

Add 1 files
Browse files- 2404/2404.07525.md +469 -0
2404/2404.07525.md
ADDED
|
@@ -0,0 +1,469 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
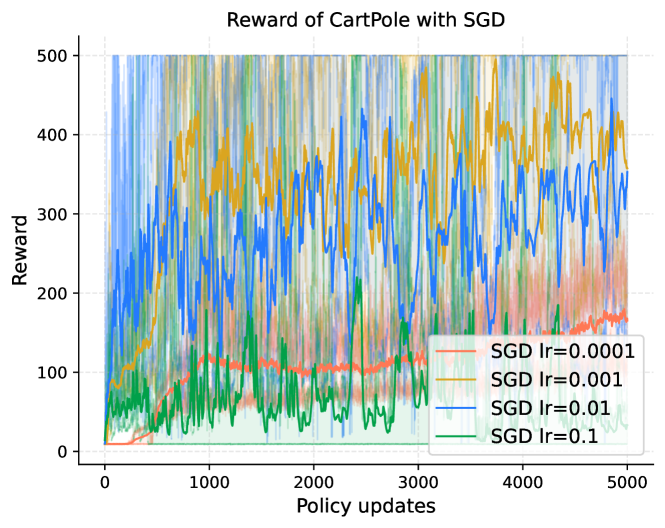
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
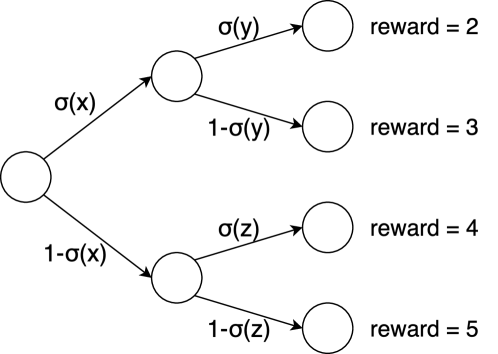
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
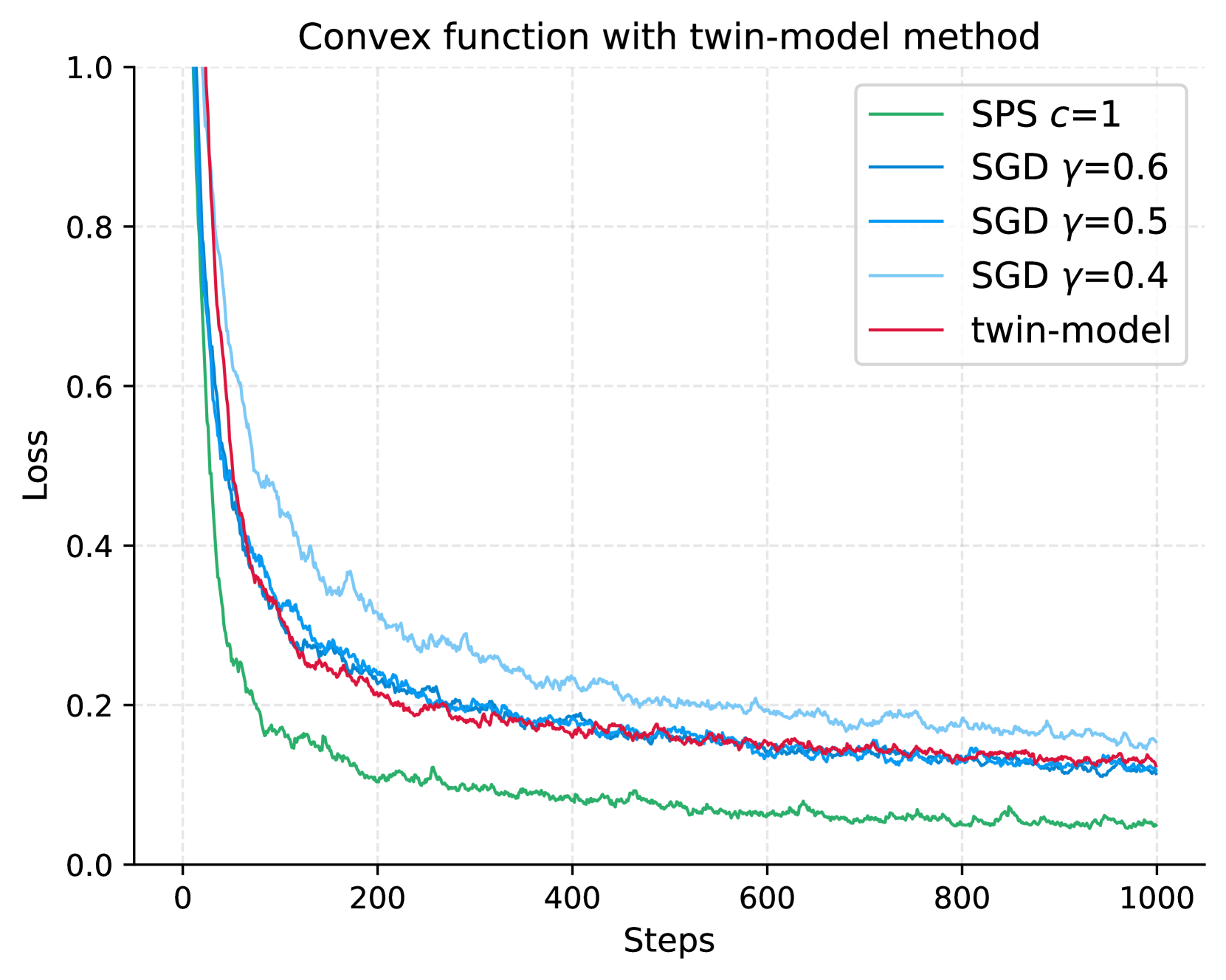
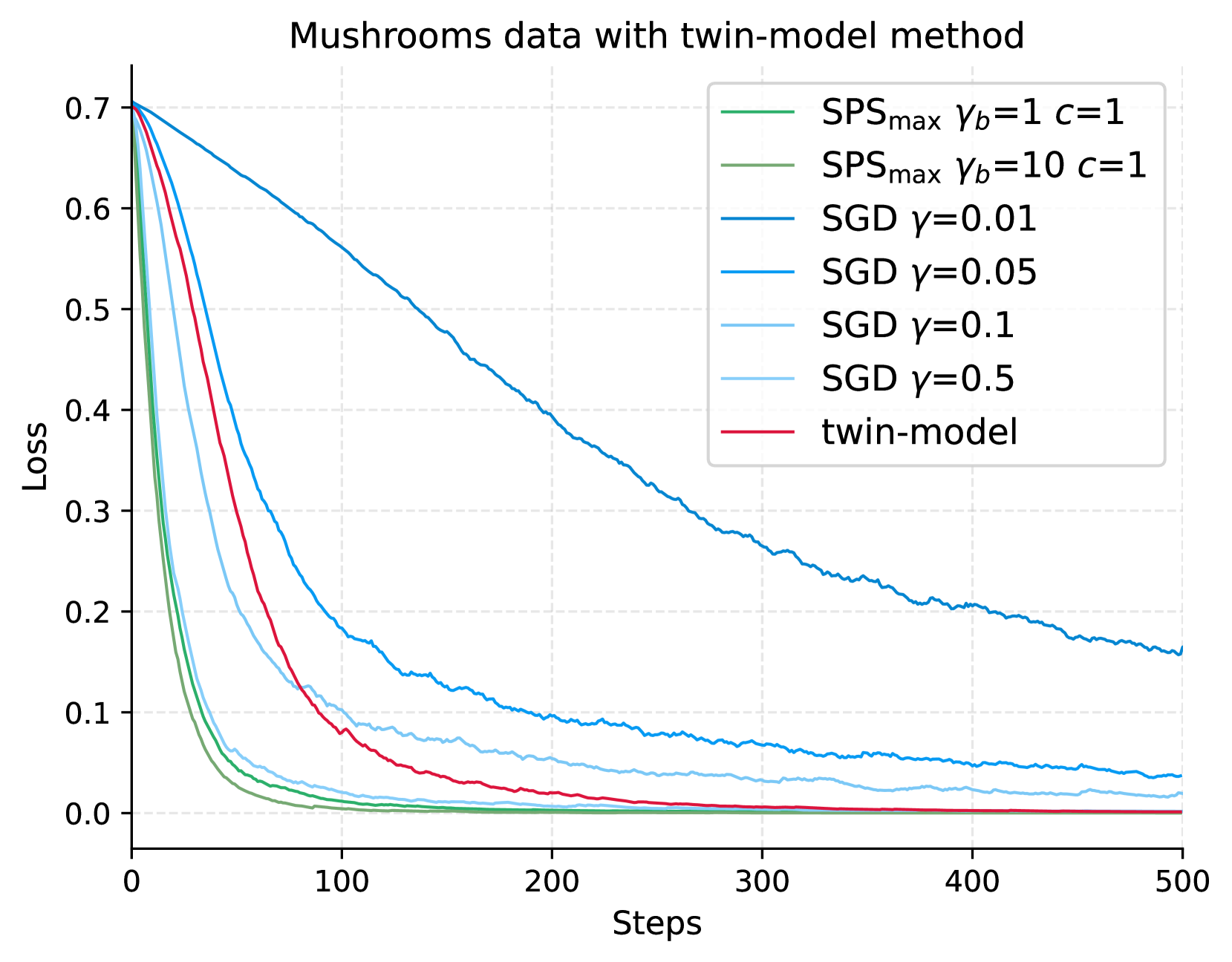
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Enhancing Policy Gradient with the Polyak Step-Size Adaption
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2404.07525
|
| 4 |
+
|
| 5 |
+
Published Time: Fri, 12 Apr 2024 00:24:45 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
\AtBeginEnvironment
|
| 9 |
+
|
| 10 |
+
algorithmic
|
| 11 |
+
|
| 12 |
+
Yunxiang Li
|
| 13 |
+
|
| 14 |
+
yunxiang.li@mbzuai.ac.ae
|
| 15 |
+
|
| 16 |
+
&Rui Yuan
|
| 17 |
+
|
| 18 |
+
rui.yuan@stellantis.com &Chen Fan
|
| 19 |
+
|
| 20 |
+
fanchen3@outlook.com
|
| 21 |
+
|
| 22 |
+
&Mark Schmidt
|
| 23 |
+
|
| 24 |
+
schmidtm@cs.ubc.ca
|
| 25 |
+
|
| 26 |
+
&Samuel Horváth
|
| 27 |
+
|
| 28 |
+
samuel.horvath@mbzuai.ac.ae
|
| 29 |
+
|
| 30 |
+
&Robert M. Gower
|
| 31 |
+
|
| 32 |
+
gowerrobert@gmail.com
|
| 33 |
+
|
| 34 |
+
&Martin Takáč
|
| 35 |
+
|
| 36 |
+
martin.takac@mbzuai.ac.ae
|
| 37 |
+
|
| 38 |
+
###### Abstract
|
| 39 |
+
|
| 40 |
+
Policy gradient is a widely utilized and foundational algorithm in the field of reinforcement learning (RL). Renowned for its convergence guarantees and stability compared to other RL algorithms, its practical application is often hindered by sensitivity to hyper-parameters, particularly the step-size. In this paper, we introduce the integration of the Polyak step-size in RL, which automatically adjusts the step-size without prior knowledge. To adapt this method to RL settings, we address several issues, including unknown f*superscript 𝑓 f^{*}italic_f start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT in the Polyak step-size. Additionally, we showcase the performance of the Polyak step-size in RL through experiments, demonstrating faster convergence and the attainment of more stable policies.
|
| 41 |
+
|
| 42 |
+
1 Introduction
|
| 43 |
+
--------------
|
| 44 |
+
|
| 45 |
+
The policy gradient serves as an essential algorithm in various cutting-edge reinforcement learning (RL) techniques, such as natural policy gradient (NPG), TD3, and SAC (Kakade, [2001](https://arxiv.org/html/2404.07525v1#bib.bib13); Fujimoto et al., [2018](https://arxiv.org/html/2404.07525v1#bib.bib9); Haarnoja et al., [2018](https://arxiv.org/html/2404.07525v1#bib.bib10)). Such method computes the gradient for the policy performance measurement and applies gradient ascent to enhance performance. Recognized for its outstanding performance in control tasks and convergence guarantees, the policy gradient has garnered considerable attention. However, similar to many RL algorithms, it exhibits a high sensitivity to hyper-parameters (Eimer et al., [2023](https://arxiv.org/html/2404.07525v1#bib.bib8)). The challenge is exacerbated by the time-consuming nature of hyper-parameter tuning, particularly in large-scale tasks.
|
| 46 |
+
|
| 47 |
+
In this paper, our focus lies on the step-size (or learning rate) in policy gradient, a parameter that significantly influences algorithm performance (Eimer et al., [2023](https://arxiv.org/html/2404.07525v1#bib.bib8)). Moreover, given the variation in reward scales and landscapes across different tasks (Bekci & Gümüs, [2020](https://arxiv.org/html/2404.07525v1#bib.bib5)), fine-tuning learning parameters from one task for application in another is impractical. Instead, the optimal step-size needs to be determined independently for each task. Traditionally, the prevailing approach for selecting a step-size involves evaluating a range of plausible values and choosing a fixed value that leads to the fastest convergence to the optimal solution. However, this method is computationally expensive. An alternative practical choice is the use of diminishing step sizes, which may offer improved convergence speed and sample efficiency empirically. Nevertheless, the effectiveness of this approach relies heavily on intuition and experience. Similar to fixed step-sizes, determining good practices for one environment is challenging when transferred to another environment. We illustrate the impact of step-size on performance and sample efficiency with Adam (Kingma & Ba, [2015](https://arxiv.org/html/2404.07525v1#bib.bib14)) and stochastic gradient descent (SGD) in Figure [1](https://arxiv.org/html/2404.07525v1#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption"). Notably, with Adam, a larger step-size reaches the local optimum faster, while a smaller step-size leads to a stable policy over time. With SGD, achieving both stability and an optimal policy is shown to be more challenging.
|
| 48 |
+
|
| 49 |
+

|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
Figure 1: The performance of Adam and SGD with various step-sizes evaluated on the CartPole environment Brockman et al. ([2016](https://arxiv.org/html/2404.07525v1#bib.bib6)). The evaluation is averaged across three unique random seeds, distinct from the training seeds. The reported evaluation rewards are presented as a moving average due to oscillations.
|
| 54 |
+
|
| 55 |
+
To address this challenge, we propose an adaptive step-size method for policy gradient. Drawing inspiration from the Polyak step-size concept (Polyak, [1987](https://arxiv.org/html/2404.07525v1#bib.bib23)), we tailor it for application in policy gradient, especially stochastic update. Unlike traditional approaches with sensitive step-sizes, our method computes the step-size for each policy update step using robust hyper-parameters. We validate the effectiveness of our approach through numerical experiments and showcase its performance compared to the widely used Adam algorithm (Kingma & Ba, [2015](https://arxiv.org/html/2404.07525v1#bib.bib14)). The key contributions of our work are outlined below:
|
| 56 |
+
|
| 57 |
+
* •Adoption of the Polyak Step-Size Idea: We integrate the Polyak step-size concept into the policy gradient framework, eliminating the need for sensitive step-size fine-tuning by employing robust hyper-parameters.
|
| 58 |
+
* •Investigation and Resolution of Issues: We systematically investigate and address the challenges associated with applying Polyak step-size to policy gradient, ensuring its practicality and effectiveness.
|
| 59 |
+
* •Demonstrated Performance: Through experiments, we provide empirical evidence that our proposed method outperforms alternative approaches, showcasing its efficacy in RL tasks. Our method excels in terms of faster convergence, enhanced sample efficiency, and the maintenance of a stable policy.
|
| 60 |
+
|
| 61 |
+
2 Related work
|
| 62 |
+
--------------
|
| 63 |
+
|
| 64 |
+
In response to the success of SGD and its central dependency on step-size for convergence, numerous works have focused on optimizing this parameter. The Stochastic Polyak Step-size (Loizou et al., [2021](https://arxiv.org/html/2404.07525v1#bib.bib16), SPS) and Stochastic Line-Search (Vaswani et al., [2019](https://arxiv.org/html/2404.07525v1#bib.bib27), SLS) introduced Polyak step-size and line-search for interpolation tasks, inspiring various subsequent variants. Noteworthy contributions include Vaswani et al. ([2022](https://arxiv.org/html/2404.07525v1#bib.bib28))’s validation of an exponentially decreasing step-size with SLS, adapting well to noise and problem-dependent constants. Orvieto et al. ([2022](https://arxiv.org/html/2404.07525v1#bib.bib19)) extended SPS to non-over-parameterized. Jiang & Stich ([2023](https://arxiv.org/html/2404.07525v1#bib.bib12)) further solved the problems in non-interpolation settings and guaranteed the convergence rate. Schaipp et al. ([2023](https://arxiv.org/html/2404.07525v1#bib.bib25)) proposed momentum-based adaptive learning rates.
