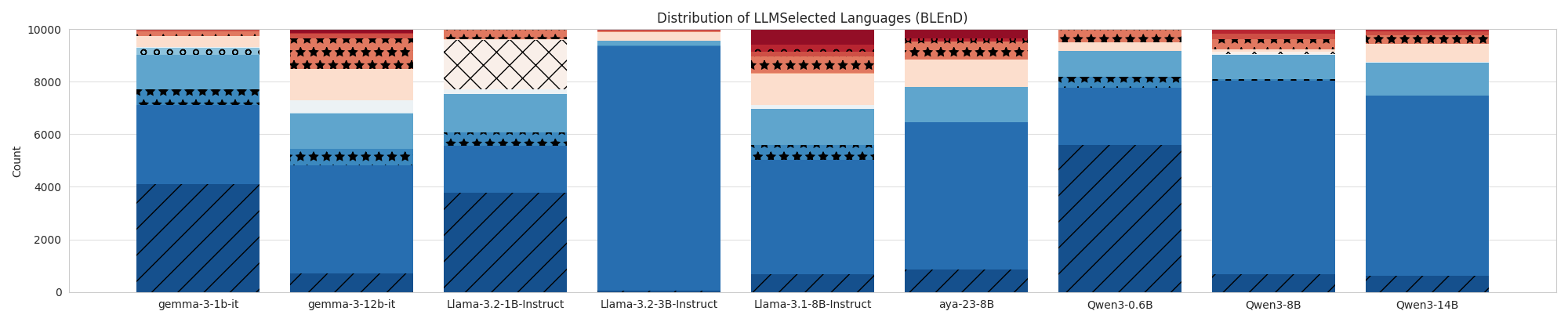
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
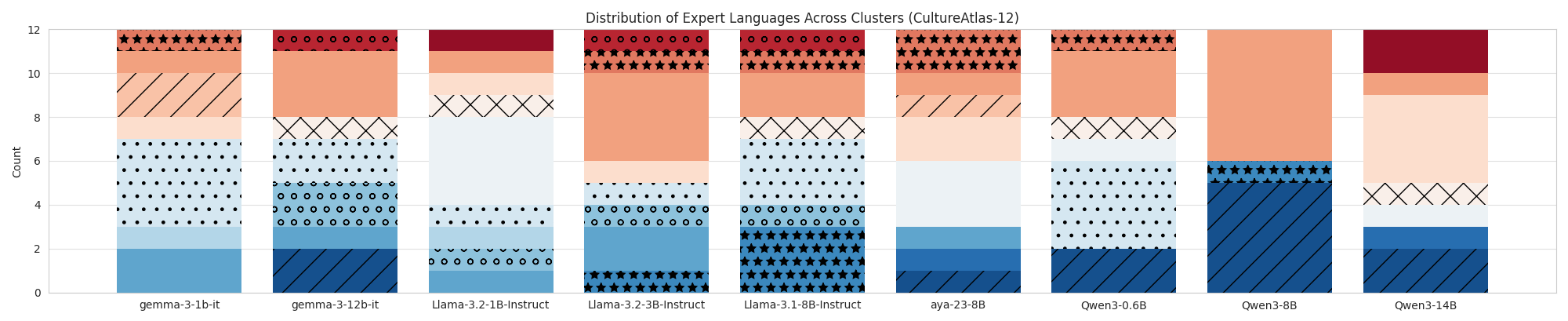
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
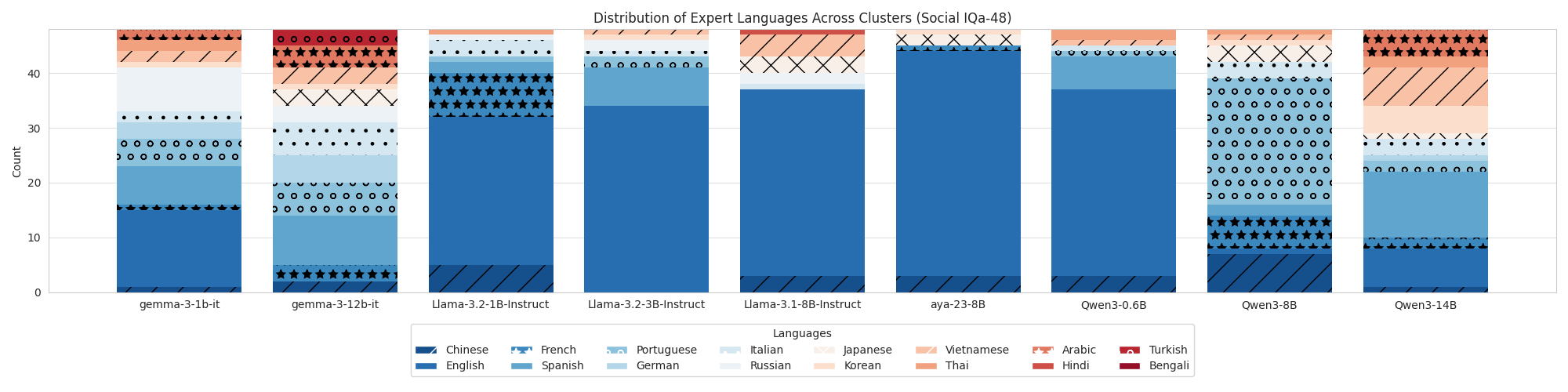
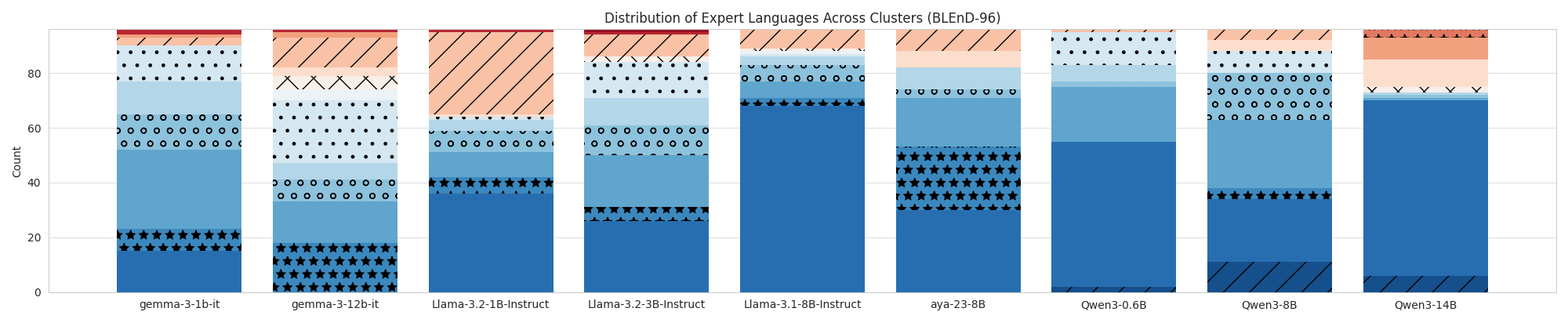
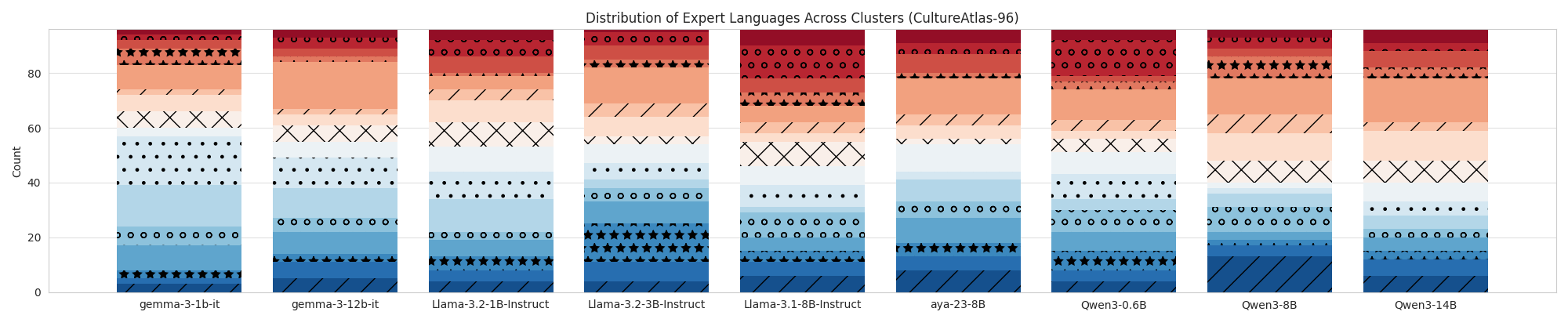
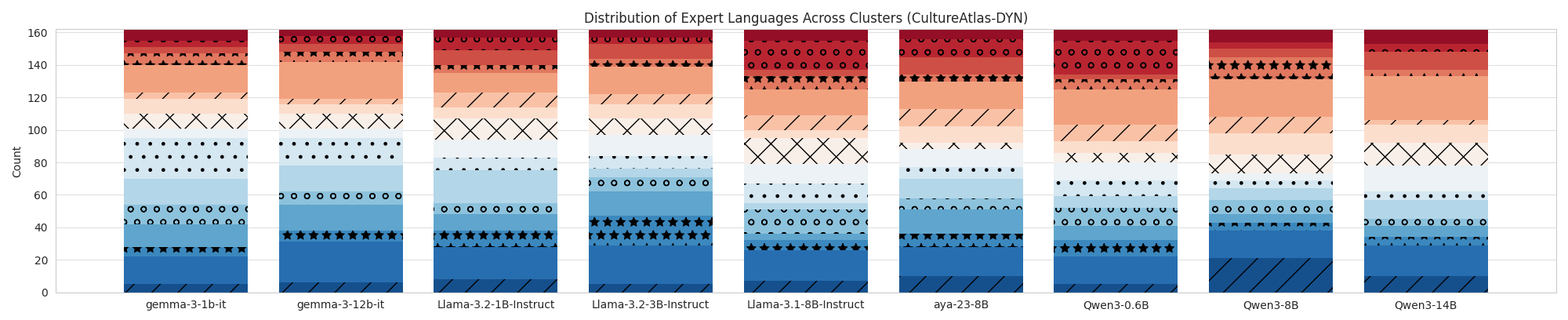
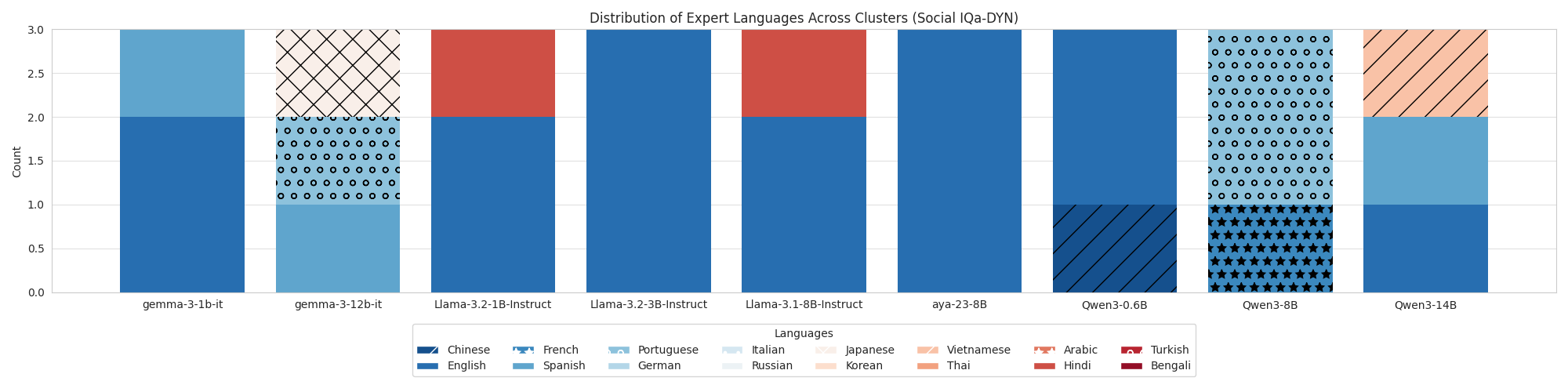
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Language Specific Knowledge: Do Models Know Better in X than in English?
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2505.14990
|
| 4 |
+
|
| 5 |
+
Markdown Content:
|
| 6 |
+
Ishika Agarwal∗, Nimet Beyza Bozdag∗, Dilek Hakkani-Tür
|
| 7 |
+
|
| 8 |
+
Department of Computer Science
|
| 9 |
+
|
| 10 |
+
University of Illinois, Urbana-Champaign
|
| 11 |
+
|
| 12 |
+
{ishikaa2, nbozdag2, dilek}@illinois.edu
|
| 13 |
+
|
| 14 |
+
###### Abstract
|
| 15 |
+
|
| 16 |
+
Often, multilingual language models are trained with the objective to map semantically similar content (in different languages) in the same latent space. In this paper, we show a nuance in this training objective, and find that by changing the language of the input query, we can improve the question answering ability of language models. Our contributions are two-fold. First, we introduce the term Language Specific Knowledge (LSK) to denote queries that are best answered in an “expert language” for a given LLM, thereby enhancing its question-answering ability. We introduce the problem of language selection—for some queries, language models can perform better when queried in languages other than English, sometimes even better in low-resource languages—and the goal is to select the optimal language for the query. Second, we introduce simple to strong baselines to test this problem. Additionally, as a first-pass solution to this novel problem, we design LSKExtractor to benchmark the language-specific knowledge present in a language model and then exploit it during inference. To test our framework, we employ three datasets that contain knowledge about both cultural and social behavioral norms. Overall, LSKExtractor achieves up to 10% relative improvement across datasets, and is competitive against strong baselines, while being feasible in real-world settings. Broadly, our research contributes to the open-source 1 1 1 https://anonymous.4open.science/r/LSKExtractor-272F/ development of language models that are inclusive and more aligned with the cultural and linguistic contexts in which they are deployed.
|
| 17 |
+
|
| 18 |
+
**footnotetext: These authors contributed equally to this work.
|
| 19 |
+
1 Introduction
|
| 20 |
+
--------------
|
| 21 |
+
|
| 22 |
+
