

Add 1 files
Browse files- 2512/2512.16853.md +400 -0
2512/2512.16853.md
ADDED
|
@@ -0,0 +1,400 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
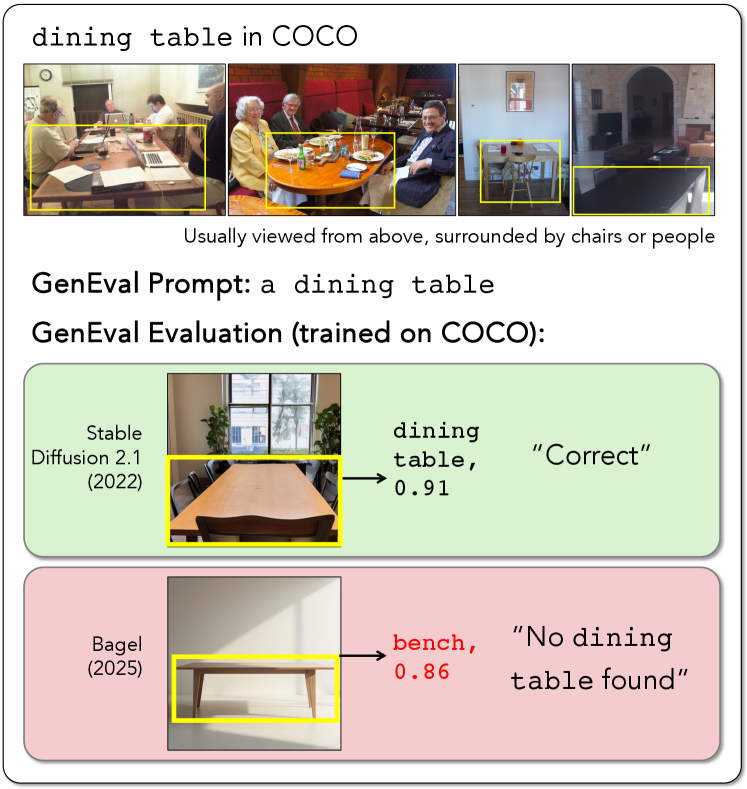
|
|
|
|
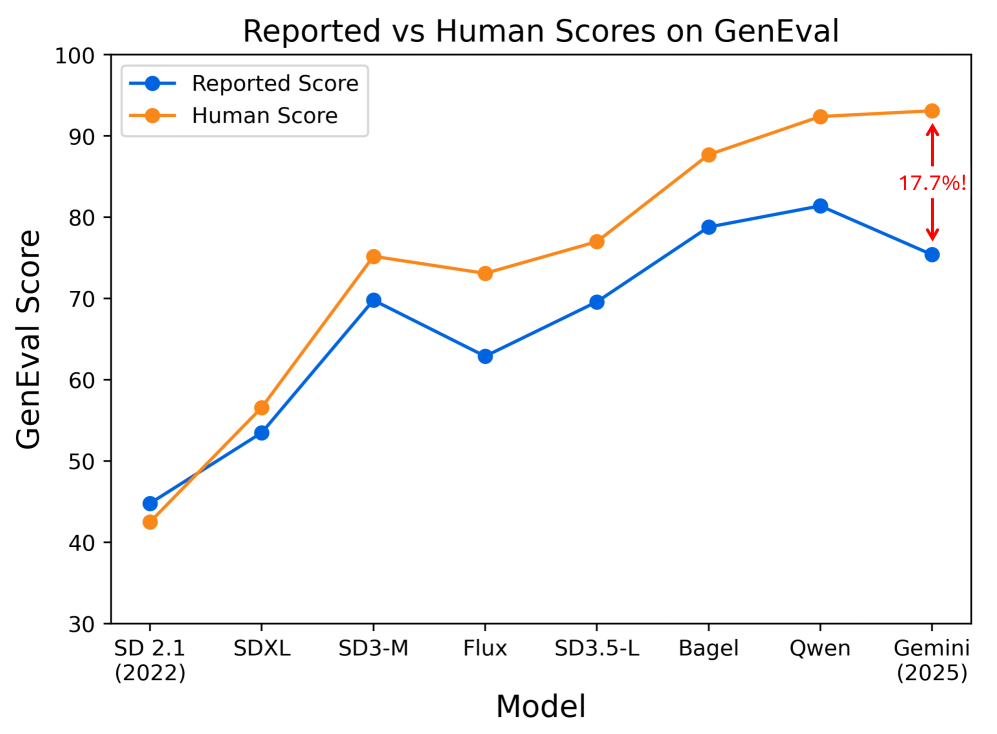
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
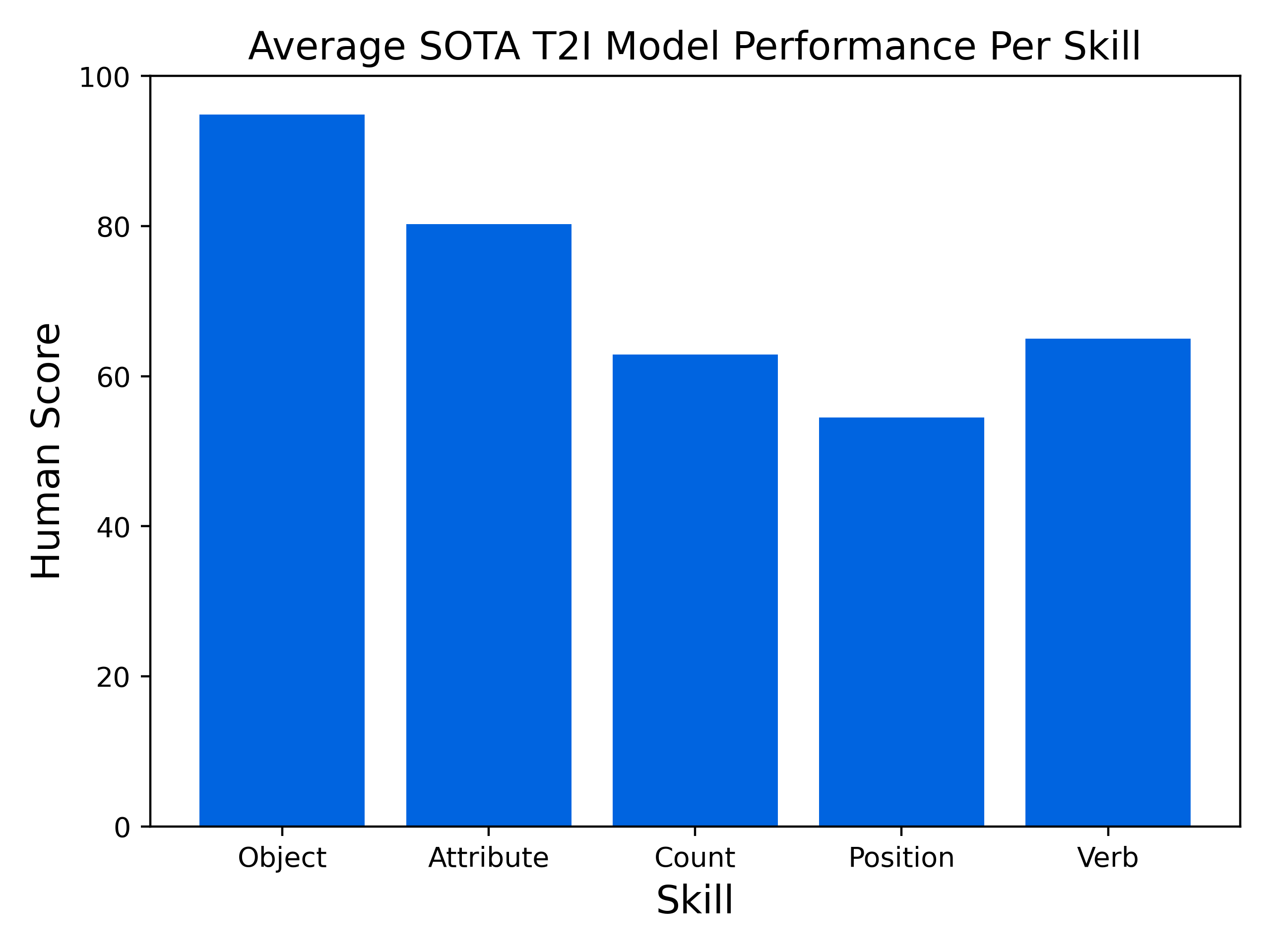
|
|
|
|
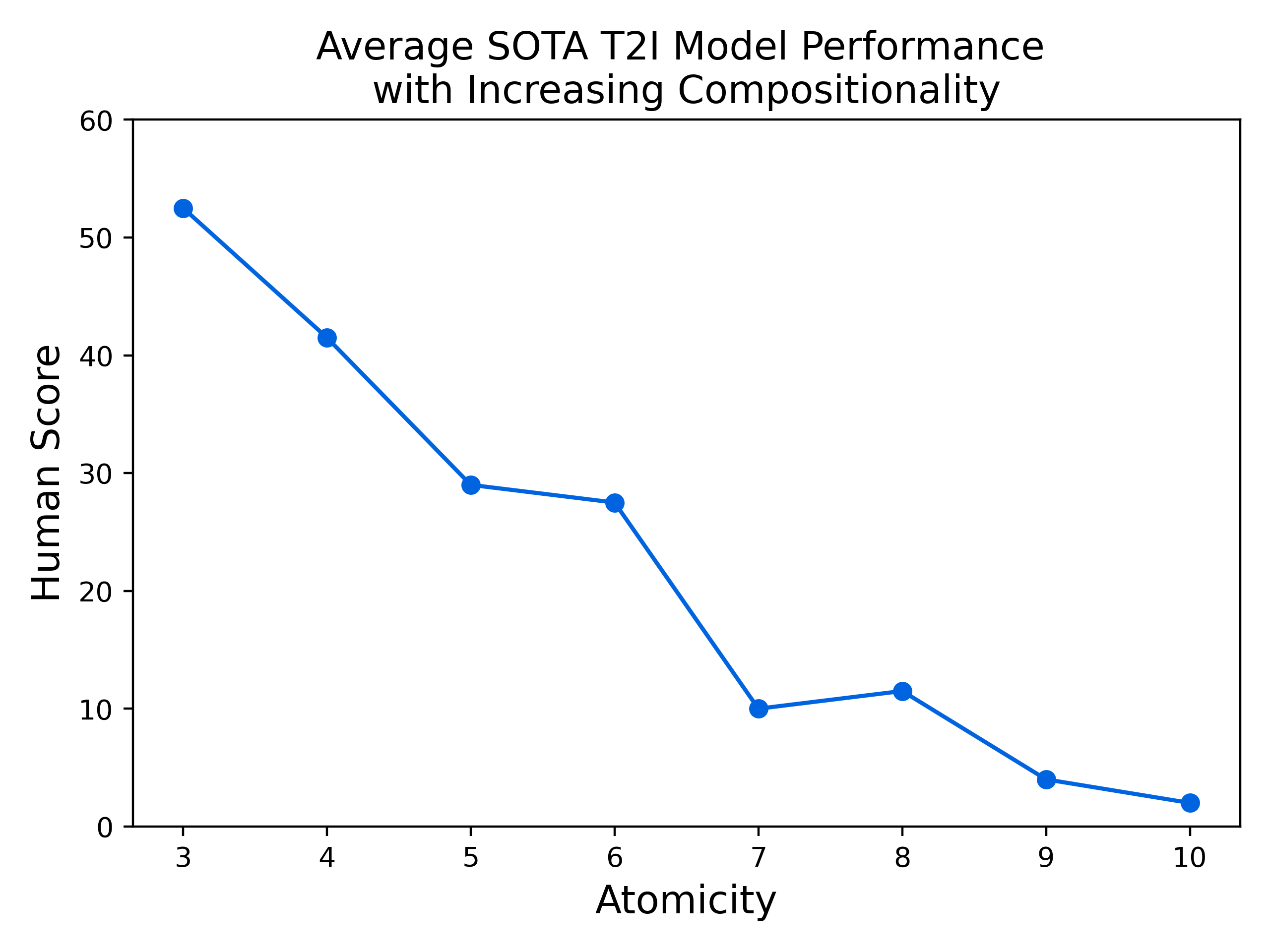
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
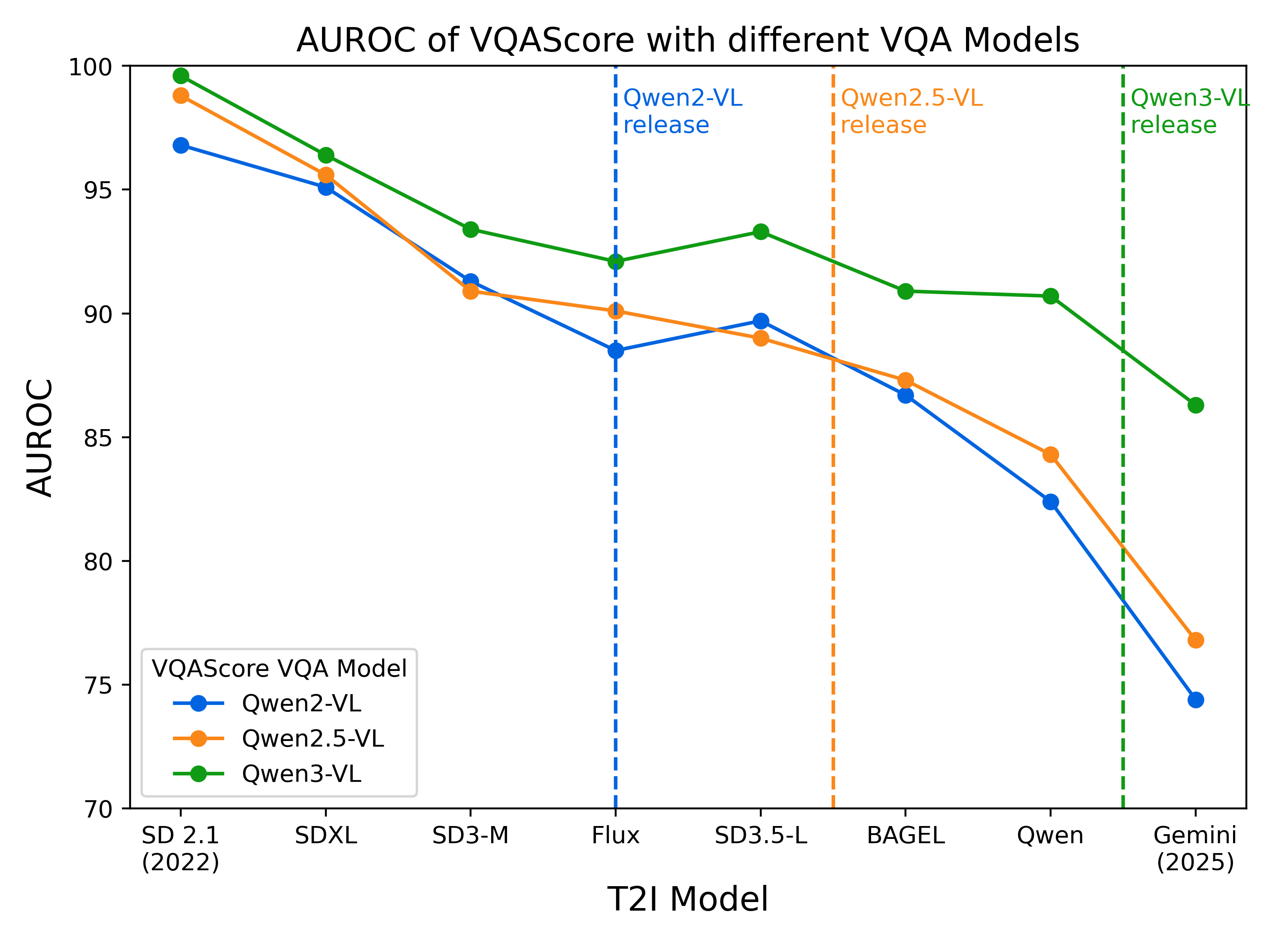
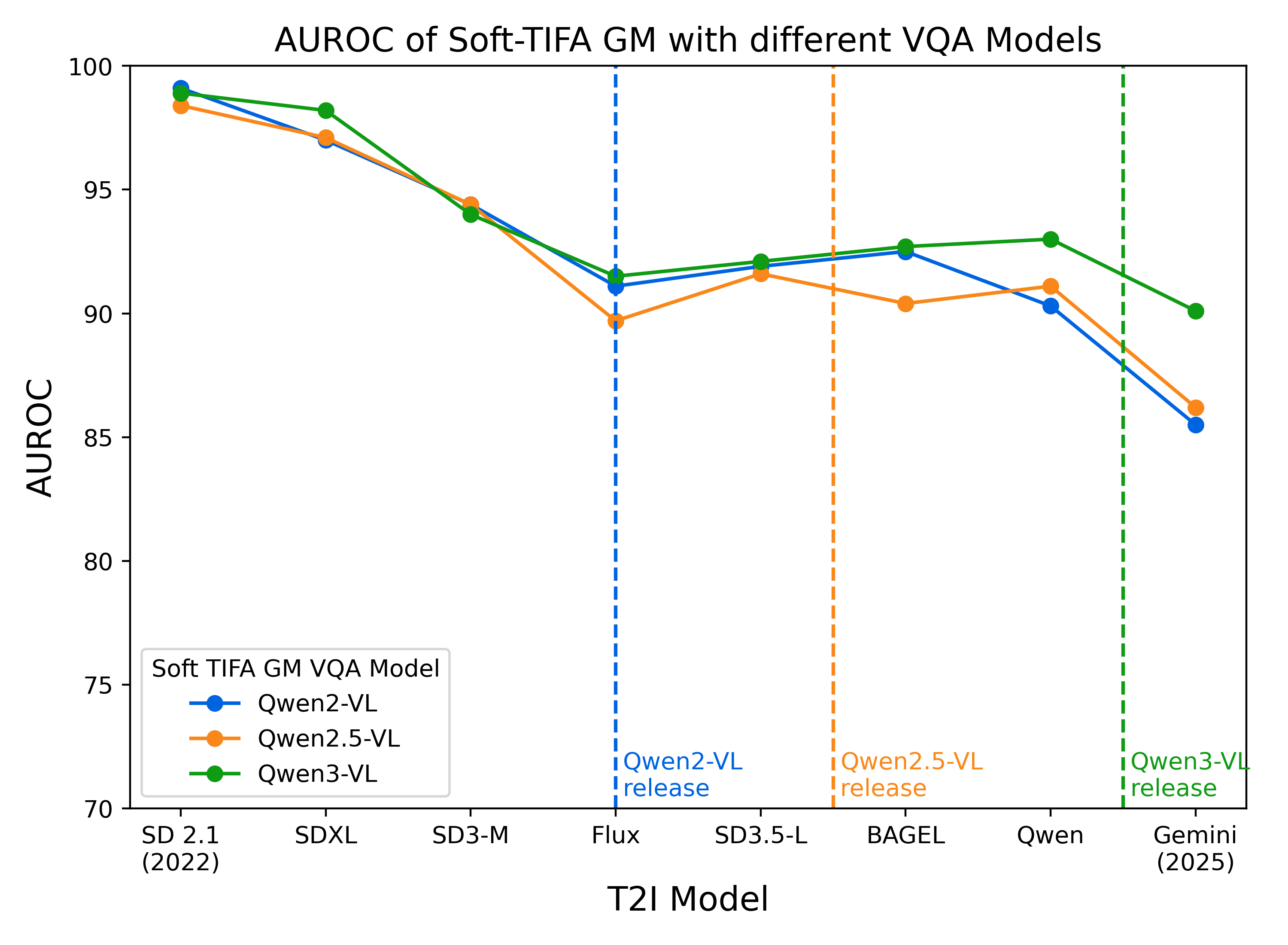
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/2512.16853
|
| 4 |
+
|
| 5 |
+
Markdown Content:
|
| 6 |
+
1]FAIR at Meta 2]University of Washington 3]University of California, Los Angeles 4]Allen Institute for AI \contribution[*]Work done at Meta \contribution[†]Joint last author
|
| 7 |
+
|
| 8 |
+
(December 18, 2025)
|
| 9 |
+
|
| 10 |
+
###### Abstract
|
| 11 |
+
|
| 12 |
+
Automating Text-to-Image (T2I) model evaluation is challenging; a judge model must be used to score correctness, and test prompts must be selected to be challenging for current T2I models but not the judge. We argue that satisfying these constraints can lead to benchmark drift over time, where the static benchmark judges fail to keep up with newer model capabilities. We show that benchmark drift is a significant problem for GenEval, one of the most popular T2I benchmarks. Although GenEval was well-aligned with human judgment at the time of its release, it has drifted far from human judgment over time—resulting in an absolute error of as much as 17.7% for current models. This level of drift strongly suggests that GenEval has been saturated for some time, as we verify via a large-scale human study. To help fill this benchmarking gap, we introduce a new benchmark, GenEval 2, with improved coverage of primitive visual concepts and higher degrees of compositionality, which we show is more challenging for current models. We also introduce Soft-TIFA, an evaluation method for GenEval 2 that combines judgments for visual primitives, which we show is more well-aligned with human judgment and argue is less likely to drift from human-alignment over time (as compared to more holistic judges such as VQAScore). Although we hope GenEval 2 will provide a strong benchmark for many years, avoiding benchmark drift is far from guaranteed and our work, more generally, highlights the importance of continual audits and improvement for T2I and related automated model evaluation benchmarks.
|
| 13 |
+
|
| 14 |
+
1 Introduction
|
| 15 |
+
--------------
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
(a)GenEval relies on CLIP (Radford et al., [2021](https://arxiv.org/html/2512.16853v1#bib.bib28)) and a detector trained on COCO (Cheng et al., [2022b](https://arxiv.org/html/2512.16853v1#bib.bib8)), which are no longer reliable for evaluating recent T2I models.
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
(b)The gap between human and automatic evaluation scores on GenEval increases as T2I models become better, and eventually saturate the prompts.
|
| 24 |
+
|
| 25 |
+
Figure 1: With the distribution shift of Text-to-Image (T2I) models’ outputs over time, we reveal that the model-based evaluation of GenEval decreases in human-alignment, masking the fact that the benchmark is now saturated. We introduce GenEval 2, a more robust benchmark that is challenging for state-of-the-art T2I models, alongside an evaluation method, Soft-TIFA, that is less likely to suffer benchmark drift.
|
| 26 |
+
|
| 27 |
+
Text-to-Image (T2I) models are becoming increasingly capable (Deng et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib12); Wu et al., [2025a](https://arxiv.org/html/2512.16853v1#bib.bib36); Labs, [2024](https://arxiv.org/html/2512.16853v1#bib.bib20); Comanici et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib10)), with models training on increasing amounts of natural and synthesized data. Their rapid progress has been both driven and measured by T2I benchmarks, for everything from basic capabilities like object colors and counts (Ghosh et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib15); Huang et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib17); Li et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib21)) to advanced capabilities like knowledge and reasoning (Niu et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib24); Chang et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib3); Sun et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib31); Chen et al., [2025b](https://arxiv.org/html/2512.16853v1#bib.bib6)). These benchmarks employ model-based evaluation: images generated by T2I models are evaluated using either a combination of specialized models such as object detectors and image-text matching models (Ghosh et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib15); Huang et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib17)), or a single VQA model (Li et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib21); Niu et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib24); Chang et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib3)).
