

Add 1 files
Browse files- 2404/2404.12386.md +343 -0
2404/2404.12386.md
ADDED
|
@@ -0,0 +1,343 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
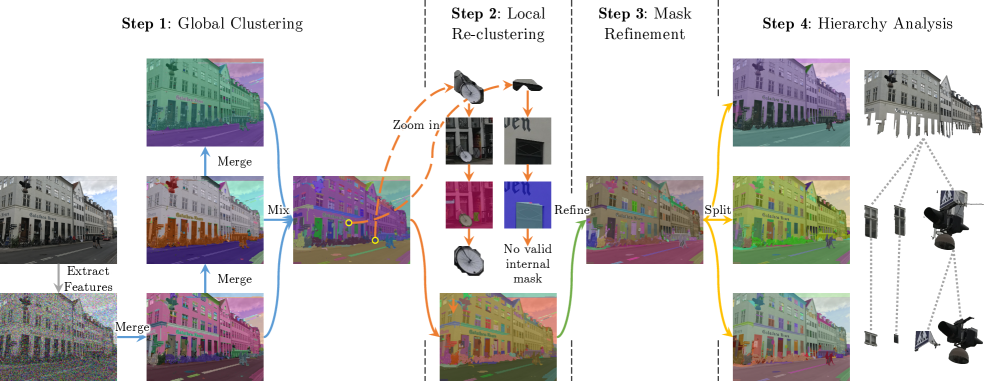
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
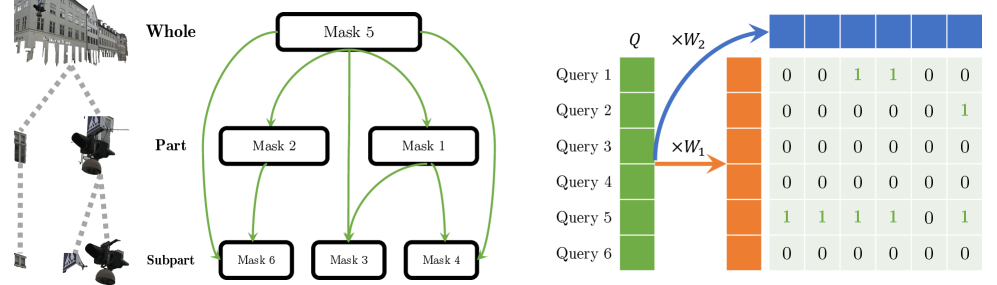
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
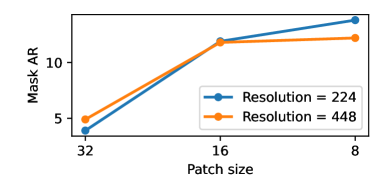
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Self-supervised Open-world Hierarchical Entity Segmentation
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2404.12386
|
| 4 |
+
|
| 5 |
+
Published Time: Fri, 17 Oct 2025 00:31:26 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
Shengcao Cao 1 Jiuxiang Gu 2 Jason Kuen 2 Hao Tan 2 Ruiyi Zhang 2
|
| 9 |
+
|
| 10 |
+
Handong Zhao 2 Ani Nenkova 2 Liang-Yan Gui 1 Tong Sun 2 Yu-Xiong Wang 1
|
| 11 |
+
|
| 12 |
+
1 University of Illinois Urbana-Champaign 2 Adobe Research
|
| 13 |
+
|
| 14 |
+
{cao44,lgui,yxw}@illinois.edu
|
| 15 |
+
|
| 16 |
+
{jigu,kuen,hatan,ruizhang,hazhao,nenkova,tsun}@adobe.com
|
| 17 |
+
|
| 18 |
+
###### Abstract
|
| 19 |
+
|
| 20 |
+
Open-world entity segmentation, as an emerging computer vision task, aims at segmenting entities in images without being restricted by pre-defined classes, offering impressive generalization capabilities on unseen images and concepts. Despite its promise, existing entity segmentation methods like Segment Anything Model (SAM) rely heavily on costly expert annotators. This work presents Self-supervised Open-world Hierarchical Entity Segmentation (SOHES), a novel approach that eliminates the need for human annotations. SOHES operates in three phases: self-exploration, self-instruction, and self-correction. Given a pre-trained self-supervised representation, we produce abundant high-quality pseudo-labels through visual feature clustering. Then, we train a segmentation model on the pseudo-labels, and rectify the noises in pseudo-labels via a teacher-student mutual-learning procedure. Beyond segmenting entities, SOHES also captures their constituent parts, providing a hierarchical understanding of visual entities. Using raw images as the sole training data, our method achieves unprecedented performance in self-supervised open-world segmentation, marking a significant milestone towards high-quality open-world entity segmentation in the absence of human-annotated masks. Project page: [https://SOHES-ICLR.github.io](https://sohes-iclr.github.io/).
|
| 21 |
+
|
| 22 |
+

|
| 23 |
+
|
| 24 |
+
Figure 1: SOHES boosts open-world entity segmentation with self-supervision on various image datasets. Compared to prior state of the art, SOHES significantly reduces the gap between self-supervised methods and the supervised Segment Anything Model (SAM)(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)), yet using only 2% unlabeled image data as SAM.
|
| 25 |
+
|
| 26 |
+
1 Introduction
|
| 27 |
+
--------------
|
| 28 |
+
|
| 29 |
+
Open-world entity segmentation(Qi et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib35); [2023](https://arxiv.org/html/2404.12386v2#bib.bib36)) is an emerging vision task for localizing semantically coherent visual entities without the constraints of pre-defined classes. This task, in contrast to traditional segmentation(Long et al., [2015](https://arxiv.org/html/2404.12386v2#bib.bib34); Chen et al., [2017](https://arxiv.org/html/2404.12386v2#bib.bib7); He et al., [2017](https://arxiv.org/html/2404.12386v2#bib.bib19); Kirillov et al., [2019](https://arxiv.org/html/2404.12386v2#bib.bib27)), aims at creating segmentation masks for visual entities inclusive of both “things” (countable objects such as persons and cars) and “stuff” (amorphous regions such as sea and sky)(Kirillov et al., [2019](https://arxiv.org/html/2404.12386v2#bib.bib27); Qi et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib35)), without regard for class labels. The inherent inclusivity and class-agnostic nature enable open-world entity segmentation to perform strongly on unfamiliar entities from unseen image domains, a frequent real-world challenge in applications such as image editing and robotics. A prominent model for this task is Segment Anything Model (SAM)(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)), which has garnered enthusiastic attention for its impressive performance in open-world segmentation. However, the efficacy of models like SAM depends on the avilability of extensively annotated datasets. To illustrate, SAM is trained on SA-1B(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)), a vast dataset comprising 11 million images and an enormous amount of 1 billion segmentation masks. While automated segmentation plays a central role in building SA-1B, human expertise and manual labor are similarly important, where it takes 14 to 34 seconds to annotate a mask. Meanwhile, it is challenging for human annotators to produce segmentation masks at a consistent granularity, because there is no universally agreed definition of objects and parts. This reliance on intricately annotated datasets and considerable human effort raises a compelling question: _Can we develop a high-quality open-world segmentation model using pure self-supervision?_ The prospect of learning from unlabeled raw images without the need for expert annotations is highly appealing.
|
| 30 |
+
|
| 31 |
+
In fact, self-supervised visual representation learning(Chen et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib8); He et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib20); Caron et al., [2021](https://arxiv.org/html/2404.12386v2#bib.bib6); He et al., [2022b](https://arxiv.org/html/2404.12386v2#bib.bib21)) has already shown promise. Such models can effectively exploit useful training signals from purely unlabeled images, resulting in high-quality visual representations that are comparable with those achieved via supervised learning. However, mainstream self-supervised representation learning approaches typically learn holistic representations for whole images, without distinguishing individual entities nor understanding region-level structures. As a result, they cannot be directly used to achieve open-world entity segmentation. Our key insight to bridge this gap is that an intelligent model can _not only learn representations from observations, but can also self-evolve to explore the open world, instruct and generalize itself, continuously refine and correct its predictions in a self-supervised manner_, and ultimately achieve open-world segmentation.
|
| 32 |
+
|
| 33 |
+
Following this key insight, we propose _Self-supervised Open-world Hierarchical Entity Segmentation (SOHES)_, a novel approach consisting of three phases – 1) Self-exploration: Starting from a pre-trained self-supervised representation DINO(Caron et al., [2021](https://arxiv.org/html/2404.12386v2#bib.bib6)), we generate initial pseudo-labels to learn from. By clustering visual features based on similarity and locality, we can discern semantically coherent continuous regions that likely represent visually meaningful entities. 2) Self-instruction: Our initial pseudo-labels are constrained by the fixed visual representation. To refine the segmentation, we train a Mask2Former(Cheng et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib10)) segmentation model on the initial pseudo-labels. Even though the initial pseudo-labels are noisy, learning a segmentation model on them can “average out” the noises, thus predicting more accurate masks. 3) Self-correction: Building upon these more accurate predictions, we employ a teacher-student mutual-learning framework(Tarvainen & Valpola, [2017](https://arxiv.org/html/2404.12386v2#bib.bib43); Liu et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib33)) to further reduce the early-stage noises and adapt the model for open-world segmentation. Throughout the three phases, we rely solely on the raw images, without any human annotations. Equally significantly, due to the compositional nature of things and stuff in natural scenes, our model learns not just to segment entities but also their constituent parts and finer subparts of these parts. During the self-exploration phase, we generate a hierarchical structure of each visual entity from individual parts to the whole. This hierarchical segmentation approach enriches our understanding of visual elements in an open-world context, ensuring a more comprehensive and versatile application.
|
| 34 |
+
|
| 35 |
+
To summarize, our key contributions include:
|
| 36 |
+
|
| 37 |
+
* •We propose Self-supervised Open-world Hierarchical Entity Segmentation (SOHES) to address the open-world segmentation challenge. We demonstrate the potential of high-quality open-world segmentation by adapting self-supervised representations and learning solely from unlabeled data.
