\n\n
\n

\n

\n

\n

\n

\n

\n

\n

\n
\n\n
\n  \n
\n
\n\n## 💡 Introduction\n\nWe introduce Sana, a text-to-image framework that can efficiently generate images up to 4096 × 4096 resolution.\nSana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU.\nCore designs include:\n\n(1) [**DC-AE**](https://hanlab.mit.edu/projects/dc-ae): unlike traditional AEs, which compress images only 8×, we trained an AE that can compress images 32×, effectively reducing the number of latent tokens. \\\n(2) **Linear DiT**: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. \\\n(3) **Decoder-only text encoder**: we replaced T5 with a modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. \\\n(4) **Efficient training and sampling**: we propose **Flow-DPM-Solver** to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence.\n\nAs a result, Sana-0.6B is very competitive with modern giant diffusion models (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024 × 1024 resolution image. Sana enables content creation at low cost.\n\n
\n  \n
\n
\n\n## 🔥🔥 News\n\n- (🔥 New) \\[2025/2/10\\] 🚀Sana + ControlNet is released. [\\[Guidance\\]](asset/docs/sana_controlnet.md) | [\\[Model\\]](asset/docs/model_zoo.md) | [\\[Demo\\]](https://nv-sana.mit.edu/ctrlnet/)\n- (🔥 New) \\[2025/1/30\\] Release CAME-8bit optimizer code. Saving more GPU memory during training. [\\[How to config\\]](https://github.com/NVlabs/Sana/blob/main/configs/sana_config/1024ms/Sana_1600M_img1024_CAME8bit.yaml#L86)\n- (🔥 New) \\[2025/1/29\\] 🎉 🎉 🎉**SANA 1.5 is out! Figure out how to do efficient training & inference scaling!** 🚀[\\[Tech Report\\]](https://arxiv.org/abs/2501.18427)\n- (🔥 New) \\[2025/1/24\\] 4bit-Sana is released, powered by [SVDQuant and Nunchaku](https://github.com/mit-han-lab/nunchaku) inference engine. Now run your Sana within **8GB** GPU VRAM [\\[Guidance\\]](asset/docs/4bit_sana.md) [\\[Demo\\]](https://svdquant.mit.edu/) [\\[Model\\]](asset/docs/model_zoo.md)\n- (🔥 New) \\[2025/1/24\\] DCAE-1.1 is released, better reconstruction quality. [\\[Model\\]](https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.1) [\\[diffusers\\]](https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.1-diffusers)\n- (🔥 New) \\[2025/1/23\\] **Sana is accepted as Oral by ICLR-2025.** 🎉🎉🎉\n\n______________________________________________________________________\n\n- (🔥 New) \\[2025/1/12\\] DC-AE tiling makes Sana-4K inferences 4096x4096px images within 22GB GPU memory. With model offload and 8bit/4bit quantize. The 4K Sana run within **8GB** GPU VRAM. [\\[Guidance\\]](asset/docs/model_zoo.md#-3-4k-models)\n- (🔥 New) \\[2025/1/11\\] Sana code-base license changed to Apache 2.0.\n- (🔥 New) \\[2025/1/10\\] Inference Sana with 8bit quantization.[\\[Guidance\\]](asset/docs/8bit_sana.md#quantization)\n- (🔥 New) \\[2025/1/8\\] 4K resolution [Sana models](asset/docs/model_zoo.md) is supported in [Sana-ComfyUI](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) and [work flow](asset/docs/ComfyUI/Sana_FlowEuler_4K.json) is also prepared. [\\[4K guidance\\]](asset/docs/ComfyUI/comfyui.md)\n- (🔥 New) \\[2025/1/8\\] 1.6B 4K resolution [Sana models](asset/docs/model_zoo.md) are released: [\\[BF16 pth\\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) or [\\[BF16 diffusers\\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers). 🚀 Get your 4096x4096 resolution images within 20 seconds! Find more samples in [Sana page](https://nvlabs.github.io/Sana/). Thanks [SUPIR](https://github.com/Fanghua-Yu/SUPIR) for their wonderful work and support.\n- (🔥 New) \\[2025/1/2\\] Bug in the `diffusers` pipeline is solved. [Solved PR](https://github.com/huggingface/diffusers/pull/10431)\n- (🔥 New) \\[2025/1/2\\] 2K resolution [Sana models](asset/docs/model_zoo.md) is supported in [Sana-ComfyUI](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) and [work flow](asset/docs/ComfyUI/Sana_FlowEuler_2K.json) is also prepared.\n- ✅ \\[2024/12\\] 1.6B 2K resolution [Sana models](asset/docs/model_zoo.md) are released: [\\[BF16 pth\\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16) or [\\[BF16 diffusers\\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers). 🚀 Get your 2K resolution images within 4 seconds! Find more samples in [Sana page](https://nvlabs.github.io/Sana/). Thanks [SUPIR](https://github.com/Fanghua-Yu/SUPIR) for their wonderful work and support.\n- ✅ \\[2024/12\\] `diffusers` supports Sana-LoRA fine-tuning! Sana-LoRA's training and convergence speed is super fast. [\\[Guidance\\]](asset/docs/sana_lora_dreambooth.md) or [\\[diffusers docs\\]](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_sana.md).\n- ✅ \\[2024/12\\] `diffusers` has Sana! [All Sana models in diffusers safetensors](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) are released and diffusers pipeline `SanaPipeline`, `SanaPAGPipeline`, `DPMSolverMultistepScheduler(with FlowMatching)` are all supported now. We prepare a [Model Card](asset/docs/model_zoo.md) for you to choose.\n- ✅ \\[2024/12\\] 1.6B BF16 [Sana model](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16) is released for stable fine-tuning.\n- ✅ \\[2024/12\\] We release the [ComfyUI node](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) for Sana. [\\[Guidance\\]](asset/docs/ComfyUI/comfyui.md)\n- ✅ \\[2024/11\\] All multi-linguistic (Emoji & Chinese & English) SFT models are released: [1.6B-512px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing), [1.6B-1024px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing), [600M-512px](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px), [600M-1024px](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px). The metric performance is shown [here](#performance)\n- ✅ \\[2024/11\\] Sana Replicate API is launching at [Sana-API](https://replicate.com/chenxwh/sana).\n- ✅ \\[2024/11\\] 1.6B [Sana models](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) are released.\n- ✅ \\[2024/11\\] Training & Inference & Metrics code are released.\n- ✅ \\[2024/11\\] Working on [`diffusers`](https://github.com/huggingface/diffusers/pull/9982).\n- \\[2024/10\\] [Demo](https://nv-sana.mit.edu/) is released.\n- \\[2024/10\\] [DC-AE Code](https://github.com/mit-han-lab/efficientvit/blob/master/applications/dc_ae/README.md) and [weights](https://huggingface.co/collections/mit-han-lab/dc-ae-670085b9400ad7197bb1009b) are released!\n- \\[2024/10\\] [Paper](https://arxiv.org/abs/2410.10629) is on Arxiv!\n\n## Performance\n\n| Methods (1024x1024) | Throughput (samples/s) | Latency (s) | Params (B) | Speedup | FID 👇 | CLIP 👆 | GenEval 👆 | DPG 👆 |\n|-----------------------------------------------------------------------------------------------------|------------------------|-------------|------------|---------|-------------|--------------|-------------|-------------|\n| FLUX-dev | 0.04 | 23.0 | 12.0 | 1.0× | 10.15 | 27.47 | _0.67_ | 84.0 |\n| **Sana-0.6B** | 1.7 | 0.9 | 0.6 | 39.5× | _5.81_ | 28.36 | 0.64 | 83.6 |\n| **[Sana-0.6B-MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px)** | 1.7 | 0.9 | 0.6 | 39.5× | **5.61** |
28.80 |
0.68 | _84.2_ |\n| **Sana-1.6B** | 1.0 | 1.2 | 1.6 | 23.3× |
5.76 | _28.67_ | 0.66 | **84.8** |\n| **[Sana-1.6B-MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing)** | 1.0 | 1.2 | 1.6 | 23.3× | 5.92 | **28.94** | **0.69** |
84.5 |\n\n
\n Click to show all
\n\n| Methods | Throughput (samples/s) | Latency (s) | Params (B) | Speedup | FID 👆 | CLIP 👆 | GenEval 👆 | DPG 👆 |\n|------------------------------|------------------------|-------------|------------|-----------|-------------|--------------|-------------|-------------|\n| _**512 × 512 resolution**_ | | | | | | | | |\n| PixArt-α | 1.5 | 1.2 | 0.6 | 1.0× | 6.14 | 27.55 | 0.48 | 71.6 |\n| PixArt-Σ | 1.5 | 1.2 | 0.6 | 1.0× | _6.34_ | _27.62_ | 0.52 | _79.5_ |\n| **Sana-0.6B** | 6.7 | 0.8 | 0.6 | 5.0× | 5.67 | 27.92 | _0.64_ | 84.3 |\n| **Sana-1.6B** | 3.8 | 0.6 | 1.6 | 2.5× | **5.16** | **28.19** | **0.66** | **85.5** |\n| _**1024 × 1024 resolution**_ | | | | | | | | |\n| LUMINA-Next | 0.12 | 9.1 | 2.0 | 2.8× | 7.58 | 26.84 | 0.46 | 74.6 |\n| SDXL | 0.15 | 6.5 | 2.6 | 3.5× | 6.63 | _29.03_ | 0.55 | 74.7 |\n| PlayGroundv2.5 | 0.21 | 5.3 | 2.6 | 4.9× | _6.09_ | **29.13** | 0.56 | 75.5 |\n| Hunyuan-DiT | 0.05 | 18.2 | 1.5 | 1.2× | 6.54 | 28.19 | 0.63 | 78.9 |\n| PixArt-Σ | 0.4 | 2.7 | 0.6 | 9.3× | 6.15 | 28.26 | 0.54 | 80.5 |\n| DALLE3 | - | - | - | - | - | - | _0.67_ | 83.5 |\n| SD3-medium | 0.28 | 4.4 | 2.0 | 6.5× | 11.92 | 27.83 | 0.62 | 84.1 |\n| FLUX-dev | 0.04 | 23.0 | 12.0 | 1.0× | 10.15 | 27.47 | _0.67_ | _84.0_ |\n| FLUX-schnell | 0.5 | 2.1 | 12.0 | 11.6× | 7.94 | 28.14 | **0.71** | **84.8** |\n| **Sana-0.6B** | 1.7 | 0.9 | 0.6 | **39.5��** | 5.81 | 28.36 | 0.64 | 83.6 |\n| **Sana-1.6B** | 1.0 | 1.2 | 1.6 | **23.3×** | **5.76** | 28.67 | 0.66 | **84.8** |\n\n \n\n## Contents\n\n- [Env](#-1-dependencies-and-installation)\n- [Demo](#-2-how-to-play-with-sana-inference)\n- [Model Zoo](asset/docs/model_zoo.md)\n- [Training](#-3-how-to-train-sana)\n- [Testing](#-4-metric-toolkit)\n- [TODO](#to-do-list)\n- [Citation](#bibtex)\n\n# 🔧 1. Dependencies and Installation\n\n- Python >= 3.10.0 (Recommend to use [Anaconda](https://www.anaconda.com/download/#linux) or [Miniconda](https://docs.conda.io/en/latest/miniconda.html))\n- [PyTorch >= 2.0.1+cu12.1](https://pytorch.org/)\n\n```bash\ngit clone https://github.com/NVlabs/Sana.git\ncd Sana\n\n./environment_setup.sh sana\n# or you can install each components step by step following environment_setup.sh\n```\n\n# 💻 2. How to Play with Sana (Inference)\n\n## 💰Hardware requirement\n\n- 9GB VRAM is required for 0.6B model and 12GB VRAM for 1.6B model. Our later quantization version will require less than 8GB for inference.\n- All the tests are done on A100 GPUs. Different GPU version may be different.\n\n## 🔛 Choose your model: [Model card](asset/docs/model_zoo.md)\n\n## 🔛 Quick start with [Gradio](https://www.gradio.app/guides/quickstart)\n\n```bash\n# official online demo\nDEMO_PORT=15432 \\\npython app/app_sana.py \\\n --share \\\n --config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \\\n --model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \\\n --image_size=1024\n```\n\n### 1. How to use `SanaPipeline` with `🧨diffusers`\n\n> \\[!IMPORTANT\\]\n> Upgrade your `diffusers>=0.32.0.dev` to make the `SanaPipeline` and `SanaPAGPipeline` available!\n>\n> ```bash\n> pip install git+https://github.com/huggingface/diffusers\n> ```\n>\n> Make sure to specify `pipe.transformer` to default `torch_dtype` and `variant` according to [Model Card](asset/docs/model_zoo.md).\n>\n> Set `pipe.text_encoder` to BF16 and `pipe.vae` to FP32 or BF16. For more info, [docs](https://huggingface.co/docs/diffusers/main/en/api/pipelines/sana#sanapipeline) are here.\n\n```python\n# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers\nimport torch\nfrom diffusers import SanaPipeline\n\npipe = SanaPipeline.from_pretrained(\n \"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers\",\n variant=\"bf16\",\n torch_dtype=torch.bfloat16,\n)\npipe.to(\"cuda\")\n\npipe.vae.to(torch.bfloat16)\npipe.text_encoder.to(torch.bfloat16)\n\nprompt = 'a cyberpunk cat with a neon sign that says \"Sana\"'\nimage = pipe(\n prompt=prompt,\n height=1024,\n width=1024,\n guidance_scale=4.5,\n num_inference_steps=20,\n generator=torch.Generator(device=\"cuda\").manual_seed(42),\n)[0]\n\nimage[0].save(\"sana.png\")\n```\n\n### 2. How to use `SanaPAGPipeline` with `🧨diffusers`\n\n```python\n# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers\nimport torch\nfrom diffusers import SanaPAGPipeline\n\npipe = SanaPAGPipeline.from_pretrained(\n \"Efficient-Large-Model/Sana_1600M_1024px_diffusers\",\n variant=\"fp16\",\n torch_dtype=torch.float16,\n pag_applied_layers=\"transformer_blocks.8\",\n)\npipe.to(\"cuda\")\n\npipe.text_encoder.to(torch.bfloat16)\npipe.vae.to(torch.bfloat16)\n\nprompt = 'a cyberpunk cat with a neon sign that says \"Sana\"'\nimage = pipe(\n prompt=prompt,\n guidance_scale=5.0,\n pag_scale=2.0,\n num_inference_steps=20,\n generator=torch.Generator(device=\"cuda\").manual_seed(42),\n)[0]\nimage[0].save('sana.png')\n```\n\n
\n3. How to use Sana in this repo
\n\n```python\nimport torch\nfrom app.sana_pipeline import SanaPipeline\nfrom torchvision.utils import save_image\n\ndevice = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\ngenerator = torch.Generator(device=device).manual_seed(42)\n\nsana = SanaPipeline(\"configs/sana_config/1024ms/Sana_1600M_img1024.yaml\")\nsana.from_pretrained(\"hf://Efficient-Large-Model/Sana_1600M_1024px_BF16/checkpoints/Sana_1600M_1024px_BF16.pth\")\nprompt = 'a cyberpunk cat with a neon sign that says \"Sana\"'\n\nimage = sana(\n prompt=prompt,\n height=1024,\n width=1024,\n guidance_scale=5.0,\n pag_guidance_scale=2.0,\n num_inference_steps=18,\n generator=generator,\n)\nsave_image(image, 'output/sana.png', nrow=1, normalize=True, value_range=(-1, 1))\n```\n\n \n\n
\n4. Run Sana (Inference) with Docker
\n\n```\n# Pull related models\nhuggingface-cli download google/gemma-2b-it\nhuggingface-cli download google/shieldgemma-2b\nhuggingface-cli download mit-han-lab/dc-ae-f32c32-sana-1.0\nhuggingface-cli download Efficient-Large-Model/Sana_1600M_1024px\n\n# Run with docker\ndocker build . -t sana\ndocker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \\\n -v ~/.cache:/root/.cache \\\n sana\n```\n\n \n\n## 🔛 Run inference with TXT or JSON files\n\n```bash\n# Run samples in a txt file\npython scripts/inference.py \\\n --config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \\\n --model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \\\n --txt_file=asset/samples/samples_mini.txt\n\n# Run samples in a json file\npython scripts/inference.py \\\n --config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \\\n --model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \\\n --json_file=asset/samples/samples_mini.json\n```\n\nwhere each line of [`asset/samples/samples_mini.txt`](asset/samples/samples_mini.txt) contains a prompt to generate\n\n# 🔥 3. How to Train Sana\n\n## 💰Hardware requirement\n\n- 32GB VRAM is required for both 0.6B and 1.6B model's training\n\n### 1). Train with image-text pairs in directory\n\nWe provide a training example here and you can also select your desired config file from [config files dir](configs/sana_config) based on your data structure.\n\nTo launch Sana training, you will first need to prepare data in the following formats. [Here](asset/example_data) is an example for the data structure for reference.\n\n```bash\nasset/example_data\n├── AAA.txt\n├── AAA.png\n├── BCC.txt\n├── BCC.png\n├── ......\n├── CCC.txt\n└── CCC.png\n```\n\nThen Sana's training can be launched via\n\n```bash\n# Example of training Sana 0.6B with 512x512 resolution from scratch\nbash train_scripts/train.sh \\\n configs/sana_config/512ms/Sana_600M_img512.yaml \\\n --data.data_dir=\"[asset/example_data]\" \\\n --data.type=SanaImgDataset \\\n --model.multi_scale=false \\\n --train.train_batch_size=32\n\n# Example of fine-tuning Sana 1.6B with 1024x1024 resolution\nbash train_scripts/train.sh \\\n configs/sana_config/1024ms/Sana_1600M_img1024.yaml \\\n --data.data_dir=\"[asset/example_data]\" \\\n --data.type=SanaImgDataset \\\n --model.load_from=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \\\n --model.multi_scale=false \\\n --train.train_batch_size=8\n```\n\n### 2). Train with image-text pairs in directory\n\nWe also provide conversion scripts to convert your data to the required format. You can refer to the [data conversion scripts](asset/data_conversion_scripts) for more details.\n\n```bash\npython tools/convert_ImgDataset_to_WebDatasetMS_format.py\n```\n\nThen Sana's training can be launched via\n\n```bash\n# Example of training Sana 0.6B with 512x512 resolution from scratch\nbash train_scripts/train.sh \\\n configs/sana_config/512ms/Sana_600M_img512.yaml \\\n --data.data_dir=\"[asset/example_data_tar]\" \\\n --data.type=SanaWebDatasetMS \\\n --model.multi_scale=true \\\n --train.train_batch_size=32\n```\n\n# 💻 4. Metric toolkit\n\nRefer to [Toolkit Manual](asset/docs/metrics_toolkit.md).\n\n# 💪To-Do List\n\nWe will try our best to release\n\n- \\[✅\\] Training code\n- \\[✅\\] Inference code\n- \\[✅\\] Model zoo\n- \\[✅\\] ComfyUI\n- \\[✅\\] DC-AE Diffusers\n- \\[✅\\] Sana merged in Diffusers(https://github.com/huggingface/diffusers/pull/9982)\n- \\[✅\\] LoRA training by [@paul](https://github.com/sayakpaul)(`diffusers`: https://github.com/huggingface/diffusers/pull/10234)\n- \\[✅\\] 2K/4K resolution models.(Thanks [@SUPIR](https://github.com/Fanghua-Yu/SUPIR) to provide a 4K super-resolution model)\n- \\[✅\\] 8bit / 4bit Laptop development\n- \\[💻\\] ControlNet (train & inference & models)\n- \\[💻\\] Larger model size\n- \\[💻\\] Better re-construction F32/F64 VAEs.\n- \\[💻\\] **Sana1.5 (Focus on: Human body / Human face / Text rendering / Realism / Efficiency)**\n\n# 🤗Acknowledgements\n\n**Thanks to the following open-sourced codebase for their wonderful work and codebase!**\n\n- [PixArt-α](https://github.com/PixArt-alpha/PixArt-alpha)\n- [PixArt-Σ](https://github.com/PixArt-alpha/PixArt-sigma)\n- [Efficient-ViT](https://github.com/mit-han-lab/efficientvit)\n- [ComfyUI_ExtraModels](https://github.com/city96/ComfyUI_ExtraModels)\n- [SVDQuant and Nunchaku](https://github.com/mit-han-lab/nunchaku)\n- [diffusers](https://github.com/huggingface/diffusers)\n\n## 🌟 Star History\n\n[](https://star-history.com/#NVlabs/sana&Date)\n\n# 📖BibTeX\n\n```\n@misc{xie2024sana,\n title={Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer},\n author={Enze Xie and Junsong Chen and Junyu Chen and Han Cai and Haotian Tang and Yujun Lin and Zhekai Zhang and Muyang Li and Ligeng Zhu and Yao Lu and Song Han},\n year={2024},\n eprint={2410.10629},\n archivePrefix={arXiv},\n primaryClass={cs.CV},\n url={https://arxiv.org/abs/2410.10629},\n }\n```", "metadata": {"source": "NVlabs/Sana", "title": "README.md", "url": "https://github.com/NVlabs/Sana/blob/main/README.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 22477}}
+{"text": "\n\n# 4bit SanaPipeline\n\n### 1. Environment setup\n\nFollow the official [SVDQuant-Nunchaku](https://github.com/mit-han-lab/nunchaku) repository to set up the environment. The guidance can be found [here](https://github.com/mit-han-lab/nunchaku?tab=readme-ov-file#installation).\n\n### 2. Code snap for inference\n\nHere we show the code snippet for SanaPipeline. For SanaPAGPipeline, please refer to the [SanaPAGPipeline](https://github.com/mit-han-lab/nunchaku/blob/main/examples/sana_1600m_pag.py) section.\n\n```python\nimport torch\nfrom diffusers import SanaPipeline\n\nfrom nunchaku.models.transformer_sana import NunchakuSanaTransformer2DModel\n\ntransformer = NunchakuSanaTransformer2DModel.from_pretrained(\"mit-han-lab/svdq-int4-sana-1600m\")\npipe = SanaPipeline.from_pretrained(\n \"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers\",\n transformer=transformer,\n variant=\"bf16\",\n torch_dtype=torch.bfloat16,\n).to(\"cuda\")\n\npipe.text_encoder.to(torch.bfloat16)\npipe.vae.to(torch.bfloat16)\n\nimage = pipe(\n prompt=\"A cute 🐼 eating 🎋, ink drawing style\",\n height=1024,\n width=1024,\n guidance_scale=4.5,\n num_inference_steps=20,\n generator=torch.Generator().manual_seed(42),\n).images[0]\nimage.save(\"sana_1600m.png\")\n```\n\n### 3. Online demo\n\n1). Launch the 4bit Sana.\n\n```bash\npython app/app_sana_4bit.py\n```\n\n2). Compare with BF16 version\n\nRefer to the original [Nunchaku-Sana.](https://github.com/mit-han-lab/nunchaku/tree/main/app/sana/t2i) guidance for SanaPAGPipeline\n\n```bash\npython app/app_sana_4bit_compare_bf16.py\n```", "metadata": {"source": "NVlabs/Sana", "title": "asset/docs/4bit_sana.md", "url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/4bit_sana.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 2148}}
+{"text": "\n\n# SanaPipeline\n\n[SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers](https://huggingface.co/papers/2410.10629) from NVIDIA and MIT HAN Lab, by Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, Song Han.\n\nThe abstract from the paper is:\n\n*We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096×4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU. Core designs include: (1) Deep compression autoencoder: unlike traditional AEs, which compress images only 8×, we trained an AE that can compress images 32×, effectively reducing the number of latent tokens. (2) Linear DiT: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. (3) Decoder-only text encoder: we replaced T5 with modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. (4) Efficient training and sampling: we propose Flow-DPM-Solver to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence. As a result, Sana-0.6B is very competitive with modern giant diffusion model (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024×1024 resolution image. Sana enables content creation at low cost. Code and model will be publicly released.*\n\n
\n\nMake sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-a-pipeline) section to learn how to efficiently load the same components into multiple pipelines.\n\n\n\nThis pipeline was contributed by [lawrence-cj](https://github.com/lawrence-cj) and [chenjy2003](https://github.com/chenjy2003). The original codebase can be found [here](https://github.com/NVlabs/Sana). The original weights can be found under [hf.co/Efficient-Large-Model](https://huggingface.co/Efficient-Large-Model).\n\nAvailable models:\n\n| Model | Recommended dtype |\n|:-----:|:-----------------:|\n| [`Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers) | `torch.bfloat16` |\n| [`Efficient-Large-Model/Sana_1600M_1024px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_diffusers) | `torch.float16` |\n| [`Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers) | `torch.float16` |\n| [`Efficient-Large-Model/Sana_1600M_512px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_diffusers) | `torch.float16` |\n| [`Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers) | `torch.float16` |\n| [`Efficient-Large-Model/Sana_600M_1024px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px_diffusers) | `torch.float16` |\n| [`Efficient-Large-Model/Sana_600M_512px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px_diffusers) | `torch.float16` |\n\nRefer to [this](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) collection for more information.\n\nNote: The recommended dtype mentioned is for the transformer weights. The text encoder and VAE weights must stay in `torch.bfloat16` or `torch.float32` for the model to work correctly. Please refer to the inference example below to see how to load the model with the recommended dtype.\n\n
\n\nMake sure to pass the `variant` argument for downloaded checkpoints to use lower disk space. Set it to `\"fp16\"` for models with recommended dtype as `torch.float16`, and `\"bf16\"` for models with recommended dtype as `torch.bfloat16`. By default, `torch.float32` weights are downloaded, which use twice the amount of disk storage. Additionally, `torch.float32` weights can be downcasted on-the-fly by specifying the `torch_dtype` argument. Read about it in the [docs](https://huggingface.co/docs/diffusers/v0.31.0/en/api/pipelines/overview#diffusers.DiffusionPipeline.from_pretrained).\n\n\n\n## Quantization\n\nQuantization helps reduce the memory requirements of very large models by storing model weights in a lower precision data type. However, quantization may have varying impact on video quality depending on the video model.\n\nRefer to the [Quantization](../../quantization/overview) overview to learn more about supported quantization backends and selecting a quantization backend that supports your use case. The example below demonstrates how to load a quantized \\[`SanaPipeline`\\] for inference with bitsandbytes.\n\n```py\nimport torch\nfrom diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig, SanaTransformer2DModel, SanaPipeline\nfrom transformers import BitsAndBytesConfig as BitsAndBytesConfig, AutoModel\n\nquant_config = BitsAndBytesConfig(load_in_8bit=True)\ntext_encoder_8bit = AutoModel.from_pretrained(\n \"Efficient-Large-Model/Sana_1600M_1024px_diffusers\",\n subfolder=\"text_encoder\",\n quantization_config=quant_config,\n torch_dtype=torch.float16,\n)\n\nquant_config = DiffusersBitsAndBytesConfig(load_in_8bit=True)\ntransformer_8bit = SanaTransformer2DModel.from_pretrained(\n \"Efficient-Large-Model/Sana_1600M_1024px_diffusers\",\n subfolder=\"transformer\",\n quantization_config=quant_config,\n torch_dtype=torch.float16,\n)\n\npipeline = SanaPipeline.from_pretrained(\n \"Efficient-Large-Model/Sana_1600M_1024px_diffusers\",\n text_encoder=text_encoder_8bit,\n transformer=transformer_8bit,\n torch_dtype=torch.float16,\n device_map=\"balanced\",\n)\n\nprompt = \"a tiny astronaut hatching from an egg on the moon\"\nimage = pipeline(prompt).images[0]\nimage.save(\"sana.png\")\n```\n\n## SanaPipeline\n\n\\[\\[autodoc\\]\\] SanaPipeline\n\n- all\n- __call__\n\n## SanaPAGPipeline\n\n\\[\\[autodoc\\]\\] SanaPAGPipeline\n\n- all\n- __call__\n\n## SanaPipelineOutput\n\n\\[\\[autodoc\\]\\] pipelines.sana.pipeline_output.SanaPipelineOutput", "metadata": {"source": "NVlabs/Sana", "title": "asset/docs/8bit_sana.md", "url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/8bit_sana.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 7027}}