|
| 65 |
+
|
| 66 |
+
While the step-size plays a crucial role in determining the performance and reproducibility of RL algorithms, only a limited number of works have addressed the challenge of sensitive step-size tuning in RL. Matsubara et al. ([2010](https://arxiv.org/html/2404.07525v1#bib.bib17)) extended the metric in natural policy gradient (NPG) and introduced the Average reward metric Policy Gradient method (APG). NPG measures the impact on the action probability distribution concerning the policy parameters, while APG introduces an average reward metric with a Riemannian metric, directly evaluating the effect on the average reward of policy improvement. The authors present two algorithms incorporating the average reward metric as a constraint. Pirotta et al. ([2013](https://arxiv.org/html/2404.07525v1#bib.bib22)) derived a lower bound for the performance difference in the context of full-batch policy gradient, demonstrating a fourth-order polynomial relationship with the step-size. They extend their analysis to Gaussian policies, providing a quadratic form of the step-size in the lower bound. By obtaining a closed form for the maximum, they ensure monotonic improvement in each iteration. Additionally, they offer a simplified version that guarantees improvement with high probability using sample trajectories. Dabney & Barto ([2012](https://arxiv.org/html/2404.07525v1#bib.bib7)) investigated step-size in the temporal difference learning problem with linear approximation. They derived an adaptive tight upper bound for the optimal step-size and presented a heuristic step-size computation method with efficient computation and storage. In contrast to manual tuning, Eimer et al. ([2023](https://arxiv.org/html/2404.07525v1#bib.bib8)) conducted a comprehensive study across state-of-the-art hyper-parameter optimization techniques, and provided easy-to-use implementations for practical use, while it requires the knowledge of problem-dependent constants.
|
| 67 |
+
|
| 68 |
+
Despite the great ideas in previous work, our contribution not only provides adaptive learning rates across various tasks without requiring the knowledge of any problem-dependent constants, but also showcases better convergence speed. In experiments, we observe that our step-size is larger than the typically used constant step-size with Adam. Unlike previous pure theory works, our conducted experiments serve to validate and ensure the reproducibility of our findings.
|
| 69 |
+
|
| 70 |
+
3 Preliminaries
|
| 71 |
+
---------------
|
| 72 |
+
|
| 73 |
+
Let ℳ=(𝒮,𝒜,ρ,P,r,γ)ℳ 𝒮 𝒜 𝜌 𝑃 𝑟 𝛾\mathcal{M}=(\mathcal{S},\mathcal{A},\rho,P,r,\gamma)caligraphic_M = ( caligraphic_S , caligraphic_A , italic_ρ , italic_P , italic_r , italic_γ ) represent a discounted Markov Decision Process (MDP) (Puterman, [1994](https://arxiv.org/html/2404.07525v1#bib.bib24)) with state space 𝒮 𝒮\mathcal{S}caligraphic_S, action space 𝒜 𝒜\mathcal{A}caligraphic_A, initial state distribution ρ 𝜌\rho italic_ρ, transition probability function P(s′∣s,a):𝒮×𝒜×𝒮→[0,1]:𝑃 conditional superscript 𝑠′𝑠 𝑎→𝒮 𝒜 𝒮 0 1 P(s^{\prime}\mid s,a):\mathcal{S}\times\mathcal{A}\times\mathcal{S}\rightarrow% [0,1]italic_P ( italic_s start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT ∣ italic_s , italic_a ) : caligraphic_S × caligraphic_A × caligraphic_S → [ 0 , 1 ], reward function r:𝒮×𝒜→ℝ:𝑟→𝒮 𝒜 ℝ r:\mathcal{S}\times\mathcal{A}\rightarrow\mathbb{R}italic_r : caligraphic_S × caligraphic_A → blackboard_R, and discounted factor γ∈[0,1]𝛾 0 1\gamma\in[0,1]italic_γ ∈ [ 0 , 1 ]. A policy on an MDP is defined as a mapping function π∈Δ(𝒜)𝒮 𝜋 Δ superscript 𝒜 𝒮\pi\in\Delta(\mathcal{A})^{\mathcal{S}}italic_π ∈ roman_Δ ( caligraphic_A ) start_POSTSUPERSCRIPT caligraphic_S end_POSTSUPERSCRIPT. A trajectory, denoted as τ=(s 0,a 0,r 0,s 1,a 1,r 1,…)𝜏 subscript 𝑠 0 subscript 𝑎 0 subscript 𝑟 0 subscript 𝑠 1 subscript 𝑎 1 subscript 𝑟 1…\tau=(s_{0},a_{0},r_{0},s_{1},a_{1},r_{1},\dots)italic_τ = ( italic_s start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT , italic_a start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT , italic_r start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT , italic_s start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_a start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_r start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , … ), is generated by following the transition function, the reward function, and the policy, with r t=r(s t,a t)subscript 𝑟 𝑡 𝑟 subscript 𝑠 𝑡 subscript 𝑎 𝑡 r_{t}=r(s_{t},a_{t})italic_r start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT = italic_r ( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ).
|
| 74 |
+
|
| 75 |
+
Given a policy π 𝜋\pi italic_π, let V π:𝒮→ℝ:superscript 𝑉 𝜋→𝒮 ℝ V^{\pi}:\mathcal{S}\rightarrow\mathbb{R}italic_V start_POSTSUPERSCRIPT italic_π end_POSTSUPERSCRIPT : caligraphic_S → blackboard_R denote the value function of state s 𝑠 s italic_s defined as
|
| 76 |
+
|
| 77 |
+
V π(s)=∫τ P(τ∣s 0=s)R(τ)𝑑 τ=𝔼 τ[∑t=0∞γ tr t∣s 0=s],superscript 𝑉 𝜋 𝑠 subscript 𝜏 𝑃 conditional 𝜏 subscript 𝑠 0 𝑠 𝑅 𝜏 differential-d 𝜏 subscript 𝔼 𝜏 delimited-[]conditional superscript subscript 𝑡 0 superscript 𝛾 𝑡 subscript 𝑟 𝑡 subscript 𝑠 0 𝑠\displaystyle V^{\pi}(s)=\int_{\tau}P(\tau\mid s_{0}=s)R(\tau)d\tau=\mathbb{E}% _{\tau}\left[\sum_{t=0}^{\infty}\gamma^{t}r_{t}\mid s_{0}=s\right],italic_V start_POSTSUPERSCRIPT italic_π end_POSTSUPERSCRIPT ( italic_s ) = ∫ start_POSTSUBSCRIPT italic_τ end_POSTSUBSCRIPT italic_P ( italic_τ ∣ italic_s start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT = italic_s ) italic_R ( italic_τ ) italic_d italic_τ = blackboard_E start_POSTSUBSCRIPT italic_τ end_POSTSUBSCRIPT [ ∑ start_POSTSUBSCRIPT italic_t = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∞ end_POSTSUPERSCRIPT italic_γ start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT italic_r start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ∣ italic_s start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT = italic_s ] ,
|
| 78 |
+
|
| 79 |
+
where P(τ∣s 0=s)=ρ(s)∏t=0∞π(a t∣s t)P(s t+1∣s t,a t)𝑃 conditional 𝜏 subscript 𝑠 0 𝑠 𝜌 𝑠 superscript subscript product 𝑡 0 𝜋 conditional subscript 𝑎 𝑡 subscript 𝑠 𝑡 𝑃 conditional subscript 𝑠 𝑡 1 subscript 𝑠 𝑡 subscript 𝑎 𝑡 P(\tau\mid s_{0}=s)=\rho(s)\prod_{t=0}^{\infty}\pi(a_{t}\mid s_{t})P(s_{t+1}% \mid s_{t},a_{t})italic_P ( italic_τ ∣ italic_s start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT = italic_s ) = italic_ρ ( italic_s ) ∏ start_POSTSUBSCRIPT italic_t = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∞ end_POSTSUPERSCRIPT italic_π ( italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ∣ italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) italic_P ( italic_s start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT ∣ italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) represents the probability of the trajectory following the transition function, the reward function, and the policy, R(τ)=∑t=0∞γ tr t 𝑅 𝜏 superscript subscript 𝑡 0 superscript 𝛾 𝑡 subscript 𝑟 𝑡 R(\tau)=\sum_{t=0}^{\infty}\gamma^{t}r_{t}italic_R ( italic_τ ) = ∑ start_POSTSUBSCRIPT italic_t = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∞ end_POSTSUPERSCRIPT italic_γ start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT italic_r start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT is the discounted sum of rewards in the trajectory τ 𝜏\tau italic_τ.
|
| 80 |
+
|
| 81 |
+
Given the starting state distribution ρ 𝜌\rho italic_ρ, our objective is to find a policy that maximizes the objective function
|
| 82 |
+
|
| 83 |
+
V π(ρ)=𝔼 s∼ρ(s)[V π(s)].superscript 𝑉 𝜋 𝜌 subscript 𝔼 similar-to 𝑠 𝜌 𝑠 delimited-[]superscript 𝑉 𝜋 𝑠 V^{\pi}(\rho)=\mathbb{E}_{s\sim\rho(s)}\left[V^{\pi}(s)\right].italic_V start_POSTSUPERSCRIPT italic_π end_POSTSUPERSCRIPT ( italic_ρ ) = blackboard_E start_POSTSUBSCRIPT italic_s ∼ italic_ρ ( italic_s ) end_POSTSUBSCRIPT [ italic_V start_POSTSUPERSCRIPT italic_π end_POSTSUPERSCRIPT ( italic_s ) ] .
|
| 84 |
+
|
| 85 |
+
In policy optimization, we also employ the useful definition of the Q 𝑄 Q italic_Q value for a state-action pair (s,a)∈𝒮×𝒜 𝑠 𝑎 𝒮 𝒜(s,a)\in\mathcal{S}\times\mathcal{A}( italic_s , italic_a ) ∈ caligraphic_S × caligraphic_A, defined as
|
| 86 |
+
|
| 87 |
+
Q π(s,a)=𝔼 τ[∑t=0∞γ tr(s t,a t)∣s 0=s,a 0=a].superscript 𝑄 𝜋 𝑠 𝑎 subscript 𝔼 𝜏 delimited-[]formulae-sequence conditional superscript subscript 𝑡 0 superscript 𝛾 𝑡 𝑟 subscript 𝑠 𝑡 subscript 𝑎 𝑡 subscript 𝑠 0 𝑠 subscript 𝑎 0 𝑎 Q^{\pi}(s,a)=\mathbb{E}_{\tau}\left[\sum_{t=0}^{\infty}\gamma^{t}r(s_{t},a_{t}% )\mid s_{0}=s,a_{0}=a\right].italic_Q start_POSTSUPERSCRIPT italic_π end_POSTSUPERSCRIPT ( italic_s , italic_a ) = blackboard_E start_POSTSUBSCRIPT italic_τ end_POSTSUBSCRIPT [ ∑ start_POSTSUBSCRIPT italic_t = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∞ end_POSTSUPERSCRIPT italic_γ start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT italic_r ( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) ∣ italic_s start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT = italic_s , italic_a start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT = italic_a ] .
|
| 88 |
+
|
| 89 |
+
In practice, we use model parameter θ 𝜃\theta italic_θ to define the policy π θ superscript 𝜋 𝜃\pi^{\theta}italic_π start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT. In this paper, we analyze policies with softmax parametrizations. For simplicity, we omit π 𝜋\pi italic_π in the notations and use θ 𝜃\theta italic_θ, namely, V θ(s),V θ(ρ),Q θ(s,a)superscript 𝑉 𝜃 𝑠 superscript 𝑉 𝜃 𝜌 superscript 𝑄 𝜃 𝑠 𝑎 V^{\theta}(s),V^{\theta}(\rho),Q^{\theta}(s,a)italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ( italic_s ) , italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ( italic_ρ ) , italic_Q start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ( italic_s , italic_a ). The gradient with respect to the model parameter θ 𝜃\theta italic_θ is
|
| 90 |
+
|
| 91 |
+
∇θ V θ(ρ)=∫s ρ(s)∫τ∇θ P(τ∣s 0=s)R(τ)𝑑 τ𝑑 s.subscript∇𝜃 superscript 𝑉 𝜃 𝜌 subscript 𝑠 𝜌 𝑠 subscript 𝜏 subscript∇𝜃 𝑃 conditional 𝜏 subscript 𝑠 0 𝑠 𝑅 𝜏 differential-d 𝜏 differential-d 𝑠\nabla_{\theta}V^{\theta}(\rho)=\int_{s}\rho(s)\int_{\tau}\nabla_{\theta}P(% \tau\mid s_{0}=s)R(\tau)d\tau ds.∇ start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ( italic_ρ ) = ∫ start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT italic_ρ ( italic_s ) ∫ start_POSTSUBSCRIPT italic_τ end_POSTSUBSCRIPT ∇ start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT italic_P ( italic_τ ∣ italic_s start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT = italic_s ) italic_R ( italic_τ ) italic_d italic_τ italic_d italic_s .(1)
|
| 92 |
+
|
| 93 |
+
Then we update the parameters θ 𝜃\theta italic_θ with the gradient
|
| 94 |
+
|
| 95 |
+
θ t+1=θ t+η t∇θ t V θ t(ρ)subscript 𝜃 𝑡 1 subscript 𝜃 𝑡 subscript 𝜂 𝑡 subscript∇subscript 𝜃 𝑡 superscript 𝑉 subscript 𝜃 𝑡 𝜌\theta_{t+1}=\theta_{t}+\eta_{t}\nabla_{\theta_{t}}V^{\theta_{t}}(\rho)italic_θ start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT = italic_θ start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT + italic_η start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ∇ start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT end_POSTSUBSCRIPT italic_V start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT end_POSTSUPERSCRIPT ( italic_ρ )
|
| 96 |
+
|
| 97 |
+
to maximize the objective function. To avoid symbol conflict, we use η t subscript 𝜂 𝑡\eta_{t}italic_η start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT to represent the step size at time t 𝑡 t italic_t. This general schema is called policy gradient (Williams, [1992](https://arxiv.org/html/2404.07525v1#bib.bib29); Sutton & Barto, [1998](https://arxiv.org/html/2404.07525v1#bib.bib26)).
|
| 98 |
+
|
| 99 |
+
### 3.1 GPOMDP
|
| 100 |
+
|
| 101 |
+
To handle the unknown transition function and intractable trajectories in the objective function and the gradient, a common approach is to sample trajectories and estimate. Specifically, for an estimate value function V^θ superscript^𝑉 𝜃\hat{V}^{\theta}over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT, we simulate m 𝑚 m italic_m truncated trajectories τ i=(s 0 i,a 0 i,r 0 i,s 1 i,⋯,s H−1 i,a H−1 i,r H−1 i)subscript 𝜏 𝑖 superscript subscript 𝑠 0 𝑖 superscript subscript 𝑎 0 𝑖 superscript subscript 𝑟 0 𝑖 superscript subscript 𝑠 1 𝑖⋯superscript subscript 𝑠 𝐻 1 𝑖 superscript subscript 𝑎 𝐻 1 𝑖 superscript subscript 𝑟 𝐻 1 𝑖\tau_{i}=\left(s_{0}^{i},a_{0}^{i},r_{0}^{i},s_{1}^{i},\cdots,s_{H-1}^{i},a_{H% -1}^{i},r_{H-1}^{i}\right)italic_τ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = ( italic_s start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT , italic_a start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT , italic_r start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT , italic_s start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT , ⋯ , italic_s start_POSTSUBSCRIPT italic_H - 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT , italic_a start_POSTSUBSCRIPT italic_H - 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT , italic_r start_POSTSUBSCRIPT italic_H - 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT ) with r t i=r(s t i,a t i)subscript superscript 𝑟 𝑖 𝑡 𝑟 superscript subscript 𝑠 𝑡 𝑖 superscript subscript 𝑎 𝑡 𝑖 r^{i}_{t}=r(s_{t}^{i},a_{t}^{i})italic_r start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT = italic_r ( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT , italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT ), and with horizon H 𝐻 H italic_H using the defined policy and compute the discounted sum of rewards. Baxter & Bartlett ([2001](https://arxiv.org/html/2404.07525v1#bib.bib4)) extended score function or likelihood ratio method ([1](https://arxiv.org/html/2404.07525v1#S3.E1 "1 ‣ 3 Preliminaries ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption")) (Williams, [1992](https://arxiv.org/html/2404.07525v1#bib.bib29), REINFORCE) and introduced GPOMDP, generating the estimate of the gradient of the parameterized stochastic policies:
|
| 102 |
+
|
| 103 |
+
∇^θV θ(ρ)=1 m∑i=1 m∑t=0 H−1(∑t′=0 t∇logπ θ(a t′i∣s t′i))γ tr t i.subscript^∇𝜃 superscript 𝑉 𝜃 𝜌 1 𝑚 superscript subscript 𝑖 1 𝑚 superscript subscript 𝑡 0 𝐻 1 superscript subscript superscript 𝑡′0 𝑡∇superscript 𝜋 𝜃 conditional superscript subscript 𝑎 superscript 𝑡′𝑖 superscript subscript 𝑠 superscript 𝑡′𝑖 superscript 𝛾 𝑡 subscript superscript 𝑟 𝑖 𝑡\widehat{\nabla}_{\theta}V^{\theta}(\rho)\;=\;\frac{1}{m}\sum_{i=1}^{m}\sum_{t% =0}^{H-1}\left(\sum_{t^{\prime}=0}^{t}\nabla\log\pi^{\theta}(a_{t^{\prime}}^{i% }\mid s_{t^{\prime}}^{i})\right)\gamma^{t}r^{i}_{t}.over^ start_ARG ∇ end_ARG start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ( italic_ρ ) = divide start_ARG 1 end_ARG start_ARG italic_m end_ARG ∑ start_POSTSUBSCRIPT italic_i = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT ∑ start_POSTSUBSCRIPT italic_t = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_H - 1 end_POSTSUPERSCRIPT ( ∑ start_POSTSUBSCRIPT italic_t start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT ∇ roman_log italic_π start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ( italic_a start_POSTSUBSCRIPT italic_t start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT ∣ italic_s start_POSTSUBSCRIPT italic_t start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT ) ) italic_γ start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT italic_r start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT .
