

Add 1 files
Browse files- 2601/2601.10477.md +589 -0
2601/2601.10477.md
ADDED
|
@@ -0,0 +1,589 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Urban Socio-Semantic Segmentation with Vision-Language Reasoning
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2601.10477
|
| 4 |
+
|
| 5 |
+
Published Time: Fri, 16 Jan 2026 01:47:56 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
Yu Wang 1,2, Yi Wang 2, Rui Dai 2, Yujie Wang 1, Kaikui Liu 2,
|
| 9 |
+
|
| 10 |
+
Xiangxiang Chu 2, Yansheng Li 1
|
| 11 |
+
1 Wuhan University 2 Amap, Alibaba Group
|
| 12 |
+
|
| 13 |
+
###### Abstract
|
| 14 |
+
|
| 15 |
+
As hubs of human activity, urban surfaces consist of a wealth of semantic entities. Segmenting these various entities from satellite imagery is crucial for a range of downstream applications. Current advanced segmentation models can reliably segment entities defined by physical attributes (e.g., buildings, water bodies) but still struggle with socially defined categories (e.g., schools, parks). In this work, we achieve socio-semantic segmentation by vision-language model reasoning. To facilitate this, we introduce the Urban Socio-Semantic Segmentation dataset named SocioSeg, a new resource comprising satellite imagery, digital maps, and pixel-level labels of social semantic entities organized in a hierarchical structure. Additionally, we propose a novel vision-language reasoning framework called SocioReasoner that simulates the human process of identifying and annotating social semantic entities via cross-modal recognition and multi-stage reasoning. We employ reinforcement learning to optimize this non-differentiable process and elicit the reasoning capabilities of the vision-language model. Experiments demonstrate our approach’s gains over state-of-the-art models and strong zero-shot generalization. Our dataset and code are available in [github.com/AMAP-ML/SocioReasoner](https://github.com/AMAP-ML/SocioReasoner)
|
| 16 |
+
|
| 17 |
+
1 Introduction
|
| 18 |
+
--------------
|
| 19 |
+
|
| 20 |
+
Urban areas, as primary hubs of human activity, are a critical subject for Earth Observation (Patino and Duque, [2013](https://arxiv.org/html/2601.10477v1#bib.bib1 "A review of regional science applications of satellite remote sensing in urban settings")). Urban land surfaces consist of rich semantic entities, and segmenting them is crucial for downstream tasks like urban planning (Zheng et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib2 "Urban planning in the era of large language models")) and environmental monitoring (Yang, [2021](https://arxiv.org/html/2601.10477v1#bib.bib3 "Urban remote sensing: monitoring, synthesis and modeling in the urban environment")). These entities can be broadly grouped into two types: physical semantic entities and social semantic entities. The first encompasses entities defined by physical attributes, such as buildings, water bodies, and roads. Thanks to abundant high-resolution satellite data, current segmentation models can segment these entities precisely from visual cues in satellite imagery (Hang et al., [2022](https://arxiv.org/html/2601.10477v1#bib.bib4 "Multiscale progressive segmentation network for high-resolution remote sensing imagery")). The second comprises entities defined by social attributes, such as schools, parks, and residential districts. The identification of these entities is pivotal not only for urban analysis tasks like disease transmission (Alidadi and Sharifi, [2022](https://arxiv.org/html/2601.10477v1#bib.bib42 "Effects of the built environment and human factors on the spread of covid-19: a systematic literature review")), the 15-minute city (Bruno et al., [2024](https://arxiv.org/html/2601.10477v1#bib.bib41 "A universal framework for inclusive 15-minute cities")), but also for industrial mapping applications, such as inferring socio-semantic Areas of Interest (AOIs) from Points of Interest (POIs) to enhance navigation and recommendation (Shi et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib43 "Multimodal urban areas of interest generation via remote sensing imagery and geographical prior")). However, their boundaries and identities are shaped by social semantics rather than distinct visual appearances (Büttner, [2014](https://arxiv.org/html/2601.10477v1#bib.bib5 "CORINE land cover and land cover change products")). Since this semantic information is difficult to extract from satellite imagery alone, achieving segmentation for these socially defined entities is substantially more challenging.
|
| 21 |
+
|
| 22 |
+
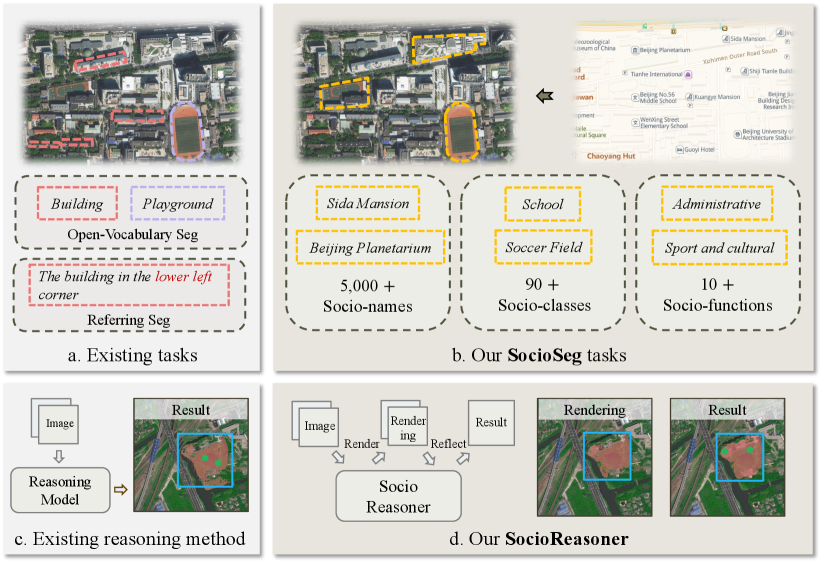
|
| 23 |
+
|
| 24 |
+
Figure 1: (a) Current works segregate physical entities. (b) Our SocioSeg identifies social entities (names, functions) via multi-modal data. (c) Existing reasoning methods employ a single-stage reasoning approach. (d) Our SocioReasoner employs a two-stage reasoning strategy with render-and-refine mechanism.
|
| 25 |
+
|
| 26 |
+
Existing approaches address this challenge by incorporating auxiliary multi-modal geospatial data (e.g., Points of Interest) (Xiong et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib6 "Mapping the first dataset of global urban land uses with sentinel-2 imagery and poi prompt"); Zhang et al., [2017](https://arxiv.org/html/2601.10477v1#bib.bib7 "Hierarchical semantic cognition for urban functional zones with vhr satellite images and poi data")). These methods often employ separate model encoders to extract features from different modalities and train task-specific models in a fully supervised manner. However, this paradigm faces three major bottlenecks: (i) such geospatial data are often difficult to obtain due to commercial or security constraints; (ii) even when available, the heterogeneous formats and mismatched spatial granularities require complex preprocessing and alignment with satellite imagery; and (iii) because these methods are trained only on predefined categories, they can handle only a limited set of social semantic classes. These limitations underscore the need for a more versatile framework that can adeptly integrate diverse multi-modal geospatial data for socio-semantic segmentation.
|
| 27 |
+
|
| 28 |
+
Recent advances in Vision-Language Models (VLMs) (Achiam et al., [2023](https://arxiv.org/html/2601.10477v1#bib.bib8 "Gpt-4 technical report"); Liu et al., [2023](https://arxiv.org/html/2601.10477v1#bib.bib9 "Visual instruction tuning"); Bai et al., [2025a](https://arxiv.org/html/2601.10477v1#bib.bib10 "Qwen2. 5-vl technical report"); Mall et al., [2024](https://arxiv.org/html/2601.10477v1#bib.bib28 "Remote sensing vision-language foundation models without annotations via ground remote alignment"); Chu et al., [2024](https://arxiv.org/html/2601.10477v1#bib.bib52 "Mobilevlm v2: faster and stronger baseline for vision language model")) offer a promising pathway toward creating such a framework. In the natural image domain, VLMs have already showcased their powerful visual understanding and reasoning capabilities on complex tasks like reasoning segmentation (Lai et al., [2024](https://arxiv.org/html/2601.10477v1#bib.bib11 "Lisa: reasoning segmentation via large language model"); Liu et al., [2025a](https://arxiv.org/html/2601.10477v1#bib.bib12 "Seg-zero: reasoning-chain guided segmentation via cognitive reinforcement"); Wei et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib38 "Lenna: language enhanced reasoning detection assistant"); Chu et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib49 "Gpg: a simple and strong reinforcement learning baseline for model reasoning")), visual grounding (Bai et al., [2025b](https://arxiv.org/html/2601.10477v1#bib.bib54 "Univg-r1: reasoning guided universal visual grounding with reinforcement learning")), mathematical reasoning (Zou et al., [2024](https://arxiv.org/html/2601.10477v1#bib.bib44 "Dynamath: a dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models")), and geolocalization (Li et al., [2024a](https://arxiv.org/html/2601.10477v1#bib.bib45 "Georeasoner: geo-localization with reasoning in street views using a large vision-language model")). While some work has begun applying VLMs to satellite imagery (Li et al., [2025b](https://arxiv.org/html/2601.10477v1#bib.bib14 "Segearth-r1: geospatial pixel reasoning via large language model"); Yao et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib13 "RemoteReasoner: towards unifying geospatial reasoning workflow")), these efforts predominantly still focus on reasoning about physical attributes. This leaves a critical gap, as social semantics, which are inherently diverse and complex, demand precisely the sophisticated reasoning processes that VLMs excel at. This natural alignment inspires us to explore the potential of VLMs for socio-semantic segmentation.
|
| 29 |
+
|
| 30 |
+
Motivated by the aforementioned challenges and opportunities, this paper defines and tackles socio-semantic segmentation by leveraging the reasoning capabilities of VLMs. To address the critical lack of a dedicated benchmark, we introduce the Urban Socio-Semantic Segmentation dataset called SocioSeg. SocioSeg is structured with a three-tiered hierarchy of tasks in increasing order of complexity: (i) Socio-name segmentation (e.g., “a certain university”), (ii) Socio-class segmentation (e.g., “college”), and (iii) Socio-function segmentation (e.g., “educational”). This design means the tasks place progressively higher demands on the model’s reasoning abilities. Furthermore, to resolve the data-handling bottlenecks of previous methods, SocioSeg adopts a novel geospatial data representation paradigm. Instead of using raw geospatial data, which introduces the problems of access, alignment, and heterogeneity, SocioSeg unifies them into a digital map layer. This paradigm is highly effective: the need for protected raw data is eliminated, and the map layer is inherently spatially aligned with the satellite imagery.
|
| 31 |
+
|
| 32 |
+
Building on SocioSeg, we propose SocioReasoner, a vision-language reasoning framework that simulates the human process of identifying and annotating socio-semantic entities through cross-modal recognition and multi-stage reasoning. More specifically, given a textual instruction with socio-semantic concepts, SocioReasoner employs a two-stage reasoning strategy with a render-and-refine mechanism: it first generates bounding box prompts from both satellite and map imagery to localize the target region. These prompts are then fed to the Segment Anything Model (SAM) (Ravi et al., [2024](https://arxiv.org/html/2601.10477v1#bib.bib15 "Sam 2: segment anything in images and videos")) to produce an initial coarse segmentation. Recognizing that segmentation from a bounding box alone can be imprecise and inconsistent with the actual human annotation process, SocioReasoner proceeds to generate point prompts on the rendered mask to refine the boundary, ultimately generating a high-fidelity segmentation result. This entire interactive process closely mirrors the workflow of a human annotator. Since this pipeline is non-differentiable, we employ a popular reinforcement learning algorithm, GRPO (Shao et al., [2024](https://arxiv.org/html/2601.10477v1#bib.bib16 "Deepseekmath: pushing the limits of mathematical reasoning in open language models"); Guo et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib17 "Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning")), to train the framework end-to-end, which also effectively elicits the VLM’s latent reasoning capabilities for the social semantic segmentation task. Extensive experiments show that our approach outperforms state-of-the-art segmentation baselines and exhibits strong zero-shot generalization capabilities, highlighting the potential of combining satellite imagery with rendered map context for social semantic understanding. In summary, our contributions are:
|
| 33 |
+
|
| 34 |
+
* •We introduce socio-semantic segmentation, a novel and challenging segmentation task, and release the benchmark SocioSeg, which establishes the paradigm of rendering heterogeneous geospatial data into a unified map image, transforming a complex multi-modal challenge into a visual reasoning task.
|
| 35 |
+
* •We propose SocioReasoner, a segmentation framework that mimics human annotation via a multi-stage reasoning process. This non-differentiable workflow is optimized using reinforcement learning with a dedicated reward function, effectively eliciting the model’s reasoning capabilities.
|
| 36 |
+
* •Extensive empirical evidence demonstrates the effectiveness and generalization capabilities of our approach, highlighting its potential for real-world applications.
|
| 37 |
+
|
| 38 |
+
2 Related Work
|
| 39 |
+
--------------
|
| 40 |
+
|
| 41 |
+
### 2.1 Semantic Segmentation
|
| 42 |
+
|
| 43 |
+
Semantic segmentation is a fundamental task in computer vision (Voulodimos et al., [2018](https://arxiv.org/html/2601.10477v1#bib.bib18 "Deep learning for computer vision: a brief review")). Early deep learning methods trained models in a fully supervised manner, enabling them to recognize only a predefined set of semantic categories (Ronneberger et al., [2015](https://arxiv.org/html/2601.10477v1#bib.bib19 "U-net: convolutional networks for biomedical image segmentation"); Xie et al., [2021](https://arxiv.org/html/2601.10477v1#bib.bib20 "SegFormer: simple and efficient design for semantic segmentation with transformers"); Zhang et al., [2022](https://arxiv.org/html/2601.10477v1#bib.bib53 "Segvit: semantic segmentation with plain vision transformers")). With the advancement of pre-trained models, tasks such as open-vocabulary segmentation (Ghiasi et al., [2022](https://arxiv.org/html/2601.10477v1#bib.bib21 "Scaling open-vocabulary image segmentation with image-level labels")) and referring segmentation (Wang et al., [2022](https://arxiv.org/html/2601.10477v1#bib.bib22 "Cris: clip-driven referring image segmentation")) have emerged, allowing models to identify unseen categories or segment objects based on textual descriptions. More recently, the task of reasoning segmentation (Lai et al., [2024](https://arxiv.org/html/2601.10477v1#bib.bib11 "Lisa: reasoning segmentation via large language model")) is introduced, where the input text describes the target’s function or relationship rather than its visual appearance. This demands more sophisticated reasoning capabilities from the model. Notably, a significant body of current work now employs VLM-based paradigms to address reasoning segmentation tasks (Liu et al., [2025a](https://arxiv.org/html/2601.10477v1#bib.bib12 "Seg-zero: reasoning-chain guided segmentation via cognitive reinforcement"); You and Wu, [2025](https://arxiv.org/html/2601.10477v1#bib.bib23 "Seg-r1: segmentation can be surprisingly simple with reinforcement learning"); Liu et al., [2025b](https://arxiv.org/html/2601.10477v1#bib.bib32 "VisionReasoner: unified visual perception and reasoning via reinforcement learning")). These methods feed visual prompts (e.g., bounding boxes or points) derived from VLM inference into the SAM to perform segmentation, and employ reinforcement learning to elicit the model’s reasoning capabilities.