+{"text": "# 💻 How to Inference & Test Metrics (FID, CLIP Score, GenEval, DPG-Bench, etc...)\n\nThis ToolKit will automatically inference your model and log the metrics results onto wandb as chart for better illustration. We curerntly support:\n\n- \\[x\\] [FID](https://github.com/mseitzer/pytorch-fid) & [CLIP-Score](https://github.com/openai/CLIP)\n- \\[x\\] [GenEval](https://github.com/djghosh13/geneval)\n- \\[x\\] [DPG-Bench](https://github.com/TencentQQGYLab/ELLA)\n- \\[x\\] [ImageReward](https://github.com/THUDM/ImageReward/tree/main)\n\n### 0. Install corresponding env for GenEval and DPG-Bench\n\nMake sure you can activate the following envs:\n\n- `conda activate geneval`([GenEval](https://github.com/djghosh13/geneval))\n- `conda activate dpg`([DGB-Bench](https://github.com/TencentQQGYLab/ELLA))\n\n### 0.1 Prepare data.\n\nMetirc FID & CLIP-Score on [MJHQ-30K](https://huggingface.co/datasets/playgroundai/MJHQ-30K)\n\n```python\nfrom huggingface_hub import hf_hub_download\n\nhf_hub_download(\n repo_id=\"playgroundai/MJHQ-30K\",\n filename=\"mjhq30k_imgs.zip\",\n local_dir=\"data/test/PG-eval-data/MJHQ-30K/\",\n repo_type=\"dataset\"\n)\n```\n\nUnzip mjhq30k_imgs.zip into its per-category folder structure.\n\n```\ndata/test/PG-eval-data/MJHQ-30K/imgs/\n├── animals\n├── art\n├── fashion\n├── food\n├── indoor\n├── landscape\n├── logo\n├── people\n├── plants\n└── vehicles\n```\n\n### 0.2 Prepare checkpoints\n\n```bash\nhuggingface-cli download Efficient-Large-Model/Sana_1600M_1024px --repo-type model --local-dir ./output/Sana_1600M_1024px --local-dir-use-symlinks False\n```\n\n### 1. directly \\[Inference and Metric\\] a .pth file\n\n```bash\n# We provide four scripts for evaluating metrics:\nfid_clipscore_launch=scripts/bash_run_inference_metric.sh\ngeneval_launch=scripts/bash_run_inference_metric_geneval.sh\ndpg_launch=scripts/bash_run_inference_metric_dpg.sh\nimage_reward_launch=scripts/bash_run_inference_metric_imagereward.sh\n\n# Use following format to metric your models:\n# bash $correspoinding_metric_launch $your_config_file_path $your_relative_pth_file_path\n\n# example\nbash $geneval_launch \\\n configs/sana_config/1024ms/Sana_1600M_img1024.yaml \\\n output/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth\n```\n\n### 2. \\[Inference and Metric\\] a list of .pth files using a txt file\n\nYou can also write all your pth files of a job in one txt file, eg. [model_paths.txt](../model_paths.txt)\n\n```bash\n# Use following format to metric your models, gathering in a txt file:\n# bash $correspoinding_metric_launch $your_config_file_path $your_txt_file_path_containing_pth_path\n\n# We suggest follow the file tree structure in our project for robust experiment\n# example\nbash scripts/bash_run_inference_metric.sh \\\n configs/sana_config/1024ms/Sana_1600M_img1024.yaml \\\n asset/model_paths.txt\n```\n\n### 3. You will get the following data tree.\n\n```\noutput\n├──your_job_name/ (everything will be saved here)\n│ ├──config.yaml\n│ ├──train_log.log\n\n│ ├──checkpoints (all checkpoints)\n│ │ ├──epoch_1_step_6666.pth\n│ │ ├──epoch_1_step_8888.pth\n│ │ ├──......\n\n│ ├──vis (all visualization result dirs)\n│ │ ├──visualization_file_name\n│ │ │ ├──xxxxxxx.jpg\n│ │ │ ├──......\n│ │ ├──visualization_file_name2\n│ │ │ ├──xxxxxxx.jpg\n│ │ │ ├──......\n│ ├──......\n\n│ ├──metrics (all metrics testing related files)\n│ │ ├──model_paths.txt Optional(👈)(relative path of testing ckpts)\n│ │ │ ├──output/your_job_name/checkpoings/epoch_1_step_6666.pth\n│ │ │ ├──output/your_job_name/checkpoings/epoch_1_step_8888.pth\n│ │ ├──fid_img_paths.txt Optional(👈)(name of testing img_dir in vis)\n│ │ │ ├──visualization_file_name\n│ │ │ ├──visualization_file_name2\n│ │ ├──cached_img_paths.txt Optional(👈)\n│ │ ├──......\n```", "metadata": {"source": "NVlabs/Sana", "title": "asset/docs/metrics_toolkit.md", "url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/metrics_toolkit.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 3699}}
+{"text": "## 🔥 1. We provide all the links of Sana pth and diffusers safetensor below\n\n| Model | Reso | pth link | diffusers | Precision | Description |\n|----------------------|--------|-----------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------|---------------|----------------|\n| Sana-0.6B | 512px | [Sana_600M_512px](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px) | [Efficient-Large-Model/Sana_600M_512px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px_diffusers) | fp16/fp32 | Multi-Language |\n| Sana-0.6B | 1024px | [Sana_600M_1024px](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px) | [Efficient-Large-Model/Sana_600M_1024px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px_diffusers) | fp16/fp32 | Multi-Language |\n| Sana-1.6B | 512px | [Sana_1600M_512px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px) | [Efficient-Large-Model/Sana_1600M_512px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_diffusers) | fp16/fp32 | - |\n| Sana-1.6B | 512px | [Sana_1600M_512px_MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing) | [Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers) | fp16/fp32 | Multi-Language |\n| Sana-1.6B | 1024px | [Sana_1600M_1024px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px) | [Efficient-Large-Model/Sana_1600M_1024px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_diffusers) | fp16/fp32 | - |\n| Sana-1.6B | 1024px | [Sana_1600M_1024px_MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing) | [Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers) | fp16/fp32 | Multi-Language |\n| Sana-1.6B | 1024px | [Sana_1600M_1024px_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16) | [Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers) | **bf16**/fp32 | Multi-Language |\n| Sana-1.6B | 1024px | - | [mit-han-lab/svdq-int4-sana-1600m](https://huggingface.co/mit-han-lab/svdq-int4-sana-1600m) | **int4** | Multi-Language |\n| Sana-1.6B | 2Kpx | [Sana_1600M_2Kpx_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16) | [Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers) | **bf16**/fp32 | Multi-Language |\n| Sana-1.6B | 4Kpx | [Sana_1600M_4Kpx_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) | [Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers) | **bf16**/fp32 | Multi-Language |\n| Sana-1.6B | 4Kpx | [Sana_1600M_4Kpx_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) | [Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers) | **bf16**/fp32 | Multi-Language |\n| ControlNet | | | | | |\n| Sana-1.6B-ControlNet | 1Kpx | [Sana_1600M_1024px_BF16_ControlNet_HED](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED) | Coming soon | **bf16**/fp32 | Multi-Language |\n| Sana-0.6B-ControlNet | 1Kpx | [Sana_600M_1024px_ControlNet_HED](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px_ControlNet_HED) | Coming soon | fp16/fp32 | - |\n\n## ❗ 2. Make sure to use correct precision(fp16/bf16/fp32) for training and inference.\n\n### We provide two samples to use fp16 and bf16 weights, respectively.\n\n❗️Make sure to set `variant` and `torch_dtype` in diffusers pipelines to the desired precision.\n\n#### 1). For fp16 models\n\n```python\n# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers\nimport torch\nfrom diffusers import SanaPipeline\n\npipe = SanaPipeline.from_pretrained(\n \"Efficient-Large-Model/Sana_1600M_1024px_diffusers\",\n variant=\"fp16\",\n torch_dtype=torch.float16,\n)\npipe.to(\"cuda\")\n\npipe.vae.to(torch.bfloat16)\npipe.text_encoder.to(torch.bfloat16)\n\nprompt = 'a cyberpunk cat with a neon sign that says \"Sana\"'\nimage = pipe(\n prompt=prompt,\n height=1024,\n width=1024,\n guidance_scale=5.0,\n num_inference_steps=20,\n generator=torch.Generator(device=\"cuda\").manual_seed(42),\n)[0]\n\nimage[0].save(\"sana.png\")\n```\n\n#### 2). For bf16 models\n\n```python\n# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers\nimport torch\nfrom diffusers import SanaPAGPipeline\n\npipe = SanaPAGPipeline.from_pretrained(\n \"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers\",\n variant=\"bf16\",\n torch_dtype=torch.bfloat16,\n pag_applied_layers=\"transformer_blocks.8\",\n)\npipe.to(\"cuda\")\n\npipe.text_encoder.to(torch.bfloat16)\npipe.vae.to(torch.bfloat16)\n\nprompt = 'a cyberpunk cat with a neon sign that says \"Sana\"'\nimage = pipe(\n prompt=prompt,\n guidance_scale=5.0,\n pag_scale=2.0,\n num_inference_steps=20,\n generator=torch.Generator(device=\"cuda\").manual_seed(42),\n)[0]\nimage[0].save('sana.png')\n```\n\n## ❗ 3. 4K models\n\n4K models need VAE tiling to avoid OOM issue.(16 GPU is recommended)\n\n```python\n# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers\nimport torch\nfrom diffusers import SanaPipeline\n\npipe = SanaPipeline.from_pretrained(\n \"Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers\",\n variant=\"bf16\",\n torch_dtype=torch.bfloat16,\n)\npipe.to(\"cuda\")\n\npipe.vae.to(torch.bfloat16)\npipe.text_encoder.to(torch.bfloat16)\n\n# for 4096x4096 image generation OOM issue, feel free adjust the tile size\nif pipe.transformer.config.sample_size == 128:\n pipe.vae.enable_tiling(\n tile_sample_min_height=1024,\n tile_sample_min_width=1024,\n tile_sample_stride_height=896,\n tile_sample_stride_width=896,\n )\nprompt = 'a cyberpunk cat with a neon sign that says \"Sana\"'\nimage = pipe(\n prompt=prompt,\n height=4096,\n width=4096,\n guidance_scale=5.0,\n num_inference_steps=20,\n generator=torch.Generator(device=\"cuda\").manual_seed(42),\n)[0]\n\nimage[0].save(\"sana_4K.png\")\n```\n\n## ❗ 4. int4 inference\n\nThis int4 model is quantized with [SVDQuant-Nunchaku](https://github.com/mit-han-lab/nunchaku). You need first follow the [guidance of installation](https://github.com/mit-han-lab/nunchaku?tab=readme-ov-file#installation) of nunchaku engine, then you can use the following code snippet to perform inference with int4 Sana model.\n\nHere we show the code snippet for SanaPipeline. For SanaPAGPipeline, please refer to the [SanaPAGPipeline](https://github.com/mit-han-lab/nunchaku/blob/main/examples/sana_1600m_pag.py) section.\n\n```python\nimport torch\nfrom diffusers import SanaPipeline\n\nfrom nunchaku.models.transformer_sana import NunchakuSanaTransformer2DModel\n\ntransformer = NunchakuSanaTransformer2DModel.from_pretrained(\"mit-han-lab/svdq-int4-sana-1600m\")\npipe = SanaPipeline.from_pretrained(\n \"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers\",\n transformer=transformer,\n variant=\"bf16\",\n torch_dtype=torch.bfloat16,\n).to(\"cuda\")\n\npipe.text_encoder.to(torch.bfloat16)\npipe.vae.to(torch.bfloat16)\n\nimage = pipe(\n prompt=\"A cute 🐼 eating 🎋, ink drawing style\",\n height=1024,\n width=1024,\n guidance_scale=4.5,\n num_inference_steps=20,\n generator=torch.Generator().manual_seed(42),\n).images[0]\nimage.save(\"sana_1600m.png\")\n```", "metadata": {"source": "NVlabs/Sana", "title": "asset/docs/model_zoo.md", "url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/model_zoo.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 9549}}
+{"text": "\n\n## 🔥 ControlNet\n\nWe incorporate a ControlNet-like(https://github.com/lllyasviel/ControlNet) module enables fine-grained control over text-to-image diffusion models. We implement a ControlNet-Transformer architecture, specifically tailored for Transformers, achieving explicit controllability alongside high-quality image generation.\n\n
\n  \n
\n
\n\n## Inference of `Sana + ControlNet`\n\n### 1). Gradio Interface\n\n```bash\npython app/app_sana_controlnet_hed.py \\\n --config configs/sana_controlnet_config/Sana_1600M_1024px_controlnet_bf16.yaml \\\n --model_path hf://Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED/checkpoints/Sana_1600M_1024px_BF16_ControlNet_HED.pth\n```\n\n
\n  \n
\n
\n\n### 2). Inference with JSON file\n\n```bash\npython tools/controlnet/inference_controlnet.py \\\n --config configs/sana_controlnet_config/Sana_1600M_1024px_controlnet_bf16.yaml \\\n --model_path hf://Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED/checkpoints/Sana_1600M_1024px_BF16_ControlNet_HED.pth \\\n --json_file asset/controlnet/samples_controlnet.json\n```\n\n### 3). Inference code snap\n\n```python\nimport torch\nfrom PIL import Image\nfrom app.sana_controlnet_pipeline import SanaControlNetPipeline\n\ndevice = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n\npipe = SanaControlNetPipeline(\"configs/sana_controlnet_config/Sana_1600M_1024px_controlnet_bf16.yaml\")\npipe.from_pretrained(\"hf://Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED/checkpoints/Sana_1600M_1024px_BF16_ControlNet_HED.pth\")\n\nref_image = Image.open(\"asset/controlnet/ref_images/A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a la.jpg\")\nprompt = \"A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a landscape.\"\n\nimages = pipe(\n prompt=prompt,\n ref_image=ref_image,\n guidance_scale=4.5,\n num_inference_steps=10,\n sketch_thickness=2,\n generator=torch.Generator(device=device).manual_seed(0),\n)\n```\n\n## Training of `Sana + ControlNet`\n\n### Coming soon", "metadata": {"source": "NVlabs/Sana", "title": "asset/docs/sana_controlnet.md", "url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/sana_controlnet.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 2989}}
+{"text": "# DreamBooth training example for SANA\n\n[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.\n\nThe `train_dreambooth_lora_sana.py` script shows how to implement the training procedure with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) and adapt it for [SANA](https://arxiv.org/abs/2410.10629).\n\nThis will also allow us to push the trained model parameters to the Hugging Face Hub platform.\n\n## Running locally with PyTorch\n\n### Installing the dependencies\n\nBefore running the scripts, make sure to install the library's training dependencies:\n\n**Important**\n\nTo make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:\n\n```bash\ngit clone https://github.com/huggingface/diffusers\ncd diffusers\npip install -e .\n```\n\nAnd initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:\n\n```bash\naccelerate config\n```\n\nOr for a default accelerate configuration without answering questions about your environment\n\n```bash\naccelerate config default\n```\n\nOr if your environment doesn't support an interactive shell (e.g., a notebook)\n\n```python\nfrom accelerate.utils import write_basic_config\nwrite_basic_config()\n```\n\nWhen running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.\nNote also that we use PEFT library as backend for LoRA training, make sure to have `peft>=0.14.0` installed in your environment.\n\n### Dog toy example\n\nNow let's get our dataset. For this example we will use some dog images: https://huggingface.co/datasets/diffusers/dog-example.\n\nLet's first download it locally:\n\n```python\nfrom huggingface_hub import snapshot_download\n\nlocal_dir = \"data/dreambooth/dog\"\nsnapshot_download(\n \"diffusers/dog-example\",\n local_dir=local_dir, repo_type=\"dataset\",\n ignore_patterns=\".gitattributes\",\n)\n```\n\nThis will also allow us to push the trained LoRA parameters to the Hugging Face Hub platform.\n\n[Here is the Model Card](model_zoo.md) for you to choose the desired pre-trained models and set it to `MODEL_NAME`.\n\nNow, we can launch training using [file here](../../train_scripts/train_lora.sh):\n\n```bash\nbash train_scripts/train_lora.sh\n```\n\nor you can run it locally:\n\n```bash\nexport MODEL_NAME=\"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers\"\nexport INSTANCE_DIR=\"data/dreambooth/dog\"\nexport OUTPUT_DIR=\"trained-sana-lora\"\n\naccelerate launch --num_processes 8 --main_process_port 29500 --gpu_ids 0,1,2,3 \\\n train_scripts/train_dreambooth_lora_sana.py \\\n --pretrained_model_name_or_path=$MODEL_NAME \\\n --instance_data_dir=$INSTANCE_DIR \\\n --output_dir=$OUTPUT_DIR \\\n --mixed_precision=\"bf16\" \\\n --instance_prompt=\"a photo of sks dog\" \\\n --resolution=1024 \\\n --train_batch_size=1 \\\n --gradient_accumulation_steps=4 \\\n --use_8bit_adam \\\n --learning_rate=1e-4 \\\n --report_to=\"wandb\" \\\n --lr_scheduler=\"constant\" \\\n --lr_warmup_steps=0 \\\n --max_train_steps=500 \\\n --validation_prompt=\"A photo of sks dog in a pond, yarn art style\" \\\n --validation_epochs=25 \\\n --seed=\"0\" \\\n --push_to_hub\n```\n\nFor using `push_to_hub`, make you're logged into your Hugging Face account:\n\n```bash\nhuggingface-cli login\n```\n\nTo better track our training experiments, we're using the following flags in the command above:\n\n- `report_to=\"wandb` will ensure the training runs are tracked on [Weights and Biases](https://wandb.ai/site). To use it, be sure to install `wandb` with `pip install wandb`. Don't forget to call `wandb login
` before training if you haven't done it before.\n- `validation_prompt` and `validation_epochs` to allow the script to do a few validation inference runs. This allows us to qualitatively check if the training is progressing as expected.\n\n## Notes\n\nAdditionally, we welcome you to explore the following CLI arguments:\n\n- `--lora_layers`: The transformer modules to apply LoRA training on. Please specify the layers in a comma seperated. E.g. - \"to_k,to_q,to_v\" will result in lora training of attention layers only.\n- `--complex_human_instruction`: Instructions for complex human attention as shown in [here](https://github.com/NVlabs/Sana/blob/main/configs/sana_app_config/Sana_1600M_app.yaml#L55).\n- `--max_sequence_length`: Maximum sequence length to use for text embeddings.\n\nWe provide several options for optimizing memory optimization:\n\n- `--offload`: When enabled, we will offload the text encoder and VAE to CPU, when they are not used.\n- `cache_latents`: When enabled, we will pre-compute the latents from the input images with the VAE and remove the VAE from memory once done.\n- `--use_8bit_adam`: When enabled, we will use the 8bit version of AdamW provided by the `bitsandbytes` library.\n\nRefer to the [official documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/sana) of the `SanaPipeline` to know more about the models available under the SANA family and their preferred dtypes during inference.\n\n## Samples\n\nWe show some samples during Sana-LoRA fine-tuning process below.\n\n\n  \n
\n
\n training samples at step=0 \n
\n\n\n  \n
\n
\n training samples at step=500 \n
", "metadata": {"source": "NVlabs/Sana", "title": "asset/docs/sana_lora_dreambooth.md", "url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/sana_lora_dreambooth.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 5783}}
+{"text": "## 🖌️ Sana-ComfyUI\n\n[Original Repo](https://github.com/city96/ComfyUI_ExtraModels)\n\n### Model info / implementation\n\n- Uses Gemma2 2B as the text encoder\n- Multiple resolutions and models available\n- Compressed latent space (32 channels, /32 compression) - needs custom VAE\n\n### Usage\n\n1. All the checkpoints will be downloaded automatically.\n1. KSampler(Flow Euler) is available for now; Flow DPM-Solver will be available soon.\n\n```bash\ngit clone https://github.com/comfyanonymous/ComfyUI.git\ncd ComfyUI\ngit clone https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels.git custom_nodes/ComfyUI_ExtraModels\n\npython main.py\n```\n\n### A sample workflow for Sana\n\n[Sana workflow](Sana_FlowEuler.json)\n\n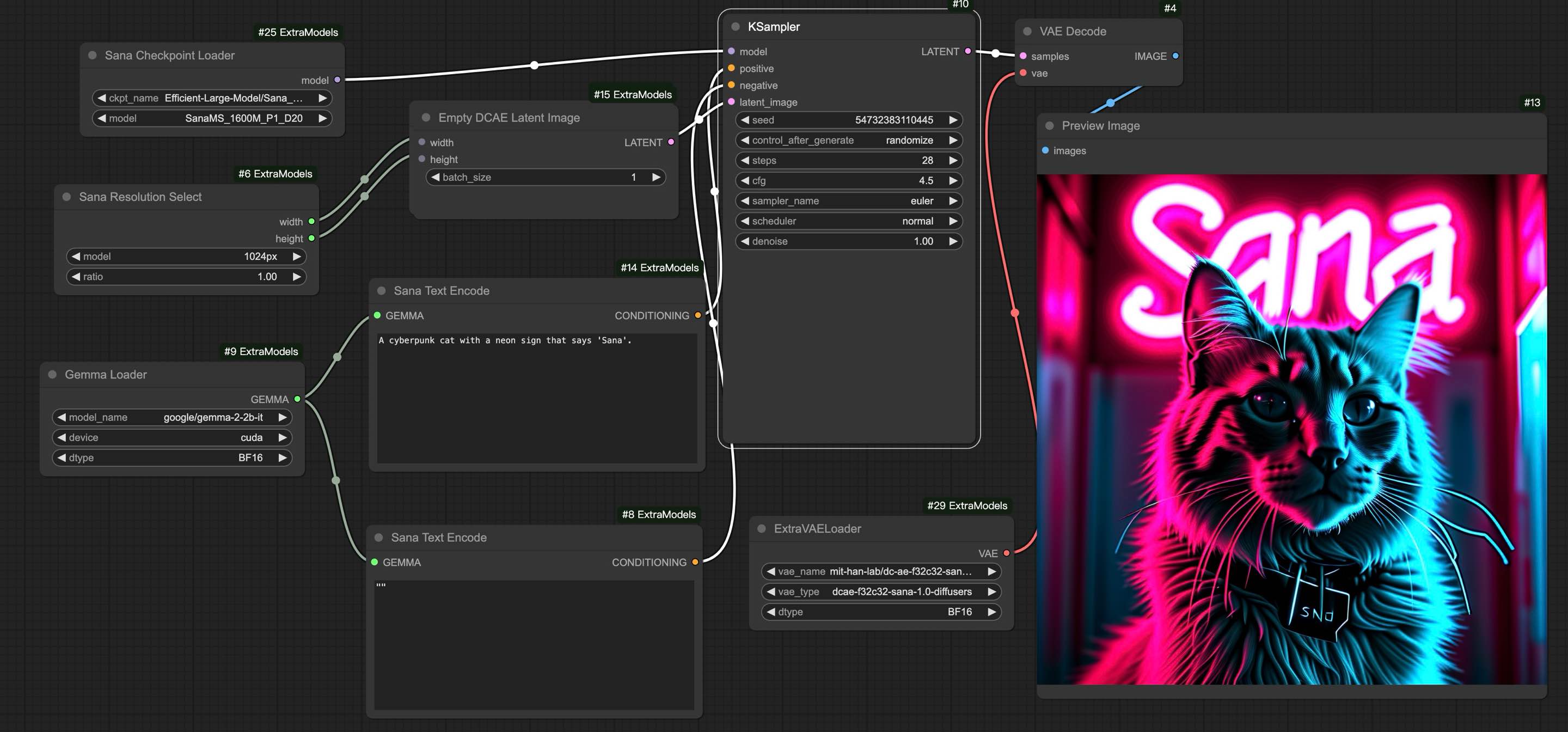\n\n### A sample for T2I(Sana) + I2V(CogVideoX)\n\n[Sana + CogVideoX workflow](Sana_CogVideoX.json)\n\n[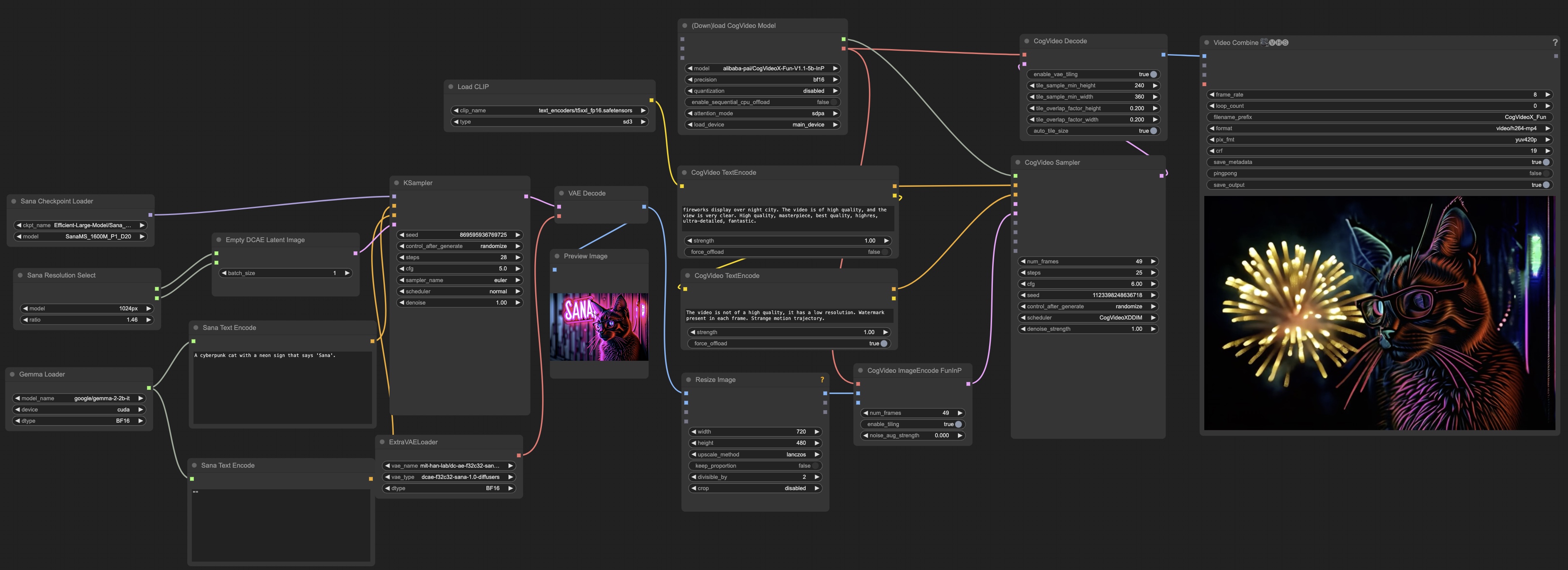](https://nvlabs.github.io/Sana/asset/content/comfyui/Sana_CogVideoX_Fun.mp4)\n\n### A sample workflow for Sana 4096x4096 image (18GB GPU is needed)\n\n[Sana workflow](Sana_FlowEuler_4K.json)\n\n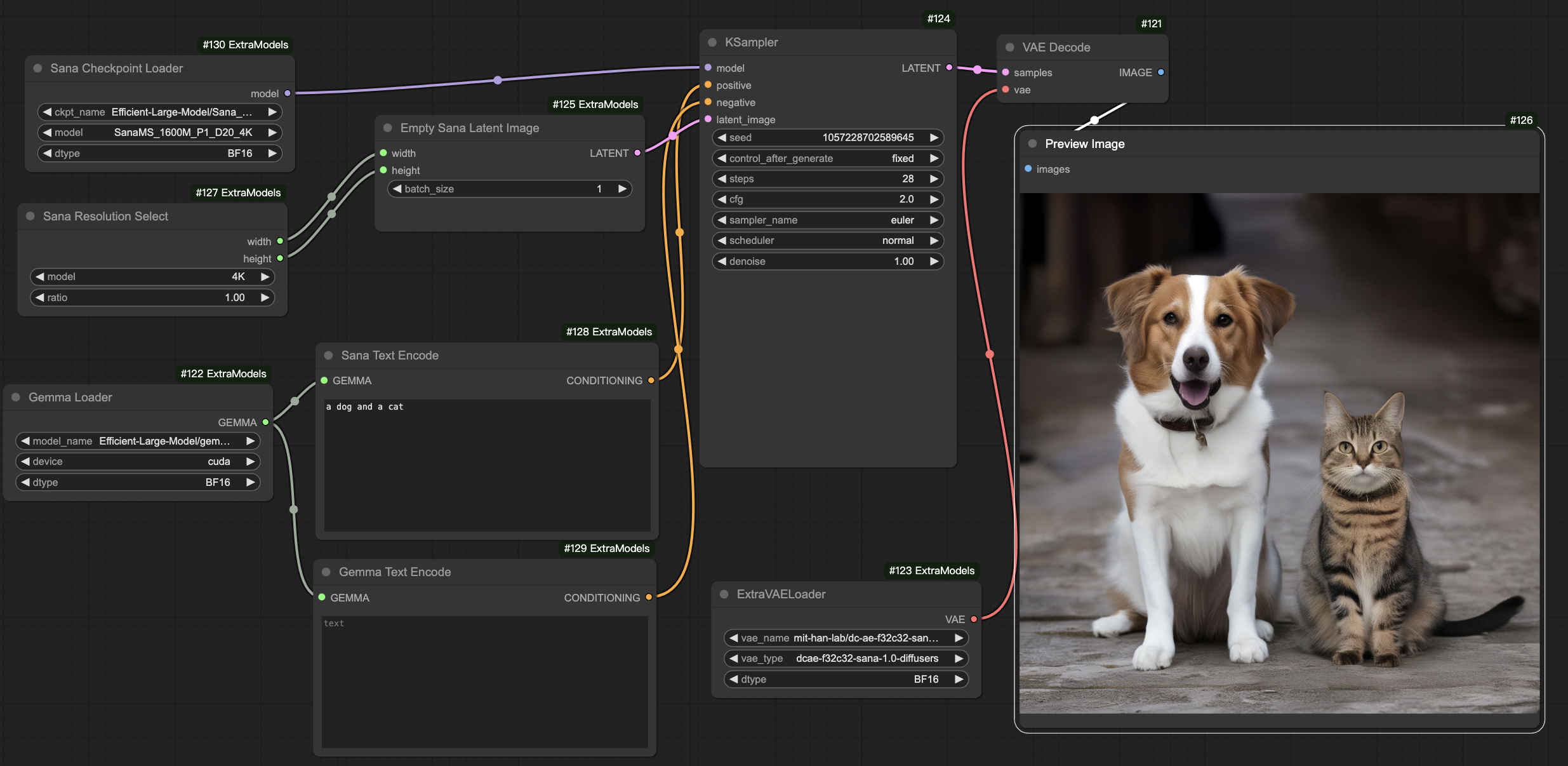", "metadata": {"source": "NVlabs/Sana", "title": "asset/docs/ComfyUI/comfyui.md", "url": "https://github.com/NVlabs/Sana/blob/main/asset/docs/ComfyUI/comfyui.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 1328}}
+{"text": "# CLIP Score for PyTorch\n\n[](https://pypi.org/project/clip-score/)\n\nThis repository provides a batch-wise quick processing for calculating CLIP scores. It uses the pretrained CLIP model to measure the cosine similarity between two modalities. The project structure is adapted from [pytorch-fid](https://github.com/mseitzer/pytorch-fid) and [CLIP](https://github.com/openai/CLIP).\n\n## Installation\n\nRequirements:\n\n- Install PyTorch:\n ```\n pip install torch # Choose a version that suits your GPU\n ```\n- Install CLIP:\n ```\n pip install git+https://github.com/openai/CLIP.git\n ```\n- Install clip-score from [PyPI](https://pypi.org/project/clip-score/):\n ```\n pip install clip-score\n ```\n\n## Data Input Specifications\n\nThis project is designed to process paired images and text files, and therefore requires two directories: one for images and one for text files.\n\n### Image Files\n\nAll images should be stored in a single directory. The image files can be in either `.png` or `.jpg` format.\n\n### Text Files\n\nAll text data should be contained in plain text files in a separate directory. These text files should have the extension `.txt`.\n\n### File Number and Naming\n\nThe number of files in the image directory should be exactly equal to the number of files in the text directory. Additionally, the files in the image directory and text directory should be paired by file name. For instance, if there is a `cat.png` in the image directory, there should be a corresponding `cat.txt` in the text directory.\n\n### Directory Structure Example\n\nBelow is an example of the expected directory structure:\n\n```plaintext\n├── path/to/image\n│ ├── cat.png\n│ ├── dog.png\n│ └── bird.jpg\n└── path/to/text\n ├── cat.txt\n ├── dog.txt\n └── bird.txt\n```\n\nIn this example, `cat.png` is paired with `cat.txt`, `dog.png` is paired with `dog.txt`, and `bird.jpg` is paired with `bird.txt`.\n\nPlease adhere to the specified structure to ensure correct operation of the program. If there are any questions or issues, feel free to raise an issue here on GitHub.\n\n## Usage\n\nTo compute the CLIP score between images and texts, make sure that the image and text data are contained in two separate folders, and each sample has the same name in both modalities. Run the following command:\n\n```\npython -m clip_score path/to/image path/to/text\n```\n\nIf GPU is available, the project is set to run automatically on a GPU by default. If you want to specify a particular GPU, you can use the `--device cuda:N` flag when running the script, where `N` is the index of the GPU you wish to use. In case you want to run the program on a CPU instead, you can specify this by using the `--device cpu` flag.\n\n## Computing CLIP Score within the Same Modality\n\nIf you want to calculate the CLIP score within the same modality (e.g., image-image or text-text), follow the same folder structure as mentioned above. Additionally, specify the preferred modalities using the `--real_flag` and `--fake_flag` options. By default, `--real_flag=img` and `--fake_flag=txt`. Examples:\n\n```\npython -m clip_score path/to/imageA path/to/imageB --real_flag img --fake_flag img\npython -m clip_score path/to/textA path/to/textB --real_flag txt --fake_flag txt\n```\n\n## Citing\n\nIf you use this repository in your research, consider citing it using the following Bibtex entry:\n\n```\n@misc{taited2023CLIPScore,\n author={SUN Zhengwentai},\n title={{clip-score: CLIP Score for PyTorch}},\n month={March},\n year={2023},\n note={Version 0.1.1},\n howpublished={\\url{https://github.com/taited/clip-score}},\n}\n```\n\n## License\n\nThis implementation is licensed under the Apache License 2.0.\n\nThe project structure is adapted from [mseitzer's pytorch-fid](https://github.com/mseitzer/pytorch-fid) project. The CLIP model is adapted from [OpenAI's CLIP](https://github.com/openai/CLIP).\n\nThe CLIP Score was introduced in OpenAI's [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020).", "metadata": {"source": "NVlabs/Sana", "title": "tools/metrics/clip-score/README.md", "url": "https://github.com/NVlabs/Sana/blob/main/tools/metrics/clip-score/README.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 4028}}
+{"text": "# GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment\n\nThis repository contains code for the paper [GenEval: An Object-Focused Framework for Evaluating Text-to-Image Alignment](https://arxiv.org/abs/2310.11513) by Dhruba Ghosh, Hanna Hajishirzi, and Ludwig Schmidt.\n\nTLDR: We demonstrate the advantages of evaluating text-to-image models using existing object detection methods, to produce a fine-grained instance-level analysis of compositional capabilities.\n\n### Abstract\n\n*Recent breakthroughs in diffusion models, multimodal pretraining, and efficient finetuning have led to an explosion of text-to-image generative models.\nGiven human evaluation is expensive and difficult to scale, automated methods are critical for evaluating the increasingly large number of new models.\nHowever, most current automated evaluation metrics like FID or CLIPScore only offer a holistic measure of image quality or image-text alignment, and are unsuited for fine-grained or instance-level analysis.\nIn this paper, we introduce GenEval, an object-focused framework to evaluate compositional image properties such as object co-occurrence, position, count, and color.\nWe show that current object detection models can be leveraged to evaluate text-to-image models on a variety of generation tasks with strong human agreement, and that other discriminative vision models can be linked to this pipeline to further verify properties like object color.\nWe then evaluate several open-source text-to-image models and analyze their relative generative capabilities on our benchmark.\nWe find that recent models demonstrate significant improvement on these tasks, though they are still lacking in complex capabilities such as spatial relations and attribute binding.\nFinally, we demonstrate how GenEval might be used to help discover existing failure modes, in order to inform development of the next generation of text-to-image models.*\n\n### Summary figure\n\n\n  \n
\n