|
| 104 |
+
|
| 105 |
+
### 3.2 The Polyak step-size
|
| 106 |
+
|
| 107 |
+
We first introduce the Polyak step-size (Polyak, [1987](https://arxiv.org/html/2404.07525v1#bib.bib23)) within the optimization context, specifically when optimizing a finite-sum function f(x)=1 n∑i=1 n f i(x)𝑓 𝑥 1 𝑛 superscript subscript 𝑖 1 𝑛 subscript 𝑓 𝑖 𝑥 f(x)=\frac{1}{n}\sum_{i=1}^{n}f_{i}(x)italic_f ( italic_x ) = divide start_ARG 1 end_ARG start_ARG italic_n end_ARG ∑ start_POSTSUBSCRIPT italic_i = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ( italic_x ). The objective is to minimize f(x)𝑓 𝑥 f(x)italic_f ( italic_x ) with the model parameter x 𝑥 x italic_x. We denote x*superscript 𝑥 x^{*}italic_x start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT as the optimal point and f*superscript 𝑓 f^{*}italic_f start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT as the minimum value of f 𝑓 f italic_f. This optimization problem can be addressed using gradient descent (GD) or SGD:
|
| 108 |
+
|
| 109 |
+
x k+1 superscript 𝑥 𝑘 1\displaystyle x^{k+1}italic_x start_POSTSUPERSCRIPT italic_k + 1 end_POSTSUPERSCRIPT=x k−γ k∇f(x k),absent superscript 𝑥 𝑘 subscript 𝛾 𝑘∇𝑓 superscript 𝑥 𝑘\displaystyle=x^{k}-\gamma_{k}\nabla f(x^{k}),= italic_x start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT - italic_γ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT ∇ italic_f ( italic_x start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) ,(GD)
|
| 110 |
+
x k+1 superscript 𝑥 𝑘 1\displaystyle x^{k+1}italic_x start_POSTSUPERSCRIPT italic_k + 1 end_POSTSUPERSCRIPT=x k−γ k∇f i(x k),absent superscript 𝑥 𝑘 subscript 𝛾 𝑘∇subscript 𝑓 𝑖 superscript 𝑥 𝑘\displaystyle=x^{k}-\gamma_{k}\nabla f_{i}(x^{k}),= italic_x start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT - italic_γ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT ∇ italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ( italic_x start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) ,(SGD)
|
| 111 |
+
|
| 112 |
+
where γ k>0 subscript 𝛾 𝑘 0\gamma_{k}>0 italic_γ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT > 0 is the step-size at iteration k 𝑘 k italic_k.
|
| 113 |
+
|
| 114 |
+
The classic Polyak step-size is defined as
|
| 115 |
+
|
| 116 |
+
γ k=f(x k)−f*‖∇f k‖2,subscript 𝛾 𝑘 𝑓 superscript 𝑥 𝑘 superscript 𝑓 superscript norm∇superscript 𝑓 𝑘 2\gamma_{k}=\frac{f(x^{k})-f^{*}}{\|\nabla f^{k}\|^{2}},italic_γ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT = divide start_ARG italic_f ( italic_x start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) - italic_f start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT end_ARG start_ARG ∥ ∇ italic_f start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG ,
|
| 117 |
+
|
| 118 |
+
which minimizes the following upper bound Q(γ)=‖x k−x*‖2−2γ[f(x k)−f*]+γ 2‖∇f(x k)‖2 𝑄 𝛾 superscript norm superscript 𝑥 𝑘 superscript 𝑥 2 2 𝛾 delimited-[]𝑓 superscript 𝑥 𝑘 superscript 𝑓 superscript 𝛾 2 superscript norm∇𝑓 superscript 𝑥 𝑘 2 Q(\gamma)=\|x^{k}-x^{*}\|^{2}-2\gamma[f(x^{k})-f^{*}]+\gamma^{2}\|\nabla f(x^{% k})\|^{2}italic_Q ( italic_γ ) = ∥ italic_x start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT - italic_x start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT - 2 italic_γ [ italic_f ( italic_x start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) - italic_f start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT ] + italic_γ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ∥ ∇ italic_f ( italic_x start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT for convex functions. In a recent work, Loizou et al. ([2021](https://arxiv.org/html/2404.07525v1#bib.bib16)) extended the Polyak step-size to the stochastic setting, namely SPS max{}_{\max}start_FLOATSUBSCRIPT roman_max end_FLOATSUBSCRIPT,
|
| 119 |
+
|
| 120 |
+
γ k=min{f i(x k)−f i*c‖∇f i(x k)‖2,γ b},subscript 𝛾 𝑘 subscript 𝑓 𝑖 superscript 𝑥 𝑘 superscript subscript 𝑓 𝑖 𝑐 superscript norm∇subscript 𝑓 𝑖 superscript 𝑥 𝑘 2 subscript 𝛾 𝑏\gamma_{k}=\min\left\{\frac{f_{i}(x^{k})-f_{i}^{*}}{c\|\nabla f_{i}(x^{k})\|^{% 2}},\gamma_{b}\right\},italic_γ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT = roman_min { divide start_ARG italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ( italic_x start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) - italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT end_ARG start_ARG italic_c ∥ ∇ italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ( italic_x start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG , italic_γ start_POSTSUBSCRIPT italic_b end_POSTSUBSCRIPT } ,
|
| 121 |
+
|
| 122 |
+
where f i*=inf x f i(x)superscript subscript 𝑓 𝑖 subscript infimum 𝑥 subscript 𝑓 𝑖 𝑥 f_{i}^{*}=\inf_{x}f_{i}(x)italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT = roman_inf start_POSTSUBSCRIPT italic_x end_POSTSUBSCRIPT italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ( italic_x ), c 𝑐 c italic_c is a positive constant, and γ b>0 subscript 𝛾 𝑏 0\gamma_{b}>0 italic_γ start_POSTSUBSCRIPT italic_b end_POSTSUBSCRIPT > 0 is to restrict SPS from being very large.
|
| 123 |
+
|
| 124 |
+
In RL settings, the goal is to maximize the objective function (_i.e_., the value function). To this end, we extend SPS max subscript SPS max\operatorname{SPS}_{\text{max}}roman_SPS start_POSTSUBSCRIPT max end_POSTSUBSCRIPT to
|
| 125 |
+
|
| 126 |
+
γ k=min{V*−V^θ k c‖∇θ k V^θ k‖2,γ b},subscript 𝛾 𝑘 superscript 𝑉 superscript^𝑉 subscript 𝜃 𝑘 𝑐 superscript norm subscript∇subscript 𝜃 𝑘 superscript^𝑉 subscript 𝜃 𝑘 2 subscript 𝛾 𝑏\gamma_{k}=\min\left\{\frac{V^{*}-\hat{V}^{\theta_{k}}}{c\|\nabla_{\theta_{k}}% \hat{V}^{\theta_{k}}\|^{2}},\gamma_{b}\right\},italic_γ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT = roman_min { divide start_ARG italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT - over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUPERSCRIPT end_ARG start_ARG italic_c ∥ ∇ start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUBSCRIPT over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUPERSCRIPT ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG , italic_γ start_POSTSUBSCRIPT italic_b end_POSTSUBSCRIPT } ,
|
| 127 |
+
|
| 128 |
+
where V*superscript 𝑉 V^{*}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT is the optimal objective function value, V^θ k superscript^𝑉 subscript 𝜃 𝑘\hat{V}^{\theta_{k}}over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUPERSCRIPT is a stochastic evaluation of the current policy parameter θ k subscript 𝜃 𝑘\theta_{k}italic_θ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT.
|
| 129 |
+
|
| 130 |
+
4 Policy gradient with the Polyak step-size
|
| 131 |
+
-------------------------------------------
|
| 132 |
+
|
| 133 |
+
In the direct application of the Polyak step-size from optimization to RL, several issues arise, which we will detail in the following sections. We will then adapt the Polyak step-size to address these issues.
|
| 134 |
+
|
| 135 |
+
### 4.1 Stochastic update issue
|
| 136 |
+
|
| 137 |
+
First, in most real-world scenarios, trajectories and transition functions are not tractable, necessitating the adoption of stochastic sampling to estimate the objective function V θ superscript 𝑉 𝜃 V^{\theta}italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT and the gradient ∇θ V θ subscript∇𝜃 superscript 𝑉 𝜃\nabla_{\theta}V^{\theta}∇ start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT. To illustrate a problem arising from stochastic updates, we employ a simplified CartPole environment from OpenAI Gym (Brockman et al., [2016](https://arxiv.org/html/2404.07525v1#bib.bib6)), where the size of the action space is 2 2 2 2. We concentrate on the initial two steps and four trajectories (seven distinct states) within the CartPole environment. Employing a softmax parametrization, our policy is defined by three parameters (x,y 𝑥 𝑦 x,y italic_x , italic_y and z 𝑧 z italic_z described in Figure [2](https://arxiv.org/html/2404.07525v1#S4.F2 "Figure 2 ‣ 4.1 Stochastic update issue ‣ 4 Policy gradient with the Polyak step-size ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption")). Distinct rewards are assigned to each trajectory, as illustrated in Figure [2](https://arxiv.org/html/2404.07525v1#S4.F2 "Figure 2 ‣ 4.1 Stochastic update issue ‣ 4 Policy gradient with the Polyak step-size ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption"). The optimal policy is deterministic, consistently selecting the trajectory with the highest reward.
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
Figure 2: A simplified two-step deterministic environment with a three-parameter policy. x 𝑥 x italic_x, y 𝑦 y italic_y, and z 𝑧 z italic_z represent the parameters of the policy. The sigmoid function is denoted by σ 𝜎\sigma italic_σ with σ(u)=1 1+e−u 𝜎 𝑢 1 1 superscript 𝑒 𝑢\sigma(u)=\frac{1}{1+e^{-u}}italic_σ ( italic_u ) = divide start_ARG 1 end_ARG start_ARG 1 + italic_e start_POSTSUPERSCRIPT - italic_u end_POSTSUPERSCRIPT end_ARG. Selecting a non-optimal trajectory at the first iteration leads to an increase in the probability of such a trajectory. Consequently, the update with the Polyak step-size is likely to approach infinity.
|
| 142 |
+
|
| 143 |
+
Suppose we initialize the parameters as zeros, indicating uniform trajectory sampling. We use a single sample trajectory to estimate both V θ superscript 𝑉 𝜃 V^{\theta}italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT and the gradient ∇θ V θ subscript∇𝜃 superscript 𝑉 𝜃\nabla_{\theta}V^{\theta}∇ start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT. If a non-optimal trajectory τ 𝜏\tau italic_τ is sampled in the first iteration, the probability of the trajectory P(τ)𝑃 𝜏 P(\tau)italic_P ( italic_τ ) is increased, because of ([1](https://arxiv.org/html/2404.07525v1#S3.E1 "1 ‣ 3 Preliminaries ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption")) and the R(τ)>0 𝑅 𝜏 0 R(\tau)>0 italic_R ( italic_τ ) > 0. The same trajectory will probably be repeatedly selected in subsequent iterations, further increasing its probability. In a softmax policy, as the probability tends toward determinism, the gradient approaches zero. In non-optimal trajectories with nearly deterministic probabilities, the Polyak step-size formula encounters an issue: V*−V θ superscript 𝑉 superscript 𝑉 𝜃 V^{*}-V^{\theta}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT - italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT is not zero while ∇θ V θ‖∇θ V θ‖2 subscript∇𝜃 superscript 𝑉 𝜃 superscript norm subscript∇𝜃 superscript 𝑉 𝜃 2\frac{\nabla_{\theta}V^{\theta}}{\|\nabla_{\theta}V^{\theta}\|^{2}}divide start_ARG ∇ start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT end_ARG start_ARG ∥ ∇ start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG approaches infinity, resulting in an explosive update. This issue extends beyond positive trajectory rewards; whenever a non-optimal trajectory has a high probability, the potential for explosive updates arises.
|
| 144 |
+
|
| 145 |
+
To mitigate this issue, we introduce an entropy penalty into the policy update loss, a practical remedy to keep the probabilities from getting too small (Williams & Peng, [1991](https://arxiv.org/html/2404.07525v1#bib.bib30); Peters et al., [2010](https://arxiv.org/html/2404.07525v1#bib.bib21); Mnih et al., [2016](https://arxiv.org/html/2404.07525v1#bib.bib18); Alfano et al., [2023](https://arxiv.org/html/2404.07525v1#bib.bib3)). This modification prevents ∇θ V θ‖∇θ V θ‖2 subscript∇𝜃 superscript 𝑉 𝜃 superscript norm subscript∇𝜃 superscript 𝑉 𝜃 2\frac{\nabla_{\theta}V^{\theta}}{\|\nabla_{\theta}V^{\theta}\|^{2}}divide start_ARG ∇ start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT end_ARG start_ARG ∥ ∇ start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG from approaching infinity, promoting exploration and ensuring the likelihood of sampling optimal trajectories. Consequently, the objective function for θ 𝜃\theta italic_θ becomes:
|
| 146 |
+
|
| 147 |
+
ℒ(θ)=V θ(ρ)+α 𝔼 s∼d π θ(s)ℋ(π θ(⋅∣s)),\mathcal{L}(\theta)=V^{\theta}(\rho)+\alpha\mathbb{E}_{s\sim d^{\pi^{\theta}}(% s)}\mathcal{H}(\pi^{\theta}(\cdot\mid s)),caligraphic_L ( italic_θ ) = italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ( italic_ρ ) + italic_α blackboard_E start_POSTSUBSCRIPT italic_s ∼ italic_d start_POSTSUPERSCRIPT italic_π start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT ( italic_s ) end_POSTSUBSCRIPT caligraphic_H ( italic_π start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ( ⋅ ∣ italic_s ) ) ,
|
| 148 |
+
|
| 149 |
+
where α 𝛼\alpha italic_α is the hyper-parameter which determines the importance of the entropy, ℋ(π θ(⋅∣s))=∑a∈𝒜−π θ(a∣s)log π θ(a∣s)\mathcal{H}(\pi^{\theta}(\cdot\mid s))=\sum_{a\in\mathcal{A}}-\pi^{\theta}(a% \mid s)\log\pi^{\theta}(a\mid s)caligraphic_H ( italic_π start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ( ⋅ ∣ italic_s ) ) = ∑ start_POSTSUBSCRIPT italic_a ∈ caligraphic_A end_POSTSUBSCRIPT - italic_π start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ( italic_a ∣ italic_s ) roman_log italic_π start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ( italic_a ∣ italic_s ) is the entropy function, d π θ(s)=(1−γ)𝔼 s 0∼ρ∑t=0∞γ tPr[s t=s∣s 0,π θ]superscript 𝑑 superscript 𝜋 𝜃 𝑠 1 𝛾 subscript 𝔼 similar-to subscript 𝑠 0 𝜌 superscript subscript 𝑡 0 superscript 𝛾 𝑡 Pr subscript 𝑠 𝑡 conditional 𝑠 subscript 𝑠 0 superscript 𝜋 𝜃 d^{\pi^{\theta}}(s)=(1-\gamma)\mathbb{E}_{s_{0}\sim\rho}\sum\nolimits_{t=0}^{% \infty}\gamma^{t}\Pr[s_{t}=s\mid s_{0},\pi^{\theta}]italic_d start_POSTSUPERSCRIPT italic_π start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT ( italic_s ) = ( 1 - italic_γ ) blackboard_E start_POSTSUBSCRIPT italic_s start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ∼ italic_ρ end_POSTSUBSCRIPT ∑ start_POSTSUBSCRIPT italic_t = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∞ end_POSTSUPERSCRIPT italic_γ start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT roman_Pr [ italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT = italic_s ∣ italic_s start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT , italic_π start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ] is the normalized discounted state visitation distribution which adjusts the weights of entropy. Intuitively, the state visitation distribution measures the probability of being at state s 𝑠 s italic_s across the entire trajectory. The entropy term is also intractable, we estimate it with sample trajectories.
|
| 150 |
+
|
| 151 |
+
### 4.2 Estimating V*superscript 𝑉 V^{*}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT with twin-model method
|
| 152 |
+
|
| 153 |
+
Computing the Polyak step-size requires knowledge of the optimal objective function values. Since the V θ(ρ)superscript 𝑉 𝜃 𝜌 V^{\theta}(\rho)italic_V start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT ( italic_ρ ) is non-concave in θ 𝜃\theta italic_θ for the softmax parameterizations (Agarwal et al., [2019](https://arxiv.org/html/2404.07525v1#bib.bib1); [2021](https://arxiv.org/html/2404.07525v1#bib.bib2)), using the true V*superscript 𝑉 V^{*}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT value could easily cause large step-size and overshooting. Additionally, in real situations, we may not know the true V*superscript 𝑉 V^{*}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT value, as we lack information about optimal policies or because of the nature of the task. To address the V*superscript 𝑉 V^{*}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT problem, we propose a twin-model method.