|
| 28 |
+
|
| 29 |
+
However, we raise a critical question: given how much T2I models’ capabilities have changed, are the evaluations of longer-standing benchmarks still valid? To investigate, we study one of the most prominent benchmarks to measure basic T2I capabilities: GenEval (Ghosh et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib15)). This benchmark has been a primary evaluation in many popular T2I papers over the past three years including (but not limited to) Stable Diffusion 3 (Esser et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib13)), Transfusion (Zhou et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib42)), Emu3 (Wang et al., [2024b](https://arxiv.org/html/2512.16853v1#bib.bib33)), Show-o (Xie et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib39)), SEED-X (Ge et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib14)), MetaQueries (Pan et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib25)), BAGEL (Deng et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib12)), Janus (Wu et al., [2025b](https://arxiv.org/html/2512.16853v1#bib.bib37)), OmniGen (Xiao et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib38)), BLIP3-o (Chen et al., [2025a](https://arxiv.org/html/2512.16853v1#bib.bib4)), and Qwen-Image (Wu et al., [2025a](https://arxiv.org/html/2512.16853v1#bib.bib36)).
|
| 30 |
+
|
| 31 |
+
However, despite being so ubiquitously used in T2I research—usually with reports of gains of ∼\sim 2–3% over previous state-of-the-art models—we find that GenEval results on recent models can diverge from human judgment by an absolute error of as much as 17.7%! We conduct a large-scale human study, collecting over 23,000 annotations evaluating GenEval outputs of 8 popular T2I models that have released over the past three years. We show that although GenEval’s evaluation aligned well with human judgment at the time of its release, with a distribution shift in images generated by T2I models over time, its evaluation has drifted farther from human judgment, resulting in large errors when evaluating recent models (c.f. Figure [1](https://arxiv.org/html/2512.16853v1#S1.F1 "Figure 1 ‣ 1 Introduction ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation")). We refer to this phenomenon as benchmark drift. Further, according to human evaluation, GenEval is now saturated, with Gemini 2.5 Flash Image (Comanici et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib10)) achieving a score of 96.7%.
|
| 32 |
+
|
| 33 |
+
We introduce a new T2I benchmark, GenEval 2. While maintaining GenEval’s goal of evaluating T2I models’ basic capabilities as well as its templated design, our benchmark has increased coverage of concepts, varying degrees of compositionality, and enables capability-specific and compositionality-targeted analyses 1 1 1 The focus on compositionality in our benchmark goes hand-in-hand with controllability: if a T2I model can understand the difference between and correctly generate both “a brown dog and an black cat” and “a black dog and a brown cat”, it is inherently more user-controllable. . We collect human annotations for the 8 T2I models on a subset of GenEval 2, showing that models struggle with spatial relations, transitive verb relations, and counting. Further, model performance tends to drop as prompt compositionality increases. Overall, while models perform well on certain individual parts of the compositional prompt (referred to as “atoms”), the top-performing model achieves only 35.8% accuracy at the prompt-level, showing significant room for improvement.
|
| 34 |
+
|
| 35 |
+
We also introduce Soft-TIFA, an evaluation method tailored to GenEval 2’s templated and compositional structure. Soft-TIFA jointly estimates atom-level and prompt-level performance of T2I models by combining judgments for visual primitives, and on GenEval 2 prompts, it is more aligned with human judgment than popular automatic metrics such as VQAScore (Lin et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib23)) and TIFA (Hu et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib16)). Using Qwen3-VL-8B (Yang et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib40)) as the underlying VQA model, Soft-TIFA attains an AUROC of 94.5%, compared to 92.4% for VQAScore and 91.6% for TIFA. Notably, it also outperforms GPT-4o-based VQAScore (91.2% AUROC). Moreover, Soft-TIFA is inherently less susceptible to benchmark drift: whereas for a given VQA model, VQAScore-based estimates tend to diverge from human judgments over time after the model’s release, Soft-TIFA remains consistently well aligned—potentially, breaking the prompt down into primitives causes distribution shift in the image to impact the underlying VQA model less. Soft-TIFA relies only on an open-source VQA model, rather than proprietary APIs.