|
| 38 |
+
* •We develop a method to generate over 100 segmentation masks per image as high-quality pseudo-labels by clustering self-supervised visual features.
|
| 39 |
+
* •We learn to segment entities and their constituent parts and perform hierarchical association between visual entities. This hierarchical segmentation approach provides a multi-granularity analysis of visual entities in complex scenes.
|
| 40 |
+
* •We achieve new state-of-the-art performance in self-supervised open-world segmentation, which enhances mask average recall (AR) on various datasets (_e.g_., improving AR on SA-1B(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)) from 26.0 to 33.3) and closes the performance gap between self-supervised and supervised paradigms, as illustrated in Figure[1](https://arxiv.org/html/2404.12386v2#S0.F1 "Figure 1 ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation").
|
| 41 |
+
|
| 42 |
+
2 Related Work
|
| 43 |
+
--------------
|
| 44 |
+
|
| 45 |
+
Open-world visual recognition. Open-world recognition(Scheirer et al., [2012](https://arxiv.org/html/2404.12386v2#bib.bib38); Bendale & Boult, [2015](https://arxiv.org/html/2404.12386v2#bib.bib2); [2016](https://arxiv.org/html/2404.12386v2#bib.bib3)) aims to recognize and classify visual concepts in an evolving environment where the model encounters unfamiliar objects, which challenges traditional models trained to recognize a fixed set of classes. The task has been extended from classification to detection(Bansal et al., [2018](https://arxiv.org/html/2404.12386v2#bib.bib1); Dhamija et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib13); Joseph et al., [2021](https://arxiv.org/html/2404.12386v2#bib.bib24); Jaiswal et al., [2021](https://arxiv.org/html/2404.12386v2#bib.bib23); Kim et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib26)), segmentation(Hu et al., [2018](https://arxiv.org/html/2404.12386v2#bib.bib22); Wang et al., [2021](https://arxiv.org/html/2404.12386v2#bib.bib48); [2022a](https://arxiv.org/html/2404.12386v2#bib.bib49); Kalluri et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib25)), and tracking(Liu et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib32)). In particular, open-world entity segmentation(Qi et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib35); [2023](https://arxiv.org/html/2404.12386v2#bib.bib36)) segments entities into semantically meaningful regions without regard for class labels. In this work, we further expand the scope to whole entities and their constituent parts.
|
| 46 |
+
|
| 47 |
+
Self-supervised object localization/discovery. Localizing objects from images in a self-supervised manner requires learning the concept of objects from visual data without any human annotations. Early explorations(Vo et al., [2019](https://arxiv.org/html/2404.12386v2#bib.bib45); [2020](https://arxiv.org/html/2404.12386v2#bib.bib46); [2021](https://arxiv.org/html/2404.12386v2#bib.bib47)) formulate an optimization problem on a graph, where the nodes are object proposals (_e.g_., by selective search(Uijlings et al., [2013](https://arxiv.org/html/2404.12386v2#bib.bib44))) and the edges are constructed based on visual similarities. Following the observation that the segmentation of the most prominent object can emerge from DINO(Caron et al., [2021](https://arxiv.org/html/2404.12386v2#bib.bib6)), Siméoni et al. ([2021](https://arxiv.org/html/2404.12386v2#bib.bib41); [2023](https://arxiv.org/html/2404.12386v2#bib.bib42)); Wang et al. ([2022b](https://arxiv.org/html/2404.12386v2#bib.bib50)) learn object detectors from saliency-based pseudo-labels. Meanwhile, Wang et al. ([2022c](https://arxiv.org/html/2404.12386v2#bib.bib52); [2023](https://arxiv.org/html/2404.12386v2#bib.bib51)) generate pseudo-labels by extending NormCut(Shi & Malik, [2000](https://arxiv.org/html/2404.12386v2#bib.bib40)), and Cao et al. ([2023](https://arxiv.org/html/2404.12386v2#bib.bib5)) cluster semantically coherent regions into pseudo-labels. We share a common multi-phase learning paradigm with these prior methods, where pseudo-labels are first discovered from self-supervised representations, and then a detection/segmentation model is learned. However, we contribute _novel and improved designs to each phase_, including 1) a global-to-local clustering algorithm for high-quality pseudo-labeling, 2) a hierarchical relation learning module, and 3) a teacher-student self-correction phase.
|
| 48 |
+
|
| 49 |
+
3 Approach
|
| 50 |
+
----------
|
| 51 |
+
|
| 52 |
+
In this section, we first provide an overview of _Self-supervised Open-world Hierarchical Entity Segmentation (SOHES)_ and then present its three learning phases in the following subsections.
|
| 53 |
+
|
| 54 |
+

|
| 55 |
+
|
| 56 |
+
Figure 2: Three phases of SOHES. In the first self-exploration phase, we cluster visual features from pre-trained DINO to generate initial pseudo-labels on unlabeled images. Then in the self-instruction phase, a segmentation model learns from the initial pseudo-labels. Finally, in the self-correction phase, we adopt a teacher-student framework to further refine the segmentation model.
|
| 57 |
+
|
| 58 |
+
Building upon and significantly enhancing the pseudo-label discovery and learning paradigm in prior self-supervised object discovery work(Siméoni et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib42); Wang et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib51); Cao et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib5)), SOHES consists of three phases: self-exploration, self-instruction, and self-correction, as shown in Figure[2](https://arxiv.org/html/2404.12386v2#S3.F2 "Figure 2 ‣ 3 Approach ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"). 1) In Phase 1 self-exploration, we start from a pre-trained self-supervised representation DINO(Caron et al., [2021](https://arxiv.org/html/2404.12386v2#bib.bib6)) with a ViT-B/8(Dosovitskiy et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib14)) architecture, and initiate our exploration on unlabeled raw images. Our strategy is based on agglomerative clustering(Hastie et al., [2009](https://arxiv.org/html/2404.12386v2#bib.bib17)), and organizes image patches into semantically consistent regions automatically. 2) With these pseudo-labels, we begin Phase 2 self-instruction. We train a segmentation model composed by a DINO pre-trained ViT backbone(Caron et al., [2021](https://arxiv.org/html/2404.12386v2#bib.bib6)), ViT-Adapter(Chen et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib9)) (for generating multi-scale features from ViT), and Mask2Former(Cheng et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib10)) (for the final mask prediction). Through self-instruction, our segmentation model can learn from common visual entities in different images and generalize better than the initial pseudo-labels produced by the frozen ViT backbone. 3) In the final Phase 3 self-correction, we exploit more self-supervision signals to lift the limit induced by noises in the initial pseudo-labels. Inspired by semi-supervised learning(Tarvainen & Valpola, [2017](https://arxiv.org/html/2404.12386v2#bib.bib43); Liu et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib33)), we employ a teacher-student mutual-learning framework, allowing the student to learn from the improved pseudo-labels generated by the teacher.
|
| 59 |
+
|
| 60 |
+
### 3.1 Self-exploration: Generate initial pseudo-labels
|
| 61 |
+
|
| 62 |
+
In the self-exploration phase, we generate initial pseudo-labels with several steps delicately designed to include potential entities and their constituent parts of diverse categories. We take a _global-to-local perspective_ to first create candidate regions at the global level, and then investigate local images to accurately discover _small_ entities. In particular, we begin by clustering patch-level self-supervised features to generate a pool of candidate regions, then filter and refine such candidates into initial pseudo-labeled masks, and finally analyze the hierarchical structure among them. Figure[3](https://arxiv.org/html/2404.12386v2#S3.F3 "Figure 3 ‣ 3.1 Self-exploration: Generate initial pseudo-labels ‣ 3 Approach ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation") depicts this process with visual examples.
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
Figure 3: Self-exploration phase for generating initial pseudo-labels. This phase consists of four steps. We first merge image patches into regions with high visual feature similarities, then zoom in on the small candidate regions and re-cluster the local images to better discover small entities. After that, we refine the mask details and identify the hierarchical structure among the masks.
|
| 67 |
+
|
| 68 |
+
Step 1 is a global clustering procedure, which merges image patches into semantically meaningful regions. Given an unlabeled image with resolution S×S S\times S, we use DINO ViT-B/8 to extract its visual features {f 1,…,f S 8×S 8}\{f_{1},\dots,f_{\frac{S}{8}\times\frac{S}{8}}\} corresponding to each 8×8 8\times 8 patch. Then, we merge these patches in a bottom-up, iterative manner. The initial seed regions are exactly these 8×8 8\times 8 patches. In each iteration, we find the pair of adjacent regions (i,j)(i,j) with the highest cosine feature similarity (f i⋅f j)/(‖f i‖2⋅‖f j‖2)(f_{i}\cdot f_{j})/(\|f_{i}\|_{2}\cdot\|f_{j}\|_{2}). These two regions i i and j j are merged into a new region k k. The visual feature of the merged region is computed as f k=a if i+a jf j a i+a j f_{k}=\frac{a_{i}f_{i}+a_{j}f_{j}}{a_{i}+a_{j}}, where a i,a j a_{i},a_{j} are the areas of the regions i,j i,j. After replacing regions i i and j j with the new merged region k k, we continue with the next iteration.
|
| 69 |
+
|
| 70 |
+
We set a series of merging thresholds θ merge,1>⋯>θ merge,m\theta_{\text{merge},1}>\dots>\theta_{\text{merge},m} as criterion for stopping the merging procedure. In general, the highest cosine feature similarity (among all unmerged region pairs) decreases as more regions are merged. When the highest cosine feature similarity goes below one threshold θ merge,t(t∈{1,…,m})\theta_{\text{merge},t}~(t\in\{1,\dots,m\}), we record the merging results that have been obtained so far. Consequently, we can generate m m sets of regions, covering various granularity levels. We mix these sets into a pool of regions that may overlap with each other. Non-maximal suppression (NMS) is applied to remove duplicate regions. The thresholds {θ merge,t}t=1 m\{\theta_{\text{merge},t}\}_{t=1}^{m} can be determined based on the desired number of pseudo-labels per image (see Appendix[D](https://arxiv.org/html/2404.12386v2#A4 "Appendix D Additional Ablation Study Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation")).
