

Add 1 files
Browse files- 2412/2412.07207.md +488 -0
2412/2412.07207.md
ADDED
|
@@ -0,0 +1,488 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: A Framework for Active Preference Learning Guided by Large Language Models
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2412.07207
|
| 4 |
+
|
| 5 |
+
Published Time: Mon, 23 Dec 2024 01:15:03 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
###### Abstract
|
| 9 |
+
|
| 10 |
+
The advent of large language models (LLMs) has sparked significant interest in using natural language for preference learning. However, existing methods often suffer from high computational burdens, taxing human supervision, and lack of interpretability. To address these issues, we introduce MAPLE, a framework for large language model-guided Bayesian active preference learning. MAPLE leverages LLMs to model the distribution over preference functions, conditioning it on both natural language feedback and conventional preference learning feedback, such as pairwise trajectory rankings. MAPLE also employs active learning to systematically reduce uncertainty in this distribution and incorporates a language-conditioned active query selection mechanism to identify informative and easy-to-answer queries, thus reducing human burden. We evaluate MAPLE’s sample efficiency and preference inference quality across two benchmarks, including a real-world vehicle route planning benchmark using OpenStreetMap data. Our results demonstrate that MAPLE accelerates the learning process and effectively improves humans’ ability to answer queries.
|
| 11 |
+
|
| 12 |
+
Introduction
|
| 13 |
+
------------
|
| 14 |
+
|
| 15 |
+
Following significant advancements in artificial intelligence, autonomous agents are increasingly being deployed in real-world applications to tackle complex tasks(Zilberstein [2015](https://arxiv.org/html/2412.07207v2#bib.bib51); Dietterich [2017](https://arxiv.org/html/2412.07207v2#bib.bib16)). A prominent method for efficiently aligning these agents with human preferences is Active Learning from Demonstration (Active LfD)(Biyik [2022](https://arxiv.org/html/2412.07207v2#bib.bib4)). Preference-based Active LfD, a variant of LfD, aims to infer a preference function from human-generated rankings over a set of observed behaviors using a Bayesian active learning approach.
|
| 16 |
+
|
| 17 |
+
Recent advancements in natural language processing have inspired many researchers to leverage language-based abstraction for learning human preferences(Soni et al. [2022](https://arxiv.org/html/2412.07207v2#bib.bib40); Guan, Sreedharan, and Kambhampati [2022](https://arxiv.org/html/2412.07207v2#bib.bib18)). This approach offers a more flexible and interpretable way to learn preferences compared to conventional methods(Sadigh et al. [2017](https://arxiv.org/html/2412.07207v2#bib.bib38); Brown, Goo, and Niekum [2019](https://arxiv.org/html/2412.07207v2#bib.bib8); Brown et al. [2019](https://arxiv.org/html/2412.07207v2#bib.bib9)). More recent work(Yu et al. [2023](https://arxiv.org/html/2412.07207v2#bib.bib47); Ma et al. [2023](https://arxiv.org/html/2412.07207v2#bib.bib30)) has focused on utilizing large language models (LLMs), such as ChatGPT(Achiam et al. [2023](https://arxiv.org/html/2412.07207v2#bib.bib2)), with prompting-based approaches to learn preferences from natural language instructions. However, these methods often require significant computational resources and taxing human supervision, as they lack a systematic querying approach.
|
| 18 |
+
|
| 19 |
+
To tackle these challenges, we introduce a novel framework—MAPLE (M odel-guided A ctive P reference Le arning). MAPLE begins by interpreting natural language instructions from humans and utilizes large language models (LLMs) to estimate a distribution over preference functions. It then applies an active learning approach to systematically reduce uncertainty about the correct preference function. This is achieved through standard Bayesian posterior updates, conditioned on both conventional preference learning feedback, such as pairwise trajectory rankings, and linguistic feedback such as clarification or explanations of the cause behind the preference. To further ease human effort, MAPLE incorporates a language-conditioned active query selection mechanism that leverages feedback on the difficulty of previous queries to choose future queries that are both informative and easy to answer. MAPLE represents preference functions as a linear combination of abstract language concepts, providing a modular structure that enables the framework to acquire new concepts over time and enhance sample efficiency for future instructions. Moreover, this interpretable structure allows for human auditing of the learning process, facilitating human-guided validation before applying the preference function to optimize behavior.
|
| 20 |
+
|
| 21 |
+
In our experiments, we evaluate the efficacy of MAPLE in terms of sample efficiency during learning, as well as the quality of the final preference function. We use an environment based on the popular Minigrid(Chevalier-Boisvert et al. [2023](https://arxiv.org/html/2412.07207v2#bib.bib14)) and introduce a new realistic vehicle routing benchmark based on OpenStreetMap (OpenStreetMap Contributors [2017](https://arxiv.org/html/2412.07207v2#bib.bib33)) data, which includes text descriptions of the road network of different cities in the USA. Our evaluation shows the effectiveness of MAPLE in preference inference and improving human’s ability to answer queries. Our contributions are threefold:
|
| 22 |
+
|
| 23 |
+
* •We propose a Bayesian preference learning framework that leverages LLMs and natural language explanations to reduce uncertainty over preference functions.
|
| 24 |
+
* •We provide a language-conditioned active query selection approach to reduce human burden.
|
| 25 |
+
* •We conduct extensive evaluations, including the design of a realistic new benchmark that can be used for future research in this area.
|
| 26 |
+
|
| 27 |
+
Related Work
|
| 28 |
+
------------
|
| 29 |
+
|
| 30 |
+
#### Learning from demonstration
|
| 31 |
+
|
| 32 |
+
Most Learning from Demonstration (LfD) algorithms learn a reward function using expert trajectories(Ng and Russell [2000](https://arxiv.org/html/2412.07207v2#bib.bib32); Abbeel and Ng [2004](https://arxiv.org/html/2412.07207v2#bib.bib1); Ziebart et al. [2008](https://arxiv.org/html/2412.07207v2#bib.bib50)). Some of these approaches utilize a Bayesian framework to learn the reward or preference function(Ramachandran and Amir [2007](https://arxiv.org/html/2412.07207v2#bib.bib37); Brown et al. [2020](https://arxiv.org/html/2412.07207v2#bib.bib10); Mahmud, Saisubramanian, and Zilberstein [2023](https://arxiv.org/html/2412.07207v2#bib.bib31)), and some pair it with active learning to reduce the number of human queries(Sadigh et al. [2017](https://arxiv.org/html/2412.07207v2#bib.bib38); Basu, Singhal, and Dragan [2018](https://arxiv.org/html/2412.07207v2#bib.bib3); Biyik [2022](https://arxiv.org/html/2412.07207v2#bib.bib4)). However, these methods are unable to utilize natural language abstraction, whereas our method can use both. In addition, we employ language-conditioned active learning to reduce user burden, an approach not previously explored in this context.
|
| 33 |
+
|
| 34 |
+
#### Natural language in intention communication
|
| 35 |
+
|
| 36 |
+
With the advent of natural language processing, several works have focused on directly communicating abstract concepts to agents(Tevet et al. [2022](https://arxiv.org/html/2412.07207v2#bib.bib42); Guo et al. [2022](https://arxiv.org/html/2412.07207v2#bib.bib21); Wang et al. [2024](https://arxiv.org/html/2412.07207v2#bib.bib45); Sontakke et al. [2024](https://arxiv.org/html/2412.07207v2#bib.bib41); Lin et al. [2022](https://arxiv.org/html/2412.07207v2#bib.bib26); Tien et al. [2024](https://arxiv.org/html/2412.07207v2#bib.bib44); Lou et al. [2024](https://arxiv.org/html/2412.07207v2#bib.bib27)). The key difference is that these works directly condition behavior on natural language, whereas we learn a language-abstracted preference function. This approach offers several advantages, including increased transparency, a more fine-grained trade-off between concepts, and enhanced transferability. The work most closely related to ours is (Lin et al. [2022](https://arxiv.org/html/2412.07207v2#bib.bib26)), which infers rewards from language but restricts them to step-wise decision-making.
|
| 37 |
+
|
| 38 |
+
Other lines of work(Yu et al. [2023](https://arxiv.org/html/2412.07207v2#bib.bib47); Ma et al. [2023](https://arxiv.org/html/2412.07207v2#bib.bib30)) aim to learn reward functions directly by prompting LLMs. However, these methods are limited by the variables available in the coding space and often struggle with identifying temporally extended abstract behaviors. Further, these approaches can not utilize conventional preference feedback, whereas MAPLE can utilize both. Additionally, they either lack a systematic way of acquiring human feedback or rely on data-hungry evolutionary algorithms. In contrast, our approach employs more efficient Bayesian active learning.
|
| 39 |
+
|
| 40 |
+
#### Abstraction in reward learning
|
| 41 |
+
|
| 42 |
+
Several works leverage abstract concepts to learn reward functions(Lyu et al. [2019](https://arxiv.org/html/2412.07207v2#bib.bib29); Illanes et al. [2020](https://arxiv.org/html/2412.07207v2#bib.bib23); Icarte et al. [2022](https://arxiv.org/html/2412.07207v2#bib.bib22); Guan, Valmeekam, and Kambhampati [2022](https://arxiv.org/html/2412.07207v2#bib.bib19); Soni et al. [2022](https://arxiv.org/html/2412.07207v2#bib.bib40); Bobu et al. [2021](https://arxiv.org/html/2412.07207v2#bib.bib6); Guan et al. [2021](https://arxiv.org/html/2412.07207v2#bib.bib20); Guan, Sreedharan, and Kambhampati [2022](https://arxiv.org/html/2412.07207v2#bib.bib18); Silver et al. [2022](https://arxiv.org/html/2412.07207v2#bib.bib39); Zhang et al. [2022](https://arxiv.org/html/2412.07207v2#bib.bib48); Bucker et al. [2023](https://arxiv.org/html/2412.07207v2#bib.bib12); Cui et al. [2023](https://arxiv.org/html/2412.07207v2#bib.bib15)). Two methods closely related to our work are PRESCA(Soni et al. [2022](https://arxiv.org/html/2412.07207v2#bib.bib40)) and RBA(Guan, Valmeekam, and Kambhampati [2022](https://arxiv.org/html/2412.07207v2#bib.bib19)). PRESCA learns state-based abstract concepts to be avoided, while RBA learns temporally extended concepts with two variants: global (eliciting preference weights directly from humans) and local (tuning weights using binary search). Our approach also leverages temporally extended concepts but learns preference functions from natural language feedback using active learning. Unlike RBA, which relies on direct preference weights from humans or binary search, our method uses LLM-guided active learning for more expressive and informative preference elicitation, thereby reducing human effort.
|
| 43 |
+
|
| 44 |
+
Some works use offline behavior datasets or demonstrations to learn diverse skills(Lee and Popović [2010](https://arxiv.org/html/2412.07207v2#bib.bib24); Wang et al. [2017](https://arxiv.org/html/2412.07207v2#bib.bib46); Zhou and Dragan [2018](https://arxiv.org/html/2412.07207v2#bib.bib49); Peng et al. [2018](https://arxiv.org/html/2412.07207v2#bib.bib34); Luo et al. [2020](https://arxiv.org/html/2412.07207v2#bib.bib28); Chebotar et al. [2021](https://arxiv.org/html/2412.07207v2#bib.bib13); Peng et al. [2021](https://arxiv.org/html/2412.07207v2#bib.bib35)), which complement our approach. While MAPLE can also utilize such datasets in pre-training, the focus of MAPLE is to encode human preference in terms of these concepts using natural language.
|
| 45 |
+
|
| 46 |
+
#### Alignment auditing
|
| 47 |
+
|
| 48 |
+
Alignment auditing ensures that an agent’s behavior aligns with human intentions by verifying that the agent has learned the correct preference function. While some works focus on alignment verification with minimal queries(Brown, Schneider, and Niekum [2021](https://arxiv.org/html/2412.07207v2#bib.bib11)), they often rely on function weights, value weights, or trajectory rankings, which are difficult to interpret. In contrast, our approach leverages natural language to communicate with humans, facilitating validation and serving as a stopping criterion for the active learning process. Mahmud, Saisubramanian, and Zilberstein ([2023](https://arxiv.org/html/2412.07207v2#bib.bib31)) presents a notable alignment auditing approach related to our method, using explanations to detect misalignment and update distributions over preferences. While they employ a feature attribution method, we use natural language explanations. Additionally, they use human-selected or randomly sampled data points from an offline dataset for auditing, whereas we employ active learning to enhance efficiency.
|
| 49 |
+
|
| 50 |
+
#### Active learning
|
| 51 |
+
|
| 52 |
+
Previous works have explored different acquisition functions for active learning, typically focusing on selecting queries that maximize certain uncertainty quantization metrics. These metrics include predictive entropy(Gal and Ghahramani [2016](https://arxiv.org/html/2412.07207v2#bib.bib17)), uncertainty volume reduction(Sadigh et al. [2017](https://arxiv.org/html/2412.07207v2#bib.bib38)), mutual information maximization(Biyik et al. [2019](https://arxiv.org/html/2412.07207v2#bib.bib5)), and maximizing variation ratios(Gal and Ghahramani [2016](https://arxiv.org/html/2412.07207v2#bib.bib17)). Our approach complements these methods by integrating language-conditioned query selection to reduce user burden. While any of these methods can be paired with MAPLE, we opt for variation ratio due to its ease of calculation and high effectiveness.
|
| 53 |
+
|
| 54 |
+

|
| 55 |
+
|
| 56 |
+
Figure 1: Application of MAPLE to the Natural Language Vehicle Routing Task.
