

Add 1 files
Browse files- 2402/2402.09949.md +227 -0
2402/2402.09949.md
ADDED
|
@@ -0,0 +1,227 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Multi-word Tokenization for Sequence Compression
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2402.09949
|
| 4 |
+
|
| 5 |
+
Markdown Content:
|
| 6 |
+
Leonidas Gee
|
| 7 |
+
|
| 8 |
+
University of Sussex, United Kingdom
|
| 9 |
+
|
| 10 |
+
jg717@sussex.ac.uk&Leonardo Rigutini
|
| 11 |
+
|
| 12 |
+
expert.ai, Siena, Italy
|
| 13 |
+
|
| 14 |
+
lrigutini@expert.ai
|
| 15 |
+
|
| 16 |
+
\AND Marco Ernandes
|
| 17 |
+
|
| 18 |
+
expert.ai, Siena, Italy
|
| 19 |
+
|
| 20 |
+
mernandes@expert.ai&Andrea Zugarini
|
| 21 |
+
|
| 22 |
+
expert.ai, Siena, Italy
|
| 23 |
+
|
| 24 |
+
azugarini@expert.ai
|
| 25 |
+
|
| 26 |
+
###### Abstract
|
| 27 |
+
|
| 28 |
+
Large Language Models have proven highly successful at modelling a variety of tasks. However, this comes at a steep computational cost that hinders wider industrial uptake. In this paper, we present MWT: a Multi-Word Tokenizer that goes beyond word boundaries by representing frequent multi-word expressions as single tokens. MWTs produce a more compact and efficient tokenization that yields two benefits: (1) Increase in performance due to a greater coverage of input data given a fixed sequence length budget; (2) Faster and lighter inference due to the ability to reduce the sequence length with negligible drops in performance. Our results show that MWT is more robust across shorter sequence lengths, thus allowing for major speedups via early sequence truncation.
|
| 29 |
+
|
| 30 |
+
1 Introduction
|
| 31 |
+
--------------
|
| 32 |
+
|
| 33 |
+
The field of Natural Language Processing (NLP) has seen major breakthroughs with the advent of Large Language Models (LLMs)(Vaswani et al., [2017](https://arxiv.org/html/2402.09949v2#bib.bib26); Devlin et al., [2018](https://arxiv.org/html/2402.09949v2#bib.bib4); Touvron et al., [2023](https://arxiv.org/html/2402.09949v2#bib.bib24); OpenAI, [2023](https://arxiv.org/html/2402.09949v2#bib.bib15)). Despite their successes, LLMs like ChatGPT(OpenAI, [2023](https://arxiv.org/html/2402.09949v2#bib.bib15); Brown et al., [2020](https://arxiv.org/html/2402.09949v2#bib.bib1)) possess hundreds of billions of parameters that entail enormous computational cost by design. Traditional model compression methods such as Knowledge Distillation(Hinton et al., [2015](https://arxiv.org/html/2402.09949v2#bib.bib8)), Pruning(Michel et al., [2019](https://arxiv.org/html/2402.09949v2#bib.bib13); Zhu and Gupta, [2017](https://arxiv.org/html/2402.09949v2#bib.bib28)), and Quantization(Shen et al., [2020](https://arxiv.org/html/2402.09949v2#bib.bib22); Gupta et al., [2015](https://arxiv.org/html/2402.09949v2#bib.bib6)) have focused on creating lighter models either by shrinking the architectural size or by reducing the number of FLOPs.
|
| 34 |
+
|
| 35 |
+
Recently, LLMs have been shown to produce impressive performance on inputs that have been carefully designed to contain all the necessary information for a given instruction. As such, there is an increasing trend in designing longer and longer prompts that has led to a significant rise in computational cost. To address this, interest has grown in compressing the input sequences from the tokenizer(Gee et al., [2022](https://arxiv.org/html/2402.09949v2#bib.bib5); Mu et al., [2023](https://arxiv.org/html/2402.09949v2#bib.bib14); Petrov et al., [2023](https://arxiv.org/html/2402.09949v2#bib.bib17)). Indeed, various works have shown the importance of tokenization in determining the length of a sequence in specialized domains(Gee et al., [2022](https://arxiv.org/html/2402.09949v2#bib.bib5)) or on underrepresented languages(Petrov et al., [2023](https://arxiv.org/html/2402.09949v2#bib.bib17)).
|
| 36 |
+
|
| 37 |
+
Input:an energizable member is operably coupled to the outer sleeve .𝒯 gen subscript 𝒯 𝑔 𝑒 𝑛\mathcal{T}_{gen}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT:an, en, ##er, ##gi, ##zable, member, is, opera, ##bly, coupled, to, the, outer, sleeve, .𝒯 gen 1000 superscript subscript 𝒯 𝑔 𝑒 𝑛 1000\mathcal{T}_{gen}^{1000}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 1000 end_POSTSUPERSCRIPT:an, en, ##er, ##gi, ##zable, member_is, opera, ##bly, coupled_to, the_outer, sleeve, .𝒯 100 subscript 𝒯 100\mathcal{T}_{100}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT:an, energizable, member, is, operably, coupled, to, the, outer, sleeve, .𝒯 100 1000 superscript subscript 𝒯 100 1000\mathcal{T}_{100}^{1000}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 1000 end_POSTSUPERSCRIPT:an, energizable, member_is, operably, coupled_to, the_outer, sleeve, .
|
| 38 |
+
|
| 39 |
+
Figure 1: Tokenization using generic 𝒯 gen subscript 𝒯 𝑔 𝑒 𝑛\mathcal{T}_{gen}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT and adapted 𝒯 100 subscript 𝒯 100\mathcal{T}_{100}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT tokenizers. 𝒯 gen 1000 superscript subscript 𝒯 𝑔 𝑒 𝑛 1000\mathcal{T}_{gen}^{1000}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 1000 end_POSTSUPERSCRIPT and 𝒯 100 1000 superscript subscript 𝒯 100 1000\mathcal{T}_{100}^{1000}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 1000 end_POSTSUPERSCRIPT are extended with the top-1000 bigrams. Tokens obtained with domain-adaptation or MWT are highlighted in orange and blue respectively. MWTs are shown to be highly complementary to existing tokenizers for sequence compression.