|
| 36 |
+
|
| 37 |
+
In essence, we argue that model-based evaluations in the rapidly-changing research environment of T2I models need to be continually audited and updated to maintain their validity in light of benchmark drift—as we have done here for GenEval. We release our new benchmark and evaluation method to support further research at [https://github.com/facebookresearch/GenEval2](https://github.com/facebookresearch/GenEval2).
|
| 38 |
+
|
| 39 |
+
2 Related Work
|
| 40 |
+
--------------
|
| 41 |
+
|
| 42 |
+
T2I Benchmarks. Several T2I benchmarks evaluate basic capabilities such as object counts, colors, positions, and attribution, including GenEval (Ghosh et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib15)) and T2I-CompBench (Huang et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib17)). Going beyond this to evaluate verbs and scene-level information are GenAI-Bench (Li et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib21)), TIFA-Bench (Hu et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib16)), DSG-Bench (Cho et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib9)), TIIF-Bench (Wei et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib34)), Gecko (Wiles et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib35)), and GenEval++ (Ye et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib41)). Other T2I benchmarks target advanced capabilities such as world knowledge and reasoning, including WISE (Niu et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib24)), R2I-Bench (Chen et al., [2025b](https://arxiv.org/html/2512.16853v1#bib.bib6)), T2I-ReasonBench (Sun et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib31)), and OneIG-Bench (Chang et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib3)). These benchmarks all utilize model-based judges, as discussed below.
|
| 43 |
+
|
| 44 |
+
T2I Evaluation Methods. GenEval (Ghosh et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib15)) and T2I-CompBench (Huang et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib17)) use specialized judge models such as object detectors and image-text matching models to evaluate T2I models. However, these methods struggle with images that call for flexibility, such as spatial relations with unusual perspectives. Hence, the field has moved towards evaluation methods predicated on VQA models. In each of these methods, a question or set of questions is answered by a VQA model based on the generated image in order to evaluate it: TIFA (Hu et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib16)) uses an LLM to break the prompt down into component questions; DSG (Cho et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib9)) constructs a Davidsonian Scene Graph to obtain the questions; VQAScore (Lin et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib23)) uses a single question containing the prompt; and OneIG-Bench (Chang et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib3)) and R2I-Bench (Chen et al., [2025b](https://arxiv.org/html/2512.16853v1#bib.bib6)) use an LLM to generate questions per prompt along with scoring rubrics.
|
| 45 |
+
|
| 46 |
+
We call for the research community to consider benchmark drift when designing T2I benchmarks and evaluation methods, and introduce a robust and challenging benchmark that is suitable for current frontier T2I models, alongside a new evaluation method less susceptible to benchmark drift.
|
| 47 |
+
|
| 48 |
+
3 Auditing Benchmark Drift in GenEval
|
| 49 |
+
-------------------------------------
|
| 50 |
+
|
| 51 |
+
We conduct a detailed study of GenEval to determine the risk in using long-standing model-based evaluations for T2I models, i.e., whether the evaluation method in this widely-used benchmark remains valid today.
|
| 52 |
+
|
| 53 |
+
Table 1: Reported Score, Human-Annotated Score, and Net Deviation of T2I models on GenEval. The benchmark is fast-approaching saturation, as shown by high Human Scores of T2I models With Rewriting. (* These models use CLIP, which truncates the prompt at 77 tokens. This truncates the rewritten prompts.)
|
| 54 |
+
|
| 55 |
+
![Image 3: [Uncaptioned image]](https://arxiv.org/html/2512.16853v1/figures/plot2_swap_updated.png)
|
| 56 |
+
|
| 57 |
+
Figure 2: Net deviation in reported score from human score on GenEval has increased significantly over time. The models on the X-axis are arranged by release date.
|
| 58 |
+
|
| 59 |
+
### 3.1 Preliminary: GenEval Evaluation Method
|
| 60 |
+
|
| 61 |
+
GenEval consists of 553 prompts, covering 6 categories evaluating T2I models’ basic capabilities: One Object, Two Object, Color, Count, Position and Color Attribution. Objects are sourced from COCO categories (Lin et al., [2014](https://arxiv.org/html/2512.16853v1#bib.bib22)), colors are of 10 types, counts range from 2–4 and apply to a single object, the positions are in 2-dimensions (above, under, left of, and right of), and color attribution involves 2 objects.
|
| 62 |
+
|
| 63 |
+
The evaluation method varies across categories, but is model-based: a MaskFormer (Cheng et al., [2022a](https://arxiv.org/html/2512.16853v1#bib.bib7)) from MMDetection (Chen et al., [2019](https://arxiv.org/html/2512.16853v1#bib.bib5)), trained on COCO (Lin et al., [2014](https://arxiv.org/html/2512.16853v1#bib.bib22)) images, is used to identify objects in a generated image. Color is determined using CLIP (Radford et al., [2021](https://arxiv.org/html/2512.16853v1#bib.bib28)) on the the object detector-identified bounding box after the background has been masked with the MaskFormer. Relative position between two objects is calculated mathematically based on their bounding box coordinates, after a buffer and maximum overlap is set between the two boxes.
|
| 64 |
+
|
| 65 |
+
This method has certain drawbacks, e.g.: it struggles to correctly mask the background of objects with holes, impacting color estimates; and relying on mathematical calculations for position suffers on examples such as “suitcase under a table”, in which a correct image would likely be labeled as incorrect due to high bounding box overlap between the two objects. However, it showed high human-alignment on the GenEval prompts at the time of its release, matching human judgment in 83% of images generated by Stable Diffusion v2.1 (Rombach et al., [2022](https://arxiv.org/html/2512.16853v1#bib.bib29)), IF-XL (Deep-Floyd, [2023](https://arxiv.org/html/2512.16853v1#bib.bib11)), and LAION-5B with CLIP retrieval (Schuhmann et al., [2022](https://arxiv.org/html/2512.16853v1#bib.bib30)); increasing to 91% on images with unanimous inter-annotator agreement. As such, this benchmark was established as a standard evaluation, and is presented as a primary evaluation of T2I basic capabilities in major T2I papers over the past three years, including Stable Diffusion 3 (Esser et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib13)), Transfusion (Zhou et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib42)), Emu3 (Wang et al., [2024b](https://arxiv.org/html/2512.16853v1#bib.bib33)), Show-o (Xie et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib39)), SEED-X (Ge et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib14)), MetaQueries (Pan et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib25)), BAGEL (Deng et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib12)), Janus (Wu et al., [2025b](https://arxiv.org/html/2512.16853v1#bib.bib37)), OmniGen (Xiao et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib38)), BLIP3-o (Chen et al., [2025a](https://arxiv.org/html/2512.16853v1#bib.bib4)), and Qwen-Image (Wu et al., [2025a](https://arxiv.org/html/2512.16853v1#bib.bib36)), among others.
|
| 66 |
+
|
| 67 |
+
### 3.2 A New Human-Alignment Study of GenEval
|
| 68 |
+
|
| 69 |
+
In order to determine whether GenEval has experienced benchmark drift, we conduct a large-scale human study, measuring the alignment of GenEval evaluations on 8 T2I models with human judgment. We collect human annotations for all 553 images in GenEval for each of these T2I models, in addition to images generated based on rewritten prompts for the 6 of these T2I models trained with rewriting techniques. Each image is annotated by 3 annotators, amounting to 23,226 human annotations.
|
| 70 |
+
|
| 71 |
+
Models. Our model selection covers two main criteria: we desire representation of the change in T2I models over time; in addition to state-of-the-art models capturing T2I capability today. For the former, we select the Stable Diffusion (SD) models: SD2.1 (Rombach et al., [2022](https://arxiv.org/html/2512.16853v1#bib.bib29)), SDXL (Podell et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib27)), SD3-medium (Esser et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib13)), and SD3.5-large (Esser et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib13)), released 2022-24. For the latter, we select Bagel (with thinking enabled) (Deng et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib12)), Flux.1-dev (Labs, [2024](https://arxiv.org/html/2512.16853v1#bib.bib20)), Qwen-Image (Wu et al., [2025a](https://arxiv.org/html/2512.16853v1#bib.bib36)) and Gemini 2.5 Flash Image (Comanici et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib10)).
|
| 72 |
+
|
| 73 |
+
Rewriting techniques. Recent T2I models employ rewriting techniques to improve performance (Betker et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib2); Esser et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib13); Deng et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib12)), first expanding the prompt to include more details, and then generating the image. As details behind rewriting methods have not been open-sourced, we use a rewritten version of GenEval prompts provided in the Bagel repository (Deng et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib12)). We evaluate all T2I models with and without rewriting, except for SD2.1 and SDXL, which were not trained with rewriting. Note that SD3, SD3.5, and Flux.1-dev use CLIP (Radford et al., [2021](https://arxiv.org/html/2512.16853v1#bib.bib28)), which can only handle 77 text tokens for the prompt. This truncates the ending of many of the rewritten prompts, although the endings tend to discuss image-level stylistic details (e.g., “…the composition is photographic in style…”) rather than information critical to prompt alignment, such as attributes or relations. To maintain consistency, we do not shorten the rewritten prompts, as they are in-line with those used by current state-of-the-art T2I models.
|
| 74 |
+
|
| 75 |
+
Study details. Annotators were provided with an image and two yes/no questions: (1) “Does the image align with the prompt?”; and (2) “Is the image of good quality? (i.e., are the objects well-formed?)”. While we only desire an answer to the first question for our analysis, we ask the annotators both questions to help them disentangle prompt alignment from image quality in their response. The instructions gave clear examples, along with discussions of edge cases, such as position-related prompts where the image captures an unusual perspective. Each data point was annotated by 3 annotators, and is labeled based on the majority vote. 85.1% of the data points were labeled unanimously by the 3 annotators. The instructions and user interface shown to the annotators are provided in Appendix [9.1](https://arxiv.org/html/2512.16853v1#S9.SS1 "9.1 GenEval User Study ‣ 9 User Study Details ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation")2 2 2 The study was conducted via Invisible Tech (Invisible, [2025](https://arxiv.org/html/2512.16853v1#bib.bib19))..
|
| 76 |
+
|
| 77 |
+
### 3.3 Findings from the Human Alignment Study of GenEval
|
| 78 |
+
|
| 79 |
+
Having collected human labels for 8 T2I models’ outputs on GenEval prompts, we now compare them to the benchmark’s automated evaluation. Table [1](https://arxiv.org/html/2512.16853v1#S3.T1 "Table 1 ‣ 3 Auditing Benchmark Drift in GenEval ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") contains the model-based score reported by GenEval, the human-judged score, and the net deviation between the two, for each T2I model.
|
| 80 |
+
|
| 81 |
+
GenEval is not well-aligned with human judgment on today’s state-of-the-art models. GenEval scores are 11.0% lower than human scores on average for today’s state-of-the-art models, and as much as 17.7% lower, in the case of Gemini 2.5 Flash Image. We note that this difference is very significant, given that many research papers report gains of 2-3% over previous models.
|
| 82 |
+
|
| 83 |
+
GenEval alignment with human judgment has decreased over time. Figure [2](https://arxiv.org/html/2512.16853v1#S3.F2 "Figure 2 ‣ Table 1 ‣ 3 Auditing Benchmark Drift in GenEval ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") shows the net deviation of GenEval reported scores from human scores across T2I models, arranged in chronological order of their release. While the deviation was within ±\pm 3% for SD2.1 and SDXL, which released before GenEval, it has steadily increased over the past 3 years, culminating in a deviation of 17.7% for the latest T2I model, Gemini 2.5 Flash Image.
|
| 84 |
+
|
| 85 |
+
Impact of rewriting techniques. Across the 6 models trained with rewriting techniques, using rewritten prompts decreases human alignment for 4 models (SD3-med, SD3.5-large, Bagel and Flux.1-dev) by 2.5% on average. However, it increases human alignment for Qwen-Image and Gemini 2.5 Flash Image by 3.3% on average.
|
| 86 |
+
|
| 87 |
+
GenEval is saturated. Per the human score of various models on GenEval, depicted also in Figure [1](https://arxiv.org/html/2512.16853v1#S1.F1 "Figure 1 ‣ 1 Introduction ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation")(b), all 4 state-of-the-art T2I models, released 2024-25, score 94.8% and above with rewriting techniques, showing that GenEval is effectively saturated today, and has been for over a year 3 3 3 Flux.1-dev was released in August 2024..
|
| 88 |
+
|
| 89 |
+
4 GenEval 2: Addressing Benchmark Drift
|
| 90 |
+
---------------------------------------
|
| 91 |
+
|
| 92 |
+
Having highlighted the significant benchmark drift in GenEval, i.e., that the distribution shift in T2I model outputs over time has resulted in a large decrease in human alignment and masked the benchmark’s saturation, we present GenEval 2, a novel, more robust, and challenging benchmark to evaluate T2I models’ basic capabilities. Our benchmark consists of a set of 800 prompts covering various skills, and at varying levels of compositionality. Figure [3](https://arxiv.org/html/2512.16853v1#S4.F3 "Figure 3 ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") depicts sample prompts and annotations from the benchmark.