|
| 57 |
+
|
| 58 |
+
Background
|
| 59 |
+
----------
|
| 60 |
+
|
| 61 |
+
#### Markov decision process (MDP)
|
| 62 |
+
|
| 63 |
+
A Markov Decision Process (MDP) M 𝑀 M italic_M is represented by the tuple M=(S,A,T,S 0,R,γ)𝑀 𝑆 𝐴 𝑇 subscript 𝑆 0 𝑅 𝛾 M=(S,A,T,S_{0},R,\gamma)italic_M = ( italic_S , italic_A , italic_T , italic_S start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT , italic_R , italic_γ ), where S 𝑆 S italic_S is the set of states, A 𝐴 A italic_A is the set of actions, T:S×A×S→[0,1]:𝑇→𝑆 𝐴 𝑆 0 1 T:S\times A\times S\rightarrow[0,1]italic_T : italic_S × italic_A × italic_S → [ 0 , 1 ] is the transition function, S 0 subscript 𝑆 0 S_{0}italic_S start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT is the initial state distribution, and γ∈[0,1)𝛾 0 1\gamma\in[0,1)italic_γ ∈ [ 0 , 1 ) is the discount factor. A history h t subscript ℎ 𝑡 h_{t}italic_h start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT is a sequence of states up to time t 𝑡 t italic_t, (s 0,…,s t)subscript 𝑠 0…subscript 𝑠 𝑡(s_{0},\dots,s_{t})( italic_s start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT , … , italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ). The reward function R:H×A→[−R max,R max]:𝑅→𝐻 𝐴 subscript 𝑅 max subscript 𝑅 max R:H\times A\rightarrow[-R_{\text{max}},R_{\text{max}}]italic_R : italic_H × italic_A → [ - italic_R start_POSTSUBSCRIPT max end_POSTSUBSCRIPT , italic_R start_POSTSUBSCRIPT max end_POSTSUBSCRIPT ] maps histories and actions to rewards. For some problems, a goal function G:H→[0,1]:𝐺→𝐻 0 1 G:H\rightarrow[0,1]italic_G : italic_H → [ 0 , 1 ] is provided that maps histories to goal achievements. In such problems, the reward function is typically R:H×A→[−R max,0]:𝑅→𝐻 𝐴 subscript 𝑅 max 0 R:H\times A\rightarrow[-R_{\text{max}},0]italic_R : italic_H × italic_A → [ - italic_R start_POSTSUBSCRIPT max end_POSTSUBSCRIPT , 0 ] and ∀a∈A for-all 𝑎 𝐴\forall a\in A∀ italic_a ∈ italic_A, T(s g,a,s g)=1 𝑇 subscript 𝑠 𝑔 𝑎 subscript 𝑠 𝑔 1 T(s_{g},a,s_{g})=1 italic_T ( italic_s start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT , italic_a , italic_s start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT ) = 1 and R(h t∪s g,a)=0 𝑅 subscript ℎ 𝑡 subscript 𝑠 𝑔 𝑎 0 R(h_{t}\cup s_{g},a)=0 italic_R ( italic_h start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ∪ italic_s start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT , italic_a ) = 0 given the final state s g∈h t subscript 𝑠 𝑔 subscript ℎ 𝑡 s_{g}\in h_{t}italic_s start_POSTSUBSCRIPT italic_g end_POSTSUBSCRIPT ∈ italic_h start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. A policy π:H×A→[0,1]:𝜋→𝐻 𝐴 0 1\pi:H\times A\rightarrow[0,1]italic_π : italic_H × italic_A → [ 0 , 1 ] is a mapping from histories to a distribution over actions. The policy π 𝜋\pi italic_π induces a value function V π:S→ℝ:superscript 𝑉 𝜋→𝑆 ℝ V^{\pi}:S\rightarrow\mathbb{R}italic_V start_POSTSUPERSCRIPT italic_π end_POSTSUPERSCRIPT : italic_S → blackboard_R, which represents the expected cumulative return V π(s)superscript 𝑉 𝜋 𝑠 V^{\pi}(s)italic_V start_POSTSUPERSCRIPT italic_π end_POSTSUPERSCRIPT ( italic_s ) that the agent can achieve from state s 𝑠 s italic_s when following policy π 𝜋\pi italic_π. An optimal policy π∗superscript 𝜋\pi^{*}italic_π start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT maximizes the expected cumulative return V∗(s)superscript 𝑉 𝑠 V^{*}(s)italic_V start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ( italic_s ) from any state s 𝑠 s italic_s, particularly from the initial state s 0 subscript 𝑠 0 s_{0}italic_s start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT.
|
| 64 |
+
|
| 65 |
+
#### Bayesian preference learning
|
| 66 |
+
|
| 67 |
+
A preference function ω 𝜔\omega italic_ω maps a trajectory τ 𝜏\tau italic_τ to a real number reflecting the alignment of the trajectory with the human’s objective. The goal of preference learning is to infer this function from various types of human feedback. A common approach involves learning this function from a pairwise preference dataset, denoted by 𝒟={(τ 1 1≻τ 1 2),(τ 2 1≻τ 2 2),…,(τ n 1≻τ n 2)}𝒟 succeeds subscript superscript 𝜏 1 1 subscript superscript 𝜏 2 1 succeeds subscript superscript 𝜏 1 2 subscript superscript 𝜏 2 2…succeeds subscript superscript 𝜏 1 𝑛 subscript superscript 𝜏 2 𝑛\mathcal{D}=\{(\tau^{1}_{1}\succ\tau^{2}_{1}),(\tau^{1}_{2}\succ\tau^{2}_{2}),% \ldots,(\tau^{1}_{n}\succ\tau^{2}_{n})\}caligraphic_D = { ( italic_τ start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ≻ italic_τ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ) , ( italic_τ start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ≻ italic_τ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ) , … , ( italic_τ start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ≻ italic_τ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ) }, where τ i 1 subscript superscript 𝜏 1 𝑖\tau^{1}_{i}italic_τ start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT and τ i 2 subscript superscript 𝜏 2 𝑖\tau^{2}_{i}italic_τ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT are two different trajectories, and τ i 1≻τ i 2 succeeds subscript superscript 𝜏 1 𝑖 subscript superscript 𝜏 2 𝑖\tau^{1}_{i}\succ\tau^{2}_{i}italic_τ start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ≻ italic_τ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT indicates that τ i 1 subscript superscript 𝜏 1 𝑖\tau^{1}_{i}italic_τ start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT is preferred to τ i 2 subscript superscript 𝜏 2 𝑖\tau^{2}_{i}italic_τ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT. A Bayesian framework for preference learning, as described in Ramachandran and Amir ([2007](https://arxiv.org/html/2412.07207v2#bib.bib37)), defines a probability distribution over preference functions given a trajectory dataset 𝒟 𝒟\mathcal{D}caligraphic_D using Bayes’ rule: P(ω∣𝒟)∝P(𝒟∣ω)P(ω)proportional-to 𝑃 conditional 𝜔 𝒟 𝑃 conditional 𝒟 𝜔 𝑃 𝜔 P(\omega\mid\mathcal{D})\propto P(\mathcal{D}\mid\omega)P(\omega)italic_P ( italic_ω ∣ caligraphic_D ) ∝ italic_P ( caligraphic_D ∣ italic_ω ) italic_P ( italic_ω ). Various algorithms define P(𝒟∣ω)𝑃 conditional 𝒟 𝜔 P(\mathcal{D}\mid\omega)italic_P ( caligraphic_D ∣ italic_ω ) differently, but we adopt the definition from BREX (Brown et al. [2020](https://arxiv.org/html/2412.07207v2#bib.bib10)) using the Bradley–Terry model(Bradley and Terry [1952](https://arxiv.org/html/2412.07207v2#bib.bib7)):
|
| 68 |
+
|
| 69 |
+
P(𝒟∣ω)=∏(τ i 1≻τ i 2)∈𝒟 e βω(τ i 1)e βω(τ i 1)+e βω(τ i 2).𝑃 conditional 𝒟 𝜔 subscript product succeeds subscript superscript 𝜏 1 𝑖 subscript superscript 𝜏 2 𝑖 𝒟 superscript 𝑒 𝛽 𝜔 subscript superscript 𝜏 1 𝑖 superscript 𝑒 𝛽 𝜔 subscript superscript 𝜏 1 𝑖 superscript 𝑒 𝛽 𝜔 subscript superscript 𝜏 2 𝑖 P(\mathcal{D}\mid\omega)=\prod_{(\tau^{1}_{i}\succ\tau^{2}_{i})\in\mathcal{D}}% \frac{e^{\beta\omega(\tau^{1}_{i})}}{e^{\beta\omega(\tau^{1}_{i})}+e^{\beta% \omega(\tau^{2}_{i})}}.italic_P ( caligraphic_D ∣ italic_ω ) = ∏ start_POSTSUBSCRIPT ( italic_τ start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ≻ italic_τ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) ∈ caligraphic_D end_POSTSUBSCRIPT divide start_ARG italic_e start_POSTSUPERSCRIPT italic_β italic_ω ( italic_τ start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) end_POSTSUPERSCRIPT end_ARG start_ARG italic_e start_POSTSUPERSCRIPT italic_β italic_ω ( italic_τ start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) end_POSTSUPERSCRIPT + italic_e start_POSTSUPERSCRIPT italic_β italic_ω ( italic_τ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) end_POSTSUPERSCRIPT end_ARG .(1)
|
| 70 |
+
|
| 71 |
+
Here, β∈[0,∞)𝛽 0\beta\in[0,\infty)italic_β ∈ [ 0 , ∞ ) is the inverse-temperature parameter.
|
| 72 |
+
|
| 73 |
+
#### Variance ratio
|
| 74 |
+
|
| 75 |
+
Given a conditional probability distribution P(⋅∣X)P(\cdot\mid X)italic_P ( ⋅ ∣ italic_X ) over {y i}i=0 k superscript subscript subscript 𝑦 𝑖 𝑖 0 𝑘\{y_{i}\}_{i=0}^{k}{ italic_y start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT } start_POSTSUBSCRIPT italic_i = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT, the variance ratio of an input X 𝑋 X italic_X is defined as follows:
|
| 76 |
+
|
| 77 |
+
Variance_Ratio(X)=1−argmax y iP(y i∣X)Variance_Ratio 𝑋 1 subscript arg max subscript 𝑦 𝑖 𝑃 conditional subscript 𝑦 𝑖 𝑋\text{Variance\_Ratio}(X)=1-\operatorname*{arg\,max}_{y_{i}}P(y_{i}\mid X)Variance_Ratio ( italic_X ) = 1 - start_OPERATOR roman_arg roman_max end_OPERATOR start_POSTSUBSCRIPT italic_y start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT italic_P ( italic_y start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ∣ italic_X )
|
| 78 |
+
|
| 79 |
+
Problem Formulation
|
| 80 |
+
-------------------
|
| 81 |
+
|
| 82 |
+
#### MAPLE
|
| 83 |
+
|
| 84 |
+
We define a MAPLE problem instance as the tuple (M−R,C,Ω,D τ,ℋ,𝕃)subscript 𝑀 𝑅 𝐶 Ω subscript 𝐷 𝜏 ℋ 𝕃(M_{-R},C,\Omega,D_{\tau},\mathcal{H},\mathbb{L})( italic_M start_POSTSUBSCRIPT - italic_R end_POSTSUBSCRIPT , italic_C , roman_Ω , italic_D start_POSTSUBSCRIPT italic_τ end_POSTSUBSCRIPT , caligraphic_H , blackboard_L ), where:
|
| 85 |
+
|
| 86 |
+
* •M−R subscript 𝑀 𝑅 M_{-R}italic_M start_POSTSUBSCRIPT - italic_R end_POSTSUBSCRIPT is an MDP with an undefined reward function R 𝑅 R italic_R.
|
| 87 |
+
* •ℋ ℋ\mathcal{H}caligraphic_H is the human interaction function that acts as the interface between the human and the MAPLE framework. Humans provide their feedback, preferences, and explanations in response to natural language queries posed by MAPLE.
|
| 88 |
+
* •𝕃 𝕃\mathbb{L}blackboard_L is the LLM interaction function that generates natural language queries to the LLM and returns structured output in text files, such as JSON format.
|
| 89 |
+
* •C 𝐶 C italic_C is an expanding set of natural language concepts {c 1,c 2,…,c n}subscript 𝑐 1 subscript 𝑐 2…subscript 𝑐 𝑛\{c_{1},c_{2},\ldots,c_{n}\}{ italic_c start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_c start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , … , italic_c start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT }. We also use C(⋅)𝐶⋅C(\cdot)italic_C ( ⋅ ) to refer to a mapping model that takes a trajectory embedding ϕ(τ)italic-ϕ 𝜏\phi(\tau)italic_ϕ ( italic_τ ) and a natural language concept embedding ψ(c i)𝜓 subscript 𝑐 𝑖\psi(c_{i})italic_ψ ( italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) and maps them to a numeric value indicating the degree to which the trajectory τ 𝜏\tau italic_τ satisfies the concept c i subscript 𝑐 𝑖 c_{i}italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT. For non-Markovian concepts, ϕ(⋅)italic-ϕ⋅\phi(\cdot)italic_ϕ ( ⋅ ) may be a sequence model such as a transformer. For Markovian concepts, we can define C(ϕ(τ),ψ(c i))=∑s∈τ C(ϕ(s),ψ(c i))𝐶 italic-ϕ 𝜏 𝜓 subscript 𝑐 𝑖 subscript 𝑠 𝜏 𝐶 italic-ϕ 𝑠 𝜓 subscript 𝑐 𝑖 C(\phi(\tau),\psi(c_{i}))=\sum_{\displaystyle s\in\tau}C(\phi(s),\psi(c_{i}))italic_C ( italic_ϕ ( italic_τ ) , italic_ψ ( italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) ) = ∑ start_POSTSUBSCRIPT italic_s ∈ italic_τ end_POSTSUBSCRIPT italic_C ( italic_ϕ ( italic_s ) , italic_ψ ( italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) ), where ϕ(s)italic-ϕ 𝑠\phi(s)italic_ϕ ( italic_s ) is the state embedding.
|
| 90 |
+
* •Ω Ω\Omega roman_Ω is the space of all preference functions. In MAPLE, the preference functions ω 𝜔\omega italic_ω over a trajectory τ 𝜏\tau italic_τ are modeled as a linear combination of the concepts and their associated weights:
|
| 91 |
+
|
| 92 |
+
ω(τ)=∑c i∈C ω c i⋅C(ϕ(τ),ψ(c i))𝜔 𝜏 subscript subscript 𝑐 𝑖 𝐶⋅subscript 𝜔 subscript 𝑐 𝑖 𝐶 italic-ϕ 𝜏 𝜓 subscript 𝑐 𝑖\omega(\tau)=\sum_{\displaystyle c_{i}\in C}\omega_{c_{i}}\cdot C(\phi(\tau),% \psi(c_{i}))italic_ω ( italic_τ ) = ∑ start_POSTSUBSCRIPT italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ∈ italic_C end_POSTSUBSCRIPT italic_ω start_POSTSUBSCRIPT italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT ⋅ italic_C ( italic_ϕ ( italic_τ ) , italic_ψ ( italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) )(2)
|
| 93 |
+
* •D τ subscript 𝐷 𝜏 D_{\tau}italic_D start_POSTSUBSCRIPT italic_τ end_POSTSUBSCRIPT is a dataset of unlabeled trajectories {τ 1,τ 2,…,τ m}subscript 𝜏 1 subscript 𝜏 2…subscript 𝜏 𝑚\{\tau_{1},\tau_{2},\ldots,\tau_{m}\}{ italic_τ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_τ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , … , italic_τ start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT }.
|
| 94 |
+
|
| 95 |
+
The objective of MAPLE is to model the repeated interaction between a human and an agent, where the human communicates their task objective 𝒜 𝒯 ℋ subscript superscript 𝒜 ℋ 𝒯\mathcal{A}^{\mathcal{H}}_{\mathcal{T}}caligraphic_A start_POSTSUPERSCRIPT caligraphic_H end_POSTSUPERSCRIPT start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT in natural language, and the agent is responsible for completing the task in alignment with that objective. MAPLE accomplishes this by actively learning a symbolic preference function ω 𝜔\omega italic_ω using large language models (LLMs), enabling the agent to optimize its behavior according to this function to ensure its actions align with human preferences.
