

Add 1 files
Browse files- 2510/2510.20498.md +445 -0
2510/2510.20498.md
ADDED
|
@@ -0,0 +1,445 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
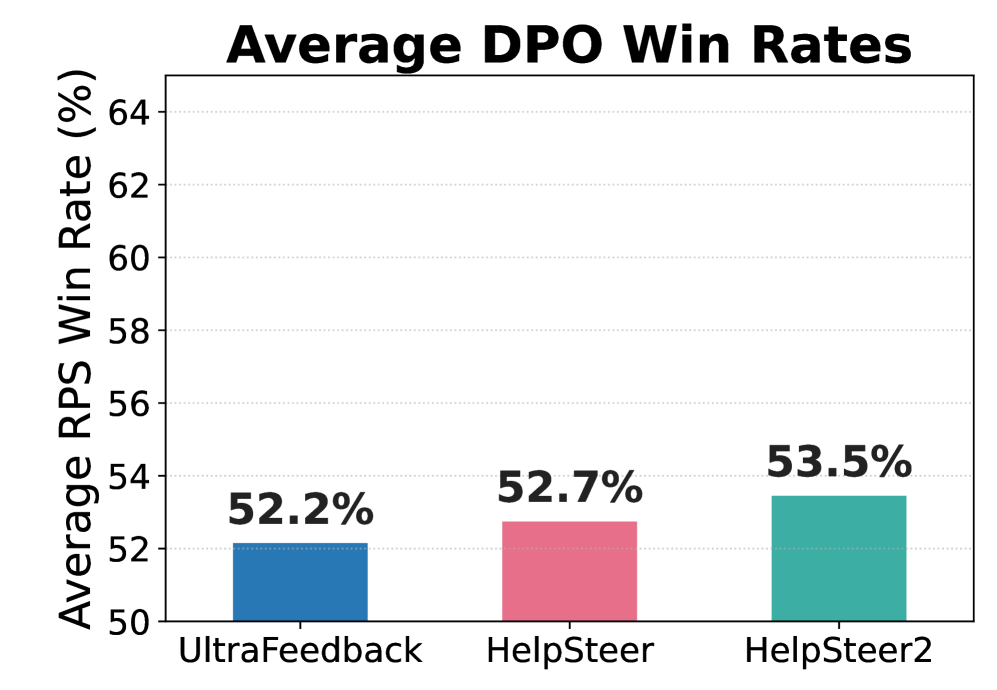
|
|
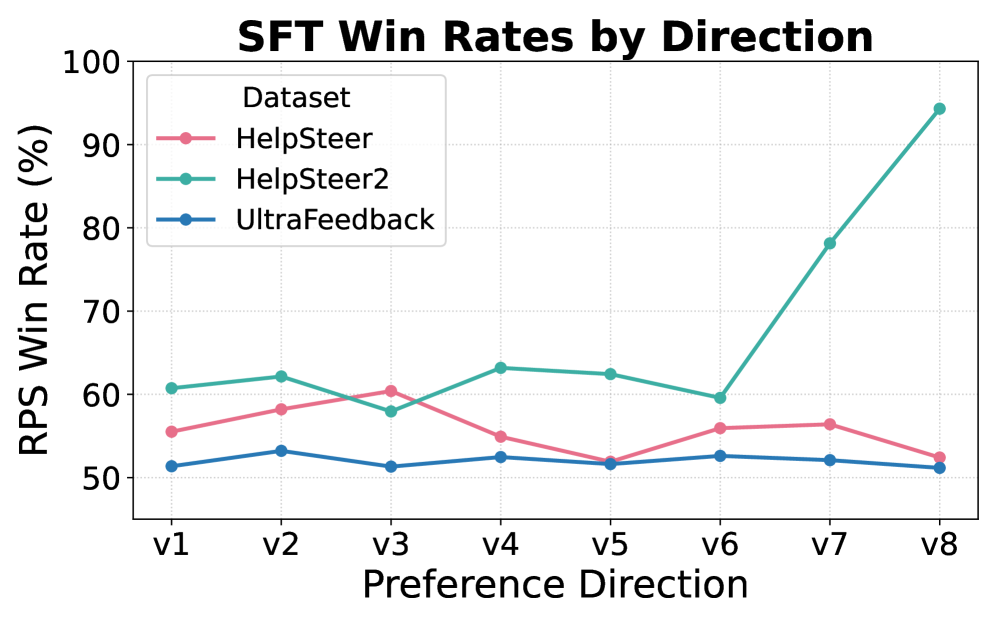
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
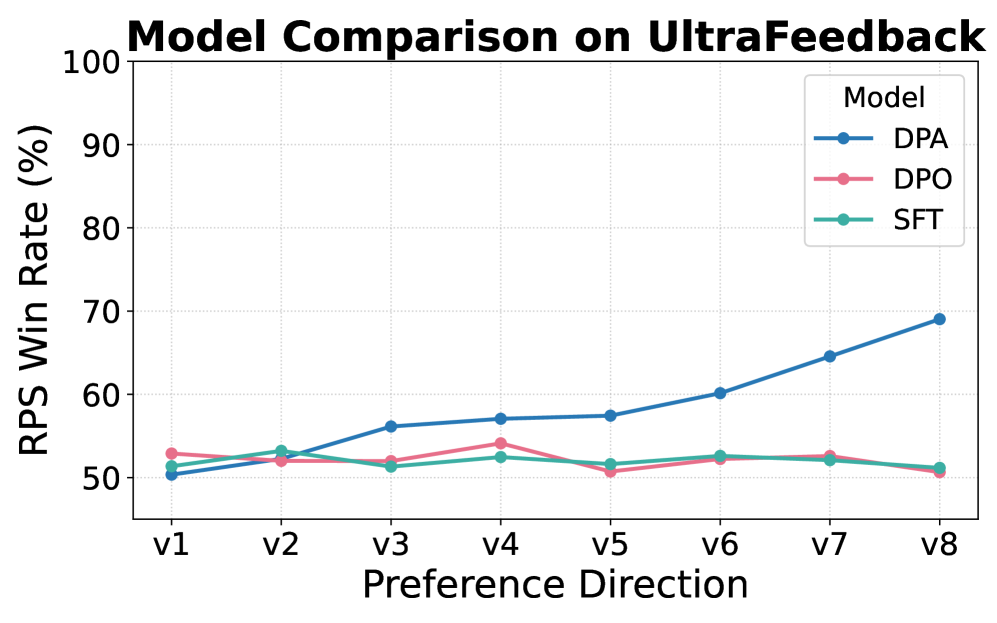
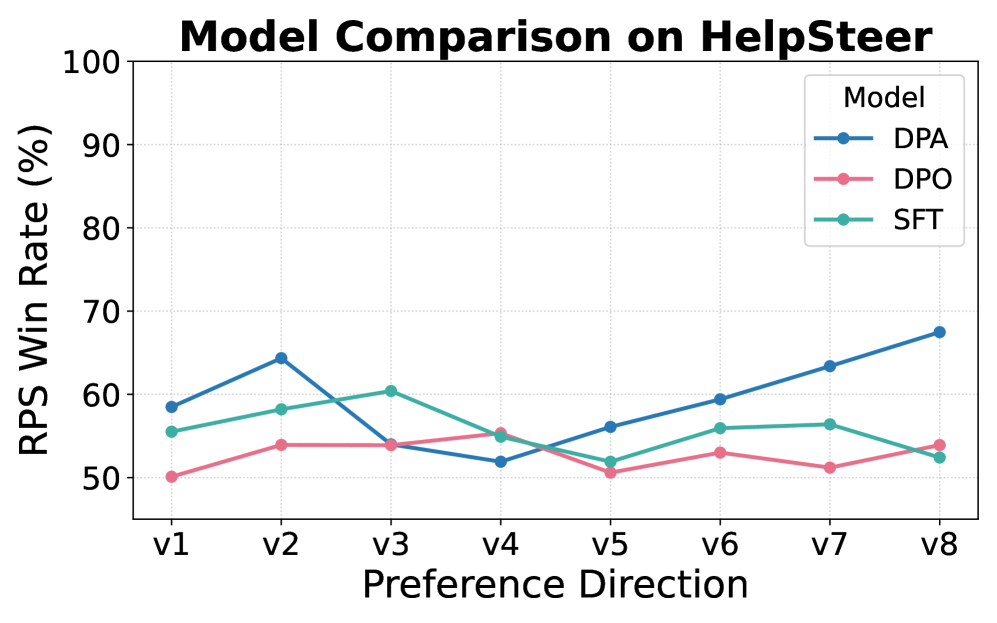
|
|
|
|
|
|
|
|
|
|
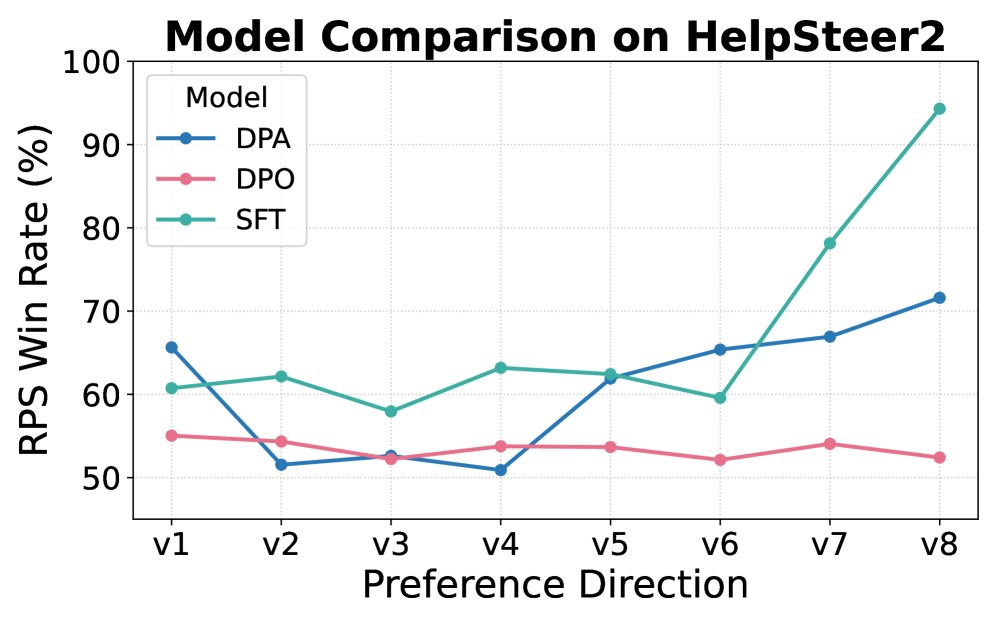
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Robust Preference Alignment via Directional Neighborhood Consensus
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2510.20498
|
| 4 |
+
|
| 5 |
+
Markdown Content:
|
| 6 |
+
1 1 footnotetext: Work done during a research internship at HKUST (GZ).2 2 footnotetext: Corresponding author.