|
| 40 |
+
|
| 41 |
+
In this paper, we propose a method for reducing the computational cost of a LLM by compressing the textual inputs using Multi-Word Tokenizers (MWTs). To achieves this, we enrich the vocabulary of the tokenizer with statistically determined multi-word expressions. By encoding the frequent n-grams with single tokens, the sequences produced are both shorter and more informative, thus allowing for major speedups via early sequence truncation. Additionally, MWTs are shown to be compatible with the aforementioned traditional compression methods. Experimentally, we assess MWTs on three text classification datasets. We show how our approach still performs well when combined with distilled models(Sanh et al., [2019](https://arxiv.org/html/2402.09949v2#bib.bib18)) and other sequence compression techniques(Gee et al., [2022](https://arxiv.org/html/2402.09949v2#bib.bib5)). The code for our paper is publicly available 1 1 1[https://github.com/LeonidasY/fast-vocabulary-transfer/tree/emnlp2023](https://github.com/LeonidasY/fast-vocabulary-transfer/tree/emnlp2023).
|
| 42 |
+
|
| 43 |
+
The rest of the paper is organized as follows. First, we review the related works in Section[2](https://arxiv.org/html/2402.09949v2#S2 "2 Related Works ‣ Multi-word Tokenization for Sequence Compression"). Then, we describe our approach in Section[3](https://arxiv.org/html/2402.09949v2#S3 "3 Multi-word Tokenizer ‣ Multi-word Tokenization for Sequence Compression") and present the experiments in Section[4](https://arxiv.org/html/2402.09949v2#S4 "4 Experiments ‣ Multi-word Tokenization for Sequence Compression"). Finally, we draw our conclusions in Section[5](https://arxiv.org/html/2402.09949v2#S5 "5 Conclusion ‣ Multi-word Tokenization for Sequence Compression").
|
| 44 |
+
|
| 45 |
+
2 Related Works
|
| 46 |
+
---------------
|
| 47 |
+
|
| 48 |
+
Most model compression research falls into one of the following categories: Knowledge Distillation(Hinton et al., [2015](https://arxiv.org/html/2402.09949v2#bib.bib8); Sanh et al., [2019](https://arxiv.org/html/2402.09949v2#bib.bib18); Jiao et al., [2020](https://arxiv.org/html/2402.09949v2#bib.bib9); Wang et al., [2020](https://arxiv.org/html/2402.09949v2#bib.bib27); Sun et al., [2020](https://arxiv.org/html/2402.09949v2#bib.bib23)), Pruning(Zhu and Gupta, [2017](https://arxiv.org/html/2402.09949v2#bib.bib28); Michel et al., [2019](https://arxiv.org/html/2402.09949v2#bib.bib13)), and Quantization(Shen et al., [2020](https://arxiv.org/html/2402.09949v2#bib.bib22)). The family of approaches is somewhat complementary and can be applied individually or jointly. Each approach alters the model’s size to obtain a more efficient architecture. Differently, other works such as FlashAttention(Dao et al., [2022](https://arxiv.org/html/2402.09949v2#bib.bib3)) seek to optimize a model’s implementation. In particular, LLMs are sped up by reducing the number of memory accesses for the self-attention mechanism.
|
| 49 |
+
|
| 50 |
+
#### Sequence Compression.
|
| 51 |
+
|
| 52 |
+
An emerging direction for reducing the cost of LLMs involves the designing of shorter input sequences. Prompting techniques such as Mu et al. ([2023](https://arxiv.org/html/2402.09949v2#bib.bib14)) compress repetitive lengthy prompts into gist tokens. Other works emphasize the role of tokenization in sequence compression. In Petrov et al. ([2023](https://arxiv.org/html/2402.09949v2#bib.bib17)), the authors show how the tokenizer of most LLMs strongly favor the English language over other languages. For underrepresented languages, the same translated sentence may consist of inputs that are up to 15 times longer. Analogously, Gee et al. ([2022](https://arxiv.org/html/2402.09949v2#bib.bib5)) investigated the tokenization efficiency of general-purpose tokenizers in vertical domains such as medicine and law. They proposed a transfer learning technique that adapts the vocabulary of a LLM to specific language domains. An effect of a dedicated vocabulary is a more efficient tokenization that reduces the number of sub-word tokens in a sequence.
|
| 53 |
+
|
| 54 |
+
In this work, we push this effect further, going beyond word boundaries by introducing Multi-Word Expressions (MWEs) in the form of n-grams into the tokenizer as shown in Figure[1](https://arxiv.org/html/2402.09949v2#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Multi-word Tokenization for Sequence Compression"). The underlying intuition behind this is that a more compact tokenization can save computations by allowing the model to process shorter sequences without a significant loss of information. The usage of MWEs is not novel with several works(Lample et al., [2018](https://arxiv.org/html/2402.09949v2#bib.bib12); Otani et al., [2020](https://arxiv.org/html/2402.09949v2#bib.bib16); Kumar and Thawani, [2022](https://arxiv.org/html/2402.09949v2#bib.bib11)) introducing phrases or n-grams to improve the quality of machine translation. In Kumar and Thawani ([2022](https://arxiv.org/html/2402.09949v2#bib.bib11)), the authors generalized BPE(Sennrich et al., [2016](https://arxiv.org/html/2402.09949v2#bib.bib20)) to multi-word tokens. However, to the best of our knowledge, we are the first to investigate MWEs in the context of sequence compression.
