

Add 1 files
Browse files- 2312/2312.12588.md +352 -0
2312/2312.12588.md
ADDED
|
@@ -0,0 +1,352 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
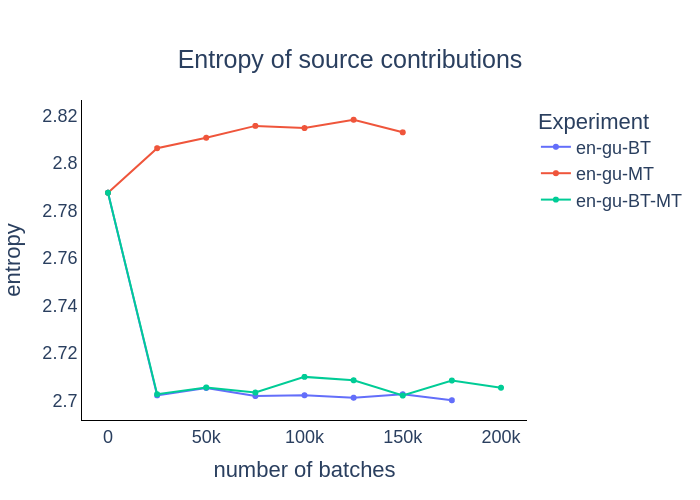
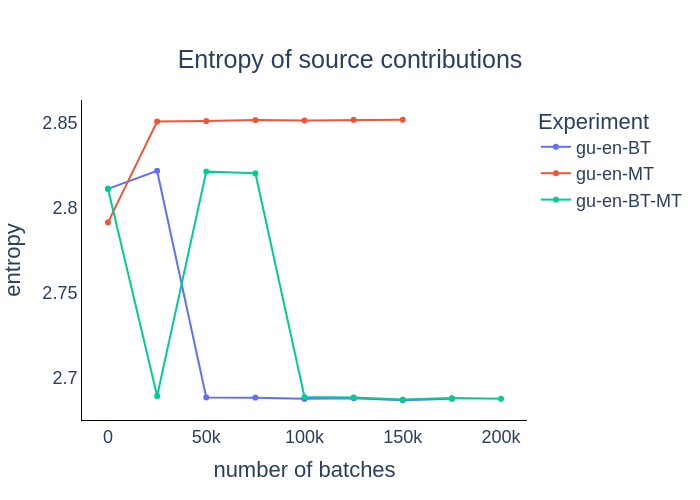
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
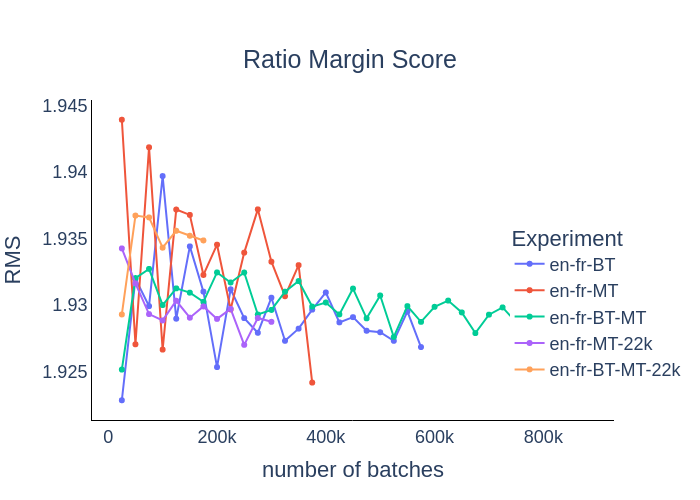
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2312.12588
|
| 4 |
+
|
| 5 |
+
Published Time: Thu, 21 Dec 2023 02:00:37 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
Isidora Chara Tourni
|
| 9 |
+
|
| 10 |
+
Boston University
|
| 11 |
+
|
| 12 |
+
isidora@bu.edu
|
| 13 |
+
|
| 14 |
+
&Derry Wijaya
|
| 15 |
+
|
| 16 |
+
Boston University
|
| 17 |
+
|
| 18 |
+
wijaya@bu.edu
|
| 19 |
+
|
| 20 |
+
###### Abstract
|
| 21 |
+
|
| 22 |
+
Unsupervised Neural Machine Translation (UNMT) focuses on improving NMT results under the assumption there is no human translated parallel data, yet little work has been done so far in highlighting its advantages compared to supervised methods and analyzing its output in aspects other than translation accuracy. We focus on three very diverse languages, French, Gujarati, and Kazakh, and train bilingual NMT models, to and from English, with various levels of supervision, in high- and low- resource setups, measure quality of the NMT output and compare the generated sequences’ word order and semantic similarity to source and reference sentences. We also use Layer-wise Relevance Propagation to evaluate the source and target sentences’ contribution to the result, expanding the findings of previous works to the UNMT paradigm.
|
| 23 |
+
|
| 24 |
+
1 Introduction
|
| 25 |
+
--------------
|
| 26 |
+
|
| 27 |
+
Unsupervised Neural Machine Translation (UNMT) has been widely studied (Wang and Zhao, [2021](https://arxiv.org/html/2312.12588v1/#bib.bib31); Marchisio et al., [2020](https://arxiv.org/html/2312.12588v1/#bib.bib20); Kim et al., [2020](https://arxiv.org/html/2312.12588v1/#bib.bib13); Lample et al., [2017](https://arxiv.org/html/2312.12588v1/#bib.bib16); Artetxe et al., [2019](https://arxiv.org/html/2312.12588v1/#bib.bib1); Su et al., [2019](https://arxiv.org/html/2312.12588v1/#bib.bib27)), in an effort to create efficient and trustworthy NMT models of excellent performance not relying on the existence of parallel data. Obtaining high-quality parallel corpora is expensive and time-consuming, especially for less-common language pairs. Unsupervised NMT hence aims to circumvent this limitation. NMT in general significantly aids in preserving indigenous languages by making global information accessible, supports migrants in overcoming language barriers to essential services, and enables the globalization of local news from smaller countries. UNMT particularly has broad applicability, especially in addressing linguistic diversity and information accessibility challenges.
|
| 28 |
+
|
| 29 |
+
However, there has been little effort on analyzing, apart from the quality of the output, the model behavior during UNMT, and the models’ inner workings and the effects of various setups on hypotheses and generated translations’ quality, monotonicity and semantic similarity, as well as model robustness and consistency. We analyze and compare UNMT approaches for two very diverse languages, French and Gujarati, translating to and from English. We research into the existence of different stages in UNMT, analyze source and target sentence tokens’ contributions to the result (Bach et al., [2015](https://arxiv.org/html/2312.12588v1/#bib.bib4)) evaluate the quality and word alignment of generated translations, and Robustness and Consistency of our model to perturbed inputs. Our paper follows up closely on the work of Voita et al. ([2020](https://arxiv.org/html/2312.12588v1/#bib.bib29), [2021](https://arxiv.org/html/2312.12588v1/#bib.bib30)); Marchisio et al. ([2022](https://arxiv.org/html/2312.12588v1/#bib.bib21)), and examines the following questions:
|
| 30 |
+
|
| 31 |
+
* •Do the distinct stages of transformer-based NMT analyzed in previous works exist in Unsupervised, and joint Supervised & Unsupervised NMT?
|
| 32 |
+
* •How does output quality, word alignment, semantic similarity, as well as source and target sentences’ token contributions to the NMT output behave across the aforementioned stages?
|
| 33 |
+
* •How Robust and Consistent are NMT models throughout training?
|
| 34 |
+
|
| 35 |
+
Our findings confirm the existence of NMT stages regardless of the level of training supervision, and show that Unsupervised methods produce translations more similar to source sentences in terms of word order, yet more semantically distant. UNMT models tend to show higher Robustness and Consistency, and can more easily recover from sentence perturbations. We also observe that in reduced training data experiments, there is a heavy reliance on the source sentence for generating translations. Our focus is not on outperforming NMT state-of-the-art results, but rather on training and examining the behavior of bilingual models in various setups.
|
| 36 |
+
|
| 37 |
+
The paper is structured as follows: in Section [2](https://arxiv.org/html/2312.12588v1/#S2 "2 Related Work ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution") we present related work in the topics of UNMT, NMT analysis and other metrics analyzed in our work. In Section [3](https://arxiv.org/html/2312.12588v1/#S3 "3 Method & Experiments ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution") we analyze the methods proposed for NMT analysis and the experiments conducted, while in Section [4](https://arxiv.org/html/2312.12588v1/#S4 "4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution") we present and discuss our findings. Finally, in Sections [5](https://arxiv.org/html/2312.12588v1/#S5 "5 Conclusions ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution"), [6](https://arxiv.org/html/2312.12588v1/#S6 "6 Limitations ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution") and [7](https://arxiv.org/html/2312.12588v1/#S7 "7 Ethical Considerations ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution") we conclude our work and highlight certain limitations and ethical considerations, respectively. We present additional experiments and results on the Robustness of the models and Semantic Similarity of input and output sentences in the appendix.
