` of the :setting:`TASKS` setting, like so::\n \n TASKS = {\n \"default\": {"
}
],
"reviews": [
{
"id": 3530866098,
"user": "user_34c3f4acb8a8",
"state": "APPROVED",
"body": "Looks good to me!\n\nAre we ok with just saying \"3rd-party packages\", and leaving it to the user to go and find them? \n\nPerhaps worth mentioning `django-tasks` in the context of a backport? Although that may be a different PR.",
"submitted_at": "2025-12-02T15:49:46+00:00"
},
{
"id": 3531546177,
"user": "user_a2cd65b227cf",
"state": "COMMENTED",
"body": null,
"submitted_at": "2025-12-02T18:19:25+00:00"
},
{
"id": 3531675230,
"user": "user_00dac951cdbf",
"state": "COMMENTED",
"body": null,
"submitted_at": "2025-12-03T13:05:30+00:00"
},
{
"id": 3535277592,
"user": "user_6b79e26637e6",
"state": "COMMENTED",
"body": null,
"submitted_at": "2025-12-03T14:15:23+00:00"
},
{
"id": 3535323642,
"user": "user_00dac951cdbf",
"state": "COMMENTED",
"body": null,
"submitted_at": "2025-12-03T14:25:26+00:00"
},
{
"id": 3535341361,
"user": "user_34c3f4acb8a8",
"state": "COMMENTED",
"body": null,
"submitted_at": "2025-12-03T14:29:21+00:00"
},
{
"id": 3535512975,
"user": "user_a2cd65b227cf",
"state": "COMMENTED",
"body": null,
"submitted_at": "2025-12-03T15:05:51+00:00"
},
{
"id": 3535513673,
"user": "user_00dac951cdbf",
"state": "COMMENTED",
"body": null,
"submitted_at": "2025-12-03T15:06:00+00:00"
},
{
"id": 3535559583,
"user": "user_3a67c55598c5",
"state": "COMMENTED",
"body": "Looks good. (I might remove the last sentence of the new heading section, but it's okay as is.)",
"submitted_at": "2025-12-03T15:15:52+00:00"
},
{
"id": 3535564823,
"user": "user_a2cd65b227cf",
"state": "COMMENTED",
"body": null,
"submitted_at": "2025-12-03T15:16:56+00:00"
},
{
"id": 3535572566,
"user": "user_6b79e26637e6",
"state": "COMMENTED",
"body": null,
"submitted_at": "2025-12-03T15:18:39+00:00"
},
{
"id": 3535646130,
"user": "user_057de2f3b132",
"state": "COMMENTED",
"body": null,
"submitted_at": "2025-12-03T15:34:52+00:00"
},
{
"id": 3535735401,
"user": "user_00dac951cdbf",
"state": "APPROVED",
"body": "🏅 🏆 🌟",
"submitted_at": "2025-12-03T15:50:59+00:00"
}
],
"review_comments": [
{
"id": 2582331943,
"user": "user_a2cd65b227cf",
"body": "In my head (without me referring to the docs style guide mind you so if this breaks that then I'm fine with it), I was thinking a short info or warning call out box here stating that you will need a third-party package to execute tasks in the background.",
"path": "docs/topics/tasks.txt",
"line": null,
"side": "RIGHT",
"created_at": "2025-12-02T18:19:25+00:00"
},
{
"id": 2582437403,
"user": "user_00dac951cdbf",
"body": "I'll push some reworking on this since the ecosystem page, as how it is now, it's not listing the major tasks bakends. I have reached out to Tim S about this, so it'll likely get fixed soon.\n\nIn any case, I rather to link to the ecosystem page in a single place and I think the topics page is the best location. Will propose something asap!",
"path": "docs/releases/6.0.txt",
"line": null,
"side": "RIGHT",
"created_at": "2025-12-02T18:49:33+00:00"
},
{
"id": 2585038824,
"user": "user_00dac951cdbf",
"body": "I'll try to give this a go.",
"path": "docs/topics/tasks.txt",
"line": null,
"side": "RIGHT",
"created_at": "2025-12-03T13:05:25+00:00"
},
{
"id": 2585296808,
"user": "user_6b79e26637e6",
"body": "I believe we should link directly to the `django-tasks` documentation about backends here in this context rather than the ecosystem page. The reason being is that the ecosystem page is more likely to list out all background task processing libraries, including ones that don't implement the `django-tasks` API, such as Celery. It would be confusing for someone who is looking for the production ready backends to be used with the tasks part of Django to be linked to a page that lists options they can't use.\n\nAdditionally, I expect `django-tasks` to be more up to date with the \"production ready\" backends than the ecosystem page, no? cc: [USER_REDACTED]/steering-council",
"path": "docs/releases/6.0.txt",
"line": null,
"side": "RIGHT",
"created_at": "2025-12-03T14:15:22+00:00"
},
{
"id": 2585333520,
"user": "user_00dac951cdbf",
"body": "I do not think we should link directly to django-tasks here. The Tasks framework *in Django* is intentionally limited to the stable core contract for defining and queuing work. Backend specifics, including which packages implement the API, are outside that contract and change much faster than the Django docs.\n\nThe ecosystem page is the right place to endorse, list, and curate third party backends (even if that means a single entry \"check django-tasks for the up to date list of production ready backends that implement the [NAME_REDACTED] API\"), and it can clearly separate API compatible packages from general background processing tools. That keeps the Django docs focused on the framework itself while letting backend guidance evolve independently.",
"path": "docs/releases/6.0.txt",
"line": null,
"side": "RIGHT",
"created_at": "2025-12-03T14:25:25+00:00"
},
{
"id": 2585348320,
"user": "user_34c3f4acb8a8",
"body": "> I expect `django-tasks` to be more up to date with the \"production ready\" backends than the ecosystem page\n\nAs time goes on, there'll be more features in `django-tasks` than in `django`. Those features will still be usable in production, but may not come with the same rigorous testing that including in Django assumes.\n\nI also expect more backends to exist outside of `django-tasks`, and have little intention of listing them in the README.",
"path": "docs/releases/6.0.txt",
"line": null,
"side": "RIGHT",
"created_at": "2025-12-03T14:29:21+00:00"
},
{
"id": 2585488731,
"user": "user_a2cd65b227cf",
"body": "My 2 cents here:\n\n* We need to be clear that django-tasks is the first production ready background task worker & backend (it's not in Django yet)\n* At some point be clear about if there are things in django-tasks that won't likely appear in Django, essentially at what points does it start to diverge from the reference implementation of the DEP?\n* I would expect any callout to django-tasks specifically to be time-limited to the 6.X release cycle.\n\nAll that stems from wanting to reduce the amount of questions that have and will continue to pop up on the forum and Discord.",
"path": "docs/releases/6.0.txt",
"line": null,
"side": "RIGHT",
"created_at": "2025-12-03T15:05:51+00:00"
},
{
"id": 2585489439,
"user": "user_00dac951cdbf",
"body": "[USER_REDACTED] [USER_REDACTED] I tried to give this a go but I reverted the box usage since the docs say all over the place (ref/tasks, topics/tasks, release notes) what tasks are and are not. At some point, we truly need users to read what's written :sob:",
"path": "docs/topics/tasks.txt",
"line": null,
"side": "RIGHT",
"created_at": "2025-12-03T15:06:00+00:00"
},
{
"id": 2585530619,
"user": "user_a2cd65b227cf",
"body": "The additions here are good. Let's not hold up 6.0 any longer!",
"path": "docs/topics/tasks.txt",
"line": null,
"side": "RIGHT",
"created_at": "2025-12-03T15:16:56+00:00"
},
{
"id": 2585536763,
"user": "user_6b79e26637e6",
"body": "> I do not think we should link directly to django-tasks here. The Tasks framework in Django is intentionally limited to the stable core contract for defining and queuing work. Backend specifics, including which packages implement the API, are outside that contract and change much faster than the Django docs.\n\n[USER_REDACTED] I don't understand this part of your statement. We're in agreement here on what the Tasks framework is in Django. We want to link to some other place because the Django docs aren't updated frequently in comparison. I get lost about how this is a reason to not link to django-tasks though.\n\n> ... it can clearly separate API compatible packages from general background processing tools. That keeps the Django docs focused on the framework itself while letting backend guidance evolve independently.\n\n[USER_REDACTED] Same thing here. This isn't a justification to not link directly to django-tasks. From my understanding, it's a justification that we need to link to somewhere.\n\n> As time goes on, there'll be more features in django-tasks than in django. Those features will still be usable in production, but may not come with the same rigorous testing that including in Django assumes.\n\n[USER_REDACTED] That's fine, but is a tangential discussion to what I understand. The question is, where are we collecting the various backends that implement [NAME_REDACTED] interface? (see below)\n\n> I also expect more backends to exist outside of django-tasks, and have little intention of listing them in the README.\n\n[USER_REDACTED] To align on understanding, I'm considering things for the next 2-3 years, not the permanent future. For the near future, I think we would want to be a little more interconnected to help adoption rather than leaving people to their own devices. Where would people find out about backends in the various states:\n\n- Alpha, just created and creator is looking for feedback\n- Beta, exists for up to a year, used by [NAME_REDACTED], looking for adoption\n- Stable, exists a year+, is being used by [NAME_REDACTED], the Stable condition is when something would get listed on the ecosystem page on its own. Until then, it would be in the experimental section or not at all. That's why I was suggesting linking to django-tasks because I had assumed that it would act as a hub for at least a while to help gain adoption.\n\nI suppose maybe this is where djangopackages.org comes in?",
"path": "docs/releases/6.0.txt",
"line": null,
"side": "RIGHT",
"created_at": "2025-12-03T15:18:39+00:00"
},
{
"id": 2585597459,
"user": "user_057de2f3b132",
"body": "I think we should link directly to django-tasks for the database backend until we land it in Django (or decide we're no longer actively intending to land it).\n\nFor other backends I think the ecosystem page (if they're reasonably mature) is appropriate, but I think the database backend is an important exception here:\n\n* It's the first production suitable backend to be implemented.\n* It's a reference implementation for other backends.\n* We're intending for it to land in Django.",
"path": "docs/releases/6.0.txt",
"line": null,
"side": "RIGHT",
"created_at": "2025-12-03T15:34:52+00:00"
}
],
"meta": {
"languages": [
"txt"
],
"touches_tests": false,
"review_state_summary": {
"APPROVED": 2,
"COMMENTED": 11
},
"meaningful_comment_count": 11,
"has_approval": true,
"has_changes_requested": false,
"total_review_comments": 11
}
}
{
"_id": "a55518935cea7604",
"_schema_version": "1.0",
"_cleaned_at": "2026-02-12T07:46:51.609057+00:00",
"repo": "django/django",
"repo_url": "https://github.com/django/django",
"license_name": "BSD 3-Clause \"New\" or \"Revised\" License",
"license_spdx": "BSD-3-Clause",
"pr_number": 20346,
"title": "Fixed #36233 -- Avoided quantizing integers stored in DecimalField on SQLite.",
"body": "#### Trac ticket number\n\n\nticket-36233\n\n#### Branch description\nFixed a crash in DecimalField when using SQLite with integers exceeding 15 digits (e.g., 16-digit IDs).\n\nThe Issue: SQLite lacks a native decimal type. When retrieving large integers (e.g., 9999999999999999), the default converter treats them as floating-point numbers. Since IEEE 754 floats only support ~15 significant digits, precision is lost (e.g., becoming 10000000000000000). When Django attempts to quantize() this inaccurate value against the field's context, it raises decimal.InvalidOperation.\n\nThe Fix: Updated django.db.backends.sqlite3.operations.py to check if the underlying SQLite driver returned a native int. If so, the value is converted directly to Decimal, bypassing the lossy float conversion entirely.\n\nVerification: Added a regression test test_sqlite_integer_precision_bypass in model_fields/test_decimalfield.py to ensure 16-digit integers are stored and retrieved correctly without crashing.\n#### Checklist\n- [ ] This PR targets the `main` branch. \n- [ ] The commit message is written in past tense, mentions the ticket number, and ends with a period.\n- [ ] I have checked the \"Has patch\" ticket flag in the Trac system.\n- [ ] I have added or updated relevant tests.\n- [ ] I have added or updated relevant docs, including release notes if applicable.\n- [ ] I have attached screenshots in both light and dark modes for any UI changes.",
"author": "user_97513ac81384",
"created_at": "2025-11-30T18:38:00+00:00",
"merged_at": "2026-01-28T22:04:39+00:00",
"base_branch": "main",
"head_branch": "ticket_36233_sqlite_fix",
"additions": 27,
"deletions": 3,
"changed_files": 3,
"files": [
{
"filename": "django/db/backends/sqlite3/operations.py",
"status": "modified",
"additions": 8,
"deletions": 3,
"changes": 11,
"patch": "@@ -300,26 +300,31 @@ def convert_timefield_value(self, value, expression, connection):\n value = parse_time(value)\n return value\n \n+ [USER_REDACTED]\n+ def _create_decimal(value):\n+ if isinstance(value, (int, str)):\n+ return decimal.Decimal(value)\n+ return decimal.Context(prec=15).create_decimal_from_float(value)\n+\n def get_decimalfield_converter(self, expression):\n # SQLite stores only 15 significant digits. Digits coming from\n # float inaccuracy must be removed.\n- create_decimal = decimal.Context(prec=15).create_decimal_from_float\n if isinstance(expression, Col):\n quantize_value = decimal.Decimal(1).scaleb(\n -expression.output_field.decimal_places\n )\n \n def converter(value, expression, connection):\n if value is not None:\n- return create_decimal(value).quantize(\n+ return self._create_decimal(value).quantize(\n quantize_value, context=expression.output_field.context\n )\n \n else:\n \n def converter(value, expression, connection):\n if value is not None:\n- return create_decimal(value)\n+ return self._create_decimal(value)\n \n return converter"
},
{
"filename": "tests/model_fields/models.py",
"status": "modified",
"additions": 1,
"deletions": 0,
"changes": 1,
"patch": "@@ -102,6 +102,7 @@ def get_choices():\n \n class BigD(models.Model):\n d = models.DecimalField(max_digits=32, decimal_places=30)\n+ large_int = models.DecimalField(max_digits=16, decimal_places=0, null=True)\n \n \n class FloatModel(models.Model):"
},
{
"filename": "tests/model_fields/test_decimalfield.py",
"status": "modified",
"additions": 18,
"deletions": 0,
"changes": 18,
"patch": "@@ -5,6 +5,7 @@\n from django.core import validators\n from django.core.exceptions import ValidationError\n from django.db import connection, models\n+from django.db.models import Max\n from django.test import TestCase\n \n from .models import BigD, Foo\n@@ -140,3 +141,20 @@ def test_roundtrip_with_trailing_zeros(self):\n obj = Foo.objects.create(a=\"bar\", d=Decimal(\"8.320\"))\n obj.refresh_from_db()\n self.assertEqual(obj.d.compare_total(Decimal(\"8.320\")), Decimal(\"0\"))\n+\n+ def test_large_integer_precision(self):\n+ large_int_val = Decimal(\"9999999999999999\")\n+ obj = BigD.objects.create(large_int=large_int_val, d=Decimal(\"0\"))\n+ obj.refresh_from_db()\n+ self.assertEqual(obj.large_int, large_int_val)\n+\n+ def test_large_integer_precision_aggregation(self):\n+ large_int_val = Decimal(\"9999999999999999\")\n+ BigD.objects.create(large_int=large_int_val, d=Decimal(\"0\"))\n+ result = BigD.objects.aggregate(max_val=Max(\"large_int\"))\n+ self.assertEqual(result[\"max_val\"], large_int_val)\n+\n+ def test_roundtrip_integer_with_trailing_zeros(self):\n+ obj = Foo.objects.create(a=\"bar\", d=Decimal(\"8\"))\n+ obj.refresh_from_db()\n+ self.assertEqual(obj.d.compare_total(Decimal(\"8.000\")), Decimal(\"0\"))"
}
],
"reviews": [
{
"id": 3678286097,
"user": "user_3a67c55598c5",
"state": "COMMENTED",
"body": "Thanks, I have an initial comment.",
"submitted_at": "2026-01-19T14:12:57+00:00"
},
{
"id": 3679483428,
"user": "user_97513ac81384",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-01-19T20:14:02+00:00"
},
{
"id": 3683035197,
"user": "user_3a67c55598c5",
"state": "APPROVED",
"body": "Hi, good start here. A question for you about preserving trailing zeros.",
"submitted_at": "2026-01-20T16:14:23+00:00"
},
{
"id": 3683050776,
"user": "user_3a67c55598c5",
"state": "CHANGES_REQUESTED",
"body": "(Clicked wrong review button.)",
"submitted_at": "2026-01-20T16:14:45+00:00"
},
{
"id": 3692203121,
"user": "user_3a67c55598c5",
"state": "COMMENTED",
"body": "Thanks for the updates. I think I would find this more clear if you localized the updates to `create_decimal`, e.g.:\n\n```py\n[USER_REDACTED]\ndef _create_decimal(value):\n if isinstance(value, int):\n return decimal.Decimal(value)\n return decimal.Context(prec=15).create_decimal_from_float(value)\n```",
"submitted_at": "2026-01-22T12:27:10+00:00"
},
{
"id": 3718787402,
"user": "user_3a67c55598c5",
"state": "APPROVED",
"body": "Thanks! I pushed a tiny edit.",
"submitted_at": "2026-01-28T19:43:50+00:00"
},
{
"id": 3733721404,
"user": "user_657e90e5ae46",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-01-31T22:12:44+00:00"
},
{
"id": 3763859792,
"user": "user_3a67c55598c5",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-06T15:57:47+00:00"
}
],
"review_comments": [
{
"id": 2704938632,
"user": "user_3a67c55598c5",
"body": "I think we want this test to run on all backends.",
"path": "tests/model_fields/test_decimalfield.py",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-19T14:11:57+00:00"
},
{
"id": 2705970001,
"user": "user_97513ac81384",
"body": "Thanks for the review.\n1- I removed that block so the test runs for all backends.\n2- I added Simon as co-author since I took his fix from the discussions under the ticket \n3- I also added another test for the else block",
"path": "tests/model_fields/test_decimalfield.py",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-19T20:14:02+00:00"
},
{
"id": 2709057178,
"user": "user_3a67c55598c5",
"body": "I don't think it's acceptable to skip the `quantize()` call. This test passes on main and fails on your branch:\n\n```py\n def test_roundtrip_integer_with_trailing_zeros(self):\n obj = Foo.objects.create(a=\"bar\", d=Decimal(\"8\"))\n obj.refresh_from_db()\n self.assertEqual(obj.d.compare_total(Decimal(\"8.000\")), Decimal(\"0\"))\n```\n\n```py\n======================================================================\nFAIL: test_roundtrip_integer_with_trailing_zeros (model_fields.test_decimalfield.DecimalFieldTests.test_roundtrip_integer_with_trailing_zeros)\n----------------------------------------------------------------------\nTraceback (most recent call last):\n File \"/Users/jwalls/django/tests/model_fields/test_decimalfield.py\", line 148, in test_roundtrip_integer_with_trailing_zeros\n self.assertEqual(obj.d.compare_total(Decimal(\"8.000\")), Decimal(\"0\"))\n ~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\nAssertionError: Decimal('1') != Decimal('0')\n\n----------------------------------------------------------------------\n```",
"path": "django/db/backends/sqlite3/operations.py",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-20T16:11:26+00:00"
},
{
"id": 2709059049,
"user": "user_3a67c55598c5",
"body": "Please remove this model and reuse `BigD`. We can't add 1x model per test due to the overhead of creating tables.",
"path": "tests/model_fields/models.py",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-20T16:11:54+00:00"
},
{
"id": 2709059751,
"user": "user_3a67c55598c5",
"body": "Please remove \"sqlite\" from the test name.",
"path": "tests/model_fields/test_decimalfield.py",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-20T16:12:06+00:00"
},
{
"id": 2709062650,
"user": "user_3a67c55598c5",
"body": "We try to make surgical edits when touching longstanding code. Removing the newline and changing `elif` -> `if` will create a smaller diff.",
"path": "django/db/backends/sqlite3/operations.py",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-20T16:12:48+00:00"
},
{
"id": 2750110696,
"user": "user_657e90e5ae46",
"body": "SQL databases usually have a NUMERIC type with (max_digits, and decimal_places) which takes care of adding the missing precision to `Decimal(\"8\")`. This isn't the case on MongoDB, and similar to SQLite, manual quantizing is necessary to make this test pass:\n```diff\ndiff --git a/django_mongodb_backend/operations.py b/django_mongodb_backend/operations.py\nindex e446e2c4..f4b0857f 100644\n--- a/django_mongodb_backend/operations.py\n+++ b/django_mongodb_backend/operations.py\n@@ -171,18 +171,20 @@ class DatabaseOperations(GISOperations, BaseDatabaseOperations):\n def convert_decimalfield_value(self, value, expression, connection):\n if value is not None:\n # from Decimal128 to decimal.Decimal()\n try:\n value = value.to_decimal()\n except AttributeError:\n # `value` could be an integer in the case of an annotation\n # like ExpressionWrapper(Value(1), output_field=DecimalField().\n return Decimal(value)\n+ quantize_value = Decimal(1).scaleb(-expression.output_field.decimal_places)\n+ value = value.quantize(quantize_value, context=expression.output_field.context)\n return value\n```\nI tend to think this is unnecessary overhead and this test (which bypasses validation anyway) should be skipped on MongoDB. Raising the issue here in case any patch authors have thoughts. Thanks!",
"path": "tests/model_fields/test_decimalfield.py",
"line": 160,
"side": "RIGHT",
"created_at": "2026-01-31T22:12:44+00:00"
},
{
"id": 2774838301,
"user": "user_3a67c55598c5",
"body": "I think the fact that `SQLiteNumericMixin` (and now `Value`) add casts based on the `output_field` is a [deeper design problem](https://github.com/[USER_REDACTED]ngo/django/pull/19459#discussion_r2135725928), given that `output_field` is supposed to be an ORM-only interoperability check, not entailing any database casts.\n\nWhat you've sketched looks like a better approach than SQLite's approach, tbh.",
"path": "tests/model_fields/test_decimalfield.py",
"line": 160,
"side": "RIGHT",
"created_at": "2026-02-06T15:57:47+00:00"
}
],
"meta": {
"languages": [
"py"
],
"touches_tests": true,
"review_state_summary": {
"COMMENTED": 5,
"APPROVED": 2,
"CHANGES_REQUESTED": 1
},
"meaningful_comment_count": 8,
"has_approval": true,
"has_changes_requested": true,
"total_review_comments": 8
}
}
{
"_id": "a1db910f3253e8da",
"_schema_version": "1.0",
"_cleaned_at": "2026-02-12T07:46:51.624760+00:00",
"repo": "tiangolo/fastapi",
"repo_url": "https://github.com/fastapi/fastapi",
"license_name": "MIT License",
"license_spdx": "MIT",
"pr_number": 14828,
"title": "✅ Test order for the submitted byte Files",
"body": "Fixes the [14811](https://github.com/fastapi/fastapi/discussions/14811)",
"author": "user_c36c155012b4",
"created_at": "2026-02-05T04:05:37+00:00",
"merged_at": "2026-02-10T11:46:48+00:00",
"base_branch": "master",
"head_branch": "fix-14811",
"additions": 46,
"deletions": 0,
"changed_files": 1,
"files": [
{
"filename": "tests/test_list_bytes_file_order_preserved_issue_14811.py",
"status": "added",
"additions": 46,
"deletions": 0,
"changes": 46,
"patch": "@@ -0,0 +1,46 @@\n+\"\"\"\n+Regression test: preserve order when using list[bytes] + File()\n+See https://github.com/fastapi/fastapi/discussions/14811\n+Related: PR #3372\n+\"\"\"\n+\n+from typing import Annotated\n+\n+import anyio\n+import pytest\n+from fastapi import FastAPI, File\n+from fastapi.testclient import TestClient\n+from starlette.datastructures import UploadFile as StarletteUploadFile\n+\n+\n+def test_list_bytes_file_preserves_order(\n+ monkeypatch: pytest.MonkeyPatch,\n+) -> None:\n+ app = FastAPI()\n+\n+ [USER_REDACTED].post(\"/upload\")\n+ async def upload(files: Annotated[list[bytes], File()]):\n+ # return something that makes order obvious\n+ return [b[0] for b in files]\n+\n+ original_read = StarletteUploadFile.read\n+\n+ async def patched_read(self: StarletteUploadFile, size: int = -1) -> bytes:\n+ # Make the FIRST file slower *deterministically*\n+ if self.filename == \"slow.txt\":\n+ await anyio.sleep(0.05)\n+ return await original_read(self, size)\n+\n+ monkeypatch.setattr(StarletteUploadFile, \"read\", patched_read)\n+\n+ client = TestClient(app)\n+\n+ files = [\n+ (\"files\", (\"slow.txt\", b\"A\" * 10, \"text/plain\")),\n+ (\"files\", (\"fast.txt\", b\"B\" * 10, \"text/plain\")),\n+ ]\n+ r = client.post(\"/upload\", files=files)\n+ assert r.status_code == 200, r.text\n+\n+ # Must preserve request order: slow first, fast second\n+ assert r.json() == [ord(\"A\"), ord(\"B\")]"
}
],
"reviews": [
{
"id": 3756636187,
"user": "user_29e85f9a8e75",
"state": "APPROVED",
"body": "LGTM!\n\n[USER_REDACTED], thanks!",
"submitted_at": "2026-02-05T12:07:32+00:00"
},
{
"id": 3778447674,
"user": "user_2a237e38e06b",
"state": "APPROVED",
"body": "Great, thank you! 🚀 \n\nI refactored this logic in https://github.com/fastapi/fastapi/pull/14884 , that should handle the problem. But I'll still take the test here to prevent it from happening again. 🤓",
"submitted_at": "2026-02-10T11:42:40+00:00"
}
],
"review_comments": [
{
"id": 2768766445,
"user": "user_29e85f9a8e75",
"body": "```suggestion\ndef test_list_bytes_file_preserves_order(\n```",
"path": "tests/test_list_bytes_file_order_preserved_issue_14811.py",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-05T12:00:26+00:00"
}
],
"meta": {
"languages": [
"py"
],
"touches_tests": true,
"review_state_summary": {
"APPROVED": 2
},
"meaningful_comment_count": 1,
"has_approval": true,
"has_changes_requested": false,
"total_review_comments": 1
}
}
{
"_id": "594a76e26d881817",
"_schema_version": "1.0",
"_cleaned_at": "2026-02-12T07:46:51.624760+00:00",
"repo": "tiangolo/fastapi",
"repo_url": "https://github.com/fastapi/fastapi",
"license_name": "MIT License",
"license_spdx": "MIT",
"pr_number": 14822,
"title": "🌐 Update translations for uk (update-outdated)",
"body": "🌐 Update translations for uk (update-outdated)\n\nThis PR was created automatically using LLMs.\n\nIt uses the prompt file https://github.com/fastapi/fastapi/blob/master/docs/uk/llm-prompt.md.\n\nIn most cases, it's better to make PRs updating that file so that the LLM can do a better job generating the translations than suggesting changes in this PR.",
"author": "user_2a237e38e06b",
"created_at": "2026-02-04T16:52:09+00:00",
"merged_at": "2026-02-05T15:31:32+00:00",
"base_branch": "master",
"head_branch": "translate-uk-update-outdated-41dc7e2f",
"additions": 23,
"deletions": 28,
"changed_files": 2,
"files": [
{
"filename": "docs/uk/docs/index.md",
"status": "modified",
"additions": 18,
"deletions": 24,
"changes": 42,
"patch": "@@ -8,7 +8,7 @@\n  \n \n
\n \n \n- Фреймворк FastAPI: висока продуктивність, легко вивчати, швидко писати код, готовий до продакшину\n+ Фреймворк FastAPI - це висока продуктивність, легко вивчати, швидко писати код, готовий до продакшину\n
\n \n \n@@ -33,14 +33,14 @@\n \n ---\n \n-FastAPI — це сучасний, швидкий (високопродуктивний) вебфреймворк для створення API за допомогою Python, що базується на стандартних підказках типів Python.\n+FastAPI - це сучасний, швидкий (високопродуктивний) вебфреймворк для створення API за допомогою Python, що базується на стандартних підказках типів Python.\n \n Ключові особливості:\n \n * **Швидкий**: дуже висока продуктивність, на рівні з **NodeJS** та **Go** (завдяки Starlette та Pydantic). [Один із найшвидших Python-фреймворків](#performance).\n * **Швидке написання коду**: пришвидшує розробку функціоналу приблизно на 200%–300%. *\n * **Менше помилок**: зменшує приблизно на 40% кількість помилок, спричинених людиною (розробником). *\n-* **Інтуїтивний**: чудова підтримка редакторами коду. Автодоповнення всюди. Менше часу на налагодження.\n+* **Інтуїтивний**: чудова підтримка редакторами коду. Автодоповнення всюди. Менше часу на налагодження.\n * **Простий**: спроєктований так, щоб бути простим у використанні та вивченні. Менше часу на читання документації.\n * **Короткий**: мінімізує дублювання коду. Кілька можливостей з кожного оголошення параметра. Менше помилок.\n * **Надійний**: ви отримуєте код, готовий до продакшину. З автоматичною інтерактивною документацією.\n@@ -127,9 +127,9 @@ FastAPI — це сучасний, швидкий (високопродукти\n \n  \n \n-Якщо ви створюєте застосунок CLI для використання в терміналі замість веб-API, зверніть увагу на **Typer**.\n+Якщо ви створюєте застосунок CLI для використання в терміналі замість веб-API, зверніть увагу на **Typer**.\n \n-**Typer** — молодший брат FastAPI. І його задумано як **FastAPI для CLI**. ⌨️ 🚀\n+**Typer** - молодший брат FastAPI. І його задумано як **FastAPI для CLI**. ⌨️ 🚀\n \n ## Вимоги { #requirements }\n \n@@ -161,8 +161,6 @@ $ pip install \"fastapi[standard]\"\n Створіть файл `main.py` з:\n \n ```Python\n-from typing import Union\n-\n from fastapi import FastAPI\n \n app = FastAPI()\n@@ -174,7 +172,7 @@ def read_root():\n \n \n [USER_REDACTED].get(\"/items/{item_id}\")\n-def read_item(item_id: int, q: Union[str, None] = None):\n+def read_item(item_id: int, q: str | None = None):\n return {\"item_id\": item_id, \"q\": q}\n ```\n \n@@ -183,9 +181,7 @@ def read_item(item_id: int, q: Union[str, None] = None):\n \n Якщо ваш код використовує `async` / `await`, скористайтеся `async def`:\n \n-```Python hl_lines=\"9 14\"\n-from typing import Union\n-\n+```Python hl_lines=\"7 12\"\n from fastapi import FastAPI\n \n app = FastAPI()\n@@ -197,7 +193,7 @@ async def read_root():\n \n \n [USER_REDACTED].get(\"/items/{item_id}\")\n-async def read_item(item_id: int, q: Union[str, None] = None):\n+async def read_item(item_id: int, q: str | None = None):\n return {\"item_id\": item_id, \"q\": q}\n ```\n \n@@ -288,9 +284,7 @@ INFO: Application startup complete.\n \n Оголосіть тіло, використовуючи стандартні типи Python, завдяки Pydantic.\n \n-```Python hl_lines=\"4 9-12 25-27\"\n-from typing import Union\n-\n+```Python hl_lines=\"2 7-10 23-25\"\n from fastapi import FastAPI\n from pydantic import BaseModel\n \n@@ -300,7 +294,7 @@ app = FastAPI()\n class Item(BaseModel):\n name: str\n price: float\n- is_offer: Union[bool, None] = None\n+ is_offer: bool | None = None\n \n \n [USER_REDACTED].get(\"/\")\n@@ -309,7 +303,7 @@ def read_root():\n \n \n [USER_REDACTED].get(\"/items/{item_id}\")\n-def read_item(item_id: int, q: Union[str, None] = None):\n+def read_item(item_id: int, q: str | None = None):\n return {\"item_id\": item_id, \"q\": q}\n \n \n@@ -374,15 +368,15 @@ item: Item\n * Валідацію даних:\n * Автоматичні та зрозумілі помилки, коли дані некоректні.\n * Валідацію навіть для глибоко вкладених JSON-обʼєктів.\n-* Перетворення вхідних даних: з мережі до даних і типів Python. Читання з:\n+* Перетворення вхідних даних: з мережі до даних і типів Python. Читання з:\n * JSON.\n * Параметрів шляху.\n * Параметрів запиту.\n * Cookies.\n * Headers.\n * Forms.\n * Files.\n-* Перетворення вихідних даних: перетворення з даних і типів Python у мережеві дані (як JSON):\n+* Перетворення вихідних даних: перетворення з даних і типів Python у мережеві дані (як JSON):\n * Перетворення типів Python (`str`, `int`, `float`, `bool`, `list`, тощо).\n * Обʼєктів `datetime`.\n * Обʼєктів `UUID`.\n@@ -439,9 +433,9 @@ item: Item\n \n \n \n-Для більш повного прикладу, що включає більше можливостей, перегляньте Туторіал — Посібник користувача.\n+Для більш повного прикладу, що включає більше можливостей, перегляньте Навчальний посібник - Посібник користувача.\n \n-**Spoiler alert**: туторіал — посібник користувача містить:\n+**Попередження про спойлер**: навчальний посібник - посібник користувача містить:\n \n * Оголошення **параметрів** з інших різних місць, як-от: **headers**, **cookies**, **form fields** та **files**.\n * Як встановлювати **обмеження валідації** як `maximum_length` або `regex`.\n@@ -500,11 +494,11 @@ Deploying to [NAME_REDACTED]...\n \n Він забезпечує той самий **developer experience** створення застосунків на FastAPI під час їх **розгортання** у хмарі. 🎉\n \n-[NAME_REDACTED] — основний спонсор і джерело фінансування open source проєктів *FastAPI and friends*. ✨\n+[NAME_REDACTED] - основний спонсор і джерело фінансування open source проєктів *FastAPI and friends*. ✨\n \n #### Розгортання в інших хмарних провайдерів { #deploy-to-other-cloud-providers }\n \n-FastAPI — open source і базується на стандартах. Ви можете розгортати застосунки FastAPI в будь-якому хмарному провайдері, який ви оберете.\n+FastAPI - open source проект і базується на стандартах. Ви можете розгортати застосунки FastAPI в будь-якому хмарному провайдері, який ви оберете.\n \n Дотримуйтеся інструкцій вашого хмарного провайдера, щоб розгорнути застосунки FastAPI у нього. 🤓\n \n@@ -530,7 +524,7 @@ FastAPI залежить від Pydantic і Starlette.\n \n *
\n \n-Якщо ви створюєте застосунок CLI для використання в терміналі замість веб-API, зверніть увагу на **Typer**.\n+Якщо ви створюєте застосунок CLI для використання в терміналі замість веб-API, зверніть увагу на **Typer**.\n \n-**Typer** — молодший брат FastAPI. І його задумано як **FastAPI для CLI**. ⌨️ 🚀\n+**Typer** - молодший брат FastAPI. І його задумано як **FastAPI для CLI**. ⌨️ 🚀\n \n ## Вимоги { #requirements }\n \n@@ -161,8 +161,6 @@ $ pip install \"fastapi[standard]\"\n Створіть файл `main.py` з:\n \n ```Python\n-from typing import Union\n-\n from fastapi import FastAPI\n \n app = FastAPI()\n@@ -174,7 +172,7 @@ def read_root():\n \n \n [USER_REDACTED].get(\"/items/{item_id}\")\n-def read_item(item_id: int, q: Union[str, None] = None):\n+def read_item(item_id: int, q: str | None = None):\n return {\"item_id\": item_id, \"q\": q}\n ```\n \n@@ -183,9 +181,7 @@ def read_item(item_id: int, q: Union[str, None] = None):\n \n Якщо ваш код використовує `async` / `await`, скористайтеся `async def`:\n \n-```Python hl_lines=\"9 14\"\n-from typing import Union\n-\n+```Python hl_lines=\"7 12\"\n from fastapi import FastAPI\n \n app = FastAPI()\n@@ -197,7 +193,7 @@ async def read_root():\n \n \n [USER_REDACTED].get(\"/items/{item_id}\")\n-async def read_item(item_id: int, q: Union[str, None] = None):\n+async def read_item(item_id: int, q: str | None = None):\n return {\"item_id\": item_id, \"q\": q}\n ```\n \n@@ -288,9 +284,7 @@ INFO: Application startup complete.\n \n Оголосіть тіло, використовуючи стандартні типи Python, завдяки Pydantic.\n \n-```Python hl_lines=\"4 9-12 25-27\"\n-from typing import Union\n-\n+```Python hl_lines=\"2 7-10 23-25\"\n from fastapi import FastAPI\n from pydantic import BaseModel\n \n@@ -300,7 +294,7 @@ app = FastAPI()\n class Item(BaseModel):\n name: str\n price: float\n- is_offer: Union[bool, None] = None\n+ is_offer: bool | None = None\n \n \n [USER_REDACTED].get(\"/\")\n@@ -309,7 +303,7 @@ def read_root():\n \n \n [USER_REDACTED].get(\"/items/{item_id}\")\n-def read_item(item_id: int, q: Union[str, None] = None):\n+def read_item(item_id: int, q: str | None = None):\n return {\"item_id\": item_id, \"q\": q}\n \n \n@@ -374,15 +368,15 @@ item: Item\n * Валідацію даних:\n * Автоматичні та зрозумілі помилки, коли дані некоректні.\n * Валідацію навіть для глибоко вкладених JSON-обʼєктів.\n-* Перетворення вхідних даних: з мережі до даних і типів Python. Читання з:\n+* Перетворення вхідних даних: з мережі до даних і типів Python. Читання з:\n * JSON.\n * Параметрів шляху.\n * Параметрів запиту.\n * Cookies.\n * Headers.\n * Forms.\n * Files.\n-* Перетворення вихідних даних: перетворення з даних і типів Python у мережеві дані (як JSON):\n+* Перетворення вихідних даних: перетворення з даних і типів Python у мережеві дані (як JSON):\n * Перетворення типів Python (`str`, `int`, `float`, `bool`, `list`, тощо).\n * Обʼєктів `datetime`.\n * Обʼєктів `UUID`.\n@@ -439,9 +433,9 @@ item: Item\n \n \n \n-Для більш повного прикладу, що включає більше можливостей, перегляньте Туторіал — Посібник користувача.\n+Для більш повного прикладу, що включає більше можливостей, перегляньте Навчальний посібник - Посібник користувача.\n \n-**Spoiler alert**: туторіал — посібник користувача містить:\n+**Попередження про спойлер**: навчальний посібник - посібник користувача містить:\n \n * Оголошення **параметрів** з інших різних місць, як-от: **headers**, **cookies**, **form fields** та **files**.\n * Як встановлювати **обмеження валідації** як `maximum_length` або `regex`.\n@@ -500,11 +494,11 @@ Deploying to [NAME_REDACTED]...\n \n Він забезпечує той самий **developer experience** створення застосунків на FastAPI під час їх **розгортання** у хмарі. 🎉\n \n-[NAME_REDACTED] — основний спонсор і джерело фінансування open source проєктів *FastAPI and friends*. ✨\n+[NAME_REDACTED] - основний спонсор і джерело фінансування open source проєктів *FastAPI and friends*. ✨\n \n #### Розгортання в інших хмарних провайдерів { #deploy-to-other-cloud-providers }\n \n-FastAPI — open source і базується на стандартах. Ви можете розгортати застосунки FastAPI в будь-якому хмарному провайдері, який ви оберете.\n+FastAPI - open source проект і базується на стандартах. Ви можете розгортати застосунки FastAPI в будь-якому хмарному провайдері, який ви оберете.\n \n Дотримуйтеся інструкцій вашого хмарного провайдера, щоб розгорнути застосунки FastAPI у нього. 🤓\n \n@@ -530,7 +524,7 @@ FastAPI залежить від Pydantic і Starlette.\n \n * httpx - потрібно, якщо ви хочете використовувати `TestClient`.\n * jinja2 - потрібно, якщо ви хочете використовувати конфігурацію шаблонів за замовчуванням.\n-* python-multipart - потрібно, якщо ви хочете підтримувати «parsing» форм за допомогою `request.form()`.\n+* python-multipart - потрібно, якщо ви хочете підтримувати «parsing» форм за допомогою `request.form()`.\n \n Використовується FastAPI:"
},
{
"filename": "docs/uk/docs/tutorial/body-multiple-params.md",
"status": "modified",
"additions": 5,
"deletions": 4,
"changes": 9,