|
| 55 |
+
|
| 56 |
+
3 Multi-word Tokenizer
|
| 57 |
+
----------------------
|
| 58 |
+
|
| 59 |
+
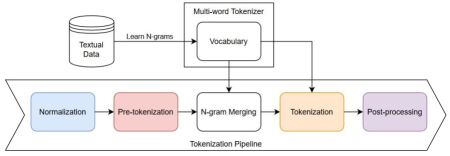
Tokenization is a necessary step in the feeding of textual data to a LLM. Typically, tokenizers split a text into a sequence of symbols which can be entire words or only subparts. To do this, a vocabulary is first constructed by statistically learning the most frequent tokens from a large general-purpose corpus(Sennrich et al., [2016](https://arxiv.org/html/2402.09949v2#bib.bib20); Schuster and Nakajima, [2012](https://arxiv.org/html/2402.09949v2#bib.bib19); Kudo and Richardson, [2018](https://arxiv.org/html/2402.09949v2#bib.bib10)). The resulting tokenizer can then be used to segment an input text by greedily looking for the solution with the least number of tokens. Building upon this, we inject into the tokenizer new symbols formed by n-grams of words. We do this by first selecting the most frequent n-grams to include in its vocabulary. Then, we place an n-gram merging step within the tokenization pipeline as sketched in Figure[2](https://arxiv.org/html/2402.09949v2#S3.F2 "Figure 2 ‣ 3 Multi-word Tokenizer ‣ Multi-word Tokenization for Sequence Compression"). The added n-grams will be treated as single tokens further down the tokenization pipeline.
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
Figure 2: Sketch of the Multi-word Tokenizer pipeline. First, n-grams are statistically learned from the training set. Then, the top-K n-grams are added to the vocabulary of the tokenizer. N-grams are merged from left to right within a sequence after pre-tokenization.
|
| 64 |
+
|
| 65 |
+
#### N-gram Selection.
|
| 66 |
+
|
| 67 |
+
In order to maximize the sequence reduction, we statistically estimate the top-K most frequent n-grams in a reference training corpus. Although the approach is greedy, hence sub-optimal, it still effectively yields significant compression while being extremely fast and easy to compute. More formally, given a corpus 𝒟 𝒟\mathcal{D}caligraphic_D and N≥2 𝑁 2 N\geq 2 italic_N ≥ 2, we compute all the possible n-grams g n∈𝒟 subscript 𝑔 𝑛 𝒟 g_{n}\in\mathcal{D}italic_g start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ∈ caligraphic_D, where n=2,…,N 𝑛 2…𝑁 n=2,\ldots,N italic_n = 2 , … , italic_N. Then, we count their frequency f(g n),∀g n∈𝒟 𝑓 subscript 𝑔 𝑛 for-all subscript 𝑔 𝑛 𝒟 f(g_{n}),\forall g_{n}\in\mathcal{D}italic_f ( italic_g start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ) , ∀ italic_g start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ∈ caligraphic_D. The K 𝐾 K italic_K most frequent n-grams 𝒢 K subscript 𝒢 𝐾\mathcal{G}_{K}caligraphic_G start_POSTSUBSCRIPT italic_K end_POSTSUBSCRIPT are included in the vocabulary 𝒱←𝒱∪𝒢 K←𝒱 𝒱 subscript 𝒢 𝐾\mathcal{V}\leftarrow\mathcal{V}\cup\mathcal{G}_{K}caligraphic_V ← caligraphic_V ∪ caligraphic_G start_POSTSUBSCRIPT italic_K end_POSTSUBSCRIPT of the tokenizer 𝒯 𝒯\mathcal{T}caligraphic_T.
|
| 68 |
+
|
| 69 |
+
#### Fast Vocabulary Transfer.
|
| 70 |
+
|
| 71 |
+
Given that the vocabulary of the tokenizer has changed, the newly added symbols 𝒢 K subscript 𝒢 𝐾\mathcal{G}_{K}caligraphic_G start_POSTSUBSCRIPT italic_K end_POSTSUBSCRIPT must be included into the embedding matrix of the language model as well. To avoid retraining the entire model from scratch which is highly resource-demanding, or a random initialization of new tokens which would perform poorly, we make use of Fast Vocabulary Transfer (FVT) instead(Gee et al., [2022](https://arxiv.org/html/2402.09949v2#bib.bib5)).
|
| 72 |
+
|
| 73 |
+
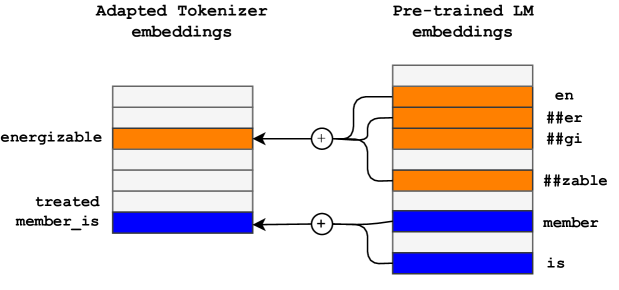
FVT is a transfer learning technique that assigns embeddings to new tokens by combining existing elements of the embedding matrix as shown in Figure[3](https://arxiv.org/html/2402.09949v2#S3.F3 "Figure 3 ‣ Fast Vocabulary Transfer. ‣ 3 Multi-word Tokenizer ‣ Multi-word Tokenization for Sequence Compression"). After initializing the multi-word embeddings with FVT, we found it beneficial to tune the model with Masked-Language Modeling (MLM) as done by Gee et al. ([2022](https://arxiv.org/html/2402.09949v2#bib.bib5)). We believe this is helpful as it aids the model in further readjusting the embeddings of the new tokens.
