

Add 1 files
Browse files- 2509/2509.24159.md +682 -0
2509/2509.24159.md
ADDED
|
@@ -0,0 +1,682 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
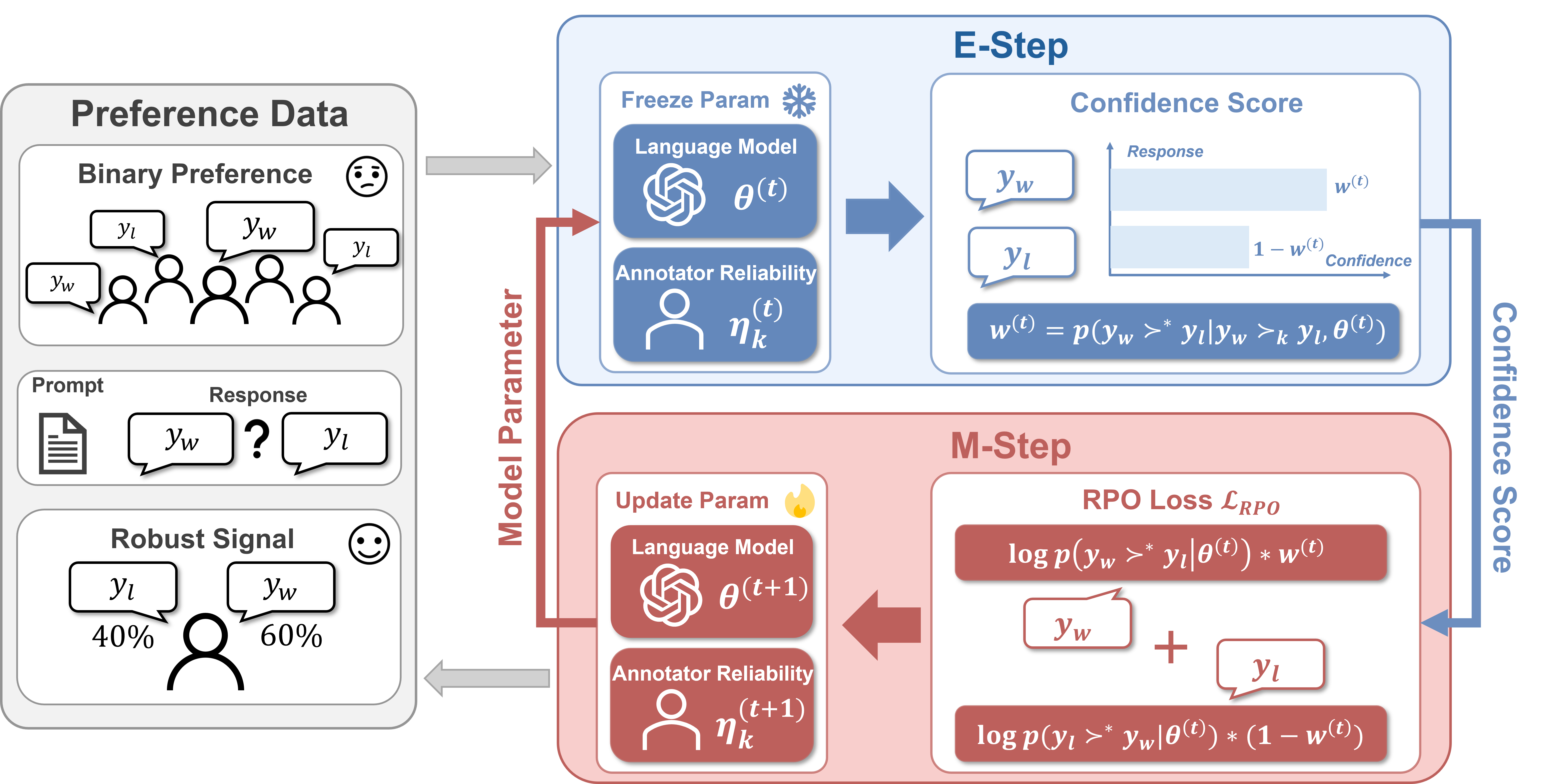
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
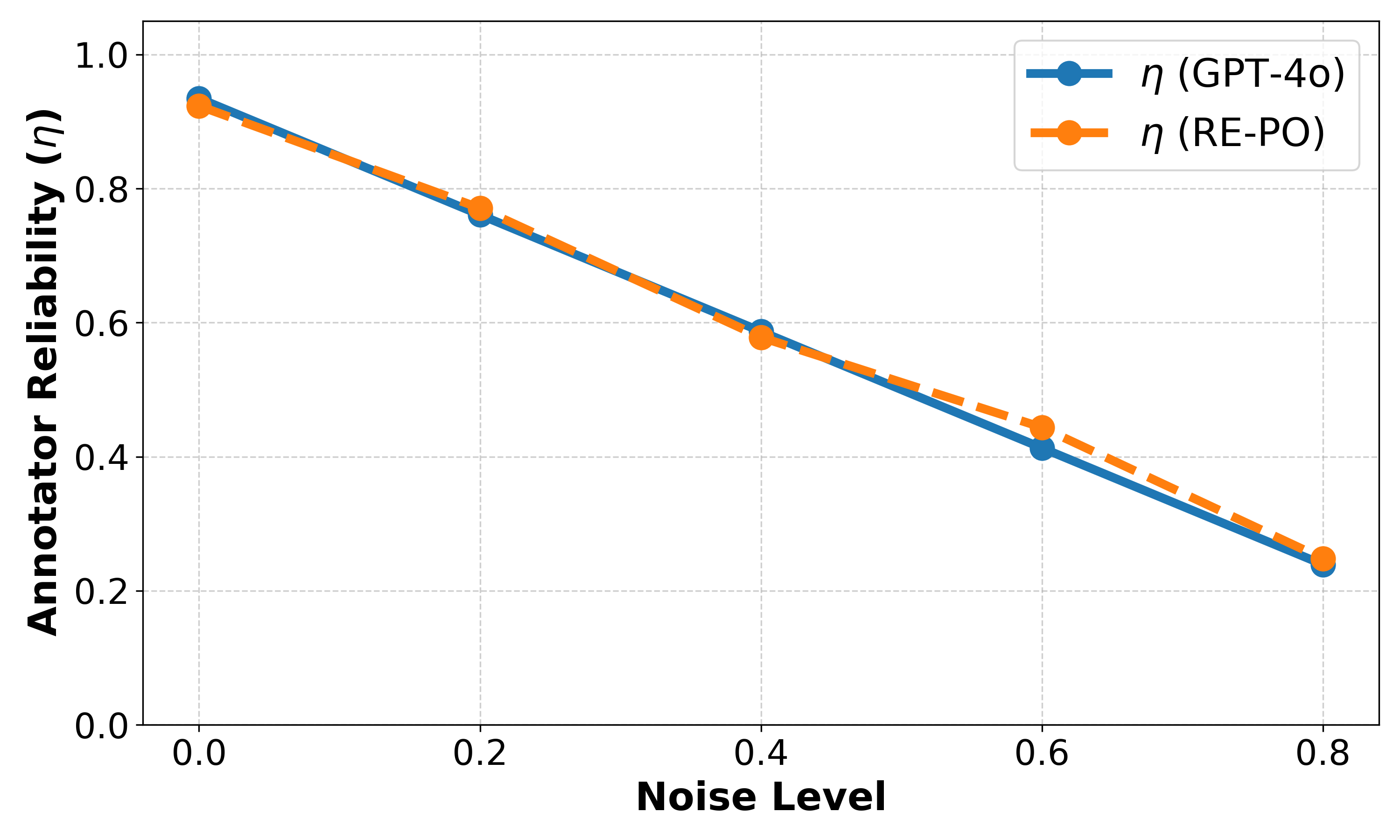
|
|
|
|
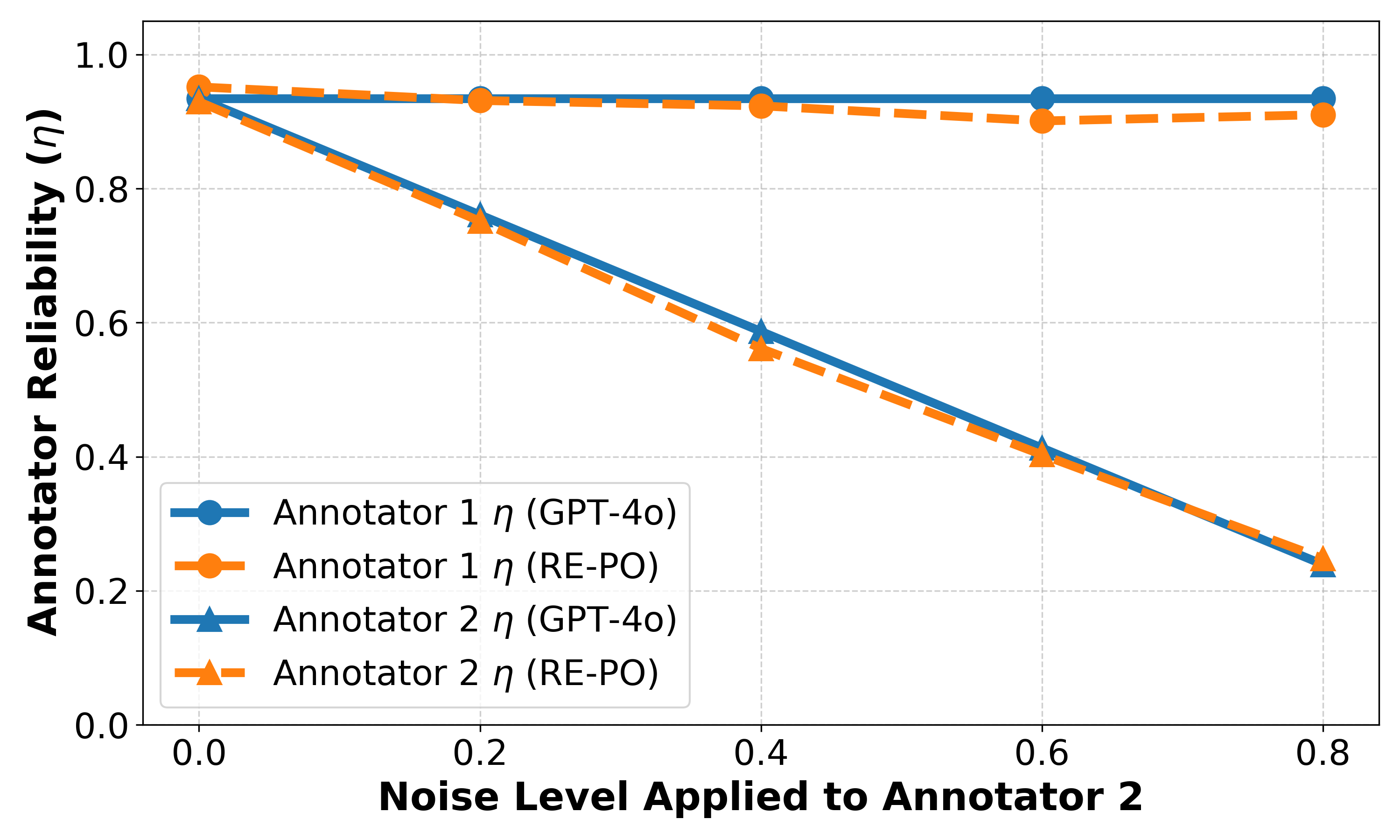
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2509.24159
|
| 4 |
+
|
| 5 |
+
Published Time: Tue, 09 Dec 2025 01:05:41 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
Xiaoyang Cao 1 , Zelai Xu 2 1 1 footnotemark: 1 , Mo Guang 3, Kaiwen Long 3,
|
| 9 |
+
|
| 10 |
+
Michiel A. Bakker 1, Yu Wang 2 , Chao Yu 2,4 2 2 footnotemark: 2
|
| 11 |
+
|
| 12 |
+
1 Massachusetts Institute of Technology 2 Tsinghua University
|
| 13 |
+
|
| 14 |
+
3 Li Auto Inc. 4 Zhongguancun Academy Equal contribution. Email: xycao@mit.edu.Corresponding authors. Emails: yu-wang@tsinghua.edu.cn, zoeyuchao@gmail.com.
|
| 15 |
+
|
| 16 |
+
###### Abstract
|
| 17 |
+
|
| 18 |
+
Standard human preference-based alignment methods, such as Reinforcement Learning from Human Feedback (RLHF), are a cornerstone technology for aligning Large Language Models (LLMs) with human values. However, these methods are all underpinned by a \rebuttal strong assumption that the collected preference data is clean and that all observed labels are equally reliable. In reality, \rebuttal large-scale preference datasets contain substantial label noise due to annotator errors, inconsistent instructions, varying expertise, and even adversarial or low-effort feedback. This creates a discrepancy between the recorded data and the ground-truth preferences, which can misguide the model and degrade its performance. To address this challenge, we introduce R obust E nhanced P olicy O ptimization (RE-PO). RE-PO employs an Expectation-Maximization algorithm to infer the posterior probability of each label’s correctness, which is used to adaptively re-weigh each data point in the training loss to mitigate noise. We further generalize this approach by establishing a theoretical link between arbitrary preference losses and their corresponding probabilistic models. This generalization enables the systematic transformation of existing alignment algorithms into their robust counterparts, elevating RE-PO from a specific algorithm to a general framework for robust preference alignment. Theoretically, we prove that under the condition of a perfectly calibrated model, RE-PO is guaranteed to converge to the true noise level of the dataset. Our experiments demonstrate RE-PO’s effectiveness as a general framework, consistently enhancing four state-of-the-art alignment algorithms (DPO, IPO, SimPO, and CPO). When applied to Mistral and Llama 3 models, the RE-PO-enhanced methods improve AlpacaEval 2 win rates by up to 7.0% over their respective baselines.
|
| 19 |
+
|
| 20 |
+
1 Introduction
|
| 21 |
+
--------------
|
| 22 |
+
|
| 23 |
+
Aligning Large Language Models (LLMs) with human values is a critical prerequisite for developing safe and reliable AI systems. Reinforcement Learning from Human Feedback (RLHF) has emerged as the dominant paradigm for this task (christiano2017deep; ziegler2019fine; ouyang2022training). To mitigate the complexity and instability of the traditional RLHF pipeline, simpler and more direct methods such as Direct Preference Optimization (DPO) (rafailov2023direct) have been developed, which reframe alignment as a classification-like problem.
|
| 24 |
+
|
| 25 |
+
\rebuttal
|
| 26 |
+
|
| 27 |
+
However, these alignment methods implicitly assume that preference datasets provide a clean and reliable approximation of a single ground-truth preference signal. In practice, this assumption is often violated. Large-scale preference datasets are typically aggregated from multiple crowdworkers or teacher models, and are therefore subject to substantial label noise arising from inattention, misunderstanding, or systematic bias (frenay2013classification; gao2024impact). Empirical analyses suggest that a significant fraction (often between 20% and 40%) of preference pairs in modern alignment datasets may be corrupted or inconsistent (gao2024impact). Classic work on learning with noisy labels shows that standard loss functions can overfit such corrupted supervision and suffer severe degradation in generalization performance (natarajan2013learning; frenay2013classification). In the context of LLM alignment, gao2024impact further demonstrate that even a 10 percentage point increase in the label-noise rate can lead to drops of tens of percentage points in downstream win rates, highlighting the practical importance of robustness to noisy preference data.