|
| 96 |
+
|
| 97 |
+
#### Motivating example
|
| 98 |
+
|
| 99 |
+
Consider an intelligent route planning system that takes a source, a destination, and user preferences about the route in natural language, as illustrated in Figure [1](https://arxiv.org/html/2412.07207v2#Sx2.F1 "Figure 1 ‣ Active learning ‣ Related Work ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models"). Datasets for several preference-defining concepts such as speed, safety, battery friendliness, smoothness, autopilot friendliness, and scenic view can be easily obtained and used to pre-train the concept mapping function C(⋅)𝐶⋅C(\cdot)italic_C ( ⋅ ). The goal of MAPLE is to take natural language instructions from a human and map them to a preference function ω 𝜔\omega italic_ω interactively so that a search algorithm can optimize it to find the preferred route. MAPLE incorporates preference feedback on top of natural language feedback to address issues like hallucination and calibration associated with directly using LLMs. Additionally, MAPLE allows the human to skip difficult queries and learns in-context which query to present, making the system more human-friendly. Furthermore, the preference function inference process in MAPLE is fully interpretable, enabling a human to audit the process thoroughly and provide the necessary feedback for improvement. Finally, the interaction with the human is repeated, allowing MAPLE to acquire new concepts over time and become more efficient for future tasks.
|
| 100 |
+
|
| 101 |
+
Detailed Description of the Proposed Method
|
| 102 |
+
-------------------------------------------
|
| 103 |
+
|
| 104 |
+
A key innovation of MAPLE is the integration of conventional feedback from the preference learning literature with more expressive linguistic feedback, formally captured within a Bayesian framework introduced in REVEALE(Mahmud, Saisubramanian, and Zilberstein [2023](https://arxiv.org/html/2412.07207v2#bib.bib31)):
|
| 105 |
+
|
| 106 |
+
P(ω∣F h,F l)∝P(F h∣ω)P(F l∣ω)P(ω)proportional-to 𝑃 conditional 𝜔 subscript 𝐹 ℎ subscript 𝐹 𝑙 𝑃 conditional subscript 𝐹 ℎ 𝜔 𝑃 conditional subscript 𝐹 𝑙 𝜔 𝑃 𝜔 P(\omega\mid F_{h},F_{l})\propto P(F_{h}\mid\omega)P(F_{l}\mid\omega)P(\omega)italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT , italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) ∝ italic_P ( italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT ∣ italic_ω ) italic_P ( italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ∣ italic_ω ) italic_P ( italic_ω )(3)
|
| 107 |
+
|
| 108 |
+
Above, F h subscript 𝐹 ℎ F_{h}italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT represents the set of feedback observed in conventional preference learning algorithms, specifically in the context of this paper pairwise trajectory ranking.1 1 1 MAPLE can handle any conventional feedback for which P(F h∣ω)𝑃 conditional subscript 𝐹 ℎ 𝜔 P(F_{h}\mid\omega)italic_P ( italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT ∣ italic_ω ) is defined.F l subscript 𝐹 𝑙 F_{l}italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT denotes the set of linguistic feedback. We can rewrite the equation as:
|
| 109 |
+
|
| 110 |
+
P(ω∣F h,F l)𝑃 conditional 𝜔 subscript 𝐹 ℎ subscript 𝐹 𝑙\displaystyle P(\omega\mid F_{h},F_{l})italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT , italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT )∝P(F h∣ω)⏟Bradley-Terry ModelP(ω∣F l)⏟LLMP(F l)⏟Uniform proportional-to absent subscript⏟𝑃 conditional subscript 𝐹 ℎ 𝜔 Bradley-Terry Model subscript⏟𝑃 conditional 𝜔 subscript 𝐹 𝑙 LLM subscript⏟𝑃 subscript 𝐹 𝑙 Uniform\displaystyle\propto\underbrace{P(F_{h}\mid\omega)}_{\text{Bradley-Terry Model% }}\underbrace{P(\omega\mid F_{l})}_{\text{LLM}}\underbrace{P(F_{l})}_{\text{% Uniform}}∝ under⏟ start_ARG italic_P ( italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT ∣ italic_ω ) end_ARG start_POSTSUBSCRIPT Bradley-Terry Model end_POSTSUBSCRIPT under⏟ start_ARG italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) end_ARG start_POSTSUBSCRIPT LLM end_POSTSUBSCRIPT under⏟ start_ARG italic_P ( italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) end_ARG start_POSTSUBSCRIPT Uniform end_POSTSUBSCRIPT(4)
|
| 111 |
+
∝P(F h∣ω)⏟Bradley-Terry ModelP(ω∣F l)⏟LLM proportional-to absent subscript⏟𝑃 conditional subscript 𝐹 ℎ 𝜔 Bradley-Terry Model subscript⏟𝑃 conditional 𝜔 subscript 𝐹 𝑙 LLM\displaystyle\propto\underbrace{P(F_{h}\mid\omega)}_{\text{Bradley-Terry Model% }}\underbrace{P(\omega\mid F_{l})}_{\text{LLM}}∝ under⏟ start_ARG italic_P ( italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT ∣ italic_ω ) end_ARG start_POSTSUBSCRIPT Bradley-Terry Model end_POSTSUBSCRIPT under⏟ start_ARG italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) end_ARG start_POSTSUBSCRIPT LLM end_POSTSUBSCRIPT(5)
|
| 112 |
+
|
| 113 |
+
Here, the likelihood of F h subscript 𝐹 ℎ F_{h}italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT given ω 𝜔\omega italic_ω is defined using the Bradley-Terry Model. The likelihood of ω 𝜔\omega italic_ω given F l subscript 𝐹 𝑙 F_{l}italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT is estimated using an LLM. Beyond incorporating linguistic feedback via LLMs, MAPLE advances conventional active learning methods. Conventional active learning typically focuses on selecting queries that reduce the maximum uncertainty of the posterior but lacks a flexible mechanism to account for human capability in responding to certain types of queries. MAPLE’s Oracle-guided active query selection enhances any conventional acquisition function by leveraging linguistic feedback to alleviate the human burden associated with difficult queries. In the rest of this section, we provide more details on MAPLE, particularly Algorithms[1](https://arxiv.org/html/2412.07207v2#alg1 "Algorithm 1 ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models") and [2](https://arxiv.org/html/2412.07207v2#alg2 "Algorithm 2 ‣ Stopping criteria ‣ LLM-Guided Active Preference Learning ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models").
|
| 114 |
+
|
| 115 |
+
Algorithm 1 MAPLE
|
| 116 |
+
|
| 117 |
+
0:Human instruction
|
| 118 |
+
|
| 119 |
+
𝒜 𝒯 ℋ subscript superscript 𝒜 ℋ 𝒯\mathcal{A}^{\mathcal{H}}_{\mathcal{T}}caligraphic_A start_POSTSUPERSCRIPT caligraphic_H end_POSTSUPERSCRIPT start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT
|
| 120 |
+
, Acquisition function
|
| 121 |
+
|
| 122 |
+
𝒜 f subscript 𝒜 𝑓\mathcal{A}_{f}caligraphic_A start_POSTSUBSCRIPT italic_f end_POSTSUBSCRIPT
|
| 123 |
+
, # of LLM query
|
| 124 |
+
|
| 125 |
+
K 𝐾 K italic_K
|
| 126 |
+
|
| 127 |
+
1:
|
| 128 |
+
|
| 129 |
+
F h,F q←∅,∅formulae-sequence←subscript 𝐹 ℎ subscript 𝐹 𝑞 F_{h},F_{q}\leftarrow\emptyset,\emptyset italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT , italic_F start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT ← ∅ , ∅
|
| 130 |
+
|
| 131 |
+
2:
|
| 132 |
+
|
| 133 |
+
F l←{𝒯}←subscript 𝐹 𝑙 𝒯 F_{l}\leftarrow\{\mathcal{T}\}italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ← { caligraphic_T }
|
| 134 |
+
|
| 135 |
+
3:
|
| 136 |
+
|
| 137 |
+
Ω 𝒯←{ω i}i=0 n∼𝕃(ω∣F l)←subscript Ω 𝒯 superscript subscript subscript 𝜔 𝑖 𝑖 0 𝑛 similar-to 𝕃 conditional 𝜔 subscript 𝐹 𝑙\Omega_{\mathcal{T}}\leftarrow\{\omega_{i}\}_{i=0}^{n}\sim\mathbb{L}(\omega% \mid F_{l})roman_Ω start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT ← { italic_ω start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT } start_POSTSUBSCRIPT italic_i = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT ∼ blackboard_L ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT )
|
| 138 |
+
|
| 139 |
+
4:while condition not met do
|
| 140 |
+
|
| 141 |
+
5:
|
| 142 |
+
|
| 143 |
+
Q←{(τ i,τ j):τ i,τ j∈𝒟 τ∧(τ i,τ j)∉F h}←𝑄 conditional-set subscript 𝜏 𝑖 subscript 𝜏 𝑗 subscript 𝜏 𝑖 subscript 𝜏 𝑗 subscript 𝒟 𝜏 subscript 𝜏 𝑖 subscript 𝜏 𝑗 subscript 𝐹 ℎ Q\leftarrow\{(\tau_{i},\tau_{j}):\tau_{i},\tau_{j}\in\mathcal{D}_{\tau}\land(% \tau_{i},\tau_{j})\not\in F_{h}\}italic_Q ← { ( italic_τ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , italic_τ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) : italic_τ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , italic_τ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ∈ caligraphic_D start_POSTSUBSCRIPT italic_τ end_POSTSUBSCRIPT ∧ ( italic_τ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , italic_τ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) ∉ italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT }
|
| 144 |
+
|
| 145 |
+
6:
|
| 146 |
+
|
| 147 |
+
q←←𝑞 absent q\leftarrow italic_q ←
|
| 148 |
+
Query Selection(
|
| 149 |
+
|
| 150 |
+
𝒜 f subscript 𝒜 𝑓\mathcal{A}_{f}caligraphic_A start_POSTSUBSCRIPT italic_f end_POSTSUBSCRIPT
|
| 151 |
+
,
|
| 152 |
+
|
| 153 |
+
Q 𝑄 Q italic_Q
|
| 154 |
+
,
|
| 155 |
+
|
| 156 |
+
F q subscript 𝐹 𝑞 F_{q}italic_F start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT
|
| 157 |
+
,
|
| 158 |
+
|
| 159 |
+
Ω 𝒯 subscript Ω 𝒯\Omega_{\mathcal{T}}roman_Ω start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT
|
| 160 |
+
,
|
| 161 |
+
|
| 162 |
+
𝕃 𝕃\mathbb{L}blackboard_L
|
| 163 |
+
,
|
| 164 |
+
|
| 165 |
+
K 𝐾 K italic_K
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
7:
|
| 169 |
+
|
| 170 |
+
(f h,f l,f q)←ℋ(q)←subscript 𝑓 ℎ subscript 𝑓 𝑙 subscript 𝑓 𝑞 ℋ 𝑞(f_{h},f_{l},f_{q})\leftarrow\mathcal{H}(q)( italic_f start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT , italic_f start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT , italic_f start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT ) ← caligraphic_H ( italic_q )
|
| 171 |
+
|
| 172 |
+
8:
|
| 173 |
+
|
| 174 |
+
F h,F l,F q←F h∪{f h},F l∪{f l},F q∪{f q}formulae-sequence←subscript 𝐹 ℎ subscript 𝐹 𝑙 subscript 𝐹 𝑞 subscript 𝐹 ℎ subscript 𝑓 ℎ subscript 𝐹 𝑙 subscript 𝑓 𝑙 subscript 𝐹 𝑞 subscript 𝑓 𝑞 F_{h},F_{l},F_{q}\leftarrow F_{h}\cup\{f_{h}\},F_{l}\cup\{f_{l}\},F_{q}\cup\{f% _{q}\}italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT , italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT , italic_F start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT ← italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT ∪ { italic_f start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT } , italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ∪ { italic_f start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT } , italic_F start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT ∪ { italic_f start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT }
|
| 175 |
+
|
| 176 |
+
9:
|
| 177 |
+
|
| 178 |
+
Ω 𝒯←{ω i}i=0 n∼P(F h∣ω)P(ω∣F l)←subscript Ω 𝒯 superscript subscript subscript 𝜔 𝑖 𝑖 0 𝑛 similar-to 𝑃 conditional subscript 𝐹 ℎ 𝜔 𝑃 conditional 𝜔 subscript 𝐹 𝑙\Omega_{\mathcal{T}}\leftarrow\{\omega_{i}\}_{i=0}^{n}\sim P(F_{h}\mid\omega)P% (\omega\mid F_{l})roman_Ω start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT ← { italic_ω start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT } start_POSTSUBSCRIPT italic_i = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT ∼ italic_P ( italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT ∣ italic_ω ) italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT )
|
| 179 |
+
|
| 180 |
+
10:end while
|
| 181 |
+
|
| 182 |
+
11:return
|
| 183 |
+
|
| 184 |
+
Ω 𝒯 subscript Ω 𝒯\Omega_{\mathcal{T}}roman_Ω start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT
|
| 185 |
+
|
| 186 |
+
### Initialization
|
| 187 |
+
|
| 188 |
+
MAPLE starts by taking natural language instruction about task preference 𝒜 𝒯 ℋ subscript superscript 𝒜 ℋ 𝒯\mathcal{A}^{\mathcal{H}}_{\mathcal{T}}caligraphic_A start_POSTSUPERSCRIPT caligraphic_H end_POSTSUPERSCRIPT start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT and initializes the pairwise preference feedback set F h subscript 𝐹 ℎ F_{h}italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT, linguistic feedback F l subscript 𝐹 𝑙 F_{l}italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT, and feedback about query difficulty F q subscript 𝐹 𝑞 F_{q}italic_F start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT (lines 1-2, Algorithm[1](https://arxiv.org/html/2412.07207v2#alg1 "Algorithm 1 ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models")). After that, the initial set of weights is sampled using the LLM from the distribution P(ω∣F l)𝑃 conditional 𝜔 subscript 𝐹 𝑙 P(\omega\mid F_{l})italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) as F h subscript 𝐹 ℎ F_{h}italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT is still empty (line 3, Algorithm[1](https://arxiv.org/html/2412.07207v2#alg1 "Algorithm 1 ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models")). To sample ω 𝜔\omega italic_ω from P(ω∣F l)𝑃 conditional 𝜔 subscript 𝐹 𝑙 P(\omega\mid F_{l})italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) we explore two sampling strategies described below.