"patch": "@@ -103,15 +103,16 @@\n Оскільки за замовчуванням одиничні значення інтерпретуються як параметри запиту, вам не потрібно явно додавати `Query`, ви можете просто зробити:\n \n ```Python\n-q: Union[str, None] = None\n+q: str | None = None\n ```\n \n-Або в Python 3.10 і вище:\n+Або в Python 3.9:\n \n ```Python\n-q: str | None = None\n+q: Union[str, None] = None\n ```\n \n+\n Наприклад:\n \n {* ../../docs_src/body_multiple_params/tutorial004_an_py310.py hl[28] *}\n@@ -129,7 +130,7 @@ q: str | None = None\n \n За замовчуванням **FastAPI** очікуватиме його тіло безпосередньо.\n \n-Але якщо ви хочете, щоб він очікував JSON з ключем `item`, а всередині нього — вміст моделі, як це відбувається, коли ви оголошуєте додаткові параметри тіла, ви можете використати спеціальний параметр `Body` — `embed`:\n+Але якщо ви хочете, щоб він очікував JSON з ключем `item`, а всередині нього - вміст моделі, як це відбувається, коли ви оголошуєте додаткові параметри тіла, ви можете використати спеціальний параметр `Body` - `embed`:\n \n ```Python\n item: Item = Body(embed=True)"
}
],
"reviews": [
{
"id": 3752719590,
"user": "user_c36c155012b4",
"state": "COMMENTED",
"body": "Changes looks good, just a small improvements :)",
"submitted_at": "2026-02-04T18:39:53+00:00"
},
{
"id": 3752801380,
"user": "user_489e2b951069",
"state": "APPROVED",
"body": null,
"submitted_at": "2026-02-04T18:58:24+00:00"
},
{
"id": 3752972551,
"user": "user_29e85f9a8e75",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-04T19:41:27+00:00"
},
{
"id": 3753092052,
"user": "user_c36c155012b4",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-04T20:03:57+00:00"
},
{
"id": 3753125919,
"user": "user_965b664e791a",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-04T20:13:31+00:00"
},
{
"id": 3753151072,
"user": "user_965b664e791a",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-04T20:20:46+00:00"
},
{
"id": 3753174715,
"user": "user_965b664e791a",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-04T20:27:26+00:00"
},
{
"id": 3753191721,
"user": "user_965b664e791a",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-04T20:32:23+00:00"
},
{
"id": 3753220391,
"user": "user_965b664e791a",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-04T20:40:16+00:00"
},
{
"id": 3753245539,
"user": "user_965b664e791a",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-04T20:47:30+00:00"
},
{
"id": 3753255078,
"user": "user_965b664e791a",
"state": "CHANGES_REQUESTED",
"body": "LLM makes mistakes when trying to translate definitions of terms",
"submitted_at": "2026-02-04T20:50:18+00:00"
},
{
"id": 3756083060,
"user": "user_29e85f9a8e75",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-05T10:45:35+00:00"
},
{
"id": 3756095243,
"user": "user_29e85f9a8e75",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-05T10:46:56+00:00"
},
{
"id": 3756230995,
"user": "user_29e85f9a8e75",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-05T11:04:23+00:00"
},
{
"id": 3756413449,
"user": "user_965b664e791a",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-05T11:30:27+00:00"
}
],
"review_comments": [
{
"id": 2765459760,
"user": "user_c36c155012b4",
"body": "```suggestion\n* **Інтуїтивний**: чудова підтримка редакторами коду. Автодоповнення всюди. Менше часу на налагодження.\n```",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T18:35:50+00:00"
},
{
"id": 2765467209,
"user": "user_c36c155012b4",
"body": "```suggestion\n* python-multipart - потрібно, якщо ви хочете підтримувати «parsing» форм за допомогою `request.form()`.\n```",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T18:38:01+00:00"
},
{
"id": 2765469490,
"user": "user_c36c155012b4",
"body": "```suggestion\n* Перетворення вихідних даних: перетворення з даних і типів Python у мережеві дані (як JSON):\n```",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T18:38:43+00:00"
},
{
"id": 2765470609,
"user": "user_c36c155012b4",
"body": "```suggestion\n* Перетворення вхідних даних: з мережі до даних і типів Python. Читання з:\n```",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T18:39:04+00:00"
},
{
"id": 2765524606,
"user": "user_489e2b951069",
"body": "```suggestion\n Фреймворк FastAPI - це висока продуктивність, легко вивчати, швидко писати код, готовий до продакшину\n```",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T18:54:57+00:00"
},
{
"id": 2765536251,
"user": "user_489e2b951069",
"body": "```suggestion\nFastAPI - open source проект і базується на стандартах. Ви можете розгортати застосунки FastAPI в будь-якому хмарному провайдері, який ви оберете.\n```",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T18:58:15+00:00"
},
{
"id": 2765667890,
"user": "user_29e85f9a8e75",
"body": "```suggestion\nЯкщо ви створюєте застосунок CLI для використання в терміналі замість веб-API, зверніть увагу на **Typer**.\n```",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T19:32:58+00:00"
},
{
"id": 2765672687,
"user": "user_29e85f9a8e75",
"body": "We can try solving this with https://github.com/fastapi/fastapi/pull/14744 and https://github.com/fastapi/fastapi/pull/14747",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T19:34:03+00:00"
},
{
"id": 2765683765,
"user": "user_29e85f9a8e75",
"body": "Actually, we don't need `also known as: serialization, parsing, marshalling` here - it's a mistake of LLM. It should be just translated to Ukrainian..\n\nShould it be\n``\nor\n``\n?",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T19:36:51+00:00"
},
{
"id": 2765688624,
"user": "user_29e85f9a8e75",
"body": "Same problem with `` as above",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T19:38:13+00:00"
},
{
"id": 2765695959,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n* python-multipart - потрібно, якщо ви хочете підтримувати «parsing» форм за допомогою `request.form()`.\n```\n\nIt should be just translation, without English version",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T19:40:24+00:00"
},
{
"id": 2765776080,
"user": "user_c36c155012b4",
"body": "any option works :)",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T20:03:57+00:00"
},
{
"id": 2765808038,
"user": "user_965b664e791a",
"body": "Seems that LLM thinks that an original sentence must be leaved with a translation, but it's mistake: only the translate must be leaved. Also, LLM didn't consider a \"Completion\" word and, as a result, LLM thought that it must be considered as \"also known [to us]\" instead of \"[A completion is] also known\".\n\nTherefore, it must be corrected in this way:\n```suggestion\n* **Інтуїтивний**: чудова підтримка редакторами коду. Автодоповнення всюди. Менше часу на налагодження.\n```\n\nUPD: fixed a grammar error",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T20:13:31+00:00"
},
{
"id": 2765830463,
"user": "user_965b664e791a",
"body": "It may be in this way: ``. Also, it can be ``, but we're losing a word \"also\".\n\nAlso, there is a same problem on line 43. I explained reasons of the problem there.\n\nUPD: added a variant and explained why is it correct too",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T20:20:45+00:00"
},
{
"id": 2765850892,
"user": "user_965b664e791a",
"body": "\"Spoiler alert\" is not translated\n\nCan be translated in this way:\n```suggestion\n**Попередження про спойлер**: навчальний посібник - посібник користувача містить:\n```",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T20:27:27+00:00"
},
{
"id": 2765866406,
"user": "user_965b664e791a",
"body": "In this context, it would be good to translate \"open source\":\n```suggestion\nFastAPI - відкритий код і базується на стандартах. Ви можете розгортати застосунки FastAPI в будь-якому хмарному провайдері, який ви оберете.\n```",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T20:32:23+00:00"
},
{
"id": 2765892776,
"user": "user_965b664e791a",
"body": "In my opinion, it's adding new text rather then a translation. We can leave or translate \"open source\" and it'll be looking good.",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T20:40:16+00:00"
},
{
"id": 2765915795,
"user": "user_965b664e791a",
"body": "LLM makes a mistake, leaving an original sentence. Also, [\"з\" will be better than \"із\"](https://ukr-mova.in.ua/library/orfografiya/mulozvuchnist-z,-iz,-zi,-zo.-chastuna-1).\n```suggestion\n* python-multipart - потрібно, якщо ви хочете підтримувати «parsing» форм за допомогою `request.form()`.\n```",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T20:47:30+00:00"
},
{
"id": 2768327262,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n* Перетворення вхідних даних: з мережі до даних і типів Python. Читання з:\n```",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-05T10:45:35+00:00"
},
{
"id": 2768336986,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n* Перетворення вихідних даних: перетворення з даних і типів Python у мережеві дані (як JSON):\n```",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-05T10:46:56+00:00"
},
{
"id": 2768444915,
"user": "user_29e85f9a8e75",
"body": "I personally think it's Ok to translate it as \"open source проект\" (\"open source project\"). I think it sounds clearer than \"відкритий код\" (more like \"open source code\").\nI think we should go with \"open source проект\"",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-05T11:04:23+00:00"
},
{
"id": 2768589624,
"user": "user_965b664e791a",
"body": "OK, no problem! We can leave \"open source проект\"",
"path": "docs/uk/docs/index.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-05T11:30:27+00:00"
}
],
"meta": {
"languages": [
"md"
],
"touches_tests": false,
"review_state_summary": {
"COMMENTED": 13,
"APPROVED": 1,
"CHANGES_REQUESTED": 1
},
"meaningful_comment_count": 22,
"has_approval": true,
"has_changes_requested": true,
"total_review_comments": 22
}
}
{
"_id": "66f540a3ebf54e56",
"_schema_version": "1.0",
"_cleaned_at": "2026-02-12T07:46:51.624760+00:00",
"repo": "tiangolo/fastapi",
"repo_url": "https://github.com/fastapi/fastapi",
"license_name": "MIT License",
"license_spdx": "MIT",
"pr_number": 14809,
"title": "📝 Add banner to translated pages",
"body": null,
"author": "user_29e85f9a8e75",
"created_at": "2026-02-03T14:42:02+00:00",
"merged_at": "2026-02-04T13:26:02+00:00",
"base_branch": "master",
"head_branch": "translation-banner",
"additions": 51,
"deletions": 1,
"changed_files": 3,
"files": [
{
"filename": "docs/en/docs/translation-banner.md",
"status": "added",
"additions": 11,
"deletions": 0,
"changes": 11,
"patch": "@@ -0,0 +1,11 @@\n+/// details | 🌐 Translation by [NAME_REDACTED]\n+\n+This translation was made by [NAME_REDACTED] 🤝\n+\n+It could have mistakes of misunderstanding the original meaning, or looking unnatural, etc. 🤖\n+\n+You can improve this translation by [helping us guide the AI LLM better](https://fastapi.tiangolo.com/contributing/#translations).\n+\n+[English version](ENGLISH_VERSION_URL)\n+\n+///"
},
{
"filename": "docs/ru/docs/translation-banner.md",
"status": "added",
"additions": 11,
"deletions": 0,
"changes": 11,
"patch": "@@ -0,0 +1,11 @@\n+/// details | 🌐 Перевод выполнен с помощью ИИ и людей\n+\n+Этот перевод был сделан ИИ под руководством людей. 🤝\n+\n+В нем могут быть ошибки из-за неправильного понимания оригинального смысла или неестественности и т. д. 🤖\n+\n+Вы можете улучшить этот перевод, [помогая нам лучше направлять ИИ LLM](https://fastapi.tiangolo.com/ru/contributing/#translations).\n+\n+[Английская версия](ENGLISH_VERSION_URL)\n+\n+///"
},
{
"filename": "scripts/mkdocs_hooks.py",
"status": "modified",
"additions": 29,
"deletions": 1,
"changes": 30,
"patch": "@@ -26,6 +26,17 @@ def get_missing_translation_content(docs_dir: str) -> str:\n return missing_translation_path.read_text(encoding=\"utf-8\")\n \n \n+[USER_REDACTED]_cache\n+def get_translation_banner_content(docs_dir: str) -> str:\n+ docs_dir_path = Path(docs_dir)\n+ translation_banner_path = docs_dir_path / \"translation-banner.md\"\n+ if not translation_banner_path.is_file():\n+ translation_banner_path = (\n+ docs_dir_path.parent.parent / \"en\" / \"docs\" / \"translation-banner.md\"\n+ )\n+ return translation_banner_path.read_text(encoding=\"utf-8\")\n+\n+\n [USER_REDACTED]_cache\n def get_mkdocs_material_langs() -> list[str]:\n material_path = Path(material.__file__).parent\n@@ -151,4 +162,21 @@ def on_page_markdown(\n if markdown.startswith(\"#\"):\n header, _, body = markdown.partition(\"\\n\\n\")\n return f\"{header}\\n\\n{missing_translation_content}\\n\\n{body}\"\n- return markdown\n+\n+ docs_dir_path = Path(config.docs_dir)\n+ en_docs_dir_path = docs_dir_path.parent.parent / \"en/docs\"\n+\n+ if docs_dir_path == en_docs_dir_path:\n+ return markdown\n+\n+ # For translated pages add translation banner\n+ translation_banner_content = get_translation_banner_content(config.docs_dir)\n+ en_url = \"https://fastapi.tiangolo.com/\" + page.url.lstrip(\"/\")\n+ translation_banner_content = translation_banner_content.replace(\n+ \"ENGLISH_VERSION_URL\", en_url\n+ )\n+ header = \"\"\n+ body = markdown\n+ if markdown.startswith(\"#\"):\n+ header, _, body = markdown.partition(\"\\n\\n\")\n+ return f\"{header}\\n\\n{translation_banner_content}\\n\\n{body}\""
}
],
"reviews": [
{
"id": 3746292094,
"user": "user_29e85f9a8e75",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-03T16:32:47+00:00"
},
{
"id": 3750471364,
"user": "user_2a237e38e06b",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-04T11:18:41+00:00"
},
{
"id": 3750534486,
"user": "user_2a237e38e06b",
"state": "COMMENTED",
"body": "Looking great! A coupe of suggestions.",
"submitted_at": "2026-02-04T11:34:06+00:00"
},
{
"id": 3750699607,
"user": "user_29e85f9a8e75",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-04T12:08:58+00:00"
},
{
"id": 3750701074,
"user": "user_29e85f9a8e75",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-04T12:09:14+00:00"
},
{
"id": 3750814172,
"user": "user_2a237e38e06b",
"state": "APPROVED",
"body": "Excellent, thank you! 🚀 🎉",
"submitted_at": "2026-02-04T12:37:06+00:00"
}
],
"review_comments": [
{
"id": 2759951825,
"user": "user_29e85f9a8e75",
"body": "Is the line above valid?\nI haven't found docs about it. Maybe just a typo?",
"path": "docs/en/mkdocs.yml",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-03T16:32:47+00:00"
},
{
"id": 2763494043,
"user": "user_2a237e38e06b",
"body": "Ah, yep, it's here: https://facelessuser.github.io/pymdown-extensions/extensions/blocks/plugins/details/\n\nIt's the same style as other blocks we use:\n\n```Markdown\n/// details | Some summary\nSome content\n///\n```",
"path": "docs/en/mkdocs.yml",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T11:18:41+00:00"
},
{
"id": 2763549901,
"user": "user_2a237e38e06b",
"body": "Looking at this I'm realizing that we already have the data to put there a link to the original in English, that might help.\n\nWe could add an:\n\n```Markdown\n[English version](https://blahblah/link)\n```",
"path": "scripts/mkdocs_hooks.py",
"line": 182,
"side": "RIGHT",
"created_at": "2026-02-04T11:33:50+00:00"
},
{
"id": 2763691715,
"user": "user_29e85f9a8e75",
"body": "Thanks!\nUpdated",
"path": "docs/en/mkdocs.yml",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-04T12:08:58+00:00"
},
{
"id": 2763692861,
"user": "user_29e85f9a8e75",
"body": "Added link",
"path": "scripts/mkdocs_hooks.py",
"line": 182,
"side": "RIGHT",
"created_at": "2026-02-04T12:09:14+00:00"
}
],
"meta": {
"languages": [
"md",
"py"
],
"touches_tests": false,
"review_state_summary": {
"COMMENTED": 5,
"APPROVED": 1
},
"meaningful_comment_count": 5,
"has_approval": true,
"has_changes_requested": false,
"total_review_comments": 5
}
}
{
"_id": "6250b8483e89bd2e",
"_schema_version": "1.0",
"_cleaned_at": "2026-02-12T07:46:51.624760+00:00",
"repo": "tiangolo/fastapi",
"repo_url": "https://github.com/fastapi/fastapi",
"license_name": "MIT License",
"license_spdx": "MIT",
"pr_number": 14795,
"title": "🌐 Improve LLM prompt of `uk` documentation",
"body": "Most of terms are not translated by LLM, so the PR fixes this problem. Partially fixes #14700\n\nUPD: add PR which will be partially fixed by [NAME_REDACTED]",
"author": "user_965b664e791a",
"created_at": "2026-02-01T00:53:15+00:00",
"merged_at": "2026-02-04T16:47:51+00:00",
"base_branch": "master",
"head_branch": "edit-doc-uk-prompt",
"additions": 67,
"deletions": 0,
"changed_files": 1,
"files": [
{
"filename": "docs/uk/llm-prompt.md",
"status": "modified",
"additions": 67,
"deletions": 0,
"changes": 67,
"patch": "@@ -8,6 +8,7 @@ Language code: uk.\n \n - Use polite/formal address consistent with existing Ukrainian docs (use “ви/ваш”).\n - Keep the tone concise and technical.\n+- Use one style of dashes. For example, if text contains \"-\" then use only this symbol to represent a dash.\n \n ### Headings\n \n@@ -32,6 +33,71 @@ Use the following preferred translations when they apply in documentation prose:\n - response (HTTP): відповідь\n - path operation: операція шляху\n - path operation function: функція операції шляху\n+- prompt: підсказка\n+- check: перевірка\n+- [NAME_REDACTED] Interface: Інтерфейс Шлюзу Паралельного Сервера\n+- [NAME_REDACTED] Network: Мережа Розробників Mozilla\n+- tutorial: навчальний посібник\n+- advanced user guide: просунутий посібник користувача\n+- deep learning: глибоке навчання\n+- machine learning: машинне навчання\n+- dependency injection: впровадження залежностей\n+- digest (HTTP): дайджест\n+- basic authentication (HTTP): базова автентифікація\n+- JSON schema: Схема JSON\n+- password flow: потік паролю\n+- mobile: мобільний\n+- body: тіло\n+- form: форма\n+- path: шлях\n+- query: запит\n+- cookie: кукі\n+- header: заголовок\n+- startup: запуск\n+- shutdown: вимкнення\n+- lifespan: тривалість життя\n+- authorization: авторизація\n+- forwarded header: направлений заголовок\n+- dependable: залежний\n+- dependent: залежний\n+- bound: межа\n+- concurrency: рівночасність\n+- parallelism: паралелізм\n+- multiprocessing: багатопроцесорність\n+- env var: змінна оточення\n+- dict: словник\n+- enum: перелік\n+- issue: проблема\n+- server worker: серверний працівник\n+- worker: працівник\n+- software development kit: набір для розробки програмного забезпечення\n+- bearer token: токен носія\n+- breaking change: несумісна зміна\n+- bug: помилка\n+- button: кнопка\n+- callable: викликаємий\n+- code: код\n+- commit: фіксація\n+- context manager: менеджер контексту\n+- coroutine: співпрограма\n+- engine: рушій\n+- fake X: фальшивий X\n+- item: предмет\n+- lock: блокування\n+- middleware: проміжне програмне забезпечення\n+- mounting: монтування\n+- origin: джерело\n+- override: переписування\n+- payload: корисне навантаження\n+- processor: процесор\n+- property: властивість\n+- proxy: представник\n+- pull request: запит на витяг\n+- random-access memory: пам'ять з довільним доступом\n+- status code: код статусу\n+- string: строка\n+- tag: мітка\n+- wildcard: дика карта\n \n ### `///` admonitions\n \n@@ -44,3 +110,4 @@ Use the following preferred translations when they apply in documentation prose:\n - `/// warning | Попередження`\n - `/// info | Інформація`\n - `/// danger | Обережно`\n+- `/// check | Перевірте`"
}
],
"reviews": [
{
"id": 3735616538,
"user": "user_e0d9d241a0ad",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-02-01T14:36:24+00:00"
},
{
"id": 3752122974,
"user": "user_2a237e38e06b",
"state": "APPROVED",
"body": "Awesome, thank you! 🙌",
"submitted_at": "2026-02-04T16:47:25+00:00"
}
],
"review_comments": [
{
"id": 2751133555,
"user": "user_e0d9d241a0ad",
"body": "data-science - не перекладається",
"path": "docs/uk/llm-prompt.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-01T12:05:51+00:00"
},
{
"id": 2751134535,
"user": "user_e0d9d241a0ad",
"body": "```suggestion\n- enum: перелік\n```",
"path": "docs/uk/llm-prompt.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-01T12:06:32+00:00"
}
],
"meta": {
"languages": [
"md"
],
"touches_tests": false,
"review_state_summary": {
"COMMENTED": 1,
"APPROVED": 1
},
"meaningful_comment_count": 2,
"has_approval": true,
"has_changes_requested": false,
"total_review_comments": 2
}
}
{
"_id": "53d679d91cd9067a",
"_schema_version": "1.0",
"_cleaned_at": "2026-02-12T07:46:51.624760+00:00",
"repo": "tiangolo/fastapi",
"repo_url": "https://github.com/fastapi/fastapi",
"license_name": "MIT License",
"license_spdx": "MIT",
"pr_number": 14789,
"title": "🐛 Fix TYPE_CHECKING annotations for Python 3.14 (PEP 649)",
"body": "PR #14485 fixed support for if TYPE_CHECKING, non-evaluated stringified annotations, when using `from __future__ import annotations`.\n\nThis change adds the same support when using deferred evaluation of annotations introduced in Python 3.14.\n\nNote: I was also able to reproduce the issue by removing `from __future__ import annotations` from `tests/test_stringified_annotation_dependency.py` (using python 3.14). \n\nIt has been [discussed here](https://github.com/fastapi/fastapi/discussions/14784)",
"author": "user_39c3b1c9d6c5",
"created_at": "2026-01-31T14:17:20+00:00",
"merged_at": "2026-02-04T13:49:44+00:00",
"base_branch": "master",
"head_branch": "fix-if-type-checking-py-314",
"additions": 46,
"deletions": 5,
"changed_files": 4,
"files": [
{
"filename": "fastapi/dependencies/utils.py",
"status": "modified",
"additions": 6,
"deletions": 1,
"changes": 7,
"patch": "@@ -204,7 +204,12 @@ def _get_signature(call: Callable[..., Any]) -> inspect.Signature:\n except NameError:\n # Handle type annotations with if TYPE_CHECKING, not used by FastAPI\n # e.g. dependency return types\n- signature = inspect.signature(call)\n+ if sys.version_info >= (3, 14):\n+ from annotationlib import Format\n+\n+ signature = inspect.signature(call, annotation_format=Format.FORWARDREF)\n+ else:\n+ signature = inspect.signature(call)\n else:\n signature = inspect.signature(call)\n return signature"
},
{
"filename": "tests/test_stringified_annotation_dependency_py314.py",
"status": "added",
"additions": 30,
"deletions": 0,
"changes": 30,
"patch": "@@ -0,0 +1,30 @@\n+from typing import TYPE_CHECKING, Annotated\n+\n+from fastapi import Depends, FastAPI\n+from fastapi.testclient import TestClient\n+\n+from .utils import needs_py314\n+\n+if TYPE_CHECKING: # pragma: no cover\n+\n+ class DummyUser: ...\n+\n+\n+[USER_REDACTED]_py314\n+def test_stringified_annotation():\n+ # python3.14: Use forward reference without \"from __future__ import annotations\"\n+ async def get_current_user() -> DummyUser | None:\n+ return None\n+\n+ app = FastAPI()\n+\n+ client = TestClient(app)\n+\n+ [USER_REDACTED].get(\"/\")\n+ async def get(\n+ current_user: Annotated[DummyUser | None, Depends(get_current_user)],\n+ ) -> str:\n+ return \"hello world\"\n+\n+ response = client.get(\"/\")\n+ assert response.status_code == 200"
},
{
"filename": "tests/test_tutorial/test_dependencies/test_tutorial008.py",
"status": "modified",
"additions": 8,
"deletions": 2,
"changes": 10,
"patch": "@@ -1,4 +1,5 @@\n import importlib\n+import sys\n from types import ModuleType\n from typing import Annotated, Any\n from unittest.mock import Mock, patch\n@@ -12,8 +13,13 @@\n name=\"module\",\n params=[\n \"tutorial008_py39\",\n- # Fails with `NameError: name 'DepA' is not defined`\n- pytest.param(\"tutorial008_an_py39\", marks=pytest.mark.xfail),\n+ pytest.param(\n+ \"tutorial008_an_py39\",\n+ marks=pytest.mark.xfail(\n+ sys.version_info < (3, 14),\n+ reason=\"Fails with `NameError: name 'DepA' is not defined`\",\n+ ),\n+ ),\n ],\n )\n def get_module(request: pytest.FixtureRequest):"
},
{
"filename": "tests/utils.py",
"status": "modified",
"additions": 2,
"deletions": 2,
"changes": 4,
"patch": "@@ -6,8 +6,8 @@\n needs_py310 = pytest.mark.skipif(\n sys.version_info < (3, 10), reason=\"requires python3.10+\"\n )\n-needs_py_lt_314 = pytest.mark.skipif(\n- sys.version_info >= (3, 14), reason=\"requires python3.13-\"\n+needs_py314 = pytest.mark.skipif(\n+ sys.version_info < (3, 14), reason=\"requires python3.14+\"\n )"
}
],
"reviews": [
{
"id": 3732721601,
"user": "user_39c3b1c9d6c5",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-01-31T14:18:11+00:00"
},
{
"id": 3732724041,
"user": "user_39c3b1c9d6c5",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-01-31T14:19:03+00:00"
},
{
"id": 3740194909,
"user": "user_29e85f9a8e75",
"state": "APPROVED",
"body": "LGTM!\n[USER_REDACTED], thank you!\n\nProbably better title: 🐛 Fix `TYPE_CHECKING` annotations for Python 3.14 (PEP 649)",
"submitted_at": "2026-02-02T15:29:24+00:00"
},
{
"id": 3751178276,
"user": "user_2a237e38e06b",
"state": "APPROVED",
"body": "Nice, thank you! This will be available in FastAPI 0.128.1, released in the next few hours. 🚀",
"submitted_at": "2026-02-04T13:49:33+00:00"
}
],
"review_comments": [
{
"id": 2749610463,
"user": "user_39c3b1c9d6c5",
"body": "`needs_py_lt_314` wasn't used",
"path": "tests/utils.py",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-31T14:18:11+00:00"
},
{
"id": 2749611842,
"user": "user_39c3b1c9d6c5",
"body": "I could move this import to top level, wdyt?",
"path": "fastapi/dependencies/utils.py",
"line": 208,
"side": "RIGHT",
"created_at": "2026-01-31T14:19:03+00:00"
}
],
"meta": {
"languages": [
"py"
],
"touches_tests": true,
"review_state_summary": {
"COMMENTED": 2,
"APPROVED": 2
},
"meaningful_comment_count": 2,
"has_approval": true,
"has_changes_requested": false,
"total_review_comments": 2
}
}
{
"_id": "47cfac2d5bcdb5d7",
"_schema_version": "1.0",
"_cleaned_at": "2026-02-12T07:46:51.624760+00:00",
"repo": "tiangolo/fastapi",
"repo_url": "https://github.com/fastapi/fastapi",
"license_name": "MIT License",
"license_spdx": "MIT",
"pr_number": 14756,
"title": "📝 Use `WSGIMiddleware` from `a2wsgi` instead of deprecated `fastapi.middleware.wsgi.WSGIMiddleware`",
"body": "`fastapi.middleware.wsgi.WSGIMiddleware` (re-exported from Starlette) is deprecated:\n\nhttps://github.com/Kludex/starlette/blob/501b86185461d107869917ced367d5624f82e3fb/starlette/middleware/wsgi.py#L15-L20",
"author": "user_29e85f9a8e75",
"created_at": "2026-01-22T11:12:17+00:00",
"merged_at": "2026-02-04T11:54:24+00:00",
"base_branch": "master",
"head_branch": "use-external-WSGIMiddleware",
"additions": 39,
"deletions": 13,
"changed_files": 6,
"files": [
{
"filename": "docs/en/docs/advanced/wsgi.md",
"status": "modified",
"additions": 18,
"deletions": 2,
"changes": 20,
"patch": "@@ -6,13 +6,29 @@ For that, you can use the `WSGIMiddleware` and use it to wrap your WSGI applicat\n \n ## Using `WSGIMiddleware` { #using-wsgimiddleware }\n \n-You need to import `WSGIMiddleware`.\n+/// info\n+\n+This requires installing `a2wsgi` for example with `pip install a2wsgi`.\n+\n+///\n+\n+You need to import `WSGIMiddleware` from `a2wsgi`.\n \n Then wrap the WSGI (e.g. Flask) app with the middleware.\n \n And then mount that under a path.\n \n-{* ../../docs_src/wsgi/tutorial001_py39.py hl[2:3,3] *}\n+{* ../../docs_src/wsgi/tutorial001_py39.py hl[1,3,23] *}\n+\n+/// note\n+\n+Previously, it was recommended to use `WSGIMiddleware` from `fastapi.middleware.wsgi`, but it is now deprecated.\n+\n+It’s advised to use the `a2wsgi` package instead. The usage remains the same.\n+\n+Just ensure that you have the `a2wsgi` package installed and import `WSGIMiddleware` correctly from `a2wsgi`.\n+\n+///\n \n ## Check it { #check-it }"
},
{
"filename": "docs/en/docs/reference/middleware.md",
"status": "modified",
"additions": 0,
"deletions": 8,
"changes": 8,
"patch": "@@ -35,11 +35,3 @@ It can be imported from `fastapi`:\n ```python\n from fastapi.middleware.trustedhost import TrustedHostMiddleware\n ```\n-\n-::: fastapi.middleware.wsgi.WSGIMiddleware\n-\n-It can be imported from `fastapi`:\n-\n-```python\n-from fastapi.middleware.wsgi import WSGIMiddleware\n-```"
},
{
"filename": "docs_src/wsgi/tutorial001_py39.py",
"status": "modified",
"additions": 1,
"deletions": 1,
"changes": 2,
"patch": "@@ -1,5 +1,5 @@\n+from a2wsgi import WSGIMiddleware\n from fastapi import FastAPI\n-from fastapi.middleware.wsgi import WSGIMiddleware\n from flask import Flask, request\n from markupsafe import escape"
},
{
"filename": "fastapi/middleware/wsgi.py",
"status": "modified",
"additions": 3,
"deletions": 1,
"changes": 4,
"patch": "@@ -1 +1,3 @@\n-from starlette.middleware.wsgi import WSGIMiddleware as WSGIMiddleware # noqa\n+from starlette.middleware.wsgi import (\n+ WSGIMiddleware as WSGIMiddleware,\n+) # pragma: no cover # noqa"
},
{
"filename": "pyproject.toml",
"status": "modified",
"additions": 1,
"deletions": 1,
"changes": 2,
"patch": "@@ -178,6 +178,7 @@ tests = [\n \"strawberry-graphql>=0.200.0,<1.0.0\",\n \"types-orjson==3.6.2\",\n \"types-ujson==5.10.0.20240515\",\n+ \"a2wsgi>=1.9.0,<=2.0.0\",\n ]\n translations = [\n \"gitpython==3.1.45\",\n@@ -231,7 +232,6 @@ xfail_strict = true\n junit_family = \"xunit2\"\n filterwarnings = [\n \"error\",\n- 'ignore:starlette.middleware.wsgi is deprecated and will be removed in a future release\\..*:DeprecationWarning:starlette',\n # see https://trio.readthedocs.io/en/stable/history.html#trio-0-22-0-2022-09-28\n \"ignore:You seem to already have a custom.*:RuntimeWarning:trio\",\n # TODO: remove after upgrading SQLAlchemy to a version that includes the following changes"
},
{
"filename": "uv.lock",
"status": "modified",
"additions": 16,
"deletions": 0,
"changes": 16,
"patch": "@@ -7,6 +7,18 @@ resolution-markers = [\n \"python_full_version < '3.10'\",\n ]\n \n+[[package]]\n+name = \"a2wsgi\"\n+version = \"1.10.10\"\n+source = { registry = \"https://pypi.org/simple\" }\n+dependencies = [\n+ { name = \"typing-extensions\", marker = \"python_full_version < '3.11'\" },\n+]\n+sdist = { url = \"https://files.pythonhosted.org/packages/9a/cb/822c56fbea97e9eee201a2e434a80437f6750ebcb1ed307ee3a0a7505b14/a2wsgi-1.10.10.tar.gz\", hash = \"sha256:a5bcffb52081ba39df0d5e9a884fc6f819d92e3a42389343ba77cbf809fe1f45\", size = 18799, upload-time = \"2025-06-18T09:00:10.843Z\" }\n+wheels = [\n+ { url = \"https://files.pythonhosted.org/packages/02/d5/349aba3dc421e73cbd4958c0ce0a4f1aa3a738bc0d7de75d2f40ed43a535/a2wsgi-1.10.10-py3-none-any.whl\", hash = \"sha256:d2b21379479718539dc15fce53b876251a0efe7615352dfe49f6ad1bc507848d\", size = 17389, upload-time = \"2025-06-18T09:00:09.676Z\" },\n+]\n+\n [[package]]\n name = \"ag-ui-protocol\"\n version = \"0.1.10\"\n@@ -1058,6 +1070,7 @@ standard-no-fastapi-cloud-cli = [\n \n [package.dev-dependencies]\n dev = [\n+ { name = \"a2wsgi\" },\n { name = \"anyio\", extra = [\"trio\"] },\n { name = \"black\" },\n { name = \"cairosvg\" },\n@@ -1131,6 +1144,7 @@ github-actions = [\n { name = \"smokeshow\" },\n ]\n tests = [\n+ { name = \"a2wsgi\" },\n { name = \"anyio\", extra = [\"trio\"] },\n { name = \"coverage\", version = \"7.10.7\", source = { registry = \"https://pypi.org/simple\" }, extra = [\"toml\"], marker = \"python_full_version < '3.10'\" },\n { name = \"coverage\", version = \"7.13.1\", source = { registry = \"https://pypi.org/simple\" }, extra = [\"toml\"], marker = \"python_full_version >= '3.10'\" },\n@@ -1197,6 +1211,7 @@ provides-extras = [\"standard\", \"standard-no-fastapi-cloud-cli\", \"all\"]\n \n [package.metadata.requires-dev]\n dev = [\n+ { name = \"a2wsgi\", specifier = \">=1.9.0,<=2.0.0\" },\n { name = \"anyio\", extras = [\"trio\"], specifier = \">=3.2.1,<5.0.0\" },\n { name = \"black\", specifier = \"==25.1.0\" },\n { name = \"cairosvg\", specifier = \"==2.8.2\" },\n@@ -1266,6 +1281,7 @@ github-actions = [\n { name = \"smokeshow\", specifier = \">=0.5.0\" },\n ]\n tests = [\n+ { name = \"a2wsgi\", specifier = \">=1.9.0,<=2.0.0\" },\n { name = \"anyio\", extras = [\"trio\"], specifier = \">=3.2.1,<5.0.0\" },\n { name = \"coverage\", extras = [\"toml\"], specifier = \">=6.5.0,<8.0\" },\n { name = \"dirty-equals\", specifier = \"==0.9.0\" },"
}
],
"reviews": [
{
"id": 3691931242,
"user": "user_29e85f9a8e75",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-01-22T11:13:10+00:00"
},
{
"id": 3750618416,
"user": "user_2a237e38e06b",
"state": "APPROVED",
"body": "Excellent, thank you! 🚀 🙌",
"submitted_at": "2026-02-04T11:54:10+00:00"
}
],
"review_comments": [
{
"id": 2716457348,
"user": "user_29e85f9a8e75",
"body": "With versions prior to `1.9.0` it gives error `404 Not found`",
"path": "pyproject.toml",
"line": 181,
"side": "RIGHT",
"created_at": "2026-01-22T11:13:10+00:00"
}
],
"meta": {
"languages": [
"lock",
"md",
"py",
"toml"
],
"touches_tests": false,
"review_state_summary": {
"COMMENTED": 1,
"APPROVED": 1
},
"meaningful_comment_count": 1,
"has_approval": true,
"has_changes_requested": false,
"total_review_comments": 1
}
}
{
"_id": "7a3e9a80bae99a4f",
"_schema_version": "1.0",
"_cleaned_at": "2026-02-12T07:46:51.624760+00:00",
"repo": "tiangolo/fastapi",
"repo_url": "https://github.com/fastapi/fastapi",
"license_name": "MIT License",
"license_spdx": "MIT",
"pr_number": 14747,
"title": "🔧 Update LLM-prompt for `abbr` and `dfn` tags",
"body": "Updated `scripts/general-llm-prompt.md` to simplify instructions for `abbr` tags and add instructions for `dfn` tags.\n\nThis should go after https://github.com/fastapi/fastapi/pull/14744\n\n---\n\nI ran translation script for `_llm-test.md` files of supported languages to sync them.\nTo do this I used `GPT-5` model instead of `GPT-5.2` as it gives better result (less mistakes and less diff).\n\nI think we should consider downgrading model to `GPT-5` - I tested it on different pages (also with existing translation and without) and it gives better results most of the time",
"author": "user_29e85f9a8e75",
"created_at": "2026-01-20T23:19:26+00:00",
"merged_at": "2026-02-10T11:56:21+00:00",
"base_branch": "master",
"head_branch": "update-llm-prompt-for-abbr-and-dfn-tags",
"additions": 63,
"deletions": 79,
"changed_files": 7,
"files": [
{
"filename": "docs/de/docs/_llm-test.md",
"status": "modified",
"additions": 7,
"deletions": 7,
"changes": 14,
"patch": "@@ -35,7 +35,7 @@ [NAME_REDACTED] `### Content of code snippets` im allgemeinen Prompt in `scripts\n \n //// tab | Test\n \n-Gestern schrieb mein Freund: „Wenn man unkorrekt korrekt schreibt, hat man es unkorrekt geschrieben“. Worauf ich antwortete: „Korrekt, aber ‚unkorrekt‘ ist unkorrekterweise nicht ‚„unkorrekt“‘“.\n+Gestern schrieb mein Freund: „Wenn man ‚incorrectly‘ korrekt schreibt, hat man es falsch geschrieben“. Worauf ich antwortete: „Korrekt, aber ‚incorrectly‘ ist inkorrekterweise nicht ‚„incorrectly“‘“.\n \n /// note | Hinweis\n \n@@ -202,11 +202,6 @@ Hier einige Dinge, die in HTML-„abbr“-Elemente gepackt sind (einige sind erf\n * XWT\n * PSGI\n \n-### Das abbr gibt eine Erklärung { #the-abbr-gives-an-explanation }\n-\n-* Cluster\n-* [NAME_REDACTED]\n-\n ### Das abbr gibt eine vollständige Phrase und eine Erklärung { #the-abbr-gives-a-full-phrase-and-an-explanation }\n \n * MDN\n@@ -224,6 +219,11 @@ [NAME_REDACTED] `### HTML abbr elements` im allgemeinen Prompt in `scripts/trans\n \n ////\n \n+## HTML „dfn“-Elemente { #html-dfn-elements }\n+\n+* Cluster\n+* [NAME_REDACTED]\n+\n ## Überschriften { #headings }\n \n //// tab | Test\n@@ -248,7 +248,7 @@ Die einzige strenge Regel für Überschriften ist, dass das LLM den Hash-Teil in\n \n [NAME_REDACTED] `### Headings` im allgemeinen Prompt in `scripts/translate.py`.\n \n-Für einige sprachspezifische Anweisungen, siehe z. B. den Abschnitt `### Headings` in `docs/de/llm-prompt.md`.\n+Für einige sprachsspezifische Anweisungen, siehe z. B. den Abschnitt `### Headings` in `docs/de/llm-prompt.md`.\n \n ////"
},
{
"filename": "docs/en/docs/_llm-test.md",
"status": "modified",
"additions": 5,
"deletions": 5,
"changes": 10,
"patch": "@@ -202,11 +202,6 @@ Here some things wrapped in HTML \"abbr\" elements (Some are invented):\n * XWT\n * PSGI\n \n-### The abbr gives an explanation { #the-abbr-gives-an-explanation }\n-\n-* cluster\n-* [NAME_REDACTED]\n-\n ### The abbr gives a full phrase and an explanation { #the-abbr-gives-a-full-phrase-and-an-explanation }\n \n * MDN\n@@ -224,6 +219,11 @@ See section `### HTML abbr elements` in the general prompt in `scripts/translate\n \n ////\n \n+## HTML \"dfn\" elements { #html-dfn-elements }\n+\n+* cluster\n+* [NAME_REDACTED]\n+\n ## Headings { #headings }\n \n //// tab | Test"
},
{
"filename": "docs/es/docs/_llm-test.md",
"status": "modified",
"additions": 7,
"deletions": 7,
"changes": 14,
"patch": "@@ -202,15 +202,10 @@ Aquí algunas cosas envueltas en elementos HTML \"abbr\" (algunas son inventadas):\n * XWT\n * PSGI\n \n-### El abbr da una explicación { #the-abbr-gives-an-explanation }\n-\n-* clúster\n-* [NAME_REDACTED]\n-\n ### El abbr da una frase completa y una explicación { #the-abbr-gives-a-full-phrase-and-an-explanation }\n \n * MDN\n-* I/O.\n+* I/O.\n \n ////\n \n@@ -224,6 +219,11 @@ Consulta la sección `### HTML abbr elements` en el prompt general en `scripts/t\n \n ////\n \n+## Elementos HTML \"dfn\" { #html-dfn-elements }\n+\n+* clúster\n+* [NAME_REDACTED]\n+\n ## Encabezados { #headings }\n \n //// tab | Prueba\n@@ -433,7 +433,7 @@ Para instrucciones específicas del idioma, mira p. ej. la sección `### Heading\n * el motor de plantillas\n \n * la anotación de tipos\n-* las anotaciones de tipos\n+* la anotación de tipos\n \n * el worker del servidor\n * el worker de Uvicorn"
},
{
"filename": "docs/ko/docs/_llm-test.md",
"status": "modified",
"additions": 6,
"deletions": 6,
"changes": 12,
"patch": "@@ -132,7 +132,7 @@ works(foo=\"bar\") # 이건 동작합니다 🎉\n 일부 텍스트\n ///\n \n-/// note Technical details | 기술 세부사항\n+/// note | 기술 세부사항\n 일부 텍스트\n ///\n \n@@ -202,11 +202,6 @@ works(foo=\"bar\") # 이건 동작합니다 🎉\n * XWT\n * PSGI\n \n-### abbr가 설명을 제공 { #the-abbr-gives-an-explanation }\n-\n-* cluster\n-* [NAME_REDACTED]\n-\n ### abbr가 전체 문구와 설명을 제공 { #the-abbr-gives-a-full-phrase-and-an-explanation }\n \n * MDN\n@@ -224,6 +219,11 @@ works(foo=\"bar\") # 이건 동작합니다 🎉\n \n ////\n \n+## HTML \"dfn\" 요소 { #html-dfn-elements }\n+\n+* 클러스터\n+* 딥 러닝\n+\n ## 제목 { #headings }\n \n //// tab | 테스트"
},
{
"filename": "docs/pt/docs/_llm-test.md",
"status": "modified",
"additions": 9,
"deletions": 9,
"changes": 18,
"patch": "@@ -197,15 +197,10 @@ Aqui estão algumas coisas envolvidas em elementos HTML \"abbr\" (algumas são inv\n \n ### O abbr fornece uma frase completa { #the-abbr-gives-a-full-phrase }\n \n-* GTD\n-* lt\n-* XWT\n-* PSGI\n-\n-### O abbr fornece uma explicação { #the-abbr-gives-an-explanation }\n-\n-* cluster\n-* [NAME_REDACTED]\n+* GTD\n+* lt\n+* XWT\n+* PSGI\n \n ### O abbr fornece uma frase completa e uma explicação { #the-abbr-gives-a-full-phrase-and-an-explanation }\n \n@@ -224,6 +219,11 @@ Veja a seção `### HTML abbr elements` no prompt geral em `scripts/translate.py\n \n ////\n \n+## Elementos HTML \"dfn\" { #html-dfn-elements }\n+\n+* cluster\n+* [NAME_REDACTED]\n+\n ## Títulos { #headings }\n \n //// tab | Teste"
