

Add 1 files
Browse files- 2601/2601.05729.md +261 -0
2601/2601.05729.md
ADDED
|
@@ -0,0 +1,261 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
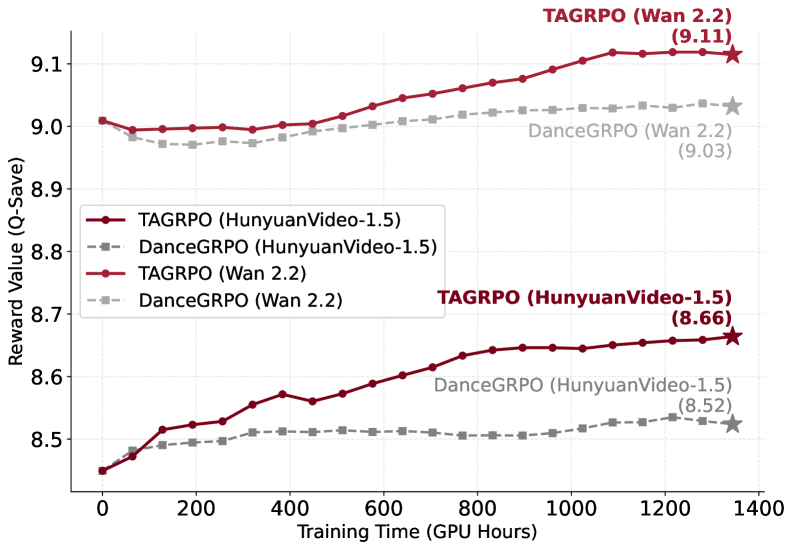
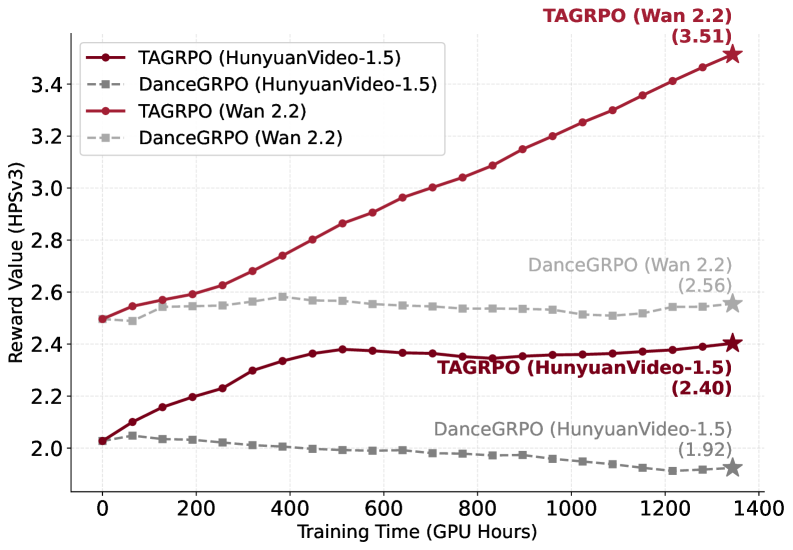
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
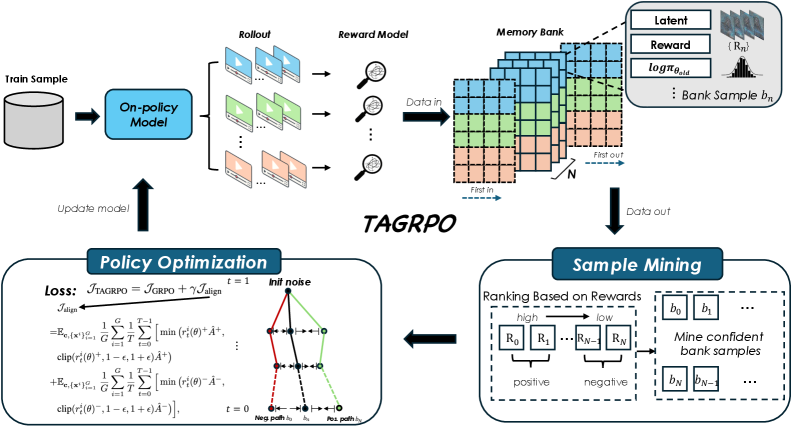
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
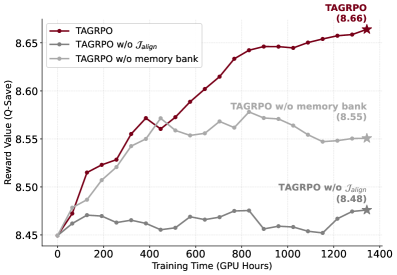
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2601.05729
|
| 4 |
+
|
| 5 |
+
Markdown Content:
|
| 6 |
+
Jianxiang Lu Guangzheng Xu Comi Chen Haoyu Yang Linqing Wang Peng Chen Mingtao Chen Zhichao Hu Longhuang Wu Shuai Shao Qinglin Lu Ping Luo
|
| 7 |
+
|
| 8 |
+
###### Abstract
|
| 9 |
+
|
| 10 |
+
Recent studies have demonstrated the efficacy of integrating Group Relative Policy Optimization (GRPO) into flow matching models, particularly for text-to-image and text-to-video generation. However, we find that directly applying these techniques to image-to-video (I2V) models often fails to yield consistent reward improvements. To address this limitation, we present TAGRPO, a robust post-training framework for I2V models inspired by contrastive learning. Our approach is grounded in the observation that rollout videos generated from identical initial noise provide superior guidance for optimization. Leveraging this insight, we propose a novel GRPO loss applied to intermediate latents, encouraging direct alignment with high-reward trajectories while maximizing distance from low-reward counterparts. Furthermore, we introduce a memory bank for rollout videos to enhance diversity and reduce computational overhead. Despite its simplicity, TAGRPO achieves significant improvements over DanceGRPO in I2V generation. Code and models will be made publicly available.
|
| 11 |
+
|
| 12 |
+
Machine Learning, ICML
|
| 13 |
+
|
| 14 |
+
\icmlcorrespondingauthorjinjin
|
| 15 |
+
|
| 16 |
+
Qinglin Lu
|
| 17 |
+
|
| 18 |
+
1 Introduction
|
| 19 |
+
--------------
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
Figure 1: Performance of the proposed TAGRPO. We mainly compared our method with DanceGRPO(Xue et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib35 "DanceGRPO: unleashing grpo on visual generation")), as existing open‑sourced implementations of visual GRPO methods (Liu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib34 "Flow-grpo: training flow matching models via online rl"); He et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib38 "Tempflow-grpo: when timing matters for grpo in flow models"); Zheng et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib39 "Diffusionnft: online diffusion reinforcement with forward process")) typically support text‑conditioned tasks, with DanceGRPO being the only exception. The results demonstrate that TAGRPO achieved faster convergence and consistently higher reward gains on both Wan 2.2 (Wan et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib29 "Wan: open and advanced large-scale video generative models")) and HunyuanVideo-1.5 (Wu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib87 "HunyuanVideo 1.5 technical report")). We used Q‑Save(Wu et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib88 "Q-save: towards scoring and attribution for generated video evaluation")) and HPSv3(Ma et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib84 "Hpsv3: towards wide-spectrum human preference score")) as reward models, and all reported reward values were averaged over the evaluation set.
|
| 26 |
+
|
| 27 |
+
With the development of diffusion models (Ho et al., [2020](https://arxiv.org/html/2601.05729v1#bib.bib21 "Denoising diffusion probabilistic models"); [Song et al.,](https://arxiv.org/html/2601.05729v1#bib.bib23 "Score-based generative modeling through stochastic differential equations"); [Lipman et al.,](https://arxiv.org/html/2601.05729v1#bib.bib15 "Flow matching for generative modeling"); [Liu et al.,](https://arxiv.org/html/2601.05729v1#bib.bib16 "Flow straight and fast: learning to generate and transfer data with rectified flow"); Peebles and Xie, [2023](https://arxiv.org/html/2601.05729v1#bib.bib24 "Scalable diffusion models with transformers"); Dhariwal and Nichol, [2021](https://arxiv.org/html/2601.05729v1#bib.bib22 "Diffusion models beat gans on image synthesis")), recent years have witnessed the success of AIGC technology in text-to-image generation (Rombach et al., [2022](https://arxiv.org/html/2601.05729v1#bib.bib18 "High-resolution image synthesis with latent diffusion models"); Esser et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib17 "Scaling rectified flow transformers for high-resolution image synthesis"); Labs, [2024](https://arxiv.org/html/2601.05729v1#bib.bib20 "FLUX"); Labs et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib19 "FLUX.1 kontext: flow matching for in-context image generation and editing in latent space"); [Chen et al.,](https://arxiv.org/html/2601.05729v1#bib.bib32 "PixArt-alpha: fast training of diffusion transformer for photorealistic text-to-image synthesis")) and text-to-video generation (Ho et al., [2022](https://arxiv.org/html/2601.05729v1#bib.bib26 "Video diffusion models"); Blattmann et al., [2023](https://arxiv.org/html/2601.05729v1#bib.bib25 "Stable video diffusion: scaling latent video diffusion models to large datasets"); Yang et al., [2024c](https://arxiv.org/html/2601.05729v1#bib.bib27 "Cogvideox: text-to-video diffusion models with an expert transformer"); Kong et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib28 "Hunyuanvideo: a systematic framework for large video generative models"); Wan et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib29 "Wan: open and advanced large-scale video generative models"); Zheng et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib30 "Open-sora: democratizing efficient video production for all"); Lin et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib31 "Open-sora plan: open-source large video generation model")). To further enhance alignment between generated content and human preferences, recent studies (Liu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib34 "Flow-grpo: training flow matching models via online rl"); Xue et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib35 "DanceGRPO: unleashing grpo on visual generation")) have applied reinforcement learning techniques, such as GRPO (Shao et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib33 "Deepseekmath: pushing the limits of mathematical reasoning in open language models")), to visual generative models, achieving significant progress.
