
script stringlengths 113 767k |
|---|
import numpy as np
import pandas as pd
from pandas_profiling import ProfileReport
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# # 1. Load Data & Check Information
df_net = pd.read_csv("../input/netflix-shows/netflix_tit... |
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
from keras import models
from keras.utils import to_categorical, np_utils
from tensorflow import convert_to_tensor
from tensorflow.image import grayscale_to_rgb
from tensorflow.data import Dataset
from tensorflow.keras.layers import Flatte... |
# #### EEMT 5400 IT for E-Commerce Applications
# ##### HW4 Max score: (1+1+1)+(1+1+2+2)+(1+2)+2
# You will use two different datasets in this homework and you can find their csv files in the below hyperlinks.
# 1. Car Seat:
# https://raw.githubusercontent.com/selva86/datasets/master/Carseats.csv
# 2. Bank Personal Loa... |
# 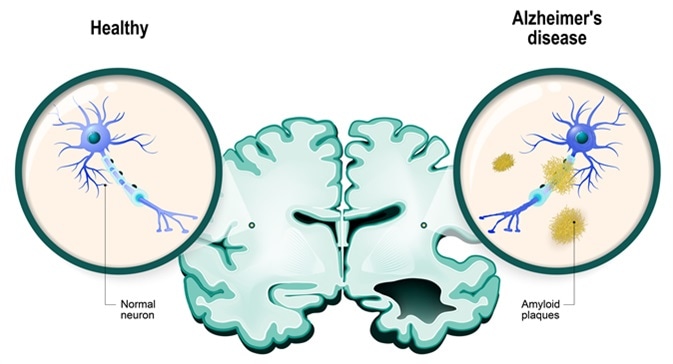
# **Alzheimer's disease** is the most common type of dementia. It is a progressive disease beginning with mild memory loss and possibly leading to loss of the ability to carry on a conversation and respond to the environment. Al... |
# # Tracking COVID-19 from New York City wastewater
# **TABLE OF CONTENTS**
# * [1. Introduction](#chapter_1)
# * [2. Data exploration](#chapter_2)
# * [3. Analysis](#chapter_3)
# * [4. Baseline model](#chapter_4)
# ## 1. Introduction
# The **New York City OpenData Project** (*link:* __[project home page](https://opend... |
# ## Project 4
# We're going to start with the dataset from Project 1.
# This time the goal is to compare data wrangling runtime by either using **Pandas** or **Polar**.
data_dir = "/kaggle/input/project-4-dataset/data-p1"
sampled = False
path_suffix = "" if not sampled else "_sampled"
from time import time
import pand... |
# This notebook reveals my solution for __RFM Analysis Task__ offered by Renat Alimbekov.
# This task is part of the __Task Series__ for Data Analysts/Scientists
# __Task Series__ - is a rubric where Alimbekov challenges his followers to solve tasks and share their solutions.
# So here I am :)
# Original solution can b... |
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
# from ... |
# Note: This notebook was referece for my self-training from https://www.kaggle.com/mathchi/ab-test-for-real-data/ by [Mehmet A.](https://www.kaggle.com/mathchi)
# Since the original dataset is private, I faked one for running it through. Some row of the data was copied data from originally showed. Others was kind of r... |
# The main goal of this notebook is provide step by step data analysis, data preprocessing and implement various machine learning tasks. The goal is not just to build a model which gives better results but also to learn various analysis and modeling techniques in the process of building the best model.