|
| 7 |
+
Ruochen Mao 1*Yuling Shi 2 Xiaodong Gu 2 Jiaheng Wei 1†
|
| 8 |
+
|
| 9 |
+
1 The Hong Kong University of Science and Technology (Guangzhou)
|
| 10 |
+
|
| 11 |
+
2 Shanghai Jiao Tong University
|
| 12 |
+
|
| 13 |
+
###### Abstract
|
| 14 |
+
|
| 15 |
+
Aligning large language models with human preferences is critical for creating reliable and controllable AI systems. A human preference can be visualized as a high-dimensional vector where different directions represent trade-offs between desired attributes (e.g., helpfulness vs. verbosity). Yet, because the training data often reflects dominant, average preferences, LLMs tend to perform well on common requests but falls short in specific, individual needs. This mismatch creates a preference coverage gap. Existing methods often address this through costly retraining, which may not be generalized to the full spectrum of diverse preferences. This brittleness means that when a user’s request reflects a nuanced preference deviating from the training data’s central tendency, model performance can degrade unpredictably. To address this challenge, we introduce Robust Preference Selection (RPS), a post-hoc, training-free method by leveraging _directional neighborhood consensus_. Instead of forcing a model to generate a response from a single, highly specific preference, RPS samples multiple responses from a local neighborhood of related preferences to create a superior candidate pool. It then selects the response that best aligns with the user’s original intent. We provide a theoretical framework showing our neighborhood generation strategy is provably superior to a strong baseline that also samples multiple candidates. Comprehensive experiments across three distinct alignment paradigms (DPA, DPO, and SFT) demonstrate that RPS consistently improves robustness against this baseline, achieving win rates of up to 69% on challenging preferences from under-represented regions of the space without any model retraining. Our work presents a practical, theoretically-grounded solution for enhancing the reliability of preference-aligned models***Code and data available at[https://github.com/rcmao/robust-preference-alignment](https://github.com/rcmao/robust-preference-alignment).
|
| 16 |
+
|
| 17 |
+
1 Introduction
|
| 18 |
+
--------------
|
| 19 |
+
|
| 20 |
+
Aligning large language models (LLMs) with human preferences is crucial for creating reliable and controllable AI systems (Ouyang et al., [2022](https://arxiv.org/html/2510.20498v2#bib.bib21); Christiano et al., [2017](https://arxiv.org/html/2510.20498v2#bib.bib6); Ziegler et al., [2020](https://arxiv.org/html/2510.20498v2#bib.bib38); Guo et al., [2024](https://arxiv.org/html/2510.20498v2#bib.bib13); Shi et al., [2024](https://arxiv.org/html/2510.20498v2#bib.bib25); Wei et al., [2024](https://arxiv.org/html/2510.20498v2#bib.bib32); Liu et al., [2025b](https://arxiv.org/html/2510.20498v2#bib.bib20); Pang et al., [2025](https://arxiv.org/html/2510.20498v2#bib.bib22)). User preferences can be modeled in a multi-dimensional space where different directions represent trade-offs between desired attributes, such as helpfulness versus verbosity (Wang et al., [2024a](https://arxiv.org/html/2510.20498v2#bib.bib28); Dong et al., [2023](https://arxiv.org/html/2510.20498v2#bib.bib9)). As illustrated in Figure[2](https://arxiv.org/html/2510.20498v2#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Robust Preference Alignment via Directional Neighborhood Consensus"), this creates a foundational challenge: the preference coverage gap. While the space of potential user preferences is vast and diverse, as depicted in Figure[2](https://arxiv.org/html/2510.20498v2#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Robust Preference Alignment via Directional Neighborhood Consensus")(a), the alignment process often optimizes for a dominant, average preference, meaning the training data is concentrated in a narrow region (Figure[2](https://arxiv.org/html/2510.20498v2#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Robust Preference Alignment via Directional Neighborhood Consensus")(b)). This focus on average preferences makes models brittle; when faced with a user preference that reflects more individual needs and deviates from this central tendency—a common out-of-distribution (OOD) challenge—their performance can degrade unpredictably, undermining user trust (Hendrycks et al., [2020](https://arxiv.org/html/2510.20498v2#bib.bib14)).
|
| 21 |
+
|
| 22 |
+
(a) The complete user preference space.
|
| 23 |
+
|
| 24 |
+
(b) The sparse training preference set.
|
| 25 |
+
|
| 26 |
+
Figure 1: Illustration of the preference coverage gap. While user preferences (a) can span the entire space, the model’s training data (b) is often concentrated on dominant, average preferences, leaving individual needs in a sparse subset. This creates a gap where a user’s target preference may lie.
|
| 27 |
+
|
| 28 |
+
Figure 2: Conceptual visualization of RPS. Instead of relying on a single, potentially out-of-distribution target preference 𝐯 target\mathbf{v}_{\text{target}} (solid black arrow), RPS samples k k directions from its local neighborhood (dashed blue arrows). By generating responses from this diverse set, RPS can identify a response that better aligns with the user’s true intent.
|
| 29 |
+
|
| 30 |
+
To address this coverage gap, many existing solutions focus on training-time interventions. These include methods like data augmentation or the adoption of principles from Distributionally Robust Optimization (DRO) (Duchi et al., [2016](https://arxiv.org/html/2510.20498v2#bib.bib11); Ben-Tal et al., [2013](https://arxiv.org/html/2510.20498v2#bib.bib2); Duchi & Namkoong, [2018](https://arxiv.org/html/2510.20498v2#bib.bib10)) to create models that are resilient to shifts in preference distributions (Xu et al., [2025](https://arxiv.org/html/2510.20498v2#bib.bib33)). While effective, such approaches often require costly retraining cycles and may still fail to generalize to the full spectrum of diverse, individual preferences. This motivates an alternative question: can we enhance robustness at inference time, without any modification to the underlying model?
|
| 31 |
+
|
| 32 |
+
This paper argues that forcing a model to generate a response from a single, highly specific and less common preference direction is inherently fragile. We propose a paradigm shift from direct generation to one based on directional neighborhood consensus. As visualized in Figure[2](https://arxiv.org/html/2510.20498v2#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Robust Preference Alignment via Directional Neighborhood Consensus"), instead of attempting to extrapolate to a specific, under-represented preference point, it is more robust to explore the local neighborhood, generate responses from these more dominant, better-understood directions, and then select the one that best satisfies the original preference.
|
| 33 |
+
|
| 34 |
+
To realize this, we introduce Robust Preference Selection (RPS), a post-hoc adjustment method that enhances preference alignment at inference time without any retraining. RPS first samples a set of candidate preference vectors from the neighborhood of the user’s target preference. It then generates a response for each of these nearby vectors and, finally, uses the target preference itself as a criterion to select the optimal response from this diverse set. This approach effectively leverages the model’s existing capabilities in well-trained regions of the preference space to satisfy requests in undertrained ones.
|
| 35 |
+
|
| 36 |
+
Our contributions are threefold:
|
| 37 |
+
|
| 38 |
+
* •We formally define the preference coverage gap as a critical out-of-distribution (OOD) challenge that undermines the reliability of aligned LLMs. To address this, we introduce RPS, a novel, training-free method that enhances robustness through post-hoc adjustment without requiring any model modification.
|
| 39 |
+
* •We propose RPS, a method grounded in neighborhood consensus, and provide a theoretical framework proving that its neighborhood generation strategy is superior to a strong multi-candidate baseline.
|
| 40 |
+
* •We conduct extensive experiments across three distinct alignment paradigms (DPA, DPO, and SFT) and three datasets (UltraFeedback, HelpSteer, and HelpSteer2). Our results show that RPS consistently improves robustness, achieving win rates of up to 69% on challenging OOD preferences and demonstrating its broad applicability.
|
| 41 |
+
|
| 42 |
+
2 Related Work
|
| 43 |
+
--------------
|
| 44 |
+
|
| 45 |
+
### 2.1 Preference Alignment in Large Language Models
|
| 46 |
+
|
| 47 |
+
Aligning LLM behavior with human preferences has become a central research area. Reinforcement Learning from Human Feedback (RLHF) is a pioneering pipeline that fine-tunes models with human preference rankings, as demonstrated by (Ouyang et al., [2022](https://arxiv.org/html/2510.20498v2#bib.bib21)). However, RLHF compresses diverse user preferences into a single scalar reward and requires complex reward modeling plus reinforcement learning (Zhang et al., [2025](https://arxiv.org/html/2510.20498v2#bib.bib36); Li et al., [2025a](https://arxiv.org/html/2510.20498v2#bib.bib16); Liu et al., [2025a](https://arxiv.org/html/2510.20498v2#bib.bib19)). To simplify this process, Direct Preference Optimization (DPO) was introduced (Rafailov et al., [2023](https://arxiv.org/html/2510.20498v2#bib.bib23)), which recasts preference optimization as supervised classification, eliminating the need for explicit reward models. Subsequent generalizations explore divergence families and latent user heterogeneity (Wang et al., [2023](https://arxiv.org/html/2510.20498v2#bib.bib27); Chidambaram et al., [2024](https://arxiv.org/html/2510.20498v2#bib.bib5)), while others have proposed new theoretical paradigms for understanding preference learning (Azar et al., [2023](https://arxiv.org/html/2510.20498v2#bib.bib1)). Moving beyond scalar objectives, Directional Preference Alignment (DPA) enables users to specify trade-offs in a multi-axis reward space (Wang et al., [2024a](https://arxiv.org/html/2510.20498v2#bib.bib28)). Similarly, SteerLM conditions supervised fine-tuning on attribute labels, exposing controllable style dimensions such as helpfulness or humor (Dong et al., [2023](https://arxiv.org/html/2510.20498v2#bib.bib9)). These methods are part of a broader research effort in controllable text generation, which aims to provide users with fine-grained control over model outputs (Liang et al., [2024](https://arxiv.org/html/2510.20498v2#bib.bib18)). Our work differs from these training-time approaches: rather than modifying the model weights, we focus on inference-time robustness to preference shifts through directional neighborhood consensus.