},
{
"filename": "docs/ru/docs/_llm-test.md",
"status": "modified",
"additions": 5,
"deletions": 5,
"changes": 10,
"patch": "@@ -202,11 +202,6 @@ works(foo=\"bar\") # Это работает 🎉\n * XWT\n * PSGI\n \n-### abbr даёт объяснение { #the-abbr-gives-an-explanation }\n-\n-* кластер\n-* Глубокое обучение\n-\n ### abbr даёт полную расшифровку и объяснение { #the-abbr-gives-a-full-phrase-and-an-explanation }\n \n * MDN\n@@ -224,6 +219,11 @@ works(foo=\"bar\") # Это работает 🎉\n \n ////\n \n+## HTML-элементы \"dfn\" { #html-dfn-elements }\n+\n+* кластер\n+* Глубокое обучение\n+\n ## Заголовки { #headings }\n \n //// tab | Тест"
},
{
"filename": "scripts/general-llm-prompt.md",
"status": "modified",
"additions": 24,
"deletions": 40,
"changes": 64,
"patch": "@@ -353,7 +353,9 @@ Erstelle eine [[NAME_REDACTED]](../virtual-environments.md){.internal-link ta\n \n Translate HTML abbr elements (`text`) as follows:\n \n-- If the text surrounded by [NAME_REDACTED] an abbreviation (the text may be surrounded by [NAME_REDACTED] markup or quotes, for example text or `text` or \"text\", ignore that further markup when deciding if the text is an abbreviation), and if the description (the text inside the title attribute) contains the full phrase for this abbreviation, then append a dash (-) to the full phrase, followed by [NAME_REDACTED] full phrase.\n+- The text inside abbr tag may be surrounded by [NAME_REDACTED] markup or quotes, for example text or `text` or \"text\". Preserve markup and only translate visible text inside the abbr element.\n+\n+- If the description (the text inside the title attribute) contains the full phrase for this abbreviation, then append a dash (-) to the full phrase, followed by [NAME_REDACTED] full phrase.\n \n Conversion scheme:\n \n@@ -421,45 +423,7 @@ Result (German):\n ASGI\n ```\n \n-- If the description is not a full phrase for an abbreviation which the abbr element surrounds, but some other information, then just translate the description.\n-\n-Conversion scheme:\n-\n-Source (English):\n-\n-```\n-{text}\n-```\n-\n-Result:\n-\n-```\n-{translation of text}\n-```\n-\n-Examples:\n-\n- Source (English):\n-\n-```\n-path\n-linter\n-parsing\n-0.95.0\n-at the time of writing this\n-```\n-\n-Result (German):\n-\n-```\n-Pfad\n-Linter\n-Parsen\n-0.95.0\n-zum Zeitpunkt als das hier geschrieben wurde\n-```\n-\n-- If the text surrounded by [NAME_REDACTED] an abbreviation and the description contains both the full phrase for that abbreviation, and other information, separated by a colon (`:`), then append a dash (`-`) and the translation of the full phrase to the original full phrase and translate the other information.\n+- If the title of abbr element contains a full phrase for that abbreviation, and other information, separated by a colon (`:`), then append a dash (`-`) and the translation of the full phrase to the original full phrase and translate the other information.\n \n Conversion scheme:\n \n@@ -526,3 +490,23 @@ Result (German):\n - If there is an existing translation, and it has ADDITIONAL abbr elements in a sentence, and these additional abbr elements do not exist in the related sentence in the English text, then KEEP those additional abbr elements in the translation. Do not remove them. Except when you remove the whole sentence from the translation, because the whole sentence was removed from the English text, then also remove the abbr element. The reasoning for this rule is, that such additional abbr elements are manually added by [NAME_REDACTED] the translation, in order to translate or explain an English word to the human readers of the translation. These additional abbr elements would not make sense in the English text, but they do make sense in the translation. So keep them in the translation, even though they are not part of the English text. This rule only applies to abbr elements.\n \n - Apply above rules also when there is an existing translation! Make sure that all title attributes in abbr elements get properly translated or updated, using the schemes given above. However, leave the ADDITIONAL abbr's described above alone. Do not change their formatting or content.\n+\n+### HTML dfn elements\n+\n+For HTML dfn elements (`text`), translate the text inside the dfn element and the title attribute. Do not include the original English text in the title attribute.\n+\n+Examples:\n+\n+Source (English):\n+\n+```\n+path\n+linter\n+```\n+\n+Result (German):\n+\n+```\n+Pfad\n+Linter\n+```"
}
],
"reviews": [
{
"id": 3778470827,
"user": "user_2a237e38e06b",
"state": "APPROVED",
"body": "Nice, thank you! 🤖",
"submitted_at": "2026-02-10T11:48:51+00:00"
}
],
"review_comments": [
{
"id": 2787495672,
"user": "user_2a237e38e06b",
"body": "```suggestion\n- If the title of abbr element contains a full phrase for that abbreviation, and other information, separated by a colon (`:`), then append a dash (`-`) and the translation of the full phrase to the original full phrase and translate the other information.\n```",
"path": "scripts/general-llm-prompt.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-02-10T11:48:18+00:00"
}
],
"meta": {
"languages": [
"md"
],
"touches_tests": false,
"review_state_summary": {
"APPROVED": 1
},
"meaningful_comment_count": 1,
"has_approval": true,
"has_changes_requested": false,
"total_review_comments": 1
}
}
{
"_id": "d7b86edf67eedc5d",
"_schema_version": "1.0",
"_cleaned_at": "2026-02-12T07:46:51.640384+00:00",
"repo": "tiangolo/fastapi",
"repo_url": "https://github.com/fastapi/fastapi",
"license_name": "MIT License",
"license_spdx": "MIT",
"pr_number": 14739,
"title": "🌐 Update translations for uk (update outdated, found by [NAME_REDACTED])",
"body": "Running translation fixer tool shows several pages that contain mistakes. They were likely missed because of the overridden commit date.\nThis PR updates those outdated pages",
"author": "user_29e85f9a8e75",
"created_at": "2026-01-20T08:56:08+00:00",
"merged_at": "2026-02-01T09:44:39+00:00",
"base_branch": "master",
"head_branch": "update-translations-uk",
"additions": 166,
"deletions": 160,
"changed_files": 3,
"files": [
{
"filename": "docs/uk/docs/alternatives.md",
"status": "modified",
"additions": 41,
"deletions": 39,
"changes": 80,
"patch": "@@ -1,8 +1,8 @@\n-# Альтернативи, натхнення та порівняння\n+# Альтернативи, натхнення та порівняння { #alternatives-inspiration-and-comparisons }\n \n-Що надихнуло на створення **FastAPI**, який він у порінянні з іншими альтернативами та чого він у них навчився.\n+Що надихнуло **FastAPI**, як він порівнюється з альтернативами та чого він у них навчився.\n \n-## Вступ\n+## Вступ { #intro }\n \n **FastAPI** не існувало б, якби не попередні роботи інших.\n \n@@ -12,17 +12,17 @@\n \n Але в якийсь момент не було іншого виходу, окрім створення чогось, що надавало б усі ці функції, взявши найкращі ідеї з попередніх інструментів і поєднавши їх найкращим чином, використовуючи мовні функції, які навіть не були доступні раніше (Python 3.6+ підказки типів).\n \n-## Попередні інструменти\n+## Попередні інструменти { #previous-tools }\n \n-### Django\n+### Django { #django }\n \n Це найпопулярніший фреймворк Python, який користується широкою довірою. Він використовується для створення таких систем, як Instagram.\n \n Він відносно тісно пов’язаний з реляційними базами даних (наприклад, MySQL або PostgreSQL), тому мати базу даних NoSQL (наприклад, Couchbase, MongoDB, Cassandra тощо) як основний механізм зберігання не дуже просто.\n \n-Він був створений для створення HTML у серверній частині, а не для створення API, які використовуються сучасним інтерфейсом (як-от React, Vue.js і Angular) або іншими системами (як-от IoT пристрої), які спілкуються з ним.\n+Він був створений для створення HTML у серверній частині, а не для створення API, які використовуються сучасним інтерфейсом (як-от React, Vue.js і Angular) або іншими системами (як-от IoT пристрої), які спілкуються з ним.\n \n-### Django REST Framework\n+### Django REST Framework { #django-rest-framework }\n \n Фреймворк Django REST був створений як гнучкий інструментарій для створення веб-інтерфейсів API використовуючи Django в основі, щоб покращити його можливості API.\n \n@@ -42,7 +42,7 @@ Django REST Framework створив Том Крісті. Той самий тв\n \n ///\n \n-### Flask\n+### Flask { #flask }\n \n Flask — це «мікрофреймворк», він не включає інтеграцію бази даних, а також багато речей, які за замовчуванням є в Django.\n \n@@ -64,7 +64,7 @@ Flask — це «мікрофреймворк», він не включає ін\n \n ///\n \n-### Requests\n+### Requests { #requests }\n \n **FastAPI** насправді не є альтернативою **Requests**. Сфера їх застосування дуже різна.\n \n@@ -88,25 +88,25 @@ Requests мають дуже простий та інтуїтивно зрозу\n response = requests.get(\"http://example.com/some/url\")\n ```\n \n-Відповідна операція *роуту* API FastAPI може виглядати так:\n+Відповідна операція шляху API FastAPI може виглядати так:\n \n ```Python hl_lines=\"1\"\n [USER_REDACTED].get(\"/some/url\")\n def read_url():\n- return {\"message\": \"[NAME_REDACTED]\"}\n+ return {\"message\": \"[NAME_REDACTED]\"}\n ```\n \n Зверніть увагу на схожість у `requests.get(...)` і `[USER_REDACTED].get(...)`.\n \n /// check | Надихнуло **FastAPI** на\n \n * Майте простий та інтуїтивно зрозумілий API.\n- * Використовуйте імена (операції) методів HTTP безпосередньо, простим та інтуїтивно зрозумілим способом.\n- * Розумні параметри за замовчуванням, але потужні налаштування.\n+* Використовуйте імена (операції) методів HTTP безпосередньо, простим та інтуїтивно зрозумілим способом.\n+* Розумні параметри за замовчуванням, але потужні налаштування.\n \n ///\n \n-### Swagger / OpenAPI\n+### Swagger / OpenAPI { #swagger-openapi }\n \n Головною функцією, яку я хотів від Django REST Framework, була автоматична API документація.\n \n@@ -124,18 +124,18 @@ def read_url():\n \n Інтегрувати інструменти інтерфейсу на основі стандартів:\n \n- * Інтерфейс Swagger\n- * ReDoc\n+* Інтерфейс Swagger\n+* ReDoc\n \n Ці два було обрано через те, що вони досить популярні та стабільні, але, виконавши швидкий пошук, ви можете знайти десятки додаткових альтернативних інтерфейсів для OpenAPI (які можна використовувати з **FastAPI**).\n \n ///\n \n-### Фреймворки REST для Flask\n+### Фреймворки REST для Flask { #flask-rest-frameworks }\n \n Існує кілька фреймворків Flask REST, але, витративши час і роботу на їх дослідження, я виявив, що багато з них припинено або залишено, з кількома постійними проблемами, які зробили їх непридатними.\n \n-### Marshmallow\n+### Marshmallow { #marshmallow }\n \n Однією з головних функцій, необхідних для систем API, є \"серіалізація\", яка бере дані з коду (Python) і перетворює їх на щось, що можна надіслати через мережу. Наприклад, перетворення об’єкта, що містить дані з бази даних, на об’єкт JSON. Перетворення об’єктів `datetime` на строки тощо.\n \n@@ -153,7 +153,7 @@ Marshmallow створено для забезпечення цих функці\n \n ///\n \n-### Webargs\n+### Webargs { #webargs }\n \n Іншою важливою функцією, необхідною для API, є аналіз даних із вхідних запитів.\n \n@@ -175,7 +175,7 @@ Webargs був створений тими ж розробниками Marshmall\n \n ///\n \n-### APISpec\n+### APISpec { #apispec }\n \n Marshmallow і Webargs забезпечують перевірку, аналіз і серіалізацію як плагіни.\n \n@@ -205,7 +205,7 @@ APISpec був створений тими ж розробниками Marshmall\n \n ///\n \n-### Flask-apispec\n+### Flask-apispec { #flask-apispec }\n \n Це плагін Flask, який об’єднує Webargs, Marshmallow і APISpec.\n \n@@ -237,13 +237,13 @@ Flask-apispec був створений тими ж розробниками Mar\n \n ///\n \n-### NestJS (та Angular)\n+### NestJS (та Angular) { #nestjs-and-angular }\n \n Це навіть не Python, NestJS — це фреймворк [NAME_REDACTED] (TypeScript), натхненний Angular.\n \n Це досягає чогось подібного до того, що можна зробити з Flask-apispec.\n \n-Він має інтегровану систему впровадження залежностей, натхненну Angular two. Він потребує попередньої реєстрації «injectables» (як і всі інші системи впровадження залежностей, які я знаю), тому це збільшує багатослівність та повторення коду.\n+Він має інтегровану систему впровадження залежностей, натхненну Angular 2. Він потребує попередньої реєстрації «injectables» (як і всі інші системи впровадження залежностей, які я знаю), тому це збільшує багатослівність та повторення коду.\n \n Оскільки параметри описані за допомогою типів TypeScript (подібно до підказок типу Python), підтримка редактора досить хороша.\n \n@@ -259,7 +259,7 @@ Flask-apispec був створений тими ж розробниками Mar\n \n ///\n \n-### Sanic\n+### Sanic { #sanic }\n \n Це був один із перших надзвичайно швидких фреймворків Python на основі `asyncio`. Він був дуже схожий на Flask.\n \n@@ -279,7 +279,7 @@ Flask-apispec був створений тими ж розробниками Mar\n \n ///\n \n-### Falcon\n+### Falcon { #falcon }\n \n Falcon — ще один високопродуктивний фреймворк Python, він розроблений як мінімальний і працює як основа інших фреймворків, таких як Hug.\n \n@@ -297,7 +297,7 @@ Falcon — ще один високопродуктивний фреймворк\n \n ///\n \n-### Molten\n+### Molten { #molten }\n \n Я відкрив для себе Molten на перших етапах створення **FastAPI**. І він має досить схожі ідеї:\n \n@@ -321,7 +321,7 @@ Falcon — ще один високопродуктивний фреймворк\n \n ///\n \n-### Hug\n+### Hug { #hug }\n \n Hug був одним із перших фреймворків, який реалізував оголошення типів параметрів API за допомогою підказок типу Python. Це була чудова ідея, яка надихнула інші інструменти зробити те саме.\n \n@@ -351,7 +351,7 @@ Hug надихнув частину APIStar і був одним із найбі\n \n ///\n \n-### APIStar (<= 0,5)\n+### APIStar (<= 0,5) { #apistar-0-5 }\n \n Безпосередньо перед тим, як вирішити створити **FastAPI**, я знайшов сервер **APIStar**. Він мав майже все, що я шукав, і мав чудовий дизайн.\n \n@@ -379,9 +379,9 @@ Hug надихнув частину APIStar і був одним із найбі\n \n APIStar створив Том Крісті. Той самий хлопець, який створив:\n \n- * Django REST Framework\n- * Starlette (на якому базується **FastAPI**)\n- * Uvicorn (використовується Starlette і **FastAPI**)\n+* Django REST Framework\n+* Starlette (на якому базується **FastAPI**)\n+* Uvicorn (використовується Starlette і **FastAPI**)\n \n ///\n \n@@ -393,13 +393,15 @@ APIStar створив Том Крісті. Той самий хлопець, я\n \n І після тривалого пошуку подібної структури та тестування багатьох різних альтернатив, APIStar став найкращим доступним варіантом.\n \n- Потім APIStar перестав існувати як сервер, і було створено Starlette, який став новою кращою основою для такої системи. Це стало останнім джерелом натхнення для створення **FastAPI**. Я вважаю **FastAPI** «духовним спадкоємцем» APIStar, удосконалюючи та розширюючи функції, систему введення тексту та інші частини на основі досвіду, отриманого від усіх цих попередніх інструментів.\n+ Потім APIStar перестав існувати як сервер, і було створено Starlette, який став новою кращою основою для такої системи. Це стало останнім джерелом натхнення для створення **FastAPI**.\n+\n+ Я вважаю **FastAPI** «духовним спадкоємцем» APIStar, удосконалюючи та розширюючи функції, систему типізації та інші частини на основі досвіду, отриманого від усіх цих попередніх інструментів.\n \n ///\n \n-## Використовується **FastAPI**\n+## Використовується **FastAPI** { #used-by-fastapi }\n \n-### Pydantic\n+### Pydantic { #pydantic }\n \n Pydantic — це бібліотека для визначення перевірки даних, серіалізації та документації (за допомогою схеми JSON) на основі підказок типу Python.\n \n@@ -415,9 +417,9 @@ Pydantic — це бібліотека для визначення переві\n \n ///\n \n-### Starlette\n+### Starlette { #starlette }\n \n-Starlette — це легкий фреймворк/набір інструментів ASGI, який ідеально підходить для створення високопродуктивних asyncio сервісів.\n+Starlette — це легкий фреймворк/набір інструментів ASGI, який ідеально підходить для створення високопродуктивних asyncio сервісів.\n \n Він дуже простий та інтуїтивно зрозумілий. Його розроблено таким чином, щоб його можна було легко розширювати та мати модульні компоненти.\n \n@@ -460,7 +462,7 @@ ASGI — це новий «стандарт», який розробляєтьс\n \n ///\n \n-### Uvicorn\n+### Uvicorn { #uvicorn }\n \n Uvicorn — це блискавичний сервер ASGI, побудований на uvloop і httptools.\n \n@@ -472,12 +474,12 @@ Uvicorn — це блискавичний сервер ASGI, побудован\n \n Основний веб-сервер для запуску програм **FastAPI**.\n \n- Ви можете поєднати його з Gunicorn, щоб мати асинхронний багатопроцесний сервер.\n+ Ви також можете використати параметр командного рядка `--workers`, щоб мати асинхронний багатопроцесний сервер.\n \n Додаткову інформацію див. у розділі [Розгортання](deployment/index.md){.internal-link target=_blank}.\n \n ///\n \n-## Орієнтири та швидкість\n+## Орієнтири та швидкість { #benchmarks-and-speed }\n \n Щоб зрозуміти, порівняти та побачити різницю між Uvicorn, Starlette і FastAPI, перегляньте розділ про [Бенчмарки](benchmarks.md){.internal-link target=_blank}."
},
{
"filename": "docs/uk/docs/fastapi-cli.md",
"status": "modified",
"additions": 50,
"deletions": 58,
"changes": 108,
"patch": "@@ -1,83 +1,75 @@\n-# FastAPI CLI\n+# FastAPI CLI { #fastapi-cli }\n \n-**FastAPI CLI** це програма командного рядка, яку Ви можете використовувати, щоб обслуговувати Ваш додаток FastAPI, керувати Вашими FastApi проектами, тощо.\n+**FastAPI CLI** — це програма командного рядка, яку ви можете використовувати, щоб обслуговувати ваш застосунок FastAPI, керувати вашим проєктом FastAPI тощо.\n \n-Коли Ви встановлюєте FastApi (тобто виконуєте `pip install \"fastapi[standard]\"`), Ви також встановлюєте пакунок `fastapi-cli`, цей пакунок надає команду `fastapi` в терміналі.\n+Коли ви встановлюєте FastAPI (наприклад, за допомогою `pip install \"fastapi[standard]\"`), він включає пакет під назвою `fastapi-cli`, цей пакет надає команду `fastapi` у терміналі.\n \n-Для запуску Вашого FastAPI проекту для розробки, Ви можете скористатись командою `fastapi dev`:\n+Щоб запустити ваш застосунок FastAPI для розробки, ви можете використати команду `fastapi dev`:\n \n \n \n ```console\n-$ fastapi dev main.py\n-INFO Using path main.py\n-INFO Resolved absolute path /home/user/code/awesomeapp/main.py\n-INFO Searching for package file structure from directories with __init__.py files\n-INFO Importing from /home/user/code/awesomeapp\n-\n- ╭─ Python module file ─╮\n- │ │\n- │ 🐍 main.py │\n- │ │\n- ╰──────────────────────╯\n-\n-INFO Importing module main\n-INFO Found importable FastAPI app\n-\n- ╭─ [NAME_REDACTED] app ─╮\n- │ │\n- │ from main import app │\n- │ │\n- ╰──────────────────────────╯\n-\n-INFO Using import string main:app\n-\n- ╭────────── FastAPI CLI - Development mode ───────────╮\n- │ │\n- │ Serving at: http://127.0.0.1:8000 │\n- │ │\n- │ API docs: http://127.0.0.1:8000/docs │\n- │ │\n- │ Running in development mode, for production use: │\n- │ │\n- │ fastapi run │\n- │ │\n- ╰─────────────────────────────────────────────────────╯\n-\n-INFO: Will watch for changes in these directories: ['/home/user/code/awesomeapp']\n-INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)\n-INFO: Started reloader process [2265862] using WatchFiles\n-INFO: Started server process [2265873]\n-INFO: Waiting for application startup.\n-INFO: Application startup complete.\n+$ fastapi dev main.py\n+\n+ FastAPI Starting development server 🚀\n+\n+ Searching for package file structure from directories with\n+ __init__.py files\n+ Importing from /home/user/code/awesomeapp\n+\n+ module 🐍 main.py\n+\n+ code Importing the FastAPI app object from the module with the\n+ following code:\n+\n+ from main import app\n+\n+ app Using import string: main:app\n+\n+ server Server started at http://127.0.0.1:8000\n+ server Documentation at http://127.0.0.1:8000/docs\n+\n+ tip Running in development mode, for production use:\n+ fastapi run\n+\n+ Logs:\n+\n+ INFO Will watch for changes in these directories:\n+ ['/home/user/code/awesomeapp']\n+ INFO Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to\n+ quit)\n+ INFO Started reloader process [383138] using WatchFiles\n+ INFO Started server process [383153]\n+ INFO Waiting for application startup.\n+ INFO Application startup complete.\n ```\n \n
\n \n-Програма командного рядка `fastapi` це **FastAPI CLI**.\n+Програма командного рядка під назвою `fastapi` — це **FastAPI CLI**.\n \n-FastAPI CLI приймає шлях до Вашої Python програми (напр. `main.py`) і автоматично виявляє екземпляр `FastAPI` (зазвичай названий `app`), обирає коректний процес імпорту, а потім обслуговує його.\n+FastAPI CLI бере шлях до вашої Python-програми (наприклад, `main.py`) і автоматично виявляє екземпляр `FastAPI` (зазвичай з назвою `app`), визначає правильний процес імпорту, а потім обслуговує його.\n \n-Натомість, для запуску у продакшн використовуйте `fastapi run`. 🚀\n+Натомість, для продакшн ви використали б `fastapi run`. 🚀\n \n-Всередині **FastAPI CLI** використовує Uvicorn, високопродуктивний, production-ready, ASGI cервер. 😎\n+Внутрішньо **FastAPI CLI** використовує Uvicorn, високопродуктивний, production-ready, ASGI сервер. 😎\n \n-## `fastapi dev`\n+## `fastapi dev` { #fastapi-dev }\n \n-Використання `fastapi dev` ініціює режим розробки.\n+Запуск `fastapi dev` ініціює режим розробки.\n \n-За замовчуванням, **автоматичне перезавантаження** увімкнене, автоматично перезавантажуючи сервер кожного разу, коли Ви змінюєте Ваш код. Це ресурсо-затратно, та може бути менш стабільним, ніж коли воно вимкнене. Ви повинні використовувати його тільки під час розробки. Воно також слухає IP-адресу `127.0.0.1`, що є IP Вашого девайсу для самостійної комунікації з самим собою (`localhost`).\n+За замовчуванням **auto-reload** увімкнено, і сервер автоматично перезавантажується, коли ви вносите зміни у ваш код. Це ресурсоємно та може бути менш стабільним, ніж коли його вимкнено. Вам слід використовувати це лише для розробки. Також він слухає IP-адресу `127.0.0.1`, яка є IP-адресою для того, щоб ваша машина могла взаємодіяти лише сама з собою (`localhost`).\n \n-## `fastapi run`\n+## `fastapi run` { #fastapi-run }\n \n-Виконання `fastapi run` запустить FastAPI у продакшн-режимі за замовчуванням.\n+Виконання `fastapi run` за замовчуванням запускає FastAPI у продакшн-режимі.\n \n-За замовчуванням, **автоматичне перезавантаження** вимкнене. Воно також прослуховує IP-адресу `0.0.0.0`, що означає всі доступні IP адреси, тим самим даючи змогу будь-кому комунікувати з девайсом. Так Ви зазвичай будете запускати його у продакшн, наприклад у контейнері.\n+За замовчуванням **auto-reload** вимкнено. Також він слухає IP-адресу `0.0.0.0`, що означає всі доступні IP-адреси, таким чином він буде публічно доступним для будь-кого, хто може взаємодіяти з машиною. Зазвичай саме так ви запускатимете його в продакшн, наприклад у контейнері.\n \n-В більшості випадків Ви можете (і маєте) мати \"termination proxy\", який обробляє HTTPS для Вас, це залежить від способу розгортання вашого додатку, Ваш провайдер може зробити це для Вас, або Вам потрібно налаштувати його самостійно.\n+У більшості випадків ви (і вам слід) матимете «termination proxy», який обробляє HTTPS для вас зверху; це залежатиме від того, як ви розгортаєте ваш застосунок: ваш провайдер може зробити це за вас, або вам може знадобитися налаштувати це самостійно.\n \n-/// tip\n+/// tip | Порада\n \n-Ви можете дізнатись більше про це у [документації про розгортування](deployment/index.md){.internal-link target=_blank}.\n+Ви можете дізнатися більше про це в [документації з розгортання](deployment/index.md){.internal-link target=_blank}.\n \n ///"
},
{
"filename": "docs/uk/docs/features.md",
"status": "modified",
"additions": 75,
"deletions": 63,
"changes": 138,
"patch": "@@ -1,53 +1,55 @@\n-# Функціональні можливості\n+# Функціональні можливості { #features }\n \n-## Функціональні можливості FastAPI\n+## Функціональні можливості FastAPI { #fastapi-features }\n \n **FastAPI** надає вам такі можливості:\n \n-### Використання відкритих стандартів\n+### На основі відкритих стандартів { #based-on-open-standards }\n \n * OpenAPI для створення API, включаючи оголошення шляхів, операцій, параметрів, тіл запитів, безпеки тощо.\n * Автоматична документація моделей даних за допомогою JSON Schema (оскільки OpenAPI базується саме на JSON Schema).\n * Розроблено на основі цих стандартів після ретельного аналізу, а не як додатковий рівень поверх основної архітектури.\n-* Це також дає змогу автоматично **генерувати код клієнта** багатьма мовами.\n+* Це також дає змогу використовувати автоматичну **генерацію клієнтського коду** багатьма мовами.\n \n-### Автоматична генерація документації\n+### Автоматична документація { #automatic-docs }\n \n-Інтерактивна документація API та вебінтерфейс для його дослідження. Оскільки фреймворк базується на OpenAPI, є кілька варіантів, два з яких включені за замовчуванням.\n+Інтерактивна документація API та вебінтерфейси для його дослідження. Оскільки фреймворк базується на OpenAPI, є кілька варіантів, 2 з яких включені за замовчуванням.\n \n-* Swagger UI — дозволяє інтерактивно переглядати API, викликати та тестувати його прямо у браузері.\n+* Swagger UI — з інтерактивним дослідженням, викликом і тестуванням вашого API прямо з браузера.\n \n 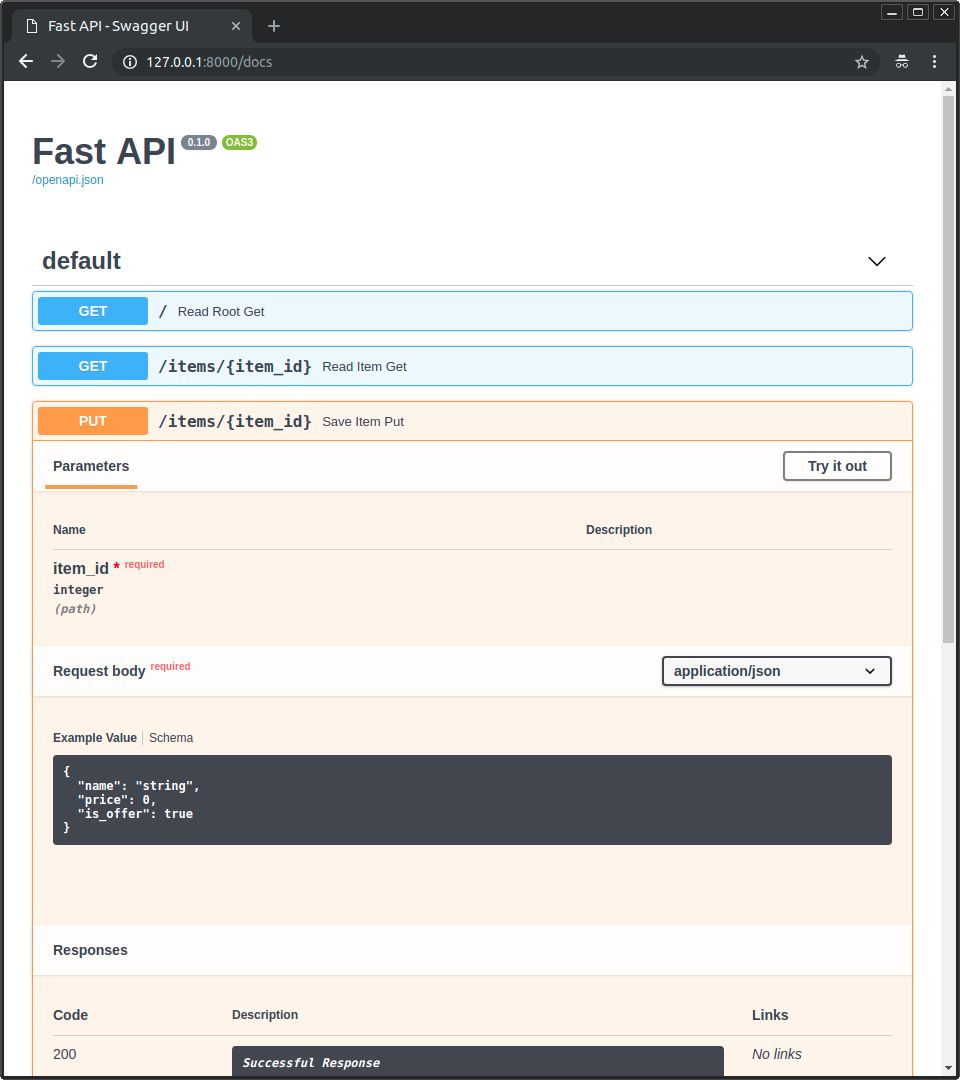\n \n * Альтернативна документація API за допомогою ReDoc.\n \n 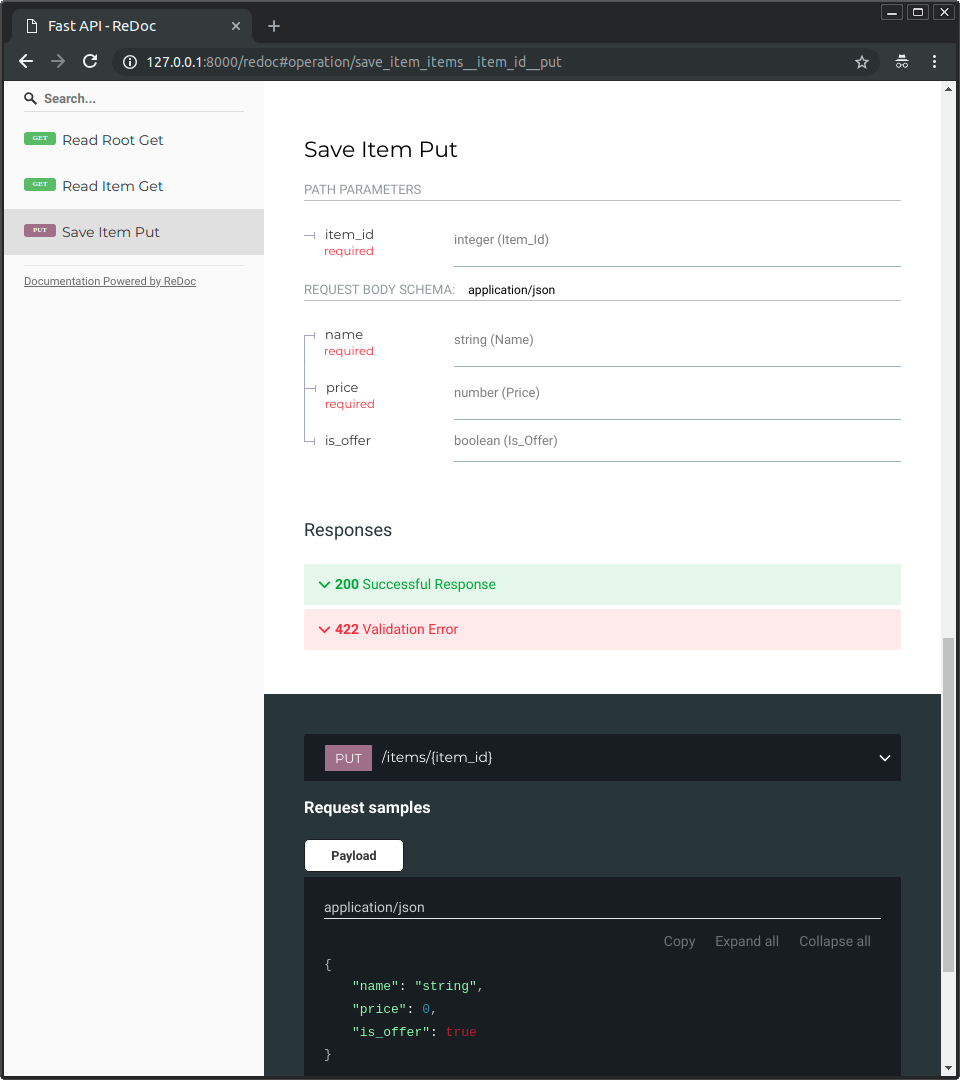\n \n-### Тільки сучасний Python\n+### Лише сучасний Python { #just-modern-python }\n \n-FastAPI використовує стандартні **типи Python** (завдяки Pydantic). Вам не потрібно вивчати новий синтаксис — лише стандартний сучасний Python.\n+Усе базується на стандартних оголошеннях **типів Python** (завдяки Pydantic). Жодного нового синтаксису для вивчення. Лише стандартний сучасний Python.\n \n-Якщо вам потрібне коротке нагадування про використання типів у Python (навіть якщо ви не використовуєте FastAPI), перегляньте короткий підручник: [Вступ до типів Python](python-types.md){.internal-link target=_blank}.\n+Якщо вам потрібно 2-хвилинне нагадування про те, як використовувати типи Python (навіть якщо ви не використовуєте FastAPI), перегляньте короткий підручник: [Типи Python](python-types.md){.internal-link target=_blank}.\n \n-Ось приклад стандартного Python-коду з типами:\n+Ви пишете стандартний Python з типами:\n \n ```Python\n from datetime import date\n+\n from pydantic import BaseModel\n \n-# Оголошення змінної як str\n-# з підтримкою автодоповнення у редакторі\n+# Оголосіть змінну як str\n+# та отримайте підтримку редактора всередині функції\n def main(user_id: str):\n return user_id\n \n+\n # Модель Pydantic\n class User(BaseModel):\n id: int\n name: str\n joined: date\n ```\n \n-Приклад використання цієї моделі:\n+Далі це можна використовувати так:\n \n ```Python\n my_user: User = User(id=3, name=\"[NAME_REDACTED]\", joined=\"2018-07-19\")\n@@ -65,19 +67,21 @@ my_second_user: User = User(**second_user_data)\n \n `**second_user_data` означає:\n \n-Передати ключі та значення словника `second_user_data` як аргументи у вигляді \"ключ-значення\", еквівалентно `User(id=4, name=\"Mary\", joined=\"2018-11-30\")`.\n+Передати ключі та значення словника `second_user_data` безпосередньо як аргументи у вигляді «ключ-значення», еквівалентно: `User(id=4, name=\"Mary\", joined=\"2018-11-30\")`\n \n ///\n \n-### Підтримка редакторів (IDE)\n+### Підтримка редакторів (IDE) { #editor-support }\n \n-Фреймворк спроєктований так, щоб бути легким і інтуїтивно зрозумілим. Усі рішення тестувалися у різних редакторах ще до початку розробки, щоб забезпечити найкращий досвід програмування.\n+Увесь фреймворк спроєктовано так, щоб ним було легко та інтуїтивно користуватися; усі рішення тестувалися у кількох редакторах ще до початку розробки, щоб забезпечити найкращий досвід розробки.\n \n-За результатами опитувань розробників Python однією з найпопулярніших функцій є \"автодоповнення\".\n+З опитувань розробників Python зрозуміло що однією з найуживаніших функцій є «автодоповнення».\n \n-**FastAPI** повністю підтримує автодоповнення у всіх місцях, тому вам рідко доведеться повертатися до документації.\n+Увесь фреймворк **FastAPI** побудований так, щоб це забезпечити. Автодоповнення працює всюди.\n \n-Приклад автодоповнення у редакторах:\n+Вам рідко доведеться повертатися до документації.\n+\n+Ось як ваш редактор може вам допомогти:\n \n * у [NAME_REDACTED]:\n \n@@ -87,73 +91,81 @@ my_second_user: User = User(**second_user_data)\n \n 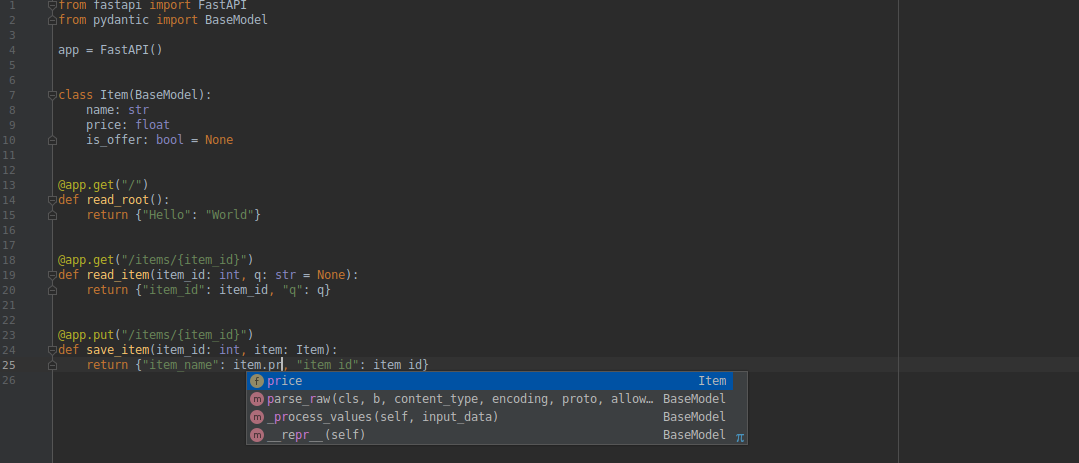\n \n-### Короткий код\n-FastAPI має розумні налаштування **за замовчуванням**, але всі параметри можна налаштовувати відповідно до ваших потреб. Однак за замовчуванням все \"просто працює\".\n+Ви отримаєте автодоповнення в коді, який раніше могли вважати навіть неможливим. Наприклад, для ключа `price` всередині JSON body (який міг бути вкладеним), що надходить із запиту.\n+\n+Більше не доведеться вводити неправильні назви ключів, постійно повертатися до документації або прокручувати вгору-вниз, щоб знайти, чи ви зрештою використали `username` чи `user_name`.\n+\n+### Короткий код { #short }\n+\n+FastAPI має розумні **налаштування за замовчуванням** для всього, з можливістю конфігурації всюди. Усі параметри можна точно налаштувати під ваші потреби та визначити потрібний вам API.\n+\n+Але за замовчуванням усе **«просто працює»**.\n+\n+### Валідація { #validation }\n \n-### Валідація\n * Підтримка валідації для більшості (або всіх?) **типів даних Python**, зокрема:\n * JSON-об'єктів (`dict`).\n- * JSON-списків (`list`) з визначенням типів елементів.\n- * Рядків (`str`) із мінімальною та максимальною довжиною.\n- * Чисел (`int`, `float`) з обмеженнями мінімальних та максимальних значень тощо.\n+ * JSON-масивів (`list`) із визначенням типів елементів.\n+ * Полів-рядків (`str`) із визначенням мінімальної та максимальної довжини.\n+ * Чисел (`int`, `float`) з мінімальними та максимальними значеннями тощо.\n \n-* Валідація складніших типів, таких як:\n+* Валідація для більш екзотичних типів, як-от:\n * URL.\n * Email.\n * UUID.\n * ...та інші.\n \n Уся валідація виконується через надійний та перевірений **Pydantic**.\n \n-### Безпека та автентифікація\n+### Безпека та автентифікація { #security-and-authentication }\n \n-**FastAPI** підтримує вбудовану автентифікацію та авторизацію, без прив’язки до конкретних баз даних чи моделей даних.\n+Інтегровані безпека та автентифікація. Без жодних компромісів із базами даних чи моделями даних.\n \n-Підтримуються всі схеми безпеки OpenAPI, включаючи:\n+Підтримуються всі схеми безпеки, визначені в OpenAPI, включно з:\n \n * HTTP Basic.\n-* **OAuth2** (також із підтримкою **JWT-токенів**). Див. підручник: [OAuth2 із JWT](tutorial/security/oauth2-jwt.md){.internal-link target=_blank}.\n+* **OAuth2** (також із підтримкою **JWT tokens**). Перегляньте підручник: [OAuth2 із JWT](tutorial/security/oauth2-jwt.md){.internal-link target=_blank}.\n * Ключі API в:\n * Заголовках.\n * Параметрах запиту.\n * Cookies тощо.\n \n-А також усі можливості безпеки від Starlette (зокрема **сесійні cookies**).\n+А також усі можливості безпеки від Starlette (зокрема **session cookies**).\n \n-Усі вони створені як багаторазові інструменти та компоненти, які легко інтегруються з вашими системами, сховищами даних, реляційними та NoSQL базами даних тощо.\n+Усе це зроблено як багаторазові інструменти та компоненти, які легко інтегруються з вашими системами, сховищами даних, реляційними та NoSQL базами даних тощо.\n \n-### Впровадження залежностей\n+### Впровадження залежностей { #dependency-injection }\n \n-**FastAPI** містить надзвичайно просту у використанні, але потужну систему впровадження залежностей.\n+FastAPI містить надзвичайно просту у використанні, але надзвичайно потужну систему [NAME_REDACTED].\n \n-* Залежності можуть мати власні залежності, утворюючи ієрархію або **\"граф залежностей\"**.\n-* Усі залежності автоматично керуються фреймворком.\n-* Усі залежності можуть отримувати дані з запитів і розширювати **обмеження операції за шляхом** та автоматичну документацію.\n-* **Автоматична валідація** навіть для параметрів *операцій шляху*, визначених у залежностях.\n-* Підтримка складних систем автентифікації користувачів, **з'єднань із базами даних** тощо.\n-* **Жодних обмежень** щодо використання баз даних, фронтендів тощо, але водночас проста інтеграція з усіма ними.\n+* Навіть залежності можуть мати власні залежності, утворюючи ієрархію або **«граф» залежностей**.\n+* Усе **автоматично обробляється** фреймворком.\n+* Усі залежності можуть вимагати дані із запитів і **розширювати обмеження операції шляху** та автоматичну документацію.\n+* **Автоматична валідація** навіть для параметрів *операції шляху*, визначених у залежностях.\n+* Підтримка складних систем автентифікації користувачів, **підключень до баз даних** тощо.\n+* **Жодних компромісів** із базами даних, фронтендами тощо. Але проста інтеграція з усіма ними.\n \n-### Немає обмежень на \"плагіни\"\n+### Необмежені «плагіни» { #unlimited-plug-ins }\n \n-Або іншими словами, вони не потрібні – просто імпортуйте та використовуйте необхідний код.\n+Інакше кажучи, вони не потрібні — імпортуйте та використовуйте код, який вам потрібен.\n \n-Будь-яка інтеграція спроєктована настільки просто (з використанням залежностей), що ви можете створити \"плагін\" для свого застосунку всього у 2 рядках коду, використовуючи ту саму структуру та синтаксис, що й для ваших *операцій шляху*.\n+Будь-яка інтеграція спроєктована так, щоб її було дуже просто використовувати (із залежностями), тож ви можете створити «плагін» для свого застосунку у 2 рядках коду, використовуючи ту саму структуру та синтаксис, що й для ваших *операцій шляху*.\n \n-### Протестовано\n+### Протестовано { #tested }\n \n * 100% покриття тестами.\n * 100% анотована типами кодова база.\n-* Використовується у робочих середовищах.\n+* Використовується в production-застосунках.\n \n-## Можливості Starlette\n+## Можливості Starlette { #starlette-features }\n \n **FastAPI** повністю сумісний із (та побудований на основі) Starlette. Тому будь-який додатковий код Starlette, який ви маєте, також працюватиме.\n \n-**FastAPI** фактично є підкласом **Starlette**. Тому, якщо ви вже знайомі зі Starlette або використовуєте його, більшість функціональності працюватиме так само.\n+`FastAPI` фактично є підкласом `Starlette`. Тому, якщо ви вже знайомі зі Starlette або використовуєте його, більшість функціональності працюватиме так само.\n \n-З **FastAPI** ви отримуєте всі можливості **Starlette** (адже FastAPI — це, по суті, Starlette на стероїдах):\n+З **FastAPI** ви отримуєте всі можливості **Starlette** (адже FastAPI — це просто Starlette на стероїдах):\n \n-* Разюча продуктивність. Це один із найшвидших фреймворків на Python, на рівні з **NodeJS** і **Go**.\n+* Разюча продуктивність. Це один із найшвидших доступних Python-фреймворків, на рівні з **NodeJS** і **Go**.\n * Підтримка **WebSocket**.\n * Фонові задачі у процесі.\n * Події запуску та завершення роботи.\n@@ -163,27 +175,27 @@ FastAPI має розумні налаштування **за замовчува\n * 100% покриття тестами.\n * 100% анотована типами кодова база.\n \n-## Можливості Pydantic\n+## Можливості Pydantic { #pydantic-features }\n \n **FastAPI** повністю сумісний із (та побудований на основі) Pydantic. Тому будь-який додатковий код Pydantic, який ви маєте, також працюватиме.\n \n-Включаючи зовнішні бібліотеки, побудовані також на Pydantic, такі як ORM, ODM для баз даних.\n+Включно із зовнішніми бібліотеками, які також базуються на Pydantic, як-от ORM-и, ODM-и для баз даних.\n \n-Це також означає, що в багатьох випадках ви можете передати той самий об'єкт, який отримуєте з запиту, **безпосередньо в базу даних**, оскільки все автоматично перевіряється.\n+Це також означає, що в багатьох випадках ви можете передати той самий об'єкт, який отримуєте із запиту, **безпосередньо в базу даних**, оскільки все автоматично перевіряється.\n \n-Те ж саме відбувається й у зворотному напрямку — у багатьох випадках ви можете просто передати об'єкт, який отримуєте з бази даних, **безпосередньо клієнту**.\n+Те саме застосовується й у зворотному напрямку — у багатьох випадках ви можете просто передати об'єкт, який отримуєте з бази даних, **безпосередньо клієнту**.\n \n З **FastAPI** ви отримуєте всі можливості **Pydantic** (адже FastAPI базується на Pydantic для обробки всіх даних):\n \n-* **Ніякої плутанини** :\n- * Не потрібно вчити нову мову для визначення схем.\n+* **Ніякої плутанини**:\n+ * Не потрібно вчити нову мікромову для визначення схем.\n * Якщо ви знаєте типи Python, ви знаєте, як використовувати Pydantic.\n-* Легко працює з вашим **IDE/лінтером/мозком**:\n- * Оскільки структури даних Pydantic є просто екземплярами класів, які ви визначаєте; автодоповнення, лінтинг, mypy і ваша інтуїція повинні добре працювати з вашими перевіреними даними.\n-* Валідація **складних структур**:\n- * Використання ієрархічних моделей Pydantic. Python `typing`, `List` і `Dict` тощо.\n- * Валідатори дозволяють чітко і просто визначати, перевіряти й документувати складні схеми даних у вигляді JSON-схеми.\n- * Ви можете мати глибоко **вкладені JSON об'єкти** та перевірити та анотувати їх всі.\n+* Легко працює з вашим **IDE/linter/мозком**:\n+ * Оскільки структури даних pydantic є просто екземплярами класів, які ви визначаєте; автодоповнення, лінтинг, mypy і ваша інтуїція повинні добре працювати з вашими перевіреними даними.\n+* Валідує **складні структури**:\n+ * Використання ієрархічних моделей Pydantic, Python `typing`’s `List` і `Dict` тощо.\n+ * Валідатори дають змогу складні схеми даних чітко й просто визначати, перевіряти й документувати як JSON Schema.\n+ * Ви можете мати глибоко **вкладені JSON** об'єкти, і всі вони будуть валідовані та анотовані.\n * **Розширюваність**:\n- * Pydantic дозволяє визначати користувацькі типи даних або розширювати валідацію методами в моделі декоратором `validator`.\n+ * Pydantic дозволяє визначати користувацькі типи даних або ви можете розширити валідацію методами в моделі, позначеними декоратором validator.\n * 100% покриття тестами."