|
| 154 |
+
|
| 155 |
+
We first introduce our method within the context of stochastic optimization, minimizing f(x)=1 n∑i=1 n f i(x)𝑓 𝑥 1 𝑛 superscript subscript 𝑖 1 𝑛 subscript 𝑓 𝑖 𝑥 f(x)=\frac{1}{n}\sum_{i=1}^{n}f_{i}(x)italic_f ( italic_x ) = divide start_ARG 1 end_ARG start_ARG italic_n end_ARG ∑ start_POSTSUBSCRIPT italic_i = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ( italic_x ). We initialize two distinct model parameters, denoted as x 1 subscript 𝑥 1 x_{1}italic_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT and x 2 subscript 𝑥 2 x_{2}italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT. At each iteration, we compute f i(x 1)subscript 𝑓 𝑖 subscript 𝑥 1 f_{i}(x_{1})italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ( italic_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ) and f j(x 2)subscript 𝑓 𝑗 subscript 𝑥 2 f_{j}(x_{2})italic_f start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ( italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ), where i 𝑖 i italic_i and j 𝑗 j italic_j are uniformly sampled with replacement 1 1 1 We can also sample i 𝑖 i italic_i first and then sample j 𝑗 j italic_j until j≠i 𝑗 𝑖 j\neq i italic_j ≠ italic_i (sampling without replacement), in this case 𝔼 j[f j(x)]=f(x)subscript 𝔼 𝑗 delimited-[]subscript 𝑓 𝑗 𝑥 𝑓 𝑥\mathbb{E}_{j}[f_{j}(x)]=f(x)blackboard_E start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT [ italic_f start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ( italic_x ) ] = italic_f ( italic_x ) also holds., select the lower value as f*superscript 𝑓 f^{*}italic_f start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT and update the other model.
|
| 156 |
+
|
| 157 |
+
For instance, at k 𝑘 k italic_k-th iteration, assuming f i(x 1 k)<f j(x 2 k)subscript 𝑓 𝑖 superscript subscript 𝑥 1 𝑘 subscript 𝑓 𝑗 superscript subscript 𝑥 2 𝑘 f_{i}(x_{1}^{k})<f_{j}(x_{2}^{k})italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ( italic_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) < italic_f start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ( italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ), the expression for the Polyak step-size is then given by:
|
| 158 |
+
|
| 159 |
+
γ k=f j(x 2 k)−f i(x 1 k)‖∇f j(x 2 k)‖2,subscript 𝛾 𝑘 subscript 𝑓 𝑗 superscript subscript 𝑥 2 𝑘 subscript 𝑓 𝑖 superscript subscript 𝑥 1 𝑘 superscript norm∇subscript 𝑓 𝑗 superscript subscript 𝑥 2 𝑘 2\gamma_{k}=\frac{f_{j}(x_{2}^{k})-f_{i}(x_{1}^{k})}{\|\nabla f_{j}(x_{2}^{k})% \|^{2}},italic_γ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT = divide start_ARG italic_f start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ( italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) - italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ( italic_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) end_ARG start_ARG ∥ ∇ italic_f start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ( italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG ,
|
| 160 |
+
|
| 161 |
+
and we freeze the parameter x 1 k superscript subscript 𝑥 1 𝑘 x_{1}^{k}italic_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT and update the parameter x 2 k superscript subscript 𝑥 2 𝑘 x_{2}^{k}italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT with:
|
| 162 |
+
|
| 163 |
+
x 2 k+1=x 2 k−γ k∇f j(x 2 k).superscript subscript 𝑥 2 𝑘 1 superscript subscript 𝑥 2 𝑘 subscript 𝛾 𝑘∇subscript 𝑓 𝑗 superscript subscript 𝑥 2 𝑘 x_{2}^{k+1}=x_{2}^{k}-\gamma_{k}\nabla f_{j}(x_{2}^{k}).italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k + 1 end_POSTSUPERSCRIPT = italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT - italic_γ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT ∇ italic_f start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ( italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) .
|
| 164 |
+
|
| 165 |
+
When f i(x 1 k)=f j(x 2 k)subscript 𝑓 𝑖 superscript subscript 𝑥 1 𝑘 subscript 𝑓 𝑗 superscript subscript 𝑥 2 𝑘 f_{i}(x_{1}^{k})=f_{j}(x_{2}^{k})italic_f start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ( italic_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ) = italic_f start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ( italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ), we don’t update the models and start a new iteration. In practical applications, our findings suggest that the stochastic update prevents the two models from converging closely. To ensure similar performance for a conservative update, we initialize the models closely.
|
| 166 |
+
|
| 167 |
+
As in the RL setting, adopting two policy models for better value estimation is a common practice (Hasselt, [2010](https://arxiv.org/html/2404.07525v1#bib.bib11); Lillicrap et al., [2016](https://arxiv.org/html/2404.07525v1#bib.bib15); Haarnoja et al., [2018](https://arxiv.org/html/2404.07525v1#bib.bib10); Fujimoto et al., [2018](https://arxiv.org/html/2404.07525v1#bib.bib9)). Since we usually use a deep neural network as model parameter θ 𝜃\theta italic_θ, one option is to use two initializations of the same structure, denoted as θ 1 subscript 𝜃 1\theta_{1}italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT and θ 2 subscript 𝜃 2\theta_{2}italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT. We evaluate them with stochastic trajectory samples in each iteration. Due to different parameters and likely different stochastic samples, we obtain distinct estimations V^θ 1 superscript^𝑉 subscript 𝜃 1\hat{V}^{\theta_{1}}over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT end_POSTSUPERSCRIPT and V^θ 2 superscript^𝑉 subscript 𝜃 2\hat{V}^{\theta_{2}}over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT end_POSTSUPERSCRIPT. We use the higher V^^𝑉\hat{V}over^ start_ARG italic_V end_ARG to update the model with the lower V^^𝑉\hat{V}over^ start_ARG italic_V end_ARG. For instance, in iteration k 𝑘 k italic_k, if V^θ 1 k>V^θ 2 k superscript^𝑉 superscript subscript 𝜃 1 𝑘 superscript^𝑉 superscript subscript 𝜃 2 𝑘\hat{V}^{\theta_{1}^{k}}>\hat{V}^{\theta_{2}^{k}}over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT > over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT, we freeze θ 1 k superscript subscript 𝜃 1 𝑘\theta_{1}^{k}italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT and update θ 2 k superscript subscript 𝜃 2 𝑘\theta_{2}^{k}italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT with a step-size:
|
| 168 |
+
|
| 169 |
+
γ^k=V^θ 1 k−V^θ 2 k‖∇^θ 2 kV θ 2 k‖2.subscript^𝛾 𝑘 superscript^𝑉 superscript subscript 𝜃 1 𝑘 superscript^𝑉 superscript subscript 𝜃 2 𝑘 superscript norm subscript^∇superscript subscript 𝜃 2 𝑘 superscript 𝑉 superscript subscript 𝜃 2 𝑘 2\hat{\gamma}_{k}=\frac{\hat{V}^{\theta_{1}^{k}}-\hat{V}^{\theta_{2}^{k}}}{\|% \widehat{\nabla}_{\theta_{2}^{k}}V^{\theta_{2}^{k}}\|^{2}}.over^ start_ARG italic_γ end_ARG start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT = divide start_ARG over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT - over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT end_ARG start_ARG ∥ over^ start_ARG ∇ end_ARG start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT end_POSTSUBSCRIPT italic_V start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG .
|
| 170 |
+
|
| 171 |
+
This constitutes a pessimistic estimation of V*superscript 𝑉 V^{*}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT, closely aligned with the current V^θ 2 k superscript^𝑉 subscript 𝜃 subscript 2 𝑘\hat{V}^{\theta_{2_{k}}}over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT 2 start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUBSCRIPT end_POSTSUPERSCRIPT. In comparison with the step-size involving the true V*superscript 𝑉 V^{*}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT, γ^k subscript^𝛾 𝑘\hat{\gamma}_{k}over^ start_ARG italic_γ end_ARG start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT is smaller and more conservative, reducing the likelihood of too large step-size. Due to the issue raised in Section [4.1](https://arxiv.org/html/2404.07525v1#S4.SS1 "4.1 Stochastic update issue ‣ 4 Policy gradient with the Polyak step-size ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption"), it is still likely to sample non-optimal trajectories which has high probability with the current policy. Thus in practice, we use the bounded stochastic variant SPS max subscript SPS max\operatorname{SPS}_{\text{max}}roman_SPS start_POSTSUBSCRIPT max end_POSTSUBSCRIPT:
|
| 172 |
+
|
| 173 |
+
γ^k=min{V^θ 1 k−V^θ 2 k c‖∇^θ 2 kV θ 2 k‖2,γ b}.subscript^𝛾 𝑘 superscript^𝑉 superscript subscript 𝜃 1 𝑘 superscript^𝑉 superscript subscript 𝜃 2 𝑘 𝑐 superscript norm subscript^∇superscript subscript 𝜃 2 𝑘 superscript 𝑉 superscript subscript 𝜃 2 𝑘 2 subscript 𝛾 𝑏\hat{\gamma}_{k}=\min\left\{\frac{\hat{V}^{\theta_{1}^{k}}-\hat{V}^{\theta_{2}% ^{k}}}{c\|\widehat{\nabla}_{\theta_{2}^{k}}V^{\theta_{2}^{k}}\|^{2}},\gamma_{b% }\right\}.over^ start_ARG italic_γ end_ARG start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT = roman_min { divide start_ARG over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT - over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT end_ARG start_ARG italic_c ∥ over^ start_ARG ∇ end_ARG start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT end_POSTSUBSCRIPT italic_V start_POSTSUPERSCRIPT italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG , italic_γ start_POSTSUBSCRIPT italic_b end_POSTSUBSCRIPT } .
|
| 174 |
+
|
| 175 |
+
### 4.3 Algorithm
|
| 176 |
+
|
| 177 |
+
Combining the twin-model method for estimating V*superscript 𝑉 V^{*}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT and the entropy penalty, where we use ℒ^(θ)^ℒ 𝜃\hat{\mathcal{L}}(\theta)over^ start_ARG caligraphic_L end_ARG ( italic_θ ) instead of V^θ superscript^𝑉 𝜃\hat{V}^{\theta}over^ start_ARG italic_V end_ARG start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT, we propose our algorithm as outlined in Algorithm [1](https://arxiv.org/html/2404.07525v1#alg1 "Algorithm 1 ‣ 4.3 Algorithm ‣ 4 Policy gradient with the Polyak step-size ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption").
|
| 178 |
+
|
| 179 |
+
Algorithm 1 Double policy gradient with the stochastic Polyak step-size
|
| 180 |
+
|
| 181 |
+
Input:
|
| 182 |
+
|
| 183 |
+
γ b subscript 𝛾 𝑏\gamma_{b}italic_γ start_POSTSUBSCRIPT italic_b end_POSTSUBSCRIPT
|
| 184 |
+
,
|
| 185 |
+
|
| 186 |
+
c 𝑐 c italic_c
|
| 187 |
+
,
|
| 188 |
+
|
| 189 |
+
α 𝛼\alpha italic_α
|
| 190 |
+
, different but close model initializations
|
| 191 |
+
|
| 192 |
+
θ 1 subscript 𝜃 1\theta_{1}italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT
|
| 193 |
+
and
|
| 194 |
+
|
| 195 |
+
θ 2 subscript 𝜃 2\theta_{2}italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT
|
| 196 |
+
|
| 197 |
+
repeat
|
| 198 |
+
|
| 199 |
+
Sample trajectories
|
| 200 |
+
|
| 201 |
+
{𝒯 1}subscript 𝒯 1\{\mathcal{T}_{1}\}{ caligraphic_T start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT }
|
| 202 |
+
and
|
| 203 |
+
|
| 204 |
+
{𝒯 2}subscript 𝒯 2\{\mathcal{T}_{2}\}{ caligraphic_T start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT }
|
| 205 |
+
with
|
| 206 |
+
|
| 207 |
+
θ 1 subscript 𝜃 1\theta_{1}italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT
|
| 208 |
+
and
|
| 209 |
+
|
| 210 |
+
θ 2 subscript 𝜃 2\theta_{2}italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT
|
| 211 |
+
accordingly
|
| 212 |
+
|
| 213 |
+
Compute
|
| 214 |
+
|
| 215 |
+
ℒ^(θ 1)^ℒ subscript 𝜃 1\hat{\mathcal{L}}(\theta_{1})over^ start_ARG caligraphic_L end_ARG ( italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT )
|
| 216 |
+
and
|
| 217 |
+
|
| 218 |
+
ℒ^(θ 2)^ℒ subscript 𝜃 2\hat{\mathcal{L}}(\theta_{2})over^ start_ARG caligraphic_L end_ARG ( italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT )
|
| 219 |
+
with
|
| 220 |
+
|
| 221 |
+
{𝒯 1}subscript 𝒯 1\{\mathcal{T}_{1}\}{ caligraphic_T start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT }
|
| 222 |
+
and
|
| 223 |
+
|
| 224 |
+
{𝒯 2}subscript 𝒯 2\{\mathcal{T}_{2}\}{ caligraphic_T start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT }
|
| 225 |
+
|
| 226 |
+
if
|
| 227 |
+
|
| 228 |
+
ℒ^(θ 1)>ℒ^(θ 2)^ℒ subscript 𝜃 1^ℒ subscript 𝜃 2\hat{\mathcal{L}}(\theta_{1})>\hat{\mathcal{L}}(\theta_{2})over^ start_ARG caligraphic_L end_ARG ( italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ) > over^ start_ARG caligraphic_L end_ARG ( italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT )
|
| 229 |
+
then
|
| 230 |
+
|
| 231 |
+
Compute
|
| 232 |
+
|
| 233 |
+
∇^θ 2ℒ(θ 2)subscript^∇subscript 𝜃 2 ℒ subscript 𝜃 2\widehat{\nabla}_{\theta_{2}}\mathcal{L}(\theta_{2})over^ start_ARG ∇ end_ARG start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT end_POSTSUBSCRIPT caligraphic_L ( italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT )
|
| 234 |
+
with
|
| 235 |
+
|
| 236 |
+
{𝒯 2}subscript 𝒯 2\{\mathcal{T}_{2}\}{ caligraphic_T start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT }
|
| 237 |
+
|
| 238 |
+
γ=min{ℒ^(θ 1)−ℒ^(θ 2)c‖∇^θ 2ℒ(θ 2)‖2,γ b}𝛾^ℒ subscript 𝜃 1^ℒ subscript 𝜃 2 𝑐 superscript norm subscript^∇subscript 𝜃 2 ℒ subscript 𝜃 2 2 subscript 𝛾 𝑏\gamma=\min\{\frac{\hat{\mathcal{L}}(\theta_{1})-\hat{\mathcal{L}}(\theta_{2})% }{c\|\widehat{\nabla}_{\theta_{2}}\mathcal{L}(\theta_{2})\|^{2}},\gamma_{b}\}italic_γ = roman_min { divide start_ARG over^ start_ARG caligraphic_L end_ARG ( italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ) - over^ start_ARG caligraphic_L end_ARG ( italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ) end_ARG start_ARG italic_c ∥ over^ start_ARG ∇ end_ARG start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT end_POSTSUBSCRIPT caligraphic_L ( italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ) ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG , italic_γ start_POSTSUBSCRIPT italic_b end_POSTSUBSCRIPT }
|
| 239 |
+
|
| 240 |
+
θ 2←θ 2+γ∇^θ 2ℒ(θ 2)←subscript 𝜃 2 subscript 𝜃 2 𝛾 subscript^∇subscript ���� 2 ℒ subscript 𝜃 2\theta_{2}\leftarrow\theta_{2}+\gamma\widehat{\nabla}_{\theta_{2}}\mathcal{L}(% \theta_{2})italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ← italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT + italic_γ over^ start_ARG ∇ end_ARG start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT end_POSTSUBSCRIPT caligraphic_L ( italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT )
|
| 241 |
+
|
| 242 |
+
else
|
| 243 |
+
|
| 244 |
+
Compute
|
| 245 |
+
|
| 246 |
+
∇^θ 1ℒ(θ 1)subscript^∇subscript 𝜃 1 ℒ subscript 𝜃 1\widehat{\nabla}_{\theta_{1}}\mathcal{L}(\theta_{1})over^ start_ARG ∇ end_ARG start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT end_POSTSUBSCRIPT caligraphic_L ( italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT )
|
| 247 |
+
with
|
| 248 |
+
|
| 249 |
+
{𝒯 1}subscript 𝒯 1\{\mathcal{T}_{1}\}{ caligraphic_T start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT }
|
| 250 |
+
|
| 251 |
+
γ=min{ℒ^(θ 2)−ℒ^(θ 1)c‖∇^θ 1ℒ(θ 1)‖2,γ b}𝛾^ℒ subscript 𝜃 2^ℒ subscript 𝜃 1 𝑐 superscript norm subscript^∇subscript 𝜃 1 ℒ subscript 𝜃 1 2 subscript 𝛾 𝑏\gamma=\min\{\frac{\hat{\mathcal{L}}(\theta_{2})-\hat{\mathcal{L}}(\theta_{1})% }{c\|\widehat{\nabla}_{\theta_{1}}\mathcal{L}(\theta_{1})\|^{2}},\gamma_{b}\}italic_γ = roman_min { divide start_ARG over^ start_ARG caligraphic_L end_ARG ( italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ) - over^ start_ARG caligraphic_L end_ARG ( italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ) end_ARG start_ARG italic_c ∥ over^ start_ARG ∇ end_ARG start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT end_POSTSUBSCRIPT caligraphic_L ( italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ) ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG , italic_γ start_POSTSUBSCRIPT italic_b end_POSTSUBSCRIPT }
|
| 252 |
+
|
| 253 |
+
θ 1←θ 1+γ∇^θ 1ℒ(θ 1)←subscript 𝜃 1 subscript 𝜃 1 𝛾 subscript^∇subscript 𝜃 1 ℒ subscript 𝜃 1\theta_{1}\leftarrow\theta_{1}+\gamma\widehat{\nabla}_{\theta_{1}}\mathcal{L}(% \theta_{1})italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ← italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT + italic_γ over^ start_ARG ∇ end_ARG start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT end_POSTSUBSCRIPT caligraphic_L ( italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT )
|
| 254 |
+
|
| 255 |
+
end if
|
| 256 |
+
|
| 257 |
+
until
|
| 258 |
+
|
| 259 |
+
γ 𝛾\gamma italic_γ
|
| 260 |
+
is small enough
|
| 261 |
+
|
| 262 |
+
5 Experiments
|
| 263 |
+
-------------
|
| 264 |
+
|
| 265 |
+
### 5.1 twin-model in optimization problems
|
| 266 |
+
|
| 267 |
+
We showcase the effectiveness of the twin-model method under interpolation conditions for simple convex function minimization, specifically logistic regression (_i.e_., the data is linearly separable). We apply simple SPS SPS\operatorname{SPS}roman_SPS with c=1 𝑐 1 c=1 italic_c = 1. In this case, we remove the requirements of f*superscript 𝑓 f^{*}italic_f start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT, c 𝑐 c italic_c and γ b subscript 𝛾 𝑏\gamma_{b}italic_γ start_POSTSUBSCRIPT italic_b end_POSTSUBSCRIPT, which means we require no hyper-parameters and no prior knowledge. The performance comparison involves the Polyak step-size with the twin-model method, SGD with varying step-sizes and SPS, as illustrated in Figure [2(a)](https://arxiv.org/html/2404.07525v1#S5.F2.sf1 "2(a) ‣ Figure 3 ‣ 5.1 twin-model in optimization problems ‣ 5 Experiments ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption"). Our evaluation incorporates three distinct random seeds, and we present the moving average of f(x)𝑓 𝑥 f(x)italic_f ( italic_x ). Notably, the twin-model method exhibits similar performance to fine-tuned SGD in addressing convex problems under interpolation conditions. Under identical experimental settings, _i.e_., no prior knowledge and no hyper-parameters available for twin-model method, we conduct a comparison between the twin-model method, SGD with different step-sizes and SPS max max{}_{\text{max}}start_FLOATSUBSCRIPT max end_FLOATSUBSCRIPT on non-convex problem (_i.e_., logistic regression with non-convex deep neural network). The results are presented in Figure [2(b)](https://arxiv.org/html/2404.07525v1#S5.F2.sf2 "2(b) ‣ Figure 3 ‣ 5.1 twin-model in optimization problems ‣ 5 Experiments ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption"). Notably, the twin-model method demonstrates comparable performance to fine-tuned SGD. In the RL setting, the main challenge lies in the uncertainty surrounding V*superscript 𝑉 V^{*}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT (f*superscript 𝑓 f^{*}italic_f start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT in optimization settings), which may not be known.