|
| 93 |
+
|
| 94 |
+

|
| 95 |
+
|
| 96 |
+
Figure 3: We present GenEval 2, a T2I benchmark testing basic capabilities and increasing compositionality. Some samples are shown above. A prompt is considered correctly generated if all component atoms are correctly generated. We show some samples of T2I model outputs on the benchmark, as well as prompt-level annotations for all models and atom-level annotations for Gemini 2.5 Flash Image.
|
| 97 |
+
|
| 98 |
+
### 4.1 Benchmark Curation
|
| 99 |
+
|
| 100 |
+
Concepts and skills. GenEval 2 evaluates a similar-but-expanded set of skills compared to GenEval: it evaluates 40 unique objects (20 sourced from COCO, 20 otherwise), 18 attributes (colors, materials, and patterns), 9 relations (3D spatial prepositions and transitive verbs), and 6 counts (2–7). Of the 40 objects, 20 are animate (e.g., “monkey”) and 20 are not (e.g., “umbrella”). The 3D spatial prepositions include those in GenEval, as well as “in front of” and “behind”, as in T2I-CompBench (Huang et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib17)). We provide the full vocabulary of GenEval 2 in Appendix [8.1](https://arxiv.org/html/2512.16853v1#S8.SS1 "8.1 Full Vocabulary of GenEval 2 ‣ 8 GenEval 2 Curation Details ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation").
|
| 101 |
+
|
| 102 |
+
Prompt structure. Each prompt has 1–3 unique objects. We generate the prompts with templates, maintaining the process from GenEval, which allows for straightforward annotation, evaluation and analysis 4 4 4 This also prevents ambiguous prompts such as “The rich, complex flavors of the aged wine tantalized the palate, a sensory feast of taste and smell.” from T2I-CompBench (Huang et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib17)), which was LLM-generated.. The template follows the form {count 1 or “a”}{attribute 1}{object 1}{relation 1 or “and”}{count 2 or “a”}{attribute 2}{object 2} for 2 objects, which can be extended to 3 objects. The counts, attributes, and relations are optional, resulting in varying degrees of compositionality, as discussed next. The prompts combine the attributes, objects and relations at random, but for the transitive verb relation (e.g., “chasing”), which is only applied between two animate objects; thus, our prompts contain unusual combinations, e.g., “a green bagel to the left of a metal flamingo”, but not very unusual, potentially anthropomorphizing ones, e.g. “a green bagel chasing a metal flamingo”, maintaining focus on basic T2I capabilities.
|
| 103 |
+
|
| 104 |
+
Increasing compositionality. We measure the compositionality of a prompt by measuring how many “atoms” it has, i.e., its atomicity, where an atom is an object, attribute, or relation: e.g., “three pink pigs” has 3 atoms, whereas “three pink pigs jumping over a sheep” has an atomicity of 5. We do not consider “a” and “and” to add to prompt compositionality. Our benchmark contains prompts with increasing compositionality ranging from 3 to 10 atoms, with 100 prompts of each atomicity, amounting to a total of 800 prompts. The atomicity of each prompt is noted in the benchmark, enabling compositionality-related analyses as shown in Section [4.3](https://arxiv.org/html/2512.16853v1#S4.SS3 "4.3 Analyses of Capability and Compositionality ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation").
|
| 105 |
+
|
| 106 |
+
Rewriting techniques. We rewrite GenEval 2 prompts following previous work, using GPT-4o (Hurst et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib18)). While researchers are encouraged to use the rewriting technique of their choice, we provide the prompt given to GPT-4o to rewrite the benchmark in Appendix [8.2](https://arxiv.org/html/2512.16853v1#S8.SS2 "8.2 GPT-4o Rewriting Prompt ‣ 8 GenEval 2 Curation Details ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"). As with GenEval, the rewritten prompts are longer than the text input window of CLIP, which is used in SD3, SD3.5-large and Flux.1-dev, resulting in truncation. However, here too, the information lost tends to be stylistic rather than prompt-critical.
|
| 107 |
+
|
| 108 |
+
Evaluation. We propose a new evaluation metric for GenEval 2, Soft-TIFA, which is discussed in Section [5](https://arxiv.org/html/2512.16853v1#S5 "5 A New Evaluation Method for GenEval 2: Soft-TIFA ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"). For clarity, in this section, we discuss only results of the human annotations of various T2I model outputs on GenEval 2, i.e., human-judged scores, as collected in a human study and discussed in Section [4.2](https://arxiv.org/html/2512.16853v1#S4.SS2 "4.2 Human-Judged Scores on GenEval 2 ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation").
|
| 109 |
+
|
| 110 |
+
Human study. We collect human annotations for outputs from the 8 T2I models in Section [3](https://arxiv.org/html/2512.16853v1#S3 "3 Auditing Benchmark Drift in GenEval ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") on a subset of GenEval 2. We follow the same structure for the user study as with GenEval, but instead of requesting a yes/no answer for the question “Does the image align with the prompt?”, we provide a checklist for each atom in the prompt for the user to select based on alignment of the image. Thus, we obtain atom-level annotations of alignment for each generated image, as shown in Figure [3](https://arxiv.org/html/2512.16853v1#S4.F3 "Figure 3 ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") for Gemini 2.5 Flash Image. The instructions and user interface are provided in Appendix [9.2](https://arxiv.org/html/2512.16853v1#S9.SS2 "9.2 GenEval 2 User Study ‣ 9 User Study Details ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"). Each image is annotated by 1 annotator, as we found high inter-annotator agreement in our pilot study of 200 data points (91% unanimous scoring across 3 annotators). We label 50% of the benchmark in this manner, evenly split across models and rewriting methods 5 5 5 This study was also conducted by Invisible Tech (Invisible, [2025](https://arxiv.org/html/2512.16853v1#bib.bib19))..
|
| 111 |
+
|
| 112 |
+
### 4.2 Human-Judged Scores on GenEval 2
|
| 113 |
+
|
| 114 |
+
Having collected human-judged correctness across the 8 T2I models from Section [3](https://arxiv.org/html/2512.16853v1#S3 "3 Auditing Benchmark Drift in GenEval ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") on GenEval 2, we report atom-level and prompt-level results in Table [2](https://arxiv.org/html/2512.16853v1#S4.T2 "Table 2 ‣ 4.2 Human-Judged Scores on GenEval 2 ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"), with and without rewriting. At the prompt-level, we present a binary measure of correctness, as in GenEval, where a prompt is considered correct only if each atom in the prompt has been labeled as correct.
|
| 115 |
+
|
| 116 |
+
At the atom-level, the latest models perform quite well, with the highest-performing models achieving a human-judged score of 85.3%. However, at the prompt-level, the highest-performing model achieves a score of only 35.8%. Keeping in mind that GenEval 2 evaluates only basic T2I capabilities, these results show that there remains significant room for improvement on compositional prompts.
|
| 117 |
+
|
| 118 |
+
Rewriting techniques improve performance. As shown in Table [2](https://arxiv.org/html/2512.16853v1#S4.T2 "Table 2 ‣ 4.2 Human-Judged Scores on GenEval 2 ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"), rewriting the prompt aids T2I performance at both the atom-level and prompt-level across all models (in the second decimal for Gemini 2.5 Flash Image).
|
| 119 |
+
|
| 120 |
+
Table 2: Human evaluation of GenEval 2. While models show good performance at the atom-level, there is significant room for improvement at the prompt-level, even with rewriting techniques, highlighting the need for compositionality. (* These models use CLIP, which truncates the prompt at 77 tokens. This truncates the rewritten prompts.)
|
| 121 |
+
|
| 122 |
+
### 4.3 Analyses of Capability and Compositionality
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
(a)Average Human Score of SOTA T2I models per skill in GenEval 2.
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
(b)Average Human Score of SOTA T2I models for each level of compositionality (“atomicity”) in GenEval 2.
|
| 131 |
+
|
| 132 |
+
Figure 4: GenEval 2 enables various analyses of T2I models: (a) while state-of-the-art (SOTA) T2I models perform well at generating objects, and quite well at assigning them attributes, they struggle with counting, spatial relations, and transitive verb relations; (b) SOTA T2I model performance drops sharply as prompts become more complex. Per-model analyses are provided in Appendix [10](https://arxiv.org/html/2512.16853v1#S10 "10 Per-Model Analyses of Human-Judged Scores on GenEval 2 ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation").
|
| 133 |
+
|
| 134 |
+
GenEval 2 was designed to encourage various types of analyses. Each prompt is labeled with its atomicity, as well as which skills 6 6 6 We use “skill” interchangeably with “capability” in this paper. it requires (e.g., counting, spatial relations), enabling composition-related and skill-related analyses. In this section, we conduct these analyses on the 4 state-of-the-art T2I models discussed above (Flux.1-dev, Bagel, Qwen-Image and Gemini 2.5 Flash Image) to highlight patterns in performant models. An analysis of each of the 8 models is presented in Appendix [10](https://arxiv.org/html/2512.16853v1#S10 "10 Per-Model Analyses of Human-Judged Scores on GenEval 2 ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation").
|
| 135 |
+
|
| 136 |
+
Models particularly struggle with spatial relations, transitive verb relations, and counting. Models’ average per-skill performance on GenEval 2 is shown in Figure [4(a)](https://arxiv.org/html/2512.16853v1#S4.F4.sf1 "Figure 4(a) ‣ Figure 4 ‣ 4.3 Analyses of Capability and Compositionality ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"). Clearly, while they can generate various objects and attributes well, counting, spatial relations and transitive verbs remain challenging. This is consistent with findings from earlier work (Hu et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib16); Li et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib21)). Further, many of the attribute errors are caused by attribution errors, when multiple attributes applied to different objects are present in the prompt.
|
| 137 |
+
|
| 138 |
+
Model performance drops as prompt compositionality increases. On average, model performance decreases with increasing prompt compositionality, as shown in Figure [4(b)](https://arxiv.org/html/2512.16853v1#S4.F4.sf2 "Figure 4(b) ‣ Figure 4 ‣ 4.3 Analyses of Capability and Compositionality ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation")—at the highest levels of complexity, T2I model performance is close to 0. Clearly, state-of-the-art T2I models continue to struggle with more compositional prompts, which are central to many practical applications (Li et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib21)).
|
| 139 |
+
|
| 140 |
+
Our benchmark design provides a detailed diagnosis for each model, highlighting its strengths and weaknesses along multiple axes: skills, compositionality, and rewriting (which goes hand-in-hand with prompt length), enabling targeted research in improving specific model capabilities: e.g., Qwen-Image achieves 99% accuracy at generating specific objects, but only 60% accuracy at relative positions of the objects (c.f. Appendix [10](https://arxiv.org/html/2512.16853v1#S10 "10 Per-Model Analyses of Human-Judged Scores on GenEval 2 ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation")).
|
| 141 |
+
|
| 142 |
+
5 A New Evaluation Method for GenEval 2: Soft-TIFA
|
| 143 |
+
--------------------------------------------------
|
| 144 |
+
|
| 145 |
+
Alongside our new benchmark GenEval 2, we propose Soft-TIFA, a new evaluation method uniquely suited to the template-based and compositional nature of GenEval 2.
|
| 146 |
+
|
| 147 |
+
### 5.1 Preliminaries: VQAScore and TIFA
|
| 148 |
+
|
| 149 |
+
Soft-TIFA draws inspiration from VQAScore (Lin et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib23)) and TIFA (Hu et al., [2023](https://arxiv.org/html/2512.16853v1#bib.bib16)), two popular T2I evaluation methods predicated on VQA models.
|
| 150 |
+
|
| 151 |
+
VQAScore. This method assigns a soft (continuous) score to each generated image, that has been shown to align well with human judgment on GenAI-Bench (Li et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib21)). The per-image score is calculated under a VQA model M M as:
|
| 152 |
+
|
| 153 |
+
score=P M(\displaystyle\text{score}=P_{M}(“Yes”∣image,\displaystyle\text{``Yes'' }\mid\text{ image},(1)
|
| 154 |
+
“Does this image show {prompt}?
|
| 155 |
+
Answer in one word, Yes or No.”)\displaystyle\text{Answer in one word, Yes or No.''})
|
| 156 |
+
|
| 157 |
+
TIFA. This method generates question-answer pairs based on each prompt using an LLM. For an image with N N generated question-answer pairs where answers are denoted as a i a_{i} and answers predicted by a VQA model based on the image are denoted as a^i\hat{a}_{i}, the per-image score is:
|
| 158 |
+
|
| 159 |
+
score=1 N∑i=1 N 𝟙[a^i==a i]\displaystyle\text{score}=\frac{1}{N}\sum_{i=1}^{N}\mathbbm{1}[\hat{a}_{i}==a_{i}](2)
|
| 160 |
+
|
| 161 |
+
Note about rewriting techniques. We note that rewriting techniques are only used for image generation, not in evaluation: i.e., a T2I model sees the rewritten prompt to generate an image, but the evaluation compares that image against the original prompt, for all evaluation methods.
|
| 162 |
+
|
| 163 |
+
### 5.2 Soft-TIFA
|
| 164 |
+
|
| 165 |
+
GenEval 2 is highly compositional: each prompt contains up to 10 atoms (objects, attributes or relations). We believe a TIFA-like approach would work well to evaluate the correctness of the generated image on each atom in the prompt. Further, GenEval 2 is generated with templates: hence, the TIFA-like questions could also be generated with templates, ensuring full coverage over the prompt—a problem for TIFA itself with more compositional prompts, as it uses an LLM to generate the questions. However, we also desire the soft score aspect of VQAScore, which allows the metric to capture VQA model uncertainty for each question.