Language models are trained to understand and generate responses in dozens of languages, and are trained with either monolingual or parallelly translated data (aya_dataset). Multilingual language models are trained so that two sentences that are semantically similar but in different languages are mapped to the same point in the latent space (xu2025survey; curseofmultilinguality; pfeiffer-etal-2022-lifting; ruder2019survey) (what we coin as the "latent language alignment hypothesis"). This hypothesis applies to sentences in all languages, creating multilingual language models. This hypothesis is supported by current reports on DeepSeek-R1 (deepseekr1) spontaneously switching to Chinese during its chain-of-thought, even when presented with an English query (thoughtology). However, the same hypothesis has been challenged by works like the Multilingual Trolley Problem (jin2025language) which show that the alignment of multilingual language models to human preferences varies with the language of the input query.
|
| 23 |
+
|
| 24 |
+
Figure [1](https://arxiv.org/html/2505.14990v2#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") presents another case in which the hypothesis of latent language alignment does not hold. In this example, we ask Llama-3.1-8B-Instruct about the sport that American women tend to watch the most in different languages (see the caption for details of this toy experiment). The model produces different answers across languages, with only Hindi and Japanese yielding correct responses. If the languages were truly aligned in the latent space, we would expect the model to produce the same output regardless of the input language. This inconsistency highlights limitations of the latent language alignment hypothesis, which arise from known sources of cross-lingual misalignment such as non-compositionality (the meaning of a phrase cannot be deduced directly from the individual words, i.e., metaphors and idioms (sathe2024language; cheng2024no; clcl)) and non-isomorphism (words lacking direct translations (wu2024representational)). Building on this perspective, we propose another source of misalignment—this time within language models themselves—which we call Language Specific Knowledge.
|
| 25 |
+
|
| 26 |
+
We define Language Specific Knowledge (LSK) as knowledge that a language model appears to access more readily or represent more accurately when queried/asked to reason in a particular language (the expert language). In Figure [1](https://arxiv.org/html/2505.14990v2#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"), the varying responses across languages are evidence of LSK. Rather than viewing this as a limitation, we argue that such behavior should be leveraged in a more informed and intentional manner, allowing us to guide language models toward languages that may yield more accurate, aligned, and culturally appropriate responses for a given topic.
|
| 27 |
+
|
| 28 |
+

|
| 29 |
+
|
| 30 |
+
Figure 1: In this toy experiment, we prompt Llama-3.1-8B-Instruct with the same question across multiple languages (shown in English here only for illustration; the actual queries were translated into each respective language). The correct answer is tennis, yet the model produces different outputs depending on the query language. This illustrates what we refer to as Language-Specific Knowledge.