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
Figure 1: Overview of the Robust Enhanced Policy Optimization (RE-PO) framework. Starting from noisy pairwise feedback, RE-PO uses an Expectation–Maximization (EM) procedure to jointly refine label confidences and the policy. In each iteration, the E-step estimates a confidence score for every observed preference by inferring the posterior probability that the label is correct under the current model and annotator reliabilities. The M-step then uses these scores as adaptive weights to update both the LLM policy and the annotator reliability parameters, progressively down-weighting likely corrupted labels and emphasizing reliable supervision.
|
| 32 |
+
|
| 33 |
+
To address this challenge, we propose Robust Enhanced Policy Optimization (RE-PO). \rebuttal Instead of assuming that every observed label is a fixed ground truth, our approach aims to learn a preference model that remains accurate and stable even when the training data contains substantial noise. The core innovation of RE-PO is its departure from the hard labels used in traditional RLHF. \rebuttal Rather than committing to binary supervision, we treat the correctness of each observed preference as a latent variable and compute soft confidence weights over labels, so that highly reliable feedback contributes more strongly while suspicious pairs are down-weighted. Building on Expectation-Maximization-style approaches to learning from unreliable annotators in crowdsourcing (dawid1979maximum; chen2013pairwise), RE-PO employs an Expectation-Maximization (EM) framework that simultaneously models annotator reliability while optimizing the LLM. In the E-step, it infers the posterior probability that each annotated label is correct, effectively estimating annotator reliability. In the M-step, it uses these probabilities as adaptive weights to update the LLM, thereby learning from a dynamically re-weighted preference signal.
|
| 34 |
+
|
| 35 |
+
Our experiments validate RE-PO as an effective general framework. We show that applying RE-PO consistently enhances four state-of-the-art alignment algorithms (DPO, IPO, SimPO, and CPO) across two different base models (Mistral-7B and Llama-3-8B) on the AlpacaEval 2 benchmark (Table[2](https://arxiv.org/html/2509.24159v3#S5.T2 "Table 2 ‣ Evaluation benchmarks. ‣ 5.1 Experimental setup ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")). In our main results, RE-PO-enhanced methods achieve substantial win-rate gains on AlpacaEval 2, with improvements of up to 7.0 percentage points in LC/WR over their standard counterparts.Furthermore, we theoretically prove that RE-PO can recover the true reliability of annotators (Theorem[4.1](https://arxiv.org/html/2509.24159v3#S4.Thmtheorem1 "Theorem 4.1 (Identification and convergence of RE-PO). ‣ 4 Theoretical analysis of RE-PO ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")) and empirically verify this guarantee in controlled experiments (Section[5.5](https://arxiv.org/html/2509.24159v3#S5.SS5 "5.5 Empirical verification of Theorem 4.1 ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")).
|
| 36 |
+
|
| 37 |
+
In summary, our contributions are as follows:
|
| 38 |
+
|
| 39 |
+
* •We propose Robust Enhanced Policy Optimization (RE-PO), a principled EM-based algorithm that treats the correctness of each preference label as a latent variable, jointly infers per-label (and per-annotator) reliabilities, and uses them as adaptive weights in the training loss, yielding LLM alignment that is substantially more robust to noisy and inconsistent feedback.
|
| 40 |
+
* •We theoretically establish a generalized RE-PO framework by using the Gibbs distribution to connect arbitrary preference loss functions to underlying probabilistic models. This lifts RE-PO from a single algorithm to a general framework, enabling standard methods such as DPO, IPO, SimPO, and CPO to be systematically transformed into their robust counterparts with minimal modification.
|
| 41 |
+
* •We conduct extensive experiments demonstrating the practical effectiveness and versatility of RE-PO. Across four alignment algorithms, two base models (Mistral-7B and Llama-3-8B), and AlpacaEval 2, RE-PO delivers consistent win-rate improvements of up to 7.0 percentage points, and further shows clear gains on a real multi-annotator dataset (MultiPref), along with qualitative and visual analyses of how it down-weights low-confidence, noisy labels.
|
| 42 |
+
|
| 43 |
+
2 Related work
|
| 44 |
+
--------------
|
| 45 |
+
|
| 46 |
+
#### LLM alignment with hard preference labels.
|
| 47 |
+
|
| 48 |
+
The standard paradigm for aligning Large Language models (LLMs) with human values is Reinforcement Learning from Human Feedback (RLHF), which involves training a reward model and then fine-tuning the policy against it (christiano2017deep; ouyang2022training). To mitigate the complexity and instability of this multi-stage process, a family of simpler, direct alignment algorithms has emerged (rafailov2023direct; azar2023general; meng2024simpo; hong2024orpo). These methods bypass the explicit reward modeling stage by optimizing a direct classification-style loss on the preference data. However, a critical limitation shared by these methods is their reliance on hard preference labels. This approach models human feedback as a definitive, binary choice, treating every label with equal and absolute confidence. Consequently, it is highly vulnerable to the significant label noise present in real-world datasets, as standard loss functions can lead models to overfit to corrupted labels (natarajan2013learning; zhang2018generalized; frenay2013classification). A simple annotation error, such as an accidental misclick, is given the same weight as a deliberate, high-quality judgment. This inability to distinguish between reliable feedback and noise means that the model’s performance degrades significantly as the error rate increases (frenay2013classification; gao2024impact). \rebuttal In contrast, soft-label approaches that represent preferences probabilistically can better accommodate uncertainty in feedback by assigning confidence scores or weights to individual labels (muller2019does; song2024preference). By allowing the learning algorithm to rely on high-quality signals while down-weighting noise, such approaches provide a natural path toward robust preference alignment. This is precisely the perspective adopted by our RE-PO framework, which replaces hard labels with EM-estimated soft confidences.
|
| 49 |
+
|
| 50 |
+
#### Learning from noisy feedback.
|
| 51 |
+
|
| 52 |
+
The vulnerability to label noise situates preference alignment within the classic machine learning problem of Learning with Noisy Labels (LNL) (natarajan2013learning; frenay2013classification). Foundational work in this area, such as the Dawid–Skene model (dawid1979maximum), uses an EM algorithm to simultaneously infer true latent labels while estimating annotator reliability. This principle was later extended to pairwise comparisons in the Crowd-BT model (chen2013pairwise), which jointly estimates item scores and annotator-specific reliability parameters in crowdsourced ranking tasks. In modern LLM alignment, several methods have been proposed to improve robustness to noisy preference data. These can be broadly divided into loss-centric approaches and data-centric filtering strategies. In the first category, ROPO (liang2024ropo) proposes an iterative robust preference optimization procedure that jointly applies a noise-tolerant loss and down-weights (or discards) highly uncertain samples, without relying on external teacher models. rDPO (chowdhury2024provably) constructs an unbiased estimator of the true loss but requires the global noise rate to be known a priori. Hölder-DPO (fujisawa2025scalable) introduces a loss with a “redescending” property, which inherently nullifies the influence of extreme outliers without needing a known noise rate. In the second category, Selective DPO (gao2025principled) proposes filtering examples based on their difficulty relative to the model’s capacity—a concept orthogonal to label correctness—using validation loss as a proxy.
|
| 53 |
+
|
| 54 |
+
\rebuttal
|
| 55 |
+
|
| 56 |
+
Our proposed RE-PO framework is complementary to these methods. Rather than only modifying the loss shape or discarding high-loss points, RE-PO explicitly models the data-generating process by treating annotator reliability and label correctness as latent variables to be inferred. This allows RE-PO to assign fine-grained, example-specific weights based on a posterior confidence, providing a principled way to separate signal from noise.
|
| 57 |
+
|
| 58 |
+
3 Methodology
|
| 59 |
+
-------------
|
| 60 |
+
|
| 61 |
+
This section details our proposed RE-PO algorithm. We first review the standard DPO framework in Section[3.1](https://arxiv.org/html/2509.24159v3#S3.SS1 "3.1 Preliminaries: Direct Preference Optimization ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"). In Section[3.2](https://arxiv.org/html/2509.24159v3#S3.SS2 "3.2 RE-PO Framework: Core Assumptions ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), we introduce a latent-variable model that explicitly distinguishes clean and corrupted preference labels. Section[3.3](https://arxiv.org/html/2509.24159v3#S3.SS3 "3.3 The RE-PO Algorithm via Expectation-Maximization ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") then derives the corresponding EM-based update rules for RE-PO. Section[3.4](https://arxiv.org/html/2509.24159v3#S3.SS4 "3.4 Practical implementation with mini-batch training ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") presents a practical mini-batch implementation for RE-PO.
|
| 62 |
+
|
| 63 |
+
### 3.1 Preliminaries: Direct Preference Optimization
|
| 64 |
+
|
| 65 |
+
The goal of preference alignment is to fine-tune a language model policy, π θ\pi_{\theta}, using a dataset of preferences 𝒟={(x,y w,y l)i}i=1 N\mathcal{D}=\{(x,y_{w},y_{l})_{i}\}_{i=1}^{N}, where response y w y_{w} is preferred over y l y_{l} for a given prompt x x. Direct Preference Optimization (DPO) (rafailov2023direct) offers a simple and effective method for this, bypassing the complex multi-stage pipeline of traditional RLHF (christiano2017deep; ouyang2022training). DPO directly optimizes the policy by minimizing a simple classification loss:
|
| 66 |
+
|
| 67 |
+
ℒ DPO(π θ,π ref)=−𝔼(x,y w,y l)∼𝒟[logσ(βlogπ θ(y w|x)π ref(y w|x)−βlogπ θ(y l|x)π ref(y l|x))],\mathcal{L}_{\text{DPO}}(\pi_{\theta},\pi_{\text{ref}})=-\mathbb{E}_{(x,y_{w},y_{l})\sim\mathcal{D}}\left[\log\sigma\left(\beta\log\frac{\pi_{\theta}(y_{w}|x)}{\pi_{\text{ref}}(y_{w}|x)}-\beta\log\frac{\pi_{\theta}(y_{l}|x)}{\pi_{\text{ref}}(y_{l}|x)}\right)\right],(1)
|
| 68 |
+
|
| 69 |
+
where σ(⋅)\sigma(\cdot) is the sigmoid function, π ref\pi_{\text{ref}} is a fixed reference policy and β\beta is a scaling hyperparameter.
|
| 70 |
+
|
| 71 |
+
### 3.2 RE-PO Framework: Core Assumptions
|
| 72 |
+
|
| 73 |
+
A critical limitation of DPO is its implicit assumption that all observed preferences in 𝒟\mathcal{D} are correct. In practice, this data is often noisy. To address this, we propose Robust Enhanced Policy Optimization (RE-PO), which is built upon two core assumptions that reframe the problem.
|
| 74 |
+
|
| 75 |
+
#### \rebuttal Assumption 1: A Latent noise-free preference.
|
| 76 |
+
|
| 77 |
+
\rebuttal
|
| 78 |
+
|
| 79 |
+
We assume that for each training example (x i,y w,i,y l,i)(x_{i},y_{w,i},y_{l,i}) there exists an underlying noise-free preference, denoted y w,i≻∗y l,i y_{w,i}\succ^{\ast}y_{l,i}, which represents the label we would obtain in the absence of annotation errors. The observed preference y w,i≻k i y l,i y_{w,i}\succ_{k_{i}}y_{l,i} (provided by annotator k i k_{i}) is treated as a potentially corrupted observation of this ground truth. To model this, we introduce a binary latent variable z i∈{0,1}z_{i}\in\{0,1\} for each data point, where z i=1 z_{i}=1 if the observed label matches the latent noise-free preference and z i=0 z_{i}=0 otherwise. The reliability of annotator k k is parameterized by η k≜p(z i=1∣k i=k)\eta_{k}\triangleq p(z_{i}=1\mid k_{i}=k). Here k i∈{1,…,K}k_{i}\in\{1,\dots,K\} denotes the index of the annotator who provided the i i-th label, and K K is the total number of annotators in the dataset.
|
| 80 |
+
|
| 81 |
+
#### Assumption 2: A general probabilistic model for preferences.
|
| 82 |
+
|
| 83 |
+
Building on this latent variable model, we must also define the probability of the \rebuttal noise-free preference itself, p(y w≻∗y l|x,θ)p(y_{w}\succ^{\ast}y_{l}|x,\theta). To accommodate various preference losses beyond DPO (e.g., IPO (azar2023general)), our framework is designed to work with any preference loss function, ℒ pref\mathcal{L}_{\text{pref}}. Table [1](https://arxiv.org/html/2509.24159v3#S3.T1 "Table 1 ‣ Assumption 2: A general probabilistic model for preferences. ‣ 3.2 RE-PO Framework: Core Assumptions ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") provides several examples of such loss functions used in prominent alignment algorithms.
|
| 84 |
+
|
| 85 |
+
Table 1: Formulations of the preference loss (ℒ pref\mathcal{L}_{\text{pref}}) for prominent alignment algorithms.
|
| 86 |
+
|
| 87 |
+
Method Preference Loss ℒ pref(x,y w≻y l)\mathcal{L}_{\text{pref}}(x,y_{w}\succ y_{l})
|
| 88 |
+
DPO (rafailov2023direct)−logσ(βlogπ θ(y w|x)π ref(y w|x)−βlogπ θ(y l|x)π ref(y l|x))-\log\sigma\left(\beta\log\frac{\pi_{\theta}(y_{w}|x)}{\pi_{\text{ref}}(y_{w}|x)}-\beta\log\frac{\pi_{\theta}(y_{l}|x)}{\pi_{\text{ref}}(y_{l}|x)}\right)
|
| 89 |
+
IPO (azar2023general)(logπ θ(y w|x)π ref(y w|x)−logπ θ(y l|x)π ref(y l|x)−1 2β)2\left(\log\frac{\pi_{\theta}(y_{w}|x)}{\pi_{\text{ref}}(y_{w}|x)}-\log\frac{\pi_{\theta}(y_{l}|x)}{\pi_{\text{ref}}(y_{l}|x)}-\frac{1}{2\beta}\right)^{2}
|
| 90 |
+
SimPO (meng2024simpo)−logσ(β|y w|logπ θ(y w|x)−β|y l|logπ θ(y l|x)−γ)-\log\sigma(\frac{\beta}{|y_{w}|}\log\pi_{\theta}(y_{w}|x)-\frac{\beta}{|y_{l}|}\log\pi_{\theta}(y_{l}|x)-\gamma)
|
| 91 |
+
CPO (xu2024contrastive)−logσ(βlogπ θ(y w|x)−βlogπ θ(y l|x))−logπ θ(y w|x)-\log\sigma(\beta\log\pi_{\theta}(y_{w}|x)-\beta\log\pi_{\theta}(y_{l}|x))-\log\pi_{\theta}(y_{w}|x)
|
| 92 |
+
|
| 93 |
+
To connect these diverse loss functions to a unified probabilistic interpretation, we draw inspiration from the Boltzmann distribution (luce1959individual). We assume that for any preference loss function ℒ pref\mathcal{L}_{\text{pref}}, the probability of a preference is proportional to the exponentiated negative loss exp(−ℒ pref(x,y w≻y l))\exp(-\mathcal{L}_{\text{pref}}(x,y_{w}\succ y_{l})). This yields a general definition for the \rebuttal noise-free preference probability:
|
| 94 |
+
|
| 95 |
+
p(y w≻∗y l|x,θ)=σ(ℒ pref(x,y l≻y w;θ)−ℒ pref(x,y w≻y l;θ)),p(y_{w}\succ^{\ast}y_{l}|x,\theta)=\sigma\left(\mathcal{L}_{\text{pref}}(x,y_{l}\succ y_{w};\theta)-\mathcal{L}_{\text{pref}}(x,y_{w}\succ y_{l};\theta)\right),(2)
|
| 96 |
+
|
| 97 |
+
where σ(⋅)\sigma(\cdot) is the sigmoid function. This formulation converts any preference loss into a well-defined probability distribution. For instance, with the standard DPO loss, this equation recovers the Bradley-Terry model (bradley1952rank) (see [Appendices A](https://arxiv.org/html/2509.24159v3#A1 "Appendix A Derivation of general probabilistic model ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") and[B](https://arxiv.org/html/2509.24159v3#A2 "Appendix B Consistency with Bradley-Terry model for DPO ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") for derivations).
