

Add 1 files
Browse files- 2205/2205.06740.md +311 -0
2205/2205.06740.md
ADDED
|
@@ -0,0 +1,311 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
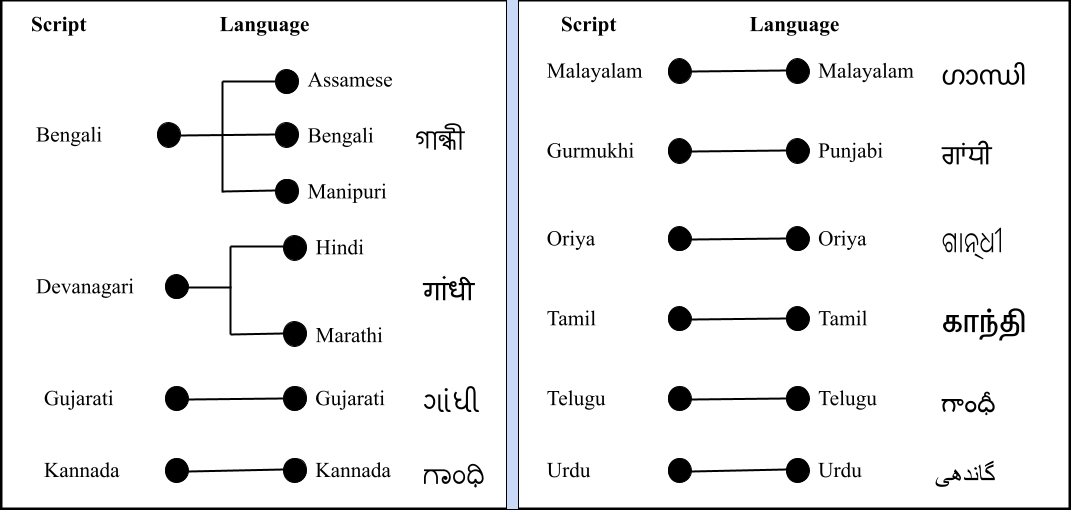
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
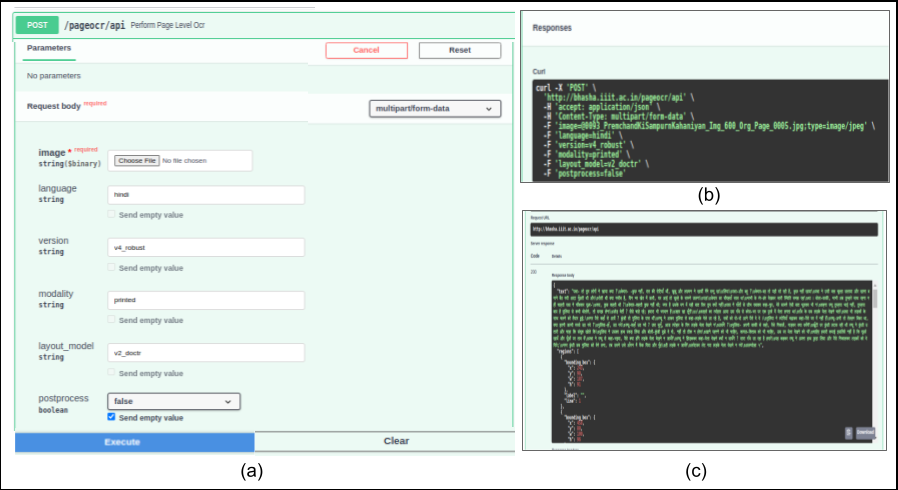
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Towards Deployable OCR Models for Indic Languages
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2205.06740
|
| 4 |
+
|
| 5 |
+
Published Time: Thu, 19 Dec 2024 01:53:04 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
1 1 institutetext: CVIT, International Institute of Information Technology, Hyderabad, India
|
| 9 |
+
|
| 10 |
+
1 1 email: minesh.mathew@gmail.com
|
| 11 |
+
|
| 12 |
+
1 1 email: {ajoy.mondal,jawahar}@iiit.ac.in
|
| 13 |
+
|
| 14 |
+
###### Abstract
|
| 15 |
+
|
| 16 |
+
The difficulty of reliably extracting characters had delayed the character recognition solutions (or OCRs) in Indian languages. Contemporary research in Indian language text recognition has shifted towards recognizing text in word or line images without requiring sub-word segmentation, leveraging Connectionist Temporal Classification (CTC) for modeling unsegmented sequences. The next challenge is the lack of public data for all these languages. And there is an immediate need to lower the entry barrier for startups or solution providers. With this in mind, (i) we introduce Mozhi dataset, a novel public dataset comprising over 1.2 million annotated word images (equivalent to approximately 120 thousand text line images) across 13 languages. (ii) We conduct a comprehensive empirical analysis of various neural network models employing CTC across 13 Indian languages. (iii) We also provide APIs for our OCR models and web-based applications that integrate these APIs to digitize Indic printed documents. We compare our model’s performance with popular publicly available OCR tools for end-to-end document image recognition. Our model outperform these OCR engines on 8 out of 13 languages. The code, trained models, and dataset are available at[https://cvit.iiit.ac.in/usodi/tdocrmil.php](https://cvit.iiit.ac.in/usodi/tdocrmil.php).
|
| 17 |
+
|
| 18 |
+
###### Keywords:
|
| 19 |
+
|
| 20 |
+
Printed text Indic OCR Indian languages CRNN CTC text recognition APIs web-based application.
|
| 21 |
+
|
| 22 |
+
1 Introduction
|
| 23 |
+
--------------
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
Figure 1: We explore printed text recognition across 13 Indian languages, covering ten unique scripts. Although many languages share a common alphabet, their scripts vary, with exceptions like Hindi and Marathi. The last column shows the name "Gandhi" in all ten scripts.
|
| 28 |
+
|
| 29 |
+

|
| 30 |
+
|
| 31 |
+

|
| 32 |
+
|
| 33 |
+

|
| 34 |
+
|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
Figure 2: Shows a few sample of cropped images of each of 13 languages from our Mozhi dataset.
|
| 38 |
+
|
| 39 |
+
Text recognition faces challenges related to language/script, text rendering, and imaging methods. This study concentrates on recognizing printed text in Indian languages, particularly on text recognition alone, assuming cropped word or line images are provided. The 2011 official census of India[[1](https://arxiv.org/html/2205.06740v2#bib.bib1)] lists 30 Indian languages with over a million native speakers, 22 of which are recognized as official languages. These languages belong to three language families: Indo-European, Dravidian, and Sino-Tibetan. Our focus is on text recognition in 13 official languages: Assamese, Bengali, Gujarati, Hindi, Kannada, Malayalam, Manipuri, Marathi, Oriya, Punjabi, Tamil, Telugu, and Urdu. While some share linguistic similarities, their scripts are distinct, with Devanagari script used in Hindi and Marathi and Bengali script in Bengali, Assamese, and Manipuri, among others. Our study explores printed text recognition across 13 Indian languages, representing ten scripts. Fig.[1](https://arxiv.org/html/2205.06740v2#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Towards Deployable OCR Models for Indic Languages") illustrates "Gandhi" written in these ten scripts. At the same time, Fig.[2](https://arxiv.org/html/2205.06740v2#S1.F2 "Figure 2 ‣ 1 Introduction ‣ Towards Deployable OCR Models for Indic Languages") depicts a sample of cropped images from 13 languages from our newly created Mozhi dataset. The APIs corresponding to our developed models are integrated into Bhashini 1 1 1[https://bhashini.gov.in/](https://bhashini.gov.in/) for public use. However, we are continuously working on including the remaining low-resource languages — Bodo, Dogri, Kashmiri, Konkani, Maithili, Nepali, Sanskrit, Santali, and Sindhi — to cover all twenty-two languages of India.