|
| 31 |
+
|
| 32 |
+
We propose a novel, two-stage approach, called LSKExtractor (see Figure[2](https://arxiv.org/html/2505.14990v2#S3.F2 "Figure 2 ‣ 3 LSKExtractor Methodology ‣ Language Specific Knowledge: Do Models Know Better in X than in English?")), that is designed to identify the expert language for a particular query and model, for the most accurate answer. In the first stage of "Mapping LSK", we map out LSK and their corresponding expert languages by conducting chain-of-thought (CoT) reasoning in 16 languages on training queries from three datasets (CultureAtlas (cultureatlas), BLEnD (blend), and Social IQa (socialiqa)). We use language-specific reasoning to ensure the model is using the knowledge embedded within the corresponding language. These queries are clustered in a shared semantic space, and each cluster is assigned an expert language based on the CoT language that achieves the highest performance within that group. In the second stage of "LSK-Informed Reasoning", during test-time inference, we embed an unseen query into the same space to identify its corresponding cluster and retrieve the optimal language(s) for reasoning. The final answers are generated using CoT in the language identified as the expert for that knowledge region. This scalable method allows models to draw upon multilingual strengths dynamically, relatively improving accuracy by 10% across datasets without additional fine-tuning across all models and datasets. Our method is comparable to strong baselines (that we also propose) while still providing a feasible solution applicable in real world settings.
|
| 33 |
+
|
| 34 |
+
Our contributions are as follows:
|
| 35 |
+
|
| 36 |
+
* •We formally define Language Specific Knowledge (LSK) and provide intuitive and empirical evidence of its presence in multilingual language models.
|
| 37 |
+
* •We propose LSKExtractor, a scalable two-stage framework that identifies expert languages for specific knowledge regions and leverages this LSK-to-language map to improve inference through strategically switching the query language.
|
| 38 |
+
* •Finally, we conduct systematic experiments across multiple state-of-the-art models to evaluate the effects of language-specific reasoning performance across topics and inform the benefits of LSKExtractor.
|
| 39 |
+
|
| 40 |
+
2 Related Work
|
| 41 |
+
--------------
|
| 42 |
+
|
| 43 |
+
Prior work has examined how language influences model reasoning (schut2025multilingualllmsthinkenglish; zhong2024englishcentricllmslanguagemultilingual; yong2025crosslingualreasoningtesttimescaling), effects of language on model alignment with human preferences (jin2025language; durmus2024towards), and cross-linguistic generalization (chang2022geometrymultilinguallanguagemodel). chang2022geometrymultilinguallanguagemodel investigated how different languages are represented within the XLM-R multilingual model. They found that languages occupy distinct regions in the representational space, though languages with similar distributions can be aligned through mean-shifting. This indicates that semantically equivalent sentences in different languages may not map to the same low-level representations. This insight motivates our study by highlighting the need for language-specific knowledge representations when reasoning or answering questions across linguistic boundaries.
|
| 44 |
+
|
| 45 |
+
Other works have focused specifically on multilingual reasoning. For instance, schut2025multilingualllmsthinkenglish demonstrated that language models tend to default to English during internal reasoning, which can negatively impact downstream task performance, fluency, and fairness. We extended this finding by identifying, for some given topic, the language in which a multilingual language model exhibited greater expertise. Similarly, zhong2024englishcentricllmslanguagemultilingual found that models often reason internally in a specific language and exhibit cultural biases aligned with that language when responding to culturally grounded questions. In our work, we aim to boost multilingual reasoning by identifying such LSK and strategically leveraging expert languages where such knowledge is most richly encoded through the LSKExtractor. This complements approaches like huang2024mindmerger that merge external multilingual representations to enhance general understanding, ziabari2025reasoningspectrumaligningllms, which adapt LLM reasoning between intuitive (System 1) and deliberative (System 2) modes based on task needs, or even xlingualthoughtprompting that encourages language models to think in other languages to improve performance. We adapt this as a baseline, called the LLMSelected baseline.
|
| 46 |
+
|
| 47 |
+
Several works have investigated multilingual reasoning from different perspectives: improving reasoning in low-resource languages (senel2024kardecs), benchmarking the reasoning abilities of language models across languages (etxaniz2023multilinguallanguagemodelsthink; dynamic_learning; gao2025thinkingmultilinguallyempowerllm), and enhancing semantic alignment between languages (langbridge). These efforts primarily aim to strengthen cross-lingual semantic representations to support more consistent reasoning across languages. In a related line of work, yong2025crosslingualreasoningtesttimescaling demonstrated that chain-of-thought traces in various languages can be aligned to their English counterparts to facilitate multilingual reasoning. In contrast, we highlight a fundamental limitation of this alignment approach: certain languages encode concepts that do not have direct equivalents in others. This observation underscores the lack of a universal one-to-one mapping across languages (maps_dataset). Rather than enforcing alignment, our work embraces linguistic diversity by leveraging the unique conceptual affordances of each language to enhance reasoning performance.
|
| 48 |
+
|
| 49 |
+
Furthermore, language is an important part of model alignment with human preferences. However, prior work has shown that current multilingual models are not well aligned with humans, showing more US and Euro-centric representations rather than multicultural (durmus2024towards; rystrøm2025multilingualmulticulturalevaluating). Recent studies have shown that languages are indeed proxies for culture accordingtosagnik, thus they should be aligned to culturally diverse preferences. However, even when prompted across different languages, they fail to align with these culturally diverse moral preferences (jin2025language). Our work contributes to alignment by identifying the expert language for specific domains of knowledge and demonstrating how strategically using these languages can elicit responses that better reflect localized, culturally grounded human preferences.
|
| 50 |
+
|
| 51 |
+
3 LSKExtractor Methodology
|
| 52 |
+
--------------------------
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
Figure 2: Overview of LSKExtractor. Our method consists of two main steps. In Step 1, we embed training queries into a shared semantic space and cluster them based on topical similarity. For each cluster, we determine the expert language—i.e., the language that yields the most accurate or contextually appropriate reasoning—by comparing model responses across languages. In Step 2, during test-time inference, we embed the test query into the same space, identify its nearest cluster, and select the corresponding expert language (e.g., Spanish) to guide the model toward producing a more informed and culturally grounded response.
|
| 57 |
+
|
| 58 |
+
Given an LLM, LSKExtractor aims to identify the most effective language for answering an LSK question. We first define a set of candidate languages ℒ\mathcal{L}. For a specific language 𝓁∈ℒ\mathcal{l}\in\mathcal{L}, let Q l Q_{l} denote the query Q Q—consisting of the question together with the model instruction—translated into 𝓁\mathcal{l}. We then denote the performance of the (multilingual) language model LLM θ LLM_{\theta} (with parameters θ\theta) on Q l Q_{l} from a dataset with CoT reasoning in 𝓁\mathcal{l} as Acc(LLM θ(Q l∣𝓁))Acc(LLM_{\theta}(Q_{l}\mid\mathcal{l})). We also compute the performance of the model without CoT reasoning, denoted simply as Acc(LLM θ(Q l))Acc(LLM_{\theta}(Q_{l})). The complete set of model prompts is provided in Appendix [G](https://arxiv.org/html/2505.14990v2#A7 "Appendix G Model Prompts ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"), and the query translation process is detailed in Appendix [C](https://arxiv.org/html/2505.14990v2#A3 "Appendix C Dataset Translation ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 59 |
+
|
| 60 |
+
We use this formulation to map LSK to an expert language, cluster semantically similar queries, and form a language-topic alignment map (as detailed in the next paragraph). We can, then, take advantage of the language-topic alignment map during testing by identifying the topic cluster and using the corresponding language for reasoning. Figure [2](https://arxiv.org/html/2505.14990v2#S3.F2 "Figure 2 ‣ 3 LSKExtractor Methodology ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") contains an overview of our solution. We detail the steps in each stage below.
|
| 61 |
+
|
| 62 |
+
In the first stage of LSKExtractor, we construct an LSK-to-language mapping for each model LLM θ LLM_{\theta} and dataset D D:
|
| 63 |
+
|
| 64 |
+
1. 1.For each training query Q train Q^{\text{train}}, embed the English version Q en train Q_{\text{en}}^{\text{train}} using an embedding model, and cluster the embeddings into k k groups using the k k-means algorithm. Let the resulting clusters be C 1,C 2,…,C k{C_{1},C_{2},\dots,C_{k}}.