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
Figure 3: Fast Vocabulary Transfer. The pre-trained embeddings of existing tokens are combined to form the embeddings of the newly adapted vocabulary.
|
| 78 |
+
|
| 79 |
+
Table 1: Average sequence length from tokenization. The generic 𝒯 gen subscript 𝒯 𝑔 𝑒 𝑛\mathcal{T}_{gen}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT and adapted 𝒯 100 subscript 𝒯 100\mathcal{T}_{100}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT tokenizers are extended with varying top-Ks of 1000, 2500, and 5000.
|
| 80 |
+
|
| 81 |
+
4 Experiments
|
| 82 |
+
-------------
|
| 83 |
+
|
| 84 |
+
Given a fixed number of tokens, a more compact input sequence preserves a greater amount of information. This can be used to either achieve a better performance with limited benefits in speedup, or vice versa, i.e. making the model faster with negligible drops in performance. The experiments aim to analyze how these two aspects interact with one another. We focus on text classification as it is a problem of particular interest for many industry-oriented applications.
|
| 85 |
+
|
| 86 |
+
### 4.1 Experimental Setup
|
| 87 |
+
|
| 88 |
+
Our experiments were conducted on the cased versions of BERT base subscript BERT 𝑏 𝑎 𝑠 𝑒\text{BERT}_{base}BERT start_POSTSUBSCRIPT italic_b italic_a italic_s italic_e end_POSTSUBSCRIPT(Devlin et al., [2018](https://arxiv.org/html/2402.09949v2#bib.bib4)) and DistilBERT base subscript DistilBERT 𝑏 𝑎 𝑠 𝑒\text{DistilBERT}_{base}DistilBERT start_POSTSUBSCRIPT italic_b italic_a italic_s italic_e end_POSTSUBSCRIPT(Sanh et al., [2019](https://arxiv.org/html/2402.09949v2#bib.bib18)). Additionally, we consider an adapted tokenizer with a vocabulary size equal to that of the generic tokenizer from a pre-trained model as done by Gee et al. ([2022](https://arxiv.org/html/2402.09949v2#bib.bib5)). We refer to the generic and adapted tokenizers as 𝒯 gen subscript 𝒯 𝑔 𝑒 𝑛\mathcal{T}_{gen}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT and 𝒯 100 subscript 𝒯 100\mathcal{T}_{100}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT respectively. Both tokenizers are extended with the top-K n-grams of 1000, 2500, and 5000. Overall, we compare eight different tokenizers indicated as: 𝒯 gen,𝒯 gen 1000,𝒯 gen 2500,𝒯 gen 5000 subscript 𝒯 𝑔 𝑒 𝑛 superscript subscript 𝒯 𝑔 𝑒 𝑛 1000 superscript subscript 𝒯 𝑔 𝑒 𝑛 2500 superscript subscript 𝒯 𝑔 𝑒 𝑛 5000\mathcal{T}_{gen},\mathcal{T}_{gen}^{1000},\mathcal{T}_{gen}^{2500},\mathcal{T% }_{gen}^{5000}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT , caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 1000 end_POSTSUPERSCRIPT , caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2500 end_POSTSUPERSCRIPT , caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 5000 end_POSTSUPERSCRIPT and 𝒯 100,𝒯 100 1000,𝒯 100 2500,𝒯 100 5000 subscript 𝒯 100 superscript subscript 𝒯 100 1000 superscript subscript 𝒯 100 2500 superscript subscript 𝒯 100 5000\mathcal{T}_{100},\mathcal{T}_{100}^{1000},\mathcal{T}_{100}^{2500},\mathcal{T% }_{100}^{5000}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT , caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 1000 end_POSTSUPERSCRIPT , caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2500 end_POSTSUPERSCRIPT , caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 5000 end_POSTSUPERSCRIPT.
|
| 89 |
+
|
| 90 |
+
#### Implementation Details.
|
| 91 |
+
|
| 92 |
+
We train each model with 5 different random initializations. The macro-F1 and inference speedup are measured as metrics. The average of all 5 initializations is taken as the final value of each metric. The inference speedup measurements were done on a V100-PCIE GPU with 16GBs of dedicated RAM.
|
| 93 |
+
|
| 94 |
+
Following Gee et al. ([2022](https://arxiv.org/html/2402.09949v2#bib.bib5)), we first apply one epoch of MLM using the in-domain dataset. Next, the model is fine-tuned for 10 epochs with early stopping on the downstream task. We set the initial learning rate to 3⋅10−5⋅3 superscript 10 5 3\cdot 10^{-5}3 ⋅ 10 start_POSTSUPERSCRIPT - 5 end_POSTSUPERSCRIPT for both MLM and downstream fine-tuning, while the batch size is set to 8 and 32 for MLM and downstream fine-tuning respectively.
|
| 95 |
+
|
| 96 |
+
#### Choice of N.
|
| 97 |
+
|
| 98 |
+
An important hyperparameter is N, i.e. the maximum number of words constituting an n-gram. In our experiments, N is set to 2 as we believe that using bigrams only provides better generalization properties. Increasing the value of N may lead to an overspecialization of n-grams which could overfit on small textual corpora.
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
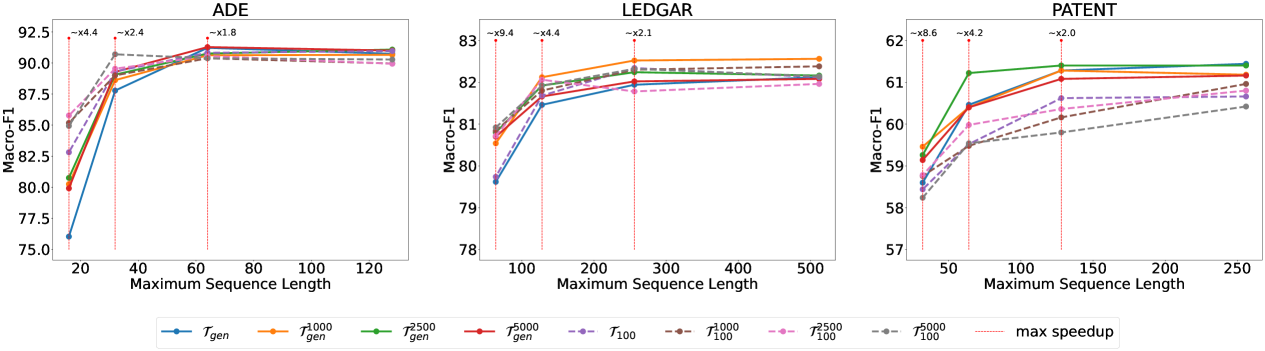
Figure 4: Plot of macro-F1 against maximum sequence length. The generic 𝒯 gen subscript 𝒯 𝑔 𝑒 𝑛\mathcal{T}_{gen}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT and adapted 𝒯 100 subscript 𝒯 100\mathcal{T}_{100}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT tokenizers are represented by solid and dashed lines respectively. MWTs are shown to be more robust on shorter sequence lengths, thus allowing for major speedups via early sequence truncation.