|
| 71 |
+
|
| 72 |
+
Step 2 is local re-clustering. In the first step, we have generated a large pool of image regions that may correspond to valid visual entities. However, many small regions tend to be noisy and lack meaningful content. We adopt a global-to-local perspective to re-examine the regions that are smaller than θ small%\theta_{\text{small}}\% of the total image area. For each small candidate region, we crop a local image around it, resize it to S′×S′S^{\prime}\times S^{\prime}, and re-cluster it with the same procedure as in Step 1 to obtain subregions of the local crop. Subregions that intersect with the boundaries of the crop are discarded, because they are incomplete within the local crop context. The remaining subregions, along with regions larger than θ small%\theta_{\text{small}}\% of the whole image (from Step 1), form our initial pseudo-labels. By “zooming in” on the small candidate regions and repeating the clustering procedure at a finer scale, we can better remove noisy pseudo-labels and improve the quality of the remaining ones.
|
| 73 |
+
|
| 74 |
+
In Step 3, we leverage the off-the-shelf mask refinement model CascadePSP(Cheng et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib11)) to further refine the boundaries of the pseduo-label masks. We compute the mask IoUs (intersection-over-union) between the pseudo-labels before and after undergoing the refinement step, and remove the ones that have poor IoUs because they are likely noisy samples.
|
| 75 |
+
|
| 76 |
+
Finally, Step 4 focuses on identifying the hierarchical structure embedded within the set of pseudo-labels, which is represented as a forest structure (_i.e_., set of trees) where the roots are whole entities, and their descendants are parts and subparts, _etc_. We test each pair of pseudo-labels i i and j j to determine their hierarchical relation: If 1) over θ cover%\theta_{\text{cover}}\% pixels of pseudo-label i i are also in pseudo-label j j (meaning that i i is covered by j j), and 2) less than θ cover%\theta_{\text{cover}}\% pixels of pseudo-label j j are in pseudo-label i i (meaning that j j is larger than i i), then pseudo-label j j is an ancestor of i i in the _hierarchy forest_. The smallest ancestor of i i is the direct parent of i i. By testing the pixel coverage between pseudo-labels, we can figure out the hierarchical structure of our pseudo-labels.
|
| 77 |
+
|
| 78 |
+
### 3.2 Self-instruction: Learn from initial pseudo-labels
|
| 79 |
+
|
| 80 |
+
In the self-instruction phase, we need to address two problems: 1) The initial pseudo-labels from the previous self-exploration phase contain noises. How to leverage self-supervised learning signals to “average out” the noises? 2) Existing general-purpose segmentation heads cannot predict the hierarchical relations among masks. How to learn the hierarchy forest from the previous phase?
|
| 81 |
+
|
| 82 |
+
To address the first problem, we train a segmentation model to learn and generalize from the initial pseudo-labels. Through this procedure, the segmentation model can observe valid entities from pseudo-labels which are more frequent than noises, and thus accurately segments unseen images. The model is composed of a ViT-based backbone and a Mask2Former(Cheng et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib10)) segmentation model. In particular, the backbone is constructed by the same DINO(Caron et al., [2021](https://arxiv.org/html/2404.12386v2#bib.bib6)) pre-trained ViT, and ViT-Adapter(Chen et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib9)) for producing multi-scale visual feature maps. The ViT backbone is not fixed, and thus we can adapt its features for the segmentation task.
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
Figure 4: Ancestor relation prediction in the self-instruction phase. The prediction target, a binary matrix of ancestor relations, is constructed from the hierarchical structure identified in the self-exploration phase. The ancestor prediction head uses two linear mappings W 1,W 2 W_{1},W_{2} to transform the query features Q Q and learns to predict the target ancestors.
|
| 87 |
+
|
| 88 |
+
To accomplish the hierarchical segmentation task, we attach a novel _ancestor prediction head_ to Mask2Former, which predicts the hierarchical relations among the predicted masks. In parallel to the existing mask and class prediction heads, our ancestor prediction head operates on the query features Q∈ℝ N×C Q\in\mathbb{R}^{N\times C}, where N N is the number of queries and C C is the query feature dimension. As shown in Figure[4](https://arxiv.org/html/2404.12386v2#S3.F4 "Figure 4 ‣ 3.2 Self-instruction: Learn from initial pseudo-labels ‣ 3 Approach ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"), the learning target of the ancestor prediction is a non-symmetric binary matrix representing the ancestor relations P∈{0,1}N×N P\in\{0,1\}^{N\times N}, where P i,j=1 P_{i,j}=1 represents that mask i i is an ancestor of mask j j, and P i,j=0 P_{i,j}=0 otherwise. It is worth noting that a mask i i may have no ancestors (as a root in the hierarchy forest), if mask i i is a whole entity; mask i i may also have more than one ancestor (as a deep node in the forest), if mask i i is a part of another part. The ancestor prediction is formulated as:
|
| 89 |
+
|
| 90 |
+
P^=sigmoid((QW 1)(QW 2)⊤/C)∈ℝ N×N,\hat{P}=\text{sigmoid}\left((QW_{1})(QW_{2})^{\top}/\sqrt{C}\right)\in\mathbb{R}^{N\times N},(1)
|
| 91 |
+
|
| 92 |
+
where W 1,W 2∈ℝ C×C W_{1},W_{2}\in\mathbb{R}^{C\times C} are learnable weights for two linear transformations. We use two different linear mappings since the ancestor relations are asymmetric. They are optimized via a binary cross-entropy (BCE) loss L ancestor=BCE(P^,P)L_{\text{ancestor}}=\text{BCE}(\hat{P},P). At inference time, we can employ topological sorting to reconstruct the forest structure from the binary ancestor relation predictions. Different from prior transformer-based hierarchical segmentation methods like GroupViT(Xu et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib54)) which are constrained by the pre-defined number of hierarchical levels, our method is able to predict a variable number of levels and entities.
|
| 93 |
+
|
| 94 |
+
### 3.3 Self-correction: Improve over initial pseudo-labels
|
| 95 |
+
|
| 96 |
+
Although we have elaborately built a pseudo-labeling process in the self-exploration phase, it is still based on a fixed self-supervised visual representation that is not optimized for image segmentation. Consequently, there may still be initial pseudo-labels that are noisy and can negatively affect our model. Meanwhile, we observe that the segmentation model learned through the self-instruction phase can predict masks that are more reliable and accurate than the clustering results from the self-exploration phase. Motivated by this observation, in the final self-correction phase, we further bootstrap our model by learning from itself and mitigating the impact of noises in the initial pseudo-labels. To achieve self-correction, we adopt a semi-supervised approach that is based on teacher-student mutual-learning(Tarvainen & Valpola, [2017](https://arxiv.org/html/2404.12386v2#bib.bib43); Liu et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib33)).
|
| 97 |
+
|
| 98 |
+

|
| 99 |
+
|
| 100 |
+
Figure 5: Teacher-student mutual-learning in the self-correction phase. We initialize both the teacher and student with the segmentation model learned in the self-instruction phase, which produces better segmentation predictions than the initial pseudo-labels. The student receives supervision from the teacher’s pseudo-labels and the initial pseudo-labels. The teacher is updated as the exponential moving average (EMA) of the student.
|
| 101 |
+
|
| 102 |
+
The self-correction phase starts off by initializing two separate segmentation models which are exact clones of the segmentation model produced by the self-instruction phase. We denote one segmentation model as the student model ℳ(⋅,Θ student)\mathcal{M}(\cdot,\Theta_{\text{student}}), which is actively updated through gradient descent; the other segmentation model is the teacher model ℳ(⋅,Θ teacher)\mathcal{M}(\cdot,\Theta_{\text{teacher}}), which is updated every iteration as an exponential moving average (EMA) of the student: Θ teacher←mΘ teacher+(1−m)Θ student\Theta_{\text{teacher}}\leftarrow m\Theta_{\text{teacher}}+(1-m)\Theta_{\text{student}}, where m∈(0,1)m\in(0,1) is the momentum. The student receives supervision from both the initial pseudo-labels and the teacher’s pseudo-labels. Thus, the total loss is computed as:
|
| 103 |
+
|
| 104 |
+
L total=L seg(ℳ(𝒯 strong(I 1),Θ student),Y initial)+L seg(ℳ(𝒯 strong(I 2),Θ student),Y teacher),L_{\text{total}}=L_{\text{seg}}(\mathcal{M}\left(\mathcal{T}_{\text{strong}}(I_{1}),\Theta_{\text{student}}),Y_{\text{initial}}\right)+L_{\text{seg}}(\mathcal{M}\left(\mathcal{T}_{\text{strong}}(I_{2}),\Theta_{\text{student}}),Y_{\text{teacher}}\right),(2)
|
| 105 |
+
|
| 106 |
+
where I 1 I_{1} and I 2 I_{2} are two image batches, Y initial Y_{\text{initial}} is the initial pseudo-labels on I 1 I_{1}, Y teacher Y_{\text{teacher}} is the teacher’s pseudo-labels by thresholding the predictions ℳ(𝒯 weak(I 2),Θ teacher)\mathcal{M}(\mathcal{T}_{\text{weak}}(I_{2}),\Theta_{\text{teacher}}), 𝒯 strong\mathcal{T}_{\text{strong}} and 𝒯 weak\mathcal{T}_{\text{weak}} denote strong and weak data augmentations respectively, and L seg L_{\text{seg}} is the segmentation loss which is composed of a classification loss L cls L_{\text{cls}}, a mask prediction loss L mask L_{\text{mask}}, and our ancestor prediction loss L ancestor L_{\text{ancestor}}. Figure[5](https://arxiv.org/html/2404.12386v2#S3.F5 "Figure 5 ‣ 3.3 Self-correction: Improve over initial pseudo-labels ‣ 3 Approach ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation") illustrates the steps in our teacher-student learning approach.