|
| 38 |
+
|
| 39 |
+
2 Related Work
|
| 40 |
+
--------------
|
| 41 |
+
|
| 42 |
+
### Unsupervised Neural Machine Translation
|
| 43 |
+
|
| 44 |
+
UNMT aims to make NMT work in the absence of parallel data. Most common approaches have focused on cross- or multilingual initialization of a language model either through an alignment of monolingual embeddings (Artetxe et al., [2017](https://arxiv.org/html/2312.12588v1/#bib.bib2); Lample et al., [2018](https://arxiv.org/html/2312.12588v1/#bib.bib17); Conneau et al., [2017](https://arxiv.org/html/2312.12588v1/#bib.bib8); Lample et al., [2017](https://arxiv.org/html/2312.12588v1/#bib.bib16)) or by model pretraining and fine-tuning (Lample and Conneau, [2019](https://arxiv.org/html/2312.12588v1/#bib.bib15); Song et al., [2019](https://arxiv.org/html/2312.12588v1/#bib.bib26); Liu et al., [2020](https://arxiv.org/html/2312.12588v1/#bib.bib19)). Back-Translation (BT) (Sennrich et al., [2015](https://arxiv.org/html/2312.12588v1/#bib.bib24)) translates monolingual data between languages, creating pseudo-parallel training corpora (Artetxe et al., [2017](https://arxiv.org/html/2312.12588v1/#bib.bib2); Lample et al., [2017](https://arxiv.org/html/2312.12588v1/#bib.bib16)). Marchisio et al. ([2022](https://arxiv.org/html/2312.12588v1/#bib.bib21)) first systematically examine the naturalness and diversity of the UNMT output, comparing it to similar quality human translations, and proposing a way to leverage UNMT to improve a classical supervised NMT system. In more recent works, Liu et al. ([2022](https://arxiv.org/html/2312.12588v1/#bib.bib18)) introduce a flow-adapter architecture to separately model the distributions of source and target languages, and He et al. ([2022](https://arxiv.org/html/2312.12588v1/#bib.bib11)) identify and mitigate a training and inference style and content gap between back-translated data and natural source sentences. Garcia et al. ([2020a](https://arxiv.org/html/2312.12588v1/#bib.bib9)) expand the paradigm to multilingual UNMT, while Garcia et al. ([2020b](https://arxiv.org/html/2312.12588v1/#bib.bib10)) use offline BT synthetic data to improve multilingual En-xx UNMT for low-resource languages xx.
|
| 45 |
+
|
| 46 |
+
### Layer-wise Relevance Propagation (LRP)
|
| 47 |
+
|
| 48 |
+
LRP (Bach et al., [2015](https://arxiv.org/html/2312.12588v1/#bib.bib4)) measures relevance of the input components, or the neurons of a network, to the next layers’ output, and is directly applicable to layer-wise architectures. Wu and Ong ([2021](https://arxiv.org/html/2312.12588v1/#bib.bib33)) use LRP as an attribution method for sequence classification tasks. We extend its usage to the Transformer, and measure the relevance of source and target sentences to the NMT output.
|
| 49 |
+
|
| 50 |
+
### Neural Machine Translation analysis
|
| 51 |
+
|
| 52 |
+
Voita et al. ([2020](https://arxiv.org/html/2312.12588v1/#bib.bib29)) examine the source and target sentences’ tokens’ relative contributions to NMT output, adapting LRP to a Transformer, and experimenting with different training objectives, training data amounts and types of target sentence prefixes, and their effect on NMT output quality and monotonicity. Following up to that work, Voita et al. ([2021](https://arxiv.org/html/2312.12588v1/#bib.bib30)) analyze NMT stages, drawing parallels to distinct SMT stages. Their findings include decomposing NMT into three phases, and using the key learning advantages of each stage to improve non-autoregressive NMT. We examine and identify if those stages exist in UNMT.
|
| 53 |
+
|
| 54 |
+
### Robustness & Consistency
|
| 55 |
+
|
| 56 |
+
Previous works examine Robustness in NLP (Yu et al., [2022](https://arxiv.org/html/2312.12588v1/#bib.bib34); Wang et al., [2021](https://arxiv.org/html/2312.12588v1/#bib.bib32); La Malfa and Kwiatkowska, [2022](https://arxiv.org/html/2312.12588v1/#bib.bib14)), measuring and improving NLP models’ performance against perturbed or unseen input. Specifically for NMT, Niu et al. ([2020](https://arxiv.org/html/2312.12588v1/#bib.bib23)) propose two metrics, Robustness and Consistency to measure sensitivity of a model to input perturbations.
|
| 57 |
+
|
| 58 |
+
3 Method & Experiments
|
| 59 |
+
----------------------
|
| 60 |
+
|
| 61 |
+
### 3.1 Model
|
| 62 |
+
|
| 63 |
+
We use a 6-layers 8-heads transformer-based model, XLM (Lample and Conneau, [2019](https://arxiv.org/html/2312.12588v1/#bib.bib15)), following the training configurations and hyperparameters suggested by the authors. We use Byte Pair Encoding to extract a 60k vocabulary, an embedding layer size of 1024, a dropout value and an attention layer dropout value of 0.1, and a sequence length of 256. We measure the quality of the Language Model (LM) with perplexity, and quality of the NMT output with BLEU both used as training stopping criteria, when there is no improvement over 10 epochs. We first pre-train a LM in each language with the MLM objective, and use it to initialize the encoder and decoder of the NMT model. We then train NMT models, using Back-Translation (BT) and denoising auto-encoding (AE) with the monolingual data used for LM pretraining for UNMT, the Machine Translation (MT) objective for the Supervised NMT model, and BT-MT for the joint Unsupervised and Supervised approach.