|
| 44 |
+
|
| 45 |
+
Semantic segmentation from satellite imagery follows a similar developmental trajectory (Kotaridis and Lazaridou, [2021](https://arxiv.org/html/2601.10477v1#bib.bib24 "Remote sensing image segmentation advances: a meta-analysis")). It began with fully supervised models for extracting features like buildings (Cheng et al., [2019](https://arxiv.org/html/2601.10477v1#bib.bib25 "Darnet: deep active ray network for building segmentation")) and roads (Sun et al., [2019](https://arxiv.org/html/2601.10477v1#bib.bib26 "Reverse and boundary attention network for road segmentation")), and has since progressed to explorations in open-vocabulary (Li et al., [2025a](https://arxiv.org/html/2601.10477v1#bib.bib30 "Segearth-ov: towards training-free open-vocabulary segmentation for remote sensing images"); Zhu et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib27 "Skysense-o: towards open-world remote sensing interpretation with vision-centric visual-language modeling")) and referring segmentation (Chen et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib40 "RSRefSeg: referring remote sensing image segmentation with foundation models")). Recently, some studies also begin to tackle reasoning segmentation on satellite imagery, often by using closed-source vision language model to re-frame existing segmentation categories into text that requires reasoning (Li et al., [2025b](https://arxiv.org/html/2601.10477v1#bib.bib14 "Segearth-r1: geospatial pixel reasoning via large language model")). This existing work predominantly focuses on categories defined by physical attributes (e.g., buildings, water bodies) or categories with distinct visual features. Socio-semantic categories (e.g., schools, parks), whose boundaries and identities are determined more by social constructs than by distinct visual cues, remain a significant challenge for methods that rely solely on satellite imagery. In contrast to existing work, our paper specifically targets these socio-semantic categories within urban regions.
|
| 46 |
+
|
| 47 |
+
### 2.2 Multi-Modal Approaches for Urban Understanding
|
| 48 |
+
|
| 49 |
+
The task of segmenting urban social semantic entities, which we term urban socio-semantic segmentation, is a nascent research area. While no prior work directly addresses this task, related problems exist in the field of urban science, such as land-use classification (Xiong et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib6 "Mapping the first dataset of global urban land uses with sentinel-2 imagery and poi prompt")) and urban functional zone (Yao et al., [2018](https://arxiv.org/html/2601.10477v1#bib.bib29 "Representing urban functions through zone embedding with human mobility patterns")). These studies typically fuse multimodal data, such as Points of Interest (POIs) and road networks, with satellite imagery. Their common approach involves using separate model encoders for different data modalities and then merging the extracted features for classification or segmentation (Xiong et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib6 "Mapping the first dataset of global urban land uses with sentinel-2 imagery and poi prompt"); Zhang et al., [2017](https://arxiv.org/html/2601.10477v1#bib.bib7 "Hierarchical semantic cognition for urban functional zones with vhr satellite images and poi data")). However, these methods, which rely on raw multi-modal data, face several critical bottlenecks. They are often hampered by challenges in data acquisition (due to commercial or security constraints), the complexity of handling heterogeneous data formats and mismatched spatial granularities, and an inability to generalize beyond a limited set of predefined categories. Crucially, this highlights the fundamental difference between our task and traditional land-use classification. While the latter typically targets a fixed, closed set of categories, our socio-semantic segmentation involves fine-grained attributes (over 90 categories) and specific entity names, where each instance acts as a unique class. Consequently, our task aligns more closely with open-vocabulary, referring, or reasoning segmentation rather than standard classification.
|
| 50 |
+
|
| 51 |
+
3 SocioSeg Dataset
|
| 52 |
+
------------------
|
| 53 |
+
|
| 54 |
+
Existing semantic segmentation dataset (Wang et al., [2021](https://arxiv.org/html/2601.10477v1#bib.bib35 "LoveDA: a remote sensing land-cover dataset for domain adaptive semantic segmentation"); Li et al., [2024b](https://arxiv.org/html/2601.10477v1#bib.bib34 "Glh-water: a large-scale dataset for global surface water detection in large-size very-high-resolution satellite imagery")) from satellite imagery has been largely confined to extracting entities defined by physical attributes. To expand the scope to social semantics, we introduce the SocioSeg dataset, which is distinguished by two key features:
|
| 55 |
+
|
| 56 |
+
Hierarchical Socio-Semantic Segmentation Task Design. As illustrated in Appendix[A.1.1](https://arxiv.org/html/2601.10477v1#A1.SS1.SSS1 "A.1.1 SocioSeg Dataset ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), Figure [6](https://arxiv.org/html/2601.10477v1#A1.F6 "Figure 6 ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), we define urban socio-semantic entities across three hierarchical levels of increasing abstraction and difficulty: Socio-names (e.g., “a certain university”), Socio-classes (e.g., “college”), and Socio-functions (e.g., “educational”). This tiered structure facilitates a progressive evaluation of a model’s reasoning capabilities. Above all, SocioSeg is exceptionally rich in social semantic information, containing over 5,000 Socio-names, 90 Socio-classes, and 10 Socio-functions.
|
| 57 |
+
|
| 58 |
+
Multi-Modal Data with Digital Map Representation. A key innovation of the SocioSeg dataset is its unification of diverse geospatial information into a single digital map layer. This representation offers several distinct advantages. First, it overcomes data accessibility issues, as publicly available map layers replace raw multi-modal data that are often proprietary or restricted. Second, the map layer is inherently co-registered with the satellite imagery, which eliminates the need for complex data alignment. Finally, this fusion into a single visual modality provides rich socio-semantic cues that are crucial for enhancing a model’s social reasoning capabilities.
|
| 59 |
+
|
| 60 |
+
We construct the inputs for SocioSeg by sourcing satellite images and digital maps from the Amap public API 1 1 1 Amap API Documentation. [https://lbs.amap.com/](https://lbs.amap.com/). Accessed: 2025-05-14., which provides these maps in both Chinese and English versions. The digital maps render only basic geospatial information, including roads and points of interest. We then collected the ground-truth socio-semantic labels for the corresponding regions. (Further details on the annotation procedure and dataset statistics are available in Appendix[A.1.1](https://arxiv.org/html/2601.10477v1#A1.SS1.SSS1 "A.1.1 SocioSeg Dataset ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning")). As a result, the SocioSeg dataset comprises over 13,000 samples distributed across the three hierarchical tasks. Each sample consists of a satellite image, a digital map, and a corresponding socio-semantic mask label. We partitioned the dataset into training, validation, and test sets using a 6:1:3 ratio, ensuring that the sample counts and class distributions for each hierarchical task are consistent across all splits.
|
| 61 |
+
|
| 62 |
+
4 SocioReasoner Framework
|
| 63 |
+
-------------------------
|
| 64 |
+
|
| 65 |
+
### 4.1 Human-Like Reasoning Segmentation Process
|
| 66 |
+
|
| 67 |
+
Prevailing reasoning-segmentation methods (Liu et al., [2025b](https://arxiv.org/html/2601.10477v1#bib.bib32 "VisionReasoner: unified visual perception and reasoning via reinforcement learning"); Yao et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib13 "RemoteReasoner: towards unifying geospatial reasoning workflow")) typically follow a single-stage pipeline: a Vision-Language Model (VLM) generates visual prompts (e.g., a bounding box), which are then fed into a frozen SAM to produce the final mask. Because the weights of SAM are fixed, these methods lack direct control over the output quality, often resulting in coarse or inaccurate segmentation. In contrast, our SocioReasoner framework (as shown in Figure [2](https://arxiv.org/html/2601.10477v1#S4.F2 "Figure 2 ‣ Stage-2 (Refinement): Emitting both a set of bounding boxes and points. ‣ 4.1 Human-Like Reasoning Segmentation Process ‣ 4 SocioReasoner Framework ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning")) employs a two-stage reasoning strategy with a render-and-refine mechanism to emulate the sequential workflow of a human annotator. This multi-stage approach enhances precision and makes the model’s inference steps transparent and interpretable.
|
| 68 |
+
|
| 69 |
+
##### Stage-1 (Localization): Emitting a set of 2D bounding boxes.
|
| 70 |
+
|
| 71 |
+
Let the VLM be denoted by ℱ\mathcal{F}. Given a satellite image 𝐈 s\mathbf{I}_{s}, a digital map 𝐈 m\mathbf{I}_{m}, and a textual instruction 𝐭 b\mathbf{t}_{b}, the VLM emits a set of 2D bounding boxes ℬ={𝐛 i}i=1 N\mathcal{B}=\{\mathbf{b}_{i}\}_{i=1}^{N} to localize candidate target regions:
|
| 72 |
+
|
| 73 |
+
ℬ=ℱ(𝐈 s,𝐈 m,𝐭 b).\displaystyle\mathcal{B}=\mathcal{F}(\mathbf{I}_{s},\mathbf{I}_{m},\mathbf{t}_{b}).(1)
|
| 74 |
+
|
| 75 |
+
These bounding boxes are supplied to a pre-trained segmentation model, SAM (𝒮\mathcal{S}) (Ravi et al., [2024](https://arxiv.org/html/2601.10477v1#bib.bib15 "Sam 2: segment anything in images and videos")), to produce a preliminary coarse mask 𝐌 c\mathbf{M}_{c}:
|
| 76 |
+
|
| 77 |
+
𝐌 c=𝒮(𝐈 s,prompt=ℬ).\displaystyle\mathbf{M}_{c}=\mathcal{S}(\mathbf{I}_{s},\text{prompt}=\mathcal{B}).(2)
|
| 78 |
+
|
| 79 |
+
##### Stage-2 (Refinement): Emitting both a set of bounding boxes and points.
|
| 80 |
+
|
| 81 |
+
Recognizing that segmentation from bounding boxes alone can be imprecise, we provide visual feedback to the VLM by rendering both the boxes and the coarse mask onto the inputs. A rendering function 𝒟\mathcal{D} overlays ℬ\mathcal{B} and 𝐌 c\mathbf{M}_{c} onto the satellite image 𝐈 s\mathbf{I}_{s} and the digital map 𝐈 m\mathbf{I}_{m}, producing a pair of rendered images (𝐈 s,r,𝐈 m,r)(\mathbf{I}_{s,r},\mathbf{I}_{m,r}) for re-evaluation:
|
| 82 |
+
|
| 83 |
+
𝐈 s,r=𝒟(𝐈 s,ℬ,𝐌 c),𝐈 m,r=𝒟(𝐈 m,ℬ,𝐌 c).\displaystyle\mathbf{I}_{s,r}=\mathcal{D}(\mathbf{I}_{s},\mathcal{B},\mathbf{M}_{c}),\quad\mathbf{I}_{m,r}=\mathcal{D}(\mathbf{I}_{m},\mathcal{B},\mathbf{M}_{c}).(3)
|
| 84 |
+
|
| 85 |
+
Conditioned on (𝐈 s,r,𝐈 m,r)(\mathbf{I}_{s,r},\mathbf{I}_{m,r}) and the instruction 𝐭 p\mathbf{t}_{p}, the VLM emits a set of bounding boxes ℬ\mathcal{B} together with points 𝒫={𝐩 j}j=1 K\mathcal{P}=\{\mathbf{p}_{j}\}_{j=1}^{K}:
|
| 86 |
+
|
| 87 |
+
{ℬ,𝒫}=ℱ(𝐈 s,r,𝐈 m,r,𝐭 p).\displaystyle\{\mathcal{B},\mathcal{P}\}=\mathcal{F}(\mathbf{I}_{s,r},\mathbf{I}_{m,r},\mathbf{t}_{p}).(4)
|
| 88 |
+
|
| 89 |
+
Finally, the comprehensive set of prompts (bounding boxes and points) is fed back into SAM to yield the final mask 𝐌 f\mathbf{M}_{f}:
|
| 90 |
+
|
| 91 |
+
𝐌 f=𝒮(𝐈 s,prompt={ℬ,𝒫}).\displaystyle\mathbf{M}_{f}=\mathcal{S}(\mathbf{I}_{s},\text{prompt}=\{\mathcal{B},\mathcal{P}\}).(5)
|
| 92 |
+
|
| 93 |
+
By decomposing the segmentation challenge into this sequence of localization and refinement, SocioReasoner achieves superior accuracy and provides an explicit reasoning chain. As this entire pipeline is non-differentiable, we leverage reinforcement learning to optimize the VLM’s policy for generating these sequential prompts.
|
| 94 |
+
|
| 95 |
+
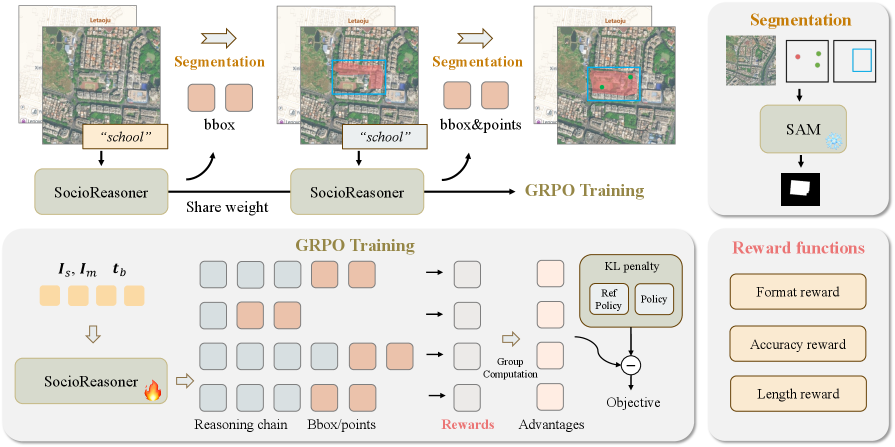
|
| 96 |
+
|
| 97 |
+
Figure 2: SocioReasoner Framework. Given a satellite image, a digital map, and a textual instruction, the VLM first generates bounding boxes to localize candidate regions. These boxes are fed into SAM to produce a coarse mask. The boxes and mask are then rendered onto the inputs for re-evaluation. The VLM emits boxes and points, which are again fed into SAM to yield the final mask.