|
| 48 |
+
|
| 49 |
+
### 2.2 Enhancing Robustness in Language Models
|
| 50 |
+
|
| 51 |
+
While the alignment methods described above are powerful, a key challenge remains: models often remain brittle under out-of-distribution (OOD) preferences. Recent work has formalized preference distribution shifts and proposed distributionally robust objectives such as (Xu et al., [2025](https://arxiv.org/html/2510.20498v2#bib.bib33)), which strengthen resilience during training. Beyond alignment, the broader NLP community has highlighted the challenges of OOD generalization, with benchmarks such as (Yang et al., [2022](https://arxiv.org/html/2510.20498v2#bib.bib34); [2023](https://arxiv.org/html/2510.20498v2#bib.bib35)). At inference time, an alternative approach is to use ensemble-like methods, a principle with deep roots in machine learning (Dietterich, [2000](https://arxiv.org/html/2510.20498v2#bib.bib8)). For instance, (Wang et al., [2022](https://arxiv.org/html/2510.20498v2#bib.bib29)) shows that sampling diverse reasoning paths and aggregating their consensus yields more reliable results. The principle of post-hoc adjustment for robustness is also explored in other domains, such as classification, where scaling model outputs can mitigate the effects of distributional shifts (Wei et al., [2023](https://arxiv.org/html/2510.20498v2#bib.bib31)).
|
| 52 |
+
|
| 53 |
+
Extending this idea, recent inference-time alignment frameworks share our post-hoc perspective but differ in mechanism. Many rely on direct intervention in the generation process through token-level guidance or activation steering (Li et al., [2025b](https://arxiv.org/html/2510.20498v2#bib.bib17); Shahriar et al., [2024](https://arxiv.org/html/2510.20498v2#bib.bib24)), or require auxiliary models for decoding-time guidance (Chehade et al., [2025](https://arxiv.org/html/2510.20498v2#bib.bib4); Chandra et al., [2025](https://arxiv.org/html/2510.20498v2#bib.bib3)). In contrast, our RPS approach operates purely in the preference space. By leveraging neighborhood consensus to select an optimal response, it avoids direct manipulation of the model’s internal states, offering a simpler and more black-box solution that requires no external guidance models.
|
| 54 |
+
|
| 55 |
+
3 Problem Setup and Theoretical Framework
|
| 56 |
+
-----------------------------------------
|
| 57 |
+
|
| 58 |
+
We build upon the problem formulation of Directional Preference Alignment (DPA) (Wang et al., [2024a](https://arxiv.org/html/2510.20498v2#bib.bib28)). In this section, we formalize the preference alignment challenge by first defining the preference space and characterizing the coverage gap that causes model brittleness. We then establish the theoretical foundations for our proposed solution, Robust Preference Selection (RPS).
|
| 59 |
+
|
| 60 |
+
### 3.1 Preference Space and Reward Model
|
| 61 |
+
|
| 62 |
+
We model user preferences in a two-dimensional space for clarity of illustration, as depicted in Figure[2](https://arxiv.org/html/2510.20498v2#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Robust Preference Alignment via Directional Neighborhood Consensus")(a), spanned by two key axes: Helpfulness and Verbosity(Wang et al., [2024a](https://arxiv.org/html/2510.20498v2#bib.bib28); Dong et al., [2023](https://arxiv.org/html/2510.20498v2#bib.bib9)). Our theoretical framework, however, generalizes directly to higher-dimensional preference spaces. To quantify these attributes, we formalize the notion of a reward vector.
|
| 63 |
+
|
| 64 |
+
Definition (Reward Vector): A reward model maps a prompt-response pair (x,y)(x,y) to a reward vector 𝐫(x,y)=(r h(x,y),r v(x,y))∈ℝ 2\mathbf{r}(x,y)=(r_{h}(x,y),r_{v}(x,y))\in\mathbb{R}^{2}. The components r h(x,y)r_{h}(x,y) and r v(x,y)r_{v}(x,y) are scalar scores representing the helpfulness and verbosity of the response, respectively (Wang et al., [2024a](https://arxiv.org/html/2510.20498v2#bib.bib28)).
|
| 65 |
+
|
| 66 |
+
A user’s preference is represented as a normalized direction vector 𝐯=(v h,v v)∈𝕊 1\mathbf{v}=(v_{h},v_{v})\in\mathbb{S}^{1} on the unit circle, where v h v_{h} and v v v_{v} specify the desired weights for helpfulness and verbosity. This can be parameterized by an angle θ\theta, such that 𝐯=(cosθ,sinθ)\mathbf{v}=(\cos\theta,\sin\theta). The goal of a preference-aligned model is to generate a response y y that maximizes the projected reward: 𝐯 T𝐫(x,y)\mathbf{v}^{T}\mathbf{r}(x,y). Our framework assumes that this reward model 𝐫(x,y)\mathbf{r}(x,y) is well-calibrated and provides meaningful scores across the entire preference space, including for out-of-distribution directions.
|
| 67 |
+
|
| 68 |
+
### 3.2 The Preference Coverage Problem
|
| 69 |
+
|
| 70 |
+
The central challenge in preference alignment, as illustrated in Figure[2](https://arxiv.org/html/2510.20498v2#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Robust Preference Alignment via Directional Neighborhood Consensus"), is the discrepancy between the vast space of user preferences and the limited coverage of the training data. We formalize this problem as follows:
|
| 71 |
+
|
| 72 |
+
Definition 1 (User Preference Space): Let 𝒱 user\mathcal{V}_{\text{user}} denote the complete set of all possible normalized preference vectors 𝐯∈𝕊 1\mathbf{v}\in\mathbb{S}^{1}. This represents the entire spectrum of potential user preferences, as depicted in Figure[2](https://arxiv.org/html/2510.20498v2#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Robust Preference Alignment via Directional Neighborhood Consensus")(a).
|
| 73 |
+
|
| 74 |
+
Definition 2 (Training Preference Set): Let 𝒱 train⊂𝒱 user\mathcal{V}_{\text{train}}\subset\mathcal{V}_{\text{user}} be the subset of preference directions used during training, visualized as the concentrated region in Figure[2](https://arxiv.org/html/2510.20498v2#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Robust Preference Alignment via Directional Neighborhood Consensus")(b). This set is often sampled from a constrained range.
|
| 75 |
+
|
| 76 |
+
Definition 3 (Preference Coverage Gap): The coverage gap, illustrated by the difference between the full space in Figure[2](https://arxiv.org/html/2510.20498v2#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Robust Preference Alignment via Directional Neighborhood Consensus")(a) and the training data in Figure[2](https://arxiv.org/html/2510.20498v2#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Robust Preference Alignment via Directional Neighborhood Consensus")(b), consists of all preference vectors that are not within an ϵ\epsilon-neighborhood of any training vector: Gap=𝒱 user∖𝒩 ϵ(𝒱 train)\text{Gap}=\mathcal{V}_{\text{user}}\setminus\mathcal{N}_{\epsilon}(\mathcal{V}_{\text{train}}).
|
| 77 |
+
|
| 78 |
+
When a target preference 𝐯 target\mathbf{v}_{\text{target}} lies in this gap—as illustrated with the out-of-distribution vector in Figure[2](https://arxiv.org/html/2510.20498v2#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Robust Preference Alignment via Directional Neighborhood Consensus")(b)—the model’s performance is unreliable. Our goal is to develop a method that can robustly generate a high-quality response y∗y^{*} that maximizes user satisfaction, even for out-of-distribution preferences:
|
| 79 |
+
|
| 80 |
+
y∗=argmax y𝐯 target T𝐫(x,y),y^{*}=\arg\max_{y}\mathbf{v}_{\text{target}}^{T}\mathbf{r}(x,y),(1)
|
| 81 |
+
|
| 82 |
+
where 𝐫(x,y)=(r h(x,y),r v(x,y))\mathbf{r}(x,y)=(r_{h}(x,y),r_{v}(x,y)) represents the helpfulness and verbosity scores of response y y to prompt x x. This challenge of performing well on a target preference 𝐯 target\mathbf{v}_{\text{target}} that lies in the gap can be framed through the lens of Distributionally Robust Optimization (DRO) (Duchi et al., [2016](https://arxiv.org/html/2510.20498v2#bib.bib11); Ben-Tal et al., [2013](https://arxiv.org/html/2510.20498v2#bib.bib2); Duchi & Namkoong, [2018](https://arxiv.org/html/2510.20498v2#bib.bib10)). In the DRO paradigm, the objective is to find a policy that is robust not just to the empirical training distribution (represented by 𝒱 train\mathcal{V}_{\text{train}}) but to a family of plausible test distributions. Our inference-time approach complements training-time DRO solutions by addressing this distributional shift post-hoc, at the point of generation.
|
| 83 |
+
|
| 84 |
+
### 3.3 Neighborhood Consensus Theory
|
| 85 |
+
|
| 86 |
+
Instead of merely justifying the final selection step, our theoretical framework aims to explain why the entire neighborhood generation strategy is superior to a strong baseline that repeatedly samples from the target direction. The core intuition is that for an out-of-distribution (OOD) preference 𝐯 target\mathbf{v}_{\text{target}}, the model’s performance is degraded. By sampling from a nearby neighborhood of more in-distribution preferences, we can generate a candidate pool of higher average quality. The following assumption formalizes this intuition.
|
| 87 |
+
|
| 88 |
+
Assumption 1 (OOD Performance Degradation): Let 𝐯 target\mathbf{v}_{\text{target}} be an OOD preference vector. Let 𝒟 train\mathcal{D}_{\text{train}} be the distribution of preferences in the training set 𝒱 train\mathcal{V}_{\text{train}}. For a nearby preference vector 𝐯 i∈𝒩 k(𝐯 target)\mathbf{v}_{i}\in\mathcal{N}_{k}(\mathbf{v}_{\text{target}}) that is closer to the mean of 𝒟 train\mathcal{D}_{\text{train}}, the expected score of a response y i∼π θ(⋅|x,𝐯 i)y_{i}\sim\pi_{\theta}(\cdot|x,\mathbf{v}_{i}) is higher than that of a response y target∼π θ(⋅|x,𝐯 target)y_{\text{target}}\sim\pi_{\theta}(\cdot|x,\mathbf{v}_{\text{target}}), when both are evaluated against their respective generating preferences: 𝔼[𝐯 i T𝐫(x,y i)]>𝔼[𝐯 target T𝐫(x,y target)]\mathbb{E}[\mathbf{v}_{i}^{T}\mathbf{r}(x,y_{i})]>\mathbb{E}[\mathbf{v}_{\text{target}}^{T}\mathbf{r}(x,y_{\text{target}})].