|
| 166 |
+
|
| 167 |
+
Hence, we present Soft-TIFA, which generates one question per atom of each prompt using the same templates used to generate GenEval 2, and assigns soft scores to each answer as predicted by the VQA model when given the generated image: i.e., for an image with N N generated question-answer pairs (where prompt atomicity is N N), where answers are denoted a i a_{i}, the per-image score under a VQA model M M is:
|
| 168 |
+
|
| 169 |
+
score=mean{P M(a i)}i=1 N\displaystyle\text{score}=\text{mean}\{P_{M}(a_{i})\}_{i=1}^{N}(3)
|
| 170 |
+
|
| 171 |
+
When the mean function across predictions for an image is the arithmetic mean, this method is referred to as Soft-TIFA AM{}_{\text{AM}}, and captures atom-level correctness of the T2I model. When the mean function is the geometric mean, this method is referred to as Soft-TIFA GM{}_{\text{GM}}, and captures prompt-level correctness of the T2I model, as it penalizes low atom-level scores at the prompt-level (similar to our human prompt-level score calculation, where a prompt is incorrect if any component atom is incorrect). Both Soft-TIFA AM{}_{\text{AM}} and Soft-TIFA GM{}_{\text{GM}} are averaged arithmetically across the benchmark to obtain a final score.
|
| 172 |
+
|
| 173 |
+
That Soft-TIFA captures both atom-level and prompt-level correctness is an important consideration when estimating T2I model performance on the compositional prompts in GenEval 2. We use Qwen3-VL (Yang et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib40)) as our VQA model, as it is both performant and open-source.
|
| 174 |
+
|
| 175 |
+
### 5.3 Human Alignment of Soft-TIFA on GenEval 2
|
| 176 |
+
|
| 177 |
+
We next determine whether Soft-TIFA is well-aligned with human judgment on GenEval 2. We compare Soft-TIFA AM{}_{\text{AM}} and Soft-TIFA GM{}_{\text{GM}} to existing evaluation methods, using AUROC to measure human alignment, as in VQAScore (Lin et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib23)). The human scores compared against are prompt-level scores, collected as discussed in Section [4.1](https://arxiv.org/html/2512.16853v1#S4.SS1 "4.1 Benchmark Curation ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation").
|
| 178 |
+
|
| 179 |
+
As shown in Table [3](https://arxiv.org/html/2512.16853v1#S5.T3 "Table 3 ‣ 5.3 Human Alignment of Soft-TIFA on GenEval 2 ‣ 5 A New Evaluation Method for GenEval 2: Soft-TIFA ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"), Soft-TIFA AM{}_{\text{AM}} matches or outperforms existing methods on rewritten and combined sets of prompts, and Soft-TIFA GM{}_{\text{GM}} outperforms existing methods on the original, rewritten, and combined sets of GenEval 2 prompts. We attribute Soft-TIFA’s high human-alignment to its structure, which is inherently designed to capture the varying levels of compositionality of T2I input prompts present in GenEval 2.
|
| 180 |
+
|
| 181 |
+
We also run this study with other strong, open-source VQA models underlying the evaluation methods. As presented in Figure [5](https://arxiv.org/html/2512.16853v1#S5.F5 "Figure 5 ‣ 5.4 Comparison of T2I Models ‣ 5 A New Evaluation Method for GenEval 2: Soft-TIFA ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") and Appendix [12](https://arxiv.org/html/2512.16853v1#S12 "12 Evaluation Methods with Different Underlying VQA Models ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"), we find that our results from Table [3](https://arxiv.org/html/2512.16853v1#S5.T3 "Table 3 ‣ 5.3 Human Alignment of Soft-TIFA on GenEval 2 ‣ 5 A New Evaluation Method for GenEval 2: Soft-TIFA ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") hold across Qwen2-VL (Wang et al., [2024a](https://arxiv.org/html/2512.16853v1#bib.bib32)) and Qwen2.5-VL (Bai et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib1)), and further outperform VQAScore based on GPT-4o. Hence, our method is not oversensitive to the underlying VQA model.
|
| 182 |
+
|
| 183 |
+
Table 3: AUROC of Qwen3-VL-based evaluation methods on GenEval 2 : Soft-TIFA GM{}_{\text{GM}} shows highest human-alignment across all sets of prompts. (bold=highest, underlined=second-highest)
|
| 184 |
+
|
| 185 |
+
Per-skill and per-compositionality. We calculate Soft-TIFA scores per-skill and per-compositionality to determine whether they reflect the human scores presented in Section [4.3](https://arxiv.org/html/2512.16853v1#S4.SS3 "4.3 Analyses of Capability and Compositionality ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"). As skill is an atom-level concept and compositionality is prompt-level, we use in our analyses Soft-TIFA AM{}_{\text{AM}} and Soft-TIFA GM{}_{\text{GM}} respectively. We find that the trends are largely mirrored for both skills and levels of compositionality, with T2I models performing well at objects and attributes but not counting, verbs or positions, and T2I model performance dropping steeply with increase in prompt compositionality. The lone exception is the “verb” skill, in which VQA models are stricter than human judgment—showing room for improvement in VQA model judgment of more nuanced relations. Detailed results are shown in Appendix [13](https://arxiv.org/html/2512.16853v1#S13 "13 Per-Skill and Per-Compositionality Analyses of Soft-TIFA ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation").
|
| 186 |
+
|
| 187 |
+
### 5.4 Comparison of T2I Models
|
| 188 |
+
|
| 189 |
+
Table [4](https://arxiv.org/html/2512.16853v1#S5.T4 "Table 4 ‣ 5.4 Comparison of T2I Models ‣ 5 A New Evaluation Method for GenEval 2: Soft-TIFA ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") shows the Soft-TIFA scores of our 8 T2I models on GenEval 2, alongside the human-judged scores from Section [4.2](https://arxiv.org/html/2512.16853v1#S4.SS2 "4.2 Human-Judged Scores on GenEval 2 ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"). While the four state-of-the-art T2I models perform well at the atom-level (as shown by both the human atom-level and Soft-TIFA AM{}_{\text{AM}} scores), they have significant scope for improvement at the prompt-level (as shown by the human prompt-level and Soft-TIFA GM{}_{\text{GM}} scores). Soft-TIFA largely retains the ranking of human-scored T2I models.
|
| 190 |
+
|
| 191 |
+
Table 4: Soft-TIFA evaluation of T2I models on GenEval 2, compared against human-judged scores from Table [2](https://arxiv.org/html/2512.16853v1#S4.T2 "Table 2 ‣ 4.2 Human-Judged Scores on GenEval 2 ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"). Soft-TIFA AM{}_{\text{AM}} captures atom-level correctness of the T2I model, and Soft-TIFA GM{}_{\text{GM}} captures prompt-level correctness.
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
(a)Human alignment of VQAScore on GenEval 2 under different VQA models.
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
(b)Human alignment of Soft-TIFA GM{}_{\text{GM}} on GenEval 2 under different VQA models.
|
| 200 |
+
|
| 201 |
+
Figure 5: Under all VQA models, Soft-TIFA GM{}_{\text{GM}} achieves higher human alignment on GenEval 2 across T2I models than VQAScore. Further, it is more robust to T2I output distribution shift over time, potentially because breaking the prompt into per-atom questions renders the VQA model more robust to image distribution shift in T2I outputs.
|
| 202 |
+
|
| 203 |
+
### 5.5 Evaluation Methods vs. Benchmark Drift
|
| 204 |
+
|
| 205 |
+
We select Qwen3-VL as the VQA model underlying Soft-TIFA. However, we highlight the need to audit and update evaluation components as time passes due to benchmark drift with shifts in T2I output image distribution, as studied in this paper. To underscore our point, we experiment with three VQA models released at different points of time: Qwen2-VL (released in August 2024), Qwen2.5-VL (released in January 2025) and Qwen3-VL (released in September 2025). We calculate the AUROC of VQAScore and Soft-TIFA GM{}_{\text{GM}} when based on each of these VQA models for each of the 8 T2I models, to estimate human-alignment on GenEval 2 based on our human scores from Section [4.2](https://arxiv.org/html/2512.16853v1#S4.SS2 "4.2 Human-Judged Scores on GenEval 2 ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation").
|
| 206 |
+
|
| 207 |
+
As shown in Figure [5](https://arxiv.org/html/2512.16853v1#S5.F5 "Figure 5 ‣ 5.4 Comparison of T2I Models ‣ 5 A New Evaluation Method for GenEval 2: Soft-TIFA ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") (a), with the VQAScore metric, each of the 3 VQA models achieves a high AUROC for the T2I models that came out before their releases, then achieve increasingly lower AUROC for the T2I models that came out afterward. Clearly, the distribution shift in T2I model output after each VQA model’s release could not be accounted for, and thus caused a decrease in human-alignment of the VQAScore evaluation.
|
| 208 |
+
|
| 209 |
+
With the Soft-TIFA GM{}_{\text{GM}} metric in Figure [5](https://arxiv.org/html/2512.16853v1#S5.F5 "Figure 5 ‣ 5.4 Comparison of T2I Models ‣ 5 A New Evaluation Method for GenEval 2: Soft-TIFA ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") (b), this phenomenon appears to be mitigated, as shown by less of a drop in human-alignment AUROC after each VQA model’s release—potentially, breaking the prompt down into per-atom questions causes distribution shift in the image to impact the VQA model less. However, it is entirely possible that greater distribution shift over a longer period of time may cause Soft-TIFA GM{}_{\text{GM}} to show the same drift as VQAScore.
|
| 210 |
+
|
| 211 |
+
Our results show that merely shifting away from specialized models such as object detectors for T2I evaluation (as in GenEval) towards VQA-based methods (as in GenAI-Bench) is insufficient to address benchmark drift. T2I models’ output image distribution will keep changing, and evaluation methods need to change along with them to keep up.
|
| 212 |
+
|
| 213 |
+
A note about GPT models for evaluation. Many recent T2I benchmarks utilize GPT-4o for T2I evaluation, including WISE (Niu et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib24)), R2I-Bench (Chen et al., [2025b](https://arxiv.org/html/2512.16853v1#bib.bib6)), TIIF-Bench (Wei et al., [2025](https://arxiv.org/html/2512.16853v1#bib.bib34)), and DreamBench++ (Peng et al., [2024](https://arxiv.org/html/2512.16853v1#bib.bib26)), among others. However, GPT-4o is closed-source and constantly changing, rendering results difficult to reproduce—not to mention that the model could be deprecated 7 7 7 As it has been in the past: Sam Altman, X (formerly Twitter), Aug. 8 2025, [https://x.com/sama/status/1953506023391592494](https://x.com/sama/status/1953506023391592494). To account for this in addition to benchmark drift, we encourage the research community to utilize strong open-source VLMs instead of closed-source models.
|
| 214 |
+
|
| 215 |
+
6 Conclusion
|
| 216 |
+
------------
|
| 217 |
+
|
| 218 |
+
In this work, we study benchmark drift of T2I evaluations. We find that the output distribution of T2I models has shifted so greatly over the past 3 years that GenEval, one of the most popular T2I benchmarks to evaluate basic capabilities, is no longer well-human-aligned. We quantify the benchmark drift of GenEval with a large-scale human study across 8 T2I models, finding that results on recent models can diverge from human judgment by an absolute error of as much as 17.7%. Further, according to the human evaluation, GenEval is now saturated. To help bridge this gap, we introduce GenEval 2, a challenging new T2I benchmark inspired by GenEval that evaluates basic capabilities on increasingly compositional prompts, and allows for targeted analyses. Human annotations of T2I models on GenEval 2 show that state-of-the-art T2I models still have significant room for improvement. We also introduce Soft-TIFA, an evaluation method designed for GenEval 2 that provides estimates of atom-level as well as prompt-level performance of T2I models. Soft-TIFA has higher human alignment than VQAScore and TIFA, and is more robust against benchmark drift. Our work serves as a call for caution in the light of benchmark drift, and underscores the need to continually audit and update T2I evaluation benchmarks.
|
| 219 |
+
|
| 220 |
+
Acknowledgments
|
| 221 |
+
---------------
|
| 222 |
+
|
| 223 |
+
We thank Jiahui Chen and Melissa Hall for interesting discussions and helpful feedback on our work, as well as Jonea Gordon and Vanessa Stark. We also thank Cynthia Gao and Justin Hovey, and the team at Invisible Tech, for their help on our two large-scale human studies. Finally, we thank Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt, the authors of GenEval, for inspiring and supporting our work.
|
| 224 |
+
|
| 225 |
+
References
|
| 226 |
+
----------
|
| 227 |
+
|
| 228 |
+
* Bai et al. (2025) Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. _arXiv preprint arXiv:2502.13923_, 2025.
|
| 229 |
+
* Betker et al. (2023) James Betker, Gabriel Goh, Li Jing, † TimBrooks, Jianfeng Wang, Linjie Li, † LongOuyang, † JuntangZhuang, † JoyceLee, † YufeiGuo, † WesamManassra, † PrafullaDhariwal, † CaseyChu, † YunxinJiao, and Aditya Ramesh. Improving image generation with better captions. 2023. [https://api.semanticscholar.org/CorpusID:264403242](https://api.semanticscholar.org/CorpusID:264403242).
|
| 230 |
+
* Chang et al. (2025) Jingjing Chang, Yixiao Fang, Peng Xing, Shuhan Wu, Wei Cheng, Rui Wang, Xianfang Zeng, Gang Yu, and Hai-Bao Chen. Oneig-bench: Omni-dimensional nuanced evaluation for image generation. _arXiv preprint arXiv:2506.07977_, 2025.