|
| 189 |
+
|
| 190 |
+
#### Preference weight sampling from LLM
|
| 191 |
+
|
| 192 |
+
We directly prompt the LLM 𝕃 𝕃\mathbb{L}blackboard_L to provide linear weights ω 𝜔\omega italic_ω over the abstract concepts. Specifically, we provide 𝕃 𝕃\mathbb{L}blackboard_L with a prompt containing the task description 𝒯 𝒯\mathcal{T}caligraphic_T, a list of known concepts C 𝐶 C italic_C, human preference 𝒜 𝒯 ℋ subscript superscript 𝒜 ℋ 𝒯\mathcal{A}^{\mathcal{H}}_{\mathcal{T}}caligraphic_A start_POSTSUPERSCRIPT caligraphic_H end_POSTSUPERSCRIPT start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT, and examples of instruction weight pairs, along with additional answer generation instructions G 𝐺 G italic_G (see Appendix for details). The LLM processes this prompt and returns an answer 𝒜 ω i 𝕃 subscript superscript 𝒜 𝕃 subscript 𝜔 𝑖\mathcal{A}^{\mathbb{L}}_{\omega_{i}}caligraphic_A start_POSTSUPERSCRIPT blackboard_L end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_ω start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT:
|
| 193 |
+
|
| 194 |
+
𝒜 ω i 𝕃←𝕃(prompt(𝒯,C,𝒜 𝒯 ℋ,D ℐ,G))←subscript superscript 𝒜 𝕃 subscript 𝜔 𝑖 𝕃 prompt 𝒯 𝐶 subscript superscript 𝒜 ℋ 𝒯 subscript 𝐷 ℐ 𝐺\mathcal{A}^{\mathbb{L}}_{\omega_{i}}\leftarrow\mathbb{L}(\text{prompt}(% \mathcal{T},C,\mathcal{A}^{\mathcal{H}}_{\mathcal{T}},D_{\mathcal{I}},G))caligraphic_A start_POSTSUPERSCRIPT blackboard_L end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_ω start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT ← blackboard_L ( prompt ( caligraphic_T , italic_C , caligraphic_A start_POSTSUPERSCRIPT caligraphic_H end_POSTSUPERSCRIPT start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT , italic_D start_POSTSUBSCRIPT caligraphic_I end_POSTSUBSCRIPT , italic_G ) )
|
| 195 |
+
|
| 196 |
+
We can take advantage of text generation temperature to collect a diverse set of samples. We define the set of all generated weights as 𝒜 ω 𝕃 subscript superscript 𝒜 𝕃 𝜔\mathcal{A}^{\mathbb{L}}_{\omega}caligraphic_A start_POSTSUPERSCRIPT blackboard_L end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_ω end_POSTSUBSCRIPT. Then P(ω j∣F l)𝑃 conditional subscript 𝜔 𝑗 subscript 𝐹 𝑙 P(\omega_{j}\mid F_{l})italic_P ( italic_ω start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) can be modeled for any arbitrary ω j subscript 𝜔 𝑗\omega_{j}italic_ω start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT as follows:
|
| 197 |
+
|
| 198 |
+
P(ω j∣F l)=exp(−β l𝔼 ω i∈𝒜 ω 𝕃[Distance(ω i,ω j)])𝑃 conditional subscript 𝜔 𝑗 subscript 𝐹 𝑙 subscript 𝛽 𝑙 subscript 𝔼 subscript 𝜔 𝑖 subscript superscript 𝒜 𝕃 𝜔 delimited-[]Distance subscript 𝜔 𝑖 subscript 𝜔 𝑗 P(\omega_{j}\mid F_{l})=\exp\left(-\beta_{l}\mathbb{E}_{\omega_{i}\in\mathcal{% A}^{\mathbb{L}}_{\omega}}[\text{Distance}(\omega_{i},\omega_{j})]\right)italic_P ( italic_ω start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) = roman_exp ( - italic_β start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT blackboard_E start_POSTSUBSCRIPT italic_ω start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ∈ caligraphic_A start_POSTSUPERSCRIPT blackboard_L end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_ω end_POSTSUBSCRIPT end_POSTSUBSCRIPT [ Distance ( italic_ω start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , italic_ω start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) ] )(6)
|
| 199 |
+
|
| 200 |
+
In this case, Euclidean or Cosine distance can be applied.
|
| 201 |
+
|
| 202 |
+
#### Distribution weight sampling using LLM
|
| 203 |
+
|
| 204 |
+
The second approach we explore is distribution modeling using an LLM. Here, we use similar prompts as in the previous approach; however, we instruct the LLM to generate parameters for P(ω∣F l)𝑃 conditional 𝜔 subscript 𝐹 𝑙 P(\omega\mid F_{l})italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ). For example, for the weight of each concept ω c i∈ω subscript 𝜔 subscript 𝑐 𝑖 𝜔\omega_{c_{i}}\in\omega italic_ω start_POSTSUBSCRIPT italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT ∈ italic_ω we prompt 𝕃 𝕃\mathbb{L}blackboard_L to generate a range ω c i range=[ω c i min,ω c i max]superscript subscript 𝜔 subscript 𝑐 𝑖 range superscript subscript 𝜔 subscript 𝑐 𝑖 min superscript subscript 𝜔 subscript 𝑐 𝑖 max\omega_{c_{i}}^{\text{range}}=[\omega_{c_{i}}^{\text{min}},\omega_{c_{i}}^{% \text{max}}]italic_ω start_POSTSUBSCRIPT italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT start_POSTSUPERSCRIPT range end_POSTSUPERSCRIPT = [ italic_ω start_POSTSUBSCRIPT italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT start_POSTSUPERSCRIPT min end_POSTSUPERSCRIPT , italic_ω start_POSTSUBSCRIPT italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT start_POSTSUPERSCRIPT max end_POSTSUPERSCRIPT ]. Then we can define P(ω∣F l)𝑃 conditional 𝜔 subscript 𝐹 𝑙 P(\omega\mid F_{l})italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) as follows:
|
| 205 |
+
|
| 206 |
+
P(ω∣F l)={1,ifω c i∈ω c i range,∀ω c i∈ω 0,otherwise.𝑃 conditional 𝜔 subscript 𝐹 𝑙 cases 1 formulae-sequence if subscript 𝜔 subscript 𝑐 𝑖 superscript subscript 𝜔 subscript 𝑐 𝑖 range for-all subscript 𝜔 subscript 𝑐 𝑖 𝜔 0 otherwise P(\omega\mid F_{l})=\begin{cases}1,&\text{if }\omega_{c_{i}}\in\omega_{c_{i}}^% {\text{range}},\forall\omega_{c_{i}}\in\omega\\ 0,&\text{otherwise}.\end{cases}italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) = { start_ROW start_CELL 1 , end_CELL start_CELL if italic_ω start_POSTSUBSCRIPT italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT ∈ italic_ω start_POSTSUBSCRIPT italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT start_POSTSUPERSCRIPT range end_POSTSUPERSCRIPT , ∀ italic_ω start_POSTSUBSCRIPT italic_c start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT ∈ italic_ω end_CELL end_ROW start_ROW start_CELL 0 , end_CELL start_CELL otherwise . end_CELL end_ROW(7)
|
| 207 |
+
|
| 208 |
+
We can similarly model this for other forms of distributions, such as the Gaussian distribution. Once the initialization process is complete, MAPLE iteratively reduces its uncertainty using human feedback.
|
| 209 |
+
|
| 210 |
+
### LLM-Guided Active Preference Learning
|
| 211 |
+
|
| 212 |
+
After initialization, MAPLE iteratively follows three steps: 1) query selection, 2) human feedback collection, and 3) preference posterior update, discussed below.
|
| 213 |
+
|
| 214 |
+
#### Oracle-guided active query selection (OAQS)
|
| 215 |
+
|
| 216 |
+
At the beginning of each iteration, MAPLE selects a query q 𝑞 q italic_q (a pair of trajectories) (lines 5-6, Algorithm [1](https://arxiv.org/html/2412.07207v2#alg1 "Algorithm 1 ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models")) from 𝒟 τ subscript 𝒟 𝜏\mathcal{D}_{\tau}caligraphic_D start_POSTSUBSCRIPT italic_τ end_POSTSUBSCRIPT that would reduce uncertainty the most while mitigating query difficulty based on human feedback. The query selection process is described in Algorithm [2](https://arxiv.org/html/2412.07207v2#alg2 "Algorithm 2 ‣ Stopping criteria ‣ LLM-Guided Active Preference Learning ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models"), which starts by sorting all the queries based on an acquisition function 𝒜 f subscript 𝒜 𝑓\mathcal{A}_{f}caligraphic_A start_POSTSUBSCRIPT italic_f end_POSTSUBSCRIPT. In this paper, we use the variance ratio for its flexibility and high efficacy. In particular, for trajectory ranking queries, the score for (τ i,τ j)subscript 𝜏 𝑖 subscript 𝜏 𝑗(\tau_{i},\tau_{j})( italic_τ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , italic_τ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) is calculated as 𝔼 ω∼Ω 𝒯[1−max(P(τ i≻τ j∣ω),P(τ j≻τ i∣ω))]subscript 𝔼 similar-to 𝜔 subscript Ω 𝒯 delimited-[]1 𝑃 succeeds subscript 𝜏 𝑖 conditional subscript 𝜏 𝑗 𝜔 𝑃 succeeds subscript 𝜏 𝑗 conditional subscript 𝜏 𝑖 𝜔\mathbb{E}_{\omega\sim\Omega_{\mathcal{T}}}[1-\max(P(\tau_{i}\succ\tau_{j}\mid% \omega),P(\tau_{j}\succ\tau_{i}\mid\omega))]blackboard_E start_POSTSUBSCRIPT italic_ω ∼ roman_Ω start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT end_POSTSUBSCRIPT [ 1 - roman_max ( italic_P ( italic_τ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ≻ italic_τ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ∣ italic_ω ) , italic_P ( italic_τ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ≻ italic_τ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ∣ italic_ω ) ) ]. Note that other acquisition functions can also be used. Once sorted, OAQS iterates over the top K 𝐾 K italic_K queries and selects the first query that the oracle (in our case an LLM) evaluates to be answerable by the human (lines 2-11). Finally, Algorithm [2](https://arxiv.org/html/2412.07207v2#alg2 "Algorithm 2 ‣ Stopping criteria ‣ LLM-Guided Active Preference Learning ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models") returns the least difficult query q 𝑞 q italic_q among the top K query selected by 𝒜 f subscript 𝒜 𝑓\mathcal{A}_{f}caligraphic_A start_POSTSUBSCRIPT italic_f end_POSTSUBSCRIPT. We now analyze the performance of OAQS based on the characterization of the oracle.2 2 2 Proofs are in the Appendix.
|
| 217 |
+
|
| 218 |
+
###### Definition 1
|
| 219 |
+
|
| 220 |
+
Let Q 𝑄 Q italic_Q denote the set of all possible queries, and Q 𝒜⊆Q subscript 𝑄 𝒜 𝑄 Q_{\mathcal{A}}\subseteq Q italic_Q start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ⊆ italic_Q represent the subset of queries answerable by ℋ ℋ\mathcal{H}caligraphic_H. The Absolute Query Success Rate (AQSR) is defined as the probability that a randomly selected query q 𝑞 q italic_q belongs to the intersection Q∩Q 𝒜 𝑄 subscript 𝑄 𝒜 Q\cap Q_{\mathcal{A}}italic_Q ∩ italic_Q start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT, i.e., P(q∈Q 𝒜)𝑃 𝑞 subscript 𝑄 𝒜 P(q\in Q_{\mathcal{A}})italic_P ( italic_q ∈ italic_Q start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ).
|
| 221 |
+
|
| 222 |
+
###### Definition 2
|
| 223 |
+
|
| 224 |
+
The Query Success Rate (QSR) of a query selection strategy is defined as the probability that a query q 𝑞 q italic_q, selected by the strategy, belongs to Q 𝒜 subscript 𝑄 𝒜 Q_{\mathcal{A}}italic_Q start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT, i.e., P(q∈Q 𝒜∣strategy)𝑃 𝑞 conditional subscript 𝑄 𝒜 strategy P(q\in Q_{\mathcal{A}}\mid\text{strategy})italic_P ( italic_q ∈ italic_Q start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ∣ strategy ).
|
| 225 |
+
|
| 226 |
+
###### Proposition 1
|
| 227 |
+
|
| 228 |
+
Assuming the independence of AQSR from acquisition function ranking, the QSR of a random query selection strategy: P(q∈Q 𝒜∣random)=AQSR 𝑃 𝑞 conditional subscript 𝑄 𝒜 random 𝐴 𝑄 𝑆 𝑅 P(q\in Q_{\mathcal{A}}\mid\text{random})=AQSR italic_P ( italic_q ∈ italic_Q start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ∣ random ) = italic_A italic_Q italic_S italic_R
|
| 229 |
+
|
| 230 |
+
###### Proposition 2
|
| 231 |
+
|
| 232 |
+
Under the same assumption of proposition 1, the QSR of a top-query selection strategy, which always selects the highest-rated query by 𝒜 f subscript 𝒜 𝑓\mathcal{A}_{f}caligraphic_A start_POSTSUBSCRIPT italic_f end_POSTSUBSCRIPT, P(q∈Q 𝒜∣top)=AQSR 𝑃 𝑞 conditional subscript 𝑄 𝒜 top 𝐴 𝑄 𝑆 𝑅 P(q\in Q_{\mathcal{A}}\mid\text{top})=AQSR italic_P ( italic_q ∈ italic_Q start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ∣ top ) = italic_A italic_Q italic_S italic_R.
|
| 233 |
+
|
| 234 |
+
###### Proposition 3
|
| 235 |
+
|
| 236 |
+
The QSR of the OAQS strategy is given by
|
| 237 |
+
|
| 238 |
+
AQSR⋅Y 1⋅1−[AQSR⋅(1−Y 0−Y 1)+Y 0]K 1−[AQSR⋅(1−Y 0−Y 1)+Y 0],⋅𝐴 𝑄 𝑆 𝑅 subscript 𝑌 1 1 superscript delimited-[]⋅AQSR 1 subscript 𝑌 0 subscript 𝑌 1 subscript 𝑌 0 𝐾 1 delimited-[]⋅AQSR 1 subscript 𝑌 0 subscript 𝑌 1 subscript 𝑌 0 AQSR\cdot Y_{1}\cdot\frac{1-\left[\text{AQSR}\cdot(1-Y_{0}-Y_{1})+Y_{0}\right]% ^{K}}{1-\left[\text{AQSR}\cdot(1-Y_{0}-Y_{1})+Y_{0}\right]},italic_A italic_Q italic_S italic_R ⋅ italic_Y start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ⋅ divide start_ARG 1 - [ AQSR ⋅ ( 1 - italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT - italic_Y start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ) + italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ] start_POSTSUPERSCRIPT italic_K end_POSTSUPERSCRIPT end_ARG start_ARG 1 - [ AQSR ⋅ ( 1 - italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT - italic_Y start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ) + italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ] end_ARG ,
|
| 239 |
+
|
| 240 |
+
where Y 0=P(𝕃(F q,q∉Q 𝒜)=False)subscript 𝑌 0 𝑃 𝕃 subscript 𝐹 𝑞 𝑞 subscript 𝑄 𝒜 False Y_{0}=P(\mathbb{L}(F_{q},q\notin Q_{\mathcal{A}})=\text{False})italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT = italic_P ( blackboard_L ( italic_F start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT , italic_q ∉ italic_Q start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ) = False ) and
|
| 241 |
+
|
| 242 |
+
Y 1=P(𝕃(F q,q∈Q 𝒜)=True)subscript 𝑌 1 𝑃 𝕃 subscript 𝐹 𝑞 𝑞 subscript 𝑄 𝒜 True Y_{1}=P(\mathbb{L}(F_{q},q\in Q_{\mathcal{A}})=\text{True})italic_Y start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT = italic_P ( blackboard_L ( italic_F start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT , italic_q ∈ italic_Q start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ) = True ). Here, we assume independence of AQSR, Y 0 subscript 𝑌 0 Y_{0}italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT, and Y 1 subscript 𝑌 1 Y_{1}italic_Y start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT from acquisition function ranking.