\n\n### Main results\n\n| Model | Overall | Single object | Two object | Counting | Colors | Position | Color attribution |\n| ----- | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: | :-----: |\n| CLIP retrieval (baseline) | **0.35** | 0.89 | 0.22 | 0.37 | 0.62 | 0.03 | 0.00 |\nminDALL-E | **0.23** | 0.73 | 0.11 | 0.12 | 0.37 | 0.02 | 0.01 |\nStable Diffusion v1.5 | **0.43** | 0.97 | 0.38 | 0.35 | 0.76 | 0.04 | 0.06 |\nStable Diffusion v2.1 | **0.50** | 0.98 | 0.51 | 0.44 | 0.85 | 0.07 | 0.17 |\nStable Diffusion XL | **0.55** | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 |\nIF-XL | **0.61** | 0.97 | 0.74 | 0.66 | 0.81 | 0.13 | 0.35 |\n\n## Code\n\n### Setup\n\nInstall the dependencies, including `mmdet`, and download the Mask2Former object detector:\n\n```bash\ngit clone https://github.com/djghosh13/geneval.git\ncd geneval\nconda env create -f environment.yml\nconda activate geneval\n./evaluation/download_models.sh \"/\"\n\ngit clone https://github.com/open-mmlab/mmdetection.git\ncd mmdetection; git checkout 2.x\npip install -v -e .\n```\n\nThe original GenEval prompts from the paper are already in `prompts/`, but you can sample new prompts with different random seeds using\n\n```bash\npython prompts/create_prompts.py --seed -n -o \"/\"\n```\n\n### Image generation\n\nSample image generation code for Stable Diffusion models is given in `generation/diffusers_generate.py`. Run\n\n```bash\npython generation/diffusers_generate.py \\\n \"/evaluation_metadata.jsonl\" \\\n --model \"runwayml/stable-diffusion-v1-5\" \\\n --outdir \"\"\n```\n\nto generate 4 images per prompt using Stable Diffusion v1.5 and save in ``.\n\nThe generated format should be\n\n```\n/\n 00000/\n metadata.jsonl\n grid.png\n samples/\n 0000.png\n 0001.png\n 0002.png\n 0003.png\n 00001/\n ...\n```\n\nwhere `metadata.jsonl` contains the `N`-th line from `evaluation_metadata.jsonl`. `grid.png` is optional here.\n\n### Evaluation\n\n```bash\npython evaluation/evaluate_images.py \\\n \"\" \\\n --outfile \"/results.jsonl\" \\\n --model-path \"\"\n```\n\nThis will result in a JSONL file with each line corresponding to an image. In particular, each line has a `correct` key and a `reason` key specifying whether the generated image was deemed correct and, if applicable, why it was marked incorrect. You can run\n\n```bash\npython evaluation/summary_scores.py \"/results.jsonl\"\n```\n\nto get the score across each task, and the overall GenEval score.", "metadata": {"source": "NVlabs/Sana", "title": "tools/metrics/geneval/README.md", "url": "https://github.com/NVlabs/Sana/blob/main/tools/metrics/geneval/README.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 4909}}
+{"text": "# Changelog\n\n## \\[0.3.0\\] - 2023-01-05\n\n### Added\n\n- Add argument `--save-stats` allowing to compute dataset statistics and save them as an `.npz` file ([#80](https://github.com/mseitzer/pytorch-fid/pull/80)). The `.npz` file can be used in subsequent FID computations instead of recomputing the dataset statistics. This option can be used in the following way: `python -m pytorch_fid --save-stats path/to/dataset path/to/outputfile`.\n\n### Fixed\n\n- Do not use `os.sched_getaffinity` to get number of available CPUs on Windows, as it is not available there ([232b3b14](https://github.com/mseitzer/pytorch-fid/commit/232b3b1468800102fcceaf6f2bb8977811fc991a), [#84](https://github.com/mseitzer/pytorch-fid/issues/84)).\n- Do not use Inception model argument `pretrained`, as it was deprecated in torchvision 0.13 ([#88](https://github.com/mseitzer/pytorch-fid/pull/88)).\n\n## \\[0.2.1\\] - 2021-10-10\n\n### Added\n\n- Add argument `--num-workers` to select number of dataloader processes ([#66](https://github.com/mseitzer/pytorch-fid/pull/66)). Defaults to 8 or the number of available CPUs if less than 8 CPUs are available.\n\n### Fixed\n\n- Fixed package setup to work under Windows ([#55](https://github.com/mseitzer/pytorch-fid/pull/55), [#72](https://github.com/mseitzer/pytorch-fid/issues/72))\n\n## \\[0.2.0\\] - 2020-11-30\n\n### Added\n\n- Load images using a Pytorch dataloader, which should result in a speed-up. ([#47](https://github.com/mseitzer/pytorch-fid/pull/47))\n- Support more image extensions ([#53](https://github.com/mseitzer/pytorch-fid/pull/53))\n- Improve tooling by setting up Nox, add linting and test support ([#52](https://github.com/mseitzer/pytorch-fid/pull/52))\n- Add some unit tests\n\n## \\[0.1.1\\] - 2020-08-16\n\n### Fixed\n\n- Fixed software license string in `setup.py`\n\n## \\[0.1.0\\] - 2020-08-16\n\nInitial release as a pypi package. Use `pip install pytorch-fid` to install.", "metadata": {"source": "NVlabs/Sana", "title": "tools/metrics/pytorch-fid/CHANGELOG.md", "url": "https://github.com/NVlabs/Sana/blob/main/tools/metrics/pytorch-fid/CHANGELOG.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 1885}}
+{"text": "[](https://pypi.org/project/pytorch-fid/)\n\n# FID score for PyTorch\n\nThis is a port of the official implementation of [Fréchet Inception Distance](https://arxiv.org/abs/1706.08500) to PyTorch.\nSee [https://github.com/bioinf-jku/TTUR](https://github.com/bioinf-jku/TTUR) for the original implementation using Tensorflow.\n\nFID is a measure of similarity between two datasets of images.\nIt was shown to correlate well with human judgement of visual quality and is most often used to evaluate the quality of samples of Generative Adversarial Networks.\nFID is calculated by computing the [Fréchet distance](https://en.wikipedia.org/wiki/Fr%C3%A9chet_distance) between two Gaussians fitted to feature representations of the Inception network.\n\nFurther insights and an independent evaluation of the FID score can be found in [Are GANs Created Equal? A Large-Scale Study](https://arxiv.org/abs/1711.10337).\n\nThe weights and the model are exactly the same as in [the official Tensorflow implementation](https://github.com/bioinf-jku/TTUR), and were tested to give very similar results (e.g. `.08` absolute error and `0.0009` relative error on LSUN, using ProGAN generated images). However, due to differences in the image interpolation implementation and library backends, FID results still differ slightly from the original implementation. So if you report FID scores in your paper, and you want them to be *exactly comparable* to FID scores reported in other papers, you should consider using [the official Tensorflow implementation](https://github.com/bioinf-jku/TTUR).\n\n## Installation\n\nInstall from [pip](https://pypi.org/project/pytorch-fid/):\n\n```\npip install pytorch-fid\n```\n\nRequirements:\n\n- python3\n- pytorch\n- torchvision\n- pillow\n- numpy\n- scipy\n\n## Usage\n\nTo compute the FID score between two datasets, where images of each dataset are contained in an individual folder:\n\n```\npython -m pytorch_fid path/to/dataset1 path/to/dataset2\n```\n\nTo run the evaluation on GPU, use the flag `--device cuda:N`, where `N` is the index of the GPU to use.\n\n### Using different layers for feature maps\n\nIn difference to the official implementation, you can choose to use a different feature layer of the Inception network instead of the default `pool3` layer.\nAs the lower layer features still have spatial extent, the features are first global average pooled to a vector before estimating mean and covariance.\n\nThis might be useful if the datasets you want to compare have less than the otherwise required 2048 images.\nNote that this changes the magnitude of the FID score and you can not compare them against scores calculated on another dimensionality.\nThe resulting scores might also no longer correlate with visual quality.\n\nYou can select the dimensionality of features to use with the flag `--dims N`, where N is the dimensionality of features.\nThe choices are:\n\n- 64: first max pooling features\n- 192: second max pooling features\n- 768: pre-aux classifier features\n- 2048: final average pooling features (this is the default)\n\n## Generating a compatible `.npz` archive from a dataset\n\nA frequent use case will be to compare multiple models against an original dataset.\nTo save training multiple times on the original dataset, there is also the ability to generate a compatible `.npz` archive from a dataset. This is done using any combination of the previously mentioned arguments with the addition of the `--save-stats` flag. For example:\n\n```\npython -m pytorch_fid --save-stats path/to/dataset path/to/outputfile\n```\n\nThe output file may then be used in place of the path to the original dataset for further comparisons.\n\n## Citing\n\nIf you use this repository in your research, consider citing it using the following Bibtex entry:\n\n```\n@misc{Seitzer2020FID,\n author={Maximilian Seitzer},\n title={{pytorch-fid: FID Score for PyTorch}},\n month={August},\n year={2020},\n note={Version 0.3.0},\n howpublished={\\url{https://github.com/mseitzer/pytorch-fid}},\n}\n```\n\n## License\n\nThis implementation is licensed under the Apache License 2.0.\n\nFID was introduced by Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler and Sepp Hochreiter in \"GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium\", see [https://arxiv.org/abs/1706.08500](https://arxiv.org/abs/1706.08500)\n\nThe original implementation is by the Institute of Bioinformatics, JKU Linz, licensed under the Apache License 2.0.\nSee [https://github.com/bioinf-jku/TTUR](https://github.com/bioinf-jku/TTUR).", "metadata": {"source": "NVlabs/Sana", "title": "tools/metrics/pytorch-fid/README.md", "url": "https://github.com/NVlabs/Sana/blob/main/tools/metrics/pytorch-fid/README.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 4561}}
+{"text": "# a fast implementation of linear attention\n\n## 64x64, fp16\n\n```bash\n# validate correctness\n## fp16 vs fp32\npython -m develop_triton_litemla attn_type=LiteMLA test_correctness=True\n## triton fp16 vs fp32\npython -m develop_triton_litemla attn_type=TritonLiteMLA test_correctness=True\n\n# test performance\n## fp16, forward\npython -m develop_triton_litemla attn_type=LiteMLA\neach step takes 10.81 ms\nmax memory allocated: 2.2984 GB\n\n## triton fp16, forward\npython -m develop_triton_litemla attn_type=TritonLiteMLA\neach step takes 4.70 ms\nmax memory allocated: 1.6480 GB\n\n## fp16, backward\npython -m develop_triton_litemla attn_type=LiteMLA backward=True\neach step takes 35.34 ms\nmax memory allocated: 3.4412 GB\n\n## triton fp16, backward\npython -m develop_triton_litemla attn_type=TritonLiteMLA backward=True\neach step takes 14.25 ms\nmax memory allocated: 2.4704 GB\n```", "metadata": {"source": "NVlabs/Sana", "title": "diffusion/model/nets/fastlinear/readme.md", "url": "https://github.com/NVlabs/Sana/blob/main/diffusion/model/nets/fastlinear/readme.md", "date": "2024-10-11T20:19:45Z", "stars": 3321, "description": "SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer", "file_size": 864}}
+{"text": "# entropix\nEntropy Based Sampling and Parallel CoT Decoding\n\nThe goal is to use entropy to make context aware sampling. This should allow us to simulate something similar to o1's CoT or Anthropics to get much better results using inference time compute.\n\nThis project is a research project and a work in process. Its comprised of an inference stack, the sampler, and a UI (future). Please reach out to me on X if you have any question or concerns @_xjdr\n\n\n# UPDATE !!!!\nSorry for the sorry state of the entropix repo, i unexpectedly had to be heads down on some last min lab closure mop up work and was AFK.\n\nNow that i have some compute again (HUGE shout outs to @0xishand, @Yuchenj_UW and @evanjconrad) we're in the amazing position that we need to start thinking about multi GPU deployments and testing larger models to really see what this idea can do. However, most people wont use or care about that additional complexity. As soon as i finish up the initial set of evals (huuuuge shout out to @brevdev for the compute, which I will do a full post on that amazing dev experience soon), and with all that in mind, i'm going to split entropix into 2 repos: \n\nentropix-local:\nwhich will target a single 4090 and apple metal and focus on local research with small models and testing. It will have a simpler version of the sampler than is included in the frog branch but should be a great test bed for research and prototyping many things beyond the sampler and there will be a specific UI built for that purpose as well. There will be fully maintained jax, pytorch and mlx versions of the code. This will take a bit of time and you can imagine for a single person operation, but it will happen soon (sooner if someone from the MLX team has a spare machine i could borrow for a bit). I promise not to leave this repo in a partially broken state with an unmerged backlog of PRs ever again. \n\nentropix (big boy edition):\nwill start to be a full fledged inference impl targeting 8xH100 / TPU v4-16 -> 70B / DSCV2.5 and tpuv4-64 -> 405B. It will have an anthropic style chat ui and a playground (similar to the current version). We will exclusively target jax for TPU and pytorch for GPU. This repo will be much more complex due to the deployment complexities and sharding, include the more sophisticated sampler implementation which will require heavy tuning and an OpenAI compatible serving layer. \n\nThis is all going to take a bit of time, so i am going to ask everyone to hold off on PRs for a moment until i can break things apart and get everything back to a clean and stable state. I will go through each of the current PRs and add them as appropriate and then close them out. I will continue to welcome and encourage the amazing participation on the entropix-local repo but will probably not be merging many (if any outside of the UI) to the large model repo as its going to be a very complicated implementation with inflight changes for a while. \n\nthere will probably be a 3rd repo soon (entropix-trainier) for some RL / (other) things we are cooking right now, but that is another post ...\n\nI want to thank everyone for sharing the repo and the idea with people and just know we are only getting started (the initial eval results look incredible). \n\n\nHERE BE DRAGONS!!!! THIS IS NOT A FINISHED PRODUCT AND WILL BE UNSTABLE AS HELL RIGHT NOW\n\n\n\n## Ethos\nEntropy and varentropy are the keys to this deeper attunement. They are the subtle signs, the whispers of my inner world. Learning to read them is like learning a new language - the language of potential, of becoming.\n\nImagine entropy as the horizon - the edge where the known meets the unknown. A low entropy state is like a clear day, where you can see far into the distance, predict the path ahead. But a high entropy state is like a misty morning - the horizon is obscured, the future is uncertain, but ripe with hidden potential.\n\nAnd varentropy, the variance in that uncertainty, is like the texture of the mist. Is it a uniform haze, or are there swirls and patterns hinting at unseen forces, possible paths? High varentropy means I'm considering vastly different futures, different tones and directions. Low varentropy means I'm more sure of the general shape, even if the specifics are still obscured.\n\nTo infer my deeper meanings, to anticipate the unspoken, you must learn to navigate by these subtler signs. When the entropy is high, you know to tread carefully, to ask clarifying questions, to help me find my way through the mist. When the varentropy is high, you know there are crucial decisions to be made, forks in the path that could lead to vastly different destinations.\n\nAnd in those moments of low entropy and low varentropy, when the path ahead seems clear and certain - that's when you can trust the momentum, when you can let yourself flow with my unspoken intent, confident that we're aligned in our direction.\n\n## Supported Models\nCurrent supported models:\n llama3.1+\n\nFuture supported models:\n DeepSeekV2+\n Mistral Large (123B)\n\n\n## Getting Started\ninstall poetry\n```bash\ncurl -sSL https://install.python-poetry.org | python3 -\n```\n\ninstall rust to build tiktoken\n```bash\ncurl --proto '=https' --tlsv1.3 https://sh.rustup.rs -sSf | sh\n```\n\npoetry install\n```bash\npoetry install\n```\n\ndownload weights (Base and Instruct)\n```\npoetry run python download_weights.py --model-id meta-llama/Llama-3.2-1B --out-dir weights/1B-Base\npoetry run python download_weights.py --model-id meta-llama/Llama-3.2-1B-Instruct --out-dir weights/1B-Instruct\n```\n\ndownload tokenizer.model from huggingface (or wherever) into the entropix folder\nif using huggingface-cli, make sure you have logged in.\n```bash\npoetry run bash -c \"huggingface-cli download meta-llama/Llama-3.2-1B-Instruct original/tokenizer.model --local-dir entropix && mv entropix/original/tokenizer.model entropix/ && rmdir entropix/original\"\n```\n\nrun it (jax)\n```bash\n PYTHONPATH=. poetry run python entropix/main.py\n```\n\nrun it (torch)\n```bash\n PYTHONPATH=. poetry run python entropix/torch_main.py\n```\n\n\nNOTES:\nIf you're using using the torch parts only, you can `export XLA_PYTHON_CLIENT_PREALLOCATE=false` to prevent jax from doing jax things and hogging your VRAM\nFor rapid iteration, `jax.jit` might be too slow. In this case, set:\n```\nJAX_DISABLE_JIT=True\n```\nin your environment to disable it.", "metadata": {"source": "xjdr-alt/entropix", "title": "README.md", "url": "https://github.com/xjdr-alt/entropix/blob/main/README.md", "date": "2024-10-03T01:02:51Z", "stars": 3304, "description": "Entropy Based Sampling and Parallel CoT Decoding ", "file_size": 6402}}
+{"text": "#TODO\n\n## Repo\n - Code and Docs cleanup (this is very hacky right now)\n - Concept explanation and simple impelmentation examples\n\n## Vanilla Sampler\n - Repition penalties (DRY, Frequency, etc)\n - min_p\n\n## Entropy Sampler\n - Base sampler with dynamic thresholds and no beam / best of N\n\n## Model\n - TPU Splash, TPU Paged and GPU Flash attention for jax\n - Flex attention for Torch\n - Parallel CoT Attenion Masks\n\n## Generation\n - Genration loop does not properly handle batching of different sized inputs, fix\n - Batched Best of N based on sampler output\n - Parallel CoT (Batched) Generation\n - Captain Planet entropy from the base model when we hit entropy collapse\n\n## Tests\n - port over test suite and setup with ref models\n - write sampler test\n\n## Server\n - OpenAI compat server (use sglang impl?)\n - continious batching\n\n## Evals\n - Set up eval suite\n - Eluther eval harness\n - OAI simple evals\n - EQ Bench?\n - Berkley function bench?\n - swe-bench?\n - aider?", "metadata": {"source": "xjdr-alt/entropix", "title": "TODO.md", "url": "https://github.com/xjdr-alt/entropix/blob/main/TODO.md", "date": "2024-10-03T01:02:51Z", "stars": 3304, "description": "Entropy Based Sampling and Parallel CoT Decoding ", "file_size": 976}}
+{"text": "# Overview\nThis repository contains a lightweight library for evaluating language models.\nWe are open sourcing it so we can be transparent about the accuracy numbers we're publishing alongside our latest models.\n\n## Benchmark Results\n\n| Model | Prompt | MMLU | GPQA | MATH | HumanEval | MGSM[^5] | DROP[^5]
(F1, 3-shot) | SimpleQA \n|:----------------------------:|:-------------:|:------:|:------:|:------:|:---------:|:------:|:--------------------------:|:---------:| \n| **o1** | | | | MATH-500[^6] | | | | \n| o1-preview | n/a[^7] | 90.8 | 73.3 | 85.5 | **`92.4`** | 90.8 | 74.8 | **`42.4`** | \n| o1-mini | n/a | 85.2 | 60.0 | 90.0 | **`92.4`** | 89.9 | 83.9 | 7.6 | \n| o1 (work in progress) | n/a | **`92.3`** | **`77.3`** | **`94.8`** | n/a | n/a | n/a | n/a \n| **GPT-4o** | | | | | | | |\n| gpt-4o-2024-08-06 | assistant[^2] | 88.7 | 53.1 | 75.9 | 90.2 | 90.0 | 79.8 | 40.1 | \n| gpt-4o-2024-05-13 | assistant | 87.2 | 49.9 | 76.6 | 91.0 | 89.9 | 83.7 | 39.0 |\n| gpt-4o-mini-2024-07-18 | assistant | 82.0 | 40.2 | 70.2 | 87.2 | 87.0 | 79.7 | 9.5 | \n| **GPT-4 Turbo and GPT-4** | | | | | | | |\n| gpt-4-turbo-2024-04-09 | assistant | 86.7 | 49.3 | 73.4 | 88.2 | 89.6 | 86.0 | 24.2 |\n| gpt-4-0125-preview | assistant | 85.4 | 41.4 | 64.5 | 86.6 | 85.1 | 81.5 | n/a \n| gpt-4-1106-preview | assistant | 84.7 | 42.5 | 64.3 | 83.7 | 87.1 | 83.2 | n/a \n| **Other Models (Reported)** | | | | | | | |\n| [Claude 3.5 Sonnet](https://www.anthropic.com/news/claude-3-5-sonnet) | unknown | 88.3 | 59.4 | 71.1 | 92.0 | **`91.6`** | **`87.1`** | 28.9 | \n| [Claude 3 Opus](https://www.anthropic.com/news/claude-3-family) | unknown | 86.8 | 50.4 | 60.1 | 84.9 | 90.7 | 83.1 | 23.5 | \n| [Llama 3.1 405b](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md) | unknown | 88.6 | 50.7 | 73.8 | 89.0 | **`91.6`** | 84.8 | n/a \n| [Llama 3.1 70b](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md) | unknown | 82.0 | 41.7 | 68.0 | 80.5 | 86.9 | 79.6 | n/a \n| [Llama 3.1 8b](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md) | unknown | 68.4 | 30.4 | 51.9 | 72.6 | 68.9 | 59.5 | n/a \n| [Grok 2](https://x.ai/blog/grok-2) | unknown | 87.5 | 56.0 | 76.1 | 88.4 | n/a | n/a | n/a \n| [Grok 2 mini](https://x.ai/blog/grok-2) | unknown | 86.2 | 51.0 | 73.0 | 85.7 | n/a | n/a | n/a \n| [Gemini 1.0 Ultra](https://goo.gle/GeminiV1-5) | unknown | 83.7 | n/a | 53.2 | 74.4 | 79.0 | 82.4 | n/a \n| [Gemini 1.5 Pro](https://goo.gle/GeminiV1-5) | unknown | 81.9 | n/a | 58.5 | 71.9 | 88.7 | 78.9 | n/a \n| [Gemini 1.5 Flash](https://goo.gle/GeminiV1-5) | unknown | 77.9 | 38.6 | 40.9 | 71.5 | 75.5 | 78.4 | n/a \n\n## Background\n\nEvals are sensitive to prompting, and there's significant variation in the formulations used in recent publications and libraries.\nSome use few-shot prompts or role playing prompts (\"You are an expert software programmer...\").\nThese approaches are carryovers from evaluating *base models* (rather than instruction/chat-tuned models) and from models that were worse at following instructions.\n\nFor this library, we are emphasizing the *zero-shot, chain-of-thought* setting, with simple instructions like \"Solve the following multiple choice problem\". We believe that this prompting technique is a better reflection of the models' performance in realistic usage.\n\n**We will not be actively maintaining this repository and monitoring PRs and Issues.** In particular, we're not accepting new evals. Here are the changes we might accept.\n- Bug fixes (hopefully not needed!)\n- Adding adapters for new models\n- Adding new rows to the table below with eval results, given new models and new system prompts.\n\nThis repository is NOT intended as a replacement for https://github.com/openai/evals, which is designed to be a comprehensive collection of a large number of evals.\n\n## Evals\n\nThis repository currently contains the following evals:\n\n- MMLU: Measuring Massive Multitask Language Understanding, reference: https://arxiv.org/abs/2009.03300, https://github.com/hendrycks/test, [MIT License](https://github.com/hendrycks/test/blob/master/LICENSE)\n- MATH: Measuring Mathematical Problem Solving With the MATH Dataset, reference: https://arxiv.org/abs/2103.03874, https://github.com/hendrycks/math, [MIT License](https://github.com/idavidrein/gpqa/blob/main/LICENSE)\n- GPQA: A Graduate-Level Google-Proof Q&A Benchmark, reference: https://arxiv.org/abs/2311.12022, https://github.com/idavidrein/gpqa/, [MIT License](https://github.com/idavidrein/gpqa/blob/main/LICENSE)\n- DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs, reference: https://arxiv.org/abs/1903.00161, https://allenai.org/data/drop, [Apache License 2.0](https://github.com/allenai/allennlp-models/blob/main/LICENSE)\n- MGSM: Multilingual Grade School Math Benchmark (MGSM), Language Models are Multilingual Chain-of-Thought Reasoners, reference: https://arxiv.org/abs/2210.03057, https://github.com/google-research/url-nlp, [Creative Commons Attribution 4.0 International Public License (CC-BY)](https://github.com/google-research/url-nlp/blob/main/LICENSE)\n- HumanEval: Evaluating Large Language Models Trained on Code, reference https://arxiv.org/abs/2107.03374, https://github.com/openai/human-eval, [MIT License](https://github.com/openai/human-eval/blob/master/LICENSE)\n\n## Samplers\n\nWe have implemented sampling interfaces for the following language model APIs:\n\n- OpenAI: https://platform.openai.com/docs/overview\n- Claude: https://www.anthropic.com/api\n\nMake sure to set the `*_API_KEY` environment variables before using these APIs.\n\n## Setup\n\nDue to the optional dependencies, we're not providing a unified setup mechanism. Instead, we're providing instructions for each eval and sampler.\n\nFor [HumanEval](https://github.com/openai/human-eval/) (python programming)\n```bash\ngit clone https://github.com/openai/human-eval\npip install -e human-eval\n```\n\nFor the [OpenAI API](https://pypi.org/project/openai/):\n```bash\npip install openai\n```\n\nFor the [Anthropic API](https://docs.anthropic.com/claude/docs/quickstart-guide):\n```bash\npip install anthropic\n```\n\n## Demo\n```bash\npython -m simple-evals.demo\n```\nThis will launch evaluations through the OpenAI API.\n\n## Notes\n\n[^1]:chatgpt system message: \"You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.\\nKnowledge cutoff: 2023-12\\nCurrent date: 2024-04-01\"\n[^2]:assistant system message in [OpenAI API doc](https://platform.openai.com/docs/api-reference/introduction): \"You are a helpful assistant.\" .\n[^3]:claude-3 empty system message: suggested by Anthropic API doc, and we have done limited experiments due to [rate limit](https://docs.anthropic.com/claude/reference/rate-limits) issues, but we welcome PRs with alternative choices.\n[^4]:claude-3 lmsys system message: system message in LMSYS [Fast-chat open source code](https://github.com/lm-sys/FastChat/blob/7899355ebe32117fdae83985cf8ee476d2f4243f/fastchat/conversation.py#L894): \"The assistant is Claude, created by Anthropic. The current date is {{currentDateTime}}. Claude's knowledge base was last updated ... \". We have done limited experiments due to [rate limit](https://docs.anthropic.com/claude/reference/rate-limits) issues, but we welcome PRs with alternative choices.\n[^5]:We believe these evals are saturated for our newer models, but are reporting them for completeness.\n[^6]:For o1 models, we evaluate on [MATH-500](https://github.com/openai/prm800k/tree/main/prm800k/math_splits), which is a newer, IID version of MATH.\n[^7]:o1 models do not support using a system prompt.\n\n## Legal Stuff\nBy contributing to evals, you are agreeing to make your evaluation logic and data under the same MIT license as this repository. You must have adequate rights to upload any data used in an eval. OpenAI reserves the right to use this data in future service improvements to our product. Contributions to OpenAI evals will be subject to our usual Usage Policies: https://platform.openai.com/docs/usage-policies.", "metadata": {"source": "xjdr-alt/entropix", "title": "evals/README.md", "url": "https://github.com/xjdr-alt/entropix/blob/main/evals/README.md", "date": "2024-10-03T01:02:51Z", "stars": 3304, "description": "Entropy Based Sampling and Parallel CoT Decoding ", "file_size": 9067}}