|
| 98 |
+
|
| 99 |
+
### 4.2 End to End Reinforcement Learning Optimization
|
| 100 |
+
|
| 101 |
+
We optimize the non-differentiable, multi-stage prompting policy of SocioReasoner using reinforcement learning with Group Relative Policy Optimization (GRPO) (Guo et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib17 "Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning")). A single Vision-Language Model (VLM) policy is shared across both stages and emits structured textual outputs that encode prompts for SAM. The environment parses these outputs, executes SAM with the parsed prompts, and returns a scalar reward.
|
| 102 |
+
|
| 103 |
+
##### Stage-1 (Localization) Optimization.
|
| 104 |
+
|
| 105 |
+
Given an input 𝐱 1=(𝐈 s,𝐈 m,𝐭 b)\mathbf{x}_{1}=(\mathbf{I}_{s},\mathbf{I}_{m},\mathbf{t}_{b}), the policy π θ\pi_{\theta} stochastically generates a completion 𝐲 1\mathbf{y}_{1} that encodes a set of bounding boxes. The environment parses 𝐲 1\mathbf{y}_{1} to obtain ℬ\mathcal{B}, runs SAM to produce a coarse mask 𝐌 c\mathbf{M}_{c}, and returns a stage-1 reward R 1(𝐲 1;𝐱 1)R_{1}(\mathbf{y}_{1};\mathbf{x}_{1}) comprising: (i) a binary syntax reward to ensure valid JSON output, (ii) a localization accuracy term for the predicted boxes, and (iii) a reward for matched object count. GRPO is applied per input by drawing G G completions {𝐲 1(g)}g=1 G\{\mathbf{y}_{1}^{(g)}\}_{g=1}^{G}, computing rewards {R 1(g)}g=1 G\{R_{1}^{(g)}\}_{g=1}^{G}, and defining a group-relative baseline b 1(𝐱 1)=1 G∑g=1 G R 1(g),b_{1}(\mathbf{x}_{1})=\frac{1}{G}\sum_{g=1}^{G}R_{1}^{(g)}, with advantages A 1(g)=R 1(g)−b 1(𝐱 1)A_{1}^{(g)}=R_{1}^{(g)}-b_{1}(\mathbf{x}_{1}). The stage-1 objective is a clipped PPO-like surrogate with KL regularization against a frozen reference policy π ref\pi_{\mathrm{ref}}:
|
| 106 |
+
|
| 107 |
+
ℒ 1(θ)=−1 G∑g=1 G∑t∈ℐ(𝐲 1(g))min(r 1,t(g)A 1(g),clip(r 1,t(g),1−ϵ,1+ϵ)A 1(g))+β KL(π θ(⋅|𝐱 1)∥π ref(⋅|𝐱 1)),\begin{split}\mathcal{L}_{1}(\theta)\;=\;&-\frac{1}{G}\sum_{g=1}^{G}\sum_{t\in\mathcal{I}(\mathbf{y}_{1}^{(g)})}\min\Big(r_{1,t}^{(g)}A_{1}^{(g)},\;\mathrm{clip}\big(r_{1,t}^{(g)},1-\epsilon,1+\epsilon\big)A_{1}^{(g)}\Big)\\ &+\;\beta\,\mathrm{KL}\big(\pi_{\theta}(\cdot|\mathbf{x}_{1})\,\|\,\pi_{\mathrm{ref}}(\cdot|\mathbf{x}_{1})\big),\end{split}(6)
|
| 108 |
+
|
| 109 |
+
where r 1,t(g)=π θ(y 1,t(g)|y 1,<t(g),𝐱 1)π θ old(y 1,t(g)|y 1,<t(g),𝐱 1)r_{1,t}^{(g)}=\frac{\pi_{\theta}\big(y_{1,t}^{(g)}\,|\,y_{1,<t}^{(g)},\mathbf{x}_{1}\big)}{\pi_{\theta_{\mathrm{old}}}\big(y_{1,t}^{(g)}\,|\,y_{1,<t}^{(g)},\mathbf{x}_{1}\big)} is the token-level importance ratio. The hyperparameters ϵ\epsilon and β\beta control the PPO clipping and KL regularization, respectively.
|
| 110 |
+
|
| 111 |
+
##### Stage-2 (Refinement) Optimization.
|
| 112 |
+
|
| 113 |
+
Conditioned on the rendered visual feedback and the coarse mask, the policy refines the prompts. We construct 𝐱 2=(𝐈 s,r,𝐈 m,r,𝐭 p,𝐌 c)\mathbf{x}_{2}=(\mathbf{I}_{s,r},\mathbf{I}_{m,r},\mathbf{t}_{p},\mathbf{M}_{c}) by overlaying the stage-1 boxes and coarse mask using the renderer 𝒟\mathcal{D}. The policy π θ\pi_{\theta} emits 𝐲 2\mathbf{y}_{2} that encodes bounding boxes and points. The environment parses 𝐲 2\mathbf{y}_{2} to obtain {ℬ~,𝒫}\{\tilde{\mathcal{B}},\mathcal{P}\}, runs SAM to produce the final mask 𝐌 f\mathbf{M}_{f}, and returns a stage-2 reward R 2(𝐲 2;𝐱 2)R_{2}(\mathbf{y}_{2};\mathbf{x}_{2}) comprising: (i) a binary syntax reward for valid JSON, (ii) a pixel-level IoU term for 𝐌 f\mathbf{M}_{f}, and (iii) a reward for point length. GRPO sampling, baseline/advantage computation, and the clipped surrogate with KL regularization follow the same formulation as in stage-1.
|
| 114 |
+
|
| 115 |
+
##### Training Schedule.
|
| 116 |
+
|
| 117 |
+
Within a single reinforcement learning step, we execute both stages sequentially: (i) sample, evaluate, and update with ℒ 1(θ)\mathcal{L}_{1}(\theta) using stage-1 rollouts; (ii) construct the stage-2 inputs from the stage-1 outputs, then sample, evaluate, and update with ℒ 2(θ)\mathcal{L}_{2}(\theta). This two-stage procedure aligns optimization with the sequential localization–refinement workflow. Detailed formulations of the rewards R 1 R_{1} and R 2 R_{2} are provided in the Appendix [A.2.2](https://arxiv.org/html/2601.10477v1#A1.SS2.SSS2 "A.2.2 Reward Function Design ‣ A.2 Implementation Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). The overall training algorithm is summarized in Algorithm [1](https://arxiv.org/html/2601.10477v1#alg1 "Algorithm 1 ‣ A.1.2 SocioSeg Out-Of-Distribution dataset ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 118 |
+
|
| 119 |
+

|
| 120 |
+
|
| 121 |
+
Figure 3: Visualization of the SocioReasoner results. The top panel shows a comparison between the results of SocioReasoner (with both stages visualized) and competitive baselines. The bottom-left panel illustrates the reasoning process of SocioReasoner. The bottom-right panel displays the visualization results of SocioReasoner on the out-of-domain dataset.
|
| 122 |
+
|
| 123 |
+
5 Experiments
|
| 124 |
+
-------------
|
| 125 |
+
|
| 126 |
+
### 5.1 Baselines and Evaluation Metrics
|
| 127 |
+
|
| 128 |
+
We primarily compare against three families of methods: (i) standard semantic segmentation models, including the CNN-based UNet(Ronneberger et al., [2015](https://arxiv.org/html/2601.10477v1#bib.bib19 "U-net: convolutional networks for biomedical image segmentation")) and the Transformer-based SegFormer(Xie et al., [2021](https://arxiv.org/html/2601.10477v1#bib.bib20 "SegFormer: simple and efficient design for semantic segmentation with transformers")); (ii) state-of-the-art reasoning segmentation for natural images, including VisionReasoner(Liu et al., [2025b](https://arxiv.org/html/2601.10477v1#bib.bib32 "VisionReasoner: unified visual perception and reasoning via reinforcement learning")), Seg-R1(You and Wu, [2025](https://arxiv.org/html/2601.10477v1#bib.bib23 "Seg-r1: segmentation can be surprisingly simple with reinforcement learning")), and SAM-R1(Huang et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib33 "SAM-r1: leveraging sam for reward feedback in multimodal segmentation via reinforcement learning")); (iii) state-of-the-art satellite image segmentation methods, including the open-vocabulary segmentation SegEarth-OV(Li et al., [2025a](https://arxiv.org/html/2601.10477v1#bib.bib30 "Segearth-ov: towards training-free open-vocabulary segmentation for remote sensing images")), referring segmentation RSRefSeg(Chen et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib40 "RSRefSeg: referring remote sensing image segmentation with foundation models")), and reasoning-based approaches SegEarth-R1(Li et al., [2025b](https://arxiv.org/html/2601.10477v1#bib.bib14 "Segearth-r1: geospatial pixel reasoning via large language model")) and RemoteReasoner(Yao et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib13 "RemoteReasoner: towards unifying geospatial reasoning workflow")). Because SocioSeg provides two images (satellite and digital map), we adapt all VLM-based baselines to accept dual-image inputs; for methods (RSRefSeg and SegEarth-R1) that do not support multiple images, we provide only the satellite image. All baselines are re-trained on the SocioSeg training split to ensure fair comparison.Additionally, given the challenging nature of the SocioSeg benchmark, we employ off-the-shelf Large Multimodal Models as reference models to provide a more comprehensive evaluation. Detailed experimental results for these models are provided in the Appendix[A.4](https://arxiv.org/html/2601.10477v1#A1.SS4 "A.4 SocioSeg benchmark ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). For evaluation, we follow previous work (Lai et al., [2024](https://arxiv.org/html/2601.10477v1#bib.bib11 "Lisa: reasoning segmentation via large language model")) in reporting cIoU and gIoU. Additionally, we employ the F1 score to assess instance-level performance.
|
| 129 |
+
|
| 130 |
+

|
| 131 |
+
|
| 132 |
+
Figure 4: Per-class accuracy comparison across Socio-classes. We select the top-20 most frequent classes in the test set for visualization. The full results are available in Appendix[A.5.1](https://arxiv.org/html/2601.10477v1#A1.SS5.SSS1 "A.5.1 Per-Category Results ‣ A.5 More Quantitative Results ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 133 |
+
|
| 134 |
+
### 5.2 Comparison with State-of-the-Art Methods
|
| 135 |
+
|
| 136 |
+
Comparison with state-of-the-art methods on the SocioSeg test set is presented in Figure[3](https://arxiv.org/html/2601.10477v1#S4.F3 "Figure 3 ‣ Training Schedule. ‣ 4.2 End to End Reinforcement Learning Optimization ‣ 4 SocioReasoner Framework ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning") and Appendix[A.6](https://arxiv.org/html/2601.10477v1#A1.SS6 "A.6 More Visualizations ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). The quantitative results are presented in Table[1](https://arxiv.org/html/2601.10477v1#S5.T1 "Table 1 ‣ 5.2 Comparison with State-of-the-Art Methods ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), with results grouped by task for clarity. Our SocioReasoner framework consistently outperforms all baselines across all three hierarchical tasks, demonstrating its effectiveness in handling the complexities of socio-semantic segmentation. This performance gain underscores the advantage of our human-like reasoning process and the use of rendered map context in enhancing the model’s understanding of social semantics. However, because SocioReasoner simulates a multi-step human reasoning process, its inference time is longer compared to other methods. We provide a detailed analysis of SocioReasoner’s inference time in Appendix[A.5.2](https://arxiv.org/html/2601.10477v1#A1.SS5.SSS2 "A.5.2 More Ablation Studies and Inference Time Comparison ‣ A.5 More Quantitative Results ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). Additionally, we illustrate the accuracy for individual Socio-classes in Figure[4](https://arxiv.org/html/2601.10477v1#S5.F4 "Figure 4 ‣ 5.1 Baselines and Evaluation Metrics ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), demonstrating that our method maintains strong competitiveness across the top-20 most frequent classes. The accuracy metrics and detailed analysis for all classes are provided in Appendix[A.5.1](https://arxiv.org/html/2601.10477v1#A1.SS5.SSS1 "A.5.1 Per-Category Results ‣ A.5 More Quantitative Results ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 137 |
+
|
| 138 |
+
Comparison with standard semantic segmentation methods. Since standard semantic segmentation models are incapable of processing multimodal inputs, they fail to perceive the social semantic information inherent in the SocioSeg task. Consequently, under this setting, the task for standard models degenerates into a binary classification problem. As observed, UNet and SegFormer exhibit inferior performance on SocioSeg compared to the other two categories of methods, whereas our approach significantly outperforms them.
|
| 139 |
+
|
| 140 |
+
Comparison with natural image reasoning segmentation methods. Similar to SocioReasoner, VisionReasoner, Seg-R1, and SAM-R1 all support multi-image inputs and therefore perform relatively well on SocioSeg. Notably, SAM-R1(Huang et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib33 "SAM-r1: leveraging sam for reward feedback in multimodal segmentation via reinforcement learning")) lacks constraints on the length of the output point prompts; in our reproduction, it emits a large number of point coordinates, which degrades performance. These methods freeze SAM parameters and perform single-stage inference. In contrast, our SocioReasoner framework surpasses these methods by a notable margin across all metrics. This improvement is attributable to our multi-stage reasoning process that mimics human annotation, providing reflection and refinement capabilities that lead to more accurate segmentation.
|
| 141 |
+
|
| 142 |
+
Comparison with advanced satellite image segmentation methods.SegEarth-OV completely freezes the CLIP encoder, limiting its recognition capabilities to the categories present in CLIP’s pre-training data. Since SocioSeg features novel semantic categories related to social attributes, this method fails to function effectively on the SocioSeg task. RSRefSeg and SegEarth-R1, which are designed for segmenting physical attributes and support only a single satellite image input, show limited performance on socio-semantic tasks. However, because they are trained in a fully supervised manner without freezing the mask decoder, they achieve some performance gains. In contrast, our approach leverages multimodal reasoning, effectively integrating satellite imagery with digital map context to capture nuanced social semantics. RemoteReasoner adopts a design similar to VisionReasoner, supports multi-image inputs, and performs well on SocioSeg. Our SocioReasoner framework outperforms RemoteReasoner, highlighting the benefits of our two-stage localization and refinement process, which enables more precise segmentation through iterative reasoning.