|
| 107 |
+
|
| 108 |
+
To obtain more reliable supervision from the teacher’s predictions ℳ(𝒯 weak(I 2),Θ teacher)\mathcal{M}(\mathcal{T}_{\text{weak}}(I_{2}),\Theta_{\text{teacher}}), we keep only those masks with confidence scores exceeding θ score\theta_{\text{score}} to form the pseudo-labels Y teacher Y_{\text{teacher}}. We observe that the teacher model tends to be less confident when segmenting smaller entities. If the threshold θ score\theta_{\text{score}} is fixed across all masks, it would result in too few pseudo-labels with small areas, and consequently, the student’s small entity segmentation performance and overall performance would be impaired. Therefore, we leverage a dynamic threshold:
|
| 109 |
+
|
| 110 |
+
θ score=(1−(1−a)γ)(θ score, large−θ score, small)+θ score, small,\theta_{\text{score}}=\left(1-(1-a)^{\gamma}\right)(\theta_{\text{score, large}}-\theta_{\text{score, small}})+\theta_{\text{score, small}},(3)
|
| 111 |
+
|
| 112 |
+
where a∈(0,1)a\in(0,1) represents the area ratio of the predicted mask to the whole image, γ>1\gamma>1 is a hyper-parameter, and θ score, small<θ score, large\theta_{\text{score, small}}<\theta_{\text{score, large}} are the pre-defined thresholds for the smallest and largest mask, respectively. This dynamic threshold across different scales allows us to better balance small, medium, and large entities in the teacher’s pseudo-labels, and encourages the student model to segment small entities more accurately.
|
| 113 |
+
|
| 114 |
+
4 Experiments
|
| 115 |
+
-------------
|
| 116 |
+
|
| 117 |
+
In this section, we thoroughly evaluate SOHES on various datasets and examine the ViT-based backbone improvement for downstream tasks. We perform a series of ablation study experiments to demonstrate the efficacy of modules and steps in SOHES. We also discuss limitations of SOHES in Appendix[E](https://arxiv.org/html/2404.12386v2#A5 "Appendix E Limitations ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"). Additional qualitative results are shown in Appendix[F](https://arxiv.org/html/2404.12386v2#A6 "Appendix F Qualitative Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation").
|
| 118 |
+
|
| 119 |
+
### 4.1 Training and evaluation data
|
| 120 |
+
|
| 121 |
+
We train our SOHES model on the SA-1B(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)) dataset. In SA-1B, there are 11 million images equally split into 1,000 packs. Unless otherwise specified, we use 20 packs of raw images (2%) for training, and 1 different pack (0.1%) for evaluation.
|
| 122 |
+
|
| 123 |
+
For evaluation purposes, we test SOHES on various image datasets with segmentation mask annotations in a _zero-shot_ manner (_i.e_., no further training on evaluation datasets). The diversity in the evaluation datasets can simulate the challenge of unseen entity classes and image domains in an open-world setting. Since the annotations in each dataset may only cover entities from a pre-defined list of classes, the commonly used MS-COCO style average precision (AP) metric for closed-world detection/segmentation would incorrectly penalize open-world predictions that cannot be matched with ground truths in known classes. More details of the AP metric are discussed in Appendix[B](https://arxiv.org/html/2404.12386v2#A2 "Appendix B Deficiency of AP Metric in Open-world Segmentation ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"). Following prior work(Kim et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib26); Wang et al., [2022a](https://arxiv.org/html/2404.12386v2#bib.bib49); Liu et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib32); Cao et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib5)), we mainly consider the average recall (AR) metric for up to 1,000 predictions per image when comparing different methods. Other implementation details are in Appendix[A](https://arxiv.org/html/2404.12386v2#A1 "Appendix A Implementation Details ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation").
|
| 124 |
+
|
| 125 |
+
### 4.2 Open-world entity segmentation
|
| 126 |
+
|
| 127 |
+
We evaluate SOHES on a variety of datasets, including MS-COCO(Lin et al., [2014](https://arxiv.org/html/2404.12386v2#bib.bib30)), LVIS(Gupta et al., [2019](https://arxiv.org/html/2404.12386v2#bib.bib16)), ADE20K(Zhou et al., [2017](https://arxiv.org/html/2404.12386v2#bib.bib55)), EntitySeg(Qi et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib36)), and SA-1B(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)). These datasets include natural images of complex scenes, in which multiple visual entities of diverse classes present and are labeled with segmentation masks. Thus, the collection of such evaluation datasets can faithfully reflect the performance of an open-world segmentation model. We compare with recent self-supervised methods FreeSOLO(Wang et al., [2022b](https://arxiv.org/html/2404.12386v2#bib.bib50)), CutLER(Wang et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib51)), and HASSOD(Cao et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib5)). We aim to close the gap between self-supervised methods and the supervised state-of-the-art model SAM(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)). _Notably, we use only 2% images as SAM for training SOHES, and we do not require any human annotations on these images._
|
| 128 |
+
|
| 129 |
+
Table 1: Zero-shot evaluation on various image datasets.SOHES sets new state-of-the-art self-supervised open-world entity segmentation performance. The collection of the evaluation datasets represents diverse classes in an open world and includes both whole entities and parts. Meanwhile, using just 2% unlabeled images as SAM, SOHES significantly closes the gap between self-supervised methods and the supervised SAM. The evaluation metric is average recall (AR).
|
| 130 |
+
|
| 131 |
+
Supervision Method Datasets w/ Whole Entities Datasets w/ Parts
|
| 132 |
+
COCO LVIS ADE Entity SA-1B PtIN PACO
|
| 133 |
+
Supervised SAM(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28))49.6 46.1 45.8 45.9 60.8 28.3 18.1
|
| 134 |
+
Self-supervised FreeSOLO(Wang et al., [2022b](https://arxiv.org/html/2404.12386v2#bib.bib50))11.6 5.9 7.3 8.0 2.2 13.8 2.4
|
| 135 |
+
CutLER(Wang et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib51))28.1 20.2 26.3 23.1 17.0 28.7 8.9
|
| 136 |
+
HASSOD(Cao et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib5))28.3 22.5 27.8 26.2 26.0 32.6 11.4
|
| 137 |
+
SOHES (Ours)30.5 29.1 31.1 33.5 33.3 36.0 17.1
|
| 138 |
+
Improvement over HASSOD+2.2+6.6+3.3+7.3+7.3+3.4+5.7
|
| 139 |
+
Reduced Gap vs. SAM-10%-28%-18%-37%-21%∗*-85%
|
| 140 |
+
|
| 141 |
+
∗*SOHES outperforms SAM on PartImagenet.
|
| 142 |
+
|
| 143 |
+
As summarized in Table[1](https://arxiv.org/html/2404.12386v2#S4.T1 "Table 1 ‣ 4.2 Open-world entity segmentation ‣ 4 Experiments ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation") and Table[4](https://arxiv.org/html/2404.12386v2#A3.T4 "Table 4 ‣ Appendix C Additional Evaluation Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"), SOHES consistently outperforms the prior state-of-the-art HASSOD by large margins (_e.g_., +7.3 AR on SA-1B and EntitySeg). Meanwhile, SOHES significantly closes the gap between self-supervised methods and supervised methods. For instance, using only 2% unlabeled data in SA-1B, SOHES already achieves over half AR of SAM. SOHES also reduces the gap between self-supervised methods and SAM on SA-1B relatively by 37%.
|
| 144 |
+
|
| 145 |
+
### 4.3 Part segmentation
|
| 146 |
+
|
| 147 |
+
In additional to whole entities, SOHES also learns to segment their constituent parts and subparts. To evaluate our hierarchical segmentation results, we compare them with the ground-truth mask annotations of object parts (_e.g_., heads and tails of animals) in two datasets, PartImageNet(He et al., [2022a](https://arxiv.org/html/2404.12386v2#bib.bib18)) and PACO-LVIS(Ramanathan et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib37)), and summarize the results in Table[1](https://arxiv.org/html/2404.12386v2#S4.T1 "Table 1 ‣ 4.2 Open-world entity segmentation ‣ 4 Experiments ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation") and Table[5](https://arxiv.org/html/2404.12386v2#A3.T5 "Table 5 ‣ Appendix C Additional Evaluation Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"). Compared with prior self-supervised baselines, SOHES more accurately localizes meaningful parts of entities, and almost doubles CutLER’s performance on PACO (8.9 AR →\rightarrow 17.1 AR). Impressively, SOHES _outperforms SAM_ on PartImageNet and is on par with SAM on PACO. The reason is that SOHES can predict more parts and subparts than SAM (see Figure[14](https://arxiv.org/html/2404.12386v2#A6.F14 "Figure 14 ‣ Appendix F Qualitative Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation")), which are the focus of the two datasets’ annotations.
|
| 148 |
+
|
| 149 |
+
### 4.4 Improved backbone features
|
| 150 |
+
|
| 151 |
+
Through our self-instruction and correction phases, we adapt self-supervised representation DINO to an open-world segmentation model. Consequently, our fine-tuned visual backbone can better fit into other dense prediction tasks. To test such abilities, we compare a) the ViT-B/8 backbone pre-trained by DINO and b) the backbone further tuned in SOHES, in downstream tasks of semantic segmentation on ADE20K and object detection on MS-COCO. The downstream fine-tuning is performed in a minimalistic style, mimicking the linear probing(Chen et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib8); He et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib20)) in self-supervised representation learning. For semantic segmentation, we directly attach a linear classifier on the feature maps from ViT-Adapter; for object detection, we attach the simplest RetinaNet(Lin et al., [2017](https://arxiv.org/html/2404.12386v2#bib.bib31)) detection head on the ViT-Adapter. We keep the ViT parameters frozen during the supervised fine-tuning. Table[7](https://arxiv.org/html/2404.12386v2#S4.F7 "Figure 7 ‣ 4.4 Improved backbone features ‣ 4 Experiments ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation") summarizes the results, demonstrating that SOHES can adapt the ViT-based backbone to generate better features for dense prediction downstream tasks.
|
| 152 |
+
|
| 153 |
+
Figure 6: Downstream performance of ViT-based backbones. We freeze the ViT and fine-tune a ViT-Adapter and a lightweight segmentation/detection head on ADE20K/MS-COCO. The backbone further fine-tuned in SOHES is more adapted to dense-prediction tasks.
