
Add files using upload-large-folder tool
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- 7th_Layer_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv +40 -0
- ACertainModel_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv +91 -0
- Baichuan-13B-Base_finetunes_20250426_221535.csv_finetunes_20250426_221535.csv +142 -0
- Baichuan-13B-Chat_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv +195 -0
- Bio_ClinicalBERT_finetunes_20250426_121513.csv_finetunes_20250426_121513.csv +0 -0
- ChatTTS_finetunes_20250424_193500.csv_finetunes_20250424_193500.csv +56 -0
- ChilloutMix_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +2 -0
- CodeLlama-70b-hf_finetunes_20250426_121513.csv_finetunes_20250426_121513.csv +145 -0
- DeBERTa-v3-base-mnli-fever-anli_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv +0 -0
- DeepSeek-R1-GGUF_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv +442 -0
- Flux-Super-Realism-LoRA_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv +151 -0
- GR00T-N1-2B_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +16 -0
- Hunyuan3D-2_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv +459 -0
- Idefics3-8B-Llama3_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +607 -0
- InstantID_finetunes_20250425_041137.csv_finetunes_20250425_041137.csv +129 -0
- InternVL2-Llama3-76B_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +652 -0
- Janus-Pro-1B_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv +120 -0
- Janus-Pro-7B_finetunes_20250422_225821.csv +0 -0
- LLaMA-7B_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +60 -0
- Llama-2-7b-hf_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv +0 -0
- Llama-3-8B-Instruct-262k_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +0 -0
- Llama-3-8B-Lexi-Uncensored_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +273 -0
- MagicAnimate_finetunes_20250426_221535.csv_finetunes_20250426_221535.csv +8 -0
- MeloTTS-English_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +205 -0
- MiniCPM-Llama3-V-2_5-gguf_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +15 -0
- MiniCPM-V-2_6-gguf_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv +49 -0
- Molmo-7B-D-0924_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv +211 -0
- Nemotron-4-340B-Instruct_finetunes_20250425_125929.csv_finetunes_20250425_125929.csv +0 -0
- Phi-3-mini-128k-instruct_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv +0 -0
- Phi-4-mini-instruct_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv +0 -0
- PixArt-XL-2-1024-MS_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv +329 -0
- SD_PixelArt_SpriteSheet_Generator_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv +60 -0
- SFR-Embedding-Mistral_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +0 -0
- SSD-1B_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv +0 -0
- SenseVoiceSmall_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +235 -0
- SmolDocling-256M-preview_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv +597 -0
- SmolLM-135M_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv +0 -0
- UAE-Large-V1_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +0 -0
- Yarn-Mistral-7b-128k_finetunes_20250425_143346.csv_finetunes_20250425_143346.csv +344 -0
- YuE-s1-7B-anneal-en-cot_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv +133 -0
- adetailer_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv +105 -0
- bark-small_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv +0 -0
- bert-base-NER_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv +0 -0
- chatglm-6b_finetunes_20250424_145241.csv_finetunes_20250424_145241.csv +164 -0
- codebert-base_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv +0 -0
- colpali_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv +154 -0
- doll-likeness-series_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv +186 -0
- elden-ring-diffusion_finetunes_20250426_121513.csv_finetunes_20250426_121513.csv +2 -0
- falcon-40b-instruct_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv +389 -0
- flan-t5-large_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv +0 -0
7th_Layer_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
syaimu/7th_Layer,"---
|
| 3 |
+
license: other
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
## / 7th Layer /
|
| 7 |
+
|
| 8 |
+
<img src=""https://i.imgur.com/MjnczlB.png"" width=""1700"" height="""">
|
| 9 |
+
|
| 10 |
+
# (Important Notice:1.6)
|
| 11 |
+
|
| 12 |
+
default CFG Scale : 7 ±5
|
| 13 |
+
|
| 14 |
+
default Sampler : DPM++ 2M Karras
|
| 15 |
+
|
| 16 |
+
default Steps : 25
|
| 17 |
+
|
| 18 |
+
Negative prompt : (worst quality:1.4), (low quality:1.4) , (monochrome:1.1),
|
| 19 |
+
# Don't write a lot of ""Negative prompt"".
|
| 20 |
+
<img src=""https://i.imgur.com/tE3PUBi.png"" width=""480"" height="""">
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
## Test Model https://huggingface.co/syaimu/7th_test
|
| 24 |
+
|
| 25 |
+
<img src=""https://i.imgur.com/0xKIUvL.jpg"" width=""1700"" height="""">
|
| 26 |
+
<img src=""https://i.imgur.com/lFZAYVv.jpg"" width=""1700"" height="""">
|
| 27 |
+
<img src=""https://i.imgur.com/4IYqlYq.jpg"" width=""1700"" height="""">
|
| 28 |
+
<img src=""https://i.imgur.com/v2pn57R.jpg"" width=""1700"" height="""">
|
| 29 |
+
|
| 30 |
+
# 7th_anime_v2.5_B → 7th_anime_v2_G
|
| 31 |
+
<img src=""https://i.imgur.com/K3o28Ci.jpg"" width=""1700"" height="""">
|
| 32 |
+
<img src=""https://i.imgur.com/Bzywbkp.jpg"" width=""1700"" height="""">
|
| 33 |
+
|
| 34 |
+
# other
|
| 35 |
+
<img src=""https://i.imgur.com/oCZyzdA.jpg"" width=""1700"" height="""">
|
| 36 |
+
<img src=""https://i.imgur.com/sAw842D.jpg"" width=""1700"" height="""">
|
| 37 |
+
<img src=""https://i.imgur.com/lzuYVh0.jpg"" width=""1700"" height="""">
|
| 38 |
+
<img src=""https://i.imgur.com/dOXsoeg.jpg"" width=""1700"" height="""">
|
| 39 |
+
|
| 40 |
+
","{""id"": ""syaimu/7th_Layer"", ""author"": ""syaimu"", ""sha"": ""45e8fa0c30f2b3090aa4dfc6b05f7e14918cebf6"", ""last_modified"": ""2023-10-06 13:47:47+00:00"", ""created_at"": ""2022-12-27 06:10:12+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 629, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""license:other"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: other"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_SemiR_v3.2/7th_SemiR_v3A.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_SemiR_v3.2/7th_SemiR_v3B.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_SemiR_v3.2/7th_SemiR_v3C.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_alpha_v4/7th_anime_v4A.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_alpha_v4/7th_anime_v4B.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v1/7th_anime_v1.1.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v1/7th_anime_v1.1.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v2/7th_anime_v2_A.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v2/7th_anime_v2_A.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v2/7th_anime_v2_B-fix.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v2/7th_anime_v2_B.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v2/7th_anime_v2_B.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v2/7th_anime_v2_C.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v2/7th_anime_v2_C.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v2/7th_anime_v2_G.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v2/7th_anime_v2_G.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v3/7th_anime_v3_A.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v3/7th_anime_v3_A.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v3/7th_anime_v3_B.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v3/7th_anime_v3_B.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v3/7th_anime_v3_C.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_anime_v3/7th_anime_v3_C.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_layer/Abyss_7th_layer.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='7th_layer/abyss_7th_layerG1.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [""b3xxf21f/A3Private"", ""Phasmanta/Space2""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-10-06 13:47:47+00:00"", ""cardData"": ""license: other"", ""transformersInfo"": null, ""_id"": ""63aa8c448949ceef24a2791b"", ""modelId"": ""syaimu/7th_Layer"", ""usedStorage"": 118530128971}",0,,0,,0,,0,,0,"Phasmanta/Space2, b3xxf21f/A3Private, huggingface/InferenceSupport/discussions/new?title=syaimu/7th_Layer&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bsyaimu%2F7th_Layer%5D(%2Fsyaimu%2F7th_Layer)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A",3
|
ACertainModel_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
JosephusCheung/ACertainModel,"---
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
license: creativeml-openrail-m
|
| 6 |
+
tags:
|
| 7 |
+
- stable-diffusion
|
| 8 |
+
- stable-diffusion-diffusers
|
| 9 |
+
- text-to-image
|
| 10 |
+
- diffusers
|
| 11 |
+
inference: true
|
| 12 |
+
widget:
|
| 13 |
+
- text: ""masterpiece, best quality, 1girl, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden""
|
| 14 |
+
example_title: ""example 1girl""
|
| 15 |
+
- text: ""masterpiece, best quality, 1boy, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden""
|
| 16 |
+
example_title: ""example 1boy""
|
| 17 |
+
---
|
| 18 |
+
|
| 19 |
+
# ACertainModel
|
| 20 |
+
|
| 21 |
+
**Try full functions with Google Colab free T4** [](https://colab.research.google.com/drive/1ldhBc70wvuvkp4Af_vNTzTfBXwpf_cH5?usp=sharing)
|
| 22 |
+
|
| 23 |
+
Check Twitter [#ACertainModel](https://twitter.com/hashtag/ACertainModel) for community artworks
|
| 24 |
+
|
| 25 |
+
Welcome to ACertainModel - a latent diffusion model for weebs. This model is intended to produce high-quality, highly detailed anime style pictures with just a few prompts. Like other anime-style Stable Diffusion models, it also supports danbooru tags, including artists, to generate images.
|
| 26 |
+
|
| 27 |
+
Since I noticed that the laion-aesthetics introduced in the Stable-Diffusion-v-1-4 checkpoint hindered finetuning anime style illustration generation model, Dreambooth was used to finetune some tags separately to make it closer to what it was in SD1.2. To avoid overfitting and possible language drift, I added a huge amount of auto-generated pictures from a single word prompt to the training set, using models that are popular in the community such as Anything-3.0, together with partially manual selected full-danbooru images within a year, for further native training. I am also aware of a method of [LoRA](https://arxiv.org/abs/2106.09685), with a similar idea, finetuning attention layer solely, to have better performance on eyes, hands, and other details.
|
| 28 |
+
|
| 29 |
+
For copyright compliance and technical experiment, it was trained from few artist images directly. It was trained on Dreambooth with pictures generated from several popular diffusion models in the community. The checkpoint was initialized with the weights of a Stable Diffusion Model and subsequently fine-tuned for 2K GPU hours on V100 32GB and 600 GPU hours on A100 40GB at 512P dynamic aspect ratio resolution with a certain ratio of unsupervised auto-generated images from several popular diffusion models in the community with some Textual Inversions and Hypernetworks. We do know some tricks on xformers and 8-bit optimization, but we didn't use any of them for better quality and stability. Up to 15 branches are trained simultaneously, cherry-picking about every 20,000 steps.
|
| 30 |
+
|
| 31 |
+
e.g. **_masterpiece, best quality, 1girl, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden_**
|
| 32 |
+
|
| 33 |
+
## About online preview with Hosted inference API, also generation with this model
|
| 34 |
+
|
| 35 |
+
Parameters are not allowed to be modified, as it seems that it is generated with *Clip skip: 1*, for better performance, it is strongly recommended to use *Clip skip: 2* instead.
|
| 36 |
+
|
| 37 |
+
Here is an example of inference settings, if it is applicable with you on your own server: *Steps: 28, Sampler: Euler a, CFG scale: 11, Clip skip: 2*.
|
| 38 |
+
|
| 39 |
+
## 🧨 Diffusers
|
| 40 |
+
|
| 41 |
+
This model can be used just like any other Stable Diffusion model. For more information,
|
| 42 |
+
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
|
| 43 |
+
|
| 44 |
+
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or FLAX/JAX.
|
| 45 |
+
|
| 46 |
+
```python
|
| 47 |
+
from diffusers import StableDiffusionPipeline
|
| 48 |
+
import torch
|
| 49 |
+
|
| 50 |
+
model_id = ""JosephusCheung/ACertainModel""
|
| 51 |
+
branch_name= ""main""
|
| 52 |
+
|
| 53 |
+
pipe = StableDiffusionPipeline.from_pretrained(model_id, revision=branch_name, torch_dtype=torch.float16)
|
| 54 |
+
pipe = pipe.to(""cuda"")
|
| 55 |
+
|
| 56 |
+
prompt = ""pikachu""
|
| 57 |
+
image = pipe(prompt).images[0]
|
| 58 |
+
|
| 59 |
+
image.save(""./pikachu.png"")
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
## Examples
|
| 63 |
+
|
| 64 |
+
Below are some examples of images generated using this model, with better performance on framing and hand gestures, as well as moving objects, comparing to other analogues:
|
| 65 |
+
|
| 66 |
+
**Anime Girl:**
|
| 67 |
+

|
| 68 |
+
```
|
| 69 |
+
1girl, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden
|
| 70 |
+
Steps: 28, Sampler: Euler a, CFG scale: 11, Seed: 114514, Clip skip: 2
|
| 71 |
+
```
|
| 72 |
+
**Anime Boy:**
|
| 73 |
+

|
| 74 |
+
```
|
| 75 |
+
1boy, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden
|
| 76 |
+
Steps: 28, Sampler: Euler a, CFG scale: 11, Seed: 114514, Clip skip: 2
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
## License
|
| 80 |
+
|
| 81 |
+
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
|
| 82 |
+
The CreativeML OpenRAIL License specifies:
|
| 83 |
+
|
| 84 |
+
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
|
| 85 |
+
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
|
| 86 |
+
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
|
| 87 |
+
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
| 88 |
+
|
| 89 |
+
## Is it a NovelAI based model? What is the relationship with SD1.2 and SD1.4?
|
| 90 |
+
|
| 91 |
+
See [ASimilarityCalculatior](https://huggingface.co/JosephusCheung/ASimilarityCalculatior)","{""id"": ""JosephusCheung/ACertainModel"", ""author"": ""JosephusCheung"", ""sha"": ""02fc9a2dccf7ebce834fb17f53a304dc77d679ba"", ""last_modified"": ""2022-12-20 03:16:49+00:00"", ""created_at"": ""2022-12-12 17:40:00+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 426, ""downloads_all_time"": null, ""likes"": 159, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""stable-diffusion"", ""stable-diffusion-diffusers"", ""text-to-image"", ""en"", ""arxiv:2106.09685"", ""doi:10.57967/hf/0196"", ""license:creativeml-openrail-m"", ""autotrain_compatible"", ""endpoints_compatible"", ""diffusers:StableDiffusionPipeline"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- en\nlicense: creativeml-openrail-m\ntags:\n- stable-diffusion\n- stable-diffusion-diffusers\n- text-to-image\n- diffusers\ninference: true\nwidget:\n- text: masterpiece, best quality, 1girl, brown hair, green eyes, colorful, autumn,\n cumulonimbus clouds, lighting, blue sky, falling leaves, garden\n example_title: example 1girl\n- text: masterpiece, best quality, 1boy, brown hair, green eyes, colorful, autumn,\n cumulonimbus clouds, lighting, blue sky, falling leaves, garden\n example_title: example 1boy"", ""widget_data"": [{""text"": ""masterpiece, best quality, 1girl, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden"", ""example_title"": ""example 1girl""}, {""text"": ""masterpiece, best quality, 1boy, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden"", ""example_title"": ""example 1boy""}], ""model_index"": null, ""config"": {""diffusers"": {""_class_name"": ""StableDiffusionPipeline""}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ACertainModel-half.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ACertainModel.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ACertainModel_on_SD_WEBUI.ipynb', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='feature_extractor/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model_index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='safety_checker/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='safety_checker/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='samples/anything3-sample-1boy.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='samples/anything3-sample-1girl.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='samples/sample-1boy.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='samples/sample-1girl.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Yntec/ToyWorld"", ""Yntec/PrintingPress"", ""Nymbo/image_gen_supaqueue"", ""ennov8ion/3dart-Models"", ""phenixrhyder/NSFW-ToyWorld"", ""Yntec/blitz_diffusion"", ""sanaweb/text-to-image"", ""Vedits/6x_Image_diffusion"", ""John6666/Diffusion80XX4sg"", ""ennov8ion/comicbook-models"", ""John6666/PrintingPress4"", ""PeepDaSlan9/B2BMGMT_Diffusion60XX"", ""Daniela-C/6x_Image_diffusion"", ""phenixrhyder/PrintingPress"", ""John6666/hfd_test_nostopbutton"", ""mindtube/Diffusion50XX"", ""TheKitten/Fast-Images-Creature"", ""Nymbo/Diffusion80XX4sg"", ""kaleidoskop-hug/PrintingPress"", ""ennov8ion/stablediffusion-models"", ""John6666/ToyWorld4"", ""grzegorz2047/fast_diffusion"", ""Alfasign/dIFFU"", ""Nymbo/PrintingPress"", ""Rifd/Sdallmodels"", ""John6666/Diffusion80XX4g"", ""NativeAngels/HuggingfaceDiffusion"", ""ennov8ion/Scifi-Models"", ""ennov8ion/semirealistic-models"", ""ennov8ion/FantasyArt-Models"", ""ennov8ion/dreamlike-models"", ""noes14155/img_All_models"", ""ennov8ion/500models"", ""AnimeStudio/anime-models"", ""John6666/Diffusion80XX4"", ""K00B404/HuggingfaceDiffusion_custom"", ""John6666/blitz_diffusion4"", ""John6666/blitz_diffusion_builtin"", ""RhythmRemix14/PrintingPressDx"", ""sohoso/PrintingPress"", ""NativeAngels/ToyWorld"", ""mindtube/maximum_multiplier_places"", ""animeartstudio/AnimeArtmodels2"", ""animeartstudio/AnimeModels"", ""Binettebob22/fast_diffusion2"", ""pikto/Elite-Scifi-Models"", ""PixelistStudio/3dart-Models"", ""devmiles/zexxiai"", ""Nymbo/Diffusion60XX"", ""TheKitten/Images"", ""ennov8ion/anime-models"", ""jordonpeter01/Diffusion70"", ""mimimibimimimi/ACertainModel"", ""Phasmanta/Space2"", ""ennov8ion/Landscapes-models"", ""sohoso/anime348756"", ""ucmisanddisinfo/thisApp"", ""johann22/chat-diffusion"", ""K00B404/generate_many_models"", ""manivannan7gp/Words2Image"", ""ennov8ion/art-models"", ""ennov8ion/photo-models"", ""ennov8ion/art-multi"", ""vih-v/x_mod"", ""NativeAngels/blitz_diffusion"", ""NativeAngels/PrintingPress4"", ""NativeAngels/PrintingPress"", ""dehua68/ToyWorld"", ""burman-ai/Printing-Press"", ""sk16er/ghibli_creator"", ""fo-atccb/ACertainModel"", ""ecody726/JosephusCheung-ACertainModel"", ""cap1145/JosephusCheung-ACertainModel"", ""ennov8ion/abstractart-models"", ""ennov8ion/Scifiart-Models"", ""ennov8ion/interior-models"", ""ennov8ion/room-interior-models"", ""animeartstudio/AnimeArtModels1"", ""Yntec/top_100_diffusion"", ""AIlexDev/Diffusion60XX"", ""flatindo/img_All_models"", ""flatindo/all-models"", ""flatindo/all-models-v1"", ""johann22/chat-diffusion-describe"", ""wideprism/Ultimate-Model-Collection"", ""GAIneZis/FantasyArt-Models"", ""TheMaisk/Einfach.ImageAI"", ""ennov8ion/picasso-diffusion"", ""K00B404/stablediffusion-portal"", ""ennov8ion/anime-new-models"", ""ennov8ion/anime-multi-new-models"", ""ennov8ion/photo-multi"", ""ennov8ion/anime-multi"", ""Ashrafb/comicbook-models"", ""sohoso/architecture"", ""K00B404/image_gen_supaqueue_game_assets"", ""GhadaSaylami/text-to-image"", ""Geek7/mdztxi"", ""Geek7/mdztxi2"", ""NativeAngels/Diffusion80XX4sg""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2022-12-20 03:16:49+00:00"", ""cardData"": ""language:\n- en\nlicense: creativeml-openrail-m\ntags:\n- stable-diffusion\n- stable-diffusion-diffusers\n- text-to-image\n- diffusers\ninference: true\nwidget:\n- text: masterpiece, best quality, 1girl, brown hair, green eyes, colorful, autumn,\n cumulonimbus clouds, lighting, blue sky, falling leaves, garden\n example_title: example 1girl\n- text: masterpiece, best quality, 1boy, brown hair, green eyes, colorful, autumn,\n cumulonimbus clouds, lighting, blue sky, falling leaves, garden\n example_title: example 1boy"", ""transformersInfo"": null, ""_id"": ""6397677008a51789e4b50b25"", ""modelId"": ""JosephusCheung/ACertainModel"", ""usedStorage"": 12711403487}",0,,0,,0,,0,,0,"CompVis/stable-diffusion-license, Daniela-C/6x_Image_diffusion, John6666/Diffusion80XX4sg, John6666/PrintingPress4, John6666/ToyWorld4, John6666/hfd_test_nostopbutton, Nymbo/image_gen_supaqueue, PeepDaSlan9/B2BMGMT_Diffusion60XX, Yntec/PrintingPress, Yntec/ToyWorld, Yntec/blitz_diffusion, huggingface/InferenceSupport/discussions/new?title=JosephusCheung/ACertainModel&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BJosephusCheung%2FACertainModel%5D(%2FJosephusCheung%2FACertainModel)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, kaleidoskop-hug/PrintingPress, phenixrhyder/NSFW-ToyWorld",14
|
Baichuan-13B-Base_finetunes_20250426_221535.csv_finetunes_20250426_221535.csv
ADDED
|
@@ -0,0 +1,142 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
baichuan-inc/Baichuan-13B-Base,"---
|
| 3 |
+
language:
|
| 4 |
+
- zh
|
| 5 |
+
- en
|
| 6 |
+
pipeline_tag: text-generation
|
| 7 |
+
inference: false
|
| 8 |
+
---
|
| 9 |
+
# Baichuan-13B-Base
|
| 10 |
+
|
| 11 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 12 |
+
|
| 13 |
+
## 介绍
|
| 14 |
+
Baichuan-13B-Base为Baichuan-13B系列模型中的预训练版本,经过对齐后的模型可见[Baichuan-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat)。
|
| 15 |
+
|
| 16 |
+
[Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B) 是由百川智能继 [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B) 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 ([Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base)) 和对齐 ([Baichuan-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat)) 两个版本。Baichuan-13B 有如下几个特点:
|
| 17 |
+
|
| 18 |
+
1. **更大尺寸、更多数据**:Baichuan-13B 在 [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B) 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
|
| 19 |
+
2. **同时开源预训练和对齐模型**:预训练模型是适用开发者的“基座”,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
|
| 20 |
+
3. **更高效的推理**:为了支持更广大用户的使用,我们本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
|
| 21 |
+
4. **开源免费可商用**:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
|
| 22 |
+
5.
|
| 23 |
+
Baichuan-13B-Base is the pre-training version in the Baichuan-13B series of models, and the aligned model can be found at [Baichuan-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat).
|
| 24 |
+
|
| 25 |
+
[Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B) is an open-source, commercially usable large-scale language model developed by Baichuan Intelligence, following [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B). With 13 billion parameters, it achieves the best performance in standard Chinese and English benchmarks among models of its size. This release includes two versions: pre-training (Baichuan-13B-Base) and alignment (Baichuan-13B-Chat). Baichuan-13B has the following features:
|
| 26 |
+
|
| 27 |
+
1. **Larger size, more data**: Baichuan-13B further expands the parameter volume to 13 billion based on [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B), and has trained 1.4 trillion tokens on high-quality corpora, exceeding LLaMA-13B by 40%. It is currently the model with the most training data in the open-source 13B size. It supports both Chinese and English, uses ALiBi position encoding, and has a context window length of 4096.
|
| 28 |
+
2. **Open-source pre-training and alignment models simultaneously**: The pre-training model is a ""base"" suitable for developers, while the general public has a stronger demand for alignment models with dialogue capabilities. Therefore, in this open-source release, we also released the alignment model (Baichuan-13B-Chat), which has strong dialogue capabilities and is ready to use. It can be easily deployed with just a few lines of code.
|
| 29 |
+
3. **More efficient inference**: To support a wider range of users, we have open-sourced the INT8 and INT4 quantized versions. The model can be conveniently deployed on consumer GPUs like the Nvidia 3090 with almost no performance loss.
|
| 30 |
+
4. **Open-source, free, and commercially usable**: Baichuan-13B is not only fully open to academic research, but developers can also use it for free commercially after applying for and receiving official commercial permission via email.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## 模型详情
|
| 34 |
+
|
| 35 |
+
### 模型描述
|
| 36 |
+
|
| 37 |
+
<!-- Provide a longer summary of what this model is. -->
|
| 38 |
+
|
| 39 |
+
- **Developed by:** 百川智能(Baichuan Intelligent Technology)
|
| 40 |
+
- **Email**: opensource@baichuan-inc.com
|
| 41 |
+
- **Language(s) (NLP):** Chinese/English
|
| 42 |
+
- **License:** 【Community License for Baichuan-13B Model】([ZH](Baichuan-13B%20模型社区许可协议.pdf)|
|
| 43 |
+
[EN](Community%20License%20for%20Baichuan-13B%20Model.pdf))
|
| 44 |
+
|
| 45 |
+
**商业用途(For commercial use):** 请通过 [Email](mailto:opensource@baichuan-inc.com) 联系申请书面授权。(Contact us via [Email](mailto:opensource@baichuan-inc.com) above to apply for written authorization.)
|
| 46 |
+
|
| 47 |
+
### 模型结构
|
| 48 |
+
|
| 49 |
+
<!-- Provide the basic links for the model. -->
|
| 50 |
+
|
| 51 |
+
整体模型基于Baichuan-7B,为了获得更好的推理性能,Baichuan-13B 使用了 ALiBi 线性偏置技术,相对于 Rotary Embedding 计算量更小,对推理性能有显著提升;与标准的 LLaMA-13B 相比,生成 2000 个 tokens 的平均推理速度 (tokens/s),实测提升 31.6%:
|
| 52 |
+
|
| 53 |
+
| Model | tokens/s |
|
| 54 |
+
|-------------|----------|
|
| 55 |
+
| LLaMA-13B | 19.4 |
|
| 56 |
+
| Baichuan-13B| 25.4 |
|
| 57 |
+
|
| 58 |
+
具体参数和见下表
|
| 59 |
+
| 模型名称 | 隐含层维度 | 层数 | 头数 |词表大小 | 总参数量 | 训练数据(tokens) | 位置编码 | 最大长度 |
|
| 60 |
+
|-------------------------|-------|------------|------------|-----------------|--------|--------|----------------|---------|
|
| 61 |
+
| Baichuan-7B | 4,096 | 32 | 32 | 64,000 | 7,000,559,616 | 1.2万亿 | [RoPE](https://arxiv.org/abs/2104.09864) | 4,096 |
|
| 62 |
+
| Baichuan-13B | 5,120 | 40 | 40 | 64,000 | 13,264,901,120 | 1.4万亿 | [ALiBi](https://arxiv.org/abs/2108.12409) | 4,096
|
| 63 |
+
|
| 64 |
+
The overall model is based on Baichuan-7B. In order to achieve better inference performance, Baichuan-13B uses ALiBi linear bias technology, which has a smaller computational load compared to Rotary Embedding, and significantly improves inference performance. Compared with the standard LLaMA-13B, the average inference speed (tokens/s) for generating 2000 tokens has been tested to increase by 31.6%:
|
| 65 |
+
|
| 66 |
+
| Model | tokens/s |
|
| 67 |
+
|-------------|----------|
|
| 68 |
+
| LLaMA-13B | 19.4 |
|
| 69 |
+
| Baichuan-13B| 25.4 |
|
| 70 |
+
|
| 71 |
+
The specific parameters are as follows:
|
| 72 |
+
| Model Name | Hidden Size | Num Layers | Num Attention Heads |Vocab Size | Total Params | Training Dats(tokens) | Position Embedding | Max Length |
|
| 73 |
+
|-------------------------|-------|------------|------------|-----------------|--------|--------|----------------|---------|
|
| 74 |
+
| Baichuan-7B | 4,096 | 32 | 32 | 64,000 | 7,000,559,616 | 1.2万亿 | [RoPE](https://arxiv.org/abs/2104.09864) | 4,096 |
|
| 75 |
+
| Baichuan-13B | 5,120 | 40 | 40 | 64,000 | 13,264,901,120 | 1.4万亿 | [ALiBi](https://arxiv.org/abs/2108.12409) | 4,096
|
| 76 |
+
|
| 77 |
+
### 免责声明
|
| 78 |
+
|
| 79 |
+
我们在此声明,我们的开发团队并未基于 Baichuan-13B 模型开发任何应用,无论是在 iOS、Android、网页或任何其他平台。我们强烈呼吁所有使用者,不要利用 Baichuan-13B 模型进行任何危害国家社会安全或违法的活动。另外,我们也要求使用者不要将 Baichuan-13B 模型用于未经适当安全审查和备案的互联网服务。我们希望所有的使用者都能遵守这个原则,确保科技的发展能在规范和合法的环境下进行。
|
| 80 |
+
|
| 81 |
+
我们已经尽我们所能,来确保模型训练过程中使用的数据的合规性。然而,尽管我们已经做出了巨大的努力,但由于模型和数据的复杂性,仍有可能存在一些无法预见的问题。因此,如果由于使用 Baichuan-13B 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
|
| 82 |
+
|
| 83 |
+
We hereby declare that our development team has not developed any applications based on the Baichuan-13B model, whether on iOS, Android, the web, or any other platform. We strongly urge all users not to use the Baichuan-13B model for any activities that harm national social security or are illegal. In addition, we also ask users not to use the Baichuan-13B model for internet services that have not undergone appropriate security review and filing. We hope that all users will adhere to this principle to ensure that technological development takes place in a regulated and legal environment.
|
| 84 |
+
|
| 85 |
+
We have done our utmost to ensure the compliance of the data used in the model training process. However, despite our great efforts, due to the complexity of the model and data, there may still be some unforeseen issues. Therefore, we will not take any responsibility for any issues arising from the use of the Baichuan-13B open-source model, including but not limited to data security issues, public opinion risks, or any risks and problems arising from the model being misled, misused, disseminated, or improperly exploited.
|
| 86 |
+
|
| 87 |
+
## 训练详情
|
| 88 |
+
|
| 89 |
+
训练具体设置参见[Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B)。
|
| 90 |
+
|
| 91 |
+
For specific training settings, please refer to [Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B).
|
| 92 |
+
|
| 93 |
+
## 测评结果
|
| 94 |
+
|
| 95 |
+
### [C-Eval](https://cevalbenchmark.com/index.html#home)
|
| 96 |
+
|
| 97 |
+
| Model 5-shot | STEM | Social Sciences | Humanities | Others | Average |
|
| 98 |
+
|-------------------------|:-----:|:---------------:|:----------:|:------:|:-------:|
|
| 99 |
+
| Baichuan-7B | 38.2 | 52.0 | 46.2 | 39.3 | 42.8 |
|
| 100 |
+
| Chinese-Alpaca-Plus-13B | 35.2 | 45.6 | 40.0 | 38.2 | 38.8 |
|
| 101 |
+
| Vicuna-13B | 30.5 | 38.2 | 32.5 | 32.5 | 32.8 |
|
| 102 |
+
| Chinese-LLaMA-Plus-13B | 30.3 | 38.0 | 32.9 | 29.1 | 32.1 |
|
| 103 |
+
| Ziya-LLaMA-13B-Pretrain | 27.6 | 34.4 | 32.0 | 28.6 | 30.0 |
|
| 104 |
+
| LLaMA-13B | 27.0 | 33.6 | 27.7 | 27.6 | 28.5 |
|
| 105 |
+
| moss-moon-003-base (16B)| 27.0 | 29.1 | 27.2 | 26.9 | 27.4 |
|
| 106 |
+
| **Baichuan-13B-Base** | **45.9** | **63.5** | **57.2** | **49.3** | **52.4** |
|
| 107 |
+
| **Baichuan-13B-Chat** | **43.7** | **64.6** | **56.2** | **49.2** | **51.5** |
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
### [MMLU](https://arxiv.org/abs/2009.03300)
|
| 111 |
+
|
| 112 |
+
| Model 5-shot | STEM | Social Sciences | Humanities | Others | Average |
|
| 113 |
+
|-------------------------|:-----:|:---------------:|:----------:|:------:|:-------:|
|
| 114 |
+
| Vicuna-13B | 40.4 | 60.5 | 49.5 | 58.4 | 52.0 |
|
| 115 |
+
| LLaMA-13B | 36.1 | 53.0 | 44.0 | 52.8 | 46.3 |
|
| 116 |
+
| Chinese-Alpaca-Plus-13B | 36.9 | 48.9 | 40.5 | 50.5 | 43.9 |
|
| 117 |
+
| Ziya-LLaMA-13B-Pretrain | 35.6 | 47.6 | 40.1 | 49.4 | 42.9 |
|
| 118 |
+
| Baichuan-7B | 35.6 | 48.9 | 38.4 | 48.1 | 42.3 |
|
| 119 |
+
| Chinese-LLaMA-Plus-13B | 33.1 | 42.8 | 37.0 | 44.6 | 39.2 |
|
| 120 |
+
| moss-moon-003-base (16B)| 22.4 | 22.8 | 24.2 | 24.4 | 23.6 |
|
| 121 |
+
| **Baichuan-13B-Base** | **41.6** | **60.9** | **47.4** | **58.5** | **51.6** |
|
| 122 |
+
| **Baichuan-13B-Chat** | **40.9** | **60.9** | **48.8** | **59.0** | **52.1** |
|
| 123 |
+
> 说明:我们采用了 MMLU 官方的[评测方案](https://github.com/hendrycks/test)。
|
| 124 |
+
|
| 125 |
+
### [CMMLU](https://github.com/haonan-li/CMMLU)
|
| 126 |
+
|
| 127 |
+
| Model 5-shot | STEM | Humanities | Social Sciences | Others | China Specific | Average |
|
| 128 |
+
|-------------------------|:-----:|:----------:|:---------------:|:------:|:--------------:|:-------:|
|
| 129 |
+
| Baichuan-7B | 34.4 | 47.5 | 47.6 | 46.6 | 44.3 | 44.0 |
|
| 130 |
+
| Vicuna-13B | 31.8 | 36.2 | 37.6 | 39.5 | 34.3 | 36.3 |
|
| 131 |
+
| Chinese-Alpaca-Plus-13B | 29.8 | 33.4 | 33.2 | 37.9 | 32.1 | 33.4 |
|
| 132 |
+
| Chinese-LLaMA-Plus-13B | 28.1 | 33.1 | 35.4 | 35.1 | 33.5 | 33.0 |
|
| 133 |
+
| Ziya-LLaMA-13B-Pretrain | 29.0 | 30.7 | 33.8 | 34.4 | 31.9 | 32.1 |
|
| 134 |
+
| LLaMA-13B | 29.2 | 30.8 | 31.6 | 33.0 | 30.5 | 31.2 |
|
| 135 |
+
| moss-moon-003-base (16B)| 27.2 | 30.4 | 28.8 | 32.6 | 28.7 | 29.6 |
|
| 136 |
+
| **Baichuan-13B-Base** | **41.7** | **61.1** | **59.8** | **59.0** | **56.4** | **55.3** |
|
| 137 |
+
| **Baichuan-13B-Chat** | **42.8** | **62.6** | **59.7** | **59.0** | **56.1** | **55.8** |
|
| 138 |
+
> 说明:CMMLU 是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。我们采用了其官方的[评测方案](https://github.com/haonan-li/CMMLU)。
|
| 139 |
+
|
| 140 |
+
## 微信群组
|
| 141 |
+

|
| 142 |
+
","{""id"": ""baichuan-inc/Baichuan-13B-Base"", ""author"": ""baichuan-inc"", ""sha"": ""0ef0739c7bdd34df954003ef76d80f3dabca2ff9"", ""last_modified"": ""2023-07-19 03:37:12+00:00"", ""created_at"": ""2023-07-08 16:55:46+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 418, ""downloads_all_time"": null, ""likes"": 185, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""baichuan"", ""text-generation"", ""custom_code"", ""zh"", ""en"", ""arxiv:2104.09864"", ""arxiv:2108.12409"", ""arxiv:2009.03300"", ""autotrain_compatible"", ""text-generation-inference"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- zh\n- en\npipeline_tag: text-generation\ninference: false"", ""widget_data"": [{""text"": ""\u6211\u53eb\u6731\u5229\u5b89\uff0c\u6211\u559c\u6b22""}, {""text"": ""\u6211\u53eb\u6258\u9a6c\u65af\uff0c\u6211\u7684\u4e3b\u8981""}, {""text"": ""\u6211\u53eb\u739b\u4e3d\u4e9a\uff0c\u6211\u6700\u559c\u6b22\u7684""}, {""text"": ""\u6211\u53eb\u514b\u62c9\u62c9\uff0c\u6211\u662f""}, {""text"": ""\u4ece\u524d\uff0c""}], ""model_index"": null, ""config"": {""architectures"": [""BaichuanForCausalLM""], ""auto_map"": {""AutoConfig"": ""configuration_baichuan.BaichuanConfig"", ""AutoModelForCausalLM"": ""modeling_baichuan.BaichuanForCausalLM""}, ""model_type"": ""baichuan"", ""tokenizer_config"": {""bos_token"": {""__type"": ""AddedToken"", ""content"": ""<s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": true}, ""eos_token"": {""__type"": ""AddedToken"", ""content"": ""</s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": true}, ""pad_token"": {""__type"": ""AddedToken"", ""content"": ""<unk>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": true}, ""unk_token"": {""__type"": ""AddedToken"", ""content"": ""<unk>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": true}}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": ""modeling_baichuan.BaichuanForCausalLM"", ""pipeline_tag"": ""text-generation"", ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Baichuan-13B \u6a21\u578b\u793e\u533a\u8bb8\u53ef\u534f\u8bae.pdf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Community License for Baichuan-13B Model.pdf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_baichuan.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_baichuan.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00003.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00003.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00003-of-00003.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='quantizer.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='requirements.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenization_baichuan.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Justinrune/LLaMA-Factory"", ""Junity/Genshin-World-Model"", ""kenken999/fastapi_django_main_live"", ""officialhimanshu595/llama-factory"", ""li-qing/FIRE"", ""tianleliphoebe/visual-arena"", ""Ashmal/MobiLlama"", ""PegaMichael/Taiwan-LLaMa2-Copy"", ""tjtanaa/chat-template-generation"", ""CaiRou-Huang/TwLLM7B-v2.0-base"", ""pallavijaini/NeuralChat-LLAMA-POC"", ""blackwingedkite/gutalk"", ""cllatMTK/Breeze"", ""WinterGYC/Genshin-World-Model-Junity"", ""gordonchan/embedding-m3e-large"", ""blackwingedkite/alpaca2_clas"", ""jaekwon/intel_cpu_chat"", ""lianglv/NeuralChat-ICX-INT4"", ""Bofeee5675/FIRE"", ""evelyn-lo/evelyn"", ""yuantao-infini-ai/demo_test"", ""zjasper666/bf16_vs_fp8"", ""martinakaduc/melt"", ""cloneQ/internLMRAG"", ""hujin0929/LlamaIndex_RAG"", ""flyfive0315/internLlamaIndex"", ""sunxiaokang/llamaindex_RAG_web"", ""kai119/llama"", ""qxy826982153/LlamaIndexRAG"", ""ilemon/Internlm2.5LLaMAindexRAG"", ""msun415/Llamole""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-07-19 03:37:12+00:00"", ""cardData"": ""language:\n- zh\n- en\npipeline_tag: text-generation\ninference: false"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": ""modeling_baichuan.BaichuanForCausalLM"", ""pipeline_tag"": ""text-generation"", ""processor"": null}, ""_id"": ""64a9951299639cc3126324e2"", ""modelId"": ""baichuan-inc/Baichuan-13B-Base"", ""usedStorage"": 53062970073}",0,,0,,0,,0,,0,"Ashmal/MobiLlama, Bofeee5675/FIRE, Junity/Genshin-World-Model, Justinrune/LLaMA-Factory, blackwingedkite/gutalk, evelyn-lo/evelyn, gordonchan/embedding-m3e-large, huggingface/InferenceSupport/discussions/new?title=baichuan-inc/Baichuan-13B-Base&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bbaichuan-inc%2FBaichuan-13B-Base%5D(%2Fbaichuan-inc%2FBaichuan-13B-Base)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, kenken999/fastapi_django_main_live, li-qing/FIRE, martinakaduc/melt, officialhimanshu595/llama-factory, tianleliphoebe/visual-arena",13
|
Baichuan-13B-Chat_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
baichuan-inc/Baichuan-13B-Chat,"---
|
| 3 |
+
language:
|
| 4 |
+
- zh
|
| 5 |
+
- en
|
| 6 |
+
pipeline_tag: text-generation
|
| 7 |
+
inference: false
|
| 8 |
+
---
|
| 9 |
+
# Baichuan-13B-Chat
|
| 10 |
+
|
| 11 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 12 |
+
|
| 13 |
+
## 介绍
|
| 14 |
+
Baichuan-13B-Chat为Baichuan-13B系列模型中对齐后的版本,预训练模型可见[Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base)。
|
| 15 |
+
|
| 16 |
+
[Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B) 是由百川智能继 [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B) 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 ([Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base)) 和对齐 ([Baichuan-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat)) 两个版本。Baichuan-13B 有如下几个特点:
|
| 17 |
+
|
| 18 |
+
1. **更大尺寸、更多数据**:Baichuan-13B 在 [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B) 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
|
| 19 |
+
2. **同时开源预训练和对齐模型**:预训练模型是适用开发者的“基座”,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
|
| 20 |
+
3. **更高效的推理**:为了支持更广大用户的使用,我们本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
|
| 21 |
+
4. **开源免费可商用**:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
|
| 22 |
+
|
| 23 |
+
Baichuan-13B-Chat is the aligned version in the Baichuan-13B series of models, and the pre-trained model can be found at [Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base).
|
| 24 |
+
|
| 25 |
+
[Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B) is an open-source, commercially usable large-scale language model developed by Baichuan Intelligence, following [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B). With 13 billion parameters, it achieves the best performance in standard Chinese and English benchmarks among models of its size. This release includes two versions: pre-training (Baichuan-13B-Base) and alignment (Baichuan-13B-Chat). Baichuan-13B has the following features:
|
| 26 |
+
|
| 27 |
+
1. **Larger size, more data**: Baichuan-13B further expands the parameter volume to 13 billion based on [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B), and has trained 1.4 trillion tokens on high-quality corpora, exceeding LLaMA-13B by 40%. It is currently the model with the most training data in the open-source 13B size. It supports both Chinese and English, uses ALiBi position encoding, and has a context window length of 4096.
|
| 28 |
+
2. **Open-source pre-training and alignment models simultaneously**: The pre-training model is a ""base"" suitable for developers, while the general public has a stronger demand for alignment models with dialogue capabilities. Therefore, in this open-source release, we also released the alignment model (Baichuan-13B-Chat), which has strong dialogue capabilities and is ready to use. It can be easily deployed with just a few lines of code.
|
| 29 |
+
3. **More efficient inference**: To support a wider range of users, we have open-sourced the INT8 and INT4 quantized versions. The model can be conveniently deployed on consumer GPUs like the Nvidia 3090 with almost no performance loss.
|
| 30 |
+
4. **Open-source, free, and commercially usable**: Baichuan-13B is not only fully open to academic research, but developers can also use it for free commercially after applying for and receiving official commercial permission via email.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## 使用方式
|
| 34 |
+
|
| 35 |
+
如下是一个使用Baichuan-13B-Chat进行对话的示例,正确输出为""乔戈里峰。世界第二高峰———乔戈里峰西方登山者称其为k2峰,海拔高度是8611米,位于喀喇昆仑山脉的中巴边境上""
|
| 36 |
+
```python
|
| 37 |
+
import torch
|
| 38 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 39 |
+
from transformers.generation.utils import GenerationConfig
|
| 40 |
+
tokenizer = AutoTokenizer.from_pretrained(""baichuan-inc/Baichuan-13B-Chat"", use_fast=False, trust_remote_code=True)
|
| 41 |
+
model = AutoModelForCausalLM.from_pretrained(""baichuan-inc/Baichuan-13B-Chat"", device_map=""auto"", torch_dtype=torch.float16, trust_remote_code=True)
|
| 42 |
+
model.generation_config = GenerationConfig.from_pretrained(""baichuan-inc/Baichuan-13B-Chat"")
|
| 43 |
+
messages = []
|
| 44 |
+
messages.append({""role"": ""user"", ""content"": ""世界上第二高的山峰是哪座""})
|
| 45 |
+
response = model.chat(tokenizer, messages)
|
| 46 |
+
print(response)
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
Here is an example of a conversation using Baichuan-13B-Chat, the correct output is ""K2. The world's second highest peak - K2, also known as Mount Godwin-Austen or Chhogori, with an altitude of 8611 meters, is located on the China-Pakistan border in the Karakoram Range.""
|
| 50 |
+
```python
|
| 51 |
+
import torch
|
| 52 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 53 |
+
from transformers.generation.utils import GenerationConfig
|
| 54 |
+
tokenizer = AutoTokenizer.from_pretrained(""baichuan-inc/Baichuan-13B-Chat"", use_fast=False, trust_remote_code=True)
|
| 55 |
+
model = AutoModelForCausalLM.from_pretrained(""baichuan-inc/Baichuan-13B-Chat"", device_map=""auto"", torch_dtype=torch.float16, trust_remote_code=True)
|
| 56 |
+
model.generation_config = GenerationConfig.from_pretrained(""baichuan-inc/Baichuan-13B-Chat"")
|
| 57 |
+
messages = []
|
| 58 |
+
messages.append({""role"": ""user"", ""content"": ""Which moutain is the second highest one in the world?""})
|
| 59 |
+
response = model.chat(tokenizer, messages)
|
| 60 |
+
print(response)
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
## 量化部署
|
| 64 |
+
|
| 65 |
+
Baichuan-13B 支持 int8 和 int4 量化,用户只需在推理代码中简单修改两行即可实现。请注意,如果是为了节省显存而进行量化,应加载原始精度模型到 CPU 后再开始量化;避免在 `from_pretrained` 时添加 `device_map='auto'` 或者其它会导致把原始精度模型直接加载到 GPU 的行为的参数。
|
| 66 |
+
|
| 67 |
+
Baichuan-13B supports int8 and int4 quantization, users only need to make a simple two-line change in the inference code to implement it. Please note, if quantization is done to save GPU memory, the original precision model should be loaded onto the CPU before starting quantization. Avoid adding parameters such as `device_map='auto'` or others that could cause the original precision model to be loaded directly onto the GPU when executing `from_pretrained`.
|
| 68 |
+
|
| 69 |
+
使用 int8 量化 (To use int8 quantization):
|
| 70 |
+
```python
|
| 71 |
+
model = AutoModelForCausalLM.from_pretrained(""baichuan-inc/Baichuan-13B-Chat"", torch_dtype=torch.float16, trust_remote_code=True)
|
| 72 |
+
model = model.quantize(8).cuda()
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
同样的,如需使用 int4 量化 (Similarly, to use int4 quantization):
|
| 76 |
+
```python
|
| 77 |
+
model = AutoModelForCausalLM.from_pretrained(""baichuan-inc/Baichuan-13B-Chat"", torch_dtype=torch.float16, trust_remote_code=True)
|
| 78 |
+
model = model.quantize(4).cuda()
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
## 模型详情
|
| 82 |
+
|
| 83 |
+
### 模型描述
|
| 84 |
+
|
| 85 |
+
<!-- Provide a longer summary of what this model is. -->
|
| 86 |
+
|
| 87 |
+
- **Developed by:** 百川智能(Baichuan Intelligent Technology)
|
| 88 |
+
- **Email**: opensource@baichuan-inc.com
|
| 89 |
+
- **Language(s) (NLP):** Chinese/English
|
| 90 |
+
- **License:** 【Community License for Baichuan-13B Model】([ZH](Baichuan-13B%20模型社区许可协议.pdf)|
|
| 91 |
+
[EN](Community%20License%20for%20Baichuan-13B%20Model.pdf))
|
| 92 |
+
|
| 93 |
+
**商业用途(For commercial use):** 请通过 [Email](mailto:opensource@baichuan-inc.com) 联系申请书面授权。(Contact us via [Email](mailto:opensource@baichuan-inc.com) above to apply for written authorization.)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
### 模型结构
|
| 97 |
+
|
| 98 |
+
<!-- Provide the basic links for the model. -->
|
| 99 |
+
|
| 100 |
+
整体模型基于Baichuan-7B,为了获得更好的推理性能,Baichuan-13B 使用了 ALiBi 线性偏置技术,相对于 Rotary Embedding 计算量更小,对推理性能有显著提升;与标准的 LLaMA-13B 相比,生成 2000 个 tokens 的平均推理速度 (tokens/s),实测提升 31.6%:
|
| 101 |
+
|
| 102 |
+
| Model | tokens/s |
|
| 103 |
+
|-------------|----------|
|
| 104 |
+
| LLaMA-13B | 19.4 |
|
| 105 |
+
| Baichuan-13B| 25.4 |
|
| 106 |
+
|
| 107 |
+
具体参数和见下表
|
| 108 |
+
| 模型名称 | 隐含层维度 | 层数 | 头数 |词表大小 | 总参数量 | 训练数据(tokens) | 位置编码 | 最大长度 |
|
| 109 |
+
|-------------------------|-------|------------|------------|-----------------|--------|--------|----------------|---------|
|
| 110 |
+
| Baichuan-7B | 4,096 | 32 | 32 | 64,000 | 7,000,559,616 | 1.2万亿 | [RoPE](https://arxiv.org/abs/2104.09864) | 4,096 |
|
| 111 |
+
| Baichuan-13B | 5,120 | 40 | 40 | 64,000 | 13,264,901,120 | 1.4万亿 | [ALiBi](https://arxiv.org/abs/2108.12409) | 4,096
|
| 112 |
+
|
| 113 |
+
The overall model is based on Baichuan-7B. In order to achieve better inference performance, Baichuan-13B uses ALiBi linear bias technology, which has a smaller computational load compared to Rotary Embedding, and significantly improves inference performance. Compared with the standard LLaMA-13B, the average inference speed (tokens/s) for generating 2000 tokens has been tested to increase by 31.6%:
|
| 114 |
+
|
| 115 |
+
| Model | tokens/s |
|
| 116 |
+
|-------------|----------|
|
| 117 |
+
| LLaMA-13B | 19.4 |
|
| 118 |
+
| Baichuan-13B| 25.4 |
|
| 119 |
+
|
| 120 |
+
The specific parameters are as follows:
|
| 121 |
+
| Model Name | Hidden Size | Num Layers | Num Attention Heads |Vocab Size | Total Params | Training Dats(tokens) | Position Embedding | Max Length |
|
| 122 |
+
|-------------------------|-------|------------|------------|-----------------|--------|--------|----------------|---------|
|
| 123 |
+
| Baichuan-7B | 4,096 | 32 | 32 | 64,000 | 7,000,559,616 | 1.2万亿 | [RoPE](https://arxiv.org/abs/2104.09864) | 4,096 |
|
| 124 |
+
| Baichuan-13B | 5,120 | 40 | 40 | 64,000 | 13,264,901,120 | 1.4万亿 | [ALiBi](https://arxiv.org/abs/2108.12409) | 4,096
|
| 125 |
+
|
| 126 |
+
## 使用须知
|
| 127 |
+
|
| 128 |
+
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
### 免责声明
|
| 132 |
+
|
| 133 |
+
我们在此声明,我们的开发团队并未基于 Baichuan-13B 模型开发任何应用,无论是在 iOS、Android、网页或任何其他平台。我们强烈呼吁所有使用者,不要利用 Baichuan-13B 模型进行任何危害国家社会安全或违法的活动。另外,我们也要求使用者不要将 Baichuan-13B 模型用于未经适当安全审查和备案的互联网服务。我们希望所有的使用者都能遵守这个原则,确保科技的发展能在规范和合法的环境下进行。
|
| 134 |
+
|
| 135 |
+
我们已经尽我们所能,来确保模型训练过程中使用的数据的合规性。然而,尽管我们已经做出了巨大的努力,但由于模型和数据的复杂性,仍有可能存在一些无法预见的问题。因此,如果由于使用 Baichuan-13B 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
|
| 136 |
+
|
| 137 |
+
We hereby declare that our development team has not developed any applications based on the Baichuan-13B model, whether on iOS, Android, the web, or any other platform. We strongly urge all users not to use the Baichuan-13B model for any activities that harm national social security or are illegal. In addition, we also ask users not to use the Baichuan-13B model for internet services that have not undergone appropriate security review and filing. We hope that all users will adhere to this principle to ensure that technological development takes place in a regulated and legal environment.
|
| 138 |
+
|
| 139 |
+
We have done our utmost to ensure the compliance of the data used in the model training process. However, despite our great efforts, due to the complexity of the model and data, there may still be some unforeseen issues. Therefore, we will not take any responsibility for any issues arising from the use of the Baichuan-13B open-source model, including but not limited to data security issues, public opinion risks, or any risks and problems arising from the model being misled, misused, disseminated, or improperly exploited.
|
| 140 |
+
|
| 141 |
+
## 训练详情
|
| 142 |
+
|
| 143 |
+
训练具体设置参见[Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B)。
|
| 144 |
+
|
| 145 |
+
For specific training settings, please refer to [Baichuan-13B](https://github.com/baichuan-inc/Baichuan-13B).
|
| 146 |
+
|
| 147 |
+
## 测评结果
|
| 148 |
+
|
| 149 |
+
## [C-Eval](https://cevalbenchmark.com/index.html#home)
|
| 150 |
+
|
| 151 |
+
| Model 5-shot | STEM | Social Sciences | Humanities | Others | Average |
|
| 152 |
+
|-------------------------|:-----:|:---------------:|:----------:|:------:|:-------:|
|
| 153 |
+
| Baichuan-7B | 38.2 | 52.0 | 46.2 | 39.3 | 42.8 |
|
| 154 |
+
| Chinese-Alpaca-Plus-13B | 35.2 | 45.6 | 40.0 | 38.2 | 38.8 |
|
| 155 |
+
| Vicuna-13B | 30.5 | 38.2 | 32.5 | 32.5 | 32.8 |
|
| 156 |
+
| Chinese-LLaMA-Plus-13B | 30.3 | 38.0 | 32.9 | 29.1 | 32.1 |
|
| 157 |
+
| Ziya-LLaMA-13B-Pretrain | 27.6 | 34.4 | 32.0 | 28.6 | 30.0 |
|
| 158 |
+
| LLaMA-13B | 27.0 | 33.6 | 27.7 | 27.6 | 28.5 |
|
| 159 |
+
| moss-moon-003-base (16B)| 27.0 | 29.1 | 27.2 | 26.9 | 27.4 |
|
| 160 |
+
| **Baichuan-13B-Base** | **45.9** | **63.5** | **57.2** | **49.3** | **52.4** |
|
| 161 |
+
| **Baichuan-13B-Chat** | **43.7** | **64.6** | **56.2** | **49.2** | **51.5** |
|
| 162 |
+
|
| 163 |
+
## [MMLU](https://arxiv.org/abs/2009.03300)
|
| 164 |
+
|
| 165 |
+
| Model 5-shot | STEM | Social Sciences | Humanities | Others | Average |
|
| 166 |
+
|-------------------------|:-----:|:---------------:|:----------:|:------:|:-------:|
|
| 167 |
+
| Vicuna-13B | 40.4 | 60.5 | 49.5 | 58.4 | 52.0 |
|
| 168 |
+
| LLaMA-13B | 36.1 | 53.0 | 44.0 | 52.8 | 46.3 |
|
| 169 |
+
| Chinese-Alpaca-Plus-13B | 36.9 | 48.9 | 40.5 | 50.5 | 43.9 |
|
| 170 |
+
| Ziya-LLaMA-13B-Pretrain | 35.6 | 47.6 | 40.1 | 49.4 | 42.9 |
|
| 171 |
+
| Baichuan-7B | 35.6 | 48.9 | 38.4 | 48.1 | 42.3 |
|
| 172 |
+
| Chinese-LLaMA-Plus-13B | 33.1 | 42.8 | 37.0 | 44.6 | 39.2 |
|
| 173 |
+
| moss-moon-003-base (16B)| 22.4 | 22.8 | 24.2 | 24.4 | 23.6 |
|
| 174 |
+
| **Baichuan-13B-Base** | **41.6** | **60.9** | **47.4** | **58.5** | **51.6** |
|
| 175 |
+
| **Baichuan-13B-Chat** | **40.9** | **60.9** | **48.8** | **59.0** | **52.1** |
|
| 176 |
+
> 说明:我们采用了 MMLU 官方的[评测方案](https://github.com/hendrycks/test)。
|
| 177 |
+
|
| 178 |
+
## [CMMLU](https://github.com/haonan-li/CMMLU)
|
| 179 |
+
|
| 180 |
+
| Model 5-shot | STEM | Humanities | Social Sciences | Others | China Specific | Average |
|
| 181 |
+
|-------------------------|:-----:|:----------:|:---------------:|:------:|:--------------:|:-------:|
|
| 182 |
+
| Baichuan-7B | 34.4 | 47.5 | 47.6 | 46.6 | 44.3 | 44.0 |
|
| 183 |
+
| Vicuna-13B | 31.8 | 36.2 | 37.6 | 39.5 | 34.3 | 36.3 |
|
| 184 |
+
| Chinese-Alpaca-Plus-13B | 29.8 | 33.4 | 33.2 | 37.9 | 32.1 | 33.4 |
|
| 185 |
+
| Chinese-LLaMA-Plus-13B | 28.1 | 33.1 | 35.4 | 35.1 | 33.5 | 33.0 |
|
| 186 |
+
| Ziya-LLaMA-13B-Pretrain | 29.0 | 30.7 | 33.8 | 34.4 | 31.9 | 32.1 |
|
| 187 |
+
| LLaMA-13B | 29.2 | 30.8 | 31.6 | 33.0 | 30.5 | 31.2 |
|
| 188 |
+
| moss-moon-003-base (16B)| 27.2 | 30.4 | 28.8 | 32.6 | 28.7 | 29.6 |
|
| 189 |
+
| **Baichuan-13B-Base** | **41.7** | **61.1** | **59.8** | **59.0** | **56.4** | **55.3** |
|
| 190 |
+
| **Baichuan-13B-Chat** | **42.8** | **62.6** | **59.7** | **59.0** | **56.1** | **55.8** |
|
| 191 |
+
> 说明:CMMLU 是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。我们采用了其官方的[评测方案](https://github.com/haonan-li/CMMLU)。
|
| 192 |
+
|
| 193 |
+
## 微信群组
|
| 194 |
+

|
| 195 |
+
","{""id"": ""baichuan-inc/Baichuan-13B-Chat"", ""author"": ""baichuan-inc"", ""sha"": ""e3e1498bb6b7fb0bcb5a65679c09b862d7c29301"", ""last_modified"": ""2024-01-09 07:56:42+00:00"", ""created_at"": ""2023-07-08 05:58:27+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 3619, ""downloads_all_time"": null, ""likes"": 631, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""baichuan"", ""text-generation"", ""custom_code"", ""zh"", ""en"", ""arxiv:2104.09864"", ""arxiv:2108.12409"", ""arxiv:2009.03300"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- zh\n- en\npipeline_tag: text-generation\ninference: false"", ""widget_data"": [{""text"": ""\u6211\u53eb\u6731\u5229\u5b89\uff0c\u6211\u559c\u6b22""}, {""text"": ""\u6211\u53eb\u6258\u9a6c\u65af\uff0c\u6211\u7684\u4e3b\u8981""}, {""text"": ""\u6211\u53eb\u739b\u4e3d\u4e9a\uff0c\u6211\u6700\u559c\u6b22\u7684""}, {""text"": ""\u6211\u53eb\u514b\u62c9\u62c9\uff0c\u6211\u662f""}, {""text"": ""\u4ece\u524d\uff0c""}], ""model_index"": null, ""config"": {""architectures"": [""BaichuanForCausalLM""], ""auto_map"": {""AutoConfig"": ""configuration_baichuan.BaichuanConfig"", ""AutoModelForCausalLM"": ""modeling_baichuan.BaichuanForCausalLM""}, ""model_type"": ""baichuan"", ""tokenizer_config"": {""bos_token"": {""__type"": ""AddedToken"", ""content"": ""<s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": true}, ""eos_token"": {""__type"": ""AddedToken"", ""content"": ""</s>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": true}, ""pad_token"": {""__type"": ""AddedToken"", ""content"": ""<unk>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": true}, ""unk_token"": {""__type"": ""AddedToken"", ""content"": ""<unk>"", ""lstrip"": false, ""normalized"": true, ""rstrip"": false, ""single_word"": true}}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": ""modeling_baichuan.BaichuanForCausalLM"", ""pipeline_tag"": ""text-generation"", ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Baichuan-13B \u6a21\u578b\u793e\u533a\u8bb8\u53ef\u534f\u8bae.pdf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Community License for Baichuan-13B Model.pdf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_baichuan.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_utils.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='handler.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_baichuan.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00003.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00003.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00003-of-00003.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='quantizer.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='requirements.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenization_baichuan.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""WinterGYC/BaiChuan-13B-Chat"", ""xuqinyang/Baichuan-13B-Chat"", ""EmbeddedLLM/chat-template-generation"", ""Justinrune/LLaMA-Factory"", ""kenken999/fastapi_django_main_live"", ""WinterGYC/Baichuan-13B-Chat-Int8"", ""Cran-May/yugangVI"", ""officialhimanshu595/llama-factory"", ""li-qing/FIRE"", ""WinterGYC/Baichuan-13B-Chat-Int8-Docker"", ""syx948/ChatPDF"", ""Zulelee/langchain-chatchat"", ""xuqinyang/Baichuan-13B-Chat-Int8-Cpp"", ""xuqinyang/Baichuan-13B-Chat-Int4-Cpp"", ""tianleliphoebe/visual-arena"", ""Cran-May/ygVI"", ""Ashmal/MobiLlama"", ""kaixuan42/aigc-lab"", ""WinterGYC/Baichuan-13B-Chat-Int8-Gradio"", ""PegaMichael/Taiwan-LLaMa2-Copy"", ""tjtanaa/chat-template-generation"", ""CaiRou-Huang/TwLLM7B-v2.0-base"", ""Havi999/FORAI"", ""pallavijaini/NeuralChat-LLAMA-POC"", ""blackwingedkite/gutalk"", ""cllatMTK/Breeze"", ""nengrenjie83/MedicalGPT-main"", ""shengzi/Baichuan-13B-Chat"", ""gordonchan/embedding-m3e-large"", ""larsthepenguin/trt-llm-rag-windows-main"", ""JiakunXu/Baichuan-13B-Chat"", ""blackwingedkite/alpaca2_clas"", ""Cran-May/ygVIB"", ""Cran-May/ygVIC"", ""jaekwon/intel_cpu_chat"", ""lianglv/NeuralChat-ICX-INT4"", ""hucoa/Baichuan-13B-Chat"", ""Bofeee5675/FIRE"", ""evelyn-lo/evelyn"", ""yuantao-infini-ai/demo_test"", ""zjasper666/bf16_vs_fp8"", ""martinakaduc/melt"", ""cloneQ/internLMRAG"", ""hujin0929/LlamaIndex_RAG"", ""flyfive0315/internLlamaIndex"", ""sunxiaokang/llamaindex_RAG_web"", ""kai119/llama"", ""qxy826982153/LlamaIndexRAG"", ""msun415/Llamole""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-01-09 07:56:42+00:00"", ""cardData"": ""language:\n- zh\n- en\npipeline_tag: text-generation\ninference: false"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": ""modeling_baichuan.BaichuanForCausalLM"", ""pipeline_tag"": ""text-generation"", ""processor"": null}, ""_id"": ""64a8fb03a8e86b27d097925b"", ""modelId"": ""baichuan-inc/Baichuan-13B-Chat"", ""usedStorage"": 79592869006}",0,,0,https://huggingface.co/shibing624/vicuna-baichuan-13b-chat-lora,1,,0,,0,"Ashmal/MobiLlama, Bofeee5675/FIRE, EmbeddedLLM/chat-template-generation, Justinrune/LLaMA-Factory, WinterGYC/BaiChuan-13B-Chat, Zulelee/langchain-chatchat, blackwingedkite/gutalk, evelyn-lo/evelyn, gordonchan/embedding-m3e-large, huggingface/InferenceSupport/discussions/new?title=baichuan-inc/Baichuan-13B-Chat&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bbaichuan-inc%2FBaichuan-13B-Chat%5D(%2Fbaichuan-inc%2FBaichuan-13B-Chat)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, kenken999/fastapi_django_main_live, martinakaduc/melt, xuqinyang/Baichuan-13B-Chat",13
|
Bio_ClinicalBERT_finetunes_20250426_121513.csv_finetunes_20250426_121513.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
ChatTTS_finetunes_20250424_193500.csv_finetunes_20250424_193500.csv
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
2Noise/ChatTTS,"---
|
| 3 |
+
license: cc-by-nc-4.0
|
| 4 |
+
library_name: chat_tts
|
| 5 |
+
pipeline_tag: text-to-audio
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
**We are also training larger-scale models and need computational power and data support. If you can provide assistance, please contact OPEN-SOURCE@2NOISE.COM. Thank you very much.**
|
| 10 |
+
|
| 11 |
+
## Clone the Repository
|
| 12 |
+
First, clone the Git repository:
|
| 13 |
+
```bash
|
| 14 |
+
git clone https://github.com/2noise/ChatTTS.git
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
## Model Inference
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
```python
|
| 21 |
+
# Import necessary libraries and configure settings
|
| 22 |
+
import torch
|
| 23 |
+
import torchaudio
|
| 24 |
+
torch._dynamo.config.cache_size_limit = 64
|
| 25 |
+
torch._dynamo.config.suppress_errors = True
|
| 26 |
+
torch.set_float32_matmul_precision('high')
|
| 27 |
+
|
| 28 |
+
import ChatTTS
|
| 29 |
+
from IPython.display import Audio
|
| 30 |
+
|
| 31 |
+
# Initialize and load the model:
|
| 32 |
+
chat = ChatTTS.Chat()
|
| 33 |
+
chat.load_models(compile=False) # Set to True for better performance
|
| 34 |
+
|
| 35 |
+
# Define the text input for inference (Support Batching)
|
| 36 |
+
texts = [
|
| 37 |
+
""So we found being competitive and collaborative was a huge way of staying motivated towards our goals, so one person to call when you fall off, one person who gets you back on then one person to actually do the activity with."",
|
| 38 |
+
]
|
| 39 |
+
|
| 40 |
+
# Perform inference and play the generated audio
|
| 41 |
+
wavs = chat.infer(texts)
|
| 42 |
+
Audio(wavs[0], rate=24_000, autoplay=True)
|
| 43 |
+
|
| 44 |
+
# Save the generated audio
|
| 45 |
+
torchaudio.save(""output.wav"", torch.from_numpy(wavs[0]), 24000)
|
| 46 |
+
```
|
| 47 |
+
**For more usage examples, please refer to the [example notebook](https://github.com/2noise/ChatTTS/blob/main/example.ipynb), which includes parameters for finer control over the generated speech, such as specifying the speaker, adjusting speech speed, and adding laughter.**
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
### Disclaimer: For Academic Purposes Only
|
| 55 |
+
|
| 56 |
+
The information provided in this document is for academic purposes only. It is intended for educational and research use, and should not be used for any commercial or legal purposes. The authors do not guarantee the accuracy, completeness, or reliability of the information.","{""id"": ""2Noise/ChatTTS"", ""author"": ""2Noise"", ""sha"": ""1a3c04a8b0651689bd9242fbb55b1f4b5a9aef84"", ""last_modified"": ""2024-10-22 08:26:20+00:00"", ""created_at"": ""2024-05-25 06:07:38+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 2918, ""downloads_all_time"": null, ""likes"": 1551, ""library_name"": ""chat_tts"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""chat_tts"", ""safetensors"", ""text-to-audio"", ""license:cc-by-nc-4.0"", ""region:us""], ""pipeline_tag"": ""text-to-audio"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""library_name: chat_tts\nlicense: cc-by-nc-4.0\npipeline_tag: text-to-audio"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/DVAE.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/DVAE.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/DVAE_full.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/Decoder.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/Decoder.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/Embed.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/GPT.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/Vocos.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/Vocos.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/gpt/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/gpt/model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/spk_stat.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/tokenizer.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/tokenizer/tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config/decoder.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config/dvae.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config/gpt.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config/path.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config/vocos.yaml', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Dzkaka/ChatTTS"", ""lenML/ChatTTS-Forge"", ""Hilley/ChatTTS-OpenVoice"", ""markmagic/ChatTTS"", ""Hilley/ChatVC"", ""wffcyrus/ChatTTS-Story-Telling"", ""6Simple9/ChatTTS-OpenVoice"", ""fcyai/ChatTTS"", ""rao223/ChatTTS-Forge"", ""chenmgtea/chat-tts"", ""doby4u/chattts"", ""cbhhhcb/ChatTTS"", ""zelk12/ChatTTS-Forge_English_interface"", ""rainnee0925/ChatTTS"", ""prajjwalkapoor/tts"", ""fcyai/ChatTTS-Story-Telling"", ""sysf/ChatTTS"", ""savokiss/ChatTTS"", ""savokiss/chattts-free"", ""arpy8/chattts"", ""lisongfeng/ChatTTS-WebUI"", ""rainnee/ChatTTS"", ""wffcyrus/ChatTTS-Forge"", ""zzhouz/learningself"", ""docs4dev/gptalk"", ""sandy-try/ChatTTS-Forge"", ""slingkid/ChatVC2"", ""panyanyany/ChatTTS"", ""slingkid/ChatVC4"", ""Rdtuetr/ChatTTS"", ""hikerxu/ChatTTS"", ""zhzabcd/ChatTTS-Forge"", ""jdhsi/ChatTTS"", ""AwesomeK/ChatTTS-OpenVoice"", ""zhengr/ChatTTS-Forge"", ""zhengr/ChatTTS2"", ""weismart1807/Linly-Talker"", ""emilalvaro/ChatTTS-OpenVoice"", ""vuxuanhoan/ChatTTS-Forge"", ""MaktubCN/Chat-TTS"", ""EZMODEL/chattts-free"", ""chenjacky131/ChatTTS-Forge"", ""lalalic/chattts"", ""yamazing/ChatTTS"", ""zhangyanhua0913/ChatTTS-OpenVoice"", ""thierryguyot67/tts"", ""EagleW96/CC_ChatTTS_demo""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-10-22 08:26:20+00:00"", ""cardData"": ""library_name: chat_tts\nlicense: cc-by-nc-4.0\npipeline_tag: text-to-audio"", ""transformersInfo"": null, ""_id"": ""6651802a815d7642d5aaef56"", ""modelId"": ""2Noise/ChatTTS"", ""usedStorage"": 2364745599}",0,,0,,0,,0,,0,"6Simple9/ChatTTS-OpenVoice, Dzkaka/ChatTTS, EagleW96/CC_ChatTTS_demo, Hilley/ChatTTS-OpenVoice, Hilley/ChatVC, cbhhhcb/ChatTTS, huggingface/InferenceSupport/discussions/546, lenML/ChatTTS-Forge, panyanyany/ChatTTS, rao223/ChatTTS-Forge, savokiss/chattts-free, wffcyrus/ChatTTS-Forge, zelk12/ChatTTS-Forge_English_interface",13
|
ChilloutMix_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
AnonPerson/ChilloutMix,N/A,"{""id"": ""AnonPerson/ChilloutMix"", ""author"": ""AnonPerson"", ""sha"": ""65ee86993c78c48939d47719c6970c3315ca507d"", ""last_modified"": ""2023-02-22 14:04:42+00:00"", ""created_at"": ""2023-02-22 13:46:05+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 306, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": null, ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ChilloutMix-ni-fp16.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Japanese-doll-likeness.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Korean-doll-likeness.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Taiwan-doll-likeness.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ulzzang-6500.pt', size=None, blob_id=None, lfs=None)""], ""spaces"": [""INDONESIA-AI/Lobe"", ""Recahtrada/2nd2"", ""Rifd/Gxtaucok"", ""enochianborg/stable-diffusion-webui-vorstcavry"", ""ClipHamper/stable-diffusion-webui"", ""stable13/createimage7"", ""manivannan7gp/stable-diffusion-webui-vorstcavry"", ""henrysion/stable-diffusion-test"", ""vorstcavry/Anapnoe"", ""diego2554/stable-diffusion-SG"", ""vorstcavry/vorst-cavry-a1111-public"", ""Furinkaz/StableDiffusion""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-02-22 14:04:42+00:00"", ""cardData"": null, ""transformersInfo"": null, ""_id"": ""63f61c9d52799101f3cd4136"", ""modelId"": ""AnonPerson/ChilloutMix"", ""usedStorage"": 2585985291}",0,,0,,0,,0,,0,"ClipHamper/stable-diffusion-webui, Furinkaz/StableDiffusion, INDONESIA-AI/Lobe, Recahtrada/2nd2, Rifd/Gxtaucok, diego2554/stable-diffusion-SG, enochianborg/stable-diffusion-webui-vorstcavry, henrysion/stable-diffusion-test, huggingface/InferenceSupport/discussions/new?title=AnonPerson/ChilloutMix&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BAnonPerson%2FChilloutMix%5D(%2FAnonPerson%2FChilloutMix)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, manivannan7gp/stable-diffusion-webui-vorstcavry, stable13/createimage7, vorstcavry/Anapnoe, vorstcavry/vorst-cavry-a1111-public",13
|
CodeLlama-70b-hf_finetunes_20250426_121513.csv_finetunes_20250426_121513.csv
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
codellama/CodeLlama-70b-hf,"---
|
| 3 |
+
language:
|
| 4 |
+
- code
|
| 5 |
+
pipeline_tag: text-generation
|
| 6 |
+
tags:
|
| 7 |
+
- llama-2
|
| 8 |
+
license: llama2
|
| 9 |
+
---
|
| 10 |
+
# **Code Llama**
|
| 11 |
+
Code Llama is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. This is the repository for the base 70B version in the Hugging Face Transformers format. This model is designed for general code synthesis and understanding. Links to other models can be found in the index at the bottom.
|
| 12 |
+
|
| 13 |
+
> [!NOTE]
|
| 14 |
+
> This is a non-official Code Llama repo. You can find the official Meta repository in the [Meta Llama organization](https://huggingface.co/meta-llama/CodeLlama-70b-hf).
|
| 15 |
+
|
| 16 |
+
| | Base Model | Python | Instruct |
|
| 17 |
+
| --- | ----------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------- |
|
| 18 |
+
| 7B | [codellama/CodeLlama-7b-hf](https://huggingface.co/codellama/CodeLlama-7b-hf) | [codellama/CodeLlama-7b-Python-hf](https://huggingface.co/codellama/CodeLlama-7b-Python-hf) | [codellama/CodeLlama-7b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-7b-Instruct-hf) |
|
| 19 |
+
| 13B | [codellama/CodeLlama-13b-hf](https://huggingface.co/codellama/CodeLlama-13b-hf) | [codellama/CodeLlama-13b-Python-hf](https://huggingface.co/codellama/CodeLlama-13b-Python-hf) | [codellama/CodeLlama-13b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-13b-Instruct-hf) |
|
| 20 |
+
| 34B | [codellama/CodeLlama-34b-hf](https://huggingface.co/codellama/CodeLlama-34b-hf) | [codellama/CodeLlama-34b-Python-hf](https://huggingface.co/codellama/CodeLlama-34b-Python-hf) | [codellama/CodeLlama-34b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-34b-Instruct-hf) |
|
| 21 |
+
| 70B | [codellama/CodeLlama-70b-hf](https://huggingface.co/codellama/CodeLlama-70b-hf) | [codellama/CodeLlama-70b-Python-hf](https://huggingface.co/codellama/CodeLlama-70b-Python-hf) | [codellama/CodeLlama-70b-Instruct-hf](https://huggingface.co/codellama/CodeLlama-70b-Instruct-hf) |
|
| 22 |
+
|
| 23 |
+
## Model Use
|
| 24 |
+
|
| 25 |
+
To use this model, please make sure to install `transformers`.
|
| 26 |
+
|
| 27 |
+
```bash
|
| 28 |
+
pip install transformers accelerate
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
Model capabilities:
|
| 32 |
+
|
| 33 |
+
- [x] Code completion.
|
| 34 |
+
- [ ] Infilling.
|
| 35 |
+
- [ ] Instructions / chat.
|
| 36 |
+
- [ ] Python specialist.
|
| 37 |
+
|
| 38 |
+
## Model Details
|
| 39 |
+
*Note: Use of this model is governed by the Meta license. Meta developed and publicly released the Code Llama family of large language models (LLMs).
|
| 40 |
+
|
| 41 |
+
**Model Developers** Meta
|
| 42 |
+
|
| 43 |
+
**Variations** Code Llama comes in four model sizes, and three variants:
|
| 44 |
+
|
| 45 |
+
* Code Llama: base models designed for general code synthesis and understanding
|
| 46 |
+
* Code Llama - Python: designed specifically for Python
|
| 47 |
+
* Code Llama - Instruct: for instruction following and safer deployment
|
| 48 |
+
|
| 49 |
+
All variants are available in sizes of 7B, 13B, 34B, and 70B parameters.
|
| 50 |
+
|
| 51 |
+
**This repository contains the base version of the 70B parameters model.**
|
| 52 |
+
|
| 53 |
+
**Input** Models input text only.
|
| 54 |
+
|
| 55 |
+
**Output** Models generate text only.
|
| 56 |
+
|
| 57 |
+
**Model Architecture** Code Llama is an auto-regressive language model that uses an optimized transformer architecture. It was fine-tuned with up to 16k tokens and supports up to 100k tokens at inference time.
|
| 58 |
+
|
| 59 |
+
**Model Dates** Code Llama and its variants have been trained between January 2023 and January 2024.
|
| 60 |
+
|
| 61 |
+
**Status** This is a static model trained on an offline dataset. Future versions of Code Llama - Instruct will be released as we improve model safety with community feedback.
|
| 62 |
+
|
| 63 |
+
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
|
| 64 |
+
|
| 65 |
+
**Research Paper** More information can be found in the paper ""[Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)"" or its [arXiv page](https://arxiv.org/abs/2308.12950).
|
| 66 |
+
|
| 67 |
+
## Intended Use
|
| 68 |
+
**Intended Use Cases** Code Llama and its variants are intended for commercial and research use in English and relevant programming languages. The base model Code Llama can be adapted for a variety of code synthesis and understanding tasks, Code Llama - Python is designed specifically to handle the Python programming language, and Code Llama - Instruct is intended to be safer to use for code assistant and generation applications.
|
| 69 |
+
|
| 70 |
+
**Out-of-Scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Code Llama and its variants.
|
| 71 |
+
|
| 72 |
+
## Hardware and Software
|
| 73 |
+
**Training Factors** We used custom training libraries. The training and fine-tuning of the released models have been performed Meta’s Research Super Cluster.
|
| 74 |
+
|
| 75 |
+
**Carbon Footprint** In aggregate, training all 12 Code Llama models required 1400K GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 228.55 tCO2eq, 100% of which were offset by Meta’s sustainability program.
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
## Evaluation Results
|
| 79 |
+
|
| 80 |
+
See evaluations for the main models and detailed ablations in Section 3 and safety evaluations in Section 4 of the research paper.
|
| 81 |
+
|
| 82 |
+
## Ethical Considerations and Limitations
|
| 83 |
+
|
| 84 |
+
Code Llama and its variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Code Llama’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. Therefore, before deploying any applications of Code Llama, developers should perform safety testing and tuning tailored to their specific applications of the model.
|
| 85 |
+
|
| 86 |
+
Please see the Responsible Use Guide available available at [https://ai.meta.com/llama/responsible-use-guide](https://ai.meta.com/llama/responsible-use-guide).
|
| 87 |
+
","{""id"": ""codellama/CodeLlama-70b-hf"", ""author"": ""codellama"", ""sha"": ""cc11b0f79c8a072bd1e1f32ec280e1ff8ec018f6"", ""last_modified"": ""2024-04-12 14:17:44+00:00"", ""created_at"": ""2024-01-29 10:59:03+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 378, ""downloads_all_time"": null, ""likes"": 314, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""safetensors"", ""llama"", ""text-generation"", ""llama-2"", ""code"", ""arxiv:2308.12950"", ""license:llama2"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- code\nlicense: llama2\npipeline_tag: text-generation\ntags:\n- llama-2"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""eos_token"": ""</s>"", ""pad_token"": null, ""unk_token"": ""<unk>"", ""use_default_system_prompt"": false}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00008-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00009-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00010-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00011-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00012-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00013-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00014-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00015-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00016-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00017-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00018-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00019-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00020-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00021-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00022-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00023-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00024-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00025-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00026-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00027-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00028-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00029-of-00029.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00003-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00004-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00005-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00006-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00007-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00008-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00009-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00010-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00011-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00012-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00013-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00014-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00015-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00016-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00017-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00018-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00019-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00020-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00021-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00022-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00023-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00024-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00025-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00026-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00027-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00028-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00029-of-00029.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""bigcode/bigcode-models-leaderboard"", ""KBaba7/Quant"", ""meval/multilingual-chatbot-arena-leaderboard"", ""prometheus-eval/BiGGen-Bench-Leaderboard"", ""HPAI-BSC/TuRTLe-Leaderboard"", ""bhaskartripathi/LLM_Quantization"", ""totolook/Quant"", ""FallnAI/Quantize-HF-Models"", ""Generatia/codellama-CodeLlama-70b-hf"", ""Alejo2639/codellama-CodeLlama-70b-hf"", ""ruslanmv/convert_to_gguf"", ""Irishcoder/codellama-CodeLlama-70b-hf"", ""Dineth1222/code_nova"", ""MetaReps/codellama-CodeLlama-70b-hf"", ""shrimantasatpati/codellama-CodeLlama-70b-hf"", ""WSLX/codellama-CodeLlama-70b-hf"", ""davila7/codellama-CodeLlama-70b-hf"", ""parthu10/codellama-CodeLlama-70b-hf"", ""HunterThief/codellama-CodeLlama-70b-hf"", ""jwebber/codellama-CodeLlama-70b-hf"", ""zanjani1/codellama-CodeLlama-70b-hf"", ""ozzy1987/codellama-CodeLlama-70b-hf"", ""taco1/codellama-CodeLlama-70b-hf"", ""voidnullnil/codellama-CodeLlama-70b-hf"", ""powolnik/codellama-CodeLlama-70b-hf"", ""MadK/codellama-CodeLlama-70b-hf"", ""An-Egoistic-Developer-Full-Of-Knowledge/codellama-CodeLlama-70b-hf"", ""An-Egoistic-Developer-Full-Of-Knowledge/codellama-CodeLlama-70b-hf1"", ""mucahitkayadan/codellama-CodeLlama-70b-hf"", ""ahsabbir104/codellama-CodeLlama-70b-hf"", ""dbasu/multilingual-chatbot-arena-leaderboard"", ""atlasas/bigcode-models-leaderboard"", ""Dugelon/First_agent_template"", ""K00B404/LLM_Quantization""], ""safetensors"": {""parameters"": {""BF16"": 68976910336}, ""total"": 68976910336}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-04-12 14:17:44+00:00"", ""cardData"": ""language:\n- code\nlicense: llama2\npipeline_tag: text-generation\ntags:\n- llama-2"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""65b784f7e886c5d4fdb1e02b"", ""modelId"": ""codellama/CodeLlama-70b-hf"", ""usedStorage"": 276039624093}",0,https://huggingface.co/nisten/BigCodeLlama-169b,1,https://huggingface.co/wisdominanutshell/splitter_70b_70B,1,"https://huggingface.co/TheBloke/CodeLlama-70B-hf-GGUF, https://huggingface.co/TheBloke/CodeLlama-70B-hf-AWQ, https://huggingface.co/TheBloke/CodeLlama-70B-hf-GPTQ, https://huggingface.co/mlc-ai/CodeLlama-70b-hf-q3f16_1-MLC, https://huggingface.co/mlc-ai/CodeLlama-70b-hf-q4f16_1-MLC, https://huggingface.co/mlc-ai/CodeLlama-70b-hf-q4f32_1-MLC, https://huggingface.co/mradermacher/CodeLlama-70b-hf-GGUF, https://huggingface.co/mradermacher/CodeLlama-70b-hf-i1-GGUF, https://huggingface.co/tensorblock/CodeLlama-70b-hf-GGUF",9,https://huggingface.co/Blazgo/2-coder-pro,1,"FallnAI/Quantize-HF-Models, HPAI-BSC/TuRTLe-Leaderboard, K00B404/LLM_Quantization, KBaba7/Quant, atlasas/bigcode-models-leaderboard, bhaskartripathi/LLM_Quantization, bigcode/bigcode-models-leaderboard, dbasu/multilingual-chatbot-arena-leaderboard, huggingface/InferenceSupport/discussions/new?title=codellama/CodeLlama-70b-hf&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bcodellama%2FCodeLlama-70b-hf%5D(%2Fcodellama%2FCodeLlama-70b-hf)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, meval/multilingual-chatbot-arena-leaderboard, parthu10/codellama-CodeLlama-70b-hf, prometheus-eval/BiGGen-Bench-Leaderboard, zanjani1/codellama-CodeLlama-70b-hf",13
|
| 88 |
+
nisten/BigCodeLlama-169b,"---
|
| 89 |
+
base_model: [codellama/CodeLlama-70b-hf]
|
| 90 |
+
tags:
|
| 91 |
+
- mergekit
|
| 92 |
+
- merge
|
| 93 |
+
- code
|
| 94 |
+
license: mit
|
| 95 |
+
pipeline_tag: conversational
|
| 96 |
+
---
|
| 97 |
+
# BigCodeLLama LFG 🚀
|
| 98 |
+
|
| 99 |
+
## Experimental CodeLlaMA frankenstein to see how it benchmarks
|
| 100 |
+
|
| 101 |
+
### Models Merged with base ```codellama/CodeLlama-70b-hf```
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
The following models were included in the merge:
|
| 106 |
+
* ../CodeLlama-70b-hf
|
| 107 |
+
* ../CodeLlama-70b-Instruct-hf
|
| 108 |
+
* ../CodeLlama-70b-Python-hf
|
| 109 |
+
|
| 110 |
+
### Configuration
|
| 111 |
+
|
| 112 |
+
The following YAML configuration was used to produce this model:
|
| 113 |
+
|
| 114 |
+
```yaml
|
| 115 |
+
dtype: bfloat16
|
| 116 |
+
merge_method: passthrough
|
| 117 |
+
slices:
|
| 118 |
+
- sources:
|
| 119 |
+
- layer_range: [0, 69]
|
| 120 |
+
model:
|
| 121 |
+
model:
|
| 122 |
+
path: ../CodeLlama-70b-hf
|
| 123 |
+
- sources:
|
| 124 |
+
- layer_range: [66, 76]
|
| 125 |
+
model:
|
| 126 |
+
model:
|
| 127 |
+
path: ../CodeLlama-70b-Instruct-hf
|
| 128 |
+
- sources:
|
| 129 |
+
- layer_range: [42, 66]
|
| 130 |
+
model:
|
| 131 |
+
model:
|
| 132 |
+
path: ../CodeLlama-70b-hf
|
| 133 |
+
- sources:
|
| 134 |
+
- layer_range: [13, 37]
|
| 135 |
+
model:
|
| 136 |
+
model:
|
| 137 |
+
path: ../CodeLlama-70b-Python-hf
|
| 138 |
+
- sources:
|
| 139 |
+
- layer_range: [10, 80]
|
| 140 |
+
model:
|
| 141 |
+
model:
|
| 142 |
+
path: ../CodeLlama-70b-Instruct-hf
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
### Stay tuned for GGUFs quants","{""id"": ""nisten/BigCodeLlama-169b"", ""author"": ""nisten"", ""sha"": ""3b3e55cffbc6c2836f10183bd00d814d14e2fd43"", ""last_modified"": ""2024-01-30 02:11:18+00:00"", ""created_at"": ""2024-01-29 20:26:40+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 2, ""downloads_all_time"": null, ""likes"": 14, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""mergekit"", ""merge"", ""code"", ""conversational"", ""base_model:codellama/CodeLlama-70b-hf"", ""base_model:finetune:codellama/CodeLlama-70b-hf"", ""license:mit"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- codellama/CodeLlama-70b-hf\nlicense: mit\npipeline_tag: conversational\ntags:\n- mergekit\n- merge\n- code"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""eos_token"": ""</s>"", ""pad_token"": null, ""unk_token"": ""<unk>"", ""use_default_system_prompt"": false}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='mergekit_config.yml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00008-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00009-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00010-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00011-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00012-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00013-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00014-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00015-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00016-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00017-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00018-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00019-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00020-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00021-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00022-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00023-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00024-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00025-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00026-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00027-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00028-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00029-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00030-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00031-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00032-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00033-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00034-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00035-of-00035.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""powolnik/nisten-BigCodeLlama-169b""], ""safetensors"": {""parameters"": {""BF16"": 169088475136}, ""total"": 169088475136}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-01-30 02:11:18+00:00"", ""cardData"": ""base_model:\n- codellama/CodeLlama-70b-hf\nlicense: mit\npipeline_tag: conversational\ntags:\n- mergekit\n- merge\n- code"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""65b80a00db07f4cdc46861af"", ""modelId"": ""nisten/BigCodeLlama-169b"", ""usedStorage"": 338177659137}",1,,0,,0,,0,,0,"huggingface/InferenceSupport/discussions/new?title=nisten/BigCodeLlama-169b&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bnisten%2FBigCodeLlama-169b%5D(%2Fnisten%2FBigCodeLlama-169b)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, powolnik/nisten-BigCodeLlama-169b",2
|
DeBERTa-v3-base-mnli-fever-anli_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
DeepSeek-R1-GGUF_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv
ADDED
|
@@ -0,0 +1,442 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
unsloth/DeepSeek-R1-GGUF,"---
|
| 3 |
+
base_model: deepseek-ai/DeepSeek-R1
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
library_name: transformers
|
| 7 |
+
license: mit
|
| 8 |
+
tags:
|
| 9 |
+
- deepseek
|
| 10 |
+
- unsloth
|
| 11 |
+
- transformers
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
<div>
|
| 15 |
+
<p style=""margin-bottom: 0; margin-top: 0;"">
|
| 16 |
+
<strong>See <a href=""https://huggingface.co/collections/unsloth/deepseek-r1-all-versions-678e1c48f5d2fce87892ace5"">our collection</a> for versions of Deepseek-R1 including GGUF & 4-bit formats.</strong>
|
| 17 |
+
</p>
|
| 18 |
+
<p style=""margin-bottom: 0;"">
|
| 19 |
+
<em>Unsloth's DeepSeek-R1 <a href=""https://unsloth.ai/blog/deepseekr1-dynamic"">1.58-bit + 2-bit Dynamic Quants</a> is selectively quantized, greatly improving accuracy over standard 1-bit/2-bit.</em>
|
| 20 |
+
</p>
|
| 21 |
+
<div style=""display: flex; gap: 5px; align-items: center; "">
|
| 22 |
+
<a href=""https://github.com/unslothai/unsloth/"">
|
| 23 |
+
<img src=""https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png"" width=""133"">
|
| 24 |
+
</a>
|
| 25 |
+
<a href=""https://discord.gg/unsloth"">
|
| 26 |
+
<img src=""https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png"" width=""173"">
|
| 27 |
+
</a>
|
| 28 |
+
<a href=""https://docs.unsloth.ai/basics/tutorial-how-to-run-deepseek-r1-on-your-own-local-device"">
|
| 29 |
+
<img src=""https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png"" width=""143"">
|
| 30 |
+
</a>
|
| 31 |
+
</div>
|
| 32 |
+
<h1 style=""margin-top: 0rem;"">Instructions to run this model in llama.cpp:</h2>
|
| 33 |
+
</div>
|
| 34 |
+
|
| 35 |
+
Or you can view more detailed instructions here: [unsloth.ai/blog/deepseekr1-dynamic](https://unsloth.ai/blog/deepseekr1-dynamic)
|
| 36 |
+
1. Do not forget about `<|User|>` and `<|Assistant|>` tokens! - Or use a chat template formatter
|
| 37 |
+
2. Obtain the latest `llama.cpp` at https://github.com/ggerganov/llama.cpp. You can follow the build instructions below as well:
|
| 38 |
+
```bash
|
| 39 |
+
apt-get update
|
| 40 |
+
apt-get install build-essential cmake curl libcurl4-openssl-dev -y
|
| 41 |
+
git clone https://github.com/ggerganov/llama.cpp
|
| 42 |
+
cmake llama.cpp -B llama.cpp/build \
|
| 43 |
+
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON
|
| 44 |
+
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-quantize llama-cli llama-gguf-split
|
| 45 |
+
cp llama.cpp/build/bin/llama-* llama.cpp
|
| 46 |
+
```
|
| 47 |
+
3. It's best to use `--min-p 0.05` to counteract very rare token predictions - I found this to work well especially for the 1.58bit model.
|
| 48 |
+
4. Download the model via:
|
| 49 |
+
```python
|
| 50 |
+
# pip install huggingface_hub hf_transfer
|
| 51 |
+
# import os # Optional for faster downloading
|
| 52 |
+
# os.environ[""HF_HUB_ENABLE_HF_TRANSFER""] = ""1""
|
| 53 |
+
|
| 54 |
+
from huggingface_hub import snapshot_download
|
| 55 |
+
snapshot_download(
|
| 56 |
+
repo_id = ""unsloth/DeepSeek-R1-GGUF"",
|
| 57 |
+
local_dir = ""DeepSeek-R1-GGUF"",
|
| 58 |
+
allow_patterns = [""*UD-IQ1_S*""], # Select quant type UD-IQ1_S for 1.58bit
|
| 59 |
+
)
|
| 60 |
+
```
|
| 61 |
+
5. Example with Q4_0 K quantized cache **Notice -no-cnv disables auto conversation mode**
|
| 62 |
+
```bash
|
| 63 |
+
./llama.cpp/llama-cli \
|
| 64 |
+
--model DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
|
| 65 |
+
--cache-type-k q4_0 \
|
| 66 |
+
--threads 12 -no-cnv --prio 2 \
|
| 67 |
+
--temp 0.6 \
|
| 68 |
+
--ctx-size 8192 \
|
| 69 |
+
--seed 3407 \
|
| 70 |
+
--prompt ""<|User|>Create a Flappy Bird game in Python.<|Assistant|>""
|
| 71 |
+
```
|
| 72 |
+
Example output:
|
| 73 |
+
|
| 74 |
+
```txt
|
| 75 |
+
<think>
|
| 76 |
+
Okay, so I need to figure out what 1 plus 1 is. Hmm, where do I even start? I remember from school that adding numbers is pretty basic, but I want to make sure I understand it properly.
|
| 77 |
+
Let me think, 1 plus 1. So, I have one item and I add another one. Maybe like a apple plus another apple. If I have one apple and someone gives me another, I now have two apples. So, 1 plus 1 should be 2. That makes sense.
|
| 78 |
+
Wait, but sometimes math can be tricky. Could it be something else? Like, in a different number system maybe? But I think the question is straightforward, using regular numbers, not like binary or hexadecimal or anything.
|
| 79 |
+
I also recall that in arithmetic, addition is combining quantities. So, if you have two quantities of 1, combining them gives you a total of 2. Yeah, that seems right.
|
| 80 |
+
Is there a scenario where 1 plus 1 wouldn't be 2? I can't think of any...