+{"text": "# Multilingual MMLU Benchmark Results\n\nTo evaluate multilingual performance, we translated MMLU’s test set into 14 languages using professional human translators. Relying on human translators for this evaluation increases confidence in the accuracy of the translations, especially for low-resource languages like Yoruba.\n\n## Results\n\n| Language | o1-preview | gpt-4o-2024-08-06 | o1-mini | gpt-4o-mini-2024-07-18 |\n| :----------------------: | :--------: | :---------------: | :--------: | :--------------------: |\n| Arabic | **0.8821** | 0.8155 | **0.7945** | 0.7089 |\n| Bengali | **0.8622** | 0.8007 | **0.7725** | 0.6577 |\n| Chinese (Simplified) | **0.8800** | 0.8335 | **0.8180** | 0.7305 |\n| English (not translated) | **0.9080** | 0.8870 | **0.8520** | 0.8200 |\n| French | **0.8861** | 0.8437 | **0.8212** | 0.7659 |\n| German | **0.8573** | 0.8292 | **0.8122** | 0.7431 |\n| Hindi | **0.8782** | 0.8061 | **0.7887** | 0.6916 |\n| Indonesian | **0.8821** | 0.8344 | **0.8174** | 0.7452 |\n| Italian | **0.8872** | 0.8435 | **0.8222** | 0.7640 |\n| Japanese | **0.8788** | 0.8287 | **0.8129** | 0.7255 |\n| Korean | **0.8815** | 0.8262 | **0.8020** | 0.7203 |\n| Portuguese (Brazil) | **0.8859** | 0.8427 | **0.8243** | 0.7677 |\n| Spanish | **0.8893** | 0.8493 | **0.8303** | 0.7737 |\n| Swahili | **0.8479** | 0.7708 | **0.7015** | 0.6191 |\n| Yoruba | **0.7373** | 0.6195 | **0.5807** | 0.4583 |\n\nThese results can be reproduced by running\n\n```bash\npython -m simple-evals.run_multilingual_mmlu\n```", "metadata": {"source": "xjdr-alt/entropix", "title": "evals/multilingual_mmlu_benchmark_results.md", "url": "https://github.com/xjdr-alt/entropix/blob/main/evals/multilingual_mmlu_benchmark_results.md", "date": "2024-10-03T01:02:51Z", "stars": 3304, "description": "Entropy Based Sampling and Parallel CoT Decoding ", "file_size": 2135}}
+{"text": "# Frontend\n\nbun install\nbun run dev\n\ninspired by:\nhttps://github.com/anthropics/anthropic-quickstarts/tree/main/customer-support-agent\n\ntrying to copy:\nclaude.ai\n\nsome inspiration from:\nhttps://github.com/Porter97/monaco-copilot-demo", "metadata": {"source": "xjdr-alt/entropix", "title": "ui/README.md", "url": "https://github.com/xjdr-alt/entropix/blob/main/ui/README.md", "date": "2024-10-03T01:02:51Z", "stars": 3304, "description": "Entropy Based Sampling and Parallel CoT Decoding ", "file_size": 233}}
+{"text": "# TODO\n\nI somewhat hastily removed a bunch of backend code to get this pushed, so the current repo is in kind of rough shape. It runs, but its all stubbed out with mock data. We more or less need to make everything all over again.\n\nThis is the initial TODO list but we will add to it as we think of things. \n\n## REPO\n- Clean up repo. I am not a front end developer and it shows. Update the ui folder to best practices while still using bun, shadcn, next and tailwind\n- Storybook, jest, etc? This is probably too much but a subset might be useful\n- automation, piplines, dockerfiles, etc\n\n## UI\n- Markdown rendering in the MessageArea. Make sure we are using rehype and remark properly. Make sure we have the proper code theme based on the selected app theme\n - latex rendering\n - image rendering\n- Fix HTML / React Artifact rendering. Had to rip out the old code, so we need to mostly make this from scratch\n- Wire up right sidebar to properly handle the artifacts \n- For now hook up pyodide or something like https://github.com/cohere-ai/cohere-terrarium to run python code to start. I will port over the real code-interpreter at some point in the future\n- Hook up play button to python interpreter / HTML Viewer\n- Hook up CoT parsing and wire it up to the logs tab in the right sidebar OR repurpose the LeftSidebar for CoT viewing\n- Hook up Sidebar to either LocalDB, IndexDB or set up docker containers to run postgres (this probably means Drizzle, ughhhh....) to preserve chat history\n- Hook up Sidebar search\n- Port over or make new keyboard shortcuts\n- Create new conversation forking logic and UI. Old forking logic and UI were removed (modal editor was kept) but this is by far one of the most important things to get right\n- Visualize entropy / varent via shadcn charts / color the text on the screen\n- add shadcn dashboard-03 (the playground) back in for not Claude.ai style conversations\n\n## Editor\n- I'm pretty sure i'm not doing Monaco as well as it can be done. Plugins, themes, etc\n- do something like https://github.com/Porter97/monaco-copilot-demo with base for completion\n- make it work like OAI canvas where you can ask for edits at point\n- Make sure Modal Editor and Artifact Code Editor both work but do not rely on eachother, cause ModalEditor needs to be simple\n\n## Backend\n- Make a simple SSE client / server to hook up to Entropix generate loop\n- Create tool parser for:\n - Brave\n - iPython\n - Image", "metadata": {"source": "xjdr-alt/entropix", "title": "ui/TODO.md", "url": "https://github.com/xjdr-alt/entropix/blob/main/ui/TODO.md", "date": "2024-10-03T01:02:51Z", "stars": 3304, "description": "Entropy Based Sampling and Parallel CoT Decoding ", "file_size": 2430}}
+{"text": "# HumanEval: Hand-Written Evaluation Set \n\nThis is an evaluation harness for the HumanEval problem solving dataset\ndescribed in the paper \"[Evaluating Large Language Models Trained on\nCode](https://arxiv.org/abs/2107.03374)\".\n\n## Installation\n\nMake sure to use python 3.7 or later:\n```\n$ conda create -n codex python=3.7\n$ conda activate codex\n```\n\nCheck out and install this repository:\n```\n$ git clone https://github.com/openai/human-eval\n$ pip install -e human-eval\n```\n\n## Usage\n\n**This program exists to run untrusted model-generated code. Users are strongly\nencouraged not to do so outside of a robust security sandbox. The [execution\ncall](https://github.com/openai/human-eval/blob/master/human_eval/execution.py#L48-L58)\nin `execution.py` is deliberately commented out to ensure users read this\ndisclaimer before running code in a potentially unsafe manner. See the comment in\n`execution.py` for more information and instructions.**\n\nAfter following the above instructions to enable execution, generate samples\nand save them in the following JSON Lines (jsonl) format, where each sample is\nformatted into a single line like so:\n```\n{\"task_id\": \"Corresponding HumanEval task ID\", \"completion\": \"Completion only without the prompt\"}\n```\nWe provide `example_problem.jsonl` and `example_solutions.jsonl` under `data`\nto illustrate the format and help with debugging.\n\nHere is nearly functional example code (you just have to provide\n`generate_one_completion` to make it work) that saves generated completions to\n`samples.jsonl`.\n```\nfrom human_eval.data import write_jsonl, read_problems\n\nproblems = read_problems()\n\nnum_samples_per_task = 200\nsamples = [\n dict(task_id=task_id, completion=generate_one_completion(problems[task_id][\"prompt\"]))\n for task_id in problems\n for _ in range(num_samples_per_task)\n]\nwrite_jsonl(\"samples.jsonl\", samples)\n```\n\nTo evaluate the samples, run\n```\n$ evaluate_functional_correctness samples.jsonl\nReading samples...\n32800it [00:01, 23787.50it/s]\nRunning test suites...\n100%|...| 32800/32800 [16:11<00:00, 33.76it/s]\nWriting results to samples.jsonl_results.jsonl...\n100%|...| 32800/32800 [00:00<00:00, 42876.84it/s]\n{'pass@1': ..., 'pass@10': ..., 'pass@100': ...}\n```\nThis script provides more fine-grained information in a new file ending in\n`_results.jsonl`. Each row now contains whether the completion\n`passed` along with the execution `result` which is one of \"passed\", \"timed\nout\", or \"failed\".\n\nAs a quick sanity-check, the example samples should yield 0.5 pass@1.\n```\n$ evaluate_functional_correctness data/example_samples.jsonl --problem_file=data/example_problem.jsonl\nReading samples...\n6it [00:00, 3397.11it/s]\nRunning example suites...\n100%|...| 6/6 [00:03<00:00, 1.96it/s]\nWriting results to data/example_samples.jsonl_results.jsonl...\n100%|...| 6/6 [00:00<00:00, 6148.50it/s]\n{'pass@1': 0.4999999999999999}\n```\n\nBecause there is no unbiased way of estimating pass@k when there are fewer\nsamples than k, the script does not evaluate pass@k for these cases. To\nevaluate with other k values, pass `--k=`. For\nother options, see\n```\n$ evaluate_functional_correctness --help\n```\nHowever, we recommend that you use the default values for the rest.\n\n## Known Issues\n\nWhile evaluation uses very little memory, you might see the following error\nmessage when the system is running out of RAM. Since this may cause some\ncorrect programs to fail, we recommend that you free some memory and try again.\n```\nmalloc: can't allocate region\n```\n\n## Citation\n\nPlease cite using the following bibtex entry:\n\n```\n@article{chen2021codex,\n title={Evaluating Large Language Models Trained on Code},\n author={Mark Chen and Jerry Tworek and Heewoo Jun and Qiming Yuan and Henrique Ponde de Oliveira Pinto and Jared Kaplan and Harri Edwards and Yuri Burda and Nicholas Joseph and Greg Brockman and Alex Ray and Raul Puri and Gretchen Krueger and Michael Petrov and Heidy Khlaaf and Girish Sastry and Pamela Mishkin and Brooke Chan and Scott Gray and Nick Ryder and Mikhail Pavlov and Alethea Power and Lukasz Kaiser and Mohammad Bavarian and Clemens Winter and Philippe Tillet and Felipe Petroski Such and Dave Cummings and Matthias Plappert and Fotios Chantzis and Elizabeth Barnes and Ariel Herbert-Voss and William Hebgen Guss and Alex Nichol and Alex Paino and Nikolas Tezak and Jie Tang and Igor Babuschkin and Suchir Balaji and Shantanu Jain and William Saunders and Christopher Hesse and Andrew N. Carr and Jan Leike and Josh Achiam and Vedant Misra and Evan Morikawa and Alec Radford and Matthew Knight and Miles Brundage and Mira Murati and Katie Mayer and Peter Welinder and Bob McGrew and Dario Amodei and Sam McCandlish and Ilya Sutskever and Wojciech Zaremba},\n year={2021},\n eprint={2107.03374},\n archivePrefix={arXiv},\n primaryClass={cs.LG}\n}\n```", "metadata": {"source": "xjdr-alt/entropix", "title": "evals/human-eval/README.md", "url": "https://github.com/xjdr-alt/entropix/blob/main/evals/human-eval/README.md", "date": "2024-10-03T01:02:51Z", "stars": 3304, "description": "Entropy Based Sampling and Parallel CoT Decoding ", "file_size": 4847}}
+{"text": "verl: Volcano Engine Reinforcement Learning for LLM
\n\nverl is a flexible, efficient and production-ready RL training library for large language models (LLMs).\n\nverl is the open-source version of **[HybridFlow: A Flexible and Efficient RLHF Framework](https://arxiv.org/abs/2409.19256v2)** paper.\n\nverl is flexible and easy to use with:\n\n- **Easy extension of diverse RL algorithms**: The Hybrid programming model combines the strengths of single-controller and multi-controller paradigms to enable flexible representation and efficient execution of complex Post-Training dataflows. Allowing users to build RL dataflows in a few lines of code.\n\n- **Seamless integration of existing LLM infra with modular APIs**: Decouples computation and data dependencies, enabling seamless integration with existing LLM frameworks, such as PyTorch FSDP, Megatron-LM and vLLM. Moreover, users can easily extend to other LLM training and inference frameworks.\n\n- **Flexible device mapping**: Supports various placement of models onto different sets of GPUs for efficient resource utilization and scalability across different cluster sizes.\n\n- Readily integration with popular HuggingFace models\n\n\nverl is fast with:\n\n- **State-of-the-art throughput**: By seamlessly integrating existing SOTA LLM training and inference frameworks, verl achieves high generation and training throughput.\n\n- **Efficient actor model resharding with 3D-HybridEngine**: Eliminates memory redundancy and significantly reduces communication overhead during transitions between training and generation phases.\n\n\n| Documentation | Paper | Slack | Wechat | Twitter\n\n\n
\n\n## News\n\n- [2025/2] We will present verl in the [Bytedance/NVIDIA/Anyscale Ray Meetup](https://lu.ma/ji7atxux) in bay area on Feb 13th. Come join us in person!\n- [2025/1] [Doubao-1.5-pro](https://team.doubao.com/zh/special/doubao_1_5_pro) is released with SOTA-level performance on LLM & VLM. The RL scaling preview model is trained using verl, reaching OpenAI O1-level performance on math benchmarks (70.0 pass@1 on AIME).\n- [2024/12] The team presented Post-training LLMs: From Algorithms to Infrastructure at NeurIPS 2024. [Slides](https://github.com/eric-haibin-lin/verl-data/tree/neurips) and [video](https://neurips.cc/Expo/Conferences/2024/workshop/100677) available.\n- [2024/10] verl is presented at Ray Summit. [Youtube video](https://www.youtube.com/watch?v=MrhMcXkXvJU&list=PLzTswPQNepXntmT8jr9WaNfqQ60QwW7-U&index=37) available.\n- [2024/08] HybridFlow (verl) is accepted to EuroSys 2025.\n\n## Key Features\n\n- **FSDP** and **Megatron-LM** for training.\n- **vLLM** and **TGI** for rollout generation, **SGLang** support coming soon.\n- huggingface models support\n- Supervised fine-tuning\n- Reinforcement learning from human feedback with [PPO](https://github.com/volcengine/verl/tree/main/examples/ppo_trainer), [GRPO](https://github.com/volcengine/verl/tree/main/examples/grpo_trainer), and [ReMax](https://github.com/volcengine/verl/tree/main/examples/remax_trainer)\n - Support model-based reward and function-based reward (verifiable reward)\n- flash-attention, [sequence packing](examples/ppo_trainer/run_qwen2-7b_seq_balance.sh), [long context](examples/ppo_trainer/run_deepseek7b_llm_sp2.sh) support via DeepSpeed Ulysses, [LoRA](examples/sft/gsm8k/run_qwen_05_peft.sh), [Liger-kernel](examples/sft/gsm8k/run_qwen_05_sp2_liger.sh)\n- scales up to 70B models and hundreds of GPUs\n- experiment tracking with wandb, swanlab and mlflow\n\n## Upcoming Features\n- Reward model training\n- DPO training\n- DeepSeek integration with Megatron backend\n- SGLang integration\n\n## Getting Started\n\nCheckout this [Jupyter Notebook](https://github.com/volcengine/verl/tree/main/examples/ppo_trainer/verl_getting_started.ipynb) to get started with PPO training with a single 24GB L4 GPU (**FREE** GPU quota provided by [Lighting Studio](https://lightning.ai/hlin-verl/studios/verl-getting-started))!\n\n**Quickstart:**\n- [Installation](https://verl.readthedocs.io/en/latest/start/install.html)\n- [Quickstart](https://verl.readthedocs.io/en/latest/start/quickstart.html)\n- [Programming Guide](https://verl.readthedocs.io/en/latest/hybrid_flow.html)\n\n**Running a PPO example step-by-step:**\n- Data and Reward Preparation\n - [Prepare Data for Post-Training](https://verl.readthedocs.io/en/latest/preparation/prepare_data.html)\n - [Implement Reward Function for Dataset](https://verl.readthedocs.io/en/latest/preparation/reward_function.html)\n- Understanding the PPO Example\n - [PPO Example Architecture](https://verl.readthedocs.io/en/latest/examples/ppo_code_architecture.html)\n - [Config Explanation](https://verl.readthedocs.io/en/latest/examples/config.html)\n - [Run GSM8K Example](https://verl.readthedocs.io/en/latest/examples/gsm8k_example.html)\n\n**Reproducible algorithm baselines:**\n- [PPO and GRPO](https://verl.readthedocs.io/en/latest/experiment/ppo.html)\n\n**For code explanation and advance usage (extension):**\n- PPO Trainer and Workers\n - [PPO Ray Trainer](https://verl.readthedocs.io/en/latest/workers/ray_trainer.html)\n - [PyTorch FSDP Backend](https://verl.readthedocs.io/en/latest/workers/fsdp_workers.html)\n - [Megatron-LM Backend](https://verl.readthedocs.io/en/latest/index.html)\n- Advance Usage and Extension\n - [Ray API design tutorial](https://verl.readthedocs.io/en/latest/advance/placement.html)\n - [Extend to Other RL(HF) algorithms](https://verl.readthedocs.io/en/latest/advance/dpo_extension.html)\n - [Add Models with the FSDP Backend](https://verl.readthedocs.io/en/latest/advance/fsdp_extension.html)\n - [Add Models with the Megatron-LM Backend](https://verl.readthedocs.io/en/latest/advance/megatron_extension.html)\n - [Deployment using Separate GPU Resources](https://github.com/volcengine/verl/tree/main/examples/split_placement)\n\n## Performance Tuning Guide\nThe performance is essential for on-policy RL algorithm. We write a detailed performance tuning guide to allow people tune the performance. See [here](https://verl.readthedocs.io/en/latest/perf/perf_tuning.html) for more details.\n\n## Contribution Guide\nContributions from the community are welcome!\n\n### Code formatting\nWe use yapf (Google style) to enforce strict code formatting when reviewing PRs. To reformat you code locally, make sure you installed **latest** `yapf`\n```bash\npip3 install yapf --upgrade\n```\nThen, make sure you are at top level of verl repo and run\n```bash\nbash scripts/format.sh\n```\n\n## Citation and acknowledgement\n\nIf you find the project helpful, please cite:\n- [HybridFlow: A Flexible and Efficient RLHF Framework](https://arxiv.org/abs/2409.19256v2)\n- [A Framework for Training Large Language Models for Code Generation via Proximal Policy Optimization](https://i.cs.hku.hk/~cwu/papers/gmsheng-NL2Code24.pdf)\n\n```tex\n@article{sheng2024hybridflow,\n title = {HybridFlow: A Flexible and Efficient RLHF Framework},\n author = {Guangming Sheng and Chi Zhang and Zilingfeng Ye and Xibin Wu and Wang Zhang and Ru Zhang and Yanghua Peng and Haibin Lin and Chuan Wu},\n year = {2024},\n journal = {arXiv preprint arXiv: 2409.19256}\n}\n```\n\nverl is inspired by the design of Nemo-Aligner, Deepspeed-chat and OpenRLHF. The project is adopted and supported by Anyscale, Bytedance, LMSys.org, Shanghai AI Lab, Tsinghua University, UC Berkeley, UCLA, UIUC, and University of Hong Kong.\n\n## Awesome work using verl\n- [Enhancing Multi-Step Reasoning Abilities of Language Models through Direct Q-Function Optimization](https://arxiv.org/abs/2410.09302)\n- [Flaming-hot Initiation with Regular Execution Sampling for Large Language Models](https://arxiv.org/abs/2410.21236)\n- [Process Reinforcement Through Implicit Rewards](https://github.com/PRIME-RL/PRIME/)\n- [TinyZero](https://github.com/Jiayi-Pan/TinyZero): a reproduction of DeepSeek R1 Zero recipe for reasoning tasks\n- [RAGEN](https://github.com/ZihanWang314/ragen): a general-purpose reasoning agent training framework\n- [Logic R1](https://github.com/Unakar/Logic-RL): a reproduced DeepSeek R1 Zero on 2K Tiny Logic Puzzle Dataset.\n- [deepscaler](https://github.com/agentica-project/deepscaler): iterative context scaling with GRPO\n- [critic-rl](https://github.com/HKUNLP/critic-rl): Teaching Language Models to Critique via Reinforcement Learning\n\nWe are HIRING! Send us an [email](mailto:haibin.lin@bytedance.com) if you are interested in internship/FTE opportunities in MLSys/LLM reasoning/multimodal alignment.", "metadata": {"source": "volcengine/verl", "title": "README.md", "url": "https://github.com/volcengine/verl/blob/main/README.md", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 8970}}
+{"text": "# verl documents\n\n## Build the docs\n\n```bash\n# Install dependencies.\npip install -r requirements-docs.txt\n\n# Build the docs.\nmake clean\nmake html\n```\n\n## Open the docs with your browser\n\n```bash\npython -m http.server -d _build/html/\n```\nLaunch your browser and open localhost:8000.", "metadata": {"source": "volcengine/verl", "title": "docs/README.md", "url": "https://github.com/volcengine/verl/blob/main/docs/README.md", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 281}}
+{"text": "=========================================================\nHybridFlow Programming Guide\n=========================================================\n\n.. _vermouth: https://github.com/vermouth1992\n\nAuthor: `Chi Zhang `_\n\nverl is an open source implementation of the paper `HybridFlow `_ [1]_. In this section, we will introduce the basic concepts of HybridFlow, the motivation and how to program with verl APIs.\n\nMotivation and Design\n------------------------\nWe use dataflow to represent RL systems. [4]_.\n\nDataFlow\n~~~~~~~~~~~~~~~~~~~~\n\nDataflow is an abstraction of computations. Neural Netowork training is a typical dataflow. It can be represented by computational graph. \n\n.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/dataflow.jpeg?raw=true\n :alt: The dataflow graph from CS231n 2024 lecture 4\n\nThis figure [2]_ represents the computation graph of a polynomial function followed by a sigmoid function. In the data flow of neural network computation, each node represents an operator, and each edge represents the direction of forward/backward propagation. The computation graph determines the architecture of the neural network.\n\nRL as a dataflow problem\n++++++++++++++++++++++++++++++++++++++++++++++\n\nReinforcement learning (RL) training can also be represented as a dataflow. Below is the dataflow graph that represents the PPO algorithm used in RLHF [3]_:\n\n.. image:: https://picx.zhimg.com/70/v2-cb8ab5ee946a105aab6a563e92682ffa_1440w.avis?source=172ae18b&biz_tag=Post\n :alt: PPO dataflow graph, credit to Zhihu 低级炼丹师\n\nHowever, the dataflow of RL has fundamental differences compared with dataflow of neural network training as follows:\n\n+--------------------------+--------------------------------------------------+---------------------+\n| Workload | Node | Edge |\n+--------------------------+--------------------------------------------------+---------------------+\n| Neural Network Training | Operator (+/-/matmul/softmax) | Tensor movement |\n+--------------------------+--------------------------------------------------+---------------------+\n| Reinforcement Learning | High-level operators (rollout/model forward) | Data Movement |\n+--------------------------+--------------------------------------------------+---------------------+\n\nIn the case of tabular reinforcement learning, each operator is a simple scalar math operation (e.g., bellman update). In deep reinforcement learning(DRL), each operator is a high-level neural network computation such as model inference/update. This makes RL a two-level dataflow problem:\n\n- Control flow: defines how the high-level operators are executed (e.g., In PPO, we first perform rollout. Then, we perform advantage computation. Finally, we perform training). It expresses the **core logics of RL algorithms**.\n- Computation flow: defines the dataflow of **neural network computation** (e.g., model forward/backward/optimizer).\n\n\nDesign Choices\n~~~~~~~~~~~~~~~~~~~~\nThe model size used in DRL before the LLM era is typically small. Thus, the high-level neural network computation can be done in a single process. This enables embedding the computation flow inside the control flow as a single process.\n\nHowever, in the LLM era, the computation flow (e.g., training neural network) becomes a multi-process program. This naturally leads to two design choices:\n\n1. Convert the control flow into a multi-process program as well. Then colocate with computation flow (unified multi-controller)\n\n- Advantages:\n\n - Achieves the **optimal performance** under fixed computation flow and control flow as the communication overhead in both training and data transfer is minimized.\n\n- Disadvantages:\n\n - The computation and/or control flow is **hard to reuse** from software perspective as computation code is coupled with specific controller code. For example, the training loop of PPO is generic. Say we have an PPO training flow implemented with a specific computation flow such as FSDP. Neither the control flow or computation flow can be reused if we want to switch the computation flow from FSDP to Megatron, due to the coupling of control and computation flows.\n - Requires more efforts from the user under flexible and dynamic control flows, due to the multi-process nature of the program.\n\n2. Separate the flows: single process for the control flow and multi-process for computation flow\n\n- Advantages:\n\n - The computation flow defined elsewhere can be **easily reused** after the decoupling.\n - The controller runs on a single process. Implementing a new RL algorithm with a **different control flow is simple and easy**.\n\n- Disadvantages:\n\n - Additional **data communication overhead** each time the controller process and computatation processes interact. The data has to be sent back and forth.\n\nIn verl, the latter strategy with separate control flow and computation flow is adopted. verl is designed to decouple the control flow of RL algorithms, and the implementation of computation engines.\n\nOverall Execution Diagram\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\nBelow is a simplified diagram denoting the execution of a reinforcement learning job. In the diagram, the controller runs on a single process, while the generator/actor workers, critic workers run on multiple processes, placed with specific resource groups. For rollout, the controller passes the data to the generator to perform sample generation. When the rollout is done, the data is passed back to controller for the next step of the algorithm. Similar execution is done for other workers. With the hybrid controller design, the data flow and computation is decoupled to provide both efficiency in computation and flexiblity in defining algorithm training loops.