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
Figure 7: Mask quality of the initial pseudo-labels produced by DINO backbones with different pre-training configurations. A small pre-training patch size leads to better fine-grained features and high-quality pseudo-labels.
|
| 158 |
+
|
| 159 |
+
### 4.5 Ablation study
|
| 160 |
+
|
| 161 |
+
In this subsection, we ablate the design choices in SOHES on SA-1B, and provide our insights for future research in self-supervised open-world segmentation. Further details about the choices of hyper-parameters and model architectures are discussed in Appendix[D](https://arxiv.org/html/2404.12386v2#A4 "Appendix D Additional Ablation Study Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation").
|
| 162 |
+
|
| 163 |
+
DINO backbone. In recent self-supervised object localization/discovery work(Siméoni et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib42); Wang et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib51)), researchers prefer the ViT backbone pre-trained by DINO, in particular ViT-B with patch size 8. We have also observed that a ViT backbone with patch size 8 leads to better mask quality in SOHES. To investigate this, we use DINO to pre-train ViT-B backbones with varying patch size and input resolution configurations, with a shorter 100-epoch training schedule (DINO originally pre-trains on ImageNet(Deng et al., [2009](https://arxiv.org/html/2404.12386v2#bib.bib12)) for 300 epochs). Then, we repeat our self-exploration phase with these backbones, and the resulting mask quality comparison is summarized in Figure[7](https://arxiv.org/html/2404.12386v2#S4.F7 "Figure 7 ‣ 4.4 Improved backbone features ‣ 4 Experiments ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation") and Table[7](https://arxiv.org/html/2404.12386v2#A4.T7 "Table 7 ‣ Appendix D Additional Ablation Study Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"). From this comparison, we can observe that the small patch size is positively correlated with the mask quality. When the patch size decreases from 32 to 8, the AR significantly improves. Meanwhile, the input resolution does not influence the mask quality as much. The small patch size may better support the ViT to capture pixel-aligned details for localizing entites, and thus is more suited in our self-supervised segmentation task. It is worth noting that we cannot further reduce the patch size due to computational constraints. Whenever the patch size is halved, ViT needs to process 4×4\times patches, and perform 16×16\times computation in self-attention. Therefore, the off-the-shelf DINO ViT-B/8 is the best choice in our task.
|
| 164 |
+
|
| 165 |
+
Steps in self-exploration. In our self-exploration phase, we have delicately designed a series of steps to generate, select, and refine the pseudo-labels. We summarize the impact of the design choices in Table[2](https://arxiv.org/html/2404.12386v2#S4.T2 "Table 2 ‣ 4.5 Ablation study ‣ 4 Experiments ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"). In the first global clustering step, if we use one fixed merging threshold θ merge\theta_{\text{merge}}, a larger θ merge\theta_{\text{merge}} leads to more masks per image and better coverage of entities (increasing AR), and also introduces noises (oscillating AP). We choose to mix the results with different thresholds together and remove duplicates, which provides the best AR and only slightly increases the number of masks compared with the largest θ merge\theta_{\text{merge}}. In the second local re-clustering step, we significantly improve the recall for small entities, relatively by 168%. This step ensures that our model receives adequate supervision from small entities. We also improve the overall recall by 2.5 AR. Finally, in the third refinement step, we adopt CascadePSP(Cheng et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib11)) because it can best boost the overall mask quality. The other two options, DenseCRF(Krähenbühl & Koltun, [2011](https://arxiv.org/html/2404.12386v2#bib.bib29)) and CRM(Shen et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib39)), are also viable, but they change the pseudo-labels more aggressively, leading to the removal of many potential entities. Overall, each step in our self-exploration phase contributes to the high-quality initial pseudo-labels for SOHES. Notably, we can parallelize the processing for each image and accelerate self-exploration with more compute nodes.
|
| 166 |
+
|
| 167 |
+
Table 2: Impact of each step in self-exploration. We mix the global clustering results from multiple merging thresholds, adopt the local re-clustering, and use the off-the-shelf CascadePSP mask refinement module to obtain the best initial pseudo-labels.
|
| 168 |
+
|
| 169 |
+
Step Choice Masks/Img Time/Img Mask Quality
|
| 170 |
+
(sec)AP AR S AR M AR L AR
|
| 171 |
+
1 θ merge=0.1\theta_{\text{merge}}=0.1 1 4.9 0.2 0.0 0.0 0.3 0.1
|
| 172 |
+
θ merge=0.2\theta_{\text{merge}}=0.2 3 4.9 0.8 0.1 0.1 0.6 0.3
|
| 173 |
+
θ merge=0.3\theta_{\text{merge}}=0.3 9 4.5 0.9 0.4 0.6 2.0 1.0
|
| 174 |
+
θ merge=0.4\theta_{\text{merge}}=0.4 23 3.8 0.6 0.7 1.5 5.4 2.6
|
| 175 |
+
θ merge=0.5\theta_{\text{merge}}=0.5 58 2.7 1.4 1.2 3.4 11.1 5.4
|
| 176 |
+
θ merge=0.6\theta_{\text{merge}}=0.6 131 2.2 0.6 1.5 6.0 15.3 8.1
|
| 177 |
+
Mix w/ NMS 148 5.3 1.1 1.9 6.5 17.2 9.1
|
| 178 |
+
2 w/ local re-clustering 115 8.4 2.0 5.1 10.1 17.5 11.6
|
| 179 |
+
3 DenseCRF(Krähenbühl & Koltun, [2011](https://arxiv.org/html/2404.12386v2#bib.bib29))61 18.2 4.7 3.5 9.5 20.7 12.0
|
| 180 |
+
CRM(Shen et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib39))71 18.7 2.7 4.7 13.5 20.2 14.1
|
| 181 |
+
CascadePSP(Cheng et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib11))101 15.2 4.7 6.0 15.8 22.6 16.4
|
| 182 |
+
|
| 183 |
+
Self-correction. In our self-correction phase, we adopt a teacher-student mutual-learning framework from semi-supervised learning, to continuously improve the segmentation model by itself. However, as shown in Table[3](https://arxiv.org/html/2404.12386v2#S4.T3 "Table 3 ‣ 4.5 Ablation study ‣ 4 Experiments ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"), the initial attempt of the mutual-learning with a fixed confidence threshold leads to worse performance. In fact, the imbalanced distribution is reinforced during this procedure, as indicated by the decreased AR for small and medium entities and increased AR for larger entities. Therefore, we need a dynamic threshold that allows more small and medium pseudo-labels from the teacher model, and balances the student’s prediction for entities of different scales. With the dynamic threshold, we can improve AR S and AR M relatively by 7.5% and 4.5%, with an acceptable cost of 2.3% AR L. Consequently, the overall AR is improved by 0.7.
|
| 184 |
+
|
| 185 |
+
Table 3: Impact of the dynamic threshold in self-correction. If the vanilla teacher-student learning is employed in the self-correction phase (row 2), the imbalance between small and large entity segmentation is intensified which leads to worse overall performance. Our dynamic threshold for filtering the teacher’s pseudo-labels (row 3) can encourage the student’s predictions for small and medium entities and improve the overall AR.
|
| 186 |
+
|
| 187 |
+
5 Conclusion
|
| 188 |
+
------------
|
| 189 |
+
|
| 190 |
+
We present SOHES, a self-supervised approach towards open-world entity segmentation with hierarchical structures. Through three phases of self-evolution, a self-supervised learner is adapted to an open-world segmentation model. By recognizing and localizing entities and their constituent parts in an open world with superior mask quality, SOHES substantially closes the gap between self-supervised and supervised methods, and sets the new state of the art on various datasets.
|
| 191 |
+
|
| 192 |
+
Acknowledgement. This work was supported in part by NSF Grant 2106825, NIFA Award 2020-67021-32799, and the Jump ARCHES endowment through the Health Care Engineering Systems Center. This work used NVIDIA GPUs at NCSA Delta through allocations CIS220014, CIS230012, and CIS230013 from the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, which is supported by NSF Grants #2138259, #2138286, #2138307, #2137603, and #2138296.
|
| 193 |
+
|
| 194 |
+
References
|
| 195 |
+
----------
|
| 196 |
+
|
| 197 |
+
* Bansal et al. (2018) Ankan Bansal, Karan Sikka, Gaurav Sharma, Rama Chellappa, and Ajay Divakaran. Zero-shot object detection. In _ECCV_, 2018.
|
| 198 |
+
* Bendale & Boult (2015) Abhijit Bendale and Terrance Boult. Towards open world recognition. In _CVPR_, 2015.
|
| 199 |
+
* Bendale & Boult (2016) Abhijit Bendale and Terrance Boult. Towards open set deep networks. In _CVPR_, 2016.
|
| 200 |
+
* Cai & Vasconcelos (2018) Zhaowei Cai and Nuno Vasconcelos. Cascade R-CNN: Delving into high quality object detection. In _CVPR_, 2018.