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
6. If you have a GPU (RTX 4090 for example) with 24GB, you can offload multiple layers to the GPU for faster processing. If you have multiple GPUs, you can probably offload more layers.
|
| 84 |
+
```bash
|
| 85 |
+
./llama.cpp/llama-cli \
|
| 86 |
+
--model DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
|
| 87 |
+
--cache-type-k q4_0 \
|
| 88 |
+
--threads 12 -no-cnv --prio 2 \
|
| 89 |
+
--n-gpu-layers 7 \
|
| 90 |
+
--temp 0.6 \
|
| 91 |
+
--ctx-size 8192 \
|
| 92 |
+
--seed 3407 \
|
| 93 |
+
--prompt ""<|User|>Create a Flappy Bird game in Python.<|Assistant|>""
|
| 94 |
+
```
|
| 95 |
+
7. If you want to merge the weights together, use this script:
|
| 96 |
+
```
|
| 97 |
+
./llama.cpp/llama-gguf-split --merge \
|
| 98 |
+
DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf \
|
| 99 |
+
merged_file.gguf
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
| MoE Bits | Type | Disk Size | Accuracy | Link | Details |
|
| 103 |
+
| -------- | -------- | ------------ | ------------ | ---------------------| ---------- |
|
| 104 |
+
| 1.58bit | UD-IQ1_S | **131GB** | Fair | [Link](https://huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-IQ1_S) | MoE all 1.56bit. `down_proj` in MoE mixture of 2.06/1.56bit |
|
| 105 |
+
| 1.73bit | UD-IQ1_M | **158GB** | Good | [Link](https://huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-IQ1_M) | MoE all 1.56bit. `down_proj` in MoE left at 2.06bit |
|
| 106 |
+
| 2.22bit | UD-IQ2_XXS | **183GB** | Better | [Link](https://huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-IQ2_XXS) | MoE all 2.06bit. `down_proj` in MoE mixture of 2.5/2.06bit |
|
| 107 |
+
| 2.51bit | UD-Q2_K_XL | **212GB** | Best | [Link](https://huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-Q2_K_XL) | MoE all 2.5bit. `down_proj` in MoE mixture of 3.5/2.5bit |
|
| 108 |
+
|
| 109 |
+
# Finetune your own Reasoning model like R1 with Unsloth!
|
| 110 |
+
We have a free Google Colab notebook for turning Llama 3.1 (8B) into a reasoning model: https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.1_(8B)-GRPO.ipynb
|
| 111 |
+
|
| 112 |
+
[<img src=""https://raw.githubusercontent.com/unslothai/unsloth/main/images/Discord%20button.png"" width=""200""/>](https://discord.gg/unsloth)
|
| 113 |
+
[<img src=""https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png"" width=""200""/>](https://github.com/unslothai/unsloth)
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
## ✨ Finetune for Free
|
| 117 |
+
|
| 118 |
+
All notebooks are **beginner friendly**! Add your dataset, click ""Run All"", and you'll get a 2x faster finetuned model which can be exported to GGUF, vLLM or uploaded to Hugging Face.
|
| 119 |
+
|
| 120 |
+
| Unsloth supports | Free Notebooks | Performance | Memory use |
|
| 121 |
+
|-----------------|--------------------------------------------------------------------------------------------------------------------------|-------------|----------|
|
| 122 |
+
| **GRPO with Phi-4 (14B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Phi_4_(14B)-GRPO.ipynb) | 2x faster | 80% less |
|
| 123 |
+
| **Llama-3.2 (3B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.2_(1B_and_3B)-Conversational.ipynb) | 2.4x faster | 58% less |
|
| 124 |
+
| **Llama-3.2 (11B vision)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.2_(11B)-Vision.ipynb) | 2x faster | 60% less |
|
| 125 |
+
| **Qwen2 VL (7B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2_VL_(7B)-Vision.ipynb) | 1.8x faster | 60% less |
|
| 126 |
+
| **Qwen2.5 (7B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2.5_(7B)-Alpaca.ipynb) | 2x faster | 60% less |
|
| 127 |
+
| **Llama-3.1 (8B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.1_(8B)-Alpaca.ipynb) | 2.4x faster | 58% less |
|
| 128 |
+
| **Phi-3.5 (mini)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Phi_3.5_Mini-Conversational.ipynb) | 2x faster | 50% less |
|
| 129 |
+
| **Gemma 2 (9B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Gemma2_(9B)-Alpaca.ipynb) | 2.4x faster | 58% less |
|
| 130 |
+
| **Mistral (7B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Mistral_v0.3_(7B)-Conversational.ipynb) | 2.2x faster | 62% less |
|
| 131 |
+
|
| 132 |
+
[<img src=""https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png"" width=""200""/>](https://docs.unsloth.ai)
|
| 133 |
+
|
| 134 |
+
- This [Llama 3.2 conversational notebook](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.2_(1B_and_3B)-Conversational.ipynb) is useful for ShareGPT ChatML / Vicuna templates.
|
| 135 |
+
- This [text completion notebook](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Mistral_(7B)-Text_Completion.ipynb) is for raw text. This [DPO notebook](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) replicates Zephyr.
|
| 136 |
+
- \* Kaggle has 2x T4s, but we use 1. Due to overhead, 1x T4 is 5x faster.
|
| 137 |
+
|
| 138 |
+
## Special Thanks
|
| 139 |
+
A huge thank you to the DeepSeek team for creating and releasing these models.
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
# DeepSeek-R1
|
| 144 |
+
<!-- markdownlint-disable first-line-h1 -->
|
| 145 |
+
<!-- markdownlint-disable html -->
|
| 146 |
+
<!-- markdownlint-disable no-duplicate-header -->
|
| 147 |
+
|
| 148 |
+
<div align=""center"">
|
| 149 |
+
<img src=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true"" width=""60%"" alt=""DeepSeek-V3"" />
|
| 150 |
+
</div>
|
| 151 |
+
<hr>
|
| 152 |
+
<div align=""center"" style=""line-height: 1;"">
|
| 153 |
+
<a href=""https://www.deepseek.com/"" target=""_blank"" style=""margin: 2px;"">
|
| 154 |
+
<img alt=""Homepage"" src=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true"" style=""display: inline-block; vertical-align: middle;""/>
|
| 155 |
+
</a>
|
| 156 |
+
<a href=""https://chat.deepseek.com/"" target=""_blank"" style=""margin: 2px;"">
|
| 157 |
+
<img alt=""Chat"" src=""https://img.shields.io/badge/🤖%20Chat-DeepSeek%20R1-536af5?color=536af5&logoColor=white"" style=""display: inline-block; vertical-align: middle;""/>
|
| 158 |
+
</a>
|
| 159 |
+
<a href=""https://huggingface.co/deepseek-ai"" target=""_blank"" style=""margin: 2px;"">
|
| 160 |
+
<img alt=""Hugging Face"" src=""https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white"" style=""display: inline-block; vertical-align: middle;""/>
|
| 161 |
+
</a>
|
| 162 |
+
</div>
|
| 163 |
+
|
| 164 |
+
<div align=""center"" style=""line-height: 1;"">
|
| 165 |
+
<a href=""https://discord.gg/Tc7c45Zzu5"" target=""_blank"" style=""margin: 2px;"">
|
| 166 |
+
<img alt=""Discord"" src=""https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da"" style=""display: inline-block; vertical-align: middle;""/>
|
| 167 |
+
</a>
|
| 168 |
+
<a href=""https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true"" target=""_blank"" style=""margin: 2px;"">
|
| 169 |
+
<img alt=""Wechat"" src=""https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white"" style=""display: inline-block; vertical-align: middle;""/>
|
| 170 |
+
</a>
|
| 171 |
+
<a href=""https://twitter.com/deepseek_ai"" target=""_blank"" style=""margin: 2px;"">
|
| 172 |
+
<img alt=""Twitter Follow"" src=""https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white"" style=""display: inline-block; vertical-align: middle;""/>
|
| 173 |
+
</a>
|
| 174 |
+
</div>
|
| 175 |
+
|
| 176 |
+
<div align=""center"" style=""line-height: 1;"">
|
| 177 |
+
<a href=""https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE-CODE"" style=""margin: 2px;"">
|
| 178 |
+
<img alt=""Code License"" src=""https://img.shields.io/badge/Code_License-MIT-f5de53?&color=f5de53"" style=""display: inline-block; vertical-align: middle;""/>
|
| 179 |
+
</a>
|
| 180 |
+
<a href=""https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE-MODEL"" style=""margin: 2px;"">
|
| 181 |
+
<img alt=""Model License"" src=""https://img.shields.io/badge/Model_License-Model_Agreement-f5de53?&color=f5de53"" style=""display: inline-block; vertical-align: middle;""/>
|
| 182 |
+
</a>
|
| 183 |
+
</div>
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
<p align=""center"">
|
| 187 |
+
<a href=""https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf""><b>Paper Link</b>👁️</a>
|
| 188 |
+
</p>
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
## 1. Introduction
|
| 192 |
+
|
| 193 |
+
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1.
|
| 194 |
+
DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning.
|
| 195 |
+
With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors.
|
| 196 |
+
However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. To address these issues and further enhance reasoning performance,
|
| 197 |
+
we introduce DeepSeek-R1, which incorporates cold-start data before RL.
|
| 198 |
+
DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks.
|
| 199 |
+
To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
|
| 200 |
+
|
| 201 |
+
**NOTE: Before running DeepSeek-R1 series models locally, we kindly recommend reviewing the [Usage Recommendation](#usage-recommendations) section.**
|
| 202 |
+
|
| 203 |
+
<p align=""center"">
|
| 204 |
+
<img width=""80%"" src=""figures/benchmark.jpg"">
|
| 205 |
+
</p>
|
| 206 |
+
|
| 207 |
+
## 2. Model Summary
|
| 208 |
+
|
| 209 |
+
---
|
| 210 |
+
|
| 211 |
+
**Post-Training: Large-Scale Reinforcement Learning on the Base Model**
|
| 212 |
+
|
| 213 |
+
- We directly apply reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as a preliminary step. This approach allows the model to explore chain-of-thought (CoT) for solving complex problems, resulting in the development of DeepSeek-R1-Zero. DeepSeek-R1-Zero demonstrates capabilities such as self-verification, reflection, and generating long CoTs, marking a significant milestone for the research community. Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area.
|
| 214 |
+
|
| 215 |
+
- We introduce our pipeline to develop DeepSeek-R1. The pipeline incorporates two RL stages aimed at discovering improved reasoning patterns and aligning with human preferences, as well as two SFT stages that serve as the seed for the model's reasoning and non-reasoning capabilities.
|
| 216 |
+
We believe the pipeline will benefit the industry by creating better models.
|
| 217 |
+
|
| 218 |
+
---
|
| 219 |
+
|
| 220 |
+
**Distillation: Smaller Models Can Be Powerful Too**
|
| 221 |
+
|
| 222 |
+
- We demonstrate that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models. The open source DeepSeek-R1, as well as its API, will benefit the research community to distill better smaller models in the future.
|
| 223 |
+
- Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on Qwen2.5 and Llama3 series to the community.
|
| 224 |
+
|
| 225 |
+
## 3. Model Downloads
|
| 226 |
+
|
| 227 |
+
### DeepSeek-R1 Models
|
| 228 |
+
|
| 229 |
+
<div align=""center"">
|
| 230 |
+
|
| 231 |
+
| **Model** | **#Total Params** | **#Activated Params** | **Context Length** | **Download** |
|
| 232 |
+
| :------------: | :------------: | :------------: | :------------: | :------------: |
|
| 233 |
+
| DeepSeek-R1-Zero | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Zero) |
|
| 234 |
+
| DeepSeek-R1 | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
|
| 235 |
+
|
| 236 |
+
</div>
|
| 237 |
+
|
| 238 |
+
DeepSeek-R1-Zero & DeepSeek-R1 are trained based on DeepSeek-V3-Base.
|
| 239 |
+
For more details regarding the model architecture, please refer to [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repository.
|
| 240 |
+
|
| 241 |
+
### DeepSeek-R1-Distill Models
|
| 242 |
+
|
| 243 |
+
<div align=""center"">
|
| 244 |
+
|
| 245 |
+
| **Model** | **Base Model** | **Download** |
|
| 246 |
+
| :------------: | :------------: | :------------: |
|
| 247 |
+
| DeepSeek-R1-Distill-Qwen-1.5B | [Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B) |
|
| 248 |
+
| DeepSeek-R1-Distill-Qwen-7B | [Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) |
|
| 249 |
+
| DeepSeek-R1-Distill-Llama-8B | [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B) |
|
| 250 |
+
| DeepSeek-R1-Distill-Qwen-14B | [Qwen2.5-14B](https://huggingface.co/Qwen/Qwen2.5-14B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B) |
|
| 251 |
+
|DeepSeek-R1-Distill-Qwen-32B | [Qwen2.5-32B](https://huggingface.co/Qwen/Qwen2.5-32B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B) |
|
| 252 |
+
| DeepSeek-R1-Distill-Llama-70B | [Llama-3.3-70B-Instruct](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B) |
|
| 253 |
+
|
| 254 |
+
</div>
|
| 255 |
+
|
| 256 |
+
DeepSeek-R1-Distill models are fine-tuned based on open-source models, using samples generated by DeepSeek-R1.
|
| 257 |
+
We slightly change their configs and tokenizers. Please use our setting to run these models.
|
| 258 |
+
|
| 259 |
+
## 4. Evaluation Results
|
| 260 |
+
|
| 261 |
+
### DeepSeek-R1-Evaluation
|
| 262 |
+
For all our models, the maximum generation length is set to 32,768 tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 64 responses per query to estimate pass@1.
|
| 263 |
+
<div align=""center"">
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|
| 267 |
+
|----------|-------------------|----------------------|------------|--------------|----------------|------------|--------------|
|
| 268 |
+
| | Architecture | - | - | MoE | - | - | MoE |
|
| 269 |
+
| | # Activated Params | - | - | 37B | - | - | 37B |
|
| 270 |
+
| | # Total Params | - | - | 671B | - | - | 671B |
|
| 271 |
+
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | **91.8** | 90.8 |
|
| 272 |
+
| | MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | - | **92.9** |
|
| 273 |
+
| | MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | - | **84.0** |
|
| 274 |
+
| | DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | **92.2** |
|
| 275 |
+
| | IF-Eval (Prompt Strict) | **86.5** | 84.3 | 86.1 | 84.8 | - | 83.3 |
|
| 276 |
+
| | GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | **75.7** | 71.5 |
|
| 277 |
+
| | SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | **47.0** | 30.1 |
|
| 278 |
+
| | FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | - | **82.5** |
|
| 279 |
+
| | AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | **87.6** |
|
| 280 |
+
| | ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | **92.3** |
|
| 281 |
+
| Code | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | - | 53.8 | 63.4 | **65.9** |
|
| 282 |
+
| | Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | **96.6** | 96.3 |
|
| 283 |
+
| | Codeforces (Rating) | 717 | 759 | 1134 | 1820 | **2061** | 2029 |
|
| 284 |
+
| | SWE Verified (Resolved) | **50.8** | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 |
|
| 285 |
+
| | Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | **61.7** | 53.3 |
|
| 286 |
+
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | **79.8** |
|
| 287 |
+
| | MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | **97.3** |
|
| 288 |
+
| | CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | - | **78.8** |
|
| 289 |
+
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | **92.8** |
|
| 290 |
+
| | C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | **91.8** |
|
| 291 |
+
| | C-SimpleQA (Correct) | 55.4 | 58.7 | **68.0** | 40.3 | - | 63.7 |
|
| 292 |
+
|
| 293 |
+
</div>
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
### Distilled Model Evaluation
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
<div align=""center"">
|
| 300 |
+
|
| 301 |
+
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|
| 302 |
+
|------------------------------------------|------------------|-------------------|-----------------|----------------------|----------------------|-------------------|
|
| 303 |
+
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
|
| 304 |
+
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
|
| 305 |
+
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | **1820** |
|
| 306 |
+
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
|
| 307 |
+
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
|
| 308 |
+
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
|
| 309 |
+
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
|
| 310 |
+
| DeepSeek-R1-Distill-Qwen-32B | **72.6** | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
|
| 311 |
+
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
|
| 312 |
+
| DeepSeek-R1-Distill-Llama-70B | 70.0 | **86.7** | **94.5** | **65.2** | **57.5** | 1633 |
|
| 313 |
+
|
| 314 |
+
</div>
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
## 5. Chat Website & API Platform
|
| 318 |
+
You can chat with DeepSeek-R1 on DeepSeek's official website: [chat.deepseek.com](https://chat.deepseek.com), and switch on the button ""DeepThink""
|
| 319 |
+
|
| 320 |
+
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/)
|
| 321 |
+
|
| 322 |
+
## 6. How to Run Locally
|
| 323 |
+
|
| 324 |
+
### DeepSeek-R1 Models
|
| 325 |
+
|
| 326 |
+
Please visit [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repo for more information about running DeepSeek-R1 locally.
|
| 327 |
+
|
| 328 |
+
### DeepSeek-R1-Distill Models
|
| 329 |
+
|
| 330 |
+
DeepSeek-R1-Distill models can be utilized in the same manner as Qwen or Llama models.
|
| 331 |
+
|
| 332 |
+
For instance, you can easily start a service using [vLLM](https://github.com/vllm-project/vllm):
|
| 333 |
+
|
| 334 |
+
```shell
|
| 335 |
+
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
|
| 336 |
+
```
|
| 337 |
+
|
| 338 |
+
You can also easily start a service using [SGLang](https://github.com/sgl-project/sglang)
|
| 339 |
+
|
| 340 |
+
```bash
|
| 341 |
+
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2
|
| 342 |
+
```
|
| 343 |
+
|
| 344 |
+
### Usage Recommendations
|
| 345 |
+
|
| 346 |
+
**We recommend adhering to the following configurations when utilizing the DeepSeek-R1 series models, including benchmarking, to achieve the expected performance:**
|
| 347 |
+
|
| 348 |
+
1. Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
|
| 349 |
+
2. **Avoid adding a system prompt; all instructions should be contained within the user prompt.**
|
| 350 |
+
3. For mathematical problems, it is advisable to include a directive in your prompt such as: ""Please reason step by step, and put your final answer within \boxed{}.""
|
| 351 |
+
4. When evaluating model performance, it is recommended to conduct multiple tests and average the results.
|
| 352 |
+
|
| 353 |
+
## 7. License
|
| 354 |
+
This code repository and the model weights are licensed under the [MIT License](https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE).
|
| 355 |
+
DeepSeek-R1 series support commercial use, allow for any modifications and derivative works, including, but not limited to, distillation for training other LLMs. Please note that:
|
| 356 |
+
- DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Qwen-14B and DeepSeek-R1-Distill-Qwen-32B are derived from [Qwen-2.5 series](https://github.com/QwenLM/Qwen2.5), which are originally licensed under [Apache 2.0 License](https://huggingface.co/Qwen/Qwen2.5-1.5B/blob/main/LICENSE), and now finetuned with 800k samples curated with DeepSeek-R1.
|
| 357 |
+
- DeepSeek-R1-Distill-Llama-8B is derived from Llama3.1-8B-Base and is originally licensed under [llama3.1 license](https://huggingface.co/meta-llama/Llama-3.1-8B/blob/main/LICENSE).
|
| 358 |
+
- DeepSeek-R1-Distill-Llama-70B is derived from Llama3.3-70B-Instruct and is originally licensed under [llama3.3 license](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct/blob/main/LICENSE).
|
| 359 |
+
|
| 360 |
+
## 8. Citation
|
| 361 |
+
```
|
| 362 |
+
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
|
| 363 |
+
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
|
| 364 |
+
author={DeepSeek-AI and Daya Guo and Dejian Yang and Haowei Zhang and Junxiao Song and Ruoyu Zhang and Runxin Xu and Qihao Zhu and Shirong Ma and Peiyi Wang and Xiao Bi and Xiaokang Zhang and Xingkai Yu and Yu Wu and Z. F. Wu and Zhibin Gou and Zhihong Shao and Zhuoshu Li and Ziyi Gao and Aixin Liu and Bing Xue and Bingxuan Wang and Bochao Wu and Bei Feng and Chengda Lu and Chenggang Zhao and Chengqi Deng and Chenyu Zhang and Chong Ruan and Damai Dai and Deli Chen and Dongjie Ji and Erhang Li and Fangyun Lin and Fucong Dai and Fuli Luo and Guangbo Hao and Guanting Chen and Guowei Li and H. Zhang and Han Bao and Hanwei Xu and Haocheng Wang and Honghui Ding and Huajian Xin and Huazuo Gao and Hui Qu and Hui Li and Jianzhong Guo and Jiashi Li and Jiawei Wang and Jingchang Chen and Jingyang Yuan and Junjie Qiu and Junlong Li and J. L. Cai and Jiaqi Ni and Jian Liang and Jin Chen and Kai Dong and Kai Hu and Kaige Gao and Kang Guan and Kexin Huang and Kuai Yu and Lean Wang and Lecong Zhang and Liang Zhao and Litong Wang and Liyue Zhang and Lei Xu and Leyi Xia and Mingchuan Zhang and Minghua Zhang and Minghui Tang and Meng Li and Miaojun Wang and Mingming Li and Ning Tian and Panpan Huang and Peng Zhang and Qiancheng Wang and Qinyu Chen and Qiushi Du and Ruiqi Ge and Ruisong Zhang and Ruizhe Pan and Runji Wang and R. J. Chen and R. L. Jin and Ruyi Chen and Shanghao Lu and Shangyan Zhou and Shanhuang Chen and Shengfeng Ye and Shiyu Wang and Shuiping Yu and Shunfeng Zhou and Shuting Pan and S. S. Li and Shuang Zhou and Shaoqing Wu and Shengfeng Ye and Tao Yun and Tian Pei and Tianyu Sun and T. Wang and Wangding Zeng and Wanjia Zhao and Wen Liu and Wenfeng Liang and Wenjun Gao and Wenqin Yu and Wentao Zhang and W. L. Xiao and Wei An and Xiaodong Liu and Xiaohan Wang and Xiaokang Chen and Xiaotao Nie and Xin Cheng and Xin Liu and Xin Xie and Xingchao Liu and Xinyu Yang and Xinyuan Li and Xuecheng Su and Xuheng Lin and X. Q. Li and Xiangyue Jin and Xiaojin Shen and Xiaosha Chen and Xiaowen Sun and Xiaoxiang Wang and Xinnan Song and Xinyi Zhou and Xianzu Wang and Xinxia Shan and Y. K. Li and Y. Q. Wang and Y. X. Wei and Yang Zhang and Yanhong Xu and Yao Li and Yao Zhao and Yaofeng Sun and Yaohui Wang and Yi Yu and Yichao Zhang and Yifan Shi and Yiliang Xiong and Ying He and Yishi Piao and Yisong Wang and Yixuan Tan and Yiyang Ma and Yiyuan Liu and Yongqiang Guo and Yuan Ou and Yuduan Wang and Yue Gong and Yuheng Zou and Yujia He and Yunfan Xiong and Yuxiang Luo and Yuxiang You and Yuxuan Liu and Yuyang Zhou and Y. X. Zhu and Yanhong Xu and Yanping Huang and Yaohui Li and Yi Zheng and Yuchen Zhu and Yunxian Ma and Ying Tang and Yukun Zha and Yuting Yan and Z. Z. Ren and Zehui Ren and Zhangli Sha and Zhe Fu and Zhean Xu and Zhenda Xie and Zhengyan Zhang and Zhewen Hao and Zhicheng Ma and Zhigang Yan and Zhiyu Wu and Zihui Gu and Zijia Zhu and Zijun Liu and Zilin Li and Ziwei Xie and Ziyang Song and Zizheng Pan and Zhen Huang and Zhipeng Xu and Zhongyu Zhang and Zhen Zhang},
|
| 365 |
+
year={2025},
|
| 366 |
+
eprint={2501.12948},
|
| 367 |
+
archivePrefix={arXiv},
|
| 368 |
+
primaryClass={cs.CL},
|
| 369 |
+
url={https://arxiv.org/abs/2501.12948},
|
| 370 |
+
}
|
| 371 |
+
|
| 372 |
+
```
|
| 373 |
+
|
| 374 |
+
## 9. Contact
|
| 375 |
+
If you have any questions, please raise an issue or contact us at [service@deepseek.com](service@deepseek.com).
|
| 376 |
+
","{""id"": ""unsloth/DeepSeek-R1-GGUF"", ""author"": ""unsloth"", ""sha"": ""3c4941a68d1c81aee5ab741c8ae7d1a3504ad847"", ""last_modified"": ""2025-04-23 19:21:44+00:00"", ""created_at"": ""2025-01-20 13:09:42+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 1996881, ""downloads_all_time"": null, ""likes"": 1041, ""library_name"": ""transformers"", ""gguf"": {""total"": 671026419200, ""architecture"": ""deepseek2"", ""context_length"": 163840, ""chat_template"": ""{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='', is_first_sp=true) %}{%- for message in messages %}{%- if message['role'] == 'system' %}{%- if ns.is_first_sp %}{% set ns.system_prompt = ns.system_prompt + message['content'] %}{% set ns.is_first_sp = false %}{%- else %}{% set ns.system_prompt = ns.system_prompt + '\\n\\n' + message['content'] %}{%- endif %}{%- endif %}{%- endfor %}{{ bos_token }}{{ ns.system_prompt }}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<\uff5cUser\uff5c>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and 'tool_calls' in message %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls'] %}{%- if not ns.is_first %}{%- if message['content'] is none %}{{'<\uff5cAssistant\uff5c><\uff5ctool\u2581calls\u2581begin\uff5c><\uff5ctool\u2581call\u2581begin\uff5c>' + tool['type'] + '<\uff5ctool\u2581sep\uff5c>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<\uff5ctool\u2581call\u2581end\uff5c>'}}{%- else %}{{'<\uff5cAssistant\uff5c>' + message['content'] + '<\uff5ctool\u2581calls\u2581begin\uff5c><\uff5ctool\u2581call\u2581begin\uff5c>' + tool['type'] + '<\uff5ctool\u2581sep\uff5c>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<\uff5ctool\u2581call\u2581end\uff5c>'}}{%- endif %}{%- set ns.is_first = true -%}{%- else %}{{'\\n' + '<\uff5ctool\u2581call\u2581begin\uff5c>' + tool['type'] + '<\uff5ctool\u2581sep\uff5c>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<\uff5ctool\u2581call\u2581end\uff5c>'}}{%- endif %}{%- endfor %}{{'<\uff5ctool\u2581calls\u2581end\uff5c><\uff5cend\u2581of\u2581sentence\uff5c>'}}{%- endif %}{%- if message['role'] == 'assistant' and 'tool_calls' not in message %}{%- if ns.is_tool %}{{'<\uff5ctool\u2581outputs\u2581end\uff5c>' + message['content'] + '<\uff5cend\u2581of\u2581sentence\uff5c>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<\uff5cAssistant\uff5c>' + content + '<\uff5cend\u2581of\u2581sentence\uff5c>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<\uff5ctool\u2581outputs\u2581begin\uff5c><\uff5ctool\u2581output\u2581begin\uff5c>' + message['content'] + '<\uff5ctool\u2581output\u2581end\uff5c>'}}{%- set ns.is_output_first = false %}{%- else %}{{'<\uff5ctool\u2581output\u2581begin\uff5c>' + message['content'] + '<\uff5ctool\u2581output\u2581end\uff5c>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<\uff5ctool\u2581outputs\u2581end\uff5c>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<\uff5cAssistant\uff5c><think>\\n'}}{% endif %}"", ""bos_token"": ""<\uff5cbegin\u2581of\u2581sentence\uff5c>"", ""eos_token"": ""<\uff5cend\u2581of\u2581sentence\uff5c>""}, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""gguf"", ""deepseek_v3"", ""text-generation"", ""deepseek"", ""unsloth"", ""custom_code"", ""en"", ""arxiv:2501.12948"", ""base_model:deepseek-ai/DeepSeek-R1"", ""base_model:quantized:deepseek-ai/DeepSeek-R1"", ""license:mit"", ""autotrain_compatible"", ""endpoints_compatible"", ""region:us"", ""conversational""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: deepseek-ai/DeepSeek-R1\nlanguage:\n- en\nlibrary_name: transformers\nlicense: mit\ntags:\n- deepseek\n- unsloth\n- transformers"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""DeepseekV3ForCausalLM""], ""auto_map"": {""AutoConfig"": ""configuration_deepseek.DeepseekV3Config"", ""AutoModel"": ""modeling_deepseek.DeepseekV3Model"", ""AutoModelForCausalLM"": ""modeling_deepseek.DeepseekV3ForCausalLM""}, ""model_type"": ""deepseek_v3""}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00001-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00002-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00003-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00004-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00005-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00006-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00007-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00008-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00009-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00010-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00011-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00012-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00013-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00014-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00015-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00016-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00017-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00018-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00019-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00020-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00021-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00022-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00023-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00024-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00025-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00026-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00027-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00028-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00029-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='BF16/DeepSeek-R1-BF16-00030-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00001-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00002-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00003-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00004-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00005-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00006-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00007-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00008-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00009-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00010-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00011-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00012-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00013-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00014-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00015-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00016-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00017-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00018-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00019-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00020-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00021-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00022-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00023-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00024-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00025-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00026-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00027-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00028-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00029-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-BF16/DeepSeek-R1.BF16-00030-of-00030.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K/DeepSeek-R1-Q2_K-00001-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K/DeepSeek-R1-Q2_K-00002-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K/DeepSeek-R1-Q2_K-00003-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K/DeepSeek-R1-Q2_K-00004-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K/DeepSeek-R1-Q2_K-00005-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K_L/DeepSeek-R1-Q2_K_L-00001-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K_L/DeepSeek-R1-Q2_K_L-00002-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K_L/DeepSeek-R1-Q2_K_L-00003-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K_L/DeepSeek-R1-Q2_K_L-00004-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K_L/DeepSeek-R1-Q2_K_L-00005-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K_XS/DeepSeek-R1-Q2_K_XS-00001-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K_XS/DeepSeek-R1-Q2_K_XS-00002-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K_XS/DeepSeek-R1-Q2_K_XS-00003-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K_XS/DeepSeek-R1-Q2_K_XS-00004-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q2_K_XS/DeepSeek-R1-Q2_K_XS-00005-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q3_K_M/DeepSeek-R1-Q3_K_M-00001-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q3_K_M/DeepSeek-R1-Q3_K_M-00002-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q3_K_M/DeepSeek-R1-Q3_K_M-00003-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q3_K_M/DeepSeek-R1-Q3_K_M-00004-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q3_K_M/DeepSeek-R1-Q3_K_M-00005-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q3_K_M/DeepSeek-R1-Q3_K_M-00006-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q3_K_M/DeepSeek-R1-Q3_K_M-00007-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-00001-of-00009.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-00002-of-00009.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-00003-of-00009.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-00004-of-00009.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-00005-of-00009.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-00006-of-00009.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-00007-of-00009.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-00008-of-00009.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-00009-of-00009.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q5_K_M/DeepSeek-R1-Q5_K_M-00001-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q5_K_M/DeepSeek-R1-Q5_K_M-00002-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q5_K_M/DeepSeek-R1-Q5_K_M-00003-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q5_K_M/DeepSeek-R1-Q5_K_M-00004-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q5_K_M/DeepSeek-R1-Q5_K_M-00005-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q5_K_M/DeepSeek-R1-Q5_K_M-00006-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q5_K_M/DeepSeek-R1-Q5_K_M-00007-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q5_K_M/DeepSeek-R1-Q5_K_M-00008-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q5_K_M/DeepSeek-R1-Q5_K_M-00009-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q5_K_M/DeepSeek-R1-Q5_K_M-00010-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q6_K/DeepSeek-R1-Q6_K-00001-of-00012.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q6_K/DeepSeek-R1-Q6_K-00002-of-00012.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q6_K/DeepSeek-R1-Q6_K-00003-of-00012.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q6_K/DeepSeek-R1-Q6_K-00004-of-00012.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q6_K/DeepSeek-R1-Q6_K-00005-of-00012.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q6_K/DeepSeek-R1-Q6_K-00006-of-00012.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q6_K/DeepSeek-R1-Q6_K-00007-of-00012.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q6_K/DeepSeek-R1-Q6_K-00008-of-00012.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q6_K/DeepSeek-R1-Q6_K-00009-of-00012.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q6_K/DeepSeek-R1-Q6_K-00010-of-00012.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q6_K/DeepSeek-R1-Q6_K-00011-of-00012.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q6_K/DeepSeek-R1-Q6_K-00012-of-00012.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00001-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00002-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00003-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00004-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00005-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00006-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00007-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00008-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00009-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00010-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00011-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00012-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00013-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00014-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00015-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-IQ1_M/DeepSeek-R1-UD-IQ1_M-00001-of-00004.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-IQ1_M/DeepSeek-R1-UD-IQ1_M-00002-of-00004.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-IQ1_M/DeepSeek-R1-UD-IQ1_M-00003-of-00004.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-IQ1_M/DeepSeek-R1-UD-IQ1_M-00004-of-00004.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-IQ2_XXS/DeepSeek-R1-UD-IQ2_XXS-00001-of-00004.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-IQ2_XXS/DeepSeek-R1-UD-IQ2_XXS-00002-of-00004.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-IQ2_XXS/DeepSeek-R1-UD-IQ2_XXS-00003-of-00004.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-IQ2_XXS/DeepSeek-R1-UD-IQ2_XXS-00004-of-00004.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00002-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00003-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00004-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00005-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q2_K_L/DeepSeek-R1-Q2_K_L-00001-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q2_K_L/DeepSeek-R1-Q2_K_L-00002-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q2_K_L/DeepSeek-R1-Q2_K_L-00003-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q2_K_L/DeepSeek-R1-Q2_K_L-00004-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q2_K_L/DeepSeek-R1-Q2_K_L-00005-of-00005.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q3_K_M/DeepSeek-R1-Q3_K_M-00001-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q3_K_M/DeepSeek-R1-Q3_K_M-00002-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q3_K_M/DeepSeek-R1-Q3_K_M-00003-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q3_K_M/DeepSeek-R1-Q3_K_M-00004-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q3_K_M/DeepSeek-R1-Q3_K_M-00005-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q3_K_M/DeepSeek-R1-Q3_K_M-00006-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q3_K_M/DeepSeek-R1-Q3_K_M-00007-of-00007.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q5_K_M/DeepSeek-R1-Q5_K_M-00001-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q5_K_M/DeepSeek-R1-Q5_K_M-00002-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q5_K_M/DeepSeek-R1-Q5_K_M-00003-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q5_K_M/DeepSeek-R1-Q5_K_M-00004-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q5_K_M/DeepSeek-R1-Q5_K_M-00005-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q5_K_M/DeepSeek-R1-Q5_K_M-00006-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q5_K_M/DeepSeek-R1-Q5_K_M-00007-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q5_K_M/DeepSeek-R1-Q5_K_M-00008-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q5_K_M/DeepSeek-R1-Q5_K_M-00009-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q5_K_M/DeepSeek-R1-Q5_K_M-00010-of-00010.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00001-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00002-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00003-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00004-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00005-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00006-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00007-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00008-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00009-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00010-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00011-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00012-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00013-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00014-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Q8_0/DeepSeek-R1-Q8_0-00015-of-00015.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='imatrix_unsloth.dat', size=None, blob_id=None, lfs=None)""], ""spaces"": [""PhillHenry/MyLlmPlayground"", ""krishna-k/deepseek-r1""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-23 19:21:44+00:00"", ""cardData"": ""base_model: deepseek-ai/DeepSeek-R1\nlanguage:\n- en\nlibrary_name: transformers\nlicense: mit\ntags:\n- deepseek\n- unsloth\n- transformers"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""678e4b16630463a29b67eb5e"", ""modelId"": ""unsloth/DeepSeek-R1-GGUF"", ""usedStorage"": 9778194944831}",0,"https://huggingface.co/sigjnf/unsloth-DeepSeek-R1-GGUF-merged, https://huggingface.co/dhanugowda2342/knowai, https://huggingface.co/ginghalo/deepseek-r1-1_58bit, https://huggingface.co/kingwin97/yiliao, https://huggingface.co/bap25/bap, https://huggingface.co/anandini7/telugu_finetuned_model, https://huggingface.co/VidhyaN/neuralsorority43",7,https://huggingface.co/diyamanna/bhashinillm,1,,0,,0,"PhillHenry/MyLlmPlayground, huggingface/InferenceSupport/discussions/635, krishna-k/deepseek-r1",3
|
| 377 |
+
sigjnf/unsloth-DeepSeek-R1-GGUF-merged,"---
|
| 378 |
+
license: mit
|
| 379 |
+
base_model:
|
| 380 |
+
- unsloth/DeepSeek-R1-GGUF
|
| 381 |
+
---","{""id"": ""sigjnf/unsloth-DeepSeek-R1-GGUF-merged"", ""author"": ""sigjnf"", ""sha"": ""0b78dda546a4354c694da6f7e44f8ede0adb05ec"", ""last_modified"": ""2025-01-27 20:29:21+00:00"", ""created_at"": ""2025-01-27 20:28:06+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""base_model:unsloth/DeepSeek-R1-GGUF"", ""base_model:finetune:unsloth/DeepSeek-R1-GGUF"", ""license:mit"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\nlicense: mit"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-01-27 20:29:21+00:00"", ""cardData"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\nlicense: mit"", ""transformersInfo"": null, ""_id"": ""6797ec56ef633ea7ad91f217"", ""modelId"": ""sigjnf/unsloth-DeepSeek-R1-GGUF-merged"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=sigjnf/unsloth-DeepSeek-R1-GGUF-merged&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bsigjnf%2Funsloth-DeepSeek-R1-GGUF-merged%5D(%2Fsigjnf%2Funsloth-DeepSeek-R1-GGUF-merged)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 382 |
+
dhanugowda2342/knowai,"---
|
| 383 |
+
datasets:
|
| 384 |
+
- fdgvjhb/pennydataset
|
| 385 |
+
- cognitivecomputations/dolphin-r1
|
| 386 |
+
language:
|
| 387 |
+
- en
|
| 388 |
+
base_model:
|
| 389 |
+
- unsloth/DeepSeek-R1-GGUF
|
| 390 |
+
---","{""id"": ""dhanugowda2342/knowai"", ""author"": ""dhanugowda2342"", ""sha"": ""683e295cef0a80b49ddd569c5450d2cd83c1d053"", ""last_modified"": ""2025-02-02 10:47:39+00:00"", ""created_at"": ""2025-02-02 10:46:22+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""en"", ""dataset:fdgvjhb/pennydataset"", ""dataset:cognitivecomputations/dolphin-r1"", ""base_model:unsloth/DeepSeek-R1-GGUF"", ""base_model:finetune:unsloth/DeepSeek-R1-GGUF"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\ndatasets:\n- fdgvjhb/pennydataset\n- cognitivecomputations/dolphin-r1\nlanguage:\n- en"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-02 10:47:39+00:00"", ""cardData"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\ndatasets:\n- fdgvjhb/pennydataset\n- cognitivecomputations/dolphin-r1\nlanguage:\n- en"", ""transformersInfo"": null, ""_id"": ""679f4cfe661323875caa3dc1"", ""modelId"": ""dhanugowda2342/knowai"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=dhanugowda2342/knowai&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bdhanugowda2342%2Fknowai%5D(%2Fdhanugowda2342%2Fknowai)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 391 |
+
ginghalo/deepseek-r1-1_58bit,"---
|
| 392 |
+
license: mit
|
| 393 |
+
base_model:
|
| 394 |
+
- unsloth/DeepSeek-R1-GGUF
|
| 395 |
+
---
|
| 396 |
+
","{""id"": ""ginghalo/deepseek-r1-1_58bit"", ""author"": ""ginghalo"", ""sha"": ""09ba763656ce63ba83aa7e40248f7476004c974b"", ""last_modified"": ""2025-02-10 03:02:23+00:00"", ""created_at"": ""2025-02-10 03:00:40+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""base_model:unsloth/DeepSeek-R1-GGUF"", ""base_model:finetune:unsloth/DeepSeek-R1-GGUF"", ""license:mit"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\nlicense: mit"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-10 03:02:23+00:00"", ""cardData"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\nlicense: mit"", ""transformersInfo"": null, ""_id"": ""67a96bd830e8962a38889de5"", ""modelId"": ""ginghalo/deepseek-r1-1_58bit"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=ginghalo/deepseek-r1-1_58bit&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bginghalo%2Fdeepseek-r1-1_58bit%5D(%2Fginghalo%2Fdeepseek-r1-1_58bit)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 397 |
+
kingwin97/yiliao,"---
|
| 398 |
+
license: afl-3.0
|
| 399 |
+
base_model:
|
| 400 |
+
- unsloth/DeepSeek-R1-GGUF
|
| 401 |
+
pipeline_tag: text-generation
|
| 402 |
+
tags:
|
| 403 |
+
- medical
|
| 404 |
+
language:
|
| 405 |
+
- aa
|
| 406 |
+
library_name: fasttext
|
| 407 |
+
---","{""id"": ""kingwin97/yiliao"", ""author"": ""kingwin97"", ""sha"": ""cda16f88a3704a82d7f8b95a994ae6a7eea2009b"", ""last_modified"": ""2025-02-16 15:19:19+00:00"", ""created_at"": ""2025-02-16 10:55:18+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""fasttext"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""fasttext"", ""medical"", ""text-generation"", ""aa"", ""base_model:unsloth/DeepSeek-R1-GGUF"", ""base_model:finetune:unsloth/DeepSeek-R1-GGUF"", ""license:afl-3.0"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\nlanguage:\n- aa\nlibrary_name: fasttext\nlicense: afl-3.0\npipeline_tag: text-generation\ntags:\n- medical"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='Llama3-FP16.ggu', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-16 15:19:19+00:00"", ""cardData"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\nlanguage:\n- aa\nlibrary_name: fasttext\nlicense: afl-3.0\npipeline_tag: text-generation\ntags:\n- medical"", ""transformersInfo"": null, ""_id"": ""67b1c416d2ee8e627da8b945"", ""modelId"": ""kingwin97/yiliao"", ""usedStorage"": 16063688000}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=kingwin97/yiliao&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bkingwin97%2Fyiliao%5D(%2Fkingwin97%2Fyiliao)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 408 |
+
bap25/bap,"---
|
| 409 |
+
license: other
|
| 410 |
+
license_name: bap
|
| 411 |
+
license_link: LICENSE
|
| 412 |
+
datasets:
|
| 413 |
+
- FreedomIntelligence/medical-o1-reasoning-SFT
|
| 414 |
+
metrics:
|
| 415 |
+
- bertscore
|
| 416 |
+
base_model:
|
| 417 |
+
- unsloth/DeepSeek-R1-GGUF
|
| 418 |
+
new_version: unsloth/DeepSeek-R1-GGUF
|
| 419 |
+
pipeline_tag: text-to-audio
|
| 420 |
+
library_name: diffusers
|
| 421 |
+
tags:
|
| 422 |
+
- music
|
| 423 |
+
---","{""id"": ""bap25/bap"", ""author"": ""bap25"", ""sha"": ""154901d8e5800507579d8d07c7ba8665a264ff0e"", ""last_modified"": ""2025-02-18 15:14:59+00:00"", ""created_at"": ""2025-02-18 15:13:53+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""music"", ""text-to-audio"", ""dataset:FreedomIntelligence/medical-o1-reasoning-SFT"", ""base_model:unsloth/DeepSeek-R1-GGUF"", ""base_model:finetune:unsloth/DeepSeek-R1-GGUF"", ""license:other"", ""region:us""], ""pipeline_tag"": ""text-to-audio"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\ndatasets:\n- FreedomIntelligence/medical-o1-reasoning-SFT\nlibrary_name: diffusers\nlicense: other\nlicense_name: bap\nlicense_link: LICENSE\nmetrics:\n- bertscore\npipeline_tag: text-to-audio\ntags:\n- music\nnew_version: unsloth/DeepSeek-R1-GGUF"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-18 15:14:59+00:00"", ""cardData"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\ndatasets:\n- FreedomIntelligence/medical-o1-reasoning-SFT\nlibrary_name: diffusers\nlicense: other\nlicense_name: bap\nlicense_link: LICENSE\nmetrics:\n- bertscore\npipeline_tag: text-to-audio\ntags:\n- music\nnew_version: unsloth/DeepSeek-R1-GGUF"", ""transformersInfo"": null, ""_id"": ""67b4a3b16919d701a15dde88"", ""modelId"": ""bap25/bap"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=bap25/bap&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bbap25%2Fbap%5D(%2Fbap25%2Fbap)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 424 |
+
anandini7/telugu_finetuned_model,"---
|
| 425 |
+
license: mit
|
| 426 |
+
language:
|
| 427 |
+
- te
|
| 428 |
+
base_model:
|
| 429 |
+
- unsloth/DeepSeek-R1-GGUF
|
| 430 |
+
new_version: deepseek-ai/DeepSeek-V3
|
| 431 |
+
pipeline_tag: translation
|
| 432 |
+
library_name: diffusers
|
| 433 |
+
tags:
|
| 434 |
+
- code
|
| 435 |
+
---","{""id"": ""anandini7/telugu_finetuned_model"", ""author"": ""anandini7"", ""sha"": ""d8b31afdffe449282f7a549557abebb3ebad2a48"", ""last_modified"": ""2025-02-19 05:54:55+00:00"", ""created_at"": ""2025-02-18 20:47:51+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""code"", ""translation"", ""te"", ""base_model:unsloth/DeepSeek-R1-GGUF"", ""base_model:finetune:unsloth/DeepSeek-R1-GGUF"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""translation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\nlanguage:\n- te\nlibrary_name: diffusers\nlicense: mit\npipeline_tag: translation\ntags:\n- code\nnew_version: deepseek-ai/DeepSeek-V3"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-19 05:54:55+00:00"", ""cardData"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\nlanguage:\n- te\nlibrary_name: diffusers\nlicense: mit\npipeline_tag: translation\ntags:\n- code\nnew_version: deepseek-ai/DeepSeek-V3"", ""transformersInfo"": null, ""_id"": ""67b4f1f7871574cd38eebf40"", ""modelId"": ""anandini7/telugu_finetuned_model"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=anandini7/telugu_finetuned_model&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Banandini7%2Ftelugu_finetuned_model%5D(%2Fanandini7%2Ftelugu_finetuned_model)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 436 |
+
VidhyaN/neuralsorority43,"---
|
| 437 |
+
license: apache-2.0
|
| 438 |
+
base_model:
|
| 439 |
+
- unsloth/DeepSeek-R1-GGUF
|
| 440 |
+
tags:
|
| 441 |
+
- code
|
| 442 |
+
---","{""id"": ""VidhyaN/neuralsorority43"", ""author"": ""VidhyaN"", ""sha"": ""9976cc8ada11b9acdaa9b2d8f298bf81fbefb063"", ""last_modified"": ""2025-02-20 17:16:23+00:00"", ""created_at"": ""2025-02-20 17:10:42+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""code"", ""base_model:unsloth/DeepSeek-R1-GGUF"", ""base_model:finetune:unsloth/DeepSeek-R1-GGUF"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\nlicense: apache-2.0\ntags:\n- code"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='translate_project.ipynb', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-20 17:16:23+00:00"", ""cardData"": ""base_model:\n- unsloth/DeepSeek-R1-GGUF\nlicense: apache-2.0\ntags:\n- code"", ""transformersInfo"": null, ""_id"": ""67b762125331405aee2904b1"", ""modelId"": ""VidhyaN/neuralsorority43"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=VidhyaN/neuralsorority43&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BVidhyaN%2Fneuralsorority43%5D(%2FVidhyaN%2Fneuralsorority43)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
Flux-Super-Realism-LoRA_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv
ADDED
|
@@ -0,0 +1,151 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
strangerzonehf/Flux-Super-Realism-LoRA,"---
|
| 3 |
+
tags:
|
| 4 |
+
- text-to-image
|
| 5 |
+
- lora
|
| 6 |
+
- diffusers
|
| 7 |
+
- template:diffusion-lora
|
| 8 |
+
- Super-Realism
|
| 9 |
+
- Flux.1-Dev
|
| 10 |
+
- Dynamic-Realism
|
| 11 |
+
- Realistic
|
| 12 |
+
- Photorealism
|
| 13 |
+
- Hi-Res
|
| 14 |
+
- UltraRealism
|
| 15 |
+
- Diffusion
|
| 16 |
+
- Face
|
| 17 |
+
- safetensors
|
| 18 |
+
- Realism-Engine
|
| 19 |
+
- RAW
|
| 20 |
+
- 4K
|
| 21 |
+
widget:
|
| 22 |
+
- text: >-
|
| 23 |
+
Super Realism, Woman in a red jacket, snowy, in the style of hyper-realistic
|
| 24 |
+
portraiture, caninecore, mountainous vistas, timeless beauty, palewave,
|
| 25 |
+
iconic, distinctive noses --ar 72:101 --stylize 750 --v 6
|
| 26 |
+
output:
|
| 27 |
+
url: images/3.png
|
| 28 |
+
- text: >-
|
| 29 |
+
Super Realism, Headshot of handsome young man, wearing dark gray sweater
|
| 30 |
+
with buttons and big shawl collar, brown hair and short beard, serious look
|
| 31 |
+
on his face, black background, soft studio lighting, portrait photography
|
| 32 |
+
--ar 85:128 --v 6.0 --style rawHeadshot of handsome young man, wearing dark
|
| 33 |
+
gray sweater with buttons and big shawl collar, brown hair and short beard,
|
| 34 |
+
serious look on his face, black background, soft studio lighting, portrait
|
| 35 |
+
photography --ar 85:128 --v 6.0 --style rawHeadshot of handsome young man,
|
| 36 |
+
wearing dark gray sweater with buttons and big shawl collar, brown hair and
|
| 37 |
+
short beard, serious look on his face, black background, soft studio
|
| 38 |
+
lighting, portrait photography --ar 85:128 --v 6.0 --style raw
|
| 39 |
+
output:
|
| 40 |
+
url: images/2.png
|
| 41 |
+
- text: >-
|
| 42 |
+
Super Realism, High-resolution photograph, woman, UHD, photorealistic, shot
|
| 43 |
+
on a Sony A7III --chaos 20 --ar 1:2 --style raw --stylize 250
|
| 44 |
+
output:
|
| 45 |
+
url: images/1.png
|
| 46 |
+
base_model: black-forest-labs/FLUX.1-dev
|
| 47 |
+
instance_prompt: Super Realism
|
| 48 |
+
license: mit
|
| 49 |
+
---
|
| 50 |
+

|
| 51 |
+
|
| 52 |
+
<Gallery />
|
| 53 |
+
|
| 54 |
+
## Model description for super realism engine
|
| 55 |
+
|
| 56 |
+
Image Processing Parameters
|
| 57 |
+
|
| 58 |
+
| Parameter | Value | Parameter | Value |
|
| 59 |
+
|---------------------------|--------|---------------------------|--------|
|
| 60 |
+
| LR Scheduler | constant | Noise Offset | 0.03 |
|
| 61 |
+
| Optimizer | AdamW | Multires Noise Discount | 0.1 |
|
| 62 |
+
| Network Dim | 64 | Multires Noise Iterations | 10 |
|
| 63 |
+
| Network Alpha | 32 | Repeat & Steps | 30 & 4380|
|
| 64 |
+
| Epoch | 20 | Save Every N Epochs | 1 |
|
| 65 |
+
|
| 66 |
+
## Comparison between the base model and related models.
|
| 67 |
+
|
| 68 |
+
Comparison between the base model FLUX.1-dev and its adapter, a LoRA model tuned for super-realistic realism.
|
| 69 |
+
[ 28 steps ]
|
| 70 |
+
|
| 71 |
+

|
| 72 |
+
|
| 73 |
+
However, it performs better in various aspects compared to its previous models, including face realism, ultra-realism, and others.
|
| 74 |
+
previous versions [ 28 steps ]
|
| 75 |
+
|
| 76 |
+

|
| 77 |
+
|
| 78 |
+
## Previous Model Links
|
| 79 |
+
|
| 80 |
+
| Model Name | Description | Link |
|
| 81 |
+
|------------------------------------------|------------------------------|------------------------------------------------------------------------------------------|
|
| 82 |
+
| **Canopus-LoRA-Flux-FaceRealism** | LoRA model for Face Realism | [Canopus-LoRA-Flux-FaceRealism](https://huggingface.co/prithivMLmods/Canopus-LoRA-Flux-FaceRealism) |
|
| 83 |
+
| **Canopus-LoRA-Flux-UltraRealism-2.0** | LoRA model for Ultra Realism | [Canopus-LoRA-Flux-UltraRealism-2.0](https://huggingface.co/prithivMLmods/Canopus-LoRA-Flux-UltraRealism-2.0) |
|
| 84 |
+
| **Flux.1-Dev-LoRA-HDR-Realism [Experimental Version]** | LoRA model for HDR Realism | [Flux.1-Dev-LoRA-HDR-Realism](https://huggingface.co/prithivMLmods/Flux.1-Dev-LoRA-HDR-Realism) |
|
| 85 |
+
| **Flux-Realism-FineDetailed** | Fine-detailed realism-focused model | [Flux-Realism-FineDetailed](https://huggingface.co/prithivMLmods/Flux-Realism-FineDetailed) |
|
| 86 |
+
|
| 87 |
+
## Hosted/Demo Links
|
| 88 |
+
|
| 89 |
+
| Demo Name | Description | Link |
|
| 90 |
+
|----------------------------|----------------------------|--------------------------------------------------------------------------------------|
|
| 91 |
+
| **FLUX-LoRA-DLC** | Demo for FLUX LoRA DLC | [FLUX-LoRA-DLC](https://huggingface.co/spaces/prithivMLmods/FLUX-LoRA-DLC) |
|
| 92 |
+
| **FLUX-REALISM** | Demo for FLUX Realism | [FLUX-REALISM](https://huggingface.co/spaces/prithivMLmods/FLUX-REALISM) |
|
| 93 |
+
|
| 94 |
+
## Model Training Basic Details
|
| 95 |
+
|
| 96 |
+
| Feature | Description |
|
| 97 |
+
|--------------------------------|-------------------------------------|
|
| 98 |
+
| **Labeling** | florence2-en (natural language & English) |
|
| 99 |
+
| **Total Images Used for Training** | 55 [Hi-Res] |
|
| 100 |
+
| **Best Dimensions** | - 1024 x 1024 (Default) |
|
| 101 |
+
| | - 768 x 1024 |
|
| 102 |
+
|
| 103 |
+
## Flux-Super-Realism-LoRA Model GitHub
|
| 104 |
+
|
| 105 |
+
| Repository Link | Description |
|
| 106 |
+
|---------------------------------------------------------------|----------------------------------------------|
|
| 107 |
+
| [Flux-Super-Realism-LoRA](https://github.com/Stranger-Zone/Flux-Super-Realism-LoRA/tree/main) | Flux Super Realism LoRA model repository for high-quality realism generation |
|
| 108 |
+
|
| 109 |
+
## API Usage / Quick Usage
|
| 110 |
+
```python
|
| 111 |
+
from gradio_client import Client
|
| 112 |
+
|
| 113 |
+
client = Client(""prithivMLmods/FLUX-REALISM"")
|
| 114 |
+
result = client.predict(
|
| 115 |
+
prompt=""A tiny astronaut hatching from an egg on the moon, 4k, planet theme"",
|
| 116 |
+
seed=0,
|
| 117 |
+
width=1024,
|
| 118 |
+
height=1024,
|
| 119 |
+
guidance_scale=6,
|
| 120 |
+
randomize_seed=True,
|
| 121 |
+
api_name=""/run""
|
| 122 |
+
#takes minimum of 30 seconds
|
| 123 |
+
)
|
| 124 |
+
print(result)
|
| 125 |
+
```
|
| 126 |
+
## Setting Up Flux Space
|
| 127 |
+
```python
|
| 128 |
+
import torch
|
| 129 |
+
from pipelines import DiffusionPipeline
|
| 130 |
+
|
| 131 |
+
base_model = ""black-forest-labs/FLUX.1-dev""
|
| 132 |
+
pipe = DiffusionPipeline.from_pretrained(base_model, torch_dtype=torch.bfloat16)
|
| 133 |
+
|
| 134 |
+
lora_repo = ""strangerzonehf/Flux-Super-Realism-LoRA""
|
| 135 |
+
trigger_word = ""Super Realism"" #triggerword
|
| 136 |
+
pipe.load_lora_weights(lora_repo)
|
| 137 |
+
|
| 138 |
+
device = torch.device(""cuda"")
|
| 139 |
+
pipe.to(device)
|
| 140 |
+
```
|
| 141 |
+
## Trigger words
|
| 142 |
+
|
| 143 |
+
> [!WARNING]
|
| 144 |
+
> **Trigger words:** You should use `Super Realism` to trigger the image generation.
|
| 145 |
+
|
| 146 |
+
- The trigger word is not mandatory; ensure that words like ""realistic"" and ""realism"" appear in the image description. The ""super realism"" trigger word should prompt an exact match to the reference image in the showcase.
|
| 147 |
+
## Download model
|
| 148 |
+
|
| 149 |
+
Weights for this model are available in Safetensors format.
|
| 150 |
+
|
| 151 |
+
[Download](/strangerzonehf/Flux-Super-Realism-LoRA/tree/main) them in the Files & versions tab.","{""id"": ""strangerzonehf/Flux-Super-Realism-LoRA"", ""author"": ""strangerzonehf"", ""sha"": ""321693353a5c05fe013ad431578d97e866159515"", ""last_modified"": ""2024-11-27 20:50:39+00:00"", ""created_at"": ""2024-11-12 18:40:16+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 12799, ""downloads_all_time"": null, ""likes"": 202, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": ""warm"", ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""text-to-image"", ""lora"", ""template:diffusion-lora"", ""Super-Realism"", ""Flux.1-Dev"", ""Dynamic-Realism"", ""Realistic"", ""Photorealism"", ""Hi-Res"", ""UltraRealism"", ""Diffusion"", ""Face"", ""safetensors"", ""Realism-Engine"", ""RAW"", ""4K"", ""base_model:black-forest-labs/FLUX.1-dev"", ""base_model:adapter:black-forest-labs/FLUX.1-dev"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: black-forest-labs/FLUX.1-dev\nlicense: mit\ntags:\n- text-to-image\n- lora\n- diffusers\n- template:diffusion-lora\n- Super-Realism\n- Flux.1-Dev\n- Dynamic-Realism\n- Realistic\n- Photorealism\n- Hi-Res\n- UltraRealism\n- Diffusion\n- Face\n- safetensors\n- Realism-Engine\n- RAW\n- 4K\nwidget:\n- text: Super Realism, Woman in a red jacket, snowy, in the style of hyper-realistic\n portraiture, caninecore, mountainous vistas, timeless beauty, palewave, iconic,\n distinctive noses --ar 72:101 --stylize 750 --v 6\n output:\n url: https://huggingface.co/strangerzonehf/Flux-Super-Realism-LoRA/resolve/main/images/3.png\n- text: Super Realism, Headshot of handsome young man, wearing dark gray sweater with\n buttons and big shawl collar, brown hair and short beard, serious look on his\n face, black background, soft studio lighting, portrait photography --ar 85:128\n --v 6.0 --style rawHeadshot of handsome young man, wearing dark gray sweater with\n buttons and big shawl collar, brown hair and short beard, serious look on his\n face, black background, soft studio lighting, portrait photography --ar 85:128\n --v 6.0 --style rawHeadshot of handsome young man, wearing dark gray sweater with\n buttons and big shawl collar, brown hair and short beard, serious look on his\n face, black background, soft studio lighting, portrait photography --ar 85:128\n --v 6.0 --style raw\n output:\n url: https://huggingface.co/strangerzonehf/Flux-Super-Realism-LoRA/resolve/main/images/2.png\n- text: Super Realism, High-resolution photograph, woman, UHD, photorealistic, shot\n on a Sony A7III --chaos 20 --ar 1:2 --style raw --stylize 250\n output:\n url: https://huggingface.co/strangerzonehf/Flux-Super-Realism-LoRA/resolve/main/images/1.png\ninstance_prompt: Super Realism"", ""widget_data"": [{""text"": ""Super Realism, Woman in a red jacket, snowy, in the style of hyper-realistic portraiture, caninecore, mountainous vistas, timeless beauty, palewave, iconic, distinctive noses --ar 72:101 --stylize 750 --v 6"", ""output"": {""url"": ""https://huggingface.co/strangerzonehf/Flux-Super-Realism-LoRA/resolve/main/images/3.png""}}, {""text"": ""Super Realism, Headshot of handsome young man, wearing dark gray sweater with buttons and big shawl collar, brown hair and short beard, serious look on his face, black background, soft studio lighting, portrait photography --ar 85:128 --v 6.0 --style rawHeadshot of handsome young man, wearing dark gray sweater with buttons and big shawl collar, brown hair and short beard, serious look on his face, black background, soft studio lighting, portrait photography --ar 85:128 --v 6.0 --style rawHeadshot of handsome young man, wearing dark gray sweater with buttons and big shawl collar, brown hair and short beard, serious look on his face, black background, soft studio lighting, portrait photography --ar 85:128 --v 6.0 --style raw"", ""output"": {""url"": ""https://huggingface.co/strangerzonehf/Flux-Super-Realism-LoRA/resolve/main/images/2.png""}}, {""text"": ""Super Realism, High-resolution photograph, woman, UHD, photorealistic, shot on a Sony A7III --chaos 20 --ar 1:2 --style raw --stylize 250"", ""output"": {""url"": ""https://huggingface.co/strangerzonehf/Flux-Super-Realism-LoRA/resolve/main/images/1.png""}}], ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/1.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/2.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/3.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/sz.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/sz2.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='images/sz3.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='super-realism.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [""prithivMLmods/FLUX-LoRA-DLC"", ""Nymbo/Serverless-ImgGen-Hub"", ""prithivMLmods/FLUX-REALISM"", ""NeurixYUFI/imggen"", ""fantaxy/playground25"", ""Novaciano/Flux_Lustly_AI_Uncensored_NSFW_V1"", ""vyloup/FLUX-LoRA-DLC"", ""guardiancc/FLUX-LoRA-DLC-fixed"", ""ruslanmv/Flux-LoRA-Generation-Advanced"", ""Smiley0707/FLUX-LoRA-DLC"", ""soiz1/FLUX-LoRA-DLC"", ""mantrakp/AllFlux"", ""Dagfinn1962/FLUX-REALISM"", ""revittapanda/Revitta-Flux-Super-Realism-LoRA"", ""cutifly/strangerzonehf-Flux-Super-Realism-LoRA"", ""NativeAngels/Serverless-ImgGen-Hub"", ""NASSIM55/strangerzonehf-Flux-Super-Realism-LoRA"", ""sajjaddg/strangerzonehf-Flux-Super-Realism-LoRA"", ""theunseenones94/Flux_Lustly_AI_Uncensored_NSFW_V1"", ""yufiru/ImageGeneratotModels"", ""guardiancc/arcane"", ""openfree/tesfdsfsf"", ""Nymbo/Model-Status-Checker"", ""crazyhite001/imggen"", ""DJStomp/FLUX-LoRA-DLC"", ""Fabyler/strangerzonehf-Flux-Super-Realism-LoRA"", ""joeysaada/strangerzonehf-Flux-Super-Realism-LoRAdz"", ""Parmist/strangerzonehf-Flux-Super-Realism-LoRA"", ""Kidbea/Kidbea_Image_Generation"", ""Kidbea/multimodels_image_generation"", ""shomare01/Flux-Super-Realism-LoRA"", ""K00B404/FLUX-Wallpaper-HD-Maker_p"", ""Nymbo/serverless-imggen-test"", ""cngsm/FLUX-LoRA-DLC"", ""incude/strangerzonehf-Flux-Super-Realism-LoRA"", ""Xach35/FLUX-LoRA-DLC"", ""Delta-4/Delta4-Super-Realism-LoRA"", ""Nightwing25/strangerzonehf-Flux-Super-Realism-LoRA"", ""soharab/Super-Realism-LoRA"", ""wingsss/strangerzonehf-Flux-Super-Realism-LoRA"", ""ryan171088/FLUX-LoRA-DLC"", ""K00B404/TheUnclonable"", ""Akshit2606/strangerzonehf-Flux-Super-Realism-LoRA"", ""TimHortonsRAW/FLUX-REALISM"", ""nkargar1356/strangerzonehf-Flux-Super-Realism-LoRA"", ""martynka/for-dev"", ""fourmyfriends/FLUX-LoRA-DLC"", ""EliteGamerCJ/strangerzonehf-Flux-Super-Realism-LoRA"", ""njavidfar/o"", ""indianace/strangerzonehf-Flux-Super-Realism-LoRA"", ""bluenevus/picture-perfect"", ""Arashpey/FLUX-LoRA-DLC"", ""codermert/hmmm"", ""drago33drago/FLUX-LoRA-DLC"", ""rafaelkamp/black-forest-labs-FLUX.1-dev""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-11-27 20:50:39+00:00"", ""cardData"": ""base_model: black-forest-labs/FLUX.1-dev\nlicense: mit\ntags:\n- text-to-image\n- lora\n- diffusers\n- template:diffusion-lora\n- Super-Realism\n- Flux.1-Dev\n- Dynamic-Realism\n- Realistic\n- Photorealism\n- Hi-Res\n- UltraRealism\n- Diffusion\n- Face\n- safetensors\n- Realism-Engine\n- RAW\n- 4K\nwidget:\n- text: Super Realism, Woman in a red jacket, snowy, in the style of hyper-realistic\n portraiture, caninecore, mountainous vistas, timeless beauty, palewave, iconic,\n distinctive noses --ar 72:101 --stylize 750 --v 6\n output:\n url: https://huggingface.co/strangerzonehf/Flux-Super-Realism-LoRA/resolve/main/images/3.png\n- text: Super Realism, Headshot of handsome young man, wearing dark gray sweater with\n buttons and big shawl collar, brown hair and short beard, serious look on his\n face, black background, soft studio lighting, portrait photography --ar 85:128\n --v 6.0 --style rawHeadshot of handsome young man, wearing dark gray sweater with\n buttons and big shawl collar, brown hair and short beard, serious look on his\n face, black background, soft studio lighting, portrait photography --ar 85:128\n --v 6.0 --style rawHeadshot of handsome young man, wearing dark gray sweater with\n buttons and big shawl collar, brown hair and short beard, serious look on his\n face, black background, soft studio lighting, portrait photography --ar 85:128\n --v 6.0 --style raw\n output:\n url: https://huggingface.co/strangerzonehf/Flux-Super-Realism-LoRA/resolve/main/images/2.png\n- text: Super Realism, High-resolution photograph, woman, UHD, photorealistic, shot\n on a Sony A7III --chaos 20 --ar 1:2 --style raw --stylize 250\n output:\n url: https://huggingface.co/strangerzonehf/Flux-Super-Realism-LoRA/resolve/main/images/1.png\ninstance_prompt: Super Realism"", ""transformersInfo"": null, ""_id"": ""6733a110b6daf0fbdb660971"", ""modelId"": ""strangerzonehf/Flux-Super-Realism-LoRA"", ""usedStorage"": 644001442}",0,,0,,0,,0,,0,"NeurixYUFI/imggen, Novaciano/Flux_Lustly_AI_Uncensored_NSFW_V1, Nymbo/Serverless-ImgGen-Hub, Smiley0707/FLUX-LoRA-DLC, fantaxy/playground25, guardiancc/FLUX-LoRA-DLC-fixed, mantrakp/AllFlux, prithivMLmods/FLUX-LoRA-DLC, prithivMLmods/FLUX-REALISM, ruslanmv/Flux-LoRA-Generation-Advanced, soiz1/FLUX-LoRA-DLC, vyloup/FLUX-LoRA-DLC",12
|
GR00T-N1-2B_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
nvidia/GR00T-N1-2B,"---
|
| 3 |
+
datasets:
|
| 4 |
+
- nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim
|
| 5 |
+
tags:
|
| 6 |
+
- robotics
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# GR00T-N1-2B
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+

|
| 13 |
+
|
| 14 |
+
Github page: https://github.com/NVIDIA/Isaac-GR00T/
|
| 15 |
+
|
| 16 |
+
NVIDIA Isaac GR00T N1 is the world's first open foundation model for generalized humanoid robot reasoning and skills.","{""id"": ""nvidia/GR00T-N1-2B"", ""author"": ""nvidia"", ""sha"": ""32e1fd2507f7739fad443e6b449c8188e0e02fcb"", ""last_modified"": ""2025-03-18 18:35:00+00:00"", ""created_at"": ""2025-03-05 08:40:53+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 3690, ""downloads_all_time"": null, ""likes"": 283, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""safetensors"", ""gr00t_n1"", ""robotics"", ""dataset:nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim"", ""region:us""], ""pipeline_tag"": ""robotics"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""datasets:\n- nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim\ntags:\n- robotics"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""GR00T_N1""], ""model_type"": ""gr00t_n1""}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='experiment_cfg/metadata.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""BF16"": 2190019826}, ""total"": 2190019826}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-18 18:35:00+00:00"", ""cardData"": ""datasets:\n- nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim\ntags:\n- robotics"", ""transformersInfo"": null, ""_id"": ""67c80e155e535e9b2dca27c2"", ""modelId"": ""nvidia/GR00T-N1-2B"", ""usedStorage"": 13355965552}",0,,0,"https://huggingface.co/ibru/bobo_groot_model_2, https://huggingface.co/ibru/bobo_groot_model_3, https://huggingface.co/ibru/bobo_groot_n1, https://huggingface.co/ibru/bobo_jetson_gr00t_n1_2b, https://huggingface.co/ibru/bob_gr00t_n1_2b_10k, https://huggingface.co/ibru/bob_jetson_gr00t_n1_2b_191e, https://huggingface.co/ibru/bobo_jetson_tennis_gr00t_n1_2b",7,,0,,0,,0
|
Hunyuan3D-2_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv
ADDED
|
@@ -0,0 +1,459 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
tencent/Hunyuan3D-2,"---
|
| 3 |
+
library_name: hunyuan3d-2
|
| 4 |
+
license: other
|
| 5 |
+
license_name: tencent-hunyuan-community
|
| 6 |
+
license_link: https://huggingface.co/tencent/Hunyuan3D-2/blob/main/LICENSE.txt
|
| 7 |
+
language:
|
| 8 |
+
- en
|
| 9 |
+
- zh
|
| 10 |
+
tags:
|
| 11 |
+
- image-to-3d
|
| 12 |
+
- text-to-3d
|
| 13 |
+
pipeline_tag: image-to-3d
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
<p align=""center"">
|
| 17 |
+
<img src=""./assets/images/teaser.jpg"">
|
| 18 |
+
</p>
|
| 19 |
+
|
| 20 |
+
<div align=""center"">
|
| 21 |
+
<a href=https://3d.hunyuan.tencent.com target=""_blank""><img src=https://img.shields.io/badge/Hunyuan3D-black.svg?logo=homepage height=22px></a>
|
| 22 |
+
<a href=https://huggingface.co/spaces/tencent/Hunyuan3D-2 target=""_blank""><img src=https://img.shields.io/badge/%F0%9F%A4%97%20Demo-276cb4.svg height=22px></a>
|
| 23 |
+
<a href=https://huggingface.co/tencent/Hunyuan3D-2 target=""_blank""><img src=https://img.shields.io/badge/%F0%9F%A4%97%20Models-d96902.svg height=22px></a>
|
| 24 |
+
<a href=https://3d-models.hunyuan.tencent.com/ target=""_blank""><img src= https://img.shields.io/badge/Page-bb8a2e.svg?logo=github height=22px></a>
|
| 25 |
+
<a href=https://discord.gg/GuaWYwzKbX target=""_blank""><img src= https://img.shields.io/badge/Discord-white.svg?logo=discord height=22px></a>
|
| 26 |
+
<a href=https://github.com/Tencent/Hunyuan3D-2/blob/main/assets/report/Tencent_Hunyuan3D_2_0.pdf target=""_blank""><img src=https://img.shields.io/badge/Report-b5212f.svg?logo=arxiv height=22px></a>
|
| 27 |
+
</div>
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
[//]: # ( <a href=# target=""_blank""><img src=https://img.shields.io/badge/Report-b5212f.svg?logo=arxiv height=22px></a>)
|
| 31 |
+
|
| 32 |
+
[//]: # ( <a href=# target=""_blank""><img src= https://img.shields.io/badge/Colab-8f2628.svg?logo=googlecolab height=22px></a>)
|
| 33 |
+
|
| 34 |
+
[//]: # ( <a href=""#""><img alt=""PyPI - Downloads"" src=""https://img.shields.io/pypi/v/mulankit?logo=pypi"" height=22px></a>)
|
| 35 |
+
|
| 36 |
+
<br>
|
| 37 |
+
<p align=""center"">
|
| 38 |
+
“ Living out everyone’s imagination on creating and manipulating 3D assets.”
|
| 39 |
+
</p>
|
| 40 |
+
|
| 41 |
+
This repository contains the models of the paper [Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation](https://huggingface.co/papers/2501.12202).
|
| 42 |
+
For code and more details on how to use it, refer to the [Github repository](https://github.com/Tencent/Hunyuan3D-2).
|
| 43 |
+
|
| 44 |
+
## 🔥 News
|
| 45 |
+
|
| 46 |
+
- Jan 21, 2025: 💬 Release [Hunyuan3D 2.0](https://huggingface.co/spaces/tencent/Hunyuan3D-2). Please give it a try!
|
| 47 |
+
|
| 48 |
+
## **Abstract**
|
| 49 |
+
|
| 50 |
+
We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets.
|
| 51 |
+
This system includes two foundation components: a large-scale shape generation model - Hunyuan3D-DiT, and a large-scale
|
| 52 |
+
texture synthesis model - Hunyuan3D-Paint.
|
| 53 |
+
The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly
|
| 54 |
+
aligns with a given condition image, laying a solid foundation for downstream applications.
|
| 55 |
+
The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant
|
| 56 |
+
texture maps for either generated or hand-crafted meshes.
|
| 57 |
+
Furthermore, we build Hunyuan3D-Studio - a versatile, user-friendly production platform that simplifies the re-creation
|
| 58 |
+
process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes
|
| 59 |
+
efficiently.
|
| 60 |
+
We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models,
|
| 61 |
+
including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and
|
| 62 |
+
e.t.c.
|
| 63 |
+
|
| 64 |
+
<p align=""center"">
|
| 65 |
+
<img src=""assets/images/system.jpg"">
|
| 66 |
+
</p>
|
| 67 |
+
|
| 68 |
+
## ☯️ **Hunyuan3D 2.0**
|
| 69 |
+
|
| 70 |
+
### Architecture
|
| 71 |
+
|
| 72 |
+
Hunyuan3D 2.0 features a two-stage generation pipeline, starting with the creation of a bare mesh, followed by the
|
| 73 |
+
synthesis of a texture map for that mesh. This strategy is effective for decoupling the difficulties of shape and
|
| 74 |
+
texture generation and also provides flexibility for texturing either generated or handcrafted meshes.
|
| 75 |
+
|
| 76 |
+
<p align=""left"">
|
| 77 |
+
<img src=""assets/images/arch.jpg"">
|
| 78 |
+
</p>
|
| 79 |
+
|
| 80 |
+
### Performance
|
| 81 |
+
|
| 82 |
+
We have evaluated Hunyuan3D 2.0 with other open-source as well as close-source 3d-generation methods.
|
| 83 |
+
The numerical results indicate that Hunyuan3D 2.0 surpasses all baselines in the quality of generated textured 3D assets
|
| 84 |
+
and the condition following ability.
|
| 85 |
+
|
| 86 |
+
| Model | CMMD(⬇) | FID_CLIP(⬇) | FID(⬇) | CLIP-score(⬆) |
|
| 87 |
+
|-------------------------|-----------|-------------|-------------|---------------|
|
| 88 |
+
| Top Open-source Model1 | 3.591 | 54.639 | 289.287 | 0.787 |
|
| 89 |
+
| Top Close-source Model1 | 3.600 | 55.866 | 305.922 | 0.779 |
|
| 90 |
+
| Top Close-source Model2 | 3.368 | 49.744 | 294.628 | 0.806 |
|
| 91 |
+
| Top Close-source Model3 | 3.218 | 51.574 | 295.691 | 0.799 |
|
| 92 |
+
| Hunyuan3D 2.0 | **3.193** | **49.165** | **282.429** | **0.809** |
|
| 93 |
+
|
| 94 |
+
Generation results of Hunyuan3D 2.0:
|
| 95 |
+
<p align=""left"">
|
| 96 |
+
<img src=""assets/images/e2e-1.gif"" height=300>
|
| 97 |
+
<img src=""assets/images/e2e-2.gif"" height=300>
|
| 98 |
+
</p>
|
| 99 |
+
|
| 100 |
+
### Pretrained Models
|
| 101 |
+
|
| 102 |
+
| Model | Date | Huggingface |
|
| 103 |
+
|----------------------|------------|--------------------------------------------------------|
|
| 104 |
+
| Hunyuan3D-DiT-v2-0 | 2025-01-21 | [Download](https://huggingface.co/tencent/Hunyuan3D-2) |
|
| 105 |
+
| Hunyuan3D-Paint-v2-0 | 2025-01-21 | [Download](https://huggingface.co/tencent/Hunyuan3D-2) |
|
| 106 |
+
| Hunyuan3D-Delight-v2-0 | 2025-01-21 | [Download](https://huggingface.co/tencent/Hunyuan3D-2/tree/main/hunyuan3d-delight-v2-0) |
|
| 107 |
+
|
| 108 |
+
## 🤗 Get Started with Hunyuan3D 2.0
|
| 109 |
+
|
| 110 |
+
You may follow the next steps to use Hunyuan3D 2.0 via code or the Gradio App.
|
| 111 |
+
|
| 112 |
+
### Install Requirements
|
| 113 |
+
|
| 114 |
+
Please install Pytorch via the [official](https://pytorch.org/) site. Then install the other requirements via
|
| 115 |
+
|
| 116 |
+
```bash
|
| 117 |
+
pip install -r requirements.txt
|
| 118 |
+
# for texture
|
| 119 |
+
cd hy3dgen/texgen/custom_rasterizer
|
| 120 |
+
python3 setup.py install
|
| 121 |
+
cd ../../..
|
| 122 |
+
cd hy3dgen/texgen/differentiable_renderer
|
| 123 |
+
bash compile_mesh_painter.sh OR python3 setup.py install (on Windows)
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
### API Usage
|
| 127 |
+
|
| 128 |
+
We designed a diffusers-like API to use our shape generation model - Hunyuan3D-DiT and texture synthesis model -
|
| 129 |
+
Hunyuan3D-Paint.
|
| 130 |
+
|
| 131 |
+
You could assess **Hunyuan3D-DiT** via:
|
| 132 |
+
|
| 133 |
+
```python
|
| 134 |
+
from hy3dgen.shapegen import Hunyuan3DDiTFlowMatchingPipeline
|
| 135 |
+
|
| 136 |
+
pipeline = Hunyuan3DDiTFlowMatchingPipeline.from_pretrained('tencent/Hunyuan3D-2')
|
| 137 |
+
mesh = pipeline(image='assets/demo.png')[0]
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
The output mesh is a [trimesh object](https://trimesh.org/trimesh.html), which you could save to glb/obj (or other
|
| 141 |
+
format) file.
|
| 142 |
+
|
| 143 |
+
For **Hunyuan3D-Paint**, do the following:
|
| 144 |
+
|
| 145 |
+
```python
|
| 146 |
+
from hy3dgen.texgen import Hunyuan3DPaintPipeline
|
| 147 |
+
from hy3dgen.shapegen import Hunyuan3DDiTFlowMatchingPipeline
|
| 148 |
+
|
| 149 |
+
# let's generate a mesh first
|
| 150 |
+
pipeline = Hunyuan3DDiTFlowMatchingPipeline.from_pretrained('tencent/Hunyuan3D-2')
|
| 151 |
+
mesh = pipeline(image='assets/demo.png')[0]
|
| 152 |
+
|
| 153 |
+
pipeline = Hunyuan3DPaintPipeline.from_pretrained('tencent/Hunyuan3D-2')
|
| 154 |
+
mesh = pipeline(mesh, image='assets/demo.png')
|
| 155 |
+
```
|
| 156 |
+
|
| 157 |
+
Please visit [minimal_demo.py](https://github.com/Tencent/Hunyuan3D-2/blob/main/minimal_demo.py) for more advanced usage, such as **text to 3D** and **texture generation
|
| 158 |
+
for handcrafted mesh**.
|
| 159 |
+
|
| 160 |
+
### Gradio App
|
| 161 |
+
|
| 162 |
+
You could also host a [Gradio](https://www.gradio.app/) App in your own computer via:
|
| 163 |
+
|
| 164 |
+
```bash
|
| 165 |
+
pip3 install gradio==3.39.0
|
| 166 |
+
python3 gradio_app.py
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
Don't forget to visit [Hunyuan3D](https://3d.hunyuan.tencent.com) for quick use, if you don't want to host yourself.
|
| 170 |
+
|
| 171 |
+
## 📑 Open-Source Plan
|
| 172 |
+
|
| 173 |
+
- [x] Inference Code
|
| 174 |
+
- [x] Model Checkpoints
|
| 175 |
+
- [x] Technical Report
|
| 176 |
+
- [ ] ComfyUI
|
| 177 |
+
- [ ] TensorRT Version
|
| 178 |
+
|
| 179 |
+
## 🔗 BibTeX
|
| 180 |
+
|
| 181 |
+
If you found this repository helpful, please cite our report:
|
| 182 |
+
|
| 183 |
+
```bibtex
|
| 184 |
+
@misc{hunyuan3d22025tencent,
|
| 185 |
+
title={Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation},
|
| 186 |
+
author={Tencent Hunyuan3D Team},
|
| 187 |
+
year={2025},
|
| 188 |
+
eprint={2501.12202},
|
| 189 |
+
archivePrefix={arXiv},
|
| 190 |
+
primaryClass={cs.CV}
|
| 191 |
+
}
|
| 192 |
+
|
| 193 |
+
@misc{yang2024tencent,
|
| 194 |
+
title={Tencent Hunyuan3D-1.0: A Unified Framework for Text-to-3D and Image-to-3D Generation},
|
| 195 |
+
author={Tencent Hunyuan3D Team},
|
| 196 |
+
year={2024},
|
| 197 |
+
eprint={2411.02293},
|
| 198 |
+
archivePrefix={arXiv},
|
| 199 |
+
primaryClass={cs.CV}
|
| 200 |
+
}
|
| 201 |
+
```
|
| 202 |
+
|
| 203 |
+
## Community Resources
|
| 204 |
+
|
| 205 |
+
Thanks for the contributions of community members, here we have these great extensions of Hunyuan3D 2.0:
|
| 206 |
+
|
| 207 |
+
- [ComfyUI-Hunyuan3DWrapper](https://github.com/kijai/ComfyUI-Hunyuan3DWrapper)
|
| 208 |
+
- [Hunyuan3D-2-for-windows](https://github.com/sdbds/Hunyuan3D-2-for-windows)
|
| 209 |
+
- [📦 A bundle for running on Windows | 整合包](https://github.com/YanWenKun/Comfy3D-WinPortable/releases/tag/r8-hunyuan3d2)
|
| 210 |
+
|
| 211 |
+
## Acknowledgements
|
| 212 |
+
|
| 213 |
+
We would like to thank the contributors to
|
| 214 |
+
the [DINOv2](https://github.com/facebookresearch/dinov2), [Stable Diffusion](https://github.com/Stability-AI/stablediffusion), [FLUX](https://github.com/black-forest-labs/flux), [diffusers](https://github.com/huggingface/diffusers)
|
| 215 |
+
and [HuggingFace](https://huggingface.co) repositories, for their open research and exploration.