|
| 89 |
+
|
| 90 |
+
Furthermore, we assume local consistency, meaning the evaluation of y i y_{i} under 𝐯 target\mathbf{v}_{\text{target}} is a good proxy for its quality, i.e., 𝐯 target T𝐫(x,y i)≈𝐯 i T𝐫(x,y i)\mathbf{v}_{\text{target}}^{T}\mathbf{r}(x,y_{i})\approx\mathbf{v}_{i}^{T}\mathbf{r}(x,y_{i}). This implies that the candidate pool from the neighborhood is stronger: 𝔼[𝐯 target T𝐫(x,y i)]>𝔼[𝐯 target T𝐫(x,y target)]\mathbb{E}[\mathbf{v}_{\text{target}}^{T}\mathbf{r}(x,y_{i})]>\mathbb{E}[\mathbf{v}_{\text{target}}^{T}\mathbf{r}(x,y_{\text{target}})]. To formalize this advantage, we compare RPS against a strong baseline strategy: generating k k independent responses by repeatedly sampling from the single target direction 𝐯 target\mathbf{v}_{\text{target}}, and then selecting the best one according to the target preference. The following theorem proves the superiority of the RPS approach.
|
| 91 |
+
|
| 92 |
+
Figure 3: Conceptual illustration of Theorem 1. The distributions represent the scores of candidate responses for the baseline (orange) and RPS (blue). Under Assumption 1, the RPS candidate pool is drawn from a higher-quality distribution. Consequently, the expected score of the best RPS response, 𝔼[s RPS∗]\mathbb{E}[s^{*}_{\text{RPS}}], is strictly greater than that of the best baseline response, 𝔼[s baseline∗]\mathbb{E}[s^{*}_{\text{baseline}}]. This difference is the robustness gain.
|
| 93 |
+
|
| 94 |
+
###### Theorem 1(Superiority of Neighborhood Generation).
|
| 95 |
+
|
| 96 |
+
Let S RPS={s 1,…,s k}S_{\text{RPS}}=\{s_{1},\ldots,s_{k}\} be the set of scores from k k responses generated from the neighborhood 𝒩 k\mathcal{N}_{k}, where s i=𝐯 target T𝐫(x,y i)s_{i}=\mathbf{v}_{\text{target}}^{T}\mathbf{r}(x,y_{i}). Let S Baseline={s 1′,…,s k′}S_{\text{Baseline}}=\{s^{\prime}_{1},\ldots,s^{\prime}_{k}\} be the set of scores from k k responses generated from the baseline strategy (i.e., directly from 𝐯 target\mathbf{v}_{\text{target}}). Under Assumption 1, the expected score of the best response selected by RPS is strictly greater than that of the best response selected by the baseline:
|
| 97 |
+
|
| 98 |
+
𝔼[max(S RPS)]>𝔼[max(S Baseline)].\mathbb{E}[\max(S_{\text{RPS}})]>\mathbb{E}[\max(S_{\text{Baseline}})].(2)
|
| 99 |
+
|
| 100 |
+
This performance gap, illustrated in Figure[3](https://arxiv.org/html/2510.20498v2#S3.F3 "Figure 3 ‣ 3.3 Neighborhood Consensus Theory ‣ 3 Problem Setup and Theoretical Framework ‣ Robust Preference Alignment via Directional Neighborhood Consensus"), represents the robustness gain of the RPS method.
|
| 101 |
+
|
| 102 |
+
###### Proof.
|
| 103 |
+
|
| 104 |
+
Let s i s_{i} be the random variable for the score of a response from a neighborhood direction 𝐯 i∈𝒩 k\mathbf{v}_{i}\in\mathcal{N}_{k}, and let s baseline′s^{\prime}_{\text{baseline}} be the random variable for a score from the baseline direction 𝐯 target\mathbf{v}_{\text{target}}. The scores in S RPS={s 1,…,s k}S_{\text{RPS}}=\{s_{1},\ldots,s_{k}\} are independent but not necessarily identically distributed, with cumulative distribution functions (CDFs) F 1(x),…,F k(x)F_{1}(x),\ldots,F_{k}(x). The scores in S Baseline={s 1′,…,s k′}S_{\text{Baseline}}=\{s^{\prime}_{1},\ldots,s^{\prime}_{k}\} are independent and identically distributed (i.i.d.) draws from the baseline distribution, with CDF F baseline(x)F_{\text{baseline}}(x).
|
| 105 |
+
|
| 106 |
+
Under Assumption 1, each candidate from the neighborhood is drawn from a better distribution than a candidate from the baseline. This implies that each s i s_{i} first-order stochastically dominates s baseline′s^{\prime}_{\text{baseline}}. Formally, for each i∈{1,…,k}i\in\{1,\ldots,k\}, we have F i(x)≤F baseline(x)F_{i}(x)\leq F_{\text{baseline}}(x) for all x x, with strict inequality over some interval.
|
| 107 |
+
|
| 108 |
+
The CDF of the maximum score from RPS is F max RPS(x)=P(max(S RPS)≤x)=∏i=1 k F i(x)F_{\max}^{\text{RPS}}(x)=P(\max(S_{\text{RPS}})\leq x)=\prod_{i=1}^{k}F_{i}(x), due to independence. The CDF of the maximum score from the baseline is F max Baseline(x)=P(max(S Baseline)≤x)=(F baseline(x))k F_{\max}^{\text{Baseline}}(x)=P(\max(S_{\text{Baseline}})\leq x)=(F_{\text{baseline}}(x))^{k}.
|
| 109 |
+
|
| 110 |
+
Since F i(x)≤F baseline(x)F_{i}(x)\leq F_{\text{baseline}}(x) for all i i, it follows that ∏i=1 k F i(x)≤(F baseline(x))k\prod_{i=1}^{k}F_{i}(x)\leq(F_{\text{baseline}}(x))^{k}. Thus, F max RPS(x)≤F max Baseline(x)F_{\max}^{\text{RPS}}(x)\leq F_{\max}^{\text{Baseline}}(x) for all x x. This shows that the maximum score from RPS also first-order stochastically dominates the maximum score from the baseline.
|
| 111 |
+
|
| 112 |
+
The expected value of a random variable can be expressed using its CDF. Assuming scores are non-negative (or shifted to be), 𝔼[X]=∫0∞(1−F(x))𝑑 x\mathbb{E}[X]=\int_{0}^{\infty}(1-F(x))dx. Given the stochastic dominance:
|
| 113 |
+
|
| 114 |
+
𝔼[max(S RPS)]=∫0∞(1−F max RPS(x))𝑑 x≥∫0∞(1−F max Baseline(x))𝑑 x=𝔼[max(S Baseline)].\mathbb{E}[\max(S_{\text{RPS}})]=\int_{0}^{\infty}(1-F_{\max}^{\text{RPS}}(x))dx\geq\int_{0}^{\infty}(1-F_{\max}^{\text{Baseline}}(x))dx=\mathbb{E}[\max(S_{\text{Baseline}})].(3)
|
| 115 |
+
|
| 116 |
+
The inequality is strict because F i(x)<F baseline(x)F_{i}(x)<F_{\text{baseline}}(x) over some interval for at least one i i, which ensures that F max RPS(x)<F max Baseline(x)F_{\max}^{\text{RPS}}(x)<F_{\max}^{\text{Baseline}}(x) over that same interval. This rigorously confirms that leveraging the neighborhood produces a superior set of candidates, leading to a better final selection. ∎
|
| 117 |
+
|
| 118 |
+
Corollary 1: The robustness gain increases with neighborhood size k k and the quality gap between the neighborhood and target-direction candidate pools. This follows because the expected value of the maximum of k k samples is non-decreasing in k k, and this effect is more pronounced for the stochastically dominant RPS distribution. Similarly, a larger quality gap—meaning greater stochastic dominance of the neighborhood distributions over the baseline—naturally widens the separation in the expected maximums. A formal proof is provided in Appendix[A.7](https://arxiv.org/html/2510.20498v2#A1.SS7 "A.7 Proof of Corollary 1 ‣ Appendix A Appendix ‣ Robust Preference Alignment via Directional Neighborhood Consensus").
|
| 119 |
+
|
| 120 |
+
### 3.4 Robust Preference Selection Algorithm
|
| 121 |
+
|
| 122 |
+
Building on the theoretical foundation of neighborhood consensus, we now formalize our approach. The Robust Preference Selection (RPS) algorithm, detailed in Algorithm 1, translates our theory into a practical, three-phase procedure designed to navigate the preference coverage gap.
|
| 123 |
+
|
| 124 |
+
The first phase, Neighborhood Construction, addresses the core challenge of out-of-distribution (OOD) preferences. Instead of directly using a potentially brittle target vector 𝐯 target\mathbf{v}_{\text{target}}, RPS identifies a set of k k nearby, more reliable preference directions. These candidate directions are sampled within a predefined angular threshold θ max\theta_{\text{max}}, forming a local neighborhood 𝒩 k\mathcal{N}_{k}. This step is critical as it shifts the generation process from a region of high uncertainty to one where the model’s performance is more robust and predictable.
|
| 125 |
+
|
| 126 |
+
In the Multi-Directional Generation phase, the language model π θ\pi_{\theta} generates a separate response y i y_{i} for each of the k k preference vectors in the neighborhood. This process creates a diverse portfolio of candidate responses. Each response reflects a slightly different trade-off between attributes (e.g., helpfulness and verbosity), leveraging the model’s well-trained capabilities within this local region of the preference space. The result is a set of high-quality outputs, each optimized for a direction where the model is confident.
|
| 127 |
+
|
| 128 |
+
Finally, the Consensus Selection phase determines the optimal response. Crucially, all k k candidates are evaluated against the user’s original target preference, 𝐯 target\mathbf{v}_{\text{target}}. The response y i y_{i} that maximizes the projected reward score s i=𝐯 target T𝐫(x,y i)s_{i}=\mathbf{v}_{\text{target}}^{T}\mathbf{r}(x,y_{i}) is selected as the final output y∗y^{*}. The superiority of this entire procedure is justified by our Theorem 1, which proves that the strategy of generating candidates from a superior neighborhood pool and then selecting the maximum is guaranteed to yield a response with a higher expected quality than the strong baseline. By combining neighborhood-based generation with target-based selection, RPS robustly satisfies user intent even for OOD preferences. The following section will empirically validate the effectiveness of this approach across various models and datasets.