|
| 201 |
+
* Cao et al. (2023) Shengcao Cao, Dhiraj Joshi, Liang-Yan Gui, and Yu-Xiong Wang. HASSOD: Hierarchical adaptive self-supervised object detection. In _NeurIPS_, 2023.
|
| 202 |
+
* Caron et al. (2021) Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In _ICCV_, 2021.
|
| 203 |
+
* Chen et al. (2017) Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. _TPAMI_, 40(4):834–848, 2017.
|
| 204 |
+
* Chen et al. (2020) Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In _ICML_, 2020.
|
| 205 |
+
* Chen et al. (2022) Zhe Chen, Yuchen Duan, Wenhai Wang, Junjun He, Tong Lu, Jifeng Dai, and Yu Qiao. Vision transformer adapter for dense predictions. In _ICLR_, 2022.
|
| 206 |
+
* Cheng et al. (2022) Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. In _CVPR_, 2022.
|
| 207 |
+
* Cheng et al. (2020) Ho Kei Cheng, Jihoon Chung, Yu-Wing Tai, and Chi-Keung Tang. CascadePSP: Toward class-agnostic and very high-resolution segmentation via global and local refinement. In _CVPR_, 2020.
|
| 208 |
+
* Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In _CVPR_, 2009.
|
| 209 |
+
* Dhamija et al. (2020) Akshay Dhamija, Manuel Gunther, Jonathan Ventura, and Terrance Boult. The overlooked elephant of object detection: Open set. In _WACV_, 2020.
|
| 210 |
+
* Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In _ICLR_, 2020.
|
| 211 |
+
* Ghiasi et al. (2021) Golnaz Ghiasi, Yin Cui, Aravind Srinivas, Rui Qian, Tsung-Yi Lin, Ekin D Cubuk, Quoc V Le, and Barret Zoph. Simple copy-paste is a strong data augmentation method for instance segmentation. In _CVPR_, 2021.
|
| 212 |
+
* Gupta et al. (2019) Agrim Gupta, Piotr Dollar, and Ross Girshick. LVIS: A dataset for large vocabulary instance segmentation. In _CVPR_, 2019.
|
| 213 |
+
* Hastie et al. (2009) Trevor Hastie, Robert Tibshirani, Jerome H Friedman, and Jerome H Friedman. _The elements of statistical learning: Data mining, inference, and prediction_. Springer, 2009.
|
| 214 |
+
* He et al. (2022a) Ju He, Shuo Yang, Shaokang Yang, Adam Kortylewski, Xiaoding Yuan, Jie-Neng Chen, Shuai Liu, Cheng Yang, Qihang Yu, and Alan Yuille. PartImageNet: A large, high-quality dataset of parts. In _ECCV_, 2022a.
|
| 215 |
+
* He et al. (2017) Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask R-CNN. In _ICCV_, 2017.
|
| 216 |
+
* He et al. (2020) Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In _CVPR_, 2020.
|
| 217 |
+
* He et al. (2022b) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In _CVPR_, 2022b.
|
| 218 |
+
* Hu et al. (2018) Ronghang Hu, Piotr Dollár, Kaiming He, Trevor Darrell, and Ross Girshick. Learning to segment every thing. In _CVPR_, 2018.
|
| 219 |
+
* Jaiswal et al. (2021) Ayush Jaiswal, Yue Wu, Pradeep Natarajan, and Premkumar Natarajan. Class-agnostic object detection. In _WACV_, 2021.
|
| 220 |
+
* Joseph et al. (2021) K J Joseph, Salman Khan, Fahad Shahbaz Khan, and Vineeth N Balasubramanian. Towards open world object detection. In _CVPR_, 2021.
|
| 221 |
+
* Kalluri et al. (2023) Tarun Kalluri, Weiyao Wang, Heng Wang, Manmohan Chandraker, Lorenzo Torresani, and Du Tran. Open-world instance segmentation: Top-down learning with bottom-up supervision. _arXiv preprint arXiv:2303.05503_, 2023.
|
| 222 |
+
* Kim et al. (2022) Dahun Kim, Tsung-Yi Lin, Anelia Angelova, In So Kweon, and Weicheng Kuo. Learning open-world object proposals without learning to classify. _IEEE Robotics and Automation Letters_, 7(2):5453–5460, 2022.
|
| 223 |
+
* Kirillov et al. (2019) Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, and Piotr Dollár. Panoptic segmentation. In _CVPR_, 2019.
|
| 224 |
+
* Kirillov et al. (2023) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything. In _ICCV_, 2023.
|
| 225 |
+
* Krähenbühl & Koltun (2011) Philipp Krähenbühl and Vladlen Koltun. Efficient inference in fully connected CRFs with Gaussian edge potentials. In _NeurIPS_, 2011.
|
| 226 |
+
* Lin et al. (2014) Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO: Common objects in context. In _ECCV_, 2014.
|
| 227 |
+
* Lin et al. (2017) Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In _ICCV_, 2017.
|
| 228 |
+
* Liu et al. (2022) Yang Liu, Idil Esen Zulfikar, Jonathon Luiten, Achal Dave, Deva Ramanan, Bastian Leibe, Aljoša Ošep, and Laura Leal-Taixé. Opening up open world tracking. In _CVPR_, 2022.
|
| 229 |
+
* Liu et al. (2020) Yen-Cheng Liu, Chih-Yao Ma, Zijian He, Chia-Wen Kuo, Kan Chen, Peizhao Zhang, Bichen Wu, Zsolt Kira, and Peter Vajda. Unbiased teacher for semi-supervised object detection. In _ICLR_, 2020.
|
| 230 |
+
* Long et al. (2015) Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In _CVPR_, 2015.
|
| 231 |
+
* Qi et al. (2022) Lu Qi, Jason Kuen, Yi Wang, Jiuxiang Gu, Hengshuang Zhao, Philip Torr, Zhe Lin, and Jiaya Jia. Open-world entity segmentation. _TPAMI_, 45(7):8743–8756, 2022.
|
| 232 |
+
* Qi et al. (2023) Lu Qi, Jason Kuen, Tiancheng Shen, Jiuxiang Gu, Weidong Guo, Jiaya Jia, Zhe Lin, and Ming-Hsuan Yang. High-quality entity segmentation. In _ICCV_, 2023.
|
| 233 |
+
* Ramanathan et al. (2023) Vignesh Ramanathan, Anmol Kalia, Vladan Petrovic, Yi Wen, Baixue Zheng, Baishan Guo, Rui Wang, Aaron Marquez, Rama Kovvuri, Abhishek Kadian, Amir Mousavi, Yiwen Song, Abhimanyu Dubey, and Dhruv Mahajan. PACO: Parts and attributes of common objects. In _CVPR_, 2023.
|
| 234 |
+
* Scheirer et al. (2012) Walter J Scheirer, Anderson de Rezende Rocha, Archana Sapkota, and Terrance Boult. Toward open set recognition. _TPAMI_, 35(7):1757–1772, 2012.
|
| 235 |
+
* Shen et al. (2022) Tiancheng Shen, Yuechen Zhang, Lu Qi, Jason Kuen, Xingyu Xie, Jianlong Wu, Zhe Lin, and Jiaya Jia. High quality segmentation for ultra high-resolution images. In _CVPR_, 2022.
|
| 236 |
+
* Shi & Malik (2000) Jianbo Shi and Jitendra Malik. Normalized cuts and image segmentation. _TPAMI_, 22(8):888–905, 2000.
|
| 237 |
+
* Siméoni et al. (2021) Oriane Siméoni, Gilles Puy, Huy V Vo, Simon Roburin, Spyros Gidaris, Andrei Bursuc, Patrick Pérez, Renaud Marlet, and Jean Ponce. Localizing objects with self-supervised transformers and no labels. In _BMVC_, 2021.
|
| 238 |
+
* Siméoni et al. (2023) Oriane Siméoni, Chloé Sekkat, Gilles Puy, Antonín Vobeckỳ, Éloi Zablocki, and Patrick Pérez. Unsupervised object localization: Observing the background to discover objects. In _CVPR_, 2023.
|
| 239 |
+
* Tarvainen & Valpola (2017) Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In _NeurIPS_, 2017.
|
| 240 |
+
* Uijlings et al. (2013) Jasper RR Uijlings, Koen EA Van De Sande, Theo Gevers, and Arnold WM Smeulders. Selective search for object recognition. _IJCV_, 104:154–171, 2013.
|
| 241 |
+
* Vo et al. (2019) Huy V Vo, Francis Bach, Minsu Cho, Kai Han, Yann LeCun, Patrick Pérez, and Jean Ponce. Unsupervised image matching and object discovery as optimization. In _CVPR_, 2019.
|
| 242 |
+
* Vo et al. (2020) Huy V Vo, Patrick Pérez, and Jean Ponce. Toward unsupervised, multi-object discovery in large-scale image collections. In _ECCV_, 2020.
|
| 243 |
+
* Vo et al. (2021) Van Huy Vo, Elena Sizikova, Cordelia Schmid, Patrick Pérez, and Jean Ponce. Large-scale unsupervised object discovery. In _NeurIPS_, 2021.
|
| 244 |
+
* Wang et al. (2021) Weiyao Wang, Matt Feiszli, Heng Wang, and Du Tran. Unidentified video objects: A benchmark for dense, open-world segmentation. In _ICCV_, 2021.
|
| 245 |
+
* Wang et al. (2022a) Weiyao Wang, Matt Feiszli, Heng Wang, Jitendra Malik, and Du Tran. Open-world instance segmentation: Exploiting pseudo ground truth from learned pairwise affinity. In _CVPR_, 2022a.
|
| 246 |
+
* Wang et al. (2022b) Xinlong Wang, Zhiding Yu, Shalini De Mello, Jan Kautz, Anima Anandkumar, Chunhua Shen, and Jose M Alvarez. FreeSOLO: Learning to segment objects without annotations. In _CVPR_, 2022b.