|
| 103 |
+
|
| 104 |
+
### 4.2 Datasets
|
| 105 |
+
|
| 106 |
+
To determine the effectiveness of MWTs, we select 3 different text classification tasks from diverse linguistic domains, namely medical (ADE), legal (LEDGAR), and tech (PATENT).
|
| 107 |
+
|
| 108 |
+
#### ADE.
|
| 109 |
+
|
| 110 |
+
A sentence classification dataset of determining whether a sentence is Adverse Drug Event (ADE)-related or not(Gurulingappa et al., [2012](https://arxiv.org/html/2402.09949v2#bib.bib7)). The sentences are characterized by the presence of medical terminologies of drugs and their adverse effects. We use the same train, validation, and test splits as in Gee et al. ([2022](https://arxiv.org/html/2402.09949v2#bib.bib5)).
|
| 111 |
+
|
| 112 |
+
#### LEDGAR.
|
| 113 |
+
|
| 114 |
+
A document classification dataset of contracts obtained from the US Securities and Exchange Commission (SEC) filings(Tuggener et al., [2020](https://arxiv.org/html/2402.09949v2#bib.bib25)). The task is to determine whether the main topic of the contract provision from a set of 100 mutually-exclusive labels. The dataset is also part of LexGLUE(Chalkidis et al., [2022](https://arxiv.org/html/2402.09949v2#bib.bib2)), which is a benchmark for legal language understanding.
|
| 115 |
+
|
| 116 |
+
#### PATENT.
|
| 117 |
+
|
| 118 |
+
A document classification dataset 2 2 2[https://huggingface.co/datasets/ccdv/patent-classification](https://huggingface.co/datasets/ccdv/patent-classification) of US patent applications filed under the Cooperative Patent Classification (CPC) code(Sharma et al., [2019](https://arxiv.org/html/2402.09949v2#bib.bib21)). A human written abstractive summary is provided for each patent application. The task is to determine the category that a patent application belongs to from 9 unbalanced classes.
|
| 119 |
+
|
| 120 |
+
### 4.3 Results
|
| 121 |
+
|
| 122 |
+
#### Preliminary Analysis.
|
| 123 |
+
|
| 124 |
+
Before measuring the effects of MWTs on LLMs, we analyze how the average sequence length changes for each dataset depending on the tokenizer. From Table[1](https://arxiv.org/html/2402.09949v2#S3.T1 "Table 1 ‣ Fast Vocabulary Transfer. ‣ 3 Multi-word Tokenizer ‣ Multi-word Tokenization for Sequence Compression"), increasing the top-K most frequent n-grams naturally yields a greater compression. However, even a 1000 bigrams is enough to achieve a reduction of about 20%. When multi-words are combined with an adapted tokenizer 𝒯 100 subscript 𝒯 100\mathcal{T}_{100}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT, the joint sequence narrowing effects appear to be highly complementary, achieving a compression rate close to 50% in ADE. In practice, a 50% reduction means that on average we can store the same amount of text in half the sequence length. Consequently, we could in principle reduce a LLM’s maximum sequence length by a factor of 2.
|
| 125 |
+
|
| 126 |
+
Method ADE LEDGAR PATENT
|
| 127 |
+
Δ Δ\Delta roman_Δ F1 Speedup Δ Δ\Delta roman_Δ F1 Speedup Δ Δ\Delta roman_Δ F1 Speedup
|
| 128 |
+
𝒯 gen subscript 𝒯 𝑔 𝑒 𝑛\mathcal{T}_{gen}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT 90.74 ±plus-or-minus\pm± 0.84 1.00 82.12 ±plus-or-minus\pm± 0.33 1.00 61.44 ±plus-or-minus\pm± 0.38 1.00
|
| 129 |
+
𝒯 gen 1000 superscript subscript 𝒯 𝑔 𝑒 𝑛 1000\mathcal{T}_{gen}^{1000}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 1000 end_POSTSUPERSCRIPT-0.09 ±plus-or-minus\pm± 0.70 1.32 0.54 ±plus-or-minus\pm± 0.24 1.14-0.42 ±plus-or-minus\pm± 0.54 1.11
|
| 130 |
+
𝒯 gen 2500 superscript subscript 𝒯 𝑔 𝑒 𝑛 2500\mathcal{T}_{gen}^{2500}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2500 end_POSTSUPERSCRIPT 0.37 ±plus-or-minus\pm± 0.54 1.38 0.05 ±plus-or-minus\pm± 0.44 1.23-0.07 ±plus-or-minus\pm± 0.46 1.16
|
| 131 |
+
𝒯 gen 5000 superscript subscript 𝒯 𝑔 𝑒 𝑛 5000\mathcal{T}_{gen}^{5000}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 5000 end_POSTSUPERSCRIPT 0.29 ±plus-or-minus\pm± 0.68 1.43-0.05 ±plus-or-minus\pm± 0.41 1.33-0.46 ±plus-or-minus\pm± 0.69 1.19
|
| 132 |
+
𝒯 100 subscript 𝒯 100\mathcal{T}_{100}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT 0.24 ±plus-or-minus\pm± 0.67 1.51 0.00 ±plus-or-minus\pm± 0.41 1.10-1.27 ±plus-or-minus\pm± 0.39 1.06
|
| 133 |
+
𝒯 100 1000 superscript subscript 𝒯 100 1000\mathcal{T}_{100}^{1000}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 1000 end_POSTSUPERSCRIPT-0.86 ±plus-or-minus\pm± 1.21 1.71 0.32 ±plus-or-minus\pm± 0.58 1.36-0.78 ±plus-or-minus\pm± 0.62 1.24
|
| 134 |
+
𝒯 100 2500 superscript subscript 𝒯 100 2500\mathcal{T}_{100}^{2500}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2500 end_POSTSUPERSCRIPT-0.88 ±plus-or-minus\pm± 0.72 1.78-0.19 ±plus-or-minus\pm± 0.57 1.47-1.04 ±plus-or-minus\pm± 0.42 1.30
|
| 135 |
+
𝒯 100 5000 superscript subscript 𝒯 100 5000\mathcal{T}_{100}^{5000}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 5000 end_POSTSUPERSCRIPT-0.51 ±plus-or-minus\pm± 0.65 1.79 0.02 ±plus-or-minus\pm± 0.58 1.57-1.66 ±plus-or-minus\pm± 0.44 1.34
|
| 136 |
+
|
| 137 |
+
Table 2: Absolute values of BERT fine-tuned on the downstream task using a sequence length of 128, 512 and 256 for ADE, LEDGAR and PATENT respectively. 𝒯 gen subscript 𝒯 𝑔 𝑒 𝑛\mathcal{T}_{gen}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT is shown on the first row, while relative values to 𝒯 gen subscript 𝒯 𝑔 𝑒 𝑛\mathcal{T}_{gen}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT are shown on subsequent rows.