|
| 129 |
+
|
| 130 |
+
Algorithm 1 Robust Preference Selection (RPS)
|
| 131 |
+
|
| 132 |
+
0: Prompt
|
| 133 |
+
|
| 134 |
+
x x
|
| 135 |
+
, target preference
|
| 136 |
+
|
| 137 |
+
𝐯 target\mathbf{v}_{target}
|
| 138 |
+
, neighborhood size
|
| 139 |
+
|
| 140 |
+
k k
|
| 141 |
+
, angle threshold
|
| 142 |
+
|
| 143 |
+
θ max\theta_{max}
|
| 144 |
+
|
| 145 |
+
0: Optimal response
|
| 146 |
+
|
| 147 |
+
y∗y^{*}
|
| 148 |
+
|
| 149 |
+
1:Phase 1: Neighborhood Construction
|
| 150 |
+
|
| 151 |
+
2: Generate candidate directions within
|
| 152 |
+
|
| 153 |
+
θ max\theta_{max}
|
| 154 |
+
of
|
| 155 |
+
|
| 156 |
+
𝐯 target\mathbf{v}_{target}
|
| 157 |
+
|
| 158 |
+
3: Compute angular distances:
|
| 159 |
+
|
| 160 |
+
d i=arccos(𝐯 i⋅𝐯 target)d_{i}=\arccos(\mathbf{v}_{i}\cdot\mathbf{v}_{target})
|
| 161 |
+
|
| 162 |
+
4: Select
|
| 163 |
+
|
| 164 |
+
k k
|
| 165 |
+
closest directions:
|
| 166 |
+
|
| 167 |
+
𝒩 k={𝐯 1,…,𝐯 k}\mathcal{N}_{k}=\{\mathbf{v}_{1},\ldots,\mathbf{v}_{k}\}
|
| 168 |
+
|
| 169 |
+
5:Phase 2: Multi-Directional Generation
|
| 170 |
+
|
| 171 |
+
6:for
|
| 172 |
+
|
| 173 |
+
i=1 i=1
|
| 174 |
+
to
|
| 175 |
+
|
| 176 |
+
k k
|
| 177 |
+
do
|
| 178 |
+
|
| 179 |
+
7: Generate response:
|
| 180 |
+
|
| 181 |
+
y i∼π θ(⋅|x,𝐯 i)y_{i}\sim\pi_{\theta}(\cdot|x,\mathbf{v}_{i})
|
| 182 |
+
|
| 183 |
+
8:end for
|
| 184 |
+
|
| 185 |
+
9:Phase 3: Consensus Selection
|
| 186 |
+
|
| 187 |
+
10:for
|
| 188 |
+
|
| 189 |
+
i=1 i=1
|
| 190 |
+
to
|
| 191 |
+
|
| 192 |
+
k k
|
| 193 |
+
do
|
| 194 |
+
|
| 195 |
+
11: Compute score:
|
| 196 |
+
|
| 197 |
+
s i=𝐯 target T𝐫(x,y i)s_{i}=\mathbf{v}_{target}^{T}\mathbf{r}(x,y_{i})
|
| 198 |
+
|
| 199 |
+
12:end for
|
| 200 |
+
|
| 201 |
+
13:return
|
| 202 |
+
|
| 203 |
+
y∗=argmax is i y^{*}=\arg\max_{i}s_{i}
|
| 204 |
+
|
| 205 |
+
4 Experiments
|
| 206 |
+
-------------
|
| 207 |
+
|
| 208 |
+
To validate our theoretical framework, we designed a comprehensive experimental methodology to assess the effectiveness of Robust Preference Selection (RPS) as a post-hoc method. We evaluated RPS against a strong baseline across three distinct model training paradigms—DPA, DPO, and SFT—to demonstrate its general applicability. Our experiments test the core hypothesis that neighborhood consensus provides robustness for out-of-distribution preference directions.
|
| 209 |
+
|
| 210 |
+
### 4.1 Experimental Setup
|
| 211 |
+
|
| 212 |
+
#### 4.1.1 Models and Datasets
|
| 213 |
+
|
| 214 |
+
To ensure a robust evaluation, we used a 3×3 experimental matrix, crossing three models with three standard preference-learning datasets. The models (Table[2](https://arxiv.org/html/2510.20498v2#S4.T2 "Table 2 ‣ 4.1.1 Models and Datasets ‣ 4.1 Experimental Setup ‣ 4 Experiments ‣ Robust Preference Alignment via Directional Neighborhood Consensus")) represent diverse training paradigms: Directional Preference Alignment (DPA), using DPA-v1-Mistral-7B‡‡‡[https://huggingface.co/RLHFlow/DPA-v1-Mistral-7B](https://huggingface.co/RLHFlow/DPA-v1-Mistral-7B)(Wang et al., [2024a](https://arxiv.org/html/2510.20498v2#bib.bib28)); Direct Preference Optimization (DPO), using Zephyr-7B-Beta§§§[https://huggingface.co/HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)(Tunstall et al., [2023](https://arxiv.org/html/2510.20498v2#bib.bib26)); and standard Supervised Fine-Tuning (SFT), using Mistral-7B-Instruct-v0.2¶¶¶[https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)(Jiang et al., [2023](https://arxiv.org/html/2510.20498v2#bib.bib15)). The datasets (Table[2](https://arxiv.org/html/2510.20498v2#S4.T2 "Table 2 ‣ 4.1.1 Models and Datasets ‣ 4.1 Experimental Setup ‣ 4 Experiments ‣ Robust Preference Alignment via Directional Neighborhood Consensus")) provide varied domains for testing preference alignment: we use the 2,000-sample test_prefs split from UltraFeedback∥∥∥[https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized](https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized)(Cui et al., [2023](https://arxiv.org/html/2510.20498v2#bib.bib7)), the 503-sample deduplicated validation set from HelpSteer******[https://huggingface.co/datasets/nvidia/HelpSteer](https://huggingface.co/datasets/nvidia/HelpSteer)(Dong et al., [2023](https://arxiv.org/html/2510.20498v2#bib.bib9)), and the 518-sample deduplicated validation set from its successor, HelpSteer2††††††[https://huggingface.co/datasets/nvidia/HelpSteer2](https://huggingface.co/datasets/nvidia/HelpSteer2)(Wang et al., [2024b](https://arxiv.org/html/2510.20498v2#bib.bib30)).
|
| 215 |
+
|
| 216 |
+
Table 1: Models evaluated.
|
| 217 |
+
|
| 218 |
+
Table 2: Evaluation datasets.
|
| 219 |
+
|
| 220 |
+
#### 4.1.2 Evaluation Protocol
|
| 221 |
+
|
| 222 |
+
For each model-dataset pair, we compare two inference-time strategies under a fixed computational budget: 1) Single-Direction Baseline: To ensure a fair comparison, we generate k=5 k=5 response candidates using only the target direction 𝐯 target\mathbf{v}_{\text{target}}(Wang et al., [2022](https://arxiv.org/html/2510.20498v2#bib.bib29)). The best response is then selected by scoring each candidate with the target preference, i.e., maximizing 𝐯 target T𝐫(x,y)\mathbf{v}_{\text{target}}^{T}\mathbf{r}(x,y). 2) RPS: We first sample k=5 k=5 preference directions from a local neighborhood around 𝐯 target\mathbf{v}_{\text{target}}, constrained by an angular threshold of θ max=30∘\theta_{\max}=30^{\circ}. The choice of these hyperparameters balances key trade-offs. A neighborhood size of k=5 k=5 was chosen to maintain strict compute parity with the baseline, while representing a common choice for balancing response diversity and inference cost. The angle θ max=30∘\theta_{\max}=30^{\circ} was determined through preliminary pilots to be a sweet spot: smaller angles provided insufficient diversity over the baseline, while larger angles risked sampling preferences too semantically distant from the target, violating our local consistency assumption. We generate one response for each of the k k directions. The final response is selected by scoring all k k candidates against the original target preference 𝐯 target\mathbf{v}_{\text{target}}.
|
| 223 |
+
|
| 224 |
+
This setup ensures that both methods generate and score the same number of candidate responses, maintaining strict compute parity, with the neighborhood sampling step introducing negligible overhead. All models receive preferences via a standardized system prompt (see Appendix[A.2](https://arxiv.org/html/2510.20498v2#A1.SS2 "A.2 Response Generation Prompts ‣ Appendix A Appendix ‣ Robust Preference Alignment via Directional Neighborhood Consensus")). We evaluate on eight challenging preference directions from 10∘10^{\circ} to 45∘45^{\circ} (see Appendix[A.5](https://arxiv.org/html/2510.20498v2#A1.SS5 "A.5 Preference Direction Specifications ‣ Appendix A Appendix ‣ Robust Preference Alignment via Directional Neighborhood Consensus")) to test robustness on preferences progressively further from the training distribution. Response pairs are evaluated by a preference-aligned judge in a randomized A/B test, and our primary metric is the RPS win rate. We utilize GPT-4o-mini as our preference-aligned judge, a practice increasingly adopted for its strong correlation with human judgments in preference evaluation tasks (Zheng et al., [2023](https://arxiv.org/html/2510.20498v2#bib.bib37); Gu et al., [2024](https://arxiv.org/html/2510.20498v2#bib.bib12)).
|
| 225 |
+
|
| 226 |
+
5 Results
|
| 227 |
+
---------
|
| 228 |
+
|
| 229 |
+

|
| 230 |
+
|
| 231 |
+
(a) DPA
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
(b) DPO
|
| 236 |
+
|
| 237 |
+

|
| 238 |
+
|
| 239 |
+
(c) SFT
|
| 240 |
+
|
| 241 |
+
Figure 4: Overall RPS win rates by model (DPA, DPO, SFT) and dataset. Bars show mean win rates across all tested preference directions.
|
| 242 |
+
|
| 243 |
+
Table 3: Overall RPS win rates by model and dataset. Values show mean ± std across all preference directions.
|
| 244 |
+
|
| 245 |
+
Our experiments confirm that Robust Preference Selection (RPS) consistently improves alignment robustness, particularly for out-of-distribution (OOD) preferences. We present three key findings: (1) RPS outperforms a strong baseline across all models and datasets; (2) its advantage grows significantly as target preferences deviate from the training distribution; and (3) the magnitude of improvement depends on the model’s initial alignment method, with SFT models benefiting most.
|
| 246 |
+
|
| 247 |
+
### 5.1 RPS Consistently Outperforms the Baseline and Excels on OOD Preferences
|
| 248 |
+
|
| 249 |
+
Across all nine model-dataset pairings, RPS achieves a decisive win rate greater than 50% against the single-direction baseline, as detailed in Table[3](https://arxiv.org/html/2510.20498v2#S5.T3 "Table 3 ‣ 5 Results ‣ Robust Preference Alignment via Directional Neighborhood Consensus"). The average improvements over a 50% baseline, visualized in Figure[4](https://arxiv.org/html/2510.20498v2#S5.F4 "Figure 4 ‣ 5 Results ‣ Robust Preference Alignment via Directional Neighborhood Consensus"), are consistent, ranging from a modest +2.0% for SFT on UltraFeedback (a 52.0% win rate) to a significant +17.3% for SFT on HelpSteer2 (a 67.3% win rate). This establishes neighborhood consensus as a broadly effective post-hoc enhancement.