|
| 247 |
+
* Wang et al. (2023) Xudong Wang, Rohit Girdhar, Stella X Yu, and Ishan Misra. Cut and learn for unsupervised object detection and instance segmentation. In _CVPR_, 2023.
|
| 248 |
+
* Wang et al. (2022c) Yangtao Wang, Xi Shen, Yuan Yuan, Yuming Du, Maomao Li, Shell Xu Hu, James L Crowley, and Dominique Vaufreydaz. TokenCut: Segmenting objects in images and videos with self-supervised transformer and normalized cut. In _CVPR_, 2022c.
|
| 249 |
+
* Xie et al. (2022) Xingyu Xie, Pan Zhou, Huan Li, Zhouchen Lin, and Shuicheng Yan. Adan: Adaptive nesterov momentum algorithm for faster optimizing deep models. _arXiv preprint arXiv:2208.06677_, 2022.
|
| 250 |
+
* Xu et al. (2022) Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, and Xiaolong Wang. GroupViT: Semantic segmentation emerges from text supervision. In _CVPR_, 2022.
|
| 251 |
+
* Zhou et al. (2017) Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ADE20K dataset. In _CVPR_, 2017.
|
| 252 |
+
|
| 253 |
+
Appendix A Implementation Details
|
| 254 |
+
---------------------------------
|
| 255 |
+
|
| 256 |
+
Self-exploration. We use DINO(Caron et al., [2021](https://arxiv.org/html/2404.12386v2#bib.bib6)) pre-trained ViT-B/8 as the feature extractor to generate patch-level visual features. During the global clustering step, we first resize unlabeled images to resolution S×S=1,024×1,024 S\times S=1,024\times 1,024, and cluster 8×8 8\times 8 patches with merging thresholds {θ merge,t}t=1 m={0.6,0.5,0.4,0.3,0.2,0.1}\{\theta_{\text{merge},t}\}_{t=1}^{m}=\{0.6,0.5,0.4,0.3,0.2,0.1\}, which are decided based on the number of pseudo-labels (see Figure[8](https://arxiv.org/html/2404.12386v2#A4.F8.fig1 "Figure 8 ‣ Appendix D Additional Ablation Study Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation")). Then in the local re-clustering step, we further investigate regions smaller than θ small%=1/1,024\theta_{\text{small}}\%=1/1,024 of the total image area, and crop local images around them. The local image is resized to S′×S′=256×256 S^{\prime}\times S^{\prime}=256\times 256 and its subregions are clustered. In the next step, we use the off-the-shelf CascadePSP(Cheng et al., [2020](https://arxiv.org/html/2404.12386v2#bib.bib11)) model to refine the masks. In the final step of hierarchy analysis, the coverage threshold is set to θ cover%=90%\theta_{\text{cover}}\%=90\%.
|
| 257 |
+
|
| 258 |
+
Self-instruction. We learn a segmentation model composed of DINO(Caron et al., [2021](https://arxiv.org/html/2404.12386v2#bib.bib6)) pre-trained ViT-B/8, ViT-Adapter(Chen et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib9)), Mask2Former(Cheng et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib10)), and our ancestor prediction head. The model is trained on 8 compute nodes, each equipped with 8 NVIDIA A100 GPUs. The total batch size is 128, and the number of training steps is 40,000. We optimize the model with the Adan optimizer(Xie et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib53)) and a base learning rate of 0.0008. The total training time is about 3 days.
|
| 259 |
+
|
| 260 |
+
Self-correction. The teacher-student mutual learning starts after the self-instruction phase. It trains the model for additional 5,000 iterations. The teacher is updated as the exponential moving average of the student, with momentum m=0.9995 m=0.9995. The loss terms from the initial pseudo-labels and the teacher’s pseudo-labels are weighted equally. In the dynamic threshold, we set θ score, large=0.7,θ score, small=0.3,γ=200\theta_{\text{score, large}}=0.7,\theta_{\text{score, small}}=0.3,\gamma=200.
|
| 261 |
+
|
| 262 |
+
Appendix B Deficiency of AP Metric in Open-world Segmentation
|
| 263 |
+
-------------------------------------------------------------
|
| 264 |
+
|
| 265 |
+
The MS-COCO(Lin et al., [2014](https://arxiv.org/html/2404.12386v2#bib.bib30)) style average precision (AP) is a prevalent metric for evaluating object detection and instance segmentation models in the traditional _closed-world_ setting with a pre-defined scope of categories. However, for the _open-world_ segmentation task, the AP metric becomes misleading and cannot accurately reflect the open-world model’s true performance: When evaluating open-world segmentation models (which try to segment “everything”) on datasets with closed-world annotations (such as MS-COCO/LVIS which only include a pre-defined, limited set of entity classes), AP would _penalize_ model predictions that are actually _valid entities_, but just not annotated by the dataset.
|
| 266 |
+
|
| 267 |
+
Consequently, when the dataset annotations cannot cover all entities, AP becomes misleading for judging the performance of open-world models. As an example, the AP of SAM(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)) is lower than CutLER(Wang et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib51)) on MS-COCO (6.1 _vs_. 9.8, Table[4](https://arxiv.org/html/2404.12386v2#A3.T4 "Table 4 ‣ Appendix C Additional Evaluation Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation")) and PartImageNet (3.4 _vs_. 5.3, Table[5](https://arxiv.org/html/2404.12386v2#A3.T5 "Table 5 ‣ Appendix C Additional Evaluation Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation")), which definitely cannot imply SAM is a model inferior to CutLER. The lower AP of SAM is due to insufficient annotations in these two datasets, not the capability of SAM. Meanwhile, on datasets which explicitly try to mitigate these annotation limitations like SA-1B(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)), AP can be more reliable than on traditional closed-world datasets like MS-COCO(Lin et al., [2014](https://arxiv.org/html/2404.12386v2#bib.bib30)). For instance, AP on SA-1B (the most densely annotated dataset evaluated in our work, see Table[4](https://arxiv.org/html/2404.12386v2#A3.T4 "Table 4 ‣ Appendix C Additional Evaluation Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation")) matches qualitative comparison and follows the same trend as AR, and our AP (12.9) significantly surpasses CutLER’s AP (7.8). Prior work(Cao et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib5)) has made a similar observation about the deficiency of MS-COCO AP evaluation in the context of self-supervised object detection.
|
| 268 |
+
|
| 269 |
+
In general, we choose the average recall (AR) as the main metric instead of AP, because AR does not penalize valid open-world predictions. Note that this choice of AR over AP is also commonly adopted in the open-world literature. Examples include (but are not limited to) detection(Kim et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib26)), segmentation(Wang et al., [2022a](https://arxiv.org/html/2404.12386v2#bib.bib49)), and tracking(Liu et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib32)).
|
| 270 |
+
|
| 271 |
+
Appendix C Additional Evaluation Results
|
| 272 |
+
----------------------------------------
|
| 273 |
+
|
| 274 |
+
We provide additional evaluation results with more metrics in Table[4](https://arxiv.org/html/2404.12386v2#A3.T4 "Table 4 ‣ Appendix C Additional Evaluation Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation") and Table[5](https://arxiv.org/html/2404.12386v2#A3.T5 "Table 5 ‣ Appendix C Additional Evaluation Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"), as a supplement to Table[1](https://arxiv.org/html/2404.12386v2#S4.T1 "Table 1 ‣ 4.2 Open-world entity segmentation ‣ 4 Experiments ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation") in the main paper.
|
| 275 |
+
|
| 276 |
+
Table 4: Detailed zero-shot evaluation results on image datasets with annotations of whole entities.
|
| 277 |
+
|
| 278 |
+
Table 5: Detailed zero-shot evaluation results on image datasets with annotations of object parts.
|
| 279 |
+
|
| 280 |
+
Appendix D Additional Ablation Study Results
|
| 281 |
+
--------------------------------------------
|
| 282 |
+
|
| 283 |
+
Since SOHES is a self-supervised approach, we do _not_ base our selection of hyper-parameters on _a posteriori_ model performance. Instead, we choose hyper-parameters by considering simple criteria such as computation constraints or small-scale experiments. In this section, we detail the design choices in SOHES.
|
| 284 |
+
|
| 285 |
+
Merging thresholds. In the first step of our self-exploration phase, we cluster patches into coherent regions and stop at pre-set merging thresholds θ merge,1>⋯>θ merge,m\theta_{\text{merge},1}>\dots>\theta_{\text{merge},m}. We choose these thresholds based on a practical computation constraint: pseudo-labels per image. When there are too many pseudo-labels, data loading, augmentation, and pre-processing would become a bottleneck in model training. Therefore, we control the number of pseudo-labels per image to be under 200. As shown in Figure[8](https://arxiv.org/html/2404.12386v2#A4.F8.fig1 "Figure 8 ‣ Appendix D Additional Ablation Study Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"), the quantity of pseudo-labels grows significantly when the merging threshold is larger. In order not to exceed 200 masks per image, we set the merging thresholds as 0.6,0.5,0.4,0.3,0.2,0.1 0.6,0.5,0.4,0.3,0.2,0.1.
|
| 286 |
+
|
| 287 |
+

|
| 288 |
+
|
| 289 |
+
Figure 8: Relation between the number of pseudo-labels and the merging thresholds. As the merging threshold increases, the number of pseudo-labels rapidly grows. To control the number of pseudo-labels per image, we choose merging thresholds no larger than 0.6.