|
| 28 |
+
|
| 29 |
+
Most existing work (He et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib38 "Tempflow-grpo: when timing matters for grpo in flow models"); Li et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib36 "Branchgrpo: stable and efficient grpo with structured branching in diffusion models"), [a](https://arxiv.org/html/2601.05729v1#bib.bib37 "Mixgrpo: unlocking flow-based grpo efficiency with mixed ode-sde"); Fu et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib42 "Dynamic-treerpo: breaking the independent trajectory bottleneck with structured sampling")) has primarily focused on text-conditioned generation paradigms. In contrast, image-to-video generation (Wan et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib29 "Wan: open and advanced large-scale video generative models"); Kong et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib28 "Hunyuanvideo: a systematic framework for large video generative models"); Chen et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib43 "Skyreels-v2: infinite-length film generative model")) remains underexplored, despite its broad applicability in domains such as animation (Hu, [2024](https://arxiv.org/html/2601.05729v1#bib.bib50 "Animate anyone: consistent and controllable image-to-video synthesis for character animation")), content creation (Yang et al., [2024a](https://arxiv.org/html/2601.05729v1#bib.bib49 "Hi3d: pursuing high-resolution image-to-3d generation with video diffusion models")), and visual effects (Mao et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib48 "Omni-effects: unified and spatially-controllable visual effects generation")). Notably, we observe that directly applying existing visual GRPO methods (Liu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib34 "Flow-grpo: training flow matching models via online rl"); Xue et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib35 "DanceGRPO: unleashing grpo on visual generation")) to state-of-the-art image-to-video models—such as Wan 2.2 (Wan et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib29 "Wan: open and advanced large-scale video generative models")) and HunyuanVideo-1.5 (Wu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib87 "HunyuanVideo 1.5 technical report"))—fails to yield consistent reward improvements. This observation raises a critical question: Can we devise an effective GRPO framework tailored for image-to-video generation?
|
| 30 |
+
|
| 31 |
+
In this paper, we present TAGRPO, an effective GRPO framework for post-training image-to-video models based on the concept of T rajectory A lignment. We observe that existing methods (Liu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib34 "Flow-grpo: training flow matching models via online rl"); Xue et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib35 "DanceGRPO: unleashing grpo on visual generation")) typically rely on reward signals to modulate the probability of each sample individually, thereby overlooking valuable relational guidance among generated samples within a group. This oversight is critical: since videos generated from the same conditioning image share significant structural content, the relative relationships among their trajectories offer rich optimization cues. Consequently, rather than merely suppressing the generation probability of a negative sample, it is more intuitive and effective to further align its trajectory with those of positive samples within the same group.
|
| 32 |
+
|
| 33 |
+
To leverage this insight, we propose to directly align the inference trajectory by applying a new trajectory-wise GRPO loss to intermediate latents based on reward rankings. Concretely, we encourage latents to align more closely with those from higher-reward videos while maintaining greater distance from lower-reward counterparts. Experiments demonstrate that this simple yet effective approach yields significant improvements, validating the importance of exploiting inter-sample relationships for image-to-video generation. Besides, inspired by the core concepts in contrastive learning (He et al., [2020](https://arxiv.org/html/2601.05729v1#bib.bib51 "Momentum contrast for unsupervised visual representation learning")), we propose to maintain a memory bank for keeping previous generated samples’ latents and reward signals in our proposed TAGRPO. This could release the burden for preparing a large batch of rollout videos for every step, allowing the model to effectively exploit previous generated samples. As shown in Figure [1](https://arxiv.org/html/2601.05729v1#S1.F1 "Figure 1 ‣ 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), we applied our method to advanced image-to-video models (Wan et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib29 "Wan: open and advanced large-scale video generative models"); Wu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib87 "HunyuanVideo 1.5 technical report")), achieving significant improvements over DanceGRPO (Xue et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib35 "DanceGRPO: unleashing grpo on visual generation")).
|
| 34 |
+
|
| 35 |
+
The contributions of our paper are summarized as follows: 1) We propose TAGRPO, a novel trajectory alignment framework that leverages relative relationships among generated samples. This approach provides more informative optimization signals for image-to-video generation. 2) We introduce a memory bank mechanism that enables efficient exploitation of historical samples, significantly reducing the computational requirements for rollout generation while maintaining optimization effectiveness. 3) Through extensive experiments on advanced image-to-video models (Wan et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib29 "Wan: open and advanced large-scale video generative models"); Wu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib87 "HunyuanVideo 1.5 technical report")), we demonstrate that TAGRPO achieves substantial improvements across multiple metrics, establishing a new state-of-the-art for GRPO-based post-training in image-to-video generation. We will open-source our code and trained models to facilitate future research.
|
| 36 |
+
|
| 37 |
+
2 Related Work
|
| 38 |
+
--------------
|
| 39 |
+
|
| 40 |
+
### 2.1 Image-to-Video Diffusion Models
|
| 41 |
+
|
| 42 |
+
Recent advancements in diffusion-based generative models (Ho et al., [2020](https://arxiv.org/html/2601.05729v1#bib.bib21 "Denoising diffusion probabilistic models"); Dhariwal and Nichol, [2021](https://arxiv.org/html/2601.05729v1#bib.bib22 "Diffusion models beat gans on image synthesis"); Rombach et al., [2022](https://arxiv.org/html/2601.05729v1#bib.bib18 "High-resolution image synthesis with latent diffusion models"); Labs, [2024](https://arxiv.org/html/2601.05729v1#bib.bib20 "FLUX")) have extended their capabilities beyond static image synthesis, giving rise to powerful image-to-video (I2V) diffusion frameworks. Unlike text-to-video generation, I2V generation aims to produce temporally coherent motion sequences from one or a few reference images, often guided by corresponding textual prompts. Early works explored different strategies to achieve this goal. Some studies (Voleti et al., [2022](https://arxiv.org/html/2601.05729v1#bib.bib58 "Mcvd-masked conditional video diffusion for prediction, generation, and interpolation"); Chen et al., [2023b](https://arxiv.org/html/2601.05729v1#bib.bib59 "Seine: short-to-long video diffusion model for generative transition and prediction")) adopted mask-based approaches to model motion dynamics while preserving static regions in the input image. Others (Zhang et al., [2023](https://arxiv.org/html/2601.05729v1#bib.bib61 "I2vgen-xl: high-quality image-to-video synthesis via cascaded diffusion models"); Chen et al., [2023a](https://arxiv.org/html/2601.05729v1#bib.bib62 "Videocrafter1: open diffusion models for high-quality video generation")) leveraged CLIP (Radford et al., [2021](https://arxiv.org/html/2601.05729v1#bib.bib60 "Learning transferable visual models from natural language supervision")) embeddings to extract semantic visual guidance for conditioning the generation process. A separate line of research (Blattmann et al., [2023](https://arxiv.org/html/2601.05729v1#bib.bib25 "Stable video diffusion: scaling latent video diffusion models to large datasets"); Zeng et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib64 "Make pixels dance: high-dynamic video generation")) focused on encoding visual embeddings within the VAE latent space to better align appearance and motion consistency across frames. In recent years, the emergence of efficient training methodologies ([Lipman et al.,](https://arxiv.org/html/2601.05729v1#bib.bib15 "Flow matching for generative modeling"); [Liu et al.,](https://arxiv.org/html/2601.05729v1#bib.bib16 "Flow straight and fast: learning to generate and transfer data with rectified flow")) and the rapid growth of large-scale video datasets (Chen et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib55 "Panda-70m: captioning 70m videos with multiple cross-modality teachers"); Wang and Yang, [2024](https://arxiv.org/html/2601.05729v1#bib.bib54 "Vidprom: a million-scale real prompt-gallery dataset for text-to-video diffusion models")) and have further accelerated progress, resulting in advanced I2V models (Zheng et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib30 "Open-sora: democratizing efficient video production for all"); Yang et al., [2024c](https://arxiv.org/html/2601.05729v1#bib.bib27 "Cogvideox: text-to-video diffusion models with an expert transformer"); Shi et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib63 "Motion-i2v: consistent and controllable image-to-video generation with explicit motion modeling"); Wang et al., [2023](https://arxiv.org/html/2601.05729v1#bib.bib65 "Videocomposer: compositional video synthesis with motion controllability"); Xing et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib66 "Dynamicrafter: animating open-domain images with video diffusion priors"); Tian et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib67 "Extrapolating and decoupling image-to-video generation models: motion modeling is easier than you think"); Guo et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib68 "I2v-adapter: a general image-to-video adapter for diffusion models")) such as Sora (OpenAI, [2024](https://arxiv.org/html/2601.05729v1#bib.bib52 "Sora: creating video from text")), Seedance (Gao et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib57 "Seedance 1.0: exploring the boundaries of video generation models")), Wan (Wan et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib29 "Wan: open and advanced large-scale video generative models")), Veo (DeepMind, [2025](https://arxiv.org/html/2601.05729v1#bib.bib56 "Veo3: our state-of-the-art video generation model")), and HunyuanVideo (Kong et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib28 "Hunyuanvideo: a systematic framework for large video generative models")). These systems deliver substantial improvements in visual quality, temporal stability, and motion fidelity. Despite these remarkable advancements in architecture and training, post-training techniques for image-to-video generation—such as reinforcement learning (RL)—remain underexplored, presenting an important direction for future research.