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
(a)
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
(b)
|
| 276 |
+
|
| 277 |
+
Figure 3: The performance of twin-model method on convex and non-convex problem comparing with SGD with various step-sizes and SPS (SPS max max{}_{\text{max}}start_FLOATSUBSCRIPT max end_FLOATSUBSCRIPT).
|
| 278 |
+
|
| 279 |
+
### 5.2 Experiments settings
|
| 280 |
+
|
| 281 |
+
#### Training.
|
| 282 |
+
|
| 283 |
+
In this section, we elaborate on the details of our experiments. We establish the baseline using the Adam optimizer as provided in PyTorch (Paszke et al., [2017](https://arxiv.org/html/2404.07525v1#bib.bib20)). For gradient estimation, we employ the GPOMDP method, utilizing 500 500 500 500 trajectories for each policy update. Our investigation includes variations of Adam with different fixed step-sizes, both with and without the incorporation of an entropy penalty.
|
| 284 |
+
|
| 285 |
+
For the Polyak step-size, we collect 500 500 500 500 trajectories for each of θ 1 subscript 𝜃 1\theta_{1}italic_θ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT and θ 2 subscript 𝜃 2\theta_{2}italic_θ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT. We use the average of the sampled trajectory rewards as V 𝑉 V italic_V and apply GPOMDP to approximate the policy gradient. Our investigation encompasses various values for the c 𝑐 c italic_c in SPS max subscript SPS max\operatorname{SPS}_{\text{max}}roman_SPS start_POSTSUBSCRIPT max end_POSTSUBSCRIPT and the upper bound of the step-size γ b subscript 𝛾 𝑏\gamma_{b}italic_γ start_POSTSUBSCRIPT italic_b end_POSTSUBSCRIPT. Both the ordinary policy gradient and our proposed method employ fully connected feed-forward neural networks with 128 128 128 128 neurons in the hidden layer.
|
| 286 |
+
|
| 287 |
+
#### Evaluation.
|
| 288 |
+
|
| 289 |
+
Since there exists a stationary deterministic policy which is an optimal policy(Agarwal et al., [2019](https://arxiv.org/html/2404.07525v1#bib.bib1)), we select the action with the highest probability from the policy in evaluation. After each policy update, we evaluate the policies with three different random seeds that are different from the training seeds and report the average of the trajectory rewards.
|
| 290 |
+
|
| 291 |
+
### 5.3 Results
|
| 292 |
+
|
| 293 |
+
We investigate multiple hyper-parameter combinations to optimize Adam’s performance, while observing consistent stability with the Polyak step-size across diverse hyper-parameters. Due to space constraints, only selected results are depicted in Figure [4](https://arxiv.org/html/2404.07525v1#S5.F4 "Figure 4 ‣ 5.3 Results ‣ 5 Experiments ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption"). Comprehensive results encompassing various hyper-parameter combinations, the trend of step-sizes, and the values of V*−V superscript 𝑉 𝑉 V^{*}-V italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT - italic_V are provided in the Appendix. We evaluate both approaches on three Gym environments with discrete action spaces: Acrobot, CartPole, and LunarLander. In Acrobot, where the agent must explore valid trajectories to achieve the target height and improve policy, Adam, while capable of finding such trajectories, exhibits inconsistent improvement. In contrast, Polyak’s method consistently leverages successful trajectories to enhance policy. In CartPole, as discussed in Section [1](https://arxiv.org/html/2404.07525v1#S1 "1 Introduction ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption"), Adam exhibits varying convergence rates with different step-sizes: larger step-sizes lead to fast but unstable convergence, while smaller ones result in slower but more stable convergence. The Polyak step-size, on the other hand, converges optimally and maintains stability. As shown in Figure [4](https://arxiv.org/html/2404.07525v1#S5.F4 "Figure 4 ‣ 5.3 Results ‣ 5 Experiments ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption") and the appendix, the Polyak step-size consistently outperforms Adam in LunarLander.
|
| 294 |
+
|
| 295 |
+
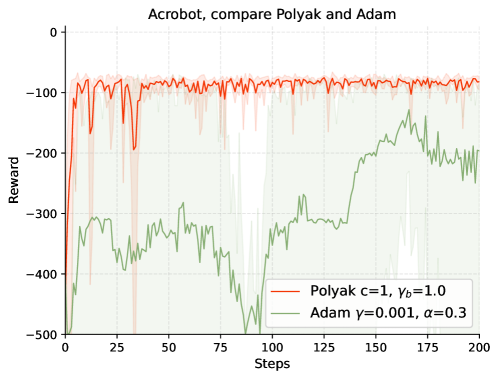
|
| 296 |
+
|
| 297 |
+
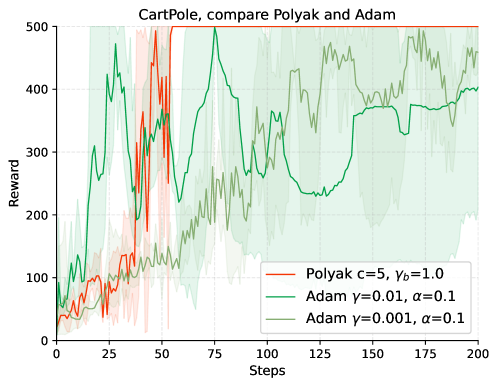
|
| 298 |
+
|
| 299 |
+
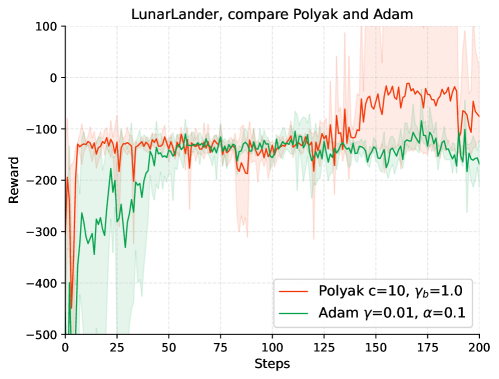
|
| 300 |
+
|
| 301 |
+
Figure 4: Compare the performance of Adam and the Polyak step-size. We select the best performance of both methods with different hyper-parameters. Polyak step-size converges faster and more stable. The line is the average of three random seeds, and the shade shows the min and max.
|
| 302 |
+
|
| 303 |
+
To illustrate the adaptive nature of the Polyak step-size, we include the step-size values from Polyak experiments with γ b=1.0 subscript 𝛾 𝑏 1.0\gamma_{b}=1.0 italic_γ start_POSTSUBSCRIPT italic_b end_POSTSUBSCRIPT = 1.0 in Figure [5](https://arxiv.org/html/2404.07525v1#S5.F5 "Figure 5 ‣ 5.3 Results ‣ 5 Experiments ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption"). Specifically, the line with c=5 𝑐 5 c=5 italic_c = 5 corresponds to the line in Figure [4](https://arxiv.org/html/2404.07525v1#S5.F4 "Figure 4 ‣ 5.3 Results ‣ 5 Experiments ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption"). It’s notable that the step-size rapidly decreases to 0.0 0.0 0.0 0.0 once the agent discovers a successful policy, ensuring policy stability.
|
| 304 |
+
|
| 305 |
+
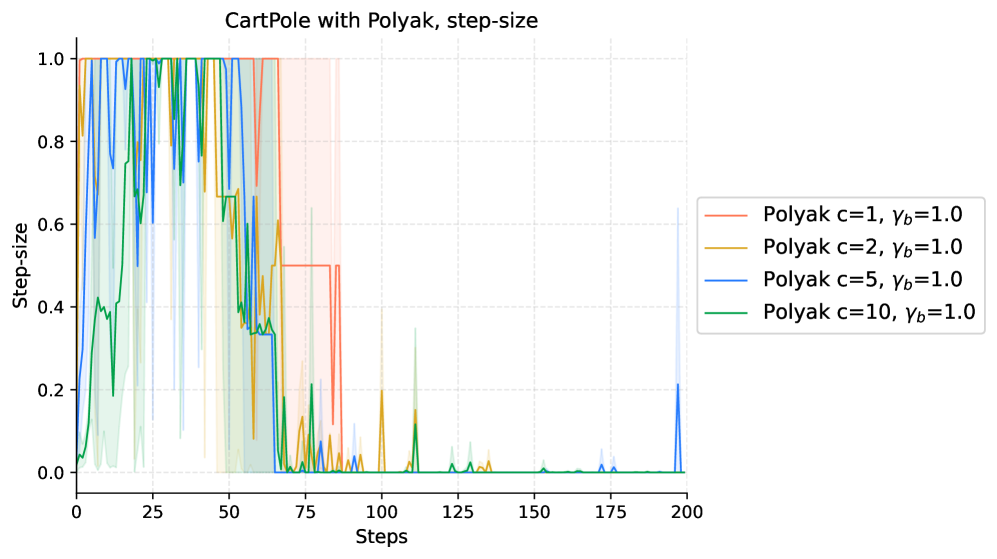
|
| 306 |
+
|
| 307 |
+
Figure 5: The step-size of the Polyak step-size with twin-model method in CartPole. The step-size decreases when the policy approaches to the optimal policy.
|
| 308 |
+
|
| 309 |
+
6 Conclusion
|
| 310 |
+
------------
|
| 311 |
+
|
| 312 |
+
In this paper, we address the challenge of sensitive step-size tuning in RL by integrating a variant of the Polyak step-size, SPS max subscript SPS max\operatorname{SPS}_{\text{max}}roman_SPS start_POSTSUBSCRIPT max end_POSTSUBSCRIPT, with policy gradient methods. We investigate concerns related to V*superscript 𝑉 V^{*}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT and explosive updates in softmax policy to ensure the applicability of the Polyak step-size in RL settings. Furthermore, we conduct experiments to evaluate the performance of our proposed method, demonstrating faster convergence and stable policy outcomes.
|
| 313 |
+
|
| 314 |
+
References
|
| 315 |
+
----------
|
| 316 |
+
|
| 317 |
+
* Agarwal et al. (2019) Alekh Agarwal, Nan Jiang, and Sham M. Kakade. Reinforcement learning: Theory and algorithms. 2019. URL [https://api.semanticscholar.org/CorpusID:148567317](https://api.semanticscholar.org/CorpusID:148567317).
|
| 318 |
+
* Agarwal et al. (2021) Alekh Agarwal, Sham M. Kakade, Jason D. Lee, and Gaurav Mahajan. On the theory of policy gradient methods: Optimality, approximation, and distribution shift. _Journal of Machine Learning Research_, 22(98):1–76, 2021.
|
| 319 |
+
* Alfano et al. (2023) Carlo Alfano, Rui Yuan, and Patrick Rebeschini. A novel framework for policy mirror descent with general parameterization and linear convergence. In _Thirty-seventh Conference on Neural Information Processing Systems_, 2023.
|
| 320 |
+
* Baxter & Bartlett (2001) Jonathan Baxter and Peter L. Bartlett. Infinite-horizon policy-gradient estimation. _J. Artif. Intell. Res._, 15:319–350, 2001. doi: [10.1613/JAIR.806](https://arxiv.org/html/2404.07525v1/10.1613/JAIR.806). URL [https://doi.org/10.1613/jair.806](https://doi.org/10.1613/jair.806).
|
| 321 |
+
* Bekci & Gümüs (2020) Recep Yusuf Bekci and Mehmet Gümüs. Visualizing the loss landscape of actor critic methods with applications in inventory optimization. _CoRR_, abs/2009.02391, 2020. URL [https://arxiv.org/abs/2009.02391](https://arxiv.org/abs/2009.02391).
|
| 322 |
+
* Brockman et al. (2016) Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym. _arXiv preprint arXiv:1606.01540_, 2016.
|
| 323 |
+
* Dabney & Barto (2012) William Dabney and Andrew G. Barto. Adaptive step-size for online temporal difference learning. In Jörg Hoffmann and Bart Selman (eds.), _Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, July 22-26, 2012, Toronto, Ontario, Canada_, pp. 872–878. AAAI Press, 2012. doi: [10.1609/AAAI.V26I1.8313](https://arxiv.org/html/2404.07525v1/10.1609/AAAI.V26I1.8313). URL [https://doi.org/10.1609/aaai.v26i1.8313](https://doi.org/10.1609/aaai.v26i1.8313).
|
| 324 |
+
* Eimer et al. (2023) Theresa Eimer, Marius Lindauer, and Roberta Raileanu. Hyperparameters in reinforcement learning and how to tune them. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), _International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA_, volume 202 of _Proceedings of Machine Learning Research_, pp. 9104–9149. PMLR, 2023. URL [https://proceedings.mlr.press/v202/eimer23a.html](https://proceedings.mlr.press/v202/eimer23a.html).
|
| 325 |
+
* Fujimoto et al. (2018) Scott Fujimoto, Herke van Hoof, and David Meger. Addressing function approximation error in actor-critic methods. In Jennifer G. Dy and Andreas Krause (eds.), _Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018_, volume 80 of _Proceedings of Machine Learning Research_, pp. 1582–1591. PMLR, 2018. URL [http://proceedings.mlr.press/v80/fujimoto18a.html](http://proceedings.mlr.press/v80/fujimoto18a.html).
|
| 326 |
+
* Haarnoja et al. (2018) Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Jennifer G. Dy and Andreas Krause (eds.), _Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018_, volume 80 of _Proceedings of Machine Learning Research_, pp. 1856–1865. PMLR, 2018. URL [http://proceedings.mlr.press/v80/haarnoja18b.html](http://proceedings.mlr.press/v80/haarnoja18b.html).
|
| 327 |
+
* Hasselt (2010) H.V. Hasselt. Double q-learning. In _Neural Information Processing Systems_, 2010. URL [https://api.semanticscholar.org/CorpusID:5155799](https://api.semanticscholar.org/CorpusID:5155799).