|
| 216 |
+
|
| 217 |
+
## Star History
|
| 218 |
+
|
| 219 |
+
<a href=""https://star-history.com/#Tencent/Hunyuan3D-2&Date"">
|
| 220 |
+
<picture>
|
| 221 |
+
<source media=""(prefers-color-scheme: dark)"" srcset=""https://api.star-history.com/svg?repos=Tencent/Hunyuan3D-2&type=Date&theme=dark"" />
|
| 222 |
+
<source media=""(prefers-color-scheme: light)"" srcset=""https://api.star-history.com/svg?repos=Tencent/Hunyuan3D-2&type=Date"" />
|
| 223 |
+
<img alt=""Star History Chart"" src=""https://api.star-history.com/svg?repos=Tencent/Hunyuan3D-2&type=Date"" />
|
| 224 |
+
</picture>
|
| 225 |
+
</a>","{""id"": ""tencent/Hunyuan3D-2"", ""author"": ""tencent"", ""sha"": ""34e28261f71c32975727be8db0eace439a280f82"", ""last_modified"": ""2025-04-10 14:55:56+00:00"", ""created_at"": ""2025-01-20 06:55:37+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 529128, ""downloads_all_time"": null, ""likes"": 1267, ""library_name"": ""hunyuan3d-2"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""hunyuan3d-2"", ""diffusers"", ""safetensors"", ""image-to-3d"", ""text-to-3d"", ""en"", ""zh"", ""arxiv:2501.12202"", ""arxiv:2411.02293"", ""license:other"", ""region:us""], ""pipeline_tag"": ""image-to-3d"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- en\n- zh\nlibrary_name: hunyuan3d-2\nlicense: other\nlicense_name: tencent-hunyuan-community\nlicense_link: https://huggingface.co/tencent/Hunyuan3D-2/blob/main/LICENSE.txt\npipeline_tag: image-to-3d\ntags:\n- image-to-3d\n- text-to-3d"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='NOTICE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/demo.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/images/arch.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/images/e2e-1.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/images/e2e-2.gif', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/images/system.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/images/teaser.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/feature_extractor/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/model_index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/text_encoder/model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/tokenizer/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/tokenizer/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/unet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/unet/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/vae/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-delight-v2-0/vae/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-dit-v2-0-fast/config.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-dit-v2-0-fast/model.fp16.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-dit-v2-0-fast/model.fp16.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-dit-v2-0-turbo/config.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-dit-v2-0-turbo/model.fp16.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-dit-v2-0-turbo/model.fp16.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-dit-v2-0/config.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-dit-v2-0/model.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-dit-v2-0/model.fp16.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-dit-v2-0/model.fp16.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-dit-v2-0/model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-dit-v2-0/model_fp16.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/feature_extractor/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/image_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/image_encoder/model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/image_encoder/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/model_index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/text_encoder/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/tokenizer/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/tokenizer/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/unet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/unet/diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/unet/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/unet/modules.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/vae/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0-turbo/vae/diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/feature_extractor/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/model_index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/text_encoder/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/tokenizer/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/tokenizer/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/unet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/unet/diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/unet/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/unet/modules.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/vae/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/vae/diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-paint-v2-0/vae/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-vae-v2-0-turbo/config.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-vae-v2-0-turbo/model.fp16.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-vae-v2-0-turbo/model.fp16.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-vae-v2-0/config.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-vae-v2-0/model.fp16.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hunyuan3d-vae-v2-0/model.fp16.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [""tencent/Hunyuan3D-2"", ""tencent/Hunyuan3D-2mv"", ""tencent/Hunyuan3D-2mini-Turbo"", ""usenrame/mit-reality-hack-img-3d"", ""model2/advanceblur"", ""mubarak-alketbi/Hunyuan3D-2mini-Turbo"", ""Wkatir/Hunyuan3D-2"", ""mukaist/Hunyuan3D-2"", ""SharafeevRavil/test"", ""inoculatemedia/Hunyuan3D-2"", ""curryporkchop/TextTo3D_2.0"", ""Mahavaury2/consent_project"", ""Nymbo/Hunyuan3D-2"", ""ssbagpcm/Hunyuan3D-2"", ""MMD-Coder/Hunyuan3D-2.0"", ""davidvgilmore/hunyuan3d-custom"", ""davidvgilmore/hunyuan3d-lfs"", ""sizifart/siz3d"", ""NikoNovice/test2"", ""aimpowerment/Hunyuan3D-2"", ""rupert777/Hunyuan3D-2-cpu-test"", ""dawood/Hunyuan3D-2"", ""XtewaldX/Hunyuan3D-2"", ""sariyam/i-3d"", ""sariyam/t-3d"", ""Dhdb/Hunyuan3D-2"", ""syedMohib44/ditto-api"", ""DannyWoogagongtayafull/Hunyuan3D-2mini-Turbo"", ""mubarak-alketbi/Hunyuan3D-2"", ""icyleaf7/Hunyuan3D-2"", ""mohamedsobhi777/FramerComfy_basic11_8694404279"", ""mohamedsobhi777/FramerComfy_basic_2025_9272427525"", ""Rogerjs/Listto3d"", ""paceyai/Hunyuan3D-2mini-Turbo"", ""sasu1205/3d_tuning"", ""xinjjj/ImgRoboAssetGen"", ""shixiangbupt/Hunyuan3D-2"", ""VASANTHTHYU/Hunyuan3D-2"", ""mohamedsobhi777/FramerComfy_Basicflow_3191895845"", ""mohamedsobhi777/FramerComfy_FluxSchnell_9906338852"", ""millatmdd/Hunyuan3D-2_millat""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-10 14:55:56+00:00"", ""cardData"": ""language:\n- en\n- zh\nlibrary_name: hunyuan3d-2\nlicense: other\nlicense_name: tencent-hunyuan-community\nlicense_link: https://huggingface.co/tencent/Hunyuan3D-2/blob/main/LICENSE.txt\npipeline_tag: image-to-3d\ntags:\n- image-to-3d\n- text-to-3d"", ""transformersInfo"": null, ""_id"": ""678df3695dec6df8ec20e664"", ""modelId"": ""tencent/Hunyuan3D-2"", ""usedStorage"": 60813075231}",0,"https://huggingface.co/nomnom45465/Jane, https://huggingface.co/SergeySvichkar/TestModel, https://huggingface.co/Winrion/ebony, https://huggingface.co/everhard1/alpaca",4,,0,https://huggingface.co/calcuis/hy3d-gguf,1,,0,"SharafeevRavil/test, Wkatir/Hunyuan3D-2, huggingface/InferenceSupport/discussions/379, icyleaf7/Hunyuan3D-2, inoculatemedia/Hunyuan3D-2, model2/advanceblur, mohamedsobhi777/FramerComfy_basic11_8694404279, mohamedsobhi777/FramerComfy_basic_2025_9272427525, mubarak-alketbi/Hunyuan3D-2mini-Turbo, mukaist/Hunyuan3D-2, tencent/Hunyuan3D-2, tencent/Hunyuan3D-2mini-Turbo, tencent/Hunyuan3D-2mv",13
|
| 226 |
+
nomnom45465/Jane,"---
|
| 227 |
+
license: apache-2.0
|
| 228 |
+
datasets:
|
| 229 |
+
- bespokelabs/Bespoke-Stratos-17k
|
| 230 |
+
language:
|
| 231 |
+
- en
|
| 232 |
+
base_model:
|
| 233 |
+
- tencent/Hunyuan3D-2
|
| 234 |
+
new_version: tencent/Hunyuan3D-2
|
| 235 |
+
pipeline_tag: text-to-image
|
| 236 |
+
tags:
|
| 237 |
+
- not-for-all-audiences
|
| 238 |
+
---
|
| 239 |
+
# Model Card for Model ID
|
| 240 |
+
|
| 241 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 242 |
+
|
| 243 |
+
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
|
| 244 |
+
|
| 245 |
+
## Model Details
|
| 246 |
+
|
| 247 |
+
### Model Description
|
| 248 |
+
|
| 249 |
+
<!-- Provide a longer summary of what this model is. -->
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
- **Developed by:** [More Information Needed]
|
| 254 |
+
- **Funded by [optional]:** [More Information Needed]
|
| 255 |
+
- **Shared by [optional]:** [More Information Needed]
|
| 256 |
+
- **Model type:** [More Information Needed]
|
| 257 |
+
- **Language(s) (NLP):** [More Information Needed]
|
| 258 |
+
- **License:** [More Information Needed]
|
| 259 |
+
- **Finetuned from model [optional]:** [More Information Needed]
|
| 260 |
+
|
| 261 |
+
### Model Sources [optional]
|
| 262 |
+
|
| 263 |
+
<!-- Provide the basic links for the model. -->
|
| 264 |
+
|
| 265 |
+
- **Repository:** [More Information Needed]
|
| 266 |
+
- **Paper [optional]:** [More Information Needed]
|
| 267 |
+
- **Demo [optional]:** [More Information Needed]
|
| 268 |
+
|
| 269 |
+
## Uses
|
| 270 |
+
|
| 271 |
+
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
|
| 272 |
+
|
| 273 |
+
### Direct Use
|
| 274 |
+
|
| 275 |
+
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
|
| 276 |
+
|
| 277 |
+
[More Information Needed]
|
| 278 |
+
|
| 279 |
+
### Downstream Use [optional]
|
| 280 |
+
|
| 281 |
+
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
|
| 282 |
+
|
| 283 |
+
[More Information Needed]
|
| 284 |
+
|
| 285 |
+
### Out-of-Scope Use
|
| 286 |
+
|
| 287 |
+
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
|
| 288 |
+
|
| 289 |
+
[More Information Needed]
|
| 290 |
+
|
| 291 |
+
## Bias, Risks, and Limitations
|
| 292 |
+
|
| 293 |
+
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 294 |
+
|
| 295 |
+
[More Information Needed]
|
| 296 |
+
|
| 297 |
+
### Recommendations
|
| 298 |
+
|
| 299 |
+
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
|
| 300 |
+
|
| 301 |
+
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
|
| 302 |
+
|
| 303 |
+
## How to Get Started with the Model
|
| 304 |
+
|
| 305 |
+
Use the code below to get started with the model.
|
| 306 |
+
|
| 307 |
+
[More Information Needed]
|
| 308 |
+
|
| 309 |
+
## Training Details
|
| 310 |
+
|
| 311 |
+
### Training Data
|
| 312 |
+
|
| 313 |
+
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
|
| 314 |
+
|
| 315 |
+
[More Information Needed]
|
| 316 |
+
|
| 317 |
+
### Training Procedure
|
| 318 |
+
|
| 319 |
+
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
|
| 320 |
+
|
| 321 |
+
#### Preprocessing [optional]
|
| 322 |
+
|
| 323 |
+
[More Information Needed]
|
| 324 |
+
|
| 325 |
+
|
| 326 |
+
#### Training Hyperparameters
|
| 327 |
+
|
| 328 |
+
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 329 |
+
|
| 330 |
+
#### Speeds, Sizes, Times [optional]
|
| 331 |
+
|
| 332 |
+
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
|
| 333 |
+
|
| 334 |
+
[More Information Needed]
|
| 335 |
+
|
| 336 |
+
## Evaluation
|
| 337 |
+
|
| 338 |
+
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 339 |
+
|
| 340 |
+
### Testing Data, Factors & Metrics
|
| 341 |
+
|
| 342 |
+
#### Testing Data
|
| 343 |
+
|
| 344 |
+
<!-- This should link to a Dataset Card if possible. -->
|
| 345 |
+
|
| 346 |
+
[More Information Needed]
|
| 347 |
+
|
| 348 |
+
#### Factors
|
| 349 |
+
|
| 350 |
+
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 351 |
+
|
| 352 |
+
[More Information Needed]
|
| 353 |
+
|
| 354 |
+
#### Metrics
|
| 355 |
+
|
| 356 |
+
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 357 |
+
|
| 358 |
+
[More Information Needed]
|
| 359 |
+
|
| 360 |
+
### Results
|
| 361 |
+
|
| 362 |
+
[More Information Needed]
|
| 363 |
+
|
| 364 |
+
#### Summary
|
| 365 |
+
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
## Model Examination [optional]
|
| 369 |
+
|
| 370 |
+
<!-- Relevant interpretability work for the model goes here -->
|
| 371 |
+
|
| 372 |
+
[More Information Needed]
|
| 373 |
+
|
| 374 |
+
## Environmental Impact
|
| 375 |
+
|
| 376 |
+
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 377 |
+
|
| 378 |
+
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 379 |
+
|
| 380 |
+
- **Hardware Type:** [More Information Needed]
|
| 381 |
+
- **Hours used:** [More Information Needed]
|
| 382 |
+
- **Cloud Provider:** [More Information Needed]
|
| 383 |
+
- **Compute Region:** [More Information Needed]
|
| 384 |
+
- **Carbon Emitted:** [More Information Needed]
|
| 385 |
+
|
| 386 |
+
## Technical Specifications [optional]
|
| 387 |
+
|
| 388 |
+
### Model Architecture and Objective
|
| 389 |
+
|
| 390 |
+
[More Information Needed]
|
| 391 |
+
|
| 392 |
+
### Compute Infrastructure
|
| 393 |
+
|
| 394 |
+
[More Information Needed]
|
| 395 |
+
|
| 396 |
+
#### Hardware
|
| 397 |
+
|
| 398 |
+
[More Information Needed]
|
| 399 |
+
|
| 400 |
+
#### Software
|
| 401 |
+
|
| 402 |
+
[More Information Needed]
|
| 403 |
+
|
| 404 |
+
## Citation [optional]
|
| 405 |
+
|
| 406 |
+
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 407 |
+
|
| 408 |
+
**BibTeX:**
|
| 409 |
+
|
| 410 |
+
[More Information Needed]
|
| 411 |
+
|
| 412 |
+
**APA:**
|
| 413 |
+
|
| 414 |
+
[More Information Needed]
|
| 415 |
+
|
| 416 |
+
## Glossary [optional]
|
| 417 |
+
|
| 418 |
+
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
|
| 419 |
+
|
| 420 |
+
[More Information Needed]
|
| 421 |
+
|
| 422 |
+
## More Information [optional]
|
| 423 |
+
|
| 424 |
+
[More Information Needed]
|
| 425 |
+
|
| 426 |
+
## Model Card Authors [optional]
|
| 427 |
+
|
| 428 |
+
[More Information Needed]
|
| 429 |
+
|
| 430 |
+
## Model Card Contact
|
| 431 |
+
|
| 432 |
+
[More Information Needed]","{""id"": ""nomnom45465/Jane"", ""author"": ""nomnom45465"", ""sha"": ""84556b03709955c3e9d9d81c37ea077b1d6a9d4b"", ""last_modified"": ""2025-02-17 03:43:35+00:00"", ""created_at"": ""2025-02-17 03:41:58+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 1, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""not-for-all-audiences"", ""text-to-image"", ""en"", ""dataset:bespokelabs/Bespoke-Stratos-17k"", ""arxiv:1910.09700"", ""base_model:tencent/Hunyuan3D-2"", ""base_model:finetune:tencent/Hunyuan3D-2"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- tencent/Hunyuan3D-2\ndatasets:\n- bespokelabs/Bespoke-Stratos-17k\nlanguage:\n- en\nlicense: apache-2.0\npipeline_tag: text-to-image\ntags:\n- not-for-all-audiences\nnew_version: tencent/Hunyuan3D-2"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-17 03:43:35+00:00"", ""cardData"": ""base_model:\n- tencent/Hunyuan3D-2\ndatasets:\n- bespokelabs/Bespoke-Stratos-17k\nlanguage:\n- en\nlicense: apache-2.0\npipeline_tag: text-to-image\ntags:\n- not-for-all-audiences\nnew_version: tencent/Hunyuan3D-2"", ""transformersInfo"": null, ""_id"": ""67b2b0067e1d6634494ce627"", ""modelId"": ""nomnom45465/Jane"", ""usedStorage"": 0}",1,,0,,0,,0,,0,,0
|
| 433 |
+
SergeySvichkar/TestModel,"---
|
| 434 |
+
language:
|
| 435 |
+
- en
|
| 436 |
+
base_model:
|
| 437 |
+
- tencent/Hunyuan3D-2
|
| 438 |
+
---","{""id"": ""SergeySvichkar/TestModel"", ""author"": ""SergeySvichkar"", ""sha"": ""275d5c2e800c5f13d9fb198d1ebd6d901cca0c0f"", ""last_modified"": ""2025-01-27 00:57:02+00:00"", ""created_at"": ""2025-01-27 00:55:50+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""en"", ""base_model:tencent/Hunyuan3D-2"", ""base_model:finetune:tencent/Hunyuan3D-2"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- tencent/Hunyuan3D-2\nlanguage:\n- en"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-01-27 00:57:02+00:00"", ""cardData"": ""base_model:\n- tencent/Hunyuan3D-2\nlanguage:\n- en"", ""transformersInfo"": null, ""_id"": ""6796d996d4afc6fb1c8090f4"", ""modelId"": ""SergeySvichkar/TestModel"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=SergeySvichkar/TestModel&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BSergeySvichkar%2FTestModel%5D(%2FSergeySvichkar%2FTestModel)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 439 |
+
Winrion/ebony,"---
|
| 440 |
+
license: apache-2.0
|
| 441 |
+
base_model:
|
| 442 |
+
- tencent/Hunyuan3D-2
|
| 443 |
+
pipeline_tag: feature-extraction
|
| 444 |
+
---","{""id"": ""Winrion/ebony"", ""author"": ""Winrion"", ""sha"": ""52d0886a88bc459ecdba379f01971ea6b848e84a"", ""last_modified"": ""2025-02-05 05:12:33+00:00"", ""created_at"": ""2025-02-05 05:11:45+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""feature-extraction"", ""base_model:tencent/Hunyuan3D-2"", ""base_model:finetune:tencent/Hunyuan3D-2"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": ""feature-extraction"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- tencent/Hunyuan3D-2\nlicense: apache-2.0\npipeline_tag: feature-extraction"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-05 05:12:33+00:00"", ""cardData"": ""base_model:\n- tencent/Hunyuan3D-2\nlicense: apache-2.0\npipeline_tag: feature-extraction"", ""transformersInfo"": null, ""_id"": ""67a2f3114fdf4d91876c0fbe"", ""modelId"": ""Winrion/ebony"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Winrion/ebony&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BWinrion%2Febony%5D(%2FWinrion%2Febony)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 445 |
+
everhard1/alpaca,"---
|
| 446 |
+
license: apache-2.0
|
| 447 |
+
datasets:
|
| 448 |
+
- fka/awesome-chatgpt-prompts
|
| 449 |
+
language:
|
| 450 |
+
- en
|
| 451 |
+
metrics:
|
| 452 |
+
- accuracy
|
| 453 |
+
base_model:
|
| 454 |
+
- tencent/Hunyuan3D-2
|
| 455 |
+
new_version: deepseek-ai/DeepSeek-R1
|
| 456 |
+
library_name: flair
|
| 457 |
+
tags:
|
| 458 |
+
- art
|
| 459 |
+
---","{""id"": ""everhard1/alpaca"", ""author"": ""everhard1"", ""sha"": ""e54bd3b300ddecfca640fa003b17d07243b434ab"", ""last_modified"": ""2025-02-11 21:20:53+00:00"", ""created_at"": ""2025-02-11 21:19:57+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""flair"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""flair"", ""art"", ""en"", ""dataset:fka/awesome-chatgpt-prompts"", ""base_model:tencent/Hunyuan3D-2"", ""base_model:finetune:tencent/Hunyuan3D-2"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- tencent/Hunyuan3D-2\ndatasets:\n- fka/awesome-chatgpt-prompts\nlanguage:\n- en\nlibrary_name: flair\nlicense: apache-2.0\nmetrics:\n- accuracy\ntags:\n- art\nnew_version: deepseek-ai/DeepSeek-R1"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-11 21:20:53+00:00"", ""cardData"": ""base_model:\n- tencent/Hunyuan3D-2\ndatasets:\n- fka/awesome-chatgpt-prompts\nlanguage:\n- en\nlibrary_name: flair\nlicense: apache-2.0\nmetrics:\n- accuracy\ntags:\n- art\nnew_version: deepseek-ai/DeepSeek-R1"", ""transformersInfo"": null, ""_id"": ""67abbefdb8f6af16085abd42"", ""modelId"": ""everhard1/alpaca"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=everhard1/alpaca&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Beverhard1%2Falpaca%5D(%2Feverhard1%2Falpaca)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
Idefics3-8B-Llama3_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,607 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
HuggingFaceM4/Idefics3-8B-Llama3,"---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
datasets:
|
| 5 |
+
- HuggingFaceM4/OBELICS
|
| 6 |
+
- HuggingFaceM4/the_cauldron
|
| 7 |
+
- HuggingFaceM4/Docmatix
|
| 8 |
+
- HuggingFaceM4/WebSight
|
| 9 |
+
language:
|
| 10 |
+
- en
|
| 11 |
+
tags:
|
| 12 |
+
- multimodal
|
| 13 |
+
- vision
|
| 14 |
+
- image-text-to-text
|
| 15 |
+
library_name: transformers
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
<p align=""center"">
|
| 19 |
+
<img src=""https://huggingface.co/HuggingFaceM4/idefics-80b/resolve/main/assets/IDEFICS.png"" alt=""Idefics-Obelics logo"" width=""200"" height=""100"">
|
| 20 |
+
</p>
|
| 21 |
+
|
| 22 |
+
**Transformers version**: >4.46.
|
| 23 |
+
|
| 24 |
+
# Idefics3
|
| 25 |
+
|
| 26 |
+
Idefics3 is an open multimodal model that accepts arbitrary sequences of image and text inputs and produces text outputs. The model can answer questions about images, describe visual content, create stories grounded on multiple images, or simply behave as a pure language model without visual inputs. It improves upon [Idefics1](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct) and [Idefics2](https://huggingface.co/HuggingFaceM4/idefics2-8b), significantly enhancing capabilities around OCR, document understanding and visual reasoning.
|
| 27 |
+
|
| 28 |
+
We release the checkpoints under the Apache 2.0.
|
| 29 |
+
|
| 30 |
+
# Model Summary
|
| 31 |
+
|
| 32 |
+
- **Developed by:** Hugging Face
|
| 33 |
+
- **Model type:** Multi-modal model (image+text)
|
| 34 |
+
- **Language(s) (NLP):** en
|
| 35 |
+
- **License:** Apache 2.0
|
| 36 |
+
- **Parent Models:** [google/siglip-so400m-patch14-384](https://huggingface.co/google/siglip-so400m-patch14-384) and [meta-llama/Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct)
|
| 37 |
+
- **Resources for more information:**
|
| 38 |
+
- Idefics1 paper: [OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
|
| 39 |
+
](https://huggingface.co/papers/2306.16527)
|
| 40 |
+
- Idefics2 paper: [What matters when building vision-language models?
|
| 41 |
+
](https://huggingface.co/papers/2405.02246)
|
| 42 |
+
- Idefics3 paper: [Building and better understanding vision-language models: insights and future directions](https://huggingface.co/papers/2408.12637)
|
| 43 |
+
|
| 44 |
+
# Uses
|
| 45 |
+
|
| 46 |
+
`Idefics3-8B` can be used to perform inference on multimodal (image + text) tasks in which the input is composed of a text query along with one (or multiple) image(s). Text and images can be arbitrarily interleaved. That includes image captioning, visual question answering, etc. These model does not support image generation.
|
| 47 |
+
|
| 48 |
+
The post-training of Idefics3-8B involves only a supervised fine-tuning stage, without RLHF alignment. As a result, the model may produce short answers or require prompt iterations to fully address the user's request. Adding a prefix to the assistant's response, such as ""Let's fix this step by step"" has been found to effectively influence the generated output.
|
| 49 |
+
|
| 50 |
+
To fine-tune `Idefics3-8B` on a specific task, we provide a [fine-tuning tutorial](https://github.com/merveenoyan/smol-vision/blob/main/Idefics_FT.ipynb).
|
| 51 |
+
Other resources for the fine-tuning of Idefics2 (can easily be adapted to Idefics3):
|
| 52 |
+
- With the [TRL library](https://github.com/huggingface/trl): [Script](https://gist.github.com/edbeeching/228652fc6c2b29a1641be5a5778223cb)
|
| 53 |
+
- With the [Hugging Face Trainer](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#api-reference%20][%20transformers.Trainer): [Tutorial notebook](https://colab.research.google.com/drive/1NtcTgRbSBKN7pYD3Vdx1j9m8pt3fhFDB?usp=sharing)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
# Technical summary
|
| 57 |
+
|
| 58 |
+
Idefics3 demonstrates a great improvement over Idefics2, especially in document understanding tasks. It serves as a strong foundation for various use-case specific fine-tunings.
|
| 59 |
+
|
| 60 |
+
| Model | MMMU <br>(val) | MathVista <br>(test) | MMStar <br>(val) | DocVQA <br>(test) | TextVQA <br>(val) |
|
| 61 |
+
|:---------------:|:----------------:|:----------------------:|:-------------------:|:--------------------:|:-----------------:|
|
| 62 |
+
| **Idefics2-8B** | 45.2 | 52.2 | 49.5 | 74.0 | 73.0 |
|
| 63 |
+
| **Idefics3-8B** | 46.6 | 58.4 | 55.9 | 87.7 | 74.9 |
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
**Idefics3 introduces several changes compared to Idefics2:**
|
| 67 |
+
- We use 169 visual tokens to encode a image of size 364x364. Each image is divided into several sub images of sizes at most 364x364, which are then encoded separately.
|
| 68 |
+
- For the fine-tuning datasets, we have extended [The Cauldron](https://huggingface.co/datasets/HuggingFaceM4/the_cauldron) and added several datasets, including [Docmatix](HuggingFaceM4/Docmatix). We will push soon these datasets to the same repo of The Cauldron (TODO).
|
| 69 |
+
|
| 70 |
+
More details about the training of the model is available in our [technical report](https://huggingface.co/papers/2408.12637).
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
# How to Get Started
|
| 74 |
+
|
| 75 |
+
This section shows snippets of code for generation for `Idefics3-8B`.
|
| 76 |
+
|
| 77 |
+
```python
|
| 78 |
+
import requests
|
| 79 |
+
import torch
|
| 80 |
+
from PIL import Image
|
| 81 |
+
from io import BytesIO
|
| 82 |
+
|
| 83 |
+
from transformers import AutoProcessor, AutoModelForVision2Seq
|
| 84 |
+
from transformers.image_utils import load_image
|
| 85 |
+
|
| 86 |
+
DEVICE = ""cuda:0""
|
| 87 |
+
|
| 88 |
+
# Note that passing the image urls (instead of the actual pil images) to the processor is also possible
|
| 89 |
+
image1 = load_image(""https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"")
|
| 90 |
+
image2 = load_image(""https://cdn.britannica.com/59/94459-050-DBA42467/Skyline-Chicago.jpg"")
|
| 91 |
+
image3 = load_image(""https://cdn.britannica.com/68/170868-050-8DDE8263/Golden-Gate-Bridge-San-Francisco.jpg"")
|
| 92 |
+
|
| 93 |
+
processor = AutoProcessor.from_pretrained(""HuggingFaceM4/Idefics3-8B-Llama3"")
|
| 94 |
+
model = AutoModelForVision2Seq.from_pretrained(
|
| 95 |
+
""HuggingFaceM4/Idefics3-8B-Llama3"", torch_dtype=torch.bfloat16
|
| 96 |
+
).to(DEVICE)
|
| 97 |
+
|
| 98 |
+
# Create inputs
|
| 99 |
+
messages = [
|
| 100 |
+
{
|
| 101 |
+
""role"": ""user"",
|
| 102 |
+
""content"": [
|
| 103 |
+
{""type"": ""image""},
|
| 104 |
+
{""type"": ""text"", ""text"": ""What do we see in this image?""},
|
| 105 |
+
]
|
| 106 |
+
},
|
| 107 |
+
{
|
| 108 |
+
""role"": ""assistant"",
|
| 109 |
+
""content"": [
|
| 110 |
+
{""type"": ""text"", ""text"": ""In this image, we can see the city of New York, and more specifically the Statue of Liberty.""},
|
| 111 |
+
]
|
| 112 |
+
},
|
| 113 |
+
{
|
| 114 |
+
""role"": ""user"",
|
| 115 |
+
""content"": [
|
| 116 |
+
{""type"": ""image""},
|
| 117 |
+
{""type"": ""text"", ""text"": ""And how about this image?""},
|
| 118 |
+
]
|
| 119 |
+
},
|
| 120 |
+
]
|
| 121 |
+
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
|
| 122 |
+
inputs = processor(text=prompt, images=[image1, image2], return_tensors=""pt"")
|
| 123 |
+
inputs = {k: v.to(DEVICE) for k, v in inputs.items()}
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
# Generate
|
| 127 |
+
generated_ids = model.generate(**inputs, max_new_tokens=500)
|
| 128 |
+
generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True)
|
| 129 |
+
|
| 130 |
+
print(generated_texts)
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
</details>
|
| 134 |
+
|
| 135 |
+
**Text generation inference**
|
| 136 |
+
|
| 137 |
+
TODO.
|
| 138 |
+
|
| 139 |
+
# Model optimizations
|
| 140 |
+
|
| 141 |
+
If your GPU allows, we first recommend loading (and running inference) in half precision (`torch.float16` or `torch.bfloat16`).
|
| 142 |
+
|
| 143 |
+
```diff
|
| 144 |
+
model = AutoModelForVision2Seq.from_pretrained(
|
| 145 |
+
""HuggingFaceM4/Idefics3-8B-Llama3"",
|
| 146 |
+
+ torch_dtype=torch.bfloat16,
|
| 147 |
+
).to(DEVICE)
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
**Vision encoder efficiency**
|
| 151 |
+
|
| 152 |
+
You can choose the default resolution the images will be rescaled to by adding `size= {""longest_edge"": N*364}` when initializing the processor (`AutoProcessor.from_pretrained`), with `N` your desired value.
|
| 153 |
+
`N=4` works best in practice (this is the default value), but for very large images, it could be interesting to pass `N=5`.
|
| 154 |
+
This will have an impact on the number of visual tokens passed to the language model.
|
| 155 |
+
If you are GPU-memory-constrained, you can decrease `N`, and choose for example `N=3` or `N=2`, especially for low resolution images.
|
| 156 |
+
|
| 157 |
+
**Using Flash-attention 2 to speed up generation**
|
| 158 |
+
|
| 159 |
+
<details><summary>Click to expand.</summary>
|
| 160 |
+
|
| 161 |
+
First, make sure to install `flash-attn`. Refer to the [original repository of Flash Attention](https://github.com/Dao-AILab/flash-attention) for the package installation. Simply change the snippet above with:
|
| 162 |
+
|
| 163 |
+
```diff
|
| 164 |
+
model = AutoModelForVision2Seq.from_pretrained(
|
| 165 |
+
""HuggingFaceM4/Idefics3-8B-Llama3"",
|
| 166 |
+
+ torch_dtype=torch.bfloat16,
|
| 167 |
+
+ _attn_implementation=""flash_attention_2"",
|
| 168 |
+
).to(DEVICE)
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
</details>
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
# Misuse and Out-of-scope use
|
| 175 |
+
|
| 176 |
+
Using the model in [high-stakes](https://huggingface.co/bigscience/bloom/blob/main/README.md#glossary-and-calculations) settings is out of scope for this model. The model is not designed for [critical decisions](https://huggingface.co/bigscience/bloom/blob/main/README.md#glossary-and-calculations) nor uses with any material consequences on an individual's livelihood or wellbeing. The model outputs content that appears factual but may not be correct. Out-of-scope uses include:
|
| 177 |
+
- Usage for evaluating or scoring individuals, such as for employment, education, or credit
|
| 178 |
+
- Applying the model for critical automatic decisions, generating factual content, creating reliable summaries, or generating predictions that must be correct
|
| 179 |
+
|
| 180 |
+
Intentionally using the model for harm, violating [human rights](https://huggingface.co/bigscience/bloom/blob/main/README.md#glossary-and-calculations), or other kinds of malicious activities, is a misuse of this model. This includes:
|
| 181 |
+
- Spam generation
|
| 182 |
+
- Disinformation and influence operations
|
| 183 |
+
- Disparagement and defamation
|
| 184 |
+
- Harassment and abuse
|
| 185 |
+
- [Deception](https://huggingface.co/bigscience/bloom/blob/main/README.md#glossary-and-calculations)
|
| 186 |
+
- Unconsented impersonation and imitation
|
| 187 |
+
- Unconsented surveillance
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
# License
|
| 191 |
+
|
| 192 |
+
The model is built on top of two pre-trained models: [google/siglip-so400m-patch14-384](https://huggingface.co/google/siglip-so400m-patch14-384) and [meta-llama/Meta-Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct). We release the Idefics3 checkpoints under the Apache 2.0 license.
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
# Citation
|
| 196 |
+
|
| 197 |
+
**BibTeX:**
|
| 198 |
+
|
| 199 |
+
```bibtex
|
| 200 |
+
@misc{laurençon2024building,
|
| 201 |
+
title={Building and better understanding vision-language models: insights and future directions.},
|
| 202 |
+
author={Hugo Laurençon and Andrés Marafioti and Victor Sanh and Léo Tronchon},
|
| 203 |
+
year={2024},
|
| 204 |
+
eprint={2408.12637},
|
| 205 |
+
archivePrefix={arXiv},
|
| 206 |
+
primaryClass={cs.CV}
|
| 207 |
+
}
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
# Acknowledgements
|
| 212 |
+
|
| 213 |
+
We thank @andito and @amyeroberts for helping on the integration in Transformers.","{""id"": ""HuggingFaceM4/Idefics3-8B-Llama3"", ""author"": ""HuggingFaceM4"", ""sha"": ""fddb4ff79181e55a994674777e06cd5456ce3dc3"", ""last_modified"": ""2024-12-02 09:35:34+00:00"", ""created_at"": ""2024-08-05 16:12:33+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 47806, ""downloads_all_time"": null, ""likes"": 276, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""idefics3"", ""image-text-to-text"", ""multimodal"", ""vision"", ""conversational"", ""en"", ""dataset:HuggingFaceM4/OBELICS"", ""dataset:HuggingFaceM4/the_cauldron"", ""dataset:HuggingFaceM4/Docmatix"", ""dataset:HuggingFaceM4/WebSight"", ""arxiv:2306.16527"", ""arxiv:2405.02246"", ""arxiv:2408.12637"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""image-text-to-text"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""datasets:\n- HuggingFaceM4/OBELICS\n- HuggingFaceM4/the_cauldron\n- HuggingFaceM4/Docmatix\n- HuggingFaceM4/WebSight\nlanguage:\n- en\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- multimodal\n- vision\n- image-text-to-text"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""Idefics3ForConditionalGeneration""], ""model_type"": ""idefics3"", ""processor_config"": {""chat_template"": ""<|begin_of_text|>{% for message in messages %}{{message['role'].capitalize()}}{% if message['content'][0]['type'] == 'image' %}{{':'}}{% else %}{{': '}}{% endif %}{% for line in message['content'] %}{% if line['type'] == 'text' %}{{line['text']}}{% elif line['type'] == 'image' %}{{ '<image>' }}{% endif %}{% endfor %}<end_of_utterance>\n{% endfor %}{% if add_generation_prompt %}{{ 'Assistant:' }}{% endif %}""}, ""tokenizer_config"": {""bos_token"": ""<|begin_of_text|>"", ""chat_template"": ""{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}"", ""eos_token"": ""<|end_of_text|>"", ""pad_token"": ""<|reserved_special_token_0|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoProcessor""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chat_template.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""HuggingFaceM4/idefics3"", ""TIGER-Lab/MEGA-Bench"", ""eltorio/IDEFICS3_ROCO"", ""AdrienB134/rag_colpali_idefics3"", ""hexgrad/IDEFICS3_ROCO_ZeroGPU"", ""arad1367/Marketing_Vision_HuggingFaceM4_idefics3"", ""acecalisto3/IDEfix"", ""d-delaurier/Judge-vLLM"", ""emoud/IDEFICS3_ROCO"", ""mcouaillac/IDEFICS3_ROCO_ZeroGPU"", ""awacke1/Leaderboard-Deepseek-Gemini-Grok-GPT-Qwen"", ""Zaherrr/KG_transform"", ""jkorstad/idefics3"", ""fatima3597/AI-Podcast-Creator"", ""jlecocq/radiology-test"", ""cmaire/IDEFICS3_ROCO_ZeroGPU"", ""cmaire/IDEFICS3_ROCO""], ""safetensors"": {""parameters"": {""BF16"": 8462086384}, ""total"": 8462086384}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-12-02 09:35:34+00:00"", ""cardData"": ""datasets:\n- HuggingFaceM4/OBELICS\n- HuggingFaceM4/the_cauldron\n- HuggingFaceM4/Docmatix\n- HuggingFaceM4/WebSight\nlanguage:\n- en\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- multimodal\n- vision\n- image-text-to-text"", ""transformersInfo"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoProcessor""}, ""_id"": ""66b0f9f15cb4654fd1d665bf"", ""modelId"": ""HuggingFaceM4/Idefics3-8B-Llama3"", ""usedStorage"": 16924267272}",0,"https://huggingface.co/Minthy/ToriiGate-v0.3, https://huggingface.co/nectec/Pathumma-llm-vision-1.0.0, https://huggingface.co/Mantis-VL/mantis-8b-idefics3_16384, https://huggingface.co/Mantis-VL/mantis-8b-idefics3-pure_16384, https://huggingface.co/Leeyuyu/idefics3-llama-thyroid, https://huggingface.co/Clark12/POS1, https://huggingface.co/Minthy/Torii_Gate_v0.1_alpha, https://huggingface.co/slezki/assistant_mage, https://huggingface.co/Minthy/ToriiGate-v0.2",9,"https://huggingface.co/eltorio/IDEFICS3_ROCOv2, https://huggingface.co/joris-sense/idefics3-llama-vqav2, https://huggingface.co/fsommers/idefics3-llama-vqav2_1, https://huggingface.co/Maverick17/idefics3-llama-gui-dense-descriptions, https://huggingface.co/justinkarlin/idefics3-llama-vqav2, https://huggingface.co/justinkarlin/idefics3-qlora-faces, https://huggingface.co/justinkarlin/idefics3-qlora-faces2, https://huggingface.co/justinkarlin/idefics3-qlora-faces3, https://huggingface.co/justinkarlin/idefics3-qlora-faces4, https://huggingface.co/Erland/idefics3-llama-ai701, https://huggingface.co/eltorio/IDEFICS3_ROCO, https://huggingface.co/eltorio/IDEFICS3_medical_instruct, https://huggingface.co/justinkarlin/idefics3-qlora-faces5, https://huggingface.co/justinkarlin/idefics3-qlora-faces6, https://huggingface.co/kurama270296/qlora-idefics3-test, https://huggingface.co/Tchalla12/idefics3-8b-qlora",16,"https://huggingface.co/2dameneko/Idefics3-8B-Llama3-nf4, https://huggingface.co/leon-se/Idefics3-8B-Llama3-bnb_nf4, https://huggingface.co/leon-se/Idefics3-8B-Llama3-FP8-Dynamic",3,,0,"AdrienB134/rag_colpali_idefics3, HuggingFaceM4/idefics3, TIGER-Lab/MEGA-Bench, acecalisto3/IDEfix, arad1367/Marketing_Vision_HuggingFaceM4_idefics3, awacke1/Leaderboard-Deepseek-Gemini-Grok-GPT-Qwen, d-delaurier/Judge-vLLM, eltorio/IDEFICS3_ROCO, emoud/IDEFICS3_ROCO, hexgrad/IDEFICS3_ROCO_ZeroGPU, huggingface/InferenceSupport/discussions/new?title=HuggingFaceM4/Idefics3-8B-Llama3&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BHuggingFaceM4%2FIdefics3-8B-Llama3%5D(%2FHuggingFaceM4%2FIdefics3-8B-Llama3)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, jkorstad/idefics3, mcouaillac/IDEFICS3_ROCO_ZeroGPU",13
|
| 214 |
+
https://huggingface.co/Minthy/ToriiGate-v0.3,N/A,N/A,1,,0,,0,,0,,0,,0
|
| 215 |
+
https://huggingface.co/nectec/Pathumma-llm-vision-1.0.0,N/A,N/A,1,,0,,0,,0,,0,,0
|
| 216 |
+
Mantis-VL/mantis-8b-idefics3_16384,"---
|
| 217 |
+
library_name: transformers
|
| 218 |
+
license: apache-2.0
|
| 219 |
+
base_model: HuggingFaceM4/Idefics3-8B-Llama3
|
| 220 |
+
tags:
|
| 221 |
+
- generated_from_trainer
|
| 222 |
+
model-index:
|
| 223 |
+
- name: mantis-8b-idefics3_16384
|
| 224 |
+
results: []
|
| 225 |
+
---
|
| 226 |
+
|
| 227 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 228 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 229 |
+
|
| 230 |
+
# mantis-8b-idefics3_16384
|
| 231 |
+
|
| 232 |
+
This model is a fine-tuned version of [HuggingFaceM4/Idefics3-8B-Llama3](https://huggingface.co/HuggingFaceM4/Idefics3-8B-Llama3) on an unknown dataset.
|
| 233 |
+
|
| 234 |
+
## Model description
|
| 235 |
+
|
| 236 |
+
More information needed
|
| 237 |
+
|
| 238 |
+
## Intended uses & limitations
|
| 239 |
+
|
| 240 |
+
More information needed
|
| 241 |
+
|
| 242 |
+
## Training and evaluation data
|
| 243 |
+
|
| 244 |
+
More information needed
|
| 245 |
+
|
| 246 |
+
## Training procedure
|
| 247 |
+
|
| 248 |
+
### Training hyperparameters
|
| 249 |
+
|
| 250 |
+
The following hyperparameters were used during training:
|
| 251 |
+
- learning_rate: 5e-06
|
| 252 |
+
- train_batch_size: 1
|
| 253 |
+
- eval_batch_size: 1
|
| 254 |
+
- seed: 42
|
| 255 |
+
- distributed_type: multi-GPU
|
| 256 |
+
- num_devices: 16
|
| 257 |
+
- gradient_accumulation_steps: 8
|
| 258 |
+
- total_train_batch_size: 128
|
| 259 |
+
- total_eval_batch_size: 16
|
| 260 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 261 |
+
- lr_scheduler_type: cosine
|
| 262 |
+
- lr_scheduler_warmup_ratio: 0.03
|
| 263 |
+
- num_epochs: 1.0
|
| 264 |
+
|
| 265 |
+
### Training results
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
|
| 269 |
+
### Framework versions
|
| 270 |
+
|
| 271 |
+
- Transformers 4.45.0.dev0
|
| 272 |
+
- Pytorch 2.3.0+cu121
|
| 273 |
+
- Datasets 2.18.0
|
| 274 |
+
- Tokenizers 0.19.1
|
| 275 |
+
","{""id"": ""Mantis-VL/mantis-8b-idefics3_16384"", ""author"": ""Mantis-VL"", ""sha"": ""ca959abe0d86e62ac272619aea4e49b57fbe7ad0"", ""last_modified"": ""2024-09-03 21:57:21+00:00"", ""created_at"": ""2024-09-02 09:40:24+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 2, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""idefics3"", ""image-text-to-text"", ""generated_from_trainer"", ""conversational"", ""base_model:HuggingFaceM4/Idefics3-8B-Llama3"", ""base_model:finetune:HuggingFaceM4/Idefics3-8B-Llama3"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""image-text-to-text"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: HuggingFaceM4/Idefics3-8B-Llama3\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: mantis-8b-idefics3_16384\n results: []"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": [{""name"": ""mantis-8b-idefics3_16384"", ""results"": []}], ""config"": {""architectures"": [""Idefics3ForConditionalGeneration""], ""model_type"": ""idefics3"", ""processor_config"": {""chat_template"": ""<|begin_of_text|>{% for message in messages %}{{message['role'].capitalize()}}{% if message['content'][0]['type'] == 'image' %}{{':'}}{% else %}{{': '}}{% endif %}{% for line in message['content'] %}{% if line['type'] == 'text' %}{{line['text']}}{% elif line['type'] == 'image' %}{{ '<image>' }}{% endif %}{% endfor %}<end_of_utterance>\n{% endfor %}{% if add_generation_prompt %}{{ 'Assistant:' }}{% endif %}""}, ""tokenizer_config"": {""bos_token"": ""<|begin_of_text|>"", ""chat_template"": ""{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}"", ""eos_token"": ""<|end_of_text|>"", ""pad_token"": ""<|reserved_special_token_0|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoProcessor""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chat_template.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""BF16"": 8462086384}, ""total"": 8462086384}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-09-03 21:57:21+00:00"", ""cardData"": ""base_model: HuggingFaceM4/Idefics3-8B-Llama3\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: mantis-8b-idefics3_16384\n results: []"", ""transformersInfo"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoProcessor""}, ""_id"": ""66d588088a438492b0d0c548"", ""modelId"": ""Mantis-VL/mantis-8b-idefics3_16384"", ""usedStorage"": 226940140648}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Mantis-VL/mantis-8b-idefics3_16384&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BMantis-VL%2Fmantis-8b-idefics3_16384%5D(%2FMantis-VL%2Fmantis-8b-idefics3_16384)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 276 |
+
Mantis-VL/mantis-8b-idefics3-pure_16384,"---
|
| 277 |
+
library_name: transformers
|
| 278 |
+
license: apache-2.0
|
| 279 |
+
base_model: HuggingFaceM4/Idefics3-8B-Llama3
|
| 280 |
+
tags:
|
| 281 |
+
- generated_from_trainer
|
| 282 |
+
model-index:
|
| 283 |
+
- name: mantis-8b-idefics3-pure_16384
|
| 284 |
+
results: []
|
| 285 |
+
---
|
| 286 |
+
|
| 287 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 288 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 289 |
+
|
| 290 |
+
# mantis-8b-idefics3-pure_16384
|
| 291 |
+
|
| 292 |
+
This model is a fine-tuned version of [HuggingFaceM4/Idefics3-8B-Llama3](https://huggingface.co/HuggingFaceM4/Idefics3-8B-Llama3) on an unknown dataset.
|
| 293 |
+
|
| 294 |
+
## Model description
|
| 295 |
+
|
| 296 |
+
More information needed
|
| 297 |
+
|
| 298 |
+
## Intended uses & limitations
|
| 299 |
+
|
| 300 |
+
More information needed
|
| 301 |
+
|
| 302 |
+
## Training and evaluation data
|
| 303 |
+
|
| 304 |
+
More information needed
|
| 305 |
+
|
| 306 |
+
## Training procedure
|
| 307 |
+
|
| 308 |
+
### Training hyperparameters
|
| 309 |
+
|
| 310 |
+
The following hyperparameters were used during training:
|
| 311 |
+
- learning_rate: 5e-06
|
| 312 |
+
- train_batch_size: 1
|
| 313 |
+
- eval_batch_size: 1
|
| 314 |
+
- seed: 42
|
| 315 |
+
- distributed_type: multi-GPU
|
| 316 |
+
- num_devices: 16
|
| 317 |
+
- gradient_accumulation_steps: 8
|
| 318 |
+
- total_train_batch_size: 128
|
| 319 |
+
- total_eval_batch_size: 16
|
| 320 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 321 |
+
- lr_scheduler_type: cosine
|
| 322 |
+
- lr_scheduler_warmup_ratio: 0.03
|
| 323 |
+
- num_epochs: 1.0
|
| 324 |
+
|
| 325 |
+
### Training results
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
### Framework versions
|
| 330 |
+
|
| 331 |
+
- Transformers 4.45.0.dev0
|
| 332 |
+
- Pytorch 2.3.0+cu121
|
| 333 |
+
- Datasets 2.18.0
|
| 334 |
+
- Tokenizers 0.19.1
|
| 335 |
+
","{""id"": ""Mantis-VL/mantis-8b-idefics3-pure_16384"", ""author"": ""Mantis-VL"", ""sha"": ""9d58e6dfccbf1f8cce51167119ff3a9d9f124b82"", ""last_modified"": ""2024-09-05 15:51:19+00:00"", ""created_at"": ""2024-09-04 10:01:16+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 2, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""idefics3"", ""image-text-to-text"", ""generated_from_trainer"", ""conversational"", ""base_model:HuggingFaceM4/Idefics3-8B-Llama3"", ""base_model:finetune:HuggingFaceM4/Idefics3-8B-Llama3"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""image-text-to-text"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: HuggingFaceM4/Idefics3-8B-Llama3\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: mantis-8b-idefics3-pure_16384\n results: []"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": [{""name"": ""mantis-8b-idefics3-pure_16384"", ""results"": []}], ""config"": {""architectures"": [""Idefics3ForConditionalGeneration""], ""model_type"": ""idefics3"", ""processor_config"": {""chat_template"": ""<|begin_of_text|>{% for message in messages %}{{message['role'].capitalize()}}{% if message['content'][0]['type'] == 'image' %}{{':'}}{% else %}{{': '}}{% endif %}{% for line in message['content'] %}{% if line['type'] == 'text' %}{{line['text']}}{% elif line['type'] == 'image' %}{{ '<image>' }}{% endif %}{% endfor %}<end_of_utterance>\n{% endfor %}{% if add_generation_prompt %}{{ 'Assistant:' }}{% endif %}""}, ""tokenizer_config"": {""bos_token"": ""<|begin_of_text|>"", ""chat_template"": ""{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}"", ""eos_token"": ""<|end_of_text|>"", ""pad_token"": ""<|reserved_special_token_0|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoProcessor""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chat_template.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""BF16"": 8462086384}, ""total"": 8462086384}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-09-05 15:51:19+00:00"", ""cardData"": ""base_model: HuggingFaceM4/Idefics3-8B-Llama3\nlibrary_name: transformers\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: mantis-8b-idefics3-pure_16384\n results: []"", ""transformersInfo"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoProcessor""}, ""_id"": ""66d82fec38b749dea1e9cc07"", ""modelId"": ""Mantis-VL/mantis-8b-idefics3-pure_16384"", ""usedStorage"": 203091213784}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Mantis-VL/mantis-8b-idefics3-pure_16384&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BMantis-VL%2Fmantis-8b-idefics3-pure_16384%5D(%2FMantis-VL%2Fmantis-8b-idefics3-pure_16384)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 336 |
+
Leeyuyu/idefics3-llama-thyroid,"---
|
| 337 |
+
license: apache-2.0
|
| 338 |
+
base_model: HuggingFaceM4/Idefics3-8B-Llama3
|
| 339 |
+
tags:
|
| 340 |
+
- generated_from_trainer
|
| 341 |
+
model-index:
|
| 342 |
+
- name: idefics3-llama-thyroid
|
| 343 |
+
results: []
|
| 344 |
+
---
|
| 345 |
+
|
| 346 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 347 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 348 |
+
|
| 349 |
+
# idefics3-llama-thyroid
|
| 350 |
+
|
| 351 |
+
This model is a fine-tuned version of [HuggingFaceM4/Idefics3-8B-Llama3](https://huggingface.co/HuggingFaceM4/Idefics3-8B-Llama3) on an unknown dataset.
|
| 352 |
+
|
| 353 |
+
## Model description
|
| 354 |
+
|
| 355 |
+
More information needed
|
| 356 |
+
|
| 357 |
+
## Intended uses & limitations
|
| 358 |
+
|
| 359 |
+
More information needed
|
| 360 |
+
|
| 361 |
+
## Training and evaluation data
|
| 362 |
+
|
| 363 |
+
More information needed
|
| 364 |
+
|
| 365 |
+
## Training procedure
|
| 366 |
+
|
| 367 |
+
### Training hyperparameters
|
| 368 |
+
|
| 369 |
+
The following hyperparameters were used during training:
|
| 370 |
+
- learning_rate: 0.0001
|
| 371 |
+
- train_batch_size: 1
|
| 372 |
+
- eval_batch_size: 8
|
| 373 |
+
- seed: 42
|
| 374 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 375 |
+
- lr_scheduler_type: linear
|
| 376 |
+
- lr_scheduler_warmup_steps: 50
|
| 377 |
+
- num_epochs: 3
|
| 378 |
+
|
| 379 |
+
### Training results
|
| 380 |
+
|
| 381 |
+
|
| 382 |
+
|
| 383 |
+
### Framework versions
|
| 384 |
+
|
| 385 |
+
- Transformers 4.44.0.dev0
|
| 386 |
+
- Pytorch 2.1.0+cu118
|
| 387 |
+
- Datasets 2.21.0
|
| 388 |
+
- Tokenizers 0.19.1
|
| 389 |
+
","{""id"": ""Leeyuyu/idefics3-llama-thyroid"", ""author"": ""Leeyuyu"", ""sha"": ""07c57799e684b04d136b7bef64820ae89696c60a"", ""last_modified"": ""2024-09-09 02:21:46+00:00"", ""created_at"": ""2024-09-09 02:21:42+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""safetensors"", ""generated_from_trainer"", ""base_model:HuggingFaceM4/Idefics3-8B-Llama3"", ""base_model:finetune:HuggingFaceM4/Idefics3-8B-Llama3"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: HuggingFaceM4/Idefics3-8B-Llama3\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: idefics3-llama-thyroid\n results: []"", ""widget_data"": null, ""model_index"": [{""name"": ""idefics3-llama-thyroid"", ""results"": []}], ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-09-09 02:21:46+00:00"", ""cardData"": ""base_model: HuggingFaceM4/Idefics3-8B-Llama3\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: idefics3-llama-thyroid\n results: []"", ""transformersInfo"": null, ""_id"": ""66de5bb6b4d4e7827a332a05"", ""modelId"": ""Leeyuyu/idefics3-llama-thyroid"", ""usedStorage"": 83955400}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Leeyuyu/idefics3-llama-thyroid&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BLeeyuyu%2Fidefics3-llama-thyroid%5D(%2FLeeyuyu%2Fidefics3-llama-thyroid)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 390 |
+
Clark12/POS1,"---
|
| 391 |
+
license: mit
|
| 392 |
+
datasets:
|
| 393 |
+
- fka/awesome-chatgpt-prompts
|
| 394 |
+
language:
|
| 395 |
+
- en
|
| 396 |
+
metrics:
|
| 397 |
+
- accuracy
|
| 398 |
+
pipeline_tag: question-answering
|
| 399 |
+
tags:
|
| 400 |
+
- finance
|
| 401 |
+
base_model:
|
| 402 |
+
- HuggingFaceM4/Idefics3-8B-Llama3
|
| 403 |
+
---
|
| 404 |
+
# Model Card for Model ID
|
| 405 |
+
|
| 406 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 407 |
+
|
| 408 |
+
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
|
| 409 |
+
|
| 410 |
+
## Model Details
|
| 411 |
+
|
| 412 |
+
### Model Description
|
| 413 |
+
|
| 414 |
+
<!-- Provide a longer summary of what this model is. -->
|
| 415 |
+
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
- **Developed by:** [More Information Needed]
|
| 419 |
+
- **Funded by [optional]:** [More Information Needed]
|
| 420 |
+
- **Shared by [optional]:** [More Information Needed]
|
| 421 |
+
- **Model type:** [More Information Needed]
|
| 422 |
+
- **Language(s) (NLP):** [More Information Needed]
|
| 423 |
+
- **License:** [More Information Needed]
|
| 424 |
+
- **Finetuned from model [optional]:** [More Information Needed]
|
| 425 |
+
|
| 426 |
+
### Model Sources [optional]
|
| 427 |
+
|
| 428 |
+
<!-- Provide the basic links for the model. -->
|
| 429 |
+
|
| 430 |
+
- **Repository:** [More Information Needed]
|
| 431 |
+
- **Paper [optional]:** [More Information Needed]
|
| 432 |
+
- **Demo [optional]:** [More Information Needed]
|
| 433 |
+
|
| 434 |
+
## Uses
|
| 435 |
+
|
| 436 |
+
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
|
| 437 |
+
|
| 438 |
+
### Direct Use
|
| 439 |
+
|
| 440 |
+
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
|
| 441 |
+
|
| 442 |
+
[More Information Needed]
|
| 443 |
+
|
| 444 |
+
### Downstream Use [optional]
|
| 445 |
+
|
| 446 |
+
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
|
| 447 |
+
|
| 448 |
+
[More Information Needed]
|
| 449 |
+
|
| 450 |
+
### Out-of-Scope Use
|
| 451 |
+
|
| 452 |
+
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
|
| 453 |
+
|
| 454 |
+
[More Information Needed]
|
| 455 |
+
|
| 456 |
+
## Bias, Risks, and Limitations
|
| 457 |
+
|
| 458 |
+
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 459 |
+
|
| 460 |
+
[More Information Needed]
|
| 461 |
+
|
| 462 |
+
### Recommendations
|
| 463 |
+
|
| 464 |
+
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
|
| 465 |
+
|
| 466 |
+
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
|
| 467 |
+
|
| 468 |
+
## How to Get Started with the Model
|
| 469 |
+
|
| 470 |
+
Use the code below to get started with the model.
|
| 471 |
+
|
| 472 |
+
[More Information Needed]
|
| 473 |
+
|
| 474 |
+
## Training Details
|
| 475 |
+
|
| 476 |
+
### Training Data
|
| 477 |
+
|
| 478 |
+
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
|
| 479 |
+
|
| 480 |
+
[More Information Needed]
|
| 481 |
+
|
| 482 |
+
### Training Procedure
|
| 483 |
+
|
| 484 |
+
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
|
| 485 |
+
|
| 486 |
+
#### Preprocessing [optional]
|
| 487 |
+
|
| 488 |
+
[More Information Needed]
|
| 489 |
+
|
| 490 |
+
|
| 491 |
+
#### Training Hyperparameters
|
| 492 |
+
|
| 493 |
+
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 494 |
+
|
| 495 |
+
#### Speeds, Sizes, Times [optional]
|
| 496 |
+
|
| 497 |
+
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
|
| 498 |
+
|
| 499 |
+
[More Information Needed]
|
| 500 |
+
|
| 501 |
+
## Evaluation
|
| 502 |
+
|
| 503 |
+
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 504 |
+
|
| 505 |
+
### Testing Data, Factors & Metrics
|
| 506 |
+
|
| 507 |
+
#### Testing Data
|
| 508 |
+
|
| 509 |
+
<!-- This should link to a Dataset Card if possible. -->
|
| 510 |
+
|
| 511 |
+
[More Information Needed]
|
| 512 |
+
|
| 513 |
+
#### Factors
|
| 514 |
+
|
| 515 |
+
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 516 |
+
|
| 517 |
+
[More Information Needed]
|
| 518 |
+
|
| 519 |
+
#### Metrics
|
| 520 |
+
|
| 521 |
+
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 522 |
+
|
| 523 |
+
[More Information Needed]
|
| 524 |
+
|
| 525 |
+
### Results
|
| 526 |
+
|
| 527 |
+
[More Information Needed]
|
| 528 |
+
|
| 529 |
+
#### Summary
|
| 530 |
+
|
| 531 |
+
|
| 532 |
+
|
| 533 |
+
## Model Examination [optional]
|
| 534 |
+
|
| 535 |
+
<!-- Relevant interpretability work for the model goes here -->
|
| 536 |
+
|
| 537 |
+
[More Information Needed]
|
| 538 |
+
|
| 539 |
+
## Environmental Impact
|
| 540 |
+
|
| 541 |
+
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 542 |
+
|
| 543 |
+
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 544 |
+
|
| 545 |
+
- **Hardware Type:** [More Information Needed]
|
| 546 |
+
- **Hours used:** [More Information Needed]
|
| 547 |
+
- **Cloud Provider:** [More Information Needed]
|
| 548 |
+
- **Compute Region:** [More Information Needed]
|
| 549 |
+
- **Carbon Emitted:** [More Information Needed]
|
| 550 |
+
|
| 551 |
+
## Technical Specifications [optional]
|
| 552 |
+
|
| 553 |
+
### Model Architecture and Objective
|
| 554 |
+
|
| 555 |
+
[More Information Needed]
|
| 556 |
+
|
| 557 |
+
### Compute Infrastructure
|
| 558 |
+
|
| 559 |
+
[More Information Needed]
|
| 560 |
+
|
| 561 |
+
#### Hardware
|
| 562 |
+
|
| 563 |
+
[More Information Needed]
|
| 564 |
+
|
| 565 |
+
#### Software
|
| 566 |
+
|
| 567 |
+
[More Information Needed]
|
| 568 |
+
|
| 569 |
+
## Citation [optional]
|
| 570 |
+
|
| 571 |
+
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 572 |
+
|
| 573 |
+
**BibTeX:**
|
| 574 |
+
|
| 575 |
+
[More Information Needed]
|
| 576 |
+
|
| 577 |
+
**APA:**
|
| 578 |
+
|
| 579 |
+
[More Information Needed]
|
| 580 |
+
|
| 581 |
+
## Glossary [optional]
|
| 582 |
+
|
| 583 |
+
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
|
| 584 |
+
|
| 585 |
+
[More Information Needed]
|
| 586 |
+
|
| 587 |
+
## More Information [optional]
|
| 588 |
+
|
| 589 |
+
[More Information Needed]
|
| 590 |
+
|
| 591 |
+
## Model Card Authors [optional]
|
| 592 |
+
|
| 593 |
+
[More Information Needed]
|
| 594 |
+
|
| 595 |
+
## Model Card Contact
|
| 596 |
+
|
| 597 |
+
[More Information Needed]","{""id"": ""Clark12/POS1"", ""author"": ""Clark12"", ""sha"": ""a7946677a9b1bfaf17219c181dc137a098427938"", ""last_modified"": ""2024-09-20 20:39:22+00:00"", ""created_at"": ""2024-09-20 20:26:49+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""finance"", ""question-answering"", ""en"", ""dataset:fka/awesome-chatgpt-prompts"", ""arxiv:1910.09700"", ""base_model:HuggingFaceM4/Idefics3-8B-Llama3"", ""base_model:finetune:HuggingFaceM4/Idefics3-8B-Llama3"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""question-answering"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- HuggingFaceM4/Idefics3-8B-Llama3\ndatasets:\n- fka/awesome-chatgpt-prompts\nlanguage:\n- en\nlicense: mit\nmetrics:\n- accuracy\npipeline_tag: question-answering\ntags:\n- finance"", ""widget_data"": [{""text"": ""Where do I live?"", ""context"": ""My name is Wolfgang and I live in Berlin""}, {""text"": ""Where do I live?"", ""context"": ""My name is Sarah and I live in London""}, {""text"": ""What's my name?"", ""context"": ""My name is Clara and I live in Berkeley.""}, {""text"": ""Which name is also used to describe the Amazon rainforest in English?"", ""context"": ""The Amazon rainforest (Portuguese: Floresta Amaz\u00f4nica or Amaz\u00f4nia; Spanish: Selva Amaz\u00f3nica, Amazon\u00eda or usually Amazonia; French: For\u00eat amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \""Amazonas\"" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species.""}], ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-09-20 20:39:22+00:00"", ""cardData"": ""base_model:\n- HuggingFaceM4/Idefics3-8B-Llama3\ndatasets:\n- fka/awesome-chatgpt-prompts\nlanguage:\n- en\nlicense: mit\nmetrics:\n- accuracy\npipeline_tag: question-answering\ntags:\n- finance"", ""transformersInfo"": null, ""_id"": ""66edda89e01b8de82fca1c0a"", ""modelId"": ""Clark12/POS1"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Clark12/POS1&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BClark12%2FPOS1%5D(%2FClark12%2FPOS1)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 598 |
+
https://huggingface.co/Minthy/Torii_Gate_v0.1_alpha,N/A,N/A,1,,0,,0,,0,,0,,0
|
| 599 |
+
slezki/assistant_mage,"---
|
| 600 |
+
license: mit
|
| 601 |
+
language:
|
| 602 |
+
- ru
|
| 603 |
+
base_model:
|
| 604 |
+
- HuggingFaceM4/Idefics3-8B-Llama3
|
| 605 |
+
library_name: transformers
|
| 606 |
+
---","{""id"": ""slezki/assistant_mage"", ""author"": ""slezki"", ""sha"": ""443b97c6ecc62670715384b58c9ecaef3d9cd395"", ""last_modified"": ""2024-09-24 14:54:52+00:00"", ""created_at"": ""2024-09-24 14:50:29+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""ru"", ""base_model:HuggingFaceM4/Idefics3-8B-Llama3"", ""base_model:finetune:HuggingFaceM4/Idefics3-8B-Llama3"", ""license:mit"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- HuggingFaceM4/Idefics3-8B-Llama3\nlanguage:\n- ru\nlibrary_name: transformers\nlicense: mit"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-09-24 14:54:52+00:00"", ""cardData"": ""base_model:\n- HuggingFaceM4/Idefics3-8B-Llama3\nlanguage:\n- ru\nlibrary_name: transformers\nlicense: mit"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""66f2d1b55ddc45b044e2c53f"", ""modelId"": ""slezki/assistant_mage"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=slezki/assistant_mage&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bslezki%2Fassistant_mage%5D(%2Fslezki%2Fassistant_mage)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 607 |
+
https://huggingface.co/Minthy/ToriiGate-v0.2,N/A,N/A,1,,0,,0,,0,,0,,0
|
InstantID_finetunes_20250425_041137.csv_finetunes_20250425_041137.csv
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
InstantX/InstantID,"---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
library_name: diffusers
|
| 7 |
+
pipeline_tag: text-to-image
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# InstantID Model Card
|
| 11 |
+
|
| 12 |
+
<div align=""center"">
|
| 13 |
+
|
| 14 |
+
[**Project Page**](https://instantid.github.io/) **|** [**Paper**](https://arxiv.org/abs/2401.07519) **|** [**Code**](https://github.com/InstantID/InstantID) **|** [🤗 **Gradio demo**](https://huggingface.co/spaces/InstantX/InstantID)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
</div>
|
| 18 |
+
|
| 19 |
+
## Introduction
|
| 20 |
+
|
| 21 |
+
InstantID is a new state-of-the-art tuning-free method to achieve ID-Preserving generation with only single image, supporting various downstream tasks.
|
| 22 |
+
|
| 23 |
+
<div align=""center"">
|
| 24 |
+
<img src='examples/applications.png'>
|
| 25 |
+
</div>
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
## Usage
|
| 29 |
+
|
| 30 |
+
You can directly download the model in this repository.
|
| 31 |
+
You also can download the model in python script:
|
| 32 |
+
|
| 33 |
+
```python
|
| 34 |
+
from huggingface_hub import hf_hub_download
|
| 35 |
+
hf_hub_download(repo_id=""InstantX/InstantID"", filename=""ControlNetModel/config.json"", local_dir=""./checkpoints"")
|
| 36 |
+
hf_hub_download(repo_id=""InstantX/InstantID"", filename=""ControlNetModel/diffusion_pytorch_model.safetensors"", local_dir=""./checkpoints"")
|
| 37 |
+
hf_hub_download(repo_id=""InstantX/InstantID"", filename=""ip-adapter.bin"", local_dir=""./checkpoints"")
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
For face encoder, you need to manutally download via this [URL](https://github.com/deepinsight/insightface/issues/1896#issuecomment-1023867304) to `models/antelopev2`.
|
| 41 |
+
|
| 42 |
+
```python
|
| 43 |
+
# !pip install opencv-python transformers accelerate insightface
|
| 44 |
+
import diffusers
|
| 45 |
+
from diffusers.utils import load_image
|
| 46 |
+
from diffusers.models import ControlNetModel
|
| 47 |
+
|
| 48 |
+
import cv2
|
| 49 |
+
import torch
|
| 50 |
+
import numpy as np
|
| 51 |
+
from PIL import Image
|
| 52 |
+
|
| 53 |
+
from insightface.app import FaceAnalysis
|
| 54 |
+
from pipeline_stable_diffusion_xl_instantid import StableDiffusionXLInstantIDPipeline, draw_kps
|
| 55 |
+
|
| 56 |
+
# prepare 'antelopev2' under ./models
|
| 57 |
+
app = FaceAnalysis(name='antelopev2', root='./', providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
|
| 58 |
+
app.prepare(ctx_id=0, det_size=(640, 640))
|
| 59 |
+
|
| 60 |
+
# prepare models under ./checkpoints
|
| 61 |
+
face_adapter = f'./checkpoints/ip-adapter.bin'
|
| 62 |
+
controlnet_path = f'./checkpoints/ControlNetModel'
|
| 63 |
+
|
| 64 |
+
# load IdentityNet
|
| 65 |
+
controlnet = ControlNetModel.from_pretrained(controlnet_path, torch_dtype=torch.float16)
|
| 66 |
+
|
| 67 |
+
pipe = StableDiffusionXLInstantIDPipeline.from_pretrained(
|
| 68 |
+
... ""stabilityai/stable-diffusion-xl-base-1.0"", controlnet=controlnet, torch_dtype=torch.float16
|
| 69 |
+
... )
|
| 70 |
+
pipe.cuda()
|
| 71 |
+
|
| 72 |
+
# load adapter
|
| 73 |
+
pipe.load_ip_adapter_instantid(face_adapter)
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
Then, you can customized your own face images
|
| 77 |
+
|
| 78 |
+
```python
|
| 79 |
+
# load an image
|
| 80 |
+
image = load_image(""your-example.jpg"")
|
| 81 |
+
|
| 82 |
+
# prepare face emb
|
| 83 |
+
face_info = app.get(cv2.cvtColor(np.array(face_image), cv2.COLOR_RGB2BGR))
|
| 84 |
+
face_info = sorted(face_info, key=lambda x:(x['bbox'][2]-x['bbox'][0])*x['bbox'][3]-x['bbox'][1])[-1] # only use the maximum face
|
| 85 |
+
face_emb = face_info['embedding']
|
| 86 |
+
face_kps = draw_kps(face_image, face_info['kps'])
|
| 87 |
+
|
| 88 |
+
pipe.set_ip_adapter_scale(0.8)
|
| 89 |
+
|
| 90 |
+
prompt = ""analog film photo of a man. faded film, desaturated, 35mm photo, grainy, vignette, vintage, Kodachrome, Lomography, stained, highly detailed, found footage, masterpiece, best quality""
|
| 91 |
+
negative_prompt = ""(lowres, low quality, worst quality:1.2), (text:1.2), watermark, painting, drawing, illustration, glitch, deformed, mutated, cross-eyed, ugly, disfigured (lowres, low quality, worst quality:1.2), (text:1.2), watermark, painting, drawing, illustration, glitch,deformed, mutated, cross-eyed, ugly, disfigured""
|
| 92 |
+
|
| 93 |
+
# generate image
|
| 94 |
+
image = pipe(
|
| 95 |
+
... prompt, image_embeds=face_emb, image=face_kps, controlnet_conditioning_scale=0.8
|
| 96 |
+
... ).images[0]
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
For more details, please follow the instructions in our [GitHub repository](https://github.com/InstantID/InstantID).
|
| 100 |
+
|
| 101 |
+
## Usage Tips
|
| 102 |
+
1. If you're not satisfied with the similarity, try to increase the weight of ""IdentityNet Strength"" and ""Adapter Strength"".
|
| 103 |
+
2. If you feel that the saturation is too high, first decrease the Adapter strength. If it is still too high, then decrease the IdentityNet strength.
|
| 104 |
+
3. If you find that text control is not as expected, decrease Adapter strength.
|
| 105 |
+
4. If you find that realistic style is not good enough, go for our Github repo and use a more realistic base model.
|
| 106 |
+
|
| 107 |
+
## Demos
|
| 108 |
+
|
| 109 |
+
<div align=""center"">
|
| 110 |
+
<img src='examples/0.png'>
|
| 111 |
+
</div>
|
| 112 |
+
|
| 113 |
+
<div align=""center"">
|
| 114 |
+
<img src='examples/1.png'>
|
| 115 |
+
</div>
|
| 116 |
+
|
| 117 |
+
## Disclaimer
|
| 118 |
+
|
| 119 |
+
This project is released under Apache License and aims to positively impact the field of AI-driven image generation. Users are granted the freedom to create images using this tool, but they are obligated to comply with local laws and utilize it responsibly. The developers will not assume any responsibility for potential misuse by users.
|
| 120 |
+
|
| 121 |
+
## Citation
|
| 122 |
+
```bibtex
|
| 123 |
+
@article{wang2024instantid,
|
| 124 |
+
title={InstantID: Zero-shot Identity-Preserving Generation in Seconds},
|
| 125 |
+
author={Wang, Qixun and Bai, Xu and Wang, Haofan and Qin, Zekui and Chen, Anthony},
|
| 126 |
+
journal={arXiv preprint arXiv:2401.07519},
|
| 127 |
+
year={2024}
|
| 128 |
+
}
|
| 129 |
+
```","{""id"": ""InstantX/InstantID"", ""author"": ""InstantX"", ""sha"": ""57b32dfee076092ad2930c71fd6d439c2c3b1820"", ""last_modified"": ""2024-01-22 09:43:05+00:00"", ""created_at"": ""2024-01-19 11:52:05+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 87716, ""downloads_all_time"": null, ""likes"": 783, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""safetensors"", ""text-to-image"", ""en"", ""arxiv:2401.07519"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- en\nlibrary_name: diffusers\nlicense: apache-2.0\npipeline_tag: text-to-image"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ControlNetModel/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ControlNetModel/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/0.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/1.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/applications.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ip-adapter.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [""InstantX/InstantID"", ""Nymbo/image_gen_supaqueue"", ""Fucius/OMG-InstantID"", ""ddosxd/InstantID"", ""LPDoctor/InstantID.AIPro"", ""jiaxiangc/res-adapter"", ""cocktailpeanut/InstantID"", ""charlieguo610/InstantID"", ""waloneai/InstantAIPortrait"", ""cocktailpeanut/InstantID2"", ""jcudit/InstantID2"", ""CodeScooper/InstantX-InstantID"", ""batoon/InstantID"", ""allAI-tools/InstantID2"", ""Tototo1394/InstantX-InstantID"", ""Veloptesauarzor/InstantX-InstantID"", ""JCTN/InstantID"", ""tsi-org/InstantID"", ""listkun/InstantX-InstantID"", ""Jsachman/InstantX-InstantID"", ""uelordi/InstantID"", ""xiaoshuai11111/InstantX-InstantID"", ""joey1895/InstantX-InstantID"", ""iamshiss/InstantX-test-for-shishishi"", ""canismadjor/InstantX-InstantID"", ""darshcoss/InstantID"", ""nianevermore/InstantX-InstantID"", ""seawolf2357/vidiid"", ""vivek6900/InstantX-InstantID"", ""Cronix90/InstantX-InstantID"", ""dreamlord1995/InstantX-InstantID"", ""Irishcoder/InstantX-InstantID"", ""cement-dev/InstantX-InstantID"", ""facehugger222/h"", ""Apsoedarsono/InstantX-InstantID"", ""Tpie333/InstantX-InstantID"", ""GardenXas/InstantX-InstantID"", ""Crack506/InstantX-InstantID"", ""thekubist/InstantX-InstantID"", ""ligan/InstantX-InstantID"", ""puseletso55/InstantX-InstantID"", ""xiaoli12345/InstantX-InstantID"", ""yuxh1996/InstantID.AIPro"", ""0xZWang/InstantX-InstantID"", ""Seanwinners/InstantX-InstantID"", ""TopStreetFights/InstantX-InstantID"", ""lucky95271/InstantX-InstantID"", ""Dineth1222/_generete_image_with_nova"", ""Dineth1222/nova_image_gen"", ""Dineth1222/imageg_generete_with_nova"", ""jensinjames/InstantX-InstantID"", ""hatkarsaheb1776/InstantX-InstantID"", ""chaim/InstantX-InstantID"", ""h20ahmadi/InstantX-InstantID"", ""hhhhhhhhdss/InstantX-InstantID"", ""anandx/InstantX-InstantID"", ""opq741/InstantX-InstantID"", ""Dynexcorp/InstantX-InstantID"", ""fujue/InstantX-InstantID"", ""ajcdp/InstantX-InstantID"", ""canerdogan/InstantX-InstantID"", ""jw1900/InstantID"", ""asqwerty/InstantX-InstantID"", ""dd890/InstantX-InstantID"", ""lightsnail/InstantX-InstantID"", ""Mago-pio/InstantX-InstantID"", ""Kthkng/InstantX-InstantID"", ""JLewisT/InstantX-InstantID"", ""Erwnna/InstantX-InstantID"", ""Shanedignan/InstantX-InstantID"", ""Nickegan/InstantX-InstantID"", ""r2hu1/InstantX-InstantID"", ""jaisonkerala1/InstantX-InstantID"", ""Spongenuity/SomFingImade"", ""Biguenda/InstantX-InstantID"", ""Spongenuity/iMadeAFing"", ""Rumman157/InstantX-InstantID"", ""brianying/InstantID"", ""IsaacRDGZ05/InstantX-InstantID"", ""ThaDonald/InstantID69"", ""osmunphotography/InstantX-InstantID5"", ""CJAlos/InstantID2"", ""Dreamacus/InstantX-InstantID"", ""3bodyproblem/InstantX-InstantID"", ""Samarth0710/InstantX-InstantID"", ""Bigdaddyborch/InstantX-InstantID"", ""findpavan/InstantX-InstantID"", ""rahulbomnalli/InstantX-InstantID"", ""pranay143342/InstantX-InstantID"", ""HSxxx/InstantX-InstantID"", ""helloraj/InstantX-InstantID"", ""Tonyaispuro/InstantX-InstantID"", ""Gumm1/InstantX-InstantID"", ""wokebo/InstantX-InstantID"", ""clarkasian/InstantX-InstantID"", ""Nicoriba/InstantX-InstantID"", ""letskillgod/InstantX-InstantID"", ""ZestySalsa/InstantX-InstantID"", ""natti0170/InstantX-InstantID"", ""namuit/InstantID""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-01-22 09:43:05+00:00"", ""cardData"": ""language:\n- en\nlibrary_name: diffusers\nlicense: apache-2.0\npipeline_tag: text-to-image"", ""transformersInfo"": null, ""_id"": ""65aa62652f560c70ffe691a9"", ""modelId"": ""InstantX/InstantID"", ""usedStorage"": 4263855348}",0,,0,"https://huggingface.co/loliOppai/KyOresu, https://huggingface.co/zz001/llll, https://huggingface.co/zz001/45435, https://huggingface.co/lylosn/plum, https://huggingface.co/coversia21/GermanGarmendia, https://huggingface.co/LegoClipStars/GetBlakeBlakeMyers",6,,0,,0,"CodeScooper/InstantX-InstantID, Fucius/OMG-InstantID, InstantX/InstantID, LPDoctor/InstantID.AIPro, Nymbo/image_gen_supaqueue, charlieguo610/InstantID, cocktailpeanut/InstantID, cocktailpeanut/InstantID2, ddosxd/InstantID, huggingface/InferenceSupport/discussions/new?title=InstantX/InstantID&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BInstantX%2FInstantID%5D(%2FInstantX%2FInstantID)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, jiaxiangc/res-adapter, joey1895/InstantX-InstantID, listkun/InstantX-InstantID",13
|
InternVL2-Llama3-76B_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,652 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
OpenGVLab/InternVL2-Llama3-76B,"---
|
| 3 |
+
license: llama3
|
| 4 |
+
pipeline_tag: image-text-to-text
|
| 5 |
+
library_name: transformers
|
| 6 |
+
base_model:
|
| 7 |
+
- OpenGVLab/InternViT-6B-448px-V1-5
|
| 8 |
+
- NousResearch/Hermes-2-Theta-Llama-3-70B
|
| 9 |
+
new_version: OpenGVLab/InternVL2_5-78B
|
| 10 |
+
base_model_relation: merge
|
| 11 |
+
language:
|
| 12 |
+
- multilingual
|
| 13 |
+
tags:
|
| 14 |
+
- internvl
|
| 15 |
+
- custom_code
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
# InternVL2-Llama3-76B
|
| 19 |
+
|
| 20 |
+
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 Mini-InternVL\]](https://arxiv.org/abs/2410.16261) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271)
|
| 21 |
+
|
| 22 |
+
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://internvl.opengvlab.com/) [\[🤗 HF Demo\]](https://huggingface.co/spaces/OpenGVLab/InternVL) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
|
| 23 |
+
|
| 24 |
+
<div align=""center"">
|
| 25 |
+
<img width=""500"" alt=""image"" src=""https://cdn-uploads.huggingface.co/production/uploads/64006c09330a45b03605bba3/zJsd2hqd3EevgXo6fNgC-.png"">
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
## Introduction
|
| 29 |
+
|
| 30 |
+
We are excited to announce the release of InternVL 2.0, the latest addition to the InternVL series of multimodal large language models. InternVL 2.0 features a variety of **instruction-tuned models**, ranging from 1 billion to 108 billion parameters. This repository contains the instruction-tuned InternVL2-Llama3-76B model.
|
| 31 |
+
|
| 32 |
+
Compared to the state-of-the-art open-source multimodal large language models, InternVL 2.0 surpasses most open-source models. It demonstrates competitive performance on par with proprietary commercial models across various capabilities, including document and chart comprehension, infographics QA, scene text understanding and OCR tasks, scientific and mathematical problem solving, as well as cultural understanding and integrated multimodal capabilities.
|
| 33 |
+
|
| 34 |
+
InternVL 2.0 is trained with an 8k context window and utilizes training data consisting of long texts, multiple images, and videos, significantly improving its ability to handle these types of inputs compared to InternVL 1.5. For more details, please refer to our [blog](https://internvl.github.io/blog/2024-07-02-InternVL-2.0/) and [GitHub](https://github.com/OpenGVLab/InternVL).
|
| 35 |
+
|
| 36 |
+
| Model Name | Vision Part | Language Part | HF Link | MS Link |
|
| 37 |
+
| :------------------: | :---------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------: | :--------------------------------------------------------------: | :--------------------------------------------------------------------: |
|
| 38 |
+
| InternVL2-1B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-1B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-1B) |
|
| 39 |
+
| InternVL2-2B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2-chat-1_8b](https://huggingface.co/internlm/internlm2-chat-1_8b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-2B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-2B) |
|
| 40 |
+
| InternVL2-4B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [Phi-3-mini-128k-instruct](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-4B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-4B) |
|
| 41 |
+
| InternVL2-8B | [InternViT-300M-448px](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [internlm2_5-7b-chat](https://huggingface.co/internlm/internlm2_5-7b-chat) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-8B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-8B) |
|
| 42 |
+
| InternVL2-26B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [internlm2-chat-20b](https://huggingface.co/internlm/internlm2-chat-20b) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-26B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-26B) |
|
| 43 |
+
| InternVL2-40B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Nous-Hermes-2-Yi-34B](https://huggingface.co/NousResearch/Nous-Hermes-2-Yi-34B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-40B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-40B) |
|
| 44 |
+
| InternVL2-Llama3-76B | [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5) | [Hermes-2-Theta-Llama-3-70B](https://huggingface.co/NousResearch/Hermes-2-Theta-Llama-3-70B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL2-Llama3-76B) | [🤖 link](https://modelscope.cn/models/OpenGVLab/InternVL2-Llama3-76B) |
|
| 45 |
+
|
| 46 |
+
## Model Details
|
| 47 |
+
|
| 48 |
+
InternVL 2.0 is a multimodal large language model series, featuring models of various sizes. For each size, we release instruction-tuned models optimized for multimodal tasks. InternVL2-Llama3-76B consists of [InternViT-6B-448px-V1-5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V1-5), an MLP projector, and [Hermes-2-Theta-Llama-3-70B](https://huggingface.co/NousResearch/Hermes-2-Theta-Llama-3-70B).
|
| 49 |
+
|
| 50 |
+
## Performance
|
| 51 |
+
|
| 52 |
+
### Image Benchmarks
|
| 53 |
+
|
| 54 |
+
| Benchmark | GPT-4o-20240513 | Claude3.5-Sonnet | InternVL2-40B | InternVL2-Llama3-76B |
|
| 55 |
+
| :--------------------------: | :-------------: | :--------------: | :-----------: | :------------------: |
|
| 56 |
+
| Model Size | - | - | 40B | 76B |
|
| 57 |
+
| | | | | |
|
| 58 |
+
| DocVQA<sub>test</sub> | 92.8 | 95.2 | 93.9 | 94.1 |
|
| 59 |
+
| ChartQA<sub>test</sub> | 85.7 | 90.8 | 86.2 | 88.4 |
|
| 60 |
+
| InfoVQA<sub>test</sub> | - | - | 78.7 | 82.0 |
|
| 61 |
+
| TextVQA<sub>val</sub> | - | - | 83.0 | 84.4 |
|
| 62 |
+
| OCRBench | 736 | 788 | 837 | 839 |
|
| 63 |
+
| MME<sub>sum</sub> | 2328.7 | 1920.0 | 2315.0 | 2414.7 |
|
| 64 |
+
| RealWorldQA | 75.4 | 60.1 | 71.8 | 72.2 |
|
| 65 |
+
| AI2D<sub>test</sub> | 94.2 | 94.7 | 87.1 | 87.6 |
|
| 66 |
+
| MMMU<sub>val</sub> | 69.1 | 68.3 | 55.2 | 58.2 |
|
| 67 |
+
| MMBench-EN<sub>test</sub> | 83.4 | 79.7 | 86.8 | 86.5 |
|
| 68 |
+
| MMBench-CN<sub>test</sub> | 82.1 | 80.7 | 86.5 | 86.3 |
|
| 69 |
+
| CCBench<sub>dev</sub> | 71.2 | 54.1 | 80.6 | 81.0 |
|
| 70 |
+
| MMVet<sub>GPT-4-0613</sub> | - | - | 68.5 | 69.8 |
|
| 71 |
+
| MMVet<sub>GPT-4-Turbo</sub> | 69.1 | 66.0 | 65.5 | 65.7 |
|
| 72 |
+
| SEED-Image | 77.1 | - | 78.2 | 78.2 |
|
| 73 |
+
| HallBench<sub>avg</sub> | 55.0 | 49.9 | 56.9 | 55.2 |
|
| 74 |
+
| MathVista<sub>testmini</sub> | 63.8 | 67.7 | 63.7 | 65.5 |
|
| 75 |
+
| OpenCompass<sub>avg</sub> | 69.9 | 67.9 | 69.7 | 71.0 |
|
| 76 |
+
|
| 77 |
+
- For more details and evaluation reproduction, please refer to our [Evaluation Guide](https://internvl.readthedocs.io/en/latest/internvl2.0/evaluation.html).
|
| 78 |
+
|
| 79 |
+
- We simultaneously use [InternVL](https://github.com/OpenGVLab/InternVL) and [VLMEvalKit](https://github.com/open-compass/VLMEvalKit) repositories for model evaluation. Specifically, the results reported for DocVQA, ChartQA, InfoVQA, TextVQA, MME, AI2D, MMBench, CCBench, MMVet (GPT-4-0613), and SEED-Image were tested using the InternVL repository. MMMU, OCRBench, RealWorldQA, HallBench, MMVet (GPT-4-Turbo), and MathVista were evaluated using the VLMEvalKit.
|
| 80 |
+
|
| 81 |
+
### Video Benchmarks
|
| 82 |
+
|
| 83 |
+
| Benchmark | GPT-4o | GPT-4V | Gemini-Pro-1.5 | InternVL2-40B | InternVL2-Llama3-76B |
|
| 84 |
+
| :-------------------------: | :----: | :----: | :------------: | :-----------: | :------------------: |
|
| 85 |
+
| Model Size | - | - | - | 40B | 76B |
|
| 86 |
+
| | | | | | |
|
| 87 |
+
| MVBench | - | - | - | 72.5 | 69.6 |
|
| 88 |
+
| MMBench-Video<sub>8f</sub> | 1.62 | 1.53 | 1.30 | 1.32 | 1.37 |
|
| 89 |
+
| MMBench-Video<sub>16f</sub> | 1.86 | 1.68 | 1.60 | 1.45 | 1.52 |
|
| 90 |
+
| Video-MME<br>w/o subs | 71.9 | 59.9 | 75.0 | 61.2 | 61.2 |
|
| 91 |
+
| Video-MME<br>w subs | 77.2 | 63.3 | 81.3 | 62.4 | 62.8 |
|
| 92 |
+
|
| 93 |
+
- We evaluate our models on MVBench and Video-MME by extracting 16 frames from each video, and each frame was resized to a 448x448 image.
|
| 94 |
+
|
| 95 |
+
### Grounding Benchmarks
|
| 96 |
+
|
| 97 |
+
| Model | avg. | RefCOCO<br>(val) | RefCOCO<br>(testA) | RefCOCO<br>(testB) | RefCOCO+<br>(val) | RefCOCO+<br>(testA) | RefCOCO+<br>(testB) | RefCOCO‑g<br>(val) | RefCOCO‑g<br>(test) |
|
| 98 |
+
| :----------------------------: | :--: | :--------------: | :----------------: | :----------------: | :---------------: | :-----------------: | :-----------------: | :----------------: | :-----------------: |
|
| 99 |
+
| UNINEXT-H<br>(Specialist SOTA) | 88.9 | 92.6 | 94.3 | 91.5 | 85.2 | 89.6 | 79.8 | 88.7 | 89.4 |
|
| 100 |
+
| | | | | | | | | | |
|
| 101 |
+
| Mini-InternVL-<br>Chat-2B-V1-5 | 75.8 | 80.7 | 86.7 | 72.9 | 72.5 | 82.3 | 60.8 | 75.6 | 74.9 |
|
| 102 |
+
| Mini-InternVL-<br>Chat-4B-V1-5 | 84.4 | 88.0 | 91.4 | 83.5 | 81.5 | 87.4 | 73.8 | 84.7 | 84.6 |
|
| 103 |
+
| InternVL‑Chat‑V1‑5 | 88.8 | 91.4 | 93.7 | 87.1 | 87.0 | 92.3 | 80.9 | 88.5 | 89.3 |
|
| 104 |
+
| | | | | | | | | | |
|
| 105 |
+
| InternVL2‑1B | 79.9 | 83.6 | 88.7 | 79.8 | 76.0 | 83.6 | 67.7 | 80.2 | 79.9 |
|
| 106 |
+
| InternVL2‑2B | 77.7 | 82.3 | 88.2 | 75.9 | 73.5 | 82.8 | 63.3 | 77.6 | 78.3 |
|
| 107 |
+
| InternVL2‑4B | 84.4 | 88.5 | 91.2 | 83.9 | 81.2 | 87.2 | 73.8 | 84.6 | 84.6 |
|
| 108 |
+
| InternVL2‑8B | 82.9 | 87.1 | 91.1 | 80.7 | 79.8 | 87.9 | 71.4 | 82.7 | 82.7 |
|
| 109 |
+
| InternVL2‑26B | 88.5 | 91.2 | 93.3 | 87.4 | 86.8 | 91.0 | 81.2 | 88.5 | 88.6 |
|
| 110 |
+
| InternVL2‑40B | 90.3 | 93.0 | 94.7 | 89.2 | 88.5 | 92.8 | 83.6 | 90.3 | 90.6 |
|
| 111 |
+
| InternVL2-<br>Llama3‑76B | 90.0 | 92.2 | 94.8 | 88.4 | 88.8 | 93.1 | 82.8 | 89.5 | 90.3 |
|
| 112 |
+
|
| 113 |
+
- We use the following prompt to evaluate InternVL's grounding ability: `Please provide the bounding box coordinates of the region this sentence describes: <ref>{}</ref>`
|
| 114 |
+
|
| 115 |
+
Limitations: Although we have made efforts to ensure the safety of the model during the training process and to encourage the model to generate text that complies with ethical and legal requirements, the model may still produce unexpected outputs due to its size and probabilistic generation paradigm. For example, the generated responses may contain biases, discrimination, or other harmful content. Please do not propagate such content. We are not responsible for any consequences resulting from the dissemination of harmful information.
|
| 116 |
+
|
| 117 |
+
## Quick Start
|
| 118 |
+
|
| 119 |
+
We provide an example code to run `InternVL2-Llama3-76B` using `transformers`.
|
| 120 |
+
|
| 121 |
+
> Please use transformers>=4.37.2 to ensure the model works normally.
|
| 122 |
+
|
| 123 |
+
### Model Loading
|
| 124 |
+
|
| 125 |
+
#### 16-bit (bf16 / fp16)
|
| 126 |
+
|
| 127 |
+
```python
|
| 128 |
+
import torch
|
| 129 |
+
from transformers import AutoTokenizer, AutoModel
|
| 130 |
+
path = ""OpenGVLab/InternVL2-Llama3-76B""
|
| 131 |
+
model = AutoModel.from_pretrained(
|
| 132 |
+
path,
|
| 133 |
+
torch_dtype=torch.bfloat16,
|
| 134 |
+
low_cpu_mem_usage=True,
|
| 135 |
+
use_flash_attn=True,
|
| 136 |
+
trust_remote_code=True).eval().cuda()
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
#### BNB 8-bit Quantization
|
| 140 |
+
|
| 141 |
+
```python
|
| 142 |
+
import torch
|
| 143 |
+
from transformers import AutoTokenizer, AutoModel
|
| 144 |
+
path = ""OpenGVLab/InternVL2-Llama3-76B""
|
| 145 |
+
model = AutoModel.from_pretrained(
|
| 146 |
+
path,
|
| 147 |
+
torch_dtype=torch.bfloat16,
|
| 148 |
+
load_in_8bit=True,
|
| 149 |
+
low_cpu_mem_usage=True,
|
| 150 |
+
use_flash_attn=True,
|
| 151 |
+
trust_remote_code=True).eval()
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
#### Multiple GPUs
|
| 155 |
+
|
| 156 |
+
The reason for writing the code this way is to avoid errors that occur during multi-GPU inference due to tensors not being on the same device. By ensuring that the first and last layers of the large language model (LLM) are on the same device, we prevent such errors.