|
| 43 |
+
|
| 44 |
+
### 2.2 RL for Diffusion Models
|
| 45 |
+
|
| 46 |
+
Research on applying reinforcement learning (RL) techniques to the visual domain has expanded rapidly in recent years. Some approaches (Xu et al., [2023](https://arxiv.org/html/2601.05729v1#bib.bib69 "Imagereward: learning and evaluating human preferences for text-to-image generation"); Shen et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib70 "Directly aligning the full diffusion trajectory with fine-grained human preference"); Clark et al., [2023](https://arxiv.org/html/2601.05729v1#bib.bib72 "Directly fine-tuning diffusion models on differentiable rewards"); Prabhudesai et al., [2023](https://arxiv.org/html/2601.05729v1#bib.bib71 "Aligning text-to-image diffusion models with reward backpropagation"), [2024](https://arxiv.org/html/2601.05729v1#bib.bib73 "Video diffusion alignment via reward gradients")) incorporated reward-based optimization, where reward signals are backpropagated through the inference process to refine generative outputs toward desired objectives. Other works (Wallace et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib75 "Diffusion model alignment using direct preference optimization"); Liu et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib76 "Videodpo: omni-preference alignment for video diffusion generation"); Yang et al., [2024b](https://arxiv.org/html/2601.05729v1#bib.bib77 "Using human feedback to fine-tune diffusion models without any reward model"); Liang et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib78 "Step-aware preference optimization: aligning preference with denoising performance at each step"); Yuan et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib79 "Self-play fine-tuning of diffusion models for text-to-image generation"); Zhang et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib80 "Onlinevpo: align video diffusion model with online video-centric preference optimization"); Furuta et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib81 "Improving dynamic object interactions in text-to-video generation with ai feedback"); Liang et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib82 "Aesthetic post-training diffusion models from generic preferences with step-by-step preference optimization")) extended Direct Preference Optimization (DPO) (Rafailov et al., [2023](https://arxiv.org/html/2601.05729v1#bib.bib74 "Direct preference optimization: your language model is secretly a reward model")) to visual generation tasks, aligning model outputs with human preferences. Building on this progress, recent studies (Liu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib34 "Flow-grpo: training flow matching models via online rl"); Xue et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib35 "DanceGRPO: unleashing grpo on visual generation")) introduced Group Relative Policy Optimization (GRPO) into the visual domain, leveraging its success in large language models (LLMs) (Shao et al., [2024](https://arxiv.org/html/2601.05729v1#bib.bib33 "Deepseekmath: pushing the limits of mathematical reasoning in open language models")) to improve training stability and reward efficiency. Subsequent works further optimized computational cost by refining the rollout procedure (Li et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib37 "Mixgrpo: unlocking flow-based grpo efficiency with mixed ode-sde"); He et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib38 "Tempflow-grpo: when timing matters for grpo in flow models"); Fu et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib42 "Dynamic-treerpo: breaking the independent trajectory bottleneck with structured sampling"); Li et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib36 "Branchgrpo: stable and efficient grpo with structured branching in diffusion models")) or by developing feed-forward alternatives that bypass iterative sampling (Zheng et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib39 "Diffusionnft: online diffusion reinforcement with forward process"); Li et al., [2025c](https://arxiv.org/html/2601.05729v1#bib.bib40 "Uniworld-v2: reinforce image editing with diffusion negative-aware finetuning and mllm implicit feedback"); Xue et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib41 "Advantage weighted matching: aligning rl with pretraining in diffusion models")). Despite these promising advances, existing RL-based approaches have predominantly focused on text-conditioned generative tasks, leaving image-to-video generation largely unexplored. This gap highlights an important opportunity for integrating reinforcement learning to enhance the generation quality in I2V diffusion models.
|
| 47 |
+
|
| 48 |
+
3 Method
|
| 49 |
+
--------
|
| 50 |
+
|
| 51 |
+
### 3.1 Preliminaries
|
| 52 |
+
|
| 53 |
+
#### 3.1.1 Image-to-Video Diffusion Models
|
| 54 |
+
|
| 55 |
+
Image-to-video (I2V) diffusion models extend conventional diffusion-based generators to the spatio-temporal setting, aiming to synthesize temporally coherent motion sequences conditioned on one or more reference images. Given a conditional signal 𝐜\mathbf{c} including an input image and its associated textual prompt, an I2V model produces a corresponding video 𝐱 0\mathbf{x}_{0}. The condition image serves as the first frame of the generated video 𝐱 0\mathbf{x}_{0}.
|
| 56 |
+
|
| 57 |
+
Following recent advances in flow-matching frameworks([Lipman et al.,](https://arxiv.org/html/2601.05729v1#bib.bib15 "Flow matching for generative modeling"); [Liu et al.,](https://arxiv.org/html/2601.05729v1#bib.bib16 "Flow straight and fast: learning to generate and transfer data with rectified flow")), the forward noising process is defined as a linear interpolation between the conditional input and Gaussian noise:
|
| 58 |
+
|
| 59 |
+
𝐱 t=(1−t)𝐱 0+t𝐱 1,𝐱 1∼𝒩(0,𝐈),\mathbf{x}_{t}=(1-t)\mathbf{x}_{0}+t\mathbf{x}_{1},\quad\mathbf{x}_{1}\sim\mathcal{N}(0,\mathbf{I}),(1)
|
| 60 |
+
|
| 61 |
+
where t∈[0,1]t\in[0,1] represents a time-dependent noise level. A neural network 𝐯 θ(𝐱 t,𝐜,t)\mathbf{v}_{\theta}(\mathbf{x}_{t},\mathbf{c},t) is trained to estimate the instantaneous velocity that defines the denoising trajectory back toward the clean video sample.
|
| 62 |
+
|
| 63 |
+
During training, the network receives random clean video samples 𝐱 0\mathbf{x}_{0}, noise samples 𝐱 1\mathbf{x}_{1}, and conditional signals 𝐜\mathbf{c}. The optimization objective corresponds to the flow-matching loss:
|
| 64 |
+
|
| 65 |
+
ℒ I2V(θ)=𝔼 t,𝐱 0,𝐱 1,𝐜[‖𝐯 θ(𝐱 t,𝐜,t)−(𝐱 1−𝐱 0)‖2 2],\mathcal{L}_{\mathrm{I2V}}(\theta)=\mathbb{E}_{t,\mathbf{x}_{0},\mathbf{x}_{1},\mathbf{c}}\left[\|\mathbf{v}_{\theta}(\mathbf{x}_{t},\mathbf{c},t)-(\mathbf{x}_{1}-\mathbf{x}_{0})\|_{2}^{2}\right],(2)
|
| 66 |
+
|
| 67 |
+
which encourages the network to predict the correct direction of denoising flow while maintaining temporal and structural consistency with the input image. At inference, a video is generated by numerically integrating the learned ordinary differential equation (ODE):
|
| 68 |
+
|
| 69 |
+
d𝐱 t dt=𝐯 θ(𝐱 t,𝐜,t),\frac{d\mathbf{x}_{t}}{dt}=\mathbf{v}_{\theta}(\mathbf{x}_{t},\mathbf{c},t),(3)
|
| 70 |
+
|
| 71 |
+
starting from 𝐱 1∼𝒩(0,𝐈)\mathbf{x}_{1}\sim\mathcal{N}(0,\mathbf{I}) and solving it backward from t=1 t=1 to t=0 t=0. This process yields a temporally smooth video that preserves the visual identity and semantics of the input image.