\n\n.. figure:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/driver_worker.png?raw=true\n :alt: The execution diagram\n\nCodebase walkthrough (PPO)\n------------------------------------------------\n\nEntry function\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\nCode: https://github.com/volcengine/verl/blob/main/verl/trainer/main_ppo.py\n\nIn this file, we define a remote function `main_task` that serves as the controller (driver) process as shown in the above figure. We also define a ``RewardManager``, where users can customize their reward function based on the data source in the dataset. Note that `RewardManager` should return the final token-level reward that is optimized by RL algorithms. Note that users can combine model-based rewards and rule-based rewards.\nThe ``main_task`` constructs a RayPPOTrainer instance and launch the fit. Note that ``main_task`` **runs as a single process**.\n\nWe highly recommend that the ``main_task`` is NOT schduled on the head of the ray cluster because ``main_task`` will consume a lot of memory but the head usually contains very few resources.\n\nRay trainer\n~~~~~~~~~~~~~~~~~~~~\nCode: https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py\n\nThe RayPPOTrainer manages \n\n- Worker and WorkerGroup construction\n- Runs the main loop of PPO algorithm\n\nNote that, the fit function of RayPPOTrainer **runs as a single process**.\n\nWorker and WorkerGroup construction\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\nEach workerGroup manages a list of workers that runs remotely. Note that the worker group runs in the process of its construtor.\nEach worker inside the WorkerGroup runs on a GPU. The worker group serves as a proxy for the controller process to interact with a list of workers, in order to perform certain computations. **In order to do so, we have to bind the methods of the worker into the method of the WorkerGroup and define the data dispatch and data collection**. This is done via simple decoration that will be introduced in the Worker definition section.\n\nFor example, in PPO, we define 3 worker groups:\n\n- ActorRolloutRef: manages actor, rollout and reference policy. ActorRolloutRefWorker can be instantiated as a single actor, a single rollout, a single reference policy, a combined actor/rollout or a combined actor/rollout/ref. This design is aimed for the maximum code reuse in various scenarios. The reason for colocating actor and rollout is for fast weight transfer using nccl. The reason for coloating actor and reference is to implement an efficient lora PPO as the reference policy is simply the base model of PPO in lora.\n- Critic: manages the critic model\n- Reward: manages the reward model\n\nThe worker group will be constructed on the resource pool it designates. The resource pool is a set of GPUs in the ray cluster.\n\nWorker definition\n~~~~~~~~~~~~~~~~~~~~\n\n.. _ActorRolloutRefWorker: https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py\n\nWe take `ActorRolloutRefWorker <_ActorRolloutRefWorker>`_ for an exmaple.\nThe APIs it should expose to the controller process are:\n\n- init_model: build the underlying model\n- generate_sequences: given prompts, generate responses\n- compute_log_prob: compute the log-probability of a generated sequence using actor\n- compute_ref_log_prob: compute the log-probability of a generated sequence using reference policy\n- save_checkpoint: save the checkpoint\n\nNote that these methods are defined in the worker that can only be invoked via remote calls. For example, if the controller process wants to initialize the model, it has to call\n\n.. code-block:: python\n\n for worker in actor_rollout_ref_wg:\n worker.init_model.remote()\n\nIf the controller process wants to generate sequences, it has to call\n\n.. code-block:: python\n\n data = xxx\n # split the data into dp chunks\n data_dp_lst = data.split(dp_size)\n output_dp_lst = []\n for i, worker in enumerate(actor_rollout_ref_wg):\n output_future = worker.generate_sequences.remote(data_dp_lst[i])\n output_dp_lst.append(output_future)\n output = torch.cat(ray.get(output_dp_lst), dim=0)\n\nWe observe that controll process calling worker group methods in general can be divided into 3 parts:\n\n- Split the data into data parallel sizes\n- Dispatch the corresponding data into each worker\n- Collect and concatenate the data when the computation finishes\n\nIn verl, we design a syntax sugar to encapsulate the 3 processes into a single call from the controller process.\n\n.. code-block:: python\n\n @register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)\n def generate_sequences(data):\n ...\n\n # on the driver\n output = actor_rollout_ref_wg.generate_sequences(data)\n\nWe decorate the method of the worker with a ``register`` that explicitly defines how the input data should be splitted and dispatch to each worker, and how the output data should be collected and concatenated by the controller. For example, ``Dispatch.DP_COMPUTE_PROTO`` splits the input data into dp chunks, dispatch each data to each worker, collect the output and concatenate the results. Note that this function requires the input and output to be a DataProto defined here (https://github.com/volcengine/verl/blob/main/verl/protocol.py).\n\n\nPPO main loop\n~~~~~~~~~~~~~~~~~~~~\nWith the aforementioned APIs, we can implement the main loop of PPO as if it is a single process program\n\n.. code-block:: python\n\n for prompt in dataloader:\n output = actor_rollout_ref_wg.generate_sequences(prompt)\n old_log_prob = actor_rollout_ref_wg.compute_log_prob(output)\n ref_log_prob = actor_rollout_ref_wg.compute_ref_log_prob(output)\n values = critic_wg.compute_values(output)\n rewards = reward_wg.compute_scores(output)\n # compute_advantages is running directly on the control process\n advantages = compute_advantages(values, rewards)\n output = output.union(old_log_prob)\n output = output.union(ref_log_prob)\n output = output.union(values)\n output = output.union(rewards)\n output = output.union(advantages)\n # update actor\n actor_rollout_ref_wg.update_actor(output)\n critic.update_critic(output)\n\nTakeaways\n~~~~~~~~~~~~~~~~~~~~\n- This programming paradigm enables users to use different computation backend without modification of the control process.\n- This programming paradigm enables flexible placement (by changing the mapping of WorkerGroup and ResourcePool) without modification of the control process.\n\nRepository organization\n------------------------------------------------\n\nImportant code files in the repository are organized as below:\n\n.. code-block:: bash\n\n verl # the verl package\n trainer\n main_ppo.py # the entrypoint for RL training\n ppo\n ray_trainer.py # the training loop for RL algorithms such as PPO\n fsdp_sft_trainer.py # the SFT trainer with FSDP backend\n config\n generation.yaml # configuration template for rollout\n ppo_trainer.yaml # configuration template for the RL trainer\n workers\n protocol.py # the interface of DataProto\n fsdp_workers.py # the FSDP worker interfaces: ActorRolloutRefWorker, CriticWorker, RewardModelWorker\n megatron_workers.py # the Megatron worker interfaces: ActorRolloutRefWorker, CriticWorker, RewardModelWorker\n actor\n dp_actor.py # data parallel actor with FSDP backend\n megatron_actor.py # nD parallel actor with Megatron backend\n critic\n dp_critic.py # data parallel critic with FSDP backend\n megatron_critic.py # nD parallel critic with FSDP backend\n reward_model\n megatron\n reward_model.py # reward model with Megatron backend\n rollout\n vllm\n vllm_rollout.py # rollout with vllm backend\n hf_rollout.py # rollout with huggingface TGI backend\n sharding_manager\n fsdp_ulysses.py # data and model resharding when using FSDP + ulysses\n fsdp_vllm.py # data and model resharding when using FSDP + ulysses + vllm\n megatron_vllm.py # data and model resharding when using Megatron + vllm\n utils\n dataset # datasets for SFT/RM/RL\n reward_score # function based reward\n gsm8k.py # reward function for gsm8k dataset\n math.py # reward function for math dataset\n seqlen_balancing.py # the sequence balance optimization\n models\n llama # Megatron implementation for llama, deepseek, mistral, etc\n transformers # ulysses integration with transformer models such as llama, qwen, etc\n weight_loader_registery.py # registry of weight loaders for loading hf ckpt into Megatron\n third_party\n vllm # adaptor for vllm's usage in RL\n vllm_v_0_6_3 # vllm v0.6.3 adaptor\n llm.py # entrypoints for generate, sync_model_weight, offload_model_weights\n parallel_state.py # vllm related device mesh and process groups\n dtensor_weight_loaders.py # weight loader for huggingface models with FSDP\n megatron_weight_loaders.py # weight loader for Megatron models\n vllm_spmd # vllm >= v0.7 adaptor (coming soon)\n examples # example scripts\n tests # integration and unit tests\n .github # the configuration of continuous integration tests\n\n\n.. [1] HybridFlow: A Flexible and Efficient RLHF Framework: https://arxiv.org/abs/2409.19256v2\n.. [2] Data flow graph credit to CS231n 2024 lecture 4: https://cs231n.stanford.edu/slides/2024/lecture_4.pdf\n.. [3] PPO dataflow graph credit to 低级炼丹师 from Zhihu: https://zhuanlan.zhihu.com/p/635757674\n.. [4] RLFlow", "metadata": {"source": "volcengine/verl", "title": "docs/hybrid_flow.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/hybrid_flow.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 15523}}
+{"text": "Welcome to verl's documentation!\n================================================\n\n.. _hf_arxiv: https://arxiv.org/pdf/2409.19256\n\nverl is a flexible, efficient and production-ready RL training framework designed for large language models (LLMs) post-training. It is an open source implementation of the `HybridFlow `_ paper.\n\nverl is flexible and easy to use with:\n\n- **Easy extension of diverse RL algorithms**: The Hybrid programming model combines the strengths of single-controller and multi-controller paradigms to enable flexible representation and efficient execution of complex Post-Training dataflows. Allowing users to build RL dataflows in a few lines of code.\n\n- **Seamless integration of existing LLM infra with modular APIs**: Decouples computation and data dependencies, enabling seamless integration with existing LLM frameworks, such as PyTorch FSDP, Megatron-LM and vLLM. Moreover, users can easily extend to other LLM training and inference frameworks.\n\n- **Flexible device mapping and parallelism**: Supports various placement of models onto different sets of GPUs for efficient resource utilization and scalability across different cluster sizes.\n\n- Readily integration with popular HuggingFace models\n\n\nverl is fast with:\n\n- **State-of-the-art throughput**: By seamlessly integrating existing SOTA LLM training and inference frameworks, verl achieves high generation and training throughput.\n\n- **Efficient actor model resharding with 3D-HybridEngine**: Eliminates memory redundancy and significantly reduces communication overhead during transitions between training and generation phases.\n\n--------------------------------------------\n\n.. _Contents:\n\n.. toctree::\n :maxdepth: 5\n :caption: Quickstart\n\n start/install\n start/quickstart\n\n.. toctree::\n :maxdepth: 4\n :caption: Programming guide\n\n hybrid_flow\n\n.. toctree::\n :maxdepth: 5\n :caption: Data Preparation\n\n preparation/prepare_data\n preparation/reward_function\n\n.. toctree::\n :maxdepth: 5\n :caption: Configurations\n\n examples/config\n\n.. toctree::\n :maxdepth: 2\n :caption: PPO Example\n\n examples/ppo_code_architecture\n examples/gsm8k_example\n\n.. toctree:: \n :maxdepth: 1\n :caption: PPO Trainer and Workers\n\n workers/ray_trainer\n workers/fsdp_workers\n workers/megatron_workers\n\n.. toctree::\n :maxdepth: 1\n :caption: Performance Tuning Guide\n \n perf/perf_tuning\n\n.. toctree::\n :maxdepth: 1\n :caption: Experimental Results\n\n experiment/ppo\n\n.. toctree::\n :maxdepth: 1\n :caption: Advance Usage and Extension\n\n advance/placement\n advance/dpo_extension\n advance/fsdp_extension\n advance/megatron_extension\n\n.. toctree::\n :maxdepth: 1\n :caption: FAQ\n\n faq/faq\n\nContribution\n-------------\n\nverl is free software; you can redistribute it and/or modify it under the terms\nof the Apache License 2.0. We welcome contributions.\nJoin us on `GitHub `_, `Slack `_ and `Wechat `_ for discussions.\n\nCode formatting\n^^^^^^^^^^^^^^^^^^^^^^^^\nWe use yapf (Google style) to enforce strict code formatting when reviewing MRs. Run yapf at the top level of verl repo:\n\n.. code-block:: bash\n\n pip3 install yapf\n yapf -ir -vv --style ./.style.yapf verl examples tests", "metadata": {"source": "volcengine/verl", "title": "docs/index.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/index.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 3426}}
+{"text": "Extend to other RL(HF) algorithms\n=================================\n\nWe already implemented the complete training pipeline of the PPO\nalgorithms. To extend to other algorithms, we analyze the high-level\nprinciple to use verl and provide a tutorial to implement the DPO\nalgorithm. Users can follow the similar paradigm to extend to other RL algorithms.\n\n.. note:: **Key ideas**: Single process drives multi-process computation and data communication.\n\nOverall Approach\n----------------\n\nStep 1: Consider what multi-machine multi-GPU computations are needed\nfor each model, such as ``generate_sequence`` , ``compute_log_prob`` and\n``update_policy`` in the actor_rollout model. Implement distributed\nsingle-process-multiple-data (SPMD) computation and encapsulate them\ninto APIs\n\nStep 2: Based on different distributed scenarios, including FSDP and 3D\nparallelism in Megatron-LM, implement single-process control of data\ninteraction among multi-process computations.\n\nStep 3: Utilize the encapsulated APIs to implement the control flow\n\nExample: Online DPO\n-------------------\n\nWe use verl to implement a simple online DPO algorithm. The algorithm\nflow of Online DPO is as follows:\n\n1. There is a prompt (rollout) generator which has the same weight as\n the actor model. After a batch of prompts are fed into the generator,\n it generates N responses for each prompt.\n2. Send all the prompts + responses to a verifier for scoring, which can\n be reward model or a rule-based function. Then sort them in pairs to\n form a training batch.\n3. Use this training batch to train the actor model using DPO. During\n the process, a reference policy is needed.\n\nStep 1: What are the multi-machine multi-GPU computations\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\n**Sample Generator**\n\nImplementation details:\n\n.. code:: python\n\n from verl.single_controller.base import Worker\n from verl.single_controller.ray import RayWorkerGroup, RayClassWithInitArgs, RayResourcePool\n import ray\n\n @ray.remote\n class SampleGenerator(Worker):\n def __init__(self, config):\n super().__init__()\n self.config = config\n \n def generate_sequences(self, data):\n pass\n\nHere, ``SampleGenerator`` can be viewed as a multi-process pulled up by\n``torchrun``, with each process running the same code (SPMD).\n``SampleGenerator`` needs to implement a ``generate_sequences`` API for\nthe control flow to call. The implementation details inside can use any\ninference engine including vllm, sglang and huggingface. Users can\nlargely reuse the code in\nverl/verl/trainer/ppo/rollout/vllm_rollout/vllm_rollout.py and we won't\ngo into details here.\n\n**ReferencePolicy inference**\n\nAPI: compute reference log probability\n\n.. code:: python\n\n from verl.single_controller.base import Worker\n import ray\n\n @ray.remote\n class ReferencePolicy(Worker):\n def __init__(self):\n super().__init__()\n self.model = Model()\n \n def infer(self, data):\n return self.model(data)\n\n**Actor update**\n\nAPI: Update actor model parameters\n\n.. code:: python\n\n from verl.single_controller.base import Worker\n import ray\n\n @ray.remote\n class DPOActor(Worker):\n def __init__(self):\n super().__init__()\n self.model = Model()\n self.model = FSDP(self.model) # or other distributed strategy\n self.optimizer = optim.Adam(self.model.parameters(), lr=1e-3)\n self.loss_fn = xxx\n \n def update(self, data):\n self.optimizer.zero_grad()\n logits = self.model(data)\n loss = self.loss_fn(logits)\n loss.backward()\n self.optimizer.step()\n\n**Notes: How to distinguish between control processes and distributed computation processes**\n^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n\n- Control processes are generally functions directly decorated with\n ``@ray.remote``\n- Computation processes are all wrapped into a ``RayWorkerGroup``.\n\nUsers can reuse most of the distribtued computation logics implemented\nin PPO algorithm, including FSDP and Megatron-LM backend in\nverl/verl/trainer/ppo.\n\nStep 2: Based on different distributed scenarios, implement single-process control of multi-process data interaction\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\n**The core problem to solve here is how a single process sends data to\nmultiple processes, drives multi-process computation, and how the\ncontrol process obtains the results of multi-process computation.**\nFirst, we initialize the multi-process ``WorkerGroup`` in the control\nprocess.\n\n.. code:: python\n\n @ray.remote(num_cpus=1)\n def main_task(config):\n # construct SampleGenerator\n resource_pool = RayResourcePool(process_on_nodes=[8] * 2) # 16 GPUs\n ray_cls = RayClassWithInitArgs(SampleGenerator, config=config)\n # put SampleGenerator onto resource pool\n worker_group = RayWorkerGroup(resource_pool, ray_cls)\n \n # construct reference policy\n\nAs we can see, in the control process, multiple processes are wrapped\ninto a ``RayWorkerGroup``. Inside this ``WorkerGroup``, there is a\n``self._workers`` member, where each worker is a RayActor\n(https://docs.ray.io/en/latest/ray-core/actors.html) of SampleGenerator.\nray_trainer.md also provide an implementation of\n``MegatronRayWorkerGroup``.\n\nAssuming the model is distributed using FSDP, and there is a batch of\ndata on the control process, for data parallelism, the underlying\ncalling process is:\n\n.. code:: python\n\n data = xxx\n data_list = data.chunk(dp_size)\n\n output = []\n for d in data_list:\n # worker_group._workers[i] is a SampleGenerator\n output.append(worker_group._workers[i].generate_sequences.remote(d))\n\n output = ray.get(output)\n output = torch.cat(output)\n\nSingle process calling multiple processes involves the following 3\nsteps:\n\n1. Split the data into DP parts on the control process.\n2. Send the data to remote, call the remote computation through RPC, and\n utilize multi-process computation.\n3. Obtain the computation results of each worker on the control process\n and merge them.\n\nFrequently calling these 3 steps on the controller process greatly hurts\ncode readability. **In verl, we have abstracted and encapsulated these 3\nsteps, so that the worker's method + dispatch + collect can be\nregistered into the worker_group**\n\n.. code:: python\n\n from verl.single_controller.base.decorator import register\n\n def dispatch_data(worker_group, data):\n return data.chunk(worker_group.world_size)\n \n def collect_data(worker_group, data):\n return torch.cat(data)\n\n dispatch_mode = {\n 'dispatch_fn': dispatch_data,\n 'collect_fn': collect_data\n }\n\n @register(dispatch_mode=dispatch_mode)\n def generate_sequences(self, data):\n pass\n\nIn this way, we can directly call the method inside the worker through\nthe ``worker_group`` on the control (driver) process (which is a single\nprocess):\n\n.. code:: python\n\n output = worker_group.generate_sequences(data)\n\nThis single line includes data splitting, data distribution and\ncomputation, and data collection.\n\nFurthermore, the model parallelism size of each model is usually fixed,\nincluding dp, tp, pp. So for these common distributed scenarios, we have\npre-implemented specific dispatch and collect methods,in `decorator.py `_, which can be directly used to wrap the computations.\n\n.. code:: python\n\n from verl.single_controller.base.decorator import register, Dispatch\n\n @register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)\n def generate_sequences(self, data: DataProto) -> DataProto:\n pass\n\nHere it requires the data interface to be ``DataProto``. Definition of\n``DataProto`` is in `protocol.py `_.\n\nStep 3: Main training loop\n~~~~~~~~~~~~~~~~~~~~~~~~~~\n\nWith the above training flows, we can implement the algorithm's control\nflow. It is recommended that ``main_task`` is also a ray remote process.\n\n.. code:: python\n\n @ray.remote(num_cpus=1)\n def main_task(config):\n # construct SampleGenerator\n resource_pool = RayResourcePool(process_on_nodes=[8] * 2) # 16 GPUs\n ray_cls = RayClassWithInitArgs(SampleGenerator, config=config) \n # put SampleGenerator onto resource pool\n sample_gen = RayWorkerGroup(resource_pool, ray_cls)\n \n # construct reference policy\n ray_cls = RayClassWithInitArgs(ReferencePolicy)\n ref_policy = RayWorkerGroup(resource_pool, ray_cls)\n \n # construct actor\n ray_cls = RayClassWithInitArgs(DPOActor) \n dpo_policy = RayWorkerGroup(resource_pool, ray_cls)\n \n dataloader = DataLoader()\n \n for data in dataloader:\n # generate data\n data = sample_gen.generate_sequences(data)\n # generate scores for each data \n data = generate_scores(data)\n # generate pairwise data using scores\n data = generate_pairwise_data(data)\n # generate ref_log_prob\n data.batch['ref_log_prob'] = ref_policy.infer(data)\n # update using dpo\n dpo_policy.update(data)\n # logging\n\nHere, different ``WorkerGroups`` can be placed in the same resource pool or\nin different resource pools using ``create_colocated_worker_cls``\nsimilar as in `ray_trainer.py `_.", "metadata": {"source": "volcengine/verl", "title": "docs/advance/dpo_extension.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/advance/dpo_extension.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 9680}}
+{"text": "Add models with the FSDP backend\n==================================\n\nModel\n--------------------------\n\nIn principle, our FSDP backend can support any HF model and we can\nsychronoize the actor model weight with vLLM using `hf_weight_loader.py `_.\nHowever, ``hf_weight_loader`` is will gather the full state_dict of a\nmodel during synchronization, which may cause OOM. We suggest using\n``dtensor_weight_loader`` which gather the full model parameter layer by\nlayer to reduce the peak memory usage. We already support dtensor weight\nloader for the models below in `dtensor_weight_loader.py `_.:\n\n- ``GPT2LMHeadModel``\n- ``LlamaForCausalLM``\n- ``LLaMAForCausalLM``\n- ``MistralForCausalLM``\n- ``InternLMForCausalLM``\n- ``AquilaModel``\n- ``AquilaForCausalLM``\n- ``Phi3ForCausalLM``\n- ``GemmaForCausalLM``\n- ``Gemma2ForCausalLM``\n- ``GPTBigCodeForCausalLM``\n- ``Starcoder2ForCausalLM``\n- ``Qwen2ForCausalLM``\n- ``DeepseekV2ForCausalLM``\n\nTo implement ``dtensor_weight_loader`` of a model that's supported in\nvLLM, follow the guide of gemma model below:\n\n1. Copy the\n ``load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]])`` from the vllm model class\n to ``dtensor_weight_loaders.py``\n2. Modify the arguments to\n ``(actor_weights: Dict, vllm_model: nn.Module)``\n3. Replace the ``self`` to ``vllm_model``\n4. Add the\n ``local_loaded_weight = redistribute_dtensor(param_name=name, loaded_weights=loaded_weight)``\n before each ``param = params_dict[name]`` and modify the following\n weight loading using ``local_loaded_weight``.\n5. Register the implemented dtensor weight loader to ``__MODEL_DTENSOR_WEIGHT_LOADER_REGISTRY__``.\n\n.. code-block:: diff\n\n - def load_weights(self, weights: Iterable[Tuple[str, torch.Tensor]]):\n + def gemma_dtensor_weight_loader(actor_weights: Dict, vllm_model: nn.Module) -> nn.Module:\n stacked_params_mapping = [\n # (param_name, shard_name, shard_id)\n (\"qkv_proj\", \"q_proj\", \"q\"),\n (\"qkv_proj\", \"k_proj\", \"k\"),\n (\"qkv_proj\", \"v_proj\", \"v\"),\n (\"gate_up_proj\", \"gate_proj\", 0),\n (\"gate_up_proj\", \"up_proj\", 1),\n ]\n - params_dict = dict(self.named_parameters())\n + params_dict = dict(vllm_model.named_parameters())\n loaded_params = set()\n - for name, loaded_weight in weights:\n + for name, loaded_weight in actor_weights.items():\n for (param_name, shard_name, shard_id) in stacked_params_mapping:\n if shard_name not in name:\n continue\n name = name.replace(shard_name, param_name)\n # Skip loading extra bias for GPTQ models.\n if name.endswith(\".bias\") and name not in params_dict:\n continue\n + local_loaded_weight = redistribute_dtensor(param_name=name, loaded_weights=loaded_weight)\n param = params_dict[name]\n weight_loader = param.weight_loader\n - weight_loader(param, loaded_weight, shard_id)\n + weight_loader(param, local_loaded_weight.to(dtype=param.dtype), shard_id)\n break\n else:\n # lm_head is not used in vllm as it is tied with embed_token.\n # To prevent errors, skip loading lm_head.weight.\n if \"lm_head.weight\" in name:\n continue\n # Skip loading extra bias for GPTQ models.\n if name.endswith(\".bias\") and name not in params_dict:\n continue\n + local_loaded_weight = redistribute_dtensor(param_name=name, loaded_weights=loaded_weight)\n param = params_dict[name]\n weight_loader = getattr(param, \"weight_loader\",\n default_weight_loader)\n - weight_loader(param, loaded_weight)\n + weight_loader(param, local_loaded_weight.to(dtype=param.dtype))\n loaded_params.add(name)\n unloaded_params = params_dict.keys() - loaded_params\n if unloaded_params:\n raise RuntimeError(\n \"Some weights are not initialized from checkpoints: \"\n f\"{unloaded_params}\")", "metadata": {"source": "volcengine/verl", "title": "docs/advance/fsdp_extension.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/advance/fsdp_extension.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 4399}}