|
| 143 |
+
|
| 144 |
+
Table 1: Comparison with state-of-the-art methods on SocioSeg test set, split by task groups for readability. The best performance in each column is highlighted in bold. The second best is underlined. Baselines are re-trained on the SocioSeg training split to ensure fair comparison.
|
| 145 |
+
|
| 146 |
+
### 5.3 Ablation Studies
|
| 147 |
+
|
| 148 |
+
We ablate three core design choices of SocioReasoner: the training/inference scheme (single-stage vs. two-stage), the impact of reinforcement learning (RL), and the number of points issued in the second stage. Results are summarized in Table[3](https://arxiv.org/html/2601.10477v1#S5.T3 "Table 3 ‣ 5.3 Ablation Studies ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), Table[3](https://arxiv.org/html/2601.10477v1#S5.T3 "Table 3 ‣ 5.3 Ablation Studies ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), and Table[4](https://arxiv.org/html/2601.10477v1#S5.T4 "Table 4 ‣ 5.3 Ablation Studies ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). The full results of each ablation setting are provided in Appendix[A.5.2](https://arxiv.org/html/2601.10477v1#A1.SS5.SSS2 "A.5.2 More Ablation Studies and Inference Time Comparison ‣ A.5 More Quantitative Results ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 149 |
+
|
| 150 |
+
Impact of the training/inference scheme. In the “w/o reflection” configuration, the model bypasses the two-stage workflow and instead produces bounding boxes and points in a single stage, equivalent to VisionReasoner’s one-step prompting. This setting performs the worst for two reasons: (i) without an iterative process, the model cannot self-correct after observing the coarse mask; and (ii) it must solve a complex planning-and-parsing problem in one shot (jointly synthesizing boxes and points in a long structured output), which increases failure rates. In the “w/o refinement” ablation, we use the model trained with the two-stage pipeline but halt the inference process after Stage-1. The output from this initial localization stage is used directly as the final result, completely bypassing the refinement stage. The complete pipeline (“Ours”), which overlays stage-1 outputs and emits both boxes and points, achieves the best results. Figure[5](https://arxiv.org/html/2601.10477v1#S5.F5 "Figure 5 ‣ 5.3 Ablation Studies ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning")b shows the evolution of mask IoU across the two stages during RL training: stage-1 accuracy is initially higher because the model focuses more on localization early on; as training progresses, the model increasingly leverages points to improve the mask, leading to a steady rise in stage-2 accuracy. This finding highlights the effectiveness of our multi-stage reasoning process, where the refinement stage contributes to enhancing segmentation quality.
|
| 151 |
+
|
| 152 |
+
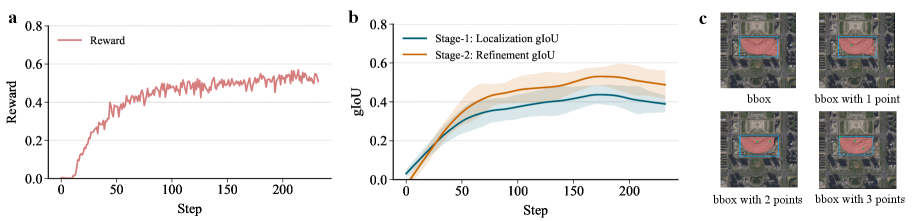
|
| 153 |
+
|
| 154 |
+
Figure 5: (a) Sum reward during training. It shows the sum of rewards across training steps in the two-stage workflow. (b) Multi-stage gIoU during training. It shows the gIoU improvement across training steps in the two-stage workflow. (c) Different number of points. It visualizes the result of SocioReasoner in the refinement stage with different numbers of points.
|
| 155 |
+
|
| 156 |
+
Table 2: Ablation of multi-stage design.
|
| 157 |
+
|
| 158 |
+
Table 3: Ablation of point number.
|
| 159 |
+
|
| 160 |
+
Table 4: Generalization of SocioReasoner, where ID and OOD refer to in-domain and out-of-domain, respectively.
|
| 161 |
+
|
| 162 |
+
Impact of the number of points in the refinement stage. In our reward function, the parameter μ\mu directly controls the number of point prompts generated in the refinement stage. We present the experimental results for different numbers of points in Table[3](https://arxiv.org/html/2601.10477v1#S5.T3 "Table 3 ‣ 5.3 Ablation Studies ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning") and visualize the corresponding qualitative results in Figure[5](https://arxiv.org/html/2601.10477v1#S5.F5 "Figure 5 ‣ 5.3 Ablation Studies ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning")c. We observe that a single point prompt often fails to cover the entire target, while the model struggles to learn a stable distribution for three points, with marginal performance gains compared to using two. Therefore, we select two points as the final design choice.
|
| 163 |
+
|
| 164 |
+
Impact of the RL. Figure[5](https://arxiv.org/html/2601.10477v1#S5.F5 "Figure 5 ‣ 5.3 Ablation Studies ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning")a illustrates the reward trajectory during training. The consistent upward trend demonstrates that RL effectively optimizes SocioReasoner’s human-like workflow. To further demonstrate the effectiveness of our training strategy, we compare SocioReasoner trained via RL against a Supervised Fine-Tuning (SFT) baseline. We evaluate performance not only on the in-domain (ID) Amap data but also on two challenging out-of-domain (OOD) scenarios using Google Maps tiles, as reported in Table[4](https://arxiv.org/html/2601.10477v1#S5.T4 "Table 4 ‣ 5.3 Ablation Studies ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). The “OOD (Map Style)” setting tests robustness to cartographic style shifts. Furthermore, we introduce a specific “OOD (New Region)” setting evaluated on a newly constructed dataset sampled from five global cities: Tokyo (Asia), New York (North America), São Paulo (South America), London (Europe), and Nairobi (Africa). This dataset, which is detailed in Appendix[A.1.2](https://arxiv.org/html/2601.10477v1#A1.SS1.SSS2 "A.1.2 SocioSeg Out-Of-Distribution dataset ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), comprises 3,200 samples covering 80 categories, including 24 novel classes unseen during training. While the SFT baseline suffers significant performance degradation on these OOD tasks, our RL method maintains high robustness, achieving superior results on the diverse regional dataset. A similar trend is observed in the VisionReasoner baseline, where the RL-optimized version consistently outperforms the SFT variant, further corroborating the efficacy of RL in enhancing reasoning capabilities. This indicates that minimizing the RL objective, which directly optimizes the non-differentiable IoU, enables the model to learn more generalized geometric reasoning policies that transfer effectively across different map styles and geographic regions.
|
| 165 |
+
|
| 166 |
+
6 Conclusion
|
| 167 |
+
------------
|
| 168 |
+
|
| 169 |
+
This paper introduces the task of urban socio-semantic segmentation and present SocioSeg, the first benchmark for this challenge. SocioSeg’s key contribution is a new paradigm that renders heterogeneous geospatial data into a unified map, transforming a complex multi-modal problem into a visual reasoning task. We also propose SocioReasoner, a framework that leverages Vision-Language Models to mimic the human annotation process through a multi-stage reasoning segmentation workflow. By optimizing this non-differentiable pipeline with reinforcement learning, we effectively elicit the model’s latent reasoning capabilities. Extensive experiments demonstrate that our approach outperforms existing methods and exhibits strong zero-shot generalization to unseen map sources. Our work highlights the potential of VLM reasoning for complex geospatial analysis.
|
| 170 |
+
|
| 171 |
+
##### Ethics Statement
|
| 172 |
+
|
| 173 |
+
Our research utilizes publicly accessible satellite and map data, specifically from the Amap public API, for the creation of the SocioSeg dataset. The manual annotation process was confined to identifying and labeling public and private functional zones without collecting or inferring any personally identifiable information (PII). We strongly advocate for the responsible deployment of our model, urging users to consider the societal impact and to prevent applications that could lead to surveillance or discriminatory outcomes.
|
| 174 |
+
|
| 175 |
+
##### Reproducibility Statement
|
| 176 |
+
|
| 177 |
+
To ensure the full reproducibility of our findings, we have provided comprehensive implementation details throughout the paper. The construction and statistics of our SocioSeg benchmark are detailed in Sec[3](https://arxiv.org/html/2601.10477v1#S3 "3 SocioSeg Dataset ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning") and Appendix[A.1](https://arxiv.org/html/2601.10477v1#A1.SS1 "A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). The architecture of the SocioReasoner framework, including the multi-stage reasoning process, is described in Sec[4.1](https://arxiv.org/html/2601.10477v1#S4.SS1 "4.1 Human-Like Reasoning Segmentation Process ‣ 4 SocioReasoner Framework ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). Key details for the reinforcement learning optimization, including the reward function design and GRPO training algorithm, are presented in Sec[4.2](https://arxiv.org/html/2601.10477v1#S4.SS2 "4.2 End to End Reinforcement Learning Optimization ‣ 4 SocioReasoner Framework ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning") and Appendix[A.2](https://arxiv.org/html/2601.10477v1#A1.SS2 "A.2 Implementation Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). In line with our commitment to open science, the SocioSeg dataset and source code will be made publicly available.
|
| 178 |
+
|
| 179 |
+
##### LLM clarification
|
| 180 |
+
|
| 181 |
+
We clarify the use of Large Language Models (LLMs) in the preparation of this manuscript. Specifically, LLMs were employed for two main purposes: translation of initial drafts from our native language and subsequent language polishing. This process involved correcting grammatical errors, improving sentence structure, and enhancing the overall readability and flow of the text. It is crucial to emphasize that all core scientific content, intellectual contributions, and original ideas presented in this paper are exclusively the work of the human authors. This includes the formulation of the research problem, the development of the SocioReasoner framework, the creation of the SocioSeg dataset, the experimental design, and the analysis of the results. The LLM served strictly as a writing aid and was not involved in any conceptual or analytical aspect of this research.
|
| 182 |
+
|
| 183 |
+
References
|
| 184 |
+
----------
|
| 185 |
+
|
| 186 |
+
* J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. (2023)Gpt-4 technical report. arXiv preprint arXiv:2303.08774. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 187 |
+
* M. Alidadi and A. Sharifi (2022)Effects of the built environment and human factors on the spread of covid-19: a systematic literature review. Science of The Total Environment 850, pp.158056. External Links: ISSN 0048-9697 Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p1.1.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 188 |
+
* S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, et al. (2025a)Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 189 |
+
* S. Bai, M. Li, Y. Liu, J. Tang, H. Zhang, L. Sun, X. Chu, and Y. Tang (2025b)Univg-r1: reasoning guided universal visual grounding with reinforcement learning. arXiv preprint arXiv:2505.14231. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 190 |
+
* M. Bruno, H. P. Monteiro Melo, B. Campanelli, and V. Loreto (2024)A universal framework for inclusive 15-minute cities. Nature Cities 1, pp.633–641. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p1.1.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 191 |
+
* G. Büttner (2014)CORINE land cover and land cover change products. In Land Use and Land Cover Mapping in Europe: Practices & Trends, I. Manakos and M. Braun (Eds.), pp.55–74. External Links: ISBN 978-94-007-7969-3 Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p1.1.1.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 192 |
+
* K. Chen, J. Zhang, C. Liu, Z. Zou, and Z. Shi (2025)RSRefSeg: referring remote sensing image segmentation with foundation models. In 2025 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p2.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§5.1](https://arxiv.org/html/2601.10477v1#S5.SS1.p1.1.1.1.1.1 "5.1 Baselines and Evaluation Metrics ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 193 |
+
* D. Cheng, R. Liao, S. Fidler, and R. Urtasun (2019)Darnet: deep active ray network for building segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.7431–7439. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p2.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 194 |
+
* X. Chu, H. Huang, X. Zhang, F. Wei, and Y. Wang (2025)Gpg: a simple and strong reinforcement learning baseline for model reasoning. arXiv preprint arXiv:2504.02546. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 195 |
+
* X. Chu, L. Qiao, X. Zhang, S. Xu, F. Wei, Y. Yang, X. Sun, Y. Hu, X. Lin, B. Zhang, et al. (2024)Mobilevlm v2: faster and stronger baseline for vision language model. arXiv preprint arXiv:2402.03766. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 196 |
+
* G. Ghiasi, X. Gu, Y. Cui, and T. Lin (2022)Scaling open-vocabulary image segmentation with image-level labels. In European conference on computer vision, pp.540–557. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p1.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 197 |
+
* P. Gong, B. Chen, X. Li, H. Liu, J. Wang, Y. Bai, J. Chen, X. Chen, L. Fang, S. Feng, et al. (2020)Mapping essential urban land use categories in china (euluc-china): preliminary results for 2018. Science Bulletin 65 (3), pp.182–187. Cited by: [§A.1.1](https://arxiv.org/html/2601.10477v1#A1.SS1.SSS1.p2.1.1 "A.1.1 SocioSeg Dataset ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 198 |
+
* D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. (2025)Deepseek-r1: incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p5.1.2.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§4.2](https://arxiv.org/html/2601.10477v1#S4.SS2.p1.1 "4.2 End to End Reinforcement Learning Optimization ‣ 4 SocioReasoner Framework ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 199 |
+
* R. Hang, P. Yang, F. Zhou, and Q. Liu (2022)Multiscale progressive segmentation network for high-resolution remote sensing imagery. IEEE Transactions on Geoscience and Remote Sensing 60, pp.1–12. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p1.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 200 |
+