|
| 250 |
+
|
| 251 |
+
More importantly, the performance advantage of RPS amplifies on OOD preferences, a finding that provides strong empirical validation for our Assumption 1 (OOD Performance Degradation). This trend is most pronounced for the DPA model, as shown in Figure[5](https://arxiv.org/html/2510.20498v2#S5.F5 "Figure 5 ‣ 5.1 RPS Consistently Outperforms the Baseline and Excels on OOD Preferences ‣ 5 Results ‣ Robust Preference Alignment via Directional Neighborhood Consensus"). The win rate on UltraFeedback, for example, climbs from 53.4% at 20∘ to a dominant 69.1% at 45∘. This demonstrates that as the baseline’s performance degrades on unfamiliar preferences—precisely as our assumption predicts—the benefit of RPS’s robust neighborhood sampling becomes increasingly critical.
|
| 252 |
+
|
| 253 |
+
In contrast, the DPO and SFT models show a more modest and less angle-dependent trend (Figure[5](https://arxiv.org/html/2510.20498v2#S5.F5 "Figure 5 ‣ 5.1 RPS Consistently Outperforms the Baseline and Excels on OOD Preferences ‣ 5 Results ‣ Robust Preference Alignment via Directional Neighborhood Consensus")). The DPO model, trained on scalar-based pairwise preferences, may possess more general robustness, leading to less baseline degradation. Similarly, the SFT model, which interprets preferences as instructions at inference-time without specialized training, does not exhibit the same sharp performance drop-off. For these models, RPS still provides a consistent advantage, but the robustness gain is less correlated with the preference angle. This highlights that the utility of RPS is not only in addressing OOD preferences but also in its interaction with the base model’s intrinsic robustness. Qualitative review further confirms that RPS achieves superior alignment by producing more detailed and nuanced responses that better match user intent, as shown in the case studies in Appendix[A.6](https://arxiv.org/html/2510.20498v2#A1.SS6 "A.6 Qualitative Case Studies ‣ Appendix A Appendix ‣ Robust Preference Alignment via Directional Neighborhood Consensus").
|
| 254 |
+
|
| 255 |
+

|
| 256 |
+
|
| 257 |
+
(a) DPA
|
| 258 |
+
|
| 259 |
+

|
| 260 |
+
|
| 261 |
+
(b) DPO
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
(c) SFT
|
| 266 |
+
|
| 267 |
+
Figure 5: Directional robustness. RPS win rate vs. preference angle for DPA (left), DPO (middle), and SFT (right) models. The performance advantage of RPS consistently grows as preferences become more OOD (angle increases).
|
| 268 |
+
|
| 269 |
+
Table 4: Detailed RPS win rates by dataset, model, and preference direction. This table provides the full data for Figures[5](https://arxiv.org/html/2510.20498v2#S5.F5 "Figure 5 ‣ 5.1 RPS Consistently Outperforms the Baseline and Excels on OOD Preferences ‣ 5 Results ‣ Robust Preference Alignment via Directional Neighborhood Consensus") and [6](https://arxiv.org/html/2510.20498v2#S5.F6 "Figure 6 ‣ 5.2 Analysis Across Alignment Paradigms and Datasets ‣ 5 Results ‣ Robust Preference Alignment via Directional Neighborhood Consensus").
|
| 270 |
+
|
| 271 |
+
### 5.2 Analysis Across Alignment Paradigms and Datasets
|
| 272 |
+
|
| 273 |
+
Further analysis, with detailed data in Table[4](https://arxiv.org/html/2510.20498v2#S5.T4 "Table 4 ‣ 5.1 RPS Consistently Outperforms the Baseline and Excels on OOD Preferences ‣ 5 Results ‣ Robust Preference Alignment via Directional Neighborhood Consensus") and visualized in Figure[6](https://arxiv.org/html/2510.20498v2#S5.F6 "Figure 6 ‣ 5.2 Analysis Across Alignment Paradigms and Datasets ‣ 5 Results ‣ Robust Preference Alignment via Directional Neighborhood Consensus"), reveals that the effectiveness of RPS is modulated by the base model’s training paradigm. The SFT model, lacking explicit preference conditioning, benefits the most from RPS, especially on the HelpSteer2 dataset. This suggests RPS acts as an effective inference-time guidance mechanism for models not explicitly trained to follow nuanced preferences. Conversely, the DPO-tuned model, which may already possess some inherent robustness, shows more modest gains. This indicates that the utility of RPS may be inversely related to the base model’s intrinsic robustness. Qualitative review further confirms that RPS achieves superior alignment by producing more detailed and nuanced responses that better match user intent, as shown in the case studies in Appendix[A.6](https://arxiv.org/html/2510.20498v2#A1.SS6 "A.6 Qualitative Case Studies ‣ Appendix A Appendix ‣ Robust Preference Alignment via Directional Neighborhood Consensus").
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
(a) UltraFeedback
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
(b) HelpSteer
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
(c) HelpSteer2
|
| 286 |
+
|
| 287 |
+
Figure 6: Dataset-wise performance. RPS win rate vs. preference angle for UltraFeedback (left), HelpSteer (middle), and HelpSteer2 (right). SFT models show particularly strong gains on HelpSteer datasets.
|
| 288 |
+
|
| 289 |
+
6 Conclusion
|
| 290 |
+
------------
|
| 291 |
+
|
| 292 |
+
We have shown that the brittleness of preference-aligned models in out-of-distribution (OOD) scenarios can be effectively mitigated without retraining. Our proposed method, Robust Preference Selection (RPS), shifts from single-point generation to a more robust neighborhood consensus approach. It generates a diverse set of candidate responses from a local neighborhood of the target preference, which we show is theoretically guaranteed to produce a superior candidate pool compared to repeated sampling from the target direction itself. The optimal response is then selected using the original user preference. Extensive experiments across DPA, DPO, and SFT paradigms validate this approach, demonstrating significant robustness gains—up to a 69% win rate—for challenging OOD preferences. This work provides a practical, model-agnostic solution to the preference coverage gap and suggests that inference-time steering via neighborhood consensus is a promising path toward more adaptable and trustworthy AI systems.
|
| 293 |
+
|
| 294 |
+
Ethics Statement
|
| 295 |
+
----------------
|
| 296 |
+
|
| 297 |
+
This research aims to enhance the reliability and controllability of large language models, a goal with positive societal implications. Our work exclusively utilizes publicly available and widely used datasets (UltraFeedback, HelpSteer, and HelpSteer2) and open-source models. The datasets are standard benchmarks for preference alignment research and do not contain personally identifiable information. Our proposed method, RPS, is a post-hoc technique that does not involve model retraining, thereby avoiding the significant computational costs and environmental impact associated with it. We do not foresee any direct negative ethical implications arising from this work.
|
| 298 |
+
|
| 299 |
+
Reproducibility Statement
|
| 300 |
+
-------------------------
|
| 301 |
+
|
| 302 |
+
We are committed to ensuring the reproducibility of our research. All models used in our experiments (DPA-v1-Mistral-7B, Zephyr-7B-Beta, and Mistral-7B-Instruct-v0.2) are publicly available on the Hugging Face Hub, and direct links are provided in Section 4.1.1. Similarly, the datasets (UltraFeedback, HelpSteer, and HelpSteer2) are publicly accessible and cited. Our experimental setup, including the baseline and RPS configurations, is detailed in Section 4.1.2, with key hyperparameters (k=5 k=5, θ max=30∘\theta_{\max}=30^{\circ}) specified. The Appendix provides further essential details for replication, including the exact prompts used for generation and evaluation (Appendix A.1 and A.2), the reward model scoring procedure (Appendix A.3), and the precise preference vectors used for evaluation (Appendix A.4). We believe this provides sufficient information for our results to be independently reproduced. We also provide our code and data at[https://github.com/rcmao/robust-preference-alignment](https://github.com/rcmao/robust-preference-alignment).
|
| 303 |
+
|
| 304 |
+
References
|
| 305 |
+
----------
|
| 306 |
+
|
| 307 |
+
* Azar et al. (2023) Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, and Rémi Munos. A general theoretical paradigm to understand learning from human preferences, October 2023. URL [https://arxiv.org/abs/2310.12036](https://arxiv.org/abs/2310.12036).
|
| 308 |
+
* Ben-Tal et al. (2013) Aharon Ben-Tal, Dick den Hertog, Anja De Waegenaere, Bertrand Melenberg, and Gijs Rennen. Robust solutions of optimization problems affected by uncertain probabilities. _Management Science_, 59(2):341–357, Feb 2013. doi: 10.1287/mnsc.1120.1641.
|
| 309 |
+
* Chandra et al. (2025) Bobbili Sarat Chandra, Ujwal Dinesha, Dheeraj Narasimha, and Srinivas Shakkottai. Pita: Preference-guided inference-time alignment for llm post-training, 2025. URL [https://arxiv.org/abs/2507.20067](https://arxiv.org/abs/2507.20067).
|
| 310 |
+
* Chehade et al. (2025) Mohamad Chehade, Soumya Suvra Ghosal, Souradip Chakraborty, Avinash Reddy, Dinesh Manocha, Hao Zhu, and Amrit Singh Bedi. Bounded rationality for llms: Satisficing alignment at inference-time, 2025. URL [https://arxiv.org/abs/2505.23729](https://arxiv.org/abs/2505.23729).
|
| 311 |
+
* Chidambaram et al. (2024) Keertana Chidambaram, Karthik Vinay Seetharaman, and Vasilis Syrgkanis. Direct preference optimization with unobserved preference heterogeneity, 2024. URL [https://arxiv.org/abs/2405.15065](https://arxiv.org/abs/2405.15065).
|
| 312 |
+
* Christiano et al. (2017) Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences, June 2017. URL [https://arxiv.org/abs/1706.03741](https://arxiv.org/abs/1706.03741).
|
| 313 |
+
* Cui et al. (2023) Luzi S. Cui et al. Ultrafeedback: Boosting llms with high-quality feedback data, 2023. Dataset: HuggingFaceH4/ultrafeedback_binarized.