|
| 64 |
+
|
| 65 |
+
### 3.2 Datasets
|
| 66 |
+
|
| 67 |
+
The languages we work with are English, French, Gujarati, and Kazakh and we’re translating in all directions, English–French (En–Fr), French–English (Fr–En), English–Gujarati (En–Gu), Gujarati–English (Gu–En), English–Kazakh (En–Kk), Kazakh–English (Kk–En). For English and French, we use 5 million News Crawl 2007-2008 monolingual sentences for each language, and 23 million WMT14 parallel sentences. For Gujarati, we have 1.4 million sentences and for Kazakh we have 9.5M monolingual sentences, collected for both languages from Wikipedia, WMT 2018, 2019 and Leipzig Corpora (2016)1 1 1 https://wortschatz.unileipzig.de/en/download/. As parallel data, we have 22k sentences from the WMT 2019 News Translation Task 2 2 2 http://data.statmt.org/news-crawl/ for Gu–En and Kk–En, respectively/ As development and test sets, we use newstest2013 and newstest2014, respectively, for En–Fr and Fr–En, WMT19 for En–Gu and Gu–En and En–Kk and Kk–En.
|
| 68 |
+
|
| 69 |
+
### 3.3 Layer-wise Relevance Propagation
|
| 70 |
+
|
| 71 |
+
Voita et al. ([2020](https://arxiv.org/html/2312.12588v1/#bib.bib29)) explain how LRP calculation in a Transformer is confusing due to the non-clear layered nature of the model. We follow their setup, with LRP to be propagated first inversely through the decoder and the encoder, up to the input model layer, and without assuming the conservation principle holds per layer, but only across processed tokens. LRP is the relevance of input neurons to the top-1 logit predicted by the model, and token contribution is the sum of the input neurons’ relevance. Total source and target sentence contributions to the result at generation step t are given by R t(source)=∑i R(x i)subscript 𝑅 𝑡 𝑠 𝑜 𝑢 𝑟 𝑐 𝑒 subscript 𝑖 𝑅 subscript 𝑥 𝑖 R_{t}(source)=\sum_{i}{R(x_{i})}italic_R start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ( italic_s italic_o italic_u italic_r italic_c italic_e ) = ∑ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT italic_R ( italic_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ), R t(target)=∑j=1 t−1 R(y j).subscript 𝑅 𝑡 𝑡 𝑎 𝑟 𝑔 𝑒 𝑡 superscript subscript 𝑗 1 𝑡 1 𝑅 subscript 𝑦 𝑗 R_{t}(target)=\sum_{j=1}^{t-1}{R(y_{j})}.italic_R start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ( italic_t italic_a italic_r italic_g italic_e italic_t ) = ∑ start_POSTSUBSCRIPT italic_j = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_t - 1 end_POSTSUPERSCRIPT italic_R ( italic_y start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) . At every step t, Relevance follows the conservation principle: R t(source)+R t(target)=1 subscript 𝑅 𝑡 𝑠 𝑜 𝑢 𝑟 𝑐 𝑒 subscript 𝑅 𝑡 𝑡 𝑎 𝑟 𝑔 𝑒 𝑡 1 R_{t}(source)+R_{t}(target)=1 italic_R start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ( italic_s italic_o italic_u italic_r italic_c italic_e ) + italic_R start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ( italic_t italic_a italic_r italic_g italic_e italic_t ) = 1. At step 1, we have R 1(source)=1 subscript 𝑅 1 𝑠 𝑜 𝑢 𝑟 𝑐 𝑒 1 R_{1}(source)=1 italic_R start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ( italic_s italic_o italic_u italic_r italic_c italic_e ) = 1, R 1(target)=0 subscript 𝑅 1 𝑡 𝑎 𝑟 𝑔 𝑒 𝑡 0 R_{1}(target)=0 italic_R start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ( italic_t italic_a italic_r italic_g italic_e italic_t ) = 0. For every target token past the currently generated one, LRP is 0.
|
| 72 |
+
|
| 73 |
+
### 3.4 Word Order
|
| 74 |
+
|
| 75 |
+
Our aim is to examine differences in word order between translations and reference or source sentences. We evaluate two different reordering metrics, Fuzzy Reordering Score (FRS) (Talbot et al., [2011](https://arxiv.org/html/2312.12588v1/#bib.bib28); Nakagawa, [2015](https://arxiv.org/html/2312.12588v1/#bib.bib22))3 3 3 https://github.com/google/topdown-btg-preordering and Translation Edit Rate (TER) (Snover et al., [2006](https://arxiv.org/html/2312.12588v1/#bib.bib25)). FRS ranges between 0 and 1, with larger values for highly monotonic alignments (higher structural similarity and closer word order). For a translation y′superscript 𝑦′{y^{\prime}}italic_y start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT and reference y 𝑦{y}italic_y (or source sentence y 𝑦{y}italic_y): FRS(y′,y)=1−C−1 M−1.𝐹 𝑅 𝑆 superscript 𝑦′𝑦 1 𝐶 1 𝑀 1 FRS(y^{\prime},y)=1-\frac{C-1}{M-1}.italic_F italic_R italic_S ( italic_y start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT , italic_y ) = 1 - divide start_ARG italic_C - 1 end_ARG start_ARG italic_M - 1 end_ARG . C is the number of chunks of contiguously aligned translation words, intuitively perceived as the number of times a reader would need to jump in order to read the system’s reordering of the sentence in the order proposed by the reference of length M. With fast_align 4 4 4 https://github.com/clab/fast_align we calculate word alignments. TER is defined as TER(y′,y)=E L y,𝑇 𝐸 𝑅 superscript 𝑦′𝑦 𝐸 subscript 𝐿 𝑦 TER(y^{\prime},y)=\frac{E}{L_{y}},italic_T italic_E italic_R ( italic_y start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT , italic_y ) = divide start_ARG italic_E end_ARG start_ARG italic_L start_POSTSUBSCRIPT italic_y end_POSTSUBSCRIPT end_ARG , where E is the number of edits needed to modify the produced translation y′superscript 𝑦′y^{\prime}italic_y start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT to match the reference sentence y 𝑦 y italic_y (or source sentence y 𝑦 y italic_y), and L y subscript 𝐿 𝑦 L_{y}italic_L start_POSTSUBSCRIPT italic_y end_POSTSUBSCRIPT is the length of the reference (or the source sentence, respectively). TER ranges between 0 and 1, and low values indicate more monotonic alignments.