# import the req... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all ... |
a = 2
print(a)
type(a)
b = 3.4
print(b)
type(b)
c = "abc"
print(c)
type(c)
# **Variable with number**
# **interger , floating , complex numbar**
d = 3 + 4j
print(d)
type(d)
# **Working with numerical variable**
Gross_profit = 30
Revenue = 100
Gross_profit_margin = (Gross_profit / Revenue) * 100
print(Gross_profit_mar... |
# # Setup
import os
import gc
import time
import warnings
gc.enable()
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
pd.set_option("display.max_columns", None)
pd.set_option("display.precision", 4)
import matplotlib.pyplot as plt
import seaborn as sns
SEED = 23
os.environ["PYTHONHASHSEED"] ... |
# # Electricity DayAhead Prices 2022
# This dataset provides hourly day ahead electricity prices for France and interconnections, sourced from the ENTSO-E Transparency Platform, which is a reputable market data provider for European electricity markets. It is valuable resource for businesses, investors, researchers, an... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Log... |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
train_csv = pd.read_csv("/kaggle/input/playground-series-s3e12/train.csv")
test_csv = pd.read_csv("/kaggle/input/playground-series-s3e12/test.csv")
train_csv.head()
train_csv.shape
train_csv.describe()
import seaborn as sns
f... |
import pandas as pd
import re
import numpy as np
sla = pd.read_excel(
r"../input/shopee-code-league-20/_DA_Logistics/SLA_matrix.xlsx", engine="openpyxl"
)
orders = pd.read_csv(
r"../input/shopee-code-league-20/_DA_Logistics/delivery_orders_march.csv"
)
sla
# 看起來很奇怪,不過從表中,大概可以猜出是一個對照表,而且index是出發地(from),column是目... |
# # Introduction
# Recommender systems are a big part of our lives, recommending products and movies that we want to buy or watch. Recommender systems have been around for decades but have recently come into the spotlight.
# In this notebook, We will discuss three types of recommender system: **(1)Association rule lear... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
# Progetto Big Data & Analytics a.a. 2022/2023
# Kaggle Competition : " UW-Madison GI Tract Image Segmentation"
# Prof : Roberto Pirrone , Studente : Luca La Barbera
# Corso di Laurea Magistrale in Ingegneria Informatica - Università degli Studi di Palermo.
# Presentazione della Competition
# Descrizione Generale
# In... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, file... |
# ## March Machine Learning Mania 2021 - NCAAM
# 
# **What to predict**
# **Stage 1** - You should submit predicted probabilities for every possible matchup in the past 5 NCAA® tournaments (2015-2019).
# **S... |
# (Case Study - 1) Analysis Books Scraping
# For this datasets use this url : https://www.kaggle.com/datasets/repl4y/books-scraping
import pandas as pd
import numpy as np
import matplotlib as mp
import matplotlib.pyplot as plt
import random as rd
df = pd.read_csv("Books_scrapingV3.csv")
# 1.Observe Column in Top and ... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
# # Intorduction
# Setup
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
# Avoid OMM Error
physical_devices = tf.config.experimental.list_physical_devices("GPU")
if len(physical_devices) > 0:
tf.config.... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all ... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
# You can wr... |
# install external libraries
# standard libraries
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os, warnings
warnings.simplefilter("ignore")
import time
# sentence transformer library
from sentence_transformers import SentenceTransformer
# FAISS l... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all ... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
# importing modules
import os
import tarfile
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn import linear_model
from sklearn.linear_mode... |
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
import matplotlib.pyplot as p... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
# TASK:
# As a part of our project for the data modelling and visualisation class at Singapore Management University, we were given the Sales Data of a fictional company, TGL, which has multiple branches.
# We utilised Tableau to visualise the performance of our assigned branch, branch 2. We measured its performance ov... |
# # Predicting Airbnb Prices
# # Importing Data
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import os
from sklearn import set_config
plt.style.use("ggplot")
pd.set_option("display.max_columns", 100)
# set_config(transform_output="pandas") #doesn... |
import numpy as np
import pandas as pd
train_labels = pd.read_csv("../input/bms-molecular-translation/train_labels.csv")
# # All training label strings start with "InChI=1S/"
train_labels["first9"] = [train_label[:9] for train_label in train_labels["InChI"]]
train_labels["drop9"] = [train_label[9:] for train_label in... |
# # Google Landmark Recognition Challenge 2020
# Simplified image similarity ranking and re-ranking implementation with:
# * EfficientNetB0 backbone for global feature similarity search
# * DELF module for local feature reranking
# Reference papers:
# * 2020 Recognition challenge winner: https://arxiv.org/abs/2010.0165... |
# # Linear Regression Explained
# This uses the data and code from the medium article [Linear Regression from Scratch](https://link.medium.com/dJlTSvMUfeb)
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# # Set up functions to do the work for us. Explanations before each line of code.