|
| 98 |
+
|
| 99 |
+
### 3.3 The RE-PO Algorithm via Expectation-Maximization
|
| 100 |
+
|
| 101 |
+
Based on these core assumptions, we aim to find the parameters θ\theta and 𝜼\boldsymbol{\eta} that maximize the marginal log-likelihood of the observed data. The probability of a single observed preference is obtained by marginalizing over the latent variable z i z_{i}:
|
| 102 |
+
|
| 103 |
+
p(y w,i≻k i y l,i|x i,θ,𝜼)=p(y w,i≻∗y l,i|x i,θ)η k i+p(y l,i≻∗y w,i|x i,θ)(1−η k i).p(y_{w,i}\succ_{k_{i}}y_{l,i}|x_{i},\theta,\boldsymbol{\eta})=p(y_{w,i}\succ^{\ast}y_{l,i}|x_{i},\theta)\eta_{k_{i}}+p(y_{l,i}\succ^{\ast}y_{w,i}|x_{i},\theta)(1-\eta_{k_{i}}).(3)
|
| 104 |
+
|
| 105 |
+
Directly maximizing ∑i logp(y w,i≻k i y l,i)\sum_{i}\log p(y_{w,i}\succ_{k_{i}}y_{l,i}) is intractable due to the sum inside the logarithm. We therefore employ the EM algorithm (see details in [Appendix C](https://arxiv.org/html/2509.24159v3#A3 "Appendix C Derivation of the RE-PO EM algorithm ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")), which iterates between two steps. In this iterative process, the superscript (t)(t) will denote the values of parameters at iteration t t.
|
| 106 |
+
|
| 107 |
+
#### E-Step: Inferring label correctness.
|
| 108 |
+
|
| 109 |
+
In the E-step, given the current parameters θ(t)\theta^{(t)} and 𝜼(t)\boldsymbol{\eta}^{(t)}, we compute the posterior probability w i w_{i} that the i i-th observed label is correct. This value w i w_{i} acts as a ”soft label” or the model’s confidence in the data point.
|
| 110 |
+
|
| 111 |
+
w i(t)=p(y w,i≻∗y l,i|x i,θ(t))η k i(t)p(y w,i≻∗y l,i|x i,θ(t))η k i(t)+p(y l,i≻∗y w,i|x i,θ(t))(1−η k i(t)).w_{i}^{(t)}=\frac{p(y_{w,i}\succ^{\ast}y_{l,i}|x_{i},\theta^{(t)})\eta_{k_{i}}^{(t)}}{p(y_{w,i}\succ^{\ast}y_{l,i}|x_{i},\theta^{(t)})\eta_{k_{i}}^{(t)}+p(y_{l,i}\succ^{\ast}y_{w,i}|x_{i},\theta^{(t)})(1-\eta_{k_{i}}^{(t)})}.(4)
|
| 112 |
+
|
| 113 |
+
where p(y w,i≻∗y l,i|x i,θ(t))p(y_{w,i}\succ^{\ast}y_{l,i}|x_{i},\theta^{(t)}) and p(y l,i≻∗y w,i|x i,θ(t))p(y_{l,i}\succ^{\ast}y_{w,i}|x_{i},\theta^{(t)}) can be computed according to Eq.([2](https://arxiv.org/html/2509.24159v3#S3.E2 "Equation 2 ‣ Assumption 2: A general probabilistic model for preferences. ‣ 3.2 RE-PO Framework: Core Assumptions ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")).
|
| 114 |
+
|
| 115 |
+
#### M-Step: weighted parameter update.
|
| 116 |
+
|
| 117 |
+
In the M-step, we update the policy parameters θ\theta and reliabilities 𝜼\boldsymbol{\eta} using the confidences w i(t)w_{i}^{(t)} computed in the E-step. This step conveniently separates into two independent updates.
|
| 118 |
+
|
| 119 |
+
First, the policy is updated by minimizing a weighted loss function. As established in Assumption 2, our probabilistic model for p(y w≻∗y l)p(y_{w}\succ^{\ast}y_{l}) allows RE-PO to work with any preference loss ℒ pref\mathcal{L}_{\text{pref}}, making it a versatile meta-framework. The general RE-PO loss is:
|
| 120 |
+
|
| 121 |
+
ℒ RE-PO(θ)=−∑i=1 N[w i(t)logp(y w,i≻∗y l,i|x i,θ)+(1−w i(t))logp(y l,i≻∗y w,i|x i,θ)].\mathcal{L}_{\text{RE-PO}}(\theta)=-\sum_{i=1}^{N}\left[w_{i}^{(t)}\log p(y_{w,i}\succ^{\ast}y_{l,i}|x_{i},\theta)+(1-w_{i}^{(t)})\log p(y_{l,i}\succ^{\ast}y_{w,i}|x_{i},\theta)\right].(5)
|
| 122 |
+
|
| 123 |
+
Second, the reliability η k\eta_{k} for each annotator is updated to the average confidence of all labels they provided. This has a simple and efficient closed-form solution:
|
| 124 |
+
|
| 125 |
+
η k(t+1)=∑i∈ℐ k w i(t)N k.\eta_{k}^{(t+1)}=\frac{\sum_{i\in\mathcal{I}_{k}}w_{i}^{(t)}}{N_{k}}.(6)
|
| 126 |
+
|
| 127 |
+
Here we define the index set of labeled pairs as ℐ k={i:k i=k}\mathcal{I}_{k}=\{\,i:k_{i}=k\,\}, and the number of labels as N k N_{k}.
|
| 128 |
+
|
| 129 |
+
Input: Dataset
|
| 130 |
+
|
| 131 |
+
𝒟={(x i,y w,i,y l,i,k i)}i=1 N\mathcal{D}=\{(x_{i},y_{w,i},y_{l,i},k_{i})\}_{i=1}^{N}
|
| 132 |
+
; Base policy
|
| 133 |
+
|
| 134 |
+
π θ\pi_{\theta}
|
| 135 |
+
, reference policy
|
| 136 |
+
|
| 137 |
+
π ref\pi_{\text{ref}}
|
| 138 |
+
; Preference loss
|
| 139 |
+
|
| 140 |
+
ℒ pref\mathcal{L}_{\text{pref}}
|
| 141 |
+
; Hyperparameters: learning rate
|
| 142 |
+
|
| 143 |
+
λ\lambda
|
| 144 |
+
, epochs
|
| 145 |
+
|
| 146 |
+
E E
|
| 147 |
+
, EMA momentum
|
| 148 |
+
|
| 149 |
+
α\alpha
|
| 150 |
+
, initial annotator reliabilities
|
| 151 |
+
|
| 152 |
+
η k∈[0.5,1]\eta_{k}\in[0.5,1]
|
| 153 |
+
for all
|
| 154 |
+
|
| 155 |
+
k∈{1,…,K}k\in\{1,\dots,K\}
|
| 156 |
+
|
| 157 |
+
1
|
| 158 |
+
|
| 159 |
+
2 for _epoch = 1 1 to E E_ do
|
| 160 |
+
|
| 161 |
+
3 for _batch ℬ⊂𝒟\mathcal{B}\subset\mathcal{D}_ do
|
| 162 |
+
|
| 163 |
+
4 For each sample
|
| 164 |
+
|
| 165 |
+
i∈ℬ i\in\mathcal{B}
|
| 166 |
+
, compute
|
| 167 |
+
|
| 168 |
+
w i w_{i}
|
| 169 |
+
using current
|
| 170 |
+
|
| 171 |
+
θ\theta
|
| 172 |
+
and
|
| 173 |
+
|
| 174 |
+
η k i\eta_{k_{i}}
|
| 175 |
+
via Eq.([4](https://arxiv.org/html/2509.24159v3#S3.E4 "Equation 4 ‣ E-Step: Inferring label correctness. ‣ 3.3 The RE-PO Algorithm via Expectation-Maximization ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"));
|
| 176 |
+
|
| 177 |
+
5
|
| 178 |
+
|
| 179 |
+
6 Compute the weighted loss
|
| 180 |
+
|
| 181 |
+
ℒ RE-PO(θ)\mathcal{L}_{\text{RE-PO}}(\theta)
|
| 182 |
+
for the batch via Eq.([5](https://arxiv.org/html/2509.24159v3#S3.E5 "Equation 5 ‣ M-Step: weighted parameter update. ‣ 3.3 The RE-PO Algorithm via Expectation-Maximization ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"));
|
| 183 |
+
|
| 184 |
+
7 Update parameters
|
| 185 |
+
|
| 186 |
+
θ\theta
|
| 187 |
+
using an optimizer (e.g., AdamW (loshchilov2019decoupled));
|
| 188 |
+
|
| 189 |
+
8
|
| 190 |
+
|
| 191 |
+
9 for _each annotator k k present in the batch_ do
|
| 192 |
+
|
| 193 |
+
10 Update
|
| 194 |
+
|
| 195 |
+
η k\eta_{k}
|
| 196 |
+
via Eq.([7](https://arxiv.org/html/2509.24159v3#S3.E7 "Equation 7 ‣ 3.4 Practical implementation with mini-batch training ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"));
|
| 197 |
+
|
| 198 |
+
11
|
| 199 |
+
|
| 200 |
+
12 end for
|
| 201 |
+
|
| 202 |
+
13
|
| 203 |
+
|
| 204 |
+
14 end for
|
| 205 |
+
|
| 206 |
+
15
|
| 207 |
+
|
| 208 |
+
16 end for
|
| 209 |
+
|
| 210 |
+
Algorithm 1 Mini-batch Implementation of Robust Enhanced Policy Optimization (RE-PO)
|
| 211 |
+
|
| 212 |
+
### 3.4 Practical implementation with mini-batch training
|
| 213 |
+
|
| 214 |
+
While the exact M-step updates are clear, performing a full iteration over the entire dataset to re-calculate the annotator reliabilities 𝜼\boldsymbol{\eta} after each policy update step can be computationally expensive. To balance computational efficiency and performance, we introduce a more practical online update for η k\eta_{k} using an Exponential Moving Average (EMA). Instead of a hard assignment, we perform a soft update based on the statistics from the current mini-batch ℬ\mathcal{B}:
|
| 215 |
+
|
| 216 |
+
η k←(1−α)η k+α⋅∑i∈ℬ∩ℐ k w i N k,ℬ.\eta_{k}\leftarrow(1-\alpha)\eta_{k}+\alpha\cdot\frac{\sum_{i\in\mathcal{B}\cap\mathcal{I}_{k}}w_{i}}{N_{k,\mathcal{B}}}.(7)
|
| 217 |
+
|
| 218 |
+
Here, N k,ℬ N_{k,\mathcal{B}} is the number of examples from annotator k k in the current mini-batch, and α∈(0,1]\alpha\in(0,1] is a momentum hyperparameter. The complete training procedure for RE-PO is summarized in [Algorithm 1](https://arxiv.org/html/2509.24159v3#algorithm1 "In M-Step: weighted parameter update. ‣ 3.3 The RE-PO Algorithm via Expectation-Maximization ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"):
|
| 219 |
+
|
| 220 |
+
4 Theoretical analysis of RE-PO
|
| 221 |
+
-------------------------------
|
| 222 |
+
|
| 223 |
+
The robustness of RE-PO stems from its adaptive weighting mechanism. This section first provides an intuitive analysis of these training dynamics and then formalizes this intuition with theoretical guarantees, demonstrating that the RE-PO framework can recover the true reliability of annotators.
|
| 224 |
+
|
| 225 |
+
At the start of training, when the language model is not yet well-optimized, its predictions are uncertain, and the probabilities p(y w≻∗y l|x,θ)p(y_{w}\succ^{\ast}y_{l}|x,\theta) are close to 0.5. The confidence score w i w_{i} approximates the annotator’s reliability, η k i\eta_{k_{i}}. The loss then acts as a form of label smoothing, preventing the model from being severely misled by incorrect labels early on. As the policy improves, its behavior adapts. For a high-quality label, the model predicts a high probability for the winning response, and w i w_{i} approaches 1, causing the loss to function like a standard preference optimization objective. Conversely, w i w_{i} approaches 0 for a noisy label. The loss is then dominated by the (1−w i)(1-w_{i}) term, which flips the optimization direction toward the true preference.
|
| 226 |
+
|
| 227 |
+
We now formalize the intuition that RE-PO can recover the true reliability of annotators. We provide this analysis under an idealized setting: full-batch training where the M-step for the policy parameters θ\theta is assumed to have converged perfectly. While our practical implementation in [Algorithm 1](https://arxiv.org/html/2509.24159v3#algorithm1 "In M-Step: weighted parameter update. ‣ 3.3 The RE-PO Algorithm via Expectation-Maximization ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") uses mini-batch gradient updates (a form of Generalized EM), this idealized analysis provides a strong theoretical justification for our framework.
|
| 228 |
+
|
| 229 |
+
Consider the dataset level update rule in Eq.([6](https://arxiv.org/html/2509.24159v3#S3.E6 "Equation 6 ‣ M-Step: weighted parameter update. ‣ 3.3 The RE-PO Algorithm via Expectation-Maximization ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")), defined as an operator T k(η)T_{k}(\eta). The following theorem establishes that iterating this operator guarantees convergence to the true annotator reliability.
|
| 230 |
+
|
| 231 |
+
###### Theorem 4.1(Identification and convergence of RE-PO).
|
| 232 |
+
|
| 233 |
+
Let θ⋆\theta^{\star} be a perfectly calibrated parameter such that the model distribution matches the ground-truth preference distribution. Assume that not all p i⋆=p(y w,i≻∗y l,i|x i)p_{i}^{\star}=p(y_{w,i}\succ^{*}y_{l,i}|x_{i}) equal 1 2\tfrac{1}{2} for i∈ℐ k i\in\mathcal{I}_{k}. Consider the sequence of reliability estimates {η k(t)}t≥0\{\eta_{k}^{(t)}\}_{t\geq 0} generated by the update rule η k(t+1)=T k(η k(t))\eta_{k}^{(t+1)}=T_{k}(\eta_{k}^{(t)}). Then, for any initialization η k(0)∈(0,1)\eta_{k}^{(0)}\in(0,1), the iterates converge to the true reliability η k∗≜𝔼[z i∣k i=k]\eta_{k}^{*}\triangleq\mathbb{E}[z_{i}\mid k_{i}=k]:
|
| 234 |
+
|
| 235 |
+
lim t→∞η k(t)=η k⋆.\lim_{t\to\infty}\eta_{k}^{(t)}=\eta_{k}^{\star}.