|
| 76 |
+
|
| 77 |
+
### 3.5 Model Robustness
|
| 78 |
+
|
| 79 |
+
Niu et al. ([2020](https://arxiv.org/html/2312.12588v1/#bib.bib23)) set TQ (y’, y) to be the model quality of model M with translation y′superscript 𝑦′y^{\prime}italic_y start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT, and reference y 𝑦 y italic_y, to define the concepts of Consistency and Robustness. Consistency of a model M on input x 𝑥 x italic_x and perturbation δ 𝛿\delta italic_δ is given by CONSIS(M|x,δ)=𝑆𝑖𝑚(yδ,y),𝐶 𝑂 𝑁 𝑆 𝐼 𝑆 conditional 𝑀 𝑥 𝛿 𝑆𝑖𝑚 𝑦 δ 𝑦 CONSIS(M|x,\delta)=\textit{Sim}(y\textsubscript{$\delta$},y),italic_C italic_O italic_N italic_S italic_I italic_S ( italic_M | italic_x , italic_δ ) = Sim ( italic_y italic_δ , italic_y ) , where y 𝑦 y italic_y is the reference translation, and y δ 𝛿\delta italic_δ is the translation of the perturbed sentence. Sim is the harmonic mean between model quality TQ(y’, y δ 𝛿\delta italic_δ’) and TQ(y δ 𝛿\delta italic_δ’, y’), measured between translations y’, y δ 𝛿\delta italic_δ’, respectively. On the other hand, Robustness of a model M is defined as the ratio between quality of the model producing translations y δ 𝛿\delta italic_δ’ and y’: ROBUST(M|x,δ)=TQ(y δ′,y)TQ(y′,y).𝑅 𝑂 𝐵 𝑈 𝑆 𝑇 conditional 𝑀 𝑥 𝛿 𝑇 𝑄 superscript subscript 𝑦 𝛿′𝑦 𝑇 𝑄 superscript 𝑦′𝑦 ROBUST(M|x,\delta)=\frac{TQ(y_{\delta}^{\prime},y)}{TQ(y^{\prime},y)}.italic_R italic_O italic_B italic_U italic_S italic_T ( italic_M | italic_x , italic_δ ) = divide start_ARG italic_T italic_Q ( italic_y start_POSTSUBSCRIPT italic_δ end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT , italic_y ) end_ARG start_ARG italic_T italic_Q ( italic_y start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT , italic_y ) end_ARG . It takes values in [0,1]. We evaluate Consistency and Robustness on test sets perturbed with two different approaches: a. misspelling - each word is misspelled (random deletion, insertion or substitution of characters) with a probability of 0.1, b. case-changing - each sentence is modified (upper-casing, lower-casing or title-casing all letters) with a probability of 0.5.
|
| 80 |
+
|
| 81 |
+
### 3.6 Semantic Similarity
|
| 82 |
+
|
| 83 |
+
In evaluating semantic similarity between human translations or source sentences and generated translations, we calculate the Ratio Margin-based Similarity Score (RMSS) between each reference or source sentence and its k-nearest neighbors among all translations (Artetxe and Schwenk, [2018](https://arxiv.org/html/2312.12588v1/#bib.bib3)). We follow Keung et al. ([2021](https://arxiv.org/html/2312.12588v1/#bib.bib12)) to obtain and mean-pool the mBERT embedding vectors of all sentences. We set cos(⋅,⋅)𝑐 𝑜 𝑠⋅⋅cos(\cdot,\cdot)italic_c italic_o italic_s ( ⋅ , ⋅ ) to be the cosine similarity and NN(x)k src{}_{k}^{src}(x)start_FLOATSUBSCRIPT italic_k end_FLOATSUBSCRIPT start_POSTSUPERSCRIPT italic_s italic_r italic_c end_POSTSUPERSCRIPT ( italic_x ) the k 𝑘 k italic_k nearest neighbors of x 𝑥 x italic_x in the reference or source sentence embedding space. RMSS is high when source and target pairs compared are closer than their respective nearest neighbors. For a hypothesis y 𝑦 y italic_y:
|
| 84 |
+
|
| 85 |
+
RMSS(x,y)=cos(x,y)∑z∈NN k tgt(x)cos(x,z)2k+∑z∈NN k src(y)cos(y,z)2k.𝑅 𝑀 𝑆 𝑆 𝑥 𝑦 𝑐 𝑜 𝑠 𝑥 𝑦 subscript 𝑧 subscript superscript NN 𝑡 𝑔 𝑡 𝑘 𝑥 𝑐 𝑜 𝑠 𝑥 𝑧 2 𝑘 subscript 𝑧 subscript superscript NN 𝑠 𝑟 𝑐 𝑘 𝑦 𝑐 𝑜 𝑠 𝑦 𝑧 2 𝑘\begin{multlined}RMSS(x,y)=\\ \frac{cos(x,y)}{\sum_{z\in\text{NN}^{tgt}_{k}(x)}\frac{cos(x,z)}{2k}+\sum_{z% \in\text{NN}^{src}_{k}(y)}\frac{cos(y,z)}{2k}}.\end{multlined}RMSS(x,y)=\\ \frac{cos(x,y)}{\sum_{z\in\text{NN}^{tgt}_{k}(x)}\frac{cos(x,z)}{2k}+\sum_{z% \in\text{NN}^{src}_{k}(y)}\frac{cos(y,z)}{2k}}.start_ROW start_CELL italic_R italic_M italic_S italic_S ( italic_x , italic_y ) = end_CELL end_ROW start_ROW start_CELL divide start_ARG italic_c italic_o italic_s ( italic_x , italic_y ) end_ARG start_ARG ∑ start_POSTSUBSCRIPT italic_z ∈ NN start_POSTSUPERSCRIPT italic_t italic_g italic_t end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT ( italic_x ) end_POSTSUBSCRIPT divide start_ARG italic_c italic_o italic_s ( italic_x , italic_z ) end_ARG start_ARG 2 italic_k end_ARG + ∑ start_POSTSUBSCRIPT italic_z ∈ NN start_POSTSUPERSCRIPT italic_s italic_r italic_c end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT ( italic_y ) end_POSTSUBSCRIPT divide start_ARG italic_c italic_o italic_s ( italic_y , italic_z ) end_ARG start_ARG 2 italic_k end_ARG end_ARG . end_CELL end_ROW
|
| 86 |
+
|
| 87 |
+
4 Results & Discussion
|
| 88 |
+
----------------------
|
| 89 |
+
|
| 90 |
+
Table 1: BLEU scores for En–Fr, Fr–En, En–Gu, Gu–En, En–Kk, Kk–En NMT. Test and validation sets are WMT19 for Gujarati and Kazakh, newstest2013-14 for French pairs. State-of-the art results given for the sake of consistency. _MT_ stands for machine translation objective, _BT_ stands for Back-Translation and _AE_ for denoising auto-encoding.
|
| 91 |
+
|
| 92 |
+
BLEU scores of converged models are seen in Table [1](https://arxiv.org/html/2312.12588v1/#S4.T1 "Table 1 ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution"). In En–Gu, En–Kk, Kk–En, BT-MT improves BLEU; Models trained with parallel data show higher BLEU, and absence of parallel data or often introduction of low quality data (eg in Gu–En) through BT lowers output quality.
|
| 93 |
+
|
| 94 |
+
Figure 1: Fuzzy Reordering Scores (FRS) between references and generated translations, for En–Fr, Fr–En, En–Gu, Gu–En, En–Kk, Kk-En during training.
|
| 95 |
+
|
| 96 |
+