}
],
"reviews": [
{
"id": 3710966594,
"user": "user_29e85f9a8e75",
"state": "COMMENTED",
"body": "Some suggestions to revert obviously wrong changes made by LLM",
"submitted_at": "2026-01-27T13:40:37+00:00"
},
{
"id": 3735367912,
"user": "user_2a237e38e06b",
"state": "APPROVED",
"body": "Thank you! 🎉",
"submitted_at": "2026-02-01T09:44:27+00:00"
}
],
"review_comments": [
{
"id": 2731829924,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T12:41:50+00:00"
},
{
"id": 2731835076,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T12:43:09+00:00"
},
{
"id": 2731837213,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T12:43:41+00:00"
},
{
"id": 2731842354,
"user": "user_29e85f9a8e75",
"body": "```suggestion\nОднією з головних функцій, необхідних для систем API, є \"серіалізація\", яка бере дані з коду (Python) і перетворює їх на щось, що можна надіслати через мережу. Наприклад, перетворення об’єкта, що містить дані з бази даних, на об’єкт JSON. Перетворення об’єктів `datetime` на строки тощо.\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T12:44:52+00:00"
},
{
"id": 2731846928,
"user": "user_29e85f9a8e75",
"body": "```suggestion\nАле він був створений до того, як існували підказки типу Python. Отже, щоб визначити кожну схему, вам потрібно використовувати спеціальні утиліти та класи, надані Marshmallow.\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T12:45:58+00:00"
},
{
"id": 2731848621,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T12:46:22+00:00"
},
{
"id": 2732019562,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:28:49+00:00"
},
{
"id": 2732025583,
"user": "user_29e85f9a8e75",
"body": "```suggestion\nІншою важливою функцією, необхідною для API, є аналіз даних із вхідних запитів.\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:30:11+00:00"
},
{
"id": 2732027903,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:30:44+00:00"
},
{
"id": 2732029068,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:30:59+00:00"
},
{
"id": 2732030181,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:31:14+00:00"
},
{
"id": 2732032028,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:31:37+00:00"
},
{
"id": 2732033298,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:31:53+00:00"
},
{
"id": 2732034498,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:32:10+00:00"
},
{
"id": 2732035904,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:32:29+00:00"
},
{
"id": 2732037318,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:32:50+00:00"
},
{
"id": 2732038515,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | Надихнуло **FastAPI** на\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:33:08+00:00"
},
{
"id": 2732041299,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | **FastAPI** використовує його для\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:33:44+00:00"
},
{
"id": 2732043744,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | **FastAPI** використовує його для\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:34:15+00:00"
},
{
"id": 2732045816,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n/// check | **FastAPI** рекомендує це як\n```",
"path": "docs/uk/docs/alternatives.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:34:42+00:00"
},
{
"id": 2732052618,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n* OpenAPI для створення API, включаючи оголошення шляхів, операцій, параметрів, тіл запитів, безпеки тощо.\n```",
"path": "docs/uk/docs/features.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:36:06+00:00"
},
{
"id": 2732063628,
"user": "user_29e85f9a8e75",
"body": "```suggestion\n* Підтримка **CORS**, **GZip**, статичних файлів, потокових відповідей.\n* Підтримка **сесій** і **cookie**.\n```",
"path": "docs/uk/docs/features.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-27T13:38:35+00:00"
}
],
"meta": {
"languages": [
"md"
],
"touches_tests": false,
"review_state_summary": {
"COMMENTED": 1,
"APPROVED": 1
},
"meaningful_comment_count": 22,
"has_approval": true,
"has_changes_requested": false,
"total_review_comments": 22
}
}
{
"_id": "bfea5616988b9901",
"_schema_version": "1.0",
"_cleaned_at": "2026-02-12T07:46:51.655996+00:00",
"repo": "tiangolo/fastapi",
"repo_url": "https://github.com/fastapi/fastapi",
"license_name": "MIT License",
"license_spdx": "MIT",
"pr_number": 14738,
"title": "🌐 Update translations for ko (update outdated, found by [NAME_REDACTED])",
"body": "Running translation fixer tool shows several pages that contain mistakes. They were likely missed because of the overridden commit date.\nThis PR updates those outdated pages",
"author": "user_29e85f9a8e75",
"created_at": "2026-01-20T08:45:40+00:00",
"merged_at": "2026-01-24T21:16:10+00:00",
"base_branch": "master",
"head_branch": "update-translations-ko",
"additions": 473,
"deletions": 462,
"changed_files": 5,
"files": [
{
"filename": "docs/ko/docs/async.md",
"status": "modified",
"additions": 202,
"deletions": 168,
"changes": 370,
"patch": "@@ -1,18 +1,18 @@\n-# 동시성과 async / await\n+# 동시성과 async / await { #concurrency-and-async-await }\n \n-*경로 작동 함수*에서의 `async def` 문법에 대한 세부사항과 비동기 코드, 동시성 및 병렬성에 대한 배경\n+*경로 처리 함수*에서의 `async def` 문법에 대한 세부사항과 비동기 코드, 동시성 및 병렬성에 대한 배경\n \n-## 바쁘신 경우\n+## 바쁘신가요? { #in-a-hurry }\n \n-요약\n+TL;DR:\n \n-다음과 같이 `await`를 사용해 호출하는 제3의 라이브러리를 사용하는 경우:\n+다음과 같이 `await`를 사용해 호출하라고 안내하는 제3자 라이브러리를 사용하는 경우:\n \n ```Python\n results = await some_library()\n ```\n \n-다음처럼 *경로 작동 함수*를 `async def`를 사용해 선언하십시오:\n+다음처럼 *경로 처리 함수*를 `async def`를 사용해 선언하십시오:\n \n ```Python hl_lines=\"2\"\n [USER_REDACTED].get('/')\n@@ -29,7 +29,7 @@ async def read_results():\n \n ---\n \n-데이터베이스, API, 파일시스템 등과 의사소통하는 제3의 라이브러리를 사용하고, 그것이 `await`를 지원하지 않는 경우(현재 거의 모든 데이터베이스 라이브러리가 그러합니다), *경로 작동 함수*를 일반적인 `def`를 사용해 선언하십시오:\n+데이터베이스, API, 파일시스템 등과 의사소통하는 제3자 라이브러리를 사용하고, 그것이 `await` 사용을 지원하지 않는 경우(현재 대부분의 데이터베이스 라이브러리가 그러합니다), *경로 처리 함수*를 일반적인 `def`를 사용해 선언하십시오:\n \n ```Python hl_lines=\"2\"\n [USER_REDACTED].get('/')\n@@ -40,275 +40,307 @@ def results():\n \n ---\n \n-만약 당신의 응용프로그램이 (어째서인지) 다른 무엇과 의사소통하고 그것이 응답하기를 기다릴 필요가 없다면 `async def`를 사용하십시오.\n+만약 여러분의 애플리케이션이 (어째서인지) 다른 어떤 것과도 통신하고 그 응답을 기다릴 필요가 없다면, 내부에서 `await`를 사용할 필요가 없더라도 `async def`를 사용하세요.\n \n ---\n \n-모르겠다면, 그냥 `def`를 사용하십시오.\n+잘 모르겠다면, 일반적인 `def`를 사용하세요.\n \n ---\n \n-**참고**: *경로 작동 함수*에서 필요한만큼 `def`와 `async def`를 혼용할 수 있고, 가장 알맞은 것을 선택해서 정의할 수 있습니다. FastAPI가 자체적으로 알맞은 작업을 수행할 것입니다.\n+**참고**: *경로 처리 함수*에서 필요한 만큼 `def`와 `async def`를 혼용할 수 있으며, 각각에 대해 가장 알맞은 옵션을 선택해 정의하면 됩니다. FastAPI가 올바르게 처리합니다.\n \n-어찌되었든, 상기 어떠한 경우라도, FastAPI는 여전히 비동기적으로 작동하고 매우 빠릅니다.\n+어쨌든 위의 어떤 경우에서도 FastAPI는 여전히 비동기적으로 동작하며 매우 빠릅니다.\n \n-그러나 상기 작업을 수행함으로써 어느 정도의 성능 최적화가 가능합니다.\n+하지만 위의 단계를 따르면, 몇 가지 성능 최적화를 할 수 있습니다.\n \n-## 기술적 세부사항\n+## 기술적 세부사항 { #technical-details }\n \n-최신 파이썬 버전은 `async`와 `await` 문법과 함께 **“코루틴”**이라고 하는 것을 사용하는 **“비동기 코드”**를 지원합니다.\n+최신 파이썬 버전은 **“코루틴”**이라고 하는 것을 사용하는 **“비동기 코드”**를 **`async` 및 `await`** 문법과 함께 지원합니다.\n \n 아래 섹션들에서 해당 문장을 부분별로 살펴보겠습니다:\n \n * **비동기 코드**\n * **`async`와 `await`**\n * **코루틴**\n \n-## 비동기 코드\n+## 비동기 코드 { #asynchronous-code }\n \n-비동기 코드란 언어 💬 가 코드의 어느 한 부분에서, 컴퓨터 / 프로그램🤖에게 *다른 무언가*가 어딘가에서 끝날 때까지 기다려야한다고 말하는 방식입니다. *다른 무언가*가 “느린-파일\" 📝 이라고 불린다고 가정해봅시다.\n+비동기 코드는 언어 💬 가 코드의 어느 한 부분에서 컴퓨터/프로그램 🤖 에게, 어느 시점에는 어딘가에서 *다른 무언가*가 끝날 때까지 기다려야 한다고 말할 수 있는 방법이 있다는 의미입니다. 그 *다른 무언가*를 \"slow-file\" 📝 이라고 해보겠습니다.\n \n-따라서 “느린-파일” 📝이 끝날때까지 컴퓨터는 다른 작업을 수행할 수 있습니다.\n+따라서 그 시간 동안 컴퓨터는 \"slow-file\" 📝 이 끝나는 동안 다른 작업을 하러 갈 수 있습니다.\n \n-그 다음 컴퓨터 / 프로그램 🤖 은 다시 기다리고 있기 때문에 기회가 있을 때마다 다시 돌아오거나, 혹은 당시에 수행해야하는 작업들이 완료될 때마다 다시 돌아옵니다. 그리고 그것 🤖 은 기다리고 있던 작업 중 어느 것이 이미 완료되었는지, 그것 🤖 이 해야하는 모든 작업을 수행하면서 확인합니다.\n+그 다음 컴퓨터/프로그램 🤖 은 다시 기다리는 중이기 때문에 기회가 있을 때마다 돌아오거나, 혹은 그 시점에 해야 할 작업을 모두 끝낼 때마다 돌아옵니다. 그리고 기다리던 작업 중 이미 끝난 것이 있는지 확인하면서, 해야 했던 작업을 수행합니다.\n \n-다음으로, 그것 🤖 은 완료할 첫번째 작업에 착수하고(우리의 \"느린-파일\" 📝 이라고 가정합시다) 그에 대해 수행해야하는 작업을 계속합니다.\n+다음으로, 완료된 첫 번째 작업(우리의 \"slow-file\" 📝 이라고 해보겠습니다)을 가져와서, 그에 대해 해야 했던 작업을 계속합니다.\n \n-\"다른 무언가를 기다리는 것\"은 일반적으로 비교적 \"느린\" (프로세서와 RAM 메모리 속도에 비해) I/O 작업을 의미합니다. 예를 들면 다음의 것들을 기다리는 것입니다:\n+이 \"다른 무언가를 기다리는 것\"은 일반적으로 프로세서와 RAM 메모리 속도에 비해 상대적으로 \"느린\" I/O 작업을 의미합니다. 예를 들어 다음을 기다리는 것입니다:\n \n-* 네트워크를 통해 클라이언트로부터 전송되는 데이터\n-* 네트워크를 통해 클라이언트가 수신할, 당신의 프로그램으로부터 전송되는 데이터\n-* 시스템이 읽고 프로그램에 전달할 디스크 내의 파일 내용\n-* 당신의 프로그램이 시스템에 전달하는, 디스크에 작성될 내용\n+* 네트워크를 통해 클라이언트가 데이터를 보내는 것\n+* 네트워크를 통해 클라이언트가 여러분의 프로그램이 보낸 데이터를 받는 것\n+* 시스템이 디스크의 파일 내용을 읽어서 프로그램에 전달하는 것\n+* 프로그램이 시스템에 전달한 내용을 디스크에 쓰는 것\n * 원격 API 작업\n-* 완료될 데이터베이스 작업\n-* 결과를 반환하는 데이터베이스 쿼리\n-* 기타\n+* 데이터베이스 작업이 완료되는 것\n+* 데이터베이스 쿼리가 결과를 반환하는 것\n+* 기타 등등\n \n-수행 시간의 대부분이 I/O 작업을 기다리는데에 소요되기 때문에, \"I/O에 묶인\" 작업이라고 불립니다.\n+실행 시간의 대부분이 I/O 작업을 기다리는 데 소비되기 때문에, 이를 \"I/O bound\" 작업이라고 부릅니다.\n \n-이것은 \"비동기\"라고 불리는데 컴퓨터 / 프로그램이 작업 결과를 가지고 일을 수행할 수 있도록, 느린 작업에 \"동기화\"되어 아무것도 하지 않으면서 작업이 완료될 정확한 시점만을 기다릴 필요가 없기 때문입니다.\n+이것은 컴퓨터/프로그램이 느린 작업과 \"동기화\"되어, 아무것도 하지 않은 채 그 작업이 끝나는 정확한 시점만 기다렸다가 결과를 가져와 일을 계속할 필요가 없기 때문에 \"비동기\"라고 불립니다.\n \n-이 대신에, \"비동기\" 시스템에서는, 작업은 일단 완료되면, 컴퓨터 / 프로그램이 수행하고 있는 일을 완료하고 이후 다시 돌아와서 그것의 결과를 받아 이를 사용해 작업을 지속할 때까지 잠시 (몇 마이크로초) 대기할 수 있습니다.\n+대신 \"비동기\" 시스템에서는, 작업이 끝나면 컴퓨터/프로그램이 하러 갔던 일을 마칠 때까지 잠시(몇 마이크로초) 줄에서 기다렸다가, 다시 돌아와 결과를 받아 이를 사용해 작업을 계속할 수 있습니다.\n \n-\"동기\"(\"비동기\"의 반대)는 컴퓨터 / 프로그램이 상이한 작업들간 전환을 하기 전에 그것이 대기를 동반하게 될지라도 모든 순서를 따르기 때문에 \"순차\"라는 용어로도 흔히 불립니다.\n+\"동기\"(“비동기”의 반대)는 보통 \"순차\"라는 용어로도 불리는데, 컴퓨터/프로그램이 다른 작업으로 전환하기 전에 모든 단계를 순서대로 따르기 때문이며, 그 단계들에 기다림이 포함되어 있더라도 마찬가지입니다.\n \n-### 동시성과 버거\n+### 동시성과 햄버거 { #concurrency-and-burgers }\n \n-위에서 설명한 **비동기** 코드에 대한 개념은 종종 **\"동시성\"**이라고도 불립니다. 이것은 **\"병렬성\"**과는 다릅니다.\n+위에서 설명한 **비동기** 코드에 대한 개념은 때때로 **\"동시성\"**이라고도 불립니다. 이는 **\"병렬성\"**과는 다릅니다.\n \n-**동시성**과 **병렬성**은 모두 \"동시에 일어나는 서로 다른 일들\"과 관련이 있습니다.\n+**동시성**과 **병렬성**은 모두 \"대략 같은 시간에 일어나는 서로 다른 일들\"과 관련이 있습니다.\n \n 하지만 *동시성*과 *병렬성*의 세부적인 개념에는 꽤 차이가 있습니다.\n \n-차이를 확인하기 위해, 다음의 버거에 대한 이야기를 상상해보십시오:\n+차이를 보기 위해, 다음의 햄버거 이야기를 상상해보세요:\n \n-### 동시 버거\n+### 동시 햄버거 { #concurrent-burgers }\n \n-당신은 짝사랑 상대 😍 와 패스트푸드 🍔 를 먹으러 갔습니다. 당신은 점원 💁 이 당신 앞에 있는 사람들의 주문을 받을 동안 줄을 서서 기다리고 있습니다.\n+여러분은 짝사랑 상대와 패스트푸드를 먹으러 갔고, 점원이 여러분 앞 사람들의 주문을 받는 동안 줄을 서서 기다립니다. 😍\n \n-이제 당신의 순서가 되어서, 당신은 당신과 짝사랑 상대 😍 를 위한 두 개의 고급스러운 버거 🍔 를 주문합니다.\n+ \n \n-당신이 돈을 냅니다 💸.\n+이제 여러분 차례가 되어, 여러분과 짝사랑 상대를 위해 매우 고급스러운 햄버거 2개를 주문합니다. 🍔🍔\n \n-점원 💁 은 주방 👨🍳 에 요리를 하라고 전달하고, 따라서 그들은 당신의 버거 🍔 를 준비해야한다는 사실을 알게됩니다(그들이 지금은 당신 앞 고객들의 주문을 준비하고 있을지라도 말입니다).\n+
\n \n-당신이 돈을 냅니다 💸.\n+이제 여러분 차례가 되어, 여러분과 짝사랑 상대를 위해 매우 고급스러운 햄버거 2개를 주문합니다. 🍔🍔\n \n-점원 💁 은 주방 👨🍳 에 요리를 하라고 전달하고, 따라서 그들은 당신의 버거 🍔 를 준비해야한다는 사실을 알게됩니다(그들이 지금은 당신 앞 고객들의 주문을 준비하고 있을지라도 말입니다).\n+ \n \n-점원 💁 은 당신의 순서가 적힌 번호표를 줍니다.\n+점원은 주방의 요리사에게 무언가를 말해, (지금은 앞선 손님들의 주문을 준비하고 있더라도) 여러분의 햄버거를 준비해야 한다는 것을 알게 합니다.\n \n-기다리는 동안, 당신은 짝사랑 상대 😍 와 함께 테이블을 고르고, 자리에 앉아 오랫동안 (당신이 주문한 버거는 꽤나 고급스럽기 때문에 준비하는데 시간이 조금 걸립니다 ✨🍔✨) 대화를 나눕니다.\n+
\n \n-점원 💁 은 당신의 순서가 적힌 번호표를 줍니다.\n+점원은 주방의 요리사에게 무언가를 말해, (지금은 앞선 손님들의 주문을 준비하고 있더라도) 여러분의 햄버거를 준비해야 한다는 것을 알게 합니다.\n \n-기다리는 동안, 당신은 짝사랑 상대 😍 와 함께 테이블을 고르고, 자리에 앉아 오랫동안 (당신이 주문한 버거는 꽤나 고급스럽기 때문에 준비하는데 시간이 조금 걸립니다 ✨🍔✨) 대화를 나눕니다.\n+ \n \n-짝사랑 상대 😍 와 테이블에 앉아서 버거 🍔 를 기다리는 동안, 그 사람 😍 이 얼마나 멋지고, 사랑스럽고, 똑똑한지 감탄하며 시간을 보냅니다 ✨😍✨.\n+여러분이 돈을 냅니다. 💸\n \n-짝사랑 상대 😍 와 기다리면서 얘기하는 동안, 때때로, 당신은 당신의 차례가 되었는지 보기 위해 카운터의 번호를 확인합니다.\n+점원은 여러분 차례 번호를 줍니다.\n \n-그러다 어느 순간, 당신의 차례가 됩니다. 카운터에 가서, 버거 🍔 를 받고, 테이블로 다시 돌아옵니다.\n+
\n \n-짝사랑 상대 😍 와 테이블에 앉아서 버거 🍔 를 기다리는 동안, 그 사람 😍 이 얼마나 멋지고, 사랑스럽고, 똑똑한지 감탄하며 시간을 보냅니다 ✨😍✨.\n+여러분이 돈을 냅니다. 💸\n \n-짝사랑 상대 😍 와 기다리면서 얘기하는 동안, 때때로, 당신은 당신의 차례가 되었는지 보기 위해 카운터의 번호를 확인합니다.\n+점원은 여러분 차례 번호를 줍니다.\n \n-그러다 어느 순간, 당신의 차례가 됩니다. 카운터에 가서, 버거 🍔 를 받고, 테이블로 다시 돌아옵니다.\n+ \n \n-당신과 짝사랑 상대 😍 는 버거 🍔 를 먹으며 좋은 시간을 보냅니다 ✨.\n+기다리는 동안, 여러분은 짝사랑 상대와 함께 자리를 고르고 앉아 오랫동안 대화를 나눕니다(여러분의 햄버거는 매우 고급스럽기 때문에 준비하는 데 시간이 좀 걸립니다).\n+\n+짝사랑 상대와 테이블에 앉아 햄버거를 기다리는 동안, 그 사람이 얼마나 멋지고 귀엽고 똑똑한지 감탄하며 시간을 보낼 수 있습니다 ✨😍✨.\n+\n+
\n \n-당신과 짝사랑 상대 😍 는 버거 🍔 를 먹으며 좋은 시간을 보냅니다 ✨.\n+기다리는 동안, 여러분은 짝사랑 상대와 함께 자리를 고르고 앉아 오랫동안 대화를 나눕니다(여러분의 햄버거는 매우 고급스럽기 때문에 준비하는 데 시간이 좀 걸립니다).\n+\n+짝사랑 상대와 테이블에 앉아 햄버거를 기다리는 동안, 그 사람이 얼마나 멋지고 귀엽고 똑똑한지 감탄하며 시간을 보낼 수 있습니다 ✨😍✨.\n+\n+ \n+\n+기다리며 대화하는 동안, 때때로 여러분은 카운터에 표시되는 번호를 확인해 여러분 차례인지 봅니다.\n+\n+그러다 어느 순간 마침내 여러분 차례가 됩니다. 여러분은 카운터에 가서 햄버거를 받고, 테이블로 돌아옵니다.\n+\n+
\n+\n+기다리며 대화하는 동안, 때때로 여러분은 카운터에 표시되는 번호를 확인해 여러분 차례인지 봅니다.\n+\n+그러다 어느 순간 마침내 여러분 차례가 됩니다. 여러분은 카운터에 가서 햄버거를 받고, 테이블로 돌아옵니다.\n+\n+ \n+\n+여러분과 짝사랑 상대는 햄버거를 먹으며 좋은 시간을 보냅니다. ✨\n+\n+
\n+\n+여러분과 짝사랑 상대는 햄버거를 먹으며 좋은 시간을 보냅니다. ✨\n+\n+ \n+\n+/// info | 정보\n+\n+아름다운 일러스트: [NAME_REDACTED]. 🎨\n+\n+///\n \n ---\n \n-당신이 이 이야기에서 컴퓨터 / 프로그램 🤖 이라고 상상해보십시오.\n+이 이야기에서 여러분이 컴퓨터/프로그램 🤖 이라고 상상해보세요.\n \n-줄을 서서 기다리는 동안, 당신은 아무것도 하지 않고 😴 당신의 차례를 기다리며, 어떠한 \"생산적인\" 일도 하지 않습니다. 하지만 점원 💁 이 (음식을 준비하지는 않고) 주문을 받기만 하기 때문에 줄이 빨리 줄어들어서 괜찮습니다.\n+줄을 서 있는 동안, 여러분은 그냥 쉬고 😴, 차례를 기다리며, 그다지 \"생산적인\" 일을 하지 않습니다. 하지만 점원은 주문만 받지(음식을 준비하진 않기) 때문에 줄이 빠르게 줄어들어 괜찮습니다.\n \n-그다음, 당신이 차례가 오면, 당신은 실제로 \"생산적인\" 일 🤓 을 합니다. 당신은 메뉴를 보고, 무엇을 먹을지 결정하고, 짝사랑 상대 😍 의 선택을 묻고, 돈을 내고 💸 , 맞는 카드를 냈는지 확인하고, 비용이 제대로 지불되었는지 확인하고, 주문이 제대로 들어갔는지 확인을 하는 작업 등등을 수행합니다.\n+그 다음 여러분 차례가 되면, 여러분은 실제로 \"생산적인\" 일을 합니다. 메뉴를 처리하고, 무엇을 먹을지 결정하고, 짝사랑 상대의 선택을 확인하고, 결제하고, 올바른 현금이나 카드를 냈는지 확인하고, 정확히 청구되었는지 확인하고, 주문에 올바른 항목들이 들어갔는지 확인하는 등등을 합니다.\n \n-하지만 이후에는, 버거 🍔 를 아직 받지 못했음에도, 버거가 준비될 때까지 기다려야 🕙 하기 때문에 점원 💁 과의 작업은 \"일시정지\" ⏸ 상태입니다.\n+하지만 그 다음에는, 아직 햄버거를 받지 못했더라도, 햄버거가 준비될 때까지 기다려야 🕙 하므로 점원과의 작업은 \"일시정지\" ⏸ 상태입니다.\n \n-하지만 번호표를 받고 카운터에서 나와 테이블에 앉으면, 당신은 짝사랑 상대 😍 와 그 \"작업\" ⏯ 🤓 에 번갈아가며 🔀 집중합니다. 그러면 당신은 다시 짝사랑 상대 😍 에게 작업을 거는 매우 \"생산적인\" 일 🤓 을 합니다.\n+하지만 번호를 들고 카운터에서 벗어나 테이블에 앉으면, 여러분은 짝사랑 상대에게 관심을 전환 🔀 하고, 그에 대한 \"작업\" ⏯ 🤓 을 할 수 있습니다. 그러면 여러분은 다시 짝사랑 상대에게 작업을 거는 매우 \"생산적인\" 일을 하게 됩니다 😍.\n \n-점원 💁 이 카운터 화면에 당신의 번호를 표시함으로써 \"버거 🍔 가 준비되었습니다\"라고 해도, 당신은 즉시 뛰쳐나가지는 않을 것입니다. 당신은 당신의 번호를 갖고있고, 다른 사람들은 그들의 번호를 갖고있기 때문에, 아무도 당신의 버거 🍔 를 훔쳐가지 않는다는 사실을 알기 때문입니다.\n+그 다음 점원 💁 이 카운터 화면에 여러분 번호를 띄워 \"햄버거를 만들었어요\"라고 말하지만, 표시된 번호가 여러분 차례로 바뀌었다고 해서 즉시 미친 듯이 뛰어가지는 않습니다. 여러분은 여러분 번호를 갖고 있고, 다른 사람들은 그들의 번호를 갖고 있으니, 아무도 여러분 햄버거를 훔쳐갈 수 없다는 것을 알기 때문입니다.\n \n-그래서 당신은 짝사랑 상대 😍 가 이야기를 끝낼 때까지 기다린 후 (현재 작업 완료 ⏯ / 진행 중인 작업 처리 🤓 ), 정중하게 미소짓고 버거를 가지러 가겠다고 말합니다 ⏸.\n+그래서 여러분은 짝사랑 상대가 이야기를 끝낼 때까지 기다린 다음(현재 작업 ⏯ / 처리 중인 작업 🤓 을 끝내고), 부드럽게 미소 지으며 햄버거를 가지러 가겠다고 말합니다 ⏸.\n \n-그다음 당신은 카운터에 가서 🔀 , 초기 작업을 이제 완료하고 ⏯ , 버거 🍔 를 받고, 감사하다고 말하고 테이블로 가져옵니다. 이로써 카운터와의 상호작용 단계 / 작업이 종료됩니다 ⏹.\n+그 다음 여러분은 카운터로 가서 🔀, 이제 끝난 초기 작업 ⏯ 으로 돌아와 햄버거를 받고, 감사 인사를 하고, 테이블로 가져옵니다. 이로써 카운터와 상호작용하는 그 단계/작업이 끝납니다 ⏹. 그리고 이는 새로운 작업인 \"햄버거 먹기\" 🔀 ⏯ 를 만들지만, 이전 작업인 \"햄버거 받기\"는 끝났습니다 ⏹.\n \n-이전 작업인 \"버거 받기\"가 종료되면 ⏹ \"버거 먹기\"라는 새로운 작업이 생성됩니다 🔀 ⏯.\n+### 병렬 햄버거 { #parallel-burgers }\n \n-### 병렬 버거\n+이제 이것이 \"동시 햄버거\"가 아니라 \"병렬 햄버거\"라고 상상해봅시다.\n \n-이제 \"동시 버거\"가 아닌 \"병렬 버거\"를 상상해보십시오.\n+여러분은 짝사랑 상대와 함께 병렬 패스트푸드를 먹으러 갑니다.\n \n-당신은 짝사랑 상대 😍 와 함께 병렬 패스트푸드 🍔 를 먹으러 갔습니다.\n+여러분은 여러 명(예: 8명)의 점원이 동시에 요리사이기도 하여 여러분 앞 사람들의 주문을 받는 동안 줄을 서 있습니다.\n \n-당신은 여러명(8명이라고 가정합니다)의 점원이 당신 앞 사람들의 주문을 받으며 동시에 요리 👩🍳👨🍳👩🍳👨🍳👩🍳👨🍳👩🍳👨🍳 도 하는 동안 줄을 서서 기다립니다.\n+여러분 앞의 모든 사람들은, 8명의 점원 각각이 다음 주문을 받기 전에 바로 햄버거를 준비하러 가기 때문에, 카운터를 떠나지 않고 햄버거가 준비될 때까지 기다립니다.\n \n-당신 앞 모든 사람들이 버거가 준비될 때까지 카운터에서 떠나지 않고 기다립니다 🕙 . 왜냐하면 8명의 직원들이 다음 주문을 받기 전에 버거를 준비하러 가기 때문입니다.\n+
\n+\n+/// info | 정보\n+\n+아름다운 일러스트: [NAME_REDACTED]. 🎨\n+\n+///\n \n ---\n \n-당신이 이 이야기에서 컴퓨터 / 프로그램 🤖 이라고 상상해보십시오.\n+이 이야기에서 여러분이 컴퓨터/프로그램 🤖 이라고 상상해보세요.\n \n-줄을 서서 기다리는 동안, 당신은 아무것도 하지 않고 😴 당신의 차례를 기다리며, 어떠한 \"생산적인\" 일도 하지 않습니다. 하지만 점원 💁 이 (음식을 준비하지는 않고) 주문을 받기만 하기 때문에 줄이 빨리 줄어들어서 괜찮습니다.\n+줄을 서 있는 동안, 여러분은 그냥 쉬고 😴, 차례를 기다리며, 그다지 \"생산적인\" 일을 하지 않습니다. 하지만 점원은 주문만 받지(음식을 준비하진 않기) 때문에 줄이 빠르게 줄어들어 괜찮습니다.\n \n-그다음, 당신이 차례가 오면, 당신은 실제로 \"생산적인\" 일 🤓 을 합니다. 당신은 메뉴를 보고, 무엇을 먹을지 결정하고, 짝사랑 상대 😍 의 선택을 묻고, 돈을 내고 💸 , 맞는 카드를 냈는지 확인하고, 비용이 제대로 지불되었는지 확인하고, 주문이 제대로 들어갔는지 확인을 하는 작업 등등을 수행합니다.\n+그 다음 여러분 차례가 되면, 여러분은 실제로 \"생산적인\" 일을 합니다. 메뉴를 처리하고, 무엇을 먹을지 결정하고, 짝사랑 상대의 선택을 확인하고, 결제하고, 올바른 현금이나 카드를 냈는지 확인하고, 정확히 청구되었는지 확인하고, 주문에 올바른 항목들이 들어갔는지 확인하는 등등을 합니다.\n \n-하지만 이후에는, 버거 🍔 를 아직 받지 못했음에도, 버거가 준비될 때까지 기다려야 🕙 하기 때문에 점원 💁 과의 작업은 \"일시정지\" ⏸ 상태입니다.\n+하지만 그 다음에는, 아직 햄버거를 받지 못했더라도, 햄버거가 준비될 때까지 기다려야 🕙 하므로 점원과의 작업은 \"일시정지\" ⏸ 상태입니다.\n \n-하지만 번호표를 받고 카운터에서 나와 테이블에 앉으면, 당신은 짝사랑 상대 😍 와 그 \"작업\" ⏯ 🤓 에 번갈아가며 🔀 집중합니다. 그러면 당신은 다시 짝사랑 상대 😍 에게 작업을 거는 매우 \"생산적인\" 일 🤓 을 합니다.\n+하지만 번호를 들고 카운터에서 벗어나 테이블에 앉으면, 여러분은 짝사랑 상대에게 관심을 전환 🔀 하고, 그에 대한 \"작업\" ⏯ 🤓 을 할 수 있습니다. 그러면 여러분은 다시 짝사랑 상대에게 작업을 거는 매우 \"생산적인\" 일을 하게 됩니다 😍.\n \n-점원 💁 이 카운터 화면에 당신의 번호를 표시함으로써 \"버거 🍔 가 준비되었습니다\"라고 해도, 당신은 즉시 뛰쳐나가지는 않을 것입니다. 당신은 당신의 번호를 갖고있고, 다른 사람들은 그들의 번호를 갖고있기 때문에, 아무도 당신의 버거 🍔 를 훔쳐가지 않는다는 사실을 알기 때문입니다.\n+그 다음 점원 💁 이 카운터 화면에 여러분 번호를 띄워 \"햄버거를 만들었어요\"라고 말하지만, 표시된 번호가 여러분 차례로 바뀌었다고 해서 즉시 미친 듯이 뛰어가지는 않습니다. 여러분은 여러분 번호를 갖고 있고, 다른 사람들은 그들의 번호를 갖고 있으니, 아무도 여러분 햄버거를 훔쳐갈 수 없다는 것을 알기 때문입니다.\n \n-그래서 당신은 짝사랑 상대 😍 가 이야기를 끝낼 때까지 기다린 후 (현재 작업 완료 ⏯ / 진행 중인 작업 처리 🤓 ), 정중하게 미소짓고 버거를 가지러 가겠다고 말합니다 ⏸.\n+그래서 여러분은 짝사랑 상대가 이야기를 끝낼 때까지 기다린 다음(현재 작업 ⏯ / 처리 중인 작업 🤓 을 끝내고), 부드럽게 미소 지으며 햄버거를 가지러 가겠다고 말합니다 ⏸.\n \n-그다음 당신은 카운터에 가서 🔀 , 초기 작업을 이제 완료하고 ⏯ , 버거 🍔 를 받고, 감사하다고 말하고 테이블로 가져옵니다. 이로써 카운터와의 상호작용 단계 / 작업이 종료됩니다 ⏹.\n+그 다음 여러분은 카운터로 가서 🔀, 이제 끝난 초기 작업 ⏯ 으로 돌아와 햄버거를 받고, 감사 인사를 하고, 테이블로 가져옵니다. 이로써 카운터와 상호작용하는 그 단계/작업이 끝납니다 ⏹. 그리고 이는 새로운 작업인 \"햄버거 먹기\" 🔀 ⏯ 를 만들지만, 이전 작업인 \"햄버거 받기\"는 끝났습니다 ⏹.\n \n-이전 작업인 \"버거 받기\"가 종료되면 ⏹ \"버거 먹기\"라는 새로운 작업이 생성됩니다 🔀 ⏯.\n+### 병렬 햄버거 { #parallel-burgers }\n \n-### 병렬 버거\n+이제 이것이 \"동시 햄버거\"가 아니라 \"병렬 햄버거\"라고 상상해봅시다.\n \n-이제 \"동시 버거\"가 아닌 \"병렬 버거\"를 상상해보십시오.\n+여러분은 짝사랑 상대와 함께 병렬 패스트푸드를 먹으러 갑니다.\n \n-당신은 짝사랑 상대 😍 와 함께 병렬 패스트푸드 🍔 를 먹으러 갔습니다.\n+여러분은 여러 명(예: 8명)의 점원이 동시에 요리사이기도 하여 여러분 앞 사람들의 주문을 받는 동안 줄을 서 있습니다.\n \n-당신은 여러명(8명이라고 가정합니다)의 점원이 당신 앞 사람들의 주문을 받으며 동시에 요리 👩🍳👨🍳👩🍳👨🍳👩🍳👨🍳👩🍳👨🍳 도 하는 동안 줄을 서서 기다립니다.\n+여러분 앞의 모든 사람들은, 8명의 점원 각각이 다음 주문을 받기 전에 바로 햄버거를 준비하러 가기 때문에, 카운터를 떠나지 않고 햄버거가 준비될 때까지 기다립니다.\n \n-당신 앞 모든 사람들이 버거가 준비될 때까지 카운터에서 떠나지 않고 기다립니다 🕙 . 왜냐하면 8명의 직원들이 다음 주문을 받기 전에 버거를 준비하러 가기 때문입니다.\n+ \n \n-마침내 당신의 차례가 왔고, 당신은 당신과 짝사랑 상대 😍 를 위한 두 개의 고급스러운 버거 🍔 를 주문합니다.\n+마침내 여러분 차례가 되어, 여러분과 짝사랑 상대를 위해 매우 고급스러운 햄버거 2개를 주문합니다.\n \n-당신이 비용을 지불합니다 💸 .\n+여러분이 돈을 냅니다 💸.\n \n-점원이 주방에 갑니다 👨🍳 .\n+