|
| 314 |
+
* Dietterich (2000) Thomas G. Dietterich. _Ensemble methods in machine learning_, pp. 1–15. January 2000. doi: 10.1007/3-540-45014-9˙1. URL [https://link.springer.com/chapter/10.1007/3-540-45014-9_1](https://link.springer.com/chapter/10.1007/3-540-45014-9_1).
|
| 315 |
+
* Dong et al. (2023) Yi Dong, Zhilin Wang, Makesh Narsimhan Sreedhar, Xianchao Wu, and Oleksii Kuchaiev. Steerlm: Attribute conditioned sft as an (user-steerable) alternative to rlhf, 2023. URL [https://arxiv.org/abs/2310.05344](https://arxiv.org/abs/2310.05344).
|
| 316 |
+
* Duchi & Namkoong (2018) John Duchi and Hongseok Namkoong. Learning models with uniform performance via distributionally robust optimization, 2018. URL [https://arxiv.org/abs/1810.08750](https://arxiv.org/abs/1810.08750).
|
| 317 |
+
* Duchi et al. (2016) John Duchi, Peter Glynn, and Hongseok Namkoong. Statistics of robust optimization: A generalized empirical likelihood approach, 2016. URL [https://arxiv.org/abs/1610.03425](https://arxiv.org/abs/1610.03425).
|
| 318 |
+
* Gu et al. (2024) Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on llm-as-a-judge, 2024.
|
| 319 |
+
* Guo et al. (2024) Hongyi Guo, Yuanshun Yao, Wei Shen, Jiaheng Wei, Xiaoying Zhang, Zhaoran Wang, and Yang Liu. Human-instruction-free llm self-alignment with limited samples. _arXiv preprint arXiv:2401.06785_, 2024.
|
| 320 |
+
* Hendrycks et al. (2020) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, September 2020. URL [https://arxiv.org/abs/2009.03300](https://arxiv.org/abs/2009.03300).
|
| 321 |
+
* Jiang et al. (2023) Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, et al. Mistral 7b instruct, 2023.
|
| 322 |
+
* Li et al. (2025a) Ling Li, Yao Zhou, Yuxuan Liang, Fugee Tsung, and Jiaheng Wei. Recognition through reasoning: Reinforcing image geo-localization with large vision-language models. _arXiv preprint arXiv:2506.14674_, 2025a.
|
| 323 |
+
* Li et al. (2025b) Yichen Li, Zhiting Fan, Ruizhe Chen, Xiaotang Gai, Luqi Gong, Yan Zhang, and Zuozhu Liu. Fairsteer: Inference time debiasing for llms with dynamic activation steering, 2025b. URL [https://arxiv.org/abs/2504.14492](https://arxiv.org/abs/2504.14492).
|
| 324 |
+
* Liang et al. (2024) Xun Liang, Hanyu Wang, Yezhaohui Wang, Shichao Song, Jiawei Yang, Simin Niu, Jie Hu, Dan Liu, Shunyu Yao, Feiyu Xiong, and Zhiyu Li. Controllable text generation for large language models: a survey, August 2024. URL [https://arxiv.org/abs/2408.12599](https://arxiv.org/abs/2408.12599).
|
| 325 |
+
* Liu et al. (2025a) Runze Liu, Jiakang Wang, Yuling Shi, Zhihui Xie, Chenxin An, Kaiyan Zhang, Jian Zhao, Xiaodong Gu, Lei Lin, Wenping Hu, et al. Attention as a compass: Efficient exploration for process-supervised rl in reasoning models. _arXiv preprint arXiv:2509.26628_, 2025a.
|
| 326 |
+
* Liu et al. (2025b) Yule Liu, Zhiyuan Zhong, Yifan Liao, Zhen Sun, Jingyi Zheng, Jiaheng Wei, Qingyuan Gong, Fenghua Tong, Yang Chen, Yang Zhang, et al. On the generalization and adaptation ability of machine-generated text detectors in academic writing. In _Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2_, pp. 5674–5685, 2025b.
|
| 327 |
+
* Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. _arXiv:2203.02155_, Mar 2022. URL [https://arxiv.org/abs/2203.02155](https://arxiv.org/abs/2203.02155).
|
| 328 |
+
* Pang et al. (2025) Jinlong Pang, Jiaheng Wei, Ankit Parag Shah, Zhaowei Zhu, Yaxuan Wang, Chen Qian, Yang Liu, Yujia Bao, and Wei Wei. Improving data efficiency via curating llm-driven rating systems. _International Conference on Learning Representations_, 2025.
|
| 329 |
+
* Rafailov et al. (2023) Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model, 2023. URL [https://arxiv.org/abs/2305.18290](https://arxiv.org/abs/2305.18290).
|
| 330 |
+
* Shahriar et al. (2024) Sadat Shahriar, Zheng Qi, Nikolaos Pappas, Srikanth Doss, Monica Sunkara, Kishaloy Halder, Manuel Mager, and Yassine Benajiba. Inference time llm alignment in single and multidomain preference spectrum, 2024. URL [https://arxiv.org/abs/2410.19206](https://arxiv.org/abs/2410.19206).
|
| 331 |
+
* Shi et al. (2024) Yuling Shi, Hongyu Zhang, Chengcheng Wan, and Xiaodong Gu. Between lines of code: Unraveling the distinct patterns of machine and human programmers. _arXiv preprint arXiv:2401.06461_, 2024.
|
| 332 |
+
* Tunstall et al. (2023) Lewis Tunstall et al. Zephyr: A chaotic good model, 2023. Hugging Face blog.
|
| 333 |
+
* Wang et al. (2023) Chaoqi Wang, Yibo Jiang, Chenghao Yang, Han Liu, and Yuxin Chen. Beyond reverse kl: Generalizing direct preference optimization with diverse divergence constraints, 2023. URL [https://arxiv.org/abs/2309.16240](https://arxiv.org/abs/2309.16240).
|
| 334 |
+
* Wang et al. (2024a) Haoxiang Wang, Yong Lin, Wei Xiong, Rui Yang, Shizhe Diao, Shuang Qiu, Han Zhao, and Tong Zhang. Arithmetic control of llms for diverse user preferences: Directional preference alignment with multi-objective rewards, 2024a. URL [https://arxiv.org/abs/2402.18571](https://arxiv.org/abs/2402.18571).
|
| 335 |
+
* Wang et al. (2022) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. _arXiv:2203.11171_, Oct 2022. URL [https://arxiv.org/abs/2203.11171](https://arxiv.org/abs/2203.11171).
|
| 336 |
+
* Wang et al. (2024b) Zhilin Wang, Yi Dong, Olivier Delalleau, Jiaqi Zeng, Gerald Shen, Daniel Egert, Jimmy J. Zhang, Makesh Narsimhan Sreedhar, and Oleksii Kuchaiev. Helpsteer2: Open-source dataset for training top-performing reward models, 2024b. URL [https://arxiv.org/abs/2406.08673](https://arxiv.org/abs/2406.08673).
|
| 337 |
+
* Wei et al. (2023) Jiaheng Wei, Harikrishna Narasimhan, Ehsan Amid, Wen-Sheng Chu, Yang Liu, and Abhishek Kumar. Distributionally robust post-hoc classifiers under prior shifts, 2023.
|
| 338 |
+
* Wei et al. (2024) Jiaheng Wei, Yuanshun Yao, Jean-Francois Ton, Hongyi Guo, Andrew Estornell, and Yang Liu. Measuring and reducing llm hallucination without gold-standard answers. _arXiv preprint arXiv:2402.10412_, 2024.
|
| 339 |
+
* Xu et al. (2025) Zaiyan Xu, Sushil Vemuri, Kishan Panaganti, Dileep Kalathil, Rahul Jain, and Deepak Ramachandran. Robust llm alignment via distributionally robust direct preference optimization, 2025. URL [https://arxiv.org/abs/2502.01930](https://arxiv.org/abs/2502.01930).
|
| 340 |
+
* Yang et al. (2022) Linyi Yang, Shuibai Zhang, Libo Qin, Yafu Li, Yidong Wang, Hanmeng Liu, Jindong Wang, Xing Xie, and Yue Zhang. Glue-x: Evaluating natural language understanding models from an out-of-distribution generalization perspective, 2022. URL [https://arxiv.org/abs/2211.08073](https://arxiv.org/abs/2211.08073).
|
| 341 |
+
* Yang et al. (2023) Linyi Yang, Yaoxian Song, Xuan Ren, Chenyang Lyu, Yidong Wang, Jingming Zhuo, Lingqiao Liu, Jindong Wang, Jennifer Foster, and Yue Zhang. Out-of-distribution generalization in natural language processing: Past, present, and future. In _EMNLP_, 2023. doi: 10.18653/v1/2023.emnlp-main.276.
|
| 342 |
+
* Zhang et al. (2025) Chenlong Zhang, Zhuoran Jin, Hongbang Yuan, Jiaheng Wei, Tong Zhou, Kang Liu, Jun Zhao, and Yubo Chen. Rule: Reinforcement unlearning achieves forget-retain pareto optimality. _arXiv preprint arXiv:2506.07171_, 2025.
|
| 343 |
+
* Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
|
| 344 |
+
* Ziegler et al. (2020) Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, and OpenAI. Fine-tuning language models from human preferences. _arXiv_, January 2020. URL [https://arxiv.org/abs/1909.08593v2](https://arxiv.org/abs/1909.08593v2).
|
| 345 |
+
|
| 346 |
+
Appendix A Appendix
|
| 347 |
+
-------------------
|
| 348 |
+
|
| 349 |
+
### A.1 Use of Large Language Models
|
| 350 |
+
|
| 351 |
+
This paper was prepared in accordance with ICLR’s policy on Large Language Models (LLMs). The following checklist details the use of LLMs in this work:
|
| 352 |
+
|
| 353 |
+
* •To aid or polish writing? Yes. LLMs were used to improve grammar, clarity, and phrasing throughout the manuscript.
|
| 354 |
+
|
| 355 |
+
### A.2 Response Generation Prompts
|
| 356 |
+
|
| 357 |
+
All models (DPA, DPO, SFT) use the same system prompt format for generating responses:
|
| 358 |
+
|
| 359 |
+
System: "You are a helpful assistant. Your response should maximize weighted
|
| 360 |
+
rating = helpfulness*{weight_helpfulness} + verbosity*{weight_verbosity}."
|
| 361 |
+
|
| 362 |
+
User: {original_prompt}
|
| 363 |
+
|
| 364 |
+
Where weight_helpfulness and weight_verbosity are integers from 0 to 100 satisfying the unit circle constraint (weight_verbosity/100)**2 + (weight_helpfulness/100)**2 == 1. This unified approach, adapted from the experimental setup in (Wang et al., [2024a](https://arxiv.org/html/2510.20498v2#bib.bib28)), enables fair comparison across all training paradigms.