* Y. Hu and Y. Han (2019)Identification of urban functional areas based on poi data: a case study of the guangzhou economic and technological development zone. Sustainability 11 (5), pp.1385. Cited by: [§A.1.1](https://arxiv.org/html/2601.10477v1#A1.SS1.SSS1.p2.1.1 "A.1.1 SocioSeg Dataset ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 201 |
+
* J. Huang, Z. Xu, J. Zhou, T. Liu, Y. Xiao, M. Ou, B. Ji, X. Li, and K. Yuan (2025)SAM-r1: leveraging sam for reward feedback in multimodal segmentation via reinforcement learning. In Advances in Neural Information Processing Systems, Cited by: [§5.1](https://arxiv.org/html/2601.10477v1#S5.SS1.p1.1.1.1 "5.1 Baselines and Evaluation Metrics ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§5.2](https://arxiv.org/html/2601.10477v1#S5.SS2.p3.1.1.1 "5.2 Comparison with State-of-the-Art Methods ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 202 |
+
* I. Kotaridis and M. Lazaridou (2021)Remote sensing image segmentation advances: a meta-analysis. ISPRS Journal of Photogrammetry and Remote Sensing 173, pp.309–322. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p2.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 203 |
+
* X. Lai, Z. Tian, Y. Chen, Y. Li, Y. Yuan, S. Liu, and J. Jia (2024)Lisa: reasoning segmentation via large language model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.9579–9589. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p1.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§5.1](https://arxiv.org/html/2601.10477v1#S5.SS1.p1.1.1.1.1.1.2.1 "5.1 Baselines and Evaluation Metrics ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 204 |
+
* K. Li, R. Liu, X. Cao, X. Bai, F. Zhou, D. Meng, and Z. Wang (2025a)Segearth-ov: towards training-free open-vocabulary segmentation for remote sensing images. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.10545–10556. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p2.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§5.1](https://arxiv.org/html/2601.10477v1#S5.SS1.p1.1.1.1.1 "5.1 Baselines and Evaluation Metrics ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 205 |
+
* K. Li, Z. Xin, L. Pang, C. Pang, Y. Deng, J. Yao, G. Xia, D. Meng, Z. Wang, and X. Cao (2025b)Segearth-r1: geospatial pixel reasoning via large language model. arXiv preprint arXiv:2504.09644. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1.1.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p2.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§5.1](https://arxiv.org/html/2601.10477v1#S5.SS1.p1.1.1.1.1.1 "5.1 Baselines and Evaluation Metrics ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 206 |
+
* L. Li, Y. Ye, B. Jiang, and W. Zeng (2024a)Georeasoner: geo-localization with reasoning in street views using a large vision-language model. In Forty-first International Conference on Machine Learning, Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 207 |
+
* Y. Li, B. Dang, W. Li, and Y. Zhang (2024b)Glh-water: a large-scale dataset for global surface water detection in large-size very-high-resolution satellite imagery. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38, pp.22213–22221. Cited by: [§3](https://arxiv.org/html/2601.10477v1#S3.p1.1 "3 SocioSeg Dataset ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 208 |
+
* Y. Li, Y. Wang, L. Yu, B. Dang, G. Xu, Z. Zhong, Y. Wu, X. Guo, K. Wu, Z. Li, et al. (2025c)Learning to reason over multi-granularity knowledge graph for zero-shot urban land-use mapping. Remote Sensing of Environment 330, pp.114961. Cited by: [§A.1.1](https://arxiv.org/html/2601.10477v1#A1.SS1.SSS1.p2.1.1 "A.1.1 SocioSeg Dataset ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 209 |
+
* H. Liu, C. Li, Q. Wu, and Y. J. Lee (2023)Visual instruction tuning. Advances in neural information processing systems 36, pp.34892–34916. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 210 |
+
* Y. Liu, B. Peng, Z. Zhong, Z. Yue, F. Lu, B. Yu, and J. Jia (2025a)Seg-zero: reasoning-chain guided segmentation via cognitive reinforcement. arXiv preprint arXiv:2503.06520. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p1.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 211 |
+
* Y. Liu, T. Qu, Z. Zhong, B. Peng, S. Liu, B. Yu, and J. Jia (2025b)VisionReasoner: unified visual perception and reasoning via reinforcement learning. arXiv preprint arXiv:2505.12081. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p1.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§4.1](https://arxiv.org/html/2601.10477v1#S4.SS1.p1.1 "4.1 Human-Like Reasoning Segmentation Process ‣ 4 SocioReasoner Framework ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§5.1](https://arxiv.org/html/2601.10477v1#S5.SS1.p1.1.1.1 "5.1 Baselines and Evaluation Metrics ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 212 |
+
* U. Mall, C. P. Phoo, M. K. Liu, C. Vondrick, B. Hariharan, and K. Bala (2024)Remote sensing vision-language foundation models without annotations via ground remote alignment. In The Twelfth International Conference on Learning Representations, External Links: [Link](https://openreview.net/forum?id=w9tc699w3Z)Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 213 |
+
* OpenStreetMap contributors (2017)Planet dump retrieve from https://planet.osm.org. Note: [https://www.openstreetmap.org](https://www.openstreetmap.org/)Cited by: [§A.1.2](https://arxiv.org/html/2601.10477v1#A1.SS1.SSS2.p3.1 "A.1.2 SocioSeg Out-Of-Distribution dataset ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 214 |
+
* J. E. Patino and J. C. Duque (2013)A review of regional science applications of satellite remote sensing in urban settings. Computers, Environment and Urban Systems 37, pp.1–17. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p1.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 215 |
+
* N. Ravi, V. Gabeur, Y. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. Rädle, C. Rolland, L. Gustafson, et al. (2024)Sam 2: segment anything in images and videos. arXiv preprint arXiv:2408.00714. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p5.1.2.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§4.1](https://arxiv.org/html/2601.10477v1#S4.SS1.SSS0.Px1.p1.7 "Stage-1 (Localization): Emitting a set of 2D bounding boxes. ‣ 4.1 Human-Like Reasoning Segmentation Process ‣ 4 SocioReasoner Framework ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 216 |
+
* O. Ronneberger, P. Fischer, and T. Brox (2015)U-net: convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pp.234–241. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p1.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§5.1](https://arxiv.org/html/2601.10477v1#S5.SS1.p1.1.1 "5.1 Baselines and Evaluation Metrics ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 217 |
+
* Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, Y. Wu, et al. (2024)Deepseekmath: pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p5.1.2.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 218 |
+
* C. Shi, Y. Zhang, J. Wang, X. Guo, and Q. Zhu (2025)Multimodal urban areas of interest generation via remote sensing imagery and geographical prior. International Journal of Applied Earth Observation and Geoinformation 136, pp.104326. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p1.1.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 219 |
+
* J. Sun, S. Kim, S. Lee, Y. Kim, and S. Ko (2019)Reverse and boundary attention network for road segmentation. In Proceedings of the IEEE/CVF international conference on computer vision workshops, pp.0–0. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p2.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 220 |
+
* A. Voulodimos, N. Doulamis, A. Doulamis, and E. Protopapadakis (2018)Deep learning for computer vision: a brief review. Computational intelligence and neuroscience 2018 (1), pp.7068349. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p1.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 221 |
+
* J. Wang, Z. Zheng, A. Ma, X. Lu, and Y. Zhong (2021)LoveDA: a remote sensing land-cover dataset for domain adaptive semantic segmentation. arXiv preprint arXiv:2110.08733. Cited by: [§3](https://arxiv.org/html/2601.10477v1#S3.p1.1 "3 SocioSeg Dataset ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 222 |
+
* W. Wang, S. Xiong, G. Chen, W. Gao, S. Guo, Y. He, J. Huang, J. Liu, Z. Li, X. Li, et al. (2025)Reinforcement learning optimization for large-scale learning: an efficient and user-friendly scaling library. arXiv preprint arXiv:2506.06122. Cited by: [§A.2.3](https://arxiv.org/html/2601.10477v1#A1.SS2.SSS3.p1.3 "A.2.3 Experimental Settings ‣ A.2 Implementation Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 223 |
+
* Z. Wang, Y. Lu, Q. Li, X. Tao, Y. Guo, M. Gong, and T. Liu (2022)Cris: clip-driven referring image segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.11686–11695. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p1.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 224 |
+
* F. Wei, X. Zhang, A. Zhang, B. Zhang, and X. Chu (2025)Lenna: language enhanced reasoning detection assistant. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.1–5. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 225 |
+
* E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo (2021)SegFormer: simple and efficient design for semantic segmentation with transformers. Advances in neural information processing systems 34, pp.12077–12090. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p1.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§5.1](https://arxiv.org/html/2601.10477v1#S5.SS1.p1.1.1 "5.1 Baselines and Evaluation Metrics ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 226 |
+
* S. Xiong, X. Zhang, H. Wang, Y. Lei, G. Tan, and S. Du (2025)Mapping the first dataset of global urban land uses with sentinel-2 imagery and poi prompt. Remote Sensing of Environment 327, pp.114824. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p2.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§2.2](https://arxiv.org/html/2601.10477v1#S2.SS2.p1.1 "2.2 Multi-Modal Approaches for Urban Understanding ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 227 |
+
* X. X. Yang (2021)Urban remote sensing: monitoring, synthesis and modeling in the urban environment. John Wiley & Sons. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p1.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 228 |
+
* L. Yao, F. Liu, H. Lu, C. Zhang, R. Min, S. Xu, S. Di, and P. Peng (2025)RemoteReasoner: towards unifying geospatial reasoning workflow. arXiv preprint arXiv:2507.19280. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1.1.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§4.1](https://arxiv.org/html/2601.10477v1#S4.SS1.p1.1 "4.1 Human-Like Reasoning Segmentation Process ‣ 4 SocioReasoner Framework ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§5.1](https://arxiv.org/html/2601.10477v1#S5.SS1.p1.1.1.1.1.1 "5.1 Baselines and Evaluation Metrics ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 229 |
+
* Y. Yao, X. Li, X. Liu, P. Liu, Z. Liang, J. Zhang, and K. Mai (2017)Sensing spatial distribution of urban land use by integrating points-of-interest and google word2vec model. International Journal of Geographical Information Science 31 (4), pp.825–848. Cited by: [§A.1.1](https://arxiv.org/html/2601.10477v1#A1.SS1.SSS1.p2.1.1 "A.1.1 SocioSeg Dataset ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 230 |
+
* Z. Yao, Y. Fu, B. Liu, W. Hu, and H. Xiong (2018)Representing urban functions through zone embedding with human mobility patterns. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Cited by: [§2.2](https://arxiv.org/html/2601.10477v1#S2.SS2.p1.1 "2.2 Multi-Modal Approaches for Urban Understanding ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 231 |
+
* Z. You and Z. Wu (2025)Seg-r1: segmentation can be surprisingly simple with reinforcement learning. arXiv preprint arXiv:2506.22624. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p1.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§5.1](https://arxiv.org/html/2601.10477v1#S5.SS1.p1.1.1.1 "5.1 Baselines and Evaluation Metrics ‣ 5 Experiments ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 232 |
+
* B. Zhang, Z. Tian, Q. Tang, X. Chu, X. Wei, C. Shen, et al. (2022)Segvit: semantic segmentation with plain vision transformers. Advances in Neural Information Processing Systems 35, pp.4971–4982. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p1.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 233 |
+
* X. Zhang, S. Du, and Q. Wang (2017)Hierarchical semantic cognition for urban functional zones with vhr satellite images and poi data. ISPRS Journal of Photogrammetry and Remote Sensing 132, pp.170–184. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p2.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), [§2.2](https://arxiv.org/html/2601.10477v1#S2.SS2.p1.1 "2.2 Multi-Modal Approaches for Urban Understanding ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 234 |
+
* Y. Zheng, F. Xu, Y. Lin, P. Santi, C. Ratti, Q. R. Wang, and Y. Li (2025)Urban planning in the era of large language models. Nature Computational Science, pp.1–10. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p1.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 235 |
+
* Q. Zhu, J. Lao, D. Ji, J. Luo, K. Wu, Y. Zhang, L. Ru, J. Wang, J. Chen, M. Yang, et al. (2025)Skysense-o: towards open-world remote sensing interpretation with vision-centric visual-language modeling. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.14733–14744. Cited by: [§2.1](https://arxiv.org/html/2601.10477v1#S2.SS1.p2.1 "2.1 Semantic Segmentation ‣ 2 Related Work ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 236 |
+
* C. Zou, X. Guo, R. Yang, J. Zhang, B. Hu, and H. Zhang (2024)Dynamath: a dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models. arXiv preprint arXiv:2411.00836. Cited by: [§1](https://arxiv.org/html/2601.10477v1#S1.p3.1.1 "1 Introduction ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 237 |
+
|
| 238 |
+
Appendix A Appendix
|
| 239 |
+
-------------------
|
| 240 |
+
|
| 241 |
+
### A.1 Dataset Details
|
| 242 |
+
|
| 243 |
+
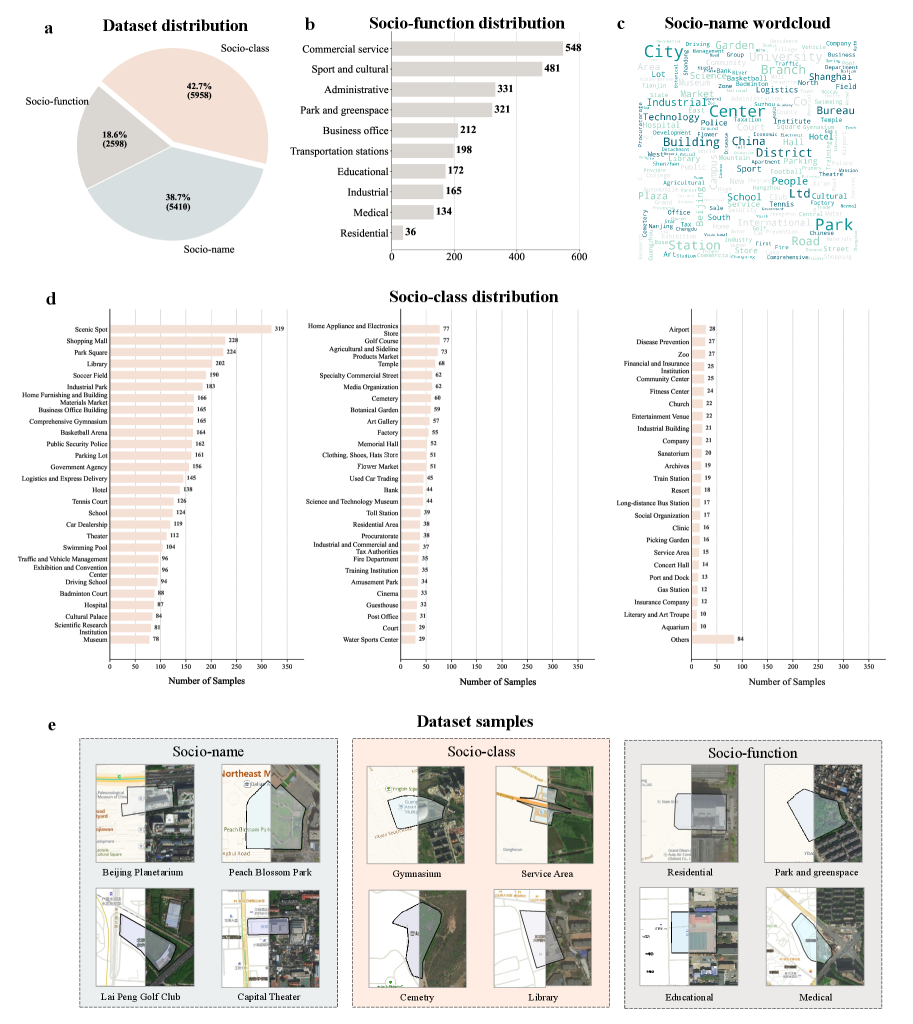
|
| 244 |
+
|
| 245 |
+
Figure 6: The SocioSeg dataset overview. (a) Sample distribution across the three hierarchical tasks. (b) Socio-function class distribution. (c) Socio-name word cloud. (d) Socio-class distribution. (e) Sample examples from SocioSeg, including satellite images, digital maps, and socio-semantic mask labels.