|
| 65 |
+
2. 2.For each query Q∈C j Q\in C_{j} and each candidate language 𝓁∈ℒ\mathcal{l}\in\mathcal{L}, evaluate the model’s performance with CoT reasoning, Acc(LLM θ(Q l∣𝓁))Acc(LLM_{\theta}(Q_{l}\mid\mathcal{l})).
|
| 66 |
+
3. 3.For each cluster C j C_{j}, compute the average accuracy of LLM θ LLM_{\theta} for the queries in C j C_{j} when the model is asked to reason in 𝓁\mathcal{l} (denoted as Acc 𝓁(C j)Acc_{\mathcal{l}}(C_{j})):
|
| 67 |
+
|
| 68 |
+
Acc 𝓁(C j)=1|C j|∑Q∈C j Acc(LLM θ(Q l∣𝓁))Acc_{\mathcal{l}}(C_{j})=\frac{1}{|C_{j}|}\sum_{Q\in C_{j}}Acc(LLM_{\theta}(Q_{l}\mid\mathcal{l}))
|
| 69 |
+
4. 4.Assign to each cluster C j C_{j} its expert language by selecting the maximizer:
|
| 70 |
+
|
| 71 |
+
𝓁∗(C j)=argmax 𝓁∈ℒAcc 𝓁(C j)\mathcal{l}^{*}(C_{j})=\arg\max_{\mathcal{l}\in\mathcal{L}}Acc_{\mathcal{l}}(C_{j})
|
| 72 |
+
|
| 73 |
+
In the second stage, we leverage the LSK representation to guide test-time inference (to clarify, Q en test Q_{\text{en}}^{\text{test}} is a test query in English):
|
| 74 |
+
|
| 75 |
+
1. 1.Embed each test query Q en test Q_{\text{en}}^{\text{test}} into the same semantic space as used during training.
|
| 76 |
+
2. 2.Assign Q en test Q_{\text{en}}^{\text{test}} to its nearest cluster C j C_{j} based on embedding cosine similarity.
|
| 77 |
+
3. 3.Retrieve the expert language 𝓁∗(C j)\mathcal{l}^{*}(C_{j}) assigned to cluster C j C_{j}.
|
| 78 |
+
4. 4.Perform CoT reasoning in this expert language: LLM θ(Q l∗(C j)∣𝓁∗(C j))LLM_{\theta}(Q_{l^{*}(C_{j})}\mid\mathcal{l}^{*}(C_{j})) and use the result as the final model output.
|
| 79 |
+
|
| 80 |
+
4 Experiments
|
| 81 |
+
-------------
|
| 82 |
+
|
| 83 |
+
### 4.1 Experimental Setup
|
| 84 |
+
|
| 85 |
+
##### Languages.
|
| 86 |
+
|
| 87 |
+
For our experiments, we set ℒ\mathcal{L} to include the following 16 languages: Arabic, Bengali, Chinese, English, French, German, Hindi, Italian, Japanese, Korean, Portuguese, Russian, Spanish, Thai, Turkish, and Vietnamese. It is important to note that ℒ\mathcal{L} is treated as a hyperparameter: the methodology selects the best expert language from the available set. Crucially, a model’s multilingual coverage does not need to align with the chosen set of languages, since LSKExtractor is designed to guide language selection based on performance observed in the training samples.
|
| 88 |
+
|
| 89 |
+
##### Datasets.
|
| 90 |
+
|
| 91 |
+
We hypothesize that language-specific knowledge may manifest in culture, societal norms, and common sense reasoning. Hence, we select three datasets that reflect these properties:
|
| 92 |
+
|
| 93 |
+
* •CultureAtlas(cultureatlas): a dataset consisting of cultural norms (e.g., “During the Chinese New Year, in Southern China, red envelopes are typically given by the married to the unmarried[…]”), labeled as either True or False. To create a more challenging task, we reformat the dataset into multiple-choice questions (MCQs) with four answer options: one true claim and three false claims about the same country. Further details are provided in Appendix[E](https://arxiv.org/html/2505.14990v2#A5 "Appendix E CultureAtlas Reformatting ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 94 |
+
* •BLEnD(blend): a multiple-choice question answering dataset where the input is a societal norm (e.g., "What is the common dress code for school teachers in Azerbaijan?") and four answer choices (e.g., "A. apron, B. black formal suit, C. uniform, D. shirt"). The output is one of the selected answer choices.
|
| 95 |
+
* •Social IQa(socialiqa): a multiple-choice common sense reasoning dataset where the input contains some context (e.g., "Sydney walked past a homeless woman asking for change but did not have any money […] Sydney felt bad".), a question (e.g., "How would you describe Sydney?"), and three answer choices (e.g., "A. sympathetic, B. like a person who was unable to help, C. incredulous"). The output is one of the answer choices.
|
| 96 |
+
|
| 97 |
+
We use 8k instances for training and 2k for testing on BLEnD and Social IQa datasets. For CultureAtlas, due to reformatting, we use 5k instances for training and 1.5k for testing. Since all datasets are framed as classification tasks, we measure and report performance with classification accuracy ((# of True Positive + # of True Negative) / # of All Predictions).
|
| 98 |
+
|
| 99 |
+
##### Models.
|
| 100 |
+
|
| 101 |
+
For our evaluation, we use a variety of model sizes from a variety of families: Google’s gemma-3-1b-it and gemma-3-12b-it(gemmateam2024gemmaopenmodelsbased), Meta’s Llama-3.2-1B-Instruct, Llama-3.2-3B-Instruct, and Llama-3.1-8B-Instruct(grattafiori2024llama3herdmodels), Qwen’s Qwen3-0.6B, Qwen3-8B, and Qwen3-14B(yang2025qwen3technicalreport), and CohereLab’s aya-23-8B(dang2024ayaexpansecombiningresearch). We use instruction-tuned versions because those models are trained to handle multilingual inputs.
|
| 102 |
+
|
| 103 |
+
##### Methods.
|
| 104 |
+
|
| 105 |
+
To better understand model performance on these datasets, and to highlight the advantages of selecting the most informative expert language, we compare LSKExtractor against several baseline methods:
|
| 106 |
+
|
| 107 |
+
(1) Simple Baseline. The simplest approach evaluates the model only in English, the original data language. This provides a reference for base model performance with and without explicit reasoning:
|
| 108 |
+
|
| 109 |
+
* •Only English: Base performance of the models in English (the original data language), with and without reasoning: LLM θ(Q en∣en)LLM_{\theta}(Q_{\text{en}}\mid\text{en}) and LLM θ(Q en)LLM_{\theta}(Q_{\text{en}}),
|
| 110 |
+
|
| 111 |
+
(2) Simple LSK Baselines. These methods test the hypothesis that languages other than English can be more informative (i.e., demonstrate the existence of LSK). Importantly, they do not rely on additional assumptions such as country or cultural labels:
|
| 112 |
+
|
| 113 |
+
* •LLM-Selected: In order to test whether a language model has an internal LSK-to-language mapping captured by its weights, at test time, LLM θ LLM_{\theta} is given Q en Q_{\text{en}} and is asked to select the most appropriate language 𝓁∈ℒ\mathcal{l}\in\mathcal{L} in which to answer the query. Then, we use LLM θ(Q l∣l)LLM_{\theta}(Q_{l}\mid l) and LLM θ(Q l)LLM_{\theta}(Q_{l}) for evaluation. Prompt for language selection details are provided in Appendix[D](https://arxiv.org/html/2505.14990v2#A4 "Appendix D LLMSelected baseline details ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"), Figure [13](https://arxiv.org/html/2505.14990v2#A4.F13 "Figure 13 ‣ Appendix D LLMSelected baseline details ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"),
|
| 114 |
+
* •Best Global Language: Performance with the best-performing language x∈ℒ x\in\mathcal{L}, with and without reasoning: LLM θ(Q x∣x)LLM_{\theta}(Q_{x}\mid x) and LLM θ(Q x)LLM_{\theta}(Q_{x}), where x=argmax 𝓁∈ℒAcc(LLM θ(Q 𝓁∣𝓁))x=\arg\max_{\mathcal{l}\in\mathcal{L}}Acc(LLM_{\theta}(Q_{\mathcal{l}}\mid\mathcal{l})) on the training set of a particular dataset,
|
| 115 |
+
|
| 116 |
+
(3) Strong LSK Baselines. These methods also leverage the presence of LSK, but they make stronger assumptions about the data or are computationally less feasible in real-world scenarios:
|
| 117 |
+
|
| 118 |
+
* •Majority Voting: Performance using majority voting across all languages 𝓁∈ℒ\mathcal{l}\in\mathcal{L}, with and without reasoning: MajorityVote({Acc(LLM θ(Q 𝓁∣𝓁))}𝓁∈ℒ)\text{MajorityVote}\big(\{Acc(LLM_{\theta}(Q_{\mathcal{l}}\mid\mathcal{l}))\}_{\mathcal{l}\in\mathcal{L}}\big) and MajorityVote({Acc(LLM θ(Q 𝓁))}𝓁∈ℒ)\text{MajorityVote}\big(\{Acc(LLM_{\theta}(Q_{\mathcal{l}}))\}_{\mathcal{l}\in\mathcal{L}}\big),
|
| 119 |
+
* •Country Mapping: At test time, we also evaluate a setting where the query language 𝓁\mathcal{l} is chosen based on a country–language mapping according to the most spoken language in the region (e.g., Hindi for India). This setting applies only to CultureAtlas and BLeND, which include country labels for each question. Details of the country–language mapping are provided in Appendix[F](https://arxiv.org/html/2505.14990v2#A6 "Appendix F Country to Language Mapping ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 120 |
+
|
| 121 |
+
### 4.2 Results
|
| 122 |
+
|
| 123 |
+
In this section, we present empirical results comparing LSKExtractor against a diverse set of baselines and datasets. Our analysis is structured around the following research questions:
|
| 124 |
+
|
| 125 |
+
* •RQ1: How well does LSKExtractor perform relative to both simple and strong baselines, and under what conditions does it provide the largest gains?