|
| 40 |
+
|
| 41 |
+
Efforts to develop OCRs for Indian scripts began in the 1970s but faced challenges in scaling across languages and achieving satisfactory results across diverse document types until recently[[29](https://arxiv.org/html/2205.06740v2#bib.bib29), [6](https://arxiv.org/html/2205.06740v2#bib.bib6), [4](https://arxiv.org/html/2205.06740v2#bib.bib4)]. Challenges such as script intricacies, linguistic diversity, and limited annotated data hindered progress in Indian language OCR. The adoption of Connectionist Temporal Classification (CTC), initially successful in speech transcription, revolutionized text recognition across various forms, including handwritten[[11](https://arxiv.org/html/2205.06740v2#bib.bib11)], printed[[31](https://arxiv.org/html/2205.06740v2#bib.bib31), [26](https://arxiv.org/html/2205.06740v2#bib.bib26)], and scene text[[30](https://arxiv.org/html/2205.06740v2#bib.bib30), [28](https://arxiv.org/html/2205.06740v2#bib.bib28)]. Popular open-source OCR tools like Tesseract[[2](https://arxiv.org/html/2205.06740v2#bib.bib2)], EasyOCR[[15](https://arxiv.org/html/2205.06740v2#bib.bib15)], and ocropy[[20](https://arxiv.org/html/2205.06740v2#bib.bib20)] now leverage CTC-based models, enabling recognition of word or line images without sub-word segmentation.
|
| 42 |
+
|
| 43 |
+
Segmenting words into sub-word units presents a significant challenge for Indian languages compared to English[[25](https://arxiv.org/html/2205.06740v2#bib.bib25)]. Developing Indian language recognizers is further complicated by the intricate relationships between script glyphs, language text, and machine representation. In the script, the atomic unit is an isolated symbol (glyph), while in the language, it’s an Akshara or an orthographic syllable. Machine text representation uses Unicode points. An Akshara can comprise multiple glyphs, and a sequence of multiple Unicode points can represent an Akshara. Splitting text at Akshara s and mapping them to Unicode sequences necessitates language and script knowledge[[25](https://arxiv.org/html/2205.06740v2#bib.bib25), [19](https://arxiv.org/html/2205.06740v2#bib.bib19)]. Therefore, adopting CTC-based sequence modeling has become the standard approach for Indian language OCR[[25](https://arxiv.org/html/2205.06740v2#bib.bib25), [3](https://arxiv.org/html/2205.06740v2#bib.bib3), [17](https://arxiv.org/html/2205.06740v2#bib.bib17)]. This approach directly maps features from word or line images to target Unicode sequences, eliminating the need for explicit alignment during training. Our study offers a comprehensive empirical analysis of various design considerations in developing a CTC-based printed text recognition model for Indian languages.
|
| 44 |
+
|
| 45 |
+
Our contributions are the following:
|
| 46 |
+
|
| 47 |
+
* •We introduce a new public dataset Mozhi for text recognition in 13 Indian languages, comprising cropped line and word segments with corresponding ground truth for all languages except Urdu. With over 1.2 million annotated word images, this dataset is the largest for text recognition in Indian languages (refer Table[1](https://arxiv.org/html/2205.06740v2#S3.T1 "Table 1 ‣ 3 Mozhi Dataset ‣ Towards Deployable OCR Models for Indic Languages") and Fig.[3](https://arxiv.org/html/2205.06740v2#S3.F3 "Figure 3 ‣ 3 Mozhi Dataset ‣ Towards Deployable OCR Models for Indic Languages")).
|
| 48 |
+
* •We empirically compare the performance of four types of CTC-based text recognition methods across 13 official languages of India, varying in feature extraction and sequence encoding. Additionally, we assess word level and line level recognition models.
|
| 49 |
+
* •We develop end-to-end page level OCR systems by integrating our best text recognition models with existing line and word segmentation tools. These systems outperform Tesseract5[[2](https://arxiv.org/html/2205.06740v2#bib.bib2)] and Google Cloud Vision OCR[[9](https://arxiv.org/html/2205.06740v2#bib.bib9)] for 8 out of 13 languages (refer Table[4](https://arxiv.org/html/2205.06740v2#S7.T4 "Table 4 ‣ 7.1 Comparing Different Encoder Configurations ‣ 7 Experiments and Results ‣ Towards Deployable OCR Models for Indic Languages")).
|
| 50 |
+
* •Offer APIs for our OCR models and web-based applications that seamlessly integrate these APIs to digitize Indic printed documents.
|
| 51 |
+
|
| 52 |
+
2 Related Work
|
| 53 |
+
--------------
|
| 54 |
+
|
| 55 |
+
Current OCRs for Indian scripts mainly rely on segmentation-free approaches, which directly produce a label sequence from word or line images. Sankaran _et al._[[26](https://arxiv.org/html/2205.06740v2#bib.bib26)] introduced CTC-based sequence modeling for printed text recognition in Indian languages. Their method utilizes an RNN encoder and CTC transcription to map features extracted from Devanagari word images to class labels. Profile-based features[[32](https://arxiv.org/html/2205.06740v2#bib.bib32)] extracted using a 25 ×\times× 1 sliding window are employed. Initially, the model maps Akshara s to class labels and uses rule-based mapping to Unicode. In a subsequent work[[25](https://arxiv.org/html/2205.06740v2#bib.bib25)], they directly map feature sequences from word images to Unicode sequences, eliminating the need for rule-based Akshara to Unicode mapping.
|
| 56 |
+
|
| 57 |
+
The introduction of the CTC-based transcription method marked a significant advancement in Indic scripts, particularly by overcoming the challenge of sub-word segmentation. Directly transcribing word images into machine-readable Unicode sequences also eliminated the need for language-specific rules to map latent output classes to valid Unicode sequences. Krishnan _et al._[[17](https://arxiv.org/html/2205.06740v2#bib.bib17)] utilized profile-based features and a CTC-based model similar to[[25](https://arxiv.org/html/2205.06740v2#bib.bib25)] for recognizing seven Indian languages. Their evaluation on a large test set per language demonstrated the effectiveness of a unified framework employing CTC transcription for multilingual text recognition, eliminating the necessity for language or script-specific modules.
|
| 58 |
+
|
| 59 |
+
Hasan _et al._[[3](https://arxiv.org/html/2205.06740v2#bib.bib3)] proposed an RNN+CTC model for printed Urdu text recognition, directly generating Unicode sequences from text line images. Utilizing a 30 ×\times× 1 sliding window for raw pixel feature extraction, their method yielded promising outcomes. Similarly, our prior work[[19](https://arxiv.org/html/2205.06740v2#bib.bib19)] centered on multilingual OCR for 12 Indian languages and English, employing a two-stage system with a script identification module and a recognition module. Chavan _et al._[[7](https://arxiv.org/html/2205.06740v2#bib.bib7)] compared RNN and multidimensional RNN (MDRNN) encoders with CTC transcription. They found the MDRNN encoder outperformed the RNN encoder, using HOG features with the former and raw pixels with the latter. Another study achieved over 99% character/symbol accuracy for Bengali script recognition[[22](https://arxiv.org/html/2205.06740v2#bib.bib22)] using an RNN+CTC model. Kundaikar and Pawar[[18](https://arxiv.org/html/2205.06740v2#bib.bib18)] explored the robustness of CTC-based Devanagari OCR to font and size variations. At the same time, Dwivedi _et al._[[8](https://arxiv.org/html/2205.06740v2#bib.bib8)] achieved a character/symbol error rate under 3% for Sanskrit recognition using an encoder-decoder model. These findings, particularly the reliance on CTC transcription, motivate our comprehensive empirical study comparing various encoder types and features for both line and word recognition in Indian languages.