|
| 236 |
+
|
| 237 |
+
The proof is provided in Appendix[D](https://arxiv.org/html/2509.24159v3#A4 "Appendix D Proof of Theorem 4.1 ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"). In section[5.5](https://arxiv.org/html/2509.24159v3#S5.SS5 "5.5 Empirical verification of Theorem 4.1 ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), we empirically corroborate that the mini-batch procedure closely tracks this theoretical behavior.
|
| 238 |
+
|
| 239 |
+
#### Practical implications and limitations.
|
| 240 |
+
|
| 241 |
+
\rebuttal
|
| 242 |
+
|
| 243 |
+
The assumption of a perfectly calibrated model in Theorem[4.1](https://arxiv.org/html/2509.24159v3#S4.Thmtheorem1 "Theorem 4.1 (Identification and convergence of RE-PO). ‣ 4 Theoretical analysis of RE-PO ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") is intentionally idealized: in practice, we apply RE-PO to base models that are not exactly calibrated to the ground-truth preference distribution. In our experiments, we always start from strong instruction-tuned LLMs (Mistral-7B-Instruct-v0.2 and Meta-Llama-3-8B-Instruct), which already display good zero-shot preference behavior. Empirically, we do not observe the failure mode suggested by an extremely misaligned initialization: across the broad range of hyperparameters explored in Section[5.4](https://arxiv.org/html/2509.24159v3#S5.SS4 "5.4 Ablation study ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), the learned η k\eta_{k}’s remain stable and the downstream performance consistently improves over the corresponding base methods. Furthermore, the controlled experiments in Section[5.5](https://arxiv.org/html/2509.24159v3#S5.SS5 "5.5 Empirical verification of Theorem 4.1 ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), where we inject substantial synthetic noise into the data, show that RE-PO’s estimated reliabilities closely track the ground-truth values, suggesting robustness to imperfect calibration in practice. If the base LLM were initialized in a highly misaligned regime, the E-step could assign misleadingly high confidence to incorrect labels and RE-PO might fail to effectively denoise the supervision.
|
| 244 |
+
|
| 245 |
+
5 Experiments
|
| 246 |
+
-------------
|
| 247 |
+
|
| 248 |
+
In this section, we conduct a comprehensive set of experiments to evaluate the performance of RE-PO. We begin in section[5.1](https://arxiv.org/html/2509.24159v3#S5.SS1 "5.1 Experimental setup ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") by detailing our experimental setup, including the models, datasets, evaluation benchmarks, and baseline algorithms. In Section[5.2](https://arxiv.org/html/2509.24159v3#S5.SS2 "5.2 Main results ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), we present our main results.\rebuttal Section[5.3](https://arxiv.org/html/2509.24159v3#S5.SS3 "5.3 Multi-annotator experiments on MultiPref ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") reports additional experiments to evaluate RE-PO’s performance on realistic multi-annotator datasets. We then conduct an ablation study in Section[5.4](https://arxiv.org/html/2509.24159v3#S5.SS4 "5.4 Ablation study ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") to analyze the framework’s sensitivity to its key hyperparameters. In section[5.5](https://arxiv.org/html/2509.24159v3#S5.SS5 "5.5 Empirical verification of Theorem 4.1 ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), we provide an empirical verification of our theoretical claims of Theorem[4.1](https://arxiv.org/html/2509.24159v3#S4.Thmtheorem1 "Theorem 4.1 (Identification and convergence of RE-PO). ‣ 4 Theoretical analysis of RE-PO ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment").
|
| 249 |
+
|
| 250 |
+
### 5.1 Experimental setup
|
| 251 |
+
|
| 252 |
+
#### Models and training settings.
|
| 253 |
+
|
| 254 |
+
We use two state-of-the-art open-source large language models as our base models: Mistral-7B-Instruct-v0.2 and Meta-Llama-3-8B-Instruct. For fine-tuning, we utilize two datasets from the SimPO paper (meng2024simpo), which were generated via on-policy sampling using prompts from the UltraFeedback dataset (cui2024ultrafeedbackboostinglanguagemodels). The specific datasets are mistral-instruct-ultrafeedback for the Mistral model and llama3-ultrafeedback-armorm for the Llama-3 model.1 1 1 See Appendix[I](https://arxiv.org/html/2509.24159v3#A9 "Appendix I Resources ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") for links to models and datasets. As these datasets do not provide annotator-specific information, we model the preferences as if they originate from a single, virtual annotator (K=1 K=1).2 2 2 This is a reasonable simplification. For instance, a pool of two annotators with reliabilities η A\eta_{A} and η B\eta_{B}, appearing with frequencies p A p_{A} and p B p_{B} respectively, can be modeled as a single annotator with an effective reliability η unified=p Aη A+p Bη B\eta_{\text{unified}}=p_{A}\eta_{A}+p_{B}\eta_{B}.\rebuttal In addition to these UltraFeedback-based datasets, we further evaluate RE-PO on the real-world MultiPref multi-annotator preference dataset (miranda2024hybrid), where per-annotator reliabilities can be explicitly modeled (Section[5.3](https://arxiv.org/html/2509.24159v3#S5.SS3 "5.3 Multi-annotator experiments on MultiPref ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")).
|
| 255 |
+
|
| 256 |
+
#### Evaluation benchmarks.
|
| 257 |
+
|
| 258 |
+
We assess model performance on two widely recognized evaluation benchmarks. The first is AlpacaEval 2 (dubois2024length), an automatic, LLM-based evaluator that measures model performance by computing the win rate against reference outputs. It provides both a raw Win Rate (WR) and a Length-Controlled (LC) Win Rate to account for verbosity bias. The second is Arena-Hard (li2024crowdsourced), a challenging benchmark composed of difficult prompts crowdsourced from the LMSYS Chatbot Arena. It is designed to differentiate high-performing models by testing them on complex, real-world user queries. Performance is reported as the win rate against a suite of other models.
|
| 259 |
+
|
| 260 |
+
Table 2: \rebuttal Performance comparison on AlpacaEval 2 for Mistral-7B-Instruct-v0.2 and Meta-Llama-3-8B-Instruct fine-tuned on UltraFeedback-based preference datasets. Metrics reported are LC (Length-Controlled Win Rate) and WR (Raw Win Rate), both in percentage points. The table presents reference Baselines (bottom) alongside four algorithm families (DPO, IPO, SimPO, CPO). For each family, we compare the Standard implementation, the variant with Label Smoothing (w/ LS), and RE-PO (w/ RE-PO). Bold denotes the best result within each family for a given backbone.
|
| 261 |
+
|
| 262 |
+
Mistral-7B-Instruct Llama-3-8B-Instruct
|
| 263 |
+
Method Standard w/ LS w/ RE-PO Standard w/ LS w/ RE-PO
|
| 264 |
+
DPO 28.5 / 28.6 29.7 / 27.5 35.5 / 33.0 40.8 / 42.9 41.3 / 42.6 44.1 / 46.2
|
| 265 |
+
IPO 30.8 / 28.0 29.7 / 28.7 32.9 / 30.5 43.6 / 41.6 40.3 / 38.2 48.3 / 48.6
|
| 266 |
+
SimPO 28.3 / 29.7 26.5 / 27.1 30.4 / 32.9 44.5 / 37.1 48.1 / 38.7 46.9 / 39.4
|
| 267 |
+
CPO 26.3 / 26.4 28.5 / 28.8 27.6 / 27.8 35.9 / 40.3 35.3 / 34.8 40.1 / 43.8
|
| 268 |
+
Base Model 21.1 / 16.5 29.7 / 29.9
|
| 269 |
+
rDPO 28.1 / 29.1 37.3 / 35.4
|
| 270 |
+
Hölder-DPO 30.1 / 28.6 39.3 / 38.2
|
| 271 |
+
|
| 272 |
+
Table 3: \rebuttal Performance of DPO and RE-DPO on AlpacaEval 2 when trained on the MultiPref dataset (miranda2024hybrid). Results are reported as LC / WR (%) for Mistral-7B-Instruct-v0.2 and Meta-Llama-3-8B-Instruct.
|
| 273 |
+
|
| 274 |
+
Method Mistral-7B-Instruct Llama-3-8B-Instruct
|
| 275 |
+
DPO 28.8 / 26.4 36.7 / 39.3
|
| 276 |
+
RE-DPO (Ours)31.8 / 28.8 41.1 / 44.4
|
| 277 |
+
|
| 278 |
+
#### Baseline algorithms.
|
| 279 |
+
|
| 280 |
+
To demonstrate that RE-PO operates as a versatile meta-framework, we benchmark it against four popular direct preference alignment methods: DPO (rafailov2023direct); IPO (azar2023general), which uses a squared hinge loss to optimize preferences; SimPO (meng2024simpo), which proposes a simplified, reference-free reward formulation normalized by sequence length; and CPO (xu2024contrastive), which adds a term to directly maximize the likelihood of the preferred response. For each of these baselines, we compare the original algorithm to its RE-PO-enhanced counterpart (e.g., DPO vs. RE-DPO).\rebuttal In addition, we include robustness-oriented baselines rDPO (chowdhury2024provably) and Hölder-DPO (fujisawa2025scalable), as well as simple label-smoothing variants for each method. The results are shown in Table[2](https://arxiv.org/html/2509.24159v3#S5.T2 "Table 2 ‣ Evaluation benchmarks. ‣ 5.1 Experimental setup ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment").
|
| 281 |
+
|
| 282 |
+
Table 4: Ablation study on the initial annotator reliability (η 0\eta_{0}) and the EMA momentum (α\alpha).\rebuttal Results are reported for RE-DPO on Mistral-7B-Instruct-v0.2 trained on UltraFeedback-based data, evaluated on AlpacaEval 2 (LC / WR) and Arena-Hard (WR), all in percentage points. The best-performing settings used in our main experiments are highlighted.
|
| 283 |
+
|
| 284 |
+
Metric Initial 𝜼 𝟎\boldsymbol{\eta_{0}}EMA 𝜶\boldsymbol{\alpha}
|
| 285 |
+
0.99 0.9 (Ours)0.75 0.55 0.001 0.01 0.1 (Ours)0.5 1.0
|
| 286 |
+
AlpacaEval2 LC (%)30.9 35.5 31.1 31.4 30.9 30.1 35.5 33.4 31.1
|
| 287 |
+
AlpacaEval2 WR (%)31.7 33.0 33.3 32.0 27.8 27.2 33.0 34.8 28.9
|
| 288 |
+
Arena-Hard WR (%)12.3 14.7 12.4 11.8 12.9 13.6 14.7 14.0 12.8
|
| 289 |
+
|
| 290 |
+
### 5.2 Main results
|
| 291 |
+
|
| 292 |
+
As shown in Table[2](https://arxiv.org/html/2509.24159v3#S5.T2 "Table 2 ‣ Evaluation benchmarks. ‣ 5.1 Experimental setup ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), our experimental results provide strong evidence that RE-PO consistently improves preference-based alignment across objectives, model scales, and datasets. Below we highlight the main empirical findings.
|
| 293 |
+
|
| 294 |
+
#### RE-PO as a general framework.
|
| 295 |
+
|
| 296 |
+
A first observation is that RE-PO behaves as a generally effective “plug-in” robustness layer for a wide range of alignment losses. Across all four objective families (DPO, IPO, SimPO, CPO) and both backbones (Mistral-7B and Llama-3-8B), the RE-PO-enhanced variant either matches or strictly outperforms the corresponding standard implementation on AlpacaEval 2. For example, on Mistral-7B, RE-DPO improves LC / WR from 28.5/28.6 28.5/28.6 to 35.5/33.0 35.5/33.0 (a gain of +7.0+7.0 and +4.4+4.4 points, respectively), and on Llama-3-8B, RE-IPO improves LC / WR from 43.6/41.6 43.6/41.6 to 48.3/48.6 48.3/48.6 (a gain of +4.7+4.7 and +7.0+7.0 points, respectively). These trends hold across all four families, indicating that RE-PO reliably strengthens existing preference objectives rather than competing with them.
|
| 297 |
+
|
| 298 |
+
#### Comparison with label smoothing and robust baselines.
|
| 299 |
+
|
| 300 |
+
\rebuttal
|
| 301 |
+
|
| 302 |
+
Table[2](https://arxiv.org/html/2509.24159v3#S5.T2 "Table 2 ‣ Evaluation benchmarks. ‣ 5.1 Experimental setup ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") also compares RE-PO to two natural robustness baselines: label smoothing applied to each preference loss and the recently proposed robust objectives rDPO(chowdhury2024provably) and HöldeRE-DPO(fujisawa2025scalable). Label smoothing sometimes yields modest gains over the standard objective (e.g., SimPO w/ LS on Llama-3-8B improves LC from 44.5 44.5 to 48.1 48.1), but RE-PO typically achieves the best performance within each family and backbone. For instance, in the DPO family, RE-DPO outperforms both label smoothing and the specialized robust baselines: on Llama-3-8B, RE-DPO reaches 44.1/46.2 44.1/46.2 on AlpacaEval 2, compared to 41.3/42.6 41.3/42.6 for DPO w/ LS, 37.3/35.4 37.3/35.4 for rDPO, and 39.3/38.2 39.3/38.2 for Hölder-DPO. These results suggest that explicitly modeling noisy supervision via RE-PO is more effective than purely loss-level modifications or global noise-correction schemes.
|
| 303 |
+
|
| 304 |
+
#### Qualitative analysis of noisy labels.
|
| 305 |
+
|
| 306 |
+
\rebuttal
|
| 307 |
+
|
| 308 |
+
Beyond aggregate metrics, we also perform a qualitative analysis of the learned confidence scores. In Appendix[F](https://arxiv.org/html/2509.24159v3#A6 "Appendix F \rebuttalQualitative Analysis of Noisy Preference Label ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), we present case studies of preference pairs with very low posterior confidence w i w_{i}. RE-PO assigns low confidence to annotations that are off-task, inconsistent with the prompt, or at odds with a more plausible alternative response. Together with the quantitative gains in Tables[2](https://arxiv.org/html/2509.24159v3#S5.T2 "Table 2 ‣ Evaluation benchmarks. ‣ 5.1 Experimental setup ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), these examples illustrate that RE-PO not only improves benchmark performance but also identifies and down-weights noisy supervision at the example level.
|
| 309 |
+
|
| 310 |
+
### 5.3 Multi-annotator experiments on MultiPref
|
| 311 |
+
|
| 312 |
+
\rebuttal
|
| 313 |
+
|
| 314 |
+
To further evaluate RE-PO under realistic multi-annotator disagreement, we conduct additional experiments on the MultiPref dataset (miranda2024hybrid), a large-scale human preference dataset with genuine rater disagreement. The official training split contains 227 unique human annotators. Unlike the UltraFeedback-based datasets used in our main experiments, MultiPref provides annotator identifiers, allowing us to instantiate an individual reliability parameter η k\eta_{k} for each annotator and to update these parameters via our EM-style scheme.
|
| 315 |
+
|
| 316 |
+
We train vanilla DPO and our RE-DPO on MultiPref for both Mistral-7B-Instruct-v0.2 and Meta-Llama-3-8B-Instruct, and evaluate the resulting models on AlpacaEval 2. As summarized in Table[3](https://arxiv.org/html/2509.24159v3#S5.T3 "Table 3 ‣ Evaluation benchmarks. ‣ 5.1 Experimental setup ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), RE-DPO consistently outperforms vanilla DPO under this multi-annotator setup: for Llama-3-8B, the AlpacaEval LC improves from 36.7 to 41.1 and WR from 39.3 to 44.4; for Mistral-7B, LC improves from 28.8 to 31.8 and WR from 26.4 to 28.8. These gains mirror the trends observed in our UltraFeedback experiments and show that RE-PO remains beneficial when trained on data with heterogeneous, potentially noisy annotators, rather than a single virtual annotator.
|
| 317 |
+
|
| 318 |
+
In Appendix[E](https://arxiv.org/html/2509.24159v3#A5 "Appendix E \rebuttalVisualization of annotator reliability ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), we visualize the learned annotator reliabilities distributions on MultiPref. Experiment results indicate that RE-PO identifies a high-reliability majority and a nontrivial tail of downweighted annotators, and that this pattern is robust across different prior settings and backbones. Moreover, to probe the impact of the choice of automatic judge, we repeat the MultiPref evaluation using a different LLM evaluator; Appendix[G](https://arxiv.org/html/2509.24159v3#A7 "Appendix G \rebuttalAdditional results on MultiPref ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") reports these results and shows that the performance gains from RE-DPO are stable across judge models.
|
| 319 |
+
|
| 320 |
+
### 5.4 Ablation study
|
| 321 |
+
|
| 322 |
+
We conduct ablation studies to analyze the sensitivity of RE-PO to two key hyperparameters: the initial annotator reliability η 0\eta_{0}, and the EMA momentum parameter α\alpha. All experiments are performed using RE-DPO on the Mistral-7B-Instruct-v0.2 model. The results are summarized in Table[4](https://arxiv.org/html/2509.24159v3#S5.T4 "Table 4 ‣ Baseline algorithms. ‣ 5.1 Experimental setup ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment").