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
Figure 2: Overview of our proposed TAGRPO. Given a training sample, we generate multiple video samples and evaluate them using a reward model. For each group of samples generated from the same initial noise, we apply both the standard GRPO loss and our trajectory-wise loss 𝒥 align\mathcal{J}_{\text{align}} on intermediate latents. 𝒥 align\mathcal{J}_{\text{align}} implicitly encourages alignment with high-reward trajectories while maintaining distance from low-reward ones. A memory bank stores historical samples and their rewards, enabling efficient exploitation of diverse past generations without requiring large per-step rollouts. For simplicity, we omit the reference model for computing KL divergence.
|
| 76 |
+
|
| 77 |
+
#### 3.1.2 GRPO for Diffusion Models
|
| 78 |
+
|
| 79 |
+
Reinforcement learning (RL) aims to optimize a policy that maximizes the expected cumulative reward under a given environment or task condition. For diffusion-based generative models, Group Relative Policy Optimization (GRPO) provides an efficient way to align model outputs with human preferences through group-wise reward normalization. Instead of optimizing a single trajectory, GRPO jointly considers a batch of samples generated under the same condition, encouraging relative ranking consistency among them.
|
| 80 |
+
|
| 81 |
+
Given a conditioning signal 𝐜\mathbf{c} (e.g., a text prompt and a corresponding image), the policy model parameterized by θ\theta samples a group of G G trajectories {(𝐱 T i,𝐱 T−1 i,…,𝐱 0 i)}i=1 G\{\left(\mathbf{x}^{i}_{T},\mathbf{x}^{i}_{T-1},\ldots,\mathbf{x}^{i}_{0}\right)\}_{i=1}^{G}. The optimization objective is defined as follows:
|
| 82 |
+
|
| 83 |
+
𝒥 GRPO(θ)\displaystyle\mathcal{J}_{\text{GRPO}}(\theta)(4)
|
| 84 |
+
=\displaystyle=𝔼 𝐜,{𝐱 i}i=1 G 1 G∑i=1 G 1 T∑t=0 T−1[min(r t i(θ)A^i,\displaystyle\mathbb{E}_{\mathbf{c},\{\mathbf{x}^{i}\}_{i=1}^{G}}\;\frac{1}{G}\sum_{i=1}^{G}\frac{1}{T}\sum_{t=0}^{T-1}\Big[\min\big(r^{i}_{t}(\theta)\hat{A}^{i},\,
|
| 85 |
+
clip(r t i(θ),1−ϵ,1+ϵ)A^i)−β D KL(π θ||π ref)],\displaystyle\text{clip}(r^{i}_{t}(\theta),1-\epsilon,1+\epsilon)\hat{A}^{i}\big)-\beta D_{\mathrm{KL}}(\pi_{\theta}||\pi_{\text{ref}})\Big],
|
| 86 |
+
|
| 87 |
+
where A^i\hat{A}^{i} denotes the normalized advantage, ϵ\epsilon is the clipping coefficient, and β\beta controls the strength of the KL regularization term. The importance ratio between the updated and old policies is computed as:
|
| 88 |
+
|
| 89 |
+
r t i(θ)=π θ(𝐱 t−1 i|𝐱 t i,𝐜)π θ old(𝐱 t−1 i|𝐱 t i,𝐜).r^{i}_{t}(\theta)=\frac{\pi_{\theta}(\mathbf{x}^{i}_{t-1}|\mathbf{x}^{i}_{t},\mathbf{c})}{\pi_{\theta_{\text{old}}}(\mathbf{x}^{i}_{t-1}|\mathbf{x}^{i}_{t},\mathbf{c})}.(5)
|
| 90 |
+
|
| 91 |
+
For each group of generated samples {𝐱 0 i}i=1 G\{\mathbf{x}^{i}_{0}\}_{i=1}^{G}, the group-relative advantage is estimated by normalizing the sample-level rewards:
|
| 92 |
+
|
| 93 |
+
A^i=R(𝐱 0 i,𝐜)−mean({R(𝐱 0 j,𝐜)}j=1 G)std({R(𝐱 0 j,𝐜)}j=1 G),\hat{A}^{i}=\frac{R(\mathbf{x}^{i}_{0},\mathbf{c})-\text{mean}\left(\{R(\mathbf{x}^{j}_{0},\mathbf{c})\}_{j=1}^{G}\right)}{\text{std}\left(\{R(\mathbf{x}^{j}_{0},\mathbf{c})\}_{j=1}^{G}\right)},(6)
|
| 94 |
+
|
| 95 |
+
where R(𝐱 0 i,𝐜)R(\mathbf{x}^{i}_{0},\mathbf{c}) represents the reward associated with the generated output 𝐱 0 i\mathbf{x}^{i}_{0} conditioned on 𝐜\mathbf{c}.
|
| 96 |
+
|
| 97 |
+
To stabilize training and encourage better sample diversity, Flow-GRPO (Liu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib34 "Flow-grpo: training flow matching models via online rl")) reformulates the deterministic ordinary differential equation (ODE) of the diffusion process into a stochastic differential equation (SDE) that preserves the same marginal probability distribution at every timestep t t. The general form is as follows,
|
| 98 |
+
|
| 99 |
+
𝐱 t+Δt\displaystyle\mathbf{x}_{t+\Delta t}(7)
|
| 100 |
+
=\displaystyle=𝐱 t+[𝐯 θ(𝐱 t,𝐜,t)+σ t 2 2t(𝐱 t+(1−t)𝐯 θ(𝐱 t,𝐜,t))]Δt\displaystyle\mathbf{x}_{t}+\Big[\mathbf{v}_{\theta}(\mathbf{x}_{t},\mathbf{c},t)+\frac{\sigma_{t}^{2}}{2t}(\mathbf{x}_{t}+(1-t)\mathbf{v}_{\theta}(\mathbf{x}_{t},\mathbf{c},t))\Big]\Delta t(8)
|
| 101 |
+
+σ tΔtϵ,\displaystyle+\sigma_{t}\sqrt{\Delta t}\boldsymbol{\epsilon},(9)
|
| 102 |
+
|
| 103 |
+
where ϵ∼𝒩(0,𝐈)\boldsymbol{\epsilon}\sim\mathcal{N}(0,\mathbf{I}) introduces stochasticity, and σ t\sigma_{t} denotes the noise scale. The KL divergence between the current policy π θ\pi_{\theta} and a reference policy π ref\pi_{\text{ref}} admits the following closed-form approximation:
|
| 104 |
+
|
| 105 |
+
D KL(π θ||π ref)\displaystyle D_{\mathrm{KL}}(\pi_{\theta}||\pi_{\text{ref}})(10)
|
| 106 |
+
=\displaystyle=Δt 2(σ t(1−t)2t+1 σ t)2‖𝐯 θ(𝐱 t,𝐜,t)−𝐯 ref(𝐱 t,𝐜,t)‖2 2.\displaystyle\frac{\Delta t}{2}\left(\frac{\sigma_{t}(1-t)}{2t}+\frac{1}{\sigma_{t}}\right)^{2}\|\mathbf{v}_{\theta}(\mathbf{x}_{t},\mathbf{c},t)-\mathbf{v}_{\text{ref}}(\mathbf{x}_{t},\mathbf{c},t)\|_{2}^{2}.(11)
|
| 107 |
+
|
| 108 |
+
Together, these formulations allow GRPO to align diffusion-based video or image generators with reward functions while maintaining stable and consistent optimization dynamics.
|
| 109 |
+
|
| 110 |
+
### 3.2 TAGRPO
|
| 111 |
+
|
| 112 |
+
Although previous GRPO-based approaches have achieved success in the visual domain, they have predominantly focused on text-conditioned generative models, overlooking the image-to-video (I2V) diffusion setting. To the best of our knowledge, DanceGRPO (Xue et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib35 "DanceGRPO: unleashing grpo on visual generation")) is the only method that has been implemented for an I2V model, i.e., SkyReels-I2V (SkyReels-AI, [2025](https://arxiv.org/html/2601.05729v1#bib.bib83 "Skyreels v1: human-centric video foundation model")), which represents a relatively weak baseline. Crucially, our experiments reveal that directly applying DanceGRPO to state-of-the-art I2V architectures—such as Wan 2.2 (Wan et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib29 "Wan: open and advanced large-scale video generative models")) and HunyuanVideo 1.5 (Wu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib87 "HunyuanVideo 1.5 technical report"))—fails to yield meaningful improvements. These findings indicate that post-training for image-to-video models remains an open challenge, necessitating specialized optimization strategies.