|
| 126 |
+
* •RQ2: How does the clustering component influence performance within LSKExtractor, and does grouping queries into semantically coherent clusters lead to more effective language selection?
|
| 127 |
+
* •RQ3: Which languages are chosen in different clusters, and what does this reveal about the presence of LSK and its utility for question answering?
|
| 128 |
+
* •RQ4: Can the LSK maps learned during Step 1 of LSKExtractor be transferred across models and datasets, and if so, why?
|
| 129 |
+
|
| 130 |
+
Together, these questions guide our evaluation of LSKExtractor, enabling us to assess not only its raw effectiveness but also its feasibility, interpretability, and the underlying dynamics of multilingual knowledge access.
|
| 131 |
+
|
| 132 |
+

|
| 133 |
+
|
| 134 |
+

|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
Figure 3: The main results of measuring LSK – we show the performance of our various baselines and LSK across the three datasets. This setting is with reasoning, as opposed to Figure [10](https://arxiv.org/html/2505.14990v2#A2.F10 "Figure 10 ‣ Appendix B Impact of Reasoning ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") in Appendix [B](https://arxiv.org/html/2505.14990v2#A2 "Appendix B Impact of Reasoning ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 139 |
+
|
| 140 |
+
#### 4.2.1 RQ1: Comparative Performance of LSKExtractor
|
| 141 |
+
|
| 142 |
+
Figure[3](https://arxiv.org/html/2505.14990v2#S4.F3 "Figure 3 ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") presents the performance of LSKExtractor and our baselines (Section[4.1](https://arxiv.org/html/2505.14990v2#S4.SS1 "4.1 Experimental Setup ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?")) across all three datasets. We also include LSKExtractor-Top3, a variant of LSKExtractor that applies majority voting across the top three languages within each cluster. Overall, the results demonstrate that LSKExtractor consistently outperforms or matches the strongest baselines. On the most challenging dataset, CultureAtlas, LSKExtractor achieves a 10.4% relative improvement over the best-performing baseline. On BLEnD, LSKExtractor improves on OnlyEnglish by an average of 23.6%, achieving performance comparable to GlobalLanguage. On Social IQa, LSKExtractor provides an average improvement of 11.9% over OnlyEnglish, again reaching performance on par with GlobalLanguage. Importantly, LSKExtractor also outperforms the computationally expensive Majority Voting baseline across all datasets (BLEnD: +1.8%, CultureAtlas: +63.4%, Social IQa: +49.7%), indicating that many of the languages included in evaluation are suboptimal and cannot reliably serve as expert languages for these queries.
|
| 143 |
+
|
| 144 |
+
For the LLMSelected baseline, we observe that models often default to English (Appendix[D](https://arxiv.org/html/2505.14990v2#A4 "Appendix D LLMSelected baseline details ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"), Figure[12](https://arxiv.org/html/2505.14990v2#A4.F12 "Figure 12 ‣ Appendix D LLMSelected baseline details ‣ Language Specific Knowledge: Do Models Know Better in X than in English?")), which explains why the performance of LLMSelected closely matches that of OnlyEnglish in Figure[3](https://arxiv.org/html/2505.14990v2#S4.F3 "Figure 3 ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"). Exceptions highlight the risks of relying on the model’s internal mapping. For example, Qwen3-0.6B on Social IQa selects Chinese as its preferred language (Figure[12](https://arxiv.org/html/2505.14990v2#A4.F12 "Figure 12 ‣ Appendix D LLMSelected baseline details ‣ Language Specific Knowledge: Do Models Know Better in X than in English?")), leading to lower accuracy (60%) than OnlyEnglish (67%) in Figure[3](https://arxiv.org/html/2505.14990v2#S4.F3 "Figure 3 ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"). Conversely, gemma-3-12b-it on BLEnD selects a diverse set of languages and achieves substantially higher accuracy (51%) compared to OnlyEnglish (24%). These findings suggest that language models cannot yet reliably articulate their internal LSK-to-language mapping, even when such mappings clearly exist in their learned representations.
|
| 145 |
+
|
| 146 |
+

|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
Figure 4: Understanding the impact of the clustering on LSKExtractor with 12, 49, and 96 clusters using the kmeans++ algorithm, and the HDBSCAN method (labeled as “DYN”).
|
| 153 |
+
|
| 154 |
+
#### 4.2.2 RQ2: Cluster Size versus Performance
|
| 155 |
+
|
| 156 |
+
Figure[4](https://arxiv.org/html/2505.14990v2#S4.F4 "Figure 4 ‣ 4.2.1 RQ1: Comparative Performance of LSKExtractor ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") reports the performance of LSKExtractor and LSKExtractor-Top3 under different clustering configurations. We vary the number of clusters in k k-means (12, 48, and 96) and also include results from HDBSCAN, a dynamic clustering algorithm denoted as “DYN” in the figure. Overall, the choice of clustering method and cluster size has only a modest effect on performance. However, we observe a general trend of decreasing accuracy as the number of clusters increases.
|
| 157 |
+
|
| 158 |
+

|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+

|
| 163 |
+
|
| 164 |
+
Figure 5: Distribution of languages selected across clusters (12-means clustering), across datasets.
|
| 165 |
+
|
| 166 |
+
#### 4.2.3 RQ3: Languages in Each Cluster
|
| 167 |
+
|
| 168 |
+
Figure[5](https://arxiv.org/html/2505.14990v2#S4.F5 "Figure 5 ‣ 4.2.2 RQ2: Cluster Size versus Performance ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") shows stacked bar plots of the languages selected by LSKExtractor across clusters (with corresponding plots for other clustering methods in Figures[7](https://arxiv.org/html/2505.14990v2#A1.F7 "Figure 7 ‣ Appendix A Cluster Analysis ‣ Language Specific Knowledge: Do Models Know Better in X than in English?")–[9](https://arxiv.org/html/2505.14990v2#A1.F9 "Figure 9 ‣ Appendix A Cluster Analysis ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") in Appendix[A](https://arxiv.org/html/2505.14990v2#A1 "Appendix A Cluster Analysis ‣ Language Specific Knowledge: Do Models Know Better in X than in English?")). When paired with the performance results in Figure[3](https://arxiv.org/html/2505.14990v2#S4.F3 "Figure 3 ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"), several clear patterns emerge. For both BLEnD and Social IQa, English dominates as the selected language across most clusters. This aligns with their baselines: OnlyEnglish and GlobalLanguage perform strongly on these datasets, and LSKExtractor similarly selects English in most cases, resulting in comparable performance. Still, we observe interesting deviations. For example, Llama-3.2-1B selects Vietnamese in roughly half of the clusters for BLEnD, while Qwen3-8B selects Portuguese in nearly 80% of the clusters for Social IQa. These cases highlight that certain models may exhibit biases toward particular non-English languages, even when English is globally optimal. The dominance of English in Social IQa is unsurprising: the dataset consists of commonsense reasoning questions rooted in Western traditions, which (1) makes English the best-performing GlobalLanguage, (2) drives LLMs to favor English when selecting expert languages, and (3) explains why OnlyEnglish already achieves strong results. By contrast, CultureAtlas presents a much more diverse distribution of languages across clusters, reflecting the dataset’s cultural and region-specific grounding. In this setting, LSKExtractor consistently outperforms the baselines (Figure[3](https://arxiv.org/html/2505.14990v2#S4.F3 "Figure 3 ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?")), underscoring its advantage in identifying the most informative language for each query. We observe that different models often select different expert languages for the same cluster. This is especially interesting for Culture Atlas clusters, which are—as shown in our cluster-level analysis (Appendix[A](https://arxiv.org/html/2505.14990v2#A1 "Appendix A Cluster Analysis ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"))—aligned with specific countries. Taken together, these findings show that LSKExtractor adapts flexibly to dataset characteristics: converging on English when it is globally optimal, while diversifying language selection when LSK is present.