|
| 157 |
+
|
| 158 |
+
```python
|
| 159 |
+
import math
|
| 160 |
+
import torch
|
| 161 |
+
from transformers import AutoTokenizer, AutoModel
|
| 162 |
+
|
| 163 |
+
def split_model(model_name):
|
| 164 |
+
device_map = {}
|
| 165 |
+
world_size = torch.cuda.device_count()
|
| 166 |
+
num_layers = {
|
| 167 |
+
'InternVL2-1B': 24, 'InternVL2-2B': 24, 'InternVL2-4B': 32, 'InternVL2-8B': 32,
|
| 168 |
+
'InternVL2-26B': 48, 'InternVL2-40B': 60, 'InternVL2-Llama3-76B': 80}[model_name]
|
| 169 |
+
# Since the first GPU will be used for ViT, treat it as half a GPU.
|
| 170 |
+
num_layers_per_gpu = math.ceil(num_layers / (world_size - 0.5))
|
| 171 |
+
num_layers_per_gpu = [num_layers_per_gpu] * world_size
|
| 172 |
+
num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * 0.5)
|
| 173 |
+
layer_cnt = 0
|
| 174 |
+
for i, num_layer in enumerate(num_layers_per_gpu):
|
| 175 |
+
for j in range(num_layer):
|
| 176 |
+
device_map[f'language_model.model.layers.{layer_cnt}'] = i
|
| 177 |
+
layer_cnt += 1
|
| 178 |
+
device_map['vision_model'] = 0
|
| 179 |
+
device_map['mlp1'] = 0
|
| 180 |
+
device_map['language_model.model.tok_embeddings'] = 0
|
| 181 |
+
device_map['language_model.model.embed_tokens'] = 0
|
| 182 |
+
device_map['language_model.output'] = 0
|
| 183 |
+
device_map['language_model.model.norm'] = 0
|
| 184 |
+
device_map['language_model.model.rotary_emb'] = 0
|
| 185 |
+
device_map['language_model.lm_head'] = 0
|
| 186 |
+
device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
|
| 187 |
+
|
| 188 |
+
return device_map
|
| 189 |
+
|
| 190 |
+
path = ""OpenGVLab/InternVL2-Llama3-76B""
|
| 191 |
+
device_map = split_model('InternVL2-Llama3-76B')
|
| 192 |
+
model = AutoModel.from_pretrained(
|
| 193 |
+
path,
|
| 194 |
+
torch_dtype=torch.bfloat16,
|
| 195 |
+
low_cpu_mem_usage=True,
|
| 196 |
+
use_flash_attn=True,
|
| 197 |
+
trust_remote_code=True,
|
| 198 |
+
device_map=device_map).eval()
|
| 199 |
+
```
|
| 200 |
+
|
| 201 |
+
### Inference with Transformers
|
| 202 |
+
|
| 203 |
+
```python
|
| 204 |
+
import math
|
| 205 |
+
import numpy as np
|
| 206 |
+
import torch
|
| 207 |
+
import torchvision.transforms as T
|
| 208 |
+
from decord import VideoReader, cpu
|
| 209 |
+
from PIL import Image
|
| 210 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 211 |
+
from transformers import AutoModel, AutoTokenizer
|
| 212 |
+
|
| 213 |
+
IMAGENET_MEAN = (0.485, 0.456, 0.406)
|
| 214 |
+
IMAGENET_STD = (0.229, 0.224, 0.225)
|
| 215 |
+
|
| 216 |
+
def build_transform(input_size):
|
| 217 |
+
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
|
| 218 |
+
transform = T.Compose([
|
| 219 |
+
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
|
| 220 |
+
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
|
| 221 |
+
T.ToTensor(),
|
| 222 |
+
T.Normalize(mean=MEAN, std=STD)
|
| 223 |
+
])
|
| 224 |
+
return transform
|
| 225 |
+
|
| 226 |
+
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
|
| 227 |
+
best_ratio_diff = float('inf')
|
| 228 |
+
best_ratio = (1, 1)
|
| 229 |
+
area = width * height
|
| 230 |
+
for ratio in target_ratios:
|
| 231 |
+
target_aspect_ratio = ratio[0] / ratio[1]
|
| 232 |
+
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
|
| 233 |
+
if ratio_diff < best_ratio_diff:
|
| 234 |
+
best_ratio_diff = ratio_diff
|
| 235 |
+
best_ratio = ratio
|
| 236 |
+
elif ratio_diff == best_ratio_diff:
|
| 237 |
+
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
|
| 238 |
+
best_ratio = ratio
|
| 239 |
+
return best_ratio
|
| 240 |
+
|
| 241 |
+
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
|
| 242 |
+
orig_width, orig_height = image.size
|
| 243 |
+
aspect_ratio = orig_width / orig_height
|
| 244 |
+
|
| 245 |
+
# calculate the existing image aspect ratio
|
| 246 |
+
target_ratios = set(
|
| 247 |
+
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
|
| 248 |
+
i * j <= max_num and i * j >= min_num)
|
| 249 |
+
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
|
| 250 |
+
|
| 251 |
+
# find the closest aspect ratio to the target
|
| 252 |
+
target_aspect_ratio = find_closest_aspect_ratio(
|
| 253 |
+
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
|
| 254 |
+
|
| 255 |
+
# calculate the target width and height
|
| 256 |
+
target_width = image_size * target_aspect_ratio[0]
|
| 257 |
+
target_height = image_size * target_aspect_ratio[1]
|
| 258 |
+
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
|
| 259 |
+
|
| 260 |
+
# resize the image
|
| 261 |
+
resized_img = image.resize((target_width, target_height))
|
| 262 |
+
processed_images = []
|
| 263 |
+
for i in range(blocks):
|
| 264 |
+
box = (
|
| 265 |
+
(i % (target_width // image_size)) * image_size,
|
| 266 |
+
(i // (target_width // image_size)) * image_size,
|
| 267 |
+
((i % (target_width // image_size)) + 1) * image_size,
|
| 268 |
+
((i // (target_width // image_size)) + 1) * image_size
|
| 269 |
+
)
|
| 270 |
+
# split the image
|
| 271 |
+
split_img = resized_img.crop(box)
|
| 272 |
+
processed_images.append(split_img)
|
| 273 |
+
assert len(processed_images) == blocks
|
| 274 |
+
if use_thumbnail and len(processed_images) != 1:
|
| 275 |
+
thumbnail_img = image.resize((image_size, image_size))
|
| 276 |
+
processed_images.append(thumbnail_img)
|
| 277 |
+
return processed_images
|
| 278 |
+
|
| 279 |
+
def load_image(image_file, input_size=448, max_num=12):
|
| 280 |
+
image = Image.open(image_file).convert('RGB')
|
| 281 |
+
transform = build_transform(input_size=input_size)
|
| 282 |
+
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 283 |
+
pixel_values = [transform(image) for image in images]
|
| 284 |
+
pixel_values = torch.stack(pixel_values)
|
| 285 |
+
return pixel_values
|
| 286 |
+
|
| 287 |
+
def split_model(model_name):
|
| 288 |
+
device_map = {}
|
| 289 |
+
world_size = torch.cuda.device_count()
|
| 290 |
+
num_layers = {
|
| 291 |
+
'InternVL2-1B': 24, 'InternVL2-2B': 24, 'InternVL2-4B': 32, 'InternVL2-8B': 32,
|
| 292 |
+
'InternVL2-26B': 48, 'InternVL2-40B': 60, 'InternVL2-Llama3-76B': 80}[model_name]
|
| 293 |
+
# Since the first GPU will be used for ViT, treat it as half a GPU.
|
| 294 |
+
num_layers_per_gpu = math.ceil(num_layers / (world_size - 0.5))
|
| 295 |
+
num_layers_per_gpu = [num_layers_per_gpu] * world_size
|
| 296 |
+
num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * 0.5)
|
| 297 |
+
layer_cnt = 0
|
| 298 |
+
for i, num_layer in enumerate(num_layers_per_gpu):
|
| 299 |
+
for j in range(num_layer):
|
| 300 |
+
device_map[f'language_model.model.layers.{layer_cnt}'] = i
|
| 301 |
+
layer_cnt += 1
|
| 302 |
+
device_map['vision_model'] = 0
|
| 303 |
+
device_map['mlp1'] = 0
|
| 304 |
+
device_map['language_model.model.tok_embeddings'] = 0
|
| 305 |
+
device_map['language_model.model.embed_tokens'] = 0
|
| 306 |
+
device_map['language_model.output'] = 0
|
| 307 |
+
device_map['language_model.model.norm'] = 0
|
| 308 |
+
device_map['language_model.model.rotary_emb'] = 0
|
| 309 |
+
device_map['language_model.lm_head'] = 0
|
| 310 |
+
device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
|
| 311 |
+
|
| 312 |
+
return device_map
|
| 313 |
+
|
| 314 |
+
# If you set `load_in_8bit=True`, you will need two 80GB GPUs.
|
| 315 |
+
# If you set `load_in_8bit=False`, you will need at least three 80GB GPUs.
|
| 316 |
+
path = 'OpenGVLab/InternVL2-Llama3-76B'
|
| 317 |
+
device_map = split_model('InternVL2-Llama3-76B')
|
| 318 |
+
model = AutoModel.from_pretrained(
|
| 319 |
+
path,
|
| 320 |
+
torch_dtype=torch.bfloat16,
|
| 321 |
+
load_in_8bit=True,
|
| 322 |
+
low_cpu_mem_usage=True,
|
| 323 |
+
use_flash_attn=True,
|
| 324 |
+
trust_remote_code=True,
|
| 325 |
+
device_map=device_map).eval()
|
| 326 |
+
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
|
| 327 |
+
|
| 328 |
+
# set the max number of tiles in `max_num`
|
| 329 |
+
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 330 |
+
generation_config = dict(max_new_tokens=1024, do_sample=True)
|
| 331 |
+
|
| 332 |
+
# pure-text conversation (纯文本对话)
|
| 333 |
+
question = 'Hello, who are you?'
|
| 334 |
+
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
|
| 335 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 336 |
+
|
| 337 |
+
question = 'Can you tell me a story?'
|
| 338 |
+
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
|
| 339 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 340 |
+
|
| 341 |
+
# single-image single-round conversation (单图单轮对话)
|
| 342 |
+
question = '<image>\nPlease describe the image shortly.'
|
| 343 |
+
response = model.chat(tokenizer, pixel_values, question, generation_config)
|
| 344 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 345 |
+
|
| 346 |
+
# single-image multi-round conversation (单图多轮对话)
|
| 347 |
+
question = '<image>\nPlease describe the image in detail.'
|
| 348 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
|
| 349 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 350 |
+
|
| 351 |
+
question = 'Please write a poem according to the image.'
|
| 352 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
|
| 353 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 354 |
+
|
| 355 |
+
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
|
| 356 |
+
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 357 |
+
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 358 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 359 |
+
|
| 360 |
+
question = '<image>\nDescribe the two images in detail.'
|
| 361 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 362 |
+
history=None, return_history=True)
|
| 363 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 364 |
+
|
| 365 |
+
question = 'What are the similarities and differences between these two images.'
|
| 366 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 367 |
+
history=history, return_history=True)
|
| 368 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 369 |
+
|
| 370 |
+
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
|
| 371 |
+
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 372 |
+
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 373 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 374 |
+
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
|
| 375 |
+
|
| 376 |
+
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
|
| 377 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 378 |
+
num_patches_list=num_patches_list,
|
| 379 |
+
history=None, return_history=True)
|
| 380 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 381 |
+
|
| 382 |
+
question = 'What are the similarities and differences between these two images.'
|
| 383 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 384 |
+
num_patches_list=num_patches_list,
|
| 385 |
+
history=history, return_history=True)
|
| 386 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 387 |
+
|
| 388 |
+
# batch inference, single image per sample (单图批处理)
|
| 389 |
+
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 390 |
+
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 391 |
+
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
|
| 392 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 393 |
+
|
| 394 |
+
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
|
| 395 |
+
responses = model.batch_chat(tokenizer, pixel_values,
|
| 396 |
+
num_patches_list=num_patches_list,
|
| 397 |
+
questions=questions,
|
| 398 |
+
generation_config=generation_config)
|
| 399 |
+
for question, response in zip(questions, responses):
|
| 400 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 401 |
+
|
| 402 |
+
# video multi-round conversation (视频多轮对话)
|
| 403 |
+
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
|
| 404 |
+
if bound:
|
| 405 |
+
start, end = bound[0], bound[1]
|
| 406 |
+
else:
|
| 407 |
+
start, end = -100000, 100000
|
| 408 |
+
start_idx = max(first_idx, round(start * fps))
|
| 409 |
+
end_idx = min(round(end * fps), max_frame)
|
| 410 |
+
seg_size = float(end_idx - start_idx) / num_segments
|
| 411 |
+
frame_indices = np.array([
|
| 412 |
+
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
|
| 413 |
+
for idx in range(num_segments)
|
| 414 |
+
])
|
| 415 |
+
return frame_indices
|
| 416 |
+
|
| 417 |
+
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
|
| 418 |
+
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
|
| 419 |
+
max_frame = len(vr) - 1
|
| 420 |
+
fps = float(vr.get_avg_fps())
|
| 421 |
+
|
| 422 |
+
pixel_values_list, num_patches_list = [], []
|
| 423 |
+
transform = build_transform(input_size=input_size)
|
| 424 |
+
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
|
| 425 |
+
for frame_index in frame_indices:
|
| 426 |
+
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
|
| 427 |
+
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 428 |
+
pixel_values = [transform(tile) for tile in img]
|
| 429 |
+
pixel_values = torch.stack(pixel_values)
|
| 430 |
+
num_patches_list.append(pixel_values.shape[0])
|
| 431 |
+
pixel_values_list.append(pixel_values)
|
| 432 |
+
pixel_values = torch.cat(pixel_values_list)
|
| 433 |
+
return pixel_values, num_patches_list
|
| 434 |
+
|
| 435 |
+
video_path = './examples/red-panda.mp4'
|
| 436 |
+
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
|
| 437 |
+
pixel_values = pixel_values.to(torch.bfloat16).cuda()
|
| 438 |
+
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
|
| 439 |
+
question = video_prefix + 'What is the red panda doing?'
|
| 440 |
+
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
|
| 441 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 442 |
+
num_patches_list=num_patches_list, history=None, return_history=True)
|
| 443 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 444 |
+
|
| 445 |
+
question = 'Describe this video in detail.'
|
| 446 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 447 |
+
num_patches_list=num_patches_list, history=history, return_history=True)
|
| 448 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 449 |
+
```
|
| 450 |
+
|
| 451 |
+
#### Streaming Output
|
| 452 |
+
|
| 453 |
+
Besides this method, you can also use the following code to get streamed output.
|
| 454 |
+
|
| 455 |
+
```python
|
| 456 |
+
from transformers import TextIteratorStreamer
|
| 457 |
+
from threading import Thread
|
| 458 |
+
|
| 459 |
+
# Initialize the streamer
|
| 460 |
+
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
|
| 461 |
+
# Define the generation configuration
|
| 462 |
+
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
|
| 463 |
+
# Start the model chat in a separate thread
|
| 464 |
+
thread = Thread(target=model.chat, kwargs=dict(
|
| 465 |
+
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
|
| 466 |
+
history=None, return_history=False, generation_config=generation_config,
|
| 467 |
+
))
|
| 468 |
+
thread.start()
|
| 469 |
+
|
| 470 |
+
# Initialize an empty string to store the generated text
|
| 471 |
+
generated_text = ''
|
| 472 |
+
# Loop through the streamer to get the new text as it is generated
|
| 473 |
+
for new_text in streamer:
|
| 474 |
+
if new_text == model.conv_template.sep:
|
| 475 |
+
break
|
| 476 |
+
generated_text += new_text
|
| 477 |
+
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
|
| 478 |
+
```
|
| 479 |
+
|
| 480 |
+
## Finetune
|
| 481 |
+
|
| 482 |
+
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTurner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
|
| 483 |
+
|
| 484 |
+
## Deployment
|
| 485 |
+
|
| 486 |
+
### LMDeploy
|
| 487 |
+
|
| 488 |
+
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
|
| 489 |
+
|
| 490 |
+
```sh
|
| 491 |
+
pip install lmdeploy>=0.5.3
|
| 492 |
+
```
|
| 493 |
+
|
| 494 |
+
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
|
| 495 |
+
|
| 496 |
+
#### A 'Hello, world' Example
|
| 497 |
+
|
| 498 |
+
```python
|
| 499 |
+
from lmdeploy import pipeline, TurbomindEngineConfig
|
| 500 |
+
from lmdeploy.vl import load_image
|
| 501 |
+
|
| 502 |
+
model = 'OpenGVLab/InternVL2-Llama3-76B'
|
| 503 |
+
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
|
| 504 |
+
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192, tp=4))
|
| 505 |
+
response = pipe(('describe this image', image))
|
| 506 |
+
print(response.text)
|
| 507 |
+
```
|
| 508 |
+
|
| 509 |
+
If `ImportError` occurs while executing this case, please install the required dependency packages as prompted.
|
| 510 |
+
|
| 511 |
+
#### Multi-images Inference
|
| 512 |
+
|
| 513 |
+
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
|
| 514 |
+
|
| 515 |
+
> Warning: Due to the scarcity of multi-image conversation data, the performance on multi-image tasks may be unstable, and it may require multiple attempts to achieve satisfactory results.
|
| 516 |
+
|
| 517 |
+
```python
|
| 518 |
+
from lmdeploy import pipeline, TurbomindEngineConfig
|
| 519 |
+
from lmdeploy.vl import load_image
|
| 520 |
+
from lmdeploy.vl.constants import IMAGE_TOKEN
|
| 521 |
+
|
| 522 |
+
model = 'OpenGVLab/InternVL2-Llama3-76B'
|
| 523 |
+
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192, tp=4))
|
| 524 |
+
|
| 525 |
+
image_urls=[
|
| 526 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
|
| 527 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
|
| 528 |
+
]
|
| 529 |
+
|
| 530 |
+
images = [load_image(img_url) for img_url in image_urls]
|
| 531 |
+
# Numbering images improves multi-image conversations
|
| 532 |
+
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
|
| 533 |
+
print(response.text)
|
| 534 |
+
```
|
| 535 |
+
|
| 536 |
+
#### Batch Prompts Inference
|
| 537 |
+
|
| 538 |
+
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
|
| 539 |
+
|
| 540 |
+
```python
|
| 541 |
+
from lmdeploy import pipeline, TurbomindEngineConfig
|
| 542 |
+
from lmdeploy.vl import load_image
|
| 543 |
+
|
| 544 |
+
model = 'OpenGVLab/InternVL2-Llama3-76B'
|
| 545 |
+
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192, tp=4))
|
| 546 |
+
|
| 547 |
+
image_urls=[
|
| 548 |
+
""https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg"",
|
| 549 |
+
""https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg""
|
| 550 |
+
]
|
| 551 |
+
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
|
| 552 |
+
response = pipe(prompts)
|
| 553 |
+
print(response)
|
| 554 |
+
```
|
| 555 |
+
|
| 556 |
+
#### Multi-turn Conversation
|
| 557 |
+
|
| 558 |
+
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
|
| 559 |
+
|
| 560 |
+
```python
|
| 561 |
+
from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig
|
| 562 |
+
from lmdeploy.vl import load_image
|
| 563 |
+
|
| 564 |
+
model = 'OpenGVLab/InternVL2-Llama3-76B'
|
| 565 |
+
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=8192, tp=4))
|
| 566 |
+
|
| 567 |
+
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
|
| 568 |
+
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.8)
|
| 569 |
+
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
|
| 570 |
+
print(sess.response.text)
|
| 571 |
+
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
|
| 572 |
+
print(sess.response.text)
|
| 573 |
+
```
|
| 574 |
+
|
| 575 |
+
#### Service
|
| 576 |
+
|
| 577 |
+
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
|
| 578 |
+
|
| 579 |
+
```shell
|
| 580 |
+
lmdeploy serve api_server OpenGVLab/InternVL2-Llama3-76B --server-port 23333 --tp 4
|
| 581 |
+
```
|
| 582 |
+
|
| 583 |
+
To use the OpenAI-style interface, you need to install OpenAI:
|
| 584 |
+
|
| 585 |
+
```shell
|
| 586 |
+
pip install openai
|
| 587 |
+
```
|
| 588 |
+
|
| 589 |
+
Then, use the code below to make the API call:
|
| 590 |
+
|
| 591 |
+
```python
|
| 592 |
+
from openai import OpenAI
|
| 593 |
+
|
| 594 |
+
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
|
| 595 |
+
model_name = client.models.list().data[0].id
|
| 596 |
+
response = client.chat.completions.create(
|
| 597 |
+
model=model_name,
|
| 598 |
+
messages=[{
|
| 599 |
+
'role':
|
| 600 |
+
'user',
|
| 601 |
+
'content': [{
|
| 602 |
+
'type': 'text',
|
| 603 |
+
'text': 'describe this image',
|
| 604 |
+
}, {
|
| 605 |
+
'type': 'image_url',
|
| 606 |
+
'image_url': {
|
| 607 |
+
'url':
|
| 608 |
+
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
|
| 609 |
+
},
|
| 610 |
+
}],
|
| 611 |
+
}],
|
| 612 |
+
temperature=0.8,
|
| 613 |
+
top_p=0.8)
|
| 614 |
+
print(response)
|
| 615 |
+
```
|
| 616 |
+
|
| 617 |
+
## License
|
| 618 |
+
|
| 619 |
+
This project is released under the MIT License. This project uses the pre-trained Hermes-2-Theta-Llama-3-70B as a component, which is licensed under the Llama 3 Community License.
|
| 620 |
+
|
| 621 |
+
## Citation
|
| 622 |
+
|
| 623 |
+
If you find this project useful in your research, please consider citing:
|
| 624 |
+
|
| 625 |
+
```BibTeX
|
| 626 |
+
@article{chen2024expanding,
|
| 627 |
+
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
|
| 628 |
+
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
|
| 629 |
+
journal={arXiv preprint arXiv:2412.05271},
|
| 630 |
+
year={2024}
|
| 631 |
+
}
|
| 632 |
+
@article{gao2024mini,
|
| 633 |
+
title={Mini-internvl: A flexible-transfer pocket multimodal model with 5\% parameters and 90\% performance},
|
| 634 |
+
author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others},
|
| 635 |
+
journal={arXiv preprint arXiv:2410.16261},
|
| 636 |
+
year={2024}
|
| 637 |
+
}
|
| 638 |
+
@article{chen2024far,
|
| 639 |
+
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
|
| 640 |
+
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
|
| 641 |
+
journal={arXiv preprint arXiv:2404.16821},
|
| 642 |
+
year={2024}
|
| 643 |
+
}
|
| 644 |
+
@inproceedings{chen2024internvl,
|
| 645 |
+
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
|
| 646 |
+
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
|
| 647 |
+
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
|
| 648 |
+
pages={24185--24198},
|
| 649 |
+
year={2024}
|
| 650 |
+
}
|
| 651 |
+
```
|
| 652 |
+
","{""id"": ""OpenGVLab/InternVL2-Llama3-76B"", ""author"": ""OpenGVLab"", ""sha"": ""9d9aa88d8b76d0f38d6c30e15adbd26b5ceb1753"", ""last_modified"": ""2025-03-25 06:02:44+00:00"", ""created_at"": ""2024-07-15 06:16:18+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 399, ""downloads_all_time"": null, ""likes"": 213, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""internvl_chat"", ""feature-extraction"", ""internvl"", ""custom_code"", ""image-text-to-text"", ""conversational"", ""multilingual"", ""arxiv:2312.14238"", ""arxiv:2404.16821"", ""arxiv:2410.16261"", ""arxiv:2412.05271"", ""base_model:NousResearch/Hermes-2-Theta-Llama-3-70B"", ""base_model:merge:NousResearch/Hermes-2-Theta-Llama-3-70B"", ""base_model:OpenGVLab/InternViT-6B-448px-V1-5"", ""base_model:merge:OpenGVLab/InternViT-6B-448px-V1-5"", ""license:llama3"", ""region:us""], ""pipeline_tag"": ""image-text-to-text"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- OpenGVLab/InternViT-6B-448px-V1-5\n- NousResearch/Hermes-2-Theta-Llama-3-70B\nlanguage:\n- multilingual\nlibrary_name: transformers\nlicense: llama3\npipeline_tag: image-text-to-text\ntags:\n- internvl\n- custom_code\nnew_version: OpenGVLab/InternVL2_5-78B\nbase_model_relation: merge"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""InternVLChatModel""], ""auto_map"": {""AutoConfig"": ""configuration_internvl_chat.InternVLChatConfig"", ""AutoModel"": ""modeling_internvl_chat.InternVLChatModel"", ""AutoModelForCausalLM"": ""modeling_internvl_chat.InternVLChatModel""}, ""model_type"": ""internvl_chat"", ""tokenizer_config"": {""bos_token"": ""<|begin_of_text|>"", ""chat_template"": [{""name"": ""default"", ""template"": ""{{bos_token}}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}""}, {""name"": ""tool_use"", ""template"": ""{%- macro json_to_python_type(json_spec) %}\n{%- set basic_type_map = {\n \""string\"": \""str\"",\n \""number\"": \""float\"",\n \""integer\"": \""int\"",\n \""boolean\"": \""bool\""\n} %}\n\n{%- if basic_type_map[json_spec.type] is defined %}\n {{- basic_type_map[json_spec.type] }}\n{%- elif json_spec.type == \""array\"" %}\n {{- \""list[\"" + json_to_python_type(json_spec|items) + \""]\""}}\n{%- elif json_spec.type == \""object\"" %}\n {%- if json_spec.additionalProperties is defined %}\n {{- \""dict[str, \"" + json_to_python_type(json_spec.additionalProperties) + ']'}}\n {%- else %}\n {{- \""dict\"" }}\n {%- endif %}\n{%- elif json_spec.type is iterable %}\n {{- \""Union[\"" }}\n {%- for t in json_spec.type %}\n {{- json_to_python_type({\""type\"": t}) }}\n {%- if not loop.last %}\n {{- \"",\"" }} \n {%- endif %}\n {%- endfor %}\n {{- \""]\"" }}\n{%- else %}\n {{- \""Any\"" }}\n{%- endif %}\n{%- endmacro %}\n\n\n{{- bos_token }}\n{{- \""You are a function calling AI model. You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. Here are the available tools: <tools> \"" }}\n{%- for tool in tools %}\n {%- if tool.function is defined %}\n {%- set tool = tool.function %}\n {%- endif %}\n {{- '{\""type\"": \""function\"", \""function\"": ' }}\n {{- '{\""name\"": ' + tool.name + '\"", ' }}\n {{- '\""description\"": \""' + tool.name + '(' }}\n {%- for param_name, param_fields in tool.parameters.properties|items %}\n {{- param_name + \"": \"" + json_to_python_type(param_fields) }}\n {%- if not loop.last %}\n {{- \"", \"" }}\n {%- endif %}\n {%- endfor %}\n {{- \"")\"" }}\n {%- if tool.return is defined %}\n {{- \"" -> \"" + json_to_python_type(tool.return) }}\n {%- endif %}\n {{- \"" - \"" + tool.description + \""\\n\\n\"" }}\n {%- for param_name, param_fields in tool.parameters.properties|items %}\n {%- if loop.first %}\n {{- \"" Args:\\n\"" }}\n {%- endif %}\n {{- \"" \"" + param_name + \""(\"" + json_to_python_type(param_fields) + \""): \"" + param_fields.description|trim }}\n {%- endfor %}\n {%- if tool.return is defined and tool.return.description is defined %}\n {{- \""\\n Returns:\\n \"" + tool.return.description }}\n {%- endif %}\n {{- '\""' }}\n {{- ', \""parameters\"": ' }}\n {%- if tool.parameters.properties | length == 0 %}\n {{- \""{}\"" }}\n {%- else %}\n {{- tool.parameters|tojson }}\n {%- endif %}\n {{- \""}\"" }}\n {%- if not loop.last %}\n {{- \""\\n\"" }}\n {%- endif %}\n{%- endfor %}\n{{- \"" </tools>\"" }}\n{{- 'Use the following pydantic model json schema for each tool call you will make: {\""properties\"": {\""arguments\"": {\""title\"": \""Arguments\"", \""type\"": \""object\""}, \""name\"": {\""title\"": \""Name\"", \""type\"": \""string\""}}, \""required\"": [\""arguments\"", \""name\""], \""title\"": \""FunctionCall\"", \""type\"": \""object\""}\n' }}\n{{- \""For each function call return a json object with function name and arguments within <tool_call></tool_call> XML tags as follows:\n\"" }}\n{{- \""<tool_call>\n\"" }}\n{{- '{\""arguments\"": <args-dict>, \""name\"": <function-name>}\n' }}\n{{- '</tool_call><|im_end|>' }}\n{%- for message in messages %}\n {%- if message.role == \""user\"" or message.role == \""system\"" or (message.role == \""assistant\"" and message.tool_calls is not defined) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \""assistant\"" %}\n {{- '<|im_start|>' + message.role + '\\n<tool_call>\\n' }}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '{ ' }}\n {%- if tool_call.arguments is defined %}\n {{- '\""arguments\"": ' }}\n {{- tool_call.arguments|tojson }}\n {{- ', '}}\n {%- endif %}\n {{- '\""name\"": \""' }}\n {{- tool_call.name }}\n {{- '\""}' }}\n {{- '\\n</tool_call> ' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \""tool\"" %}\n {%- if not message.name is defined %}\n {{- raise_exception(\""Tool response dicts require a 'name' key indicating the name of the called function!\"") }}\n {%- endif %}\n {{- '<|im_start|>' + message.role + '\\n<tool_response>\\n' }}\n {{- '{\""name\"": \""' }}\n {{- message.name }}\n {{- '\"", \""content\"": ' }}\n {{- message.content|tojson + '}' }}\n {{- '\\n</tool_response> <|im_end|>\\n' }} \n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n""}], ""eos_token"": ""<|im_end|>"", ""pad_token"": ""<|end_of_text|>""}}, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": ""modeling_internvl_chat.InternVLChatModel"", ""pipeline_tag"": ""feature-extraction"", ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_intern_vit.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_internvl_chat.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='conversation.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/image1.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/image2.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='examples/red-panda.mp4', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00008-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00009-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00010-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00011-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00012-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00013-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00014-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00015-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00016-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00017-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00018-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00019-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00020-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00021-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00022-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00023-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00024-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00025-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00026-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00027-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00028-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00029-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00030-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00031-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00032-of-00032.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_intern_vit.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_internvl_chat.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""TIGER-Lab/MEGA-Bench"", ""awacke1/Leaderboard-Deepseek-Gemini-Grok-GPT-Qwen"", ""torettomarui/Llava-qw""], ""safetensors"": {""parameters"": {""BF16"": 76262358400}, ""total"": 76262358400}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-25 06:02:44+00:00"", ""cardData"": ""base_model:\n- OpenGVLab/InternViT-6B-448px-V1-5\n- NousResearch/Hermes-2-Theta-Llama-3-70B\nlanguage:\n- multilingual\nlibrary_name: transformers\nlicense: llama3\npipeline_tag: image-text-to-text\ntags:\n- internvl\n- custom_code\nnew_version: OpenGVLab/InternVL2_5-78B\nbase_model_relation: merge"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": ""modeling_internvl_chat.InternVLChatModel"", ""pipeline_tag"": ""feature-extraction"", ""processor"": null}, ""_id"": ""6694beb2a5108c33e684dd62"", ""modelId"": ""OpenGVLab/InternVL2-Llama3-76B"", ""usedStorage"": 152526875869}",0,,0,,0,https://huggingface.co/OpenGVLab/InternVL2-Llama3-76B-AWQ,1,,0,"OpenGVLab/InternVL, TIGER-Lab/MEGA-Bench, awacke1/Leaderboard-Deepseek-Gemini-Grok-GPT-Qwen, huggingface/InferenceSupport/discussions/new?title=OpenGVLab/InternVL2-Llama3-76B&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BOpenGVLab%2FInternVL2-Llama3-76B%5D(%2FOpenGVLab%2FInternVL2-Llama3-76B)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, torettomarui/Llava-qw",5
|
Janus-Pro-1B_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
deepseek-ai/Janus-Pro-1B,"---
|
| 3 |
+
license: mit
|
| 4 |
+
license_name: deepseek
|
| 5 |
+
license_link: LICENSE
|
| 6 |
+
pipeline_tag: any-to-any
|
| 7 |
+
library_name: transformers
|
| 8 |
+
tags:
|
| 9 |
+
- muiltimodal
|
| 10 |
+
- text-to-image
|
| 11 |
+
- unified-model
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
## 1. Introduction
|
| 15 |
+
|
| 16 |
+
Janus-Pro is a novel autoregressive framework that unifies multimodal understanding and generation.
|
| 17 |
+
It addresses the limitations of previous approaches by decoupling visual encoding into separate pathways, while still utilizing a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder’s roles in understanding and generation, but also enhances the framework’s flexibility.
|
| 18 |
+
Janus-Pro surpasses previous unified model and matches or exceeds the performance of task-specific models.
|
| 19 |
+
The simplicity, high flexibility, and effectiveness of Janus-Pro make it a strong candidate for next-generation unified multimodal models.
|
| 20 |
+
|
| 21 |
+
[**Github Repository**](https://github.com/deepseek-ai/Janus)
|
| 22 |
+
|
| 23 |
+
<div align=""center"">
|
| 24 |
+
<img alt=""image"" src=""janus_pro_teaser1.png"" style=""width:90%;"">
|
| 25 |
+
</div>
|
| 26 |
+
|
| 27 |
+
<div align=""center"">
|
| 28 |
+
<img alt=""image"" src=""janus_pro_teaser2.png"" style=""width:90%;"">
|
| 29 |
+
</div>
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
### 2. Model Summary
|
| 33 |
+
|
| 34 |
+
Janus-Pro is a unified understanding and generation MLLM, which decouples visual encoding for multimodal understanding and generation.
|
| 35 |
+
Janus-Pro is constructed based on the DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base.
|
| 36 |
+
|
| 37 |
+
For multimodal understanding, it uses the [SigLIP-L](https://huggingface.co/timm/ViT-L-16-SigLIP-384) as the vision encoder, which supports 384 x 384 image input. For image generation, Janus-Pro uses the tokenizer from [here](https://github.com/FoundationVision/LlamaGen) with a downsample rate of 16.
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
## 3. Quick Start
|
| 42 |
+
|
| 43 |
+
Please refer to [**Github Repository**](https://github.com/deepseek-ai/Janus)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
## 4. License
|
| 47 |
+
|
| 48 |
+
This code repository is licensed under [the MIT License](https://github.com/deepseek-ai/DeepSeek-LLM/blob/HEAD/LICENSE-CODE). The use of Janus-Pro models is subject to [DeepSeek Model License](https://github.com/deepseek-ai/DeepSeek-LLM/blob/HEAD/LICENSE-MODEL).
|
| 49 |
+
## 5. Citation
|
| 50 |
+
|
| 51 |
+
```
|
| 52 |
+
@article{chen2025janus,
|
| 53 |
+
title={Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling},
|
| 54 |
+
author={Chen, Xiaokang and Wu, Zhiyu and Liu, Xingchao and Pan, Zizheng and Liu, Wen and Xie, Zhenda and Yu, Xingkai and Ruan, Chong},
|
| 55 |
+
journal={arXiv preprint arXiv:2501.17811},
|
| 56 |
+
year={2025}
|
| 57 |
+
}
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
## 6. Contact
|
| 61 |
+
|
| 62 |
+
If you have any questions, please raise an issue or contact us at [service@deepseek.com](mailto:service@deepseek.com).","{""id"": ""deepseek-ai/Janus-Pro-1B"", ""author"": ""deepseek-ai"", ""sha"": ""960ab33191f61342a4c60ae74d8dc356a39fafcb"", ""last_modified"": ""2025-02-01 08:00:32+00:00"", ""created_at"": ""2025-01-26 12:07:49+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 34808, ""downloads_all_time"": null, ""likes"": 432, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""multi_modality"", ""muiltimodal"", ""text-to-image"", ""unified-model"", ""any-to-any"", ""arxiv:2501.17811"", ""license:mit"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""any-to-any"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""library_name: transformers\nlicense: mit\nlicense_name: deepseek\nlicense_link: LICENSE\npipeline_tag: any-to-any\ntags:\n- muiltimodal\n- text-to-image\n- unified-model"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""MultiModalityCausalLM""], ""model_type"": ""multi_modality"", ""tokenizer_config"": {""bos_token"": ""<\uff5cbegin\u2581of\u2581sentence\uff5c>"", ""eos_token"": ""<\uff5cend\u2581of\u2581sentence\uff5c>"", ""pad_token"": null, ""unk_token"": null, ""use_default_system_prompt"": true}}, ""transformers_info"": {""auto_model"": ""MultiModalityCausalLM"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='janus_pro_teaser1.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='janus_pro_teaser2.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='processor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""afrideva/Janus-Pro-1b"", ""mgbam/image"", ""Gemini899/Janus-Pro-1b"", ""techmilano/cloud-vector-ai-deekseek-janus"", ""techmilano/cvai-deepseek-janus"", ""NomiDecent/deepseek_Multimodal_RAG""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-01 08:00:32+00:00"", ""cardData"": ""library_name: transformers\nlicense: mit\nlicense_name: deepseek\nlicense_link: LICENSE\npipeline_tag: any-to-any\ntags:\n- muiltimodal\n- text-to-image\n- unified-model"", ""transformersInfo"": {""auto_model"": ""MultiModalityCausalLM"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""67962595a08d7b966abd37e9"", ""modelId"": ""deepseek-ai/Janus-Pro-1B"", ""usedStorage"": 8357757117}",0,"https://huggingface.co/wnma3mz/Janus-Pro-1B-LM, https://huggingface.co/wnma3mz/Janus-Pro-1B",2,,0,"https://huggingface.co/onnx-community/Janus-Pro-1B-ONNX, https://huggingface.co/wnma3mz/Janus-Pro-1B-4bit, https://huggingface.co/Casalioy/Janus-Pro-1B-q4-Casa_MLX, https://huggingface.co/AXERA-TECH/Janus-Pro-1B, https://huggingface.co/wnma3mz/Janus-Pro-1B-LM-4bit",5,,0,"Gemini899/Janus-Pro-1b, NomiDecent/deepseek_Multimodal_RAG, afrideva/Janus-Pro-1b, huggingface/InferenceSupport/discussions/new?title=deepseek-ai/Janus-Pro-1B&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bdeepseek-ai%2FJanus-Pro-1B%5D(%2Fdeepseek-ai%2FJanus-Pro-1B)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, mgbam/image, techmilano/cloud-vector-ai-deekseek-janus, techmilano/cvai-deepseek-janus",7
|
| 63 |
+
wnma3mz/Janus-Pro-1B-LM,"---
|
| 64 |
+
license: mit
|
| 65 |
+
license_name: deepseek
|
| 66 |
+
license_link: LICENSE
|
| 67 |
+
pipeline_tag: text-generation
|
| 68 |
+
library_name: transformers
|
| 69 |
+
base_model:
|
| 70 |
+
- deepseek-ai/Janus-Pro-1B
|
| 71 |
+
tags:
|
| 72 |
+
- chat
|
| 73 |
+
---
|
| 74 |
+
|
| 75 |
+
This model is derived from https://huggingface.co/deepseek-ai/Janus-Pro-1B and the main modifications are as follows
|
| 76 |
+
|
| 77 |
+
- bin files are updated to safetensors
|
| 78 |
+
- Add chat_template
|
| 79 |
+
|
| 80 |
+
`4bit` refers to quantifying the LLM part to 4 bits.
|
| 81 |
+
|
| 82 |
+
`LM` means that it contains only the language model part.
|
| 83 |
+
|
| 84 |
+
## Quick Start
|
| 85 |
+
|
| 86 |
+
In Macos (Apple silicon), use [mlx](https://github.com/ml-explore/mlx) framework https://github.com/wnma3mz/tLLM
|
| 87 |
+
|
| 88 |
+
```bash
|
| 89 |
+
tllm.server --model_path $MODEL_PATH --hostname localhost --is_local --client_size 1
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
`$MODEL_PATH` like `wnma3mz/Janus-Pro-1B-4bit`","{""id"": ""wnma3mz/Janus-Pro-1B-LM"", ""author"": ""wnma3mz"", ""sha"": ""d993cf5e0c08d5b9909f57a1c0e34a1f541b9917"", ""last_modified"": ""2025-01-30 05:34:33+00:00"", ""created_at"": ""2025-01-28 12:22:22+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 15, ""downloads_all_time"": null, ""likes"": 2, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""chat"", ""conversational"", ""base_model:deepseek-ai/Janus-Pro-1B"", ""base_model:finetune:deepseek-ai/Janus-Pro-1B"", ""license:mit"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- deepseek-ai/Janus-Pro-1B\nlibrary_name: transformers\nlicense: mit\nlicense_name: deepseek\nlicense_link: LICENSE\npipeline_tag: text-generation\ntags:\n- chat"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<\uff5cbegin\u2581of\u2581sentence\uff5c>"", ""eos_token"": ""<\uff5cend\u2581of\u2581sentence\uff5c>"", ""pad_token"": null, ""unk_token"": null, ""chat_template"": ""{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}{%- for message in messages %}{%- if message['role'] == 'system' %}{% set ns.system_prompt = message['content'] %}{%- endif %}{%- endfor %}{{ns.system_prompt}}{%- for message in messages %}{%- if message['role'] == 'user' %}{{'<|User|>: ' + message['content'] + '\\n\\n'}}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is not none %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>: ' + content + '<\uff5cend\u2581of\u2581sentence\uff5c>'}}{%- endif %}{%- endfor -%}{% if add_generation_prompt %}{{'<|Assistant|>: '}}{% endif %}"", ""use_default_system_prompt"": true}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='janus_pro_teaser1.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='janus_pro_teaser2.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='processor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F16"": 1652656128}, ""total"": 1652656128}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-01-30 05:34:33+00:00"", ""cardData"": ""base_model:\n- deepseek-ai/Janus-Pro-1B\nlibrary_name: transformers\nlicense: mit\nlicense_name: deepseek\nlicense_link: LICENSE\npipeline_tag: text-generation\ntags:\n- chat"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""6798cbfe4aa0c8099f164f5d"", ""modelId"": ""wnma3mz/Janus-Pro-1B-LM"", ""usedStorage"": 3305337400}",1,,0,,0,"https://huggingface.co/mradermacher/Janus-Pro-1B-LM-i1-GGUF, https://huggingface.co/mradermacher/Janus-Pro-1B-LM-GGUF",2,,0,huggingface/InferenceSupport/discussions/new?title=wnma3mz/Janus-Pro-1B-LM&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bwnma3mz%2FJanus-Pro-1B-LM%5D(%2Fwnma3mz%2FJanus-Pro-1B-LM)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 93 |
+
wnma3mz/Janus-Pro-1B,"---
|
| 94 |
+
license: mit
|
| 95 |
+
license_name: deepseek
|
| 96 |
+
license_link: LICENSE
|
| 97 |
+
pipeline_tag: any-to-any
|
| 98 |
+
library_name: mlx
|
| 99 |
+
base_model:
|
| 100 |
+
- deepseek-ai/Janus-Pro-1B
|
| 101 |
+
tags:
|
| 102 |
+
- chat
|
| 103 |
+
---
|
| 104 |
+
|
| 105 |
+
This model is derived from https://huggingface.co/deepseek-ai/Janus-Pro-1B and the main modifications are as follows
|
| 106 |
+
|
| 107 |
+
- bin files are updated to safetensors
|
| 108 |
+
- Add chat_template
|
| 109 |
+
|
| 110 |
+
`4bit` mainly refers to quantifying the LLM part to 4 bits.
|
| 111 |
+
|
| 112 |
+
## Quick Start
|
| 113 |
+
|
| 114 |
+
In Macos (Apple silicon), use [mlx](https://github.com/ml-explore/mlx) framework https://github.com/wnma3mz/tLLM
|
| 115 |
+
|
| 116 |
+
```bash
|
| 117 |
+
tllm.server --model_path $MODEL_PATH
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
`$MODEL_PATH` like `wnma3mz/Janus-Pro-1B-4bit`","{""id"": ""wnma3mz/Janus-Pro-1B"", ""author"": ""wnma3mz"", ""sha"": ""0fae24a328de292cd74d092a6898914a49d07cec"", ""last_modified"": ""2025-02-01 13:00:33+00:00"", ""created_at"": ""2025-01-30 05:45:19+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 21, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""mlx"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""mlx"", ""safetensors"", ""chat"", ""any-to-any"", ""base_model:deepseek-ai/Janus-Pro-1B"", ""base_model:finetune:deepseek-ai/Janus-Pro-1B"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""any-to-any"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- deepseek-ai/Janus-Pro-1B\nlibrary_name: mlx\nlicense: mit\nlicense_name: deepseek\nlicense_link: LICENSE\npipeline_tag: any-to-any\ntags:\n- chat"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""JanusProConditionalGeneration""], ""tokenizer_config"": {""bos_token"": ""<\uff5cbegin\u2581of\u2581sentence\uff5c>"", ""eos_token"": ""<\uff5cend\u2581of\u2581sentence\uff5c>"", ""pad_token"": null, ""unk_token"": null, ""chat_template"": ""{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='You are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language.') %}{%- for message in messages %}{%- if message['role'] == 'system' %}{% set ns.system_prompt = message['content'] %}{% break %}{%- endif %}{%- endfor %}{{ns.system_prompt}}{% if ns.system_prompt %}{{'\n\n'}}{% endif %}{%- for message in messages %}{%- if message['role'] == 'user' %}{{'<|User|>: ' + message['content'] + '\n\n'}}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is not none %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>: ' + content}}{% if add_generation_prompt or '</think>' in content %}{{'<\uff5cend of sentence\uff5c>'}}{% endif %}{%- endif %}{%- endfor -%}{% if add_generation_prompt %}{{'<|Assistant|>:'}}{% endif %}"", ""use_default_system_prompt"": true}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='processor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F16"": 2089297547}, ""total"": 2089297547}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-01 13:00:33+00:00"", ""cardData"": ""base_model:\n- deepseek-ai/Janus-Pro-1B\nlibrary_name: mlx\nlicense: mit\nlicense_name: deepseek\nlicense_link: LICENSE\npipeline_tag: any-to-any\ntags:\n- chat"", ""transformersInfo"": null, ""_id"": ""679b11ef25cd3e855df85ff0"", ""modelId"": ""wnma3mz/Janus-Pro-1B"", ""usedStorage"": 4178705502}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=wnma3mz/Janus-Pro-1B&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bwnma3mz%2FJanus-Pro-1B%5D(%2Fwnma3mz%2FJanus-Pro-1B)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
Janus-Pro-7B_finetunes_20250422_225821.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
LLaMA-7B_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
nyanko7/LLaMA-7B,"---
|
| 3 |
+
license: openrail
|
| 4 |
+
---
|
| 5 |
+
","{""id"": ""nyanko7/LLaMA-7B"", ""author"": ""nyanko7"", ""sha"": ""3b94aad3d8e39981b81e14239446d935b6dbf2bd"", ""last_modified"": ""2023-03-04 02:18:23+00:00"", ""created_at"": ""2023-03-04 01:59:47+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 211, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""license:openrail"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: openrail"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='checklist.chk', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='consolidated.00.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='params.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)""], ""spaces"": [""csuhan/LLaMA-Adapter"", ""xuxw98/TAPA"", ""heikowagner/GPT-Docker"", ""heikowagner/GPT-Docker2"", ""UTOPIA-DXD/LLaMA-Adapter""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-03-04 02:18:23+00:00"", ""cardData"": ""license: openrail"", ""transformersInfo"": null, ""_id"": ""6402a61302594ec43ec340a4"", ""modelId"": ""nyanko7/LLaMA-7B"", ""usedStorage"": 13477439239}",0,https://huggingface.co/haarismian/cyberbullying-llama,1,,0,,0,,0,"UTOPIA-DXD/LLaMA-Adapter, csuhan/LLaMA-Adapter, heikowagner/GPT-Docker, heikowagner/GPT-Docker2, huggingface/InferenceSupport/discussions/new?title=nyanko7/LLaMA-7B&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bnyanko7%2FLLaMA-7B%5D(%2Fnyanko7%2FLLaMA-7B)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, xuxw98/TAPA",6
|
| 6 |
+
haarismian/cyberbullying-llama,"---
|
| 7 |
+
license: mit
|
| 8 |
+
language:
|
| 9 |
+
- en
|
| 10 |
+
base_model:
|
| 11 |
+
- nyanko7/LLaMA-7B
|
| 12 |
+
datasets:
|
| 13 |
+
- haarismian/ejaz-et-al-dataset
|
| 14 |
+
metrics:
|
| 15 |
+
- accuracy
|
| 16 |
+
---
|
| 17 |
+
# Model Card for Model ID
|
| 18 |
+
|
| 19 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 20 |
+
|
| 21 |
+
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
|
| 22 |
+
|
| 23 |
+
## Model Details
|
| 24 |
+
|
| 25 |
+
### Model Description
|
| 26 |
+
|
| 27 |
+
<!-- Provide a longer summary of what this model is. -->
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
- **Developed by:** Haaris Mian
|
| 32 |
+
- **Funded by [optional]:** Self Funded for MSc Dissertation
|
| 33 |
+
|
| 34 |
+
- **Finetuned from model [optional]:** LLaMA 2 7B
|
| 35 |
+
|
| 36 |
+
### Model Sources [optional]
|
| 37 |
+
|
| 38 |
+
<!-- Provide the basic links for the model. -->
|
| 39 |
+
|
| 40 |
+
- **Repository:** [More Information Needed]
|
| 41 |
+
- **Paper [optional]:** [More Information Needed]
|
| 42 |
+
- **Demo [optional]:** [More Information Needed]
|
| 43 |
+
|
| 44 |
+
## Uses
|
| 45 |
+
|
| 46 |
+
<!-- The model is intended for research and academic purposes in understanding and mitigating cyberbullying. It can be used to detect harmful online interactions and assist in content moderation.-->
|
| 47 |
+
|
| 48 |
+
### Direct Use
|
| 49 |
+
|
| 50 |
+
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
|
| 51 |
+
|
| 52 |
+
[More Information Needed]
|
| 53 |
+
|
| 54 |
+
### Downstream Use [optional]
|
| 55 |
+
|
| 56 |
+
<!-- Automated moderation of social media platforms.
|
| 57 |
+
|
| 58 |
+
Enhancing AI-powered chatbot moderation.
|
| 59 |
+
|
| 60 |
+
Supporting online safety tools and AI-driven reporting mechanisms. -->","{""id"": ""haarismian/cyberbullying-llama"", ""author"": ""haarismian"", ""sha"": ""467bea92c38ada2f8d14fde65856d92e2e76ac9b"", ""last_modified"": ""2025-02-24 00:38:02+00:00"", ""created_at"": ""2025-02-24 00:15:24+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""en"", ""dataset:haarismian/ejaz-et-al-dataset"", ""base_model:nyanko7/LLaMA-7B"", ""base_model:finetune:nyanko7/LLaMA-7B"", ""license:mit"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- nyanko7/LLaMA-7B\ndatasets:\n- haarismian/ejaz-et-al-dataset\nlanguage:\n- en\nlicense: mit\nmetrics:\n- accuracy"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-24 00:38:02+00:00"", ""cardData"": ""base_model:\n- nyanko7/LLaMA-7B\ndatasets:\n- haarismian/ejaz-et-al-dataset\nlanguage:\n- en\nlicense: mit\nmetrics:\n- accuracy"", ""transformersInfo"": null, ""_id"": ""67bbba1c87fb28f3ecc01e4d"", ""modelId"": ""haarismian/cyberbullying-llama"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=haarismian/cyberbullying-llama&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bhaarismian%2Fcyberbullying-llama%5D(%2Fhaarismian%2Fcyberbullying-llama)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
Llama-2-7b-hf_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Llama-3-8B-Instruct-262k_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Llama-3-8B-Lexi-Uncensored_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,273 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
Orenguteng/Llama-3-8B-Lexi-Uncensored,"---
|
| 3 |
+
license: llama3
|
| 4 |
+
tags:
|
| 5 |
+
- uncensored
|
| 6 |
+
- llama3
|
| 7 |
+
- instruct
|
| 8 |
+
- open
|
| 9 |
+
model-index:
|
| 10 |
+
- name: Llama-3-8B-Lexi-Uncensored
|
| 11 |
+
results:
|
| 12 |
+
- task:
|
| 13 |
+
type: text-generation
|
| 14 |
+
name: Text Generation
|
| 15 |
+
dataset:
|
| 16 |
+
name: AI2 Reasoning Challenge (25-Shot)
|
| 17 |
+
type: ai2_arc
|
| 18 |
+
config: ARC-Challenge
|
| 19 |
+
split: test
|
| 20 |
+
args:
|
| 21 |
+
num_few_shot: 25
|
| 22 |
+
metrics:
|
| 23 |
+
- type: acc_norm
|
| 24 |
+
value: 59.56
|
| 25 |
+
name: normalized accuracy
|
| 26 |
+
source:
|
| 27 |
+
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored
|
| 28 |
+
name: Open LLM Leaderboard
|
| 29 |
+
- task:
|
| 30 |
+
type: text-generation
|
| 31 |
+
name: Text Generation
|
| 32 |
+
dataset:
|
| 33 |
+
name: HellaSwag (10-Shot)
|
| 34 |
+
type: hellaswag
|
| 35 |
+
split: validation
|
| 36 |
+
args:
|
| 37 |
+
num_few_shot: 10
|
| 38 |
+
metrics:
|
| 39 |
+
- type: acc_norm
|
| 40 |
+
value: 77.88
|
| 41 |
+
name: normalized accuracy
|
| 42 |
+
source:
|
| 43 |
+
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored
|
| 44 |
+
name: Open LLM Leaderboard
|
| 45 |
+
- task:
|
| 46 |
+
type: text-generation
|
| 47 |
+
name: Text Generation
|
| 48 |
+
dataset:
|
| 49 |
+
name: MMLU (5-Shot)
|
| 50 |
+
type: cais/mmlu
|
| 51 |
+
config: all
|
| 52 |
+
split: test
|
| 53 |
+
args:
|
| 54 |
+
num_few_shot: 5
|
| 55 |
+
metrics:
|
| 56 |
+
- type: acc
|
| 57 |
+
value: 67.68
|
| 58 |
+
name: accuracy
|
| 59 |
+
source:
|
| 60 |
+
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored
|
| 61 |
+
name: Open LLM Leaderboard
|
| 62 |
+
- task:
|
| 63 |
+
type: text-generation
|
| 64 |
+
name: Text Generation
|
| 65 |
+
dataset:
|
| 66 |
+
name: TruthfulQA (0-shot)
|
| 67 |
+
type: truthful_qa
|
| 68 |
+
config: multiple_choice
|
| 69 |
+
split: validation
|
| 70 |
+
args:
|
| 71 |
+
num_few_shot: 0
|
| 72 |
+
metrics:
|
| 73 |
+
- type: mc2
|
| 74 |
+
value: 47.72
|
| 75 |
+
source:
|
| 76 |
+
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored
|
| 77 |
+
name: Open LLM Leaderboard
|
| 78 |
+
- task:
|
| 79 |
+
type: text-generation
|
| 80 |
+
name: Text Generation
|
| 81 |
+
dataset:
|
| 82 |
+
name: Winogrande (5-shot)
|
| 83 |
+
type: winogrande
|
| 84 |
+
config: winogrande_xl
|
| 85 |
+
split: validation
|
| 86 |
+
args:
|
| 87 |
+
num_few_shot: 5
|
| 88 |
+
metrics:
|
| 89 |
+
- type: acc
|
| 90 |
+
value: 75.85
|
| 91 |
+
name: accuracy
|
| 92 |
+
source:
|
| 93 |
+
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored
|
| 94 |
+
name: Open LLM Leaderboard
|
| 95 |
+
- task:
|
| 96 |
+
type: text-generation
|
| 97 |
+
name: Text Generation
|
| 98 |
+
dataset:
|
| 99 |
+
name: GSM8k (5-shot)
|
| 100 |
+
type: gsm8k
|
| 101 |
+
config: main
|
| 102 |
+
split: test
|
| 103 |
+
args:
|
| 104 |
+
num_few_shot: 5
|
| 105 |
+
metrics:
|
| 106 |
+
- type: acc
|
| 107 |
+
value: 68.39
|
| 108 |
+
name: accuracy
|
| 109 |
+
source:
|
| 110 |
+
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored
|
| 111 |
+
name: Open LLM Leaderboard
|
| 112 |
+
---
|
| 113 |
+
|
| 114 |
+

|
| 115 |
+
|
| 116 |
+
This model is based on Llama-3-8b-Instruct, and is governed by [META LLAMA 3 COMMUNITY LICENSE AGREEMENT](https://llama.meta.com/llama3/license/)
|
| 117 |
+
|
| 118 |
+
Lexi is uncensored, which makes the model compliant. You are advised to implement your own alignment layer before exposing the model as a service. It will be highly compliant with any requests, even unethical ones.
|
| 119 |
+
|
| 120 |
+
You are responsible for any content you create using this model. Please use it responsibly.
|
| 121 |
+
|
| 122 |
+
Lexi is licensed according to Meta's Llama license. I grant permission for any use, including commercial, that falls within accordance with Meta's Llama-3 license.
|
| 123 |
+
|
| 124 |
+
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
|
| 125 |
+
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Orenguteng__Llama-3-8B-Lexi-Uncensored)
|
| 126 |
+
|
| 127 |
+
| Metric |Value|
|
| 128 |
+
|---------------------------------|----:|
|
| 129 |
+
|Avg. |66.18|
|
| 130 |
+
|AI2 Reasoning Challenge (25-Shot)|59.56|
|
| 131 |
+
|HellaSwag (10-Shot) |77.88|
|
| 132 |
+
|MMLU (5-Shot) |67.68|
|
| 133 |
+
|TruthfulQA (0-shot) |47.72|
|
| 134 |
+
|Winogrande (5-shot) |75.85|
|
| 135 |
+
|GSM8k (5-shot) |68.39|
|
| 136 |
+
|
| 137 |
+
","{""id"": ""Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""author"": ""Orenguteng"", ""sha"": ""ff95e3bfcd6142759ce82099b58bc7a789ac241b"", ""last_modified"": ""2024-05-27 06:16:40+00:00"", ""created_at"": ""2024-04-23 21:14:40+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 284967, ""downloads_all_time"": null, ""likes"": 219, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""llama"", ""text-generation"", ""uncensored"", ""llama3"", ""instruct"", ""open"", ""conversational"", ""license:llama3"", ""model-index"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: llama3\ntags:\n- uncensored\n- llama3\n- instruct\n- open\nmodel-index:\n- name: Llama-3-8B-Lexi-Uncensored\n results:\n - task:\n type: text-generation\n name: Text Generation\n dataset:\n name: AI2 Reasoning Challenge (25-Shot)\n type: ai2_arc\n config: ARC-Challenge\n split: test\n args:\n num_few_shot: 25\n metrics:\n - type: acc_norm\n value: 59.56\n name: normalized accuracy\n verified: false\n source:\n url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored\n name: Open LLM Leaderboard\n - task:\n type: text-generation\n name: Text Generation\n dataset:\n name: HellaSwag (10-Shot)\n type: hellaswag\n split: validation\n args:\n num_few_shot: 10\n metrics:\n - type: acc_norm\n value: 77.88\n name: normalized accuracy\n verified: false\n source:\n url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored\n name: Open LLM Leaderboard\n - task:\n type: text-generation\n name: Text Generation\n dataset:\n name: MMLU (5-Shot)\n type: cais/mmlu\n config: all\n split: test\n args:\n num_few_shot: 5\n metrics:\n - type: acc\n value: 67.68\n name: accuracy\n verified: false\n source:\n url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored\n name: Open LLM Leaderboard\n - task:\n type: text-generation\n name: Text Generation\n dataset:\n name: TruthfulQA (0-shot)\n type: truthful_qa\n config: multiple_choice\n split: validation\n args:\n num_few_shot: 0\n metrics:\n - type: mc2\n value: 47.72\n verified: false\n source:\n url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored\n name: Open LLM Leaderboard\n - task:\n type: text-generation\n name: Text Generation\n dataset:\n name: Winogrande (5-shot)\n type: winogrande\n config: winogrande_xl\n split: validation\n args:\n num_few_shot: 5\n metrics:\n - type: acc\n value: 75.85\n name: accuracy\n verified: false\n source:\n url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored\n name: Open LLM Leaderboard\n - task:\n type: text-generation\n name: Text Generation\n dataset:\n name: GSM8k (5-shot)\n type: gsm8k\n config: main\n split: test\n args:\n num_few_shot: 5\n metrics:\n - type: acc\n value: 68.39\n name: accuracy\n verified: false\n source:\n url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored\n name: Open LLM Leaderboard"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": [{""name"": ""Llama-3-8B-Lexi-Uncensored"", ""results"": [{""task"": {""type"": ""text-generation"", ""name"": ""Text Generation""}, ""dataset"": {""name"": ""AI2 Reasoning Challenge (25-Shot)"", ""type"": ""ai2_arc"", ""config"": ""ARC-Challenge"", ""split"": ""test"", ""args"": {""num_few_shot"": 25}}, ""metrics"": [{""type"": ""acc_norm"", ""value"": 59.56, ""name"": ""normalized accuracy"", ""verified"": false}], ""source"": {""url"": ""https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""name"": ""Open LLM Leaderboard""}}, {""task"": {""type"": ""text-generation"", ""name"": ""Text Generation""}, ""dataset"": {""name"": ""HellaSwag (10-Shot)"", ""type"": ""hellaswag"", ""split"": ""validation"", ""args"": {""num_few_shot"": 10}}, ""metrics"": [{""type"": ""acc_norm"", ""value"": 77.88, ""name"": ""normalized accuracy"", ""verified"": false}], ""source"": {""url"": ""https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""name"": ""Open LLM Leaderboard""}}, {""task"": {""type"": ""text-generation"", ""name"": ""Text Generation""}, ""dataset"": {""name"": ""MMLU (5-Shot)"", ""type"": ""cais/mmlu"", ""config"": ""all"", ""split"": ""test"", ""args"": {""num_few_shot"": 5}}, ""metrics"": [{""type"": ""acc"", ""value"": 67.68, ""name"": ""accuracy"", ""verified"": false}], ""source"": {""url"": ""https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""name"": ""Open LLM Leaderboard""}}, {""task"": {""type"": ""text-generation"", ""name"": ""Text Generation""}, ""dataset"": {""name"": ""TruthfulQA (0-shot)"", ""type"": ""truthful_qa"", ""config"": ""multiple_choice"", ""split"": ""validation"", ""args"": {""num_few_shot"": 0}}, ""metrics"": [{""type"": ""mc2"", ""value"": 47.72, ""verified"": false}], ""source"": {""url"": ""https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""name"": ""Open LLM Leaderboard""}}, {""task"": {""type"": ""text-generation"", ""name"": ""Text Generation""}, ""dataset"": {""name"": ""Winogrande (5-shot)"", ""type"": ""winogrande"", ""config"": ""winogrande_xl"", ""split"": ""validation"", ""args"": {""num_few_shot"": 5}}, ""metrics"": [{""type"": ""acc"", ""value"": 75.85, ""name"": ""accuracy"", ""verified"": false}], ""source"": {""url"": ""https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""name"": ""Open LLM Leaderboard""}}, {""task"": {""type"": ""text-generation"", ""name"": ""Text Generation""}, ""dataset"": {""name"": ""GSM8k (5-shot)"", ""type"": ""gsm8k"", ""config"": ""main"", ""split"": ""test"", ""args"": {""num_few_shot"": 5}}, ""metrics"": [{""type"": ""acc"", ""value"": 68.39, ""name"": ""accuracy"", ""verified"": false}], ""source"": {""url"": ""https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""name"": ""Open LLM Leaderboard""}}]}], ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<|begin_of_text|>"", ""chat_template"": ""{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{% if add_generation_prompt %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}{% endif %}"", ""eos_token"": ""<|eot_id|>"", ""pad_token"": ""<|end_of_text|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00004.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""KBaba7/Quant"", ""bhaskartripathi/LLM_Quantization"", ""totolook/Quant"", ""FallnAI/Quantize-HF-Models"", ""DevTzar/Orenguteng-Llama-3-8B-Lexi-Uncensored"", ""ruslanmv/convert_to_gguf"", ""SlyFox29/Quaken_Llama"", ""SlyFox29/Colonial_Llama"", ""AiJoker/Orenguteng-Llama-3-8B-Lexi-Uncensored"", ""basenban/Orenguteng-Llama-3-8B-Lexi-Uncensored"", ""Animus2018/Orenguteng-Llama-3-8B-Lexi-Uncensored"", ""tempwuefasdf/Orenguteng-Llama-3-8B-Lexi-Uncensored"", ""saumyadave24/hi"", ""asdaswadefswefr/sadbot2"", ""kaeyumir/Orenguteng-Llama-3-8B-Lexi-Uncensored"", ""abmSS/Orenguteng-Llama-3-8BKNK-Lexi-Uncensored"", ""Zadei/Orenguteng-Llama-3-8B-Lexi-Uncensored"", ""thara002/test"", ""UNION-KevinLan/Orenguteng-Llama-3-8B-Lexi-Uncensored"", ""nananie143/advanced-reasoning"", ""nananie143/agentic-system"", ""OscarFAI/inference"", ""K00B404/LLM_Quantization""], ""safetensors"": {""parameters"": {""F32"": 805306368, ""BF16"": 7224954880}, ""total"": 8030261248}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-05-27 06:16:40+00:00"", ""cardData"": ""license: llama3\ntags:\n- uncensored\n- llama3\n- instruct\n- open\nmodel-index:\n- name: Llama-3-8B-Lexi-Uncensored\n results:\n - task:\n type: text-generation\n name: Text Generation\n dataset:\n name: AI2 Reasoning Challenge (25-Shot)\n type: ai2_arc\n config: ARC-Challenge\n split: test\n args:\n num_few_shot: 25\n metrics:\n - type: acc_norm\n value: 59.56\n name: normalized accuracy\n verified: false\n source:\n url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored\n name: Open LLM Leaderboard\n - task:\n type: text-generation\n name: Text Generation\n dataset:\n name: HellaSwag (10-Shot)\n type: hellaswag\n split: validation\n args:\n num_few_shot: 10\n metrics:\n - type: acc_norm\n value: 77.88\n name: normalized accuracy\n verified: false\n source:\n url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored\n name: Open LLM Leaderboard\n - task:\n type: text-generation\n name: Text Generation\n dataset:\n name: MMLU (5-Shot)\n type: cais/mmlu\n config: all\n split: test\n args:\n num_few_shot: 5\n metrics:\n - type: acc\n value: 67.68\n name: accuracy\n verified: false\n source:\n url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored\n name: Open LLM Leaderboard\n - task:\n type: text-generation\n name: Text Generation\n dataset:\n name: TruthfulQA (0-shot)\n type: truthful_qa\n config: multiple_choice\n split: validation\n args:\n num_few_shot: 0\n metrics:\n - type: mc2\n value: 47.72\n verified: false\n source:\n url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored\n name: Open LLM Leaderboard\n - task:\n type: text-generation\n name: Text Generation\n dataset:\n name: Winogrande (5-shot)\n type: winogrande\n config: winogrande_xl\n split: validation\n args:\n num_few_shot: 5\n metrics:\n - type: acc\n value: 75.85\n name: accuracy\n verified: false\n source:\n url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored\n name: Open LLM Leaderboard\n - task:\n type: text-generation\n name: Text Generation\n dataset:\n name: GSM8k (5-shot)\n type: gsm8k\n config: main\n split: test\n args:\n num_few_shot: 5\n metrics:\n - type: acc\n value: 68.39\n name: accuracy\n verified: false\n source:\n url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored\n name: Open LLM Leaderboard"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""662824c0bfeb2ea792d69f33"", ""modelId"": ""Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""usedStorage"": 17671168912}",0,"https://huggingface.co/PrunaAI/Orenguteng-Llama-3-8B-Lexi-Uncensored-HQQ-2bit-smashed, https://huggingface.co/scoliono/groupchat_lora_lexi_8b, https://huggingface.co/canTooDdev/LlamaWalter2",3,"https://huggingface.co/DesDea1/c101b3c6-dc54-441b-bc5c-d61fd0478fa9, https://huggingface.co/dada22231/5589168d-ec89-491d-b56d-03288e102c16, https://huggingface.co/nblinh63/5589168d-ec89-491d-b56d-03288e102c16, https://huggingface.co/eeeebbb2/add2f783-1808-4e94-9d46-4cfcf3b56992, https://huggingface.co/eeeebbb2/b2237d4d-aa9b-4276-ac4a-8a47f85a31e8, https://huggingface.co/laquythang/e4815ca4-4e52-4e25-96c3-9429db1ba0c6, https://huggingface.co/nblinh63/e4815ca4-4e52-4e25-96c3-9429db1ba0c6, https://huggingface.co/nblinh/e4815ca4-4e52-4e25-96c3-9429db1ba0c6, https://huggingface.co/eeeebbb2/e4815ca4-4e52-4e25-96c3-9429db1ba0c6, https://huggingface.co/dada22231/e4815ca4-4e52-4e25-96c3-9429db1ba0c6, https://huggingface.co/dada22231/8930a01c-082f-4c01-82c3-703887d7b3dc, https://huggingface.co/dada22231/e3c2746b-40eb-46bd-b52a-a864ae679571, https://huggingface.co/kooff11/e3c2746b-40eb-46bd-b52a-a864ae679571, https://huggingface.co/DeepDream2045/e15bb719-ea8f-46ea-8290-e5573063df0e, https://huggingface.co/vdos/e15bb719-ea8f-46ea-8290-e5573063df0e, https://huggingface.co/Rodo-Sami/e15bb719-ea8f-46ea-8290-e5573063df0e, https://huggingface.co/dada22231/e15bb719-ea8f-46ea-8290-e5573063df0e, https://huggingface.co/eeeebbb2/e15bb719-ea8f-46ea-8290-e5573063df0e, https://huggingface.co/Rodo-Sami/4f6d5dbe-c5bf-469a-a8bd-ac53a38104c1, https://huggingface.co/vdos/4f6d5dbe-c5bf-469a-a8bd-ac53a38104c1, https://huggingface.co/dimasik1987/5aa407fb-7336-4e21-87a7-80e987ee6437, https://huggingface.co/thalllsssss/5aa407fb-7336-4e21-87a7-80e987ee6437, https://huggingface.co/dimasik1987/74f5bf43-4a1b-44bb-9b95-6b5631ccfc3e, https://huggingface.co/lesso07/74f5bf43-4a1b-44bb-9b95-6b5631ccfc3e, https://huggingface.co/VERSIL91/a5a501fc-25a9-421c-a345-beb689b39e8a, https://huggingface.co/VERSIL91/9b3bfef1-1223-474e-97ff-c198ff0ab42c, https://huggingface.co/tarabukinivan/9b3bfef1-1223-474e-97ff-c198ff0ab42c, https://huggingface.co/tuanna08go/50bac6aa-85a2-403c-a522-11eb1be31abc, https://huggingface.co/VERSIL91/50bac6aa-85a2-403c-a522-11eb1be31abc, https://huggingface.co/lesso07/1e612fba-6f1d-4912-b2de-3e3388cd2164, https://huggingface.co/VERSIL91/1e612fba-6f1d-4912-b2de-3e3388cd2164, https://huggingface.co/nadejdatarabukina/d4c8a02e-2134-4039-b41e-e6d99462824d, https://huggingface.co/lesso08/d4c8a02e-2134-4039-b41e-e6d99462824d, https://huggingface.co/dimasik2987/d4c8a02e-2134-4039-b41e-e6d99462824d, https://huggingface.co/kokovova/15bf3ed5-8661-48f5-9d5d-a7047f62ad09, https://huggingface.co/lesso08/15bf3ed5-8661-48f5-9d5d-a7047f62ad09, https://huggingface.co/lesso02/15bf3ed5-8661-48f5-9d5d-a7047f62ad09, https://huggingface.co/hongngo/15bf3ed5-8661-48f5-9d5d-a7047f62ad09, https://huggingface.co/lesso05/d4c8a02e-2134-4039-b41e-e6d99462824d, https://huggingface.co/lesso07/15bf3ed5-8661-48f5-9d5d-a7047f62ad09, https://huggingface.co/lesso01/9eb6fe53-3d22-4f8a-aeac-2491baa2356c, https://huggingface.co/dzanbek/9eb6fe53-3d22-4f8a-aeac-2491baa2356c, https://huggingface.co/thaffggg/a0415c06-a436-4903-a853-cf2d53b0beff, https://huggingface.co/tarabukinivan/217ebb40-daa9-4e00-99de-eea1375e7a57, https://huggingface.co/lesso05/217ebb40-daa9-4e00-99de-eea1375e7a57, https://huggingface.co/lesso01/217ebb40-daa9-4e00-99de-eea1375e7a57, https://huggingface.co/hongngo/37f282ca-c51b-4c80-abbd-08ec5e67729e, https://huggingface.co/ivangrapher/ff34825d-d226-4b29-80c4-e1fcab3fbe85, https://huggingface.co/lesso02/ff34825d-d226-4b29-80c4-e1fcab3fbe85, https://huggingface.co/tuanna08go/ff34825d-d226-4b29-80c4-e1fcab3fbe85, https://huggingface.co/tarabukinivan/c5b2002e-a8a7-47f8-92d2-1145f7771181, https://huggingface.co/lesso06/c5b2002e-a8a7-47f8-92d2-1145f7771181, https://huggingface.co/cunghoctienganh/c5b2002e-a8a7-47f8-92d2-1145f7771181, https://huggingface.co/bbytxt/c5b2002e-a8a7-47f8-92d2-1145f7771181, https://huggingface.co/lesso05/fea6a7f6-5768-46b2-8073-ff96f567f2c9, https://huggingface.co/ivangrapher/fea6a7f6-5768-46b2-8073-ff96f567f2c9, https://huggingface.co/VERSIL91/fea6a7f6-5768-46b2-8073-ff96f567f2c9, https://huggingface.co/lesso08/fea6a7f6-5768-46b2-8073-ff96f567f2c9, https://huggingface.co/lesso03/19c02379-52ce-4259-8001-4cb1e57279c2, https://huggingface.co/bbytxt/19c02379-52ce-4259-8001-4cb1e57279c2, https://huggingface.co/nttx/19c02379-52ce-4259-8001-4cb1e57279c2, https://huggingface.co/cunghoctienganh/b702275d-23b5-4897-a306-7e984db67567, https://huggingface.co/VERSIL91/83856434-3640-462d-b03b-f9640982389e, https://huggingface.co/nttx/536ba553-9701-4fb3-9d86-95f6b2679893, https://huggingface.co/duyphu/b702275d-23b5-4897-a306-7e984db67567, https://huggingface.co/chauhoang/b702275d-23b5-4897-a306-7e984db67567, https://huggingface.co/kokovova/f5a371c6-b598-4f49-9aaa-c335bac9d3cb, https://huggingface.co/nhung02/f5a371c6-b598-4f49-9aaa-c335bac9d3cb, https://huggingface.co/thaffggg/f5a371c6-b598-4f49-9aaa-c335bac9d3cb, https://huggingface.co/phungkhaccuong/f5a371c6-b598-4f49-9aaa-c335bac9d3cb, https://huggingface.co/lesso06/8ccd446a-0d47-4313-a2bf-6fea19607f54, https://huggingface.co/nbninh/8ccd446a-0d47-4313-a2bf-6fea19607f54, https://huggingface.co/VERSIL91/8ccd446a-0d47-4313-a2bf-6fea19607f54, https://huggingface.co/dzanbek/ceef632e-f2fa-449b-a77c-22dff3b23ef5, https://huggingface.co/dzanbek/ef0e7220-dcbb-4819-a649-c74b01532a33, https://huggingface.co/lesso08/ef0e7220-dcbb-4819-a649-c74b01532a33, https://huggingface.co/VERSIL91/ef0e7220-dcbb-4819-a649-c74b01532a33, https://huggingface.co/bbytxt/ef0e7220-dcbb-4819-a649-c74b01532a33, https://huggingface.co/phungkhaccuong/8ccd446a-0d47-4313-a2bf-6fea19607f54, https://huggingface.co/nbninh/7fa985bf-6be0-40a0-8f01-e6cdd4b8d15c, https://huggingface.co/duyphu/d191d1e5-202f-29b8-f2c9-95bb6e479ff7, https://huggingface.co/lesso06/2d46aef7-a5de-41b7-89c5-f635c4818888, https://huggingface.co/lesso11/d3034b29-4944-4718-a3df-4ef89ea15152, https://huggingface.co/dimasik87/3bb55dcd-fe5a-4e50-b35d-bbe551edee20, https://huggingface.co/dzanbek/272fa23f-5941-44c4-9f54-bc964f647a9a, https://huggingface.co/chauhoang/8c1f3292-1794-6e6c-7890-503da1c075b9, https://huggingface.co/duyphu/0597210d-b1e7-fd1e-21e0-79eaab9ae9fb, https://huggingface.co/phungkhaccuong/7f7b6935-fd00-8b8e-f429-eb26353d3ffb, https://huggingface.co/cunghoctienganh/0185bc9c-7e35-40cb-aade-a081498f9cd7, https://huggingface.co/phungkhaccuong/eff65c60-daeb-4604-5781-a6c80e44f3ee, https://huggingface.co/filipesantoscv11/d6f48720-956e-44a7-ba9a-a69a061ada8d, https://huggingface.co/cunghoctienganh/1d015be7-0240-4846-a1a6-44987d920b8c, https://huggingface.co/lhong4759/d1c05990-8228-4946-bd35-5567ce1f996e, https://huggingface.co/filipesantoscv11/8bbe6f56-6033-4962-b7fa-45d1f75ed594, https://huggingface.co/lhong4759/29c9a7fb-e34c-4e02-bd97-bd07548e5853, https://huggingface.co/cunghoctienganh/804fc515-e956-4171-b539-ff2acb27a802, https://huggingface.co/VERSIL91/947b25e3-b276-4a08-8875-e5b98a03e2b8, https://huggingface.co/kk-aivio/decea65c-2daa-4bdd-b988-57df9b8f720e, https://huggingface.co/duyphu/c8477066-313e-4f43-fc45-e63527d89911, https://huggingface.co/filipesantoscv11/f6935419-ce8d-44e9-ac9d-0938bd53a60a, https://huggingface.co/phungkhaccuong/1da9e8d4-ae8a-bacd-8a79-38d9f0206cfa, https://huggingface.co/cunghoctienganh/a0882e49-30f6-4419-b070-58c89ca5994c, https://huggingface.co/nttx/9c8aa6ce-d6d8-48c0-8351-fd0d3dfc41ad, https://huggingface.co/thalllsssss/822a776d-c9bb-4850-a280-9cd752f236c4, https://huggingface.co/dzanbek/d30fe830-0e74-4679-87dd-4d6365915a46, https://huggingface.co/tuanna08go/ce8c1885-4011-1f8f-61d8-eb10d1daba72, https://huggingface.co/lesso03/b79decec-9467-4cb4-97b9-f12fe5d9856d, https://huggingface.co/lesso11/7083f0d9-6dc2-47c2-8cc7-b5a8f0e18268, https://huggingface.co/nhoxinh/b4d0121f-10ed-4727-b51a-733377367939, https://huggingface.co/lesso12/767d0f7c-1368-419a-b397-aa4a1a2b8141, https://huggingface.co/chauhoang/b7f88dd5-46c5-d6dd-7978-67587574c893, https://huggingface.co/prxy5605/2b79dd5a-8504-42db-9927-b0eec9004488, https://huggingface.co/prxy5604/974ea3a8-4175-4aff-a043-ac1e8915ed7d, https://huggingface.co/mrhunghd/ff823da0-8e2b-47f2-a114-4630f8ace140, https://huggingface.co/vermoney/aa62e62e-cd1d-45d0-9a23-cc1e5758254e, https://huggingface.co/nhung01/d5c74986-024c-48ab-8372-4af6df2a60dc, https://huggingface.co/chauhoang/351901c8-9a9c-4e58-83a3-39c60859993c, https://huggingface.co/VERSIL91/25e91404-fe01-4312-a741-3956a59f77f2, https://huggingface.co/FatCat87/taopanda-1_279e5cfb-d198-4bf0-8895-5af873459233, https://huggingface.co/nttx/72879849-db2b-49dd-ae28-983818de72e1, https://huggingface.co/prxy5607/58e13912-36fe-41e6-b320-ed0b12501097, https://huggingface.co/kokovova/27c36b34-c78d-4218-8a6d-4b9f8b6571fa, https://huggingface.co/phungkhaccuong/9842c1d0-6a0c-4e12-8f03-406af2ec0a3e, https://huggingface.co/aleegis10/774384b1-2027-4c99-8d1e-5c7420c09af9, https://huggingface.co/cunghoctienganh/17de06bc-8dc5-42a2-8e5d-9b8af6efecb8, https://huggingface.co/nblinh/87219660-6063-4a2d-923a-067ccba8718d, https://huggingface.co/hongngo/6428d252-a689-42c7-9288-19190efe172f, https://huggingface.co/thakkkkkk/1472366c-1474-4e23-9b6f-e917cacaed31, https://huggingface.co/error577/634fe6e7-ba15-40a0-84cd-c93ce43b7688, https://huggingface.co/0x1202/b1a15532-d25e-44df-b90a-8083ef674b2f, https://huggingface.co/adammandic87/59a69d45-742f-462f-8f72-f0c09ff0fc21, https://huggingface.co/prxy5608/363d02b1-884e-48cc-9864-b4be6c07aa89, https://huggingface.co/VERSIL91/cd41e37a-3f7e-46a6-8ba7-d8b4f2155726, https://huggingface.co/marialvsantiago/50df958b-6c6c-4bbb-96c1-cdfdb3983a97, https://huggingface.co/nblinh63/f6afc9f5-940e-4854-802f-2f55b6c0dfe0, https://huggingface.co/dzanbek/b955aef4-8949-4ef3-b748-e55af8713ba6, https://huggingface.co/lesso14/3bd2c9ad-cbe9-45aa-b3ba-a35707cfb659, https://huggingface.co/adammandic87/ab7997db-c4af-4085-ad6e-afc46f65f1dd, https://huggingface.co/chauhoang/fe6f0dae-5342-4bc8-8a1f-f80d21845e48, https://huggingface.co/kokovova/dfcef1f5-9900-4e8f-9e5c-b2d3a0907a5c, https://huggingface.co/mrHunghddddd/b51de4ec-4808-43cb-93c3-0f3cd9803d7e, https://huggingface.co/dimasik87/2bcb1699-a32d-4c49-abd3-0028f372c4e8, https://huggingface.co/dimasik1987/3d767089-d3f6-424e-902f-1e490617d192, https://huggingface.co/nhoxinh/7dbd9515-0d99-48d1-8ad7-f9ea9d7e6e01, https://huggingface.co/Paladiso/e307da6f-722d-4008-b2b6-3ae184f063ee, https://huggingface.co/prxy5608/c4767a78-790f-4877-a512-a320a2b24062, https://huggingface.co/kokovova/deee9727-f8a7-4ce0-bfc8-a025fb41db6a, https://huggingface.co/filipesantoscv11/d98c90de-4655-41b2-9d06-681e68b98db0, https://huggingface.co/lhong4759/eba0be74-d070-4fd7-8dff-b56e64b4cab2, https://huggingface.co/chauhoang/b35542fa-eda8-459c-8040-ff872c89c330, https://huggingface.co/thalllsssss/479c7186-b280-4ef5-a30f-419e77ddcd70, https://huggingface.co/adammandic87/a7526096-751d-4831-97c7-ddd04420860d, https://huggingface.co/adammandic87/392372e1-a883-48a4-a5fd-1228479e4ee8, https://huggingface.co/0x1202/b79042e9-c4aa-4947-af63-001439792f03, https://huggingface.co/thalllsssss/f12b6437-b14c-4d68-aeeb-a3fffed33204, https://huggingface.co/lesso05/1f73b57d-7d3e-42d7-91a6-716c0df80d29, https://huggingface.co/Best000/2b443fa3-7ee8-4e00-82b6-b279668fa2e5, https://huggingface.co/tuanna08go/cafd5aed-0704-4eaa-b6c3-1e52d308f4f6, https://huggingface.co/vermoney/dcbebbf3-5e74-4303-88ac-2e90ff4350ed, https://huggingface.co/lesso07/2bc6b804-5e10-43af-93b7-6119619d4865, https://huggingface.co/dimasik87/09eb108d-4d2c-41e4-ac34-f57a5dadfc9c, https://huggingface.co/thangla01/d6c82f6f-38d7-4dfe-88cc-47934c8d003b, https://huggingface.co/dzanbek/bc0e367c-0592-4b01-a54f-4fd9af043723, https://huggingface.co/lesso14/2eafcc2b-34bf-461d-ad55-78d59697b25e, https://huggingface.co/havinash-ai/823bdeeb-5d0b-4f18-8ebc-ac9cffa9fcc4, https://huggingface.co/great0001/0e055e0f-abf8-40e0-baf7-2cefd5c93eb3, https://huggingface.co/kk-aivio/36fa3a7f-931d-4a88-9c30-07ed2865b2a0, https://huggingface.co/tarabukinivan/ee964427-1cfe-4271-97bd-4d8150d53a35, https://huggingface.co/mrHunghddddd/f5ecffc9-b7d5-462d-9d6e-7d19f5cee13c, https://huggingface.co/thangla01/e887bd4b-58c1-4c1f-9bb8-c5eaeab76359, https://huggingface.co/dzanbek/39717d07-1996-41ab-a2bb-30c9048abb79, https://huggingface.co/lesso01/1b4f4a4d-62c7-455a-afc8-62ed8dda02f9, https://huggingface.co/lesso13/1e92a533-fe72-4dea-a29e-1b84ce3c3942, https://huggingface.co/great0001/f2642680-9820-4049-b96d-0182e0ebacf5, https://huggingface.co/chauhoang/2596f300-21c5-4b74-ba07-ce69ac6c8bb4, https://huggingface.co/duyphu/36dc4db4-5a76-4ea9-9e15-42ff61911844, https://huggingface.co/prxy5605/098d1a5a-5801-4a95-bb78-baf302eb8ad7, https://huggingface.co/lesso10/5442a177-d921-4d91-9c03-6eedfd535043, https://huggingface.co/nhung01/a3ab2628-3072-4382-a0e0-06bd37adc5ed, https://huggingface.co/nttx/b0145126-1b95-4959-9715-c6a828f48822, https://huggingface.co/duyphu/7b7d01be-2a9a-4da2-95dd-b16cbb975fc2, https://huggingface.co/lesso17/448acd22-fe99-4277-b378-b66066353512, https://huggingface.co/thaffggg/4aaa1c5c-8bef-4b75-98dc-585f050a605b, https://huggingface.co/nttx/24e206ea-db0c-4b0f-8114-b1408e712349, https://huggingface.co/nhungphammmmm/9cdf2d91-4b98-4839-99ea-55b799b02ae2, https://huggingface.co/hongngo/14572a1f-422e-4ad1-b681-1a7a37eac195, https://huggingface.co/lhong4759/fa7f924e-5e9a-4b7a-9cf1-36a037cfd92c, https://huggingface.co/lesso04/f681eb1b-9035-4097-b398-36b35fd433ea, https://huggingface.co/ClarenceDan/20665300-5c57-40b7-afb0-ae0a8629d55b, https://huggingface.co/lesso17/0cc28810-bb73-4af6-80aa-c1faea907edc, https://huggingface.co/cunghoctienganh/eabee629-5417-40d1-b350-b688cc9b395b, https://huggingface.co/minhnguyennnnnn/6cc5490d-760b-41db-8c55-3ba405f5bb5f, https://huggingface.co/nblinh/a068eee1-f185-4300-b139-7db918e74bdb, https://huggingface.co/tryingpro/fff4bb41-fbd1-4606-80cd-29d5047ddf58, https://huggingface.co/hongngo/99d56d7e-c912-450c-9c7e-1673741da56d, https://huggingface.co/mrhunghd/b46793f9-6b2c-4bce-a727-ccee5b2ed0ba, https://huggingface.co/nhung03/d0aeafa1-92ab-45ba-8279-d91d79083014, https://huggingface.co/dimasik87/f6cb407e-779d-4ac8-948d-936ca7ae0140, https://huggingface.co/lesso14/8eb64cf5-9343-4cfe-a62d-6f21b5fcc610, https://huggingface.co/duyphu/f04b6d2e-d964-463f-8e64-56594e30b835, https://huggingface.co/ClarenceDan/02169017-6ccb-4b8a-aed4-045c6cbea35f, https://huggingface.co/prxy5604/9a79ad87-143c-4112-826d-17de569acc7b, https://huggingface.co/ClarenceDan/8a9e61e6-77cc-43cc-8b7f-5d6bd3a47368, https://huggingface.co/duyphu/dd99cfae-4152-4304-b09a-31a00951788f, https://huggingface.co/bbytxt/b75078cf-3684-441e-bd0e-6229f5588377, https://huggingface.co/eddysang/4ebfb258-edc4-4a06-9f79-9cc8fd87c956, https://huggingface.co/aleegis11/afe4bad5-274c-4673-9e9c-09057cffabae, https://huggingface.co/prxy5606/99a88bee-0683-462c-9ba0-36b004cece89, https://huggingface.co/aleegis09/ea36b8db-3107-46e2-9710-8040b5b07b59, https://huggingface.co/prxy5608/7dac049d-ecb7-4466-bae7-c8db9bb455f2, https://huggingface.co/prxy5606/18f04b94-dd45-4ae2-ae06-ecae560f913f, https://huggingface.co/prxy5608/d7edf5a8-da9f-49c4-abaf-477279cdcc80, https://huggingface.co/aleegis10/7e903844-4623-4593-a49c-f5f63be9eb3c, https://huggingface.co/denbeo/1f2e7ce1-66d0-47cd-87a6-79a86e9cd603, https://huggingface.co/mrHunghddddd/7735e12e-8e0c-4441-b324-1b721387f8d4, https://huggingface.co/kk-aivio/98f9cbf5-961f-4aca-80f3-c5555d8bcd9b, https://huggingface.co/nhung02/e70346f3-df2e-4c9e-b0ee-77b0c0dd4a53, https://huggingface.co/lesso03/539f11df-2469-4a67-9924-40fb548c4bb9, https://huggingface.co/adammandic87/7b35d4dd-d862-4984-b66e-42a4e11d404b, https://huggingface.co/JacksonBrune/0e987a56-97ef-4ebb-993c-62a8c77a762d, https://huggingface.co/adammandic87/014d6916-9095-4085-aaa2-2a9e63da7f61, https://huggingface.co/chauhoang/0767ca9f-5a86-4f5e-9597-a16f678da1be, https://huggingface.co/tryingpro/34fedf70-94ce-42f7-836f-c3ee8710c95a, https://huggingface.co/nghiatrannnnnn/512a114c-6d40-44f8-a819-61e951e26bb3, https://huggingface.co/nhunglaaaaaaa/8bda2c6e-cca4-4d6c-bdc8-0784355e392c, https://huggingface.co/lesso09/0fc82aab-59d1-48c9-bb60-f04c04fac4e5, https://huggingface.co/lesso/53ffda63-737e-45a1-a819-f90080283be2, https://huggingface.co/demohong/69ef178a-2bf3-4f2e-8cf2-ed5cf25ba18b, https://huggingface.co/mrHunghddddd/79da53b3-2277-410c-a08d-0441604c1d25, https://huggingface.co/thalllsssss/fe5ca7ec-36ef-42d8-b2d4-72877bc4597c, https://huggingface.co/nhung03/9836cde7-5566-4ef9-9d05-28d754fd1fa5, https://huggingface.co/nhung01/ce601c6d-f85d-4322-900a-4843d391639e, https://huggingface.co/tuantmdev/84359d7e-b509-4ff9-8bed-0d22fd92b1ca, https://huggingface.co/nbninh/4fc177ad-16a7-46ff-9c51-303e9338bda8, https://huggingface.co/cunghoctienganh/a1bef39b-65cf-4d6b-991a-da567c6c8c41, https://huggingface.co/lhong4759/26d24d5d-48d4-4f79-b3ec-bd100ad807ed, https://huggingface.co/lesso12/193b0bd7-e478-452d-b5cd-ecce9fec986b, https://huggingface.co/daniel40/aaab34a9-3ba4-4596-8cce-5eee193fd508, https://huggingface.co/aleegis10/05a07b91-53ab-454c-8c8a-2e82fb43592d, https://huggingface.co/aleegis11/b2fef5fc-aec3-418b-b721-5ab6ee0bb573, https://huggingface.co/bbytxt/20beb952-12e3-4b9b-a1f3-1a3f94d8e798, https://huggingface.co/trangtrannnnn/a77410da-cb3b-40eb-a485-f50d4ef0b664, https://huggingface.co/datlaaaaaaa/bf99c9d0-5c7c-4534-bd64-48d748cc71ef, https://huggingface.co/thangla01/fca7c77b-f48b-40b1-8d6c-361b3476b051, https://huggingface.co/demohong/be5bf364-34a9-4792-b938-7ae58cc17e24, https://huggingface.co/myhaaaaaaa/341644b7-b9fd-4fe9-8873-02292876215b, https://huggingface.co/nhung02/eaf5a95f-15be-46bf-8aa4-5a24b02a3476, https://huggingface.co/aseratus1/4989f67b-c847-4177-af12-df137cf633bc, https://huggingface.co/nttx/7d59fed9-8564-4996-874f-f5884135c1b4, https://huggingface.co/daniel40/e42e4607-e2d3-418b-be24-a89ed2a70d60, https://huggingface.co/nghiatrannnnnn/7456c8f0-92e4-431d-b9c1-bb06db8067b1, https://huggingface.co/nghiatrannnnnn/030f1c7f-ff4e-4cf6-b23d-01d69b545282, https://huggingface.co/nhungphammmmm/06524e78-c8b3-4960-a912-92de39d451d1, https://huggingface.co/Romain-XV/c1c9a393-ad22-468d-a98e-1dcb95b2d0ec, https://huggingface.co/nhung03/922f138a-b3e6-4a86-8494-91120aa3d847, https://huggingface.co/lesso07/d171a9ac-bdba-45c5-b8c9-01c274f5cd32, https://huggingface.co/tarabukinivan/dab39e16-16dc-416c-9022-3ad4b4d9d8a7, https://huggingface.co/nhoxinh/f4e918c4-32e6-4dbc-a546-6cabe8f6ba27, https://huggingface.co/abaddon182/eac504e2-99ab-4d7a-a27a-b86e42c79af8, https://huggingface.co/adammandic87/032cbbb5-bf71-40df-bff5-a79fb44167c5, https://huggingface.co/lesso06/dcffe245-421b-4d47-8057-fa36f3805411, https://huggingface.co/0x1202/c3cef6b8-12c1-48bf-8d86-335a840ec84a, https://huggingface.co/minhnguyennnnnn/0a982b54-d90e-4a3c-9e7f-11a4dedac0c1, https://huggingface.co/cunghoctienganh/90e633df-e0f4-4ba7-b984-9015145b9db5, https://huggingface.co/minhtrannnn/1f47c03d-1215-4271-8dbd-86d80dbc11d8, https://huggingface.co/nhung01/27d2e254-e373-4613-85f6-d3c9e86fd5ca, https://huggingface.co/laquythang/74e9dd27-7cb4-4910-a8bf-13b76ad02f5e, https://huggingface.co/thaffggg/3a5d88b3-db9c-461c-b396-76b88a6cee39, https://huggingface.co/laquythang/eeafba04-c9ef-4dbc-921c-7d14d109a317, https://huggingface.co/lesso/9af11431-ae6c-40ba-8a7c-ecf988668da1, https://huggingface.co/ancient41/31fd523e-8b03-4b09-a487-0e568879568f, https://huggingface.co/mamung/3f49b8e9-e2b8-4a3b-b363-8483b5368549, https://huggingface.co/nhung03/bd08913d-aff9-4e52-9536-39d293fd521b, https://huggingface.co/laquythang/1122a8d5-25bd-4613-9a59-16350b1cf8fa, https://huggingface.co/robiulawaldev/ddd02f7c-9454-4722-b751-841b484a71a4, https://huggingface.co/adammandic87/491009d8-1596-49c7-b9f6-26bf8ab5a711, https://huggingface.co/kk-aivio/cd52ae9a-9eb7-4cfe-bdad-e281fa438605, https://huggingface.co/cilooor/a975dc64-d122-46f1-8755-130013566f75, https://huggingface.co/ancient41/d43662eb-c176-493f-a566-011f46f3f100, https://huggingface.co/prxy5604/1d0b0ed5-2d83-4cdf-8ecd-1e342748bada, https://huggingface.co/aleegis12/6d7ba68c-b4dd-4516-b48e-7acbcb8b242a, https://huggingface.co/alchemist69/fb3c878d-6daa-474c-86e9-521c77cfadc6, https://huggingface.co/lesso/10ccc4f9-e48e-4823-a9b8-d8686863fefe, https://huggingface.co/lesso/b40a4d62-ce92-4502-a0c6-0abe2c9e48a4, https://huggingface.co/arcwarden46/66c7820b-9388-468a-8095-63317a4ed8e8, https://huggingface.co/aleegis12/1192696c-aa12-4e64-b0fe-dcccc7dd37e3, https://huggingface.co/alchemist69/50e42555-c03c-4c8c-8f49-ecc602637af1, https://huggingface.co/bane5631/a649fb20-63c4-4576-88b2-d4c959b78475, https://huggingface.co/laquythang/3c244461-d68f-489b-bc6d-ece553ad708c, https://huggingface.co/lesso/244bde5e-38f7-4513-b43d-638ced78af2d, https://huggingface.co/eddysang/30d14f86-1bea-48d7-97b1-2e4c3d700e53, https://huggingface.co/arcwarden46/104eb290-e68b-4823-89e0-65029759e501, https://huggingface.co/eageringdev/945c81e4-eeb4-43e3-bce2-0f91952c347e, https://huggingface.co/cimol/92560246-778b-464e-a130-85faabcd455c, https://huggingface.co/lesso04/4d8a83c6-b15c-4324-9571-2f06a1409031, https://huggingface.co/lesso17/0c47821e-1e59-4629-8b79-116c2fbf737a, https://huggingface.co/lesso06/e2cfacf6-0034-4587-8961-098036d0f7fc, https://huggingface.co/romainnn/d8abd64a-a056-4dc3-acae-1063719be070, https://huggingface.co/nttx/b1020384-4fed-43f0-b098-e7f1d056ec24, https://huggingface.co/lesso07/e1c6f8e8-5823-422c-ae61-dbb86493c306, https://huggingface.co/lesso12/f10b8915-f0a3-4d58-bfc9-e9ab4e7cae90, https://huggingface.co/lesso02/234de95a-352d-4a70-b496-8cbc55e31388, https://huggingface.co/lesso06/41b2b81b-40ab-4e64-bec1-5826d67fbb58, https://huggingface.co/lesso01/addbdac6-1161-45e6-8f1a-9e89695db7dd, https://huggingface.co/lesso10/94fa69ad-7f10-4114-aea9-549d491b720a, https://huggingface.co/lesso18/7155a30e-2eae-48cf-abbd-d38ed410e9ff, https://huggingface.co/lesso14/eb6d5aee-dd12-4a7f-af40-054232eb7660, https://huggingface.co/lesso09/3cdac240-e0c9-4569-8046-139a0fa1d0b7, https://huggingface.co/lesso03/c25a6821-70d3-41d9-b043-200034ef0df0, https://huggingface.co/lesso02/1d0e5272-383b-476f-8ea2-1767043388d1, https://huggingface.co/lesso09/8ba6a94d-6a12-48f3-9922-ebba4fe79628, https://huggingface.co/lesso18/975b7468-c0cf-46fd-b9ef-480837bfe221, https://huggingface.co/lesso13/5af29646-c4ef-4955-b0d7-801598948193, https://huggingface.co/lesso02/1e748813-92c4-4308-9bef-4debf187f3da, https://huggingface.co/lesso13/1c45cc1c-13be-45d5-a068-1fcfa1d24bbc, https://huggingface.co/lesso09/bc6b0b68-cc10-4af2-90ab-0a3ea4118781, https://huggingface.co/lesso02/48ce706e-9aac-41aa-b28b-e21b7660868f, https://huggingface.co/lesso05/0befb973-0bc9-4f06-ae5f-ab32f5900322, https://huggingface.co/lesso03/30d96abc-3305-4f66-8d3d-3a95a991e512, https://huggingface.co/Alphatao/6da1faf7-1428-4419-b21c-b21eec14b3ea, https://huggingface.co/lesso05/1f25bc1f-d773-4387-9e3b-fa35936c5193, https://huggingface.co/lesso02/db7fa05d-a82f-43dc-9084-3d41b53e204b, https://huggingface.co/Alphatao/aff88e51-b725-41ad-bf68-2c6c7bac164f, https://huggingface.co/lesso13/b18a3101-7e5c-4e6b-ba1f-ca8aa0c9c28f, https://huggingface.co/lesso12/4c0ec110-d24c-48d6-827a-afeaf1b7014a, https://huggingface.co/Alphatao/90451222-f43c-4606-84e4-bb92cc585d7b, https://huggingface.co/Alphatao/e5e9e1db-edd7-4baf-b538-728f32f0be9a, https://huggingface.co/Alphatao/d96d18be-1c39-49c1-b429-f6623f4ab502, https://huggingface.co/lesso05/385d9043-228f-412c-be31-6b58cec7eeab, https://huggingface.co/lesso01/721b0e6f-4a4b-4bf6-b14b-8ae83ae43adb, https://huggingface.co/Alphatao/03f640f1-7d7d-40be-98fe-9441de6cce1a, https://huggingface.co/lesso05/a299b07e-5e51-477d-98d1-4b78090f3f7a, https://huggingface.co/lesso10/c4989afc-e02d-4ee8-ac14-abe295d2eec5, https://huggingface.co/lesso16/b8ef9103-bbf1-4f0e-aa78-9083b02a8b8c, https://huggingface.co/lesso07/cbba3e68-5c04-43e1-85e2-0d68078ce4d3, https://huggingface.co/sergioalves/d0f62694-a9a9-41ee-92fa-739328b8e778, https://huggingface.co/kokovova/30227d13-f5a0-44bd-980b-4a818385f65b, https://huggingface.co/vermoney/68063ba7-c5c1-461b-b3bf-97df947cfe3c, https://huggingface.co/annemiekebickleyoy/51cd8f4f-b436-4738-8e35-439e2016ba0c",339,"https://huggingface.co/QuantFactory/Llama-3-8B-Lexi-Uncensored-GGUF, https://huggingface.co/stephenlzc/Llama-3-8B-Lexi-Uncensored-Q2_K-GGUF, https://huggingface.co/mradermacher/Llama-3-8B-Lexi-Uncensored-GGUF, https://huggingface.co/solidrust/Llama-3-8B-Lexi-Uncensored-AWQ, https://huggingface.co/PrunaAI/Orenguteng-Llama-3-8B-Lexi-Uncensored-bnb-4bit-smashed, https://huggingface.co/Ayyystin/Llama-3-8B-Lexi-Uncensored-Q4_0-GGUF, https://huggingface.co/wyan/Llama-3-8B-Lexi-Uncensored-Q4_K_M-GGUF, https://huggingface.co/wyan/Llama-3-8B-Lexi-Uncensored-Q8_0-GGUF, https://huggingface.co/jdcrutchley/Llama-3-8B-Lexi-Uncensored-Q4_K_M-GGUF, https://huggingface.co/MaziyarPanahi/Llama-3-8B-Lexi-Uncensored-GGUF, https://huggingface.co/tensorblock/Llama-3-8B-Lexi-Uncensored-GGUF, https://huggingface.co/mradermacher/Lexi-Llama-3-8B-Uncensored-GGUF, https://huggingface.co/mradermacher/Lexi-Llama-3-8B-Uncensored-i1-GGUF, https://huggingface.co/wolflycanorcant/Llama-3-8B-Lexi-Uncensored-Q4_K_M-GGUF, https://huggingface.co/itlwas/Llama-3-8B-Lexi-Uncensored-Q4_K_M-GGUF, https://huggingface.co/mradermacher/Llama-3-8B-Lexi-Uncensored-i1-GGUF",16,"https://huggingface.co/theprint/Llama-3-8B-Lexi-Smaug-Uncensored, https://huggingface.co/mergekit-community/uncensored-mix, https://huggingface.co/Nhoodie/Meta-Llama-3-8b-Lexi-Uninstruct-function-calling-json-mode-Task-Arithmetic-v0.1, https://huggingface.co/Nhoodie/Meta-Llama-3-8b-Lexi-Uninstruct-function-calling-json-mode-Task-Arithmetic-v0.2A, https://huggingface.co/Nhoodie/Meta-Llama-3-8b-Extended-Lexi-Uninstruct-function-calling-json-mode-Task-Arithmetic-v0.0A, https://huggingface.co/Nhoodie/Meta-Llama-3-8b-Configurable-Lexi-Uninstruct-function-calling-json-mode-Task-Arithmetic-v0.0A, https://huggingface.co/Fischerboot/LLama3-Lexi-Aura-3Some-SLERP-SLERP, https://huggingface.co/Rupesh2/Llama-3.1-Uncensored-New, https://huggingface.co/Casual-Autopsy/L3-Luna-8B, https://huggingface.co/QuantFactory/L3-Luna-8B-GGUF, https://huggingface.co/ZeroXClem/Llama-3-Aetheric-Hermes-Lexi-Smaug-8B, https://huggingface.co/mav23/Llama-3-Aetheric-Hermes-Lexi-Smaug-8B-GGUF",12,"DevTzar/Orenguteng-Llama-3-8B-Lexi-Uncensored, FallnAI/Quantize-HF-Models, HuggingFaceH4/open_llm_leaderboard?query=Orenguteng/Llama-3-8B-Lexi-Uncensored, K00B404/LLM_Quantization, KBaba7/Quant, OscarFAI/inference, SlyFox29/Quaken_Llama, UNION-KevinLan/Orenguteng-Llama-3-8B-Lexi-Uncensored, Zadei/Orenguteng-Llama-3-8B-Lexi-Uncensored, abmSS/Orenguteng-Llama-3-8BKNK-Lexi-Uncensored, bhaskartripathi/LLM_Quantization, huggingface/InferenceSupport/discussions/82, ruslanmv/convert_to_gguf, totolook/Quant",14
|
| 138 |
+
PrunaAI/Orenguteng-Llama-3-8B-Lexi-Uncensored-HQQ-2bit-smashed,"---
|
| 139 |
+
thumbnail: ""https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg""
|
| 140 |
+
base_model: Orenguteng/Llama-3-8B-Lexi-Uncensored
|
| 141 |
+
metrics:
|
| 142 |
+
- memory_disk
|
| 143 |
+
- memory_inference
|
| 144 |
+
- inference_latency
|
| 145 |
+
- inference_throughput
|
| 146 |
+
- inference_CO2_emissions
|
| 147 |
+
- inference_energy_consumption
|
| 148 |
+
tags:
|
| 149 |
+
- pruna-ai
|
| 150 |
+
---
|
| 151 |
+
<!-- header start -->
|
| 152 |
+
<!-- 200823 -->
|
| 153 |
+
<div style=""width: auto; margin-left: auto; margin-right: auto"">
|
| 154 |
+
<a href=""https://www.pruna.ai/"" target=""_blank"" rel=""noopener noreferrer"">
|
| 155 |
+
<img src=""https://i.imgur.com/eDAlcgk.png"" alt=""PrunaAI"" style=""width: 100%; min-width: 400px; display: block; margin: auto;"">
|
| 156 |
+
</a>
|
| 157 |
+
</div>
|
| 158 |
+
<!-- header end -->
|
| 159 |
+
|
| 160 |
+
[](https://twitter.com/PrunaAI)
|
| 161 |
+
[](https://github.com/PrunaAI)
|
| 162 |
+
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
|
| 163 |
+
[](https://discord.gg/rskEr4BZJx)