|
| 60 |
+
|
| 61 |
+
3 Mozhi Dataset
|
| 62 |
+
---------------
|
| 63 |
+
|
| 64 |
+
To our knowledge, no extensive public datasets are available for printed text recognition in Indian languages. Early studies often utilized datasets with cropped characters or isolated symbols for character classification[[24](https://arxiv.org/html/2205.06740v2#bib.bib24), [5](https://arxiv.org/html/2205.06740v2#bib.bib5)]. Later research relied on either internal datasets or large-scale synthetically generated samples for word or line level annotations[[26](https://arxiv.org/html/2205.06740v2#bib.bib26), [17](https://arxiv.org/html/2205.06740v2#bib.bib17), [19](https://arxiv.org/html/2205.06740v2#bib.bib19), [7](https://arxiv.org/html/2205.06740v2#bib.bib7), [16](https://arxiv.org/html/2205.06740v2#bib.bib16), [8](https://arxiv.org/html/2205.06740v2#bib.bib8), [18](https://arxiv.org/html/2205.06740v2#bib.bib18), [3](https://arxiv.org/html/2205.06740v2#bib.bib3)]. While recent efforts have introduced public datasets for Hindi and Urdu, they typically contain a limited number of samples intended solely for model evaluation[[19](https://arxiv.org/html/2205.06740v2#bib.bib19), [16](https://arxiv.org/html/2205.06740v2#bib.bib16)]. However, due to variations in training data among these studies, comparing methods can be challenging. To address the scarcity of annotated data for training printed text recognition models in Indian languages, we introduce the Mozhi dataset. This public dataset encompasses both line and word level annotations for all 13 languages examined in this study. It includes cropped line images, corresponding ground truth text annotations for all languages, and word images and ground truths for all languages except Urdu. With 1.2 million word annotations (approximately 100,000 words per language), it is the largest public dataset of real word images for text recognition in Indian languages. For each language, the line level data is divided randomly into training, validation, and test splits in an 80:10:10 ratio, with words cropped from line images forming corresponding splits for training, validation, and testing. Table[1](https://arxiv.org/html/2205.06740v2#S3.T1 "Table 1 ‣ 3 Mozhi Dataset ‣ Towards Deployable OCR Models for Indic Languages") shows statistics of Mozhi.
|
| 65 |
+
|
| 66 |
+
Script Language Train Validation Test
|
| 67 |
+
Lines Words Lines Words Lines Words
|
| 68 |
+
Bengali Assamese 9566 79959 1196 9945 1196 10146
|
| 69 |
+
Bengali Bengali 7579 80113 948 9787 947 10113
|
| 70 |
+
Gujarati Gujarati 8632 79910 1080 10016 1079 10090
|
| 71 |
+
Devanagari Hindi 6525 79762 816 10114 816 10173
|
| 72 |
+
Kannada Kannada 13462 80085 1683 10088 1683 9838
|
| 73 |
+
Malayalam Malayalam 15112 80146 1889 9893 1889 9980
|
| 74 |
+
Bengali Manipuri 9765 79691 1221 10254 1221 10061
|
| 75 |
+
Devanagari Marathi 8380 80151 1048 10005 1048 9855
|
| 76 |
+
Oriya Oriya 8260 79945 1033 10089 1033 9994
|
| 77 |
+
Gurumukhi Punjabi 6726 79931 841 10036 841 10038
|
| 78 |
+
Tamil Tamil 16074 80022 2010 10021 2009 9974
|
| 79 |
+
Telugu Telugu 12722 80337 1591 9811 1590 9876
|
| 80 |
+
Nastaliq Urdu 9100-1138-1137-
|
| 81 |
+
|
| 82 |
+
Table 1: Statistics for the new Mozhi dataset, a public resource for recognizing printed text in cropped words and lines, reveal over 1.2 million annotated words in total. Notably, only cropped lines are annotated for Urdu.
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
Figure 3: A few sample of word level images from our Mozhi dataset.
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
Figure 4: Shows screen shot of our web-based APIs to digitize Indic printed documents.
|
| 91 |
+
|
| 92 |
+
4 APIs and Web-based Applications
|
| 93 |
+
---------------------------------
|
| 94 |
+
|
| 95 |
+
We develop APIs for page level recognition models across 13 languages and built a web-based application available at[https://ilocr.iiit.ac.in/fastocr/](https://ilocr.iiit.ac.in/fastocr/) that integrates these APIs for digitizing printed documents in Indic languages. Fig.[4](https://arxiv.org/html/2205.06740v2#S3.F4 "Figure 4 ‣ 3 Mozhi Dataset ‣ Towards Deployable OCR Models for Indic Languages") illustrates the steps for utilizing our web-based APIs to digitize Indic printed documents. Users can upload a document image, select the language, OCR model version, layout version, and execute to obtain OCR output.
|
| 96 |
+
|
| 97 |
+
5 Text Recognition using CTC Transcription
|
| 98 |
+
------------------------------------------
|
| 99 |
+
|
| 100 |
+

|
| 101 |
+
|
| 102 |
+
Figure 5: We examine four CTC-based text recognition methods — Col_RNN, Win_RNN, CNN_only, and CRNN, distinguished by their feature extraction and sequence encoding. W 𝑊 W italic_W and H 𝐻 H italic_H represent the width and height of the input image I 𝐼 I italic_I, respectively. |L′|superscript 𝐿′|L^{\prime}|| italic_L start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT | indicates the number of class labels, including the blank label. Hid j 𝐻 𝑖 subscript 𝑑 𝑗 Hid_{j}italic_H italic_i italic_d start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT signifies the number of hidden units in the last RNN layer. In the case of Win_RNN, W W subscript 𝑊 𝑊 W_{W}italic_W start_POSTSUBSCRIPT italic_W end_POSTSUBSCRIPT, and S W subscript 𝑆 𝑊 S_{W}italic_S start_POSTSUBSCRIPT italic_W end_POSTSUBSCRIPT denote the width and step size of the sliding window, respectively.
|
| 103 |
+
|
| 104 |
+
Given an input image I 𝐼 I italic_I containing a word or a line, text recognition involves converting the text on the image into a machine-readable format. We frame this task as a sequence modeling problem utilizing CTC. The input comprises a sequence of features 𝐱=x 1,x 2,…,x T 𝐱 subscript 𝑥 1 subscript 𝑥 2…subscript 𝑥 𝑇\mathbf{x}=x_{1},x_{2},...,x_{T}bold_x = italic_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , … , italic_x start_POSTSUBSCRIPT italic_T end_POSTSUBSCRIPT, where x t∈ℝ D subscript 𝑥 𝑡 superscript ℝ 𝐷 x_{t}\in\mathbb{R}^{D}italic_x start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_D end_POSTSUPERSCRIPT is extracted from the image I 𝐼 I italic_I. The output is a sequence of class labels 𝐥=l 1,l 2,…,l N 𝐥 subscript 𝑙 1 subscript 𝑙 2…subscript 𝑙 𝑁\mathbf{l}=l_{1},l_{2},...,l_{N}bold_l = italic_l start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_l start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , … , italic_l start_POSTSUBSCRIPT italic_N end_POSTSUBSCRIPT, where l n∈L subscript 𝑙 𝑛 𝐿 l_{n}\in{L}italic_l start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ∈ italic_L and L 𝐿 L italic_L represents the output alphabet, i.e., the set of unique class labels. In our scenario, L 𝐿{L}italic_L corresponds to all Unicode code points we aim to recognize. We adopt an encoder-decoder interpretation of the CTC framework, as described in[[12](https://arxiv.org/html/2205.06740v2#bib.bib12)].