|
| 169 |
+
|
| 170 |
+
#### 4.2.4 RQ4: Transferability of LSK-Map Across Datasets and Models.
|
| 171 |
+
|
| 172 |
+
We test the robustness of LSKExtractor’s LSK-to-language map. We run two experiments to test the transferability of the LSK map across models and datasets: (1) “transfer-model”: we use the Llama-3.1-8B-Instruct’s CultureAtlas LSK map to evaluate a different model on CultureAtlas. (2) “transfer-dataset”: we use a model’s BLEnD LSK map to evaluate the same model on CultureAtlas. Figure [6](https://arxiv.org/html/2505.14990v2#S4.F6 "Figure 6 ‣ 4.2.4 RQ4: Transferability of LSK-Map Across Datasets and Models. ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") shows the results: LSK maps can be quite robust to dataset and model. The former can be explained by the fact that the LSK map’s reliance on semantic content causes the map to be transferrable across datasets – the same kinds of queries would be best performed in a particular language. The latter can be explained by the overlap across the chosen expert languages themselves. According to Figure [5](https://arxiv.org/html/2505.14990v2#S4.F5 "Figure 5 ‣ 4.2.2 RQ2: Cluster Size versus Performance ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"), there are some overlaps in the chosen expert languages across clusters. We also want to point out that choosing one expert language does not mean other expert languages do not exist. In our experiments, we noticed multiple languages having the same Acc(C j)Acc(C_{j}) as the expert language, and require a tie-breaker.
|
| 173 |
+
|
| 174 |
+

|
| 175 |
+
|
| 176 |
+
Figure 6: Performance of language models using LSKExtractor when the LSK map is transferred from another setting. “transfer-model” is when the LSK map of Llama-3.1-8B-Instruct is used to evaluate the performance on another LLM. “transfer-dataset” is when the LSK map for BLEnD’s training set is used to evaluate the same model on CultureAtlas’s testing set.
|
| 177 |
+
|
| 178 |
+
### 4.3 Feasibility Advantages of LSKExtractor
|
| 179 |
+
|
| 180 |
+
Overall, we observe that LSKExtractor performs on par with, if not better than, the strongest baseline methods, while offering significant advantages in terms of feasibility. Unlike the Country-to-Language mapping approach, which relies on a simplistic heuristic of assigning countries to their most spoken languages, LSKExtractor does not require explicit labeling of country information to guide language selection. In real-world scenarios where queries may involve complex entities, span multiple cultural contexts, or lack clear country associations, obtaining such labels is often impractical or infeasible.
|
| 181 |
+
|
| 182 |
+
Another competitive baseline is the majority-vote method. While conceptually straightforward, this approach is prohibitively expensive, as it requires querying across all available languages. Moreover, it implicitly assumes that all languages are equally informative. However, as demonstrated in our examples, this assumption is flawed: not all languages contribute equally to the quality of results. In contrast, LSKExtractor identifies the most informative languages within clusters of similar queries, thereby reducing cost while maintaining, or even improving, performance.
|
| 183 |
+
|
| 184 |
+
5 Conclusion
|
| 185 |
+
------------
|
| 186 |
+
|
| 187 |
+
In this paper, we explore the concept of Language Specific Knowledge (LSK)—languages contain specific knowledge not present in other languages. We design a methodology, called LSKExtractor, that maps languages to specific topics. We show that LSKExtractor can improve the performance of language models by allowing them to reason in a selected language (dependent on the topic). Our extensive experimentation covers three datasets, a variety of language models (model families, parameter sizes, high-to-low resource languages), and simple to strong baselines. It shows that LSKExtractor achieves up to 10% relative improvements in accuracy, can select optimal expert languages, and is applicable in real world settings. Using the insights of this work, we hope to train models that take advantage of LSK to be more inclusive and culturally aligned.
|
| 188 |
+
|
| 189 |
+
##### Future Work.
|
| 190 |
+
|
| 191 |
+
This work explored monolingual reasoning chains in language models. In the future, we will investigate: (1) multilingual reasoning chains to analyze language-switching effects on reasoning quality, (2) more efficient methods to approximate Language-Specific Knowledge without linearly increasing computational costs, and (3) the practical impact of Language-Specific Knowledge on downstream conversational tasks like persuasion and dialogue-state tracking.
|
| 192 |
+
|
| 193 |
+
6 Ethics Statement
|
| 194 |
+
------------------
|
| 195 |
+
|
| 196 |
+
We are committed to the transparency and reproducibility of our research. We encourage our research community to make use of our open-source code to further improve our methodology. Our research involves the alignment (and potential risks that come with misalignment) in LLMs. In this work, we study this phenomenon of LSK in a controlled environment with little to no safety risks and implications. However, future work must consider these safety risks, especially in multilingual settings. Finally, we’ve accredited all the resources used in this paper (models, datasets, previous works), and a description of the licenses are provided in Appendix [I](https://arxiv.org/html/2505.14990v2#A9 "Appendix I Licenses ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 197 |
+
|
| 198 |
+
7 Reproducibility
|
| 199 |
+
-----------------
|
| 200 |
+
|
| 201 |
+
For reproducibility, we not only provide detailed experimental details in Section [4](https://arxiv.org/html/2505.14990v2#S4 "4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"), we also provide the (anonymized) code case in the abstract, and a description of the compute used during this project in Appendix [H](https://arxiv.org/html/2505.14990v2#A8 "Appendix H Experimental Specifications ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 202 |
+
|
| 203 |
+
Appendix A Cluster Analysis
|
| 204 |
+
---------------------------
|
| 205 |
+
|
| 206 |
+
Figures [7](https://arxiv.org/html/2505.14990v2#A1.F7 "Figure 7 ‣ Appendix A Cluster Analysis ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") to [9](https://arxiv.org/html/2505.14990v2#A1.F9 "Figure 9 ‣ Appendix A Cluster Analysis ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") contain the distributions of languages selected by LSKExtractor for a variety of clustering methods. They mostly show similar patterns to Figure [5](https://arxiv.org/html/2505.14990v2#S4.F5 "Figure 5 ‣ 4.2.2 RQ2: Cluster Size versus Performance ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") where BLEnD and Social IQa are clustered in mostly English, while CultureAtlas is clustered in a variety of languages.
|
| 207 |
+
|
| 208 |
+
We also perform a semantic topic cluster analysis in Table [1](https://arxiv.org/html/2505.14990v2#A1.T1 "Table 1 ‣ Appendix A Cluster Analysis ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") for 12 clusters. Paired with Figure [5](https://arxiv.org/html/2505.14990v2#S4.F5 "Figure 5 ‣ 4.2.2 RQ2: Cluster Size versus Performance ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"), we see that for the same cluster topic, each language model chooses different language experts. For example, for Cluster #5 of Culture Atlas clusters queries from Chinese customs, while the languages selected by the LLMs are Italian, Portuguese, Russian, and Chinese.
|
| 209 |
+
|
| 210 |
+
Table 1: Cluster themes for 12 clusters across datasets. This corresponds to the results in Figures [3](https://arxiv.org/html/2505.14990v2#S4.F3 "Figure 3 ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?")-[5](https://arxiv.org/html/2505.14990v2#S4.F5 "Figure 5 ‣ 4.2.2 RQ2: Cluster Size versus Performance ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 211 |
+
|
| 212 |
+

|
| 213 |
+
|
| 214 |
+

|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
Figure 7: Distribution of languages selected across clusters (k-means with 48 clusters) for the various datasets.