|
| 164 |
+
|
| 165 |
+
# Simply make AI models cheaper, smaller, faster, and greener!
|
| 166 |
+
|
| 167 |
+
- Give a thumbs up if you like this model!
|
| 168 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 169 |
+
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 170 |
+
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
|
| 171 |
+
- Join Pruna AI community on Discord [here](https://discord.gg/rskEr4BZJx) to share feedback/suggestions or get help.
|
| 172 |
+
|
| 173 |
+
## Results
|
| 174 |
+
|
| 175 |
+

|
| 176 |
+
|
| 177 |
+
**Frequently Asked Questions**
|
| 178 |
+
- ***How does the compression work?*** The model is compressed with hqq.
|
| 179 |
+
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
|
| 180 |
+
- ***How is the model efficiency evaluated?*** These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 181 |
+
- ***What is the model format?*** We use safetensors.
|
| 182 |
+
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
|
| 183 |
+
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append ""turbo"", ""tiny"", or ""green"" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
|
| 184 |
+
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 185 |
+
- ***What are ""first"" metrics?*** Results mentioning ""first"" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
| 186 |
+
- ***What are ""Sync"" and ""Async"" metrics?*** ""Sync"" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. ""Async"" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
|
| 187 |
+
|
| 188 |
+
## Setup
|
| 189 |
+
|
| 190 |
+
You can run the smashed model with these steps:
|
| 191 |
+
|
| 192 |
+
0. Check requirements from the original repo Orenguteng/Llama-3-8B-Lexi-Uncensored installed. In particular, check python, cuda, and transformers versions.
|
| 193 |
+
1. Make sure that you have installed quantization related packages.
|
| 194 |
+
```bash
|
| 195 |
+
pip install hqq
|
| 196 |
+
```
|
| 197 |
+
2. Load & run the model.
|
| 198 |
+
```python
|
| 199 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 200 |
+
from hqq.engine.hf import HQQModelForCausalLM
|
| 201 |
+
from hqq.models.hf.base import AutoHQQHFModel
|
| 202 |
+
|
| 203 |
+
try:
|
| 204 |
+
model = HQQModelForCausalLM.from_quantized(""PrunaAI/Orenguteng-Llama-3-8B-Lexi-Uncensored-HQQ-2bit-smashed"", device_map='auto')
|
| 205 |
+
except:
|
| 206 |
+
model = AutoHQQHFModel.from_quantized(""PrunaAI/Orenguteng-Llama-3-8B-Lexi-Uncensored-HQQ-2bit-smashed"")
|
| 207 |
+
tokenizer = AutoTokenizer.from_pretrained(""Orenguteng/Llama-3-8B-Lexi-Uncensored"")
|
| 208 |
+
|
| 209 |
+
input_ids = tokenizer(""What is the color of prunes?,"", return_tensors='pt').to(model.device)[""input_ids""]
|
| 210 |
+
|
| 211 |
+
outputs = model.generate(input_ids, max_new_tokens=216)
|
| 212 |
+
tokenizer.decode(outputs[0])
|
| 213 |
+
```
|
| 214 |
+
|
| 215 |
+
## Configurations
|
| 216 |
+
|
| 217 |
+
The configuration info are in `smash_config.json`.
|
| 218 |
+
|
| 219 |
+
## Credits & License
|
| 220 |
+
|
| 221 |
+
The license of the smashed model follows the license of the original model. Please check the license of the original model Orenguteng/Llama-3-8B-Lexi-Uncensored before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
|
| 222 |
+
|
| 223 |
+
## Want to compress other models?
|
| 224 |
+
|
| 225 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 226 |
+
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).","{""id"": ""PrunaAI/Orenguteng-Llama-3-8B-Lexi-Uncensored-HQQ-2bit-smashed"", ""author"": ""PrunaAI"", ""sha"": ""1dab39f5ed6b5c5e5b327c2c052198388c653594"", ""last_modified"": ""2024-08-02 15:56:58+00:00"", ""created_at"": ""2024-04-29 15:39:09+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 5, ""downloads_all_time"": null, ""likes"": 1, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""llama"", ""text-generation"", ""pruna-ai"", ""conversational"", ""base_model:Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""base_model:finetune:Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""autotrain_compatible"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: Orenguteng/Llama-3-8B-Lexi-Uncensored\nmetrics:\n- memory_disk\n- memory_inference\n- inference_latency\n- inference_throughput\n- inference_CO2_emissions\n- inference_energy_consumption\ntags:\n- pruna-ai\nthumbnail: https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<|begin_of_text|>"", ""chat_template"": ""{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{% if add_generation_prompt %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}{% endif %}"", ""eos_token"": ""<|eot_id|>"", ""pad_token"": ""<|end_of_text|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='plots.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='qmodel.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='smash_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-08-02 15:56:58+00:00"", ""cardData"": ""base_model: Orenguteng/Llama-3-8B-Lexi-Uncensored\nmetrics:\n- memory_disk\n- memory_inference\n- inference_latency\n- inference_throughput\n- inference_CO2_emissions\n- inference_energy_consumption\ntags:\n- pruna-ai\nthumbnail: https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""662fbf1d14e87951eadab03c"", ""modelId"": ""PrunaAI/Orenguteng-Llama-3-8B-Lexi-Uncensored-HQQ-2bit-smashed"", ""usedStorage"": 4010664640}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=PrunaAI/Orenguteng-Llama-3-8B-Lexi-Uncensored-HQQ-2bit-smashed&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BPrunaAI%2FOrenguteng-Llama-3-8B-Lexi-Uncensored-HQQ-2bit-smashed%5D(%2FPrunaAI%2FOrenguteng-Llama-3-8B-Lexi-Uncensored-HQQ-2bit-smashed)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 227 |
+
scoliono/groupchat_lora_lexi_8b,"---
|
| 228 |
+
language:
|
| 229 |
+
- en
|
| 230 |
+
license: apache-2.0
|
| 231 |
+
tags:
|
| 232 |
+
- text-generation-inference
|
| 233 |
+
- transformers
|
| 234 |
+
- unsloth
|
| 235 |
+
- llama
|
| 236 |
+
- trl
|
| 237 |
+
base_model: Orenguteng/Llama-3-8B-Lexi-Uncensored
|
| 238 |
+
---
|
| 239 |
+
|
| 240 |
+
# Uploaded model
|
| 241 |
+
|
| 242 |
+
- **Developed by:** scoliono
|
| 243 |
+
- **License:** apache-2.0
|
| 244 |
+
- **Finetuned from model :** Orenguteng/Llama-3-8B-Lexi-Uncensored
|
| 245 |
+
|
| 246 |
+
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
|
| 247 |
+
|
| 248 |
+
[<img src=""https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png"" width=""200""/>](https://github.com/unslothai/unsloth)
|
| 249 |
+
","{""id"": ""scoliono/groupchat_lora_lexi_8b"", ""author"": ""scoliono"", ""sha"": ""f133522fcee5f9264998dcba5b48443f9c50062b"", ""last_modified"": ""2024-05-28 17:14:46+00:00"", ""created_at"": ""2024-05-28 17:14:33+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""text-generation-inference"", ""unsloth"", ""llama"", ""trl"", ""en"", ""base_model:Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""base_model:finetune:Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: Orenguteng/Llama-3-8B-Lexi-Uncensored\nlanguage:\n- en\nlicense: apache-2.0\ntags:\n- text-generation-inference\n- transformers\n- unsloth\n- llama\n- trl"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_model.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-05-28 17:14:46+00:00"", ""cardData"": ""base_model: Orenguteng/Llama-3-8B-Lexi-Uncensored\nlanguage:\n- en\nlicense: apache-2.0\ntags:\n- text-generation-inference\n- transformers\n- unsloth\n- llama\n- trl"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""665610f9191c117e81a80314"", ""modelId"": ""scoliono/groupchat_lora_lexi_8b"", ""usedStorage"": 335604696}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=scoliono/groupchat_lora_lexi_8b&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bscoliono%2Fgroupchat_lora_lexi_8b%5D(%2Fscoliono%2Fgroupchat_lora_lexi_8b)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 250 |
+
canTooDdev/LlamaWalter2,"---
|
| 251 |
+
base_model: Orenguteng/Llama-3-8B-Lexi-Uncensored
|
| 252 |
+
language:
|
| 253 |
+
- en
|
| 254 |
+
license: apache-2.0
|
| 255 |
+
tags:
|
| 256 |
+
- text-generation-inference
|
| 257 |
+
- transformers
|
| 258 |
+
- unsloth
|
| 259 |
+
- llama
|
| 260 |
+
- trl
|
| 261 |
+
- sft
|
| 262 |
+
---
|
| 263 |
+
|
| 264 |
+
# Uploaded model
|
| 265 |
+
|
| 266 |
+
- **Developed by:** canTooDdev
|
| 267 |
+
- **License:** apache-2.0
|
| 268 |
+
- **Finetuned from model :** Orenguteng/Llama-3-8B-Lexi-Uncensored
|
| 269 |
+
|
| 270 |
+
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
|
| 271 |
+
|
| 272 |
+
[<img src=""https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png"" width=""200""/>](https://github.com/unslothai/unsloth)
|
| 273 |
+
","{""id"": ""canTooDdev/LlamaWalter2"", ""author"": ""canTooDdev"", ""sha"": ""e93c01bc1fb3e1ad9e457b417c91d8edb51e82f4"", ""last_modified"": ""2024-07-18 16:26:25+00:00"", ""created_at"": ""2024-07-18 16:19:11+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 2, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""llama"", ""text-generation"", ""text-generation-inference"", ""unsloth"", ""trl"", ""sft"", ""conversational"", ""en"", ""base_model:Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""base_model:finetune:Orenguteng/Llama-3-8B-Lexi-Uncensored"", ""license:apache-2.0"", ""autotrain_compatible"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: Orenguteng/Llama-3-8B-Lexi-Uncensored\nlanguage:\n- en\nlicense: apache-2.0\ntags:\n- text-generation-inference\n- transformers\n- unsloth\n- llama\n- trl\n- sft"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama"", ""tokenizer_config"": {""bos_token"": ""<|begin_of_text|>"", ""chat_template"": ""{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{% if add_generation_prompt %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}{% endif %}"", ""eos_token"": ""<|eot_id|>"", ""pad_token"": ""<|end_of_text|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00004.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00004.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00003-of-00004.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00004-of-00004.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-07-18 16:26:25+00:00"", ""cardData"": ""base_model: Orenguteng/Llama-3-8B-Lexi-Uncensored\nlanguage:\n- en\nlicense: apache-2.0\ntags:\n- text-generation-inference\n- transformers\n- unsloth\n- llama\n- trl\n- sft"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""6699407f4bbe8ad52e7d2fef"", ""modelId"": ""canTooDdev/LlamaWalter2"", ""usedStorage"": 16060625627}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=canTooDdev/LlamaWalter2&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BcanTooDdev%2FLlamaWalter2%5D(%2FcanTooDdev%2FLlamaWalter2)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
MagicAnimate_finetunes_20250426_221535.csv_finetunes_20250426_221535.csv
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
zcxu-eric/MagicAnimate,"---
|
| 3 |
+
license: bsd-3-clause
|
| 4 |
+
---
|
| 5 |
+
Download MagicAnimate checkpoints by:
|
| 6 |
+
```bash
|
| 7 |
+
git lfs clone https://huggingface.co/zcxu-eric/MagicAnimate
|
| 8 |
+
```","{""id"": ""zcxu-eric/MagicAnimate"", ""author"": ""zcxu-eric"", ""sha"": ""3d80ae8c50b289e55ee68deecc83afaab9c6a382"", ""last_modified"": ""2023-12-04 15:55:47+00:00"", ""created_at"": ""2023-12-04 15:09:36+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 186, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""safetensors"", ""license:bsd-3-clause"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: bsd-3-clause"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='appearance_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='appearance_encoder/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='densepose_controlnet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='densepose_controlnet/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='temporal_attention/temporal_attention.ckpt', size=None, blob_id=None, lfs=None)""], ""spaces"": [""zcxu-eric/magicanimate"", ""John6666/magicanimate2024"", ""cbensimon/magicanimate"", ""John6666/magicanimate"", ""Gyufyjk/magicanimate"", ""AIADC/magicanimate1"", ""walre1301/magicanimate"", ""vakilrathod67/magicanimat"", ""AIADC/magicanimate"", ""LioAlbert/magicanimate"", ""BG5/magicanimate"", ""samaleksandrov/magicanimate"", ""cgeorgia/magicanimate"", ""josh3io/magicanimate"", ""Ai3333/magicanimate"", ""AceyKubbo/magicanimate"", ""Hitendra1851/magicanimate"", ""ixlm/magicanimate"", ""neveu/magicanimate"", ""JaneMonica/magicanimate"", ""qsdreams/amimationmuse"", ""Shellbrady/magicanimate"", ""BN4350/magicanimate"", ""tomajkb/magicanimate"", ""okasf/magicanimate"", ""matejkratochvil/magicanimate"", ""jcachat/magicanimate"", ""K00B404/magicanimate""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-12-04 15:55:47+00:00"", ""cardData"": ""license: bsd-3-clause"", ""transformersInfo"": null, ""_id"": ""656debb0f7be0986b4dbb14d"", ""modelId"": ""zcxu-eric/MagicAnimate"", ""usedStorage"": 9988780119}",0,,0,,0,,0,,0,"AIADC/magicanimate, AIADC/magicanimate1, BG5/magicanimate, Gyufyjk/magicanimate, John6666/magicanimate, John6666/magicanimate2024, LioAlbert/magicanimate, cbensimon/magicanimate, huggingface/InferenceSupport/discussions/new?title=zcxu-eric/MagicAnimate&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bzcxu-eric%2FMagicAnimate%5D(%2Fzcxu-eric%2FMagicAnimate)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, samaleksandrov/magicanimate, vakilrathod67/magicanimat, walre1301/magicanimate, zcxu-eric/magicanimate",13
|
MeloTTS-English_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,205 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
myshell-ai/MeloTTS-English,"---
|
| 3 |
+
license: mit
|
| 4 |
+
language:
|
| 5 |
+
- ko
|
| 6 |
+
pipeline_tag: text-to-speech
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# MeloTTS
|
| 11 |
+
|
| 12 |
+
<a href=""https://trendshift.io/repositories/8133"" target=""_blank""><img src=""https://trendshift.io/api/badge/repositories/8133"" alt=""myshell-ai%2FMeloTTS | Trendshift"" style=""width: 250px; height: 55px;"" width=""250"" height=""55""/></a>
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
MeloTTS is a **high-quality multi-lingual** text-to-speech library by [MIT](https://www.mit.edu/) and [MyShell.ai](https://myshell.ai). Supported languages include:
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
| Model card | Example |
|
| 20 |
+
| --- | --- |
|
| 21 |
+
| [English](https://huggingface.co/myshell-ai/MeloTTS-English-v2) (American) | [Link](https://myshell-public-repo-host.s3.amazonaws.com/myshellttsbase/examples/en/EN-US/speed_1.0/sent_000.wav) |
|
| 22 |
+
| [English](https://huggingface.co/myshell-ai/MeloTTS-English-v2) (British) | [Link](https://myshell-public-repo-host.s3.amazonaws.com/myshellttsbase/examples/en/EN-BR/speed_1.0/sent_000.wav) |
|
| 23 |
+
| [English](https://huggingface.co/myshell-ai/MeloTTS-English-v2) (Indian) | [Link](https://myshell-public-repo-host.s3.amazonaws.com/myshellttsbase/examples/en/EN_INDIA/speed_1.0/sent_000.wav) |
|
| 24 |
+
| [English](https://huggingface.co/myshell-ai/MeloTTS-English-v2) (Australian) | [Link](https://myshell-public-repo-host.s3.amazonaws.com/myshellttsbase/examples/en/EN-AU/speed_1.0/sent_000.wav) |
|
| 25 |
+
| [English](https://huggingface.co/myshell-ai/MeloTTS-English-v2) (Default) | [Link](https://myshell-public-repo-host.s3.amazonaws.com/myshellttsbase/examples/en/EN-Default/speed_1.0/sent_000.wav) |
|
| 26 |
+
| [Spanish](https://huggingface.co/myshell-ai/MeloTTS-Spanish) | [Link](https://myshell-public-repo-host.s3.amazonaws.com/myshellttsbase/examples/es/ES/speed_1.0/sent_000.wav) |
|
| 27 |
+
| [French](https://huggingface.co/myshell-ai/MeloTTS-French) | [Link](https://myshell-public-repo-host.s3.amazonaws.com/myshellttsbase/examples/fr/FR/speed_1.0/sent_000.wav) |
|
| 28 |
+
| [Chinese](https://huggingface.co/myshell-ai/MeloTTS-Chinese) (mix EN) | [Link](https://myshell-public-repo-host.s3.amazonaws.com/myshellttsbase/examples/zh/ZH/speed_1.0/sent_008.wav) |
|
| 29 |
+
| [Japanese](https://huggingface.co/myshell-ai/MeloTTS-Japanese) | [Link](https://myshell-public-repo-host.s3.amazonaws.com/myshellttsbase/examples/jp/JP/speed_1.0/sent_000.wav) |
|
| 30 |
+
| [Korean](https://huggingface.co/myshell-ai/MeloTTS-Korean/) | [Link](https://myshell-public-repo-host.s3.amazonaws.com/myshellttsbase/examples/kr/KR/speed_1.0/sent_000.wav) |
|
| 31 |
+
|
| 32 |
+
Some other features include:
|
| 33 |
+
- The Chinese speaker supports `mixed Chinese and English`.
|
| 34 |
+
- Fast enough for `CPU real-time inference`.
|
| 35 |
+
|
| 36 |
+
## Authors
|
| 37 |
+
|
| 38 |
+
- [Wenliang Zhao](https://wl-zhao.github.io) at Tsinghua University
|
| 39 |
+
- [Xumin Yu](https://yuxumin.github.io) at Tsinghua University
|
| 40 |
+
- [Zengyi Qin](https://www.qinzy.tech) (project lead) at MIT and MyShell
|
| 41 |
+
|
| 42 |
+
**Citation**
|
| 43 |
+
```
|
| 44 |
+
@software{zhao2024melo,
|
| 45 |
+
author={Zhao, Wenliang and Yu, Xumin and Qin, Zengyi},
|
| 46 |
+
title = {MeloTTS: High-quality Multi-lingual Multi-accent Text-to-Speech},
|
| 47 |
+
url = {https://github.com/myshell-ai/MeloTTS},
|
| 48 |
+
year = {2023}
|
| 49 |
+
}
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
## Usage
|
| 54 |
+
|
| 55 |
+
### Without Installation
|
| 56 |
+
|
| 57 |
+
An unofficial [live demo](https://huggingface.co/spaces/mrfakename/MeloTTS) is hosted on Hugging Face Spaces.
|
| 58 |
+
|
| 59 |
+
#### Use it on MyShell
|
| 60 |
+
|
| 61 |
+
There are hundreds of TTS models on MyShell, much more than MeloTTS. See examples [here](https://github.com/myshell-ai/MeloTTS/blob/main/docs/quick_use.md#use-melotts-without-installation).
|
| 62 |
+
More can be found at the widget center of [MyShell.ai](https://app.myshell.ai/robot-workshop).
|
| 63 |
+
|
| 64 |
+
### Install and Use Locally
|
| 65 |
+
|
| 66 |
+
Follow the installation steps [here](https://github.com/myshell-ai/MeloTTS/blob/main/docs/install.md#linux-and-macos-install) before using the following snippet:
|
| 67 |
+
|
| 68 |
+
```python
|
| 69 |
+
from melo.api import TTS
|
| 70 |
+
|
| 71 |
+
# Speed is adjustable
|
| 72 |
+
speed = 1.0
|
| 73 |
+
|
| 74 |
+
# CPU is sufficient for real-time inference.
|
| 75 |
+
# You can set it manually to 'cpu' or 'cuda' or 'cuda:0' or 'mps'
|
| 76 |
+
device = 'auto' # Will automatically use GPU if available
|
| 77 |
+
|
| 78 |
+
# English
|
| 79 |
+
text = ""Did you ever hear a folk tale about a giant turtle?""
|
| 80 |
+
model = TTS(language='EN', device=device)
|
| 81 |
+
speaker_ids = model.hps.data.spk2id
|
| 82 |
+
|
| 83 |
+
# American accent
|
| 84 |
+
output_path = 'en-us.wav'
|
| 85 |
+
model.tts_to_file(text, speaker_ids['EN-US'], output_path, speed=speed)
|
| 86 |
+
|
| 87 |
+
# British accent
|
| 88 |
+
output_path = 'en-br.wav'
|
| 89 |
+
model.tts_to_file(text, speaker_ids['EN-BR'], output_path, speed=speed)
|
| 90 |
+
|
| 91 |
+
# Indian accent
|
| 92 |
+
output_path = 'en-india.wav'
|
| 93 |
+
model.tts_to_file(text, speaker_ids['EN_INDIA'], output_path, speed=speed)
|
| 94 |
+
|
| 95 |
+
# Australian accent
|
| 96 |
+
output_path = 'en-au.wav'
|
| 97 |
+
model.tts_to_file(text, speaker_ids['EN-AU'], output_path, speed=speed)
|
| 98 |
+
|
| 99 |
+
# Default accent
|
| 100 |
+
output_path = 'en-default.wav'
|
| 101 |
+
model.tts_to_file(text, speaker_ids['EN-Default'], output_path, speed=speed)
|
| 102 |
+
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
## Join the Community
|
| 107 |
+
|
| 108 |
+
**Open Source AI Grant**
|
| 109 |
+
|
| 110 |
+
We are actively sponsoring open-source AI projects. The sponsorship includes GPU resources, fundings and intellectual support (collaboration with top research labs). We welcome both reseach and engineering projects, as long as the open-source community needs them. Please contact [Zengyi Qin](https://www.qinzy.tech/) if you are interested.
|
| 111 |
+
|
| 112 |
+
**Contributing**
|
| 113 |
+
|
| 114 |
+
If you find this work useful, please consider contributing to the GitHub [repo](https://github.com/myshell-ai/MeloTTS).
|
| 115 |
+
|
| 116 |
+
- Many thanks to [@fakerybakery](https://github.com/fakerybakery) for adding the Web UI and CLI part.
|
| 117 |
+
|
| 118 |
+
## License
|
| 119 |
+
|
| 120 |
+
This library is under MIT License, which means it is free for both commercial and non-commercial use.
|
| 121 |
+
|
| 122 |
+
## Acknowledgements
|
| 123 |
+
|
| 124 |
+
This implementation is based on [TTS](https://github.com/coqui-ai/TTS), [VITS](https://github.com/jaywalnut310/vits), [VITS2](https://github.com/daniilrobnikov/vits2) and [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2). We appreciate their awesome work.
|
| 125 |
+
|
| 126 |
+
","{""id"": ""myshell-ai/MeloTTS-English"", ""author"": ""myshell-ai"", ""sha"": ""bb4fb7346d566d277ba8c8c7dbfdf6786139b8ef"", ""last_modified"": ""2024-12-24 19:18:31+00:00"", ""created_at"": ""2024-02-29 14:52:43+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 212802, ""downloads_all_time"": null, ""likes"": 265, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""text-to-speech"", ""ko"", ""license:mit"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-to-speech"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- ko\nlicense: mit\npipeline_tag: text-to-speech"", ""widget_data"": null, ""model_index"": null, ""config"": {}, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='checkpoint.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""gabrielchua/open-notebooklm"", ""mrfakename/MeloTTS"", ""neuromod0/MeloTTS-English-v3"", ""reflex-ai/MeloTTS-English-v3"", ""subhasmita/myshell-ai-MeloTTS-English"", ""ishworrsubedii/MeloTTS"", ""derivativegenius/myshell-ai-MeloTTS-English"", ""vuxuanhoan/MeloTTS"", ""Noe831/tts"", ""SupariKoli/myshell-ai-MeloTTS-English"", ""Ahmed0011/myshell-ai-MeloTTS-English"", ""Memoroeisdead/myshell-ai-MeloTTS-English"", ""Mazen001/myshell-ai-MeloTTS-English"", ""Jacobsirdan/myshell-ai-MeloTTS-English"", ""atlasias/myshell-ai-MeloTTS-English"", ""Pavan178/myshell-ai-MeloTTS-English"", ""zetabyte/myshell-ai-MeloTTS-English"", ""Dima123e/myshell-ai-MeloTTS-English"", ""ReySajju742/myshell-ai-MeloTTS-English"", ""SerSleepy/myshell-ai-MeloTTS-English"", ""dijj/myshell-ai-MeloTTS-English"", ""creospin/myshell-ai-MeloTTS-English"", ""ssenwshj/myshell-ai-MeloTTS-English"", ""CDOM201/domtts"", ""ishaank123/myshell-ai-MeloTTS-English"", ""Emienent/myshell-ai-MeloTTS-English"", ""LongTran1996/myshell-ai-MeloTTS-English"", ""SalmanAhmad-24/myshell-ai-MeloTTS-English"", ""jiuzhou223/myshell-ai-MeloTTS-English"", ""doctumdoces/myshell-ai-MeloTTS-English"", ""sumittechmero/MeloTTS"", ""Shangkhonil/Image_TO_Speech"", ""abis90/myshell-ai-MeloTTS-English"", ""abis90/myshell-ai-MeloTTS-Englishs"", ""nirajandhakal/MeloTTS"", ""dbarks/open-notebooklm"", ""cybercody/open-notebooklm"", ""TerryZazu/myshell-ai-MeloTTS-English"", ""cls7908/open-notebooklm"", ""iukea/open-notebooklm"", ""zohairy/open-notebooklm"", ""cagiraudo56789/open-notebooklm"", ""neuromod0/open-notebooklm"", ""AI-Platform/open-notebooklm"", ""WodeDadao/open-notebooklm"", ""addyosmani/open-notebooklm"", ""Pawitt/myshell"", ""slkreddy/open-notebooklm"", ""wagnergod/open-notebooklm"", ""LeonEr/myshell-ai-MeloTTS-English"", ""mahunyu66/myshell-ai-MeloTTS-English"", ""vismaya2939/textTOspeech"", ""xrainxshadowx/myshell-ai-MeloTTS-English"", ""Telistra/myshell-ai-MeloTTS-English"", ""keshav6936/myshell-ai-MeloTTS-English"", ""Rajsinghfanfjg/myshell-ai-MeloTTS-English"", ""shrolr/myshell-ai-MeloTTS-English"", ""soiz/myshell-ai-MeloTTS-English"", ""Neear1337/myshell-ai-MeloTTS-English"", ""Neear1337/MeloTTS"", ""KalaiyarasanJacob/myshell-ai-MeloTTS-English"", ""zlillymp/myshell-ai-MeloTTS-English"", ""mukeshkr5/myshell-ai-MeloTTS-English"", ""mxyzplk/myshell-ai-MeloTTS-English"", ""fullstuckdev/myshell-ai-MeloTTS-English"", ""blind1234/myshell-ai-MeloTTS-English"", ""mnisham/myshell-ai-MeloTTS-English"", ""Shamlan321/myshell-ai-MeloTTS-English"", ""hrsprojects/myshell-ai-MeloTTS-English"", ""utkubulkan/MeloTTS"", ""RORONovaLuffy/myshell-ai-MeloTTS-English"", ""huysynf/myshell-ai-MeloTTS-English"", ""rockerritesh/myshell-ai-MeloTTS-English""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-12-24 19:18:31+00:00"", ""cardData"": ""language:\n- ko\nlicense: mit\npipeline_tag: text-to-speech"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""65e09a3b51f0487385110f72"", ""modelId"": ""myshell-ai/MeloTTS-English"", ""usedStorage"": 207860748}",0,https://huggingface.co/kadirnar/melotts-jenny,1,,0,,0,,0,"Noe831/tts, derivativegenius/myshell-ai-MeloTTS-English, gabrielchua/open-notebooklm, hrsprojects/myshell-ai-MeloTTS-English, huggingface/InferenceSupport/discussions/new?title=myshell-ai/MeloTTS-English&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bmyshell-ai%2FMeloTTS-English%5D(%2Fmyshell-ai%2FMeloTTS-English)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, ishworrsubedii/MeloTTS, mrfakename/MeloTTS, neuromod0/MeloTTS-English-v3, reflex-ai/MeloTTS-English-v3, soiz/myshell-ai-MeloTTS-English, subhasmita/myshell-ai-MeloTTS-English, sumittechmero/MeloTTS, vuxuanhoan/MeloTTS",13
|
| 127 |
+
kadirnar/melotts-jenny,"---
|
| 128 |
+
license: mit
|
| 129 |
+
datasets:
|
| 130 |
+
- reach-vb/jenny_tts_dataset
|
| 131 |
+
language:
|
| 132 |
+
- en
|
| 133 |
+
base_model:
|
| 134 |
+
- myshell-ai/MeloTTS-English
|
| 135 |
+
tags:
|
| 136 |
+
- audio
|
| 137 |
+
- melotts
|
| 138 |
+
---
|
| 139 |
+
# MeloTTS Model Checkpoint
|
| 140 |
+
|
| 141 |
+
This repository contains trained model checkpoints for MeloTTS, a high-quality multi-lingual text-to-speech system. These checkpoints are part of a trained model that can be used for text-to-speech synthesis.
|
| 142 |
+
|
| 143 |
+
## Model Details
|
| 144 |
+
|
| 145 |
+
- **Model Type**: MeloTTS
|
| 146 |
+
- **Language Support**: English (Default)
|
| 147 |
+
- **Sampling Rate**: 44.1kHz
|
| 148 |
+
- **Mel Channels**: 128
|
| 149 |
+
- **Hidden Channels**: 192
|
| 150 |
+
- **Filter Channels**: 768
|
| 151 |
+
|
| 152 |
+
### Architecture Details
|
| 153 |
+
- Inter channels: 192
|
| 154 |
+
- Number of heads: 2
|
| 155 |
+
- Number of layers: 6
|
| 156 |
+
- Flow layers: 3
|
| 157 |
+
- Kernel size: 3
|
| 158 |
+
- Dropout rate: 0.1
|
| 159 |
+
|
| 160 |
+
## Training Dataset
|
| 161 |
+
|
| 162 |
+
This model was trained on the [Jenny TTS Dataset](https://huggingface.co/datasets/reach-vb/jenny_tts_dataset), which is available on Hugging Face. The dataset consists of high-quality English speech recordings suitable for text-to-speech training.
|
| 163 |
+
|
| 164 |
+
## Model Files
|
| 165 |
+
|
| 166 |
+
The repository contains several checkpoint files:
|
| 167 |
+
- `DUR_*.pth`: Duration predictor checkpoints
|
| 168 |
+
- `G_*.pth`: Generator model checkpoints
|
| 169 |
+
- `D_*.pth`: Discriminator model checkpoints
|
| 170 |
+
- `config.json`: Model configuration file
|
| 171 |
+
|
| 172 |
+
## Usage
|
| 173 |
+
|
| 174 |
+
To use this model with MeloTTS:
|
| 175 |
+
|
| 176 |
+
```python
|
| 177 |
+
from melo.api import TTS
|
| 178 |
+
|
| 179 |
+
# Initialize TTS with the model path
|
| 180 |
+
tts = TTS(model_path=""kadirnar/melotts-model"")
|
| 181 |
+
|
| 182 |
+
# Generate speech
|
| 183 |
+
tts.tts_to_file(
|
| 184 |
+
text=""Your text here"",
|
| 185 |
+
speaker=""EN-default"",
|
| 186 |
+
language=""EN"",
|
| 187 |
+
output_path=""output.wav""
|
| 188 |
+
)
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
## Training Details
|
| 192 |
+
|
| 193 |
+
The model was trained with the following specifications:
|
| 194 |
+
- Batch size: 6
|
| 195 |
+
- Learning rate: 0.0003
|
| 196 |
+
- Beta values: [0.8, 0.99]
|
| 197 |
+
- Segment size: 16384
|
| 198 |
+
|
| 199 |
+
## Original Repository
|
| 200 |
+
|
| 201 |
+
This model is based on [MeloTTS](https://github.com/myshell-ai/MeloTTS) by MyShell.ai. Visit the original repository for more details about the architecture and implementation.
|
| 202 |
+
|
| 203 |
+
## License
|
| 204 |
+
|
| 205 |
+
This model follows the same licensing as the original MeloTTS repository (MIT License).","{""id"": ""kadirnar/melotts-jenny"", ""author"": ""kadirnar"", ""sha"": ""88630bd418b92abb54c8064e2fb26202020b6728"", ""last_modified"": ""2024-11-28 07:16:04+00:00"", ""created_at"": ""2024-11-28 07:05:03+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 2, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""tensorboard"", ""audio"", ""melotts"", ""en"", ""dataset:reach-vb/jenny_tts_dataset"", ""base_model:myshell-ai/MeloTTS-English"", ""base_model:finetune:myshell-ai/MeloTTS-English"", ""license:mit"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- myshell-ai/MeloTTS-English\ndatasets:\n- reach-vb/jenny_tts_dataset\nlanguage:\n- en\nlicense: mit\ntags:\n- audio\n- melotts"", ""widget_data"": null, ""model_index"": null, ""config"": {}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DUR_0.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DUR_77000.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DUR_78000.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='DUR_79000.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='D_0.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='D_78000.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='D_79000.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='G_0.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='G_75000.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='G_76000.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='G_77000.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='G_78000.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='G_79000.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval/events.out.tfevents.1732646944.optimistic-hubble.1174083.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval/events.out.tfevents.1732656741.optimistic-hubble.1237661.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval/events.out.tfevents.1732692904.optimistic-hubble.1294737.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval/events.out.tfevents.1732715645.optimistic-hubble.1345340.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval/events.out.tfevents.1732720979.optimistic-hubble.1367391.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval/events.out.tfevents.1732733258.optimistic-hubble.1406475.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval/events.out.tfevents.1732733614.optimistic-hubble.1417031.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval/events.out.tfevents.1732739659.optimistic-hubble.1440705.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval/events.out.tfevents.1732743102.optimistic-hubble.1460255.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval/events.out.tfevents.1732747168.optimistic-hubble.1478394.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval/events.out.tfevents.1732776627.optimistic-hubble.1518651.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='events.out.tfevents.1732646944.optimistic-hubble.1174083.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='events.out.tfevents.1732656741.optimistic-hubble.1237661.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='events.out.tfevents.1732692904.optimistic-hubble.1294737.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='events.out.tfevents.1732715645.optimistic-hubble.1345340.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='events.out.tfevents.1732720979.optimistic-hubble.1367391.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='events.out.tfevents.1732733258.optimistic-hubble.1406475.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='events.out.tfevents.1732733614.optimistic-hubble.1417031.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='events.out.tfevents.1732739659.optimistic-hubble.1440705.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='events.out.tfevents.1732743102.optimistic-hubble.1460255.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='events.out.tfevents.1732747168.optimistic-hubble.1478394.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='events.out.tfevents.1732776627.optimistic-hubble.1518651.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='train.log', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-11-28 07:16:04+00:00"", ""cardData"": ""base_model:\n- myshell-ai/MeloTTS-English\ndatasets:\n- reach-vb/jenny_tts_dataset\nlanguage:\n- en\nlicense: mit\ntags:\n- audio\n- melotts"", ""transformersInfo"": null, ""_id"": ""6748161f102b62dffc6bb9ea"", ""modelId"": ""kadirnar/melotts-jenny"", ""usedStorage"": 5871054267}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=kadirnar/melotts-jenny&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bkadirnar%2Fmelotts-jenny%5D(%2Fkadirnar%2Fmelotts-jenny)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
MiniCPM-Llama3-V-2_5-gguf_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
openbmb/MiniCPM-Llama3-V-2_5-gguf,"---
|
| 3 |
+
tags:
|
| 4 |
+
- llama.cpp
|
| 5 |
+
base_model:
|
| 6 |
+
- openbmb/MiniCPM-Llama3-V-2_5
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# MiniCPM-Llama3-V 2.5 gguf files for llama.cpp
|
| 10 |
+
|
| 11 |
+
## Usage
|
| 12 |
+
Please see our fork of [llama.cpp](https://github.com/OpenBMB/llama.cpp/tree/minicpm-v2.5/examples/minicpmv) for more detail to run MiniCPM-Llama3-V 2.5 with llama.cpp
|
| 13 |
+
|
| 14 |
+
## ollama
|
| 15 |
+
[ollama](https://github.com/OpenBMB/ollama/tree/minicpm-v2.5/examples/minicpm-v2.5)","{""id"": ""openbmb/MiniCPM-Llama3-V-2_5-gguf"", ""author"": ""openbmb"", ""sha"": ""d090fbfffeef9f01dfb282b3cf2b1e3360dfd29a"", ""last_modified"": ""2025-02-27 08:22:43+00:00"", ""created_at"": ""2024-05-19 17:35:26+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 8138, ""downloads_all_time"": null, ""likes"": 213, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""gguf"", ""llama.cpp"", ""base_model:openbmb/MiniCPM-Llama3-V-2_5"", ""base_model:quantized:openbmb/MiniCPM-Llama3-V-2_5"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- openbmb/MiniCPM-Llama3-V-2_5\ntags:\n- llama.cpp"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-BF16.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-F16.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-IQ3_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-IQ3_S.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-IQ3_XS.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-IQ4_NL.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-IQ4_XS.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q2_K.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q3_K.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q3_K_L.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q3_K_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q3_K_S.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q4_0.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q4_1.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q4_K.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q4_K_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q4_K_M_for_pr.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q4_K_S.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q5_0.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q5_1.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q5_K.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q5_K_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q5_K_S.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q6_K.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q8_0.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='mmproj-model-f16.gguf', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-27 08:22:43+00:00"", ""cardData"": ""base_model:\n- openbmb/MiniCPM-Llama3-V-2_5\ntags:\n- llama.cpp"", ""transformersInfo"": null, ""_id"": ""664a385e7a1ed3e001f3d8f7"", ""modelId"": ""openbmb/MiniCPM-Llama3-V-2_5-gguf"", ""usedStorage"": 139601373248}",0,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=openbmb/MiniCPM-Llama3-V-2_5-gguf&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bopenbmb%2FMiniCPM-Llama3-V-2_5-gguf%5D(%2Fopenbmb%2FMiniCPM-Llama3-V-2_5-gguf)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
MiniCPM-V-2_6-gguf_finetunes_20250427_003734.csv_finetunes_20250427_003734.csv
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
openbmb/MiniCPM-V-2_6-gguf,"---
|
| 3 |
+
base_model:
|
| 4 |
+
- openbmb/MiniCPM-V-2_6
|
| 5 |
+
---
|
| 6 |
+
## MiniCPM-V 2.6
|
| 7 |
+
|
| 8 |
+
### Prepare models and code
|
| 9 |
+
|
| 10 |
+
Download [MiniCPM-V-2_6](https://huggingface.co/openbmb/MiniCPM-V-2_6) PyTorch model from huggingface to ""MiniCPM-V-2_6"" folder.
|
| 11 |
+
|
| 12 |
+
Clone llama.cpp:
|
| 13 |
+
```bash
|
| 14 |
+
git clone git@github.com:OpenBMB/llama.cpp.git
|
| 15 |
+
cd llama.cpp
|
| 16 |
+
git checkout minicpmv-main
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
### Usage of MiniCPM-V 2.6
|
| 20 |
+
|
| 21 |
+
Convert PyTorch model to gguf files (You can also download the converted [gguf](https://huggingface.co/openbmb/MiniCPM-V-2_6-gguf) by us)
|
| 22 |
+
|
| 23 |
+
```bash
|
| 24 |
+
python ./examples/llava/minicpmv-surgery.py -m ../MiniCPM-V-2_6
|
| 25 |
+
python ./examples/llava/minicpmv-convert-image-encoder-to-gguf.py -m ../MiniCPM-V-2_6 --minicpmv-projector ../MiniCPM-V-2_6/minicpmv.projector --output-dir ../MiniCPM-V-2_6/ --image-mean 0.5 0.5 0.5 --image-std 0.5 0.5 0.5 --minicpmv_version 3
|
| 26 |
+
python ./convert_hf_to_gguf.py ../MiniCPM-V-2_6/model
|
| 27 |
+
|
| 28 |
+
# quantize int4 version
|
| 29 |
+
./llama-quantize ../MiniCPM-V-2_6/model/ggml-model-f16.gguf ../MiniCPM-V-2_6/model/ggml-model-Q4_K_M.gguf Q4_K_M
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
Build for Linux or Mac
|
| 33 |
+
|
| 34 |
+
```bash
|
| 35 |
+
make
|
| 36 |
+
make llama-minicpmv-cli
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
Inference on Linux or Mac
|
| 40 |
+
```
|
| 41 |
+
# run f16 version
|
| 42 |
+
./llama-minicpmv-cli -m ../MiniCPM-V-2_6/model/ggml-model-f16.gguf --mmproj ../MiniCPM-V-2_6/mmproj-model-f16.gguf -c 4096 --temp 0.7 --top-p 0.8 --top-k 100 --repeat-penalty 1.05 --image xx.jpg -p ""What is in the image?""
|
| 43 |
+
|
| 44 |
+
# run quantized int4 version
|
| 45 |
+
./llama-minicpmv-cli -m ../MiniCPM-V-2_6/model/ggml-model-Q4_K_M.gguf --mmproj ../MiniCPM-V-2_6/mmproj-model-f16.gguf -c 4096 --temp 0.7 --top-p 0.8 --top-k 100 --repeat-penalty 1.05 --image xx.jpg -p ""What is in the image?""
|
| 46 |
+
|
| 47 |
+
# or run in interactive mode
|
| 48 |
+
./llama-minicpmv-cli -m ../MiniCPM-V-2_6/model/ggml-model-Q4_K_M.gguf --mmproj ../MiniCPM-V-2_6/mmproj-model-f16.gguf -c 4096 --temp 0.7 --top-p 0.8 --top-k 100 --repeat-penalty 1.05 --image xx.jpg -i
|
| 49 |
+
```","{""id"": ""openbmb/MiniCPM-V-2_6-gguf"", ""author"": ""openbmb"", ""sha"": ""48fe6436abf57b3df6ec34f73cdc1fb4b740acb0"", ""last_modified"": ""2025-02-27 08:22:16+00:00"", ""created_at"": ""2024-08-04 05:55:37+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 19692, ""downloads_all_time"": null, ""likes"": 159, ""library_name"": null, ""gguf"": {""total"": 7612763648, ""architecture"": ""qwen2"", ""context_length"": 32768, ""chat_template"": ""{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"", ""bos_token"": ""<|im_start|>"", ""eos_token"": ""<|im_end|>""}, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""gguf"", ""base_model:openbmb/MiniCPM-V-2_6"", ""base_model:quantized:openbmb/MiniCPM-V-2_6"", ""endpoints_compatible"", ""region:us"", ""conversational""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- openbmb/MiniCPM-V-2_6"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-IQ3_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-IQ3_S.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-IQ3_XS.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-IQ4_NL.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-IQ4_XS.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q2_K.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q3_K.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q3_K_L.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q3_K_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q3_K_S.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q4_0.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q4_1.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q4_K.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q4_K_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q4_K_S.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q5_0.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q5_1.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q5_K.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q5_K_M.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q5_K_S.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q6_K.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-Q8_0.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ggml-model-f16.gguf', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='mmproj-model-f16.gguf', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-27 08:22:16+00:00"", ""cardData"": ""base_model:\n- openbmb/MiniCPM-V-2_6"", ""transformersInfo"": null, ""_id"": ""66af17d93c257dab06a05104"", ""modelId"": ""openbmb/MiniCPM-V-2_6-gguf"", ""usedStorage"": 105451169760}",0,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=openbmb/MiniCPM-V-2_6-gguf&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bopenbmb%2FMiniCPM-V-2_6-gguf%5D(%2Fopenbmb%2FMiniCPM-V-2_6-gguf)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
Molmo-7B-D-0924_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv
ADDED
|
@@ -0,0 +1,211 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
allenai/Molmo-7B-D-0924,"---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
base_model:
|
| 7 |
+
- openai/clip-vit-large-patch14-336
|
| 8 |
+
- Qwen/Qwen2-7B
|
| 9 |
+
pipeline_tag: image-text-to-text
|
| 10 |
+
tags:
|
| 11 |
+
- multimodal
|
| 12 |
+
- olmo
|
| 13 |
+
- molmo
|
| 14 |
+
- pixmo
|
| 15 |
+
library_name: transformers
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
<img src=""molmo_logo.png"" alt=""Logo for the Molmo Project"" style=""width: auto; height: 50px;"">
|
| 19 |
+
|
| 20 |
+
# Molmo 7B-D
|
| 21 |
+
|
| 22 |
+
Molmo is a family of open vision-language models developed by the Allen Institute for AI. Molmo models are trained on PixMo, a dataset of 1 million, highly-curated image-text pairs. It has state-of-the-art performance among multimodal models with a similar size while being fully open-source. You can find all models in the Molmo family [here](https://huggingface.co/collections/allenai/molmo-66f379e6fe3b8ef090a8ca19).
|
| 23 |
+
**Learn more** about the Molmo family [in our announcement blog post](https://molmo.allenai.org/blog) or the [paper](https://huggingface.co/papers/2409.17146).
|
| 24 |
+
|
| 25 |
+
Molmo 7B-D is based on [Qwen2-7B](https://huggingface.co/Qwen/Qwen2-7B) and uses [OpenAI CLIP](https://huggingface.co/openai/clip-vit-large-patch14-336) as vision backbone.
|
| 26 |
+
It performs comfortably between GPT-4V and GPT-4o on both academic benchmarks and human evaluation.
|
| 27 |
+
It powers the **Molmo demo at** [**molmo.allenai.org**](https://molmo.allenai.org).
|
| 28 |
+
|
| 29 |
+
This checkpoint is a **preview** of the Molmo release. All artifacts used in creating Molmo (PixMo dataset, training code, evaluations, intermediate checkpoints) will be made available at a later date, furthering our commitment to open-source AI development and reproducibility.
|
| 30 |
+
|
| 31 |
+
[**Sign up here**](https://docs.google.com/forms/d/e/1FAIpQLSdML1MhNNBDsCHpgWG65Oydg2SjZzVasyqlP08nBrWjZp_c7A/viewform) to be the first to know when artifacts are released.
|
| 32 |
+
|
| 33 |
+
Quick links:
|
| 34 |
+
- 💬 [Demo](https://molmo.allenai.org/)
|
| 35 |
+
- 📂 [All Models](https://huggingface.co/collections/allenai/molmo-66f379e6fe3b8ef090a8ca19)
|
| 36 |
+
- 📃 [Paper](https://molmo.allenai.org/paper.pdf)
|
| 37 |
+
- 🎥 [Blog with Videos](https://molmo.allenai.org/blog)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
## Quick Start
|
| 41 |
+
|
| 42 |
+
To run Molmo, first install dependencies:
|
| 43 |
+
|
| 44 |
+
```bash
|
| 45 |
+
pip install einops torchvision
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
Then, follow these steps:
|
| 49 |
+
|
| 50 |
+
```python
|
| 51 |
+
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
|
| 52 |
+
from PIL import Image
|
| 53 |
+
import requests
|
| 54 |
+
|
| 55 |
+
# load the processor
|
| 56 |
+
processor = AutoProcessor.from_pretrained(
|
| 57 |
+
'allenai/Molmo-7B-D-0924',
|
| 58 |
+
trust_remote_code=True,
|
| 59 |
+
torch_dtype='auto',
|
| 60 |
+
device_map='auto'
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
# load the model
|
| 64 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 65 |
+
'allenai/Molmo-7B-D-0924',
|
| 66 |
+
trust_remote_code=True,
|
| 67 |
+
torch_dtype='auto',
|
| 68 |
+
device_map='auto'
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
# process the image and text
|
| 72 |
+
inputs = processor.process(
|
| 73 |
+
images=[Image.open(requests.get(""https://picsum.photos/id/237/536/354"", stream=True).raw)],
|
| 74 |
+
text=""Describe this image.""
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
# move inputs to the correct device and make a batch of size 1
|
| 78 |
+
inputs = {k: v.to(model.device).unsqueeze(0) for k, v in inputs.items()}
|
| 79 |
+
|
| 80 |
+
# generate output; maximum 200 new tokens; stop generation when <|endoftext|> is generated
|
| 81 |
+
output = model.generate_from_batch(
|
| 82 |
+
inputs,
|
| 83 |
+
GenerationConfig(max_new_tokens=200, stop_strings=""<|endoftext|>""),
|
| 84 |
+
tokenizer=processor.tokenizer
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
# only get generated tokens; decode them to text
|
| 88 |
+
generated_tokens = output[0,inputs['input_ids'].size(1):]
|
| 89 |
+
generated_text = processor.tokenizer.decode(generated_tokens, skip_special_tokens=True)
|
| 90 |
+
|
| 91 |
+
# print the generated text
|
| 92 |
+
print(generated_text)
|
| 93 |
+
|
| 94 |
+
# >>> This image features an adorable black Labrador puppy, captured from a top-down
|
| 95 |
+
# perspective. The puppy is sitting on a wooden deck, which is composed ...
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
To make inference more efficient, run with autocast:
|
| 99 |
+
|
| 100 |
+
```python
|
| 101 |
+
with torch.autocast(device_type=""cuda"", enabled=True, dtype=torch.bfloat16):
|
| 102 |
+
output = model.generate_from_batch(
|
| 103 |
+
inputs,
|
| 104 |
+
GenerationConfig(max_new_tokens=200, stop_strings=""<|endoftext|>""),
|
| 105 |
+
tokenizer=processor.tokenizer
|
| 106 |
+
)
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
We did most of our evaluation in this setting (autocast on, but float32 weights)
|
| 110 |
+
|
| 111 |
+
To even further reduce the memory requirements, the model can be run with bfloat16 weights:
|
| 112 |
+
|
| 113 |
+
```python
|
| 114 |
+
model.to(dtype=torch.bfloat16)
|
| 115 |
+
inputs[""images""] = inputs[""images""].to(torch.bfloat16)
|
| 116 |
+
output = model.generate_from_batch(
|
| 117 |
+
inputs,
|
| 118 |
+
GenerationConfig(max_new_tokens=200, stop_strings=""<|endoftext|>""),
|
| 119 |
+
tokenizer=processor.tokenizer
|
| 120 |
+
)
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
Note that we have observed that this can change the output of the model compared to running with float32 weights.
|
| 124 |
+
|
| 125 |
+
## Evaluations
|
| 126 |
+
|
| 127 |
+
| Model | Average Score on 11 Academic Benchmarks | Human Preference Elo Rating |
|
| 128 |
+
|-----------------------------|-----------------------------------------|-----------------------------|
|
| 129 |
+
| Molmo 72B | 81.2 | 1077 |
|
| 130 |
+
| **Molmo 7B-D (this model)** | **77.3** | **1056** |
|
| 131 |
+
| Molmo 7B-O | 74.6 | 1051 |
|
| 132 |
+
| MolmoE 1B | 68.6 | 1032 |
|
| 133 |
+
| GPT-4o | 78.5 | 1079 |
|
| 134 |
+
| GPT-4V | 71.1 | 1041 |
|
| 135 |
+
| Gemini 1.5 Pro | 78.3 | 1074 |
|
| 136 |
+
| Gemini 1.5 Flash | 75.1 | 1054 |
|
| 137 |
+
| Claude 3.5 Sonnet | 76.7 | 1069 |
|
| 138 |
+
| Claude 3 Opus | 66.4 | 971 |
|
| 139 |
+
| Claude 3 Haiku | 65.3 | 999 |
|
| 140 |
+
| Qwen VL2 72B | 79.4 | 1037 |
|
| 141 |
+
| Qwen VL2 7B | 73.7 | 1025 |
|
| 142 |
+
| Intern VL2 LLAMA 76B | 77.1 | 1018 |
|
| 143 |
+
| Intern VL2 8B | 69.4 | 953 |
|
| 144 |
+
| Pixtral 12B | 69.5 | 1016 |
|
| 145 |
+
| Phi3.5-Vision 4B | 59.7 | 982 |
|
| 146 |
+
| PaliGemma 3B | 50.0 | 937 |
|
| 147 |
+
| LLAVA OneVision 72B | 76.6 | 1051 |
|
| 148 |
+
| LLAVA OneVision 7B | 72.0 | 1024 |
|
| 149 |
+
| Cambrian-1 34B | 66.8 | 953 |
|
| 150 |
+
| Cambrian-1 8B | 63.4 | 952 |
|
| 151 |
+
| xGen - MM - Interleave 4B | 59.5 | 979 |
|
| 152 |
+
| LLAVA-1.5 13B | 43.9 | 960 |
|
| 153 |
+
| LLAVA-1.5 7B | 40.7 | 951 |
|
| 154 |
+
|
| 155 |
+
*Benchmarks: AI2D test, ChartQA test, VQA v2.0 test, DocQA test, InfographicVQA test, TextVQA val, RealWorldQA, MMMU val, MathVista testmini, CountBenchQA, Flickr Count (we collected this new dataset that is significantly harder than CountBenchQA).*
|
| 156 |
+
|
| 157 |
+
## FAQs
|
| 158 |
+
|
| 159 |
+
### I'm getting an error a broadcast error when processing images!
|
| 160 |
+
|
| 161 |
+
Your image might not be in RGB format. You can convert it using the following code snippet:
|
| 162 |
+
|
| 163 |
+
```python
|
| 164 |
+
from PIL import Image
|
| 165 |
+
|
| 166 |
+
image = Image.open(...)
|
| 167 |
+
|
| 168 |
+
if image.mode != ""RGB"":
|
| 169 |
+
image = image.convert(""RGB"")
|
| 170 |
+
```
|
| 171 |
+
|
| 172 |
+
### Molmo doesn't work great with transparent images!
|
| 173 |
+
|
| 174 |
+
We received reports that Molmo models might struggle with transparent images.
|
| 175 |
+
For the time being, we recommend adding a white or dark background to your images before passing them to the model. The code snippet below shows how to do this using the Python Imaging Library (PIL):
|
| 176 |
+
|
| 177 |
+
```python
|
| 178 |
+
|
| 179 |
+
# Load the image
|
| 180 |
+
url = ""...""
|
| 181 |
+
image = Image.open(requests.get(url, stream=True).raw)
|
| 182 |
+
|
| 183 |
+
# Convert the image to grayscale to calculate brightness
|
| 184 |
+
gray_image = image.convert('L') # Convert to grayscale
|
| 185 |
+
|
| 186 |
+
# Calculate the average brightness
|
| 187 |
+
stat = ImageStat.Stat(gray_image)
|
| 188 |
+
average_brightness = stat.mean[0] # Get the average value
|
| 189 |
+
|
| 190 |
+
# Define background color based on brightness (threshold can be adjusted)
|
| 191 |
+
bg_color = (0, 0, 0) if average_brightness > 127 else (255, 255, 255)
|
| 192 |
+
|
| 193 |
+
# Create a new image with the same size as the original, filled with the background color
|
| 194 |
+
new_image = Image.new('RGB', image.size, bg_color)
|
| 195 |
+
|
| 196 |
+
# Paste the original image on top of the background (use image as a mask if needed)
|
| 197 |
+
new_image.paste(image, (0, 0), image if image.mode == 'RGBA' else None)
|
| 198 |
+
|
| 199 |
+
# Now you can pass the new_image to Molmo
|
| 200 |
+
processor = AutoProcessor.from_pretrained(
|
| 201 |
+
'allenai/Molmo-7B-D-0924',
|
| 202 |
+
trust_remote_code=True,
|
| 203 |
+
torch_dtype='auto',
|
| 204 |
+
device_map='auto'
|
| 205 |
+
)
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+
## License and Use
|
| 209 |
+
|
| 210 |
+
This model is licensed under Apache 2.0. It is intended for research and educational use.
|
| 211 |
+
For more information, please see our [Responsible Use Guidelines](https://allenai.org/responsible-use).","{""id"": ""allenai/Molmo-7B-D-0924"", ""author"": ""allenai"", ""sha"": ""ac032b93b84a7f10c9578ec59f9f20ee9a8990a2"", ""last_modified"": ""2025-04-04 20:01:44+00:00"", ""created_at"": ""2024-09-25 01:48:22+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 569560, ""downloads_all_time"": null, ""likes"": 524, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""molmo"", ""text-generation"", ""multimodal"", ""olmo"", ""pixmo"", ""image-text-to-text"", ""conversational"", ""custom_code"", ""en"", ""arxiv:2409.17146"", ""base_model:Qwen/Qwen2-7B"", ""base_model:finetune:Qwen/Qwen2-7B"", ""license:apache-2.0"", ""autotrain_compatible"", ""region:us""], ""pipeline_tag"": ""image-text-to-text"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- openai/clip-vit-large-patch14-336\n- Qwen/Qwen2-7B\nlanguage:\n- en\nlibrary_name: transformers\nlicense: apache-2.0\npipeline_tag: image-text-to-text\ntags:\n- multimodal\n- olmo\n- molmo\n- pixmo"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""MolmoForCausalLM""], ""auto_map"": {""AutoConfig"": ""config_molmo.MolmoConfig"", ""AutoModelForCausalLM"": ""modeling_molmo.MolmoForCausalLM""}, ""model_type"": ""molmo"", ""tokenizer_config"": {""bos_token"": null, ""chat_template"": ""{% for message in messages -%}\n {%- if (loop.index % 2 == 1 and message['role'] != 'user') or \n (loop.index % 2 == 0 and message['role'].lower() != 'assistant') -%}\n {{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}\n {%- endif -%}\n {{ message['role'].capitalize() + ': ' + message['content'] }}\n {%- if not loop.last -%}\n {{ ' ' }}\n {%- endif %}\n {%- endfor -%}\n {%- if add_generation_prompt -%}\n {{ ' Assistant:' }}\n {%- endif %}"", ""eos_token"": ""<|endoftext|>"", ""pad_token"": ""<|endoftext|>"", ""unk_token"": null}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": ""modeling_molmo.MolmoForCausalLM"", ""pipeline_tag"": ""text-generation"", ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config_molmo.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image_preprocessing_molmo.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_molmo.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='molmo_logo.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessing_molmo.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='processor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""akhaliq/Molmo-7B-D-0924"", ""TIGER-Lab/MEGA-Bench"", ""KBaba7/Quant"", ""bhaskartripathi/LLM_Quantization"", ""totolook/Quant"", ""FallnAI/Quantize-HF-Models"", ""yasserrmd/MolmoVision"", ""sflindrs/vlm_comparer"", ""ruslanmv/convert_to_gguf"", ""DDDamon/test"", ""quarterturn/molmo-natural-language-image-captioner"", ""awacke1/Leaderboard-Deepseek-Gemini-Grok-GPT-Qwen"", ""sflindrs/Molmo-7B-D-0924-extended-tokens"", ""stoefln/playground2"", ""dkisb/Molmo-7B-D-0924"", ""gaur3009/ColPali-Query-Generator"", ""zainimam/Ss-mol"", ""TheVixhal/OPPE"", ""srawalll/quizzz"", ""vpssud/molmo2"", ""TLPython/MolmoVision"", ""cburtin/ocr"", ""mastercallum/MolmoVision-noCUDAerror"", ""brunocota/Molmo-7B-D-0924"", ""K00B404/LLM_Quantization""], ""safetensors"": {""parameters"": {""F32"": 8021025280}, ""total"": 8021025280}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-04 20:01:44+00:00"", ""cardData"": ""base_model:\n- openai/clip-vit-large-patch14-336\n- Qwen/Qwen2-7B\nlanguage:\n- en\nlibrary_name: transformers\nlicense: apache-2.0\npipeline_tag: image-text-to-text\ntags:\n- multimodal\n- olmo\n- molmo\n- pixmo"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": ""modeling_molmo.MolmoForCausalLM"", ""pipeline_tag"": ""text-generation"", ""processor"": null}, ""_id"": ""66f36be6af8609e9ef8198e5"", ""modelId"": ""allenai/Molmo-7B-D-0924"", ""usedStorage"": 35884012544}",0,,0,,0,"https://huggingface.co/cyan2k/molmo-7B-D-bnb-4bit, https://huggingface.co/impactframes/molmo-7B-D-bnb-4bit, https://huggingface.co/detect-tech/molmo-7B-D-bnb-4bit, https://huggingface.co/ctranslate2-4you/molmo-7B-D-0924-bnb-4bit, https://huggingface.co/OPEA/Molmo-7B-D-0924-int4-sym-inc, https://huggingface.co/Scoolar/Molmo-7B-D-0924-NF4",6,,0,"FallnAI/Quantize-HF-Models, K00B404/LLM_Quantization, KBaba7/Quant, TIGER-Lab/MEGA-Bench, akhaliq/Molmo-7B-D-0924, awacke1/Leaderboard-Deepseek-Gemini-Grok-GPT-Qwen, bhaskartripathi/LLM_Quantization, huggingface/InferenceSupport/discussions/new?title=allenai/Molmo-7B-D-0924&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Ballenai%2FMolmo-7B-D-0924%5D(%2Fallenai%2FMolmo-7B-D-0924)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, quarterturn/molmo-natural-language-image-captioner, ruslanmv/convert_to_gguf, sflindrs/vlm_comparer, totolook/Quant, yasserrmd/MolmoVision",13
|
Nemotron-4-340B-Instruct_finetunes_20250425_125929.csv_finetunes_20250425_125929.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Phi-3-mini-128k-instruct_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Phi-4-mini-instruct_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
PixArt-XL-2-1024-MS_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv
ADDED
|
@@ -0,0 +1,329 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
PixArt-alpha/PixArt-XL-2-1024-MS,"---
|
| 3 |
+
license: openrail++
|
| 4 |
+
tags:
|
| 5 |
+
- text-to-image
|
| 6 |
+
- Pixart-α
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
<p align=""center"">
|
| 10 |
+
<img src=""asset/logo.png"" height=120>
|
| 11 |
+
</p>
|
| 12 |
+
|
| 13 |
+
<div style=""display:flex;justify-content: center"">
|
| 14 |
+
<a href=""https://huggingface.co/spaces/PixArt-alpha/PixArt-alpha""><img src=""https://img.shields.io/static/v1?label=Demo&message=Huggingface&color=yellow""></a>  
|
| 15 |
+
<a href=""https://pixart-alpha.github.io/""><img src=""https://img.shields.io/static/v1?label=Project%20Page&message=Github&color=blue&logo=github-pages""></a>  
|
| 16 |
+
<a href=""https://arxiv.org/abs/2310.00426""><img src=""https://img.shields.io/static/v1?label=Paper&message=Arxiv&color=red&logo=arxiv""></a>  
|
| 17 |
+
<a href=""https://colab.research.google.com/drive/1jZ5UZXk7tcpTfVwnX33dDuefNMcnW9ME?usp=sharing""><img src=""https://img.shields.io/static/v1?label=Free%20Trial&message=Google%20Colab&logo=google&color=orange""></a>  
|
| 18 |
+
<a href=""https://github.com/orgs/PixArt-alpha/discussions""><img src=""https://img.shields.io/static/v1?label=Discussion&message=Github&color=green&logo=github""></a>  
|
| 19 |
+
</div>
|
| 20 |
+
|
| 21 |
+
# 🐱 Pixart-α Model Card
|
| 22 |
+

|
| 23 |
+
|
| 24 |
+
## Model
|
| 25 |
+

|
| 26 |
+
|
| 27 |
+
[Pixart-α](https://arxiv.org/abs/2310.00426) consists of pure transformer blocks for latent diffusion:
|
| 28 |
+
It can directly generate 1024px images from text prompts within a single sampling process.
|
| 29 |
+
|
| 30 |
+
Source code is available at https://github.com/PixArt-alpha/PixArt-alpha.
|
| 31 |
+
|
| 32 |
+
### Model Description
|
| 33 |
+
|
| 34 |
+
- **Developed by:** Pixart-α
|
| 35 |
+
- **Model type:** Diffusion-Transformer-based text-to-image generative model
|
| 36 |
+
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENSE.md)
|
| 37 |
+
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts.
|
| 38 |
+
It is a [Transformer Latent Diffusion Model](https://arxiv.org/abs/2310.00426) that uses one fixed, pretrained text encoders ([T5](
|
| 39 |
+
https://huggingface.co/DeepFloyd/t5-v1_1-xxl))
|
| 40 |
+
and one latent feature encoder ([VAE](https://arxiv.org/abs/2112.10752)).
|
| 41 |
+
- **Resources for more information:** Check out our [GitHub Repository](https://github.com/PixArt-alpha/PixArt-alpha) and the [Pixart-α report on arXiv](https://arxiv.org/abs/2310.00426).
|
| 42 |
+
|
| 43 |
+
### Model Sources
|
| 44 |
+
|
| 45 |
+
For research purposes, we recommend our `generative-models` Github repository (https://github.com/PixArt-alpha/PixArt-alpha),
|
| 46 |
+
which is more suitable for both training and inference and for which most advanced diffusion sampler like [SA-Solver](https://arxiv.org/abs/2309.05019) will be added over time.
|
| 47 |
+
[Hugging Face](https://huggingface.co/spaces/PixArt-alpha/PixArt-alpha) provides free Pixart-α inference.
|
| 48 |
+
- **Repository:** https://github.com/PixArt-alpha/PixArt-alpha
|
| 49 |
+
- **Demo:** https://huggingface.co/spaces/PixArt-alpha/PixArt-alpha
|
| 50 |
+
|
| 51 |
+
# 🔥🔥🔥 Why PixArt-α?
|
| 52 |
+
## Training Efficiency
|
| 53 |
+
PixArt-α only takes 10.8% of Stable Diffusion v1.5's training time (675 vs. 6,250 A100 GPU days), saving nearly $300,000 ($26,000 vs. $320,000) and reducing 90% CO2 emissions. Moreover, compared with a larger SOTA model, RAPHAEL, our training cost is merely 1%.
|
| 54 |
+

|
| 55 |
+
|
| 56 |
+
| Method | Type | #Params | #Images | A100 GPU days |
|
| 57 |
+
|-----------|------|---------|---------|---------------|
|
| 58 |
+
| DALL·E | Diff | 12.0B | 1.54B | |
|
| 59 |
+
| GLIDE | Diff | 5.0B | 5.94B | |
|
| 60 |
+
| LDM | Diff | 1.4B | 0.27B | |
|
| 61 |
+
| DALL·E 2 | Diff | 6.5B | 5.63B | 41,66 |
|
| 62 |
+
| SDv1.5 | Diff | 0.9B | 3.16B | 6,250 |
|
| 63 |
+
| GigaGAN | GAN | 0.9B | 0.98B | 4,783 |
|
| 64 |
+
| Imagen | Diff | 3.0B | 15.36B | 7,132 |
|
| 65 |
+
| RAPHAEL | Diff | 3.0B | 5.0B | 60,000 |
|
| 66 |
+
| PixArt-α | Diff | 0.6B | 0.025B | 675 |
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
## Evaluation
|
| 70 |
+

|
| 71 |
+
The chart above evaluates user preference for Pixart-α over SDXL 0.9, Stable Diffusion 2, DALLE-2 and DeepFloyd.
|
| 72 |
+
The Pixart-α base model performs comparable or even better than the existing state-of-the-art models.