|
| 113 |
+
|
| 114 |
+
To address this, we present TAGRPO, an effective framework for post-training I2V models based on the idea of T rajectory A lignment, as shown in Figure [2](https://arxiv.org/html/2601.05729v1#S3.F2 "Figure 2 ‣ 3.1.1 Image-to-Video Diffusion Models ‣ 3.1 Preliminaries ‣ 3 Method ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"). Our main motivation is that exploiting these inter-sample relationships can significantly boost optimization. Specifically, we identify the video latents with the highest (𝐱 t+\mathbf{x}^{+}_{t}) and lowest (𝐱 t−\mathbf{x}^{-}_{t}) rewards within a group and treat them as global positive and negative anchors of the group. Consequently, every latent 𝐱 t i\mathbf{x}^{i}_{t} in the group is optimized to align its trajectory with the best sample while diverging from the worst. Mathematically, we introduce a trajectory alignment loss, 𝒥 align\mathcal{J}_{\text{align}}, defined as:
|
| 115 |
+
|
| 116 |
+
𝒥 align\displaystyle\mathcal{J}_{\text{align}}(12)
|
| 117 |
+
=\displaystyle=𝔼 𝐜,{𝐱 i}i=1 G 1 G∑i=1 G 1 T∑t=0 T−1[min(r t i(θ)+A^+,\displaystyle\mathbb{E}_{\mathbf{c},\{\mathbf{x}^{i}\}_{i=1}^{G}}\;\frac{1}{G}\sum_{i=1}^{G}\frac{1}{T}\sum_{t=0}^{T-1}\Big[\min\big(r^{i}_{t}(\theta)^{+}\hat{A}^{+},\,(13)
|
| 118 |
+
clip(r t i(θ)+,1−ϵ,1+ϵ)A^+)\displaystyle\text{clip}(r^{i}_{t}(\theta)^{+},1-\epsilon,1+\epsilon)\hat{A}^{+}\big)(14)
|
| 119 |
+
+\displaystyle+𝔼 𝐜,{𝐱 i}i=1 G 1 G∑i=1 G 1 T∑t=0 T−1[min(r t i(θ)−A^−,\displaystyle\mathbb{E}_{\mathbf{c},\{\mathbf{x}^{i}\}_{i=1}^{G}}\;\frac{1}{G}\sum_{i=1}^{G}\frac{1}{T}\sum_{t=0}^{T-1}\Big[\min\big(r^{i}_{t}(\theta)^{-}\hat{A}^{-},\,(15)
|
| 120 |
+
clip(r t i(θ)−,1−ϵ,1+ϵ)A^−)],\displaystyle\text{clip}(r^{i}_{t}(\theta)^{-},1-\epsilon,1+\epsilon)\hat{A}^{-}\big)\Big],(16)
|
| 121 |
+
|
| 122 |
+
where A^+\hat{A}^{+} and A^−\hat{A}^{-} denote the normalized advantage of the most positive and negative generated videos, respectively. The importance ratios r t i(θ)+r^{i}_{t}(\theta)^{+} and r t i(θ)−r^{i}_{t}(\theta)^{-} measure the likelihood of sample i i following the positive or negative trajectory of the group:
|
| 123 |
+
|
| 124 |
+
r t i(θ)+=π θ(𝐱 t−1+|𝐱 t i,𝐜)π θ old(𝐱 t−1+|𝐱 t i,𝐜).r^{i}_{t}(\theta)^{+}=\frac{\pi_{\theta}(\mathbf{x}^{+}_{t-1}|\mathbf{x}^{i}_{t},\mathbf{c})}{\pi_{\theta_{\text{old}}}(\mathbf{x}^{+}_{t-1}|\mathbf{x}^{i}_{t},\mathbf{c})}.(17)
|
| 125 |
+
|
| 126 |
+
r t i(θ)−=π θ(𝐱 t−1−|𝐱 t i,𝐜)π θ old(𝐱 t−1−|𝐱 t i,𝐜).r^{i}_{t}(\theta)^{-}=\frac{\pi_{\theta}(\mathbf{x}^{-}_{t-1}|\mathbf{x}^{i}_{t},\mathbf{c})}{\pi_{\theta_{\text{old}}}(\mathbf{x}^{-}_{t-1}|\mathbf{x}^{i}_{t},\mathbf{c})}.(18)
|
| 127 |
+
|
| 128 |
+
This formulation implicitly encourages all generated samples in the same group to mimic the transitions of the most positive trajectory and avoid those of the most negative one, providing effective directional guidance based on inter-sample relationships. The final objective function is:
|
| 129 |
+
|
| 130 |
+
𝒥 TAGRPO=𝒥 GRPO+γ𝒥 align.\displaystyle\mathcal{J}_{\text{TAGRPO}}=\mathcal{J}_{\text{GRPO}}+\gamma\mathcal{J}_{\text{align}}.(19)
|
| 131 |
+
|
| 132 |
+

|
| 133 |
+
|
| 134 |
+
Figure 3: Qualitative comparison among TAGRPO, DanceGRPO and the base model Wan 2.2. Models trained with TAGRPO demonstrate superior visual quality with improved aesthetics, reduced distortion artifacts and better motion realism in animation scenes.
|
| 135 |
+
|
| 136 |
+
To maximize the effectiveness of 𝒥 align\mathcal{J}_{\text{align}}, sufficient rollout videos with diverse rewards are essential. However, generating these videos per step incurs significant computational costs and substantially slows the training process. Inspired by contrastive learning principles (He et al., [2020](https://arxiv.org/html/2601.05729v1#bib.bib51 "Momentum contrast for unsupervised visual representation learning")), we propose maintaining a memory bank for TAGRPO that stores previously generated video latents and their corresponding reward signals from past iterations. This approach enables us to accumulate a diverse collection of generated videos while keeping the per-step generation count low, thereby reducing computational overhead. Furthermore, this memory mechanism helps prevent the model from diverging significantly from its original parameters by leveraging previously generated samples, thus providing optimization stability.
|
| 137 |
+
|
| 138 |
+
4 Experiments
|
| 139 |
+
-------------
|
| 140 |
+
|
| 141 |
+
### 4.1 Implementation Details
|
| 142 |
+
|
| 143 |
+
We applied our method to advanced image-to-video models, Wan 2.2 (Wan et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib29 "Wan: open and advanced large-scale video generative models")) and HunyuanVideo 1.5 (Wu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib87 "HunyuanVideo 1.5 technical report")). As demonstrated in previous studies (He et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib38 "Tempflow-grpo: when timing matters for grpo in flow models"); Li et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib37 "Mixgrpo: unlocking flow-based grpo efficiency with mixed ode-sde")), higher timesteps exert a greater influence on the quality of generated videos. Consequently, for Wan 2.2, we propose to optimize the high-noise model of Wan 2.2 while keeping its low-noise counterpart unchanged. For HunyuanVideo 1.5, we also optimize the early timestep values, which are greater than 900 900 in experiments.
|
| 144 |
+
|
| 145 |
+
Regarding reward models, given the scarcity of effective open-source reward models designed specifically for image-to-video generative models, we leveraged the image reward model, HPSv3 (Ma et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib84 "Hpsv3: towards wide-spectrum human preference score")) and the Q-Save evaluation model (Wu et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib88 "Q-save: towards scoring and attribution for generated video evaluation")) in our experiments. For HPSv3, we uniformly sampled two frames per second from each generated video and computed the average reward across these frames as the overall video reward. For Q-Save, we used the combination of Visual Quality (VQ), Dynamic Quality (DQ) and Image Alignment (IA) as the overall reward for generated videos.
|
| 146 |
+
|
| 147 |
+
Following previous studies (Xue et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib35 "DanceGRPO: unleashing grpo on visual generation"); He et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib38 "Tempflow-grpo: when timing matters for grpo in flow models"); Li et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib37 "Mixgrpo: unlocking flow-based grpo efficiency with mixed ode-sde")), we focus on samples generated from the same initial noise to control variations in the inference process. We set the group size G=8 G=8, with hyperparameters γ=1\gamma=1. To speed up the training process, we set the training resolution of generated videos as 320 320 p with 53 53 frames in total. The inference step number was set 16 16 and the classifier free guidance was set 3.5 3.5. For 𝒥 align\mathcal{J}_{\text{align}}, x t+x_{t}^{+} was set as the latent representation of the video achieving the highest reward, while x t−x_{t}^{-} corresponded to the latent of the video with the lowest reward within that group.
|
| 148 |
+
|
| 149 |
+
For the memory bank, we implemented a first-in-first-out (FIFO) strategy to continuously refresh stored samples, thereby maintaining both relevance and diversity throughout training. For training data, we used an internal dataset containing approximately 10K image-text pairs, featuring diverse scenes and image styles. The dataset encompasses a wide range of visual content, including natural landscapes, urban environments, portraits, anime, and abstract compositions, with corresponding text descriptions that vary in length and complexity to ensure robust learning. Moreover, to evaluate the effectiveness of our proposed method, we then subsampled an evaluation set from our training data, dubbed TAGRPO-Bench, containing 200 200 challenging image-text pairs for the task of image-to-video generation.
|
| 150 |
+
|
| 151 |
+
### 4.2 Qualitative Comparisons
|
| 152 |
+
|
| 153 |
+

|
| 154 |
+
|
| 155 |
+
Figure 4: Qualitative comparison among TAGRPO, DanceGRPO and the base model HunyuanVideo 1.5 (HY-1.5). Models trained with TAGRPO exhibit superior generation fidelity, characterized by sharper structural details and significantly fewer temporal artifacts.