|
| 138 |
+
|
| 139 |
+
#### Multi-word Tokenization.
|
| 140 |
+
|
| 141 |
+
As a first evaluation, we assess the macro-F1 and inference speedups achieved by fine-tuned BERT models with multi-word tokenizers: 𝒯 gen 1000,𝒯 gen 2500,𝒯 gen 5000 superscript subscript 𝒯 𝑔 𝑒 𝑛 1000 superscript subscript 𝒯 𝑔 𝑒 𝑛 2500 superscript subscript 𝒯 𝑔 𝑒 𝑛 5000\mathcal{T}_{gen}^{1000},\mathcal{T}_{gen}^{2500},\mathcal{T}_{gen}^{5000}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 1000 end_POSTSUPERSCRIPT , caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2500 end_POSTSUPERSCRIPT , caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 5000 end_POSTSUPERSCRIPT. The pre-trained BERT with a generic tokenizer 𝒯 gen subscript 𝒯 𝑔 𝑒 𝑛\mathcal{T}_{gen}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT is considered as the reference model. From Table[2](https://arxiv.org/html/2402.09949v2#S4.T2 "Table 2 ‣ Preliminary Analysis. ‣ 4.3 Results ‣ 4 Experiments ‣ Multi-word Tokenization for Sequence Compression"), MWTs are shown to either improve the reference performance or induce a relatively negligible degradation. At the same time, the sequence compression from MWTs yields a natural speedup that depending on the dataset varies from about x1.1 to x1.4.
|
| 142 |
+
|
| 143 |
+
#### MWT and Domain Adaptation.
|
| 144 |
+
|
| 145 |
+
Additionally, we investigate the application of MWTs with tokenizers adapted to the dataset: 𝒯 100 1000,𝒯 100 2500,𝒯 100 5000 superscript subscript 𝒯 100 1000 superscript subscript 𝒯 100 2500 superscript subscript 𝒯 100 5000\mathcal{T}_{100}^{1000},\mathcal{T}_{100}^{2500},\mathcal{T}_{100}^{5000}caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 1000 end_POSTSUPERSCRIPT , caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2500 end_POSTSUPERSCRIPT , caligraphic_T start_POSTSUBSCRIPT 100 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 5000 end_POSTSUPERSCRIPT. With the exception of PATENT, most models are shown to achieve significant inference speedups of up to x1.8 with minimal degradation in performance from Table[2](https://arxiv.org/html/2402.09949v2#S4.T2 "Table 2 ‣ Preliminary Analysis. ‣ 4.3 Results ‣ 4 Experiments ‣ Multi-word Tokenization for Sequence Compression"). We hypothesize that this is due to the fact that the language domain of PATENT is not as specialized as ADE and LEDGAR, which reduces the benefits of using an adapted tokenizer.
|
| 146 |
+
|
| 147 |
+
#### MWT and Truncation.
|
| 148 |
+
|
| 149 |
+
Based on the preliminary analysis, we analyze how truncating sequences with different maximum lengths affects both the performance and inference speedup. Reducing the maximum sequence length has a double impact on the inference speedup given a fixed amount of resources. First, latency linearly grows with respect to the sequence length. Second, reducing the sequence length releases GPU resources that can be used to enlarge the batch size. We consider 4 maximum sequence lengths for each dataset by progressively halving the initial maximum sequence length, i.e. {128,64,32,16}128 64 32 16\{128,64,32,16\}{ 128 , 64 , 32 , 16 } for ADE, {256,128,64,32}256 128 64 32\{256,128,64,32\}{ 256 , 128 , 64 , 32 } for LEDGAR, and {512,256,128,64}512 256 128 64\{512,256,128,64\}{ 512 , 256 , 128 , 64 } for PATENT.