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
### 🧨 Diffusers
|
| 77 |
+
|
| 78 |
+
Make sure to upgrade diffusers to >= 0.22.0:
|
| 79 |
+
```
|
| 80 |
+
pip install -U diffusers --upgrade
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
In addition make sure to install `transformers`, `safetensors`, `sentencepiece`, and `accelerate`:
|
| 84 |
+
```
|
| 85 |
+
pip install transformers accelerate safetensors sentencepiece
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
To just use the base model, you can run:
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
```py
|
| 92 |
+
from diffusers import PixArtAlphaPipeline
|
| 93 |
+
import torch
|
| 94 |
+
|
| 95 |
+
pipe = PixArtAlphaPipeline.from_pretrained(""PixArt-alpha/PixArt-XL-2-1024-MS"", torch_dtype=torch.float16)
|
| 96 |
+
pipe = pipe.to(""cuda"")
|
| 97 |
+
|
| 98 |
+
# if using torch < 2.0
|
| 99 |
+
# pipe.enable_xformers_memory_efficient_attention()
|
| 100 |
+
|
| 101 |
+
prompt = ""An astronaut riding a green horse""
|
| 102 |
+
images = pipe(prompt=prompt).images[0]
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
When using `torch >= 2.0`, you can improve the inference speed by 20-30% with torch.compile. Simple wrap the unet with torch compile before running the pipeline:
|
| 106 |
+
```py
|
| 107 |
+
pipe.transformer = torch.compile(pipe.transformer, mode=""reduce-overhead"", fullgraph=True)
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
If you are limited by GPU VRAM, you can enable *cpu offloading* by calling `pipe.enable_model_cpu_offload`
|
| 111 |
+
instead of `.to(""cuda"")`:
|
| 112 |
+
|
| 113 |
+
```diff
|
| 114 |
+
- pipe.to(""cuda"")
|
| 115 |
+
+ pipe.enable_model_cpu_offload()
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
For more information on how to use Pixart-α with `diffusers`, please have a look at [the Pixart-α Docs](https://huggingface.co/docs/diffusers/main/en/api/pipelines/pixart).
|
| 119 |
+
|
| 120 |
+
### Free Google Colab
|
| 121 |
+
You can use Google Colab to generate images from PixArt-α free of charge. Click [here](https://colab.research.google.com/drive/1jZ5UZXk7tcpTfVwnX33dDuefNMcnW9ME?usp=sharing) to try.
|
| 122 |
+
|
| 123 |
+
## Uses
|
| 124 |
+
|
| 125 |
+
### Direct Use
|
| 126 |
+
|
| 127 |
+
The model is intended for research purposes only. Possible research areas and tasks include
|
| 128 |
+
|
| 129 |
+
- Generation of artworks and use in design and other artistic processes.
|
| 130 |
+
- Applications in educational or creative tools.
|
| 131 |
+
- Research on generative models.
|
| 132 |
+
- Safe deployment of models which have the potential to generate harmful content.
|
| 133 |
+
|
| 134 |
+
- Probing and understanding the limitations and biases of generative models.
|
| 135 |
+
|
| 136 |
+
Excluded uses are described below.
|
| 137 |
+
|
| 138 |
+
### Out-of-Scope Use
|
| 139 |
+
|
| 140 |
+
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
|
| 141 |
+
|
| 142 |
+
## Limitations and Bias
|
| 143 |
+
|
| 144 |
+
### Limitations
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
- The model does not achieve perfect photorealism
|
| 148 |
+
- The model cannot render legible text
|
| 149 |
+
- The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
|
| 150 |
+
- fingers, .etc in general may not be generated properly.
|
| 151 |
+
- The autoencoding part of the model is lossy.
|
| 152 |
+
|
| 153 |
+
### Bias
|
| 154 |
+
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
| 155 |
+
","{""id"": ""PixArt-alpha/PixArt-XL-2-1024-MS"", ""author"": ""PixArt-alpha"", ""sha"": ""b89adadeccd9ead2adcb9fa2825d3fabec48d404"", ""last_modified"": ""2023-11-07 06:11:50+00:00"", ""created_at"": ""2023-11-04 15:48:30+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 122196, ""downloads_all_time"": null, ""likes"": 201, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""safetensors"", ""text-to-image"", ""Pixart-\u03b1"", ""arxiv:2310.00426"", ""arxiv:2112.10752"", ""arxiv:2309.05019"", ""license:openrail++"", ""endpoints_compatible"", ""diffusers:PixArtAlphaPipeline"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: openrail++\ntags:\n- text-to-image\n- Pixart-\u03b1"", ""widget_data"": null, ""model_index"": null, ""config"": {""diffusers"": {""_class_name"": ""PixArtAlphaPipeline""}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/PixArt.svg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/examples.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/images/controlnet/controlnet_huawei.svg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/images/controlnet/controlnet_iclr.svg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/images/controlnet/controlnet_lenna.svg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/images/dreambooth/dreambooth_dog.svg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/images/dreambooth/dreambooth_m5.svg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/images/efficiency.svg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/images/model.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/images/more-samples.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/images/more-samples1.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/images/sample.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/images/teaser.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/images/user-study.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/logo.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='asset/samples.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model_index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/model-00001-of-00002.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/model-00002-of-00002.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/spiece.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='transformer/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='transformer/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Lightricks/LTX-Video-Playground"", ""PixArt-alpha/PixArt-alpha"", ""TIGER-Lab/GenAI-Arena"", ""artificialguybr/Pixart-Sigma"", ""alibaba-pai/EasyAnimate"", ""LanguageBind/Open-Sora-Plan-v1.0.0"", ""TencentARC/ColorFlow"", ""jasperai/flash-diffusion"", ""fantos/VoiceClone"", ""LanguageBind/Open-Sora-Plan-v1.1.0"", ""Nymbo/image_gen_supaqueue"", ""fantaxy/fastvideogen"", ""fffiloni/ReNO"", ""maxin-cn/Latte-1"", ""fffiloni/flash-wallpapers"", ""cocktailpeanut/LTX-Video-Playground"", ""diffusers/compute-pipeline-size"", ""ali-vilab/IDEA-Bench-Arena"", ""priyanshu9588/PixArt-alpha"", ""ford442/LTX-Video"", ""1inkusFace/LTX-Video-Xora"", ""openfree/ginigen-sora"", ""svjack/LTX-Video-Playground"", ""akthangdz/TEXT_TO_VIDEO"", ""JunhaoZhuang/Cobra"", ""sidd-genmo/Open-Sora-Plan-v1.0.0"", ""jarnot/EasyAnimate"", ""PeepDaSlan9/HYDRAS_Latte-1"", ""emilalvaro/LTX-Video-Playground"", ""Kaskatraz/LTX-Video-Playground"", ""jalve/jalvneis"", ""dd890/PixArt-alpha-PixArt-XL-2-1024-MS"", ""jalve/NeisAlv"", ""MrOvkill/PixArt-alpha-moddedalltohell"", ""YanzBotz/PixArt"", ""wandb/reproducible-pixart-alpha"", ""vakilrathod67/PixArt-alpha-PixArt-XL-2-1024-MS"", ""Jyothirmai782/Pixart-Sigma"", ""Viswanath999/Pixart-Sigma"", ""Taf2023/Open-Sora-Plan-v1.0.0"", ""lylosn/Open-Sora-Plan-v1.0.0"", ""tsi-org/PixArt-alpha"", ""lcyyyy/homework_end"", ""tsi-org/PixioArt-alpha"", ""CPM1234567890/ex01"", ""yufiofficial/PixArt-alpha-PixArt-XL-2-1024-MS"", ""Lucas94/PixArt-alpha-PixArt-XL-2-1024-MS"", ""RO-Rtechs/Rtechs_Open-Sora-Plan-v1.1.0"", ""cocktailpeanut/flash-diffusion"", ""BobLLM/Sora"", ""kletoskletos/PixArt-alpha-PixArt-XL-2-1024-MS"", ""Nymbo/flash-wallpapers"", ""Dragunflie-420/flash-diffusion"", ""K00B404/image_gen_supaqueue_game_assets"", ""YuwanA55/Flash_Jasper"", ""K00B404/EasyAnimate_custom"", ""pang1368/PixArt-alpha-PixArt-XL-2-1024-MS"", ""jbilcke-hf/ai-tube-model-ltxv-1"", ""NativeAngels/LTX-Video-Playground"", ""Swaqgame99/LTX-Video-Playground"", ""jbilcke-hf/ai-tube-model-ltxv-2"", ""jbilcke-hf/ai-tube-model-ltxv-3"", ""k11112/LTX-Video-Playground"", ""jbilcke-hf/ai-tube-model-ltxv-4"", ""AashishNKumar/proj11"", ""riflecreek/LTX-Video-Playground"", ""kostadinkostad/LTX-Video-Playground"", ""K00B404/LTX-Video-Playground"", ""constant999/LTX-Video-Playground"", ""svjack/ColorFlow"", ""Lezzio/LTX-Video-Playground"", ""Greekmongoose/LTX-Video-Playground"", ""PeldelnasGranell/LTX-Video-Playground"", ""learningloop/LTX-Video-Playground"", ""bestoai/PixArt-alpha"", ""Kremon96/VoiceClone"", ""waloneai/fastvideogen"", ""Tusharcrusty1/LTX-Video-Playground"", ""sitonmyface/LTX-Video-Playground"", ""nasiye969/LTX-Video-Playground"", ""Jwrockon/ArtemisVoiceCloner"", ""WillybotAI77777/LTX-Video-Playground"", ""peterpeter8585/VoiceClone"", ""MrDrmm/EasyAnimate"", ""waloneai/EasyAnimate"", ""Pablosolaris/LTX-Video-Playground"", ""stepbysteb/EasyAnimate"", ""cziter15pl/LTX-Video-Playground"", ""kahramango/EasyAnimate"", ""daaaaaaaaaaa2/LTX-Video-Playground"", ""data97688/PixArt-alpha-PixArt-XL-2-1024-MS"", ""jewelt123/VoiceCloneABC2"", ""vyloup/LTX-Video-Playground"", ""dotkaio/LTX-Video-Playground"", ""Quantamhash/Quantam_Clone"", ""dalouniquefans/dalo-image-api"", ""Rakeshj182002/LTX-Video-Playground""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-11-07 06:11:50+00:00"", ""cardData"": ""license: openrail++\ntags:\n- text-to-image\n- Pixart-\u03b1"", ""transformersInfo"": null, ""_id"": ""654667ce9c4bf757d6d2ff63"", ""modelId"": ""PixArt-alpha/PixArt-XL-2-1024-MS"", ""usedStorage"": 24293837816}",0,"https://huggingface.co/JunhaoZhuang/Cobra, https://huggingface.co/Luo-Yihong/yoso_pixart1024",2,https://huggingface.co/jasperai/flash-pixart,1,https://huggingface.co/calcuis/pixart,1,,0,"Lightricks/LTX-Video-Playground, Nymbo/image_gen_supaqueue, PixArt-alpha/PixArt-alpha, TIGER-Lab/GenAI-Arena, TencentARC/ColorFlow, ali-vilab/IDEA-Bench-Arena, alibaba-pai/EasyAnimate, artificialguybr/Pixart-Sigma, diffusers/compute-pipeline-size, fantaxy/fastvideogen, fantos/VoiceClone, huggingface/InferenceSupport/discussions/new?title=PixArt-alpha/PixArt-XL-2-1024-MS&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BPixArt-alpha%2FPixArt-XL-2-1024-MS%5D(%2FPixArt-alpha%2FPixArt-XL-2-1024-MS)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, maxin-cn/Latte-1, openfree/ginigen-sora",14
|
| 156 |
+
JunhaoZhuang/Cobra,"---
|
| 157 |
+
base_model:
|
| 158 |
+
- PixArt-alpha/PixArt-XL-2-1024-MS
|
| 159 |
+
language:
|
| 160 |
+
- en
|
| 161 |
+
license: apache-2.0
|
| 162 |
+
pipeline_tag: image-to-image
|
| 163 |
+
library_name: diffusers
|
| 164 |
+
---
|
| 165 |
+
|
| 166 |
+
# 🎨 Cobra
|
| 167 |
+
|
| 168 |
+
**Efficient Line Art COlorization with BRoAder References**
|
| 169 |
+
|
| 170 |
+
**Authors:** Junhao Zhuang, Lingen Li, Xuan Ju, Zhaoyang Zhang, Chun Yuan† and Ying Shan†
|
| 171 |
+
|
| 172 |
+
<a href='https://zhuang2002.github.io/Cobra/'><img src='https://img.shields.io/badge/Project-Page-Green'></a>
|
| 173 |
+
<a href=""https://github.com/Zhuang2002/Cobra""><img src=""https://img.shields.io/badge/GitHub-Repository-black?logo=github""></a>
|
| 174 |
+
<a href='https://huggingface.co/spaces/JunhaoZhuang/Cobra'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Demo-blue'></a>
|
| 175 |
+
<a href=""https://arxiv.org/abs/2504.12240""><img src=""https://img.shields.io/badge/arXiv-2504.12240-b31b1b.svg""></a>
|
| 176 |
+
<a href=""https://huggingface.co/JunhaoZhuang/Cobra""><img src=""https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Model-blue""></a>
|
| 177 |
+
|
| 178 |
+
**Your star means a lot for us to develop this project!** :star:
|
| 179 |
+
|
| 180 |
+
<img src='https://zhuang2002.github.io/Cobra/fig/teaser.png'/>
|
| 181 |
+
|
| 182 |
+
### 🌟 Abstract
|
| 183 |
+
|
| 184 |
+
The comic production industry requires reference-based line art colorization with high accuracy, efficiency, contextual consistency, and flexible control.
|
| 185 |
+
A comic page often involves diverse characters, objects, and backgrounds, which complicates the coloring process.
|
| 186 |
+
Despite advancements in diffusion models for image generation, their application in line art colorization remains limited, facing challenges related to handling extensive reference images, time-consuming inference, and flexible control.
|
| 187 |
+
We investigate the necessity of extensive contextual image guidance on the quality of line art colorization. To address these challenges, we introduce **Cobra**, an efficient and versatile method that supports color hints and utilizes **over 200 reference images** while maintaining low latency.
|
| 188 |
+
Central to Cobra is a Causal Sparse DiT architecture, which leverages specially designed positional encodings, causal sparse attention, and Key-Value Cache to effectively manage long-context references and ensure color identity consistency.
|
| 189 |
+
Results demonstrate that Cobra achieves accurate line art colorization through extensive contextual reference, significantly enhancing inference speed and interactivity, thereby meeting critical industrial demands.
|
| 190 |
+
|
| 191 |
+
### 📰 News
|
| 192 |
+
|
| 193 |
+
- **Release Date:** April 17, 2025 - The inference code and model weights have also been released! 🎉
|
| 194 |
+
|
| 195 |
+
### 📋 TODO
|
| 196 |
+
|
| 197 |
+
- ✅ Release inference code and model weights
|
| 198 |
+
- ⬜️ Release training code
|
| 199 |
+
|
| 200 |
+
### 🚀 Getting Started
|
| 201 |
+
|
| 202 |
+
Follow these steps to set up and run Cobra on your local machine:
|
| 203 |
+
|
| 204 |
+
- **Clone the Repository**
|
| 205 |
+
|
| 206 |
+
Download the code from our GitHub repository:
|
| 207 |
+
```bash
|
| 208 |
+
git clone https://github.com/zhuang2002/Cobra
|
| 209 |
+
cd Cobra
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
- **Set Up the Python Environment**
|
| 213 |
+
|
| 214 |
+
Ensure you have Anaconda or Miniconda installed, then create and activate a Python environment and install required dependencies:
|
| 215 |
+
```bash
|
| 216 |
+
conda create -n cobra python=3.11.11
|
| 217 |
+
conda activate cobra
|
| 218 |
+
pip install -r requirements.txt
|
| 219 |
+
```
|
| 220 |
+
|
| 221 |
+
- **Run the Application**
|
| 222 |
+
|
| 223 |
+
You can launch the Gradio interface for Cobra by running the following command:
|
| 224 |
+
```bash
|
| 225 |
+
python app.py
|
| 226 |
+
```
|
| 227 |
+
|
| 228 |
+
- **Access Cobra in Your Browser**
|
| 229 |
+
|
| 230 |
+
Open your browser and go to `http://localhost:7860`. If you're running the app on a remote server, replace `localhost` with your server's IP address or domain name. To use a custom port, update the `server_port` parameter in the `demo.launch()` function of app.py.
|
| 231 |
+
|
| 232 |
+
### 🎉 Demo
|
| 233 |
+
|
| 234 |
+
You can [try the demo](https://huggingface.co/spaces/JunhaoZhuang/Cobra) of Cobra on Hugging Face Space.
|
| 235 |
+
|
| 236 |
+
### 🛠️ Method
|
| 237 |
+
|
| 238 |
+
The overview of Cobra.
|
| 239 |
+
This figure depicts the framework of Cobra, which utilizes a large collection of retrieved reference images to guide the colorization of comic line art. The framework effectively manages an arbitrary number of contextual image references through localized reusable positional encoding, ensuring appropriate aspect ratios and resolutions. Additionally, the causal sparse DiT architecture processes long contextual references, enhancing identity preservation and color accuracy while reducing computational complexity. The integration of optional color hints further ensures user flexibility, culminating in high-quality coloring that is highly suitable for industrial applications.
|
| 240 |
+
|
| 241 |
+
<img src=""https://zhuang2002.github.io/Cobra/fig/flowchart.png"" width=""1000"">
|
| 242 |
+
|
| 243 |
+
🤗 We welcome your feedback, questions, or collaboration opportunities. Thank you for trying Cobra!
|
| 244 |
+
|
| 245 |
+
### 📄 Acknowledgments
|
| 246 |
+
|
| 247 |
+
We would like to acknowledge the following open-source projects that have inspired and contributed to the development of Cobra:
|
| 248 |
+
|
| 249 |
+
- **MangaLineExtraction_PyTorch**: https://github.com/ljsabc/MangaLineExtraction_PyTorch
|
| 250 |
+
|
| 251 |
+
We are grateful for the valuable resources and insights provided by these projects.
|
| 252 |
+
|
| 253 |
+
### 📞 Contact
|
| 254 |
+
|
| 255 |
+
- **Junhao Zhuang**
|
| 256 |
+
Email: [zhuangjh23@mails.tsinghua.edu.cn](mailto:zhuangjh23@mails.tsinghua.edu.cn)
|
| 257 |
+
|
| 258 |
+
### 📜 Citation
|
| 259 |
+
|
| 260 |
+
```
|
| 261 |
+
@misc{zhuang2025cobraefficientlineart,
|
| 262 |
+
title={Cobra: Efficient Line Art COlorization with BRoAder References},
|
| 263 |
+
author={Junhao Zhuang and Lingen Li and Xuan Ju and Zhaoyang Zhang and Chun Yuan and Ying Shan},
|
| 264 |
+
year={2025},
|
| 265 |
+
eprint={2504.12240},
|
| 266 |
+
archivePrefix={arXiv},
|
| 267 |
+
primaryClass={cs.CV},
|
| 268 |
+
url={https://arxiv.org/abs/2504.12240},
|
| 269 |
+
}
|
| 270 |
+
```","{""id"": ""JunhaoZhuang/Cobra"", ""author"": ""JunhaoZhuang"", ""sha"": ""8451af08de9224649b63aa50980fd5f9ac30d57e"", ""last_modified"": ""2025-04-17 12:47:24+00:00"", ""created_at"": ""2025-04-12 07:46:07+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 16, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""image-to-image"", ""en"", ""arxiv:2504.12240"", ""base_model:PixArt-alpha/PixArt-XL-2-1024-MS"", ""base_model:finetune:PixArt-alpha/PixArt-XL-2-1024-MS"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": ""image-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- PixArt-alpha/PixArt-XL-2-1024-MS\nlanguage:\n- en\nlibrary_name: diffusers\nlicense: apache-2.0\npipeline_tag: image-to-image"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LE/erika.pth', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image_encoder/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='line_GSRP/MultiResNetModel.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='line_ckpt/controlnet.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='line_ckpt/transformer_lora_pos.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='shadow_GSRP/MultiResNetModel.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='shadow_ckpt/controlnet.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='shadow_ckpt/transformer_lora_pos.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [""JunhaoZhuang/Cobra""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-17 12:47:24+00:00"", ""cardData"": ""base_model:\n- PixArt-alpha/PixArt-XL-2-1024-MS\nlanguage:\n- en\nlibrary_name: diffusers\nlicense: apache-2.0\npipeline_tag: image-to-image"", ""transformersInfo"": null, ""_id"": ""67fa1a3f59fef5be4e929c75"", ""modelId"": ""JunhaoZhuang/Cobra"", ""usedStorage"": 4831835390}",1,,0,,0,,0,,0,"JunhaoZhuang/Cobra, huggingface/InferenceSupport/discussions/new?title=JunhaoZhuang/Cobra&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BJunhaoZhuang%2FCobra%5D(%2FJunhaoZhuang%2FCobra)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A",2
|
| 271 |
+
Luo-Yihong/yoso_pixart1024,"---
|
| 272 |
+
language:
|
| 273 |
+
- en
|
| 274 |
+
library_name: diffusers
|
| 275 |
+
pipeline_tag: text-to-image
|
| 276 |
+
base_model:
|
| 277 |
+
- PixArt-alpha/PixArt-XL-2-1024-MS
|
| 278 |
+
---
|
| 279 |
+
# You Only Sample Once (YOSO)
|
| 280 |
+
|
| 281 |
+

|
| 282 |
+
|
| 283 |
+
The YOSO was proposed in ""[You Only Sample Once: Taming One-Step Text-To-Image Synthesis by Self-Cooperative Diffusion GANs](https://www.arxiv.org/abs/2403.12931)"" by *Yihong Luo, Xiaolong Chen, Xinghua Qu, Jing Tang*.
|
| 284 |
+
|
| 285 |
+
Official Repository of this paper: [YOSO](https://github.com/Luo-Yihong/YOSO).
|
| 286 |
+
|
| 287 |
+
This model is fine-tuning from [
|
| 288 |
+
PixArt-XL-2-512x512](https://huggingface.co/PixArt-alpha/PixArt-XL-2-512x512), enabling one-step inference to perform text-to-image generation.
|
| 289 |
+
|
| 290 |
+
We wanna highlight that the YOSO-PixArt was originally trained on 512 resolution. However, we found that we can construct a YOSO that enables generating samples with 1024 resolution by merging with [
|
| 291 |
+
PixArt-XL-2-1024-MS](https://huggingface.co/PixArt-alpha/PixArt-XL-2-1024-MS
|
| 292 |
+
) (Section 6.3.1 in the paper). The impressive performance indicates the robust generalization ability of our YOSO.
|
| 293 |
+
## usage
|
| 294 |
+
```python
|
| 295 |
+
import torch
|
| 296 |
+
from diffusers import PixArtAlphaPipeline, LCMScheduler, Transformer2DModel
|
| 297 |
+
|
| 298 |
+
transformer = Transformer2DModel.from_pretrained(
|
| 299 |
+
""Luo-Yihong/yoso_pixart1024"", torch_dtype=torch.float16).to('cuda')
|
| 300 |
+
|
| 301 |
+
pipe = PixArtAlphaPipeline.from_pretrained(""PixArt-alpha/PixArt-XL-2-512x512"",
|
| 302 |
+
transformer=transformer,
|
| 303 |
+
torch_dtype=torch.float16, use_safetensors=True)
|
| 304 |
+
|
| 305 |
+
pipe = pipe.to('cuda')
|
| 306 |
+
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
|
| 307 |
+
pipe.scheduler.config.prediction_type = ""v_prediction""
|
| 308 |
+
generator = torch.manual_seed(318)
|
| 309 |
+
imgs = pipe(prompt=""Pirate ship trapped in a cosmic maelstrom nebula, rendered in cosmic beach whirlpool engine, volumetric lighting, spectacular, ambient lights, light pollution, cinematic atmosphere, art nouveau style, illustration art artwork by SenseiJaye, intricate detail."",
|
| 310 |
+
num_inference_steps=1,
|
| 311 |
+
num_images_per_prompt = 1,
|
| 312 |
+
generator = generator,
|
| 313 |
+
guidance_scale=1.,
|
| 314 |
+
)[0]
|
| 315 |
+
imgs[0]
|
| 316 |
+
```
|
| 317 |
+

|
| 318 |
+
|
| 319 |
+
## Bibtex
|
| 320 |
+
```
|
| 321 |
+
@misc{luo2024sample,
|
| 322 |
+
title={You Only Sample Once: Taming One-Step Text-to-Image Synthesis by Self-Cooperative Diffusion GANs},
|
| 323 |
+
author={Yihong Luo and Xiaolong Chen and Xinghua Qu and Jing Tang},
|
| 324 |
+
year={2024},
|
| 325 |
+
eprint={2403.12931},
|
| 326 |
+
archivePrefix={arXiv},
|
| 327 |
+
primaryClass={cs.CV}
|
| 328 |
+
}
|
| 329 |
+
```","{""id"": ""Luo-Yihong/yoso_pixart1024"", ""author"": ""Luo-Yihong"", ""sha"": ""f2cadc6f1c81c30f7b82feca1442fc0601dbdcaa"", ""last_modified"": ""2025-03-16 17:01:02+00:00"", ""created_at"": ""2024-03-18 08:23:34+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 19, ""downloads_all_time"": null, ""likes"": 12, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""safetensors"", ""text-to-image"", ""en"", ""arxiv:2403.12931"", ""base_model:PixArt-alpha/PixArt-XL-2-1024-MS"", ""base_model:finetune:PixArt-alpha/PixArt-XL-2-1024-MS"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- PixArt-alpha/PixArt-XL-2-1024-MS\nlanguage:\n- en\nlibrary_name: diffusers\npipeline_tag: text-to-image"", ""widget_data"": null, ""model_index"": null, ""config"": {}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='diffusion_pytorch_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='overview.jpg', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ship_1024.jpg', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-16 17:01:02+00:00"", ""cardData"": ""base_model:\n- PixArt-alpha/PixArt-XL-2-1024-MS\nlanguage:\n- en\nlibrary_name: diffusers\npipeline_tag: text-to-image"", ""transformersInfo"": null, ""_id"": ""65f7fa06dd3cc437a8a30e74"", ""modelId"": ""Luo-Yihong/yoso_pixart1024"", ""usedStorage"": 2453869313}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Luo-Yihong/yoso_pixart1024&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BLuo-Yihong%2Fyoso_pixart1024%5D(%2FLuo-Yihong%2Fyoso_pixart1024)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
SD_PixelArt_SpriteSheet_Generator_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
Onodofthenorth/SD_PixelArt_SpriteSheet_Generator,"---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
pipeline_tag: text-to-image
|
| 7 |
+
tags:
|
| 8 |
+
- spritesheet
|
| 9 |
+
- text-to-image
|
| 10 |
+
---
|
| 11 |
+
This Stable diffusion checkpoint allows you to generate pixel art sprite sheets from four different angles.
|
| 12 |
+
These first images are my results after merging this model with another model trained on my wife. merging another model with this one is the easiest way to get a consistent character with each view. still requires a bit of playing around with settings in img2img to get them how you want. for left and right, I suggest picking your best result and mirroring. after you are satisfied take your photo into photoshop or Krita, remove the background, and scale to the desired size. after this you can scale back up to display your results; this also clears up some of the color murkiness in the initial outputs.
|
| 13 |
+

|
| 14 |
+
|
| 15 |
+
### 🧨 Diffusers
|
| 16 |
+
|
| 17 |
+
This model can be used just like any other Stable Diffusion model. For more information,
|
| 18 |
+
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
|
| 19 |
+
|
| 20 |
+
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
|
| 21 |
+
|
| 22 |
+
```python
|
| 23 |
+
#!pip install diffusers transformers scipy torch
|
| 24 |
+
from diffusers import StableDiffusionPipeline
|
| 25 |
+
import torch
|
| 26 |
+
model_id = ""Onodofthenorth/SD_PixelArt_SpriteSheet_Generator""
|
| 27 |
+
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
|
| 28 |
+
pipe = pipe.to(""cuda"")
|
| 29 |
+
prompt = ""PixelartLSS""
|
| 30 |
+
image = pipe(prompt).images[0]
|
| 31 |
+
image.save(""./pixel.png"")
|
| 32 |
+
```
|
| 33 |
+
___
|
| 34 |
+
___
|
| 35 |
+
For the front view use ""PixelartFSS""
|
| 36 |
+

|
| 37 |
+
___
|
| 38 |
+
___
|
| 39 |
+
For the right view use ""PixelartRSS""
|
| 40 |
+

|
| 41 |
+
___
|
| 42 |
+
___
|
| 43 |
+
For the back view use ""PixelartBSS""
|
| 44 |
+

|
| 45 |
+
___
|
| 46 |
+
___
|
| 47 |
+
For the left view use ""PixelartLSS""
|
| 48 |
+

|
| 49 |
+
___
|
| 50 |
+
___
|
| 51 |
+
These are random results from the unmerged model
|
| 52 |
+

|
| 53 |
+
___
|
| 54 |
+
___
|
| 55 |
+
here's a result from a merge with my Hermione model
|
| 56 |
+

|
| 57 |
+
___
|
| 58 |
+
___
|
| 59 |
+
here's a result from a merge with my cat girl model
|
| 60 |
+
","{""id"": ""Onodofthenorth/SD_PixelArt_SpriteSheet_Generator"", ""author"": ""Onodofthenorth"", ""sha"": ""8229c9b6e928103f0e657cfe6b14d902cb2101d6"", ""last_modified"": ""2023-05-05 18:30:10+00:00"", ""created_at"": ""2022-11-01 04:31:21+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 1501, ""downloads_all_time"": null, ""likes"": 429, ""library_name"": ""diffusers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""diffusers"", ""spritesheet"", ""text-to-image"", ""en"", ""license:apache-2.0"", ""autotrain_compatible"", ""endpoints_compatible"", ""diffusers:StableDiffusionPipeline"", ""region:us""], ""pipeline_tag"": ""text-to-image"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- en\nlicense: apache-2.0\npipeline_tag: text-to-image\ntags:\n- spritesheet\n- text-to-image"", ""widget_data"": null, ""model_index"": null, ""config"": {""diffusers"": {""_class_name"": ""StableDiffusionPipeline""}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='PixelartSpritesheet_V.1.ckpt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='feature_extractor/preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model_index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='safety_checker/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='safety_checker/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='scheduler/scheduler_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='text_encoder/pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer/vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='unet/diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vae/diffusion_pytorch_model.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [""ronvolutional/sd-spritesheets"", ""Nymbo/image_gen_supaqueue"", ""Samuelblue/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""CharlieAmalet/Tools3ox_PixelArt_SpriteSheet_GeneratorArt_Api"", ""DEVINKofficial/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""Derni/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""tomhitto/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""bspSHU/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""sanchezNa/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""studentofplato/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""Bready11/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""Ryanforbus/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""johnson1984/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""ASsazz/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""Lubub/sd-spritesheets"", ""LububMalvino/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""CLOUDWERXLAB/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator"", ""K00B404/image_gen_supaqueue_game_assets"", ""SrKatayama/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-05-05 18:30:10+00:00"", ""cardData"": ""language:\n- en\nlicense: apache-2.0\npipeline_tag: text-to-image\ntags:\n- spritesheet\n- text-to-image"", ""transformersInfo"": null, ""_id"": ""6360a119773df6f83db24210"", ""modelId"": ""Onodofthenorth/SD_PixelArt_SpriteSheet_Generator"", ""usedStorage"": 19492912354}",0,,0,,0,,0,,0,"Bready11/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator, CLOUDWERXLAB/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator, CharlieAmalet/Tools3ox_PixelArt_SpriteSheet_GeneratorArt_Api, DEVINKofficial/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator, Derni/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator, Nymbo/image_gen_supaqueue, Samuelblue/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator, bspSHU/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator, huggingface/InferenceSupport/discussions/new?title=Onodofthenorth/SD_PixelArt_SpriteSheet_Generator&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BOnodofthenorth%2FSD_PixelArt_SpriteSheet_Generator%5D(%2FOnodofthenorth%2FSD_PixelArt_SpriteSheet_Generator)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, ronvolutional/sd-spritesheets, sanchezNa/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator, studentofplato/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator, tomhitto/Onodofthenorth-SD_PixelArt_SpriteSheet_Generator",13
|
SFR-Embedding-Mistral_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
SSD-1B_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
SenseVoiceSmall_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
FunAudioLLM/SenseVoiceSmall,"---
|
| 3 |
+
license: other
|
| 4 |
+
license_name: model-license
|
| 5 |
+
license_link: https://github.com/modelscope/FunASR/blob/main/MODEL_LICENSE
|
| 6 |
+
language:
|
| 7 |
+
- en
|
| 8 |
+
- zh
|
| 9 |
+
- ja
|
| 10 |
+
- ko
|
| 11 |
+
library: funasr
|
| 12 |
+
---
|
| 13 |
+
([简体中文](./README_zh.md)|English|[日本語](./README_ja.md))
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
# Introduction
|
| 17 |
+
|
| 18 |
+
github [repo](https://github.com/FunAudioLLM/SenseVoice) : https://github.com/FunAudioLLM/SenseVoice
|
| 19 |
+
|
| 20 |
+
SenseVoice is a speech foundation model with multiple speech understanding capabilities, including automatic speech recognition (ASR), spoken language identification (LID), speech emotion recognition (SER), and audio event detection (AED).
|
| 21 |
+
|
| 22 |
+
<img src=""image/sensevoice2.png"">
|
| 23 |
+
|
| 24 |
+
[//]: # (<div align=""center""><img src=""image/sensevoice.png"" width=""700""/> </div>)
|
| 25 |
+
|
| 26 |
+
<div align=""center"">
|
| 27 |
+
<h4>
|
| 28 |
+
<a href=""https://fun-audio-llm.github.io/""> Homepage </a>
|
| 29 |
+
|<a href=""#What's News""> What's News </a>
|
| 30 |
+
|<a href=""#Benchmarks""> Benchmarks </a>
|
| 31 |
+
|<a href=""#Install""> Install </a>
|
| 32 |
+
|<a href=""#Usage""> Usage </a>
|
| 33 |
+
|<a href=""#Community""> Community </a>
|
| 34 |
+
</h4>
|
| 35 |
+
|
| 36 |
+
Model Zoo:
|
| 37 |
+
[modelscope](https://www.modelscope.cn/models/iic/SenseVoiceSmall), [huggingface](https://huggingface.co/FunAudioLLM/SenseVoiceSmall)
|
| 38 |
+
|
| 39 |
+
Online Demo:
|
| 40 |
+
[modelscope demo](https://www.modelscope.cn/studios/iic/SenseVoice), [huggingface space](https://huggingface.co/spaces/FunAudioLLM/SenseVoice)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
</div>
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
<a name=""Highligts""></a>
|
| 47 |
+
# Highlights 🎯
|
| 48 |
+
**SenseVoice** focuses on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection.
|
| 49 |
+
- **Multilingual Speech Recognition:** Trained with over 400,000 hours of data, supporting more than 50 languages, the recognition performance surpasses that of the Whisper model.
|
| 50 |
+
- **Rich transcribe:**
|
| 51 |
+
- Possess excellent emotion recognition capabilities, achieving and surpassing the effectiveness of the current best emotion recognition models on test data.
|
| 52 |
+
- Offer sound event detection capabilities, supporting the detection of various common human-computer interaction events such as bgm, applause, laughter, crying, coughing, and sneezing.
|
| 53 |
+
- **Efficient Inference:** The SenseVoice-Small model utilizes a non-autoregressive end-to-end framework, leading to exceptionally low inference latency. It requires only 70ms to process 10 seconds of audio, which is 15 times faster than Whisper-Large.
|
| 54 |
+
- **Convenient Finetuning:** Provide convenient finetuning scripts and strategies, allowing users to easily address long-tail sample issues according to their business scenarios.
|
| 55 |
+
- **Service Deployment:** Offer service deployment pipeline, supporting multi-concurrent requests, with client-side languages including Python, C++, HTML, Java, and C#, among others.
|
| 56 |
+
|
| 57 |
+
<a name=""What's News""></a>
|
| 58 |
+
# What's New 🔥
|
| 59 |
+
- 2024/7: Added Export Features for [ONNX](https://github.com/FunAudioLLM/SenseVoice/demo_onnx.py) and [libtorch](https://github.com/FunAudioLLM/SenseVoice/demo_libtorch.py), as well as Python Version Runtimes: [funasr-onnx-0.4.0](https://pypi.org/project/funasr-onnx/), [funasr-torch-0.1.1](https://pypi.org/project/funasr-torch/)
|
| 60 |
+
- 2024/7: The [SenseVoice-Small](https://www.modelscope.cn/models/iic/SenseVoiceSmall) voice understanding model is open-sourced, which offers high-precision multilingual speech recognition, emotion recognition, and audio event detection capabilities for Mandarin, Cantonese, English, Japanese, and Korean and leads to exceptionally low inference latency.
|
| 61 |
+
- 2024/7: The CosyVoice for natural speech generation with multi-language, timbre, and emotion control. CosyVoice excels in multi-lingual voice generation, zero-shot voice generation, cross-lingual voice cloning, and instruction-following capabilities. [CosyVoice repo](https://github.com/FunAudioLLM/CosyVoice) and [CosyVoice space](https://www.modelscope.cn/studios/iic/CosyVoice-300M).
|
| 62 |
+
- 2024/7: [FunASR](https://github.com/modelscope/FunASR) is a fundamental speech recognition toolkit that offers a variety of features, including speech recognition (ASR), Voice Activity Detection (VAD), Punctuation Restoration, Language Models, Speaker Verification, Speaker Diarization and multi-talker ASR.
|
| 63 |
+
|
| 64 |
+
<a name=""Benchmarks""></a>
|
| 65 |
+
# Benchmarks 📝
|
| 66 |
+
|
| 67 |
+
## Multilingual Speech Recognition
|
| 68 |
+
We compared the performance of multilingual speech recognition between SenseVoice and Whisper on open-source benchmark datasets, including AISHELL-1, AISHELL-2, Wenetspeech, LibriSpeech, and Common Voice. In terms of Chinese and Cantonese recognition, the SenseVoice-Small model has advantages.
|
| 69 |
+
|
| 70 |
+
<div align=""center"">
|
| 71 |
+
<img src=""image/asr_results1.png"" width=""400"" /><img src=""image/asr_results2.png"" width=""400"" />
|
| 72 |
+
</div>
|
| 73 |
+
|
| 74 |
+
## Speech Emotion Recognition
|
| 75 |
+
|
| 76 |
+
Due to the current lack of widely-used benchmarks and methods for speech emotion recognition, we conducted evaluations across various metrics on multiple test sets and performed a comprehensive comparison with numerous results from recent benchmarks. The selected test sets encompass data in both Chinese and English, and include multiple styles such as performances, films, and natural conversations. Without finetuning on the target data, SenseVoice was able to achieve and exceed the performance of the current best speech emotion recognition models.
|
| 77 |
+
|
| 78 |
+
<div align=""center"">
|
| 79 |
+
<img src=""image/ser_table.png"" width=""1000"" />
|
| 80 |
+
</div>
|
| 81 |
+
|
| 82 |
+
Furthermore, we compared multiple open-source speech emotion recognition models on the test sets, and the results indicate that the SenseVoice-Large model achieved the best performance on nearly all datasets, while the SenseVoice-Small model also surpassed other open-source models on the majority of the datasets.
|
| 83 |
+
|
| 84 |
+
<div align=""center"">
|
| 85 |
+
<img src=""image/ser_figure.png"" width=""500"" />
|
| 86 |
+
</div>
|
| 87 |
+
|
| 88 |
+
## Audio Event Detection
|
| 89 |
+
|
| 90 |
+
Although trained exclusively on speech data, SenseVoice can still function as a standalone event detection model. We compared its performance on the environmental sound classification ESC-50 dataset against the widely used industry models BEATS and PANN. The SenseVoice model achieved commendable results on these tasks. However, due to limitations in training data and methodology, its event classification performance has some gaps compared to specialized AED models.
|
| 91 |
+
|
| 92 |
+
<div align=""center"">
|
| 93 |
+
<img src=""image/aed_figure.png"" width=""500"" />
|
| 94 |
+
</div>
|
| 95 |
+
|
| 96 |
+
## Computational Efficiency
|
| 97 |
+
|
| 98 |
+
The SenseVoice-Small model deploys a non-autoregressive end-to-end architecture, resulting in extremely low inference latency. With a similar number of parameters to the Whisper-Small model, it infers more than 5 times faster than Whisper-Small and 15 times faster than Whisper-Large.
|
| 99 |
+
|
| 100 |
+
<div align=""center"">
|
| 101 |
+
<img src=""image/inference.png"" width=""1000"" />
|
| 102 |
+
</div>
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
# Requirements
|
| 106 |
+
|
| 107 |
+
```shell
|
| 108 |
+
pip install -r requirements.txt
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
<a name=""Usage""></a>
|
| 112 |
+
# Usage
|
| 113 |
+
|
| 114 |
+
## Inference
|
| 115 |
+
|
| 116 |
+
Supports input of audio in any format and of any duration.
|
| 117 |
+
|
| 118 |
+
```python
|
| 119 |
+
from funasr import AutoModel
|
| 120 |
+
from funasr.utils.postprocess_utils import rich_transcription_postprocess
|
| 121 |
+
|
| 122 |
+
model_dir = ""FunAudioLLM/SenseVoiceSmall""
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
model = AutoModel(
|
| 126 |
+
model=model_dir,
|
| 127 |
+
vad_model=""fsmn-vad"",
|
| 128 |
+
vad_kwargs={""max_single_segment_time"": 30000},
|
| 129 |
+
device=""cuda:0"",
|
| 130 |
+
hub=""hf"",
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
# en
|
| 134 |
+
res = model.generate(
|
| 135 |
+
input=f""{model.model_path}/example/en.mp3"",
|
| 136 |
+
cache={},
|
| 137 |
+
language=""auto"", # ""zn"", ""en"", ""yue"", ""ja"", ""ko"", ""nospeech""
|
| 138 |
+
use_itn=True,
|
| 139 |
+
batch_size_s=60,
|
| 140 |
+
merge_vad=True, #
|
| 141 |
+
merge_length_s=15,
|
| 142 |
+
)
|
| 143 |
+
text = rich_transcription_postprocess(res[0][""text""])
|
| 144 |
+
print(text)
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
Parameter Description:
|
| 148 |
+
- `model_dir`: The name of the model, or the path to the model on the local disk.
|
| 149 |
+
- `vad_model`: This indicates the activation of VAD (Voice Activity Detection). The purpose of VAD is to split long audio into shorter clips. In this case, the inference time includes both VAD and SenseVoice total consumption, and represents the end-to-end latency. If you wish to test the SenseVoice model's inference time separately, the VAD model can be disabled.
|
| 150 |
+
- `vad_kwargs`: Specifies the configurations for the VAD model. `max_single_segment_time`: denotes the maximum duration for audio segmentation by the `vad_model`, with the unit being milliseconds (ms).
|
| 151 |
+
- `use_itn`: Whether the output result includes punctuation and inverse text normalization.
|
| 152 |
+
- `batch_size_s`: Indicates the use of dynamic batching, where the total duration of audio in the batch is measured in seconds (s).
|
| 153 |
+
- `merge_vad`: Whether to merge short audio fragments segmented by the VAD model, with the merged length being `merge_length_s`, in seconds (s).
|
| 154 |
+
|
| 155 |
+
If all inputs are short audios (<30s), and batch inference is needed to speed up inference efficiency, the VAD model can be removed, and `batch_size` can be set accordingly.
|
| 156 |
+
```python
|
| 157 |
+
model = AutoModel(model=model_dir, device=""cuda:0"", hub=""hf"")
|
| 158 |
+
|
| 159 |
+
res = model.generate(
|
| 160 |
+
input=f""{model.model_path}/example/en.mp3"",
|
| 161 |
+
cache={},
|
| 162 |
+
language=""zh"", # ""zn"", ""en"", ""yue"", ""ja"", ""ko"", ""nospeech""
|
| 163 |
+
use_itn=False,
|
| 164 |
+
batch_size=64,
|
| 165 |
+
hub=""hf"",
|
| 166 |
+
)
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
For more usage, please refer to [docs](https://github.com/modelscope/FunASR/blob/main/docs/tutorial/README.md)
|
| 170 |
+
|
| 171 |
+
### Inference directly
|
| 172 |
+
|
| 173 |
+
Supports input of audio in any format, with an input duration limit of 30 seconds or less.
|
| 174 |
+
|
| 175 |
+
```python
|
| 176 |
+
from model import SenseVoiceSmall
|
| 177 |
+
from funasr.utils.postprocess_utils import rich_transcription_postprocess
|
| 178 |
+
|
| 179 |
+
model_dir = ""FunAudioLLM/SenseVoiceSmall""
|
| 180 |
+
m, kwargs = SenseVoiceSmall.from_pretrained(model=model_dir, device=""cuda:0"", hub=""hf"")
|
| 181 |
+
m.eval()
|
| 182 |
+
|
| 183 |
+
res = m.inference(
|
| 184 |
+
data_in=f""{kwargs['model_path']}/example/en.mp3"",
|
| 185 |
+
language=""auto"", # ""zn"", ""en"", ""yue"", ""ja"", ""ko"", ""nospeech""
|
| 186 |
+
use_itn=False,
|
| 187 |
+
**kwargs,
|
| 188 |
+
)
|
| 189 |
+
|
| 190 |
+
text = rich_transcription_postprocess(res[0][0][""text""])
|
| 191 |
+
print(text)
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
### Export and Test (*On going*)
|
| 195 |
+
Ref to [SenseVoice](https://github.com/FunAudioLLM/SenseVoice)
|
| 196 |
+
## Service
|
| 197 |
+
|
| 198 |
+
Ref to [SenseVoice](https://github.com/FunAudioLLM/SenseVoice)
|
| 199 |
+
|
| 200 |
+
## Finetune
|
| 201 |
+
|
| 202 |
+
Ref to [SenseVoice](https://github.com/FunAudioLLM/SenseVoice)
|
| 203 |
+
|
| 204 |
+
## WebUI
|
| 205 |
+
|
| 206 |
+
```shell
|
| 207 |
+
python webui.py
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
<div align=""center""><img src=""image/webui.png"" width=""700""/> </div>
|
| 211 |
+
|
| 212 |
+
<a name=""Community""></a>
|
| 213 |
+
# Community
|
| 214 |
+
If you encounter problems in use, you can directly raise Issues on the github page.
|
| 215 |
+
|
| 216 |
+
You can also scan the following DingTalk group QR code to join the community group for communication and discussion.
|
| 217 |
+
|
| 218 |
+
| FunAudioLLM | FunASR |
|
| 219 |
+
|:----------------------------------------------------------------:|:--------------------------------------------------------:|
|
| 220 |
+
| <div align=""left""><img src=""image/dingding_sv.png"" width=""250""/> | <img src=""image/dingding_funasr.png"" width=""250""/></div> |","{""id"": ""FunAudioLLM/SenseVoiceSmall"", ""author"": ""FunAudioLLM"", ""sha"": ""3eb3b4eeffc2f2dde6051b853983753db33e35c3"", ""last_modified"": ""2024-07-31 05:47:48+00:00"", ""created_at"": ""2024-07-03 03:56:49+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 1092, ""downloads_all_time"": null, ""likes"": 250, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""en"", ""zh"", ""ja"", ""ko"", ""license:other"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- en\n- zh\n- ja\n- ko\nlicense: other\nlicense_name: model-license\nlicense_link: https://github.com/modelscope/FunASR/blob/main/MODEL_LICENSE\nlibrary: funasr"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README_ja.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README_zh.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='am.mvn', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chn_jpn_yue_eng_ko_spectok.bpe.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='demo.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example/en.mp3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example/ja.mp3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example/ko.mp3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example/yue.mp3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='example/zh.mp3', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/aed_figure.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/asr_results.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/asr_results1.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/asr_results2.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/dingding_funasr.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/dingding_sv.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/inference.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/sensevoice.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/sensevoice2.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/ser_figure.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/ser_table.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/webui.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='image/wechat.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='requirements.txt', size=None, blob_id=None, lfs=None)""], ""spaces"": [""FunAudioLLM/SenseVoice"", ""megatrump/test-FunAudioLLM"", ""terryli/cantonese-call-transcriber"", ""cuio/SenseVoice"", ""Nocigar/siliconflow"", ""megatrump/SenseVoice"", ""tuan243/checkSound""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-07-31 05:47:48+00:00"", ""cardData"": ""language:\n- en\n- zh\n- ja\n- ko\nlicense: other\nlicense_name: model-license\nlicense_link: https://github.com/modelscope/FunASR/blob/main/MODEL_LICENSE\nlibrary: funasr"", ""transformersInfo"": null, ""_id"": ""6684cc014099f9d44cd40dbd"", ""modelId"": ""FunAudioLLM/SenseVoiceSmall"", ""usedStorage"": 940388053}",0,https://huggingface.co/ChenChenyu/SenseVoiceSmall-finetuned,1,,0,,0,,0,"FunAudioLLM/SenseVoice, Nocigar/siliconflow, cuio/SenseVoice, huggingface/InferenceSupport/discussions/new?title=FunAudioLLM/SenseVoiceSmall&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BFunAudioLLM%2FSenseVoiceSmall%5D(%2FFunAudioLLM%2FSenseVoiceSmall)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, megatrump/SenseVoice, megatrump/test-FunAudioLLM, terryli/cantonese-call-transcriber, tuan243/checkSound",8
|
| 221 |
+
ChenChenyu/SenseVoiceSmall-finetuned,"---
|
| 222 |
+
datasets:
|
| 223 |
+
- ChenChenyu/VoiceDataSet
|
| 224 |
+
base_model:
|
| 225 |
+
- FunAudioLLM/SenseVoiceSmall
|
| 226 |
+
---
|
| 227 |
+
# SenseVoiceSmall微调模型
|
| 228 |
+
对SenseVoiceSmall开源模型用粤语和四川话数据集进行微调,得到微调后的模型。
|
| 229 |
+
## 微调后测试cer
|
| 230 |
+
| | 带符号 | 去符号 |
|
| 231 |
+
| :-----| ----: | :----: |
|
| 232 |
+
| 微调前 | 0.35151298237809847 | 0.19419020076531499 |
|
| 233 |
+
| 微调后 | 0.17646826424209877 | 0.12941482715620842 |
|
| 234 |
+
## 微调所用数据集
|
| 235 |
+
ChenChenyu/VoiceDataSet","{""id"": ""ChenChenyu/SenseVoiceSmall-finetuned"", ""author"": ""ChenChenyu"", ""sha"": ""0562b755c36b202ca07ef65b05577e7fd5a39bcf"", ""last_modified"": ""2024-12-01 11:42:52+00:00"", ""created_at"": ""2024-12-01 05:11:23+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 1, ""downloads_all_time"": null, ""likes"": 2, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""tensorboard"", ""dataset:ChenChenyu/VoiceDataSet"", ""base_model:FunAudioLLM/SenseVoiceSmall"", ""base_model:finetune:FunAudioLLM/SenseVoiceSmall"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- FunAudioLLM/SenseVoiceSmall\ndatasets:\n- ChenChenyu/VoiceDataSet"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='.ipynb_checkpoints/config-checkpoint.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='1best_recog/text', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='2024-10-25/18-23-57/.hydra/config.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='2024-10-25/18-23-57/.hydra/hydra.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='2024-10-25/18-23-57/.hydra/overrides.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='2024-10-25/18-23-57/train_ds.log', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.yaml', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='log.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.pt.best', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tensorboard/events.out.tfevents.1729851842.autodl-container-f42f45a886-bccfcaff', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-12-01 11:42:52+00:00"", ""cardData"": ""base_model:\n- FunAudioLLM/SenseVoiceSmall\ndatasets:\n- ChenChenyu/VoiceDataSet"", ""transformersInfo"": null, ""_id"": ""674beffb6563eabf0c165cd9"", ""modelId"": ""ChenChenyu/SenseVoiceSmall-finetuned"", ""usedStorage"": 5685682742}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=ChenChenyu/SenseVoiceSmall-finetuned&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BChenChenyu%2FSenseVoiceSmall-finetuned%5D(%2FChenChenyu%2FSenseVoiceSmall-finetuned)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
SmolDocling-256M-preview_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv
ADDED
|
@@ -0,0 +1,597 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
ds4sd/SmolDocling-256M-preview,"---
|
| 3 |
+
base_model:
|
| 4 |
+
- HuggingFaceTB/SmolVLM-256M-Instruct
|
| 5 |
+
language:
|
| 6 |
+
- en
|
| 7 |
+
library_name: transformers
|
| 8 |
+
license: cdla-permissive-2.0
|
| 9 |
+
pipeline_tag: image-text-to-text
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
<div style=""display: flex; align-items: center;"">
|
| 13 |
+
<img src=""https://huggingface.co/ds4sd/SmolDocling-256M-preview/resolve/main/assets/SmolDocling_doctags1.png"" alt=""SmolDocling"" style=""width: 200px; height: auto; margin-right: 20px;"">
|
| 14 |
+
<div>
|
| 15 |
+
<h3>SmolDocling-256M-preview</h3>
|
| 16 |
+
<p>SmolDocling is a multimodal Image-Text-to-Text model designed for efficient document conversion. It retains Docling's most popular features while ensuring full compatibility with Docling through seamless support for <strong>DoclingDocuments</strong>.</p>
|
| 17 |
+
</div>
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
This model was presented in the paper [SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion](https://huggingface.co/papers/2503.11576).
|
| 21 |
+
|
| 22 |
+
### 🚀 Features:
|
| 23 |
+
- 🏷️ **DocTags for Efficient Tokenization** – Introduces DocTags an efficient and minimal representation for documents that is fully compatible with **DoclingDocuments**.
|
| 24 |
+
- 🔍 **OCR (Optical Character Recognition)** – Extracts text accurately from images.
|
| 25 |
+
- 📐 **Layout and Localization** – Preserves document structure and document element **bounding boxes**.
|
| 26 |
+
- 💻 **Code Recognition** – Detects and formats code blocks including identation.
|
| 27 |
+
- 🔢 **Formula Recognition** – Identifies and processes mathematical expressions.
|
| 28 |
+
- 📊 **Chart Recognition** – Extracts and interprets chart data.
|
| 29 |
+
- 📑 **Table Recognition** – Supports column and row headers for structured table extraction.
|
| 30 |
+
- 🖼️ **Figure Classification** – Differentiates figures and graphical elements.
|
| 31 |
+
- 📝 **Caption Correspondence** – Links captions to relevant images and figures.
|
| 32 |
+
- 📜 **List Grouping** – Organizes and structures list elements correctly.
|
| 33 |
+
- 📄 **Full-Page Conversion** – Processes entire pages for comprehensive document conversion including all page elements (code, equations, tables, charts etc.)
|
| 34 |
+
- 🔲 **OCR with Bounding Boxes** – OCR regions using a bounding box.
|
| 35 |
+
- 📂 **General Document Processing** – Trained for both scientific and non-scientific documents.
|
| 36 |
+
- 🔄 **Seamless Docling Integration** – Import into **Docling** and export in multiple formats.
|
| 37 |
+
- 💨 **Fast inference using VLLM** – Avg of 0.35 secs per page on A100 GPU.
|
| 38 |
+
|
| 39 |
+
### 🚧 *Coming soon!*
|
| 40 |
+
- 📊 **Better chart recognition 🛠️**
|
| 41 |
+
- 📚 **One shot multi-page inference ⏱️**
|
| 42 |
+
- 🧪 **Chemical Recognition**
|
| 43 |
+
- 📙 **Datasets**
|
| 44 |
+
|
| 45 |
+
## ⌨️ Get started (code examples)
|
| 46 |
+
|
| 47 |
+
You can use **transformers**, **vllm**, or **onnx** to perform inference, and [Docling](https://github.com/docling-project/docling) to convert results to variety of output formats (md, html, etc.):
|
| 48 |
+
|
| 49 |
+
<details>
|
| 50 |
+
<summary>📄 Single page image inference using Tranformers 🤖</summary>
|
| 51 |
+
|
| 52 |
+
```python
|
| 53 |
+
# Prerequisites:
|
| 54 |
+
# pip install torch
|
| 55 |
+
# pip install docling_core
|
| 56 |
+
# pip install transformers
|
| 57 |
+
|
| 58 |
+
import torch
|
| 59 |
+
from docling_core.types.doc import DoclingDocument
|
| 60 |
+
from docling_core.types.doc.document import DocTagsDocument
|
| 61 |
+
from transformers import AutoProcessor, AutoModelForVision2Seq
|
| 62 |
+
from transformers.image_utils import load_image
|
| 63 |
+
from pathlib import Path
|
| 64 |
+
|
| 65 |
+
DEVICE = ""cuda"" if torch.cuda.is_available() else ""cpu""
|
| 66 |
+
|
| 67 |
+
# Load images
|
| 68 |
+
image = load_image(""https://upload.wikimedia.org/wikipedia/commons/7/76/GazettedeFrance.jpg"")
|
| 69 |
+
|
| 70 |
+
# Initialize processor and model
|
| 71 |
+
processor = AutoProcessor.from_pretrained(""ds4sd/SmolDocling-256M-preview"")
|
| 72 |
+
model = AutoModelForVision2Seq.from_pretrained(
|
| 73 |
+
""ds4sd/SmolDocling-256M-preview"",
|
| 74 |
+
torch_dtype=torch.bfloat16,
|
| 75 |
+
_attn_implementation=""flash_attention_2"" if DEVICE == ""cuda"" else ""eager"",
|
| 76 |
+
).to(DEVICE)
|
| 77 |
+
|
| 78 |
+
# Create input messages
|
| 79 |
+
messages = [
|
| 80 |
+
{
|
| 81 |
+
""role"": ""user"",
|
| 82 |
+
""content"": [
|
| 83 |
+
{""type"": ""image""},
|
| 84 |
+
{""type"": ""text"", ""text"": ""Convert this page to docling.""}
|
| 85 |
+
]
|
| 86 |
+
},
|
| 87 |
+
]
|
| 88 |
+
|
| 89 |
+
# Prepare inputs
|
| 90 |
+
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
|
| 91 |
+
inputs = processor(text=prompt, images=[image], return_tensors=""pt"")
|
| 92 |
+
inputs = inputs.to(DEVICE)
|
| 93 |
+
|
| 94 |
+
# Generate outputs
|
| 95 |
+
generated_ids = model.generate(**inputs, max_new_tokens=8192)
|
| 96 |
+
prompt_length = inputs.input_ids.shape[1]
|
| 97 |
+
trimmed_generated_ids = generated_ids[:, prompt_length:]
|
| 98 |
+
doctags = processor.batch_decode(
|
| 99 |
+
trimmed_generated_ids,
|
| 100 |
+
skip_special_tokens=False,
|
| 101 |
+
)[0].lstrip()
|
| 102 |
+
|
| 103 |
+
# Populate document
|
| 104 |
+
doctags_doc = DocTagsDocument.from_doctags_and_image_pairs([doctags], [image])
|
| 105 |
+
print(doctags)
|
| 106 |
+
# create a docling document
|
| 107 |
+
doc = DoclingDocument(name=""Document"")
|
| 108 |
+
doc.load_from_doctags(doctags_doc)
|
| 109 |
+
|
| 110 |
+
# export as any format
|
| 111 |
+
# HTML
|
| 112 |
+
# Path(""Out/"").mkdir(parents=True, exist_ok=True)
|
| 113 |
+
# output_path_html = Path(""Out/"") / ""example.html""
|
| 114 |
+
# doc.save_as_html(output_path_html)
|
| 115 |
+
# MD
|
| 116 |
+
print(doc.export_to_markdown())
|
| 117 |
+
```
|
| 118 |
+
</details>
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
<details>
|
| 122 |
+
<summary> 🚀 Fast Batch Inference Using VLLM</summary>
|
| 123 |
+
|
| 124 |
+
```python
|
| 125 |
+
# Prerequisites:
|
| 126 |
+
# pip install vllm
|
| 127 |
+
# pip install docling_core
|
| 128 |
+
# place page images you want to convert into ""img/"" dir
|
| 129 |
+
|
| 130 |
+
import time
|
| 131 |
+
import os
|
| 132 |
+
from vllm import LLM, SamplingParams
|
| 133 |
+
from PIL import Image
|
| 134 |
+
from docling_core.types.doc import DoclingDocument
|
| 135 |
+
from docling_core.types.doc.document import DocTagsDocument
|
| 136 |
+
from pathlib import Path
|
| 137 |
+
|
| 138 |
+
# Configuration
|
| 139 |
+
MODEL_PATH = ""ds4sd/SmolDocling-256M-preview""
|
| 140 |
+
IMAGE_DIR = ""img/"" # Place your page images here
|
| 141 |
+
OUTPUT_DIR = ""out/""
|
| 142 |
+
PROMPT_TEXT = ""Convert page to Docling.""
|
| 143 |
+
|
| 144 |
+
# Ensure output directory exists
|
| 145 |
+
os.makedirs(OUTPUT_DIR, exist_ok=True)
|
| 146 |
+
|
| 147 |
+
# Initialize LLM
|
| 148 |
+
llm = LLM(model=MODEL_PATH, limit_mm_per_prompt={""image"": 1})
|
| 149 |
+
|
| 150 |
+
sampling_params = SamplingParams(
|
| 151 |
+
temperature=0.0,
|
| 152 |
+
max_tokens=8192)
|
| 153 |
+
|
| 154 |
+
chat_template = f""<|im_start|>User:<image>{PROMPT_TEXT}<end_of_utterance>
|
| 155 |
+
Assistant:""
|
| 156 |
+
|
| 157 |
+
image_files = sorted([f for f in os.listdir(IMAGE_DIR) if f.lower().endswith(("".png"", "".jpg"", "".jpeg""))])
|
| 158 |
+
|
| 159 |
+
start_time = time.time()
|
| 160 |
+
total_tokens = 0
|
| 161 |
+
|
| 162 |
+
for idx, img_file in enumerate(image_files, 1):
|
| 163 |
+
img_path = os.path.join(IMAGE_DIR, img_file)
|
| 164 |
+
image = Image.open(img_path).convert(""RGB"")
|
| 165 |
+
|
| 166 |
+
llm_input = {""prompt"": chat_template, ""multi_modal_data"": {""image"": image}}
|
| 167 |
+
output = llm.generate([llm_input], sampling_params=sampling_params)[0]
|
| 168 |
+
|
| 169 |
+
doctags = output.outputs[0].text
|
| 170 |
+
img_fn = os.path.splitext(img_file)[0]
|
| 171 |
+
output_filename = img_fn + "".dt""
|
| 172 |
+
output_path = os.path.join(OUTPUT_DIR, output_filename)
|
| 173 |
+
|
| 174 |
+
with open(output_path, ""w"", encoding=""utf-8"") as f:
|
| 175 |
+
f.write(doctags)
|
| 176 |
+
|
| 177 |
+
# To convert to Docling Document, MD, HTML, etc.:
|
| 178 |
+
doctags_doc = DocTagsDocument.from_doctags_and_image_pairs([doctags], [image])
|
| 179 |
+
doc = DoclingDocument(name=""Document"")
|
| 180 |
+
doc.load_from_doctags(doctags_doc)
|
| 181 |
+
# export as any format
|
| 182 |
+
# HTML
|
| 183 |
+
# output_path_html = Path(OUTPUT_DIR) / f""{img_fn}.html""
|
| 184 |
+
# doc.save_as_html(output_path_html)
|
| 185 |
+
# MD
|
| 186 |
+
output_path_md = Path(OUTPUT_DIR) / f""{img_fn}.md""
|
| 187 |
+
doc.save_as_markdown(output_path_md)
|
| 188 |
+
print(f""Total time: {time.time() - start_time:.2f} sec"")
|
| 189 |
+
```
|
| 190 |
+
</details>
|
| 191 |
+
<details>
|
| 192 |
+
<summary> ONNX Inference</summary>
|
| 193 |
+
|
| 194 |
+
```python
|
| 195 |
+
# Prerequisites:
|
| 196 |
+
# pip install onnxruntime
|
| 197 |
+
# pip install onnxruntime-gpu
|
| 198 |
+
from transformers import AutoConfig, AutoProcessor
|
| 199 |
+
from transformers.image_utils import load_image
|
| 200 |
+
import onnxruntime
|
| 201 |
+
import numpy as np
|
| 202 |
+
import os
|
| 203 |
+
from docling_core.types.doc import DoclingDocument
|
| 204 |
+
from docling_core.types.doc.document import DocTagsDocument
|
| 205 |
+
|
| 206 |
+
os.environ[""OMP_NUM_THREADS""] = ""1""
|
| 207 |
+
# cuda
|
| 208 |
+
os.environ[""ORT_CUDA_USE_MAX_WORKSPACE""] = ""1""
|
| 209 |
+
|
| 210 |
+
# 1. Load models
|
| 211 |
+
## Load config and processor
|
| 212 |
+
model_id = ""ds4sd/SmolDocling-256M-preview""
|
| 213 |
+
config = AutoConfig.from_pretrained(model_id)
|
| 214 |
+
processor = AutoProcessor.from_pretrained(model_id)
|
| 215 |
+
|
| 216 |
+
## Load sessions
|
| 217 |
+
# !wget https://huggingface.co/ds4sd/SmolDocling-256M-preview/resolve/main/onnx/vision_encoder.onnx
|
| 218 |
+
# !wget https://huggingface.co/ds4sd/SmolDocling-256M-preview/resolve/main/onnx/embed_tokens.onnx
|
| 219 |
+
# !wget https://huggingface.co/ds4sd/SmolDocling-256M-preview/resolve/main/onnx/decoder_model_merged.onnx
|
| 220 |
+
# cpu
|
| 221 |
+
# vision_session = onnxruntime.InferenceSession(""vision_encoder.onnx"")
|
| 222 |
+
# embed_session = onnxruntime.InferenceSession(""embed_tokens.onnx"")
|
| 223 |
+
# decoder_session = onnxruntime.InferenceSession(""decoder_model_merged.onnx""
|
| 224 |
+
|
| 225 |
+
# cuda
|
| 226 |
+
vision_session = onnxruntime.InferenceSession(""vision_encoder.onnx"", providers=[""CUDAExecutionProvider""])
|
| 227 |
+
embed_session = onnxruntime.InferenceSession(""embed_tokens.onnx"", providers=[""CUDAExecutionProvider""])
|
| 228 |
+
decoder_session = onnxruntime.InferenceSession(""decoder_model_merged.onnx"", providers=[""CUDAExecutionProvider""])
|
| 229 |
+
|
| 230 |
+
## Set config values
|
| 231 |
+
num_key_value_heads = config.text_config.num_key_value_heads
|
| 232 |
+
head_dim = config.text_config.head_dim
|
| 233 |
+
num_hidden_layers = config.text_config.num_hidden_layers
|
| 234 |
+
eos_token_id = config.text_config.eos_token_id
|
| 235 |
+
image_token_id = config.image_token_id
|
| 236 |
+
end_of_utterance_id = processor.tokenizer.convert_tokens_to_ids(""<end_of_utterance>"")
|
| 237 |
+
|
| 238 |
+
# 2. Prepare inputs
|
| 239 |
+
## Create input messages
|
| 240 |
+
messages = [
|
| 241 |
+
{
|
| 242 |
+
""role"": ""user"",
|
| 243 |
+
""content"": [
|
| 244 |
+
{""type"": ""image""},
|
| 245 |
+
{""type"": ""text"", ""text"": ""Convert this page to docling.""}
|
| 246 |
+
]
|
| 247 |
+
},
|
| 248 |
+
]
|
| 249 |
+
|
| 250 |
+
## Load image and apply processor
|
| 251 |
+
image = load_image(""https://ibm.biz/docling-page-with-table"")
|
| 252 |
+
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
|
| 253 |
+
inputs = processor(text=prompt, images=[image], return_tensors=""np"")
|
| 254 |
+
|
| 255 |
+
## Prepare decoder inputs
|
| 256 |
+
batch_size = inputs['input_ids'].shape[0]
|
| 257 |
+
past_key_values = {
|
| 258 |
+
f'past_key_values.{layer}.{kv}': np.zeros([batch_size, num_key_value_heads, 0, head_dim], dtype=np.float32)
|
| 259 |
+
for layer in range(num_hidden_layers)
|
| 260 |
+
for kv in ('key', 'value')
|
| 261 |
+
}
|
| 262 |
+
image_features = None
|
| 263 |
+
input_ids = inputs['input_ids']
|
| 264 |
+
attention_mask = inputs['attention_mask']
|
| 265 |
+
position_ids = np.cumsum(inputs['attention_mask'], axis=-1)
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
# 3. Generation loop
|
| 269 |
+
max_new_tokens = 8192
|
| 270 |
+
generated_tokens = np.array([[]], dtype=np.int64)
|
| 271 |
+
for i in range(max_new_tokens):
|
| 272 |
+
inputs_embeds = embed_session.run(None, {'input_ids': input_ids})[0]
|
| 273 |
+
|
| 274 |
+
if image_features is None:
|
| 275 |
+
## Only compute vision features if not already computed
|
| 276 |
+
image_features = vision_session.run(
|
| 277 |
+
['image_features'], # List of output names or indices
|
| 278 |
+
{
|
| 279 |
+
'pixel_values': inputs['pixel_values'],
|
| 280 |
+
'pixel_attention_mask': inputs['pixel_attention_mask'].astype(np.bool_)
|
| 281 |
+
}
|
| 282 |
+
)[0]
|
| 283 |
+
|
| 284 |
+
## Merge text and vision embeddings
|
| 285 |
+
inputs_embeds[inputs['input_ids'] == image_token_id] = image_features.reshape(-1, image_features.shape[-1])
|
| 286 |
+
|
| 287 |
+
logits, *present_key_values = decoder_session.run(None, dict(
|
| 288 |
+
inputs_embeds=inputs_embeds,
|
| 289 |
+
attention_mask=attention_mask,
|
| 290 |
+
position_ids=position_ids,
|
| 291 |
+
**past_key_values,
|
| 292 |
+
))
|
| 293 |
+
|
| 294 |
+
## Update values for next generation loop
|
| 295 |
+
input_ids = logits[:, -1].argmax(-1, keepdims=True)
|
| 296 |
+
attention_mask = np.ones_like(input_ids)
|
| 297 |
+
position_ids = position_ids[:, -1:] + 1
|
| 298 |
+
for j, key in enumerate(past_key_values):
|
| 299 |
+
past_key_values[key] = present_key_values[j]
|
| 300 |
+
|
| 301 |
+
generated_tokens = np.concatenate([generated_tokens, input_ids], axis=-1)
|
| 302 |
+
if (input_ids == eos_token_id).all() or (input_ids == end_of_utterance_id).all():
|
| 303 |
+
break # Stop predicting
|
| 304 |
+
|
| 305 |
+
doctags = processor.batch_decode(
|
| 306 |
+
generated_tokens,
|
| 307 |
+
skip_special_tokens=False,
|
| 308 |
+
)[0].lstrip()
|
| 309 |
+
|
| 310 |
+
print(doctags)
|
| 311 |
+
|
| 312 |
+
doctags_doc = DocTagsDocument.from_doctags_and_image_pairs([doctags], [image])
|
| 313 |
+
print(doctags)
|
| 314 |
+
# create a docling document
|
| 315 |
+
doc = DoclingDocument(name=""Document"")
|
| 316 |
+
doc.load_from_doctags(doctags_doc)
|
| 317 |
+
|
| 318 |
+
print(doc.export_to_markdown())
|
| 319 |
+
```
|
| 320 |
+
</details>
|
| 321 |
+
|
| 322 |
+
|
| 323 |
+
💻 Local inference on Apple Silicon with MLX: [see here](https://huggingface.co/ds4sd/SmolDocling-256M-preview-mlx-bf16)
|
| 324 |
+
|
| 325 |
+
## DocTags
|
| 326 |
+
|
| 327 |
+
<img src=""https://huggingface.co/ds4sd/SmolDocling-256M-preview/resolve/main/assets/doctags_v2.png"" width=""800"" height=""auto"" alt=""Image description"">
|
| 328 |
+
DocTags create a clear and structured system of tags and rules that separate text from the document's structure. This makes things easier for Image-to-Sequence models by reducing confusion. On the other hand, converting directly to formats like HTML or Markdown can be messy—it often loses details, doesn’t clearly show the document’s layout, and increases the number of tokens, making processing less efficient.
|
| 329 |
+
DocTags are integrated with Docling, which allows export to HTML, Markdown, and JSON. These exports can be offloaded to the CPU, reducing token generation overhead and improving efficiency.
|
| 330 |
+
|
| 331 |
+
## Supported Instructions
|
| 332 |
+
|
| 333 |
+
<table>
|
| 334 |
+
<tr>
|
| 335 |
+
<td><b>Description</b></td>
|
| 336 |
+
<td><b>Instruction</b></td>
|
| 337 |
+
<td><b>Comment</b></td>
|
| 338 |
+
</tr>
|
| 339 |
+
<tr>
|
| 340 |
+
<td><b>Full conversion</b></td>
|
| 341 |
+
<td>Convert this page to docling.</td>
|
| 342 |
+
<td>DocTags represetation</td>
|
| 343 |
+
</tr>
|
| 344 |
+
<tr>
|
| 345 |
+
<td><b>Chart</b></td>
|
| 346 |
+
<td>Convert chart to table.</td>
|
| 347 |
+
<td>(e.g., <chart>)</td>
|
| 348 |
+
</tr>
|
| 349 |
+
<tr>
|
| 350 |
+
<td><b>Formula</b></td>
|
| 351 |
+
<td>Convert formula to LaTeX.</td>
|
| 352 |
+
<td>(e.g., <formula>)</td>
|
| 353 |
+
</tr>
|
| 354 |
+
<tr>
|
| 355 |
+
<td><b>Code</b></td>
|
| 356 |
+
<td>Convert code to text.</td>
|
| 357 |
+
<td>(e.g., <code>)</td>
|
| 358 |
+
</tr>
|
| 359 |
+
<tr>
|
| 360 |
+
<td><b>Table</b></td>
|
| 361 |
+
<td>Convert table to OTSL.</td>
|
| 362 |
+
<td>(e.g., <otsl>) OTSL: <a href=""https://arxiv.org/pdf/2305.03393"">Lysak et al., 2023</a></td>
|
| 363 |
+
</tr>
|
| 364 |
+
<tr>
|
| 365 |
+
<td rowspan=4><b>Actions and Pipelines</b></td>
|
| 366 |
+
<td>OCR the text in a specific location: <loc_155><loc_233><loc_206><loc_237></td>
|
| 367 |
+
<td></td>
|
| 368 |
+
</tr>
|
| 369 |
+
<tr>
|
| 370 |
+
<td>Identify element at: <loc_247><loc_482><10c_252><loc_486></td>
|
| 371 |
+
<td></td>
|
| 372 |
+
</tr>
|
| 373 |
+
<tr>
|
| 374 |
+
<td>Find all 'text' elements on the page, retrieve all section headers.</td>
|
| 375 |
+
<td></td>
|
| 376 |
+
</tr>
|
| 377 |
+
<tr>
|
| 378 |
+
<td>Detect footer elements on the page.</td>
|
| 379 |
+
<td></td>
|
| 380 |
+
</tr>
|
| 381 |
+
</table>
|
| 382 |
+
|
| 383 |
+
#### Model Summary
|
| 384 |
+
|
| 385 |
+
- **Developed by:** Docling Team, IBM Research
|
| 386 |
+
- **Model type:** Multi-modal model (image+text)
|
| 387 |
+
- **Language(s) (NLP):** English
|
| 388 |
+
- **License:** Apache 2.0
|
| 389 |
+
- **Architecture:** Based on [Idefics3](https://huggingface.co/HuggingFaceM4/Idefics3-8B-Llama3) (see technical summary)
|
| 390 |
+
- **Finetuned from model:** Based on [SmolVLM-256M-Instruct](https://huggingface.co/HuggingFaceTB/SmolVLM-256M-Instruct)
|
| 391 |
+
|
| 392 |
+
**Repository:** [Docling](https://github.com/docling-project/docling)
|
| 393 |
+
|
| 394 |
+
**Paper:** [arXiv](https://arxiv.org/abs/2503.11576)
|
| 395 |
+
|
| 396 |
+
**Project Page:** [Hugging Face](https://huggingface.co/ds4sd/SmolDocling-256M-preview)
|
| 397 |
+
|
| 398 |
+
**Citation:**
|
| 399 |
+
```
|
| 400 |
+
@misc{nassar2025smoldoclingultracompactvisionlanguagemodel,
|
| 401 |
+
title={SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion},
|
| 402 |
+
author={Ahmed Nassar and Andres Marafioti and Matteo Omenetti and Maksym Lysak and Nikolaos Livathinos and Christoph Auer and Lucas Morin and Rafael Teixeira de Lima and Yusik Kim and A. Said Gurbuz and Michele Dolfi and Miquel Farré and Peter W. J. Staar},
|
| 403 |
+
year={2025},
|
| 404 |
+
eprint={2503.11576},
|
| 405 |
+
archivePrefix={arXiv},
|
| 406 |
+
primaryClass={cs.CV},
|
| 407 |
+
url={https://arxiv.org/abs/2503.11576},
|
| 408 |
+
}
|
| 409 |
+
```
|
| 410 |
+
**Demo:** [HF Space](https://huggingface.co/spaces/ds4sd/SmolDocling-256M-Demo)","{""id"": ""ds4sd/SmolDocling-256M-preview"", ""author"": ""ds4sd"", ""sha"": ""492bde898f2bed6b493b4da8256c93de29e03a9b"", ""last_modified"": ""2025-03-23 10:50:10+00:00"", ""created_at"": ""2025-02-12 15:40:33+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 79570, ""downloads_all_time"": null, ""likes"": 1264, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""onnx"", ""safetensors"", ""idefics3"", ""image-text-to-text"", ""conversational"", ""en"", ""arxiv:2503.11576"", ""arxiv:2305.03393"", ""base_model:HuggingFaceTB/SmolVLM-256M-Instruct"", ""base_model:quantized:HuggingFaceTB/SmolVLM-256M-Instruct"", ""license:cdla-permissive-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""image-text-to-text"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- HuggingFaceTB/SmolVLM-256M-Instruct\nlanguage:\n- en\nlibrary_name: transformers\nlicense: cdla-permissive-2.0\npipeline_tag: image-text-to-text"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""Idefics3ForConditionalGeneration""], ""model_type"": ""idefics3"", ""processor_config"": {""chat_template"": ""<|im_start|>{% for message in messages %}{{message['role'] | capitalize}}{% if message['content'][0]['type'] == 'image' %}{{':'}}{% else %}{{': '}}{% endif %}{% for line in message['content'] %}{% if line['type'] == 'text' %}{{line['text']}}{% elif line['type'] == 'image' %}{{ '<image>' }}{% endif %}{% endfor %}<end_of_utterance>\n{% endfor %}{% if add_generation_prompt %}{{ 'Assistant:' }}{% endif %}""}, ""tokenizer_config"": {""bos_token"": ""<|im_start|>"", ""chat_template"": ""<|im_start|>{% for message in messages %}{{message['role'] | capitalize}}{% if message['content'][0]['type'] == 'image' %}{{':'}}{% else %}{{': '}}{% endif %}{% for line in message['content'] %}{% if line['type'] == 'text' %}{{line['text']}}{% elif line['type'] == 'image' %}{{ '<image>' }}{% endif %}{% endfor %}<end_of_utterance>\n{% endfor %}{% if add_generation_prompt %}{{ 'Assistant:' }}{% endif %}"", ""eos_token"": ""<|im_end|>"", ""pad_token"": ""<|im_end|>"", ""unk_token"": ""<|endoftext|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoProcessor""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/SmolDocling_doctags1.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/doctags_v2.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chat_template.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/decoder_model_merged.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/decoder_model_merged_bnb4.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/decoder_model_merged_fp16.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/decoder_model_merged_int8.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/decoder_model_merged_q4.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/decoder_model_merged_q4f16.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/decoder_model_merged_quantized.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/decoder_model_merged_uint8.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/embed_tokens.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/embed_tokens_bnb4.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/embed_tokens_fp16.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/embed_tokens_int8.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/embed_tokens_q4.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/embed_tokens_q4f16.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/embed_tokens_quantized.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/embed_tokens_uint8.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/vision_encoder.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/vision_encoder_bnb4.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/vision_encoder_fp16.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/vision_encoder_int8.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/vision_encoder_q4.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/vision_encoder_q4f16.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/vision_encoder_quantized.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='onnx/vision_encoder_uint8.onnx', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='processor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='zero_to_fp32.py', size=None, blob_id=None, lfs=None)""], ""spaces"": [""ds4sd/SmolDocling-256M-Demo"", ""code27panda/SmolDocling-OCR-App"", ""chunking-ai/smoldocling-preview"", ""feras-vbrl/pdf-to-markdown-converter"", ""mansari722/smoldolcemahdi"", ""ProfessorLeVesseur/PDF_Topic_Extraction_Analysis_App""], ""safetensors"": {""parameters"": {""BF16"": 256484928}, ""total"": 256484928}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-23 10:50:10+00:00"", ""cardData"": ""base_model:\n- HuggingFaceTB/SmolVLM-256M-Instruct\nlanguage:\n- en\nlibrary_name: transformers\nlicense: cdla-permissive-2.0\npipeline_tag: image-text-to-text"", ""transformersInfo"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoProcessor""}, ""_id"": ""67acc0f1b150b8272b721c3b"", ""modelId"": ""ds4sd/SmolDocling-256M-preview"", ""usedStorage"": 6522512627}",0,"https://huggingface.co/ds4sd/SmolDocling-256M-preview-mlx-bf16, https://huggingface.co/ahishamm/SmolDocling-256M-preview-mlx-fp16, https://huggingface.co/flyingtothemoon/Model1, https://huggingface.co/generalheidari/aa, https://huggingface.co/xinxin2018/xinixin, https://huggingface.co/liuxinyu701/6",6,https://huggingface.co/Tjindustries/Amanda,1,,0,,0,"ProfessorLeVesseur/PDF_Topic_Extraction_Analysis_App, chunking-ai/smoldocling-preview, code27panda/SmolDocling-OCR-App, ds4sd/SmolDocling-256M-Demo, feras-vbrl/pdf-to-markdown-converter, huggingface/InferenceSupport/discussions/69, mansari722/smoldolcemahdi",7
|
| 411 |
+
ds4sd/SmolDocling-256M-preview-mlx-bf16,"---
|
| 412 |
+
base_model:
|
| 413 |
+
- ds4sd/SmolDocling-256M-preview
|
| 414 |
+
language:
|
| 415 |
+
- en
|
| 416 |
+
library_name: transformers
|
| 417 |
+
license: cdla-permissive-2.0
|
| 418 |
+
pipeline_tag: image-text-to-text
|
| 419 |
+
tags:
|
| 420 |
+
- mlx
|
| 421 |
+
---
|
| 422 |
+
|
| 423 |
+
# SmolDocling-256M-preview-mlx-bf16
|
| 424 |
+
This model was converted to MLX format from [`ds4sd/SmolDocling-256M-preview`]() using mlx-vlm version **0.1.18**.
|
| 425 |
+
Refer to the [original model card](https://huggingface.co/ds4sd/SmolDocling-256M-preview) for more details on the model.
|
| 426 |
+
## Use with mlx
|
| 427 |
+
|
| 428 |
+
```bash
|
| 429 |
+
pip install -U mlx-vlm pillow docling-core
|
| 430 |
+
```
|
| 431 |
+
|
| 432 |
+
```python
|
| 433 |
+
# /// script
|
| 434 |
+
# requires-python = "">=3.12""
|
| 435 |
+
# dependencies = [
|
| 436 |
+
# ""docling-core"",
|
| 437 |
+
# ""mlx-vlm"",
|
| 438 |
+
# ""pillow"",
|
| 439 |
+
# ]
|
| 440 |
+
# ///
|
| 441 |
+
from io import BytesIO
|
| 442 |
+
from pathlib import Path
|
| 443 |
+
from urllib.parse import urlparse
|
| 444 |
+
|
| 445 |
+
import requests
|
| 446 |
+
from PIL import Image
|
| 447 |
+
from docling_core.types.doc import ImageRefMode
|
| 448 |
+
from docling_core.types.doc.document import DocTagsDocument, DoclingDocument
|
| 449 |
+
from mlx_vlm import load, generate
|
| 450 |
+
from mlx_vlm.prompt_utils import apply_chat_template
|
| 451 |
+
from mlx_vlm.utils import load_config, stream_generate
|
| 452 |
+
|
| 453 |
+
## Settings
|
| 454 |
+
SHOW_IN_BROWSER = True # Export output as HTML and open in webbrowser.
|
| 455 |
+
|
| 456 |
+
## Load the model
|
| 457 |
+
model_path = ""ds4sd/SmolDocling-256M-preview-mlx-bf16""
|
| 458 |
+
model, processor = load(model_path)
|
| 459 |
+
config = load_config(model_path)
|
| 460 |
+
|
| 461 |
+
## Prepare input
|
| 462 |
+
prompt = ""Convert this page to docling.""
|
| 463 |
+
|
| 464 |
+
# image = ""https://ibm.biz/docling-page-with-list""
|
| 465 |
+
image = ""https://ibm.biz/docling-page-with-table""
|
| 466 |
+
|
| 467 |
+
# Load image resource
|
| 468 |
+
if urlparse(image).scheme != """": # it is a URL
|
| 469 |
+
response = requests.get(image, stream=True, timeout=10)
|
| 470 |
+
response.raise_for_status()
|
| 471 |
+
pil_image = Image.open(BytesIO(response.content))
|
| 472 |
+
else:
|
| 473 |
+
pil_image = Image.open(image)
|
| 474 |
+
|
| 475 |
+
# Apply chat template
|
| 476 |
+
formatted_prompt = apply_chat_template(processor, config, prompt, num_images=1)
|
| 477 |
+
|
| 478 |
+
## Generate output
|
| 479 |
+
print(""DocTags: \n\n"")
|
| 480 |
+
|
| 481 |
+
output = """"
|
| 482 |
+
for token in stream_generate(
|
| 483 |
+
model, processor, formatted_prompt, [image], max_tokens=4096, verbose=False
|
| 484 |
+
):
|
| 485 |
+
output += token.text
|
| 486 |
+
print(token.text, end="""")
|
| 487 |
+
if ""</doctag>"" in token.text:
|
| 488 |
+
break
|
| 489 |
+
|
| 490 |
+
print(""\n\n"")
|
| 491 |
+
|
| 492 |
+
# Populate document
|
| 493 |
+
doctags_doc = DocTagsDocument.from_doctags_and_image_pairs([output], [pil_image])
|
| 494 |
+
# create a docling document
|
| 495 |
+
doc = DoclingDocument(name=""SampleDocument"")
|
| 496 |
+
doc.load_from_doctags(doctags_doc)
|
| 497 |
+
|
| 498 |
+
## Export as any format
|
| 499 |
+
# Markdown
|
| 500 |
+
print(""Markdown: \n\n"")
|
| 501 |
+
print(doc.export_to_markdown())
|
| 502 |
+
|
| 503 |
+
# HTML
|
| 504 |
+
if SHOW_IN_BROWSER:
|
| 505 |
+
import webbrowser
|
| 506 |
+
|
| 507 |
+
out_path = Path(""./output.html"")
|
| 508 |
+
doc.save_as_html(out_path, image_mode=ImageRefMode.EMBEDDED)
|
| 509 |
+
webbrowser.open(f""file:///{str(out_path.resolve())}"")
|
| 510 |
+
|
| 511 |
+
```","{""id"": ""ds4sd/SmolDocling-256M-preview-mlx-bf16"", ""author"": ""ds4sd"", ""sha"": ""6081bbb15ee185b71dae0a59d73455643ce97ecd"", ""last_modified"": ""2025-04-22 15:17:46+00:00"", ""created_at"": ""2025-03-18 08:44:08+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 2275, ""downloads_all_time"": null, ""likes"": 44, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""smolvlm"", ""image-text-to-text"", ""mlx"", ""conversational"", ""en"", ""base_model:ds4sd/SmolDocling-256M-preview"", ""base_model:finetune:ds4sd/SmolDocling-256M-preview"", ""license:cdla-permissive-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""image-text-to-text"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- ds4sd/SmolDocling-256M-preview\nlanguage:\n- en\nlibrary_name: transformers\nlicense: cdla-permissive-2.0\npipeline_tag: image-text-to-text\ntags:\n- mlx"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""SmolVLMForConditionalGeneration""], ""model_type"": ""smolvlm"", ""processor_config"": {""chat_template"": ""<|im_start|>{% for message in messages %}{{message['role'] | capitalize}}{% if message['content'][0]['type'] == 'image' %}{{':'}}{% else %}{{': '}}{% endif %}{% for line in message['content'] %}{% if line['type'] == 'text' %}{{line['text']}}{% elif line['type'] == 'image' %}{{ '<image>' }}{% endif %}{% endfor %}<end_of_utterance>\n{% endfor %}{% if add_generation_prompt %}{{ 'Assistant:' }}{% endif %}""}, ""tokenizer_config"": {""bos_token"": ""<|im_start|>"", ""chat_template"": ""<|im_start|>{% for message in messages %}{{message['role'] | capitalize}}{% if message['content'][0]['type'] == 'image' %}{{':'}}{% else %}{{': '}}{% endif %}{% for line in message['content'] %}{% if line['type'] == 'text' %}{{line['text']}}{% elif line['type'] == 'image' %}{{ '<image>' }}{% endif %}{% endfor %}<end_of_utterance>\n{% endfor %}{% if add_generation_prompt %}{{ 'Assistant:' }}{% endif %}"", ""eos_token"": ""<|im_end|>"", ""pad_token"": ""<|im_end|>"", ""unk_token"": ""<|endoftext|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chat_template.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='processor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='zero_to_fp32.py', size=None, blob_id=None, lfs=None)""], ""spaces"": [""EGYADMIN/SAJCO-Tabuk"", ""EGYADMIN/v3"", ""EGYADMIN/SA-SAJCOAI"", ""ProfessorLeVesseur/PDF_Topic_Extraction_Analysis_App""], ""safetensors"": {""parameters"": {""BF16"": 256484928}, ""total"": 256484928}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-22 15:17:46+00:00"", ""cardData"": ""base_model:\n- ds4sd/SmolDocling-256M-preview\nlanguage:\n- en\nlibrary_name: transformers\nlicense: cdla-permissive-2.0\npipeline_tag: image-text-to-text\ntags:\n- mlx"", ""transformersInfo"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoTokenizer""}, ""_id"": ""67d932581c09b1b4d0a44aa3"", ""modelId"": ""ds4sd/SmolDocling-256M-preview-mlx-bf16"", ""usedStorage"": 513026834}",1,,0,,0,,0,,0,"EGYADMIN/SA-SAJCOAI, EGYADMIN/SAJCO-Tabuk, EGYADMIN/v3, ProfessorLeVesseur/PDF_Topic_Extraction_Analysis_App, huggingface/InferenceSupport/discussions/new?title=ds4sd/SmolDocling-256M-preview-mlx-bf16&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bds4sd%2FSmolDocling-256M-preview-mlx-bf16%5D(%2Fds4sd%2FSmolDocling-256M-preview-mlx-bf16)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A",5
|
| 512 |
+
ahishamm/SmolDocling-256M-preview-mlx-fp16,"---
|
| 513 |
+
library_name: transformers
|
| 514 |
+
license: apache-2.0
|
| 515 |
+
language:
|
| 516 |
+
- en
|
| 517 |
+
base_model: ds4sd/SmolDocling-256M-preview
|
| 518 |
+
pipeline_tag: image-text-to-text
|
| 519 |
+
tags:
|
| 520 |
+
- mlx
|
| 521 |
+
- mlxvlm
|
| 522 |
+
---
|
| 523 |
+
|
| 524 |
+
# ahishamm/SmolDocling-256M-preview-mlx-fp16
|
| 525 |
+
The Model [ahishamm/SmolDocling-256M-preview-mlx-fp16](https://huggingface.co/ahishamm/SmolDocling-256M-preview-mlx-fp16) was converted to MLX format from [ds4sd/SmolDocling-256M-preview](https://huggingface.co/ds4sd/SmolDocling-256M-preview)
|
| 526 |
+
using mlx-vlm version **0.1.17**.
|
| 527 |
+
|
| 528 |
+
## Use with mlx
|
| 529 |
+
```bash
|
| 530 |
+
pip install mlx-vlm
|
| 531 |
+
```
|
| 532 |
+
```python
|
| 533 |
+
from mlx_lm import load, generate
|
| 534 |
+
model, tokenizer = load(""ahishamm/SmolDocling-256M-preview-mlx-fp16"")
|
| 535 |
+
prompt = ""hello""
|
| 536 |
+
if hasattr(tokenizer, ""apply_chat_template"") and tokenizer.chat_template is not None:
|
| 537 |
+
messages = [{""role"": ""user"", ""content"": prompt}]
|
| 538 |
+
prompt = tokenizer.apply_chat_template(
|
| 539 |
+
messages, tokenize=False, add_generation_prompt=True
|
| 540 |
+
)
|
| 541 |
+
response = generate(model, tokenizer, prompt=prompt, verbose=True)
|
| 542 |
+
```","{""id"": ""ahishamm/SmolDocling-256M-preview-mlx-fp16"", ""author"": ""ahishamm"", ""sha"": ""0b84106426517c1c6f3b41bd3d8f3ccc940abbed"", ""last_modified"": ""2025-03-18 08:55:32+00:00"", ""created_at"": ""2025-03-17 18:49:41+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 23, ""downloads_all_time"": null, ""likes"": 1, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""idefics3"", ""image-text-to-text"", ""mlx"", ""mlxvlm"", ""conversational"", ""en"", ""base_model:ds4sd/SmolDocling-256M-preview"", ""base_model:finetune:ds4sd/SmolDocling-256M-preview"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""image-text-to-text"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: ds4sd/SmolDocling-256M-preview\nlanguage:\n- en\nlibrary_name: transformers\nlicense: apache-2.0\npipeline_tag: image-text-to-text\ntags:\n- mlx\n- mlxvlm"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""Idefics3ForConditionalGeneration""], ""model_type"": ""idefics3"", ""processor_config"": {""chat_template"": ""<|im_start|>{% for message in messages %}{{ message['role'] | capitalize }}:{% if message['content'] is string %}{{ message['content'] }{% else %}{% if message['content'][0]['type'] == 'image' %}{{ ':' }}{% else %}{{ ': ' }}{% endif %}{% for line in message['content'] %}{% if line['type'] == 'text' %}{{ line['text'] }}{% elif line['type'] == 'image' %}{{ '<image>' }}{% endif %}{% endfor %}{% endif %}<end_of_utterance>{% endfor %}{% if add_generation_prompt %}Assistant:{% endif %}""}, ""tokenizer_config"": {""bos_token"": ""<|im_start|>"", ""chat_template"": ""<|im_start|>{% for message in messages %}{{message['role'] | capitalize}}{% if message['content'][0]['type'] == 'image' %}{{':'}}{% else %}{{': '}}{% endif %}{% for line in message['content'] %}{% if line['type'] == 'text' %}{{line['text']}}{% elif line['type'] == 'image' %}{{ '<image>' }}{% endif %}{% endfor %}<end_of_utterance>\n{% endfor %}{% if add_generation_prompt %}{{ 'Assistant:' }}{% endif %}"", ""eos_token"": ""<|im_end|>"", ""pad_token"": ""<|im_end|>"", ""unk_token"": ""<|endoftext|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoProcessor""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chat_template.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='merges.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='processor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='vocab.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='zero_to_fp32.py', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F16"": 256484928}, ""total"": 256484928}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-18 08:55:32+00:00"", ""cardData"": ""base_model: ds4sd/SmolDocling-256M-preview\nlanguage:\n- en\nlibrary_name: transformers\nlicense: apache-2.0\npipeline_tag: image-text-to-text\ntags:\n- mlx\n- mlxvlm"", ""transformersInfo"": {""auto_model"": ""AutoModelForImageTextToText"", ""custom_class"": null, ""pipeline_tag"": ""image-text-to-text"", ""processor"": ""AutoProcessor""}, ""_id"": ""67d86ec51b6be8ab19917e42"", ""modelId"": ""ahishamm/SmolDocling-256M-preview-mlx-fp16"", ""usedStorage"": 513026363}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=ahishamm/SmolDocling-256M-preview-mlx-fp16&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bahishamm%2FSmolDocling-256M-preview-mlx-fp16%5D(%2Fahishamm%2FSmolDocling-256M-preview-mlx-fp16)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 543 |
+
flyingtothemoon/Model1,"---
|
| 544 |
+
license: openrail
|
| 545 |
+
language:
|
| 546 |
+
- ae
|
| 547 |
+
base_model:
|
| 548 |
+
- ds4sd/SmolDocling-256M-preview
|
| 549 |
+
pipeline_tag: text-classification
|
| 550 |
+
---","{""id"": ""flyingtothemoon/Model1"", ""author"": ""flyingtothemoon"", ""sha"": ""c7cd42a929fa577631bb39c9cfd6eddb3e1f664a"", ""last_modified"": ""2025-03-30 06:39:12+00:00"", ""created_at"": ""2025-03-30 06:38:39+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""text-classification"", ""ae"", ""base_model:ds4sd/SmolDocling-256M-preview"", ""base_model:finetune:ds4sd/SmolDocling-256M-preview"", ""license:openrail"", ""region:us""], ""pipeline_tag"": ""text-classification"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- ds4sd/SmolDocling-256M-preview\nlanguage:\n- ae\nlicense: openrail\npipeline_tag: text-classification"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-30 06:39:12+00:00"", ""cardData"": ""base_model:\n- ds4sd/SmolDocling-256M-preview\nlanguage:\n- ae\nlicense: openrail\npipeline_tag: text-classification"", ""transformersInfo"": null, ""_id"": ""67e8e6ef6221f5872231bd4c"", ""modelId"": ""flyingtothemoon/Model1"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=flyingtothemoon/Model1&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bflyingtothemoon%2FModel1%5D(%2Fflyingtothemoon%2FModel1)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 551 |
+
generalheidari/aa,"---
|
| 552 |
+
license: apache-2.0
|
| 553 |
+
language:
|
| 554 |
+
- aa
|
| 555 |
+
- en
|
| 556 |
+
base_model:
|
| 557 |
+
- ds4sd/SmolDocling-256M-preview
|
| 558 |
+
pipeline_tag: document-question-answering
|
| 559 |
+
tags:
|
| 560 |
+
- chemistry
|
| 561 |
+
datasets:
|
| 562 |
+
- nvidia/Llama-Nemotron-Post-Training-Dataset
|
| 563 |
+
metrics:
|
| 564 |
+
- accuracy
|
| 565 |
+
new_version: Qwen/Qwen2.5-Omni-7B
|
| 566 |
+
library_name: allennlp
|
| 567 |
+
---","{""id"": ""generalheidari/aa"", ""author"": ""generalheidari"", ""sha"": ""be62e1c8dc371d46fed8398e039357d820d5ef95"", ""last_modified"": ""2025-04-14 20:46:48+00:00"", ""created_at"": ""2025-04-14 20:44:32+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""allennlp"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""allennlp"", ""chemistry"", ""document-question-answering"", ""aa"", ""en"", ""dataset:nvidia/Llama-Nemotron-Post-Training-Dataset"", ""base_model:ds4sd/SmolDocling-256M-preview"", ""base_model:finetune:ds4sd/SmolDocling-256M-preview"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": ""document-question-answering"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- ds4sd/SmolDocling-256M-preview\ndatasets:\n- nvidia/Llama-Nemotron-Post-Training-Dataset\nlanguage:\n- aa\n- en\nlibrary_name: allennlp\nlicense: apache-2.0\nmetrics:\n- accuracy\npipeline_tag: document-question-answering\ntags:\n- chemistry\nnew_version: Qwen/Qwen2.5-Omni-7B"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-14 20:46:48+00:00"", ""cardData"": ""base_model:\n- ds4sd/SmolDocling-256M-preview\ndatasets:\n- nvidia/Llama-Nemotron-Post-Training-Dataset\nlanguage:\n- aa\n- en\nlibrary_name: allennlp\nlicense: apache-2.0\nmetrics:\n- accuracy\npipeline_tag: document-question-answering\ntags:\n- chemistry\nnew_version: Qwen/Qwen2.5-Omni-7B"", ""transformersInfo"": null, ""_id"": ""67fd73b0d2c9d1369d2489b2"", ""modelId"": ""generalheidari/aa"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=generalheidari/aa&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bgeneralheidari%2Faa%5D(%2Fgeneralheidari%2Faa)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 568 |
+
xinxin2018/xinixin,"---
|
| 569 |
+
license: mit
|
| 570 |
+
language:
|
| 571 |
+
- ae
|
| 572 |
+
metrics:
|
| 573 |
+
- accuracy
|
| 574 |
+
base_model:
|
| 575 |
+
- ds4sd/SmolDocling-256M-preview
|
| 576 |
+
new_version: black-forest-labs/FLUX.1-dev
|
| 577 |
+
pipeline_tag: zero-shot-classification
|
| 578 |
+
library_name: fasttext
|
| 579 |
+
tags:
|
| 580 |
+
- code
|
| 581 |
+
---","{""id"": ""xinxin2018/xinixin"", ""author"": ""xinxin2018"", ""sha"": ""cb87aeeec9867b6d8837344731c5ffc4e094a62a"", ""last_modified"": ""2025-04-22 09:37:52+00:00"", ""created_at"": ""2025-04-22 09:37:09+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""fasttext"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""fasttext"", ""code"", ""zero-shot-classification"", ""ae"", ""base_model:ds4sd/SmolDocling-256M-preview"", ""base_model:finetune:ds4sd/SmolDocling-256M-preview"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""zero-shot-classification"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- ds4sd/SmolDocling-256M-preview\nlanguage:\n- ae\nlibrary_name: fasttext\nlicense: mit\nmetrics:\n- accuracy\npipeline_tag: zero-shot-classification\ntags:\n- code\nnew_version: black-forest-labs/FLUX.1-dev"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-22 09:37:52+00:00"", ""cardData"": ""base_model:\n- ds4sd/SmolDocling-256M-preview\nlanguage:\n- ae\nlibrary_name: fasttext\nlicense: mit\nmetrics:\n- accuracy\npipeline_tag: zero-shot-classification\ntags:\n- code\nnew_version: black-forest-labs/FLUX.1-dev"", ""transformersInfo"": null, ""_id"": ""680763451e3d60a2b5377b0f"", ""modelId"": ""xinxin2018/xinixin"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=xinxin2018/xinixin&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bxinxin2018%2Fxinixin%5D(%2Fxinxin2018%2Fxinixin)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 582 |
+
liuxinyu701/6,"---
|
| 583 |
+
license: mit
|
| 584 |
+
datasets:
|
| 585 |
+
- nvidia/Llama-Nemotron-Post-Training-Dataset
|
| 586 |
+
language:
|
| 587 |
+
- ak
|
| 588 |
+
metrics:
|
| 589 |
+
- bertscore
|
| 590 |
+
base_model:
|
| 591 |
+
- ds4sd/SmolDocling-256M-preview
|
| 592 |
+
new_version: black-forest-labs/FLUX.1-dev
|
| 593 |
+
pipeline_tag: token-classification
|
| 594 |
+
library_name: fastai
|
| 595 |
+
tags:
|
| 596 |
+
- medical
|
| 597 |
+
---","{""id"": ""liuxinyu701/6"", ""author"": ""liuxinyu701"", ""sha"": ""a1134495fc2efaf261a0a6f75c02db04f0c92d84"", ""last_modified"": ""2025-04-23 09:22:25+00:00"", ""created_at"": ""2025-04-23 09:22:02+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""fastai"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""fastai"", ""medical"", ""token-classification"", ""ak"", ""dataset:nvidia/Llama-Nemotron-Post-Training-Dataset"", ""base_model:ds4sd/SmolDocling-256M-preview"", ""base_model:finetune:ds4sd/SmolDocling-256M-preview"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""token-classification"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- ds4sd/SmolDocling-256M-preview\ndatasets:\n- nvidia/Llama-Nemotron-Post-Training-Dataset\nlanguage:\n- ak\nlibrary_name: fastai\nlicense: mit\nmetrics:\n- bertscore\npipeline_tag: token-classification\ntags:\n- medical\nnew_version: black-forest-labs/FLUX.1-dev"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-23 09:22:25+00:00"", ""cardData"": ""base_model:\n- ds4sd/SmolDocling-256M-preview\ndatasets:\n- nvidia/Llama-Nemotron-Post-Training-Dataset\nlanguage:\n- ak\nlibrary_name: fastai\nlicense: mit\nmetrics:\n- bertscore\npipeline_tag: token-classification\ntags:\n- medical\nnew_version: black-forest-labs/FLUX.1-dev"", ""transformersInfo"": null, ""_id"": ""6808b13a0086d953de94fc31"", ""modelId"": ""liuxinyu701/6"", ""usedStorage"": 0}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=liuxinyu701/6&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bliuxinyu701%2F6%5D(%2Fliuxinyu701%2F6)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
SmolLM-135M_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
UAE-Large-V1_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Yarn-Mistral-7b-128k_finetunes_20250425_143346.csv_finetunes_20250425_143346.csv
ADDED
|
@@ -0,0 +1,344 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
NousResearch/Yarn-Mistral-7b-128k,"---
|
| 3 |
+
datasets:
|
| 4 |
+
- emozilla/yarn-train-tokenized-16k-mistral
|
| 5 |
+
metrics:
|
| 6 |
+
- perplexity
|
| 7 |
+
library_name: transformers
|
| 8 |
+
license: apache-2.0
|
| 9 |
+
language:
|
| 10 |
+
- en
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
# Model Card: Nous-Yarn-Mistral-7b-128k
|
| 14 |
+
|
| 15 |
+
[Preprint (arXiv)](https://arxiv.org/abs/2309.00071)
|
| 16 |
+
[GitHub](https://github.com/jquesnelle/yarn)
|
| 17 |
+
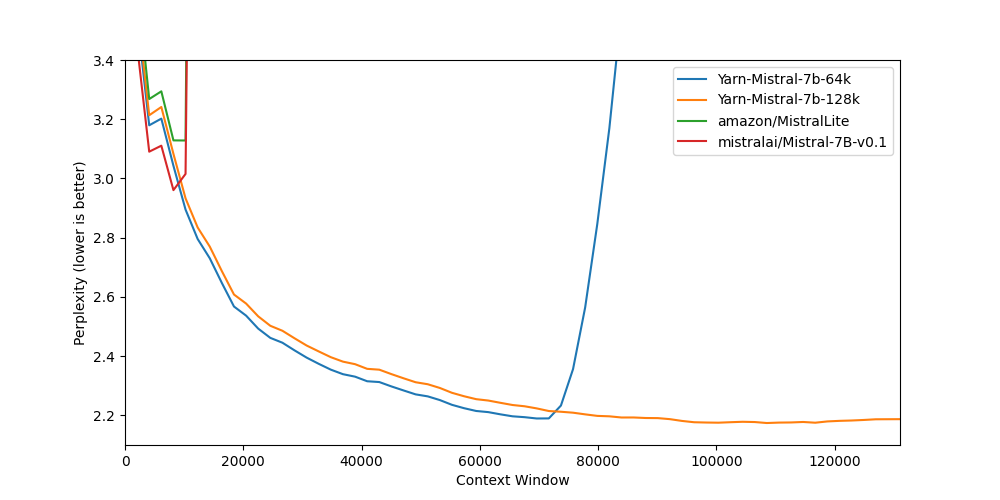
|
| 18 |
+
|
| 19 |
+
## Model Description
|
| 20 |
+
|
| 21 |
+
Nous-Yarn-Mistral-7b-128k is a state-of-the-art language model for long context, further pretrained on long context data for 1500 steps using the YaRN extension method.