|
| 290 |
+
|
| 291 |
+
Local re-clustering threshold. In the second step of self-exploration, we use a threshold θ small%\theta_{\text{small}}\% to select small regions that require a local re-examination. Pseudo-labels with areas smaller than θ small%\theta_{\text{small}}\% of the whole image are processed via local re-clustering, and this step improves the coverage of small entities. We choose θ small%=1/1,024\theta_{\text{small}}\%=1/1,024 because 1) the commonly adopted MS-COCO style evaluation(Lin et al., [2014](https://arxiv.org/html/2404.12386v2#bib.bib30)) defines small objects as objects whose area is smaller than 32×32 32\times 32 pixels; 2) our images are resized to 1,024×1,024 1,024\times 1,024 in the self-exploration phase; 3) (32×32)/(1,024×1,024)=1/1,024(32\times 32)/(1,024\times 1,024)=1/1,024. In fact, if the threshold θ small%\theta_{\text{small}}\% is larger, the coverage of small entities could not be significantly improved further, and the processing time would be longer, as shown in Table[6(a)](https://arxiv.org/html/2404.12386v2#A4.T6.st1 "In Table 6 ‣ Appendix D Additional Ablation Study Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation").
|
| 292 |
+
|
| 293 |
+
Table 6: Impact of hyper-parameters θ small%\theta_{\text{small}}\% and θ cover%\theta_{\text{cover}}\%.
|
| 294 |
+
|
| 295 |
+
(a) Choice of the local re-clustering threshold θ small%\theta_{\text{small}}\%. We set θ small%=1/1,024\theta_{\text{small}}\%=1/1,024 by considering the relative areas of small entities. Using a larger θ small%\theta_{\text{small}}\% does not further improve the coverage of small entities, but introduces additional computation overheads.
|
| 296 |
+
|
| 297 |
+
(b) Choice of the coverage threshold θ cover%\theta_{\text{cover}}\%. We set θ cover%=0.9\theta_{\text{cover}}\%=0.9 for robust hierarchical relations between our pseudo-labels. When θ cover%\theta_{\text{cover}}\% varies within [0.6,0.95][0.6,0.95], the hierarchical relations are stable.
|
| 298 |
+
|
| 299 |
+
Coverage threshold. In the final step of self-exploration, we analyze the hierarchical relations between pseudo-labels. The pairwise test involves a coverage threshold θ cover%\theta_{\text{cover}}\%. For robustness, we choose θ cover%=0.9\theta_{\text{cover}}\%=0.9 to allow an ancestor pseudo-label to not necessarily cover all of its descendants’ pixels. Indeed, when θ cover%∈[0.6,0.95]\theta_{\text{cover}}\%\in[0.6,0.95], the induced hierarchical relations are relatively stable, as shown in Table[6(b)](https://arxiv.org/html/2404.12386v2#A4.T6.st2 "In Table 6 ‣ Appendix D Additional Ablation Study Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation").
|
| 300 |
+
|
| 301 |
+
DINO backbone. As a supplement to Figure[7](https://arxiv.org/html/2404.12386v2#S4.F7 "Figure 7 ‣ 4.4 Improved backbone features ‣ 4 Experiments ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation") in the main paper, Table[7](https://arxiv.org/html/2404.12386v2#A4.T7 "Table 7 ‣ Appendix D Additional Ablation Study Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation") summarizes the detailed statistics of the mask quality of initial pseudo-labels produced by DINO backbones pre-trained with different configurations. It also includes the mask quality after each self-exploration step.
|
| 302 |
+
|
| 303 |
+
Table 7: Comparison of DINO backbones pre-trained with different configurations. A small pre-training patch size is critical for producing fine-grained visual features and high-quality pseudo-label masks. The steps 1, 2, and 3 refer to global clustering, local re-clustering, and mask refinement, respectively.
|
| 304 |
+
|
| 305 |
+
Segmentation head. In SOHES, we choose Mask2Former(Cheng et al., [2022](https://arxiv.org/html/2404.12386v2#bib.bib10)) as our segmentation head mainly for making hierarchical predictions. In Cascade Mask R-CNN(Cai & Vasconcelos, [2018](https://arxiv.org/html/2404.12386v2#bib.bib4)) used by prior work(Wang et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib51); Cao et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib5)), each proposal is predicted independently, and therefore, analyzing hierarchical relations between entities would be challenging. In contrast, the attention modules in Mask2Former allow information exchange among queries, so we can build our ancestor prediction head on Mask2Former (see Figure[4](https://arxiv.org/html/2404.12386v2#S3.F4 "Figure 4 ‣ 3.2 Self-instruction: Learn from initial pseudo-labels ‣ 3 Approach ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation")). For a more comprehensive comparison with prior work, we train a segmentation model based on Cascade Mask R-CNN using SOHES without the entity hierarchy. As shown in Table[8](https://arxiv.org/html/2404.12386v2#A4.T8 "Table 8 ‣ Appendix D Additional Ablation Study Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"), this model still significantly outperforms CutLER and HASSOD with the same segmentation head.
|
| 306 |
+
|
| 307 |
+
When using the Mask2Former segmentation head, we can extend it with our proposed ancestor prediction head to perform the additional task of hierarchical relation predictions. This module can be considered as an add-on to the original segmentation head with minimal influence on the mask quality, since this ancestor prediction head operates in parallel to the mask prediction head. In fact, the segmentation performance of a SOHES model trained _without_ the ancestor prediction head is close to that of the standard SOHES model (_e.g_., on SA-1B, 33.0 Mask AR without ancestor prediction _vs_. 33.3 Mask AR with ancestor prediction), but the former model cannot predict hierarchical relations.
|
| 308 |
+
|
| 309 |
+
Table 8: Comparison of models trained with the Cascade Mask R-CNN segmentation head. In the main paper, we choose the Mask2Former segmentation head to model hierarchical relations between predictions, while prior methods usually use Cascade Mask R-CNN. With the same Cascade Mask R-CNN segmentation head, SOHES still outperforms prior work.
|
| 310 |
+
|
| 311 |
+
Appendix E Limitations
|
| 312 |
+
----------------------
|
| 313 |
+
|
| 314 |
+
In Figure[9](https://arxiv.org/html/2404.12386v2#A5.F9 "Figure 9 ‣ Appendix E Limitations ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"), we visualize some failure cases of SOHES: 1) When there are discontinuous entities or occlusion (_e.g_., sky separated by foreground objects), SOHES may not correctly associate the disconnected segments of the same entity. The reason is that in the self-exploration phase, we only merge adjacent regions. The model rarely observes one entity separated in multiple disconnected regions. We observe that the copy-paste data augmentation(Ghiasi et al., [2021](https://arxiv.org/html/2404.12386v2#bib.bib15)) can simulate occlusion and partially mitigate this issue, so we have adopted such data augmentation in SOHES training. 2) SOHES often produces imprecise segmentation masks for letters and characters. The boundary is not perfectly aligned with strokes and the mask is often larger than the letter. 3) When there are blurry backgrounds, SOHES tends not to predict a mask for the background. Similar failure cases can be observed when applying prior methods(Wang et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib51); Cao et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib5); Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)) to images affected by occlusion, text overlays, or blurring. We aim to resolve these issues with improved pseudo-labeling strategies in future work.
|
| 315 |
+
|
| 316 |
+

|
| 317 |
+
|
| 318 |
+
Figure 9: Limitations of SOHES. Our method sometimes fail to accurately segment discontinuous or occluded entities (left), letters or characters (middle), and blurred background (right).
|
| 319 |
+
|
| 320 |
+
Appendix F Qualitative Results
|
| 321 |
+
------------------------------
|
| 322 |
+
|
| 323 |
+
In Figures[10](https://arxiv.org/html/2404.12386v2#A6.F10 "Figure 10 ‣ Appendix F Qualitative Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"), [11](https://arxiv.org/html/2404.12386v2#A6.F11 "Figure 11 ‣ Appendix F Qualitative Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"), [12](https://arxiv.org/html/2404.12386v2#A6.F12 "Figure 12 ‣ Appendix F Qualitative Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"), [13](https://arxiv.org/html/2404.12386v2#A6.F13 "Figure 13 ‣ Appendix F Qualitative Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"), and [14](https://arxiv.org/html/2404.12386v2#A6.F14 "Figure 14 ‣ Appendix F Qualitative Results ‣ SOHES: Self-supervised Open-world Hierarchical Entity Segmentation"), we visualize the segmentation results of SOHES, and qualitatively compare SOHES with the supervised model SAM on the evaluation datasets we have used in the main paper.
|
| 324 |
+
|
| 325 |
+

|
| 326 |
+
|
| 327 |
+
Figure 10: Qualitative results on MS-COCO images. In each group of images, from top to bottom we show the original input image, segmentation by SAM(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)), and segmentation by SOHES. As a self-supervised method, SOHES can achieve results that are comparable to those produced by the supervised model SAM.
|
| 328 |
+
|
| 329 |
+

|
| 330 |
+
|
| 331 |
+
Figure 11: Qualitative results on ADE20K images. In each group of images, from top to bottom we show the original input image, segmentation by SAM(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)), and segmentation by SOHES. As a self-supervised method, SOHES can achieve results that are comparable to those produced by the supervised model SAM.
|
| 332 |
+
|
| 333 |
+

|
| 334 |
+
|
| 335 |
+
Figure 12: Qualitative results on EntitySeg images. In each group of images, from top to bottom we show the original input image, segmentation by SAM(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)), and segmentation by SOHES. As a self-supervised method, SOHES can achieve results that are comparable to those produced by the supervised model SAM.
|
| 336 |
+
|
| 337 |
+

|
| 338 |
+
|
| 339 |
+
Figure 13: Qualitative results on SA-1B images. In each group of images, from top to bottom we show the original input image, segmentation by SAM(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)), and segmentation by SOHES. As a self-supervised method, SOHES can achieve results that are comparable to those produced by the supervised model SAM.
|
| 340 |
+
|
| 341 |
+

|
| 342 |
+
|
| 343 |
+
Figure 14: Qualitative results on PartImageNet images. In each group of images, from top to bottom we show the original input image, segmentation by SAM(Kirillov et al., [2023](https://arxiv.org/html/2404.12386v2#bib.bib28)), and segmentation by SOHES. As a self-supervised method, SOHES can achieve results that are comparable to those produced by the supervised model SAM.
|