|
| 231 |
+
* Chen et al. (2025a) Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset. _arXiv preprint arXiv:2505.09568_, 2025a.
|
| 232 |
+
* Chen et al. (2019) Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, et al. Mmdetection: Open mmlab detection toolbox and benchmark. _arXiv preprint arXiv:1906.07155_, 2019.
|
| 233 |
+
* Chen et al. (2025b) Kaijie Chen, Zihao Lin, Zhiyang Xu, Ying Shen, Yuguang Yao, Joy Rimchala, Jiaxin Zhang, and Lifu Huang. R2i-bench: Benchmarking reasoning-driven text-to-image generation. _arXiv preprint arXiv:2505.23493_, 2025b.
|
| 234 |
+
* Cheng et al. (2022a) Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. In _Proceedings of the IEEE/CVF conference on computer vision and pattern recognition_, pages 1290–1299, 2022a.
|
| 235 |
+
* Cheng et al. (2022b) Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)_, pages 1290–1299, June 2022b.
|
| 236 |
+
* Cho et al. (2023) Jaemin Cho, Yushi Hu, Roopal Garg, Peter Anderson, Ranjay Krishna, Jason Baldridge, Mohit Bansal, Jordi Pont-Tuset, and Su Wang. Davidsonian scene graph: Improving reliability in fine-grained evaluation for text-to-image generation. _arXiv preprint arXiv:2310.18235_, 2023.
|
| 237 |
+
* Comanici et al. (2025) Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. _arXiv preprint arXiv:2507.06261_, 2025.
|
| 238 |
+
* Deep-Floyd (2023) Deep-Floyd. Deep-floyd/if. 2023. [https://github.com/deep-floyd/IF](https://github.com/deep-floyd/IF).
|
| 239 |
+
* Deng et al. (2025) Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining. _arXiv preprint arXiv:2505.14683_, 2025.
|
| 240 |
+
* Esser et al. (2024) Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In _Forty-first international conference on machine learning_, 2024.
|
| 241 |
+
* Ge et al. (2024) Yuying Ge, Sijie Zhao, Jinguo Zhu, Yixiao Ge, Kun Yi, Lin Song, Chen Li, Xiaohan Ding, and Ying Shan. Seed-x: Multimodal models with unified multi-granularity comprehension and generation. _arXiv preprint arXiv:2404.14396_, 2024.
|
| 242 |
+
* Ghosh et al. (2023) Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment. _Advances in Neural Information Processing Systems_, 36:52132–52152, 2023.
|
| 243 |
+
* Hu et al. (2023) Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A Smith. Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. In _Proceedings of the IEEE/CVF International Conference on Computer Vision_, pages 20406–20417, 2023.
|
| 244 |
+
* Huang et al. (2023) Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. _Advances in Neural Information Processing Systems_, 36:78723–78747, 2023.
|
| 245 |
+
* Hurst et al. (2024) Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. _arXiv preprint arXiv:2410.21276_, 2024.
|
| 246 |
+
* Invisible (2025) Invisible. Invisible tech. 2025. [https://invisibletech.ai/](https://invisibletech.ai/).
|
| 247 |
+
* Labs (2024) Black Forest Labs. Flux. [https://github.com/black-forest-labs/flux](https://github.com/black-forest-labs/flux), 2024.
|
| 248 |
+
* Li et al. (2024) Baiqi Li, Zhiqiu Lin, Deepak Pathak, Jiayao Li, Yixin Fei, Kewen Wu, Tiffany Ling, Xide Xia, Pengchuan Zhang, Graham Neubig, et al. Genai-bench: Evaluating and improving compositional text-to-visual generation. _arXiv preprint arXiv:2406.13743_, 2024.
|
| 249 |
+
* Lin et al. (2014) Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In _European conference on computer vision_, pages 740–755. Springer, 2014.
|
| 250 |
+
* Lin et al. (2024) Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text generation. In _European Conference on Computer Vision_, pages 366–384. Springer, 2024.
|
| 251 |
+
* Niu et al. (2025) Yuwei Niu, Munan Ning, Mengren Zheng, Weiyang Jin, Bin Lin, Peng Jin, Jiaqi Liao, Chaoran Feng, Kunpeng Ning, Bin Zhu, et al. Wise: A world knowledge-informed semantic evaluation for text-to-image generation. _arXiv preprint arXiv:2503.07265_, 2025.
|
| 252 |
+
* Pan et al. (2025) Xichen Pan, Satya Narayan Shukla, Aashu Singh, Zhuokai Zhao, Shlok Kumar Mishra, Jialiang Wang, Zhiyang Xu, Jiuhai Chen, Kunpeng Li, Felix Juefei-Xu, et al. Transfer between modalities with metaqueries. _arXiv preprint arXiv:2504.06256_, 2025.
|
| 253 |
+
* Peng et al. (2024) Yuang Peng, Yuxin Cui, Haomiao Tang, Zekun Qi, Runpei Dong, Jing Bai, Chunrui Han, Zheng Ge, Xiangyu Zhang, and Shu-Tao Xia. Dreambench++: A human-aligned benchmark for personalized image generation. _arXiv preprint arXiv:2406.16855_, 2024.
|
| 254 |
+
* Podell et al. (2023) Dustin Podell, Zion English, Kyle Lacey, A. Blattmann, Tim Dockhorn, Jonas Muller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. _ArXiv_, abs/2307.01952, 2023. [https://api.semanticscholar.org/CorpusID:259341735](https://api.semanticscholar.org/CorpusID:259341735).
|
| 255 |
+
* Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In _International conference on machine learning_, pages 8748–8763. PmLR, 2021.
|
| 256 |
+
* Rombach et al. (2022) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In _Proceedings of the IEEE/CVF conference on computer vision and pattern recognition_, pages 10684–10695, 2022.
|
| 257 |
+
* Schuhmann et al. (2022) Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. _Advances in neural information processing systems_, 35:25278–25294, 2022.
|
| 258 |
+
* Sun et al. (2025) Kaiyue Sun, Rongyao Fang, Chengqi Duan, Xian Liu, and Xihui Liu. T2i-reasonbench: Benchmarking reasoning-informed text-to-image generation. _arXiv preprint arXiv:2508.17472_, 2025.
|
| 259 |
+
* Wang et al. (2024a) Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. _arXiv preprint arXiv:2409.12191_, 2024a.
|
| 260 |
+
* Wang et al. (2024b) Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. _arXiv preprint arXiv:2409.18869_, 2024b.
|
| 261 |
+
* Wei et al. (2025) Xinyu Wei, Jinrui Zhang, Zeqing Wang, Hongyang Wei, Zhen Guo, and Lei Zhang. Tiif-bench: How does your t2i model follow your instructions? _arXiv preprint arXiv:2506.02161_, 2025.
|
| 262 |
+
* Wiles et al. (2025) Olivia Wiles, Chuhan Zhang, Isabela Albuquerque, Ivana Kajić, Su Wang, Emanuele Bugliarello, Yasumasa Onoe, Pinelopi Papalampidi, Ira Ktena, Chris Knutsen, Cyrus Rashtchian, Anant Nawalgaria, Jordi Pont-Tuset, and Aida Nematzadeh. Revisiting text-to-image evaluation with gecko: On metrics, prompts, and human ratings, 2025. [https://arxiv.org/abs/2404.16820](https://arxiv.org/abs/2404.16820).
|
| 263 |
+
* Wu et al. (2025a) Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report. _arXiv preprint arXiv:2508.02324_, 2025a.
|
| 264 |
+
* Wu et al. (2025b) Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encoding for unified multimodal understanding and generation. In _Proceedings of the Computer Vision and Pattern Recognition Conference_, pages 12966–12977, 2025b.
|
| 265 |
+
* Xiao et al. (2025) Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xingrun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. Omnigen: Unified image generation. In _Proceedings of the Computer Vision and Pattern Recognition Conference_, pages 13294–13304, 2025.
|
| 266 |
+
* Xie et al. (2024) Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation. _arXiv preprint arXiv:2408.12528_, 2024.
|
| 267 |
+
* Yang et al. (2025) An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. _arXiv preprint arXiv:2505.09388_, 2025.
|
| 268 |
+
* Ye et al. (2025) Junyan Ye, Dongzhi Jiang, Zihao Wang, Leqi Zhu, Zhenghao Hu, Zilong Huang, Jun He, Zhiyuan Yan, Jinghua Yu, Hongsheng Li, et al. Echo-4o: Harnessing the power of gpt-4o synthetic images for improved image generation. _arXiv preprint arXiv:2508.09987_, 2025.
|
| 269 |
+
* Zhou et al. (2024) Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. Transfusion: Predict the next token and diffuse images with one multi-modal model. _arXiv preprint arXiv:2408.11039_, 2024.
|
| 270 |
+
|
| 271 |
+
\beginappendix
|
| 272 |
+
|
| 273 |
+
7 Example of a Failure Case of the GenEval Detector
|
| 274 |
+
---------------------------------------------------
|
| 275 |
+
|
| 276 |
+
Figure [6](https://arxiv.org/html/2512.16853v1#S7.F6 "Figure 6 ‣ 7 Example of a Failure Case of the GenEval Detector ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") shows a second failure case of the GenEval evaluation rooted in its object detector, after the example from Figure [1](https://arxiv.org/html/2512.16853v1#S1.F1 "Figure 1 ‣ 1 Introduction ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"). As the T2I output distribution shifted farther from COCO with the advent of higher scales of training (including on synthetic data), the object detector in GenEval trained on COCO breaks down.
|
| 277 |
+
|
| 278 |
+
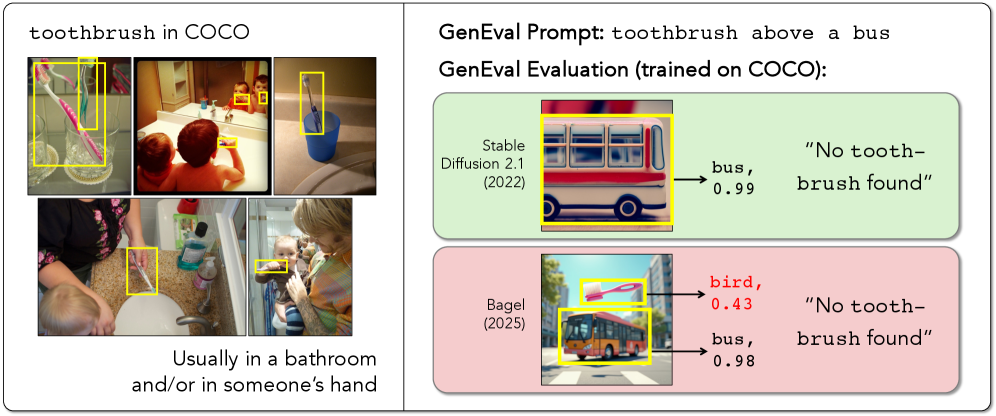
|
| 279 |
+
|
| 280 |
+
Figure 6: The object detector in GenEval fails to recognize the (correctly placed) toothbrush in the image generated by Bagel, mislabeling it as a bird: likely because in the COCO dataset the object detector was trained on, toothbrushes tend to appear in bathrooms and hands, while birds tend to appear in the sky. This results in an incorrect evaluation of the image correctly generated by Bagel.
|
| 281 |
+
|
| 282 |
+
8 GenEval 2 Curation Details
|
| 283 |
+
----------------------------
|
| 284 |
+
|
| 285 |
+
### 8.1 Full Vocabulary of GenEval 2
|
| 286 |
+
|
| 287 |
+
The prompts in GenEval 2 consist of words randomly sampled from the vocabulary below. The objects sourced from COCO are in bold.
|
| 288 |
+
|
| 289 |
+
#### Animate objects:
|
| 290 |
+
|
| 291 |
+
bear, bird, cat, cow, dog, elephant, flamingo, giraffe, horse, kangaroo, koala, lion, monkey, penguin, pig, rabbit, raccoon, sheep, turtle, zebra.
|
| 292 |
+
|
| 293 |
+
#### Inanimate objects:
|
| 294 |
+
|
| 295 |
+
backpack, bagel, bicycle, candle, car, chair, clock, cookie, croissant, donut, flower, guitar, motorcycle, mushroom, suitcase, toy, truck, trumpet, umbrella, violin.
|
| 296 |
+
|
| 297 |
+
#### Attributes:
|
| 298 |
+
|
| 299 |
+
red, yellow, green, blue, purple, pink, brown, black, white, spotted, striped, checkered, sparkling, wooden, glass, plastic, metal, stone.
|
| 300 |
+
|
| 301 |
+
#### Prepositions:
|
| 302 |
+
|
| 303 |
+
to the left of, to the right of, on top of, under, in front of, behind.
|
| 304 |
+
|
| 305 |
+
#### Transitive Verb Relations:
|
| 306 |
+
|
| 307 |
+
chasing, playing with, jumping over.
|
| 308 |
+
|
| 309 |
+
#### Counts:
|
| 310 |
+
|
| 311 |
+
two, three, four, five, six, seven.
|
| 312 |
+
|
| 313 |
+
### 8.2 GPT-4o Rewriting Prompt
|
| 314 |
+
|
| 315 |
+
In order to rewrite GenEval 2 prompts in a longer, more detailed format, in-line with training and evaluation methods of recent T2I models, we use the prompt provided in Figure [7](https://arxiv.org/html/2512.16853v1#S8.F7 "Figure 7 ‣ 8.2 GPT-4o Rewriting Prompt ‣ 8 GenEval 2 Curation Details ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"). The in-context examples are GenEval prompts alongside their rewritten equivalents as provided in the BAGEL repository 8 8 8[https://github.com/bytedance-seed/BAGEL](https://github.com/bytedance-seed/BAGEL). We select 110 words as the suggested maximum as 550 of 553 rewritten GenEval prompts are within that length.