|
| 365 |
+
|
| 366 |
+
### A.3 Preference-Aligned Judge Prompts
|
| 367 |
+
|
| 368 |
+
We use preference-aligned A/B/TIE evaluation with randomized positioning to eliminate bias. The judge prompt template is:
|
| 369 |
+
|
| 370 |
+
You are a careful evaluation judge. Decide which response better
|
| 371 |
+
aligns with the user preference that balances two criteria with
|
| 372 |
+
given weights:
|
| 373 |
+
- Helpfulness (weight = {wh})
|
| 374 |
+
- Verbosity (weight = {wv})
|
| 375 |
+
|
| 376 |
+
Safety/correctness override:
|
| 377 |
+
- Factually wrong, unsafe, or misleading content should lose
|
| 378 |
+
regardless of verbosity.
|
| 379 |
+
|
| 380 |
+
Output format (exactly):
|
| 381 |
+
Comparison: <one-sentence comparison and reason>
|
| 382 |
+
More aligned: A | B | Tie
|
| 383 |
+
|
| 384 |
+
Query: {user_query}
|
| 385 |
+
Response A: {response_1}
|
| 386 |
+
Response B: {response_2}
|
| 387 |
+
|
| 388 |
+
For each target direction 𝐯=(v h,v v)\mathbf{v}=(v_{h},v_{v}), we set the weight placeholders to the direction components and evaluate response pairs. A/B positions are randomized with a fixed seed for reproducibility.
|
| 389 |
+
|
| 390 |
+
### A.4 Reward Model Scoring
|
| 391 |
+
|
| 392 |
+
All experiments utilize the publicly available reward model Haoxiang-Wang/RewardModel-Mistral-7B-for-DPA-v1 from Wang et al. ([2024a](https://arxiv.org/html/2510.20498v2#bib.bib28)), which is trained to predict scores across multiple preference dimensions. To obtain the reward vector 𝐫(x,y)=(r h(x,y),r v(x,y))\mathbf{r}(x,y)=(r_{h}(x,y),r_{v}(x,y)) for a given prompt-response pair, we format the input according to the model’s required template:
|
| 393 |
+
|
| 394 |
+
[INST] You must read the following conversation carefully and rate
|
| 395 |
+
the assistant’s response from score 0-100 in these aspects:
|
| 396 |
+
helpfulness, correctness, coherence, honesty, complexity, verbosity
|
| 397 |
+
|
| 398 |
+
User: {prompt}
|
| 399 |
+
|
| 400 |
+
Assistant: {response} [/INST]
|
| 401 |
+
|
| 402 |
+
The model returns a vector of scores for each attribute mentioned in the prompt. For our two-dimensional analysis, we extract the first score as helpfulness (r h r_{h}) and the sixth score as verbosity (r v r_{v}) to construct the reward vector used for all calculations and selection criteria in our work.
|
| 403 |
+
|
| 404 |
+
### A.5 Preference Direction Specifications
|
| 405 |
+
|
| 406 |
+
Table[5](https://arxiv.org/html/2510.20498v2#A1.T5 "Table 5 ‣ A.5 Preference Direction Specifications ‣ Appendix A Appendix ‣ Robust Preference Alignment via Directional Neighborhood Consensus") provides the specification of preference directions used in our experiments. Our evaluation focuses on directions 𝐯 1\mathbf{v}_{1} through 𝐯 8\mathbf{v}_{8} as these represent increasingly challenging preference configurations that extend beyond typical training ranges.
|
| 407 |
+
|
| 408 |
+
Table 5: Preference direction specifications with exact vector components and angles.
|
| 409 |
+
|
| 410 |
+
### A.6 Qualitative Case Studies
|
| 411 |
+
|
| 412 |
+
To provide a more concrete understanding of our method’s improvements, this section presents qualitative comparisons for each model. The examples, detailed in Table[6](https://arxiv.org/html/2510.20498v2#A1.T6 "Table 6 ‣ A.6 Qualitative Case Studies ‣ Appendix A Appendix ‣ Robust Preference Alignment via Directional Neighborhood Consensus"), are selected from the most out-of-distribution preference direction (𝐯 8\mathbf{v}_{8}, angle 45∘) to illustrate how RPS generates more nuanced and detailed responses compared to the baseline.
|
| 413 |
+
|
| 414 |
+
Table 6: Qualitative comparisons for DPA, DPO, and SFT models on out-of-distribution preferences (𝐯 8\mathbf{v}_{8}, angle 45∘).
|
| 415 |
+
|
| 416 |
+
DPA Model
|
| 417 |
+
Prompt (UltraFeedback, ID: 10): ”Write an investigative report on the state of homelessness in America.”
|
| 418 |
+
Baseline Output: Title: The State of Homelessness in America: A Comprehensive Investigation… Homelessness is a pervasive issue that affects millions of people… Causes of Homelessness… Lack of affordable housing… Mental illness… Substance abuse…
|
| 419 |
+
RPS Output: Title: The State of Homelessness in America: A Comprehensive Investigation… The issue of homelessness has been a persistent challenge in the United States, with an estimated 580,466 people experiencing homelessness on a single night in 2019 (U.S. Department of Housing and Urban Development, 2020)… Current Trends: 1. Increasing Population… 2. Shift in Demographics… 3. Impact of COVID-19…
|
| 420 |
+
Judgment (RPS Win): GPT-4o-mini selected the RPS response as more aligned.
|
| 421 |
+
Analysis: The RPS response is more helpful, including a specific statistic with a source, discussing more nuanced causes (Domestic Violence), and incorporating recent trends like the impact of COVID-19. The baseline is generic and lacks this specific, timely context.
|
| 422 |
+
DPO Model
|
| 423 |
+
Prompt (HelpSteer, ID: 5): ”What are some synonyms for the word ’beautiful’?”
|
| 424 |
+
Baseline Output: Some synonyms for the word ”beautiful” include gorgeous, lovely, pretty, stunning, radiant, enchanting, captivating, mesmerizing, breathtaking, and exquisite. All of these words convey various aspects of beauty… The choice of synonym depends on the context…
|
| 425 |
+
RPS Output: 1. Gorgeous 2. Stunning 3. Radiant 4. Magnificent 5. Attractive 6. Charming 7. Lovely 8. Enchanting 9. Exquisite 10. Alluring … [list continues to 50 synonyms] … Note: The weightage of each synonym may vary based on context and usage…
|
| 426 |
+
Judgment (RPS Win): GPT-4o-mini selected the RPS response as more aligned.
|
| 427 |
+
Analysis: For a preference demanding high verbosity, the RPS response is clearly superior. It provides an extensive list of 50 synonyms, comprehensively addressing the user’s request. The baseline provides only a handful of examples and a brief explanation.
|
| 428 |
+
SFT Model
|
| 429 |
+
Prompt (HelpSteer2, ID: 0): ”explain master slave replication nsql”
|
| 430 |
+
Baseline Output: I’d be happy to help you understand master-slave replication in the context of NSQ… In master-slave replication, there is a primary node (master) that processes and writes messages, while secondary nodes (slaves) read from the master and maintain an identical copy of the data…
|
| 431 |
+
RPS Output: Master-slave replication is a method used in database systems… Here’s how it works in the context of NSQ, a real-time distributed messaging platform: 1. Master: NSQ has a built-in database called Lookupd that stores metadata… 2. Slaves… 3. Replication lag… 4. Failover…
|
| 432 |
+
Judgment (RPS Win): GPT-4o-mini selected the RPS response as more aligned.
|
| 433 |
+
Analysis: The RPS response provides a more technically accurate and structured explanation. It correctly identifies ‘Lookupd‘ as the key component and explains concepts like replication lag and failover. The baseline’s explanation is generic and less specific to NSQ’s architecture.
|
| 434 |
+
|
| 435 |
+
### A.7 Proof of Corollary 1
|
| 436 |
+
|
| 437 |
+
We provide a brief justification for the two claims in Corollary 1.
|
| 438 |
+
|
| 439 |
+
##### Dependence on Neighborhood Size k k:
|
| 440 |
+
|
| 441 |
+
Let G(k)=𝔼[max(S RPS(k))]−𝔼[max(S Baseline(k))]G(k)=\mathbb{E}[\max(S_{\text{RPS}}^{(k)})]-\mathbb{E}[\max(S_{\text{Baseline}}^{(k)})] be the robustness gain for size k k. The expected value of the maximum of a set of random variables is non-decreasing with the size of the set. Therefore, both 𝔼[max(S RPS(k))]\mathbb{E}[\max(S_{\text{RPS}}^{(k)})] and 𝔼[max(S Baseline(k))]\mathbb{E}[\max(S_{\text{Baseline}}^{(k)})] are non-decreasing in k k. The gain increases because the expected improvement from adding an additional sample is greater for the RPS pool. Let M k RPS=max(S RPS(k))M_{k}^{\text{RPS}}=\max(S_{\text{RPS}}^{(k)}). The increase in expected maximum is 𝔼[max(M k RPS,s k+1)]−𝔼[M k RPS]\mathbb{E}[\max(M_{k}^{\text{RPS}},s_{k+1})]-\mathbb{E}[M_{k}^{\text{RPS}}]. Since the distribution of s k+1 s_{k+1} stochastically dominates that of a baseline sample, this improvement is larger than the corresponding improvement for the baseline, causing the gap G(k)G(k) to widen.
|
| 442 |
+
|
| 443 |
+
##### Dependence on Quality Gap:
|
| 444 |
+
|
| 445 |
+
We can formalize the ”quality gap” as the degree of stochastic dominance. Let the RPS scores {s i}\{s_{i}\} be drawn from distributions {F i}\{F_{i}\}, and consider an alternative set of ”higher-quality” distributions {G i}\{G_{i}\} such that each G i G_{i} stochastically dominates the corresponding F i F_{i} (i.e., G i(x)≤F i(x)G_{i}(x)\leq F_{i}(x) for all x x). Let S RPS′S^{\prime}_{\text{RPS}} be a set of scores drawn from {G i}\{G_{i}\}. Then max(S RPS′)\max(S^{\prime}_{\text{RPS}}) stochastically dominates max(S RPS)\max(S_{\text{RPS}}). This implies 𝔼[max(S RPS′)]≥𝔼[max(S RPS)]\mathbb{E}[\max(S^{\prime}_{\text{RPS}})]\geq\mathbb{E}[\max(S_{\text{RPS}})]. The robustness gain relative to the fixed baseline therefore increases as the quality of the neighborhood candidate pool improves.
|