|
| 156 |
+
|
| 157 |
+
We present visual comparisons on our TAGRPO-Bench to evaluate the perceptual quality and prompt adherence of generated videos across different backbones. Figures[3](https://arxiv.org/html/2601.05729v1#S3.F3 "Figure 3 ‣ 3.2 TAGRPO ‣ 3 Method ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment") and [4](https://arxiv.org/html/2601.05729v1#S4.F4 "Figure 4 ‣ 4.2 Qualitative Comparisons ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment") present qualitative comparisons on Wan 2.2 and HunyuanVideo-1.5, respectively. In Figure[3](https://arxiv.org/html/2601.05729v1#S3.F3 "Figure 3 ‣ 3.2 TAGRPO ‣ 3 Method ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), TAGRPO demonstrates superior motion control: it executed the creature’s head turn with a coherent ”wide grin” and maintains the fairy’s anatomical correctness, whereas baselines suffered from significant facial distortions. Figure[4](https://arxiv.org/html/2601.05729v1#S4.F4 "Figure 4 ‣ 4.2 Qualitative Comparisons ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment") highlights fidelity and stability; TAGRPO preserved sharp details in the blonde hair (top) and maintained rigid geometric consistency during the sci-fi camera pan, avoiding the structural warping and texture drift observed in other models. These results confirm that our trajectory alignment mechanism effectively pruned generation paths leading to visual artifacts and instability.
|
| 158 |
+
|
| 159 |
+
### 4.3 Quantitative Comparisons
|
| 160 |
+
|
| 161 |
+
In this section, we performed quantitative comparisons to evaluate TAGRPO against both the base model and DanceGRPO on the TAGRPO-Bench, utilizing the HunyuanVideo-1.5 (HY-1.5) and Wan 2.2 backbones across both 320p and 720p resolutions. As summarized in Table [1](https://arxiv.org/html/2601.05729v1#S4.T1 "Table 1 ‣ 4.3 Quantitative Comparisons ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment") and Table [2](https://arxiv.org/html/2601.05729v1#S4.T2 "Table 2 ‣ 4.3 Quantitative Comparisons ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), our method consistently achieved the best performance across both backbones, demonstrating the effectiveness of our trajectory alignment strategy. Notably, although our models were trained exclusively under the 320p setting, they still achieved significant improvements at 720p, highlighting the strong generalization capability of our approach.
|
| 162 |
+
|
| 163 |
+
Table 1: Quantitative comparison on the HunyuanVideo 1.5 (HY-1.5) baseline. We evaluated performance using Q-Save and HPSv3 metrics across 320p and 720p resolutions. TAGRPO consistently outperformed both the base model and DanceGRPO.
|
| 164 |
+
|
| 165 |
+
Table 2: Quantitative comparison on the Wan 2.2 baseline. We reported Q-Save and HPSv3 scores at 320p and 720p resolutions. TAGRPO demonstrated robust improvements over the baseline and DanceGRPO, achieving the highest scores in all settings.
|
| 166 |
+
|
| 167 |
+
### 4.4 Ablation Studies
|
| 168 |
+
|
| 169 |
+
In this section, we performed ablation studies on the effectiveness of our proposed methods.
|
| 170 |
+
|
| 171 |
+
#### 4.4.1 Components Effectiveness
|
| 172 |
+
|
| 173 |
+
In this section, we conducted an ablation study to evaluate the contributions of the 𝒥 align\mathcal{J}_{\text{align}} loss and memory bank mechanism in our proposed TAGRPO. As illustrated in Figure [5](https://arxiv.org/html/2601.05729v1#S4.F5 "Figure 5 ‣ 4.4.1 Components Effectiveness ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), we conducted three experiments comparing: (1) TAGRPO, (2) TAGRPO without the memory bank, and (3) TAGRPO without 𝒥 align\mathcal{J}_{\text{align}}, using the combination of Visual Quality (VQ), Dynamic Quality (DQ) and Image Alignment (IA) in Q-Save (Wu et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib88 "Q-save: towards scoring and attribution for generated video evaluation")) as the reward metrics. The reported values in the figure were averaged over the evaluation dataset, which was a small subset of our internal training data. The results demonstrate that TAGRPO achieved the greatest reward improvement, confirming the necessity of each component. Specifically, removing either the memory bank or 𝒥 align\mathcal{J}_{\text{align}} resulted in slower convergence and lower reward values, indicating that both components play roles in effective policy optimization. This validates our hypothesis that combining trajectory-wise supervision with diverse historical samples leads to more robust and efficient fine-tuning.
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
Figure 5: Ablation study on the contributions of 𝒥 align\mathcal{J}_{\text{align}} loss and memory bank mechanism. TAGRPO achieves the highest reward improvement, while removing either component results in slower convergence and lower final performance.
|
| 178 |
+
|
| 179 |
+
#### 4.4.2 Generalization to Other Settings
|
| 180 |
+
|
| 181 |
+
To demonstrate the generalization capability of our proposed method, we conducted new experiments by extending our approach to text to video tasks, including Wan2.2-T2V-A14B(Wan et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib29 "Wan: open and advanced large-scale video generative models")) and HunyuanVideo-1.5-720P-T2V(Wu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib87 "HunyuanVideo 1.5 technical report")). We still used HPSv3 (Ma et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib84 "Hpsv3: towards wide-spectrum human preference score")) as the reward model. To maintain the content similarity among rollout videos in each group, we also used the same initial noise for video generations. As shown in Figure[6](https://arxiv.org/html/2601.05729v1#S4.F6 "Figure 6 ‣ 4.4.2 Generalization to Other Settings ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), we compared our method against DanceGRPO(Xue et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib35 "DanceGRPO: unleashing grpo on visual generation")) when applied to this alternative setting. The results demonstrate that our method still achieved faster convergence and higher final reward scores, indicating the potential our approach to other AIGC settings.
|
| 182 |
+
|
| 183 |
+

|
| 184 |
+
|
| 185 |
+
Figure 6: Generalization to other settings. We applied our method to state-of-the-art text-conditioned AIGC models, i.e., Wan2.2-T2V-A14B(Wan et al., [2025](https://arxiv.org/html/2601.05729v1#bib.bib29 "Wan: open and advanced large-scale video generative models")) and HunyuanVideo-1.5-720P-T2V(Wu et al., [2025a](https://arxiv.org/html/2601.05729v1#bib.bib87 "HunyuanVideo 1.5 technical report")), and compared with DanceGRPO(Xue et al., [2025b](https://arxiv.org/html/2601.05729v1#bib.bib35 "DanceGRPO: unleashing grpo on visual generation")). Our method demonstrated faster convergence and achieved higher final rewards compared to DanceGRPO, showing the potential of our approach to other AIGC tasks. All reported reward values were averaged over the evaluation set.
|
| 186 |
+
|
| 187 |
+
5 Conclusion
|
| 188 |
+
------------
|
| 189 |
+
|
| 190 |
+
In this paper, we have presented TAGRPO, a novel framework for post-training image-to-video generation models via reinforcement learning. By introducing trajectory-wise alignment loss and a memory bank mechanism, TAGRPO has effectively exploited relative relationships among generated samples and historical trajectories, achieving significant improvements over DanceGRPO. Our extensive experiments on advanced image-to-video models have demonstrated the effectiveness and efficiency of our approach. A key insight of our work is that for the task of image to video generation, explicitly aligning intermediate denoising trajectories based on reward rankings provides more informative optimization signals than treating samples independently. We will publicly release our code, models, and benchmarks to facilitate further research. We believe TAGRPO establishes a new paradigm for efficient alignment in video generation and opens promising avenues for extending these trajectory-aware principles to other image-conditioned multimodal tasks.