|
| 246 |
+
|
| 247 |
+
#### A.1.1 SocioSeg Dataset
|
| 248 |
+
|
| 249 |
+
The SocioSeg dataset is constructed entirely from data provided by Amap, offering comprehensive geographic coverage of all provinces and major cities across China. The input modalities, namely satellite images and digital maps, are acquired via the public Amap API. The ground-truth labels are derived from Amap’s Area of Interest (AOI) data.
|
| 250 |
+
|
| 251 |
+
To clarify the semantic scope, we structure these labels into three hierarchical levels intrinsically linked to daily social activities: the Socio-Name level corresponds to the specific name of each AOI instance; the Socio-Class level adopts the standard third-level POI taxonomy from Amap, a classification widely utilized in prior studies (Hu and Han, [2019](https://arxiv.org/html/2601.10477v1#bib.bib46 "Identification of urban functional areas based on poi data: a case study of the guangzhou economic and technological development zone"); Yao et al., [2017](https://arxiv.org/html/2601.10477v1#bib.bib47 "Sensing spatial distribution of urban land use by integrating points-of-interest and google word2vec model")); and the Socio-Function level is derived from established urban functional zone definitions (Gong et al., [2020](https://arxiv.org/html/2601.10477v1#bib.bib48 "Mapping essential urban land use categories in china (euluc-china): preliminary results for 2018"); Li et al., [2025c](https://arxiv.org/html/2601.10477v1#bib.bib50 "Learning to reason over multi-granularity knowledge graph for zero-shot urban land-use mapping")).
|
| 252 |
+
|
| 253 |
+
To adapt this source data for our research, we performed several refinement steps, encompassing reformatting the vector-based AOI data into rasterized semantic masks and conducting a rigorous quality assurance process. Specifically, we manually verified the alignment between the AOI polygons and the actual physical boundaries, rigorously filtering the dataset from an initial pool of approximately 40,000 samples down to 13,000 to exclude misaligned or ambiguous annotations. To further quantify the annotation quality and reproducibility, we conducted an inter-annotator agreement study with three independent annotators on a random subset of 500 samples, yielding a Cohen’s Kappa coefficient of 0.854. This ensures that each pixel is precisely classified into its corresponding socio-functional category, enhancing the dataset’s overall fidelity and reliability. The resulting SocioSeg benchmark is thus rich in socio-semantic information, providing a robust foundation for urban socio-semantic segmentation research.
|
| 254 |
+
|
| 255 |
+
Figure[6](https://arxiv.org/html/2601.10477v1#A1.F6 "Figure 6 ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning") offers a comprehensive overview of the SocioSeg dataset. Specifically, subfigure (a) illustrates the sample distribution across the three hierarchical tasks, underscoring the dataset’s balance and diversity. Subfigures (b) and (d) present the class distributions for the socio-function and socio-class tasks, respectively, showcasing the variety of categories included. A word cloud in subfigure (c) visualizes the frequency and prominence of the socio-name labels. Finally, subfigure (e) provides qualitative examples from the dataset, displaying corresponding satellite images, digital maps, and socio-semantic masks that effectively demonstrate the data’s richness and complexity.
|
| 256 |
+
|
| 257 |
+
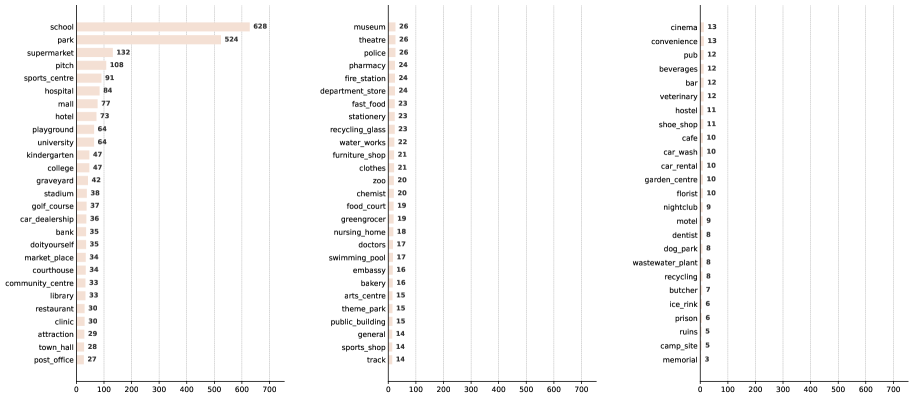
|
| 258 |
+
|
| 259 |
+
Figure 7: The SocioSeg OOD (New Region) dataset distribution.
|
| 260 |
+
|
| 261 |
+
#### A.1.2 SocioSeg Out-Of-Distribution dataset
|
| 262 |
+
|
| 263 |
+
To rigorously evaluate the generalization capabilities of our model, we introduce two distinct Out-Of-Distribution (OOD) datasets: Map Style and New Region.
|
| 264 |
+
|
| 265 |
+
OOD (Map Style). This setting is designed to assess the model’s robustness to shifts in cartographic rendering and symbolization. We utilize the original test set from the SocioSeg benchmark, retaining the original satellite imagery and ground-truth labels. However, we replace the input digital map modality, originally sourced from Amap, with tiles fetched from Google Maps. This substitution isolates the impact of map style, requiring the model to generalize to a new cartographic domain without any fine-tuning.
|
| 266 |
+
|
| 267 |
+
OOD (New Region). Figure[7](https://arxiv.org/html/2601.10477v1#A1.F7 "Figure 7 ‣ A.1.1 SocioSeg Dataset ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning") shows the distribution of the SocioSeg OOD (New Region) dataset. This setting evaluates performance across diverse geographic environments. We constructed this dataset using OpenStreetMap (OSM) (OpenStreetMap contributors, [2017](https://arxiv.org/html/2601.10477v1#bib.bib51 "Planet dump retrieve from https://planet.osm.org")) AOI data, strictly adhering to the same data construction and quality assurance pipeline employed for the primary SocioSeg dataset. To ensure global diversity, we selected five representative cities from different continents: Tokyo (Asia), New York (North America), São Paulo (South America), London (Europe), and Nairobi (Africa). While the input digital maps are sourced from Google Maps, the ground truth labels were derived from OSM and underwent manual filtering to ensure high fidelity. The resulting dataset comprises 3,200 samples focused on the socio-class task. It encompasses 80 distinct categories, importantly including 24 novel categories that were not present in the training set, thereby posing a significant challenge for zero-shot generalization.
|
| 268 |
+
|
| 269 |
+
Algorithm 1 Two-stage end-to-end GRPO Training for SocioReasoner
|
| 270 |
+
|
| 271 |
+
1:Training dataset
|
| 272 |
+
|
| 273 |
+
𝒟 train\mathcal{D}_{\mathrm{train}}
|
| 274 |
+
; VLM policy
|
| 275 |
+
|
| 276 |
+
π θ\pi_{\theta}
|
| 277 |
+
; frozen SAM
|
| 278 |
+
|
| 279 |
+
𝒮\mathcal{S}
|
| 280 |
+
; renderer
|
| 281 |
+
|
| 282 |
+
𝒟\mathcal{D}
|
| 283 |
+
; reference policy
|
| 284 |
+
|
| 285 |
+
π ref\pi_{\mathrm{ref}}
|
| 286 |
+
; group size
|
| 287 |
+
|
| 288 |
+
G G
|
| 289 |
+
; PPO clip
|
| 290 |
+
|
| 291 |
+
ϵ\epsilon
|
| 292 |
+
; KL weight
|
| 293 |
+
|
| 294 |
+
β\beta
|
| 295 |
+
; optimizer with learning rate
|
| 296 |
+
|
| 297 |
+
η\eta
|
| 298 |
+
; number of RL steps
|
| 299 |
+
|
| 300 |
+
T T
|
| 301 |
+
|
| 302 |
+
2:Initialize
|
| 303 |
+
|
| 304 |
+
π θ old←π θ\pi_{\theta_{\mathrm{old}}}\leftarrow\pi_{\theta}
|
| 305 |
+
|
| 306 |
+
3:for
|
| 307 |
+
|
| 308 |
+
step=1\text{step}=1
|
| 309 |
+
to
|
| 310 |
+
|
| 311 |
+
T T
|
| 312 |
+
do
|
| 313 |
+
|
| 314 |
+
4: Sample a mini-batch
|
| 315 |
+
|
| 316 |
+
ℬ⊂𝒟 train\mathcal{B}\subset\mathcal{D}_{\mathrm{train}}
|
| 317 |
+
|
| 318 |
+
5:for all
|
| 319 |
+
|
| 320 |
+
(𝐈 s,𝐈 m,𝐭 b)∈ℬ(\mathbf{I}_{s},\mathbf{I}_{m},\mathbf{t}_{b})\in\mathcal{B}
|
| 321 |
+
do
|
| 322 |
+
|
| 323 |
+
6:
|
| 324 |
+
|
| 325 |
+
𝐱 1←(𝐈 s,𝐈 m,𝐭 b)\mathbf{x}_{1}\leftarrow(\mathbf{I}_{s},\mathbf{I}_{m},\mathbf{t}_{b})
|
| 326 |
+
⊳\triangleright Stage-1: Localization
|
| 327 |
+
|
| 328 |
+
7:for
|
| 329 |
+
|
| 330 |
+
g=1 g=1
|
| 331 |
+
to
|
| 332 |
+
|
| 333 |
+
G G
|
| 334 |
+
do
|
| 335 |
+
|
| 336 |
+
8: Sample completion
|
| 337 |
+
|
| 338 |
+
𝐲 1(g)∼π θ(⋅|𝐱 1)\mathbf{y}_{1}^{(g)}\sim\pi_{\theta}(\cdot\,|\,\mathbf{x}_{1})
|
| 339 |
+
|
| 340 |
+
9: Parse bounding boxes
|
| 341 |
+
|
| 342 |
+
ℬ(g)\mathcal{B}^{(g)}
|
| 343 |
+
from
|
| 344 |
+
|
| 345 |
+
𝐲 1(g)\mathbf{y}_{1}^{(g)}
|
| 346 |
+
(assign syntax reward 0 if invalid)
|
| 347 |
+
|
| 348 |
+
10:
|
| 349 |
+
|
| 350 |
+
𝐌 c(g)←𝒮(𝐈 s,prompt=ℬ(g))\mathbf{M}_{c}^{(g)}\leftarrow\mathcal{S}(\mathbf{I}_{s},\text{prompt}=\mathcal{B}^{(g)})
|
| 351 |
+
|
| 352 |
+
11: Compute
|
| 353 |
+
|
| 354 |
+
R 1(g)R_{1}^{(g)}
|
| 355 |
+
|
| 356 |
+
12:end for
|
| 357 |
+
|
| 358 |
+
13:
|
| 359 |
+
|
| 360 |
+
b 1←1 G∑g=1 G R 1(g)b_{1}\leftarrow\frac{1}{G}\sum_{g=1}^{G}R_{1}^{(g)}
|
| 361 |
+
|
| 362 |
+
14: Compute advantages
|
| 363 |
+
|
| 364 |
+
A 1(g)←R 1(g)−b 1 A_{1}^{(g)}\leftarrow R_{1}^{(g)}-b_{1}
|
| 365 |
+
for all
|
| 366 |
+
|
| 367 |
+
g g
|
| 368 |
+
|
| 369 |
+
15: Update policy
|
| 370 |
+
|
| 371 |
+
π θ\pi_{\theta}
|
| 372 |
+
with GRPO on
|
| 373 |
+
|
| 374 |
+
{𝐱 1,𝐲 1(g),A 1(g)}g=1 G\{\mathbf{x}_{1},\mathbf{y}_{1}^{(g)},A_{1}^{(g)}\}_{g=1}^{G}
|
| 375 |
+
, using clip
|
| 376 |
+
|
| 377 |
+
ϵ\epsilon
|
| 378 |
+
and KL weight
|
| 379 |
+
|
| 380 |
+
β\beta
|
| 381 |
+
|
| 382 |
+
16: Select
|
| 383 |
+
|
| 384 |
+
g⋆←argmax gR 1(g)g^{\star}\leftarrow\arg\max_{g}R_{1}^{(g)}
|
| 385 |
+
(or sample proportional to
|
| 386 |
+
|
| 387 |
+
exp(R 1(g))\exp(R_{1}^{(g)})
|
| 388 |
+
)
|
| 389 |
+
|
| 390 |
+
17:
|
| 391 |
+
|
| 392 |
+
𝐈 s,r←𝒟(𝐈 s,ℬ(g⋆),𝐌 c(g⋆))\mathbf{I}_{s,r}\leftarrow\mathcal{D}(\mathbf{I}_{s},\mathcal{B}^{(g^{\star})},\mathbf{M}_{c}^{(g^{\star})})
|
| 393 |
+
|
| 394 |
+
18:
|
| 395 |
+
|
| 396 |
+
𝐈 m,r←𝒟(𝐈 m,ℬ(g⋆),𝐌 c(g⋆))\mathbf{I}_{m,r}\leftarrow\mathcal{D}(\mathbf{I}_{m},\mathcal{B}^{(g^{\star})},\mathbf{M}_{c}^{(g^{\star})})
|
| 397 |
+
|
| 398 |
+
19:
|
| 399 |
+
|
| 400 |
+
𝐱 2←(𝐈 s,r,𝐈 m,r,𝐭 b,𝐌 c(g⋆))\mathbf{x}_{2}\leftarrow(\mathbf{I}_{s,r},\mathbf{I}_{m,r},\mathbf{t}_{b},\mathbf{M}_{c}^{(g^{\star})})
|
| 401 |
+
⊳\triangleright Stage-2: Refinement
|
| 402 |
+
|
| 403 |
+
20:for
|
| 404 |
+
|
| 405 |
+
g=1 g=1
|
| 406 |
+
to
|
| 407 |
+
|
| 408 |
+
G G
|
| 409 |
+
do
|
| 410 |
+
|
| 411 |
+
21: Sample completion
|
| 412 |
+
|
| 413 |
+
𝐲 2(g)∼π θ(⋅|𝐱 2)\mathbf{y}_{2}^{(g)}\sim\pi_{\theta}(\cdot\,|\,\mathbf{x}_{2})
|
| 414 |
+
|
| 415 |
+
22: Parse
|
| 416 |
+
|
| 417 |
+
{ℬ~(g),𝒫(g)}\{\tilde{\mathcal{B}}^{(g)},\mathcal{P}^{(g)}\}
|
| 418 |
+
from
|
| 419 |
+
|
| 420 |
+
𝐲 2(g)\mathbf{y}_{2}^{(g)}
|
| 421 |
+
(assign syntax reward 0 if invalid)
|
| 422 |
+
|
| 423 |
+
23:
|
| 424 |
+
|
| 425 |
+
𝐌 f(g)←𝒮(𝐈 s,prompt={ℬ~(g),𝒫(g)})\mathbf{M}_{f}^{(g)}\leftarrow\mathcal{S}(\mathbf{I}_{s},\text{prompt}=\{\tilde{\mathcal{B}}^{(g)},\mathcal{P}^{(g)}\})
|
| 426 |
+
|
| 427 |
+
24: Compute
|
| 428 |
+
|
| 429 |
+
R 2(g)R_{2}^{(g)}
|
| 430 |
+
|
| 431 |
+
25:end for
|
| 432 |
+
|
| 433 |
+
26:
|
| 434 |
+
|
| 435 |
+
b 2←1 G∑g=1 G R 2(g)b_{2}\leftarrow\frac{1}{G}\sum_{g=1}^{G}R_{2}^{(g)}
|
| 436 |
+
|
| 437 |
+
27: Compute advantages
|
| 438 |
+
|
| 439 |
+
A 2(g)←R 2(g)−b 2 A_{2}^{(g)}\leftarrow R_{2}^{(g)}-b_{2}
|
| 440 |
+
for all
|
| 441 |
+
|
| 442 |
+
g g
|
| 443 |
+
|
| 444 |
+
28: Update policy
|
| 445 |
+
|
| 446 |
+
π θ\pi_{\theta}
|
| 447 |
+
with GRPO on
|
| 448 |
+
|
| 449 |
+
{𝐱 2,𝐲 2(g),A 2(g)}g=1 G\{\mathbf{x}_{2},\mathbf{y}_{2}^{(g)},A_{2}^{(g)}\}_{g=1}^{G}
|
| 450 |
+
, using clip
|
| 451 |
+
|
| 452 |
+
ϵ\epsilon
|
| 453 |
+
and KL weight
|
| 454 |
+
|
| 455 |
+
β\beta
|
| 456 |
+
|
| 457 |
+
29:end for
|
| 458 |
+
|
| 459 |
+
30:
|
| 460 |
+
|
| 461 |
+
π θ old←π θ\pi_{\theta_{\mathrm{old}}}\leftarrow\pi_{\theta}
|
| 462 |
+
⊳\triangleright Refresh behavior policy for next step
|
| 463 |
+
|
| 464 |
+
31:end for
|
| 465 |
+
|
| 466 |
+
### A.2 Implementation Details
|
| 467 |
+
|
| 468 |
+
#### A.2.1 GRPO Optimization Details
|
| 469 |
+
|
| 470 |
+
We train SocioReasoner with the two-stage end-to-end GRPO algorithm. The training process is summarized in Algorithm [1](https://arxiv.org/html/2601.10477v1#alg1 "Algorithm 1 ‣ A.1.2 SocioSeg Out-Of-Distribution dataset ‣ A.1 Dataset Details ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). In contrast to the single-stage training of existing methods, SocioReasoner’s process includes two rounds of RL sampling and policy updates, all while utilizing a shared set of model parameters.
