

Add 1 files
Browse files- 2510/2510.24469.md +355 -0
2510/2510.24469.md
ADDED
|
@@ -0,0 +1,355 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
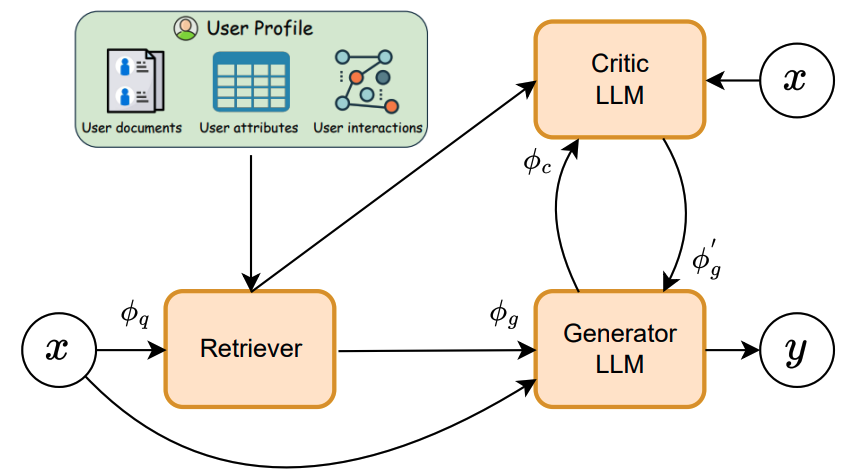
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
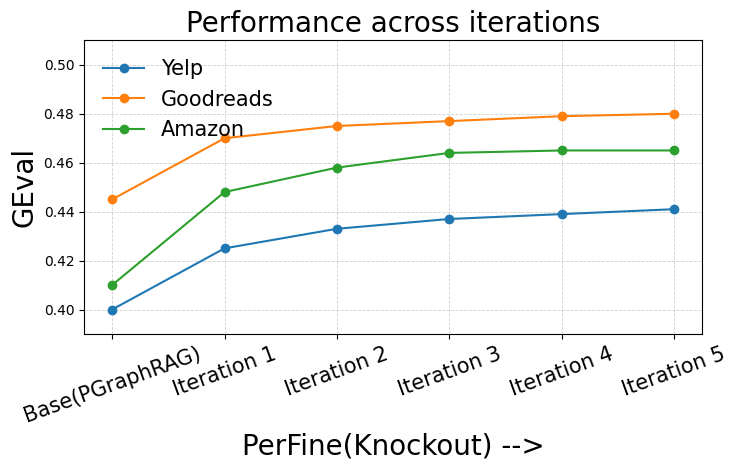
|
|
|
|
|
|
|
|
|
|
|
|
|
|
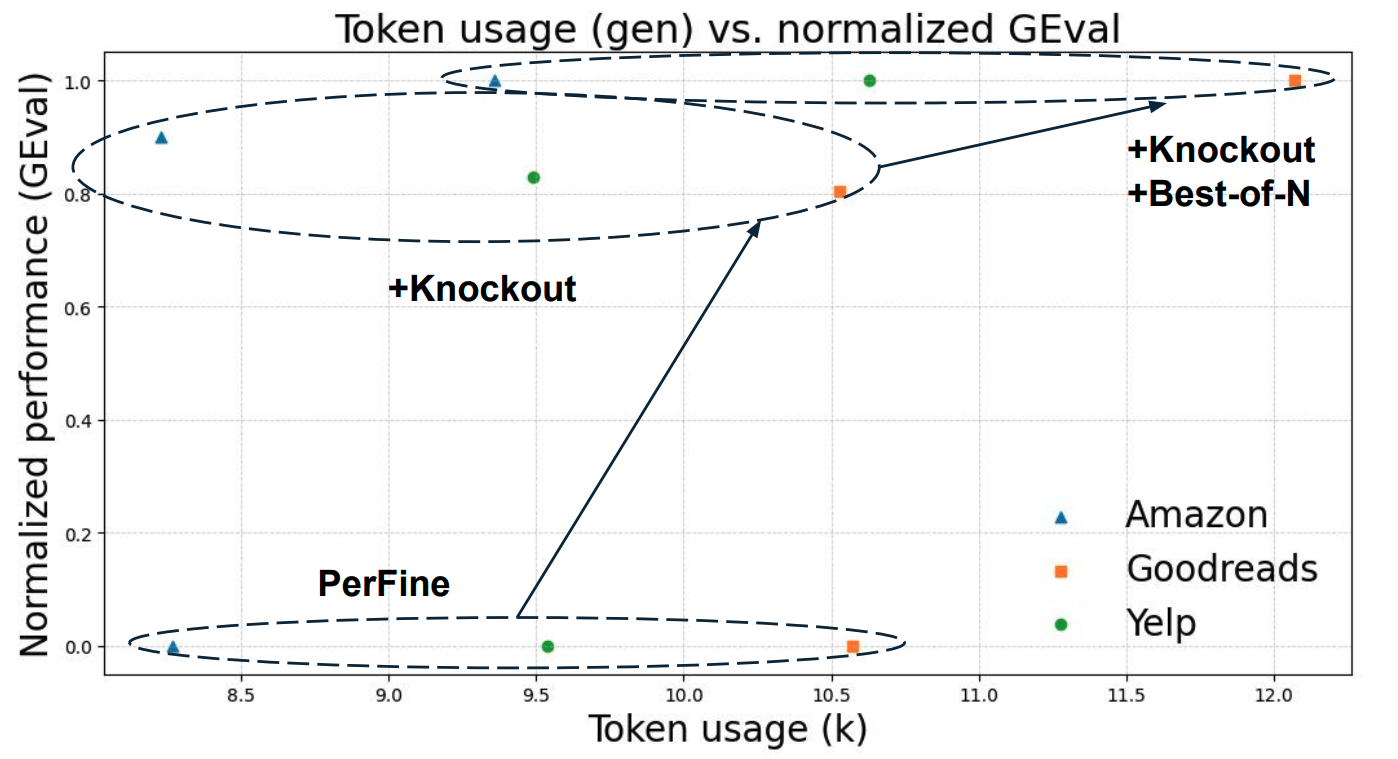
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Iterative Critique-Refine Framework for Enhancing LLM Personalization
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2510.24469
|
| 4 |
+
|
| 5 |
+
Markdown Content:
|
| 6 |
+
Durga Prasad Maram 1 , Dhruvin Gandhi 1 , Zonghai Yao 1 , Gayathri Akkinapalli 1 ,
|
| 7 |
+
|
| 8 |
+
Franck Dernoncourt 2, Yu Wang 3 , Ryan A. Rossi 2 , Nesreen K. Ahmed 4
|
| 9 |
+
|
| 10 |
+
University of Massachusetts Amherst 1 , Adobe Research 2 , University of Oregon 3 , Cisco AI Research 4
|
| 11 |
+
|
| 12 |
+
###### Abstract
|
| 13 |
+
|
| 14 |
+
Personalized text generation requires models not only to produce coherent text but also to align with a target user’s style, tone, and topical focus. Existing retrieval-augmented approaches such as LaMP and PGraphRAG enrich profiles with user and neighbor histories, but they stop at generation and often yield outputs that drift in tone, topic, or style. We present PerFine, a unified, training-free critique–refine framework that enhances personalization through iterative, profile-grounded feedback. In each iteration, an LLM generator produces a draft conditioned on the retrieved profile, and a critic LLM - also conditioned on the same profile - provides structured feedback on tone, vocabulary, sentence structure, and topicality. The generator then revises, while a novel knockout strategy retains the stronger draft across iterations. We further study additional inference-time strategies such as Best-of-N N and Topic Extraction to balance quality and efficiency. Across Yelp, Goodreads, and Amazon datasets, PerFine consistently improves personalization over PGraphRAG, with GEval gains of +7 7–13 13%, steady improvements over 3 3–5 5 refinement iterations, and scalability with increasing critic size. These results highlight that post-hoc, profile-aware feedback offers a powerful paradigm for personalized LLM generation that is both training-free and model-agnostic.
|
| 15 |
+
|
| 16 |
+
Iterative Critique-Refine Framework for Enhancing LLM Personalization
|
| 17 |
+
|
| 18 |
+
Durga Prasad Maram 1 , Dhruvin Gandhi 1 , Zonghai Yao 1 , Gayathri Akkinapalli 1 ,Franck Dernoncourt 2, Yu Wang 3 , Ryan A. Rossi 2 , Nesreen K. Ahmed 4 University of Massachusetts Amherst 1 , Adobe Research 2 , University of Oregon 3 , Cisco AI Research 4
|
| 19 |
+
|
| 20 |
+
1 Introduction
|
| 21 |
+
--------------
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
Figure 1: Overview of our framework for personalized text generation. User profile information is retrieved to guide the generator, whose outputs are iteratively critiqued and refined by PerFine, enabling multi-round personalization.