|
| 328 |
+
* Jiang & Stich (2023) Xiaowen Jiang and Sebastian U. Stich. Adaptive SGD with polyak stepsize and line-search: Robust convergence and variance reduction. _CoRR_, abs/2308.06058, 2023. doi: [10.48550/ARXIV.2308.06058](https://arxiv.org/html/2404.07525v1/10.48550/ARXIV.2308.06058). URL [https://doi.org/10.48550/arXiv.2308.06058](https://doi.org/10.48550/arXiv.2308.06058).
|
| 329 |
+
* Kakade (2001) Sham M. Kakade. A natural policy gradient. In Thomas G. Dietterich, Suzanna Becker, and Zoubin Ghahramani (eds.), _Advances in Neural Information Processing Systems 14 [Neural Information Processing Systems: Natural and Synthetic, NIPS 2001, December 3-8, 2001, Vancouver, British Columbia, Canada]_, pp. 1531–1538. MIT Press, 2001. URL [https://proceedings.neurips.cc/paper/2001/hash/4b86abe48d358ecf194c56c69108433e-Abstract.html](https://proceedings.neurips.cc/paper/2001/hash/4b86abe48d358ecf194c56c69108433e-Abstract.html).
|
| 330 |
+
* Kingma & Ba (2015) Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun (eds.), _3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings_, 2015. URL [http://arxiv.org/abs/1412.6980](http://arxiv.org/abs/1412.6980).
|
| 331 |
+
* Lillicrap et al. (2016) Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. In Yoshua Bengio and Yann LeCun (eds.), _4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings_, 2016. URL [http://arxiv.org/abs/1509.02971](http://arxiv.org/abs/1509.02971).
|
| 332 |
+
* Loizou et al. (2021) Nicolas Loizou, Sharan Vaswani, Issam Hadj Laradji, and Simon Lacoste-Julien. Stochastic polyak step-size for SGD: an adaptive learning rate for fast convergence. In Arindam Banerjee and Kenji Fukumizu (eds.), _The 24th International Conference on Artificial Intelligence and Statistics, AISTATS 2021, April 13-15, 2021, Virtual Event_, volume 130 of _Proceedings of Machine Learning Research_, pp. 1306–1314. PMLR, 2021. URL [http://proceedings.mlr.press/v130/loizou21a.html](http://proceedings.mlr.press/v130/loizou21a.html).
|
| 333 |
+
* Matsubara et al. (2010) Takamitsu Matsubara, Tetsuro Morimura, and Jun Morimoto. Adaptive step-size policy gradients with average reward metric. In Masashi Sugiyama and Qiang Yang (eds.), _Proceedings of the 2nd Asian Conference on Machine Learning, ACML 2010, Tokyo, Japan, November 8-10, 2010_, volume 13 of _JMLR Proceedings_, pp. 285–298. JMLR.org, 2010. URL [http://proceedings.mlr.press/v13/matsubara10a.html](http://proceedings.mlr.press/v13/matsubara10a.html).
|
| 334 |
+
* Mnih et al. (2016) Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In _Proceedings of The 33rd International Conference on Machine Learning_, volume 48 of _Proceedings of Machine Learning Research_, pp. 1928–1937, New York, New York, USA, 20–22 Jun 2016. PMLR.
|
| 335 |
+
* Orvieto et al. (2022) Antonio Orvieto, Simon Lacoste-Julien, and Nicolas Loizou. Dynamics of SGD with stochastic polyak stepsizes: Truly adaptive variants and convergence to exact solution. In Sanmi Koyejo, S.Mohamed, A.Agarwal, Danielle Belgrave, K.Cho, and A.Oh (eds.), _Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022_, 2022. URL [http://papers.nips.cc/paper_files/paper/2022/hash/ac662d74829e4407ce1d126477f4a03a-Abstract-Conference.html](http://papers.nips.cc/paper_files/paper/2022/hash/ac662d74829e4407ce1d126477f4a03a-Abstract-Conference.html).
|
| 336 |
+
* Paszke et al. (2017) Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. 2017.
|
| 337 |
+
* Peters et al. (2010) Jan Peters, Katharina Mülling, and Yasemin Altün. Relative entropy policy search. In _Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence_, pp. 1607–1612. AAAI Press, 2010.
|
| 338 |
+
* Pirotta et al. (2013) Matteo Pirotta, Marcello Restelli, and Luca Bascetta. Adaptive step-size for policy gradient methods. In Christopher J.C. Burges, Léon Bottou, Zoubin Ghahramani, and Kilian Q. Weinberger (eds.), _Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States_, pp. 1394–1402, 2013. URL [https://proceedings.neurips.cc/paper/2013/hash/f64eac11f2cd8f0efa196f8ad173178e-Abstract.html](https://proceedings.neurips.cc/paper/2013/hash/f64eac11f2cd8f0efa196f8ad173178e-Abstract.html).
|
| 339 |
+
* Polyak (1987) B.T. Polyak. Introduction to optimization. 1987. URL [https://api.semanticscholar.org/CorpusID:260584402](https://api.semanticscholar.org/CorpusID:260584402).
|
| 340 |
+
* Puterman (1994) Martin L. Puterman. _Markov Decision Processes: Discrete Stochastic Dynamic Programming_. John Wiley and Sons, Inc., USA, 1994. ISBN 0471619779.
|
| 341 |
+
* Schaipp et al. (2023) Fabian Schaipp, Ruben Ohana, Michael Eickenberg, Aaron Defazio, and Robert M. Gower. Momo: Momentum models for adaptive learning rates. _CoRR_, abs/2305.07583, 2023. doi: [10.48550/ARXIV.2305.07583](https://arxiv.org/html/2404.07525v1/10.48550/ARXIV.2305.07583). URL [https://doi.org/10.48550/arXiv.2305.07583](https://doi.org/10.48550/arXiv.2305.07583).
|
| 342 |
+
* Sutton & Barto (1998) Richard S. Sutton and Andrew G. Barto. Reinforcement learning: An introduction. _IEEE Trans. Neural Networks_, 9:1054–1054, 1998. URL [https://api.semanticscholar.org/CorpusID:60035920](https://api.semanticscholar.org/CorpusID:60035920).
|
| 343 |
+
* Vaswani et al. (2019) Sharan Vaswani, Aaron Mishkin, Issam H. Laradji, Mark Schmidt, Gauthier Gidel, and Simon Lacoste-Julien. Painless stochastic gradient: Interpolation, line-search, and convergence rates. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett (eds.), _Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada_, pp. 3727–3740, 2019. URL [https://proceedings.neurips.cc/paper/2019/hash/2557911c1bf75c2b643afb4ecbfc8ec2-Abstract.html](https://proceedings.neurips.cc/paper/2019/hash/2557911c1bf75c2b643afb4ecbfc8ec2-Abstract.html).
|
| 344 |
+
* Vaswani et al. (2022) Sharan Vaswani, Benjamin Dubois-Taine, and Reza Babanezhad. Towards noise-adaptive, problem-adaptive (accelerated) stochastic gradient descent. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato (eds.), _International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA_, volume 162 of _Proceedings of Machine Learning Research_, pp. 22015–22059. PMLR, 2022. URL [https://proceedings.mlr.press/v162/vaswani22a.html](https://proceedings.mlr.press/v162/vaswani22a.html).
|
| 345 |
+
* Williams (1992) R.J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. _Machine Learning_, 8:229–256, 1992.
|
| 346 |
+
* Williams & Peng (1991) Ronald J. Williams and Jing Peng. Function optimization using connectionist reinforcement learning algorithms. _Connection Science_, 3(3):241–268, 1991. doi: [10.1080/09540099108946587](https://arxiv.org/html/2404.07525v1/10.1080/09540099108946587).
|
| 347 |
+
|
| 348 |
+
Appendix
|
| 349 |
+
--------
|
| 350 |
+
|
| 351 |
+
Here, we provide a comprehensive overview of all experiment results.
|
| 352 |
+
|
| 353 |
+
### Performance with Adam
|
| 354 |
+
|
| 355 |
+
In this section, we present Adam’s performance in the Acrobot, CartPole, and LunarLander environments. We compare different step-sizes lr lr\operatorname{lr}roman_lr and also include exploration coefficient α 𝛼\alpha italic_α as mentioned in Section [4.1](https://arxiv.org/html/2404.07525v1#S4.SS1 "4.1 Stochastic update issue ‣ 4 Policy gradient with the Polyak step-size ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption"). As outlined in Section [5.3](https://arxiv.org/html/2404.07525v1#S5.SS3 "5.3 Results ‣ 5 Experiments ‣ Enhancing Policy Gradient with the Polyak Step-Size Adaption"), we observe that relatively large step-sizes lead to fast convergence but unstable results, while small step-sizes result in slower convergence but slightly greater stability.
|
| 356 |
+
|
| 357 |
+
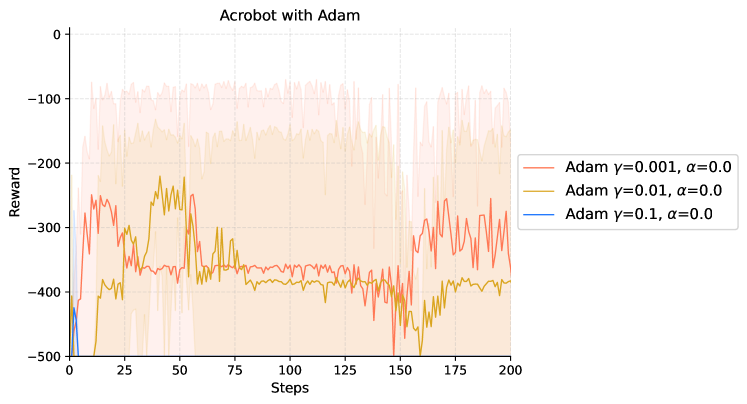
|
| 358 |
+
|
| 359 |
+
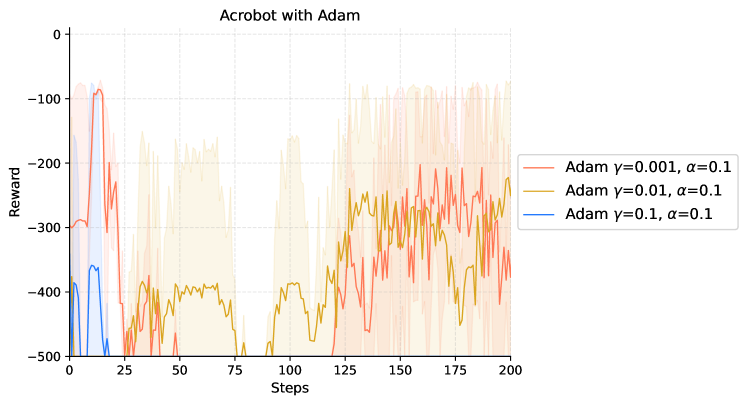
|
| 360 |
+
|
| 361 |
+
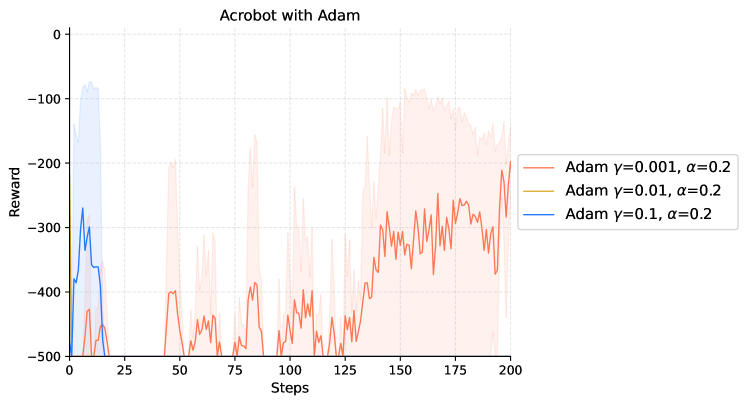
|
| 362 |
+
|
| 363 |
+
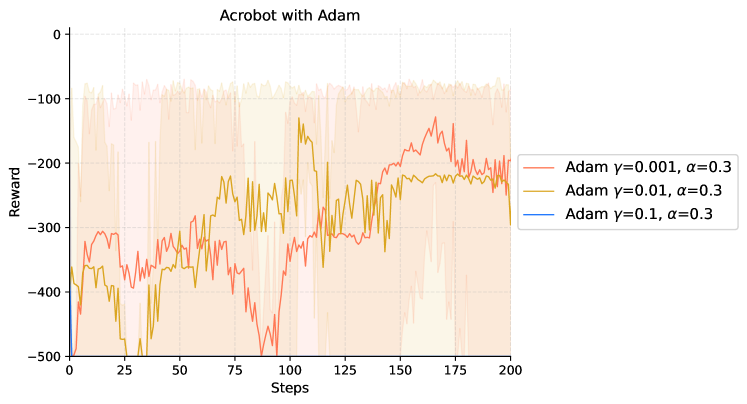
|
| 364 |
+
|
| 365 |
+
Figure 6: Performance of Adam in Acrobot.
|
| 366 |
+
|
| 367 |
+
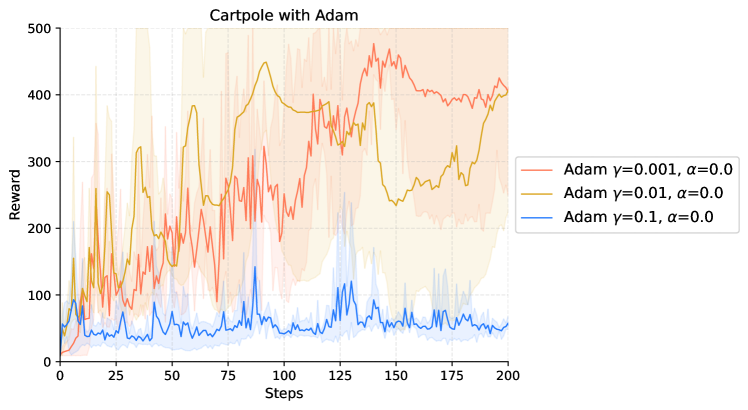
|
| 368 |
+
|
| 369 |
+
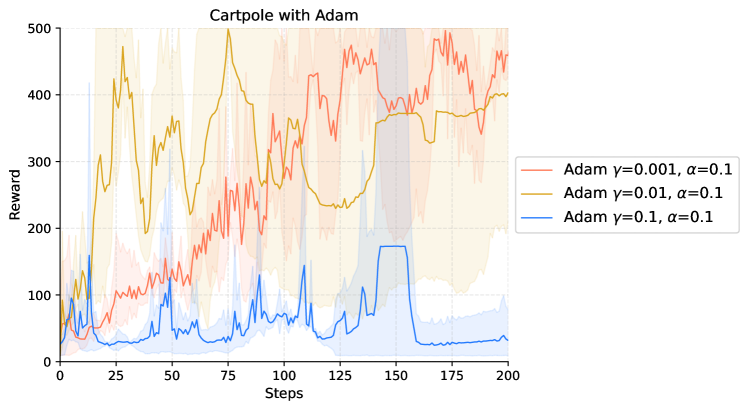
|
| 370 |
+
|
| 371 |
+
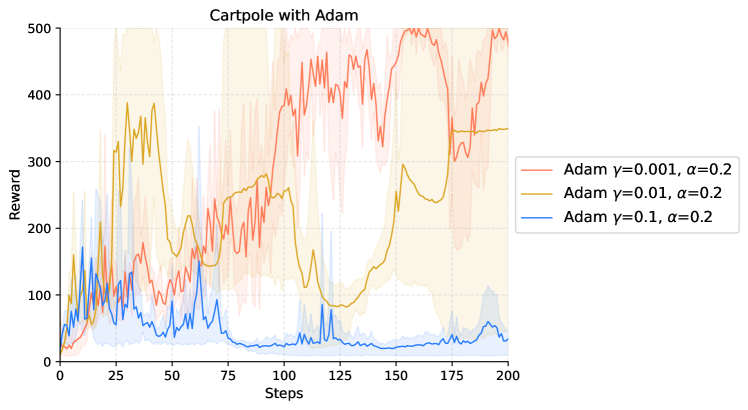
|
| 372 |
+
|
| 373 |
+
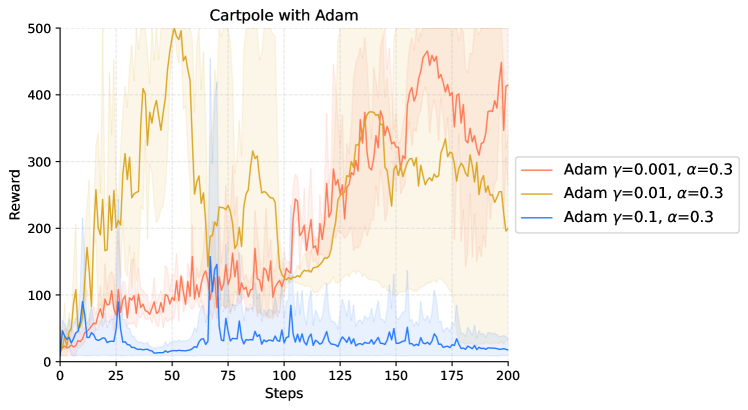
|
| 374 |
+
|
| 375 |
+
Figure 7: Performance of Adam in CartPole.