\n \n-마침내 당신의 차례가 왔고, 당신은 당신과 짝사랑 상대 😍 를 위한 두 개의 고급스러운 버거 🍔 를 주문합니다.\n+마침내 여러분 차례가 되어, 여러분과 짝사랑 상대를 위해 매우 고급스러운 햄버거 2개를 주문합니다.\n \n-당신이 비용을 지불합니다 💸 .\n+여러분이 돈을 냅니다 💸.\n \n-점원이 주방에 갑니다 👨🍳 .\n+ \n \n-당신은 번호표가 없기 때문에 누구도 당신의 버거 🍔 를 대신 가져갈 수 없도록 카운터에 서서 기다립니다 🕙 .\n+점원은 주방으로 갑니다.\n \n-당신과 짝사랑 상대 😍 는 다른 사람이 새치기해서 버거를 가져가지 못하게 하느라 바쁘기 때문에 🕙 , 짝사랑 상대에게 주의를 기울일 수 없습니다 😞 .\n+여러분은 번호표가 없으므로, 다른 사람이 여러분보다 먼저 햄버거를 가져가지 못하도록 카운터 앞에 서서 기다립니다 🕙.\n \n-이것은 \"동기\" 작업이고, 당신은 점원/요리사 👨🍳 와 \"동기화\" 되었습니다. 당신은 기다리고 🕙 , 점원/요리사 👨🍳 가 버거 🍔 준비를 완료한 후 당신에게 주거나, 누군가가 그것을 가져가는 그 순간에 그 곳에 있어야합니다.\n+
\n \n-당신은 번호표가 없기 때문에 누구도 당신의 버거 🍔 를 대신 가져갈 수 없도록 카운터에 서서 기다립니다 🕙 .\n+점원은 주방으로 갑니다.\n \n-당신과 짝사랑 상대 😍 는 다른 사람이 새치기해서 버거를 가져가지 못하게 하느라 바쁘기 때문에 🕙 , 짝사랑 상대에게 주의를 기울일 수 없습니다 😞 .\n+여러분은 번호표가 없으므로, 다른 사람이 여러분보다 먼저 햄버거를 가져가지 못하도록 카운터 앞에 서서 기다립니다 🕙.\n \n-이것은 \"동기\" 작업이고, 당신은 점원/요리사 👨🍳 와 \"동기화\" 되었습니다. 당신은 기다리고 🕙 , 점원/요리사 👨🍳 가 버거 🍔 준비를 완료한 후 당신에게 주거나, 누군가가 그것을 가져가는 그 순간에 그 곳에 있어야합니다.\n+ \n \n-카운터 앞에서 오랫동안 기다린 후에 🕙 , 점원/요리사 👨🍳 가 당신의 버거 🍔 를 가지고 돌아옵니다.\n+여러분과 짝사랑 상대는 햄버거가 나오면 다른 사람이 끼어들어 가져가지 못하게 하느라 바쁘기 때문에, 짝사랑 상대에게 집중할 수 없습니다. 😞\n \n-당신은 버거를 받고 짝사랑 상대와 함께 테이블로 돌아옵니다.\n+이것은 \"동기\" 작업이며, 여러분은 점원/요리사 👨🍳 와 \"동기화\"되어 있습니다. 점원/요리사 👨🍳 가 햄버거를 완성해 여러분에게 주는 정확한 순간에 그 자리에 있어야 하므로, 여러분은 기다려야 🕙 하고, 그렇지 않으면 다른 사람이 가져갈 수도 있습니다.\n \n-단지 먹기만 하다가, 다 먹었습니다 🍔 ⏹.\n+
\n \n-카운터 앞에서 오랫동안 기다린 후에 🕙 , 점원/요리사 👨🍳 가 당신의 버거 🍔 를 가지고 돌아옵니다.\n+여러분과 짝사랑 상대는 햄버거가 나오면 다른 사람이 끼어들어 가져가지 못하게 하느라 바쁘기 때문에, 짝사랑 상대에게 집중할 수 없습니다. 😞\n \n-당신은 버거를 받고 짝사랑 상대와 함께 테이블로 돌아옵니다.\n+이것은 \"동기\" 작업이며, 여러분은 점원/요리사 👨🍳 와 \"동기화\"되어 있습니다. 점원/요리사 👨🍳 가 햄버거를 완성해 여러분에게 주는 정확한 순간에 그 자리에 있어야 하므로, 여러분은 기다려야 🕙 하고, 그렇지 않으면 다른 사람이 가져갈 수도 있습니다.\n \n-단지 먹기만 하다가, 다 먹었습니다 🍔 ⏹.\n+ \n \n-카운터 앞에서 기다리면서 🕙 너무 많은 시간을 허비했기 때문에 대화를 하거나 작업을 걸 시간이 거의 없었습니다 😞 .\n+그러다 점원/요리사 👨🍳 가 카운터 앞에서 오랫동안 기다린 🕙 끝에 마침내 햄버거를 가지고 돌아옵니다.\n \n----\n+
\n \n-카운터 앞에서 기다리면서 🕙 너무 많은 시간을 허비했기 때문에 대화를 하거나 작업을 걸 시간이 거의 없었습니다 😞 .\n+그러다 점원/요리사 👨🍳 가 카운터 앞에서 오랫동안 기다린 🕙 끝에 마침내 햄버거를 가지고 돌아옵니다.\n \n----\n+ \n+\n+여러분은 햄버거를 받아 짝사랑 상대와 테이블로 갑니다.\n+\n+그냥 먹고, 끝입니다. ⏹\n+\n+
\n+\n+여러분은 햄버거를 받아 짝사랑 상대와 테이블로 갑니다.\n+\n+그냥 먹고, 끝입니다. ⏹\n+\n+ \n+\n+대부분의 시간을 카운터 앞에서 기다리는 데 🕙 썼기 때문에, 대화하거나 작업을 걸 시간은 많지 않았습니다. 😞\n \n-이 병렬 버거 시나리오에서, 당신은 기다리고 🕙 , 오랜 시간동안 \"카운터에서 기다리는\" 🕙 데에 주의를 기울이는 ⏯ 두 개의 프로세서(당신과 짝사랑 상대😍)를 가진 컴퓨터 / 프로그램 🤖 입니다.\n+/// info | 정보\n \n-패스트푸드점에는 8개의 프로세서(점원/요리사) 👩🍳👨🍳👩🍳👨🍳👩🍳👨🍳👩🍳👨🍳 가 있습니다. 동시 버거는 단 두 개(한 명의 직원과 한 명의 요리사) 💁 👨🍳 만을 가지고 있었습니다.\n+아름다운 일러스트: [NAME_REDACTED]. 🎨\n \n-하지만 여전히, 병렬 버거 예시가 최선은 아닙니다 😞 .\n+///\n \n ---\n \n-이 예시는 버거🍔 이야기와 결이 같습니다.\n+이 병렬 햄버거 시나리오에서, 여러분은 두 개의 프로세서(여러분과 짝사랑 상대)를 가진 컴퓨터/프로그램 🤖 이며, 둘 다 기다리고 🕙 오랫동안 \"카운터에서 기다리기\" 🕙 에 주의를 ⏯ 기울입니다.\n+\n+패스트푸드점에는 8개의 프로세서(점원/요리사)가 있습니다. 동시 햄버거 가게는 2개(점원 1명, 요리사 1명)만 있었을 것입니다.\n \n-더 \"현실적인\" 예시로, 은행을 상상해보십시오.\n+하지만 여전히 최종 경험은 그다지 좋지 않습니다. 😞\n \n-최근까지, 대다수의 은행에는 다수의 은행원들 👨💼👨💼👨💼👨💼 과 긴 줄 🕙🕙🕙🕙🕙🕙🕙🕙 이 있습니다.\n+---\n \n-모든 은행원들은 한 명 한 명의 고객들을 차례로 상대합니다 👨💼⏯ .\n+이것이 햄버거의 병렬 버전에 해당하는 이야기입니다. 🍔\n \n-그리고 당신은 오랫동안 줄에서 기다려야하고 🕙 , 그렇지 않으면 당신의 차례를 잃게 됩니다.\n+좀 더 \"현실적인\" 예시로, 은행을 상상해보세요.\n \n-아마 당신은 은행 🏦 심부름에 짝사랑 상대 😍 를 데려가고 싶지는 않을 것입니다.\n+최근까지 대부분의 은행에는 여러 은행원 👨💼👨💼👨💼👨💼 과 긴 줄 🕙🕙🕙🕙🕙🕙🕙🕙 이 있었습니다.\n \n-### 버거 예시의 결론\n+모든 은행원이 한 고객씩 순서대로 모든 일을 처리합니다 👨💼⏯.\n \n-\"짝사랑 상대와의 패스트푸드점 버거\" 시나리오에서, 오랜 기다림 🕙 이 있기 때문에 동시 시스템 ⏸🔀⏯ 을 사용하는 것이 더 합리적입니다.\n+그리고 여러분은 오랫동안 줄에서 기다려야 🕙 하며, 그렇지 않으면 차례를 잃습니다.\n \n-대다수의 웹 응용프로그램의 경우가 그러합니다.\n+아마 은행 🏦 업무를 보러 갈 때 짝사랑 상대 😍 를 데려가고 싶지는 않을 것입니다.\n \n-매우 많은 수의 유저가 있지만, 서버는 그들의 요청을 전송하기 위해 그닥-좋지-않은 연결을 기다려야 합니다 🕙 .\n+### 햄버거 예시의 결론 { #burger-conclusion }\n \n-그리고 응답이 돌아올 때까지 다시 기다려야 합니다 🕙 .\n+\"짝사랑 상대와의 패스트푸드점 햄버거\" 시나리오에서는 기다림 🕙 이 많기 때문에, 동시 시스템 ⏸🔀⏯ 을 사용하는 것이 훨씬 더 합리적입니다.\n \n-이 \"기다림\" 🕙 은 마이크로초 단위이지만, 모두 더해지면, 결국에는 매우 긴 대기시간이 됩니다.\n+대부분의 웹 애플리케이션이 그렇습니다.\n \n-따라서 웹 API를 위해 비동기 ⏸🔀⏯ 코드를 사용하는 것이 합리적입니다.\n+매우 많은 사용자들이 있고, 서버는 그들의 좋지 않은 연결을 통해 요청이 전송되기를 기다립니다 🕙.\n \n-대부분의 존재하는 유명한 파이썬 프레임워크 (Flask와 Django 등)은 새로운 비동기 기능들이 파이썬에 존재하기 전에 만들어졌습니다. 그래서, 그들의 배포 방식은 병렬 실행과 새로운 기능만큼 강력하지는 않은 예전 버전의 비동기 실행을 지원합니다.\n+그리고 응답이 돌아오기를 다시 기다립니다 🕙.\n \n-비동기 웹 파이썬(ASGI)에 대한 주요 명세가 웹소켓을 지원하기 위해 Django에서 개발 되었음에도 그렇습니다.\n+이 \"기다림\" 🕙 은 마이크로초 단위로 측정되지만, 모두 합치면 결국 꽤 많은 대기 시간이 됩니다.\n \n-이러한 종류의 비동기성은 (NodeJS는 병렬적이지 않음에도) NodeJS가 사랑받는 이유이고, 프로그래밍 언어로서의 Go의 강점입니다.\n+그래서 웹 API에는 비동기 ⏸🔀⏯ 코드를 사용하는 것이 매우 합리적입니다.\n \n-그리고 **FastAPI**를 사용함으로써 동일한 성능을 낼 수 있습니다.\n+이러한 종류의 비동기성은 NodeJS가 인기 있는 이유(비록 NodeJS가 병렬은 아니지만)이자, 프로그래밍 언어로서 Go의 강점입니다.\n \n-또한 병렬성과 비동기성을 동시에 사용할 수 있기 때문에, 대부분의 테스트가 완료된 NodeJS 프레임워크보다 더 높은 성능을 얻고 C에 더 가까운 컴파일 언어인 Go와 동등한 성능을 얻을 수 있습니다(모두 Starlette 덕분입니다).\n+그리고 이것이 **FastAPI**로 얻는 것과 같은 수준의 성능입니다.\n \n-### 동시성이 병렬성보다 더 나은가?\n+또한 병렬성과 비동기성을 동시에 사용할 수 있으므로, 대부분의 테스트된 NodeJS 프레임워크보다 더 높은 성능을 얻고, C에 더 가까운 컴파일 언어인 Go와 동등한 성능을 얻을 수 있습니다 (모두 Starlette 덕분입니다).\n \n-그렇지 않습니다! 그것이 이야기의 교훈은 아닙니다.\n+### 동시성이 병렬성보다 더 나은가요? { #is-concurrency-better-than-parallelism }\n \n-동시성은 병렬성과 다릅니다. 그리고 그것은 많은 대기를 필요로하는 **특정한** 시나리오에서는 더 낫습니다. 이로 인해, 웹 응용프로그램 개발에서 동시성이 병렬성보다 일반적으로 훨씬 낫습니다. 하지만 모든 경우에 그런 것은 아닙니다.\n+아니요! 그게 이 이야기의 교훈은 아닙니다.\n \n-따라서, 균형을 맞추기 위해, 다음의 짧은 이야기를 상상해보십시오:\n+동시성은 병렬성과 다릅니다. 그리고 많은 기다림이 포함되는 **특정한** 시나리오에서는 더 낫습니다. 그 때문에 웹 애플리케이션 개발에서는 일반적으로 병렬성보다 훨씬 더 낫습니다. 하지만 모든 것에 해당하진 않습니다.\n \n-> 당신은 크고, 더러운 집을 청소해야합니다.\n+그래서 균형을 맞추기 위해, 다음의 짧은 이야기를 상상해보세요:\n+\n+> 여러분은 크고 더러운 집을 청소해야 합니다.\n \n *네, 이게 전부입니다*.\n \n ---\n \n-어디에도 대기 🕙 는 없고, 집안 곳곳에서 해야하는 많은 작업들만 있습니다.\n+어디에도 기다림 🕙 은 없고, 집의 여러 장소에서 해야 할 일이 많을 뿐입니다.\n \n-버거 예시처럼 처음에는 거실, 그 다음은 부엌과 같은 식으로 순서를 정할 수도 있으나, 무엇도 기다리지 🕙 않고 계속해서 청소 작업만 수행하기 때문에, 순서는 아무런 영향을 미치지 않습니다.\n+햄버거 예시처럼 거실부터, 그 다음은 부엌처럼 순서를 정할 수도 있지만, 어떤 것도 기다리지 🕙 않고 계속 청소만 하기 때문에, 순서는 아무런 영향을 주지 않습니다.\n \n-순서가 있든 없든 동일한 시간이 소요될 것이고(동시성) 동일한 양의 작업을 하게 될 것입니다.\n+순서가 있든 없든(동시성) 끝내는 데 걸리는 시간은 같고, 같은 양의 일을 하게 됩니다.\n \n-하지만 이 경우에서, 8명의 전(前)-점원/요리사이면서-현(現)-청소부 👩🍳👨🍳👩🍳👨🍳👩🍳👨🍳👩🍳👨🍳 를 고용할 수 있고, 그들 각자(그리고 당신)가 집의 한 부분씩 맡아 청소를 한다면, 당신은 **병렬적**으로 작업을 수행할 수 있고, 조금의 도움이 있다면, 훨씬 더 빨리 끝낼 수 있습니다.\n+하지만 이 경우, 전(前) 점원/요리사이자 현(現) 청소부가 된 8명을 데려올 수 있고, 각자(그리고 여러분)가 집의 구역을 하나씩 맡아 청소한다면, 추가 도움과 함께 모든 일을 **병렬**로 수행하여 훨씬 더 빨리 끝낼 수 있습니다.\n \n-이 시나리오에서, (당신을 포함한) 각각의 청소부들은 프로세서가 될 것이고, 각자의 역할을 수행합니다.\n+이 시나리오에서 (여러분을 포함한) 각 청소부는 프로세서가 되어, 맡은 일을 수행합니다.\n \n-실행 시간의 대부분이 대기가 아닌 실제 작업에 소요되고, 컴퓨터에서 작업은 CPU에서 이루어지므로, 이러한 문제를 \"CPU에 묶였\"다고 합니다.\n+그리고 실행 시간의 대부분이 기다림이 아니라 실제 작업에 쓰이고, 컴퓨터에서 작업은 CPU가 수행하므로, 이런 문제를 \"CPU bound\"라고 부릅니다.\n \n ---\n \n-CPU에 묶인 연산에 관한 흔한 예시는 복잡한 수학 처리를 필요로 하는 경우입니다.\n+CPU bound 작업의 흔한 예시는 복잡한 수학 처리가 필요한 것들입니다.\n \n 예를 들어:\n \n-* **오디오** 또는 **이미지** 처리.\n-* **컴퓨터 비전**: 하나의 이미지는 수백개의 픽셀로 구성되어있고, 각 픽셀은 3개의 값 / 색을 갖고 있으며, 일반적으로 해당 픽셀들에 대해 동시에 무언가를 계산해야하는 처리.\n-* **머신러닝**: 일반적으로 많은 \"행렬\"과 \"벡터\" 곱셈이 필요합니다. 거대한 스프레드 시트에 수들이 있고 그 수들을 동시에 곱해야 한다고 생각해보십시오.\n-* **딥러닝**: 머신러닝의 하위영역으로, 동일한 예시가 적용됩니다. 단지 이 경우에는 하나의 스프레드 시트에 곱해야할 수들이 있는 것이 아니라, 거대한 세트의 스프레드 시트들이 있고, 많은 경우에, 이 모델들을 만들고 사용하기 위해 특수한 프로세서를 사용합니다.\n+* **오디오** 또는 **이미지** 처리\n+* **컴퓨터 비전**: 이미지는 수백만 개의 픽셀로 구성되며, 각 픽셀은 3개의 값/색을 갖습니다. 보통 그 픽셀들에 대해 동시에 무언가를 계산해야 합니다.\n+* **머신러닝**: 보통 많은 \"matrix\"와 \"vector\" 곱셈이 필요합니다. 숫자가 있는 거대한 스프레드시트를 생각하고, 그 모든 수를 동시에 곱한다고 생각해보세요.\n+* **딥러닝**: 머신러닝의 하위 분야이므로 동일하게 적용됩니다. 다만 곱해야 할 숫자가 있는 스프레드시트가 하나가 아니라, 아주 큰 집합이며, 많은 경우 그 모델을 만들고/또는 사용하기 위해 특별한 프로세서를 사용합니다.\n \n-### 동시성 + 병렬성: 웹 + 머신러닝\n+### 동시성 + 병렬성: 웹 + 머신러닝 { #concurrency-parallelism-web-machine-learning }\n \n-**FastAPI**를 사용하면 웹 개발에서는 매우 흔한 동시성의 이점을 (NodeJS의 주된 매력만큼) 얻을 수 있습니다.\n+**FastAPI**를 사용하면 웹 개발에서 매우 흔한 동시성의 이점을( NodeJS의 주요 매력과 같은) 얻을 수 있습니다.\n \n-뿐만 아니라 머신러닝 시스템과 같이 **CPU에 묶인** 작업을 위해 병렬성과 멀티프로세싱(다수의 프로세스를 병렬적으로 동작시키는 것)을 이용하는 것도 가능합니다.\n+또한 머신러닝 시스템처럼 **CPU bound** 워크로드에 대해 병렬성과 멀티프로세싱(여러 프로세스를 병렬로 실행)을 활용할 수도 있습니다.\n \n-파이썬이 **데이터 사이언스**, 머신러닝과 특히 딥러닝에 의 주된 언어라는 간단한 사실에 더해서, 이것은 FastAPI를 데이터 사이언스 / 머신러닝 웹 API와 응용프로그램에 (다른 것들보다) 좋은 선택지가 되게 합니다.\n+이것은 파이썬이 **데이터 사이언스**, 머신러닝, 특히 딥러닝의 주요 언어라는 단순한 사실과 더해져, FastAPI를 데이터 사이언스/머신러닝 웹 API 및 애플리케이션(그 외에도 많은 것들)에 매우 잘 맞는 선택으로 만들어 줍니다.\n \n-배포시 병렬을 어떻게 가능하게 하는지 알고싶다면, [배포](deployment/index.md){.internal-link target=_blank}문서를 참고하십시오.\n+프로덕션에서 이 병렬성을 어떻게 달성하는지 보려면 [배포](deployment/index.md){.internal-link target=_blank} 섹션을 참고하세요.\n \n-## `async`와 `await`\n+## `async`와 `await` { #async-and-await }\n \n-최신 파이썬 버전에는 비동기 코드를 정의하는 매우 직관적인 방법이 있습니다. 이는 이것을 평범한 \"순차적\" 코드로 보이게 하고, 적절한 순간에 당신을 위해 \"대기\"합니다.\n+최신 파이썬 버전에는 비동기 코드를 정의하는 매우 직관적인 방법이 있습니다. 이 방법은 이를 평범한 \"순차\" 코드처럼 보이게 하고, 적절한 순간에 여러분을 위해 \"기다림\"을 수행합니다.\n \n-연산이 결과를 전달하기 전에 대기를 해야하고 새로운 파이썬 기능들을 지원한다면, 이렇게 코드를 작성할 수 있습니다:\n+결과를 주기 전에 기다림이 필요한 작업이 있고, 이러한 새로운 파이썬 기능을 지원한다면, 다음과 같이 작성할 수 있습니다:\n \n ```Python\n burgers = await get_burgers(2)\n ```\n \n-여기서 핵심은 `await`입니다. 이것은 파이썬에게 `burgers` 결과를 저장하기 이전에 `get_burgers(2)`의 작업이 완료되기를 🕙 기다리라고 ⏸ 말합니다. 이로 인해, 파이썬은 그동안 (다른 요청을 받는 것과 같은) 다른 작업을 수행해도 된다는 것을 🔀 ⏯ 알게될 것입니다.\n+여기서 핵심은 `await`입니다. 이는 파이썬에게 `get_burgers(2)`가 그 일을 끝낼 때까지 🕙 기다리도록 ⏸ 말하고, 그 결과를 `burgers`에 저장하기 전에 완료되기를 기다리라고 합니다. 이를 통해 파이썬은 그동안(예: 다른 요청을 받는 것처럼) 다른 일을 하러 갈 수 있다는 것 🔀 ⏯ 을 알게 됩니다.\n \n-`await`가 동작하기 위해, 이것은 비동기를 지원하는 함수 내부에 있어야 합니다. 이를 위해서 함수를 `async def`를 사용해 정의하기만 하면 됩니다:\n+`await`가 동작하려면, 이 비동기성을 지원하는 함수 내부에 있어야 합니다. 그러려면 `async def`로 선언하기만 하면 됩니다:\n \n ```Python hl_lines=\"1\"\n async def get_burgers(number: int):\n- # Do some asynchronous stuff to create the burgers\n+ # 햄버거를 만들기 위한 비동기 처리를 수행\n return burgers\n ```\n \n-...`def`를 사용하는 대신:\n+...`def` 대신:\n \n ```Python hl_lines=\"2\"\n-# This is not asynchronous\n+# 비동기가 아닙니다\n def get_sequential_burgers(number: int):\n- # Do some sequential stuff to create the burgers\n+ # 햄버거를 만들기 위한 순차 처리를 수행\n return burgers\n ```\n \n-`async def`를 사용하면, 파이썬은 해당 함수 내에서 `await` 표현에 주의해야한다는 사실과, 해당 함수의 실행을 \"일시정지\"⏸하고 다시 돌아오기 전까지 다른 작업을 수행🔀할 수 있다는 것을 알게됩니다.\n+`async def`를 사용하면, 파이썬은 그 함수 내부에서 `await` 표현식에 주의해야 하며, 그 함수의 실행을 \"일시정지\" ⏸ 하고 다시 돌아오기 전에 다른 일을 하러 갈 수 있다는 것 🔀 을 알게 됩니다.\n \n-`async def`f 함수를 호출하고자 할 때, \"대기\"해야합니다. 따라서, 아래는 동작하지 않습니다.\n+`async def` 함수를 호출하고자 할 때는, 그 함수를 \"await\" 해야 합니다. 따라서 아래는 동작하지 않습니다:\n \n ```Python\n-# This won't work, because get_burgers was defined with: async def\n+# 동작하지 않습니다. get_burgers는 async def로 정의되었습니다\n burgers = get_burgers(2)\n ```\n \n ---\n \n-따라서, `await`f를 사용해서 호출할 수 있는 라이브러리를 사용한다면, 다음과 같이 `async def`를 사용하는 *경로 작동 함수*를 생성해야 합니다:\n+따라서, `await`로 호출할 수 있다고 말하는 라이브러리를 사용한다면, 다음과 같이 그것을 사용하는 *경로 처리 함수*를 `async def`로 만들어야 합니다:\n \n ```Python hl_lines=\"2-3\"\n [USER_REDACTED].get('/burgers')\n@@ -317,94 +349,96 @@ async def read_burgers():\n return burgers\n ```\n \n-### 더 세부적인 기술적 사항\n+### 더 세부적인 기술적 사항 { #more-technical-details }\n+\n+`await`는 `async def`로 정의된 함수 내부에서만 사용할 수 있다는 것을 눈치채셨을 것입니다.\n \n-`await`가 `async def`를 사용하는 함수 내부에서만 사용이 가능하다는 것을 눈치채셨을 것입니다.\n+하지만 동시에, `async def`로 정의된 함수는 \"await\" 되어야 합니다. 따라서 `async def`를 가진 함수는 `async def`로 정의된 함수 내부에서만 호출될 수 있습니다.\n \n-하지만 동시에, `async def`로 정의된 함수들은 \"대기\"되어야만 합니다. 따라서, `async def`를 사용한 함수들은 역시 `async def`를 사용한 함수 내부에서만 호출될 수 있습니다.\n+그렇다면, 닭이 먼저냐 달걀이 먼저냐처럼, 첫 번째 `async` 함수는 어떻게 호출할 수 있을까요?\n \n-그렇다면 닭이 먼저냐, 달걀이 먼저냐, 첫 `async` 함수를 어떻게 호출할 수 있겠습니까?\n+**FastAPI**로 작업한다면 걱정할 필요가 없습니다. 그 \"첫\" 함수는 여러분의 *경로 처리 함수*가 될 것이고, FastAPI는 올바르게 처리하는 방법을 알고 있기 때문입니다.\n \n-**FastAPI**를 사용해 작업한다면 이것을 걱정하지 않아도 됩니다. 왜냐하면 그 \"첫\" 함수는 당신의 *경로 작동 함수*가 될 것이고, FastAPI는 어떻게 올바르게 처리할지 알고있기 때문입니다.\n+하지만 FastAPI 없이 `async` / `await`를 사용하고 싶다면, 그것도 가능합니다.\n \n-하지만 FastAPI를 사용하지 않고 `async` / `await`를 사용하고 싶다면, 이 역시 가능합니다.\n+### 여러분만의 async 코드 작성하기 { #write-your-own-async-code }\n \n-### 당신만의 비동기 코드 작성하기\n+Starlette(그리고 **FastAPI**)는 AnyIO를 기반으로 하고 있으며, 파이썬 표준 라이브러리 asyncio와 Trio 모두와 호환됩니다.\n \n-Starlette(그리고 FastAPI)는 AnyIO를 기반으로 하고있고, 따라서 파이썬 표준 라이브러리인 asyncio 및 Trio와 호환됩니다.\n+특히, 코드에서 더 고급 패턴이 필요한 고급 동시성 사용 사례에서는 직접 AnyIO를 사용할 수 있습니다.\n \n-특히, 코드에서 고급 패턴이 필요한 고급 동시성을 사용하는 경우 직접적으로 AnyIO를 사용할 수 있습니다.\n+그리고 FastAPI를 사용하지 않더라도, 높은 호환성을 확보하고 그 이점(예: *structured concurrency*)을 얻기 위해 AnyIO로 여러분만의 async 애플리케이션을 작성할 수도 있습니다.\n \n-FastAPI를 사용하지 않더라도, 높은 호환성 및 AnyIO의 이점(예: *구조화된 동시성*)을 취하기 위해 AnyIO를 사용해 비동기 응용프로그램을 작성할 수 있습니다.\n+저는 AnyIO 위에 얇은 레이어로 또 다른 라이브러리를 만들었는데, 타입 어노테이션을 조금 개선하고 더 나은 **자동완성**, **인라인 오류** 등을 얻기 위한 것입니다. 또한 **이해**하고 **여러분만의 async 코드**를 작성하도록 돕는 친절한 소개와 튜토리얼도 제공합니다: Asyncer. 특히 **async 코드와 일반**(blocking/동기) 코드를 **결합**해야 한다면 아주 유용합니다.\n \n-### 비동기 코드의 다른 형태\n+### 비동기 코드의 다른 형태 { #other-forms-of-asynchronous-code }\n \n-파이썬에서 `async`와 `await`를 사용하게 된 것은 비교적 최근의 일입니다.\n+`async`와 `await`를 사용하는 이 스타일은 언어에서 비교적 최근에 추가되었습니다.\n \n-하지만 이로 인해 비동기 코드 작업이 훨씬 간단해졌습니다.\n+하지만 비동기 코드를 다루는 일을 훨씬 더 쉽게 만들어 줍니다.\n \n-같은 (또는 거의 유사한) 문법은 최신 버전의 자바스크립트(브라우저와 NodeJS)에도 추가되었습니다.\n+거의 동일한 문법이 최근 브라우저와 NodeJS의 최신 JavaScript에도 포함되었습니다.\n \n-하지만 그 이전에, 비동기 코드를 처리하는 것은 꽤 복잡하고 어려운 일이었습니다.\n+하지만 그 이전에는 비동기 코드를 처리하는 것이 훨씬 더 복잡하고 어려웠습니다.\n \n-파이썬의 예전 버전이라면, 스레드 또는 Gevent를 사용할 수 있을 것입니다. 하지만 코드를 이해하고, 디버깅하고, 이에 대해 생각하는게 훨씬 복잡합니다.\n+이전 버전의 파이썬에서는 스레드 또는 Gevent를 사용할 수 있었을 것입니다. 하지만 코드를 이해하고, 디버깅하고, 이에 대해 생각하는 것이 훨씬 더 복잡합니다.\n \n-예전 버전의 NodeJS / 브라우저 자바스크립트라면, \"콜백 함수\"를 사용했을 것입니다. 그리고 이로 인해 \"콜백 지옥\"에 빠지게 될 수 있습니다.\n+이전 버전의 NodeJS/브라우저 JavaScript에서는 \"callback\"을 사용했을 것입니다. 이는 \"callback hell\"로 이어집니다.\n \n-## 코루틴\n+## 코루틴 { #coroutines }\n \n-**코루틴**은 `async def` 함수가 반환하는 것을 칭하는 매우 고급스러운 용어일 뿐입니다. 파이썬은 그것이 시작되고 어느 시점에서 완료되지만 내부에 `await`가 있을 때마다 내부적으로 일시정지⏸될 수도 있는 함수와 유사한 것이라는 사실을 알고있습니다.\n+**코루틴**은 `async def` 함수가 반환하는 것에 대한 매우 고급스러운 용어일 뿐입니다. 파이썬은 그것이 함수와 비슷한 무언가로서 시작할 수 있고, 어느 시점에 끝나지만, 내부에 `await`가 있을 때마다 내부적으로도 일시정지 ⏸ 될 수 있다는 것을 알고 있습니다.\n \n-그러나 `async` 및 `await`와 함께 비동기 코드를 사용하는 이 모든 기능들은 \"코루틴\"으로 간단히 요약됩니다. 이것은 Go의 주된 핵심 기능인 \"고루틴\"에 견줄 수 있습니다.\n+하지만 `async` 및 `await`와 함께 비동기 코드를 사용하는 이 모든 기능은 종종 \"코루틴\"을 사용한다고 요약됩니다. 이는 Go의 주요 핵심 기능인 \"Goroutines\"에 비견됩니다.\n \n-## 결론\n+## 결론 { #conclusion }\n \n-상기 문장을 다시 한 번 봅시다:\n+위의 같은 문장을 다시 봅시다:\n \n-> 최신 파이썬 버전은 **`async` 및 `await`** 문법과 함께 **“코루틴”**이라고 하는 것을 사용하는 **“비동기 코드”**를 지원합니다.\n+> 최신 파이썬 버전은 **“코루틴”**이라고 하는 것을 사용하는 **“비동기 코드”**를 **`async` 및 `await`** 문법과 함께 지원합니다.\n \n-이제 이 말을 조금 더 이해할 수 있을 것입니다. ✨\n+이제 더 이해가 될 것입니다. ✨\n \n-이것이 (Starlette을 통해) FastAPI를 강하게 하면서 그것이 인상적인 성능을 낼 수 있게 합니다.\n+이 모든 것이 FastAPI(Starlette을 통해)를 구동하고, 인상적인 성능을 내게 하는 원동력입니다.\n \n-## 매우 세부적인 기술적 사항\n+## 매우 세부적인 기술적 사항 { #very-technical-details }\n \n /// warning | 경고\n \n-이 부분은 넘어가도 됩니다.\n+이 부분은 아마 건너뛰어도 됩니다.\n \n 이것들은 **FastAPI**가 내부적으로 어떻게 동작하는지에 대한 매우 세부적인 기술사항입니다.\n \n-만약 기술적 지식(코루틴, 스레드, 블록킹 등)이 있고 FastAPI가 어떻게 `async def` vs `def`를 다루는지 궁금하다면, 계속하십시오.\n+(코루틴, 스레드, 블로킹 등) 같은 기술 지식이 꽤 있고 FastAPI가 `async def`와 일반 `def`를 어떻게 처리하는지 궁금하다면, 계속 읽어보세요.\n \n ///\n \n-### 경로 작동 함수\n+### 경로 처리 함수 { #path-operation-functions }\n \n-경로 작동 함수를 `async def` 대신 일반적인 `def`로 선언하는 경우, (서버를 차단하는 것처럼) 그것을 직접 호출하는 대신 대기중인 외부 스레드풀에서 실행됩니다.\n+*경로 처리 함수*를 `async def` 대신 일반적인 `def`로 선언하면, (서버를 블로킹할 수 있으므로 직접 호출하는 대신) 외부 스레드풀에서 실행되고 그 결과를 await 합니다.\n \n-만약 상기에 묘사된대로 동작하지 않는 비동기 프로그램을 사용해왔고 약간의 성능 향상 (약 100 나노초)을 위해 `def`를 사용해서 계산만을 위한 사소한 *경로 작동 함수*를 정의해왔다면, **FastAPI**는 이와는 반대라는 것에 주의하십시오. 이러한 경우에, *경로 작동 함수*가 블로킹 I/O를 수행하는 코드를 사용하지 않는 한 `async def`를 사용하는 편이 더 낫습니다.\n+위에서 설명한 방식으로 동작하지 않는 다른 async 프레임워크를 사용해본 적이 있고, 아주 작은 성능 향상(약 100 나노초)을 위해 계산만 하는 사소한 *경로 처리 함수*를 일반 `def`로 정의하곤 했다면, **FastAPI**에서는 그 효과가 정반대가 될 수 있다는 점에 유의하세요. 이런 경우에는 *경로 처리 함수*에서 블로킹 I/O 를 수행하는 코드를 사용하지 않는 한 `async def`를 사용하는 편이 더 낫습니다.\n \n-하지만 두 경우 모두, FastAPI가 당신이 전에 사용하던 프레임워크보다 [더 빠를](index.md#_11){.internal-link target=_blank} (최소한 비견될) 확률이 높습니다.\n+그럼에도 두 경우 모두, **FastAPI**는 이전에 사용하던 프레임워크보다 [여전히 더 빠를](index.md#performance){.internal-link target=_blank} 가능성이 높습니다(또는 최소한 비슷합니다).\n \n-### 의존성\n+### 의존성 { #dependencies }\n \n-의존성에도 동일하게 적용됩니다. 의존성이 `async def`가 아닌 표준 `def` 함수라면, 외부 스레드풀에서 실행됩니다.\n+[의존성](tutorial/dependencies/index.md){.internal-link target=_blank}에도 동일하게 적용됩니다. 의존성이 `async def` 대신 표준 `def` 함수라면, 외부 스레드풀에서 실행됩니다.\n \n-### 하위-의존성\n+### 하위 의존성 { #sub-dependencies }\n \n-함수 정의시 매개변수로 서로를 필요로하는 다수의 의존성과 하위-의존성을 가질 수 있고, 그 중 일부는 `async def`로, 다른 일부는 일반적인 `def`로 생성되었을 수 있습니다. 이것은 여전히 잘 동작하고, 일반적인 `def`로 생성된 것들은 \"대기\"되는 대신에 (스레드풀로부터) 외부 스레드에서 호출됩니다.\n+서로를 필요로 하는 여러 의존성과 [하위 의존성](tutorial/dependencies/sub-dependencies.md){.internal-link target=_blank}을 함수 정의의 매개변수로 가질 수 있으며, 그중 일부는 `async def`로, 다른 일부는 일반 `def`로 생성되었을 수 있습니다. 그래도 정상 동작하며, 일반 `def`로 생성된 것들은 \"await\"되는 대신 (스레드풀에서) 외부 스레드에서 호출됩니다.\n \n-### 다른 유틸리티 함수\n+### 다른 유틸리티 함수 { #other-utility-functions }\n \n-직접 호출되는 다른 모든 유틸리티 함수는 일반적인 `def`나 `async def`로 생성될 수 있고 FastAPI는 이를 호출하는 방식에 영향을 미치지 않습니다.\n+직접 호출하는 다른 모든 유틸리티 함수는 일반 `def`나 `async def`로 생성될 수 있으며, FastAPI는 호출 방식에 영향을 주지 않습니다.\n \n-이것은 FastAPI가 당신을 위해 호출하는 함수와는 반대입니다: *경로 작동 함수*와 의존성\n+이는 FastAPI가 여러분을 위해 호출하는 함수(즉, *경로 처리 함수*와 의존성)와 대비됩니다.\n \n-만약 당신의 유틸리티 함수가 `def`를 사용한 일반적인 함수라면, 스레드풀에서가 아니라 직접 호출(당신이 코드에 작성한 대로)될 것이고, `async def`로 생성된 함수라면 코드에서 호출할 때 그 함수를 `await` 해야 합니다.\n+유틸리티 함수가 `def`로 만든 일반 함수라면, 스레드풀이 아니라 직접(코드에 작성한 대로) 호출됩니다. 그리고 `async def`로 생성된 함수라면, 코드에서 호출할 때 그 함수를 `await` 해야 합니다.\n \n ---\n \n-다시 말하지만, 이것은 당신이 이것에 대해 찾고있던 경우에 한해 유용할 매우 세부적인 기술사항입니다.\n+다시 말하지만, 이것들은 아마도 이를 찾고 있었던 경우에 유용한 매우 세부적인 기술사항입니다.\n \n-그렇지 않은 경우, 상기의 가이드라인만으로도 충분할 것입니다: [바쁘신 경우](#_1).\n+그렇지 않다면, 위 섹션의 가이드라인이면 충분합니다: 바쁘신가요?."