|
| 97 |
+
|
| 98 |
+

|
| 99 |
+
|
| 100 |
+

|
| 101 |
+
|
| 102 |
+

|
| 103 |
+
|
| 104 |
+

|
| 105 |
+
|
| 106 |
+

|
| 107 |
+
|
| 108 |
+

|
| 109 |
+
|
| 110 |
+

|
| 111 |
+
|
| 112 |
+

|
| 113 |
+
|
| 114 |
+

|
| 115 |
+
|
| 116 |
+

|
| 117 |
+
|
| 118 |
+

|
| 119 |
+
|
| 120 |
+
Figure 1: Fuzzy Reordering Scores (FRS) between references and generated translations, for En–Fr, Fr–En, En–Gu, Gu–En, En–Kk, Kk-En during training.
|
| 121 |
+
|
| 122 |
+
Figure 2: Fuzzy Reordering Scores (FRS) between source sentences and generated translations for En–Fr, Fr–En, En–Gu, Gu–En, En–Kk, Kk–En during training.
|
| 123 |
+
|
| 124 |
+
### FRS
|
| 125 |
+
|
| 126 |
+
In most En–Fr, Fr–En experiments, there is a large fluctuation yet a small and gradual FRS increase between translations and references (Fig. [2](https://arxiv.org/html/2312.12588v1/#S4.F2 "Figure 2 ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution")), and then a small decrease. Higher FRS shows more monotonic alignments. Starting from non-monotonic alignments in the first stage, we get maximum FRS values in the second stage of training - highly aligned translations and references - which slightly decrease in the third stage until model convergence. With parallel data we get the most monotonic alignments, while we have the least identical reorderings between references and translations in BT-only cases, in both high- and low-resource setups. Similar patterns are observed in En–Kk and Kk–En, where we have the least monotonic alignments for few/no parallel data (MT-22k, BT-MT-22k, BT), and the most for experiments with parallel data (MT, BT-MT), with values slightly increasing and then remaining stable throughout training in most cases. BT En–Gu, Gu–En models show high and steady FRS values: between languages with a complicated and non-monotonic alignment, BT produces translations more aligned with the reference.
|
| 127 |
+
|
| 128 |
+
For En–Fr, Fr–En, FRS (Fig. [2](https://arxiv.org/html/2312.12588v1/#S4.F2 "Figure 2 ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution")) values are stable throughout training, and BT, BT-MT experiments’ results imply highly monotonic alignments; with BT, translations are closer to source sentences in terms of word order. FRS is lower in MT only experiments, as source and translation alignments are less monotonic when models are trained with parallel data alone. Results are similar in En–Gu, Gu–En. BT, BT-MT give an almost perfect alignment between source sentences and translations.
|
| 129 |
+
|
| 130 |
+
For En–Kk, Kk–En, we observe that in the majority of experiments, source sentences are highly monotonic to translations, with steady FRS values throughout training.
|
| 131 |
+
|
| 132 |
+
We see that BT yields more stable and higher alignment scores compared to models trained only on parallel data, suggesting it offers a significant advantage for improving translation quality.
|
| 133 |
+
|
| 134 |
+
Figure 3: Translation Edit Rate (TER) between references and generated translations for En–Fr, Fr–En, En–Gu, Gu–En, En–Kk, Kk–En during training.
|
| 135 |
+
|
| 136 |
+

|
| 137 |
+
|
| 138 |
+

|
| 139 |
+
|
| 140 |
+

|
| 141 |
+
|
| 142 |
+

|
| 143 |
+
|
| 144 |
+

|
| 145 |
+
|
| 146 |
+

|
| 147 |
+
|
| 148 |
+

|
| 149 |
+
|
| 150 |
+

|
| 151 |
+
|
| 152 |
+

|
| 153 |
+
|
| 154 |
+

|
| 155 |
+
|
| 156 |
+

|
| 157 |
+
|
| 158 |
+

|
| 159 |
+
|
| 160 |
+
Figure 3: Translation Edit Rate (TER) between references and generated translations for En–Fr, Fr–En, En–Gu, Gu–En, En–Kk, Kk–En during training.
|
| 161 |
+
|
| 162 |
+
Figure 4: Translation Edit Rate (TER) between source sentences and generated translations for En–Fr, Fr–En, En–Gu, Gu–En, En–Kk, Kk–En during training.
|
| 163 |
+
|
| 164 |
+
### TER
|
| 165 |
+
|
| 166 |
+
Observing TER between translations and references (Fig. [4](https://arxiv.org/html/2312.12588v1/#S4.F4 "Figure 4 ‣ FRS ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution")), in En–Fr and Fr–En, low TER for MT, BT-MT means more monotonic alignments, in contrast to higher TER in low-resource and BT-only experiments. TER gradually decreases for all models, as sentences generated at the end of training highly resemble human translations. Results are different for En–Gu and Gu–En; TER is low in BT- only and BT-MT models, but rather high, and increasing, in the MT-only model, with translations in the former case very close to references. BT produces more monotonic to the reference translations for a language diverse in terms of script, morphological complexity and word order from English.
|
| 167 |
+
|
| 168 |
+
Stable or slightly increasing TER values between source sentences and translations (Fig. [4](https://arxiv.org/html/2312.12588v1/#S4.F4 "Figure 4 ‣ FRS ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution")) mean high structural resemblance. For En–Fr and Fr–En, BT and BT-MT show the lowest TER values, hence generated with BT sequences and source sentences have high monotonicity. Similarly, in En–Gu and Gu–En, BT, BT-MT models show lower TER and higher and more monotonic alignment of translations and source sentences.
|
| 169 |
+
|
| 170 |
+
For En–Kk, Kk–En, we see that we have higher monotonicity in higher/no supervision experiments, and lower in low-resource models- we can assume training with few parallel data and for few epochs highly cannot help the model properly align produced translations and references or source sentences. Between translations and source sentences, when the model is sufficiently trained, we surprisingly observe high monotonicity across experimental setups.
|
| 171 |
+
|
| 172 |
+
We deduce that for En–Fr, Fr–En, translations have higher monotonicity to references in MT, BT-MT, lower in BT-only experiments, but higher to source sentences in BT, BT-MT and lower in MT. Training supervision leads to better translation to hypothesis alignment, while BT induces better translation to source sentence alignment.
|
| 173 |
+
|
| 174 |
+
Hence, we see that the effectiveness of different training methods like MT and BT varies by language pair, with BT showing particular promise for languages are structurally diverse from English.
|
| 175 |
+
|
| 176 |
+
### LRP analysis
|
| 177 |
+
|
| 178 |
+
Our observations from average source contribution, entropy of source contributions and entropy of target contributions during training confirm the findings of Voita et al. ([2020](https://arxiv.org/html/2312.12588v1/#bib.bib29), [2021](https://arxiv.org/html/2312.12588v1/#bib.bib30)). Changes in sentence contributions are not necessarily monotonic to the result, can help distinguish different training stages, and identify the balance between source and target sequences’ relevance to the result (Fig. [9](https://arxiv.org/html/2312.12588v1/#S4.F9 "Figure 9 ‣ LRP analysis ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution"), [9](https://arxiv.org/html/2312.12588v1/#S4.F9 "Figure 9 ‣ LRP analysis ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution"), [9](https://arxiv.org/html/2312.12588v1/#S4.F9 "Figure 9 ‣ LRP analysis ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution"), [9](https://arxiv.org/html/2312.12588v1/#S4.F9 "Figure 9 ‣ LRP analysis ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution")).
|
| 179 |
+
|
| 180 |
+
For En–Fr and Fr–En, En–Kk and Kk–En NMT models (Fig. [9](https://arxiv.org/html/2312.12588v1/#S4.F9 "Figure 9 ‣ LRP analysis ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution"), [9](https://arxiv.org/html/2312.12588v1/#S4.F9 "Figure 9 ‣ LRP analysis ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution")) average source sentence contributions drop at the very beginning of training, while contributions are lowest in both directions in MT, and slightly higher in BT, BT-MT experiments; using only parallel (natural) data during training, average source contributions are lower (Voita et al., [2020](https://arxiv.org/html/2312.12588v1/#bib.bib29)) and the model relies more on the target prefix for sequence generation, while BT boosts the influence of source sentence to the result. Average contributions are mostly stable or slightly decrease as training progresses, and the source sentence becomes less important in sequence generation. For models trained with less data, contributions and relevance of the source sentence tokens to the generated sentence is high, due to the lack of substantial supervision.
|
| 181 |
+
|
| 182 |
+
Entropy of source contributions is high for MT-only experiments, contributions are more focused, and the model is more confident in choosing the important source tokens, while in BT-only and BT-MT experiments it requires broader source context for target sequence generation, and entropy of contributions is high, for both evaluation directions. In MT-setups, training converges faster.
|
| 183 |
+
|
| 184 |
+
Studying the entropy of the target contributions, in both En–Fr and Fr–En directions, target entropy is more focused during the first part of training. We then notice either a small (BT, MT-22k, BT-MT-22k) or a larger (MT, BT-MT) increase, which gradually evens out as the model converges. Experiments with a small amount of training data, and/or BT have significantly lower entropy contributions than MT-only, with BT contributing to the model having higher confidence in choosing the target tokens generated. On the contrary, in Fr–En, combined experiments seem to have the highest, hence less focused target contributions;
|
| 185 |
+
|
| 186 |
+
Contributions’ patterns are not similar for En–Gu and Gu–En models (Fig. [9](https://arxiv.org/html/2312.12588v1/#S4.F9 "Figure 9 ‣ LRP analysis ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution"), [9](https://arxiv.org/html/2312.12588v1/#S4.F9 "Figure 9 ‣ LRP analysis ‣ 4 Results & Discussion ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution")). Average source contributions in MT experiments are higher than those with BT, implying that using parallel data in training forces the model to rely on source tokens more heavily. Average source contributions are lowest in BT-only experiment and target sentence reliance for generation is highest.
|
| 187 |
+
|
| 188 |
+
Patterns in entropy of source contributions resemble those in En–Fr, Fr–En experiments. Entropy is low in MT-only; training with parallel data increases model confidence in selecting the important source tokens for target generation, while entropy in BT, BT-MT experiments is similarly high. We notice an increase in entropy of target contributions and high values in MT-only experiments in both directions, which validates our hypothesis that source contributions are more focused in these cases while the entropy in BT experiments is lower. Looking for differences between evaluation directions, En–Gu contributions in MT- and BT-MT are similar to those in the En–Fr low resource experiments, in contrast to training in the other direction.
|
| 189 |
+
|
| 190 |
+
We conclude that back-translation (BT) boosts the influence of source sentences, particularly in low-resource settings, while also highlighting that sentence contributions are not necessarily monotonic and indicate different training stages.
|
| 191 |
+
|
| 192 |
+
Figure 5: En–Fr Average Source Contribution, Entropy of Source Contributions and Entropy of Target Contributions during training.
|
| 193 |
+
|
| 194 |
+
Figure 6: Fr–En Average Source contribution, Entropy of Source Contributions and Entropy of Target Contributions during training.
|
| 195 |
+
|
| 196 |
+
Figure 7: En–Gu Average Source Contribution, Entropy of Source Contributions and Entropy of Target Contributions during training.
|
| 197 |
+
|
| 198 |
+
Figure 8: En–Kk Average Source Contribution, Entropy of Source Contributions and Entropy of Target Contributions during training.
|
| 199 |
+
|
| 200 |
+