|
| 191 |
+
|
| 192 |
+
References
|
| 193 |
+
----------
|
| 194 |
+
|
| 195 |
+
* A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y. Levi, Z. English, V. Voleti, A. Letts, et al. (2023)Stable video diffusion: scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 196 |
+
* G. Chen, D. Lin, J. Yang, C. Lin, J. Zhu, M. Fan, H. Zhang, S. Chen, Z. Chen, C. Ma, et al. (2025)Skyreels-v2: infinite-length film generative model. arXiv preprint arXiv:2504.13074. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 197 |
+
* H. Chen, M. Xia, Y. He, Y. Zhang, X. Cun, S. Yang, J. Xing, Y. Liu, Q. Chen, X. Wang, et al. (2023a)Videocrafter1: open diffusion models for high-quality video generation. arXiv preprint arXiv:2310.19512. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 198 |
+
* [4]J. Chen, Y. Jincheng, G. Chongjian, L. Yao, E. Xie, Z. Wang, J. Kwok, P. Luo, H. Lu, and Z. Li PixArt-alpha: fast training of diffusion transformer for photorealistic text-to-image synthesis. In The Twelfth International Conference on Learning Representations, Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 199 |
+
* T. Chen, A. Siarohin, W. Menapace, E. Deyneka, H. Chao, B. E. Jeon, Y. Fang, H. Lee, J. Ren, M. Yang, et al. (2024)Panda-70m: captioning 70m videos with multiple cross-modality teachers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.13320–13331. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 200 |
+
* X. Chen, Y. Wang, L. Zhang, S. Zhuang, X. Ma, J. Yu, Y. Wang, D. Lin, Y. Qiao, and Z. Liu (2023b)Seine: short-to-long video diffusion model for generative transition and prediction. In The Twelfth International Conference on Learning Representations, Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 201 |
+
* K. Clark, P. Vicol, K. Swersky, and D. J. Fleet (2023)Directly fine-tuning diffusion models on differentiable rewards. arXiv preprint arXiv:2309.17400. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 202 |
+
* G. DeepMind (2025)Veo3: our state-of-the-art video generation model. Note: Accessed: 2025-11-07 Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 203 |
+
* P. Dhariwal and A. Nichol (2021)Diffusion models beat gans on image synthesis. Advances in neural information processing systems 34, pp.8780–8794. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 204 |
+
* P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y. Levi, D. Lorenz, A. Sauer, F. Boesel, et al. (2024)Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning, Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 205 |
+
* X. Fu, L. Ma, Z. Guo, G. Zhou, C. Wang, S. Dong, S. Zhou, X. Liu, J. Fu, T. L. Sin, et al. (2025)Dynamic-treerpo: breaking the independent trajectory bottleneck with structured sampling. arXiv preprint arXiv:2509.23352. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 206 |
+
* H. Furuta, H. Zen, D. Schuurmans, A. Faust, Y. Matsuo, P. Liang, and S. Yang (2024)Improving dynamic object interactions in text-to-video generation with ai feedback. arXiv preprint arXiv:2412.02617. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 207 |
+
* Y. Gao, H. Guo, T. Hoang, W. Huang, L. Jiang, F. Kong, H. Li, J. Li, L. Li, X. Li, et al. (2025)Seedance 1.0: exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 208 |
+
* X. Guo, M. Zheng, L. Hou, Y. Gao, Y. Deng, P. Wan, D. Zhang, Y. Liu, W. Hu, Z. Zha, et al. (2024)I2v-adapter: a general image-to-video adapter for diffusion models. In ACM SIGGRAPH 2024 Conference Papers, pp.1–12. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 209 |
+
* K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick (2020)Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.9729–9738. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p4.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§3.2](https://arxiv.org/html/2601.05729v1#S3.SS2.p3.1 "3.2 TAGRPO ‣ 3 Method ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 210 |
+
* X. He, S. Fu, Y. Zhao, W. Li, J. Yang, D. Yin, F. Rao, and B. Zhang (2025)Tempflow-grpo: when timing matters for grpo in flow models. arXiv preprint arXiv:2508.04324. Cited by: [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1.6.2.1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.1](https://arxiv.org/html/2601.05729v1#S4.SS1.p1.1 "4.1 Implementation Details ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.1](https://arxiv.org/html/2601.05729v1#S4.SS1.p3.9 "4.1 Implementation Details ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 211 |
+
* J. Ho, A. Jain, and P. Abbeel (2020)Denoising diffusion probabilistic models. Advances in neural information processing systems 33, pp.6840–6851. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 212 |
+
* J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet (2022)Video diffusion models. Advances in neural information processing systems 35, pp.8633–8646. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 213 |
+
* L. Hu (2024)Animate anyone: consistent and controllable image-to-video synthesis for character animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.8153–8163. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 214 |
+
* W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhang, et al. (2024)Hunyuanvideo: a systematic framework for large video generative models. arXiv preprint arXiv:2412.03603. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 215 |
+
* B. F. Labs, S. Batifol, A. Blattmann, F. Boesel, S. Consul, C. Diagne, T. Dockhorn, J. English, Z. English, P. Esser, S. Kulal, K. Lacey, Y. Levi, C. Li, D. Lorenz, J. Müller, D. Podell, R. Rombach, H. Saini, A. Sauer, and L. Smith (2025)FLUX.1 kontext: flow matching for in-context image generation and editing in latent space. External Links: 2506.15742, [Link](https://arxiv.org/abs/2506.15742)Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 216 |
+
* B. F. Labs (2024)FLUX. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 217 |
+
* J. Li, Y. Cui, T. Huang, Y. Ma, C. Fan, M. Yang, and Z. Zhong (2025a)Mixgrpo: unlocking flow-based grpo efficiency with mixed ode-sde. arXiv preprint arXiv:2507.21802. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.1](https://arxiv.org/html/2601.05729v1#S4.SS1.p1.1 "4.1 Implementation Details ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.1](https://arxiv.org/html/2601.05729v1#S4.SS1.p3.9 "4.1 Implementation Details ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 218 |
+
* Y. Li, Y. Wang, Y. Zhu, Z. Zhao, M. Lu, Q. She, and S. Zhang (2025b)Branchgrpo: stable and efficient grpo with structured branching in diffusion models. arXiv preprint arXiv:2509.06040. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 219 |
+
* Z. Li, Z. Liu, Q. Zhang, B. Lin, S. Yuan, Z. Yan, Y. Ye, W. Yu, Y. Niu, and L. Yuan (2025c)Uniworld-v2: reinforce image editing with diffusion negative-aware finetuning and mllm implicit feedback. arXiv preprint arXiv:2510.16888. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 220 |
+
* Z. Liang, Y. Yuan, S. Gu, B. Chen, T. Hang, M. Cheng, J. Li, and L. Zheng (2025)Aesthetic post-training diffusion models from generic preferences with step-by-step preference optimization. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.13199–13208. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 221 |
+
* Z. Liang, Y. Yuan, S. Gu, B. Chen, T. Hang, J. Li, and L. Zheng (2024)Step-aware preference optimization: aligning preference with denoising performance at each step. arXiv preprint arXiv:2406.04314 2 (5), pp.7. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 222 |
+
* B. Lin, Y. Ge, X. Cheng, Z. Li, B. Zhu, S. Wang, X. He, Y. Ye, S. Yuan, L. Chen, et al. (2024)Open-sora plan: open-source large video generation model. arXiv preprint arXiv:2412.00131. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 223 |
+
* [29]Y. Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le Flow matching for generative modeling. In The Eleventh International Conference on Learning Representations, Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§3.1.1](https://arxiv.org/html/2601.05729v1#S3.SS1.SSS1.p2.3 "3.1.1 Image-to-Video Diffusion Models ‣ 3.1 Preliminaries ‣ 3 Method ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 224 |
+
* J. Liu, G. Liu, J. Liang, Y. Li, J. Liu, X. Wang, P. Wan, D. Zhang, and W. Ouyang (2025a)Flow-grpo: training flow matching models via online rl. arXiv preprint arXiv:2505.05470. Cited by: [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1.6.2.1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p3.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§3.1.2](https://arxiv.org/html/2601.05729v1#S3.SS1.SSS2.p3.1 "3.1.2 GRPO for Diffusion Models ‣ 3.1 Preliminaries ‣ 3 Method ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 225 |
+
* R. Liu, H. Wu, Z. Zheng, C. Wei, Y. He, R. Pi, and Q. Chen (2025b)Videodpo: omni-preference alignment for video diffusion generation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.8009–8019. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 226 |
+
* [32]X. Liu, C. Gong, et al.Flow straight and fast: learning to generate and transfer data with rectified flow. In The Eleventh International Conference on Learning Representations, Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§3.1.1](https://arxiv.org/html/2601.05729v1#S3.SS1.SSS1.p2.3 "3.1.1 Image-to-Video Diffusion Models ‣ 3.1 Preliminaries ‣ 3 Method ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 227 |
+
* Y. Ma, X. Wu, K. Sun, and H. Li (2025)Hpsv3: towards wide-spectrum human preference score. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.15086–15095. Cited by: [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1.6.2.1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.1](https://arxiv.org/html/2601.05729v1#S4.SS1.p2.1 "4.1 Implementation Details ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.4.2](https://arxiv.org/html/2601.05729v1#S4.SS4.SSS2.p1.1 "4.4.2 Generalization to Other Settings ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 228 |
+
* F. Mao, A. Hao, J. Chen, D. Liu, X. Feng, J. Zhu, M. Wu, C. Chen, J. Wu, and X. Chu (2025)Omni-effects: unified and spatially-controllable visual effects generation. arXiv preprint arXiv:2508.07981. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 229 |
+
* OpenAI (2024)Sora: creating video from text. Note: Accessed: 2025-11-07 Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 230 |
+
* W. Peebles and S. Xie (2023)Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pp.4195–4205. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 231 |
+
* M. Prabhudesai, A. Goyal, D. Pathak, and K. Fragkiadaki (2023)Aligning text-to-image diffusion models with reward backpropagation. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 232 |
+
* M. Prabhudesai, R. Mendonca, Z. Qin, K. Fragkiadaki, and D. Pathak (2024)Video diffusion alignment via reward gradients. arXiv preprint arXiv:2407.08737. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 233 |