|
| 105 |
+
|
| 106 |
+
### 5.1 Extracting Feature Sequence
|
| 107 |
+
|
| 108 |
+
Graves _et al._[[10](https://arxiv.org/html/2205.06740v2#bib.bib10)] introduced CTC for speech-to-text transcription, employing a sliding window method to extract features from the time axis of the speech signal. They used a window size of 10 milliseconds (ms) and a step size of 5 ms, extracting a fixed-size feature vector termed a time-step or a frame at each instance of the sliding window. However, grey-scale images represent 2D scalar-valued spatial signals in contrast to speech signals. Thus, approaches employing CTC for text transcription from images typically extract features along the horizontal axis of the image[[25](https://arxiv.org/html/2205.06740v2#bib.bib25), [3](https://arxiv.org/html/2205.06740v2#bib.bib3), [28](https://arxiv.org/html/2205.06740v2#bib.bib28)]. We follow a methodology similar to that outlined in[[25](https://arxiv.org/html/2205.06740v2#bib.bib25), [3](https://arxiv.org/html/2205.06740v2#bib.bib3), [28](https://arxiv.org/html/2205.06740v2#bib.bib28)], where feature vectors in the input sequence 𝐱 𝐱\mathbf{x}bold_x represent horizontal segments of the image. Each instance of the input sequence is referred to as a time-step or a frame, consistent with the original approach[[10](https://arxiv.org/html/2205.06740v2#bib.bib10)]. The horizontal span of a frame varies depending on the feature extraction method. The feature sequence, 𝐱 𝐱\mathbf{x}bold_x, is extracted in alignment with the script direction. Specifically, for languages other than Urdu, features are extracted from left to right, whereas they are extracted in the opposite direction for Urdu. In summary, given a document image I∈ℝ W×H 𝐼 superscript ℝ 𝑊 𝐻 I\in\mathbb{R}^{W\times H}italic_I ∈ blackboard_R start_POSTSUPERSCRIPT italic_W × italic_H end_POSTSUPERSCRIPT (grey-scale), the feature sequence is obtained as follows:
|
| 109 |
+
|
| 110 |
+
𝐱∈ℝ T×D=FeatureExtract(I).𝐱 superscript ℝ 𝑇 𝐷 𝐹 𝑒 𝑎 𝑡 𝑢 𝑟 𝑒 𝐸 𝑥 𝑡 𝑟 𝑎 𝑐 𝑡 𝐼\mathbf{x}\in\mathbb{R}^{T\times D}=FeatureExtract(I).bold_x ∈ blackboard_R start_POSTSUPERSCRIPT italic_T × italic_D end_POSTSUPERSCRIPT = italic_F italic_e italic_a italic_t italic_u italic_r italic_e italic_E italic_x italic_t italic_r italic_a italic_c italic_t ( italic_I ) .(1)
|
| 111 |
+
|
| 112 |
+
#### Encoder:
|
| 113 |
+
|
| 114 |
+
The sequence encoder’s task is to transform the input sequence 𝐱 𝐱\mathbf{x}bold_x into an encoded representation 𝐱′∈ℝ T×D′superscript 𝐱′superscript ℝ 𝑇 superscript 𝐷′\mathbf{x^{\prime}}\in\mathbb{R}^{T\times D^{\prime}}bold_x start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_T × italic_D start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT, where D′superscript 𝐷′D^{\prime}italic_D start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT represents the encoding size — i.e., the fixed dimensional to which each feature vector is encoded.
|
| 115 |
+
|
| 116 |
+
𝐱′∈ℝ T×D′=Encoder(𝐱).superscript 𝐱′superscript ℝ 𝑇 superscript 𝐷′𝐸 𝑛 𝑐 𝑜 𝑑 𝑒 𝑟 𝐱\mathbf{x^{\prime}}\in\mathbb{R}^{T\times D^{\prime}}=Encoder(\mathbf{x}).bold_x start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_T × italic_D start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT = italic_E italic_n italic_c italic_o italic_d italic_e italic_r ( bold_x ) .(2)
|
| 117 |
+
|
| 118 |
+
In this work, we explore several encoder configurations — Col_RNN, Win_RNN, CNN_only, and CRNN for feature extraction.
|
| 119 |
+
|
| 120 |
+
#### Decoder:
|
| 121 |
+
|
| 122 |
+
The encoded features 𝐱′superscript 𝐱′\mathbf{x^{\prime}}bold_x start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT undergo a linear projection layer followed by Softmax normalization, aligning their size with the number of output classes. This procedure, resembling the decoding phase of CTC as interpreted in[[12](https://arxiv.org/html/2205.06740v2#bib.bib12)], extends the original output alphabet L 𝐿 L italic_L with an extra label for blank, denoted as ∼similar-to\sim∼. The blank label signifies instances where no label is assigned to an input. Softmax normalization at each time step yields class conditional probabilities, forming the posterior distribution over the classes. Essentially, given the sequence of encoded features,
|
| 123 |
+
|
| 124 |
+
𝐲∈ℝ T×L′=Decoder(𝐱′),𝐲 superscript ℝ 𝑇 superscript 𝐿′𝐷 𝑒 𝑐 𝑜 𝑑 𝑒 𝑟 superscript 𝐱′\mathbf{y}\in\mathbb{R}^{T\times L^{\prime}}=Decoder(\mathbf{x^{\prime}}),bold_y ∈ blackboard_R start_POSTSUPERSCRIPT italic_T × italic_L start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT = italic_D italic_e italic_c italic_o italic_d italic_e italic_r ( bold_x start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT ) ,(3)
|
| 125 |
+
|
| 126 |
+
where each y t∈R L′subscript 𝑦 𝑡 superscript 𝑅 superscript 𝐿′y_{t}\in R^{L^{\prime}}italic_y start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ∈ italic_R start_POSTSUPERSCRIPT italic_L start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT represent activations at time step t 𝑡 t italic_t. Thus y t k superscript subscript 𝑦 𝑡 𝑘{y}_{t}^{k}italic_y start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT is a score indicating the probability of k th superscript 𝑘 𝑡 ℎ k^{th}italic_k start_POSTSUPERSCRIPT italic_t italic_h end_POSTSUPERSCRIPT label at time step t 𝑡 t italic_t.
|
| 127 |
+
|
| 128 |
+
We utilize CTC transcription to determine the most likely sequence of class labels given 𝐲 𝐲\mathbf{y}bold_y.