|
| 243 |
+
|
| 244 |
+
###### Corollary 1
|
| 245 |
+
|
| 246 |
+
Based on Proposition [3](https://arxiv.org/html/2412.07207v2#Thmproposition3 "Proposition 3 ‣ Oracle-guided active query selection (OAQS) ‣ LLM-Guided Active Preference Learning ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models"), the OAQS will have a higher QSR than the random query selection strategy and top-query selection strategy iff, Y 0+Y 1>1 subscript 𝑌 0 subscript 𝑌 1 1 Y_{0}+Y_{1}>1 italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT + italic_Y start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT > 1 as K→∞→𝐾 K\rightarrow\infty italic_K → ∞.
|
| 247 |
+
|
| 248 |
+
###### Definition 3
|
| 249 |
+
|
| 250 |
+
The Optimal Query Success Rate (OQSR) of a strategy is defined as the probability that the strategy returns the query q∗superscript 𝑞 q^{*}italic_q start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT with the highest value according to an acquisition function 𝒜 f subscript 𝒜 𝑓\mathcal{A}_{f}caligraphic_A start_POSTSUBSCRIPT italic_f end_POSTSUBSCRIPT, among all answerable queries, i.e.,
|
| 251 |
+
|
| 252 |
+
P(q∗=argmax q∈Q𝒜 f(q)𝕀(q∈Q 𝒜)),𝑃 superscript 𝑞 subscript 𝑞 𝑄 subscript 𝒜 𝑓 𝑞 𝕀 𝑞 subscript 𝑄 𝒜 P(q^{*}=\arg\max_{q\in Q}\mathcal{A}_{f}(q)\mathbb{I}(q\in Q_{\mathcal{A}})),italic_P ( italic_q start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT = roman_arg roman_max start_POSTSUBSCRIPT italic_q ∈ italic_Q end_POSTSUBSCRIPT caligraphic_A start_POSTSUBSCRIPT italic_f end_POSTSUBSCRIPT ( italic_q ) blackboard_I ( italic_q ∈ italic_Q start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ) ) ,
|
| 253 |
+
|
| 254 |
+
where q∗superscript 𝑞 q^{*}italic_q start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT is the query returned by the strategy.
|
| 255 |
+
|
| 256 |
+
###### Proposition 4
|
| 257 |
+
|
| 258 |
+
Under the similar assumption of proposition 1. assumption, the OQSR of a random query selection strategy is equal to 1/|Q|1 𝑄 1/|Q|1 / | italic_Q |.
|
| 259 |
+
|
| 260 |
+
###### Proposition 5
|
| 261 |
+
|
| 262 |
+
Under the similar assumption of proposition 1, the OQSR of a Top-Query Selection Strategy is equal to the AQSR.
|
| 263 |
+
|
| 264 |
+
###### Proposition 6
|
| 265 |
+
|
| 266 |
+
Under the same assumption of Proposition 3, the OQSR of the OAQS strategy is given by
|
| 267 |
+
|
| 268 |
+
OQSR=AQSR⋅Y 1⋅1−[(1−AQSR)Y 0]K 1−(1−AQSR)Y 0.OQSR⋅𝐴 𝑄 𝑆 𝑅 subscript 𝑌 1 1 superscript delimited-[]1 𝐴 𝑄 𝑆 𝑅 subscript 𝑌 0 𝐾 1 1 𝐴 𝑄 𝑆 𝑅 subscript 𝑌 0\text{OQSR}=AQSR\cdot Y_{1}\cdot\frac{1-[(1-AQSR)Y_{0}]^{K}}{1-(1-AQSR)Y_{0}}.OQSR = italic_A italic_Q italic_S italic_R ⋅ italic_Y start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ⋅ divide start_ARG 1 - [ ( 1 - italic_A italic_Q italic_S italic_R ) italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ] start_POSTSUPERSCRIPT italic_K end_POSTSUPERSCRIPT end_ARG start_ARG 1 - ( 1 - italic_A italic_Q italic_S italic_R ) italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT end_ARG .
|
| 269 |
+
|
| 270 |
+
###### Corollary 2
|
| 271 |
+
|
| 272 |
+
Based on Proposition [6](https://arxiv.org/html/2412.07207v2#Sx5.Ex5 "Proposition 6 ‣ Oracle-guided active query selection (OAQS) ‣ LLM-Guided Active Preference Learning ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models"), the OAQS strategy will have a higher OQSR than the top-query selection strategy if (1−AQSR)Y 0+Y 1>1 1 𝐴 𝑄 𝑆 𝑅 subscript 𝑌 0 subscript 𝑌 1 1(1-AQSR)Y_{0}+Y_{1}>1( 1 - italic_A italic_Q italic_S italic_R ) italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT + italic_Y start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT > 1 as K→∞→𝐾 K\rightarrow\infty italic_K → ∞, and then random query selection strategy if AQSR⋅Y 1>1−(1−AQSR)Y 0|Q|⋅AQSR subscript 𝑌 1 1 1 AQSR subscript 𝑌 0 𝑄\mathrm{AQSR}\cdot Y_{1}>\frac{1-(1-\mathrm{AQSR})Y_{0}}{|Q|}roman_AQSR ⋅ italic_Y start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT > divide start_ARG 1 - ( 1 - roman_AQSR ) italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT end_ARG start_ARG | italic_Q | end_ARG as K→∞→𝐾 K\rightarrow\infty italic_K → ∞.
|
| 273 |
+
|
| 274 |
+
#### Human feedback collection
|
| 275 |
+
|
| 276 |
+
MAPLE queries the human ℋ ℋ\mathcal{H}caligraphic_H using the query q 𝑞 q italic_q returned by Algorithm [2](https://arxiv.org/html/2412.07207v2#alg2 "Algorithm 2 ‣ Stopping criteria ‣ LLM-Guided Active Preference Learning ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models") to collect feedback. For each query q 𝑞 q italic_q, MAPLE provides a pair of trajectories, and ℋ ℋ\mathcal{H}caligraphic_H returns an answer 𝒜 τ ℋ=(f h,f l,f q)subscript superscript 𝒜 ℋ 𝜏 subscript 𝑓 ℎ subscript 𝑓 𝑙 subscript 𝑓 𝑞\mathcal{A}^{\mathcal{H}}_{\tau}=(f_{h},f_{l},f_{q})caligraphic_A start_POSTSUPERSCRIPT caligraphic_H end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_τ end_POSTSUBSCRIPT = ( italic_f start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT , italic_f start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT , italic_f start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT ), where f h subscript 𝑓 ℎ f_{h}italic_f start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT is binary feedback, f l subscript 𝑓 𝑙 f_{l}italic_f start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT is an optional natural language explanation associated with that feedback—possibly empty if the human does not provide an explanation—and f q subscript 𝑓 𝑞 f_{q}italic_f start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT is a optional natural language feedback about the difficulty of the query. Each piece of feedback is then added to the corresponding feedback set (lines 7-8, Algorithm [1](https://arxiv.org/html/2412.07207v2#alg1 "Algorithm 1 ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models")).
|
| 277 |
+
|
| 278 |
+
#### LLM-guided posterior update
|
| 279 |
+
|
| 280 |
+
Once feedback is added to the set, we update our current weight sample Ω 𝒯 subscript Ω 𝒯\Omega_{\mathcal{T}}roman_Ω start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT by sampling P(F h∣ω)P(ω∣F l)𝑃 conditional subscript 𝐹 ℎ 𝜔 𝑃 conditional 𝜔 subscript 𝐹 𝑙 P(F_{h}\mid\omega)P(\omega\mid F_{l})italic_P ( italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT ∣ italic_ω ) italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) using MCMC sampling, where P(ω∣F h)𝑃 conditional 𝜔 subscript 𝐹 ℎ P(\omega\mid F_{h})italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_h end_POSTSUBSCRIPT ) is given by Equation[1](https://arxiv.org/html/2412.07207v2#Sx3.E1 "In Bayesian preference learning ‣ Background ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models"), and P(ω∣F l)𝑃 conditional 𝜔 subscript 𝐹 𝑙 P(\omega\mid F_{l})italic_P ( italic_ω ∣ italic_F start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ) is given by Equations[6](https://arxiv.org/html/2412.07207v2#Sx5.E6 "In Preference weight sampling from LLM ‣ Initialization ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models") and [7](https://arxiv.org/html/2412.07207v2#Sx5.E7 "In Distribution weight sampling using LLM ‣ Initialization ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models").
|
| 281 |
+
|
| 282 |
+
#### Stopping criteria
|
| 283 |
+
|
| 284 |
+
MAPLE can employ various stopping criteria for active query generation, including:
|
| 285 |
+
|
| 286 |
+
* •A fixed budget approach, where MAPLE operates within a predefined maximum query limit.
|
| 287 |
+
* •A human-gated stopping criterion, based on the human’s assessment of the system’s competence. MAPLE’s interpretability enhances this process, allowing the inclusion of its current predictions and explanations in each query for human evaluation (line 7, Algorithm [1](https://arxiv.org/html/2412.07207v2#alg1 "Algorithm 1 ‣ Detailed Description of the Proposed Method ‣ MAPLE: A Framework for Active Preference Learning Guided by Large Language Models")).
|
| 288 |
+
|
| 289 |
+
Algorithm 2 Oracle-Guided Query Selection
|
| 290 |
+
|
| 291 |
+
0:Acquisition function
|
| 292 |
+
|
| 293 |
+
𝒜 f subscript 𝒜 𝑓\mathcal{A}_{f}caligraphic_A start_POSTSUBSCRIPT italic_f end_POSTSUBSCRIPT
|
| 294 |
+
, List of queries
|
| 295 |
+
|
| 296 |
+
Q 𝑄 Q italic_Q
|
| 297 |
+
, Query preference feedback
|
| 298 |
+
|
| 299 |
+
F q subscript 𝐹 𝑞 F_{q}italic_F start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT
|
| 300 |
+
, Set of weights from current posterior
|
| 301 |
+
|
| 302 |
+
Ω 𝒯 subscript Ω 𝒯\Omega_{\mathcal{T}}roman_Ω start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT
|
| 303 |
+
, Oracle
|
| 304 |
+
|
| 305 |
+
𝒪 𝒪\mathcal{O}caligraphic_O
|
| 306 |
+
, # of Oracle queries
|
| 307 |
+
|
| 308 |
+
K 𝐾 K italic_K
|
| 309 |
+
|
| 310 |
+
1:
|
| 311 |
+
|
| 312 |
+
Q sort←sort(Q|𝒜 f,Ω 𝒯)←subscript 𝑄 𝑠 𝑜 𝑟 𝑡 sort conditional 𝑄 subscript 𝒜 𝑓 subscript Ω 𝒯 Q_{sort}\leftarrow\text{sort}(Q|\mathcal{A}_{f},\Omega_{\mathcal{T}})italic_Q start_POSTSUBSCRIPT italic_s italic_o italic_r italic_t end_POSTSUBSCRIPT ← sort ( italic_Q | caligraphic_A start_POSTSUBSCRIPT italic_f end_POSTSUBSCRIPT , roman_Ω start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT )
|
| 313 |
+
|
| 314 |
+
2:
|
| 315 |
+
|
| 316 |
+
Q top←Q sort[0:K]Q_{top}\leftarrow Q_{sort}[0:K]italic_Q start_POSTSUBSCRIPT italic_t italic_o italic_p end_POSTSUBSCRIPT ← italic_Q start_POSTSUBSCRIPT italic_s italic_o italic_r italic_t end_POSTSUBSCRIPT [ 0 : italic_K ]
|
| 317 |
+
|
| 318 |
+
3:for
|
| 319 |
+
|
| 320 |
+
q∈Q top 𝑞 subscript 𝑄 𝑡 𝑜 𝑝 q\in Q_{top}italic_q ∈ italic_Q start_POSTSUBSCRIPT italic_t italic_o italic_p end_POSTSUBSCRIPT
|
| 321 |
+
do
|
| 322 |
+
|
| 323 |
+
4:
|
| 324 |
+
|
| 325 |
+
s q←𝒪(prompt(F q,q))←subscript 𝑠 𝑞 𝒪 prompt subscript 𝐹 𝑞 𝑞 s_{q}\leftarrow\mathcal{O}(\text{prompt}(F_{q},q))italic_s start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT ← caligraphic_O ( prompt ( italic_F start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT , italic_q ) )
|
| 326 |
+
|
| 327 |
+
5:if
|
| 328 |
+
|
| 329 |
+
s q subscript 𝑠 𝑞 s_{q}italic_s start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT
|
| 330 |
+
is True then
|
| 331 |
+
|
| 332 |
+
6:return
|
| 333 |
+
|
| 334 |
+
q 𝑞 q italic_q
|
| 335 |
+
|
| 336 |
+
7:end if
|
| 337 |
+
|
| 338 |
+
8:end for
|
| 339 |
+
|
| 340 |
+
9:return
|
| 341 |
+
|
| 342 |
+
Q sort[0]subscript 𝑄 𝑠 𝑜 𝑟 𝑡 delimited-[]0 Q_{sort}[0]italic_Q start_POSTSUBSCRIPT italic_s italic_o italic_r italic_t end_POSTSUBSCRIPT [ 0 ]
|
| 343 |
+
|
| 344 |
+
#### Handling unknown concepts
|
| 345 |
+
|
| 346 |
+
It should be noted that humans may provide instructions 𝒜 𝒯 ℋ subscript superscript 𝒜 ℋ 𝒯\mathcal{A}^{\mathcal{H}}_{\mathcal{T}}caligraphic_A start_POSTSUPERSCRIPT caligraphic_H end_POSTSUPERSCRIPT start_POSTSUBSCRIPT caligraphic_T end_POSTSUBSCRIPT that cannot be sufficiently captured by the available concepts in the concept maps. While this case is beyond the scope of this paper, several remedies exist in the literature to address this issue. LLMs can be prompted to add new concepts when generating weights. By leveraging the generalization capability of C(⋅)𝐶⋅C(\cdot)italic_C ( ⋅ ) we can attempt to apply these new concepts directly. If the new concept is significantly different from those in C 𝐶 C italic_C, few-shot-learning techniques can be employed. In particular, during interactions, if a new concept is important, we can use non-parametric few-shot learning from human feedback, such as nearest neighbor search, to improve concept mapping(Tian et al. [2024](https://arxiv.org/html/2412.07207v2#bib.bib43)). Finally, if a new concept arises repeatedly, it can be added to the concept map by retraining C 𝐶 C italic_C with data collected from multiple interactions through few-shot learning, as considered in(Soni et al. [2022](https://arxiv.org/html/2412.07207v2#bib.bib40)).
|
| 347 |
+
|
| 348 |
+
### Policy Optimization
|
| 349 |
+
|
| 350 |
+
The method for utilizing the weights generated by MAPLE to optimize policy varies based on the trajectory encoding and the chosen policy solver algorithm. For example, for Markovian preferences, the weights can be directly used with an MDP solver. In non-Markovian settings, the weights can be used to rank trajectories and directly align the policy with algorithms such as DPO(Rafailov et al. [2024](https://arxiv.org/html/2412.07207v2#bib.bib36)), or train a dense reward function(Guan, Valmeekam, and Kambhampati [2022](https://arxiv.org/html/2412.07207v2#bib.bib19)) using preference learning algorithms such as TREX(Brown et al. [2019](https://arxiv.org/html/2412.07207v2#bib.bib9)), and then use that reward function with reinforcement learning algorithms.