|
| 376 |
+
|
| 377 |
+
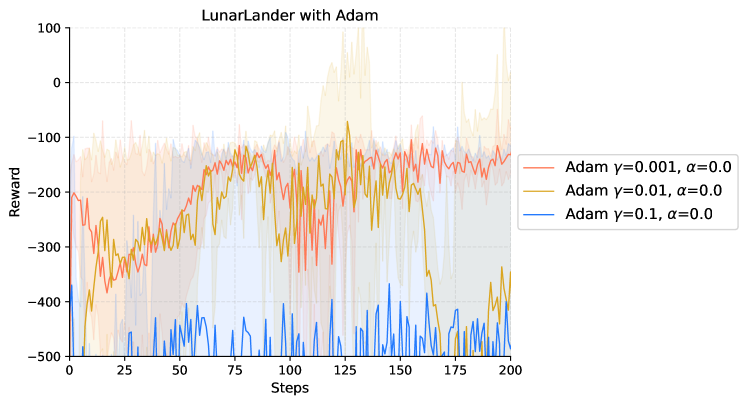
|
| 378 |
+
|
| 379 |
+
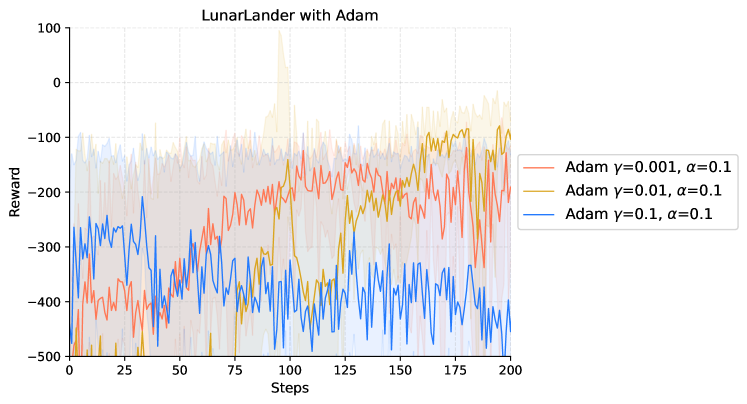
|
| 380 |
+
|
| 381 |
+
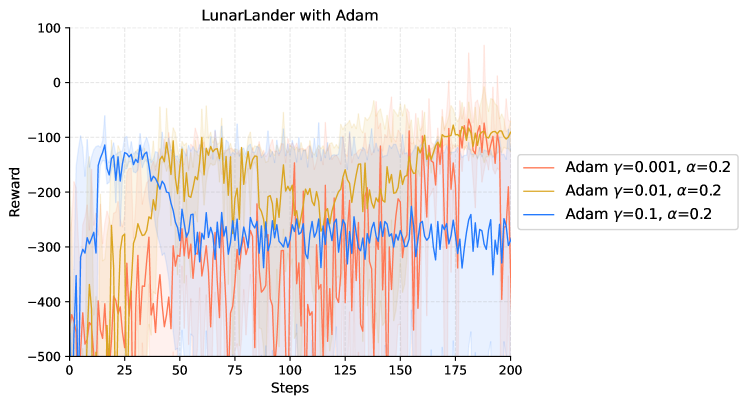
|
| 382 |
+
|
| 383 |
+
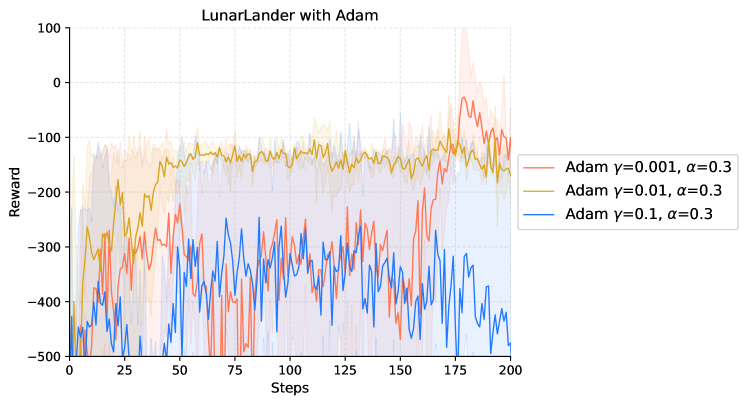
|
| 384 |
+
|
| 385 |
+
Figure 8: Performance of Adam in LunarLander.
|
| 386 |
+
|
| 387 |
+
### Performance with Polyak
|
| 388 |
+
|
| 389 |
+
Here, we showcase the performance of the Polyak method with varying values of c 𝑐 c italic_c and γ b subscript 𝛾 𝑏\gamma_{b}italic_γ start_POSTSUBSCRIPT italic_b end_POSTSUBSCRIPT in the environment Acrobot, CartPole and LunarLander. Our method exhibits robustness across different hyper-parameter combinations.
|
| 390 |
+
|
| 391 |
+
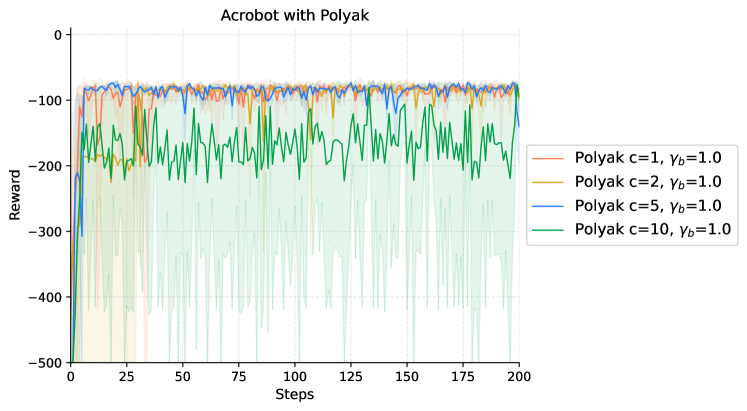
|
| 392 |
+
|
| 393 |
+
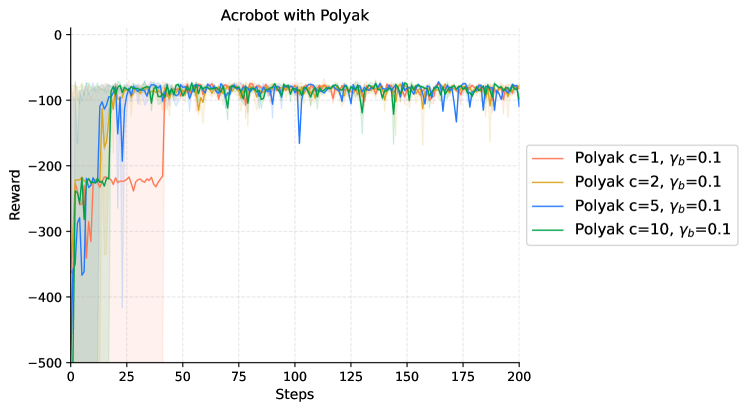
|
| 394 |
+
|
| 395 |
+
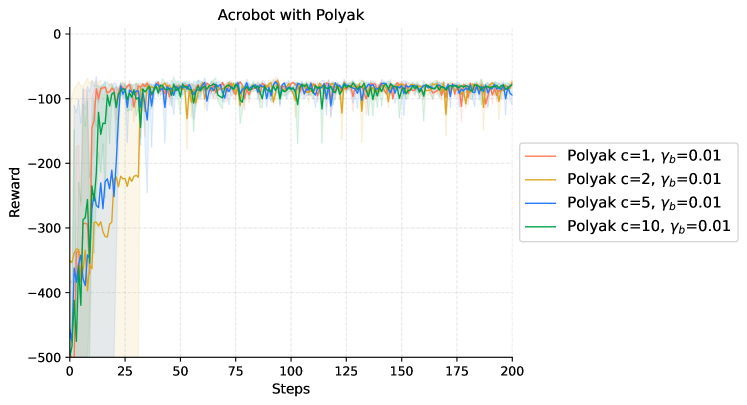
|
| 396 |
+
|
| 397 |
+
Figure 9: Performance of Polyak in Acrobot.
|
| 398 |
+
|
| 399 |
+
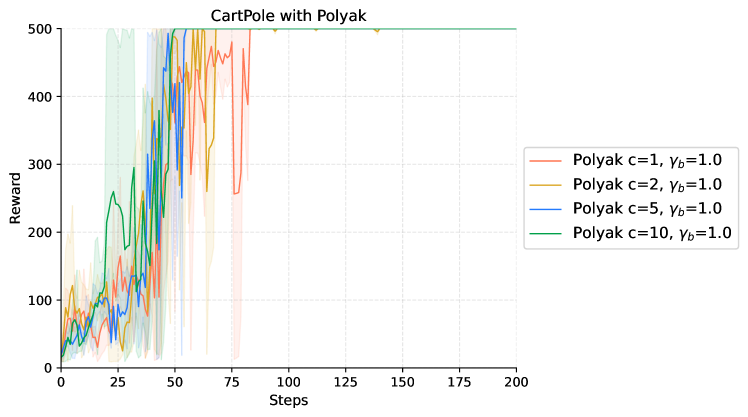
|
| 400 |
+
|
| 401 |
+
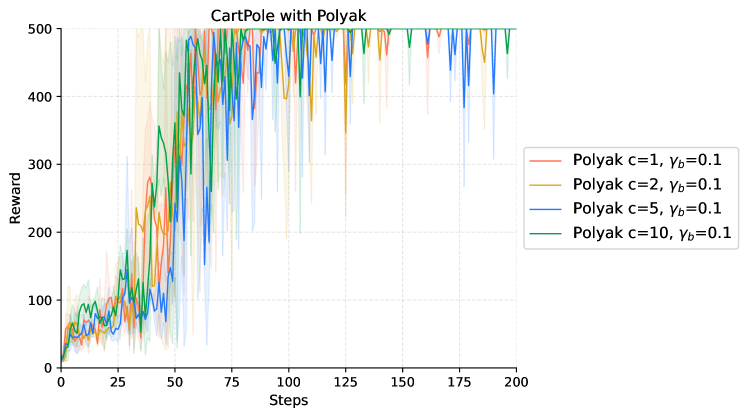
|
| 402 |
+
|
| 403 |
+
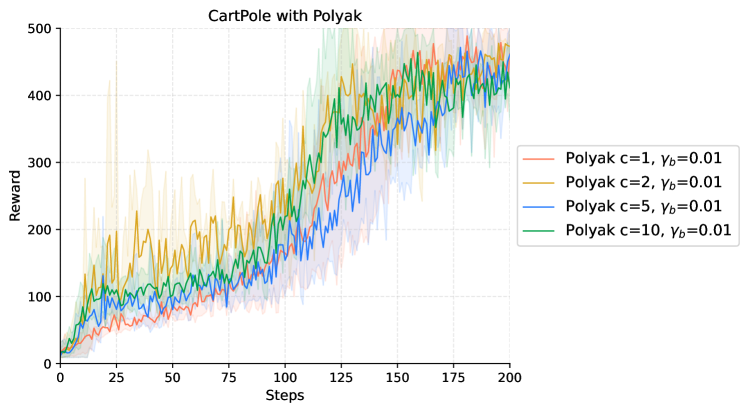
|
| 404 |
+
|
| 405 |
+
Figure 10: Performance of Polyak in CartPole.
|
| 406 |
+
|
| 407 |
+
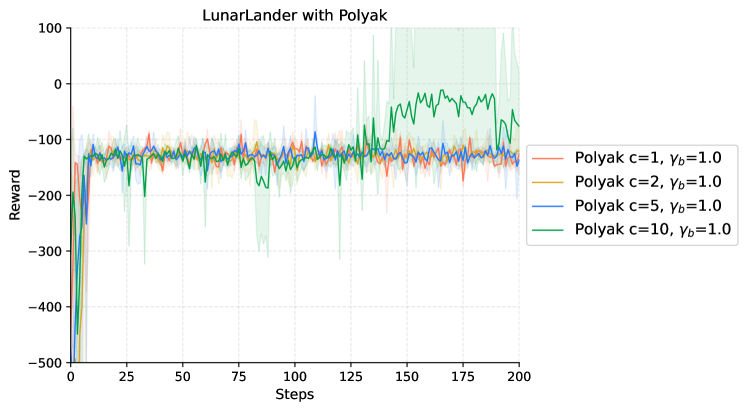
|
| 408 |
+
|
| 409 |
+
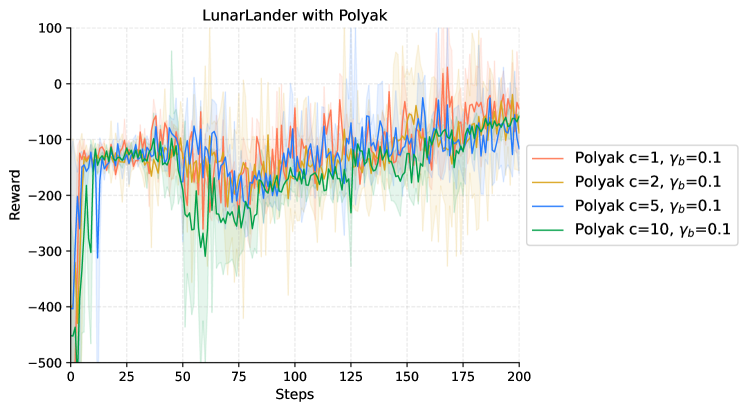
|
| 410 |
+
|
| 411 |
+
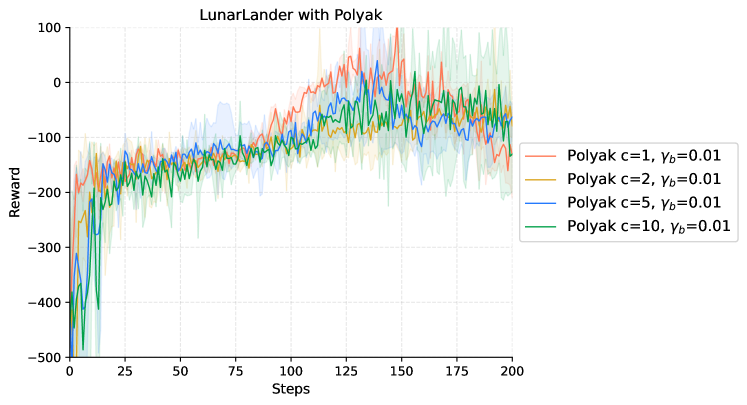
|
| 412 |
+
|
| 413 |
+
Figure 11: Performance of Polyak in LunarLander.
|
| 414 |
+
|
| 415 |
+
### Step-size in Polyak method
|
| 416 |
+
|
| 417 |
+
Here, we display the step sizes corresponding to the Polyak experiments. It is evident that our method automatically adjusts the step size.
|
| 418 |
+
|
| 419 |
+
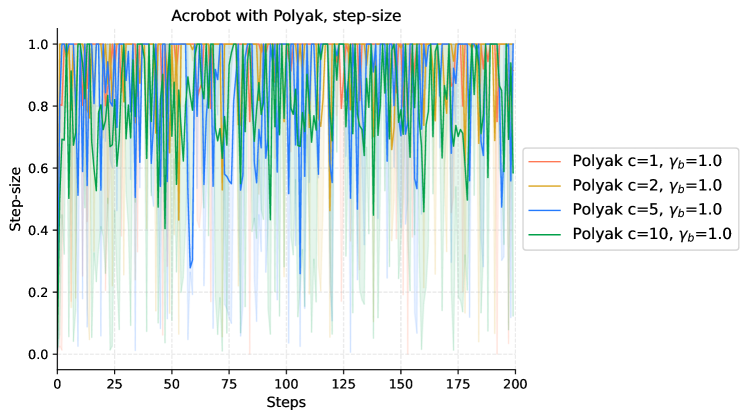
|
| 420 |
+
|
| 421 |
+
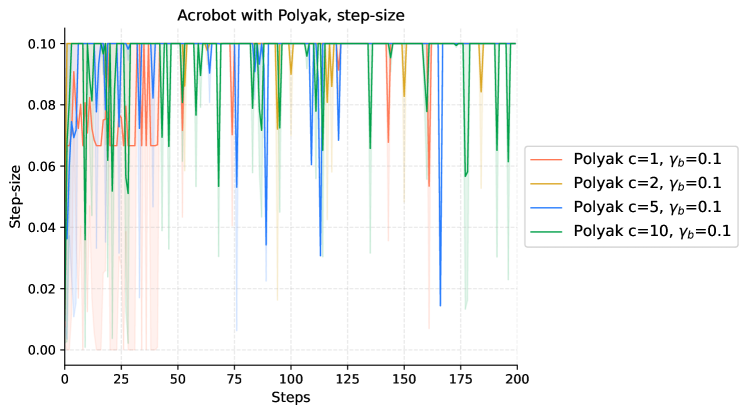
|
| 422 |
+
|
| 423 |
+
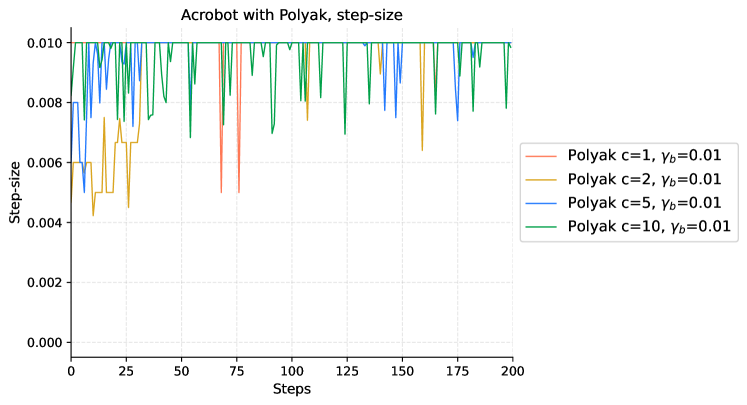
|
| 424 |
+
|
| 425 |
+
Figure 12: Step-size of Polyak method in Acrobot.