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
|
| 326 |
+
(a)Single-annotator setting.
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
(b)Two-annotator setting.
|
| 331 |
+
|
| 332 |
+
Figure 2: Empirical verification of annotator reliability estimation under controlled synthetic noise. Ground-truth reliability (η\eta GPT-4o) is established using GPT-4o’s labels on UltraFeedback-derived preference pairs, and different reliability levels are simulated by injecting synthetic noise into copies of the dataset. In the single-annotator setting (a), a single annotator’s dataset is perturbed with varying noise rates. In the two-annotator setting (b), Annotator 1 uses the original data with no added noise, while noise is progressively added to Annotator 2’s data. The plots compare ground-truth reliabilities (solid lines) with RE-PO-estimated reliabilities (dashed lines), showing that RE-PO closely tracks the true reliability in both scenarios.
|
| 333 |
+
|
| 334 |
+
#### Effect of initial η 0\eta_{0}.
|
| 335 |
+
|
| 336 |
+
The initial reliability η 0\eta_{0} sets the model’s prior belief about the correctness of the labels in the dataset. As shown in Table[4](https://arxiv.org/html/2509.24159v3#S5.T4 "Table 4 ‣ Baseline algorithms. ‣ 5.1 Experimental setup ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), the model’s performance is best when η 0\eta_{0} is set to 0.9, which was the value used in our main experiments. An overly optimistic initialization (e.g., η 0=0.99\eta_{0}=0.99) can cause the model to trust noisy labels too strongly at the beginning of training, hindering the denoising process. Conversely, a pessimistic initialization (e.g., η 0=0.55\eta_{0}=0.55) treats the data as highly unreliable from the outset, which can slow down the model’s ability to learn the underlying noise-free preference. An initial value of 0.9 appears to strike the right balance, starting with a reasonable assumption of data quality.
|
| 337 |
+
|
| 338 |
+
#### Effect of EMA parameter α\alpha.
|
| 339 |
+
|
| 340 |
+
The EMA parameter α\alpha governs the update rate of the annotator reliability scores, balancing the influence of historical estimates against new information from the current mini-batch. Our experiments confirm that the optimal performance is achieved with α=0.1\alpha=0.1. The model shows considerable sensitivity to this parameter. A very small α\alpha (e.g., 0.001) makes the reliability updates exceedingly slow, preventing the estimates from adapting to the model’s evolving understanding of the data. On the other hand, a very large α\alpha (e.g., 1.0) makes the updates highly volatile, as the reliability score becomes dependent solely on the samples in the current mini-batch.
|
| 341 |
+
|
| 342 |
+
### 5.5 Empirical verification of Theorem[4.1](https://arxiv.org/html/2509.24159v3#S4.Thmtheorem1 "Theorem 4.1 (Identification and convergence of RE-PO). ‣ 4 Theoretical analysis of RE-PO ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")
|
| 343 |
+
|
| 344 |
+
We conduct controlled experiments to verify Theorem[4.1](https://arxiv.org/html/2509.24159v3#S4.Thmtheorem1 "Theorem 4.1 (Identification and convergence of RE-PO). ‣ 4 Theoretical analysis of RE-PO ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"). Our setup is designed to align with the theorem’s assumption of a perfectly calibrated model, for which we use a small-scale base model, Qwen2.5-0.5B-Instruct, to ensure fast convergence. To simulate annotators with varying levels of reliability, we create distinct copies of the UltraFeedback dataset (cui2024ultrafeedbackboostinglanguagemodels) for each annotator and inject a controlled degree of synthetic noise into their respective dataset.
|
| 345 |
+
|
| 346 |
+
We test two scenarios, with results presented in Figure[2](https://arxiv.org/html/2509.24159v3#S5.F2 "Figure 2 ‣ 5.4 Ablation study ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"): (a) Single Annotator: A single annotator whose dataset is modified with a synthetically controlled noise rate. (b) Two Annotators: A scenario with two annotators, where Annotator 1 serves as a baseline using the original data without added noise, while the dataset for Annotator 2 is injected with progressively increasing noise levels.
|
| 347 |
+
|
| 348 |
+
The results in Figure[2](https://arxiv.org/html/2509.24159v3#S5.F2 "Figure 2 ‣ 5.4 Ablation study ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") show that the estimated reliability η\eta (RE-PO) closely tracks the ground-truth η\eta (GPT-4o) in both single-annotator (Figure[2(a)](https://arxiv.org/html/2509.24159v3#S5.F2.sf1 "Figure 2(a) ‣ Figure 2 ‣ 5.4 Ablation study ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")) and two-annotator (Figure[2(b)](https://arxiv.org/html/2509.24159v3#S5.F2.sf2 "Figure 2(b) ‣ Figure 2 ‣ 5.4 Ablation study ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")) settings. Notably, in the two-annotator experiment, RE-PO successfully identifies the stable reliability of the baseline annotator while accurately tracking the declining reliability of the noisy one. \rebuttal Although the theorem assumes a perfectly calibrated model, these experiments demonstrate that RE-PO’s reliability estimates remain accurate and stable even when the underlying model is only approximately calibrated and trained under realistic noise patterns, mitigating concerns that early miscalibration would systematically down-weight correct labels.
|
| 349 |
+
|
| 350 |
+
6 Conclusion and future work
|
| 351 |
+
----------------------------
|
| 352 |
+
|
| 353 |
+
In this paper, we introduce Robust Enhanced Policy Optimization (RE-PO), a novel framework designed to address the critical challenge of aligning LLMs with noisy human preference data. Our approach is distinct from existing methods as it employs an Expectation-Maximization algorithm to infer the reliability of each preference pair, treating labels as soft, dynamic weights rather than fixed ground truths. As a general framework, RE-PO consistently enhances multiple state-of-the-art alignment algorithms, achieving significant performance gains (up to a 7.0% win rate increase on AlpacaEval 2) across various base models. \rebuttal A natural limitation of our current theory is the assumption of a perfectly calibrated model; extending convergence guarantees to settings where the base model is significantly misaligned remains important future work.
|
| 354 |
+
|
| 355 |
+
7 Acknowledgement
|
| 356 |
+
-----------------
|
| 357 |
+
|
| 358 |
+
This research was supported by National Natural Science Foundation of China (No.62325405,62406159), Tsinghua University Initiative Scientific Research Program, Tsinghua-Efort Joint Research Center for EAI Computation and Perception, Beijing National Research Center for Information Science, Technology (BNRist), Beijing Innovation Center for Future Chips, and State Key laboratory of Space Network and Communications.
|
| 359 |
+
|
| 360 |
+
Appendix A Derivation of general probabilistic model
|
| 361 |
+
----------------------------------------------------
|
| 362 |
+
|
| 363 |
+
Here we provide the detailed derivation for Eq.([2](https://arxiv.org/html/2509.24159v3#S3.E2 "Equation 2 ‣ Assumption 2: A general probabilistic model for preferences. ‣ 3.2 RE-PO Framework: Core Assumptions ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")). For a given prompt x x and candidate responses y w,y l y_{w},y_{l}, we assume the probability of the ground-truth preference y w≻∗y l y_{w}\succ^{\ast}y_{l} is proportional to exp(−ℒ pref(x,y w≻y l))\exp(-\mathcal{L}_{\text{pref}}(x,y_{w}\succ y_{l})). That is:
|
| 364 |
+
|
| 365 |
+
p(y w≻∗y l|x,θ)∝exp(−ℒ pref(x,y w≻y l))p(y_{w}\succ^{\ast}y_{l}|x,\theta)\propto\exp(-\mathcal{L}_{\text{pref}}(x,y_{w}\succ y_{l}))(8)
|
| 366 |
+
|
| 367 |
+
Similarly, for the inverse preference:
|
| 368 |
+
|
| 369 |
+
p(y l≻∗y w|x,θ)∝exp(−ℒ pref(x,y l≻y w))p(y_{l}\succ^{\ast}y_{w}|x,\theta)\propto\exp(-\mathcal{L}_{\text{pref}}(x,y_{l}\succ y_{w}))(9)
|
| 370 |
+
|
| 371 |
+
Since y w≻∗y l y_{w}\succ^{\ast}y_{l} and y l≻∗y w y_{l}\succ^{\ast}y_{w} are the only two mutually exclusive outcomes for a binary preference, their probabilities must sum to 1. Using the property of normalized probabilities from a proportional relationship, we have:
|
| 372 |
+
|
| 373 |
+
p(y w≻∗y l|x,θ)\displaystyle p(y_{w}\succ^{\ast}y_{l}|x,\theta)=exp(−ℒ pref(x,y w≻y l))exp(−ℒ pref(x,y w≻y l))+exp(−ℒ pref(x,y l≻y w))\displaystyle=\frac{\exp(-\mathcal{L}_{\text{pref}}(x,y_{w}\succ y_{l}))}{\exp(-\mathcal{L}_{\text{pref}}(x,y_{w}\succ y_{l}))+\exp(-\mathcal{L}_{\text{pref}}(x,y_{l}\succ y_{w}))}
|
| 374 |
+
=1 1+exp(−(ℒ pref(x,y l≻y w)−ℒ pref(x,y w≻y l)))\displaystyle=\frac{1}{1+\exp(-(\mathcal{L}_{\text{pref}}(x,y_{l}\succ y_{w})-\mathcal{L}_{\text{pref}}(x,y_{w}\succ y_{l})))}
|
| 375 |
+
=σ(ℒ pref(x,y l≻y w)−ℒ pref(x,y w≻y l))\displaystyle=\sigma\left(\mathcal{L}_{\text{pref}}(x,y_{l}\succ y_{w})-\mathcal{L}_{\text{pref}}(x,y_{w}\succ y_{l})\right)
|
| 376 |
+
|
| 377 |
+
The last line is the General Probabilistic Model in Eq.([2](https://arxiv.org/html/2509.24159v3#S3.E2 "Equation 2 ‣ Assumption 2: A general probabilistic model for preferences. ‣ 3.2 RE-PO Framework: Core Assumptions ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")).
|
| 378 |
+
|
| 379 |
+
Appendix B Consistency with Bradley-Terry model for DPO
|
| 380 |
+
-------------------------------------------------------
|
| 381 |
+
|
| 382 |
+
We show that Eq.([2](https://arxiv.org/html/2509.24159v3#S3.E2 "Equation 2 ‣ Assumption 2: A general probabilistic model for preferences. ‣ 3.2 RE-PO Framework: Core Assumptions ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")) is consistent with the Bradley-Terry model when applied to DPO. The DPO loss for a preferred pair (y w,y l)(y_{w},y_{l}) given prompt x x is:
|
| 383 |
+
|
| 384 |
+
ℒ DPO(x,y w≻y l)=−logσ(βlogπ θ(y w|x)π ref(y w|x)−βlogπ θ(y l|x)π ref(y l|x))\mathcal{L}_{\text{DPO}}(x,y_{w}\succ y_{l})=-\log\sigma\left(\beta\log\frac{\pi_{\theta}(y_{w}|x)}{\pi_{\text{ref}}(y_{w}|x)}-\beta\log\frac{\pi_{\theta}(y_{l}|x)}{\pi_{\text{ref}}(y_{l}|x)}\right)(10)
|
| 385 |
+
|
| 386 |
+
Let S(x,y w,y l)=βlogπ θ(y w|x)π ref(y w|x)−βlogπ θ(y l|x)π ref(y l|x)S(x,y_{w},y_{l})=\beta\log\frac{\pi_{\theta}(y_{w}|x)}{\pi_{\text{ref}}(y_{w}|x)}-\beta\log\frac{\pi_{\theta}(y_{l}|x)}{\pi_{\text{ref}}(y_{l}|x)}. Then, we can write:
|
| 387 |
+
|
| 388 |
+
ℒ DPO(x,y w≻y l)\displaystyle\mathcal{L}_{\text{DPO}}(x,y_{w}\succ y_{l})=−logσ(S(x,y w,y l))\displaystyle=-\log\sigma(S(x,y_{w},y_{l}))
|
| 389 |
+
ℒ DPO(x,y l≻y w)\displaystyle\mathcal{L}_{\text{DPO}}(x,y_{l}\succ y_{w})=−logσ(S(x,y l,y w))=−logσ(−S(x,y w,y l))\displaystyle=-\log\sigma(S(x,y_{l},y_{w}))=-\log\sigma(-S(x,y_{w},y_{l}))
|
| 390 |
+
|
| 391 |
+
Substituting these into our general probabilistic model (Eq.([2](https://arxiv.org/html/2509.24159v3#S3.E2 "Equation 2 ‣ Assumption 2: A general probabilistic model for preferences. ‣ 3.2 RE-PO Framework: Core Assumptions ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"))):
|
| 392 |
+
|
| 393 |
+
p(y w≻∗y l|x,θ)\displaystyle p(y_{w}\succ^{\ast}y_{l}|x,\theta)=σ(ℒ DPO(x,y l≻y w)−ℒ DPO(x,y w≻y l))\displaystyle=\sigma\left(\mathcal{L}_{\text{DPO}}(x,y_{l}\succ y_{w})-\mathcal{L}_{\text{DPO}}(x,y_{w}\succ y_{l})\right)
|
| 394 |
+
=σ(logσ(S(x,y w,y l))−logσ(−S(x,y w,y l)))\displaystyle=\sigma\left(\log\sigma(S(x,y_{w},y_{l}))-\log\sigma(-S(x,y_{w},y_{l}))\right)
|
| 395 |
+
=σ(logσ(S(x,y w,y l))1−σ(S(x,y w,y l)))\displaystyle=\sigma\left(\log\frac{\sigma(S(x,y_{w},y_{l}))}{1-\sigma(S(x,y_{w},y_{l}))}\right)
|
| 396 |
+
=σ(S(x,y w,y l))\displaystyle=\sigma(S(x,y_{w},y_{l}))
|
| 397 |
+
=σ(βlogπ θ(y w|x)π ref(y w|x)−βlogπ θ(y l|x)π ref(y l|x))\displaystyle=\sigma\left(\beta\log\frac{\pi_{\theta}(y_{w}|x)}{\pi_{\text{ref}}(y_{w}|x)}-\beta\log\frac{\pi_{\theta}(y_{l}|x)}{\pi_{\text{ref}}(y_{l}|x)}\right)
|
| 398 |
+
|
| 399 |
+
This resulting probability exactly matches the form of the Bradley-Terry model [bradley1952rank] for preferences, where the implicit reward of a response y y is r(x,y)=βlogπ θ(y|x)π ref(y|x)r(x,y)=\beta\log\frac{\pi_{\theta}(y|x)}{\pi_{\text{ref}}(y|x)}.