|
| 351 |
+
|
| 352 |
+
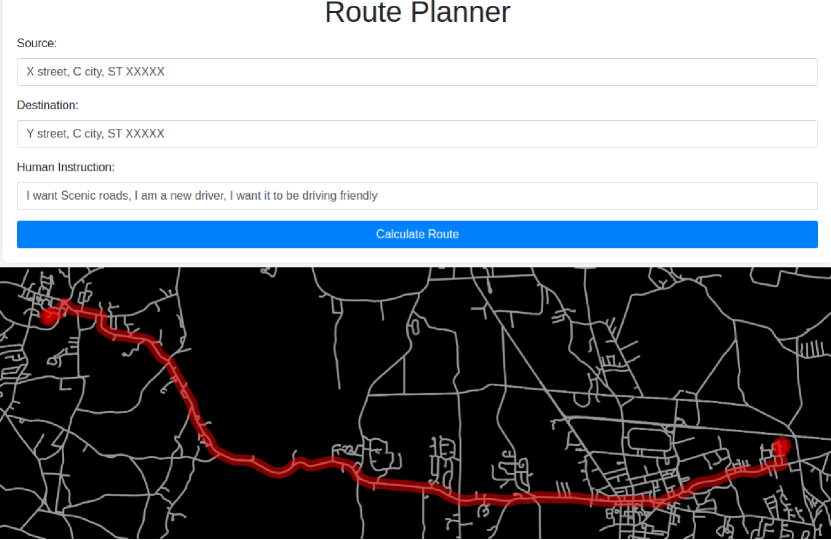
|
| 353 |
+
|
| 354 |
+
Figure 2: OpenStreetMap Routing
|
| 355 |
+
|
| 356 |
+
Experiments
|
| 357 |
+
-----------
|
| 358 |
+
|
| 359 |
+
In this section, we describe a comprehensive evaluation of MAPLE within the two environments detailed below. It is important to note that none of the models used in our experiments were fine-tuned; they were utilized in their publicly available form. We ran the local language model, specifically Mistral-7B-instruct-v0.3 (4-bit quantization), on a computer equipped with 64GB RAM and an Nvidia RTX 4090 24GB graphics card. For larger models, we relied on public API infrastructure. Note that we present results using preference weight sampling as it outperformed distribution weight sampling in both benchmarks (Appendix for details).
|
| 360 |
+
|
| 361 |
+
#### OpenStreetMap Routing
|
| 362 |
+
|
| 363 |
+
We use OpenStreetMap to generate routing graphs for different U.S. states. The environment includes a concept mapping function capable of using ten different concepts: 1) Time, 2) Speed, 3) Safety, 4) Scenic, 5) Battery Friendly, 6) Gas Station Nearby, 7) Charging Station Nearby, 8) Human Driving Friendly, 9) Battery ReGen Friendly, and 10) Autopilot Friendly. The goal is to find a route between a given source and destination that aligns with user preferences. To generate D τ subscript 𝐷 𝜏 D_{\tau}italic_D start_POSTSUBSCRIPT italic_τ end_POSTSUBSCRIPT, we used 200 random source and destination pairs with randomly sampled weights from Ω Ω\Omega roman_Ω. For modeling human interaction, we utilized two different datasets, each containing 50 human interaction templates. The first dataset, called “Clear,” provides clear, knowledgeable instructions. The second dataset, called “Natural,” obfuscates the “Clear” dataset with more natural-sounding language typical of everyday conversation and contextual information, for example:
|
| 364 |
+
|
| 365 |
+
> Clear: “I prefer routes that are safe and scenic, with a moderate focus on speed and low importance on time.”
|
| 366 |
+
|
| 367 |
+
> Natural: “I’m planning a weekend drive to enjoy the countryside, so I’m not in a hurry. I want the route to be as safe as possible because I’ll be driving with my family. It would be great if the drive is scenic too, so we could take in the beautiful views along the way. Speed isn’t a top concern, and we’re really just out to enjoy the journey rather than worry about how long it takes to get there.”
|
| 368 |
+
|
| 369 |
+
For modeling f l subscript 𝑓 𝑙 f_{l}italic_f start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT, the human clarifies the type of car (gas, autonomous, or electric) with a probability of 0.2 per feedback. For f q subscript 𝑓 𝑞 f_{q}italic_f start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT, the human is unable to answer when the top two highest-weighted (based on ground-truth weights) concepts in both trajectories are closer than a predefined threshold.
|
| 370 |
+
|
| 371 |
+

|
| 372 |
+
|
| 373 |
+
Figure 3: HomeGrid
|
| 374 |
+
|
| 375 |
+
#### HomeGrid
|
| 376 |
+
|
| 377 |
+
The HomGrid environment is a simplified Minigrid(Chevalier-Boisvert et al. [2023](https://arxiv.org/html/2412.07207v2#bib.bib14)) setting designed to simulate a robot performing household tasks(Lin et al. [2023](https://arxiv.org/html/2412.07207v2#bib.bib25)). It features a discrete, finite action space and a partially observable language observation space for a 3×3 3 3 3\times 3 3 × 3 grid, detailing the objects and flooring in each grid square, within a truncated 12×14 12 14 12\times 14 12 × 14 grid. The initial abstract concepts include: 1) avoiding objects such as tables and chairs, 2) avoiding walls, 3) avoiding placing objects like bottles and plates on the floor, 4) avoiding placing objects on the stove, and 5) avoiding placing objects on the left chairs. A total of 60 trajectories were manually generated to update the posterior distribution of the weights ω 𝜔\omega italic_ω for each method. For modeling f l subscript 𝑓 𝑙 f_{l}italic_f start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT, the human highlights the concept that was most influential for their preference. The modeling of f q subscript 𝑓 𝑞 f_{q}italic_f start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT follows a similar approach to that used in OSM Routing.
|
| 378 |
+
|
| 379 |
+
### Experimental Results
|
| 380 |
+
|
| 381 |
+

|
| 382 |
+
|
| 383 |
+
(a) Test accuracy (OSM Routing)
|
| 384 |
+
|
| 385 |
+
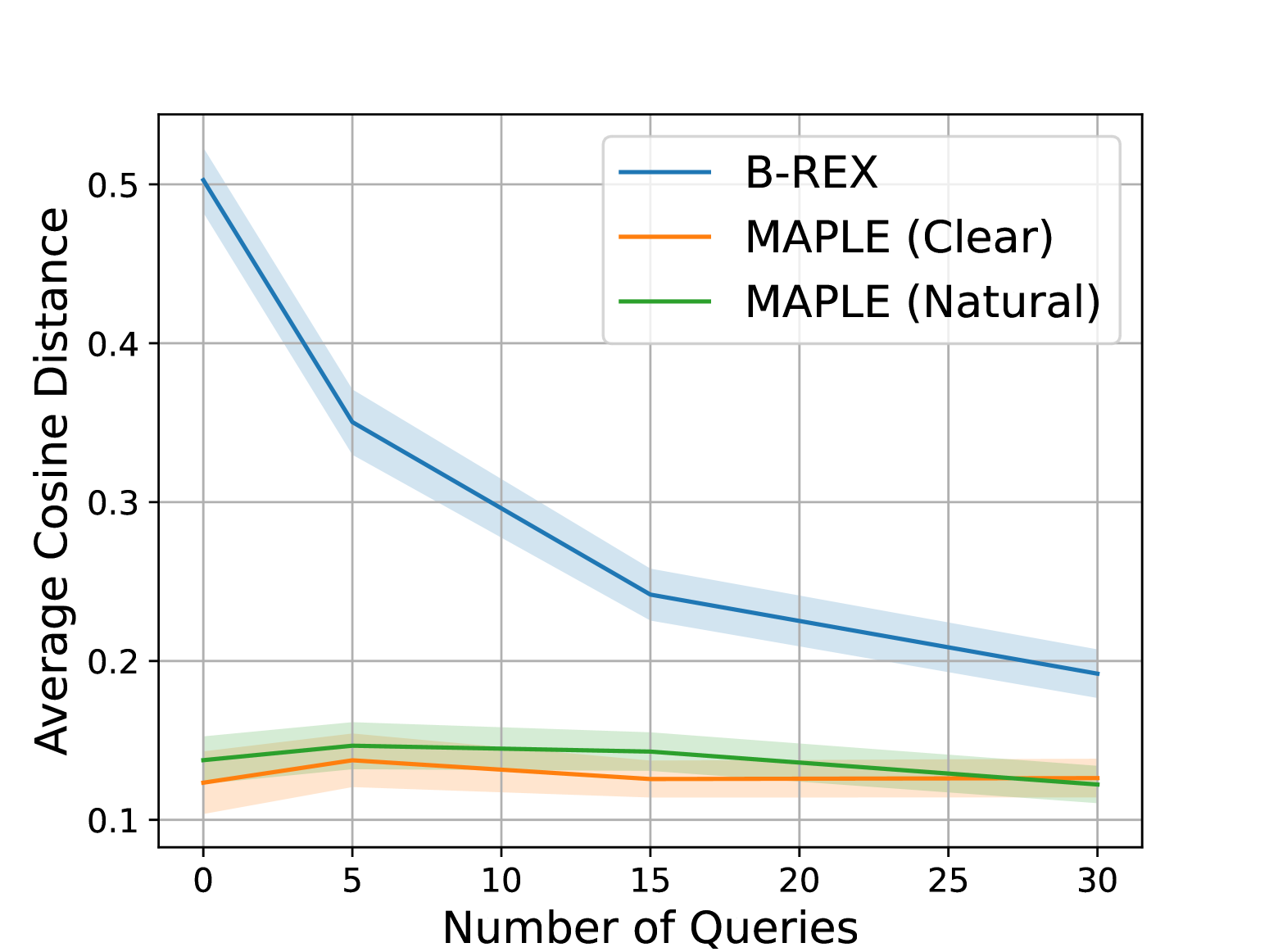
|
| 386 |
+
|
| 387 |
+
(b) Cosine distance (OSM Routing)
|
| 388 |
+
|
| 389 |
+
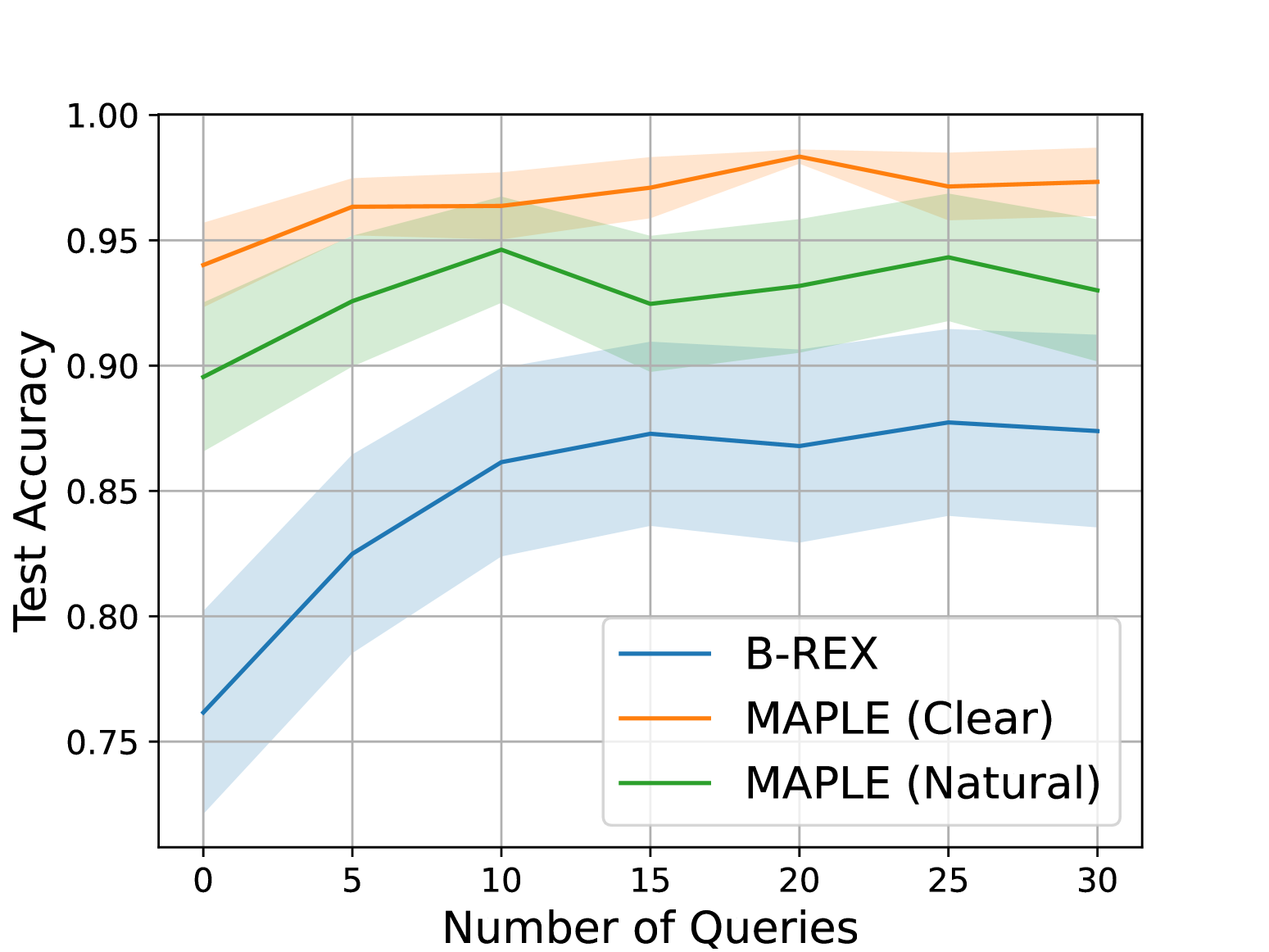
|
| 390 |
+
|
| 391 |
+
(d) Test accuracy (HomeGrid)
|
| 392 |
+
|
| 393 |
+
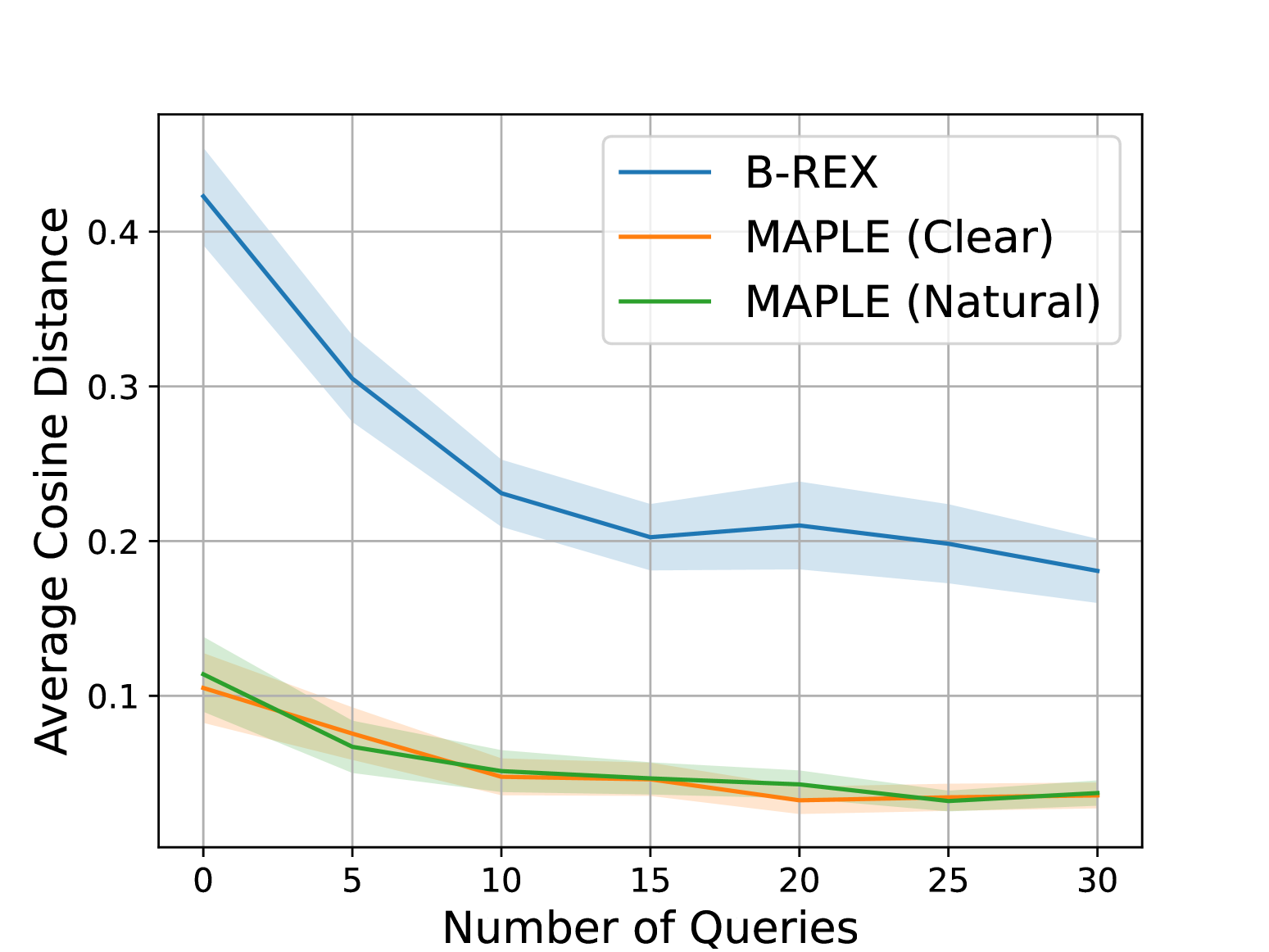
|
| 394 |
+
|
| 395 |
+
(e) Cosine distance (HomeGrid)
|
| 396 |
+
|
| 397 |
+
Figure 4: Comparison of efficacy of language feedback for preference inference.