},
{
"filename": "docs/ko/docs/fastapi-cli.md",
"status": "modified",
"additions": 50,
"deletions": 58,
"changes": 108,
"patch": "@@ -1,83 +1,75 @@\n-# FastAPI CLI\n+# FastAPI CLI { #fastapi-cli }\n \n-**FastAPI CLI**는 FastAPI 애플리케이션을 실행하고, 프로젝트를 관리하는 등 다양한 작업을 수행할 수 있는 커맨드 라인 프로그램입니다.\n+**FastAPI CLI**는 FastAPI 애플리케이션을 서빙하고, FastAPI 프로젝트를 관리하는 등 다양한 작업에 사용할 수 있는 커맨드 라인 프로그램입니다.\n \n-FastAPI를 설치할 때 (예: `pip install \"fastapi[standard]\"` 명령어를 사용할 경우), `fastapi-cli`라는 패키지가 포함됩니다. 이 패키지는 터미널에서 사용할 수 있는 `fastapi` 명령어를 제공합니다.\n+FastAPI를 설치할 때(예: `pip install \"fastapi[standard]\"`), `fastapi-cli`라는 패키지가 포함되며, 이 패키지는 터미널에서 `fastapi` 명령어를 제공합니다.\n \n-개발용으로 FastAPI 애플리케이션을 실행하려면 다음과 같이 `fastapi dev` 명령어를 사용할 수 있습니다:\n+개발용으로 FastAPI 애플리케이션을 실행하려면 `fastapi dev` 명령어를 사용할 수 있습니다:\n \n
\n+\n+대부분의 시간을 카운터 앞에서 기다리는 데 🕙 썼기 때문에, 대화하거나 작업을 걸 시간은 많지 않았습니다. 😞\n \n-이 병렬 버거 시나리오에서, 당신은 기다리고 🕙 , 오랜 시간동안 \"카운터에서 기다리는\" 🕙 데에 주의를 기울이는 ⏯ 두 개의 프로세서(당신과 짝사랑 상대😍)를 가진 컴퓨터 / 프로그램 🤖 입니다.\n+/// info | 정보\n \n-패스트푸드점에는 8개의 프로세서(점원/요리사) 👩🍳👨🍳👩🍳👨🍳👩🍳👨🍳👩🍳👨🍳 가 있습니다. 동시 버거는 단 두 개(한 명의 직원과 한 명의 요리사) 💁 👨🍳 만을 가지고 있었습니다.\n+아름다운 일러스트: [NAME_REDACTED]. 🎨\n \n-하지만 여전히, 병렬 버거 예시가 최선은 아닙니다 😞 .\n+///\n \n ---\n \n-이 예시는 버거🍔 이야기와 결이 같습니다.\n+이 병렬 햄버거 시나리오에서, 여러분은 두 개의 프로세서(여러분과 짝사랑 상대)를 가진 컴퓨터/프로그램 🤖 이며, 둘 다 기다리고 🕙 오랫동안 \"카운터에서 기다리기\" 🕙 에 주의를 ⏯ 기울입니다.\n+\n+패스트푸드점에는 8개의 프로세서(점원/요리사)가 있습니다. 동시 햄버거 가게는 2개(점원 1명, 요리사 1명)만 있었을 것입니다.\n \n-더 \"현실적인\" 예시로, 은행을 상상해보십시오.\n+하지만 여전히 최종 경험은 그다지 좋지 않습니다. 😞\n \n-최근까지, 대다수의 은행에는 다수의 은행원들 👨💼👨💼👨💼👨💼 과 긴 줄 🕙🕙🕙🕙🕙🕙🕙🕙 이 있습니다.\n+---\n \n-모든 은행원들은 한 명 한 명의 고객들을 차례로 상대합니다 👨💼⏯ .\n+이것이 햄버거의 병렬 버전에 해당하는 이야기입니다. 🍔\n \n-그리고 당신은 오랫동안 줄에서 기다려야하고 🕙 , 그렇지 않으면 당신의 차례를 잃게 됩니다.\n+좀 더 \"현실적인\" 예시로, 은행을 상상해보세요.\n \n-아마 당신은 은행 🏦 심부름에 짝사랑 상대 😍 를 데려가고 싶지는 않을 것입니다.\n+최근까지 대부분의 은행에는 여러 은행원 👨💼👨💼👨💼👨💼 과 긴 줄 🕙🕙🕙🕙🕙🕙🕙🕙 이 있었습니다.\n \n-### 버거 예시의 결론\n+모든 은행원이 한 고객씩 순서대로 모든 일을 처리합니다 👨💼⏯.\n \n-\"짝사랑 상대와의 패스트푸드점 버거\" 시나리오에서, 오랜 기다림 🕙 이 있기 때문에 동시 시스템 ⏸🔀⏯ 을 사용하는 것이 더 합리적입니다.\n+그리고 여러분은 오랫동안 줄에서 기다려야 🕙 하며, 그렇지 않으면 차례를 잃습니다.\n \n-대다수의 웹 응용프로그램의 경우가 그러합니다.\n+아마 은행 🏦 업무를 보러 갈 때 짝사랑 상대 😍 를 데려가고 싶지는 않을 것입니다.\n \n-매우 많은 수의 유저가 있지만, 서버는 그들의 요청을 전송하기 위해 그닥-좋지-않은 연결을 기다려야 합니다 🕙 .\n+### 햄버거 예시의 결론 { #burger-conclusion }\n \n-그리고 응답이 돌아올 때까지 다시 기다려야 합니다 🕙 .\n+\"짝사랑 상대와의 패스트푸드점 햄버거\" 시나리오에서는 기다림 🕙 이 많기 때문에, 동시 시스템 ⏸🔀⏯ 을 사용하는 것이 훨씬 더 합리적입니다.\n \n-이 \"기다림\" 🕙 은 마이크로초 단위이지만, 모두 더해지면, 결국에는 매우 긴 대기시간이 됩니다.\n+대부분의 웹 애플리케이션이 그렇습니다.\n \n-따라서 웹 API를 위해 비동기 ⏸🔀⏯ 코드를 사용하는 것이 합리적입니다.\n+매우 많은 사용자들이 있고, 서버는 그들의 좋지 않은 연결을 통해 요청이 전송되기를 기다립니다 🕙.\n \n-대부분의 존재하는 유명한 파이썬 프레임워크 (Flask와 Django 등)은 새로운 비동기 기능들이 파이썬에 존재하기 전에 만들어졌습니다. 그래서, 그들의 배포 방식은 병렬 실행과 새로운 기능만큼 강력하지는 않은 예전 버전의 비동기 실행을 지원합니다.\n+그리고 응답이 돌아오기를 다시 기다립니다 🕙.\n \n-비동기 웹 파이썬(ASGI)에 대한 주요 명세가 웹소켓을 지원하기 위해 Django에서 개발 되었음에도 그렇습니다.\n+이 \"기다림\" 🕙 은 마이크로초 단위로 측정되지만, 모두 합치면 결국 꽤 많은 대기 시간이 됩니다.\n \n-이러한 종류의 비동기성은 (NodeJS는 병렬적이지 않음에도) NodeJS가 사랑받는 이유이고, 프로그래밍 언어로서의 Go의 강점입니다.\n+그래서 웹 API에는 비동기 ⏸🔀⏯ 코드를 사용하는 것이 매우 합리적입니다.\n \n-그리고 **FastAPI**를 사용함으로써 동일한 성능을 낼 수 있습니다.\n+이러한 종류의 비동기성은 NodeJS가 인기 있는 이유(비록 NodeJS가 병렬은 아니지만)이자, 프로그래밍 언어로서 Go의 강점입니다.\n \n-또한 병렬성과 비동기성을 동시에 사용할 수 있기 때문에, 대부분의 테스트가 완료된 NodeJS 프레임워크보다 더 높은 성능을 얻고 C에 더 가까운 컴파일 언어인 Go와 동등한 성능을 얻을 수 있습니다(모두 Starlette 덕분입니다).\n+그리고 이것이 **FastAPI**로 얻는 것과 같은 수준의 성능입니다.\n \n-### 동시성이 병렬성보다 더 나은가?\n+또한 병렬성과 비동기성을 동시에 사용할 수 있으므로, 대부분의 테스트된 NodeJS 프레임워크보다 더 높은 성능을 얻고, C에 더 가까운 컴파일 언어인 Go와 동등한 성능을 얻을 수 있습니다 (모두 Starlette 덕분입니다).\n \n-그렇지 않습니다! 그것이 이야기의 교훈은 아닙니다.\n+### 동시성이 병렬성보다 더 나은가요? { #is-concurrency-better-than-parallelism }\n \n-동시성은 병렬성과 다릅니다. 그리고 그것은 많은 대기를 필요로하는 **특정한** 시나리오에서는 더 낫습니다. 이로 인해, 웹 응용프로그램 개발에서 동시성이 병렬성보다 일반적으로 훨씬 낫습니다. 하지만 모든 경우에 그런 것은 아닙니다.\n+아니요! 그게 이 이야기의 교훈은 아닙니다.\n \n-따라서, 균형을 맞추기 위해, 다음의 짧은 이야기를 상상해보십시오:\n+동시성은 병렬성과 다릅니다. 그리고 많은 기다림이 포함되는 **특정한** 시나리오에서는 더 낫습니다. 그 때문에 웹 애플리케이션 개발에서는 일반적으로 병렬성보다 훨씬 더 낫습니다. 하지만 모든 것에 해당하진 않습니다.\n \n-> 당신은 크고, 더러운 집을 청소해야합니다.\n+그래서 균형을 맞추기 위해, 다음의 짧은 이야기를 상상해보세요:\n+\n+> 여러분은 크고 더러운 집을 청소해야 합니다.\n \n *네, 이게 전부입니다*.\n \n ---\n \n-어디에도 대기 🕙 는 없고, 집안 곳곳에서 해야하는 많은 작업들만 있습니다.\n+어디에도 기다림 🕙 은 없고, 집의 여러 장소에서 해야 할 일이 많을 뿐입니다.\n \n-버거 예시처럼 처음에는 거실, 그 다음은 부엌과 같은 식으로 순서를 정할 수도 있으나, 무엇도 기다리지 🕙 않고 계속해서 청소 작업만 수행하기 때문에, 순서는 아무런 영향을 미치지 않습니다.\n+햄버거 예시처럼 거실부터, 그 다음은 부엌처럼 순서를 정할 수도 있지만, 어떤 것도 기다리지 🕙 않고 계속 청소만 하기 때문에, 순서는 아무런 영향을 주지 않습니다.\n \n-순서가 있든 없든 동일한 시간이 소요될 것이고(동시성) 동일한 양의 작업을 하게 될 것입니다.\n+순서가 있든 없든(동시성) 끝내는 데 걸리는 시간은 같고, 같은 양의 일을 하게 됩니다.\n \n-하지만 이 경우에서, 8명의 전(前)-점원/요리사이면서-현(現)-청소부 👩🍳👨🍳👩🍳👨🍳👩🍳👨🍳👩🍳👨🍳 를 고용할 수 있고, 그들 각자(그리고 당신)가 집의 한 부분씩 맡아 청소를 한다면, 당신은 **병렬적**으로 작업을 수행할 수 있고, 조금의 도움이 있다면, 훨씬 더 빨리 끝낼 수 있습니다.\n+하지만 이 경우, 전(前) 점원/요리사이자 현(現) 청소부가 된 8명을 데려올 수 있고, 각자(그리고 여러분)가 집의 구역을 하나씩 맡아 청소한다면, 추가 도움과 함께 모든 일을 **병렬**로 수행하여 훨씬 더 빨리 끝낼 수 있습니다.\n \n-이 시나리오에서, (당신을 포함한) 각각의 청소부들은 프로세서가 될 것이고, 각자의 역할을 수행합니다.\n+이 시나리오에서 (여러분을 포함한) 각 청소부는 프로세서가 되어, 맡은 일을 수행합니다.\n \n-실행 시간의 대부분이 대기가 아닌 실제 작업에 소요되고, 컴퓨터에서 작업은 CPU에서 이루어지므로, 이러한 문제를 \"CPU에 묶였\"다고 합니다.\n+그리고 실행 시간의 대부분이 기다림이 아니라 실제 작업에 쓰이고, 컴퓨터에서 작업은 CPU가 수행하므로, 이런 문제를 \"CPU bound\"라고 부릅니다.\n \n ---\n \n-CPU에 묶인 연산에 관한 흔한 예시는 복잡한 수학 처리를 필요로 하는 경우입니다.\n+CPU bound 작업의 흔한 예시는 복잡한 수학 처리가 필요한 것들입니다.\n \n 예를 들어:\n \n-* **오디오** 또는 **이미지** 처리.\n-* **컴퓨터 비전**: 하나의 이미지는 수백개의 픽셀로 구성되어있고, 각 픽셀은 3개의 값 / 색을 갖고 있으며, 일반적으로 해당 픽셀들에 대해 동시에 무언가를 계산해야하는 처리.\n-* **머신러닝**: 일반적으로 많은 \"행렬\"과 \"벡터\" 곱셈이 필요합니다. 거대한 스프레드 시트에 수들이 있고 그 수들을 동시에 곱해야 한다고 생각해보십시오.\n-* **딥러닝**: 머신러닝의 하위영역으로, 동일한 예시가 적용됩니다. 단지 이 경우에는 하나의 스프레드 시트에 곱해야할 수들이 있는 것이 아니라, 거대한 세트의 스프레드 시트들이 있고, 많은 경우에, 이 모델들을 만들고 사용하기 위해 특수한 프로세서를 사용합니다.\n+* **오디오** 또는 **이미지** 처리\n+* **컴퓨터 비전**: 이미지는 수백만 개의 픽셀로 구성되며, 각 픽셀은 3개의 값/색을 갖습니다. 보통 그 픽셀들에 대해 동시에 무언가를 계산해야 합니다.\n+* **머신러닝**: 보통 많은 \"matrix\"와 \"vector\" 곱셈이 필요합니다. 숫자가 있는 거대한 스프레드시트를 생각하고, 그 모든 수를 동시에 곱한다고 생각해보세요.\n+* **딥러닝**: 머신러닝의 하위 분야이므로 동일하게 적용됩니다. 다만 곱해야 할 숫자가 있는 스프레드시트가 하나가 아니라, 아주 큰 집합이며, 많은 경우 그 모델을 만들고/또는 사용하기 위해 특별한 프로세서를 사용합니다.\n \n-### 동시성 + 병렬성: 웹 + 머신러닝\n+### 동시성 + 병렬성: 웹 + 머신러닝 { #concurrency-parallelism-web-machine-learning }\n \n-**FastAPI**를 사용하면 웹 개발에서는 매우 흔한 동시성의 이점을 (NodeJS의 주된 매력만큼) 얻을 수 있습니다.\n+**FastAPI**를 사용하면 웹 개발에서 매우 흔한 동시성의 이점을( NodeJS의 주요 매력과 같은) 얻을 수 있습니다.\n \n-뿐만 아니라 머신러닝 시스템과 같이 **CPU에 묶인** 작업을 위해 병렬성과 멀티프로세싱(다수의 프로세스를 병렬적으로 동작시키는 것)을 이용하는 것도 가능합니다.\n+또한 머신러닝 시스템처럼 **CPU bound** 워크로드에 대해 병렬성과 멀티프로세싱(여러 프로세스를 병렬로 실행)을 활용할 수도 있습니다.\n \n-파이썬이 **데이터 사이언스**, 머신러닝과 특히 딥러닝에 의 주된 언어라는 간단한 사실에 더해서, 이것은 FastAPI를 데이터 사이언스 / 머신러닝 웹 API와 응용프로그램에 (다른 것들보다) 좋은 선택지가 되게 합니다.\n+이것은 파이썬이 **데이터 사이언스**, 머신러닝, 특히 딥러닝의 주요 언어라는 단순한 사실과 더해져, FastAPI를 데이터 사이언스/머신러닝 웹 API 및 애플리케이션(그 외에도 많은 것들)에 매우 잘 맞는 선택으로 만들어 줍니다.\n \n-배포시 병렬을 어떻게 가능하게 하는지 알고싶다면, [배포](deployment/index.md){.internal-link target=_blank}문서를 참고하십시오.\n+프로덕션에서 이 병렬성을 어떻게 달성하는지 보려면 [배포](deployment/index.md){.internal-link target=_blank} 섹션을 참고하세요.\n \n-## `async`와 `await`\n+## `async`와 `await` { #async-and-await }\n \n-최신 파이썬 버전에는 비동기 코드를 정의하는 매우 직관적인 방법이 있습니다. 이는 이것을 평범한 \"순차적\" 코드로 보이게 하고, 적절한 순간에 당신을 위해 \"대기\"합니다.\n+최신 파이썬 버전에는 비동기 코드를 정의하는 매우 직관적인 방법이 있습니다. 이 방법은 이를 평범한 \"순차\" 코드처럼 보이게 하고, 적절한 순간에 여러분을 위해 \"기다림\"을 수행합니다.\n \n-연산이 결과를 전달하기 전에 대기를 해야하고 새로운 파이썬 기능들을 지원한다면, 이렇게 코드를 작성할 수 있습니다:\n+결과를 주기 전에 기다림이 필요한 작업이 있고, 이러한 새로운 파이썬 기능을 지원한다면, 다음과 같이 작성할 수 있습니다:\n \n ```Python\n burgers = await get_burgers(2)\n ```\n \n-여기서 핵심은 `await`입니다. 이것은 파이썬에게 `burgers` 결과를 저장하기 이전에 `get_burgers(2)`의 작업이 완료되기를 🕙 기다리라고 ⏸ 말합니다. 이로 인해, 파이썬은 그동안 (다른 요청을 받는 것과 같은) 다른 작업을 수행해도 된다는 것을 🔀 ⏯ 알게될 것입니다.\n+여기서 핵심은 `await`입니다. 이는 파이썬에게 `get_burgers(2)`가 그 일을 끝낼 때까지 🕙 기다리도록 ⏸ 말하고, 그 결과를 `burgers`에 저장하기 전에 완료되기를 기다리라고 합니다. 이를 통해 파이썬은 그동안(예: 다른 요청을 받는 것처럼) 다른 일을 하러 갈 수 있다는 것 🔀 ⏯ 을 알게 됩니다.\n \n-`await`가 동작하기 위해, 이것은 비동기를 지원하는 함수 내부에 있어야 합니다. 이를 위해서 함수를 `async def`를 사용해 정의하기만 하면 됩니다:\n+`await`가 동작하려면, 이 비동기성을 지원하는 함수 내부에 있어야 합니다. 그러려면 `async def`로 선언하기만 하면 됩니다:\n \n ```Python hl_lines=\"1\"\n async def get_burgers(number: int):\n- # Do some asynchronous stuff to create the burgers\n+ # 햄버거를 만들기 위한 비동기 처리를 수행\n return burgers\n ```\n \n-...`def`를 사용하는 대신:\n+...`def` 대신:\n \n ```Python hl_lines=\"2\"\n-# This is not asynchronous\n+# 비동기가 아닙니다\n def get_sequential_burgers(number: int):\n- # Do some sequential stuff to create the burgers\n+ # 햄버거를 만들기 위한 순차 처리를 수행\n return burgers\n ```\n \n-`async def`를 사용하면, 파이썬은 해당 함수 내에서 `await` 표현에 주의해야한다는 사실과, 해당 함수의 실행을 \"일시정지\"⏸하고 다시 돌아오기 전까지 다른 작업을 수행🔀할 수 있다는 것을 알게됩니다.\n+`async def`를 사용하면, 파이썬은 그 함수 내부에서 `await` 표현식에 주의해야 하며, 그 함수의 실행을 \"일시정지\" ⏸ 하고 다시 돌아오기 전에 다른 일을 하러 갈 수 있다는 것 🔀 을 알게 됩니다.\n \n-`async def`f 함수를 호출하고자 할 때, \"대기\"해야합니다. 따라서, 아래는 동작하지 않습니다.\n+`async def` 함수를 호출하고자 할 때는, 그 함수를 \"await\" 해야 합니다. 따라서 아래는 동작하지 않습니다:\n \n ```Python\n-# This won't work, because get_burgers was defined with: async def\n+# 동작하지 않습니다. get_burgers는 async def로 정의되었습니다\n burgers = get_burgers(2)\n ```\n \n ---\n \n-따라서, `await`f를 사용해서 호출할 수 있는 라이브러리를 사용한다면, 다음과 같이 `async def`를 사용하는 *경로 작동 함수*를 생성해야 합니다:\n+따라서, `await`로 호출할 수 있다고 말하는 라이브러리를 사용한다면, 다음과 같이 그것을 사용하는 *경로 처리 함수*를 `async def`로 만들어야 합니다:\n \n ```Python hl_lines=\"2-3\"\n [USER_REDACTED].get('/burgers')\n@@ -317,94 +349,96 @@ async def read_burgers():\n return burgers\n ```\n \n-### 더 세부적인 기술적 사항\n+### 더 세부적인 기술적 사항 { #more-technical-details }\n+\n+`await`는 `async def`로 정의된 함수 내부에서만 사용할 수 있다는 것을 눈치채셨을 것입니다.\n \n-`await`가 `async def`를 사용하는 함수 내부에서만 사용이 가능하다는 것을 눈치채셨을 것입니다.\n+하지만 동시에, `async def`로 정의된 함수는 \"await\" 되어야 합니다. 따라서 `async def`를 가진 함수는 `async def`로 정의된 함수 내부에서만 호출될 수 있습니다.\n \n-하지만 동시에, `async def`로 정의된 함수들은 \"대기\"되어야만 합니다. 따라서, `async def`를 사용한 함수들은 역시 `async def`를 사용한 함수 내부에서만 호출될 수 있습니다.\n+그렇다면, 닭이 먼저냐 달걀이 먼저냐처럼, 첫 번째 `async` 함수는 어떻게 호출할 수 있을까요?\n \n-그렇다면 닭이 먼저냐, 달걀이 먼저냐, 첫 `async` 함수를 어떻게 호출할 수 있겠습니까?\n+**FastAPI**로 작업한다면 걱정할 필요가 없습니다. 그 \"첫\" 함수는 여러분의 *경로 처리 함수*가 될 것이고, FastAPI는 올바르게 처리하는 방법을 알고 있기 때문입니다.\n \n-**FastAPI**를 사용해 작업한다면 이것을 걱정하지 않아도 됩니다. 왜냐하면 그 \"첫\" 함수는 당신의 *경로 작동 함수*가 될 것이고, FastAPI는 어떻게 올바르게 처리할지 알고있기 때문입니다.\n+하지만 FastAPI 없이 `async` / `await`를 사용하고 싶다면, 그것도 가능합니다.\n \n-하지만 FastAPI를 사용하지 않고 `async` / `await`를 사용하고 싶다면, 이 역시 가능합니다.\n+### 여러분만의 async 코드 작성하기 { #write-your-own-async-code }\n \n-### 당신만의 비동기 코드 작성하기\n+Starlette(그리고 **FastAPI**)는 AnyIO를 기반으로 하고 있으며, 파이썬 표준 라이브러리 asyncio와 Trio 모두와 호환됩니다.\n \n-Starlette(그리고 FastAPI)는 AnyIO를 기반으로 하고있고, 따라서 파이썬 표준 라이브러리인 asyncio 및 Trio와 호환됩니다.\n+특히, 코드에서 더 고급 패턴이 필요한 고급 동시성 사용 사례에서는 직접 AnyIO를 사용할 수 있습니다.\n \n-특히, 코드에서 고급 패턴이 필요한 고급 동시성을 사용하는 경우 직접적으로 AnyIO를 사용할 수 있습니다.\n+그리고 FastAPI를 사용하지 않더라도, 높은 호환성을 확보하고 그 이점(예: *structured concurrency*)을 얻기 위해 AnyIO로 여러분만의 async 애플리케이션을 작성할 수도 있습니다.\n \n-FastAPI를 사용하지 않더라도, 높은 호환성 및 AnyIO의 이점(예: *구조화된 동시성*)을 취하기 위해 AnyIO를 사용해 비동기 응용프로그램을 작성할 수 있습니다.\n+저는 AnyIO 위에 얇은 레이어로 또 다른 라이브러리를 만들었는데, 타입 어노테이션을 조금 개선하고 더 나은 **자동완성**, **인라인 오류** 등을 얻기 위한 것입니다. 또한 **이해**하고 **여러분만의 async 코드**를 작성하도록 돕는 친절한 소개와 튜토리얼도 제공합니다: Asyncer. 특히 **async 코드와 일반**(blocking/동기) 코드를 **결합**해야 한다면 아주 유용합니다.\n \n-### 비동기 코드의 다른 형태\n+### 비동기 코드의 다른 형태 { #other-forms-of-asynchronous-code }\n \n-파이썬에서 `async`와 `await`를 사용하게 된 것은 비교적 최근의 일입니다.\n+`async`와 `await`를 사용하는 이 스타일은 언어에서 비교적 최근에 추가되었습니다.\n \n-하지만 이로 인해 비동기 코드 작업이 훨씬 간단해졌습니다.\n+하지만 비동기 코드를 다루는 일을 훨씬 더 쉽게 만들어 줍니다.\n \n-같은 (또는 거의 유사한) 문법은 최신 버전의 자바스크립트(브라우저와 NodeJS)에도 추가되었습니다.\n+거의 동일한 문법이 최근 브라우저와 NodeJS의 최신 JavaScript에도 포함되었습니다.\n \n-하지만 그 이전에, 비동기 코드를 처리하는 것은 꽤 복잡하고 어려운 일이었습니다.\n+하지만 그 이전에는 비동기 코드를 처리하는 것이 훨씬 더 복잡하고 어려웠습니다.\n \n-파이썬의 예전 버전이라면, 스레드 또는 Gevent를 사용할 수 있을 것입니다. 하지만 코드를 이해하고, 디버깅하고, 이에 대해 생각하는게 훨씬 복잡합니다.\n+이전 버전의 파이썬에서는 스레드 또는 Gevent를 사용할 수 있었을 것입니다. 하지만 코드를 이해하고, 디버깅하고, 이에 대해 생각하는 것이 훨씬 더 복잡합니다.\n \n-예전 버전의 NodeJS / 브라우저 자바스크립트라면, \"콜백 함수\"를 사용했을 것입니다. 그리고 이로 인해 \"콜백 지옥\"에 빠지게 될 수 있습니다.\n+이전 버전의 NodeJS/브라우저 JavaScript에서는 \"callback\"을 사용했을 것입니다. 이는 \"callback hell\"로 이어집니다.\n \n-## 코루틴\n+## 코루틴 { #coroutines }\n \n-**코루틴**은 `async def` 함수가 반환하는 것을 칭하는 매우 고급스러운 용어일 뿐입니다. 파이썬은 그것이 시작되고 어느 시점에서 완료되지만 내부에 `await`가 있을 때마다 내부적으로 일시정지⏸될 수도 있는 함수와 유사한 것이라는 사실을 알고있습니다.\n+**코루틴**은 `async def` 함수가 반환하는 것에 대한 매우 고급스러운 용어일 뿐입니다. 파이썬은 그것이 함수와 비슷한 무언가로서 시작할 수 있고, 어느 시점에 끝나지만, 내부에 `await`가 있을 때마다 내부적으로도 일시정지 ⏸ 될 수 있다는 것을 알고 있습니다.\n \n-그러나 `async` 및 `await`와 함께 비동기 코드를 사용하는 이 모든 기능들은 \"코루틴\"으로 간단히 요약됩니다. 이것은 Go의 주된 핵심 기능인 \"고루틴\"에 견줄 수 있습니다.\n+하지만 `async` 및 `await`와 함께 비동기 코드를 사용하는 이 모든 기능은 종종 \"코루틴\"을 사용한다고 요약됩니다. 이는 Go의 주요 핵심 기능인 \"Goroutines\"에 비견됩니다.\n \n-## 결론\n+## 결론 { #conclusion }\n \n-상기 문장을 다시 한 번 봅시다:\n+위의 같은 문장을 다시 봅시다:\n \n-> 최신 파이썬 버전은 **`async` 및 `await`** 문법과 함께 **“코루틴”**이라고 하는 것을 사용하는 **“비동기 코드”**를 지원합니다.\n+> 최신 파이썬 버전은 **“코루틴”**이라고 하는 것을 사용하는 **“비동기 코드”**를 **`async` 및 `await`** 문법과 함께 지원합니다.\n \n-이제 이 말을 조금 더 이해할 수 있을 것입니다. ✨\n+이제 더 이해가 될 것입니다. ✨\n \n-이것이 (Starlette을 통해) FastAPI를 강하게 하면서 그것이 인상적인 성능을 낼 수 있게 합니다.\n+이 모든 것이 FastAPI(Starlette을 통해)를 구동하고, 인상적인 성능을 내게 하는 원동력입니다.\n \n-## 매우 세부적인 기술적 사항\n+## 매우 세부적인 기술적 사항 { #very-technical-details }\n \n /// warning | 경고\n \n-이 부분은 넘어가도 됩니다.\n+이 부분은 아마 건너뛰어도 됩니다.\n \n 이것들은 **FastAPI**가 내부적으로 어떻게 동작하는지에 대한 매우 세부적인 기술사항입니다.\n \n-만약 기술적 지식(코루틴, 스레드, 블록킹 등)이 있고 FastAPI가 어떻게 `async def` vs `def`를 다루는지 궁금하다면, 계속하십시오.\n+(코루틴, 스레드, 블로킹 등) 같은 기술 지식이 꽤 있고 FastAPI가 `async def`와 일반 `def`를 어떻게 처리하는지 궁금하다면, 계속 읽어보세요.\n \n ///\n \n-### 경로 작동 함수\n+### 경로 처리 함수 { #path-operation-functions }\n \n-경로 작동 함수를 `async def` 대신 일반적인 `def`로 선언하는 경우, (서버를 차단하는 것처럼) 그것을 직접 호출하는 대신 대기중인 외부 스레드풀에서 실행됩니다.\n+*경로 처리 함수*를 `async def` 대신 일반적인 `def`로 선언하면, (서버를 블로킹할 수 있으므로 직접 호출하는 대신) 외부 스레드풀에서 실행되고 그 결과를 await 합니다.\n \n-만약 상기에 묘사된대로 동작하지 않는 비동기 프로그램을 사용해왔고 약간의 성능 향상 (약 100 나노초)을 위해 `def`를 사용해서 계산만을 위한 사소한 *경로 작동 함수*를 정의해왔다면, **FastAPI**는 이와는 반대라는 것에 주의하십시오. 이러한 경우에, *경로 작동 함수*가 블로킹 I/O를 수행하는 코드를 사용하지 않는 한 `async def`를 사용하는 편이 더 낫습니다.\n+위에서 설명한 방식으로 동작하지 않는 다른 async 프레임워크를 사용해본 적이 있고, 아주 작은 성능 향상(약 100 나노초)을 위해 계산만 하는 사소한 *경로 처리 함수*를 일반 `def`로 정의하곤 했다면, **FastAPI**에서는 그 효과가 정반대가 될 수 있다는 점에 유의하세요. 이런 경우에는 *경로 처리 함수*에서 블로킹 I/O 를 수행하는 코드를 사용하지 않는 한 `async def`를 사용하는 편이 더 낫습니다.\n \n-하지만 두 경우 모두, FastAPI가 당신이 전에 사용하던 프레임워크보다 [더 빠를](index.md#_11){.internal-link target=_blank} (최소한 비견될) 확률이 높습니다.\n+그럼에도 두 경우 모두, **FastAPI**는 이전에 사용하던 프레임워크보다 [여전히 더 빠를](index.md#performance){.internal-link target=_blank} 가능성이 높습니다(또는 최소한 비슷합니다).\n \n-### 의존성\n+### 의존성 { #dependencies }\n \n-의존성에도 동일하게 적용됩니다. 의존성이 `async def`가 아닌 표준 `def` 함수라면, 외부 스레드풀에서 실행됩니다.\n+[의존성](tutorial/dependencies/index.md){.internal-link target=_blank}에도 동일하게 적용됩니다. 의존성이 `async def` 대신 표준 `def` 함수라면, 외부 스레드풀에서 실행됩니다.\n \n-### 하위-의존성\n+### 하위 의존성 { #sub-dependencies }\n \n-함수 정의시 매개변수로 서로를 필요로하는 다수의 의존성과 하위-의존성을 가질 수 있고, 그 중 일부는 `async def`로, 다른 일부는 일반적인 `def`로 생성되었을 수 있습니다. 이것은 여전히 잘 동작하고, 일반적인 `def`로 생성된 것들은 \"대기\"되는 대신에 (스레드풀로부터) 외부 스레드에서 호출됩니다.\n+서로를 필요로 하는 여러 의존성과 [하위 의존성](tutorial/dependencies/sub-dependencies.md){.internal-link target=_blank}을 함수 정의의 매개변수로 가질 수 있으며, 그중 일부는 `async def`로, 다른 일부는 일반 `def`로 생성되었을 수 있습니다. 그래도 정상 동작하며, 일반 `def`로 생성된 것들은 \"await\"되는 대신 (스레드풀에서) 외부 스레드에서 호출됩니다.\n \n-### 다른 유틸리티 함수\n+### 다른 유틸리티 함수 { #other-utility-functions }\n \n-직접 호출되는 다른 모든 유틸리티 함수는 일반적인 `def`나 `async def`로 생성될 수 있고 FastAPI는 이를 호출하는 방식에 영향을 미치지 않습니다.\n+직접 호출하는 다른 모든 유틸리티 함수는 일반 `def`나 `async def`로 생성될 수 있으며, FastAPI는 호출 방식에 영향을 주지 않습니다.\n \n-이것은 FastAPI가 당신을 위해 호출하는 함수와는 반대입니다: *경로 작동 함수*와 의존성\n+이는 FastAPI가 여러분을 위해 호출하는 함수(즉, *경로 처리 함수*와 의존성)와 대비됩니다.\n \n-만약 당신의 유틸리티 함수가 `def`를 사용한 일반적인 함수라면, 스레드풀에서가 아니라 직접 호출(당신이 코드에 작성한 대로)될 것이고, `async def`로 생성된 함수라면 코드에서 호출할 때 그 함수를 `await` 해야 합니다.\n+유틸리티 함수가 `def`로 만든 일반 함수라면, 스레드풀이 아니라 직접(코드에 작성한 대로) 호출됩니다. 그리고 `async def`로 생성된 함수라면, 코드에서 호출할 때 그 함수를 `await` 해야 합니다.\n \n ---\n \n-다시 말하지만, 이것은 당신이 이것에 대해 찾고있던 경우에 한해 유용할 매우 세부적인 기술사항입니다.\n+다시 말하지만, 이것들은 아마도 이를 찾고 있었던 경우에 유용한 매우 세부적인 기술사항입니다.\n \n-그렇지 않은 경우, 상기의 가이드라인만으로도 충분할 것입니다: [바쁘신 경우](#_1).\n+그렇지 않다면, 위 섹션의 가이드라인이면 충분합니다: 바쁘신가요?."