|
| 26 |
+
|
| 27 |
+
Personalization is increasingly important for HCI, recommender systems, and natural language generation Chen ([2023](https://arxiv.org/html/2510.24469v1#bib.bib6)); Alhafni et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib3)). Prior work on personalized text generation has largely relied on retrieval-augmented generation (RAG) from user profiles. However, the challenge extends beyond retrieving relevant history: generated text must also match a user’s _style_, tone, and topical focus. Benchmarks such as LaMP, LongLaMP, and PGraphRAG broaden the evaluation of personalization in long-text generation Salemi et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib46)); Au et al. ([2025](https://arxiv.org/html/2510.24469v1#bib.bib4)); Kumar et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib21)). More recently, graph-based retrieval has been proposed to address the cold-start problem where users have sparse profiles, by leveraging neighbor user profiles in user-centric knowledge graphs Au et al. ([2025](https://arxiv.org/html/2510.24469v1#bib.bib4)). Yet existing personalization methods primarily optimize what to retrieve and how many few-shot samples to include. They often lack a _post-hoc, profile-aware refinement_ step that aligns both style and content once the full draft has been generated. We conjecture that such a refinement stage, enabled by a _critic LLM_, is crucial: it allows evaluation of the entire output against the user profile, correction of tone drift and topical gaps that retrieval cannot address, and avoidance of local heuristics from stepwise scoring. A profile-aware critic also acts as a model-agnostic oracle at inference. This makes iterative refinement a promising direction for personalization compared to pure retrieval-based or one-shot prompting, as it decouples retrieval from alignment and enables feedback to reshape the final text.
|
| 28 |
+
|
| 29 |
+
Personalized text generation is particularly challenging Wan et al. ([2025](https://arxiv.org/html/2510.24469v1#bib.bib54)); Zhang et al. ([2024a](https://arxiv.org/html/2510.24469v1#bib.bib66)): it requires capturing nuanced writing styles and implicit preferences, retrieving relevant content, and tailoring that content to align with those preferences. A natural way to address this complexity is through iterative refinement, inspired by how humans revise their writing based on feedback. Automated feedback has already proven effective in addressing LLM errors such as hallucinations, unfaithful reasoning, and biased content Pan et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib37)), either during training, during generation, or through post-hoc correction. Post-hoc correction is especially suitable for personalization, since it evaluates the _entire_ draft after generation and provides comprehensive feedback beyond stepwise scoring. Building on this paradigm, we introduce an external iterative refinement framework that generates structured feedback on style and content—the two core dimensions of personalized text generation.
|
| 30 |
+
|
| 31 |
+
We propose PerFine, a training-free iterative refinement framework that operates entirely at inference time. Figure[1](https://arxiv.org/html/2510.24469v1#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization") illustrates the architecture. We first retrieve top-k k entries from a user–item graph using GraphRAG. A generator LLM produces an initial draft y 0 y_{0}. A critic LLM, conditioned on the same profile, returns feedback along four dimensions: tone consistency, vocabulary match, sentence structure, and topic relevance. The generator revises accordingly, while a novel _knockout_ strategy retains the stronger draft across iterations. The loop treats style and content as first-class constraints and is compatible with any base model that accepts natural language feedback.
|
| 32 |
+
|
| 33 |
+
Beyond this basic _PerFine_ loop, we explore inference-time extensions that trace the quality–efficiency frontier (Figures[3](https://arxiv.org/html/2510.24469v1#S4.F3 "Figure 3 ‣ 4.1 Baseline Comparison ‣ 4 Results ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"), [4](https://arxiv.org/html/2510.24469v1#S4.F4 "Figure 4 ‣ 4.1 Baseline Comparison ‣ 4 Results ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization")). _Topic Extraction_ distills the profile into compact style and content hints. _Best-of-N N_, layered on Knockout, samples multiple revisions per iteration and allows the critic to select the best candidate, yielding the highest quality at higher token cost. Balancing quality and efficiency, _PerFine with Knockout_ is our default.
|
| 34 |
+
|
| 35 |
+
We address three questions. First, does a profile-grounded critique–refine loop improve personalized text generation compared to state-of-the-art methods such as LaMP and PGraphRAG? Second, how do critic scale and inference strategy trade off quality against efficiency? Third, how do improvements evolve across refinement iterations, and when do they plateau?
|
| 36 |
+
|
| 37 |
+
Our results show consistent gains. On GEval, PerFine outperforms PGraphRAG by +10.25% (Yelp), +7.8% (Goodreads), and +13.41% (Amazon). METEOR also improves across datasets (0.180→\to 0.195 on Yelp, 0.206→\to 0.216 on Goodreads, 0.190→\to 0.204 on Amazon). Gains accumulate over 3–5 refinement rounds before leveling off. Larger critics provide monotonic improvements (e.g., Yelp GEval climbs from 0.441 to 0.470 when scaling from 14B to 32B). Among inference-time strategies, Best-of-N N variant yields the strongest quality, while Knockout variant balances performance and efficiency.
|
| 38 |
+
|
| 39 |
+
Contributions.
|
| 40 |
+
|
| 41 |
+
* •We frame personalized text generation as _profile-grounded, post-hoc critique and refinement_, separating retrieval from alignment.
|
| 42 |
+
* •We introduce PerFine, a training-free iterative refinement framework for personalized text generation.
|
| 43 |
+
* •We propose inference-time strategies (Knockout, Topic Extraction, Knockout + Best-of-N N) that enable flexible trade-offs between quality and efficiency.
|
| 44 |
+
* •We provide an empirical study across three real-world datasets, showing stable gains within a few iterations, monotonic benefits from larger critics, and practical trade-offs that keep the method training-free and model-agnostic.
|
| 45 |
+
|
| 46 |
+
2 Proposed Framework
|
| 47 |
+
--------------------
|
| 48 |
+
|
| 49 |
+
#### Problem Definition:
|
| 50 |
+
|
| 51 |
+
Given an input x x provided by a user u u, and a target output generation y y, the goal of the _personalized text generation_ problem is to generate y~\tilde{y} that is aligned to the style and content of y y, conditioned on the user’s personal data P u P_{u} (e.g., documents, histories, preferences). This is achieved by transforming the input x x into a personalized input x~\tilde{x} using query (ϕ q\phi_{q}) and generation (ϕ g\phi_{g}) functions, along with a retriever module R R with an optional parameter k k , before passing it to a text generation module, an LLM denoted as Generator.
|
| 52 |
+
|
| 53 |
+
x~\displaystyle\tilde{x}=ϕ g(x,R(ϕ q(x),P u,k))\displaystyle=\phi_{g}\big(x,R(\phi_{q}(x),P_{u},k)\big)
|
| 54 |
+
y~\displaystyle\tilde{y}=Generator(x~)\displaystyle=\textrm{Generator}(\tilde{x})
|
| 55 |
+
|
| 56 |
+
#### PerFine:
|
| 57 |
+
|
| 58 |
+
Our iterative refinement framework, as depicted in Figure [1](https://arxiv.org/html/2510.24469v1#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"), iteratively critiques and refines outputs to produce the final personalized generation y~\tilde{y}. The framework comprises of the following core components: (1) Retriever, (2) Generator, and (3) Critic. The Retriever fetches the subset of user’s profile data most relevant to user query. The Generator produces the initial draft and refines the outputs based on feedback in subsequent rounds, while the Critic generates feedback. Both the Generator and Critic components are LLMs and are conditioned on the user profile. We also introduce and elaborate various inference-time stratergies on top of PerFine to enhance the potential of our framework.
|
| 59 |
+
|
| 60 |
+
#### Retriever:
|
| 61 |
+
|
| 62 |
+
Since a user’s profile can be large, using it in its entirety may lead to high computational costs, over-reliance on an LLM’s ability to process long contexts, and the inclusion of irrelevant profile information. To mitigate these issues, we leverage the retrieval-augmented generation (RAG) paradigm Lewis et al. ([2021](https://arxiv.org/html/2510.24469v1#bib.bib23)), which uses only the most relevant user-profile entries, controlled by the hyperparameter k k, as the context.
|
| 63 |
+
|
| 64 |
+
ℛ(P u)=R(ϕ q(x),P u,k)\mathcal{R}(P_{u})=R(\phi_{q}(x),P_{u},k)
|
| 65 |
+
|
| 66 |
+
where R R is the retriever and ℛ(P u)\mathcal{R}(P_{u}) represents the top-k k subset of the user profile P u P_{u} (ℛ(P u)⊆P u\mathcal{R}(P_{u})\subseteq P_{u}). The query function ϕ q(x)\phi_{q}(x) is an identity function in our setting.
|
| 67 |
+
|
| 68 |
+
#### Generator:
|
| 69 |
+
|
| 70 |
+
The generator LLM produces an initial draft y 0 y_{0} from the user query and the top-k k relevant profile entries, using the generation prompt construction function ϕ g\phi_{g}. It also refines the output in further rounds based on the personalized feedback given by critic using the refinement prompt construction function ϕ g′\phi_{g}^{{}^{\prime}}.
|
| 71 |
+
|
| 72 |
+
y 0=Generator(ϕ g(x,ℛ(P u)))y_{0}=\textrm{Generator}\big(\phi_{g}(x,\mathcal{R}(P_{u}))\big)
|
| 73 |
+
|
| 74 |
+
y t+1=Generator(ϕ g′(x,y t,f t,ℛ(P u))),0≤t<T y_{t+1}=\textrm{Generator}\big(\phi_{g}^{{}^{\prime}}(x,y_{t},f_{t},\mathcal{R}(P_{u}))\big),0\leq t<T
|
| 75 |
+
|
| 76 |
+
where y t y_{t} and f t f_{t} are the output and feedback in the t th t^{th} iteration, while T T is the maximum feedback iteration count.