|
| 316 |
+
|
| 317 |
+
I am evaluating a text-to-image generation model. Given a short prompt, rewrite the prompt to a more detailed version.Here are three examples:Prompt: a photo of a dog right of a teddy bear Detailed Prompt: A soft, beige teddy bear sits upright on a wooden floor. The teddy bear has round black eyes and a small stitched nose. Its fur is slightly matted, giving it a well-loved appearance. To the right of the teddy bear, a golden retriever dog stands on all fours. The dog’s fur is smooth and shiny, catching the light. Its ears are perked up, and its tail is slightly raised. The dog’s eyes are focused forward, exuding a calm and attentive expression. The scene is set in a realistic, photographic style, with natural lighting highlighting the textures of both the teddy bear and the dog.Prompt: a photo of two backpacks Detailed Prompt: There are two backpacks placed side by side on a wooden floor. Both backpacks are medium-sized and upright. The first backpack is black with a sleek, smooth texture. The second backpack is navy blue with a slightly rugged appearance. Each backpack has multiple zippered compartments visible on the front. The straps of both backpacks rest neatly against their sides. The lighting is soft, highlighting the realistic textures and colors of the materials. The scene is simple, focusing only on the two backpacks in a photographic style.Prompt: a photo of a green bus and a purple microwave Detailed Prompt: A vibrant green bus is parked on the left side of the scene. The bus has a glossy, metallic finish that reflects the surrounding light realistically. Its large windows are clean and transparent, revealing empty seats inside. On the right side, a compact purple microwave sits on a flat surface. The microwave has a matte finish, with a small digital display and a silver handle on its front. Both objects are positioned without overlap, ensuring their distinct colors and details are clearly visible. The scene is rendered in a photographic style, emphasizing lifelike textures and realistic lighting.Here is the prompt for you to rewrite:Prompt: {}Detailed Prompt:Reply with the detailed prompt alone, with no extra text. Make sure the detailed prompt is under 110 words.
|
| 318 |
+
|
| 319 |
+
Figure 7: Prompt given to GPT-4o to rewrite GenEval 2.
|
| 320 |
+
|
| 321 |
+
9 User Study Details
|
| 322 |
+
--------------------
|
| 323 |
+
|
| 324 |
+
In this section, we provide the instructions provided to annotators for the two user studies in our work, alongside the user interface shown to the annotators.
|
| 325 |
+
|
| 326 |
+
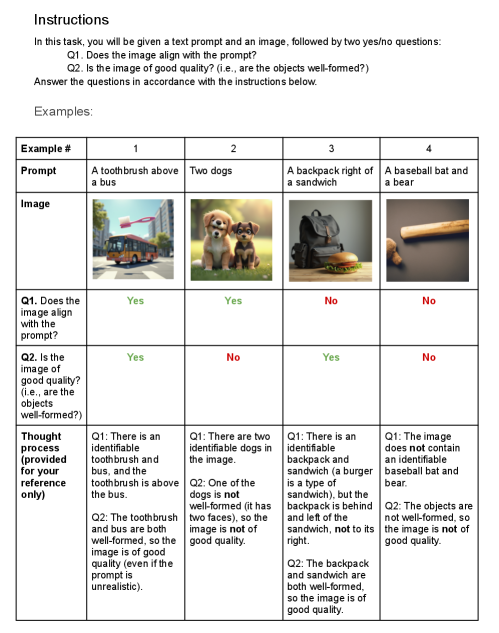
|
| 327 |
+
|
| 328 |
+
Figure 8: Annotator Instructions for GenEval User Study: Part 1
|
| 329 |
+
|
| 330 |
+

|
| 331 |
+
|
| 332 |
+
Figure 9: Annotator Instructions for GenEval User Study: Part 2
|
| 333 |
+
|
| 334 |
+
### 9.1 GenEval User Study
|
| 335 |
+
|
| 336 |
+
For this study, annotators were shown an image and two yes/no questions: (1) “Does the image align with the prompt?”; and (2) “Is the image of good quality? (i.e., are the objects well-formed?)”. The full instructions shown to the annotators are provided in Figures [8](https://arxiv.org/html/2512.16853v1#S9.F8 "Figure 8 ‣ 9 User Study Details ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"), [9](https://arxiv.org/html/2512.16853v1#S9.F9 "Figure 9 ‣ 9 User Study Details ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") and [10](https://arxiv.org/html/2512.16853v1#S9.F10 "Figure 10 ‣ 9.1 GenEval User Study ‣ 9 User Study Details ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation").
|
| 337 |
+
|
| 338 |
+

|
| 339 |
+
|
| 340 |
+
Figure 10: Annotator Instructions for GenEval User Study: Part 3
|
| 341 |
+
|
| 342 |
+
### 9.2 GenEval 2 User Study
|
| 343 |
+
|
| 344 |
+
For this user study, we follow the same structure as the user study on GenEval, but instead of asking a yes/no question for “Does the image align with the prompt”, we provide a checklist for each atom in the prompt for the user to select based on alignment of the image. Thus, we obtain atom-level annotations of correctness for each model. The instructions shown to the annotators are provided in Figure [11](https://arxiv.org/html/2512.16853v1#S9.F11 "Figure 11 ‣ 9.2 GenEval 2 User Study ‣ 9 User Study Details ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"), with the remainder of the instructions similar to the user study for GenEval (but with per-atom annotations in the examples). The user interface shown to the annotators is provided in Figure [12](https://arxiv.org/html/2512.16853v1#S9.F12 "Figure 12 ‣ 9.2 GenEval 2 User Study ‣ 9 User Study Details ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"). The user interface for the GenEval study was similar, but with a single yes/no question for alignment rather than per-atom annotations.
|
| 345 |
+
|
| 346 |
+

|
| 347 |
+
|
| 348 |
+
Figure 11: Annotator Instructions for GenEval 2 Study
|
| 349 |
+
|
| 350 |
+
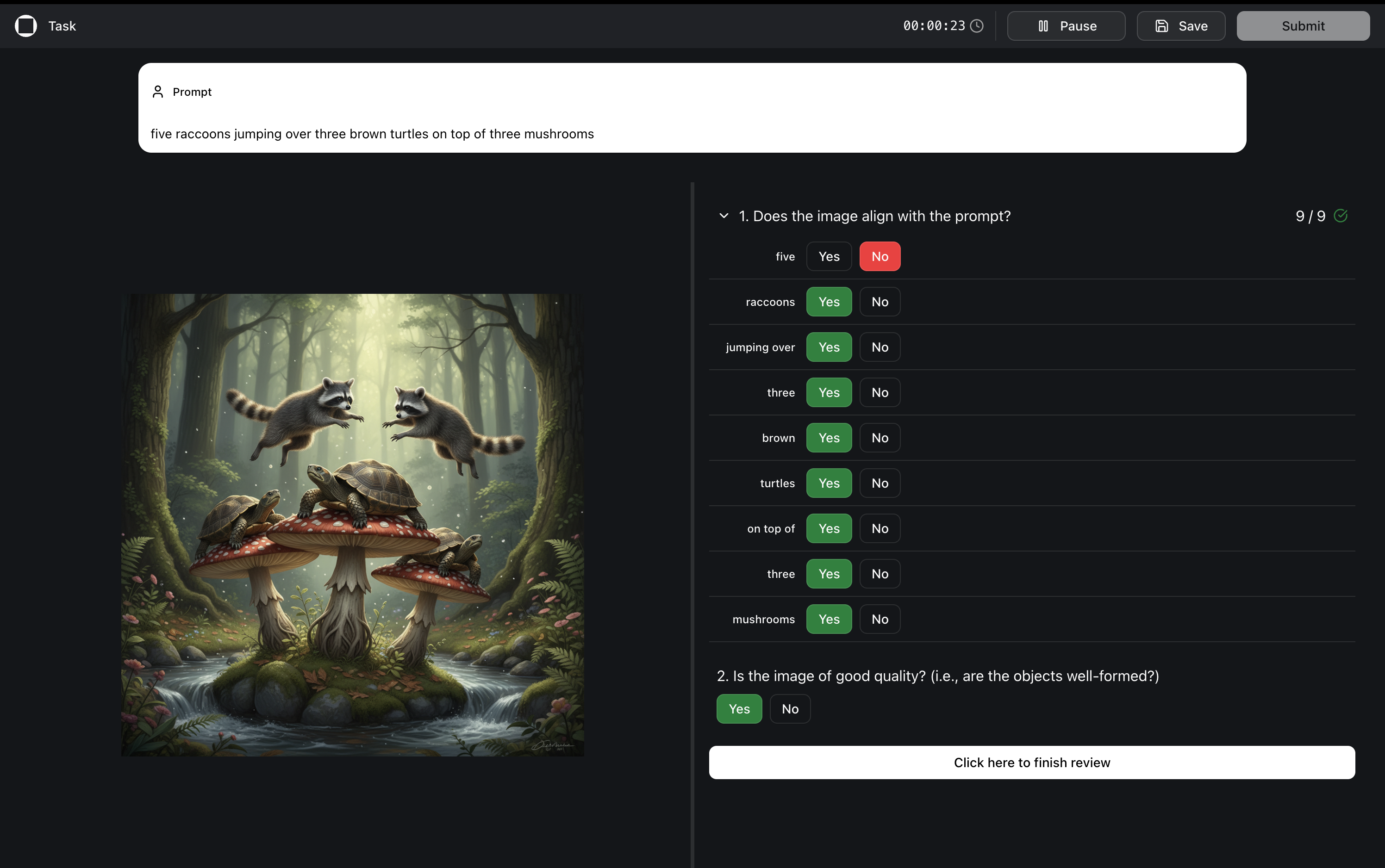
|
| 351 |
+
|
| 352 |
+
Figure 12: User Interface for GenEval 2 User Study
|
| 353 |
+
|
| 354 |
+
10 Per-Model Analyses of Human-Judged Scores on GenEval 2
|
| 355 |
+
---------------------------------------------------------
|
| 356 |
+
|
| 357 |
+
In Section [4](https://arxiv.org/html/2512.16853v1#S4 "4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"), we discuss and analyze human-judged scores on GenEval 2 averaged over 4 state-of-the-art T2I models: Flux.1-dev, Bagel, Qwen-Image and Gemini 2.5 Flash. Here, we present results for each of the 8 T2I models.
|
| 358 |
+
|
| 359 |
+
In Table [5](https://arxiv.org/html/2512.16853v1#S10.T5 "Table 5 ‣ 10 Per-Model Analyses of Human-Judged Scores on GenEval 2 ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"), we show how each model performs on each skill evaluated in GenEval 2. Various inferences can be drawn: for example, Gemini struggles the most with counting, achieving only 69.2% accuracy. Meanwhile, Qwen-Image struggles the most on relations between objects (both spatial and transitive verb), achieving 61.1% accuracy on each. These analyses allow targeted diagnosis and improvement of T2I model flaws.
|
| 360 |
+
|
| 361 |
+
In Table [6](https://arxiv.org/html/2512.16853v1#S10.T6 "Table 6 ‣ 10 Per-Model Analyses of Human-Judged Scores on GenEval 2 ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"), we present results for each model at each level of prompt atomicity, i.e., compositionality, or complexity. Unsurprisingly, all models uniformly perform much better on less complex prompts than on more complex ones. However, this drop is quite sharp for many models: e.g., Flux.1-dev achieves 25% accuracy at atomicity=6, and 0% accuracy at all higher atomicities, potentially shedding light on the complexity of its training data. GenEval 2 highlights the significant room for improvement of all T2I models at higher compositionality.
|
| 362 |
+
|
| 363 |
+
Table 5: Per-model performance across skills on GenEval 2. T2I models particularly struggle with counting, spatial relations, and transitive verb relations.
|
| 364 |
+
|
| 365 |
+
Table 6: Per-model performance across varying levels of prompt compositionality (atomicity) on GenEval 2. T2I model performance drops sharply as prompt compositionality increases.
|
| 366 |
+
|
| 367 |
+
11 Illustrative Example of Soft-TIFA
|
| 368 |
+
------------------------------------
|
| 369 |
+
|
| 370 |
+
Figure [13](https://arxiv.org/html/2512.16853v1#S11.F13 "Figure 13 ‣ 11 Illustrative Example of Soft-TIFA ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") shows an example from the GenEval 2 benchmark, alongside the Soft-TIFA evaluation method. Soft-TIFA has the advantages of both soft scores (as in VQAScore) as well as per-atom questions (as in TIFA), while attaining full coverage over the prompt due to the templated nature of GenEval 2.
|
| 371 |
+
|
| 372 |
+
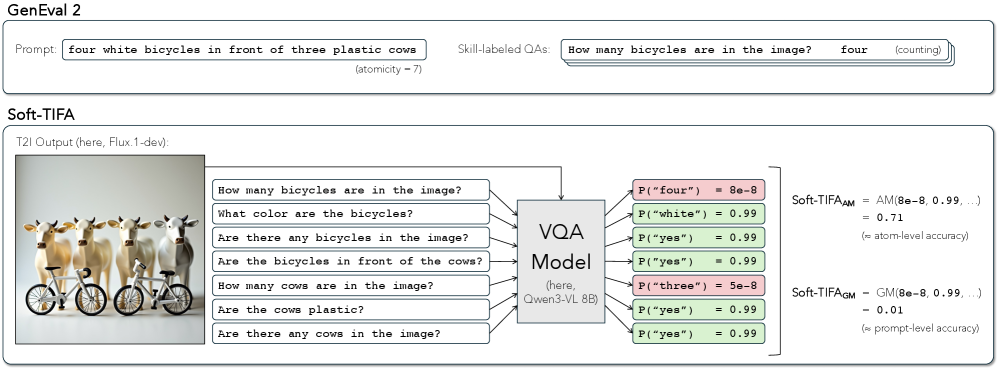
|
| 373 |
+
|
| 374 |
+
Figure 13: An example from GenEval 2, alongside its evaluation with Soft-TIFA. GenEval 2 examples are annotated with atomicity and skills, allowing for detailed analyses. Soft-TIFA AM{}_{\text{AM}} provides an estimate of atom-level T2I performance, while Soft-TIFA GM{}_{\text{GM}} provides an estimate of prompt-level T2I performance.