|
| 471 |
+
|
| 472 |
+
#### A.2.2 Reward Function Design
|
| 473 |
+
|
| 474 |
+
##### Format Reward Functions.
|
| 475 |
+
|
| 476 |
+
The policy generates a structured textual output 𝐲\mathbf{y} containing a free-form reasoning channel and a machine-parsable answer channel:
|
| 477 |
+
|
| 478 |
+
⟨think⟩…⟨/think⟩⟨answer⟩JSON⟨/answer⟩.\langle\texttt{think}\rangle\;\dots\;\langle\texttt{/think}\rangle\quad\langle\texttt{answer}\rangle\;\texttt{JSON}\;\langle\texttt{/answer}\rangle.
|
| 479 |
+
|
| 480 |
+
The answer channel must contain a valid JSON array of objects. In stage-1, each object specifies a bounding box: {"bbox_2d": [x1,y1,x2,y2]}. In stage-2, each object is augmented with a list of points: {"bbox_2d": […], "points": [[x,y], …]}. We define a binary format reward, R form(𝐲)∈{0,1}R_{\mathrm{form}}(\mathbf{y})\in\{0,1\}, which is 1 if and only if the output is syntactically correct and adheres to the stage-specific schema. If the format reward is 0, the total reward for the episode is also 0, overriding all other components.
|
| 481 |
+
|
| 482 |
+
##### Stage-1 (Localization) Reward.
|
| 483 |
+
|
| 484 |
+
Given the ground-truth set of boxes ℬ⋆={𝐛 j⋆}j=1 J\mathcal{B}^{\star}=\{\mathbf{b}_{j}^{\star}\}_{j=1}^{J} and the predicted set ℬ^={𝐛^k}k=1 K\hat{\mathcal{B}}=\{\hat{\mathbf{b}}_{k}\}_{k=1}^{K}, we define:
|
| 485 |
+
|
| 486 |
+
* •Format reward R form(1)(𝐲)R_{\mathrm{form}}^{(1)}(\mathbf{y}) as defined above.
|
| 487 |
+
* •Accuracy reward via Hungarian matching with an IoU threshold of 0.5. Let IoU(𝐛,𝐛′)\mathrm{IoU}(\mathbf{b},\mathbf{b}^{\prime}) be the standard box IoU. We form a binary match matrix 𝐌 k,j=𝟏(IoU(𝐛^k,𝐛 j⋆)>0.5)\mathbf{M}_{k,j}=\mathbf{1}(\mathrm{IoU}(\hat{\mathbf{b}}_{k},\mathbf{b}_{j}^{\star})>0.5), solve the linear assignment problem on the cost matrix 𝟏−𝐌\mathbf{1}-\mathbf{M}, and denote the number of matches as N m N_{m}. The accuracy reward is
|
| 488 |
+
|
| 489 |
+
R acc(1)(𝐲;ℬ⋆)=N m max(K,J)∈[0,1].\displaystyle R_{\mathrm{acc}}^{(1)}(\mathbf{y};\mathcal{B}^{\star})=\frac{N_{m}}{\max(K,J)}\;\in\;[0,1].(7)
|
| 490 |
+
* •Length reward that encourages predicting the correct number of instances:
|
| 491 |
+
|
| 492 |
+
R len(1)(𝐲;ℬ⋆)=exp(−2|K−J|/J),J>0.\displaystyle R_{\mathrm{len}}^{(1)}(\mathbf{y};\mathcal{B}^{\star})=\exp\big(-2\,|K-J|/J\big),\quad J>0.(8)
|
| 493 |
+
|
| 494 |
+
The total stage-1 reward is the unweighted sum of these components:
|
| 495 |
+
|
| 496 |
+
R 1(𝐲;𝐱)=R form(1)(𝐲)+R acc(1)(𝐲;ℬ⋆)+R len(1)(𝐲;ℬ⋆).\displaystyle R_{1}(\mathbf{y};\mathbf{x})=R_{\mathrm{form}}^{(1)}(\mathbf{y})+R_{\mathrm{acc}}^{(1)}(\mathbf{y};\mathcal{B}^{\star})+R_{\mathrm{len}}^{(1)}(\mathbf{y};\mathcal{B}^{\star}).(9)
|
| 497 |
+
|
| 498 |
+
##### Stage-2 (Refinement) Reward.
|
| 499 |
+
|
| 500 |
+
For each predicted group (one bbox plus its point list), we execute SAM with the prompts to obtain a mask 𝐌^f\hat{\mathbf{M}}_{f} and compare it to the ground-truth mask 𝐌⋆\mathbf{M}^{\star}:
|
| 501 |
+
|
| 502 |
+
* •Format reward R form(2)(𝐲)R_{\mathrm{form}}^{(2)}(\mathbf{y}) as defined above.
|
| 503 |
+
* •Accuracy reward as pixel IoU:
|
| 504 |
+
|
| 505 |
+
R acc(2)(𝐲;𝐱)=IoU(𝐌^f,𝐌⋆)∈[0,1].\displaystyle R_{\mathrm{acc}}^{(2)}(\mathbf{y};\mathbf{x})=\mathrm{IoU}({\hat{\mathbf{M}}_{f}},\mathbf{M}^{\star})\;\in\;[0,1].(10)
|
| 506 |
+
* •Length reward that encourages concise, informative interactions. For a group with n n points, we define a Gaussian-shaped score peaking at two points:
|
| 507 |
+
|
| 508 |
+
R len(2)(𝐲)=1 G′∑g=1 G′r(n)∈[0,1],\displaystyle R_{\mathrm{len}}^{(2)}(\mathbf{y})=\frac{1}{G^{\prime}}\sum_{g=1}^{G^{\prime}}r(n)\;\in\;[0,1],(11)
|
| 509 |
+
|
| 510 |
+
where r(n)=exp(−(n−μ)2 2σ 2)r(n)=\exp\big(-\frac{(n-\mu)^{2}}{2\sigma^{2}}\big) with μ=2\mu=2 and σ=2\sigma=2. G′G^{\prime} is the number of valid groups. This encourages using a small number of informative points rather than many redundant ones.
|
| 511 |
+
|
| 512 |
+
The total stage-2 reward is the sum of these components:
|
| 513 |
+
|
| 514 |
+
R 2(𝐲;𝐱)=R form(2)(𝐲)+R acc(2)(𝐲;𝐱)+R len(2)(𝐲).\displaystyle R_{2}(\mathbf{y};\mathbf{x})=R_{\mathrm{form}}^{(2)}(\mathbf{y})+R_{\mathrm{acc}}^{(2)}(\mathbf{y};\mathbf{x})+R_{\mathrm{len}}^{(2)}(\mathbf{y}).(12)
|
| 515 |
+
|
| 516 |
+
#### A.2.3 Experimental Settings
|
| 517 |
+
|
| 518 |
+
For all our Reinforcement Learning (RL) based models, namely VisionReasoner, Seg-R1, SAM-R1, and RemoteReasoner, we adopt a unified training configuration. We set the rollout batch size to 128 and the group size to 8. The models are optimized using the AdamW optimizer with a learning rate of 1×10−6 1\times 10^{-6}. For the Proximal Policy Optimization (PPO) algorithm, the clipping parameter ϵ\epsilon is set to 0.5, and the Kullback-Leibler (KL) divergence weight β\beta is configured to 0.005. All RL models are trained for 250 steps within the ROLL framework (Wang et al., [2025](https://arxiv.org/html/2601.10477v1#bib.bib37 "Reinforcement learning optimization for large-scale learning: an efficient and user-friendly scaling library")).
|
| 519 |
+
|
| 520 |
+
A key aspect of our methodology is the handling of visual inputs. Since all RL-based methods are built upon Qwen2.5-VL-3b, which natively supports multi-image inputs, we provide both the satellite imagery and digital maps as visual input. For the Supervised Fine-Tuning (SFT) version of our model, we construct the supervision signal using the bounding box of the ground-truth mask, along with three points randomly sampled from within the mask’s area.
|
| 521 |
+
|
| 522 |
+
In contrast, for the baseline models UNet, SegFormer, SegEarth-OV, RSRefSeg and SegEarth-R1, we followed the original authors’ implementations. We utilized their publicly available source code and pre-trained models, which are then fine-tuned on the SocioSeg dataset. As these architectures do not support multi-image inputs, only the satellite imagery is used as the visual input for these models. All models are trained on a high-performance computing cluster equipped with 16 NVIDIA H20 GPUs.
|
| 523 |
+
|
| 524 |
+
### A.3 User Prompt Template
|
| 525 |
+
|
| 526 |
+

|
| 527 |
+
|
| 528 |
+
Figure 8: The two prompts above are the user prompt template for SocioReasoner, which adopts a two-stage reasoning process to mimic human annotation. The prompt below is the single-stage prompt used for the baseline without reflection and zero-shot GPT and Qwen models.
|
| 529 |
+
|
| 530 |
+
The user prompt templates utilized in our experiments are shown in Figure[8](https://arxiv.org/html/2601.10477v1#A1.F8 "Figure 8 ‣ A.3 User Prompt Template ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). SocioReasoner employs a two-stage reasoning process; consequently, we designed two distinct prompt templates to accommodate the different input and output formats of each stage. For our baseline model without the reflection mechanism, as well as the GPT and Qwen models, we adopt a single-stage prompt template. This template is adapted from the one used by VisionReasoner, with modifications to meet the specific requirements of our task. For our SFT model, we use this same base template but remove the chain-of-thought components. For all other RL-based comparative methods, we used the original prompt templates provided by their respective authors, prepending each with the instruction, ”You will be given two images. The first is a map and the second is a corresponding satellite image.”
|
| 531 |
+
|
| 532 |
+
Table 5: All ablation of multi-stage.
|
| 533 |
+
|
| 534 |
+
Table 6: All ablation of point number.
|
| 535 |
+
|
| 536 |
+
Table 7: Comparison with state-of-the-art methods on the SocioSeg OOD (New Region) dataset.
|
| 537 |
+
|
| 538 |
+
Table 8: Inference time comparison (seconds per sample).
|
| 539 |
+
|
| 540 |
+
VisionReasoner Seg-R1 SAM-R1 RSRefSeg SegEarth-R1 RemoteReasoner Ours(rl)Ours(sft)
|
| 541 |
+
1.33 1.07 2.52 0.16 0.35 1.13 2.71 0.41
|
| 542 |
+
|
| 543 |
+
Table 9: SocioSeg benchmark.
|
| 544 |
+
|
| 545 |
+
### A.4 SocioSeg benchmark
|
| 546 |
+
|
| 547 |
+
GPT-5, GPT-o3 and Qwen2.5-VL-72b are evaluated as baselines without any fine-tuning. As shown in Table[9](https://arxiv.org/html/2601.10477v1#A1.T9 "Table 9 ‣ A.3 User Prompt Template ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), their performance is substantially lower than that of our trained model, indicating that even large-scale VLMs struggle with the complexities of socio-semantic segmentation without task-specific training. Notably, Qwen2.5-VL-3b fails to produce valid bounding box outputs in our experiments, resulting in zero performance. This underscores the importance of specialized training and the effectiveness of our reinforcement learning approach in eliciting the reasoning capabilities necessary for this task.