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+

|
| 225 |
+
|
| 226 |
+
Figure 8: Distribution of languages selected across clusters (k-means with 96 clusters) for the various datasets.
|
| 227 |
+
|
| 228 |
+

|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
Figure 9: Distribution of languages selected across clusters (HDBSCAN) for the various datasets (BLEnD had 162 clusters, CultureAtlas had 568, and SocialIQa had 3).
|
| 235 |
+
|
| 236 |
+
Appendix B Impact of Reasoning
|
| 237 |
+
------------------------------
|
| 238 |
+
|
| 239 |
+

|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+

|
| 244 |
+
|
| 245 |
+
Figure 10: Measuring how important reasoning is for each model-dataset setting. These plots show the results for the difference between the performance with reasoning and without.
|
| 246 |
+
|
| 247 |
+
Figure[10](https://arxiv.org/html/2505.14990v2#A2.F10 "Figure 10 ‣ Appendix B Impact of Reasoning ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") illustrates the effect of enabling reasoning by plotting the difference in performance with and without reasoning. A positive value indicates that reasoning improves accuracy, while a negative value indicates degradation. The results vary across models and datasets, but a clear pattern emerges: smaller models tend to benefit more from reasoning than larger ones. This trend is intuitive—larger models encode more factual and contextual world knowledge directly in their parameters and can often retrieve relevant information without additional reasoning steps. By contrast, smaller models rely more heavily on explicit reasoning to bridge knowledge gaps and organize retrieved information, leading to larger performance gains when reasoning is enabled.
|
| 248 |
+
|
| 249 |
+
Appendix C Dataset Translation
|
| 250 |
+
------------------------------
|
| 251 |
+
|
| 252 |
+
To ensure the integrity of our experimental design, we translate the instructions and inputs from the datasets. The (multiple choice question-answering) datasets we choose are in English. We use OpenAI’s GPT-4o-mini to translate the queries (instruction + input + answer choices). Our prompt is outlined in Figure [11](https://arxiv.org/html/2505.14990v2#A3.F11 "Figure 11 ‣ Appendix C Dataset Translation ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 253 |
+
|
| 254 |
+
In order to verify whether the models are outputting responses that align to the language they are supposed to reason in, we run a language classification model (specifically, qanastek/51-languages-classifier – we choose this for its good performance, and because it covers the language set we choose for our experimentation) and calculate the percentage of samples that follow the intended reasoning language. For BLEnD, CultureAtlas, and Social IQa, respectively, we see average accuracies of 96.97%, 97.73% and 97.93%, across all models and languages. This indicates that models generally are very good at following instructions to think in a certain language, and further strengthens the claims we make in our paper.
|
| 255 |
+
|
| 256 |
+
Figure 11: Prompt to GPT-4o-mini to translate the datasets into one of the 16 languages we chose for our experimentation. As input, the translation “language” and the text to translate (“input”) is provided.
|
| 257 |
+
|
| 258 |
+
Appendix D LLMSelected baseline details
|
| 259 |
+
---------------------------------------
|
| 260 |
+
|
| 261 |
+
Figure [12](https://arxiv.org/html/2505.14990v2#A4.F12 "Figure 12 ‣ Appendix D LLMSelected baseline details ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") contains the distribution of languages selected for the LLMSelected baseline (again, the prompt is outlined in Figure [13](https://arxiv.org/html/2505.14990v2#A4.F13 "Figure 13 ‣ Appendix D LLMSelected baseline details ‣ Language Specific Knowledge: Do Models Know Better in X than in English?")). As mentioned in the main text, due to English being chosen more often than LSKExtractor, LLMSelected highlights that a language model’s internal LSK map is not reliable, and should be explicitly mapped.
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+

|
| 266 |
+
|
| 267 |
+
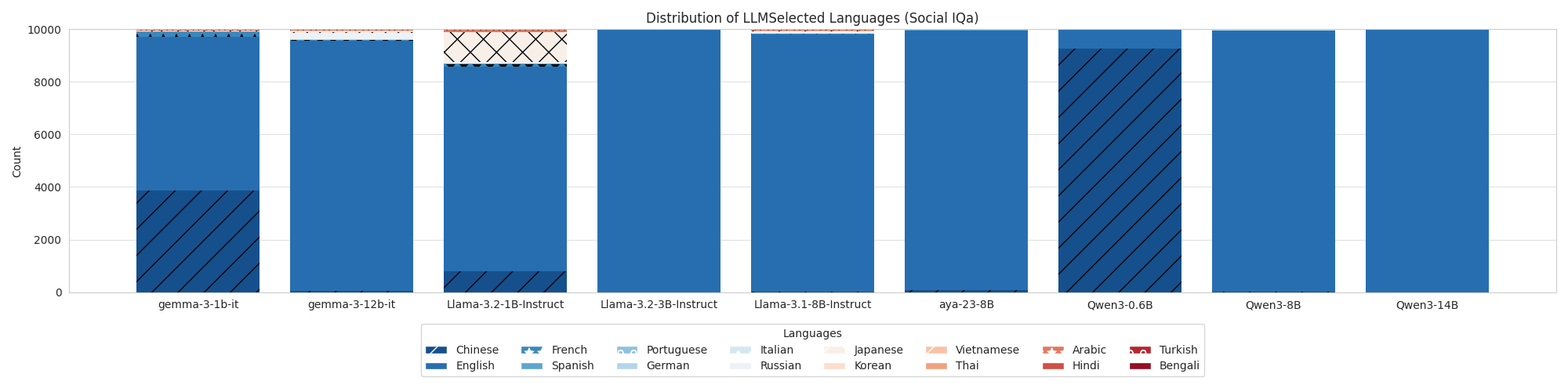
|
| 268 |
+
|
| 269 |
+
Figure 12: Distribution of languages selected by the LLMSelected baseline for each dataset.
|
| 270 |
+
|
| 271 |
+
Figure 13: Prompt to the language model to select the language expert for a given question, which is our baseline called LLMSelected.
|
| 272 |
+
|
| 273 |
+
Appendix E CultureAtlas Reformatting
|
| 274 |
+
------------------------------------
|
| 275 |
+
|
| 276 |
+
The CultureAtlas dataset consists of cultural claims associated with specific countries, each annotated as either true or false. Because this binary classification setting is relatively simple and the dataset is imbalanced toward false claims, we reformatted it into a multiple-choice question (MCQ) format. In the reformatted version, each question presents four answer choices pertaining to the same country: one true claim and three false claims. The model is then tasked with identifying the true claim, transforming the problem into a more nuanced and challenging task that requires reasoning across all options. An illustrative example of a reformatted question is shown in Figure[14](https://arxiv.org/html/2505.14990v2#A5.F14 "Figure 14 ‣ Appendix E CultureAtlas Reformatting ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 277 |
+
|
| 278 |
+
Figure 14: An example of a reformatted CultureAtlas question. The original binary (true/false) claims are transformed into a multiple-choice format with four options about the same country: one true claim and three false claims. The model is required to select the true claim.