|
| 150 |
+
|
| 151 |
+
From Figure[4](https://arxiv.org/html/2402.09949v2#S4.F4 "Figure 4 ‣ Choice of N. ‣ 4.1 Experimental Setup ‣ 4 Experiments ‣ Multi-word Tokenization for Sequence Compression"), we can see the performance of 𝒯 gen subscript 𝒯 𝑔 𝑒 𝑛\mathcal{T}_{gen}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT dropping more rapidly than MWTs as truncation increases (maximum sequence length decreases). In the extreme 8-times truncation, the performance of 𝒯 gen subscript 𝒯 𝑔 𝑒 𝑛\mathcal{T}_{gen}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT falls dramatically for both ADE and LEDGAR. However, MWTs are shown to be more robust to truncation, hence their degradation in performance is smoother and without sudden collapses. In both ADE and LEDGAR, a 4-times truncation leads to nearly identical or better performance, while bringing significant inference speedups of ∼similar-to\sim∼x2.4 and ∼similar-to\sim∼x4.4 respectively. If a certain performance degradation is acceptable, the inference speedup can be maximized, reaching up to ∼similar-to\sim∼x9.4 in LEDGAR.
|
| 152 |
+
|
| 153 |
+
#### MWT and Distillation.
|
| 154 |
+
|
| 155 |
+
Additionally, we investigate the interaction between sequence compression and knowledge distillation in Table[3](https://arxiv.org/html/2402.09949v2#S4.T3 "Table 3 ‣ MWT and Distillation. ‣ 4.3 Results ‣ 4 Experiments ‣ Multi-word Tokenization for Sequence Compression"). To this end, we utilize a DistilBERT model with MWTs. For simplicity, we restrict our analysis to LEDGAR and to a single multi-word tokenizer 𝒯 gen 2500 superscript subscript 𝒯 𝑔 𝑒 𝑛 2500\mathcal{T}_{gen}^{2500}caligraphic_T start_POSTSUBSCRIPT italic_g italic_e italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2500 end_POSTSUPERSCRIPT on different maximum sequence lengths. From the table, our MWT is shown to retain most of its performance with a quarter of the sequence length and an inference speedup of ∼similar-to\sim∼x8.8. Even with an extreme sequence truncation to only 64 tokens, we can still achieve a ∼similar-to\sim∼x18.1 inference speedup with only a 2.7% drop in relative performance.
|
| 156 |
+
|
| 157 |
+
Table 3: The macro-F1 and inference speedup results on LEDGAR with DistilBERT. MWTs are shown to be highly compatible with distilled models.
|
| 158 |
+
|
| 159 |
+
5 Conclusion
|
| 160 |
+
------------
|
| 161 |
+
|
| 162 |
+
In this work, we proposed a sequence compression approach that reduces textual inputs by exploiting the use of multi-word expressions drawn from the training set according to their top-K frequencies. We conducted an investigation on 3 different datasets by evaluating each model in conjunction with other compression methods(Gee et al., [2022](https://arxiv.org/html/2402.09949v2#bib.bib5); Sanh et al., [2019](https://arxiv.org/html/2402.09949v2#bib.bib18)). Our approach is shown to be highly robust to shorter sequence lengths, thus yielding a more than x4 reduction in computational cost with negligible drops in performance. In the future, we expect to extend our analysis to other language models and tasks such as language generation in the scope of sequence compression.
|
| 163 |
+
|
| 164 |
+
6 Limitations
|
| 165 |
+
-------------
|
| 166 |
+
|
| 167 |
+
As demonstrated in the paper, MWTs work well on text classification problems. Despite not having conducted experiments on generative tasks, there are no limitations in extending MWTs to them. Differently, the application of MWTs to token classification problems can be challenging. Specifically, when merging multiple words together, it is unclear how to label such fused tokens.
|
| 168 |
+
|
| 169 |
+
Acknowledgements
|
| 170 |
+
----------------
|
| 171 |
+
|
| 172 |
+
This work was supported by the IBRIDAI project, a project financed by the Regional Operational Program “FESR 2014-2020” of Emilia Romagna (Italy), resolution of the Regional Council n. 863/2021.
|
| 173 |
+
|
| 174 |
+
References
|
| 175 |
+
----------
|
| 176 |
+
|
| 177 |
+
* Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. _Advances in neural information processing systems_, 33:1877–1901.
|
| 178 |
+
* Chalkidis et al. (2022) Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion Androutsopoulos, Daniel Katz, and Nikolaos Aletras. 2022. [LexGLUE: A benchmark dataset for legal language understanding in English](https://doi.org/10.18653/v1/2022.acl-long.297). In _Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)_, pages 4310–4330, Dublin, Ireland. Association for Computational Linguistics.
|
| 179 |
+
* Dao et al. (2022) Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashattention: Fast and memory-efficient exact attention with io-awareness. _Advances in Neural Information Processing Systems_, 35:16344–16359.
|
| 180 |
+
* Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of deep bidirectional transformers for language understanding. _arXiv preprint arXiv:1810.04805_.
|
| 181 |
+
* Gee et al. (2022) Leonidas Gee, Andrea Zugarini, Leonardo Rigutini, and Paolo Torroni. 2022. [Fast vocabulary transfer for language model compression](https://aclanthology.org/2022.emnlp-industry.41). In _Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track_, pages 409–416, Abu Dhabi, UAE. Association for Computational Linguistics.
|
| 182 |
+
* Gupta et al. (2015) Suyog Gupta, Ankur Agrawal, Kailash Gopalakrishnan, and Pritish Narayanan. 2015. Deep learning with limited numerical precision. In _International conference on machine learning_, pages 1737–1746. PMLR.
|
| 183 |
+
* Gurulingappa et al. (2012) Harsha Gurulingappa, Abdul Mateen Rajput, Angus Roberts, Juliane Fluck, Martin Hofmann-Apitius, and Luca Toldo. 2012. [Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports](https://doi.org/https://doi.org/10.1016/j.jbi.2012.04.008). _Journal of Biomedical Informatics_, 45(5):885 – 892. Text Mining and Natural Language Processing in Pharmacogenomics.
|
| 184 |
+
* Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, Jeff Dean, et al. 2015. Distilling the knowledge in a neural network. _arXiv preprint arXiv:1503.02531_, 2(7).
|
| 185 |
+
* Jiao et al. (2020) Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2020. TinyBERT: Distilling BERT for natural language understanding. In _Findings of the Association for Computational Linguistics: EMNLP 2020_, pages 4163–4174.