+
* A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. (2021)Learning transferable visual models from natural language supervision. In International conference on machine learning, pp.8748–8763. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 234 |
+
* R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn (2023)Direct preference optimization: your language model is secretly a reward model. Advances in neural information processing systems 36, pp.53728–53741. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 235 |
+
* R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer (2022)High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.10684–10695. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 236 |
+
* Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. Li, et al. (2024)Deepseekmath: pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 237 |
+
* X. Shen, Z. Li, Z. Yang, S. Zhang, Y. Zhang, D. Li, C. Wang, Q. Lu, and Y. Tang (2025)Directly aligning the full diffusion trajectory with fine-grained human preference. arXiv preprint arXiv:2509.06942. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 238 |
+
* X. Shi, Z. Huang, F. Wang, W. Bian, D. Li, Y. Zhang, M. Zhang, K. C. Cheung, S. See, H. Qin, et al. (2024)Motion-i2v: consistent and controllable image-to-video generation with explicit motion modeling. In ACM SIGGRAPH 2024 Conference Papers, pp.1–11. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 239 |
+
* SkyReels-AI (2025)Skyreels v1: human-centric video foundation model. GitHub. Note: [https://github.com/SkyworkAI/SkyReels-V1](https://github.com/SkyworkAI/SkyReels-V1)Cited by: [§3.2](https://arxiv.org/html/2601.05729v1#S3.SS2.p1.1 "3.2 TAGRPO ‣ 3 Method ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 240 |
+
* [46]Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 241 |
+
* J. Tian, X. Qu, Z. Lu, W. Wei, S. Liu, and Y. Cheng (2025)Extrapolating and decoupling image-to-video generation models: motion modeling is easier than you think. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.12512–12521. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 242 |
+
* V. Voleti, A. Jolicoeur-Martineau, and C. Pal (2022)Mcvd-masked conditional video diffusion for prediction, generation, and interpolation. Advances in neural information processing systems 35, pp.23371–23385. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 243 |
+
* B. Wallace, M. Dang, R. Rafailov, L. Zhou, A. Lou, S. Purushwalkam, S. Ermon, C. Xiong, S. Joty, and N. Naik (2024)Diffusion model alignment using direct preference optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.8228–8238. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 244 |
+
* T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. (2025)Wan: open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314. Cited by: [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1.6.2.1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p4.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p5.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§3.2](https://arxiv.org/html/2601.05729v1#S3.SS2.p1.1 "3.2 TAGRPO ‣ 3 Method ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 6](https://arxiv.org/html/2601.05729v1#S4.F6 "In 4.4.2 Generalization to Other Settings ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 6](https://arxiv.org/html/2601.05729v1#S4.F6.4.2 "In 4.4.2 Generalization to Other Settings ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.1](https://arxiv.org/html/2601.05729v1#S4.SS1.p1.1 "4.1 Implementation Details ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.4.2](https://arxiv.org/html/2601.05729v1#S4.SS4.SSS2.p1.1 "4.4.2 Generalization to Other Settings ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 245 |
+
* W. Wang and Y. Yang (2024)Vidprom: a million-scale real prompt-gallery dataset for text-to-video diffusion models. Advances in Neural Information Processing Systems 37, pp.65618–65642. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 246 |
+
* X. Wang, H. Yuan, S. Zhang, D. Chen, J. Wang, Y. Zhang, Y. Shen, D. Zhao, and J. Zhou (2023)Videocomposer: compositional video synthesis with motion controllability. Advances in Neural Information Processing Systems 36, pp.7594–7611. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 247 |
+
* B. Wu, C. Zou, C. Li, D. Huang, F. Yang, H. Tan, J. Peng, J. Wu, J. Xiong, J. Jiang, et al. (2025a)HunyuanVideo 1.5 technical report. arXiv preprint arXiv:2511.18870. Cited by: [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1.6.2.1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p4.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p5.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§3.2](https://arxiv.org/html/2601.05729v1#S3.SS2.p1.1 "3.2 TAGRPO ‣ 3 Method ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 6](https://arxiv.org/html/2601.05729v1#S4.F6 "In 4.4.2 Generalization to Other Settings ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 6](https://arxiv.org/html/2601.05729v1#S4.F6.4.2 "In 4.4.2 Generalization to Other Settings ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.1](https://arxiv.org/html/2601.05729v1#S4.SS1.p1.1 "4.1 Implementation Details ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.4.2](https://arxiv.org/html/2601.05729v1#S4.SS4.SSS2.p1.1 "4.4.2 Generalization to Other Settings ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 248 |
+
* X. Wu, Z. Zhang, M. Chen, Y. Liu, Y. Liu, S. Wang, Z. Hu, Y. Liu, G. Zhai, and X. Liu (2025b)Q-save: towards scoring and attribution for generated video evaluation. arXiv preprint arXiv:2511.18825. Cited by: [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1.6.2.1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.1](https://arxiv.org/html/2601.05729v1#S4.SS1.p2.1 "4.1 Implementation Details ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.4.1](https://arxiv.org/html/2601.05729v1#S4.SS4.SSS1.p1.3 "4.4.1 Components Effectiveness ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 249 |
+
* J. Xing, M. Xia, Y. Zhang, H. Chen, W. Yu, H. Liu, G. Liu, X. Wang, Y. Shan, and T. Wong (2024)Dynamicrafter: animating open-domain images with video diffusion priors. In European Conference on Computer Vision, pp.399–417. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 250 |
+
* J. Xu, X. Liu, Y. Wu, Y. Tong, Q. Li, M. Ding, J. Tang, and Y. Dong (2023)Imagereward: learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems 36, pp.15903–15935. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 251 |
+
* S. Xue, C. Ge, S. Zhang, Y. Li, and Z. Ma (2025a)Advantage weighted matching: aligning rl with pretraining in diffusion models. arXiv preprint arXiv:2509.25050. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 252 |
+
* Z. Xue, J. Wu, Y. Gao, F. Kong, L. Zhu, M. Chen, Z. Liu, W. Liu, Q. Guo, W. Huang, et al. (2025b)DanceGRPO: unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818. Cited by: [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1.6.2.1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p3.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§1](https://arxiv.org/html/2601.05729v1#S1.p4.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§3.2](https://arxiv.org/html/2601.05729v1#S3.SS2.p1.1 "3.2 TAGRPO ‣ 3 Method ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 6](https://arxiv.org/html/2601.05729v1#S4.F6 "In 4.4.2 Generalization to Other Settings ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 6](https://arxiv.org/html/2601.05729v1#S4.F6.4.2 "In 4.4.2 Generalization to Other Settings ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.1](https://arxiv.org/html/2601.05729v1#S4.SS1.p3.9 "4.1 Implementation Details ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§4.4.2](https://arxiv.org/html/2601.05729v1#S4.SS4.SSS2.p1.1 "4.4.2 Generalization to Other Settings ‣ 4.4 Ablation Studies ‣ 4 Experiments ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 253 |
+
* H. Yang, Y. Chen, Y. Pan, T. Yao, Z. Chen, C. Ngo, and T. Mei (2024a)Hi3d: pursuing high-resolution image-to-3d generation with video diffusion models. In Proceedings of the 32nd ACM International Conference on Multimedia, pp.6870–6879. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p2.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 254 |
+
* K. Yang, J. Tao, J. Lyu, C. Ge, J. Chen, W. Shen, X. Zhu, and X. Li (2024b)Using human feedback to fine-tune diffusion models without any reward model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.8941–8951. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 255 |
+
* Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y. Yang, W. Hong, X. Zhang, G. Feng, et al. (2024c)Cogvideox: text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 256 |
+
* H. Yuan, Z. Chen, K. Ji, and Q. Gu (2024)Self-play fine-tuning of diffusion models for text-to-image generation. Advances in Neural Information Processing Systems 37, pp.73366–73398. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 257 |
+
* Y. Zeng, G. Wei, J. Zheng, J. Zou, Y. Wei, Y. Zhang, and H. Li (2024)Make pixels dance: high-dynamic video generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.8850–8860. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 258 |
+
* J. Zhang, J. Wu, W. Chen, Y. Ji, X. Xiao, W. Huang, and K. Han (2024)Onlinevpo: align video diffusion model with online video-centric preference optimization. arXiv preprint arXiv:2412.15159. Cited by: [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 259 |
+
* S. Zhang, J. Wang, Y. Zhang, K. Zhao, H. Yuan, Z. Qin, X. Wang, D. Zhao, and J. Zhou (2023)I2vgen-xl: high-quality image-to-video synthesis via cascaded diffusion models. arXiv preprint arXiv:2311.04145. Cited by: [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 260 |
+
* K. Zheng, H. Chen, H. Ye, H. Wang, Q. Zhang, K. Jiang, H. Su, S. Ermon, J. Zhu, and M. Liu (2025)Diffusionnft: online diffusion reinforcement with forward process. arXiv preprint arXiv:2509.16117. Cited by: [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [Figure 1](https://arxiv.org/html/2601.05729v1#S1.F1.6.2.1 "In 1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.2](https://arxiv.org/html/2601.05729v1#S2.SS2.p1.1 "2.2 RL for Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|
| 261 |
+
* Z. Zheng, X. Peng, T. Yang, C. Shen, S. Li, H. Liu, Y. Zhou, T. Li, and Y. You (2024)Open-sora: democratizing efficient video production for all. arXiv preprint arXiv:2412.20404. Cited by: [§1](https://arxiv.org/html/2601.05729v1#S1.p1.1 "1 Introduction ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment"), [§2.1](https://arxiv.org/html/2601.05729v1#S2.SS1.p1.1 "2.1 Image-to-Video Diffusion Models ‣ 2 Related Work ‣ TAGRPO: Boosting GRPO on Image-to-Video Generation with Direct Trajectory Alignment").
|