# variabl... |
# ## Instalação e Importação de Pacotes
# Instalando o DuckDB:
# Importando os pacotes que serão utilizados e configurando o Pandas para mostrar até 200 linhas e 200 colunas, bem como tentar exibir valores decimais com 4 casas depois da vírgula (evitando notação científica):
import pandas as pd
import plotly.express a... |
# # Diffusion Source Images View & Prompts
import os
import cv2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import pyarrow.parquet as pq
paths = []
for dirname, _, filenames in os.walk("/kaggle/input/"):
for filename in filenames:
if filename[-4:] == ".png":
paths += ... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import seaborn as sns
import matplotlib.pyplot as plt
from scipy import stats
from scipy.stats import randint
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
f... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import random
import string
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
df = pd.read_csv("/kaggle/input/wikipedia-movie-plots/wiki_movie_plots_ded... |
import numpy as np
import pandas as pd
from typing import Sequence, Tuple
from collections import defaultdict
import matplotlib.pyplot as plt
kaggle = False
if kaggle:
root = "/kaggle/input/amp-parkinsons-disease-progression-prediction"
else:
root = "data/"
# load dataset
train_proteins = pd.read_csv(f"{root}/... |
# First step to do pricing of a options derivative is Binomial Model.
# - Short call derivative and buy $\Delta$ units stock to evaluate the derivative price
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only ".... |
# # Cricket Umpire Mediapipe Images
# Mediapipe pose detection
import cv2
import os
import math
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import mediapipe as mp
mp_pose = mp.solutions.pose
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles... |
# # RSNA Pneumonia Detection Challenge
# building an algorithm that automatically detects potential pneumonia cases using Pytorch Lightning
# **About Challenge:** The competition challenges us to create an algorithm that can detect lung opacities on chest radiographs to aid in the accurate diagnosis of pneumonia, which... |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
# # 特徵
# * session_id - user_id
# * index - the index of the event for the session:一個user會有多個index
# * elapsed_time - how much time has passed (in milliseconds) between the start of the session and when the event was rec... |
# Problem statement
# Predict on building satety during an earthquake
# Import libraries
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
import seaborn as sns
# Get files
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(di... |
# Semantic segmentation chalenges expose us to a lot of metrics. So I have decided to make a list of as many
# as I can and try to explain each one.
# Let's go.
# # Semantic segmentation targets
# In semantic segmentation tasks, we predict a mask, i.e. where the object of interest is present.
# To make things simple, l... |
# Tabular Playground Series(feb)
# Table Playground Series are beginner friendly monthly competitions organised by kaggle.
#
# In this competition we have to make a regrssion model based on categorical and continous features provided
# This notebook is beginner friendly guide for creating supercool EDA and making basel... |
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid")
# Reading the csv
ds_salaries = pd.read_csv("/kaggle/input/data-science-job-salaries/ds_salaries.csv")
ds_salaries.head(10)
# Check data
ds_salaries.info()
# Check for missing values
ds_salarie... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
data = pd.read_csv("../input/diamonds/diamonds.csv")
print(data.info())
print("No Null Value")
data.head()
data.drop("Unnamed: 0", axis=1, inplace=True)
# **Description of data:**
# price price in US d... |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
train = pd.read_csv(
"/kaggle/input/competitive-data-science-predict-future-sales/sales_train.csv",
parse_dates=["date"],
infer_datetime_format=True,
dayfirst=True,
)
test = pd.read_csv(
"/kaggle/input/comp... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import tree