|
| 186 |
+
* Kudo and Richardson (2018) Taku Kudo and John Richardson. 2018. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. _arXiv preprint arXiv:1808.06226_.
|
| 187 |
+
* Kumar and Thawani (2022) Dipesh Kumar and Avijit Thawani. 2022. Bpe beyond word boundary: How not to use multi word expressions in neural machine translation. In _Proceedings of the Third Workshop on Insights from Negative Results in NLP_, pages 172–179.
|
| 188 |
+
* Lample et al. (2018) Guillaume Lample, Myle Ott, Alexis Conneau, Ludovic Denoyer, and Marc’Aurelio Ranzato. 2018. Phrase-based & neural unsupervised machine translation. _arXiv preprint arXiv:1804.07755_.
|
| 189 |
+
* Michel et al. (2019) Paul Michel, Omer Levy, and Graham Neubig. 2019. Are sixteen heads really better than one? _Advances in neural information processing systems_, 32.
|
| 190 |
+
* Mu et al. (2023) Jesse Mu, Xiang Lisa Li, and Noah Goodman. 2023. Learning to compress prompts with gist tokens. _arXiv preprint arXiv:2304.08467_.
|
| 191 |
+
* OpenAI (2023) OpenAI. 2023. [Gpt-4 technical report](http://arxiv.org/abs/2303.08774).
|
| 192 |
+
* Otani et al. (2020) Naoki Otani, Satoru Ozaki, Xingyuan Zhao, Yucen Li, Micaelah St Johns, and Lori Levin. 2020. [Pre-tokenization of multi-word expressions in cross-lingual word embeddings](https://doi.org/10.18653/v1/2020.emnlp-main.360). In _Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)_, pages 4451–4464, Online. Association for Computational Linguistics.
|
| 193 |
+
* Petrov et al. (2023) Aleksandar Petrov, Emanuele La Malfa, Philip HS Torr, and Adel Bibi. 2023. Language model tokenizers introduce unfairness between languages. _arXiv preprint arXiv:2305.15425_.
|
| 194 |
+
* Sanh et al. (2019) Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. [Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter](https://doi.org/10.48550/ARXIV.1910.01108).
|
| 195 |
+
* Schuster and Nakajima (2012) Mike Schuster and Kaisuke Nakajima. 2012. Japanese and korean voice search. In _2012 IEEE international conference on acoustics, speech and signal processing (ICASSP)_, pages 5149–5152. IEEE.
|
| 196 |
+
* Sennrich et al. (2016) Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural machine translation of rare words with subword units. In _Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)_, pages 1715–1725.
|
| 197 |
+
* Sharma et al. (2019) Eva Sharma, Chen Li, and Lu Wang. 2019. [BIGPATENT: A large-scale dataset for abstractive and coherent summarization](https://doi.org/10.18653/v1/P19-1212). In _Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics_, pages 2204–2213, Florence, Italy. Association for Computational Linguistics.
|
| 198 |
+
* Shen et al. (2020) Sheng Shen, Zhen Dong, Jiayu Ye, Linjian Ma, Zhewei Yao, Amir Gholami, Michael W Mahoney, and Kurt Keutzer. 2020. Q-BERT: Hessian based ultra low precision quantization of BERT. In _Proceedings of the AAAI Conference on Artificial Intelligence_, volume 34, pages 8815–8821.
|
| 199 |
+
* Sun et al. (2020) Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou. 2020. MobileBERT: a compact task-agnostic BERT for resource-limited devices. _arXiv preprint arXiv:2004.02984_.
|
| 200 |
+
* Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. _arXiv preprint arXiv:2302.13971_.
|
| 201 |
+
* Tuggener et al. (2020) Don Tuggener, Pius von Däniken, Thomas Peetz, and Mark Cieliebak. 2020. Ledgar: A large-scale multi-label corpus for text classification of legal provisions in contracts. In _Proceedings of the 12th Language Resources and Evaluation Conference_, pages 1235–1241.
|
| 202 |
+
* Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. _Advances in neural information processing systems_, 30.
|
| 203 |
+
* Wang et al. (2020) Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. 2020. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. _Advances in Neural Information Processing Systems_, 33:5776–5788.
|
| 204 |
+
* Zhu and Gupta (2017) Michael Zhu and Suyog Gupta. 2017. To prune, or not to prune: exploring the efficacy of pruning for model compression. _arXiv preprint arXiv:1710.01878_.
|
| 205 |
+
|
| 206 |
+
Appendix A Further Details
|
| 207 |
+
--------------------------
|
| 208 |
+
|
| 209 |
+
### A.1 Results
|
| 210 |
+
|
| 211 |
+
We tabulate the complete results for BERT and DistilBERT on ADE, LEDGAR, and PATENT in Tables [4](https://arxiv.org/html/2402.09949v2#A1.T4 "Table 4 ‣ A.1 Results ‣ Appendix A Further Details ‣ Multi-word Tokenization for Sequence Compression") and [5](https://arxiv.org/html/2402.09949v2#A1.T5 "Table 5 ‣ A.1 Results ‣ Appendix A Further Details ‣ Multi-word Tokenization for Sequence Compression") respectively. The values in each table are averaged across 5 seeds.
|
| 212 |
+
|
| 213 |
+
(a) ADE
|
| 214 |
+
|
| 215 |
+
(b) LEDGAR
|
| 216 |
+
|
| 217 |
+
(c) PATENT
|
| 218 |
+
|
| 219 |
+
Table 4: Model performance of BERT averaged across 5 seeds.
|
| 220 |
+
|
| 221 |
+
(a) ADE
|
| 222 |
+
|
| 223 |
+
(b) LEDGAR
|
| 224 |
+
|
| 225 |
+
(c) PATENT
|
| 226 |
+
|
| 227 |
+
Table 5: Model performance of DistilBERT averaged across 5 seeds.
|