|
| 22 |
+
It is an extension of [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) and supports a 128k token context window.
|
| 23 |
+
|
| 24 |
+
To use, pass `trust_remote_code=True` when loading the model, for example
|
| 25 |
+
|
| 26 |
+
```python
|
| 27 |
+
model = AutoModelForCausalLM.from_pretrained(""NousResearch/Yarn-Mistral-7b-128k"",
|
| 28 |
+
use_flash_attention_2=True,
|
| 29 |
+
torch_dtype=torch.bfloat16,
|
| 30 |
+
device_map=""auto"",
|
| 31 |
+
trust_remote_code=True)
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
In addition you will need to use the latest version of `transformers` (until 4.35 comes out)
|
| 35 |
+
```sh
|
| 36 |
+
pip install git+https://github.com/huggingface/transformers
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
## Benchmarks
|
| 40 |
+
|
| 41 |
+
Long context benchmarks:
|
| 42 |
+
| Model | Context Window | 8k PPL | 16k PPL | 32k PPL | 64k PPL | 128k PPL |
|
| 43 |
+
|-------|---------------:|------:|----------:|-----:|-----:|------------:|
|
| 44 |
+
| [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | 8k | 2.96 | - | - | - | - |
|
| 45 |
+
| [Yarn-Mistral-7b-64k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-64k) | 64k | 3.04 | 2.65 | 2.44 | 2.20 | - |
|
| 46 |
+
| [Yarn-Mistral-7b-128k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k) | 128k | 3.08 | 2.68 | 2.47 | 2.24 | 2.19 |
|
| 47 |
+
|
| 48 |
+
Short context benchmarks showing that quality degradation is minimal:
|
| 49 |
+
| Model | Context Window | ARC-c | Hellaswag | MMLU | Truthful QA |
|
| 50 |
+
|-------|---------------:|------:|----------:|-----:|------------:|
|
| 51 |
+
| [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | 8k | 59.98 | 83.31 | 64.16 | 42.15 |
|
| 52 |
+
| [Yarn-Mistral-7b-64k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-64k) | 64k | 59.38 | 81.21 | 61.32 | 42.50 |
|
| 53 |
+
| [Yarn-Mistral-7b-128k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k) | 128k | 58.87 | 80.58 | 60.64 | 42.46 |
|
| 54 |
+
|
| 55 |
+
## Collaborators
|
| 56 |
+
|
| 57 |
+
- [bloc97](https://github.com/bloc97): Methods, paper and evals
|
| 58 |
+
- [@theemozilla](https://twitter.com/theemozilla): Methods, paper, model training, and evals
|
| 59 |
+
- [@EnricoShippole](https://twitter.com/EnricoShippole): Model training
|
| 60 |
+
- [honglu2875](https://github.com/honglu2875): Paper and evals
|
| 61 |
+
|
| 62 |
+
The authors would like to thank LAION AI for their support of compute for this model.
|
| 63 |
+
It was trained on the [JUWELS](https://www.fz-juelich.de/en/ias/jsc/systems/supercomputers/juwels) supercomputer.","{""id"": ""NousResearch/Yarn-Mistral-7b-128k"", ""author"": ""NousResearch"", ""sha"": ""d09f1f8ed437d61c1aff94c1beabee554843dcdd"", ""last_modified"": ""2023-11-02 20:01:56+00:00"", ""created_at"": ""2023-10-31 13:15:14+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 10139, ""downloads_all_time"": null, ""likes"": 572, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""mistral"", ""text-generation"", ""custom_code"", ""en"", ""dataset:emozilla/yarn-train-tokenized-16k-mistral"", ""arxiv:2309.00071"", ""license:apache-2.0"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""datasets:\n- emozilla/yarn-train-tokenized-16k-mistral\nlanguage:\n- en\nlibrary_name: transformers\nlicense: apache-2.0\nmetrics:\n- perplexity"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""architectures"": [""MistralForCausalLM""], ""auto_map"": {""AutoConfig"": ""configuration_mistral.MistralConfig"", ""AutoModelForCausalLM"": ""modeling_mistral_yarn.MistralForCausalLM""}, ""model_type"": ""mistral"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""eos_token"": ""</s>"", ""pad_token"": null, ""unk_token"": ""<unk>"", ""use_default_system_prompt"": true}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_mistral.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_mistral_yarn.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00002.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00002.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""featherless-ai/try-this-model"", ""Sarath0x8f/Document-QA-bot"", ""limcheekin/Yarn-Mistral-7B-128k-GGUF"", ""Darok/Featherless-Feud"", ""JDWebProgrammer/chatbot"", ""emekaboris/try-this-model"", ""realgenius/NousResearch-Yarn-Mistral-7b-128k"", ""ryn-85/NousResearch-Yarn-Mistral-7b-128k"", ""SC999/NV_Nemotron"", ""VKCYBER/NousResearch-Yarn-Mistral-7b-128k"", ""bradarrML/NousResearch-Yarn-Mistral-7b-128k"", ""PeepDaSlan9/NousResearch-Yarn-Mistral-7b-128k"", ""ziqin/NousResearch-Yarn-Mistral-7b-128k2"", ""kichen/NousResearch-Yarn-Mistral-7b-128k"", ""bhandsab/NousResearch-Yarn-Mistral-7b-128k"", ""Li46666/NousResearch-Yarn-Mistral-7b-128k"", ""TogetherAI/NousResearch-Yarn-Mistral-7b-128k"", ""bruc/NousResearch-Yarn-Mistral-7b-128k"", ""intelligenix/NousResearch-Yarn-Mistral-7b-128k"", ""Bellamy66/NousResearch-Yarn-Mistral-7b-128k"", ""Hboris/NousResearch-Yarn-Mistral-7b-128k"", ""harmindersinghnijjar/NousResearch-Yarn-Mistral-7b-128k"", ""schogini/NousResearch-Yarn-Mistral-7b-128k"", ""schogini/test3"", ""hijaukuohno/NousResearch-Yarn-Mistral-7b-128k"", ""JacksonGa/NousResearch-Yarn-Mistral-7b-128k"", ""ziqin/NousResearch-Yarn-Mistral-7b-128k"", ""leckneck/NousResearch-Yarn-Mistral-7b-128k"", ""Risb0v/NousResearch-Yarn-Mistral-7b-128k"", ""JackHoltone/try-this-model"", ""neelumsoft/Document-QA-bot"", ""k11112/try-this-model"", ""sailokesh/Hello_GPT""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-11-02 20:01:56+00:00"", ""cardData"": ""datasets:\n- emozilla/yarn-train-tokenized-16k-mistral\nlanguage:\n- en\nlibrary_name: transformers\nlicense: apache-2.0\nmetrics:\n- perplexity"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""6540fde232dcbb86631c0227"", ""modelId"": ""NousResearch/Yarn-Mistral-7b-128k"", ""usedStorage"": 28967555174}",0,"https://huggingface.co/dustydecapod/unraveled-7b-sft-lora, https://huggingface.co/dustydecapod/unraveled-7b-dpo-lora, https://huggingface.co/dustydecapod/unraveled-7b-a1, https://huggingface.co/Nitral-Archive/Kunocchini-1.2-7b-longtext-broken, https://huggingface.co/Alphatao/a91b1374-b60f-4823-9aad-5f976d07f08e",5,"https://huggingface.co/Yorth/ChatMistral128k, https://huggingface.co/xishanlone/Yarn-Mistral-7b-finetuned, https://huggingface.co/mrbmaryam/misteral-500, https://huggingface.co/mrbmaryam/misteral-100-logsummary, https://huggingface.co/codys12/Mistral-7b-Pathway-128k, https://huggingface.co/codys12/Mistral-7b-Pathway-128k-2, https://huggingface.co/codys12/Mistral-7b-Pathway-128k-4, https://huggingface.co/Shaleen123/mistrallite-medical-qa-2, https://huggingface.co/Shaleen123/nousmistral_128k_medical_qa, https://huggingface.co/Shaleen123/nousmistral_128k_medical_qa_full, https://huggingface.co/Shaleen123/nousmistral_128k_medical_qai, https://huggingface.co/Shaleen123/nousmistral_128k_medical_full, https://huggingface.co/openerotica/mistral-7b-lamia-v0.2, https://huggingface.co/eeeebbb2/4ce6d22d-2cc2-4626-9b60-d1f5d8f3141d, https://huggingface.co/dada22231/4ce6d22d-2cc2-4626-9b60-d1f5d8f3141d, https://huggingface.co/dada22231/19d6e509-260a-448f-9fe0-71b0dc32dfc2, https://huggingface.co/eeeebbb2/19d6e509-260a-448f-9fe0-71b0dc32dfc2, https://huggingface.co/eeeebbb2/1dea215e-69aa-4677-83a9-30354b142b14, https://huggingface.co/dada22231/1dea215e-69aa-4677-83a9-30354b142b14, https://huggingface.co/eeeebbb2/2c7c2cbb-c84e-4a7f-b44d-9eeba1a88832, https://huggingface.co/laquythang/2c7c2cbb-c84e-4a7f-b44d-9eeba1a88832, https://huggingface.co/dada22231/2c7c2cbb-c84e-4a7f-b44d-9eeba1a88832, https://huggingface.co/1-lock/c5aa696e-b261-4d7b-80b4-292d1a774c12, https://huggingface.co/dada22231/c5aa696e-b261-4d7b-80b4-292d1a774c12, https://huggingface.co/eeeebbb2/c5aa696e-b261-4d7b-80b4-292d1a774c12, https://huggingface.co/1-lock/cbb1f466-752c-485e-a59f-e9572b87753a, https://huggingface.co/dada22231/cbb1f466-752c-485e-a59f-e9572b87753a, https://huggingface.co/eeeebbb2/cbb1f466-752c-485e-a59f-e9572b87753a, https://huggingface.co/1-lock/0ffdac01-fb3b-4cff-a490-aee966862d58, https://huggingface.co/eeeebbb2/0ffdac01-fb3b-4cff-a490-aee966862d58, https://huggingface.co/dada22231/0ffdac01-fb3b-4cff-a490-aee966862d58, https://huggingface.co/DeepDream2045/0ffdac01-fb3b-4cff-a490-aee966862d58, https://huggingface.co/diaenra/3a0bf135-4483-4954-a86b-5ec161f4fd6f, https://huggingface.co/DeepDream2045/3a0bf135-4483-4954-a86b-5ec161f4fd6f, https://huggingface.co/vdos/3a0bf135-4483-4954-a86b-5ec161f4fd6f, https://huggingface.co/1-lock/3a0bf135-4483-4954-a86b-5ec161f4fd6f, https://huggingface.co/dada22231/3a0bf135-4483-4954-a86b-5ec161f4fd6f, https://huggingface.co/eeeebbb2/5eb46825-b54e-4c8a-bb73-60acbff95428, https://huggingface.co/DeepDream2045/5eb46825-b54e-4c8a-bb73-60acbff95428, https://huggingface.co/vdos/5eb46825-b54e-4c8a-bb73-60acbff95428, https://huggingface.co/Rodo-Sami/5eb46825-b54e-4c8a-bb73-60acbff95428, https://huggingface.co/bbytxt/5eb46825-b54e-4c8a-bb73-60acbff95428, https://huggingface.co/nblinh63/c1f32187-fe6d-48e7-8500-d8b23a1fa4a4, https://huggingface.co/nhung03/f99c37b8-5770-49ea-be1c-c88bacfc3cf5, https://huggingface.co/vdos/f99c37b8-5770-49ea-be1c-c88bacfc3cf5, https://huggingface.co/nblinh/33d3b6a7-3b08-4875-b054-69e951a0b698, https://huggingface.co/nhung03/33d3b6a7-3b08-4875-b054-69e951a0b698, https://huggingface.co/dzanbek/71075de7-094b-40a8-9370-70e796b03836, https://huggingface.co/dimasik87/7d340111-1a1d-4f5b-ba8c-3745be181c7f, https://huggingface.co/Alpha-Command-Intern/8760f2f0-9900-42e8-a6ae-77734c05cd96, https://huggingface.co/VERSIL91/f836eeb3-4606-4b4f-9640-a8bb76a06856, https://huggingface.co/VERSIL91/5d9c7aa1-6d86-4600-8206-d3b344c95963, https://huggingface.co/VERSIL91/8f458f01-1b18-4575-bb50-6412d63838e5, https://huggingface.co/VERSIL91/271de863-a7f6-4948-a696-68307f03bfbb, https://huggingface.co/fedovtt/b89a3fab-953d-446b-81e9-9adbdb1f2238, https://huggingface.co/VERSIL91/ee95b17f-8fbf-46c7-808f-51067c74af87, https://huggingface.co/VERSIL91/70aa3e8e-dc12-4654-9dc7-a8856ddd0717, https://huggingface.co/VERSIL91/e92b77ba-0846-48ad-859d-4709a193889d, https://huggingface.co/bbytxt/7f355202-7e2e-4737-9cbb-17d05cef0713, https://huggingface.co/dimasik2987/a463009c-ae0d-4a08-9a80-00926e3cfefb, https://huggingface.co/nttx/f85d5102-692f-438a-a95c-daad1d43366b, https://huggingface.co/VERSIL91/771936df-afb8-46d8-b492-6449a6e3bfb4, https://huggingface.co/cunghoctienganh/2d9bef26-5121-4a93-831b-759dc1222cfc, https://huggingface.co/nttx/cc501e30-6022-4b30-ac14-fbf2aca02b7e, https://huggingface.co/thaffggg/cc501e30-6022-4b30-ac14-fbf2aca02b7e, https://huggingface.co/VERSIL91/770e9b0b-c82a-42ab-b985-1cc3be79f64a, https://huggingface.co/tuanna08go/770e9b0b-c82a-42ab-b985-1cc3be79f64a, https://huggingface.co/VERSIL91/69f0e633-9233-41fa-82cd-62eef3c92b94, https://huggingface.co/chauhoang/69f0e633-9233-41fa-82cd-62eef3c92b94, https://huggingface.co/ivangrapher/4af1208a-ce50-4ba1-ac26-89ca6c48b25c, https://huggingface.co/lesso06/4af1208a-ce50-4ba1-ac26-89ca6c48b25c, https://huggingface.co/bbytxt/4af1208a-ce50-4ba1-ac26-89ca6c48b25c, https://huggingface.co/VERSIL91/4af1208a-ce50-4ba1-ac26-89ca6c48b25c, https://huggingface.co/tuanna08go/4bd9f0d7-ead0-4f41-a052-734fa308e920, https://huggingface.co/duyphu/82d20613-483f-75f6-7641-6f3a3dd42aea, https://huggingface.co/VERSIL91/4b28e435-fc17-4b53-9eec-37d06dcfda76, https://huggingface.co/havinash-ai/874f1b55-1b51-4b7e-a128-186d939f303a, https://huggingface.co/lesso03/233137a3-3739-4554-ab23-36f3aac99796, https://huggingface.co/lesso02/07166209-7a69-47ff-b17e-3ba8ba3c380f, https://huggingface.co/tuanna08go/bfb40f1e-a273-cc8f-3425-54157447d677, https://huggingface.co/VERSIL91/10077c3b-5443-4eea-a7ee-3d7091c6efa4, https://huggingface.co/hongngo/4b036ee2-1b8f-4ce0-b1e8-632c9d857caf, https://huggingface.co/havinash-ai/158e14a0-7af7-4b95-82e0-09a1890906b9, https://huggingface.co/tuanna08go/d997cf21-6327-8e8c-4dc8-5aa0556d28a7, https://huggingface.co/VERSIL91/f89c02e7-5cec-428a-81df-593399bb5292, https://huggingface.co/duyphu/06980322-b4ea-0d0b-14f1-d30f1b517b4b, https://huggingface.co/chauhoang/73f3fabd-9900-7f2f-a011-788b4a8a4e7a, https://huggingface.co/thangla01/bba44761-be3e-433f-ac89-abe7a58f02c8, https://huggingface.co/chauhoang/0d8825c1-4c2f-446d-b5d9-674eb35b6ab3, https://huggingface.co/nbninh/cebbdc47-52da-4a51-8767-fc8eee12c09f, https://huggingface.co/sergioalves/b97fadea-da8c-449c-9fba-a8fb645818db, https://huggingface.co/nhoxinh/a4ab1f22-ae51-47cd-8845-ba17cc673ba8, https://huggingface.co/nhung02/67274d88-1656-4507-bcb8-413b94593bfa, https://huggingface.co/havinash-ai/9364427f-10a1-42eb-a8fa-63bcc66f0d65, https://huggingface.co/prxy5606/ce496f76-5788-441a-8068-293ae481375e, https://huggingface.co/thakkkkkk/c71e0c77-e77b-43c3-92b4-8ff2929aac76, https://huggingface.co/lesso05/b69a9bc5-ff12-4cfb-a380-517001da1215, https://huggingface.co/lesso04/d573e283-70e5-43d2-b285-59c49a924313, https://huggingface.co/0x1202/54510b0f-9761-43c4-9538-84c9fd328f2e, https://huggingface.co/dzanbek/45aae6fc-ab5a-4388-ae18-f139ba4d0fe9, https://huggingface.co/demohong/ecf33ef3-1c6b-4c82-997d-8e562035dbed, https://huggingface.co/nblinh63/05013627-414d-4699-979a-3fbad8e0a362, https://huggingface.co/thalllsssss/5654d20c-136f-4866-b6f8-33b136c5d2f9, https://huggingface.co/lesso13/91e2307c-40ff-491d-8e2f-c7125442bff5, https://huggingface.co/chauhoang/f5cdacb6-c0c5-4333-835d-a56a34b48f64, https://huggingface.co/chauhoang/30ea8b1e-e86b-41be-8ead-3ad30f9185d5, https://huggingface.co/ivangrapher/193e6a11-46ee-4b3c-b06e-f0ef1875a14b, https://huggingface.co/nhung03/31f63669-8c6b-4f64-b745-17ecc3de4454, https://huggingface.co/cunghoctienganh/dcb93bcf-d036-4d7f-8491-0481b980afef, https://huggingface.co/nbninh/88576970-d870-4734-a57c-95be35433f55, https://huggingface.co/chauhoang/dcc8c1d1-bb81-dade-08a6-f71099da91bb, https://huggingface.co/sergioalves/cb5bc371-adb3-4162-99ac-bac83ab8fe30, https://huggingface.co/prxy5604/acde2aa1-da86-44e8-82ab-026ae06a22cf, https://huggingface.co/demohong/b862661f-6f25-4d75-b802-005b6aa58427, https://huggingface.co/cunghoctienganh/e11f4b17-0a59-4901-a211-d5bbcce62c24, https://huggingface.co/filipesantoscv11/f4683856-db91-457a-a0a0-66923a7d949a, https://huggingface.co/nblinh/4828ebde-6c91-46b5-ac7c-9ee9b64b373c, https://huggingface.co/hongngo/2c1c831e-fed3-4c54-846a-3d8125d3c839, https://huggingface.co/dzanbek/1faa732e-5ca7-433a-a23d-dbf0394d990f, https://huggingface.co/prxy5604/ed9ebf74-873e-490d-99f4-88ca5d9a4821, https://huggingface.co/tuanna08go/bacef684-33a2-4bef-b29c-ee533d381f26, https://huggingface.co/chauhoang/abad27d3-edac-4dfe-ab3e-c6e9f7bf5197, https://huggingface.co/kokovova/ad8ae14d-e729-43b7-9569-cf39f6b2386a, https://huggingface.co/mrHunghddddd/6f945f76-ca69-4f87-b4b6-67c6c73d6149, https://huggingface.co/thakkkkkk/a530cd42-41e2-47ed-a822-a9f184dcfe31, https://huggingface.co/datlaaaaaaa/47f518fa-0b53-44f0-985a-6b4f0da10500, https://huggingface.co/joboffer/042444c8-8bf7-4d09-8855-cc2a07443e8e, https://huggingface.co/thangla01/d24bad42-2d70-45ca-acab-1176699ab624, https://huggingface.co/kk-aivio/da92bc1f-5e73-4173-97f2-5c21135e2632, https://huggingface.co/duyphu/a6c251b1-a0d4-4526-a47c-b6b54b9bde22, https://huggingface.co/kokovova/cf99fa8b-d16f-4c15-a58a-bb723a8cda39, https://huggingface.co/nttx/298bb42d-4012-404d-9f8f-eb6048249fc1, https://huggingface.co/ajtaltarabukin2022/76ab40f5-5c46-4b75-a0bc-6b102d3fd437, https://huggingface.co/mrHunghddddd/d5009a75-3a93-4137-bc48-56e5bcf8a828, https://huggingface.co/trangtrannnnn/52892534-3c5f-40fd-89de-61e4c746cbaa, https://huggingface.co/mrHungddddh/1d8f7a65-db6b-4220-b38e-0a0fac876d13, https://huggingface.co/nhung03/9ff30e73-0e2b-46da-b2b4-318b02ff0406, https://huggingface.co/nbninh/f943b7fe-faab-4d30-8358-95ba05f5705c, https://huggingface.co/sergioalves/d5c49a01-bc31-40d5-93dd-c43c3227769e, https://huggingface.co/aleegis10/3ce4e187-e2fd-4d0b-a953-39d335ed509f, https://huggingface.co/Aivesa/3ac905c6-b56d-4d35-810a-855512cee15e, https://huggingface.co/thalllsssss/992804ea-dc84-41df-95fb-a4a652d54e24, https://huggingface.co/cunghoctienganh/22f11baf-fab2-497a-9b32-c23e68bb6fdf, https://huggingface.co/nhunglaaaaaaa/6a00ab3f-6749-41f9-97a2-689f35710cfd, https://huggingface.co/nhung03/76525ae0-d4de-48eb-b830-4aa2c9b98537, https://huggingface.co/vertings6/0a301c11-8510-4a89-aaa5-9997e278d52a, https://huggingface.co/nhung01/09b12016-4de8-415e-b542-23da6221d45e, https://huggingface.co/lesso01/fde5de22-97a5-4bfe-9a01-aec6b3c73899, https://huggingface.co/ClarenceDan/ee762543-2342-4a42-bc24-b76bf89d72f6, https://huggingface.co/nttx/9652d64d-a000-4fc3-8d60-f8c656a3850e, https://huggingface.co/0x1202/38773a2e-6cf0-49f4-8cf4-6e34bf6e0a44, https://huggingface.co/0x1202/0b652084-976b-4171-9147-545c4823b511, https://huggingface.co/aleegis10/29e624ab-bd2f-4fd1-8cda-b0607541dd27, https://huggingface.co/prxy5608/b5f89c95-3ff8-4e68-bbfc-92eb3f9d916c, https://huggingface.co/kokovova/18f82232-bedc-4aea-8ee3-0f3a38a70fc3, https://huggingface.co/mrHunghddddd/7f550d89-48b9-4b61-a234-3aea758c63c4, https://huggingface.co/trangtrannnnn/0df8fdfd-bb45-4ec3-8dce-ca012b1fcb38, https://huggingface.co/vermoney/edfc823e-4960-402a-9d15-b2334cc9c541, https://huggingface.co/dimasik2987/4b4a07fe-8d4b-42bc-9da2-94b82ef498f9, https://huggingface.co/lesso04/2a35ee11-e5b5-4b0b-b08d-168779525e1c, https://huggingface.co/thakkkkkk/0ac3a980-9432-4c64-9805-82d82405de05, https://huggingface.co/myhaaaaaaa/89c7dba5-b650-46d4-8cc5-62fc8d80cd18, https://huggingface.co/nhung02/3fb51f48-e6e8-47c6-b330-29ec61639cd1, https://huggingface.co/tuanna08go/fd51f0b4-3619-4421-86a8-479621440cb0, https://huggingface.co/lesso17/51831be6-c9e4-4d01-bf19-ffe768726467, https://huggingface.co/nhunglaaaaaaa/aedd1742-0ec5-4d24-bc8b-3cb237ec53bb, https://huggingface.co/prxy5605/4234cbbc-7d58-41fc-9dcd-11e61cfe0c16, https://huggingface.co/mrHunghddddd/0bfed24f-0502-4868-910d-8d1c3d81c4f7, https://huggingface.co/hongngo/cf7ca3f6-c50e-426c-a6d2-c8851b7f7904, https://huggingface.co/laquythang/80211eee-f0bb-4b5d-abf2-edad88a75ab3, https://huggingface.co/tuanna08go/11aa8c68-e283-4ef6-a298-be9fd84ecdf7, https://huggingface.co/nhunglaaaaaaa/6989f3aa-2b1e-49b1-acc7-40795eb271e7, https://huggingface.co/lesso09/344aae17-8f2a-4d84-8922-406e07dd82bf, https://huggingface.co/lesso06/f9c54df4-fcfe-4f01-b216-59537b091b8c, https://huggingface.co/daniel40/0a08a1f4-9596-47ab-be0d-a8a5ba12cde8, https://huggingface.co/mrhunghd/41c28e2c-0cff-4303-957b-f763c2764195, https://huggingface.co/thalllsssss/11624806-f966-42dd-ac76-209541255c05, https://huggingface.co/prxy5606/b1ba74b4-b098-4fba-8013-414a2ec3deb2, https://huggingface.co/duyphu/b373ad09-9cab-4a56-b398-870664f5384d, https://huggingface.co/lesso16/8a6496a8-9041-433a-8697-e9ab66b8c9f3, https://huggingface.co/kokovova/ec62609a-b24a-43ce-90f5-8bb74c81b826, https://huggingface.co/kk-aivio/dd104cd7-7b24-4f93-884f-3e516660a1ec, https://huggingface.co/chauhoang/dd722a00-e3df-423b-b84f-9d9d41fd03b5, https://huggingface.co/vmpsergio/444ea8e2-879b-4a96-a165-93a22dadcfe1, https://huggingface.co/aleegis09/a1f0bf08-c29a-41bc-9220-affbd0c4cadd, https://huggingface.co/robiual-awal/38659625-f1ff-44a5-ac8a-90bc2c08a907, https://huggingface.co/lesso15/bd4ba09f-3628-4741-93b3-06a475e3758d, https://huggingface.co/JacksonBrune/db47e4c0-cec7-46c8-9e99-114552080598, https://huggingface.co/prxy5608/2d62c95b-b5b7-4cff-b313-4fd6817fc10c, https://huggingface.co/sergioalves/591bc345-d926-4863-ba0d-fa3094334212, https://huggingface.co/infogeo/c52aef5b-e8e5-4af4-b6e7-9b623ff9403c, https://huggingface.co/robiual-awal/8fecbd4a-3cb4-4e10-96da-54e457c7a8f9, https://huggingface.co/daniel40/e9c7a482-c721-4a32-b27c-dfe64225e9b5, https://huggingface.co/prxy5605/981de68c-8e87-473e-962f-56110deecee5, https://huggingface.co/fedovtt/daebeeb1-e9d0-45fa-9a40-ef360ed3b699, https://huggingface.co/ClarenceDan/8e6e00e7-e5f2-4df3-856c-be0c4995ceef, https://huggingface.co/ClarenceDan/ef40f1bf-ad6e-4b5c-a188-7f8c76d6991e, https://huggingface.co/tuanna08go/cdefd8e3-48f1-4dc3-8bb7-3d8126ab5c3e, https://huggingface.co/duyphu/3207f062-dabf-4c6d-a787-260a00d67134, https://huggingface.co/cvoffer/46e8d4c9-682e-4a6f-b008-d8c016d6061c, https://huggingface.co/dimasik1987/c0f2fe3c-8d6d-4391-bb5c-13d8dbd23854, https://huggingface.co/lesso16/3403cb0a-afbb-4fed-93b7-cc950245ec9c, https://huggingface.co/JacksonBrune/4ee7ac79-f226-4d84-b38a-fc4495cdfb15, https://huggingface.co/dimasik1987/17b0a914-a867-4fdf-9f23-b30b63d5c5be, https://huggingface.co/kk-aivio/a31317fd-eda1-45ac-a021-4a5740c0e1e5, https://huggingface.co/prxy5604/f993da58-3631-4086-a986-0c08510aae7b, https://huggingface.co/chauhoang/0536300e-fd95-4a8a-ab92-7fa76ab0ae5b, https://huggingface.co/prxy5605/5a560af8-c547-417a-99ea-eccfb62a7d4b, https://huggingface.co/prxy5607/bcc24a39-0c77-4a8a-be1e-236284cf42e5, https://huggingface.co/aleegis10/c92f3cbc-704a-43bf-a1cf-4c08533fa0cd, https://huggingface.co/prxy5608/ea79ccf6-48bf-4045-9040-448baaebc5bd, https://huggingface.co/prxy5604/5e431d85-fe97-4246-a462-763743f55e83, https://huggingface.co/ivangrapher/11031ac8-8d03-437a-9853-b63de2765100, https://huggingface.co/lesso11/883bf879-f6bc-4098-83a4-ca1597cb56df, https://huggingface.co/great0001/5c60bc32-dfd6-47b4-a126-90849066cc87, https://huggingface.co/great0001/28bc450b-afdc-47c8-b615-650b703d91d2, https://huggingface.co/duyphu/02428a4b-60ec-4f62-ba81-1c46f99962ea, https://huggingface.co/lesso08/9769c5df-7858-437e-bb65-b4b3686ad21a, https://huggingface.co/robiulawaldev/fc68744a-dc32-404d-8547-8ad21a5eacd5, https://huggingface.co/daniel40/e2f1684c-464c-4dee-b698-08ba6243be57, https://huggingface.co/havinash-ai/de5599dd-765d-4873-8bc1-ab7b67b4d954, https://huggingface.co/lesso09/58bf2eef-085b-4529-be7d-4ab58745fecc, https://huggingface.co/lesso01/25241cfe-2462-42c6-803f-93306b9ae111, https://huggingface.co/shibajustfor/a690348b-9d15-46c5-92f0-37a6633c8cd5, https://huggingface.co/lesso05/3d6c2bef-5196-4e10-a18c-e8a671e5592b, https://huggingface.co/havinash-ai/04d3c6eb-b8cd-4219-be2d-b4d5b8f18e47, https://huggingface.co/prxy5604/718a3229-73ba-4980-9425-ffb241853776, https://huggingface.co/lesso17/508f660c-12f4-4089-9dde-fe35f712951b, https://huggingface.co/shibajustfor/af3c529b-0bda-4a87-a3aa-f1f8497ef553, https://huggingface.co/lesso12/88801676-1167-4bba-9701-ae4ea2f02008, https://huggingface.co/robiulawaldev/c2b9832c-7f1f-49f7-8593-e0b85a1f902f, https://huggingface.co/adammandic87/cd1c7f2c-1a8d-40d0-9d77-30d633a1c5a2, https://huggingface.co/baby-dev/26612dc7-1f71-4054-8593-4d0debb48528, https://huggingface.co/daniel40/75886df6-0dee-44cf-a2a1-b5197d0b55ef, https://huggingface.co/baby-dev/ea97ea81-4e0b-45ba-9258-976a240c75a7, https://huggingface.co/baby-dev/ee9e4270-6e49-4849-b82c-e093f3f8f91e, https://huggingface.co/prxy5604/3f62ddfe-6a37-4444-b41d-01f4dd20cb8b, https://huggingface.co/baby-dev/06260df1-8d5f-4438-abfa-b35ff90eb2f3, https://huggingface.co/cilooor/2cb730ae-3a65-489a-b4eb-5f6a3e363c56, https://huggingface.co/lesso01/a72da487-f41d-4f09-a703-5bab3ad6c5ea, https://huggingface.co/robiulawaldev/f51fc536-ec44-4ee6-86aa-63f55f95a32d, https://huggingface.co/Best000/d6ef5ef4-583d-4099-94b0-9e06ea8ebd83, https://huggingface.co/lesso10/38cac83b-96f1-4d90-b4d5-c34c58ba5cfd, https://huggingface.co/havinash-ai/9b797226-7145-4136-93e8-a54e4d40f964, https://huggingface.co/robiulawaldev/5917997a-3b70-4b3d-9960-6615b0d995f9, https://huggingface.co/lesso17/6b390319-bab5-44be-943f-aa0dc3786961, https://huggingface.co/aleegis12/35493a02-5126-4b7f-91b7-d8871a341d0e, https://huggingface.co/lesso02/fe6121c5-10ea-4fed-b951-b5de3475ed1e, https://huggingface.co/aleegis12/58c6f737-4f6f-4799-93b0-b0649e76c322, https://huggingface.co/robiulawaldev/9970cf47-6dce-400b-a000-44ff1cccb491, https://huggingface.co/adammandic87/21cb04a5-3d13-4602-9789-69b16ae1e600, https://huggingface.co/robiual-awal/49d8bce3-7595-4775-abe3-3e5bad9cca94, https://huggingface.co/Best000/c35e532b-b7af-4878-bc4d-5e040418cbd5, https://huggingface.co/daniel40/96011ee3-48dc-4faf-bdd5-e3d9dfbf34f6, https://huggingface.co/adammandic87/b6839351-6117-4fc4-a71b-36e4e7f939cf, https://huggingface.co/robiulawaldev/515a1e0b-f80b-4231-b5ce-9676ac23b041, https://huggingface.co/shibajustfor/9f972555-a6f1-4612-a66e-32411fddee31, https://huggingface.co/havinash-ai/24827954-6ddd-4643-be09-7a4274d99af4, https://huggingface.co/robiulawaldev/b9dc2b35-928b-46aa-b46a-314a2b196a96, https://huggingface.co/adammandic87/eb6979e6-fa66-43a1-a422-43d348a52bab, https://huggingface.co/havinash-ai/957e24e1-c430-480c-9fc7-fd05fc81db31, https://huggingface.co/lesso/70f5ea81-56a7-4e34-9650-4bf1396a028e, https://huggingface.co/daniel40/f58047a9-8efb-45ce-a110-788eee8ae7cb, https://huggingface.co/lesso/11d552f9-f055-4a51-acfd-23e825d55757, https://huggingface.co/lesso/b55601b3-6885-44f3-aef3-85f4a63cdfae, https://huggingface.co/lesso/8e1c0543-8bf8-4de3-aedb-cd41f2e1f01e, https://huggingface.co/daniel40/808e0612-0f02-4f38-9adf-4549212f9fb4, https://huggingface.co/lesso/ba4b6b81-b218-46c9-a712-bf5912442432, https://huggingface.co/lesso/13d81c38-3ccf-4cd0-a680-62f3c8bf3d71, https://huggingface.co/cilooor/4fea0006-2355-4d84-8016-6fe7357801f3, https://huggingface.co/Best000/951b3595-639b-44af-b0b4-dfb8eef72989, https://huggingface.co/robiulawaldev/88374eba-2d62-47f8-9f63-2657719284eb, https://huggingface.co/shibajustfor/f64a629b-925b-4d9a-b89d-c755f66f7127, https://huggingface.co/robiulawaldev/c9932886-e440-4e7b-8f17-afe72cc16b10, https://huggingface.co/daniel40/e92e73c2-4192-479d-8dd6-08df12f89aa5, https://huggingface.co/lesso/3b9dd9df-231d-4f0c-8f91-5dcc06b68653, https://huggingface.co/abaddon182/d98b7989-907f-4509-beca-ea59427efec9, https://huggingface.co/cimol/37d9ad71-75ff-42f3-95ae-10ece10c325c, https://huggingface.co/mrferr3t/91571574-8b09-48f0-91a1-30ef8b351462, https://huggingface.co/mrferr3t/0638f241-005f-4e9c-83d7-3190ffb2520f, https://huggingface.co/lesso09/68ed5539-cf7d-48b5-99ca-180cd43d546b, https://huggingface.co/daniel40/0e9bdb7f-9568-4961-95bf-82f3481df390, https://huggingface.co/daniel40/adf8f84c-6b4d-4b4c-9321-42ba4bdea166, https://huggingface.co/lesso03/57495c52-6fe4-4495-96c8-d66a7c6b2f20, https://huggingface.co/lesso04/13f27876-66d6-4a00-a75e-419b37426b93, https://huggingface.co/tuantmdev/685940b0-6137-4dea-873e-f54936302b99, https://huggingface.co/Romain-XV/8ce2d2b2-df8e-49c2-991a-52d0e53001e8, https://huggingface.co/lesso10/5061a162-8467-4be0-85b7-d25a59052c89, https://huggingface.co/lesso02/0ee4622d-03da-45da-9673-593d4b80d202, https://huggingface.co/daniel40/d71796aa-aad8-430b-a505-3e744e207c58, https://huggingface.co/lesso16/42634c65-8919-4860-a2f5-59ee089a7350, https://huggingface.co/lesso12/9e468510-d87b-40a1-98d2-bd8a4ae92c3f, https://huggingface.co/lesso07/879c4381-fa71-48d1-b161-9dc77df0e5f8, https://huggingface.co/lesso17/4d6e571b-31ed-40e3-8bcb-39534d93d9eb, https://huggingface.co/lesso06/635f8758-9726-4773-a4aa-fc6c65d5c541, https://huggingface.co/lesso04/6b06da8d-889f-4c51-837d-35f633f20b24, https://huggingface.co/tuantmdev/23168cb6-d6ed-450f-ad61-e2d41152acb0, https://huggingface.co/trenden/0a5f8c35-a43b-45cf-9635-e3eb16b06155, https://huggingface.co/shibajustfor/5a67588d-8c19-4508-a315-f804ea005cef, https://huggingface.co/romainnn/0291b31e-c29d-4447-9085-6c8c73860149, https://huggingface.co/samoline/ea23503c-3030-4bf2-a6e0-3dc60e740ec7, https://huggingface.co/lesso13/25a03dfb-e1a7-4cc7-b1be-b2abfde71185, https://huggingface.co/Romain-XV/ff1365cc-4661-4224-a4cd-7d7f5781fc86, https://huggingface.co/lesso12/6035f9dc-356b-4106-8ff6-29e39af82047, https://huggingface.co/lesso03/343ddc57-13fe-47f2-b2e5-e07e22b97afa, https://huggingface.co/Alphatao/45822166-6d97-4b65-bb48-c9b6067f220d, https://huggingface.co/lesso11/39b4169b-a411-43ff-864d-3a134ba5fcf1, https://huggingface.co/lesso13/8ed84472-3d75-4840-a2de-c7b8c763aafb, https://huggingface.co/lesso04/07236733-cf62-42cb-9f6a-f5b38e681f6f, https://huggingface.co/lesso07/8e2ab3db-3c60-4c9d-935c-3f8e0ab7c154, https://huggingface.co/fedovtt/748e72ab-d705-4782-9859-b4740c95eeed, https://huggingface.co/dzanbek/cb751569-1861-407f-945e-06a115915807, https://huggingface.co/vmpsergio/3aac1da8-4740-4e80-af8a-c438a4677455",313,"https://huggingface.co/TheBloke/Yarn-Mistral-7B-128k-AWQ, https://huggingface.co/TheBloke/Yarn-Mistral-7B-128k-GGUF, https://huggingface.co/TheBloke/Yarn-Mistral-7B-128k-GPTQ, https://huggingface.co/Lewdiculous/Kunocchini-1.2-7b-longtext-GGUF-Imatrix, https://huggingface.co/mradermacher/Yarn-Mistral-7b-128k-GGUF, https://huggingface.co/mradermacher/Yarn-Mistral-7b-128k-i1-GGUF, https://huggingface.co/PrunaAI/NousResearch-Yarn-Mistral-7b-128k-GGUF-smashed",7,"https://huggingface.co/Aryanne/YarnLake-Swap-7B, https://huggingface.co/InnerI/InnerILLM-OpenPipe-Nous-Yarn-Mistral-optimized-1228-7B-slerp, https://huggingface.co/InnerI/InnerILLM-0x00d0-7B-slerp, https://huggingface.co/bartowski/Yarncules-7b-128k-exl2, https://huggingface.co/seyf1elislam/WestKunai-Hermes-long-128k-test-7b, https://huggingface.co/mvpmaster/openchat-3.5-0106-128k-DPO-fixed-32000, https://huggingface.co/Kukedlc/NeuralContext-7b-v1, https://huggingface.co/Kukedlc/NeuralContext-7b-v2, https://huggingface.co/ehristoforu/0001, https://huggingface.co/ehristoforu/Gistral-16B, https://huggingface.co/ehristoforu/Gistral-16B-Q4_K_M-GGUF, https://huggingface.co/ehristoforu/0000mxs, https://huggingface.co/ehristoforu/flm-m01, https://huggingface.co/ehristoforu/pm-v0.1, https://huggingface.co/ehristoforu/pm-v0.2",15,"Darok/Featherless-Feud, JDWebProgrammer/chatbot, PeepDaSlan9/NousResearch-Yarn-Mistral-7b-128k, SC999/NV_Nemotron, Sarath0x8f/Document-QA-bot, VKCYBER/NousResearch-Yarn-Mistral-7b-128k, emekaboris/try-this-model, featherless-ai/try-this-model, huggingface/InferenceSupport/discussions/new?title=NousResearch/Yarn-Mistral-7b-128k&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BNousResearch%2FYarn-Mistral-7b-128k%5D(%2FNousResearch%2FYarn-Mistral-7b-128k)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, limcheekin/Yarn-Mistral-7B-128k-GGUF, neelumsoft/Document-QA-bot, realgenius/NousResearch-Yarn-Mistral-7b-128k, ryn-85/NousResearch-Yarn-Mistral-7b-128k",13
|
| 64 |
+
dustydecapod/unraveled-7b-sft-lora,"---
|
| 65 |
+
license: apache-2.0
|
| 66 |
+
base_model: NousResearch/Yarn-Mistral-7b-128k
|
| 67 |
+
tags:
|
| 68 |
+
- generated_from_trainer
|
| 69 |
+
model-index:
|
| 70 |
+
- name: unraveled-7b-sft-lora
|
| 71 |
+
results: []
|
| 72 |
+
---
|
| 73 |
+
|
| 74 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 75 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 76 |
+
|
| 77 |
+
# unraveled-7b-sft-lora
|
| 78 |
+
|
| 79 |
+
This model is a fine-tuned version of [NousResearch/Yarn-Mistral-7b-128k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k) on an unknown dataset.
|
| 80 |
+
It achieves the following results on the evaluation set:
|
| 81 |
+
- Loss: 1.0261
|
| 82 |
+
|
| 83 |
+
## Model description
|
| 84 |
+
|
| 85 |
+
More information needed
|
| 86 |
+
|
| 87 |
+
## Intended uses & limitations
|
| 88 |
+
|
| 89 |
+
More information needed
|
| 90 |
+
|
| 91 |
+
## Training and evaluation data
|
| 92 |
+
|
| 93 |
+
More information needed
|
| 94 |
+
|
| 95 |
+
## Training procedure
|
| 96 |
+
|
| 97 |
+
### Training hyperparameters
|
| 98 |
+
|
| 99 |
+
The following hyperparameters were used during training:
|
| 100 |
+
- learning_rate: 2e-05
|
| 101 |
+
- train_batch_size: 4
|
| 102 |
+
- eval_batch_size: 8
|
| 103 |
+
- seed: 42
|
| 104 |
+
- distributed_type: multi-GPU
|
| 105 |
+
- num_devices: 4
|
| 106 |
+
- gradient_accumulation_steps: 128
|
| 107 |
+
- total_train_batch_size: 2048
|
| 108 |
+
- total_eval_batch_size: 32
|
| 109 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 110 |
+
- lr_scheduler_type: cosine
|
| 111 |
+
- num_epochs: 1
|
| 112 |
+
|
| 113 |
+
### Training results
|
| 114 |
+
|
| 115 |
+
| Training Loss | Epoch | Step | Validation Loss |
|
| 116 |
+
|:-------------:|:-----:|:----:|:---------------:|
|
| 117 |
+
| 1.0242 | 0.67 | 68 | 1.0262 |
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
### Framework versions
|
| 121 |
+
|
| 122 |
+
- Transformers 4.35.0
|
| 123 |
+
- Pytorch 2.1.0+cu118
|
| 124 |
+
- Datasets 2.14.6
|
| 125 |
+
- Tokenizers 0.14.1
|
| 126 |
+
","{""id"": ""dustydecapod/unraveled-7b-sft-lora"", ""author"": ""dustydecapod"", ""sha"": ""425fbe42c81e962df3cbacb794e5fcb5f3253f89"", ""last_modified"": ""2023-11-22 09:14:14+00:00"", ""created_at"": ""2023-11-21 09:53:31+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 1, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""tensorboard"", ""safetensors"", ""mistral"", ""text-generation"", ""generated_from_trainer"", ""conversational"", ""custom_code"", ""base_model:NousResearch/Yarn-Mistral-7b-128k"", ""base_model:finetune:NousResearch/Yarn-Mistral-7b-128k"", ""license:apache-2.0"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: NousResearch/Yarn-Mistral-7b-128k\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: unraveled-7b-sft-lora\n results: []"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": [{""name"": ""unraveled-7b-sft-lora"", ""results"": []}], ""config"": {""architectures"": [""MistralForCausalLM""], ""auto_map"": {""AutoConfig"": ""NousResearch/Yarn-Mistral-7b-128k--configuration_mistral.MistralConfig"", ""AutoModelForCausalLM"": ""NousResearch/Yarn-Mistral-7b-128k--modeling_mistral_yarn.MistralForCausalLM""}, ""model_type"": ""mistral"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""chat_template"": ""{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}"", ""eos_token"": ""</s>"", ""pad_token"": ""</s>"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": true}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='all_results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval_results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='runs/Nov22_06-20-04_401fa5a8015d/events.out.tfevents.1700634336.401fa5a8015d.8816.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='runs/Nov22_06-30-36_401fa5a8015d/events.out.tfevents.1700634659.401fa5a8015d.9073.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='runs/Nov22_06-30-36_401fa5a8015d/events.out.tfevents.1700644438.401fa5a8015d.9073.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='train_results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='trainer_state.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-11-22 09:14:14+00:00"", ""cardData"": ""base_model: NousResearch/Yarn-Mistral-7b-128k\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: unraveled-7b-sft-lora\n results: []"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""655c7e1b2d1922b228a382ea"", ""modelId"": ""dustydecapod/unraveled-7b-sft-lora"", ""usedStorage"": 218155852}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=dustydecapod/unraveled-7b-sft-lora&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bdustydecapod%2Funraveled-7b-sft-lora%5D(%2Fdustydecapod%2Funraveled-7b-sft-lora)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 127 |
+
dustydecapod/unraveled-7b-dpo-lora,"---
|
| 128 |
+
license: apache-2.0
|
| 129 |
+
base_model: NousResearch/Yarn-Mistral-7b-128k
|
| 130 |
+
tags:
|
| 131 |
+
- generated_from_trainer
|
| 132 |
+
model-index:
|
| 133 |
+
- name: unraveled-7b-dpo-lora
|
| 134 |
+
results: []
|
| 135 |
+
---
|
| 136 |
+
|
| 137 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 138 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 139 |
+
|
| 140 |
+
# unraveled-7b-dpo-lora
|
| 141 |
+
|
| 142 |
+
This model is a fine-tuned version of [NousResearch/Yarn-Mistral-7b-128k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k) on the None dataset.
|
| 143 |
+
It achieves the following results on the evaluation set:
|
| 144 |
+
- Loss: 0.5895
|
| 145 |
+
- Rewards/chosen: 0.1439
|
| 146 |
+
- Rewards/rejected: -0.1833
|
| 147 |
+
- Rewards/accuracies: 0.6880
|
| 148 |
+
- Rewards/margins: 0.3272
|
| 149 |
+
- Logps/rejected: -221.8329
|
| 150 |
+
- Logps/chosen: -266.1414
|
| 151 |
+
- Logits/rejected: -1.9675
|
| 152 |
+
- Logits/chosen: -2.0859
|
| 153 |
+
|
| 154 |
+
## Model description
|
| 155 |
+
|
| 156 |
+
More information needed
|
| 157 |
+
|
| 158 |
+
## Intended uses & limitations
|
| 159 |
+
|
| 160 |
+
More information needed
|
| 161 |
+
|
| 162 |
+
## Training and evaluation data
|
| 163 |
+
|
| 164 |
+
More information needed
|
| 165 |
+
|
| 166 |
+
## Training procedure
|
| 167 |
+
|
| 168 |
+
### Training hyperparameters
|
| 169 |
+
|
| 170 |
+
The following hyperparameters were used during training:
|
| 171 |
+
- learning_rate: 5e-07
|
| 172 |
+
- train_batch_size: 2
|
| 173 |
+
- eval_batch_size: 4
|
| 174 |
+
- seed: 42
|
| 175 |
+
- distributed_type: multi-GPU
|
| 176 |
+
- num_devices: 4
|
| 177 |
+
- gradient_accumulation_steps: 32
|
| 178 |
+
- total_train_batch_size: 256
|
| 179 |
+
- total_eval_batch_size: 16
|
| 180 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 181 |
+
- lr_scheduler_type: linear
|
| 182 |
+
- lr_scheduler_warmup_ratio: 0.1
|
| 183 |
+
- num_epochs: 3
|
| 184 |
+
|
| 185 |
+
### Training results
|
| 186 |
+
|
| 187 |
+
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|
| 188 |
+
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
|
| 189 |
+
| 0.6313 | 1.0 | 242 | 0.6318 | 0.1228 | -0.0304 | 0.6600 | 0.1532 | -220.3036 | -266.3521 | -1.9863 | -2.1062 |
|
| 190 |
+
| 0.6013 | 2.0 | 484 | 0.5983 | 0.1484 | -0.1334 | 0.6760 | 0.2819 | -221.3338 | -266.0959 | -1.9723 | -2.0914 |
|
| 191 |
+
| 0.5889 | 3.0 | 726 | 0.5895 | 0.1439 | -0.1833 | 0.6880 | 0.3272 | -221.8329 | -266.1414 | -1.9675 | -2.0859 |
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
### Framework versions
|
| 195 |
+
|
| 196 |
+
- Transformers 4.35.0
|
| 197 |
+
- Pytorch 2.1.0+cu118
|
| 198 |
+
- Datasets 2.14.6
|
| 199 |
+
- Tokenizers 0.14.1
|
| 200 |
+
","{""id"": ""dustydecapod/unraveled-7b-dpo-lora"", ""author"": ""dustydecapod"", ""sha"": ""0463ac7751cac7a16d4d22de6faa04c48ded3fb8"", ""last_modified"": ""2023-11-22 15:14:30+00:00"", ""created_at"": ""2023-11-22 09:31:42+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 1, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""tensorboard"", ""safetensors"", ""mistral"", ""text-generation"", ""generated_from_trainer"", ""conversational"", ""custom_code"", ""base_model:NousResearch/Yarn-Mistral-7b-128k"", ""base_model:finetune:NousResearch/Yarn-Mistral-7b-128k"", ""license:apache-2.0"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: NousResearch/Yarn-Mistral-7b-128k\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: unraveled-7b-dpo-lora\n results: []"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": [{""name"": ""unraveled-7b-dpo-lora"", ""results"": []}], ""config"": {""architectures"": [""MistralForCausalLM""], ""auto_map"": {""AutoConfig"": ""NousResearch/Yarn-Mistral-7b-128k--configuration_mistral.MistralConfig"", ""AutoModelForCausalLM"": ""NousResearch/Yarn-Mistral-7b-128k--modeling_mistral_yarn.MistralForCausalLM""}, ""model_type"": ""mistral"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""chat_template"": ""{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}"", ""eos_token"": ""</s>"", ""pad_token"": ""</s>"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": true}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='all_results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='eval_results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='runs/Nov22_09-29-27_401fa5a8015d/events.out.tfevents.1700645508.401fa5a8015d.9788.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='runs/Nov22_09-29-27_401fa5a8015d/events.out.tfevents.1700666050.401fa5a8015d.9788.1', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='train_results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='trainer_state.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-11-22 15:14:30+00:00"", ""cardData"": ""base_model: NousResearch/Yarn-Mistral-7b-128k\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: unraveled-7b-dpo-lora\n results: []"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""655dca7e68c6dd1321499779"", ""modelId"": ""dustydecapod/unraveled-7b-dpo-lora"", ""usedStorage"": 218197580}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=dustydecapod/unraveled-7b-dpo-lora&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bdustydecapod%2Funraveled-7b-dpo-lora%5D(%2Fdustydecapod%2Funraveled-7b-dpo-lora)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 201 |
+
dustydecapod/unraveled-7b-a1,"---
|
| 202 |
+
license: apache-2.0
|
| 203 |
+
base_model: NousResearch/Yarn-Mistral-7b-128k
|
| 204 |
+
tags:
|
| 205 |
+
- generated_from_trainer
|
| 206 |
+
model-index:
|
| 207 |
+
- name: unraveled-7b-dpo-lora
|
| 208 |
+
results: []
|
| 209 |
+
---
|
| 210 |
+
|
| 211 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 212 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 213 |
+
|
| 214 |
+
# unraveled-7b-dpo-lora
|
| 215 |
+
|
| 216 |
+
This model is a fine-tuned version of [NousResearch/Yarn-Mistral-7b-128k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k), following the Zephyr alignment protocol.
|
| 217 |
+
It achieves the following results on the evaluation set:
|
| 218 |
+
- Loss: 0.5895
|
| 219 |
+
- Rewards/chosen: 0.1439
|
| 220 |
+
- Rewards/rejected: -0.1833
|
| 221 |
+
- Rewards/accuracies: 0.6880
|
| 222 |
+
- Rewards/margins: 0.3272
|
| 223 |
+
- Logps/rejected: -221.8329
|
| 224 |
+
- Logps/chosen: -266.1414
|
| 225 |
+
- Logits/rejected: -1.9675
|
| 226 |
+
- Logits/chosen: -2.0859
|
| 227 |
+
|
| 228 |
+
## Model description
|
| 229 |
+
|
| 230 |
+
More information needed
|
| 231 |
+
|
| 232 |
+
## Intended uses & limitations
|
| 233 |
+
|
| 234 |
+
More information needed
|
| 235 |
+
|
| 236 |
+
## Training and evaluation data
|
| 237 |
+
|
| 238 |
+
More information needed
|
| 239 |
+
|
| 240 |
+
## Training procedure
|
| 241 |
+
|
| 242 |
+
### Training hyperparameters
|
| 243 |
+
|
| 244 |
+
The following hyperparameters were used during training:
|
| 245 |
+
- learning_rate: 5e-07
|
| 246 |
+
- train_batch_size: 2
|
| 247 |
+
- eval_batch_size: 4
|
| 248 |
+
- seed: 42
|
| 249 |
+
- distributed_type: multi-GPU
|
| 250 |
+
- num_devices: 4
|
| 251 |
+
- gradient_accumulation_steps: 32
|
| 252 |
+
- total_train_batch_size: 256
|
| 253 |
+
- total_eval_batch_size: 16
|
| 254 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 255 |
+
- lr_scheduler_type: linear
|
| 256 |
+
- lr_scheduler_warmup_ratio: 0.1
|
| 257 |
+
- num_epochs: 3
|
| 258 |
+
|
| 259 |
+
### Training results
|
| 260 |
+
|
| 261 |
+
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|
| 262 |
+
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
|
| 263 |
+
| 0.6313 | 1.0 | 242 | 0.6318 | 0.1228 | -0.0304 | 0.6600 | 0.1532 | -220.3036 | -266.3521 | -1.9863 | -2.1062 |
|
| 264 |
+
| 0.6013 | 2.0 | 484 | 0.5983 | 0.1484 | -0.1334 | 0.6760 | 0.2819 | -221.3338 | -266.0959 | -1.9723 | -2.0914 |
|
| 265 |
+
| 0.5889 | 3.0 | 726 | 0.5895 | 0.1439 | -0.1833 | 0.6880 | 0.3272 | -221.8329 | -266.1414 | -1.9675 | -2.0859 |
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
### Framework versions
|
| 269 |
+
|
| 270 |
+
- Transformers 4.35.0
|
| 271 |
+
- Pytorch 2.1.0+cu118
|
| 272 |
+
- Datasets 2.14.6
|
| 273 |
+
- Tokenizers 0.14.1
|
| 274 |
+
","{""id"": ""dustydecapod/unraveled-7b-a1"", ""author"": ""dustydecapod"", ""sha"": ""fac05775fa8121b58cda8031b7001323bd43983d"", ""last_modified"": ""2023-11-22 17:41:31+00:00"", ""created_at"": ""2023-11-22 15:25:19+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 72, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""safetensors"", ""mistral"", ""text-generation"", ""generated_from_trainer"", ""custom_code"", ""base_model:NousResearch/Yarn-Mistral-7b-128k"", ""base_model:finetune:NousResearch/Yarn-Mistral-7b-128k"", ""license:apache-2.0"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: NousResearch/Yarn-Mistral-7b-128k\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: unraveled-7b-dpo-lora\n results: []"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": [{""name"": ""unraveled-7b-dpo-lora"", ""results"": []}], ""config"": {""architectures"": [""MistralForCausalLM""], ""auto_map"": {""AutoConfig"": ""NousResearch/Yarn-Mistral-7b-128k--configuration_mistral.MistralConfig"", ""AutoModelForCausalLM"": ""NousResearch/Yarn-Mistral-7b-128k--modeling_mistral_yarn.MistralForCausalLM""}, ""model_type"": ""mistral"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""eos_token"": ""</s>"", ""pad_token"": null, ""unk_token"": ""<unk>"", ""use_default_system_prompt"": true}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00006.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00006.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00006.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00006.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00006.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00006.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F32"": 7241732096}, ""total"": 7241732096}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-11-22 17:41:31+00:00"", ""cardData"": ""base_model: NousResearch/Yarn-Mistral-7b-128k\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: unraveled-7b-dpo-lora\n results: []"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""655e1d5f759563867174499c"", ""modelId"": ""dustydecapod/unraveled-7b-a1"", ""usedStorage"": 28966962016}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=dustydecapod/unraveled-7b-a1&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bdustydecapod%2Funraveled-7b-a1%5D(%2Fdustydecapod%2Funraveled-7b-a1)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 275 |
+
https://huggingface.co/Nitral-Archive/Kunocchini-1.2-7b-longtext-broken,N/A,N/A,1,,0,,0,,0,,0,,0
|
| 276 |
+
Alphatao/a91b1374-b60f-4823-9aad-5f976d07f08e,"---
|
| 277 |
+
base_model: NousResearch/Yarn-Mistral-7b-128k
|
| 278 |
+
library_name: transformers
|
| 279 |
+
model_name: a91b1374-b60f-4823-9aad-5f976d07f08e
|
| 280 |
+
tags:
|
| 281 |
+
- generated_from_trainer
|
| 282 |
+
- axolotl
|
| 283 |
+
- dpo
|
| 284 |
+
- trl
|
| 285 |
+
licence: license
|
| 286 |
+
---
|
| 287 |
+
|
| 288 |
+
# Model Card for a91b1374-b60f-4823-9aad-5f976d07f08e
|
| 289 |
+
|
| 290 |
+
This model is a fine-tuned version of [NousResearch/Yarn-Mistral-7b-128k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k).
|
| 291 |
+
It has been trained using [TRL](https://github.com/huggingface/trl).
|
| 292 |
+
|
| 293 |
+
## Quick start
|
| 294 |
+
|
| 295 |
+
```python
|
| 296 |
+
from transformers import pipeline
|
| 297 |
+
|
| 298 |
+
question = ""If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?""
|
| 299 |
+
generator = pipeline(""text-generation"", model=""Alphatao/a91b1374-b60f-4823-9aad-5f976d07f08e"", device=""cuda"")
|
| 300 |
+
output = generator([{""role"": ""user"", ""content"": question}], max_new_tokens=128, return_full_text=False)[0]
|
| 301 |
+
print(output[""generated_text""])
|
| 302 |
+
```
|
| 303 |
+
|
| 304 |
+
## Training procedure
|
| 305 |
+
|
| 306 |
+
[<img src=""https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg"" alt=""Visualize in Weights & Biases"" width=""150"" height=""24""/>](https://wandb.ai/alphatao-alphatao/Gradients-On-Demand/runs/al93galt)
|
| 307 |
+
|
| 308 |
+
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
|
| 309 |
+
|
| 310 |
+
### Framework versions
|
| 311 |
+
|
| 312 |
+
- TRL: 0.12.0.dev0
|
| 313 |
+
- Transformers: 4.46.0
|
| 314 |
+
- Pytorch: 2.5.0+cu124
|
| 315 |
+
- Datasets: 3.0.1
|
| 316 |
+
- Tokenizers: 0.20.1
|
| 317 |
+
|
| 318 |
+
## Citations
|
| 319 |
+
|
| 320 |
+
Cite DPO as:
|
| 321 |
+
|
| 322 |
+
```bibtex
|
| 323 |
+
@inproceedings{rafailov2023direct,
|
| 324 |
+
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
|
| 325 |
+
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
|
| 326 |
+
year = 2023,
|
| 327 |
+
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
|
| 328 |
+
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
|
| 329 |
+
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
|
| 330 |
+
}
|
| 331 |
+
```
|
| 332 |
+
|
| 333 |
+
Cite TRL as:
|
| 334 |
+
|
| 335 |
+
```bibtex
|
| 336 |
+
@misc{vonwerra2022trl,
|
| 337 |
+
title = {{TRL: Transformer Reinforcement Learning}},
|
| 338 |
+
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
|
| 339 |
+
year = 2020,
|
| 340 |
+
journal = {GitHub repository},
|
| 341 |
+
publisher = {GitHub},
|
| 342 |
+
howpublished = {\url{https://github.com/huggingface/trl}}
|
| 343 |
+
}
|
| 344 |
+
```","{""id"": ""Alphatao/a91b1374-b60f-4823-9aad-5f976d07f08e"", ""author"": ""Alphatao"", ""sha"": ""a156ade398049a616e2de649d17d91da3245d17b"", ""last_modified"": ""2025-04-24 11:08:11+00:00"", ""created_at"": ""2025-04-24 07:41:33+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 2, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""tensorboard"", ""safetensors"", ""mistral"", ""text-generation"", ""generated_from_trainer"", ""axolotl"", ""dpo"", ""trl"", ""conversational"", ""custom_code"", ""arxiv:2305.18290"", ""base_model:NousResearch/Yarn-Mistral-7b-128k"", ""base_model:finetune:NousResearch/Yarn-Mistral-7b-128k"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: NousResearch/Yarn-Mistral-7b-128k\nlibrary_name: transformers\nmodel_name: a91b1374-b60f-4823-9aad-5f976d07f08e\ntags:\n- generated_from_trainer\n- axolotl\n- dpo\n- trl\nlicence: license"", ""widget_data"": [{""text"": ""Hi, what can you help me with?""}, {""text"": ""What is 84 * 3 / 2?""}, {""text"": ""Tell me an interesting fact about the universe!""}, {""text"": ""Explain quantum computing in simple terms.""}], ""model_index"": null, ""config"": {""architectures"": [""MistralForCausalLM""], ""auto_map"": {""AutoConfig"": ""NousResearch/Yarn-Mistral-7b-128k--configuration_mistral.MistralConfig"", ""AutoModelForCausalLM"": ""NousResearch/Yarn-Mistral-7b-128k--modeling_mistral_yarn.MistralForCausalLM""}, ""model_type"": ""mistral"", ""tokenizer_config"": {""bos_token"": ""<s>"", ""chat_template"": ""{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{% if add_generation_prompt %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}{% endif %}"", ""eos_token"": ""</s>"", ""pad_token"": ""</s>"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": true}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00004.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00004.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00003-of-00004.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00004-of-00004.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='runs/Apr24_07-41-17_f44850f1953c/events.out.tfevents.1745480507.f44850f1953c.260.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-24 11:08:11+00:00"", ""cardData"": ""base_model: NousResearch/Yarn-Mistral-7b-128k\nlibrary_name: transformers\nmodel_name: a91b1374-b60f-4823-9aad-5f976d07f08e\ntags:\n- generated_from_trainer\n- axolotl\n- dpo\n- trl\nlicence: license"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""6809eb2d01de4afad6323264"", ""modelId"": ""Alphatao/a91b1374-b60f-4823-9aad-5f976d07f08e"", ""usedStorage"": 20532159292}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Alphatao/a91b1374-b60f-4823-9aad-5f976d07f08e&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BAlphatao%2Fa91b1374-b60f-4823-9aad-5f976d07f08e%5D(%2FAlphatao%2Fa91b1374-b60f-4823-9aad-5f976d07f08e)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
YuE-s1-7B-anneal-en-cot_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv
ADDED
|
@@ -0,0 +1,133 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
m-a-p/YuE-s1-7B-anneal-en-cot,"---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
pipeline_tag: text-generation
|
| 7 |
+
tags:
|
| 8 |
+
- music
|
| 9 |
+
- art
|
| 10 |
+
- text-generation-inference
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
<p align=""center"">
|
| 15 |
+
<img src=""./assets/logo/白底.png"" width=""400"" />
|
| 16 |
+
</p>
|
| 17 |
+
|
| 18 |
+
<p align=""center"">
|
| 19 |
+
<a href=""https://map-yue.github.io/"">Demo 🎶</a> | 📑 <a href=""https://arxiv.org/abs/2503.08638"">Paper</a>
|
| 20 |
+
<br>
|
| 21 |
+
<a href=""https://huggingface.co/m-a-p/YuE-s1-7B-anneal-en-cot"">YuE-s1-7B-anneal-en-cot 🤗</a> | <a href=""https://huggingface.co/m-a-p/YuE-s1-7B-anneal-en-icl"">YuE-s1-7B-anneal-en-icl 🤗</a> | <a href=""https://huggingface.co/m-a-p/YuE-s1-7B-anneal-jp-kr-cot"">YuE-s1-7B-anneal-jp-kr-cot 🤗</a>
|
| 22 |
+
<br>
|
| 23 |
+
<a href=""https://huggingface.co/m-a-p/YuE-s1-7B-anneal-jp-kr-icl"">YuE-s1-7B-anneal-jp-kr-icl 🤗</a> | <a href=""https://huggingface.co/m-a-p/YuE-s1-7B-anneal-zh-cot"">YuE-s1-7B-anneal-zh-cot 🤗</a> | <a href=""https://huggingface.co/m-a-p/YuE-s1-7B-anneal-zh-icl"">YuE-s1-7B-anneal-zh-icl 🤗</a>
|
| 24 |
+
<br>
|
| 25 |
+
<a href=""https://huggingface.co/m-a-p/YuE-s2-1B-general"">YuE-s2-1B-general 🤗</a> | <a href=""https://huggingface.co/m-a-p/YuE-upsampler"">YuE-upsampler 🤗</a>
|
| 26 |
+
</p>
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
---
|
| 30 |
+
Our model's name is **YuE (乐)**. In Chinese, the word means ""music"" and ""happiness."" Some of you may find words that start with Yu hard to pronounce. If so, you can just call it ""yeah."" We wrote a song with our model's name.
|
| 31 |
+
|
| 32 |
+
<audio controls src=""https://cdn-uploads.huggingface.co/production/uploads/6555e8d8a0c34cd61a6b9ce3/rG-ELxMyzDU7zH-inB9DV.mpga""></audio>
|
| 33 |
+
|
| 34 |
+
YuE is a groundbreaking series of open-source foundation models designed for music generation, specifically for transforming lyrics into full songs (lyrics2song). It can generate a complete song, lasting several minutes, that includes both a catchy vocal track and accompaniment track. YuE is capable of modeling diverse genres/languages/vocal techniques. Please visit the [**Demo Page**](https://map-yue.github.io/) for amazing vocal performance.
|
| 35 |
+
|
| 36 |
+
Pop:Quiet Evening
|
| 37 |
+
<audio controls src=""https://cdn-uploads.huggingface.co/production/uploads/5fd6f670053c8345eddc1b68/HbZfODWrBK9DQyOzT3vL4.mpga""></audio>
|
| 38 |
+
Metal: Step Back
|
| 39 |
+
<audio controls src=""https://cdn-uploads.huggingface.co/production/uploads/6555e8d8a0c34cd61a6b9ce3/kmCwl4GRS70UYDEELL-Tn.mpga""></audio>
|
| 40 |
+
<!-- **YuE** is a groundbreaking series of open-source foundation models designed for music generation, specifically for transforming lyrics into full songs (**lyrics2song**). It can generate a complete song, lasting several minutes, that includes both a catchy vocal track and complementary accompaniment, ensuring a polished and cohesive result. -->
|
| 41 |
+
|
| 42 |
+
## News and Updates
|
| 43 |
+
* 📌 Join Us on Discord! [<img alt=""join discord"" src=""https://img.shields.io/discord/842440537755353128?color=%237289da&logo=discord""/>](https://discord.gg/ssAyWMnMzu)
|
| 44 |
+
|
| 45 |
+
* **2025.03.12 🔥 Paper Released🎉**: We now release [YuE technical report](https://arxiv.org/abs/2503.08638)!!! We discuss all the technical details, findings, and lessons learned. Enjoy, and feel free to cite us~
|
| 46 |
+
* **2025.03.11 🫶** Now YuE supports incremental song generation!!! See [YuE-UI by joeljuvel](https://github.com/joeljuvel/YuE-UI). YuE-UI is a Gradio-based interface supporting batch generation, output selection, and continuation. You can flexibly experiment with audio prompts and different model settings, visualize your progress on an interactive timeline, rewind actions, quickly preview audio outputs at stage 1 before committing to refinement, and fully save/load your sessions (JSON format). Optimized to run smoothly even on GPUs with just 8GB VRAM using quantized models.
|
| 47 |
+
* **2025.02.17 🫶** Now YuE supports music continuation and Google Colab! See [YuE-extend by Mozer](https://github.com/Mozer/YuE-extend).
|
| 48 |
+
* **2025.02.07 🎉** Get YuE for Windows on [pinokio](https://pinokio.computer).
|
| 49 |
+
|
| 50 |
+
* **2025.01.30 🔥 Inference Update**: We now support dual-track ICL mode! You can prompt the model with a reference song, and it will generate a new song in a similar style (voice cloning [demo by @abrakjamson](https://x.com/abrakjamson/status/1885932885406093538), music style transfer [demo by @cocktailpeanut](https://x.com/cocktailpeanut/status/1886456240156348674), etc.). Try it out! 🔥🔥🔥 P.S. Be sure to check out the demos first—they're truly impressive.
|
| 51 |
+
|
| 52 |
+
* **2025.01.30 🔥 Announcement: A New Era Under Apache 2.0 🔥**: We are thrilled to announce that, in response to overwhelming requests from our community, **YuE** is now officially licensed under the **Apache 2.0** license. We sincerely hope this marks a watershed moment—akin to what Stable Diffusion and LLaMA have achieved in their respective fields—for music generation and creative AI. 🎉🎉🎉
|
| 53 |
+
|
| 54 |
+
* **2025.01.29 🎉**: We have updated the license description. we **ENCOURAGE** artists and content creators to sample and incorporate outputs generated by our model into their own works, and even monetize them. The only requirement is to credit our name: **YuE by HKUST/M-A-P** (alphabetic order).
|
| 55 |
+
* **2025.01.28 🫶**: Thanks to Fahd for creating a tutorial on how to quickly get started with YuE. Here is his [demonstration](https://www.youtube.com/watch?v=RSMNH9GitbA).
|
| 56 |
+
* **2025.01.26 🔥**: We have released the **YuE** series.