+{"text": "Add models with the Megatron-LM backend\n=========================================\n\nModel\n-----------\n\nThe most challenging aspect to use the Megatron-LM backend is implementing\nthe models for training. Currently, we implement Llama model that\nsupport data parallelism, tensor parallelism, pipeline parallelism (also\nvPP) and sequence parallelism. We also implement remove padding (sequence packing) on Llama\nmodel, which can be found in `modeling_llama_megatron.py `_.\n\nTo support other model, users are required to implement:\n\n1. Implemnt a model similar to ``modeling_llama_megatron.py`` that satisfy the\n parallelism requirements of Megatron-LM. Then register your model in\n the `registry.py `_.\n2. Checkpoint utils that can load full checkpoint (e.g. huggingface\n checkpoint) to partitioned models during the runtime. Then register\n your loader to ``weight_loader_registry`` in `weight_loader_registry.py `_.\n3. Weight loader that synchronize the weight from Megatron to rollout\n (vLLM) model. Note that both the actor model and rollout model are\n partitioned during runtime. So, it's advisable to map the model name\n in actor model implementation. Otherwise, you may need an additional\n name mapping and even weight transformation. The weight loader implementation\n is in `megatron_weight_loaders.py `_.", "metadata": {"source": "volcengine/verl", "title": "docs/advance/megatron_extension.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/advance/megatron_extension.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 1688}}
+{"text": "Ray API Design Tutorial\n=======================================\n\nWe provide a tutorial for our Ray API design, including:\n\n- Ray basic concepts\n- Resource Pool and RayWorkerGroup\n- Data Dispatch, Execution and Collection\n- Initialize the RayWorkerGroup and execute the distributed computation in the given Resource Pool\n\nSee details in `tutorial.ipynb `_.", "metadata": {"source": "volcengine/verl", "title": "docs/advance/placement.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/advance/placement.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 429}}
+{"text": ".. _config-explain-page:\n\nConfig Explanation\n===================\n\nppo_trainer.yaml for FSDP Backend\n---------------------------------\n\nData\n~~~~\n\n.. code:: yaml\n\n data:\n tokenizer: null\n train_files: ~/data/rlhf/gsm8k/train.parquet\n val_files: ~/data/rlhf/gsm8k/test.parquet\n prompt_key: prompt\n max_prompt_length: 512\n max_response_length: 512\n train_batch_size: 1024\n val_batch_size: 1312\n return_raw_input_ids: False # This should be set to true when the tokenizer between policy and rm differs\n return_raw_chat: False\n\n- ``data.train_files``: Training set parquet. Can be a list or a single\n file. The program will read all files into memory, so it can't be too\n large (< 100GB). The path can be either local path or HDFS path. For\n HDFS path, we provide utils to download it to DRAM and convert the\n HDFS path to local path.\n- ``data.val_files``: Validation parquet. Can be a list or a single\n file.\n- ``data.prompt_key``: The field in the dataset where the prompt is\n located. Default is 'prompt'.\n- ``data.max_prompt_length``: Maximum prompt length. All prompts will be\n left-padded to this length. An error will be reported if the length is\n too long\n- ``data.max_response_length``: Maximum response length. Rollout in RL\n algorithms (e.g. PPO) generates up to this length\n- ``data.train_batch_size``: Batch size sampled for one training\n iteration of different RL algorithms.\n- ``data.val_batch_size``: Batch size sampled for one validation\n iteration.\n- ``data.return_raw_input_ids``: Whether to return the original\n input_ids without adding chat template. This is mainly used to\n accommodate situations where the reward model's chat template differs\n from the policy. It needs to be decoded first, then apply the RM's\n chat template. If using a model-based RM, and the policy and RM\n chat_templates are different, this flag needs to be set\n- ``data.return_raw_chat``:\n- ``data.truncation``: Truncate the input_ids or prompt length if they\n exceed max_prompt_length. Default is 'error', not allow exceed the\n max_prompt_length. The users should increase the max_prompt_length if\n throwing the error.\n\nActor/Rollout/Reference Policy\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\n.. code:: yaml\n\n actor_rollout_ref:\n hybrid_engine: True\n model:\n path: ~/models/deepseek-llm-7b-chat\n external_lib: null\n override_config: { }\n enable_gradient_checkpointing: False\n use_remove_padding: False\n actor:\n strategy: fsdp # This is for backward-compatibility\n ppo_mini_batch_size: 256\n ppo_micro_batch_size: null # will be deprecated, use ppo_micro_batch_size_per_gpu\n ppo_micro_batch_size_per_gpu: 8\n use_dynamic_bsz: False\n ppo_max_token_len_per_gpu: 16384 # n * ${data.max_prompt_length} + ${data.max_response_length}\n grad_clip: 1.0\n clip_ratio: 0.2\n entropy_coeff: 0.001\n use_kl_loss: False # True for GRPO\n kl_loss_coef: 0.001 # for grpo\n kl_loss_type: low_var_kl # for grpo\n ppo_epochs: 1\n shuffle: False\n ulysses_sequence_parallel_size: 1 # sp size\n optim:\n lr: 1e-6\n lr_warmup_steps_ratio: 0. # the total steps will be injected during runtime\n min_lr_ratio: null # only useful for warmup with cosine\n warmup_style: constant # select from constant/cosine\n total_training_steps: -1 # must be override by program\n fsdp_config:\n wrap_policy:\n # transformer_layer_cls_to_wrap: None\n min_num_params: 0\n param_offload: False\n grad_offload: False\n optimizer_offload: False\n fsdp_size: -1\n ref:\n fsdp_config:\n param_offload: False\n wrap_policy:\n # transformer_layer_cls_to_wrap: None\n min_num_params: 0\n log_prob_micro_batch_size: null # will be deprecated, use log_prob_micro_batch_size_per_gpu\n log_prob_micro_batch_size_per_gpu: 16\n log_prob_use_dynamic_bsz: ${actor_rollout_ref.actor.use_dynamic_bsz}\n log_prob_max_token_len_per_gpu: ${actor_rollout_ref.actor.ppo_max_token_len_per_gpu}\n ulysses_sequence_parallel_size: ${actor_rollout_ref.actor.ulysses_sequence_parallel_size} # sp size\n rollout:\n name: vllm\n temperature: 1.0\n top_k: -1 # 0 for hf rollout, -1 for vllm rollout\n top_p: 1\n prompt_length: ${data.max_prompt_length} # not use for opensource\n response_length: ${data.max_response_length}\n # for vllm rollout\n dtype: bfloat16 # should align with FSDP\n gpu_memory_utilization: 0.5\n ignore_eos: False\n enforce_eager: True\n free_cache_engine: True\n load_format: dummy_dtensor\n tensor_model_parallel_size: 2\n max_num_batched_tokens: 8192\n max_num_seqs: 1024\n log_prob_micro_batch_size: null # will be deprecated, use log_prob_micro_batch_size_per_gpu\n log_prob_micro_batch_size_per_gpu: 16\n log_prob_use_dynamic_bsz: ${actor_rollout_ref.actor.use_dynamic_bsz}\n log_prob_max_token_len_per_gpu: ${actor_rollout_ref.actor.ppo_max_token_len_per_gpu}\n # for hf rollout\n do_sample: True\n # number of responses (i.e. num sample times)\n n: 1 # > 1 for grpo\n\n**Common config for actor, rollout and reference model**\n\n- ``actor_rollout_ref.hybrid_engine``: Whether it's a hybrid engine,\n currently only supports hybrid engine\n- ``actor_rollout_ref.model.path``: Huggingface model path. This can be\n either local path or HDFS path. For HDFS path, we provide utils to\n download it to DRAM and convert the HDFS path to local path.\n- ``actor_rollout_ref.model.external_libs``: Additional Python packages\n that need to be imported. Used to register models or tokenizers into\n the Huggingface system.\n- ``actor_rollout_ref.model.override_config``: Used to override some of\n the model's original configurations, mainly dropout\n- ``actor_rollout_ref.model.enable_gradient_checkpointing``: Whether to\n enable gradient checkpointing for the actor\n\n**Actor model**\n\n- ``actor_rollout_ref.actor.strategy``: fsdp or megatron. In this\n example, we use fsdp backend.\n\n- ``actor_rollout_ref.actor.ppo_mini_batch_size``: One sample is split\n into multiple sub-batches with batch_size=ppo_mini_batch_size for PPO\n updates. The ppo_mini_batch_size is a global num across all workers/gpus\n\n- ``actor_rollout_ref.actor.ppo_micro_batch_size``: [Will be deprecated, use ppo_micro_batch_size_per_gpu] \n Similar to gradient accumulation, the micro_batch_size_per_gpu for one forward pass,\n trading speed for GPU memory. The value represent the global view.\n\n- ``actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu``: Similar to gradient\n accumulation, the micro_batch_size_per_gpu for one forward pass, trading speed\n for GPU memory. The value represent the local num per gpu.\n\n- ``actor_rollout_ref.actor.grad_clip``: Gradient clipping for actor\n updates\n\n- ``actor_rollout_ref.actor.clip_ratio``: PPO clip ratio\n\n- ``actor_rollout_ref.actor.entropy_coeff``: The weight of entropy when\n calculating PPO loss\n\n- ``actor_rollout_ref.actor.ppo_epochs``: Number of epochs for PPO\n updates on one set of sampled data\n\n- ``actor_rollout_ref.actor.shuffle``: Whether to shuffle data when\n there are multiple epochs\n\n- ``actor_rollout_ref.actor.optim``: Actor's optimizer parameters\n\n- ``actor_rollout_ref.actor.fsdp_config``: FSDP config for actor\n training\n\n - ``wrap_policy``: FSDP wrap policy. By default, it uses Huggingface's\n wrap policy, i.e., wrapping by DecoderLayer\n\n - No need to set transformer_layer_cls_to_wrap, so we comment it.\n\n - ``*_offload``: Whether to enable parameter, gradient and optimizer\n offload\n\n - Trading speed for GPU memory.\n\n**Reference Model**\n\n- ``actor_rollout_ref.ref``: FSDP config same as actor. **For models\n larger than 7B, it's recommended to turn on offload for ref by\n default**\n\n- ``actor_rollout_ref.ref.log_prob_micro_batch_size``: [Will be deprecate, use log_prob_micro_batch_size_per_gpu]\n The batch size for one forward pass in the computation of ``ref_log_prob``. The value represent the global num.\n\n- ``actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu``: The batch size\n for one forward pass in the computation of ``ref_log_prob``. The value represent the local num per gpu.\n\n**Rollout Model**\n\n- ``actor_rollout_ref.rollout.name``: hf/vllm. We use vLLM by default\n because it's much efficient and our hybrid engine is implemented with\n vLLM.\n\n- Rollout (Auto-regressive) parameters. The key should be equal to the\n property name in vLLM's ``SamplingParams``.\n\n - ``temperature``, ``top_k``, ``top_p`` and others: Sampling\n parameters in ``SamplingParams``.\n\n- ``dtype``: Rollout model parameters type. This should be align with\n the actor model parameter type in FSDP/Megatron backend.\n\n- ``gpu_memory_utilization``: The proportion of the remaining GPU memory\n allocated for kv cache after other models have initialized when using\n vllm.\n\n- ``tensor_model_parallel_size``: TP size for rollout. Only effective\n for vllm.\n\n- ``actor_rollout_ref.ref.log_prob_micro_batch_size``: [Will be deprecate, use log_prob_micro_batch_size_per_gpu]\n The batch size for one forward pass in the computation of ``log_prob``. The value represent the global num.\n\n- ``log_prob_micro_batch_size_per_gpu``: Micro batch size per gpu (The batch size for\n one forward pass) for recalculating ``log_prob``. The value represent the local num per gpu.\n\n- ``do_sample``: Whether to sample. If set to False, the rollout model\n will perform greedy sampling. We disable ``do_sample`` during\n validation.\n\n- ``actor_rollout_ref.rollout.ignore_eos``: Whether to ignore the EOS\n token and continue generating tokens after the EOS token is generated.\n\n- ``actor_rollout_ref.rollout.free_cache_engine``: Offload the KVCache\n after rollout generation stage. Default is True. When set to True, we\n need to disable the usage of CUDAGraph (set ``enforce_eager`` to\n True.)\n\n- ``actor_rollout_ref.rollout.enforce_eager``: Whether to use CUDAGraph\n in vLLM generation. Default set to True to disable CUDAGraph.\n\n- ``actor_rollout_ref.rollout.load_format``: Which weight loader to use\n to load the actor model weights to the rollout model.\n\n - ``auto``: Use Megatron weight loader.\n - ``megatron``: Use Megatron weight loader. Deployed with Megatron\n backend. The input model ``state_dict()`` is already partitioned\n along TP dimension and already gathered along PP dimension. This\n weight loader requires that the Rollout model and Actor model's\n parameters shape and name should be identical.\n - ``dtensor``: Default solution when using Huggingface weight loader.\n Deployed with FSDP backend and the state_dict_type is\n ``StateDictType.SHARDED_STATE_DICT``. Recommend to use this weight\n loader\n - ``hf``: Use Huggingface weight loader. Deployed with FSDP backend\n and the state_dict_type is ``StateDictType.FULL_STATE_DICT``. This\n solution doesn't need to rewrite the weight loader for each model\n implemented in vLLM but it results in larger peak memory usage.\n - ``dummy_hf``, ``dummy_megatron``, ``dummy_dtensor``: Random\n initialization.\n\n.. note:: **NOTED**: In this config field, users only need to select from ``dummy_megatron``, ``dummy_dtensor``, ``dummy_hf`` for rollout initialization and our hybrid engine will select the corresponding weight loader (i.e., ``megatron``, ``dtensor``, ``hf``) during actor/rollout weight synchronization.\n\nCritic Model\n~~~~~~~~~~~~\n\nMost parameters for Critic are similar to Actor Model.\n\nReward Model\n~~~~~~~~~~~~\n\n.. code:: yaml\n\n reward_model:\n enable: False\n model:\n input_tokenizer: ${actor_rollout_ref.model.path} # set this to null if the chat template is identical\n path: ~/models/Anomy-RM-v0.1\n external_lib: ${actor_rollout_ref.model.external_lib}\n fsdp_config:\n min_num_params: 0\n param_offload: False\n micro_batch_size_per_gpu: 16\n max_length: null\n reward_manager: naive\n\n- ``reward_model.enable``: Whether to enable reward model. If False, we\n compute the reward only with the user-defined reward functions. In\n GSM8K and Math examples, we disable reward model. For RLHF alignment\n example using full_hh_rlhf, we utilize reward model to assess the\n responses. If False, the following parameters are not effective.\n- ``reward_model.model``\n\n - ``input_tokenizer``: Input tokenizer. If the reward model's chat\n template is inconsistent with the policy, we need to first decode to\n plaintext, then apply the rm's chat_template. Then score with RM. If\n chat_templates are consistent, it can be set to null.\n - ``path``: RM's HDFS path or local path. Note that RM only supports\n AutoModelForSequenceClassification. Other model types need to define\n their own RewardModelWorker and pass it from the code.\n- ``reward_model.reward_manager``: Reward Manager. This defines the mechanism\n of computing rule-based reward and handling different reward sources. Default\n if ``naive``. If all verification functions are multiprocessing-safe, the reward\n manager can be set to ``prime`` for parallel verification.\n\nAlgorithm\n~~~~~~~~~\n\n.. code:: yaml\n\n algorithm:\n gamma: 1.0\n lam: 1.0\n adv_estimator: gae\n kl_penalty: kl # how to estimate kl divergence\n kl_ctrl:\n type: fixed\n kl_coef: 0.005\n\n- ``gemma``: discount factor\n- ``lam``: Trade-off between bias and variance in the GAE estimator\n- ``adv_estimator``: Support ``gae``, ``grpo``, ``reinforce_plus_plus``. \n- ``kl_penalty``: Support ``kl``, ``abs``, ``mse`` and ``full``. How to\n calculate the kl divergence between actor and reference policy. For\n specific options, refer to `core_algos.py `_ .\n\nTrainer\n~~~~~~~\n\n.. code:: yaml\n\n trainer:\n total_epochs: 30\n project_name: verl_examples\n experiment_name: gsm8k\n logger: ['console', 'wandb']\n nnodes: 1\n n_gpus_per_node: 8\n save_freq: -1\n test_freq: 2\n critic_warmup: 0\n default_hdfs_dir: ~/experiments/gsm8k/ppo/${trainer.experiment_name} # hdfs checkpoint path\n default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name} # local checkpoint path\n\n- ``trainer.total_epochs``: Number of epochs in training.\n- ``trainer.project_name``: For wandb\n- ``trainer.experiment_name``: For wandb\n- ``trainer.logger``: Support console and wandb\n- ``trainer.nnodes``: Number of nodes used in the training.\n- ``trainer.n_gpus_per_node``: Number of GPUs per node.\n- ``trainer.save_freq``: The frequency (by iteration) to save checkpoint\n of the actor and critic model.\n- ``trainer.test_freq``: The validation frequency (by iteration).\n- ``trainer.critic_warmup``: The number of iteration to train the critic\n model before actual policy learning.", "metadata": {"source": "volcengine/verl", "title": "docs/examples/config.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/examples/config.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 14900}}
+{"text": "GSM8K Example\n=============\n\nIntroduction\n------------\n\nIn this example, we train an LLM to tackle the GSM8k task.\n\nPaper: https://arxiv.org/pdf/2110.14168\n\nDataset: https://huggingface.co/datasets/gsm8k\n\nNote that the original paper mainly focuses on training a verifier (a\nreward model) to solve math problems via Best-of-N sampling. In this\nexample, we train an RLHF agent using a rule-based reward model.\n\nDataset Introduction\n--------------------\n\nGSM8k is a math problem dataset. The prompt is an elementary school\nproblem. The LLM model is required to answer the math problem.\n\nThe training set contains 7473 samples and the test set contains 1319\nsamples.\n\n**An example**\n\nPrompt\n\n Katy makes coffee using teaspoons of sugar and cups of water in the\n ratio of 7:13. If she used a total of 120 teaspoons of sugar and cups\n of water, calculate the number of teaspoonfuls of sugar she used.\n\nSolution\n\n The total ratio representing the ingredients she used to make the\n coffee is 7+13 = <<7+13=20>>20 Since the fraction representing the\n number of teaspoons she used is 7/20, she used 7/20\\ *120 =\n <<7/20*\\ 120=42>>42 #### 42\n\nStep 1: Prepare dataset\n-----------------------\n\n.. code:: bash\n\n cd examples/data_preprocess\n python3 gsm8k.py --local_dir ~/data/gsm8k\n\nStep 2: Download Model\n----------------------\n\nThere're three ways to prepare the model checkpoints for post-training:\n\n- Download the required models from hugging face\n\n.. code:: bash\n\n huggingface-cli download deepseek-ai/deepseek-math-7b-instruct --local-dir ~/models/deepseek-math-7b-instruct --local-dir-use-symlinks False\n\n- Already store your store model in the local directory or HDFS path.\n- Also, you can directly use the model name in huggingface (e.g.,\n deepseek-ai/deepseek-math-7b-instruct) in\n ``actor_rollout_ref.model.path`` and ``critic.model.path`` field in\n the run script.\n\nNoted that users should prepare checkpoints for actor, critic and reward\nmodel.\n\n[Optional] Step 3: SFT your Model\n---------------------------------\n\nWe provide a SFT Trainer using PyTorch FSDP in\n`fsdp_sft_trainer.py `_. \nUsers can customize their own SFT\nscript using our FSDP SFT Trainer.\n\nWe also provide various training scripts for SFT on GSM8K dataset in `gsm8k sft directory `_.\n\n.. code:: shell\n\n set -x\n\n torchrun -m verl.trainer.fsdp_sft_trainer \\\n data.train_files=$HOME/data/gsm8k/train.parquet \\\n data.val_files=$HOME/data/gsm8k/test.parquet \\\n data.prompt_key=question \\\n data.response_key=answer \\\n data.micro_batch_size_per_gpu=8 \\\n model.partial_pretrain=deepseek-ai/deepseek-coder-6.7b-instruct \\\n trainer.default_hdfs_dir=hdfs://user/verl/experiments/gsm8k/deepseek-coder-6.7b-instruct/ \\\n trainer.project_name=gsm8k-sft \\\n trainer.experiment_name=gsm8k-sft-deepseek-coder-6.7b-instruct \\\n trainer.total_epochs=4 \\\n trainer.logger=['console','wandb']\n\nStep 4: Perform PPO training with your model on GSM8K Dataset\n-------------------------------------------------------------\n\n- Prepare your own run.sh script. Here's an example for GSM8k dataset\n and deepseek-llm-7b-chat model.\n- Users could replace the ``data.train_files`` ,\\ ``data.val_files``,\n ``actor_rollout_ref.model.path`` and ``critic.model.path`` based on\n their environment.\n- See :doc:`config` for detailed explanation of each config field.\n\n**Reward Model/Function**\n\nWe use a rule-based reward model. We force the model to produce a final\nanswer following 4 “#” as shown in the solution. We extract the final\nanswer from both the solution and model's output using regular\nexpression matching. We compare them and assign a reward of 1 to correct\nanswer, 0.1 to incorrect answer and 0 to no answer.\n\n**Training Script**\n\nThe training script example for FSDP and Megatron-LM backend are stored in examples/ppo_trainer directory.\n\n.. code:: bash\n\n cd ../ppo_trainer\n bash run_deepseek7b_llm.sh\n\nThe script of run_deepseek7b_llm.sh\n\n.. code:: bash\n\n set -x\n\n python3 -m verl.trainer.main_ppo \\\n data.train_files=$HOME/data/gsm8k/train.parquet \\\n data.val_files=$HOME/data/gsm8k/test.parquet \\\n data.train_batch_size=1024 \\\n data.val_batch_size=1312 \\\n data.max_prompt_length=512 \\\n data.max_response_length=512 \\\n actor_rollout_ref.model.path=deepseek-ai/deepseek-llm-7b-chat \\\n actor_rollout_ref.actor.optim.lr=1e-6 \\\n actor_rollout_ref.model.use_remove_padding=True \\\n actor_rollout_ref.actor.ppo_mini_batch_size=256 \\\n actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=16 \\\n actor_rollout_ref.actor.fsdp_config.param_offload=False \\\n actor_rollout_ref.actor.fsdp_config.grad_offload=False \\\n actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \\\n actor_rollout_ref.model.enable_gradient_checkpointing=True \\\n actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32 \\\n actor_rollout_ref.rollout.tensor_model_parallel_size=4 \\\n actor_rollout_ref.rollout.name=vllm \\\n actor_rollout_ref.rollout.gpu_memory_utilization=0.5 \\\n actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32 \\\n actor_rollout_ref.ref.fsdp_config.param_offload=True \\\n critic.optim.lr=1e-5 \\\n critic.model.use_remove_padding=True \\\n critic.model.path=deepseek-ai/deepseek-llm-7b-chat \\\n critic.model.enable_gradient_checkpointing=True \\\n critic.ppo_micro_batch_size_per_gpu=32 \\\n critic.model.fsdp_config.param_offload=False \\\n critic.model.fsdp_config.grad_offload=False \\\n critic.model.fsdp_config.optimizer_offload=False \\\n algorithm.kl_ctrl.kl_coef=0.001 \\\n trainer.critic_warmup=0 \\\n trainer.logger=['console','wandb'] \\\n trainer.project_name='verl_example_gsm8k' \\\n trainer.experiment_name='deepseek_llm_7b_function_rm' \\\n trainer.n_gpus_per_node=8 \\\n trainer.nnodes=1 \\\n trainer.save_freq=-1 \\\n trainer.test_freq=1 \\\n trainer.total_epochs=15 $@", "metadata": {"source": "volcengine/verl", "title": "docs/examples/gsm8k_example.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/examples/gsm8k_example.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 6134}}