|
| 77 |
+
|
| 78 |
+
#### Critic:
|
| 79 |
+
|
| 80 |
+
The Critic LLM, conditioned on x x and ℛ(P u)\mathcal{R}(P_{u}) is instructed to provide feedback f t f_{t} on y t y_{t} along the following four personalization criteria:
|
| 81 |
+
|
| 82 |
+
* •Tone Consistency: Evaluate whether the tone and sentiment align with the user’s writing style.
|
| 83 |
+
* •Vocabulary Match: Evaluate whether the vocabulary level is consistent with the user’s lexicon.
|
| 84 |
+
* •Sentence Structure: Evaluate if the sentence lengths, complexity, and syntactic structures align with that of the user’s style.
|
| 85 |
+
* •Topic Relevance: Evaluate if the generated content is relevant to the query, free of off-topic information, and inclusive of important aspects.
|
| 86 |
+
|
| 87 |
+
f t=Critic(ϕ c(x,y t,ℛ(P u))),0≤t≤T f_{t}=\textrm{Critic}\big(\phi_{c}(x,y_{t},\mathcal{R}(P_{u}))\big),0\leq t\leq T
|
| 88 |
+
|
| 89 |
+
where ϕ c\phi_{c} is the feedback prompt construction function.
|
| 90 |
+
|
| 91 |
+
#### PerFine Setting:
|
| 92 |
+
|
| 93 |
+
The generator and critic LLMs operate in a zero-shot setting. The refinement process stops when a predefined stopping criterion is met, which here is a fixed number of iterations T T.
|
| 94 |
+
|
| 95 |
+
In our setup, a user’s profile consists of their own history as well as interactions with other users, represented in a user-centric bipartite graph with users and items as partitions. This results in a user profile being a collection of text samples from both the user and their neighbors. We employ Graph-based Retrieval-Augmented Generation (GraphRAG), where retrieval is performed over the graph to extract the most relevant information.
|
| 96 |
+
|
| 97 |
+
For any user u, we define the user profile P u P_{u} as the set of previous texts written by user u (i.e., {(u,j)∈E}\{(u,j)\in E\}, and the set of texts written by other users v for the same items connected to user u (i.e., {(v,j)∈E∣(u,j)∈E}\{(v,j)\in E\mid(u,j)\in E\}) Edge et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib11)).
|
| 98 |
+
|
| 99 |
+
P u={(u,j)∈E}∪{(v,j)∈E∣(v,j)∈E},P_{u}=\{(u,j)\in E\}\cup\{(v,j)\in E\mid(v,j)\in E\},
|
| 100 |
+
|
| 101 |
+
∀j∈I,u,v∈U,u≠v\quad\forall j\in I,\quad u,v\in U,\quad u\neq v
|
| 102 |
+
|
| 103 |
+
where U U is the set of user nodes, I I is the set of item nodes and E E is the set of interaction edges. The prompt construction functions ϕ g\phi_{g}, ϕ c\phi_{c}, ϕ g′\phi_{g}^{{}^{\prime}}, and the query x x template are shared in Appendix [A.1](https://arxiv.org/html/2510.24469v1#A1.SS1 "A.1 Prompts ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization").
|
| 104 |
+
|
| 105 |
+
Inference-time stratergies
|
| 106 |
+
--------------------------
|
| 107 |
+
|
| 108 |
+
We further explore the following three inference-time variants of PerFine.
|
| 109 |
+
|
| 110 |
+
(1) PerFine + Knockout: In this setting, after each generation, the critic LLM compares the output y t y_{t} at iteration t t with that of the previous round y t−1 y_{t-1}, and selects the more personalized output, which then proceeds to the next round of feedback and refinement. To determine which output is more personalized, critic is instructed to evaluate the alignment in terms of style and topical relevance, referencing the profile ℛ(P u)\mathcal{R}(P_{u}) and the query x x.
|
| 111 |
+
|
| 112 |
+
y t=Critic(ϕ k(x,y t,y(t−1),ℛ(P u))),t>0 y_{t}=\textrm{Critic}\big(\phi_{k}(x,y_{t},y_{(t-1)},\mathcal{R}(P_{u}))\big),t>0
|
| 113 |
+
|
| 114 |
+
where ϕ k\phi_{k} is the knockout prompt construction function (shared in Figure [A.1](https://arxiv.org/html/2510.24469v1#A1.SS1 "A.1 Prompts ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization")). y t y_{t} is followed by f t f_{t} and y(t+1)y_{(t+1)}.
|
| 115 |
+
|
| 116 |
+
For the default setting, we operate the critic in this Best-of-T T kind of framework, which retains the most personalized generation across iterations. The results are shown in Table [1](https://arxiv.org/html/2510.24469v1#Sx1.T1 "Table 1 ‣ Inference-time stratergies ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization").
|
| 117 |
+
|
| 118 |
+
(2) PerFine + Knockout + Best-of-N: In this setting, for every refinement step, we do Best-of-N N sampling and ask the critic to compare the n n sampled revisions and select the more personalized output, which is then passed on to the next round of knockout, feedback, and refinement steps.
|
| 119 |
+
|
| 120 |
+
y(t+1)1,…y(t+1)n=Generator(ϕ g′(x,y t,f t,ℛ(P u)))y_{(t+1)}^{1},...y_{(t+1)}^{n}=\textrm{Generator}\big(\phi_{g}^{{}^{\prime}}(x,y_{t},f_{t},{\mathcal{R}(P_{u})})\big)
|
| 121 |
+
|
| 122 |
+
y(t+1)=Critic(ϕ n(x,y(t+1)1,…y(t+1)n,ℛ(P u)))y_{(t+1)}=\textrm{Critic}\big(\phi_{n}(x,y_{(t+1)}^{1},...y_{(t+1)}^{n},\mathcal{R}(P_{u}))\big)
|
| 123 |
+
|
| 124 |
+
where ϕ n\phi_{n} is the Best-of-N N prompt construction function (shared in Figure [A.1](https://arxiv.org/html/2510.24469v1#A1.SS1 "A.1 Prompts ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization")). y(t+1)y_{(t+1)} is followed by knockout, feedback and refinement steps.
|
| 125 |
+
|
| 126 |
+
Table 1: Baseline Comparison. The table compares the performance of PerFine+Knockout against two baselines: LaMP, where the user profile contains samples only from the user’s own history, and PGraphRAG, which also includes samples from the profile histories of neighboring users. The output of PGraphRAG is taken as the initial generation y 0 y_{0}, over which PerFine+Knockout performs the feedback refinement process. Llama-3.1-8B-Instruct is used as the generator LLM, and Qwen-2.5-14B-Instruct serves as the critic LLM.
|
| 127 |
+
|
| 128 |
+
(3) PerFine + Topic Extraction: In this setting, instead of conditioning the critic on raw text samples from the user profile, we extract personalized aspects along the dimensions of style and content, which are then used as context. The writing style is derived from the user’s history, while the content aspects are taken from the neighbors’ profile.
|
| 129 |
+
|
| 130 |
+
S\displaystyle S=Topic_Extractor(ϕ ts(ℛ(P u)U))\displaystyle=\textrm{Topic\_Extractor}\big(\phi_{ts}(\mathcal{R}(P_{u})_{U})\big)
|
| 131 |
+
C\displaystyle C=Topic_Extractor(ϕ tc(ℛ(P u)N))\displaystyle=\textrm{Topic\_Extractor}\big(\phi_{tc}(\mathcal{R}(P_{u})_{N})\big)
|
| 132 |
+
f t\displaystyle f_{t}=Critic(ϕ t(x,y t,S,C))\displaystyle=\textrm{Critic}\big(\phi_{t}(x,y_{t},S,C)\big)
|
| 133 |
+
|
| 134 |
+
where ℛ(P u)U\mathcal{R}(P_{u})_{U} has samples only from user’s history, while ℛ(P u)N\mathcal{R}(P_{u})_{N} has samples from neighbor’s history. S S and C C are the extracted style and content topics by a Topic_Extractor module, an LLM. By leveraging an explicitly summarized representation of the personalized aspects, this approach enables the critic to reference the profile information more easily during feedback generation at each iteration, while also reducing the length of the input context. The extraction prompts ϕ ts,ϕ tc\phi_{ts},\phi_{tc} are shared in Figure [A.2](https://arxiv.org/html/2510.24469v1#A1.SS2 "A.2 Topic Extraction ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"). Critic prompt ϕ t\phi_{t} is shared in Figure [A.2](https://arxiv.org/html/2510.24469v1#A1.SS2 "A.2 Topic Extraction ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization").