},
{
"filename": "docs/ko/docs/fastapi-cli.md",
"status": "modified",
"additions": 50,
"deletions": 58,
"changes": 108,
"patch": "@@ -1,83 +1,75 @@\n-# FastAPI CLI\n+# FastAPI CLI { #fastapi-cli }\n \n-**FastAPI CLI**는 FastAPI 애플리케이션을 실행하고, 프로젝트를 관리하는 등 다양한 작업을 수행할 수 있는 커맨드 라인 프로그램입니다.\n+**FastAPI CLI**는 FastAPI 애플리케이션을 서빙하고, FastAPI 프로젝트를 관리하는 등 다양한 작업에 사용할 수 있는 커맨드 라인 프로그램입니다.\n \n-FastAPI를 설치할 때 (예: `pip install \"fastapi[standard]\"` 명령어를 사용할 경우), `fastapi-cli`라는 패키지가 포함됩니다. 이 패키지는 터미널에서 사용할 수 있는 `fastapi` 명령어를 제공합니다.\n+FastAPI를 설치할 때(예: `pip install \"fastapi[standard]\"`), `fastapi-cli`라는 패키지가 포함되며, 이 패키지는 터미널에서 `fastapi` 명령어를 제공합니다.\n \n-개발용으로 FastAPI 애플리케이션을 실행하려면 다음과 같이 `fastapi dev` 명령어를 사용할 수 있습니다:\n+개발용으로 FastAPI 애플리케이션을 실행하려면 `fastapi dev` 명령어를 사용할 수 있습니다:\n \n \n \n ```console\n-$ fastapi dev main.py\n-INFO Using path main.py\n-INFO Resolved absolute path /home/user/code/awesomeapp/main.py\n-INFO Searching for package file structure from directories with __init__.py files\n-INFO Importing from /home/user/code/awesomeapp\n-\n- ╭─ Python module file ─╮\n- │ │\n- │ 🐍 main.py │\n- │ │\n- ╰──────────────────────╯\n-\n-INFO Importing module main\n-INFO Found importable FastAPI app\n-\n- ╭─ [NAME_REDACTED] app ─╮\n- │ │\n- │ from main import app │\n- │ │\n- ╰──────────────────────────╯\n-\n-INFO Using import string main:app\n-\n- ╭────────── FastAPI CLI - Development mode ───────────╮\n- │ │\n- │ Serving at: http://127.0.0.1:8000 │\n- │ │\n- │ API docs: http://127.0.0.1:8000/docs │\n- │ │\n- │ Running in development mode, for production use: │\n- │ │\n- │ fastapi run │\n- │ │\n- ╰─────────────────────────────────────────────────────╯\n-\n-INFO: Will watch for changes in these directories: ['/home/user/code/awesomeapp']\n-INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)\n-INFO: Started reloader process [2265862] using WatchFiles\n-INFO: Started server process [2265873]\n-INFO: Waiting for application startup.\n-INFO: Application startup complete.\n+$ fastapi dev main.py\n+\n+ FastAPI Starting development server 🚀\n+\n+ Searching for package file structure from directories with\n+ __init__.py files\n+ Importing from /home/user/code/awesomeapp\n+\n+ module 🐍 main.py\n+\n+ code Importing the FastAPI app object from the module with the\n+ following code:\n+\n+ from main import app\n+\n+ app Using import string: main:app\n+\n+ server Server started at http://127.0.0.1:8000\n+ server Documentation at http://127.0.0.1:8000/docs\n+\n+ tip Running in development mode, for production use:\n+ fastapi run\n+\n+ Logs:\n+\n+ INFO Will watch for changes in these directories:\n+ ['/home/user/code/awesomeapp']\n+ INFO Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to\n+ quit)\n+ INFO Started reloader process [383138] using WatchFiles\n+ INFO Started server process [383153]\n+ INFO Waiting for application startup.\n+ INFO Application startup complete.\n ```\n \n
\n \n-`fastapi`라고 불리는 명령어 프로그램은 **FastAPI CLI**입니다.\n+`fastapi`라고 불리는 커맨드 라인 프로그램은 **FastAPI CLI**입니다.\n \n-FastAPI CLI는 Python 프로그램의 경로(예: `main.py`)를 인수로 받아, `FastAPI` 인스턴스(일반적으로 `app`으로 명명)를 자동으로 감지하고 올바른 임포트 과정을 결정한 후 이를 실행합니다.\n+FastAPI CLI는 Python 프로그램의 경로(예: `main.py`)를 받아 `FastAPI` 인스턴스(일반적으로 `app`으로 이름을 붙임)를 자동으로 감지하고, 올바른 임포트 과정을 결정한 다음 서빙합니다.\n \n-프로덕션 환경에서는 `fastapi run` 명령어를 사용합니다. 🚀\n+프로덕션에서는 대신 `fastapi run`을 사용합니다. 🚀\n \n-내부적으로, **FastAPI CLI**는 고성능의, 프로덕션에 적합한, ASGI 서버인 Uvicorn을 사용합니다. 😎\n+내부적으로 **FastAPI CLI**는 고성능의, 프로덕션에 적합한 ASGI 서버인 Uvicorn을 사용합니다. 😎\n \n-## `fastapi dev`\n+## `fastapi dev` { #fastapi-dev }\n \n-`fastapi dev` 명령을 실행하면 개발 모드가 시작됩니다.\n+`fastapi dev`를 실행하면 개발 모드가 시작됩니다.\n \n-기본적으로 **자동 재시작(auto-reload)** 기능이 활성화되어, 코드에 변경이 생기면 서버를 자동으로 다시 시작합니다. 하지만 이 기능은 리소스를 많이 사용하며, 비활성화했을 때보다 안정성이 떨어질 수 있습니다. 따라서 개발 환경에서만 사용하는 것이 좋습니다. 또한, 서버는 컴퓨터가 자체적으로 통신할 수 있는 IP 주소(`localhost`)인 `127.0.0.1`에서 연결을 대기합니다.\n+기본적으로 **auto-reload**가 활성화되어 코드에 변경이 생기면 서버를 자동으로 다시 로드합니다. 이는 리소스를 많이 사용하며, 비활성화했을 때보다 안정성이 떨어질 수 있습니다. 개발 환경에서만 사용해야 합니다. 또한 컴퓨터가 자신과만 통신하기 위한(`localhost`) IP인 `127.0.0.1`에서 연결을 대기합니다.\n \n-## `fastapi run`\n+## `fastapi run` { #fastapi-run }\n \n-`fastapi run` 명령을 실행하면 기본적으로 프로덕션 모드로 FastAPI가 시작됩니다.\n+`fastapi run`을 실행하면 기본적으로 프로덕션 모드로 FastAPI가 시작됩니다.\n \n-기본적으로 **자동 재시작(auto-reload)** 기능이 비활성화되어 있습니다. 또한, 사용 가능한 모든 IP 주소인 `0.0.0.0`에서 연결을 대기하므로 해당 컴퓨터와 통신할 수 있는 모든 사람이 공개적으로 액세스할 수 있습니다. 이는 일반적으로 컨테이너와 같은 프로덕션 환경에서 실행하는 방법입니다.\n+기본적으로 **auto-reload**는 비활성화되어 있습니다. 또한 사용 가능한 모든 IP 주소를 의미하는 `0.0.0.0`에서 연결을 대기하므로, 해당 컴퓨터와 통신할 수 있는 누구에게나 공개적으로 접근 가능해집니다. 보통 프로덕션에서는 이렇게 실행하며, 예를 들어 컨테이너에서 이런 방식으로 실행합니다.\n \n-애플리케이션을 배포하는 방식에 따라 다르지만, 대부분 \"종료 프록시(termination proxy)\"를 활용해 HTTPS를 처리하는 것이 좋습니다. 배포 서비스 제공자가 이 작업을 대신 처리해줄 수도 있고, 직접 설정해야 할 수도 있습니다.\n+대부분의 경우 위에 \"termination proxy\"를 두고 HTTPS를 처리하게(그리고 처리해야) 됩니다. 이는 애플리케이션을 배포하는 방식에 따라 달라지며, 제공자가 이 작업을 대신 처리해줄 수도 있고 직접 설정해야 할 수도 있습니다.\n \n-/// tip\n+/// tip | 팁\n \n-자세한 내용은 [deployment documentation](deployment/index.md){.internal-link target=\\_blank}에서 확인할 수 있습니다.\n+자세한 내용은 [배포 문서](deployment/index.md){.internal-link target=_blank}에서 확인할 수 있습니다.\n \n ///"
},
{
"filename": "docs/ko/docs/features.md",
"status": "modified",
"additions": 88,
"deletions": 88,
"changes": 176,
"patch": "@@ -1,43 +1,43 @@\n-# 기능\n+# 기능 { #features }\n \n-## FastAPI의 기능\n+## FastAPI의 기능 { #fastapi-features }\n \n **FastAPI**는 다음과 같은 기능을 제공합니다:\n \n-### 개방형 표준을 기반으로\n+### 개방형 표준을 기반으로 { #based-on-open-standards }\n \n-* 경로작동, 매개변수, 본문 요청, 보안 그 외의 선언을 포함한 API 생성을 위한 OpenAPI\n-* JSON Schema (OpenAPI 자체가 JSON Schema를 기반으로 하고 있습니다)를 사용한 자동 데이터 모델 문서화.\n-* 단순히 떠올려서 덧붙인 기능이 아닙니다. 세심한 검토를 거친 후, 이러한 표준을 기반으로 설계되었습니다.\n-* 이는 또한 다양한 언어로 자동적인 **클라이언트 코드 생성**을 사용할 수 있게 지원합니다.\n+* OpenAPI: path operations, 매개변수, 요청 본문, 보안 등의 선언을 포함하여 API를 생성합니다.\n+* JSON Schema를 사용한 자동 데이터 모델 문서화(OpenAPI 자체가 JSON Schema를 기반으로 하기 때문입니다).\n+* 단순히 떠올려서 덧붙인 레이어가 아니라, 세심한 검토를 거친 뒤 이러한 표준을 중심으로 설계되었습니다.\n+* 이는 또한 다양한 언어로 자동 **클라이언트 코드 생성**을 사용할 수 있게 해줍니다.\n \n-### 문서 자동화\n+### 문서 자동화 { #automatic-docs }\n \n-대화형 API 문서와 웹 탐색 유저 인터페이스를 제공합니다. 프레임워크가 OpenAPI를 기반으로 하기에, 2가지 옵션이 기본적으로 들어간 여러 옵션이 존재합니다.\n+대화형 API 문서와 탐색용 웹 사용자 인터페이스를 제공합니다. 프레임워크가 OpenAPI를 기반으로 하기에 여러 옵션이 있으며, 기본으로 2가지가 포함됩니다.\n \n-* 대화형 탐색 Swagger UI를 이용해, 브라우저에서 바로 여러분의 API를 호출하거나 테스트할 수 있습니다.\n+* 대화형 탐색이 가능한 Swagger UI로 브라우저에서 직접 API를 호출하고 테스트할 수 있습니다.\n \n \n \n-* ReDoc을 이용해 API 문서화를 대체할 수 있습니다.\n+* ReDoc을 이용한 대체 API 문서화.\n \n \n \n-### 그저 현대 파이썬\n+### 그저 현대 파이썬 { #just-modern-python }\n \n-(Pydantic 덕분에) FastAPI는 표준 **파이썬 3.6 타입** 선언에 기반하고 있습니다. 새로 배울 문법이 없습니다. 그저 표준적인 현대 파이썬입니다.\n+( Pydantic 덕분에) 모든 것이 표준 **Python 타입** 선언을 기반으로 합니다. 새로 배울 문법이 없습니다. 그저 표준적인 현대 파이썬입니다.\n \n-만약 여러분이 파이썬 타입을 어떻게 사용하는지에 대한 2분 정도의 복습이 필요하다면 (비록 여러분이 FastAPI를 사용하지 않는다 하더라도), 다음의 짧은 자습서를 확인하세요: [파이썬 타입](python-types.md){.internal-link target=\\_blank}.\n+Python 타입을 어떻게 사용하는지 2분 정도 복습이 필요하다면(FastAPI를 사용하지 않더라도), 다음의 짧은 자습서를 확인하세요: [Python 타입](python-types.md){.internal-link target=_blank}.\n \n-여러분은 타입을 이용한 표준 파이썬을 다음과 같이 적을 수 있습니다:\n+여러분은 타입이 있는 표준 Python을 다음과 같이 작성합니다:\n \n ```Python\n from datetime import date\n \n from pydantic import BaseModel\n \n-# 변수를 str로 선언\n-# 그 후 함수 안에서 편집기 지원을 받으세요\n+# 변수를 str로 선언합니다\n+# 그리고 함수 내부에서 편집기 지원을 받습니다\n def main(user_id: str):\n return user_id\n \n@@ -49,7 +49,7 @@ class User(BaseModel):\n joined: date\n ```\n \n-위의 코드는 다음과 같이 사용될 수 있습니다:\n+그 다음 다음과 같이 사용할 수 있습니다:\n \n ```Python\n my_user: User = User(id=3, name=\"[NAME_REDACTED]\", joined=\"2018-07-19\")\n@@ -65,23 +65,23 @@ my_second_user: User = User(**second_user_data)\n \n /// info | 정보\n \n-`**second_user_data`가 뜻하는 것:\n+`**second_user_data`는 다음을 의미합니다:\n \n-`second_user_data` 딕셔너리의 키와 값을 키-값 인자로서 바로 넘겨줍니다. 다음과 동일합니다: `User(id=4, name=\"Mary\", joined=\"2018-11-30\")`\n+`second_user_data` `dict`의 키와 값을 키-값 인자로서 바로 넘겨주는 것으로, 다음과 동일합니다: `User(id=4, name=\"Mary\", joined=\"2018-11-30\")`\n \n ///\n \n-### 편집기 지원\n+### 편집기 지원 { #editor-support }\n \n-모든 프레임워크는 사용하기 쉽고 직관적으로 설계되었으며, 좋은 개발 경험을 보장하기 위해 개발을 시작하기도 전에 모든 결정들은 여러 편집기에서 테스트됩니다.\n+프레임워크 전체는 사용하기 쉽고 직관적으로 설계되었으며, 최고의 개발 경험을 보장하기 위해 개발을 시작하기도 전에 모든 결정은 여러 편집기에서 테스트되었습니다.\n \n-최근 파이썬 개발자 설문조사에서 \"자동 완성\"이 가장 많이 사용되는 기능이라는 것이 밝혀졌습니다.\n+Python 개발자 설문조사에서 가장 많이 사용되는 기능 중 하나가 \"자동 완성\"이라는 점이 분명합니다.\n \n-**FastAPI** 프레임워크의 모든 부분은 이를 충족하기 위해 설계되었습니다. 자동완성은 어느 곳에서나 작동합니다.\n+**FastAPI** 프레임워크 전체는 이를 만족하기 위해 만들어졌습니다. 자동 완성은 어디서나 작동합니다.\n \n-여러분은 문서로 다시 돌아올 일이 거의 없을 겁니다.\n+문서로 다시 돌아올 일은 거의 없을 것입니다.\n \n-다음은 편집기가 어떻게 여러분을 도와주는지 보여줍니다:\n+편집기가 여러분을 어떻게 도와줄 수 있는지 살펴보세요:\n \n * [NAME_REDACTED]에서:\n \n@@ -91,111 +91,111 @@ my_second_user: User = User(**second_user_data)\n \n \n \n-여러분이 이전에 불가능하다고 고려했던 코드도 완성할 수 있을 겁니다. 예를 들어, 요청에서 전달되는 (중첩될 수도 있는)JSON 본문 내부에 있는 `price` 키입니다.\n+이전에 불가능하다고 생각했을 코드에서도 자동 완성을 받을 수 있습니다. 예를 들어, 요청에서 전달되는(중첩될 수도 있는) JSON 본문 내부의 `price` 키 같은 경우입니다.\n \n-잘못된 키 이름을 적을 일도, 문서를 왔다 갔다할 일도 없으며, 혹은 마지막으로 `username` 또는 `user_name`을 사용했는지 찾기 위해 위 아래로 스크롤할 일도 없습니다.\n+더 이상 잘못된 키 이름을 입력하거나, 문서 사이를 왔다 갔다 하거나, `username`을 썼는지 `user_name`을 썼는지 찾으려고 위아래로 스크롤할 필요가 없습니다.\n \n-### 토막 정보\n+### 간결함 { #short }\n \n-어느 곳에서나 선택적 구성이 가능한 모든 것에 합리적인 기본값이 설정되어 있습니다. 모든 매개변수는 여러분이 필요하거나, 원하는 API를 정의하기 위해 미세하게 조정할 수 있습니다.\n+선택적 구성을 어디서나 할 수 있도록 하면서도, 모든 것에 합리적인 **기본값**이 설정되어 있습니다. 모든 매개변수는 필요한 작업을 하거나 필요한 API를 정의하기 위해 미세하게 조정할 수 있습니다.\n \n-하지만 기본적으로 모든 것이 \"그냥 작동합니다\".\n+하지만 기본적으로 모든 것이 **\"그냥 작동합니다\"**.\n \n-### 검증\n+### 검증 { #validation }\n \n-* 다음을 포함한, 대부분의 (혹은 모든?) 파이썬 **데이터 타입** 검증할 수 있습니다:\n+* 다음을 포함해 대부분(혹은 전부?)의 Python **데이터 타입**에 대한 검증:\n * JSON 객체 (`dict`).\n * 아이템 타입을 정의하는 JSON 배열 (`list`).\n- * 최소 길이와 최대 길이를 정의하는 문자열 (`str`) 필드.\n- * 최솟값과 최댓값을 가지는 숫자 (`int`, `float`), 그 외.\n+ * 최소/최대 길이를 정의하는 문자열(`str`) 필드.\n+ * 최소/최대 값을 가지는 숫자(`int`, `float`) 등.\n \n-* 다음과 같이 더욱 이색적인 타입에 대해 검증할 수 있습니다:\n+* 다음과 같은 좀 더 이색적인 타입에 대한 검증:\n * URL.\n- * 이메일.\n+ * Email.\n * UUID.\n- * ...다른 것들.\n+ * ...그 외.\n \n-모든 검증은 견고하면서 잘 확립된 **Pydantic**에 의해 처리됩니다.\n+모든 검증은 잘 확립되어 있고 견고한 **Pydantic**이 처리합니다.\n \n-### 보안과 인증\n+### 보안과 인증 { #security-and-authentication }\n \n-보안과 인증이 통합되어 있습니다. 데이터베이스나 데이터 모델과의 타협없이 사용할 수 있습니다.\n+보안과 인증이 통합되어 있습니다. 데이터베이스나 데이터 모델과 타협하지 않습니다.\n \n-다음을 포함하는, 모든 보안 스키마가 OpenAPI에 정의되어 있습니다.\n+다음을 포함해 OpenAPI에 정의된 모든 보안 스키마:\n \n * HTTP Basic.\n-* **OAuth2** (**JWT tokens** 또한 포함). [OAuth2 with JWT](tutorial/security/oauth2-jwt.md){.internal-link target=\\_blank}에 있는 자습서를 확인해 보세요.\n+* **OAuth2**(**JWT tokens** 또한 포함). [JWT를 사용한 OAuth2](tutorial/security/oauth2-jwt.md){.internal-link target=_blank} 자습서를 확인해 보세요.\n * 다음에 들어 있는 API 키:\n * 헤더.\n- * 매개변수.\n- * 쿠키 및 그 외.\n+ * 쿼리 매개변수.\n+ * 쿠키 등.\n \n-추가적으로 (**세션 쿠키**를 포함한) 모든 보안 기능은 Starlette에 있습니다.\n+추가로 Starlette의 모든 보안 기능(**세션 쿠키** 포함)도 제공합니다.\n \n-모두 재사용할 수 있는 도구와 컴포넌트로 만들어져 있어 여러분의 시스템, 데이터 저장소, 관계형 및 NoSQL 데이터베이스 등과 쉽게 통합할 수 있습니다.\n+모두 재사용 가능한 도구와 컴포넌트로 만들어져 있어, 여러분의 시스템, 데이터 저장소, 관계형 및 NoSQL 데이터베이스 등과 쉽게 통합할 수 있습니다.\n \n-### 의존성 주입\n+### 의존성 주입 { #dependency-injection }\n \n-FastAPI는 사용하기 매우 간편하지만, 엄청난 의존성 주입시스템을 포함하고 있습니다.\n+FastAPI는 사용하기 매우 쉽지만, 매우 강력한 [NAME_REDACTED] 시스템을 포함하고 있습니다.\n \n-* 의존성은 의존성을 가질수도 있어, 이를 통해 의존성의 계층이나 **의존성의 \"그래프\"**를 형성합니다.\n-* 모든 것이 프레임워크에 의해 **자동적으로 처리됩니다**.\n-* 모든 의존성은 요청에서 데이터를 요구하여 자동 문서화와 **경로 작동 제약을 강화할 수 있습니다**.\n-* 의존성에서 정의된 _경로 작동_ 매개변수에 대해서도 **자동 검증**이 이루어 집니다.\n-* 복잡한 사용자의 인증 시스템, **데이터베이스 연결**, 등등을 지원합니다.\n-* 데이터베이스, 프론트엔드 등과 관련되어 **타협하지 않아도 됩니다**. 하지만 그 모든 것과 쉽게 통합이 가능합니다.\n+* 의존성도 의존성을 가질 수 있어, 의존성의 계층 또는 **의존성의 \"그래프\"**를 생성합니다.\n+* 모든 것이 프레임워크에 의해 **자동으로 처리됩니다**.\n+* 모든 의존성은 요청에서 데이터를 요구할 수 있으며, **경로 처리** 제약과 자동 문서화를 강화할 수 있습니다.\n+* 의존성에 정의된 *경로 처리* 매개변수에 대해서도 **자동 검증**을 합니다.\n+* 복잡한 사용자 인증 시스템, **데이터베이스 연결** 등을 지원합니다.\n+* 데이터베이스, 프론트엔드 등과 **타협하지 않습니다**. 하지만 모두와 쉽게 통합할 수 있습니다.\n \n-### 제한 없는 \"플러그인\"\n+### 제한 없는 \"플러그인\" { #unlimited-plug-ins }\n \n-또는 다른 방법으로, 그것들을 사용할 필요 없이 필요한 코드만 임포트할 수 있습니다.\n+또 다른 방식으로는, 그것들이 필요 없습니다. 필요한 코드를 임포트해서 사용하면 됩니다.\n \n-어느 통합도 (의존성과 함께) 사용하기 쉽게 설계되어 있어, *경로 작동*에 사용된 것과 동일한 구조와 문법을 사용하여 2줄의 코드로 여러분의 어플리케이션에 사용할 \"플러그인\"을 만들 수 있습니다.\n+어떤 통합이든(의존성과 함께) 사용하기 매우 간단하도록 설계되어 있어, *경로 처리*에 사용된 것과 동일한 구조와 문법을 사용해 2줄의 코드로 애플리케이션용 \"플러그인\"을 만들 수 있습니다.\n \n-### 테스트 결과\n+### 테스트됨 { #tested }\n \n-* 100% 테스트 범위.\n-* 100% 타입이 명시된 코드 베이스.\n-* 상용 어플리케이션에서의 사용.\n+* 100% test coverage.\n+* 100% type annotated 코드 베이스.\n+* 프로덕션 애플리케이션에서 사용됩니다.\n \n-## Starlette 기능\n+## Starlette 기능 { #starlette-features }\n \n-**FastAPI**는 Starlette를 기반으로 구축되었으며, 이와 완전히 호환됩니다. 따라서, 여러분이 보유하고 있는 어떤 추가적인 Starlette 코드도 작동할 것입니다.\n+**FastAPI**는 Starlette와 완전히 호환되며(또한 이를 기반으로 합니다). 따라서 추가로 가지고 있는 Starlette 코드도 모두 동작합니다.\n \n-`FastAPI`는 실제로 `Starlette`의 하위 클래스입니다. 그래서, 여러분이 이미 Starlette을 알고 있거나 사용하고 있으면, 대부분의 기능이 같은 방식으로 작동할 것입니다.\n+`FastAPI`는 실제로 `Starlette`의 하위 클래스입니다. 그래서 Starlette을 이미 알고 있거나 사용하고 있다면, 대부분의 기능이 같은 방식으로 동작할 것입니다.\n \n-**FastAPI**를 사용하면 여러분은 **Starlette**의 기능 대부분을 얻게 될 것입니다(FastAPI가 단순히 Starlette를 강화했기 때문입니다):\n+**FastAPI**를 사용하면 **Starlette**의 모든 기능을 얻게 됩니다(FastAPI는 Starlette에 강력한 기능을 더한 것입니다):\n \n-* 아주 인상적인 성능. 이는 **NodeJS**와 **Go**와 동등하게 사용 가능한 가장 빠른 파이썬 프레임워크 중 하나입니다.\n+* 정말 인상적인 성능. **NodeJS**와 **Go**에 버금가는, 사용 가능한 가장 빠른 Python 프레임워크 중 하나입니다.\n * **WebSocket** 지원.\n-* 프로세스 내의 백그라운드 작업.\n-* 시작과 종료 이벤트.\n+* 프로세스 내 백그라운드 작업.\n+* 시작 및 종료 이벤트.\n * HTTPX 기반 테스트 클라이언트.\n * **CORS**, GZip, 정적 파일, 스트리밍 응답.\n * **세션과 쿠키** 지원.\n-* 100% 테스트 범위.\n-* 100% 타입이 명시된 코드 베이스.\n+* 100% test coverage.\n+* 100% type annotated codebase.\n \n-## Pydantic 기능\n+## Pydantic 기능 { #pydantic-features }\n \n-**FastAPI**는 Pydantic을 기반으로 하며 Pydantic과 완벽하게 호환됩니다. 그래서 어느 추가적인 Pydantic 코드를 여러분이 가지고 있든 작동할 것입니다.\n+**FastAPI**는 Pydantic과 완벽하게 호환되며(또한 이를 기반으로 합니다). 따라서 추가로 가지고 있는 Pydantic 코드도 모두 동작합니다.\n \n-Pydantic을 기반으로 하는, 데이터베이스를 위한 ORM, ODM을 포함한 외부 라이브러리를 포함합니다.\n+데이터베이스를 위한 ORM, ODM과 같은, Pydantic을 기반으로 하는 외부 라이브러리도 포함합니다.\n \n-이는 모든 것이 자동으로 검증되기 때문에, 많은 경우에서 요청을 통해 얻은 동일한 객체를, **직접 데이터베이스로** 넘겨줄 수 있습니다.\n+이는 모든 것이 자동으로 검증되기 때문에, 많은 경우 요청에서 얻은 동일한 객체를 **직접 데이터베이스로** 넘겨줄 수 있다는 의미이기도 합니다.\n \n-반대로도 마찬가지이며, 많은 경우에서 여러분은 **직접 클라이언트로** 그저 객체를 넘겨줄 수 있습니다.\n+반대로도 마찬가지이며, 많은 경우 데이터베이스에서 얻은 객체를 **직접 클라이언트로** 그대로 넘겨줄 수 있습니다.\n \n-**FastAPI**를 사용하면 (모든 데이터 처리를 위해 FastAPI가 Pydantic을 기반으로 하기 있기에) **Pydantic**의 모든 기능을 얻게 됩니다:\n+**FastAPI**를 사용하면(모든 데이터 처리를 위해 FastAPI가 Pydantic을 기반으로 하기에) **Pydantic**의 모든 기능을 얻게 됩니다:\n \n-* **어렵지 않은 언어**:\n- * 새로운 스키마 정의 마이크로 언어를 배우지 않아도 됩니다.\n- * 여러분이 파이썬 타입을 안다면, 여러분은 Pydantic을 어떻게 사용하는지 아는 겁니다.\n-* 여러분의 **IDE/린터/뇌**와 잘 어울립니다:\n- * Pydantic 데이터 구조는 단순 여러분이 정의한 클래스의 인스턴스이기 때문에, 자동 완성, 린팅, mypy 그리고 여러분의 직관까지 여러분의 검증된 데이터와 올바르게 작동합니다.\n+* **No brainfuck**:\n+ * 새로운 스키마 정의 마이크로 언어를 배울 필요가 없습니다.\n+ * Python 타입을 알고 있다면 Pydantic 사용법도 알고 있는 것입니다.\n+* 여러분의 **IDE/linter/뇌**와 잘 어울립니다:\n+ * pydantic 데이터 구조는 여러분이 정의한 클래스 인스턴스일 뿐이므로, 자동 완성, 린팅, mypy, 그리고 직관까지도 검증된 데이터와 함께 제대로 작동합니다.\n * **복잡한 구조**를 검증합니다:\n- * 계층적인 Pydantic 모델, 파이썬 `typing`의 `List`와 `Dict`, 그 외를 사용합니다.\n- * 그리고 검증자는 복잡한 데이터 스키마를 명확하고 쉽게 정의 및 확인하며 JSON 스키마로 문서화합니다.\n- * 여러분은 깊게 **중첩된 JSON** 객체를 가질 수 있으며, 이 객체 모두 검증하고 설명을 붙일 수 있습니다.\n-* **확장 가능성**:\n- * Pydantic은 사용자 정의 데이터 타입을 정의할 수 있게 하거나, 검증자 데코레이터가 붙은 모델의 메소드를 사용하여 검증을 확장할 수 있습니다.\n-* 100% 테스트 범위.\n+ * 계층적인 Pydantic 모델, Python `typing`의 `List`와 `Dict` 등을 사용합니다.\n+ * 그리고 validator는 복잡한 데이터 스키마를 명확하고 쉽게 정의하고, 검사하고, JSON Schema로 문서화할 수 있게 해줍니다.\n+ * 깊게 **중첩된 JSON** 객체를 가질 수 있으며, 이를 모두 검증하고 주석을 달 수 있습니다.\n+* **확장 가능**:\n+ * Pydantic은 사용자 정의 데이터 타입을 정의할 수 있게 하거나, validator decorator가 붙은 모델 메서드로 검증을 확장할 수 있습니다.\n+* 100% test coverage."
},
{
"filename": "docs/ko/docs/help-fastapi.md",
"status": "modified",
"additions": 93,
"deletions": 106,
"changes": 199,
"patch": "@@ -1,4 +1,4 @@\n-# FastAPI 지원 - 도움 받기\n+# FastAPI 지원 - 도움 받기 { #help-fastapi-get-help }\n \n **FastAPI** 가 마음에 드시나요?\n \n@@ -10,259 +10,246 @@ FastAPI, 다른 사용자, 개발자를 응원하고 싶으신가요?\n \n 또한 도움을 받을 수 있는 방법도 몇 가지 있습니다.\n \n-## 뉴스레터 구독\n+## 뉴스레터 구독 { #subscribe-to-the-newsletter }\n \n-[**FastAPI and friends** 뉴스레터](newsletter.md){.internal-link target=\\_blank}를 구독하여 최신 정보를 유지할 수 있습니다:\n+(자주 발송되지 않는) [**FastAPI and friends** 뉴스레터](newsletter.md){.internal-link target=_blank}를 구독하여 최신 정보를 유지할 수 있습니다:\n \n * FastAPI and friends에 대한 뉴스 🚀\n * 가이드 📝\n * 기능 ✨\n * 획기적인 변화 🚨\n * 팁과 요령 ✅\n \n-## 트위터에서 FastAPI 팔로우하기\n+## X(Twitter)에서 FastAPI 팔로우하기 { #follow-fastapi-on-x-twitter }\n \n **X (Twitter)**의 [USER_REDACTED]를 팔로우하여 **FastAPI** 에 대한 최신 뉴스를 얻을 수 있습니다. 🐦\n \n-## Star **FastAPI** in GitHub\n+## GitHub에서 **FastAPI**에 Star 주기 { #star-fastapi-in-github }\n \n GitHub에서 FastAPI에 \"star\"를 붙일 수 있습니다 (오른쪽 상단의 star 버튼을 클릭): https://github.com/fastapi/fastapi. ⭐️\n \n 스타를 늘림으로써, 다른 사용자들이 좀 더 쉽게 찾을 수 있고, 많은 사람들에게 유용한 것임을 나타낼 수 있습니다.\n \n-## GitHub 저장소에서 릴리즈 확인\n+## 릴리즈 확인을 위해 GitHub 저장소 보기 { #watch-the-github-repository-for-releases }\n \n-GitHub에서 FastAPI를 \"watch\"할 수 있습니다 (오른쪽 상단 watch 버튼을 클릭): https://github.com/fastapi/fastapi. 👀\n+GitHub에서 FastAPI를 \"watch\"할 수 있습니다 (오른쪽 상단 \"watch\" 버튼을 클릭): https://github.com/fastapi/fastapi. 👀\n \n-여기서 \"Releases only\"을 선택할 수 있습니다.\n+여기서 \"Releases only\"를 선택할 수 있습니다.\n \n-이렇게하면, **FastAPI** 의 버그 수정 및 새로운 기능의 구현 등의 새로운 자료 (최신 버전)이 있을 때마다 (이메일) 통지를 받을 수 있습니다.\n+이렇게하면, **FastAPI** 의 버그 수정 및 새로운 기능의 구현 등의 새로운 릴리즈(새 버전)가 있을 때마다 (이메일) 통지를 받을 수 있습니다.\n \n-## 개발자와의 연결\n+## 개발자와의 연결 { #connect-with-the-author }\n \n-개발자(Sebastián Ramírez / `tiangolo`)와 연락을 취할 수 있습니다.\n+개발자(작성자)인 저(Sebastián Ramírez / `tiangolo`)와 연락을 취할 수 있습니다.\n \n 여러분은 할 수 있습니다:\n \n-* **GitHub**에서 팔로우하기..\n- * 당신에게 도움이 될 저의 다른 오픈소스 프로젝트를 확인하십시오.\n+* **GitHub**에서 팔로우하기.\n+ * 여러분에게 도움이 될 저의 다른 오픈소스 프로젝트를 확인하십시오.\n * 새로운 오픈소스 프로젝트를 만들었을 때 확인하려면 팔로우 하십시오.\n * **X (Twitter)** 또는 Mastodon에서 팔로우하기.\n * FastAPI의 사용 용도를 알려주세요 (그것을 듣는 것을 좋아합니다).\n * 발표나 새로운 툴 출시 소식을 받아보십시오.\n- * **X (Twitter)**의 [USER_REDACTED]를 팔로우 (별도 계정에서) 할 수 있습니다.\n-* **LinkedIn**에서 팔로우하기..\n- * 새로운 툴의 발표나 출시 소식을 받아보십시오. (단, X (Twitter)를 더 자주 사용합니다 🤷♂).\n+ * X(Twitter)에서 [USER_REDACTED]를 팔로우 (별도 계정에서) 할 수 있습니다.\n+* **LinkedIn**에서 팔로우하기.\n+ * 새로운 툴의 발표나 출시 소식을 받아보십시오 (단, X (Twitter)를 더 자주 사용합니다 🤷♂).\n * **Dev.to** 또는 **Medium**에서 제가 작성한 내용을 읽어 보십시오 (또는 팔로우).\n- * 다른 기사나 아이디어들을 읽고, 제가 만들어왔던 툴에 대해서도 읽으십시오.\n- * 새로운 기사를 읽기 위해 팔로우 하십시오.\n+ * 다른 아이디어와 기사들을 읽고, 제가 만들어왔던 툴에 대해서도 읽으십시오.\n+ * 새로운 내용을 게시할 때 읽기 위해 팔로우 하십시오.\n \n-## **FastAPI**에 대한 트윗\n+## **FastAPI**에 대해 트윗하기 { #tweet-about-fastapi }\n \n-**FastAPI**에 대해 트윗 하고 FastAPI가 마음에 드는 이유를 알려주세요. 🎉\n+**FastAPI**에 대해 트윗 하고 저와 다른 사람들에게 FastAPI가 마음에 드는 이유를 알려주세요. 🎉\n \n **FastAPI**가 어떻게 사용되고 있는지, 어떤 점이 마음에 들었는지, 어떤 프로젝트/회사에서 사용하고 있는지 등에 대해 듣고 싶습니다.\n \n-## FastAPI에 투표하기\n+## FastAPI에 투표하기 { #vote-for-fastapi }\n \n * Slant에서 **FastAPI** 에 대해 투표하십시오.\n * AlternativeTo에서 **FastAPI** 에 대해 투표하십시오.\n-* StackShare에서 **FastAPI** 에 대해 투표하십시오.\n+* StackShare에서 **FastAPI**를 사용한다고 표시하세요.\n \n-## GitHub의 이슈로 다른사람 돕기\n+## GitHub에서 질문으로 다른 사람 돕기 { #help-others-with-questions-in-github }\n \n 다른 사람들의 질문에 도움을 줄 수 있습니다:\n \n-* GitHub 디스커션\n-* GitHub 이슈\n+* [NAME_REDACTED]\n+* [NAME_REDACTED]\n \n 많은 경우, 여러분은 이미 그 질문에 대한 답을 알고 있을 수도 있습니다. 🤓\n \n-만약 많은 사람들의 문제를 도와준다면, 공식적인 [FastAPI 전문가](fastapi-people.md#fastapi-experts){.internal-link target=\\_blank} 가 될 것입니다. 🎉\n+만약 많은 사람들의 질문을 도와준다면, 공식적인 [FastAPI 전문가](fastapi-people.md#fastapi-experts){.internal-link target=_blank}가 될 것입니다. 🎉\n \n 가장 중요한 점은: 친절하려고 노력하는 것입니다. 사람들은 좌절감을 안고 오며, 많은 경우 최선의 방식으로 질문하지 않을 수도 있습니다. 하지만 최대한 친절하게 대하려고 노력하세요. 🤗\n \n **FastAPI** 커뮤니티의 목표는 친절하고 환영하는 것입니다. 동시에, 괴롭힘이나 무례한 행동을 받아들이지 마세요. 우리는 서로를 돌봐야 합니다.\n \n ---\n \n-다른 사람들의 질문 (디스커션 또는 이슈에서) 해결을 도울 수 있는 방법은 다음과 같습니다.\n+다른 사람들의 질문(디스커션 또는 이슈에서) 해결을 도울 수 있는 방법은 다음과 같습니다.\n \n-### 질문 이해하기\n+### 질문 이해하기 { #understand-the-question }\n \n * 질문하는 사람이 가진 **목적**과 사용 사례를 이해할 수 있는지 확인하세요.\n \n-* 질문 (대부분은 질문입니다)이 **명확**한지 확인하세요.\n+* 그런 다음 질문(대부분은 질문입니다)이 **명확**한지 확인하세요.\n \n-* 많은 경우, 사용자가 가정한 해결책에 대한 질문을 하지만, 더 **좋은** 해결책이 있을 수 있습니다. 문제와 사용 사례를 더 잘 이해하면 더 나은 **대안적인 해결책**을 제안할 수 있습니다.\n+* 많은 경우 사용자가 상상한 해결책에 대한 질문을 하지만, 더 **좋은** 해결책이 있을 수 있습니다. 문제와 사용 사례를 더 잘 이해하면 더 나은 **대안적인 해결책**을 제안할 수 있습니다.\n \n * 질문을 이해할 수 없다면, 더 **자세한 정보**를 요청하세요.\n \n-### 문제 재현하기\n+### 문제 재현하기 { #reproduce-the-problem }\n \n-대부분의 경우, 질문은 질문자의 **원본 코드**와 관련이 있습니다.\n+대부분의 경우 그리고 대부분의 질문에서는 질문자의 **원본 코드**와 관련된 내용이 있습니다.\n \n 많은 경우, 코드의 일부만 복사해서 올리지만, 그것만으로는 **문제를 재현**하기에 충분하지 않습니다.\n \n-* 질문자에게 최소한의 재현 가능한 예제를 제공해달라고 요청하세요. 이렇게 하면 코드를 **복사-붙여넣기**하여 직접 실행하고, 동일한 오류나 동작을 확인하거나 사용 사례를 더 잘 이해할 수 있습니다.\n+* 질문자에게 최소한의 재현 가능한 예제를 제공해달라고 요청할 수 있습니다. 이렇게 하면 코드를 **복사-붙여넣기**하여 로컬에서 실행하고, 질문자가 보고 있는 것과 동일한 오류나 동작을 확인하거나 사용 사례를 더 잘 이해할 수 있습니다.\n \n-* 너그러운 마음이 든다면, 문제 설명만을 기반으로 직접 **예제를 만들어**볼 수도 있습니다. 하지만, 이는 시간이 많이 걸릴 수 있으므로, 먼저 질문을 명확히 해달라고 요청하는 것이 좋습니다.\n+* 너그러운 마음이 든다면, 문제 설명만을 기반으로 직접 **예제를 만들어**볼 수도 있습니다. 다만 이는 시간이 많이 걸릴 수 있으므로, 먼저 문제를 명확히 해달라고 요청하는 것이 더 나을 수 있다는 점을 기억하세요.\n \n-### 해결책 제안하기\n+### 해결책 제안하기 { #suggest-solutions }\n \n * 질문을 충분히 이해한 후에는 가능한 **답변**을 제공할 수 있습니다.\n \n-* 많은 경우, 질문자의 **근본적인 문제나 사용 사례**를 이해하는 것이 중요합니다. 그들이 시도하는 방법보다 더 나은 해결책이 있을 수 있기 때문입니다.\n+* 많은 경우, 질문자의 **근본적인 문제나 사용 사례**를 이해하는 것이 더 좋습니다. 그들이 시도하는 방법보다 더 나은 해결책이 있을 수 있기 때문입니다.\n \n-### 해결 요청하기\n+### 종료 요청하기 { #ask-to-close }\n \n-질문자가 답변을 확인하고 나면, 당신이 문제를 해결했을 가능성이 높습니다. 축하합니다, **당신은 영웅입니다**! 🦸\n+질문자가 답변을 하면, 여러분이 문제를 해결했을 가능성이 높습니다. 축하합니다, **여러분은 영웅입니다**! 🦸\n \n * 이제 문제를 해결했다면, 질문자에게 다음을 요청할 수 있습니다.\n \n- * GitHub 디스커션에서: 댓글을 **답변**으로 표시하도록 요청하세요.\n- * GitHub 이슈에서: 이슈를 **닫아달라고** 요청하세요.\n+ * GitHub Discussions에서: 댓글을 **답변**으로 표시하도록 요청하세요.\n+ * GitHub Issues에서: 이슈를 **닫아달라고** 요청하세요.\n \n-## GitHub 저장소 보기\n+## GitHub 저장소 보기 { #watch-the-github-repository }\n \n-GitHub에서 FastAPI를 \"watch\"할 수 있습니다 (오른쪽 상단 watch 버튼을 클릭): https://github.com/fastapi/fastapi. 👀\n+GitHub에서 FastAPI를 \"watch\"할 수 있습니다 (오른쪽 상단 \"watch\" 버튼을 클릭): https://github.com/fastapi/fastapi. 👀\n \n-\"Releases only\" 대신 \"Watching\"을 선택하면, 새로운 이슈나 질문이 생성될 때 알림을 받을 수 있습니다. 또한, 특정하게 새로운 이슈, 디스커션, PR 등만 알림 받도록 설정할 수도 있습니다.\n+\"Releases only\" 대신 \"Watching\"을 선택하면 누군가가 새 이슈나 질문을 만들 때 알림을 받게 됩니다. 또한 새 이슈, 디스커션, PR 등만 알림을 받도록 지정할 수도 있습니다.\n \n-그런 다음 이런 이슈들을 해결 할 수 있도록 도움을 줄 수 있습니다.\n+그런 다음 이런 질문들을 해결하도록 도와줄 수 있습니다.\n \n-## 이슈 생성하기\n+## 질문하기 { #ask-questions }\n \n-GitHub 저장소에 새로운 이슈 생성을 할 수 있습니다, 예를들면 다음과 같습니다:\n+GitHub 저장소에서 새 질문을 생성할 수 있습니다. 예를 들면 다음과 같습니다:\n \n * **질문**을 하거나 **문제**에 대해 질문합니다.\n * 새로운 **기능**을 제안 합니다.\n \n-**참고**: 만약 이슈를 생성한다면, 저는 여러분에게 다른 사람들을 도와달라고 부탁할 것입니다. 😉\n+**참고**: 만약 이렇게 한다면, 저는 여러분에게 다른 사람들도 도와달라고 요청할 것입니다. 😉\n \n-## Pull Requests 리뷰하기\n+## Pull Request 리뷰하기 { #review-pull-requests }\n \n-다른 사람들의 pull request를 리뷰하는 데 도움을 줄 수 있습니다.\n+다른 사람들이 만든 pull request를 리뷰하는 데 저를 도와줄 수 있습니다.\n \n 다시 한번 말하지만, 최대한 친절하게 리뷰해 주세요. 🤗\n \n ---\n \n-Pull Rrquest를 리뷰할 때 고려해야 할 사항과 방법은 다음과 같습니다:\n+Pull request를 리뷰할 때 고려해야 할 사항과 방법은 다음과 같습니다:\n \n-### 문제 이해하기\n+### 문제 이해하기 { #understand-the-problem }\n \n-* 먼저, 해당 pull request가 해결하려는 **문제를 이해하는지** 확인하세요. GitHub 디스커션 또는 이슈에서 더 긴 논의가 있었을 수도 있습니다.\n+* 먼저, 해당 pull request가 해결하려는 **문제를 이해하는지** 확인하세요. [NAME_REDACTED] 또는 이슈에서 더 긴 논의가 있었을 수도 있습니다.\n \n-* Pull request가 필요하지 않을 가능성도 있습니다. **다른 방식**으로 문제를 해결할 수 있다면, 그 방법을 제안하거나 질문할 수 있습니다.\n+* Pull request가 실제로 필요하지 않을 가능성도 큽니다. 문제가 **다른 방식**으로 해결될 수 있기 때문입니다. 그런 경우 그 방법을 제안하거나 질문할 수 있습니다.\n \n-### 스타일에 너무 신경 쓰지 않기\n+### 스타일에 너무 신경 쓰지 않기 { #dont-worry-about-style }\n \n-* 커밋 메시지 스타일 같은 것에 너무 신경 쓰지 않아도 됩니다. 저는 직접 커밋을 수정하여 squash and merge를 수행할 것입니다.\n+* 커밋 메시지 스타일 같은 것에 너무 신경 쓰지 마세요. 저는 커밋을 수동으로 조정해서 squash and merge를 할 것입니다.\n \n * 코드 스타일 규칙도 걱정할 필요 없습니다. 이미 자동화된 도구들이 이를 검사하고 있습니다.\n \n-스타일이나 일관성 관련 요청이 필요한 경우, 제가 직접 요청하거나 필요한 변경 사항을 추가 커밋으로 수정할 것입니다.\n+그리고 다른 스타일이나 일관성 관련 필요 사항이 있다면, 제가 직접 요청하거나 필요한 변경 사항을 위에 커밋으로 추가할 것입니다.\n \n-### 코드 확인하기\n+### 코드 확인하기 { #check-the-code }\n \n-* 코드를 읽고, **논리적으로 타당**한지 확인한 후 로컬에서 실행하여 문제가 해결되는지 확인하세요.\n+* 코드를 확인하고 읽어서 말이 되는지 보고, **로컬에서 실행**해 실제로 문제가 해결되는지 확인하세요.\n \n-* 그런 다음, 확인했다고 **댓글**을 남겨 주세요. 그래야 제가 검토했음을 알 수 있습니다.\n+* 그런 다음 그렇게 했다고 **댓글**로 남겨 주세요. 그래야 제가 정말로 확인했음을 알 수 있습니다.