|
| 426 |
+
|
| 427 |
+
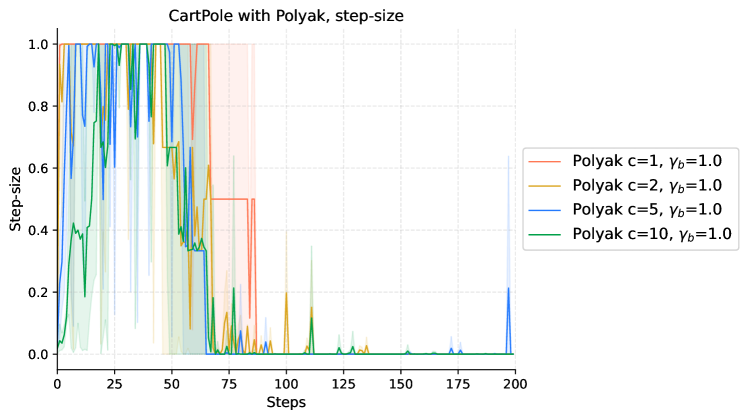
|
| 428 |
+
|
| 429 |
+
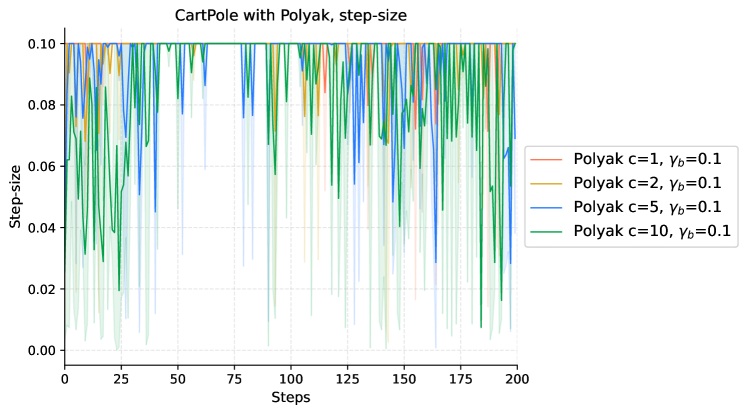
|
| 430 |
+
|
| 431 |
+
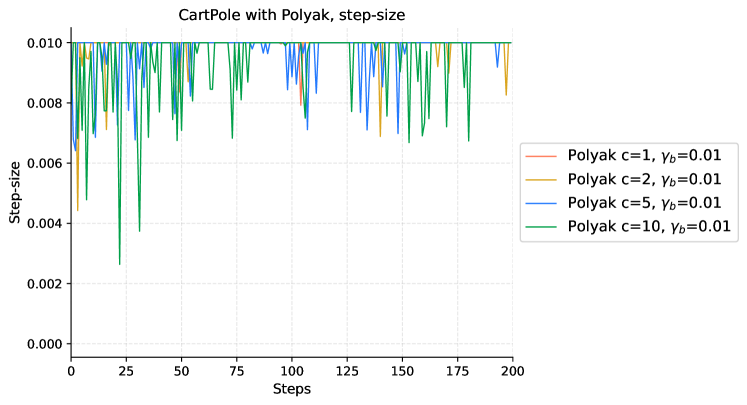
|
| 432 |
+
|
| 433 |
+
Figure 13: step-size of Polyak method in CartPole.
|
| 434 |
+
|
| 435 |
+
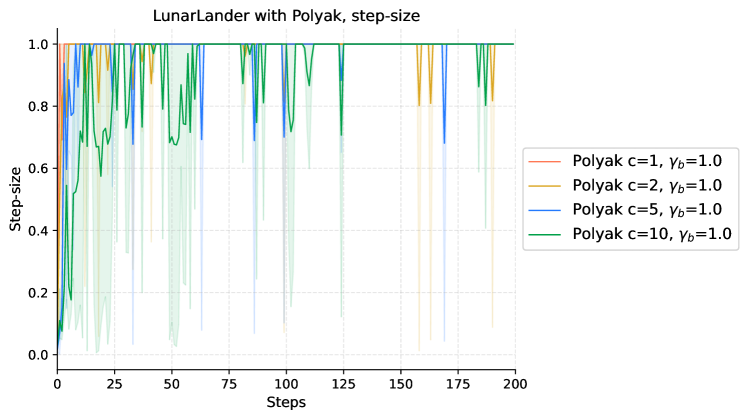
|
| 436 |
+
|
| 437 |
+
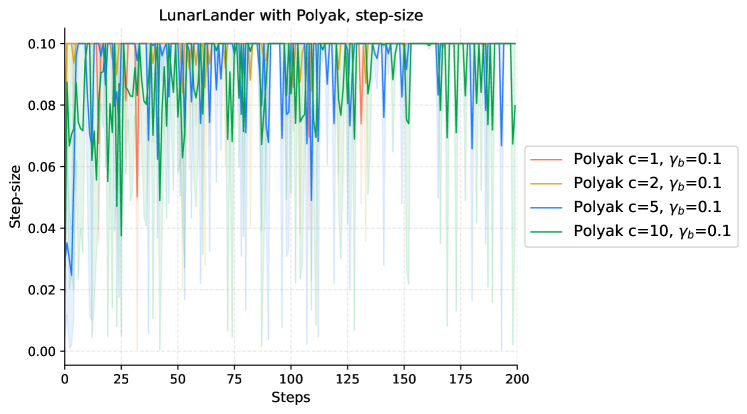
|
| 438 |
+
|
| 439 |
+
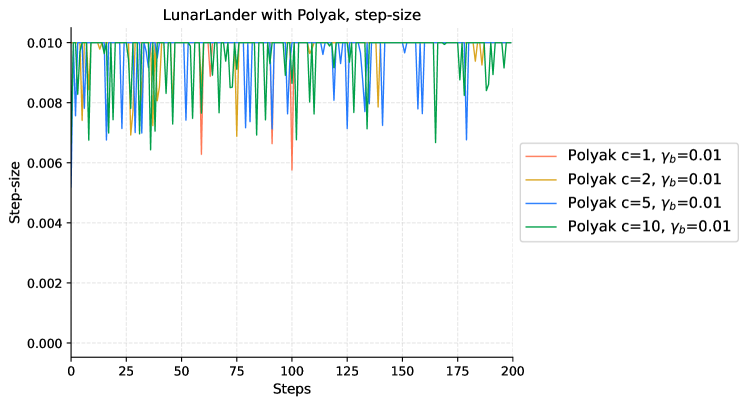
|
| 440 |
+
|
| 441 |
+
Figure 14: step-size of Polyak method in LunarLander.
|
| 442 |
+
|
| 443 |
+
### Value of V*−V superscript 𝑉 𝑉 V^{*}-V italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT - italic_V in Polyak method
|
| 444 |
+
|
| 445 |
+
Here, we present the difference between the value functions V*superscript 𝑉 V^{*}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT and V 𝑉 V italic_V, where V*superscript 𝑉 V^{*}italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT represents the larger value function and V 𝑉 V italic_V represents the smaller one between two models. We illustrate how both models are updated simultaneously.
|
| 446 |
+
|
| 447 |
+
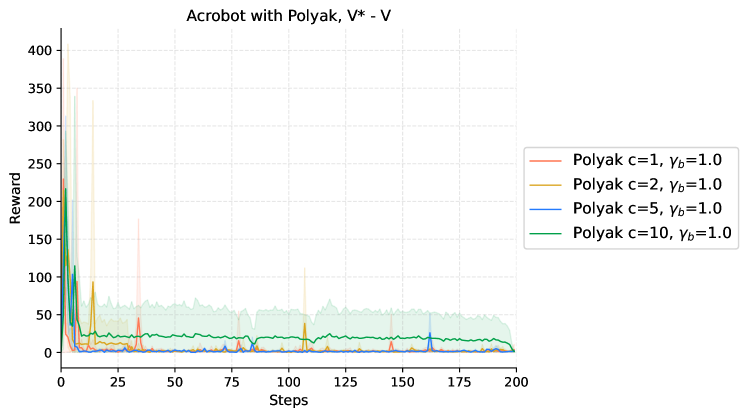
|
| 448 |
+
|
| 449 |
+
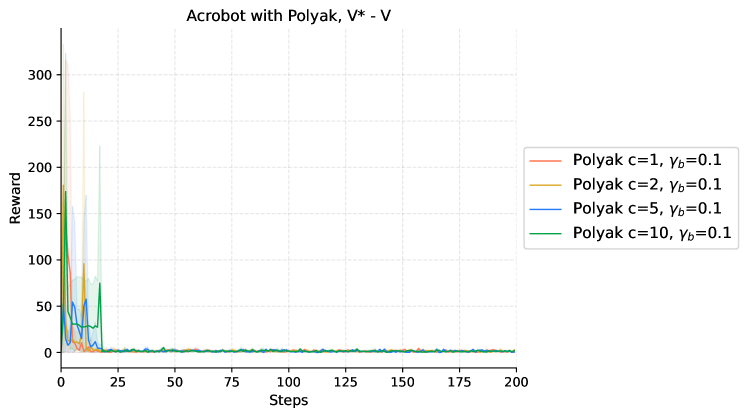
|
| 450 |
+
|
| 451 |
+
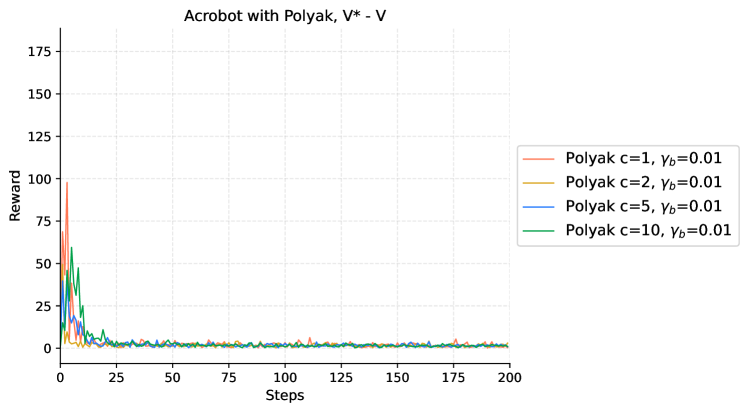
|
| 452 |
+
|
| 453 |
+
Figure 15: Value of V*−V superscript 𝑉 𝑉 V^{*}-V italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT - italic_V in Polyak method in Acrobot.
|
| 454 |
+
|
| 455 |
+
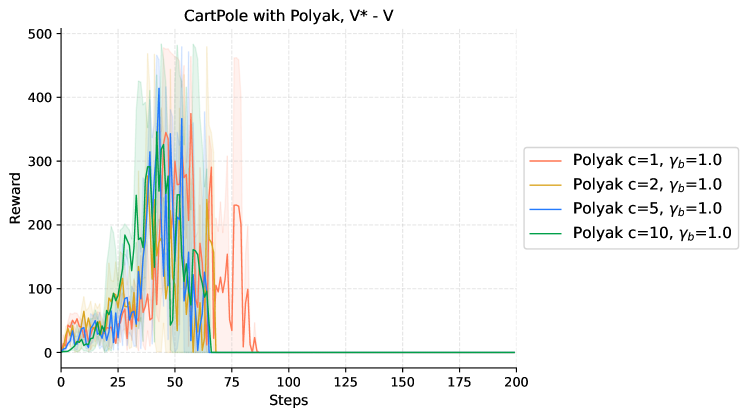
|
| 456 |
+
|
| 457 |
+
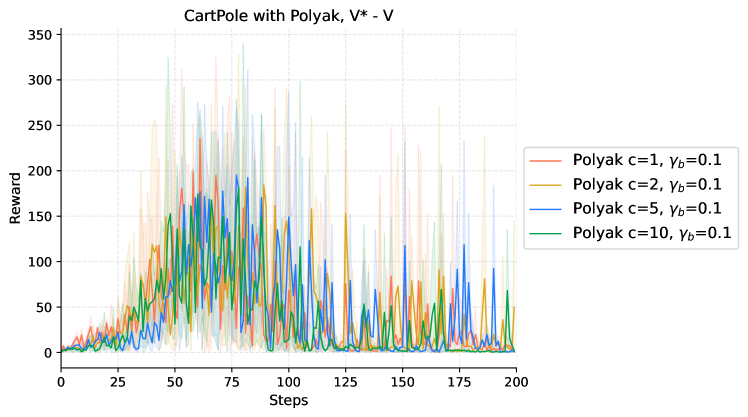
|
| 458 |
+
|
| 459 |
+
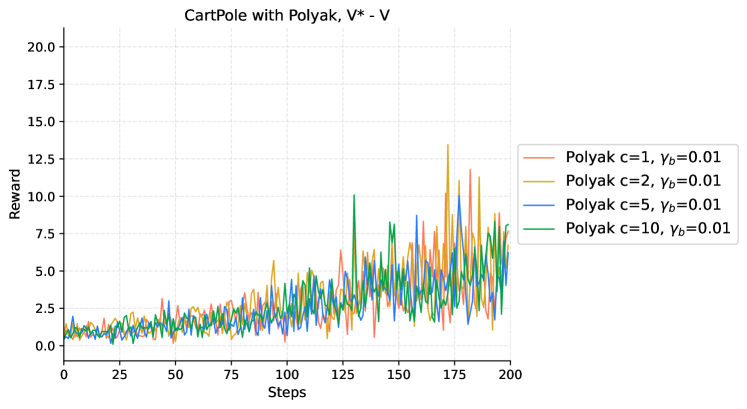
|
| 460 |
+
|
| 461 |
+
Figure 16: Value of V*−V superscript 𝑉 𝑉 V^{*}-V italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT - italic_V in Polyak method in CartPole.
|
| 462 |
+
|
| 463 |
+
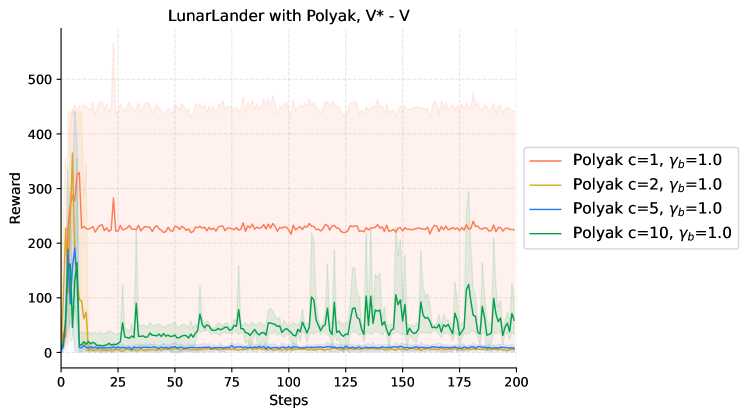
|
| 464 |
+
|
| 465 |
+
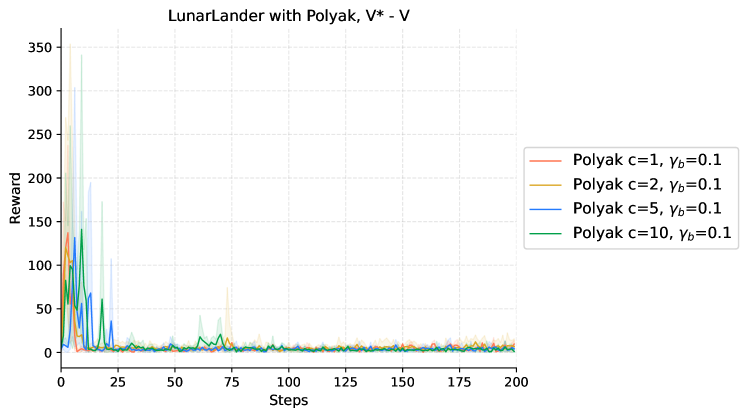
|
| 466 |
+
|
| 467 |
+
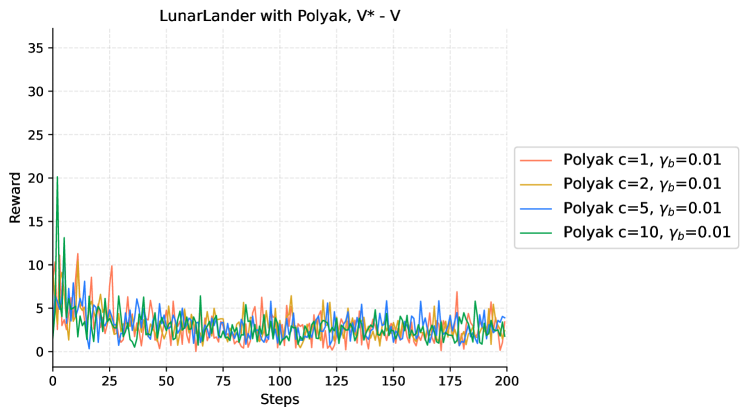
|
| 468 |
+
|
| 469 |
+
Figure 17: Value of V*−V superscript 𝑉 𝑉 V^{*}-V italic_V start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT - italic_V in Polyak method in LunarLander.
|