|
| 135 |
+
|
| 136 |
+
3 Experiments Design
|
| 137 |
+
--------------------
|
| 138 |
+
|
| 139 |
+
### 3.1 Dataset and Graph Construction
|
| 140 |
+
|
| 141 |
+
We evaluate our approach on the product review writing task using the AgentSociety Challenge dataset Yan et al. ([2025](https://arxiv.org/html/2510.24469v1#bib.bib61)), which is a curated collection of user–item-review triplets (user, review, item) from Yelp, Amazon Hou et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib14)), and Goodreads Wan and McAuley ([2018](https://arxiv.org/html/2510.24469v1#bib.bib55)); Wan et al. ([2019](https://arxiv.org/html/2510.24469v1#bib.bib56)). In the graph representation, one partition of the bipartite graph represents users, while the other represents items (businesses, products, or books being reviewed). An edge corresponds to a review. For each dataset, we prepare development and test splits, each containing 2,500 randomly sampled users with no overlap. For each user, we randomly take a review and add it in the split for evaluation, with the remaining reviews forming the user’s profile history. We consider only users who have at least one profile entry.
|
| 142 |
+
|
| 143 |
+
For Amazon reviews Hou et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib14)), we consider the domains Industrial and Scientific, Musical Instruments, and Video Games. For Goodreads reviews Wan and McAuley ([2018](https://arxiv.org/html/2510.24469v1#bib.bib55)); Wan et al. ([2019](https://arxiv.org/html/2510.24469v1#bib.bib56)), we consider the domains Comics, Poetry, and Children’s Books. To describe a business in Yelp data, we consider the city, state, attributes, and categories fields. To describe Amazon products, we consider the title, description, and categories fields. For Goodreads, we use the title and description fields from raw data. Reviews that are not in English are filtered out.
|
| 144 |
+
|
| 145 |
+
### 3.2 Metrics and Evaluation
|
| 146 |
+
|
| 147 |
+
We use both term-based matching metrics and LLM-as-a-Judge metrics. For term-based matching, we use METEOR, while for LLM-as-a-Judge, we use G-Eval Liu et al. ([2023b](https://arxiv.org/html/2510.24469v1#bib.bib32)), in which an LLM is prompted to generate an absolute score based on the comparison between the generation and the ground-truth reference. Further, G-Eval computes the final score by averaging over the possible scores, weighted by the probabilities assigned to each score by the backbone LLM. Evaluation prompt is shared in Appendix [A.3](https://arxiv.org/html/2510.24469v1#A1.SS3 "A.3 Evaluation Prompt ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization").
|
| 148 |
+
|
| 149 |
+
### 3.3 Experimental Setup
|
| 150 |
+
|
| 151 |
+
We chose Llama-3.1-8B-Instruct as our generator LLM. For the critic, we primarily use the Qwen-2.5-Instruct models in both 14B and 32B sizes in addition to experimenting with gpt-5-mini, which is our choice of the closed-source model. We also use the same Llama-3.1-8B-Instruct model as the critic to evaluate the approach in a self-refinement setting. We used vLLM with a maximum completion token limit of 512 and a temperature of 0.6 for both LLMs. The feedback iteration count T T is set to 5. For G-Eval, we used Qwen-3-32B as the backbone LLM. G-Eval was run 20 times at a temperature of 1 to obtain the probability distribution over scores. We choose Contriever Lei et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib22)) as the retriever with top-k k set to 4, where a max of k k entries are retrieved from each of the user’s and neighbor’s profiles. The same top-k k are used for baselines as well. For PerFine + Knockout + Best-of-N N, we choose n n to be 3.
|
| 152 |
+
|
| 153 |
+
4 Results
|
| 154 |
+
---------
|
| 155 |
+
|
| 156 |
+
### 4.1 Baseline Comparison
|
| 157 |
+
|
| 158 |
+
We compare our method with two personalized baselines. They are (1) LaMP Salemi et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib46)), in which the augmented information for RAG consists of only the target user’s history. (2) PGraphRAG Edge et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib11)), where the retrieval is performed to fetch information from both the target user and the neighbors (from the interaction graph).
|
| 159 |
+
|
| 160 |
+
Table[1](https://arxiv.org/html/2510.24469v1#Sx1.T1 "Table 1 ‣ Inference-time stratergies ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization") demonstrates that PerFine+Knockout consistently outperforms the baselines, achieving improvements of 10.25% on Yelp, 7.8% on Goodreads, and 13.41% on Amazon in the GEval scores.
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
Figure 2: Performance across iterations on Yelp, Goodreads, and Amazon datasets. PerFine+Knockout starts from the PGraphRAG baseline and exhibits steady improvements, with gains plateauing after a few iterations.
|
| 165 |
+
|
| 166 |
+
The performance trend across time is shown in Figure [2](https://arxiv.org/html/2510.24469v1#S4.F2 "Figure 2 ‣ 4.1 Baseline Comparison ‣ 4 Results ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"). We observe that the scores increase with the number of iterations and converge after a few rounds of feedback, suggesting controlled and incremental alignments with the user profile over time. These evidences highlight the impact of incorporating feedback in enhancing the personalization capability of LLMs. A case study illustrating the end-to-end iterative refinement process is presented in Appendix [A.4](https://arxiv.org/html/2510.24469v1#A1.SS4 "A.4 Case study ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization").
|
| 167 |
+
|
| 168 |
+
Table 2: Evaluation of different critic models in the PerFine+Knockout setup (all are instruct models). Llama-3.1-8B-Instruct is the generator.
|
| 169 |
+
|
| 170 |
+
Table 3: Comparison of performance and token usage (prompt+completion) across various inference stratergies. We observe that the scores improve as we scale the inference time token usage. However, the additional gains from Best-of-N N sampling are marginal, while the associated token usage increases significantly. Token count is per query for 5 iterations in K. Llama-3.1-8B-Instruct is used as the generator, and Qwen-2.5-14B-Instruct is the critic.
|
| 171 |
+
|
| 172 |
+

|
| 173 |
+
|
| 174 |
+
Figure 3: Vizualization of the critic’s token usage (prompt + completion) vs normalized GEval performance on the Amazon, Goodreads, and Yelp datasets. Notably, PerFine+Knockout improves performance, while PerFine+Knockout+Best-of-N achieves the highest scores, with increased token cost. Considering both efficiency and effectiveness, we ultimately select PerFine+Knockout.
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
Figure 4: Figure showing generator’s token usage (prompt + completion) vs normalized GEval performance on the Amazon, Goodreads, and Yelp datasets. While the token usage for PerFine and PerFine+Knockout is similar, the token footprint increases for PerFine+Knockout+Best-of-N due to the sampling of multiple revisions, while yielding only a marginal improvement in performance.
|
| 179 |
+
|
| 180 |
+
### 4.2 Ablation Studies
|
| 181 |
+
|
| 182 |
+
#### Critic Model Ablation:
|
| 183 |
+
|
| 184 |
+
In Table [2](https://arxiv.org/html/2510.24469v1#S4.T2 "Table 2 ‣ 4.1 Baseline Comparison ‣ 4 Results ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"), we present an ablation study by varying both the size and the family of the critic model. All experimental configurations outperform the baselines, demonstrating that the PerFine framework is compatible with a wide range of base models. For analyzing the impact of model size, we evaluate the Qwen-2.5 model in 7B, 14B, and 32B variants, and observe that performance consistently improves with larger critics. Larger critics provide more targeted feedback and refinement suggestions, thereby simplifying the generator’s incorporation of corrections. We also evaluate a self-refinement setting, in which the critic and generator are identical. This setting is resource-efficient, as it avoids the need for a separate LLM to serve as the critic, thereby reducing the overall memory footprint. Even in this configuration, PerFine achieves superior performance compared to the baselines.
|
| 185 |
+
|
| 186 |
+
The performance gain achieved with the closed-source model (gpt-5-mini) suggests that powerful proprietary models can be readily leveraged via APIs for generating feedback in PerFine framework. Furthermore, the observed gains with gpt-5-mini were obtained under a low reasoning efficiency setting, indicating that large reasoning models used as critics may be highly effective in the context of personalization and may lead to faster convergence.
|
| 187 |
+
|
| 188 |
+
#### Inference-Strategies Ablation:
|
| 189 |
+
|
| 190 |
+
Table [3](https://arxiv.org/html/2510.24469v1#S4.T3 "Table 3 ‣ 4.1 Baseline Comparison ‣ 4 Results ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization") compares the performance of different inference-time strategies for the critic. The total token usage per query by the critic and generator is shown in Figure[3](https://arxiv.org/html/2510.24469v1#S4.F3 "Figure 3 ‣ 4.1 Baseline Comparison ‣ 4 Results ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization") and Figure[4](https://arxiv.org/html/2510.24469v1#S4.F4 "Figure 4 ‣ 4.1 Baseline Comparison ‣ 4 Results ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"), respectively. The PerFine+Knockout strategy, when combined with Best-of-N N, outperforms all other configurations. In both PerFine+Knockout and PerFine+Knockout+Best-of-N N settings, multiple candidate revisions are laid out for the critic to compare, either across iterations or within the same iteration, which increases the likelihood of producing an optimized output. However, this performance gain comes at the cost of higher token usage and increased latency, as shown in Figures [3](https://arxiv.org/html/2510.24469v1#S4.F3 "Figure 3 ‣ 4.1 Baseline Comparison ‣ 4 Results ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization") and [4](https://arxiv.org/html/2510.24469v1#S4.F4 "Figure 4 ‣ 4.1 Baseline Comparison ‣ 4 Results ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"). The spike in generator token usage for the PerFine+Knockout+Best-of-N N setting arises from sampling multiple revision outputs, while the spike in critic token usage arises from the step to select the best out of those N N. The incremental improvement provided by Best-of-N N sampling is relatively small, and PerFine+Knockout offers a nice balance between performance and efficiency. The quality of PerFine+Topic_Extraction setting is discussed in Appendix [A.2](https://arxiv.org/html/2510.24469v1#A1.SS2 "A.2 Topic Extraction ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization").