|
| 398 |
+
|
| 399 |
+
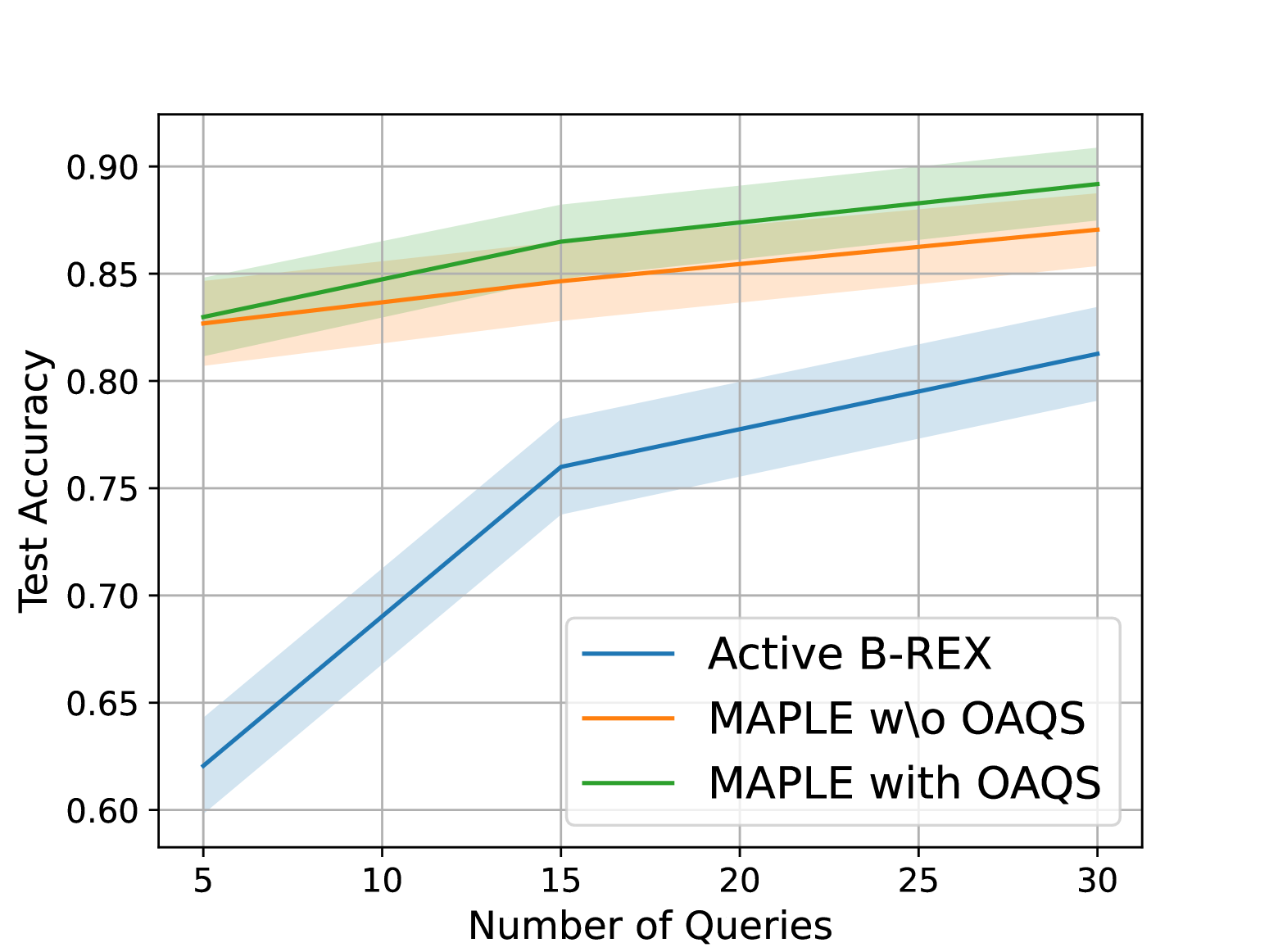
|
| 400 |
+
|
| 401 |
+
(a) Test accuracy (OSM Routing)
|
| 402 |
+
|
| 403 |
+
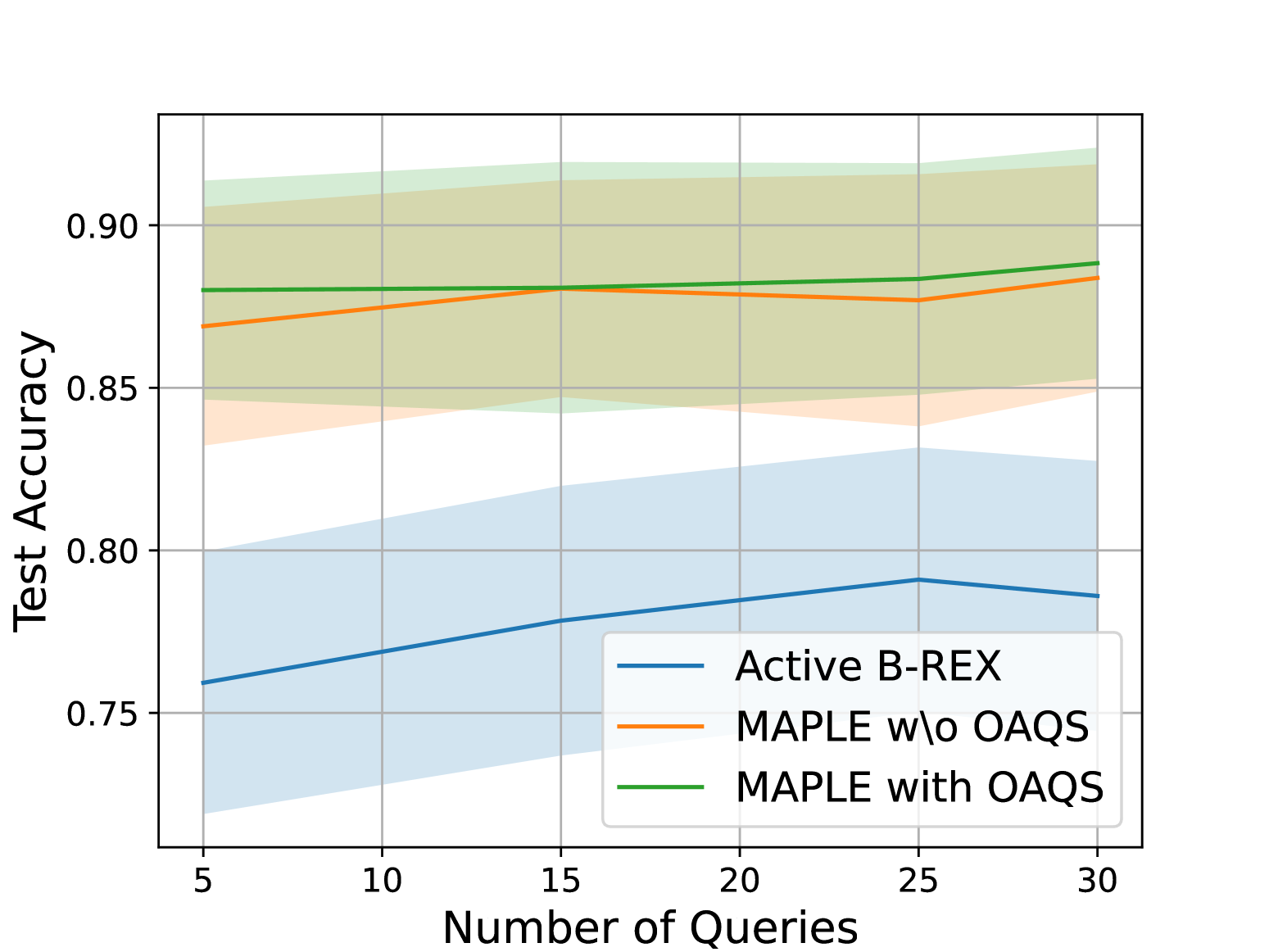
|
| 404 |
+
|
| 405 |
+
(b) Test accuracy (HomeGrid)
|
| 406 |
+
|
| 407 |
+
Figure 5: Efficacy of Oracle-guided Active Query Selection (OAQS).
|
| 408 |
+
|
| 409 |
+
We use three key metrics for evaluation: 1) the cosine distance between inferred preference weights (MAP of the distribution) and ground truth preference weights; 2) preference prediction accuracy, which evaluates the model’s ability to generalize and accurately predict human preferences from an unseen set of trajectories; and 3) the policy cost difference, which compares the true cost of policies calculated using the ground truth preference function and the learned preference function.
|
| 410 |
+
|
| 411 |
+
#### Impact of linguistic feedback
|
| 412 |
+
|
| 413 |
+
Figure 4a-c presents the results of the OSM routing domain experiments. In this experiment, we did not apply OAQS; instead, we selected queries randomly from the dataset to isolate the impact of language. Several noteworthy insights emerge from the results. First, we observe that MAPLE outperforms B-REX on both the natural and clear datasets, demonstrating the effectiveness of integrating complex language feedback with conventional feedback. Additionally, as feedback increases, B-REX’s accuracy begins to approach that of MAPLE. This suggests that MAPLE is particularly advantageous when feedback is limited, such as in online settings where the agent must quickly infer rewards.
|
| 414 |
+
|
| 415 |
+
Examining the cosine distance offers further insight. Language alone appears almost sufficient to align the reward angle, as the cosine distance remains static despite the increasing number of queries. This suggests that preference feedback is more effective for calibrating the magnitude of the preference vector rather than its direction. In contrast, while B-REX achieves good accuracy with large amounts of feedback, it seems to exhibit significant misalignment, which could suggest overfitting and potential failure in out-of-distribution scenarios. Lastly, we evaluated existing publicly available models and found that both GPT-4o and GPT-4o-mini outperformed other models. However, the small local model (Mistral-7B Instruct) proved to be competitive, so we used it to generate all the results shown in Figures 4a, 4b, 4d, and 4e.
|
| 416 |
+
|
| 417 |
+
Figure 4d-f shows the results of the HomeGrid experiments. In this environment, we observe that natural instructions do affect performance, but MAPLE still significantly outperforms B-REX in both datasets. Notably, the Mistral-Large-2 models surpassed B-REX by a wide margin, achieving nearly one-third of the cost difference. Surprisingly, GPT-4-mini performed poorly, with a worse cost difference than B-REX. This is due to its inference of highly misaligned preference weights for certain instructions. In this environment, we also see that most of the angle alignment was done using the language feedback and B-REX remains highly misaligned even after 30 feedback.
|
| 418 |
+
|
| 419 |
+
#### Impact of OAQS
|
| 420 |
+
|
| 421 |
+
The results of the Oracle-Guided Active Query Selection (OAQS) using an LLM as an oracle are shown in Figure 5. In the routing environment, the Active Query Success Rate (AQSR) is approximately 0.64, while in the HomeGrid environment, it is 0.46. We first evaluated the capability of various models for in-context query selection (Figure 5c) using a dataset of 500 queries. The Mistral-7B model, used in the previous experiment, failed to meet the condition Y 0+Y 1>1 subscript 𝑌 0 subscript 𝑌 1 1 Y_{0}+Y_{1}>1 italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT + italic_Y start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT > 1 in both environments. The Gemini-1.5-Pro model showed the best overall performance among publicly available models and was used to generate Figures 5a and 5b.
|
| 422 |
+
|
| 423 |
+
Figures 5a and 5b compare the test accuracy of Active B-REX with MAPLE, both with and without OAQS. In both environments, MAPLE with OAQS achieved the highest performance, with a significant margin in the OSM routing environment. We also calculated the Query Success Rate (QSR) for all three algorithms: 0.43 for Active B-REX, 0.43 for MAPLE without OAQS, and 0.58 for MAPLE with OAQS in the routing domain. The QSR was lower than the AQSR for the top-query selection strategy due to a violation of the independence assumption, suggesting that the variance ratio is more likely to select more challenging queries. We refer to this experimental metric as the Effective Query Success Rate (EQSR). Based on Proposition 3, the QSR for MAPLE with OAQS should be 0.77, but it was observed to be lower for the same reason. Replacing AQSR with EQSR in Proposition 3 gives us a value of 0.59, which closely matches the experimental value. Therefore, we conclude that EQSR is a more practical metric for estimating a model’s success based on Y 0 subscript 𝑌 0 Y_{0}italic_Y start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT and Y 1 subscript 𝑌 1 Y_{1}italic_Y start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT. This phenomenon is also observed in HomeGrid. Finally, in the HomeGrid environment, the overall EQSR was low (around 0.2); therefore, even with OAQS, we saw an increase of 2-3 feedback signals after 30 queries, which was not enough to create a large margin and therefore we see only a modest difference between MAPLE with and without OAQS.