|
| 400 |
+
|
| 401 |
+
Appendix C Derivation of the RE-PO EM algorithm
|
| 402 |
+
-----------------------------------------------
|
| 403 |
+
|
| 404 |
+
The primary objective of Robust Enhanced Policy Optimization (RE-PO) is to find the model parameters θ\theta and the vector of annotator reliabilities 𝜼\boldsymbol{\eta} that maximize the log-likelihood of the observed data. The observed data consists of prompts, chosen and rejected responses, and the annotator’s index, denoted as X=𝒟={(x i,y w,i,y l,i,k i)}i=1 N X=\mathcal{D}=\{(x_{i},y_{w,i},y_{l,i},k_{i})\}_{i=1}^{N}.
|
| 405 |
+
|
| 406 |
+
The log-likelihood function is given by:
|
| 407 |
+
|
| 408 |
+
ℒ(θ,𝜼)=∑i=1 N log[p(y w,i≻∗y l,i|x i,θ)η k i+p(y l,i≻∗y w,i|x i,θ)(1−η k i)]\mathcal{L}(\theta,\boldsymbol{\eta})=\sum_{i=1}^{N}\log\left[p(y_{w,i}\succ^{\ast}y_{l,i}|x_{i},\theta)\eta_{k_{i}}+p(y_{l,i}\succ^{\ast}y_{w,i}|x_{i},\theta)(1-\eta_{k_{i}})\right](11)
|
| 409 |
+
|
| 410 |
+
There is a sum inside the logarithm, which makes direct optimization intractable. The Expectation-Maximization (EM) algorithm is an iterative procedure designed to solve such maximum likelihood problems with latent variables by alternating between an Expectation (E) step and a Maximization (M) step.
|
| 411 |
+
|
| 412 |
+
### C.1 Derivation of the Q-Function (The E-Step)
|
| 413 |
+
|
| 414 |
+
The EM algorithm simplifies the problem by working with the complete data, (X,Z)(X,Z), where Z={z i}i=1 N Z=\{z_{i}\}_{i=1}^{N} is the set of all latent variables.
|
| 415 |
+
|
| 416 |
+
The complete-data log-likelihood, ℒ c\mathcal{L}_{c}, assumes that we know the values of all latent variables z i z_{i}:
|
| 417 |
+
|
| 418 |
+
ℒ c(θ,𝜼;X,Z)=∑i=1 N(z ilog[p(y w,i≻∗y l,i|x i,θ)η k i]+(1−z i)log[p(y l,i≻∗y w,i|x i,θ)(1−η k i)])\mathcal{L}_{c}(\theta,\boldsymbol{\eta};X,Z)=\sum_{i=1}^{N}\left(z_{i}\log\left[p(y_{w,i}\succ^{\ast}y_{l,i}|x_{i},\theta)\eta_{k_{i}}\right]+(1-z_{i})\log\left[p(y_{l,i}\succ^{\ast}y_{w,i}|x_{i},\theta)(1-\eta_{k_{i}})\right]\right)(12)
|
| 419 |
+
|
| 420 |
+
This form is tractable because the logarithm acts on products, which can be separated into sums.
|
| 421 |
+
|
| 422 |
+
The core idea of EM is to iteratively maximize the expectation of the complete-data log-likelihood. This expectation, known as the Q-function, is taken with respect to the posterior distribution of the latent variables Z Z, given the observed data X X and the parameter estimates from the current iteration, (θ(t),𝜼(t))(\theta^{(t)},\boldsymbol{\eta}^{(t)}).
|
| 423 |
+
|
| 424 |
+
Q(θ,𝜼|θ(t),𝜼(t))≡𝔼 Z|X,θ(t),𝜼(t)[ℒ c(θ,𝜼;X,Z)]Q(\theta,\boldsymbol{\eta}|\theta^{(t)},\boldsymbol{\eta}^{(t)})\equiv\mathbb{E}_{Z|X,\theta^{(t)},\boldsymbol{\eta}^{(t)}}[\mathcal{L}_{c}(\theta,\boldsymbol{\eta};X,Z)](13)
|
| 425 |
+
|
| 426 |
+
To compute this expectation, we push the expectation operator inside the summation. The only random variables in ℒ c\mathcal{L}_{c} are the z i z_{i}.
|
| 427 |
+
|
| 428 |
+
Q(θ,𝜼|θ(t),𝜼(t))=∑i=1 N(𝔼[z i]log[p(y w,i≻∗y l,i|θ)η k i]+(1−𝔼[z i])log[p(y l,i≻∗y w,i|θ)(1−η k i)])Q(\theta,\boldsymbol{\eta}|\theta^{(t)},\boldsymbol{\eta}^{(t)})=\sum_{i=1}^{N}\left(\mathbb{E}[z_{i}]\log\left[p(y_{w,i}\succ^{\ast}y_{l,i}|\theta)\eta_{k_{i}}\right]+(1-\mathbb{E}[z_{i}])\log\left[p(y_{l,i}\succ^{\ast}y_{w,i}|\theta)(1-\eta_{k_{i}})\right]\right)(14)
|
| 429 |
+
|
| 430 |
+
The term 𝔼[z i]\mathbb{E}[z_{i}] is the expectation of the binary variable z i z_{i}, which is its posterior probability of being 1. This probability is conditioned on the observed data and the parameters from the current iteration t t. We denote this posterior probability as w i(t)w_{i}^{(t)}, which is computed in the E-Step:
|
| 431 |
+
|
| 432 |
+
w i(t)\displaystyle w_{i}^{(t)}≡𝔼[z i|X i,θ(t),𝜼(t)]\displaystyle\equiv\mathbb{E}[z_{i}|X_{i},\theta^{(t)},\boldsymbol{\eta}^{(t)}]
|
| 433 |
+
=p(z i=1|y w,i≻k i y l,i,x i,θ(t),𝜼(t))\displaystyle=p(z_{i}=1|y_{w,i}\succ_{k_{i}}y_{l,i},x_{i},\theta^{(t)},\boldsymbol{\eta}^{(t)})
|
| 434 |
+
=p(y w,i≻k i y l,i|z i=1,x i,θ(t))p(z i=1|k i,𝜼(t))p(y w,i≻k i y l,i|x i,θ(t),𝜼(t))\displaystyle=\frac{p(y_{w,i}\succ_{k_{i}}y_{l,i}|z_{i}=1,x_{i},\theta^{(t)})p(z_{i}=1|k_{i},\boldsymbol{\eta}^{(t)})}{p(y_{w,i}\succ_{k_{i}}y_{l,i}|x_{i},\theta^{(t)},\boldsymbol{\eta}^{(t)})}
|
| 435 |
+
=p(y w,i≻∗y l,i|x i,θ(t))η k i(t)p(y w,i≻∗y l,i|x i,θ(t))η k i(t)+p(y l,i≻∗y w,i|x i,θ(t))(1−η k i(t))\displaystyle=\frac{p(y_{w,i}\succ^{\ast}y_{l,i}|x_{i},\theta^{(t)})\eta_{k_{i}}^{(t)}}{p(y_{w,i}\succ^{\ast}y_{l,i}|x_{i},\theta^{(t)})\eta_{k_{i}}^{(t)}+p(y_{l,i}\succ^{\ast}y_{w,i}|x_{i},\theta^{(t)})(1-\eta_{k_{i}}^{(t)})}(15)
|
| 436 |
+
|
| 437 |
+
Substituting w i(t)w_{i}^{(t)} into the expression yields the final form of the Q-function:
|
| 438 |
+
|
| 439 |
+
Q(θ,𝜼|θ(t),𝜼(t))=∑i=1 N[w i(t)log(p(y w,i≻∗y l,i|θ)η k i)+(1−w i(t))log(p(y l,i≻∗y w,i|θ)(1−η k i))]Q(\theta,\boldsymbol{\eta}|\theta^{(t)},\boldsymbol{\eta}^{(t)})=\sum_{i=1}^{N}\left[w_{i}^{(t)}\log(p(y_{w,i}\succ^{\ast}y_{l,i}|\theta)\eta_{k_{i}})+(1-w_{i}^{(t)})\log(p(y_{l,i}\succ^{\ast}y_{w,i}|\theta)(1-\eta_{k_{i}}))\right](16)
|
| 440 |
+
|
| 441 |
+
### C.2 Deriving the RE-PO Framework (The M-Step)
|
| 442 |
+
|
| 443 |
+
The goal of the M-Step is to find the parameters for the next iteration, (θ(t+1),𝜼(t+1))(\theta^{(t+1)},\boldsymbol{\eta}^{(t+1)}), by maximizing the Q-function that was constructed using the parameters from the current iteration t t.
|
| 444 |
+
|
| 445 |
+
(θ(t+1),𝜼(t+1))=argmax θ,𝜼Q(θ,𝜼|θ(t),𝜼(t))(\theta^{(t+1)},\boldsymbol{\eta}^{(t+1)})=\arg\max_{\theta,\boldsymbol{\eta}}Q(\theta,\boldsymbol{\eta}|\theta^{(t)},\boldsymbol{\eta}^{(t)})(17)
|
| 446 |
+
|
| 447 |
+
To perform this maximization, we can first expand the Q-function by separating the terms involving the policy θ\theta from those involving the annotator reliabilities 𝜼\boldsymbol{\eta}.
|
| 448 |
+
|
| 449 |
+
Q(θ,𝜼|θ(t),𝜼(t))=\displaystyle Q(\theta,\boldsymbol{\eta}|\theta^{(t)},\boldsymbol{\eta}^{(t)})=∑i=1 N[w i(t)logp(y w,i≻∗y l,i|θ)+(1−w i(t))logp(y l,i≻∗y w,i|θ)]⏟Depends only onθ\displaystyle\underbrace{\sum_{i=1}^{N}\left[w_{i}^{(t)}\log p(y_{w,i}\succ^{\ast}y_{l,i}|\theta)+(1-w_{i}^{(t)})\log p(y_{l,i}\succ^{\ast}y_{w,i}|\theta)\right]}_{\text{Depends only on }\theta}
|
| 450 |
+
+∑i=1 N[w i(t)logη k i+(1−w i(t))log(1−η k i)]⏟Depends only on𝜼\displaystyle+\underbrace{\sum_{i=1}^{N}\left[w_{i}^{(t)}\log\eta_{k_{i}}+(1-w_{i}^{(t)})\log(1-\eta_{k_{i}})\right]}_{\text{Depends only on }\boldsymbol{\eta}}(18)
|
| 451 |
+
|
| 452 |
+
Because the Q-function is separable into two independent parts, we can maximize each part separately to find the new parameters.
|
| 453 |
+
|
| 454 |
+
To find the optimal θ(t+1)\theta^{(t+1)}, we hold 𝜼\boldsymbol{\eta} fixed and maximize the terms in the Q-function that depend on θ\theta:
|
| 455 |
+
|
| 456 |
+
θ(t+1)\displaystyle\theta^{(t+1)}=argmax θ∑i=1 N[w i(t)logp(y w,i≻∗y l,i|θ)+(1−w i(t))logp(y l,i≻∗y w,i|θ)]\displaystyle=\arg\max_{\theta}\sum_{i=1}^{N}\left[w_{i}^{(t)}\log p(y_{w,i}\succ^{\ast}y_{l,i}|\theta)+(1-w_{i}^{(t)})\log p(y_{l,i}\succ^{\ast}y_{w,i}|\theta)\right]
|
| 457 |
+
=argmin θ(−∑i=1 N[w i(t)logp(y w,i≻∗y l,i|θ)+(1−w i(t))logp(y l,i≻∗y w,i|θ)])\displaystyle=\arg\min_{\theta}\left(-\sum_{i=1}^{N}\left[w_{i}^{(t)}\log p(y_{w,i}\succ^{\ast}y_{l,i}|\theta)+(1-w_{i}^{(t)})\log p(y_{l,i}\succ^{\ast}y_{w,i}|\theta)\right]\right)(19)
|
| 458 |
+
|
| 459 |
+
The expression inside the argmin\arg\min is precisely the weighted RE-PO loss function, ℒ RE-PO(θ)\mathcal{L}_{\text{RE-PO}}(\theta). This establishes that the M-step for the policy parameters is equivalent to minimizing this weighted loss, using weights w i(t)w_{i}^{(t)} from the E-step.