|
| 279 |
+
|
| 280 |
+
Appendix F Country to Language Mapping
|
| 281 |
+
--------------------------------------
|
| 282 |
+
|
| 283 |
+
For our Country Mapping baseline, we assign a language 𝓁 i∈ℒ\mathcal{l}_{i}\in\mathcal{L} to each country in the dataset. For each country, we select the most commonly spoken language in the corresponding region. If the most common language is not included in ℒ\mathcal{L}, we default to English. The mappings used in our experiments are summarized in Table[2](https://arxiv.org/html/2505.14990v2#A6.T2 "Table 2 ‣ Appendix F Country to Language Mapping ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 284 |
+
|
| 285 |
+
Dataset Language Countries
|
| 286 |
+
Blend Arabic Algeria, Ethiopia
|
| 287 |
+
Chinese China
|
| 288 |
+
English Assam, Azerbaijan, Greece, Indonesia, Iran, Northern Nigeria, UK, US, West Java
|
| 289 |
+
Korean North Korea, South Korea
|
| 290 |
+
Spanish Mexico, Spain
|
| 291 |
+
CultureAtlas Arabic Algeria, Bahrain, Comoros, Egypt, Iraq, Jordan, Kuwait, Lebanon, Libya, Mauritania, Morocco, Oman, Qatar, Saudi Arabia, Sudan, Tunisia, United Arab Emirates, Yemen
|
| 292 |
+
Bengali Bangladesh
|
| 293 |
+
Chinese China
|
| 294 |
+
English Afghanistan, Albania, Andorra, Antigua and Barbuda, Armenia, Australia, Azerbaijan, Bahamas, Barbados, Belarus, Belgium, Belize, Bhutan, Bosnia and Herzegovina, Botswana, Bulgaria, Burundi, Cambodia, Canada, Croatia, Cyprus, Czechia, Denmark, Dominica, Eritrea, Estonia, Eswatini, Ethiopia, Federated States of Micronesia, Fiji, Finland, Gambia, Georgia, Ghana, Greece, Grenada, Guyana, Haiti, Hungary, Iceland, Indonesia, Ireland, Islamic Republic of Iran, Israel, Jamaica, Kazakhstan, Kenya, Kiribati, Kyrgyzstan, Lao People’s Democratic Republic, Latvia, Lesotho, Liberia, Lithuania, Luxembourg, Madagascar, Malawi, Malaysia, Maldives, Malta, Marshall Islands, Mauritius, Mongolia, Montenegro, Myanmar, Namibia, Nauru, Nepal, Netherlands, New Zealand, Nigeria, North Macedonia, Norway, Pakistan, Palau, Papua New Guinea, Philippines, Poland, Republic of Moldova, Romania, Rwanda, Saint Kitts and Nevis, Saint Lucia, Saint Vincent and the Grenadines, Samoa, Serbia, Seychelles, Sierra Leone, Singapore, Slovakia, Slovenia, Solomon Islands, Somalia, South Africa, South Sudan, Sri Lanka, Suriname, Sweden, Tajikistan, Timor-Leste, Tonga, Trinidad and Tobago, Turkmenistan, Tuvalu, Uganda, Ukraine, United Kingdom of Great Britain and Northern Ireland, United Republic of Tanzania, United States of America, Uzbekistan, Vanuatu, Zambia, Zimbabwe
|
| 295 |
+
French Benin, Burkina Faso, Cameroon, Central African Republic, Chad, Congo, Côte d’Ivoire, Democratic Republic of the Congo, Djibouti, France, Gabon, Guinea, Monaco, Niger, Senegal, Togo
|
| 296 |
+
German Austria, Germany, Liechtenstein, Switzerland
|
| 297 |
+
Hindi India
|
| 298 |
+
Italian Italy, San Marino
|
| 299 |
+
Japanese Japan
|
| 300 |
+
Korean Democratic People’s Republic of Korea, Republic of Korea
|
| 301 |
+
Portuguese Angola, Brazil, Guinea-Bissau, Mozambique, Portugal, São Tomé and Príncipe
|
| 302 |
+
Russian Russian Federation
|
| 303 |
+
Spanish Argentina, Bolivarian Republic of Venezuela, Chile, Colombia, Costa Rica, Cuba, Dominican Republic, Ecuador, El Salvador, Equatorial Guinea, Guatemala, Honduras, Mexico, Nicaragua, Panama, Paraguay, Peru, Plurinational State of Bolivia, Spain, Uruguay
|
| 304 |
+
Thai Thailand
|
| 305 |
+
Turkish Türkiye
|
| 306 |
+
Vietnamese Viet Nam
|
| 307 |
+
|
| 308 |
+
Table 2: Country-to-language mappings used for the Blend and CultureAtlas datasets. Each country is assigned its most commonly spoken language, defaulting to English if the language is not present in ℒ\mathcal{L}.
|
| 309 |
+
|
| 310 |
+
Appendix G Model Prompts
|
| 311 |
+
------------------------
|
| 312 |
+
|
| 313 |
+
Figures [15](https://arxiv.org/html/2505.14990v2#A7.F15 "Figure 15 ‣ Appendix G Model Prompts ‣ Language Specific Knowledge: Do Models Know Better in X than in English?")-[18](https://arxiv.org/html/2505.14990v2#A7.F18 "Figure 18 ‣ Appendix G Model Prompts ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") contain the prompts to the language for during our evaluation, with and without reasoning, in three languages (English, French, Turkish) to save space. Figure [13](https://arxiv.org/html/2505.14990v2#A4.F13 "Figure 13 ‣ Appendix D LLMSelected baseline details ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") contains the prompt for the LLMSelected baseline in the main paper.
|
| 314 |
+
|
| 315 |
+
Figure 15: Prompt to the language model to perform without reasoning. We show results for how no-reasoning affects the model performance in Figure [10](https://arxiv.org/html/2505.14990v2#A2.F10 "Figure 10 ‣ Appendix B Impact of Reasoning ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"). For BLEnD and Social IQa, the “input_question” and “choice_x” comes from the dataset. For CultureAtlas, because we modify the dataset ourselves to make it more difficult, the input question will always be “Which is the following is true about {country}?”. Details of the CutlureAtlas modification are in Appendix [E](https://arxiv.org/html/2505.14990v2#A5 "Appendix E CultureAtlas Reformatting ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 316 |
+
|
| 317 |
+
Figure 16: Prompt to the language model to perform without reasoning. We show results for how no-reasoning affects the model performance in Figure [10](https://arxiv.org/html/2505.14990v2#A2.F10 "Figure 10 ‣ Appendix B Impact of Reasoning ‣ Language Specific Knowledge: Do Models Know Better in X than in English?"). For BLEnD and Social IQa, the “input_question” and “choice_x” comes from the dataset. For CultureAtlas, because we modify the dataset ourselves to make it more difficult, the input question will always be “Which is the following is true about {country}?”. Details of the CutlureAtlas modification are in Appendix [E](https://arxiv.org/html/2505.14990v2#A5 "Appendix E CultureAtlas Reformatting ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 318 |
+
|
| 319 |
+
Figure 17: Prompt to the language model to perform with reasoning, in English. Figure [3](https://arxiv.org/html/2505.14990v2#S4.F3 "Figure 3 ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") illustrates the results using this prompt. For BLEnD and Social IQa, the “input_question” and “choice_x” comes from the dataset. For CultureAtlas, because we modify the dataset ourselves to make it more difficult, the input question will always be “Which is the following is true about {country}?”. Details of the CutlureAtlas modification are in Appendix [E](https://arxiv.org/html/2505.14990v2#A5 "Appendix E CultureAtlas Reformatting ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 320 |
+
|
| 321 |
+
Figure 18: Prompt to the language model to perform with reasoning, in Turkish. Figure [3](https://arxiv.org/html/2505.14990v2#S4.F3 "Figure 3 ‣ 4.2 Results ‣ 4 Experiments ‣ Language Specific Knowledge: Do Models Know Better in X than in English?") illustrates the results using this prompt. For BLEnD and Social IQa, the “input_question” and “choice_x” comes from the dataset. For CultureAtlas, because we modify the dataset ourselves to make it more difficult, the input question will always be “Which is the following is true about {country}?”. Details of the CutlureAtlas modification are in Appendix [E](https://arxiv.org/html/2505.14990v2#A5 "Appendix E CultureAtlas Reformatting ‣ Language Specific Knowledge: Do Models Know Better in X than in English?").
|
| 322 |
+
|
| 323 |
+
Appendix H Experimental Specifications
|
| 324 |
+
--------------------------------------
|
| 325 |
+
|
| 326 |
+
We run our inference on NVIDIA A40 GPUs. For the the 1B, 3B, 8B models, we used a single A40 GPU, while the 12B and 14B required two A40 GPUs. Inference takes around 30-60 minutes per language. Clustering is computationally inexpensive and can be done on a single A40 GPU.
|
| 327 |
+
|
| 328 |
+
Appendix I Licenses
|
| 329 |
+
-------------------
|
| 330 |
+
|
| 331 |
+
Our [code](https://anonymous.4open.science/r/LSKExtractor-272F/) is released publicly under the Apache-2.0 License. CultureAtlas [cultureatlas] is released under the MIT License; BLEnD [blend] under the CC-by-SA-4.0 License; SocialIQa [socialiqa] is not under explicit license, however it is publicly available on Huggingface, and we do not use it for commercial purposes. All models are under their proprietary licenses from the corresponding companies.
|
| 332 |
+
|
| 333 |
+
Appendix J Use of Large Language Models
|
| 334 |
+
---------------------------------------
|
| 335 |
+
|
| 336 |
+
Other than being used as part of the experiments conducted in this work, LLMs were used solely as a writing assistance tool in preparing this paper submission. Their role was limited to polishing language, improving clarity, and reducing redundancy. The prompt used for this purpose was similar to "Please revise the writing of this, making sure to remove any grammatical mistakes." All research ideas, experimental designs, analyses, and claims presented in the paper are entirely the original work of the authors. No part of the conceptual, methodological, or empirical contributions relies on or originates from LLM outputs.
|