|
| 129 |
+
|
| 130 |
+
### 5.2 Training
|
| 131 |
+
|
| 132 |
+
Let the training dataset be denoted as S=I i,𝐥 i 𝑆 subscript 𝐼 𝑖 subscript 𝐥 𝑖 S={I_{i},\mathbf{l}_{i}}italic_S = italic_I start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , bold_l start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT, where I i subscript 𝐼 𝑖 I_{i}italic_I start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT represents a word or line image and 𝐥 i subscript 𝐥 𝑖\mathbf{l}_{i}bold_l start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT represents its corresponding ground truth labeling. The objective function for training the encoder-decoder neural network for CTC transcription is derived from Maximum Likelihood principles. The aim is to minimize this objective function to maximize the log-likelihoods of the ground truth labeling. Therefore, the objective function utilized is:
|
| 133 |
+
|
| 134 |
+
𝕆=−∑I i,𝐥 i∈S logp(𝐥 i|𝐲 i),𝕆 subscript subscript 𝐼 𝑖 subscript 𝐥 𝑖 𝑆 𝑝 conditional subscript 𝐥 𝑖 subscript 𝐲 𝑖\mathbb{O}=-\sum_{I_{i},\mathbf{l}_{i}\in S}\log p(\mathbf{l}_{i}|\mathbf{y}_{% i}),blackboard_O = - ∑ start_POSTSUBSCRIPT italic_I start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , bold_l start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ∈ italic_S end_POSTSUBSCRIPT roman_log italic_p ( bold_l start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT | bold_y start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) ,(4)
|
| 135 |
+
|
| 136 |
+
where 𝐲 i subscript 𝐲 𝑖\mathbf{y}_{i}bold_y start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT is the decoder output for the i th sample. The above objective function can be optimized using gradient descent and back-propagation.
|
| 137 |
+
|
| 138 |
+
### 5.3 Inference
|
| 139 |
+
|
| 140 |
+
During inference, the CTC-based classifier aims to output the labeling 𝐥∗superscript 𝐥\mathbf{l}^{*}bold_l start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT with the highest probability, as defined in Eq.([5](https://arxiv.org/html/2205.06740v2#S5.E5 "In 5.3 Inference ‣ 5 Text Recognition using CTC Transcription ‣ Towards Deployable OCR Models for Indic Languages")).
|
| 141 |
+
|
| 142 |
+
p(𝐥|𝐱)=∑π∈𝓑−1(𝐥)p(π|𝐱).𝑝 conditional 𝐥 𝐱 subscript 𝜋 superscript 𝓑 1 𝐥 𝑝 conditional 𝜋 𝐱 p(\mathbf{l}|\mathbf{x})=\sum_{\pi\in{\boldsymbol{\mathcal{B}}^{-1}(\mathbf{l}% )}}p(\pi|\mathbf{x}).italic_p ( bold_l | bold_x ) = ∑ start_POSTSUBSCRIPT italic_π ∈ bold_caligraphic_B start_POSTSUPERSCRIPT - 1 end_POSTSUPERSCRIPT ( bold_l ) end_POSTSUBSCRIPT italic_p ( italic_π | bold_x ) .(5)
|
| 143 |
+
|
| 144 |
+
6 Experimental Setup
|
| 145 |
+
--------------------
|
| 146 |
+
|
| 147 |
+
### 6.1 Implementation Details
|
| 148 |
+
|
| 149 |
+
In all experiments, cropped word or line images are resized to a height of 32 pixels and converted to grayscale, maintaining the original aspect ratio. To establish a validation split, we randomly select 5% of pages from each book in the train split for all languages. It ensures that the validation split reflects the pages in the train split while the test split comprises pages from different sets of books. In Win_RNN, the sliding window width W W subscript 𝑊 𝑊 W_{W}italic_W start_POSTSUBSCRIPT italic_W end_POSTSUBSCRIPT is set to 20 20 20 20, and the step size W S subscript 𝑊 𝑆 W_{S}italic_W start_POSTSUBSCRIPT italic_S end_POSTSUBSCRIPT is set to 5 5 5 5. For Col_RNN, Win_RNN, and CRNN, we utilize a bi-directional LSTM with 256 hidden units per direction across two layers, resulting in an output size of 2×256 2 256 2\times 256 2 × 256 at each time step. The CNN architecture in CNN_only and CRNN follows the original CRNN paper[[28](https://arxiv.org/html/2205.06740v2#bib.bib28)]. Our models are implemented using PyTorch[[21](https://arxiv.org/html/2205.06740v2#bib.bib21)]. We utilize an existing CRNN implementation[[14](https://arxiv.org/html/2205.06740v2#bib.bib14)] for our experiments, conducting training on a single Nvidia GeForce 1080 Ti GPU. Training is set for 30 epochs. Word recognition models have a batch size of 64, while line recognition models use a batch size of 16. RMSProp[[13](https://arxiv.org/html/2205.06740v2#bib.bib13)] is employed as the optimizer. Col_RNN and Win_RNN are assigned a learning rate of 10e−03 10 𝑒 03 10e-03 10 italic_e - 03, while CNN_only and CRNN variants converge faster with a lower learning rate of 10e−04 10 𝑒 04 10e-04 10 italic_e - 04.
|
| 150 |
+
|
| 151 |
+
### 6.2 Evaluation
|
| 152 |
+
|
| 153 |
+
We need to assess text recognition in three scenarios: (i) word OCR: recognizing cropped word images, (ii) line OCR: recognizing cropped line images, and (iii) page OCR: end-to-end text recognition from document images. Our main evaluation metric in all cases is Character Accuracy (CA), determined by the Levenshtein distance between predicted and ground truth strings. For a formal definition of CA, let us denote the predicted text for a word/line/page as l i subscript 𝑙 𝑖 l_{i}italic_l start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT and the corresponding ground truth as g i subscript 𝑔 𝑖 g_{i}italic_g start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT. If there are N 𝑁 N italic_N such samples, CA is defined as
|
| 154 |
+
|
| 155 |
+
CA=∑i len(g i)−∑i LD(l i,g i)∑i len(g i)×100,𝐶 𝐴 subscript 𝑖 𝑙 𝑒 𝑛 subscript 𝑔 𝑖 subscript 𝑖 𝐿 𝐷 subscript 𝑙 𝑖 subscript 𝑔 𝑖 subscript 𝑖 𝑙 𝑒 𝑛 subscript 𝑔 𝑖 100 CA=\frac{\sum_{i}len(g_{i})-\sum_{i}LD(l_{i},g_{i})}{\sum_{i}len(g_{i})}\times 1% 00,italic_C italic_A = divide start_ARG ∑ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT italic_l italic_e italic_n ( italic_g start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) - ∑ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT italic_L italic_D ( italic_l start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , italic_g start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) end_ARG start_ARG ∑ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT italic_l italic_e italic_n ( italic_g start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) end_ARG × 100 ,(6)
|
| 156 |
+
|
| 157 |
+
where len 𝑙 𝑒 𝑛 len italic_l italic_e italic_n is a function that returns the length of the given string, and LD 𝐿 𝐷 LD italic_L italic_D is a function that computes the Levenshtein distance between the given pair of strings. Note that Character Error Rate (CER), another commonly used metric for OCR evaluation, is essentially 100−CA 100 𝐶 𝐴 100-CA 100 - italic_C italic_A. We also include Sequence Accuracy (SA) alongside CA for word OCR and line OCR. SA represents the percentage of samples where the prediction is entirely correct (i.e., LD(l i,g i)=0 𝐿 𝐷 subscript 𝑙 𝑖 subscript 𝑔 𝑖 0 LD(l_{i},g_{i})=0 italic_L italic_D ( italic_l start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , italic_g start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) = 0). In the context of word recognition models, SA is equivalent to ’word accuracy’ and is commonly used in scene text recognition literature.