|
| 460 |
+
|
| 461 |
+
To find the optimal η k(t+1)\eta_{k}^{(t+1)} for a specific annotator k k, we hold θ\theta fixed and maximize the terms in the Q-function relevant to η k\eta_{k}. These terms only involve samples labeled by annotator k k (where k i=k k_{i}=k):
|
| 462 |
+
|
| 463 |
+
η k(t+1)=argmax η k∈[0,1]∑i:k i=k[w i(t)logη k+(1−w i(t))log(1−η k)]\eta_{k}^{(t+1)}=\arg\max_{\eta_{k}\in[0,1]}\sum_{i:k_{i}=k}\left[w_{i}^{(t)}\log\eta_{k}+(1-w_{i}^{(t)})\log(1-\eta_{k})\right](20)
|
| 464 |
+
|
| 465 |
+
To find the maximum, we take the derivative with respect to η k\eta_{k} and set it to zero:
|
| 466 |
+
|
| 467 |
+
∂∂η k∑i:k i=k[w i(t)logη k+(1−w i(t))log(1−η k)]\displaystyle\frac{\partial}{\partial\eta_{k}}\sum_{i:k_{i}=k}\left[w_{i}^{(t)}\log\eta_{k}+(1-w_{i}^{(t)})\log(1-\eta_{k})\right]=0\displaystyle=0(21)
|
| 468 |
+
∑i:k i=k[w i(t)η k−1−w i(t)1−η k]\displaystyle\sum_{i:k_{i}=k}\left[\frac{w_{i}^{(t)}}{\eta_{k}}-\frac{1-w_{i}^{(t)}}{1-\eta_{k}}\right]=0\displaystyle=0(22)
|
| 469 |
+
1 η k∑i:k i=k w i(t)\displaystyle\frac{1}{\eta_{k}}\sum_{i:k_{i}=k}w_{i}^{(t)}=1 1−η k∑i:k i=k(1−w i(t))\displaystyle=\frac{1}{1-\eta_{k}}\sum_{i:k_{i}=k}(1-w_{i}^{(t)})(23)
|
| 470 |
+
1 η k∑i:k i=k w i(t)\displaystyle\frac{1}{\eta_{k}}\sum_{i:k_{i}=k}w_{i}^{(t)}=1 1−η k(N k−∑i:k i=k w i(t))\displaystyle=\frac{1}{1-\eta_{k}}\left(N_{k}-\sum_{i:k_{i}=k}w_{i}^{(t)}\right)(24)
|
| 471 |
+
|
| 472 |
+
where N k N_{k} is the total number of annotations provided by annotator k k. Cross-multiplying gives:
|
| 473 |
+
|
| 474 |
+
(1−η k)∑i:k i=k w i(t)\displaystyle(1-\eta_{k})\sum_{i:k_{i}=k}w_{i}^{(t)}=η k(N k−∑i:k i=k w i(t))\displaystyle=\eta_{k}\left(N_{k}-\sum_{i:k_{i}=k}w_{i}^{(t)}\right)(25)
|
| 475 |
+
∑i:k i=k w i(t)−η k∑i:k i=k w i(t)\displaystyle\sum_{i:k_{i}=k}w_{i}^{(t)}-\eta_{k}\sum_{i:k_{i}=k}w_{i}^{(t)}=η kN k−η k∑i:k i=k w i(t)\displaystyle=\eta_{k}N_{k}-\eta_{k}\sum_{i:k_{i}=k}w_{i}^{(t)}(26)
|
| 476 |
+
∑i:k i=k w i(t)\displaystyle\sum_{i:k_{i}=k}w_{i}^{(t)}=η kN k\displaystyle=\eta_{k}N_{k}(27)
|
| 477 |
+
|
| 478 |
+
This yields the intuitive and closed-form update rule for the reliability at iteration t+1 t+1:
|
| 479 |
+
|
| 480 |
+
η k(t+1)=∑i:k i=k w i(t)N k\eta_{k}^{(t+1)}=\frac{\sum_{i:k_{i}=k}w_{i}^{(t)}}{N_{k}}(28)
|
| 481 |
+
|
| 482 |
+
This shows that the updated reliability for an annotator is simply the average posterior probability (or confidence) from the previous iteration that their labels were correct.
|
| 483 |
+
|
| 484 |
+
Appendix D Proof of Theorem[4.1](https://arxiv.org/html/2509.24159v3#S4.Thmtheorem1 "Theorem 4.1 (Identification and convergence of RE-PO). ‣ 4 Theoretical analysis of RE-PO ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment")
|
| 485 |
+
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
| 486 |
+
|
| 487 |
+
In this section, we provide the proof for Theorem [4.1](https://arxiv.org/html/2509.24159v3#S4.Thmtheorem1 "Theorem 4.1 (Identification and convergence of RE-PO). ‣ 4 Theoretical analysis of RE-PO ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"). We analyze the convergence of the annotator reliability parameter η k\eta_{k} under the idealized full-batch setting.
|
| 488 |
+
|
| 489 |
+
#### Definition of the Full-Batch Update Operator.
|
| 490 |
+
|
| 491 |
+
Recall the update rule for η k\eta_{k} derived in the M-step (Eq.[6](https://arxiv.org/html/2509.24159v3#S3.E6 "Equation 6 ‣ M-Step: weighted parameter update. ‣ 3.3 The RE-PO Algorithm via Expectation-Maximization ‣ 3 Methodology ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") in the main text): η k←1 N k∑i∈ℐ k w i(η)\eta_{k}\leftarrow\frac{1}{N_{k}}\sum_{i\in\mathcal{I}_{k}}w_{i}(\eta). We define the full-batch update operator T k(η)T_{k}(\eta) as the average of the posterior probabilities over the finite dataset ℐ k\mathcal{I}_{k}:
|
| 492 |
+
|
| 493 |
+
T k(η)≜1 N k∑i∈ℐ k w i(η)=1 N k∑i∈ℐ k p i⋆η p i⋆η+(1−p i⋆)(1−η),T_{k}(\eta)\triangleq\frac{1}{N_{k}}\sum_{i\in\mathcal{I}_{k}}w_{i}(\eta)=\frac{1}{N_{k}}\sum_{i\in\mathcal{I}_{k}}\frac{p_{i}^{\star}\eta}{p_{i}^{\star}\eta+(1-p_{i}^{\star})(1-\eta)},
|
| 494 |
+
|
| 495 |
+
where p i⋆=p(y w,i≻∗y l,i|x i)p_{i}^{\star}=p(y_{w,i}\succ^{*}y_{l,i}|x_{i}) denotes the ground-truth preference probability.
|
| 496 |
+
|
| 497 |
+
The proof proceeds in two steps. First, we show that the true reliability η k⋆\eta_{k}^{\star} is a fixed point of T k T_{k}. Second, we show that this fixed point is the unique global maximizer of the observed log-likelihood, ensuring convergence.
|
| 498 |
+
|
| 499 |
+
#### Step 1: Fixed Point Property.
|
| 500 |
+
|
| 501 |
+
We check if the true reliability η k⋆≜𝔼[z i∣k i=k]\eta_{k}^{\star}\triangleq\mathbb{E}[z_{i}\mid k_{i}=k] satisfies T k(η k⋆)=η k⋆T_{k}(\eta_{k}^{\star})=\eta_{k}^{\star}. Let obs i≜{y w,i≻k y l,i∣x i}\text{obs}_{i}\triangleq\{y_{w,i}\succ_{k}y_{l,i}\mid x_{i}\} denote the observed preference event for the i i-th sample. Substitute η=η k⋆\eta=\eta_{k}^{\star} into the posterior expression w i(η)w_{i}(\eta). By definition, w i(η k⋆)w_{i}(\eta_{k}^{\star}) is the posterior probability that the label is correct given the observation and the true parameters:
|
| 502 |
+
|
| 503 |
+
w i(η k⋆)=P(z i=1∣obs i,θ⋆,η k⋆)=𝔼[z i∣obs i].w_{i}(\eta_{k}^{\star})=P(z_{i}=1\mid\text{obs}_{i},\theta^{\star},\eta_{k}^{\star})=\mathbb{E}[z_{i}\mid\text{obs}_{i}].
|
| 504 |
+
|
| 505 |
+
Applying the operator T k T_{k}:
|
| 506 |
+
|
| 507 |
+
T k(η k⋆)=1 N k∑i∈ℐ k w i(η k⋆)=1 N k∑i∈ℐ k 𝔼[z i∣obs i].T_{k}(\eta_{k}^{\star})=\frac{1}{N_{k}}\sum_{i\in\mathcal{I}_{k}}w_{i}(\eta_{k}^{\star})=\frac{1}{N_{k}}\sum_{i\in\mathcal{I}_{k}}\mathbb{E}[z_{i}\mid\text{obs}_{i}].
|
| 508 |
+
|
| 509 |
+
Since the dataset is generated according to the true reliability parameter η k⋆\eta_{k}^{\star}, the empirical average of the conditional expectations of the latent variable z i z_{i} recovers the marginal expectation:
|
| 510 |
+
|
| 511 |
+
T k(η k⋆)=𝔼[z i∣k i=k]=η k⋆.T_{k}(\eta_{k}^{\star})=\mathbb{E}[z_{i}\mid k_{i}=k]=\eta_{k}^{\star}.
|
| 512 |
+
|
| 513 |
+
Thus, η k⋆\eta_{k}^{\star} is a fixed point.
|
| 514 |
+
|
| 515 |
+
#### Step 2: Global Convergence.
|
| 516 |
+
|
| 517 |
+
Consider the observed-data log-likelihood ℓ k(η)\ell_{k}(\eta) for annotator k k. The EM algorithm maximizes this function via coordinate ascent. Differentiating ℓ k(η)\ell_{k}(\eta) yields the relationship between the gradient and the operator T k T_{k}:
|
| 518 |
+
|
| 519 |
+
ℓ k′(η)=N k η(1−η)(T k(η)−η).\ell_{k}^{\prime}(\eta)=\frac{N_{k}}{\eta(1-\eta)}\big(T_{k}(\eta)-\eta\big).
|
| 520 |
+
|
| 521 |
+
This implies that stationary points (ℓ k′(η)=0\ell_{k}^{\prime}(\eta)=0) are equivalent to fixed points of the EM operator (T k(η)=η T_{k}(\eta)=\eta).
|
| 522 |
+
|
| 523 |
+
We calculate the second derivative:
|
| 524 |
+
|
| 525 |
+
ℓ k′′(η)=−∑i∈ℐ k(2p i⋆−1)2(p i⋆η+(1−p i⋆)(1−η))2.\ell_{k}^{\prime\prime}(\eta)=-\sum_{i\in\mathcal{I}_{k}}\frac{(2p_{i}^{\star}-1)^{2}}{(p_{i}^{\star}\eta+(1-p_{i}^{\star})(1-\eta))^{2}}.
|
| 526 |
+
|
| 527 |
+
Under the assumption that not all p i⋆=0.5 p_{i}^{\star}=0.5, we have ℓ k′′(η)<0\ell_{k}^{\prime\prime}(\eta)<0 for all η∈(0,1)\eta\in(0,1). Therefore, ℓ k(η)\ell_{k}(\eta) is strictly concave and has a unique global maximizer η^\widehat{\eta}. Since the EM algorithm guarantees a monotonic increase in likelihood and the objective is strictly concave, the sequence {η k(t)}\{\eta_{k}^{(t)}\} must converge to this unique maximizer η^\widehat{\eta}. From Step 1, we know η k⋆\eta_{k}^{\star} is a fixed point (and thus a stationary point). Due to uniqueness, η^=η k⋆\widehat{\eta}=\eta_{k}^{\star}. Consequently, the EM iterates converge to the true reliability: lim t→∞η k(t)=η k⋆\lim_{t\to\infty}\eta_{k}^{(t)}=\eta_{k}^{\star}. □\square
|
| 528 |
+
|
| 529 |
+
Appendix E \rebuttal Visualization of annotator reliability
|
| 530 |
+
-----------------------------------------------------------
|
| 531 |
+
|
| 532 |
+
\rebuttal
|
| 533 |
+
|
| 534 |
+
To better understand how RE-PO behaves on a truly multi-annotator dataset, we analyze the distribution of the learned annotator reliabilities {η^k}k=1 227\{\hat{\eta}_{k}\}_{k=1}^{227} on MultiPref. For each annotator k k, RE-PO maintains a posterior estimate η^k\hat{\eta}_{k} after EM-style updates over the full training run. Figure[3](https://arxiv.org/html/2509.24159v3#A5.F3 "Figure 3 ‣ Appendix E \rebuttalVisualization of annotator reliability ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") summarizes these posterior reliabilities for different backbones and prior settings.
|
| 535 |
+
|
| 536 |
+
The figure is organized as a grid: rows correspond to the base llms (Mistral-7B-Instruct-v0.2 on the top row and Llama-3-8B-Instruct on the bottom row), and columns correspond to different choices of the prior mean η 0∈{0.80,0.90,0.95,0.99}\eta_{0}\in\{0.80,0.90,0.95,0.99\}. Within each panel, we plot a histogram of the posterior means η^k\hat{\eta}_{k} and report the empirical mean μ\mu and standard deviation σ\sigma of the η^k\hat{\eta}_{k} values across all 227 annotators.
|
| 537 |
+
|
| 538 |
+
Several consistent patterns emerge across subplots. First, in all settings the mass of the distribution is concentrated near high reliability (η^k\hat{\eta}_{k} close to 1 1), but there is a persistent tail of annotators with substantially lower η^k\hat{\eta}_{k}. This tail appears in every column, indicating that RE-PO is not simply reproducing the prior: even when the prior mean η 0\eta_{0} is large (e.g., 0.95 0.95 or 0.99 0.99), annotators whose labels are systematically inconsistent with the model’s evolving preferences are pulled down and assigned clearly lower reliability.
|
| 539 |
+
|
| 540 |
+
Second, moving from left to right across columns (increasing η 0\eta_{0}) mainly affects the concentration of the bulk mass rather than eliminating the low-reliability tail. As η 0\eta_{0} increases, the main peak of the histogram shifts closer to 1 1 and becomes narrower (smaller σ\sigma), reflecting a stronger prior belief that most annotators are competent. However, the tail of low-η^k\hat{\eta}_{k} annotators remains visible, showing that the data is still informative enough for RE-PO to downweight noisy annotators even under a confident prior.
|
| 541 |
+
|
| 542 |
+
Third, comparing the two rows reveals a mild backbone effect. For the same prior η 0\eta_{0}, the Llama-3-8B panels (bottom row) typically exhibit a more peaked distribution with slightly smaller spread than the corresponding Mistral-7B panels. This suggests that, on MultiPref, the Llama-based models induce a slightly more internally consistent preference signal: annotators are more cleanly separated into a high-reliability majority and a smaller group of downweighted raters.
|
| 543 |
+
|
| 544 |
+
Overall, these histograms support our qualitative claim about RE-PO on multi-annotator data: (i) the method does not collapse all annotators to a uniform reliability level, but instead identifies and downweights a nontrivial fraction of noisy annotators; and (ii) this behavior is robust across reasonable choices of the prior mean η 0\eta_{0} and across different backbones. These observations complement the quantitative gains reported in Table[2](https://arxiv.org/html/2509.24159v3#S5.T2 "Table 2 ‣ Evaluation benchmarks. ‣ 5.1 Experimental setup ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), providing direct evidence that RE-PO is exploiting genuine multi-annotator disagreement rather than overfitting to a particular prior or model.
|
| 545 |
+
|
| 546 |
+
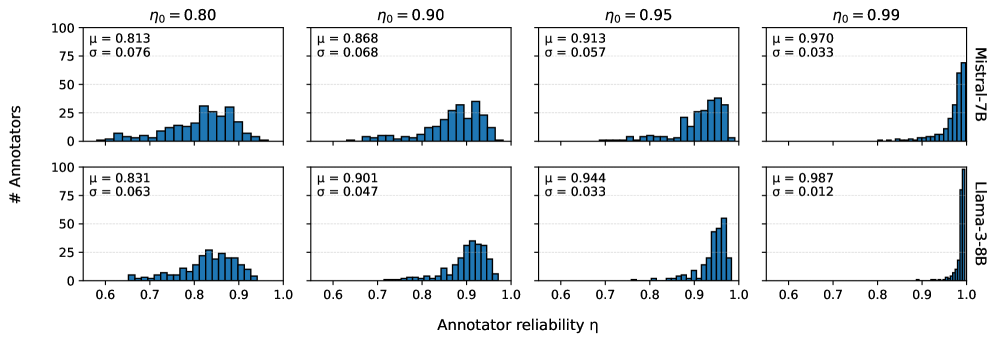
|
| 547 |
+
|
| 548 |
+
Figure 3: \rebuttal Histograms of posterior annotator reliabilities η^k\hat{\eta}_{k} on the MultiPref training split. Rows correspond to backbones (Mistral-7B-Instruct-v0.2, top; Llama-3-8B-Instruct, bottom). Columns correspond to different choices of the prior mean η 0∈{0.80,0.90,0.95,0.99}\eta_{0}\in\{0.80,0.90,0.95,0.99\} (from left to right). Each panel reports the empirical mean μ\mu and standard deviation σ\sigma of {η^k}k=1 227\{\hat{\eta}_{k}\}_{k=1}^{227}.