from sklearn.metrics import roc_auc_score
... |
import random
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import seaborn as sns
import missingno
import matplotlib.pyplot as plt
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or press... |
# Data Preprocessing
#
import os
import cv2
import numpy as np
import pandas as pd
from keras.utils import np_utils
from keras.datasets import mnist
from sklearn.utils import shuffle
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
data_root = (
"/kaggle/input/az-handwritte... |
from pathlib import Path
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torchinfo
from tqdm import tqdm
import onnx
import onnxruntime
import onnx_tf
import tensorflow as tf
import tflite_runtime.interpreter as tflite
INPUT_... |
# # MNIST Baseline
# In this notebook, we create a baseline model to predict labels on the MNIST data set.
# ## Import packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.prep... |
# # House Prices: Advanced Regression Techniques
# _[Link to kaggle](https://www.kaggle.com/c/house-prices-advanced-regression-techniques)_
# **Author: Piotr Cichacki**
# ## Goal of the data analysis: predict the sales prices for each house
# ### Loading necessary libraries
# Data manipulation
import numpy as np
import... |
import io
import os
import cv2
import csv
import time
import copy
import math
import torch
import shutil
import logging
import argparse
import numpy as np
import torchvision
import numpy as np
import pandas as pd
import seaborn as sb
import torch.nn as nn
from PIL import Image
from tqdm import tqdm
import torch.optim a... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input ... |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from scipy import integrate
# ## Homework
# * Get the trainning part of weather dataset at https://www.kaggle.com/c/australian-weather-prediction, a goal is... |
# # Library
import os
import random
import numpy as np
import pandas as pd
from PIL import Image
from tqdm.notebook import tqdm
from scipy import spatial
from sklearn.model_selection import train_test_split
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torch.optim.lr_scheduler ... |
# # 🛳 Titanic 3D modeling
# Hey sailor ! 🧜
# In this notebook we try a different an intuitive approach on the titanic dataset.
# We will model the cabins in 3D and then apply a quick kNN algorithm on this new space.
# 
# You can find the tit... |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# ## Contents
# - [Introduction](#introduction)
# * [Problem Statement](#problem-statement)
# - [Exploratory Data Analysis](#eda)
# - [Feature Engineering](#feature-engineering)
# - [Model Building](#model-building)
# * [Linear Regression](#linear-... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
import os
import tensorflow as tf
from tensorflow.keras import Model, callbacks
from tensorflow.keras.applications.densenet import DenseNet201
from tensorflow.keras.applications.mobilenet_v2 import MobileNetV2, preprocess_input
from tensorflow.keras.layers import Dense, Dropout, GlobalAveragePooling2D, Input
from tenso... |
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPool2D, Dropout
from keras.utils import np_utils
import pandas as pd
from sklearn.model_selection import train_test_split
from keras.layers.normalization import BatchNormalization
import numpy as np
... |
# # Importing the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.metrics import roc_auc_score
from lightgbm import LGBMClassifier
from lightgbm.callback import early_stopping, log_e... |
#
# $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$' `$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
# $$$$$$$$$$$$$$$$$$$$$$$$$$$$' `$$$$$$$$$$$$$$$$$$$$$$$$$$$$
# $$$'`$$$$$$$$$$$$$'`$$$$$$! !$$$$$$'`$$$$$$$$$$$$$'`$$$
# $$$$ $$$$$$$$$$$ $$$$$$$ $$$$$$$ $$$$$$$$$$$ $$$... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) zwill list all files under the input directory
import os
for dirnam... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
# Import statements
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from sklearn.preprocessing import MinMaxScaler
from sklearn import tree
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sk... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