|
| 191 |
+
|
| 192 |
+
5 Related Work
|
| 193 |
+
--------------
|
| 194 |
+
|
| 195 |
+
### 5.1 Personalization via RAG
|
| 196 |
+
|
| 197 |
+
RAG retrieves user-relevant segments from an external store with semantic similarity and then conditions generation on these segments Gao et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib12)). It is common in IR and recommendation pipelines Zhao et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib68)); Rajput et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib40)); Di Palma ([2023](https://arxiv.org/html/2510.24469v1#bib.bib8)); Wang et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib58)). It can also reduce hallucinations by grounding outputs in factual context Shuster et al. ([2021](https://arxiv.org/html/2510.24469v1#bib.bib50)); Li et al. ([2024b](https://arxiv.org/html/2510.24469v1#bib.bib26)). In personalization, large user profiles act as external knowledge, and a retriever picks a compact subset before decoding Gao et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib12)). Work in the survey groups retrievers into _sparse_ and _dense_ Gao et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib12)).
|
| 198 |
+
|
| 199 |
+
Sparse retrieval methods like TF–IDF and BM25 are efficient and strong baselines, yet they rely on lexical overlap and so miss semantic preference signals Sparck Jones ([1972](https://arxiv.org/html/2510.24469v1#bib.bib51)); Robertson et al. ([1995](https://arxiv.org/html/2510.24469v1#bib.bib43)); Salemi et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib45)); Li et al. ([2023a](https://arxiv.org/html/2510.24469v1#bib.bib25)); Richardson et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib42)).
|
| 200 |
+
|
| 201 |
+
Dense retrieval methods encode queries and documents into a continuous space for similarity search Johnson et al. ([2019](https://arxiv.org/html/2510.24469v1#bib.bib18)), with off-the-shelf encoders such as Sentence-BERT Reimers and Gurevych ([2019](https://arxiv.org/html/2510.24469v1#bib.bib41)) and task-trained dual encoders like DPR Karpukhin et al. ([2020](https://arxiv.org/html/2510.24469v1#bib.bib19)) and Contriever Izacard et al. ([2021](https://arxiv.org/html/2510.24469v1#bib.bib15)). In personalization, researchers also build training data and losses for user-centric retrieval, and they use fusion-at-decoder with encoder–decoder LMs; Sentence-T5 and GTR are widely used as well Izacard and Grave ([2020](https://arxiv.org/html/2510.24469v1#bib.bib16)); Raffel et al. ([2020](https://arxiv.org/html/2510.24469v1#bib.bib39)); Ni et al. ([2021a](https://arxiv.org/html/2510.24469v1#bib.bib35), [b](https://arxiv.org/html/2510.24469v1#bib.bib36)); Mysore et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib34)). Dense retrievers tend to perform better yet require careful data design and extra cost Richardson et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib42)). Hybrid and black-box retrieval also appear, but they add tool specificity and less transparency Gao et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib12)).
|
| 202 |
+
|
| 203 |
+
Graph-based retrieval. Traditional RAG can struggle under cold-start and fragmented histories. GraphRAG builds a user–item bipartite graph and expands the search space with neighbor profiles so it can find transferable evidence when the target user is sparse Edge et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib11)). This brings three advantages in our setting Xiang et al. ([2025](https://arxiv.org/html/2510.24469v1#bib.bib60)). First, it increases topical coverage for long-form writing, since neighbors who reviewed the same item (j) supply complementary content cues. Second, it enhances style conditioning by allowing us to separate signals: we utilize the target user’s own texts for style and neighbors for query-relevant content, then merge them into the prompt. Third, it keeps control simple: we use only 1–2 hops and cap at most k k texts from the user and at most k k from neighbors, with Contriever to pick them Lei et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib22)). After generation, we fix any drift with a profile-conditioned critic and iterative revision. We take PGraphRAG’s output as the initial draft y 0 y_{0} and apply PerFine to turn “what was retrieved” into “how it reads,” showing stable gains under a fixed token budget Edge et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib11)); Salemi et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib45), [2024](https://arxiv.org/html/2510.24469v1#bib.bib46)).
|
| 204 |
+
|
| 205 |
+
### 5.2 Personalization via Prompting
|
| 206 |
+
|
| 207 |
+
Personalization via prompting can be grouped into four categories: _contextual prompting_, _profile-augmented prompting_, _persona-based prompting_, and _prompt refinement_ Zhang et al. ([2024b](https://arxiv.org/html/2510.24469v1#bib.bib67)).
|
| 208 |
+
|
| 209 |
+
Contextual prompting. One can insert segments of a user’s demographic information, history, and item metadata into the prompt so the model performs downstream personalized tasks with context Di Palma ([2023](https://arxiv.org/html/2510.24469v1#bib.bib8)); Wang and Lim ([2023](https://arxiv.org/html/2510.24469v1#bib.bib57)); Sanner et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib47)); Li et al. ([2023b](https://arxiv.org/html/2510.24469v1#bib.bib27)); Christakopoulou et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib7)); Tran et al. ([2025b](https://arxiv.org/html/2510.24469v1#bib.bib53), [a](https://arxiv.org/html/2510.24469v1#bib.bib52)). This is simple and interpretable. It is also sensitive to prompt wording and scale when profiles are large or noisy, and context limits can be hit Jin et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib17)); Ding et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib9)); Lin et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib29)); Liu et al. ([2023a](https://arxiv.org/html/2510.24469v1#bib.bib30)).
|
| 210 |
+
|
| 211 |
+
Profile-augmented prompting. Many systems summarize, factorize, or hierarchically structure profiles, then inject distilled preferences back into the prompt to ease context bloat and cold-start. Examples include task-aware user summaries, topic/region distillation from browsing histories, and factorization prompting that turns preferences into structured attributes for downstream models Richardson et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib42)); Liu et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib31)); Zheng et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib69)); Wu et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib59)). These improve signal density. They still run as one-shot generation with little ability to fix post-generation drift Gao et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib12)).
|
| 212 |
+
|
| 213 |
+
Persona-based prompting. A complementary line specifies an explicit persona in the prompt to guide style or behavior; representative variants span demographic, character, and individualized personas, but also introduce risks such as bias and “character hallucination”Aher et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib1)); Horton ([2023](https://arxiv.org/html/2510.24469v1#bib.bib13)); Chen et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib5)); Lim et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib28)).
|
| 214 |
+
|
| 215 |
+
Prompt refinement. Beyond hand-crafted templates, some works iteratively optimize prompts to reduce manual trial-and-error in personalization, though they remain pre-generation interventions Kim and Yang ([2024](https://arxiv.org/html/2510.24469v1#bib.bib20)); Li et al. ([2024a](https://arxiv.org/html/2510.24469v1#bib.bib24)); Yao et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib62)); Santurkar et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib48)); Durmus et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib10)).
|
| 216 |
+
|
| 217 |
+
We _do not_ use persona prompts or learned prompt refiners. Instead, our method can be partially categorized as _contextual prompting_ (we directly condition on profile snippets) and _profile-augmented prompting_ (we distill and structure profile signals via retrieval). The key difference is that we place _natural-language feedback_ at inference time and make it _profile-conditioned_: the critic returns structured feedback on tone, vocabulary, sentence structure, and topicality, the generator revises, and Knockout/Best-of-N N selects stronger drafts. This post-hoc alignment complements pre-generation prompting and directly corrects style/topic drift after a full draft is available.
|
| 218 |
+
|
| 219 |
+
### 5.3 Feedback for LLMs
|
| 220 |
+
|
| 221 |
+
Post-hoc feedback has proven effective in multiple domains. Self-Refine shows that a single model can generate, critique, and iteratively improve its own outputs without additional training Madaan et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib33)). Reflexion stores verbalized reflections to improve subsequent decision making and long-horizon performance Shinn et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib49)). External critics decouple the target generator from the feedback provider and can be trained to deliver actionable signals; examples include RL-based critics for feedback optimization and systems that supervise intermediate reasoning steps (REFINER)Akyurek et al. ([2023](https://arxiv.org/html/2510.24469v1#bib.bib2)); Paul et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib38)). Broader surveys categorize feedback channels (scalar vs. natural language), sources (self vs. external), and intervention points (during training, during generation, or post-hoc)Pan et al. ([2024](https://arxiv.org/html/2510.24469v1#bib.bib37)); most reported gains concentrate on code, math, and QA, or other stepwise reasoning in different domains, where verification signals are available Zhang et al. ([2023a](https://arxiv.org/html/2510.24469v1#bib.bib64), [b](https://arxiv.org/html/2510.24469v1#bib.bib65)); Yao et al. ([2025](https://arxiv.org/html/2510.24469v1#bib.bib63)). Despite these advances, inference-time feedback for personalization has received limited attention. Prior work rarely operationalizes a profile-conditioned critic that evaluates full generations against a user’s style and content preferences and then drives iterative revision. Our framework fills this gap by (i) specifying four feedback dimensions tailored to personalization (tone, vocabulary, sentence structure, topicality), (ii) coupling them with inference-time selection strategies (Knockout, Best-of-N N), and (iii) demonstrating training-free, model-agnostic improvements on profile-grounded generation beyond strong RAG baselines.