|
| 201 |
+
|
| 202 |
+

|
| 203 |
+
|
| 204 |
+

|
| 205 |
+
|
| 206 |
+

|
| 207 |
+
|
| 208 |
+

|
| 209 |
+
|
| 210 |
+

|
| 211 |
+
|
| 212 |
+

|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+

|
| 217 |
+
|
| 218 |
+

|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+

|
| 223 |
+
|
| 224 |
+

|
| 225 |
+
|
| 226 |
+

|
| 227 |
+
|
| 228 |
+

|
| 229 |
+
|
| 230 |
+

|
| 231 |
+
|
| 232 |
+

|
| 233 |
+
|
| 234 |
+

|
| 235 |
+
|
| 236 |
+
Figure 5: En–Fr Average Source Contribution, Entropy of Source Contributions and Entropy of Target Contributions during training.
|
| 237 |
+
|
| 238 |
+
Figure 6: Fr–En Average Source contribution, Entropy of Source Contributions and Entropy of Target Contributions during training.
|
| 239 |
+
|
| 240 |
+
Figure 7: En–Gu Average Source Contribution, Entropy of Source Contributions and Entropy of Target Contributions during training.
|
| 241 |
+
|
| 242 |
+
Figure 8: En–Kk Average Source Contribution, Entropy of Source Contributions and Entropy of Target Contributions during training.
|
| 243 |
+
|
| 244 |
+
Figure 9: Kk–En Average Source Contribution, Entropy of Source Contributions and Entropy of Target Contributions during training.
|
| 245 |
+
|
| 246 |
+
In Tables [3](https://arxiv.org/html/2312.12588v1/#Sx1.T3 "Table 3 ‣ Semantic Similarity ‣ Appendix ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution"), [4](https://arxiv.org/html/2312.12588v1/#Sx1.T4 "Table 4 ‣ Semantic Similarity ‣ Appendix ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution") in the Appendix we show a few example sentences and their translations, at the beginning and end of training of each model. Examples of sentences and their perturbations are given in Table [5](https://arxiv.org/html/2312.12588v1/#Sx1.T5 "Table 5 ‣ Semantic Similarity ‣ Appendix ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution").
|
| 247 |
+
|
| 248 |
+
5 Conclusions
|
| 249 |
+
-------------
|
| 250 |
+
|
| 251 |
+
We conduct an extensive analysis of Supervised and/or Unsupervised NMT models’ behavior for French, Gujarati and Kazakh NMT, to and from English, and examine the output in terms of quality, word order, semantic similarity and reliance on source and reference sentences. Our results highlight the importance of supervision for output quality, yet outline the superiority of UNMT in generating sentences highly aligned to references and in preserving models’ robustness. We hope our work sets the ground for better understanding and improving UNMT and our findings can be utilized to improve real-world UNMT systems.
|
| 252 |
+
|
| 253 |
+
6 Limitations
|
| 254 |
+
-------------
|
| 255 |
+
|
| 256 |
+
It is a computationally hard task to train large Neural Machine Translation models from scratch and the complexity of the training process is high, calling for more efficient training solutions, in terms of memory distribution of the model and parallelization. It is strongly recommended to design a more systematic approach to addressing those factors and expand to more languages, in order to achieve further generalization of the method and overcome all current limitations. Moreover, results for low-resource NMT systems may often be poor, or marginally improving state-of-the-art, calling for improvement in NMT methods to boost performance.
|
| 257 |
+
|
| 258 |
+
7 Ethical Considerations
|
| 259 |
+
------------------------
|
| 260 |
+
|
| 261 |
+
The authors of the paper are aware that when training large language models, several issues ought to be taken into account, related to quality, toxicity and bias related to their training process and output Bender et al. ([2021](https://arxiv.org/html/2312.12588v1/#bib.bib5)); Chowdhery et al. ([2022](https://arxiv.org/html/2312.12588v1/#bib.bib7)); Brown et al. ([2020](https://arxiv.org/html/2312.12588v1/#bib.bib6)).
|
| 262 |
+
|
| 263 |
+
References
|
| 264 |
+
----------
|
| 265 |
+
|
| 266 |
+
* Artetxe et al. (2019) Mikel Artetxe, Gorka Labaka, and Eneko Agirre. 2019. [An effective approach to unsupervised machine translation](https://arxiv.org/pdf/1902.01313.pdf). _arXiv preprint arXiv:1902.01313_.
|
| 267 |
+
* Artetxe et al. (2017) Mikel Artetxe, Gorka Labaka, Eneko Agirre, and Kyunghyun Cho. 2017. [Unsupervised neural machine translation](https://arxiv.org/pdf/1710.11041.pdf). _arXiv preprint arXiv:1710.11041_.
|
| 268 |
+
* Artetxe and Schwenk (2018) Mikel Artetxe and Holger Schwenk. 2018. [Margin-based parallel corpus mining with multilingual sentence embeddings](https://arxiv.org/pdf/1811.01136.pdf). _arXiv preprint arXiv:1811.01136_.
|
| 269 |
+
* Bach et al. (2015) Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. 2015. [On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation](https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0130140). _PloS one_, 10(7):e0130140.
|
| 270 |
+
* Bender et al. (2021) Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. [On the dangers of stochastic parrots: Can language models be too big?](https://doi.org/10.1145/3442188.3445922)In _Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency_, FAccT ’21, page 610–623, New York, NY, USA. Association for Computing Machinery.
|
| 271 |
+
* Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. [Language models are few-shot learners](http://arxiv.org/abs/2005.14165).
|
| 272 |
+
* Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. 2022. [Palm: Scaling language modeling with pathways](http://arxiv.org/abs/2204.02311).
|
| 273 |
+
* Conneau et al. (2017) Alexis Conneau, Guillaume Lample, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. 2017. [Word translation without parallel data](https://arxiv.org/pdf/1710.04087.pdf). _arXiv preprint arXiv:1710.04087_.
|
| 274 |
+
* Garcia et al. (2020a) Xavier Garcia, Pierre Foret, Thibault Sellam, and Ankur P Parikh. 2020a. [A multilingual view of unsupervised machine translation](http://aclanthology.lst.uni-saarland.de/2020.findings-emnlp.283.pdf). _arXiv preprint arXiv:2002.02955_.
|
| 275 |
+
* Garcia et al. (2020b) Xavier Garcia, Aditya Siddhant, Orhan Firat, and Ankur P Parikh. 2020b. [Harnessing multilinguality in unsupervised machine translation for rare languages](https://aclanthology.org/2021.naacl-main.89.pdf). _arXiv preprint arXiv:2009.11201_.
|
| 276 |
+
* He et al. (2022) Zhiwei He, Xing Wang, Rui Wang, Shuming Shi, and Zhaopeng Tu. 2022. [Bridging the data gap between training and inference for unsupervised neural machine translation](https://aclanthology.org/2022.acl-long.456.pdf). _arXiv preprint arXiv:2203.08394_.
|
| 277 |
+
* Keung et al. (2021) Phillip Keung, Julian Salazar, Yichao Lu, and Noah A. Smith. 2021. [Unsupervised Bitext Mining and Translation via Self-Trained Contextual Embeddings](https://doi.org/10.1162/tacl_a_00348). _Transactions of the Association for Computational Linguistics_, 8:828–841.
|
| 278 |
+
* Kim et al. (2020) Yunsu Kim, Miguel Graça, and Hermann Ney. 2020. [When and why is unsupervised neural machine translation useless?](https://arxiv.org/pdf/2004.10581.pdf)_arXiv preprint arXiv:2004.10581_.
|
| 279 |
+
* La Malfa and Kwiatkowska (2022) Emanuele La Malfa and Marta Kwiatkowska. 2022. [The king is naked: on the notion of robustness for natural language processing](https://aaai-2022.virtualchair.net/poster_aaai5939). In _Proceedings of the AAAI Conference on Artificial Intelligence_, volume 36, pages 11047–11057.
|
| 280 |
+
* Lample and Conneau (2019) Guillaume Lample and Alexis Conneau. 2019. [Cross-lingual language model pretraining](https://proceedings.neurips.cc/paper/2019/file/c04c19c2c2474dbf5f7ac4372c5b9af1-Paper.pdf). _arXiv preprint arXiv:1901.07291_.
|
| 281 |
+
* Lample et al. (2017) Guillaume Lample, Alexis Conneau, Ludovic Denoyer, and Marc’Aurelio Ranzato. 2017. [Unsupervised machine translation using monolingual corpora only](https://arxiv.org/pdf/1711.00043.pdf). _arXiv preprint arXiv:1711.00043_.
|
| 282 |
+