# #### EEMT 5400 IT for E-Commerce Applications
# ##### HW4 Max score: (1+1+1)+(1+1+2+2)+(1+2)+2
# You will use two different datasets in this homework and you can find their csv files in the below hyperlinks.
# 1. Car Seat:
# https://raw.githubusercontent.com/selva86/datasets/master/Carseats.csv
# 2. Bank Personal Loa... |
import pandas as pd
import numpy as np
from glob import glob
from collections import defaultdict
from tqdm import tqdm
import time
import os
import copy
import gc
from PIL import Image
# visualization
import cv2
import matplotlib.pyplot as plt
from scipy import spatial
# Sklearn
# PyTorch
import torch
import torch.nn... |
# ## Table of Contents
# 1. [Introduction](#Introduction)
# 2. [Import Libraries and Read Dataset](#Import_Libraries_and_Read_Dataset)
# 3. [Data Exploration](#Data_Exploration)
# 4. [Data Cleaning](#Data_Cleaning)
# 5. [Data Visualization](#Data_Visualization)
# 6. [Data Preprocessing](#Data_Preprocessing)
# 7.... |
# # Tabular Data Classification and Baseline with EDA
# **Table of Contents:**
# 1. [Load Data and Inspect Top Level Features](#load)
# 2. [Exploratory Data Analysis (EDA)](#eda)
# 3. [Data Preparation and Preprocessing](#data-preprocessing)
# 4. [Model Training and Evaluation](#model-training)
# - 4.1. [Basic Analysis... |
# # 1 Dataset
import pandas as pd
import matplotlib.pyplot as plt
import re
import nltk
data = pd.read_csv("/kaggle/input/nlp-ulta-skincare-reviews/Ulta Skincare Reviews.csv")
data.head()
data.info()
data.isnull().sum()
data.fillna("Unknown", inplace=True)
data.isnull().sum()
# # 2 Auto Labeling Sentiment Using Vader... |
import pandas as pd
import numpy as np
from gensim.parsing import (
strip_tags,
strip_numeric,
strip_multiple_whitespaces,
stem_text,
strip_punctuation,
remove_stopwords,
)
from gensim.parsing import preprocess_string
from gensim import parsing
import re
from rouge import Rouge
rouge = Rouge()
... |
# #### Import required libraries
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import (
confusion_matrix,
classification_report,
ConfusionMatrixDisplay,
roc_curve,
precision_recall_curve,
auc,... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
import pandas as pd
import numpy as np
from scipy.stats import chi2_contingency
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv("../input/mushroom-classification/mushrooms.csv")
df.head()
# # EDA
plt.subplots(4, 6, figsize=(20, 10))
a = 1
for i, s in enumerate(df.columns):
plt.subplot(4, 6,... |
#
#
import numpy as np
import pandas as pd
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, models, transforms
from torch.utils.data.sampler import SubsetRandomSampler
import matplotlib.pyplot as plt
import time
import copy
from random import shuffle
im... |
import os # import the data file
import numpy as np # calculations
import pandas as pd # dataframes
pd.set_option("max_columns", None) # to show all the columns
import matplotlib.pyplot as plt # visualization
import seaborn as sns # visualization
from sklearn.model_selection import train_test_split # train test... |
from huggingface_hub import login
login(token="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")
import torch
from transformers import (
AutoTokenizer,
AutoModelForSeq2SeqLM,
Seq2SeqTrainingArguments,
Seq2SeqTrainer,
T5Tokenizer,
)
from datasets import load_dataset
raw_datasets = load_dataset("cfilt/iitb-en... |
key = "AIzaSyCLx1cVxGxez6FsHD0uE671_B2W7q7q8XE"
import requests
import json, os
import urllib.request
from shapely.geometry import Point, Polygon
from matplotlib import pyplot as plt
import shapely
import pickle
import random
import numpy as np
import pandas as pd
from PIL import Image
from tqdm import tqdm
# output d... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.express as px
import missingno as msno
from plotly.subplots import make_subplots
import plotly.graph_objects as go
import warnings
warnings.fi... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
# # HR Analytics: Job Change of Data Scientists
# 
# ## 1. Moduls to Use
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.simplefilter(action="ignore", category=Futur... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
import os, sys, shutil, random
root_address = "/kaggle/input/diabetic-retinopathy-224x224-gaussian-filtered"
import imagehash
import numpy as np
import pandas as pd
import seaborn as sns
import tensorflow as tf
import matplotlib.pyplot as plt
from PIL import Image
from sklearn.model_selection import train_test_split
... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
# # Extreme Fine Tuning of LGBM using Incremental training
# In my efforts to push leaderboard i stumbled across a small trick to improve predictions in 4th to 5th decimal using same parameters and a single model, essentially it is a trick to improve prediction of your best parameter, squeezing more out of them!!. Tric... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.