|
| 158 |
+
|
| 159 |
+
Language Word Recognition
|
| 160 |
+
Col_RNN Win_RNN CNN_only CRNN
|
| 161 |
+
CA SA CA SA CA SA CA SA
|
| 162 |
+
Assamese 98.6 95.4 97.6 92.9 98.3 96.0 99.0 96.5
|
| 163 |
+
Bengali 99.1 97.0 98.3 94.5 99.2 97.3 99.4 97.9
|
| 164 |
+
Guajrati 96.2 92.4 95.1 89.5 96.2 90.9 96.5 93.9
|
| 165 |
+
Hindi 97.6 95.1 96.3 92.3 97.4 94.2 98.2 96.3
|
| 166 |
+
Kannada 97.4 88.9 96.4 84.7 96.7 85.8 97.7 90.7
|
| 167 |
+
Malayalam 99.5 96.6 99.3 95.6 98.0 83.7 99.7 97.7
|
| 168 |
+
Manipuri 98.6 95.4 97.8 92.8 98.2 93.1 99.0 96.9
|
| 169 |
+
Marathi 99.0 96.2 98.5 94.2 98.9 95.0 99.2 96.9
|
| 170 |
+
Odia 96.8 93.5 95.7 90.8 96.9 93.7 97.2 94.8
|
| 171 |
+
Punjabi 99.1 97.7 98.4 96.4 99.2 97.8 99.5 98.7
|
| 172 |
+
Tamil 97.9 91.0 97.4 88.4 97.3 87.2 98.0 91.8
|
| 173 |
+
Telugu 96.3 91.4 95.3 86.8 96.4 92.0 96.8 93.6
|
| 174 |
+
Urdu--------
|
| 175 |
+
|
| 176 |
+
Table 2: Results for recognition-only tasks are presented for each language individually on validation set of Mozhi dataset. Each model configuration (Col_RNN, Win_RNN, CNN_only, and CRNN) is trained separately for each language. Character Accuracy (CA) and Sequence Accuracy (SA) are reported for word recognition. The highest CA and SA values among the four encoder configurations are highlighted in bold.
|
| 177 |
+
|
| 178 |
+
We employ a standard OCR evaluation toolkit for page OCR, where the input is a document image. Specifically, we utilize a modern adaptation[[27](https://arxiv.org/html/2205.06740v2#bib.bib27)] of the original ISRI Analytic Tools for OCR Evaluation[[23](https://arxiv.org/html/2205.06740v2#bib.bib23)]. Using this toolkit, we compute Character Accuracy (CA) and Word Accuracy (WA). CA is calculated following the method described in Eq.([6](https://arxiv.org/html/2205.06740v2#S6.E6 "In 6.2 Evaluation ‣ 6 Experimental Setup ‣ Towards Deployable OCR Models for Indic Languages")). Word accuracy is determined by aligning the sequences of words in the prediction l i subscript 𝑙 𝑖 l_{i}italic_l start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT with those in the ground truth g i subscript 𝑔 𝑖 g_{i}italic_g start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT and identifying the Longest Common Sub-sequence (LCS) between them. For a set of pages,
|
| 179 |
+
|
| 180 |
+
WA=∑i len(LCS(l i,g i))∑i len(g i)×100 𝑊 𝐴 subscript 𝑖 𝑙 𝑒 𝑛 𝐿 𝐶 𝑆 subscript 𝑙 𝑖 subscript 𝑔 𝑖 subscript 𝑖 𝑙 𝑒 𝑛 subscript 𝑔 𝑖 100 WA=\frac{\sum_{i}{len(LCS(l_{i},g_{i}))}}{\sum_{i}len(g_{i})}\times 100 italic_W italic_A = divide start_ARG ∑ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT italic_l italic_e italic_n ( italic_L italic_C italic_S ( italic_l start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , italic_g start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) ) end_ARG start_ARG ∑ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT italic_l italic_e italic_n ( italic_g start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) end_ARG × 100(7)
|
| 181 |
+
|
| 182 |
+
where len 𝑙 𝑒 𝑛 len italic_l italic_e italic_n returns the number of words in a given sequence of words.
|
| 183 |
+
|
| 184 |
+
7 Experiments and Results
|
| 185 |
+
-------------------------
|
| 186 |
+
|
| 187 |
+
### 7.1 Comparing Different Encoder Configurations
|
| 188 |
+
|
| 189 |
+
We assess the performance of four encoder configurations on the validation set of Mozhi dataset for word recognition. Results are presented in Table[2](https://arxiv.org/html/2205.06740v2#S6.T2 "Table 2 ‣ 6.2 Evaluation ‣ 6 Experimental Setup ‣ Towards Deployable OCR Models for Indic Languages"). Each CA and SA pair in the table corresponds to a CTC-based network trained separately for a specific combination of language, recognition unit (word), and encoder configuration (Col_RNN, Win_RNN, CNN_only, and CRNN). Across all cases except for Urdu word recognition, CRNN emerges as the top performer among the four configurations. The superior performance of CRNN over the CNN configuration highlights the necessity of capturing long-term dependencies in word or line images. Unlike fully connected networks, CNN layers have limited receptive fields, necessitating numerous layers to cover the entire input. Our seven-layer CNN lacks the depth to model extensive horizontal dependencies adequately. This deficiency is mitigated by employing a sequence encoder (bi-directional LSTM) that proficiently captures long-term dependencies in both directions.
|
| 190 |
+
|
| 191 |
+
Language Test
|
| 192 |
+
Word Line
|
| 193 |
+
CA SA CA SA
|
| 194 |
+
Assamese 98.9 96.2 99.2 76.8
|
| 195 |
+
Bengali 99.0 96.9 98.1 68.4
|
| 196 |
+
Gujarati 98.0 94.9 97.4 63.1
|
| 197 |
+
Hindi 98.1 95.5 98.8 63.5
|
| 198 |
+
Kannada 97.1 88.7 97.5 53.9
|
| 199 |
+
Malayalam 99.5 97.3 99.5 87.3
|
| 200 |
+
Manipuri 98.4 95.9 99.2 79.4
|
| 201 |
+
Marathi 99.3 97.0 99.3 73.8
|
| 202 |
+
Oriya 97.5 94.3 98.8 73.1
|
| 203 |
+
Punjabi 99.2 98.2 99.3 79.7
|
| 204 |
+
Tamil 98.0 91.6 98.3 68.1
|
| 205 |
+
Telugu 99.1 95.4 98.9 71.7
|
| 206 |
+
Urdu--93.8 24.2
|
| 207 |
+
|
| 208 |
+
Table 3: CRNN evaluation on test set of Mozhi dataset. For each language, we train both word and line level CRNN models on the respective train split of the Mozhi dataset.