|
| 424 |
+
|
| 425 |
+
Conclusions and Future Works
|
| 426 |
+
----------------------------
|
| 427 |
+
|
| 428 |
+
We introduced MAPLE, a framework for active preference learning guided by large language models (LLMs). Our experiments in the OpenStreetMap Routing and HomeGrid environments demonstrated that incorporating language descriptions and explanations significantly improves preference alignment, and that LLM-guided active query selection enhances sample efficiency while reducing the burden on users. Future work could extend MAPLE to more complex environments and tasks, explore different types of linguistic feedback, and conduct user studies to evaluate its usability and effectiveness in real-world applications.
|
| 429 |
+
|
| 430 |
+
Acknowledgments
|
| 431 |
+
---------------
|
| 432 |
+
|
| 433 |
+
This research was supported in part by the U.S.Army DEVCOM Analysis Center(DAC) under contract number W911QX23D0009, and by the National Science Foundation under grants 2321786, 2326054, and 2416459.
|
| 434 |
+
|
| 435 |
+
References
|
| 436 |
+
----------
|
| 437 |
+
|
| 438 |
+
* Abbeel and Ng (2004) Abbeel, P.; and Ng, A.Y. 2004. Apprenticeship learning via inverse reinforcement learning. In _Proceedings of the 21st International Conference on Machine learning_.
|
| 439 |
+
* Achiam et al. (2023) Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. 2023. GPT-4 technical report. _arXiv preprint arXiv:2303.08774_.
|
| 440 |
+
* Basu, Singhal, and Dragan (2018) Basu, C.; Singhal, M.; and Dragan, A.D. 2018. Learning from richer human guidance: Augmenting comparison-based learning with feature queries. In _13th International Conference on Human-Robot Interaction_, 132–140.
|
| 441 |
+
* Biyik (2022) Biyik, E. 2022. _Learning preferences for interactive autonomy_. Ph.D. thesis, Stanford University.
|
| 442 |
+
* Biyik et al. (2019) Biyik, E.; Palan, M.; Landolfi, N.C.; Losey, D.P.; and Sadigh, D. 2019. Asking easy questions: A user-friendly approach to active reward learning. In _Proceedings of the 3rd Annual Conference on Robot Learning_, 1177–1190.
|
| 443 |
+
* Bobu et al. (2021) Bobu, A.; Paxton, C.; Yang, W.; Sundaralingam, B.; Chao, Y.-W.; Cakmak, M.; and Fox, D. 2021. Learning perceptual concepts by bootstrapping from human queries. _arXiv preprint arXiv:2111.05251_.
|
| 444 |
+
* Bradley and Terry (1952) Bradley, R.A.; and Terry, M.E. 1952. Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons. _Biometrika_, 39: 324.
|
| 445 |
+
* Brown, Goo, and Niekum (2019) Brown, D.S.; Goo, W.; and Niekum, S. 2019. Better-than-demonstrator imitation learning via automatically-ranked demonstrations. In _3rd Annual Conference on Robot Learning_, 330–359.
|
| 446 |
+
* Brown et al. (2019) Brown, D.S.; Goo, W.; Prabhat, N.; and Niekum, S. 2019. Extrapolating beyond suboptimal demonstrations via inverse reinforcement learning from observations. In _36th International Conference on Machine Learning_, 783–792.
|
| 447 |
+
* Brown et al. (2020) Brown, D.S.; Niekum, S.; Coleman, R.; and Srinivasan, R. 2020. Safe imitation learning via fast Bayesian reward inference from preferences. In _37th International Conference on Machine Learning_, 1165–1177.
|
| 448 |
+
* Brown, Schneider, and Niekum (2021) Brown, D.S.; Schneider, J.J.; and Niekum, S. 2021. Value alignment verification. In _38th International Conference on Machine Learning_, 1105–1115.
|
| 449 |
+
* Bucker et al. (2023) Bucker, A.; Figueredo, L. F.C.; Haddadin, S.; Kapoor, A.; Ma, S.; Vemprala, S.; and Bonatti, R. 2023. LATTE: LAnguage Trajectory TransformEr. In _IEEE International Conference on Robotics and Automation_, 7287–7294.
|
| 450 |
+
* Chebotar et al. (2021) Chebotar, Y.; Hausman, K.; Lu, Y.; Xiao, T.; Kalashnikov, D.; Varley, J.; Irpan, A.; Eysenbach, B.; Julian, R.; Finn, C.; et al. 2021. Actionable models: Unsupervised offline reinforcement learning of robotic skills. _arXiv preprint arXiv:2104.07749_.
|
| 451 |
+
* Chevalier-Boisvert et al. (2023) Chevalier-Boisvert, M.; Dai, B.; Towers, M.; Perez-Vicente, R.; Willems, L.; Lahlou, S.; Pal, S.; Castro, P.S.; and Terry, J. 2023. Minigrid & Miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks. In _Advances in Neural Information Processing Systems 36_.
|
| 452 |
+
* Cui et al. (2023) Cui, Y.; Karamcheti, S.; Palleti, R.; Shivakumar, N.; Liang, P.; and Sadigh, D. 2023. “No, to the Right” – Online language corrections for robotic manipulation via shared autonomy. _arXiv preprint arXiv:2301.02555_.
|
| 453 |
+
* Dietterich (2017) Dietterich, T.G. 2017. Steps toward robust artificial intelligence. _AI Magazine_, 38(3): 3–24.
|
| 454 |
+
* Gal and Ghahramani (2016) Gal, Y.; and Ghahramani, Z. 2016. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. In _33nd International Conference on Machine Learning_, 1050–1059.
|
| 455 |
+
* Guan, Sreedharan, and Kambhampati (2022) Guan, L.; Sreedharan, S.; and Kambhampati, S. 2022. Leveraging approximate symbolic models for reinforcement learning via skill diversity. _arXiv preprint arXiv:2202.02886_.
|
| 456 |
+
* Guan, Valmeekam, and Kambhampati (2022) Guan, L.; Valmeekam, K.; and Kambhampati, S. 2022. Relative behavioral attributes: Filling the gap between symbolic goal specification and reward learning from human preferences. _arXiv preprint arXiv:2210.15906_.
|
| 457 |
+
* Guan et al. (2021) Guan, L.; Verma, M.; Guo, S.S.; Zhang, R.; and Kambhampati, S. 2021. Widening the pipeline in human-guided reinforcement learning with explanation and context-aware data augmentation. _Advances in Neural Information Processing Systems_, 34: 21885–21897.
|
| 458 |
+
* Guo et al. (2022) Guo, C.; Zou, S.; Zuo, X.; Wang, S.; Ji, W.; Li, X.; and Cheng, L. 2022. Generating diverse and natural 3D human motions from text. In _IEEE/CVF Conference on Computer Vision and Pattern Recognition_, 5152–5161.
|
| 459 |
+
* Icarte et al. (2022) Icarte, R.T.; Klassen, T.Q.; Valenzano, R.; and McIlraith, S.A. 2022. Reward machines: Exploiting reward function structure in reinforcement learning. _Journal of Artificial Intelligence Research_, 73: 173–208.
|
| 460 |
+
* Illanes et al. (2020) Illanes, L.; Yan, X.; Icarte, R.T.; and McIlraith, S.A. 2020. Symbolic plans as high-level instructions for reinforcement learning. In _30th International Conference on Automated Planning and Scheduling_, 540–550.
|
| 461 |
+
* Lee and Popović (2010) Lee, S.J.; and Popović, Z. 2010. Learning behavior styles with inverse reinforcement learning. _ACM transactions on graphics_, 29(4): 1–7.
|
| 462 |
+
* Lin et al. (2023) Lin, J.; Du, Y.; Watkins, O.; Hafner, D.; Abbeel, P.; Klein, D.; and Dragan, A. 2023. Learning to model the world with language. _arXiv preprint arXiv:2308.01399_.
|
| 463 |
+
* Lin et al. (2022) Lin, J.; Fried, D.; Klein, D.; and Dragan, A. 2022. Inferring rewards from language in context. _arXiv preprint arXiv:2204.02515_.
|
| 464 |
+
* Lou et al. (2024) Lou, X.; Zhang, J.; Wang, Z.; Huang, K.; and Du, Y. 2024. Safe reinforcement learning with free-form natural language constraints and pre-trained language models. _arXiv preprint arXiv:2401.07553_.
|
| 465 |
+
* Luo et al. (2020) Luo, Y.-S.; Soeseno, J.H.; Chen, T. P.-C.; and Chen, W.-C. 2020. CARL: Controllable agent with reinforcement learning for quadruped locomotion. _ACM Transactions on Graphics_, 39(4): 38–1.
|
| 466 |
+
* Lyu et al. (2019) Lyu, D.; Yang, F.; Liu, B.; and Gustafson, S. 2019. SDRL: interpretable and data-efficient deep reinforcement learning leveraging symbolic planning. In _33rd AAAI Conference on Artificial Intelligence_, 2970–2977.
|
| 467 |
+
* Ma et al. (2023) Ma, Y.J.; Liang, W.; Wang, G.; Huang, D.-A.; Bastani, O.; Jayaraman, D.; Zhu, Y.; Fan, L.; and Anandkumar, A. 2023. Eureka: Human-level reward design via coding large language models. _arXiv preprint arXiv:2310.12931_.
|
| 468 |
+
* Mahmud, Saisubramanian, and Zilberstein (2023) Mahmud, S.; Saisubramanian, S.; and Zilberstein, S. 2023. Explanation-guided reward alignment. In _32nd International Joint Conference on Artificial Intelligence_, 473–482.
|
| 469 |
+
* Ng and Russell (2000) Ng, A.Y.; and Russell, S.J. 2000. Algorithms for inverse reinforcement learning. In _17th International Conference on Machine Learning_, 663–670.
|
| 470 |
+
* OpenStreetMap Contributors (2017) OpenStreetMap Contributors. 2017. Planet dump retrieved from https://planet.osm.org . https://www.openstreetmap.org.
|
| 471 |
+
* Peng et al. (2018) Peng, X.B.; Kanazawa, A.; Malik, J.; Abbeel, P.; and Levine, S. 2018. SFV: Reinforcement learning of physical skills from videos. _ACM Transactions On Graphics_, 37(6): 178:1–178:14.
|
| 472 |
+
* Peng et al. (2021) Peng, X.B.; Ma, Z.; Abbeel, P.; Levine, S.; and Kanazawa, A. 2021. AMP: Adversarial motion priors for stylized physics-based character control. _ACM Transactions On Graphics_, 40(4): 144:1–144:20.
|
| 473 |
+
* Rafailov et al. (2024) Rafailov, R.; Sharma, A.; Mitchell, E.; Manning, C.D.; Ermon, S.; and Finn, C. 2024. Direct preference optimization: Your language model is secretly a reward model. _Advances in Neural Information Processing Systems_, 36.
|
| 474 |
+
* Ramachandran and Amir (2007) Ramachandran, D.; and Amir, E. 2007. Bayesian inverse reinforcement learning. In _20th International Joint Conference on Artifical intelligence_, 2586–2591.
|
| 475 |
+
* Sadigh et al. (2017) Sadigh, D.; Dragan, A.D.; Sastry, S.S.; and Seshia, S.A. 2017. Active preference-based learning of reward functions. In _Robotics: Science and Systems XIII_.
|
| 476 |
+
* Silver et al. (2022) Silver, T.; Athalye, A.; Tenenbaum, J.B.; Lozano-Perez, T.; and Kaelbling, L.P. 2022. Learning neuro-symbolic skills for bilevel planning. _arXiv preprint arXiv:2206.10680_.
|
| 477 |
+
* Soni et al. (2022) Soni, U.; Thakur, N.; Sreedharan, S.; Guan, L.; Verma, M.; Marquez, M.; and Kambhampati, S. 2022. Towards customizable reinforcement learning agents: Enabling preference specification through online vocabulary expansion. _arXiv preprint arXiv:2210.15096_.
|
| 478 |
+
* Sontakke et al. (2024) Sontakke, S.; Zhang, J.; Arnold, S.; Pertsch, K.; Biyik, E.; Sadigh, D.; Finn, C.; and Itti, L. 2024. RoboCLIP: One demonstration is enough to learn robot policies. _Advances in Neural Information Processing Systems_, 36.
|
| 479 |
+
* Tevet et al. (2022) Tevet, G.; Raab, S.; Gordon, B.; Shafir, Y.; Cohen-Or, D.; and Bermano, A.H. 2022. Human motion diffusion model. _arXiv preprint arXiv:2209.14916_.
|
| 480 |
+
* Tian et al. (2024) Tian, S.; Li, L.; Li, W.; Ran, H.; Ning, X.; and Tiwari, P. 2024. A survey on few-shot class-incremental learning. _Neural Networks_, 169: 307–324.
|
| 481 |
+
* Tien et al. (2024) Tien, J.; Yang, Z.; Jun, M.; Russell, S.J.; Dragan, A.; and Biyik, E. 2024. Optimizing robot behavior via comparative language feedback. In _3rd HRI Workshop on Human-Interactive Robot Learning_.
|
| 482 |
+
* Wang et al. (2024) Wang, Y.; Sun, Z.; Zhang, J.; Xian, Z.; Biyik, E.; Held, D.; and Erickson, Z. 2024. RL-VLM-F: Reinforcement learning from vision language foundation model feedback. _arXiv preprint arXiv:2402.03681_.
|
| 483 |
+
* Wang et al. (2017) Wang, Z.; Merel, J.S.; Reed, S.E.; de Freitas, N.; Wayne, G.; and Heess, N. 2017. Robust imitation of diverse behaviors. _Advances in Neural Information Processing Systems_, 30.
|
| 484 |
+
* Yu et al. (2023) Yu, W.; Gileadi, N.; Fu, C.; Kirmani, S.; Lee, K.-H.; Arenas, M.G.; Chiang, H.-T.L.; Erez, T.; Hasenclever, L.; Humplik, J.; et al. 2023. Language to rewards for robotic skill synthesis. _arXiv preprint arXiv:2306.08647_.
|
| 485 |
+
* Zhang et al. (2022) Zhang, R.; Bansal, D.; Hao, Y.; Hiranaka, A.; Gao, J.; Wang, C.; Martín-Martín, R.; Fei-Fei, L.; and Wu, J. 2022. A dual representation framework for robot learning with human guidance. In _6th Annual Conference on Robot Learning_, 738–750.
|
| 486 |
+
* Zhou and Dragan (2018) Zhou, A.; and Dragan, A.D. 2018. Cost functions for robot motion style. In _2018 IEEE/RSJ International Conference on Intelligent Robots and Systems_, 3632–3639. IEEE.
|
| 487 |
+
* Ziebart et al. (2008) Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; and Dey, A.K. 2008. Maximum entropy inverse reinforcement learning. In _Proceedings of the 23rd AAAI Conference on Artificial Intelligence_, 1433–1438.
|
| 488 |
+
* Zilberstein (2015) Zilberstein, S. 2015. Building strong semi-autonomous systems. In _29th AAAI Conference on Artificial Intelligence_, 4088–4092.
|