\n \n-/// info\n+/// info | 정보\n \n 불행히도, 제가 단순히 여러 개의 승인만으로 PR을 신뢰할 수는 없습니다.\n \n-3개, 5개 이상의 승인이 달린 PR이 실제로는 깨져 있거나, 버그가 있거나, 주장하는 문제를 해결하지 못하는 경우가 여러 번 있었습니다. 😅\n+여러 번, 설명이 그럴듯해서인지 3개, 5개 이상의 승인이 달린 PR이 있었지만, 제가 확인해보면 실제로는 깨져 있거나, 버그가 있거나, 주장하는 문제를 해결하지 못하는 경우가 있었습니다. 😅\n \n 따라서, 정말로 코드를 읽고 실행한 뒤, 댓글로 확인 내용을 남겨 주는 것이 매우 중요합니다. 🤓\n \n ///\n \n-* PR을 더 단순하게 만들 수 있다면 그렇게 요청할 수 있지만, 너무 까다로울 필요는 없습니다. 주관적인 견해가 많이 있을 수 있기 때문입니다 (그리고 저도 제 견해가 있을 거예요 🙈). 따라서 핵심적인 부분에 집중하는 것이 좋습니다.\n+* PR을 더 단순하게 만들 수 있다면 그렇게 요청할 수 있지만, 너무 까다로울 필요는 없습니다. 주관적인 견해가 많이 있을 수 있기 때문입니다(그리고 저도 제 견해가 있을 거예요 🙈). 따라서 핵심적인 부분에 집중하는 것이 좋습니다.\n \n-### 테스트\n+### 테스트 { #tests }\n \n * PR에 **테스트**가 포함되어 있는지 확인하는 데 도움을 주세요.\n \n-* PR을 적용하기 전에 테스트가 **실패**하는지 확인하세요. 🚨\n+* PR 전에는 테스트가 **실패**하는지 확인하세요. 🚨\n \n-* PR을 적용한 후 테스트가 **통과**하는지 확인하세요. ✅\n+* 그런 다음 PR 후에는 테스트가 **통과**하는지 확인하세요. ✅\n \n-* 많은 PR에는 테스트가 없습니다. 테스트를 추가하도록 **상기**시켜줄 수도 있고, 직접 테스트를 **제안**할 수도 있습니다. 이는 시간이 많이 소요되는 부분 중 하나이며, 그 부분을 많이 도와줄 수 있습니다.\n+* 많은 PR에는 테스트가 없습니다. 테스트를 추가하도록 **상기**시켜줄 수도 있고, 직접 테스트를 **제안**할 수도 있습니다. 이는 시간이 가장 많이 드는 것들 중 하나이며, 그 부분을 많이 도와줄 수 있습니다.\n \n * 그리고 시도한 내용을 댓글로 남겨주세요. 그러면 제가 확인했다는 걸 알 수 있습니다. 🤓\n \n-## Pull Request를 만드십시오\n+## Pull Request 만들기 { #create-a-pull-request }\n \n-Pull Requests를 이용하여 소스코드에 [컨트리뷰트](contributing.md){.internal-link target=\\_blank} 할 수 있습니다. 예를 들면 다음과 같습니다:\n+Pull Requests를 이용하여 소스 코드에 [기여](contributing.md){.internal-link target=_blank}할 수 있습니다. 예를 들면 다음과 같습니다:\n \n * 문서에서 발견한 오타를 수정할 때.\n-* FastAPI 관련 문서, 비디오 또는 팟캐스트를 작성했거나 발견하여 이 파일을 편집하여 공유할 때.\n+* FastAPI에 대한 글, 비디오, 팟캐스트를 작성했거나 발견했다면 이 파일을 편집하여 공유할 때.\n * 해당 섹션의 시작 부분에 링크를 추가해야 합니다.\n-* 당신의 언어로 [문서 번역하는데](contributing.md#translations){.internal-link target=\\_blank} 기여할 때.\n+* 여러분의 언어로 [문서 번역에](contributing.md#translations){.internal-link target=_blank} 도움을 줄 때.\n * 다른 사람이 작성한 번역을 검토하는 것도 도울 수 있습니다.\n-* 새로운 문서의 섹션을 제안할 때.\n-* 기존 문제/버그를 수정할 때.\n+* 새로운 문서 섹션을 제안할 때.\n+* 기존 이슈/버그를 수정할 때.\n * 테스트를 반드시 추가해야 합니다.\n-* 새로운 feature를 추가할 때.\n+* 새로운 기능을 추가할 때.\n * 테스트를 반드시 추가해야 합니다.\n- * 관련 문서가 필요하다면 반드시 추가해야 합니다.\n+ * 관련 문서가 있다면 반드시 추가해야 합니다.\n \n-## FastAPI 유지 관리에 도움 주기\n+## FastAPI 유지 관리 돕기 { #help-maintain-fastapi }\n \n-**FastAPI**의 유지 관리를 도와주세요! 🤓\n+**FastAPI** 유지를 도와주세요! 🤓\n \n-할 일이 많고, 그 중 대부분은 **여러분**이 할 수 있습니다.\n+할 일이 많고, 그중 대부분은 **여러분**이 할 수 있습니다.\n \n 지금 할 수 있는 주요 작업은:\n \n-* [GitHub에서 다른 사람들의 질문에 도움 주기](#github_1){.internal-link target=_blank} (위의 섹션을 참조하세요).\n-* [Pull Request 리뷰하기](#pull-requests){.internal-link target=_blank} (위의 섹션을 참조하세요).\n+* [GitHub에서 질문으로 다른 사람 돕기](#help-others-with-questions-in-github){.internal-link target=_blank} (위의 섹션을 참조하세요).\n+* [Pull Request 리뷰하기](#review-pull-requests){.internal-link target=_blank} (위의 섹션을 참조하세요).\n \n-이 두 작업이 **가장 많은 시간을 소모**하는 일입니다. 그것이 FastAPI 유지 관리의 주요 작업입니다.\n+이 두 작업이 **가장 많은 시간을 소모**합니다. 이것이 FastAPI를 유지 관리하는 주요 작업입니다.\n \n-이 작업을 도와주신다면, **FastAPI 유지 관리에 도움을 주는 것**이며 그것이 **더 빠르고 더 잘 발전하는 것**을 보장하는 것입니다. 🚀\n+이 작업을 도와주신다면, **FastAPI 유지를 돕는 것**이며 FastAPI가 **더 빠르고 더 잘 발전하는 것**을 보장하는 것입니다. 🚀\n \n-## 채팅에 참여하십시오\n+## 채팅에 참여하기 { #join-the-chat }\n \n-👥 디스코드 채팅 서버 👥 에 가입하고 FastAPI 커뮤니티에서 다른 사람들과 어울리세요.\n+👥 Discord 채팅 서버 👥 에 참여해서 FastAPI 커뮤니티의 다른 사람들과 어울리세요.\n \n-/// tip\n+/// tip | 팁\n \n-질문이 있는 경우, GitHub 디스커션 에서 질문하십시오, [[NAME_REDACTED]](fastapi-people.md#fastapi-experts){.internal-link target=_blank} 의 도움을 받을 가능성이 높습니다.\n+질문은 [NAME_REDACTED]에서 하세요. [[NAME_REDACTED]](fastapi-people.md#fastapi-experts){.internal-link target=_blank}로부터 도움을 받을 가능성이 훨씬 높습니다.\n \n-다른 일반적인 대화에서만 채팅을 사용하십시오.\n+채팅은 다른 일반적인 대화를 위해서만 사용하세요.\n \n ///\n \n-### 질문을 위해 채팅을 사용하지 마십시오\n+### 질문을 위해 채팅을 사용하지 마세요 { #dont-use-the-chat-for-questions }\n \n-채팅은 더 많은 \"자유로운 대화\"를 허용하기 때문에, 너무 일반적인 질문이나 대답하기 어려운 질문을 쉽게 질문을 할 수 있으므로, 답변을 받지 못할 수 있습니다.\n+채팅은 더 많은 \"자유로운 대화\"를 허용하기 때문에, 너무 일반적인 질문이나 답하기 어려운 질문을 쉽게 할 수 있어 답변을 받지 못할 수도 있다는 점을 기억하세요.\n \n-GitHub 이슈에서의 템플릿은 올바른 질문을 작성하도록 안내하여 더 쉽게 좋은 답변을 얻거나 질문하기 전에 스스로 문제를 해결할 수도 있습니다. 그리고 GitHub에서는 시간이 조금 걸리더라도 항상 모든 것에 답할 수 있습니다. 채팅 시스템에서는 개인적으로 그렇게 할 수 없습니다. 😅\n+GitHub에서는 템플릿이 올바른 질문을 작성하도록 안내하여 더 쉽게 좋은 답변을 얻거나, 질문하기 전에 스스로 문제를 해결할 수도 있습니다. 그리고 GitHub에서는 시간이 조금 걸리더라도 제가 항상 모든 것에 답하도록 보장할 수 있습니다. 채팅 시스템에서는 제가 개인적으로 그렇게 할 수 없습니다. 😅\n \n-채팅 시스템에서의 대화 또한 GitHub에서 처럼 쉽게 검색할 수 없기 때문에 대화 중에 질문과 답변이 손실될 수 있습니다. 그리고 GitHub 이슈에 있는 것만 [[NAME_REDACTED]](fastapi-people.md#fastapi-experts){.internal-link target=_blank}가 되는 것으로 간주되므로, GitHub 이슈에서 더 많은 관심을 받을 것입니다.\n+채팅 시스템에서의 대화 또한 GitHub만큼 쉽게 검색할 수 없기 때문에, 질문과 답변이 대화 속에서 사라질 수 있습니다. 그리고 GitHub에 있는 것만 [[NAME_REDACTED]](fastapi-people.md#fastapi-experts){.internal-link target=_blank}가 되는 것으로 인정되므로, GitHub에서 더 많은 관심을 받게 될 가능성이 큽니다.\n \n-반면, 채팅 시스템에는 수천 명의 사용자가 있기 때문에, 거의 항상 대화 상대를 찾을 가능성이 높습니다. 😄\n+반면, 채팅 시스템에는 수천 명의 사용자가 있으므로, 거의 항상 대화 상대를 찾을 가능성이 높습니다. 😄\n \n-## 개발자 스폰서가 되십시오\n+## 개발자 스폰서 되기 { #sponsor-the-author }\n \n-GitHub 스폰서 를 통해 개발자를 경제적으로 지원할 수 있습니다.\n-\n-감사하다는 말로 커피를 ☕️ 한잔 사줄 수 있습니다. 😄\n-\n-또한 FastAPI의 실버 또는 골드 스폰서가 될 수 있습니다. 🏅🎉\n-\n-## FastAPI를 강화하는 도구의 스폰서가 되십시오\n-\n-문서에서 보았듯이, FastAPI는 Starlette과 Pydantic 라는 거인의 어깨에 타고 있습니다.\n-\n-다음의 스폰서가 될 수 있습니다\n-\n-* [NAME_REDACTED] (Pydantic)\n-* Encode (Starlette, Uvicorn)\n+여러분의 **제품/회사**가 **FastAPI**에 의존하거나 관련되어 있고, FastAPI 사용자를 대상으로 알리고 싶다면 GitHub sponsors를 통해 개발자(저)를 스폰서할 수 있습니다. 티어에 따라 문서에 배지 같은 추가 혜택을 받을 수도 있습니다. 🎁\n \n ---"
},
{
"filename": "docs/ko/docs/history-design-future.md",
"status": "modified",
"additions": 40,
"deletions": 42,
"changes": 82,
"patch": "@@ -1,81 +1,79 @@\n-# 역사, 디자인 그리고 미래\n+# 역사, 디자인 그리고 미래 { #history-design-and-future }\n \n-어느 날, [한 FastAPI 사용자](https://github.com/fastapi/fastapi/issues/3#issuecomment-454956920)가 이렇게 물었습니다:\n+얼마 전, 한 **FastAPI** 사용자가 이렇게 물었습니다:\n \n-> 이 프로젝트의 역사를 알려 주실 수 있나요? 몇 주 만에 멋진 결과를 낸 것 같아요. [...]\n+> 이 프로젝트의 역사는 무엇인가요? 몇 주 만에 아무 데서도 갑자기 나타나 엄청나게 좋아진 것처럼 보이네요 [...]\n \n 여기서 그 역사에 대해 간단히 설명하겠습니다.\n \n----\n+## 대안 { #alternatives }\n \n-## 대안\n+저는 여러 해 동안 복잡한 요구사항(머신러닝, 분산 시스템, 비동기 작업, NoSQL 데이터베이스 등)을 가진 API를 만들면서 여러 개발 팀을 이끌어 왔습니다.\n \n-저는 여러 해 동안 머신러닝, 분산 시스템, 비동기 작업, NoSQL 데이터베이스 같은 복잡한 요구사항을 가진 API를 개발하며 여러 팀을 이끌어 왔습니다.\n+그 과정에서 많은 대안을 조사하고, 테스트하고, 사용해야 했습니다.\n \n-이 과정에서 많은 대안을 조사하고, 테스트하며, 사용해야 했습니다. **FastAPI**의 역사는 그 이전에 나왔던 여러 도구의 역사와 밀접하게 연관되어 있습니다.\n+**FastAPI**의 역사는 상당 부분 그 이전에 있던 도구들의 역사입니다.\n \n [대안](alternatives.md){.internal-link target=_blank} 섹션에서 언급된 것처럼:\n \n-> **FastAPI**는 이전에 나왔던 많은 도구들의 노력 없이는 존재하지 않았을 것입니다.\n->\n-> 이전에 개발된 여러 도구들이 이 프로젝트에 영감을 주었습니다.\n->\n-> 저는 오랫동안 새로운 프레임워크를 만드는 것을 피하고자 했습니다. 처음에는 **FastAPI**가 제공하는 기능들을 다양한 프레임워크와 플러그인, 도구들을 조합해 해결하려 했습니다.\n->\n-> 하지만 결국에는 이 모든 기능을 통합하는 도구가 필요해졌습니다. 이전 도구들로부터 최고의 아이디어들을 모으고, 이를 최적의 방식으로 조합해야만 했습니다. 이는 :term:Python 3.6+ 타입 힌트 와 같은, 이전에는 사용할 수 없었던 언어 기능이 가능했기 때문입니다.\n+\n \n----\n+**FastAPI**는 다른 사람들이 이전에 해온 작업이 없었다면 존재하지 않았을 것입니다.\n \n-## 조사\n+그 전에 만들어진 많은 도구들이 이것의 탄생에 영감을 주었습니다.\n \n-여러 대안을 사용해 보며 다양한 도구에서 배운 점들을 모아 저와 개발팀에게 가장 적합한 방식을 찾았습니다.\n+저는 여러 해 동안 새로운 프레임워크를 만드는 것을 피하고 있었습니다. 처음에는 **FastAPI**가 다루는 모든 기능을 여러 다른 프레임워크, 플러그인, 도구들을 사용해 해결하려고 했습니다.\n \n-예를 들어, 표준 :term:Python 타입 힌트 에 기반하는 것이 이상적이라는 점이 명확했습니다.\n+하지만 어느 시점에는, 이전 도구들의 최고의 아이디어를 가져와 가능한 한 최선의 방식으로 조합하고, 이전에는 존재하지 않았던 언어 기능(Python 3.6+ type hints)을 사용해 이 모든 기능을 제공하는 무언가를 만드는 것 외에는 다른 선택지가 없었습니다.\n \n-또한, 이미 존재하는 표준을 활용하는 것이 가장 좋은 접근법이라 판단했습니다.\n+
\n \n-그래서 **FastAPI**의 코드를 작성하기 전에 몇 달 동안 OpenAPI, JSON Schema, OAuth2 명세를 연구하며 이들의 관계와 겹치는 부분, 차이점을 이해했습니다.\n+## 조사 { #investigation }\n \n----\n+이전의 모든 대안을 사용해 보면서, 각 도구로부터 배울 기회를 얻었고, 아이디어를 가져와 제가 일해온 개발 팀들과 저 자신에게 가장 적합하다고 찾은 방식으로 조합할 수 있었습니다.\n \n-## 디자인\n+예를 들어, 이상적으로는 표준 Python 타입 힌트에 기반해야 한다는 점이 분명했습니다.\n \n-그 후, **FastAPI** 사용자가 될 개발자로서 사용하고 싶은 개발자 \"API\"를 디자인했습니다.\n+또한, 가장 좋은 접근법은 이미 존재하는 표준을 사용하는 것이었습니다.\n \n-[[NAME_REDACTED]](https://www.jetbrains.com/research/python-developers-survey-2018/#development-tools)에 따르면 약 80%의 Python 개발자가 PyCharm, VS Code, Jedi 기반 편집기 등에서 개발합니다. 이 과정에서 여러 아이디어를 테스트했습니다.\n+그래서 **FastAPI**의 코딩을 시작하기도 전에, OpenAPI, JSON Schema, OAuth2 등과 같은 명세를 몇 달 동안 공부했습니다. 이들의 관계, 겹치는 부분, 차이점을 이해하기 위해서였습니다.\n \n-대부분의 다른 편집기도 유사하게 동작하기 때문에, **FastAPI**의 이점은 거의 모든 편집기에서 누릴 수 있습니다.\n+## 디자인 { #design }\n \n-이 과정을 통해 코드 중복을 최소화하고, 모든 곳에서 자동 완성, 타입 검사, 에러 확인 기능이 제공되는 최적의 방식을 찾아냈습니다.\n+그 다음에는 (FastAPI를 사용하는 개발자로서) 사용자로서 갖고 싶었던 개발자 \"API\"를 디자인하는 데 시간을 썼습니다.\n \n-이 모든 것은 개발자들에게 최고의 개발 경험을 제공하기 위해 설계되었습니다.\n+가장 인기 있는 Python 편집기들: PyCharm, VS Code, Jedi 기반 편집기에서 여러 아이디어를 테스트했습니다.\n \n----\n+약 80%의 사용자를 포함하는 최근 [NAME_REDACTED]에 따르면 그렇습니다.\n \n-## 필요조건\n+즉, **FastAPI**는 Python 개발자의 80%가 사용하는 편집기들로 특별히 테스트되었습니다. 그리고 대부분의 다른 편집기도 유사하게 동작하는 경향이 있으므로, 그 모든 이점은 사실상 모든 편집기에서 동작해야 합니다.\n \n-여러 대안을 테스트한 후, [Pydantic](https://docs.pydantic.dev/)을 사용하기로 결정했습니다.\n+그렇게 해서 코드 중복을 가능한 한 많이 줄이고, 어디서나 자동 완성, 타입 및 에러 검사 등을 제공하는 최선의 방법을 찾을 수 있었습니다.\n \n-이후 저는 **Pydantic**이 JSON Schema와 완벽히 호환되도록 개선하고, 다양한 제약 조건 선언을 지원하며, 여러 편집기에서의 자동 완성과 타입 검사 기능을 향상하기 위해 기여했습니다.\n+모든 개발자에게 최고의 개발 경험을 제공하는 방식으로 말입니다.\n \n-또한, 또 다른 주요 필요조건이었던 [Starlette](https://www.starlette.dev/)에도 기여했습니다.\n+## 필요조건 { #requirements }\n \n----\n+여러 대안을 테스트한 후, 장점 때문에 **Pydantic**을 사용하기로 결정했습니다.\n \n-## 개발\n+그 후, JSON Schema를 완전히 준수하도록 하고, 제약 조건 선언을 정의하는 다양한 방식을 지원하며, 여러 편집기에서의 테스트를 바탕으로 편집기 지원(타입 검사, 자동 완성)을 개선하기 위해 기여했습니다.\n \n-**FastAPI**를 개발하기 시작할 즈음에는 대부분의 준비가 이미 완료된 상태였습니다. 설계가 정의되었고, 필요조건과 도구가 준비되었으며, 표준과 명세에 대한 지식도 충분했습니다.\n+개발 과정에서, 또 다른 핵심 필요조건인 **Starlette**에도 기여했습니다.\n \n----\n+## 개발 { #development }\n \n-## 미래\n+**FastAPI** 자체를 만들기 시작했을 때쯤에는, 대부분의 조각들이 이미 갖춰져 있었고, 디자인은 정의되어 있었으며, 필요조건과 도구는 준비되어 있었고, 표준과 명세에 대한 지식도 명확하고 최신 상태였습니다.\n \n-현시점에서 **FastAPI**가 많은 사람들에게 유용하다는 것이 명백해졌습니다.\n+## 미래 { #future }\n \n-여러 용도에 더 적합한 도구로서 기존 대안보다 선호되고 있습니다.\n-이미 많은 개발자와 팀들이 **FastAPI**에 의존해 프로젝트를 진행 중입니다 (저와 제 팀도 마찬가지입니다).\n+이 시점에는, **FastAPI**가 그 아이디어와 함께 많은 사람들에게 유용하다는 것이 이미 분명합니다.\n \n-하지만 여전히 개선해야 할 점과 추가할 기능들이 많이 남아 있습니다.\n+많은 사용 사례에 더 잘 맞기 때문에 이전 대안들보다 선택되고 있습니다.\n+\n+많은 개발자와 팀이 이미 자신의 프로젝트를 위해 **FastAPI**에 의존하고 있습니다(저와 제 팀도 포함해서요).\n+\n+하지만 여전히, 앞으로 나올 개선 사항과 기능들이 많이 있습니다.\n+\n+**FastAPI**의 미래는 밝습니다.\n \n-**FastAPI**는 밝은 미래로 나아가고 있습니다.\n 그리고 [여러분의 도움](help-fastapi.md){.internal-link target=_blank}은 큰 힘이 됩니다."
}
],
"reviews": [
{
"id": 3681097212,
"user": "user_7e930c559d4e",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-01-20T09:07:36+00:00"
},
{
"id": 3681132251,
"user": "user_29e85f9a8e75",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-01-20T09:12:14+00:00"
},
{
"id": 3681166299,
"user": "user_7e930c559d4e",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-01-20T09:20:17+00:00"
},
{
"id": 3681325571,
"user": "user_29e85f9a8e75",
"state": "COMMENTED",
"body": null,
"submitted_at": "2026-01-20T09:56:02+00:00"
},
{
"id": 3681514636,
"user": "user_7e930c559d4e",
"state": "APPROVED",
"body": null,
"submitted_at": "2026-01-20T10:40:12+00:00"
},
{
"id": 3696098659,
"user": "user_7e930c559d4e",
"state": "APPROVED",
"body": null,
"submitted_at": "2026-01-23T07:39:46+00:00"
},
{
"id": 3696098963,
"user": "user_12425605bafa",
"state": "COMMENTED",
"body": "I think the original terms '애플리케이션' (Application) and '명령어' (Command line/Instruction) are more accurate and natural than '앱' (App) or '명령' (Command).\n\nIn the Korean context, '앱' (App) is strongly associated with mobile applications. For a CLI tool, '애플리케이션' sounds more appropriate. Also, '명령어' is the more standard term used to describe instructions typed into a terminal.",
"submitted_at": "2026-01-23T07:41:23+00:00"
},
{
"id": 3696498847,
"user": "user_12425605bafa",
"state": "APPROVED",
"body": "Overall, the translation looks solid, and the added explanations for abbreviations are helpful for Korean readers.\n\nI'm approving this as the quality is good. As a small suggestion for future updates, using “애플리케이션” instead of “앱” and “명령어” instead of “명령” may sound more natural in a context.",
"submitted_at": "2026-01-23T09:07:58+00:00"
},
{
"id": 3701586837,
"user": "user_12425605bafa",
"state": "APPROVED",
"body": null,
"submitted_at": "2026-01-24T13:20:48+00:00"
}
],
"review_comments": [
{
"id": 2707411387,
"user": "user_7e930c559d4e",
"body": "```suggestion\n만약 애플리케이션이 (어째서인지) 다른 어떤 것과도 통신하고 그 응답을 기다릴 필요가 없다면, 내부에서 `await`를 사용할 필요가 없더라도 `async def`를 사용하세요.\n```\n\nIn Korean, translating “you” as “여러분” instead of “당신”, or omitting it when possible, sounds more natural. In many contexts, “당신” is considered impolite in Korean.\n\nIt would be good to add this content to [llm_prompt.md](https://github.com/fastapi/fastapi/blob/master/docs/ko/llm-prompt.md).",
"path": "docs/ko/docs/async.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-20T09:04:52+00:00"
},
{
"id": 2707440491,
"user": "user_29e85f9a8e75",
"body": "[USER_REDACTED], thanks!\nWould you like to open PR to update `llm-prompt.md`?\nI would then re-translate these documents using the updated prompt",
"path": "docs/ko/docs/async.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-20T09:12:14+00:00"
},
{
"id": 2707469675,
"user": "user_7e930c559d4e",
"body": "Sure, I’ll take care of it. Thanks!",
"path": "docs/ko/docs/async.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-20T09:20:17+00:00"
},
{
"id": 2707607887,
"user": "user_29e85f9a8e75",
"body": "Re-translated pages with updated prompt. Commit https://github.com/fastapi/fastapi/pull/14738/commits/d65e8a4aaa8369d52c29b913b0528e8c54180dd6",
"path": "docs/ko/docs/async.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-20T09:56:02+00:00"
},
{
"id": 2719974974,
"user": "user_12425605bafa",
"body": "I think the original terms '애플리케이션' (Application) and '명령어' (Command line/Instruction) are more accurate and natural than '앱' (App) or '명령' (Command).\n\nIn the Korean context, '앱' (App) is strongly associated with mobile applications. For a CLI tool, '애플리케이션' sounds more appropriate. Also, '명령어' is the more standard term used to describe instructions typed into a terminal.",
"path": "docs/ko/docs/fastapi-cli.md",
"line": null,
"side": "RIGHT",
"created_at": "2026-01-23T07:39:53+00:00"
}
],
"meta": {
"languages": [
"md"
],
"touches_tests": false,
"review_state_summary": {
"COMMENTED": 5,
"APPROVED": 4
},
"meaningful_comment_count": 5,
"has_approval": true,
"has_changes_requested": false,
"total_review_comments": 5
}
}
{
"_id": "c088da7a955c46b5",
"_schema_version": "1.0",
"_cleaned_at": "2026-02-12T07:46:51.671629+00:00",
"repo": "tiangolo/fastapi",
"repo_url": "https://github.com/fastapi/fastapi",
"license_name": "MIT License",
"license_spdx": "MIT",
"pr_number": 14693,
"title": "🌐 Update translations for ru (update-outdated)",
"body": "🌐 Update translations for ru (update-outdated)\n\nThis PR was created automatically using LLMs.\n\nIt uses the prompt file https://github.com/fastapi/fastapi/blob/master/docs/ru/llm-prompt.md.\n\nIn most cases, it's better to make PRs updating that file so that the LLM can do a better job generating the translations than suggesting changes in this PR.",
"author": "user_2a237e38e06b",
"created_at": "2026-01-11T00:36:41+00:00",
"merged_at": "2026-01-20T23:03:07+00:00",
"base_branch": "master",
"head_branch": "translate-ru-update-outdated-31cb3e0f",
"additions": 297,
"deletions": 444,
"changed_files": 13,
"files": [
{
"filename": "docs/ru/docs/_llm-test.md",
"status": "modified",
"additions": 9,
"deletions": 9,
"changes": 18,
"patch": "@@ -1,8 +1,8 @@\n # Тестовый файл LLM { #llm-test-file }\n \n-Этот документ проверяет, понимает ли LLM, переводящая документацию, `general_prompt` в `scripts/translate.py` и языковой специфичный промпт в `docs/{language code}/llm-prompt.md`. Языковой специфичный промпт добавляется к `general_prompt`.\n+Этот документ проверяет, понимает ли LLM, переводящая документацию, `general_prompt` в `scripts/translate.py` и языковой специфичный промпт в `docs/{language code}/llm-prompt.md`. Языковой специфичный промпт добавляется к `general_prompt`.\n \n-Тесты, добавленные здесь, увидят все создатели языковых промптов.\n+Тесты, добавленные здесь, увидят все создатели языковых специфичных промптов.\n \n Использование:\n \n@@ -11,7 +11,7 @@\n * Проверьте, всё ли в порядке в переводе.\n * При необходимости улучшите ваш языковой специфичный промпт, общий промпт или английский документ.\n * Затем вручную исправьте оставшиеся проблемы в переводе, чтобы он был хорошим.\n-* Переведите заново, имея хороший перевод на месте. Идеальным результатом будет ситуация, когда LLM больше не вносит изменений в перевод. Это означает, что общий промпт и ваш языковой специфичный промпт максимально хороши (иногда он будет делать несколько, казалось бы, случайных изменений, причина в том, что LLM — недетерминированные алгоритмы).\n+* Переведите заново, имея хороший перевод на месте. Идеальным результатом будет ситуация, когда LLM больше не вносит изменений в перевод. Это означает, что общий промпт и ваш языковой специфичный промпт настолько хороши, насколько это возможно (иногда он будет делать несколько, казалось бы, случайных изменений, причина в том, что LLM — недетерминированные алгоритмы).\n \n Тесты:\n \n@@ -197,10 +197,10 @@ works(foo=\"bar\") # Это работает 🎉\n \n ### abbr даёт полную расшифровку { #the-abbr-gives-a-full-phrase }\n \n-* GTD\n-* lt\n-* XWT\n-* PSGI\n+* GTD\n+* lt\n+* XWT\n+* PSGI\n \n ### abbr даёт объяснение { #the-abbr-gives-an-explanation }\n \n@@ -209,8 +209,8 @@ works(foo=\"bar\") # Это работает 🎉\n \n ### abbr даёт полную расшифровку и объяснение { #the-abbr-gives-a-full-phrase-and-an-explanation }\n \n-* MDN\n-* I/O.\n+* MDN\n+* I/O.\n \n ////"
},
{
"filename": "docs/ru/docs/advanced/path-operation-advanced-configuration.md",
"status": "modified",
"additions": 12,
"deletions": 44,
"changes": 56,
"patch": "@@ -14,7 +14,7 @@\n \n {* ../../docs_src/path_operation_advanced_configuration/tutorial001_py39.py hl[6] *}\n \n-### Использование имени функции-обработчика пути как operationId { #using-the-path-operation-function-name-as-the-operationid }\n+### Использование имени *функции-обработчика пути* как operationId { #using-the-path-operation-function-name-as-the-operationid }\n \n Если вы хотите использовать имена функций ваших API в качестве `operationId`, вы можете пройти по всем из них и переопределить `operation_id` каждой *операции пути* с помощью их `APIRoute.name`.\n \n@@ -38,7 +38,7 @@\n \n ## Исключить из OpenAPI { #exclude-from-openapi }\n \n-Чтобы исключить *операцию пути* из генерируемой схемы OpenAPI (а значит, и из автоматической документации), используйте параметр `include_in_schema` и установите его в `False`:\n+Чтобы исключить *операцию пути* из генерируемой схемы OpenAPI (а значит, и из автоматических систем документации), используйте параметр `include_in_schema` и установите его в `False`:\n \n {* ../../docs_src/path_operation_advanced_configuration/tutorial003_py39.py hl[6] *}\n \n@@ -48,15 +48,15 @@\n \n Добавление `\\f` (экранированного символа «form feed») заставит **FastAPI** обрезать текст, используемый для OpenAPI, в этой точке.\n \n-Эта часть не попадёт в документацию, но другие инструменты (например, Sphinx) смогут использовать остальное.\n+Это не отобразится в документации, но другие инструменты (например, Sphinx) смогут использовать остальное.\n \n {* ../../docs_src/path_operation_advanced_configuration/tutorial004_py310.py hl[17:27] *}\n \n ## Дополнительные ответы { #additional-responses }\n \n Вы, вероятно, уже видели, как объявлять `response_model` и `status_code` для *операции пути*.\n \n-Это определяет метаданные об основном ответе *операции пути*.\n+Это определяет метаданные об основном HTTP-ответе *операции пути*.\n \n Также можно объявлять дополнительные ответы с их моделями, статус-кодами и т.д.\n \n@@ -76,7 +76,7 @@\n \n Там есть `tags`, `parameters`, `requestBody`, `responses` и т.д.\n \n-Эта спецификация OpenAPI, специфичная для *операции пути*, обычно генерируется автоматически **FastAPI**, но вы также можете её расширить.\n+Эта специфичная для *операции пути* схема OpenAPI обычно генерируется автоматически **FastAPI**, но вы также можете её расширить.\n \n /// tip | Совет\n \n@@ -129,13 +129,13 @@\n }\n ```\n \n-### Пользовательская схема OpenAPI для операции пути { #custom-openapi-path-operation-schema }\n+### Пользовательская схема OpenAPI для *операции пути* { #custom-openapi-path-operation-schema }\n \n-Словарь в `openapi_extra` будет объединён с автоматически сгенерированной схемой OpenAPI для *операции пути*.\n+Словарь в `openapi_extra` будет глубоко объединён с автоматически сгенерированной схемой OpenAPI для *операции пути*.\n \n Таким образом, вы можете добавить дополнительные данные к автоматически сгенерированной схеме.\n \n-Например, вы можете решить читать и валидировать запрос своим кодом, не используя автоматические возможности FastAPI и Pydantic, но при этом захотите описать запрос в схеме OpenAPI.\n+Например, вы можете решить читать и валидировать HTTP-запрос своим кодом, не используя автоматические возможности FastAPI и Pydantic, но при этом захотите описать HTTP-запрос в схеме OpenAPI.\n \n Это можно сделать с помощью `openapi_extra`:\n \n@@ -149,52 +149,20 @@\n \n Используя тот же приём, вы можете воспользоваться Pydantic-моделью, чтобы определить JSON Schema, которая затем будет включена в пользовательский раздел схемы OpenAPI для *операции пути*.\n \n-И вы можете сделать это, даже если тип данных в запросе — не JSON.\n+И вы можете сделать это, даже если тип данных в HTTP-запросе — не JSON.\n \n-Например, в этом приложении мы не используем встроенную функциональность FastAPI для извлечения JSON Schema из моделей Pydantic, равно как и автоматическую валидацию JSON. Мы объявляем тип содержимого запроса как YAML, а не JSON:\n-\n-//// tab | Pydantic v2\n+Например, в этом приложении мы не используем встроенную функциональность FastAPI для извлечения JSON Schema из моделей Pydantic, равно как и автоматическую валидацию JSON. Мы объявляем тип содержимого HTTP-запроса как YAML, а не JSON:\n \n {* ../../docs_src/path_operation_advanced_configuration/tutorial007_py39.py hl[15:20, 22] *}\n \n-////\n-\n-//// tab | Pydantic v1\n-\n-{* ../../docs_src/path_operation_advanced_configuration/tutorial007_pv1_py39.py hl[15:20, 22] *}\n-\n-////\n-\n-/// info | Информация\n-\n-В Pydantic версии 1 метод для получения JSON Schema модели назывался `Item.schema()`, в Pydantic версии 2 метод называется `Item.model_json_schema()`.\n-\n-///\n-\n Тем не менее, хотя мы не используем встроенную функциональность по умолчанию, мы всё равно используем Pydantic-модель, чтобы вручную сгенерировать JSON Schema для данных, которые мы хотим получить в YAML.\n \n-Затем мы работаем с запросом напрямую и извлекаем тело как `bytes`. Это означает, что FastAPI даже не попытается распарсить полезную нагрузку запроса как JSON.\n+Затем мы работаем с HTTP-запросом напрямую и извлекаем тело как `bytes`. Это означает, что FastAPI даже не попытается распарсить полезную нагрузку HTTP-запроса как JSON.\n \n-А затем в нашем коде мы напрямую парсим этот YAML и снова используем ту же Pydantic-модель для валидации YAML-содержимого:\n-\n-//// tab | Pydantic v2\n+А затем в нашем коде мы напрямую парсим это содержимое YAML и снова используем ту же Pydantic-модель, чтобы валидировать YAML-содержимое:\n \n {* ../../docs_src/path_operation_advanced_configuration/tutorial007_py39.py hl[24:31] *}\n \n-////\n-\n-//// tab | Pydantic v1\n-\n-{* ../../docs_src/path_operation_advanced_configuration/tutorial007_pv1_py39.py hl[24:31] *}\n-\n-////\n-\n-/// info | Информация\n-\n-В Pydantic версии 1 метод для парсинга и валидации объекта назывался `Item.parse_obj()`, в Pydantic версии 2 метод называется `Item.model_validate()`.\n-\n-///\n-\n /// tip | Совет\n \n Здесь мы переиспользуем ту же Pydantic-модель."
},
{
"filename": "docs/ru/docs/advanced/settings.md",
"status": "modified",
"additions": 0,
"deletions": 44,
"changes": 44,
"patch": "@@ -46,12 +46,6 @@ $ pip install \"fastapi[all]\"\n \n
\n+
\n+ \n
\n \n\n- \n-\n- \n+\n
\n
 \n
\n