|
| 209 |
+
|
| 210 |
+
Language End-to-End OCR GT Detection+CRNN
|
| 211 |
+
Tesseract Google GT word GT line
|
| 212 |
+
CA SA CA SA CA SA CA SA
|
| 213 |
+
Assamese 90.0 86.0 92.7 91.2 99.3 97.0 99.4 97.2
|
| 214 |
+
Bengali 91.3 84.0 96.2 93.5 99.1 97.3 99.0 96.8
|
| 215 |
+
Gujarati 96.9 92.4 95.2 93.0 98.0 93.7 97.7 91.9
|
| 216 |
+
Hindi 95.0 93.3 97.3 95.2 98.1 96.0 98.0 95.6
|
| 217 |
+
Kannada 85.7 84.6 94.9 85.1 95.6 89.2 95.9 86.4
|
| 218 |
+
Malayalam 88.0 74.8 96.2 89.7 99.4 98.0 99.3 97.9
|
| 219 |
+
Manipuri 85.7 77.4 90.9 84.6 98.4 94.7 98.7 94.9
|
| 220 |
+
Marathi 97.9 97.4 98.4 98.3 99.6 98.2 99.5 98.0
|
| 221 |
+
Oriya 94.0 83.6 92.6 90.0 98.6 95.4 98.0 94.5
|
| 222 |
+
Punjabi 93.2 89.8 96.7 92.7 99.2 98.3 99.3 97.9
|
| 223 |
+
Tamil 79.3 42.4 93.1 92.5 96.1 85.6 96.5 85.4
|
| 224 |
+
Telugu 93.7 79.3 94.2 89.2 99.1 95.1 98.9 94.0
|
| 225 |
+
Urdu 68.3 26.2 92.7 85.7--94.7 81.5
|
| 226 |
+
|
| 227 |
+
Table 4: Performance of our page OCR pipelines compared to other public OCR tools. In this setting, we evaluate text recognition in an end-to-end manner on the test split of our dataset. Since the focus of this work is on text recognition, for end-to-end settings, for text detection, gold standard word/line bounding boxes are used. Under ‘End-to-End OCR’ we show results of Tesseract[[2](https://arxiv.org/html/2205.06740v2#bib.bib2)] and Google Cloud Vision OCR[[9](https://arxiv.org/html/2205.06740v2#bib.bib9)]. Given a document image, these tools output a transcription of the page along with the bounding boxes of the lines and words detected. Under ‘GT Detection+CRNN’, we show results of an end-to-end pipeline where gold standard word and line detection are used. For instance, ’GT Word’ means we used ground truth (GT) word bounding boxes and the CRNN model trained for recognizing words, for that particular language. Bold value indicates the best result.
|
| 228 |
+
|
| 229 |
+
### 7.2 Evaluating CRNN on Test Set of Mozhi
|
| 230 |
+
|
| 231 |
+
Table[2](https://arxiv.org/html/2205.06740v2#S6.T2 "Table 2 ‣ 6.2 Evaluation ‣ 6 Experimental Setup ‣ Towards Deployable OCR Models for Indic Languages") highlights that among four different models — Col_RNN, Win_RNN, CNN_only, and RCNN, RCNN obtained the best results for all languages on validation set of Mozhi dataset with respect to CA and SA metrices for word recognition task. Since RCNN, highest performing model for validation set, we evaluated these models on test set of the same dataset. Table[3](https://arxiv.org/html/2205.06740v2#S7.T3 "Table 3 ‣ 7.1 Comparing Different Encoder Configurations ‣ 7 Experiments and Results ‣ Towards Deployable OCR Models for Indic Languages") presents obtained results for word and line recognition on test set.
|
| 232 |
+
|
| 233 |
+
### 7.3 Page Level OCR Evaluation
|
| 234 |
+
|
| 235 |
+
In page level OCR, the goal is to transcribe the text within a document image by segmenting it into lines or words and then recognizing the text at the word or line level. Our focus lies solely on text recognition, excluding layout analysis and reading order identification. To construct an end-to-end page OCR pipeline, we combine existing text detection methods with our CRNN models for recognition. Transcriptions from individual segments are arranged in the detected reading order. We evaluate the end-to-end pipeline by using gold standard detection to establish an upper bound on our CRNN model’s performance. Additionally, we compare our OCR results with two public OCR tools: Tesseract and Google Cloud Vision OCR. Results from all end-to-end evaluations are summarized in Table[4](https://arxiv.org/html/2205.06740v2#S7.T4 "Table 4 ‣ 7.1 Comparing Different Encoder Configurations ‣ 7 Experiments and Results ‣ Towards Deployable OCR Models for Indic Languages").
|
| 236 |
+
|
| 237 |
+

|
| 238 |
+
|
| 239 |
+
(a)(b)
|
| 240 |
+
|
| 241 |
+

|
| 242 |
+
|
| 243 |
+
(c)(d)(e)
|
| 244 |
+
|
| 245 |
+
Figure 6: Displays qualitative results at the page level using Tesseract, Google OCR, and our method on a Hindi document image. For optimal viewing, zoom in. (a) original document image, (b) ground truth textual transcription, (c) predicted text by Tesseract, (d) predicted text by Google OCR, and (e) predicted text by our approach.
|
| 246 |
+
|
| 247 |
+
In Fig.[6](https://arxiv.org/html/2205.06740v2#S7.F6 "Figure 6 ‣ 7.3 Page Level OCR Evaluation ‣ 7 Experiments and Results ‣ Towards Deployable OCR Models for Indic Languages"), visual results at the page level using Tesseract, Google OCR, and our approach are depicted. Panel (a) presents the original document image, while panels (b) to (e) display the ground truth and the predicted text by Tesseract, Google OCR, and our approach, respectively. Wrongly recognized texts are highlighted in red. This figure emphasizes that our approach outperforms existing OCR tools in producing accurate text outputs.
|
| 248 |
+
|
| 249 |
+
### 7.4 Use Cases
|
| 250 |
+
|
| 251 |
+
We leverage our OCR APIs for various significant applications. Notable examples include the pages of the Punjab Vidhan Sabha, Loksabha records, and Telugu Upanishads. These digitization efforts enable easier access, preservation, and analysis of these valuable texts. The output and effectiveness of our OCR technology in these diverse use cases are illustrated in Fig.[7](https://arxiv.org/html/2205.06740v2#S7.F7 "Figure 7 ‣ 7.4 Use Cases ‣ 7 Experiments and Results ‣ Towards Deployable OCR Models for Indic Languages"). These applications showcase the versatility and reliability of our OCR APIs in handling different scripts and document types, ensuring high accuracy and efficiency.
|
| 252 |
+
|
| 253 |
+

|
| 254 |
+
|
| 255 |
+
(a) (b)
|
| 256 |
+
|
| 257 |
+

|
| 258 |
+
|
| 259 |
+
(c) (d)
|
| 260 |
+
|
| 261 |
+
Figure 7: Illustrates use cases for the digitization of Loksabha records and Telugu Upanishad pages. (a) and (b) display cropped regions from the original images of Loksabha and Upanishad documents, respectively. Panels (c) and (d) present the corresponding text outputs generated using our OCR APIs.
|
| 262 |
+
|
| 263 |
+
### 7.5 Discussion
|
| 264 |
+
|
| 265 |
+
Our method performs better in page level recognition than Tesseract across all 13 languages, as evidenced by the results in Table[4](https://arxiv.org/html/2205.06740v2#S7.T4 "Table 4 ‣ 7.1 Comparing Different Encoder Configurations ‣ 7 Experiments and Results ‣ Towards Deployable OCR Models for Indic Languages"). Specifically, our approach surpasses Google for eight languages, as indicated in the same table when considering ground truth bounding boxes. However, our dataset predominantly comprises pages from books, resulting in limited font, style, layout, and distortion diversity. Nevertheless, this dataset can serve as valuable pre-training data. Moving forward, we aim to enrich the dataset by gathering diverse documents with varying layouts, content, fonts, styles, and distortions, enhancing its comprehensiveness and utility for developing robust recognition models.