|
| 222 |
+
|
| 223 |
+
6 Conclusion
|
| 224 |
+
------------
|
| 225 |
+
|
| 226 |
+
In this work, we introduce PerFine, an iterative refinement framework for personalized text generation. We demonstrate that a simple post-hoc personalized feedback methodology, which requires no training, can improve performance. We also introduce and experiment with various inference-time scaling mechanisms to enhance the critic’s potential, observing consistent performance gains. This work opens up promising research directions in the area of feedback for personalized LLMs.
|
| 227 |
+
|
| 228 |
+
Limitations
|
| 229 |
+
-----------
|
| 230 |
+
|
| 231 |
+
One of the main limitations of our approach is the fixed number of feedback iterations. Different queries require different levels of refinement, and dynamically judging when to stop helps to avoid both overcorrection and undercorrection, while also reducing token usage and latency. In the PerFine framework, although smaller critics do improve performance, the most significant gains come from bigger LLMs. In resource-constrained deployment settings, this presents a challenge, making it crucial to train smaller LLMs as personalized critics for improved efficiency. However, obtaining training signals for such supervision is difficult, and exploring synthetic data creation techniques may be helpful. Several possible extensions to PerFine can be explored to enhance its capabilities further. One promising direction is to make the retrieval process dynamic, where the top-k k profile is updated at every iteration based on feedback. In-context learning can also be effective in guiding the critic to structure its feedback in a specific way (through few-shot examples) tailored to the target task. Another important research direction is the reliable evaluation of personalized text generation, not only against ground-truth reference but also with respect to complex user preference patterns inferred from a user’s profile.
|
| 232 |
+
|
| 233 |
+
References
|
| 234 |
+
----------
|
| 235 |
+
|
| 236 |
+
* Aher et al. (2023) Gati V Aher, Rosa I Arriaga, and Adam Tauman Kalai. 2023. Using large language models to simulate multiple humans and replicate human subject studies. In _International conference on machine learning_, pages 337–371. PMLR.
|
| 237 |
+
* Akyurek et al. (2023) Afra Feyza Akyurek, Ekin Akyurek, Ashwin Kalyan, Peter Clark, Derry Tanti Wijaya, and Niket Tandon. 2023. [RL4F: Generating natural language feedback with reinforcement learning for repairing model outputs](https://doi.org/10.18653/v1/2023.acl-long.427). In _Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)_, pages 7716–7733, Toronto, Canada. Association for Computational Linguistics.
|
| 238 |
+
* Alhafni et al. (2024) Bashar Alhafni, Vivek Kulkarni, Dhruv Kumar, and Vipul Raheja. 2024. [Personalized text generation with fine-grained linguistic control](https://aclanthology.org/2024.personalize-1.8/). In _Proceedings of the 1st Workshop on Personalization of Generative AI Systems (PERSONALIZE 2024)_, pages 88–101, St. Julians, Malta. Association for Computational Linguistics.
|
| 239 |
+
* Au et al. (2025) Steven Au, Cameron J. Dimacali, Ojasmitha Pedirappagari, Namyong Park, Franck Dernoncourt, Yu Wang, Nikos Kanakaris, Hanieh Deilamsalehy, Ryan Rossi, and Nesreen K. Ahmed. 2025. [Personalized graph-based retrieval for large language models](https://api.semanticscholar.org/CorpusID:275336507). _ArXiv_, abs/2501.02157.
|
| 240 |
+
* Chen et al. (2024) Jiangjie Chen, Xintao Wang, Rui Xu, Siyu Yuan, Yikai Zhang, Wei Shi, Jian Xie, Shuang Li, Ruihan Yang, Tinghui Zhu, and 1 others. 2024. From persona to personalization: A survey on role-playing language agents. _arXiv preprint arXiv:2404.18231_.
|
| 241 |
+
* Chen (2023) Junyi Chen. 2023. [A survey on large language models for personalized and explainable recommendations](https://arxiv.org/abs/2311.12338). _Preprint_, arXiv:2311.12338.
|
| 242 |
+
* Christakopoulou et al. (2023) Konstantina Christakopoulou, Alberto Lalama, Cj Adams, Iris Qu, Yifat Amir, Samer Chucri, Pierce Vollucci, Fabio Soldo, Dina Bseiso, Sarah Scodel, and 1 others. 2023. Large language models for user interest journeys. _arXiv preprint arXiv:2305.15498_.
|
| 243 |
+
* Di Palma (2023) Dario Di Palma. 2023. Retrieval-augmented recommender system: Enhancing recommender systems with large language models. In _Proceedings of the 17th ACM Conference on Recommender Systems_, pages 1369–1373.
|
| 244 |
+
* Ding et al. (2024) Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, and Mao Yang. 2024. Longrope: Extending llm context window beyond 2 million tokens. _arXiv preprint arXiv:2402.13753_.
|
| 245 |
+
* Durmus et al. (2023) Esin Durmus, Karina Nguyen, Thomas I Liao, Nicholas Schiefer, Amanda Askell, Anton Bakhtin, Carol Chen, Zac Hatfield-Dodds, Danny Hernandez, Nicholas Joseph, and 1 others. 2023. Towards measuring the representation of subjective global opinions in language models. _arXiv preprint arXiv:2306.16388_.
|
| 246 |
+
* Edge et al. (2024) Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. 2024. [From local to global: A graph rag approach to query-focused summarization](https://arxiv.org/abs/2404.16130). _Preprint_, arXiv:2404.16130.
|
| 247 |
+
* Gao et al. (2023) Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey. _arXiv preprint arXiv:2312.10997_, 2(1).
|
| 248 |
+
* Horton (2023) John J Horton. 2023. Large language models as simulated economic agents: What can we learn from homo silicus? Technical report, National Bureau of Economic Research.
|
| 249 |
+
* Hou et al. (2024) Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. 2024. Bridging language and items for retrieval and recommendation. _arXiv preprint arXiv:2403.03952_.
|
| 250 |
+
* Izacard et al. (2021) Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2021. Unsupervised dense information retrieval with contrastive learning. _arXiv preprint arXiv:2112.09118_.
|
| 251 |
+
* Izacard and Grave (2020) Gautier Izacard and Edouard Grave. 2020. Leveraging passage retrieval with generative models for open domain question answering. _arXiv preprint arXiv:2007.01282_.
|
| 252 |
+
* Jin et al. (2024) Hongye Jin, Xiaotian Han, Jingfeng Yang, Zhimeng Jiang, Zirui Liu, Chia-Yuan Chang, Huiyuan Chen, and Xia Hu. 2024. Llm maybe longlm: Self-extend llm context window without tuning. _arXiv preprint arXiv:2401.01325_.
|
| 253 |
+
* Johnson et al. (2019) Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with gpus. _IEEE Transactions on Big Data_, 7(3):535–547.
|
| 254 |
+
* Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In _EMNLP (1)_, pages 6769–6781.
|
| 255 |
+
* Kim and Yang (2024) Jaehyung Kim and Yiming Yang. 2024. Few-shot personalization of llms with mis-aligned responses. _arXiv preprint arXiv:2406.18678_.
|
| 256 |
+
* Kumar et al. (2024) Ishita Kumar, Snigdha Viswanathan, Sushrita Yerra, Alireza Salemi, Ryan Rossi, Franck Dernoncourt, Hanieh Deilamsalehy, Xiang Chen, Ruiyi Zhang, Shubham Agarwal, Nedim Lipka, and Hamed Zamani. 2024. [Longlamp: A benchmark for personalized long-form text generation](https://api.semanticscholar.org/CorpusID:271218187).
|
| 257 |
+
* Lei et al. (2023) Yibin Lei, Liang Ding, Yu Cao, Changtong Zan, Andrew Yates, and Dacheng Tao. 2023. [Unsupervised dense retrieval with relevance-aware contrastive pre-training](https://doi.org/10.18653/v1/2023.findings-acl.695). In _Findings of the Association for Computational Linguistics: ACL 2023_, pages 10932–10940, Toronto, Canada. Association for Computational Linguistics.
|
| 258 |
+
* Lewis et al. (2021) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. [Retrieval-augmented generation for knowledge-intensive nlp tasks](https://arxiv.org/abs/2005.11401). _Preprint_, arXiv:2005.11401.
|
| 259 |
+
* Li et al. (2024a) Cheng Li, Mingyang Zhang, Qiaozhu Mei, Weize Kong, and Michael Bendersky. 2024a. Learning to rewrite prompts for personalized text generation. In _Proceedings of the ACM Web Conference 2024_, pages 3367–3378.
|
| 260 |
+
* Li et al. (2023a) Cheng Li, Mingyang Zhang, Qiaozhu Mei, Yaqing Wang, Spurthi Amba Hombaiah, Yi Liang, and Michael Bendersky. 2023a. Teach llms to personalize–an approach inspired by writing education. _arXiv preprint arXiv:2308.07968_.