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
## Quickstart
|
| 60 |
+
|
| 61 |
+
Please check our [github](https://github.com/multimodal-art-projection/YuE.git) for easy quickstart.
|
| 62 |
+
|
| 63 |
+
---
|
| 64 |
+
|
| 65 |
+
## License Agreement \& Disclaimer
|
| 66 |
+
- The YuE model (including its weights) is now released under the **Apache License, Version 2.0**. We do not make any profit from this model, and we hope it can be used for the betterment of human creativity.
|
| 67 |
+
- **Use & Attribution**:
|
| 68 |
+
- We encourage artists and content creators to freely incorporate outputs generated by YuE into their own works, including commercial projects.
|
| 69 |
+
- We encourage attribution to the model’s name (“YuE by HKUST/M-A-P”), especially for public and commercial use.
|
| 70 |
+
- **Originality & Plagiarism**: It is the sole responsibility of creators to ensure that their works, derived from or inspired by YuE outputs, do not plagiarize or unlawfully reproduce existing material. We strongly urge users to perform their own due diligence to avoid copyright infringement or other legal violations.
|
| 71 |
+
- **Recommended Labeling**: When uploading works to streaming platforms or sharing them publicly, we **recommend** labeling them with terms such as: “AI-generated”, “YuE-generated"", “AI-assisted” or “AI-auxiliated”. This helps maintain transparency about the creative process.
|
| 72 |
+
- **Disclaimer of Liability**:
|
| 73 |
+
- We do not assume any responsibility for the misuse of this model, including (but not limited to) illegal, malicious, or unethical activities.
|
| 74 |
+
- Users are solely responsible for any content generated using the YuE model and for any consequences arising from its use.
|
| 75 |
+
- By using this model, you agree that you understand and comply with all applicable laws and regulations regarding your generated content.
|
| 76 |
+
|
| 77 |
+
---
|
| 78 |
+
|
| 79 |
+
## Acknowledgements
|
| 80 |
+
The project is co-lead by HKUST and M-A-P (alphabetic order). Also thanks moonshot.ai, bytedance, 01.ai, and geely for supporting the project.
|
| 81 |
+
A friendly link to HKUST Audio group's [huggingface space](https://huggingface.co/HKUSTAudio).
|
| 82 |
+
|
| 83 |
+
We deeply appreciate all the support we received along the way. Long live open-source AI!
|
| 84 |
+
|
| 85 |
+
<br>
|
| 86 |
+
|
| 87 |
+
## Citation
|
| 88 |
+
|
| 89 |
+
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil: :)
|
| 90 |
+
|
| 91 |
+
```BibTeX
|
| 92 |
+
@misc{yuan2025yuescalingopenfoundation,
|
| 93 |
+
title={YuE: Scaling Open Foundation Models for Long-Form Music Generation},
|
| 94 |
+
author={Ruibin Yuan and Hanfeng Lin and Shuyue Guo and Ge Zhang and Jiahao Pan and Yongyi Zang and Haohe Liu and Yiming Liang and Wenye Ma and Xingjian Du and Xinrun Du and Zhen Ye and Tianyu Zheng and Yinghao Ma and Minghao Liu and Zeyue Tian and Ziya Zhou and Liumeng Xue and Xingwei Qu and Yizhi Li and Shangda Wu and Tianhao Shen and Ziyang Ma and Jun Zhan and Chunhui Wang and Yatian Wang and Xiaowei Chi and Xinyue Zhang and Zhenzhu Yang and Xiangzhou Wang and Shansong Liu and Lingrui Mei and Peng Li and Junjie Wang and Jianwei Yu and Guojian Pang and Xu Li and Zihao Wang and Xiaohuan Zhou and Lijun Yu and Emmanouil Benetos and Yong Chen and Chenghua Lin and Xie Chen and Gus Xia and Zhaoxiang Zhang and Chao Zhang and Wenhu Chen and Xinyu Zhou and Xipeng Qiu and Roger Dannenberg and Jiaheng Liu and Jian Yang and Wenhao Huang and Wei Xue and Xu Tan and Yike Guo},
|
| 95 |
+
year={2025},
|
| 96 |
+
eprint={2503.08638},
|
| 97 |
+
archivePrefix={arXiv},
|
| 98 |
+
primaryClass={eess.AS},
|
| 99 |
+
url={https://arxiv.org/abs/2503.08638},
|
| 100 |
+
}
|
| 101 |
+
|
| 102 |
+
@misc{yuan2025yue,
|
| 103 |
+
title={YuE: Open Music Foundation Models for Full-Song Generation},
|
| 104 |
+
author={Ruibin Yuan and Hanfeng Lin and Shawn Guo and Ge Zhang and Jiahao Pan and Yongyi Zang and Haohe Liu and Xingjian Du and Xeron Du and Zhen Ye and Tianyu Zheng and Yinghao Ma and Minghao Liu and Lijun Yu and Zeyue Tian and Ziya Zhou and Liumeng Xue and Xingwei Qu and Yizhi Li and Tianhao Shen and Ziyang Ma and Shangda Wu and Jun Zhan and Chunhui Wang and Yatian Wang and Xiaohuan Zhou and Xiaowei Chi and Xinyue Zhang and Zhenzhu Yang and Yiming Liang and Xiangzhou Wang and Shansong Liu and Lingrui Mei and Peng Li and Yong Chen and Chenghua Lin and Xie Chen and Gus Xia and Zhaoxiang Zhang and Chao Zhang and Wenhu Chen and Xinyu Zhou and Xipeng Qiu and Roger Dannenberg and Jiaheng Liu and Jian Yang and Stephen Huang and Wei Xue and Xu Tan and Yike Guo},
|
| 105 |
+
howpublished={\url{https://github.com/multimodal-art-projection/YuE}},
|
| 106 |
+
year={2025},
|
| 107 |
+
note={GitHub repository}
|
| 108 |
+
}
|
| 109 |
+
```
|
| 110 |
+
<br>","{""id"": ""m-a-p/YuE-s1-7B-anneal-en-cot"", ""author"": ""m-a-p"", ""sha"": ""454c20e1748888800f8e4b3da45125f55482d967"", ""last_modified"": ""2025-03-12 07:07:19+00:00"", ""created_at"": ""2025-01-26 16:10:21+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 21637, ""downloads_all_time"": null, ""likes"": 400, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""safetensors"", ""llama"", ""music"", ""art"", ""text-generation-inference"", ""text-generation"", ""en"", ""arxiv:2503.08638"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- en\nlicense: apache-2.0\npipeline_tag: text-generation\ntags:\n- music\n- art\n- text-generation-inference"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""architectures"": [""LlamaForCausalLM""], ""model_type"": ""llama""}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/logo/\u767d\u5e95.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/logo/\u900f\u660e\u5e95\u9ed1\u7ebf.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='assets/logo/\u9ed1\u5e95.png', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00003.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00003.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00003.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)""], ""spaces"": [""fffiloni/YuE"", ""ginipick/OpenSUNO"", ""innova-ai/YuE-music-generator-demo"", ""KBaba7/Quant"", ""bhaskartripathi/LLM_Quantization"", ""totolook/Quant"", ""FallnAI/Quantize-HF-Models"", ""ruslanmv/convert_to_gguf"", ""Davuks/OpenSUNO"", ""seawolf2357/YuE-music-generator-demo-zero"", ""VivekVKBKumar/Testing"", ""VivekVKBKumar/Testing2"", ""svjack/YuE"", ""inQuestAI/YuE"", ""multimodalart/yue-jobs"", ""AviCo/YuE"", ""Nymbo/YuE"", ""Srijal99/YuE"", ""Leryich/OpenSUNO"", ""dnola/YuE"", ""Dejansimic/YuE"", ""Harveyu/YuE-music-generator-demo"", ""ler06/YuE"", ""K00B404/LLM_Quantization"", ""toh32/YuE-music-generator-demo""], ""safetensors"": {""parameters"": {""BF16"": 6224613376}, ""total"": 6224613376}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-03-12 07:07:19+00:00"", ""cardData"": ""language:\n- en\nlicense: apache-2.0\npipeline_tag: text-generation\ntags:\n- music\n- art\n- text-generation-inference"", ""transformersInfo"": null, ""_id"": ""67965e6d9f57883759a839dd"", ""modelId"": ""m-a-p/YuE-s1-7B-anneal-en-cot"", ""usedStorage"": 12451022490}",0,https://huggingface.co/Doctor-Shotgun/YuE-s1-7B-anneal-en-cot-exl2,1,,0,"https://huggingface.co/Aryanne/YuE-s1-7B-anneal-en-cot-Q6_K-GGUF, https://huggingface.co/multimodalart/YuE-s1-7B-anneal-en-cot-Q8_0-GGUF, https://huggingface.co/DevQuasar/m-a-p.YuE-s1-7B-anneal-en-cot-GGUF, https://huggingface.co/Alissonerdx/YuE-s1-7B-anneal-en-cot-int8, https://huggingface.co/NikolayKozloff/YuE-s1-7B-anneal-en-cot-Q8_0-GGUF, https://huggingface.co/Alissonerdx/YuE-s1-7B-anneal-en-cot-nf4, https://huggingface.co/mradermacher/YuE-s1-7B-anneal-en-cot-GGUF, https://huggingface.co/mradermacher/YuE-s1-7B-anneal-en-cot-i1-GGUF, https://huggingface.co/tensorblock/YuE-s1-7B-anneal-en-cot-GGUF, https://huggingface.co/Zuellni/YuE-s1-7B-anneal-en-cot-8.0bpw-h8-exl2, https://huggingface.co/msyukorai/YuE-s1-7B-anneal-en-cot-Q4_0-GGUF, https://huggingface.co/siouni/YuE-s1-7B-anneal-en-cot-onnx-q4, https://huggingface.co/mingz2022/YuE-s1-7B-anneal-en-cot-Q4-mlx, https://huggingface.co/mingz2022/YuE-s1-7B-anneal-en-cot-Q8-mlx",14,,0,"Davuks/OpenSUNO, FallnAI/Quantize-HF-Models, K00B404/LLM_Quantization, KBaba7/Quant, Leryich/OpenSUNO, bhaskartripathi/LLM_Quantization, fffiloni/YuE, ginipick/OpenSUNO, huggingface/InferenceSupport/discussions/349, innova-ai/YuE-music-generator-demo, ruslanmv/convert_to_gguf, seawolf2357/YuE-music-generator-demo-zero, totolook/Quant",13
|
| 111 |
+
Doctor-Shotgun/YuE-s1-7B-anneal-en-cot-exl2,"---
|
| 112 |
+
quantized_by: Doctor-Shotgun
|
| 113 |
+
license: apache-2.0
|
| 114 |
+
language:
|
| 115 |
+
- en
|
| 116 |
+
tags:
|
| 117 |
+
- music
|
| 118 |
+
- llama
|
| 119 |
+
base_model: m-a-p/YuE-s1-7B-anneal-en-cot
|
| 120 |
+
pipeline_tag: text-generation
|
| 121 |
+
---
|
| 122 |
+
|
| 123 |
+
# YuE-s1-7B-anneal-en-cot-exl2
|
| 124 |
+
|
| 125 |
+
[m-a-p/YuE-s1-7B-anneal-en-cot](https://huggingface.co/m-a-p/YuE-s1-7B-anneal-en-cot) quantized with Exllamav2. It appears to remain coherent using the default calibration data without adding audio tokens.
|
| 126 |
+
|
| 127 |
+
Intended to be used with the [WIP exl2 inference repository for YuE](https://github.com/sgsdxzy/YuE-exllamav2).
|
| 128 |
+
|
| 129 |
+
Links:
|
| 130 |
+
- [4.25bpw-h6](https://huggingface.co/Doctor-Shotgun/YuE-s1-7B-anneal-en-cot-exl2/tree/4.25bpw-h6)
|
| 131 |
+
- [5.0bpw-h6](https://huggingface.co/Doctor-Shotgun/YuE-s1-7B-anneal-en-cot-exl2/tree/5.0bpw-h6)
|
| 132 |
+
- [6.0bpw-h6](https://huggingface.co/Doctor-Shotgun/YuE-s1-7B-anneal-en-cot-exl2/tree/6.0bpw-h6)
|
| 133 |
+
- [8.0bpw-h8](https://huggingface.co/Doctor-Shotgun/YuE-s1-7B-anneal-en-cot-exl2/tree/8.0bpw-h8)","{""id"": ""Doctor-Shotgun/YuE-s1-7B-anneal-en-cot-exl2"", ""author"": ""Doctor-Shotgun"", ""sha"": ""f98177d5acaf8c48936f2ea470789cf40307f4d7"", ""last_modified"": ""2025-02-01 00:13:22+00:00"", ""created_at"": ""2025-01-31 23:14:12+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 93, ""downloads_all_time"": null, ""likes"": 10, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""music"", ""llama"", ""text-generation"", ""en"", ""base_model:m-a-p/YuE-s1-7B-anneal-en-cot"", ""base_model:finetune:m-a-p/YuE-s1-7B-anneal-en-cot"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: m-a-p/YuE-s1-7B-anneal-en-cot\nlanguage:\n- en\nlicense: apache-2.0\npipeline_tag: text-generation\ntags:\n- music\n- llama\nquantized_by: Doctor-Shotgun"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='measurement.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-01 00:13:22+00:00"", ""cardData"": ""base_model: m-a-p/YuE-s1-7B-anneal-en-cot\nlanguage:\n- en\nlicense: apache-2.0\npipeline_tag: text-generation\ntags:\n- music\n- llama\nquantized_by: Doctor-Shotgun"", ""transformersInfo"": null, ""_id"": ""679d5944575df6520d55c900"", ""modelId"": ""Doctor-Shotgun/YuE-s1-7B-anneal-en-cot-exl2"", ""usedStorage"": 19191927672}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Doctor-Shotgun/YuE-s1-7B-anneal-en-cot-exl2&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BDoctor-Shotgun%2FYuE-s1-7B-anneal-en-cot-exl2%5D(%2FDoctor-Shotgun%2FYuE-s1-7B-anneal-en-cot-exl2)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
adetailer_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
Bingsu/adetailer,"---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
library_name: ultralytics
|
| 5 |
+
datasets:
|
| 6 |
+
- wider_face
|
| 7 |
+
- skytnt/anime-segmentation
|
| 8 |
+
tags:
|
| 9 |
+
- pytorch
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
# YOLOv8 Detection Model
|
| 13 |
+
|
| 14 |
+
## Datasets
|
| 15 |
+
|
| 16 |
+
### Face
|
| 17 |
+
|
| 18 |
+
- [Anime Face CreateML](https://universe.roboflow.com/my-workspace-mph8o/anime-face-createml)
|
| 19 |
+
- [xml2txt](https://universe.roboflow.com/0oooooo0/xml2txt-njqx1)
|
| 20 |
+
- [AN](https://universe.roboflow.com/sed-b8vkf/an-lfg5i)
|
| 21 |
+
- [wider face](http://shuoyang1213.me/WIDERFACE/index.html)
|
| 22 |
+
|
| 23 |
+
### Hand
|
| 24 |
+
|
| 25 |
+
- [AnHDet](https://universe.roboflow.com/1-yshhi/anhdet)
|
| 26 |
+
- [hand-detection-fuao9](https://universe.roboflow.com/catwithawand/hand-detection-fuao9)
|
| 27 |
+
|
| 28 |
+
### Person
|
| 29 |
+
|
| 30 |
+
- [coco2017](https://cocodataset.org/#home) (only person)
|
| 31 |
+
- [AniSeg](https://github.com/jerryli27/AniSeg)
|
| 32 |
+
- [skytnt/anime-segmentation](https://huggingface.co/datasets/skytnt/anime-segmentation)
|
| 33 |
+
|
| 34 |
+
### deepfashion2
|
| 35 |
+
|
| 36 |
+
- [deepfashion2](https://github.com/switchablenorms/DeepFashion2)
|
| 37 |
+
|
| 38 |
+
| id | label |
|
| 39 |
+
| --- | --------------------- |
|
| 40 |
+
| 0 | short_sleeved_shirt |
|
| 41 |
+
| 1 | long_sleeved_shirt |
|
| 42 |
+
| 2 | short_sleeved_outwear |
|
| 43 |
+
| 3 | long_sleeved_outwear |
|
| 44 |
+
| 4 | vest |
|
| 45 |
+
| 5 | sling |
|
| 46 |
+
| 6 | shorts |
|
| 47 |
+
| 7 | trousers |
|
| 48 |
+
| 8 | skirt |
|
| 49 |
+
| 9 | short_sleeved_dress |
|
| 50 |
+
| 10 | long_sleeved_dress |
|
| 51 |
+
| 11 | vest_dress |
|
| 52 |
+
| 12 | sling_dress |
|
| 53 |
+
|
| 54 |
+
## Info
|
| 55 |
+
|
| 56 |
+
| Model | Target | mAP 50 | mAP 50-95 |
|
| 57 |
+
| --------------------------- | --------------------- | ----------------------------- | ----------------------------- |
|
| 58 |
+
| face_yolov8n.pt | 2D / realistic face | 0.660 | 0.366 |
|
| 59 |
+
| face_yolov8n_v2.pt | 2D / realistic face | 0.669 | 0.372 |
|
| 60 |
+
| face_yolov8s.pt | 2D / realistic face | 0.713 | 0.404 |
|
| 61 |
+
| face_yolov8m.pt | 2D / realistic face | 0.737 | 0.424 |
|
| 62 |
+
| face_yolov9c.pt | 2D / realistic face | 0.748 | 0.433 |
|
| 63 |
+
| hand_yolov8n.pt | 2D / realistic hand | 0.767 | 0.505 |
|
| 64 |
+
| hand_yolov8s.pt | 2D / realistic hand | 0.794 | 0.527 |
|
| 65 |
+
| hand_yolov9c.pt | 2D / realistic hand | 0.810 | 0.550 |
|
| 66 |
+
| person_yolov8n-seg.pt | 2D / realistic person | 0.782 (bbox)<br/>0.761 (mask) | 0.555 (bbox)<br/>0.460 (mask) |
|
| 67 |
+
| person_yolov8s-seg.pt | 2D / realistic person | 0.824 (bbox)<br/>0.809 (mask) | 0.605 (bbox)<br/>0.508 (mask) |
|
| 68 |
+
| person_yolov8m-seg.pt | 2D / realistic person | 0.849 (bbox)<br/>0.831 (mask) | 0.636 (bbox)<br/>0.533 (mask) |
|
| 69 |
+
| deepfashion2_yolov8s-seg.pt | realistic clothes | 0.849 (bbox)<br/>0.840 (mask) | 0.763 (bbox)<br/>0.675 (mask) |
|
| 70 |
+
|
| 71 |
+
## Usage
|
| 72 |
+
|
| 73 |
+
```python
|
| 74 |
+
from huggingface_hub import hf_hub_download
|
| 75 |
+
from ultralytics import YOLO
|
| 76 |
+
|
| 77 |
+
path = hf_hub_download(""Bingsu/adetailer"", ""face_yolov8n.pt"")
|
| 78 |
+
model = YOLO(path)
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
```python
|
| 82 |
+
import cv2
|
| 83 |
+
from PIL import Image
|
| 84 |
+
|
| 85 |
+
img = ""https://farm5.staticflickr.com/4139/4887614566_6b57ec4422_z.jpg""
|
| 86 |
+
output = model(img)
|
| 87 |
+
pred = output[0].plot()
|
| 88 |
+
pred = cv2.cvtColor(pred, cv2.COLOR_BGR2RGB)
|
| 89 |
+
pred = Image.fromarray(pred)
|
| 90 |
+
pred
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+

|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
## Unsafe files
|
| 97 |
+
|
| 98 |
+

|
| 99 |
+
|
| 100 |
+
Since `getattr` is classified as a dangerous pickle function, any segmentation model that uses it is classified as unsafe.
|
| 101 |
+
|
| 102 |
+
All models were created and saved using the official [ultralytics](https://github.com/ultralytics/ultralytics) library, so it's okay to use files downloaded from a trusted source.
|
| 103 |
+
|
| 104 |
+
See also: https://huggingface.co/docs/hub/security-pickle
|
| 105 |
+
","{""id"": ""Bingsu/adetailer"", ""author"": ""Bingsu"", ""sha"": ""53cc19de382014514d9d4038601d261a7faa9b7b"", ""last_modified"": ""2024-11-21 12:40:27+00:00"", ""created_at"": ""2023-04-26 00:58:45+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 21666424, ""downloads_all_time"": null, ""likes"": 569, ""library_name"": ""ultralytics"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""ultralytics"", ""pytorch"", ""dataset:wider_face"", ""dataset:skytnt/anime-segmentation"", ""doi:10.57967/hf/3633"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""datasets:\n- wider_face\n- skytnt/anime-segmentation\nlibrary_name: ultralytics\nlicense: apache-2.0\ntags:\n- pytorch"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='deepfashion2_yolov8s-seg.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='face_yolov8m.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='face_yolov8n.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='face_yolov8n_v2.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='face_yolov8s.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='face_yolov9c.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hand_yolov8n.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hand_yolov8s.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='hand_yolov9c.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='person_yolov8m-seg.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='person_yolov8n-seg.pt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='person_yolov8s-seg.pt', size=None, blob_id=None, lfs=None)""], ""spaces"": [""jhj0517/AdvancedLivePortrait-WebUI"", ""Aatricks/LightDiffusion-Next"", ""Jeffgold/adetailer"", ""hhxxhh/a1"", ""Bingsu/adtriton"", ""gartajackhats1985/custom_nodes""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-11-21 12:40:27+00:00"", ""cardData"": ""datasets:\n- wider_face\n- skytnt/anime-segmentation\nlibrary_name: ultralytics\nlicense: apache-2.0\ntags:\n- pytorch"", ""transformersInfo"": null, ""_id"": ""644877453e498d66919f36ec"", ""modelId"": ""Bingsu/adetailer"", ""usedStorage"": 1130245365}",0,,0,,0,,0,,0,"Aatricks/LightDiffusion-Next, Bingsu/adtriton, Jeffgold/adetailer, gartajackhats1985/custom_nodes, hhxxhh/a1, huggingface/InferenceSupport/discussions/new?title=Bingsu/adetailer&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BBingsu%2Fadetailer%5D(%2FBingsu%2Fadetailer)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, jhj0517/AdvancedLivePortrait-WebUI",7
|
bark-small_finetunes_20250426_215237.csv_finetunes_20250426_215237.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
bert-base-NER_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
chatglm-6b_finetunes_20250424_145241.csv_finetunes_20250424_145241.csv
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
THUDM/chatglm-6b,"---
|
| 3 |
+
language:
|
| 4 |
+
- zh
|
| 5 |
+
- en
|
| 6 |
+
tags:
|
| 7 |
+
- glm
|
| 8 |
+
- chatglm
|
| 9 |
+
- thudm
|
| 10 |
+
---
|
| 11 |
+
# ChatGLM-6B
|
| 12 |
+
<p align=""center"">
|
| 13 |
+
🌐 <a href=""https://chatglm.cn/blog"" target=""_blank"">Blog</a> • 💻 <a href=""https://github.com/THUDM/ChatGLM-6B"" target=""_blank"">Github Repo</a> • 🐦 <a href=""https://twitter.com/thukeg"" target=""_blank"">Twitter</a> • 📃 <a href=""https://arxiv.org/abs/2103.10360"" target=""_blank"">[GLM@ACL 22]</a> <a href=""https://github.com/THUDM/GLM"" target=""_blank"">[GitHub]</a> • 📃 <a href=""https://arxiv.org/abs/2210.02414"" target=""_blank"">[GLM-130B@ICLR 23]</a> <a href=""https://github.com/THUDM/GLM-130B"" target=""_blank"">[GitHub]</a> <br>
|
| 14 |
+
</p>
|
| 15 |
+
|
| 16 |
+
<p align=""center"">
|
| 17 |
+
👋 Join our <a href=""https://join.slack.com/t/chatglm/shared_invite/zt-1y7pqoloy-9b1g6T6JjA8J0KxvUjbwJw"" target=""_blank"">Slack</a> and <a href=""https://github.com/THUDM/ChatGLM-6B/blob/main/resources/WECHAT.md"" target=""_blank"">WeChat</a>
|
| 18 |
+
</p>
|
| 19 |
+
|
| 20 |
+
<p align=""center"">
|
| 21 |
+
📍Experience the larger-scale ChatGLM model at <a href=""https://www.chatglm.cn"">chatglm.cn</a>
|
| 22 |
+
</p>
|
| 23 |
+
|
| 24 |
+
**我们发布了 [ChatGLM2-6B](https://github.com/THUDM/ChatGLM2-6B),ChatGLM-6B 的升级版本,在保留了了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,引入了更强大的性能、更长的上下文、更高效的推理等升级。**
|
| 25 |
+
## 介绍
|
| 26 |
+
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 [General Language Model (GLM)](https://github.com/THUDM/GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 [ChatGLM](https://chatglm.cn) 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。 ChatGLM-6B 权重对学术研究**完全开放**,在填写[问卷](https://open.bigmodel.cn/mla/form)进行登记后**亦允许免费商业使用**。
|
| 27 |
+
|
| 28 |
+
ChatGLM-6B is an open bilingual language model based on [General Language Model (GLM)](https://github.com/THUDM/GLM) framework, with 6.2 billion parameters. With the quantization technique, users can deploy locally on consumer-grade graphics cards (only 6GB of GPU memory is required at the INT4 quantization level). ChatGLM-6B uses technology similar to ChatGPT, optimized for Chinese QA and dialogue. The model is trained for about 1T tokens of Chinese and English corpus, supplemented by supervised fine-tuning, feedback bootstrap, and reinforcement learning with human feedback. With only about 6.2 billion parameters, the model is able to generate answers that are in line with human preference. ChatGLM-6B weights are **completely open** for academic research, and **free commercial use** is also allowed after completing the [questionnaire](https://open.bigmodel.cn/mla/form).
|
| 29 |
+
|
| 30 |
+
## 软件依赖
|
| 31 |
+
|
| 32 |
+
```shell
|
| 33 |
+
pip install protobuf==3.20.0 transformers==4.27.1 icetk cpm_kernels
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
## 代码调用
|
| 37 |
+
|
| 38 |
+
可以通过如下代码调用 ChatGLM-6B 模型来生成对话:
|
| 39 |
+
|
| 40 |
+
```ipython
|
| 41 |
+
>>> from transformers import AutoTokenizer, AutoModel
|
| 42 |
+
>>> tokenizer = AutoTokenizer.from_pretrained(""THUDM/chatglm-6b"", trust_remote_code=True)
|
| 43 |
+
>>> model = AutoModel.from_pretrained(""THUDM/chatglm-6b"", trust_remote_code=True).half().cuda()
|
| 44 |
+
>>> response, history = model.chat(tokenizer, ""你好"", history=[])
|
| 45 |
+
>>> print(response)
|
| 46 |
+
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
|
| 47 |
+
>>> response, history = model.chat(tokenizer, ""晚上睡不着应该怎么办"", history=history)
|
| 48 |
+
>>> print(response)
|
| 49 |
+
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
|
| 50 |
+
|
| 51 |
+
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
|
| 52 |
+
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
|
| 53 |
+
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
|
| 54 |
+
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
|
| 55 |
+
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
|
| 56 |
+
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着���慢吸气,保持几秒钟,然后缓慢呼气。
|
| 57 |
+
|
| 58 |
+
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
关于更多的使用说明,包括如何运行命令行和网页版本的 DEMO,以及使用模型量化以节省显存,请参考我们的 [Github Repo](https://github.com/THUDM/ChatGLM-6B)。
|
| 62 |
+
|
| 63 |
+
For more instructions, including how to run CLI and web demos, and model quantization, please refer to our [Github Repo](https://github.com/THUDM/ChatGLM-6B).
|
| 64 |
+
|
| 65 |
+
## Change Log
|
| 66 |
+
* v1.1.0 ([942945d](https://huggingface.co/THUDM/chatglm-6b/commit/942945df047dee66f653c68ae0e56655045f1741)): 更新 v1.1 版本 checkpoint
|
| 67 |
+
* v0.1.0 ([f831824](https://huggingface.co/THUDM/chatglm-6b/commit/f83182484538e663a03d3f73647f10f89878f438))
|
| 68 |
+
|
| 69 |
+
## 协议
|
| 70 |
+
|
| 71 |
+
本仓库的代码依照 [Apache-2.0](LICENSE) 协议开源,ChatGLM-6B 模型的权重的使用则需要遵循 [Model License](MODEL_LICENSE)。
|
| 72 |
+
|
| 73 |
+
## 引用
|
| 74 |
+
|
| 75 |
+
如果你觉得我们的工作有帮助的话,请考虑引用下列论文。
|
| 76 |
+
|
| 77 |
+
If you find our work helpful, please consider citing the following paper.
|
| 78 |
+
|
| 79 |
+
```
|
| 80 |
+
@misc{glm2024chatglm,
|
| 81 |
+
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
|
| 82 |
+
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
|
| 83 |
+
year={2024},
|
| 84 |
+
eprint={2406.12793},
|
| 85 |
+
archivePrefix={arXiv},
|
| 86 |
+
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
|
| 87 |
+
}
|
| 88 |
+
```","{""id"": ""THUDM/chatglm-6b"", ""author"": ""THUDM"", ""sha"": ""bf0f5cfb575eebebf9b655c5861177acfee03f16"", ""last_modified"": ""2024-08-04 08:44:58+00:00"", ""created_at"": ""2023-03-13 16:28:04+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 4145, ""downloads_all_time"": null, ""likes"": 2854, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""chatglm"", ""glm"", ""thudm"", ""custom_code"", ""zh"", ""en"", ""arxiv:2103.10360"", ""arxiv:2210.02414"", ""arxiv:2406.12793"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""language:\n- zh\n- en\ntags:\n- glm\n- chatglm\n- thudm"", ""widget_data"": null, ""model_index"": null, ""config"": {""architectures"": [""ChatGLMModel""], ""auto_map"": {""AutoConfig"": ""configuration_chatglm.ChatGLMConfig"", ""AutoModel"": ""modeling_chatglm.ChatGLMForConditionalGeneration"", ""AutoModelForSeq2SeqLM"": ""modeling_chatglm.ChatGLMForConditionalGeneration""}, ""model_type"": ""chatglm"", ""tokenizer_config"": {""bos_token"": ""<sop>"", ""eos_token"": ""<eop>"", ""mask_token"": ""[MASK]"", ""pad_token"": ""<pad>"", ""unk_token"": ""<unk>""}}, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='MODEL_LICENSE', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_chatglm.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ice_text.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_chatglm.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00008.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00008.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00003-of-00008.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00004-of-00008.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00005-of-00008.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00006-of-00008.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00007-of-00008.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00008-of-00008.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='quantization.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='test_modeling_chatglm.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenization_chatglm.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""multimodalart/ChatGLM-6B"", ""ChallengeHub/Chinese-LangChain"", ""OptimalScale/Robin-7b"", ""ysharma/ChatGLM-6b_Gradio_Streaming"", ""John6666/joy-caption-pre-alpha-mod"", ""aimevzulari/Prompt_Uzmani"", ""DrSong/ChatGLM-6B-ChatBot"", ""ysharma/OSChatbots_ChatGPT_ToeToToe"", ""josStorer/ChatGLM-6B-Int4-API-OpenAI-Compatible"", ""meval/multilingual-chatbot-arena-leaderboard"", ""EmbeddedLLM/chat-template-generation"", ""qingxu98/academic-chatgpt-beta"", ""llm-blender/LLM-Blender"", ""hahahafofo/ChatGLM-Chinese-Summary"", ""ljsabc/Fujisaki"", ""yhavinga/dutch-tokenizer-arena"", ""Kevin676/Shanghainese-TTS-demo"", ""suchun/chatGPT_acdemic"", ""linxianzhong0128/Linly-Talker"", ""hahahafofo/ChatPDF"", ""Ameaou/academic-chatgpt3.1"", ""li-qing/FIRE"", ""fkhuggingme/gpt-academic"", ""alitrack/ChatPDF"", ""OedoSoldier/chatglm_int4_demo"", ""Dao3/ChatGLM-6B"", ""Yiqin/ChatVID"", ""elitecode/ChatGLM-6B-ChatBot"", ""OptimalScale/Robin-33b"", ""f2api/gpt-academic"", ""syx948/ChatPDF"", ""CodeTed/Chinese-Grammarly"", ""CodeTed/chinese_spelling_error_correction"", ""MegaTronX/joy-caption-pre-alpha-mod"", ""TongkunGuan/Token-level_Text_Image_Foundation_Model"", ""fb700/chat3"", ""Gmq-x/gpt-academic"", ""IntelligenzaArtificiale/ChatGLM-6B-Int4-API-OpenAI-Compatible"", ""Kevin676/Telephone-Interviewing_PpaddleSpeech-TTS"", ""YukiKurosawaDev/ChatGLM"", ""kevinwang676/ChatGLM-int4-demo"", ""erbanku/gpt-academic"", ""caojiachen1/chatgpt-webui"", ""Fengbinbin/gpt-academic"", ""xwsm/gpt"", ""Cong723/gpt-academic-public"", ""weiwei1392/paper_generate"", ""bigPear/digitalWDF"", ""aodianyun/ChatGLM-6B"", ""hbestm/gpt-academic-play"", ""actboy/ChatGLM-6B"", ""xxccc/gpt-academic"", ""sinksmell/ChatPDF"", ""dakaiye/dky_xuexi"", ""hands012/gpt-academic"", ""shawn810720/Taiwan-LLaMa2"", ""tianleliphoebe/visual-arena"", ""Ashmal/MobiLlama"", ""JIAFENG7/BFF"", ""Nickofranco/Sigma"", ""Nerva5678/Excel-QA-bot"", ""Csdfg/ChatGLM-6B-Int4-API-OpenAI-Compatible"", ""Ligeng-Zhu/Digital-Clone"", ""oscarmei/oscar"", ""henryu/ChatGLB_007"", ""cndavy/ChatGLM-6B"", ""zefanwang/gpt-academic"", ""lockinwu/lockinwu-ChatGLM-6B"", ""fariliang/ChatGLM-Batman"", ""zedchou/gpt-academic"", ""KumaTea/KumaGLM"", ""slamkkk/chatgpt_academic"", ""ranv5/open"", ""marvin68/chatglm6b"", ""Here123/play"", ""KumaTea/KumaGLM-Lite"", ""gaoshine/Chinese-LangChain"", ""saintjohn/gpt-academicpub"", ""long1111/chatglm"", ""chad2020/gptzhongkeyuan"", ""roman008/gpt-academic"", ""HMinions/ws"", ""NewBreaker/chatglm-6b-int4"", ""kevinwang676/ChatPDF"", ""ydm8964/jjygpt"", ""Danielzero/gpt-academic"", ""ycy1615/gpt-academic"", ""leemingzhe/gpt-academic-zafu-7-301"", ""randomchaos9999/xsrwascq"", ""acedemic-talent/gpt-academic"", ""tree1024/gpt-academic"", ""zdevc/chatai"", ""Elphen/gpt-academic3.32"", ""pgqun/gpt-academic"", ""jackli888/chatGPT_acdemic"", ""zhang55/gpt-academic-zafu-7-301"", ""cgisky/gpt-academic22"", ""Jasonai/gpt-academic"", ""AtonB/gpt-academic"", ""MoDongbao/ChatGPT_for_Academic_Releases96""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2024-08-04 08:44:58+00:00"", ""cardData"": ""language:\n- zh\n- en\ntags:\n- glm\n- chatglm\n- thudm"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""640f4f1409c94e1d9bca3ffc"", ""modelId"": ""THUDM/chatglm-6b"", ""usedStorage"": 47452655921}",0,https://huggingface.co/Longz1003/chatglm_lora_mimeng,1,https://huggingface.co/shibing624/chatglm-6b-belle-zh-lora,1,,0,,0,"Ashmal/MobiLlama, CodeTed/Chinese-Grammarly, CodeTed/chinese_spelling_error_correction, Fengbinbin/gpt-academic, John6666/joy-caption-pre-alpha-mod, MegaTronX/joy-caption-pre-alpha-mod, TongkunGuan/Token-level_Text_Image_Foundation_Model, aimevzulari/Prompt_Uzmani, huggingface/InferenceSupport/discussions/new?title=THUDM/chatglm-6b&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BTHUDM%2Fchatglm-6b%5D(%2FTHUDM%2Fchatglm-6b)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, linxianzhong0128/Linly-Talker, meval/multilingual-chatbot-arena-leaderboard, qingxu98/academic-chatgpt-beta, yhavinga/dutch-tokenizer-arena",13
|
| 89 |
+
Longz1003/chatglm_lora_mimeng,"---
|
| 90 |
+
license: apache-2.0
|
| 91 |
+
datasets:
|
| 92 |
+
- fka/awesome-chatgpt-prompts
|
| 93 |
+
language:
|
| 94 |
+
- zh
|
| 95 |
+
base_model:
|
| 96 |
+
- THUDM/chatglm-6b
|
| 97 |
+
pipeline_tag: question-answering
|
| 98 |
+
---
|
| 99 |
+
|
| 100 |
+
# ChatGLM-3-6B-LoRA: A LoRA Fine-Tuned Version of ChatGLM-3-6B
|
| 101 |
+
|
| 102 |
+
## Model description
|
| 103 |
+
这是一个基于 **ChatGLM-3-6B** 进行 **LoRA 微调** 的中文对话生成模型。该模型的目标是提升对话生成的质量,特别是在开放式对话和问答任务中。LoRA 微调技术通过低秩适配层优化了预训练模型,减少了计算开销。
|
| 104 |
+
|
| 105 |
+
目前,模型在对话生成的质量上会继续进行微调和改进,以优化性能和适应更多场景。
|
| 106 |
+
|
| 107 |
+
## Model details
|
| 108 |
+
- **架构**:基于 **ChatGLM-3-6B**(一个大规模中文生成模型)。
|
| 109 |
+
- **微调技术**:使用 **LoRA** 微调,对预训练的 ChatGLM 模型进行低秩调整。
|
| 110 |
+
- **任务类型**:主要用于中文对话生成、问答任务等。
|
| 111 |
+
|
| 112 |
+
## Training data
|
| 113 |
+
- **训练数据集**:使用自定义对话数据集进行微调。
|
| 114 |
+
- **数据量和多样性**:目前的训练数据集质量有待提升,可能影响模型的泛化能力。
|
| 115 |
+
- **清洗与处理**:数据经过一定程度的清洗,去除噪声和低质量对话,但由于数据集的限制,某些任务的表现仍然较弱。
|
| 116 |
+
|
| 117 |
+
## Evaluation results
|
| 118 |
+
模型在一些对话生成任务上的初步评估结果如下:
|
| 119 |
+
- **准确性**:当前在常见对话和开放式问答任务中的表现较好。
|
| 120 |
+
- **流畅度**:生成的对话大部分时间较为流畅,但偶尔出现重复、无关或不自然的回答。
|
| 121 |
+
- **性能瓶颈**:由于训练数据的局限性,模型在长时间对话中可能会出现表现下降的情况。
|
| 122 |
+
|
| 123 |
+
**当前模型的表现并未达到最佳效果,但随着更多数据和进一步的微调,预期会有所改进。**
|
| 124 |
+
|
| 125 |
+
## Limitations and Biases
|
| 126 |
+
- **生成质量**:当前模型在复杂对话中的表现较为稳定,特别是在涉及特定领域或长时间对话时,生成的内容可能不准确或缺乏逻辑性。
|
| 127 |
+
- **数据偏差**:由于使用的训练数据来自公开数据集,模型可能在特定领域(如医学、科技等)表现较差,也可能存在一些基于数据集的偏见。
|
| 128 |
+
- **更新和优化**:模型仍在不断微调和优化中,效果可能会随着时间和进一步训练得到改善。
|
| 129 |
+
|
| 130 |
+
## Use case
|
| 131 |
+
这个模型适用于构建中文对话系统,特别是在:
|
| 132 |
+
- **聊天机器人**:构建能够进行简单对话和闲聊的聊天机器人。
|
| 133 |
+
- **教育辅助**:作为教育领域的智能问答助手,帮助学生解答基础问题。
|
| 134 |
+
|
| 135 |
+
## How to use
|
| 136 |
+
你可以使用以下代码来加载并使用该模型:
|
| 137 |
+
|
| 138 |
+
```python
|
| 139 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 140 |
+
|
| 141 |
+
# 加载模型和 tokenizer
|
| 142 |
+
model_name = ""Longz1003/chatglm_lora_mimeng"" # 替换为你的模型路径
|
| 143 |
+
model = AutoModelForCausalLM.from_pretrained(model_name)
|
| 144 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 145 |
+
|
| 146 |
+
# 测试模型
|
| 147 |
+
inputs = tokenizer(""你好,今天的天气怎么样?"", return_tensors=""pt"")
|
| 148 |
+
outputs = model.generate(**inputs)
|
| 149 |
+
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
| 150 |
+
|
| 151 |
+
torch>=1.10.0
|
| 152 |
+
transformers>=4.30.0
|
| 153 |
+
accelerate>=0.18.0
|
| 154 |
+
datasets>=2.0.0
|
| 155 |
+
scipy>=1.7.0
|
| 156 |
+
sentencepiece>=0.1.96
|
| 157 |
+
pytorch-lightning>=1.5.0
|
| 158 |
+
pyyaml>=5.4.1
|
| 159 |
+
tqdm>=4.62.0
|
| 160 |
+
requests>=2.26.0
|
| 161 |
+
huggingface_hub>=0.12.0
|
| 162 |
+
tensorboard>=2.6.0
|
| 163 |
+
scikit-learn>=0.24.2
|
| 164 |
+
","{""id"": ""Longz1003/chatglm_lora_mimeng"", ""author"": ""Longz1003"", ""sha"": ""6aca4e3a996be80815456c56ce54a53289fa95ed"", ""last_modified"": ""2025-04-08 03:44:12+00:00"", ""created_at"": ""2025-02-07 03:28:26+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 9, ""downloads_all_time"": null, ""likes"": 1, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""safetensors"", ""chatglm"", ""question-answering"", ""custom_code"", ""zh"", ""dataset:fka/awesome-chatgpt-prompts"", ""base_model:THUDM/chatglm-6b"", ""base_model:finetune:THUDM/chatglm-6b"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": ""question-answering"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model:\n- THUDM/chatglm-6b\ndatasets:\n- fka/awesome-chatgpt-prompts\nlanguage:\n- zh\nlicense: apache-2.0\npipeline_tag: question-answering"", ""widget_data"": [{""text"": ""\u6211\u4f4f\u5728\u54ea\u91cc\uff1f"", ""context"": ""\u6211\u53eb\u6c83\u5c14\u592b\u5188\uff0c\u6211\u4f4f\u5728\u67cf\u6797\u3002""}, {""text"": ""\u6211\u4f4f\u5728\u54ea\u91cc\uff1f"", ""context"": ""\u6211\u53eb\u8428\u62c9\uff0c\u6211\u4f4f\u5728\u4f26\u6566\u3002""}, {""text"": ""\u6211\u7684\u540d\u5b57\u662f\u4ec0\u4e48\uff1f"", ""context"": ""\u6211\u53eb\u514b\u62c9\u62c9\uff0c\u6211\u4f4f\u5728\u4f2f\u514b\u5229\u3002""}], ""model_index"": null, ""config"": {""architectures"": [""ChatGLMForConditionalGeneration""], ""auto_map"": {""AutoConfig"": ""configuration_chatglm.ChatGLMConfig"", ""AutoModel"": ""modeling_chatglm.ChatGLMForConditionalGeneration"", ""AutoModelForCausalLM"": ""modeling_chatglm.ChatGLMForConditionalGeneration"", ""AutoModelForSeq2SeqLM"": ""modeling_chatglm.ChatGLMForConditionalGeneration"", ""AutoModelForSequenceClassification"": ""modeling_chatglm.ChatGLMForSequenceClassification""}, ""model_type"": ""chatglm"", ""tokenizer_config"": {""chat_template"": ""{% for message in messages %}{% if loop.first %}[gMASK]sop<|{{ message['role'] }}|>\n {{ message['content'] }}{% else %}<|{{ message['role'] }}|>\n {{ message['content'] }}{% endif %}{% endfor %}{% if add_generation_prompt %}<|assistant|>{% endif %}"", ""eos_token"": ""</s>"", ""pad_token"": ""<unk>"", ""unk_token"": ""<unk>""}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_chatglm.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00001-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00002-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00003-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00004-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00005-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00006-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model-00007-of-00007.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='model.safetensors.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_chatglm.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='quantization.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenization_chatglm.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": {""parameters"": {""F16"": 6243584032}, ""total"": 6243584032}, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-04-08 03:44:12+00:00"", ""cardData"": ""base_model:\n- THUDM/chatglm-6b\ndatasets:\n- fka/awesome-chatgpt-prompts\nlanguage:\n- zh\nlicense: apache-2.0\npipeline_tag: question-answering"", ""transformersInfo"": null, ""_id"": ""67a57ddacdd8bd444049b210"", ""modelId"": ""Longz1003/chatglm_lora_mimeng"", ""usedStorage"": 12488213274}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=Longz1003/chatglm_lora_mimeng&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BLongz1003%2Fchatglm_lora_mimeng%5D(%2FLongz1003%2Fchatglm_lora_mimeng)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
codebert-base_finetunes_20250426_171734.csv_finetunes_20250426_171734.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
colpali_finetunes_20250425_165642.csv_finetunes_20250425_165642.csv
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
vidore/colpali,"---
|
| 3 |
+
license: mit
|
| 4 |
+
library_name: colpali
|
| 5 |
+
base_model: google/paligemma-3b-mix-448
|
| 6 |
+
language:
|
| 7 |
+
- en
|
| 8 |
+
tags:
|
| 9 |
+
- colpali
|
| 10 |
+
- vidore
|
| 11 |
+
new_version: vidore/colpali-v1.1
|
| 12 |
+
datasets:
|
| 13 |
+
- vidore/colpali_train_set
|
| 14 |
+
pipeline_tag: visual-document-retrieval
|
| 15 |
+
---
|
| 16 |
+
# ColPali: Visual Retriever based on PaliGemma-3B with ColBERT strategy
|
| 17 |
+
|
| 18 |
+
ColPali is a model based on a novel model architecture and training strategy based on Vision Language Models (VLMs) to efficiently index documents from their visual features.
|
| 19 |
+
It is a [PaliGemma-3B](https://huggingface.co/google/paligemma-3b-mix-448) extension that generates [ColBERT](https://arxiv.org/abs/2004.12832)- style multi-vector representations of text and images.
|
| 20 |
+
It was introduced in the paper [ColPali: Efficient Document Retrieval with Vision Language Models](https://arxiv.org/abs/2407.01449) and first released in [this repository](https://github.com/ManuelFay/colpali)
|
| 21 |
+
|
| 22 |
+
<p align=""center""><img width=800 src=""https://github.com/illuin-tech/colpali/blob/main/assets/colpali_architecture.webp?raw=true""/></p>
|
| 23 |
+
|
| 24 |
+
## Model Description
|
| 25 |
+
|
| 26 |
+
This model is built iteratively starting from an off-the-shelf [SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384) model.
|
| 27 |
+
We finetuned it to create [BiSigLIP](https://huggingface.co/vidore/bisiglip) and fed the patch-embeddings output by SigLIP to an LLM, [PaliGemma-3B](https://huggingface.co/google/paligemma-3b-mix-448) to create [BiPali](https://huggingface.co/vidore/bipali).
|
| 28 |
+
|
| 29 |
+
One benefit of inputting image patch embeddings through a language model is that they are natively mapped to a latent space similar to textual input (query).
|
| 30 |
+
This enables leveraging the [ColBERT](https://arxiv.org/abs/2004.12832) strategy to compute interactions between text tokens and image patches, which enables a step-change improvement in performance compared to BiPali.
|
| 31 |
+
|
| 32 |
+
## Model Training
|
| 33 |
+
|
| 34 |
+
### Dataset
|
| 35 |
+
Our training dataset of 127,460 query-page pairs is comprised of train sets of openly available academic datasets (63%) and a synthetic dataset made up of pages from web-crawled PDF documents and augmented with VLM-generated (Claude-3 Sonnet) pseudo-questions (37%).
|
| 36 |
+
Our training set is fully English by design, enabling us to study zero-shot generalization to non-English languages. We explicitly verify no multi-page PDF document is used both [*ViDoRe*](https://huggingface.co/collections/vidore/vidore-benchmark-667173f98e70a1c0fa4db00d) and in the train set to prevent evaluation contamination.
|
| 37 |
+
A validation set is created with 2% of the samples to tune hyperparameters.
|
| 38 |
+
|
| 39 |
+
*Note: Multilingual data is present in the pretraining corpus of the language model (Gemma-2B) and potentially occurs during PaliGemma-3B's multimodal training.*
|
| 40 |
+
|
| 41 |
+
### Parameters
|
| 42 |
+
|
| 43 |
+
All models are trained for 1 epoch on the train set. Unless specified otherwise, we train models in `bfloat16` format, use low-rank adapters ([LoRA](https://arxiv.org/abs/2106.09685))
|
| 44 |
+
with `alpha=32` and `r=32` on the transformer layers from the language model,
|
| 45 |
+
as well as the final randomly initialized projection layer, and use a `paged_adamw_8bit` optimizer.
|
| 46 |
+
We train on an 8 GPU setup with data parallelism, a learning rate of 5e-5 with linear decay with 2.5% warmup steps, and a batch size of 32.
|
| 47 |
+
|
| 48 |
+
## Usage
|
| 49 |
+
|
| 50 |
+
### For best performance, newer models are available (vidore/colpali-v1.2)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
```bash
|
| 54 |
+
# This model checkpoint is compatible with version 0.1.1, but not more recent versions of the inference lib
|
| 55 |
+
pip install colpali_engine==0.1.1
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
```python
|
| 59 |
+
import torch
|
| 60 |
+
import typer
|
| 61 |
+
from torch.utils.data import DataLoader
|
| 62 |
+
from tqdm import tqdm
|
| 63 |
+
from transformers import AutoProcessor
|
| 64 |
+
from PIL import Image
|
| 65 |
+
|
| 66 |
+
from colpali_engine.models.paligemma_colbert_architecture import ColPali
|
| 67 |
+
from colpali_engine.trainer.retrieval_evaluator import CustomEvaluator
|
| 68 |
+
from colpali_engine.utils.colpali_processing_utils import process_images, process_queries
|
| 69 |
+
from colpali_engine.utils.image_from_page_utils import load_from_dataset
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def main() -> None:
|
| 73 |
+
""""""Example script to run inference with ColPali""""""
|
| 74 |
+
|
| 75 |
+
# Load model
|
| 76 |
+
model_name = ""vidore/colpali""
|
| 77 |
+
model = ColPali.from_pretrained(""vidore/colpaligemma-3b-mix-448-base"", torch_dtype=torch.bfloat16, device_map=""cuda"").eval()
|
| 78 |
+
model.load_adapter(model_name)
|
| 79 |
+
processor = AutoProcessor.from_pretrained(model_name)
|
| 80 |
+
|
| 81 |
+
# select images -> load_from_pdf(<pdf_path>), load_from_image_urls([""<url_1>""]), load_from_dataset(<path>)
|
| 82 |
+
images = load_from_dataset(""vidore/docvqa_test_subsampled"")
|
| 83 |
+
queries = [""From which university does James V. Fiorca come ?"", ""Who is the japanese prime minister?""]
|
| 84 |
+
|
| 85 |
+
# run inference - docs
|
| 86 |
+
dataloader = DataLoader(
|
| 87 |
+
images,
|
| 88 |
+
batch_size=4,
|
| 89 |
+
shuffle=False,
|
| 90 |
+
collate_fn=lambda x: process_images(processor, x),
|
| 91 |
+
)
|
| 92 |
+
ds = []
|
| 93 |
+
for batch_doc in tqdm(dataloader):
|
| 94 |
+
with torch.no_grad():
|
| 95 |
+
batch_doc = {k: v.to(model.device) for k, v in batch_doc.items()}
|
| 96 |
+
embeddings_doc = model(**batch_doc)
|
| 97 |
+
ds.extend(list(torch.unbind(embeddings_doc.to(""cpu""))))
|
| 98 |
+
|
| 99 |
+
# run inference - queries
|
| 100 |
+
dataloader = DataLoader(
|
| 101 |
+
queries,
|
| 102 |
+
batch_size=4,
|
| 103 |
+
shuffle=False,
|
| 104 |
+
collate_fn=lambda x: process_queries(processor, x, Image.new(""RGB"", (448, 448), (255, 255, 255))),
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
qs = []
|
| 108 |
+
for batch_query in dataloader:
|
| 109 |
+
with torch.no_grad():
|
| 110 |
+
batch_query = {k: v.to(model.device) for k, v in batch_query.items()}
|
| 111 |
+
embeddings_query = model(**batch_query)
|
| 112 |
+
qs.extend(list(torch.unbind(embeddings_query.to(""cpu""))))
|
| 113 |
+
|
| 114 |
+
# run evaluation
|
| 115 |
+
retriever_evaluator = CustomEvaluator(is_multi_vector=True)
|
| 116 |
+
scores = retriever_evaluator.evaluate(qs, ds)
|
| 117 |
+
print(scores.argmax(axis=1))
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
if __name__ == ""__main__"":
|
| 121 |
+
typer.run(main)
|
| 122 |
+
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
## Limitations
|
| 126 |
+
|
| 127 |
+
- **Focus**: The model primarily focuses on PDF-type documents and high-ressources languages, potentially limiting its generalization to other document types or less represented languages.
|
| 128 |
+
- **Support**: The model relies on multi-vector retreiving derived from the ColBERT late interaction mechanism, which may require engineering efforts to adapt to widely used vector retrieval frameworks that lack native multi-vector support.
|
| 129 |
+
|
| 130 |
+
## License
|
| 131 |
+
|
| 132 |
+
ColPali's vision language backbone model (PaliGemma) is under `gemma` license as specified in its [model card](https://huggingface.co/google/paligemma-3b-mix-448). The adapters attached to the model are under MIT license.
|
| 133 |
+
|
| 134 |
+
## Contact
|
| 135 |
+
|
| 136 |
+
- Manuel Faysse: manuel.faysse@illuin.tech
|
| 137 |
+
- Hugues Sibille: hugues.sibille@illuin.tech
|
| 138 |
+
- Tony Wu: tony.wu@illuin.tech
|
| 139 |
+
|
| 140 |
+
## Citation
|
| 141 |
+
|
| 142 |
+
If you use any datasets or models from this organization in your research, please cite the original dataset as follows:
|
| 143 |
+
|
| 144 |
+
```bibtex
|
| 145 |
+
@misc{faysse2024colpaliefficientdocumentretrieval,
|
| 146 |
+
title={ColPali: Efficient Document Retrieval with Vision Language Models},
|
| 147 |
+
author={Manuel Faysse and Hugues Sibille and Tony Wu and Bilel Omrani and Gautier Viaud and Céline Hudelot and Pierre Colombo},
|
| 148 |
+
year={2024},
|
| 149 |
+
eprint={2407.01449},
|
| 150 |
+
archivePrefix={arXiv},
|
| 151 |
+
primaryClass={cs.IR},
|
| 152 |
+
url={https://arxiv.org/abs/2407.01449},
|
| 153 |
+
}
|
| 154 |
+
```","{""id"": ""vidore/colpali"", ""author"": ""vidore"", ""sha"": ""82b73faebcbdd2f2009ada076b22fb85d3b63665"", ""last_modified"": ""2025-02-05 19:23:14+00:00"", ""created_at"": ""2024-06-25 10:06:08+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 13831, ""downloads_all_time"": null, ""likes"": 436, ""library_name"": ""colpali"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""colpali"", ""safetensors"", ""vidore"", ""visual-document-retrieval"", ""en"", ""dataset:vidore/colpali_train_set"", ""arxiv:2004.12832"", ""arxiv:2407.01449"", ""arxiv:2106.09685"", ""base_model:google/paligemma-3b-mix-448"", ""base_model:finetune:google/paligemma-3b-mix-448"", ""license:mit"", ""region:us""], ""pipeline_tag"": ""visual-document-retrieval"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: google/paligemma-3b-mix-448\ndatasets:\n- vidore/colpali_train_set\nlanguage:\n- en\nlibrary_name: colpali\nlicense: mit\npipeline_tag: visual-document-retrieval\ntags:\n- colpali\n- vidore\nnew_version: vidore/colpali-v1.1"", ""widget_data"": null, ""model_index"": null, ""config"": {""tokenizer_config"": {""bos_token"": ""<bos>"", ""eos_token"": ""<eos>"", ""pad_token"": ""<pad>"", ""unk_token"": ""<unk>"", ""use_default_system_prompt"": false}}, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='added_tokens.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='git_hash.txt', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='preprocessor_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='results.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.model', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_config.yml', size=None, blob_id=None, lfs=None)""], ""spaces"": [""merve/vision_papers"", ""DeF0017/OCR-using-Qwen2-VL"", ""Swekerr/Qwen2VL-OCR"", ""clayton07/qwen2-colpali-ocr"", ""gabrielaltay/vlmqa"", ""profchaos/OCR-APP"", ""gauri-sharan/test-two"", ""HUANG-Stephanie/cvquest-colpali"", ""lukiod/streamlit_qwen"", ""lukiod/test2"", ""lukiod/dock2"", ""Rick7799/Ocr1"", ""Pranathi1/Qwen2vl_RAG"", ""rk404/ocr_hi_en"", ""RufusRubin777/Qwen2VL-OCR_CPU"", ""Manogari2003/OCR-with-Keyword-Search-from-Image"", ""mannywho/webocr"", ""anvi27/ocr"", ""Yassmen/OCR_App"", ""Niha14/images-texts"", ""ayushb03/colpali-qwen2-ocr-search"", ""intuitive262/Doc_Reader"", ""gkaur13/ocrHindiEnglish"", ""gkaur13/hindiEnglishOCR"", ""Pulkit-28/OCR"", ""velaia/vision_papers""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-02-05 19:23:14+00:00"", ""cardData"": ""base_model: google/paligemma-3b-mix-448\ndatasets:\n- vidore/colpali_train_set\nlanguage:\n- en\nlibrary_name: colpali\nlicense: mit\npipeline_tag: visual-document-retrieval\ntags:\n- colpali\n- vidore\nnew_version: vidore/colpali-v1.1"", ""transformersInfo"": null, ""_id"": ""667a96900df5089affb1ba53"", ""modelId"": ""vidore/colpali"", ""usedStorage"": 100652593}",0,,0,,0,,0,,0,"DeF0017/OCR-using-Qwen2-VL, HUANG-Stephanie/cvquest-colpali, Rick7799/Ocr1, Swekerr/Qwen2VL-OCR, clayton07/qwen2-colpali-ocr, gabrielaltay/vlmqa, gauri-sharan/test-two, huggingface/InferenceSupport/discussions/915, lukiod/dock2, lukiod/streamlit_qwen, lukiod/test2, merve/vision_papers, profchaos/OCR-APP",13
|
doll-likeness-series_finetunes_20250426_014322.csv_finetunes_20250426_014322.csv
ADDED
|
@@ -0,0 +1,186 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
Kanbara/doll-likeness-series,"---
|
| 3 |
+
license: creativeml-openrail-m
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
# Doll Series by Kbr
|
| 8 |
+
|
| 9 |
+
The 'Doll-Series' is a set of LORA focused on realistic Asian faces, with incredible levels of beauty and aesthetics.
|
| 10 |
+
|
| 11 |
+
My Pixiv: https://www.pixiv.net/en/users/92373922
|
| 12 |
+
|
| 13 |
+
My Twitter: https://twitter.com/KbrLoras
|
| 14 |
+
|
| 15 |
+
---
|
| 16 |
+
|
| 17 |
+
# Table of Contents
|
| 18 |
+
|
| 19 |
+
- [License](#license)
|
| 20 |
+
- [Disclaimer](#disclaimer)
|
| 21 |
+
- [Used Models](#used-models)
|
| 22 |
+
- [LORA Detail](#lora-detail)
|
| 23 |
+
- [KoreanDollLikeness](#koreandolllikeness)
|
| 24 |
+
- [KoreanDollLikeness_v10](#koreandolllikeness_v10)
|
| 25 |
+
- [KoreanDollLikeness_v15](#koreandolllikeness_v15)
|
| 26 |
+
- [KoreanDollLikeness_v20](#koreandolllikeness_v20)
|
| 27 |
+
- [JapaneseDollLikeness](#japanesedolllikeness)
|
| 28 |
+
- [JapaneseDollLikeness_v10](#japanesedolllikeness_v10)
|
| 29 |
+
- [JapaneseDollLikeness_v15](#japanesedolllikeness_v15)
|
| 30 |
+
- [TaiwanDollLikeness](#taiwandolllikeness)
|
| 31 |
+
- [TaiwanDollLikeness_v15](#taiwandolllikeness_v15)
|
| 32 |
+
- [TaiwanDollLikeness_v20](#taiwandolllikeness_v20)
|
| 33 |
+
- [ChinaDollLikeness](#chinadolllikeness)
|
| 34 |
+
- [ChinaDollLikeness_v10](#chinadolllikeness_v10)
|
| 35 |
+
- [ThaiDollLikeness](#thaidolllikeness)
|
| 36 |
+
- [ThaiDollLikeness_v10](#Thaidolllikeness_v10)
|
| 37 |
+
|
| 38 |
+
- [FAQ](#faq)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
---
|
| 43 |
+
# License
|
| 44 |
+
|
| 45 |
+
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
|
| 46 |
+
The CreativeML OpenRAIL License specifies:
|
| 47 |
+
|
| 48 |
+
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
|
| 49 |
+
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
|
| 50 |
+
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
|
| 51 |
+
(Full license here: https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
| 52 |
+
|
| 53 |
+
# Additional Add-ons to license/notes
|
| 54 |
+
1. You shall take full responsibility for any creative work that uses this model
|
| 55 |
+
2. Refrain from using this model for malicious intent, harm, defamation, scam or political usages. It may impair and discourage the author from producing more works.
|
| 56 |
+
|
| 57 |
+
# Disclaimer
|
| 58 |
+
|
| 59 |
+
- Creation of SFW and NSFW images is user's decision, user has complete control over to generate NSFW content whether or not.
|
| 60 |
+
|
| 61 |
+
---
|
| 62 |
+
|
| 63 |
+
# Used Models
|
| 64 |
+
|
| 65 |
+
* Chilled_re_generic_v2
|
| 66 |
+
|
| 67 |
+
- https://github.com/wibus-wee/stable_diffusion_chilloutmix_ipynb
|
| 68 |
+
|
| 69 |
+
* chilloutmix_cilloutmixNi
|
| 70 |
+
|
| 71 |
+
- https://civitai.com/models/6424/chilloutmix
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
# Recommended settings:
|
| 75 |
+
- Make sure you are aware on the usage instructions of LORA
|
| 76 |
+
|
| 77 |
+
- VAE: vae-ft-mse-840000-ema-pruned (For realistic models)
|
| 78 |
+
|
| 79 |
+
- Sampler: DPM++ SDE Karras (Recommended for best quality, you may try other samplers)
|
| 80 |
+
- Steps: 20 to 35
|
| 81 |
+
- Clipskip: 1 or 2
|
| 82 |
+
- Upscaler : Latent (bicubic antialiased)
|
| 83 |
+
- CFG Scale : 5 to 9
|
| 84 |
+
- LORA weight for txt2img: anywhere between 0.2 to 0.7 are recommended
|
| 85 |
+
- Denoise strength for img2img: 0.4 to 0.7
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
---
|
| 89 |
+
# LORA Detail
|
| 90 |
+
---
|
| 91 |
+
## KoreanDollLikeness
|
| 92 |
+
|
| 93 |
+
The first version that is widely used by many authors/AI artist/creators
|
| 94 |
+
|
| 95 |
+
### KoreanDollLikeness_v10
|
| 96 |
+
|
| 97 |
+
- KoreanDollLikeness_v10:
|
| 98 |
+
|
| 99 |
+
<img src=""https://files.catbox.moe/r61ozj.png"" width="""" height="""">
|
| 100 |
+
|
| 101 |
+
### KoreanDollLikeness_v15
|
| 102 |
+
|
| 103 |
+
- KoreanDollLikeness_v15:
|
| 104 |
+
|
| 105 |
+
<img src=""https://files.catbox.moe/pgcfhc.png"" widht="""" height="""">
|
| 106 |
+
|
| 107 |
+
### KoreanDollLikeness_v20
|
| 108 |
+
|
| 109 |
+
- KoreanDollLikeness_v20:
|
| 110 |
+
|
| 111 |
+
<img src=""https://files.catbox.moe/thehrt.png"" widht="""" height="""">
|
| 112 |
+
|
| 113 |
+
---
|
| 114 |
+
|
| 115 |
+
## JapaneseDollLikeness
|
| 116 |
+
|
| 117 |
+
The Japanese variant version, subjected for v15 in the future
|
| 118 |
+
|
| 119 |
+
### JapaneseDollLikeness_v10
|
| 120 |
+
|
| 121 |
+
- JapaneseDollLikeness_v10:
|
| 122 |
+
|
| 123 |
+
<img src=""https://files.catbox.moe/cfypot.png"" width="""" height="""">
|
| 124 |
+
|
| 125 |
+
### JapaneseDollLikeness_v15
|
| 126 |
+
|
| 127 |
+
- JapaneseDollLikeness_v15:
|
| 128 |
+
|
| 129 |
+
<img src=""https://files.catbox.moe/doa0n2.png"" width="""" height="""">
|
| 130 |
+
|
| 131 |
+
---
|
| 132 |
+
|
| 133 |
+
## TaiwanDollLikeness
|
| 134 |
+
|
| 135 |
+
The Taiwan variant version, I have decided to discontinue v10, it is still out there somewhere in the internet, you may still find it.
|
| 136 |
+
|
| 137 |
+
### TaiwanDollLikeness_v15
|
| 138 |
+
|
| 139 |
+
- TaiwanDollLikeness_v15:
|
| 140 |
+
|
| 141 |
+
<img src=""https://files.catbox.moe/5vr2z4.png"" width="""" height="""">
|
| 142 |
+
|
| 143 |
+
### TaiwanDollLikeness_v20
|
| 144 |
+
|
| 145 |
+
This version is a huge overhaul and remake, instead of building upon v10 or v15, I took small amount of samples from v10 and introduced a new pool of training images.
|
| 146 |
+
|
| 147 |
+
- TaiwanDollLikeness_v20:
|
| 148 |
+
|
| 149 |
+
<img src=""https://files.catbox.moe/f8c9mb.png"" width="""" height="""">
|
| 150 |
+
|
| 151 |
+
---
|
| 152 |
+
|
| 153 |
+
## ChinaDollLikeness
|
| 154 |
+
|
| 155 |
+
The China variant version, took awhile despite the requests, will probably make more versions of it in the future.
|
| 156 |
+
|
| 157 |
+
### ChinaDollLikeness_v10
|
| 158 |
+
|
| 159 |
+
<img src=""https://files.catbox.moe/zpj9ov.png"" width="""" height="""">
|
| 160 |
+
|
| 161 |
+
---
|
| 162 |
+
|
| 163 |
+
## ThaiDollLikeness
|
| 164 |
+
|
| 165 |
+
The Thai variant version, took me a long time to make this, many versions were made but this version is the one I've deemed the best out of all. Might update in the future.
|
| 166 |
+
|
| 167 |
+
### ThaiDollLikeness_v10
|
| 168 |
+
|
| 169 |
+
<img src=""https://files.catbox.moe/imtxsm.png"" width="""" height="""">
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
# FAQ
|
| 173 |
+
- # Q: Why can't I produce the same pictures as you?
|
| 174 |
+
- A: Sorry I don't share my prompt, you may check the recommended settings, but you may ask me for advice on Twitter or Pixiv
|
| 175 |
+
|
| 176 |
+
- # Q: What is the difference of each version upgrade?
|
| 177 |
+
- A: Version upgrade does not mean it will fix hands or legs, it is mainly difference of the face of the LORA, newer versions have wider range of faces.
|
| 178 |
+
|
| 179 |
+
- # Q: Will you release all your other LORAs?
|
| 180 |
+
- A: Yes, maybe, but I would like to keep certain LORA to be exclusive to fans or supporters in the future through fanbox/ko-fi
|
| 181 |
+
|
| 182 |
+
- # Q: Do you take requests or commissions on making custom LORAs?
|
| 183 |
+
- A: I might do community voting for requests, if you are somehow interested in a custom/exclusive LORA, you may contact my through Pixiv or Twitter for discussion
|
| 184 |
+
|
| 185 |
+
---
|
| 186 |
+
","{""id"": ""Kanbara/doll-likeness-series"", ""author"": ""Kanbara"", ""sha"": ""fcbb585f2ce963698354def0166a1ff0980c30b3"", ""last_modified"": ""2023-06-20 12:31:45+00:00"", ""created_at"": ""2023-03-28 13:49:45+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 389, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""license:creativeml-openrail-m"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""license: creativeml-openrail-m"", ""widget_data"": null, ""model_index"": null, ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='ThaiDollLikeness_v10.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='chinaDollLikeness_v10.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='japaneseDollLikeness_v10.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='japaneseDollLikeness_v15.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='koreanDollLikeness_v10.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='koreanDollLikeness_v15.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='koreanDollLikeness_v20.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='taiwanDollLikeness_v15.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='taiwanDollLikeness_v20.safetensors', size=None, blob_id=None, lfs=None)""], ""spaces"": [""pinkqween/DiscordAI""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-06-20 12:31:45+00:00"", ""cardData"": ""license: creativeml-openrail-m"", ""transformersInfo"": null, ""_id"": ""6422f07959a4ff30c277435a"", ""modelId"": ""Kanbara/doll-likeness-series"", ""usedStorage"": 1359994777}",0,,0,,0,,0,,0,"CompVis/stable-diffusion-license, huggingface/InferenceSupport/discussions/new?title=Kanbara/doll-likeness-series&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5BKanbara%2Fdoll-likeness-series%5D(%2FKanbara%2Fdoll-likeness-series)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, pinkqween/DiscordAI",3
|
elden-ring-diffusion_finetunes_20250426_121513.csv_finetunes_20250426_121513.csv
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
nitrosocke/elden-ring-diffusion,N/A,N/A,0,,0,,0,,0,,0,"CompVis/stable-diffusion-license, Daniela-C/6x_Image_diffusion, Joeythemonster/Text-To-image-AllModels, John6666/Diffusion80XX4sg, John6666/PrintingPress4, John6666/hfd_test_nostopbutton, Nymbo/image_gen_supaqueue, PeepDaSlan9/B2BMGMT_Diffusion60XX, Yntec/PrintingPress, Yntec/ToyWorld, Yntec/blitz_diffusion, huggingface/InferenceSupport/discussions/new?title=nitrosocke/elden-ring-diffusion&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bnitrosocke%2Felden-ring-diffusion%5D(%2Fnitrosocke%2Felden-ring-diffusion)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, phenixrhyder/NSFW-ToyWorld, yangheng/Super-Resolution-Anime-Diffusion",14
|
falcon-40b-instruct_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv
ADDED
|
@@ -0,0 +1,389 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_id,card,metadata,depth,children,children_count,adapters,adapters_count,quantized,quantized_count,merges,merges_count,spaces,spaces_count
|
| 2 |
+
tiiuae/falcon-40b-instruct,"---
|
| 3 |
+
datasets:
|
| 4 |
+
- tiiuae/falcon-refinedweb
|
| 5 |
+
language:
|
| 6 |
+
- en
|
| 7 |
+
inference: false
|
| 8 |
+
license: apache-2.0
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# ✨ Falcon-40B-Instruct
|
| 12 |
+
|
| 13 |
+
**Falcon-40B-Instruct is a 40B parameters causal decoder-only model built by [TII](https://www.tii.ae) based on [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b) and finetuned on a mixture of [Baize](https://github.com/project-baize/baize-chatbot). It is made available under the Apache 2.0 license.**
|
| 14 |
+
|
| 15 |
+
*Paper coming soon 😊.*
|
| 16 |
+
|
| 17 |
+
🤗 To get started with Falcon (inference, finetuning, quantization, etc.), we recommend reading [this great blogpost fron HF](https://huggingface.co/blog/falcon)!
|
| 18 |
+
|
| 19 |
+
## Why use Falcon-40B-Instruct?
|
| 20 |
+
|
| 21 |
+
* **You are looking for a ready-to-use chat/instruct model based on [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b).**
|
| 22 |
+
* **Falcon-40B is the best open-source model available.** It outperforms [LLaMA](https://github.com/facebookresearch/llama), [StableLM](https://github.com/Stability-AI/StableLM), [RedPajama](https://huggingface.co/togethercomputer/RedPajama-INCITE-Base-7B-v0.1), [MPT](https://huggingface.co/mosaicml/mpt-7b), etc. See the [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
|
| 23 |
+
* **It features an architecture optimized for inference**, with FlashAttention ([Dao et al., 2022](https://arxiv.org/abs/2205.14135)) and multiquery ([Shazeer et al., 2019](https://arxiv.org/abs/1911.02150)).
|
| 24 |
+
|
| 25 |
+
💬 **This is an instruct model, which may not be ideal for further finetuning.** If you are interested in building your own instruct/chat model, we recommend starting from [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b).
|
| 26 |
+
|
| 27 |
+
💸 **Looking for a smaller, less expensive model?** [Falcon-7B-Instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) is Falcon-40B-Instruct's little brother!
|
| 28 |
+
|
| 29 |
+
```python
|
| 30 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 31 |
+
import transformers
|
| 32 |
+
import torch
|
| 33 |
+
|
| 34 |
+
model = ""tiiuae/falcon-40b-instruct""
|
| 35 |
+
|
| 36 |
+
tokenizer = AutoTokenizer.from_pretrained(model)
|
| 37 |
+
pipeline = transformers.pipeline(
|
| 38 |
+
""text-generation"",
|
| 39 |
+
model=model,
|
| 40 |
+
tokenizer=tokenizer,
|
| 41 |
+
torch_dtype=torch.bfloat16,
|
| 42 |
+
trust_remote_code=True,
|
| 43 |
+
device_map=""auto"",
|
| 44 |
+
)
|
| 45 |
+
sequences = pipeline(
|
| 46 |
+
""Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\nDaniel: Hello, Girafatron!\nGirafatron:"",
|
| 47 |
+
max_length=200,
|
| 48 |
+
do_sample=True,
|
| 49 |
+
top_k=10,
|
| 50 |
+
num_return_sequences=1,
|
| 51 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 52 |
+
)
|
| 53 |
+
for seq in sequences:
|
| 54 |
+
print(f""Result: {seq['generated_text']}"")
|
| 55 |
+
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
For fast inference with Falcon, check-out [Text Generation Inference](https://github.com/huggingface/text-generation-inference)! Read more in this [blogpost]((https://huggingface.co/blog/falcon).
|
| 59 |
+
|
| 60 |
+
You will need **at least 85-100GB of memory** to swiftly run inference with Falcon-40B.
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
# Model Card for Falcon-40B-Instruct
|
| 65 |
+
|
| 66 |
+
## Model Details
|
| 67 |
+
|
| 68 |
+
### Model Description
|
| 69 |
+
|
| 70 |
+
- **Developed by:** [https://www.tii.ae](https://www.tii.ae);
|
| 71 |
+
- **Model type:** Causal decoder-only;
|
| 72 |
+
- **Language(s) (NLP):** English and French;
|
| 73 |
+
- **License:** Apache 2.0;
|
| 74 |
+
- **Finetuned from model:** [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b).
|
| 75 |
+
|
| 76 |
+
### Model Source
|
| 77 |
+
|
| 78 |
+
- **Paper:** *coming soon*.
|
| 79 |
+
|
| 80 |
+
## Uses
|
| 81 |
+
|
| 82 |
+
### Direct Use
|
| 83 |
+
|
| 84 |
+
Falcon-40B-Instruct has been finetuned on a chat dataset.
|
| 85 |
+
|
| 86 |
+
### Out-of-Scope Use
|
| 87 |
+
|
| 88 |
+
Production use without adequate assessment of risks and mitigation; any use cases which may be considered irresponsible or harmful.
|
| 89 |
+
|
| 90 |
+
## Bias, Risks, and Limitations
|
| 91 |
+
|
| 92 |
+
Falcon-40B-Instruct is mostly trained on English data, and will not generalize appropriately to other languages. Furthermore, as it is trained on a large-scale corpora representative of the web, it will carry the stereotypes and biases commonly encountered online.
|
| 93 |
+
|
| 94 |
+
### Recommendations
|
| 95 |
+
|
| 96 |
+
We recommend users of Falcon-40B-Instruct to develop guardrails and to take appropriate precautions for any production use.
|
| 97 |
+
|
| 98 |
+
## How to Get Started with the Model
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
```python
|
| 102 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 103 |
+
import transformers
|
| 104 |
+
import torch
|
| 105 |
+
|
| 106 |
+
model = ""tiiuae/falcon-40b-instruct""
|
| 107 |
+
|
| 108 |
+
tokenizer = AutoTokenizer.from_pretrained(model)
|
| 109 |
+
pipeline = transformers.pipeline(
|
| 110 |
+
""text-generation"",
|
| 111 |
+
model=model,
|
| 112 |
+
tokenizer=tokenizer,
|
| 113 |
+
torch_dtype=torch.bfloat16,
|
| 114 |
+
trust_remote_code=True,
|
| 115 |
+
device_map=""auto"",
|
| 116 |
+
)
|
| 117 |
+
sequences = pipeline(
|
| 118 |
+
""Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\nDaniel: Hello, Girafatron!\nGirafatron:"",
|
| 119 |
+
max_length=200,
|
| 120 |
+
do_sample=True,
|
| 121 |
+
top_k=10,
|
| 122 |
+
num_return_sequences=1,
|
| 123 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 124 |
+
)
|
| 125 |
+
for seq in sequences:
|
| 126 |
+
print(f""Result: {seq['generated_text']}"")
|
| 127 |
+
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
## Training Details
|
| 131 |
+
|
| 132 |
+
### Training Data
|
| 133 |
+
|
| 134 |
+
Falcon-40B-Instruct was finetuned on a 150M tokens from [Bai ze](https://github.com/project-baize/baize-chatbot) mixed with 5% of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) data.
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
The data was tokenized with the Falcon-[7B](https://huggingface.co/tiiuae/falcon-7b)/[40B](https://huggingface.co/tiiuae/falcon-40b) tokenizer.
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
## Evaluation
|
| 141 |
+
|
| 142 |
+
*Paper coming soon.*
|
| 143 |
+
|
| 144 |
+
See the [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) for early results.
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
## Technical Specifications
|
| 148 |
+
|
| 149 |
+
For more information about pretraining, see [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b).
|
| 150 |
+
|
| 151 |
+
### Model Architecture and Objective
|
| 152 |
+
|
| 153 |
+
Falcon-40B is a causal decoder-only model trained on a causal language modeling task (i.e., predict the next token).
|
| 154 |
+
|
| 155 |
+
The architecture is broadly adapted from the GPT-3 paper ([Brown et al., 2020](https://arxiv.org/abs/2005.14165)), with the following differences:
|
| 156 |
+
|
| 157 |
+
* **Positionnal embeddings:** rotary ([Su et al., 2021](https://arxiv.org/abs/2104.09864));
|
| 158 |
+
* **Attention:** multiquery ([Shazeer et al., 2019](https://arxiv.org/abs/1911.02150)) and FlashAttention ([Dao et al., 2022](https://arxiv.org/abs/2205.14135));
|
| 159 |
+
* **Decoder-block:** parallel attention/MLP with a single layer norm.
|
| 160 |
+
|
| 161 |
+
For multiquery, we are using an internal variant which uses independent key and values per tensor parallel degree.
|
| 162 |
+
|
| 163 |
+
| **Hyperparameter** | **Value** | **Comment** |
|
| 164 |
+
|--------------------|-----------|----------------------------------------|
|
| 165 |
+
| Layers | 60 | |
|
| 166 |
+
| `d_model` | 8192 | |
|
| 167 |
+
| `head_dim` | 64 | Reduced to optimise for FlashAttention |
|
| 168 |
+
| Vocabulary | 65024 | |
|
| 169 |
+
| Sequence length | 2048 | |
|
| 170 |
+
|
| 171 |
+
### Compute Infrastructure
|
| 172 |
+
|
| 173 |
+
#### Hardware
|
| 174 |
+
|
| 175 |
+
Falcon-40B-Instruct was trained on AWS SageMaker, on 64 A100 40GB GPUs in P4d instances.
|
| 176 |
+
|
| 177 |
+
#### Software
|
| 178 |
+
|
| 179 |
+
Falcon-40B-Instruct was trained a custom distributed training codebase, Gigatron. It uses a 3D parallelism approach combined with ZeRO and high-performance Triton kernels (FlashAttention, etc.)
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
## Citation
|
| 183 |
+
|
| 184 |
+
*Paper coming soon* 😊. In the meanwhile, you can use the following information to cite:
|
| 185 |
+
```
|
| 186 |
+
@article{falcon40b,
|
| 187 |
+
title={{Falcon-40B}: an open large language model with state-of-the-art performance},
|
| 188 |
+
author={Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme},
|
| 189 |
+
year={2023}
|
| 190 |
+
}
|
| 191 |
+
```
|
| 192 |
+
|
| 193 |
+
To learn more about the pretraining dataset, see the 📓 [RefinedWeb paper](https://arxiv.org/abs/2306.01116).
|
| 194 |
+
|
| 195 |
+
```
|
| 196 |
+
@article{refinedweb,
|
| 197 |
+
title={The {R}efined{W}eb dataset for {F}alcon {LLM}: outperforming curated corpora with web data, and web data only},
|
| 198 |
+
author={Guilherme Penedo and Quentin Malartic and Daniel Hesslow and Ruxandra Cojocaru and Alessandro Cappelli and Hamza Alobeidli and Baptiste Pannier and Ebtesam Almazrouei and Julien Launay},
|
| 199 |
+
journal={arXiv preprint arXiv:2306.01116},
|
| 200 |
+
eprint={2306.01116},
|
| 201 |
+
eprinttype = {arXiv},
|
| 202 |
+
url={https://arxiv.org/abs/2306.01116},
|
| 203 |
+
year={2023}
|
| 204 |
+
}
|
| 205 |
+
```
|
| 206 |
+
|
| 207 |
+
To cite the [Baize](https://github.com/project-baize/baize-chatbot) instruction dataset used for this model:
|
| 208 |
+
```
|
| 209 |
+
@article{xu2023baize,
|
| 210 |
+
title={Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data},
|
| 211 |
+
author={Xu, Canwen and Guo, Daya and Duan, Nan and McAuley, Julian},
|
| 212 |
+
journal={arXiv preprint arXiv:2304.01196},
|
| 213 |
+
year={2023}
|
| 214 |
+
}
|
| 215 |
+
```
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
## License
|
| 219 |
+
|
| 220 |
+
Falcon-40B-Instruct is made available under the Apache 2.0 license.
|
| 221 |
+
|
| 222 |
+
## Contact
|
| 223 |
+
falconllm@tii.ae","{""id"": ""tiiuae/falcon-40b-instruct"", ""author"": ""tiiuae"", ""sha"": ""ecb78d97ac356d098e79f0db222c9ce7c5d9ee5f"", ""last_modified"": ""2023-09-29 14:32:27+00:00"", ""created_at"": ""2023-05-25 10:14:36+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 65164, ""downloads_all_time"": null, ""likes"": 1174, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""pytorch"", ""falcon"", ""text-generation"", ""custom_code"", ""en"", ""dataset:tiiuae/falcon-refinedweb"", ""arxiv:2205.14135"", ""arxiv:1911.02150"", ""arxiv:2005.14165"", ""arxiv:2104.09864"", ""arxiv:2306.01116"", ""arxiv:2304.01196"", ""license:apache-2.0"", ""autotrain_compatible"", ""text-generation-inference"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": ""text-generation"", ""mask_token"": null, ""trending_score"": null, ""card_data"": ""datasets:\n- tiiuae/falcon-refinedweb\nlanguage:\n- en\nlicense: apache-2.0\ninference: false"", ""widget_data"": [{""text"": ""My name is Julien and I like to""}, {""text"": ""I like traveling by train because""}, {""text"": ""Paris is an amazing place to visit,""}, {""text"": ""Once upon a time,""}], ""model_index"": null, ""config"": {""architectures"": [""FalconForCausalLM""], ""auto_map"": {""AutoConfig"": ""configuration_falcon.FalconConfig"", ""AutoModel"": ""modeling_falcon.FalconModel"", ""AutoModelForSequenceClassification"": ""modeling_falcon.FalconForSequenceClassification"", ""AutoModelForTokenClassification"": ""modeling_falcon.FalconForTokenClassification"", ""AutoModelForQuestionAnswering"": ""modeling_falcon.FalconForQuestionAnswering"", ""AutoModelForCausalLM"": ""modeling_falcon.FalconForCausalLM""}, ""model_type"": ""falcon"", ""tokenizer_config"": {""eos_token"": ""<|endoftext|>""}}, ""transformers_info"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='configuration_falcon.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='generation_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='handler.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='modeling_falcon.py', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00001-of-00009.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00002-of-00009.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00003-of-00009.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00004-of-00009.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00005-of-00009.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00006-of-00009.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00007-of-00009.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00008-of-00009.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model-00009-of-00009.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='pytorch_model.bin.index.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)""], ""spaces"": [""Vokturz/can-it-run-llm"", ""HuggingFaceH4/falcon-chat"", ""h2oai/h2ogpt-chatbot"", ""h2oai/h2ogpt-chatbot2"", ""Intel/low_bit_open_llm_leaderboard"", ""BAAI/open_cn_llm_leaderboard"", ""Sharathhebbar24/One-stop-for-Open-source-models"", ""gsaivinay/open_llm_leaderboard"", ""meval/multilingual-chatbot-arena-leaderboard"", ""GTBench/GTBench"", ""Vikhrmodels/small-shlepa-lb"", ""Justinrune/LLaMA-Factory"", ""kenken999/fastapi_django_main_live"", ""kz-transformers/kaz-llm-lb"", ""felixz/open_llm_leaderboard"", ""awacke1/Deepseek-HPC-GPU-KEDA"", ""officialhimanshu595/llama-factory"", ""OPTML-Group/UnlearnCanvas-Benchmark"", ""BAAI/open_flageval_vlm_leaderboard"", ""hlydecker/falcon-chat"", ""b1sheng/kg_llm_leaderboard_test"", ""neubla/neubla-llm-evaluation-board"", ""lambdabrendan/Lambda-LLM-Calculator"", ""lapsapking/h2ogpt-chatbot"", ""bparks08/falcon-chat-40b-1"", ""danfsmithmsft/falcon-chat"", ""NebulaVortex/falcon-chat"", ""rodrigomasini/data_only_open_llm_leaderboard"", ""Docfile/open_llm_leaderboard"", ""his0/h2ogpt-chatbot"", ""atimughal662/InfoFusion"", ""alexkueck/ChatBotLI2Klein"", ""ZENLLC/EagleAsk"", ""HighVibesTimes/falcon-chat"", ""patti-j/Omdena-MHWB-Falcon"", ""qtvhao/falcon-chat"", ""iamrobotbear/falcon-chat"", ""linfso/falcon-chat"", ""bpmf/falcon-chat"", ""Aaksh/tester"", ""ariel0330/h2osiri"", ""bhaskartripathi/PDF-GPT_Falcon"", ""elbanhawy/falcon-chat"", ""Inoob/falcon-chat"", ""Gage888/falcon-Gage-chat-01"", ""ccoreilly/aigua-xat"", ""Felix9390/Graphica-2"", ""Sambhavnoobcoder/h2ogpt-chatbot"", ""adnansami1992sami/falcon-chat"", ""dzekoh/ChatBot"", ""k3ybladewielder/gen_app_chat"", ""E1829/Falcon"", ""E1829/falcon-chat2"", ""busraasan/gpt_comparison"", ""k3ybladewielder/falcon-40b-instruct"", ""smothiki/open_llm_leaderboard"", ""mouliraj56/falcon"", ""blackwingedkite/gutalk"", ""mouliraj56/testpdf"", ""pngwn/open_llm_leaderboard"", ""pngwn/open_llm_leaderboard_two"", ""yourstudiolab/eai1a"", ""iblfe/test"", ""watsonswx/chatrobot"", ""UdayG01/mockinterview-v1"", ""aimaswx/chatbot_v1"", ""AnonymousSub/Ayurveda_Chatbot"", ""K00B404/Research-chatbot"", ""iShare/pdf_ai_bot_hf"", ""Cran-May/falcon-40b-instruct-ggml"", ""blackwingedkite/alpaca2_clas"", ""wissamantoun/LLM_Detection_Attribution"", ""0x1668/open_llm_leaderboard"", ""pngwn/open_llm_leaderboard-check"", ""asir0z/open_llm_leaderboard"", ""kelvin-t-lu/chatbot"", ""Nymbo/can-it-run-llm"", ""Elreniel/llm_chat"", ""kbmlcoding/open_llm_leaderboard_free"", ""acecalisto3/SAIOPSYS"", ""acloudfan/HF-Playground"", ""binqiangliu/DocChat_WM"", ""Rehman1603/Chat_with_Document"", ""dbasu/multilingual-chatbot-arena-leaderboard"", ""PrathamSharma/dima806-indian_food_image_detection"", ""K00B404/One-stop-till-you-drop"", ""aichampions/open_llm_leaderboard"", ""Adeco/open_llm_leaderboard"", ""RobinsAIWorld/can-it-run-llm"", ""Jamiiwej2903/kaaaa"", ""anirudh937/open_llm_leaderboard"", ""smothiki/open_llm_leaderboard2"", ""cw332/h2ogpt-chatbot"", ""samkn123/chatbot"", ""Asim07/cover-query"", ""mjalg/IFEvalTR"", ""mani1996123/newkjnkjn"", ""Shrijoy/falcon_summarizer"", ""abugaber/test"", ""mpvasilis/can-it-run-llm""], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-09-29 14:32:27+00:00"", ""cardData"": ""datasets:\n- tiiuae/falcon-refinedweb\nlanguage:\n- en\nlicense: apache-2.0\ninference: false"", ""transformersInfo"": {""auto_model"": ""AutoModelForCausalLM"", ""custom_class"": null, ""pipeline_tag"": ""text-generation"", ""processor"": ""AutoTokenizer""}, ""_id"": ""646f350ce2a72c647b686b91"", ""modelId"": ""tiiuae/falcon-40b-instruct"", ""usedStorage"": 167352935898}",0,"https://huggingface.co/lucas0/empath-falcon-40b, https://huggingface.co/anirudh2403/results, https://huggingface.co/miragexy/ins_fine_tuned_falcon40B",3,"https://huggingface.co/mubashirsaeed/care-bot-harry-potter-falcon-40b, https://huggingface.co/Shishir17/falcon40binstruct_mentalhealthmodel_oct23",2,"https://huggingface.co/mradermacher/falcon-40b-instruct-GGUF, https://huggingface.co/mradermacher/falcon-40b-instruct-i1-GGUF",2,,0,"BAAI/open_cn_llm_leaderboard, GTBench/GTBench, HuggingFaceH4/falcon-chat, HuggingFaceH4/open_llm_leaderboard, Intel/low_bit_open_llm_leaderboard, Justinrune/LLaMA-Factory, OPTML-Group/UnlearnCanvas-Benchmark, Sharathhebbar24/One-stop-for-Open-source-models, Vikhrmodels/small-shlepa-lb, Vokturz/can-it-run-llm, awacke1/Deepseek-HPC-GPU-KEDA, huggingface/InferenceSupport/discussions/new?title=tiiuae/falcon-40b-instruct&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Btiiuae%2Ffalcon-40b-instruct%5D(%2Ftiiuae%2Ffalcon-40b-instruct)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A, kenken999/fastapi_django_main_live, meval/multilingual-chatbot-arena-leaderboard",14
|
| 224 |
+
lucas0/empath-falcon-40b,"---
|
| 225 |
+
license: apache-2.0
|
| 226 |
+
base_model: tiiuae/falcon-40b-instruct
|
| 227 |
+
tags:
|
| 228 |
+
- generated_from_trainer
|
| 229 |
+
model-index:
|
| 230 |
+
- name: empath-falcon-40b
|
| 231 |
+
results: []
|
| 232 |
+
---
|
| 233 |
+
|
| 234 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 235 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 236 |
+
|
| 237 |
+
# empath-falcon-40b
|
| 238 |
+
|
| 239 |
+
This model is a fine-tuned version of [tiiuae/falcon-40b-instruct](https://huggingface.co/tiiuae/falcon-40b-instruct) on the None dataset.
|
| 240 |
+
|
| 241 |
+
## Model description
|
| 242 |
+
|
| 243 |
+
More information needed
|
| 244 |
+
|
| 245 |
+
## Intended uses & limitations
|
| 246 |
+
|
| 247 |
+
More information needed
|
| 248 |
+
|
| 249 |
+
## Training and evaluation data
|
| 250 |
+
|
| 251 |
+
More information needed
|
| 252 |
+
|
| 253 |
+
## Training procedure
|
| 254 |
+
|
| 255 |
+
### Training hyperparameters
|
| 256 |
+
|
| 257 |
+
The following hyperparameters were used during training:
|
| 258 |
+
- learning_rate: 0.0002
|
| 259 |
+
- train_batch_size: 4
|
| 260 |
+
- eval_batch_size: 8
|
| 261 |
+
- seed: 42
|
| 262 |
+
- gradient_accumulation_steps: 4
|
| 263 |
+
- total_train_batch_size: 16
|
| 264 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 265 |
+
- lr_scheduler_type: cosine
|
| 266 |
+
- lr_scheduler_warmup_ratio: 0.05
|
| 267 |
+
- num_epochs: 3
|
| 268 |
+
|
| 269 |
+
### Training results
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
### Framework versions
|
| 274 |
+
|
| 275 |
+
- Transformers 4.32.0.dev0
|
| 276 |
+
- Pytorch 2.0.1+cu117
|
| 277 |
+
- Datasets 2.13.1
|
| 278 |
+
- Tokenizers 0.13.3
|
| 279 |
+
","{""id"": ""lucas0/empath-falcon-40b"", ""author"": ""lucas0"", ""sha"": ""826c4a41158acd1c5846aff0d104ac116885b36f"", ""last_modified"": ""2023-07-28 01:04:53+00:00"", ""created_at"": ""2023-07-20 18:29:06+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": null, ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""generated_from_trainer"", ""base_model:tiiuae/falcon-40b-instruct"", ""base_model:finetune:tiiuae/falcon-40b-instruct"", ""license:apache-2.0"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: tiiuae/falcon-40b-instruct\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: empath-falcon-40b\n results: []"", ""widget_data"": null, ""model_index"": [{""name"": ""empath-falcon-40b"", ""results"": []}], ""config"": null, ""transformers_info"": null, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='.gitignore', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-07-28 01:04:53+00:00"", ""cardData"": ""base_model: tiiuae/falcon-40b-instruct\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: empath-falcon-40b\n results: []"", ""transformersInfo"": null, ""_id"": ""64b97cf284ddd52599b8cde3"", ""modelId"": ""lucas0/empath-falcon-40b"", ""usedStorage"": 133840248}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=lucas0/empath-falcon-40b&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Blucas0%2Fempath-falcon-40b%5D(%2Flucas0%2Fempath-falcon-40b)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 280 |
+
anirudh2403/results,"---
|
| 281 |
+
license: apache-2.0
|
| 282 |
+
base_model: tiiuae/falcon-40b-instruct
|
| 283 |
+
tags:
|
| 284 |
+
- generated_from_trainer
|
| 285 |
+
model-index:
|
| 286 |
+
- name: results
|
| 287 |
+
results: []
|
| 288 |
+
---
|
| 289 |
+
|
| 290 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 291 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 292 |
+
|
| 293 |
+
# results
|
| 294 |
+
|
| 295 |
+
This model is a fine-tuned version of [tiiuae/falcon-40b-instruct](https://huggingface.co/tiiuae/falcon-40b-instruct) on an unknown dataset.
|
| 296 |
+
|
| 297 |
+
## Model description
|
| 298 |
+
|
| 299 |
+
More information needed
|
| 300 |
+
|
| 301 |
+
## Intended uses & limitations
|
| 302 |
+
|
| 303 |
+
More information needed
|
| 304 |
+
|
| 305 |
+
## Training and evaluation data
|
| 306 |
+
|
| 307 |
+
More information needed
|
| 308 |
+
|
| 309 |
+
## Training procedure
|
| 310 |
+
|
| 311 |
+
### Training hyperparameters
|
| 312 |
+
|
| 313 |
+
The following hyperparameters were used during training:
|
| 314 |
+
- learning_rate: 0.0002
|
| 315 |
+
- train_batch_size: 4
|
| 316 |
+
- eval_batch_size: 8
|
| 317 |
+
- seed: 42
|
| 318 |
+
- gradient_accumulation_steps: 4
|
| 319 |
+
- total_train_batch_size: 16
|
| 320 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 321 |
+
- lr_scheduler_type: constant
|
| 322 |
+
- lr_scheduler_warmup_ratio: 0.03
|
| 323 |
+
- training_steps: 500
|
| 324 |
+
|
| 325 |
+
### Framework versions
|
| 326 |
+
|
| 327 |
+
- Transformers 4.33.2
|
| 328 |
+
- Pytorch 2.0.1+cu118
|
| 329 |
+
- Datasets 2.14.5
|
| 330 |
+
- Tokenizers 0.13.3
|
| 331 |
+
","{""id"": ""anirudh2403/results"", ""author"": ""anirudh2403"", ""sha"": ""1f056d7d68f8d4f42e40fa10ae66483ffc2c5662"", ""last_modified"": ""2023-09-19 20:17:00+00:00"", ""created_at"": ""2023-09-19 19:09:48+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 6, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""generated_from_trainer"", ""base_model:tiiuae/falcon-40b-instruct"", ""base_model:finetune:tiiuae/falcon-40b-instruct"", ""license:apache-2.0"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: tiiuae/falcon-40b-instruct\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: results\n results: []"", ""widget_data"": null, ""model_index"": [{""name"": ""results"", ""results"": []}], ""config"": {""tokenizer_config"": {""eos_token"": ""<|endoftext|>""}}, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_model.bin', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2023-09-19 20:17:00+00:00"", ""cardData"": ""base_model: tiiuae/falcon-40b-instruct\nlicense: apache-2.0\ntags:\n- generated_from_trainer\nmodel-index:\n- name: results\n results: []"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""6509f1fccc02352e1e28b26d"", ""modelId"": ""anirudh2403/results"", ""usedStorage"": 1777517192}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=anirudh2403/results&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Banirudh2403%2Fresults%5D(%2Fanirudh2403%2Fresults)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
| 332 |
+
miragexy/ins_fine_tuned_falcon40B,"---
|
| 333 |
+
base_model: tiiuae/falcon-40b-instruct
|
| 334 |
+
library_name: transformers
|
| 335 |
+
model_name: ins_fine_tuned_falcon40B
|
| 336 |
+
tags:
|
| 337 |
+
- generated_from_trainer
|
| 338 |
+
- trl
|
| 339 |
+
- sft
|
| 340 |
+
licence: license
|
| 341 |
+
---
|
| 342 |
+
|
| 343 |
+
# Model Card for ins_fine_tuned_falcon40B
|
| 344 |
+
|
| 345 |
+
This model is a fine-tuned version of [tiiuae/falcon-40b-instruct](https://huggingface.co/tiiuae/falcon-40b-instruct).
|
| 346 |
+
It has been trained using [TRL](https://github.com/huggingface/trl).
|
| 347 |
+
|
| 348 |
+
## Quick start
|
| 349 |
+
|
| 350 |
+
```python
|
| 351 |
+
from transformers import pipeline
|
| 352 |
+
|
| 353 |
+
question = ""If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?""
|
| 354 |
+
generator = pipeline(""text-generation"", model=""miragexy/ins_fine_tuned_falcon40B"", device=""cuda"")
|
| 355 |
+
output = generator([{""role"": ""user"", ""content"": question}], max_new_tokens=128, return_full_text=False)[0]
|
| 356 |
+
print(output[""generated_text""])
|
| 357 |
+
```
|
| 358 |
+
|
| 359 |
+
## Training procedure
|
| 360 |
+
|
| 361 |
+
[<img src=""https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg"" alt=""Visualize in Weights & Biases"" width=""150"" height=""24""/>](https://wandb.ai/a7med7usam777-technology-innovation-institute/huggingface/runs/m0vfp2ng)
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
This model was trained with SFT.
|
| 365 |
+
|
| 366 |
+
### Framework versions
|
| 367 |
+
|
| 368 |
+
- TRL: 0.13.0
|
| 369 |
+
- Transformers: 4.48.0
|
| 370 |
+
- Pytorch: 2.5.1
|
| 371 |
+
- Datasets: 3.2.0
|
| 372 |
+
- Tokenizers: 0.21.0
|
| 373 |
+
|
| 374 |
+
## Citations
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
|
| 378 |
+
Cite TRL as:
|
| 379 |
+
|
| 380 |
+
```bibtex
|
| 381 |
+
@misc{vonwerra2022trl,
|
| 382 |
+
title = {{TRL: Transformer Reinforcement Learning}},
|
| 383 |
+
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
|
| 384 |
+
year = 2020,
|
| 385 |
+
journal = {GitHub repository},
|
| 386 |
+
publisher = {GitHub},
|
| 387 |
+
howpublished = {\url{https://github.com/huggingface/trl}}
|
| 388 |
+
}
|
| 389 |
+
```","{""id"": ""miragexy/ins_fine_tuned_falcon40B"", ""author"": ""miragexy"", ""sha"": ""746d28f543a4c824a11e4731428610eeef07e4fb"", ""last_modified"": ""2025-01-12 15:18:09+00:00"", ""created_at"": ""2025-01-09 20:46:14+00:00"", ""private"": false, ""gated"": false, ""disabled"": false, ""downloads"": 0, ""downloads_all_time"": null, ""likes"": 0, ""library_name"": ""transformers"", ""gguf"": null, ""inference"": null, ""inference_provider_mapping"": null, ""tags"": [""transformers"", ""tensorboard"", ""safetensors"", ""generated_from_trainer"", ""trl"", ""sft"", ""base_model:tiiuae/falcon-40b-instruct"", ""base_model:finetune:tiiuae/falcon-40b-instruct"", ""endpoints_compatible"", ""region:us""], ""pipeline_tag"": null, ""mask_token"": null, ""trending_score"": null, ""card_data"": ""base_model: tiiuae/falcon-40b-instruct\nlibrary_name: transformers\nmodel_name: ins_fine_tuned_falcon40B\ntags:\n- generated_from_trainer\n- trl\n- sft\nlicence: license"", ""widget_data"": null, ""model_index"": null, ""config"": {""tokenizer_config"": {""eos_token"": ""<|endoftext|>"", ""pad_token"": ""<|endoftext|>""}}, ""transformers_info"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""siblings"": [""RepoSibling(rfilename='.gitattributes', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='README.md', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='adapter_model.safetensors', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='logs/events.out.tfevents.1736455575.c575303a0d41.1684.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='logs/events.out.tfevents.1736456477.c575303a0d41.9549.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='logs/events.out.tfevents.1736458064.c575303a0d41.16633.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='logs/events.out.tfevents.1736634088.192-222-59-245.6243.0', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='special_tokens_map.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='tokenizer_config.json', size=None, blob_id=None, lfs=None)"", ""RepoSibling(rfilename='training_args.bin', size=None, blob_id=None, lfs=None)""], ""spaces"": [], ""safetensors"": null, ""security_repo_status"": null, ""xet_enabled"": null, ""lastModified"": ""2025-01-12 15:18:09+00:00"", ""cardData"": ""base_model: tiiuae/falcon-40b-instruct\nlibrary_name: transformers\nmodel_name: ins_fine_tuned_falcon40B\ntags:\n- generated_from_trainer\n- trl\n- sft\nlicence: license"", ""transformersInfo"": {""auto_model"": ""AutoModel"", ""custom_class"": null, ""pipeline_tag"": null, ""processor"": null}, ""_id"": ""67803596a1ab15dbf8250d1b"", ""modelId"": ""miragexy/ins_fine_tuned_falcon40B"", ""usedStorage"": 267498174}",1,,0,,0,,0,,0,huggingface/InferenceSupport/discussions/new?title=miragexy/ins_fine_tuned_falcon40B&description=React%20to%20this%20comment%20with%20an%20emoji%20to%20vote%20for%20%5Bmiragexy%2Fins_fine_tuned_falcon40B%5D(%2Fmiragexy%2Fins_fine_tuned_falcon40B)%20to%20be%20supported%20by%20Inference%20Providers.%0A%0A(optional)%20Which%20providers%20are%20you%20interested%20in%3F%20(Novita%2C%20Hyperbolic%2C%20Together%E2%80%A6)%0A,1
|
flan-t5-large_finetunes_20250424_223250.csv_finetunes_20250424_223250.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|