* Lample et al. (2018) Guillaume Lample, Myle Ott, Alexis Conneau, Ludovic Denoyer, and Marc’Aurelio Ranzato. 2018. [Phrase-based & neural unsupervised machine translation](https://aclanthology.org/D18-1549.pdf). _arXiv preprint arXiv:1804.07755_.
|
| 283 |
+
* Liu et al. (2022) Yihong Liu, Haris Jabbar, and Hinrich Schütze. 2022. [Flow-adapter architecture for unsupervised machine translation](https://aclanthology.org/2022.acl-long.89.pdf). _arXiv preprint arXiv:2204.12225_.
|
| 284 |
+
* Liu et al. (2020) Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. 2020. [Multilingual denoising pre-training for neural machine translation](https://aclanthology.org/2020.tacl-1.47.pdf). _Transactions of the Association for Computational Linguistics_, 8:726–742.
|
| 285 |
+
* Marchisio et al. (2020) Kelly Marchisio, Kevin Duh, and Philipp Koehn. 2020. [When does unsupervised machine translation work?](https://arxiv.org/pdf/2004.05516.pdf)_arXiv preprint arXiv:2004.05516_.
|
| 286 |
+
* Marchisio et al. (2022) Kelly Marchisio, Markus Freitag, and David Grangier. 2022. [On systematic style differences between unsupervised and supervised mt and an application for high-resource machine translation](https://aclanthology.org/2022.naacl-main.161.pdf). In _Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies_, pages 2214–2225.
|
| 287 |
+
* Nakagawa (2015) Tetsuji Nakagawa. 2015. [Efficient top-down btg parsing for machine translation preordering](https://aclanthology.org/P15-1021.pdf). In _Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)_, pages 208–218.
|
| 288 |
+
* Niu et al. (2020) Xing Niu, Prashant Mathur, Georgiana Dinu, and Yaser Al-Onaizan. 2020. [Evaluating robustness to input perturbations for neural machine translation](https://aclanthology.org/2020.acl-main.755.pdf). _arXiv preprint arXiv:2005.00580_.
|
| 289 |
+
* Sennrich et al. (2015) Rico Sennrich, Barry Haddow, and Alexandra Birch. 2015. [Improving neural machine translation models with monolingual data](https://aclanthology.org/P16-1009.pdf). _arXiv preprint arXiv:1511.06709_.
|
| 290 |
+
* Snover et al. (2006) Matthew Snover, Bonnie Dorr, Richard Schwartz, Linnea Micciulla, and John Makhoul. 2006. [A study of translation edit rate with targeted human annotation](https://aclanthology.org/2006.amta-papers.25.pdf). In _Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers_, pages 223–231.
|
| 291 |
+
* Song et al. (2019) Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. 2019. [Mass: Masked sequence to sequence pre-training for language generation](http://proceedings.mlr.press/v97/song19d/song19d.pdf). _arXiv preprint arXiv:1905.02450_.
|
| 292 |
+
* Su et al. (2019) Yuanhang Su, Kai Fan, Nguyen Bach, C-C Jay Kuo, and Fei Huang. 2019. [Unsupervised multi-modal neural machine translation](https://openaccess.thecvf.com/content_CVPR_2019/papers/Su_Unsupervised_Multi-Modal_Neural_Machine_Translation_CVPR_2019_paper.pdf). In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_, pages 10482–10491.
|
| 293 |
+
* Talbot et al. (2011) David Talbot, Hideto Kazawa, and Hiroshi Ichikawa. 2011. [A lightweight evaluation framework for machine translation reordering](https://aclanthology.org/W11-2102.pdf).
|
| 294 |
+
* Voita et al. (2020) Elena Voita, Rico Sennrich, and Ivan Titov. 2020. [Analyzing the source and target contributions to predictions in neural machine translation](https://aclanthology.org/2021.acl-long.91.pdf). _arXiv preprint arXiv:2010.10907_.
|
| 295 |
+
* Voita et al. (2021) Elena Voita, Rico Sennrich, and Ivan Titov. 2021. [Language modeling, lexical translation, reordering: The training process of nmt through the lens of classical smt](https://aclanthology.org/2021.emnlp-main.667.pdf). _arXiv preprint arXiv:2109.01396_.
|
| 296 |
+
* Wang and Zhao (2021) Rui Wang and Hai Zhao. 2021. [Advances and challenges in unsupervised neural machine translation](https://aclanthology.org/2021.eacl-tutorials.5/). In _Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Tutorial Abstracts_, pages 17–21.
|
| 297 |
+
* Wang et al. (2021) Xuezhi Wang, Haohan Wang, and Diyi Yang. 2021. [Measure and improve robustness in nlp models: A survey](https://aclanthology.org/2022.naacl-main.339.pdf). _arXiv preprint arXiv:2112.08313_.
|
| 298 |
+
* Wu and Ong (2021) Zhengxuan Wu and Desmond C Ong. 2021. [On explaining your explanations of bert: An empirical study with sequence classification](https://arxiv.org/pdf/2101.00196.pdf). _arXiv preprint arXiv:2101.00196_.
|
| 299 |
+
* Yu et al. (2022) Yu Yu, Abdul Rafae Khan, and Jia Xu. 2022. [Measuring robustness for nlp](https://aclanthology.org/2022.coling-1.343.pdf). In _Proceedings of the 29th International Conference on Computational Linguistics_, pages 3908–3916.
|
| 300 |
+
|
| 301 |
+
Appendix
|
| 302 |
+
--------
|
| 303 |
+
|
| 304 |
+
### Robustness
|
| 305 |
+
|
| 306 |
+
En–Fr and Fr–En NMT models are highly robust in all MT, BT-MT setups (Table [2](https://arxiv.org/html/2312.12588v1/#Sx1.T2 "Table 2 ‣ Robustness ‣ Appendix ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution")), especially when test sets are misspelled. On the contrary, En–Gu and Gu–En models are highly robust on BT, BT-MT experiments, on test sets perturbed by case-changing; for highly morphological complex languages, BT may help boost model robustness.
|
| 307 |
+
|
| 308 |
+
A similar behavior is observed for En–Kk, Kk–En. Models are highly robust on case-changing in all unsupervised, supervised and semi-supervised scenarios, and as the amount parallel sentences increases, we see an expected increased robustness to sentences’ misspelling; the models become more robust to a high percentage of sentence perturbations with higher training supervision. In En–Fr and Fr–En NMT models, consistency patterns are similar to those found for Robustness: models are highly consistent in MT, BT-MT experiments, primarily when test sentences are misspelled, with their consistency increasing by the amount of parallel train data. BT-only training does not seem to help. Model consistency patterns for En–Gu, Gu–En follow those of Robustness, with BT outperforming other methods.
|
| 309 |
+
|
| 310 |
+
Table 2: BLEU scores, Robustness (R) and Consistency (C) values for Unsupervised (BT), Supervised (MT), and Unsupervised + Supervised (BT+AE+MT) NMT experiments, for the converged model for En–Fr, Fr–En, En–Gu, Gu–En and En–Kk, Kk–En. Test and validation sets are from WMT19 for Gujarati and Kazakh, and newstest 2013-14 for French, and are perturbed following the method suggested in (Niu et al., [2020](https://arxiv.org/html/2312.12588v1/#bib.bib23)) for misspelling and case-changing.
|
| 311 |
+
|
| 312 |
+
### Semantic Similarity
|
| 313 |
+
|
| 314 |
+
MT-only and BT-MT experiments show high RMSS values in En–Fr, Fr–En between translations and references (Fig. [11](https://arxiv.org/html/2312.12588v1/#Sx1.F11 "Figure 11 ‣ Semantic Similarity ‣ Appendix ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution")), which have a higher semantic similarity than in BT-only or in reduced dataset experiments, On the contrary, in En–Gu and Gu–En, translations from MT models are less similar to references, and most similar in BT-only experiments, for which RMSS is highest. Source sentences show high semantic similarity to translations in MT-only experiments, followed by reduced-data model training results, outperforming BT-only or BT-MT models, in En–Fr and Fr–En; in the first direction, RMSS is very similar across models, while in the latter, behavior of the model in different setups is significantly more distinct. For En–Gu and Gu–En, BT-only experiments show highest semantic similarity between source sentences and translations (Fig. [11](https://arxiv.org/html/2312.12588v1/#Sx1.F11 "Figure 11 ‣ Semantic Similarity ‣ Appendix ‣ An Empirical study of Unsupervised Neural Machine Translation: analyzing NMT output, model’s behavior and sentences’ contribution")).
|
| 315 |
+
|
| 316 |
+
Figure 10: RMSS between references and generated translations for En–Fr, Fr–En, En–Gu, Gu–En, En–Kk, Kk–En during training.
|
| 317 |
+
|
| 318 |
+