|
| 261 |
+
* Li et al. (2024b) Jiarui Li, Ye Yuan, and Zehua Zhang. 2024b. Enhancing llm factual accuracy with rag to counter hallucinations: A case study on domain-specific queries in private knowledge-bases. _arXiv preprint arXiv:2403.10446_.
|
| 262 |
+
* Li et al. (2023b) Xinyi Li, Yongfeng Zhang, and Edward C Malthouse. 2023b. A preliminary study of chatgpt on news recommendation: Personalization, provider fairness, fake news. _arXiv preprint arXiv:2306.10702_.
|
| 263 |
+
* Lim et al. (2024) Jung Hoon Lim, Sunjae Kwon, Zonghai Yao, John P Lalor, and Hong Yu. 2024. Large language model-based role-playing for personalized medical jargon extraction. _arXiv preprint arXiv:2408.05555_.
|
| 264 |
+
* Lin et al. (2024) Bin Lin, Chen Zhang, Tao Peng, Hanyu Zhao, Wencong Xiao, Minmin Sun, Anmin Liu, Zhipeng Zhang, Lanbo Li, Xiafei Qiu, and 1 others. 2024. Infinite-llm: Efficient llm service for long context with distattention and distributed kvcache. _arXiv preprint arXiv:2401.02669_.
|
| 265 |
+
* Liu et al. (2023a) Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023a. Lost in the middle: How language models use long contexts. _arXiv preprint arXiv:2307.03172_.
|
| 266 |
+
* Liu et al. (2024) Qijiong Liu, Nuo Chen, Tetsuya Sakai, and Xiao-Ming Wu. 2024. Once: Boosting content-based recommendation with both open-and closed-source large language models. In _Proceedings of the 17th ACM International Conference on Web Search and Data Mining_, pages 452–461.
|
| 267 |
+
* Liu et al. (2023b) Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023b. [G-eval: NLG evaluation using gpt-4 with better human alignment](https://doi.org/10.18653/v1/2023.emnlp-main.153). In _Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing_, pages 2511–2522, Singapore. Association for Computational Linguistics.
|
| 268 |
+
* Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. [Self-refine: Iterative refinement with self-feedback](https://arxiv.org/abs/2303.17651). _Preprint_, arXiv:2303.17651.
|
| 269 |
+
* Mysore et al. (2023) Sheshera Mysore, Zhuoran Lu, Mengting Wan, Longqi Yang, Steve Menezes, Tina Baghaee, Emmanuel Barajas Gonzalez, Jennifer Neville, and Tara Safavi. 2023. Pearl: Personalizing large language model writing assistants with generation-calibrated retrievers. _arXiv preprint arXiv:2311.09180_.
|
| 270 |
+
* Ni et al. (2021a) Jianmo Ni, Gustavo Hernandez Abrego, Noah Constant, Ji Ma, Keith B Hall, Daniel Cer, and Yinfei Yang. 2021a. Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models. _arXiv preprint arXiv:2108.08877_.
|
| 271 |
+
* Ni et al. (2021b) Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Hernandez Abrego, Ji Ma, Vincent Y Zhao, Yi Luan, Keith B Hall, Ming-Wei Chang, and 1 others. 2021b. Large dual encoders are generalizable retrievers. _arXiv preprint arXiv:2112.07899_.
|
| 272 |
+
* Pan et al. (2024) Liangming Pan, Michael Saxon, Wenda Xu, Deepak Nathani, Xinyi Wang, and William Yang Wang. 2024. [Automatically correcting large language models: Surveying the landscape of diverse automated correction strategies](https://doi.org/10.1162/tacl_a_00660). _Transactions of the Association for Computational Linguistics_, 12:484–506.
|
| 273 |
+
* Paul et al. (2024) Debjit Paul, Mete Ismayilzada, Maxime Peyrard, Beatriz Borges, Antoine Bosselut, Robert West, and Boi Faltings. 2024. [Refiner: Reasoning feedback on intermediate representations](https://arxiv.org/abs/2304.01904). _Preprint_, arXiv:2304.01904.
|
| 274 |
+
* Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. _Journal of machine learning research_, 21(140):1–67.
|
| 275 |
+
* Rajput et al. (2023) Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, and 1 others. 2023. Recommender systems with generative retrieval. _Advances in Neural Information Processing Systems_, 36:10299–10315.
|
| 276 |
+
* Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. _arXiv preprint arXiv:1908.10084_.
|
| 277 |
+
* Richardson et al. (2023) Chris Richardson, Yao Zhang, Kellen Gillespie, Sudipta Kar, Arshdeep Singh, Zeynab Raeesy, Omar Zia Khan, and Abhinav Sethy. 2023. Integrating summarization and retrieval for enhanced personalization via large language models. _arXiv preprint arXiv:2310.20081_.
|
| 278 |
+
* Robertson et al. (1995) Stephen E Robertson, Steve Walker, Susan Jones, Micheline M Hancock-Beaulieu, Mike Gatford, and 1 others. 1995. _Okapi at TREC-3_. British Library Research and Development Department.
|
| 279 |
+
* Salemi et al. (2025) Alireza Salemi, Julian Killingback, and Hamed Zamani. 2025. [Expert: Effective and explainable evaluation of personalized long-form text generation](https://arxiv.org/abs/2501.14956). _Preprint_, arXiv:2501.14956.
|
| 280 |
+
* Salemi et al. (2023) Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. 2023. [Lamp: When large language models meet personalization](https://api.semanticscholar.org/CorpusID:258298303).
|
| 281 |
+
* Salemi et al. (2024) Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. 2024. [Lamp: When large language models meet personalization](https://arxiv.org/abs/2304.11406). _Preprint_, arXiv:2304.11406.
|
| 282 |
+
* Sanner et al. (2023) Scott Sanner, Krisztian Balog, Filip Radlinski, Ben Wedin, and Lucas Dixon. 2023. Large language models are competitive near cold-start recommenders for language-and item-based preferences. In _Proceedings of the 17th ACM conference on recommender systems_, pages 890–896.
|
| 283 |
+
* Santurkar et al. (2023) Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. 2023. Whose opinions do language models reflect? In _International Conference on Machine Learning_, pages 29971–30004. PMLR.
|
| 284 |
+
* Shinn et al. (2023) Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. [Reflexion: Language agents with verbal reinforcement learning](https://arxiv.org/abs/2303.11366). _Preprint_, arXiv:2303.11366.
|
| 285 |
+
* Shuster et al. (2021) Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston. 2021. Retrieval augmentation reduces hallucination in conversation. _arXiv preprint arXiv:2104.07567_.
|
| 286 |
+
* Sparck Jones (1972) Karen Sparck Jones. 1972. A statistical interpretation of term specificity and its application in retrieval. _Journal of documentation_, 28(1):11–21.
|
| 287 |
+
* Tran et al. (2025a) Hieu Tran, Zonghai Yao, Won Seok Jang, Sharmin Sultana, Allen Chang, Yuan Zhang, and Hong Yu. 2025a. Medreadctrl: Personalizing medical text generation with readability-controlled instruction learning. _arXiv preprint arXiv:2507.07419_.
|
| 288 |
+
* Tran et al. (2025b) Hieu Tran, Zonghai Yao, Lingxi Li, and Hong Yu. 2025b. Readctrl: Personalizing text generation with readability-controlled instruction learning. In _Proceedings of the Fourth Workshop on Intelligent and Interactive Writing Assistants (In2Writing 2025)_, pages 19–36.
|
| 289 |
+
* Wan et al. (2025) Kaiyang Wan, Honglin Mu, Rui Hao, Haoran Luo, Tianle Gu, and Xiuying Chen. 2025. [A cognitive writing perspective for constrained long-form text generation](https://arxiv.org/abs/2502.12568). _Preprint_, arXiv:2502.12568.
|
| 290 |
+
* Wan and McAuley (2018) Mengting Wan and Julian J. McAuley. 2018. [Item recommendation on monotonic behavior chains](https://doi.org/10.1145/3240323.3240369). In _Proceedings of the 12th ACM Conference on Recommender Systems, RecSys 2018, Vancouver, BC, Canada, October 2-7, 2018_, pages 86–94. ACM.
|
| 291 |
+
* Wan et al. (2019) Mengting Wan, Rishabh Misra, Ndapa Nakashole, and Julian J. McAuley. 2019. [Fine-grained spoiler detection from large-scale review corpora](https://doi.org/10.18653/V1/P19-1248). In _Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers_, pages 2605–2610. Association for Computational Linguistics.
|
| 292 |
+
* Wang and Lim (2023) Lei Wang and Ee-Peng Lim. 2023. Zero-shot next-item recommendation using large pretrained language models. _arXiv preprint arXiv:2304.03153_.
|
| 293 |
+
* Wang et al. (2024) Yu Wang, Nedim Lipka, Ryan A Rossi, Alexa Siu, Ruiyi Zhang, and Tyler Derr. 2024. Knowledge graph prompting for multi-document question answering. In _Proceedings of the AAAI conference on artificial intelligence_, volume 38, pages 19206–19214.