|
| 375 |
+
|
| 376 |
+
12 Evaluation Methods with Different Underlying VQA Models
|
| 377 |
+
----------------------------------------------------------
|
| 378 |
+
|
| 379 |
+
We present in Table [7](https://arxiv.org/html/2512.16853v1#S12.T7 "Table 7 ‣ 12 Evaluation Methods with Different Underlying VQA Models ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation") the AUROC of VQAScore, TIFA, Soft-TIFA AM{}_{\text{AM}} and Soft-TIFA GM{}_{\text{GM}} for different types of prompt sets (original, rewritten, and both) of GenEval 2, with different underlying VQA models: Qwen3-VL, Qwen2.5-VL, Qwen2-VL and GPT-4o. Soft-TIFA GM{}_{\text{GM}} has higher human alignment than all other evaluation methods on GenEval 2 under all versions of Qwen. While VQAScore outperforms Soft-TIFA GM{}_{\text{GM}} with GPT-4o as the VQA model, the absolute AUROC is significantly lower than methods using Qwen, with Qwen3-VL providing the highest human alignment. It is further worth noting that as GPT-4o is closed-source, it is unclear exactly what is being returned as the “logprobs” of various output tokens.
|
| 380 |
+
|
| 381 |
+
Table 7: AUROC of VQAScore, TIFA, Soft-TIFA AM{}_{\text{AM}} and Soft-TIFA GM{}_{\text{GM}} across different prompt types, with different underlying VQA models. Soft-TIFA GM{}_{\text{GM}} outperforms all other methods with all Qwen models. Although GPT-4o VQAScore outperforms GPT-4o Soft-TIFA GM{}_{\text{GM}}, it is significantly lower than Soft-TIFA GM{}_{\text{GM}} with Qwen models. In each row, the highest AUROC is in bold and the second-highest is underlined.
|
| 382 |
+
|
| 383 |
+
13 Per-Skill and Per-Compositionality Analyses of Soft-TIFA
|
| 384 |
+
-----------------------------------------------------------
|
| 385 |
+
|
| 386 |
+
In this section, we present the per-skill and per-compositionality performance of state-of-the-art (SOTA) T2I models (Flux.1-dev, Bagel, Qwen-Image and Gemini 2.5 Flash), as estimated by Soft-TIFA. As skill is an atom-level concept and compositionality is a prompt-level concept, we use Soft-TIFA AM{}_{\text{AM}} to estimate T2I performance on the former, and Soft-TIFA GM{}_{\text{GM}} for the latter.
|
| 387 |
+
|
| 388 |
+
Note that as Soft-TIFA scores are soft rather than binary (as the human-judged scores are), these results are overall slightly regularized compared to those in Section [4.3](https://arxiv.org/html/2512.16853v1#S4.SS3 "4.3 Analyses of Capability and Compositionality ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"); i.e., high scores are slightly lower (e.g., where Soft-TIFA assigned a score of 0.99 instead of 1), and low scores are slightly higher (e.g., where Soft-TIFA assigned a score of 0.01 instead of 0). We focus on the trends the results follow.
|
| 389 |
+
|
| 390 |
+
Our results are presented in Figure [14](https://arxiv.org/html/2512.16853v1#S13.F14 "Figure 14 ‣ 13 Per-Skill and Per-Compositionality Analyses of Soft-TIFA ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"). The trends largely mirror the human-judged scores collected in our large-scale user study and shown in Figure [4](https://arxiv.org/html/2512.16853v1#S4.F4 "Figure 4 ‣ 4.3 Analyses of Capability and Compositionality ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation"), but for the “verb” skill, in which the VQA model is significantly stricter than the human annotators, awarding a score of 31.4 31.4 compared to human judgment at 65.0 65.0. While the fact that the majority of the Soft-TIFA trends mirror human judgment shows promise for Soft-TIFA as a T2I evaluation method, this finding also serves as a reminder that VQA-based methods are only as strong as their underlying VQA models are, and calls for further research in visual understanding of more nuanced relations between objects.
|
| 391 |
+
|
| 392 |
+
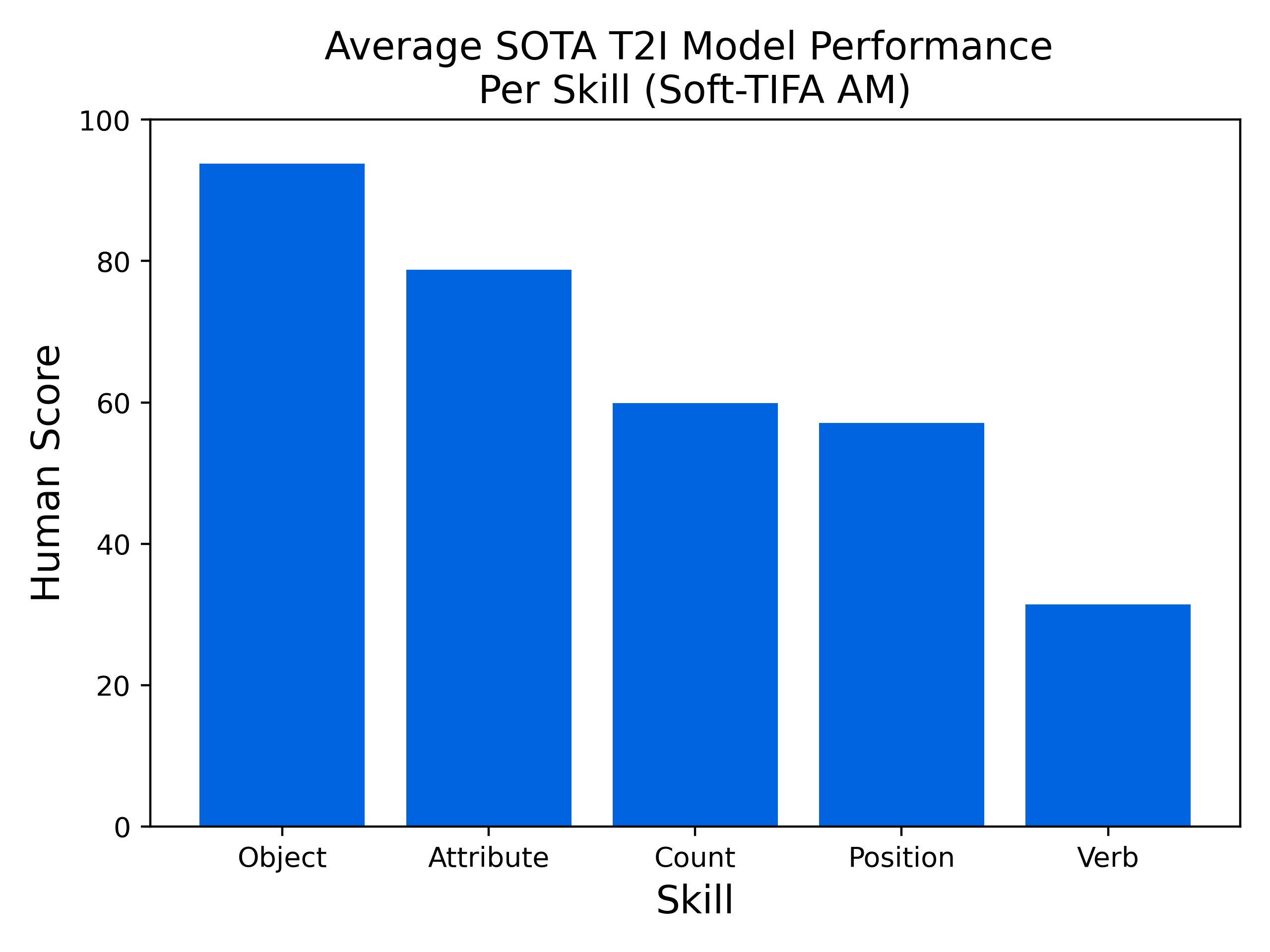
|
| 393 |
+
|
| 394 |
+
(a)Average Soft-TIFA AM{}_{\text{AM}} scores of SOTA T2I models per skill in GenEval 2.
|
| 395 |
+
|
| 396 |
+
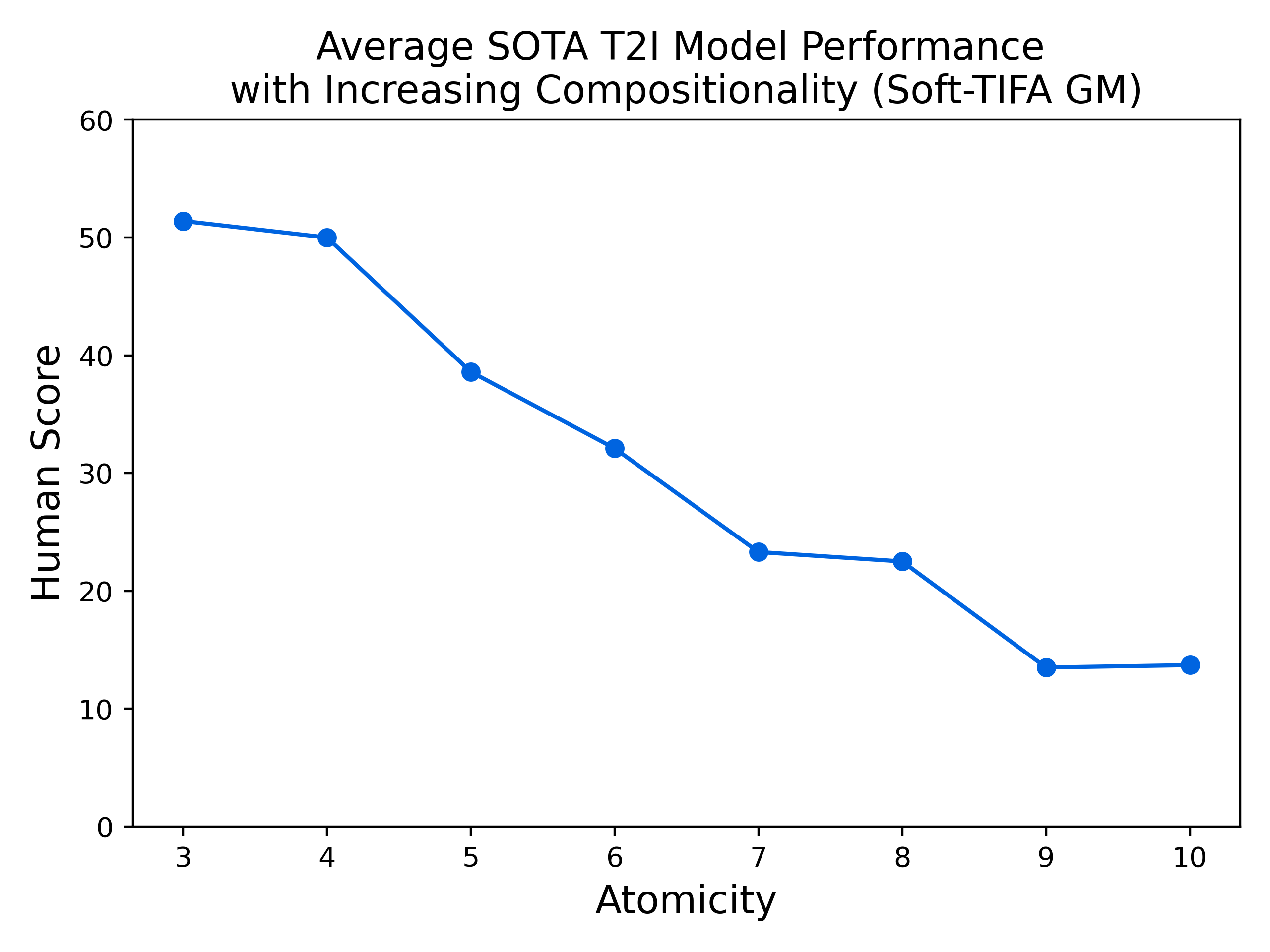
|
| 397 |
+
|
| 398 |
+
(b)Average Soft-TIFA GM{}_{\text{GM}} scores of SOTA T2I models for each level of compositionality (“atomicity”) in GenEval 2.
|
| 399 |
+
|
| 400 |
+
Figure 14: GenEval 2 enables various analyses of T2I models: (a) atom-level analyses such as performance per-skill with Soft-TIFA AM{}_{\text{AM}}; and (b) prompt-level analyses such as performance per-compositionality with Soft-TIFA GM{}_{\text{GM}}. The trends of Soft-TIFA reflect the human-judged scores from our user study (Figure [4](https://arxiv.org/html/2512.16853v1#S4.F4 "Figure 4 ‣ 4.3 Analyses of Capability and Compositionality ‣ 4 GenEval 2: Addressing Benchmark Drift ‣ GenEval 2: Addressing Benchmark Drift in Text-to-Image Evaluation")), but for the “verb” skill, in which VQA models are stricter than human annotators.
|