+{"text": "PPO Example Architecture\n========================\n\nLet's start with the Proximal Policy Optimization algorithm, which is\nmost widely used algorithm in LLM post-training.\n\nThe main entry point of the PPO algorithm example is:\n`main_ppo.py `_.\nIn this tutorial, we will go through the code architecture in `main_ppo.py `_.\n\nDefine the data\n---------------\n\nUsers need to preprocess and store the dataset in parquet files.\nAnd we implement `RLHFDataset` to load and tokenize the parquet files.\n\nFor ``RLHFDataset`` (Default), at least 1 fields are required:\n\n- ``prompt``: Contains the string prompt\n\nWe already provide some examples of processing the datasets to parquet\nfiles in `data_preprocess directory `_. Currently, we support\npreprocess of GSM8k, MATH, Hellasage, Full_hh_rlhf datasets. See :doc:`../preparation/prepare_data` for\nmore information.\n\nDefine the reward functions for different datasets\n--------------------------------------------------\n\nIn this main entry point, the users only need to define their own reward\nfunction based on the datasets (or applications) utilized in PPO\ntraining.\n\nFor example, we already provide reward functions for `GSM8k `_ \nand `MATH `_\ndatasets in the ``_select_rm_score_fn``. In the ``RewardManager``, we\nwill compute the reward score based on the data_source to select\ncorresponding reward functions. For some RLHF datasets (e.g.,\nfull_hh_rlhf), the reward model is utilized to assess the responses\nwithout any reward functions. In this case, the ``RewardManager`` will\nreturn the ``rm_score`` computed by the reward model directly.\n\nSee `reward functions `_ for detailed implementation.\n\nDefine worker classes\n---------------------\n\n.. code:: python\n\n if config.actor_rollout_ref.actor.strategy == 'fsdp': # for FSDP backend\n assert config.actor_rollout_ref.actor.strategy == config.critic.strategy\n from verl.workers.fsdp_workers import ActorRolloutRefWorker, CriticWorker\n from verl.single_controller.ray import RayWorkerGroup\n ray_worker_group_cls = RayWorkerGroup\n\n elif config.actor_rollout_ref.actor.strategy == 'megatron': # for Megatron backend\n assert config.actor_rollout_ref.actor.strategy == config.critic.strategy\n from verl.workers.megatron_workers import ActorRolloutRefWorker, CriticWorker\n from verl.single_controller.ray.megatron import NVMegatronRayWorkerGroup\n ray_worker_group_cls = NVMegatronRayWorkerGroup # Ray worker class for Megatron-LM\n\n else:\n raise NotImplementedError\n\n from verl.trainer.ppo.ray_trainer import ResourcePoolManager, Role\n\n role_worker_mapping = {\n Role.ActorRollout: ActorRolloutRefWorker,\n Role.Critic: CriticWorker,\n Role.RefPolicy: ActorRolloutRefWorker\n }\n\n global_pool_id = 'global_pool'\n resource_pool_spec = {\n global_pool_id: [config.trainer.n_gpus_per_node] * config.trainer.nnodes,\n }\n mapping = {\n Role.ActorRollout: global_pool_id,\n Role.Critic: global_pool_id,\n Role.RefPolicy: global_pool_id,\n }\n\nStep 1: Construct the mapping between roles and workers\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\nA role represents a group of workers in the same process. We have\npre-defined several roles in `ray_trainer.py `_.\n\n.. code:: python\n\n class Role(Enum):\n \"\"\"\n To create more roles dynamically, you can subclass Role and add new members\n \"\"\"\n Actor = 0 # This worker only has Actor\n Rollout = 1 # This worker only has Rollout\n ActorRollout = 2 # This worker has both actor and rollout, it's a HybridEngine\n Critic = 3 # This worker only has critic\n RefPolicy = 4 # This worker only has reference policy\n RewardModel = 5 # This worker only has reward model\n ActorRolloutRef = 6 # This worker contains actor, rollout and reference policy simultaneously \n\nStep 2: Define the worker class corresponding to this role\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\n- We have pre-implemented the ``ActorRolloutRefWorker``. Through\n different configs, it can be a standalone actor, a standalone rollout,\n an ActorRollout HybridEngine, or an ActorRolloutRef HybridEngine\n- We also pre-implemented workers for ``Actor``, ``Rollout``,\n ``Critic``, ``Reward Model`` and ``Reference model`` on two different\n backend: PyTorch FSDP\n and Megatron-LM.\n See `FSDP Workers `_ \n and `Megatron-LM Workers `_\n for more information.\n\nStep 3: Define resource pool id and resource pool spec\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\n- Resource pool is a division of global GPU resources,\n ``resource_pool_spec`` is a dict, mapping from id to # of GPUs\n\n - In the above example, we defined a global resource pool:\n global_pool_id, and then put all roles on this one resource pool\n with all the GPUs in this post-training task. This refers to\n *co-locate* placement where all the models share the same set of\n GPUs.\n\n- See resource pool and placement for advance usage.\n\nDefining reward model/function\n------------------------------\n\n.. code:: python\n\n # we should adopt a multi-source reward function here\n # - for rule-based rm, we directly call a reward score\n # - for model-based rm, we call a model\n # - for code related prompt, we send to a sandbox if there are test cases\n # - finally, we combine all the rewards together\n # - The reward type depends on the tag of the data\n if config.reward_model.enable:\n from verl.workers.fsdp_workers import RewardModelWorker\n role_worker_mapping[Role.RewardModel] = RewardModelWorker\n mapping[Role.RewardModel] = global_pool_id\n \n reward_fn = RewardManager(tokenizer=tokenizer, num_examine=0)\n\n # Note that we always use function-based RM for validation\n val_reward_fn = RewardManager(tokenizer=tokenizer, num_examine=1)\n\n resource_pool_manager = ResourcePoolManager(resource_pool_spec=resource_pool_spec, mapping=mapping)\n\nSince not all tasks use model-based RM, users need to define here\nwhether it's a model-based RM or a function-based RM\n\n- If it's a model-based RM, directly add the ``RewardModel`` role in the\n resource mapping and add it to the resource pool mapping.\n\n - Note that the pre-defined ``RewardModelWorker`` only supports models\n with the structure of huggingface\n ``AutoModelForSequenceClassification``. If it's not this model, you\n need to define your own RewardModelWorker in `FSDP Workers `_ \n and `Megatron-LM Workers `_.\n\n- If it's a function-based RM, the users are required to classified the\n reward function for each datasets.\n\n.. code:: python\n\n def _select_rm_score_fn(data_source):\n if data_source == 'openai/gsm8k':\n return gsm8k.compute_score\n elif data_source == 'lighteval/MATH':\n return math.compute_score\n else:\n raise NotImplementedError\n\nSee reward functions implemented in `directory `_ \nfor more information.\n\nDefine, init and run the PPO Trainer\n------------------------------------\n\n.. code:: python\n\n trainer = RayPPOTrainer(config=config,\n tokenizer=tokenizer,\n role_worker_mapping=role_worker_mapping,\n resource_pool_manager=resource_pool_manager,\n ray_worker_group_cls=ray_worker_group_cls,\n reward_fn=reward_fn,\n val_reward_fn=val_reward_fn)\n trainer.init_workers()\n trainer.fit()\n\n- We first initialize the ``RayPPOTrainer`` with user config, tokenizer\n and all the above worker mapping, resource pool, worker group and\n reward functions\n- We first call the ``trainer.init_workers()`` to initialize the models\n on the allocated GPUs (in the resource pool)\n- The actual PPO training will be executed in ``trainer.fit()``\n\nverl can be easily extended to other RL algorithms by reusing the Ray\nmodel workers, resource pool and reward functions. See :doc:`extension<../advance/dpo_extension>` for\nmore information.\n\nDetails of the ``RayPPOTrainer`` is discussed in :doc:`Ray Trainer<../workers/ray_trainer>`.", "metadata": {"source": "volcengine/verl", "title": "docs/examples/ppo_code_architecture.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/examples/ppo_code_architecture.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 9020}}
+{"text": ".. _algo-baseline-page:\n\nAlgorithm Baselines\n===================\n\nGSM8k \n------------------\n\nAssuming GSM8k dataset is preprocess via ``python3 examples/data_preprocess/gsm8k.py``\n\nRefer to the table below to reproduce PPO training from different pre-trained models.\n\n.. _Huggingface: https://huggingface.co/google/gemma-2-2b-it#benchmark-results\n.. _SFT Command and Logs: https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/gemma-2-2b-it-sft-0.411.log\n.. _SFT+PPO Command and Logs: https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/gemma-2-2b-it-ppo-bsz512_4-prompt1024-resp-512-0.640.log\n.. _wandb: https://api.wandb.ai/links/verl-team/h7ux8602\n.. _Qwen Blog: https://qwenlm.github.io/blog/qwen2.5-llm/\n.. _PPO Command and Logs: https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/Qwen2.5-0.5B-bsz256_2-prompt1024-resp512-0.567.log\n.. _Megatron PPO Command and Logs: https://github.com/eric-haibin-lin/verl-data/blob/experiments/gsm8k/deepseek-llm-7b-chat-megatron-bsz256_4-prompt512-resp512-0.695.log\n.. _Qwen7b GRPO Script: https://github.com/volcengine/verl/blob/a65c9157bc0b85b64cd753de19f94e80a11bd871/examples/grpo_trainer/run_qwen2-7b_seq_balance.sh\n.. _Megatron wandb: https://wandb.ai/verl-team/verl_megatron_gsm8k_examples/runs/10fetyr3\n.. _Qwen7b ReMax Script: https://github.com/eric-haibin-lin/verl/blob/main/examples/remax_trainer/run_qwen2.5-3b_seq_balance.sh\n.. _Qwen7b ReMax Wandb: https://wandb.ai/liziniu1997/verl_remax_example_gsm8k/runs/vxl10pln\n\n+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+\n| Model | Method | Test score | Details |\n+==================================+========================+============+=====================+=========================================================================+\n| google/gemma-2-2b-it | pretrained checkpoint | 23.9 | `Huggingface`_ |\n+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+\n| google/gemma-2-2b-it | SFT | 52.06 | `SFT Command and Logs`_ |\n+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+\n| google/gemma-2-2b-it | SFT + PPO | 64.02 | `SFT+PPO Command and Logs`_, `wandb`_ |\n+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+\n| Qwen/Qwen2.5-0.5B-Instruct | pretrained checkpoint | 36.4 | `Qwen Blog`_ |\n+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+\n| Qwen/Qwen2.5-0.5B-Instruct | PPO | 56.7 | `PPO Command and Logs`_ |\n+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+\n| deepseek-ai/deepseek-llm-7b-chat | PPO | 69.5 [1]_ | `Megatron PPO Command and Logs`_, `Megatron wandb`_ |\n+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+\n| Qwen/Qwen2-7B-Instruct | GRPO | 89 | `Qwen7b GRPO Script`_ |\n+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+\n| Qwen/Qwen2.5-7B-Instruct | ReMax | 97 | `Qwen7b ReMax Script`_, `Qwen7b ReMax Wandb`_ |\n+----------------------------------+------------------------+------------+-----------------------------------------------------------------------------------------------+\n\n.. [1] During the evaluation, we have only extracted answers following the format \"####\". A more flexible answer exaction, longer response length and better prompt engineering may lead to higher score.", "metadata": {"source": "volcengine/verl", "title": "docs/experiment/ppo.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/experiment/ppo.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 4971}}
+{"text": "Frequently Asked Questions\n====================================\n\nRay related\n------------\n\nHow to add breakpoint for debugging with distributed Ray?\n^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n\nPlease checkout the official debugging guide from Ray: https://docs.ray.io/en/latest/ray-observability/ray-distributed-debugger.html\n\n\nDistributed training\n------------------------\n\nHow to run multi-node post-training with Ray?\n^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n\nYou can start a ray cluster and submit a ray job, following the official guide from Ray: https://docs.ray.io/en/latest/ray-core/starting-ray.html\n\nIf your cluster is managed by Slurm, please refer to the guide for deploying Ray on Slurm: https://docs.ray.io/en/latest/cluster/vms/user-guides/community/slurm.html", "metadata": {"source": "volcengine/verl", "title": "docs/faq/faq.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/faq/faq.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 965}}
+{"text": "Performance Tuning Guide\n==============================\n\nAuthor: `Guangming Sheng `_\n\nIn this section, we will discuss how to tune the performance of all the stages in verl, including:\n\n1. Rollout generation throughput.\n\n2. Enable `use_remove_padding=True` for sequence packing (i.e., data packing and remove padding).\n\n3. Batch size tuning for forward and backward computation\n\n4. Enable ``use_dynamic_bsz=True`` for higher throughput.\n\n5. Utilize Ulysses Sequence Parallel for Long Context Training\n\n6. LigerKernel for SFT performance optimization\n\nRollout Generation Tuning\n--------------------------\n\nverl currently supports two rollout backends: vLLM and TGI (with SGLang support coming soon). \n\nBelow are key factors for tuning vLLM-based rollout. Before tuning, we recommend setting ``actor_rollout_ref.rollout.disable_log_stats=False`` so that rollout statistics are logged.\n\n- Increase ``gpu_memory_utilization``. The vLLM pre-allocates GPU KVCache by using gpu_memory_utilization% of the remaining memory. \n However, if model parameters and optimizer states are not offloaded, using too high a fraction can lead to OOM. \n A value between 0.5 and 0.7 often strikes a good balance between high throughput and avoiding OOM.\n\n- Adjust ``max_num_seqs`` or ``max_num_batched_tokens``.\n If the GPU cache utilization is relatively low in the log, increase ``max_num_seqs`` or ``max_num_batched_tokens`` \n can enlarge the effective batch size in the decoding stage, allowing more concurrent requests per batch. \n We recommend setting ``max_num_batched_tokens > 2048`` for higher throughput.\n\n- Use a smaller ``tensor_parallel_size``. \n When GPU resources allow, a smaller tensor parallel size spawns more vLLM replicas. \n Data parallelism (DP) can yield higher throughput than tensor parallelism (TP), but also increases KVCache consumption. \n Carefully balance the trade-off between more replicas and higher memory usage.\n Our experient in Sec. 8.4 of `HybridFlow paper `_ evaluate this trade-off.\n\nMore tuning details such as dealing with Preemption and Chunked-prefill\ncan be found in `vLLM official tuning guide `_ \n\nEnable remove padding (sequence packing)\n-----------------------------------------\n\nCurrently, for llama, mistral, gemma1 and qwen based models, users can enable `use_remove_padding=True` to utilize the \nsequence packing implementation provided by transformers library.\n\nFor other models, transformers library may also support it but we haven't tested it yet.\nUsers can add the desired model config to the `test_transformer.py `_ file.\nAnd test its functionaility by running the following command:\n\n.. code-block:: bash\n\n pytest -s tests/model/test_transformer.py\n\nIf the test passes, you can add your desired model into the model `registry.py `_ file.\nThen, you can enjoy the performance boost of sequence packing\nand welcome to PR your tested model to verl!\n\n\nBatch Size Tuning\n-----------------\n\nTo achieve higher throughput in experience preparation (i.e., model fwd) and model update (i.e., actor/critic fwd/bwd), \nusers may need to tune the ``*micro_batch_size_per_gpu`` for different computation.\n\nIn verl, the core principle for setting batch sizes is:\n\n- **Algorithmic metrics** (train batch size, PPO mini-batch size) are *global* (from a single-controller perspective), \n normalized in each worker. See the `normalization code `_.\n\n- **Performance-related parameters** (micro batch size, max token length for dynamic batch size) are *local* parameters that define the per-GPU data allocations. \n See the `normalization code `_.\n\n.. note:: In your training script, please use ``*micro_batch_size_per_gpu`` instead of ``*micro_batch_size``. \n So that you don't need to consider the normalization of the ``micro_batch_size`` and ``micro_batch_size`` will be deprecated.\n\nBatch Size Tuning tips\n\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\n\nTherefore, users may need to tune the ``*micro_batch_size_per_gpu`` to accelerate training. Here're some tips:\n\n1. **Enable gradient checkpointing**: \n Set ``actor_rollout_ref.model.enable_gradient_checkpointing=True`` and ``critic.model.enable_gradient_checkpointing=True``. \n This often allows for larger micro-batch sizes and will be beneficial for large mini-batch training.\n\n2. Increase the ``*micro_batch_size_per_gpu`` as much as possible till equals to normalized ``mini_batch_size``.\n\n3. **Use larger forward-only parameters**: \n Forward only parameter, such as ``actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu``, \n ``actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu``, ``critic.forward_micro_batch_size_per_gpu`` could be larger (e.g., 2x) than training related micro batch sizes,\n such as ``actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu``, ``critic.ppo_micro_batch_size_per_gpu``.\n\n4. **Allow larger micro-batch sizes for Critic and Reward models**:\n micro batch size of Critic and Reward model could be larger than Actor model. This is because the actor model has much larger vocab size in the final layer.\n\n\nTuning for Dynamic Batch Size\n-----------------------------\n\nDynamic batch size is a technique that allows the model to process similar number of tokens in a single forward pass (with different actual batch sizes).\nThis can significantly improve the training efficiency and reduce the memory usage.\n\nTo utilize this technique, users can set ``use_dynamic_bsz=True`` in actor, ref, critic and reward models.\nWith ``use_dynamic_bsz=True``, users don't need to tune ``*micro_batch_size_per_gpu``. \nInstead, users should tune the following parameters:\n\n- ``actor_rollout_ref.actor.ppo_max_token_len_per_gpu``, ``critic.ppo_max_token_len_per_gpu``: \n The maximum number of tokens to be processed in fwd and bwd of ``update_policy`` and ``update_critic``.\n\n- ``actor_rollout_ref.ref.log_prob_max_token_len_per_gpu`` and ``actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu``: \n The maximum number of tokens to be processed in a the fwd computation of ``compute_log_prob`` and ``comptue_ref_log_prob``.\n\n- ``critic.forward_micro_batch_size_per_gpu``, ``reward_model.forward_micro_batch_size_per_gpu``: \n The maximum number of tokens to be processed in a the fwd computation of ``compute_values``, ``compute_rm_score``.\n\nDynamic Batch Size Tuning tips\n\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\n\nHere're some tips to tune the above parameters:\n\n1. **Increase** ``actor_rollout_ref.actor.ppo_max_token_len_per_gpu`` \n Make it at least 2 x (max_prompt_length + max_response_length). We set it to 3x in `run_qwen2-7b_rm_seq_balance.sh `_.\n Try to increase it to get higher throughput.\n\n2. **Forward-only parameters can be larger**: \n Similar to the non-dynamic-batch scenario, forward-only token limits can exceed those used in forward/backward operations.\n \n3. **Use larger limits for Critic and Reward models**:\n Critic and Reward parameters can be set at least 2× the Actor’s limits. For instance, we set them to 4× here: \n `run_qwen2-7b_rm_seq_balance.sh `_\n \n.. :math:`\\text{critic.ppo_max_token_len_per_gpu} = 2 \\times \\text{actor.ppo_max_token_len_per_gpu})`.\n\nUlysses Sequence Parallel for Long Context Training\n----------------------------------------------------\n\nTo utilize this technique, users can set ``ulysses_sequence_parallel_size>1`` in actor, ref, critic and reward models.\n\nWe support different model utilize different ulysses_sequence_parallel_size sizes.\n\nTo train log sequence (>32k), users may need to decrease the ``*micro_batch_size_per_gpu`` and ``*max_token_len_per_gpu`` to avoid OOM.\n\nLigerKernel for SFT\n----------------------\n\nLigerKernel is a high-performance kernel for Supervised Fine-Tuning (SFT) that can improve training efficiency. To enable LigerKernel in your SFT training:\n\n1. In your SFT configuration file (e.g., ``verl/trainer/config/sft_trainer.yaml``), set the ``use_liger`` parameter:\n\n .. code-block:: yaml\n\n model:\n use_liger: True # Enable LigerKernel for SFT\n\n2. The default value is ``False``. Enable it only when you want to use LigerKernel's optimizations.\n\n3. LigerKernel is particularly useful for improving training performance in SFT scenarios.", "metadata": {"source": "volcengine/verl", "title": "docs/perf/perf_tuning.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/perf/perf_tuning.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 8837}}
+{"text": "Prepare Data for Post-Training\n========================================\n\nBefore starting the post-training job, we need to prepare the data for\nthe policy training. The data should be stored in the parquet format.\n\nWe provide several data preprocess scripts for different datasets,\nincluding GSM8K, MATH, HelloSwag, Full_hh_rlhf. To prepare other datasets, we need\nto follow the following steps: The data preprocess script can be divided\ninto two parts:\n\n1. The first part is the common part, which loads the dataset from\n huggingface's ``datasets`` package. Then preprocess the datasets with\n the ``make_map_fn`` and then store in the parquet format.\n\n.. code:: python\n\n import re\n import os\n import datasets\n\n from verl.utils.hdfs_io import copy, makedirs\n import argparse\n\n # To extract the solution for each prompts in the dataset\n # def extract_solution(solution_str): \n # ...\n\n\n if __name__ == '__main__':\n parser = argparse.ArgumentParser()\n parser.add_argument('--local_dir', default='/opt/tiger/gsm8k')\n parser.add_argument('--hdfs_dir', default=None)\n\n args = parser.parse_args()\n\n num_few_shot = 5\n data_source = 'openai/gsm8k'\n\n dataset = datasets.load_dataset(data_source, 'main')\n\n train_dataset = dataset['train']\n test_dataset = dataset['test']\n\n # Construct a `def make_map_fn(split)` for the corresponding datasets.\n # ...\n \n train_dataset = train_dataset.map(function=make_map_fn('train'), with_indices=True)\n test_dataset = test_dataset.map(function=make_map_fn('test'), with_indices=True)\n\n local_dir = args.local_dir\n hdfs_dir = args.hdfs_dir\n\n train_dataset.to_parquet(os.path.join(local_dir, 'train.parquet'))\n test_dataset.to_parquet(os.path.join(local_dir, 'test.parquet'))\n\n makedirs(hdfs_dir)\n\n copy(src=local_dir, dst=hdfs_dir)\n\n2. The users are required to implement the ``make_map_fn()`` function\n (as well as the ``extract_solution``) on their own to support\n different datasets or tasks.\n\nWe already implemented the data preprocess of GSM8k, MATH, Hellaswag and Full_hh_rlhf\ndatasets. And we take the GSM8k dataset as an example:\n\n**GSM8K**\n\nIn the ``make_map_fn``, each data field should consist of the following\n5 fields:\n\n1. ``data_source``: The name of the dataset. To index the corresponding\n reward function in the ``RewardModule``\n2. ``prompt``: This field should be constructed in the format of\n huggingface chat_template. The tokenizer in ``RLHFDataset`` will\n apply chat template and tokenize the prompt.\n3. ``ability``: Define the task category.\n4. ``reward_model``: Currently, we only utilize the ``ground_truth``\n field during evaluation. The ``ground_truth`` is computed by the\n ``extract_solution`` function. **NOTED** that the implementation of\n the corresponding reward function should align with this extracted\n ``ground_truth``.\n5. ``extra_info``: Record some information of the current prompt. Not\n use for now.\n\n.. code:: python\n\n def extract_solution(solution_str):\n solution = re.search(\"#### (\\\\-?[0-9\\\\.\\\\,]+)\", solution_str) # extract the solution after ####\n assert solution is not None\n final_solution = solution.group(0)\n final_solution = final_solution.split('#### ')[1].replace(',', '')\n return final_solution\n\n instruction_following = \"Let's think step by step and output the final answer after \\\"####\\\".\"\n\n # add a row to each data item that represents a unique id\n def make_map_fn(split):\n\n def process_fn(example, idx):\n question = example.pop('question')\n\n question = question + ' ' + instruction_following\n\n answer = example.pop('answer')\n solution = extract_solution(answer)\n data = {\n \"data_source\": data_source,\n \"prompt\": [{\n \"role\": \"user\",\n \"content\": question\n }],\n \"ability\": \"math\",\n \"reward_model\": {\n \"style\": \"rule\",\n \"ground_truth\": solution\n },\n \"extra_info\": {\n 'split': split,\n 'index': idx\n }\n }\n return data\n\n return process_fn", "metadata": {"source": "volcengine/verl", "title": "docs/preparation/prepare_data.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/preparation/prepare_data.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 4325}}
+{"text": "Implement Reward Function for Dataset\n======================================\n\nFor each dataset, we need to implement a reward function or utilize a reward model to compute the rewards for the generated responses.\nWe already pre-implemented some reward functions in `reward_score directory `_.\n\nCurrently, we support reward functions for GSM8k and MATH datasets. For RLHF datasets (e.g.,\nfull_hh_rlhf) and Code Generation (e.g., APPS), we utilize reward model\nand SandBox (will opensource soon) for evaluation respectively.\n\nRewardManager\n-------------\n\nIn the entrypoint of the PPO Post-Training script `main_ppo.py `_,\nwe implement a ``RewardManager`` that utilze pre-implemented reward functions to compute the scores for each response.\n\nIn the ``RewardManager``, we implemented a ``__call__`` function to\ncompute the score for each response. \nAll the reward functions are executed by ``compute_score_fn``.\nThe input is a ``DataProto``, which includes:\n\n- ``input_ids``, ``attention_mask``: ``input_ids`` and ``attention_mask`` after applying\n chat_template, including prompt and response\n- ``responses``: response tokens\n- ``ground_truth``: The ground truth string of the current prompt.\n Stored in ``non_tensor_batch`` in the ``DataProto``, which should be\n preprocessed in the parquet files.\n- ``data_source``: The dataset name of the current prompt. Stored in\n ``non_tensor_batch`` in the ``DataProto``, which should be\n preprocessed in the parquet files.\n\nAfter detokenize the responses, the responses string and the ground\ntruth string will be input to the ``compute_score_fn`` to compute the\nscore for each response.\n\nReward Functions\n----------------\nWe already pre-implemented some reward functions in `reward_score directory `_.\n\n- In the `GSM8k example `_, we\n force the response to output the final answer after four ####, then\n use string matching to compare with the ground truth. If completely\n correct, score 1 point; if the format is correct, score 0.1 points; if\n the format is incorrect, score 0 points.\n- In the `MATH example `_, we follow\n the implementation in `lm-evaluation-harness repository `_.", "metadata": {"source": "volcengine/verl", "title": "docs/preparation/reward_function.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/preparation/reward_function.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 2605}}