|
| 319 |
+
|
| 320 |
+

|
| 321 |
+
|
| 322 |
+

|
| 323 |
+
|
| 324 |
+

|
| 325 |
+
|
| 326 |
+

|
| 327 |
+
|
| 328 |
+

|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+

|
| 333 |
+
|
| 334 |
+

|
| 335 |
+
|
| 336 |
+

|
| 337 |
+
|
| 338 |
+

|
| 339 |
+
|
| 340 |
+

|
| 341 |
+
|
| 342 |
+
Figure 10: RMSS between references and generated translations for En–Fr, Fr–En, En–Gu, Gu–En, En–Kk, Kk–En during training.
|
| 343 |
+
|
| 344 |
+
Figure 11: RMSS between source sentences and generated translations for En–Fr, Fr–En, En–Gu, Gu–En, En–Kk, Kk–En during training.
|
| 345 |
+
|
| 346 |
+
Table 3: Two examples of a French sentence, their English ground-truth translation, and their English translations with each model’s first and last checkpoint (en - FC, en - LC respectively).
|
| 347 |
+
|
| 348 |
+
Original sentence gu![Image 55: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_bt_hyp0.png)en The militants are constantly intimidating the politician not to participate in the election.BT en - FC![Image 56: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_bt_hyp0.png)en - LC![Image 57: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_bt_hyp_last.png)MT en - FC![Image 58: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_mt_hyp0.png)en - LC![Image 59: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_mt_hyp_last.png)BT-MT en - FC![Image 60: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_bt_mt_hyp0.png)en - LC![Image 61: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_bt_mt_hyp_last.png)Original sentence gu![Image 62: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_ref_2.png)en In which seven Nepalese guides were found dead and many were injured.BT en - FC![Image 63: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_bt_hyp0_2.png)en - LC![Image 64: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_bt_hyp_last_2.png)MT en - FC![Image 65: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_mt_hyp0_2.png)en - LC![Image 66: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_mt_hyp_last_2.png)BT-MT en - FC![Image 67: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_bt_mt_hyp0_2.png)en - LC![Image 68: [Uncaptioned image]](https://arxiv.org/html/2312.12588v1/extracted/5306087/gu_sentences/gu_bt_mt_hyp_last_2.png)
|
| 349 |
+
|
| 350 |
+
Table 4: Two examples of a Gujarati sentence, their English ground-truth translation, and their English translations with each model’s first and last checkpoint (en - FC, en - LC respectively)
|
| 351 |
+
|
| 352 |
+
Table 5: Examples of sentences in our test dataset, and their perturbed versions after misspelling and case-changing
|