|
| 266 |
+
|
| 267 |
+
8 Conclusions
|
| 268 |
+
-------------
|
| 269 |
+
|
| 270 |
+
We empirically study different CTC-based word and line recognition models in 13 Indian languages. Our study concludes that CRNN, which uses a CNN for feature representation and a dedicated RNN-based sequential encoder, works best. Using existing text detection tools and our recognition models, we build page level OCR pipeline and show that our approach works better than two popular OCR tools for most of the languages. We also introduce a new public Mozhi dataset for cropped word/line recognition in 13 Indian languages with more than 1.2 million annotated words. Additionally, we provide APIs for our page level OCR models and web-based applications that integrate these APIs to digitize Indic printed documents. We believe our study, the Mozhi dataset, and available APIs will encourage research on OCR of Indian languages.
|
| 271 |
+
|
| 272 |
+
Acknowledgment
|
| 273 |
+
--------------
|
| 274 |
+
|
| 275 |
+
This work is supported by MeitY, Government of India, through the NLTM-Bhashini project.
|
| 276 |
+
|
| 277 |
+
References
|
| 278 |
+
----------
|
| 279 |
+
|
| 280 |
+
* [1] Census 2011. [https://censusindia.gov.in/2011-Common/CensusData2011.Html](https://censusindia.gov.in/2011-Common/CensusData2011.Html), accessed on 1 November 2021
|
| 281 |
+
* [2] Tesseract (2021), [https://github.com/tesseract-ocr/tesseract](https://github.com/tesseract-ocr/tesseract), accessed on 20 November 2021
|
| 282 |
+
* [3] Adnan Ul-Hasan and Saad Bin Ahmed and Sheikh Faisal Rashid and Faisal Shafait and Thomas M. Breuel: Offline Printed Urdu Nastaleeq Script Recognition with Bidirectional LSTM Networks. In: ICDAR (2013)
|
| 283 |
+
* [4] Arya, D., Patnaik, T., Chaudhury, S., Jawahar, C.V., B.B.Chaudhuri, A.G.Ramakrishna, Bhagvati, C., Lehal, G.S.: Experiences of Integration and Performance Testing of Multilingual OCR for Printed Indian Scripts. In: J-MOCR Workshop,ICDAR (2011)
|
| 284 |
+
* [5] C. V. Jawahar, MNSSK Pavan Kumar and S. S. Ravikiran: A Bilingual OCR system for Hindi-Telugu Documents and its Applications. In: International Conference on Document Analysis and Recognition(ICDAR) (2003)
|
| 285 |
+
* [6] Chaudhuri, B.B., Pal, U.: A complete printed bangla ocr system. Pattern Recognition 31, 531–549 (1998)
|
| 286 |
+
* [7] Chavan, V., Malage, A., Mehrotra, K., Gupta, M.K.: Printed text recognition using blstm and mdlstm for indian languages. In: ICIIP (2017)
|
| 287 |
+
* [8] Dwivedi, A., Saluja, R., Sarvadevabhatla, R.K.: An ocr for classical indic documents containing arbitrarily long words. In: CVPR Workshops (2020)
|
| 288 |
+
* [9] Google: Google Cloud Vision OCR. [https://cloud.google.com/vision/docs/ocr](https://cloud.google.com/vision/docs/ocr) (2021), accessed on 10 November 2021
|
| 289 |
+
* [10] Graves, A., Fernández, S., Gomez, F.J., Schmidhuber, J.: Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In: ICML (2006)
|
| 290 |
+
* [11] Graves, A., Liwicki, M., Fernandez, S., Bertolami, R., Bunke, H., Schmidhuber, J.: A Novel Connectionist System for Unconstrained Handwriting Recognition. IEEE Trans. Pattern Anal. Mach. Intell. (2009)
|
| 291 |
+
* [12] Hannun, A.: Sequence modeling with ctc. Distill (2017). https://doi.org/10.23915/distill.00008, https://distill.pub/2017/ctc
|
| 292 |
+
* [13] Hinton: Neural Networks for Machine Learning, Lecture 6. [http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf](http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf) (2012), accessed on 10 November 2021
|
| 293 |
+
* [14] Holmeyoung: crnn-pytorch. [https://github.com/Holmeyoung/crnn-pytorch](https://github.com/Holmeyoung/crnn-pytorch) (2019), accessed on 3 February 2021
|
| 294 |
+
* [15] jaidedAI: Easyocr (2022), [https://github.com/JaidedAI/EasyOCR](https://github.com/JaidedAI/EasyOCR)
|
| 295 |
+
* [16] Jain, M., Mathew, M., Jawahar, C.V.: Unconstrained ocr for urdu using deep cnn-rnn hybrid networks. In: ACPR. p.6 (2017)
|
| 296 |
+
* [17] Krishnan, P., Sankaran, N., Singh, A.K., Jawahar, C.V.: Towards a robust OCR system for indic scripts. In: DAS (2014)
|
| 297 |
+
* [18] Kundaikar, T., Pawar, J.D.: Multi-font devanagari text recognition using lstm neural networks. In: ICCIGST (2020)
|
| 298 |
+
* [19] Mathew, M., Singh, A.K., Jawahar, C.V.: Multilingual OCR for indic scripts. In: DAS (2016)
|
| 299 |
+
* [20] ocropus: ocropy (2022), [https://github.com/ocropus/ocropy](https://github.com/ocropus/ocropy)
|
| 300 |
+
* [21] Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S.: Pytorch: An imperative style, high-performance deep learning library. In: NeurIPS (2019)
|
| 301 |
+
* [22] Paul, D., Chaudhuri, B.B.: A blstm network for printed bengali ocr system with high accuracy. ArXiv abs/1908.08674 (2019)
|
| 302 |
+
* [23] Rice, S.V., Nartker, T.A.: The isri analytic tools for ocr evaluation version 5.1. [https://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.216.9427](https://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.216.9427) (1996), accessed on 3 December 2021
|
| 303 |
+
* [24] Sanjeev Kunte, R., Sudhaker Samuel, R.: A simple and efficient optical character recognition system for basic symbols in printed kannada text. Sadhana 32(5) (2007)
|
| 304 |
+
* [25] Sankaran, N., Jawahar, C.V.: Devanagari Text Recognition:A Transcription Based Formulation. In: ICDAR (2013)
|
| 305 |
+
* [26] Sankaran, N., Jawahar, C.: Recognition of Printed Devanagari text using BLSTM neural network. In: ICPR (2012)
|
| 306 |
+
* [27] Santos, E.A.: OCR evaluation tools for the 21st century. In: Workshop on the Use of Computational Methods in the Study of Endangered Languages (2019)
|
| 307 |
+
* [28] Shi, B., Bai, X., Yao, C.: An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. CoRR (2015)
|
| 308 |
+
* [29] Sinha, R.M.K., Mahabala, H.: Machine recognition of devnagari script. In: IEEE Trans. on SMC (1979)
|
| 309 |
+
* [30] Su, B., Lu, S.: Accurate scene text recognition based on recurrent neural network. In: ACCV (2014)
|
| 310 |
+
* [31] Thomas M. Breuel and Adnan Ul-Hasan and Mayce Ibrahim Ali Al Azawi and Faisal Shafait: High-Performance OCR for Printed English and Fraktur Using LSTM Networks. In: ICDAR (2013)
|
| 311 |
+
* [32] Toni M. Rath and R. Manmatha: Features for Word Spotting in Historical Manuscripts. In: ICDAR (2003)
|