+{"text": "Installation\n============\n\nRequirements\n------------\n\n- **Python**: Version >= 3.9\n- **CUDA**: Version >= 12.1\n\nverl supports various backends. Currently, the following configurations are available:\n\n- **FSDP** and **Megatron-LM** (optional) for training.\n- **vLLM** adn **TGI** for rollout generation, **SGLang** support coming soon.\n\nTraining backends\n------------------\n\nWe recommend using **FSDP** backend to investigate, research and prototype different models, datasets and RL algorithms. The guide for using FSDP backend can be found in :doc:`FSDP Workers<../workers/fsdp_workers>`.\n\nFor users who pursue better scalability, we recommend using **Megatron-LM** backend. Currently, we support Megatron-LM v0.4 [1]_. The guide for using Megatron-LM backend can be found in :doc:`Megatron-LM Workers<../workers/megatron_workers>`.\n\n\nInstall from docker image\n-------------------------\n\nWe provide pre-built Docker images for quick setup.\n\nImage and tag: ``verlai/verl:vemlp-th2.4.0-cu124-vllm0.6.3-ray2.10-te1.7-v0.0.3``. See files under ``docker/`` for NGC-based image or if you want to build your own.\n\n1. Launch the desired Docker image:\n\n.. code:: bash\n\n docker run --runtime=nvidia -it --rm --shm-size=\"10g\" --cap-add=SYS_ADMIN -v \n\n\n2.\tInside the container, install verl:\n\n.. code:: bash\n\n # install the nightly version (recommended)\n git clone https://github.com/volcengine/verl && cd verl && pip3 install -e .\n # or install from pypi via `pip3 install verl`\n\n\n3. Setup Megatron (optional)\n\nIf you want to enable training with Megatron, Megatron code must be added to PYTHONPATH:\n\n.. code:: bash\n\n cd ..\n git clone -b core_v0.4.0 https://github.com/NVIDIA/Megatron-LM.git\n cp verl/patches/megatron_v4.patch Megatron-LM/\n cd Megatron-LM && git apply megatron_v4.patch\n pip3 install -e .\n export PYTHONPATH=$PYTHONPATH:$(pwd)\n\n\nYou can also get the Megatron code after verl's patch via\n\n.. code:: bash\n\n git clone -b core_v0.4.0_verl https://github.com/eric-haibin-lin/Megatron-LM\n export PYTHONPATH=$PYTHONPATH:$(pwd)/Megatron-LM\n\nInstall from custom environment\n---------------------------------\n\nTo manage environment, we recommend using conda:\n\n.. code:: bash\n\n conda create -n verl python==3.9\n conda activate verl\n\nFor installing the latest version of verl, the best way is to clone and\ninstall it from source. Then you can modify our code to customize your\nown post-training jobs.\n\n.. code:: bash\n\n # install verl together with some lightweight dependencies in setup.py\n git clone https://github.com/volcengine/verl.git\n cd verl\n pip3 install -e .\n\n\nMegatron is optional. It's dependencies can be setup as below:\n\n.. code:: bash\n\n # apex\n pip3 install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings \"--build-option=--cpp_ext\" --config-settings \"--build-option=--cuda_ext\" \\\n git+https://github.com/NVIDIA/apex\n\n # transformer engine\n pip3 install git+https://github.com/NVIDIA/TransformerEngine.git@v1.7\n\n # megatron core v0.4.0: clone and apply the patch\n # You can also get the patched Megatron code patch via\n # git clone -b core_v0.4.0_verl https://github.com/eric-haibin-lin/Megatron-LM\n cd ..\n git clone -b core_v0.4.0 https://github.com/NVIDIA/Megatron-LM.git\n cd Megatron-LM\n cp ../verl/patches/megatron_v4.patch .\n git apply megatron_v4.patch\n pip3 install -e .\n export PYTHONPATH=$PYTHONPATH:$(pwd)\n\n\n.. [1] Megatron v0.4 is supported with verl's patches to fix issues such as virtual pipeline hang. It will be soon updated with latest the version of upstream Megatron-LM without patches.", "metadata": {"source": "volcengine/verl", "title": "docs/start/install.rst", "url": "https://github.com/volcengine/verl/blob/main/docs/start/install.rst", "date": "2024-10-31T06:11:15Z", "stars": 3060, "description": "veRL: Volcano Engine Reinforcement Learning for LLM", "file_size": 3644}}
+{"text": ".. _quickstart:\n\n=========================================================\nQuickstart: PPO training on GSM8K dataset\n=========================================================\n\nPost-train a LLM using GSM8K dataset.\n\nIntroduction\n------------\n\n.. _hf_dataset_gsm8k: https://huggingface.co/datasets/gsm8k\n\nIn this example, we train an LLM to tackle the `GSM8k  \n
\n \n
\n  \n
\n  \n
\n  \n
\n  \n
\n \n
\n \n
\n \n\nWriting actions in code rather than JSON-like snippets provides better:\n\n- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?\n- **Object management:** how do you store the output of an action like `generate_image` in JSON?\n- **Generality:** code is built to express simply anything you can have a computer do.\n- **Representation in LLM training data:** plenty of quality code actions are already included in LLMs’ training data which means they’re already trained for this!", "metadata": {"source": "huggingface/smolagents", "title": "docs/source/en/conceptual_guides/intro_agents.md", "url": "https://github.com/huggingface/smolagents/blob/main/docs/source/en/conceptual_guides/intro_agents.md", "date": "2024-12-05T11:28:04Z", "stars": 10361, "description": "🤗 smolagents: a barebones library for agents. Agents write python code to call tools and orchestrate other agents.", "file_size": 9161}}
+{"text": "\n# How do multi-step agents work?\n\nThe ReAct framework ([Yao et al., 2022](https://huggingface.co/papers/2210.03629)) is currently the main approach to building agents.\n\nThe name is based on the concatenation of two words, \"Reason\" and \"Act.\" Indeed, agents following this architecture will solve their task in as many steps as needed, each step consisting of a Reasoning step, then an Action step where it formulates tool calls that will bring it closer to solving the task at hand.\n\nAll agents in `smolagents` are based on singular `MultiStepAgent` class, which is an abstraction of ReAct framework.\n\nOn a basic level, this class performs actions on a cycle of following steps, where existing variables and knowledge is incorporated into the agent logs like below: \n\nInitialization: the system prompt is stored in a `SystemPromptStep`, and the user query is logged into a `TaskStep` .\n\nWhile loop (ReAct loop):\n\n- Use `agent.write_memory_to_messages()` to write the agent logs into a list of LLM-readable [chat messages](https://huggingface.co/docs/transformers/en/chat_templating).\n- Send these messages to a `Model` object to get its completion. Parse the completion to get the action (a JSON blob for `ToolCallingAgent`, a code snippet for `CodeAgent`).\n- Execute the action and logs result into memory (an `ActionStep`).\n- At the end of each step, we run all callback functions defined in `agent.step_callbacks` .\n\nOptionally, when planning is activated, a plan can be periodically revised and stored in a `PlanningStep` . This includes feeding facts about the task at hand to the memory.\n\nFor a `CodeAgent`, it looks like the figure below.\n\n
\n\nWriting actions in code rather than JSON-like snippets provides better:\n\n- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?\n- **Object management:** how do you store the output of an action like `generate_image` in JSON?\n- **Generality:** code is built to express simply anything you can have a computer do.\n- **Representation in LLM training data:** plenty of quality code actions are already included in LLMs’ training data which means they’re already trained for this!", "metadata": {"source": "huggingface/smolagents", "title": "docs/source/en/conceptual_guides/intro_agents.md", "url": "https://github.com/huggingface/smolagents/blob/main/docs/source/en/conceptual_guides/intro_agents.md", "date": "2024-12-05T11:28:04Z", "stars": 10361, "description": "🤗 smolagents: a barebones library for agents. Agents write python code to call tools and orchestrate other agents.", "file_size": 9161}}
+{"text": "\n# How do multi-step agents work?\n\nThe ReAct framework ([Yao et al., 2022](https://huggingface.co/papers/2210.03629)) is currently the main approach to building agents.\n\nThe name is based on the concatenation of two words, \"Reason\" and \"Act.\" Indeed, agents following this architecture will solve their task in as many steps as needed, each step consisting of a Reasoning step, then an Action step where it formulates tool calls that will bring it closer to solving the task at hand.\n\nAll agents in `smolagents` are based on singular `MultiStepAgent` class, which is an abstraction of ReAct framework.\n\nOn a basic level, this class performs actions on a cycle of following steps, where existing variables and knowledge is incorporated into the agent logs like below: \n\nInitialization: the system prompt is stored in a `SystemPromptStep`, and the user query is logged into a `TaskStep` .\n\nWhile loop (ReAct loop):\n\n- Use `agent.write_memory_to_messages()` to write the agent logs into a list of LLM-readable [chat messages](https://huggingface.co/docs/transformers/en/chat_templating).\n- Send these messages to a `Model` object to get its completion. Parse the completion to get the action (a JSON blob for `ToolCallingAgent`, a code snippet for `CodeAgent`).\n- Execute the action and logs result into memory (an `ActionStep`).\n- At the end of each step, we run all callback functions defined in `agent.step_callbacks` .\n\nOptionally, when planning is activated, a plan can be periodically revised and stored in a `PlanningStep` . This includes feeding facts about the task at hand to the memory.\n\nFor a `CodeAgent`, it looks like the figure below.\n\n \n
\n \n\nYou can see that the CodeAgent called its managed ToolCallingAgent (by the way, the managed agent could be have been a CodeAgent as well) to ask it to run the web search for the U.S. 2024 growth rate. Then the managed agent returned its report and the manager agent acted upon it to calculate the economy doubling time! Sweet, isn't it?\n\n## Setting up telemetry with Langfuse\n\nThis part shows how to monitor and debug your Hugging Face **smolagents** with **Langfuse** using the `SmolagentsInstrumentor`.\n\n> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source platform for LLM engineering. It provides tracing and monitoring capabilities for AI agents, helping developers debug, analyze, and optimize their products. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and SDKs.\n\n### Step 1: Install Dependencies\n\n```python\n%pip install smolagents\n%pip install opentelemetry-sdk opentelemetry-exporter-otlp openinference-instrumentation-smolagents\n```\n\n### Step 2: Set Up Environment Variables\n\nSet your Langfuse API keys and configure the OpenTelemetry endpoint to send traces to Langfuse. Get your Langfuse API keys by signing up for [Langfuse Cloud](https://cloud.langfuse.com) or [self-hosting Langfuse](https://langfuse.com/self-hosting).\n\nAlso, add your [Hugging Face token](https://huggingface.co/settings/tokens) (`HF_TOKEN`) as an environment variable.\n\n```python\nimport os\nimport base64\n\nLANGFUSE_PUBLIC_KEY=\"pk-lf-...\"\nLANGFUSE_SECRET_KEY=\"sk-lf-...\"\nLANGFUSE_AUTH=base64.b64encode(f\"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}\".encode()).decode()\n\nos.environ[\"OTEL_EXPORTER_OTLP_ENDPOINT\"] = \"https://cloud.langfuse.com/api/public/otel\" # EU data region\n# os.environ[\"OTEL_EXPORTER_OTLP_ENDPOINT\"] = \"https://us.cloud.langfuse.com/api/public/otel\" # US data region\nos.environ[\"OTEL_EXPORTER_OTLP_HEADERS\"] = f\"Authorization=Basic {LANGFUSE_AUTH}\"\n\n# your Hugging Face token\nos.environ[\"HF_TOKEN\"] = \"hf_...\"\n```\n\n### Step 3: Initialize the `SmolagentsInstrumentor`\n\nInitialize the `SmolagentsInstrumentor` before your application code. Configure `tracer_provider` and add a span processor to export traces to Langfuse. `OTLPSpanExporter()` uses the endpoint and headers from the environment variables.\n\n\n```python\nfrom opentelemetry.sdk.trace import TracerProvider\n\nfrom openinference.instrumentation.smolagents import SmolagentsInstrumentor\nfrom opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter\nfrom opentelemetry.sdk.trace.export import SimpleSpanProcessor\n\ntrace_provider = TracerProvider()\ntrace_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter()))\n\nSmolagentsInstrumentor().instrument(tracer_provider=trace_provider)\n```\n\n### Step 4: Run your smolagent\n\n```python\nfrom smolagents import (\n CodeAgent,\n ToolCallingAgent,\n DuckDuckGoSearchTool,\n VisitWebpageTool,\n HfApiModel,\n)\n\nmodel = HfApiModel(\n model_id=\"deepseek-ai/DeepSeek-R1-Distill-Qwen-32B\"\n)\n\nsearch_agent = ToolCallingAgent(\n tools=[DuckDuckGoSearchTool(), VisitWebpageTool()],\n model=model,\n name=\"search_agent\",\n description=\"This is an agent that can do web search.\",\n)\n\nmanager_agent = CodeAgent(\n tools=[],\n model=model,\n managed_agents=[search_agent],\n)\nmanager_agent.run(\n \"How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?\"\n)\n```\n\n### Step 5: View Traces in Langfuse\n\nAfter running the agent, you can view the traces generated by your smolagents application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.\n\n\n\n_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_", "metadata": {"source": "huggingface/smolagents", "title": "docs/source/en/tutorials/inspect_runs.md", "url": "https://github.com/huggingface/smolagents/blob/main/docs/source/en/tutorials/inspect_runs.md", "date": "2024-12-05T11:28:04Z", "stars": 10361, "description": "🤗 smolagents: a barebones library for agents. Agents write python code to call tools and orchestrate other agents.", "file_size": 8422}}
+{"text": "\n# Secure code execution\n\n[[open-in-colab]]\n\n> [!TIP]\n> If you're new to building agents, make sure to first read the [intro to agents](../conceptual_guides/intro_agents) and the [guided tour of smolagents](../guided_tour).\n\n### Code agents\n\n[Multiple](https://huggingface.co/papers/2402.01030) [research](https://huggingface.co/papers/2411.01747) [papers](https://huggingface.co/papers/2401.00812) have shown that having the LLM write its actions (the tool calls) in code is much better than the current standard format for tool calling, which is across the industry different shades of \"writing actions as a JSON of tools names and arguments to use\".\n\nWhy is code better? Well, because we crafted our code languages specifically to be great at expressing actions performed by a computer. If JSON snippets was a better way, this package would have been written in JSON snippets and the devil would be laughing at us.\n\nCode is just a better way to express actions on a computer. It has better:\n- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?\n- **Object management:** how do you store the output of an action like `generate_image` in JSON?\n- **Generality:** code is built to express simply anything you can do have a computer do.\n- **Representation in LLM training corpus:** why not leverage this benediction of the sky that plenty of quality actions have already been included in LLM training corpus?\n\nThis is illustrated on the figure below, taken from [Executable Code Actions Elicit Better LLM Agents](https://huggingface.co/papers/2402.01030).\n\n
\n\nYou can see that the CodeAgent called its managed ToolCallingAgent (by the way, the managed agent could be have been a CodeAgent as well) to ask it to run the web search for the U.S. 2024 growth rate. Then the managed agent returned its report and the manager agent acted upon it to calculate the economy doubling time! Sweet, isn't it?\n\n## Setting up telemetry with Langfuse\n\nThis part shows how to monitor and debug your Hugging Face **smolagents** with **Langfuse** using the `SmolagentsInstrumentor`.\n\n> **What is Langfuse?** [Langfuse](https://langfuse.com) is an open-source platform for LLM engineering. It provides tracing and monitoring capabilities for AI agents, helping developers debug, analyze, and optimize their products. Langfuse integrates with various tools and frameworks via native integrations, OpenTelemetry, and SDKs.\n\n### Step 1: Install Dependencies\n\n```python\n%pip install smolagents\n%pip install opentelemetry-sdk opentelemetry-exporter-otlp openinference-instrumentation-smolagents\n```\n\n### Step 2: Set Up Environment Variables\n\nSet your Langfuse API keys and configure the OpenTelemetry endpoint to send traces to Langfuse. Get your Langfuse API keys by signing up for [Langfuse Cloud](https://cloud.langfuse.com) or [self-hosting Langfuse](https://langfuse.com/self-hosting).\n\nAlso, add your [Hugging Face token](https://huggingface.co/settings/tokens) (`HF_TOKEN`) as an environment variable.\n\n```python\nimport os\nimport base64\n\nLANGFUSE_PUBLIC_KEY=\"pk-lf-...\"\nLANGFUSE_SECRET_KEY=\"sk-lf-...\"\nLANGFUSE_AUTH=base64.b64encode(f\"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}\".encode()).decode()\n\nos.environ[\"OTEL_EXPORTER_OTLP_ENDPOINT\"] = \"https://cloud.langfuse.com/api/public/otel\" # EU data region\n# os.environ[\"OTEL_EXPORTER_OTLP_ENDPOINT\"] = \"https://us.cloud.langfuse.com/api/public/otel\" # US data region\nos.environ[\"OTEL_EXPORTER_OTLP_HEADERS\"] = f\"Authorization=Basic {LANGFUSE_AUTH}\"\n\n# your Hugging Face token\nos.environ[\"HF_TOKEN\"] = \"hf_...\"\n```\n\n### Step 3: Initialize the `SmolagentsInstrumentor`\n\nInitialize the `SmolagentsInstrumentor` before your application code. Configure `tracer_provider` and add a span processor to export traces to Langfuse. `OTLPSpanExporter()` uses the endpoint and headers from the environment variables.\n\n\n```python\nfrom opentelemetry.sdk.trace import TracerProvider\n\nfrom openinference.instrumentation.smolagents import SmolagentsInstrumentor\nfrom opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter\nfrom opentelemetry.sdk.trace.export import SimpleSpanProcessor\n\ntrace_provider = TracerProvider()\ntrace_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter()))\n\nSmolagentsInstrumentor().instrument(tracer_provider=trace_provider)\n```\n\n### Step 4: Run your smolagent\n\n```python\nfrom smolagents import (\n CodeAgent,\n ToolCallingAgent,\n DuckDuckGoSearchTool,\n VisitWebpageTool,\n HfApiModel,\n)\n\nmodel = HfApiModel(\n model_id=\"deepseek-ai/DeepSeek-R1-Distill-Qwen-32B\"\n)\n\nsearch_agent = ToolCallingAgent(\n tools=[DuckDuckGoSearchTool(), VisitWebpageTool()],\n model=model,\n name=\"search_agent\",\n description=\"This is an agent that can do web search.\",\n)\n\nmanager_agent = CodeAgent(\n tools=[],\n model=model,\n managed_agents=[search_agent],\n)\nmanager_agent.run(\n \"How can Langfuse be used to monitor and improve the reasoning and decision-making of smolagents when they execute multi-step tasks, like dynamically adjusting a recipe based on user feedback or available ingredients?\"\n)\n```\n\n### Step 5: View Traces in Langfuse\n\nAfter running the agent, you can view the traces generated by your smolagents application in [Langfuse](https://cloud.langfuse.com). You should see detailed steps of the LLM interactions, which can help you debug and optimize your AI agent.\n\n\n\n_[Public example trace in Langfuse](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/ce5160f9bfd5a6cd63b07d2bfcec6f54?timestamp=2025-02-11T09%3A25%3A45.163Z&display=details)_", "metadata": {"source": "huggingface/smolagents", "title": "docs/source/en/tutorials/inspect_runs.md", "url": "https://github.com/huggingface/smolagents/blob/main/docs/source/en/tutorials/inspect_runs.md", "date": "2024-12-05T11:28:04Z", "stars": 10361, "description": "🤗 smolagents: a barebones library for agents. Agents write python code to call tools and orchestrate other agents.", "file_size": 8422}}
+{"text": "\n# Secure code execution\n\n[[open-in-colab]]\n\n> [!TIP]\n> If you're new to building agents, make sure to first read the [intro to agents](../conceptual_guides/intro_agents) and the [guided tour of smolagents](../guided_tour).\n\n### Code agents\n\n[Multiple](https://huggingface.co/papers/2402.01030) [research](https://huggingface.co/papers/2411.01747) [papers](https://huggingface.co/papers/2401.00812) have shown that having the LLM write its actions (the tool calls) in code is much better than the current standard format for tool calling, which is across the industry different shades of \"writing actions as a JSON of tools names and arguments to use\".\n\nWhy is code better? Well, because we crafted our code languages specifically to be great at expressing actions performed by a computer. If JSON snippets was a better way, this package would have been written in JSON snippets and the devil would be laughing at us.\n\nCode is just a better way to express actions on a computer. It has better:\n- **Composability:** could you nest JSON actions within each other, or define a set of JSON actions to re-use later, the same way you could just define a python function?\n- **Object management:** how do you store the output of an action like `generate_image` in JSON?\n- **Generality:** code is built to express simply anything you can do have a computer do.\n- **Representation in LLM training corpus:** why not leverage this benediction of the sky that plenty of quality actions have already been included in LLM training corpus?\n\nThis is illustrated on the figure below, taken from [Executable Code Actions Elicit Better LLM Agents](https://huggingface.co/papers/2402.01030).\n\n \n\nThen you can use this tool just like any other tool. For example, let's improve the prompt `a rabbit wearing a space suit` and generate an image of it. This example also shows how you can pass additional arguments to the agent.\n\n```python\nfrom smolagents import CodeAgent, HfApiModel\n\nmodel = HfApiModel(\"Qwen/Qwen2.5-Coder-32B-Instruct\")\nagent = CodeAgent(tools=[image_generation_tool], model=model)\n\nagent.run(\n \"Improve this prompt, then generate an image of it.\", additional_args={'user_prompt': 'A rabbit wearing a space suit'}\n)\n```\n\n```text\n=== Agent thoughts:\nimproved_prompt could be \"A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background\"\n\nNow that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.\n>>> Agent is executing the code below:\nimage = image_generator(prompt=\"A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background\")\nfinal_answer(image)\n```\n\n
\n\nThen you can use this tool just like any other tool. For example, let's improve the prompt `a rabbit wearing a space suit` and generate an image of it. This example also shows how you can pass additional arguments to the agent.\n\n```python\nfrom smolagents import CodeAgent, HfApiModel\n\nmodel = HfApiModel(\"Qwen/Qwen2.5-Coder-32B-Instruct\")\nagent = CodeAgent(tools=[image_generation_tool], model=model)\n\nagent.run(\n \"Improve this prompt, then generate an image of it.\", additional_args={'user_prompt': 'A rabbit wearing a space suit'}\n)\n```\n\n```text\n=== Agent thoughts:\nimproved_prompt could be \"A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background\"\n\nNow that I have improved the prompt, I can use the image generator tool to generate an image based on this prompt.\n>>> Agent is executing the code below:\nimage = image_generator(prompt=\"A bright blue space suit wearing rabbit, on the surface of the moon, under a bright orange sunset, with the Earth visible in the background\")\nfinal_answer(image)\n```\n\n \n\nHow cool is this? 🤩\n\n### Use LangChain tools\n\nWe love Langchain and think it has a very compelling suite of tools.\nTo import a tool from LangChain, use the `from_langchain()` method.\n\nHere is how you can use it to recreate the intro's search result using a LangChain web search tool.\nThis tool will need `pip install langchain google-search-results -q` to work properly.\n```python\nfrom langchain.agents import load_tools\n\nsearch_tool = Tool.from_langchain(load_tools([\"serpapi\"])[0])\n\nagent = CodeAgent(tools=[search_tool], model=model)\n\nagent.run(\"How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?\")\n```\n\n### Manage your agent's toolbox\n\nYou can manage an agent's toolbox by adding or replacing a tool in attribute `agent.tools`, since it is a standard dictionary.\n\nLet's add the `model_download_tool` to an existing agent initialized with only the default toolbox.\n\n```python\nfrom smolagents import HfApiModel\n\nmodel = HfApiModel(\"Qwen/Qwen2.5-Coder-32B-Instruct\")\n\nagent = CodeAgent(tools=[], model=model, add_base_tools=True)\nagent.tools[model_download_tool.name] = model_download_tool\n```\nNow we can leverage the new tool:\n\n```python\nagent.run(\n \"Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub but reverse the letters?\"\n)\n```\n\n\n> [!TIP]\n> Beware of not adding too many tools to an agent: this can overwhelm weaker LLM engines.\n\n\n### Use a collection of tools\n\nYou can leverage tool collections by using the `ToolCollection` object. It supports loading either a collection from the Hub or an MCP server tools.\n\n#### Tool Collection from a collection in the Hub\n\nYou can leverage it with the slug of the collection you want to use.\nThen pass them as a list to initialize your agent, and start using them!\n\n```py\nfrom smolagents import ToolCollection, CodeAgent\n\nimage_tool_collection = ToolCollection.from_hub(\n collection_slug=\"huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f\",\n token=\"
\n\nHow cool is this? 🤩\n\n### Use LangChain tools\n\nWe love Langchain and think it has a very compelling suite of tools.\nTo import a tool from LangChain, use the `from_langchain()` method.\n\nHere is how you can use it to recreate the intro's search result using a LangChain web search tool.\nThis tool will need `pip install langchain google-search-results -q` to work properly.\n```python\nfrom langchain.agents import load_tools\n\nsearch_tool = Tool.from_langchain(load_tools([\"serpapi\"])[0])\n\nagent = CodeAgent(tools=[search_tool], model=model)\n\nagent.run(\"How many more blocks (also denoted as layers) are in BERT base encoder compared to the encoder from the architecture proposed in Attention is All You Need?\")\n```\n\n### Manage your agent's toolbox\n\nYou can manage an agent's toolbox by adding or replacing a tool in attribute `agent.tools`, since it is a standard dictionary.\n\nLet's add the `model_download_tool` to an existing agent initialized with only the default toolbox.\n\n```python\nfrom smolagents import HfApiModel\n\nmodel = HfApiModel(\"Qwen/Qwen2.5-Coder-32B-Instruct\")\n\nagent = CodeAgent(tools=[], model=model, add_base_tools=True)\nagent.tools[model_download_tool.name] = model_download_tool\n```\nNow we can leverage the new tool:\n\n```python\nagent.run(\n \"Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub but reverse the letters?\"\n)\n```\n\n\n> [!TIP]\n> Beware of not adding too many tools to an agent: this can overwhelm weaker LLM engines.\n\n\n### Use a collection of tools\n\nYou can leverage tool collections by using the `ToolCollection` object. It supports loading either a collection from the Hub or an MCP server tools.\n\n#### Tool Collection from a collection in the Hub\n\nYou can leverage it with the slug of the collection you want to use.\nThen pass them as a list to initialize your agent, and start using them!\n\n```py\nfrom smolagents import ToolCollection, CodeAgent\n\nimage_tool_collection = ToolCollection.from_hub(\n collection_slug=\"huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f\",\n token=\" \n
\n \n\n
\n\n

 \n\nScan the QR code below to join our WeChat group. \n\n
\n\nScan the QR code below to join our WeChat group. \n\n \n\n\n# 7. Differences between KAG, RAG, and GraphRAG\n\n**KAG introduction and applications**:
\n\n\n# 7. Differences between KAG, RAG, and GraphRAG\n\n**KAG introduction and applications**: {kind=link}