|
| 294 |
+
* Wu et al. (2024) Likang Wu, Zhaopeng Qiu, Zhi Zheng, Hengshu Zhu, and Enhong Chen. 2024. Exploring large language model for graph data understanding in online job recommendations. In _Proceedings of the AAAI conference on artificial intelligence_, volume 38, pages 9178–9186.
|
| 295 |
+
* Xiang et al. (2025) Zhishang Xiang, Chuanjie Wu, Qinggang Zhang, Shengyuan Chen, Zijin Hong, Xiao Huang, and Jinsong Su. 2025. When to use graphs in rag: A comprehensive analysis for graph retrieval-augmented generation. _arXiv preprint arXiv:2506.05690_.
|
| 296 |
+
* Yan et al. (2025) Yuwei Yan, Yu Shang, Qingbin Zeng, Yu Li, Keyu Zhao, Zhiheng Zheng, Xuefei Ning, Tianji Wu, Shengen Yan, Yu Wang, and 1 others. 2025. Agentsociety challenge: Designing llm agents for user modeling and recommendation on web platforms. _arXiv preprint arXiv:2502.18754_.
|
| 297 |
+
* Yao et al. (2024) Zonghai Yao, Ahmed Jaafar, Beining Wang, Zhichao Yang, and Hong Yu. 2024. Do clinicians know how to prompt? the need for automatic prompt optimization help in clinical note generation. In _Proceedings of the 23rd Workshop on Biomedical Natural Language Processing_, pages 182–201.
|
| 298 |
+
* Yao et al. (2025) Zonghai Yao, Aditya Parashar, Huixue Zhou, Won Seok Jang, Feiyun Ouyang, Zhichao Yang, and Hong Yu. 2025. Mcqg-srefine: Multiple choice question generation and evaluation with iterative self-critique, correction, and comparison feedback. In _Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)_, pages 10728–10777.
|
| 299 |
+
* Zhang et al. (2023a) Kechi Zhang, Zhuo Li, Jia Li, Ge Li, and Zhi Jin. 2023a. [Self-edit: Fault-aware code editor for code generation](https://arxiv.org/abs/2305.04087). _Preprint_, arXiv:2305.04087.
|
| 300 |
+
* Zhang et al. (2023b) Kexun Zhang, Danqing Wang, Jingtao Xia, William Yang Wang, and Lei Li. 2023b. [Algo: Synthesizing algorithmic programs with llm-generated oracle verifiers](https://arxiv.org/abs/2305.14591). _Preprint_, arXiv:2305.14591.
|
| 301 |
+
* Zhang et al. (2024a) Zhehao Zhang, Ryan A. Rossi, Branislav Kveton, Yijia Shao, Diyi Yang, Hamed Zamani, Franck Dernoncourt, Joe Barrow, Tong Yu, Sungchul Kim, Ruiyi Zhang, Jiuxiang Gu, Tyler Derr, Hongjie Chen, Junda Wu, Xiang Chen, Zichao Wang, Subrata Mitra, Nedim Lipka, and 2 others. 2024a. [Personalization of large language models: A survey](https://arxiv.org/abs/2411.00027). _Preprint_, arXiv:2411.00027.
|
| 302 |
+
* Zhang et al. (2024b) Zhehao Zhang, Ryan A Rossi, Branislav Kveton, Yijia Shao, Diyi Yang, Hamed Zamani, Franck Dernoncourt, Joe Barrow, Tong Yu, Sungchul Kim, and 1 others. 2024b. Personalization of large language models: A survey. _arXiv preprint arXiv:2411.00027_.
|
| 303 |
+
* Zhao et al. (2024) Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, and 1 others. 2024. Recommender systems in the era of large language models (llms). _IEEE Transactions on Knowledge and Data Engineering_, 36(11):6889–6907.
|
| 304 |
+
* Zheng et al. (2023) Zhi Zheng, Zhaopeng Qiu, Xiao Hu, Likang Wu, Hengshu Zhu, and Hui Xiong. 2023. Generative job recommendations with large language model. _arXiv preprint arXiv:2307.02157_.
|
| 305 |
+
|
| 306 |
+
Appendix A Appendix
|
| 307 |
+
-------------------
|
| 308 |
+
|
| 309 |
+
### A.1 Prompts
|
| 310 |
+
|
| 311 |
+
Figure [A.1](https://arxiv.org/html/2510.24469v1#A1.SS1 "A.1 Prompts ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"): Query Template
|
| 312 |
+
|
| 313 |
+
Figure [A.1](https://arxiv.org/html/2510.24469v1#A1.SS1 "A.1 Prompts ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"): Generation Prompt Template
|
| 314 |
+
|
| 315 |
+
Figure [A.1](https://arxiv.org/html/2510.24469v1#A1.SS1 "A.1 Prompts ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"): Critic Prompt Template
|
| 316 |
+
|
| 317 |
+
Figure [A.1](https://arxiv.org/html/2510.24469v1#A1.SS1 "A.1 Prompts ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"): Refinement Prompt Template. The [GENERATION PROMPT] in the above template is shared in Figure [A.1](https://arxiv.org/html/2510.24469v1#A1.SS1 "A.1 Prompts ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization")
|
| 318 |
+
|
| 319 |
+
Figure [A.1](https://arxiv.org/html/2510.24469v1#A1.SS1 "A.1 Prompts ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"): Knockout Prompt Template
|
| 320 |
+
|
| 321 |
+
Figure [A.1](https://arxiv.org/html/2510.24469v1#A1.SS1 "A.1 Prompts ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"): Knockout + Best-of-N Prompt Template
|
| 322 |
+
|
| 323 |
+
The prompt templates for the other two datasets follow the same structure, with the word ‘business’ replaced by ‘book’ for Goodreads and by ‘product’ for Amazon throughout.
|
| 324 |
+
|
| 325 |
+
### A.2 Topic Extraction
|
| 326 |
+
|
| 327 |
+
Table 4: Performance and Token usage for Topic Extraction method
|
| 328 |
+
|
| 329 |
+
The topic extraction method outperforms the baselines and achieves performance comparable to the vanilla setting, while requiring fewer critic tokens during feedback rounds. However, it introduces an initial overhead for extracting topics, which increases the overall token consumption. Qwen-2.5-32B-Instruct is used for extracting the topics.
|
| 330 |
+
|
| 331 |
+
Figure [A.2](https://arxiv.org/html/2510.24469v1#A1.SS2 "A.2 Topic Extraction ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"): Topic Extraction Prompts.
|
| 332 |
+
|
| 333 |
+
Figure [A.2](https://arxiv.org/html/2510.24469v1#A1.SS2 "A.2 Topic Extraction ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization"): Critic prompt using extracted topics.
|
| 334 |
+
|
| 335 |
+
### A.3 Evaluation Prompt
|
| 336 |
+
|
| 337 |
+
The prompt is borrowed from Salemi et al. ([2025](https://arxiv.org/html/2510.24469v1#bib.bib44))
|
| 338 |
+
|
| 339 |
+
Figure [A.3](https://arxiv.org/html/2510.24469v1#A1.SS3 "A.3 Evaluation Prompt ‣ Appendix A Appendix ‣ Iterative Critique-Refine Framework for Enhancing LLM Personalization") : GEval Prompt
|
| 340 |
+
|
| 341 |
+
### A.4 Case study
|
| 342 |
+
|
| 343 |
+
This case study illustrates the refinement process over five iterations. The PGraphRAG baseline does provide an appropriate response for a three-star rating. However, it could still be better personalized.
|
| 344 |
+
|
| 345 |
+
We can observe how the critic incrementally aligns the tone across iterations. In feedback 1, it suggests using a more enthusiastic and playful tone. Once this is addressed in the refined generations, it then notes in feedback 2 that the user prefers a more casual style, while in feedback 4 and feedback 5 it recommends incorporating more specific descriptions. After these aspects are integrated, the final feedback comments that the text is well aligned, balanced, and slightly critical (Highlighted in blue).
|
| 346 |
+
|
| 347 |
+
A similar pattern occurs with sentence structure, where the critic consistently suggests making it more varied and complex (inline with user’s sytle) across all feedback iterations. This is finally corrected after five iterations, with the final feedback confirming that it is well aligned (Highlighted in orange).
|
| 348 |
+
|
| 349 |
+
When it comes to vocabulary, the critic clearly recommends adopting a more colloquial style (inline with user’s style) in feedback 1 and feedback 2. Unlike tone and sentence structure, this aspect is resolved early, after two iterations, and in the remaining feedback the critic signals that it is well aligned and requires no further improvement (Highlighted in violet).
|
| 350 |
+
|
| 351 |
+
The critic is able to analyze the user’s writing samples, infer the style, and compare it against the baseline generation.
|
| 352 |
+
|
| 353 |
+
On the content side, to ensure topic relevance, it provides useful suggestions regarding common aspects of restaurant reviews, such as service quality, ambiance, and friendly staff. These aspects are also present in the ground truth, leading to better topical relevance overall (Highlighted in green).
|
| 354 |
+
|
| 355 |
+
Another important observation is that generation 3 and generation 4 are identical. The critic judged the initial generation 4 as less personalized compared to generation 3, as a result of which the newly generated output was knocked-out and generation 3 was advanced as generation 4 (Highlighted in navyblue).
|