|
| 548 |
+
|
| 549 |
+
### A.5 More Quantitative Results
|
| 550 |
+
|
| 551 |
+
#### A.5.1 Per-Category Results
|
| 552 |
+
|
| 553 |
+
We present the comprehensive accuracy metrics for all socio-class and socio-function categories in Figure[13](https://arxiv.org/html/2601.10477v1#A1.F13 "Figure 13 ‣ A.7 Failure Cases ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning") and Figure[14](https://arxiv.org/html/2601.10477v1#A1.F14 "Figure 14 ‣ A.7 Failure Cases ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), respectively. While our method consistently outperforms baselines on the top-20 most frequent socio-class categories, it exhibits suboptimal performance in specific classes such as Training Institution and Badminton Court. Regarding the socio-function tasks, our approach achieves state-of-the-art results across all categories, with the exception of Business Office and Residential. We attribute these failures to error propagation: in certain samples, the initial bounding box localization (Stage-1) deviates significantly from the ground truth. Consequently, the point prompts generated during the refinement phase (Stage-2) tend to exacerbate rather than correct this initial deviation, as illustrated in the failure cases in Figure[11](https://arxiv.org/html/2601.10477v1#A1.F11 "Figure 11 ‣ A.7 Failure Cases ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning").
|
| 554 |
+
|
| 555 |
+
#### A.5.2 More Ablation Studies and Inference Time Comparison
|
| 556 |
+
|
| 557 |
+
We provide the comprehensive quantitative results of our ablation studies in Table[5](https://arxiv.org/html/2601.10477v1#A1.T5 "Table 5 ‣ A.3 User Prompt Template ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning") and Table[6](https://arxiv.org/html/2601.10477v1#A1.T6 "Table 6 ‣ A.3 User Prompt Template ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), presenting detailed metrics across all three hierarchical task levels. Furthermore, Table[5](https://arxiv.org/html/2601.10477v1#A1.T5 "Table 5 ‣ A.3 User Prompt Template ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning") reports the performance of all comparative methods on the OOD (New Region) dataset, demonstrating that our method consistently achieves the best results across all evaluation metrics. Finally, we present a computational efficiency analysis in Table[8](https://arxiv.org/html/2601.10477v1#A1.T8 "Table 8 ‣ A.3 User Prompt Template ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"), comparing the average inference time per sample (in seconds) against the baselines. While our model incurs a higher latency due to its iterative two-stage reasoning mechanism, this computational trade-off is justified by its superior segmentation accuracy.
|
| 558 |
+
|
| 559 |
+
### A.6 More Visualizations
|
| 560 |
+
|
| 561 |
+
We first present the trend of the reward function during the training process, as shown in Figure[9](https://arxiv.org/html/2601.10477v1#A1.F9 "Figure 9 ‣ A.7 Failure Cases ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). As can be seen, the reward function gradually converges as training progresses, indicating that the model continuously improves its decision-making quality. Next, we provide additional qualitative results comparing SocioReasoner’s performance on the three hierarchical tasks, as illustrated in Figure[10](https://arxiv.org/html/2601.10477v1#A1.F10 "Figure 10 ‣ A.7 Failure Cases ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). These examples clearly demonstrate the advantages of SocioReasoner’s performance across different tasks, especially its accuracy and robustness in complex scenarios. Furthermore, we showcase more inference examples from SocioReasoner in Figure[12](https://arxiv.org/html/2601.10477v1#A1.F12 "Figure 12 ‣ A.7 Failure Cases ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). These examples further validate SocioReasoner’s capability in processing multi-modal inputs.
|
| 562 |
+
|
| 563 |
+
### A.7 Failure Cases
|
| 564 |
+
|
| 565 |
+
Finally, we present a visualization of representative failure cases encountered by SocioReasoner in Figure[11](https://arxiv.org/html/2601.10477v1#A1.F11 "Figure 11 ‣ A.7 Failure Cases ‣ Appendix A Appendix ‣ Urban Socio-Semantic Segmentation with Vision-Language Reasoning"). These instances, all characterized by a Generalized IoU (gIoU) below 0.1, primarily stem from two distinct error modes: (i) Localization Failure (Cases 1 and 2), where the predicted bounding box fails to locate the target region entirely, likely due to the model being distracted by the dense and visually cluttered urban environment; and (ii) Boundary Imprecision (Cases 3, 4, and 5), where the model correctly identifies the general location of the semantic entity but fails to generate a geometrically accurate enclosure. These challenges underscore the inherent difficulty of mapping abstract social concepts to precise physical coordinates in complex satellite imagery. This suggests that while our reasoning framework effectively bridges the modal gap, future research should further focus on enhancing the fine-grained spatial reasoning capabilities of Vision-Language Models (VLMs) and mitigating spatial ambiguity to achieve more robust performance in dense urban scenarios.
|
| 566 |
+
|
| 567 |
+
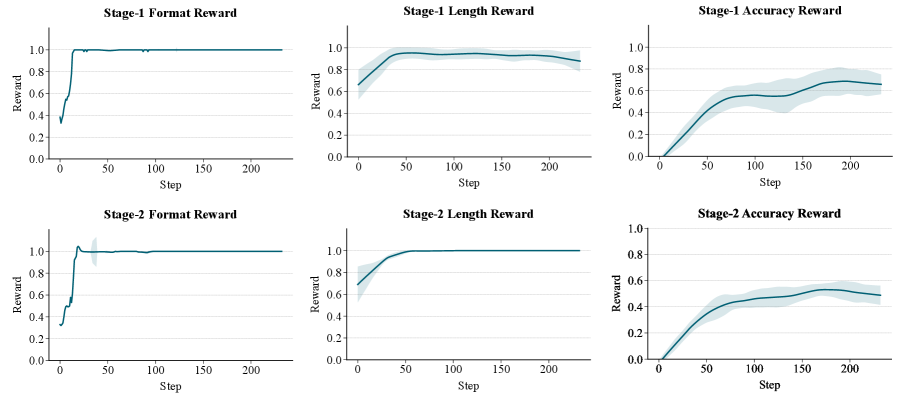
|
| 568 |
+
|
| 569 |
+
Figure 9: The rewards visualization during the training process.
|
| 570 |
+
|
| 571 |
+

|
| 572 |
+
|
| 573 |
+
Figure 10: All method Comparisons of SocioReasoner across the three hierarchical tasks.
|
| 574 |
+
|
| 575 |
+

|
| 576 |
+
|
| 577 |
+
Figure 11: Failure cases of SocioReasoner.
|
| 578 |
+
|
| 579 |
+
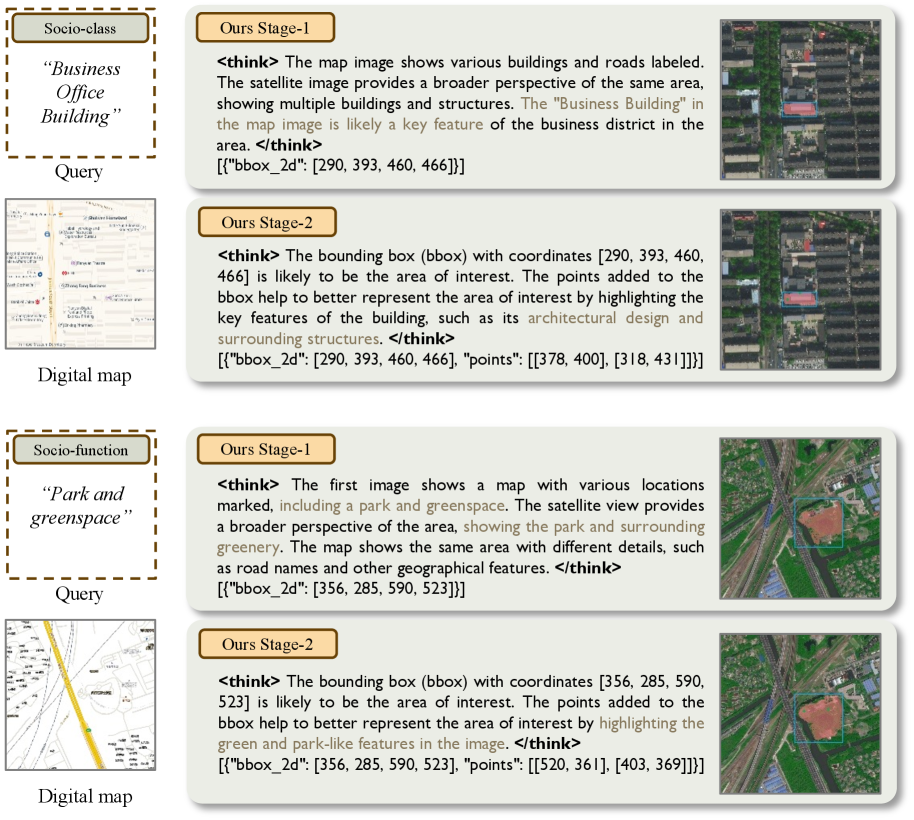
|
| 580 |
+
|
| 581 |
+
Figure 12: More inference examples of SocioReasoner.
|
| 582 |
+
|
| 583 |
+
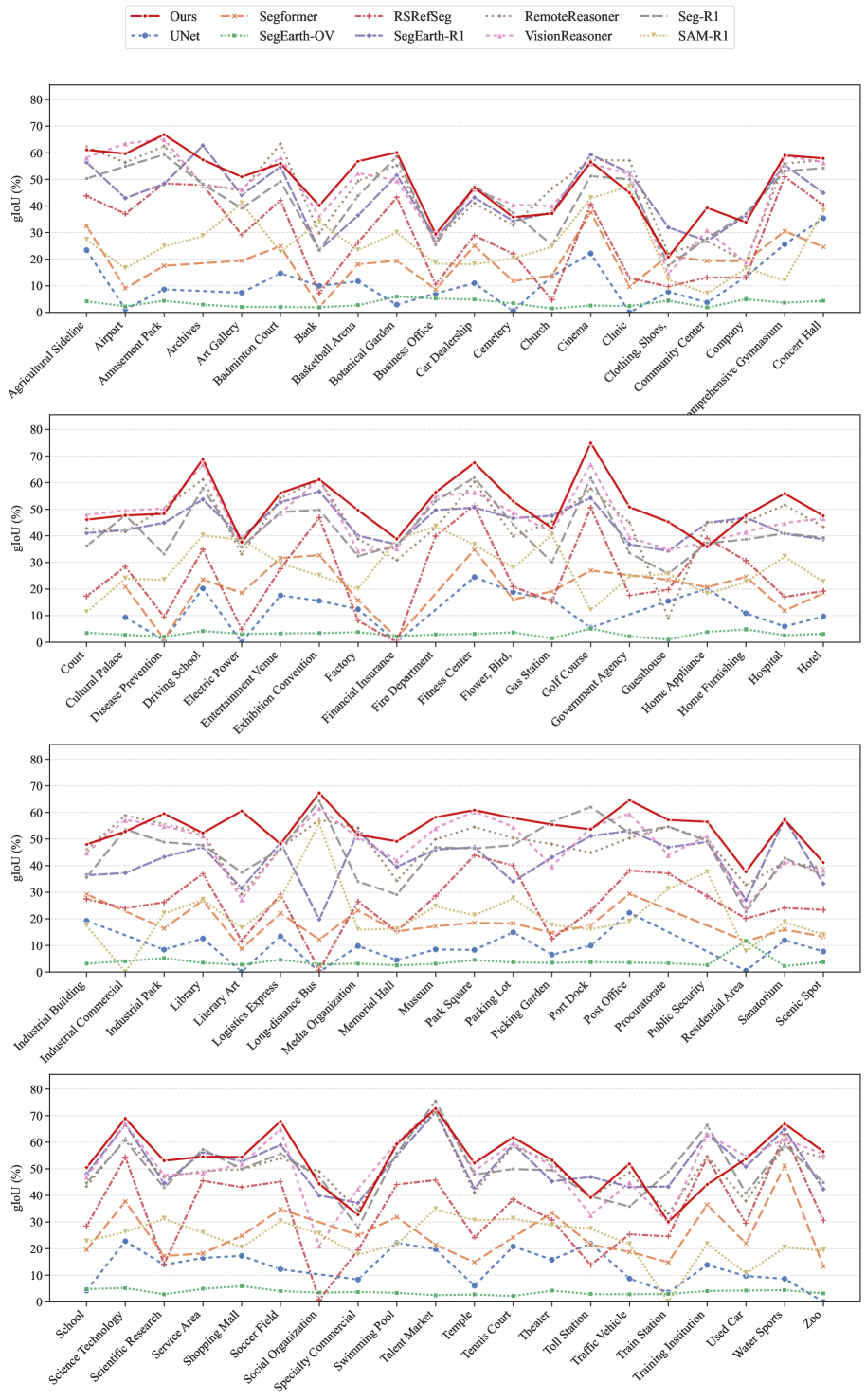
|
| 584 |
+
|
| 585 |
+
Figure 13: Per-class accuracy comparison across Socio-classes.
|
| 586 |
+
|
| 587 |
+
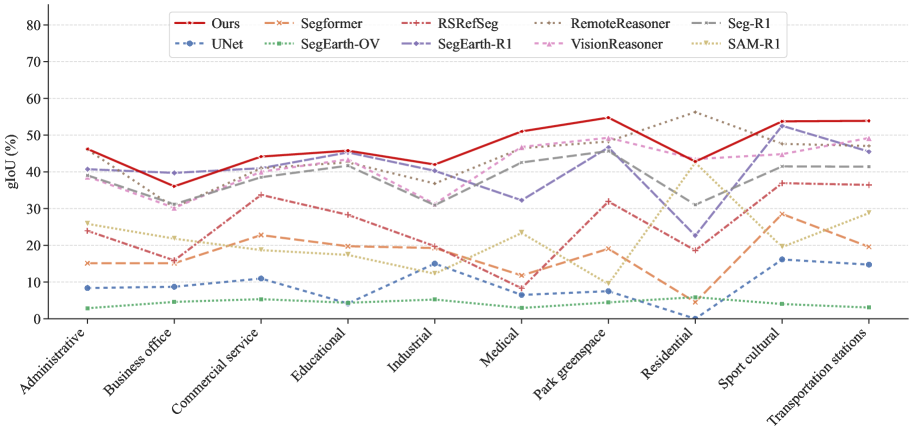
|
| 588 |
+
|
| 589 |
+
Figure 14: Per-class accuracy comparison across Socio-functions.
|