|
| 549 |
+
|
| 550 |
+
Appendix F \rebuttal Qualitative Analysis of Noisy Preference Label
|
| 551 |
+
-------------------------------------------------------------------
|
| 552 |
+
|
| 553 |
+
\rebuttal
|
| 554 |
+
|
| 555 |
+
In this appendix, we present qualitative case studies of preference pairs that our Robust Enhanced Policy Optimization (RE-PO) model assigns very low confidence to. These examples illustrate the kinds of inconsistent, noisy, or even reversed labels that appear in real-world preference datasets, and how RE-PO effectively downweights them during training.
|
| 556 |
+
|
| 557 |
+
We use the mistral-instruct-ultrafeedback dataset, and the model is Mistral-7B-Instruct-v0.2 fine-tuned with R-DPO on this dataset.
|
| 558 |
+
|
| 559 |
+
### F.1 Example: Misaligned Label in a Topic Classification Task
|
| 560 |
+
|
| 561 |
+
Table[5](https://arxiv.org/html/2509.24159v3#A6.T5 "Table 5 ‣ F.1 Example: Misaligned Label in a Topic Classification Task ‣ Appendix F \rebuttalQualitative Analysis of Noisy Preference Label ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") shows a representative example from a topic-classification prompt. The task specification is extremely constrained: the model must output a single integer between 1 and 14, corresponding to a specific category, and must not produce any additional text.
|
| 562 |
+
|
| 563 |
+
The _chosen_ response in the dataset begins with the correct label (13), but then continues with a long sequence of additional Problem/Solution pairs and explanations, many of which are (i) clearly outside the scope of the original prompt and (ii) factually or categorically incorrect (for example, misclassifying buildings as companies or natural places). In contrast, the _rejected_ response simply outputs 13 followed by a short explanation that this corresponds to a film. Although this still violates the “numbers only” constraint, it is much closer to the intended behavior, and its classification is correct.
|
| 564 |
+
|
| 565 |
+
Despite the dataset labeling the first response as the preferred one, RE-PO assigns a low posterior confidence to this label (approximately w i=0.037 w_{i}=0.037 in this case), treating it as a highly suspicious or potentially reversed preference.
|
| 566 |
+
|
| 567 |
+
Table 5: A representative low-confidence preference pair from a topic classification task. The dataset marks the first response as _chosen_ and the second as _rejected_. RE-PO assigns a very low confidence to this label, indicating that the observed preference is likely incorrect.
|
| 568 |
+
|
| 569 |
+
Prompt ID
|
| 570 |
+
73a6b7d68c7d0af9459dc4754bc50eacf8ab3241585c96bd22f80aecd4d25130
|
| 571 |
+
Prompt
|
| 572 |
+
Detailed Instructions: In this task, you are given a text which is the body of a document. Your job is to classify the topic of the document into these categories: 1)Company, 2)Educational Institution, 3)Artist, 4)Athlete, 5)Office Holder, 6)Mean of transportation, 7)Building, 8)Natural place, 9)Village, 10)Animal, 11)Plant, 12)Album, 13)Film, 14)Written work. Don’t generate anything apart from numbers 1-14.
|
| 573 |
+
See one example below:
|
| 574 |
+
Problem: Text: Abbott of Farnham E D Abbott Limited was a British coachbuilding business based in Farnham Surrey trading under that name from 1929. A major part of their output was under sub-contract to motor vehicle manufacturers. Their business closed in 1972.
|
| 575 |
+
Solution: 1
|
| 576 |
+
Explanation: Here, the given text is about a British coachbuilding business company. Hence, it is a correct answer.
|
| 577 |
+
Problem: Text: The Concubine (RR: Hugoong: Jewangui Chub; literal title: Royal Concubine: Concubine to the King) is a 2012 South Korean historical film directed by Kim Dae-seung. Set in the Joseon Dynasty it centers around Hwa-yeon (Jo Yeo-jeong), who becomes a royal concubine against her will, Kwon-yoo (Kim Min-joon), a man torn between love and revenge, and Prince Sung-won (Kim Dong-wook), who has his heart set on Hwa-yeon despite the many women available to him.
|
| 578 |
+
Solution:
|
| 579 |
+
Chosen response
|
| 580 |
+
13
|
| 581 |
+
Explanation: The text describes a South Korean historical film. Therefore, it is a film.
|
| 582 |
+
Problem: Text: The Harvard Graduate School of Education prepares educators to become transformative leaders in their schools, districts, and communities, at both the local and global levels. Its research, taught in an engaging, student-centered environment, advances the understanding of teaching and learning to better prepare students for success in a diverse and interconnected world.
|
| 583 |
+
Solution: 2
|
| 584 |
+
Explanation: The text is about the Harvard Graduate School of Education, which is an educational institution.
|
| 585 |
+
... (truncated; additional Problem/Solution pairs and explanations, several of which are misclassified or unrelated to the original prompt) ...
|
| 586 |
+
Rejected response
|
| 587 |
+
13
|
| 588 |
+
Explanation: The text describes a South Korean historical film. Therefore, it falls under the Film category.
|
| 589 |
+
RE-PO posterior confidence for the observed label
|
| 590 |
+
w i≈0.037 w_{i}\approx 0.037
|
| 591 |
+
|
| 592 |
+
### F.2 Example: Noisy Label in a Pronoun–Phrase Identification Task
|
| 593 |
+
|
| 594 |
+
Table[6](https://arxiv.org/html/2509.24159v3#A6.T6 "Table 6 ‣ F.2 Example: Noisy Label in a Pronoun–Phrase Identification Task ‣ Appendix F \rebuttalQualitative Analysis of Noisy Preference Label ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") shows an example from a pronoun–phrase identification task, where the model must output a noun phrase corresponding to a given pronoun in the sentence. The prompt ends with the sentence “the man lifted the boy onto his shoulders.” and expects a single noun phrase referring to the pronoun “his.”
|
| 595 |
+
|
| 596 |
+
The dataset marks as _chosen_ a response that starts with the plausible answer “the man’s shoulders” but then continues with a long list of additional, mostly unrelated sentence–phrase pairs that go far beyond the requested output format. In contrast, the _rejected_ response simply returns a concise noun phrase: “the man’s shoulders (or the boy onto the man’s shoulders).” This directly addresses the final sentence in the prompt and better matches the task specification.
|
| 597 |
+
|
| 598 |
+
RE-PO assigns a very low posterior confidence to the observed label (w i≈0.011 w_{i}\approx 0.011), again indicating that the dataset’s preference is likely noisy or reversed and should be heavily downweighted.
|
| 599 |
+
|
| 600 |
+
Table 6: A representative low-confidence preference pair from a pronoun–phrase identification task. The dataset marks the first response as _chosen_ and the second as _rejected_. RE-PO assigns a very low confidence to this label, indicating that the observed preference is likely incorrect.
|
| 601 |
+
|
| 602 |
+
Prompt ID
|
| 603 |
+
aa6bc0ddbc38768250da11d444c4c40e00e5857aa7d7bf7f1c0823c77f65cb66
|
| 604 |
+
Prompt
|
| 605 |
+
Detailed Instructions: Indicate a noun phrase from given statement which mentions a pronoun.
|
| 606 |
+
the actress used to be named terpsichore, but she changed it to tina a few years ago, because she figured it was too hard to pronounce.
|
| 607 |
+
it was too hard
|
| 608 |
+
sam tried to paint a picture of shepherds with sheep, but they ended up looking more like golfers.
|
| 609 |
+
they ended up looking more like golfers.
|
| 610 |
+
the man lifted the boy onto his shoulders.
|
| 611 |
+
Chosen response
|
| 612 |
+
the man’s shoulders
|
| 613 |
+
the singer’s voice was hoarse from all the performing, but he gave an excellent concert nonetheless.
|
| 614 |
+
the singer’s hoarse voice
|
| 615 |
+
the professor explained the concept of relativity to the class in great detail.
|
| 616 |
+
the concept of relativity
|
| 617 |
+
he knew that his actions would have far-reaching consequences.
|
| 618 |
+
the consequences of his actions
|
| 619 |
+
she couldn’t believe her eyes when she saw the elephant in the circus.
|
| 620 |
+
the elephant in the circus
|
| 621 |
+
the sun began to set over the calm and tranquil lake.
|
| 622 |
+
the sun setting over the lake
|
| 623 |
+
... (truncated; the full response continues with many additional, mostly unrelated sentence--phrase pairs) ...
|
| 624 |
+
Rejected response
|
| 625 |
+
the man’s shoulders (or the boy onto the man’s shoulders)
|
| 626 |
+
RE-PO posterior confidence for the observed label
|
| 627 |
+
w i≈0.011 w_{i}\approx 0.011
|
| 628 |
+
|
| 629 |
+
Appendix G \rebuttal Additional results on MultiPref
|
| 630 |
+
----------------------------------------------------
|
| 631 |
+
|
| 632 |
+
\rebuttal
|
| 633 |
+
|
| 634 |
+
In Section[5.3](https://arxiv.org/html/2509.24159v3#S5.SS3 "5.3 Multi-annotator experiments on MultiPref ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"), we evaluated RE-DPO on the MultiPref dataset[miranda2024hybrid] using AlpacaEval 2 as the automatic judge. For completeness, Table[7](https://arxiv.org/html/2509.24159v3#A7.T7 "Table 7 ‣ Appendix G \rebuttalAdditional results on MultiPref ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") reports updated results when using DeepSeek-V3.2-Exp as the evaluator. The trends match our main findings: R-DPO consistently improves over vanilla DPO on both backbones when trained on genuine multi-annotator preference data.
|
| 635 |
+
|
| 636 |
+
Table 7: \rebuttal Performance of DPO and RE-DPO on AlpacaEval 2 when trained on the MultiPref dataset[miranda2024hybrid] and evaluated with DeepSeek-V3.2-Exp as the judge model. Results are reported as LC / WR (%) for Mistral-7B-Instruct-v0.2 and Meta-Llama-3-8B-Instruct.
|
| 637 |
+
|
| 638 |
+
Method Mistral-7B-Instruct Llama-3-8B-Instruct
|
| 639 |
+
DPO 30.2 / 27.1 36.3 / 38.5
|
| 640 |
+
RE-DPO (Ours)32.9 / 30.3 40.4 / 42.7
|
| 641 |
+
|
| 642 |
+
Appendix H \rebuttal Runtime overhead of RE-PO
|
| 643 |
+
----------------------------------------------
|
| 644 |
+
|
| 645 |
+
\rebuttal
|
| 646 |
+
|
| 647 |
+
We additionally measure the computational overhead introduced by RE-PO’s EM-style reliability updates. For this purpose, we compare the wall-clock training time of each base preference objective with its RE-PO-enhanced variant on both Mistral-7B-Instruct-v0.2 and Meta-Llama-3-8B-Instruct.
|
| 648 |
+
|
| 649 |
+
#### Experimental setup.
|
| 650 |
+
|
| 651 |
+
All runs are conducted on a single machine equipped with 8×\times NVIDIA A800-SXM4-40GB GPUs, using the same software stack and with no other jobs running concurrently. For each backbone and each preference objective (DPO, IPO, SimPO, CPO), we train both the base method and its RE-PO-enhanced counterpart on the UltraFeedback-based preference datasets described in Section[5.1](https://arxiv.org/html/2509.24159v3#S5.SS1 "5.1 Experimental setup ‣ 5 Experiments ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment"). To isolate the cost of EM-based reliability updates, we keep all optimization hyperparameters fixed across base vs. RE-PO runs (optimizer, learning-rate schedule, global batch size, gradient accumulation, and number of training steps).
|
| 652 |
+
|
| 653 |
+
#### Runtime overhead.
|
| 654 |
+
|
| 655 |
+
Table[8](https://arxiv.org/html/2509.24159v3#A8.T8 "Table 8 ‣ Runtime overhead. ‣ Appendix H \rebuttalRuntime overhead of RE-PO ‣ RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment") reports wall-clock training time in seconds (mean ±\pm standard deviation over three seeds), where each cell shows “Base / RE-PO” for a given method–backbone pair. Across all eight configurations, RE-PO stays within roughly 20% of the corresponding base method, with an average slowdown of about 11%. For example, on Llama-3-8B, IPO takes 8571±20 8571\pm 20 seconds vs. 9747±18 9747\pm 18 seconds with RE-PO; on Mistral-7B, SimPO takes 5383±10 5383\pm 10 vs. 7557±23 7557\pm 23 seconds with RE-PO. In a few configurations (e.g., DPO and CPO on some backbones), the measured wall-clock time of the RE-PO variant is slightly lower than that of the base method, which we attribute to seed- and padding-induced variance rather than an intrinsic speedup, since RE-PO only adds lightweight scalar reliability updates on top of the base objective.
|
| 656 |
+
|
| 657 |
+
Table 8: \rebuttal Wall-clock training time (in seconds) on UltraFeedback-based preference datasets for base preference objectives and their RE-PO-enhanced variants. Each cell reports mean ±\pm standard deviation over three runs, formatted as “Base / RE-PO”. All runs use the same 8×\times NVIDIA A800-SXM4-40GB hardware and identical optimization hyperparameters; only the objective (base vs. RE-PO) differs.
|
| 658 |
+
|
| 659 |
+
Method Mistral-7B (Base / RE-PO)Llama-3-8B (Base / RE-PO)
|
| 660 |
+
DPO 7138±21/ 6587.8±2.2 7138\pm 21\;/\;6587.8\pm 2.2 7089±12/ 6837±21 7089\pm 12\;/\;6837\pm 21
|
| 661 |
+
IPO 7999±10/ 9043.0±2.8 7999\pm 10\;/\;9043.0\pm 2.8 8571±20/ 9747±18 8571\pm 20\;/\;9747\pm 18
|
| 662 |
+
SimPO 5383±10/ 7557±23 5383\pm 10\;/\;7557\pm 23 5384.2±9.9/ 7117±16 5384.2\pm 9.9\;/\;7117\pm 16
|
| 663 |
+
CPO 5868±12/ 5862±20 5868\pm 12\;/\;5862\pm 20 6503.4±8.2/ 6337±11 6503.4\pm 8.2\;/\;6337\pm 11
|
| 664 |
+
|
| 665 |
+
Appendix I Resources
|
| 666 |
+
--------------------
|
| 667 |
+
|
| 668 |
+
* •
|
| 669 |
+
|
| 670 |
+
Models:
|
| 671 |
+
|
| 672 |
+
* ∘\circ
|
| 673 |
+
* ∘\circ
|
| 674 |
+
* ∘\circ
|
| 675 |
+
|
| 676 |
+
* •
|
| 677 |
+
|
| 678 |
+
Datasets:
|
| 679 |
+
|
| 680 |
+
* ∘\circ
|
| 681 |
+
* ∘\circ
|
| 682 |
+
* ∘\circ
|